2.2. 分布式缓存
Data Grid 会尝试在缓存中保留任何条目的固定数量(配置为 numOwners )。这允许分布式缓存线性扩展,在向集群添加节点时存储更多数据。
当节点加入并离开集群时,当键有超过个或小于 numOwners 副本时,会出现一些时间。特别是,如果 numOwners 节点存在快速连续,某些条目将会丢失,因此我们表示分布式缓存容许 numOwners - 1 节点失败。
副本数代表在性能和数据的持久性之间权衡。您维护的更多副本,性能越低,但会降低由于服务器或网络故障而丢失数据的风险。
Data Grid 将密钥的所有者分成一个 主要所有者,它将协调对密钥的写入,以及零个或多个 备份所有者。
下图显示了客户端发送到备份所有者的写入操作。在这种情况下,备份节点将写入转发到主所有者,然后将写入复制到备份。
图 2.2. 集群复制
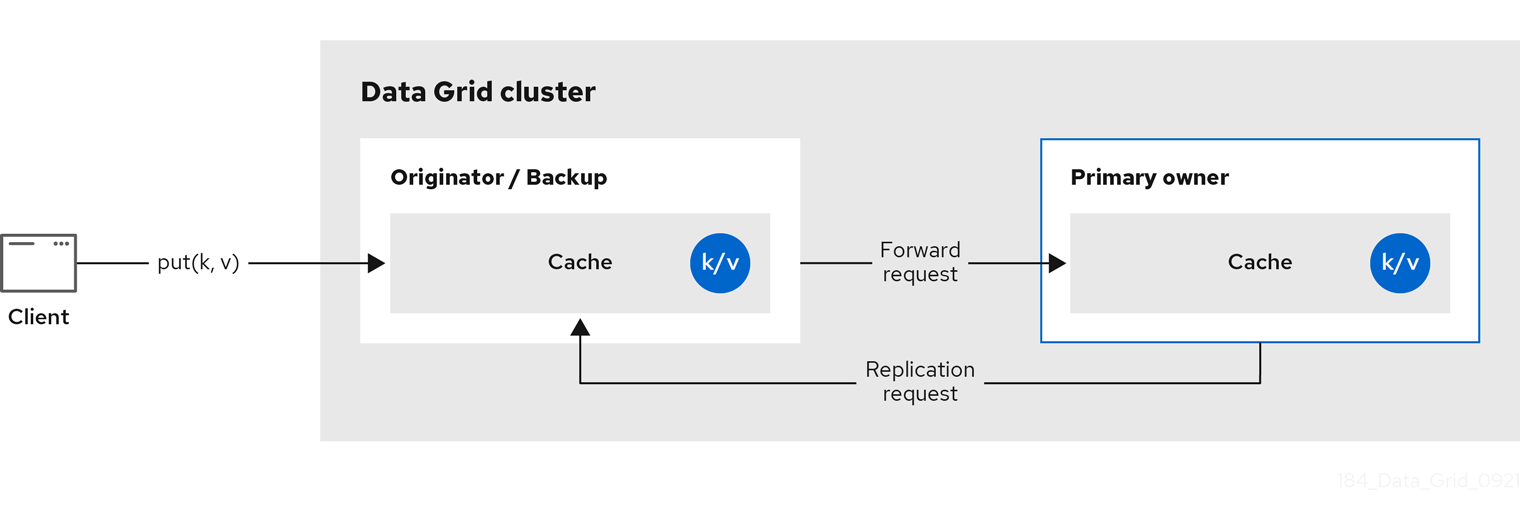
图 2.3. 分布式缓存

读取操作
读取操作从主所有者请求值。如果主所有者没有以合理的时间响应,Data Grid 也从备份所有者请求值。
如果本地缓存中存在密钥,或者所有所有者都较慢,则读取操作可能需要 0 个信息,或者最多 2 个 * numOwners 信息。
写操作
写入操作最多会导致 2 个 * numOwners 信息。来自 originator 到主所有者和 numOwners - 1 消息从主到备份节点的消息以及相应的确认消息。
缓存拓扑更改可能会导致读取和写入操作重试和额外信息。
同步或异步复制
不建议异步复制,因为它可能会丢失更新。除了丢失更新外,当线程写入到键时,异步分布式缓存也可以看到 stale 值,然后立即读取同一密钥。
Transactions
事务分布式缓存将 lock/prepare/commit/unlock 消息发送到受影响的节点,这意味着至少有一个密钥受事务影响。作为优化,如果事务写入单个密钥,并且 originator 是密钥的主所有者,则不会复制锁定信息。
2.2.1. 读取一致性
即使是同步复制,分布式缓存也不可线性。对于事务缓存,它们不支持序列化/快照隔离。
例如,线程正在执行单个放置请求:
cache.get(k) -> v1
cache.put(k, v2)
cache.get(k) -> v2但是另一个线程可能会以不同顺序看到值:
cache.get(k) -> v2
cache.get(k) -> v1该原因是从任何所有者返回值,具体取决于主所有者回复的速度。写入不是所有所有者的原子性。实际上,只有在从备份收到确认后,才会提交更新。在主等待备份的确认消息时,从备份中读取会显示新值,但从主读取将看到旧值。
2.2.2. 密钥所有权
分布式缓存将条目分成固定数量的片段,并将每个片段分配给所有者节点列表。复制缓存执行相同的操作,但每个节点都是一个所有者。
owners 列表中的第一个节点 是主所有者。列表中的其他节点是 备份所有者。当缓存拓扑更改时,因为节点加入或离开集群时,片段所有权表会广播到每个节点。这允许节点定位密钥,而无需为每个密钥发出多播请求或维护元数据。
numSegments 属性配置可用的片段数量。但是,除非集群重启,片段数量不会改变。
同样,键到网段映射无法更改。无论集群拓扑更改是什么,键必须始终映射到同一片段。务必要确保 key-to-segment 映射平均分配分配给每个节点的片段数量,同时尽量减少集群拓扑更改时必须移动的片段数量。
| 一致的哈希工厂实现 | 描述 |
|---|---|
|
