6.3. Ferramentas
Existem diversas ferramentas disponíveis para ajduar nos problemas com o desempenho de diagnose no subsistema de E/S. O vmstat provê uma visão geral do desempenho do sistema. As colunas a seguir são as mais relevantes para a E/S:
si (swap in), so (swap out), bi (block in), bo (block out), e wa (E/S tempo de espera). si e so são úteis quando o espaço swap estiver no mesmo dispositivo que sua partição de dados, e como um indicador de pressão de memória generalizada. O si e bi são operações de leitura, enquanto o so e bo são operações de gravação. Cada uma destas categorias é reportada em kilobytes. O wa é o tempo ocioso, ele indica qual porção de fila de execução está bloqueada esperando pela E/S ser concluída.
Analisar seu sistema com o vmstatlhe dárá uma idéia de se o subsistema da E/S deve ser responsável ou não pelos problemas de desempenho. As colunas
free, buff, e cache também valem ser observadas. O valor cache crescendo junto do valor boseguido de uma caída de sistema cache e um aumento no free indica que o sistema está realizando um write-back e invalidação do cache da página.
Observe que os números de E/S reportados pelo vmstat são agregados de todos os E/S em todos os dispositivos. Depois que você determinou que pode existir o gap de desempenho no subsistema de E/S, você pode examinar o problema mais detalhadamente com o iostat, que dividirá a reportagem da E/S por dispositivo. Você também pode recuperar mais informações detalhadas, tal como a média do tamanho da requisição, o número e gravações por segundo e a quantia de mesclagem de E/S que está ocorrendo.
Utilizando a média de tamanho de requisição e a média de tamanho de fila
avgqu-sz), você poderá estimar sobre como o armazenamento deveria funcionar utilizando gráficos que você gerou ao caracterizar o desempenho de seu armazenamento. Algumas generalizações se aplicam: por exemplo, se a media de tamanho de requisição é de 4KB e a média de tamanho de fila é de 1, a produtividade pode não ser tão útil.
Se os números de desempenho não mapeiam o desempenho que você espera, você pode realizar uma análise mais refinada, com o blktrace. O suite de utilitários do blktrace fornece informações refinadas sobre quanto tempo se gasta no subsistema de E/S. O resultado do blktrace é um conjunto de arquivos de traço binários que podem ser processados posteriormente por outros utilitários tal como blkparce.
blkparse é o utilitário companheiro doblktrace. Ele lê resultados brutos do traço e produz uma versão textual resumida.
Este é um exemplo do resultado do blktrace :
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
Como você pode ver, o resultado é denso e difícil de se ler. Você pode dizer quais processos são responsável a fim de expressar E/S para seu dispositivo, o qual é utilizado mas o blkparse pode lhe fornecer informações adicionais de formato fácil em seu sumário. As informações do sumário do blkparse são impressas no final do resultado:
Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0
O resumo demonstra a média de taxas de E/S, mescla de atividades e compara a carga de trabalho de leitura com a carga de trabalho de gravação. Para a maior parte, no entanto, o resultado do blkparse é muito volumoso para ser útil sozinho. Felizmente, existem diversas ferramentas para assistir na visualização de dados.
btt fornece uma análise da quantia de tempo que a E/S gasta em diferentes áreas da pilha de E/S. São estas as áreas:
- Q — Uma E/S de bloco é Enfileirada
- G — Obtenha RequisiçãoUma E/S de bloco enfileirada recentemente, não foi um candidato para mesclar com qualquer requisição existente, portanto uma requisição de camada de bloco nova é alocada.
- M — Uma E/S de bloco é Mesclada com uma requisição existente.
- I — Uma requisição é inserida na fila dos dispositivos.
- D — Uma requisição é enviada ao Dipositivo
- C — Uma requisição é concluída pelo motorista
- P — A fila do dispositivo de bloco é Ligada, para permitir a agregação de requisições.
