노드
OpenShift Container Platform에서 노드 구성 및 관리
초록
1장. 노드 개요
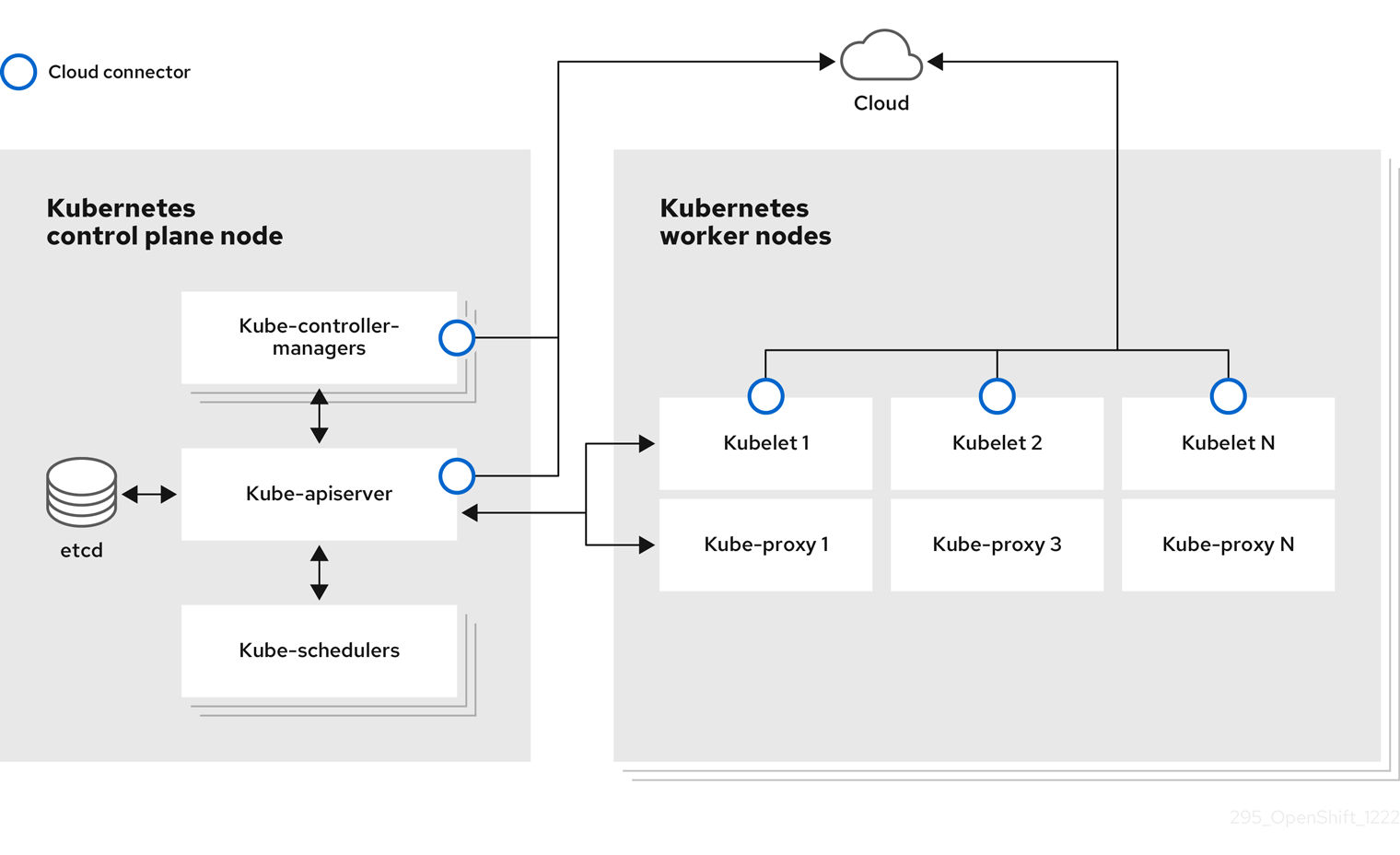
1.1. 노드 정보
노드는 Kubernetes 클러스터의 가상 또는 베어 메탈 머신입니다. 작업자 노드는 포드로 그룹화된 애플리케이션 컨테이너를 호스팅합니다. 컨트롤 플레인 노드는 Kubernetes 클러스터를 제어하는 데 필요한 서비스를 실행합니다. OpenShift Container Platform에서 컨트롤 플레인 노드에는 OpenShift Container Platform 클러스터를 관리하기 위한 Kubernetes 서비스 이상이 포함되어 있습니다.
클러스터에서 안정적이고 정상적인 노드를 보유하는 것은 호스팅된 애플리케이션의 원활한 작동을 위한 필수 요소입니다. OpenShift Container Platform에서는 노드를 나타내는 Node 오브젝트를 통해 노드에 액세스, 관리 및 모니터링할 수 있습니다. OpenShift CLI(oc) 또는 웹 콘솔을 사용하여 노드에서 다음 작업을 수행할 수 있습니다.
노드의 다음 구성 요소는 Pod의 실행을 유지 관리하고 Kubernetes 런타임 환경을 제공합니다.
- 컨테이너 런타임
- 컨테이너 런타임은 컨테이너 실행을 담당합니다. Kubernetes는 containerd, cri-o, rktlet 및 Docker와 같은 여러 런타임을 제공합니다.
- kubelet
- kubelet은 노드에서 실행되며 컨테이너 매니페스트를 읽습니다. 이렇게 하면 정의된 컨테이너가 시작되어 실행 중인지 확인합니다. kubelet 프로세스는 작업 상태와 노드 서버를 유지 관리합니다. kubelet은 네트워크 규칙 및 포트 전달을 관리합니다. kubelet은 Kubernetes에서만 생성된 컨테이너를 관리합니다.
- kube-proxy
- kube-proxy는 클러스터의 모든 노드에서 실행되며 Kubernetes 리소스 간의 네트워크 트래픽을 유지합니다. Kube-proxy를 사용하면 네트워킹 환경이 분리되어 액세스할 수 있습니다.
- DNS
- 클러스터 DNS는 Kubernetes 서비스에 대한 DNS 레코드를 제공하는 DNS 서버입니다. Kubernetes로 시작한 컨테이너는 DNS 검색에 이 DNS 서버를 자동으로 포함합니다.
읽기 작업
읽기 작업을 사용하면 관리자 또는 개발자가 OpenShift Container Platform 클러스터의 노드에 대한 정보를 가져올 수 있습니다.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.