이 콘텐츠는 선택한 언어로 제공되지 않습니다.
Chapter 10. Message Transformation
Abstract
The message transformation patterns describe how to modify the contents of messages for various purposes.
10.1. Content Enricher
Overview
The content enricher pattern describes a scenario where the message destination requires more data than is present in the original message. In this case, you would use a message translator, an arbitrary processor in the routing logic, or a content enricher method to pull in the extra data from an external resource.
Figure 10.1. Content Enricher Pattern
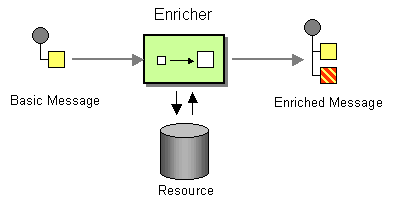
Alternatives for enriching content
Apache Camel supports several ways to enrich content:
- Message translator with arbitrary processor in the routing logic
-
The
enrich()method obtains additional data from the resource by sending a copy of the current exchange to a producer endpoint and then using the data in the resulting reply. The exchange created by the enricher is always an InOut exchange. -
The
pollEnrich()method obtains additional data by polling a consumer endpoint for data. Effectively, the consumer endpoint from the main route and the consumer endpoint inpollEnrich()operation are coupled. That is, an incoming message on the initial consumer in the route triggers thepollEnrich()method on the consumer to be polled.
The enrich() and pollEnrich() methods support dynamic endpoint URIs. You can compute URIs by specifying an expression that enables you to obtain values from the current exchange. For example, you can poll a file with a name that is computed from the data exchange. This behavior was introduced in Camel 2.16. This change breaks the XML DSL and enables you to migrate easily. The Java DSL stays backwards compatible.
Using message translators and processors to enrich content
Camel provides fluent builders for creating routing and mediation rules using a type-safe IDE-friendly way that provides smart completion and is refactoring safe. When you are testing distributed systems it is a very common requirement to have to stub out certain external systems so that you can test other parts of the system until a specific system is available or written. One way to do this is to use some kind of template system to generate responses to requests by generating a dynamic message that has a mostly-static body. Another way to use templates is to consume a message from one destination, transform it with something like Velocity or XQuery, and then send it to another destination. The following example shows this for an InOnly (one way) message:
from("activemq:My.Queue").
to("velocity:com/acme/MyResponse.vm").
to("activemq:Another.Queue");
Suppose you want to use InOut (request-reply) messaging to process requests on the My.Queue queue on ActiveMQ. You want a template-generated response that goes to a JMSReplyTo destination. The following example shows how to do this:
from("activemq:My.Queue").
to("velocity:com/acme/MyResponse.vm");The following simple example shows how to use DSL to transform the message body:
from("direct:start").setBody(body().append(" World!")).to("mock:result");The following example uses explicit Java code to add a processor:
from("direct:start").process(new Processor() {
public void process(Exchange exchange) {
Message in = exchange.getIn();
in.setBody(in.getBody(String.class) + " World!");
}
}).to("mock:result");The next example uses bean integration to enable the use of any bean to act as the transformer:
from("activemq:My.Queue").
beanRef("myBeanName", "myMethodName").
to("activemq:Another.Queue");The following example shows a Spring XML implementation:
<route>
<from uri="activemq:Input"/>
<bean ref="myBeanName" method="doTransform"/>
<to uri="activemq:Output"/>
</route>/>Using the enrich() method to enrich content
AggregationStrategy aggregationStrategy = ...
from("direct:start")
.enrich("direct:resource", aggregationStrategy)
.to("direct:result");
from("direct:resource")
...
The content enricher (enrich) retrieves additional data from a resource endpoint in order to enrich an incoming message (contained in the orginal exchange). An aggregation strategy combines the original exchange and the resource exchange. The first parameter of the AggregationStrategy.aggregate(Exchange, Exchange) method corresponds to the the original exchange, and the second parameter corresponds to the resource exchange. The results from the resource endpoint are stored in the resource exchange’s Out message. Here is a sample template for implementing your own aggregation strategy class:
public class ExampleAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange original, Exchange resource) {
Object originalBody = original.getIn().getBody();
Object resourceResponse = resource.getOut().getBody();
Object mergeResult = ... // combine original body and resource response
if (original.getPattern().isOutCapable()) {
original.getOut().setBody(mergeResult);
} else {
original.getIn().setBody(mergeResult);
}
return original;
}
}Using this template, the original exchange can have any exchange pattern. The resource exchange created by the enricher is always an InOut exchange.
