第 84 章 决定引擎中的 Phreak 规则算法
Red Hat Process Automation Manager 中的决策引擎使用 Phreak 算法来进行规则评估。Phreak 从 Rete 算法发展,包括面向对象系统以前版本的 Red Hat Process Automation Manager 中引入的增强 Rete algorithm ReteOO。总体而言,Phreak 比 Rete 和 ReteOO 更容易进行扩展,并在大型系统中速度快。
当 Rete 被视为"不良规则评估)和面向数据的情况下,Phreak 被视为 lazy(推迟的规则评估)和目标。Rete 算法在插入、更新和删除操作过程中执行许多操作,以便查找所有规则的部分匹配。规则匹配期间的 Rete 算法数量需要很多时间,在最终执行规则前需要很多时间,特别是在大型系统中。使用 Phreak 时,这个部分规则匹配会有意延迟,以便更有效地处理大量数据。
Phreak 算法为之前的 Rete 算法添加了以下一组改进:
- 上下文内存的三个层:节点、网段和规则内存类型
- 基于规则、基于网段和节点的连接
- lazy(delayed)规则评估
- 基于堆栈的评估会暂停和恢复
- 隔离规则评估
- set-oriented propagations
84.1. Phreak 中的规则评估
当决策引擎启动时,所有规则均被视为与可触发规则的模式匹配数据。在这个阶段,决策引擎中的 Phreak 算法不会评估规则。insert、update 和 delete 操作会被放入排队,Phreak 使用了高流(根据规则最有可能执行)来计算并选择下一个评估规则。当为规则填充了所有必要的输入值时,该规则被视为与相关模式匹配数据相关联。然后,Phreak 会创建代表此规则的目标,并将目标置于优先级队列中,根据规则排序。只有评估了创建目标的规则,且其他潜在的规则评估会延迟。评估单个规则时,仍会通过分段过程来实现节点共享。
与面向 tuple 的 Rete 不同,Phreak propagation 是以集合为导向。对于正在评估的规则,决策引擎会访问第一个节点,并处理所有已排队插入、更新和删除操作。结果添加到集合中,集合会传播到子节点。在子节点中,处理所有已排队的插入、更新和删除操作,将结果添加到同一集合中。然后,集合会传播到下一个子节点,并重复相同的进程,直到它到达终端节点。此周期会创建一个批处理进程效果,可为某些规则结构提供性能优势。
规则的链接和取消链接通过基于网络分段的分层位掩码系统进行。在构建规则网络时,会为由同一组规则共享的规则网络节点创建网段。规则由片段的路径组成。如果某个规则不与任何其他规则共享任何节点,则会成为单个网段。
