8.5. 수집기
8.5.1. 개요
그림 8.5. “수집기 패턴” 에 표시된 수집기 패턴을 사용하면 관련 메시지 배치를 단일 메시지에 결합할 수 있습니다.
그림 8.5. 수집기 패턴
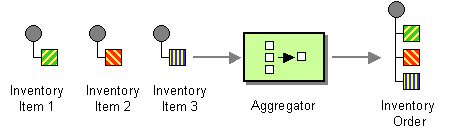
수집기 동작을 제어하기 위해 Apache Camel을 사용하면 다음과 같이 엔터프라이즈 통합 패턴에 설명된 속성을 지정할 수 있습니다.
- 상관 관계 표현식 밀리초-단순으로 집계해야 하는 메시지를 결정합니다. 상관관계 표현식은 들어오는 각 메시지에 대해 평가되어 상관관계 키를 생성합니다. 그런 다음 동일한 상관 관계 키를 가진 들어오는 메시지는 동일한 일괄 처리로 그룹화됩니다. 예를 들어 들어오는 모든 메시지를 단일 메시지로 집계하려면 상수 표현식을 사용할 수 있습니다.
- completeness 조건 Cryo stat- Cryostat 메시지의 일괄 처리가 완료된 시기를 결정합니다. 이를 간단한 크기 제한으로 지정하거나 일반적으로 배치가 완료되면 플래그를 지정하는 서술자 조건을 지정할 수 있습니다.
- 집계 알고리즘은 단일 상관 키의 메시지 교환을 단일 메시지 교환으로 결합합니다.
예를 들어 초당 Cryostat 메시지를 수신하는 주식 시장 데이터 시스템을 고려해 보십시오. GUI 툴이 이러한 대규모 업데이트 속도로 대처할 수 없는 경우 메시지 흐름을 제한해야 할 수 있습니다. 들어오는 주식 견적은 최신 견적을 선택하고 이전 가격을 폐기하여 간단히 집계 할 수 있습니다. (히스토리 중 일부를 캡처하려는 경우 delta 처리 알고리즘을 적용할 수 있습니다.)
이제 Aggregator가 자세한 정보를 포함하는 ManagedAggregateProcessorMBean 을 사용하여 Cryostat에 등록되었습니다. 이를 통해 집계 컨트롤러를 사용하여 제어할 수 있습니다.
8.5.2. 수집기 작동 방식
그림 8.6. “수집기 구현” 집계기가 작동하는 방식에 대한 개요를 보여줍니다. A, B, C 또는 D와 같은 상관관계 키를 갖는 교환 스트림이 있다고 가정하면 됩니다.
그림 8.6. 수집기 구현
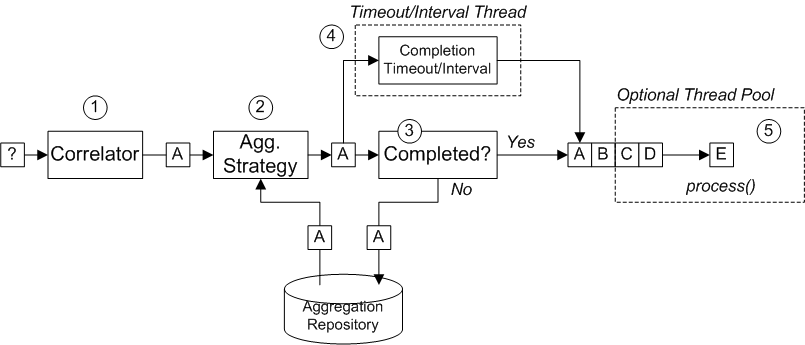
그림 8.6. “수집기 구현” 에 표시된 교환의 수신 스트림은 다음과 같이 처리됩니다.
- Corre lator 는 상관 관계 키를 기반으로 교환 정렬을 담당합니다. 들어오는 각 교환에 대해 상관관계 표현식이 평가되어 상관 관계 키를 생성합니다. 예를 들어 그림 8.6. “수집기 구현” 에 표시된 교환의 경우 상관 관계 키는 A로 평가됩니다.
