2.5. 故障排除
您可以查看迁移自定义资源 (CR),并下载日志来排除迁移失败的问题。
如果应用程序在迁移失败时停止,您必须手动回滚,以防止数据崩溃。
如果应用程序在迁移过程中没有停止,则不需要手动回滚,因为原始应用程序仍然在源集群中运行。
2.5.1. 查看迁移自定义资源 (CR)
集群应用程序迁移 (CAM) 工具会创建以下 CR 用于迁移:
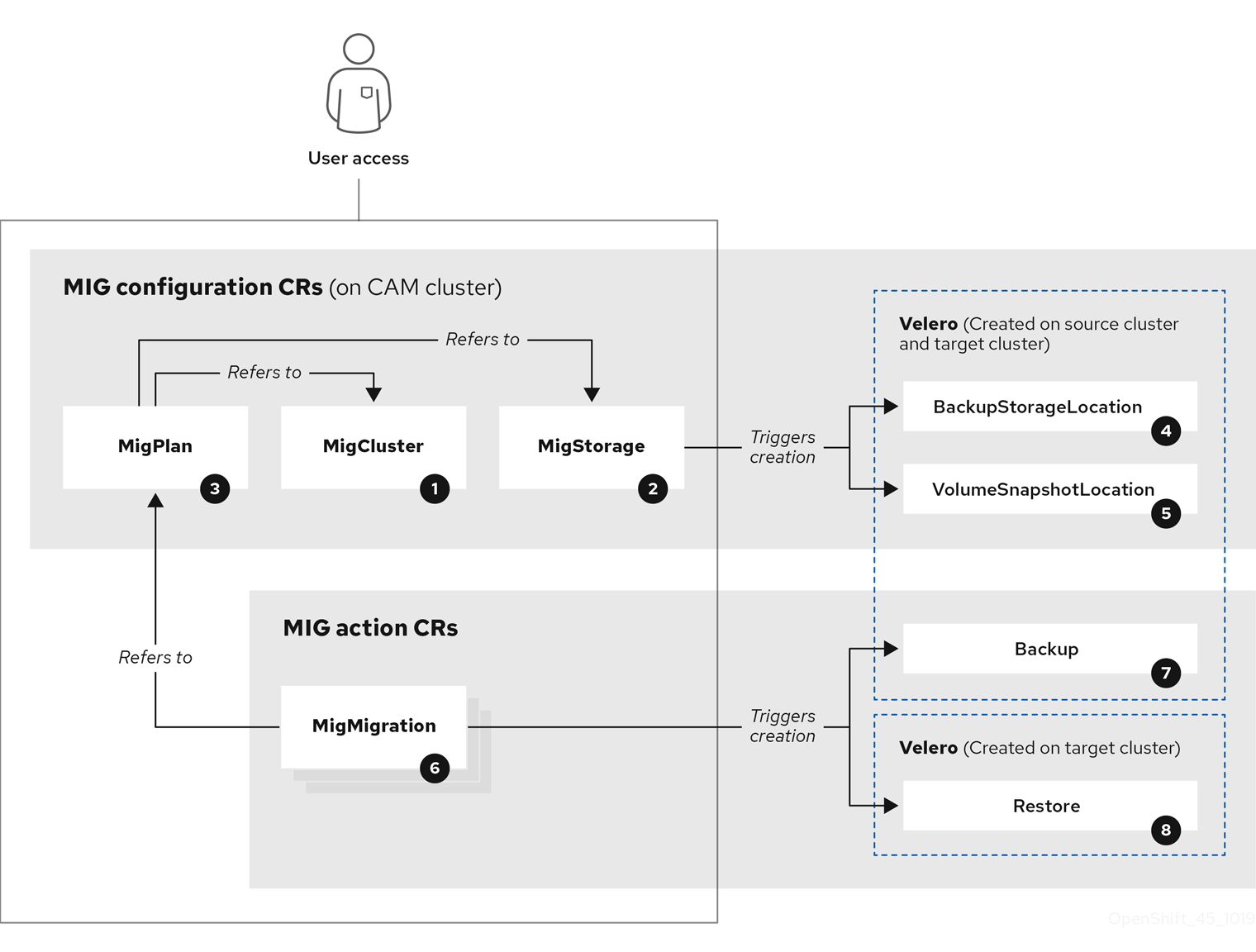
![]() MigCluster (配置,CAM 集群): 集群定义
MigCluster (配置,CAM 集群): 集群定义
![]() MigStorage (配置,CAM 集群): 存储定义
MigStorage (配置,CAM 集群): 存储定义
![]() MigPlan (配置,CAM 集群):迁移计划
MigPlan (配置,CAM 集群):迁移计划
MigPlan CR 描述了要迁移的源和目标集群、存储库和命名空间。它与 0 个 、1 个 或多个 MigMigration CR 关联。
删除 MigPlan CR 会删除关联的 MigMigration CR。
![]() BackupStorageLocation (配置,CAM 集群): Velero 备份对象的位置
BackupStorageLocation (配置,CAM 集群): Velero 备份对象的位置
![]() VolumeSnapshotLocation (配置,CAM 集群): Velero 卷快照的位置
VolumeSnapshotLocation (配置,CAM 集群): Velero 卷快照的位置
![]() MigMigration(操作,CAM 集群):Migration,在迁移期间创建
MigMigration(操作,CAM 集群):Migration,在迁移期间创建
在每次进行 stage 或迁移数据时都会创建一个 MigMigration CR。每个 MigMigration CR 都会与一个 MigPlan CR 关联。
![]() Backup(操作,源集群):当运行迁移计划时,MigMigration CR 在每个源集群上创建两个 Velero 备份 CR:
Backup(操作,源集群):当运行迁移计划时,MigMigration CR 在每个源集群上创建两个 Velero 备份 CR:
- 备份 CR #1 用于Kubernetes 对象
- 备份 CR #2 用于 PV 数据
![]() Restore (操作,目标集群):在运行迁移计划时,MigMigration CR 在目标集群上创建两个 Velero 恢复 CR:
Restore (操作,目标集群):在运行迁移计划时,MigMigration CR 在目标集群上创建两个 Velero 恢复 CR:
- 恢复 CR #1(使用备份 CR #2)用于 PV 数据
- 恢复 CR #2(使用备份 CR #1)用于 Kubernetes 对象
流程
获取 CR 名称:
$ oc get <cr> -n openshift-migration1 NAME AGE 88435fe0-c9f8-11e9-85e6-5d593ce65e10 6m42s- 1
- 指定您要查看的迁移 CR。
查看 CR:
$ oc describe <cr> 88435fe0-c9f8-11e9-85e6-5d593ce65e10 -n openshift-migration输出结果类似以下示例。
MigMigration 示例
$ oc describe migmigration 88435fe0-c9f8-11e9-85e6-5d593ce65e10 -n openshift-migration
Name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10
Namespace: openshift-migration
Labels: <none>
Annotations: touch: 3b48b543-b53e-4e44-9d34-33563f0f8147
API Version: migration.openshift.io/v1alpha1
Kind: MigMigration
Metadata:
Creation Timestamp: 2019-08-29T01:01:29Z
Generation: 20
Resource Version: 88179
Self Link: /apis/migration.openshift.io/v1alpha1/namespaces/openshift-migration/migmigrations/88435fe0-c9f8-11e9-85e6-5d593ce65e10
UID: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
Spec:
Mig Plan Ref:
Name: socks-shop-mig-plan
Namespace: openshift-migration
Quiesce Pods: true
Stage: false
Status:
Conditions:
Category: Advisory
Durable: true
Last Transition Time: 2019-08-29T01:03:40Z
Message: The migration has completed successfully.
