호스팅된 컨트롤 플레인
OpenShift Container Platform에서 호스팅된 컨트롤 플레인 사용
초록
1장. 호스팅된 제어 평면 릴리스 노트
릴리스 노트에는 새로운 기능과 더 이상 사용되지 않는 기능, 변경 사항, 알려진 문제에 대한 정보가 포함되어 있습니다.
1.1. OpenShift Container Platform 4.19에 대한 호스팅 제어 평면 릴리스 노트
이 릴리스에서는 OpenShift Container Platform 4.19용 호스팅 제어 평면을 사용할 수 있습니다. OpenShift Container Platform 4.19용 호스팅 제어 평면은 Kubernetes Operator 버전 2.9에 대한 멀티클러스터 엔진을 지원합니다.
1.1.1. 새로운 기능 및 개선 사항
1.1.1.1. 사용자 정의 DNS 이름 정의
클러스터 관리자는 이제 호스팅된 클러스터에 대한 사용자 정의 DNS 이름을 정의하여 DNS 이름을 관리하고 사용하는 방법에 있어 더 큰 유연성을 제공할 수 있습니다. 자세한 내용은 사용자 지정 DNS 이름 정의를 참조하세요.
1.1.1.2. 호스팅된 클러스터에 대한 AWS 태그 추가 또는 업데이트
클러스터 관리자는 여러 유형의 리소스에 대한 Amazon Web Services(AWS) 태그를 추가하거나 업데이트할 수 있습니다. 자세한 내용은 호스팅된 클러스터에 대한 AWS 태그 추가 또는 업데이트를 참조하세요.
1.1.1.3. OADP를 사용하여 호스팅된 클러스터에 대한 자동 재해 복구
베어 메탈 또는 Amazon Web Services(AWS) 플랫폼에서 OpenShift API for Data Protection(OADP)을 사용하여 호스팅된 클러스터의 재해 복구를 자동화할 수 있습니다. 자세한 내용은 OADP를 사용하여 호스팅된 클러스터에 대한 자동 재해 복구를 참조하세요.
1.1.1.4. 베어 메탈 플랫폼의 호스팅 클러스터에 대한 재해 복구
베어 메탈 플랫폼의 호스팅 클러스터의 경우 OADP를 사용하여 재해 복구 작업을 완료할 수 있습니다. 여기에는 데이터 플레인과 제어 플레인 워크로드를 백업하고 동일한 관리 클러스터나 새 관리 클러스터로 복원하는 작업이 포함됩니다. 자세한 내용은 OADP를 사용하여 호스팅된 클러스터에 대한 재해 복구를 참조하세요.
1.1.1.5. Red Hat OpenStack Platform(RHOSP) 17.1(기술 미리보기)의 호스팅 제어 플레인
RHOSP 17.1의 호스팅 제어 평면은 이제 기술 미리 보기 기능으로 지원됩니다.
자세한 내용은 OpenStack에 호스팅된 제어 평면 배포를 참조하세요.
1.1.1.6. AWS에서 노드 풀 용량 블록 구성
이제 Amazon Web Services(AWS)에서 호스팅된 제어 평면에 대한 노드 풀 용량 블록을 구성할 수 있습니다. 자세한 내용은 AWS에서 노드 풀 용량 블록 구성을 참조하세요.
1.1.2. 버그 수정
이전에는 관리 OpenShift 클러스터의 IDMS 또는 ICSP가 registry.redhat.io 또는 registry.redhat.io/redhat를 가리키는 소스를 정의하고 미러 레지스트리에 필요한 OLM 카탈로그 이미지가 없는 경우, 승인되지 않은 이미지 풀로 인해
HostedCluster리소스에 대한 프로비저닝이 중단되었습니다. 결과적으로HostedCluster리소스는 배포되지 않았고, 차단된 상태로 남아 미러링된 레지스트리에서 필수 카탈로그 이미지를 가져올 수 없었습니다.이 릴리스에서는 권한 오류로 인해 필요한 이미지를 가져올 수 없는 경우 프로비저닝이 명시적으로 실패합니다. OLM CatalogSource 이미지 확인을 위해 레지스트리 오버라이드 논리가 개선되어 registry.redhat.io와 같은 레지스트리 루트에서 일치 항목을 허용합니다. 레지스트리 재정의로 작동하는 이미지가 생성되지 않을 경우 원래
ImageReference를사용하기 위한 대체 메커니즘도 도입되었습니다.그 결과, 미러 레지스트리에 필요한 OLM 카탈로그 이미지가 없는 상황에서도
HostedCluster리소스를 성공적으로 배포할 수 있습니다. 적절한 경우 시스템이 원본 소스에서 가져오기를 올바르게 수행하기 때문입니다. (OCPBUGS-58118)- 이전에는 제어 평면 컨트롤러가 기능 세트에 대한 올바른 CVO 매니페스트를 제대로 선택하지 못했습니다. 결과적으로, 기능 세트에 대한 잘못된 CVO 매니페스트가 호스팅 클러스터에 배포되었을 수 있습니다. 실제로 CVO 매니페스트는 기능 세트 간에 차이가 없었으므로 이 문제는 실질적인 영향을 미치지 않았습니다. 이 릴리스에서는 제어 평면 컨트롤러가 기능 세트에 맞는 올바른 CVO 매니페스트를 올바르게 선택합니다. 결과적으로, 기능 세트에 대한 올바른 CVO 매니페스트가 호스팅된 클러스터에 배포됩니다. (OCPBUGS-44438)
-
이전에는 사용자 지정 CA가 서명한 인증서를 제공하는
HostedCluster리소스에 대한 보안 프록시를 설정하는 경우 해당 CA가 노드의 초기 점화 구성에 포함되지 않았습니다. 결과적으로 점화에 실패하여 노드가 부팅되지 않았습니다. 이 릴리스에서는 초기 점화 구성에 프록시에 대한 신뢰할 수 있는 CA를 포함시켜서 문제를 해결했으며, 이를 통해 노드 부팅 및 점화가 성공적으로 이루어졌습니다. (OCPBUGS-58118) - 이전에는 관리 클러스터의 IDMS 또는 ICSP 리소스가 사용자가 이미지 교체를 위한 미러 또는 소스로 루트 레지스트리 이름만 지정할 수 있다는 점을 고려하지 않고 처리되었습니다. 결과적으로 루트 레지스트리 이름만 사용하는 IDMS 또는 ICSP 항목은 예상대로 작동하지 않았습니다. 이 릴리스에서는 루트 레지스트리 이름만 제공된 경우를 미러 교체 논리가 올바르게 처리합니다. 결과적으로 이 문제는 더 이상 발생하지 않으며 루트 레지스트리 미러 대체가 이제 지원됩니다. (OCPBUGS-55693)
-
이전에는 OADP 플러그인이 잘못된 네임스페이스에서
DataUpload객체를 찾았습니다. 결과적으로 백업 프로세스가 무기한 중단되었습니다. 이 릴리스에서는 플러그인이 백업 개체의 소스 네임스페이스를 사용하므로 이 문제는 더 이상 발생하지 않습니다. (OCPBUGS-58118) -
이전에는 사용자가
hc.spec.configuration.apiServer.servingCerts.namedCertificates필드에 추가한 사용자 지정 인증서의 SAN이 Kubernetes 에이전트 서버(KAS)의hc.spec.services.servicePublishingStrategy필드에 설정된 호스트 이름과 충돌했습니다. 결과적으로 KAS 인증서는 새로운 페이로드를 생성하는 인증서 세트에 추가되지 않았고,HostedCluster리소스에 가입하려는 모든 새 노드에서 인증서 유효성 검사 문제가 발생했습니다. 이 릴리스에서는 더 일찍 실패하고 사용자에게 문제에 대해 경고하는 검증 단계가 추가되어 문제가 더 이상 발생하지 않습니다. (OCPBUGS-53261) - 이전에는 공유 VPC에 호스팅된 클러스터를 생성할 때 개인 링크 컨트롤러가 공유 VPC의 VPC 엔드포인트를 관리하는 공유 VPC 역할을 맡지 못하는 경우가 있었습니다. 이 릴리스에서는 개인 링크 컨트롤러의 모든 조정에 대해 클라이언트가 생성되어 잘못된 클라이언트로부터 복구할 수 있습니다. 결과적으로 호스팅된 클러스터 엔드포인트와 호스팅된 클러스터가 성공적으로 생성되었습니다. (OCPBUGS-45184)
-
이전에는 Agent 플랫폼의
NodePoolAPI에서 ARM64 아키텍처가 허용되지 않았습니다. 결과적으로 Agent 플랫폼에 이기종 클러스터를 배포할 수 없습니다. 이 릴리스에서는 API를 통해 Agent 플랫폼에서 ARM64 기반NodePool리소스를 사용할 수 있습니다. (OCPBUGS-58118) - 이전에는 HyperShift Operator가 항상 Kubernetes API 서버에 대한 SAN(주체 대체 이름)을 검증했습니다. 이 릴리스에서는 PKI 조정이 활성화된 경우에만 운영자가 SAN을 검증합니다. (OCPBUGS-56562)
- 이전에는 1년 이상 존재한 호스팅 클러스터에서 내부 제공 인증서가 갱신되면 제어 플레인 워크로드가 다시 시작되지 않아 갱신된 인증서를 가져오지 못했습니다. 결과적으로 제어 평면이 저하되었습니다. 이 릴리스에서는 인증서가 갱신되면 제어 플레인 워크로드가 자동으로 다시 시작됩니다. 결과적으로 제어 평면은 안정적으로 유지됩니다. (OCPBUGS-52331)
-
이전에는 사용자나 그룹 등 OpenShift OAuth API 서버가 관리하는 리소스에 대한 유효성 검사 웹훅을 생성하면 유효성 검사 웹훅이 실행되지 않았습니다. 이 릴리스에서는
Konnectivity프록시 사이드카를 추가하여 OpenShift OAuth API 서버와 데이터 플레인 간의 통신을 수정합니다. 그 결과, 사용자 및 그룹의 웹훅을 검증하는 프로세스가 예상대로 작동합니다. (OCPBUGS-58118) -
이전에는
HostedCluster리소스를 사용할 수 없는 경우 해당 이유가 조건의HostedControlPlane리소스에서 올바르게 전파되지 않았습니다.HostedCluster사용자 지정 리소스의사용 가능조건에 대한상태및메시지정보가 전파되었지만리소스값은 전파되지 않았습니다. 이번 릴리스에서는 그 이유도 전파되어, 사용할 수 없는 근본 원인을 파악하는 데 필요한 정보를 더 많이 얻을 수 있습니다. (OCPBUGS-50907) -
이전에는
관리형 신뢰 번들볼륨 마운트와신뢰할 수 있는 CA 번들 관리구성 맵이 필수 구성 요소로 도입되었습니다. OpenShift API 서버가신뢰할 수 있는 CA 번들 관리구성 맵이 있어야 한다고 예상했기 때문에 자체 공개 키 인프라(PKI)를 사용하는 경우 이 요구 사항으로 인해 배포가 실패했습니다. 이 문제를 해결하기 위해 이제 이러한 구성 요소는 선택 사항이므로 사용자 지정 PKI를 사용하는 경우신뢰할 수 있는 CA 번들 관리구성 맵 없이도 클러스터를 성공적으로 배포할 수 있습니다. (OCPBUGS-58118) -
이전에는
IBMPowerVSImage리소스가 삭제되었는지 확인할 방법이 없었기 때문에 불필요한 클러스터 검색 시도가 발생했습니다. 결과적으로 IBM Power Virtual Server에 호스팅된 클러스터는 파괴 상태에 갇혔습니다. 이 릴리스에서는 이미지가 삭제 중이 아닌 경우에만 이미지와 연관된 클러스터를 검색하고 처리할 수 있습니다. (OCPBUGS-58118) -
이전에는 보안 프록시가 활성화된 클러스터를 생성하고 인증서 구성을
configuration.proxy.trustCA로 설정하면 클러스터 설치가 실패했습니다. 또한 OpenShift OAuth API 서버는 관리 클러스터 프록시를 사용하여 클라우드 API에 도달할 수 없습니다. 이 릴리스에서는 이러한 문제를 방지하기 위한 수정 사항이 도입되었습니다. (OCPBUGS-51050) -
이전에는
NodePool컨트롤러와 클러스터 API 컨트롤러가 모두NodePool사용자 정의 리소스에 대해updatingConfig상태 조건을 설정했습니다. 결과적으로,updatingConfig상태는 지속적으로 변경되었습니다. 이 릴리스에서는 두 컨트롤러 간에updatingConfig상태를 업데이트하는 논리가 통합되었습니다. 결과적으로,updatingConfig상태가 올바르게 설정됩니다. (OCPBUGS-58118) - 이전에는 컨테이너 이미지 아키텍처를 검증하는 프로세스가 이미지 메타데이터 제공자를 거치지 않았습니다. 결과적으로 이미지 재정의가 적용되지 않았고 연결이 끊긴 배포는 실패했습니다. 이번 릴리스에서는 이미지 메타데이터 공급자의 메서드가 다중 아키텍처 검증을 허용하도록 수정되었으며, 이미지 검증을 위해 모든 구성 요소에 전파되었습니다. 결과적으로 문제가 해결되었습니다. (OCPBUGS-44655)
-
이전에는 Kubernetes API 서버의
--goaway-chance플래그를 구성할 수 없었습니다. 플래그의 기본값은0입니다. 이 릴리스에서는HostedCluster사용자 정의 리소스에 주석을 추가하여--goaway-chance플래그의 값을 변경할 수 있습니다. (OCPBUGS-58118) -
이전에는 OVN이 아닌 클러스터에서 호스팅된 제어 평면을 기반으로 하는 IBM Cloud의 Red Hat OpenShift 인스턴스에서 클러스터 네트워크 운영자가
monitoring.coreos.comAPI 그룹의 서비스 모니터와 Prometheus 규칙에 패치를 적용할 수 없었습니다. 결과적으로 클러스터 네트워크 운영자 로그에 권한 오류와 "적용할 수 없음" 메시지가 표시되었습니다. 이 릴리스에서는 OVN이 아닌 클러스터의 클러스터 네트워크 운영자에 서비스 모니터와 Prometheus 규칙에 대한 권한이 추가되었습니다. 결과적으로 클러스터 네트워크 운영자 로그에 더 이상 권한 오류가 표시되지 않습니다. (OCPBUGS-58118) - 이전에는 호스팅된 제어 평면 명령줄 인터페이스(CLI)를 사용하여 연결이 끊긴 클러스터를 생성하려고 하면 CLI가 페이로드에 액세스할 수 없어 생성에 실패했습니다. 이 릴리스에서는 CLI가 실행되는 컴퓨터에서 호스팅되는 레지스트리에 일반적으로 액세스할 수 없기 때문에 연결이 끊긴 환경에서 릴리스 페이로드 아키텍처 검사가 건너뜁니다. 그 결과, 이제 CLI를 사용하여 연결이 끊긴 클러스터를 만들 수 있습니다. (OCPBUGS-47715)
-
이전에는 Control Plane Operator가 API 엔드포인트 가용성을 확인할 때 설정된
_*PROXY변수를 따르지 않았습니다. 결과적으로, 프록시를 통한 경우를 제외하고 송신 트래픽이 차단되면 Kubernetes API 서버를 검증하는 HTTP 요청이 실패하고 호스팅된 제어 평면과 호스팅된 클러스터를 사용할 수 없게 됩니다. 이번 릴리스에서는 이 문제가 해결되었습니다. (OCPBUGS-58118) -
이전에는 호스팅 제어 플레인 CLI(
hcp)를 사용하여 호스팅 클러스터를 생성할 때 etcd 저장소 크기를 구성할 수 없었습니다. 결과적으로 일부 대규모 클러스터에는 디스크 크기가 충분하지 않았습니다. 이 릴리스에서는HostedCluster리소스에서 플래그를 설정하여 etcd 저장소 크기를 설정할 수 있습니다. 이 플래그는 원래 OpenShift 성능 팀이 HCP를 사용하여 ROSA에서 더 높은NodePool리소스를 테스트하는 데 도움을 주기 위해 추가되었습니다. 그 결과, 이제hcpCLI를 사용하여 호스팅된 클러스터를 생성할 때 etcd 저장소 크기를 설정할 수 있습니다. (OCPBUGS-58118) - 이전에는 내부 업데이트를 사용하는 호스팅 클러스터를 업데이트하려고 하면 프록시 변수가 적용되지 않아 업데이트가 실패했습니다. 이 릴리스에서는 제자리 업그레이드를 수행하는 Pod가 클러스터 프록시 설정을 따릅니다. 결과적으로, 이제 업데이트는 내부 업데이트를 사용하는 호스팅된 클러스터에서 작동합니다. (OCPBUGS-48540)
-
이전에는 호스팅된 제어 평면의 OpenShift API 서버와 연관된 활성 및 준비 프로브가 설치 프로그램에서 제공하는 인프라에 사용되는 프로브와 일치하지 않았습니다. 이 릴리스에서는 /
healthz엔드포인트 대신/livez및/readyz엔드포인트를 사용하도록 활성 상태 및 준비 상태 프로브를 업데이트합니다. (OCPBUGS-54819) - 이전에는 호스팅된 제어 평면의 Konnectivity 에이전트에 준비 상태 검사가 없었습니다. 이 릴리스에서는 Konnectivity 서버와의 연결이 끊어졌을 때 Pod 준비 상태를 나타내기 위해 Konnectivity 에이전트에 준비 프로브를 추가합니다. (OCPBUGS-58118)
- 이전에는 HyperShift Operator가 호스팅된 클러스터와 노드 풀의 하위 집합으로 범위가 지정되었을 때 Operator가 제어 평면 네임스페이스에서 토큰 및 사용자 데이터 비밀을 제대로 정리하지 못했습니다. 그 결과, 비밀이 쌓이게 되었다. 이번 릴리스에서는 Operator가 비밀을 제대로 정리합니다. (OCPBUGS-54272)
1.1.3. 확인된 문제
-
주석과
ManagedCluster리소스 이름이 일치하지 않으면 Kubernetes Operator 콘솔의 멀티클러스터 엔진에 클러스터가보류 중인 가져오기로 표시됩니다. 클러스터는 멀티클러스터 엔진 운영자에 의해 사용될 수 없습니다. 주석이 없고ManagedCluster이름이HostedCluster리소스의Infra-ID값과 일치하지 않는 경우에도 동일한 문제가 발생합니다. - Kubernetes Operator 콘솔의 멀티클러스터 엔진을 사용하여 기존 호스팅 클러스터에 새 노드 풀을 추가하는 경우, 동일한 버전의 OpenShift Container Platform이 옵션 목록에 두 번 이상 나타날 수 있습니다. 원하는 버전의 인스턴스를 목록에서 선택할 수 있습니다.
노드 풀의 작업자 수가 0명으로 줄어들면 콘솔의 호스트 목록에는 여전히 노드가
준비상태로 표시됩니다. 노드의 수는 두 가지 방법으로 확인할 수 있습니다.- 콘솔에서 노드 풀로 이동하여 노드가 0개 있는지 확인합니다.
명령줄 인터페이스에서 다음 명령을 실행합니다.
다음 명령을 실행하여 노드 풀에 노드가 0개 있는지 확인하세요.
$ oc get nodepool -A다음 명령을 실행하여 클러스터에 노드가 0개 있는지 확인하세요.
$ oc get nodes --kubeconfig다음 명령을 실행하여 클러스터에 바인딩된 에이전트가 0개로 보고되었는지 확인하세요.
$ oc get agents -A
-
듀얼 스택 네트워크를 사용하는 환경에서 호스팅된 클러스터를 생성하는 경우 Pod가
ContainerCreating상태에 갇힐 수 있습니다. 이 문제는openshift-service-ca-operator리소스가 DNS 포드가 DNS 확인에 필요한metrics-tls비밀을 생성할 수 없기 때문에 발생합니다. 결과적으로 포드는 Kubernetes API 서버를 확인할 수 없습니다. 이 문제를 해결하려면 듀얼 스택 네트워크에 대한 DNS 서버 설정을 구성하세요. 관리형 클러스터와 동일한 네임스페이스에 호스팅 클러스터를 만든 경우, 관리형 호스팅 클러스터를 분리하면 호스팅 클러스터를 포함한 관리형 클러스터 네임스페이스의 모든 항목이 삭제됩니다. 다음 상황에서는 관리되는 클러스터와 동일한 네임스페이스에 호스팅된 클러스터가 생성될 수 있습니다.
- Kubernetes Operator 콘솔의 멀티클러스터 엔진을 통해 기본 호스팅 클러스터 클러스터 네임스페이스를 사용하여 Agent 플랫폼에 호스팅된 클러스터를 생성했습니다.
- 명령줄 인터페이스나 API를 통해 호스팅 클러스터 네임스페이스를 호스팅 클러스터 이름과 동일하게 지정하여 호스팅 클러스터를 생성했습니다.
-
호스팅된 클러스터의
spec.services.servicePublishingStrategy.nodePort.address필드에 대한 IPv6 주소를 지정하기 위해 콘솔이나 API를 사용하는 경우 8개의 헥스테트로 구성된 전체 IPv6 주소가 필요합니다. 예를 들어,2620:52:0:1306::30을지정하는 대신2620:52:0:1306:0:0:0:30을지정해야 합니다. 4.19.3 이전 버전에서는 베어메탈 에이전트 플랫폼에서 호스팅 클러스터를 생성하고 MetalLB Operator를 사용하면 호스팅 클러스터의 Cluster Network Operator가 시작되지 않습니다. 다음 오류가 발생합니다.
"Error while updating operator configuration: could not apply (apps/v1, Kind=Deployment) openshift-frr-k8s/frr-k8s-webhook-server: failed to apply / update (apps/v1, Kind=Deployment) openshift-frr-k8s/frr-k8s-webhook-server: Deployment.apps \"frr-k8s-webhook-server\" is invalid: spec.template.spec.containers[0].image: Required value"이 문제를 해결하려면 버전 4.19.4 이상으로 업그레이드하세요.
1.1.4. 일반 공급 및 기술 미리 보기 기능
이 릴리스의 일부 기능은 현재 기술 프리뷰 단계에 있습니다. 이러한 실험적 기능은 프로덕션용이 아닙니다. 이러한 기능에 대한 지원 범위에 대한 자세한 내용은 Red Hat 고객 포털의 기술 미리 보기 기능 지원 범위를 참조하세요.
IBM Power 및 IBM Z의 경우 64비트 x86 아키텍처를 기반으로 하는 머신 유형에서 제어 플레인을 실행해야 하며, IBM Power 또는 IBM Z의 노드 풀에서 실행해야 합니다.
| 기능 | 4.17 | 4.18 | 4.19 |
|---|---|---|---|
| 베어메탈이 아닌 에이전트 머신을 사용하는 OpenShift Container Platform용 호스팅 제어 평면 | 기술 프리뷰 | 기술 프리뷰 | 기술 프리뷰 |
| Amazon Web Services의 ARM64 OpenShift Container Platform 클러스터를 위한 호스팅 제어 평면 | 정식 출시일 (GA) | 정식 출시일 (GA) | 정식 출시일 (GA) |
| IBM Power 기반 OpenShift Container Platform용 호스팅 제어 플레인 | 정식 출시일 (GA) | 정식 출시일 (GA) | 정식 출시일 (GA) |
| OpenShift Container Platform에서 호스팅되는 컨트롤 플레인 | 정식 출시일 (GA) | 정식 출시일 (GA) | 정식 출시일 (GA) |
| OpenShift Container Platform에서 호스팅되는 컨트롤 플레인 | 개발자 프리뷰 | 개발자 프리뷰 | 기술 프리뷰 |
2장. 호스팅된 컨트롤 플레인 개요
독립 실행형 또는 호스팅된 컨트롤 플레인 구성의 두 가지 다른 컨트롤 플레인 구성을 사용하여 OpenShift Container Platform 클러스터를 배포할 수 있습니다. 독립 실행형 구성은 전용 가상 머신 또는 물리적 시스템을 사용하여 컨트롤 플레인을 호스팅합니다. OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 각 컨트롤 플레인의 전용 가상 또는 물리적 머신 없이도 호스팅 클러스터에서 컨트롤 플레인을 Pod로 생성합니다.
2.1. 호스트된 컨트롤 플레인 소개
다음 플랫폼에서 Kubernetes Operator용 멀티클러스터 엔진의 지원되는 버전을 사용하면 호스팅된 제어 평면을 사용할 수 있습니다.
- 에이전트 공급자를 사용하여 베어 메탈
- 베어메탈이 아닌 에이전트 머신, 기술 미리보기 기능으로서
- OpenShift Virtualization
- AWS(Amazon Web Services)
- IBM Z
- IBM Power
- 기술 미리 보기 기능으로 Red Hat OpenStack Platform(RHOSP) 17.1
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management(RHACM)의 필수적인 부분이며 RHACM에서 기본적으로 활성화됩니다. 하지만 호스팅된 제어 평면을 사용하려면 RHACM이 필요하지 않습니다.
2.1.1. 호스트된 컨트롤 플레인 아키텍처
OpenShift Container Platform은 종종 클러스터가 컨트롤 플레인과 데이터 플레인으로 구성된 결합형 또는 독립 실행형 모델로 배포됩니다. 컨트롤 플레인에는 상태를 확인하는 API 끝점, 스토리지 끝점, 워크로드 스케줄러, 작업자가 포함됩니다. 데이터 플레인에는 워크로드 및 애플리케이션이 실행되는 컴퓨팅, 스토리지 및 네트워킹이 포함됩니다.
독립 실행형 컨트롤 플레인은 쿼럼을 보장하기 위해 최소 수를 사용하여 물리적 또는 가상 노드 전용 그룹에 의해 호스팅됩니다. 네트워크 스택이 공유됩니다. 클러스터에 대한 관리자 액세스는 클러스터의 컨트롤 플레인, 머신 관리 API 및 클러스터 상태에 기여하는 기타 구성 요소를 시각화할 수 있습니다.
독립 실행형 모델이 제대로 작동하지만 일부 상황에서는 컨트롤 플레인 및 데이터 플레인이 분리되는 아키텍처가 필요합니다. 이러한 경우 데이터 플레인은 전용 물리적 호스팅 환경을 사용하는 별도의 네트워크 도메인에 있습니다. 컨트롤 플레인은 Kubernetes의 네이티브 배포 및 상태 저장 세트와 같은 고급 프리미티브를 사용하여 호스팅됩니다. 컨트롤 플레인은 다른 워크로드로 처리됩니다.
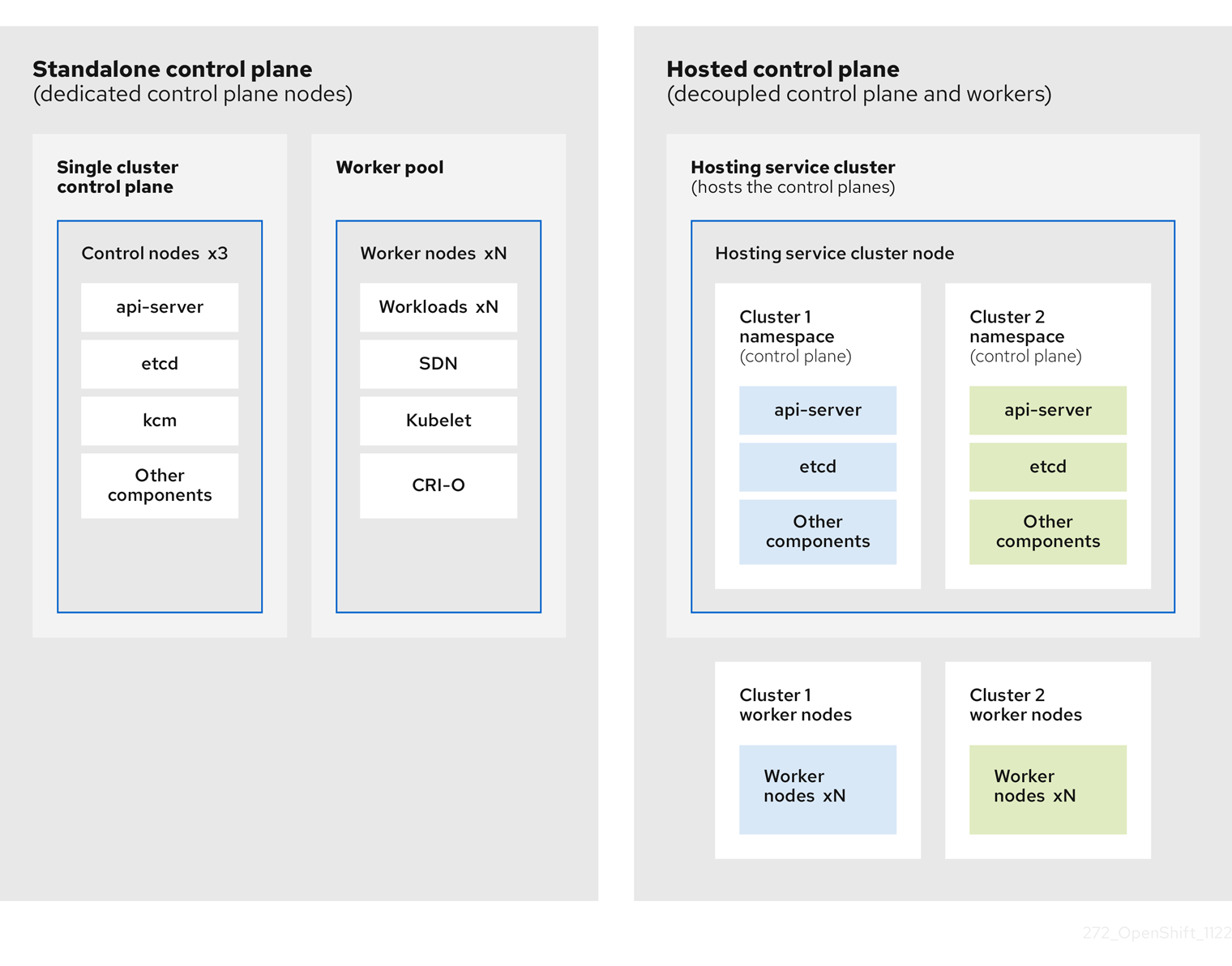
2.1.2. 호스팅된 컨트롤 플레인의 장점
ROSA용 호스팅된 컨트롤 플레인을 사용하면 진정한 하이브리드 클라우드 접근 방식을 찾고 다른 여러 가지 이점을 누릴 수 있습니다.
- 컨트롤 플레인이 분리되고 전용 호스팅 서비스 클러스터에서 호스팅되므로 관리와 워크로드 간의 보안 경계가 더욱 강화됩니다. 결과적으로 클러스터의 인증 정보를 다른 사용자에게 유출될 가능성이 줄어듭니다. 인프라 시크릿 계정 관리도 분리되므로 클러스터 인프라 관리자는 실수로 컨트롤 플레인 인프라를 삭제할 수 없습니다.
- 호스팅된 컨트롤 플레인을 사용하면 더 적은 수의 노드에서 많은 컨트롤 플레인을 실행할 수 있습니다. 이로 인해 클러스터 비용이 더 경제적이 됩니다.
- 컨트롤 플레인은 OpenShift Container Platform에서 시작되는 Pod로 구성되므로 컨트롤 플레인이 빠르게 시작됩니다. 모니터링, 로깅, 자동 확장과 같은 컨트롤 플레인 및 워크로드에 동일한 원칙이 적용됩니다.
- 인프라 화면에서 레지스트리, HAProxy, 클러스터 모니터링, 스토리지 노드 및 기타 인프라 구성 요소를 테넌트의 클라우드 공급자 계정으로 푸시하여 테넌트에서 사용을 분리할 수 있습니다.
- 운영 화면에서 다중 클러스터 관리는 더 중앙 집중화되어 클러스터 상태 및 일관성에 영향을 미치는 외부 요인이 줄어듭니다. 사이트 안정성 엔지니어는 문제를 디버그하고 클러스터 데이터 플레인으로 이동하여 문제 해결 시간 (TTR: Time to Resolution)이 단축되고 생산성 향상으로 이어질 수 있습니다.
2.2. 호스팅된 제어 평면과 OpenShift 컨테이너 플랫폼의 차이점
호스팅된 제어 평면은 OpenShift Container Platform의 폼 팩터입니다. 호스팅된 클러스터와 독립형 OpenShift Container Platform 클러스터는 다르게 구성되고 관리됩니다. OpenShift Container Platform과 호스팅된 제어 평면의 차이점을 알아보려면 다음 표를 참조하세요.
2.2.1. 클러스터 생성 및 수명 주기
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
|
|
2.2.2. 클러스터 구성
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
|
|
2.2.3. etcd 암호화
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
AES-GCM 또는 AES-CBC와 함께 |
Amazon Web Services의 경우 AES-CBC 또는 KMS와 함께 |
2.2.4. 운영자 및 제어 평면
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
| 독립형 OpenShift Container Platform 클러스터에는 각 제어 평면 구성 요소에 대한 별도의 운영자가 포함되어 있습니다. | 호스팅된 클러스터에는 관리 클러스터의 호스팅된 제어 평면 네임스페이스에서 실행되는 Control Plane Operator라는 단일 연산자가 포함됩니다. |
| etcd는 제어 평면 노드에 마운트된 저장소를 사용합니다. etcd 클러스터 운영자는 etcd를 관리합니다. | etcd는 저장소에 대한 영구 볼륨 클레임을 사용하며 Control Plane Operator에 의해 관리됩니다. |
| Ingress Operator, 네트워크 관련 Operator, Operator Lifecycle Manager(OLM)는 클러스터에서 실행됩니다. | Ingress Operator, 네트워크 관련 Operator 및 Operator Lifecycle Manager(OLM)는 관리 클러스터의 호스팅된 제어 평면 네임스페이스에서 실행됩니다. |
| OAuth 서버는 클러스터 내부에서 실행되며 클러스터의 경로를 통해 노출됩니다. | OAuth 서버는 제어 평면 내부에서 실행되며 관리 클러스터의 경로, 노드 포트 또는 로드 밸런서를 통해 노출됩니다. |
2.2.5. updates[]
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
클러스터 버전 운영자(CVO)는 업데이트 프로세스를 조정하고 |
호스팅된 제어 평면 업데이트로 인해 |
| OpenShift Container Platform 클러스터를 업데이트하면 제어 평면과 컴퓨팅 머신이 모두 업데이트됩니다. | 호스팅된 클러스터를 업데이트하면 제어 평면만 업데이트됩니다. 노드 풀 업데이트는 별도로 수행합니다. |
2.2.6. 기계 구성 및 관리
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
|
|
|
| 제어 평면 머신 세트를 사용할 수 있습니다. | 제어 평면 머신 세트가 존재하지 않습니다. |
|
|
|
|
|
|
| 클러스터에는 기계와 기계 세트가 노출되어 있습니다. | 업스트림 클러스터 CAPI 운영자의 머신, 머신 세트 및 머신 배포는 머신을 관리하는 데 사용되지만 사용자에게 노출되지 않습니다. |
| 클러스터를 업데이트하면 모든 머신 세트가 자동으로 업그레이드됩니다. | 호스팅된 클러스터 업데이트와 별도로 노드 풀을 업데이트합니다. |
| 클러스터에서는 기존 업그레이드만 지원됩니다. | 호스팅된 클러스터에서는 교체 및 기존 업그레이드가 모두 지원됩니다. |
| 머신 구성 운영자는 머신의 구성을 관리합니다. | 호스팅된 제어 평면에는 Machine Config Operator가 존재하지 않습니다. |
|
|
|
| 머신 구성 데몬은 각 노드의 구성 변경 및 업데이트를 관리합니다. | 기존 업그레이드의 경우, 노드 풀 컨트롤러는 구성에 따라 머신을 업데이트하는 한 번 실행되는 포드를 생성합니다. |
| SR-IOV 연산자와 같은 머신 구성 리소스를 수정할 수 있습니다. | 머신 구성 리소스를 수정할 수 없습니다. |
2.2.7. 네트워킹
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
| Kube API 서버는 노드와 직접 통신합니다. Kube API 서버와 노드는 동일한 Virtual Private Cloud(VPC)에 있기 때문입니다. | Kube API 서버는 Konnectivity를 통해 노드와 통신합니다. Kube API 서버와 노드는 다른 Virtual Private Cloud(VPC)에 있습니다. |
| 노드는 내부 로드 밸런서를 통해 Kube API 서버와 통신합니다. | 노드는 외부 로드 밸런서나 노드 포트를 통해 Kube API 서버와 통신합니다. |
2.2.8. 웹 콘솔
| OpenShift Container Platform | 호스팅된 컨트롤 플레인 |
|---|---|
| 웹 콘솔은 제어 평면의 상태를 보여줍니다. | 웹 콘솔에는 제어 평면의 상태가 표시되지 않습니다. |
| 웹 콘솔을 사용하여 클러스터를 업데이트할 수 있습니다. | 웹 콘솔을 사용하여 호스팅된 클러스터를 업데이트할 수 없습니다. |
| 웹 콘솔은 머신과 같은 인프라 리소스를 표시합니다. | 웹 콘솔에는 인프라 리소스가 표시되지 않습니다. |
|
웹 콘솔을 사용하여 | 웹 콘솔을 사용하여 머신을 구성할 수 없습니다. |
2.3. 호스팅된 제어 평면, 멀티클러스터 엔진 운영자 및 RHACM 간의 관계
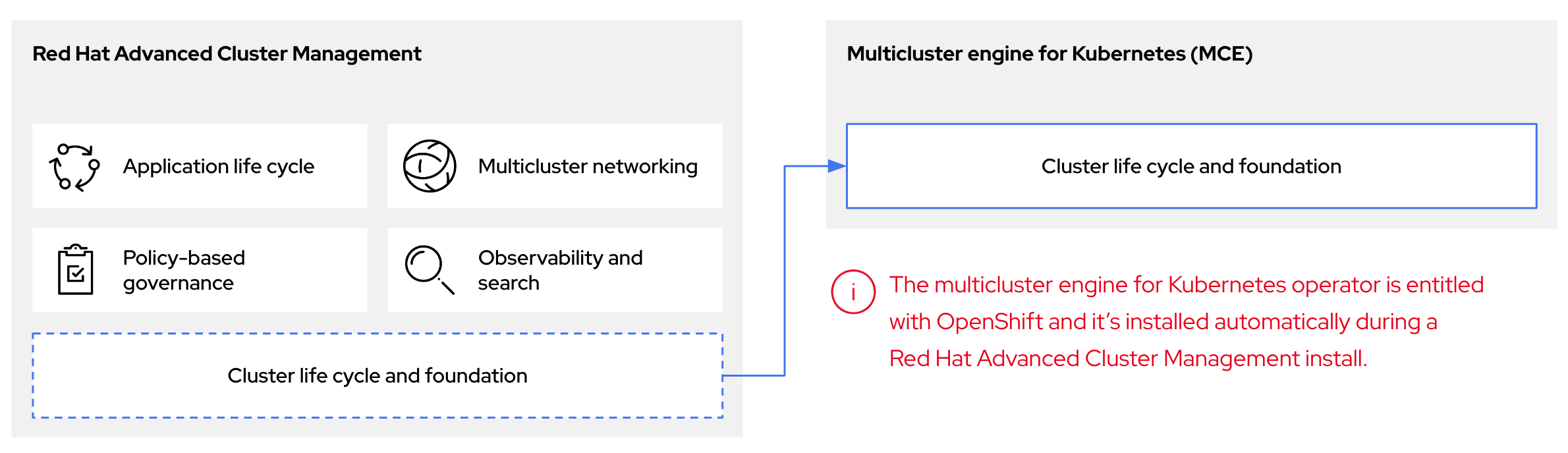
Kubernetes Operator용 멀티클러스터 엔진을 사용하여 호스팅된 제어 평면을 구성할 수 있습니다. 멀티클러스터 엔진 Operator 클러스터 수명 주기는 다양한 인프라 클라우드 공급자, 프라이빗 클라우드 및 온프레미스 데이터 센터에서 Kubernetes 클러스터를 생성, 가져오기, 관리 및 삭제하는 프로세스를 정의합니다.
멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management(RHACM)의 필수적인 부분이며 RHACM에서 기본적으로 활성화됩니다. 하지만 호스팅된 제어 평면을 사용하려면 RHACM이 필요하지 않습니다.
멀티클러스터 엔진 Operator는 OpenShift Container Platform 및 RHACM 허브 클러스터에 대한 클러스터 관리 기능을 제공하는 클러스터 수명 주기 Operator입니다. 멀티클러스터 엔진 Operator는 클러스터 플릿 관리를 향상시키고 클라우드와 데이터 센터 전반에서 OpenShift Container Platform 클러스터 수명 주기 관리를 지원합니다.
그림 2.1. 클러스터 수명 주기 및 기반
OpenShift Container Platform에서 멀티클러스터 엔진 Operator를 독립형 클러스터 관리자로 사용하거나 RHACM 허브 클러스터의 일부로 사용할 수 있습니다.
관리 클러스터는 호스팅 클러스터라고도 합니다.
독립 실행형 또는 호스팅된 컨트롤 플레인 구성의 두 가지 다른 컨트롤 플레인 구성을 사용하여 OpenShift Container Platform 클러스터를 배포할 수 있습니다. 독립 실행형 구성은 전용 가상 머신 또는 물리적 시스템을 사용하여 컨트롤 플레인을 호스팅합니다. OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 각 컨트롤 플레인의 전용 가상 또는 물리적 머신 없이도 호스팅 클러스터에서 컨트롤 플레인을 Pod로 생성합니다.
그림 2.2. RHACM 및 멀티클러스터 엔진 운영자 소개 다이어그램
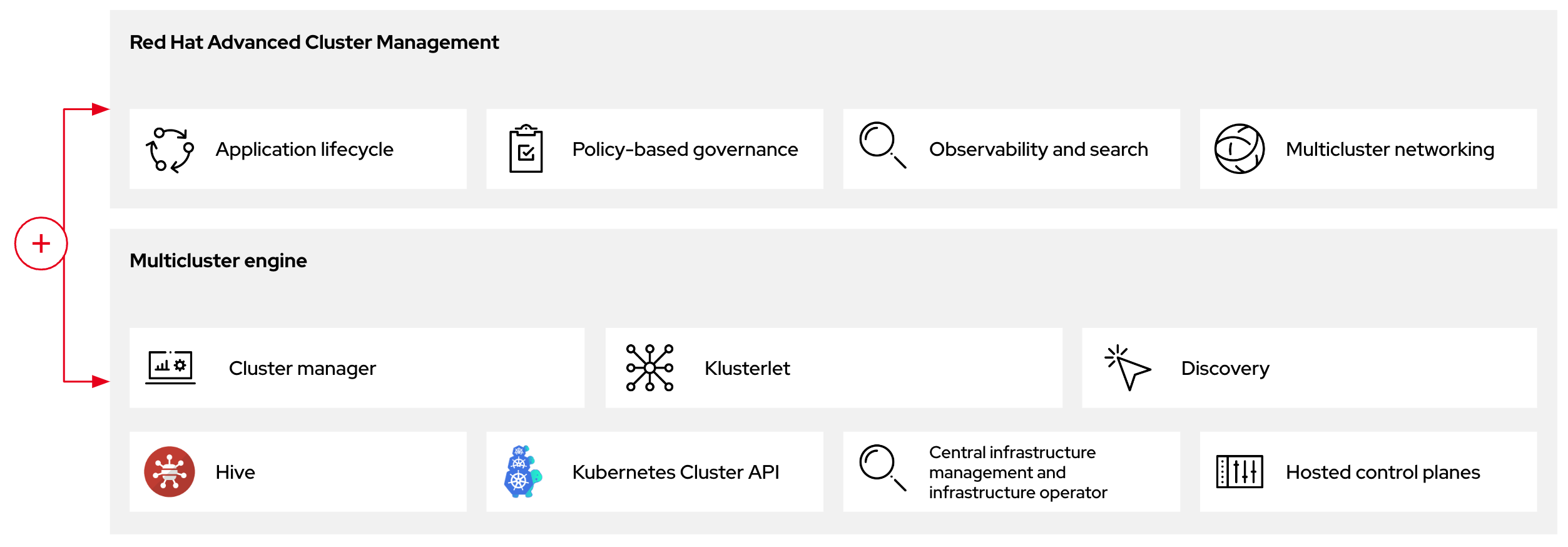
2.3.1. RHACM에서 멀티클러스터 엔진 운영자가 호스팅하는 클러스터 검색
호스팅된 클러스터를 RHACM(Red Hat Advanced Cluster Management) 허브 클러스터로 가져와서 RHACM 관리 구성 요소로 관리하려면 Red Hat Advanced Cluster Management 공식 문서 의 지침을 참조하세요.
2.4. 호스팅된 컨트롤 플레인 버전 관리
호스팅된 제어 평면 기능에는 다음과 같은 구성 요소가 포함되어 있으며, 이러한 구성 요소에는 독립적인 버전 관리 및 지원 수준이 필요할 수 있습니다.
- 관리 클러스터
- HyperShift Operator
-
호스팅 제어 평면(
hcp) 명령줄 인터페이스(CLI) - hypershift.openshift.io API
- control-plane-operator
2.4.1. 관리 클러스터
프로덕션용 관리 클러스터에는 OperatorHub에서 사용할 수 있는 Kubernetes Operator용 멀티클러스터 엔진이 필요합니다. 멀티클러스터 엔진 Operator는 지원되는 HyperShift Operator 빌드를 번들로 제공합니다. 관리 클러스터가 계속 지원되도록 하려면 멀티클러스터 엔진 Operator가 실행되는 OpenShift Container Platform 버전을 사용해야 합니다. 일반적으로 멀티클러스터 엔진 Operator의 새로운 릴리스는 다음 버전의 OpenShift Container Platform에서 실행됩니다.
- OpenShift 컨테이너 플랫폼의 최신 일반 가용성 버전
- OpenShift Container Platform의 최신 일반 가용성 버전 이전의 두 가지 버전
관리 클러스터에서 HyperShift Operator를 통해 설치할 수 있는 OpenShift Container Platform 버전의 전체 목록은 HyperShift Operator 버전에 따라 달라집니다. 그러나 목록에는 항상 관리 클러스터와 동일한 OpenShift Container Platform 버전과 관리 클러스터와 관련된 이전 두 개의 마이너 버전이 포함됩니다. 예를 들어, 관리 클러스터가 4.17과 지원되는 버전의 멀티클러스터 엔진 Operator를 실행 중인 경우 HyperShift Operator는 4.17, 4.16, 4.15, 4.14 호스팅 클러스터를 설치할 수 있습니다.
OpenShift Container Platform의 각 메이저, 마이너 또는 패치 버전 릴리스에서 호스팅되는 컨트롤 플레인의 두 가지 구성 요소가 릴리스됩니다.
- HyperShift 연산자
-
hcp명령줄 인터페이스(CLI)
2.4.2. HyperShift Operator
HyperShift Operator는 HostedCluster API 리소스에서 나타내는 호스팅 클러스터의 라이프사이클을 관리합니다. HyperShift Operator는 각 OpenShift Container Platform 릴리스와 함께 릴리스됩니다. HyperShift Operator는 hypershift 네임스페이스에 지원되는 버전 구성 맵을 생성합니다. 구성 맵에는 지원되는 호스팅 클러스터 버전이 포함되어 있습니다.
동일한 관리 클러스터에서 다양한 버전의 제어 평면을 호스팅할 수 있습니다.
지원되는 버전 구성 맵 객체의 예
apiVersion: v1
data:
supported-versions: '{"versions":["4.19"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift2.4.3. 호스팅된 제어 평면 CLI
hcp CLI를 사용하여 호스팅 클러스터를 만들 수 있습니다. CLI는 multicluster engine Operator에서 다운로드할 수 있습니다. hcp version 명령을 실행하면 kubeconfig 파일에 대해 CLI가 지원하는 최신 OpenShift Container Platform이 출력에 표시됩니다.
2.4.4. hypershift.openshift.io API
HostedCluster 및 NodePool 과 같은 hypershift.openshift.io API 리소스를 사용하면 대규모로 OpenShift Container Platform 클러스터를 만들고 관리할 수 있습니다. HostedCluster 리소스에는 제어 평면과 공통 데이터 평면 구성이 포함되어 있습니다. HostedCluster 리소스를 생성할 때 연결된 노드가 없는 완전히 작동하는 컨트롤 플레인이 있습니다. NodePool 리소스는 HostedCluster 리소스에 연결된 확장 가능한 작업자 노드 집합입니다.
API 버전 정책은 일반적으로 Kubernetes API 버전 관리 정책과 일치합니다.
호스팅된 컨트롤 플레인을 업데이트하려면 호스팅된 클러스터 및 노드 풀을 업데이트해야 합니다. 자세한 내용은 "호스팅된 제어 평면에 대한 업데이트"를 참조하세요.
2.4.5. control-plane-operator
Control Plane Operator는 다음 아키텍처에 대한 각 OpenShift Container Platform 페이로드 릴리스 이미지의 일부로 릴리스됩니다.
- amd64
- arm64
- 멀티 아치
2.5. 호스팅된 컨트롤 플레인의 일반 개념 및 가상 사용자집
OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하는 경우 주요 개념과 관련 가상 사용자를 이해하는 것이 중요합니다.
2.5.1. 개념
- 데이터 플레인
- 워크로드와 애플리케이션이 실행되는 컴퓨팅, 스토리지, 네트워킹을 포함하는 클러스터의 일부입니다.
- 호스트된 클러스터
- 관리 클러스터에서 호스팅되는 컨트롤 플레인 및 API 끝점이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
- 호스트된 클러스터 인프라
- 테넌트 또는 최종 사용자 클라우드 계정에 존재하는 네트워크, 컴퓨팅 및 스토리지 리소스입니다.
- 호스트된 컨트롤 플레인
- 호스팅된 클러스터의 API 끝점에 의해 노출되는 관리 클러스터에서 실행되는 OpenShift Container Platform 컨트롤 플레인입니다. 컨트롤 플레인의 구성 요소에는 etcd, Kubernetes API 서버, Kubernetes 컨트롤러 관리자 및 VPN이 포함됩니다.
- 호스트 클러스터
- 관리 클러스터를 참조하십시오.
- 관리형 클러스터
- 허브 클러스터가 관리하는 클러스터입니다. 이 용어는 Kubernetes Operator의 다중 클러스터 엔진에서 Red Hat Advanced Cluster Management에서 관리하는 클러스터 라이프사이클에 따라 다릅니다. 관리형 클러스터는 관리 클러스터와 동일하지 않습니다. 자세한 내용은 관리 클러스터를 참조하십시오.
- 관리 클러스터
- HyperShift Operator가 배포되고 호스팅된 클러스터의 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 관리 클러스터는 호스팅 클러스터와 동일합니다.
- 관리 클러스터 인프라
- 관리 클러스터의 네트워크, 컴퓨팅 및 스토리지 리소스입니다.
- 노드 풀
- 호스팅된 클러스터와 연관된 일련의 컴퓨팅 노드를 관리하는 리소스입니다. 컴퓨팅 노드는 호스팅된 클러스터 내에서 애플리케이션과 워크로드를 실행합니다.
2.5.2. 가상 사용자
- 클러스터 인스턴스 관리자
-
이 역할의 사용자는 독립 실행형 OpenShift Container Platform의 관리자와 동일한 것으로 간주됩니다. 이 사용자에게는 프로비저닝된 클러스터에
cluster-admin역할이 있지만 클러스터 업데이트 또는 구성 시 전원이 켜지지 않을 수 있습니다. 이 사용자는 클러스터에 예상된 일부 구성을 확인하기 위해 읽기 전용 액세스 권한이 있을 수 있습니다. - 클러스터 인스턴스 사용자
- 이 역할의 사용자는 독립 실행형 OpenShift Container Platform의 개발자와 동일한 것으로 간주됩니다. 이 사용자에게는 OperatorHub 또는 머신에 대한 보기가 없습니다.
- 클러스터 서비스 소비자
- 이 역할에서 컨트롤 플레인 및 작업자 노드를 요청하거나, 드라이브 업데이트를 요청하거나, 외부화된 구성을 수정할 수 있다고 가정합니다. 일반적으로 이 사용자는 클라우드 인증 정보 또는 인프라 암호화 키를 관리하거나 액세스하지 않습니다. 클러스터 서비스 소비자 가상 사용자는 호스트된 클러스터를 요청하고 노드 풀과 상호 작용할 수 있습니다. 이 역할에는 논리 경계 내에서 호스팅된 클러스터 및 노드 풀을 생성, 읽기, 업데이트 또는 삭제하는 RBAC가 있다고 가정합니다.
- 클러스터 서비스 공급자
이 역할에는 일반적으로 관리 클러스터에 대한
cluster-admin역할이 있고 HyperShift Operator의 가용성을 모니터링하고 소유할 수 있는 RBAC와 테넌트의 호스트 클러스터에 대한 컨트롤 플레인이 있는 사용자입니다. 클러스터 서비스 공급자 개인은 다음 예제를 포함하여 여러 활동을 담당합니다.- 컨트롤 플레인 가용성, 가동 시간 및 안정성에 대한 서비스 수준 오브젝트 보유
- 컨트롤 플레인을 호스팅할 관리 클러스터의 클라우드 계정 구성
- 사용 가능한 컴퓨팅 리소스에 대한 호스트 인식이 포함된 사용자 프로비저닝 인프라 구성
3장. 호스팅된 제어 평면 배포 준비
3.1. 호스팅된 제어 평면에 대한 요구 사항
호스팅된 제어 평면의 컨텍스트에서 관리 클러스터는 HyperShift Operator가 배포되고 호스팅된 클러스터의 제어 평면이 호스팅되는 OpenShift Container Platform 클러스터입니다.
제어 평면은 호스팅된 클러스터와 연결되며 단일 네임스페이스의 포드로 실행됩니다. 클러스터 서비스 소비자가 호스팅 클러스터를 생성하면 제어 평면과 독립적인 작업자 노드가 생성됩니다.
호스팅된 제어 평면에는 다음 요구 사항이 적용됩니다.
- HyperShift Operator를 실행하려면 관리 클러스터에 최소 3개의 작업자 노드가 필요합니다.
-
도메인 이름 서비스(DNS) 프로토콜이 예상대로 작동하려면 전송 제어 프로토콜(TCP)과 사용자 데이터그램 프로토콜(UDP)에서 방화벽 포트
53을열어야 합니다. - 베어 메탈 플랫폼이나 OpenShift Virtualization 등 온프레미스에서 관리 클러스터와 작업자 노드를 모두 실행할 수 있습니다. 또한 Amazon Web Services(AWS)와 같은 클라우드 인프라에서 관리 클러스터와 작업자 노드를 모두 실행할 수 있습니다.
-
AWS에서 관리 클러스터를 실행하고 온프레미스에서 작업자 노드를 실행하거나 AWS에서 작업자 노드를 실행하고 온프레미스에서 관리 클러스터를 실행하는 등 혼합 인프라를 사용하는 경우
PublicAndPrivate게시 전략을 사용하고 지원 매트릭스의 대기 시간 요구 사항을 따라야 합니다. - 베어 메탈 운영자가 머신을 시작하는 베어 메탈 호스트(BMH) 배포에서 호스팅된 제어 플레인은 베이스보드 관리 컨트롤러(BMC)에 도달할 수 있어야 합니다. 보안 프로필에서 클러스터 베어메탈 운영자가 BMH가 BMC를 보유한 네트워크에 액세스하여 Redfish 자동화를 활성화하는 것을 허용하지 않는 경우 BYO ISO 지원을 사용할 수 있습니다. 하지만 BYO 모드에서는 OpenShift Container Platform이 BMH의 전원 켜기를 자동화할 수 없습니다.
3.1.1. 호스팅된 제어 평면에 대한 지원 매트릭스
Kubernetes Operator용 멀티클러스터 엔진에는 HyperShift Operator가 포함되어 있으므로 호스팅된 제어 평면의 릴리스는 멀티클러스터 엔진 Operator의 릴리스와 일치합니다. 자세한 내용은 OpenShift Operator Life Cycles를 참조하세요.
3.1.1.1. 관리 클러스터 지원
지원되는 모든 독립형 OpenShift Container Platform 클러스터는 관리 클러스터가 될 수 있습니다.
단일 노드 OpenShift Container Platform 클러스터는 관리 클러스터로 지원되지 않습니다. 리소스 제약이 있는 경우 독립형 OpenShift Container Platform 제어 평면과 호스팅된 제어 평면 간에 인프라를 공유할 수 있습니다. 자세한 내용은 "호스팅 및 독립형 제어 평면 간의 공유 인프라"를 참조하세요.
다음 표는 멀티클러스터 엔진 운영자 버전을 이를 지원하는 관리 클러스터 버전에 매핑합니다.
| 관리 클러스터 버전 | 지원되는 멀티클러스터 엔진 운영자 버전 |
|---|---|
| 4.14 - 4.15 | 2.4 |
| 4.14 - 4.16 | 2.5 |
| 4.14 - 4.17 | 2.6 |
| 4.15 - 4.17 | 2.7 |
| 4.16 - 4.18 | 2.8 |
| 4.17 - 4.19 | 2.9 |
3.1.1.2. 호스팅 클러스터 지원
호스팅 클러스터의 경우 관리 클러스터 버전과 호스팅 클러스터 버전 사이에 직접적인 관계가 없습니다. 호스팅된 클러스터 버전은 멀티클러스터 엔진 Operator 버전에 포함된 HyperShift Operator에 따라 달라집니다.
관리 클러스터와 호스팅 클러스터 간에 최대 200ms의 지연 시간을 보장합니다. 이러한 요구 사항은 관리 클러스터가 AWS에 있고 컴퓨팅 노드가 온프레미스에 있는 경우와 같이 혼합 인프라 배포에 특히 중요합니다.
다음 표는 멀티클러스터 엔진 Operator 버전과 연관된 HyperShift Operator를 사용하여 만들 수 있는 호스팅 클러스터 버전을 보여줍니다.
HyperShift Operator는 다음 표에 나와 있는 호스팅 클러스터 버전을 지원하지만, 멀티클러스터 엔진 Operator는 현재 버전보다 2개 이전 버전만 지원합니다. 예를 들어, 현재 호스팅 클러스터 버전이 4.19인 경우 멀티클러스터 엔진 Operator는 최대 4.17 버전까지 지원합니다. 멀티클러스터 엔진 오퍼레이터가 지원하는 버전보다 이전 버전의 호스팅 클러스터를 사용하려는 경우, 멀티클러스터 엔진 오퍼레이터에서 호스팅 클러스터를 분리하여 관리되지 않도록 하거나, 이전 버전의 멀티클러스터 엔진 오퍼레이터를 사용할 수 있습니다. 호스팅된 클러스터를 멀티클러스터 엔진 Operator에서 분리하는 방법에 대한 자세한 내용은 관리에서 클러스터 제거 (RHACM 문서)를 참조하세요. 멀티클러스터 엔진 운영자 지원에 대한 자세한 내용은 Kubernetes 운영자 2.9 지원 매트릭스(Red Hat 지식 기반)를 위한 멀티클러스터 엔진을 참조하세요.
| 호스팅된 클러스터 버전 | 멀티클러스터 엔진 Operator 2.4의 HyperShift Operator | 멀티클러스터 엔진 Operator 2.5의 HyperShift Operator | 멀티클러스터 엔진 Operator 2.6의 HyperShift Operator | 멀티클러스터 엔진 Operator 2.7의 HyperShift Operator | 멀티클러스터 엔진 Operator 2.8의 HyperShift Operator | 멀티클러스터 엔진 Operator 2.9의 HyperShift Operator |
|---|---|---|---|---|---|---|
| 4.14 | 제공됨 | 제공됨 | 제공됨 | 제공됨 | 제공됨 | 제공됨 |
| 4.15 | 없음 | 제공됨 | 제공됨 | 제공됨 | 제공됨 | 제공됨 |
| 4.16 | 없음 | 없음 | 제공됨 | 제공됨 | 제공됨 | 제공됨 |
| 4.17 | 없음 | 없음 | 없음 | 제공됨 | 제공됨 | 제공됨 |
| 4.18 | 없음 | 없음 | 없음 | 없음 | 제공됨 | 제공됨 |
| 4.19 | 없음 | 없음 | 없음 | 없음 | 없음 | 제공됨 |
3.1.1.3. 호스팅 클러스터 플랫폼 지원
호스팅된 클러스터는 단 하나의 인프라 플랫폼만 지원합니다. 예를 들어, 서로 다른 인프라 플랫폼에 여러 개의 노드 풀을 만들 수 없습니다.
다음 표는 호스팅된 제어 평면의 각 플랫폼에서 지원되는 OpenShift Container Platform 버전을 나타냅니다.
IBM Power 및 IBM Z의 경우 64비트 x86 아키텍처를 기반으로 하는 머신 유형에서 제어 플레인을 실행해야 하며, IBM Power 또는 IBM Z의 노드 풀에서 실행해야 합니다.
다음 표에서 관리 클러스터 버전은 멀티클러스터 엔진 Operator가 활성화된 OpenShift Container Platform 버전입니다.
| 호스팅 클러스터 플랫폼 | 관리 클러스터 버전 | 호스팅된 클러스터 버전 |
|---|---|---|
| Amazon Web Services | 4.16 - 4.19 | 4.16 - 4.19 |
| IBM Power | 4.17 - 4.19 | 4.17 - 4.19 |
| IBM Z | 4.17 - 4.19 | 4.17 - 4.19 |
| OpenShift Virtualization | 4.14 - 4.19 | 4.14 - 4.19 |
| 베어 메탈 | 4.14 - 4.19 | 4.14 - 4.19 |
| 베어메탈이 아닌 에이전트 머신(기술 미리보기) | 4.16 - 4.19 | 4.16 - 4.19 |
| Red Hat OpenStack Platform(RHOSP)(기술 미리보기) | 4.19 | 4.19 |
3.1.1.4. 다중 아키텍처 지원
다음 표는 플랫폼별로 정리된 여러 아키텍처의 호스팅 제어 평면에 대한 지원 상태를 나타냅니다.
| OpenShift Container Platform 버전 | ARM64 제어 평면 | ARM64 컴퓨트 노드 |
|---|---|---|
| 4.19 | 정식 출시일 (GA) | 정식 출시일 (GA) |
| 4.18 | 정식 출시일 (GA) | 정식 출시일 (GA) |
| 4.17 | 정식 출시일 (GA) | 정식 출시일 (GA) |
| 4.16 | 기술 프리뷰 | 정식 출시일 (GA) |
| 4.15 | 기술 프리뷰 | 정식 출시일 (GA) |
| 4.14 | 기술 프리뷰 | 정식 출시일 (GA) |
| OpenShift Container Platform 버전 | ARM64 제어 평면 | ARM64 컴퓨트 노드 |
|---|---|---|
| 4.19 | 사용할 수 없음 | 기술 프리뷰 |
| 4.18 | 사용할 수 없음 | 기술 프리뷰 |
| 4.17 | 사용할 수 없음 | 기술 프리뷰 |
| 4.16 | 사용할 수 없음 | 기술 프리뷰 |
| 4.15 | 사용할 수 없음 | 기술 프리뷰 |
| 4.14 | 사용할 수 없음 | 기술 프리뷰 |
| OpenShift Container Platform 버전 | ARM64 제어 평면 | ARM64 컴퓨트 노드 |
|---|---|---|
| 4.19 | 사용할 수 없음 | 사용할 수 없음 |
| 4.18 | 사용할 수 없음 | 사용할 수 없음 |
| 4.17 | 사용할 수 없음 | 사용할 수 없음 |
| OpenShift Container Platform 버전 | Control-plane-0 | 컴퓨팅 노드 |
|---|---|---|
| 4.19 |
|
|
| 4.18 |
|
|
| 4.17 |
|
|
| OpenShift Container Platform 버전 | Control-plane-0 | 컴퓨팅 노드 |
|---|---|---|
| 4.19 |
|
|
| 4.18 |
|
|
| 4.17 |
|
|
| OpenShift Container Platform 버전 | ARM64 제어 평면 | ARM64 컴퓨트 노드 |
|---|---|---|
| 4.19 | 사용할 수 없음 | 사용할 수 없음 |
| 4.18 | 사용할 수 없음 | 사용할 수 없음 |
| 4.17 | 사용할 수 없음 | 사용할 수 없음 |
| 4.16 | 사용할 수 없음 | 사용할 수 없음 |
| 4.15 | 사용할 수 없음 | 사용할 수 없음 |
| 4.14 | 사용할 수 없음 | 사용할 수 없음 |
3.1.1.5. 멀티클러스터 엔진 오퍼레이터 업데이트
멀티클러스터 엔진 Operator의 다른 버전으로 업데이트하는 경우, 멀티클러스터 엔진 Operator 버전에 포함된 HyperShift Operator가 호스팅 클러스터 버전을 지원하는 경우 호스팅된 클러스터를 계속 실행할 수 있습니다. 다음 표는 어떤 업데이트된 멀티클러스터 엔진 운영자 버전에서 어떤 호스팅 클러스터 버전이 지원되는지 보여줍니다.
HyperShift Operator는 다음 표에 나와 있는 호스팅 클러스터 버전을 지원하지만, 멀티클러스터 엔진 Operator는 현재 버전보다 2개 이전 버전만 지원합니다. 예를 들어, 현재 호스팅 클러스터 버전이 4.19인 경우 멀티클러스터 엔진 Operator는 최대 4.17 버전까지 지원합니다. 멀티클러스터 엔진 오퍼레이터가 지원하는 버전보다 이전 버전의 호스팅 클러스터를 사용하려는 경우, 멀티클러스터 엔진 오퍼레이터에서 호스팅 클러스터를 분리하여 관리되지 않도록 하거나, 이전 버전의 멀티클러스터 엔진 오퍼레이터를 사용할 수 있습니다. 호스팅된 클러스터를 멀티클러스터 엔진 Operator에서 분리하는 방법에 대한 자세한 내용은 관리에서 클러스터 제거 (RHACM 문서)를 참조하세요. 멀티클러스터 엔진 운영자 지원에 대한 자세한 내용은 Kubernetes 운영자 2.9 지원 매트릭스(Red Hat 지식 기반)를 위한 멀티클러스터 엔진을 참조하세요.
| 업데이트된 멀티클러스터 엔진 운영자 버전 | 지원되는 호스팅 클러스터 버전 |
|---|---|
| 2.4에서 2.5로 업데이트되었습니다 | OpenShift Container Platform 3.11 |
| 2.5에서 2.6으로 업데이트되었습니다. | OpenShift Container Platform |
| 2.6에서 2.7로 업데이트되었습니다. | OpenShift Container Platform |
| 2.7에서 2.8로 업데이트되었습니다. | OpenShift Container Platform |
| 2.8에서 2.9로 업데이트되었습니다. | OpenShift Container Platform |
예를 들어, 관리 클러스터에 OpenShift Container Platform 4.14 호스팅 클러스터가 있고 멀티클러스터 엔진 Operator 2.4에서 2.5로 업데이트하는 경우 호스팅 클러스터를 계속 실행할 수 있습니다.
3.1.1.6. 기술 프리뷰 기능
다음 목록은 이 릴리스에서 기술 미리 보기 상태인 기능을 나타냅니다.
- 연결이 끊긴 환경에서 IBM Z의 호스팅된 제어 평면
- 호스팅된 제어 평면에 대한 사용자 정의 오염 및 허용
- OpenShift 가상화를 위한 호스팅된 제어 평면의 NVIDIA GPU 장치
- Red Hat OpenStack Platform(RHOSP)에서 호스팅되는 제어 플레인
3.1.2. FIPS 지원 호스팅 클러스터
호스팅된 제어 평면의 바이너리는 FIP를 준수하지만 호스팅된 제어 평면 명령줄 인터페이스인 hcp 는 예외입니다.
FIPS 지원 호스팅 클러스터를 배포하려면 FIPS 지원 관리 클러스터를 사용해야 합니다. 관리 클러스터에 대해 FIPS 모드를 활성화하려면 FIPS 모드에서 작동하도록 구성된 Red Hat Enterprise Linux(RHEL) 컴퓨터에서 설치 프로그램을 실행해야 합니다. RHEL에서 FIPS 모드를 구성하는 방법에 대한 자세한 내용은 RHEL을 FIPS 모드로 전환을 참조하세요.
FIPS 모드로 부팅된 Red Hat Enterprise Linux(RHEL) 또는 Red Hat Enterprise Linux CoreOS(RHCOS)를 실행할 때 OpenShift Container Platform 핵심 구성 요소는 x86_64, ppc64le 및 s390x 아키텍처에서만 FIPS 140-2/140-3 검증을 위해 NIST에 제출된 RHEL 암호화 라이브러리를 사용합니다.
FIPS 모드로 관리 클러스터를 설정하면 호스팅 클러스터 생성 프로세스가 해당 관리 클러스터에서 실행됩니다.
3.1.3. 호스팅된 제어 평면의 CIDR 범위
OpenShift Container Platform에 호스팅된 제어 평면을 배포하려면 다음과 같은 필수 CIDR(Classless Inter-Domain Routing) 서브넷 범위를 사용하세요.
-
v4InternalSubnet: 100.65.0.0/16(OVN-Kubernetes) -
clusterNetwork: 10.132.0.0/14(pod 네트워크) -
serviceNetwork: 172.31.0.0/16
OpenShift Container Platform CIDR 범위 정의에 대한 자세한 내용은 "CIDR 범위 정의"를 참조하세요.
