管理、监控和更新内核
在 Red Hat Enterprise Linux 8 中管理 Linux 内核的指南
摘要
对红帽文档提供反馈
我们感谢您对我们文档的反馈。让我们了解如何改进它。
通过 Jira 提交反馈(需要帐户)
- 登录到 Jira 网站。
- 单击顶部导航栏中的 Create。
- 在 Summary 字段中输入描述性标题。
- 在 Description 字段中输入您对改进的建议。包括文档相关部分的链接。
- 点对话框底部的 Create。
第 1 章 Linux 内核
了解由红帽(红帽内核)提供和维护的 Linux 内核和 Linux 内核 RPM 软件包。使红帽内核保持更新,这可以确保操作系统具有最新的程序错误修复、性能增强和补丁,并与新硬件兼容。
1.1. 内核是什么
内核是 Linux 操作系统的核心部分,其管理系统资源,并提供硬件和软件应用程序之间的接口。
红帽内核是一个基于上游 Linux 主线内核的定制内核,红帽工程师对其进行了进一步的开发和强化,专注于稳定性和与最新技术和硬件的兼容性。
在红帽发布新内核版本前,内核需要通过一组严格的质量保证测试。
红帽内核以 RPM 格式打包,以便它们可以通过 YUM 软件包管理器轻松地升级和验证。
红帽不支持 不是 由红帽编译的内核。
1.2. RPM 软件包
RPM 软件包由用于安装和删除这些文件的文件和元数据的存档组成。具体来说,RPM 软件包包含以下部分:
- GPG 签名
- GPG 签名用于验证软件包的完整性。
- 标头(软件包元数据)
- RPM 软件包管理器使用此元数据来确定软件包依赖项、安装文件的位置及其他信息。
- payload
-
有效负载是一个
cpio归档,其中包含要安装到系统的文件。
RPM 软件包有两种类型。这两种类型都共享文件格式和工具,但内容不同,并实现不同的目的:
源 RPM(SRPM)
SRPM 包含源代码和一个
spec文件,该文件描述了如何将源代码构建为二进制 RPM。另外,SRPM 可以包含源代码的补丁。二进制 RPM
一个二进制 RPM 包含了根据源代码和补丁构建的二进制文件。
1.3. Linux 内核 RPM 软件包概述
kernel RPM 是一个元数据软件包,它不包含任何文件,而是保证正确安装了以下子软件包:
kernel-core-
提供内核的二进制镜像、所有与
initramfs相关的对象来引导系统,以及确保核心功能的最小内核模块数量。仅在虚拟和云环境中使用这个子软件包来为 Red Hat Enterprise Linux 8 内核提供一个快速引导时间和小磁盘空间。 kernel-modules-
提供
kernel-core中不存在的其余内核模块。
上述 kernel 子软件包中的一部分旨在帮助系统管理员减少需要维护的范围,特别是在虚拟化和云环境中。
例如,可选内核软件包:
kernel-modules-extra- 为罕见硬件提供内核模块。默认禁用模块的加载。
kernel-debug- 提供了启用了许多调试选项的内核,以便进行内核诊断,以降低性能为代价。
kernel-tools- 提供了操作 Linux 内核和支持文档的工具。
kernel-devel-
提供了内核标头和 makefile,来足以针对
kernel软件包构建模块。 kernel-abi-stablelists-
提供与 RHEL 内核 ABI 相关的信息,包括外部 Linux 内核模块所需的内核符号列表和
yum插件以协助执行。 kernel-headers- 包括指定 Linux 内核和用户空间库以及程序间接口的 C 标头文件。头文件定义构建大多数标准程序所需的结构和常量。
1.4. 显示内核软件包的内容
通过查询存储库,您可以看到内核软件包是否提供了一个特定的文件,如模块。不需要下载或安装软件包来显示文件列表。
使用 dnf 工具查询文件列表,例如 kernel-core、kernel-modules-core 或 kernel-modules 软件包的文件列表。请注意,kernel 软件包是一个不包含任何文件的元数据软件包。
流程
列出软件包的可用版本:
yum repoquery <package_name>
$ yum repoquery <package_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 显示软件包中的文件列表:
yum repoquery -l <package_name>
$ yum repoquery -l <package_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.5. 安装特定的内核版本
使用 yum 软件包管理器安装新内核。
流程
要安装特定的内核版本,请输入以下命令:
yum install kernel-5.14.0
# yum install kernel-5.14.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
1.6. 更新内核
使用 yum 软件包管理器更新内核。
流程
要更新内核,请输入以下命令:
yum update kernel
# yum update kernelCopy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令将内核以及所有依赖项更新至最新可用版本。
- 重启您的系统以使更改生效。
当从 RHEL 7 升级到 RHEL 8 时,请遵循 从 RHEL 7 升级到 RHEL 8 文档中的相关部分。
1.7. 将内核设置为默认
使用 grubby 命令行工具和 GRUB 将特定内核设置为默认。
流程
使用
grubby工具将内核设置为默认。输入以下命令,使用
grubby工具将内核设置为默认:grubby --set-default $kernel_path
# grubby --set-default $kernel_pathCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令使用不带
.conf后缀的计算机 ID 作为参数。注意机器 ID 位于
/boot/loader/entries/目录中。
使用
id参数将内核设置为默认。使用
id参数列出引导条目,然后将所需的内核设置为默认:grubby --info ALL | grep id grubby --set-default /boot/vmlinuz-<version>.<architecture>
# grubby --info ALL | grep id # grubby --set-default /boot/vmlinuz-<version>.<architecture>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意要使用
title参数列出引导条目,请执行# grubby --info=ALL | grep title命令。
仅为下次引导设置默认内核。
执行以下命令,仅在下次使用
grub2-reboot命令重新引导时设置默认内核:grub2-reboot <index|title|id>
# grub2-reboot <index|title|id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告小心地为下次启动设置默认内核。安装新的内核 RPM、自构建内核,以及手动将条目添加到
/boot/loader/entries/目录中可能会更改索引值。
第 2 章 管理内核模块
了解内核模块、如何显示其信息,以及如何使用内核模块执行基本的管理任务。
2.1. 内核模块简介
Red Hat Enterprise Linux 内核可以使用内核模块进行扩展,该模块提供可选的附加功能,而无需重启系统。在 RHEL 8 中,内核模块是内置于压缩的 < KERNEL_MODULE_NAME>.ko.xz 对象文件中的额外内核代码。
内核模块启用的最常见功能是:
- 添加用于支持新硬件的设备驱动程序
- 支持文件系统,如 GFS2 或者 NFS
- 系统调用
在现代系统中,在需要时会自动载入内核模块。但在某些情况下,需要手动加载或卸载模块。
与内核类似,模块也接受自定义其行为的参数。
您可以使用内核工具对模块执行以下操作:
- 检查当前运行的模块。
- 检查可用来加载到内核的模块。
- 检查模块接受的参数。
- 启用一种机制,来将内核模块加载和卸载到运行的内核中。
2.2. 内核模块依赖关系
某些内核模块有时依赖一个或多个内核模块。/lib/modules/<KERNEL_VERSION>/modules.dep 文件包含相应内核版本的内核模块依赖项的完整列表。
depmod
依赖项文件由 depmod 程序生成,包含在 kmod 软件包中。kmod 提供的很多工具会在执行操作时考虑模块依赖项。因此,很少需要 手动 跟踪依赖项。
内核模块的代码在不受限制的模式下在内核空间中执行。请注意您加载的模块。
weak-modules
除了 depmod 外,Red Hat Enterprise Linux 还提供了 weak-modules 脚本,这是 kmod 软件包的一部分。weak-modules 决定与安装的内核 kABI 兼容的模块。在检查模块内核的兼容性时,weak-modules 按照它们构建的内核的从高到低版本处理符号依赖项。它独立于内核版本单独处理每个模块。
2.3. 列出已安装的内核模块
grubby --info=ALL 命令显示在 !BLS 和 BLS 安装中安装的内核的一个索引列表。
步骤
使用以下命令列出安装的内核:
grubby --info=ALL | grep title
# grubby --info=ALL | grep titleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 下面是所有安装的内核列表:
title=Red Hat Enterprise Linux (4.18.0-20.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-19.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-12.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0) 8.0 (Ootpa) title=Red Hat Enterprise Linux (0-rescue-2fb13ddde2e24fde9e6a246a942caed1) 8.0 (Ootpa)
title=Red Hat Enterprise Linux (4.18.0-20.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-19.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-12.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0) 8.0 (Ootpa) title=Red Hat Enterprise Linux (0-rescue-2fb13ddde2e24fde9e6a246a942caed1) 8.0 (Ootpa)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
这是 GRUB 菜单中安装的 grubby-8.40-17 内核的列表。
2.4. 列出当前载入的内核模块
查看当前载入的内核模块。
先决条件
-
已安装
kmod软件包。
步骤
要列出所有当前载入的内核模块,请输入:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在上例中:
-
Module列提供了当前载入的模块的 名称。 -
Size列显示每个模块的 内存 量(以 KB 为单位)。 -
Used by列显示 依赖于 特定模块的模块的编号,以及名称(可选)。
-
2.5. 列出所有安装的内核
使用 grubby 实用程序列出系统上所有安装的内核。
先决条件
- 您有 root 权限。
流程
要列出所有安装的内核,请输入:
grubby --info=ALL | grep ^kernel
# grubby --info=ALL | grep ^kernel kernel="/boot/vmlinuz-4.18.0-305.10.2.el8_4.x86_64" kernel="/boot/vmlinuz-4.18.0-240.el8.x86_64" kernel="/boot/vmlinuz-0-rescue-41eb2e172d7244698abda79a51778f1b"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
输出显示了安装的所有内核的路径和版本。
2.6. 显示内核模块信息
使用 modinfo 命令显示指定内核模块的一些详细信息。
先决条件
-
已安装
kmod软件包。
步骤
要显示关于任何内核模块的信息,请输入:
modinfo <KERNEL_MODULE_NAME>
$ modinfo <KERNEL_MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您可以查询所有可用模块的信息,无论它们是否已加载。
parm条目显示用户可以为模块设置的参数,以及它们预期的值类型。注意在输入内核模块的名称时,不要将
.ko.xz扩展附加到名称的末尾。内核模块名称没有扩展名,它们对应的文件有。
2.7. 在系统运行时载入内核模块
扩展 Linux 内核功能的最佳方法是加载内核模块。使用 modprobe 命令查找并将内核模块载入到当前运行的内核中。
重启系统后,这个过程中描述的更改不会保留。有关如何在系统重启后将内核模块载入为 持久性 的详情,请参考 在系统引导时自动载入内核模块。
先决条件
- 根权限
-
已安装
kmod软件包。 - 相关的内核模块没有被加载。要确保情况如此,请列出 当前载入的内核模块 的列表。
流程
选择您要载入的内核模块。
模块位于
/lib/modules/$(uname -r)/kernel/<SUBSYSTEM>/目录中。载入相关内核模块:
modprobe <MODULE_NAME>
# modprobe <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在输入内核模块的名称时,不要将
.ko.xz扩展附加到名称的末尾。内核模块名称没有扩展名,它们对应的文件有。
验证
(可选)验证载入了相关模块:
lsmod | grep <MODULE_NAME>
$ lsmod | grep <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果正确加载了模块,这个命令会显示相关的内核模块。例如:
lsmod | grep serio_raw
$ lsmod | grep serio_raw serio_raw 16384 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
2.8. 在系统运行时卸载内核模块
要从正在运行的内核中卸载某些内核模块,请使用 modprobe 命令,在系统运行时从当前加载的内核查找和卸载内核模块。
您不能卸载正在运行的系统所使用的内核模块,因为它可能会导致不稳定或系统无法正常工作。
完成不活跃内核模块的卸载后,定义为在引导时自动载入的模块,在重启系统后不会保持卸载状态。有关如何防止此结果的详情,请参考 防止内核模块在系统引导时被自动载入。
先决条件
- 您有 root 权限。
-
kmod软件包已安装。
流程
列出所有载入的内核模块:
lsmod
# lsmodCopy to Clipboard Copied! Toggle word wrap Toggle overflow 选择您要卸载的内核模块。
如果内核模块有依赖项,请在卸载内核模块前卸载它们。有关识别使用依赖项的模块的详情,请参阅列出当前载入的内核模块和内核模块依赖项。
卸载相关内核模块:
modprobe -r <MODULE_NAME>
# modprobe -r <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在输入内核模块的名称时,不要将
.ko.xz扩展附加到名称的末尾。内核模块名称没有扩展名,它们对应的文件有。
验证
(可选)验证相关模块是否已卸载:
lsmod | grep <MODULE_NAME>
$ lsmod | grep <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果模块被成功卸载,这个命令不显示任何输出。
2.9. 在启动过程早期卸载内核模块
在某些情况下,例如,当内核模块有导致系统变得无响应的代码时,用户无法达到永久禁用恶意内核模块的阶段时,您可能需要在引导过程的早期卸载内核模块。要临时阻止内核模块的加载,您可以使用引导装载程序。
您可以在引导序列继续前编辑相关的引导装载程序条目,来卸载所需的内核模块。
此流程中描述的更改在下次重启后 不会持久存在 。有关如何将内核模块添加到 denylist 中,以便在引导过程中不会被自动载入,请参阅 防止在系统引导时自动载入内核模块。
先决条件
- 您有一个可加载的内核模块,但出于某种原因您要防止其加载。
流程
- 将系统启动到引导装载程序中。
- 使用光标键突出显示相关的引导装载程序条目。
按 e 键编辑条目。
图 2.1. 内核引导菜单
- 使用光标键导航到以 linux 开头的行。
将
modprobe.blacklist=module_name附加到行尾。图 2.2. 内核引导条目
serio_raw内核模块演示了一个要在引导过程早期卸载的恶意模块。- 按 Ctrl+X 使用修改后的配置启动。


验证
系统引导后,验证相关内核模块是否没有载入:
lsmod | grep serio_raw
# lsmod | grep serio_rawCopy to Clipboard Copied! Toggle word wrap Toggle overflow
2.10. 在系统引导时自动载入内核模块
配置内核模块,来在引导过程中自动载入它。
先决条件
- 根权限
-
kmod软件包已安装。
步骤
选择您要在引导过程中载入的内核模块。
模块位于
/lib/modules/$(uname -r)/kernel/<SUBSYSTEM>/目录中。为模块创建配置文件:
echo <MODULE_NAME> > /etc/modules-load.d/<MODULE_NAME>.conf
# echo <MODULE_NAME> > /etc/modules-load.d/<MODULE_NAME>.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在输入内核模块的名称时,不要将
.ko.xz扩展附加到名称的末尾。内核模块名称没有扩展名,它们对应的文件有。
验证
重启后,验证相关模块是否已载入:
lsmod | grep <MODULE_NAME>
$ lsmod | grep <MODULE_NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
重启系统后,这个过程中描述的更改将会保留。
2.11. 防止在系统引导时自动载入内核模块
您可以通过使用相应的命令在 modprobe 配置文件中列出模块,来防止系统在引导过程中自动载入内核模块。
先决条件
-
此流程中的命令需要 root 权限。使用
su -切换到 root 用户,或在命令前使用sudo。 -
kmod软件包已安装。 - 确定您当前的系统配置不需要您计划拒绝的内核模块。
流程
使用
lsmod命令列出载入到当前运行的内核的模块:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在输出中,识别您要防止加载的模块。
或者,识别您要防止在
/lib/modules/<KERNEL-VERSION>/kernel/<SUBSYSTEM>/目录中加载的而未加载的内核模块,例如:ls /lib/modules/4.18.0-477.20.1.el8_8.x86_64/kernel/crypto/
$ ls /lib/modules/4.18.0-477.20.1.el8_8.x86_64/kernel/crypto/ ansi_cprng.ko.xz chacha20poly1305.ko.xz md4.ko.xz serpent_generic.ko.xz anubis.ko.xz cmac.ko.xz…Copy to Clipboard Copied! Toggle word wrap Toggle overflow
创建一个配置文件作为 denylist :
touch /etc/modprobe.d/denylist.conf
# touch /etc/modprobe.d/denylist.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在您选择的文本编辑器中,使用
blacklist配置命令将您要从自动加载到内核中排除的模块的名称组合在一起,例如:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 因为
blacklist命令不会阻止模块作为不在 denylist 中的另一个内核模块的依赖项加载,所以您还必须定义install行。在这种情况下,系统运行/bin/false,而不是安装模块。以哈希符号开头的行是注释,您可以用来使文件更易读。注意在输入内核模块的名称时,不要将
.ko.xz扩展附加到名称的末尾。内核模块名称没有扩展名,它们对应的文件有。在重建前,创建当前初始 RAM 磁盘镜像的一个备份副本:
cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).img
# cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).imgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者,创建与您要阻止内核模块自动载入的内核版本对应的初始 RAM 磁盘镜像的一个备份副本:
cp /boot/initramfs-<VERSION>.img /boot/initramfs-<VERSION>.img.bak.$(date +%m-%d-%H%M%S)
# cp /boot/initramfs-<VERSION>.img /boot/initramfs-<VERSION>.img.bak.$(date +%m-%d-%H%M%S)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
生成一个新的初始 RAM 磁盘镜像以应用更改:
dracut -f -v
# dracut -f -vCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果您为与您系统当前使用的内核版本不同的系统构建初始 RAM 磁盘镜像,请指定目标
initramfs和内核版本:dracut -f -v /boot/initramfs-<TARGET-VERSION>.img <CORRESPONDING-TARGET-KERNEL-VERSION>
# dracut -f -v /boot/initramfs-<TARGET-VERSION>.img <CORRESPONDING-TARGET-KERNEL-VERSION>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
重启系统:
reboot
$ rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
此流程中描述的更改将在重启后生效并保留。如果您在 denylist 中错误地列出了关键内核模块,您可以将系统切换到不稳定或无法正常工作的状态。
2.12. 编译自定义的内核模块
您可以根据硬件和软件级别的各种配置的要求构建一个采样内核模块。
先决条件
kernel-devel、gcc和elfutils-libelf-devel软件包已安装。dnf install kernel-devel-$(uname -r) gcc elfutils-libelf-devel
# dnf install kernel-devel-$(uname -r) gcc elfutils-libelf-develCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 您有 root 权限。
-
您创建了
/root/testmodule/目录,在此编译自定义的内核模块。
步骤
创建包含以下内容的
/root/testmodule/test.c文件:Copy to Clipboard Copied! Toggle word wrap Toggle overflow test.c文件是一个源文件,其向内核模块提供主要功能。出于组织需要,该文件已创建在专用的/root/testmodule/目录中。在模块编译后,/root/testmodule/目录将包含多个文件。test.c文件包含来自系统库的文件:-
示例代码中的
printk()函数需要linux/kernel.h头文件。 -
linux/module.h头文件包含在多个 C 源文件之间共享的功能声明和宏定义。
-
示例代码中的
-
按照
init_module ()和cleanup_module ()函数启动和结束内核日志记录函数printk (),后者会打印文本。 使用以下内容创建
/root/testmodule/Makefile文件。obj-m := test.o
obj-m := test.oCopy to Clipboard Copied! Toggle word wrap Toggle overflow Makefile 包含编译器的说明,以生成名为
test.o的对象文件。obj-m指令指定生成的test.ko文件将编译为可加载的内核模块。或者,obj-y指令可指示将test.ko作为内置内核模块构建。编译内核模块。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 编译器将它们链接成最终内核模块(
test.ko)之前,会为每个源文件(test.c)创建一个对象文件(test.c)来作为中间步骤。成功编译后,
/root/testmodule/包含与编译的自定义内核模块相关的其他文件。已编译的模块本身由test.ko文件表示。
验证
可选:检查
/root/testmodule/目录的内容:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将内核模块复制到
/lib/modules/$(uname -r)/目录中:cp /root/testmodule/test.ko /lib/modules/$(uname -r)/
# cp /root/testmodule/test.ko /lib/modules/$(uname -r)/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 更新模块依赖项列表:
depmod -a
# depmod -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 载入内核模块:
modprobe -v test
# modprobe -v test insmod /lib/modules/4.18.0-305.el8.x86_64/test.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow 验证内核模块是否成功载入:
lsmod | grep test
# lsmod | grep test test 16384 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 从内核环缓冲中读取最新的消息:
dmesg
# dmesg [74422.545004] Hello World This is a testCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 3 章 为安全引导签名内核和模块
您可以使用签名的内核和签名的内核模块来加强系统的安全性。在启用了安全引导机制的基于 UEFI 的构建系统中,您可以自我签名一个私有构建的内核或内核模块。另外,您可以将公钥导入到要部署内核或内核模块的目标系统中。
如果启用了安全引导机制,则必须使用私钥签名以下所有组件,并使用对应的公钥进行身份验证:
- UEFI 操作系统引导装载程序
- Red Hat Enterprise Linux 内核
- 所有内核模块
如果这些组件中的任何一个都没有签名和验证,则系统将无法完成引导过程。
RHEL 8 包括:
- 签名的引导装载程序
- 签名的内核
- 签名的内核模块
此外,签名的第一阶段引导装载程序和签名的内核包括嵌入的红帽公钥。这些签名的可执行二进制文件和嵌入式密钥可让 RHEL 8 安装、引导和使用 Microsoft UEFI 安全引导认证认证机构密钥运行。这些密钥由支持 UEFI 安全引导的系统上的 UEFI 固件提供。
- 不是所有基于 UEFI 的系统都包括对安全引导的支持。
- 构建系统(构建和签署内核模块)不需要启用 UEFI 安全引导,甚至不需要是基于 UEFI 的系统。
3.1. 先决条件
要能够为外部构建的内核模块签名,请从以下软件包安装工具:
yum install pesign openssl kernel-devel mokutil keyutils
# yum install pesign openssl kernel-devel mokutil keyutilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow Expand 表 3.1. 所需工具 工具 由软件包提供 用于 用途 efikeygenpesign构建系统
生成公共和专用 X.509 密钥对
opensslopenssl构建系统
导出未加密的私钥
sign-filekernel-devel构建系统
用来使用私钥为内核模块签名的可执行文件
mokutilmokutil目标系统
用于手动注册公钥的可选工具
keyctlkeyutils目标系统
用于在系统密钥环中显示公钥的可选工具
3.2. 什么是 UEFI 安全引导
使用 Unified Extensible Firmware Interface (UEFI)安全引导技术,您可以防止不是由可信密钥签名的内核空间代码的执行。系统引导装载程序使用加密密钥进行签名。固件中的公钥数据库授权密钥签名的过程。然后,您可以在下一个阶段引导装载程序和内核中验证签名。
UEFI 安全引导建立了一个从固件到签名驱动程序和内核模块的信任链,如下所示:
-
UEFI 私钥签名,公钥验证
shim第一阶段引导装载程序。证书颁发机构 (CA)反过来签署公钥。CA 存储在固件数据库中。 -
shim文件包含红帽公钥 Red Hat Secure Boot (CA 密钥 1) 来验证 GRUB 引导装载程序和内核。 - 内核又包含用于验证驱动程序和模块的公钥。
安全引导是 UEFI 规范的引导路径验证组件。规范定义:
- 用于非易失性存储中加密保护的 UEFI 变量的编程接口。
- 在 UEFI 变量中存储可信的 X.509 根证书。
- UEFI 应用程序的验证,如引导装载程序和驱动程序。
- 撤销已知错误的证书和应用程序哈希的流程。
UEFI 安全引导版主可以检测未经授权的更改,但不会 :
- 防止安装或删除第二阶段引导装载程序。
- 需要用户明确确认此类更改。
- 停止引导路径操作。签名在引导过程中被验证,但不会在安装或更新引导装载程序时验证。
如果引导装载程序或内核不是由系统可信密钥签名的,则安全引导会阻止它们启动。
3.3. UEFI 安全引导支持
如果内核和所有载入的驱动程序都使用可信密钥签名了,您可以在启用了 UEFI 安全引导的系统上安装并运行 RHEL 8。红帽提供了由相关红帽密钥签名和验证的内核和驱动程序。
如果要加载外部构建的内核或驱动程序,还必须给它们签名。
UEFI 安全引导施加的限制
- 系统仅在签名被正确验证后才运行 kernel-mode 代码。
- GRUB 模块加载被禁用,因为没有签名和验证 GRUB 模块的基础架构。允许模块加载将在安全引导定义的安全范围内运行不受信任的代码。
- 红帽提供了一个签名的 GRUB 二进制文件,它在 RHEL 8 中具有所有支持的模块。
3.4. 使用 X.509 密钥验证内核模块的要求
在 RHEL 8 中,当加载内核模块时,内核会根据内核系统密钥环中的公共 X.509 密钥检查模块的签名(.builtin_trusted_keys)以及内核平台密钥环(.platform)。.platform 密钥环从第三方平台提供商提供密钥和自定义公钥。内核系统 .blacklist 密钥环中的密钥不包括在验证中。
您需要满足某些条件,才能在启用了 UEFI 安全引导功能的系统上载入内核模块:
如果启用了 UEFI 安全引导,或者指定了
module.sig_enforce内核参数:-
您只能加载那些签名是通过系统密钥环 (
.builtin_trusted_keys) 和平台密钥环 (.platform) 验证的已签名内核模块。 -
公钥不能在系统中被撤销的密钥环 (
.blacklist)。
-
您只能加载那些签名是通过系统密钥环 (
如果禁用了 UEFI 安全引导且未指定
module.sig_enforce内核参数:- 您可以加载未签名的内核模块和签名的内核模块,而无需公钥。
如果系统不基于 UEFI,或者禁用 UEFI 安全引导:
-
只有内核中嵌入的密钥才会加载到
.builtin_trusted_keys和.platform。 - 您无法在不重新构建内核的情况下添加这组密钥。
-
只有内核中嵌入的密钥才会加载到
| 模块已签名 | 找到公钥,且签名有效 | UEFI 安全引导状态 | sig_enforce | 模块载入 | 内核污点 |
|---|---|---|---|---|---|
| 未签名 | - | 未启用 | 未启用 | 成功 | 是 |
| 未启用 | Enabled | Fails | - | ||
| Enabled | - | Fails | - | ||
