4장. CPU
CPU 즉 central processing unit은 대부분의 시스템에 대해 잘못된 명칭입니다. 왜냐햐면 중앙화 (central)는 하나 (single)를 의미하지만 대부분의 현대적인 시스템에는 하나 이상의 처리 장치 또는 코어가 있기 때문입니다. 물리적으로 CPU는 소켓에 있는 마더보드에 설치된 패키지에 들어 있습니다. 마더보드에 있는 각 소켓에는 다른 CPU 소켓, 메모리 컨트롤러, 인터럽트 컨트롤러, 기타 주변 장치와 같은 다양한 연결 장치가 있습니다. 운영 체제의 소켓은 관련된 리소스 및 CPU의 논리적 그룹입니다. 이러한 개념은 대부분의 CPU 튜닝 논의에서 중심이 됩니다.
Red Hat Enterprise Linux는 시스템 CPU 이벤트에 대한 통계를 보관합니다. 이러한 통계는 CPU 성능 향상을 위해 튜닝 전략을 계획할 때 유용합니다. 4.1.2절. “CPU 성능 튜닝 ”에서는 보다 더 유용한 통계의 일부와 이러한 통계의 위치, 성능 튜닝을 위해 이를 분석하는 방법에 대해 설명합니다.
토폴로지
오래된 컴퓨터에는 시스템 당 CPU 수가 비교적 적어 SMP (Symmetric Multi-Processor)라는 아키텍처를 허용했습니다. 즉 이는 시스템에 있는 각각의 CPU는 사용 가능한 메모리로 유사하게 (또는 대칭) 액세스할 수 있음을 의미합니다. 최근에는 소켓 당 CPU 수가 많아졌기 때문에 시스템에 있는 모든 RAM에 대해 대칭 액세스를 제공하는 것은 고가의 비용이 들게 됩니다. CPU 수가 많은 시스템의 대부분에서는 SMP 대신 NUMA (Non-Uniform Memory Access)라는 아키텍처가 사용되고 있습니다.
AMD 프로세서는 HT (Hyper Transport) 상호 연결과 함께 이러한 유형의 아키텍처를 사용하고 있는 반면 Intel은 QPI (Quick Path Interconnect) 디자인에서 NUMA를 구현하기 시작했습니다. 애플리케이션에 리소스를 할당할 때 시스템의 토폴로지를 설명할 필요가 있으므로 NUMA 및 SMP는 다르게 튜닝됩니다.
스레드
Linux 운영 체제에서 실행 단위는 스레드라고 합니다. 스레드에는 레지스터 컨텍스트, 스택, CPU에서 실행되는 실행 가능한 코드의 세그먼트가 있습니다. 사용 가능한 CPU에서 이러한 스레드의 스케줄을 관리하는 것은 운영 체제의 일입니다.
OS는 사용 가능한 코어에 걸쳐 스레드 작업 부하의 균형을 유지하여 CPU 사용률을 극대화합니다. OS는 주로 CPU를 지속적으로 작동하게 하는 것이므로 애플리케이션 성능에 관해서는 최적의 판단을 내리지 않을 수 있습니다. 애플리케이션 스레드를 다른 소켓에 있는 CPU로 이동하는 것은 메모리 액세스 작업이 소켓에 걸쳐 크게 저하될 수 있기 때문에 간단하게 현재의 CPU를 사용할 수 있을 때까지 대기하는 것 보다 성능이 더 악화될 수 있습니다. 고성능 애플리케이션의 경우 일반적으로 스레드를 배치할 위치는 설계자가 결정하는 것이 더 좋습니다. 4.2절. “CPU 스케줄링 ”에서는 애플리케이션 스레드를 최고로 실행하기 위해 최선의 CPU 및 메모리 할당 방법에 대해 설명합니다.
인터럽트
애플리케이션 성능에 영향을 미치는 시스템 이벤트 중에서 다소 명확하지 않은 (하지만 중요한)것 중 하나는 인터럽트 (Linux에서 IRQ라고 함)입니다. 이러한 이벤트는 운영 체제가 처리하고 데이터 도착 또는 네트워크 쓰기나 타이머 이벤트와 같은 작업의 완료를 알리기 위해 주변 장치를 사용합니다.