집계 전략은 동일한 상관 관계 키를 사용하여 교환을 병합합니다. 새로운 교환인 A가 들어오면 집계 리포지토리에서 해당 집계 교환, A'를 조회하여 새 교환과 결합합니다.
특정 집계 사이클이 완료될 때까지 들어오는 교환은 해당 집계 교환과 지속적으로 집계됩니다. 집계 주기는 완료 메커니즘 중 하나에 의해 종료될 때까지 지속됩니다.
참고Camel 2.16에서 새로운 XSLT 집계 전략을 사용하면 두 개의 메시지를 XSLT 파일과 병합할 수 있습니다. toolbox에서
AggregationStrategies.xslt()파일에 액세스할 수 있습니다.완료 서술자가 집계기에 지정된 경우 집계 교환은 경로의 다음 프로세서로 전송할 준비가 되었는지 여부를 확인하기 위해 테스트됩니다. 처리는 다음과 같이 계속됩니다.
- 완료되면 집계 교환은 경로의 마지막 부분에 의해 처리됩니다. 이에 대한 두 가지 대체 모델이 있습니다. 동기 (기본값)는 호출 스레드를 차단하거나 비동기 ( 병렬 처리가 활성화된 경우)를 실행자 스레드 풀( 그림 8.6. “수집기 구현”에 표시)에 제출합니다.
- 완료되지 않으면 집계 교환이 다시 집계 리포지토리에 저장됩니다.
-
동기 완료 테스트와 동시에
completionTimeout옵션 또는completionInterval옵션을 활성화 하여 비동기 완료 테스트를 활성화할 수 있습니다. 이러한 완료 테스트는 별도의 스레드에서 실행되며 완료 테스트가 충족될 때마다 해당 교환은 완료로 표시되고 경로의 후자 부분에 의해 처리됩니다(행 처리 활성화 여부에 따라 동기적으로 또는 비동기적으로). - 병렬 처리가 활성화된 경우 스레드 풀은 경로의 후자 부분에서 교환 처리를 담당합니다. 기본적으로 이 스레드 풀에는 10개의 스레드가 포함되어 있지만 풀(“스레드 옵션”)을 사용자 정의할 수 있습니다.
8.5.3. Java DSL 예
다음 예제에서는 UseLatestAggregationStrategy 집계 전략을 사용하여 동일한 Cryostat Symbol 헤더 값으로 교환을 집계합니다. 지정된 symbol 값에 대해 해당 상관 관계 키와 마지막 교환이 수신된 이후 3초 이상 경과하면 집계된 교환은 완료된 것으로 간주되고 mock 엔드포인트로 전송됩니다.
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");8.5.4. XML DSL 예
다음 예제에서는 XML로 동일한 경로를 구성하는 방법을 보여줍니다.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>8.5.5. 상관 관계 표현식 지정
Java DSL에서 상관 관계 표현식은 항상 aggregate() DSL 명령에 첫 번째 인수로 전달됩니다. 여기에서 Simple Expression Language를 사용하는 것은 아닙니다. expressions 언어 또는 스크립팅 언어(예: Cryostat, XQuery, SQL 등)를 사용하여 상관 관계 표현식을 지정할 수 있습니다.
Exampe의 경우 Cryostat 표현식을 사용하여 서로 상호 작용하기 위해 다음 Java DSL 경로를 사용할 수 있습니다.
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
특정 들어오는 교환에서 상관 관계 표현식을 평가할 수 없는 경우 집계기가 기본적으로 CamelExchangeException 을 throw합니다. ignoreInvalidCorrelationKeys 옵션을 설정하여 이 예외를 비활성화할 수 있습니다. 예를 들어 Java DSL에서는 다음과 같습니다.
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
XML DSL에서 ignoreInvalidCorrelationKeys 옵션은 다음과 같이 속성으로 설정할 수 있습니다.