| 已签名 | 否 | 未启用 | 未启用 | 成功 | 是 |
| 未启用 | Enabled | Fails | - | ||
| Enabled | - | Fails | - | ||
| 已签名 | 是 | 未启用 | 未启用 | 成功 | 否 |
| 未启用 | Enabled | 成功 | 否 | ||
| Enabled | - | 成功 | 否 |
3.5. 公钥的源
在引导过程中,内核会从一组持久性密钥中加载 X.509 密钥到以下密钥环中:
-
系统密钥环 (
.builtin_trusted_keys) -
.platform密钥环 -
系统
.blacklist密钥环
| X.509 密钥源 | 用户可以添加密钥 | UEFI 安全引导状态 | 引导过程中载入的密钥 |
|---|---|---|---|
| 嵌入于内核中 | 否 | - |
|
|
UEFI | 有限 | 未启用 | 否 |
| Enabled |
| ||
|
嵌入在 | 否 | 未启用 | 否 |
| Enabled |
| ||
| Machine Owner Key(MOK)列表 | 是 | 未启用 | 否 |
| Enabled |
|
.builtin_trusted_keys- 在引导时构建的密钥环。
- 提供可信的公钥。
-
查看密钥需要
root权限。
.platform- 在引导时构建的密钥环。
- 从第三方平台提供商和自定义公钥提供密钥。
-
查看密钥需要
root权限。
.blacklist- 带有 X.509 密钥的密钥环,该密钥已被撤销。
-
使用来自
.blacklist的密钥签名的模块将会失败,即使您的公钥位于.builtin_trusted_keys中。
- UEFI 安全引导
db - 签名数据库。
- 存储 UEFI 应用程序、UEFI 驱动程序和引导装载程序的密钥(哈希)。
- 密钥可以加载到机器上。
- UEFI 安全引导
dbx - 已撤销的签名数据库。
- 防止加载密钥。
-
从此数据库撤销的密钥添加到
.blacklist密钥环中。
3.6. 生成公钥和私钥对
要在启用了安全引导的系统上使用自定义内核或自定义内核模块,您必须生成一个公钥和私有 X.509 密钥对。您可以使用生成的私钥为内核或内核模块签名。您还可以通过在向安全引导的 Machine Owner Key (MOK)中添加相应的公钥来验证签名的内核或内核模块。
应用强大的安全措施和访问策略来保护您的私钥内容。对于一个恶意的用户,可以使用这个密钥破坏所有由对应公钥验证的系统。
步骤
创建一个 X.509 公钥和私钥对:
如果您只想为自定义内核 模块 签名:
efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --module \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'# efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --module \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果要为自定义 内核 签名:
efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --kernel \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'# efikeygen --dbdir /etc/pki/pesign \ --self-sign \ --kernel \ --common-name 'CN=Organization signing key' \ --nickname 'Custom Secure Boot key'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 当 RHEL 系统运行 FIPS 模式时:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意在 FIPS 模式下,您必须使用
--token选项,以便efikeygen在 PKI 数据库中找到默认的"NSS Certificate DB"令牌。公钥和私钥现在存储在
/etc/pki/pesign/目录中。
好的安全实践是在签名密钥的有效周期内为内核和内核模块签名。但是,sign-file 工具不会警告您,无论有效期日期是什么,密钥在 RHEL 8 中都可用。
3.7. 系统密钥环输出示例
您可以使用 keyutils 软件包中的 keyctl 工具显示系统密钥环上的密钥信息。
先决条件
- 您有 root 权限。
-
您已从
keyutils软件包中安装了keyctl工具。
例 3.1. 密钥环输出
以下是启用了 UEFI 安全引导的 RHEL 8 系统中的 .builtin_trusted_keys、.platform 和 .blacklist 密钥环的简化示例输出。
示例中的 .builtin_trusted_keys 密钥环显示从 UEFI 安全引导 db 密钥以及 Red Hat Secure Boot (CA 密钥 1) (其嵌入在 shim 引导装载程序中)中添加两个密钥。
例 3.2. 内核控制台输出
以下示例显示了内核控制台的输出结果。消息标识带有 UEFI 安全引导相关源的密钥。这包括 UEFI 安全引导 db、嵌入的 shim 和 MOK 列表。
3.8. 通过在 MOK 列表中添加公钥在目标系统中注册公钥
您必须在系统中验证您的公钥以进行内核或内核模块访问,并将其注册到目标系统的平台密钥环(.platform)中。当 RHEL 8 在启用了安全引导机制的基于 UEFI 的系统上引导时,内核会从 db key 数据库导入公钥,并从 dbx 数据库排除撤销的密钥。
Machine Owner Key (MOK)工具允许扩展 UEFI 安全引导密钥数据库。当在启用了安全引导机制的 UEFI 系统中引导 RHEL 8 时,MOK 列表中的密钥会添加到平台密钥环(.platform)中,以及安全引导数据库中的密钥。MOK 密钥列表以同样的方式安全而持久存储,但它是与安全引导数据库独立的工具。
MOK 工具由 shim、MMokManager、GRUB 和 mokutil 实用程序支持,它为基于 UEFI 的系统启用安全密钥管理和身份验证。
要在您的系统中获取内核模块的身份验证服务,请考虑您的系统厂商将公钥合并到其工厂固件镜像中的 UEFI 安全引导密钥数据库中。
先决条件
- 您已生成了一个公钥和私钥对,并了解公钥的有效日期。详情请参阅生成公钥和私钥对。
步骤
将您的公钥导出到
sb_cert.cer文件中:certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cer# certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将您的公钥导入到 MOK 列表中:
mokutil --import sb_cert.cer
# mokutil --import sb_cert.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 输入此 MOK 注册请求的新密码。
重启机器。
shim引导装载程序会注意到待处理的 MOK 密钥注册请求,并启动MokManager.efi,以使您从 UEFI 控制台完成注册。选择
Enroll MOK,在提示时输入之前与此请求关联的密码,并确认注册。您的公钥已添加到 MOK 列表中,这是永久的。
密钥位于 MOK 列表中后,它将会在启用 UEFI 安全引导时自动将其传播到此列表上的
.platform密钥环中。
3.9. 使用私钥签名内核
如果启用了 UEFI 安全引导机制,您可以通过载入签名的内核在系统上获得增强的安全好处。
先决条件
- 您已生成了一个公钥和私钥对,并了解公钥的有效日期。详情请参阅生成公钥和私钥对。
- 您已在目标系统上注册了公钥。详情请查看在 MOK 列表中添加公钥在目标系统中注册公钥。
- 您有一个可用于签名的 ELF 格式的内核镜像。
步骤
在 x64 构架上:
创建一个签名的镜像:
pesign --certificate 'Custom Secure Boot key' \ --in vmlinuz-version \ --sign \ --out vmlinuz-version.signed# pesign --certificate 'Custom Secure Boot key' \ --in vmlinuz-version \ --sign \ --out vmlinuz-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
vmlinuz文件的版本后缀替换version,使用您之前选择的名称替换Custom Secure Boot key。可选:检查签名:
pesign --show-signature \ --in vmlinuz-version.signed# pesign --show-signature \ --in vmlinuz-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用签名镜像覆盖未签名的镜像:
mv vmlinuz-version.signed vmlinuz-version
# mv vmlinuz-version.signed vmlinuz-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在 64 位 ARM 架构中:
解压缩
vmlinuz文件:zcat vmlinuz-version > vmlinux-version
# zcat vmlinuz-version > vmlinux-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个签名的镜像:
pesign --certificate 'Custom Secure Boot key' \ --in vmlinux-version \ --sign \ --out vmlinux-version.signed# pesign --certificate 'Custom Secure Boot key' \ --in vmlinux-version \ --sign \ --out vmlinux-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:检查签名:
pesign --show-signature \ --in vmlinux-version.signed# pesign --show-signature \ --in vmlinux-version.signedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 压缩
vmlinux文件:gzip --to-stdout vmlinux-version.signed > vmlinuz-version
# gzip --to-stdout vmlinux-version.signed > vmlinuz-versionCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除未压缩的
vmlinux文件:rm vmlinux-version*
# rm vmlinux-version*Copy to Clipboard Copied! Toggle word wrap Toggle overflow
3.10. 使用私钥签名 GRUB 构建
在启用了 UEFI 安全引导机制的系统上,您可以使用自定义的现有私钥为 GRUB 构建签名。如果您使用自定义 GRUB 构建,或者已经从系统中删除 Microsoft 信任锚,则您必须执行此操作。
先决条件
- 您已生成了一个公钥和私钥对,并了解公钥的有效日期。详情请参阅生成公钥和私钥对。
- 您已在目标系统上注册了公钥。详情请查看在 MOK 列表中添加公钥在目标系统中注册公钥。
- 您有一个可用于签名的 GRUB EFI 二进制文件。
流程
在 x64 构架上:
创建一个签名的 GRUB EFI 二进制文件:
pesign --in /boot/efi/EFI/redhat/grubx64.efi \ --out /boot/efi/EFI/redhat/grubx64.efi.signed \ --certificate 'Custom Secure Boot key' \ --sign# pesign --in /boot/efi/EFI/redhat/grubx64.efi \ --out /boot/efi/EFI/redhat/grubx64.efi.signed \ --certificate 'Custom Secure Boot key' \ --signCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
Custom Secure Boot key替换为您之前选择的名称。可选:检查签名:
pesign --in /boot/efi/EFI/redhat/grubx64.efi.signed \ --show-signature# pesign --in /boot/efi/EFI/redhat/grubx64.efi.signed \ --show-signatureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用签名的二进制文件覆盖未签名的二进制文件:
mv /boot/efi/EFI/redhat/grubx64.efi.signed \ /boot/efi/EFI/redhat/grubx64.efi# mv /boot/efi/EFI/redhat/grubx64.efi.signed \ /boot/efi/EFI/redhat/grubx64.efiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在 64 位 ARM 架构中:
创建一个签名的 GRUB EFI 二进制文件:
pesign --in /boot/efi/EFI/redhat/grubaa64.efi \ --out /boot/efi/EFI/redhat/grubaa64.efi.signed \ --certificate 'Custom Secure Boot key' \ --sign# pesign --in /boot/efi/EFI/redhat/grubaa64.efi \ --out /boot/efi/EFI/redhat/grubaa64.efi.signed \ --certificate 'Custom Secure Boot key' \ --signCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将
Custom Secure Boot key替换为您之前选择的名称。可选:检查签名:
pesign --in /boot/efi/EFI/redhat/grubaa64.efi.signed \ --show-signature# pesign --in /boot/efi/EFI/redhat/grubaa64.efi.signed \ --show-signatureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用签名的二进制文件覆盖未签名的二进制文件:
mv /boot/efi/EFI/redhat/grubaa64.efi.signed \ /boot/efi/EFI/redhat/grubaa64.efi# mv /boot/efi/EFI/redhat/grubaa64.efi.signed \ /boot/efi/EFI/redhat/grubaa64.efiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.11. 使用私钥签名内核模块
如果启用了 UEFI 安全引导机制,您可以通过加载签名的内核模块来提高系统的安全性。
在禁用了 UEFI 安全引导的系统上或非 UEFI 系统上,您签名的内核模块也是可以加载的。因此,您不需要提供内核模块的签名和未签名版本。
先决条件
- 您已生成了一个公钥和私钥对,并了解公钥的有效日期。详情请参阅生成公钥和私钥对。
- 您已在目标系统上注册了公钥。详情请查看在 MOK 列表中添加公钥在目标系统中注册公钥。
- 您有一个可以签注的 ELF 镜像格式的内核模块。
流程
将您的公钥导出到
sb_cert.cer文件中:certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cer# certutil -d /etc/pki/pesign \ -n 'Custom Secure Boot key' \ -Lr \ > sb_cert.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 从 NSS 数据库中提取密钥作为 PKCS #12 文件:
pk12util -o sb_cert.p12 \ -n 'Custom Secure Boot key' \ -d /etc/pki/pesign# pk12util -o sb_cert.p12 \ -n 'Custom Secure Boot key' \ -d /etc/pki/pesignCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 当上一命令提示时,输入加密私钥的新密码。
导出未加密的私钥:
openssl pkcs12 \ -in sb_cert.p12 \ -out sb_cert.priv \ -nocerts \ -nodes# openssl pkcs12 \ -in sb_cert.p12 \ -out sb_cert.priv \ -nocerts \ -nodesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要保持未加密的私钥的安全。
为内核模块签名。以下命令将签名直接附加到内核模块文件中的 ELF 镜像中:
/usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ sb_cert.priv \ sb_cert.cer \ my_module.ko# /usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ sb_cert.priv \ sb_cert.cer \ my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow
您的内核模块现在可以被加载。
在 RHEL 8 中,密钥对的有效性日期非常重要。这个密钥没有过期,但必须在其签名密钥的有效周期内对内核模块进行签名。sign-file 实用程序不会提醒您这样做。例如:一个只在 2019 年有效的密钥可用来验证在 2019 年中使用该密钥签名的内核模块。但是,用户无法使用这个密钥在 2020 年签注一个内核模块。
验证
显示关于内核模块签名的信息:
modinfo my_module.ko | grep signer
# modinfo my_module.ko | grep signer signer: Your Name KeyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 检查签名中是否列出了您在生成过程中输入的名称。
注意附加的签名不包含在 ELF 镜像部分,不是 ELF 镜像的一个正式部分。因此,
readelf等工具无法在内核模块上显示签名。载入模块:
insmod my_module.ko
# insmod my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除(未加载)模块:
modprobe -r my_module.ko
# modprobe -r my_module.koCopy to Clipboard Copied! Toggle word wrap Toggle overflow
3.12. 载入经过签名的内核模块
在系统密钥环中注册您的公钥(.builtin_trusted_keys)和 MOK 列表,并使用您的私钥签署内核模块,您可以使用 modprobe 命令加载它们。
先决条件
- 您已生成了公钥和私钥对。详情请参阅生成公钥和私钥对。
- 您已经在系统密钥环中注册了公钥。详情请查看在 MOK 列表中添加公钥在目标系统中注册公钥。
- 您用私钥签名了一个内核模块。详情请查看使用私钥签名内核模块。
安装
kernel-modules-extra软件包,它会创建/lib/modules/$(uname -r)/extra/目录:yum -y install kernel-modules-extra
# yum -y install kernel-modules-extraCopy to Clipboard Copied! Toggle word wrap Toggle overflow
流程
验证您的公钥是否在系统密钥环中:
keyctl list %:.platform
# keyctl list %:.platformCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将内核模块复制到您想要的内核的
extra/目录中:cp my_module.ko /lib/modules/$(uname -r)/extra/
# cp my_module.ko /lib/modules/$(uname -r)/extra/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 更新模块依赖项列表:
depmod -a
# depmod -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 载入内核模块:
modprobe -v my_module
# modprobe -v my_moduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选: 要在引导时载入模块,将其添加到
/etc/modules-loaded.d/my_module.conf文件中:echo "my_module" > /etc/modules-load.d/my_module.conf
# echo "my_module" > /etc/modules-load.d/my_module.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
验证模块是否被成功载入:
lsmod | grep my_module
# lsmod | grep my_moduleCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 4 章 配置内核命令行参数
使用内核命令行参数,您可以在引导时更改 Red Hat Enterprise Linux 内核的某些方面的行为。作为系统管理员,您可以控制在引导时设置哪些选项。请注意,某些内核行为只能在引导时设置。
通过修改内核命令行参数来更改系统行为可能会对您的系统造成负面影响。在生产环境中部署更改前,始终测试更改。如需进一步指导,请联系红帽支持团队。
4.1. 什么是内核命令行参数
使用内核命令行参数,您可以覆盖默认值并设置特定的硬件设置。在引导时,您可以配置以下功能:
- Red Hat Enterprise Linux 内核
- 初始 RAM 磁盘
- 用户空间特性
默认情况下,使用 GRUB 引导装载程序的系统的内核命令行参数定义在每个内核引导条目的 /boot/grub2/grubenv 文件的 kernelopts 变量中。
对于 IBM Z,内核命令行参数保存在引导条目配置文件中,因为 zipl 引导装载程序不支持环境变量。因此,无法使用 kernelopts 环境变量。
您可以使用 grubby 工具操作引导装载程序配置文件。使用 grubby,您可以执行以下操作:
- 更改默认的引导条目。
- 从 GRUB 菜单条目中添加或删除参数。
4.2. 了解引导条目
引导条目是存储在配置文件中并绑定到特定内核版本的选项集合。在实践中,您的引导条目至少与您所安装的系统数量相同。引导条目配置文件位于 /boot/loader/entries/ 目录中:
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
以上文件名由存储在 /etc/machine-id 文件中的计算机 ID 和内核版本组成。
引导条目配置文件包含有关内核版本、初始 ramdisk 镜像和包含内核命令行参数的 kernelopts 环境变量的信息。配置文件可以包含以下内容:
kernelopts 环境变量在 /boot/grub2/grubenv 文件中定义。
4.3. 为所有引导条目更改内核命令行参数
更改系统上所有引导条目的内核命令行参数。
先决条件
-
grubby工具安装在您的系统上。 -
zipl工具安装在 IBM Z 系统中。
流程
添加参数:
grubby --update-kernel=ALL --args="<NEW_PARAMETER>"
# grubby --update-kernel=ALL --args="<NEW_PARAMETER>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 对于使用 GRUB 引导加载程序的系统,该命令会通过向该文件中的
kernelopts变量添加一个新内核参数来更新/boot/grub2/grubenv文件。在 IBM Z 上,更新引导菜单:
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
删除参数:
grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"
# grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在 IBM Z 上,更新引导菜单:
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
新安装的内核继承之前配置的内核中的内核命令行参数。
4.4. 为单一引导条目更改内核命令行参数
对系统上单个引导条目的内核命令行参数进行更改。
先决条件
-
在您的系统上安装了
grubby和zipl工具。
流程
添加参数:
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在 IBM Z 上,更新引导菜单:
grubby --args="<NEW_PARAMETER> --update-kernel=ALL --zipl
# grubby --args="<NEW_PARAMETER> --update-kernel=ALL --ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
删除参数:
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在 IBM Z 上,更新引导菜单:
grubby --args="<PARAMETER_TO_REMOVE> --update-kernel=ALL --zipl
# grubby --args="<PARAMETER_TO_REMOVE> --update-kernel=ALL --ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
在使用 grub.cfg 文件的系统上,默认情况下每个内核引导条目的 options 参数设置为 kernelopts 变量。此变量在 /boot/grub2/grubenv 配置文件中定义。
在 GRUB 系统中:
-
如果为所有引导条目修改了内核命令行参数,
grubby实用程序会更新/boot/grub2/grubenv文件中的kernelopts变量。 -
如果为单个引导条目修改了内核命令行参数,则扩展
kernelopts变量,修改内核参数,结果值存储在相应的引导条目的/boot/loader/entries/<RELEVANT_KERNEL_BOOT_ENTRY.conf>文件中。
在 zIPL 系统中:
-
grubby修改单个内核引导条目的内核命令行参数并将其存储在/boot/loader/entries/<ENTRY>.conf文件中。
4.5. 在引导时临时更改内核命令行参数
通过在单个引导过程中更改内核参数,对内核惨淡条目进行临时更改。
这个过程只适用于单一引导,且不会永久进行更改。
流程
- 引导进入 GRUB 引导菜单。
- 选择您要启动的内核。
- 按 e 键编辑内核参数。
-
通过移动光标来找到内核命令行。在 64 位 IBM Power 系列和基于 x86-64 BIOS 的系统上内核命令行以
linux开头,或在 UEFI 系统上以linuxefi开头。 将光标移至行末。
注意按 Ctrl+a 跳到行首,按 Ctrl+e 跳到行尾。在某些系统上,Home 和 End 键也可能会正常工作。
根据需要编辑内核参数。例如,要在紧急模式下运行系统,请在
linux行末尾添加emergency参数:linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergency
linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergencyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要启用系统消息,请删除
rhgb和quiet参数。- 按 Ctrl+x 使用所选内核以及修改的命令行参数进行引导。
如果按 Esc 键离开命令行编辑,它将丢弃用户做的所有更改。
4.6. 配置 GRUB 设置以启用串行控制台连接
当您需要连接到无头服务器或嵌入式系统,且网络中断时,串行控制台非常有用。或者,当您需要避免安全规则,并获得不同系统上的登录访问权限时。
您需要配置一些默认的 GRUB 设置,以使用串行控制台连接。
先决条件
- 您有 root 权限。
流程
将下面两行添加到
/etc/default/grub文件中:GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"
GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 第一行将禁用图形终端。
GRUB_TERMINAL键覆盖GRUB_TERMINAL_INPUT和GRUB_TERMINAL_OUTPUT键的值。第二行调整了波特率(
--speed),奇偶校验和其他值以适合您的环境和硬件。请注意,对于以下日志文件等任务,最好使用更高的波特率,如 115200。更新 GRUB 配置文件。
在基于 BIOS 的机器上:
grub2-mkconfig -o /boot/grub2/grub.cfg
# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在基于 UEFI 的机器上:
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- 重启系统以使更改生效。
第 5 章 在运行时配置内核参数
作为系统管理员,您可以修改 Red Hat Enterprise Linux 内核在运行时行为的很多方面。使用 sysctl 命令,并修改 /etc/sysctl.d/ 和 /proc/sys/ 目录中的配置文件来在运行时配置内核参数。
在产品系统中配置内核参数需要仔细规划。非计划的更改可能会导致内核不稳定,需要重启系统。在更改任何内核值之前,验证您是否正在使用有效选项。
有关在 IBM DB2 上调整内核的更多信息,请参阅 为 IBM DB2 调整 Red Hat Enterprise Linux。
5.1. 什么是内核参数
内核参数是您可以在系统运行时调整的可调整值。请注意,要使更改生效,您不需要重启系统或重新编译内核。
可以通过以下方法处理内核参数:
-
sysctl命令 -
挂载于
/proc/sys/目录的虚拟文件系统 -
/etc/sysctl.d/目录中的配置文件
Tunables 被内核子系统划分为不同的类。Red Hat Enterprise Linux 有以下可调整类:
| 可调整类 | 子系统 |
|---|---|
|
| 执行域和个人 |
|
| 加密接口 |
|
| 内核调试接口 |
|
| 特定于设备的信息 |
|
| 全局和特定文件系统的 tunables |
|
| 全局内核 tunables |
|
| 网络 tunables |
|
| Sun 远程过程调用 (NFS) |
|
| 用户命名空间限制 |
|
| 调整和管理内存、缓冲和缓存 |
5.2. 使用 sysctl 临时配置内核参数
使用 sysctl 命令在运行时临时设置内核参数。命令也可用于列出和过滤可调项。
先决条件
- 根权限
流程
列出所有参数及其值。
sysctl -a
# sysctl -a# sysctl -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意# sysctl -a命令显示内核参数,可在运行时和系统启动时调整。要临时配置一个参数,请输入:
sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>
# sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上面的示例命令在系统运行时更改了参数值。更改将立即生效,无需重新启动。
注意在系统重启后,所在的改变会返回到默认状态。
5.3. 使用 sysctl 永久配置内核参数
使用 sysctl 命令永久设置内核参数。
先决条件
- 根权限
流程
列出所有参数。
sysctl -a
# sysctl -a# sysctl -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 该命令显示所有可在运行时配置的内核参数。
永久配置一个参数:
sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.conf
# sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例命令会更改可调值,并将其写入
/etc/sysctl.conf文件,该文件会覆盖内核参数的默认值。更改会立即并永久生效,无需重启。
要永久修改内核参数,您还可以手动更改 /etc/sysctl.d/ 目录中的配置文件。
5.4. 使用 /etc/sysctl.d/ 中的配置文件调整内核参数
您必须手动修改 /etc/sysctl.d/ 目录中的配置文件来永久设置内核参数。
先决条件
- 您有 root 权限。
流程
在
/etc/sysctl.d/中创建新配置文件:vim /etc/sysctl.d/<some_file.conf>
# vim /etc/sysctl.d/<some_file.conf># vim /etc/sysctl.d/<some_file.conf>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 包括内核参数,每行一个:
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存配置文件。
重启机器以使更改生效。
或者,在不重启的情况下应用更改:
sysctl -p /etc/sysctl.d/<some_file.conf>
# sysctl -p /etc/sysctl.d/<some_file.conf># sysctl -p /etc/sysctl.d/<some_file.conf>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 该命令允许您从之前创建的配置文件中读取值。
5.5. 通过 /proc/sys/ 临时配置内核参数
通过 /proc/sys/ 虚拟文件系统目录中的文件临时设置内核参数。
先决条件
- 根权限
流程
确定您要配置的内核参数。
ls -l /proc/sys/<TUNABLE_CLASS>/
# ls -l /proc/sys/<TUNABLE_CLASS>/# ls -l /proc/sys/<TUNABLE_CLASS>/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令返回的可写入文件可以用来配置内核。具有只读权限的文件提供了对当前设置的反馈。
为内核参数分配一个目标值。
echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
# echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER># echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用命令应用的配置更改不是永久的,将在系统重启后消失。
验证
验证新设置内核参数的值。
cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
# cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER># cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 6 章 对 GRUB 菜单进行临时更改
您可以修改 GRUB 菜单条目,或将参数传递给内核,这只适用于当前引导。在引导装载程序菜单中的所选菜单条目中,您可以:
- 按 e 键显示菜单条目编辑器界面。
- 按 Esc 键丢弃所有更改并重新载入标准菜单界面。
- 按 c 键载入命令行。
- 输入所有相关 GRUB 命令,然后按 Enter 键输入它们。
- 按 Tab 键,根据上下文完成命令。
- 按 Ctrl+a 组合键移动到行的开头。
- 按 Ctrl+e 组合键移动到行尾。
以下流程提供了在单一引导过程中更改 GRUB 菜单的说明。
6.1. GRUB 简介
您可以使用 GNU GRand Unified Bootloader (GRUB)执行以下操作:
- 选择要在系统引导时载入的操作系统或内核。
- 将参数传递给内核。
使用 GRUB 引导时,您可以使用菜单界面或命令行界面( GRUB 命令 shell )。当您启动系统时,会显示菜单界面。

您可以通过按 c 键切换到命令行。

您可以输入 exit 并按 Enter 键来返回到菜单界面。
GRUB BLS 文件
引导装载程序菜单条目被定义为引导加载程序规格(BLS)文件。此文件格式管理置入目录中每个引导选项的引导装载程序配置,而不操作引导装载程序配置文件。grubby 工具可编辑这些 BLS 文件。
GRUB 配置文件
/boot/grub2/grub.cfg 配置文件不定义菜单条目。
6.3. 引导至救援模式
救援模式提供了一个方便的单用户环境,在此环境中,您可以在无法完成正常引导过程时修复您的系统。在救援模式下,系统会尝试挂载所有本地文件系统,并启动一些重要的系统服务。但是,它不会激活网络接口,或者允许更多的用户同时登录到系统。
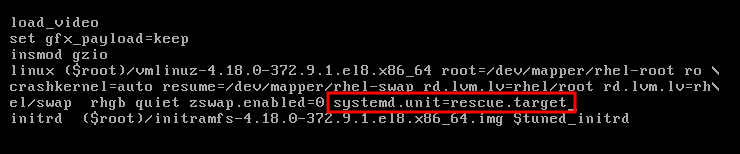
流程
- 在 GRUB 引导屏幕上,按 e 键进行编辑。
在
linux行末尾添加以下参数:systemd.unit=rescue.target
systemd.unit=rescue.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 按 Ctrl+x 引导至救援模式。

6.4. 引导至紧急模式
紧急模式提供尽可能小的环境,在此环境中,您可以在系统无法进入到救援模式时修复您的系统。
在紧急模式下,系统:
-
仅为读取挂载
root文件系统 - 启动几个基本服务
但是,系统 不会 :
- 尝试挂载任何其他本地文件系统
- 激活网络接口
流程
- 在 GRUB 引导屏幕上,按 e 键进行编辑。
在
linux行末尾添加以下参数:systemd.unit=emergency.target
systemd.unit=emergency.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 按 Ctrl+x 引导至紧急模式。


6.5. 引导至 debug shell
systemd debug shell 在启动过程早期提供了一个 shell 提示符。在 debug shell 中,您可以使用 systemctl 命令,如 systemctl list-jobs 和 systemctl list-units ,搜索与引导问题相关的 systemd 的原因。
流程
- 在 GRUB 引导屏幕上,按 e 键进行编辑。
在
linux行末尾添加以下参数:systemd.debug-shell
systemd.debug-shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:添加
debug选项。注意向内核命令行添加
debug选项会增加日志消息的数量。对于systemd,内核命令行选项debug现在是systemd.log_level=debug的快捷方式。- 按 Ctrl+x 启动到 debug shell。

永久启用 debug shell 是一个安全风险,因为不需要进行身份验证。建议您在调试会话结束时禁用它。
6.6. 连接到 debug shell
在启动过程中,systemd-debug-generator 在 TTY9 上配置 debug shell。
先决条件
- 您已成功引导至 debug shell。请参阅 引导至 debug shell。
流程
按 Ctrl+Alt+F9 连接到 debug shell。
如果您使用虚拟机,发送此组合键需要虚拟化应用程序的支持。例如,如果使用 虚拟机管理器,请从菜单中选择 → 。
- debug shell 不需要身份验证,因此您可以在 TTY9 上看到类似如下的提示:
sh-4.4#
sh-4.4#验证
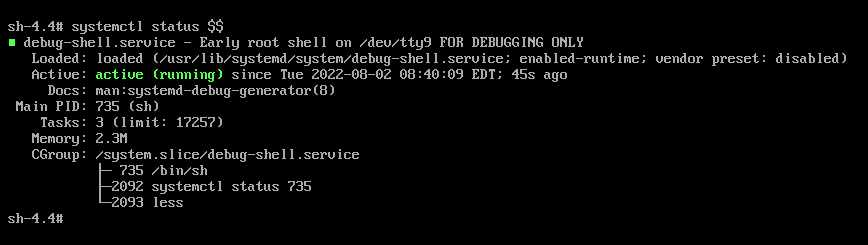
按照如下所示输入命令:
systemctl status $$
sh-4.4# systemctl status $$Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 要返回到默认 shell,如果引导成功,请按 Ctrl+Alt+F1。
6.7. 使用安装盘重置 root 密码
如果您忘记或丢失了 root 密码,您可以重置它。
流程
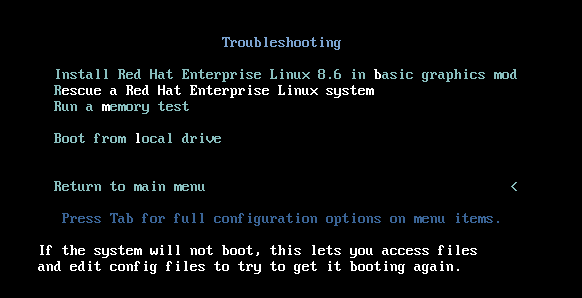
- 从安装源引导主机。
在安装介质的引导菜单中,选择
Troubleshooting选项。在 Troubleshooting 菜单中选择
Rescue a Red Hat Enterprise Linux system选项。在 Rescue 菜单中,选择
1,并按 Enter 键继续。按如下所示更改文件系统
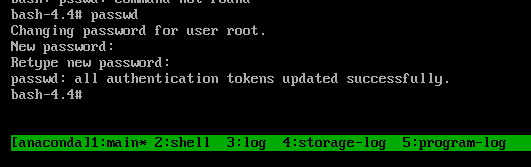
root:chroot /mnt/sysimage
sh-4.4# chroot /mnt/sysimageCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输入
passwd命令,并按照命令行上显示的指令更改root密码。删除
autorelable文件,以防止耗时的磁盘的 SELinux 重新标记:rm -f /.autorelabel
sh-4.4# rm -f /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
输入
exit命令退出chroot环境。 -
再次输入
exit命令,以恢复初始化并完成系统启动。



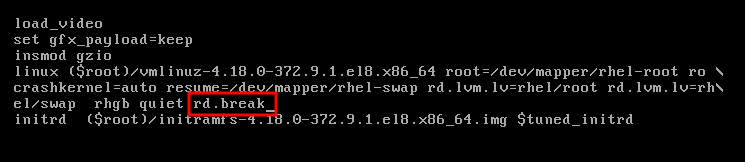
6.8. 使用 rd.break 重置 root 密码
如果您忘记或丢失了 root 密码,您可以重置它。
流程
- 启动系统,并在 GRUB 引导屏幕上按 e 键进行编辑。
在
linux行末尾添加rd.break参数:按 Ctrl+x 使用更改的参数引导系统。
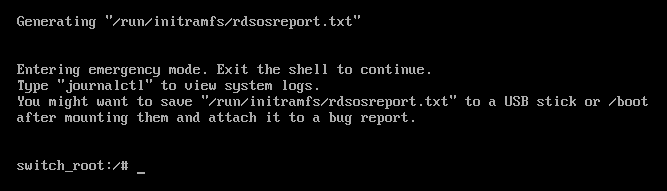
将文件系统重新挂载为可写。
switch_root:/# mount -o remount,rw /sysroot
switch_root:/# mount -o remount,rw /sysrootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 更改文件系统的
root。switch_root:/# chroot /sysroot
switch_root:/# chroot /sysrootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 输入
passwd命令,并按照命令行上显示的说明进行操作。在下次系统引导时重新标记所有文件。
touch /.autorelabel
sh-4.4# touch /.autorelabelCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重新将文件系统挂载为 只读 :
mount -o remount,ro /
sh-4.4# mount -o remount,ro /Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
输入
exit命令退出chroot环境。 再次输入
exit命令,以恢复初始化并完成系统启动。注意SELinux 重新标记过程可能需要很长时间。系统会在进程完成后自动重启。
您可以通过添加 enforcing=0 选项来省略耗时的 SELinux 重新标记过程。
流程
当在
linux行末尾添加rd.break参数时,请附加enforcing=0。rd.break enforcing=0
rd.break enforcing=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 恢复
/etc/shadow文件的 SELinux 安全上下文。restorecon /etc/shadow
# restorecon /etc/shadowCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重新打开 SELinux 策略强制,并确认它是否开启。
setenforce 1 getenforce
# setenforce 1 # getenforce EnforcingCopy to Clipboard Copied! Toggle word wrap Toggle overflow
请注意,如果您在第 3 步中添加了 enforcing=0 选项,您可以在第 8 步中省略输入 touch /.autorelabel 命令。
第 7 章 对 GRUB 引导装载程序进行永久性更改
使用 grubby 工具在 GRUB 中进行永久更改。
7.1. 先决条件
- 您已在您的系统上成功安装了 RHEL。
- 您有 root 权限。
7.2. 列出默认的内核
通过列出默认内核,您可以找到默认内核的文件名和索引号,以对 GRUB 引导装载程序进行永久更改。
流程
- 要获取默认内核的文件名,请输入:
grubby --default-kernel
# grubby --default-kernel
/boot/vmlinuz-4.18.0-372.9.1.el8.x86_64- 要获取默认内核的索引号,请输入:
grubby --default-index
# grubby --default-index
07.4. 编辑内核参数
您可以更改现有内核参数中的值。例如,您可以更改虚拟控制台(屏幕)字体和大小。
流程
将虚拟控制台字体更改为
latarcyrheb-sun,大小为32:grubby --args=vconsole.font=latarcyrheb-sun32 --update-kernel /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64
# grubby --args=vconsole.font=latarcyrheb-sun32 --update-kernel /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow
7.6. 添加一个新的引导条目
您可以在引导装载程序菜单条目中添加一个新的引导条目。
流程
将来自默认内核的所有内核参数复制到这个新内核条目中:
grubby --add-kernel=new_kernel --title="entry_title" --initrd="new_initrd" --copy-default
# grubby --add-kernel=new_kernel --title="entry_title" --initrd="new_initrd" --copy-defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow 获取可用引导条目列表:
ls -l /boot/loader/entries/*
# ls -l /boot/loader/entries/* -rw-r--r--. 1 root root 408 May 27 06:18 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-0-rescue.conf -rw-r--r--. 1 root root 536 Jun 30 07:53 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-4.18.0-372.9.1.el8.x86_64.conf -rw-r--r-- 1 root root 336 Aug 15 15:12 /boot/loader/entries/d88fa2c7ff574ae782ec8c4288de4e85-4.18.0-193.el8.x86_64.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个新的引导条目。例如,对于 4.18.0-193.el8.x86_64 内核,请按如下所示运行命令:
grubby --grub2 --add-kernel=/boot/vmlinuz-4.18.0-193.el8.x86_64 --title="Red Hat Enterprise 8 Test" --initrd=/boot/initramfs-4.18.0-193.el8.x86_64.img --copy-default
# grubby --grub2 --add-kernel=/boot/vmlinuz-4.18.0-193.el8.x86_64 --title="Red Hat Enterprise 8 Test" --initrd=/boot/initramfs-4.18.0-193.el8.x86_64.img --copy-defaultCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
验证新添加的引导条目是否在可用的引导条目中列出:
ls -l /boot/loader/entries/*
# ls -l /boot/loader/entries/* -rw-r--r--. 1 root root 408 May 27 06:18 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-0-rescue.conf -rw-r--r--. 1 root root 536 Jun 30 07:53 /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-4.18.0-372.9.1.el8.x86_64.conf -rw-r--r-- 1 root root 287 Aug 16 15:17 /boot/loader/entries/d88fa2c7ff574ae782ec8c4288de4e85-4.18.0-193.el8.x86_64.0~custom.conf -rw-r--r-- 1 root root 287 Aug 16 15:29 /boot/loader/entries/d88fa2c7ff574ae782ec8c4288de4e85-4.18.0-193.el8.x86_64.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7.7. 使用 grubby 更改默认引导条目
使用 grubby 工具,您可以更改默认引导条目。
流程
- 要在指定为默认内核的内核中进行持久更改,请输入:
grubby --set-default /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64
# grubby --set-default /boot/vmlinuz-4.18.0-372.9.1.el8.x86_64
The default is /boot/loader/entries/67db13ba8cdb420794ef3ee0a8313205-4.18.0-372.9.1.el8.x86_64.conf with index 0 and kernel /boot/vmlinuz-4.18.0-372.9.1.el8.x86_647.9. 为当前和将来的内核更改默认内核选项
通过使用 kernelopts 变量,您可以为当前和将来的内核更改默认内核选项。
流程
列出
kernelopts变量中的内核参数:grub2-editenv - list | grep kernelopts
# grub2-editenv - list | grep kernelopts kernelopts=root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quietCopy to Clipboard Copied! Toggle word wrap Toggle overflow 对内核命令行参数进行更改。您可以添加、删除或修改参数。例如,要添加
debug参数,请输入:grub2-editenv - set "$(grub2-editenv - list | grep kernelopts) <debug>"
# grub2-editenv - set "$(grub2-editenv - list | grep kernelopts) <debug>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:验证新添加到
kernelopts中的参数:grub2-editenv - list | grep kernelopts
# grub2-editenv - list | grep kernelopts kernelopts=root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet debugCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 重启系统以使更改生效。
另一种方法,您可以使用 grubby 命令将参数传递给当前和将来的内核:
grubby --update-kernel ALL --args="<PARAMETER>"
# grubby --update-kernel ALL --args="<PARAMETER>"第 9 章 重新安装 GRUB
您可以重新安装 GRUB 引导装载程序来修复某些问题,通常是由于 GRUB 的安装不正确、缺少文件或损坏的系统造成的。您可以通过恢复缺少的文件并更新引导信息来解决这些问题。
重新安装 GRUB 的原因:
- 升级 GRUB 引导装载程序软件包。
- 将引导信息添加到另一个驱动器中。
- 用户需要 GRUB 引导装载程序来控制安装的操作系统。但是,一些操作系统是使用自己的引导装载程序安装的,重新安装 GRUB 将控制权返回给所需的操作系统。
只有在文件没有损坏时,GRUB 才能恢复这些文件。
9.1. 在基于 BIOS 的机器上重新安装 GRUB
您可以在基于 BIOS 的系统上重新安装 GRUB 引导装载程序。在更新 GRUB 软件包后,总是重新安装 GRUB。
这会覆盖现有的 GRUB ,以安装新的 GRUB。确定系统在安装过程中不会导致数据损坏或引导崩溃。
流程
在安装了它的设备上重新安装 GRUB。例如:如果
sda是您的设备:grub2-install /dev/sda
# grub2-install /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启您的系统以使更改生效:
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.2. 在基于 UEFI 的机器上重新安装 GRUB
您可以在基于 UEFI 的系统上重新安装 GRUB 引导装载程序。
确定系统在安装过程中不会导致数据损坏或引导崩溃。
流程
重新安装
grub2-efi和shim引导装载程序文件:yum reinstall grub2-efi shim
# yum reinstall grub2-efi shimCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启您的系统以使更改生效:
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3. 在 IBM Power 机器上重新安装 GRUB
您可以在 IBM Power 系统的 Power PC Reference Platform (PReP)引导分区上重新安装 GRUB 引导装载程序。在更新 GRUB 软件包后,总是重新安装 GRUB。
这会覆盖现有的 GRUB ,以安装新的 GRUB。确定系统在安装过程中不会导致数据损坏或引导崩溃。
流程
确定存储 GRUB 的磁盘分区:
bootlist -m normal -o
# bootlist -m normal -o sda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在磁盘分区上重新安装 GRUB:
grub2-install partition
# grub2-install partitionCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用标识的 GRUB 分区(如
/dev/sda1)替换partition。重启您的系统以使更改生效:
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.4. 重置 GRUB
重置 GRUB 会完全删除所有 GRUB 配置文件和系统设置,并重新安装引导装载程序。您可以将所有配置设置重置回其默认值,因此可以修复由文件损坏和无效配置导致的故障。
以下流程将删除用户所做的所有自定义。
流程
删除配置文件:
rm /etc/grub.d/* rm /etc/sysconfig/grub
# rm /etc/grub.d/* # rm /etc/sysconfig/grubCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重新安装软件包。
在基于 BIOS 的机器上:
yum reinstall grub2-tools
# yum reinstall grub2-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在基于 UEFI 的机器上:
yum reinstall grub2-efi shim grub2-tools grub2-common
# yum reinstall grub2-efi shim grub2-tools grub2-commonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
重建
grub.cfg文件以使更改生效。在基于 BIOS 的机器上:
grub2-mkconfig -o /boot/grub2/grub.cfg
# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在基于 UEFI 的机器上:
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
按照 重新安装 GRUB 流程来在
/boot/分区上恢复 GRUB。
第 10 章 使用密码保护 GRUB
您可以通过两种方式使用密码保护 GRUB:
- 修改菜单条目需要密码,但引导现有菜单条目不需要。
- 修改菜单条目和引导现有菜单条目时需要密码。
第 11 章 在虚拟环境中保留内核 panic 参数
在 RHEL 8 中配置虚拟机时,请不要启用 softlockup_panic 和 nmi_watchdog 内核参数,因为虚拟机可能会遇到错误的软锁定。这不需要一个内核 panic。
在以下部分中找到此建议背后的原因。
11.1. 什么是软锁定
当任务在不重新调度的情况下在 CPU 上的内核空间中执行时,软锁定通常是由程序错误造成的。该任务也不允许任何其他任务在特定 CPU 上执行。因此,用户通过系统控制台会显示警告信息。这个问题也被称为软锁定触发。
11.2. 控制内核 panic 的参数
可设置以下内核参数来控制当检测到软锁定时的系统行为。
softlockup_panic控制当检测到软锁定时内核是否 panic。
Expand 类型 值 效果 整数
0
内核在软锁定时不 panic
整数
1
软锁定中的内核 panics
默认情况下,在 RHEL 8 上这个值为 0。
系统需要首先检测硬锁定才能 panic。检测由
nmi_watchdog参数控制。nmi_watchdog控制锁定检测机制 (
watchdogs) 是否处于活动状态。这个参数是整数类型。Expand 值 效果 0
禁用锁定检测器
1
启用锁定检测器
硬锁定检测器会监控每个 CPU 是否有响应中断的能力。
watchdog_thresh控制 watchdog
hrtimer的频率、NMI 事件和软或硬锁定阈值。Expand 默认阈值 软锁定阈值 10 秒
2 *
watchdog_thresh将此参数设置为 0 可禁用锁定检测。
11.3. 在虚拟环境中有伪装的软锁定
在物理主机上触发的 软锁定 通常代表内核或硬件 bug 。在虚拟环境中的客户机操作系统上发生的同样的现象可能代表假的警告。
主机上的重工作负载或对某些特定资源(如内存)的竞争可能导致错误的软锁定的触发,因为主机可能会调度客户端 CPU 的时间超过 20 秒。当客户机 CPU 再次被调度到在主机上运行时,它会经历一个触发 到期计时器的 时间跳跃。计时器还包括 hrtimer watchdog,其可报告客户机 CPU 上的软锁定。
虚拟化环境中的软锁定可能是假的。当报告对客户机 CPU 的一个软锁定时,您不必启用触发系统 panic 的内核参数。
若要了解客户机中的软锁定,必须了解,主机会作为一个任务调度客户机,客户机然后会调度自己的任务。
第 12 章 为数据库服务器调整内核参数
为确保数据库服务器和数据库的有效操作,您必须配置所需的内核参数集。
12.1. 介绍
数据库服务器是一种提供数据库管理系统 (DBMS) 功能的服务。DBMS 提供数据库管理的实用程序,并与最终用户、应用程序和数据库交互。
Red Hat Enterprise Linux 8 提供以下数据库管理系统:
- MariaDB 10.3
- MariaDB 10.5 - 从 RHEL 8.4 开始提供
- MariaDB 10.11 - 从 RHEL 8.10 开始提供
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - 从 RHEL 8.1.1 开始提供
- PostgreSQL 13 - 从 RHEL 8.4 开始提供
- PostgreSQL 15 - 从 RHEL 8.8 开始提供
- PostgreSQL 16 - 从 RHEL 8.10 开始提供
12.2. 影响数据库应用程序性能的参数
以下内核参数会影响数据库应用程序的性能。
- fs.aio-max-nr
定义系统可在服务器中处理的异步 I/O 操作的最大数目。
注意增加
fs.aio-max-nr参数不会在增加 aio 限制外产生任何变化。- fs.file-max
定义系统在任何实例上支持的最大文件句柄数(临时文件名或者分配给打开文件的 ID)。
内核会在应用程序请求文件句柄时动态分配文件。但是,当这些文件被应用程序释放时,内核不会释放这些文件句柄。而是回收这些文件句柄。分配的文件句柄的总数将随时间而增加,即使当前使用的文件句柄的数可能较少。
kernel.shmall-
定义可用于系统范围的共享内存页面总数。要使用整个主内存,
kernel.shmall参数的值应当为主内存大小总计。 kernel.shmmax- 定义 Linux 进程在其虚拟地址空间中可分配的单个共享内存段的最大字节大小。
kernel.shmmni- 定义数据库服务器能够处理的共享内存段的最大数量。
net.ipv4.ip_local_port_range- 系统将此端口范围用于连接到数据库服务器的程序,而无需指定端口号。
net.core.rmem_default- 通过传输控制协议 (TCP) 定义默认接收套接字内存。
net.core.rmem_max- 通过传输控制协议 (TCP) 定义最大接收套接字内存。
net.core.wmem_default- 通过传输控制协议 (TCP) 定义默认发送套接字内存。
net.core.wmem_max- 通过传输控制协议 (TCP) 定义最大发送套接字内存。
vm.dirty_bytes/vm.dirty_ratio-
定义以脏内存百分比为单位的字节/阈值,在该阈值中,生成脏数据的进程会在
write()函数中启动。
一个 vm.dirty_bytes 或 vm.dirty_ratio 可以在同一时间被指定。
vm.dirty_background_bytes/vm.dirty_background_ratio- 定义以脏内存百分比为单位的字节/阈值,达到此阈值时内核会尝试主动将脏数据写入硬盘。
一个 vm.dirty_background_bytes 或 vm.dirty_background_ratio 可以一次指定。
vm.dirty_writeback_centisecs定义负责将脏数据写入硬盘的内核线程定期唤醒之间的时间间隔。
这个内核参数以 100 分之一秒为单位。
vm.dirty_expire_centisecs定义将变旧的脏数据写入硬盘的时间。
这个内核参数以 100 分之一秒为单位。
第 13 章 内核日志记录入门
日志文件提供有关系统的消息,包括内核、服务及其上运行的应用程序。syslog 服务为登录 Red Hat Enterprise Linux 提供了原生支持。各种实用程序使用此系统记录事件并将其整理到日志文件中。这些文件在审核操作系统或故障排除问题时非常有用。
13.1. 什么是内核环缓冲
在引导过程中,控制台提供有关系统启动的初始阶段的重要信息。为避免丢失早期的消息,内核使用环缓冲。此缓冲区会保存由内核代码中的 printk() 函数所产生的所有消息(包括引导消息)。来自内核环缓冲的消息随后由 syslog 服务读取并存储在永久存储上的日志文件中。
环缓冲是一个具有固定大小的循环数据结构,并硬编码到内核中。用户可以通过 dmesg 命令或 /var/log/boot.log 文件显示存储在内核环缓冲中的数据。当环形缓冲区满时,新数据将覆盖旧数据。
13.2. 日志级别和内核日志记录上的 printk 角色
内核报告的每条消息都有一个与它关联的日志级别,用于定义消息的重要性。如什么是内核环缓冲区中所述,内核环缓冲会收集所有日志级别的内核消息。kernel.printk 参数用于定义缓冲区中哪些消息打印到控制台中。
日志级别值按以下顺序划分:
- 0
- 内核紧急情况。系统不可用。
- 1
- 内核警报。必须立即采取行动。
- 2
- 内核情况被视为是关键的。
- 3
- 常见内核错误情况。
- 4
- 常见内核警告情况。
- 5
- 内核注意到一个正常但严重的情况。
- 6
- 内核信息性消息.