애플리케이션 코드를 실행하는 OS 또는 CPU가 인터럽트를 처리하는 방법은 애플리케이션의 기능에 영향을 주지 않습니다. 하지만 이는 애플리케이션의 성능에 영향을 미칠 수 있습니다. 다음 부분에서는 인터럽트가 애플리케이션 성능에 부정적인 영향을 주지 않도록 하는 방법에 대해 설명합니다.
4.1. CPU 토폴로지
링크 복사링크가 클립보드에 복사되었습니다!
4.1.1. CPU 및 NUMA 토폴로지
링크 복사링크가 클립보드에 복사되었습니다!
최초의 컴퓨터 프로세서는 단일 프로세서 (uniprocessors)로 시스템에는 하나의 CPU만 있었습니다. 운영 체제가 단일 CPU를 하나의 실행 (프로세스) 스레드에서 다른 스레드로 신속하게 전환함으로써 프로세스의 병렬 처리라는 환상이 이루어 졌습니다. 시스템 성능을 향상시키기 위해 설계자는 지시 사항을 빠르게 실행하기 위해 클럭 속도를 높여도 어느 지점 (주로 현재의 기술로 안정적인 클럭 파형을 생성할 수 있는 한계) 까지만 작동함을 인지했습니다. 전체적인 시스템 성능을 향상시키기 위해 설계자는 다른 CPU를 시스템에 추가하여 두 개의 병렬 스트림에서 실행할 수 있게 했습니다. 이러한 프로세서를 추가하는 경향은 오랫동안 계속될 것입니다.
대부분의 초기 멀티 프로세서 시스템에서 각각의 CPU는 각각의 메모리 위치에 동일한 논리적 경로를 가지고 있도록 설계되었습니다 (일반적으로 병렬 버스). 이를 통해 각각의 CPU는 시스템에 있는 다른 CPU와 동일한 시간에 모든 메모리 위치에 액세스할 수 있습니다. 이러한 유형의 아키텍처는 SMP (Symmetric Multi-Processor) 시스템이라고 합니다. SMP는 CPU 수가 적은 경우 잘 작동하지만 CPU 수가 일정 수 (8 또는 16)를 초과하면 메모리에 동일한 액세스를 허용하는데 필요한 병렬 추적 번호가 사용 가능한 보드 공간을 너무 많이 사용하여 주변 장치에 대한 공간이 부족해 집니다.
시스템에서 다수의 CPU를 허용하기 위해 두 가지 새로운 개념이 결합되었습니다:
- 직렬 버스
- NUMA 토폴로지
직렬 버스는 패킷 버스트로 데이터를 전송하는 매우 높은 클럭 속도를 갖는 단일 와이어 통신 경로입니다. 하드웨어 설계자는 직렬 버스를 CPU 간이나 CPU와 메모리 컨트롤러 및 기타 주변 장치 사이에서 고속의 상호 연결로 사용하기 시작했습니다. 즉, 각각의 CPU에서 메모리 서브 시스템 보드에 32에서 64의 추적을 필요로하는 대신 하나의 추적을 필요로 하기 때문에 보드에서 필요한 공간이 크게 감소되었습니다.
동시에 하드웨어 설계자는 다이 크기를 줄임으로써 동일한 공간에 더 많은 트랜지스터를 정리했습니다. 메인 보드에 개별 CPU를 두지 않고 멀티 코어 프로세서로 프로세서 패키지에 이를 정리하기 시작했습니다. 그 후 각 프로세서 패키지에서 메모리에 동일한 액세스를 제공하는 것이 아니라 설계자는 NUMA (Non-Uniform Memory Access) 전략에 의지하였습니다. 즉 각 패키지/소켓의 조합으로 고속 액세스의 전용 메모리 영역이 하나 이상 있는 것입니다. 각 소켓은 다른 소켓 메모리로 느리게 액세스하기 위해 다른 소켓에 대해 상호 연결을 갖고 있습니다.
간단한 NUMA의 예로 소켓이 2개 있는 마더보드가 있다고 가정합니다. 여기서 각 소켓은 쿼드 코어 패키지로 채워져 있습니다. 즉, 시스템에 총 8 개의 CPU가 있고 각 소켓에 4개씩 있는 것입니다. 각 소켓은 4GB RAM 메모리 뱅크가 부착되어 있어 시스템의 전체 메모리는 8GB가 됩니다. 이러한 예의 경우 CPU 0-3은 소켓 0에 있고 CPU 4-7은 소켓 1에 있습니다. 예에서 각 소켓은 NUMA 노드에 해당합니다.