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>8.5.6. 집계 전략 지정
Java DSL에서는 집계 전략을 두 번째 인수로 aggregate() DSL 명령에 전달하거나 aggregationStrategy() 절을 사용하여 지정할 수 있습니다. 예를 들어 aggregationStrategy() 절을 다음과 같이 사용할 수 있습니다.
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel은 다음과 같은 기본 집계 전략을 제공합니다(클래스가 org.apache.camel.processor.aggregate Java 패키지에 속하는 경우).
UseLatestAggregationStrategy- 지정된 상관 관계 키에 대한 마지막 교환을 반환하여 이 키와 이전 교환을 모두 삭제합니다. 예를 들어, 이 전략은 특정 주식 기호의 최신 가격을 알고 싶은 주식 교환에서 피드를 제한하는 데 유용할 수 있습니다.
UseOriginalAggregationStrategy-
지정된 상관 관계 키에 대한 첫 번째 교환을 반환하여 이 키와 이후의 모든 교환을 삭제합니다. 이 전략을 사용하려면
UseOriginalAggregationStrategy.setOriginal()를 호출하여 첫 번째 교환을 설정해야 합니다. GroupedExchangeAggregationStrategy-
지정된 상관 관계 키에 대한 모든 교환을 목록에 연결합니다. 이는
Exchange.GROUPED_EXCHANGE교환 속성에 저장됩니다. “그룹화된 교환”을 참조하십시오.
8.5.7. 사용자 정의 집계 전략 구현
다른 집계 전략을 적용하려면 다음 집계 전략 기본 인터페이스 중 하나를 구현할 수 있습니다.
org.apache.camel.processor.aggregate.AggregationStrategy- 기본 집계 전략 인터페이스입니다.
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategy집계 주기 시간이 초과될 때 구현에서 알림을 수신하려면 이 인터페이스를 구현합니다.
시간 초과알림 방법에는 다음과 같은 서명이 있습니다.void timeout(Exchange oldExchange, int index, int total, long timeout)org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategy집계 주기가 정상적으로 완료되면 구현에서 알림을 수신하도록 하려면 이 인터페이스를 구현합니다. 알림 방법에는 다음과 같은 서명이 있습니다.
void onCompletion(Exchange exchange)
예를 들어 다음 코드는 StringAggregationStrategy 및 Cryostat AggregationStrategy: 두 가지 다른 사용자 정의 집계 전략입니다.
//simply combines Exchange String body values using '' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
}
Apache Camel 2.0부터 AggregationStrategy.aggregate() 콜백 방법도 첫 번째 교환에 대해 호출됩니다. 집계 메서드를 처음 호출하면 oldExchange 매개 변수는 null 이고 newExchange 매개 변수에는 처음 들어오는 교환이 포함되어 있습니다.
사용자 정의 전략 클래스를 사용하여 메시지를 집계하려면 Cryostat AggregationStrategy 에서는 다음과 같은 경로를 정의합니다.
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");다음과 같이 XML에서 사용자 정의 집계 전략을 사용하여 경로를 구성할 수도 있습니다.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>8.5.8. 사용자 정의 집계 전략의 라이프사이클 제어
라이프사이클이 이를 제어하는 엔터프라이즈 통합 패턴의 라이프사이클과 일치하도록 사용자 정의 집계 전략을 구현할 수 있습니다. 이는 집계 전략이 정상적으로 종료될 수 있는지 확인하는 데 유용할 수 있습니다.
라이프사이클 지원을 통해 집계 전략을 구현하려면 org.apache.camel.Service 인터페이스( AggregationStrategy 인터페이스 외에도)를 구현하고 start() 및 stop() 라이프사이클 메서드 구현을 제공해야 합니다. 예를 들어 다음 코드 예제에서는 라이프사이클 지원이 포함된 집계 전략에 대한 개요를 보여줍니다.
