Capítulo 4. CPU
O termo CPU, o que significa unidade central de processamento , é um equívoco para a maioria dos sistemas, uma vez que centro implica único, enquanto que a maioria dos sistemas modernos têm mais de uma unidade de processamento, ou o núcleo. Fisicamente, as CPUs estão contidas num pacote ligado a uma placa-mãe em um soquete. Cada soquete na placa-mãe tem várias conexões:com outros soquetes da CPU, controladores de memória, controladores de interrupção e outros dispositivos periféricos. O soquete para o sistema operacional é um agrupamento lógico de recursos de CPUs e associados. Este conceito é central para a maioria das nossas discussões sobre o ajuste da CPU.
O Red Hat Enterprise Linux mantém uma riqueza de estatísticas sobre os eventos de CPU do sistema, estas estatísticas são úteis no planejamento de uma estratégia de ajuste para melhorar o desempenho da CPU. Seção 4.1.2, “Ajustando Desempenho de CPU” discute algumas das estatísticas mais úteis, onde encontrá-las, e como analisá-las para ajuste de desempenho.
Topologia
Computadores mais antigos tinham relativamente poucas CPUs por sistema, o que permitia uma arquitetura conhecida como Symmetric Multi-Processor (SMP). Isto significa que cada CPU no sistema semelhante (ou simétrico) tinha acesso à memória disponível. Nos últimos anos, a contagem de CPU por soquete cresceu até ao ponto que a tentativa de dar acesso a toda a memória RAM simétrica no sistema tornou-se muito dispendiosa. Mais elevados sistemas de contagem de CPU estes dias possuem uma arquitetura conhecida como Non-Uniform Memory Access (NUMA) ao invés de SMP.
Os processadores AMD tinham este tipo de arquitetura durante algum tempo com suas interconexões Hyper Transport (HT), enquanto a Intel começou a implementar NUMA em suas criações de Interconexão de Caminho Rápida (QPI). O NUMA e SMP são ajustados de forma diferente, pois você precisa levar em conta a topologia do sistema ao alocar recursos para um aplicativo.
Threads
Dentro do sistema operacional Linux, a unidade de execução é conhecida como um thread . Threads tem um contexto de registro, uma pilha e um segmento de código executável, o qual eles executam em uma CPU. É o trabalho do sistema operacional (OS) de agendar esses tópicos sobre as CPUs disponíveis.
O OS maximiza a utilização da CPU de balanceamento de carga dos threads por núcleos disponíveis. Uma vez que o sistema operacional é principalmente preocupado com a manutenção de CPUs ocupados, ele pode não tomar decisões adequadas com relação ao desempenho do aplicativo. Mover um segmento do aplicativo para a CPU em outro soquete pode piorar o desempenho mais do que simplesmente esperar a CPU atual se tornar disponível, uma vez que as operações de acesso à memória podem diminuir drasticamente através de sockets. Para aplicações de alto desempenho, geralmente é melhor o designer determinar onde os tópicos devem ser colocados. O Seção 4.2, “Agendamento da CPU” discute a melhor forma de alocar a CPU e memória para melhor executar threads da aplicação.
Interrupções
Um dos eventos de sistema menos óbvios (mas importante) que podem afetar o desempenho do aplicativo é a interrupção (também conhecida como IRQs em Linux). Estes eventos são tratados pelo sistema operacional, e são utilizados pelos periféricos para sinalizar a chegada de dados ou a conclusão de uma operação, como a gravação de rede ou um evento timer.
A maneira pela qual o sistema operacional ou processador que está executando o código do aplicativo lida com uma interrupção não afeta a funcionalidade do aplicativo. No entanto, pode afetar o desempenho da aplicação. Este capítulo também discute dicas sobre prevenção de interrupções que impactam negativamente o desempenho do aplicativo.
4.1. Topologia da CPU
Copiar o linkLink copiado para a área de transferência!
4.1.1. CPU e a Topologia NUMA
Copiar o linkLink copiado para a área de transferência!
