2.3. 集群
2.3.1. 集群简介
集群是共享相同存储域且相同类型的 CPU (Intel 或 AMD)的主机的逻辑分组。如果主机具有不同的 CPU 模型生成,则只使用所有模型中的功能。
系统中的每个集群都必须属于一个数据中心,系统中的每一主机都必须属于一个集群。虚拟机会动态分配到集群中的任何主机,并根据虚拟机中定义的策略在它们之间进行迁移。集群是可定义电源和加载共享策略的最高级别。
属于集群的主机和虚拟机数量分别显示在 Host Count 和 VM Count 下的结果列表中。
集群运行虚拟机或 Red Hat Gluster Storage 服务器。这两个目的是相互排斥的:单个集群无法支持虚拟化和存储主机。
Red Hat Virtualization 在安装过程中在默认数据中心创建一个默认集群。
图 2.2. 集群
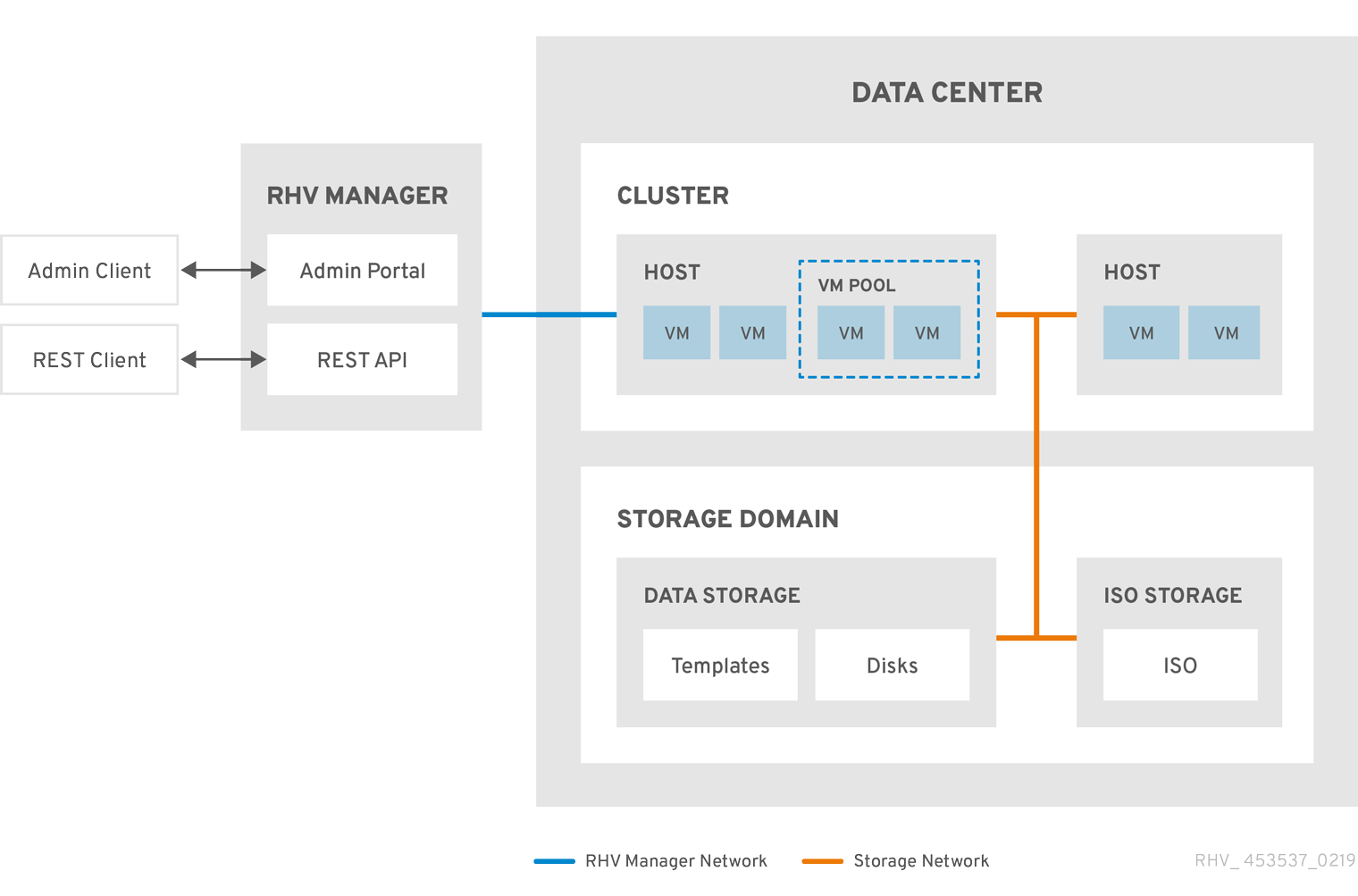
2.3.2. 集群任务
有些集群选项不适用于 Gluster 集群。有关在 Red Hat Virtualization 中使用 Red Hat Gluster Storage 的更多信息,请参阅使用 Red Hat Gluster Storage 配置 Red Hat Virtualization。
2.3.2.1. 创建新集群
数据中心可以包含多个集群,一个集群可以包含多个主机。集群中的所有主机都必须具有相同的 CPU 架构。要优化 CPU 类型,请在创建集群时创建主机。创建集群后,您可以使用 引导我按钮配置主机。
流程
-
单击
。 - 单击 New。
- 从下拉列表中选择集群将属于 的数据中心。
- 输入集群的名称和描述。
- 从 Management Network 下拉列表中选择一个网络来分配管理网络角色。
- 选择 CPU 架构。
对于 CPU Type,请在要属于此群集的主机中选择最旧的 CPU 处理器系列。CPU 类型按顺序从最旧的到最新的列出。
重要其 CPU 处理器系列的主机早于您为 CPU 类型指定的主机 不能是此集群的一部分。详情请查看 RHEV3 或 RHV4 集群应该设置为哪个 CPU 系列?