为网段中的每个节点分配一个位掩码偏移。根据这些要求,为规则路径中的每个片段分配另一个位掩码:
-
如果至少有一个输入节点存在,节点位将设置为
on状态。 -
如果网段中的每个节点都被设置为
on状态,则片段位也被设置为on状态。 -
如果有任何节点位设置为
off状态,则该片段也会设置为off状态。 -
如果规则路径中的每个部分设置为
on状态,则会被视为链接,并创建一个目标来调度评估规则。
相同的位掩码技术用于跟踪修改的节点、网段和规则。通过此跟踪功能,已经连接了从评估中未调度的规则(如果自其创建的评估目标)被修改过。因此,无法评估部分匹配规则。
在 Phreak 中可以进行规则评估的过程,因为与 Rete 的单个内存单位不同,Phreak 有三个带有节点、网段和规则内存类型的上下文内存层。这种分层可在评估规则的过程中更多上下文理解。
图 84.1. Phreak 三层内存系统

以下示例演示了如何在 Phreak 中对规则进行组织和评估。
示例 1: 具有三种模式的单一规则(R1):A、B 和 C。规则形成单一片段,其位为 1、2 和 4。单个片段具有位偏移 1。
图 84.2. 示例 1:单一规则

示例 2: 添加了规则 R2 并共享模式 A。
图 84.3. 示例 2:使用模式共享的两个规则

Pattern A 放置在自己的网段中,为每个规则产生两个片段。这两个片段组成了对应规则的路径。第一个部分由两个路径共享。当特征 A 被链接时,该片段将会被链接。然后,该片段会迭代该片段共享的每个路径,在 上将 位 1 设置为。如果模式 B 和 C 稍后打开,则路径 R1 的第二个片段将链接,这会导致为 R1 打开位 2。当为 R1 打开位 1 并位 2 被打开后,该规则现已被链接,并创建了一个目标来计划以后评估和执行规则。
评估规则时,该片段支持共享匹配的结果。每个片段都有一个临时内存,用于队列所有插入、更新和删除该片段。评估 R1 时,规则进程模式 A,这会导致一组元组。该算法检测分段分割,为每个插入、更新和删除创建对等的元组,并在集合中添加它们到 R2 暂存内存。然后,这些元组将与任何现有的已暂存元组合并,并在最终评估 R2 时执行。
示例 3: 添加了规则 R3 和 R4,并共享模式 A 和 B。
图 84.4. 示例 3:使用模式共享的三个规则
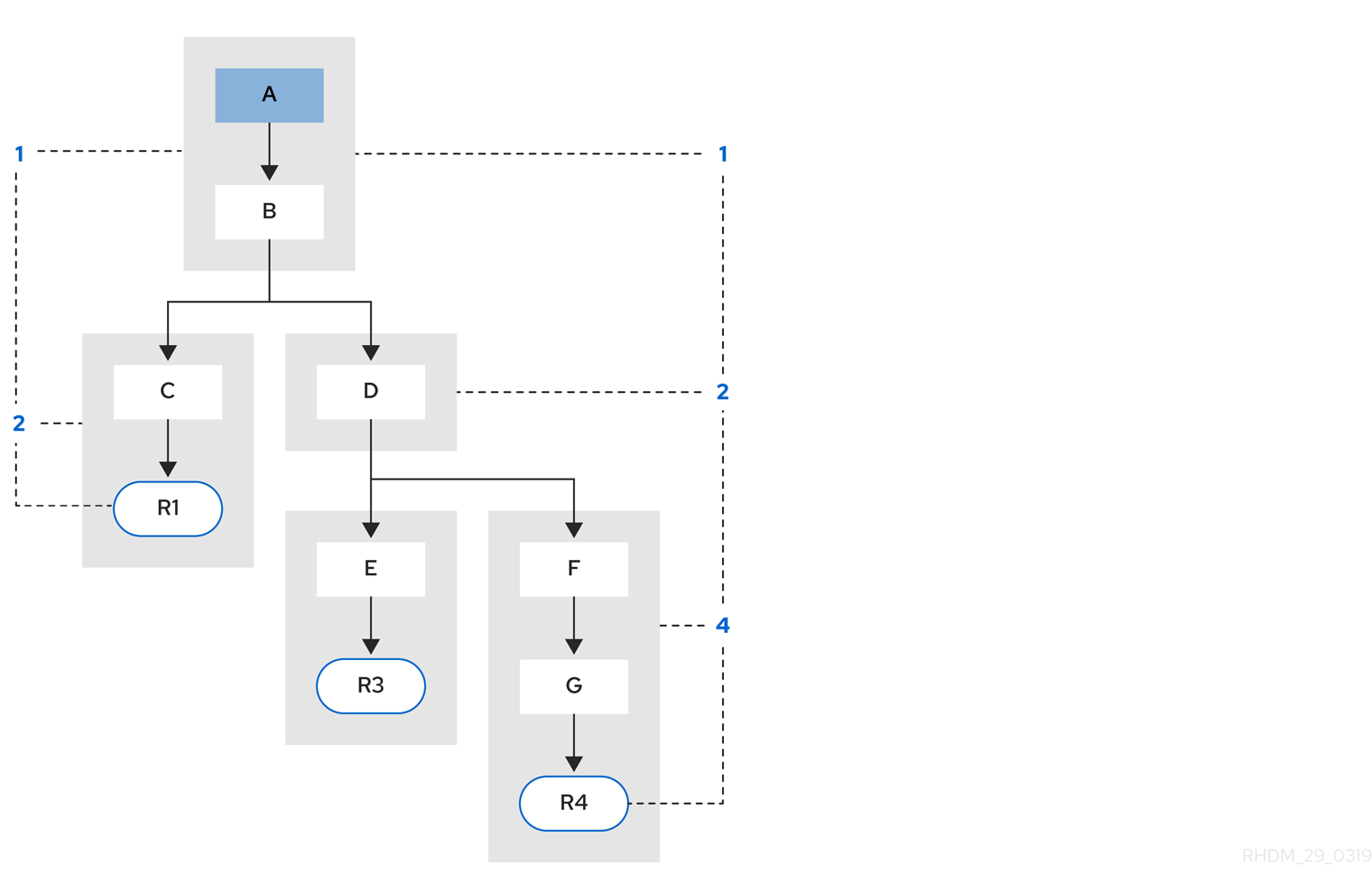
规则 R3 和 R4 有三个网段,R1 有两个网段。模式 A 和 B 由 R1、R3 和 R4 共享,而模式 D 则由 R3 和 R4 共享。
示例 4: 一个具有子网且没有模式共享的规则(R1)。
