第 1 章 观察环境简介
启用可观察(observability)服务后,您可以使用 Red Hat Advanced Cluster Management for Kubernetes 深入了解受管集群并进行优化。这些信息可以帮助节约成本并防止不必要的事件发生。
1.1. 观察环境
您可以使用 Red Hat Advanced Cluster Management for Kubernetes 深入了解受管集群并进行优化。在 hub 集群中启用 observability 服务 operator( multicluster-observability-operator )以监控受管集群的健康状态。在以下部分了解多集群观察服务的架构。
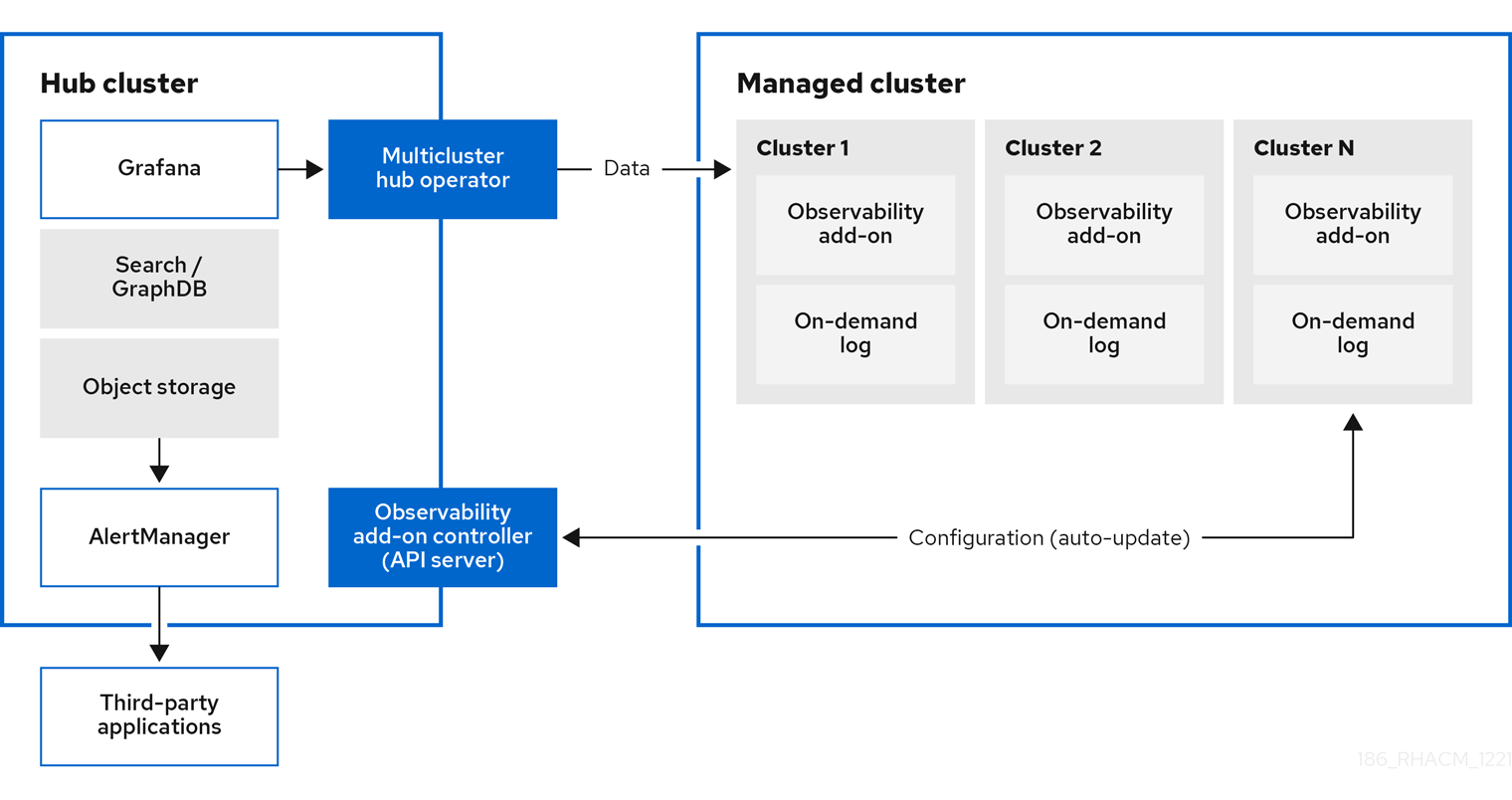
注:on-demand 日志可让工程师实时获取给定 pod 的日志。hub 集群的日志不会被聚合。这些日志可以通过搜索服务以及控制台的其他部分进行访问。
1.1.1. 观察(Observability)服务
默认情况下,产品安装中包含了可观察性(observability)功能,但不启用它。由于对持久性存储的要求,observability 服务默认不会启用。有关可观察性的信息,请参阅 支持 部分。
启用该服务后,observability-endpoint-operator 会自动部署到每个导入或创建的集群中。此控制器从 Red Hat OpenShift Container Platform Prometheus 收集数据,然后将其发送到 Red Hat Advanced Cluster Management hub 集群。如果 hub 集群导入为 local-cluster,则在它上也会启用可观察性,并从 hub 集群收集指标。
observability 服务部署了一个 Prometheus AlertManager 实例,它允许通过第三方应用程序转发警报。它还包括一个 Grafana 实例,通过仪表板(静态)或数据探索启用数据视觉化。Red Hat Advanced Cluster Management 支持 Grafana 的版本 8.1.3。您还可以设计自己的 Grafana 仪表板。如需更多信息,请参阅指定 Grafana 仪表板。您可以通过创建自定义记录规则或警报规则来自定义可观察性服务。
1.1.2. 支持
- Red Hat Advanced Cluster Management 已测试并被 Red Hat OpenShift Data Foundation(以前称为 Red Hat OpenShift Container Storage)完全支持。
- Red Hat Advanced Cluster Management 支持在用户提供的兼容 S3 API 的第三方对象存储中多集群可观察 Operator 的功能。Observability 服务使用 Thanos 支持的、稳定的对象存储。
- Red Hat Advanced Cluster Management 使用商业、合理的努力来帮助识别根本原因。如果创建了相关的支持问题,且确定问题的根本原因是客户提供的兼容 S3 对象存储,则需要通过客户支持频道解决问题。
- Red Hat Advanced Cluster Management 不会承诺修复客户提供的、问题的根本原因是 S3 兼容对象存储供应商的支持问题单。
1.1.3. 指标类型