3.2. 호스팅된 제어 평면에 대한 크기 조정 지침
호스팅된 클러스터 작업 부하와 작업자 노드 수를 포함한 여러 요소가 특정 수의 작업자 노드에 얼마나 많은 호스팅된 제어 평면이 들어갈 수 있는지에 영향을 미칩니다. 이 크기 조정 가이드를 활용하여 호스팅 클러스터 용량 계획을 세우세요. 이 지침에서는 가용성이 높은 호스팅 제어 평면 토폴로지를 가정합니다. 부하 기반 크기 조정 사례는 베어 메탈 클러스터에서 측정되었습니다. 클라우드 기반 인스턴스에는 메모리 크기와 같은 다양한 제한 요소가 있을 수 있습니다.
다음 리소스 활용도 크기 측정을 재정의하고 메트릭 서비스 모니터링을 비활성화할 수 있습니다.
OpenShift Container Platform 버전 4.12.9 이상에서 테스트된 다음의 고가용성 호스팅 제어 평면 요구 사항을 참조하세요.
- pods
- etcd용 8GiB PV 3개
- 최소 vCPU: 약 5.5개 코어
- 최소 메모리: 약 19GiB
3.2.1. Pod 제한
각 노드의 maxPods 설정은 제어 평면 노드에 들어갈 수 있는 호스팅 클러스터 수에 영향을 미칩니다. 모든 제어 평면 노드에서 maxPods 값을 기록하는 것이 중요합니다. 가용성이 높은 호스팅 제어 평면마다 약 75개의 포드를 계획합니다.
베어 메탈 노드의 경우, 기본 maxPods 설정인 250은 각 노드에 대략 3개의 호스팅된 제어 평면이 적합하기 때문에 제한 요소가 될 가능성이 높습니다. 머신에 여유 리소스가 충분하더라도 마찬가지입니다. KubeletConfig 값을 구성하여 maxPods 값을 500으로 설정하면 호스팅된 제어 평면 밀도가 더 높아지고, 이를 통해 추가 컴퓨팅 리소스를 활용하는 데 도움이 됩니다.
3.2.2. 요청 기반 리소스 제한
클러스터가 호스팅할 수 있는 호스팅된 제어 평면의 최대 수는 포드의 호스팅된 제어 평면 CPU 및 메모리 요청을 기반으로 계산됩니다.
고가용성 호스팅 제어 평면은 5개의 vCPU와 18GiB 메모리를 요청하는 78개의 포드로 구성됩니다. 이러한 기준 수치는 클러스터 워커 노드 리소스 용량과 비교되어 호스팅된 제어 평면의 최대 수를 추정합니다.
3.2.3. 부하 기반 한도
클러스터가 호스팅할 수 있는 호스팅된 제어 평면의 최대 수는 일부 작업 부하가 호스팅된 제어 평면 Kubernetes API 서버에 적용될 때 호스팅된 제어 평면 Pod의 CPU 및 메모리 사용률을 기반으로 계산됩니다.
다음 방법은 작업 부하가 증가함에 따라 호스팅된 제어 평면 리소스 사용률을 측정하는 데 사용됩니다.
- KubeVirt 플랫폼을 사용하면서 각각 8개의 vCPU와 32GiB를 사용하는 9개의 작업자가 있는 호스팅 클러스터
다음 정의를 기반으로 API 제어 평면 스트레스에 초점을 맞추도록 구성된 워크로드 테스트 프로필입니다.
- 각 네임스페이스에 대해 객체를 생성하여 총 100개의 네임스페이스까지 확장 가능
- 지속적인 객체 삭제 및 생성으로 인한 추가 API 스트레스
- 클라이언트 측 제한을 제거하기 위해 초당 작업 쿼리 수(QPS) 및 버스트 설정을 높게 설정했습니다.
부하가 1000 QPS 증가하면 호스팅된 제어 평면 리소스 사용률은 vCPU 9개와 메모리 2.5GB만큼 증가합니다.
일반적인 크기 조정 목적으로 중간 규모의 호스팅 클러스터 부하인 1000 QPS API 속도와, 무거운 호스팅 클러스터 부하인 2000 QPS API 속도를 고려하세요.
이 테스트는 예상되는 API 부하에 따라 컴퓨팅 리소스 활용도를 높이기 위한 추정 계수를 제공합니다. 정확한 활용률은 클러스터 작업 부하의 유형과 속도에 따라 달라질 수 있습니다.
다음 예에서는 작업 부하 및 API 속도 정의에 대한 호스팅된 제어 평면 리소스 확장을 보여줍니다.
| QPS(API 비율) | CPU 사용량 | 메모리 사용량(GiB) |
|---|---|---|
| 낮은 부하(50 QPS 미만) | 2.9 | 11.1 |
| 중간 부하(1000 QPS) | 11.9 | 13.6 |
| 고부하(2000 QPS) | 20.9 | 16.1 |
호스팅된 제어 평면 크기 조정은 API 활동, etcd 활동 또는 둘 다를 유발하는 제어 평면 부하와 작업 부하에 관한 것입니다. 데이터베이스 실행과 같은 데이터 플레인 부하에 초점을 맞춘 호스팅된 포드 워크로드는 높은 API 속도를 가져오지 못할 수 있습니다.
3.2.4. 크기 계산 예
이 예에서는 다음 시나리오에 대한 크기 조정 지침을 제공합니다.
-
hypershift.openshift.io/control-plane노드로 표시된 세 개의 베어 메탈 작업자 -
maxPods값이 500으로 설정됨 - 예상 API 속도는 부하 기반 제한에 따라 중간 또는 약 1000입니다.
| 제한 설명 | server | server |
|---|---|---|
| 워커 노드의 vCPU 수 | 64 | 128 |
| 워커 노드의 메모리(GiB) | 128 | 256 |
| 작업자당 최대 포드 수 | 500 | 500 |
| 제어 평면을 호스팅하는 데 사용되는 작업자 수 | 3 | 3 |
| 최대 QPS 목표 속도(초당 API 요청 수) | 1000 | 1000 |
| 워커 노드 크기 및 API 비율을 기반으로 계산된 값 | server | server | 계산 노트 |
| vCPU 요청에 따른 작업자당 최대 호스팅 제어 평면 | 12.8 | 25.6 | 작업자 vCPU 수 ÷ 호스팅된 제어 평면당 총 5개의 vCPU 요청 |
| vCPU 사용량에 따른 작업자당 최대 호스팅 제어 평면 | 5.4 | 10.7 | vCPUS 수 ÷ (2.9 측정된 유휴 vCPU 사용량 + (QPS 목표 비율 ÷ 1000) × 1000 QPS 증가당 9.0 측정된 vCPU 사용량) |
| 메모리 요청에 따른 작업자당 최대 호스팅 제어 평면 | 7.1 | 14.2 | 작업자 메모리 GiB ÷ 호스팅된 제어 평면당 총 메모리 요청 18GiB |
| 메모리 사용량에 따른 작업자당 최대 호스팅 제어 평면 | 9.4 | 18.8 | 작업자 메모리 GiB ÷ (11.1 측정된 유휴 메모리 사용량 + (QPS 대상 속도 ÷ 1000) × 2.5 측정된 메모리 사용량(1000 QPS 증가당)) |
| 노드당 Pod 제한에 따른 작업자당 최대 호스팅 제어 평면 | 6.7 | 6.7 |
최대 500개 |
| 이전에 언급된 최대값의 최소값 | 5.4 | 6.7 | |
| vCPU 제한 요소 |
| ||
| 관리 클러스터 내 호스팅 제어 평면의 최대 수 | 16 | 20 | 이전에 언급된 최대값의 최소값 × 3개의 제어 평면 작업자 |
| 이름 | 설명 |
|
| 고가용성 호스팅 제어 평면 리소스 요청을 기반으로 클러스터가 호스팅할 수 있는 호스팅 제어 평면의 최대 예상 수입니다. |
|
| 모든 호스팅 제어 평면이 클러스터 Kube API 서버에 약 50 QPS를 보내는 경우 클러스터가 호스팅할 수 있는 호스팅 제어 평면의 최대 추정 수입니다. |
|
| 모든 호스팅 제어 평면이 클러스터 Kube API 서버에 약 1000 QPS를 보내는 경우 클러스터가 호스팅할 수 있는 호스팅 제어 평면의 최대 추정 수입니다. |
|
| 모든 호스팅 제어 평면이 클러스터 Kube API 서버에 약 2000 QPS를 보내는 경우 클러스터가 호스팅할 수 있는 호스팅 제어 평면의 최대 추정 수는 얼마입니까? |
|
| 클러스터가 호스팅할 수 있는 호스팅 제어 평면의 최대 개수는 호스팅 제어 평면의 기존 평균 QPS를 기준으로 추정됩니다. 활성화된 호스팅 제어 평면이 없으면 QPS가 낮아질 수 있습니다. |
3.3. 리소스 활용도 측정 재정의
리소스 활용도에 대한 기준 측정 세트는 호스팅된 클러스터마다 다를 수 있습니다.
3.3.1. 호스팅된 클러스터에 대한 리소스 활용 측정 재정의
클러스터 작업 부하의 유형과 속도에 따라 리소스 활용도 측정을 재정의할 수 있습니다.
프로세스
다음 명령을 실행하여
ConfigMap리소스를 만듭니다.$ oc create -f <your-config-map-file.yaml><your-config-map-file.yaml>을hcp-sizing-baseline구성 맵이 포함된 YAML 파일 이름으로 바꾸세요.로컬 클러스터네임스페이스에hcp-sizing-baseline구성 맵을 만들어 재정의하려는 측정값을 지정합니다. 구성 맵은 다음 YAML 파일과 유사할 수 있습니다.kind: ConfigMap apiVersion: v1 metadata: name: hcp-sizing-baseline namespace: local-cluster data: incrementalCPUUsagePer1KQPS: "9.0" memoryRequestPerHCP: "18" minimumQPSPerHCP: "50.0"다음 명령을 실행하여
hypershift-addon-agent배포를 삭제하고hypershift-addon-agent포드를 다시 시작합니다.$ oc delete deployment hypershift-addon-agent \ -n open-cluster-management-agent-addon
검증
hypershift-addon-agentpod 로그를 관찰합니다. 다음 명령을 실행하여 재정의된 측정값이 구성 맵에서 업데이트되었는지 확인하세요.$ oc logs hypershift-addon-agent -n open-cluster-management-agent-addon로그는 다음과 같은 출력과 유사할 수 있습니다.
출력 예
2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:793 setting cpuRequestPerHCP to 5 2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:802 setting memoryRequestPerHCP to 18 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:141 The worker nodes have 12.000000 vCPUs 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:142 The worker nodes have 49.173369 GB memory재정의된 측정값이
hcp-sizing-baseline구성 맵에서 제대로 업데이트되지 않으면hypershift-addon-agent포드 로그에 다음과 같은 오류 메시지가 표시될 수 있습니다.오류 예시
2024-01-05T19:53:54.052Z ERROR agent.agent-reconciler agent/agent.go:788 failed to get configmap from the hub. Setting the HCP sizing baseline with default values. {"error": "configmaps \"hcp-sizing-baseline\" not found"}
3.3.2. 메트릭 서비스 모니터링 비활성화
hypershift-addon 관리형 클러스터 애드온을 활성화하면 기본적으로 메트릭 서비스 모니터링이 구성되어 OpenShift Container Platform 모니터링에서 hypershift-addon 에서 메트릭을 수집할 수 있습니다.
프로세스
다음 단계를 완료하여 메트릭 서비스 모니터링을 비활성화할 수 있습니다.
다음 명령을 실행하여 허브 클러스터에 로그인하세요.
$ oc login다음 명령을 실행하여
hypershift-addon-deploy-config애드온 배포 구성 사양을 편집합니다.$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine다음 예와 같이
disableMetrics=true사용자 정의 변수를 사양에 추가합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: disableMetrics1 value: "true"- 1
disableMetrics=true사용자 정의 변수는 새HyperShift-Addon 관리 클러스터 애드온과 기존 HyperShift-Addon관리 클러스터 애드온 모두에 대한 메트릭 서비스 모니터링을 비활성화합니다.
다음 명령을 실행하여 구성 사양에 변경 사항을 적용합니다.
$ oc apply -f <filename>.yaml
3.4. 호스팅된 제어 평면 명령줄 인터페이스 설치
호스팅된 제어 플레인 명령줄 인터페이스인 hcp 는 호스팅된 제어 플레인을 시작하는 데 사용할 수 있는 도구입니다. 관리 및 구성과 같은 2일차 작업에는 GitOps나 자체 자동화 도구를 사용하세요.
3.4.1. 터미널에서 호스팅된 제어 평면 명령줄 인터페이스 설치
터미널에서 호스팅된 제어 플레인 명령줄 인터페이스(CLI)인 hcp를 설치할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에서 Kubernetes Operator 2.5 이상용 멀티클러스터 엔진을 설치했습니다. 멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management를 설치하면 자동으로 설치됩니다. Red Hat Advanced Management 없이도 OpenShift Container Platform OperatorHub의 Operator로 멀티클러스터 엔진 Operator를 설치할 수 있습니다.
프로세스
다음 명령을 실행하여
hcp바이너리를 다운로드할 수 있는 URL을 얻으세요.$ oc get ConsoleCLIDownload hcp-cli-download -o json | jq -r ".spec"다음 명령을 실행하여
hcp바이너리를 다운로드하세요.$ wget <hcp_cli_download_url>1 - 1
hcp_cli_download_url을이전 단계에서 얻은 URL로 바꾸세요.
다음 명령을 실행하여 다운로드한 아카이브의 압축을 풉니다.
$ tar xvzf hcp.tar.gz다음 명령을 실행하여
hcp바이너리 파일을 실행 가능하게 만듭니다.$ chmod +x hcp다음 명령을 실행하여
hcp바이너리 파일을 경로의 디렉토리로 이동합니다.$ sudo mv hcp /usr/local/bin/.
Mac 컴퓨터에 CLI를 다운로드하면 hcp 바이너리 파일에 대한 경고가 표시될 수 있습니다. 바이너리 파일을 실행할 수 있도록 보안 설정을 조정해야 합니다.
검증
다음 명령을 실행하여 사용 가능한 매개변수 목록이 표시되는지 확인하세요.
$ hcp create cluster <platform> --help1 - 1
hcp create cluster명령을 사용하면 호스팅된 클러스터를 만들고 관리할 수 있습니다. 지원되는 플랫폼은aws,agent,kubevirt입니다.
3.4.2. 웹 콘솔을 사용하여 호스팅된 제어 평면 명령줄 인터페이스 설치
OpenShift Container Platform 웹 콘솔을 사용하여 호스팅된 제어 평면 명령줄 인터페이스(CLI)인 hcp를 설치할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에서 Kubernetes Operator 2.5 이상용 멀티클러스터 엔진을 설치했습니다. 멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management를 설치하면 자동으로 설치됩니다. Red Hat Advanced Management 없이도 OpenShift Container Platform OperatorHub의 Operator로 멀티클러스터 엔진 Operator를 설치할 수 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에서 도움말 아이콘 → 명령줄 도구를 클릭합니다.
- 플랫폼에 맞는 hcp CLI 다운로드를 클릭하세요.
다음 명령을 실행하여 다운로드한 아카이브의 압축을 풉니다.
$ tar xvzf hcp.tar.gz다음 명령을 실행하여 바이너리 파일을 실행 가능하게 만듭니다.
$ chmod +x hcp다음 명령을 실행하여 바이너리 파일을 경로에 있는 디렉토리로 이동합니다.
$ sudo mv hcp /usr/local/bin/.
Mac 컴퓨터에 CLI를 다운로드하면 hcp 바이너리 파일에 대한 경고가 표시될 수 있습니다. 바이너리 파일을 실행할 수 있도록 보안 설정을 조정해야 합니다.
검증
다음 명령을 실행하여 사용 가능한 매개변수 목록이 표시되는지 확인하세요.
$ hcp create cluster <platform> --help1 - 1
hcp create cluster명령을 사용하면 호스팅된 클러스터를 만들고 관리할 수 있습니다. 지원되는 플랫폼은aws,agent,kubevirt입니다.
3.4.3. 콘텐츠 게이트웨이를 사용하여 호스팅된 제어 평면 명령줄 인터페이스 설치
콘텐츠 게이트웨이를 사용하여 호스팅된 제어 평면 명령줄 인터페이스(CLI)인 hcp를 설치할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터에서 Kubernetes Operator 2.5 이상용 멀티클러스터 엔진을 설치했습니다. 멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management를 설치하면 자동으로 설치됩니다. Red Hat Advanced Management 없이도 OpenShift Container Platform OperatorHub의 Operator로 멀티클러스터 엔진 Operator를 설치할 수 있습니다.
프로세스
-
콘텐츠 게이트웨이 로 이동하여
hcp바이너리를 다운로드합니다. 다음 명령을 실행하여 다운로드한 아카이브의 압축을 풉니다.
$ tar xvzf hcp.tar.gz다음 명령을 실행하여
hcp바이너리 파일을 실행 가능하게 만듭니다.$ chmod +x hcp다음 명령을 실행하여
hcp바이너리 파일을 경로의 디렉토리로 이동합니다.$ sudo mv hcp /usr/local/bin/.
Mac 컴퓨터에 CLI를 다운로드하면 hcp 바이너리 파일에 대한 경고가 표시될 수 있습니다. 바이너리 파일을 실행할 수 있도록 보안 설정을 조정해야 합니다.
검증
다음 명령을 실행하여 사용 가능한 매개변수 목록이 표시되는지 확인하세요.
$ hcp create cluster <platform> --help1 - 1
hcp create cluster명령을 사용하면 호스팅된 클러스터를 만들고 관리할 수 있습니다. 지원되는 플랫폼은aws,agent,kubevirt입니다.
3.5. 호스팅된 클러스터 워크로드 분산
OpenShift Container Platform용 호스팅 제어 플레인을 시작하기 전에 노드에 적절한 레이블을 지정하여 호스팅된 클러스터의 포드를 인프라 노드에 예약할 수 있도록 해야 합니다. 노드 라벨링은 다음과 같은 이유로도 중요합니다.
-
높은 가용성과 적절한 작업 부하 배포를 보장합니다. 예를 들어, 제어 평면 워크로드가 OpenShift Container Platform 구독에 포함되지 않도록 하려면
node-role.kubernetes.io/infra레이블을 설정하면 됩니다. - 관리 클러스터의 다른 워크로드와 제어 평면 워크로드가 분리되도록 보장합니다.
배포에 맞게 제어 평면 워크로드가 올바른 다중 테넌시 배포 수준으로 구성되었는지 확인합니다. 분포 수준은 다음과 같습니다.
- 모든 것이 공유됨: 호스팅된 클러스터의 제어 평면은 제어 평면에 지정된 모든 노드에서 실행될 수 있습니다.
- 요청 제공 격리: 제공 포드는 자체 전용 노드에서 요청됩니다.
- 공유되는 것이 없습니다. 각 제어 평면에는 전용 노드가 있습니다.
단일 호스팅 클러스터에 노드를 전용하는 방법에 대한 자세한 내용은 "관리 클러스터 노드 레이블 지정"을 참조하세요.
작업 부하에 관리 클러스터를 사용하지 마세요. 작업 부하는 제어 평면이 실행되는 노드에서 실행되어서는 안 됩니다.
3.5.1. 레이블링 관리 클러스터 노드
호스팅된 제어 평면을 배포하려면 적절한 노드 레이블이 필요합니다.
관리 클러스터 관리자는 관리 클러스터 노드에서 다음 레이블과 테인을 사용하여 제어 평면 작업 부하를 예약합니다.
-
hypershift.openshift.io/control-plane: true: 이 레이블과 taint를 사용하여 호스팅된 제어 평면 워크로드를 실행하기 위한 노드를 전담합니다. 값을true로 설정하면 관리 클러스터의 인프라 구성 요소나 실수로 배포된 다른 작업 부하 등 다른 구성 요소와 제어 평면 노드를 공유하는 것을 방지할 수 있습니다. -
hypershift.openshift.io/cluster: ${HostedControlPlane Namespace}: 노드를 단일 호스팅 클러스터에 전용하려는 경우 이 레이블과 taint를 사용합니다.
제어 평면 Pod를 호스팅하는 노드에 다음 레이블을 적용합니다.
-
node-role.kubernetes.io/infra: 이 레이블을 사용하면 제어 평면 워크로드가 구독에 포함되지 않습니다. topology.kubernetes.io/zone: 이 레이블을 관리 클러스터 노드에서 사용하여 장애 도메인 전반에 고가용성 클러스터를 배포합니다. 영역은 영역이 설정된 노드의 위치, 랙 이름 또는 호스트 이름이 될 수 있습니다. 예를 들어, 관리 클러스터에는 다음과 같은 노드가 있습니다:worker-1a,worker-1b,worker-2a,worker-2b.worker-1a및worker-1b노드는rack1에 있고,worker-2a및 worker-2b 노드는rack2에 있습니다. 각 랙을 가용성 영역으로 사용하려면 다음 명령을 입력하세요.$ oc label node/worker-1a node/worker-1b topology.kubernetes.io/zone=rack1$ oc label node/worker-2a node/worker-2b topology.kubernetes.io/zone=rack2
호스팅된 클러스터의 Pod에는 허용 범위가 있으며, 스케줄러는 친화성 규칙을 사용하여 이를 스케줄링합니다. 포드는 제어 평면 과 포드의 클러스터 에 대한 오염을 허용합니다. 스케줄러는 hypershift.openshift.io/control-plane 및 hypershift.openshift.io/cluster: ${HostedControlPlane Namespace} 로 레이블이 지정된 노드에 Pod 예약에 우선순위를 지정합니다.
ControllerAvailabilityPolicy 옵션의 경우 호스팅된 컨트롤 플레인 명령줄 인터페이스인 hcp, deploy의 기본값인 HighlyAvailable 을 사용합니다. 이 옵션을 사용하면 topology.kubernetes.io/zone 을 토폴로지 키로 설정하여 다양한 장애 도메인에서 호스트된 클러스터 내에서 각 배포에 대한 Pod를 예약할 수 있습니다. 다른 장애 도메인에서 호스팅된 클러스터 내에서 배포에 대한 Pod 예약은 고가용성 컨트롤 플레인에만 사용할 수 있습니다.
프로세스
호스팅된 클러스터가 해당 Pod를 인프라 노드에 예약하도록 요구하려면 다음 예와 같이 HostedCluster.spec.nodeSelector를 설정합니다.
spec:
nodeSelector:
node-role.kubernetes.io/infra: ""이렇게 하면 각 호스팅 클러스터에 대한 호스팅된 제어 평면이 적격 인프라 노드 워크로드가 되고, 기본 OpenShift Container Platform 노드에 권한을 부여할 필요가 없습니다.
3.5.2. 우선 순위 수업
4개의 기본 제공 우선 순위 클래스는 호스팅된 클러스터 포드의 우선 순위와 선점에 영향을 미칩니다. 관리 클러스터에서 포드를 가장 높은 순서부터 가장 낮은 순서로 생성할 수 있습니다.
-
hypershift-operator: HyperShift Operator 포드. -
hypershift-etcd: etcd용 Pod. -
hypershift-api-critical: API 호출과 리소스 수용이 성공하는 데 필요한 Pod입니다. 이러한 포드에는kube-apiserver, 집계된 API 서버, 웹 후크와 같은 포드가 포함됩니다. -
hypershift-control-plane: API에 중요하지 않지만 클러스터 버전 Operator와 같이 높은 우선순위가 필요한 제어 평면의 Pod입니다.
3.5.3. 사용자 정의 오염 및 허용 범위
기본적으로 호스팅된 클러스터의 포드는 제어 평면 및 클러스터 오염을 허용합니다. 하지만 HostedCluster.spec.tolerations를 설정하여 호스트된 클러스터가 호스트된 클러스터별로 해당 오염을 허용하도록 노드에서 사용자 정의 오염을 사용할 수도 있습니다.
호스팅된 클러스터에 대한 허용 범위를 전달하는 것은 기술 미리 보기 기능에만 해당됩니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
설정 예
spec:
tolerations:
- effect: NoSchedule
key: kubernetes.io/custom
operator: Exists
--tolerations hcp CLI 인수를 사용하여 클러스터를 생성하는 동안 호스트된 클러스터에 허용 오차를 설정할 수도 있습니다.
CLI 인수 예
--toleration="key=kubernetes.io/custom,operator=Exists,effect=NoSchedule"
호스트별로 호스팅된 클러스터 Pod 배치를 세밀하게 제어하려면 nodeSelectors 와 함께 사용자 정의 허용 오차를 사용합니다. 호스트 클러스터 그룹을 공동 배치하고 다른 호스팅 클러스터에서 격리할 수 있습니다. 인프라 및 컨트롤 플레인 노드에 호스팅 클러스터를 배치할 수도 있습니다.
호스팅된 클러스터의 허용 오차는 컨트롤 플레인의 Pod에만 분배됩니다. 가상 머신을 실행하기 위해 pod와 같은 관리 클러스터 및 인프라 관련 Pod에서 실행되는 다른 Pod를 구성하려면 다른 프로세스를 사용해야 합니다.
3.5.4. 컨트롤 플레인 격리
호스트된 컨트롤 플레인을 구성하여 네트워크 트래픽 또는 컨트롤 플레인 Pod를 분리할 수 있습니다.
3.5.4.1. 네트워크 정책 격리
호스트된 각 컨트롤 플레인은 전용 Kubernetes 네임스페이스에서 실행되도록 할당됩니다. 기본적으로 Kubernetes 네임스페이스는 모든 네트워크 트래픽을 거부합니다.
다음 네트워크 트래픽은 Kubernetes CNI(Container Network Interface)에서 강제 적용하는 네트워크 정책을 통해 허용됩니다.
- 동일한 네임스페이스(Intra-tenant)의 수신 pod-to-pod 통신
-
테넌트의 호스트된
kube-apiserverPod에 포트 6443의 수신 -
network.openshift.io/policy-group: 모니터링 라벨을 사용하여 관리 클러스터 Kubernetes 네임스페이스의 메트릭 스크랩을 모니터링할 수 있습니다.
3.5.4.2. 컨트롤 플레인 Pod 격리
네트워크 정책 외에도 각 호스팅된 컨트롤 플레인 포드는 restricted 보안 컨텍스트 제약 조건을 사용하여 실행됩니다. 이 정책은 모든 호스트 기능에 대한 액세스를 거부하고 고객 컨트롤 플레인을 호스팅하는 각 네임스페이스에 고유하게 할당된 SELinux 컨텍스트를 사용하여 Pod를 UID로 실행해야 합니다.
이 정책은 다음 제약 조건을 확인합니다.
- Pod는 권한으로 실행할 수 없습니다.
- Pod는 호스트 디렉터리 볼륨을 마운트할 수 없습니다.
- Pod는 사전 할당된 UID 범위에서 사용자로 실행해야 합니다.
- Pod는 사전 할당된 MCS 라벨을 사용하여 실행해야 합니다.
- Pod는 호스트 네트워크 네임스페이스에 액세스할 수 없습니다.
- Pod는 호스트 네트워크 포트를 노출할 수 없습니다.
- Pod는 호스트 PID 네임스페이스에 액세스할 수 없습니다.
-
기본적으로 Pod는
KILL,MKNOD,SETUID및SETGID와 같은 Linux 기능을 삭제합니다.
각 관리 클러스터 작업자 노드에서 kubelet 및 crio 와 같은 관리 구성 요소는 호스팅된 컨트롤 플레인을 지원하는 Pod의 SELinux 컨텍스트에 액세스할 수 없는 SELinux 레이블로 보호됩니다.
다음 SELinux 레이블은 주요 프로세스 및 소켓에 사용됩니다.
-
kubelet:
system_u:system_r:unconfined_service_t:s0 -
crio:
system_u:system_r:container_runtime_t:s0 -
crio.sock:
system_u:object_r:container_var_run_t:s0 -
<example user container processes>:
system_u:system_r:container_t:s0:c14,c24
3.6. 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화
호스팅된 컨트롤 플레인 기능 및 hypershift-addon 관리 클러스터 애드온은 기본적으로 활성화되어 있습니다. 기능을 비활성화하거나 비활성화한 후 수동으로 활성화하려면 다음 절차를 참조하십시오.
3.6.1. 수동으로 호스트된 컨트롤 플레인 기능 활성화
호스팅된 컨트롤 플레인을 수동으로 활성화해야 하는 경우 다음 단계를 완료합니다.
프로세스
다음 명령을 실행하여 기능을 활성화합니다.
$ oc patch mce multiclusterengine --type=merge -p \ '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'1 - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
다음 명령을 실행하여
MultiClusterEngine사용자 정의 리소스에서hypershift및hypershift-local-hosting기능이 활성화되어 있는지 확인합니다.$ oc get mce multiclusterengine -o yaml1 - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
출력 예
apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: true - name: hypershift-local-hosting enabled: true
3.6.1.1. local-cluster의 하이퍼shift-addon 관리 클러스터 애드온 수동 활성화
호스팅된 컨트롤 플레인 기능을 활성화하면 하이퍼shift-addon 관리 클러스터 애드온이 자동으로 활성화됩니다. hypershift-addon 관리 클러스터 애드온을 수동으로 활성화해야 하는 경우 hypershift-addon 을 사용하여 local-cluster 에 HyperShift Operator를 설치하려면 다음 단계를 완료합니다.
프로세스
다음 예와 유사한 파일을 생성하여
hypershift-addon이라는ManagedClusterAddon애드온을 생성합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: hypershift-addon namespace: local-cluster spec: installNamespace: open-cluster-management-agent-addon다음 명령을 실행하여 파일을 적용합니다.
$ oc apply -f <filename>filename을 생성한 파일의 이름으로 바꿉니다.다음 명령을 실행하여
hypershift-addon관리 클러스터 애드온이 설치되었는지 확인합니다.$ oc get managedclusteraddons -n local-cluster hypershift-addon애드온이 설치된 경우 출력은 다음 예와 유사합니다.
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True
하이퍼shift-addon 관리 클러스터 애드온이 설치되어 있으며 호스팅 클러스터를 사용하여 호스팅 클러스터를 생성하고 관리할 수 있습니다.
3.6.2. 호스트된 컨트롤 플레인 기능 비활성화
HyperShift Operator를 설치 제거하고 호스팅된 컨트롤 플레인 기능을 비활성화할 수 있습니다. 호스팅된 컨트롤 플레인 기능을 비활성화할 때 호스트 클러스터 항목 관리에 설명된 대로 다중 클러스터 엔진 Operator에서 호스팅 클러스터 및 관리 클러스터 리소스를 제거해야 합니다.
3.6.2.1. HyperShift Operator 설치 제거
HyperShift Operator를 설치 제거하고 local-cluster 에서 hypershift-addon 을 비활성화하려면 다음 단계를 완료하십시오.
프로세스
다음 명령을 실행하여 호스트 클러스터가 실행되고 있지 않은지 확인합니다.
$ oc get hostedcluster -A중요호스트 클러스터가 실행 중인 경우
hypershift-addon이 비활성화된 경우에도 HyperShift Operator가 제거되지 않습니다.다음 명령을 실행하여
hypershift-addon을 비활성화합니다.$ oc patch mce multiclusterengine --type=merge -p \1 '{"spec":{"overrides":{"components":[{"name":"hypershift-local-hosting","enabled": false}]}}}'- 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
참고hypershift-addon을 비활성화한 후 다중 클러스터 엔진 Operator 콘솔에서local-cluster의hypershift-addon을 비활성화할 수도 있습니다.
3.6.2.2. 호스트된 컨트롤 플레인 기능 비활성화
호스팅된 컨트롤 플레인 기능을 비활성화하려면 다음 단계를 완료합니다.
사전 요구 사항
- HyperShift Operator를 설치 제거했습니다. 자세한 내용은 "HyperShift Operator 제거"를 참조하십시오.
프로세스
다음 명령을 실행하여 호스팅된 컨트롤 플레인 기능을 비활성화합니다.
$ oc patch mce multiclusterengine --type=merge -p \1 '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": false}]}}}'- 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
다음 명령을 실행하여
MultiClusterEngine사용자 지정 리소스에서hypershift및hypershift-local-hosting기능이 비활성화되었는지 확인할 수 있습니다.$ oc get mce multiclusterengine -o yaml1 - 1
- 기본
MultiClusterEngine리소스 인스턴스 이름은multiclusterengine이지만 다음 명령을 실행하여 클러스터에서MultiClusterEngine이름을 가져올 수 있습니다.$ oc get mce.
다음 예제에서는
hypershift와hypershift-local-hosting이활성화되어 있습니다.플래그가false로 설정되어 있습니다.apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: false - name: hypershift-local-hosting enabled: false
4장. 호스팅된 제어 평면 배포
4.1. AWS에 호스팅된 제어 평면 배포
호스팅 클러스터 는 관리 클러스터에 호스팅된 API 엔드포인트와 제어 평면을 갖춘 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다. 온프레미스에서 호스팅된 제어 평면을 구성하려면 관리 클러스터에 Kubernetes Operator용 멀티클러스터 엔진을 설치해야 합니다. hypershift-addon 관리형 클러스터 애드온을 사용하여 기존 관리형 클러스터에 HyperShift Operator를 배포하면 해당 클러스터를 관리 클러스터로 활성화하고 호스팅 클러스터를 만들 수 있습니다. Hypershift-addon 관리형 클러스터 추가 기능은 로컬 클러스터 관리형 클러스터에 대해 기본적으로 활성화됩니다.
멀티클러스터 엔진 운영자 콘솔이나 호스팅 제어 평면 명령줄 인터페이스(CLI)인 hcp 를 사용하여 호스팅 클러스터를 생성할 수 있습니다. 호스팅된 클러스터는 자동으로 관리형 클러스터로 가져옵니다. 하지만 멀티클러스터 엔진 Operator에 대한 이 자동 가져오기 기능을 비활성화 할 수 있습니다.
4.1.1. AWS에 호스팅된 제어 평면을 배포할 준비
Amazon Web Services(AWS)에 호스팅된 제어 평면을 배포할 준비를 할 때 다음 정보를 고려하세요.
- 호스팅된 각 클러스터에는 클러스터 전체에서 고유한 이름이 있어야 합니다. 멀티클러스터 엔진 운영자가 관리할 수 있도록 호스팅된 클러스터 이름은 기존 관리형 클러스터와 동일할 수 없습니다.
-
호스팅된 클러스터 이름으로
클러스터를사용하지 마세요. - 호스팅된 제어 평면에 대해 동일한 플랫폼에서 관리 클러스터와 작업자를 실행합니다.
- 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에는 호스팅된 클러스터를 만들 수 없습니다.
4.1.1.1. 관리 클러스터를 구성하기 위한 전제 조건
관리 클러스터를 구성하려면 다음과 같은 필수 구성 요소가 있어야 합니다.
- OpenShift Container Platform 클러스터에 Kubernetes Operator 2.5 이상용 멀티클러스터 엔진을 설치했습니다. 멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management(RHACM)를 설치하면 자동으로 설치됩니다. 멀티클러스터 엔진 Operator는 RHACM 없이도 OpenShift Container Platform OperatorHub의 Operator로 설치할 수 있습니다.
멀티클러스터 엔진 운영자를 위한 관리형 OpenShift Container Platform 클러스터가 하나 이상 있습니다.
로컬 클러스터는 멀티클러스터 엔진 Operator 버전 2.5 이상에 자동으로 가져옵니다. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.$ oc get managedclusters local-cluster-
aws명령줄 인터페이스(CLI)를 설치했습니다. -
호스팅된 제어 평면 CLI인
hcp를설치했습니다.
4.1.2. hcp CLI를 사용하여 AWS에서 호스팅된 클러스터에 액세스
hcp 명령줄 인터페이스(CLI)를 사용하여 kubeconfig 파일을 생성하면 호스팅된 클러스터에 액세스할 수 있습니다.
프로세스
다음 명령을 입력하여
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfig파일을 저장한 후 다음 명령을 입력하여 호스팅된 클러스터에 액세스할 수 있습니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
4.1.3. Amazon Web Services S3 버킷 및 S3 OIDC 비밀 생성
Amazon Web Services(AWS)에서 호스팅된 클러스터를 만들고 관리하려면 먼저 S3 버킷과 S3 OIDC 비밀을 만들어야 합니다.
프로세스
다음 명령을 실행하여 클러스터의 OIDC 검색 문서를 호스팅할 수 있는 공개 액세스 권한이 있는 S3 버킷을 만듭니다.
$ aws s3api create-bucket --bucket <bucket_name> \1 --create-bucket-configuration LocationConstraint=<region> \2 --region <region>3 $ aws s3api delete-public-access-block --bucket <bucket_name>1 - 1
<bucket_name>을생성하려는 S3 버킷의 이름으로 바꾸세요.
$ echo '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<bucket_name>/*"1 } ] }' | envsubst > policy.json- 1
<bucket_name>을생성하려는 S3 버킷의 이름으로 바꾸세요.
$ aws s3api put-bucket-policy --bucket <bucket_name> \1 --policy file://policy.json- 1
<bucket_name>을생성하려는 S3 버킷의 이름으로 바꾸세요.
참고Mac 컴퓨터를 사용하는 경우 정책이 작동하려면 버킷 이름을 내보내야 합니다.
-
HyperShift Operator에 대해
hypershift-operator-oidc-provider-s3-credentials라는 이름의 OIDC S3 비밀을 생성합니다. -
로컬 클러스터네임스페이스에 비밀을 저장합니다. 다음 표를 참조하여 비밀번호에 다음 필드가 포함되어 있는지 확인하세요.
Expand 표 4.1. AWS 비밀에 대한 필수 필드 필드 이름 설명 bucket호스팅된 클러스터의 OIDC 검색 문서를 호스팅할 수 있는 공개 액세스 권한이 있는 S3 버킷이 포함되어 있습니다.
credentials버킷에 액세스할 수 있는
기본프로필의 자격 증명이 포함된 파일에 대한 참조입니다. 기본적으로 HyperShift는기본프로필만 사용하여버킷을작동합니다.regionS3 버킷의 지역을 지정합니다.
AWS 비밀번호를 생성하려면 다음 명령을 실행하세요.
$ oc create secret generic <secret_name> \ --from-file=credentials=<path>/.aws/credentials \ --from-literal=bucket=<s3_bucket> \ --from-literal=region=<region> \ -n local-cluster참고비밀에 대한 재해 복구 백업이 자동으로 활성화되지 않습니다. 재해 복구를 위해
hypershift-operator-oidc-provider-s3-credentials비밀번호를 백업할 수 있는 레이블을 추가하려면 다음 명령을 실행하세요.$ oc label secret hypershift-operator-oidc-provider-s3-credentials \ -n local-cluster cluster.open-cluster-management.io/backup=true
4.1.4. 호스팅된 클러스터에 대한 라우팅 가능한 공용 영역 만들기
호스팅된 클러스터의 애플리케이션에 액세스하려면 라우팅 가능한 공개 영역을 구성해야 합니다. 공개 영역이 있는 경우 이 단계를 건너뜁니다. 그렇지 않으면 공공 구역은 기존 기능에 영향을 미칩니다.
프로세스
DNS 레코드에 대한 라우팅 가능한 공개 영역을 만들려면 다음 명령을 입력하세요.
$ aws route53 create-hosted-zone \ --name <basedomain> \1 --caller-reference $(whoami)-$(date --rfc-3339=date)- 1
<basedomain>을기본 도메인(예:www.example.com)으로 바꾸세요.
4.1.5. AWS IAM 역할 및 STS 자격 증명 생성
Amazon Web Services(AWS)에서 호스팅 클러스터를 생성하기 전에 AWS IAM 역할과 STS 자격 증명을 생성해야 합니다.
프로세스
다음 명령을 실행하여 사용자의 Amazon 리소스 이름(ARN)을 가져옵니다.
$ aws sts get-caller-identity --query "Arn" --output text출력 예
arn:aws:iam::1234567890:user/<aws_username>다음 단계에서 이 출력을
<arn>값으로 사용합니다.역할에 대한 신뢰 관계 구성을 포함하는 JSON 파일을 만듭니다. 다음 예제를 참조하십시오.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<arn>"1 }, "Action": "sts:AssumeRole" } ] }- 1
<arn>을이전 단계에서 기록한 사용자의 ARN으로 바꾸세요.
다음 명령을 실행하여 IAM(Identity and Access Management) 역할을 만듭니다.
$ aws iam create-role \ --role-name <name> \1 --assume-role-policy-document file://<file_name>.json \2 --query "Role.Arn"출력 예
arn:aws:iam::820196288204:role/myrole역할에 대한 다음 권한 정책이 포함된
policy.json이라는 JSON 파일을 만듭니다.{ "Version": "2012-10-17", "Statement": [ { "Sid": "EC2", "Effect": "Allow", "Action": [ "ec2:CreateDhcpOptions", "ec2:DeleteSubnet", "ec2:ReplaceRouteTableAssociation", "ec2:DescribeAddresses", "ec2:DescribeInstances", "ec2:DeleteVpcEndpoints", "ec2:CreateNatGateway", "ec2:CreateVpc", "ec2:DescribeDhcpOptions", "ec2:AttachInternetGateway", "ec2:DeleteVpcEndpointServiceConfigurations", "ec2:DeleteRouteTable", "ec2:AssociateRouteTable", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:CreateRoute", "ec2:CreateInternetGateway", "ec2:RevokeSecurityGroupEgress", "ec2:ModifyVpcAttribute", "ec2:DeleteInternetGateway", "ec2:DescribeVpcEndpointConnections", "ec2:RejectVpcEndpointConnections", "ec2:DescribeRouteTables", "ec2:ReleaseAddress", "ec2:AssociateDhcpOptions", "ec2:TerminateInstances", "ec2:CreateTags", "ec2:DeleteRoute", "ec2:CreateRouteTable", "ec2:DetachInternetGateway", "ec2:DescribeVpcEndpointServiceConfigurations", "ec2:DescribeNatGateways", "ec2:DisassociateRouteTable", "ec2:AllocateAddress", "ec2:DescribeSecurityGroups", "ec2:RevokeSecurityGroupIngress", "ec2:CreateVpcEndpoint", "ec2:DescribeVpcs", "ec2:DeleteSecurityGroup", "ec2:DeleteDhcpOptions", "ec2:DeleteNatGateway", "ec2:DescribeVpcEndpoints", "ec2:DeleteVpc", "ec2:CreateSubnet", "ec2:DescribeSubnets" ], "Resource": "*" }, { "Sid": "ELB", "Effect": "Allow", "Action": [ "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DeleteTargetGroup" ], "Resource": "*" }, { "Sid": "IAMPassRole", "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:*:iam::*:role/*-worker-role", "Condition": { "ForAnyValue:StringEqualsIfExists": { "iam:PassedToService": "ec2.amazonaws.com" } } }, { "Sid": "IAM", "Effect": "Allow", "Action": [ "iam:CreateInstanceProfile", "iam:DeleteInstanceProfile", "iam:GetRole", "iam:UpdateAssumeRolePolicy", "iam:GetInstanceProfile", "iam:TagRole", "iam:RemoveRoleFromInstanceProfile", "iam:CreateRole", "iam:DeleteRole", "iam:PutRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateOpenIDConnectProvider", "iam:ListOpenIDConnectProviders", "iam:DeleteRolePolicy", "iam:UpdateRole", "iam:DeleteOpenIDConnectProvider", "iam:GetRolePolicy" ], "Resource": "*" }, { "Sid": "Route53", "Effect": "Allow", "Action": [ "route53:ListHostedZonesByVPC", "route53:CreateHostedZone", "route53:ListHostedZones", "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets", "route53:DeleteHostedZone", "route53:AssociateVPCWithHostedZone", "route53:ListHostedZonesByName" ], "Resource": "*" }, { "Sid": "S3", "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets", "s3:ListBucket", "s3:DeleteObject", "s3:DeleteBucket" ], "Resource": "*" } ] }다음 명령을 실행하여
policy.json파일을 역할에 첨부합니다.$ aws iam put-role-policy \ --role-name <role_name> \1 --policy-name <policy_name> \2 --policy-document file://policy.json3 다음 명령을 실행하여
sts-creds.json이라는 JSON 파일에서 STS 자격 증명을 검색합니다.$ aws sts get-session-token --output json > sts-creds.jsonsts-creds.json파일 예시{ "Credentials": { "AccessKeyId": "<access_key_id", "SecretAccessKey": "<secret_access_key>”, "SessionToken": "<session_token>", "Expiration": "<time_stamp>" } }
4.1.6. 호스팅된 제어 평면에 AWS PrivateLink 활성화
PrivateLink를 사용하여 Amazon Web Services(AWS)에서 호스팅된 제어 평면을 프로비저닝하려면 호스팅된 제어 평면에 대해 AWS PrivateLink를 활성화합니다.
프로세스
-
HyperShift Operator에 대한 AWS 자격 증명 비밀번호를 만들고 이름을
hypershift-operator-private-link-credentials로 지정합니다. 비밀은 관리 클러스터로 사용되는 관리 클러스터의 네임스페이스인 관리 클러스터 네임스페이스에 있어야 합니다.local-cluster를사용한 경우local-cluster네임스페이스에 비밀을 생성합니다. - 다음 표를 참조하여 비밀번호에 필수 필드가 포함되어 있는지 확인하세요.
| 필드 이름 | 설명 | 선택사항 또는 필수사항 |
|---|---|---|
|
| Private Link를 사용할 수 있는 지역 | 필수 항목 |
|
| 자격 증명 액세스 키 ID입니다. | 필수 항목 |
|
| 자격 증명 액세스 키 비밀번호입니다. | 필수 항목 |
AWS 비밀번호를 생성하려면 다음 명령을 실행하세요.
$ oc create secret generic <secret_name> \
--from-literal=aws-access-key-id=<aws_access_key_id> \
--from-literal=aws-secret-access-key=<aws_secret_access_key> \
--from-literal=region=<region> -n local-cluster
비밀에 대한 재해 복구 백업이 자동으로 활성화되지 않습니다. 다음 명령을 실행하여 재해 복구를 위해 hypershift-operator-private-link-credentials 비밀번호를 백업할 수 있는 레이블을 추가합니다.
$ oc label secret hypershift-operator-private-link-credentials \
-n local-cluster \
cluster.open-cluster-management.io/backup=""4.1.7. AWS에서 호스팅되는 제어 평면에 대한 외부 DNS 활성화
호스팅된 제어 평면에서는 제어 평면과 데이터 평면이 분리됩니다. 두 개의 독립적인 영역에서 DNS를 구성할 수 있습니다.
-
*.apps.service-consumer-domain.com과 같은 호스팅된 클러스터 내의 워크로드에 대한 수신. -
서비스 공급자 도메인을 통한 API 또는 OAuth 엔드포인트와 같은 관리 클러스터 내의 서비스 엔드포인트에 대한 수신:
*.service-provider-domain.com.
hostedCluster.spec.dns 에 대한 입력은 호스팅 클러스터 내의 워크로드에 대한 수신을 관리합니다. hostedCluster.spec.services.servicePublishingStrategy.route.hostname 에 대한 입력은 관리 클러스터 내의 서비스 엔드포인트에 대한 수신을 관리합니다.
외부 DNS는 LoadBalancer 또는 Route 의 게시 유형을 지정하고 해당 게시 유형에 대한 호스트 이름을 제공하는 호스팅된 클러스터 서비스 에 대한 이름 레코드를 생성합니다. Private 또는 PublicAndPrivate 엔드포인트 액세스 유형이 있는 호스팅 클러스터의 경우 APIServer 및 OAuth 서비스만 호스트 이름을 지원합니다. 개인 호스팅 클러스터의 경우 DNS 레코드는 VPC의 Virtual Private Cloud(VPC) 엔드포인트의 개인 IP 주소로 확인됩니다.
호스팅된 제어 평면은 다음 서비스를 제공합니다.
-
APIServer -
OIDC
HostedCluster 사양의 servicePublishingStrategy 필드를 사용하여 이러한 서비스를 노출할 수 있습니다. 기본적으로 servicePublishingStrategy 의 LoadBalancer 및 Route 유형의 경우 다음 방법 중 하나로 서비스를 게시할 수 있습니다.
-
LoadBalancer유형의서비스상태에 있는 로드 밸런서의 호스트 이름을 사용합니다. -
Route리소스의status.host필드를 사용합니다.
그러나 관리형 서비스 컨텍스트에서 호스팅된 제어 평면을 배포하는 경우 해당 방법은 기본 관리 클러스터의 수신 하위 도메인을 노출하고 관리 클러스터 수명 주기 및 재해 복구에 대한 옵션을 제한할 수 있습니다.
DNS 간접 설정이 LoadBalancer 및 경로 게시 유형에 적용되는 경우 관리 서비스 운영자는 서비스 수준 도메인을 사용하여 모든 공용 호스팅 클러스터 서비스를 게시할 수 있습니다. 이 아키텍처를 사용하면 DNS 이름을 새로운 LoadBalancer 또는 경로 로 다시 매핑할 수 있으며 관리 클러스터의 수신 도메인을 노출하지 않습니다. 호스팅된 제어 평면은 외부 DNS를 사용하여 간접 계층을 구현합니다.
관리 클러스터의 HyperShift 네임스페이스에서 HyperShift Operator와 함께 external-dns를 배포할 수 있습니다. 외부 DNS는 external-dns.alpha.kubernetes.io/hostname 주석이 있는 서비스 나 경로 를 감시합니다. 해당 주석은 A 레코드와 같은 Service 를 가리키는 DNS 레코드나 CNAME 레코드와 같은 Route를 가리키는 DNS 레코드를 만드는 데 사용됩니다.
외부 DNS는 클라우드 환경에서만 사용할 수 있습니다. 다른 환경에서는 DNS 및 서비스를 수동으로 구성해야 합니다.
외부 DNS에 대한 자세한 내용은 외부 DNS를 참조하세요.
4.1.7.1. 사전 요구 사항
Amazon Web Services(AWS)에서 호스팅된 제어 평면에 대한 외부 DNS를 설정하려면 먼저 다음 필수 구성 요소를 충족해야 합니다.
- 외부 공개 도메인을 생성했습니다.
- AWS Route53 관리 콘솔에 액세스할 수 있습니다.
- 호스팅된 제어 평면에 대해 AWS PrivateLink를 활성화했습니다.
4.1.7.2. 호스팅된 제어 평면에 대한 외부 DNS 설정
외부 DNS 또는 서비스 수준 DNS를 사용하여 호스팅된 제어 평면을 프로비저닝할 수 있습니다.
-
HyperShift Operator에 대한 Amazon Web Services(AWS) 자격 증명 비밀을 만들고
로컬 클러스터 네임스페이스에hypershift-operator-external-dns-credentials라는이름을 지정합니다. 다음 표를 참조하여 비밀번호에 필수 필드가 있는지 확인하세요.
Expand 표 4.3. AWS 비밀에 대한 필수 필드 필드 이름 설명 선택사항 또는 필수사항 provider서비스 수준 DNS 영역을 관리하는 DNS 공급자입니다.
필수 항목
domain-filter서비스 수준 도메인.
필수 항목
credentials모든 외부 DNS 유형을 지원하는 자격 증명 파일입니다.
AWS 키를 사용하는 경우 선택 사항
aws-access-key-id자격 증명 액세스 키 ID입니다.
AWS DNS 서비스를 사용하는 경우 선택 사항
aws-secret-access-key자격 증명 액세스 키 비밀번호입니다.
AWS DNS 서비스를 사용하는 경우 선택 사항
AWS 비밀번호를 생성하려면 다음 명령을 실행하세요.
$ oc create secret generic <secret_name> \ --from-literal=provider=aws \ --from-literal=domain-filter=<domain_name> \ --from-file=credentials=<path_to_aws_credentials_file> -n local-cluster참고비밀에 대한 재해 복구 백업이 자동으로 활성화되지 않습니다. 재해 복구를 위해 비밀번호를 백업하려면 다음 명령을 입력하여
hypershift-operator-external-dns-credentials를추가합니다.$ oc label secret hypershift-operator-external-dns-credentials \ -n local-cluster \ cluster.open-cluster-management.io/backup=""
4.1.7.3. 공개 DNS 호스팅 영역 생성
외부 DNS 운영자는 공개 DNS 호스팅 영역을 사용하여 공개 호스팅 클러스터를 생성합니다.
외부 DNS 도메인 필터로 사용할 공개 DNS 호스팅 영역을 만들 수 있습니다. AWS Route 53 관리 콘솔에서 다음 단계를 완료하세요.
프로세스
- Route 53 관리 콘솔에서 호스팅 영역 만들기를 클릭합니다.
- 호스팅 영역 구성 페이지에서 도메인 이름을 입력하고 유형으로 공용 호스팅 영역이 선택되어 있는지 확인한 다음 호스팅 영역 만들기를 클릭합니다.
- 영역이 생성된 후, 레코드 탭에서 값/경로 트래픽 열의 값을 기록해 둡니다.
- 기본 도메인에서 DNS 요청을 위임된 영역으로 리디렉션하기 위해 NS 레코드를 만듭니다. 값 필드에 이전 단계에서 기록한 값을 입력합니다.
- 레코드 만들기를 클릭합니다.
다음 예와 같이 새 하위 영역에 테스트 항목을 만들고
dig명령으로 테스트하여 DNS 호스팅 영역이 작동하는지 확인합니다.$ dig +short test.user-dest-public.aws.kerberos.com출력 예
192.168.1.1LoadBalancer및Route서비스에 대한 호스트 이름을 설정하는 호스팅 클러스터를 만들려면 다음 명령을 입력하세요.$ hcp create cluster aws --name=<hosted_cluster_name> \ --endpoint-access=PublicAndPrivate \ --external-dns-domain=<public_hosted_zone> ...1 - 1
<public_hosted_zone>을사용자가 만든 공개 호스팅 영역으로 바꾸세요.
호스팅 클러스터에 대한
서비스블록 예platform: aws: endpointAccess: PublicAndPrivate ... services: - service: APIServer servicePublishingStrategy: route: hostname: api-example.service-provider-domain.com type: Route - service: OAuthServer servicePublishingStrategy: route: hostname: oauth-example.service-provider-domain.com type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: Ignition servicePublishingStrategy: type: Route
제어 평면 운영자는 서비스 및 경로 리소스를 생성하고 여기에 external-dns.alpha.kubernetes.io/hostname 주석을 추가합니다. 서비스 및 경로 의 경우, 제어 평면 운영자는 서비스 엔드포인트에 대한 servicePublishingStrategy 필드의 호스트 이름 매개변수 값을 사용합니다. DNS 레코드를 생성하려면 외부 DNS 배포와 같은 메커니즘을 사용할 수 있습니다.
공개 서비스에 대해서만 서비스 수준 DNS 간접 설정을 구성할 수 있습니다. 개인 서비스는 hypershift.local 개인 영역을 사용하기 때문에 호스트 이름을 설정할 수 없습니다.
다음 표는 서비스와 엔드포인트 조합에 대한 호스트 이름을 설정하는 것이 유효한 경우를 보여줍니다.
| 서비스 | 퍼블릭 | PublicAndPrivate | 프라이빗 |
|---|---|---|---|
|
| Y | Y | N |
|
| Y | Y | N |
|
| Y | N | N |
|
| Y | N | N |
4.1.7.4. AWS의 외부 DNS를 사용하여 호스팅 클러스터 만들기
Amazon Web Services(AWS)에서 PublicAndPrivate 또는 Public 게시 전략을 사용하여 호스팅 클러스터를 생성하려면 관리 클러스터에 다음 아티팩트를 구성해야 합니다.
- 공개 DNS 호스팅 영역
- 외부 DNS 운영자
- HyperShift 연산자
hcp 명령줄 인터페이스(CLI)를 사용하여 호스팅된 클러스터를 배포할 수 있습니다.
프로세스
관리 클러스터에 액세스하려면 다음 명령을 입력하세요.
$ export KUBECONFIG=<path_to_management_cluster_kubeconfig>다음 명령을 입력하여 외부 DNS 운영자가 실행 중인지 확인하세요.
$ oc get pod -n hypershift -lapp=external-dns출력 예
NAME READY STATUS RESTARTS AGE external-dns-7c89788c69-rn8gp 1/1 Running 0 40s외부 DNS를 사용하여 호스팅 클러스터를 생성하려면 다음 명령을 입력하세요.
$ hcp create cluster aws \ --role-arn <arn_role> \1 --instance-type <instance_type> \2 --region <region> \3 --auto-repair \ --generate-ssh \ --name <hosted_cluster_name> \4 --namespace clusters \ --base-domain <service_consumer_domain> \5 --node-pool-replicas <node_replica_count> \6 --pull-secret <path_to_your_pull_secret> \7 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --external-dns-domain=<service_provider_domain> \9 --endpoint-access=PublicAndPrivate10 --sts-creds <path_to_sts_credential_file>11 - 1
- Amazon 리소스 이름(ARN)을 지정합니다(예:
arn:aws:iam::820196288204:role/myrole). - 2
- 인스턴스 유형을 지정합니다(예:
m6i.xlarge). - 3
- AWS 지역을 지정합니다(예:
us-east-1). - 4
- 호스팅된 클러스터 이름을 지정합니다(예:
my-external-aws ). - 5
- 서비스 소비자가 소유한 공개 호스팅 영역을 지정합니다(예:
service-consumer-domain.com). - 6
- 노드 복제본 수를 지정합니다(예:
2). - 7
- 풀 시크릿 파일의 경로를 지정하세요.
- 8
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.19.0-multi). - 9
- 서비스 제공자가 소유한 공개 호스팅 영역(예:
service-provider-domain.com)을 지정합니다. - 10
PublicAndPrivate로 설정합니다.공개또는PublicAndPrivate구성에서만 외부 DNS를 사용할 수 있습니다.- 11
- AWS STS 자격 증명 파일의 경로를 지정합니다(예:
/home/user/sts-creds/sts-creds.json).
4.1.7.5. 사용자 정의 DNS 이름 정의
클러스터 관리자는 노드 부트스트랩 및 제어 평면 통신에 사용되는 내부 엔드포인트와 다른 외부 API DNS 이름을 사용하여 호스팅된 클러스터를 만들 수 있습니다. 다음과 같은 이유로 다른 DNS 이름을 정의할 수 있습니다.
- 내부 루트 CA에 바인딩되는 제어 평면 기능을 손상시키지 않고 사용자 대상 TLS 인증서를 공개 CA의 인증서로 교체합니다.
- 분할 수평 DNS 및 NAT 시나리오를 지원합니다.
-
올바른
kubeconfig및 DNS 구성을 사용하면Show Login Command기능과 같은 기능을 사용할 수 있는 독립 실행형 제어 평면과 유사한 환경을 보장할 수 있습니다.
HostedCluster 개체의 kubeAPIServerDNSName 매개변수에 도메인 이름을 입력하여 초기 설정 중이나 설치 후 작업 중에 DNS 이름을 정의할 수 있습니다.
사전 요구 사항
-
kubeAPIServerDNSName매개변수에 설정한 DNS 이름을 포함하는 유효한 TLS 인증서가 있습니다. - 올바른 주소에 도달하고 이를 가리킬 수 있는 확인 가능한 DNS 이름 URI가 있습니다.
프로세스
HostedCluster개체에 대한 사양에서kubeAPIServerDNSName매개변수와 도메인 주소를 추가하고 다음 예와 같이 사용할 인증서를 지정합니다.#... spec: configuration: apiServer: servingCerts: namedCertificates: - names: - xxx.example.com - yyy.example.com servingCertificate: name: <my_serving_certificate> kubeAPIServerDNSName: <custom_address>1 - 1
kubeAPIServerDNSName매개변수의 값은 유효하고 주소 지정이 가능한 도메인이어야 합니다.
kubeAPIServerDNSName 매개변수를 정의하고 인증서를 지정하면 Control Plane Operator 컨트롤러가 custom-admin-kubeconfig 라는 kubeconfig 파일을 생성하고, 이 파일은 HostedControlPlane 네임스페이스에 저장됩니다. 인증서 생성은 루트 CA에서 이루어지며, HostedControlPlane 네임스페이스는 인증서의 만료 및 갱신을 관리합니다.
Control Plane Operator는 HostedControlPlane 네임스페이스에 CustomKubeconfig 라는 새로운 kubeconfig 파일을 보고합니다. 해당 파일은 kubeAPIServerDNSName 매개변수에 정의된 새 서버를 사용합니다.
사용자 정의 kubeconfig 파일에 대한 참조는 HostedCluster 개체의 CustomKubeconfig 라는 상태 매개변수에 있습니다. CustomKubeConfig 매개변수는 선택 사항이며, kubeAPIServerDNSName 매개변수가 비어 있지 않은 경우에만 매개변수를 추가할 수 있습니다. CustomKubeConfig 매개변수를 설정하면 해당 매개변수는 HostedCluster 네임스페이스에 <hosted_cluster_name>-custom-admin-kubeconfig 라는 이름의 비밀을 생성합니다. 이 비밀을 사용하여 HostedCluster API 서버에 액세스할 수 있습니다. 설치 후 작업 중에 CustomKubeConfig 매개변수를 제거하면 관련된 모든 비밀과 상태 참조가 삭제됩니다.
사용자 지정 DNS 이름을 정의해도 데이터 플레인에 직접적인 영향을 미치지 않으므로 예상 롤아웃이 발생하지 않습니다. HostedControlPlane 네임스페이스는 HyperShift Operator로부터 변경 사항을 수신하고 해당 매개변수를 삭제합니다.
HostedCluster 개체의 사양에서 kubeAPIServerDNSName 매개변수를 제거하면 새로 생성된 모든 비밀과 CustomKubeconfig 참조가 클러스터와 status 매개변수에서 제거됩니다.
4.1.8. AWS에서 호스팅 클러스터 생성
hcp 명령줄 인터페이스(CLI)를 사용하여 Amazon Web Services(AWS)에서 호스팅 클러스터를 만들 수 있습니다.
기본적으로 Amazon Web Services(AWS)의 호스팅 제어 평면에서는 AMD64 호스팅 클러스터를 사용합니다. 하지만 호스팅된 제어 평면을 ARM64 호스팅 클러스터에서 실행하도록 설정할 수 있습니다. 자세한 내용은 "ARM64 아키텍처에서 호스팅된 클러스터 실행"을 참조하세요.
노드 풀과 호스팅 클러스터의 호환 조합은 다음 표를 참조하세요.
| 호스트된 클러스터 | 노드 풀 |
|---|---|
| AMD64 | AMD64 또는 ARM64 |
| ARM64 | ARM64 또는 AMD64 |
사전 요구 사항
-
호스팅된 제어 평면 CLI인
hcp를설정했습니다. -
로컬 클러스터관리 클러스터를 관리 클러스터로 활성화했습니다. - AWS Identity and Access Management(IAM) 역할과 AWS Security Token Service(STS) 자격 증명을 생성했습니다.
프로세스
AWS에서 호스팅 클러스터를 만들려면 다음 명령을 실행하세요.
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --base-domain <basedomain> \3 --sts-creds <path_to_sts_credential_file> \4 --pull-secret <path_to_pull_secret> \5 --region <region> \6 --generate-ssh \ --node-pool-replicas <node_pool_replica_count> \7 --namespace <hosted_cluster_namespace> \8 --role-arn <role_name> \9 --render-into <file_name>.yaml10 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 인프라 이름을 지정하세요.
<hosted_cluster_name>과<infra_id>에 동일한 값을 제공해야 합니다. 그렇지 않으면 클러스터가 Kubernetes Operator 콘솔의 멀티클러스터 엔진에 올바르게 나타나지 않을 수 있습니다. - 3
- 기본 도메인을 지정하세요(예:
example.com). - 4
- AWS STS 자격 증명 파일의 경로를 지정합니다(예:
/home/user/sts-creds/sts-creds.json). - 5
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 6
- AWS 지역 이름을 지정합니다(예:
us-east-1). - 7
- 노드 풀 복제본 수를 지정합니다(예:
3). - 8
- 기본적으로 모든
HostedCluster및NodePool사용자 정의 리소스는클러스터네임스페이스에 생성됩니다.--namespace <네임스페이스>매개변수를 사용하면 특정 네임스페이스에HostedCluster및NodePool사용자 정의 리소스를 만들 수 있습니다. - 9
- Amazon 리소스 이름(ARN)을 지정합니다(예:
arn:aws:iam::820196288204:role/myrole). - 10
- EC2 인스턴스가 공유 또는 단일 테넌트 하드웨어에서 실행되는지 여부를 표시하려면 이 필드를 포함합니다.
--render-into플래그는 이 필드에 지정한 YAML 파일에 Kubernetes 리소스를 렌더링합니다. 그런 다음 다음 단계로 진행하여 YAML 파일을 편집합니다.
이전 명령에
--render-into플래그를 포함한 경우 지정된 YAML 파일을 편집합니다. 다음 예와 유사하게 EC2 인스턴스를 공유 또는 단일 테넌트 하드웨어에서 실행해야 하는지 여부를 나타내기 위해 YAML 파일에서NodePool사양을 편집합니다.YAML 파일 예시
apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <nodepool_name>1 spec: platform: aws: placement: tenancy: "default"2
검증
호스팅된 클러스터의 상태를 확인하여
AVAILABLE값이True인지 확인하세요. 다음 명령을 실행합니다.$ oc get hostedclusters -n <hosted_cluster_namespace>다음 명령을 실행하여 노드 풀 목록을 가져옵니다.
$ oc get nodepools --namespace <hosted_cluster_namespace>
4.1.8.1. AWS에서 호스팅된 클러스터에 액세스
리소스에서 직접 kubeconfig 파일과 kubeadmin 자격 증명을 가져와서 호스팅된 클러스터에 액세스할 수 있습니다.
호스팅된 클러스터의 액세스 비밀을 알고 있어야 합니다. 호스팅 클러스터 네임스페이스에는 호스팅 클러스터 리소스가 포함되고, 호스팅 제어 플레인 네임스페이스는 호스팅 제어 플레인이 실행되는 곳입니다. 비밀 이름 형식은 다음과 같습니다.
-
kubeconfig비밀:<호스트 클러스터 네임스페이스>-<이름>-admin-kubeconfig. 예를 들어,clusters-hypershift-demo-admin-kubeconfig. -
kubeadmin비밀번호:<hosted-cluster-namespace>-<name>-kubeadmin-password. 예를 들어,clusters-hypershift-demo-kubeadmin-password.
프로세스
kubeconfig비밀에는 Base64로 인코딩된kubeconfig필드가 포함되어 있으며, 이를 디코딩하여 다음 명령으로 파일에 저장하여 사용할 수 있습니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodeskubeadmin비밀번호도 Base64로 인코딩되었습니다. 이를 디코딩하고 비밀번호를 사용하여 호스팅된 클러스터의 API 서버나 콘솔에 로그인할 수 있습니다.
4.1.8.2. kubeadmin 자격 증명을 사용하여 AWS에서 호스팅된 클러스터에 액세스
Amazon Web Services(AWS)에서 호스팅 클러스터를 생성한 후에는 kubeconfig 파일, 액세스 비밀, kubeadmin 자격 증명을 가져와서 호스팅 클러스터에 액세스할 수 있습니다.
호스팅된 클러스터 네임스페이스에는 호스팅된 클러스터 리소스와 액세스 비밀이 포함되어 있습니다. 호스팅된 제어 평면은 호스팅된 제어 평면 네임스페이스에서 실행됩니다.
비밀 이름 형식은 다음과 같습니다.
-
kubeconfig비밀:<hosted_cluster_namespace>-<name>-admin-kubeconfig. 예를 들어,clusters-hypershift-demo-admin-kubeconfig. -
kubeadmin비밀번호:<hosted_cluster_namespace>-<name>-kubeadmin-password. 예를 들어,clusters-hypershift-demo-kubeadmin-password.
kubeadmin 비밀번호 비밀은 Base64로 인코딩되어 있고 kubeconfig 비밀에는 Base64로 인코딩된 kubeconfig 구성이 포함되어 있습니다. Base64로 인코딩된 kubeconfig 구성을 디코딩하여 <hosted_cluster_name>.kubeconfig 파일에 저장해야 합니다.
프로세스
디코딩된
kubeconfig구성이 포함된<hosted_cluster_name>.kubeconfig파일을 사용하여 호스팅 클러스터에 액세스합니다. 다음 명령을 실행합니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodesAPI 서버나 호스팅된 클러스터의 콘솔에 로그인하려면
kubeadmin비밀번호 시크릿을 디코딩해야 합니다.
4.1.8.3. hcp CLI를 사용하여 AWS에서 호스팅된 클러스터에 액세스
hcp 명령줄 인터페이스(CLI)를 사용하여 호스팅된 클러스터에 액세스할 수 있습니다.
프로세스
다음 명령을 입력하여
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfig파일을 저장한 후 다음 명령을 입력하여 호스팅된 클러스터에 액세스합니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
4.1.9. 호스팅된 클러스터에서 사용자 정의 API 서버 인증서 구성
API 서버에 대한 사용자 정의 인증서를 구성하려면 HostedCluster 구성의 spec.configuration.apiServer 섹션에서 인증서 세부 정보를 지정하세요.
1일차 또는 2일차 작업 중에 사용자 정의 인증서를 구성할 수 있습니다. 그러나 서비스 게시 전략은 호스팅 클러스터를 생성하는 동안 설정한 후에는 변경할 수 없으므로 구성하려는 Kubernetes API 서버의 호스트 이름을 알아야 합니다.
사전 요구 사항
관리 클러스터에 사용자 정의 인증서가 포함된 Kubernetes 비밀을 생성했습니다. 비밀에는 다음과 같은 키가 포함되어 있습니다.