图 84.5. 示例 4:带有子网且没有模式共享的规则

当 非 Exists 或 Accumulate 节点包含多个元素时,会形成子网。在本例中,元素 B not(C) 组成了子网。元素 not(C) 是一个不需要子网且在 Not 节点内合并的一个元素。该子网使用了专用网段。规则 R1 仍具有两个网段的路径,子网形成另一个内部路径。子网链接后,也会链接到外部网段。
示例 5: 包含由规则 R2 共享的子网的组 R1。
图 84.6. 示例 5:两个规则,分别具有子网和模式共享
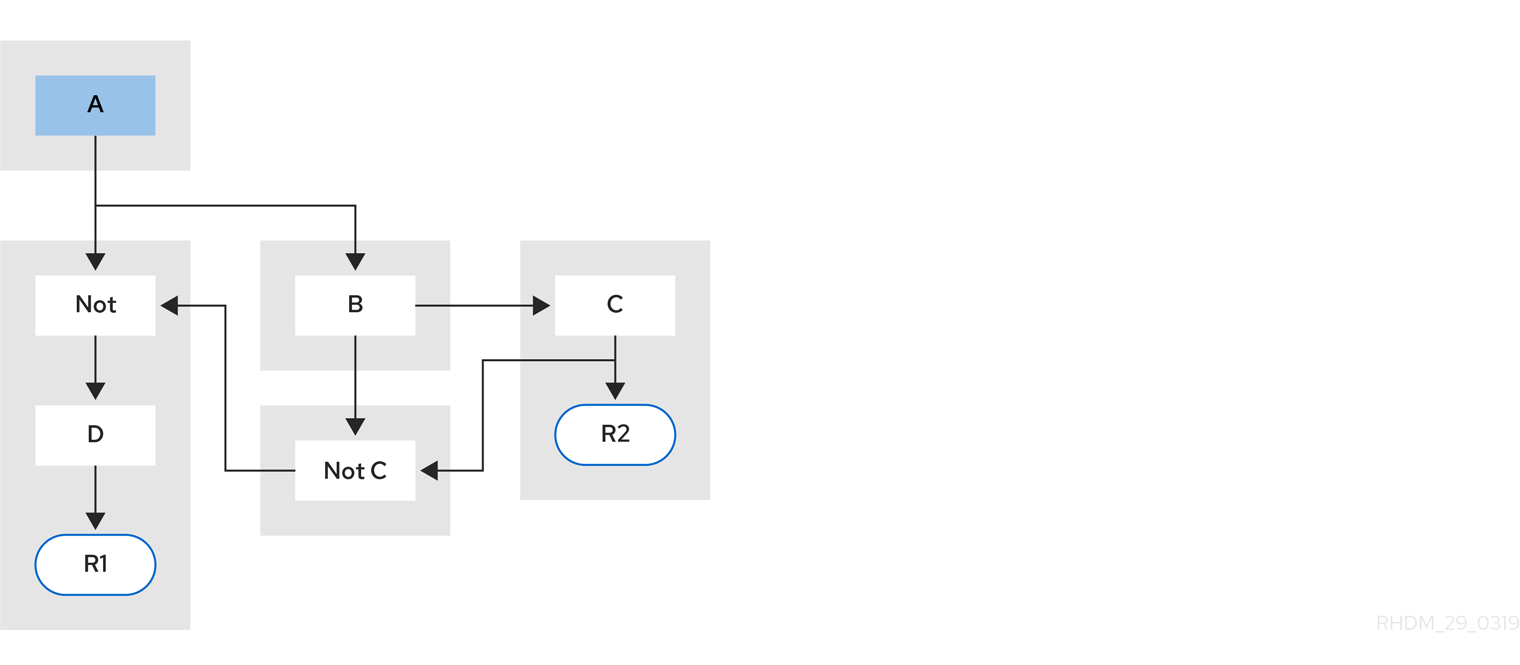
规则中的子网节点可以通过另一个没有子网的规则共享。这种共享会导致子网片段分成两个片段。
受限制的 Not nodes 和 Accumulate 节点永远不会取消链接一个网段,而且始终被视为启用了其位。
Phreak 评估算法基于堆栈,而非基于方法的。当 StackEntry 用于代表当前正在评估的节点时,可以随时暂停规则评估并恢复。
当规则评估到达子网时,会为外部路径网段和子网片段创建一个 StackEntry 对象。子网片段首先评估,当集合达到子网路径的末尾时,该片段将合并到该网段馈送节点的 staging 列表中。之前的 StackEntry 对象随后恢复,现在可以处理子网的结果。此过程具有添加的好处,特别是对于聚合的节点,对于聚合节点之前,所有工作都将以批处理形式完成。
相同的堆栈系统用于高效的向后兼容性。当规则评估到达查询节点时,评估将暂停,并将查询添加到堆栈中。然后,查询会被评估来生成结果集,该设置保存在 resumed StackEntry 对象的内存位置中,以提取并传播到子节点。如果查询本身被称为其他查询,该过程会重复,而当前查询已暂停,并为当前查询节点设置新的评估。
84.1.1. 带有转发和向后链的规则评估
Red Hat Process Automation Manager 中的决策引擎是一个混合原因系统,它使用转发链和后向链来评估规则。forward-chaining 规则系统是一个由数据驱动的系统,它从决策引擎的工作内存从事实开始,并对事实做出响应。当对象插入到工作内存时,因为更改是由日程表计划执行而变为 true 的任何规则条件。
相反,反向链接规则系统是一个由目标驱动的系统,从结论开始,决定引擎尝试满足,通常使用递归。如果系统无法达到结论或目标,它会搜索部分当前目标的子项。系统会继续这个过程,直到初始的结论是满足或者所有子语满意。
下图显示了如何使用转发链在逻辑流中的反向链接片段评估规则:
图 84.7. 使用转发和向后链的规则评估逻辑