默认情况下,OpenShift Container Platform 使用 Telemetry 服务向红帽发送指标数据。acm_managed_cluster_info 由 Red Hat Advanced Cluster Management 提供,包含在 Telemetry 中,但不会显示在 Red Hat Advanced Cluster Management Observe 环境概述 仪表板中。
查看框架支持的指标类型表:
| 指标名称 | 指标类型 | 标签/标签 | Status |
|---|---|---|---|
|
| 量表 |
| 稳定 |
|
| 量表 |
| 稳定。如需了解更多详细信息,请参阅监管指标。 |
|
| 量表 |
| 稳定。如需了解更多详细信息,请参阅管理 Insights PolicyReports。 |
|
| Histogram | 无。 | 稳定。如需了解更多详细信息,请参阅监管指标。 |
|
| Histogram | 无。 | 稳定。如需了解更多详细信息,请参阅监管指标。 |
|
| Histogram | 无。 | 稳定。如需了解更多详细信息,请参阅监管指标。 |
1.1.4. Observability pod 容量请求
Observability 组件需要 2701mCPU 和 11972Mi 内存来安装可观察性服务。下表是启用了 observability-addons 的五个受管集群的 pod 容量请求列表:
| Deployment 或 StatefulSet | 容器名称 | CPU(mCPU) | 内存(Mi) | Replicas | Pod 总计 CPU | Pod 内存总量 |
|---|---|---|---|---|---|---|
| observability-alertmanager | alertmanager | 4 | 200 | 3 | 12 | 600 |
| config-reloader | 4 | 25 | 3 | 12 | 75 | |
| alertmanager-proxy | 1 | 20 | 3 | 3 | 60 | |
| observability-grafana | grafana | 4 | 100 | 2 | 8 | 200 |
| grafana-dashboard-loader | 4 | 50 | 2 | 8 | 100 | |
| observability-observatorium-api | observatorium-api | 20 | 128 | 2 | 40 | 256 |
| observability-observatorium-operator | observatorium-operator | 100 | 100 | 1 | 10 | 50 |
| observability-rbac-query-proxy | rbac-query-proxy | 20 | 100 | 2 | 40 | 200 |
| oauth-proxy | 1 | 20 | 2 | 2 | 40 | |
| observability-thanos-compact | thanos-compact | 100 | 512 | 1 | 100 | 512 |
| observability-thanos-query | thanos-query | 300 | 1024 | 2 | 600 | 2048 |
| observability-thanos-query-frontend | thanos-query-frontend | 100 | 256 | 2 | 200 | 512 |