CPU 0의 경우 뱅크 0에서 메모리에 액세스하려면 3 클럭 사이클이 필요할 수 있습니다. 메모리 컨트롤러에 주소를 표시하는 사이클, 메모리 위치에 대한 액세스를 설정하는 사이클, 위치를 읽기 또는 쓰기하는 사이클입니다. 하지만 CPU 4의 경우 동일한 위치에서 메모리에 액세스하려면 6 클럭 사이클이 필요할 수 있습니다. 이는 다른 소켓에 있으므로 소켓 1의 로컬 메모리 컨트롤러와 소켓 0에 있는 원격 메모리 컨트롤러라는 두 개의 메모리 컨트롤러를 통과해야 하기 때문입니다. 메모리가 해당 위치에서 경쟁하는 경우 (즉, 두 개 이상의 CPU가 동일한 위치의 메모리에 동시에 액세스하려고 하는 경우) 메모리 컨트롤러는 메모리에 대한 액세스를 중재하고 직렬화해야 하므로 메모리 액세스 시간이 더 오래 걸릴 수 있습니다. 캐시 일관성을 추가하면 (로컬 CPU 캐시에 동일한 메모리 위치에 대해 동일한 데이터가 포함되어 있는지 확인하는) 프로세스는 더욱 복잡해 집니다.
Intel (Xeon) 및 AMD (Opteron)의 최신 하이엔드 프로세서에는 NUMA 토폴로지가 있습니다. AMD 프로세서는 HyperTransport 또는 HT라는 상호 연결을 사용하며 반면 Intel은 QuickPath Interconnect 또는 QPI라는 상호 연결을 사용합니다. 상호 연결은 다른 상호 연결, 메모리, 주변 장치로의 물리적 연결 방법에 차이가 있지만 실질적으로 다른 연결된 장치에서 하나의 연결된 장치로 투명한 액세스를 허용하는 스위치입니다. 이 경우 '투명성'은 "비용 없음" 옵션이 아니라 상호 연결을 사용하기 위해 특별한 프로그래밍 API가 필요하지 않다는 것을 의미합니다.
시스템 아키텍처는 매우 다양하므로 비로컬 메모리에 액세스하여 부과되는 성능 패널티를 구체적으로 특징화하는 것은 현실적이지 않습니다. 상호 연결의 각 홉이 홉 당 적어도 비교적 일정한 성능 패널티를 부과하고 있다는 것은 말할 수 있습니다. 현재 CPU에서 두 개의 상호 연결의 메모리 위치를 참조하면 적어도 2N + 메모리 사이클 시간 단위를 액세스 시간에 부과합니다. 여기서 N은 홉 당 패널티입니다.
성능 패널티를 고려하면 성능에 민감한 애플리케이션은 NUMA 토폴로지 시스템에 있는 원격 메모리에 정기적으로 액세스하지 않도록 해야 합니다. 이러한 애플리케이션은 특정 노드에서 유지하고 해당 노드에서 메모리를 할당하도록 설정해야 합니다.
이를 위해 애플리케이션은 다음과 같은 사항을 알고 있어야 합니다:
- 시스템의 토폴로지는 무엇입니까?
- 현재 애플리케이션은 어디에서 실행되고 있습니까?
- 가장 가까운 메모리 뱅크는 어디에 있습니까?
4.1.2. CPU 성능 튜닝
링크 복사링크가 클립보드에 복사되었습니다!
다음 부분에서는 CPU 성능 튜닝 방법의 이해를 돕고 프로세스에 도움이 되는 여러 도구에 대해 소개합니다.
원래 NUMA는 단일 프로세서를 여러 메모리 뱅크에 연결하는데 사용되었습니다. CPU 제조 업체가 프로세서를 정교하게 하고 die 크기가 축소되면서 여러 CPU 코어는 하나의 패키지에 포함될 수 있었습니다. 이러한 CPU 코어는 클러스터되고 각각은 로컬 메모리 뱅크에 대한 액세스 시간이 동일하게 되어 코어 간에 캐시를 공유할 수 있었습니다. 하지만 코어, 메모리, 캐시 간의 상호 연결을 통한 각각의 '홉 (hop)'에는 약간의 성능 패널티가 발생했습니다.