Spring XML enrich example
The preceding example can also be implemented in Spring XML:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<enrich strategyRef="aggregationStrategy">
<constant>direct:resource</constant>
<to uri="direct:result"/>
</route>
<route>
<from uri="direct:resource"/>
...
</route>
</camelContext>
<bean id="aggregationStrategy" class="..." />Default aggregation strategy when enriching content
The aggregation strategy is optional. If you do not provide it, Apache Camel will use the body obtained from the resource by default. For example:
from("direct:start")
.enrich("direct:resource")
.to("direct:result");
In the preceding route, the message sent to the direct:result endpoint contains the output from the direct:resource, because this example does not use any custom aggregation.
In XML DSL, just omit the strategyRef attribute, as follows:
<route>
<from uri="direct:start"/>
<enrich uri="direct:resource"/>
<to uri="direct:result"/>
</route>Options supported by the enrich() method
The enrich DSL command supports the following options:
| Name | Default Value | Description |
|
| None | Starting with Camel 2.16, this option is required. Specify an expression for configuring the URI of the external service to enrich from. You can use the Simple expression language, the Constant expression language, or any other language that can dynamically compute the URI from values in the current exchange. |
|
|
These options have been removed. Specify the | |
|
|
Refers to the endpoint for the external service to enrich from. You must use either | |
|
|
Refers to an AggregationStrategy to be used to merge the reply from the external service into a single outgoing message. By default, Camel uses the reply from the external service as the outgoing message. You can use a POJO as the | |
|
|
When using POJOs as the | |
|
| false |
The default behavior is that the aggregate method is not used if there is no data to enrich. If this option is true then null values are used as the |
|
| false |
The default behavior is that the aggregate method is not used if there was an exception thrown while trying to retrieve the data to enrich from the resource. Setting this option to |
|
| false | Starting with Camel 2.16, the default behavior is that the enrich operation does not share the unit of work between the parent exchange and the resource exchange. This means that the resource exchange has its own individual unit of work. For more information, see the documentation for the Splitter pattern. |
|
|
|
Starting with Camel 2.16, specify this option to configure the cache size for the |
|
| false | Starting with Camel 2.16, this option indicates whether or not to ignore an endpoint URI that cannot be resolved. The default behavior is that Camel throws an exception that identifies the invalid endpoint URI. |
Specifying an aggregation strategy when using the enrich() method
The enrich() method retrieves additional data from a resource endpoint to enrich an incoming message, which is contained in the original exchange. You can use an aggregation strategy to combine the original exchange and the resource exchange. The first parameter of the AggregationStrategy.aggregate(Exchange, Exchange) method corresponds to the original exchange. The second parameter corresponds to the resource exchange. The results from the resource endpoint are stored in the resource exchange’s Out message. For example:
AggregationStrategy aggregationStrategy = ...
from("direct:start")
.enrich("direct:resource", aggregationStrategy)
.to("direct:result");
from("direct:resource")
...The following code is a template for implementing an aggregation strategy. In an implementation that uses this template, the original exchange can be any message exchange pattern. The resource exchange created by the enricher is always an InOut message exchange pattern.
public class ExampleAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange original, Exchange resource) {
Object originalBody = original.getIn().getBody();
Object resourceResponse = resource.getIn().getBody();
Object mergeResult = ... // combine original body and resource response
if (original.getPattern().isOutCapable()) {
original.getOut().setBody(mergeResult);
} else {
original.getIn().setBody(mergeResult);
}
return original;
}
}The following example shows the use of the Spring XML DSL to implement an aggregation strategy:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<enrich strategyRef="aggregationStrategy">
<constant>direct:resource</constant>
</enrich>
<to uri="direct:result"/>
</route>
<route>
<from uri="direct:resource"/>
...