-
tls.crt: 인증서 -
tls.key: 개인 키
-
-
HostedCluster구성에 부하 분산 장치를 사용하는 서비스 게시 전략이 포함된 경우 인증서의 SAN(주체 대체 이름)이 내부 API 엔드포인트(api-int)와 충돌하지 않는지 확인하세요. 내부 API 엔드포인트는 플랫폼에서 자동으로 생성되고 관리됩니다. 사용자 정의 인증서와 내부 API 엔드포인트 모두에서 동일한 호스트 이름을 사용하면 라우팅 충돌이 발생할 수 있습니다. 이 규칙의 유일한 예외는 AWS를Private또는PublicAndPrivate구성으로 공급자로 사용하는 경우입니다. 이런 경우 SAN 충돌은 플랫폼에 의해 관리됩니다. - 인증서는 외부 API 엔드포인트에 대해 유효해야 합니다.
- 인증서의 유효 기간은 클러스터의 예상 수명 주기와 일치합니다.
프로세스
다음 명령을 입력하여 사용자 지정 인증서로 비밀을 만듭니다.
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>다음 예와 같이 사용자 지정 인증서 세부 정보로
HostedCluster구성을 업데이트합니다.spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert다음 명령을 입력하여
HostedCluster구성에 변경 사항을 적용합니다.$ oc apply -f <hosted_cluster_config>.yaml
검증
- API 서버 포드를 확인하여 새 인증서가 마운트되었는지 확인하세요.
- 사용자 지정 도메인 이름을 사용하여 API 서버에 대한 연결을 테스트합니다.
-
브라우저나
openssl과 같은 도구를 사용하여 인증서 세부 정보를 확인하세요.
4.1.10. AWS의 여러 영역에 호스팅 클러스터 생성
hcp 명령줄 인터페이스(CLI)를 사용하여 Amazon Web Services(AWS)의 여러 영역에 호스팅된 클러스터를 만들 수 있습니다.
사전 요구 사항
- AWS Identity and Access Management(IAM) 역할과 AWS Security Token Service(STS) 자격 증명을 생성했습니다.
프로세스
다음 명령을 실행하여 AWS의 여러 영역에 호스팅된 클러스터를 만듭니다.
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas=<node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --role-arn <arn_role> \5 --region <region> \6 --zones <zones> \7 --sts-creds <path_to_sts_credential_file>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 노드 풀 복제본 수를 지정합니다(예:
2). - 3
- 기본 도메인을 지정하세요(예:
example.com). - 4
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 5
- Amazon 리소스 이름(ARN)을 지정합니다(예:
arn:aws:iam::820196288204:role/myrole). - 6
- AWS 지역 이름을 지정합니다(예:
us-east-1). - 7
- AWS 지역 내에서 가용성 영역을 지정합니다(예:
us-east-1a및us-east-1b). - 8
- AWS STS 자격 증명 파일의 경로를 지정합니다(예:
/home/user/sts-creds/sts-creds.json).
지정된 각 구역에 대해 다음과 같은 인프라가 생성됩니다.
- 퍼블릭 서브넷
- 프라이빗 서브넷
- NAT 게이트웨이
- 개인 경로 테이블
공개 경로 테이블은 공개 서브넷에서 공유됩니다.
각 영역에 대해 하나의 NodePool 리소스가 생성됩니다. 노드 풀 이름 뒤에는 영역 이름이 붙습니다. zone의 개인 서브넷은 spec.platform.aws.subnet.id 에 설정됩니다.
4.1.10.1. AWS STS 자격 증명을 제공하여 호스팅 클러스터 생성
hcp create cluster aws 명령을 사용하여 호스팅 클러스터를 생성하는 경우 호스팅 클러스터에 대한 인프라 리소스를 생성할 수 있는 권한이 있는 Amazon Web Services(AWS) 계정 자격 증명을 제공해야 합니다.
인프라 리소스에는 다음이 포함됩니다.
- Virtual Private Cloud (VPC)
- 서브넷
- 네트워크 주소 변환(NAT) 게이트웨이
다음 방법 중 하나를 사용하여 AWS 자격 증명을 제공할 수 있습니다.
- AWS 보안 토큰 서비스(STS) 자격 증명
- 멀티클러스터 엔진 운영자의 AWS 클라우드 공급자 비밀
프로세스
AWS STS 자격 증명을 제공하여 AWS에서 호스팅된 클러스터를 생성하려면 다음 명령을 입력하세요.
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --role-arn <arn_role>7 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 노드 풀 복제본 수를 지정합니다(예:
2). - 3
- 기본 도메인을 지정하세요(예:
example.com). - 4
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 5
- AWS STS 자격 증명 파일의 경로를 지정합니다(예:
/home/user/sts-creds/sts-creds.json). - 6
- AWS 지역 이름을 지정합니다(예:
us-east-1). - 7
- Amazon 리소스 이름(ARN)을 지정합니다(예:
arn:aws:iam::820196288204:role/myrole).
4.1.11. ARM64 아키텍처에서 호스팅 클러스터 실행
기본적으로 Amazon Web Services(AWS)의 호스팅 제어 평면에서는 AMD64 호스팅 클러스터를 사용합니다. 하지만 호스팅된 제어 평면을 ARM64 호스팅 클러스터에서 실행하도록 설정할 수 있습니다.
노드 풀과 호스팅 클러스터의 호환 조합은 다음 표를 참조하세요.
| 호스트된 클러스터 | 노드 풀 |
|---|---|
| AMD64 | AMD64 또는 ARM64 |
| ARM64 | ARM64 또는 AMD64 |
4.1.11.1. ARM64 OpenShift Container Platform 클러스터에 호스팅된 클러스터 생성
Amazon Web Services(AWS)의 ARM64 OpenShift Container Platform 클러스터에서 호스팅된 클러스터를 실행하려면 기본 릴리스 이미지를 다중 아키텍처 릴리스 이미지로 재정의하면 됩니다.
다중 아키텍처 릴리스 이미지를 사용하지 않으면 노드 풀의 컴퓨트 노드가 생성되지 않고, 호스팅된 클러스터에서 다중 아키텍처 릴리스 이미지를 사용하거나 릴리스 이미지에 따라 NodePool 사용자 지정 리소스를 업데이트할 때까지 노드 풀 조정이 중지됩니다.
사전 요구 사항
- AWS에 설치된 64비트 ARM 인프라가 있는 OpenShift Container Platform 클러스터가 있어야 합니다. 자세한 내용은 OpenShift 컨테이너 플랫폼 클러스터 만들기: AWS(ARM)를 참조하세요.
- AWS Identity and Access Management(IAM) 역할과 AWS Security Token Service(STS) 자격 증명을 생성해야 합니다. 자세한 내용은 "AWS IAM 역할 및 STS 자격 증명 만들기"를 참조하세요.
프로세스
다음 명령을 입력하여 ARM64 OpenShift Container Platform 클러스터에 호스팅된 클러스터를 만듭니다.
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \7 --role-arn <role_name>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 노드 풀 복제본 수를 지정합니다(예:
3). - 3
- 기본 도메인을 지정하세요(예:
example.com). - 4
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 5
- AWS STS 자격 증명 파일의 경로를 지정합니다(예:
/home/user/sts-creds/sts-creds.json). - 6
- AWS 지역 이름을 지정합니다(예:
us-east-1). - 7
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.19.0-multi). 연결이 끊긴 환경을 사용하는 경우 <ocp_release_image>를 다이제스트 이미지로 교체합니다. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 "OpenShift Container Platform 릴리스 이미지 다이제스트 추출"을 참조하십시오. - 8
- Amazon 리소스 이름(ARN)을 지정합니다(예:
arn:aws:iam::820196288204:role/myrole).
4.1.11.2. AWS 호스팅 클러스터에서 ARM 또는 AMD NodePool 오브젝트 생성
동일한 호스팅 컨트롤 플레인의 64비트 ARM 및 AMD에서 NodePool 오브젝트인 애플리케이션 워크로드를 예약할 수 있습니다. NodePool 사양에 arch 필드를 정의하여 NodePool 오브젝트에 필요한 프로세서 아키텍처를 설정할 수 있습니다. arch 필드에 유효한 값은 다음과 같습니다.
-
arm64 -
amd64
사전 요구 사항
-
HostedCluster사용자 정의 리소스를 사용하려면 다중 아키텍처 이미지가 있어야 합니다. 여러 아키텍처의 Nightly 이미지에 액세스할 수 있습니다.
프로세스
다음 명령을 실행하여 ARM 또는 AMD
NodePool오브젝트를 AWS의 호스팅 클러스터에 추가합니다.$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <node_pool_name> \2 --node-count <node_pool_replica_count> \3 --arch <architecture>4
4.1.12. AWS에서 개인 호스트 클러스터 생성
local-cluster 를 호스팅 클러스터로 활성화한 후 AWS(Amazon Web Services)에 호스팅 클러스터 또는 개인 호스팅 클러스터를 배포할 수 있습니다.
기본적으로 호스팅된 클러스터는 퍼블릭 DNS와 관리 클러스터의 기본 라우터를 통해 공개적으로 액세스할 수 있습니다.
AWS의 프라이빗 클러스터의 경우 호스팅 클러스터와의 모든 통신은 AWS PrivateLink를 통해 수행됩니다.
사전 요구 사항
- AWS PrivateLink를 활성화했습니다. 자세한 내용은 "AWS PrivateLink 활성화"를 참조하십시오.
- AWS IAM(Identity and Access Management) 역할 및 AWS STS(Security Token Service) 인증 정보를 생성하셨습니다. 자세한 내용은 "AWS IAM 역할 및 STS 인증 정보 생성" 및 "IAM(Identity and Access Management) 권한"을 참조하십시오.
- AWS에서 배스천 인스턴스를 구성했습니다.
프로세스
다음 명령을 입력하여 AWS에서 개인 호스팅 클러스터를 만듭니다.
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas=<node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --endpoint-access Private \7 --role-arn <role_name>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 노드 풀 복제본 수를 지정합니다(예:
3). - 3
- 기본 도메인을 지정하세요(예:
example.com). - 4
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 5
- AWS STS 자격 증명 파일의 경로를 지정합니다(예:
/home/user/sts-creds/sts-creds.json). - 6
- AWS 지역 이름을 지정합니다(예:
us-east-1). - 7
- 클러스터가 공개인지 비공개인지 정의합니다.
- 8
- Amazon 리소스 이름(ARN)을 지정합니다(예:
arn:aws:iam::820196288204:role/myrole). ARN 역할에 대한 자세한 내용은 "IAM(ID 및 액세스 관리) 권한"을 참조하세요.
호스팅된 클러스터의 다음 API 엔드포인트는 개인 DNS 영역을 통해 액세스할 수 있습니다.
-
api.<hosted_cluster_name>.hypershift.local -
*.apps.<hosted_cluster_name>.hypershift.local
4.1.12.1. AWS에서 개인 관리 클러스터에 액세스
명령줄 인터페이스(CLI)를 사용하여 개인 관리 클러스터에 액세스할 수 있습니다.
프로세스
다음 명령을 입력하여 노드의 개인 IP를 찾으세요.
$ aws ec2 describe-instances \ --filter="Name=tag:kubernetes.io/cluster/<infra_id>,Values=owned" \ | jq '.Reservations[] | .Instances[] | select(.PublicDnsName=="") \ | .PrivateIpAddress'다음 명령을 입력하여 노드에 복사할 수 있는 호스팅된 클러스터에 대한
kubeconfig파일을 만듭니다.$ hcp create kubeconfig > <hosted_cluster_kubeconfig>요새를 통해 노드 중 하나에 SSH를 실행하려면 다음 명령을 입력하세요.
$ ssh -o ProxyCommand="ssh ec2-user@<bastion_ip> \ -W %h:%p" core@<node_ip>SSH 셸에서 다음 명령을 입력하여
kubeconfig파일 내용을 노드의 파일에 복사합니다.$ mv <path_to_kubeconfig_file> <new_file_name>다음 명령을 입력하여
kubeconfig파일을 내보냅니다.$ export KUBECONFIG=<path_to_kubeconfig_file>다음 명령을 입력하여 호스팅된 클러스터 상태를 확인하세요.
$ oc get clusteroperators clusterversion
4.2. 베어 메탈에 호스팅된 제어 평면 배포
클러스터를 관리 클러스터로 구성하여 호스팅된 제어 평면을 배포할 수 있습니다. 관리 클러스터는 제어 평면이 호스팅되는 OpenShift Container Platform 클러스터입니다. 일부 맥락에서는 관리 클러스터를 호스팅 클러스터라고도 합니다.
관리 클러스터는 관리되는 클러스터와 다릅니다. 관리형 클러스터는 허브 클러스터가 관리하는 클러스터입니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
멀티클러스터 엔진 Operator는 관리되는 허브 클러스터인 기본 local-cluster 와 관리 클러스터인 허브 클러스터만 지원합니다. Red Hat Advanced Cluster Management가 설치되어 있으면 로컬 클러스터 라고도 하는 관리형 허브 클러스터를 관리 클러스터로 사용할 수 있습니다.
호스팅 클러스터 는 관리 클러스터에 호스팅된 API 엔드포인트와 제어 평면을 갖춘 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다. 멀티클러스터 엔진 운영자 콘솔이나 호스팅 제어 평면 명령줄 인터페이스( hcp )를 사용하여 호스팅 클러스터를 생성할 수 있습니다.
호스팅된 클러스터는 자동으로 관리형 클러스터로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 "호스팅된 클러스터를 멀티클러스터 엔진 Operator로 자동 가져오기 비활성화"를 참조하세요.
4.2.1. 베어 메탈에 호스팅된 제어 평면을 배포할 준비 중
베어 메탈에 호스팅된 제어 평면을 배포할 준비를 할 때 다음 정보를 고려하세요.
- 호스팅된 제어 평면에 대해 동일한 플랫폼에서 관리 클러스터와 작업자를 실행합니다.
-
모든 베어 메탈 호스트는 중앙 인프라 관리에서 제공하는 Discovery Image ISO를 사용하여 수동으로 시작해야 합니다.
Cluster-Baremetal-Operator를사용하여 수동으로 또는 자동화를 통해 호스트를 시작할 수 있습니다. 각 호스트가 시작된 후에는 에이전트 프로세스를 실행하여 호스트 세부 정보를 검색하고 설치를 완료합니다.에이전트사용자 정의 리소스는 각 호스트를 나타냅니다. - 호스팅된 제어 평면에 대한 스토리지를 구성할 때 권장되는 etcd 사례를 고려하세요. 지연 시간 요구 사항을 충족하려면 각 제어 평면 노드에서 실행되는 모든 호스팅된 제어 평면 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정하세요. LVM 스토리지를 사용하여 호스팅된 etcd 포드에 대한 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 "권장되는 etcd 사례" 및 "논리적 볼륨 관리자 스토리지를 사용한 영구 스토리지"를 참조하세요.
4.2.1.1. 관리 클러스터를 구성하기 위한 전제 조건
- OpenShift Container Platform 클러스터에 Kubernetes Operator 2.2 이상용 멀티클러스터 엔진을 설치해야 합니다. OpenShift Container Platform OperatorHub에서 Operator로 멀티클러스터 엔진 Operator를 설치할 수 있습니다.
멀티클러스터 엔진 운영자는 최소한 하나의 관리되는 OpenShift Container Platform 클러스터를 가져야 합니다.
로컬 클러스터는 멀티클러스터 엔진 Operator 2.2 이상에 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 Red Hat Advanced Cluster Management 문서의 고급 구성을 참조하세요. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.$ oc get managedclusters local-cluster-
관리 클러스터의 베어 메탈 호스트에
topology.kubernetes.io/zone레이블을 추가해야 합니다. 각 호스트에topology.kubernetes.io/zone에 대한 고유한 값이 있는지 확인하세요. 그렇지 않으면 호스팅된 모든 제어 평면 포드가 단일 노드에 예약되어 단일 장애 지점이 발생합니다. - 베어 메탈에서 호스팅된 제어 평면을 프로비저닝하려면 Agent 플랫폼을 사용할 수 있습니다. Agent 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스팅된 클러스터에 워커 노드를 추가합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하세요.
- 호스팅된 제어 평면 명령줄 인터페이스를 설치해야 합니다.
4.2.1.2. 베어메탈 방화벽, 포트 및 서비스 요구 사항
관리 클러스터, 제어 평면 및 호스팅 클러스터 간에 포트가 통신할 수 있도록 방화벽, 포트 및 서비스 요구 사항을 충족해야 합니다.
서비스는 기본 포트에서 실행됩니다. 하지만 NodePort 게시 전략을 사용하면 서비스는 NodePort 서비스에서 할당한 포트에서 실행됩니다.
방화벽 규칙, 보안 그룹 또는 기타 액세스 제어를 사용하여 필요한 소스에만 액세스를 제한합니다. 필요하지 않은 이상 포트를 공개적으로 노출하지 마십시오. 실제 운영 환경에 배포하는 경우, 로드 밸런서를 사용하여 단일 IP 주소를 통해 액세스를 간소화합니다.
허브 클러스터에 프록시 구성이 있는 경우 모든 호스팅 클러스터 API 엔드포인트를 Proxy 개체의 noProxy 필드에 추가하여 호스팅 클러스터 API 엔드포인트에 도달할 수 있는지 확인하세요. 자세한 내용은 클러스터 전체 프록시 구성을 참조하십시오.
호스팅된 제어 평면은 베어 메탈에서 다음 서비스를 제공합니다.
APIServer-
APIServer서비스는 기본적으로 포트 6443에서 실행되며 제어 평면 구성 요소 간 통신을 위해 인그레스 액세스가 필요합니다. - MetalLB 부하 분산을 사용하는 경우 부하 분산 장치 IP 주소에 사용되는 IP 범위에 대한 수신 액세스를 허용합니다.
-
OAuthServer-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
OAuthServer서비스는 기본적으로 포트 443에서 실행됩니다. -
NodePort게시 전략을 사용하는 경우OAuthServer서비스에 대한 방화벽 규칙을 사용하세요.
-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
연결성-
경로와 인그레스를 사용하여 서비스를 노출하는 경우
Konnectivity서비스는 기본적으로 포트 443에서 실행됩니다. -
Konnectivity에이전트는 제어 평면이 호스팅된 클러스터의 네트워크에 액세스할 수 있도록 역방향 터널을 설정합니다. 에이전트는 출구를 통해Konnectivity서버에 연결합니다. 서버는 포트 443의 경로나 수동으로 할당된NodePort를사용하여 노출됩니다. - 클러스터 API 서버 주소가 내부 IP 주소인 경우 포트 6443의 IP 주소로 워크로드 서브넷에서 액세스를 허용합니다.
- 해당 주소가 외부 IP 주소인 경우 노드에서 해당 외부 IP 주소로 포트 6443을 통해 유출을 허용합니다.
-
경로와 인그레스를 사용하여 서비스를 노출하는 경우
Ignition-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
Ignition서비스는 기본적으로 포트 443에서 실행됩니다. -
NodePort게시 전략을 사용하는 경우Ignition서비스에 대한 방화벽 규칙을 사용하세요.
-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
베어 메탈에서는 다음 서비스가 필요하지 않습니다.
-
OVNSbDb -
OIDC
4.2.1.3. 베어 메탈 인프라 요구 사항
Agent 플랫폼은 어떠한 인프라도 생성하지 않지만 인프라에 대한 다음과 같은 요구 사항을 갖추고 있습니다.
- 에이전트: 에이전트는 검색 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝될 준비가 된 호스트를 나타냅니다.
- DNS: API 및 수신 엔드포인트는 라우팅 가능해야 합니다.
4.2.2. 베어 메탈의 DNS 구성
호스팅된 클러스터의 API 서버는 NodePort 서비스로 노출됩니다. API 서버에 도달할 수 있는 대상을 가리키는 api.<hosted_cluster_name>.<base_domain> 에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 제어 평면을 실행하는 관리 클러스터의 노드 중 하나를 가리키는 레코드만큼 간단할 수 있습니다. 또한, 진입점은 유입 트래픽을 인그레스 포드로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
DNS 구성 예
api.example.krnl.es. IN A 192.168.122.20
api.example.krnl.es. IN A 192.168.122.21
api.example.krnl.es. IN A 192.168.122.22
api-int.example.krnl.es. IN A 192.168.122.20
api-int.example.krnl.es. IN A 192.168.122.21
api-int.example.krnl.es. IN A 192.168.122.22
`*`.apps.example.krnl.es. IN A 192.168.122.23
이전 예에서, *.apps.example.krnl.es. 192.168.122.23에서 호스팅된 클러스터의 노드이거나 로드 밸런서가 구성된 경우 로드 밸런서입니다.
IPv6 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 구성은 다음 예와 같습니다.
IPv6 네트워크에 대한 DNS 구성 예
api.example.krnl.es. IN A 2620:52:0:1306::5
api.example.krnl.es. IN A 2620:52:0:1306::6
api.example.krnl.es. IN A 2620:52:0:1306::7
api-int.example.krnl.es. IN A 2620:52:0:1306::5
api-int.example.krnl.es. IN A 2620:52:0:1306::6
api-int.example.krnl.es. IN A 2620:52:0:1306::7
`*`.apps.example.krnl.es. IN A 2620:52:0:1306::10듀얼 스택 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 IPv4와 IPv6에 대한 DNS 항목을 모두 포함해야 합니다.
듀얼 스택 네트워크를 위한 DNS 구성 예
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10
host-record=api.hub-dual.dns.base.domain.name,192.168.126.10
address=/apps.hub-dual.dns.base.domain.name/192.168.126.11
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2
host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2
address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6]
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7]
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8]
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]4.2.2.1. 사용자 정의 DNS 이름 정의
클러스터 관리자는 노드 부트스트랩 및 제어 평면 통신에 사용되는 내부 엔드포인트와 다른 외부 API DNS 이름을 사용하여 호스팅된 클러스터를 만들 수 있습니다. 다음과 같은 이유로 다른 DNS 이름을 정의할 수 있습니다.
- 내부 루트 CA에 바인딩되는 제어 평면 기능을 손상시키지 않고 사용자 대상 TLS 인증서를 공개 CA의 인증서로 교체합니다.
- 분할 수평 DNS 및 NAT 시나리오를 지원합니다.
-
올바른
kubeconfig및 DNS 구성을 사용하면Show Login Command기능과 같은 기능을 사용할 수 있는 독립 실행형 제어 평면과 유사한 환경을 보장할 수 있습니다.
HostedCluster 개체의 kubeAPIServerDNSName 매개변수에 도메인 이름을 입력하여 초기 설정 중이나 설치 후 작업 중에 DNS 이름을 정의할 수 있습니다.
사전 요구 사항
-
kubeAPIServerDNSName매개변수에 설정한 DNS 이름을 포함하는 유효한 TLS 인증서가 있습니다. - 올바른 주소에 도달하고 이를 가리킬 수 있는 확인 가능한 DNS 이름 URI가 있습니다.
프로세스
HostedCluster개체에 대한 사양에서kubeAPIServerDNSName매개변수와 도메인 주소를 추가하고 다음 예와 같이 사용할 인증서를 지정합니다.#... spec: configuration: apiServer: servingCerts: namedCertificates: - names: - xxx.example.com - yyy.example.com servingCertificate: name: <my_serving_certificate> kubeAPIServerDNSName: <custom_address>1 - 1
kubeAPIServerDNSName매개변수의 값은 유효하고 주소 지정이 가능한 도메인이어야 합니다.
kubeAPIServerDNSName 매개변수를 정의하고 인증서를 지정하면 Control Plane Operator 컨트롤러가 custom-admin-kubeconfig 라는 kubeconfig 파일을 생성하고, 이 파일은 HostedControlPlane 네임스페이스에 저장됩니다. 인증서 생성은 루트 CA에서 이루어지며, HostedControlPlane 네임스페이스는 인증서의 만료 및 갱신을 관리합니다.
Control Plane Operator는 HostedControlPlane 네임스페이스에 CustomKubeconfig 라는 새로운 kubeconfig 파일을 보고합니다. 해당 파일은 kubeAPIServerDNSName 매개변수에 정의된 새 서버를 사용합니다.
사용자 정의 kubeconfig 파일에 대한 참조는 HostedCluster 개체의 CustomKubeconfig 라는 상태 매개변수에 있습니다. CustomKubeConfig 매개변수는 선택 사항이며, kubeAPIServerDNSName 매개변수가 비어 있지 않은 경우에만 매개변수를 추가할 수 있습니다. CustomKubeConfig 매개변수를 설정하면 해당 매개변수는 HostedCluster 네임스페이스에 <hosted_cluster_name>-custom-admin-kubeconfig 라는 이름의 비밀을 생성합니다. 이 비밀을 사용하여 HostedCluster API 서버에 액세스할 수 있습니다. 설치 후 작업 중에 CustomKubeConfig 매개변수를 제거하면 관련된 모든 비밀과 상태 참조가 삭제됩니다.
사용자 지정 DNS 이름을 정의해도 데이터 플레인에 직접적인 영향을 미치지 않으므로 예상 롤아웃이 발생하지 않습니다. HostedControlPlane 네임스페이스는 HyperShift Operator로부터 변경 사항을 수신하고 해당 매개변수를 삭제합니다.
HostedCluster 개체의 사양에서 kubeAPIServerDNSName 매개변수를 제거하면 새로 생성된 모든 비밀과 CustomKubeconfig 참조가 클러스터와 status 매개변수에서 제거됩니다.
4.2.3. InfraEnv 리소스 생성
베어 메탈에서 호스팅 클러스터를 생성하려면 InfraEnv 리소스가 필요합니다.
4.2.3.1. InfraEnv 리소스 생성 및 노드 추가
호스팅된 제어 평면에서 제어 평면 구성 요소는 관리 클러스터의 포드로 실행되는 반면, 데이터 평면은 전용 노드에서 실행됩니다. 지원 서비스를 사용하면 하드웨어를 하드웨어 인벤토리에 추가하는 검색 ISO로 하드웨어를 부팅할 수 있습니다. 나중에 호스팅 클러스터를 생성하면 인벤토리의 하드웨어가 데이터 플레인 노드를 프로비저닝하는 데 사용됩니다. 검색 ISO를 가져오는 데 사용되는 객체는 InfraEnv 리소스입니다. 검색 ISO에서 베어 메탈 노드를 부팅하도록 클러스터를 구성하는 BareMetalHost 객체를 만들어야 합니다.
프로세스
다음 명령을 입력하여 하드웨어 인벤토리를 저장할 네임스페이스를 만듭니다.
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig create \ namespace <namespace_example>다음과 같습니다.
- <directory_example>
-
관리 클러스터의
kubeconfig파일이 저장되는 디렉토리의 이름입니다. - <namespace_example>
생성하려는 네임스페이스의 이름입니다(예:
hardware-inventory ).출력 예
namespace/hardware-inventory created
다음 명령을 입력하여 관리 클러스터의 풀 시크릿을 복사합니다.
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n openshift-config get secret pull-secret -o yaml \ | grep -vE "uid|resourceVersion|creationTimestamp|namespace" \ | sed "s/openshift-config/<namespace_example>/g" \ | oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n <namespace> apply -f -다음과 같습니다.
- <directory_example>
-
관리 클러스터의
kubeconfig파일이 저장되는 디렉토리의 이름입니다. - <namespace_example>
생성하려는 네임스페이스의 이름입니다(예:
hardware-inventory ).출력 예
secret/pull-secret created
다음 내용을 YAML 파일에 추가하여
InfraEnv리소스를 만듭니다.apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: hosted namespace: <namespace_example> spec: additionalNTPSources: - <ip_address> pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key> # ...다음 명령을 입력하여 YAML 파일에 변경 사항을 적용합니다.
$ oc apply -f <infraenv_config>.yaml<infraenv_config>를파일 이름으로 바꾸세요.다음 명령을 입력하여
InfraEnv리소스가 생성되었는지 확인하세요.$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n <namespace_example> get infraenv hosted다음 두 가지 방법 중 하나를 따라 베어 메탈 호스트를 추가합니다.
Metal3 Operator를 사용하지 않는 경우
InfraEnv리소스에서 검색 ISO를 얻고 다음 단계를 완료하여 호스트를 수동으로 부팅하세요.다음 명령을 입력하여 라이브 ISO를 다운로드하세요.
$ oc get infraenv -A$ oc get infraenv <namespace_example> -o jsonpath='{.status.isoDownloadURL}' -n <namespace_example> <iso_url>-
ISO를 부팅합니다. 노드는 지원 서비스와 통신하고
InfraEnv리소스와 동일한 네임스페이스에 에이전트로 등록됩니다. 각 에이전트에 대해 설치 디스크 ID와 호스트 이름을 설정하고, 이를 승인하여 에이전트가 사용 준비가 되었음을 나타냅니다. 다음 명령을 입력하세요:
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign$ oc -n <hosted_control_plane_namespace> \ patch agent 86f7ac75-4fc4-4b36-8130-40fa12602218 \ -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-0.example.krnl.es"}}' \ --type merge$ oc -n <hosted_control_plane_namespace> \ patch agent 23d0c614-2caa-43f5-b7d3-0b3564688baa -p \ '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-1.example.krnl.es"}}' \ --type merge$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
Metal3 Operator를 사용하면 다음 객체를 생성하여 베어 메탈 호스트 등록을 자동화할 수 있습니다.
YAML 파일을 만들고 다음 내용을 추가하세요.
apiVersion: v1 kind: Secret metadata: name: hosted-worker0-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: hosted-worker1-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: hosted-worker2-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker0 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker0 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker0-bmc-secret bootMACAddress: aa:aa:aa:aa:02:01 online: true --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker1 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker1 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker1-bmc-secret bootMACAddress: aa:aa:aa:aa:02:02 online: true --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker2 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker2 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker2-bmc-secret bootMACAddress: aa:aa:aa:aa:02:03 online: true --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: capi-provider-role namespace: <namespace_example> rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'다음과 같습니다.
- <namespace_example>
- 귀하의 네임스페이스입니다.
- <password>
- 비밀의 비밀번호입니다.
- <username>
- 비밀번호에 대한 사용자 이름입니다.
- <bmc_address>
BareMetalHost개체의 BMC 주소입니다.참고이 YAML 파일을 적용하면 다음 개체가 생성됩니다.
- Baseboard Management Controller(BMC)에 대한 자격 증명이 포함된 비밀
-
BareMetalHost객체 - HyperShift Operator가 에이전트를 관리할 수 있는 역할
BareMetalHost개체에서infraenvs.agent-install.openshift.io:hosted사용자 지정 레이블을 사용하여InfraEnv리소스가 참조되는 방식에 주목하세요. 이렇게 하면 노드가 생성된 ISO로 부팅됩니다.
다음 명령을 입력하여 YAML 파일에 변경 사항을 적용합니다.
$ oc apply -f <bare_metal_host_config>.yaml<bare_metal_host_config>를파일 이름으로 바꾸세요.
다음 명령을 입력한 후
BareMetalHost개체가프로비저닝상태로 전환될 때까지 몇 분간 기다립니다.$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig -n <namespace_example> get bmh출력 예
NAME STATE CONSUMER ONLINE ERROR AGE hosted-worker0 provisioning true 106s hosted-worker1 provisioning true 106s hosted-worker2 provisioning true 106s다음 명령을 입력하여 노드가 부팅되고 에이전트로 표시되는지 확인하세요. 이 과정은 몇 분 정도 걸릴 수 있으며, 명령을 두 번 이상 입력해야 할 수도 있습니다.
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig -n <namespace_example> get agent출력 예
NAME CLUSTER APPROVED ROLE STAGE aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0201 true auto-assign aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0202 true auto-assign aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0203 true auto-assign
4.2.3.2. 콘솔을 사용하여 InfraEnv 리소스 만들기
콘솔을 사용하여 InfraEnv 리소스를 생성하려면 다음 단계를 완료하세요.
프로세스
- OpenShift Container Platform 웹 콘솔을 열고 관리자 자격 증명을 입력하여 로그인합니다. 콘솔을 여는 방법에 대한 지침은 "웹 콘솔에 액세스하기"를 참조하세요.
- 콘솔 헤더에서 모든 클러스터가 선택되어 있는지 확인하세요.
- 인프라 → 호스트 인벤토리 → 인프라 환경 생성을 클릭합니다.
-
InfraEnv리소스를 만든 후 InfraEnv 보기에서 호스트 추가 를 클릭하고 사용 가능한 옵션 중에서 선택하여 베어 메탈 호스트를 추가합니다.
4.2.4. 베어 메탈에 호스팅된 클러스터 생성
명령줄 인터페이스(CLI), 콘솔 또는 미러 레지스트리를 사용하여 베어 메탈에서 호스팅 클러스터를 만들 수 있습니다.
4.2.4.1. CLI를 사용하여 호스팅 클러스터 만들기
베어메탈 인프라에서는 호스팅된 클러스터를 만들거나 가져올 수 있습니다. 멀티클러스터 엔진 Operator에 대한 추가 기능으로 Assisted Installer를 활성화하고 Agent 플랫폼으로 호스팅된 클러스터를 생성하면 HyperShift Operator가 호스팅된 제어 평면 네임스페이스에 Agent Cluster API 공급자를 설치합니다. 에이전트 클러스터 API 공급자는 제어 평면을 호스팅하는 관리 클러스터와 컴퓨팅 노드만으로 구성된 호스팅 클러스터를 연결합니다.
사전 요구 사항
- 호스팅된 각 클러스터에는 클러스터 전체에서 고유한 이름이 있어야 합니다. 호스팅된 클러스터 이름은 기존 관리형 클러스터와 동일할 수 없습니다. 그렇지 않으면 멀티클러스터 엔진 운영자는 호스팅된 클러스터를 관리할 수 없습니다.
-
호스팅된 클러스터 이름으로
'클러스터'라는단어를 사용하지 마세요. - 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에 호스팅된 클러스터를 만들 수 없습니다.
- 최상의 보안 및 관리 관행을 위해 다른 호스팅 클러스터와 별도로 호스팅 클러스터를 만드세요.
- 클러스터에 기본 스토리지 클래스가 구성되어 있는지 확인하세요. 그렇지 않으면 보류 중인 영구 볼륨 클레임(PVC)이 표시될 수 있습니다.
-
기본적으로
hcp create cluster agent명령을 사용하면 명령은 구성된 노드 포트를 사용하여 호스팅된 클러스터를 생성합니다. 베어 메탈에서 호스팅되는 클러스터의 기본 게시 전략은 로드 밸런서를 통해 서비스를 노출하는 것입니다. 웹 콘솔이나 Red Hat Advanced Cluster Management를 사용하여 호스팅 클러스터를 생성하는 경우 Kubernetes API 서버 외에 서비스에 대한 게시 전략을 설정하려면HostedCluster사용자 정의 리소스에서servicePublishingStrategy정보를 수동으로 지정해야 합니다. 인프라, 방화벽, 포트 및 서비스와 관련된 요구 사항을 포함하여 "베어 메탈에서 호스팅되는 제어 평면에 대한 요구 사항"에 설명된 요구 사항을 충족하는지 확인하세요. 예를 들어, 해당 요구 사항은 다음 예제 명령에서 볼 수 있듯이 관리 클러스터의 베어 메탈 호스트에 적절한 영역 레이블을 추가하는 방법을 설명합니다.
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- 하드웨어 인벤토리에 베어 메탈 노드를 추가했는지 확인하세요.
프로세스
다음 명령을 입력하여 네임스페이스를 만듭니다.
$ oc create ns <hosted_cluster_namespace><hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스의 식별자로 바꾸세요. HyperShift 연산자는 네임스페이스를 생성합니다. 베어 메탈 인프라에서 호스팅된 클러스터를 생성하는 동안 생성된 클러스터 API 공급자 역할에는 네임스페이스가 이미 존재해야 합니다.다음 명령을 입력하여 호스팅된 클러스터에 대한 구성 파일을 만듭니다.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
/user/name/pullsecret과 같이 풀 시크릿의 경로를 지정합니다.- 3
clusters-example과 같이 호스팅된 제어 평면 네임스페이스를 지정합니다.oc get agent -n <hosted_control_plane_namespace>명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다.- 4
krnl.es와 같이 기본 도메인을 지정하세요.- 5
--api-server-address플래그는 호스팅된 클러스터에서 Kubernetes API 통신에 사용되는 IP 주소를 정의합니다.--api-server-address플래그를 설정하지 않으면 관리 클러스터에 연결하려면 로그인해야 합니다.- 6
lvm-storageclass와 같이 etcd 스토리지 클래스 이름을 지정합니다.- 7
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 9
- 호스팅된 제어 평면 구성 요소에 대한 가용성 정책을 지정합니다. 지원되는 옵션은
SingleReplica및HighlyAvailable입니다. 기본값은HighlyAvailable입니다. - 10
- 사용하려는 지원되는 OpenShift Container Platform 버전(예:
4.19.0-multi )을 지정합니다. 연결이 끊긴 환경을 사용하는 경우<ocp_release_image>를다이제스트 이미지로 바꾸세요. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하세요. - 11
- 노드 풀 복제본 수를 지정합니다(예:
3). 동일한 수의 복제본을 생성하려면 복제본 수를0이상으로 지정해야 합니다. 그렇지 않으면 노드 풀을 생성하지 않습니다. - 12
--ssh-key플래그 뒤에user/.ssh/id_rsa와 같이 SSH 키의 경로를 지정합니다.
서비스 게시 전략을 구성합니다. 기본적으로 호스팅 클러스터는
NodePort서비스 게시 전략을 사용합니다. 이는 노드 포트가 추가 인프라 없이도 항상 사용 가능하기 때문입니다. 하지만 로드 밸런서를 사용하도록 서비스 게시 전략을 구성할 수 있습니다.-
기본
NodePort전략을 사용하는 경우 관리 클러스터 노드가 아닌 호스팅된 클러스터 컴퓨팅 노드를 가리키도록 DNS를 구성합니다. 자세한 내용은 "베어 메탈의 DNS 구성"을 참조하세요. 프로덕션 환경에서는
LoadBalancer전략을 사용하세요. 이 전략은 인증서 처리와 자동 DNS 확인을 제공합니다. 다음 예제에서는 호스팅된 클러스터 구성 파일에서 서비스 게시LoadBalancer전략을 변경하는 방법을 보여줍니다.# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- API 서버 유형으로
LoadBalancer를지정합니다. 다른 모든 서비스의 경우 유형으로경로를지정합니다.
-
기본
다음 명령을 입력하여 호스팅된 클러스터 구성 파일에 변경 사항을 적용합니다.
$ oc apply -f hosted_cluster_config.yaml다음 명령을 입력하여 호스팅된 클러스터, 노드 풀 및 포드가 생성되었는지 확인하세요.
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
호스팅된 클러스터가 준비되었는지 확인하세요.
사용 가능: True상태는 클러스터의 준비 상태를 나타내고 노드 풀 상태는AllMachinesReady: True를나타냅니다. 이러한 상태는 모든 클러스터 운영자의 상태를 나타냅니다. 호스팅된 클러스터에 MetalLB를 설치하세요:
호스팅된 클러스터에서
kubeconfig파일을 추출하고 다음 명령을 입력하여 호스팅된 클러스터 액세스를 위한 환경 변수를 설정합니다.$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"install-metallb-operator.yaml파일을 만들어 MetalLB Operator를 설치합니다.apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...다음 명령을 입력하여 파일을 적용합니다.
$ oc apply -f install-metallb-operator.yamldeploy-metallb-ipaddresspool.yaml파일을 만들어 MetalLB IP 주소 풀을 구성합니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f deploy-metallb-ipaddresspool.yaml다음 명령을 입력하여 운영자 상태, IP 주소 풀,
L2Advertisement리소스를 확인하여 MetalLB가 설치되었는지 확인하세요.$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
수신을 위해 로드 밸런서를 구성합니다.
ingress-loadbalancer.yaml파일을 만듭니다.apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f ingress-loadbalancer.yaml다음 명령을 입력하여 로드 밸런서 서비스가 예상대로 작동하는지 확인하세요.
$ oc get svc metallb-ingress -n openshift-ingress출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
로드 밸런서와 함께 작동하도록 DNS를 구성합니다.
-
*.apps.<hosted_cluster_namespace>.<base_domain>와일드카드 DNS 레코드를 로드 밸런서 IP 주소로 가리켜앱도메인에 대한 DNS를 구성합니다. 다음 명령을 입력하여 DNS 확인을 확인하세요.
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>출력 예
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
검증
다음 명령을 입력하여 클러스터 운영자를 확인하세요.
$ oc get clusteroperators모든 연산자가
AVAILABLE: True,PROGRESSING: False,DEGRADED: False로표시되는지 확인하세요.다음 명령을 입력하여 노드를 확인하세요.
$ oc get nodes각 노드가
READY상태인지 확인하세요.웹 브라우저에 다음 URL을 입력하여 콘솔에 대한 액세스를 테스트하세요.
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.2.4.2. 콘솔을 사용하여 베어 메탈에 호스팅된 클러스터 만들기
콘솔을 사용하여 호스팅 클러스터를 만들려면 다음 단계를 완료하세요.
프로세스
- OpenShift Container Platform 웹 콘솔을 열고 관리자 자격 증명을 입력하여 로그인합니다. 콘솔을 여는 방법에 대한 지침은 "웹 콘솔에 액세스하기"를 참조하세요.
- 콘솔 헤더에서 모든 클러스터가 선택되어 있는지 확인하세요.
- 인프라 → 클러스터를 클릭합니다.
클러스터 만들기 → 호스트 인벤토리 → 호스팅된 제어 평면을 클릭합니다.
클러스터 만들기 페이지가 표시됩니다.
클러스터 만들기 페이지에서 프롬프트에 따라 클러스터, 노드 풀, 네트워킹 및 자동화에 대한 세부 정보를 입력합니다.
참고클러스터에 대한 세부 정보를 입력할 때 다음 팁이 유용할 수 있습니다.
- 미리 정의된 값을 사용하여 콘솔의 필드를 자동으로 채우려면 호스트 인벤토리 자격 증명을 만들 수 있습니다. 자세한 내용은 "온-프레미스 환경에 대한 자격 증명 만들기"를 참조하세요.
- 클러스터 세부 정보 페이지에서 풀 시크릿은 OpenShift Container Platform 리소스에 액세스하는 데 사용하는 OpenShift Container Platform 풀 시크릿입니다. 호스트 인벤토리 자격 증명을 선택한 경우 풀 비밀이 자동으로 채워집니다.
- 노드 풀 페이지에서 네임스페이스에는 노드 풀의 호스트가 포함되어 있습니다. 콘솔을 사용하여 호스트 인벤토리를 만든 경우 콘솔은 전용 네임스페이스를 만듭니다.
-
네트워킹 페이지에서 API 서버 게시 전략을 선택합니다. 호스팅된 클러스터의 API 서버는 기존 로드 밸런서를 사용하거나
NodePort유형의 서비스로 노출될 수 있습니다. API 서버에 도달할 수 있는 대상을 가리키는api.<hosted_cluster_name>.<base_domain>설정에 대한 DNS 항목이 있어야 합니다. 이 항목은 관리 클러스터의 노드 중 하나를 가리키는 레코드이거나, 수신 트래픽을 Ingress 포드로 리디렉션하는 로드 밸런서를 가리키는 레코드일 수 있습니다.
입력 내용을 검토하고 '만들기'를 클릭하세요.
호스팅된 클러스터 뷰가 표시됩니다.
- 호스팅된 클러스터 보기에서 호스팅된 클러스터의 배포를 모니터링합니다.
- 호스팅된 클러스터에 대한 정보가 보이지 않으면 모든 클러스터가 선택되어 있는지 확인한 다음 클러스터 이름을 클릭하세요.
- 컨트롤 플레인 구성 요소가 준비될 때까지 기다립니다. 이 과정은 몇 분 정도 걸릴 수 있습니다.
- 노드 풀 상태를 보려면 NodePool 섹션으로 스크롤하세요. 노드를 설치하는 데 걸리는 시간은 약 10분입니다. 노드를 클릭하여 노드가 호스팅된 클러스터에 참여하고 있는지 확인할 수도 있습니다.
다음 단계
- 웹 콘솔에 액세스하려면 웹 콘솔 액세스를 참조하세요.
4.2.4.3. 미러 레지스트리를 사용하여 베어 메탈에 호스팅된 클러스터 만들기
hcp create cluster 명령에서 --image-content-sources 플래그를 지정하여 미러 레지스트리를 사용하여 베어 메탈에 호스팅된 클러스터를 만들 수 있습니다.
프로세스
ICSP(이미지 콘텐츠 소스 정책)를 정의하기 위해 YAML 파일을 만듭니다. 다음 예제를 참조하십시오.
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
파일을
icsp.yaml로 저장합니다. 이 파일에는 미러 레지스트리가 포함되어 있습니다. 미러 레지스트리를 사용하여 호스팅 클러스터를 만들려면 다음 명령을 실행하세요.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --image-content-sources icsp.yaml \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>9 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 3
- 호스팅된 제어 평면 네임스페이스를 지정합니다(예:
clusters-example).oc get agent -n <hosted-control-plane-namespace>명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다. - 4
- 기본 도메인을 지정하세요(예:
krnl.es). - 5
--api-server-address플래그는 호스팅된 클러스터에서 Kubernetes API 통신에 사용되는 IP 주소를 정의합니다.--api-server-address플래그를 설정하지 않으면 관리 클러스터에 연결하려면 로그인해야 합니다.- 6
- ICSP와 미러 레지스트리를 정의하는
icsp.yaml파일을 지정합니다. - 7
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 9
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.19.0-multi). 연결이 끊긴 환경을 사용하는 경우<ocp_release_image>를다이제스트 이미지로 바꾸세요. OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트를 추출하려면 "OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트 추출"을 참조하세요.
다음 단계
- 콘솔을 사용하여 호스팅된 클러스터를 생성할 때 재사용할 수 있는 자격 증명을 만들려면 온-프레미스 환경에 대한 자격 증명 만들기를 참조하세요.
- 호스팅된 클러스터에 액세스하려면 호스팅된 클러스터 액세스를 참조하세요.
- Discovery Image를 사용하여 호스트 인벤토리에 호스트를 추가하려면 Discovery Image를 사용하여 호스트 인벤토리에 호스트 추가를 참조하세요.
- OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트를 추출하려면 OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트 추출을 참조하세요.
4.2.5. 호스팅된 클러스터 생성 확인
배포 프로세스가 완료되면 호스팅된 클러스터가 성공적으로 생성되었는지 확인할 수 있습니다. 호스팅 클러스터를 만든 후 몇 분 후에 다음 단계를 따르세요.
프로세스
extract 명령을 입력하여 새로 호스팅된 클러스터에 대한 kubeconfig를 가져옵니다.
$ oc extract -n <hosted-control-plane-namespace> secret/admin-kubeconfig \ --to=- > kubeconfig-<hosted-cluster-name>kubeconfig를 사용하여 호스팅된 클러스터의 클러스터 운영자를 확인합니다. 다음 명령을 실행합니다.
$ oc get co --kubeconfig=kubeconfig-<hosted-cluster-name>출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s dns 4.10.26 True False False 2m52s image-registry 4.10.26 True False False 2m8s ingress 4.10.26 True False False 22m다음 명령을 입력하여 호스팅 클러스터에서 실행 중인 Pod를 볼 수도 있습니다.
$ oc get pods -A --kubeconfig=kubeconfig-<hosted-cluster-name>출력 예
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-node-tuning-operator tuned-dhw5p 1/1 Running 0 109s openshift-cluster-storage-operator cluster-storage-operator-5f784969f5-vwzgz 1/1 Running 1 (113s ago) 20m openshift-cluster-storage-operator csi-snapshot-controller-6b7687b7d9-7nrfw 1/1 Running 0 3m8s openshift-console console-5cbf6c7969-6gk6z 1/1 Running 0 119s openshift-console downloads-7bcd756565-6wj5j 1/1 Running 0 4m3s openshift-dns-operator dns-operator-77d755cd8c-xjfbn 2/2 Running 0 21m openshift-dns dns-default-kfqnh 2/2 Running 0 113s
4.2.6. 호스팅된 클러스터에서 사용자 정의 API 서버 인증서 구성
API 서버에 대한 사용자 정의 인증서를 구성하려면 HostedCluster 구성의 spec.configuration.apiServer 섹션에서 인증서 세부 정보를 지정하세요.
1일차 또는 2일차 작업 중에 사용자 정의 인증서를 구성할 수 있습니다. 그러나 서비스 게시 전략은 호스팅 클러스터를 생성하는 동안 설정한 후에는 변경할 수 없으므로 구성하려는 Kubernetes API 서버의 호스트 이름을 알아야 합니다.
사전 요구 사항
관리 클러스터에 사용자 정의 인증서가 포함된 Kubernetes 비밀을 생성했습니다. 비밀에는 다음과 같은 키가 포함되어 있습니다.
-
tls.crt: 인증서 -
tls.key: 개인 키
-
-
HostedCluster구성에 부하 분산 장치를 사용하는 서비스 게시 전략이 포함된 경우 인증서의 SAN(주체 대체 이름)이 내부 API 엔드포인트(api-int)와 충돌하지 않는지 확인하세요. 내부 API 엔드포인트는 플랫폼에서 자동으로 생성되고 관리됩니다. 사용자 정의 인증서와 내부 API 엔드포인트 모두에서 동일한 호스트 이름을 사용하면 라우팅 충돌이 발생할 수 있습니다. 이 규칙의 유일한 예외는 AWS를Private또는PublicAndPrivate구성으로 공급자로 사용하는 경우입니다. 이런 경우 SAN 충돌은 플랫폼에 의해 관리됩니다. - 인증서는 외부 API 엔드포인트에 대해 유효해야 합니다.
- 인증서의 유효 기간은 클러스터의 예상 수명 주기와 일치합니다.
프로세스
다음 명령을 입력하여 사용자 지정 인증서로 비밀을 만듭니다.
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>다음 예와 같이 사용자 지정 인증서 세부 정보로
HostedCluster구성을 업데이트합니다.spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert다음 명령을 입력하여
HostedCluster구성에 변경 사항을 적용합니다.$ oc apply -f <hosted_cluster_config>.yaml
검증
- API 서버 포드를 확인하여 새 인증서가 마운트되었는지 확인하세요.
- 사용자 지정 도메인 이름을 사용하여 API 서버에 대한 연결을 테스트합니다.
-
브라우저나
openssl과 같은 도구를 사용하여 인증서 세부 정보를 확인하세요.
4.3. OpenShift Virtualization에 호스팅된 제어 평면 배포
호스팅된 제어 평면과 OpenShift 가상화를 사용하면 KubeVirt 가상 머신에서 호스팅되는 작업자 노드가 있는 OpenShift Container Platform 클러스터를 만들 수 있습니다. OpenShift Virtualization의 호스팅 제어 평면은 다음과 같은 여러 가지 이점을 제공합니다.
- 동일한 기본 베어메탈 인프라에 호스팅된 제어 평면과 호스팅된 클러스터를 패키징하여 리소스 사용을 향상시킵니다.
- 강력한 격리를 제공하기 위해 호스팅된 제어 평면과 호스팅된 클러스터를 분리합니다.
- 베어 메탈 노드 부트스트래핑 프로세스를 제거하여 클러스터 프로비저닝 시간을 줄입니다.
- 동일한 기반 OpenShift Container Platform 클러스터에서 여러 릴리스를 관리합니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
호스팅된 제어 평면 명령줄 인터페이스인 hcp 를 사용하여 OpenShift Container Platform 호스팅 클러스터를 생성할 수 있습니다. 호스팅된 클러스터는 자동으로 관리형 클러스터로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 "호스팅된 클러스터를 멀티클러스터 엔진 Operator로 자동 가져오기 비활성화"를 참조하세요.
4.3.1. OpenShift Virtualization에 호스팅된 제어 평면을 배포하기 위한 요구 사항
OpenShift Virtualization에 호스팅된 제어 평면을 배포할 준비를 할 때 다음 정보를 고려하세요.
- 베어메탈에서 관리 클러스터를 실행합니다.
- 호스팅된 각 클러스터에는 클러스터 전체에서 고유한 이름이 있어야 합니다.
-
호스팅된 클러스터 이름으로
클러스터를사용하지 마세요. - 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에는 호스팅된 클러스터를 만들 수 없습니다.
- 호스팅된 제어 평면에 대한 스토리지를 구성할 때 권장되는 etcd 사례를 고려하세요. 지연 시간 요구 사항을 충족하려면 각 제어 평면 노드에서 실행되는 모든 호스팅된 제어 평면 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정하세요. LVM 스토리지를 사용하여 호스팅된 etcd 포드에 대한 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 "권장되는 etcd 사례" 및 "논리 볼륨 관리자 스토리지를 사용한 영구 스토리지"를 참조하세요.
4.3.1.1. 사전 요구 사항
OpenShift Virtualization에서 OpenShift Container Platform 클러스터를 생성하려면 다음 전제 조건을 충족해야 합니다.
-
KUBECONFIG환경 변수에 지정된 OpenShift Container Platform 클러스터 버전 4.14 이상에 대한 관리자 액세스 권한이 있습니다. OpenShift Container Platform 관리 클러스터에는 다음 명령에 표시된 것처럼 와일드카드 DNS 경로가 활성화되어 있어야 합니다.
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'- OpenShift Container Platform 관리 클러스터에는 OpenShift Virtualization 버전 4.14 이상이 설치되어 있습니다. 자세한 내용은 "웹 콘솔을 사용하여 OpenShift Virtualization 설치"를 참조하세요.
- OpenShift Container Platform 관리 클러스터는 온프레미스 베어 메탈입니다.
-
OpenShift Container Platform 관리 클러스터는 기본 Pod 네트워크 컨테이너 네트워크 인터페이스(CNI)로
OVNKubernetes를사용하여 구성되어야 합니다. CNI가 OVN-Kubernetes인 경우에만 노드에 대한 라이브 마이그레이션이 지원됩니다. OpenShift Container Platform 관리 클러스터에는 기본 스토리지 클래스가 있습니다. 자세한 내용은 "Postinstallation storage configuration"을 참조하십시오. 다음 예제에서는 기본 저장소 클래스를 설정하는 방법을 보여줍니다.
$ oc patch storageclass ocs-storagecluster-ceph-rbd \ -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'-
quay.io/openshift-release-dev저장소에 대한 유효한 풀 시크릿 파일이 있습니다. 자세한 내용은 "사용자 제공 인프라를 갖춘 x86_64 플랫폼에 OpenShift 설치"를 참조하세요. - 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치했습니다.
- 로드 밸런서를 구성했습니다. 자세한 내용은 "MetalLB 구성"을 참조하세요.
최적의 네트워크 성능을 위해 KubeVirt 가상 머신을 호스팅하는 OpenShift Container Platform 클러스터에서 네트워크 최대 전송 단위(MTU)를 사용하고 있습니다. 낮은 MTU 설정을 사용하면 네트워크 지연 시간과 호스팅된 Pod의 처리량에 영향을 미칩니다. MTU가 9000 이상일 때만 노드 풀에서 멀티큐를 활성화합니다.
중요클러스터의 MTU 값은 설치 후 작업으로 변경할 수 없습니다.
멀티클러스터 엔진 Operator에는 최소한 하나의 관리형 OpenShift Container Platform 클러스터가 있습니다.
로컬 클러스터는 자동으로 가져옵니다.로컬 클러스터에 대한 자세한 내용은 멀티클러스터 엔진 운영자 설명서의 "고급 구성"을 참조하세요. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.$ oc get managedclusters local-cluster-
OpenShift Virtualization 가상 머신을 호스팅하는 OpenShift Container Platform 클러스터에서 라이브 마이그레이션을 활성화할 수 있도록
ReadWriteMany(RWX) 스토리지 클래스를 사용하고 있습니다.
4.3.1.2. 방화벽 및 포트 요구 사항
관리 클러스터, 제어 평면 및 호스팅 클러스터 간에 포트가 통신할 수 있도록 방화벽 및 포트 요구 사항을 충족하는지 확인하세요.
kube-apiserver서비스는 기본적으로 포트 6443에서 실행되며 제어 평면 구성 요소 간 통신을 위해 인그레스 액세스가 필요합니다.-
NodePort게시 전략을 사용하는 경우kube-apiserver서비스에 할당된 노드 포트가 노출되는지 확인하세요. - MetalLB 부하 분산을 사용하는 경우 부하 분산 장치 IP 주소에 사용되는 IP 범위에 대한 수신 액세스를 허용합니다.
-
-
NodePort게시 전략을 사용하는 경우ignition-server및Oauth-server설정에 대한 방화벽 규칙을 사용하세요. 호스팅된 클러스터에서 양방향 통신을 허용하는 역방향 터널을 구축하는
konnectivity에이전트는 포트 6443에서 클러스터 API 서버 주소로의 출구 액세스가 필요합니다. 해당 출구 접근 권한을 통해 에이전트는kube-apiserver서비스에 접속할 수 있습니다.- 클러스터 API 서버 주소가 내부 IP 주소인 경우 포트 6443의 IP 주소로 워크로드 서브넷에서 액세스를 허용합니다.
- 해당 주소가 외부 IP 주소인 경우 노드에서 해당 외부 IP 주소로 포트 6443을 통해 유출을 허용합니다.
- 기본 포트인 6443을 변경하는 경우 해당 변경 사항을 반영하도록 규칙을 조정하세요.
- 클러스터에서 실행되는 작업 부하에 필요한 모든 포트를 열어야 합니다.
- 방화벽 규칙, 보안 그룹 또는 기타 액세스 제어를 사용하여 필요한 소스에만 액세스를 제한합니다. 필요하지 않은 이상 포트를 공개적으로 노출하지 마십시오.
- 실제 운영 환경에 배포하는 경우, 로드 밸런서를 사용하여 단일 IP 주소를 통해 액세스를 간소화합니다.
4.3.2. 컴퓨팅 노드에 대한 라이브 마이그레이션
호스팅된 클러스터 가상 머신(VM)의 관리 클러스터가 업데이트나 유지 관리를 받는 동안, 호스팅된 클러스터 VM은 호스팅된 클러스터 작업 부하를 방해하지 않도록 자동으로 라이브 마이그레이션될 수 있습니다. 그 결과, KubeVirt 플랫폼에서 호스팅되는 클러스터의 가용성과 운영에 영향을 주지 않고 관리 클러스터를 업데이트할 수 있습니다.
KubeVirt VM의 라이브 마이그레이션은 VM이 루트 볼륨과 kubevirt-csi CSI 공급자에 매핑된 스토리지 클래스 모두에 대해 ReadWriteMany (RWX) 스토리지를 사용하는 경우 기본적으로 활성화됩니다.
NodePool 객체의 상태 섹션에서 KubeVirtNodesLiveMigratable 조건을 확인하여 노드 풀의 VM이 라이브 마이그레이션이 가능한지 확인할 수 있습니다.
다음 예에서는 RWX 스토리지가 사용되지 않기 때문에 VM을 라이브 마이그레이션할 수 없습니다.
VM을 실시간 마이그레이션할 수 없는 구성의 예
- lastTransitionTime: "2024-10-08T15:38:19Z"
message: |
3 of 3 machines are not live migratable
Machine user-np-ngst4-gw2hz: DisksNotLiveMigratable: user-np-ngst4-gw2hz is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-gw2hz-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
Machine user-np-ngst4-npq7x: DisksNotLiveMigratable: user-np-ngst4-npq7x is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-npq7x-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
Machine user-np-ngst4-q5nkb: DisksNotLiveMigratable: user-np-ngst4-q5nkb is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-q5nkb-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
observedGeneration: 1
reason: DisksNotLiveMigratable
status: "False"
type: KubeVirtNodesLiveMigratable다음 예에서는 VM이 라이브 마이그레이션 요구 사항을 충족합니다.
VM을 라이브 마이그레이션할 수 있는 구성 예
- lastTransitionTime: "2024-10-08T15:38:19Z"
message: "All is well"
observedGeneration: 1
reason: AsExpected
status: "True"
type: KubeVirtNodesLiveMigratable라이브 마이그레이션은 일반적인 상황에서 VM을 중단으로부터 보호할 수 있지만 인프라 노드 장애와 같은 이벤트가 발생하면 장애가 발생한 노드에서 호스팅되는 모든 VM이 강제로 다시 시작될 수 있습니다. 라이브 마이그레이션이 성공하려면 VM이 호스팅되는 소스 노드가 올바르게 작동해야 합니다.
노드 풀의 VM을 라이브 마이그레이션할 수 없는 경우 관리 클러스터의 유지 관리 중에 호스팅된 클러스터에서 작업 중단이 발생할 수 있습니다. 기본적으로 호스팅된 제어 평면 컨트롤러는 VM이 중지되기 전에 라이브 마이그레이션이 불가능한 KubeVirt VM에 호스팅된 워크로드를 비우려고 시도합니다. VM을 중지하기 전에 호스팅된 클러스터 노드를 비우면 Pod 중단 예산을 통해 호스팅된 클러스터 내의 워크로드 가용성을 보호할 수 있습니다.
4.3.3. KubeVirt 플랫폼을 사용하여 호스트 클러스터 생성
OpenShift Container Platform 4.14 이상에서는 KubeVirt로 클러스터를 생성하여 외부 인프라로 생성할 수 있습니다.
4.3.3.1. CLI를 사용하여 KubeVirt 플랫폼에서 호스트 클러스터 생성
호스트된 클러스터를 생성하려면 호스트된 컨트롤 플레인 명령줄 인터페이스인 hcp 를 사용할 수 있습니다.
프로세스
다음 명령을 입력하여 KubeVirt 플랫폼을 사용하여 호스팅된 클러스터를 생성합니다.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --etcd-storage-class=<etcd_storage_class>6 참고--release-image플래그를 사용하여 특정 OpenShift Container Platform 릴리스로 호스팅 클러스터를 설정할 수 있습니다.--node-pool-replicas플래그에 따라 두 개의 가상 머신 작업자 복제본이 있는 클러스터에 대한 기본 노드 풀이 생성됩니다.잠시 후 다음 명령을 입력하여 호스팅된 컨트롤 플레인 포드가 실행 중인지 확인합니다.
$ oc -n clusters-<hosted-cluster-name> get pods출력 예
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66sKubeVirt 가상 머신에서 지원하는 작업자 노드가 있는 호스팅된 클러스터는 일반적으로 완전히 프로비저닝되는 데 10-15분이 걸립니다.
검증
호스트 클러스터의 상태를 확인하려면 다음 명령을 입력하여 해당
HostedCluster리소스를 참조하십시오.$ oc get --namespace clusters hostedclusters완전히 프로비저닝된
HostedCluster오브젝트를 설명하는 다음 예제 출력을 참조하십시오.NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters my-hosted-cluster <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available&
lt;4.x.0>을 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다.
4.3.3.2. 외부 인프라를 사용하여 KubeVirt 플랫폼으로 호스트 클러스터 생성
기본적으로 HyperShift Operator는 동일한 클러스터 내에서 호스팅되는 클러스터의 컨트롤 플레인 Pod와 KubeVirt 작업자 VM을 모두 호스팅합니다. 외부 인프라 기능을 사용하면 작업자 노드 VM을 컨트롤 플레인 Pod와 별도의 클러스터에 배치할 수 있습니다.
- 관리 클러스터 는 HyperShift Operator를 실행하고 호스팅된 클러스터의 컨트롤 플레인 Pod를 호스팅하는 OpenShift Container Platform 클러스터입니다.
- 인프라 클러스터 는 호스팅된 클러스터의 KubeVirt 작업자 VM을 실행하는 OpenShift Container Platform 클러스터입니다.
- 기본적으로 관리 클러스터는 VM을 호스팅하는 인프라 클러스터 역할을 합니다. 그러나 외부 인프라의 경우 관리 및 인프라 클러스터는 다릅니다.
사전 요구 사항
- KubeVirt 노드를 호스팅하려면 외부 인프라 클러스터에 네임스페이스가 있어야 합니다.
-
외부 인프라 클러스터에 대한
kubeconfig파일이 있어야 합니다.
프로세스
hcp 명령줄 인터페이스를 사용하여 호스팅된 클러스터를 만들 수 있습니다.
인프라 클러스터에 KubeVirt 워커 VM을 배치하려면 다음 예와 같이
--infra-kubeconfig-file및--infra-namespace인수를 사용합니다.$ hcp create cluster kubevirt \ --name <hosted-cluster-name> \1 --node-pool-replicas <worker-count> \2 --pull-secret <path-to-pull-secret> \3 --memory <value-for-memory> \4 --cores <value-for-cpu> \5 --infra-namespace=<hosted-cluster-namespace>-<hosted-cluster-name> \6 --infra-kubeconfig-file=<path-to-external-infra-kubeconfig>7 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
my-hosted-cluster ). - 2
- 작업자 수를 지정합니다(예:
2). - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 예를 들어
6Gi와 같이 메모리 값을 지정합니다. - 5
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 6
- 예를 들어
clusters-example과같이 인프라 네임스페이스를 지정합니다. - 7
- 인프라 클러스터에 대한
kubeconfig파일의 경로를 지정합니다(예:/user/name/external-infra-kubeconfig ).
해당 명령을 입력한 후, 제어 플레인 포드는 HyperShift Operator가 실행되는 관리 클러스터에 호스팅되고, KubeVirt VM은 별도의 인프라 클러스터에 호스팅됩니다.
4.3.3.3. 콘솔을 사용하여 호스팅 클러스터 만들기
콘솔을 사용하여 KubeVirt 플랫폼으로 호스팅 클러스터를 생성하려면 다음 단계를 완료하세요.
프로세스
- OpenShift Container Platform 웹 콘솔을 열고 관리자 자격 증명을 입력하여 로그인합니다.
- 콘솔 헤더에서 모든 클러스터가 선택되어 있는지 확인하세요.
- 인프라 > 클러스터를 클릭합니다.
- 클러스터 만들기 > Red Hat OpenShift Virtualization > 호스팅을 클릭합니다.
클러스터 만들기 페이지에서 프롬프트에 따라 클러스터 및 노드 풀에 대한 세부 정보를 입력합니다.
참고- 미리 정의된 값을 사용하여 콘솔의 필드를 자동으로 채우려면 OpenShift Virtualization 자격 증명을 만들 수 있습니다. 자세한 내용은 "온-프레미스 환경에 대한 자격 증명 만들기"를 참조하세요.
- 클러스터 세부 정보 페이지에서 풀 시크릿은 OpenShift Container Platform 리소스에 액세스하는 데 사용하는 OpenShift Container Platform 풀 시크릿입니다. OpenShift Virtualization 자격 증명을 선택한 경우 풀 비밀이 자동으로 채워집니다.
노드 풀 페이지에서 네트워킹 옵션 섹션을 확장하고 노드 풀에 대한 네트워킹 옵션을 구성합니다.
-
추가 네트워크 필드에
<네임스페이스>/<이름>형식으로 네트워크 이름을 입력합니다(예:my-namespace/network1). 네임스페이스와 이름은 유효한 DNS 레이블이어야 합니다. 여러 네트워크가 지원됩니다. - 기본적으로 기본 Pod 네트워크 연결 확인란이 선택되어 있습니다. 추가 네트워크가 있는 경우에만 이 확인란을 선택 취소할 수 있습니다.
-
추가 네트워크 필드에
입력 내용을 검토하고 '만들기'를 클릭하세요.
호스팅된 클러스터 뷰가 표시됩니다.
검증
- 호스팅된 클러스터 보기에서 호스팅된 클러스터의 배포를 모니터링합니다. 호스팅된 클러스터에 대한 정보가 보이지 않으면 모든 클러스터가 선택되어 있는지 확인하고 클러스터 이름을 클릭하세요.
- 컨트롤 플레인 구성 요소가 준비될 때까지 기다립니다. 이 과정은 몇 분 정도 걸릴 수 있습니다.
- 노드 풀 상태를 보려면 NodePool 섹션으로 스크롤하세요. 노드를 설치하는 데 걸리는 시간은 약 10분입니다. 노드를 클릭하여 노드가 호스팅된 클러스터에 참여하고 있는지 확인할 수도 있습니다.
4.3.4. OpenShift Virtualization에서 호스팅된 제어 평면에 대한 기본 수신 및 DNS 구성
모든 OpenShift Container Platform 클러스터에는 기본 애플리케이션 Ingress Controller가 포함되어 있으며, 이와 연결된 와일드카드 DNS 레코드가 있어야 합니다. 기본적으로 HyperShift KubeVirt 공급자를 사용하여 생성된 호스팅 클러스터는 KubeVirt 가상 머신이 실행되는 OpenShift Container Platform 클러스터의 하위 도메인이 됩니다.
예를 들어, OpenShift Container Platform 클러스터에는 다음과 같은 기본 수신 DNS 항목이 있을 수 있습니다.
*.apps.mgmt-cluster.example.com
결과적으로, guest 라는 이름의 KubeVirt 호스팅 클러스터가 해당 기본 OpenShift Container Platform 클러스터에서 실행되면 다음과 같은 기본 수신이 발생합니다.
*.apps.guest.apps.mgmt-cluster.example.com프로세스
기본 수신 DNS가 제대로 작동하려면 KubeVirt 가상 머신을 호스팅하는 클러스터에서 와일드카드 DNS 경로를 허용해야 합니다.
다음 명령을 입력하여 이 동작을 구성할 수 있습니다.
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'
기본 호스팅 클러스터 인그레스를 사용하면 연결이 포트 443을 통한 HTTPS 트래픽으로 제한됩니다. 포트 80을 통한 일반 HTTP 트래픽은 거부됩니다. 이 제한은 기본 수신 동작에만 적용됩니다.
4.3.4.1. 사용자 정의 DNS 이름 정의
클러스터 관리자는 노드 부트스트랩 및 제어 평면 통신에 사용되는 내부 엔드포인트와 다른 외부 API DNS 이름을 사용하여 호스팅된 클러스터를 만들 수 있습니다. 다음과 같은 이유로 다른 DNS 이름을 정의할 수 있습니다.