그림 4.1. “NUMA 토폴로지에서 로컬 및 원격 메모리 액세스 ”에 있는 예시 시스템에는 두 개의 NUMA 노드가 있습니다. 각 노드에는 네 개의 CPU, 메모리 뱅크, 메모리 컨트롤러가 있습니다. 노드에 있는 CPU는 해당 노드의 메모리 뱅크에 직접 액세스할 수 있습니다. 노드 1에 있는 화살표를 따라 가면 다음과 같은 단계가 있습니다:
- CPU (0-3 중 하나)는 로컬 메모리 컨트롤러로의 메모리 주소를 표시합니다.
- 메모리 컨트롤러는 메모리 주소로의 액세스를 설정합니다.
- CPU는 해당 메모리 주소에서 읽기/쓰기 작업을 수행합니다.
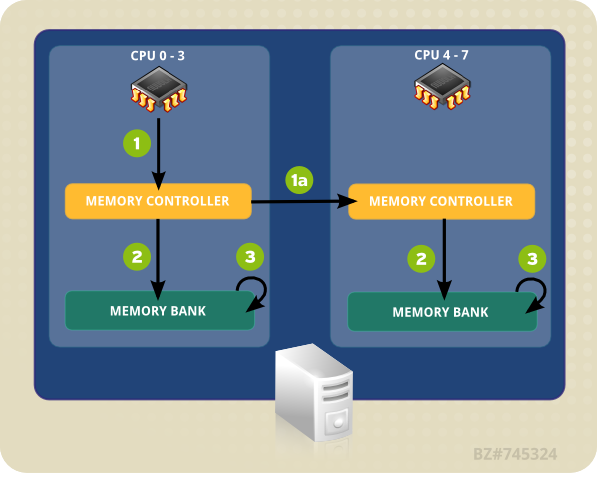
그림 4.1. NUMA 토폴로지에서 로컬 및 원격 메모리 액세스
하지만 하나의 노드에 있는 CPU가 다른 NUMA 노드의 메모리 뱅크에 있는 코드에 액세스해야 하는 경우 직접적인 경로가 아닙니다:
- CPU (0-3 중 하나)는 로컬 메모리 컨트롤러에 원격 메모리 액세스를 표시합니다.
- 원격 메모리 주소의 CPU 요청은 메모리 주소가 있는 노드로의 로컬, 원격 메모리 컨트롤러에 전달됩니다.
- 원격 메모리 컨트롤러는 원격 메모리 주소로의 액세스를 설정합니다.
- CPU는 해당 원격 메모리 주소에서 읽기 또는 쓰기 작업을 수행합니다.
원격 메모리 주소를 액세스하려고 할 때 모든 작업은 여러 메모리 컨트롤러를 통과해야 하기 때문에 액세스에 두 배 이상의 시간이 걸릴 수 있습니다. 따라서 멀티 코어 시스템에서 성능의 주요 관심사는 정보가 가장 짧거나 빠른 경로로 가능한 효율적으로 이동할 수 있도록 하는 것입니다.
최적의 CPU 성능을 위해 애플리케이션을 설정하려면 다음과 같은 사항을 알고 있어야 합니다:
- 시스템의 토폴로지 (구성 요소가 연결된 방법)
- 애플리케이션을 실행하는 코어
- 가장 가까운 메모리 뱅크 위치
Red Hat Enterprise Linux 6에는 이러한 정보를 검색하고 이에 따라 시스템을 튜닝하는데 도움이 되는 여러 도구가 탑재되어 있습니다. 다음 부분에서는 CPU 성능 튜닝에 유용한 도구에 대한 개요를 설명합니다.
4.1.2.1. taskset으로 CPU 친화도 설정
링크 복사링크가 클립보드에 복사되었습니다!
taskset은 실행 중인 프로세스 (프로세스 ID에 따라)의 CPU 친화도를 검색 및 설정합니다. 이는 주어진 CPU 친화도를 사용하여 프로세스를 시작하는데 사용될 수 있으며, 이 경우 특정 프로세스를 특정 CPU또는 CPU 모음에 연결합니다. 하지만 taskset은 로컬 메모리 할당을 보장하지 않습니다. 로컬 메모리 할당의 추가적 성능 향상이 필요한 경우 taskset 대신 numactl을 사용하는 것이 좋습니다. 보다 자세한 내용은 4.1.2.2절. “numactl로 NUMA 정책 제어 ”에서 참조하십시오.