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}8.5.9. 속성 교환
다음 속성은 집계된 각 교환에 대해 설정됩니다.
| 헤더 | 유형 | 집계된 교환 속성 설명 |
|---|---|---|
|
|
| 이 교환에 포함된 총 거래 거래 수입니다. |
|
|
|
집계 교환을 완료하는 메커니즘을 나타냅니다. 가능한 값은 |
다음 속성은 SQL 구성 요소 집계 리포지터리에 의해 재전송되는 교환에 설정되어 있습니다( “영구 집계 리포지토리”참조).
| 헤더 | 유형 | Redelivered Exchange Properties 설명 |
|---|---|---|
|
|
|
현재 재전송 시도의 시퀀스 번호( |
8.5.10. 완료 조건 지정
집계 교환이 수집기를 떠나 경로의 다음 노드로 진행하는 시기를 결정하는 완료 조건을 하나 이상 지정해야 합니다. 다음 완료 조건을 지정할 수 있습니다.
completionPredicate-
각 교환이 집계된 후 서술자를 평가하여 완전성을 결정합니다.
true값은 집계 교환이 완료되었음을 나타냅니다. 또는 이 옵션을 설정하는 대신Predicate인터페이스를 구현하는 사용자 정의AggregationStrategy를 정의할 수 있습니다. 이 경우AggregationStrategy가 completion 서술자로 사용됩니다. completionSize- 지정된 수의 교환이 집계된 후 집계 교환을 완료합니다.
completionTimeout(
completionInterval과 호환되지 않음) 지정된 타임아웃 내에 들어오는 교환이 집계되지 않는 경우 집계 교환을 완료합니다.즉, 타임아웃 메커니즘은 각 상관 관계 키 값에 대한 타임아웃을 추적합니다. 클록은 특정 키 값을 사용한 최신 교환이 수신된 후 진드기가 시작됩니다. 동일한 키 값을 가진 다른 교환이 지정된 시간 내에 수신 되지 않으면 해당 집계 교환이 완료로 표시되고 경로의 다음 노드로 전송됩니다.
completionInterval(
completionTimeout과 호환되지 않음) 각 시간 간격 (특정 길이)이 경과한 후 모든 미결한 집계 교환을 완료합니다.시간 간격은 각 집계 교환에 맞게 조정 되지 않습니다. 이 메커니즘은 모든 미결 집계 교환을 동시에 완료하도록 합니다. 따라서 경우에 따라 이 메커니즘은 집계를 시작한 직후 집계 교환을 완료할 수 있습니다.
completionFromBatchConsumer- 배치 소비자 메커니즘을 지원하는 소비자 끝점과 함께 사용되는 경우, 이 완료 옵션은 소비자 끝점에서 수신하는 정보를 기반으로 현재 교환 처리가 완료된 시기를 자동으로 파악합니다. “배치 소비자”을 참조하십시오.
forceCompletionOnStop- 이 옵션을 사용하면 현재 경로 컨텍스트가 중지될 때 모든 미결 집계 교환이 강제 완료됩니다.
이전 완료 조건은 동시에 활성화할 수 없는 completionTimeout 및 completionInterval 조건을 제외하고 임의로 결합할 수 있습니다. 조건이 함께 사용되는 경우 일반적인 규칙은 트리거하는 첫 번째 완료 조건이 효과적인 완료 조건이라는 것입니다.
8.5.11. 완료 서술자 지정
집계된 교환이 완료된 시기를 결정하는 임의의 서술자 표현식을 지정할 수 있습니다. 서술자 표현식을 평가하는 방법은 다음 두 가지가 있습니다.
- 최신 집계 교환에서 기본 동작입니다.
-
가장 최근에 들어오는 교환 Cryostat-침반 동작에서는
eagerCheckCompletion옵션을 활성화할 때 이 동작이 선택됩니다.
예를 들어 ALERT 메시지를 받을 때마다 주식 따옴표의 스트림을 종료하려는 경우(최신 들어오는 교환에서 MsgType 헤더 값으로 표시됨) 다음과 같은 경로를 정의할 수 있습니다.
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");다음 예제에서는 XML을 사용하여 동일한 경로를 구성하는 방법을 보여줍니다.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>8.5.12. 동적 완료 시간 지정
들어오는 모든 교환에 대해 시간 초과 값이 다시 계산되는 동적 완료 시간 초과를 지정할 수 있습니다. 예를 들어 들어오는 각 교환에서 시간 초과 값을 설정하려면 다음과 같이 경로를 정의할 수 있습니다.