</route>
</camelContext>
<bean id="aggregationStrategy" class="..." />Using dynamic URIs with enrich()
Starting with Camel 2.16, the enrich() and pollEnrich() methods support the use of dynamic URIs that are computed based on information from the current exchange. For example, to enrich from an HTTP endpoint where the header with the orderId key is used as part of the content path of the HTTP URL, you can do something like this:
from("direct:start")
.enrich().simple("http:myserver/${header.orderId}/order")
.to("direct:result");Following is the same example in XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<enrich>
<simple>http:myserver/${header.orderId}/order</simple>
</enrich>
<to uri="direct:result"/>
</route>Using the pollEnrich() method to enrich content
The pollEnrich command treats the resource endpoint as a consumer. Instead of sending an exchange to the resource endpoint, it polls the endpoint. By default, the poll returns immediately, if there is no exchange available from the resource endpoint. For example, the following route reads a file whose name is extracted from the header of an incoming JMS message:
from("activemq:queue:order")
.pollEnrich("file://order/data/additional?fileName=orderId")
.to("bean:processOrder");You can limit the time to wait for the file to be ready. The following example shows a maximum wait of 20 seconds:
from("activemq:queue:order")
.pollEnrich("file://order/data/additional?fileName=orderId", 20000) // timeout is in milliseconds
.to("bean:processOrder");
You can also specify an aggregation strategy for pollEnrich(), for example:
.pollEnrich("file://order/data/additional?fileName=orderId", 20000, aggregationStrategy)
The pollEnrich() method supports consumers that are configured with consumer.bridgeErrorHandler=true. This lets any exceptions from the poll propagate to the route error handler, which could, for example, retry the poll.
Support for consumer.bridgeErrorHandler=true is new in Camel 2.18. This behavior is not supported in Camel 2.17.
The resource exchange passed to the aggregation strategy’s aggregate() method might be null if the poll times out before an exchange is received.
Polling methods used by pollEnrich()
The pollEnrich() method polls the consumer endpoint by calling one of the following polling methods:
-
receiveNoWait()(This is the default.) -
receive() -
receive(long timeout)
The pollEnrich() command’s timeout argument (specified in milliseconds) determines which method to call, as follows:
-
When the timeout is
0or not specified,pollEnrich()callsreceiveNoWait. -
When the timeout is negative,
pollEnrich()callsreceive. -
Otherwise,
pollEnrich()callsreceive(timeout).
If there is no data then the newExchange in the aggregation strategy is null.
Examples of using the pollEnrich() method
The following example shows enrichment of the message by loading the content from the inbox/data.txt file:
from("direct:start")
.pollEnrich("file:inbox?fileName=data.txt")
.to("direct:result");Following is the same example in XML DSL:
<route>
<from uri="direct:start"/>
<pollEnrich>
<constant>file:inbox?fileName=data.txt"</constant>
</pollEnrich>
<to uri="direct:result"/>
</route>If the specified file does not exist then the message is empty. You can specify a timeout to wait (potentially forever) until a file exists or to wait up to a particular length of time. In the following example, the command waits no more than 5 seconds:
<route>
<from uri="direct:start"/>
<pollEnrich timeout="5000">
<constant>file:inbox?fileName=data.txt"</constant>
</pollEnrich>
<to uri="direct:result"/>
</route>Using dynamic URIs with pollEnrich()
Starting with Camel 2.16, the enrich() and pollEnrich() methods support the use of dynamic URIs that are computed based on information from the current exchange. For example, to poll enrich from an endpoint that uses a header to indicate a SEDA queue name, you can do something like this:
from("direct:start")
.pollEnrich().simple("seda:${header.name}")
.to("direct:result");Following is the same example in XML DSL:
<route>
<from uri="direct:start"/>
<pollEnrich>
<simple>seda${header.name}</simple>
</pollEnrich>
<to uri="direct:result"/>
</route>Options supported by the pollEnrich() method
The pollEnrich DSL command supports the following options:
| Name | Default Value | Description |
|
| None | Starting with Camel 2.16, this option is required. Specify an expression for configuring the URI of the external service to enrich from. You can use the Simple expression language, the Constant expression language, or any other language that can dynamically compute the URI from values in the current exchange. |
|
|
These options have been removed. Specify the | |
|
|
Refers to the endpoint for the external service to enrich from. You must use either | |
|
|
Refers to an AggregationStrategy to be used to merge the reply from the external service into a single outgoing message. By default, Camel uses the reply from the external service as the outgoing message. You can use a POJO as the | |
|
|
When using POJOs as the | |
|
| false |
The default behavior is that the aggregate method is not used if there is no data to enrich. If this option is true then null values are used as the |
|
|
|
The maximum length of time, in milliseconds, to wait for a response when polling from the external service. The default behavior is that the |
|
| false |
The default behavior is that the aggregate method is not used if there was an exception thrown while trying to retrieve the data to enrich from the resource. Setting this option to |
|
|
|
Specify this option to configure the cache size for the |
|
| false | Indicates whether or not to ignore an endpoint URI that cannot be resolved. The default behavior is that Camel throws an exception that identifies the invalid endpoint URI. |
10.2. Content Filter
Overview
The content filter pattern describes a scenario where you need to filter out extraneous content from a message before delivering it to its intended recipient. For example, you might employ a content filter to strip out confidential information from a message.