Os primeiros processadores de computador foram uniprocessadores , o que significa que o sistema tinha uma única CPU. A ilusão de executar processos em paralelo foi feita pelo sistema operacional mudando rapidamente o único CPU de um thread de execução (processo) para outro. Na procura de aumentar o desempenho do sistema, os criadores notaram que o aumento da taxa de relógio para executar instruções mais rápido funcionava apenas até um ponto (geralmente as limitações ao criar uma forma de onda de relógio estável com a tecnologia actual). Em um esforço para obter um desempenho mais geral do sistema, os criadores acrescentaram outra CPU para o sistema, permitindo duas correntes paralelas de execução. Esta tendência de adicionar processadores tem continuado ao longo do tempo.
Sistemas multiprocessadores mais antigos foram projetados de modo que cada CPU tinha o mesmo caminho lógico para cada local de memória (geralmente um barramento paralelo). Isto deixa cada CPU acessar qualquer local de memória na mesma quantidade de tempo, como qualquer outra CPU no sistema. Esse tipo de arquitetura é conhecida como um sistema multi-processador (SMP) simétrico. SMP é bom para algumas CPUs, mas uma vez que a contagem de CPU fica acima de um certo ponto (8 ou 16), o número de rastreamentos paralelos necessários para permitir a igualdade de acesso à memória, usa muito do estado real da placa disponível, deixando menos espaço para periféricos.
Dois novos conceitos combinados para permitir um número maior de CPUs em um sistema:
- Barramentos em série
- Topologias NUMA
Um barramento de série é um caminho de comunicação de um único fio com uma taxa muito elevada de relógio, que transfere dados como intermitências em pacotes. Criadores de hardware começaram a usar barramentos seriais como interconexões de alta velocidade entre as CPUs, e entre os processadores e controladores de memória e outros periféricos. Isto significa que, em vez de exigir entre 32 e 64 rastreamentos na placa de cada CPU para o subsistema de memória, agora existe um rastreamento, reduzindo substancialmente a quantidade de espaço necessária na placa.
Ao mesmo tempo, os criadores de hardware empacotavam mais transistores no mesmo espaço reduzindo tamanhos de matrizes. Em vez de colocar CPUs individuais diretamente na placa principal, eles começaram a empacotá-las em um pacote de processador como processadores multi-core. Então, em vez de tentar proporcionar igualdade de acesso à memória de cada pacote do processador, os criadores recorreram a estratégia de acesso de memória não-uniforme (NUMA), onde cada combinação de pacote / socket possui um ou mais área de memória dedicada para acesso de alta velocidade. Cada socket também possui uma interconexão com outras bases de acesso mais lento à memória dos outros sockets.
Como um exemplo simples do NUMA, suponha que temos uma placa-mãe de dois soquetes, onde cada soquete foi preenchido com um pacote de quad-core. Isso significa que o número total de processadores no sistema é de oito; quatro em cada tomada. Cada tomada também tem um banco de memória anexado a quatro gigabytes de RAM, para uma memória total do sistema de oito gigabytes. Como propósito deste exemplo, processadores 0-3 estão em soquete 0, e as CPUs 4-7 estão no socket 1. Cada socket neste exemplo também corresponde a um nó NUMA.
Pode levar três ciclos de relógio para que a CPU 0 acesse a memória do banco 0: um ciclo para apresentar o endereço ao controlador de memória, um ciclo para configurar o acesso no local de memória, e um ciclo para ler ou gravar no local. No entanto, pode levar seis ciclos de relógio para a CPU 4 acessar a memória do mesmo local, pois como está em um soquete separado, ele deve passar por dois controladores de memória: o controlador de memória local no socket 1, e, em seguida, o controlador de memória remoto no soquete 0. Se a memória é contestada naquele local (ou seja, se mais de uma CPU estiver tentando acessar o mesmo lugar ao mesmo tempo), controladores de memória precisarão arbitrar e serializar o acesso à memória, por isso o acesso à memória demorará mais tempo. Adicionando consistência de cache (garantindo que caches da CPU locais contenham os mesmos dados para o mesmo local da memória) complica ainda mais o processo.