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");다음과 같이 XML DSL에서 동일한 경로를 구성할 수 있습니다.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
동적 값이 null 또는 0 인 경우 Apache Camel이 이 값을 사용하도록 고정 시간 초과 값을 추가할 수도 있습니다.
8.5.13. 동적 완료 크기 지정
들어오는 모든 교환에 대해 완료 크기가 다시 계산되는 동적 완료 크기를 지정할 수 있습니다. 예를 들어 들어오는 각 교환에서 mySize 헤더에서 완료 크기를 설정하려면 다음과 같이 경로를 정의할 수 있습니다.
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");Spring XML을 사용하는 것과 동일한 예:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
동적 값이 null 또는 0 인 경우 Apache Camel이 이 값을 사용하도록 고정 크기 값을 추가할 수도 있습니다.
8.5.14. AggregationStrategy 내에서 단일 그룹 강제 완료
사용자 정의 집계Strategy 클래스를 구현하는 경우 AggregationStrategy. aggregate() 메서드에서 반환된 교환 시 Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP 교환 속성을 true 로 설정하여 현재 메시지 그룹을 강제로 완료할 수 있는 메커니즘이 있습니다. 이 메커니즘은 현재 그룹에 만 영향을 미칩니다. 다른 메시지 그룹(다른 상관관계 ID 포함)은 완료 하지 않습니다. 이 메커니즘은 서술자, 크기, 시간 초과 등과 같은 기타 완료 메커니즘을 재정의합니다.
예를 들어 다음 샘플 AggregationStrategy 클래스는 메시지 본문 크기가 5보다 큰 경우 현재 그룹을 완료합니다.
// Java
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}8.5.15. 특수 메시지로 모든 그룹 강제 완료
특수 헤더가 있는 메시지를 경로로 전송하여 모든 미해결 집계 메시지를 강제로 완료할 수 있습니다. 강제 완료에 사용할 수 있는 두 가지 대체 헤더 설정이 있습니다.
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS-
현재 집계 주기를 강제 완료하려면
true로 설정합니다. 이 메시지는 순전히 신호 역할을 하며 집계 주기에 포함되지 않습니다. 이 신호 메시지를 처리하면 메시지의 콘텐츠가 삭제됩니다. Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE-
현재 집계 주기를 강제 완료하려면
true로 설정합니다. 이 메시지는 현재 집계 주기에 포함됩니다.
8.5.16. AggregateController 사용
org.apache.camel.processor.aggregate.AggregateController 를 사용하면 Java 또는 Cryostat API를 사용하여 런타임 시 집계를 제어할 수 있습니다. 이는 교환 그룹을 강제 수행하거나 현재 런타임 통계를 쿼리하는 데 사용할 수 있습니다.
사용자 지정이 구성되지 않은 경우 집계기는 getAggregateController() 메서드를 사용하여 액세스할 수 있는 기본 구현을 제공합니다. 그러나 aggregateController를 사용하여 경로에서 컨트롤러를 쉽게 구성할 수 있습니다.
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy()).completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");
또한 AggregateController에서 API를 사용하여 강제로 완료할 수 있습니다. 예를 들어, foo 키가 있는 그룹을 완료하려면 다음을 수행합니다.
int groups = controller.forceCompletionOfGroup("foo");반환되는 수는 완료된 그룹 수입니다. 다음은 모든 그룹을 완료하는 API입니다.
int groups = controller.forceCompletionOfAllGroups();8.5.17. 고유한 상관 관계 키 강제 적용
일부 집계 시나리오에서는 상관 관계 키가 교환 배치마다 고유한 조건을 적용해야 할 수 있습니다. 즉, 특정 상관 키의 집계 교환이 완료되면 해당 상관 키와의 집계 교환이 더 이상 진행되지 않도록 해야 합니다. 예를 들어 경로의 후자 부분이 고유한 상관관계 키 값으로 교환을 처리할 것으로 예상되는 경우 이 조건을 시행할 수 있습니다.