- U — A fila de dispositivo é Desligada, permitindo que as requisições agregadas sejam enviadas ao dispositivo.
btt divide em tempo gasto em cada uma destas áreas, assim como o tempo gasto transicionando entre eles, assim como:
- Q2Q — tempo entre requisições enviadas à camada de bloco.
- Q2G —quanto tempo leva do tempo que uma E/S de bloco é enfileirada até o tempo que ela obtém uma requisição alocada para isto.
- G2I — quanto tempo leva desde que um pedido é atribuído até o momento em que é inserido na fila do dispositivo
- Q2M — quanto tempo leva desde quando um bloco de E/S foi enfileiirado até que se mescle com um pedido existente
- I2D — quanto tempo demora a partir do momento que um pedido é inserido na fila do dispositivo até que seja realmente emitido para o dispositivo
- M2D — quanto tempo leva desde que um bloco E/S seja mesclado com um pedido de saída até que o pedido seja emitido para o dispositivo
- D2C —tempo de serviço da requisição por dispositivo
- Q2C — tempo total gasto em camada de bloco para uma requisição
Você pode deduzir muito de uma carga de trabalho a partir da tabela acima. Por exemplo, se Q2Q é muito maior do que Q2C, isso significa que o aplicativo não está emitindo E/S em sucessão rápida. Assim, todos os problemas de desempenho que você tem podem não estar relacionados ao subsistema de E/S. Se D2C é muito elevado, então o dispositivo está demorando muito para servir as requisições. Isto pode indicar que o dispositivo simplesmente está sobrecarregado (que pode ser devido ao fato de que é um recurso compartilhado), ou pode ser devido à carga de trabalho enviada para o dispositivo ser sub-óptima. Se Q2G é muito alto, isso significa que há um grande número de solicitações na fila ao mesmo tempo. Isso pode indicar que o armazenamento é incapaz de manter-se com a carga de E/S.
Finalmente, o seekwatcher consome dados de binários do blktracee gera conjuntos de plotagens, incluindo o Logical Block Address (LBA), rendimento, procuras por segundo, e I/Os Per Second (IOPS).
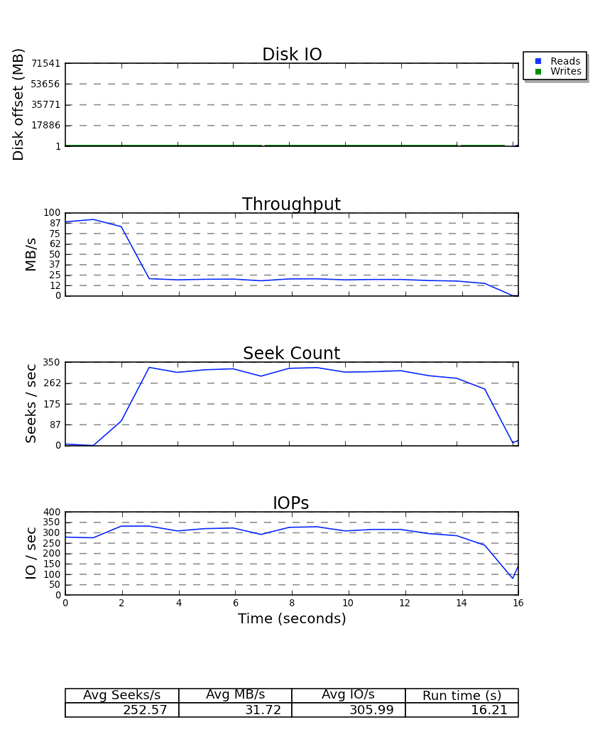
Figura 6.2. Exemplo de resultado do seekwatcher
Todos os lotes utilizam o tempo como o eixo X. A plotagem mostra as leituras e gravações em cores diferentes. É interessante observar a relação entre os gráficos de rendimento e procura/por seg. Para o armazenamento sensível à busca, existe uma relação inversa entre as duas plotagens. O gráfico IOPS é útil se, por exemplo, você não está recebendo o rendimento que se espera de um dispositivo, mas você está batendo suas limitações IOPS.