- 내부 루트 CA에 바인딩되는 제어 평면 기능을 손상시키지 않고 사용자 대상 TLS 인증서를 공개 CA의 인증서로 교체합니다.
- 분할 수평 DNS 및 NAT 시나리오를 지원합니다.
-
올바른
kubeconfig및 DNS 구성을 사용하면Show Login Command기능과 같은 기능을 사용할 수 있는 독립 실행형 제어 평면과 유사한 환경을 보장할 수 있습니다.
HostedCluster 개체의 kubeAPIServerDNSName 매개변수에 도메인 이름을 입력하여 초기 설정 중이나 설치 후 작업 중에 DNS 이름을 정의할 수 있습니다.
사전 요구 사항
-
kubeAPIServerDNSName매개변수에 설정한 DNS 이름을 포함하는 유효한 TLS 인증서가 있습니다. - 올바른 주소에 도달하고 이를 가리킬 수 있는 확인 가능한 DNS 이름 URI가 있습니다.
프로세스
HostedCluster개체에 대한 사양에서kubeAPIServerDNSName매개변수와 도메인 주소를 추가하고 다음 예와 같이 사용할 인증서를 지정합니다.#... spec: configuration: apiServer: servingCerts: namedCertificates: - names: - xxx.example.com - yyy.example.com servingCertificate: name: <my_serving_certificate> kubeAPIServerDNSName: <custom_address>1 - 1
kubeAPIServerDNSName매개변수의 값은 유효하고 주소 지정이 가능한 도메인이어야 합니다.
kubeAPIServerDNSName 매개변수를 정의하고 인증서를 지정하면 Control Plane Operator 컨트롤러가 custom-admin-kubeconfig 라는 kubeconfig 파일을 생성하고, 이 파일은 HostedControlPlane 네임스페이스에 저장됩니다. 인증서 생성은 루트 CA에서 이루어지며, HostedControlPlane 네임스페이스는 인증서의 만료 및 갱신을 관리합니다.
Control Plane Operator는 HostedControlPlane 네임스페이스에 CustomKubeconfig 라는 새로운 kubeconfig 파일을 보고합니다. 해당 파일은 kubeAPIServerDNSName 매개변수에 정의된 새 서버를 사용합니다.
사용자 정의 kubeconfig 파일에 대한 참조는 HostedCluster 개체의 CustomKubeconfig 라는 상태 매개변수에 있습니다. CustomKubeConfig 매개변수는 선택 사항이며, kubeAPIServerDNSName 매개변수가 비어 있지 않은 경우에만 매개변수를 추가할 수 있습니다. CustomKubeConfig 매개변수를 설정하면 해당 매개변수는 HostedCluster 네임스페이스에 <hosted_cluster_name>-custom-admin-kubeconfig 라는 이름의 비밀을 생성합니다. 이 비밀을 사용하여 HostedCluster API 서버에 액세스할 수 있습니다. 설치 후 작업 중에 CustomKubeConfig 매개변수를 제거하면 관련된 모든 비밀과 상태 참조가 삭제됩니다.
사용자 지정 DNS 이름을 정의해도 데이터 플레인에 직접적인 영향을 미치지 않으므로 예상 롤아웃이 발생하지 않습니다. HostedControlPlane 네임스페이스는 HyperShift Operator로부터 변경 사항을 수신하고 해당 매개변수를 삭제합니다.
HostedCluster 개체의 사양에서 kubeAPIServerDNSName 매개변수를 제거하면 새로 생성된 모든 비밀과 CustomKubeconfig 참조가 클러스터와 status 매개변수에서 제거됩니다.
4.3.5. 수신 및 DNS 동작 사용자 지정
기본 수신 및 DNS 동작을 사용하지 않으려면 생성 시점에 고유한 기본 도메인을 사용하여 KubeVirt 호스팅 클러스터를 구성할 수 있습니다. 이 옵션을 사용하려면 생성 중에 수동 구성 단계가 필요하며 클러스터 생성, 로드 밸런서 생성, 와일드카드 DNS 구성이라는 세 가지 주요 단계가 포함됩니다.
4.3.5.1. 기본 도메인을 지정하는 호스팅 클러스터 배포
기본 도메인을 지정하는 호스팅 클러스터를 만들려면 다음 단계를 완료하세요.
프로세스
다음 명령을 실행합니다.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --base-domain <basedomain>6 결과적으로 호스팅된 클러스터에는 클러스터 이름과 기본 도메인에 대해 구성된 수신 와일드카드가 있습니다(예:
.apps.example.hypershift.lab). 호스팅 클러스터는 고유한 기본 도메인으로 호스팅 클러스터를 만든 후에는 필요한 DNS 레코드와 부하 분산 장치를 구성해야 하므로부분적상태로 유지됩니다.
검증
다음 명령을 입력하여 호스팅된 클러스터의 상태를 확인하세요.
$ oc get --namespace clusters hostedclusters출력 예
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available다음 명령을 입력하여 클러스터에 액세스하세요.
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console <4.x.0> False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress <4.x.0> True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)<4.x.0>을사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
다음 단계
출력의 오류를 수정하려면 "로드 밸런서 설정" 및 "와일드카드 DNS 설정"의 단계를 완료하세요.
호스팅된 클러스터가 베어 메탈인 경우 로드 밸런서 서비스를 설정하기 위해 MetalLB가 필요할 수 있습니다. 자세한 내용은 "MetalLB 구성"을 참조하세요.
4.3.5.2. 로드 밸런서 설정
KubeVirt VM으로 수신 트래픽을 라우팅하고 로드 밸런서 IP 주소에 와일드카드 DNS 항목을 할당하는 로드 밸런서 서비스를 설정합니다.
프로세스
호스팅된 클러스터 수신을 노출하는
NodePort서비스가 이미 있습니다. 노드 포트를 내보내고 해당 포트를 타겟으로 하는 로드 밸런서 서비스를 만들 수 있습니다.다음 명령을 입력하여 HTTP 노드 포트를 확인하세요.
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'다음 단계에서 사용할 HTTP 노드 포트 값을 기록해 두세요.
다음 명령을 입력하여 HTTPS 노드 포트를 가져옵니다.
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'다음 단계에서 사용할 HTTPS 노드 포트 값을 기록해 두세요.
YAML 파일에 다음 정보를 입력하세요.
apiVersion: v1 kind: Service metadata: labels: app: <hosted_cluster_name> name: <hosted_cluster_name>-apps namespace: clusters-<hosted_cluster_name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https_node_port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http_node_port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer다음 명령을 실행하여 로드 밸런서 서비스를 만듭니다.
$ oc create -f <file_name>.yaml
4.3.5.3. 와일드카드 DNS 설정
로드 밸런서 서비스의 외부 IP를 참조하는 와일드카드 DNS 레코드 또는 CNAME을 설정합니다.
프로세스
다음 명령을 입력하여 외부 IP 주소를 가져옵니다.
$ oc -n clusters-<hosted_cluster_name> get service <hosted-cluster-name>-apps \ -o jsonpath='{.status.loadBalancer.ingress[0].ip}'출력 예
192.168.20.30외부 IP 주소를 참조하는 와일드카드 DNS 항목을 구성합니다. 다음 DNS 항목 예를 확인하세요.
*.apps.<hosted_cluster_name\>.<base_domain\>.DNS 항목은 클러스터 내부와 외부로 라우팅할 수 있어야 합니다.
DNS 확인 예
dig +short test.apps.example.hypershift.lab 192.168.20.30
검증
다음 명령을 입력하여 호스팅된 클러스터 상태가
Partial(부분)에서Completed(완료)로 변경되었는지 확인하세요.$ oc get --namespace clusters hostedclusters출력 예
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available<4.x.0>을사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
4.3.6. MetalLB 구성
MetalLB를 구성하기 전에 MetalLB Operator를 설치해야 합니다.
프로세스
호스팅된 클러스터에서 MetalLB를 구성하려면 다음 단계를 완료하세요.
다음 샘플 YAML 콘텐츠를
configure-metallb.yaml파일에 저장하여MetalLB리소스를 만듭니다.apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system다음 명령을 입력하여 YAML 콘텐츠를 적용합니다.
$ oc apply -f configure-metallb.yaml출력 예
metallb.metallb.io/metallb created다음 샘플 YAML 콘텐츠를
create-ip-address-pool.yaml파일에 저장하여IPAddressPool리소스를 만듭니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: addresses: - 192.168.216.32-192.168.216.1221 - 1
- 노드 네트워크 내에서 사용 가능한 IP 주소 범위로 주소 풀을 만듭니다. IP 주소 범위를 네트워크에서 사용 가능한 IP 주소 풀로 바꿉니다.
다음 명령을 입력하여 YAML 콘텐츠를 적용합니다.
$ oc apply -f create-ip-address-pool.yaml출력 예
ipaddresspool.metallb.io/metallb created다음 샘플 YAML 콘텐츠를
l2advertisement.yaml파일에 저장하여L2Advertisement리소스를 만듭니다.apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb다음 명령을 입력하여 YAML 콘텐츠를 적용합니다.
$ oc apply -f l2advertisement.yaml출력 예
l2advertisement.metallb.io/metallb created
4.3.7. 노드 풀에 대한 추가 네트워크, 보장된 CPU 및 VM 스케줄링 구성
노드 풀에 대한 추가 네트워크를 구성하거나, 가상 머신(VM)에 대한 보장된 CPU 액세스를 요청하거나, KubeVirt VM의 일정을 관리해야 하는 경우 다음 절차를 참조하세요.
4.3.7.1. 노드 풀에 여러 네트워크 추가
기본적으로 노드 풀에서 생성된 노드는 Pod 네트워크에 연결됩니다. Multus와 NetworkAttachmentDefinitions를 사용하여 노드에 추가 네트워크를 연결할 수 있습니다.
프로세스
노드에 여러 네트워크를 추가하려면 다음 명령을 실행하여
--additional-network인수를 사용합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --additional-network name:<namespace/name> \6 –-additional-network name:<namespace/name>- 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
my-hosted-cluster ). - 2
- 예를 들어, 작업자 노드 수를
2로지정합니다. - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 메모리 값을 지정합니다(예:
8Gi). - 5
- CPU 값을 지정합니다(예:
2). - 6
–additional-network인수의 값을name:<namespace/name>으로 설정합니다.<namespace/name>을NetworkAttachmentDefinitions의 네임스페이스와 이름으로 바꾸세요.
4.3.7.1.1. 추가 네트워크를 기본값으로 사용
기본 Pod 네트워크를 비활성화하여 추가 네트워크를 노드의 기본 네트워크로 추가할 수 있습니다.
프로세스
노드에 기본 네트워크를 추가하려면 다음 명령을 실행하세요.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --attach-default-network false \6 --additional-network name:<namespace>/<network_name>7
4.3.7.2. 보장된 CPU 리소스 요청
기본적으로 KubeVirt VM은 노드의 다른 워크로드와 CPU를 공유할 수 있습니다. 이는 VM의 성능에 영향을 미칠 수 있습니다. 성능 저하를 방지하려면 VM에 대해 보장된 CPU 액세스를 요청할 수 있습니다.
프로세스
보장된 CPU 리소스를 요청하려면 다음 명령을 실행하여
--qos-class인수를Guaranteed로 설정합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --qos-class Guaranteed6
4.3.7.3. 노드 세트에서 KubeVirt VM 예약
기본적으로 노드 풀에서 생성된 KubeVirt VM은 사용 가능한 모든 노드에 예약됩니다. VM을 실행할 수 있는 충분한 용량이 있는 특정 노드 집합에 KubeVirt VM을 예약할 수 있습니다.
프로세스
특정 노드 집합의 노드 풀 내에서 KubeVirt VM을 예약하려면 다음 명령을 실행하여
--vm-node-selector인수를 사용합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --vm-node-selector <label_key>=<label_value>,<label_key>=<label_value>6
4.3.8. 노드 풀 확장
oc scale 명령을 사용하여 노드 풀의 크기를 수동으로 조정할 수 있습니다.
프로세스
다음 명령을 실행합니다.
NODEPOOL_NAME=${CLUSTER_NAME}-work NODEPOOL_REPLICAS=5 $ oc scale nodepool/$NODEPOOL_NAME --namespace clusters \ --replicas=$NODEPOOL_REPLICAS잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인하세요.
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes출력 예
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca
4.3.8.1. 노드 풀 추가
이름, 복제본 수, 메모리 및 CPU 요구 사항과 같은 추가 정보를 지정하여 호스팅된 클러스터에 대한 노드 풀을 만들 수 있습니다.
프로세스
노드 풀을 생성하려면 다음 정보를 입력하세요. 이 예에서 노드 풀에는 VM에 할당된 CPU가 더 많습니다.
export NODEPOOL_NAME=${CLUSTER_NAME}-extra-cpu export WORKER_COUNT="2" export MEM="6Gi" export CPU="4" export DISK="16" $ hcp create nodepool kubevirt \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $WORKER_COUNT \ --memory $MEM \ --cores $CPU \ --root-volume-size $DISK클러스터네임스페이스에 있는노드 풀리소스를 나열하여 노드 풀의 상태를 확인하세요.$ oc get nodepools --namespace clusters출력 예
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False <4.x.0> example-extra-cpu example 2 False False True True Minimum availability requires 2 replicas, current 0 available<4.x.0>을사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
검증
시간이 지나면 다음 명령을 입력하여 노드 풀의 상태를 확인할 수 있습니다.
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes출력 예
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca example-extra-cpu-zh9l5 Ready worker 2m6s v1.27.4+18eadca example-extra-cpu-zr8mj Ready worker 102s v1.27.4+18eadca다음 명령을 입력하여 노드 풀이 예상한 상태인지 확인하세요.
$ oc get nodepools --namespace clusters출력 예
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False <4.x.0> example-extra-cpu example 2 2 False False <4.x.0><4.x.0>을사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
4.3.9. OpenShift Virtualization에서 호스팅된 클러스터 생성 확인
호스팅된 클러스터가 성공적으로 생성되었는지 확인하려면 다음 단계를 완료하세요.
프로세스
다음 명령을 입력하여
HostedCluster리소스가완료상태로 전환되었는지 확인하세요.$ oc get --namespace clusters hostedclusters <hosted_cluster_name>출력 예
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters example 4.12.2 example-admin-kubeconfig Completed True False The hosted control plane is available다음 명령을 입력하여 호스팅된 클러스터의 모든 클러스터 운영자가 온라인 상태인지 확인하세요.
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc get co --kubeconfig=<hosted_cluster_name>-kubeconfig출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.12.2 True False False 2m38s csi-snapshot-controller 4.12.2 True False False 4m3s dns 4.12.2 True False False 2m52s image-registry 4.12.2 True False False 2m8s ingress 4.12.2 True False False 22m kube-apiserver 4.12.2 True False False 23m kube-controller-manager 4.12.2 True False False 23m kube-scheduler 4.12.2 True False False 23m kube-storage-version-migrator 4.12.2 True False False 4m52s monitoring 4.12.2 True False False 69s network 4.12.2 True False False 4m3s node-tuning 4.12.2 True False False 2m22s openshift-apiserver 4.12.2 True False False 23m openshift-controller-manager 4.12.2 True False False 23m openshift-samples 4.12.2 True False False 2m15s operator-lifecycle-manager 4.12.2 True False False 22m operator-lifecycle-manager-catalog 4.12.2 True False False 23m operator-lifecycle-manager-packageserver 4.12.2 True False False 23m service-ca 4.12.2 True False False 4m41s storage 4.12.2 True False False 4m43s
4.3.10. 호스팅된 클러스터에서 사용자 정의 API 서버 인증서 구성
API 서버에 대한 사용자 정의 인증서를 구성하려면 HostedCluster 구성의 spec.configuration.apiServer 섹션에서 인증서 세부 정보를 지정하세요.
1일차 또는 2일차 작업 중에 사용자 정의 인증서를 구성할 수 있습니다. 그러나 서비스 게시 전략은 호스팅 클러스터를 생성하는 동안 설정한 후에는 변경할 수 없으므로 구성하려는 Kubernetes API 서버의 호스트 이름을 알아야 합니다.
사전 요구 사항
관리 클러스터에 사용자 정의 인증서가 포함된 Kubernetes 비밀을 생성했습니다. 비밀에는 다음과 같은 키가 포함되어 있습니다.
-
tls.crt: 인증서 -
tls.key: 개인 키
-
-
HostedCluster구성에 부하 분산 장치를 사용하는 서비스 게시 전략이 포함된 경우 인증서의 SAN(주체 대체 이름)이 내부 API 엔드포인트(api-int)와 충돌하지 않는지 확인하세요. 내부 API 엔드포인트는 플랫폼에서 자동으로 생성되고 관리됩니다. 사용자 정의 인증서와 내부 API 엔드포인트 모두에서 동일한 호스트 이름을 사용하면 라우팅 충돌이 발생할 수 있습니다. 이 규칙의 유일한 예외는 AWS를Private또는PublicAndPrivate구성으로 공급자로 사용하는 경우입니다. 이런 경우 SAN 충돌은 플랫폼에 의해 관리됩니다. - 인증서는 외부 API 엔드포인트에 대해 유효해야 합니다.
- 인증서의 유효 기간은 클러스터의 예상 수명 주기와 일치합니다.
프로세스
다음 명령을 입력하여 사용자 지정 인증서로 비밀을 만듭니다.
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>다음 예와 같이 사용자 지정 인증서 세부 정보로
HostedCluster구성을 업데이트합니다.spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert다음 명령을 입력하여
HostedCluster구성에 변경 사항을 적용합니다.$ oc apply -f <hosted_cluster_config>.yaml
검증
- API 서버 포드를 확인하여 새 인증서가 마운트되었는지 확인하세요.
- 사용자 지정 도메인 이름을 사용하여 API 서버에 대한 연결을 테스트합니다.
-
브라우저나
openssl과 같은 도구를 사용하여 인증서 세부 정보를 확인하세요.
4.4. 베어메탈이 아닌 에이전트 머신에 호스팅된 제어 평면 배포
클러스터를 호스팅 클러스터로 구성하여 호스팅된 제어 평면을 배포할 수 있습니다. 호스팅 클러스터는 제어 평면이 호스팅되는 OpenShift Container Platform 클러스터입니다. 호스팅 클러스터는 관리 클러스터라고도 합니다.
베어메탈이 아닌 에이전트 머신에 호스팅된 제어 평면은 Technology Preview 기능에만 해당됩니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
관리 클러스터는 관리되는 클러스터와 다릅니다. 관리형 클러스터는 허브 클러스터가 관리하는 클러스터입니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
멀티클러스터 엔진 Operator는 기본 로컬 클러스터 관리 허브 클러스터만 지원합니다. Red Hat Advanced Cluster Management(RHACM) 2.10에서는 로컬 클러스터 관리 허브 클러스터를 호스팅 클러스터로 사용할 수 있습니다.
호스팅 클러스터 는 API 엔드포인트와 제어 평면이 호스팅 클러스터에 호스팅되는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다. 멀티클러스터 엔진 운영자 콘솔이나 hcp 명령줄 인터페이스(CLI)를 사용하여 호스팅 클러스터를 만들 수 있습니다.
호스팅된 클러스터는 자동으로 관리형 클러스터로 가져옵니다. 이 자동 가져오기 기능을 비활성화하려면 "호스팅된 클러스터를 멀티클러스터 엔진 Operator로 자동 가져오기 비활성화"를 참조하세요.
4.4.1. 베어메탈이 아닌 에이전트 머신에 호스팅된 제어 평면을 배포할 준비 중
베어 메탈에 호스팅된 제어 평면을 배포할 준비를 할 때 다음 정보를 고려하세요.
- Agent 플랫폼을 사용하면 호스팅된 클러스터에 에이전트 머신을 워커 노드로 추가할 수 있습니다. 에이전트 머신은 Discovery Image로 부팅되어 OpenShift Container Platform 노드로 프로비저닝될 준비가 된 호스트를 나타냅니다. Agent 플랫폼은 중앙 인프라 관리 서비스의 일부입니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하세요.
- 베어 메탈이 아닌 모든 호스트는 중앙 인프라 관리에서 제공하는 Discovery Image ISO를 사용하여 수동 부팅해야 합니다.
- 노드 풀을 확장하면 모든 복제본에 대해 머신이 생성됩니다. 각 머신에 대해 클러스터 API 공급자는 승인되고, 검증을 통과하고, 현재 사용 중이 아니며, 노드 풀 사양에 지정된 요구 사항을 충족하는 에이전트를 찾아 설치합니다. 에이전트의 상태와 조건을 확인하여 에이전트의 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩 해제됩니다. 에이전트를 재사용하려면 먼저 Discovery 이미지를 사용하여 에이전트를 다시 시작해야 합니다.
- 호스팅된 제어 평면에 대한 스토리지를 구성할 때 권장되는 etcd 사례를 고려하세요. 대기 시간 요구 사항을 충족하려면 각 제어 평면 노드에서 실행되는 모든 호스팅 제어 평면 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정하세요. LVM 스토리지를 사용하여 호스팅된 etcd 포드에 대한 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 OpenShift Container Platform 설명서의 "권장되는 etcd 사례" 및 "논리적 볼륨 관리자 스토리지를 사용한 영구 스토리지"를 참조하세요.
4.4.1.1. 베어메탈이 아닌 에이전트 머신에 호스팅된 제어 평면을 배포하기 위한 전제 조건
베어메탈이 아닌 에이전트 머신에 호스팅된 제어 평면을 배포하기 전에 다음 필수 구성 요소를 충족하는지 확인하세요.
- OpenShift Container Platform 클러스터에 Kubernetes Operator 2.5 이상용 멀티클러스터 엔진이 설치되어 있어야 합니다. OpenShift Container Platform OperatorHub에서 Operator로 멀티클러스터 엔진 Operator를 설치할 수 있습니다.
멀티클러스터 엔진 운영자의 경우 관리되는 OpenShift Container Platform 클러스터가 하나 이상 있어야 합니다.
로컬 클러스터관리 클러스터가 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 Red Hat Advanced Cluster Management 문서의 고급 구성을 참조하세요. 다음 명령을 실행하여 관리 클러스터의 상태를 확인할 수 있습니다.$ oc get managedclusters local-cluster- 중앙 인프라 관리를 활성화했습니다. 자세한 내용은 Red Hat Advanced Cluster Management 문서에서 중앙 인프라 관리 서비스 활성화를 참조하세요.
-
hcp명령줄 인터페이스를 설치했습니다. - 호스팅된 클러스터에는 클러스터 전체에서 고유한 이름이 있습니다.
- 동일한 인프라에서 관리 클러스터와 작업자를 실행하고 있습니다.
4.4.1.2. 베어메탈이 아닌 에이전트 머신에 대한 방화벽, 포트 및 서비스 요구 사항
관리 클러스터, 제어 평면 및 호스팅 클러스터 간에 포트가 통신할 수 있도록 방화벽 및 포트 요구 사항을 충족해야 합니다.
서비스는 기본 포트에서 실행됩니다. 하지만 NodePort 게시 전략을 사용하면 서비스는 NodePort 서비스에서 할당한 포트에서 실행됩니다.
방화벽 규칙, 보안 그룹 또는 기타 액세스 제어를 사용하여 필요한 소스에만 액세스를 제한합니다. 필요하지 않은 이상 포트를 공개적으로 노출하지 마십시오. 실제 운영 환경에 배포하는 경우, 로드 밸런서를 사용하여 단일 IP 주소를 통해 액세스를 간소화합니다.
호스팅된 제어 평면은 베어메탈이 아닌 에이전트 머신에서 다음 서비스를 제공합니다.
APIServer-
APIServer서비스는 기본적으로 포트 6443에서 실행되며 제어 평면 구성 요소 간 통신을 위해 인그레스 액세스가 필요합니다. - MetalLB 부하 분산을 사용하는 경우 부하 분산 장치 IP 주소에 사용되는 IP 범위에 대한 수신 액세스를 허용합니다.
-
OAuthServer-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
OAuthServer서비스는 기본적으로 포트 443에서 실행됩니다. -
NodePort게시 전략을 사용하는 경우OAuthServer서비스에 대한 방화벽 규칙을 사용하세요.
-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
연결성-
경로와 인그레스를 사용하여 서비스를 노출하는 경우
Konnectivity서비스는 기본적으로 포트 443에서 실행됩니다. -
Konnectivity에이전트는 제어 평면이 호스팅된 클러스터의 네트워크에 액세스할 수 있도록 역방향 터널을 설정합니다. 에이전트는 출구를 통해Konnectivity서버에 연결합니다. 서버는 포트 443의 경로나 수동으로 할당된NodePort를사용하여 노출됩니다. - 클러스터 API 서버 주소가 내부 IP 주소인 경우 포트 6443의 IP 주소로 워크로드 서브넷에서 액세스를 허용합니다.
- 해당 주소가 외부 IP 주소인 경우 노드에서 해당 외부 IP 주소로 포트 6443을 통해 유출을 허용합니다.
-
경로와 인그레스를 사용하여 서비스를 노출하는 경우
Ignition-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
Ignition서비스는 기본적으로 포트 443에서 실행됩니다. -
NodePort게시 전략을 사용하는 경우Ignition서비스에 대한 방화벽 규칙을 사용하세요.
-
라우트와 인그레스를 사용하여 서비스를 노출하는 경우
베어메탈이 아닌 에이전트 머신에서는 다음 서비스가 필요하지 않습니다.
-
OVNSbDb -
OIDC
4.4.1.3. 베어메탈이 아닌 에이전트 머신에 대한 인프라 요구 사항
Agent 플랫폼은 어떠한 인프라도 생성하지 않지만, 다음과 같은 인프라 요구 사항을 갖추고 있습니다.
- 에이전트: 에이전트는 검색 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝될 준비가 된 호스트를 나타냅니다.
- DNS: API 및 수신 엔드포인트는 라우팅 가능해야 합니다.
4.4.2. 베어메탈이 아닌 에이전트 머신에서 DNS 구성
호스팅된 클러스터의 API 서버는 NodePort 서비스로 노출됩니다. API 서버에 도달할 수 있는 대상을 가리키는 api.<hosted_cluster_name>.<basedomain> 에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 제어 평면을 실행하는 관리되는 클러스터의 노드 중 하나를 가리키는 레코드만큼 간단할 수 있습니다. 또한, 진입점은 유입 트래픽을 인그레스 포드로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
IPv4 네트워크에서 연결된 환경에 대한 DNS를 구성하는 경우 다음 DNS 구성 예를 참조하세요.
api.example.krnl.es. IN A 192.168.122.20 api.example.krnl.es. IN A 192.168.122.21 api.example.krnl.es. IN A 192.168.122.22 api-int.example.krnl.es. IN A 192.168.122.20 api-int.example.krnl.es. IN A 192.168.122.21 api-int.example.krnl.es. IN A 192.168.122.22 `*`.apps.example.krnl.es. IN A 192.168.122.23IPv6 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 다음 DNS 구성 예를 참조하세요.
api.example.krnl.es. IN A 2620:52:0:1306::5 api.example.krnl.es. IN A 2620:52:0:1306::6 api.example.krnl.es. IN A 2620:52:0:1306::7 api-int.example.krnl.es. IN A 2620:52:0:1306::5 api-int.example.krnl.es. IN A 2620:52:0:1306::6 api-int.example.krnl.es. IN A 2620:52:0:1306::7 `*`.apps.example.krnl.es. IN A 2620:52:0:1306::10듀얼 스택 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 IPv4와 IPv6에 대한 DNS 항목을 모두 포함해야 합니다. 다음 DNS 구성 예를 참조하세요.
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10 host-record=api.hub-dual.dns.base.domain.name,192.168.126.10 address=/apps.hub-dual.dns.base.domain.name/192.168.126.11 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20 dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21 dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22 dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25 dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26 host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2 host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2 address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5] dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6] dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7] dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8] dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]
4.4.2.1. 사용자 정의 DNS 이름 정의
클러스터 관리자는 노드 부트스트랩 및 제어 평면 통신에 사용되는 내부 엔드포인트와 다른 외부 API DNS 이름을 사용하여 호스팅된 클러스터를 만들 수 있습니다. 다음과 같은 이유로 다른 DNS 이름을 정의할 수 있습니다.
- 내부 루트 CA에 바인딩되는 제어 평면 기능을 손상시키지 않고 사용자 대상 TLS 인증서를 공개 CA의 인증서로 교체합니다.
- 분할 수평 DNS 및 NAT 시나리오를 지원합니다.
-
올바른
kubeconfig및 DNS 구성을 사용하면Show Login Command기능과 같은 기능을 사용할 수 있는 독립 실행형 제어 평면과 유사한 환경을 보장할 수 있습니다.
HostedCluster 개체의 kubeAPIServerDNSName 매개변수에 도메인 이름을 입력하여 초기 설정 중이나 설치 후 작업 중에 DNS 이름을 정의할 수 있습니다.
사전 요구 사항
-
kubeAPIServerDNSName매개변수에 설정한 DNS 이름을 포함하는 유효한 TLS 인증서가 있습니다. - 올바른 주소에 도달하고 이를 가리킬 수 있는 확인 가능한 DNS 이름 URI가 있습니다.
프로세스
HostedCluster개체에 대한 사양에서kubeAPIServerDNSName매개변수와 도메인 주소를 추가하고 다음 예와 같이 사용할 인증서를 지정합니다.#... spec: configuration: apiServer: servingCerts: namedCertificates: - names: - xxx.example.com - yyy.example.com servingCertificate: name: <my_serving_certificate> kubeAPIServerDNSName: <custom_address>1 - 1
kubeAPIServerDNSName매개변수의 값은 유효하고 주소 지정이 가능한 도메인이어야 합니다.
kubeAPIServerDNSName 매개변수를 정의하고 인증서를 지정하면 Control Plane Operator 컨트롤러가 custom-admin-kubeconfig 라는 kubeconfig 파일을 생성하고, 이 파일은 HostedControlPlane 네임스페이스에 저장됩니다. 인증서 생성은 루트 CA에서 이루어지며, HostedControlPlane 네임스페이스는 인증서의 만료 및 갱신을 관리합니다.
Control Plane Operator는 HostedControlPlane 네임스페이스에 CustomKubeconfig 라는 새로운 kubeconfig 파일을 보고합니다. 해당 파일은 kubeAPIServerDNSName 매개변수에 정의된 새 서버를 사용합니다.
사용자 정의 kubeconfig 파일에 대한 참조는 HostedCluster 개체의 CustomKubeconfig 라는 상태 매개변수에 있습니다. CustomKubeConfig 매개변수는 선택 사항이며, kubeAPIServerDNSName 매개변수가 비어 있지 않은 경우에만 매개변수를 추가할 수 있습니다. CustomKubeConfig 매개변수를 설정하면 해당 매개변수는 HostedCluster 네임스페이스에 <hosted_cluster_name>-custom-admin-kubeconfig 라는 이름의 비밀을 생성합니다. 이 비밀을 사용하여 HostedCluster API 서버에 액세스할 수 있습니다. 설치 후 작업 중에 CustomKubeConfig 매개변수를 제거하면 관련된 모든 비밀과 상태 참조가 삭제됩니다.
사용자 지정 DNS 이름을 정의해도 데이터 플레인에 직접적인 영향을 미치지 않으므로 예상 롤아웃이 발생하지 않습니다. HostedControlPlane 네임스페이스는 HyperShift Operator로부터 변경 사항을 수신하고 해당 매개변수를 삭제합니다.
HostedCluster 개체의 사양에서 kubeAPIServerDNSName 매개변수를 제거하면 새로 생성된 모든 비밀과 CustomKubeconfig 참조가 클러스터와 status 매개변수에서 제거됩니다.
4.4.3. CLI를 사용하여 베어메탈이 아닌 에이전트 머신에 호스팅된 클러스터 만들기
Agent 플랫폼을 사용하여 호스팅 클러스터를 생성하면 HyperShift Operator가 호스팅 제어 평면 네임스페이스에 Agent Cluster API 공급자를 설치합니다. 베어 메탈에서 호스팅 클러스터를 만들거나 가져올 수 있습니다.
호스팅 클러스터를 생성할 때 다음 지침을 검토하세요.
- 호스팅된 각 클러스터에는 클러스터 전체에서 고유한 이름이 있어야 합니다. 멀티클러스터 엔진 운영자가 관리할 수 있도록 호스팅된 클러스터 이름은 기존 관리형 클러스터와 동일할 수 없습니다.
-
호스팅된 클러스터 이름으로
클러스터를사용하지 마세요. - 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에는 호스팅된 클러스터를 만들 수 없습니다.
프로세스
다음 명령을 입력하여 호스팅된 제어 평면 네임스페이스를 만듭니다.
$ oc create ns <hosted_cluster_namespace>-<hosted_cluster_name>1 - 1
<hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스 이름(예:clusters )으로 바꾸세요.<hosted_cluster_name>을호스팅 클러스터 이름으로 바꾸세요.
다음 명령을 입력하여 호스팅 클러스터를 만듭니다.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --control-plane-availability-policy HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release> \10 --node-pool-replicas <node_pool_replica_count>11 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 3
- 호스팅된 제어 평면 네임스페이스를 지정합니다(예:
clusters-example).oc get agent -n <hosted-control-plane-namespace>명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다. - 4
- 기본 도메인을 지정하세요(예:
krnl.es). - 5
--api-server-address플래그는 호스팅된 클러스터에서 Kubernetes API 통신에 사용되는 IP 주소를 정의합니다.--api-server-address플래그를 설정하지 않으면 관리 클러스터에 연결하려면 로그인해야 합니다.- 6
- 클러스터에 기본 스토리지 클래스가 구성되어 있는지 확인하세요. 그렇지 않으면 보류 중인 PVC가 생길 수 있습니다. 예를 들어
lvm-storageclass와 같이 etcd 스토리지 클래스 이름을 지정합니다. - 7
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 9
- 호스팅된 제어 평면 구성 요소에 대한 가용성 정책을 지정합니다. 지원되는 옵션은
SingleReplica및HighlyAvailable입니다. 기본값은HighlyAvailable입니다. - 10
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.19.0-multi). - 11
- 노드 풀 복제본 수를 지정합니다(예:
3). 동일한 수의 복제본을 생성하려면 복제본 수를0이상으로 지정해야 합니다. 그렇지 않으면 노드 풀이 생성되지 않습니다.
검증
잠시 후 다음 명령을 입력하여 호스팅된 제어 평면 포드가 작동 중인지 확인하세요.
$ oc -n <hosted_cluster_namespace>-<hosted_cluster_name> get pods출력 예
NAME READY STATUS RESTARTS AGE catalog-operator-6cd867cc7-phb2q 2/2 Running 0 2m50s control-plane-operator-f6b4c8465-4k5dh 1/1 Running 0 4m32s
4.4.3.1. 웹 콘솔을 사용하여 베어메탈이 아닌 에이전트 머신에 호스팅된 클러스터 만들기
OpenShift Container Platform 웹 콘솔을 사용하여 베어메탈이 아닌 에이전트 머신에 호스팅된 클러스터를 만들 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - OpenShift Container Platform 웹 콘솔에 액세스할 수 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔을 열고 관리자 자격 증명을 입력하여 로그인합니다.
- 콘솔 헤더에서 모든 클러스터를 선택합니다.
- 인프라 → 클러스터를 클릭합니다.
클러스터 호스트 인벤토리 만들기 → 호스팅된 제어 평면을 클릭합니다.
클러스터 만들기 페이지가 표시됩니다.
- 클러스터 만들기 페이지에서 프롬프트에 따라 클러스터, 노드 풀, 네트워킹 및 자동화에 대한 세부 정보를 입력합니다.
클러스터에 대한 세부 정보를 입력할 때 다음 팁이 유용할 수 있습니다.
- 미리 정의된 값을 사용하여 콘솔의 필드를 자동으로 채우려면 호스트 인벤토리 자격 증명을 만들 수 있습니다. 자세한 내용은 온-프레미스 환경에 대한 인증 정보 만들기 를 참조하십시오.
- 클러스터 세부 정보 페이지에서 풀 시크릿은 OpenShift Container Platform 리소스에 액세스하는 데 사용하는 OpenShift Container Platform 풀 시크릿입니다. 호스트 인벤토리 인증 정보를 선택한 경우 가져오기 보안이 자동으로 채워집니다.
- 노드 풀 페이지에서 네임스페이스에는 노드 풀의 호스트가 포함되어 있습니다. 콘솔을 사용하여 호스트 인벤토리를 생성한 경우 콘솔은 전용 네임스페이스를 생성합니다.
네트워킹 페이지에서 API 서버 게시 전략을 선택합니다. 호스팅된 클러스터의 API 서버는 기존 로드 밸런서를 사용하거나
NodePort유형의 서비스로 노출될 수 있습니다. API 서버에 연결할 수 있는 대상을 가리키는api.<hosted_cluster_name>.<basedomain> 설정에 대한 DNS 항목이 있어야 합니다. 이 항목은 관리 클러스터의 노드 중 하나를 가리키는 레코드이거나 수신 트래픽을 Ingress pod로 리디렉션하는 로드 밸런서를 가리키는 레코드일 수 있습니다.- 항목을 검토하고 생성 을 클릭합니다.
호스팅된 클러스터 보기가 표시됩니다.
- Hosted 클러스터 보기에서 호스팅된 클러스터의 배포를 모니터링합니다. 호스팅된 클러스터에 대한 정보가 표시되지 않는 경우 모든 클러스터가 선택되어 있는지 확인하고 클러스터 이름을 클릭합니다. 컨트롤 플레인 구성 요소가 준비될 때까지 기다립니다. 이 프로세스는 몇 분 정도 걸릴 수 있습니다.
- 노드 풀 상태를 보려면 NodePool 섹션으로 스크롤합니다. 노드를 설치하는 프로세스에는 약 10분이 걸립니다. 노드를 클릭하여 노드가 호스팅된 클러스터에 참여하고 있는지 확인할 수도 있습니다.
다음 단계
- 웹 콘솔에 액세스하려면 웹 콘솔 액세스를 참조하십시오.
4.4.3.2. 미러 레지스트리를 사용하여 베어메탈이 아닌 에이전트 머신에 호스팅된 클러스터 만들기
hcp create cluster 명령에서 --image-content-sources 플래그를 지정하여 베어메탈이 아닌 에이전트 머신에 호스팅된 클러스터를 생성하기 위해 미러 레지스트리를 사용할 수 있습니다.
프로세스
YAML 파일을 생성하여 ICSP(Image Content Source Policies)를 정의합니다. 다음 예제를 참조하십시오.
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
파일을
icsp.yaml로 저장합니다. 이 파일에는 미러 레지스트리가 포함되어 있습니다. 미러 레지스트리를 사용하여 호스팅된 클러스터를 생성하려면 다음 명령을 실행합니다.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --image-content-sources icsp.yaml \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>9 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
- 풀 시크릿의 경로를 지정합니다(예:
/user/name/pullsecret). - 3
- 호스팅된 컨트롤 플레인 네임스페이스를 지정합니다(예: cluster
-example).oc get agent -n <hosted-control-plane-namespace> 명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다. - 4
- 기본 도메인을 지정합니다(예:
krnl.es). - 5
--api-server-address플래그는 호스팅된 클러스터의 Kubernetes API 통신에 사용되는 IP 주소를 정의합니다.--api-server-address플래그를 설정하지 않으면 관리 클러스터에 연결하려면 로그인해야 합니다.- 6
- ICSP 및 미러 레지스트리를 정의하는
icsp.yaml파일을 지정합니다. - 7
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 9
- 사용하려는 지원되는 OpenShift Container Platform 버전을 지정합니다(예:
4.19.0-multi). 연결이 끊긴 환경을 사용하는 경우 <ocp_release_image>를 다이제스트 이미지로 교체합니다. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하세요.
다음 단계
- 콘솔을 사용하여 호스팅된 클러스터를 생성할 때 재사용할 수 있는 자격 증명을 만들려면 온-프레미스 환경에 대한 자격 증명 만들기를 참조하세요.
- 호스트된 클러스터에 액세스하려면 호스팅 된 클러스터 액세스를 참조하십시오.
- Discovery Image를 사용하여 호스트 인벤토리에 호스트를 추가하려면 Discovery Image를 사용하여 호스트 인벤토리에 호스트 추가를 참조하세요.
- OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트를 추출하려면 OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트 추출을 참조하세요.
4.4.4. 베어 메탈이 아닌 에이전트 시스템에서 호스트 클러스터 생성 확인
배포 프로세스가 완료되면 호스트 클러스터가 성공적으로 생성되었는지 확인할 수 있습니다. 호스팅된 클러스터를 생성한 후 몇 분 후에 다음 단계를 수행합니다.
프로세스
다음 명령을 입력하여 새 호스팅 클러스터의
kubeconfig파일을 가져옵니다.$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>kubeconfig파일을 사용하여 호스팅된 클러스터의 클러스터 Operator를 확인합니다. 다음 명령을 실행합니다.$ oc get co --kubeconfig=kubeconfig-<hosted_cluster_name>출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s csi-snapshot-controller 4.10.26 True False False 4m3s dns 4.10.26 True False False 2m52s다음 명령을 입력하여 호스팅 클러스터에서 실행 중인 Pod를 볼 수도 있습니다.
$ oc get pods -A --kubeconfig=kubeconfig-<hosted_cluster_name>출력 예
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-samples-operator cluster-samples-operator-6b5bcb9dff-kpnbc 2/2 Running 0 20m openshift-monitoring alertmanager-main-0 6/6 Running 0 100s openshift-monitoring openshift-state-metrics-677b9fb74f-qqp6g 3/3 Running 0 104s
4.4.5. 호스팅된 클러스터에서 사용자 정의 API 서버 인증서 구성
API 서버에 대한 사용자 정의 인증서를 구성하려면 HostedCluster 구성의 spec.configuration.apiServer 섹션에서 인증서 세부 정보를 지정하세요.
1일차 또는 2일차 작업 중에 사용자 정의 인증서를 구성할 수 있습니다. 그러나 서비스 게시 전략은 호스팅 클러스터를 생성하는 동안 설정한 후에는 변경할 수 없으므로 구성하려는 Kubernetes API 서버의 호스트 이름을 알아야 합니다.
사전 요구 사항
관리 클러스터에 사용자 정의 인증서가 포함된 Kubernetes 비밀을 생성했습니다. 비밀에는 다음과 같은 키가 포함되어 있습니다.
-
tls.crt: 인증서 -
tls.key: 개인 키
-
-
HostedCluster구성에 부하 분산 장치를 사용하는 서비스 게시 전략이 포함된 경우 인증서의 SAN(주체 대체 이름)이 내부 API 엔드포인트(api-int)와 충돌하지 않는지 확인하세요. 내부 API 엔드포인트는 플랫폼에서 자동으로 생성되고 관리됩니다. 사용자 정의 인증서와 내부 API 엔드포인트 모두에서 동일한 호스트 이름을 사용하면 라우팅 충돌이 발생할 수 있습니다. 이 규칙의 유일한 예외는 AWS를Private또는PublicAndPrivate구성으로 공급자로 사용하는 경우입니다. 이런 경우 SAN 충돌은 플랫폼에 의해 관리됩니다. - 인증서는 외부 API 엔드포인트에 대해 유효해야 합니다.
- 인증서의 유효 기간은 클러스터의 예상 수명 주기와 일치합니다.
프로세스
다음 명령을 입력하여 사용자 지정 인증서로 비밀을 만듭니다.
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>다음 예와 같이 사용자 지정 인증서 세부 정보로
HostedCluster구성을 업데이트합니다.spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert다음 명령을 입력하여
HostedCluster구성에 변경 사항을 적용합니다.$ oc apply -f <hosted_cluster_config>.yaml
검증
- API 서버 포드를 확인하여 새 인증서가 마운트되었는지 확인하세요.
- 사용자 지정 도메인 이름을 사용하여 API 서버에 대한 연결을 테스트합니다.
-
브라우저나
openssl과 같은 도구를 사용하여 인증서 세부 정보를 확인하세요.
4.5. IBM Power에 호스팅된 컨트롤 플레인 배포
IBM Z에서 호스팅되는 제어 플레인의 경우 64비트 x86 아키텍처 기반 머신 유형과 IBM Power 또는 IBM Z의 노드 풀에서 제어 플레인을 실행해야 합니다. 다른 아키텍처에서 실행되는 IBM Z의 호스팅되는 제어 플레인에 대한 자세한 내용은 호스팅되는 제어 플레인에 대한 지원 매트릭스를 참조하세요.
관리 클러스터로 작동하도록 클러스터를 구성하여 호스팅되는 컨트롤 플레인을 배포할 수 있습니다. 관리 클러스터는 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 관리 클러스터를 호스팅 클러스터라고도 합니다.
관리 클러스터는 관리 클러스터가 아닙니다. 관리형 클러스터는 hub 클러스터가 관리하는 클러스터입니다.
hypershift 애드온을 사용하여 해당 클러스터에 HyperShift Operator를 배포하여 관리형 클러스터를 관리 클러스터로 변환할 수 있습니다. 그런 다음 호스팅된 클러스터를 생성할 수 있습니다.
다중 클러스터 엔진 Operator는 관리하는 허브 클러스터인 기본 로컬 클러스터 및 hub 클러스터만 관리 클러스터로 지원합니다.
베어 메탈에서 호스팅되는 컨트롤 플레인을 프로비저닝하려면 에이전트 플랫폼을 사용할 수 있습니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스트된 클러스터에 작업자 노드를 추가합니다. 자세한 내용은 "중앙 인프라 관리 서비스 활성화"를 참조하십시오.
각 IBM Z 시스템 호스트는 중앙 인프라 관리에서 제공하는 PXE 이미지로 시작해야 합니다. 각 호스트가 시작되면 에이전트 프로세스를 실행하여 호스트의 세부 정보를 검색하고 설치를 완료합니다. 에이전트 사용자 정의 리소스는 각 호스트를 나타냅니다.
에이전트 플랫폼을 사용하여 호스팅된 클러스터를 생성하면 HyperShift Operator가 호스팅된 컨트롤 플레인 네임스페이스에 에이전트 클러스터 API 공급자를 설치합니다.
4.5.1. IBM Z에서 호스팅된 컨트롤 플레인을 구성하기 위한 사전 요구 사항
- Kubernetes Operator 버전 2.5 이상의 멀티 클러스터 엔진은 OpenShift Container Platform 클러스터에 설치해야 합니다. OpenShift Container Platform OperatorHub에서 다중 클러스터 엔진 Operator를 Operator로 설치할 수 있습니다.
다중 클러스터 엔진 Operator에는 하나 이상의 관리형 OpenShift Container Platform 클러스터가 있어야 합니다.
local-cluster는 다중 클러스터 엔진 Operator 2.5 이상에서 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 Red Hat Advanced Cluster Management 설명서의 고급 구성 을 참조하십시오. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.$ oc get managedclusters local-cluster- HyperShift Operator를 실행하려면 작업자 노드가 3개 이상 있는 호스팅 클러스터가 필요합니다.
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 중앙 인프라 관리 서비스 활성화를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스를 설치해야 합니다. 자세한 내용은 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치를 참조하십시오.
4.5.2. IBM Z 인프라 요구사항
에이전트 플랫폼은 인프라를 생성하지 않지만 인프라를 위해 다음 리소스가 필요합니다.
- 에이전트: 에이전트 는 검색 이미지 또는 PXE 이미지로 부팅되고 OpenShift Container Platform 노드로 프로비저닝할 준비가 된 호스트를 나타냅니다.
- DNS: API 및 Ingress 끝점은 라우팅할 수 있어야 합니다.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다. 기능을 비활성화하고 수동으로 활성화하거나 기능을 비활성화해야 하는 경우 호스팅된 컨트롤 플레인 기능 활성화 또는 비활성화를 참조하십시오.
4.5.3. IBM Z에서 호스팅된 컨트롤 플레인의 DNS 구성
호스팅된 클러스터의 API 서버는 NodePort 서비스로 노출됩니다. API 서버에 연결할 수 있는 대상을 가리키는 api.<hosted_cluster_name>.<base_domain >에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 컨트롤 플레인을 실행하는 관리형 클러스터의 노드 중 하나를 가리키는 레코드만큼 단순할 수 있습니다.
이 항목은 들어오는 트래픽을 Ingress Pod로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
DNS 구성의 다음 예제를 참조하십시오.
$ cat /var/named/<example.krnl.es.zone>출력 예
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- 레코드는 호스팅된 컨트롤 플레인의 수신 및 송신 트래픽을 처리하는 API 로드 밸런서의 IP 주소를 나타냅니다.
IBM z/VM의 경우 에이전트의 IP 주소에 해당하는 IP 주소를 추가합니다.
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy4.5.3.1. 사용자 정의 DNS 이름 정의
클러스터 관리자는 노드 부트스트랩 및 제어 평면 통신에 사용되는 내부 엔드포인트와 다른 외부 API DNS 이름을 사용하여 호스팅된 클러스터를 만들 수 있습니다. 다음과 같은 이유로 다른 DNS 이름을 정의할 수 있습니다.
- 내부 루트 CA에 바인딩되는 제어 평면 기능을 손상시키지 않고 사용자 대상 TLS 인증서를 공개 CA의 인증서로 교체합니다.
- 분할 수평 DNS 및 NAT 시나리오를 지원합니다.
-
올바른
kubeconfig및 DNS 구성을 사용하면Show Login Command기능과 같은 기능을 사용할 수 있는 독립 실행형 제어 평면과 유사한 환경을 보장할 수 있습니다.
HostedCluster 개체의 kubeAPIServerDNSName 매개변수에 도메인 이름을 입력하여 초기 설정 중이나 설치 후 작업 중에 DNS 이름을 정의할 수 있습니다.
사전 요구 사항
-
kubeAPIServerDNSName매개변수에 설정한 DNS 이름을 포함하는 유효한 TLS 인증서가 있습니다. - 올바른 주소에 도달하고 이를 가리킬 수 있는 확인 가능한 DNS 이름 URI가 있습니다.
프로세스
HostedCluster개체에 대한 사양에서kubeAPIServerDNSName매개변수와 도메인 주소를 추가하고 다음 예와 같이 사용할 인증서를 지정합니다.#... spec: configuration: apiServer: servingCerts: namedCertificates: - names: - xxx.example.com - yyy.example.com servingCertificate: name: <my_serving_certificate> kubeAPIServerDNSName: <custom_address>1 - 1
kubeAPIServerDNSName매개변수의 값은 유효하고 주소 지정이 가능한 도메인이어야 합니다.
kubeAPIServerDNSName 매개변수를 정의하고 인증서를 지정하면 Control Plane Operator 컨트롤러가 custom-admin-kubeconfig 라는 kubeconfig 파일을 생성하고, 이 파일은 HostedControlPlane 네임스페이스에 저장됩니다. 인증서 생성은 루트 CA에서 이루어지며, HostedControlPlane 네임스페이스는 인증서의 만료 및 갱신을 관리합니다.
Control Plane Operator는 HostedControlPlane 네임스페이스에 CustomKubeconfig 라는 새로운 kubeconfig 파일을 보고합니다. 해당 파일은 kubeAPIServerDNSName 매개변수에 정의된 새 서버를 사용합니다.
사용자 정의 kubeconfig 파일에 대한 참조는 HostedCluster 개체의 CustomKubeconfig 라는 상태 매개변수에 있습니다. CustomKubeConfig 매개변수는 선택 사항이며, kubeAPIServerDNSName 매개변수가 비어 있지 않은 경우에만 매개변수를 추가할 수 있습니다. CustomKubeConfig 매개변수를 설정하면 해당 매개변수는 HostedCluster 네임스페이스에 <hosted_cluster_name>-custom-admin-kubeconfig 라는 이름의 비밀을 생성합니다. 이 비밀을 사용하여 HostedCluster API 서버에 액세스할 수 있습니다. 설치 후 작업 중에 CustomKubeConfig 매개변수를 제거하면 관련된 모든 비밀과 상태 참조가 삭제됩니다.
사용자 지정 DNS 이름을 정의해도 데이터 플레인에 직접적인 영향을 미치지 않으므로 예상 롤아웃이 발생하지 않습니다. HostedControlPlane 네임스페이스는 HyperShift Operator로부터 변경 사항을 수신하고 해당 매개변수를 삭제합니다.
HostedCluster 개체의 사양에서 kubeAPIServerDNSName 매개변수를 제거하면 새로 생성된 모든 비밀과 CustomKubeconfig 참조가 클러스터와 status 매개변수에서 제거됩니다.
4.5.4. CLI를 사용하여 호스팅 클러스터 만들기
베어메탈 인프라에서는 호스팅된 클러스터를 만들거나 가져올 수 있습니다. 멀티클러스터 엔진 Operator에 대한 추가 기능으로 Assisted Installer를 활성화하고 Agent 플랫폼으로 호스팅된 클러스터를 생성하면 HyperShift Operator가 호스팅된 제어 평면 네임스페이스에 Agent Cluster API 공급자를 설치합니다. 에이전트 클러스터 API 공급자는 제어 평면을 호스팅하는 관리 클러스터와 컴퓨팅 노드만으로 구성된 호스팅 클러스터를 연결합니다.
사전 요구 사항
- 각 호스트 클러스터에는 클러스터 전체 이름이 있어야 합니다. 호스팅된 클러스터 이름은 기존 관리형 클러스터와 동일할 수 없습니다. 그렇지 않으면 멀티클러스터 엔진 운영자는 호스팅된 클러스터를 관리할 수 없습니다.
-
호스팅된 클러스터 이름으로
'클러스터'라는단어를 사용하지 마세요. - 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에 호스팅된 클러스터를 만들 수 없습니다.
- 최상의 보안 및 관리 관행을 위해 다른 호스팅 클러스터와 별도로 호스팅 클러스터를 만드세요.
- 클러스터에 대해 기본 스토리지 클래스가 구성되어 있는지 확인합니다. 그렇지 않으면 보류 중인 영구 볼륨 클레임(PVC)이 표시될 수 있습니다.
-
기본적으로
hcp create cluster agent명령을 사용하면 명령은 구성된 노드 포트를 사용하여 호스팅된 클러스터를 생성합니다. 베어 메탈에서 호스팅되는 클러스터의 기본 게시 전략은 로드 밸런서를 통해 서비스를 노출하는 것입니다. 웹 콘솔이나 Red Hat Advanced Cluster Management를 사용하여 호스팅 클러스터를 생성하는 경우 Kubernetes API 서버 외에 서비스에 대한 게시 전략을 설정하려면HostedCluster사용자 정의 리소스에서servicePublishingStrategy정보를 수동으로 지정해야 합니다. 인프라, 방화벽, 포트 및 서비스와 관련된 요구 사항을 포함하여 "베어 메탈에서 호스팅되는 제어 평면에 대한 요구 사항"에 설명된 요구 사항을 충족하는지 확인하세요. 예를 들어, 해당 요구 사항은 다음 예제 명령에서 볼 수 있듯이 관리 클러스터의 베어 메탈 호스트에 적절한 영역 레이블을 추가하는 방법을 설명합니다.
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- 하드웨어 인벤토리에 베어 메탈 노드를 추가했는지 확인하세요.
프로세스
다음 명령을 입력하여 네임스페이스를 만듭니다.
$ oc create ns <hosted_cluster_namespace><hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스의 식별자로 바꾸세요. HyperShift 연산자는 네임스페이스를 생성합니다. 베어 메탈 인프라에서 호스팅된 클러스터를 생성하는 동안 생성된 클러스터 API 공급자 역할에는 네임스페이스가 이미 존재해야 합니다.다음 명령을 입력하여 호스팅된 클러스터에 대한 구성 파일을 만듭니다.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
/user/name/pullsecret과 같이 풀 시크릿의 경로를 지정합니다.- 3
clusters-example과 같이 호스팅된 제어 평면 네임스페이스를 지정합니다.oc get agent -n <hosted_control_plane_namespace>명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다.- 4
krnl.es와 같이 기본 도메인을 지정하세요.- 5
--api-server-address플래그는 호스팅된 클러스터에서 Kubernetes API 통신에 사용되는 IP 주소를 정의합니다.--api-server-address플래그를 설정하지 않으면 관리 클러스터에 연결하려면 로그인해야 합니다.- 6
lvm-storageclass와 같이 etcd 스토리지 클래스 이름을 지정합니다.- 7
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 9
- 호스팅된 컨트롤 플레인 구성 요소의 가용성 정책을 지정합니다. 지원되는 옵션은
SingleReplica및HighlyAvailable입니다. 기본값은HighlyAvailable입니다. - 10
- 사용하려는 지원되는 OpenShift Container Platform 버전(예:
4.19.0-multi )을 지정합니다. 연결이 끊긴 환경을 사용하는 경우 <ocp_release_image>를 다이제스트 이미지로 교체합니다. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하세요. - 11
- 노드 풀 복제본 수를 지정합니다(예:
3). 동일한 수의 복제본을 생성하려면 복제본 수를0이상으로 지정해야 합니다. 그렇지 않으면 노드 풀을 생성하지 않습니다. - 12
--ssh-key플래그 뒤에user/.ssh/id_rsa와 같이 SSH 키의 경로를 지정합니다.
서비스 게시 전략을 구성합니다. 기본적으로 호스팅 클러스터는
NodePort서비스 게시 전략을 사용합니다. 이는 노드 포트가 추가 인프라 없이도 항상 사용 가능하기 때문입니다. 하지만 로드 밸런서를 사용하도록 서비스 게시 전략을 구성할 수 있습니다.-
기본
NodePort전략을 사용하는 경우 관리 클러스터 노드가 아닌 호스팅된 클러스터 컴퓨팅 노드를 가리키도록 DNS를 구성합니다. 자세한 내용은 "베어 메탈의 DNS 구성"을 참조하세요. 프로덕션 환경에서는
LoadBalancer전략을 사용하세요. 이 전략은 인증서 처리와 자동 DNS 확인을 제공합니다. 다음 예제에서는 호스팅된 클러스터 구성 파일에서 서비스 게시LoadBalancer전략을 변경하는 방법을 보여줍니다.# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- API 서버 유형으로
LoadBalancer를지정합니다. 다른 모든 서비스의 경우 유형으로경로를지정합니다.
-
기본
다음 명령을 입력하여 호스팅된 클러스터 구성 파일에 변경 사항을 적용합니다.
$ oc apply -f hosted_cluster_config.yaml다음 명령을 입력하여 호스팅된 클러스터, 노드 풀 및 포드가 생성되었는지 확인하세요.
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
호스팅된 클러스터가 준비되었는지 확인하세요.
사용 가능: True상태는 클러스터의 준비 상태를 나타내고 노드 풀 상태는AllMachinesReady: True를나타냅니다. 이러한 상태는 모든 클러스터 운영자의 상태를 나타냅니다. 호스팅된 클러스터에 MetalLB를 설치하세요:
호스팅된 클러스터에서
kubeconfig파일을 추출하고 다음 명령을 입력하여 호스팅된 클러스터 액세스를 위한 환경 변수를 설정합니다.$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"install-metallb-operator.yaml파일을 만들어 MetalLB Operator를 설치합니다.apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...다음 명령을 입력하여 파일을 적용합니다.
$ oc apply -f install-metallb-operator.yamldeploy-metallb-ipaddresspool.yaml파일을 만들어 MetalLB IP 주소 풀을 구성합니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f deploy-metallb-ipaddresspool.yaml다음 명령을 입력하여 운영자 상태, IP 주소 풀,
L2Advertisement리소스를 확인하여 MetalLB가 설치되었는지 확인하세요.$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
수신을 위해 로드 밸런서를 구성합니다.
ingress-loadbalancer.yaml파일을 만듭니다.apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f ingress-loadbalancer.yaml다음 명령을 입력하여 로드 밸런서 서비스가 예상대로 작동하는지 확인하세요.
$ oc get svc metallb-ingress -n openshift-ingress출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
로드 밸런서와 함께 작동하도록 DNS를 구성합니다.
-
*.apps.<hosted_cluster_namespace>.<base_domain>와일드카드 DNS 레코드를 로드 밸런서 IP 주소로 가리켜앱도메인에 대한 DNS를 구성합니다. 다음 명령을 입력하여 DNS 확인을 확인하세요.
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>출력 예
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
검증
다음 명령을 입력하여 클러스터 운영자를 확인하세요.
$ oc get clusteroperators모든 연산자가
AVAILABLE: True,PROGRESSING: False,DEGRADED: False로표시되는지 확인하세요.다음 명령을 입력하여 노드를 확인하세요.
$ oc get nodes각 노드가
READY상태인지 확인하세요.웹 브라우저에 다음 URL을 입력하여 콘솔에 대한 액세스를 테스트하세요.
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.5.5. IBM Z에서 호스팅된 컨트롤 플레인에 대한 InfraEnv 리소스 생성
InfraEnv 는 PXE 이미지로 부팅되는 호스트가 에이전트로 참여할 수 있는 환경입니다. 이 경우 에이전트는 호스팅된 컨트롤 플레인과 동일한 네임스페이스에 생성됩니다.
프로세스
구성을 포함할 YAML 파일을 생성합니다. 다음 예제를 참조하십시오.
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_control_plane_namespace> spec: cpuArchitecture: s390x pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key>-
파일을
infraenv-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f infraenv-config.yamlIBM Z 머신이 에이전트로 결합할 수 있는
initrd.img,kernel.img,rootfs.img와 같은 PXE 이미지를 다운로드하여 URL을 가져오려면 다음 명령을 입력합니다.$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name> -o json
4.5.6. InfraEnv 리소스에 IBM Z 에이전트 추가
호스팅된 컨트롤 플레인에 컴퓨팅 노드를 연결하려면 노드 풀을 확장하는 데 도움이 되는 에이전트를 생성합니다. IBM Z 환경에 에이전트를 추가하려면 이 섹션에 자세히 설명된 추가 단계가 필요합니다.
달리 명시하지 않는 한, 이러한 절차는 IBM Z 및 IBM LinuxONE의 z/VM 및 RHEL KVM 설치에 모두 적용됩니다.
4.5.6.1. IBM Z KVM을 에이전트로 추가
IBM Z with KVM의 경우 다음 명령을 실행하여 InfraEnv 리소스에서 다운로드한 PXE 이미지로 IBM Z 환경을 시작합니다. 에이전트가 생성된 후 호스트는 지원 서비스와 통신하고 관리 클러스터의 InfraEnv 리소스와 동일한 네임스페이스에 등록됩니다.
프로세스
다음 명령을 실행합니다.
virt-install \ --name "<vm_name>" \1 --autostart \ --ram=16384 \ --cpu host \ --vcpus=4 \ --location "<path_to_kernel_initrd_image>,kernel=kernel.img,initrd=initrd.img" \2 --disk <qcow_image_path> \3 --network network:macvtap-net,mac=<mac_address> \4 --graphics none \ --noautoconsole \ --wait=-1 --extra-args "rd.neednet=1 nameserver=<nameserver> coreos.live.rootfs_url=http://<http_server>/rootfs.img random.trust_cpu=on rd.luks.options=discard ignition.firstboot ignition.platform.id=metal console=tty1 console=ttyS1,115200n8 coreos.inst.persistent-kargs=console=tty1 console=ttyS1,115200n8"5 ISO 부팅의 경우
InfraEnv리소스에서 ISO를 다운로드하고 다음 명령을 실행하여 노드를 부팅합니다.virt-install \ --name "<vm_name>" \1 --autostart \ --memory=16384 \ --cpu host \ --vcpus=4 \ --network network:macvtap-net,mac=<mac_address> \2 --cdrom "<path_to_image.iso>" \3 --disk <qcow_image_path> \ --graphics none \ --noautoconsole \ --os-variant <os_version> \4 --wait=-1
4.5.6.2. IBM Z LPAR을 에이전트로 추가
IBM Z 또는 IBM LinuxONE의 논리 파티션(LPAR)을 호스팅된 제어 평면에 컴퓨팅 노드로 추가할 수 있습니다.
프로세스
에이전트에 대한 부팅 매개변수 파일을 만듭니다.
예제 매개변수 파일
rd.neednet=1 cio_ignore=all,!condev \ console=ttysclp0 \ ignition.firstboot ignition.platform.id=metal coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \1 coreos.inst.persistent-kargs=console=ttysclp0 ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \2 rd.znet=qeth,<network_adaptor_range>,layer2=1 rd.<disk_type>=<adapter> \3 zfcp.allow_lun_scan=0 ai.ip_cfg_override=1 \4 random.trust_cpu=on rd.luks.options=discard- 1
coreos.live.rootfs_url아티팩트의 경우, 시작하려는커널과initramfs에 맞는rootfs아티팩트를 지정합니다. HTTP 및 HTTPS 프로토콜만 지원됩니다.- 2
ip매개변수의 경우 IBM Z 및 IBM LinuxONE에 z/VM을 사용하여 클러스터 설치 에 설명된 대로 IP 주소를 수동으로 지정합니다.- 3
- DASD 유형 디스크에 설치하는 경우
rd.dasd를사용하여 Red Hat Enterprise Linux CoreOS(RHCOS)를 설치할 DASD를 지정합니다. FCP 유형 디스크에 설치하는 경우rd.zfcp=<adapter>,<wwpn>,<lun>을사용하여 RHCOS를 설치할 FCP 디스크를 지정합니다. - 4
- OSA(Open Systems Adapter) 또는 HiperSockets를 사용하는 경우 이 매개변수를 지정합니다.
InfraEnv리소스에서.ins및initrd.img.addrsize파일을 다운로드합니다.기본적으로
.ins및initrd.img.addrsize파일의 URL은InfraEnv리소스에서 사용할 수 없습니다. 해당 아티팩트를 가져오려면 URL을 편집해야 합니다.다음 명령을 실행하여
ins-file을포함하도록 커널 URL 엔드포인트를 업데이트합니다.$ curl -k -L -o generic.ins "< url for ins-file >"예시 URL
https://…/boot-artifacts/ins-file?arch=s390x&version=4.17.0s390x-initrd-addrsize를포함하도록initrdURL 엔드포인트를 업데이트합니다.예시 URL
https://…./s390x-initrd-addrsize?api_key=<api-key>&arch=s390x&version=4.17.0
-
initrd,kernel,generic.ins및initrd.img.addrsize매개변수 파일을 파일 서버로 전송합니다. FTP를 사용하여 파일을 전송하고 부팅하는 방법에 대한 자세한 내용은 "LPAR에 설치"를 참조하세요. - 기계를 작동시킵니다.
- 클러스터의 다른 모든 컴퓨터에 대해 이 절차를 반복합니다.
4.5.6.3. IBM z/VM을 에이전트로 추가
z/VM 게스트에 고정 IP를 사용하려면 z/VM 에이전트에 대한 NMStateConfig 속성을 구성하여 두 번째 시작 시 IP 매개변수가 유지되도록 해야 합니다.
InfraEnv 리소스에서 다운로드한 PXE 이미지로 IBM Z 환경을 시작하려면 다음 단계를 완료하세요. 에이전트가 생성된 후 호스트는 지원 서비스와 통신하고 관리 클러스터의 InfraEnv 리소스와 동일한 네임스페이스에 등록됩니다.
프로세스
매개변수 파일을 업데이트하여
rootfs_url,network_adaptor및disk_type값을 추가합니다.예제 매개변수 파일
rd.neednet=1 cio_ignore=all,!condev \ console=ttysclp0 \ ignition.firstboot ignition.platform.id=metal \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \1 coreos.inst.persistent-kargs=console=ttysclp0 ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \2 rd.znet=qeth,<network_adaptor_range>,layer2=1 rd.<disk_type>=<adapter> \3 zfcp.allow_lun_scan=0 ai.ip_cfg_override=1 \4 - 1
coreos.live.rootfs_url아티팩트의 경우, 시작하려는커널과initramfs에 맞는rootfs아티팩트를 지정합니다. HTTP 및 HTTPS 프로토콜만 지원됩니다.- 2
ip매개변수의 경우 IBM Z 및 IBM LinuxONE에 z/VM을 사용하여 클러스터 설치 에 설명된 대로 IP 주소를 수동으로 지정합니다.- 3
- DASD 유형 디스크에 설치하는 경우
rd.dasd를사용하여 Red Hat Enterprise Linux CoreOS(RHCOS)를 설치할 DASD를 지정합니다. FCP 유형 디스크에 설치하는 경우rd.zfcp=<adapter>,<wwpn>,<lun>을사용하여 RHCOS를 설치할 FCP 디스크를 지정합니다.참고FCP 다중 경로 구성의 경우 1개 대신 2개의 디스크를 제공하세요.
예
rd.zfcp=<adapter1>,<wwpn1>,<lun1> \ rd.zfcp=<adapter2>,<wwpn2>,<lun2> - 4
- OSA(Open Systems Adapter) 또는 HiperSockets를 사용하는 경우 이 매개변수를 지정합니다.
다음 명령을 실행하여
initrd, 커널 이미지 및 매개변수 파일을 게스트 VM으로 이동합니다.vmur pun -r -u -N kernel.img $INSTALLERKERNELLOCATION/<image name>vmur pun -r -u -N generic.parm $PARMFILELOCATION/paramfilenamevmur pun -r -u -N initrd.img $INSTALLERINITRAMFSLOCATION/<image name>게스트 VM 콘솔에서 다음 명령을 실행합니다.
cp ipl c에이전트와 해당 속성을 나열하려면 다음 명령을 입력하세요.
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a auto-assign다음 명령을 실행하여 에이전트를 승인합니다.
$ oc -n <hosted_control_plane_namespace> patch agent \ 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d -p \ '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-zvm-0.hostedn.example.com"}}' \1 --type merge- 1
- 선택적으로 사양에서 에이전트 ID
<installation_disk_id>및<hostname>을설정할 수 있습니다.
다음 명령을 실행하여 에이전트가 승인되었는지 확인하세요.