Reason: Completed
Status: True
Type: Succeeded
Phase: Completed
Start Timestamp: 2019-08-29T01:01:29Z
Events: <none>Velero 备份 CR #2 示例(PV 数据)
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.105.179:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-44dd3bd5-c9f8-11e9-95ad-0205fe66cbb6
creationTimestamp: "2019-08-29T01:03:15Z"
generateName: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-
generation: 1
labels:
app.kubernetes.io/part-of: migration
migmigration: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
migration-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
velero.io/storage-location: myrepo-vpzq9
name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
namespace: openshift-migration
resourceVersion: "87313"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/backups/88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
uid: c80dbbc0-c9f8-11e9-95ad-0205fe66cbb6
spec:
excludedNamespaces: []
excludedResources: []
hooks:
resources: []
includeClusterResources: null
includedNamespaces:
- sock-shop
includedResources:
- persistentvolumes
- persistentvolumeclaims
- namespaces
- imagestreams
- imagestreamtags
- secrets
- configmaps
- pods
labelSelector:
matchLabels:
migration-included-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
storageLocation: myrepo-vpzq9
ttl: 720h0m0s
volumeSnapshotLocations:
- myrepo-wv6fx
status:
completionTimestamp: "2019-08-29T01:02:36Z"
errors: 0
expiration: "2019-09-28T01:02:35Z"
phase: Completed
startTimestamp: "2019-08-29T01:02:35Z"
validationErrors: null
version: 1
volumeSnapshotsAttempted: 0
volumeSnapshotsCompleted: 0
warnings: 0Velero 恢复 CR #2 示例(Kubernetes 资源)
apiVersion: velero.io/v1
kind: Restore
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.90.187:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-36f54ca7-c925-11e9-825a-06fa9fb68c88
creationTimestamp: "2019-08-28T00:09:49Z"
generateName: e13a1b60-c927-11e9-9555-d129df7f3b96-
generation: 3
labels:
app.kubernetes.io/part-of: migration
migmigration: e18252c9-c927-11e9-825a-06fa9fb68c88
migration-final-restore: e18252c9-c927-11e9-825a-06fa9fb68c88
name: e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
namespace: openshift-migration
resourceVersion: "82329"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/restores/e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
uid: 26983ec0-c928-11e9-825a-06fa9fb68c88
spec:
backupName: e13a1b60-c927-11e9-9555-d129df7f3b96-sz24f
excludedNamespaces: null
excludedResources:
- nodes
- events
- events.events.k8s.io
- backups.velero.io
- restores.velero.io
- resticrepositories.velero.io
includedNamespaces: null
includedResources: null
namespaceMapping: null
restorePVs: true
status:
errors: 0
failureReason: ""
phase: Completed
validationErrors: null
warnings: 152.5.2. 下载迁移日志
您可以在 CAM web 控制台中下载 Velero 、Restic 和 Migration controller 日志,以排除出现故障的迁移问题。
流程
- 登录到 CAM 控制台。
- 点击 Plans 查看迁移计划列表。
-
点一个迁移计划的 Options 菜单
 并选择 Logs。
并选择 Logs。
- 点 Download Logs 为所有集群下载迁移控制器、Velero 和 Restic 的日志。
要下载特定的日志:
指定日志选项:
- Cluster:选择源、目标或 CAM 主机集群。
- Log source:选择 Velero、Restic 或 Controller。
Pod source:选择 Pod 名称,例如:
controller-manager-78c469849c-v6wcf此时会显示所选日志。
