2장. Red Hat OpenShift Dev Spaces를 대규모로 실행
Kubernetes 는 대규모로 컨테이너화된 워크로드를 배포 및 관리하기 위한 강력한 기반이 되었습니다. 이를 통해 특히 수천 개의 동시 작업 영역에서 클라우드 개발 환경(CDE)을 통한 규모를 달성하면 큰 문제가 발생합니다.
이러한 규모는 높은 인프라 요구 사항을 적용하고 전체 시스템의 성능과 안정성에 영향을 미칠 수 있는 잠재적인 병목 현상을 초래합니다. 이러한 문제를 해결하려면 많은 사용자에게 원활하고 효율적인 개발 환경을 보장하기 위해 세심한 계획, 전략적 아키텍처 선택, 모니터링 및 지속적인 최적화가 필요합니다.
CDE 워크로드는 주로 Visual Studio Code - Open Source("Code - OSS") 와 같은 기본 IDE 솔루션이 다중 테넌트 서비스가 아닌 단일 사용자 애플리케이션으로 설계되었기 때문에 확장하기가 어렵습니다. https://www.jetbrains.com/remote-development/gateway/
리소스 수량 및 오브젝트 최대값
Kubernetes 클러스터의 리소스 수에 대한 엄격한 제한은 없지만 대규모 클러스터가 기억할 때 고려해야 할 몇 가지 고려 사항이 있습니다.
Kubernetes Podcast의 "Scalability, with Wojciech Tyczynski"에서 Kubernetes 확장성에 대해 자세히 알아보십시오.
Kubernetes의 인증된 배포인 OpenShift Container Platform 은 다양한 리소스에 대해 테스트된 최대값 세트도 제공합니다. 이 최대값은 환경 계획의 초기 지침으로 사용할 수 있습니다.
| 리소스 유형 | 테스트된 최대값 |
|---|---|
| 노드 수 | 2000 |
| Pod 수 | 150000 |
| 노드당 Pod 수 | 2500 |
| 네임스페이스 수 | 10000 |
| 서비스 수 | 10000 |
| 보안 수 | 80000 |
| 구성 맵 수 | 90000 |
표 1: OpenShift Container Platform 테스트된 클러스터 최대값은 다양한 리소스에 적용됩니다.
OpenShift Container Platform 테스트된 오브젝트 최대값에 대한 자세한 내용은 공식 문서에서 확인할 수 있습니다.
예를 들어 잠재적인 성능 및 관리 오버헤드로 인해 일반적으로 10,000개 이상의 네임스페이스를 사용하지 않는 것이 좋습니다. Red Hat OpenShift Dev Spaces에서 각 사용자에게 네임스페이스가 할당됩니다. 사용자 기반이 커질 것으로 예상되는 경우 여러 "지원용" 클러스터에 워크로드를 분배하고 멀티 클러스터 오케스트레이션에 대한 솔루션을 활용하는 것이 좋습니다.
리소스 요구 사항
Kubernetes에 Red Hat OpenShift Dev Spaces를 배포할 때 리소스 요구 사항을 정확하게 계산하고 각 CDE가 클러스터의 올바른 크기 조정에 필요한 메모리 및 CPU/ GPU를 결정하는 것이 중요합니다. 일반적으로 CDE 크기는 작업자 노드 크기보다 클 수 없습니다. CDE의 리소스 요구 사항은 특정 워크로드 및 구성에 따라 크게 다를 수 있습니다. 예를 들어 간단한 CDE에는 몇 백 메가바이트의 메모리만 필요할 수 있지만 더 복잡한 메모리에는 여러 기가바이트의 메모리와 여러 CPU 코어가 필요할 수 있습니다.
리소스 요구 사항을 계산하는 방법에 대한 자세한 내용은 공식 문서에서 확인할 수 있습니다.
etcd 사용
Kubernetes 클러스터 구성 및 상태의 기본 데이터 저장소는 etcd 입니다. 노드, Pod, 서비스 및 사용자 정의 리소스에 대한 정보를 포함하여 클러스터 상태 및 구성이 있습니다. 분산 키-값 저장소로서 etcd는 특정 임계값을 초과하지 않으며 etcd의 크기가 증가함에 따라 클러스터의 로드가 증가하여 안정성을 위협합니다.
기본 etcd 크기는 2GB이며 권장 최대값은 8GB입니다. 최대 제한을 초과하면 Kubernetes 클러스터가 불안정하고 응답하지 않을 수 있습니다.
개체 크기를 요인으로
전체 수뿐만 아니라 etcd에 저장된 오브젝트의 크기도 성능과 안정성에 크게 영향을 줄 수 있는 중요한 요소입니다. etcd에 저장된 각 오브젝트는 공간을 사용하며 오브젝트 수가 증가함에 따라 etcd의 전체 크기도 증가합니다. 오브젝트가 클수록 etcd에서 더 많은 공간을 차지할 수 있습니다. 예를 들어 비교적 큰 Kubernetes 오브젝트의 수천 개만으로 etcd를 오버로드할 수 있습니다.