Os processadores de alta tecnologia mais recentes, tanto da Intel (Xeon) quanto da AMD (Opteron), possuiem topologias NUMA. Os processadores AMD utilizam uma interconexão conhecida como HyperTransport, ou HT, enquanto a Intel usa um chamado QuickPath Interconnect, ou QPI. As interconexões diferem na forma como se conectam fisicamente com outras interconexões, memória ou dispositivos periféricos, mas na verdade eles são a chave que permite o acesso transparente para um dispositivo conectado a partir de outro dispositivo conectado. Neste caso, o termo 'transparente' se refere ao facto de que não há nenhuma API de programação especial necessária para utilizar a interconexão, não a opção "sem custo".
Como as arquiteturas de sistema são tão diversas, é impraticável caracterizar especificamente a penalidade de desempenho imposto ao acessar a memória não-local. Podemos dizer que cada hop em uma interconexão impõe pelo menos alguma perda de desempenho relativamente constante por hop, assim referenciando uma posição de memória que seja duas interconexões a partir da CPU atual, impõe pelo menos 2N + tempo de ciclo de memória unidades para acessar tempo, onde N é a penalidade por hop.
Dada essa penalidade de desempenho, os aplicativos de desempenho sensíveis devem evitar acessar regularmente a memória remota em um sistema de topologia NUMA. O aplicativo deve ser configurado para que ele permaneça em um nó privado e que aloque memória daquele nó.
Para fazer isto, existem algumas coisas que este aplicativo precisará saber:
- Qual a topologia do sistema?
- Onde o aplicativo está executando atualmente?
- Onde está o banco de memória mais próximo?
4.1.2. Ajustando Desempenho de CPU
Copiar o linkLink copiado para a área de transferência!
Leia esta seção para entender como ajustar para obter melhor desempenho de CPU,
NUMA foi originalmente usado para conectar um único processador com vários bancos de memória. A medida que os fabricantes de CPU refinaram seus processos e os tamanhos de dados encolheram, múltiplos núcleos de CPU puderam ser incluídos em um pacote. Esses núcleos foram agrupados de modo que cada um deles tinha tempo de acesso igual a um banco de memória local, e o cache pôde ser compartilhado entre os núcleos, no entanto, cada 'hop' em uma interligação entre o núcleo, memória, e cache envolve uma pequena perda de desempenho.
O sistema de exemplo em Figura 4.1, “Acesso Remoto e Local de Memória em topologia NUMA” contém dois nós NUMA. Cada nó tem quatro processadores, um banco de memória, e um controlador de memória. Qualquer CPU em um nó tem acesso direto ao banco de memória nesse nó. Seguindo as setas no nó 1, os passos são como se segue:
- Uma CPU (qualquer um dos 0-3) apresenta o endereço de memória para o controlador da memória local.
- O controlador de memória define o acesso ao endereço de memória.
- A CPU executa a leitura ou gravação de operações naquele endereço de memória.
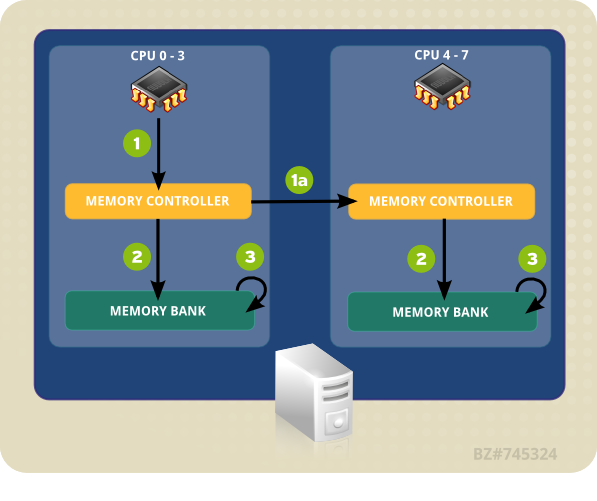
Figura 4.1. Acesso Remoto e Local de Memória em topologia NUMA
No entanto, se uma CPU em um nó precisa acessar o código que reside no banco de memória de um nó NUMA diferente, o caminho que deve tomar é menos direto:
- Uma CPU (qualquer um dos 0-3) apresenta o endereço de memória remota ao controlador da memória local.
