第 5 章 Prometheus Cluster Monitoring
5.1. 概述
OpenShift Container Platform 附带一个预先配置和自我更新的监控堆栈,它基于 Prometheus 开源项目及其更广泛的生态系统。它提供对集群组件的监控,并附带一组警报,以便立即通知集群管理员任何出现的问题,以及一组 Grafana 仪表板。
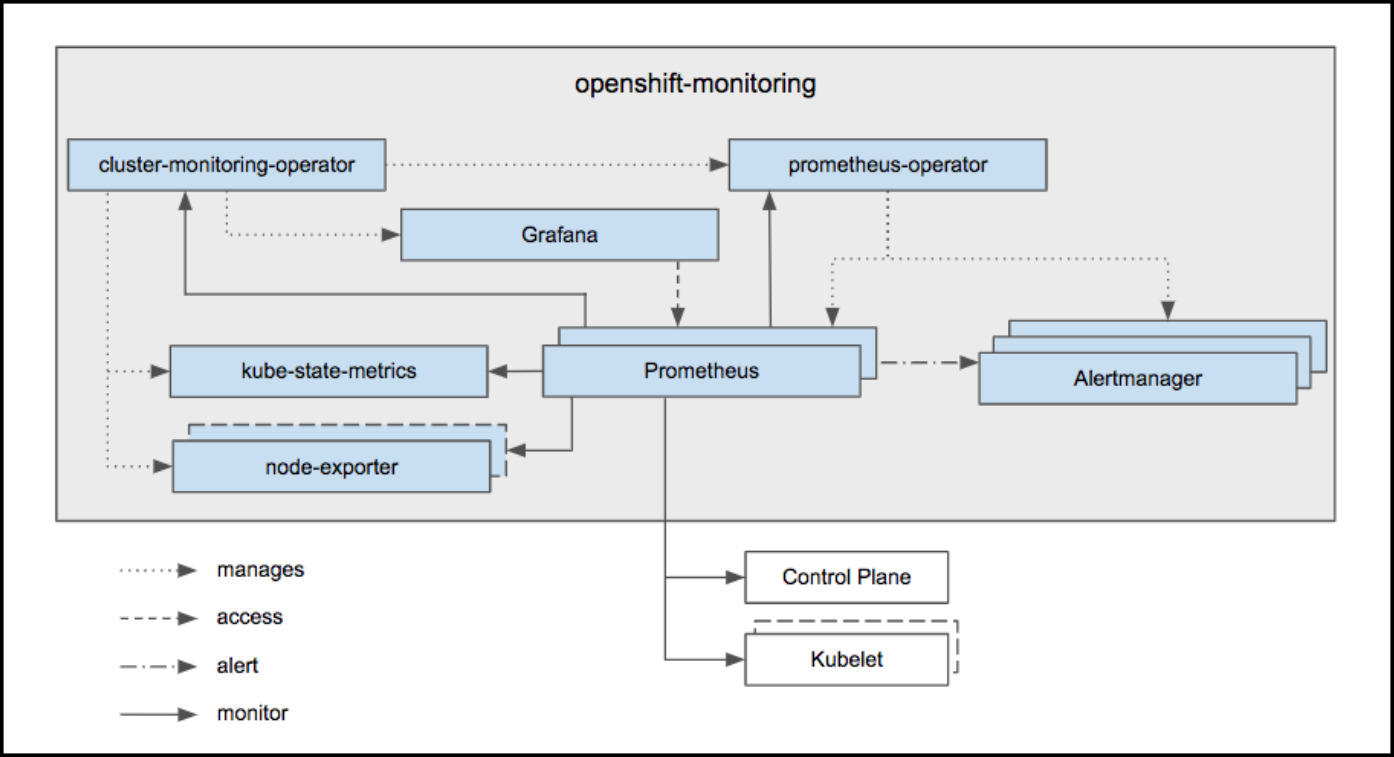
上图中突出显示,监控堆栈的核心是 OpenShift Container Platform Cluster Monitoring Operator(CMO),它监视部署的监控组件和资源,并确保它们始终保持最新状态。
Prometheus Operator (PO) 可以创建、配置和管理 Prometheus 和 Alertmanager 实例。还能根据熟悉的 Kubernetes 标签查询来自动生成监控目标配置。
除了 Prometheus 和 Alertmanager 外,OpenShift Container Platform 监控还包括 node-exporter 和 kube-state-metrics。node-exporter 是部署在每个节点上的代理,用于收集有关它的指标。kube-state-metrics 导出器代理将 Kubernetes 对象转换为 Prometheus 可使用的指标。
作为集群监控的一部分监控的目标有:
- Prometheus 本身
- Prometheus-Operator
- cluster-monitoring-operator
- Alertmanager 集群实例
- Kubernetes apiserver
- kubelet(kubelet 为每个容器指标嵌入 cAdvisor)
- kube-controllers
- kube-state-metrics
- node-exporter
- etcd(如果启用了 etcd 监控)
所有这些组件都会自动更新。
如需有关 OpenShift Container Platform Cluster Monitoring Operator 的更多信息,请参阅 Cluster Monitoring Operator GitHub 项目。
为了能够提供具有保证兼容性的更新,OpenShift Container Platform 监控堆栈的可配置性仅限于明确可用的选项。