CPU 친화도는 비트 마스트로 표시됩니다. 가장 낮은 순서의 비트는 첫 번째 논리 CPU에 해당하고 가장 높은 순서의 비트는 마지막 논리 CPU에 해당합니다. 이러한 마스크는 일반적으로 16 진수로 제공되어
0x00000001은 프로세서 0을 0x00000003은 프로세스 0 및 1을 나타냅니다.
실행 중인 프로세스의 CPU 친화도를 설정하려면 다음과 같은 명령을 실행합니다. mask는 프로세스를 연결하려는 프로세서 또는 프로세서의 마스크로 대체하고 pid는 변경하려는 친화도의 프로세스의 프로세스 ID로 대체합니다.
# taskset -p mask pid
주어진 친화도로 프로세스를 시작하려면 다음과 같은 명령을 실행합니다. 여기서 mask는 프로세스를 연결하려는 프로세서 또는 프로세서 마스크로 대체하고 program은 실행하려는 프로그램의 프로그램, 옵션, 인수로 대체합니다.
# taskset mask -- program
프로세서를 비트 마스크로 지정하는 대신
-c 옵션을 사용하여 별도의 프로세서를 콤마로 구분한 목록 또는 프로세서 범위를 제공할 수 있습니다. 예:
# taskset -c 0,5,7-9 -- myprogram
taskset에 관한 보다 자세한 내용은
man taskset man 페이지에서 참조하십시오.
4.1.2.2. numactl로 NUMA 정책 제어
링크 복사링크가 클립보드에 복사되었습니다!
numactl은 지정된 스케줄링 또는 메모리 배치 정책으로 프로세스를 실행합니다. 선택된 정책은 해당 프로세스 및 모든 자식 프로세스에 설정됩니다. numactl은 공유 메모리 세그먼트 또는 파일 용 영구 정책을 설정할 수 있고 프로세스의 CPU 친화도 및 메모리 친화도를 설정할 수 있습니다. 이는 /sys 파일 시스템을 사용하여 시스템 토폴로지를 지정합니다.
/sys 파일 시스템에는 CPU, 메모리, 주변 장치가 NUMA 상호 연결을 통해 연결된 방법에 관한 정보가 들어 있습니다. 특히 /sys/devices/system/cpu 디렉토리에는 시스템의 CPU가 각각 연결된 방법에 대한 정보가 들어 있습니다. /sys/devices/system/node 디렉토리에는 시스템의 NUMA 노드와 노드 간의 상대 거리에 대한 정보가 들어 있습니다.
NUMA 시스템에서 프로세서와 메모리 뱅크 간의 거리가 길수록 메모리 뱅크로의 프로세서의 액세스는 느려집니다. 따라서 성능 의존형 애플리케이션은 가장 가까운 메모리 뱅크에서 메모리를 할당하도록 설정해야 합니다.
성능 의존형 애플리케이션은 코어 설정 수에서 실행하도록 설정해야 합니다. 멀티 스레드 애플리케이션의 경우 특히 그러합니다. 첫 번째 레벨 캐시는 일반적으로 적기 때문에 여러 스레드가 하나의 코어에서 실행되는 경우 각 스레드는 이전 스레드가 액세스한 캐시된 데이터를 제거할 수 있습니다. 운영 체제가 이러한 스레드 사이에서 멀티 태스킹을 시도할 때 스레드가 서로의 캐시된 데이터를 지속적으로 제거하면 실행 시간 중 많은 부분이 캐시 라인 교체에 소요되어 버립니다. 이러한 문제는 캐시 스레싱 (cache thrashing)이라고 합니다. 따라서 멀티 스레드 애플리케이션을 단일 코어가 아닌 노드에 연결하는 것이 좋습니다. 이는 스레드가 여러 레벨 (첫번째, 두번째, 마지막 레벨 캐시)에서 캐시 라인을 공유하는 것을 허용하고 캐시 충족 조작의 필요성을 최소화하기 때문입니다. 하지만 모든 스레드가 동일하게 캐시된 데이터에 액세스하는 경우 애플리케이션을 단일 코어에 바인딩하면 성능이 향상될 수 있습니다.
numactl을 사용하여 애플리케이션을 특정 코어 또는 NUMA 노드에 바인딩하여 코어 또는 코어 세트에 관련된 메모리를 할당할 수 있습니다. numactl이 제공하는 유용한 옵션은 다음과 같습니다:
--show- 현재 프로세스의 NUMA 정책 설정을 표시합니다. 이 매개 변수는 추가 매개 변수를 필요로 하지 않으며 다음과 같이 사용할 수 있습니다:
numactl --show --hardware- 시스템에서 사용 가능한 노드의 인벤토리를 표시합니다.