Figure 10.2. Content Filter Pattern
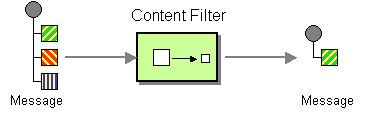
A common way to filter messages is to use an expression in the DSL, written in one of the supported scripting languages (for example, XSLT, XQuery or JoSQL).
Implementing a content filter
A content filter is essentially an application of a message processing technique for a particular purpose. To implement a content filter, you can employ any of the following message processing techniques:
- Message translator — see Section 5.6, “Message Translator”.
- Processors — see Chapter 35, Implementing a Processor.
- Bean integration.
XML configuration example
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="activemq:My.Queue"/>
<to uri="xslt:classpath:com/acme/content_filter.xsl"/>
<to uri="activemq:Another.Queue"/>
</route>
</camelContext>Using an XPath filter
You can also use XPath to filter out part of the message you are interested in:
<route>
<from uri="activemq:Input"/>
<setBody><xpath resultType="org.w3c.dom.Document">//foo:bar</xpath></setBody>
<to uri="activemq:Output"/>
</route>10.3. Normalizer
Overview
The normalizer pattern is used to process messages that are semantically equivalent, but arrive in different formats. The normalizer transforms the incoming messages into a common format.
In Apache Camel, you can implement the normalizer pattern by combining a Section 8.1, “Content-Based Router”, which detects the incoming message’s format, with a collection of different Section 5.6, “Message Translator”, which transform the different incoming formats into a common format.
Figure 10.3. Normalizer Pattern
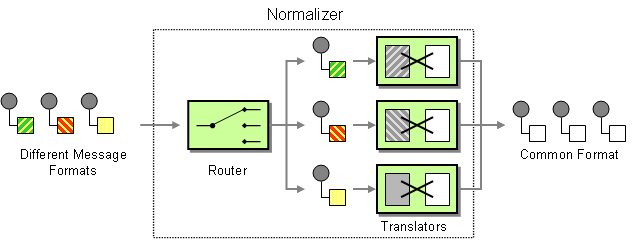
Java DSL example
This example shows a Message Normalizer that converts two types of XML messages into a common format. Messages in this common format are then filtered.
Using the Fluent Builders
// we need to normalize two types of incoming messages
from("direct:start")
.choice()
.when().xpath("/employee").to("bean:normalizer?method=employeeToPerson")
.when().xpath("/customer").to("bean:normalizer?method=customerToPerson")
.end()
.to("mock:result");In this case we’re using a Java bean as the normalizer. The class looks like this
// Java
public class MyNormalizer {
public void employeeToPerson(Exchange exchange, @XPath("/employee/name/text()") String name) {
exchange.getOut().setBody(createPerson(name));
}
public void customerToPerson(Exchange exchange, @XPath("/customer/@name") String name) {
exchange.getOut().setBody(createPerson(name));
}
private String createPerson(String name) {
return "<person name=\"" + name + "\"/>";
}
}XML configuration example
The same example in the XML DSL
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<choice>
<when>
<xpath>/employee</xpath>
<to uri="bean:normalizer?method=employeeToPerson"/>
</when>
<when>
<xpath>/customer</xpath>
<to uri="bean:normalizer?method=customerToPerson"/>
</when>
</choice>
<to uri="mock:result"/>
</route>
</camelContext>
<bean id="normalizer" class="org.apache.camel.processor.MyNormalizer"/>10.4. Claim Check EIP
Claim Check EIP
The claim check EIP pattern, shown in Figure 10.4, “Claim Check Pattern”, allows you to replace the message content with a claim check (a unique key). Use the claim check EIP pattern to retrieve the message content at a later time. You can store the message content temporarily in a persistent store like a database or file system. This pattern is useful when the message content is very large (and, expensive to send around) and not all components require all the information.