- 从下拉列表中选择集群的 FIPS Mode。
- 从下拉列表中选择集群的 Compatibility Version。
- 从下拉列表中选择 Switch Type。
选择 集群中主机的防火墙类型,可以是 Firewalld (默认)或 iptables。
注意只有在具有兼容性版本 4.2 或 4.3 的集群中的 Red Hat Enterprise Linux 7 主机才支持 iptables。您只能将 Red Hat Enterprise Linux 8 主机添加到使用防火墙类型为 firewalld的集群
- 选中 Enable Virt Service 或 Enable Gluster Service 复选框,以定义集群是否用虚拟主机填充或启用了 Gluster 的节点。
- (可选)选择 Enable to set VM Maintenance reason 复选框,以便在从 Manager 关闭虚拟机时启用可选的 reason 字段,让管理员能够为维护提供说明。
- (可选)选择 Enable to set Host maintenance reason 复选框,以便在主机从 Manager 放置到维护模式时启用可选的 reason 字段,让管理员能够针对维护提供说明。
- (可选)选择 /dev/hwrng source (外部硬件设备)复选框来指定集群中所有主机要使用的随机数生成器设备。默认启用 /dev/urandom 源 (Linux 提供的设备)。
- 单击 Optimization 选项卡,以选择集群的内存页面共享阈值,并选择性地在集群中的主机上启用 CPU 线程处理和内存膨胀。
- 点击 Migration Policy 选项卡定义集群的虚拟机迁移策略。
- 点 Scheduling Policy 选项卡,以选择性地配置调度策略,配置调度程序优化设置,为集群中的主机启用可信服务,启用 HA Reservation,然后选择序列号策略。
- 点击 Console 选项卡可以选择性地覆盖全局 SPICE 代理(如果有),并为集群中的主机指定 SPICE 代理地址。
- 点击 隔离策略 选项卡在集群中启用或禁用隔离,然后选择隔离选项。
- 单击 MAC Address Pool 选项卡,为集群指定默认池的 MAC 地址池。有关创建、编辑或删除 MAC 地址池的更多信息,请参阅 MAC 地址池。
- 点 创建集群并打开 Cluster - Guide Me 窗口。
-
Guide Me 窗口列出了需要为集群配置的实体。点 Configure Later 按钮配置这些实体或 postpone 配置。通过选择集群并点 More Actions (
 )来恢复配置,然后点 Guide Me。
)来恢复配置,然后点 Guide Me。
2.3.2.2. 常规集群设置说明
下表描述了新集群和编辑集群窗口中常规选项卡的设置。当您单击 时,无效的条目会在 orange 中列出,从而禁止接受更改。另外,字段提示指定预期的值或值范围。
| 字段 | description/Action |
|---|---|
| 数据中心 | 将包含集群的数据中心。必须在添加集群前创建数据中心。 |
| Name | 集群的名称。此文本字段的限制为 40 个字符,且必须是唯一的名称,其中含有大写字母和小写字母、数字、连字符和下划线的任意组合。 |
| 描述/评论 | 集群的描述或其他备注。建议使用这些字段,但不强制要求。 |
| 管理网络 | 将被分配管理网络角色的逻辑网络。默认为 ovirtmgmt。如果迁移网络没有正确附加到源或目标主机,则此网络也将用于迁移虚拟机。 在现有集群中,只有使用详情视图中的 Logical Networks 标签页中的 Manage Networks 按钮可以更改管理网络。 |
| CPU 架构 | 集群的 CPU 架构。集群中的所有主机都必须运行您指定的架构。不同的 CPU 类型取决于选择哪个 CPU 架构。
|
| CPU Type | 集群中最旧的 CPU 系列。有关 CPU 类型列表,请参阅《 规划和前提条件指南》 中的 CPU 要求。在不发生重大中断的情况下创建集群后,您无法更改它。将 CPU 类型设置为集群中最旧的 CPU 模型。只能使用所有模型中的功能。对于 Intel 和 AMD CPU 类型,列出的 CPU 型号从最旧的到最新状态的顺序排列。 |
| 芯片组/固件类型 | 只有当集群的 CPU 架构 设置为 x86_64 时,此设置才可用。此设置指定芯片组和固件类型。选项是:
如需更多信息,请参阅管理指南中的 UEFI 和 Q35 芯片组。 |
| 使用 Bios 将现有 VM/Templates 从 1440fx 改为 Q35 Chipset | 当集群的芯片组从 I440FX 改为 Q35 时,选择此复选框来更改现有工作负载。 |
| FIPS 模式 | 集群使用的 FIPS 模式。集群中的所有主机都必须运行您指定的 FIPS 模式,或者它们将无法操作。
|
| 兼容性版本 | Red Hat Virtualization 的版本。您将无法选择比为数据中心指定的版本更早的版本。 |
| 切换类型 | 集群使用的交换机类型。Linux Bridge 是标准 Red Hat Virtualization 交换机。OVS 支持 Open vSwitch 网络功能。 |
| 防火墙类型 | 指定集群中主机的防火墙类型,即 firewalld (默认)或 iptables。只有在具有兼容性版本 4.2 或 4.3 的集群中的 Red Hat Enterprise Linux 7 主机才支持 iptables。您只能将 Red Hat Enterprise Linux 8 主机添加到类型为 firewalld 的集群中。如果更改现有集群的防火墙类型,您必须重新安装集群中的所有主机以应用更改。 |
| 默认网络提供程序 | 指定集群要使用的默认外部网络供应商。如果您选择 Open Virtual Network (OVN),则添加到集群的主机会自动配置为与 OVN 供应商通信。 如果更改默认网络供应商,您必须重新安装集群中的所有主机以应用更改。 |
| 最大日志内存阈值 |
以百分比或绝对值(以 MB 为单位)形式指定最大内存消耗的日志记录阈值。如果主机的内存用量超过百分比,或者主机可用内存低于写值,则会记录消息。默认值为 |
| 启用 Virt Service | 如果选中此复选框,则此集群中的主机将用于运行虚拟机。 |