--membind- 지정된 노드에서 메모리만 할당합니다. 노드가 사용 중이고 이러한 노드에 있는 메모리가 충분하지 않을 경우 할당은 실패하게 됩니다. 이러한 매개 변수의 사용 방법은
numactl --membind=nodes program입니다. 여기서 nodes는 메모리를 할당하고자 하는 노드 목록이고, program은 메모리 요구 사항을 해당 노드에서 할당해야 하는 프로그램입니다. 노드 번호는 콤마로 구분된 목록, 범위, 또는 이 두 가지 조합으로 지정할 수 있습니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오. --cpunodebind- 지정된 노드에 속한 CPU에 있는 명령 (및 자식 프로세스)만을 실행합니다. 이 매개 변수의 사용 방법은
numactl --cpunodebind=nodes program입니다. 여기서 nodes는 지정된 프로그램 (program)이 바인딩되어야 하는 CPU의 노드 목록입니다. 노드 번호는 쉼표로 구분된 목록 또는 범위 또는 이 두가지 조합으로 지정할 수 있습니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오. --physcpubind- 지정된 CPU에 있는 명령 (및 자식 프로세스)만을 수행합니다. 이 매개 변수의 사용 방법은
numactl --physcpubind=cpu program입니다. 여기서 cpu는/proc/cpuinfo의 프로세서 필드에 표시된 물리적 CPU 번호를 콤마로 구분한 목록이고 program은 이러한 CPU에서만 실행해야 하는 프로그램입니다. CPU는 현재cpuset에 상대적으로 지정될 수 있습니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오. --localalloc- 현재 노드에 항상 할당되어야 하는 메모리를 지정합니다.
--preferred- 가능한 경우, 메모리는 지정된 노드에 할당됩니다. 메모리를 지정된 노드에 할당할 수 없는 경우 다른 노드로 대체합니다. 이 옵션은
numactl --preferred=node과 같이 하나의 노드 번호만을 사용합니다. 보다 자세한 내용은 numactl man 페이지인man numactl에서 참조하십시오.
numactl 패키지에 포함된 libnuma 라이브러리는 커널이 지원하는 NUMA 정책에 간단한 프로그래밍 인터페이스를 제공합니다. 이는 numactl 보다 정교한 튜닝에 유용합니다. 보다 자세한 내용은
man numa(3) man 페이지에서 참조하십시오.
4.1.3. numastat
링크 복사링크가 클립보드에 복사되었습니다!
중요
이전에 numastat 도구는 Andi Kleen에 의해 작성된 Perl 스크립트였습니다. 이는 Red Hat Enterprise Linux 6.4 용으로 다시 작성되었습니다.
기본 명령 (
numastat, 옵션이나 매개 변수 없이)은 도구의 이전 버전과 엄격하게 호환성을 유지하고 있지만 이 명령에 추가되는 옵션이나 매개 변수는 출력 내용과 포맷 모두가 변경됨에 유의합니다.
numastat는 프로세스 및 운영 체제에 대해 시스템의 메모리 통계 (할당 수 및 누락 등)를 NUMA 노드 당으로 표시합니다. 기본적으로
numastat를 실행하면 각 노드에 대해 다음과 같이 이벤트 카테고리에 의해 점유된 메모리 페이지 수를 표시합니다.
numa_miss 및 numa_foreign 값이 낮으면 CPU 성능이 최적화되어 있음을 나타냅니다.
numastat의 업데이트된 버전도 프로세스 메모리가 시스템에 걸쳐 확산되어 있는지 또는 numactl을 사용하여 특정 노드에 중앙 집중화되어 있는지를 표시합니다.
메모리가 할당된 노드와 동일한 노드에서 프로세스 스레드가 실행되고 있는지를 확인하려면 CPU 당 top 출력을 사용하여 numastat 출력을 상호 참조합니다.
