31.4.2. 2 단계: I/O 요청 크기의 효과
이 테스트의 목표는 이전 단계에서 결정된 최적의 I/O 깊이에서 테스트 중인 시스템의 최상의 성능을 생성하는 블록 크기를 이해하는 것입니다.
- 범위 8KB에서 1MB까지 다양한 블록 크기( 2)를 사용하여 고정 I/O 깊이에서 4파티너 테스트를 수행합니다. 모든 영역을 미리 입력하고 테스트 간에 볼륨을 다시 생성합니다.
- I/O Depth를 31.4.1절. “1 단계 : I/O Depth의 효과, 수정된 4 KB 블록” 에 정의된 값으로 설정합니다.테스트 입력 stimulus(쓰기)의 예:
# z=[see previous step] # for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write --bs=$iosize\k --name=vdo --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300 --direct=1 --iodepth=$z --scramble_buffers=1 --offset=0 --size=100g done - 각 데이터 지점에서 처리량 및 대기 시간을 기록한 다음 그래프를 표시합니다.
- 테스트를 반복하여 4개의업체 테스트(
--rw=randwrite,--rw=read,--rw=randread)를 완료합니다.
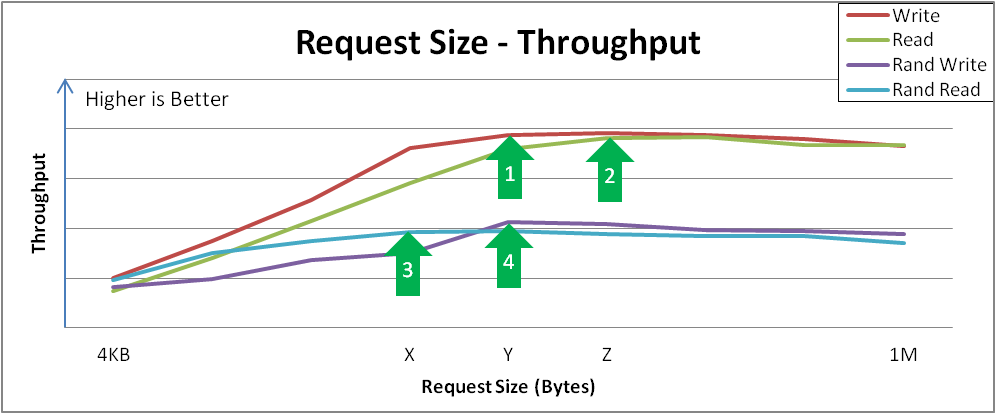
결과에서 찾을 수있는 몇 가지 관심 지점이 있습니다. 이 예제에서는 다음을 수행합니다.
- 순차적 쓰기는 요청 크기 Y의 최대 처리량에 도달합니다. 이 곡선은 특정 요청 크기에 의해 구성 가능하거나 자연적으로 관리하는 애플리케이션이 성능을 인식할 수 있는 방법을 보여줍니다. 4KB I/O는 병합할 수 있으므로 요청 크기가 더 많은 처리량을 제공하는 경우가 많습니다.
- 순차적 읽기는 Z 포인트에서 유사한 최대 처리량에 도달합니다. I/O가 완료되기 전에 전체 대기 시간은 추가 처리량 없이 증가합니다. 이 크기보다 큰 I/O를 허용하지 않도록 장치를 조정하는 것이 좋습니다.
- 랜덤 읽기는 점 X에서 최대 처리량을 달성합니다. 일부 장치는 대규모 요청 크기 임의 액세스에서 가까운 처리량 속도를 달성하는 반면, 다른 장치는 순차 액세스가 다양할 때 더 많은 페널티를 겪게 됩니다.
- 임의 쓰기는 Y 지점에서 최대 처리량을 달성합니다. Random 쓰기에는 중복 제거 장치의 가장 많은 상호 작용이 포함되며 VDO는 요청 크기 및/또는 I/O 깊이가 큰 경우 고성능을 수행합니다.
이 테스트 그림 31.3. “요청 크기와 크기 비교. throughput Analysis and Key Inflection Points” 의 결과는 스토리지 장치의 특성과 특정 애플리케이션에 대한 사용자 환경을 이해하는 데 도움이 됩니다. Red Hat 영업 엔지니어에게 문의하여 요청 규모의 성능 향상을 위해 추가 튜닝이 필요한지 확인하십시오.
그림 31.3. 요청 크기와 크기 비교. throughput Analysis and Key Inflection Points