| 启用 Gluster 服务 | 如果选中此复选框,则此集群中的主机将用作 Red Hat Gluster Storage Server 节点,而不用于运行虚拟机。 |
| 导入现有的 gluster 配置 | 只有选择了 Enable Gluster Service 单选按钮时,此复选框才可用。通过此选项,您可以将当前启用了 Gluster 的集群及其所有附加的主机导入到 Red Hat Virtualization Manager。 集群中被导入的每个主机都需要以下选项:
|
| 额外的随机数字生成器源 | 如果选中了复选框,集群中的所有主机都有额外的随机数生成器设备。这可实现从随机数生成器设备到虚拟机传递熵。 |
| Gluster Tuned 配置集 | 只有选择了 Enable Gluster Service 复选框时,此复选框才可用。此选项指定 virtual-host 调优配置文件,以便提高脏内存页面的主动写回,这将使主机性能受益。 |
2.3.2.3. 优化设置说明
内存注意事项
内存页面共享可让虚拟机利用其他虚拟机中未使用的内存,最多使用 200% 的分配内存。此过程基于您 Red Hat Virtualization 环境中的虚拟机不会全部同时运行容量,允许将未使用的内存临时分配给特定虚拟机。
CPU 注意事项
对于非 CPU 密集型工作负载,您可以使用大于主机内核数(单个虚拟机的处理器内核数)的处理器内核总数来运行虚拟机。可以实现以下优点:
- 您可以运行更多虚拟机,从而降低硬件要求。
- 您可以使用原本无法实现的 CPU 拓扑配置虚拟机,例如,虚拟内核的数量在主机内核数和主机线程数量之间。
- 为了获得最佳性能,尤其是 CPU 密集型工作负载,您应该在虚拟机中使用与主机中相同的拓扑,因此主机和虚拟机预计同样的缓存使用量。主机启用了超线程后,QEMU 会将主机的超线程视为内核,因此虚拟机不知道它在具有多个线程的单一核心上运行。此行为可能会影响虚拟机的性能,因为实际对应于主机核心中的超线程的虚拟核心可能会与同一主机核心中的另一个超线程共享一个缓存,而虚拟机则将其视为一个单独的核心。
下表描述了新集群和编辑集群窗口中优化选项卡的设置。
| 字段 | description/Action |
|---|---|
| Memory Optimization |
|
| CPU 线程 | 选择 Count Threads As Cores 复选框可让主机运行虚拟机,处理器内核总数大于主机中的内核数(单个虚拟机的处理器内核数不得超过主机中的内核数)。 选择了此复选框后,公开的主机线程将被视为虚拟机可以使用的内核。例如,一个有 24 个内核,每个内核有 2 个线程的核系统(总共 48 个线程)可以运行最多 48 个虚拟机,用于计算主机 CPU 负载的算法会与潜在的内核的两倍相比。 |
| 内存 Balloon | 选择 Enable Memory Balloon Optimization 复选框可在此集群中运行的虚拟机上启用内存过量使用。选择了此复选框后,内存过量使用管理器(MoM)会尽可能启动膨胀,但会限制每个虚拟机的保证内存大小。
要运行气球功能,虚拟机需要有一个带有相关驱动程序的气球设备。每个虚拟机都包含 balloon 设备,除非特别删除。此集群中的每个主机在状态更改为 务必要清楚,在某些情况下,ballooning 可能会与 KSM 冲突。在这种情况下,MoM 将尝试调整气球的大小,以最大程度减少冲突。此外,在某些情况下,ballooning 可能会导致虚拟机的最优性能。建议管理员小心使用膨胀优化。 |
| KSM 控制 | 选择 启用 KSM 复选框可让 MoM在需要时运行 Kernel Same-page Merging (KSM),并且当它生成内存可节省能降低其 CPU 的成本时。 |
2.3.2.4. 迁移策略设置说明
迁移策略定义了在主机发生故障时实时迁移虚拟机的条件。这些条件包括迁移期间虚拟机的停机时间、网络带宽以及虚拟机优先级方式。
| 策略 | Description |
|---|---|
| Cluster default (Minimal downtime) |
|
| Minimal downtime | 允许虚拟机在典型的情况下迁移的策略。虚拟机不应遇到任何显著的停机时间。如果虚拟机迁移经过长时间后还没有被聚合,则迁移过程会被终止(取决于 QEMU 的迭代,最长为 500 millisecond)。客户机代理 hook 机制已启用。 |
| post-copy migration | 使用后复制迁移时,将暂停源主机上的迁移虚拟机 vCPU,仅传输最小内存页面,激活目标主机上的虚拟机 vCPU,并在虚拟机运行目标时传输其余内存页面。 后复制策略首先尝试预复制,以验证是否可能发生聚合。如果虚拟机迁移在很长时间后没有聚合,迁移会切换到后复制。 这可显著减少迁移的虚拟机停机时间,还可以确保无论源虚拟机的内存页面变化速度如何快。对于迁移大量连续使用的虚拟机来说,这是最佳选择,无法使用标准预复制迁移进行迁移。 此策略的缺点在于,在复制后阶段,虚拟机可能会显著下降,因为主机之间缺少内存部分传输。 警告 如果在完成后复制进程前网络连接中断,管理器将暂停,然后终止正在运行的虚拟机。如果虚拟机可用性至关重要,或者迁移网络不稳定,请不要使用复制后迁移。 |
| 如果需要,挂起工作负载 | 允许虚拟机在大多数情况下迁移的策略,包括运行繁重工作负载的虚拟机。因此,与某些其他设置相比,虚拟机可能会出现停机时间更大。迁移可能仍然针对极端工作负载中止。客户机代理 hook 机制已启用。 |
带宽设置定义每个主机传出和传入迁移的最大带宽。
| 策略 | Description |
|---|---|
| auto | 带宽从数据中心主机网络 QoS 中的 Rate Limit [Mbps] 设置中复制。如果尚未定义速率限制,则会计算为发送和接收网络接口最少的链接速度。如果没有设置速率限值,且链路速度不可用,将由发送主机上的本地 VDSM 设置确定。 |
| Hypervisor 默认 | 带宽由发送主机上的本地 VDSM 设置控制。 |
| Custom | 由用户(以 Mbps)定义。这个值被并发迁移数量除以 2 个,以考虑正在进行和传出的迁移。因此,用户定义的带宽必须足够大,以适应所有并发迁移。
例如,如果 |
弹性策略定义了虚拟机在迁移中的优先级。
| 字段 | description/Action |