- 7
- 内核调试级别消息。
默认情况下,RHEL 8 中的 kernel.printk 有以下值:
sysctl kernel.printk
# sysctl kernel.printk
kernel.printk = 7 4 1 7四个值按顺序定义了以下情况:
- 控制台日志级别,定义打印到控制台的消息的最低优先级。
- 消息没有显式附加日志级别的默认日志级别。
- 为控制台日志级别设置最低的日志级别配置。
在引导时为控制台日志级别设置默认值。
这些值的每一个都定义不同的处理错误消息的规则。
默认的 7 4 1 7 printk 值可以更好地调试内核活动。但是,当与串行控制台耦合时,这个 printk 设置可能会导致大量 I/O 突发,这可能会导致 RHEL 系统变得暂时不响应。为避免这种情况,把 printk 值设置为 4 4 1 7 通常可以正常工作,但其代价是丢失额外的调试信息。
另请注意,某些内核命令行参数(如 quiet 或 debug)会更改默认的 kernel.printk 值。
第 14 章 安装 kdump
在 RHEL 8 安装的新版本上,默认安装并激活 kdump 服务。
14.1. kdump
kdump 是提供崩溃转储机制的服务,并生成崩溃转储或 vmcore 转储文件。vmcore 包括系统内存的内容,以用于分析和故障排除。kdump 使用 kexec 系统调用引导到第二个内核,捕获内核,而不重启。这个内核捕获崩溃的内核的内存内容,并将其保存到一个文件中。第二个内核位于系统内存的保留部分。
当系统出现故障时,内核崩溃转储是唯一可用的信息。因此,在关键任务环境中操作 kdump 非常重要。红帽建议在常规内核更新周期中定期更新和测试 kexec-tools。这在安装新内核功能时非常重要。
如果您在机器上有多个内核,则可以为所有安装的内核或只为指定的内核启用 kdump。安装 kdump 时,系统会创建一个默认的 /etc/kdump.conf 文件。/etc/kdump.conf 包含默认最小 kdump 配置,您可以编辑它来自定义 kdump 配置。
14.2. 使用 Anaconda 安装 kdump
Anaconda 安装程序在交互安装过程中为 kdump 配置提供了一个图形界面屏幕。您可以启用 kdump ,并保留所需的内存量。
流程
在 Anaconda 安装程序上,点 KDUMP 并启用
kdump:- 在 Kdump Memory Reservation 中,如果您必须自定义内存保留,请选择 Manual'。
在 KDUMP > Memory for Reserved (MB) 中,设置
kdump所需的内存保留。


14.3. 在命令行中安装 kdump
安装选项,如自定义 Kickstart 安装,在某些情况下 不会 默认安装或启用 kdump。以下流程帮助您在这种情况下启用 kdump。
先决条件
- 一个有效的 RHEL 订阅。
-
包含用于您系统 CPU 架构的
kexec-tools软件包的存储库。 -
满足
kdump配置和目标的要求。详情请查看 支持的 kdump 配置和目标。
流程
检查您的系统上是否已安装了
kdump:rpm -q kexec-tools
# rpm -q kexec-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果安装了该软件包,输出:
kexec-tools-2.0.17-11.el8.x86_64
kexec-tools-2.0.17-11.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 如果没有安装该软件包,输出:
package kexec-tools is not installed
package kexec-tools is not installedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 安装
kdump和其他必要的软件包:dnf install kexec-tools
# dnf install kexec-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
从 kernel-3.10.0-693.el7 开始,kdump 支持 Intel IOMMU 驱动程序。对于 kernel-3.10.0-514[.XYZ].el7 及早期版本,您必须确保 Intel IOMMU 被禁用,以防止无响应的捕获内核。
第 15 章 在命令行中配置 kdump
在系统引导过程中为 kdump 保留内存。您可以在系统的 Grand Unified Bootloader (GRUB)配置文件中配置内存大小。内存大小取决于配置文件中指定的 crashkernel= 值,以及系统的物理内存的大小。
15.1. 估算 kdump 大小
在规划和构建 kdump 环境时,务必要知道崩溃转储文件所需的空间。
makedumpfile --mem-usage 命令估计崩溃转储文件所需的空间。它生成一个内存使用率报告。报告帮助您决定转储级别以及可以安全排除的页。
流程
输入以下命令生成内存用量报告:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
makedumpfile --mem-usage 命令会以页为单位报告所需的内存。这意味着您必须根据内核页面大小计算所使用的内存大小。
默认情况下,RHEL 内核在 AMD64 和 Intel 64 CPU 构架上使用 4 KB 大小的页,在 IBM POWER 构架上使用 64 KB 大小的页。
15.2. 配置 kdump 内存用量
为 kdump 的内存保留在系统引导过程中发生。内存大小是在系统的 Grand Unified Bootloader (GRUB)配置中设定的。内存大小取决于配置文件中指定的 crashkernel= 选项的值以及系统物理内存的大小。
您可以使用多种方式定义 crashkernel= 选项。您可以指定 crashkernel= 值或配置 auto 选项。crashkernel=auto 参数根据系统中的物理内存总量自动保留内存。配置后,内核将自动为捕获内核保留适当数量的所需内存。这有助于防止内存不足(OOM)错误。
kdump 的自动内存分配因系统硬件架构和可用内存大小而异。
例如,在 AMD64 和 Intel 64 上,crashkernel=auto 参数仅在可用内存超过 1GB 时才起作用。64 位 ARM 架构和 IBM Power 系统需要超过 2 GB 的可用内存。
如果系统自动分配低于最小内存阈值,您可以手动配置保留内存量。
先决条件
- 您在系统上具有 root 权限。
-
满足
kdump配置和目标的要求。详情请查看 支持的 kdump 配置和目标。
流程
准备
crashkernel=选项。例如:要保留 128 MB 内存,请使用:
crashkernel=128M
crashkernel=128MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 或者,您可以根据安装的内存总量将保留内存量设置为变量。变量中的内存保留语法为
crashkernel=<range1>:<size1>,<range2>:<size2>。例如:crashkernel=512M-2G:64M,2G-:128M
crashkernel=512M-2G:64M,2G-:128MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果系统内存总量为 512 MB 和 2 GB,则命令保留 64 MB 内存。如果内存量超过 2 GB,则内存保留为 128 MB。
保留内存的偏移。
有些系统需要保留具有特定固定偏移量的内存,因为
crashkernel保留在早期发生,您可能需要为特殊用途保留更多内存。当您定义了一个偏移时,保留的内存将从这个偏移位置开始。要偏移保留的内存,请使用以下语法:crashkernel=128M@16M
crashkernel=128M@16MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在这个示例中,
kdump从 16 MB 开始保留 128 MB 内存(物理地址0x01000000)。如果将偏移参数设置为 0 或完全省略,kdump会自动偏移保留内存。在设置变量内存保留时,也可以使用此语法。在这种情况下,偏移总是指定最后一个。例如:crashkernel=512M-2G:64M,2G-:128M@16M
crashkernel=512M-2G:64M,2G-:128M@16MCopy to Clipboard Copied! Toggle word wrap Toggle overflow
将
crashkernel=选项应用到引导装载程序配置:grubby --update-kernel=ALL --args="crashkernel=<value>"
# grubby --update-kernel=ALL --args="crashkernel=<value>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将
<value>替换为您在上一步中准备的crashkernel=选项的值。
15.3. 配置 kdump 目标
崩溃转储通常以一个文件形式存储在本地文件系统中,直接写入设备。另外,您可以使用 NFS 或 SSH 协议通过网络发送崩溃转储。一次只能设置其中一个选项来保留崩溃转储文件。默认行为是将其存储在本地文件系统的 /var/crash/ 目录中。
先决条件
- 您在系统上具有 root 权限。
-
满足
kdump配置和目标的要求。详情请查看 支持的 kdump 配置和目标。
流程
要将崩溃转储文件保存在本地文件系统的
/var/crash/目录中,请编辑/etc/kdump.conf文件并指定路径:path /var/crash
path /var/crashCopy to Clipboard Copied! Toggle word wrap Toggle overflow 选项
path /var/crash代表kdump在其中保存崩溃转储文件的文件系统的路径。注意-
当您在
/etc/kdump.conf文件中指定转储目标时,路径是相对于指定的转储目标。 -
当您没有在
/etc/kdump.conf文件中指定转储目标时,该路径表示根目录的绝对路径。
根据当前系统中挂载的文件系统,会自动配置转储目标和调整的转储路径。
-
当您在
要保护
kdump生成的崩溃转储文件以及附带文件,您应该为目标目的地目录设置正确的属性,如用户权限和 SELinux 上下文。另外,您可以定义一个脚本,如kdump.conf文件中的kdump_post.sh,如下所示:kdump_post <path_to_kdump_post.sh>
kdump_post <path_to_kdump_post.sh>Copy to Clipboard Copied! Toggle word wrap Toggle overflow kdump_post指令指定kdump完成捕获并将崩溃转储保存到指定的目的地 后 执行的 shell 脚本或命令。您可以使用此机制扩展kdump的功能,以执行包括调整文件权限在内的操作。-
kdump目标配置
*grep -v ^# /etc/kdump.conf | grep -v ^$*
# *grep -v ^# /etc/kdump.conf | grep -v ^$*
ext4 /dev/mapper/vg00-varcrashvol
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
转储目标已指定了(ext4 /dev/mapper/vg00-varcrashvol),因此它被挂载到 /var/crash。path 选项也被设置为 /var/crash。因此,kdump 将 vmcore 文件保存在 /var/crash/var/crash 目录中。
要更改保存崩溃转储的本地目录,以
root用户身份编辑/etc/kdump.conf配置文件:-
从
#path /var/crash行的开头删除哈希符号(#)。 使用预期的目录路径替换该值。例如:
path /usr/local/cores
path /usr/local/coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重要在 RHEL 8 中,当
kdumpsystemd服务启动时,使用path指令定义为kdump目标的目录必须存在,以避免失败。与早期版本的 RHEL 不同,如果服务启动时目录不存在,则不再自动创建该目录。
-
从
要将文件写入不同的分区,请编辑
/etc/kdump.conf配置文件:根据您的选择,从
#ext4行的开头删除哈希符号(#)。-
设备名称(
#ext4 /dev/vg/lv_kdump行) -
文件系统标签(
#ext4 LABEL=/boot行) -
UUID(
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937行)
-
设备名称(
将文件系统类型和设备名称、标签或 UUID 改为所需的值。指定 UUID 值的正确语法是
UUID="correct-uuid"和UUID=correct-uuid。例如:ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937
ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要建议使用
LABEL=或UUID=指定存储设备。无法保证/dev/sda3等磁盘设备名称在重启后保持一致。当您在 IBM Z 硬件上使用 Direct Access Storage Device (DASD)时,请确保在执行
kdump之前,转储设备已在/etc/dasd.conf中正确指定了。
要将崩溃转储直接写入设备,请编辑
/etc/kdump.conf配置文件:-
从
#raw /dev/vg/lv_kdump行的开头删除哈希符号(#)。 使用预期的设备名称替换该值。例如:
raw /dev/sdb1
raw /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
从
使用
NFS协议将崩溃转储保存到远程机器上:-
从
#nfs my.server.com:/export/tmp行的开头删除哈希符号(#)。 使用有效的主机名和目录路径替换该值。例如:
nfs penguin.example.com:/export/cores
nfs penguin.example.com:/export/coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启
kdump服务以使更改生效:sudo systemctl restart kdump.service
sudo systemctl restart kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 注意当使用 NFS 指令指定 NFS 目标时,
kdump.service会自动尝试挂载 NFS 目标,来检查磁盘空间。不需要提前挂载 NFS 目标。要防止kdump.service挂载目标,请在kdump.conf中使用dracut_args --mount指令。这将启用kdump.service,通过--mount参数指定 NFS 目标来调用dracut工具。
-
从
使用 SSH 协议将崩溃转储保存到远程机器上:
-
从
#ssh user@my.server.com行的开头删除哈希符号(#)。 - 使用有效的用户名和密码替换该值。
在配置中包含您的 SSH 密钥。
-
从
#sshkey /root/.ssh/kdump_id_rsa行的开头删除哈希符号。 将该值改为您要转储的服务器中有效密钥的位置。例如:
ssh john@penguin.example.com sshkey /root/.ssh/mykey
ssh john@penguin.example.com sshkey /root/.ssh/mykeyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
从
-
从
15.4. 配置 kdump 核心收集器
kdump 服务使用 core_collector 程序捕获崩溃转储镜像。在 RHEL 中,makedumpfile 工具是默认的内核收集器。它通过以下方式帮助缩小转储文件:
- 压缩崩溃转储文件的大小,并使用各种转储级别仅复制必要的页。
- 排除不必要的崩溃转储页。
- 过滤崩溃转储中包含的页面类型。
RHEL 7 及更高版本中默认启用了崩溃转储文件压缩。
如果您需要自定义崩溃转储文件压缩,请按照以下流程操作。
语法
core_collector makedumpfile -l --message-level 1 -d 31
core_collector makedumpfile -l --message-level 1 -d 31选项
-
-c、-l或-p:指定每个页的压缩 dump 文件的格式,使用zlib用于-c选项、使用lzo用于-l新选项,或snappy用于-p选项。 -
-d(dump_level):排除页面,它们不会复制到转储文件中。 -
--message-level:指定消息类型。您可以通过使用这个选项指定message_level来限制打印的输出。例如,把message_level设置为 7 可打印常见消息和错误消息。message_level的最大值为 31。
先决条件
- 您在系统上具有 root 权限。
-
满足
kdump配置和目标的要求。详情请查看 支持的 kdump 配置和目标。
流程
-
以
root用户身份编辑/etc/kdump.conf配置文件,并删除#core_collector makedumpfile -l --message-level 1 -d 31开头的哈希符号("#")。 - 输入以下命令来启用崩溃转储文件压缩:
core_collector makedumpfile -l --message-level 1 -d 31
core_collector makedumpfile -l --message-level 1 -d 31
-l 选项指定 转储 压缩的文件格式。-d 选项将转储级别指定为 31。message-level 选项将消息级别指定为 1。
另外,请考虑使用 -c 和 -p 选项的示例:
使用
-c压缩崩溃转储文件:core_collector makedumpfile -c -d 31 --message-level 1
core_collector makedumpfile -c -d 31 --message-level 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
-p压缩崩溃转储文件:core_collector makedumpfile -p -d 31 --message-level 1
core_collector makedumpfile -p -d 31 --message-level 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.5. 配置 kdump 默认失败响应
默认情况下,当 kdump 不能在配置的目标位置创建崩溃转储文件时,系统会重启,转储在此过程中会丢失。您可以更改默认失败响应,并将 kdump 配置为在将内核转储保存到主目标时执行不同的操作。额外的操作是:
dump_to_rootfs-
将内核转储保存到
root文件系统。 reboot- 重启系统,在此过程中会丢失内核转储。
halt- 停止系统,在此过程中会丢失内核转储。
poweroff- 关闭系统,在此过程中会丢失内核转储。
shell-
从
initramfs中运行 shell 会话,您可以手动记录内核转储。 final_action-
在
kdump成功或在 shell 或dump_to_rootfs失败操作完成后,启用额外的操作,如reboot、halt和poweroff。默认为reboot。 failure_action-
指定在内核崩溃中转储可能失败时要执行的操作。默认为
reboot。
先决条件
- root 权限。
-
满足
kdump配置和目标的要求。详情请查看 支持的 kdump 配置和目标。
流程
-
作为
root用户,从/etc/kdump.conf配置文件中的#failure_action 将值替换为所需操作。
failure_action poweroff
failure_action poweroffCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.6. kdump 的配置文件
kdump 内核的配置文件是 /etc/sysconfig/kdump。此文件控制 kdump 内核命令行参数。对于大多数配置,请使用默认选项。然而,在某些情况下,您可能需要修改某些参数来控制 kdump 内核行为。例如:修改 KDUMP_COMMANDLINE_APPEND 选项,以附加 kdump 内核命令行来获取详细的调试输出或修改 KDUMP_COMMANDLINE_REMOVE 选项,以从 kdump 命令行中删除参数。
KDUMP_COMMANDLINE_REMOVE这个选项从当前
kdump命令行中删除参数。它删除了可能导致kdump错误或kdump内核引导失败的参数。这些参数可能已从之前的KDUMP_COMMANDLINE进程解析了,或者从/proc/cmdline文件继承了。如果未配置此变量,它将继承
/proc/cmdline文件中的所有值。配置此选项还提供了有助于调试问题的信息。要删除某些参数,请将其添加到
KDUMP_COMMANDLINE_REMOVE中,如下所示:
KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"
# KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"KDUMP_COMMANDLINE_APPEND此选项将参数附加到当前命令行。这些参数可能已被之前的
KDUMP_COMMANDLINE_REMOVE变量解析了。对于
kdump内核,禁用某些模块,如mce、cgroup、numa,hest_disable有助于防止内核错误。这些模块可能会消耗为kdump保留的大部分内核内存,或者导致kdump内核引导失败。要在
kdump内核命令行中禁用内存cgroups,请运行以下命令:
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"15.7. 测试 kdump 配置
配置 kdump 后,您必须手动测试系统崩溃,并确保在定义的 kdump 目标中生成了 vmcore 文件。vmcore 文件是从新引导的内核的上下文中捕获的。因此,vmcore 有用于调试内核崩溃的重要信息。
不要对活动状态的生产环境系统测试 kdump。测试 kdump 的命令将导致内核崩溃,且数据丢失。根据您的系统架构,确保您安排了充足的维护时间,因为 kdump 测试可能需要多次重启,且启动时间很长。
如果 vmcore 文件在 kdump 测试过程中没有生成 ,请在再次运行测试前识别并修复问题,以使 kdump 测试成功。
如果进行任何手动系统修改,您必须在任何系统修改的最后测试 kdump 配置。例如,如果您进行以下任何更改,请确保为以下情形测试 kdump 配置,以获取最佳 kdump 性能:
- 软件包升级。
- 硬件级别的更改,如存储或网络更改。
- 固件升级。
- 包括第三方模块的新安装和应用程序升级。
- 如果您使用热插拔机制在支持此机制的硬件上添加更多内存。
-
在
/etc/kdump.conf或/etc/sysconfig/kdump文件中进行更改后。
先决条件
- 您在系统上具有 root 权限。
-
您已保存了所有重要数据。测试
kdump的命令导致内核崩溃及数据丢失。 - 您已根据系统架构安排了大量机器维护时间。
流程
启用
kdump服务:kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
kdumpctl检查kdump服务的状态:kdumpctl status
# kdumpctl status kdump:Kdump is operationalCopy to Clipboard Copied! Toggle word wrap Toggle overflow 另外,如果您使用
systemctl命令,输出会打印在systemd日志中。启动内核崩溃来测试
kdump配置。sysrq-trigger组合键导致内核崩溃,并在需要时可能重启系统。echo c > /proc/sysrq-trigger
# echo c > /proc/sysrq-triggerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在内核重启时,
address-YYYY-MM-DD-HH:MM:SS/vmcore文件在您在/etc/kdump.conf文件中指定的位置创建。默认值为/var/crash/。
15.8. 系统崩溃后 kdump 生成的文件
系统崩溃后,kdump 服务会将内核内存捕获在转储文件(vmcore)中,它还会生成额外的诊断文件,以帮助故障排除和事后分析。
kdump 生成的文件:
-
vmcore- 崩溃时包含系统内存的主内核内存转储文件。它包含根据kdump配置中指定的core_collector程序配置的数据。默认情况下,包含内核数据结构、进程信息、堆栈跟踪和其他诊断信息。 -
vmcore-dmesg.txt- panic 的主内核中的内核环缓冲区日志的内容(dmesg)。 -
kexec-dmesg.log- 有从收集vmcore数据的辅助kexec内核执行中得到的内核和系统日志消息。
15.9. 启用和禁用 kdump 服务
您可以配置,以对特定的内核或所有安装的内核启用或禁用 kdump 功能。您必须定期测试 kdump 功能,并验证其是否正确运行。
先决条件
- 您在系统上具有 root 权限。
-
您已为配置和目标完成了
kdump要求。请参阅 支持的 kdump 配置和目标。 -
用于安装
kdump的所有配置都是根据需要设置的。
流程
为
multi-user.target启用kdump服务:systemctl enable kdump.service
# systemctl enable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在当前会话中启动服务:
systemctl start kdump.service
# systemctl start kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 停止
kdump服务:systemctl stop kdump.service
# systemctl stop kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 禁用
kdump服务:systemctl disable kdump.service
# systemctl disable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
建议将 kptr_restrict=1 设置为默认值。当将 kptr_restrict 设置为(1)作为默认值时,kdumpctl 服务会加载崩溃内核,而无论是否启用了内核地址空间布局(KASLR)。
如果 kptr_restrict 没有被设置为 1,并且 KASLR 被启用了,则生成的 /proc/kore 文件的内容全为零。kdumpctl 服务无法访问 /proc/kcore 文件,并加载崩溃内核。kexec-kdump-howto.txt 文件显示一条警告信息,建议您设置 kptr_restrict=1。验证 sysctl.conf 文件中的以下内容,以确保 kdumpctl 服务加载崩溃内核:
-
sysctl.conf文件中的内核kptr_restrict=1。
15.10. 防止内核驱动程序为 kdump 加载
您可以通过在 /etc/sysconfig/kdump 配置文件中添加 KDUMP_COMMANDLINE_APPEND= 变量来从加载某些内核驱动程序中控制捕获内核。使用这个方法,您可以防止来自加载指定的内核模块中的 kdump 初始 RAM 磁盘镜像 initramfs 。这有助于防止内存不足(OOM) killer 错误或其他崩溃内核失败。
您可以使用以下配置选项之一附加 KDUMP_COMMANDLINE_APPEND= 变量:
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
先决条件
- 您在系统上具有 root 权限。
流程
显示载入到当前运行内核的模块的列表。选择您要阻止其加载的内核模块:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 更新
/etc/sysconfig/kdump文件中的KDUMP_COMMANDLINE_APPEND=变量。例如:KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"
KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 另外,考虑以下使用
modprobe.blacklist=<modules>配置选项的示例:KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"
KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重启
kdump服务:systemctl restart kdump
# systemctl restart kdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.11. 在使用加密磁盘的系统中运行 kdump
当您运行 LUKS 加密的分区时,系统需要一定数量的可用内存。如果系统可用内存量小于所需的可用内存量,则 cryptsetup 实用程序无法挂载分区。因此,在第二个内核(捕获内核)中将 vmcore 文件捕获到加密的目标位置会失败。
kdumpctl estimate 命令可帮助您估算 kdump 所需的内存量。kdumpctl estimate 打印推荐的 crashkernel 值,这是 kdump 所需的最合适的内存大小。
推荐的 crashkernel 值是根据当前的内核大小、内核模块、initramfs 和 LUKS 加密的目标内存要求计算的。
如果您使用自定义 crashkernel= 选项,kdumpctl estimate 会打印 LUKS required size 的值。值是 LUKS 加密目标所需的内存大小。
流程
输出估计的
crashkernel=值:Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
通过增加
crashkernel=值来配置所需的内存量。 - 重启系统。
如果 kdump 服务仍无法将转储文件保存到加密的目标,请根据需要增大 crashkernel= 值。
第 16 章 在 web 控制台中配置 kdump
您可以使用 RHEL 8 web 控制台设置并测试 kdump 配置。Web 控制台可以在引导时启用 kdump 服务。使用 web 控制台,您可以为 kdump 配置保留的内存,并以未压缩或压缩格式选择 vmcore 的保存位置。
16.1. 在 web 控制台中配置 kdump 内存使用率和目标位置
您可以为 kdump 内核配置内存保留,并指定目标位置,来使用 RHEL web 控制台界面捕获 vmcore 转储文件。
先决条件
- 必须安装并可以访问 Web 控制台。详情请参阅安装 Web 控制台。
流程
-
在 web 控制台中,打开 选项卡,并通过将 Kernel crash dump 开关设置为 on 来启动
kdump服务。 在终端中配置
kdump内存使用情况,例如:sudo grubby --update-kernel ALL --args crashkernel=512M
$ sudo grubby --update-kernel ALL --args crashkernel=512MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启系统以应用更改。
- 在 Kernel dump 选项卡中,点 Crash dump location 字段末尾的 Edit。
指定保存
vmcore转储文件的目标目录:- 对于本地文件系统,从下拉菜单中选择 Local Filesystem。
对于使用 SSH 协议的远程系统,从下拉菜单中选择 Remote over SSH ,并指定以下字段:
- 在 Server 字段中,输入远程服务器地址。
- 在 SSH key 字段中,输入 SSH 密钥位置。
- 在 Directory 字段中,输入目标目录。
对于使用 NFS 协议的远程系统,从下拉菜单中选择 Remote over NFS ,并指定以下字段:
- 在 Server 字段中,输入远程服务器地址。
- 在 Export 字段中,输入 NFS 服务器的共享文件夹的位置。
在 Directory 字段中,输入目标目录。
注意您可以通过选择 Compression 复选框来减小
vmcore文件的大小。
可选:点击 View automation script 显示自动化脚本。
此时会打开一个带有生成的脚本的窗口。您可以浏览 shell 脚本和 Ansible playbook 生成选项选项卡。
可选:点击 Copy to clipboard 复制脚本。
您可以使用此脚本在多台机器上应用相同的配置。
验证
- 单击 。
在 Test kdump settings 下点 Crash system。
警告当您启动系统崩溃时,内核操作会停止,导致系统崩溃,并造成数据丢失。
第 17 章 启用 kdump
对于 RHEL 8 系统,您可以在特定内核或所有安装的内核中配置或者禁用 kdump 功能。但是,您必须定期测试 kdump 功能,并验证其工作状态。
17.1. 为所有安装的内核启用 kdump
在 kexec 工具安装后,kdump 服务通过启用 kdump.service 启动。您可以为在机器上安装的所有内核启用并启动 kdump 服务。
先决条件
- 有管理员特权。
流程
将
crashkernel=命令行参数添加到所有安装的内核中:grubby --update-kernel=ALL --args="crashkernel=xxM"
# grubby --update-kernel=ALL --args="crashkernel=xxM"Copy to Clipboard Copied! Toggle word wrap Toggle overflow xxM是所需的内存(以 MB 为单位)。重启系统:
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 启用
kdump服务:systemctl enable --now kdump.service
# systemctl enable --now kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
检查
kdump服务是否正在运行:systemctl status kdump.service
# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
17.2. 为特定安装的内核启用 kdump
您可以为机器上的特定内核启用 kdump 服务。
先决条件
- 有管理员特权。
流程
列出安装在机器上的内核。
ls -a /boot/vmlinuz-*
# ls -a /boot/vmlinuz-* /boot/vmlinuz-0-rescue-2930657cd0dc43c2b75db480e5e5b4a9 /boot/vmlinuz-4.18.0-330.el8.x86_64 /boot/vmlinuz-4.18.0-330.rt7.111.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 向系统的 Grand Unified Bootloader (GRUB)配置中添加特定的
kdump内核。例如:
grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"
# grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"Copy to Clipboard Copied! Toggle word wrap Toggle overflow xxM是所需的内存保留(以 MB 为单位)。启用
kdump服务。systemctl enable --now kdump.service
# systemctl enable --now kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
检查
kdump服务是否正在运行。systemctl status kdump.service
# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
17.3. 禁用 kdump 服务
您可以停止 kdump.service ,并在 RHEL 8 系统上禁用该服务。
先决条件
-
满足
kdump配置和目标的要求。详情请查看支持的 kdump 配置和目标。 -
安装
kdump的所有配置都是根据您的需要设置的。详情请参阅 安装 kdump。
流程
要在当前会话中停止
kdump服务:systemctl stop kdump.service
# systemctl stop kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要禁用
kdump服务:systemctl disable kdump.service
# systemctl disable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
建议将 kptr_restrict=1 设置为默认值。当将 kptr_restrict 设置为(1)作为默认值时,kdumpctl 服务会加载崩溃内核,而无论是否启用了内核地址空间布局(KASLR)。
如果 kptr_restrict 没有设置为 1,且 KASLR 被启用了,则 /proc/kore 文件的内容被生成为全零。kdumpctl 服务无法访问 /proc/kcore 文件,并加载崩溃内核。kexec-kdump-howto.txt 文件显示一条警告信息,建议您设置 kptr_restrict=1。验证 sysctl.conf 文件中的以下内容,以确保 kdumpctl 服务加载崩溃内核:
-
sysctl.conf文件中的内核kptr_restrict=1。
第 18 章 支持的 kdump 配置和目标
kdump 机制是 Linux 内核的一个功能,它在发生内核崩溃时生成一个崩溃转储文件。内核转储文件有关键的信息,可帮助分析和确定内核崩溃的根本原因。崩溃可能是因为各种因素,举几个例子,如硬件问题或第三方内核模块问题。
通过使用提供的信息和流程,您可以执行以下操作:
- 识别 RHEL 8 系统支持的配置和目标。
- 配置 kdump。
- 验证 kdump 操作。
18.1. kdump 的内存要求
要让 kdump 捕获内核崩溃转储,并保存它以便进一步分析,应该为捕获内核永久保留系统内存的一部分。保留时,主内核无法使用系统内存的这一部分。
内存要求因某些系统参数而异。主要因素之一就是系统的硬件构架。要识别确切的机器架构,如 Intel 64 和 AMD64,也称为 x86_64,并将其输出到标准输出,请使用以下命令:
uname -m
$ uname -m$ uname -m
使用上述最小内存要求的列表,您可以设置合适的内存大小,来在最新可用版本上为 kdump 自动保留内存。内存大小取决于系统的架构和总可用物理内存。
| 架构 | 可用内存 | 最小保留内存 |
|---|---|---|
|
AMD64 和 Intel 64 ( | 1 GB 到 4 GB | 192 MB 内存 |
| 4 GB 到 64 GB | 256 MB 内存 | |
| 64 GB 及更多 | 512 MB 内存 | |
|
64 位 ARM 架构 ( | 2 GB 及更多 | 480 MB 内存 |
|
IBM Power 系统 ( | 2 GB 到 4 GB | 384 MB 内存 |
| 4 GB 到 16 GB | 512 MB 内存 | |
| 16 GB 到 64 GB | 1 GB 内存 | |
| 64 GB 到 128 GB | 2 GB 内存 | |
| 128 GB 及更多 | 4 GB 内存 | |
|
IBM Z ( | 1 GB 到 4 GB | 192 MB 内存 |
| 4 GB 到 64 GB | 256 MB 内存 | |
| 64 GB 及更多 | 512 MB 内存 |
在很多系统中,kdump 可以估算所需内存量并自动保留。默认情况下,此行为是启用的,但仅适用于内存总量超过特定数量的系统,这些内存因系统架构而异。
根据系统中内存总量自动配置保留内存是最佳工作量估算。实际需要的内存可能因其他因素(如 I/O 设备)而异。内存不足可能导致在出现内核 panic 时,debug 内核无法作为捕获内核引导。要避免这个问题,请充分增加崩溃内核内存。
18.2. 自动内存保留的最小阈值
默认情况下,kexec-tools 工具配置 crashkernel 命令行参数,并为 kdump 保留一定的内存量。但是,在某些系统上,仍可在引导装载程序配置文件中使用 crashkernel=auto 参数,或者在图形配置工具中启用这个选项来为 kdump 分配内存。要使此自动保留正常工作,系统中需要有一定数量的总内存。内存要求因系统架构而异。如果系统内存小于指定的阈值,则您必须手动配置内存。
| 构架 | 所需的内存 |
|---|---|
|
AMD64 和 Intel 64 ( | 2 GB |
|
IBM Power 系统 ( | 2 GB |
|
IBM Z ( | 4 GB |
RHEL 9 及更新的版本不再支持引导命令行中的 crashkernel=auto 选项。
18.3. 支持的 kdump 目标
当发生内核崩溃时,操作系统会将转储文件保存在配置的或默认的目标位置上。您可以将转储文件直接保存到设备上,将其作为文件存储在本地文件系统上,或者通过网络发送转储文件。使用以下转储目标的列表,您可以知道 kdump 目前支持的或不支持的目标。
| 目标类型 | 支持的目标 | 不支持的目标 |
|---|---|---|
| 物理存储 |
|
|
| 网络 |
|
|
| 虚拟机监控程序(Hypervisor) |
| |
| 文件系统 | ext[234]、XFS 和 NFS 文件系统。 |
|
| 固件 |
|
18.4. 支持的 kdump 过滤等级
要缩小转储文件的大小,kdump 使用 makedumpfile 内核收集器压缩数据,并排除不需要的信息,例如,您可以使用 -8 级别来删除 hugepages 和 hugetlbfs 页。makedumpfile 当前支持的级别可在 Filtering levels for `kdump` 表中看到。
| 选项 | 描述 |
|---|---|
|
| 零页 |
|
| 缓存页 |
|
| 缓存私有 |
|
| 用户页 |
|
| 可用页 |
18.5. 支持的默认故障响应
默认情况下,当 kdump 创建内核转储失败时,操作系统会重启。但是,当无法将内核转储保存到主目标上时,您可以将 kdump 配置为执行不同的操作。
| 选项 | 描述 |
|---|---|
|
| 尝试将内核转储保存到 root 文件系统。这个选项在与网络目标合并时特别有用:如果网络目标无法访问,这个选项配置 kdump 以在本地保存内核转储。之后会重启该系统。 |
|
| 重启系统,这个过程会丢失 core 转储文件。 |
|
| 关闭系统,这个过程会丢失 core 转储文件。 |
|
| 关闭系统,这个此过程会丢失 core 转储。 |
|
| 从 initramfs 内运行 shell 会话,允许用户手动记录核心转储。 |
|
|
在 |
18.6. 使用 final_action 参数
当 kdump 成功或者 kdump 无法在配置的目标处保存 vmcore 文件时,您可以使用 final_action 参数执行额外的操作,如 reboot、halt 和 poweroff。如果没有指定 final_action 参数,则 reboot 是默认的响应。
流程
要配置
final_action,请编辑/etc/kdump.conf文件并添加以下选项之一:-
final_action reboot -
final_action halt -
final_action poweroff
-
重启
kdump服务,以使更改生效。kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.7. 使用 failure_action 参数
failure_action 参数指定在内核崩溃时转储失败时要执行的操作。failure_action 的默认操作是 重启 系统。
参数接受以下要执行的操作:
reboot- 转储失败后重启系统。
dump_to_rootfs- 当配置了非 root 转储目标时,将转储文件保存在 root 文件系统上。
halt- 关闭系统。
poweroff- 停止系统上正在运行的操作。
shell-
在
initramfs中启动 shell 会话,您可以从中手动执行其他恢复操作。
流程
要将操作配置为在转储失败时执行的操作,请编辑
/etc/kdump.conf文件并指定其中一个failure_action选项:-
failure_action reboot -
failure_action halt -
failure_action poweroff -
failure_action shell -
failure_action dump_to_rootfs
-
重启
kdump服务,以使更改生效。kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 19 章 固件支持的转储机制
固件支持的转储 (fadump) 是一个转储捕获机制,作为 IBM POWER 系统中 kdump 机制的替代选择。kexec 和 kdump 机制可用于在 AMD64 和 Intel 64 系统中捕获内核转储。但是,一些硬件(如小型系统和大型机计算机)使用板上固件来隔离内存区域,并防止意外覆盖对分析崩溃很重要的数据。fadump 工具针对 fadump 机制及其与 IBM POWER 系统上 RHEL 的集成进行了优化。
19.1. IBM PowerPC 硬件支持转储固件
fadump 实用程序从带有 PCI 和 I/O 设备的完全重设系统中捕获 vmcore 文件。这种机制使用固件在崩溃期间保留内存区域,然后重复使用 kdump 用户空间脚本保存 vmcore 文件。内存区域由所有系统内存内容组成,但引导内存、系统注册和硬件页面表条目 (PTE) 除外。
fadump 机制通过重新引导分区并使用新内核转储之前内核崩溃中的数据,提供比传统转储类型的更高可靠性。fadump 需要一个基于 IBM POWER6 处理器或更高版本的硬件平台。
有关 fadump 机制的详情,包括针对 PowerPC 重置硬件的方法,请查看 /usr/share/doc/kexec-tools/fadump-howto.txt 文件。
未保留的内存区域(称为引导内存)是在崩溃事件后成功引导内核所需的 RAM 量。默认情况下,引导内存大小为 256MB 或系统 RAM 总量的 5%,以较大者为准。
与 kexec-initiated 事件不同,fadump 机制使用 production 内核恢复崩溃转储。崩溃后引导时,PowerPC 硬件使设备节点 /proc/device-tree/rtas/ibm.kernel-dump 可供 proc 文件系统 (procfs) 使用。fadump-aware kdump 脚本,检查存储的 vmcore,然后完全完成系统重启。
19.2. 启用固件支持的转储机制
您可以通过启用固件支持的转储(fadump)机制来增强 IBM POWER 系统的崩溃转储功能。
在安全引导环境中,GRUB 引导装载程序分配一个引导内存区域,称为 Real Mode Area (RMA)。RMA 有 512 MB 大小的内存,在引导组件之间分配。如果组件超过其大小分配,则 GRUB 会失败,并显示内存不足(OOM)错误。
不要在 RHEL 8.7 和 8.6 版本的安全引导环境中启用固件支持的转储(fadump)机制。GRUB2 引导装载程序失败,并显示以下错误:
error: ../../grub-core/kern/mm.c:376:out of memory. Press any key to continue…
error: ../../grub-core/kern/mm.c:376:out of memory.