It can also be useful when you cannot trust the information with an outside party. In this case, use the Claim Check to hide the sensitive portions of data.
The Camel implementation of the EIP pattern stores the message content temporarily in an internal memory store.
Figure 10.4. Claim Check Pattern
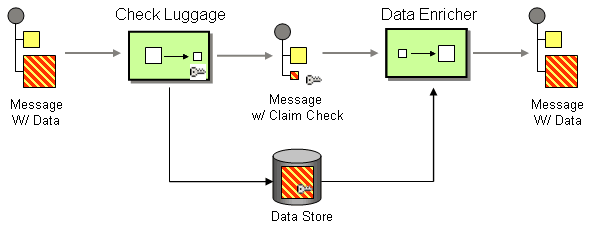
10.4.1. Claim Check EIP Options
The Claim Check EIP supports the options listed in the following table:
| Name | Description | Default | Type |
| operation | Need to use the claim check operation. It supports the following operations:
*
*
*
*
*
When using the | ClaimCheckOperation | |
| key | To use a specific key for claim check-id. | String | |
| filter | Specify a filter to control the data that you want to merge back from the claim check repository. | String | |
| strategyRef |
To use a custom | String |
Filter Option
Use the Filter option to define the data to merge back when using the Get or the Pop operations. Merge the data back by using an AggregationStrategy. The default strategy uses the filter option to easily specify the data to be merged back.
The filter option takes a String value with the following syntax:
-
body: To aggregate the message body -
attachments: To aggregate all the message attachments -
headers: To aggregate all the message headers -
header:pattern: To aggregate all the message headers that match the pattern
The pattern rule supports wildcard and regular expression.
-
Wildcard match (pattern ends with a
*and the name starts with the pattern) - Regular expression match
To specify multiple rules, separate them by commas (,).
Following are the basic filter examples to include the message body and all headers starting with foo:
body, header:foo*-
To merge the message body only:
body -
To merge the message attachments only:
attachments -
To merge headers only:
headers -
To merge a header name
fooonly:header:foo
If you specify the filter rule as empty or as wildcard, you can merge everything. For more information, see Filter what data to merge back.
When you merge the data back, the system overwrites any existing data. Also, it stores the existing data.
10.4.2. Filter Option with Include and Exclude Pattern
Following is the syntax that supports the prefixes that you can use to specify include,exclude, or remove options.
- + : to include (which is the default mode)
- - : to exclude (exclude takes precedence over include)
- -- : to remove (remove takes precedence)
For example:
-
To skip the message body and mergemeverything else, use-
-body -
To skip the message header
fooand merge everything else, use--header:foo
You can also instruct the system to remove headers when merging the data. For example, to remove all headers starting with bar, use- --headers:bar*.
Do not use both the include (+) and exclude (-) header:pattern at the same time.
10.4.3. Java Examples
The following example shows the Push and Pop operations in action:
from("direct:start")
.to("mock:a")
.claimCheck(ClaimCheckOperation.Push)
.transform().constant("Bye World")
.to("mock:b")
.claimCheck(ClaimCheckOperation.Pop)
.to("mock:c");
Following is an example of using the Get and Set operations. The example, uses the foo key.
from("direct:start")
.to("mock:a")
.claimCheck(ClaimCheckOperation.Set, "foo")
.transform().constant("Bye World")
.to("mock:b")
.claimCheck(ClaimCheckOperation.Get, "foo")
.to("mock:c")
.transform().constant("Hi World")
.to("mock:d")
.claimCheck(ClaimCheckOperation.Get, "foo")
.to("mock:e");
You can get the same data twice using the Get operation because it does not remove the data. However, if you want to get the data only once, use GetAndRemove operation.