|---|---|
| 迁移虚拟机 | 按照其定义的优先级迁移所有虚拟机。 |
| 只迁移高度可用的虚拟机 | 仅迁移高度可用的虚拟机,以防止超载其他主机。 |
| 不迁移虚拟机 | 防止虚拟机被迁移。 |
| 字段 | description/Action |
|---|---|
| 启用迁移加密 | 允许在迁移过程中对虚拟机进行加密。
|
| 并行迁移 | 允许您指定是否使用多少并行迁移连接。
|
| VM 迁移连接数 | 此设置仅在选择 Custom 时可用。自定义并行迁移的首选数量,2 到 255 之间。 |
2.3.2.5. 调度策略设置说明
通过调度策略,您可以指定可用主机之间虚拟机的使用和分配。定义调度策略,以启用集群中主机之间自动负载平衡。无论调度策略如何,虚拟机都不会在 CPU 过载的主机上启动。默认情况下,如果主机的 CPU 的负载超过 80% 达到 5 分钟,则主机 CPU 被视为过载,但这些值可以使用调度策略来更改。如需更多信息,请参阅管理指南中的调度策略。
| 字段 | description/Action |
|---|---|
| 选择 Policy | 从下拉列表中选择策略。
|
| Properties | 根据所选的策略,会出现以下属性:如果需要,编辑它们:
|
| 调度程序优化 | 为主机权衡/订购优化调度。
|
| 启用信任服务 |
启用与 OpenAttestation 服务器集成。启用此选项之前,使用 |
| 启用 HA 保留 | 启用 Manager 以监控高可用性虚拟机的集群容量。Manager 确保集群中存在适当的容量,以便在现有主机意外发生故障时将其指定为高度可用的虚拟机来迁移。 |
| 序列号策略 | 配置策略,以将序列号分配给集群中的每个新虚拟机:
|
| 自定义序列号 | 指定要应用到集群中的新虚拟机的自定义序列号。 |
当主机的可用内存低于 20% 时,如 mom.Controllers.Balloon - INFO Ballooning guest:half1 from 1096400 to 1991580 的气球命令会记录到 /var/log/vdsm/mom.log。/var/log/vdsm/mom.log 是 Memory Overcommit Manager 日志文件。
调度程序有一个后台进程,它根据当前的集群调度策略及其参数迁移虚拟机。根据策略中的各种条件及其相对权重,调度程序持续将主机归类为源主机或目标主机,并将个别虚拟机从前迁移到后者。
以下描述解释了 evenly_distributed 和 power_saving 集群调度策略如何与 MaxFreeMemoryForOverUtilized 和 MinFreeMemoryForUnderUtilized 属性进行交互。虽然两个策略都考虑 CPU 和内存负载,但 CPU 负载与 MaxFreeMemoryForOverUtilized 和 MinFreeMemoryForUnderUtilized 属性无关。
如果您将 MaxFreeMemoryForOverUtilized 和 MinFreeMemoryForUnderUtilized 属性定义为 evenly_distributed 策略的一部分:
- 可用内存低于 MaxFreeMemoryForOverUtilized 的可用内存较少,并成为源主机。
- 具有比 MinFreeMemoryForUnderUtilized 可用内存更大且成为目标主机的主机。
- 如果没有定义 MaxFreeMemoryForOverUtilized,调度程序不会根据内存负载迁移虚拟机。(它会根据策略的其他条件(如 CPU 负载)继续迁移虚拟机。)
- 如果没有定义 MinFreeMemoryForUnderUtilized,调度程序会认为所有主机有资格成为目标主机。
如果您将 MaxFreeMemoryForOverUtilized 和 MinFreeMemoryForUnderUtilized 属性定义为 power_saving 策略的一部分:
- 可用内存低于 MaxFreeMemoryForOverUtilized 的可用内存较少,并成为源主机。
- 具有比 MinFreeMemoryForUnderUtilized 可用内存更高且成为源主机的主机。
- 超过 MaxFreeMemoryForOverUtilized 的可用内存数量超过 MaxFreeMemoryForOverUtilized 并不被过度利用,并成为目标主机。
- 低于 MinFreeMemoryForUnderUtilized 的可用内存较少,并未被充分利用且成为目标主机。
- 调度程序更喜欢将虚拟机迁移到既不被过度利用或未被充分利用的主机。如果这些主机没有足够的主机,调度程序可将虚拟机迁移到使用率低的主机。如果不需要充分利用主机来实现这一目的,调度程序就可以关闭它们。
- 如果没有定义 MaxFreeMemoryForOverUtilized,则没有主机被过度使用。因此,只有利用率不足的主机是源主机,目标主机包括集群中的所有主机。
- 如果没有定义 MinFreeMemoryForUnderUtilized,则只有过度利用的主机是源主机,不是被过度利用的主机。
要防止主机过度使用所有物理 CPU,请在 0.1 和 2.9 之间定义虚拟 CPU 到物理 CPU 比率 - VCpuToPhysicalCpuRatio。当设置此参数时,在调度虚拟机时首选使用较低 CPU 的主机。
如果添加虚拟机会导致比例超过限制,则考虑 VCpuToPhysicalCpuRatio 和 CPU 使用率。
在运行的环境中,如果主机 VCpuToPhysicalCpuRatio 超过 2.5,一些虚拟机可能会平衡负载,并移到具有较低 VCpuToPhysicalCpuRatio 的主机。
其他资源
2.3.2.7. 集群控制台设置说明
下表描述了 New Cluster 和 Edit Cluster 窗口中的 Console 选项卡的设置。
| 字段 | description/Action |
|---|---|
| 为集群定义 SPICE 代理 | 选中此复选框可覆盖全局配置中定义的 SPICE 代理。当用户(例如,通过虚拟机门户进行连接)位于虚拟机监控程序所在的网络之外时,此功能很有用。 |
| 覆盖的 SPICE 代理地址 | SPICE 客户端连接到虚拟机时使用的代理。地址必须采用以下格式: protocol://[host]:[port] |
