3.9. 处理大型消息大小
消息的默认批处理大小为 1MB,在大多数用例中最适合最大吞吐量。假设有足够的磁盘容量,Kafka 可以以较低的吞吐量容纳更大的批处理。
大型消息大小以三种方式处理:
- 生成者消息压缩 将压缩消息写入日志。
- 基于参考的消息仅发送对存储在消息值中的一些其他系统中的数据的引用。
- 内联消息传递将信息分成使用相同键的块,然后使用像 Kafka Streams 这样的流处理器组合在输出中。
- 为处理更大的消息大小而构建代理和制作者/消费者客户端应用程序配置。
建议使用基于参考的消息和消息压缩选项,并涵盖大多数情况。使用任何这些选项时,必须小心以避免出现性能问题。
制作者侧压缩
对于制作者配置,您可以指定一个 compression.type,如 Gzip,然后应用于制作者生成的数据的批处理。使用代理配置 compression.type=producer,代理会保留制作者使用的任何压缩。每当生成者和主题压缩不匹配时,代理必须在将批处理附加到日志之前再次压缩,这会影响代理性能。
压缩还增加生成者上的额外的处理开销,但在批处理中包含更多数据,因此在消息数据压缩时通常很有用。
将生成者压缩与批处理大小的微调合并,以促进最佳吞吐量。使用指标有助于量化所需的平均批处理大小。
基于参考的消息
当您不知道消息将如何多大时,基于参考的消息对于数据复制非常有用。外部数据存储必须为 fast、durable,且高可用性才能使此配置正常工作。数据被写入数据存储,并返回对数据的引用。producer 发送一个包含对 Kafka 引用的消息。消费者从消息获取引用,并使用它来从数据存储中获取数据。
图 3.4. 基于参考的消息流
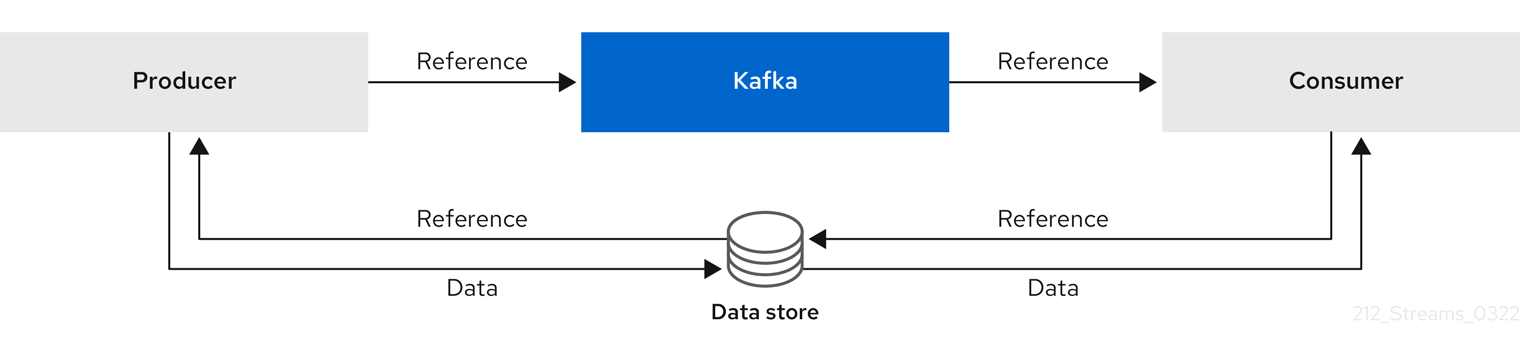