- A requisição da CPU para o endereço de memória remota é passado para um controlador de memória remota, local para o nó que contém o endereço de memória.
- O controlador de memória remota define o acesso ao endereço de memória remota.
- A CPU executa a leitura ou gravação de operações naquele endereço de memória remota.
Toda ação precisa passar por vários controladores de memória, para que o acesso possa demorar mais do que o dobro do tempo ao tentar acessar endereços de memória remota. A principal preocupação com o desempenho em um sistema de vários núcleos é, portanto, garantir que a informação viaje tão eficientemente quanto possível, através do mais curto, ou mais rápido, caminho.
Para configurar um aplicativo para o melhor desempenho da CPU, você precisa saber:
- a topologia do sistema (como os seus componentes estão conectados),
- o núcleo no qual o aplicativo é executado, e
- a localização do banco de memória mais próximo.
O Red Hat Enterprise Linux 6 é apresentado com uma série de ferramentas para ajudá-lo a encontrar essas informações e ajustar o seu sistema de acordo com suas necessidades. As seções a seguir fornecem uma visão geral das ferramentas úteis para ajuste do desempenho da CPU.
4.1.2.1. Configuração, Afinidade da CPU com o taskset
Copiar o linkLink copiado para a área de transferência!
O taskset recupera e define a afinidade de CPU de um processo em execução (por processo de ID). Ele também pode ser usado para iniciar um processo com uma determinada afinidade da CPU, que vincula o processo especificado à uma CPU especificada ou conjunto de CPUs. No entanto, taskset não vai garantir a alocação de memória local. Se você precisar dos benefícios de desempenho adicionais de alocação de memória local, recomendamos numactl sobre taskset , veja Seção 4.1.2.2, “Controlling NUMA Policy with numactl” para mais detalhes.
A CPU afinidade é representado como um bitmask. O bit de ordem mais baixa corresponde à primeira CPU lógica, e o bit de ordem mais alta corresponde à última CPU lógica. Estas máscaras são normalmente fornecidas em hexadecimal, assim o
0x00000001 representa o processador 0, e o 0x00000003 representa processadores 0 e 1.
Para definir a afinidade da CPU de um processo em execução, execute o seguinte comando, substituindo mask pela máscara do processador ou processadores que você quer que o processo se vincule, e pid pelo ID do processo do processo cuja afinidade que você deseja alterar.
# taskset -p mask pid
Para iniciar um processo com uma determinada afinidade, execute o seguinte comando, substituindo mask pela máscara do processador ou processadores que você quer que o processo se vincule, e program pelo programa , opções e argumentos do programa que você deseja executar.
# taskset mask -- program
Em vez de especificar os processadores como uma máscara de bits, você também pode usar o
-c opção para fornecer uma lista delimitada por vírgulas de processadores separados, ou uma variedade de processadores, assim:
# taskset -c 0,5,7-9 -- myprogram
Mais informações sobre taskset estão disponíveis na página do manual:
taskset .
4.1.2.2. Controlling NUMA Policy with numactl
Copiar o linkLink copiado para a área de transferência!
numactl executa processos com um agendamento específico ou política de colocação de memória. A política selecionado está definido para o processo e todos os seus filhos. numactl pode também definir uma política persistente de segmentos de memória compartilhada ou arquivos e definir a afinidade da CPU e afinidade de memória de um processo. Ele usa o / sys sistema de arquivos para determinar a topologia do sistema.
O
/ sys sistema de arquivos contém informações sobre como CPUs, memória e dispositivos periféricos são conectados via NUMA interconexões. Especificamente, o / sys / devices /system/cpu contém informações sobre como CPUs de um sistema estão ligados um ao outro. O / sys / devices / system / node contém informações sobre os nós NUMA no sistema, e as distâncias relativas entre os nós.