2.3.2.8. 隔离策略设置说明
下表描述了新集群和编辑集群窗口中的隔离策略选项卡的设置。
| 字段 | description/Action |
|---|---|
| 启用隔离 | 在集群中启用隔离功能。默认情况下启用隔离,但可以根据需要禁用;例如,如果临时网络问题发生或预期,管理员可以禁用隔离,直到诊断或维护活动完成为止。请注意,如果禁用隔离,在不响应的主机中运行的高可用性虚拟机不会在其他位置重启。 |
| 如果主机在存储上有实时租用,则跳过围栏 | 如果选中此复选框,则集群中任何不响应且仍然连接到存储的主机都不会被隔离。 |
| 在集群连接问题中跳过隔离 | 如果选中此复选框,如果遇到连接问题的主机百分比大于或等于定义的 Threshold,则隔离将临时禁用。Threshold 值可以从下拉列表中选择,有效值为 25, 50, 75, 和 100。 |
| 如果 gluster brick 已启动,则跳过隔离 | 只有在启用 Red Hat Gluster Storage 功能时,这个选项才可用。如果选中此复选框,则在 brick 正在运行并且可以从其他同级服务器访问时将跳过隔离。请参阅 Chapter 2。使用隔离策略配置高可用性 和 以及 维护 Red Hat Hyperconverged Infrastructure 中的 Red Hat Gluster 存储附录 A. 隔离策略以获得更多信息。 |
| 如果没有满足 gluster 仲裁,请跳过隔离 | 只有在启用 Red Hat Gluster Storage 功能时,这个选项才可用。如果选中此复选框,在 brick 正在运行并关闭主机时将跳过隔离,则主机将会导致仲裁丢失。请参阅 Chapter 2。使用隔离策略配置高可用性 和 以及 维护 Red Hat Hyperconverged Infrastructure 中的 Red Hat Gluster 存储附录 A. 隔离策略以获得更多信息。 |
2.3.2.9. 为集群中的主机设置负载和电源管理策略
evenly_distributed 和 power_saving 调度策略允许您指定可接受的内存和 CPU 用量值,以及虚拟机必须迁移到主机或从主机中的点。vm_evenly_distributed 调度策略根据虚拟机数量在主机之间平均分配虚拟机。定义调度策略,以启用集群中主机之间自动负载平衡。有关每个调度策略的详细说明,请参阅 集群调度策略设置。
流程
-
点
并选择集群。 - 点 Edit。
- 单击 Scheduling Policy 选项卡。
选择以下策略之一:
- none
vm_evenly_distributed
- 设置必须至少在一台主机上运行的虚拟机数量,以便在 HighVmCount 字段中启用负载平衡。
- 在 MigrationThreshold 字段中定义最高利用率主机上的虚拟机数量和最低利用主机的虚拟机数量之间可接受的最大区别。
- 在 SpmVmGrace 字段中定义要在 SPM 主机上保留虚拟机的插槽数量。
- (可选)在 HeSparesCount 字段中,输入额外自托管引擎节点的数量,以便保留足够的可用内存,以便在 Manager 虚拟机迁移或关闭时启动它。如需更多信息 ,请参阅为自托管引擎配置 Memory Slots Reserved。
evenly_distributed
- 在调度策略在 CpuOverCommitDurationMinutes 字段中采取行动前,设置主机可在定义的使用值外运行 CPU 负载的时间(以分钟为单位)。
- 在 HighUtilization 字段中输入虚拟机开始迁移到其他主机的 CPU 使用率百分比。
- (可选)在 HeSparesCount 字段中,输入额外自托管引擎节点的数量,以便保留足够的可用内存,以便在 Manager 虚拟机迁移或关闭时启动它。如需更多信息 ,请参阅为自托管引擎配置 Memory Slots Reserved。
另外,为了避免主机过度利用所有物理 CPU,请定义虚拟 CPU 到物理 CPU 比例 - VCpuToPhysicalCpuRatio,其值介于 0.1 和 2.9 之间。当设置此参数时,在调度虚拟机时首选使用较低 CPU 的主机。
如果添加虚拟机会导致比例超过限制,则考虑 VCpuToPhysicalCpuRatio 和 CPU 使用率。
在运行的环境中,如果主机 VCpuToPhysicalCpuRatio 超过 2.5,一些虚拟机可能会平衡负载,并移到具有较低 VCpuToPhysicalCpuRatio 的主机。
power_saving
- 在调度策略在 CpuOverCommitDurationMinutes 字段中采取行动前,设置主机可在定义的使用值外运行 CPU 负载的时间(以分钟为单位)。
- 在 LowUtilization 字段中输入主机的 CPU 使用率百分比。
- 在 HighUtilization 字段中输入虚拟机开始迁移到其他主机的 CPU 使用率百分比。
- (可选)在 HeSparesCount 字段中,输入额外自托管引擎节点的数量,以便保留足够的可用内存,以便在 Manager 虚拟机迁移或关闭时启动它。如需更多信息 ,请参阅为自托管引擎配置 Memory Slots Reserved。
选择以下之一作为集群的调度程序优化 :
- 选择 Optimize for Utilization 在调度中包含权重模块,以允许选择最佳。
- 如果请求超过十个,选择 Optimize for Speed 以跳过主机权重。
-
如果您使用 OpenAttestation 服务器验证您的主机,并使用
engine-config工具设置服务器详情,请选择 Enable Trusted Service 复选框。
OpenAttestation 和 Intel Trusted Execution Technology (Intel TXT)不再可用。
- (可选)选择 启用 HA Reservation 复选框,使 Manager 能够监控高可用性虚拟机的集群容量。
(可选)为集群中的虚拟机选择 Serial Number 策略 :
- 点击 。
2.3.2.10. 更新集群中的主机上的 MoM 策略