| 使用基于 一致哈希的算法。当禁用服务器提示时,默认选择。 这种实现始终将密钥分配给每个缓存中的同一节点,只要集群是对称的。换句话说,所有缓存在所有节点上运行。这种实施确实有一些负点,负载分布稍微不均匀。它还比加入或离开更严格要求更多片段。 |
|
|
等同于 |
|
|
实现比 |
|
|
等同于 |
|
| 用于内部实施复制缓存。您不应该在分布式缓存中显式选择此算法。 |
哈希配置
您可以配置 ConsistentHashFactory 实现,包括自定义的带有嵌入式缓存。
XML
<distributed-cache name="distributedCache"
owners="2"
segments="100"
capacity-factor="2" />ConfigurationBuilder
Configuration c = new ConfigurationBuilder()
.clustering()
.cacheMode(CacheMode.DIST_SYNC)
.hash()
.numOwners(2)
.numSegments(100)
.capacityFactor(2)
.build();2.2.3. 容量因素
容量因素根据集群中每个节点的可用资源分配片段数量。
节点的容量因素适用于该节点是主所有者和备份所有者的片段。换句话说,容量因素指定节点与集群中的其他节点相比的总容量。
默认值为 1,这意味着集群中的所有节点都有相等的容量,Data Grid 为集群中的所有节点分配相同的片段数量。
但是,如果节点有不同数量的可用内存,您可以配置容量因素,以便 Data Grid 哈希算法为每个节点分配大量按其容量权重的片段。
容量因素配置的值必须是正数,可以是 1.5 所示的比例。您还可以配置容量因数 0, 但建议临时加入集群的节点,应该改为使用零容量配置。
2.2.3.1. 零容量节点
您可以为每个缓存、用户定义的缓存和内部缓存配置容量因子为 0 的节点。在定义零容量节点时,该节点不会保存任何数据。
零容量节点配置
XML
<infinispan>
<cache-container zero-capacity-node="true" />
</infinispan>JSON
{
"infinispan" : {
"cache-container" : {
"zero-capacity-node" : "true"
}
}
}YAML
infinispan:
cacheContainer:
zeroCapacityNode: "true"ConfigurationBuilder
new GlobalConfigurationBuilder().zeroCapacityNode(true);2.2.4. 一级(L1)缓存
Data Grid 节点会在从集群中的另一节点检索条目时创建本地副本。L1 缓存避免在主所有者节点上重复查找条目并提高性能。
下图演示了 L1 缓存的工作方式:
图 2.4. L1 缓存

在 "L1 缓存"图中:
-
客户端调用
cache.get ()来读取集群中另一个节点是主所有者的条目。 - 原始器节点将读取操作转发到主所有者。
- 主所有者返回键/值条目。
- 原始器节点会创建一个本地副本。
-
后续的
cache.get ()调用会返回本地条目,而不是转发到主所有者。
L1 缓存性能
启用 L1 提高了读取操作的性能,但需要主所有者节点在修改条目时广播失效消息。这样可确保 Data Grid 在集群中删除任何过时的副本。但是,这也降低了写操作的性能并增加内存用量,从而减少缓存的整体容量。
与任何其他缓存条目一样,Data Grid 驱除和过期本地副本或 L1 条目。
L1 缓存配置