Press any key to continue…
仅当您因为 fadump 配置而增加默认 initramfs 大小时,系统才是可恢复的。
有关恢复系统的临时解决方案方法的详情,请参考 GRUB 内存不足(OOM)中的系统引导结束 文章。
流程
-
安装和配置
kdump。 启用
fadump=on内核选项:grubby --update-kernel=ALL --args="fadump=on"
# grubby --update-kernel=ALL --args="fadump=on"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:如果要指定保留引导内存而不是使用默认值,请启用
crashkernel=xxM选项,其中xx是以 MB 为单位所需的内存量:grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"
# grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重要当指定引导选项时,在运行前测试所有引导选项。如果
kdump内核无法引导,请逐渐增加crashkernel=参数中指定的值来设置适当的值。
19.3. IBM Z 硬件支持的固件转储机制
IBM Z 系统支持以下固件支持的转储机制:
-
独立转储 (sadump) -
VMDUMP
IBM Z 系统支持并使用 kdump 基础架构。但是,使用 IBM Z 的固件支持的转储(fadump)方法之一有以下优点:
-
系统控制台启动和控制
sadump机制,并将其存储在IPL可引导设备中。 -
VMDUMP机制与sadump类似。此工具也从系统控制台启动,但会从硬件检索生成的转储并将其复制到系统以进行分析。 -
这些方法(与其他基于硬件的转储机制类似)能够在
kdump服务启动前捕获机器在早期启动阶段的状态。 -
虽然
VMDUMP包含接收转储文件到 Red Hat Enterprise Linux 系统的机制,但VMDUMP的配置和控制是从 IBM Z 硬件控制台管理的。
19.4. 在 Fujitsu PRIMEQUEST 系统中使用 sadump
当 kdump 无法成功完成时,Fujitsu sadump 机制提供了一个 回退 转储捕获。您可以从系统管理局(MMB)接口手动调用 sadump。使用 MMB,为 Intel 64 或 AMD64 服务器配置 kdump,然后继续启用 sadump。
流程
在
/etc/sysctl.conf文件中添加或编辑以下行,以确保sadump的kdump按预期启动:kernel.panic=0 kernel.unknown_nmi_panic=1
kernel.panic=0 kernel.unknown_nmi_panic=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告特别是,请确保在
kdump后系统不会重启。如果系统在kdump保存vmcore文件失败后重启,则无法调用sadump。适当地将
/etc/kdump.conf中的failure_action参数设置为halt或shell。failure_action shell
failure_action shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow
第 20 章 分析内核转储
要识别系统崩溃的原因,您可以使用 crash 工具,它提供类似于 GNU Debugger (GDB)的交互式提示。通过使用 crash,您可以分析由 kdump、netdump、diskdump 或 xendump 创建的内核转储以及正在运行的 Linux 系统。另外,您可以使用 Kernel Oops Analyzer 或 Kdump Helper 工具。
20.1. 安装 crash 工具
使用提供的信息,了解所需的软件包,以及安装 crash 工具的流程。默认情况下,在 RHEL 8 系统中可能无法安装 crash 工具。crash 是一个工具,可在内核崩溃发生并且创建内核转储文件时以交互方式分析系统状态。内核转储文件也称为 vmcore 文件。
流程
启用相关的软件仓库:
subscription-manager repos --enable baseos repository
# subscription-manager repos --enable baseos repositoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow subscription-manager repos --enable appstream repository
# subscription-manager repos --enable appstream repositoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpms
# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 安装
crash软件包:yum install crash
# yum install crashCopy to Clipboard Copied! Toggle word wrap Toggle overflow 安装
kernel-debuginfo软件包:yum install kernel-debuginfo
# yum install kernel-debuginfoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 软件包
kernel-debuginfo将对应于正在运行的内核,并提供用于转储分析所需的数据。
20.2. 运行和退出 crash 工具
crash 工具是分析 kdump 的强大工具。通过在崩溃转储文件中运行 崩溃,您可以在崩溃时了解系统状态,识别问题的根原因,并对内核相关的问题进行故障排除。
先决条件
-
确定当前运行的内核(例如
4.18.0-5.el8.x86_64)。
流程
要启动
crash工具,请传递以下两个必要的参数:-
debug-info(解压缩的 vmlinuz 镜像),如
/usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux,通过特定的kernel-debuginfo软件包提供。 实际的 vmcore 文件,如
/var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore。生成的
crash命令如下所示:crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore
# crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
kdump捕获的相同 <kernel> 版本。例 20.1. 运行 crash 工具
以下示例演示了使用 4.18.0-5.el8.x86_64 内核分析在 2018 年 10 月 6 日下午 14:05 时创建的内核转储。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
debug-info(解压缩的 vmlinuz 镜像),如
要退出交互式提示并停止
crash,请输入exit或q。crash> exit ~]#
crash> exit ~]#Copy to Clipboard Copied! Toggle word wrap Toggle overflow
crash 命令也用作调试实时系统的强大工具。但是,您必须谨慎使用它,以避免系统级问题。
20.3. 在 crash 工具中显示各种指示符
使用 crash 工具来显示各种指示符,如内核消息缓冲区、回溯追踪、进程状态、虚拟内存信息以及打开文件。
显示消息缓冲
要显示内核消息缓冲区,请在互动提示符下输入
log命令:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输入
help log以了解有关命令用法的更多信息。注意内核消息缓冲区包含有关系统崩溃的最重要信息。它始终首先转储到
vmcore-dmesg.txt文件。如果您无法获取完整的vmcore文件,例如由于目标位置空间不足,您可以从内核消息缓冲中获取所需的信息。默认情况下,vmcore-dmesg.txt放置在/var/crash/目录中。
显示后端
若要显示内核堆栈跟踪,可使用
bt命令。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输入
bt <pid>来显示特定进程的回溯追踪,或者输入help bt以了解有关bt用法的更多信息。
显示进程状态
若要显示系统中进程的状态,可使用
ps命令。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
ps <pid>显示单个进程的状态。使用 help ps 了解有关ps用法的更多信息。
显示虚拟内存信息
要显示基本虚拟内存信息,请在交互式提示符下键入
vm命令。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
vm <pid>显示有关单个特定进程的信息,或使用help vm了解有关vm用法的更多信息。
显示打开的文件
要显示有关打开文件的信息,请使用
files命令。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
files <pid>仅显示一个选定进程打开的文件,或者使用help files来获取有关files用法的更多信息。
20.4. 使用 Kernel Oops Analyzer
Kernel Oops Analyzer 工具通过将 oops 消息与知识库中的已知问题进行比较,分析崩溃转储。
先决条件
-
oops消息被保护以提供内核 Oops 分析器。
流程
- 访问内核 Oops 分析器工具.
要诊断内核崩溃问题,请上传
vmcore中生成的内核oops 日志。-
或者,您可以通过提供文本消息或
vmcore-dmesg.txt作为输入来诊断内核崩溃问题。
-
或者,您可以通过提供文本消息或
-
点
DETECT,根据makedumpfile中的信息与已知解决方案比较oops消息。
20.5. Kdump Helper 工具
Kdump Helper 工具有助于使用提供的信息设置 kdump。kdump 帮助程序根据您的偏好生成配置脚本。在服务器中启动并运行该脚本可设置 kdump 服务。
第 21 章 使用早期 kdump 来捕获引导时间崩溃
早期 kdump 是 kdump 机制的一个特性,可在系统服务启动前在引导过程的早期阶段捕获 vmcore 文件。早期 kdump 在内存中加载崩溃内核和崩溃内核的 initramfs。
在 kdump 服务启动前的早期引导阶段过程中,内核崩溃有时会发生,可以捕获并保存崩溃的内核内存的内容。因此,在进行故障排除时,与崩溃相关的重要信息将会丢失。要解决这个问题,您可以使用 early kdump 功能,它是 kdump 服务的一部分。
21.1. 启用早期 kdump
early kdump 功能设置崩溃内核和初始 RAM 磁盘镜像(initramfs),以便早期加载以捕获早期崩溃的 vmcore 信息。这有助于消除丢失早期引导内核崩溃信息的风险。
先决条件
- 一个有效的 RHEL 订阅。
-
包含用于您系统 CPU 架构的
kexec-tools软件包的存储库。 -
实现了
kdump配置和目标要求。如需更多信息,请参阅 支持的 kdump 配置和目标。
流程
验证
kdump服务是否已启用并活跃:systemctl is-enabled kdump.service && systemctl is-active kdump.service
# systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled activeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果没有启用并运行
kdump,请设置所有必要的配置,并验证是否已启用kdump服务。使用
早期 kdump功能重建引导内核的initramfs镜像:dracut -f --add earlykdump
# dracut -f --add earlykdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 添加
rd.earlykdump内核命令行参数:grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重启系统以反映更改:
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
验证
rd.earlykdump是否已成功添加,并启用early kdump功能:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 22 章 使用内核实时修补程序应用补丁
您可以使用 Red Hat Enterprise Linux 内核实时补丁解决方案在不重启或重启任何进程的情况下对运行的内核进行补丁。
使用这个解决方案,系统管理员需要:
- 可以在内核中立即应用重要的安全补丁。
- 不必等待长时间运行的任务完成、关闭或调度停机时间。
- 可以控制系统的正常运行时间,且不会牺牲安全性和稳定性。
通过使用内核实时补丁,您可以减少安全补丁所需的重启数量。但请注意,您无法解决所有关键或重要的 CVE。有关实时补丁范围的详情,请查看红帽知识库解决方案 Red Hat Enterprise Linux 中是否支持实时内核补丁(kpatch)?
内核实时补丁和其它内核子组件之间存在一些不兼容。在使用内核实时补丁前,请仔细阅读 kpatch 的限制。
有关内核实时补丁更新支持节奏的详情,请参考:
22.1. kpatch 的限制
-
通过使用
kpatch功能,您可以应用简单的安全性和 bug 修复更新,这些更新不需要立即重启系统。 -
在载入补丁期间或之后,您不能使用
SystemTap或kprobe工具。在探测被删除后,补丁可能无法生效。
22.2. 对第三方实时补丁的支持
kpatch 实用程序是红帽通过红帽软件仓库提供的 RPM 模块支持的唯一内核实时补丁程序。红帽不支持由第三方提供的实时补丁。
有关第三方软件支持政策的更多信息,请参阅 作为客户如何在使用第三方组件时支持我?
22.3. 获得内核实时补丁
内核模块(kmod)实现内核实时补丁功能,并作为 RPM 软件包提供。
所有客户都可以访问内核实时补丁,这些补丁通过常用的通道提供。但是,在下一个次版本发布后,未订阅延长支持服务的客户将无法访问当前次要版本的新修补程序。例如,具有标准订阅的客户只能在 RHEL 8.3 内核发布前提供 RHEL 8.2 内核补丁。
内核实时补丁的组件如下:
- 内核补丁模块
- 内核实时补丁的交付机制。
- 为内核构建的一个内核模块被修补。
- patch 模块包含内核所需修复的代码。
-
patch 模块使用
livepatch内核子系统注册,并指定要替换的原始功能,以及指向替换功能的指针。内核补丁模块以 RPM 的形式提供。 -
命名规则为
kpatch_<kernel version>_<kpatch version>_<kpatch release>。名称中"kernel version"部分的点被下划线替代。
kpatch工具- 用于管理补丁模块的命令行工具。
kpatch服务-
multiuser.target所需的systemd服务。这个目标会在引导时载入内核补丁模块。 kpatch-dnf软件包- 以 RPM 软件包的形式提供的 DNF 插件。此插件管理内核实时补丁的自动订阅。
22.4. 实时补丁内核的过程
kpatch 内核补丁解决方案使用 livepatch 内核子系统将过时的功能重定向到更新的功能。将实时内核补丁应用到系统会触发以下进程:
-
内核补丁模块复制到
/var/lib/kpatch/目录中,并在下次引导时由systemd注册以重新应用到内核。 -
kpatch模块加载到运行的内核中,新的功能会注册到ftrace机制中,其中包含指向新代码内存中位置的指针。
当内核访问补丁的功能时,ftrace 机制会重定向它,绕过原始功能,并将内核发送到函数的补丁版本。
图 22.1. 内核实时补丁如何工作
22.5. 将当前安装的内核订阅到实时补丁流
内核补丁模块在 RPM 软件包中提供,具体取决于被修补的内核版本。每个 RPM 软件包将随着时间不断累积更新。
以下流程解释了如何订阅以后为给定内核的所有累积实时补丁更新。因为实时补丁是累计的,所以您无法选择为一个特定的内核部署哪些单独的补丁。
红帽不支持任何适用于红帽支持的系统的第三方实时补丁。
先决条件
- 您有 root 权限。
流程
可选:检查您的内核版本:
uname -r
# uname -r 4.18.0-94.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 搜索与内核版本对应的实时补丁软件包:
yum search $(uname -r)
# yum search $(uname -r)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 安装实时补丁(live patching)软件包:
yum install "kpatch-patch = $(uname -r)"
# yum install "kpatch-patch = $(uname -r)"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以上命令只为特定内核安装并应用最新的实时补丁。
如果实时补丁软件包的版本是 1-1 或更高版本,则软件包将包含补丁模块。在这种情况下,内核会在安装 live patching 软件包期间自动修补。
内核补丁模块也安装到
/var/lib/kpatch/目录中,供systemd系统和服务管理器以后重启时载入。注意当给定内核没有可用的实时补丁时,将安装空的实时补丁软件包。空的 live patching 软件包会有一个 0-0 的 kpatch_version-kpatch_release,如
kpatch-patch-4_18_0-94-0-0.el8.x86_64.rpm。空 RPM 安装会将系统订阅到以后为给定内核提供的所有实时补丁。
验证
验证是否所有安装的内核都已打了补丁:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出显示内核补丁模块已加载到内核,该内核现在已使用
kpatch-patch-4_18_0-94-1-1.el8.x86_64.rpm软件包的最新修复打了补丁。注意输入
kpatch list命令不会返回一个空的实时补丁软件包。使用rpm -qa | grep kpatch命令替代。rpm -qa | grep kpatch
# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarchCopy to Clipboard Copied! Toggle word wrap Toggle overflow
22.6. 自动订阅将来的内核到实时补丁流
您可以使用 kpatch-dnf YUM 插件向您的系统订阅内核补丁模块(也称为内核实时补丁)提供的修复。该插件为系统当前使用的任何内核启用自动订阅,以及在以后安装地内核。
先决条件
- 您有 root 权限。
流程
可选:检查所有安装的内核和您当前运行的内核:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 安装
kpatch-dnf插件:yum install kpatch-dnf
# yum install kpatch-dnfCopy to Clipboard Copied! Toggle word wrap Toggle overflow 启用自动订阅内核实时补丁:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这个命令订阅所有当前安装的内核,以接收内核实时补丁。命令还会为所有安装的内核安装并应用最新的累积实时补丁(如果有)。
当您更新内核时,会在新的内核安装过程中自动安装实时补丁。
内核补丁模块也安装到
/var/lib/kpatch/目录中,供systemd系统和服务管理器以后重启时载入。注意当给定内核没有可用的实时补丁时,将安装空的实时补丁软件包。空的 live patching 软件包会有一个 0-0 的 kpatch_version-kpatch_release,如
kpatch-patch-4_18_0-240-0-0.el8.x86_64.rpm。空 RPM 安装会将系统订阅到以后为给定内核提供的所有实时补丁。
验证
验证是否所有安装的内核都已修补:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 输出显示您正在运行的内核,另一个安装的内核已分别修补了来自
kpatch-patch-4_18_0-240_10_1-0-1.rpm和kpatch-patch-4_18_0-240_15_1-0-1.rpm软件包的修复。注意输入
kpatch list命令不会返回一个空的实时补丁软件包。使用rpm -qa | grep kpatch命令替代。rpm -qa | grep kpatch
# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarchCopy to Clipboard Copied! Toggle word wrap Toggle overflow
22.7. 禁用实时补丁流的自动订阅
当您向内核补丁模块提供的修复订阅系统时,您的订阅是 自动的。您可以禁用此功能,以禁用 kpatch-patch 软件包的自动安装。
先决条件
- 您有 root 权限。
流程
可选:检查所有安装的内核和您当前运行的内核:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 禁用向内核实时补丁的自动订阅:
yum kpatch manual
# yum kpatch manual Updating Subscription Management repositories.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
您可以检查成功的结果:
yum kpatch status
# yum kpatch status ... Updating Subscription Management repositories. Last metadata expiration check: 0:30:41 ago on Tue Jun 14 15:59:26 2022. Kpatch update setting: manualCopy to Clipboard Copied! Toggle word wrap Toggle overflow
22.8. 更新内核补丁模块
内核补丁模块通过 RPM 软件包提供并应用。更新累积内核补丁模块的过程与更新任何其他 RPM 软件包类似。
先决条件
- 系统已订阅实时补丁流,如将当前安装的内核订阅到实时补丁流中所述。
流程
更新至当前内核的新累计版本:
yum update "kpatch-patch = $(uname -r)"
# yum update "kpatch-patch = $(uname -r)"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 以上命令会自动安装并应用所有当前运行的内核可用的更新。包括将来发布的所有实时补丁。
另外,更新所有安装的内核补丁模块:
yum update "kpatch-patch"
# yum update "kpatch-patch"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
当系统重启到同一内核时,kpatch.service systemd 服务会再次对内核进行补丁。
22.9. 删除 live patching 软件包
通过删除实时补丁软件包来禁用 Red Hat Enterprise Linux 内核实时补丁解决方案。
先决条件
- 根权限
- 已安装 live patching 软件包。
流程
选择实时补丁软件包。
yum list installed | grep kpatch-patch
# yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出列出了您安装的实时补丁软件包。
删除实时补丁软件包。
yum remove kpatch-patch-4_18_0-94.x86_64
# yum remove kpatch-patch-4_18_0-94.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 删除实时补丁软件包后,内核将保持补丁,直到下次重启为止,但内核补丁模块会从磁盘中删除。将来重启时,对应的内核将不再被修补。
- 重启您的系统。
验证 live patching 软件包是否已删除:
yum list installed | grep kpatch-patch
# yum list installed | grep kpatch-patchCopy to Clipboard Copied! Toggle word wrap Toggle overflow 如果软件包已被成功删除,命令不会显示任何输出。
验证
验证内核实时补丁解决方案是否已禁用:
kpatch list
# kpatch list Loaded patch modules:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出显示内核没有补丁,实时补丁解决方案没有激活,因为目前没有加载补丁模块。
目前,红帽不支持在不重启系统的情况下还原实时补丁。如有任何问题,请联系我们的支持团队。
22.10. 卸载内核补丁模块
防止 Red Hat Enterprise Linux 内核实时补丁解决方案在以后的引导时应用内核补丁模块。
先决条件
- 根权限
- 已安装实时补丁软件包。
- 已安装并载入内核补丁模块。
流程
选择内核补丁模块:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 卸载所选的内核补丁模块。
kpatch uninstall kpatch_4_18_0_94_1_1
# kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,卸载的内核补丁模块仍然被加载:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 卸载所选模块后,内核将保持补丁,直到下次重启为止,但已从磁盘中删除内核补丁模块。
- 重启您的系统。
验证
验证内核补丁模块是否已卸载:
kpatch list
# kpatch list Loaded patch modules: …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这个示例输出显示没有加载或已安装的内核补丁模块,因此内核没有被修补,且内核实时补丁解决方案没有激活。
22.11. 禁用 kpatch.service
防止 Red Hat Enterprise Linux 内核实时补丁解决方案在以后的引导中全局应用所有内核补丁模块。
先决条件
- 根权限
- 已安装实时补丁软件包。
- 已安装并载入内核补丁模块。
流程
验证
kpatch.service是否已启用。systemctl is-enabled kpatch.service
# systemctl is-enabled kpatch.service enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow 禁用
kpatch.service。systemctl disable kpatch.service
# systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,应用的内核补丁模块仍然被载入:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 重启您的系统。
可选:验证
kpatch.service的状态。systemctl status kpatch.service
# systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出测试
kpatch.service已禁用。因此,内核实时修补解决方案不活跃。验证内核补丁模块是否已卸载。
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 上面的示例输出显示内核补丁模块仍处于安装状态,但没有修补内核。
目前,红帽不支持在不重启系统的情况下还原实时补丁。如有任何问题,请联系我们的支持团队。
第 23 章 使用控制组群为应用程序设置系统资源限制
使用控制组(cgroups)内核功能,您可以控制应用程序的资源使用情况来更有效地使用它们。
您可以为以下任务使用 cgroups :
- 为系统资源分配设置限制。
- 将硬件资源优先分配给特定的进程。
- 防止某些进程获取硬件资源。
23.1. 控制组简介
使用 控制组 Linux 内核功能,您可以将进程组织为按层排序的组 - cgroups。您可以通过为 cgroup 虚拟文件系统提供结构来定义层次结构(控制组树),默认挂载到 /sys/fs/cgroup/ 目录。
systemd 服务管理器使用 cgroups 来组织它管理的所有单元和服务。您可以通过创建和删除 /sys/fs/cgroup/ 目录中的子目录来手动管理 cgroups 的层次结构。
然后,内核中的资源控制器通过限制、优先处理或分配这些进程的系统资源来在 cgroups 中修改进程的行为。这些资源包括以下内容:
- CPU 时间
- 内存
- 网络带宽
- 这些资源的组合
cgroups 的主要用例是聚合系统进程,并在应用程序和用户之间划分硬件资源。这样可以提高环境的效率、稳定性和安全性。
- 控制组群版本 1
控制组版本 1 (
cgroups-v1) 提供按资源控制器层次结构。每个资源(如 CPU、内存或 I/O)都有自己的控制组层次结构。您可以组合不同的控制组层次结构,使一个控制器可以与另一个控制器协调管理各自的资源。但是,当两个控制器属于不同的进程层次结构时,协调会被限制。cgroups-v1控制器在大型时间跨度开发,从而造成控制文件的行为和命名不一致。- 控制组群版本 2
控制组版本 2 (
cgroups-v2)提供单一控制组层次结构,用于挂载所有资源控制器。控制文件行为和命名在不同控制器之间保持一致。
注意RHEL 8.2 及更新的版本完全支持
cgroups-v2。如需更多信息,请参阅 RHEL 8 现在完全支持控制组群 v2。
23.2. 内核资源控制器简介
内核资源控制器启用控制组的功能。RHEL 8 支持 控制组群版本 1 (cgroups-v1 )和 控制组版本 2 (cgroups-v2) 的各种控制器。
资源控制器也称为控制组子系统,是一个代表单一资源的内核子系统,如 CPU 时间、内存、网络带宽或磁盘 I/O。Linux 内核提供由 systemd 服务管理器自动挂载的一系列资源控制器。您可以在 /proc/cgroups 文件中找到当前挂载的资源控制器的列表。
cgroups-v1 提供的控制器:
blkio- 设置对块设备的输入/输出访问的限制。
cpu-
调整控制组任务的完全公平调度程序(CFS)的参数。
cpu控制器与cpuacct控制器一起挂载在同一挂载上。 cpuacct-
创建控制组群中任务所使用的有关 CPU 资源的自动报告。
cpuacct控制器与cpu控制器一起挂载在同一挂载上。 cpuset- 将控制组任务限制为仅在指定 CPU 子集上运行,并指示任务仅使用指定内存节点上的内存。
devices- 控制控制组群中任务对设备的访问。
freezer- 暂停或恢复控制组中的任务。
内存- 设置控制组中任务对内存使用的限制,并对这些任务使用的内存资源生成自动报告。
net_cls-
使用类标识符(
classid)标记网络数据包,使 Linux 流量控制器(tc命令)能够识别来自特定控制组任务的数据包。net_cls子系统net_filter(iptables) 也可使用此标签对此类数据包执行操作。net_filter使用防火墙标识符(fwid)标记网络套接字,它允许 Linux 防火墙识别来自特定控制组任务的数据包(通过使用iptables命令)。 net_prio- 设置网络流量的优先级。
pids- 为控制组群中的多个进程及其子进程设置限制。
perf_event-
通过
perf性能监控和报告工具对监控的任务进行分组。 rdma- 对控制组群中远程直接内存访问/InfiniBand 特定资源设置限制。
hugetlb- 按控制组群中的任务限制大量虚拟内存页面的使用。
cgroups-v2 提供的控制器:
io- 设置对块设备的输入/输出访问的限制。
内存- 设置控制组中任务对内存使用的限制,并对这些任务使用的内存资源生成自动报告。
pids- 为控制组群中的多个进程及其子进程设置限制。