Num sistema NUMA, quanto maior a distância entre um processador e um banco de memória, mais lento o acesso do processador para que banco de memória. Aplicações sensíveis ao desempenho deve ser configurado de forma que eles alocar memória o mais próximo possível do banco de memória.
Desempenho aplicações sensíveis devem também ser configurado para executar em um determinado número de núcleos, particularmente no caso de aplicações multi-threaded. Porque caches de primeiro nível são geralmente pequenas, se vários segmentos executar em um núcleo, cada segmento potencialmente expulsar os dados em cache acessados por um fio anterior. Quando o sistema operacional tenta multitarefa entre estes tópicos, e os fios continuam a despejar uns dos outros dados em cache, uma grande porcentagem de seu tempo de execução é gasto em substituição linha de cache. Este problema é conhecido como cache de goleada . Portanto, recomenda-se ligar uma aplicação multi-threaded para um nó ao invés de um único núcleo, uma vez que este permite que os fios para compartilhar linhas de cache em vários níveis (cache de primeira,, segunda e último nível) e minimiza a necessidade de armazenar em cache encher operações. No entanto, a ligação de um aplicativo para um único núcleo pode ser performance se os tópicos estão acessando os mesmos dados em cache.
numactl permite vincular um aplicativo para um núcleo específico ou nó NUMA, e alocar a memória associada a um núcleo ou conjunto de núcleos para esse aplicativo. Algumas opções úteis fornecidas pelos numactl são:
--show- Mostrar as definições de política NUMA do processo atual. Este parâmetro não necessita de outros parâmetros, e pode ser usado assim:
numactl - espetáculo. --hardware- Exibe um inventário de nós disponíveis no sistema
--membind- Alocar memória somente de nós específicos. Quando esta configuração estiver em uso, a alocação falhará se a memória nesses nós for insuficiente. A utilização para este parâmetro é
numactl - membind = nós programa, onde nós é a lista de nós que você deseja alocar a memória programa é o programa cujos requisitos de memória devem ser alocados a partir desse nó. Números de nó podem ser dados como uma lista delimitada por vírgulas, um intervalo, ou uma combinação dos dois. Mais detalhes estão disponíveis na página do manual numactl :man numactl. --cpunodebind- Só executar um comando (e seus processos filhos) em CPUs que pertencem ao nó especificado (s). Uso para este parâmetro é
numactl - cpunodebind = nós programa, onde nós é a lista de nós a cuja CPUs o programa especificado ( programa ) deve estar vinculado. Números nó pode ser dada como uma lista delimitado por vírgulas, um intervalo, ou uma combinação dos dois. Mais detalhes estão disponíveis no numactl página man:man numactl. --physcpubind- Somente execute um comando (e seus processos filho) em CPUs especificadas. O uso para este parâmetro é
numactl --physcpubind=cpu program, onde cpu é uma lista separada por vírgulas de números de CPU físicos como exibido nos campos do processador do/proc/cpuinfo, e program é o programaque deve executar somente naqueles CPUs. Os CPUs podem também ser especificados dependendo docpusetatual. Consulte a página man do numactl para obter mais informações:man numactl. --localalloc- Especifica se a memória deve sempre ser alocada no nó atual.
--preferred- Sempre que possível, a memória é alocada no nó especificado. Se a memória não pode ser alocada no nó especificado, recorrerá a outros nós. Esta opção aceita apenas um único número de nó, assim: nó
numactl - preferred =. Consulte a página do manual numactl para mais informações:man numactl.
A biblioteca libnuma incluída no pacote numactl oferece uma interface de programação simples para a política NUMA suportada pelo kernel. É mais útil para ajustes de alta-granularidade do que a utilidade numactl . Mais informações estão disponíveis na página do manual:
man numa (3) .
4.1.3. numastat
Copiar o linkLink copiado para a área de transferência!
Importante
Anteriormente, a ferramenta numastat era um script do Perl escrito por Andi Kleen. Ele foi reescrito de forma significante para o Red Hat Enterprise Linux 6.4.