완료 조건을 구성하는 방법에 따라 특정 상관 관계를 사용하여 여러 집계 교환이 생성될 위험이 있을 수 있습니다. 예를 들어 특정 상관 키와의 모든 교환이 수신될 때까지 대기하도록 설계된 완료 서술자를 정의할 수 있지만 해당 키로의 모든 교환이 도달하기 전에 실행될 수 있는 완료 시간 초과를 정의할 수도 있습니다. 이 경우 늦은 교환으로 인해 동일한 상관 관계 키 값을 사용하여 두 번째 집계 교환이 발생할 수 있습니다.
이러한 시나리오의 경우 closeCorrelationKeyOnCompletion 옵션을 설정하여 이전 상관 키 값을 복제하는 집계 교환을 억제하도록 집계기를 구성할 수 있습니다. 중복된 상관관계 키 값을 억제하려면 집계자가 캐시에 이전 상관관계 키 값을 기록해야 합니다. 이 캐시의 크기(캐시된 상관 키 수)는 closeCorrelationKeyOnCompletion() DSL 명령에 대한 인수로 지정됩니다. 무제한 크기의 캐시를 지정하려면 0 또는 음수 정수 값을 전달할 수 있습니다. 예를 들어 캐시 크기를 10000 키 값으로 지정하려면 다음을 수행합니다.
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
집계 교환이 중복된 상관관계 키 값으로 완료되면 수집기에서 ClosedCorrelationKeyException 예외를 throw합니다.
8.5.18. 단순 표현식을 사용한 스트림 기반 처리
스트리밍 모드에서 tokenize XML 하위 명령을 사용하여 간단한 언어 표현식을 토큰으로 사용할 수 있습니다. 간단한 언어 표현식을 사용하면 동적 토큰을 지원할 수 있습니다.
예를 들어 Java를 사용하여 태그 사람이 구분하는 일련의 이름을 분할하기 위해 tokenize XML files 및 Simple 언어 토큰을 사용하여 파일을 name 요소로 분할할 수 있습니다.
public void testTokenizeXMLPairSimple() throws Exception {
Expression exp = TokenizeLanguage.tokenizeXML("${header.foo}", null);
< person>로 구분되는 이름의 입력 문자열을 가져오고 토큰으로 < person >를 설정합니다.
exchange.getIn().setHeader("foo", "<person>");
exchange.getIn().setBody("<persons><person>James</person><person>Claus</person><person>Jonathan</person><person>Hadrian</person></persons>");입력에서 분리된 이름을 나열합니다.
List<?> names = exp.evaluate(exchange, List.class);
assertEquals(4, names.size());
assertEquals("<person>James</person>", names.get(0));
assertEquals("<person>Claus</person>", names.get(1));
assertEquals("<person>Jonathan</person>", names.get(2));
assertEquals("<person>Hadrian</person>", names.get(3));
}8.5.19. 그룹화된 교환
발신 배치에서 집계된 모든 교환을 단일 org.apache.camel.impl.GroupedExchange 홀더 클래스로 결합할 수 있습니다. 그룹화된 교환을 활성화하려면 다음 Java DSL 경로에 표시된 것처럼 group exchanges() 옵션을 지정합니다.
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
mock:result 로 전송된 그룹화된 교환에는 메시지 본문에 집계된 교환 목록이 포함되어 있습니다. 다음 코드 줄은 후속 프로세서가 목록 형태로 그룹화된 교환의 콘텐츠에 액세스하는 방법을 보여줍니다.
// Java
List<Exchange> grouped = ex.getIn().getBody(List.class);그룹화된 교환 기능을 활성화하면 집계 전략을 구성 해서는 안 됩니다(그룹화된 교환 기능은 집계 전략 자체임).
발신 교환의 자산에서 그룹화된 교환에 액세스하는 오래된 접근 방식은 더 이상 사용되지 않으며 향후 릴리스에서 제거됩니다.