기본 추적 카테고리
- numa_hit
- 해당 노드에 할당을 시도하여 성공한 수 입니다.
- numa_miss
- 다른 노드에 할당 시도한 것으로 원래 의도된 노드에 메모리가 부족하여 해당 노드에 할당된 수입니다. 각각의
numa_miss이벤트는 해당하는numa_foreign이벤트가 다른 노드에 있습니다. - numa_foreign
- 처음에는 해당 노드에 할당 의도한 것으로 대신 다른 노드에 할당된 수입니다. 각각의
numa_foreign이벤트는 해당하는numa_miss이벤트가 다른 노드에 있습니다. - interleave_hit
- 해당 노드에 인터리브 정책 할당을 시도하여 성공한 수 입니다.
- local_node
- 해당 노드의 프로세스가 해당 노드에 있는 메모리 할당에 성공한 횟수입니다.
- other_node
- 다른 노드의 프로세스가 해당 노드에 있는 메모리를 할당한 횟수입니다.
다음 옵션 중 하나를 적용하면 메모리의 표시 단위가 메가바이트로 변경됩니다. (소수점 두 자리 까지 반올림됨) 다음에서 설명하고 있듯이 다른 특정 numastat 동작을 변경합니다.
-c- 표시된 정보 테이블을 가로로 축소합니다. 이는 NUMA 노드 수가 많은 시스템에서 유용하지만 열의 폭과 열 사이의 간격은 예측 불가능합니다. 이 옵션을 사용하면 메모리 양은 가장 가까운 메가바이트로 반올림됩니다.
-m- 노드 당 시스템 전체 메모리 사용량을 표시합니다. 이는
/proc/meminfo에 있는 정보와 유사합니다. -n- 원래 측정 단위로 메가 바이트를 사용하여 업데이트된 형식으로
numastat명령 (numa_hit, numa_miss, numa_foreign, interleave_hit, local_node, and other_node)과 동일한 정보가 표시됩니다. -p pattern- 지정된 패턴의 노드 당 메모리 정보를 표시합니다. pattern의 값이 숫자로 구성되면 numastat는 이를 숫자 프로세스 식별자로 간주합니다. 그렇지 않을 경우 numastat는 지정된 패턴의 프로세스 명령행을 검색합니다.
-p옵션 값 다음에 입력되는 명령행 인수는 필터링 추가 패턴으로 간주됩니다. 추가 패턴은 필터를 좁히는 것이 아니라 확장합니다. -s- 표시된 데이터를 내림 차순으로 정렬하므로 (
total란에 따라) 메모리 사용량이 많은 것이 먼저 나열됩니다.옵션으로 node를 지정하면 표는 node 란에 따라 정렬됩니다. 이 옵션을 사용할 때 다음과 같이 node 값은-s옵션 바로 뒤에 와야 합니다.numastat -s2옵션과 값 사이에 공백을 넣지 마십시오. -v- 자세한 정보를 표시합니다. 즉 여러 프로세스의 프로세스 정보는 각 프로세스에 대해 자세한 정보를 표시합니다.
-V- numastat 버전 정보를 표시합니다.
-z- 표시된 정보에서 제로 값을 갖는 표의 행과 열을 생략합니다. 표시 목적으로 제로로 반올림된 제로에 가까운 값은 표시된 출력에서 생략되지 않음에 유의합니다.
4.1.4. NUMA 친화도 관리 데몬 (numad)
링크 복사링크가 클립보드에 복사되었습니다!
numad는 자동 NUMA 친화도 관리 데몬입니다. 이는 시스템의 NUMA 토폴로지 및 리소스 사용량을 모니터링하여 동적으로 NUMA 리소스 할당 및 관리 (즉 시스템 성능)를 향상시킵니다.