XML
<distributed-cache l1-lifespan="5000"
l1-cleanup-interval="60000">
</distributed-cache>JSON
{
"distributed-cache": {
"l1-lifespan": "5000",
"l1-cleanup-interval": "60000"
}
}YAML
distributedCache:
l1Lifespan: "5000"
l1-cleanup-interval: "60000"ConfigurationBuilder
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.clustering().cacheMode(CacheMode.DIST_SYNC)
.l1()
.lifespan(5000, TimeUnit.MILLISECONDS)
.cleanupTaskFrequency(60000, TimeUnit.MILLISECONDS);2.2.5. 服务器提示
服务器提示通过尽可能在多个服务器、机架和数据中心中复制条目来提高分布式缓存中数据的可用性。
服务器提示仅适用于分布式缓存。
当 Data Grid 分发您的数据的副本时,它遵循优先级顺序:site、rack、machine 和 node。所有配置属性都是可选的。例如,当您只指定机架 ID 时,Data Grid 会将副本分布到不同的机架和节点上。
如果缓存的片段数量过低,服务器提示可能会影响集群重新平衡操作。
多个数据中心中的集群的替代方法是跨站点复制。
服务器提示配置
XML
<cache-container>
<transport cluster="MyCluster"
machine="LinuxServer01"
rack="Rack01"
site="US-WestCoast"/>
</cache-container>JSON
{
"infinispan" : {
"cache-container" : {
"transport" : {
"cluster" : "MyCluster",
"machine" : "LinuxServer01",
"rack" : "Rack01",
"site" : "US-WestCoast"
}
}
}
}YAML
cacheContainer:
transport:
cluster: "MyCluster"
machine: "LinuxServer01"
rack: "Rack01"
site: "US-WestCoast"GlobalConfigurationBuilder
GlobalConfigurationBuilder global = GlobalConfigurationBuilder.defaultClusteredBuilder()
.transport()
.clusterName("MyCluster")
.machineId("LinuxServer01")
.rackId("Rack01")
.siteId("US-WestCoast");2.2.6. 关键关联性服务
在分布式缓存中,使用不透明算法将密钥分配给节点列表。无法反转计算并生成映射到特定节点的密钥。但是,Data Grid 可以生成一系列(pseudo-) random 键,查看其主所有者,并在需要关键映射到特定节点时将其移入应用程序。
以下代码片段演示了如何获取和使用对此服务的引用。
// 1. Obtain a reference to a cache
Cache cache = ...