Embora o comando padrão (
numastat, sem nenhuma opção ou parâmetro) mantém a compatibilidade severa com as versões anteriores da ferramenta, note que as opções ou parâmetros fornecidos à este comando, muda significantemente o conteúdo de resultado e seu formato.
O numastat exibe a estatística de memória (tal como as alocações de acertos e erros) para processos e o sistema operacional baseado em nó de NUMA. Por padrão, executar o
numastat exibe como muitas páginas de memória estão ocupadas pelas seguintes categorias de evento para cada nó.
O desempenho da CPU adequado é indicado por baixo
numa_miss e valores numa_foreign.
Esta versão atualizada do numastat também mostra se a memória do processo é distribuiída em um sistema ou centralizada em nós específicos utilizando o numactl.
O resultado de referência cruzada donumastat com o resultado top por CPU, para verificar se os threads do processo estão executando no mesmos nós para o qual a memória foi alocada.
Categorias de Rastreamento Padrão
- numa_hit
- O número de tentativas de alocações neste nós que foram bem sucedidas.
- numa_miss
- O número de tentativas de alocações em outro nó que foram alocadas neste nó porcausa da baixa memória no nó pretendido. Cada evento
numa_misspossui um eventonuma_foreigncorrespondente em outro nó. - numa_foreign
- O número de alocações pretendidas inicialmente para este nó que foram alocadas à outro nó. Cada evento
numa_foreignpossui um eventonuma_misscorrespondente em outro nó. - interleave_hit
- O número de tentativas de alocações de políticas de intercalação neste nó que foram bem sucedidas.
- local_node
- O número de vezes que um processo neste nó alocou memória com sucesso neste nó.
- other_node
- O número de vezes que um processo em outro nó alocou memória neste nó.
Fornecer qualquer outra mudança muda as unidades exibidas em megabytes de memória (arredondadas para dois decimais) e modifica outros comportamentos específicos do numastatcomo descrito abaixo.
-c- Horizontalmente condensa a tabela da informação exibida. Isso é útil em sistemas com um elevado número de nós NUMA, mas a largura da coluna e do espaçamento entre colunas são um tanto imprevisíveis. Quando esta opção é utilizada, a quantidade de memória é arredondado para o próximo megabyte.
-m- Exibe as informações de uso de memória em todo o sistema baseado por nó, semelhante à informação encontrada em
/proc/meminfo. -n- Exibe a mesma informação que o comando original
numastat(numa_hit, numa_miss, numa_foreign, interleave_hit, local_node, e other_node), com um formato atualizado, utilizando megabytes como unidade de medida. -p pattern- Exibe informações por nó para o modelo específico. Se o valor para o modelo é composto de dígitos, o numastat entende que seja um identificador de processo numérico. Caso contrário, o numastat procura por linhas de comando do processo para um modelo em específico.Os argumentos de linha de comando inseridos após o valor da opção
-pdevem ser modelos adicionais para o qual filtrar. Modelos adicionais expandem, ao em vez de estreitarem o filtro. -s- Filtra os dados exibidos em ordem descendente para que os maiores consumidores de memória (de acordo com a coluna
total) são listados primeiro.Opcionalmente, você pode especificar o node, e a tabela será filtrada de acordo com a coluna do node.Ao utilizar esta opção, o valor do nodedeve seguir a opção-simediatamente, como demonstrado aqui:numastat -s2Não inclui o espaço em branco entre a opção e seu valor. -v- Exibe mais informações de verbosidade. De modo que as informações do processo para processos múltiplos exibirão informações detalhadas para cada processo.
-V- Exibe as informações da versão numastat.
-z- Omite a faixa da tabela e colunas com valores zero de informações exibidas. Note que alguns valores quase zero que são arredondados para zero para exibir propósitos, não serão omitidos do resultado exibido.
4.1.4. NUMA Daemon de Gerenciamento de Afinidade (numad)
Copiar o linkLink copiado para a área de transferência!
numadé um daemon de gerenciamento de afinidade do NUMA automático. Ele monitora a topologia do e uso de recursos dentro de um sistema para aprimorar a alocação e gerenciamento de recurso do NUMA de forma dinâmica (e assim o desempenho do sistema).