rdma- 对控制组群中远程直接内存访问/InfiniBand 特定资源设置限制。
cpu- 为控制组的任务调整完全公平调度程序(CFS)的参数,并创建控制组中任务所使用的 CPU 资源的自动报告。
cpuset-
将控制组任务限制为仅在指定 CPU 子集上运行,并指示任务仅使用指定内存节点上的内存。仅支持具有新分区功能的核心功能(
cpus{,.effective},mems{,.effective})。 perf_event-
通过
perf性能监控和报告工具对监控的任务进行分组。perf_event在 v2 层次结构上自动启用。
资源控制器可以在 cgroups-v1 层次结构或 cgroups-v2 层次结构中使用,不能同时在两者中使用。
23.3. 命名空间简介
命名空间为组织和识别软件对象创建单独的空间。这使得它们不会互相影响。因此,每个软件对象都包含其自己的一组资源,如挂载点、网络设备或主机名,即使它们共享同一系统。
使用命名空间的最常见技术是容器。
对特定全局资源的更改仅对该命名空间中的进程可见,不影响系统或其他命名空间的其余部分。
要检查进程所属的命名空间,您可以在 /proc/<PID>/ns/ 目录中检查符号链接。
| Namespace | Isolates |
|---|---|
| Mount | 挂载点 |
| UTS | 主机名和 NIS 域名 |
| IPC | 系统 V IPC, POSIX 消息队列 |
| PID | 进程 ID |
| Network | 网络设备、堆栈、端口等 |
| User | 用户和组群 ID |
| Control groups | 控制组群根目录 |
23.4. 使用 cgroups-v1 为应用程序设置 CPU 限制
要使用 控制组版本 1 ( cgroups-v1)配置对应用程序的 CPU 限制,请使用 /sys/fs/ 虚拟文件系统。
先决条件
- 您有 root 权限。
- 您有一个安装在系统上的限制其 CPU 消耗的应用程序。
您确认已挂载了
cgroups-v1控制器:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
流程
识别您要限制 CPU 消耗的应用程序的进程 ID (PID):
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PID 6955的sha1sum示例应用程序消耗大量的 CPU 资源。在
cpu资源控制器目录中创建子目录:mkdir /sys/fs/cgroup/cpu/Example/
# mkdir /sys/fs/cgroup/cpu/Example/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此目录代表控制组,您可以在其中放置特定进程,并向进程应用某些 CPU 限制。同时,目录中将创建多个
cgroups-v1接口文件和cpu特定于控制器的文件。可选:检查新创建的控制组:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow cpuacct.usage,cpu.cfs._period_us等文件代表特定的配置和/或限制,可以为Example控制组中的进程设置它们。请注意,文件名是以它们所属的控制组控制器的名称为前缀的。默认情况下,新创建的控制组继承对系统整个 CPU 资源的访问权限,且无限制。
为控制组群配置 CPU 限制:
echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us
# echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us # echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_usCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
cpu.cfs_period_us文件表示必须重新分配的控制组访问 CPU 资源的频率。时间段为微秒(µs, "us")。上限为 1000 000 微秒,下限为 1000 微秒。 cpu.cfs_quota_us文件表示控制组中的所有进程在一段时间内共同运行的总时间(以微秒为单位),如cpu.cfs_period_us所定义的那样。当控制组中的进程在单个时间段内用完配额指定的所有时间时,它们在该时段的剩余时间内受到限制,并且不允许运行,直到下一个时间段为止。下限为 1000 微秒。上面的示例命令设定 CPU 时间限值,使得
Example控制组中的所有进程仅能每 1 秒(cpu.cfs_quota_us定义)每 1 秒(由cpu.cfs_period_us定义)运行 0.2 秒。
-
可选:验证限制:
cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000
# cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将应用程序的 PID 添加到
Example控制组群中:echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procs
# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令可确保特定的应用成为
Example控制组的一员,并且不超过为Example控制组配置的 CPU 限制。PID 必须代表系统中一个存在的进程。此处的PID 6955被分配给sha1sum /dev/zero &进程,用来演示cpu控制器的用例。
验证
验证应用程序是否在指定的控制组群中运行:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 应用程序的进程在
Example控制组中运行,后者将 CPU 限制应用到应用程序的进程。确定节流应用程序的当前 CPU 消耗:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,
PID 6955的 CPU 消耗从 99% 减少到 20%。
cpu.cfs_period_us 和 cpu.cfs_quota_us 的 cgroups-v2对应项是 cpu.max 文件。cpu.max 文件可以通过 cpu 控制器获得。
第 24 章 使用 cgroups-v2 控制应用程序的 CPU 时间分布
有些应用程序占用太多的 CPU 时间,这可能会对您环境的整体健康状况造成负面影响。您可以将应用程序置于 控制组版本 2 (cgroups-v2) 中,并为这些控制组配置 CPU 限制。因此,您可以控制应用程序的 CPU 消耗。
关于如何控制分配给控制组群的 CPU 时间分布,用户有两种方法:
24.1. 挂载 cgroups-v2
在启动过程中,RHEL 8 默认挂载 cgroup-v1 虚拟文件系统。要利用 cgroup-v2 功能限制应用程序的资源,请手动配置系统。您可以使用 systemd 控制系统资源的使用。您应该只在特殊情况下手动配置 cgroups 虚拟文件系统。例如,当您需要使用在 cgroup-v2 层次结构中没有对应的 cgroup-v1 控制器时。
先决条件
- 您有 root 权限。
流程
通过
systemd系统和服务管理器系统,在系统引导期间将系统配置为默认挂载cgroups-v2:grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="systemd.unified_cgroup_hierarchy=1"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="systemd.unified_cgroup_hierarchy=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 这会向当前引导条目中添加必要的内核命令行参数。
向所有内核引导条目中添加
systemd.unified_cgroup_hierarchy=1参数:grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1"
# grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 重启系统以使更改生效。
验证
验证
cgroups-v2文件系统是否已挂载:mount -l | grep cgroup
# mount -l | grep cgroup cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,seclabel,nsdelegate)Copy to Clipboard Copied! Toggle word wrap Toggle overflow cgroups-v2文件系统已成功挂载到/sys/fs/cgroup/目录。检查
/sys/fs/cgroup/目录的内容:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 默认情况下,
/sys/fs/cgroup/目录也称为 root 控制组,提供接口文件(通过cgroup启动)和特定于控制器的文件,如cpuset.cpus.effective。此外,还有一些与systemd相关的目录,如/sys/fs/cgroup/init.scope、/sys/fs/cgroup/system.slice和/sys/fs/cgroup/user.slice。
24.2. 为 CPU 时间分布准备 cgroup
要控制应用程序的 CPU 消耗,您需要启用特定的 CPU 控制器,并创建一个专用的控制组。建议您在 /sys/fs/cgroup/ 根控制组中至少创建两个级别的子控制组,以保持 cgroup 文件的组织清晰性。
先决条件
- 您有 root 权限。
- 您已确定了要控制的进程的 PID。
-
您已挂载了
cgroups-v2文件系统。如需更多信息,请参阅 挂载 cgroups-v2。
流程
识别您要限制其 CPU 消耗的应用程序的进程 ID(PID):
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出显示
PID 34578和34579(sha1sum的两个图形应用程序)消耗大量资源,即 CPU。这两个应用程序都是用于演示cgroups-v2功能管理的示例应用程序。验证
/sys/fs/cgroup/cgroup.controllers文件中是否提供了cpu和cpuset控制器:cat /sys/fs/cgroup/cgroup.controllers cpuset cpu io memory hugetlb pids rdma
# cat /sys/fs/cgroup/cgroup.controllers cpuset cpu io memory hugetlb pids rdmaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 启用与 CPU 相关的控制器:
echo "+cpu" >> /sys/fs/cgroup/cgroup.subtree_control echo "+cpuset" >> /sys/fs/cgroup/cgroup.subtree_control
# echo "+cpu" >> /sys/fs/cgroup/cgroup.subtree_control # echo "+cpuset" >> /sys/fs/cgroup/cgroup.subtree_controlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这些命令为
/sys/fs/cgroup/根控制组的直接子组启用了cpu和cpuset控制器。子组 是您可以指定进程,并根据您的标准对每个进程应用控制检查的地方。您可以在任何级别上查看
cgroup.subtree_control文件,以识别可在直接子组中启用的控制器。注意默认情况下,根控制组中的
/sys/fs/cgroup/cgroup.subtree_control文件包含memory和pids控制器。创建
/sys/fs/cgroup/Example/目录:mkdir /sys/fs/cgroup/Example/
# mkdir /sys/fs/cgroup/Example/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /sys/fs/cgroup/Example/目录定义了一个子组。此外,上一步为这个子组启用了cpu和cpuset控制器。创建
/sys/fs/cgroup/Example/目录时,一些cgroups-v2接口文件以及cpu和cpuset特定于控制器的文件也会在目录中自动创建。/sys/fs/cgroup/Example/目录还为memory和pids控制器提供特定于控制器的文件。可选:检查新创建的子控制组:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出显示
cpuset.cpus和cpu.max等文件。这些文件特定于cpuset和cpu控制器。使用/sys/fs/cgroup/cgroup.subtree_control文件,为根的(/sys/fs/cgroup/)直接子控制组 手动启用cpuset和cpu控制器。目录还包含通用
cgroup控制接口文件,如cgroup.procs或cgroup.controllers,它们对所有控制组都通用,无论启用的控制器是什么。memory.high和pids.max等文件与memory和pids控制器有关,它们位于根控制组中(/sys/fs/cgroup/),默认情况下总是启用的。默认情况下,新创建的子组继承了对系统所有 CPU 和内存资源的访问权限,没有任何限制。
启用
/sys/fs/cgroup/Example/中与 CPU 相关的控制器,以获取仅与 CPU 相关的控制器:echo "+cpu" >> /sys/fs/cgroup/Example/cgroup.subtree_control echo "+cpuset" >> /sys/fs/cgroup/Example/cgroup.subtree_control
# echo "+cpu" >> /sys/fs/cgroup/Example/cgroup.subtree_control # echo "+cpuset" >> /sys/fs/cgroup/Example/cgroup.subtree_controlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这些命令确保直接子控制组将 只能 有与控制 CPU 时间相关的控制器,而不是
memory或pids控制器。创建
/sys/fs/cgroup/Example/tasks/目录:mkdir /sys/fs/cgroup/Example/tasks/
# mkdir /sys/fs/cgroup/Example/tasks/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /sys/fs/cgroup/Example/tasks/目录定义了一个子组,以及只与cpu和cpuset控制器相关的文件。可选:检查另一个子控制组群:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 确保您要控制 CPU 时间的进程在同一 CPU 上竞争:
echo "1" > /sys/fs/cgroup/Example/tasks/cpuset.cpus
# echo "1" > /sys/fs/cgroup/Example/tasks/cpuset.cpusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这样可确保您将放入
Example/tasks子控制组中的进程,在同一 CPU 上竞争。此设置对于要激活的cpu控制器非常重要。重要只有在相关子组至少有 2 个进程在单个 CPU 上竞争时,才会激活
cpu控制器。
验证
可选:确保为直接子 cgroup 启用与 CPU 相关的控制器:
cat /sys/fs/cgroup/cgroup.subtree_control /sys/fs/cgroup/Example/cgroup.subtree_control cpuset cpu memory pids cpuset cpu
# cat /sys/fs/cgroup/cgroup.subtree_control /sys/fs/cgroup/Example/cgroup.subtree_control cpuset cpu memory pids cpuset cpuCopy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:确保您要控制 CPU 时间的进程在同一 CPU 上竞争:
cat /sys/fs/cgroup/Example/tasks/cpuset.cpus 1
# cat /sys/fs/cgroup/Example/tasks/cpuset.cpus 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
24.3. 通过调整 CPU 带宽来控制应用程序的 CPU 时间分布
您需要为 cpu 控制器的相关文件分配值,以控制分发到特定 cgroup 树下应用程序的 CPU 时间。
先决条件
- 您有 root 权限。
- 您至少有两个用于控制 CPU 时间分发的应用程序。
- 您确保相关的应用程序在同一 CPU 上竞争 CPU 时间,如 为 CPU 时间分布准备 cgroup 中所述。
-
您已挂载了
cgroups-v2文件系统,如 挂载 cgroups-v2 中所述。 -
您在父控制组和子控制组中启用了
cpu和cpuset控制器,如 为 CPU 时间分布准备 cgroup 中所述。 您在
/sys/fs/cgroup/根控制组 中创建了两级 子控制组,如下例所示:… ├── Example │ ├── tasks …
… ├── Example │ ├── tasks …Copy to Clipboard Copied! Toggle word wrap Toggle overflow
流程
配置 CPU 带宽以在控制组群内实现资源限制:
echo "200000 1000000" > /sys/fs/cgroup/Example/tasks/cpu.max
# echo "200000 1000000" > /sys/fs/cgroup/Example/tasks/cpu.maxCopy to Clipboard Copied! Toggle word wrap Toggle overflow 第一个值是允许的时间配额(以微秒为单位),用于子组中的所有进程可以在一段时间内运行。第二个值指定时间段的长度。
在一段时间内,当控制组中的进程共同耗尽此配额指定的时间时,它们会在该时间段的剩余时间内节流,并且直到下一个时间段才允许运行。
此命令设置 CPU 时间分布控制,以便
/sys/fs/cgroup/Example/tasks子组中的所有进程每 1 秒只能在 CPU 上运行 0.2 秒。也就是说,每秒的五分之一。可选:验证时间配额:
cat /sys/fs/cgroup/Example/tasks/cpu.max 200000 1000000
# cat /sys/fs/cgroup/Example/tasks/cpu.max 200000 1000000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将应用的 PID 添加到
Example/tasks子组中:echo "34578" > /sys/fs/cgroup/Example/tasks/cgroup.procs echo "34579" > /sys/fs/cgroup/Example/tasks/cgroup.procs
# echo "34578" > /sys/fs/cgroup/Example/tasks/cgroup.procs # echo "34579" > /sys/fs/cgroup/Example/tasks/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例命令确保所需的应用程序成为
Example/tasks子组的成员,并且不超过为此子组配置的 CPU 时间分布。
验证
验证应用程序是否在指定的控制组群中运行:
cat /proc/34578/cgroup /proc/34579/cgroup 0::/Example/tasks 0::/Example/tasks
# cat /proc/34578/cgroup /proc/34579/cgroup 0::/Example/tasks 0::/Example/tasksCopy to Clipboard Copied! Toggle word wrap Toggle overflow 上面的输出显示了在
Example/tasks子组中运行的指定应用程序的进程。检查节流应用程序的当前 CPU 消耗:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,
PID 34578和PID 34579的 CPU 消耗已减少到 10%。Example/tasks子组将其进程控制到 CPU 时间的 20%。由于控制组中有 2 个进程,因此每个进程可以使用 10% 的 CPU 时间。
24.4. 通过调整 CPU 权重来控制应用程序的 CPU 时间分布
您需要为 cpu 控制器的相关文件分配值,以控制分发到特定 cgroup 树下应用程序的 CPU 时间。
先决条件
- 您有 root 权限。
- 您有要控制 CPU 时间分布的应用程序。
- 您确保相关的应用程序在同一 CPU 上竞争 CPU 时间,如 为 CPU 时间分布准备 cgroup 中所述。
-
您已挂载了
cgroups-v2文件系统,如 挂载 cgroups-v2 中所述。 您在
/sys/fs/cgroup/根控制组 中创建了两级 子控制组,如下例所示:Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
您在父控制组中和子控制组中启用了
cpu和cpuset控制器,如 为 CPU 时间分布准备 cgroup 中所述。
流程
配置所需的 CPU 权重以便在控制组群内实现资源限制:
echo "150" > /sys/fs/cgroup/Example/g1/cpu.weight echo "100" > /sys/fs/cgroup/Example/g2/cpu.weight echo "50" > /sys/fs/cgroup/Example/g3/cpu.weight
# echo "150" > /sys/fs/cgroup/Example/g1/cpu.weight # echo "100" > /sys/fs/cgroup/Example/g2/cpu.weight # echo "50" > /sys/fs/cgroup/Example/g3/cpu.weightCopy to Clipboard Copied! Toggle word wrap Toggle overflow 将应用程序的 PID 添加到
g1、g2和g3子组中:echo "33373" > /sys/fs/cgroup/Example/g1/cgroup.procs echo "33374" > /sys/fs/cgroup/Example/g2/cgroup.procs echo "33377" > /sys/fs/cgroup/Example/g3/cgroup.procs
# echo "33373" > /sys/fs/cgroup/Example/g1/cgroup.procs # echo "33374" > /sys/fs/cgroup/Example/g2/cgroup.procs # echo "33377" > /sys/fs/cgroup/Example/g3/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例命令可确保所需的应用程序成为
Example/g*/子 cgroup 的成员,并按照这些 cgroup 配置获取发布的 CPU 时间。已运行进程的子 cgroup (
g1,g2,g3) 的权重在父 cgroup(Example)级别上相加。然后,根据对应的权重按比例分布 CPU 资源。因此,当所有进程同时运行时,内核会根据相应的 cgroup 的
cpu.weight文件为每个进程按比例分配 CPU 时间:Expand 子 cgroup cpu.weight文件CPU 时间分配 g1
150
~50% (150/300)
g2
100
~33% (100/300)
g3
50
~16% (50/300)
cpu.weight控制器文件的值不是一个百分比。如果一个进程停止运行,使 cgroup
g2没有运行进程,则计算将省略 cgroupg2,仅计算 cgroupg1和g3的帐户权重:Expand 子 cgroup cpu.weight文件CPU 时间分配 g1
150
~75% (150/200)
g3
50
~25% (50/200)
重要如果子 cgroup 有多个正在运行的进程,则分配给 cgroup 的 CPU 时间在其成员进程中平均分配。
验证
验证应用程序是否运行在指定的控制组中:
cat /proc/33373/cgroup /proc/33374/cgroup /proc/33377/cgroup 0::/Example/g1 0::/Example/g2 0::/Example/g3
# cat /proc/33373/cgroup /proc/33374/cgroup /proc/33377/cgroup 0::/Example/g1 0::/Example/g2 0::/Example/g3Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令输出显示了运行在
Example/g*/子 cgroup 中指定的应用程序的进程。检查节流应用程序的当前 CPU 消耗:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意为了清晰地说明,所有进程都在一个 CPU 上运行。当在多个 CPU 上使用时,CPU 权重会应用同样的原则。
请注意,
PID 33373、PID 33374和PID 33377的 CPU 资源根据您分配给相应子 cgroup 的 150、100 和 50 权重进行分配。权重对应于每个应用程序分配的 CPU 时间的大约 50%、33% 和 16%。
第 25 章 使用带有 systemd 的控制组群版本 1
您可以使用 systemd 系统和服务管理器及其提供的实用程序来管理 cgroups。这也是 cgroups 管理的首选方式。
25.1. 控制组群版本 1 中的 systemd 角色
RHEL 8 通过将 cgroup 层次结构与 systemd 单元树绑定,将资源管理设置从进程级移到应用程序级。因此,您可以使用 systemctl 命令或通过修改 systemd 单元文件来管理系统资源。
默认情况下,systemd 系统和服务管理器使用 slice、scope 和 service 单元来整理和整理控制组中的进程。systemctl 命令可以通过创建自定义 片段 来进一步修改此结构。systemd 还会在 /sys/fs/cgroup/ 目录中自动挂载重要内核资源控制器的层次结构。
三种 systemd 单元类型用于资源控制:
Service -
systemd根据单元配置文件启动的进程或一组进程。服务封装指定的进程,以作为一个集合启动和停止。服务使用以下方法命名:<name>.service
<name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow Scope - 外部创建的进程组。范围封装通过
fork()函数由任意进程启动和停止的进程,然后在运行时由systemd注册。例如,用户会话、容器和虚拟机被视为范围。范围命名如下:<name>.scope
<name>.scopeCopy to Clipboard Copied! Toggle word wrap Toggle overflow slice - 一组分级组织单元。片段组织了一个分级,其中放置范围和服务。实际的进程包含在范围或服务中。slice 单元的每个名称对应层次结构中的位置的路径。短划线 ("-") 字符充当了分隔符的作用,它把路径组件从
-.sliceroot slice 中分隔。在以下示例中,包含进程的服务和范围将放置在没有其自身进程的片段中:<parent-name>.slice
<parent-name>.sliceCopy to Clipboard Copied! Toggle word wrap Toggle overflow parent-name.slice是parent.slice的子分片,它是-.sliceroot 片段的子分片。parent-name.slice可以有自己的子slice 名为parent-name-name2.slice,以此类推。
service、scope 和 slice 单元直接映射到控制组层次结构中的对象。激活这些单元后,它们直接映射到从单元名称构建的控制组路径。
控制组群层次结构示例
包含进程的服务和范围放置在没有其自身进程的片段中。
25.2. 创建临时控制组群
临时 cgroup 设置运行时期间由单元(服务或范围)消耗的资源的限制。
流程
要创建一个临时控制组群,使用以下格式的
systemd-run命令:systemd-run --unit=<name> --slice=<name>.slice <command>
# systemd-run --unit=<name> --slice=<name>.slice <command>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此命令会创建并启动临时服务或范围单元,并在此类单元中运行自定义命令。
-
--unit=<name>选项为单元取一个名称。如果未指定--unit,则会自动生成名称。 -
--slice=<name>.slice选项使您的服务或范围单元成为指定片段的成员。将<name>.slice替换为现有片段的名称(如systemctl -t slice输出中所示),或通过传递唯一名称来创建新片段。默认情况下,服务和范围作为system.slice的成员创建。 使用您要在服务或范围单元中输入的命令替换
<command>。此时会显示以下信息,以确认您已创建并启动了该服务,或者已成功启动范围:
Running as unit <name>.service
# Running as unit <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
可选 :在其进程完成收集运行时信息后保持单元运行:
systemd-run --unit=<name> --slice=<name>.slice --remain-after-exit <command>
# systemd-run --unit=<name> --slice=<name>.slice --remain-after-exit <command>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令会创建并启动临时服务单元,并在单元中运行自定义命令。
--remain-after-exit选项可确保服务在其进程完成后继续运行。
25.3. 创建持久的控制组群
要为服务分配持久的控制组,您需要编辑其单元配置文件。配置会在系统重启后保留,以管理自动启动的服务。
流程
要创建一个持久控制组,请输入:
systemctl enable <name>.service
# systemctl enable <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 这个命令会在
/usr/lib/systemd/system/目录中自动创建单元配置文件,并默认将 <name>.service分配给system.slice单元。
25.4. 在命令行中配置内存资源控制设置
在命令行中执行命令是为进程组设置限制、优先级或控制对硬件资源的访问的一种方式。
流程
要限制服务的内存用量,请运行以下命令:
systemctl set-property example.service MemoryMax=1500K
# systemctl set-property example.service MemoryMax=1500KCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令会立即将 1,500 KB 的内存限值分配给
example.service服务所属的控制组中执行的进程。此配置变体中的MemoryMax参数在/etc/systemd/system.control/example.service.d/50-MemoryMax.conf文件中定义,并控制/sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes文件的值。另外,要临时限制服务的内存用量,请运行:
systemctl set-property --runtime example.service MemoryMax=1500K
# systemctl set-property --runtime example.service MemoryMax=1500KCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令会立即为
example.service服务分配内存限值。MemoryMax参数被定义,直到/run/systemd/system.control/example.service.d/50-MemoryMax.conf文件中的下一个重启为止。重启后,整个/run/systemd/system.control/目录和MemoryMax会被删除。
50-MemoryMax.conf 文件存储内存限制,为 4096 字节的倍数 - 特定于 AMD64 和 Intel 64 的内核页大小。实际的字节数量取决于 CPU 构架。
25.5. 使用单元文件配置内存资源控制设置
每个持久性单元都由 systemd 系统和服务管理器监管,并在 /usr/lib/systemd/system/ 目录中有一个单元配置文件。要更改永久单元的资源控制设置,请在文本编辑器中手动或从命令行修改其单元配置文件。
手动修改单元文件是为进程组设置限制、优先级或控制对硬件资源的访问的一种方式。
流程
要限制服务的内存用量,请修改
/usr/lib/systemd/system/example.service文件,如下所示:… [Service] MemoryMax=1500K …
… [Service] MemoryMax=1500K …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 此配置对控制组中执行的进程的最大内存消耗限制,
example.service是该控制组中的一部分。注意使用后缀 K、M、G 或 T 将 Kilobyte、Megabyte、Gigabyte 或 Terabyte 识别为一个测量单位。
重新载入所有单元配置文件:
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重启服务:
systemctl restart example.service
# systemctl restart example.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 重启系统。
验证
检查更改是否生效:
cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 1536000
# cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 1536000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 内存消耗限制为大约 1,500 KB。
注意memory.limit_in_bytes文件将内存限制存储为 4096 字节的倍数 - 一个内核页面大小,专用于 AMD64 和 Intel 64。实际的字节数量取决于 CPU 构架。
25.6. 删除临时控制组群
如果您不再需要限制、确定或控制对进程组的硬件资源的访问,您可以使用 systemd 系统和服务管理器删除临时控制组 (cgroup)。
当服务或范围单元包含的所有进程都完成时,临时 cgroup 会被自动释放。
流程
要停止带有所有进程的服务单元,请输入:
systemctl stop <name>.service
# systemctl stop <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要终止一个或多个单元进程,请输入:
systemctl kill <name>.service --kill-who=PID,… --signal=<signal>
# systemctl kill <name>.service --kill-who=PID,… --signal=<signal>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令使用
--kill-who选项从您要终止的控制组中选择进程。要同时终止多个进程,请传递以逗号分隔的 PID 列表。--signal决定要发送到指定进程的 POSIX 信号的类型。默认信号是 SIGTERM。
25.7. 删除持久的控制组群
如果您不再需要限制、确定或控制对进程组的硬件资源的访问,您可以使用 systemd 系统和服务管理器删除持久性控制组 (cgroup)。
当停止或禁用服务或范围单元并删除其配置文件时,永久 cgroup 就会发布。
流程
停止服务单元:
systemctl stop <name>.service
# systemctl stop <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 禁用服务单元:
systemctl disable <name>.service
# systemctl disable <name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 删除相关的单元配置文件:
rm /usr/lib/systemd/system/<name>.service
# rm /usr/lib/systemd/system/<name>.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重新载入所有单元配置文件以使更改生效:
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
25.8. 列出 systemd 单元
使用 systemd 系统和服务管理器列出其单元。
流程
使用
systemctl工具列出系统上所有活动的单元。终端返回一个类似于以下示例的输出:Copy to Clipboard Copied! Toggle word wrap Toggle overflow UNIT- 还反映控制组层次结构中单元位置的单元名称。与资源控制相关的单元是 slice、scope 和 service
LOAD- 指示单元配置文件是否被正确加载。如果单元文件加载失败,字段会提供状态 error,而不是 loaded。其他单元负载状态为: stub 、merge 和 masked。
ACTIVE-
高级单元激活状态,其是
SUB的一个泛论。 SUB- 低级单元激活状态。可能的值的范围取决于单元类型。
DESCRIPTION- 单元内容和功能的描述。
列出所有活跃的和不活跃的单元:
systemctl --all
# systemctl --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 限制输出中的信息量:
systemctl --type service,masked
# systemctl --type service,maskedCopy to Clipboard Copied! Toggle word wrap Toggle overflow --type选项需要一个以逗号分隔的单元类型列表,如 service 和 slice,或者单元载入状态,如 loaded 和 masked。
25.9. 查看 systemd cgroups 层次结构
显示控制组(cgroup)层次结构以及在特定 cgroups 中运行的进程。
流程
使用
systemd-cgls命令显示系统上整个cgroups层次结构。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出返回整个
cgroups层次结构,其中最高级别由 slices 组成。使用
systemd-cgls <resource_controller>命令显示资源控制器过滤的cgroups层次结构。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出列出了与所选控制器交互的服务。
使用
systemctl status <system_unit>命令显示某个单元及其cgroups层次结构部分的详细信息。Copy to Clipboard Copied! Toggle word wrap Toggle overflow
25.10. 查看资源控制器
识别使用资源控制器的进程。
流程
要查看一个进程与哪些资源控制器进行交互,输入
cat proc/<PID>/cgroup命令。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出是进程
PID 11269,属于example.service单元。您可以验证进程是否放置在systemd单元文件规格定义的正确控制组中。注意默认情况下,在资源控制器列表中的项目及其排序对于
systemd启动的所有单元来说是相同的,因为它会自动挂载所有默认资源控制器。
25.11. 监控资源消耗
查看当前运行的控制组(cgroup)的列表及其实时资源消耗。
流程
使用
systemd-cgtop命令显示当前运行的cgroups的动态帐户。Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出显示当前运行的
cgroups,按照资源使用量排序(CPU、内存、磁盘 I/O 负载)。这个列表默认每 1 秒刷新一次。因此,它提供了一个动态洞察每个控制组的实际资源使用情况。
第 26 章 使用 cgroups-v2 和 systemd 配置资源管理
systemd 套件的主要功能是服务管理和监督。因此,systemd 确保合适的服务在合适的时间启动,并在引导过程中按正确的顺序启动。服务运行时,它们必须顺利运行,才能以最佳的方式使用底层硬件平台。因此,systemd 还提供定义资源管理策略和调优各种选项的能力,这可以提高服务的性能。
26.1. 先决条件
- Linux cgroup 子系统的基础知识.
26.2. 资源分配模型简介
对于资源管理,systemd 使用控制组版本 2 (cgroups-v2)接口。
默认情况下,RHEL 8 使用 cgroups-v1。因此,您必须启用 cgroups-v2,以便 systemd 可以使用 cgroups-v2 接口进行资源管理。有关如何启用 cgroups-v2 的更多信息,请参阅 挂载 cgroups-v2。
要修改系统资源的发布,您可以应用以下一个或多个资源分发模型:
- Weights(权重)
通过添加所有子组的权重来分发资源,并根据与所有权重的总和相比的权重为每个子组分配一部分资源。
例如,如果您有 10 个
cgroups,每个权重值为 100,则总和为 1000,每个cgroup接收十分之一的资源。权重通常用于分发无状态资源。要调整控制组的权重,请使用 CPUWeight= 选项。
- Limits
cgroup可以最多可消耗配置的资源量,但您也可以过量使用资源。因此,子组的总限制可能会超过父cgroup的限制。要调整控制组的限制,请使用 MemoryMax= 选项。
- Protections
您可以为
cgroup设置受保护的资源量。如果资源使用率低于保护边界,内核将尽量不惩罚该cgroup,而支持竞争同一资源的其它cgroups。可以过量使用。要调整控制组的受保护的资源量,请使用 MemoryLow= 选项。
- Allocations
- 有限资源特定数量的独占分配,如实时预算。过量使用是可能的。
26.3. 使用 systemd 分配 CPU 资源
在由 systemd 管理的系统上,每个系统服务在其 cgroup 中启动。通过启用对 CPU cgroup 控制器的支持,系统使用对 CPU 资源的服务感知分布,而不是按进程分布。在服务感知型发行版中,每个服务都收到与系统上运行的所有其他服务相比的相同 CPU 时间的 CPU 时间,无论进程数量如何使用相同的服务。
如果特定的服务需要更多 CPU 资源,您可以通过更改该服务的 CPU 时间分配策略来授予它们。
流程
在使用 systemd 时设置 CPU 时间分配策略选项:
在您选择的服务中检查 CPU 时间分配策略选项的分配值:
systemctl show --property <CPU time allocation policy option> <service name>
$ systemctl show --property <CPU time allocation policy option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将 CPU 时间分配策略选项的所需值设置为 root:
systemctl set-property <service name> <CPU time allocation policy option>=<value>
# systemctl set-property <service name> <CPU time allocation policy option>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cgroup 属性在设置后立即应用。因此,该服务不需要重启。
验证
要验证您是否成功为服务修改了 CPU 时间分配策略选项的所需值,请输入:
systemctl show --property <CPU time allocation policy option> <service name>
$ systemctl show --property <CPU time allocation policy option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.4. systemd 的 CPU 时间分配策略选项
最常用的 CPU 时间分配策略选项包括:
CPUWeight=在所有其他服务上为特定服务分配更高的优先级。您可以从间隔 1 - 10,000 中选择一个值。默认值为 100。
例如,若要将
httpd.service的 CPU 数量与所有其他服务数量相同,可将值设置为CPUWeight=200。请注意,
CPUWeight=仅在可用 CPU 资源已部署时才能应用。CPUQuota=为服务分配绝对 CPU 时间配额。此选项的值指定服务收到的 CPU 时间相对于可用 CPU 总时间的最大百分比,如
CPUQuota=30%。请注意,
CPUQuota=代表特定资源分布模式的限制值,如 Weights 和 Limits。有关
CPUQuota=的更多信息,请参阅系统中的systemd.resource-control (5)手册页。
26.5. 使用 systemd 分配内存资源
要使用 systemd 分配内存资源,请使用任何一个内存配置选项:
-
MemoryMin -
MemoryLow -
MemoryHigh -
MemoryMax -
MemorySwapMax
流程
在使用 systemd 时设置内存分配配置选项:
在您选择的服务中检查内存分配配置选项的分配值。
systemctl show --property <memory allocation configuration option> <service name>
$ systemctl show --property <memory allocation configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将内存分配配置选项所需的值设置为
root。systemctl set-property <service name> <memory allocation configuration option>=<value>
# systemctl set-property <service name> <memory allocation configuration option>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cgroup 属性在设置后立即应用。因此,该服务不需要重启。
验证
要验证您是否成功为服务更改了内存分配配置选项所需的值,请输入:
systemctl show --property <memory allocation configuration option> <service name>
$ systemctl show --property <memory allocation configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.6. systemd 的内存分配配置选项
在使用 systemd 配置系统内存分配时,您可以使用以下选项:
MemoryMin- 硬内存保护。如果内存使用低于指定的限制,则不会回收 cgroup 内存。
MemoryLow- 软内存保护.如果内存使用低于指定的限制,则只有在没有从未保护的 cgroup 中回收内存时才能回收 cgroup 内存。
MemoryHigh- 内存节流限制。如果内存使用超过指定的限制,则 cgroup 中的进程会被节流,并置于严重的回收压力下。
MemoryMax-
内存用量的绝对限制。您可以使用 kilo(K)、MB(M)、giga(G)、tera(T) 后缀,如
MemoryMax=1G。 MemorySwapMax- 交换内存使用的硬性限制。
当您用尽内存限值时,内存不足 (OOM) 终止程序将停止正在运行的服务。要防止这种情况,请降低 OOMScoreAdjust= 值,以提高内存容错能力。
26.7. 使用 systemd 配置 I/O 带宽
要提高 RHEL 8 中特定服务的性能,您可以使用 systemd 为该服务分配 I/O 带宽资源。
要做到这一点,您可以使用以下 I/O 配置选项:
- IOWeight
- IODeviceWeight
- IOReadBandwidthMax
- IOWriteBandwidthMax
- IOReadIOPSMax
- IOWriteIOPSMax
流程
使用 systemd 设置 I/O 带宽配置选项 :
在您选择的服务中检查 I/O 带宽配置选项的分配值:
systemctl show --property <I/O bandwidth configuration option> <service name>
$ systemctl show --property <I/O bandwidth configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 将 I/O 带宽配置选项所需的值设置为
root:systemctl set-property <service name> <I/O bandwidth configuration option>=<value>
# systemctl set-property <service name> <I/O bandwidth configuration option>=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
当设置 cgroup 属性时,它们会被立即应用。因此,不需要重启该服务。
验证
要验证您是否成功更改了服务的 I/O 带宽配置选项所需的值,请输入:
systemctl show --property <I/O bandwidth configuration option> <service name>
$ systemctl show --property <I/O bandwidth configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.8. systemd 的 I/O 带宽配置选项
要使用 systemd 管理块层 I/O 策略,可以使用以下配置选项:
IOWeight- 设置默认 I/O 权重。权重值用作计算服务与其他服务相比实际 I/O 带宽数量的基础。
IODeviceWeight设置特定块设备的 I/O 权重。
注意只有在块设备使用 CFQ I/O 调度程序时,才支持基于权重的选项。如果设备使用了多队列块 I/O 排队机制,则不支持选项。
例如,IODeviceWeight=/dev/disk/by-id/dm-name-rhel-root 200。
IOReadBandwidthMax,IOWriteBandwidthMax设置每个设备或挂载点的绝对带宽。
例如:
IOWriteBandwith=/var/log 5M。注意systemd自动处理文件系统-到-设备转换。IOReadIOPSMax、IOWriteIOPSMax- 每秒输入/输出操作中设置绝对带宽(IOPS)。
26.9. 使用 systemd 配置 CPUSET 控制器
使用 systemd 资源管理 API,您可以对服务可以使用的一组 CPU 和 NUMA 节点配置限制。这个限制限制对进程使用的系统资源的访问。请求的配置写在 cpuset.cpus 和 cpuset.mems 文件中。
但是,可能无法使用请求的配置,因为父 cgroup 限制 cpus 或 mems。若要访问当前的配置,将 cpuset.cpus.effective 和 cpuset.mems.ff 文件导出到用户。
流程
设置
AllowedCPUs:systemctl set-property <service name>.service AllowedCPUs=<value>
# systemctl set-property <service name>.service AllowedCPUs=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
systemctl set-property <service name>.service AllowedCPUs=0-5
# systemctl set-property <service name>.service AllowedCPUs=0-5Copy to Clipboard Copied! Toggle word wrap Toggle overflow 设置
AllowedMemoryNodes:systemctl set-property <service name>.service AllowedMemoryNodes=<value>
# systemctl set-property <service name>.service AllowedMemoryNodes=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
systemctl set-property <service name>.service AllowedMemoryNodes=0
# systemctl set-property <service name>.service AllowedMemoryNodes=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 27 章 使用 systemd 配置 CPU 关联性和 NUMA 策略
CPU 管理、内存管理和 I/O 带宽选项处理可用资源的分区。
27.1. 使用 systemd 配置 CPU 关联性
CPU 关联性设置可帮助您将特定进程的访问限制到某些 CPU。实际上,CPU 调度程序永远不会将进程调度到不在进程的关联性掩码中的 CPU 上运行。
默认 CPU 关联性掩码应用到 systemd 管理的所有服务。
要为特定 systemd 服务配置 CPU 关联性掩码,systemd 提供 CPUAffinity= 作为单元文件选项和 /etc/systemd/system.conf 文件中的管理器配置选项。
CPUAffinity= 单元文件选项 设置 CPU 或 CPU 范围列表,这些范围合并并用作关联性掩码。/etc/systemd/system.conf 文件中的 CPUAffinity 选项 为进程识别号 (PID)1 和从 PID1 分叉的所有进程定义关联性掩码。然后,您可以基于每个服务覆盖 CPUAffinity。
在为特定 systemd 服务配置 CPU 关联性掩码后,您必须重启系统以应用更改。
流程
使用 CPUAffinity 单元文件选项 为特定 systemd 服务设置 CPU 关联性掩码:
在您选择的服务中检查
CPUAffinity单元文件选项的值:systemctl show --property <CPU affinity configuration option> <service name>
$ systemctl show --property <CPU affinity configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 作为 root 用户,为用作关联性掩码的 CPU 范围设置
CPUAffinity单元文件选项的所需值:systemctl set-property <service name> CPUAffinity=<value>
# systemctl set-property <service name> CPUAffinity=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重新启动服务以应用更改。
systemctl restart <service name>
# systemctl restart <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
使用 manager configuration 选项为特定 systemd 服务设置 CPU 关联性掩码:
编辑
/etc/systemd/system.conf文件:vi /etc/systemd/system.conf
# vi /etc/systemd/system.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
搜索
CPUAffinity=选项并设置 CPU 号 - 保存编辑后的文件并重新启动服务器以应用更改。
27.2. 使用 systemd 配置 NUMA 策略
非统一内存访问(NUMA)是一种计算机内存子系统设计,其中内存访问时间取决于相对于处理器的物理内存位置。
靠近 CPU 的内存比不同 CPU 的本地内存(外部内存)或一组 CPU 之间共享的内存具有更低的延迟(本地内存)。
就 Linux 内核而言,NUMA 策略管理内核为进程分配物理内存页面的位置(例如,在哪些 NUMA 节点上)。
systemd 提供单元文件选项 NUMAPolicy 和 NUMAMask,以控制服务的内存分配策略。
流程
通过 NUMAPolicy 单元文件选项设置 NUMA 内存策略:
在您选择的服务中检查
NUMAPolicy单元文件选项的值:systemctl show --property <NUMA policy configuration option> <service name>
$ systemctl show --property <NUMA policy configuration option> <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 作为根目录,设置
NUMAPolicy单元文件选项所需的策略类型:systemctl set-property <service name> NUMAPolicy=<value>
# systemctl set-property <service name> NUMAPolicy=<value>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 重新启动服务以应用更改。
systemctl restart <service name>
# systemctl restart <service name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
要使用 [Manager] 配置选项设置全局 NUMAPolicy 设置:
-
在
/etc/systemd/system.conf文件中搜索文件的 [Manager] 部分中的NUMAPolicy选项。 - 编辑策略类型并保存文件。
重新载入
systemd配置:systemd daemon-reload
# systemd daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 重启服务器。
当您配置严格的 NUMA 策略时,例如 bind,请确保您也正确地设置了 CPUAffinity= 单元文件选项。
27.3. systemd 的 NUMA 策略配置选项
Systemd 提供以下选项来配置 NUMA 策略:
NUMAPolicy控制已执行进程的 NUMA 内存策略。您可以使用这些策略类型:
- default
- preferred
- bind
- interleave
- local
NUMAMask控制与所选 NUMA 策略关联的 NUMA 节点列表。
请注意,您不必为以下策略指定
NUMAMask选项:- default
- local
对于首选策略,列表仅指定单个 NUMA 节点。
第 28 章 使用 BPF Compiler Collection 分析系统性能
BPF Compiler Collection (BCC)通过组合 Berkeley Packet Filter (BPF)的功能来分析系统性能。使用 BPF,您可以安全地运行内核中的自定义程序,以访问系统事件和数据,以性能监控、追踪和调试。BCC 简化了 BPF 程序的开发和部署,用户可使用工具和库从其系统中提取重要见解。
28.1. 安装 bcc-tools 软件包
安装 bcc-tools 软件包,该软件包还会将 BPF Compiler Collection (BCC)库作为依赖项安装。
流程
安装
bcc-tools。yum install bcc-tools
# yum install bcc-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow BCC 工具安装在
/usr/share/bcc/tools/目录中。
验证
检查安装的工具:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 列表中的
doc目录提供了每个工具的文档。
28.2. 使用所选 bcc-tools 进行性能调整
使用 BPF Compiler Collection (BCC)库中的某些预先创建的程序来在每个事件基础上高效、安全地分析系统性能。BCC 库中预创建的程序集可作为创建其他程序的示例。
先决条件
流程
- 使用
execsnoop检查系统进程 -
在一个终端中运行
execsnoop程序:
/usr/share/bcc/tools/execsnoop
# /usr/share/bcc/tools/execsnoopCopy to Clipboard Copied! Toggle word wrap Toggle overflow 要创建一个短暂的
ls命令的进程,请在另一个终端中输入:ls /usr/share/bcc/tools/doc/
$ ls /usr/share/bcc/tools/doc/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 运行
execsnoop的终端显示类似如下的输出:PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...
PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow execsnoop程序为消耗系统资源的每个新进程打印一行输出。它甚至会检测很快运行的程序(如ls)的进程,大多数监控工具也不会进行注册。execsnoop输出显示以下字段:
-
在一个终端中运行
- PCOMM
-
父进程名称。(
ls) - PID
-
进程 ID。(
8382) - PPID
-
父进程 ID。(
8287) - RET
-
exec()系统调用的返回值(0),其将程序代码加载到新进程中。 - ARGS
- 启动的程序的参数的位置。
要查看 execsnoop 的详情、示例和选项,请参阅 /usr/share/bcc/tools/doc/execsnoop_example.txt 文件。
有关 exec () 的详情,请查看 exec (3) 手册页。
- 使用
opensnoop跟踪命令打开了哪些文件 -
在一个终端中,运行
opensnoop程序,以打印仅由uname命令进程打开的文件的输出:
/usr/share/bcc/tools/opensnoop -n uname
# /usr/share/bcc/tools/opensnoop -n unameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 在另一个终端中,输入命令来打开某些文件:
uname
$ unameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行
opensnoop的终端显示类似如下的输出:PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...
PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow opensnoop程序在整个系统中监视open ()系统调用,并为uname尝试打开的每个文件打印一行输出。opensnoop输出显示以下字段:- PID
-
进程 ID。(
8596) - COMM
-
进程名称。(
uname) - FD
-
文件描述符 -
open()返回的值,以指向打开的文件。(3) - ERR
- 任何错误。
- PATH
-
open()试图打开的文件的位置。
如果命令尝试读取不存在的文件,则
FD列返回-1,ERR列将打印与相关错误对应的值。因此,Opennoop可以帮助您识别行为不正确的应用程序。
-
在一个终端中,运行
要查看 opensnoop 的更多详细信息、示例和选项,请参阅 /usr/share/bcc/tools/doc/opensnoop_example.txt 文件。
有关 open () 的更多信息,请参阅 open (2) 手册页。
- 使用
biotop监控在磁盘上执行 I/O 操作的排在前面的进程 -
在一个终端中使用参数
30运行biotop程序来生成 30 秒概述:
/usr/share/bcc/tools/biotop 30
# /usr/share/bcc/tools/biotop 30Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果未提供任何参数,则默认情况下输出屏幕会每 1 秒刷新一次。
在另一个终端中,输入命令从本地硬盘设备读取内容,并将结果写入
/dev/zero文件:dd if=/dev/vda of=/dev/zero
# dd if=/dev/vda of=/dev/zeroCopy to Clipboard Copied! Toggle word wrap Toggle overflow 此步骤会生成特定的 I/O 流量来演示
biotop。运行
biotop的终端显示类似如下的输出:Copy to Clipboard Copied! Toggle word wrap Toggle overflow biotop输出显示以下字段:
-
在一个终端中使用参数
- PID
-
进程 ID。(
9568) - COMM
-
进程名称。(
dd) - DISK
-
执行读操作的磁盘。(
vda) - I/O
- 执行的读操作的数量。(16294)
- Kbytes
- 读操作达到的 Kbytes 量。(14,440,636)
- AVGms
- 读操作的平均 I/O 时间。(3.69)
有关 biotop 的详情、示例和选项,请查看 /usr/share/bcc/tools/doc/biotop_example.txt 文件。
有关 dd 的更多信息,请参阅 dd (1) 手册页。
使用 xfsslower 来公开意外慢的文件系统操作
xfsslower 测量 XFS 文件系统执行读、写、打开或同步(fsync)操作所花费的时间。1 参数可确保程序仅显示比 1 ms 较慢的操作。
在一个终端中运行
xfsslower程序:/usr/share/bcc/tools/xfsslower 1
# /usr/share/bcc/tools/xfsslower 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 注意如果未提供任何参数,
xfsslower默认会显示比 10 ms 慢的操作。在另一个终端中,输入命令在
vim编辑器中创建一个文本文件,以开始与 XFS 文件系统进行交互:vim text
$ vim textCopy to Clipboard Copied! Toggle word wrap Toggle overflow 运行
xfsslower的终端显示在保存上一步中的文件时:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 每行代表文件系统中的一个操作,它花费的时间超过特定阈值。
xfsslower检测到可能的文件系统问题,这可能会意外地减慢操作的速度。xfsslower输出显示以下字段:- COMM
-
进程名称。(
b'bash') - T
操作类型。(
R)- Read
- Write
- Sync
- OFF_KB
- KB 为单位的文件偏移。(0)
- FILENAME
- 读取、写入或同步的文件。
要查看 xfsslower 的详情、示例和选项,请参阅 /usr/share/bcc/tools/doc/xfsslower_example.txt 文件。
有关 fsync 的详情请参考 fsync (2) 手册页。
第 29 章 使用内核完整性子系统提高安全性
您可以使用内核完整性子系统的组件来提高系统的保护。了解有关相关组件及其配置的更多信息。
29.1. 内核完整性子系统
完整性子系统通过检测文件篡改并根据加载的策略拒绝访问来保护系统的完整性。它还收集访问日志,以便远程方可以通过远程测试来验证系统的完整性。内核完整性子系统包括 Integrity 测量架构(IMA)和扩展验证模块(EVM)。
IMA 和 EVM 概述
完整性测量架构(IMA)维护文件内容的完整性。它包括您可以通过 IMA 策略启用的三个功能:
IMA-Measurement- 收集文件内容散列或签名,并将测量保存在内核中。如果有 TPM 可用,每个测量都会扩展 TPM PCR,它启用了认证引用的远程测试。
IMA-Appraisal- 通过将计算的文件哈希与已知良好的参考值进行比较,或者验证存储在 security.ima 属性中的签名,来验证文件的完整性。如果验证失败,系统会拒绝访问。
IMA-Audit- 将计算的文件内容哈希或签名存储在系统审计日志中。
扩展验证模块(EVM)保护文件元数据,包括与系统安全性相关的扩展属性,如 security.ima 和 security.selinux。EVM 在 security.evm 中存储这些安全属性的引用哈希或 HMAC,并使用它来检测文件元数据是否已被恶意更改。
29.2. 可信和加密的密钥
可信密钥 和 加密密钥 是增强系统安全性的一个重要部分。
可信和加密的密钥是由使用内核密钥环服务的内核生成的可变长度对称密钥。您可以验证密钥的完整性,例如,以允许扩展的验证模块(EVM)验证并确认正在运行的系统的完整性。用户级别程序只能访问加密的 Blob 格式的密钥。
- 可信密钥
可信密钥需要受信任的平台模块(TPM)芯片,用于创建和加密(密封)密钥。每个 TPM 都有一个主包装密钥,称为存储根密钥,其存储在 TPM 本身。
注意Red Hat Enterprise Linux 8 支持 TPM 1.2 和 TPM 2.0。如需更多信息,请参阅红帽知识库解决方案 红帽是否支持信任的平台模块(TPM)?。
您可以验证 TPM 2.0 芯片的状态:
cat /sys/class/tpm/tpm0/tpm_version_major 2
$ cat /sys/class/tpm/tpm0/tpm_version_major 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 您还可以启用 TPM 2.0 芯片,并通过机器固件中的设置管理 TPM 2.0 设备。
此外,您还可以使用特定的 TPM 的 平台配置寄存器 (PCR)值集密封可信的密钥。PCR 包含一组完整性管理值,它们反映了固件、引导装载程序和操作系统。PCR 密封的密钥只能被加密它的系统上的 TPM 解密。但是,当您将 PCR 密封的可信密钥加载到密钥环时,会验证其关联的 PCR 值。验证后,您可以使用新的或将来的 PCR 值更新密钥,例如,以支持引导新内核。另外,您可以将单个密钥保存为多个 blob,每个 blob 都有一个不同的 PCR 值。
- 加密的密钥
- 加密的密钥不需要 TPM,因为它们使用内核高级加密标准(AES),这使其比可信密钥更快。加密的密钥是使用内核生成的随机数字创建的,并在导入到用户空间 Blob 时由主密钥加密。
主密钥可以是可信密钥或用户密钥。如果主密钥不被信任,则加密密钥的安全取决于用于加密它的用户密钥。
29.3. 使用可信密钥
您可以使用 keyctl 工具创建、导出、加载和更新可信密钥来提高系统安全性。
先决条件
对于 64 位 ARM 架构和 IBM Z,
可信内核模块已载入。modprobe trusted
# modprobe trustedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 有关如何载入内核模块的更多信息,请参阅 在系统运行时载入内核模块。
- 受信任的平台模块(TPM)已启用并处于活动状态。请参阅内核完整性子系统以及受信任的和加密的密钥。
Red Hat Enterprise Linux 8 支持 TPM 1.2 和 TPM 2.0。如果使用 TPM 1.2,请跳过第 1 步。
流程
使用具有持久句柄的 SHA-256 主存储密钥创建一个 2048 位 RSA 密钥,例如 81000001,使用以下工具之一:
使用
tss2软件包:TPM_DEVICE=/dev/tpm0 tsscreateprimary -hi o -st TPM_DEVICE=/dev/tpm0 tssevictcontrol -hi o -ho 80000000 -hp 81000001
# TPM_DEVICE=/dev/tpm0 tsscreateprimary -hi o -st Handle 80000000 # TPM_DEVICE=/dev/tpm0 tssevictcontrol -hi o -ho 80000000 -hp 81000001Copy to Clipboard Copied! Toggle word wrap Toggle overflow 使用
tpm2-tools软件包:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
创建一个可信密钥:
按照
keyctl add trusted <NAME> "new <KEY_LENGTH> keyhandle=<PERSISTENT-HANDLE> [options]" <KEYRING>语法使用 TPM 2.0。在本例中,持久性句柄为 81000001。keyctl add trusted kmk "new 32 keyhandle=0x81000001" @u
# keyctl add trusted kmk "new 32 keyhandle=0x81000001" @u 642500861Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令创建一个名为
kmk的可信密钥,长度为32字节(256 位),并将其放置在用户密钥环 (@u) 中。密钥长度为 32 到 128 字节(256 到 1024 位)。按照
keyctl add trusted <NAME> "new <KEY_LENGTH>" <KEYRING>语法使用 TPM 1.2 :keyctl add trusted kmk "new 32" @u
# keyctl add trusted kmk "new 32" @uCopy to Clipboard Copied! Toggle word wrap Toggle overflow
列出内核密钥环的当前结构:
keyctl show
# keyctl show Session Keyring -3 --alswrv 500 500 keyring: ses 97833714 --alswrv 500 -1 \ keyring: uid.1000 642500861 --alswrv 500 500 \ trusted: kmkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 使用可信密钥的序列号将密钥导出到用户空间 blob 中:
keyctl pipe 642500861 > kmk.blob
# keyctl pipe 642500861 > kmk.blobCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令使用
pipe子命令和kmk的序列号。从 user-space blob 加载可信密钥:
keyctl add trusted kmk "load `cat kmk.blob`" @u 268728824
# keyctl add trusted kmk "load `cat kmk.blob`" @u 268728824Copy to Clipboard Copied! Toggle word wrap Toggle overflow 创建使用 TPM 密封的可信密钥的安全加密密钥(
kmk)。按照此语法:keyctl add encrypted <NAME> "new [FORMAT] <KEY_TYPE>:<PRIMARY_KEY_NAME> <KEY_LENGTH>" <KEYRING>:keyctl add encrypted encr-key "new trusted:kmk 32" @u
# keyctl add encrypted encr-key "new trusted:kmk 32" @u 159771175Copy to Clipboard Copied! Toggle word wrap Toggle overflow
29.4. 使用加密密钥
您可以通过管理加密密钥来改进不提供受信任的平台模块(TPM)的系统上的系统安全性。
加密的密钥(除非由可信主密钥密封)继承用于加密的用户主密钥(随机数密钥)的安全级别。因此,强烈建议安全地载入主用户密钥,最好在引导过程的早期载入。
先决条件
对于 64 位 ARM 架构和 IBM Z,载入
encrypted-keys内核模块:modprobe encrypted-keys
# modprobe encrypted-keysCopy to Clipboard Copied! Toggle word wrap Toggle overflow 有关如何载入内核模块的更多信息,请参阅 在系统运行时载入内核模块。
流程
使用随机数字序列生成用户密钥:
keyctl add user kmk-user "$(dd if=/dev/urandom bs=1 count=32 2>/dev/null)" @u
# keyctl add user kmk-user "$(dd if=/dev/urandom bs=1 count=32 2>/dev/null)" @u 427069434Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令生成名为
kmk-user的用户密钥,该密钥充当 主密钥,用于密封实际加密的密钥。使用上一步中的主密钥生成加密密钥:
keyctl add encrypted encr-key "new user:kmk-user 32" @u
# keyctl add encrypted encr-key "new user:kmk-user 32" @u 1012412758Copy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
列出指定的用户密钥环中的所有密钥:
keyctl list @u
# keyctl list @u 2 keys in keyring: 427069434: --alswrv 1000 1000 user: kmk-user 1012412758: --alswrv 1000 1000 encrypted: encr-keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.5. 启用 IMA 和 EVM
您可以启用并配置完整性测量架构(IMA)和扩展验证模块(EVM)以提高操作系统的安全性。
始终将 EVM 与 IMA 一起启用。
虽然您可以单独启用 EVM,但 EVM 评估仅由 IMA 评估规则触发。因此,EVM 不会保护文件元数据,如 SELinux 属性。如果文件元数据在离线情况下被篡改了,则 EVMVM 只能防止文件元数据被更改。它不会阻止文件访问,如执行文件。
先决条件
安全引导被临时禁用。
注意启用安全引导后,
ima_appraise=fix内核命令行参数无法正常工作。securityfs文件系统挂载到/sys/kernel/security/目录,并且/sys/kernel/security/integrity/ima/目录存在。您可以使用mount命令验证securityfs挂载的位置:mount
# mount ... securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow systemd服务管理器打了补丁,以在引导时支持 IMA 和 EVM。使用以下命令验证:grep <options> pattern <files>
# grep <options> pattern <files>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 例如:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 流程
在 修复 模式下为当前引导条目启用 IMA 和 EVM,并通过添加以下内核命令行参数来允许用户收集和更新 IMA 测量:
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="ima_policy=appraise_tcb ima_appraise=fix evm=fix"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="ima_policy=appraise_tcb ima_appraise=fix evm=fix"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令在 fix 模式下为当前引导条目启用 IMA 和 EVM ,来收集并更新 IMA 测量。
ima_policy=appraise_tcb内核命令行参数确保内核使用默认的可信计算基础(TCB)测量策略和评估步骤。评估步骤禁止访问之前和当前测量结果不匹配的文件。- 重启以使更改生效。
可选:验证添加到内核命令行中的参数:
cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ima_policy=appraise_tcb ima_appraise=fix evm=fix
# cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ima_policy=appraise_tcb ima_appraise=fix evm=fixCopy to Clipboard Copied! Toggle word wrap Toggle overflow 创建一个内核主密钥来保护 EVM 密钥:
keyctl add user kmk "$(dd if=/dev/urandom bs=1 count=32 2> /dev/null)" @u
# keyctl add user kmk "$(dd if=/dev/urandom bs=1 count=32 2> /dev/null)" @u 748544121Copy to Clipboard Copied! Toggle word wrap Toggle overflow kmk完全保留在内核空间内存中。kmk的 32 字节长值是从/dev/urandom文件中的随机字节生成的,并放在用户(@u)密钥环中。密钥序列号位于前面输出的第一行。根据
kmk创建加密的 EVM 密钥:keyctl add encrypted evm-key "new user:kmk 64" @u
# keyctl add encrypted evm-key "new user:kmk 64" @u 641780271Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令使用
kmk生成并加密 64 字节长用户密钥(名为evm-key),并将其放在用户(@u)密钥环中。密钥序列号位于前面输出的第一行。重要用户密钥必须命名为 evm-key,因为它是 EVM 子系统预期使用的且正在使用的名称。
为导出的密钥创建一个目录。
mkdir -p /etc/keys/
# mkdir -p /etc/keys/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 搜索
kmk,并将其未加密的值导出到新目录中。keyctl pipe $(keyctl search @u user kmk) > /etc/keys/kmk
# keyctl pipe $(keyctl search @u user kmk) > /etc/keys/kmkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 搜索
evm-key,并将其加密值导出到新目录中。keyctl pipe $(keyctl search @u encrypted evm-key) > /etc/keys/evm-key
# keyctl pipe $(keyctl search @u encrypted evm-key) > /etc/keys/evm-keyCopy to Clipboard Copied! Toggle word wrap Toggle overflow evm-key已在早期由内核主密钥加密。可选:查看新创建的密钥:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 可选:如果密钥从密钥环中删除了,例如在系统重启后,您可以导入已导出的
kmk和evm-key,而不是创建新的。导入
kmk。keyctl add user kmk "$(cat /etc/keys/kmk)" @u 451342217
# keyctl add user kmk "$(cat /etc/keys/kmk)" @u 451342217Copy to Clipboard Copied! Toggle word wrap Toggle overflow 导入
evm-key。keyctl add encrypted evm-key "load $(cat /etc/keys/evm-key)" @u 924537557
# keyctl add encrypted evm-key "load $(cat /etc/keys/evm-key)" @u 924537557Copy to Clipboard Copied! Toggle word wrap Toggle overflow
激活 EVM。
echo 1 > /sys/kernel/security/evm
# echo 1 > /sys/kernel/security/evmCopy to Clipboard Copied! Toggle word wrap Toggle overflow 重新标记整个系统。
find / -fstype xfs -type f -uid 0 -exec head -n 1 '{}' >/dev/null \;# find / -fstype xfs -type f -uid 0 -exec head -n 1 '{}' >/dev/null \;Copy to Clipboard Copied! Toggle word wrap Toggle overflow 警告在不重新标记系统的情况下启用 IMA 和 EVM 可能会导致系统上的大多数文件无法访问。
验证
验证 EVM 是否已被初始化:
dmesg | tail -1
# dmesg | tail -1 […] evm: key initializedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.6. 使用完整性测量架构收集文件哈希
在 测量 阶段,您可以创建文件哈希,并将其存储为这些文件的扩展属性(xattrs)。使用文件哈希,您可以生成基于 RSA 的数字签名或基于哈希的消息身份验证代码(HMAC-SHA1),并防止对扩展属性的离线篡改攻击。
先决条件
- IMA 和 EVM 已启用。如需更多信息,请参阅 启用完整性测量架构和扩展验证模块。
- 有效的可信密钥或加密的密钥保存在内核密钥环中。
-
ima-evm-utils、attr和keyutils软件包已安装。
流程
创建测试文件:
echo <Test_text> > test_file
# echo <Test_text> > test_fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow IMA 和 EVM 确保
test_file示例文件已分配了哈希值,该值被存储为其扩展属性。检查文件的扩展属性:
getfattr -m . -d test_file file: test_file
# getfattr -m . -d test_file # file: test_file security.evm=0sAnDIy4VPA0HArpPO/EqiutnNyBql security.ima=0sAQOEDeuUnWzwwKYk+n66h/vby3eDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 示例输出显示带有 IMA 和 EVM 哈希值和 SELinux 上下文的扩展属性。EVM 添加了一个与其他属性相关的
security.evm扩展属性。此时,您可以在security.evm上使用evmctl工具来生成基于 RSA 的数字签名或基于哈希的消息身份验证代码(HMAC-SHA1)的数字签名。
第 30 章 使用 RHEL 系统角色永久配置内核参数
您可以使用 kernel_settings RHEL 系统角色在多个客户端上同时配置内核参数。同时配置有以下优点:
- 提供带有有效输入设置的友好接口。
- 保留所有预期的内核参数。
从控制计算机运行 kernel_settings 角色后,内核参数将立即应用于受管系统,并在重新启动后保留。
请注意,通过 RHEL 渠道提供的 RHEL 系统角色在默认的 AppStream 存储库中作为 RPM 软件包提供给 RHEL 客户。RHEL 系统角色也可作为集合提供给具有通过 Ansible Automation Hub 的 Ansible 订阅的客户。
30.1. 使用 kernel_settings RHEL 系统角色应用所选的内核参数
您可以使用 kernel_settings RHEL 系统角色在多个受管操作系统间远程配置各种内核参数,并具有持久性效果。例如,您可以配置:
- 透明巨页,通过减少管理较小页的开销来提高性能。
- 通过带有回环接口的网络传输的最大数据包大小。
- 对同时打开的文件的限制。
先决条件
- 您已准备好控制节点和受管节点
- 以可在受管主机上运行 playbook 的用户登录到控制节点。
-
您用于连接到受管节点的帐户对它们具有
sudo权限。
流程
创建一个包含以下内容的 playbook 文件,如
~/playbook.yml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例 playbook 中指定的设置包括如下:
kernel_settings_sysfs: <list_of_sysctl_settings>-
sysctl设置的 YAML 列表以及您要分配给这些设置的值。 kernel_settings_transparent_hugepages: <value>-
控制内存子系统透明巨页(THP)设置。您可以禁用 THP 支持(
never)、在系统范围(always)或在MAD_HUGEPAGE区域内(madvise)启用它。 kernel_settings_reboot_ok: <true|false>-
默认值为
false。如果设置为true,则系统角色将确定是否需要重启受管主机,以使请求的更改生效,并重启。如果设置为false,则角色将返回值为true的变量kernel_settings_reboot_required,表示需要重启。在这种情况下,用户必须手动重启受管节点。
有关 playbook 中使用的所有变量的详情,请查看控制节点上的 /usr/share/ansible/roles/rhel-system-roles.kdump/README.md 文件。
验证 playbook 语法:
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,这个命令只验证语法,不能防止错误的、但有效的配置。
运行 playbook:
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
验证受影响的内核参数:
ansible managed-node-01.example.com -m command -a 'sysctl fs.file-max kernel.threads-max net.ipv6.conf.lo.mtu' ansible managed-node-01.example.com -m command -a 'cat /sys/kernel/mm/transparent_hugepage/enabled'
# ansible managed-node-01.example.com -m command -a 'sysctl fs.file-max kernel.threads-max net.ipv6.conf.lo.mtu' # ansible managed-node-01.example.com -m command -a 'cat /sys/kernel/mm/transparent_hugepage/enabled'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
第 31 章 使用 RHEL 系统角色配置 GRUB 引导装载程序
通过使用 bootloader RHEL 系统角色,您可以自动化与 GRUB 引导装载程序相关的配置和管理任务。
此角色目前支持配置在以下 CPU 构架上运行的 GRUB 引导装载程序:
- AMD 和 Intel 64 位构架(x86-64)
- 64 位 ARM 架构(ARMv8.0)
- IBM Power Systems, Little Endian(POWER9)
31.1. 使用 bootloader RHEL 系统角色更新现有的引导装载程序条目
您可以使用 bootloader RHEL 系统角色,以自动的方式更新 GRUB 引导菜单中的现有条目。这样,您可以有效地传递可以优化系统性能或行为的特定的内核命令行参数。
例如,如果您使用不需要来自内核和 init 系统的详细引导消息的系统,请使用 bootloader 将 quiet 参数应用到受管节点上的现有引导装载程序条目中,以实现更干净、更整洁、更用户友好的引导体验。
先决条件
- 您已准备好控制节点和受管节点
- 以可在受管主机上运行 playbook 的用户登录到控制节点。
-
用于连接到受管节点的帐户具有
sudo权限。 - 您识别了与您要更新的引导装载程序条目对应的内核。
流程
创建一个包含以下内容的 playbook 文件,如
~/playbook.yml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例 playbook 中指定的设置包括如下:
kernel- 指定与您要更新的引导装载程序条目关联的内核。
options- 指定要更新您所选的引导装载程序条目(内核)的内核命令行参数。
bootloader_reboot_ok: true- 角色检测到需要重启才能使更改生效,并对受管节点执行重启。
有关 playbook 中使用的所有变量的详情,请查看控制节点上的
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.md文件。验证 playbook 语法:
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,这个命令只验证语法,不能防止错误的、但有效的配置。
运行 playbook:
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
检查您指定的引导装载程序条目是否有更新的内核命令行参数:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
31.2. 使用 bootloader RHEL 系统角色,使用密码保护引导菜单
您可以使用 bootloader RHEL 系统角色,以自动的方式为 GRUB 引导菜单设置密码。这样,您可以有效地防止未经授权的用户修改引导参数,并更好地控制系统引导。
先决条件
- 您已准备好控制节点和受管节点
- 以可在受管主机上运行 playbook 的用户登录到控制节点。
-
您用于连接到受管节点的帐户对它们具有
sudo权限。
流程
将敏感变量存储在加密的文件中:
创建 vault :
ansible-vault create ~/vault.yml
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在
ansible-vault create命令打开编辑器后,以<key>: <value>格式输入敏感数据:pwd: <password>
pwd: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 保存更改,并关闭编辑器。Ansible 加密 vault 中的数据。
创建一个包含以下内容的 playbook 文件,如
~/playbook.yml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例 playbook 中指定的设置包括如下:
bootloader_password: "{{ pwd }}"- 变量确保使用密码保护引导参数。
bootloader_reboot_ok: true- 角色检测到需要重启才能使更改生效,并对受管节点执行重启。
重要更改引导装载程序密码不是幂等的事务。这意味着,如果您再次应用同样的 Ansible playbook,则结果将不一样,并且受管节点的状态将改变。
有关 playbook 中使用的所有变量的详情,请查看控制节点上的
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.md文件。验证 playbook 语法:
ansible-playbook --syntax-check --ask-vault-pass ~/playbook.yml
$ ansible-playbook --syntax-check --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,这个命令只验证语法,不能防止错误的、但有效的配置。
运行 playbook:
ansible-playbook --ask-vault-pass ~/playbook.yml
$ ansible-playbook --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
在受管节点上的 GRUB 引导菜单屏幕中,按 e 键进行编辑。
提示您输入用户名和密码:
输入用户名: root-
引导装载程序用户名始终是
root,您不需要在 Ansible playbook 中指定它。 输入 password: <password>-
引导装载程序密码对应于您在
vault.yml文件中定义的pwd变量。
您可以查看或编辑特定引导装载程序条目的配置:



31.3. 使用 bootloader RHEL 系统角色为引导装载程序菜单设置超时
您可以使用 bootloader RHEL 系统角色,以自动的方式为 GRUB 引导装载程序菜单配置超时。您可以更新要进行干预的时间,并为各种目的选择一个非默认引导条目。
先决条件
- 您已准备好控制节点和受管节点
- 以可在受管主机上运行 playbook 的用户登录到控制节点。
-
您用于连接到受管节点的帐户对它们具有
sudo权限。
流程
创建一个包含以下内容的 playbook 文件,如
~/playbook.yml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 示例 playbook 中指定的设置包括如下:
bootloader_timeout: 10- 输入一个整数,以控制在引导默认条目之前 GRUB 引导装载程序菜单显示多长时间。
有关 playbook 中使用的所有变量的详情,请查看控制节点上的
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.md文件。验证 playbook 语法:
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,这个命令只验证语法,不能防止错误的、但有效的配置。
运行 playbook:
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
远程重启受管节点:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 在受管节点上,观察 GRUB 引导菜单屏幕。
突出显示的条目将在 10s 后自动执行在 GRUB 自动使用默认条目之前,此引导菜单显示多长时间。
替代方案:您可以远程查询受管节点的
/boot/grub2/grub.cfg文件中的"timeout"设置:Copy to Clipboard Copied! Toggle word wrap Toggle overflow

31.4. 使用 bootloader RHEL 系统角色收集引导装载程序配置信息
您可以使用 bootloader RHEL 系统角色,以自动的方式收集有关 GRUB 引导装载程序条目的信息。您可以使用这些信息来验证系统引导参数的配置是否正确,如内核和初始 RAM 磁盘镜像路径。
因此,您可以,例如:
- 防止引导失败。
- 在故障排除时恢复到已知的良好状态。
- 确保与安全相关的内核命令行参数被正确配置。
先决条件
- 您已准备好控制节点和受管节点
- 以可在受管主机上运行 playbook 的用户登录到控制节点。
-
您用于连接到受管节点的帐户对它们具有
sudo权限。
流程
创建一个包含以下内容的 playbook 文件,如
~/playbook.yml:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 有关 playbook 中使用的所有变量的详情,请查看控制节点上的
/usr/share/ansible/roles/rhel-system-roles.bootloader/README.md文件。验证 playbook 语法:
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 请注意,这个命令只验证语法,不能防止错误的、但有效的配置。
运行 playbook:
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
验证
在控制节点上运行前面的 playbook 后,您会看到类似的命令行输出,如下例中所示:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 命令行输出显示以下有关引导条目的显著的配置信息:
args- 在引导过程中,命令行参数被 GRUB2 引导装载程序传递给内核。它们配置内核的各种设置和行为、initramfs 和其他引导时组件。
id- 分配给引导装载程序菜单中每个引导条目的唯一标识符。它由机器 ID 和内核版本组成。
root- 要挂载的内核的根文件系统,并在启动过程中用作主文件系统。
第 32 章 使用高级错误报告
当您使用 高级错误报告 (AER)时,您会收到 Peripheral Component Interconnect Express (PCIe)设备的错误事件通知。RHEL 默认启用此内核功能,并收集内核日志中报告的错误。如果您使用 rasdaemon 程序,这些错误会被解析并存储在其数据库中。
32.1. AER 概述
高级错误报告 (AER)是一个内核功能,可为 Peripheral Component Interconnect Express (PCIe)设备提供增强的错误报告。AER 内核驱动程序附加在支持 PCIe AER 功能的 root 端口,以便:
- 收集全面的错误信息
- 向用户报告错误
- 执行错误恢复操作
当 AER 捕获到错误时,它会将向控制台发送一条 错误 消息。对于可修复的错误,控制台输出是一条 警告。
例 32.1. AER 输出示例
32.2. 收集并显示 AER 消息
要收集和显示 AER 消息,请使用 rasdaemon 程序。
流程
安装
rasdaemon软件包。yum install rasdaemon
# yum install rasdaemonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 启用并启动
rasdaemon服务。systemctl enable --now rasdaemon
# systemctl enable --now rasdaemon Created symlink /etc/systemd/system/multi-user.target.wants/rasdaemon.service → /usr/lib/systemd/system/rasdaemon.service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 发出
ras-mc-ctl命令。ras-mc-ctl --summary ras-mc-ctl --errors
# ras-mc-ctl --summary # ras-mc-ctl --errorsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 命令显示日志记录错误的摘要(
--summary选项),或者显示存储在错误数据库中的错误(--errors选项)。