1.2. 了解监控堆栈
OpenShift Dedicated 监控堆栈基于 Prometheus 开源项目及其更广泛的生态系统。监控堆栈包括以下组件:
默认平台监控组件。在 OpenShift Dedicated 安装过程中,默认会在
openshift-monitoring项目中安装一组平台监控组件。Red Hat Site Reliability Engineers (SRE) 使用这些组件来监控核心集群组件,包括 Kubernetes 服务。这包括关键指标,如 CPU 和内存,从每个命名空间中的所有工作负载收集。下图中的默认安装部分说明了这些组件。
-
用于监控用户定义项目的组件。在 OpenShift Dedicated 安装过程中,默认会在
openshift-user-workload-monitoring项目中安装一组用户定义的项目监控组件。您可以使用这些组件来监控用户定义的项目中的服务和 Pod。下图中的用户部分说明了这些组件。
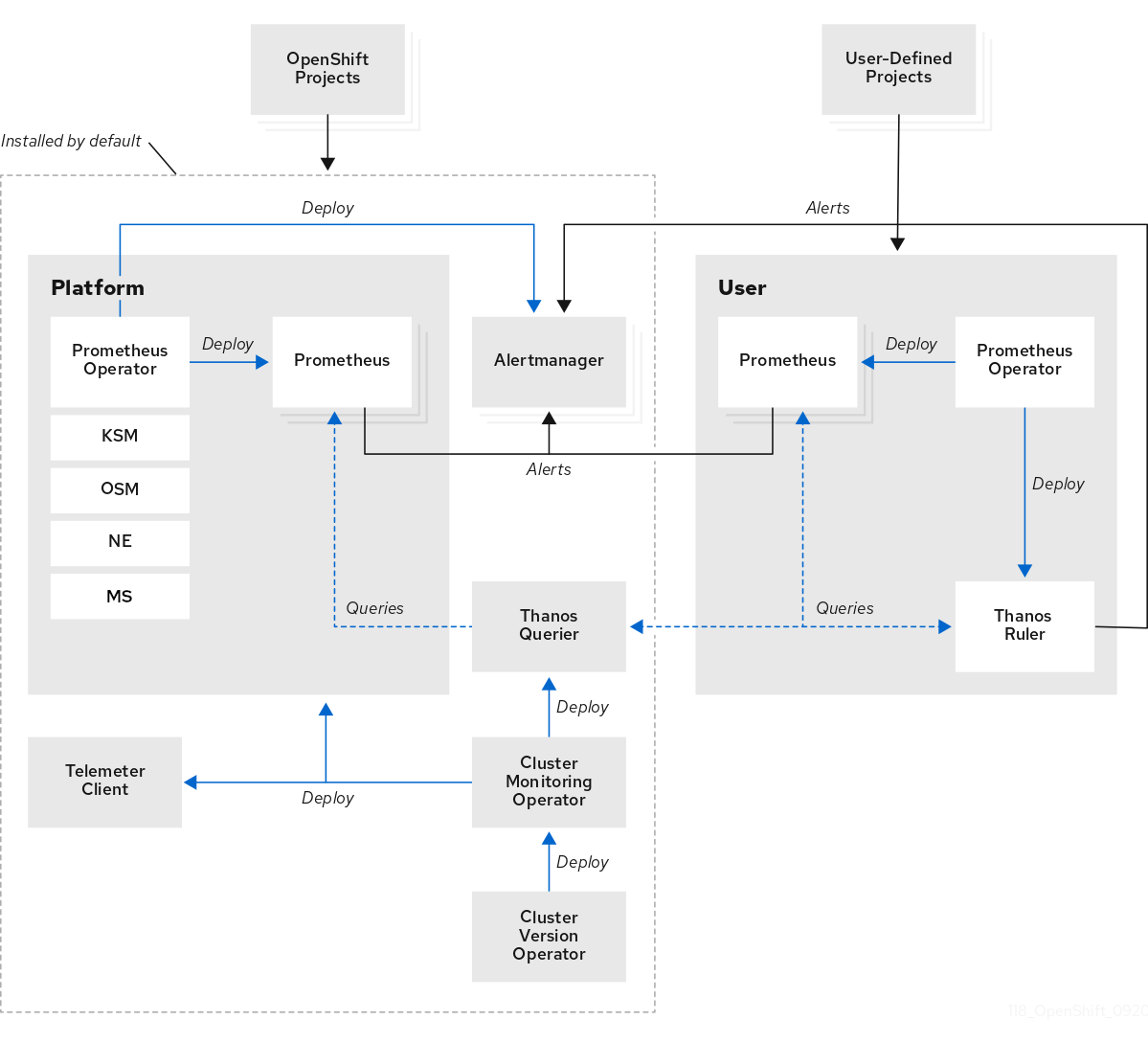
1.2.1. 默认监控目标
以下是 OpenShift Dedicated 集群中由 Red Hat Site Reliability engineerss (SRE)监控的目标示例:
- CoreDNS
- etcd
- HAProxy
- 镜像 registry
- Kubelets
- Kubernetes API 服务器
- Kubernetes 控制器管理器
- Kubernetes 调度程序
- OpenShift API 服务器
- OpenShift Controller Manager
- Operator Lifecycle Manager (OLM)
具体目标列表可能会因集群功能和安装的组件而异。
1.2.2. 用于监控用户定义的项目的组件
OpenShift Dedicated 包括对监控堆栈的可选增强,供您用于监控用户定义的项目中的服务和 Pod。此功能包括以下组件:
| 组件 | 描述 |
|---|---|
| Prometheus Operator |
|
| Prometheus | Prometheus 是为用户定义的项目提供监控的监控系统。Prometheus 将警报发送到 Alertmanager 进行处理。 |
| Thanos Ruler | Thanos Ruler 是 Prometheus 的一个规则评估引擎,作为一个独立的进程来部署。在 OpenShift Dedicated 中,Thanos Ruler 为监控用户定义的项目提供规则和警报评估。 |
| Alertmanager | Alertmanager 服务处理从 Prometheus 和 Thanos Ruler 接收的警报。Alertmanager 还负责将用户定义的警报发送到外部通知系统。部署该服务是可选的。 |
所有这些组件都由堆栈监控,并在 OpenShift Dedicated 更新时自动更新。
1.2.3. 用户定义的项目的监控目标
OpenShift Dedicated 用户定义的项目默认启用监控。您可以监控:
- 通过用户定义的项目中的服务端点提供的指标。
- 在用户定义的项目中运行的 Pod。
1.2.4. 了解高可用性集群中的监控堆栈
默认情况下,在多节点集群中,以下组件以高可用性(HA)模式运行,以防止数据丢失和服务中断:
- Prometheus
- Alertmanager
- Thanos Ruler
组件在两个 pod 之间复制,每个 pod 在单独的节点上运行。这意味着监控堆栈可以容忍一个 pod 的丢失。
- Prometheus 处于 HA 模式
- 这两个副本都独立提取同一目标并评估相同的规则。
- 副本不会相互通信。因此,数据在 pod 之间可能会有所不同。
- 处于 HA 模式的 Alertmanager
- 这两个副本将通知和静默状态相互同步。这样可确保每个通知至少发送一次。
- 如果副本无法通信,或者接收端有问题,则通知仍然会被发送,但可能会重复。
Prometheus、Alertmanager 和 Thanos Ruler 是有状态组件。为确保高可用性,您必须使用持久性存储进行配置。