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign
4.5.7. IBM Z에서 호스팅되는 클러스터에 대한 NodePool 객체 확장
NodePool 개체는 호스팅 클러스터를 생성할 때 생성됩니다. NodePool 객체를 확장하면 호스팅된 제어 평면에 더 많은 컴퓨팅 노드를 추가할 수 있습니다.
노드 풀을 확장하면 머신이 생성됩니다. 클러스터 API 공급자는 승인되고, 검증을 통과하고, 현재 사용 중이 아니며, 노드 풀 사양에 지정된 요구 사항을 충족하는 에이전트를 찾습니다. 에이전트의 상태와 조건을 확인하여 에이전트의 설치를 모니터링할 수 있습니다.
프로세스
다음 명령을 실행하여
NodePool객체를 두 개의 노드로 확장합니다.$ oc -n <clusters_namespace> scale nodepool <nodepool_name> --replicas 2클러스터 API 에이전트 제공자는 무작위로 두 개의 에이전트를 선택한 후 이를 호스팅된 클러스터에 할당합니다. 이러한 에이전트는 여러 상태를 거쳐 마침내 OpenShift Container Platform 노드로 호스팅된 클러스터에 합류합니다. 에이전트는 다음 순서에 따라 전환 단계를 거칩니다.
-
제본 -
발견하다 -
불충분하다 - 설치
-
installing-in-progress -
added-to-existing-cluster
-
특정 확장된 에이전트의 상태를 보려면 다음 명령을 실행하세요.
$ oc -n <hosted_control_plane_namespace> get agent -o \ jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} \ Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'출력 예
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient다음 명령을 실행하여 전환 단계를 확인하세요.
$ oc -n <hosted_control_plane_namespace> get agent출력 예
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign다음 명령을 실행하여 호스팅된 클러스터에 액세스하기 위한
kubeconfig파일을 생성합니다.$ hcp create kubeconfig \ --namespace <clusters_namespace> \ --name <hosted_cluster_namespace> > <hosted_cluster_name>.kubeconfig에이전트가
기존 클러스터에 추가됨상태에 도달하면 다음 명령을 입력하여 OpenShift Container Platform 노드를 볼 수 있는지 확인하세요.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes출력 예
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8f클러스터 운영자는 노드에 작업 부하를 추가하여 조정을 시작합니다.
NodePool객체를 확장할 때 두 개의 머신이 생성되었는지 확인하려면 다음 명령을 입력하세요.$ oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io출력 예
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0클러스터 버전을 확인하려면 다음 명령을 실행하세요.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0-ec.2 True False 40h Cluster version is 4.15.0-ec.2클러스터 운영자 상태를 확인하려면 다음 명령을 실행하세요.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators
클러스터의 각 구성 요소에 대해 출력에는 다음과 같은 클러스터 운영자 상태가 표시됩니다. NAME , VERSION , AVAILABLE , PROGRESSING , DEGRADED , SINCE , MESSAGE .
출력 예는 초기 연산자 구성을 참조하세요.
4.6. IBM Power에 호스팅된 컨트롤 플레인 배포
클러스터를 호스팅 클러스터로 구성하여 호스팅된 제어 평면을 배포할 수 있습니다. 이 구성은 여러 클러스터를 관리하기 위한 효율적이고 확장 가능한 솔루션을 제공합니다. 호스팅 클러스터는 제어 평면을 호스팅하는 OpenShift Container Platform 클러스터입니다. 호스팅 클러스터는 관리 클러스터라고도 합니다.
관리 클러스터는 관리되는 클러스터가 아닙니다. 관리형 클러스터는 허브 클러스터가 관리하는 클러스터입니다.
멀티클러스터 엔진 Operator는 관리형 허브 클러스터인 기본 local-cluster 와 호스팅 클러스터인 허브 클러스터만 지원합니다.
베어메탈 인프라에서 호스팅된 제어 평면을 프로비저닝하려면 Agent 플랫폼을 사용할 수 있습니다. Agent 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스팅된 클러스터에 컴퓨팅 노드를 추가합니다. 자세한 내용은 "중앙 인프라 관리 서비스 활성화"를 참조하세요.
중앙 인프라 관리에서 제공하는 Discovery 이미지로 각 IBM Power 호스트를 시작해야 합니다. 각 호스트가 시작된 후에는 에이전트 프로세스를 실행하여 호스트의 세부 정보를 검색하고 설치를 완료합니다. 에이전트 사용자 정의 리소스는 각 호스트를 나타냅니다.
Agent 플랫폼을 사용하여 호스팅 클러스터를 생성하면 HyperShift는 호스팅 제어 평면 네임스페이스에 Agent Cluster API 공급자를 설치합니다.
4.6.1. IBM Power에서 호스팅된 제어 평면을 구성하기 위한 전제 조건
- OpenShift Container Platform 클러스터에 설치된 Kubernetes Operator 버전 2.7 이상용 멀티클러스터 엔진입니다. 멀티클러스터 엔진 Operator는 Red Hat Advanced Cluster Management(RHACM)를 설치하면 자동으로 설치됩니다. OpenShift Container Platform OperatorHub에서 RHACM 없이 멀티클러스터 엔진 Operator를 Operator로 설치할 수도 있습니다.
멀티클러스터 엔진 운영자는 최소한 하나의 관리되는 OpenShift Container Platform 클러스터를 가져야 합니다.
로컬 클러스터관리 허브 클러스터는 멀티클러스터 엔진 Operator 버전 2.7 이상에 자동으로 가져옵니다.local-cluster에 대한 자세한 내용은 RHACM 설명서의 고급 구성을 참조하세요. 다음 명령을 실행하여 허브 클러스터의 상태를 확인할 수 있습니다.$ oc get managedclusters local-cluster- HyperShift Operator를 실행하려면 최소 3개의 컴퓨팅 노드가 있는 호스팅 클러스터가 필요합니다.
- 중앙 인프라 관리 서비스를 활성화해야 합니다. 자세한 내용은 "중앙 인프라 관리 서비스 활성화"를 참조하세요.
- 호스팅된 제어 평면 명령줄 인터페이스를 설치해야 합니다. 자세한 내용은 "호스트 제어 평면 명령줄 인터페이스 설치"를 참조하세요.
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다. 해당 기능을 비활성화한 후 수동으로 활성화하려면 "호스팅된 제어 평면 기능을 수동으로 활성화"를 참조하세요. 해당 기능을 비활성화해야 하는 경우 "호스팅된 제어 평면 기능 비활성화"를 참조하세요.
4.6.2. IBM Power 인프라 요구 사항
Agent 플랫폼은 어떠한 인프라도 생성하지 않지만 인프라를 위해 다음과 같은 리소스가 필요합니다.
- 에이전트: 에이전트는 Discovery 이미지로 부팅하고 OpenShift Container Platform 노드로 프로비저닝할 수 있는 호스트를 나타냅니다.
- DNS: API 및 Ingress 엔드포인트는 라우팅 가능해야 합니다.
4.6.3. IBM Power에서 호스팅되는 제어 평면에 대한 DNS 구성
네트워크 외부의 클라이언트는 호스팅된 클러스터의 API 서버에 액세스할 수 있습니다. API 서버에 도달할 수 있는 대상을 가리키는 api.<hosted_cluster_name>.<basedomain> 항목에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 제어 평면을 실행하는 관리되는 클러스터의 노드 중 하나를 가리키는 레코드만큼 간단할 수 있습니다.
또한, 진입점은 배포된 로드 밸런서를 가리켜 수신 트래픽을 인그레스 포드로 리디렉션할 수도 있습니다.
다음은 DNS 구성의 예입니다.
$ cat /var/named/<example.krnl.es.zone>출력 예
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps.<hosted_cluster_name>.<basedomain> IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- 해당 레코드는 호스팅된 제어 평면의 수신 및 송신 트래픽을 처리하는 API 로드 밸런서의 IP 주소를 참조합니다.
IBM Power의 경우 에이전트의 IP 주소에 해당하는 IP 주소를 추가합니다.
설정 예
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy4.6.3.1. 사용자 정의 DNS 이름 정의
클러스터 관리자는 노드 부트스트랩 및 제어 평면 통신에 사용되는 내부 엔드포인트와 다른 외부 API DNS 이름을 사용하여 호스팅된 클러스터를 만들 수 있습니다. 다음과 같은 이유로 다른 DNS 이름을 정의할 수 있습니다.
- 내부 루트 CA에 바인딩되는 제어 평면 기능을 손상시키지 않고 사용자 대상 TLS 인증서를 공개 CA의 인증서로 교체합니다.
- 분할 수평 DNS 및 NAT 시나리오를 지원합니다.
-
올바른
kubeconfig및 DNS 구성을 사용하면Show Login Command기능과 같은 기능을 사용할 수 있는 독립 실행형 제어 평면과 유사한 환경을 보장할 수 있습니다.
HostedCluster 개체의 kubeAPIServerDNSName 매개변수에 도메인 이름을 입력하여 초기 설정 중이나 설치 후 작업 중에 DNS 이름을 정의할 수 있습니다.
사전 요구 사항
-
kubeAPIServerDNSName매개변수에 설정한 DNS 이름을 포함하는 유효한 TLS 인증서가 있습니다. - 올바른 주소에 도달하고 이를 가리킬 수 있는 확인 가능한 DNS 이름 URI가 있습니다.
프로세스
HostedCluster개체에 대한 사양에서kubeAPIServerDNSName매개변수와 도메인 주소를 추가하고 다음 예와 같이 사용할 인증서를 지정합니다.#... spec: configuration: apiServer: servingCerts: namedCertificates: - names: - xxx.example.com - yyy.example.com servingCertificate: name: <my_serving_certificate> kubeAPIServerDNSName: <custom_address>1 - 1
kubeAPIServerDNSName매개변수의 값은 유효하고 주소 지정이 가능한 도메인이어야 합니다.
kubeAPIServerDNSName 매개변수를 정의하고 인증서를 지정하면 Control Plane Operator 컨트롤러가 custom-admin-kubeconfig 라는 kubeconfig 파일을 생성하고, 이 파일은 HostedControlPlane 네임스페이스에 저장됩니다. 인증서 생성은 루트 CA에서 이루어지며, HostedControlPlane 네임스페이스는 인증서의 만료 및 갱신을 관리합니다.
Control Plane Operator는 HostedControlPlane 네임스페이스에 CustomKubeconfig 라는 새로운 kubeconfig 파일을 보고합니다. 해당 파일은 kubeAPIServerDNSName 매개변수에 정의된 새 서버를 사용합니다.
사용자 정의 kubeconfig 파일에 대한 참조는 HostedCluster 개체의 CustomKubeconfig 라는 상태 매개변수에 있습니다. CustomKubeConfig 매개변수는 선택 사항이며, kubeAPIServerDNSName 매개변수가 비어 있지 않은 경우에만 매개변수를 추가할 수 있습니다. CustomKubeConfig 매개변수를 설정하면 해당 매개변수는 HostedCluster 네임스페이스에 <hosted_cluster_name>-custom-admin-kubeconfig 라는 이름의 비밀을 생성합니다. 이 비밀을 사용하여 HostedCluster API 서버에 액세스할 수 있습니다. 설치 후 작업 중에 CustomKubeConfig 매개변수를 제거하면 관련된 모든 비밀과 상태 참조가 삭제됩니다.
사용자 지정 DNS 이름을 정의해도 데이터 플레인에 직접적인 영향을 미치지 않으므로 예상 롤아웃이 발생하지 않습니다. HostedControlPlane 네임스페이스는 HyperShift Operator로부터 변경 사항을 수신하고 해당 매개변수를 삭제합니다.
HostedCluster 개체의 사양에서 kubeAPIServerDNSName 매개변수를 제거하면 새로 생성된 모든 비밀과 CustomKubeconfig 참조가 클러스터와 status 매개변수에서 제거됩니다.
4.6.4. CLI를 사용하여 호스팅 클러스터 만들기
베어메탈 인프라에서는 호스팅된 클러스터를 만들거나 가져올 수 있습니다. 멀티클러스터 엔진 Operator에 대한 추가 기능으로 Assisted Installer를 활성화하고 Agent 플랫폼으로 호스팅된 클러스터를 생성하면 HyperShift Operator가 호스팅된 제어 평면 네임스페이스에 Agent Cluster API 공급자를 설치합니다. 에이전트 클러스터 API 공급자는 제어 평면을 호스팅하는 관리 클러스터와 컴퓨팅 노드만으로 구성된 호스팅 클러스터를 연결합니다.
사전 요구 사항
- 호스팅된 각 클러스터에는 클러스터 전체에서 고유한 이름이 있어야 합니다. 호스팅된 클러스터 이름은 기존 관리형 클러스터와 동일할 수 없습니다. 그렇지 않으면 멀티클러스터 엔진 운영자는 호스팅된 클러스터를 관리할 수 없습니다.
-
호스팅된 클러스터 이름으로
'클러스터'라는단어를 사용하지 마세요. - 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에 호스팅된 클러스터를 만들 수 없습니다.
- 최상의 보안 및 관리 관행을 위해 다른 호스팅 클러스터와 별도로 호스팅 클러스터를 만드세요.
- 클러스터에 기본 스토리지 클래스가 구성되어 있는지 확인하세요. 그렇지 않으면 보류 중인 영구 볼륨 클레임(PVC)이 표시될 수 있습니다.
-
기본적으로
hcp create cluster agent명령을 사용하면 명령은 구성된 노드 포트를 사용하여 호스팅된 클러스터를 생성합니다. 베어 메탈에서 호스팅되는 클러스터의 기본 게시 전략은 로드 밸런서를 통해 서비스를 노출하는 것입니다. 웹 콘솔이나 Red Hat Advanced Cluster Management를 사용하여 호스팅 클러스터를 생성하는 경우 Kubernetes API 서버 외에 서비스에 대한 게시 전략을 설정하려면HostedCluster사용자 정의 리소스에서servicePublishingStrategy정보를 수동으로 지정해야 합니다. 인프라, 방화벽, 포트 및 서비스와 관련된 요구 사항을 포함하여 "베어 메탈에서 호스팅되는 제어 평면에 대한 요구 사항"에 설명된 요구 사항을 충족하는지 확인하세요. 예를 들어, 해당 요구 사항은 다음 예제 명령에서 볼 수 있듯이 관리 클러스터의 베어 메탈 호스트에 적절한 영역 레이블을 추가하는 방법을 설명합니다.
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- 하드웨어 인벤토리에 베어 메탈 노드를 추가했는지 확인하세요.
프로세스
다음 명령을 입력하여 네임스페이스를 만듭니다.
$ oc create ns <hosted_cluster_namespace><hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스의 식별자로 바꾸세요. HyperShift 연산자는 네임스페이스를 생성합니다. 베어 메탈 인프라에서 호스팅된 클러스터를 생성하는 동안 생성된 클러스터 API 공급자 역할에는 네임스페이스가 이미 존재해야 합니다.다음 명령을 입력하여 호스팅된 클러스터에 대한 구성 파일을 만듭니다.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- 호스팅된 클러스터의 이름을 지정합니다(
예: ). - 2
/user/name/pullsecret과 같이 풀 시크릿의 경로를 지정합니다.- 3
clusters-example과 같이 호스팅된 제어 평면 네임스페이스를 지정합니다.oc get agent -n <hosted_control_plane_namespace>명령을 사용하여 이 네임스페이스에서 에이전트를 사용할 수 있는지 확인합니다.- 4
krnl.es와 같이 기본 도메인을 지정하세요.- 5
--api-server-address플래그는 호스팅된 클러스터에서 Kubernetes API 통신에 사용되는 IP 주소를 정의합니다.--api-server-address플래그를 설정하지 않으면 관리 클러스터에 연결하려면 로그인해야 합니다.- 6
lvm-storageclass와 같이 etcd 스토리지 클래스 이름을 지정합니다.- 7
- SSH 공개 키의 경로를 지정합니다. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 8
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 9
- 호스팅된 제어 평면 구성 요소에 대한 가용성 정책을 지정합니다. 지원되는 옵션은
SingleReplica및HighlyAvailable입니다. 기본값은HighlyAvailable입니다. - 10
- 사용하려는 지원되는 OpenShift Container Platform 버전(예:
4.19.0-multi )을 지정합니다. 연결이 끊긴 환경을 사용하는 경우<ocp_release_image>를다이제스트 이미지로 바꾸세요. OpenShift Container Platform 릴리스 이미지 다이제스트를 추출하려면 OpenShift Container Platform 릴리스 이미지 다이제스트 추출을 참조하세요. - 11
- 노드 풀 복제본 수를 지정합니다(예:
3). 동일한 수의 복제본을 생성하려면 복제본 수를0이상으로 지정해야 합니다. 그렇지 않으면 노드 풀을 생성하지 않습니다. - 12
--ssh-key플래그 뒤에user/.ssh/id_rsa와 같이 SSH 키의 경로를 지정합니다.
서비스 게시 전략을 구성합니다. 기본적으로 호스팅 클러스터는
NodePort서비스 게시 전략을 사용합니다. 이는 노드 포트가 추가 인프라 없이도 항상 사용 가능하기 때문입니다. 하지만 로드 밸런서를 사용하도록 서비스 게시 전략을 구성할 수 있습니다.-
기본
NodePort전략을 사용하는 경우 관리 클러스터 노드가 아닌 호스팅된 클러스터 컴퓨팅 노드를 가리키도록 DNS를 구성합니다. 자세한 내용은 "베어 메탈의 DNS 구성"을 참조하세요. 프로덕션 환경에서는
LoadBalancer전략을 사용하세요. 이 전략은 인증서 처리와 자동 DNS 확인을 제공합니다. 다음 예제에서는 호스팅된 클러스터 구성 파일에서 서비스 게시LoadBalancer전략을 변경하는 방법을 보여줍니다.# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- API 서버 유형으로
LoadBalancer를지정합니다. 다른 모든 서비스의 경우 유형으로경로를지정합니다.
-
기본
다음 명령을 입력하여 호스팅된 클러스터 구성 파일에 변경 사항을 적용합니다.
$ oc apply -f hosted_cluster_config.yaml다음 명령을 입력하여 호스팅된 클러스터, 노드 풀 및 포드가 생성되었는지 확인하세요.
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
호스팅된 클러스터가 준비되었는지 확인하세요.
사용 가능: True상태는 클러스터의 준비 상태를 나타내고 노드 풀 상태는AllMachinesReady: True를나타냅니다. 이러한 상태는 모든 클러스터 운영자의 상태를 나타냅니다. 호스팅된 클러스터에 MetalLB를 설치하세요:
호스팅된 클러스터에서
kubeconfig파일을 추출하고 다음 명령을 입력하여 호스팅된 클러스터 액세스를 위한 환경 변수를 설정합니다.$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"install-metallb-operator.yaml파일을 만들어 MetalLB Operator를 설치합니다.apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...다음 명령을 입력하여 파일을 적용합니다.
$ oc apply -f install-metallb-operator.yamldeploy-metallb-ipaddresspool.yaml파일을 만들어 MetalLB IP 주소 풀을 구성합니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f deploy-metallb-ipaddresspool.yaml다음 명령을 입력하여 운영자 상태, IP 주소 풀,
L2Advertisement리소스를 확인하여 MetalLB가 설치되었는지 확인하세요.$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
수신을 위해 로드 밸런서를 구성합니다.
ingress-loadbalancer.yaml파일을 만듭니다.apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f ingress-loadbalancer.yaml다음 명령을 입력하여 로드 밸런서 서비스가 예상대로 작동하는지 확인하세요.
$ oc get svc metallb-ingress -n openshift-ingress출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
로드 밸런서와 함께 작동하도록 DNS를 구성합니다.
-
*.apps.<hosted_cluster_namespace>.<base_domain>와일드카드 DNS 레코드를 로드 밸런서 IP 주소로 가리켜앱도메인에 대한 DNS를 구성합니다. 다음 명령을 입력하여 DNS 확인을 확인하세요.
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>출력 예
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
검증
다음 명령을 입력하여 클러스터 운영자를 확인하세요.
$ oc get clusteroperators모든 연산자가
AVAILABLE: True,PROGRESSING: False,DEGRADED: False로표시되는지 확인하세요.다음 명령을 입력하여 노드를 확인하세요.
$ oc get nodes각 노드가
READY상태인지 확인하세요.웹 브라우저에 다음 URL을 입력하여 콘솔에 대한 액세스를 테스트하세요.
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.6.5. 에이전트 호스팅 클러스터에서 이기종 노드 풀 생성에 관하여
노드 풀은 동일한 구성을 공유하는 클러스터 내의 노드 그룹입니다. 이기종 노드 풀은 구성이 다양하므로 풀을 만들고 다양한 작업 부하에 맞게 최적화할 수 있습니다.
에이전트 플랫폼에서 이기종 노드 풀을 생성할 수 있습니다. 이 플랫폼을 사용하면 단일 호스팅 클러스터 내에서 x86_64 나 ppc64le 등 다양한 머신 유형을 실행할 수 있습니다.
이기종 노드 풀을 생성하려면 다음과 같은 일반 단계를 완료해야 합니다.
-
데이터베이스 및 파일 시스템과 같은 구성 요소에 필요한 저장 공간의 양을 운영자에게 알려주는
AgentServiceConfig사용자 정의 리소스(CR)를 만듭니다. CR은 또한 지원할 OpenShift 컨테이너 플랫폼 버전을 정의합니다. - 에이전트 클러스터를 생성합니다.
- 이기종 노드 풀을 생성합니다.
- 호스팅된 제어 평면에 대한 DNS 구성
-
각 아키텍처에 대해
InfraEnv사용자 정의 리소스(CR)를 만듭니다. - 이기종 클러스터에 에이전트를 추가합니다.
4.6.5.1. AgentServiceConfig 사용자 정의 리소스 생성
에이전트 호스팅 클러스터에서 이기종 노드 풀을 만들려면 두 개의 이기종 아키텍처 운영 체제(OS) 이미지를 사용하여 AgentServiceConfig CR을 만들어야 합니다.
프로세스
다음 명령을 실행합니다.
$ envsubst <<"EOF" | oc apply -f - apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent spec: databaseStorage: accessModes: - ReadWriteOnce resources: requests: storage: <db_volume_name>1 filesystemStorage: accessModes: - ReadWriteOnce resources: requests: storage: <fs_volume_name>2 osImages: - openshiftVersion: <ocp_version>3 version: <ocp_release_version_x86>4 url: <iso_url_x86>5 rootFSUrl: <root_fs_url_x8>6 cpuArchitecture: <arch_x86>7 - openshiftVersion: <ocp_version>8 version: <ocp_release_version_ppc64le>9 url: <iso_url_ppc64le>10 rootFSUrl: <root_fs_url_ppc64le>11 cpuArchitecture: <arch_ppc64le>12 EOF- 1
- Kubernetes Operator
agentserviceconfigconfig, 데이터베이스 볼륨 이름에 대한 멀티클러스터 엔진을 지정합니다. - 2
- 멀티클러스터 엔진 운영자
agentserviceconfig구성, 파일 시스템 볼륨 이름을 지정합니다. - 3
- OpenShift Container Platform의 현재 버전을 지정합니다.
- 4
- x86에 대한 현재 OpenShift 컨테이너 플랫폼 릴리스 버전을 지정합니다.
- 5
- x86에 대한 ISO URL을 지정합니다.
- 6
- x86에 대한 루트 파일 시스템 URL을 지정합니다.
- 7
- x86에 대한 CPU 아키텍처를 지정하세요.
- 8
- 현재 OpenShift 컨테이너 플랫폼 버전을 지정합니다.
- 9
ppc64le에 대한 OpenShift 컨테이너 플랫폼 릴리스 버전을 지정합니다.- 10
ppc64le에 대한 ISO URL을 지정합니다.- 11
ppc64le에 대한 루트 파일 시스템 URL을 지정합니다.- 12
ppc64le에 대한 CPU 아키텍처를 지정합니다.
4.6.5.2. 에이전트 클러스터 생성
에이전트 기반 접근 방식은 에이전트 클러스터를 관리하고 프로비저닝합니다. 에이전트 클러스터는 이기종 노드 풀을 사용할 수 있으므로 동일한 클러스터 내에서 다양한 유형의 컴퓨팅 노드를 사용할 수 있습니다.
사전 요구 사항
- 호스팅 클러스터를 생성할 때 이기종 노드 풀에 대한 지원을 활성화하기 위해 다중 아키텍처 릴리스 이미지를 사용했습니다. 최신 다중 아키텍처 이미지는 다중 아키텍처 릴리스 이미지 페이지에서 확인하세요.
프로세스
다음 명령을 실행하여 클러스터 네임스페이스에 대한 환경 변수를 만듭니다.
$ export CLUSTERS_NAMESPACE=<hosted_cluster_namespace>다음 명령을 실행하여 머신 클래스 없는 도메인 간 라우팅(CIDR) 표기법에 대한 환경 변수를 만듭니다.
$ export MACHINE_CIDR=192.168.122.0/24다음 명령을 실행하여 호스팅된 컨트롤 네임스페이스를 만듭니다.
$ oc create ns <hosted_control_plane_namespace>다음 명령을 실행하여 클러스터를 만듭니다.
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<pull_secret_file> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \ --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release>5
4.6.5.3. 이기종 노드 풀 생성
NodePool 사용자 정의 리소스(CR)를 사용하여 이기종 노드 풀을 만들면 다양한 작업 부하를 특정 하드웨어에 연결하여 비용과 성능을 최적화할 수 있습니다.
프로세스
NodePoolCR을 정의하려면 다음 예와 유사한 YAML 파일을 만듭니다.envsubst <<"EOF" | oc apply -f - apiVersion:apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name> namespace: <clusters_namespace> spec: arch: <arch_ppc64le> clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: InPlace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: agent: agentLabelSelector: matchLabels: inventory.agent-install.openshift.io/cpu-architecture: <arch_ppc64le>1 type: Agent release: image: quay.io/openshift-release-dev/ocp-release:<ocp_release> replicas: 0 EOF- 1
- 선택기 블록은 지정된 레이블과 일치하는 에이전트를 선택합니다. 복제본이 없는
ppc64le아키텍처의 노드 풀을 생성하려면ppc64le을지정합니다. 이렇게 하면 스케일링 작업 중에 선택기 블록이ppc64le아키텍처의 에이전트만 선택하게 됩니다.
4.6.5.4. 호스팅된 제어 평면에 대한 DNS 구성
호스팅된 제어 평면에 대한 DNS(도메인 이름 서비스) 구성은 외부 클라이언트가 수신 컨트롤러에 접속할 수 있음을 의미하며, 이를 통해 클라이언트는 트래픽을 내부 구성 요소로 라우팅할 수 있습니다. 이 설정을 구성하면 트래픽이 ppc64le 또는 x86_64 컴퓨트 노드로 라우팅됩니다.
*.apps.<cluster_name> 레코드를 인그레스 애플리케이션을 호스팅하는 두 컴퓨팅 노드 중 하나로 지정할 수 있습니다. 또는 컴퓨팅 노드 위에 로드 밸런서를 설정할 수 있는 경우 레코드를 이 로드 밸런서로 가리키세요. 이기종 노드 풀을 생성할 때는 컴퓨팅 노드가 서로 통신할 수 있는지 또는 동일한 네트워크에 있는지 확인하세요.
4.6.5.5. 인프라 환경 자원 생성
이기종 노드 풀의 경우 아키텍처마다 infraEnv 사용자 정의 리소스(CR)를 만들어야 합니다. 이 구성을 사용하면 노드 프로비저닝 프로세스 중에 올바른 아키텍처별 운영 체제와 부팅 아티팩트가 사용됩니다. 예를 들어, x86_64 및 ppc64le 아키텍처를 사용하는 노드 풀의 경우 x86_64 및 ppc64le 에 대한 InfraEnv CR을 만듭니다.
절차를 시작하기 전에 x86_64 및 ppc64le 아키텍처에 대한 운영 체제 이미지를 AgentServiceConfig 리소스에 추가했는지 확인하세요. 그런 다음 InfraEnv 리소스를 사용하여 최소 ISO 이미지를 얻을 수 있습니다.
프로세스
다음 명령을 실행하여 이기종 노드 풀에 대한
x86_64아키텍처의InfraEnv리소스를 만듭니다.$ envsubst <<"EOF" | oc apply -f - apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name>-<arch_x86>1 2 namespace: <hosted_control_plane_namespace>3 spec: cpuArchitecture: <arch_x86> pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_pub_key>4 EOF다음 명령을 실행하여 이기종 노드 풀에 대한
ppc64le아키텍처를 갖춘InfraEnv리소스를 만듭니다.envsubst <<"EOF" | oc apply -f - apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name>-<arch_ppc64le>1 2 namespace: <hosted_control_plane_namespace>3 spec: cpuArchitecture: <arch_ppc64le> pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_pub_key>4 EOF다음 명령을 실행하여
InfraEnv리소스가 성공적으로 생성되었는지 확인하세요.x86_64InfraEnv리소스가 성공적으로 생성되었는지 확인하세요.$ oc describe InfraEnv <hosted_cluster_name>-<arch_x86>ppc64leInfraEnv리소스가 성공적으로 생성되었는지 확인하세요.$ oc describe InfraEnv <hosted_cluster_name>-<arch_ppc64le>
다음 명령을 실행하여 가상 머신이나 베어 메탈 머신이 에이전트로 참여할 수 있는 라이브 ISO를 생성합니다.
x86_64용 라이브 ISO 생성:$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name>-<arch_x86> -ojsonpath="{.status.isoDownloadURL}"ppc64le에 대한 라이브 ISO 생성:$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name>-<arch_ppc64le> -ojsonpath="{.status.isoDownloadURL}"
4.6.5.6. 이기종 클러스터에 에이전트 추가
라이브 ISO로 부팅하도록 시스템을 수동으로 구성하여 에이전트를 추가합니다. 라이브 ISO를 다운로드하여 베어 메탈 노드나 가상 머신을 부팅할 수 있습니다. 부팅 시, 노드는 지원 서비스 와 통신하고 InfraEnv 리소스와 동일한 네임스페이스에 에이전트로 등록됩니다. 각 에이전트를 생성한 후에는 선택적으로 사양에서 installation_disk_id 및 hostname 매개변수를 설정할 수 있습니다. 그런 다음 에이전트를 승인하여 에이전트가 사용 가능한 상태로 표시되도록 할 수 있습니다.
프로세스
다음 명령을 실행하여 에이전트 목록을 얻습니다.
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign다음 명령을 실행하여 에이전트에 패치를 적용하세요.
$ oc -n <hosted_control_plane_namespace> patch agent 86f7ac75-4fc4-4b36-8130-40fa12602218 -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-0.example.krnl.es"}}' --type merge다음 명령을 실행하여 두 번째 에이전트에 패치를 적용합니다.
$ oc -n <hosted_control_plane_namespace> patch agent 23d0c614-2caa-43f5-b7d3-0b3564688baa -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-1.example.krnl.es"}}' --type merge다음 명령을 실행하여 에이전트 승인 상태를 확인하세요.
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
4.6.5.7. 노드 풀 확장
에이전트를 승인한 후 노드 풀을 확장할 수 있습니다. 노드 풀에서 구성한 agentLabelSelector 값은 일치하는 에이전트만 클러스터에 추가되도록 보장합니다. 이는 또한 노드 풀의 규모를 줄이는 데 도움이 됩니다. 클러스터에서 특정 아키텍처 노드를 제거하려면 해당 노드 풀의 규모를 줄입니다.
프로세스
다음 명령을 실행하여 노드 풀을 확장합니다.
$ oc -n <clusters_namespace> scale nodepool <nodepool_name> --replicas 2참고클러스터 API 에이전트 제공자는 호스팅된 클러스터에 할당할 두 개의 에이전트를 무작위로 선택합니다. 이러한 에이전트는 다양한 상태를 거친 후 호스팅된 클러스터에 OpenShift Container Platform 노드로 합류합니다. 다양한 에이전트 상태는
바인딩,검색,불충분,설치 중,설치 중,기존 클러스터에 추가됨입니다.
검증
다음 명령을 실행하여 에이전트를 나열하세요.
$ oc -n <hosted_control_plane_namespace> get agent출력 예
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign다음 명령을 실행하여 특정 확장된 에이전트의 상태를 확인하세요.
$ oc -n <hosted_control_plane_namespace> get agent -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'출력 예
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficient에이전트가
기존 클러스터에 추가됨상태에 도달하면 다음 명령을 실행하여 OpenShift Container Platform 노드가 준비되었는지 확인합니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes출력 예
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8f노드에 작업 부하를 추가하면 일부 클러스터 운영자를 조정할 수 있습니다. 다음 명령은 노드 풀을 확장한 후 발생한 두 대의 머신 생성을 표시합니다.
$ oc -n <hosted_control_plane_namespace> get machines출력 예
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.11.5 hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.11.5
4.7. OpenStack에 호스팅된 제어 평면 배포
Red Hat OpenStack Platform(RHOSP)에 호스팅된 제어 플레인 클러스터를 배포하는 것은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
Red Hat OpenStack Platform(RHOSP) 17.1에서 실행되는 호스팅 클러스터를 사용하여 호스팅된 제어 플레인을 배포할 수 있습니다.
호스팅 클러스터 는 관리 클러스터에 호스팅된 API 엔드포인트와 제어 평면을 갖춘 OpenShift Container Platform 클러스터입니다. 호스팅된 제어 평면을 사용하면 제어 평면이 관리 클러스터의 포드로 존재하므로 각 제어 평면에 대한 전용 가상 또는 물리적 머신이 필요하지 않습니다.
4.7.1. OpenStack의 전제 조건
Red Hat OpenStack Platform(RHOSP)에서 호스팅 클러스터를 생성하기 전에 다음 요구 사항을 충족하는지 확인하세요.
- 관리 OpenShift Container Platform 클러스터 버전 4.17 이상에 대한 관리 액세스 권한이 있습니다. 이 클러스터는 베어 메탈, RHOSP 또는 지원되는 퍼블릭 클라우드에서 실행될 수 있습니다.
- HyperShift Operator는 "호스팅된 제어 평면 배포 준비"에 지정된 대로 관리 클러스터에 설치됩니다.
- 관리 클러스터는 기본 Pod 네트워크 CNI로 OVN-Kubernetes로 구성됩니다.
-
OpenShift CLI(
oc)와 호스팅 제어 평면 CLI,hcp가설치됩니다. 예를 들어 Octavia와 같은 로드 밸런서 백엔드는 관리 OCP 클러스터에 설치됩니다. 각 호스팅 클러스터에 대해
kube-api서비스를 생성하려면 로드 밸런서가 필요합니다.- Octavia 부하 분산으로 수신이 구성된 경우 RHOSP Octavia 서비스는 게스트 클러스터를 호스팅하는 클라우드에서 실행됩니다.
-
quay.io/openshift-release-dev저장소에 유효한 풀 비밀 파일이 있습니다. -
관리 클러스터의 기본 외부 네트워크는 게스트 클러스터에서 접근할 수 있습니다. 이 네트워크에
kube-apiserver로드 밸런서 유형 서비스가 생성됩니다. 수신을 위해 미리 정의된 부동 IP 주소를 사용하는 경우 다음 와일드카드 도메인에 대해 해당 주소를 가리키는 DNS 레코드가 생성됩니다.
*.apps.<cluster_name>.<base_domain>, 여기서:-
<cluster_name>은 관리 클러스터의 이름입니다. -
<base_domain>은 클러스터의 애플리케이션이 있는 부모 DNS 도메인입니다.
-
4.7.2. etcd 로컬 스토리지를 위한 관리 클러스터 준비
Red Hat OpenStack Platform(RHOSP)의 호스팅 제어 평면(HCP) 배포에서 기본 Cinder 기반 영구 볼륨 클레임(PVC)에 의존하는 대신 TopoLVM CSI 드라이버로 프로비저닝된 로컬 임시 스토리지를 사용하면 etcd 성능을 개선할 수 있습니다.
사전 요구 사항
- HyperShift가 설치된 관리 클러스터에 액세스할 수 있습니다.
- RHOSP 플레이버와 머신 세트를 만들고 관리할 수 있습니다.
-
oc및openstackCLI 도구를 설치하고 구성했습니다. - TopoLVM 및 LVM(Logical Volume Manager) 저장 개념에 대해 잘 알고 있습니다.
- 관리 클러스터에 LVM 스토리지 운영자를 설치했습니다. 자세한 내용은 OpenShift Container Platform 설명서의 스토리지 섹션에서 "CLI를 사용하여 LVM 스토리지 설치"를 참조하세요.
프로세스
openstackCLI를 사용하여 추가 임시 디스크가 있는 Nova 플레이버를 만듭니다. 예를 들면 다음과 같습니다.$ openstack flavor create \ --id auto \ --ram 8192 \ --disk 0 \ --ephemeral 100 \ --vcpus 4 \ --public \ hcp-etcd-ephemeral참고Nova는 서버가 해당 플레이버로 생성될 때 임시 디스크를 인스턴스에 자동으로 연결하고 이를
vfat로 포맷합니다.- 새로운 플레이버를 사용하는 컴퓨팅 머신 세트를 만듭니다. 자세한 내용은 OpenShift Container Platform 설명서의 "OpenStack에서 컴퓨팅 머신 세트 만들기"를 참조하세요.
- 귀하의 요구 사항에 맞게 기계 세트를 확장하세요. 고가용성을 위해 클러스터를 배포하는 경우 최소 3개의 작업자를 배포해야 포드를 적절히 분산할 수 있습니다.
etcd에서 사용할 수 있도록 새로운 워커 노드에 레이블을 지정합니다. 예를 들면 다음과 같습니다.
$ oc label node <node_name> hypershift-capable=true이 라벨은 임의적입니다. 나중에 업데이트할 수 있습니다.
lvmcluster.yaml이라는 파일에서 etcd에 대한 로컬 스토리지 구성에 대한 다음LVMCluster사용자 지정 리소스를 만듭니다.apiVersion: lvm.topolvm.io/v1alpha1 kind: LVMCluster metadata: name: etcd-hcp namespace: openshift-storage spec: storage: deviceClasses: - name: etcd-class default: true nodeSelector: nodeSelectorTerms: - matchExpressions: - key: hypershift-capable operator: In values: - "true" deviceSelector: forceWipeDevicesAndDestroyAllData: true paths: - /dev/vdb이 예제 리소스에서는:
-
임시 디스크 위치는
/dev/vdb이며, 대부분의 경우에 해당합니다. 귀하의 경우 이 위치가 맞는지 확인하고, 심볼릭 링크는 지원되지 않는다는 점에 유의하세요. -
기본 Nova 임시 디스크는 VFAT로 포맷되어 제공되므로
forceWipeDevicesAndDestroyAllData매개변수는True값으로 설정됩니다.
-
임시 디스크 위치는
다음 명령을 실행하여
LVMCluster리소스를 적용합니다.oc apply -f lvmcluster.yaml다음 명령을 실행하여
LVMCluster리소스를 확인하세요.$ oc get lvmcluster -A출력 예
NAMESPACE NAME STATUS openshift-storage etcd-hcp Ready다음 명령을 실행하여
StorageClass리소스를 확인하세요.$ oc get storageclass출력 예
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE lvms-etcd-class topolvm.io Delete WaitForFirstConsumer true 23m standard-csi (default) cinder.csi.openstack.org Delete WaitForFirstConsumer true 56m
이제 성능이 뛰어난 etcd 구성으로 호스팅된 클러스터를 배포할 수 있습니다. 배포 프로세스는 "OpenStack에서 호스팅된 클러스터 만들기"에 설명되어 있습니다.
4.7.3. 수신을 위한 플로팅 IP 생성
수동 개입 없이 호스팅된 클러스터에서 인그레스를 사용할 수 있도록 하려면 미리 해당 클러스터에 대한 플로팅 IP 주소를 만들 수 있습니다.
사전 요구 사항
- Red Hat OpenStack Platform(RHOSP) 클라우드에 액세스할 수 있습니다.
수신을 위해 미리 정의된 부동 IP 주소를 사용하는 경우 다음 와일드카드 도메인에 대해 해당 주소를 가리키는 DNS 레코드가 생성됩니다.
*.apps.<cluster_name>.<base_domain>, 여기서:-
<cluster_name>은 관리 클러스터의 이름입니다. -
<base_domain>은 클러스터의 애플리케이션이 있는 부모 DNS 도메인입니다.
-
프로세스
다음 명령을 실행하여 부동 IP 주소를 만듭니다.
$ openstack floating ip create <external_network_id>다음과 같습니다.
<external_network_id>- 외부 네트워크의 ID를 지정합니다.
--openstack-ingress-floating-ip 플래그를 사용하여 미리 IP 주소를 생성하지 않고 해당 IP 주소를 지정하면 cloud-provider-openstack 구성 요소가 자동으로 해당 IP 주소를 생성하려고 시도합니다. 이 프로세스는 Neutron API 정책이 특정 IP 주소로 부동 IP 주소를 생성하는 것을 허용하는 경우에만 성공합니다.
4.7.4. OpenStack에 RHCOS 이미지 업로드
호스팅된 제어 플레인과 Red Hat OpenStack Platform(RHOSP) 배포에 노드 풀을 배포할 때 사용할 RHCOS 이미지를 지정하려면 이미지를 RHOSP 클라우드에 업로드합니다. 이미지를 업로드하지 않으면 OpenStack Resource Controller(ORC)가 OpenShift Container Platform 미러에서 이미지를 다운로드하고 호스팅된 클러스터를 삭제한 후 해당 이미지를 삭제합니다.
사전 요구 사항
- OpenShift Container Platform 미러에서 RHCOS 이미지를 다운로드했습니다.
- RHOSP 클라우드에 액세스할 수 있습니다.
프로세스
다음 명령을 실행하여 RHCOS 이미지를 RHOSP에 업로드합니다.
$ openstack image create --disk-format qcow2 --file <image_file_name> rhcos다음과 같습니다.
<image_file_name>- RHCOS 이미지의 파일 이름을 지정합니다.
4.7.5. OpenStack에서 호스팅 클러스터 생성
hcp CLI를 사용하여 Red Hat OpenStack Platform(RHOSP)에서 호스팅 클러스터를 생성할 수 있습니다.
사전 요구 사항
- "호스팅된 제어 평면 배포 준비"의 모든 필수 단계를 완료했습니다.
- "OpenStack의 필수 구성 요소"를 검토했습니다.
- "etcd 로컬 스토리지를 위한 관리 클러스터 준비"의 모든 단계를 완료했습니다.
- 관리 클러스터에 액세스할 수 있습니다.
- RHOSP 클라우드에 액세스할 수 있습니다.
프로세스
hcp create명령을 실행하여 호스팅 클러스터를 만듭니다. 예를 들어, "etcd 로컬 스토리지를 위한 관리 클러스터 준비"에 자세히 설명된 고성능 etcd 구성을 활용하는 클러스터의 경우 다음을 입력합니다.$ hcp create cluster openstack \ --name my-hcp-cluster \ --openstack-node-flavor m1.xlarge \ --base-domain example.com \ --pull-secret /path/to/pull-secret.json \ --release-image quay.io/openshift-release-dev/ocp-release:4.19.0-x86_64 \ --node-pool-replicas 3 \ --etcd-storage-class lvms-etcd-class
클러스터 생성 시에는 다양한 옵션을 사용할 수 있습니다. RHOSP 관련 옵션에 대한 자세한 내용은 "OpenStack에서 호스팅된 제어 평면 클러스터를 생성하기 위한 옵션"을 참조하세요. 일반 옵션에 대한 내용은 hcp 문서를 참조하세요.
검증
다음 명령을 실행하여 호스팅된 클러스터가 준비되었는지 확인하세요.
$ oc -n clusters-<cluster_name> get pods다음과 같습니다.
<cluster_name>- 클러스터의 이름을 지정합니다.
몇 분 후에는 호스팅된 제어 평면 포드가 실행 중이라는 출력이 표시됩니다.
출력 예
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s ... ... ... redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0클러스터의 etcd 구성을 검증하려면:
다음 명령을 실행하여 etcd 영구 볼륨 클레임(PVC)을 검증합니다.
$ oc get pvc -A호스팅된 제어 평면 etcd Pod 내부에서 다음 명령을 실행하여 마운트 경로와 장치를 확인하세요.
$ df -h /var/lib
클러스터 API 공급자가 생성하는 RHOSP 리소스에는 openshiftClusterID=<infraID> 레이블이 지정됩니다.
호스팅 클러스터를 생성하는 데 사용하는 YAML 매니페스트의 HostedCluster.Spec.Platform.OpenStack.Tags 필드의 값으로 리소스에 대한 추가 태그를 정의할 수 있습니다. 노드 풀을 확장한 후에는 태그가 리소스에 적용됩니다.
4.7.5.1. OpenStack에서 호스팅 제어 평면 클러스터를 생성하기 위한 옵션
Red Hat OpenStack Platform(RHOSP)에서 호스팅 제어 플레인 클러스터를 배포하는 동안 hcp CLI에 여러 옵션을 제공할 수 있습니다.
| 옵션 | 설명 | 필수 항목 |
|---|---|---|
|
|
OpenStack CA 인증서 파일의 경로입니다. 제공되지 않으면 | 없음 |
|
|
| 없음 |
|
|
OpenStack 자격 증명 파일의 경로입니다. 제공되지 않으면
| 없음 |
|
| 서브넷을 생성할 때 제공되는 DNS 서버 주소 목록입니다. | 없음 |
|
| OpenStack 외부 네트워크의 ID입니다. | 없음 |
|
| OpenShift 수신을 위한 플로팅 IP. | 없음 |
|
|
노드에 연결할 추가 포트. 유효한 값은 | 없음 |
|
| 노드 풀의 가용성 영역입니다. | 없음 |
|
| 노드 풀에 대한 설명입니다. | 제공됨 |
|
| 노드 풀의 이미지 이름입니다. | 없음 |
5장. 호스팅된 컨트롤 플레인 관리
5.1. AWS에서 호스팅된 제어 평면 관리
Amazon Web Services(AWS)에서 OpenShift Container Platform에 호스팅된 제어 평면을 사용하는 경우 인프라 요구 사항은 설정에 따라 달라집니다.
5.1.1. AWS 인프라 및 IAM 권한을 관리하기 위한 필수 조건
Amazon Web Services(AWS)에서 OpenShift Container Platform에 대한 호스팅 제어 평면을 구성하려면 다음 인프라 요구 사항을 충족해야 합니다.
- 호스팅 클러스터를 생성하기 전에 호스팅 제어 평면을 구성해야 합니다.
- AWS Identity and Access Management(IAM) 역할과 AWS Security Token Service(STS) 자격 증명을 생성했습니다.
5.1.1.1. AWS 인프라 요구 사항
Amazon Web Services(AWS)에서 호스팅된 제어 평면을 사용하는 경우 인프라 요구 사항은 다음 범주에 해당합니다.
- 임의의 AWS 계정에서 HyperShift Operator를 위한 사전 요구 사항 및 관리되지 않는 인프라
- 호스팅된 클러스터 AWS 계정의 필수 및 관리되지 않는 인프라
- 관리 AWS 계정의 호스팅 제어 플레인 관리 인프라
- 호스팅된 클러스터 AWS 계정의 호스팅 제어 플레인 관리 인프라
- 호스팅된 클러스터 AWS 계정의 Kubernetes 관리 인프라
필수 조건은 호스팅된 제어 평면이 제대로 작동하려면 AWS 인프라가 필요하다는 것을 의미합니다. 관리되지 않는다는 것은 운영자나 관리자가 사용자를 위해 인프라를 생성하지 않는다는 것을 의미합니다.
5.1.1.2. AWS 계정의 HyperShift Operator에 대한 관리되지 않는 인프라
임의의 Amazon Web Services(AWS) 계정은 호스팅된 제어 평면 서비스 제공자에 따라 달라집니다.
자체 관리형 호스팅 제어 평면에서는 클러스터 서비스 공급자가 AWS 계정을 제어합니다. 클러스터 서비스 제공자는 클러스터 제어 평면을 호스팅하고 가동 시간에 대한 책임을 지는 관리자입니다. 관리형 호스팅 제어 평면에서 AWS 계정은 Red Hat에 속합니다.
HyperShift Operator의 필수 및 관리되지 않는 인프라에서 관리 클러스터 AWS 계정에 대한 다음 인프라 요구 사항이 적용됩니다.
S3 버킷 1개
- OpenID Connect(OIDC)
53번 국도 호스팅 구역
- 호스팅된 클러스터에 대한 개인 및 공개 항목을 호스팅하는 도메인
5.1.1.3. 관리 AWS 계정에 대한 관리되지 않는 인프라 요구 사항
인프라가 호스팅 클러스터 Amazon Web Services(AWS) 계정에서 사전 요구되고 관리되지 않는 경우 모든 액세스 모드에 대한 인프라 요구 사항은 다음과 같습니다.
- 하나의 VPC
- 하나의 DHCP 옵션
두 개의 서브넷
- 내부 데이터 플레인 서브넷인 개인 서브넷
- 데이터 플레인에서 인터넷에 액세스할 수 있도록 하는 공용 서브넷
- 하나의 인터넷 게이트웨이
- 하나의 탄력적 IP
- 하나의 NAT 게이트웨이
- 하나의 보안 그룹(워커 노드)
- 두 개의 경로 테이블(하나는 비공개이고 하나는 공개)
- 2개의 Route 53 호스팅 구역
다음 품목에 대한 할당량이 충분합니다.
- 공용 호스팅 클러스터를 위한 하나의 Ingress 서비스 로드 밸런서
- 개인 호스팅 클러스터를 위한 하나의 개인 링크 엔드포인트
개인 링크 네트워킹이 작동하려면 호스팅 클러스터 AWS 계정의 엔드포인트 영역이 관리 클러스터 AWS 계정의 서비스 엔드포인트에서 확인되는 인스턴스의 영역과 일치해야 합니다. AWS에서 영역 이름은 us-east-2b와 같은 별칭이며, 반드시 다른 계정의 동일한 영역에 매핑되는 것은 아닙니다. 결과적으로 개인 링크가 작동하려면 관리 클러스터에 해당 지역의 모든 영역에 서브넷이나 작업자가 있어야 합니다.
5.1.1.4. 관리 AWS 계정에 대한 인프라 요구 사항
인프라가 관리 AWS 계정의 호스팅된 제어 평면에 의해 관리되는 경우, 클러스터가 공개형, 비공개형 또는 이들의 조합형인지에 따라 인프라 요구 사항이 달라집니다.
공개 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
네트워크 로드 밸런서: Kube API 서버 로드 밸런서
- 쿠버네티스는 보안 그룹을 생성합니다.
volumes[]
- etcd의 경우(고가용성에 따라 1개 또는 3개)
- OVN-Kube용
개인 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 네트워크 로드 밸런서: 로드 밸런서 개인 라우터
- 엔드포인트 서비스(개인 링크)
공개 및 비공개 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 네트워크 로드 밸런서: 로드 밸런서 공용 라우터
- 네트워크 로드 밸런서: 로드 밸런서 개인 라우터
- 엔드포인트 서비스(개인 링크)
volumes[]
- etcd의 경우(고가용성에 따라 1개 또는 3개)
- OVN-Kube용
5.1.1.5. 호스팅 클러스터의 AWS 계정에 대한 인프라 요구 사항
인프라가 호스팅 클러스터 Amazon Web Services(AWS) 계정의 호스팅 제어 평면에서 관리되는 경우, 클러스터가 공개, 비공개 또는 조합인지에 따라 인프라 요구 사항이 달라집니다.
공개 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
-
노드 풀에는
Role과RolePolicy가 정의된 EC2 인스턴스가 있어야 합니다.
개인 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 각 가용성 영역에 대한 하나의 개인 링크 엔드포인트
- 노드 풀을 위한 EC2 인스턴스
공개 및 비공개 클러스터가 있는 계정의 경우 인프라 요구 사항은 다음과 같습니다.
- 각 가용성 영역에 대한 하나의 개인 링크 엔드포인트
- 노드 풀을 위한 EC2 인스턴스
5.1.1.6. 호스팅된 클러스터 AWS 계정의 Kubernetes 관리 인프라
Kubernetes가 호스팅된 클러스터 Amazon Web Services(AWS) 계정에서 인프라를 관리하는 경우 인프라 요구 사항은 다음과 같습니다.
- 기본 Ingress를 위한 네트워크 로드 밸런서
- 레지스트리를 위한 S3 버킷
5.1.2. ID 및 액세스 관리(IAM) 권한
호스팅된 제어 평면의 컨텍스트에서 소비자는 Amazon 리소스 이름(ARN) 역할을 생성할 책임이 있습니다. 소비자는 권한 파일을 생성하는 자동화된 프로세스입니다. 소비자는 CLI 또는 OpenShift 클러스터 관리자일 수 있습니다. 호스팅된 제어 평면은 최소 권한 구성 요소의 원칙을 존중하기 위해 세분성을 활성화할 수 있습니다. 즉, 각 구성 요소는 자체 역할을 사용하여 Amazon Web Services(AWS) 객체를 작동하거나 생성하고 해당 역할은 제품이 정상적으로 작동하는 데 필요한 것으로 제한됩니다.
호스팅된 클러스터는 ARN 역할을 입력으로 받고 소비자는 각 구성 요소에 대한 AWS 권한 구성을 만듭니다. 결과적으로 해당 구성 요소는 STS 및 사전 구성된 OIDC IDP를 통해 인증할 수 있습니다.
다음 역할은 제어 평면에서 실행되고 데이터 평면에서 작동하는 호스팅된 제어 평면의 일부 구성 요소에 의해 사용됩니다.
-
controlPlaneOperatorARN -
imageRegistryARN -
ingressARN -
kubeCloudControllerARN -
nodePoolManagementARN -
storageARN -
networkARN
다음 예제에서는 호스팅된 클러스터의 IAM 역할에 대한 참조를 보여줍니다.
...
endpointAccess: Public
region: us-east-2
resourceTags:
- key: kubernetes.io/cluster/example-cluster-bz4j5
value: owned
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-controller
networkARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-node-pool
storageARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-aws-ebs-csi-driver-controller
type: AWS
...호스팅된 제어 평면이 사용하는 역할은 다음 예에서 표시됩니다.
ingressARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "elasticloadbalancing:DescribeLoadBalancers", "tag:GetResources", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets" ], "Resource": [ "arn:aws:route53:::PUBLIC_ZONE_ID", "arn:aws:route53:::PRIVATE_ZONE_ID" ] } ] }imageRegistryARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketTagging", "s3:GetBucketTagging", "s3:PutBucketPublicAccessBlock", "s3:GetBucketPublicAccessBlock", "s3:PutEncryptionConfiguration", "s3:GetEncryptionConfiguration", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:GetBucketLocation", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucketMultipartUploads", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": "\*" } ] }storageARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:AttachVolume", "ec2:CreateSnapshot", "ec2:CreateTags", "ec2:CreateVolume", "ec2:DeleteSnapshot", "ec2:DeleteTags", "ec2:DeleteVolume", "ec2:DescribeInstances", "ec2:DescribeSnapshots", "ec2:DescribeTags", "ec2:DescribeVolumes", "ec2:DescribeVolumesModifications", "ec2:DetachVolume", "ec2:ModifyVolume" ], "Resource": "\*" } ] }networkARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "ec2:DescribeInstanceTypes", "ec2:UnassignPrivateIpAddresses", "ec2:AssignPrivateIpAddresses", "ec2:UnassignIpv6Addresses", "ec2:AssignIpv6Addresses", "ec2:DescribeSubnets", "ec2:DescribeNetworkInterfaces" ], "Resource": "\*" } ] }kubeCloudControllerARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:DescribeInstances", "ec2:DescribeImages", "ec2:DescribeRegions", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVolumes", "ec2:CreateSecurityGroup", "ec2:CreateTags", "ec2:CreateVolume", "ec2:ModifyInstanceAttribute", "ec2:ModifyVolume", "ec2:AttachVolume", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateRoute", "ec2:DeleteRoute", "ec2:DeleteSecurityGroup", "ec2:DeleteVolume", "ec2:DetachVolume", "ec2:RevokeSecurityGroupIngress", "ec2:DescribeVpcs", "elasticloadbalancing:AddTags", "elasticloadbalancing:AttachLoadBalancerToSubnets", "elasticloadbalancing:ApplySecurityGroupsToLoadBalancer", "elasticloadbalancing:CreateLoadBalancer", "elasticloadbalancing:CreateLoadBalancerPolicy", "elasticloadbalancing:CreateLoadBalancerListeners", "elasticloadbalancing:ConfigureHealthCheck", "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DeleteLoadBalancerListeners", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeLoadBalancerAttributes", "elasticloadbalancing:DetachLoadBalancerFromSubnets", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:ModifyLoadBalancerAttributes", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:SetLoadBalancerPoliciesForBackendServer", "elasticloadbalancing:AddTags", "elasticloadbalancing:CreateListener", "elasticloadbalancing:CreateTargetGroup", "elasticloadbalancing:DeleteListener", "elasticloadbalancing:DeleteTargetGroup", "elasticloadbalancing:DescribeListeners", "elasticloadbalancing:DescribeLoadBalancerPolicies", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DescribeTargetHealth", "elasticloadbalancing:ModifyListener", "elasticloadbalancing:ModifyTargetGroup", "elasticloadbalancing:RegisterTargets", "elasticloadbalancing:SetLoadBalancerPoliciesOfListener", "iam:CreateServiceLinkedRole", "kms:DescribeKey" ], "Resource": [ "\*" ], "Effect": "Allow" } ] }nodePoolManagementARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:AllocateAddress", "ec2:AssociateRouteTable", "ec2:AttachInternetGateway", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateInternetGateway", "ec2:CreateNatGateway", "ec2:CreateRoute", "ec2:CreateRouteTable", "ec2:CreateSecurityGroup", "ec2:CreateSubnet", "ec2:CreateTags", "ec2:DeleteInternetGateway", "ec2:DeleteNatGateway", "ec2:DeleteRouteTable", "ec2:DeleteSecurityGroup", "ec2:DeleteSubnet", "ec2:DeleteTags", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeAvailabilityZones", "ec2:DescribeImages", "ec2:DescribeInstances", "ec2:DescribeInternetGateways", "ec2:DescribeNatGateways", "ec2:DescribeNetworkInterfaces", "ec2:DescribeNetworkInterfaceAttribute", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs", "ec2:DescribeVpcAttribute", "ec2:DescribeVolumes", "ec2:DetachInternetGateway", "ec2:DisassociateRouteTable", "ec2:DisassociateAddress", "ec2:ModifyInstanceAttribute", "ec2:ModifyNetworkInterfaceAttribute", "ec2:ModifySubnetAttribute", "ec2:ReleaseAddress", "ec2:RevokeSecurityGroupIngress", "ec2:RunInstances", "ec2:TerminateInstances", "tag:GetResources", "ec2:CreateLaunchTemplate", "ec2:CreateLaunchTemplateVersion", "ec2:DescribeLaunchTemplates", "ec2:DescribeLaunchTemplateVersions", "ec2:DeleteLaunchTemplate", "ec2:DeleteLaunchTemplateVersions" ], "Resource": [ "\*" ], "Effect": "Allow" }, { "Condition": { "StringLike": { "iam:AWSServiceName": "elasticloadbalancing.amazonaws.com" } }, "Action": [ "iam:CreateServiceLinkedRole" ], "Resource": [ "arn:*:iam::*:role/aws-service-role/elasticloadbalancing.amazonaws.com/AWSServiceRoleForElasticLoadBalancing" ], "Effect": "Allow" }, { "Action": [ "iam:PassRole" ], "Resource": [ "arn:*:iam::*:role/*-worker-role" ], "Effect": "Allow" } ] }controlPlaneOperatorARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:CreateVpcEndpoint", "ec2:DescribeVpcEndpoints", "ec2:ModifyVpcEndpoint", "ec2:DeleteVpcEndpoints", "ec2:CreateTags", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets" ], "Resource": "arn:aws:route53:::%s" } ] }
5.1.3. AWS 인프라와 IAM 리소스를 별도로 생성
기본적으로 hcp create cluster aws 명령은 호스팅된 클러스터로 클라우드 인프라를 생성하고 적용합니다. 클라우드 인프라 부분을 별도로 생성한 후 hcp create cluster aws 명령을 사용하여 클러스터만 생성하거나, 렌더링하여 적용하기 전에 수정할 수 있습니다.
클라우드 인프라 부분을 별도로 생성하려면 Amazon Web Services(AWS) 인프라를 생성하고, AWS Identity and Access(IAM) 리소스를 생성하고, 클러스터를 생성해야 합니다.
5.1.3.1. AWS 인프라를 별도로 생성
Amazon Web Services(AWS) 인프라를 생성하려면 클러스터에 대한 VPC(가상 사설 클라우드) 및 기타 리소스를 생성해야 합니다. AWS 콘솔이나 인프라 자동화 및 프로비저닝 도구를 사용할 수 있습니다. AWS 콘솔을 사용하는 방법에 대한 자세한 내용은 AWS 설명서에서 VPC 및 기타 VPC 리소스 만들기를 참조하세요.
VPC에는 외부 액세스를 위한 개인 및 공용 서브넷과 리소스(예: 네트워크 주소 변환(NAT) 게이트웨이 및 인터넷 게이트웨이)가 포함되어야 합니다. VPC 외에도 클러스터의 유입을 위한 개인 호스팅 영역이 필요합니다. PrivateLink( Private 또는 PublicAndPrivate 액세스 모드)를 사용하는 클러스터를 생성하는 경우 PrivateLink에 대한 추가 호스팅 영역이 필요합니다.
다음 예제 구성을 사용하여 호스팅된 클러스터에 대한 AWS 인프라를 만듭니다.
---
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: clusters
spec: {}
status: {}
---
apiVersion: v1
data:
.dockerconfigjson: xxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <pull_secret_name>
namespace: clusters
---
apiVersion: v1
data:
key: xxxxxxxxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <etcd_encryption_key_name>
namespace: clusters
type: Opaque
---
apiVersion: v1
data:
id_rsa: xxxxxxxxx
id_rsa.pub: xxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <ssh-key-name>
namespace: clusters
---
apiVersion: hypershift.openshift.io/v1beta1
kind: HostedCluster
metadata:
creationTimestamp: null
name: <hosted_cluster_name>
namespace: clusters
spec:
autoscaling: {}
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: <dns_domain>
privateZoneID: xxxxxxxx
publicZoneID: xxxxxxxx
etcd:
managed:
storage:
persistentVolume:
size: 8Gi
storageClassName: gp3-csi
type: PersistentVolume
managementType: Managed
fips: false
infraID: <infra_id>
issuerURL: <issuer_url>
networking:
clusterNetwork:
- cidr: 10.132.0.0/14
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- cidr: 172.31.0.0/16
olmCatalogPlacement: management
platform:
aws:
cloudProviderConfig:
subnet:
id: <subnet_xxx>
vpc: <vpc_xxx>
zone: us-west-1b
endpointAccess: Public
multiArch: false
region: us-west-1
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/<infra_id>-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/<infra_id>-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/<infra_id>-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/<infra_id>-cloud-controller
networkARN: arn:aws:iam::820196288204:role/<infra_id>-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/<infra_id>-node-pool
storageARN: arn:aws:iam::820196288204:role/<infra_id>-aws-ebs-csi-driver-controller
type: AWS
pullSecret:
name: <pull_secret_name>
release:
image: quay.io/openshift-release-dev/ocp-release:4.16-x86_64
secretEncryption:
aescbc:
activeKey:
name: <etcd_encryption_key_name>
type: aescbc
services:
- service: APIServer
servicePublishingStrategy:
type: LoadBalancer
- service: OAuthServer
servicePublishingStrategy:
type: Route
- service: Konnectivity
servicePublishingStrategy:
type: Route
- service: Ignition
servicePublishingStrategy:
type: Route
- service: OVNSbDb
servicePublishingStrategy:
type: Route
sshKey:
name: <ssh_key_name>
status:
controlPlaneEndpoint:
host: ""
port: 0
---
apiVersion: hypershift.openshift.io/v1beta1
kind: NodePool
metadata:
creationTimestamp: null
name: <node_pool_name>
namespace: clusters
spec:
arch: amd64
clusterName: <hosted_cluster_name>
management:
autoRepair: true
upgradeType: Replace
nodeDrainTimeout: 0s
platform:
aws:
instanceProfile: <instance_profile_name>
instanceType: m6i.xlarge
rootVolume:
size: 120
type: gp3
subnet:
id: <subnet_xxx>
type: AWS
release:
image: quay.io/openshift-release-dev/ocp-release:4.16-x86_64
replicas: 2
status:
replicas: 0- 1
<pull_secret_name>을풀 시크릿의 이름으로 바꾸세요.- 2
<etcd_encryption_key_name>을etcd 암호화 키의 이름으로 바꾸세요.- 3
<ssh_key_name>을SSH 키 이름으로 바꾸세요.- 4
<hosted_cluster_name>을호스팅 클러스터의 이름으로 바꾸세요.- 5
<dns_domain>을example.com과 같은 기본 DNS 도메인으로 바꾸세요.- 6
<infra_id>를호스팅된 클러스터와 연결된 IAM 리소스를 식별하는 값으로 바꿉니다.- 7
<issuer_url>을infra_id값으로 끝나는 발급자 URL로 바꾸세요. 예를 들어,https://example-hosted-us-west-1.s3.us-west-1.amazonaws.com/example-hosted-infra-id.- 8
<subnet_xxx>를서브넷 ID로 바꾸세요. 개인 서브넷과 공용 서브넷 모두에 태그가 지정되어야 합니다. 공용 서브넷의 경우kubernetes.io/role/elb=1을사용합니다. 개인 서브넷의 경우kubernetes.io/role/internal-elb=1을사용합니다.- 9
<vpc_xxx>를VPC ID로 바꾸세요.- 10
<node_pool_name>을NodePool리소스의 이름으로 바꾸세요.- 11
<instance_profile_name>을AWS 인스턴스의 이름으로 바꾸세요.
5.1.3.2. AWS IAM 리소스 생성
Amazon Web Services(AWS)에서는 다음 IAM 리소스를 생성해야 합니다.
- STS 인증을 활성화하는 데 필요한 IAM의 OpenID Connect(OIDC) ID 공급자입니다 .
- Kubernetes 컨트롤러 관리자, 클러스터 API 공급자, 레지스트리와 같이 공급자와 상호 작용하는 모든 구성 요소에 대해 별도로 지정된 7가지 역할
- 클러스터의 모든 작업자 인스턴스에 할당되는 프로필인 인스턴스 프로필
5.1.3.3. 호스팅 클러스터를 별도로 생성
Amazon Web Services(AWS)에서 호스팅 클러스터를 별도로 생성할 수 있습니다.
호스팅된 클러스터를 별도로 생성하려면 다음 명령을 입력하세요.
$ hcp create cluster aws \
--infra-id <infra_id> \
--name <hosted_cluster_name> \
--sts-creds <path_to_sts_credential_file> \
--pull-secret <path_to_pull_secret> \
--generate-ssh \
--node-pool-replicas 3
--role-arn <role_name> - 1
<infra_id>를create infra aws명령에서 지정한 것과 동일한 ID로 바꾸세요. 이 값은 호스팅된 클러스터와 연결된 IAM 리소스를 식별합니다.- 2
<hosted_cluster_name>을호스팅 클러스터의 이름으로 바꾸세요.- 3
<path_to_sts_credential_file>을create infra aws명령에서 지정한 것과 동일한 이름으로 바꾸세요.- 4
<path_to_pull_secret>을유효한 OpenShift Container Platform 풀 비밀이 포함된 파일 이름으로 바꾸세요.- 5
--generate-ssh플래그는 선택 사항이지만, 작업자에 SSH를 사용해야 하는 경우 포함하는 것이 좋습니다. SSH 키가 생성되어 호스팅된 클러스터와 동일한 네임스페이스에 비밀로 저장됩니다.- 6
<role_name>을Amazon 리소스 이름(ARN)으로 바꿉니다(예:arn:aws:iam::820196288204:role/myrole). Amazon 리소스 이름(ARN)을 지정합니다(예:arn:aws:iam::820196288204:role/myrole). ARN 역할에 대한 자세한 내용은 "IAM(ID 및 액세스 관리) 권한"을 참조하세요.
명령에 --render 플래그를 추가하고 클러스터에 적용하기 전에 리소스를 편집할 수 있는 파일로 출력을 리디렉션할 수도 있습니다.
명령을 실행하면 다음 리소스가 클러스터에 적용됩니다.
- 네임스페이스
- 당신의 풀 시크릿을 이용한 비밀
-
A
HostedCluster -
A
NodePool - 제어 평면 구성 요소를 위한 세 가지 AWS STS 비밀
-
--generate-ssh플래그를 지정한 경우 SSH 키 비밀 하나가 생성됩니다.
5.1.4. 단일 아키텍처에서 다중 아키텍처로 호스팅 클러스터 전환
Amazon Web Services(AWS)에서 단일 아키텍처 64비트 AMD 호스팅 클러스터를 다중 아키텍처 호스팅 클러스터로 전환하면 클러스터에서 워크로드를 실행하는 데 드는 비용을 줄일 수 있습니다. 예를 들어, 64비트 ARM으로 전환하는 동안 64비트 AMD에서 기존 워크로드를 실행할 수 있으며, 이러한 워크로드를 중앙 Kubernetes 클러스터에서 관리할 수 있습니다.
단일 아키텍처 호스팅 클러스터는 특정 CPU 아키텍처 하나만의 노드 풀을 관리할 수 있습니다. 하지만 다중 아키텍처 호스팅 클러스터는 서로 다른 CPU 아키텍처를 갖춘 노드 풀을 관리할 수 있습니다. AWS에서는 다중 아키텍처 호스팅 클러스터가 64비트 AMD와 64비트 ARM 노드 풀을 모두 관리할 수 있습니다.