8.5.20. 배치 소비자
집계기를 배치 소비자 패턴과 함께 작동하여 배치 소비자가 보고한 총 메시지 수를 집계할 수 있습니다(배치 소비자 엔드포인트는 들어오는 교환에 CamelBatchSize,CamelBatchIndex , CamelBatchComplete 속성 설정). 예를 들어 File 소비자 엔드포인트에서 찾은 모든 파일을 집계하려면 다음과 같은 경로를 사용할 수 있습니다.
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");현재 다음 엔드포인트는 파일, FTP, 메일, iBatis 및 JPA와 같은 배치 소비자 메커니즘을 지원합니다.
8.5.21. 영구 집계 리포지토리
기본 집계자는 메모리 내 전용 AggregationRepository 를 사용합니다. 보류 중인 집계된 리테일링을 영구적으로 저장하려면 SQL 구성 요소를 영구 집계 리포지토리로 사용할 수 있습니다. SQL 구성 요소에는 집계된 메시지를 on-the-fly로 유지하고 메시지를 손실하지 않는 JdbcAggregationRepository 가 포함되어 있습니다.
교환이 성공적으로 처리되면 리포지토리에서 확인 메서드를 호출할 때 완료로 표시됩니다. 즉, 동일한 교환이 다시 실패하면 성공할 때까지 다시 시도됩니다.
camel-sql에 대한 종속성 추가
SQL 구성 요소를 사용하려면 프로젝트에 camel-sql 에 대한 종속성을 포함해야 합니다. 예를 들어 Maven pom.xml 파일을 사용하는 경우:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-sql</artifactId>
<version>x.x.x</version>
<!-- use the same version as your Camel core version -->
</dependency>집계 데이터베이스 테이블 생성
지속성을 위해 별도의 집계 및 완료된 데이터베이스 테이블을 생성해야 합니다. 예를 들어 다음 쿼리는 my_aggregation_repo 라는 데이터베이스에 대한 테이블을 생성합니다.
CREATE TABLE my_aggregation_repo (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_pk PRIMARY KEY (id)
);
CREATE TABLE my_aggregation_repo_completed (
id varchar(255) NOT NULL,
exchange blob NOT NULL,
constraint aggregation_completed_pk PRIMARY KEY (id)
);
}집계 리포지토리 구성
프레임워크 XML 파일에서 집계 리포지토리를 구성해야 합니다(예: Spring 또는 블루프린트).
<bean id="my_repo"
class="org.apache.camel.processor.aggregate.jdbc.JdbcAggregationRepository">
<property name="repositoryName" value="my_aggregation_repo"/>
<property name="transactionManager" ref="my_tx_manager"/>
<property name="dataSource" ref="my_data_source"/>
...
</bean>
repositoryName,transactionManager 및 dataSource 속성이 필요합니다. 영구 집계 리포지토리에 대한 자세한 내용은 Apache Camel 구성 요소 참조 가이드의 SQL 구성 요소를 참조하십시오.
8.5.22. 스레드 옵션
그림 8.6. “수집기 구현” 에 표시된 대로 집계기는 경로의 후자 부분과 분리되며, 경로의 후자 부분으로 전송된 교환은 전용 스레드 풀에 의해 처리됩니다. 기본적으로 이 풀에는 단일 스레드만 포함됩니다. 여러 스레드가 있는 풀을 지정하려면 다음과 같이 parallelProcessing 옵션을 활성화합니다.
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");기본적으로 10개의 작업자 스레드가 있는 풀이 생성됩니다.
생성된 스레드 풀을 더 많이 제어하려면 executorService 옵션을 사용하여 사용자 지정 java.util.concurrent.ExecutorService 인스턴스를 지정합니다(이 경우 병렬Processing 옵션을 활성화할 필요가 없음).
8.5.23. 목록에 집계
일반적인 집계 시나리오에서는 일련의 들어오는 메시지 본문을 List 오브젝트에 집계해야 합니다. 이 시나리오를 용이하게 하기 위해 Apache Camel은 AbstractListAggregationStrategy 추상 클래스를 제공합니다. 이 클래스를 빠르게 확장하여 이 사례에 대한 집계 전략을 생성할 수 있습니다. 유형 T 의 들어오는 메시지 본문은 List<T> 유형의 메시지 본문을 사용하여 완료된 교환으로 집계됩니다.