시스템 작업 부하에 따라 numad는 벤치 마크 성능을 최대 50% 까지 개선할 수 있습니다. 이러한 성능을 개선하기 위해 numad는 정기적으로
/proc 파일 시스템에서 정보에 액세스하여 노드 당 사용 가능한 시스템 리소스를 모니터링합니다. 그 후 데몬은 충분히 정렬된 메모리와 최적의 NUMA 성능을 위한 CPU 리소스를 갖는 NUMA 노드에 중요한 프로세스를 배치합니다. 프로세스 관리의 최신 임계값은 하나의 CPU의 최소 50%와 300 MB 메모리입니다. numad는 리소스 사용량 수준을 유지하고 필요시 NUMA 노드 간 프로세스를 이동하여 할당 균형을 다시 조정합니다.
numad는 다양한 작업 관리 시스템을 쿼리할 수 있는 사전 배포 컨설팅 서비스도 제공하고 있으며 프로세스의 CPU 및 메모리 리소스의 초기 바인딩으로 도움을 제공합니다. 이러한 사전 배포 컨설팅 서비스는 시스템에서 numad가 데몬으로 실행되고 있는지에 대한 여부와 상관 없이 사용 가능합니다. 사전 배포 컨설팅 서비스의
-w 옵션을 사용하는 방법에 대한 보다 자세한 내용은 man numad man 페이지에서 참조하십시오.
4.1.4.1. numad의 장점
링크 복사링크가 클립보드에 복사되었습니다!
numad는 주로 상당한 리소스 양을 소비하는 장기 실행 프로세스를 갖는 시스템에 이점을 제공합니다. 이러한 프로세스가 전체 시스템 리소스의 하위 집합에 포함되는 경우 특히 그러합니다.
numad는 여러 NUMA 노드의 리소스를 사용하는 애플리케이션에 유용합니다. 하지만 시스템에서 사용되는 리소스의 비율이 증가함에 따라 numad가 제공하는 혜택은 감소합니다.
프로세스의 실행 시간이 몇 분이거나 많은 리소스를 소비하지 않는 경우 numad는 성능을 개선하지 않을 가능성이 높습니다. 대형 메모리 데이터베이스와 같은 지속적으로 예상치 못한 메모리 액세스 패턴을 갖는 시스템도 numad의 사용으로 혜택을 얻을 가능성이 낮습니다.
4.1.4.2. 운영 모드
링크 복사링크가 클립보드에 복사되었습니다!
참고
커널 메모리 계산 통계는 대량의 병합 후 서로 상충하는 경우가 있습니다. 따라서 KSM 데몬이 대량의 메모리를 병합하면 numad에 혼란을 일으킬 수 있습니다. 차후 릴리즈에서 KSM 데몬은 보다 더 NUMA를 인식하게 됩니다. 하지만 현재는 시스템의 사용하지 않는 메모리의 양이 많은 경우 KSM 데몬을 튜닝 해제 및 비활성화하여 성능을 향상시킬 수 있습니다.
numad는 두 가지 방법으로 사용할 수 있습니다:
- 서비스로 사용
- 실행 파일로 사용
4.1.4.2.1. numad를 서비스로 사용
링크 복사링크가 클립보드에 복사되었습니다!
numad 서비스를 실행하는 동안 작업 부하에 따라 시스템을 동적으로 튜닝하려 합니다.
서비스를 시작하려면 다음 명령을 실행합니다:
# service numad start
재부팅 후에도 서비스를 유지하려면 다음 명령을 실행합니다:
# chkconfig numad on4.1.4.2.2. numad를 실행 파일로 사용
링크 복사링크가 클립보드에 복사되었습니다!
numad를 실행 파일로 사용하려면 다음 명령을 실행합니다:
# numad
numad가 중지될 때 까지 계속 실행됩니다. 실행되는 동안 실행 동작은
/var/log/numad.log에 기록됩니다.
numad 관리를 특정 프로세스로 제한하려면 다음과 같은 옵션을 사용하여 시작합니다.
# numad -S 0 -p pid-p pid- 지정된 pid를 명시적 대상 목록에 추가합니다. 지정된 프로세스는 numad 프로세스 중요도 임계값에 도달할 때 까지 관리되지 않습니다.
-S mode-S매개 변수는 프로세스 스캔 유형을 지정합니다. 다음에서 볼 수 있듯이 이를0으로 설정하면 numad 관리를 명시적으로 추가 프로세스에 한정합니다.
numad를 중지하려면 다음 명령을 실행합니다:
# numad -i 0
numad를 중지해도 NUMA 친화도를 개선하기 위해 변경한 내용이 삭제되지 않습니다. 시스템 사용이 크게 변경되는 경우 numad를 다시 실행하여 친화도를 조정하고 새로운 조건 하에서 성능이 향상됩니다.
사용 가능한 numad 옵션에 대한 보다 자세한 내용은 numad man 페이지
man numad에서 참조하십시오.