| observability-thanos-query-frontend-memcached | memcached | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-receive-controller | thanos-receive-controller | 4 | 32 | 1 | 4 | 32 |
| observability-thanos-receive-default | thanos-receive | 300 | 512 | 3 | 900 | 1536 |
| observability-thanos-rule | thanos-rule | 50 | 512 | 3 | 150 | 1536 |
| configmap-reloader | 4 | 25 | 3 | 12 | 75 | |
| observability-thanos-store-memcached | memcached | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-store-shard | thanos-store | 100 | 1024 | 3 | 300 | 3072 |
1.1.5. Observability 服务中使用的持久性存储
安装 Red Hat Advanced Cluster Management 时,必须创建以下持久性卷(PV),以便 PVC 可以自动附加到 PVC。请注意,当没有指定默认存储类或想要使用非默认存储类来托管 PV 时,您必须在 MultiClusterObservability CR 中定义存储类。建议您使用 Block Storage,类似于 Prometheus 使用的存储。另外,alertmanager、thanos-compactor、thanos-ruler、thanos-receive-default 和 thanos-store-shard 的每个副本必须具有自己的 PV。查看下表:
| 持久性卷名称 | 目的 |
| alertmanager |
Alertmanager 将 |
| thanos-compact | 紧凑器需要本地磁盘空间来存储用于处理的中间数据,以及 bucket 状态缓存。所需空间取决于基础块的大小。紧凑器必须有足够的空间下载所有源块,然后在磁盘上构建紧凑块。磁盘上的数据可以安全地在重新启动之间删除,并且应该是首次尝试使崩溃循环解压器。不过,建议为紧凑器永久磁盘提供压缩器持久磁盘,以便在重启期间高效地使用存储桶状态缓存。 |
| thanos-rule |
thanos 标尺通过以固定间隔发出查询来评估 Prometheus 记录和警报规则。规则结果以 Prometheus 2.0 存储格式写回磁盘。在这个有状态集合中保留的数据量在 API 版本 |
| thanos-receive-default |
Thanos 接收器接受传入数据(Prometheus 远程写入请求),并将这些数据写入 Prometheus TSDB 的一个本地实例。TSDB 块定期(每 2 小时)上传到对象存储,以进行长期存储和压缩。在这个有状态集合中保留的小时数或天数。有状态集合作为一个本地的缓存,它在 API 版本 |
| thanos-store-shard | 它主要充当一个 API 网关,因此不需要大量的本地磁盘空间。它在启动时加入 Thanos 集群,并公告它可以访问的数据。它在本地磁盘上保留少量的、与所有远程块相关的信息,并与存储桶保持同步。这些数据通常在重启时会被安全地删除,这会增加启动时间。 |
注意 :时间序列历史数据存储在对象存储中。Thanos 使用对象存储作为指标和与其相关的元数据的主存储。有关对象存储和降级的详情,请参阅启用可观察性服务。