Memory Overcommit Manager 处理主机上的内存 balloon 和 KSM 功能。下一次主机重启后,对这些功能的更改会传递到主机,或处于维护模式后进入 Up 状态。但是,如果需要,您可以对一个主机立刻应用重要的变化,方法是在主机状态为 Up 时同步 MoM 策略。以下过程必须单独在每个主机上执行。
流程
-
单击
。 - 点集群名称。这会打开详情视图。
- 单击 Hosts 选项卡,再选择需要更新的 MoM 策略的主机。
- 单击 Sync MoM Policy。
主机上的 MoM 策略可以在不必将主机移至维护模式任何在重新变为 Up 的情况下进行更新。
2.3.2.11. 创建 CPU 配置集
CPU 配置文件定义集群中的一个虚拟机在其上运行的主机上可以访问的最大处理能力,以对该主机可用的总处理能力的百分比表示。CPU 配置集基于数据中心中定义的 CPU 配置集创建,且不会自动应用到集群中的所有虚拟机;它们必须手动分配给各个虚拟机才能使配置文件生效。
此流程假设您已在集群所属的数据中心下定义了一个或多个服务条目的 CPU 质量。
流程
-
单击
。 - 点集群名称。这会打开详情视图。
- 点 CPU Profiles 选项卡。
- 单击 New。
- 为 CPU 配置集输入 Name 和 Description。
- 从 QoS 列表中选择要应用到 CPU 配置集的服务质量。
- 点击 。
2.3.2.12. 删除 CPU 配置集
从 Red Hat Virtualization 环境中删除现有 CPU 配置集。
流程
-
单击
。 - 点集群名称。这会打开详情视图。
- 单击 CPU Profiles 选项卡,再选择要删除的 CPU 配置集。
- 单击 Remove。
- 点击 。
如果 CPU 配置集被分配给任何虚拟机,则这些虚拟机会自动 分配默认 CPU 配置集。
2.3.2.13. 导入现有的 Red Hat Gluster Storage 集群
您可以将一个 Red Hat Gluster Storage 集群和属于集群的所有主机都导入到 Red Hat Virtualization Manager。
当您提供集群中任何主机的 IP 地址或主机名等详情时,gluster peer status 命令将通过 SSH 在那个主机上执行,然后显示属于集群一部分的主机列表。您必须手动验证每个主机的指纹,并为它们提供密码。如果集群中的一个主机停机或无法访问,您将无法导入集群。当新导入的主机没有安装 VDSM 时,bootstrap 脚本会在主机上安装所有需要的 VDSM 软件包,并重新启动它们。
流程
-
单击
。 - 单击 New。
- 选择集群将属于的数据中心。
- 输入集群的名称和描述。
选中 Enable Gluster Service 复选框,再选择 Import existing gluster configuration 复选框。
只有在选择了 Enable Gluster Service 时,才会显示 Import existing gluster configuration 字段。
在 Hostname 字段中,输入集群中任何服务器的主机名或 IP 地址。
显示主机 SSH 指纹,以确保您使用正确的主机进行连接。如果主机无法访问,或者有网络错误,则在 Fingerprint 字段中会显示一个 Error in fetching fingerprint 错误。
- 输入服务器的密码,然后单击。
- 这时将打开 Add Hosts 窗口,并显示属于集群一部分的主机列表。
- 对于每个主机,输入 Name 和 Root Password。
如果要对所有主机使用相同的密码,请选择 Use a Common Password 复选框,以在提供的文本字段中输入密码。
单击 Apply 以设置输入的密码 all hosts。
单击 OK,验证指纹是否有效,并提交您的更改。
引导脚本会在主机上安装所有必需的 VDSM 软件包,并重新启动它们。现在,您已成功将现有的 Red Hat Gluster Storage 集群导入到 Red Hat Virtualization Manager。
2.3.2.14. Add Hosts 窗口中的设置信息
通过 Add Hosts 窗口,您可以指定导入为支持 Gluster 的集群一部分的主机的详细信息。在选择了 New Cluster 窗口中的 Enable Gluster Service 复选框后,将显示此窗口并提供必要的主机详细信息。
| 字段 | Description |
|---|---|
| 使用常用密码 | 选择此复选框,对属于一个集群中的所有主机使用相同的密码。在密码字段中输入密码,然后单击应用按钮以在所有主机上设置密码。 |
| Name | 输入主机的名称。 |
| hostname/IP | 此字段会自动填充您在 New Cluster 窗口中提供的主机的完全限定域名或 IP。 |
| Root 密码 | 在此字段中输入密码,为每个主机使用不同的 root 密码。此字段覆盖为集群中的所有主机提供的通用密码。 |
| 指纹 | 此时会显示主机指纹,以确保您使用正确的主机进行连接。此字段会自动填充您在 New Cluster 窗口中提供的主机的指纹。 |
2.3.2.15. 删除集群
在删除前,将所有主机从集群移出。
您无法删除 Default 集群,因为它包含 空白模板。但是,您可以重命名 Default 集群,并将其添加到新数据中心。
流程
-
点
并选择集群。 - 确保集群中没有主机。
- 单击 Remove。
- 点
2.3.2.16. Memory Optimization
要增加主机上的虚拟机数量,您可以使用 内存过量使用,在其中为虚拟机分配的内存超过 RAM,并依赖于交换空间。
但是,内存过量使用有潜在的问题:
- 交换性能 - 交换空间较慢,消耗的 CPU 资源比 RAM 多,会影响虚拟机性能。过量交换会导致 CPU 增大。
- 内存不足 (OOM) killer - 如果主机耗尽交换空间,新进程无法启动,内核的 OOM 终止程序守护进程开始关闭活跃的进程,如虚拟机客户机。
为了帮助克服这些不足,您可以执行以下操作:
- 使用内存优化设置和内存过量使用管理器 (MoM) 限制内存过量使用。
- 使交换空间足够大,以适应虚拟内存的最大潜力需求,并且剩余安全利润。
- 通过启用内存气球和内核同页合并 (KSM) 减少虚拟内存大小。
2.3.2.17. 内存优化和内存过量使用
您可以通过选择其中一个内存优化设置来限制内存过量使用:None (0%), 150%, or 200%.