예를 들어 일련의 Integer 메시지 본문을 List <Integer> 오브젝트에 집계하려면 다음과 같이 정의된 집계 전략을 사용할 수 있습니다.
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}8.5.24. 수집기 옵션
수집기는 다음 옵션을 지원합니다.
| 옵션 | Default | 설명 |
|---|---|---|
|
|
집계에 사용할 상관관계 키를 평가하는 필수 표현식입니다. 동일한 상관관계 키가 있는 교환은 함께 집계됩니다. correlation 키를 평가할 수 없는 경우 예외가 발생합니다. | |
|
|
들어오는 교환을 이미 병합한 교환과 병합 하는 데 사용되는 필수 | |
|
|
레지스트리에서 | |
|
|
집계가 완료되기 전에 집계된 메시지 수입니다. 이 옵션은 고정 값으로 설정하거나 동적으로 크기를 평가할 수 있는 Expression을 사용하여 설정할 수 있으며 결과적으로 | |
|
|
집계된 교환이 완료되기 전에 비활성화되어야 하는 시간(밀리초)입니다. 이 옵션을 고정 값으로 설정하거나 시간 초과를 동적으로 평가할 수 있는 Expression을 사용하면 | |
|
| 집계자가 현재 집계된 모든 교환을 완료하는 밀리 초 단위의 반복 기간입니다. Camel에는 매번 트리거되는 백그라운드 작업이 있습니다. completionTimeout과 함께 이 옵션을 사용할 수 없으며 그 중 하나만 사용할 수 있습니다. | |
|
|
집계된 교환이 완료되면 신호인 | |
|
|
|
이 옵션은 교환이 배치 소비자에서 오는 경우입니다. 그런 다음 8.5절. “수집기” 는 메시지 헤더 |
|
|
|
새로 들어오는 교환이 수신될 때 완료를 신속하게 점검할지 여부입니다. 이 옵션은 그에 따라 변경 사항이 전달될 때 |
|
|
|
|
|
|
|
활성화된 경우 Camel은 집계된 모든 교환을 집계된 모든 교환을 하나의 결합된 |
|
|
| 값으로 평가할 수 없는 상관관계 키를 무시할지 여부입니다. 기본적으로 Camel은 예외를 발생하지만 이 옵션을 활성화하고 대신 이 상황을 무시할 수 있습니다. |
|
|
늦은 교환을 수락하거나 허용하지 않는지 여부입니다. 이를 통해 상관관계 키가 이미 완료된 경우 동일한 상관 관계 키를 가진 새로운 교환이 거부됨을 나타낼 수 있습니다. 그런 다음 Camel은 | |
|
|
| Camel 2.5: 시간 초과로 인해 완료되는 교환이 취소되어야 하는지의 여부입니다. 활성화하면 시간 초과가 발생하면 집계된 메시지가 전송 되지 않고 삭제되지 않습니다 (거부됨). |
|
|
| |
|
|
레지스트리에서 | |
|
|
| 집계가 완료되면 수집기에서 전송됩니다. 이 옵션은 Camel에서 동시성에 여러 스레드가 있는 스레드 풀을 사용해야 하는지 여부를 나타냅니다. 사용자 지정 스레드 풀이 지정되지 않은 경우 Camel은 10개의 동시 스레드가 있는 기본 풀을 생성합니다. |
|
|
| |
|
|
레지스트리에서 | |
|
|
completionTimeout , | |
|
|
레지스트리에서 | |
|
| Aggregator를 중지하면 이 옵션을 사용하면 집계 리포지토리에서 보류 중인 모든 리스터를 완료할 수 있습니다. | |
|
|
| 집계 리포지토리와 함께 사용할 수 있는 최적의 잠금을 설정합니다. |
|
| 최적화 잠금에 대한 재시도 정책을 구성합니다. |