ConfigMap 에 저장된 데이터는 설계상 1MiB를 초과할 수 없지만 비교적 큰 ConfigMap 오브젝트는 etcd 스토리지를 과부하시킬 수 있습니다.
Red Hat OpenShift Dev Spaces의 컨텍스트에서 기본적으로 Operator는 모든 사용자 네임스페이스에서 CA(인증 기관) 번들을 포함하는 'ca-certs-merged' ConfigMap을 생성하고 관리합니다. 클러스터에 많은 수의 TLS 인증서가 있으면 추가 etcd 사용이 발생합니다.
/etc/pki/ca-trust/extracted/pem 경로에서 ConfigMap 을 사용하여 CA 번들 마운트를 비활성화하려면 disableWorkspaceCaBundleMount 속성을 true 로 설정하여 CheCluster 사용자 정의 리소스를 구성합니다. 이 구성을 사용하면 사용자 정의 인증서만 경로 /public-certs 아래에 마운트됩니다.
spec:
devEnvironments:
trustedCerts:
disableWorkspaceCaBundleMount: truedev Workspace 오브젝트
대규모 Kubernetes 배포의 경우, 특히 CDE를 나타내는 DevWorkspace 오브젝트와 같은 많은 사용자 지정 리소스가 포함된 경우 etcd는 상당한 성능 장애가 될 수 있습니다.
6,000 DevWorkspace 개체의 로드 테스트를 기반으로 etcd의 스토리지 사용량은 약 2.5GB였습니다.
Dev Workspace Operator 버전 0.34.0부터 특정 기간 동안 사용되지 않은 DevWorkspace 오브젝트를 자동으로 정리하는 정리기를 구성할 수 있습니다. 정리기를 설정하려면 다음과 같이 DevWorkspaceOperatorConfig 오브젝트를 구성합니다.
apiVersion: controller.devfile.io/v1alpha1
kind: DevWorkspaceOperatorConfig
metadata:
name: devworkspace-operator-config
namespace: crw
config:
workspace:
cleanupCronJob:
enabled: true
dryRun: false
retainTime: 2592000
schedule: “0 0 1 * *” olmConfig
OLM(Operator Lifecycle Manager)에서 Operator 를 설치하면 Operator가 조사하도록 구성된 모든 네임스페이스에서 CSV의 제거가 생성됩니다. 이러한 제거 CSV는 "복사된 CSV"라고 하며 지정된 네임스페이스에서 리소스 이벤트를 적극적으로 조정하는 컨트롤러와 통신합니다. 특히 대규모 클러스터에서 수백 또는 수천 개의 경향이 있는 네임스페이스와 설치된 Operator가 있는 경우 Copied CSV는 지속할 수 없는 리소스(예: OLM 메모리 사용량, 클러스터 etcd 제한, 네트워킹 등)를 사용합니다. 모든 네임스페이스에 복사된 CSV를 제거하려면 그에 따라 OLMConfig 오브젝트를 구성합니다.
apiVersion: operators.coreos.com/v1
kind: OLMConfig
metadata:
name: cluster
spec:
features:
disableCopiedCSVs: true
disableCopiedCSVs 기능에 대한 추가 정보는 원래 개선 제안 에서 확인할 수 있습니다.
etcd에 disableCopiedCSVs 속성의 주요 영향은 리소스 사용과 관련이 있습니다. 다수의 네임스페이스와 클러스터 전체 Operator가 있는 클러스터에서는 여러 Copied CSV를 생성 및 유지 관리하면 etcd 스토리지 사용량 및 메모리 소비가 증가할 수 있습니다. 복사된 CSV를 비활성화하면 etcd에 저장된 데이터의 양이 크게 감소하여 전체 클러스터 성능과 안정성을 향상시킬 수 있습니다.
이는 네임스페이스와 Operator가 상당한 양의 데이터를 빠르게 추가할 수 있는 대규모 클러스터에서 특히 중요합니다. 복사된 CSV를 비활성화하면 etcd의 부하를 줄여 클러스터의 성능과 응답성을 향상시킬 수 있습니다. 또한 이러한 추가 리소스를 더 이상 유지 관리하고 관리할 필요가 없으므로 OLM의 메모리 공간을 줄일 수 있습니다.
"복사된 CSV 비활성화"에 대한 자세한 내용은 공식 문서에서 확인할 수 있습니다.