Dependendo da carga de trabalho do sistema, numad pode fornecer as melhorias de desempenho do parâmetro de comparação do numad acessa informações periodicamente a partir do sistema de arquivo do
/proc para monitorar recursos de sistemas disponíveis por nó. O daemon então tenta colocar processos significativos em nós do NUMA que possuam memória alinhada suficientes e recursos de CPU para o desempenho adequado do NUMA. Limites atuais para o gerenciamento do processo são de ao menos 50% de uma CPU e de ao menos 300 MB de memória. O numad tenta manter um nível de uso de recurso e rebalancear alocações quando necessárias, movendo processos entre nós de NUMA.
O numad também fornece um serviço de conselho de pré-colocação que pode ser pesquisado por diversos sistemas de gerenciamento de empregos para fornecer assistência com a vinculação inicial de recursos da CPU e memória para seus processos. Este serviço de conselho de pré-colocação está disponível não importando se o numad está executando como um daemon em um sistema. Consulte as páginas man para detalhes futuros sobre a utilização da opção
-w para o aconselhamento de pré-colocação: man numad.
4.1.4.1. Benefícios do numad
Copiar o linkLink copiado para a área de transferência!
O numadbeneficia primeiramente os sistemas com processos de longa duração que consomem quantidades significativas de recursos, especialmente quando esses processos estão contidos em um subconjunto do total de recursos do sistema.
numad também pode beneficiar aplicativos que consomem nós NUMA que valem os recursos. No entanto, os benefícios que o numad fornece, diminui a medida que a porcentagem de recursos consumidos em um sistema aumenta.
É improvável que o numad melhore o desempenho quando os processos são executados por apenas alguns minutos, ou não consomem muitos recursos. Sistemas com padrões contínuos imprevisíveis memória de acesso, como grandes bancos de dados na memória, são também susceptíveis de beneficiar do uso do NUMAD .
4.1.4.2. Modos de operação
Copiar o linkLink copiado para a área de transferência!
Nota
Estatísticas de contabilidade de memória do kernel podem se contradizer depois de grandes quantidades de fusão. Como tal, o NUMAD pode ser confuso quando o daemon KSM mescla grandes quantidades de memória. O daemon KSM será mais focado em NUMA em versões futuras. No entanto, atualmente, se o seu sistema tem uma grande quantidade de memória livre, você pode atingir um melhor desempenho, desligando e desabilitando o daemon KSM.
numad pode ser utilizado de duas formas:
- como um serviço
- como um executável
4.1.4.2.1. Utilizando o numad como um serviço
Copiar o linkLink copiado para a área de transferência!
Enquanto o serviço numad é executado, ele tentará ajustar de forma dinâmica o sistema baseado em sua carga de trabalho.
Para iniciar um serviço, execute:
# service numad start
Para fazer com que o serviço persista em reinicializações, execute:
# chkconfig numad on4.1.4.2.2. Usando o numadcomo um executável
Copiar o linkLink copiado para a área de transferência!
Para usar o numad como um executável, execute somente o:
# numad
numad será executado até que seja interrompido. Enquanto estiver em execução, suas atividades serão autenticadas em
/var/log/numad.log.
Para restringir o gerenciamento do numad à um processo específico, inicie-o com as seguintes opções.
# numad -S 0 -p pid-p pid- Adiciona o pid especificado à uma lista de inclusão explícita. O processo especificado não será gerenciado até que ele atenda ao limite de significância do processo do numad.
-S mode- O parâmetro do
-Sespecifica o tipo de escaneamento do processo. Configurá-lo para0como demonstrado, limita o gerenciamento do numad para processos explicitamente incluídos.
Para interromper o numad, execute:
# numad -i 0
Interromper o numad não remove as mudanças que fez para aprimorar a afinidade do NUMA. Se o sistema utilizar mudanças de forma significativa, a execução do numad novamente irá ajustar a afinidade para aprimorar o desempenho sob as novas condições.
Para informações futuras sobre as opções do numad disponíveis, consulte a página man numad:
man numad.