The following example shows how to use the filter option where you only want to get back header as foo or bar.
from("direct:start")
.to("mock:a")
.claimCheck(ClaimCheckOperation.Push)
.transform().constant("Bye World")
.setHeader("foo", constant(456))
.removeHeader("bar")
.to("mock:b")
// only merge in the message headers foo or bar
.claimCheck(ClaimCheckOperation.Pop, null, "header:(foo|bar)")
.to("mock:c");10.4.4. XML Examples
The following example shows the Push and Pop operations in action.
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<claimCheck operation="Push"/>
<transform>
<constant>Bye World</constant>
</transform>
<to uri="mock:b"/>
<claimCheck operation="Pop"/>
<to uri="mock:c"/>
</route>
Following is an example of using the Get and Set operations. The example, uses the foo key.
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<claimCheck operation="Set" key="foo"/>
<transform>
<constant>Bye World</constant>
</transform>
<to uri="mock:b"/>
<claimCheck operation="Get" key="foo"/>
<to uri="mock:c"/>
<transform>
<constant>Hi World</constant>
</transform>
<to uri="mock:d"/>
<claimCheck operation="Get" key="foo"/>
<to uri="mock:e"/>
</route>
You can get the same data twice by using the Get operation because it does not remove the data. However, if you want to get the data once, you can use GetAndRemove operation.
The following example shows how to use the filter option to get back the header as foo or bar.
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<claimCheck operation="Push"/>
<transform>
<constant>Bye World</constant>
</transform>
<setHeader headerName="foo">
<constant>456</constant>
</setHeader>
<removeHeader headerName="bar"/>
<to uri="mock:b"/>
<!-- only merge in the message headers foo or bar -->
<claimCheck operation="Pop" filter="header:(foo|bar)"/>
<to uri="mock:c"/>
</route>10.5. Sort
Sort
The sort pattern is used to sort the contents of a message body, assuming that the message body contains a list of items that can be sorted.
By default, the contents of the message are sorted using a default comparator that handles numeric values or strings. You can provide your own comparator and you can specify an expression that returns the list to be sorted (the expression must be convertible to java.util.List).
Java DSL example
The following example generates the list of items to sort by tokenizing on the line break character:
from("file://inbox").sort(body().tokenize("\n")).to("bean:MyServiceBean.processLine");
You can pass in your own comparator as the second argument to sort():
from("file://inbox").sort(body().tokenize("\n"), new MyReverseComparator()).to("bean:MyServiceBean.processLine");XML configuration example
You can configure the same routes in Spring XML.
The following example generates the list of items to sort by tokenizing on the line break character:
<route>
<from uri="file://inbox"/>
<sort>
<simple>body</simple>
</sort>
<beanRef ref="myServiceBean" method="processLine"/>
</route>And to use a custom comparator, you can reference it as a Spring bean:
<route>
<from uri="file://inbox"/>
<sort comparatorRef="myReverseComparator">
<simple>body</simple>
</sort>
<beanRef ref="MyServiceBean" method="processLine"/>
</route>
<bean id="myReverseComparator" class="com.mycompany.MyReverseComparator"/>
Besides <simple>, you can supply an expression using any language you like, so long as it returns a list.
Options
The sort DSL command supports the following options:
| Name | Default Value | Description |
|
|
Refers to a custom |
10.6. Transformer
Transformer performs declarative transformation of the message according to the declared Input Type and/or Output Type on a route definition. The default camel message implements DataTypeAware, which holds the message type represented by DataType.
10.6.1. How the Transformer works?
The route definition declares the Input Type and/or Output Type. If the Input Type and/or Output Type are different from the message type at runtime, the camel internal processor looks for a Transformer. The Transformer transforms the current message type to the expected message type. Once the message is transformed successfully or if the message is already in expected type, then the message data type is updated.
10.6.1.1. Data type format
The format for the data type is scheme:name, where scheme is the type of data model such as java, xml or json and name is the data type name.
If you only specify scheme then it matches all the data types with that scheme.