您可以通过更改您的选择来清除日志选择设置。
- 点 Download Selected 下载所选日志。
另外,您可以使用 CLI 访问日志,如下例所示:
$ oc get pods -n openshift-migration | grep controller
controller-manager-78c469849c-v6wcf 1/1 Running 0 4h49m
$ oc logs controller-manager-78c469849c-v6wcf -f -n openshift-migration2.5.3. Restic 超时错误
如果因为 Restic 超时造成迁移失败,以下出错信息会出现在 Velero 日志中:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete" error.file="/go/src/github.com/heptio/velero/pkg/restic/backupper.go:165" error.function="github.com/heptio/velero/pkg/restic.(*backupper).BackupPodVolumes" group=v1
restic_timeout 的默认值为一小时。您可以为大型迁移增加这个值,请注意,高的值可能会延迟返回出错信息。
流程
-
在 OpenShift Container Platform web 控制台中导航至 Operators
Installed Operators。 - 点 Cluster Application Migration Operator。
- 在 MigrationController 标签页中点 migration-controller。
在 YAML 标签页中,更新以下参数值:
spec: restic_timeout: 1h1 - 1
- 有效单元是
h(小时)、m(分钟)和s(秒),例如3h30m15s。
- 点 Save。
2.5.4. 手动回滚迁移
如果您的应用程序在迁移失败时停止,您必须手动回滚,以防止 PV 中的数据被破坏。
如果应用程序在迁移过程中没有停止,则不需要进行手动回滚,因为原始应用程序仍然在源集群中运行。
流程
在目标集群中,切换到迁移的项目:
$ oc project <project>获取部署的资源:
$ oc get all删除部署的资源以确保应用程序没有在目标集群中运行,并访问 PVC 上的数据:
$ oc delete <resource_type>要停止 DaemonSet 而不删除它,在 YAML 文件中更新
nodeSelector:apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: hello-daemonset spec: selector: matchLabels: name: hello-daemonset template: metadata: labels: name: hello-daemonset spec: nodeSelector: role: worker1 - 1
- 指定一个没有存在于任何节点上的
nodeSelector值。
更新每个 PV 的重新声明策略,以便删除不必要的数据。在迁移过程中,绑定 PV 的重新声明策略是
reclaim,以确保应用程序从源集群中被删除时不会丢失数据。您可以在回滚过程中删除这些 PV。apiVersion: v1 kind: PersistentVolume metadata: name: pv0001 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain1 ... status: ...- 1
- 指定
Recycle或Delete。
在源集群中,切换到迁移的项目并获取其部署的资源:
$ oc project <project> $ oc get all启动每个部署资源的一个或多个副本:
$ oc scale --replicas=1 <resource_type>/<resource_name>-
如果在操作中被更改了,把 DaemonSet 的
nodeSelector改回其原始值。
2.5.5. 为客户支持问题单收集数据
如果创建一个客户支持问题单,您可以使用 openshift-migration-must-gather-rhel8 镜像的 must-gather 工具来收集与您的集群相关的信息,并把这些信息上传到红帽客户门户网站。
openshift-migration-must-gather-rhel8 镜像会收集默认的 must-gather 镜像不收集的日志和 CR 数据。
流程
-
进入要存储
must-gather数据的目录。 运行
oc adm must-gather命令:$ oc adm must-gather --image=registry.redhat.io/rhcam-1-2/openshift-migration-must-gather-rhel8must-gather工具程序收集集群数据,并把它保存在must-gather.local.<uid>目录中。-
从
must-gather数据中删除验证密钥和其他敏感信息。 创建一个包含
must-gather.local.<uid>目录内容的归档文件:$ tar cvaf must-gather.tar.gz must-gather.local.<uid>/在红帽客户门户中,为您的问题单附上这个压缩文件。
2.5.6. 已知问题
这个版本有以下已知问题:
在迁移过程中,CAM 工具会保留以下命名空间注解:
-
openshift.io/sa.scc.mcs -
openshift.io/sa.scc.supplemental-groups openshift.io/sa.scc.uid-range这些注解会保留 UID 范围,确保容器在目标集群中保留其文件系统权限。这可能会存在一定的风险。因为迁移的 UID 可能已存在于目标集群的现有或将来的命名空间中。(BZ#1748440)
-
-
当在 CAM web 控制台中添加 S3 端点时,只有 AWS 支持
https://。对于其他 S3 供应商,请使用http://。 -
如果一个 AWS 存储桶被添加到 CAM web 控制台,然后将其删除,则其状态会保持为
True,这是因为 MigStorage CR 没有被更新。(BZ#1738564) -
如果迁移控制器在目标集群以外的集群中运行,迁移将失败。
EnsureCloudSecretPropagated阶段会跳过,并给出一个日志警告。(BZ#1757571) - 目前,集群范围的资源,包括集群角色绑定和安全上下文约束,还没有由 CAM 处理。如果应用程序需要集群范围的资源,则必须在目标集群中手动创建它们。(BZ#1759804)
- 创建迁移计划时会显示不正确的源集群存储类。(BZ#1777869)
- 如果 CAM web 控制台中的一个集群变得无法访问,它会阻止尝试关闭打开的迁移计划。(BZ#1758269)
- 如果迁移失败,则迁移计划不会为静默的 pod 保留自定义 PV 设置。您必须手动回滚,删除迁移计划,并使用 PV 设置创建新的迁移计划。(BZ#1784899)