사전 요구 사항
- Kubernetes Operator용 멀티클러스터 엔진이 포함된 Red Hat Advanced Cluster Management(RHACM)에서 AWS용 OpenShift Container Platform 관리 클러스터를 설치했습니다.
- OpenShift Container Platform 릴리스 페이로드의 64비트 AMD 변형을 사용하는 기존 단일 아키텍처 호스팅 클러스터가 있습니다.
- OpenShift Container Platform 릴리스 페이로드의 동일한 64비트 AMD 변형을 사용하고 기존 호스팅 클러스터에서 관리되는 기존 노드 풀입니다.
다음 명령줄 도구를 설치했는지 확인하세요.
-
oc -
kubectl -
hcp -
skopeo
-
프로세스
다음 명령을 실행하여 단일 아키텍처 호스팅 클러스터의 기존 OpenShift Container Platform 릴리스 이미지를 검토하세요.
$ oc get hostedcluster/<hosted_cluster_name> \1 -o jsonpath='{.spec.release.image}'- 1
<hosted_cluster_name>을호스팅 클러스터 이름으로 바꾸세요.
출력 예
quay.io/openshift-release-dev/ocp-release:<4.y.z>-x86_641 - 1
<4.yz>를사용하는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
OpenShift Container Platform 릴리스 이미지에서 태그 대신 다이제스트를 사용하는 경우 릴리스 이미지의 다중 아키텍처 태그 버전을 찾으세요.
다음 명령을 실행하여 OpenShift Container Platform 버전에 대한
OCP_VERSION환경 변수를 설정합니다.$ OCP_VERSION=$(oc image info quay.io/openshift-release-dev/ocp-release@sha256:ac78ebf77f95ab8ff52847ecd22592b545415e1ff6c7ff7f66bf81f158ae4f5e \ -o jsonpath='{.config.config.Labels["io.openshift.release"]}')다음 명령을 실행하여 릴리스 이미지의 다중 아키텍처 태그 버전에 대한
MULTI_ARCH_TAG환경 변수를 설정합니다.$ MULTI_ARCH_TAG=$(skopeo inspect docker://quay.io/openshift-release-dev/ocp-release@sha256:ac78ebf77f95ab8ff52847ecd22592b545415e1ff6c7ff7f66bf81f158ae4f5e \ | jq -r '.RepoTags' | sed 's/"//g' | sed 's/,//g' \ | grep -w "$OCP_VERSION-multi$" | xargs)다음 명령을 실행하여 다중 아키텍처 릴리스 이미지 이름에 대한
IMAGE환경 변수를 설정합니다.$ IMAGE=quay.io/openshift-release-dev/ocp-release:$MULTI_ARCH_TAG다중 아키텍처 이미지 다이제스트 목록을 보려면 다음 명령을 실행하세요.
$ oc image info $IMAGE출력 예
OS DIGEST linux/amd64 sha256:b4c7a91802c09a5a748fe19ddd99a8ffab52d8a31db3a081a956a87f22a22ff8 linux/ppc64le sha256:66fda2ff6bd7704f1ba72be8bfe3e399c323de92262f594f8e482d110ec37388 linux/s390x sha256:b1c1072dc639aaa2b50ec99b530012e3ceac19ddc28adcbcdc9643f2dfd14f34 linux/arm64 sha256:7b046404572ac96202d82b6cb029b421dddd40e88c73bbf35f602ffc13017f21
호스팅된 클러스터를 단일 아키텍처에서 다중 아키텍처로 전환:
호스팅된 클러스터에 대해 다중 아키텍처 OpenShift Container Platform 릴리스 이미지를 설정하려면 호스팅된 클러스터와 동일한 OpenShift Container Platform 버전을 사용해야 합니다. 다음 명령을 실행합니다.
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p \ '{"spec":{"release":{"image":"quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi"}}}' \1 --type=merge- 1
<4.yz>를사용하는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
다음 명령을 실행하여 호스팅된 클러스터에 다중 아키텍처 이미지가 설정되었는지 확인하세요.
$ oc get hostedcluster/<hosted_cluster_name> \ -o jsonpath='{.spec.release.image}'
다음 명령을 실행하여
HostedControlPlane리소스의 상태가진행중인지 확인하세요.$ oc get hostedcontrolplane -n <hosted_control_plane_namespace> -oyaml출력 예
#... - lastTransitionTime: "2024-07-28T13:07:18Z" message: HostedCluster is deploying, upgrading, or reconfiguring observedGeneration: 5 reason: Progressing status: "True" type: Progressing #...다음 명령을 실행하여
HostedCluster리소스의 상태가진행중인지 확인하세요.$ oc get hostedcluster <hosted_cluster_name> \ -n <hosted_cluster_namespace> -oyaml
검증
다음 명령을 실행하여 노드 풀이
HostedControlPlane리소스에서 다중 아키텍처 릴리스 이미지를 사용하고 있는지 확인하세요.$ oc get hostedcontrolplane -n clusters-example -oyaml출력 예
#... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi1 url: https://access.redhat.com/errata/RHBA-2024:4855 version: 4.16.5 history: - completionTime: "2024-07-28T13:10:58Z" image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi startedTime: "2024-07-28T13:10:27Z" state: Completed verified: false version: <4.x.y>- 1
<4.yz>를사용하는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
참고다중 아키텍처 OpenShift Container Platform 릴리스 이미지는
HostedCluster,HostedControlPlane리소스 및 호스팅 제어 평면 Pod에서 업데이트됩니다. 하지만 릴리스 이미지 전환은 호스팅된 클러스터와 노드 풀 사이에서 분리되어 있기 때문에 기존 노드 풀은 다중 아키텍처 이미지와 함께 자동으로 전환되지 않습니다. 새로운 다중 아키텍처 호스팅 클러스터에 새 노드 풀을 만들어야 합니다.
다음 단계
- 다중 아키텍처 호스팅 클러스터에서 노드 풀 생성
5.1.5. 다중 아키텍처 호스팅 클러스터에서 노드 풀 생성
호스팅된 클러스터를 단일 아키텍처에서 다중 아키텍처로 전환한 후 64비트 AMD 및 64비트 ARM 아키텍처를 기반으로 하는 컴퓨팅 머신에 노드 풀을 만듭니다.
프로세스
다음 명령을 입력하여 64비트 ARM 아키텍처를 기반으로 노드 풀을 만듭니다.
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count=<node_count> \3 --arch arm64다음 명령을 입력하여 64비트 AMD 아키텍처를 기반으로 노드 풀을 만듭니다.
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count=<node_count> \3 --arch amd64
검증
다음 명령을 입력하여 노드 풀이 다중 아키텍처 릴리스 이미지를 사용하고 있는지 확인하세요.
$ oc get nodepool/<nodepool_name> -oyaml64비트 AMD 노드 풀에 대한 출력 예
#... spec: arch: amd64 #... release: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi1 - 1
<4.yz>를사용하는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
64비트 ARM 노드 풀에 대한 예제 출력
#... spec: arch: arm64 #... release: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi
5.1.6. 호스팅된 클러스터에 대한 AWS 태그 추가 또는 업데이트
클러스터 인스턴스 관리자는 호스팅된 클러스터를 다시 만들지 않고도 Amazon Web Services(AWS) 태그를 추가하거나 업데이트할 수 있습니다. 태그는 관리 및 자동화를 위해 AWS 리소스에 첨부되는 키-값 쌍입니다.
다음과 같은 목적으로 태그를 사용할 수 있습니다.
- 접근 제어 관리.
- 환불 또는 쇼백 추적.
- 클라우드 IAM 조건부 권한 관리.
- 태그를 기준으로 리소스를 집계합니다. 예를 들어, 태그를 쿼리하여 리소스 사용량과 청구 비용을 계산할 수 있습니다.
EFS 액세스 포인트, 로드 밸런서 리소스, Amazon EBS 볼륨, IAM 사용자, AWS S3를 비롯한 여러 유형의 리소스에 대한 태그를 추가하거나 업데이트할 수 있습니다.
네트워크 로드 밸런서에서는 태그를 추가하거나 업데이트할 수 없습니다. AWS 로드 밸런서는 HostedCluster 리소스에 있는 모든 태그를 조정합니다. 태그를 추가하거나 업데이트하려고 하면 로드 밸런서가 태그를 덮어씁니다.
또한 호스팅된 제어 평면에서 직접 생성된 기본 보안 그룹 리소스에서는 태그를 업데이트할 수 없습니다.
사전 요구 사항
- AWS에서 호스팅된 클러스터에 대한 클러스터 관리자 권한이 있어야 합니다.
프로세스
EFS 액세스 포인트에 대한 태그를 추가하거나 업데이트하려면 1단계와 2단계를 완료하세요. 다른 유형의 리소스에 대한 태그를 추가하거나 업데이트하는 경우 2단계만 완료하세요.
aws-efs-csi-driver-operator서비스 계정에서 다음 예와 같이 두 개의 주석을 추가합니다. 이러한 주석은 클러스터에서 실행되는 AWS EKS Pod ID 웹훅이 EFS 운영자가 사용하는 Pod에 AWS 역할을 올바르게 할당할 수 있도록 하는 데 필요합니다.apiVersion: v1 kind: ServiceAccount metadata: name: <service_account_name> namespace: <project_name> annotations: eks.amazonaws.com/role-arn:<role_arn> eks.amazonaws.com/audience:sts.amazonaws.com-
Operator 포드를 삭제하거나
aws-efs-csi-driver-operator배포를 다시 시작합니다.
HostedCluster리소스에서 다음 예와 같이resourceTags필드에 정보를 입력합니다.HostedCluster리소스 예시apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: #... spec: autoscaling: {} clusterID: <cluster_id> configuration: {} controllerAvailabilityPolicy: SingleReplica dns: #... etcd: #... fips: false infraID: <infra_id> infrastructureAvailabilityPolicy: SingleReplica issuerURL: https://<issuer_url>.s3.<region>.amazonaws.com networking: #... olmCatalogPlacement: management platform: aws: #... resourceTags: - key: kubernetes.io/cluster/<tag>1 value: owned rolesRef: #... type: AWS
- 1
- 리소스에 추가하려는 태그를 지정하세요.
5.1.7. AWS에서 노드 풀 용량 블록 구성
호스팅 클러스터를 만든 후 Amazon Web Services(AWS)에서 GPU(그래픽 처리 장치) 예약을 위한 노드 풀 용량 블록을 구성할 수 있습니다.
프로세스
다음 명령을 실행하여 AWS에서 GPU 예약을 생성합니다.
중요GPU 예약 영역은 호스팅된 클러스터 영역과 일치해야 합니다.
$ aws ec2 describe-capacity-block-offerings \ --instance-type "p4d.24xlarge"\1 --instance-count "1" \2 --start-date-range "$(date -u +"%Y-%m-%dT%H:%M:%SZ")" \3 --end-date-range "$(date -u -d "2 day" +"%Y-%m-%dT%H:%M:%SZ")" \4 --capacity-duration-hours 24 \5 --output json다음 명령을 실행하여 최소 수수료 용량 블록을 구매하세요.
$ aws ec2 purchase-capacity-block \ --capacity-block-offering-id "${MIN_FEE_ID}" \1 --instance-platform "Linux/UNIX"\2 --tag-specifications 'ResourceType=capacity-reservation,Tags=[{Key=usage-cluster-type,Value=hypershift-hosted}]' \3 --output json > "${CR_OUTPUT_FILE}"다음 명령을 실행하여 용량 예약 ID를 설정하는 환경 변수를 만듭니다.
$ CB_RESERVATION_ID=$(jq -r '.CapacityReservation.CapacityReservationId' "${CR_OUTPUT_FILE}")GPU 예약이 가능해질 때까지 몇 분간 기다리세요.
다음 명령을 실행하여 GPU 예약을 사용할 노드 풀을 추가합니다.
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <node_pool_name> \2 --node-count 1 \3 --instance-type p4d.24xlarge \4 --arch amd64 \5 --release-image <release_image> \6 --render > /tmp/np.yaml다음 예제 구성을 사용하여
NodePool리소스에capacityReservation설정을 추가합니다.# ... spec: arch: amd64 clusterName: cb-np-hcp management: autoRepair: false upgradeType: Replace platform: aws: instanceProfile: cb-np-hcp-dqppw-worker instanceType: p4d.24xlarge rootVolume: size: 120 type: gp3 subnet: id: subnet-00000 placement: capacityReservation: id: ${CB_RESERVATION_ID} marketType: CapacityBlocks type: AWS # ...다음 명령을 실행하여 노드 풀 구성을 적용합니다.
$ oc apply -f /tmp/np.yaml
검증
다음 명령을 실행하여 새 노드 풀이 성공적으로 생성되었는지 확인하세요.
$ oc get np -n clusters출력 예
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters cb-np cb-np-hcp 1 1 False False 4.20.0-0.nightly-2025-06-05-224220 False False다음 명령을 실행하여 호스팅된 클러스터에 새 컴퓨팅 노드가 생성되었는지 확인하세요.
$ oc get nodes출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-132-74.ec2.internal Ready worker 17m v1.32.5 ip-10-0-134-183.ec2.internal Ready worker 4h5m v1.32.5
5.1.7.1. 노드 풀 용량 블록을 구성한 후 호스팅된 클러스터 삭제
노드 풀 용량 블록을 구성한 후에는 선택적으로 호스팅된 클러스터를 삭제하고 HyperShift Operator를 제거할 수 있습니다.
프로세스
호스팅된 클러스터를 파괴하려면 다음 예제 명령을 실행하세요.
$ hcp destroy cluster aws \ --name cb-np-hcp \ --aws-creds $HOME/.aws/credentials \ --namespace clusters \ --region us-east-2HyperShift Operator를 제거하려면 다음 명령을 실행하세요.
$ hcp install render --format=yaml | oc delete -f -
5.2. 베어 메탈에서 호스트된 컨트롤 플레인 관리
베어 메탈에 호스팅되는 컨트롤 플레인을 배포한 후 다음 작업을 완료하여 호스팅 클러스터를 관리할 수 있습니다.
5.2.1. 호스트된 클러스터에 액세스
리소스에서 직접 kubeconfig 파일 및 kubeadmin 자격 증명을 가져오거나 hcp 명령줄 인터페이스를 사용하여 kubeconfig 파일을 생성하여 호스팅된 클러스터에 액세스할 수 있습니다.
사전 요구 사항
리소스에서 직접 kubeconfig 파일 및 인증 정보를 가져와 호스팅된 클러스터에 액세스하려면 호스팅 클러스터의 액세스 시크릿을 숙지해야 합니다. 호스팅된 클러스터(호스트링) 네임스페이스에는 호스팅 된 클러스터 리소스 및 액세스 보안이 포함되어 있습니다. 호스팅된 컨트롤 플레인 네임스페이스는 호스팅된 컨트롤 플레인이 실행되는 위치입니다.
보안 이름 형식은 다음과 같습니다.
-
kubeconfig시크릿: <hosted_cluster_namespace>-<name>-admin-kubeconfig. 예를 들어 cluster-hypershift-demo-admin-kubeconfig. -
kubeadmin암호 시크릿: <hosted_cluster_namespace>-<name>-kubeadmin-password. 예를 들어 cluster-hypershift-demo-kubeadmin-password.
kubeconfig 시크릿에는 Base64로 인코딩된 kubeconfig 필드가 포함되어 있으며 다음 명령과 함께 사용할 파일에 디코딩하고 저장할 수 있습니다.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin 암호 시크릿도 Base64로 인코딩됩니다. 이를 디코딩하고 암호를 사용하여 호스팅된 클러스터의 API 서버 또는 콘솔에 로그인할 수 있습니다.
프로세스
hcpCLI를 사용하여kubeconfig파일을 생성하여 호스팅된 클러스터에 액세스하려면 다음 단계를 수행합니다.다음 명령을 입력하여
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfig파일을 저장한 후 다음 예제 명령을 입력하여 호스팅된 클러스터에 액세스할 수 있습니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.2.2. 호스트 클러스터의 NodePool 오브젝트 스케일링
호스팅된 클러스터에 노드를 추가하여 NodePool 오브젝트를 확장할 수 있습니다. 노드 풀을 확장할 때 다음 정보를 고려하십시오.
- 노드 풀로 복제본을 확장하면 머신이 생성됩니다. 모든 머신에 대해 클러스터 API 공급자는 노드 풀 사양에 지정된 요구 사항을 충족하는 에이전트를 찾아 설치합니다. 에이전트의 상태 및 조건을 확인하여 에이전트 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩되지 않습니다. 에이전트를 재사용하려면 먼저 Discovery 이미지를 사용하여 다시 시작해야 합니다.
프로세스
NodePool오브젝트를 두 개의 노드로 확장합니다.$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 에이전트 공급자는 호스트 클러스터에 할당된 두 개의 에이전트를 임의로 선택합니다. 이러한 에이전트는 다른 상태를 통과하고 마지막으로 호스팅된 클러스터에 OpenShift Container Platform 노드로 참여합니다. 에이전트는 다음 순서로 상태를 통과합니다.
-
binding -
검색 -
충분하지 않음 - 설치
-
installing-in-progress -
added-to-existing-cluster
-
다음 명령을 실행합니다.
$ oc -n <hosted_control_plane_namespace> get agent출력 예
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign다음 명령을 실행합니다.
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'출력 예
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficientextract 명령을 입력하여 새 호스팅 클러스터에 대한 kubeconfig를 가져옵니다.
$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>에이전트가
add-to-existing-cluster상태에 도달한 후 다음 명령을 입력하여 호스팅된 클러스터에 OpenShift Container Platform 노드를 볼 수 있는지 확인합니다.$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get nodes출력 예
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8f클러스터 Operator는 노드에 워크로드를 추가하여 조정하기 시작합니다.
다음 명령을 입력하여
NodePool오브젝트를 확장할 때 두 개의 머신이 생성되었는지 확인합니다.$ oc -n <hosted_control_plane_namespace> get machines출력 예
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.x.z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.x.zclusterversion조정 프로세스는 결국 Ingress 및 Console 클러스터 Operator만 누락된 지점에 도달합니다.다음 명령을 실행합니다.
$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get clusterversion,co출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.x.z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
5.2.2.1. 노드 풀 추가
이름, 복제본 수 및 에이전트 라벨 선택기와 같은 추가 정보를 지정하여 호스팅된 클러스터에 대한 노드 풀을 생성할 수 있습니다.
각 호스팅 클러스터에는 단일 에이전트 네임스페이스만 지원됩니다. 결과적으로 호스팅된 클러스터에 노드 풀을 추가할 때 노드 풀은 단일 InfraEnv 리소스에 속하거나 동일한 에이전트 네임스페이스에 있는 InfraEnv 리소스에 속해야 합니다.
프로세스
노드 풀을 생성하려면 다음 정보를 입력합니다.
$ hcp create nodepool agent \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <worker_node_count> \3 --agentLabelSelector size=medium4 cluster 네임스페이스에
nodepool리소스를 나열하여 노드 풀의상태를확인합니다.$ oc get nodepools --namespace clusters다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.$ oc extract -n <hosted_control_plane_namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인할 수 있습니다.
$ oc --kubeconfig ./hostedcluster-secrets get nodes
검증
다음 명령을 입력하여 사용 가능한 노드 풀 수가 예상 노드 풀 수와 일치하는지 확인합니다.
$ oc get nodepools --namespace clusters
5.2.2.2. 호스트 클러스터의 노드 자동 확장 활성화
호스팅된 클러스터에 용량이 더 필요하고 예비 에이전트를 사용할 수 있는 경우 자동 확장을 활성화하여 새 작업자 노드를 설치할 수 있습니다.
프로세스
자동 확장을 활성화하려면 다음 명령을 입력합니다.
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'참고이 예에서 최소 노드 수는 2이고 최대값은 5입니다. 추가할 수 있는 최대 노드 수는 플랫폼에 바인딩될 수 있습니다. 예를 들어 에이전트 플랫폼을 사용하는 경우 사용 가능한 에이전트 수에 따라 최대 노드 수가 바인딩됩니다.
새 노드가 필요한 워크로드를 생성합니다.
다음 예제를 사용하여 워크로드 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
파일을
workload-config.yaml로 저장합니다. 다음 명령을 입력하여 YAML을 적용합니다.
$ oc apply -f workload-config.yaml
다음 명령을 입력하여
admin-kubeconfig비밀번호를 추출합니다.$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 새 노드가
준비상태인지 확인할 수 있습니다.$ oc --kubeconfig ./hostedcluster-secrets get nodes노드를 제거하려면 다음 명령을 입력하여 작업 부하를 삭제하세요.
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>추가 용량이 필요하지 않을 때까지 몇 분간 기다리세요. Agent 플랫폼에서는 Agent가 폐기되고 재사용될 수 있습니다. 다음 명령을 입력하면 노드가 제거되었는지 확인할 수 있습니다.
$ oc --kubeconfig ./hostedcluster-secrets get nodes참고IBM Z® 에이전트의 경우 PR/SM(Processor Resource/Systems Manager) 모드에서 OSA 네트워크 장치를 사용하는 경우 자동 크기 조정이 지원되지 않습니다. 축소 프로세스 중에 새 에이전트가 합류하므로 기존 에이전트를 수동으로 삭제하고 노드 풀을 확장해야 합니다.
5.2.2.3. 호스팅된 클러스터에 대한 노드 자동 크기 조정 비활성화
노드 자동 크기 조정을 비활성화하려면 다음 절차를 완료하세요.
프로세스
호스팅된 클러스터에 대한 노드 자동 크기 조정을 비활성화하려면 다음 명령을 입력하세요.
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify_value_to_scale_replicas>]'이 명령은 YAML 파일에서
"spec.autoScaling"을제거하고,"spec.replicas"를추가하고,"spec.replicas"를지정한 정수 값으로 설정합니다.
5.2.3. 베어 메탈에서 호스팅된 클러스터에서 수신 처리
모든 OpenShift Container Platform 클러스터에는 일반적으로 외부 DNS 레코드가 연결된 기본 애플리케이션 Ingress Controller가 있습니다. 예를 들어, 기본 도메인을 krnl.es 로 하여 example 이라는 이름의 호스팅 클러스터를 생성하면 와일드카드 도메인 *.apps.example.krnl.es 가 라우팅될 것으로 예상할 수 있습니다.
프로세스
*.apps 도메인에 대한 로드 밸런서와 와일드카드 DNS 레코드를 설정하려면 게스트 클러스터에서 다음 작업을 수행하세요.
MetalLB Operator에 대한 구성을 포함하는 YAML 파일을 만들어 MetalLB를 배포합니다.
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
파일을
metallb-operator-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f metallb-operator-config.yamlOperator가 실행된 후 MetalLB 인스턴스를 생성합니다.
MetalLB 인스턴스에 대한 구성을 포함하는 YAML 파일을 만듭니다.
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
파일을
metallb-instance-config.yaml로 저장합니다. 다음 명령을 입력하여 MetalLB 인스턴스를 만듭니다.
$ oc apply -f metallb-instance-config.yaml
단일 IP 주소로
IPAddressPool리소스를 만듭니다. 이 IP 주소는 클러스터 노드가 사용하는 네트워크와 동일한 서브넷에 있어야 합니다.다음 예와 같은 내용을 사용하여
addresspool.yaml과 같은 파일을 생성합니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb name: <ip_address_pool_name>1 spec: addresses: - <ingress_ip>-<ingress_ip>2 autoAssign: false다음 명령을 입력하여 IP 주소 풀에 대한 구성을 적용합니다.
$ oc apply -f ipaddresspool.yaml
L2 광고를 만드세요.
다음 예시와 같은 내용을 담은
l2advertisement.yaml과 같은 파일을 만듭니다.apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: <l2_advertisement_name>1 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>2 다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f l2advertisement.yaml
LoadBalancer유형의 서비스를 생성한 후 MetalLB는 해당 서비스에 대한 외부 IP 주소를 추가합니다.metallb-loadbalancer-service.yaml이라는 YAML 파일을 만들어 수신 트래픽을 수신 배포로 라우팅하는 새로운 로드 밸런서 서비스를 구성합니다.kind: Service apiVersion: v1 metadata: annotations: metallb.io/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
metallb-loadbalancer-service.yaml파일을 저장합니다. YAML 구성을 적용하려면 다음 명령을 입력하세요.
$ oc apply -f metallb-loadbalancer-service.yamlOpenShift Container Platform 콘솔에 접속하려면 다음 명령을 입력하세요.
$ curl -kI https://console-openshift-console.apps.example.krnl.es출력 예
HTTP/1.1 200 OKclusterversion및clusteroperator값을 확인하여 모든 것이 제대로 실행되고 있는지 확인하세요. 다음 명령을 실행합니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m<4.xy>를사용하려는 지원되는 OpenShift Container Platform 버전(예:4.19.0-multi )으로 바꾸세요.
5.2.4. 베어 메탈에서 머신 상태 점검 활성화
베어 메탈에서 머신 상태 검사를 활성화하여 상태가 좋지 않은 관리형 클러스터 노드를 자동으로 복구하고 교체할 수 있습니다. 관리되는 클러스터에 설치할 준비가 된 추가 에이전트 머신이 있어야 합니다.
머신 상태 검사를 활성화하기 전에 다음 제한 사항을 고려하세요.
-
MachineHealthCheck객체를 수정할 수 없습니다. -
머신 상태 검사는 최소 두 개의 노드가 8분 이상
False또는Unknown상태를 유지하는 경우에만 노드를 교체합니다.
관리되는 클러스터 노드에 대한 머신 상태 검사를 활성화하면 호스팅된 클러스터에 MachineHealthCheck 개체가 생성됩니다.
프로세스
호스팅된 클러스터에서 머신 상태 검사를 활성화하려면 NodePool 리소스를 수정하세요. 다음 단계를 완료하세요.
NodePool리소스의spec.nodeDrainTimeout값이0보다 큰지 확인하세요.<hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스의 이름으로 바꾸고<nodepool_name>을노드 풀 이름으로 바꾸세요. 다음 명령을 실행합니다.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep nodeDrainTimeout출력 예
nodeDrainTimeout: 30sspec.nodeDrainTimeout값이0s보다 크지 않으면 다음 명령을 실행하여 값을 수정합니다.$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec":{"nodeDrainTimeout": "30m"}}' --type=mergeNodePool리소스에서spec.management.autoRepair필드를true로 설정하여 머신 상태 검사를 활성화합니다. 다음 명령을 실행합니다.$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":true}}}' --type=merge다음 명령을 실행하여
NodePool리소스가autoRepair: true값으로 업데이트되었는지 확인하세요.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.2.5. 베어 메탈에서 머신 상태 검사 비활성화
관리되는 클러스터 노드에 대한 머신 상태 검사를 비활성화하려면 NodePool 리소스를 수정합니다.
프로세스
NodePool리소스에서spec.management.autoRepair필드를false로 설정하여 머신 상태 검사를 비활성화합니다. 다음 명령을 실행합니다.$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":false}}}' --type=merge다음 명령을 실행하여
NodePool리소스가autoRepair: false값으로 업데이트되었는지 확인하세요.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.3. OpenShift Virtualization에서 호스팅된 제어 평면 관리
OpenShift Virtualization에 호스팅된 클러스터를 배포한 후 다음 절차를 완료하여 클러스터를 관리할 수 있습니다.
5.3.1. 호스팅된 클러스터에 액세스
호스팅된 클러스터에 액세스하려면 리소스에서 직접 kubeconfig 파일과 kubeadmin 자격 증명을 가져오거나 hcp 명령줄 인터페이스를 사용하여 kubeconfig 파일을 생성하면 됩니다.
사전 요구 사항
리소스에서 직접 kubeconfig 파일과 자격 증명을 가져와 호스팅된 클러스터에 액세스하려면 호스팅된 클러스터의 액세스 비밀을 알고 있어야 합니다. 호스팅 클러스터(호스팅) 네임스페이스에는 호스팅 클러스터 리소스와 액세스 비밀이 포함되어 있습니다. 호스팅된 제어 평면 네임스페이스는 호스팅된 제어 평면이 실행되는 곳입니다.
비밀 이름 형식은 다음과 같습니다.
-
kubeconfig비밀:<hosted_cluster_namespace>-<name>-admin-kubeconfig(클러스터-hypershift-demo-admin-kubeconfig) -
kubeadmin비밀번호:<hosted_cluster_namespace>-<name>-kubeadmin-password(클러스터-hypershift-demo-kubeadmin-password)
kubeconfig 비밀에는 Base64로 인코딩된 kubeconfig 필드가 포함되어 있으며, 이를 디코딩하여 다음 명령으로 파일에 저장하여 사용할 수 있습니다.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin 비밀번호도 Base64로 인코딩되었습니다. 이를 디코딩하고 비밀번호를 사용하여 호스팅된 클러스터의 API 서버나 콘솔에 로그인할 수 있습니다.
프로세스
hcpCLI를 사용하여kubeconfig파일을 생성하여 호스팅된 클러스터에 액세스하려면 다음 단계를 따르세요.다음 명령을 입력하여
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfig파일을 저장한 후 다음 예제 명령을 입력하여 호스팅된 클러스터에 액세스할 수 있습니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.3.2. 호스팅된 클러스터에 대한 노드 자동 크기 조정 활성화
호스팅된 클러스터에 더 많은 용량이 필요하고 예비 에이전트를 사용할 수 있는 경우 자동 크기 조정을 활성화하여 새로운 워커 노드를 설치할 수 있습니다.
프로세스
자동 크기 조정을 활성화하려면 다음 명령을 입력하세요.
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'참고이 예에서 노드의 최소 개수는 2개이고, 최대 개수는 5개입니다. 추가할 수 있는 노드의 최대 수는 플랫폼에 따라 제한될 수 있습니다. 예를 들어, Agent 플랫폼을 사용하는 경우 최대 노드 수는 사용 가능한 Agent 수에 따라 제한됩니다.
새로운 노드가 필요한 작업 부하를 만듭니다.
다음 예를 사용하여 워크로드 구성을 포함하는 YAML 파일을 만듭니다.
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
파일을
workload-config.yaml로 저장합니다. 다음 명령을 입력하여 YAML을 적용합니다.
$ oc apply -f workload-config.yaml
다음 명령을 입력하여
admin-kubeconfig비밀번호를 추출합니다.$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 새 노드가
준비상태인지 확인할 수 있습니다.$ oc --kubeconfig ./hostedcluster-secrets get nodes노드를 제거하려면 다음 명령을 입력하여 작업 부하를 삭제하세요.
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>추가 용량이 필요하지 않을 때까지 몇 분간 기다리세요. Agent 플랫폼에서는 Agent가 폐기되고 재사용될 수 있습니다. 다음 명령을 입력하면 노드가 제거되었는지 확인할 수 있습니다.
$ oc --kubeconfig ./hostedcluster-secrets get nodes참고IBM Z® 에이전트의 경우 PR/SM(Processor Resource/Systems Manager) 모드에서 OSA 네트워크 장치를 사용하는 경우 자동 크기 조정이 지원되지 않습니다. 축소 프로세스 중에 새 에이전트가 합류하므로 기존 에이전트를 수동으로 삭제하고 노드 풀을 확장해야 합니다.
5.3.3. OpenShift Virtualization에서 호스팅된 제어 평면에 대한 스토리지 구성
고급 스토리지 구성을 제공하지 않으면 KubeVirt 가상 머신(VM) 이미지, KubeVirt 컨테이너 스토리지 인터페이스(CSI) 매핑 및 etcd 볼륨에 기본 스토리지 클래스가 사용됩니다.
다음 표는 호스팅 클러스터에서 영구 저장소를 지원하기 위해 인프라가 제공해야 하는 기능을 나열합니다.
| 인프라 CSI 제공업체 | 호스팅 클러스터 CSI 공급자 | 호스팅 클러스터 기능 |
|---|---|---|
|
모든 RWX |
|
|
|
모든 RWX | Red Hat OpenShift Data Foundation |
Red Hat OpenShift Data Foundation 기능 세트. 외부 모드는 차지하는 공간이 더 작고 독립형 Red Hat Ceph Storage를 사용합니다. 내부 모드는 차지하는 공간이 더 크지만 독립적이고 RWX |
OpenShift Virtualization은 호스팅된 클러스터의 스토리지를 처리하며, 특히 블록 스토리지에 대한 요구 사항이 제한적인 고객에게 도움이 됩니다.
5.3.3.1. KubeVirt CSI 스토리지 클래스 매핑
KubeVirt CSI는 ReadWriteMany (RWX) 액세스가 가능한 인프라 스토리지 클래스 매핑을 지원합니다. 클러스터를 생성하는 동안 인프라 스토리지 클래스를 호스팅된 스토리지 클래스에 매핑할 수 있습니다.
프로세스
인프라 스토리지 클래스를 호스팅된 스토리지 클래스에 매핑하려면 다음 명령을 실행하여
--infra-storage-class-mapping인수를 사용합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class> \6 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 작업자 수를 지정합니다(예:
2). - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 예를 들어
8Gi와 같이 메모리 값을 지정합니다. - 5
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 6
<infrastructure_storage_class>를인프라 스토리지 클래스 이름으로,<hosted_storage_class>를호스팅된 클러스터 스토리지 클래스 이름으로 바꿉니다.hcp create cluster명령 내에서--infra-storage-class-mapping인수를 여러 번 사용할 수 있습니다.
호스팅 클러스터를 생성한 후에는 호스팅 클러스터 내에서 인프라 스토리지 클래스가 표시됩니다. 해당 스토리지 클래스 중 하나를 사용하는 호스팅된 클러스터 내에서 영구 볼륨 클레임(PVC)을 생성하면 KubeVirt CSI는 클러스터 생성 중에 구성한 인프라 스토리지 클래스 매핑을 사용하여 해당 볼륨을 프로비저닝합니다.
KubeVirt CSI는 RWX 액세스가 가능한 인프라 스토리지 클래스만 매핑을 지원합니다.
다음 표는 볼륨 및 액세스 모드 기능이 KubeVirt CSI 스토리지 클래스에 어떻게 매핑되는지 보여줍니다.
| 인프라 CSI 기능 | 호스팅 클러스터 CSI 기능 | VM 라이브 마이그레이션 지원 | 참고 |
|---|---|---|---|
|
RWX: |
| 지원됨 |
|
|
RWO |
RWO | 지원되지 않음 | 라이브 마이그레이션 지원이 부족하면 KubeVirt VM을 호스팅하는 기본 인프라 클러스터를 업데이트하는 기능에 영향을 미칩니다. |
|
RWO |
RWO | 지원되지 않음 |
라이브 마이그레이션 지원이 부족하면 KubeVirt VM을 호스팅하는 기본 인프라 클러스터를 업데이트하는 기능에 영향을 미칩니다. 인프라 |
5.3.3.2. 단일 KubeVirt CSI 볼륨 스냅샷 클래스 매핑
KubeVirt CSI를 사용하면 인프라 볼륨 스냅샷 클래스를 호스팅된 클러스터에 노출할 수 있습니다.
프로세스
호스팅된 클러스터에 볼륨 스냅샷 클래스를 매핑하려면 호스팅된 클러스터를 생성할 때
--infra-volumesnapshot-class-mapping인수를 사용합니다. 다음 명령을 실행합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class> \6 --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>7 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 작업자 수를 지정합니다(예:
2). - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 예를 들어
8Gi와 같이 메모리 값을 지정합니다. - 5
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 6
<infrastructure_storage_class>를인프라 클러스터에 있는 스토리지 클래스로 바꿉니다.<hosted_storage_class>를호스팅 클러스터에 있는 스토리지 클래스로 바꾸세요.- 7
<infrastructure_volume_snapshot_class>를인프라 클러스터에 있는 볼륨 스냅샷 클래스로 바꿉니다.<hosted_volume_snapshot_class>를호스팅된 클러스터에 있는 볼륨 스냅샷 클래스로 바꿉니다.
참고--infra-storage-class-mapping및--infra-volumesnapshot-class-mapping인수를 사용하지 않으면 기본 스토리지 클래스와 볼륨 스냅샷 클래스를 사용하여 호스팅된 클러스터가 생성됩니다. 따라서 인프라 클러스터에서 기본 저장소 클래스와 볼륨 스냅샷 클래스를 설정해야 합니다.
5.3.3.3. 여러 KubeVirt CSI 볼륨 스냅샷 클래스 매핑
특정 그룹에 할당하여 여러 볼륨 스냅샷 클래스를 호스팅된 클러스터에 매핑할 수 있습니다. 인프라 스토리지 클래스와 볼륨 스냅샷 클래스는 동일한 그룹에 속하는 경우에만 서로 호환됩니다.
프로세스
호스팅된 클러스터에 여러 볼륨 스냅샷 클래스를 매핑하려면 호스팅된 클러스터를 생성할 때
그룹옵션을 사용합니다. 다음 명령을 실행합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \6 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \ --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \ --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>,group=<group_name> \7 --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>,group=<group_name>- 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 작업자 수를 지정합니다(예:
2). - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 예를 들어
8Gi와 같이 메모리 값을 지정합니다. - 5
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 6
<infrastructure_storage_class>를인프라 클러스터에 있는 스토리지 클래스로 바꿉니다.<hosted_storage_class>를호스팅 클러스터에 있는 스토리지 클래스로 바꾸세요.<그룹_이름>을그룹 이름으로 바꾸세요. 예를 들어,infra-storage-class-mygroup/hosted-storage-class-mygroup,group=mygroup및infra-storage-class-mymap/hosted-storage-class-mymap,group=mymap입니다.- 7
<infrastructure_volume_snapshot_class>를인프라 클러스터에 있는 볼륨 스냅샷 클래스로 바꿉니다.<hosted_volume_snapshot_class>를호스팅된 클러스터에 있는 볼륨 스냅샷 클래스로 바꿉니다. 예를 들어,infra-vol-snap-mygroup/hosted-vol-snap-mygroup,group=mygroup및infra-vol-snap-mymap/hosted-vol-snap-mymap,group=mymap입니다.
5.3.3.4. KubeVirt VM 루트 볼륨 구성
클러스터 생성 시 --root-volume-storage-class 인수를 사용하여 KubeVirt VM 루트 볼륨을 호스팅하는 데 사용되는 스토리지 클래스를 구성할 수 있습니다.
프로세스
KubeVirt VM에 대한 사용자 지정 스토리지 클래스와 볼륨 크기를 설정하려면 다음 명령을 실행하세요.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --root-volume-storage-class <root_volume_storage_class> \6 --root-volume-size <volume_size>7 결과적으로 PVC에 호스팅된 VM으로 생성된 호스팅 클러스터를 얻게 됩니다.
5.3.3.5. KubeVirt VM 이미지 캐싱 활성화
KubeVirt VM 이미지 캐싱을 사용하면 클러스터 시작 시간과 스토리지 사용량을 모두 최적화할 수 있습니다. KubeVirt VM 이미지 캐싱은 스마트 복제와 ReadWriteMany 액세스 모드가 가능한 스토리지 클래스 사용을 지원합니다. 스마트 클로닝에 대한 자세한 내용은 스마트 클로닝을 사용하여 데이터 볼륨 복제를 참조하세요.
이미지 캐싱은 다음과 같이 작동합니다.
- VM 이미지는 호스팅된 클러스터와 연결된 PVC로 가져옵니다.
- 클러스터에 작업자 노드로 추가된 모든 KubeVirt VM에 대해 해당 PVC의 고유한 복제본이 생성됩니다.
이미지 캐싱은 단 하나의 이미지 가져오기만 요구하므로 VM 시작 시간을 줄여줍니다. 스토리지 클래스가 복사-쓰기 복제를 지원하는 경우 전체 클러스터 스토리지 사용량을 더욱 줄일 수 있습니다.
프로세스
클러스터를 생성하는 동안 이미지 캐싱을 활성화하려면 다음 명령을 실행하여
--root-volume-cache-strategy=PVC인수를 사용합니다.$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --root-volume-cache-strategy=PVC6
5.3.3.6. KubeVirt CSI 스토리지 보안 및 격리
KubeVirt 컨테이너 스토리지 인터페이스(CSI)는 기본 인프라 클러스터의 스토리지 기능을 호스팅된 클러스터로 확장합니다. CSI 드라이버는 다음과 같은 보안 제약 조건을 사용하여 인프라 스토리지 클래스와 호스팅 클러스터에 대한 안전하고 격리된 액세스를 보장합니다.
- 호스팅된 클러스터의 저장소는 다른 호스팅된 클러스터와 격리됩니다.
- 호스팅된 클러스터의 워커 노드는 인프라 클러스터에 대한 직접적인 API 액세스 권한이 없습니다. 호스팅된 클러스터는 제어된 KubeVirt CSI 인터페이스를 통해서만 인프라 클러스터에 스토리지를 프로비저닝할 수 있습니다.
- 호스팅된 클러스터는 KubeVirt CSI 클러스터 컨트롤러에 액세스할 수 없습니다. 결과적으로 호스팅된 클러스터는 호스팅된 클러스터와 연결되지 않은 인프라 클러스터의 임의의 스토리지 볼륨에 액세스할 수 없습니다. KubeVirt CSI 클러스터 컨트롤러는 호스팅된 제어 평면 네임스페이스의 포드에서 실행됩니다.
- KubeVirt CSI 클러스터 컨트롤러의 역할 기반 액세스 제어(RBAC)는 영구 볼륨 클레임(PVC) 액세스를 호스팅된 제어 평면 네임스페이스로만 제한합니다. 따라서 KubeVirt CSI 구성 요소는 다른 네임스페이스의 저장소에 액세스할 수 없습니다.
5.3.3.7. etcd 스토리지 구성
클러스터 생성 시 --etcd-storage-class 인수를 사용하여 etcd 데이터를 호스팅하는 데 사용되는 스토리지 클래스를 구성할 수 있습니다.
프로세스
etcd에 대한 스토리지 클래스를 구성하려면 다음 명령을 실행하세요.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --etcd-storage-class=<etcd_storage_class_name>6
5.3.4. hcp CLI를 사용하여 NVIDIA GPU 장치 연결
OpenShift Virtualization에서 호스팅된 클러스터의 hcp 명령줄 인터페이스(CLI)를 사용하여 하나 이상의 NVIDIA 그래픽 처리 장치(GPU) 장치를 노드 풀에 연결할 수 있습니다.
NVIDIA GPU 장치를 노드 풀에 연결하는 것은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
사전 요구 사항
- GPU 장치가 있는 노드에서 NVIDIA GPU 장치를 리소스로 노출했습니다. 자세한 내용은 OpenShift 가상화를 지원하는 NVIDIA GPU Operator를 참조하세요.
- 노드 풀에 할당하기 위해 NVIDIA GPU 장치를 노드의 확장 리소스 로 노출했습니다.
프로세스
다음 명령을 실행하여 클러스터 생성 중에 GPU 장치를 노드 풀에 연결할 수 있습니다.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --host-device-name="<gpu_device_name>,count:<value>"6 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 작업자 수를 지정합니다(예:
2). - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 예를 들어
16Gi와 같이 메모리 값을 지정합니다. - 5
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 6
- GPU 장치 이름과 개수를 지정합니다(예:
--host-device-name="nvidia-a100,count:2").--host-device-name인수는 인프라 노드의 GPU 장치 이름과 노드 풀의 각 가상 머신(VM)에 연결하려는 GPU 장치 수를 나타내는 선택적 개수를 사용합니다. 기본 개수는1입니다. 예를 들어, 2개의 GPU 장치를 3개의 노드 풀 복제본에 연결하면 노드 풀에 있는 3개의 VM이 모두 2개의 GPU 장치에 연결됩니다.
작은 정보--host-device-name인수를 여러 번 사용하여 다양한 유형의 여러 장치를 연결할 수 있습니다.
5.3.5. NodePool 리소스를 사용하여 NVIDIA GPU 장치 연결
NodePool 리소스에서 nodepool.spec.platform.kubevirt.hostDevices 필드를 구성하여 하나 이상의 NVIDIA 그래픽 처리 장치(GPU) 장치를 노드 풀에 연결할 수 있습니다.
NVIDIA GPU 장치를 노드 풀에 연결하는 것은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
프로세스
하나 이상의 GPU 장치를 노드 풀에 연결합니다.
단일 GPU 장치를 연결하려면 다음 예제 구성을 사용하여
NodePool리소스를 구성하세요.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: kubevirt: attachDefaultNetwork: true compute: cores: <cpu>3 memory: <memory>4 hostDevices:5 - count: <count>6 deviceName: <gpu_device_name>7 networkInterfaceMultiqueue: Enable rootVolume: persistent: size: 32Gi type: Persistent type: KubeVirt replicas: <worker_node_count>8 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
). - 2
- 호스팅된 클러스터 네임스페이스의 이름을 지정합니다(예:
clusters ). - 3
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 4
- 예를 들어
16Gi와 같이 메모리 값을 지정합니다. - 5
hostDevices필드는 노드 풀에 연결할 수 있는 다양한 유형의 GPU 장치 목록을 정의합니다.- 6
- 노드 풀의 각 가상 머신(VM)에 연결할 GPU 장치 수를 지정합니다. 예를 들어, 2개의 GPU 장치를 3개의 노드 풀 복제본에 연결하면 노드 풀에 있는 3개의 VM이 모두 2개의 GPU 장치에 연결됩니다. 기본 개수는
1입니다. - 7
- GPU 장치 이름을 지정합니다(예:
nvidia-a100 ). - 8
- 작업자 수를 지정합니다(예:
2).
여러 GPU 장치를 연결하려면 다음 예제 구성을 사용하여
NodePool리소스를 구성하세요.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: kubevirt: attachDefaultNetwork: true compute: cores: <cpu> memory: <memory> hostDevices: - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> networkInterfaceMultiqueue: Enable rootVolume: persistent: size: 32Gi type: Persistent type: KubeVirt replicas: <worker_node_count>
5.3.6. KubeVirt 가상 머신 퇴출
GPU 패스스루를 사용하는 경우와 같이 KubeVirt 가상 머신(VM)을 라이브 마이그레이션할 수 없는 경우, 호스팅된 클러스터의 NodePool 리소스와 동시에 VM을 제거해야 합니다. 그렇지 않으면 컴퓨팅 노드가 작업 부하에서 벗어나지 못하고 종료될 수 있습니다. OpenShift Virtualization Operator를 업그레이드하는 경우에도 이런 일이 발생할 수 있습니다. 동기화된 재시작을 달성하려면 하이퍼컨버지 드 리소스에서 evictionStrategy 매개변수를 설정하여 워크로드에서 비워진 VM만 재부팅되도록 할 수 있습니다.
프로세스
하이퍼컨버지드 리소스와evictionStrategy매개변수에 허용되는 값에 대해 자세히 알아보려면 다음 명령을 입력하세요.$ oc explain hyperconverged.spec.evictionStrategy다음 명령을 입력하여
하이퍼컨버지드 리소스에 패치를 적용합니다.$ oc -n openshift-cnv patch hyperconverged kubevirt-hyperconverged \ --type=merge \ -p '{"spec": {"evictionStrategy": "External"}}'다음 명령을 입력하여 워크로드 업데이트 전략과 워크로드 업데이트 방법을 패치합니다.
$ oc -n openshift-cnv patch hyperconverged kubevirt-hyperconverged \ --type=merge \ -p '{"spec": {"workloadUpdateStrategy": {"workloadUpdateMethods": ["LiveMigrate","Evict"]}}}'이 패치를 적용하면 가능한 경우 VM을 라이브 마이그레이션하고, 라이브 마이그레이션할 수 없는 VM만 제거하도록 지정할 수 있습니다.
검증
다음 명령을 입력하여 패치 명령이 제대로 적용되었는지 확인하세요.
$ oc -n openshift-cnv get hyperconverged kubevirt-hyperconverged -ojsonpath='{.spec.evictionStrategy}'출력 예
External
5.3.7. topologySpreadConstraint를 사용하여 노드 풀 VM 확산
기본적으로 노드 풀에서 생성된 KubeVirt 가상 머신(VM)은 VM을 실행할 수 있는 용량이 있는 모든 사용 가능한 노드에 예약됩니다. 기본적으로 topologySpreadConstraint 제약 조건은 여러 노드에서 VM을 예약하도록 설정됩니다.
일부 시나리오에서는 노드 풀 VM이 동일한 노드에서 실행될 수 있으며, 이로 인해 가용성 문제가 발생할 수 있습니다. 단일 노드에 VM이 분산되는 것을 방지하려면 descheduler를 사용하여 topologySpreadConstraint 제약 조건을 지속적으로 준수하여 VM을 여러 노드에 분산합니다.
사전 요구 사항
- Kube Descheduler Operator를 설치했습니다. 자세한 내용은 "디스케줄러 설치"를 참조하세요.
프로세스
다음 명령을 입력하여
KubeDescheduler사용자 지정 리소스(CR)를 열고KubeDeschedulerCR을 수정하여SoftTopologyAndDuplicates및DevKubeVirtRelieveAndMigrate프로필을 사용하여topologySpreadConstraint제약 조건 설정을 유지합니다.KubeDeschedulerCR이라는 이름의클러스터는openshift-kube-descheduler-operator네임스페이스에서 실행됩니다.$ oc edit kubedescheduler cluster -n openshift-kube-descheduler-operatorKubeDescheduler구성 예시apiVersion: operator.openshift.io/v1 kind: KubeDescheduler metadata: name: cluster namespace: openshift-kube-descheduler-operator spec: mode: Automatic managementState: Managed deschedulingIntervalSeconds: 301 profiles: - SoftTopologyAndDuplicates2 - DevKubeVirtRelieveAndMigrate3 profileCustomizations: devDeviationThresholds: AsymmetricLow devActualUtilizationProfile: PrometheusCPUCombined # ...
5.4. 베어메탈이 아닌 에이전트 머신에서 호스팅된 제어 평면 관리
베어메탈이 아닌 에이전트 머신에 호스팅된 제어 평면을 배포한 후 다음 작업을 완료하여 호스팅된 클러스터를 관리할 수 있습니다.
5.4.1. 호스팅된 클러스터에 액세스
호스팅된 클러스터에 액세스하려면 리소스에서 직접 kubeconfig 파일과 kubeadmin 자격 증명을 가져오거나 hcp 명령줄 인터페이스를 사용하여 kubeconfig 파일을 생성하면 됩니다.
사전 요구 사항
리소스에서 직접 kubeconfig 파일과 자격 증명을 가져와 호스팅된 클러스터에 액세스하려면 호스팅된 클러스터의 액세스 비밀을 알고 있어야 합니다. 호스팅 클러스터(호스팅) 네임스페이스에는 호스팅 클러스터 리소스와 액세스 비밀이 포함되어 있습니다. 호스팅된 제어 평면 네임스페이스는 호스팅된 제어 평면이 실행되는 곳입니다.
비밀 이름 형식은 다음과 같습니다.
-
kubeconfig비밀:<hosted_cluster_namespace>-<name>-admin-kubeconfig. 예를 들어,clusters-hypershift-demo-admin-kubeconfig. -
kubeadmin비밀번호:<hosted_cluster_namespace>-<name>-kubeadmin-password. 예를 들어,clusters-hypershift-demo-kubeadmin-password.
kubeconfig 비밀에는 Base64로 인코딩된 kubeconfig 필드가 포함되어 있으며, 이를 디코딩하여 다음 명령으로 파일에 저장하여 사용할 수 있습니다.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin 비밀번호도 Base64로 인코딩되었습니다. 이를 디코딩하고 비밀번호를 사용하여 호스팅된 클러스터의 API 서버나 콘솔에 로그인할 수 있습니다.
프로세스
hcpCLI를 사용하여kubeconfig파일을 생성하여 호스팅된 클러스터에 액세스하려면 다음 단계를 따르세요.다음 명령을 입력하여
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfig파일을 저장한 후 다음 예제 명령을 입력하여 호스팅된 클러스터에 액세스할 수 있습니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.4.2. 호스팅된 클러스터에 대한 NodePool 객체 확장
호스팅된 클러스터에 노드를 추가하여 NodePool 객체를 확장할 수 있습니다. 노드 풀을 확장할 때 다음 정보를 고려하세요.
- 노드 풀로 복제본을 확장하면 머신이 생성됩니다. 각 머신에 대해 클러스터 API 공급자는 노드 풀 사양에 지정된 요구 사항을 충족하는 에이전트를 찾아 설치합니다. 에이전트의 상태와 조건을 확인하여 에이전트의 설치를 모니터링할 수 있습니다.
- 노드 풀을 축소하면 에이전트가 해당 클러스터에서 바인딩 해제됩니다. 에이전트를 재사용하려면 먼저 Discovery 이미지를 사용하여 에이전트를 다시 시작해야 합니다.
프로세스
NodePool객체를 두 개의 노드로 확장합니다.$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2클러스터 API 에이전트 제공자는 무작위로 두 개의 에이전트를 선택한 후 이를 호스팅된 클러스터에 할당합니다. 이러한 에이전트는 여러 상태를 거쳐 마침내 OpenShift Container Platform 노드로 호스팅된 클러스터에 합류합니다. 에이전트는 다음 순서로 상태를 통과합니다.
-
제본 -
발견하다 -
불충분하다 - 설치
-
installing-in-progress -
added-to-existing-cluster
-
다음 명령을 실행합니다.
$ oc -n <hosted_control_plane_namespace> get agent출력 예
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign다음 명령을 실행합니다.
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'출력 예
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficientextract 명령을 입력하여 새로 호스팅된 클러스터에 대한 kubeconfig를 가져옵니다.
$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>에이전트가
기존 클러스터에 추가됨상태에 도달하면 다음 명령을 입력하여 호스팅된 클러스터에서 OpenShift Container Platform 노드를 볼 수 있는지 확인하세요.$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get nodes출력 예
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8f클러스터 운영자는 노드에 작업 부하를 추가하여 조정을 시작합니다.
NodePool객체를 확장할 때 두 개의 머신이 생성되었는지 확인하려면 다음 명령을 입력하세요.$ oc -n <hosted_control_plane_namespace> get machines출력 예
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.x.z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.x.z클러스터 버전조정 프로세스는 결국 Ingress와 Console 클러스터 운영자만 누락되는 지점에 도달합니다.다음 명령을 실행합니다.
$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get clusterversion,co출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.x.z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
5.4.2.1. 노드 풀 추가
이름, 복제본 수, 에이전트 레이블 선택기 등의 추가 정보를 지정하여 호스팅된 클러스터에 대한 노드 풀을 만들 수 있습니다.
각 호스팅 클러스터에는 단일 에이전트 네임스페이스만 지원됩니다. 결과적으로 호스팅된 클러스터에 노드 풀을 추가할 때 노드 풀은 단일 InfraEnv 리소스에 속하거나 동일한 에이전트 네임스페이스에 있는 InfraEnv 리소스에 속해야 합니다.
프로세스
노드 풀을 생성하려면 다음 정보를 입력합니다.
$ hcp create nodepool agent \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <worker_node_count> \3 --agentLabelSelector size=medium4 cluster 네임스페이스에
nodepool리소스를 나열하여 노드 풀의상태를확인합니다.$ oc get nodepools --namespace clusters다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.$ oc extract -n <hosted_control_plane_namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig잠시 후 다음 명령을 입력하여 노드 풀의 상태를 확인할 수 있습니다.
$ oc --kubeconfig ./hostedcluster-secrets get nodes
검증
다음 명령을 입력하여 사용 가능한 노드 풀 수가 예상 노드 풀 수와 일치하는지 확인합니다.
$ oc get nodepools --namespace clusters
5.4.2.2. 호스트 클러스터의 노드 자동 확장 활성화
호스팅된 클러스터에 용량이 더 필요하고 예비 에이전트를 사용할 수 있는 경우 자동 확장을 활성화하여 새 작업자 노드를 설치할 수 있습니다.
프로세스
자동 확장을 활성화하려면 다음 명령을 입력합니다.
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'참고이 예에서 최소 노드 수는 2이고 최대값은 5입니다. 추가할 수 있는 최대 노드 수는 플랫폼에 바인딩될 수 있습니다. 예를 들어 에이전트 플랫폼을 사용하는 경우 사용 가능한 에이전트 수에 따라 최대 노드 수가 바인딩됩니다.
새 노드가 필요한 워크로드를 생성합니다.
다음 예제를 사용하여 워크로드 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
파일을
workload-config.yaml로 저장합니다. 다음 명령을 입력하여 YAML을 적용합니다.
$ oc apply -f workload-config.yaml
다음 명령을 입력하여
admin-kubeconfig시크릿을 추출합니다.$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 새 노드가
Ready상태에 있는지 확인할 수 있습니다.$ oc --kubeconfig ./hostedcluster-secrets get nodes노드를 제거하려면 다음 명령을 입력하여 워크로드를 삭제합니다.
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>추가 용량을 요구하지 않고 몇 분 정도 경과할 때까지 기다립니다. 에이전트 플랫폼에서 에이전트는 해제되어 재사용될 수 있습니다. 다음 명령을 입력하여 노드가 제거되었는지 확인할 수 있습니다.
$ oc --kubeconfig ./hostedcluster-secrets get nodes참고IBM Z® 에이전트의 경우 Processor Resource/Systems Manager (PR/SM) 모드에서 OSA 네트워크 장치를 사용하는 경우 자동 확장이 지원되지 않습니다. 축소 프로세스 중 새 에이전트가 결합되므로 기존 에이전트를 수동으로 삭제하고 노드 풀을 확장해야 합니다.
5.4.2.3. 호스트 클러스터의 노드 자동 확장 비활성화
노드 자동 확장을 비활성화하려면 다음 절차를 완료합니다.
프로세스
다음 명령을 입력하여 호스팅된 클러스터의 노드 자동 스케일링을 비활성화합니다.
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify_value_to_scale_replicas>]'이 명령은 YAML 파일에서
"spec.autoScaling"을 제거하고"spec.replicas"를 추가하고 지정한 정수 값에"spec.replicas"를 설정합니다.
5.4.3. 비bare-metal 에이전트 시스템의 호스트 클러스터에서 수신 처리
모든 OpenShift Container Platform 클러스터에는 일반적으로 연결된 외부 DNS 레코드가 있는 기본 애플리케이션 Ingress 컨트롤러가 있습니다. 예를 들어 기본 도메인 krnl.es 를 사용하여 example 이라는 호스팅 클러스터를 생성하는 경우 와일드카드 도메인 *.apps.example.krnl.es 를 라우팅할 수 있을 것으로 예상할 수 있습니다.
프로세스
*.apps 도메인의 로드 밸런서 및 와일드카드 DNS 레코드를 설정하려면 게스트 클러스터에서 다음 작업을 수행합니다.
MetalLB Operator의 구성이 포함된 YAML 파일을 생성하여 MetalLB를 배포합니다.
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
파일을
metallb-operator-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f metallb-operator-config.yamlOperator가 실행되면 MetalLB 인스턴스를 생성합니다.
MetalLB 인스턴스의 구성이 포함된 YAML 파일을 생성합니다.
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
파일을
metallb-instance-config.yaml로 저장합니다. 다음 명령을 입력하여 MetalLB 인스턴스를 생성합니다.
$ oc apply -f metallb-instance-config.yaml
단일 IP 주소를 사용하여
IPAddressPool리소스를 만듭니다. 이 IP 주소는 클러스터 노드에서 사용하는 네트워크와 동일한 서브넷에 있어야 합니다.다음 예와 같은 내용을 사용하여
addresspool.yaml과 같은 파일을 생성합니다.apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb name: <ip_address_pool_name>1 spec: addresses: - <ingress_ip>-<ingress_ip>2 autoAssign: false다음 명령을 입력하여 IP 주소 풀에 대한 구성을 적용합니다.
$ oc apply -f ipaddresspool.yaml
L2 광고를 생성합니다.
다음 예와 같은 콘텐츠를 사용하여
l2advertisement.yaml과 같은 파일을 생성합니다.apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: <l2_advertisement_name>1 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>2 다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f l2advertisement.yaml
LoadBalancer유형의 서비스를 생성한 후 MetalLB는 해당 서비스에 대한 외부 IP 주소를 추가합니다.metallb-loadbalancer-service.yaml이라는 YAML 파일을 만들어 수신 트래픽을 수신 배포로 라우팅하는 새로운 로드 밸런서 서비스를 구성합니다.kind: Service apiVersion: v1 metadata: annotations: metallb.io/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
metallb-loadbalancer-service.yaml파일을 저장합니다. YAML 구성을 적용하려면 다음 명령을 입력하세요.
$ oc apply -f metallb-loadbalancer-service.yamlOpenShift Container Platform 콘솔에 접속하려면 다음 명령을 입력하세요.
$ curl -kI https://console-openshift-console.apps.example.krnl.es출력 예
HTTP/1.1 200 OKclusterversion및clusteroperator값을 확인하여 모든 것이 제대로 실행되고 있는지 확인하세요. 다음 명령을 실행합니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m<4.xy>를사용하려는 지원되는 OpenShift Container Platform 버전(예:4.19.0-multi )으로 바꾸세요.
5.4.4. 베어메탈이 아닌 에이전트 머신에서 머신 상태 점검 활성화
베어 메탈에서 머신 상태 검사를 활성화하여 상태가 좋지 않은 관리형 클러스터 노드를 자동으로 복구하고 교체할 수 있습니다. 관리되는 클러스터에 설치할 준비가 된 추가 에이전트 머신이 있어야 합니다.
머신 상태 검사를 활성화하기 전에 다음 제한 사항을 고려하세요.
-
MachineHealthCheck객체를 수정할 수 없습니다. -
머신 상태 검사는 최소 두 개의 노드가 8분 이상
False또는Unknown상태를 유지하는 경우에만 노드를 교체합니다.
관리되는 클러스터 노드에 대한 머신 상태 검사를 활성화하면 호스팅된 클러스터에 MachineHealthCheck 개체가 생성됩니다.
프로세스
호스팅된 클러스터에서 머신 상태 검사를 활성화하려면 NodePool 리소스를 수정하세요. 다음 단계를 완료하세요.
NodePool리소스의spec.nodeDrainTimeout값이0보다 큰지 확인하세요.<hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스의 이름으로 바꾸고<nodepool_name>을노드 풀 이름으로 바꾸세요. 다음 명령을 실행합니다.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep nodeDrainTimeout출력 예
nodeDrainTimeout: 30sspec.nodeDrainTimeout값이0s보다 크면 다음 명령을 실행하여 값을 수정합니다.$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec":{"nodeDrainTimeout": "30m"}}' --type=mergeNodePool리소스에서spec.management.autoRepair필드를true로 설정하여 머신 상태 점검을 활성화합니다. 다음 명령을 실행합니다.$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":true}}}' --type=merge다음 명령을 실행하여
NodePool리소스가autoRepair: true값으로 업데이트되었는지 확인하세요.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.4.5. 베어메탈이 아닌 에이전트 머신에서 머신 상태 검사 비활성화
관리되는 클러스터 노드에 대한 머신 상태 검사를 비활성화하려면 NodePool 리소스를 수정합니다.
프로세스
NodePool리소스에서spec.management.autoRepair필드를false로 설정하여 머신 상태 검사를 비활성화합니다. 다음 명령을 실행합니다.$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":false}}}' --type=merge다음 명령을 실행하여
NodePool리소스가autoRepair: false값으로 업데이트되었는지 확인하세요.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.5. IBM Power에 호스팅된 컨트롤 플레인 배포
IBM Power에 호스팅된 제어 플레인을 배포한 후 다음 작업을 완료하여 호스팅된 클러스터를 관리할 수 있습니다.
5.5.1. IBM Power에서 호스팅되는 제어 평면에 대한 InfraEnv 리소스 생성
InfraEnv는 라이브 ISO를 시작하는 호스트가 에이전트로 참여할 수 있는 환경입니다. 이 경우 에이전트는 호스팅된 제어 평면과 동일한 네임스페이스에 생성됩니다.
IBM Power 컴퓨트 노드의 64비트 x86 베어 메탈에서 호스팅된 제어 평면에 대한 InfraEnv 리소스를 생성할 수 있습니다.
프로세스
InfraEnv리소스를 구성하려면 YAML 파일을 만듭니다. 다음 예제를 참조하십시오.apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> \1 namespace: <hosted_control_plane_namespace> \2 spec: cpuArchitecture: ppc64le pullSecretRef: name: pull-secret sshAuthorizedKey: <path_to_ssh_public_key>3 -
파일을
infraenv-config.yaml로 저장합니다. 다음 명령을 입력하여 구성을 적용합니다.
$ oc apply -f infraenv-config.yamlIBM Power 머신이 에이전트로 참여할 수 있도록 라이브 ISO를 다운로드할 수 있는 URL을 가져오려면 다음 명령을 입력하세요.
$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name> \ -o json
5.5.2. InfraEnv 리소스에 IBM Power 에이전트 추가
라이브 ISO로 시작하도록 장비를 수동으로 구성하여 에이전트를 추가할 수 있습니다.
프로세스
-
라이브 ISO를 다운로드하여 베어 메탈 또는 가상 머신(VM) 호스트를 시작합니다. 라이브 ISO의 URL은
InfraEnv리소스의status.isoDownloadURL필드에서 찾을 수 있습니다. 시작 시 호스트는 지원 서비스와 통신하고InfraEnv리소스와 동일한 네임스페이스에 에이전트로 등록됩니다. 에이전트와 해당 속성 중 일부를 나열하려면 다음 명령을 입력하세요.
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign각 에이전트가 생성된 후에는 선택적으로 에이전트의
installation_disk_id와hostname을설정할 수 있습니다.에이전트의
installation_disk_id필드를 설정하려면 다음 명령을 입력하세요.$ oc -n <hosted_control_plane_namespace> patch agent <agent_name> -p '{"spec":{"installation_disk_id":"<installation_disk_id>","approved":true}}' --type merge에이전트의
호스트 이름필드를 설정하려면 다음 명령을 입력하세요.$ oc -n <hosted_control_plane_namespace> patch agent <agent_name> -p '{"spec":{"hostname":"<hostname>","approved":true}}' --type merge
검증
에이전트가 사용 승인을 받았는지 확인하려면 다음 명령을 입력하세요.
$ oc -n <hosted_control_plane_namespace> get agents출력 예
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
5.5.3. IBM Power에서 호스팅되는 클러스터에 대한 NodePool 객체 확장
NodePool 개체는 호스팅 클러스터를 생성할 때 생성됩니다. NodePool 객체를 확장하면 호스팅된 제어 평면에 더 많은 컴퓨팅 노드를 추가할 수 있습니다.
프로세스
다음 명령을 실행하여
NodePool객체를 두 개의 노드로 확장합니다.$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2클러스터 API 에이전트 제공자는 무작위로 두 개의 에이전트를 선택한 후 이를 호스팅된 클러스터에 할당합니다. 이러한 에이전트는 여러 상태를 거쳐 마침내 OpenShift Container Platform 노드로 호스팅된 클러스터에 합류합니다. 에이전트는 다음 순서에 따라 전환 단계를 거칩니다.
-
제본 -
발견하다 -
불충분하다 - 설치
-
installing-in-progress -
added-to-existing-cluster
-
특정 확장된 에이전트의 상태를 보려면 다음 명령을 실행하세요.
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'출력 예
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient다음 명령을 실행하여 전환 단계를 확인하세요.
$ oc -n <hosted_control_plane_namespace> get agent출력 예
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign다음 명령을 실행하여 호스팅된 클러스터에 액세스하기 위한
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig에이전트가
기존 클러스터에 추가됨상태에 도달하면 다음 명령을 입력하여 OpenShift Container Platform 노드를 볼 수 있는지 확인하세요.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes출력 예
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8fNodePool객체를 확장할 때 두 개의 머신이 생성되었는지 확인하려면 다음 명령을 입력하세요.$ oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io출력 예
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0클러스터 버전을 확인하려면 다음 명령을 실행하세요.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion출력 예
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0 True False 40h Cluster version is 4.15.0다음 명령을 실행하여 클러스터 운영자 상태를 확인하세요.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators클러스터의 각 구성 요소에 대해 출력에는 다음과 같은 클러스터 운영자 상태가 표시됩니다.
-
<NAME> -
VERSION - AVAILABLE
-
PROGRESSING -
DEGRADED -
--SINCE -
MESSAGE
-
5.6. OpenStack에서 호스팅된 제어 평면 관리
Red Hat OpenStack Platform(RHOSP) 에이전트 머신에 호스팅된 제어 플레인을 배포한 후 다음 작업을 완료하여 호스팅된 클러스터를 관리할 수 있습니다.
5.6.1. 호스팅된 클러스터에 액세스
oc CLI를 사용하여 리소스에서 직접 kubeconfig 비밀을 추출하여 Red Hat OpenStack Platform(RHOSP)에서 호스팅되는 클러스터에 액세스할 수 있습니다.
호스팅 클러스터(호스팅) 네임스페이스에는 호스팅 클러스터 리소스와 액세스 비밀이 포함되어 있습니다. 호스팅된 제어 평면 네임스페이스는 호스팅된 제어 평면이 실행되는 곳입니다.
비밀 이름 형식은 다음과 같습니다.
-
kubeconfig비밀:<hosted_cluster_namespace>-<name>-admin-kubeconfig. 예를 들어,clusters-hypershift-demo-admin-kubeconfig. -
kubeadmin비밀번호:<hosted_cluster_namespace>-<name>-kubeadmin-password. 예를 들어,clusters-hypershift-demo-kubeadmin-password.
kubeconfig 비밀에는 Base64로 인코딩된 kubeconfig 필드가 포함되어 있습니다. kubeadmin 비밀번호도 Base64로 인코딩되어 있습니다. 이를 추출한 후 비밀번호를 사용하여 호스팅된 클러스터의 API 서버나 콘솔에 로그인할 수 있습니다.