클러스터 자동 확장
클러스터 자동 스케일링은 강력한 Kubernetes 기능이지만 항상 대체할 수는 없습니다. 항상 환경의 로드 데이터를 분석하여 일일 또는 매주 사용 패턴을 감지하여 예측 스케일링을 고려해야 합니다. 워크로드가 패턴을 따르고 하루 동안 급증하는 경우 그에 따라 작업자 노드 프로비저닝을 고려해야 합니다. 예를 들어 업무 시간 동안 작업 공간 수가 증가하고 시간 초과로 감소하는 예측 가능한 로드 패턴이 있는 경우 예측 스케일링을 사용하여 예상되는 부하를 기반으로 작업자 노드 수를 조정할 수 있습니다. 이를 통해 사용량이 적은 시간에 비용을 최소화하면서 최대 부하를 처리할 수 있는 충분한 리소스를 확보할 수 있습니다.
작업자 노드의 구성 및 라이프사이클 관리를 위해 Karpenter 와 같은 오픈 소스 솔루션을 활용하는 것이 좋습니다. Karpenter는 워크로드의 특정 요구 사항에 따라 작업자 노드를 동적으로 프로비저닝 및 최적화하여 리소스 사용률을 개선하고 비용을 절감할 수 있습니다.
multi-cluster
Red Hat OpenShift Dev Spaces는 멀티 클러스터를 인식하지 못하며 클러스터당 인스턴스가 하나만 있을 수 있습니다. 그러나 각 다른 클러스터에 Red Hat OpenShift Dev Spaces를 배포하고 로드 밸런서 또는 DNS 기반 라우팅을 사용하여 사용자의 위치 또는 기타 기준에 따라 트래픽을 적절한 인스턴스로 보내어 멀티 클러스터 환경에서 Red Hat OpenShift Dev Spaces를 실행할 수 있습니다. 이 접근 방식은 여러 클러스터에 워크로드를 배포하고 클러스터 장애 발생 시 중복성을 제공하여 성능 및 안정성을 개선하는 데 도움이 될 수 있습니다.
그림 2.1. 다중 클러스터 환경 구성
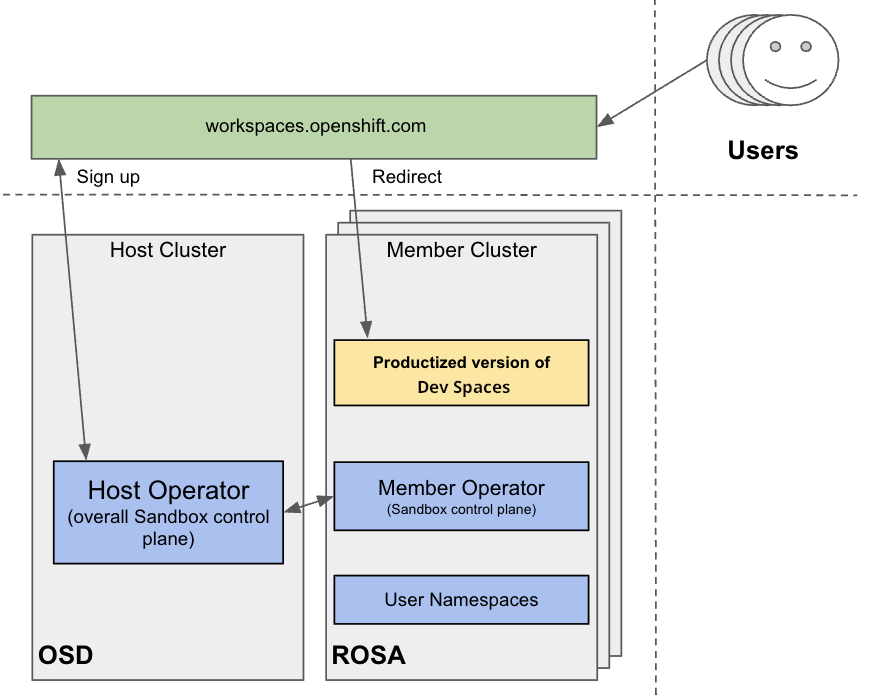
사전 구성된 툴 및 서비스가 있는 Red Hat의 무료 평가판 환경인 Developer Sandbox 를 사용하여 다중 클러스터에서 OpenShift Dev Spaces 실행을 테스트할 수 있습니다. 인프라 관점에서 Developer Sandbox는 여러 ROSA 클러스터로 구성됩니다. 각 클러스터에서 Argo CD 를 사용하여 Red Hat OpenShift Dev Spaces의 제품화된 버전이 설치 및 구성됩니다. 사용자 기반은 여러 클러스터에 분산되어 있으므로 workspaces.openshift.com 은 제품화된 Red Hat OpenShift Dev Spaces 인스턴스를 위한 단일 진입점으로 사용됩니다. 다음 GitHub 리포지토리에서 다중 클러스터 리디렉션에 대한 구현 세부 정보를 확인할 수 있습니다.
workspaces.openshift.com 의 다중 클러스터 아키텍처는 개발자 샌드박스 의 일부입니다. 다른 환경에서와 같이 재사용할 수 없는 Developer Sandbox 특정 솔루션입니다. 그러나 특정 다중 클러스터 요구 사항에 따라 유사한 솔루션을 구현하기 위한 참조로 사용할 수 있습니다.