由于消息传递需要更多往返,因此端到端延迟会增加。这个方法的另一个显著缺陷是在清理 Kafka 消息时,外部系统中没有自动清理数据。混合方法是仅向数据存储和进程标准消息发送大型消息。
内联消息传递
内联消息传递比较复杂,但它没有依赖于外部系统的开销,如基于参考的消息。
生成的客户端应用程序必须序列化,然后在消息太大时阻止数据。然后,生成者使用 Kafka ByteArraySerializer 或与发送每个块前再次序列化每个块类似。消费者跟踪消息和缓冲区块,直到它有完整的消息。消耗客户端应用程序接收块,这些块在反序列化前被编译。根据每个一组块消息的第一个或最后一个块的偏移,将完整的消息传送到消耗的应用程序的其余部分。检查通过偏移元数据进行的成功发送完整消息,以避免在重新平衡过程中重复。
图 3.5. 内联消息传递流
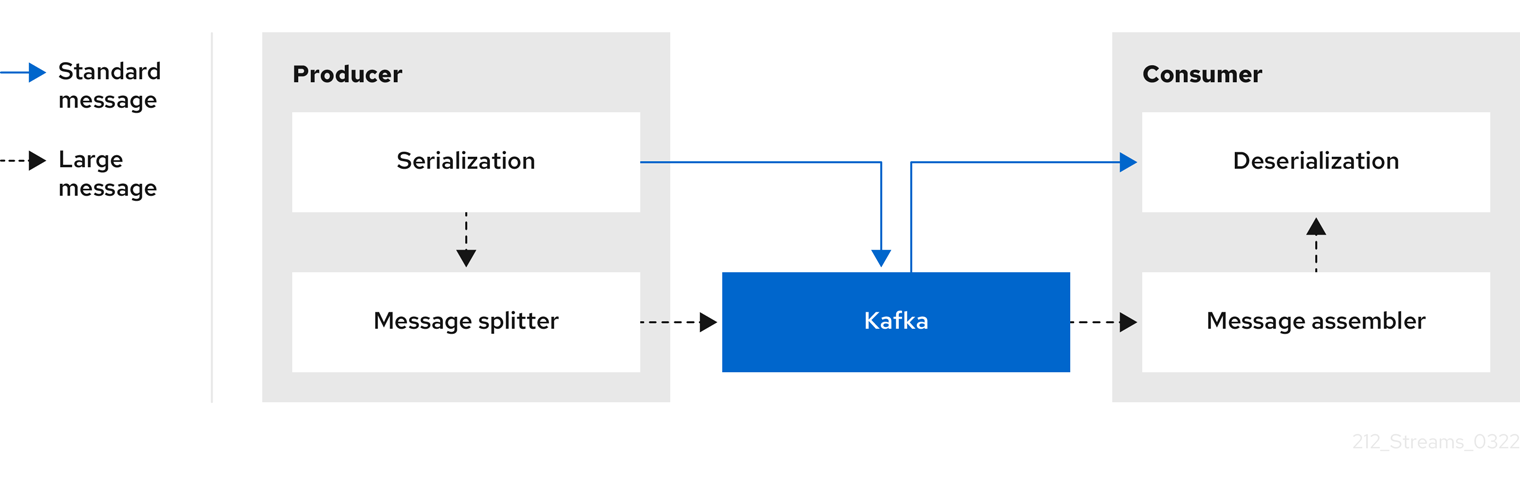
因为缓冲区需要,内联消息传递在消费者端性能开销,特别是在并行处理一系列大型消息时。大型消息的块可能会变为交集,因此如果缓冲区中另一个大消息的块不完整,则无法提交消息的所有块。因此,通常通过保留消息区块或实施提交逻辑来支持缓冲区。
处理更大消息的配置
如果无法避免更大的消息,并避免在消息流的任意点上的块,您可以提高消息限值。为此,请在主题级别配置 message.max.bytes,为单个主题设置最大记录批处理大小。如果您在代理级别上设置了 message.max.bytes,则所有主题都允许更大的消息。
代理将拒绝任何大于 message. max.bytes 设置的消息。生产者(max.request.size)和消费者(message.max.bytes)的缓冲区大小必须能够容纳更大的消息。