10.6.1.2. Supported Transformers
| Transformer | Description |
|---|---|
| Data Format Transformer | Transforms by using Data Format |
| Endpoint Transformer | Transforms by using Endpoint |
| Custom Transformer | Transforms by using custom transformer class. |
10.6.1.3. Common Options
All transformers have the following common options to specify the supported data type by the transformer.
Either scheme or both fromType and toType must be specified.
10.6.1.4. DataFormat Transformer Options
| Name | Description |
|---|---|
| type | Data Format type |
| ref | Reference to the Data Format ID |
An example to specify bindy DataFormat type:
Java DSL:
BindyDataFormat bindy = new BindyDataFormat();
bindy.setType(BindyType.Csv);
bindy.setClassType(com.example.Order.class);
transformer()
.fromType(com.example.Order.class)
.toType("csv:CSVOrder")
.withDataFormat(bindy);XML DSL:
<dataFormatTransformer fromType="java:com.example.Order" toType="csv:CSVOrder">
<bindy id="csvdf" type="Csv" classType="com.example.Order"/>
</dataFormatTransformer>10.6.2. Endpoint Transformer Options
| Name | Description |
|---|---|
| ref | Reference to the Endpoint ID |
| uri | Endpoint URI |
An example to specify endpoint URI in Java DSL:
transformer()
.fromType("xml")
.toType("json")
.withUri("dozer:myDozer?mappingFile=myMapping.xml...");An example to specify endpoint ref in XML DSL:
<transformers>
<endpointTransformer ref="myDozerEndpoint" fromType="xml" toType="json"/>
</transformers>10.6.3. Custom Transformer Options
Transformer must be a subclass of org.apache.camel.spi.Transformer
| Name | Description |
|---|---|
| ref | Reference to the custom Transformer bean ID |
| className | Fully qualified class name of the custom Transformer class |
An example to specify custom Transformer class:
Java DSL:
transformer()
.fromType("xml")
.toType("json")
.withJava(com.example.MyCustomTransformer.class);XML DSL:
<transformers>
<customTransformer className="com.example.MyCustomTransformer" fromType="xml" toType="json"/>
</transformers>10.6.4. Transformer Example
This example is in two parts, the first part declares the Endpoint Transformer which transforms the message. The second part shows how the transformer is applied to a route.
10.6.4.1. Part I
Declares the Endpoint Transformer which uses xslt component to transform from xml:ABCOrder to xml:XYZOrder.
Java DSL:
transformer()
.fromType("xml:ABCOrder")
.toType("xml:XYZOrder")
.withUri("xslt:transform.xsl");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<transformers>
<endpointTransformer uri="xslt:transform.xsl" fromType="xml:ABCOrder" toType="xml:XYZOrder"/>
</transformers>
....
</camelContext>10.6.4.2. Part II
The above transformer is applied to the following route definition when direct:abc endpoint sends the message to direct:xyz:
Java DSL:
from("direct:abc")
.inputType("xml:ABCOrder")
.to("direct:xyz");
from("direct:xyz")
.inputType("xml:XYZOrder")
.to("somewhere:else");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:abc"/>
<inputType urn="xml:ABCOrder"/>
<to uri="direct:xyz"/>
</route>
<route>
<from uri="direct:xyz"/>
<inputType urn="xml:XYZOrder"/>
<to uri="somewhere:else"/>
</route>
</camelContext>10.7. Validator
Validator performs declarative validation of the message according to the declared Input Type and/or Output Type on a route definition which declares the expected message type.
The validation is performed only if the validate attribute on the type declaration is true.
If the validate attribute is true on an Input Type and/or Output Type declaration, camel internal processor looks for a corresponding Validator from the registry.
10.7.1. Data type format
The format for the data type is scheme:name, where scheme is the type of data model such as java, xml, or json and name is the data type name.
10.7.2. Supported Validators
| Validator | Description |
|---|---|
| Predicate Validator | Validate by using Expression or Predicate |
| Endpoint Validator | Validate by forwarding to the Endpoint to be used with the validation component such as Validation Component or Bean Validation Component. |
| Custom Validator |
Validate using custom validator class. Validator must be a subclass of |
10.7.3. Common Option
All validators must include the type option that specifies the Data type to validate.