每个设置代表 RAM 百分比。例如,有一个具有 64 GB RAM 的主机,选择 150% 表示您可以增加 32 GB 的内存,总内存为 96 GB。如果主机使用总共 4 GB 的 4 GB,则剩余的 92 GB 可用。您可以将其大部分分配给虚拟机(System 标签页中的 Memory Size),但应该考虑保留一些空间以减少出问题的可能。
对虚拟内存的需求激增可能会影响M、内存膨胀和 KSM 重新定义虚拟内存的时间。要减少这个影响,请选择适合您运行的应用程序和工作负载的限制:
- 对于内存需求递增的工作负载,请选择较高的百分比,如 200% 或 150%。
- 对于更关键的应用程序或工作负载在内存需求增加时增加,请选择 150% 或 None (0%)百分比。选择 None 有助于防止内存过量使用,但允许 MoM、内存 balloon 设备和 KSM 继续优化虚拟内存。
在将配置部署到生产环境之前,请始终通过对各种条件进行测试来测试您的 内存优化 设置。
要配置 Memory Optimization 设置,点 New Cluster 或 Edit Cluster 窗口中的 Optimization 选项卡。请参阅 集群优化设置说明。
其他评论:
- Host Statistics 视图显示 有用的历史信息,以调整过量使用比率。
- 实际可用的内存无法实时确定,因为 KSM 和内存膨胀更改达到的内存大小。
- 当虚拟机达到虚拟内存限制时,新的应用程序无法启动。
- 当您计划在主机上运行的虚拟机数量时,请使用最大虚拟内存(物理内存大小和 内存优化 设置)作为起点。不要因内存优化而实现的较小的虚拟内存中因素,如内存膨胀和 KSM。
2.3.2.18. swap Space 和 Memory Overcommitment
在应用这些建议时,请按照指导将交换空间大小调整为"最后工作量内存"以获得最糟糕的情况。使用物理内存大小和 内存优化 设置作为估算总虚拟内存大小的基础。MoM、内存膨胀和 KSM 禁止虚拟内存的优化减少。
为帮助防止 OOM 条件,使交换空间足够大,以处理最糟糕的情况,并且仍然具有安全利润。在部署到生产环境之前,始终在各种条件下测试您的配置。
2.3.2.19. Memory Overcommit Manager (MoM)
Memory Overcommit Manager (MoM) 分为两个事务:
- 它通过将 Memory Optimization 设置应用到集群中的主机来限制内存过量使用,如上一节中所述。
- 它通过管理 内存 ballooning 和 KSM 来优化内存,具体如以下部分所述。
您不需要启用或禁用 MoM。
当主机的可用内存低于 20% 时,像 mom.Controllers.Balloon - INFO Ballooning guest:half1 from 1096400 to 1991580 的气球命令会记录到 Memory Overcommit Manager 日志文件(/var/log/vdsm/mom.log)。
2.3.2.20. 内存膨胀
虚拟机从您分配给它们的完整虚拟内存数量开始。由于虚拟内存使用量超过 RAM,因此主机需要更多 swap 空间。如果启用,内存膨胀 可让虚拟机提供该内存中未使用的部分。空闲的内存可以被主机上的其他进程和虚拟机重复使用。减少内存占用率会降低交换的可能性,并提高性能。
virtio-balloon 软件包提供了内存膨胀设备和驱动程序,作为可加载的内核模块(LKM)。默认情况下,它被配置为自动加载。将模块添加到 denyist 或卸载时禁用 ballooning。
内存膨胀设备不直接协调;它们依赖于主机的 Memory Overcommit Manager (MoM)流程来持续监控每个虚拟机的需求,并指示 balloon 设备增加或降低虚拟内存。
性能考虑:
- 对于需要持续高性能和低延迟的工作负载,红帽不推荐使用内存膨胀和过量使用。请参阅配置高性能虚拟机、模板和池。
- 当增加虚拟机密度(经济)比性能更重要时,使用内存膨胀。
- 内存膨胀不会影响 CPU 使用率。(KSM 消耗一些 CPU 资源,但消耗会保持在压力下的一致性。)
要启用内存膨胀,请单击 New Cluster 或 Edit Cluster 窗口中的 Optimization 选项卡。然后选择 Enable Memory Balloon Optimization 复选框。这个设置可在此集群中运行的虚拟机上启用内存使用过量。选择此复选框后,M 会尽可能启动膨胀,但会限制每个虚拟机的保证内存大小。请参阅 集群优化设置说明。
此集群中的每个主机在状态更改为开机时会收到 balloon 策略更新。如果需要,您可以手动更新主机上的 balloon 策略,而无需更改状态。请参阅在集群的主机上更新 MoM 策略。
2.3.2.21. 内核同页合并(KSM)
当虚拟机运行时,它通常会为常见库和高使用数据等项目创建重复的内存页面。另外,运行类似客户机操作系统和应用程序的虚拟机会在虚拟内存中生成重复的内存页面。
启用后,内核同页合并 (KSM)检查主机上的虚拟内存,消除了重复内存页面,并在多个应用程序和虚拟机间共享剩余的内存页面。这些共享内存页面标记为写时复制;如果虚拟机需要向该页面写入更改,它会首先进行复制,然后再将其修改写入到该副本。
启用 KSM 时,M 会管理 KSM。您不需要手动配置或控制 KSM。
KSM 通过两种方式增加虚拟内存性能:由于更频繁地使用共享内存页面,因此主机更有可能将其存储在缓存中或主内存中,从而提高了内存访问速度。另外,有内存过量使用,KSM 会减少虚拟内存空间,从而减少交换性能的可能性。
KSM 消耗的 CPU 资源超过内存膨胀。在压力下,CPU KSM 消耗量保持一致性。在主机上运行相同的虚拟机和应用程序,与运行相同虚拟机和应用程序相比,KSM 有机会合并内存页面。如果您运行大多数不同的虚拟机和应用程序,使用 KSM 的 CPU 成本可能会降低其好处。
性能考虑:
- 在 KSM 守护进程合并大量内存后,内核内存核算统计最终可能会相互冲突。如果您的系统有大量可用内存,可以通过禁用 KSM 来提高性能。
- 对于需要持续高性能和低延迟的工作负载,红帽不推荐使用 KSM 和过量使用。请参阅配置高性能虚拟机、模板和池。
- 在增加虚拟机密度(经济)时,使用 KSM 比性能更重要。
要启用 KSM,请单击 New Cluster 或 Edit Cluster 窗口中的 Optimization 选项卡。然后选择" 启用 KSM "复选框。此设置可让 MoM 在需要时运行 KSM,并在生成内存时可以降低其 CPU 的成本。请参阅 集群优化设置说明。
2.3.2.22. UEFI 和 Q35 芯片组
Intel Q35 芯片组(新虚拟机的默认芯片组)包括支持统一可扩展固件接口(UEFI),取代传统的 BIOS。