Address address = cache.getCacheManager().getAddress();
// 2. Create the affinity service
KeyAffinityService keyAffinityService = KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
// 3. Obtain a key for which the local node is the primary owner
Object localKey = keyAffinityService.getKeyForAddress(address);
// 4. Insert the key in the cache
cache.put(localKey, "yourValue");服务在第 2 步启动:此时,它使用提供的 Executor 生成和队列密钥。在第 3 步,我们从服务获得密钥,在第 4 步中使用该密钥。
生命周期
KeyAffinityService 扩展 生命周期,它允许停止和(重新)启动它:
public interface Lifecycle {
void start();
void stop();
}
服务通过 KeyAffinityServiceFactory 实例化。所有工厂方法都有一个 Executor 参数,用于异步密钥生成(因此它不会在调用者的线程中发生)。用户负责处理此可执行文件的关闭 。
启动后,KeyAffinityService 需要被显式停止。这会停止后台密钥生成,并释放其他保存的资源。
在 KeyAffinityService 停止它的唯一情况下,当它被注册的缓存管理器被关闭时。
拓扑更改
当缓存拓扑更改时,KeyAffinityService 生成的密钥的所有权可能会改变。key affinity 服务跟踪这些拓扑更改,且不会返回当前映射到不同节点的键,但它不会对之前生成的密钥进行任何操作。
因此,应用程序应该只将 KeyAffinityService 视为优化,它们不应该依赖生成的密钥的位置来获得正确的。
特别是,应用程序不应依赖 KeyAffinityService 生成的密钥,以便始终位于同一地址。密钥共存仅由 Grouping API 提供。
2.2.7. Grouping API
与 Key affinity 服务补充,分组 API 允许您在同一节点上并置一组条目,但不能选择实际节点。
默认情况下,使用密钥的 hashCode () 计算密钥的片段。如果您使用 Grouping API,Data Grid 将计算组的网段,并将其用作密钥的网段。
使用 Grouping API 时,务必要确保每个节点仍然可以计算每个密钥的所有者,而无需联系其他节点。因此,无法手动指定组。组可以刻录到条目(由密钥类生成)或 extrinsic (由外部函数生成)。
要使用 Grouping API,您必须启用组。
Configuration c = new ConfigurationBuilder()
.clustering().hash().groups().enabled()
.build();<distributed-cache>
<groups enabled="true"/>
</distributed-cache>
如果您有关键类的控制(您可以更改类定义,它不是一个不可修改的库的一部分),我们建议使用一个内部组。内部组通过向方法添加 @Group 注释来指定,例如:
class User {
...
String office;
...
public int hashCode() {
// Defines the hash for the key, normally used to determine location
...
}
// Override the location by specifying a group
// All keys in the same group end up with the same owners
@Group
public String getOffice() {
return office;
}
}
}
group 方法必须返回 String
如果您没有对密钥类的控制权,或者组的确定是关键类的正面问题,我们建议使用 extrinsic 组。通过实施 Grouper 接口来指定 extrinsic 组。
public interface Grouper<T> {
String computeGroup(T key, String group);
Class<T> getKeyType();
}
如果为同一密钥类型配置了多个 Grouper 类,则会调用它们的所有类,接收上一个密钥计算的值。如果密钥类也具有 @Group 注释,则第一个 组 将接收由注释方法计算的组。这允许您在使用 内部组时对组进行更大的控制。
Grouper 实现示例
public class KXGrouper implements Grouper<String> {
// The pattern requires a String key, of length 2, where the first character is
// "k" and the second character is a digit. We take that digit, and perform
// modular arithmetic on it to assign it to group "0" or group "1".
private static Pattern kPattern = Pattern.compile("(^k)(<a>\\d</a>)$");
public String computeGroup(String key, String group) {
Matcher matcher = kPattern.matcher(key);
if (matcher.matches()) {
String g = Integer.parseInt(matcher.group(2)) % 2 + "";
return g;
} else {
return null;
}
}
public Class<String> getKeyType() {
return String.class;
}
}
组群 实现必须在缓存配置中显式注册。如果您要以编程方式配置 Data Grid:
Configuration c = new ConfigurationBuilder()
.clustering().hash().groups().enabled().addGrouper(new KXGrouper())
.build();或者,如果您使用 XML:
<distributed-cache>
<groups enabled="true">
<grouper class="com.example.KXGrouper" />
</groups>
</distributed-cache>高级 API
AdvancedCache 有两个特定于组的方法:
-
getGroup (groupName)检索属于组的所有密钥。 -
removeGroup (groupName)会删除属于组的所有密钥。
两种方法会迭代整个数据容器和存储(如果存在),因此当缓存包含大量小组时,它们可能会较慢。