10.7.4. Predicate Validator Option
| Name | Description |
|---|---|
| expression | Expression or Predicate to use for validation. |
An example that specifies a validation predicate:
Java DSL:
validator()
.type("csv:CSVOrder")
.withExpression(bodyAs(String.class).contains("{name:XOrder}"));XML DSL:
<predicateValidator Type="csv:CSVOrder">
<simple>${body} contains 'name:XOrder'</simple>
</predicateValidator>10.7.5. Endpoint Validator Options
| Name | Description |
|---|---|
| ref | Reference to the Endpoint ID. |
| uri | Endpoint URI. |
An example that specifies endpoint URI in Java DSL:
validator()
.type("xml")
.withUri("validator:xsd/schema.xsd");An example that specifies endpoint ref in XML DSL:
<validators>
<endpointValidator uri="validator:xsd/schema.xsd" type="xml"/>
</validators>
The Endpoint Validator forwards the message to the specified endpoint. In above example, camel forwards the message to the validator: endpoint, which is a Validation Component. You can also use a different validation component, such as Bean Validation Component.
10.7.6. Custom Validator Options
The Validator must be a subclass of org.apache.camel.spi.Validator
| Name | Description |
|---|---|
| ref | Reference to the custom Validator bean ID. |
| className | Fully qualified class name of the custom Validator class. |
An example that specifies custom Validator class:
Java DSL:
validator()
.type("json")
.withJava(com.example.MyCustomValidator.class);XML DSL:
<validators>
<customValidator className="com.example.MyCustomValidator" type="json"/>
</validators>10.7.7. Validator Examples
This example is in two parts, the first part declares the Endpoint Validator which validates the message. The second part shows how the validator is applied to a route.
10.7.7.1. Part I
Declares the Endpoint Validator which uses validator component to validate from xml:ABCOrder.
Java DSL:
validator()
.type("xml:ABCOrder")
.withUri("validator:xsd/schema.xsd");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<validators>
<endpointValidator uri="validator:xsd/schema.xsd" type="xml:ABCOrder"/>
</validators>
</camelContext>10.7.7.2. Part II
The above validator is applied to the following route definition when direct:abc endpoint receives the message.
The inputTypeWithValidate is used instead of inputType in Java DSL, and the validate attribute on the inputType declaration is set to true in XML DSL:
Java DSL:
from("direct:abc")
.inputTypeWithValidate("xml:ABCOrder")
.log("${body}");XML DSL:
<camelContext id="camel" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:abc"/>
<inputType urn="xml:ABCOrder" validate="true"/>
<log message="${body}"/>
</route>
</camelContext>10.8. Validate
Overview
The validate pattern provides a convenient syntax to check whether the content of a message is valid. The validate DSL command takes a predicate expression as its sole argument: if the predicate evaluates to true, the route continues processing normally; if the predicate evaluates to false, a PredicateValidationException is thrown.
Java DSL example
The following route validates the body of the current message using a regular expression:
from("jms:queue:incoming")
.validate(body(String.class).regex("^\\w{10}\\,\\d{2}\\,\\w{24}$"))
.to("bean:MyServiceBean.processLine");You can also validate a message header — for example:
from("jms:queue:incoming")
.validate(header("bar").isGreaterThan(100))
.to("bean:MyServiceBean.processLine");And you can use validate with the simple expression language:
from("jms:queue:incoming")
.validate(simple("${in.header.bar} == 100"))
.to("bean:MyServiceBean.processLine");XML DSL example
To use validate in the XML DSL, the recommended approach is to use the simple expression language:
<route>
<from uri="jms:queue:incoming"/>
<validate>
<simple>${body} regex ^\\w{10}\\,\\d{2}\\,\\w{24}$</simple>
</validate>
<beanRef ref="myServiceBean" method="processLine"/>
</route>
<bean id="myServiceBean" class="com.mycompany.MyServiceBean"/>You can also validate a message header — for example:
<route>
<from uri="jms:queue:incoming"/>
<validate>
<simple>${in.header.bar} == 100</simple>
</validate>
<beanRef ref="myServiceBean" method="processLine"/>
</route>
<bean id="myServiceBean" class="com.mycompany.MyServiceBean"/>