或者,您可以将虚拟机或集群配置为使用旧的 Intel i440fx 芯片组,该芯片组不支持 UEFI。
UEFI 与旧的 BIOS 相比提供了几个优势,包括:
- 现代引导装载程序
- SecureBoot,用于验证引导装载程序的数字签名
- GUID 分区表(GPT),它启用大于 2 TB 的磁盘
要在虚拟机上使用 UEFI,您必须将虚拟机的集群配置为 4.4 或更高版本。然后,您可以为任何现有虚拟机设置 UEFI,或者设置为集群中新虚拟机的默认 BIOS 类型。可用的选项如下:
| BIOS 类型 | Description |
|---|---|
| 带有传统 BIOS 的 Q35 Chipset | 没有 UEFI 的旧 BIOS (用于兼容版本 4.4 的集群的默认设置) |
| 使用 UEFI BIOS 的 Q35 Chipset | 使用 UEFI 的 BIOS |
| 带有 SecureBoot 的 Q35 Chipset | 带有 SecureBoot 的 UEFI,它验证引导装载程序的数字签名 |
| legacy | 带有传统 BIOS 的 i440fx 芯片组 |
在安装操作系统前设置 BIOS 类型
在安装操作系统前,您可以将虚拟机配置为使用 Q35 芯片组和 UEFI。在安装操作系统后,不支持将虚拟机从旧的 BIOS 转换为 UEFI。
2.3.2.23. 配置集群以使用 Q35 Chipset 和 UEFI
将集群升级到 Red Hat Virtualization 4.4 后,集群中的所有虚拟机都运行 4.4 版本 VDSM。您可以配置集群的默认 BIOS 类型,该类型决定了集群中您创建的任何新虚拟机的默认 BIOS 类型。如果需要,您可以在创建虚拟机时指定不同的 BIOS 类型来覆盖集群的默认 BIOS 类型。
流程
-
在虚拟机门户或管理门户中,点
。 - 选择一个集群并点 Edit。
- 点 General。
点 BIOS 类型下拉菜单在集群中的新虚拟机定义默认 BIOS 类型,并选择以下任一操作:
- legacy
- 带有传统 BIOS 的 Q35 Chipset
- 使用 UEFI BIOS 的 Q35 Chipset
- 带有 SecureBoot 的 Q35 Chipset
- 从 兼容性版本 下拉菜单中选择 4.4。Manager 检查所有正在运行的主机是否都与 4.4 兼容,如果兼容,则 Manager 使用 4.4 功能。
- 如果集群中的任何现有虚拟机应该使用新的 BIOS 类型,请将它们配置为这样做。现在,集群中配置为使用 BIOS 类型 Cluster default 的新虚拟机现在使用您选择的 BIOS 类型。如需更多信息,请参阅配置虚拟机以使用 Q35 Chipset 和 UEFI。
由于只能在安装操作系统前更改 BIOS 类型,所以对于配置为使用 BIOS 类型 Cluster default 的任何现有虚拟机,请将 BIOS 类型更改为之前的默认集群 BIOS 类型。否则,虚拟机可能无法引导。或者,您可以重新安装虚拟机的操作系统。
2.3.2.24. 配置虚拟机以使用 Q35 Chipset 和 UEFI
在安装操作系统前,您可以将虚拟机配置为使用 Q35 芯片组和 UEFI。将虚拟机从旧的 BIOS 转换为 UEFI,或从 UEFI 转换为旧 BIOS 可能会阻止虚拟机引导。如果更改现有虚拟机的 BIOS 类型,请重新安装操作系统。
如果虚拟机的 BIOS 类型设为 Cluster default,更改集群的 BIOS 类型会更改虚拟机的 BIOS 类型。如果虚拟机安装了操作系统,更改集群 BIOS 类型可能会导致引导虚拟机失败。
流程
配置虚拟机以使用 Q35 芯片组和 UEFI:
-
在虚拟机门户或管理门户中点
。 - 选择虚拟机并点 Edit。
- 在 General 选项卡中,单击 Show Advanced Options。
-
单击
。 从 BIOS 类型下拉菜单中选择 以下内容之一:
- 集群默认
- 带有传统 BIOS 的 Q35 Chipset
- 使用 UEFI BIOS 的 Q35 Chipset
- 带有 SecureBoot 的 Q35 Chipset
- 点击 。
- 在 Virtual Machine Portal 或 Administration Portal 中关闭虚拟机。下次启动虚拟机时,它将使用您选择的新 BIOS 类型运行。
2.3.2.25. 更改集群兼容性版本
Red Hat Virtualization 集群有一个兼容版本。集群兼容性版本表示集群中所有主机支持的 Red Hat Virtualization 的功能。集群兼容性根据集群中功能最低的主机操作系统版本来设置。
先决条件
- 要更改集群兼容性级别,您必须首先将集群中的所有主机更新为支持您需要的兼容性级别。检查主机旁边是否存在指示有可用的更新的图标。
限制
在将集群兼容性级别升级到 4.6 后,virtio NIC 会作为不同的设备枚举。因此,可能需要重新配置 NIC。红帽建议您在升级集群前测试虚拟机,方法是在虚拟机上将集群兼容性级别设置为 4.6 并验证网络连接。
如果虚拟机的网络连接失败,在升级集群前,使用与当前模拟机器匹配的自定义模拟机器配置虚拟机,例如 pc-q35-rhel8.3.0 适用于 4.5 兼容性版本。
流程
-
在管理门户中,点
。 - 选择要更改的集群并点击 。
- 在 General 选项卡中,将 Compatibility Version 更改为所需的值。
- 点击 。此时会打开 Change Cluster Compatibility Version 确认对话框。
- 点 确认。
错误消息可能会警告某些虚拟机和模板配置不正确。要修复此错误,请手动编辑每个虚拟机。Edit Virtual Machine 窗口提供了额外的验证和警告来显示正确的内容。有时问题会自动解决,虚拟机的配置只需要再次保存。编辑完每个虚拟机后,您将能够更改集群兼容性版本。
在更新了集群兼容性版本后,您必须通过从管理门户重启或使用 REST API 来更新所有正在运行的或暂停虚拟机的集群兼容性版本,或使用客户端操作系统中的 REST API 更新它们。需要重启的虚拟机将标记为待处理更改图标(
 )。您无法更改处于预览的虚拟机快照的集群兼容性版本。您必须首先提交或撤销预览。
)。您无法更改处于预览的虚拟机快照的集群兼容性版本。您必须首先提交或撤销预览。
在自托管引擎环境中,管理器虚拟机不需要重新启动。
虽然您可以在以后方便的时候重新启动虚拟机,但强烈建议您立即重新启动,以便虚拟机使用最新的配置。旧配置没有更新运行的虚拟机,在重启前,如果对虚拟机进行其他更改,新的配置会被覆盖。
在更新了数据中心中所有集群和虚拟机的兼容性版本后,您可以更改数据中心本身的兼容性版本。