사전 요구 사항
-
ocCLI가 설치되었습니다.
프로세스
다음 명령을 입력하여
admin-kubeconfig비밀번호를 추출합니다.$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 호스팅된 클러스터의 노드 목록을 보고 액세스를 확인하세요.
$ oc --kubeconfig ./hostedcluster-secrets/kubeconfig get nodes
5.6.2. 호스팅된 클러스터에 대한 노드 자동 크기 조정 활성화
Red Hat OpenStack Platform(RHOSP)에서 호스팅되는 클러스터에 더 많은 용량이 필요하고 예비 에이전트를 사용할 수 있는 경우 자동 크기 조정을 활성화하여 새로운 워커 노드를 설치할 수 있습니다.
프로세스
자동 크기 조정을 활성화하려면 다음 명령을 입력하세요.
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'새로운 노드가 필요한 작업 부하를 만듭니다.
다음 예를 사용하여 워크로드 구성을 포함하는 YAML 파일을 만듭니다.
apiVersion: apps/v1 kind: Deployment metadata: labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords template: metadata: labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi-
workload-config.yaml이라는 이름으로 파일을 저장합니다. 다음 명령을 입력하여 YAML을 적용합니다.
$ oc apply -f workload-config.yaml
다음 명령을 입력하여
admin-kubeconfig비밀번호를 추출합니다.$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm출력 예
hostedcluster-secrets/kubeconfig다음 명령을 입력하여 새 노드가
준비상태인지 확인할 수 있습니다.$ oc --kubeconfig ./hostedcluster-secrets get nodes노드를 제거하려면 다음 명령을 입력하여 작업 부하를 삭제하세요.
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>추가 용량이 필요하지 않을 때까지 몇 분간 기다리세요. 다음 명령을 입력하면 노드가 제거되었는지 확인할 수 있습니다.
$ oc --kubeconfig ./hostedcluster-secrets get nodes
5.6.3. 가용성 영역에 대한 노드 풀 구성
여러 Red Hat OpenStack Platform(RHOSP) Nova 가용성 영역에 노드 풀을 분산하여 호스팅 클러스터의 고가용성을 개선할 수 있습니다.
가용성 영역은 반드시 장애 도메인과 일치하지 않으며 본질적으로 높은 가용성 이점을 제공하지 않습니다.
사전 요구 사항
- 호스팅된 클러스터를 생성했습니다.
- 관리 클러스터에 액세스할 수 있습니다.
-
hcp및ocCLI가 설치되었습니다.
프로세스
사용자의 필요에 맞는 환경 변수를 설정하세요. 예를 들어,
az1가용성 영역에 두 대의 추가 머신을 생성하려면 다음을 입력할 수 있습니다.$ export NODEPOOL_NAME="${CLUSTER_NAME}-az1" \ && export WORKER_COUNT="2" \ && export FLAVOR="m1.xlarge" \ && export AZ="az1"다음 명령을 입력하여 환경 변수를 사용하여 노드 풀을 만듭니다.
$ hcp create nodepool openstack \ --cluster-name <cluster_name> \ --name $NODEPOOL_NAME \ --replicas $WORKER_COUNT \ --openstack-node-flavor $FLAVOR \ --openstack-node-availability-zone $AZ다음과 같습니다.
<cluster_name>- 호스팅된 클러스터의 이름을 지정합니다.
다음 명령을 실행하여 클러스터 네임스페이스의
노드 풀리소스를 나열하여 노드 풀의 상태를 확인하세요.$ oc get nodepools --namespace clusters출력 예
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False 4.17.0 example-az1 example 2 False False True True Minimum availability requires 2 replicas, current 0 available다음 명령을 실행하여 호스팅된 클러스터에서 시작되는 메모를 확인하세요.
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes출력 예
NAME STATUS ROLES AGE VERSION ... example-extra-az-zh9l5 Ready worker 2m6s v1.27.4+18eadca example-extra-az-zr8mj Ready worker 102s v1.27.4+18eadca ...다음 명령을 실행하여 노드 풀이 생성되었는지 확인하세요.
$ oc get nodepools --namespace clusters출력 예
NAME CLUSTER DESIRED CURRENT AVAILABLE PROGRESSING MESSAGE <node_pool_name> <cluster_name> 2 2 2 False All replicas are available
5.6.4. 노드 풀에 대한 추가 포트 구성
SR-IOV나 여러 네트워크와 같은 고급 네트워킹 시나리오를 지원하기 위해 노드 풀에 대한 추가 포트를 구성할 수 있습니다.
5.6.4.1. 노드 풀에 대한 추가 포트 사용 사례
노드 풀에 추가 포트를 구성하는 일반적인 이유는 다음과 같습니다.
- SR-IOV(단일 루트 I/O 가상화)
- 물리적 네트워크 장치가 여러 개의 가상 기능(VF)으로 나타나도록 합니다. 노드 풀에 추가 포트를 연결하면 워크로드에서 SR-IOV 인터페이스를 사용하여 지연 시간이 짧고 성능이 뛰어난 네트워킹을 구현할 수 있습니다.
- DPDK(데이터 플레인 개발 키트)
- 커널을 우회하여 사용자 공간에서 빠른 패킷 처리를 제공합니다. 추가 포트가 있는 노드 풀은 DPDK를 사용하여 네트워크 성능을 개선하는 워크로드에 대한 인터페이스를 노출할 수 있습니다.
- NFS의 마닐라 RWX 볼륨
-
NFS를 통한
ReadWriteMany(RWX) 볼륨을 지원하여 여러 노드가 공유 스토리지에 액세스할 수 있습니다. 노드 풀에 추가 포트를 연결하면 마닐라에서 사용하는 NFS 네트워크에 워크로드가 도달할 수 있습니다. - 멀투스 CNI
- 여러 네트워크 인터페이스에 포드를 연결할 수 있습니다. 추가 포트가 있는 노드 풀은 듀얼 스택 연결 및 트래픽 분리를 포함하여 보조 네트워크 인터페이스가 필요한 사용 사례를 지원합니다.
5.6.4.2. 노드 풀에 대한 추가 포트 옵션
--openstack-node-additional-port 플래그를 사용하면 OpenStack에서 호스팅된 클러스터의 노드에 추가 포트를 연결할 수 있습니다. 플래그는 쉼표로 구분된 매개변수 목록을 사용합니다. 매개변수를 여러 번 사용하여 여러 개의 추가 포트를 노드에 연결할 수 있습니다.
매개변수는 다음과 같습니다.
| 매개변수 | 설명 | 필수 항목 | 기본 |
|---|---|---|---|
|
| 노드에 연결할 네트워크의 ID입니다. | 제공됨 | 해당 없음 |
|
|
포트에 사용할 VNIC 유형입니다. 지정하지 않으면 Neutron은 기본 유형 | 없음 | 해당 없음 |
|
| 포트에 대한 포트 보안을 비활성화할지 여부입니다. 지정하지 않으면 Neutron은 네트워크 수준에서 명시적으로 비활성화하지 않는 한 포트 보안을 활성화합니다. | 없음 | 해당 없음 |
|
|
포트에 할당할 IP 주소 쌍 목록입니다. 형식은 | 없음 | 해당 없음 |
5.6.4.3. 노드 풀에 대한 추가 포트 생성
Red Hat OpenStack Platform(RHOSP)에서 실행되는 호스팅 클러스터의 노드 풀에 대한 추가 포트를 구성할 수 있습니다.
사전 요구 사항
- 호스팅된 클러스터를 생성했습니다.
- 관리 클러스터에 액세스할 수 있습니다.
-
hcpCLI가 설치되었습니다. - RHOSP에서 추가 네트워크가 생성됩니다.
- 호스팅된 클러스터에서 사용되는 프로젝트는 추가 네트워크에 액세스할 수 있어야 합니다.
- "노드 풀에 대한 추가 포트 옵션"에 나열된 옵션을 검토했습니다.
프로세스
--openstack-node-additional-port옵션과 함께hcp create nodepool openstack명령을 실행하여 추가 포트가 연결된 호스팅 클러스터를 만듭니다. 예를 들면 다음과 같습니다.$ hcp create nodepool openstack \ --cluster-name <cluster_name> \ --name <nodepool_name> \ --replicas <replica_count> \ --openstack-node-flavor <flavor> \ --openstack-node-additional-port "network-id=<sriov_net_id>,vnic-type=direct,disable-port-security=true" \ --openstack-node-additional-port "network-id=<lb_net_id>,address-pairs:192.168.0.1-192.168.0.2"다음과 같습니다.
<cluster_name>- 호스팅된 클러스터의 이름을 지정합니다.
<nodepool_name>- 노드 풀의 이름을 지정합니다.
<replica_count>- 원하는 복제본 수를 지정합니다.
<flavor>- 사용할 RHOSP 플레이버를 지정합니다.
<sriov_net_id>- SR-IOV 네트워크 ID를 지정합니다.
<lb_net_id>- 로드 밸런서 네트워크 ID를 지정합니다.
5.6.5. 노드 풀에 대한 추가 포트 구성
클라우드 기반 네트워크 기능(CNF)과 같은 고성능 워크로드를 위해 RHOSP에서 호스팅된 클러스터 노드 성능을 조정할 수 있습니다. 성능 튜닝에는 RHOSP 리소스 구성, 성능 프로필 생성, 튜닝된 NodePool 리소스 배포, SR-IOV 장치 지원 활성화가 포함됩니다.
CNF는 클라우드 기반 환경에서 실행되도록 설계되었습니다. 라우팅, 방화벽, 부하 분산 등의 네트워크 서비스를 제공할 수 있습니다. 고성능 컴퓨팅 및 네트워킹 장치를 사용하여 CNF를 실행하도록 노드 풀을 구성할 수 있습니다.
5.6.5.1. 호스팅된 클러스터 노드의 성능 조정
성능 프로필을 만들고 조정된 NodePool 리소스를 배포하여 Red Hat OpenStack Platform(RHOSP) 호스팅 제어 평면에서 고성능 워크로드를 실행합니다.
사전 요구 사항
- 전용 CPU, 메모리, 호스트 집계 정보 등 워크로드를 실행하는 데 필요한 리소스를 갖춘 RHOSP 플레이버가 있습니다.
- SR-IOV 또는 DPDK 지원 NIC에 연결된 RHOSP 네트워크가 있습니다. 네트워크는 호스팅된 클러스터에서 사용하는 프로젝트에서 사용할 수 있어야 합니다.
프로세스
perfprofile.yaml이라는 파일에 요구 사항을 충족하는 성능 프로필을 만듭니다. 예를 들면 다음과 같습니다.구성 맵의 성능 프로필 예시
apiVersion: v1 kind: ConfigMap metadata: name: perfprof-1 namespace: clusters data: tuning: | apiVersion: v1 kind: ConfigMap metadata: name: cnf-performanceprofile namespace: "${HYPERSHIFT_NAMESPACE}" data: tuning: | apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: cnf-performanceprofile spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - idle=poll - intel_idle.max_cstate=0 - amd_iommu=on cpu: isolated: "${CPU_ISOLATED}" reserved: "${CPU_RESERVED}" hugepages: defaultHugepagesSize: "1G" pages: - count: ${HUGEPAGES} node: 0 size: 1G nodeSelector: node-role.kubernetes.io/worker: '' realTimeKernel: enabled: false globallyDisableIrqLoadBalancing: true중요HyperShift Operator 네임스페이스, 격리되고 예약된 CPU, 대규모 페이지 수에 대한 환경 변수가 아직 설정되지 않은 경우 성능 프로필을 적용하기 전에 이를 만듭니다.
다음 명령을 실행하여 성능 프로필 구성을 적용합니다.
$ oc apply -f perfprof.yaml-
클러스터 이름에 대한
CLUSTER_NAME환경 변수가 아직 설정되어 있지 않으면 해당 변수를 정의합니다. 다음 명령을 실행하여 노드 풀 이름 환경 변수를 설정합니다.
$ export NODEPOOL_NAME=$CLUSTER_NAME-cnf다음 명령을 실행하여 플레이버 환경 변수를 설정합니다.
$ export FLAVOR="m1.xlarge.nfv"다음 명령을 실행하여 성능 프로필을 사용하는 노드 풀을 만듭니다.
$ hcp create nodepool openstack \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count 0 \ --openstack-node-flavor $FLAVOR다음 명령을 실행하여
PerformanceProfile리소스를 참조하도록 노드 풀에 패치를 적용합니다.$ oc patch nodepool -n ${HYPERSHIFT_NAMESPACE} ${CLUSTER_NAME} \ -p '{"spec":{"tuningConfig":[{"name":"cnf-performanceprofile"}]}}' --type=merge다음 명령을 실행하여 노드 풀을 확장합니다.
$ oc scale nodepool/$CLUSTER_NAME --namespace ${HYPERSHIFT_NAMESPACE} --replicas=1노드가 준비될 때까지 기다리세요.
다음 명령을 실행하여 노드가 준비될 때까지 기다리세요.
$ oc wait --for=condition=UpdatingConfig=True nodepool \ -n ${HYPERSHIFT_NAMESPACE} ${CLUSTER_NAME} \ --timeout=5m다음 명령을 실행하여 구성 업데이트가 완료될 때까지 기다리세요.
$ oc wait --for=condition=UpdatingConfig=False nodepool \ -n ${HYPERSHIFT_NAMESPACE} ${CLUSTER_NAME} \ --timeout=30m다음 명령을 실행하여 모든 노드가 정상화될 때까지 기다리세요.
$ oc wait --for=condition=AllNodesHealthy nodepool \ -n ${HYPERSHIFT_NAMESPACE} ${CLUSTER_NAME} \ --timeout=5m
노드에 SSH 연결을 만들거나 oc debug 명령을 사용하여 성능 구성을 확인할 수 있습니다.
5.6.5.2. 호스팅된 클러스터에서 SR-IOV 네트워크 운영자 활성화
SR-IOV 네트워크 운영자가 NodePool 리소스에 의해 배포된 노드에서 SR-IOV 지원 장치를 관리하도록 설정할 수 있습니다. 운영자는 호스팅된 클러스터에서 실행되며 레이블이 지정된 작업자 노드가 필요합니다.
프로세스
다음 명령을 실행하여 호스팅된 클러스터에 대한
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --name $CLUSTER_NAME > $CLUSTER_NAME-kubeconfig다음 명령을 실행하여
kubeconfig리소스 환경 변수를 만듭니다.$ export KUBECONFIG=$CLUSTER_NAME-kubeconfig다음 명령을 실행하여 SR-IOV 기능을 나타내도록 각 작업자 노드에 레이블을 지정합니다.
$ oc label node <worker_node_name> feature.node.kubernetes.io/network-sriov.capable=true다음과 같습니다.
<worker_node_name>- 호스팅된 클러스터의 워커 노드 이름을 지정합니다.
- "SR-IOV 네트워크 운영자 설치"의 지침에 따라 호스팅된 클러스터에 SR-IOV 네트워크 운영자를 설치합니다.
- 설치 후 독립 실행형 클러스터와 동일한 프로세스를 사용하여 호스팅된 클러스터에서 SR-IOV 워크로드를 구성합니다.
6장. 연결이 끊긴 환경에서 호스팅된 제어 평면 배포
6.1. 연결이 끊긴 환경에서 호스팅된 제어 평면 소개
호스팅된 제어 평면의 맥락에서 연결이 끊긴 환경은 인터넷에 연결되지 않고 호스팅된 제어 평면을 기반으로 사용하는 OpenShift Container Platform 배포를 말합니다. 베어 메탈 또는 OpenShift 가상화를 기반으로 연결이 끊긴 환경에 호스팅된 제어 평면을 배포할 수 있습니다.
연결이 끊긴 환경에서 호스팅된 제어 평면은 독립형 OpenShift Container Platform과 다르게 작동합니다.
- 제어 평면은 관리 클러스터에 있습니다. 제어 평면은 호스팅된 제어 평면의 포드가 제어 평면 운영자에 의해 실행되고 관리되는 곳입니다.
- 데이터 플레인은 호스팅된 클러스터의 작업자에 있습니다. 데이터 플레인은 워크로드와 다른 포드가 실행되는 곳으로, 모두 HostedClusterConfig Operator에 의해 관리됩니다.
포드가 실행되는 위치에 따라 관리 클러스터에서 생성된 ImageDigestMirrorSet (IDMS) 또는 ImageContentSourcePolicy (ICSP)의 영향을 받거나, 호스팅된 클러스터의 매니페스트에 있는 spec 필드에 설정된 ImageContentSource의 영향을 받습니다. 사양 필드는 호스팅된 클러스터의 IDMS 개체로 변환됩니다.
IPv4, IPv6 및 듀얼 스택 네트워크의 연결되지 않은 환경에 호스팅된 제어 평면을 배포할 수 있습니다. IPv4는 연결이 끊긴 환경에서 호스팅된 제어 평면을 배포하는 가장 간단한 네트워크 구성 중 하나입니다. IPv4 범위는 IPv6 또는 듀얼 스택 설정보다 외부 구성 요소가 덜 필요합니다. 연결이 끊긴 환경에서 OpenShift Virtualization의 호스팅된 제어 평면의 경우 IPv4 또는 듀얼 스택 네트워크를 사용하세요.
6.2. 연결이 끊긴 환경에서 OpenShift Virtualization에 호스팅된 제어 평면 배포
연결이 끊긴 환경에서 호스팅된 제어 평면을 배포하는 경우 일부 단계는 사용하는 플랫폼에 따라 다릅니다. 다음 절차는 OpenShift Virtualization에서의 배포에만 적용됩니다.
6.2.1. 사전 요구 사항
- 관리 클러스터 역할을 하는 연결이 끊긴 OpenShift Container Platform 환경이 있습니다.
- 이미지를 미러링할 내부 레지스트리가 있습니다. 자세한 내용은 연결이 끊긴 설치 미러링에 대한 정보를 참조하세요.
6.2.2. 연결이 끊긴 환경에서 호스팅된 제어 평면에 대한 이미지 미러링 구성
이미지 미러링은 registry.redhat.com 이나 quay.io 와 같은 외부 레지스트리에서 이미지를 가져와서 개인 레지스트리에 저장하는 프로세스입니다.
다음 절차에서는 ImageSetConfiguration 객체를 사용하는 바이너리인 oc-mirror 도구를 사용합니다. 파일에서 다음 정보를 지정할 수 있습니다.
-
미러링할 OpenShift 컨테이너 플랫폼 버전입니다. 해당 버전은
quay.io에 있습니다. - 미러링할 추가 연산자입니다. 패키지를 개별적으로 선택하세요.
- 저장소에 추가하려는 추가 이미지입니다.
사전 요구 사항
- 미러링 프로세스를 시작하기 전에 레지스트리 서버가 실행 중인지 확인하세요.
프로세스
이미지 미러링을 구성하려면 다음 단계를 완료하세요.
-
미러링할 레지스트리와 이미지를 푸시할 개인 레지스트리로
${HOME}/.docker/config.json파일이 업데이트되었는지 확인하세요. 다음 예제를 사용하여 미러링에 사용할
ImageSetConfiguration객체를 만듭니다. 필요에 따라 값을 환경과 일치하도록 바꾸세요.apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: channels: - name: candidate-4.19 minVersion: <4.x.y-build>1 maxVersion: <4.x.y-build>2 type: ocp kubeVirtContainer: true3 graph: true operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.19 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged4 다음 명령을 입력하여 미러링 프로세스를 시작합니다.
$ oc-mirror --v2 --config imagesetconfig.yaml \ --workspace file://mirror-file docker://<registry>미러링 프로세스가 완료되면
mirror-file이라는 새 폴더가 생성되는데, 여기에는ImageDigestMirrorSet(IDMS),ImageTagMirrorSet(ITMS) 및 호스팅된 클러스터에 적용할 카탈로그 소스가 포함됩니다.다음과 같이
imagesetconfig.yaml파일을 구성하여 OpenShift Container Platform의 야간 버전이나 CI 버전을 미러링합니다.apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: graph: true release: registry.ci.openshift.org/ocp/release:<4.x.y-build>1 kubeVirtContainer: true2 # ...부분적으로 연결이 끊긴 환경이 있는 경우 다음 명령을 입력하여 이미지 세트 구성의 이미지를 레지스트리로 미러링합니다.
$ oc mirror -c imagesetconfig.yaml \ --workspace file://<file_path> docker://<mirror_registry_url> --v2자세한 내용은 "부분적으로 연결이 끊긴 환경에서 이미지 세트 미러링"을 참조하세요.
완전히 연결이 끊긴 환경인 경우 다음 단계를 수행하세요.
다음 명령을 입력하여 지정된 이미지 세트 구성의 이미지를 디스크로 미러링합니다.
$ oc mirror -c imagesetconfig.yaml file://<file_path> --v2자세한 내용은 "완전히 연결되지 않은 환경에서 이미지 세트 미러링"을 참조하세요.
다음 명령을 입력하여 디스크에 있는 이미지 세트 파일을 처리하고 내용을 대상 미러 레지스트리로 미러링합니다.
$ oc mirror -c imagesetconfig.yaml \ --from file://<file_path> docker://<mirror_registry_url> --v2
- 연결이 끊긴 네트워크에 설치 단계에 따라 최신 멀티클러스터 엔진 Operator 이미지를 미러링합니다.
6.2.3. 관리 클러스터에 객체 적용
미러링 프로세스가 완료되면 관리 클러스터에 두 개의 객체를 적용해야 합니다.
-
ImageContentSourcePolicy(ICSP) 또는ImageDigestMirrorSet(IDMS) - 카탈로그 소스
oc-mirror 도구를 사용하면 출력 아티팩트는 oc-mirror-workspace/results-XXXXXX/ 라는 폴더에 저장됩니다.
ICSP 또는 IDMS는 노드를 다시 시작하지 않고 각 노드에서 kubelet을 다시 시작하는 MachineConfig 변경을 시작합니다. 노드가 READY 로 표시된 후 새로 생성된 카탈로그 소스를 적용해야 합니다.
카탈로그 소스는 openshift-marketplace Operator에서 카탈로그 이미지를 다운로드하고 해당 이미지에 포함된 모든 PackageManifest를 검색하기 위해 처리하는 등의 작업을 시작합니다.
프로세스
새로운 소스를 확인하려면 새
CatalogSource를소스로 사용하여 다음 명령을 실행하세요.$ oc get packagemanifest아티팩트를 적용하려면 다음 단계를 완료하세요.
다음 명령을 입력하여 ICSP 또는 IDMS 아티팩트를 만듭니다.
$ oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml노드가 준비될 때까지 기다린 후 다음 명령을 입력하세요.
$ oc apply -f catalogSource-XXXXXXXX-index.yaml
OLM 카탈로그를 미러링하고 호스팅된 클러스터가 미러를 가리키도록 구성합니다.
관리(기본값) OLMCatalogPlacement 모드를 사용하면 OLM 카탈로그에 사용되는 이미지 스트림이 관리 클러스터의 ICSP에서 제공하는 재정의 정보로 자동으로 수정되지 않습니다.-
OLM 카탈로그가 원래 이름과 태그를 사용하여 내부 레지스트리에 올바르게 미러링된 경우,
Hypershift.openshift.io/olm-catalogs-is-registry-overrides주석을HostedCluster리소스에 추가합니다. 형식은"sr1=dr1,sr2=dr2"이며, 여기서 소스 레지스트리 문자열은 키이고 대상 레지스트리는 값입니다. OLM 카탈로그 이미지 스트림 메커니즘을 우회하려면
HostedCluster리소스에서 다음 네 가지 주석을 사용하여 OLM 운영자 카탈로그에 사용할 네 가지 이미지의 주소를 직접 지정합니다.-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
-
-
OLM 카탈로그가 원래 이름과 태그를 사용하여 내부 레지스트리에 올바르게 미러링된 경우,
이 경우 이미지 스트림이 생성되지 않으며, 내부 미러가 새로 고쳐질 때 주석 값을 업데이트하여 Operator 업데이트를 가져와야 합니다.
다음 단계
연결이 끊긴 호스팅 제어 평면 설치에 대한 멀티클러스터 엔진 연산자 배포의 단계를 완료하여 멀티클러스터 엔진 연산자 를 배포합니다.
6.2.4. 호스팅된 제어 평면의 연결이 끊긴 설치를 위한 멀티클러스터 엔진 운영자 배포
Kubernetes Operator용 멀티클러스터 엔진은 공급업체 전반에 클러스터를 배포하는 데 중요한 역할을 합니다. 멀티클러스터 엔진 Operator가 설치되어 있지 않은 경우 다음 문서를 검토하여 설치에 필요한 전제 조건과 단계를 파악하세요.
6.2.5. 호스팅된 제어 평면의 연결이 끊긴 설치를 위한 TLS 인증서 구성
연결이 끊긴 배포에서 적절한 기능을 보장하려면 관리 클러스터와 호스팅된 클러스터의 작업자 노드에서 레지스트리 CA 인증서를 구성해야 합니다.
6.2.5.1. 관리 클러스터에 레지스트리 CA 추가
관리 클러스터에 레지스트리 CA를 추가하려면 다음 단계를 완료하세요.
프로세스
다음 예와 유사한 구성 맵을 만듭니다.
apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <config_map_namespace>2 data:3 <registry_name>..<port>: |4 -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----클러스터 전체 개체인
image.config.openshift.io에 패치를 적용하여 다음 사양을 포함합니다.spec: additionalTrustedCA: - name: registry-config이 패치의 결과로 제어 평면 노드는 개인 레지스트리에서 이미지를 검색할 수 있으며 HyperShift Operator는 호스팅된 클러스터 배포를 위해 OpenShift Container Platform 페이로드를 추출할 수 있습니다.
객체에 패치를 적용하는 과정은 완료되기까지 몇 분 정도 걸릴 수 있습니다.
6.2.5.2. 호스팅된 클러스터의 작업자 노드에 레지스트리 CA 추가
호스팅된 클러스터의 데이터 플레인 작업자가 개인 레지스트리에서 이미지를 검색할 수 있도록 하려면 작업자 노드에 레지스트리 CA를 추가해야 합니다.
프로세스
hc.spec.additionalTrustBundle파일에 다음 사양을 추가합니다.spec: additionalTrustBundle: - name: user-ca-bundle1 - 1
user-ca-bundle항목은 다음 단계에서 생성하는 구성 맵입니다.
HostedCluster개체가 생성된 동일한 네임스페이스에서user-ca-bundle구성 맵을 생성합니다. 구성 맵은 다음 예와 유사합니다.apiVersion: v1 data: ca-bundle.crt: | // Registry1 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry2 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry3 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 - 1
HostedCluster객체가 생성되는 네임스페이스를 지정합니다.
6.2.6. OpenShift Virtualization에서 호스팅 클러스터 생성
호스팅 클러스터는 제어 평면과 API 엔드포인트가 관리 클러스터에 호스팅된 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
6.2.6.1. OpenShift Virtualization에 호스팅된 제어 평면을 배포하기 위한 요구 사항
OpenShift Virtualization에 호스팅된 제어 평면을 배포할 준비를 할 때 다음 정보를 고려하세요.
- 베어메탈에서 관리 클러스터를 실행합니다.
- 호스팅된 각 클러스터에는 클러스터 전체에서 고유한 이름이 있어야 합니다.
-
호스팅된 클러스터 이름으로
클러스터를사용하지 마세요. - 멀티클러스터 엔진 운영자가 관리하는 클러스터의 네임스페이스에는 호스팅된 클러스터를 만들 수 없습니다.
- 호스팅된 제어 평면에 대한 스토리지를 구성할 때 권장되는 etcd 사례를 고려하세요. 지연 시간 요구 사항을 충족하려면 각 제어 평면 노드에서 실행되는 모든 호스팅된 제어 평면 etcd 인스턴스에 빠른 스토리지 장치를 전용으로 지정하세요. LVM 스토리지를 사용하여 호스팅된 etcd 포드에 대한 로컬 스토리지 클래스를 구성할 수 있습니다. 자세한 내용은 "권장되는 etcd 사례" 및 "논리 볼륨 관리자 스토리지를 사용한 영구 스토리지"를 참조하세요.
6.2.6.2. CLI를 사용하여 KubeVirt 플랫폼으로 호스팅 클러스터 만들기
호스트된 클러스터를 생성하려면 호스트된 컨트롤 플레인 명령줄 인터페이스인 hcp 를 사용할 수 있습니다.
프로세스
다음 명령을 입력하여 KubeVirt 플랫폼으로 호스팅 클러스터를 만듭니다.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --etcd-storage-class=<etcd_storage_class>6 - 1
- 호스팅된 클러스터의 이름을 지정합니다(예:
my-hosted-cluster ). - 2
- 노드 풀 복제본 수를 지정합니다(예:
3). 동일한 수의 복제본을 생성하려면 복제본 수를0이상으로 지정해야 합니다. 그렇지 않으면 노드 풀이 생성되지 않습니다. - 3
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿의 경로를 지정합니다. - 4
- 예를 들어
6Gi와 같이 메모리 값을 지정합니다. - 5
- 예를 들어 CPU에
2와 같은값을 지정합니다. - 6
- 예를 들어
lvm-storageclass와 같이 etcd 스토리지 클래스 이름을 지정합니다.
참고--release-image플래그를 사용하면 특정 OpenShift Container Platform 릴리스로 호스팅된 클러스터를 설정할 수 있습니다.--node-pool-replicas플래그에 따라 두 개의 가상 머신 워커 복제본이 있는 클러스터에 대한 기본 노드 풀이 생성됩니다.잠시 후 다음 명령을 입력하여 호스팅된 제어 평면 포드가 실행 중인지 확인하세요.
$ oc -n clusters-<hosted-cluster-name> get pods출력 예
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66sKubeVirt 가상 머신으로 지원되는 작업자 노드가 있는 호스팅 클러스터는 일반적으로 완전히 프로비저닝되는 데 10~15분이 걸립니다.
검증
호스팅된 클러스터의 상태를 확인하려면 다음 명령을 입력하여 해당
HostedCluster리소스를 확인하세요.$ oc get --namespace clusters hostedclusters완전히 프로비저닝된
HostedCluster개체를 보여주는 다음 예제 출력을 참조하세요.NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters my-hosted-cluster <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available<4.x.0>을사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.
6.2.6.3. OpenShift Virtualization에서 호스팅된 제어 평면에 대한 기본 수신 및 DNS 구성
모든 OpenShift Container Platform 클러스터에는 기본 애플리케이션 Ingress Controller가 포함되어 있으며, 이와 연결된 와일드카드 DNS 레코드가 있어야 합니다. 기본적으로 HyperShift KubeVirt 공급자를 사용하여 생성된 호스팅 클러스터는 KubeVirt 가상 머신이 실행되는 OpenShift Container Platform 클러스터의 하위 도메인이 됩니다.
예를 들어, OpenShift Container Platform 클러스터에는 다음과 같은 기본 수신 DNS 항목이 있을 수 있습니다.
*.apps.mgmt-cluster.example.com
결과적으로, guest 라는 이름의 KubeVirt 호스팅 클러스터가 해당 기본 OpenShift Container Platform 클러스터에서 실행되면 다음과 같은 기본 수신이 발생합니다.
*.apps.guest.apps.mgmt-cluster.example.com프로세스
기본 수신 DNS가 제대로 작동하려면 KubeVirt 가상 머신을 호스팅하는 클러스터에서 와일드카드 DNS 경로를 허용해야 합니다.
다음 명령을 입력하여 이 동작을 구성할 수 있습니다.
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'
기본 호스팅 클러스터 인그레스를 사용하면 연결이 포트 443을 통한 HTTPS 트래픽으로 제한됩니다. 포트 80을 통한 일반 HTTP 트래픽은 거부됩니다. 이 제한은 기본 수신 동작에만 적용됩니다.
6.2.6.4. 수신 및 DNS 동작 사용자 지정
기본 수신 및 DNS 동작을 사용하지 않으려면 생성 시 KubeVirt 호스팅 클러스터를 고유 기본 도메인으로 구성할 수 있습니다. 이 옵션을 사용하려면 생성 중에 수동 구성 단계가 필요하며 클러스터 생성, 로드 밸런서 생성 및 와일드카드 DNS 구성의 세 가지 주요 단계가 포함됩니다.
6.2.6.4.1. 기본 도메인을 지정하는 호스팅된 클러스터 배포
기본 도메인을 지정하는 호스팅 클러스터를 생성하려면 다음 단계를 완료합니다.
프로세스
다음 명령을 실행합니다.
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --base-domain <basedomain>6 결과적으로 호스팅된 클러스터에는 클러스터 이름과 기본 도메인(예:
.apps.example.hypershift.lab)에 대해 구성된 수신 와일드카드가 있습니다. 호스트 클러스터는 고유한 기본 도메인을 사용하여 호스팅 클러스터를 생성한 후 필요한 DNS 레코드 및 로드 밸런서를 구성해야 하므로부분적상태로 유지됩니다.
검증
다음 명령을 입력하여 호스팅 클러스터의 상태를 확인합니다.
$ oc get --namespace clusters hostedclusters출력 예
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available다음 명령을 입력하여 클러스터에 액세스합니다.
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get co출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console <4.x.0> False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress <4.x.0> True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)&
lt;4.x.0>을 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다.
다음 단계
출력에서 오류를 수정하려면 "로드 밸런서 설정" 및 " 와일드카드 DNS 설정"의 단계를 완료합니다.
호스팅 클러스터가 베어 메탈에 있는 경우 로드 밸런서 서비스를 설정하려면 MetalLB가 필요할 수 있습니다. 자세한 내용은 " MetalLB 구성"을 참조하십시오.
6.2.6.4.2. 로드 밸런서 설정
Ingress 트래픽을 KubeVirt VM으로 라우팅하고 로드 밸런서 IP 주소에 와일드카드 DNS 항목을 할당하는 로드 밸런서 서비스를 설정합니다.
프로세스
호스팅된 클러스터 인그레스를 노출하는
NodePort서비스가 이미 존재합니다. 노드 포트를 내보내고 해당 포트를 대상으로 하는 로드 밸런서 서비스를 생성할 수 있습니다.다음 명령을 입력하여 HTTP 노드 포트를 가져옵니다.
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'다음 단계에서 사용할 HTTP 노드 포트 값을 확인합니다.
다음 명령을 입력하여 HTTPS 노드 포트를 가져옵니다.
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'다음 단계에서 사용할 HTTPS 노드 포트 값을 확인합니다.
YAML 파일에 다음 정보를 입력하세요.
apiVersion: v1 kind: Service metadata: labels: app: <hosted_cluster_name> name: <hosted_cluster_name>-apps namespace: clusters-<hosted_cluster_name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https_node_port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http_node_port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer다음 명령을 실행하여 로드 밸런서 서비스를 만듭니다.
$ oc create -f <file_name>.yaml
6.2.6.4.3. 와일드카드 DNS 설정
로드 밸런서 서비스의 외부 IP를 참조하는 와일드카드 DNS 레코드 또는 CNAME을 설정합니다.
프로세스
다음 명령을 입력하여 외부 IP 주소를 가져옵니다.
$ oc -n clusters-<hosted_cluster_name> get service <hosted-cluster-name>-apps \ -o jsonpath='{.status.loadBalancer.ingress[0].ip}'출력 예
192.168.20.30외부 IP 주소를 참조하는 와일드카드 DNS 항목을 구성합니다. 다음 예제 DNS 항목을 확인합니다.
*.apps.<hosted_cluster_name\>.<base_domain\>.DNS 항목은 클러스터 내부 및 외부에서 라우팅할 수 있어야 합니다.
DNS 확인 예
dig +short test.apps.example.hypershift.lab 192.168.20.30
검증
다음 명령을 입력하여 호스팅 클러스터 상태가
Partial에서Completed로 이동했는지 확인합니다.$ oc get --namespace clusters hostedclusters출력 예
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available&
lt;4.x.0>을 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꿉니다.
6.2.7. 배포 완료
컨트롤 플레인과 데이터 플레인의 두 가지 관점에서 호스팅 클러스터 배포를 모니터링할 수 있습니다.
6.2.7.1. 컨트롤 플레인 모니터링
배포가 진행되는 동안 다음 아티팩트에 대한 정보를 수집하여 컨트롤 플레인을 모니터링할 수 있습니다.
- HyperShift Operator
-
HostedControlPlanePod - 베어 메탈 호스트
- 에이전트
-
InfraEnv리소스 -
HostedCluster및NodePool리소스
프로세스
다음 명령을 입력하여 컨트롤 플레인을 모니터링합니다.
$ export KUBECONFIG=/root/.kcli/clusters/hub-ipv4/auth/kubeconfig$ watch "oc get pod -n hypershift;echo;echo;\ oc get pod -n clusters-hosted-ipv4;echo;echo;\ oc get bmh -A;echo;echo;\ oc get agent -A;echo;echo;\ oc get infraenv -A;echo;echo;\ oc get hostedcluster -A;echo;echo;\ oc get nodepool -A;echo;echo;"
6.2.7.2. 데이터 플레인 모니터링
배포가 진행되는 동안 다음 아티팩트에 대한 정보를 수집하여 데이터 플레인을 모니터링할 수 있습니다.
- 클러스터 버전
- 특히 노드가 클러스터에 참여하는지 여부에 대한 노드
- 클러스터 Operator
프로세스
다음 명령을 입력합니다.
$ oc get secret -n clusters-hosted-ipv4 admin-kubeconfig \ -o jsonpath='{.data.kubeconfig}' | base64 -d > /root/hc_admin_kubeconfig.yaml$ export KUBECONFIG=/root/hc_admin_kubeconfig.yaml$ watch "oc get clusterversion,nodes,co"
6.3. 연결이 끊긴 환경의 베어 메탈에 호스팅된 컨트롤 플레인 배포
베어 메탈에서 호스팅되는 컨트롤 플레인을 프로비저닝할 때 에이전트 플랫폼을 사용합니다. Kubernetes Operator의 에이전트 플랫폼과 다중 클러스터 엔진은 함께 작동하여 연결이 끊긴 배포를 활성화합니다. 에이전트 플랫폼은 중앙 인프라 관리 서비스를 사용하여 호스트된 클러스터에 작업자 노드를 추가합니다. 중앙 인프라 관리 서비스에 대한 소개는 중앙 인프라 관리 서비스 활성화를 참조하세요.
6.3.1. 베어 메탈의 연결이 끊긴 환경 아키텍처
다음 다이어그램은 연결이 끊긴 환경의 예제 아키텍처를 보여줍니다.

- 연결이 끊긴 배포가 작동하는지 확인하기 위해 TLS 지원, 웹 서버 및 DNS를 사용하여 레지스트리 인증서 배포를 포함한 인프라 서비스를 구성합니다.
openshift-config네임스페이스에 구성 맵을 생성합니다. 이 예에서 구성 맵의 이름은registry-config입니다. 구성 맵의 내용은 레지스트리 CA 인증서입니다. 구성 맵의 data 필드에는 다음 키/값이 포함되어야 합니다.-
키: <
registry_dns_domain_name>..<port> (예:registry.hypershiftdomain.lab..5000:). 포트를 지정할 때 레지스트리 DNS 도메인 이름 뒤에..를 배치해야 합니다. value: 인증서 콘텐츠
구성 맵 생성에 대한 자세한 내용은 호스팅된 컨트롤 플레인의 연결이 끊긴 설치에 대한 TLS 인증서 구성 을 참조하십시오.
-
키: <
-
images.config.openshift.ioCR(사용자 정의 리소스) 사양을 수정하고 이름이registry-config인additionalTrustedCA라는 새 필드를 추가합니다. 두 개의 데이터 필드가 포함된 구성 맵을 생성합니다. 한 필드에는
RAW형식의registries.conf파일이 포함되어 있고 다른 필드에는 레지스트리 CA가 포함되어 있으며ca-bundle.crt라는 이름이 있습니다. 구성 맵은multicluster-engine네임스페이스에 속하며 구성 맵 이름은 다른 오브젝트에서 참조됩니다. 구성 맵의 예는 다음 샘플 구성을 참조하십시오.apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- # ... -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.ocp-edge-cluster-0.qe.lab.redhat.com:5000/openshift4" [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true # ... # ...-
다중 클러스터 엔진 Operator 네임스페이스에서 Agent 및
hypershift-addon애드온을 둘 다 활성화하는multiclusterengineCR을 생성합니다. 다중 클러스터 엔진 Operator 네임스페이스에는 연결이 끊긴 배포에서 동작을 수정하려면 구성 맵이 포함되어야 합니다. 네임스페이스에는multicluster-engine,assisted-service,hypershift-addon-managerPod도 포함되어 있습니다. 호스팅된 클러스터를 배포하는 데 필요한 다음 객체를 만듭니다.
- 비밀: 비밀에는 풀 비밀, SSH 키, etcd 암호화 키가 포함되어 있습니다.
- 구성 맵: 구성 맵에는 개인 레지스트리의 CA 인증서가 포함되어 있습니다.
-
HostedCluster:HostedCluster리소스는 사용자가 생성하려는 클러스터의 구성을 정의합니다. -
NodePool:NodePool리소스는 데이터 플레인에 사용할 머신을 참조하는 노드 풀을 식별합니다.
-
호스팅된 클러스터 객체를 생성한 후 HyperShift Operator는 제어 평면 포드를 수용하기 위해
HostedControlPlane네임스페이스를 설정합니다. 네임스페이스는 에이전트, 베어 메탈 호스트(BMH),InfraEnv리소스와 같은 구성 요소도 호스팅합니다. 나중에InfraEnv리소스를 만들고 ISO를 만든 후 베이스보드 관리 컨트롤러(BMC) 자격 증명이 포함된 BMH와 해당 비밀을 만듭니다. -
openshift-machine-api네임스페이스의 Metal3 Operator는 새로운 BMH를 검사합니다. 그런 다음 Metal3 Operator는 멀티클러스터 엔진 Operator 네임스페이스의AgentServiceConfigCR을 통해 지정된 구성된LiveISO및RootFS값을 사용하여 BMC에 연결하여 시작하려고 시도합니다. -
HostedCluster리소스의 작업자 노드가 시작된 후 에이전트 컨테이너가 시작됩니다. 이 에이전트는 배포를 완료하기 위한 작업을 조율하는 지원 서비스와 연락을 취합니다. 처음에는HostedCluster리소스의 워커 노드 수에 맞춰NodePool리소스를 확장해야 합니다. 지원 서비스는 나머지 업무를 관리합니다. - 이 시점에서 배포 프로세스가 완료될 때까지 기다립니다.
6.3.2. 연결이 끊긴 환경에서 베어 메탈에 호스팅된 제어 평면을 배포하기 위한 요구 사항
연결이 끊긴 환경에서 호스팅된 제어 평면을 구성하려면 다음 필수 조건을 충족해야 합니다.
- CPU: 제공된 CPU 수는 동시에 실행할 수 있는 호스팅 클러스터의 수를 결정합니다. 일반적으로 3개의 노드의 경우 각 노드에 16개의 CPU를 사용합니다. 최소한의 개발이라면 각 노드에 12개의 CPU를 사용하여 3개의 노드를 만들 수 있습니다.
- 메모리: RAM 용량은 호스팅할 수 있는 클러스터 수에 영향을 미칩니다. 각 노드에 48GB의 RAM을 사용하세요. 최소한의 개발이라면 18GB RAM이면 충분할 수 있습니다.
저장소: 멀티클러스터 엔진 운영자의 경우 SSD 저장소를 사용합니다.
- 관리 클러스터: 250GB.
- 레지스트리: 필요한 저장 공간은 호스팅되는 릴리스, 연산자 및 이미지의 수에 따라 달라집니다. 허용 가능한 크기는 500GB이며, 호스팅된 클러스터를 호스팅하는 디스크와 분리하는 것이 좋습니다.
- 웹 서버: 필요한 저장 공간은 호스팅되는 ISO와 이미지의 수에 따라 달라집니다. 허용 가능한 크기는 500GB입니다.
운영: 운영 환경의 경우 관리 클러스터, 레지스트리, 웹 서버를 서로 다른 디스크에 분리합니다. 이 예는 프로덕션을 위한 가능한 구성을 보여줍니다.
- 레지스트리: 2TB
- 관리 클러스터: 500GB
- 웹 서버: 2TB
6.3.3. 릴리스 이미지 다이제스트 추출
태그가 지정된 이미지를 사용하여 OpenShift 컨테이너 플랫폼 릴리스 이미지 다이제스트를 추출할 수 있습니다.
프로세스
다음 명령을 실행하여 이미지 다이제스트를 얻으세요.
$ oc adm release info <tagged_openshift_release_image> | grep "Pull From"<tagged_openshift_release_image>를지원되는 OpenShift Container Platform 버전의 태그가 지정된 이미지로 바꾸세요(예:quay.io/openshift-release-dev/ocp-release:4.14.0-x8_64).출력 예
Pull From: quay.io/openshift-release-dev/ocp-release@sha256:69d1292f64a2b67227c5592c1a7d499c7d00376e498634ff8e1946bc9ccdddfe
6.3.4. 베어 메탈의 DNS 구성
호스팅된 클러스터의 API 서버는 NodePort 서비스로 노출됩니다. API 서버에 도달할 수 있는 대상을 가리키는 api.<hosted_cluster_name>.<base_domain> 에 대한 DNS 항목이 있어야 합니다.
DNS 항목은 호스팅된 제어 평면을 실행하는 관리 클러스터의 노드 중 하나를 가리키는 레코드만큼 간단할 수 있습니다. 또한, 진입점은 유입 트래픽을 인그레스 포드로 리디렉션하기 위해 배포된 로드 밸런서를 가리킬 수도 있습니다.
DNS 구성 예
api.example.krnl.es. IN A 192.168.122.20
api.example.krnl.es. IN A 192.168.122.21
api.example.krnl.es. IN A 192.168.122.22
api-int.example.krnl.es. IN A 192.168.122.20
api-int.example.krnl.es. IN A 192.168.122.21
api-int.example.krnl.es. IN A 192.168.122.22
`*`.apps.example.krnl.es. IN A 192.168.122.23
이전 예에서, *.apps.example.krnl.es. 192.168.122.23에서 호스팅된 클러스터의 노드이거나 로드 밸런서가 구성된 경우 로드 밸런서입니다.
IPv6 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 구성은 다음 예와 같습니다.
IPv6 네트워크에 대한 DNS 구성 예
api.example.krnl.es. IN A 2620:52:0:1306::5
api.example.krnl.es. IN A 2620:52:0:1306::6
api.example.krnl.es. IN A 2620:52:0:1306::7
api-int.example.krnl.es. IN A 2620:52:0:1306::5
api-int.example.krnl.es. IN A 2620:52:0:1306::6
api-int.example.krnl.es. IN A 2620:52:0:1306::7
`*`.apps.example.krnl.es. IN A 2620:52:0:1306::10듀얼 스택 네트워크에서 연결이 끊긴 환경에 대한 DNS를 구성하는 경우 IPv4와 IPv6에 대한 DNS 항목을 모두 포함해야 합니다.
듀얼 스택 네트워크를 위한 DNS 구성 예
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10
host-record=api.hub-dual.dns.base.domain.name,192.168.126.10
address=/apps.hub-dual.dns.base.domain.name/192.168.126.11
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2
host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2
address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6]
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7]
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8]
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]6.3.5. 연결이 끊긴 환경에서 호스팅된 제어 평면에 대한 레지스트리 배포
개발 환경의 경우 Podman 컨테이너를 사용하여 소규모의 자체 호스팅 레지스트리를 배포합니다. 프로덕션 환경의 경우 Red Hat Quay, Nexus 또는 Artifactory와 같은 엔터프라이즈 호스팅 레지스트리를 배포합니다.
프로세스
Podman을 사용하여 소규모 레지스트리를 배포하려면 다음 단계를 완료하세요.
권한이 있는 사용자로서
${HOME}디렉토리에 액세스하여 다음 스크립트를 만듭니다.#!/usr/bin/env bash set -euo pipefail PRIMARY_NIC=$(ls -1 /sys/class/net | grep -v podman | head -1) export PATH=/root/bin:$PATH export PULL_SECRET="/root/baremetal/hub/openshift_pull.json"1 if [[ ! -f $PULL_SECRET ]];then echo "Pull Secret not found, exiting..." exit 1 fi dnf -y install podman httpd httpd-tools jq skopeo libseccomp-devel export IP=$(ip -o addr show $PRIMARY_NIC | head -1 | awk '{print $4}' | cut -d'/' -f1) REGISTRY_NAME=registry.$(hostname --long) REGISTRY_USER=dummy REGISTRY_PASSWORD=dummy KEY=$(echo -n $REGISTRY_USER:$REGISTRY_PASSWORD | base64) echo "{\"auths\": {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\", \"email\": \"sample-email@domain.ltd\"}}}" > /root/disconnected_pull.json mv ${PULL_SECRET} /root/openshift_pull.json.old jq ".auths += {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\",\"email\": \"sample-email@domain.ltd\"}}" < /root/openshift_pull.json.old > $PULL_SECRET mkdir -p /opt/registry/{auth,certs,data,conf} cat <<EOF > /opt/registry/conf/config.yml version: 0.1 log: fields: service: registry storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry delete: enabled: true http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 compatibility: schema1: enabled: true EOF openssl req -newkey rsa:4096 -nodes -sha256 -keyout /opt/registry/certs/domain.key -x509 -days 3650 -out /opt/registry/certs/domain.crt -subj "/C=US/ST=Madrid/L=San Bernardo/O=Karmalabs/OU=Guitar/CN=$REGISTRY_NAME" -addext "subjectAltName=DNS:$REGISTRY_NAME" cp /opt/registry/certs/domain.crt /etc/pki/ca-trust/source/anchors/ update-ca-trust extract htpasswd -bBc /opt/registry/auth/htpasswd $REGISTRY_USER $REGISTRY_PASSWORD podman create --name registry --net host --security-opt label=disable --replace -v /opt/registry/data:/var/lib/registry:z -v /opt/registry/auth:/auth:z -v /opt/registry/conf/config.yml:/etc/docker/registry/config.yml -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry" -e "REGISTRY_HTTP_SECRET=ALongRandomSecretForRegistry" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry/certs:/certs:z -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key docker.io/library/registry:latest [ "$?" == "0" ] || !! systemctl enable --now registry- 1
PULL_SECRET의 위치를 설정에 적합한 위치로 바꾸세요.
스크립트 파일 이름을
registry.sh로지정하고 저장합니다. 스크립트를 실행하면 다음 정보가 가져옵니다.- 하이퍼바이저 호스트 이름을 기반으로 하는 레지스트리 이름
- 필요한 자격 증명 및 사용자 액세스 세부 정보
다음과 같이 실행 플래그를 추가하여 권한을 조정합니다.
$ chmod u+x ${HOME}/registry.sh매개변수 없이 스크립트를 실행하려면 다음 명령을 입력하세요.
$ ${HOME}/registry.sh스크립트가 서버를 시작합니다. 스크립트는 관리 목적으로
systemd서비스를 사용합니다.스크립트를 관리해야 하는 경우 다음 명령을 사용할 수 있습니다.
$ systemctl status$ systemctl start$ systemctl stop
레지스트리의 루트 폴더는 /opt/registry 디렉토리에 있으며 다음과 같은 하위 디렉토리를 포함합니다.
-
certs에는 TLS 인증서가 포함되어 있습니다. -
auth에는 자격 증명이 포함되어 있습니다. -
데이터에는 레지스트리 이미지가 포함되어 있습니다. -
conf에는 레지스트리 구성이 포함되어 있습니다.
6.3.6. 연결이 끊긴 환경에서 호스팅된 제어 평면에 대한 관리 클러스터 설정
OpenShift Container Platform 관리 클러스터를 설정하려면 Kubernetes Operator용 멀티클러스터 엔진이 설치되어 있는지 확인해야 합니다. 멀티클러스터 엔진 운영자는 공급업체 전반에 클러스터를 배포하는 데 중요한 역할을 합니다.
사전 요구 사항
- 관리 클러스터와 대상 베어 메탈 호스트(BMH)의 베이스보드 관리 컨트롤러(BMC) 사이에는 양방향 연결이 있어야 합니다. 또는 에이전트 제공자를 통해 Boot It Yourself 방식을 따를 수도 있습니다.
호스팅된 클러스터는 관리 클러스터 호스트 이름과
*.apps호스트 이름의 API 호스트 이름을 확인하고 연결할 수 있어야 합니다. 다음은 관리 클러스터의 API 호스트 이름과*.apps호스트 이름의 예입니다.-
api.management-cluster.internal.domain.com -
console-openshift-console.apps.management-cluster.internal.domain.com
-
관리 클러스터는 호스팅된 클러스터의 API 및
*.apps호스트 이름을 확인하고 연결할 수 있어야 합니다. 다음은 호스팅된 클러스터의 API 호스트 이름과*.apps호스트 이름의 예입니다.-
api.sno-hosted-cluster-1.internal.domain.com -
console-openshift-console.apps.sno-hosted-cluster-1.internal.domain.com
-
프로세스
- OpenShift Container Platform 클러스터에 멀티클러스터 엔진 Operator 2.4 이상을 설치합니다. OpenShift Container Platform OperatorHub에서 Operator로 멀티클러스터 엔진 Operator를 설치할 수 있습니다. HyperShift Operator는 멀티클러스터 엔진 Operator에 포함되어 있습니다. 멀티클러스터 엔진 오퍼레이터 설치에 대한 자세한 내용은 Red Hat Advanced Cluster Management 문서의 "멀티클러스터 엔진 오퍼레이터 설치 및 업그레이드"를 참조하세요.
- HyperShift Operator가 설치되어 있는지 확인하세요. HyperShift Operator는 멀티클러스터 엔진 Operator에 자동으로 포함되지만, 수동으로 설치해야 하는 경우 "로컬 클러스터에 대한 HyperShift-addon 관리형 클러스터 애드온을 수동으로 활성화"의 단계를 따르세요.
다음 단계
다음으로, 웹 서버를 구성합니다.
6.3.7. 연결이 끊긴 환경에서 호스팅된 제어 평면에 대한 웹 서버 구성
호스팅 클러스터로 배포하는 OpenShift Container Platform 릴리스와 연관된 Red Hat Enterprise Linux CoreOS(RHCOS) 이미지를 호스팅하려면 추가 웹 서버를 구성해야 합니다.
프로세스
웹 서버를 구성하려면 다음 단계를 완료하세요.
다음 명령을 입력하여 사용하려는 OpenShift Container Platform 릴리스에서
openshift-install바이너리를 추출합니다.$ oc adm -a ${LOCAL_SECRET_JSON} release extract --command=openshift-install \ "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"다음 스크립트를 실행합니다. 스크립트는
/opt/srv디렉토리에 폴더를 생성합니다. 이 폴더에는 작업자 노드를 프로비저닝하는 RHCOS 이미지가 들어 있습니다.#!/bin/bash WEBSRV_FOLDER=/opt/srv ROOTFS_IMG_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.pxe.rootfs.location')"1 LIVE_ISO_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location')"2 mkdir -p ${WEBSRV_FOLDER}/images curl -Lk ${ROOTFS_IMG_URL} -o ${WEBSRV_FOLDER}/images/${ROOTFS_IMG_URL##*/} curl -Lk ${LIVE_ISO_URL} -o ${WEBSRV_FOLDER}/images/${LIVE_ISO_URL##*/} chmod -R 755 ${WEBSRV_FOLDER}/* ## Run Webserver podman ps --noheading | grep -q websrv-ai if [[ $? == 0 ]];then echo "Launching Registry pod..." /usr/bin/podman run --name websrv-ai --net host -v /opt/srv:/usr/local/apache2/htdocs:z quay.io/alosadag/httpd:p8080 fi
다운로드가 완료되면 컨테이너가 실행되어 웹 서버에서 이미지를 호스팅합니다. 컨테이너는 공식 HTTPd 이미지의 변형을 사용하는데, 이를 통해 IPv6 네트워크에서도 작동할 수 있습니다.
6.3.8. 연결이 끊긴 환경에서 호스팅된 제어 평면에 대한 이미지 미러링 구성
이미지 미러링은 registry.redhat.com 이나 quay.io 와 같은 외부 레지스트리에서 이미지를 가져와서 개인 레지스트리에 저장하는 프로세스입니다.
다음 절차에서는 ImageSetConfiguration 객체를 사용하는 바이너리인 oc-mirror 도구를 사용합니다. 파일에서 다음 정보를 지정할 수 있습니다.
-
미러링할 OpenShift 컨테이너 플랫폼 버전입니다. 해당 버전은
quay.io에 있습니다. - 미러링할 추가 연산자입니다. 패키지를 개별적으로 선택하세요.
- 저장소에 추가하려는 추가 이미지입니다.
사전 요구 사항
- 미러링 프로세스를 시작하기 전에 레지스트리 서버가 실행 중인지 확인하세요.
프로세스
이미지 미러링을 구성하려면 다음 단계를 완료하세요.
-
미러링할 레지스트리와 이미지를 푸시할 개인 레지스트리로
${HOME}/.docker/config.json파일이 업데이트되었는지 확인하세요. 다음 예제를 사용하여 미러링에 사용할
ImageSetConfiguration객체를 만듭니다. 필요에 따라 값을 환경과 일치하도록 바꾸세요.apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: channels: - name: candidate-4.19 minVersion: <4.x.y-build>1 maxVersion: <4.x.y-build>2 type: ocp kubeVirtContainer: true3 graph: true operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.19 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged4 다음 명령을 입력하여 미러링 프로세스를 시작합니다.
$ oc-mirror --v2 --config imagesetconfig.yaml \ --workspace file://mirror-file docker://<registry>미러링 프로세스가 완료되면
mirror-file이라는 새 폴더가 생성되는데, 여기에는ImageDigestMirrorSet(IDMS),ImageTagMirrorSet(ITMS) 및 호스팅된 클러스터에 적용할 카탈로그 소스가 포함됩니다.다음과 같이
imagesetconfig.yaml파일을 구성하여 OpenShift Container Platform의 야간 버전이나 CI 버전을 미러링합니다.apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: graph: true release: registry.ci.openshift.org/ocp/release:<4.x.y-build>1 kubeVirtContainer: true2 # ...부분적으로 연결이 끊긴 환경이 있는 경우 다음 명령을 입력하여 이미지 세트 구성의 이미지를 레지스트리로 미러링합니다.
$ oc mirror -c imagesetconfig.yaml \ --workspace file://<file_path> docker://<mirror_registry_url> --v2자세한 내용은 "부분적으로 연결이 끊긴 환경에서 이미지 세트 미러링"을 참조하세요.
완전히 연결이 끊긴 환경인 경우 다음 단계를 수행하세요.
다음 명령을 입력하여 지정된 이미지 세트 구성의 이미지를 디스크로 미러링합니다.
$ oc mirror -c imagesetconfig.yaml file://<file_path> --v2자세한 내용은 "완전히 연결되지 않은 환경에서 이미지 세트 미러링"을 참조하세요.
다음 명령을 입력하여 디스크에 있는 이미지 세트 파일을 처리하고 내용을 대상 미러 레지스트리로 미러링합니다.
$ oc mirror -c imagesetconfig.yaml \ --from file://<file_path> docker://<mirror_registry_url> --v2
- 연결이 끊긴 네트워크에 설치 단계에 따라 최신 멀티클러스터 엔진 Operator 이미지를 미러링합니다.
6.3.9. 관리 클러스터에 객체 적용
미러링 프로세스가 완료되면 관리 클러스터에 두 개의 객체를 적용해야 합니다.
-
ImageContentSourcePolicy(ICSP) 또는ImageDigestMirrorSet(IDMS) - 카탈로그 소스
oc-mirror 도구를 사용하면 출력 아티팩트는 oc-mirror-workspace/results-XXXXXX/ 라는 폴더에 저장됩니다.
ICSP 또는 IDMS는 노드를 다시 시작하지 않고 각 노드에서 kubelet을 다시 시작하는 MachineConfig 변경을 시작합니다. 노드가 READY 로 표시된 후 새로 생성된 카탈로그 소스를 적용해야 합니다.
카탈로그 소스는 openshift-marketplace Operator에서 카탈로그 이미지를 다운로드하고 해당 이미지에 포함된 모든 PackageManifest를 검색하기 위해 처리하는 등의 작업을 시작합니다.
프로세스
새로운 소스를 확인하려면 새
CatalogSource를소스로 사용하여 다음 명령을 실행하세요.$ oc get packagemanifest아티팩트를 적용하려면 다음 단계를 완료하세요.
다음 명령을 입력하여 ICSP 또는 IDMS 아티팩트를 만듭니다.
$ oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml노드가 준비될 때까지 기다린 후 다음 명령을 입력하세요.
$ oc apply -f catalogSource-XXXXXXXX-index.yaml
OLM 카탈로그를 미러링하고 호스팅된 클러스터가 미러를 가리키도록 구성합니다.
관리(기본값) OLMCatalogPlacement 모드를 사용하면 OLM 카탈로그에 사용되는 이미지 스트림이 관리 클러스터의 ICSP에서 제공하는 재정의 정보로 자동으로 수정되지 않습니다.-
OLM 카탈로그가 원래 이름과 태그를 사용하여 내부 레지스트리에 올바르게 미러링된 경우,
Hypershift.openshift.io/olm-catalogs-is-registry-overrides주석을HostedCluster리소스에 추가합니다. 형식은"sr1=dr1,sr2=dr2"이며, 여기서 소스 레지스트리 문자열은 키이고 대상 레지스트리는 값입니다. OLM 카탈로그 이미지 스트림 메커니즘을 우회하려면
HostedCluster리소스에서 다음 네 가지 주석을 사용하여 OLM 운영자 카탈로그에 사용할 네 가지 이미지의 주소를 직접 지정합니다.-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
-
-
OLM 카탈로그가 원래 이름과 태그를 사용하여 내부 레지스트리에 올바르게 미러링된 경우,
이 경우 이미지 스트림이 생성되지 않으며, 내부 미러가 새로 고쳐질 때 주석 값을 업데이트하여 Operator 업데이트를 가져와야 합니다.
다음 단계
연결이 끊긴 호스팅 제어 평면 설치에 대한 멀티클러스터 엔진 연산자 배포의 단계를 완료하여 멀티클러스터 엔진 연산자 를 배포합니다.
6.3.10. AgentServiceConfig 리소스 배포
AgentServiceConfig 사용자 정의 리소스는 멀티클러스터 엔진 Operator의 일부인 Assisted Service 추가 기능의 필수 구성 요소입니다. 베어 메탈 클러스터 배포를 담당합니다. 추가 기능이 활성화되면 AgentServiceConfig 리소스를 배포하여 추가 기능을 구성합니다.
AgentServiceConfig 리소스를 구성하는 것 외에도, 멀티클러스터 엔진 Operator가 연결이 끊긴 환경에서도 제대로 작동하도록 하려면 추가 구성 맵을 포함해야 합니다.
프로세스
다음 구성 맵을 추가하여 사용자 정의 레지스트리를 구성합니다. 이 맵에는 배포를 사용자 정의하기 위한 연결 해제된 세부 정보가 포함되어 있습니다.
apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.dns.base.domain.name:5000/openshift4"1 [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true # ... # ...- 1
dns.base.domain.name을DNS 기반 도메인 이름으로 바꾸세요.
객체에는 두 개의 필드가 포함되어 있습니다.
- 사용자 지정 CA: 이 필드에는 배포의 다양한 프로세스에 로드되는 인증 기관(CA)이 포함되어 있습니다.
-
레지스트리:
Registries.conf필드에는 원본 소스 레지스트리가 아닌 미러 레지스트리에서 사용해야 하는 이미지와 네임스페이스에 대한 정보가 들어 있습니다.
다음 예와 같이
AssistedServiceConfig객체를 추가하여 지원 서비스를 구성합니다.apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: annotations: unsupported.agent-install.openshift.io/assisted-service-configmap: assisted-service-config1 name: agent namespace: multicluster-engine spec: mirrorRegistryRef: name: custom-registries2 databaseStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi filesystemStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 20Gi osImages:3 - cpuArchitecture: x86_644 openshiftVersion: "4.14" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live-rootfs.x86_64.img5 url: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live.x86_64.iso version: 414.92.202308281054-0 - cpuArchitecture: x86_64 openshiftVersion: "4.15" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-415.92.202403270524-0-live-rootfs.x86_64.img url: http://registry.dns.base.domain.name:8080/images/rhcos-415.92.202403270524-0-live.x86_64.iso version: 415.92.202403270524-0- 1
metadata.annotations["unsupported.agent-install.openshift.io/assisted-service-configmap"]주석은 운영자가 동작을 사용자 정의하는 데 사용하는 구성 맵 이름을 참조합니다.- 2
spec.mirrorRegistryRef.name주석은 지원 서비스 운영자가 사용하는 연결이 끊긴 레지스트리 정보를 포함하는 구성 맵을 가리킵니다. 이 구성 맵은 배포 프로세스 중에 해당 리소스를 추가합니다.- 3
spec.osImages필드에는 이 운영자가 배포할 수 있는 다양한 버전이 포함되어 있습니다. 이 필드는 필수입니다. 이 예에서는RootFS및LiveISO파일을 이미 다운로드했다고 가정합니다.- 4
- 배포하려는 모든 OpenShift Container Platform 릴리스에 대해
cpuArchitecture하위 섹션을 추가합니다. 이 예에서는 4.14와 4.15에 대한cpuArchitecture하위 섹션이 포함되었습니다. - 5
rootFSUrl및url필드에서dns.base.domain.name을DNS 기본 도메인 이름으로 바꿉니다.
모든 객체를 하나의 파일에 연결하여 배포하고 관리 클러스터에 적용합니다. 그렇게 하려면 다음 명령을 입력하세요.
$ oc apply -f agentServiceConfig.yaml이 명령은 두 개의 포드를 작동시킵니다.
출력 예
assisted-image-service-0 1/1 Running 2 11d1 assisted-service-668b49548-9m7xw 2/2 Running 5 11d2
다음 단계
TLS 인증서를 구성합니다.
6.3.11. 호스팅된 제어 평면의 연결이 끊긴 설치를 위한 TLS 인증서 구성
연결이 끊긴 배포에서 적절한 기능을 보장하려면 관리 클러스터와 호스팅된 클러스터의 작업자 노드에서 레지스트리 CA 인증서를 구성해야 합니다.
6.3.11.1. 관리 클러스터에 레지스트리 CA 추가
관리 클러스터에 레지스트리 CA를 추가하려면 다음 단계를 완료하세요.
프로세스
다음 예와 유사한 구성 맵을 만듭니다.
apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <config_map_namespace>2 data:3 <registry_name>..<port>: |4 -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----클러스터 전체 개체인
image.config.openshift.io에 패치를 적용하여 다음 사양을 포함합니다.spec: additionalTrustedCA: - name: registry-config이 패치의 결과로 제어 평면 노드는 개인 레지스트리에서 이미지를 검색할 수 있으며 HyperShift Operator는 호스팅된 클러스터 배포를 위해 OpenShift Container Platform 페이로드를 추출할 수 있습니다.
객체에 패치를 적용하는 과정은 완료되기까지 몇 분 정도 걸릴 수 있습니다.
6.3.11.2. 호스팅된 클러스터의 작업자 노드에 레지스트리 CA 추가
호스팅된 클러스터의 데이터 플레인 작업자가 개인 레지스트리에서 이미지를 검색할 수 있도록 하려면 작업자 노드에 레지스트리 CA를 추가해야 합니다.
프로세스
hc.spec.additionalTrustBundle파일에 다음 사양을 추가합니다.spec: additionalTrustBundle: - name: user-ca-bundle1 - 1
user-ca-bundle항목은 다음 단계에서 생성하는 구성 맵입니다.
HostedCluster개체가 생성된 동일한 네임스페이스에서user-ca-bundle구성 맵을 생성합니다. 구성 맵은 다음 예와 유사합니다.apiVersion: v1 data: ca-bundle.crt: | // Registry1 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry2 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry3 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 - 1
HostedCluster객체가 생성되는 네임스페이스를 지정합니다.
6.3.12. 베어 메탈에 호스팅된 클러스터 생성
호스팅 클러스터는 제어 평면과 API 엔드포인트가 관리 클러스터에 호스팅된 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
6.3.12.1. 호스팅된 클러스터 객체 배포
일반적으로 HyperShift Operator는 HostedControlPlane 네임스페이스를 생성합니다. 하지만 이 경우에는 HyperShift Operator가 HostedCluster 개체를 조정하기 전에 모든 개체를 포함해야 합니다. 그런 다음 운영자가 조정 프로세스를 시작하면 모든 개체가 제자리에 있는 것을 찾을 수 있습니다.
프로세스
네임스페이스에 대한 다음 정보를 포함하는 YAML 파일을 만듭니다.
--- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: <hosted_cluster_namespace>-<hosted_cluster_name>1 spec: {} status: {} --- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: <hosted_cluster_namespace>2 spec: {} status: {}HostedCluster배포에 포함할 구성 맵과 비밀에 대한 다음 정보를 포함하는 YAML 파일을 만듭니다.--- apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 --- apiVersion: v1 data: .dockerconfigjson: xxxxxxxxx kind: Secret metadata: creationTimestamp: null name: <hosted_cluster_name>-pull-secret2 namespace: <hosted_cluster_namespace>3 --- apiVersion: v1 kind: Secret metadata: name: sshkey-cluster-<hosted_cluster_name>4 namespace: <hosted_cluster_namespace>5 stringData: id_rsa.pub: ssh-rsa xxxxxxxxx --- apiVersion: v1 data: key: nTPtVBEt03owkrKhIdmSW8jrWRxU57KO/fnZa8oaG0Y= kind: Secret metadata: creationTimestamp: null name: <hosted_cluster_name>-etcd-encryption-key6 namespace: <hosted_cluster_namespace>7 type: OpaqueRBAC 역할이 포함된 YAML 파일을 생성하여 지원 서비스 에이전트가 호스팅 제어 평면과 동일한
HostedControlPlane네임스페이스에 있고 클러스터 API에서 계속 관리될 수 있도록 합니다.apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: capi-provider-role namespace: <hosted_cluster_namespace>-<hosted_cluster_name>1 2 rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'HostedCluster개체에 대한 정보가 포함된 YAML 파일을 만들고 필요에 따라 값을 바꿉니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: additionalTrustBundle: name: "user-ca-bundle" olmCatalogPlacement: guest imageContentSources:3 - source: quay.io/openshift-release-dev/ocp-v4.0-art-dev mirrors: - registry.<dns.base.domain.name>:5000/openshift/release4 - source: quay.io/openshift-release-dev/ocp-release mirrors: - registry.<dns.base.domain.name>:5000/openshift/release-images5 - mirrors: ... ... autoscaling: {} controllerAvailabilityPolicy: SingleReplica dns: baseDomain: <dns.base.domain.name>6 etcd: managed: storage: persistentVolume: size: 8Gi restoreSnapshotURL: null type: PersistentVolume managementType: Managed fips: false networking: clusterNetwork: - cidr: 10.132.0.0/14 - cidr: fd01::/48 networkType: OVNKubernetes serviceNetwork: - cidr: 172.31.0.0/16 - cidr: fd02::/112 platform: agent: agentNamespace: <hosted_cluster_namespace>-<hosted_cluster_name>7 8 type: Agent pullSecret: name: <hosted_cluster_name>-pull-secret9 release: image: registry.<dns.base.domain.name>:5000/openshift/release-images:<4.x.y>-x86_6410 11 secretEncryption: aescbc: activeKey: name: <hosted_cluster_name>-etcd-encryption-key12 type: aescbc services: - service: APIServer servicePublishingStrategy: type: LoadBalancer - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: Ignition servicePublishingStrategy: type: Route sshKey: name: sshkey-cluster-<hosted_cluster_name>13 status: controlPlaneEndpoint: host: "" port: 0YAML 파일에서 정의한 모든 객체를 연결하여 파일로 만들고 관리 클러스터에 적용합니다. 그렇게 하려면 다음 명령을 입력하세요.
$ oc apply -f 01-4.14-hosted_cluster-nodeport.yaml출력 예
NAME READY STATUS RESTARTS AGE capi-provider-5b57dbd6d5-pxlqc 1/1 Running 0 3m57s catalog-operator-9694884dd-m7zzv 2/2 Running 0 93s cluster-api-f98b9467c-9hfrq 1/1 Running 0 3m57s cluster-autoscaler-d7f95dd5-d8m5d 1/1 Running 0 93s cluster-image-registry-operator-5ff5944b4b-648ht 1/2 Running 0 93s cluster-network-operator-77b896ddc-wpkq8 1/1 Running 0 94s cluster-node-tuning-operator-84956cd484-4hfgf 1/1 Running 0 94s cluster-policy-controller-5fd8595d97-rhbwf 1/1 Running 0 95s cluster-storage-operator-54dcf584b5-xrnts 1/1 Running 0 93s cluster-version-operator-9c554b999-l22s7 1/1 Running 0 95s control-plane-operator-6fdc9c569-t7hr4 1/1 Running 0 3m57s csi-snapshot-controller-785c6dc77c-8ljmr 1/1 Running 0 77s csi-snapshot-controller-operator-7c6674bc5b-d9dtp 1/1 Running 0 93s csi-snapshot-webhook-5b8584875f-2492j 1/1 Running 0 77s dns-operator-6874b577f-9tc6b 1/1 Running 0 94s etcd-0 3/3 Running 0 3m39s hosted-cluster-config-operator-f5cf5c464-4nmbh 1/1 Running 0 93s ignition-server-6b689748fc-zdqzk 1/1 Running 0 95s ignition-server-proxy-54d4bb9b9b-6zkg7 1/1 Running 0 95s ingress-operator-6548dc758b-f9gtg 1/2 Running 0 94s konnectivity-agent-7767cdc6f5-tw782 1/1 Running 0 95s kube-apiserver-7b5799b6c8-9f5bp 4/4 Running 0 3m7s kube-controller-manager-5465bc4dd6-zpdlk 1/1 Running 0 44s kube-scheduler-5dd5f78b94-bbbck 1/1 Running 0 2m36s machine-approver-846c69f56-jxvfr 1/1 Running 0 92s oauth-openshift-79c7bf44bf-j975g 2/2 Running 0 62s olm-operator-767f9584c-4lcl2 2/2 Running 0 93s openshift-apiserver-5d469778c6-pl8tj 3/3 Running 0 2m36s openshift-controller-manager-6475fdff58-hl4f7 1/1 Running 0 95s openshift-oauth-apiserver-dbbc5cc5f-98574 2/2 Running 0 95s openshift-route-controller-manager-5f6997b48f-s9vdc 1/1 Running 0 95s packageserver-67c87d4d4f-kl7qh 2/2 Running 0 93s호스팅된 클러스터를 사용할 수 있는 경우 출력은 다음 예와 같습니다.
출력 예
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters hosted-dual hosted-admin-kubeconfig Partial True False The hosted control plane is available
6.3.12.2. 호스팅된 클러스터에 대한 NodePool 객체 생성
NodePool 은 호스팅된 클러스터와 연관된 확장 가능한 작업자 노드 집합입니다. NodePool 머신 아키텍처는 특정 풀 내에서 일관성을 유지하며 제어 평면의 머신 아키텍처와 독립적입니다.
프로세스
NodePool객체에 대한 다음 정보를 포함하는 YAML 파일을 만들고 필요에 따라 값을 바꿉니다.apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: <hosted_cluster_name> \1 namespace: <hosted_cluster_namespace> \2 spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false \3 upgradeType: InPlace \4 nodeDrainTimeout: 0s platform: type: Agent release: image: registry.<dns.base.domain.name>:5000/openshift/release-images:4.x.y-x86_64 \5 replicas: 26 status: replicas: 2- 1
<hosted_cluster_name>을호스팅 클러스터로 바꾸세요.- 2
<hosted_cluster_namespace>를호스팅된 클러스터 네임스페이스의 이름으로 바꾸세요.- 3
- 노드가 제거되면 다시 생성되지 않으므로
autoRepair필드는false로 설정됩니다. - 4
upgradeType이InPlace로 설정되는데, 이는 업그레이드 중에 동일한 베어 메탈 노드가 재사용됨을 나타냅니다.- 5
- 이
NodePool에 포함된 모든 노드는 다음 OpenShift Container Platform 버전을 기반으로 합니다:4.xy-x86_64.<dns.base.domain.name>값을 DNS 기반 도메인 이름으로 바꾸고4.xy값을 사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요. - 6
- 호스팅된 클러스터에 두 개의 노드 풀 복제본을 생성하려면
복제본값을2로 설정할 수 있습니다.
다음 명령을 입력하여
NodePool객체를 만듭니다.$ oc apply -f 02-nodepool.yaml출력 예
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted-dual hosted 0 False False 4.x.y-x86_64
6.3.12.3. 호스팅된 클러스터에 대한 InfraEnv 리소스 생성
InfraEnv 리소스는 pullSecretRef 및 sshAuthorizedKey 와 같은 필수 세부 정보를 포함하는 지원 서비스 개체입니다. 이러한 세부 정보는 호스팅된 클러스터에 맞게 사용자 정의된 Red Hat Enterprise Linux CoreOS(RHCOS) 부팅 이미지를 만드는 데 사용됩니다.
두 개 이상의 InfraEnv 리소스를 호스팅할 수 있으며, 각 리소스는 특정 유형의 호스트를 채택할 수 있습니다. 예를 들어, RAM 용량이 더 큰 호스트에 서버 팜을 나눌 수 있습니다.
프로세스
InfraEnv리소스에 대한 다음 정보를 포함하는 YAML 파일을 만들고 필요에 따라 값을 바꿉니다.apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: pullSecretRef: name: pull-secret sshAuthorizedKey: ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDk7ICaUE+/k4zTpxLk4+xFdHi4ZuDi5qjeF52afsNkw0w/glILHhwpL5gnp5WkRuL8GwJuZ1VqLC9EKrdmegn4MrmUlq7WTsP0VFOZFBfq2XRUxo1wrRdor2z0Bbh93ytR+ZsDbbLlGngXaMa0Vbt+z74FqlcajbHTZ6zBmTpBVq5RHtDPgKITdpE1fongp7+ZXQNBlkaavaqv8bnyrP4BWahLP4iO9/xJF9lQYboYwEEDzmnKLMW1VtCE6nJzEgWCufACTbxpNS7GvKtoHT/OVzw8ArEXhZXQUS1UY8zKsX2iXwmyhw5Sj6YboA8WICs4z+TrFP89LmxXY0j6536TQFyRz1iB4WWvCbH5n6W+ABV2e8ssJB1AmEy8QYNwpJQJNpSxzoKBjI73XxvPYYC/IjPFMySwZqrSZCkJYqQ023ySkaQxWZT7in4KeMu7eS2tC+Kn4deJ7KwwUycx8n6RHMeD8Qg9flTHCv3gmab8JKZJqN3hW1D378JuvmIX4V0=다음과 같습니다.
- <hosted_cluster_namespace>
- 호스팅된 클러스터 네임스페이스의 이름을 지정합니다.
- pullSecretRef
-
풀 시크릿이 사용되는
InfraEnv와 동일한 네임스페이스에 있는 구성 맵 참조를 지정합니다. - sshAuthorizedKey
-
부트 이미지에 배치되는 SSH 공개 키를 지정합니다. SSH 키를 사용하면
핵심사용자로 워커 노드에 액세스할 수 있습니다.
다음 명령을 입력하여
InfraEnv리소스를 만듭니다.$ oc apply -f 03-infraenv.yaml출력 예
NAMESPACE NAME ISO CREATED AT clusters-hosted-dual hosted 2023-09-11T15:14:10Z
6.3.12.4. 호스팅된 클러스터에 대한 베어 메탈 호스트 생성
베어 메탈 호스트는 Metal3 운영자가 식별할 수 있도록 물리적, 논리적 세부 정보를 포함하는 오픈시프트 머신 API 객체입니다. 이러한 세부 정보는 에이전트 라고 하는 다른 지원 서비스 개체와 연결됩니다.
사전 요구 사항
- 베어 메탈 호스트와 대상 노드를 만들기 전에 대상 머신을 준비해야 합니다.
- 클러스터에서 사용하기 위해 베어 메탈 인프라에 Red Hat Enterprise Linux CoreOS(RHCOS) 컴퓨팅 머신을 설치했습니다.
프로세스
베어 메탈 호스트를 생성하려면 다음 단계를 완료하세요.
다음 정보를 사용하여 YAML 파일을 만듭니다. 베어 메탈 호스트에 입력해야 할 세부 정보에 대한 자세한 내용은 "BMO를 사용하여 사용자 프로비저닝 클러스터에 새 호스트 프로비저닝"을 참조하세요.
베어 메탈 호스트 자격 증명을 보관하는 비밀이 하나 이상 있으므로 각 작업자 노드에 대해 최소 두 개의 객체를 만들어야 합니다.
apiVersion: v1 kind: Secret metadata: name: <hosted_cluster_name>-worker0-bmc-secret namespace: <hosted_cluster_namespace> data: password: YWRtaW4= username: YWRtaW4= type: Opaque # ... apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <hosted_cluster_name>-worker0 namespace: <hosted_cluster_namespace> labels: infraenvs.agent-install.openshift.io: <hosted_cluster_name> annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: <hosted_cluster_name>-worker0 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: true address: redfish-virtualmedia://[192.168.126.1]:9000/redfish/v1/Systems/local/<hosted_cluster_name>-worker0 credentialsName: <hosted_cluster_name>-worker0-bmc-secret bootMACAddress: aa:aa:aa:aa:02:11 online: true다음과 같습니다.
- <hosted_cluster_name>
- 호스팅된 클러스터의 이름을 지정합니다.
- <hosted_cluster_namespace>
- 호스팅된 클러스터 네임스페이스의 이름을 지정합니다.
- 암호
- Base64 형식으로 베이스보드 관리 컨트롤러(BMC)의 비밀번호를 지정합니다.
- 사용자 이름
- Base64 형식으로 BMC의 사용자 이름을 지정합니다.
- infraenvs.agent-install.openshift.io
-
Assisted Installer와
BareMetalHost개체 간의 링크 역할을 합니다. - bmac.agent-install.openshift.io/hostname
- 배포 중에 채택된 노드 이름을 나타냅니다.
- automatedCleaningMode
- Metal3 Operator에 의해 노드가 지워지는 것을 방지합니다.
- disableCertificateVerification
-
클라이언트에서 인증서 유효성 검사를 우회하려면
true로 설정합니다. - address
- 워커 노드의 BMC 주소를 나타냅니다.
- credentialsName
- 사용자 및 비밀번호 자격 증명이 저장된 비밀을 가리킵니다.
- bootMACAddress
- 노드가 시작되는 인터페이스 MAC 주소를 나타냅니다.
- 온라인
-
BareMetalHost개체가 생성된 후 노드의 상태를 정의합니다.
다음 명령을 입력하여
BareMetalHost객체를 배포합니다.$ oc apply -f 04-bmh.yaml이 과정에서 다음과 같은 출력을 볼 수 있습니다.
이 출력은 프로세스가 노드에 도달하려고 시도하고 있음을 나타냅니다.
출력 예
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 registering true 2s clusters-hosted hosted-worker1 registering true 2s clusters-hosted hosted-worker2 registering true 2s이 출력은 노드가 시작되고 있음을 나타냅니다.
출력 예
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioning true 16s clusters-hosted hosted-worker1 provisioning true 16s clusters-hosted hosted-worker2 provisioning true 16s이 출력은 노드가 성공적으로 시작되었음을 나타냅니다.
출력 예
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioned true 67s clusters-hosted hosted-worker1 provisioned true 67s clusters-hosted hosted-worker2 provisioned true 67s
노드가 시작된 후, 이 예에서 볼 수 있듯이 네임스페이스의 에이전트를 확인하세요.
출력 예
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 true auto-assign에이전트는 설치 가능한 노드를 나타냅니다. 호스팅된 클러스터에 노드를 할당하려면 노드 풀을 확장합니다.
6.3.12.5. 노드 풀 확장
베어 메탈 호스트를 생성한 후에는 상태가 등록 에서 프로비저닝 , 프로비저닝 됨으로 변경됩니다. 노드는 에이전트의 LiveISO 와 agent 라는 이름의 기본 포드로 시작합니다. 해당 에이전트는 지원 서비스 운영자로부터 OpenShift 컨테이너 플랫폼 페이로드를 설치하라는 지시를 받는 역할을 합니다.
프로세스
노드 풀을 확장하려면 다음 명령을 입력하세요.
$ oc -n <hosted_cluster_namespace> scale nodepool <hosted_cluster_name> \ --replicas 3다음과 같습니다.
-
<hosted_cluster_namespace>는 호스팅된 클러스터 네임스페이스의 이름입니다. -
<hosted_cluster_name>은 호스팅된 클러스터의 이름입니다.
-
확장 프로세스가 완료되면 에이전트가 호스팅된 클러스터에 할당된 것을 확인할 수 있습니다.
출력 예
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 hosted true auto-assign또한 노드 풀 복제본이 설정되어 있는지 확인하세요.
출력 예
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted hosted 3 False False <4.x.y>-x86_64 Minimum availability requires 3 replicas, current 0 available<4.xy>를사용하려는 지원되는 OpenShift Container Platform 버전으로 바꾸세요.- 노드가 클러스터에 가입할 때까지 기다립니다. 이 과정에서 에이전트는 자신의 단계와 상태에 대한 업데이트를 제공합니다.
6.4. 연결이 끊긴 환경에서 IBM Z에 호스팅된 제어 평면 배포
연결이 끊긴 환경에서 IBM Z의 호스팅된 제어 평면은 기술 미리 보기 기능에 불과합니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
연결이 끊긴 환경에서 호스팅된 제어 평면을 배포하는 방식은 독립형 OpenShift Container Platform과 다르게 작동합니다.
호스팅된 제어 평면에는 두 가지 서로 다른 환경이 포함됩니다.
- 제어 평면: 관리 클러스터에 위치하며, 호스팅된 제어 평면 포드는 제어 평면 운영자에 의해 실행되고 관리됩니다.
- 데이터 플레인: 호스팅 클러스터의 작업자에 위치하며, 작업 부하와 몇 가지 다른 포드가 실행되고 호스팅 클러스터 구성 운영자가 관리합니다.
데이터 플레인의 ImageContentSourcePolicy (ICSP) 사용자 정의 리소스는 호스팅된 클러스터 매니페스트의 ImageContentSources API를 통해 관리됩니다.
제어 평면의 경우 ICSP 객체는 관리 클러스터에서 관리됩니다. 이러한 객체는 HyperShift Operator에 의해 구문 분석되고 Control Plane Operator와 레지스트리 재정의 항목으로 공유됩니다. 이러한 항목은 호스팅된 제어 평면 네임스페이스의 사용 가능한 배포 중 하나에 인수로 삽입됩니다.
호스팅된 제어 평면에서 연결이 끊긴 레지스트리를 사용하려면 먼저 관리 클러스터에서 적절한 ICSP를 만들어야 합니다. 그런 다음, 데이터 플레인에서 연결이 끊긴 워크로드를 배포하려면 호스팅된 클러스터 매니페스트의 ImageContentSources 필드에 원하는 항목을 추가해야 합니다.
6.4.1. 연결이 끊긴 환경에서 IBM Z에 호스팅된 제어 평면을 배포하기 위한 전제 조건
- mirror_registry 자세한 내용은 "Red Hat OpenShift용 미러 레지스트리를 사용하여 미러 레지스트리 만들기"를 참조하세요.
- 연결이 끊어진 설치에 대한 미러 이미지입니다. 자세한 내용은 oc-mirror 플러그인을 사용하여 연결이 끊긴 설치의 이미지 미러링을 참조하십시오.
6.4.2. 관리 클러스터에 자격 증명 및 레지스트리 인증 기관 추가
관리 클러스터에서 미러 레지스트리 이미지를 가져오려면 먼저 미러 레지스트리의 자격 증명과 인증 기관을 관리 클러스터에 추가해야 합니다. 다음 절차를 따르세요.
프로세스
다음 명령을 실행하여 미러 레지스트리의 인증서로
ConfigMap을만듭니다.$ oc apply -f registry-config.yamlregistry-config.yaml 파일 예시
apiVersion: v1 kind: ConfigMap metadata: name: registry-config namespace: openshift-config data: <mirror_registry>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----image.config.openshift.io클러스터 전체 개체에 패치를 적용하여 다음 항목을 포함합니다.spec: additionalTrustedCA: - name: registry-config미러 레지스트리의 자격 증명을 추가하려면 관리 클러스터 풀 시크릿을 업데이트합니다.
다음 명령을 실행하여 JSON 형식으로 클러스터에서 풀 시크릿을 가져옵니다.
$ oc get secret/pull-secret -n openshift-config -o json \ | jq -r '.data.".dockerconfigjson"' \ | base64 -d > authfile인증 기관의 자격 증명이 있는 섹션을 포함하도록 가져온 비밀 JSON 파일을 편집합니다.
"auths": { "<mirror_registry>": {1 "auth": "<credentials>",2 "email": "you@example.com" } },다음 명령을 실행하여 클러스터의 풀 시크릿을 업데이트합니다.
$ oc set data secret/pull-secret -n openshift-config \ --from-file=.dockerconfigjson=authfile
6.4.3. AgentServiceConfig 리소스의 레지스트리 인증 기관을 미러 레지스트리로 업데이트합니다.
이미지에 미러 레지스트리를 사용하는 경우 에이전트는 레지스트리의 인증서를 신뢰하여 이미지를 안전하게 가져와야 합니다. ConfigMap을 생성하여 AgentServiceConfig 사용자 지정 리소스에 미러 레지스트리의 인증 기관을 추가할 수 있습니다.
사전 요구 사항
- Kubernetes Operator를 사용하려면 멀티클러스터 엔진을 설치해야 합니다.
프로세스
멀티클러스터 엔진 Operator를 설치한 동일한 네임스페이스에서 미러 레지스트리 세부정보로
ConfigMap리소스를 만듭니다. 이ConfigMap리소스는 호스팅된 클러스터 작업자에게 미러 레지스트리에서 이미지를 검색하는 기능을 부여합니다.예제 ConfigMap 파일
apiVersion: v1 kind: ConfigMap metadata: name: mirror-config namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | [[registry]] location = "registry.stage.redhat.io" insecure = false blocked = false mirror-by-digest-only = true prefix = "" [[registry.mirror]] location = "<mirror_registry>" insecure = false [[registry]] location = "registry.redhat.io/multicluster-engine" insecure = false blocked = false mirror-by-digest-only = true prefix = "" [[registry.mirror]] location = "<mirror_registry>/multicluster-engine"1 insecure = false- 1
- 여기서:
<mirror_registry>는 미러 레지스트리의 이름입니다.
AgentServiceConfig리소스에 패치를 적용하여 생성한ConfigMap리소스를 포함합니다.AgentServiceConfig리소스가 없으면 다음 콘텐츠를 내장하여AgentServiceConfig리소스를 만듭니다.spec: mirrorRegistryRef: name: mirror-config
6.4.4. 호스팅된 클러스터에 레지스트리 인증 기관 추가
연결이 끊긴 환경에서 IBM Z에 호스팅된 제어 평면을 배포하는 경우 additional-trust-bundle 및 image-content-sources 리소스를 포함합니다. 이러한 리소스를 사용하면 호스팅된 클러스터가 인증 기관을 데이터 플레인 작업자에 주입하여 레지스트리에서 이미지를 가져올 수 있습니다.
image-content-sources정보로icsp.yaml파일을 만듭니다.oc-mirror를사용하여 이미지를 미러링한 후 생성되는ImageContentSourcePolicyYAML 파일에서이미지-콘텐츠-소스정보를 사용할 수 있습니다.ImageContentSourcePolicy 파일 예시
# cat icsp.yaml - mirrors: - <mirror_registry>/openshift/release source: quay.io/openshift-release-dev/ocp-v4.0-art-dev - mirrors: - <mirror_registry>/openshift/release-images source: quay.io/openshift-release-dev/ocp-release다음 예와 같이 호스팅된 클러스터를 만들고
추가 신뢰 번들인증서를 제공하여 인증서로 컴퓨팅 노드를 업데이트합니다.$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \ --etcd-storage-class=<etcd_storage_class> \5 --ssh-key <path_to_ssh_public_key> \6 --namespace <hosted_cluster_namespace> \7 --control-plane-availability-policy SingleReplica \ --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --additional-trust-bundle <path for cert> \9 --image-content-sources icsp.yaml- 1
<hosted_cluster_name>을호스팅 클러스터의 이름으로 바꾸세요.- 2
- 예를 들어
/user/name/pullsecret 과같이 풀 시크릿 경로를 바꾸세요. - 3
<hosted_control_plane_namespace>를 호스트된 컨트롤 플레인 네임스페이스의 이름으로 바꿉니다(예:클러스터 호스팅).- 4
- 이름을 기본 도메인으로 바꾸세요(예:
example.com). - 5
- 예를 들어
lvm-storageclass와 같이 etcd 스토리지 클래스 이름을 바꿉니다. - 6
- SSH 공개 키의 경로를 바꾸세요. 기본 파일 경로는
~/.ssh/id_rsa.pub입니다. - 7 8
- 사용하려는 지원되는 OpenShift Container Platform 버전(예:
4.19.0-multi )으로 바꿉니다. - 9
- 미러 레지스트리의 인증 기관 경로를 교체합니다.
6.5. 연결이 끊긴 환경에서 사용자 워크로드 모니터링
하이퍼shift-addon 관리 클러스터 애드온은 HyperShift Operator에서 --enable-uwm-telemetry-remote-write 옵션을 활성화합니다. 이 옵션을 활성화하면 사용자 워크로드 모니터링이 활성화되고 컨트롤 플레인에서 Telemetry 메트릭을 원격으로 작성할 수 있습니다.
6.5.1. 사용자 워크로드 모니터링 문제 해결
인터넷에 연결되지 않은 OpenShift Container Platform 클러스터에 다중 클러스터 엔진 Operator를 설치하는 경우 다음 명령을 입력하여 HyperShift Operator의 사용자 워크로드 모니터링 기능을 실행하려고 하면 오류와 함께 기능이 실패합니다.
$ oc get events -n hypershift오류 예
LAST SEEN TYPE REASON OBJECT MESSAGE
4m46s Warning ReconcileError deployment/operator Failed to ensure UWM telemetry remote write: cannot get telemeter client secret: Secret "telemeter-client" not found
오류를 해결하려면 local-cluster 네임스페이스에 구성 맵을 생성하여 사용자 워크로드 모니터링 옵션을 비활성화해야 합니다. 애드온을 활성화하기 전이나 후에 구성 맵을 생성할 수 있습니다. 애드온 에이전트는 HyperShift Operator를 재구성합니다.
프로세스
다음 구성 맵을 생성합니다.
kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "" installFlagsToRemove: "--enable-uwm-telemetry-remote-write"다음 명령을 실행하여 구성 맵을 편집합니다.
$ oc apply -f <filename>.yaml
6.5.2. 호스트된 컨트롤 플레인 기능의 상태 확인
호스트된 컨트롤 플레인 기능은 기본적으로 활성화되어 있습니다.
프로세스
기능이 비활성화되고 이를 활성화하려면 다음 명령을 입력합니다. &
lt;multiclusterengine>을 다중 클러스터 엔진 Operator 인스턴스의 이름으로 바꿉니다.$ oc patch mce <multiclusterengine> --type=merge -p \ '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'기능을 활성화하면
hypershift-addon관리 클러스터 애드온이로컬 클러스터 관리 클러스터에설치되고 애드온 에이전트는 다중 클러스터 엔진 Operator 허브 클러스터에 HyperShift Operator를 설치합니다.다음 명령을 입력하여
hypershift-addon관리 클러스터 애드온이 설치되었는지 확인합니다.$ oc get managedclusteraddons -n local-cluster hypershift-addon출력 예
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True False이 프로세스 중에 시간 초과를 방지하려면 다음 명령을 입력합니다.
$ oc wait --for=condition=Degraded=True managedclusteraddons/hypershift-addon \ -n local-cluster --timeout=5m$ oc wait --for=condition=Available=True managedclusteraddons/hypershift-addon \ -n local-cluster --timeout=5m프로세스가 완료되면
hypershift-addon관리 클러스터 애드온 및 HyperShift Operator가 설치되고로컬 클러스터관리 클러스터를 호스팅 및 관리할 수 있습니다.
6.5.3. 인프라 노드에서 실행되도록 하이퍼shift-addon 관리 클러스터 애드온 구성
기본적으로 hypershift-addon 관리 클러스터 애드온에 노드 배치 기본 설정은 지정되지 않습니다. 인프라 노드에서 애드온을 실행하는 것이 좋습니다. 이렇게 하면 서브스크립션 수와 별도의 유지 관리 및 관리 작업에 대해 청구 비용이 발생하지 않도록 할 수 있습니다.
프로세스
- hub 클러스터에 로그인합니다.
다음 명령을 입력하여 편집할
hypershift-addon-deploy-config배포 구성 사양을 엽니다.$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine다음 예와 같이
nodePlacement필드를 사양에 추가합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: nodePlacement: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra operator: Exists-
변경 사항을 저장합니다.
하이퍼shift-addon관리 클러스터 애드온은 신규 및 기존 관리 클러스터를 위해 인프라 노드에 배포됩니다.
7장. 호스팅된 제어 평면에 대한 인증서 구성
호스팅된 제어 평면을 사용하는 경우 인증서를 구성하는 단계는 독립 실행형 OpenShift Container Platform의 단계와 다릅니다.
7.1. 호스팅된 클러스터에서 사용자 정의 API 서버 인증서 구성
API 서버에 대한 사용자 정의 인증서를 구성하려면 HostedCluster 구성의 spec.configuration.apiServer 섹션에서 인증서 세부 정보를 지정하세요.
1일차 또는 2일차 작업 중에 사용자 정의 인증서를 구성할 수 있습니다. 그러나 서비스 게시 전략은 호스팅 클러스터를 생성하는 동안 설정한 후에는 변경할 수 없으므로 구성하려는 Kubernetes API 서버의 호스트 이름을 알아야 합니다.
사전 요구 사항
관리 클러스터에 사용자 정의 인증서가 포함된 Kubernetes 비밀을 생성했습니다. 비밀에는 다음과 같은 키가 포함되어 있습니다.
-
tls.crt: 인증서 -
tls.key: 개인 키
-
-
HostedCluster구성에 부하 분산 장치를 사용하는 서비스 게시 전략이 포함된 경우 인증서의 SAN(주체 대체 이름)이 내부 API 엔드포인트(api-int)와 충돌하지 않는지 확인하세요. 내부 API 엔드포인트는 플랫폼에서 자동으로 생성되고 관리됩니다. 사용자 정의 인증서와 내부 API 엔드포인트 모두에서 동일한 호스트 이름을 사용하면 라우팅 충돌이 발생할 수 있습니다. 이 규칙의 유일한 예외는 AWS를Private또는PublicAndPrivate구성으로 공급자로 사용하는 경우입니다. 이런 경우 SAN 충돌은 플랫폼에 의해 관리됩니다. - 인증서는 외부 API 엔드포인트에 대해 유효해야 합니다.
- 인증서의 유효 기간은 클러스터의 예상 수명 주기와 일치합니다.
프로세스
다음 명령을 입력하여 사용자 지정 인증서로 비밀을 만듭니다.
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>다음 예와 같이 사용자 지정 인증서 세부 정보로
HostedCluster구성을 업데이트합니다.spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert다음 명령을 입력하여
HostedCluster구성에 변경 사항을 적용합니다.$ oc apply -f <hosted_cluster_config>.yaml
검증
- API 서버 포드를 확인하여 새 인증서가 마운트되었는지 확인하세요.
- 사용자 지정 도메인 이름을 사용하여 API 서버에 대한 연결을 테스트합니다.
-
브라우저나
openssl과 같은 도구를 사용하여 인증서 세부 정보를 확인하세요.
7.2. 호스팅된 클러스터에 대한 Kubernetes API 서버 구성
호스팅된 클러스터에 맞게 Kubernetes API 서버를 사용자 지정하려면 다음 단계를 완료하세요.
사전 요구 사항
- 실행 중인 호스팅 클러스터가 있습니다.
-
HostedCluster리소스를 수정할 수 있는 권한이 있습니다. Kubernetes API 서버에 사용할 사용자 지정 DNS 도메인이 있습니다.
- 사용자 지정 DNS 도메인은 적절하게 구성되고 확인 가능해야 합니다.
- DNS 도메인에는 유효한 TLS 인증서가 구성되어 있어야 합니다.
- 도메인에 대한 네트워크 액세스는 사용자 환경에서 올바르게 구성되어야 합니다.
- 사용자 지정 DNS 도메인은 호스팅된 클러스터 전체에서 고유해야 합니다.
- 사용자 정의 인증서가 구성되어 있습니다. 자세한 내용은 "호스팅된 클러스터에서 사용자 정의 API 서버 인증서 구성"을 참조하세요.
프로세스
공급자 플랫폼에서 DNS 레코드를 구성하여
kubeAPIServerDNSNameURL이 Kubernetes API 서버가 노출되는 IP 주소를 가리키도록 합니다. DNS 레코드는 올바르게 구성되어야 하며 클러스터에서 확인 가능해야 합니다.DNS 레코드를 구성하는 예제 명령
$ dig + short kubeAPIServerDNSNameHostedCluster사양에서 다음 예와 같이kubeAPIServerDNSName필드를 수정합니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert kubeAPIServerDNSName: api-custom-cert-sample-hosted.sample-hosted.example.com3 # ...다음 명령을 입력하여 구성을 적용합니다.
$ oc -f <hosted_cluster_spec>.yaml구성이 적용된 후 HyperShift Operator는 사용자 지정 DNS 도메인을 가리키는 새로운
kubeconfig비밀번호를 생성합니다.CLI나 콘솔을 사용하여
kubeconfig비밀번호를 검색합니다.CLI를 사용하여 비밀을 검색하려면 다음 명령을 입력하세요.
$ kubectl get secret <hosted_cluster_name>-custom-admin-kubeconfig \ -n <cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' | base64 -d콘솔을 사용하여 비밀을 검색하려면 호스팅된 클러스터로 이동하여 Kubeconfig 다운로드를 클릭합니다.
참고콘솔에서 show login 명령 옵션을 사용하여 새로운
kubeconfig비밀번호를 사용할 수 없습니다.
7.3. 사용자 지정 DNS를 사용하여 호스팅된 클러스터에 액세스하는 문제 해결
사용자 지정 DNS를 사용하여 호스팅된 클러스터에 액세스할 때 문제가 발생하는 경우 다음 단계를 완료하세요.
절차
- DNS 레코드가 올바르게 구성되고 확인되었는지 확인하세요.
다음 명령을 입력하여 사용자 지정 도메인의 TLS 인증서가 유효한지 확인하고 SAN이 도메인에 맞는지 확인합니다.
$ oc get secret \ -n clusters <serving_certificate_name> \ -o jsonpath='{.data.tls\.crt}' | base64 \ -d |openssl x509 -text -noout -- 사용자 지정 도메인에 대한 네트워크 연결이 작동하는지 확인하세요.
HostedCluster리소스에서 다음 예와 같이 상태가 올바른 사용자 지정kubeconfig정보를 표시하는지 확인하세요.HostedCluster상태 예시status: customKubeconfig: name: sample-hosted-custom-admin-kubeconfig다음 명령을 입력하여
HostedControlPlane네임스페이스의kube-apiserver로그를 확인하세요.$ oc logs -n <hosted_control_plane_namespace> \ -l app=kube-apiserver -f -c kube-apiserver
8장. 호스트된 컨트롤 플레인 업데이트
호스팅된 컨트롤 플레인을 업데이트하려면 호스팅된 클러스터 및 노드 풀을 업데이트해야 합니다. 업데이트 프로세스 중에 클러스터가 완전히 작동하려면 컨트롤 플레인 및 노드 업데이트를 완료하는 동안 Kubernetes 버전 스큐 정책의 요구 사항을 충족해야 합니다.
8.1. 호스팅된 컨트롤 플레인을 업그레이드하기 위한 요구사항
Kubernetes Operator용 멀티클러스터 엔진은 하나 이상의 OpenShift Container Platform 클러스터를 관리할 수 있습니다. OpenShift Container Platform에서 호스팅 클러스터를 만든 후에는 멀티클러스터 엔진 Operator에서 호스팅 클러스터를 관리형 클러스터로 가져와야 합니다. 그러면 OpenShift Container Platform 클러스터를 관리 클러스터로 사용할 수 있습니다.
호스팅된 제어 평면을 업데이트하기 전에 다음 요구 사항을 고려하세요.
- OpenShift Virtualization을 공급자로 사용하는 경우 OpenShift Container Platform 클러스터에 대해 베어 메탈 플랫폼을 사용해야 합니다.
-
호스팅된 클러스터의 클라우드 플랫폼으로 베어 메탈 또는 OpenShift 가상화를 사용해야 합니다. 호스팅된 클러스터의 플랫폼 유형은
HostedCluster사용자 정의 리소스(CR)의spec.Platform.type사양에서 찾을 수 있습니다.
다음 순서에 따라 호스팅된 제어 평면을 업데이트해야 합니다.
- OpenShift Container Platform 클러스터를 최신 버전으로 업그레이드합니다. 자세한 내용은 "웹 콘솔을 사용하여 클러스터 업데이트" 또는 "CLI를 사용하여 클러스터 업데이트"를 참조하세요.
- 멀티클러스터 엔진 Operator를 최신 버전으로 업그레이드하세요. 자세한 내용은 설치된 Operator 업데이트를 참조하십시오.
- 이전 OpenShift Container Platform 버전에서 호스팅된 클러스터와 노드 풀을 최신 버전으로 업그레이드합니다. 자세한 내용은 "호스팅된 클러스터에서 제어 평면 업데이트" 및 "호스팅된 클러스터에서 노드 풀 업데이트"를 참조하세요.
8.2. 호스트 클러스터에서 채널 설정
HostedCluster CR(사용자 정의 리소스)의 HostedCluster.Status 필드에서 사용 가능한 업데이트를 확인할 수 있습니다.
사용 가능한 업데이트는 호스팅된 클러스터의 CVO(Cluster Version Operator)에서 가져오지 않습니다. 사용 가능한 업데이트 목록은 HostedCluster CR(사용자 정의 리소스)의 다음 필드에서 사용 가능한 업데이트와 다를 수 있습니다.
-
status.version.availableUpdates -
status.version.conditionalUpdates
초기 HostedCluster CR에는 status.version.availableUpdates 및 status.version.conditionalUpdates 필드에 정보가 없습니다. spec.channel 필드를 안정적인 OpenShift Container Platform 릴리스 버전으로 설정하면 HyperShift Operator가 HostedCluster CR을 조정하고 사용 가능한 조건부 업데이트로 status.version 필드를 업데이트합니다.
채널 구성이 포함된 HostedCluster CR의 다음 예제를 참조하십시오.
spec:
autoscaling: {}
channel: stable-4.y
clusterID: d6d42268-7dff-4d37-92cf-691bd2d42f41
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: dev11.red-chesterfield.com
privateZoneID: Z0180092I0DQRKL55LN0
publicZoneID: Z00206462VG6ZP0H2QLWK- 1
- &
lt;4.y>를spec.release에서 지정한 OpenShift Container Platform 릴리스 버전으로 바꿉니다. 예를 들어spec.release를ocp-release:4.16.4-multi로 설정하는 경우spec.channel을stable-4.16으로 설정해야 합니다.
HostedCluster CR에서 채널을 구성한 후 status.version. availableUpdates 및 필드의 출력을 보려면 다음 명령을 실행합니다.
status.version.conditionalUpdates
$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> -o yaml출력 예
version:
availableUpdates:
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:b7517d13514c6308ae16c5fd8108133754eb922cd37403ed27c846c129e67a9a
url: https://access.redhat.com/errata/RHBA-2024:6401
version: 4.16.11
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:d08e7c8374142c239a07d7b27d1170eae2b0d9f00ccf074c3f13228a1761c162
url: https://access.redhat.com/errata/RHSA-2024:6004
version: 4.16.10
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:6a80ac72a60635a313ae511f0959cc267a21a89c7654f1c15ee16657aafa41a0
url: https://access.redhat.com/errata/RHBA-2024:5757
version: 4.16.9
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:ea624ae7d91d3f15094e9e15037244679678bdc89e5a29834b2ddb7e1d9b57e6
url: https://access.redhat.com/errata/RHSA-2024:5422
version: 4.16.8
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:e4102eb226130117a0775a83769fe8edb029f0a17b6cbca98a682e3f1225d6b7
url: https://access.redhat.com/errata/RHSA-2024:4965
version: 4.16.6
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:f828eda3eaac179e9463ec7b1ed6baeba2cd5bd3f1dd56655796c86260db819b
url: https://access.redhat.com/errata/RHBA-2024:4855
version: 4.16.5
conditionalUpdates:
- conditions:
- lastTransitionTime: "2024-09-23T22:33:38Z"
message: |-
Could not evaluate exposure to update risk SRIOVFailedToConfigureVF (creating PromQL round-tripper: unable to load specified CA cert /etc/tls/service-ca/service-ca.crt: open /etc/tls/service-ca/service-ca.crt: no such file or directory)
SRIOVFailedToConfigureVF description: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions include kernel datastructure changes which are not compatible with older versions of the SR-IOV operator. Please update SR-IOV operator to versions dated 20240826 or newer before updating OCP.
SRIOVFailedToConfigureVF URL: https://issues.redhat.com/browse/NHE-1171
reason: EvaluationFailed
status: Unknown
type: Recommended
release:
channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:fb321a3f50596b43704dbbed2e51fdefd7a7fd488ee99655d03784d0cd02283f
url: https://access.redhat.com/errata/RHSA-2024:5107
version: 4.16.7
risks:
- matchingRules:
- promql:
promql: |
group(csv_succeeded{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41", name=~"sriov-network-operator[.].*"})
or
0 * group(csv_count{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41"})
type: PromQL
message: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions
include kernel datastructure changes which are not compatible with older
versions of the SR-IOV operator. Please update SR-IOV operator to versions
dated 20240826 or newer before updating OCP.
name: SRIOVFailedToConfigureVF
url: https://issues.redhat.com/browse/NHE-11718.3. 호스트된 클러스터에서 OpenShift Container Platform 버전 업데이트
호스팅된 컨트롤 플레인을 사용하면 컨트롤 플레인과 데이터 플레인 간의 업데이트를 분리할 수 있습니다.
클러스터 서비스 공급자 또는 클러스터 관리자는 컨트롤 플레인과 데이터를 별도로 관리할 수 있습니다.
NodePool CR을 수정하여 HostedCluster CR(사용자 정의 리소스) 및 노드를 수정하여 컨트롤 플레인을 업데이트할 수 있습니다. HostedCluster 및 NodePool CR 모두 .release 필드에 OpenShift Container Platform 릴리스 이미지를 지정합니다.
업데이트 프로세스 중에 호스팅 클러스터를 완전히 작동하려면 컨트롤 플레인 및 노드 업데이트가 Kubernetes 버전 스큐 정책을 따라야 합니다.
8.3.1. 다중 클러스터 엔진 Operator 허브 관리 클러스터
Kubernetes Operator용 멀티 클러스터 엔진에는 관리 클러스터가 지원되는 상태로 유지되려면 특정 OpenShift Container Platform 버전이 필요합니다. OpenShift Container Platform 웹 콘솔의 OperatorHub에서 다중 클러스터 엔진 Operator를 설치할 수 있습니다.
다중 클러스터 엔진 Operator 버전은 다음과 같은 지원을 참조하십시오.
멀티 클러스터 엔진 Operator는 다음 OpenShift Container Platform 버전을 지원합니다.
- 릴리스되지 않은 최신 버전
- 최신 릴리스 버전
- 최신 릴리스 버전 이전 두 버전
또한 RHACM(Red Hat Advanced Cluster Management)의 일부로 다중 클러스터 엔진 Operator 버전을 가져올 수도 있습니다.
8.3.2. 호스트 클러스터에서 지원되는 OpenShift Container Platform 버전
호스트 클러스터를 배포할 때 관리 클러스터의 OpenShift Container Platform 버전은 호스팅된 클러스터의 OpenShift Container Platform 버전에 영향을 미치지 않습니다.
HyperShift Operator는 hypershift 네임스페이스에 supported-versions ConfigMap을 생성합니다. supported-versions ConfigMap은 배포할 수 있는 지원되는 OpenShift Container Platform 버전 범위를 설명합니다.
supported-versions ConfigMap의 다음 예제를 참조하십시오.
apiVersion: v1
data:
server-version: 2f6cfe21a0861dea3130f3bed0d3ae5553b8c28b
supported-versions: '{"versions":["4.17","4.16","4.15","4.14"]}'
kind: ConfigMap
metadata:
creationTimestamp: "2024-06-20T07:12:31Z"
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
resourceVersion: "927029"
uid: f6336f91-33d3-472d-b747-94abae725f70
호스트된 클러스터를 생성하려면 지원 버전 범위에서 OpenShift Container Platform 버전을 사용해야 합니다. 그러나 다중 클러스터 엔진 Operator는 n+1 과 n-2 OpenShift Container Platform 버전 간에만 관리할 수 있습니다. 여기서 n 은 현재 마이너 버전을 정의합니다. 다중 클러스터 엔진 Operator 지원 매트릭스를 확인하여 다중 클러스터 엔진 Operator에서 관리하는 호스트 클러스터가 지원되는 OpenShift Container Platform 범위 내에 있는지 확인할 수 있습니다.
OpenShift Container Platform에 호스트된 클러스터의 상위 버전을 배포하려면 새 버전의 Hypershift Operator를 배포하려면 multicluster 엔진 Operator를 새 마이너 버전 릴리스로 업데이트해야 합니다. 다중 클러스터 엔진 Operator를 새 패치 또는 z-stream으로 업그레이드해도 HyperShift Operator가 다음 버전으로 업데이트되지 않습니다.
관리 클러스터에서 OpenShift Container Platform 4.16에 지원되는 OpenShift Container Platform 버전을 보여주는 hcp version 명령의 다음 예제 출력을 참조하십시오.
Client Version: openshift/hypershift: fe67b47fb60e483fe60e4755a02b3be393256343. Latest supported OCP: 4.17.0
Server Version: 05864f61f24a8517731664f8091cedcfc5f9b60d
Server Supports OCP Versions: 4.17, 4.16, 4.15, 4.148.4. 호스팅된 클러스터 업데이트
spec.release 값은 컨트롤 플레인의 버전을 나타냅니다. HostedCluster 오브젝트는 의도한 spec.release 값을 HostedControlPlane.spec.release 값으로 전송하고 적절한 Control Plane Operator 버전을 실행합니다.
호스팅된 컨트롤 플레인은 새로운 버전의 CVO(Cluster Version Operator)를 통해 OpenShift Container Platform 구성 요소와 함께 새 버전의 컨트롤 플레인 구성 요소의 롤아웃을 관리합니다.
호스팅된 컨트롤 플레인에서 NodeHealthCheck 리소스는 CVO의 상태를 감지할 수 없습니다. 클러스터 관리자는 새 수정 작업이 클러스터 업데이트를 방해하지 않도록 클러스터 업데이트와 같은 중요한 작업을 수행하기 전에 NodeHealthCheck 에서 트리거한 수정을 수동으로 일시 중지해야 합니다.
수정을 일시 중지하려면 NodeHealthCheck 리소스의 pauseRequests 필드 값으로 pause-test-cluster 와 같은 문자열 배열을 입력합니다. 자세한 내용은 Node Health Check Operator 정보를 참조하십시오.
클러스터 업데이트가 완료되면 수정을 편집하거나 삭제할 수 있습니다. Compute → NodeHealthCheck 페이지로 이동하여 노드 상태 점검을 클릭한 다음 드롭다운 목록이 표시되는 작업을 클릭합니다.
8.5. 노드 풀 업데이트
노드 풀을 사용하면 spec.release 및 spec.config 값을 노출하여 노드에서 실행 중인 소프트웨어를 구성할 수 있습니다. 다음과 같은 방법으로 롤링 노드 풀 업데이트를 시작할 수 있습니다.
-
spec.release또는spec.config값을 변경합니다. - AWS 인스턴스 유형과 같은 플랫폼별 필드를 변경합니다. 결과는 새 유형의 새 인스턴스 집합입니다.
- 클러스터 구성을 변경하면 변경 사항이 노드로 전파됩니다.
노드 풀은 업데이트 및 인플레이스 업데이트를 교체할 수 있습니다. nodepool.spec.release 값은 특정 노드 풀의 버전을 지정합니다. NodePool 오브젝트는 .spec.management.upgradeType 값에 따라 교체 또는 인플레이스 롤링 업데이트를 완료합니다.
노드 풀을 생성한 후에는 업데이트 유형을 변경할 수 없습니다. 업데이트 유형을 변경하려면 노드 풀을 생성하고 다른 노드를 삭제해야 합니다.
8.5.1. 노드 풀 교체 업데이트
교체 업데이트는 이전 버전에서 이전 인스턴스를 제거하는 동안 새 버전에 인스턴스를 생성합니다. 이 업데이트 유형은 이러한 수준의 불변성을 비용 효율적으로 사용하는 클라우드 환경에서 효과가 있습니다.
교체 업데이트에서는 노드가 완전히 다시 프로비저닝되므로수동 변경 사항이 유지되지 않습니다.
8.5.2. 노드 풀의 인플레이스 업데이트
인플레이스 업데이트는 인스턴스의 운영 체제를 직접 업데이트합니다. 이 유형은 베어 메탈과 같이 인프라 제약 조건이 높은 환경에 적합합니다.
인플레이스 업데이트는 수동 변경 사항을 유지할 수 있지만 kubelet 인증서와 같이 클러스터가 직접 관리하는 파일 시스템 또는 운영 체제 구성을 수동으로 변경하면 오류를 보고합니다.
8.6. 호스팅된 클러스터의 노드 풀 업데이트
호스팅된 클러스터의 노드 풀을 업데이트하여 OpenShift Container Platform 버전을 업데이트할 수 있습니다. 노드 풀 버전은 호스팅된 컨트롤 플레인 버전을 초과해서는 안 됩니다.
NodePool 사용자 정의 리소스(CR)의 .spec.release 필드는 노드 풀의 버전을 보여줍니다.
프로세스
다음 명령을 입력하여 노드 풀의
spec.release.image값을 변경합니다.$ oc patch nodepool <node_pool_name> -n <hosted_cluster_namespace> \1 --type=merge \ -p '{"spec":{"nodeDrainTimeout":"60s","release":{"image":"<openshift_release_image>"}}}'2
검증
새 버전이 출시되었는지 확인하려면 다음 명령을 실행하여 노드 풀에서
.status.conditions값을 확인하세요.$ oc get -n <hosted_cluster_namespace> nodepool <node_pool_name> -o yaml출력 예
status: conditions: - lastTransitionTime: "2024-05-20T15:00:40Z" message: 'Using release image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64'1 reason: AsExpected status: "True" type: ValidReleaseImage- 1
<4.yz>를지원되는 OpenShift Container Platform 버전으로 바꾸세요.
8.7. 호스팅된 클러스터에서 제어 평면 업데이트
호스팅된 제어 평면에서 호스팅된 클러스터를 업데이트하여 OpenShift Container Platform 버전을 업그레이드할 수 있습니다. HostedCluster 사용자 지정 리소스(CR)의 .spec.release 는 제어 평면의 버전을 보여줍니다. HostedCluster 는 .spec.release 필드를 HostedControlPlane.spec.release 로 업데이트하고 적절한 Control Plane Operator 버전을 실행합니다.
HostedControlPlane 리소스는 클러스터 버전 운영자(CVO)의 새 버전을 통해 데이터 플레인의 OpenShift Container Platform 구성 요소와 함께 제어 플레인 구성 요소의 새 버전 출시를 조율합니다. HostedControlPlane 에는 다음과 같은 아티팩트가 포함됩니다.
- CVO
- CNO(Cluster Network Operator)
- cluster-ingress-operator
- Kube API 서버, 스케줄러 및 관리자를 위한 매니페스트
- 기계 승인자
- 자동 확장기
- Kube API 서버, ignition 및 konnectivity와 같은 제어 평면 엔드포인트에 대한 수신을 활성화하는 인프라 리소스
HostedCluster CR에서 .spec.release 필드를 설정하면 status.version.availableUpdates 및 status.version.conditionalUpdates 필드의 정보를 사용하여 제어 평면을 업데이트할 수 있습니다.
프로세스
다음 명령을 입력하여 호스팅된 클러스터에
hypershift.openshift.io/force-upgrade-to=<openshift_release_image>주석을 추가합니다.$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> <hosted_cluster_name> \1 "hypershift.openshift.io/force-upgrade-to=<openshift_release_image>" \2 --overwrite다음 명령을 입력하여 호스팅된 클러스터의
spec.release.image값을 변경합니다.$ oc patch hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ --type=merge \ -p '{"spec":{"release":{"image":"<openshift_release_image>"}}}'
검증
새 버전이 출시되었는지 확인하려면 다음 명령을 실행하여 호스팅된 클러스터에서
.status.conditions및.status.version값을 확인하세요.$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> \ -o yaml출력 예
status: conditions: - lastTransitionTime: "2024-05-20T15:01:01Z" message: Payload loaded version="4.y.z" image="quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64"1 status: "True" type: ClusterVersionReleaseAccepted #... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_642 version: 4.y.z
8.8. 멀티클러스터 엔진 운영자 콘솔을 사용하여 호스팅된 클러스터 업데이트
멀티클러스터 엔진 운영자 콘솔을 사용하여 호스팅된 클러스터를 업데이트할 수 있습니다.
호스팅된 클러스터를 업데이트하기 전에 호스팅된 클러스터의 사용 가능한 업데이트와 조건부 업데이트를 참조해야 합니다. 잘못된 릴리스 버전을 선택하면 호스팅된 클러스터가 손상될 수 있습니다.
프로세스
- 모든 클러스터를 선택하세요.
- 관리되는 호스팅 클러스터를 보려면 인프라 → 클러스터 로 이동하세요.
- 업그레이드 가능 링크를 클릭하여 제어 평면과 노드 풀을 업데이트합니다.
9장. 호스트된 컨트롤 플레인의 고가용성 정보
9.1. 호스트된 컨트롤 플레인의 고가용성 정보
다음 작업을 구현하여 호스트된 컨트롤 플레인의 HA(고가용성)를 유지 관리할 수 있습니다.
- 호스트 클러스터의 etcd 멤버를 복구합니다.
- 호스트 클러스터의 etcd를 백업하고 복원합니다.
- 호스트된 클러스터에 대한 재해 복구 프로세스를 수행합니다.
9.1.1. 실패한 관리 클러스터 구성 요소의 영향
관리 클러스터 구성 요소가 실패하면 워크로드에 영향을 미치지 않습니다. OpenShift Container Platform 관리 클러스터에서 컨트롤 플레인은 데이터 플레인과 분리되어 복원력을 제공합니다.
다음 표에서는 컨트롤 플레인 및 데이터 플레인에 실패한 관리 클러스터 구성 요소의 영향을 설명합니다. 그러나 표에는 관리 클러스터 구성 요소 실패의 모든 시나리오가 포함되어 있지 않습니다.
| 실패한 구성 요소의 이름 | 호스팅된 컨트롤 플레인 API 상태 | 호스트된 클러스터 데이터 플레인 상태 |
|---|---|---|
| 작업자 노드 | Available | Available |
| 가용성 영역 | Available | Available |
| 관리 클러스터 컨트롤 플레인 | Available | Available |
| 관리 클러스터 컨트롤 플레인 및 작업자 노드 | 사용할 수 없음 | Available |
9.2. 호스팅된 제어 평면에 대한 비정상적 etcd 클러스터 복구
고가용성 제어 평면에서 세 개의 etcd 포드가 etcd 클러스터의 상태 저장 세트의 일부로 실행됩니다. etcd 클러스터를 복구하려면 etcd 클러스터 상태를 확인하여 비정상인 etcd 포드를 식별합니다.
9.2.1. etcd 클러스터 상태 확인
etcd 포드에 로그인하여 etcd 클러스터 상태를 확인할 수 있습니다.
프로세스
다음 명령을 입력하여 etcd Pod에 로그인합니다.
$ oc rsh -n openshift-etcd -c etcd <etcd_pod_name>다음 명령을 입력하여 etcd 클러스터의 상태를 출력합니다.
sh-4.4# etcdctl endpoint status -w table출력 예
+------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://192.168.1xxx.20:2379 | 8fxxxxxxxxxx | 3.5.12 | 123 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.21:2379 | a5xxxxxxxxxx | 3.5.12 | 122 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.22:2379 | 7cxxxxxxxxxx | 3.5.12 | 124 MB | true | false | 10 | 180156 | 180156 | | +-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
9.2.2. 실패한 etcd 포드 복구
3노드 클러스터의 각 etcd 포드에는 데이터를 저장하기 위한 자체 영구 볼륨 클레임(PVC)이 있습니다. etcd pod는 데이터가 손상되거나 누락되어 실패할 수 있습니다. 오류가 발생한 etcd Pod와 해당 PVC를 복구할 수 있습니다.
프로세스
etcd pod가 실패했는지 확인하려면 다음 명령을 입력하세요.
$ oc get pods -l app=etcd -n openshift-etcd출력 예
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 64m etcd-1 2/2 Running 0 45m etcd-2 1/2 CrashLoopBackOff 1 (5s ago) 64m오류가 발생한 etcd Pod는
CrashLoopBackOff또는Error상태일 수 있습니다.다음 명령을 입력하여 오류가 발생한 포드와 해당 PVC를 삭제합니다.
$ oc delete pods etcd-2 -n openshift-etcd
검증
다음 명령을 입력하여 새로운 etcd 포드가 실행 중인지 확인하세요.
$ oc get pods -l app=etcd -n openshift-etcd출력 예
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 67m etcd-1 2/2 Running 0 48m etcd-2 2/2 Running 0 2m2s
9.3. 온프레미스 환경에서 etcd 백업 및 복원
온프레미스 환경의 호스팅된 클러스터에서 etcd를 백업하고 복원하여 오류를 해결할 수 있습니다.
9.3.1. 온프레미스 환경의 호스팅 클러스터에서 etcd 백업 및 복원
호스트 클러스터에서 etcd를 백업하고 복원하면 3개의 노드 클러스터의 etcd 멤버의 손상된 데이터 또는 누락된 데이터와 같은 오류를 해결할 수 있습니다. etcd 클러스터의 여러 멤버가 데이터 손실을 겪거나 CrashLoopBackOff 상태가 되는 경우 이 방법은 etcd 쿼럼 손실을 방지하는 데 도움이 됩니다.
베어 메탈을 위해 다른 관리 클러스터에 etcd를 복원하는 것은 기술 미리 보기 기능에만 해당됩니다. 기술 미리 보기 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat Technology Preview 기능의 지원 범위에 대한 자세한 내용은 다음 링크를 참조하세요.
사전 요구 사항
-
oc및jq바이너리가 설치되었습니다.
절차
먼저 환경 변수를 설정하세요.
다음 명령을 입력하여 호스팅된 클러스터에 대한 환경 변수를 설정하고 필요에 따라 값을 바꿉니다.
$ CLUSTER_NAME=my-cluster$ HOSTED_CLUSTER_NAMESPACE=clusters$ CONTROL_PLANE_NAMESPACE="${HOSTED_CLUSTER_NAMESPACE}-${CLUSTER_NAME}"다음 명령을 입력하여 호스팅된 클러스터의 조정을 일시 중지하고 필요에 따라 값을 바꿉니다.
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"true"}}' --type=merge
다음으로, 다음 방법 중 하나를 사용하여 etcd의 스냅샷을 찍습니다.
- 이전에 백업한 etcd 스냅샷을 사용합니다.
사용 가능한 etcd Pod가 있는 경우 다음 단계를 완료하여 활성 etcd Pod에서 스냅샷을 찍습니다.
다음 명령을 입력하여 etcd 포드를 나열하세요.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd다음 명령을 입력하여 포드 데이터베이스의 스냅샷을 찍고 로컬 컴퓨터에 저장합니다.
$ ETCD_POD=etcd-0$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- \ env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=https://localhost:2379 \ snapshot save /var/lib/snapshot.db다음 명령을 입력하여 스냅샷이 성공적으로 생성되었는지 확인하세요.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- \ env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status \ /var/lib/snapshot.db
다음 명령을 입력하여 스냅샷의 로컬 복사본을 만듭니다.
$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/snapshot.db \ /tmp/etcd.snapshot.dbetcd 영구 저장소에서 스냅샷 데이터베이스의 복사본을 만듭니다.
다음 명령을 입력하여 etcd 포드를 나열하세요.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd실행 중인 Pod를 찾아 해당 이름을
ETCD_POD의 값으로 설정합니다: ETCD_POD=etcd-0, 그리고 다음 명령을 입력하여 스냅샷 데이터베이스를 복사합니다:$ oc cp -c etcd \ ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/data/member/snap/db \ /tmp/etcd.snapshot.db
다음으로, 다음 명령을 입력하여 etcd statefulset의 규모를 줄입니다.
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=0다음 명령을 입력하여 두 번째 및 세 번째 멤버의 볼륨을 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pvc/data-etcd-2첫 번째 etcd 멤버의 데이터에 액세스하기 위한 포드를 만듭니다.
다음 명령을 입력하여 etcd 이미지를 가져옵니다.
$ ETCD_IMAGE=$(oc get -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd \ -o jsonpath='{ .spec.template.spec.containers[0].image }')etcd 데이터에 액세스할 수 있는 pod를 만듭니다.
$ cat << EOF | oc apply -n ${CONTROL_PLANE_NAMESPACE} -f - apiVersion: apps/v1 kind: Deployment metadata: name: etcd-data spec: replicas: 1 selector: matchLabels: app: etcd-data template: metadata: labels: app: etcd-data spec: containers: - name: access image: $ETCD_IMAGE volumeMounts: - name: data mountPath: /var/lib command: - /usr/bin/bash args: - -c - |- while true; do sleep 1000 done volumes: - name: data persistentVolumeClaim: claimName: data-etcd-0 EOF다음 명령을 입력하여
etcd-data포드의 상태를 확인하고 실행될 때까지 기다리세요.$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd-data다음 명령을 입력하여
etcd-datapod의 이름을 가져옵니다.$ DATA_POD=$(oc get -n ${CONTROL_PLANE_NAMESPACE} pods --no-headers \ -l app=etcd-data -o name | cut -d/ -f2)
다음 명령을 입력하여 etcd 스냅샷을 Pod에 복사합니다.
$ oc cp /tmp/etcd.snapshot.db \ ${CONTROL_PLANE_NAMESPACE}/${DATA_POD}:/var/lib/restored.snap.db다음 명령을 입력하여
etcd-datapod에서 이전 데이터를 제거합니다.$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm -rf /var/lib/data$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- mkdir -p /var/lib/data다음 명령을 입력하여 etcd 스냅샷을 복원합니다.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- \ etcdutl snapshot restore /var/lib/restored.snap.db \ --data-dir=/var/lib/data --skip-hash-check \ --name etcd-0 \ --initial-cluster-token=etcd-cluster \ --initial-cluster etcd-0=https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-1=https://etcd-1.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-2=https://etcd-2.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380 \ --initial-advertise-peer-urls https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380다음 명령을 입력하여 Pod에서 임시 etcd 스냅샷을 제거합니다.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- \ rm /var/lib/restored.snap.db다음 명령을 입력하여 데이터 액세스 배포를 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} deployment/etcd-data다음 명령을 입력하여 etcd 클러스터를 확장합니다.
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=3다음 명령을 입력하여 etcd 멤버 포드가 반환되어 사용 가능하다고 보고할 때까지 기다리세요.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd -w
다음 명령을 입력하여 호스팅된 클러스터의 조정을 복원합니다.
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"null"}}' --type=merge다음 명령을 입력하여 호스팅된 클러스터를 수동으로 롤아웃합니다.
$ oc annotate hostedcluster -n \ <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)Multus 입장 컨트롤러와 네트워크 노드 ID 포드가 아직 시작되지 않았습니다.
다음 명령을 입력하여 etcd의 두 번째 및 세 번째 멤버와 해당 PVC에 대한 포드를 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pod/etcd-1 --wait=false$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-2 pod/etcd-2 --wait=false다음 명령을 입력하여 호스팅된 클러스터를 수동으로 다시 롤아웃합니다.
$ oc annotate hostedcluster -n \ <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds) \ --overwrite몇 분 후, 제어 평면 포드가 실행되기 시작합니다.
9.4. AWS에서 etcd 백업 및 복원
Amazon Web Services(AWS)에 호스팅된 클러스터에서 etcd를 백업하고 복원하여 오류를 해결할 수 있습니다.
9.4.1. 호스팅된 클러스터에 대한 etcd 스냅샷 찍기
호스팅된 클러스터의 etcd를 백업하려면 etcd의 스냅샷을 만들어야 합니다. 나중에 스냅샷을 사용하여 etcd를 복원할 수 있습니다.
이 절차에는 API 다운타임이 필요합니다.
프로세스
다음 명령을 입력하여 호스팅된 클러스터의 조정을 일시 중지합니다.
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"true"}}' --type=merge다음 명령을 입력하여 모든 etcd-writer 배포를 확장합니다.
$ oc scale deployment -n <hosted_cluster_namespace> --replicas=0 \ kube-apiserver openshift-apiserver openshift-oauth-apiserveretcd 스냅샷을 찍으려면 다음 명령을 입력하여 각 etcd 컨테이너에서
exec명령을 사용합니다.$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- \ env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=localhost:2379 \ snapshot save /var/lib/data/snapshot.db스냅샷 상태를 확인하려면 다음 명령을 실행하여 각 etcd 컨테이너에서
exec명령을 사용합니다.$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- \ env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status \ /var/lib/data/snapshot.db나중에 검색할 수 있는 위치(예: S3 버킷)에 스냅샷 데이터를 복사합니다. 다음 예제를 참조하십시오.
참고다음 예제에서는 서명 버전 2를 사용합니다. 서명 버전 4를 지원하는 리전에 있는 경우 us-east-2 리전과 같이 서명 버전 4를 사용합니다. 그렇지 않으면 스냅샷을 S3 버킷에 복사할 때 업로드가 실패합니다.
예
BUCKET_NAME=somebucket CLUSTER_NAME=cluster_name FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` HOSTED_CLUSTER_NAMESPACE=hosted_cluster_namespace oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db나중에 새 클러스터에서 스냅샷을 복원하려면 호스팅된 클러스터가 참조하는 암호화 비밀번호를 저장합니다.
다음 명령을 입력하여 비밀 암호화 키를 얻으세요.
$ oc get hostedcluster <hosted_cluster_name> \ -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"<hosted_cluster_name>-etcd-encryption-key"}}다음 명령을 입력하여 비밀 암호화 키를 저장합니다.
$ oc get secret <hosted_cluster_name>-etcd-encryption-key \ -o=jsonpath='{.data.key}'새 클러스터에서 스냅샷을 복원할 때 이 키를 해독할 수 있습니다.
다음 명령을 입력하여 모든 etcd-writer 배포를 확장합니다.
$ oc scale deployment -n <control_plane_namespace> --replicas=3 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver다음 명령을 입력하여 호스팅된 클러스터의 조정을 재개합니다.
$ oc patch -n <hosted_cluster_namespace> \ -p '[\{"op": "remove", "path": "/spec/pausedUntil"}]' --type=json
다음 단계
etcd 스냅샷을 복원하십시오.
9.4.2. 호스트 클러스터에서 etcd 스냅샷 복원
호스팅된 클러스터에서 etcd 스냅샷이 있는 경우 복원할 수 있습니다. 현재 클러스터 생성 중에만 etcd 스냅샷을 복원할 수 있습니다.
etcd 스냅샷을 복원하려면 create cluster --render 명령에서 출력을 수정하고 HostedCluster 사양의 etcd 섹션에 restoreSnapshotURL 값을 정의합니다.
hcp create 명령의 --render 플래그는 비밀을 렌더링하지 않습니다. 비밀을 렌더링하려면 hcp create 명령에서 --render 및 --render-sensitive 플래그를 모두 사용해야 합니다.
사전 요구 사항
호스팅된 클러스터에서 etcd 스냅샷을 작성했습니다.
절차
awsCLI(명령줄 인터페이스)에서 인증 정보를 etcd 배포에 전달하지 않고 S3에서 etcd 스냅샷을 다운로드할 수 있도록 사전 서명된 URL을 생성합니다.ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})URL을 참조하도록
HostedCluster사양을 수정합니다.spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
spec.secretEncryption.aescbc값에서 참조한 보안에 이전 단계에서 저장한 것과 동일한 AES 키가 포함되어 있는지 확인합니다.
9.5. OpenShift Virtualization에서 호스팅된 클러스터 백업 및 복원
OpenShift Virtualization에서 호스팅된 클러스터를 백업하고 복원하여 오류를 해결할 수 있습니다.
9.5.1. OpenShift Virtualization에서 호스팅된 클러스터 백업
OpenShift Virtualization에서 호스팅된 클러스터를 백업하면 호스팅된 클러스터는 계속 실행될 수 있습니다. 백업에는 호스팅된 제어 평면 구성 요소와 호스팅된 클러스터의 etcd가 포함되어 있습니다.
호스팅된 클러스터가 외부 인프라에서 컴퓨팅 노드를 실행하지 않는 경우 KubeVirt CSI에서 프로비저닝한 영구 볼륨 클레임(PVC)에 저장된 호스팅된 클러스터 워크로드 데이터도 백업됩니다. 백업에는 컴퓨팅 노드로 사용되는 KubeVirt 가상 머신(VM)이 포함되어 있지 않습니다. 해당 VM은 복원 프로세스가 완료된 후 자동으로 다시 생성됩니다.
프로세스
다음 예와 유사한 YAML 파일을 만들어 Velero 백업 리소스를 만듭니다.
apiVersion: velero.io/v1 kind: Backup metadata: name: hc-clusters-hosted-backup namespace: openshift-adp labels: velero.io/storage-location: default spec: includedNamespaces:1 - clusters - clusters-hosted includedResources: - sa - role - rolebinding - deployment - statefulset - pv - pvc - bmh - configmap - infraenv - priorityclasses - pdb - hostedcluster - nodepool - secrets - hostedcontrolplane - cluster - datavolume - service - route excludedResources: [ ] labelSelector:2 matchExpressions: - key: 'hypershift.openshift.io/is-kubevirt-rhcos' operator: 'DoesNotExist' storageLocation: default preserveNodePorts: true ttl: 4h0m0s snapshotMoveData: true3 datamover: "velero"4 defaultVolumesToFsBackup: false5 - 1
- 이 필드는 백업할 객체에서 네임스페이스를 선택합니다. 호스팅된 클러스터와 호스팅된 제어 평면 모두의 네임스페이스를 포함합니다. 이 예에서
clusters는 호스팅된 클러스터의 네임스페이스이고clusters-hosted는호스팅된 제어 평면의 네임스페이스입니다. 기본적으로HostedControlPlane네임스페이스는clusters-<hosted_cluster_name>입니다. - 2
- 호스팅된 클러스터 노드로 사용되는 VM의 부트 이미지는 대규모 PVC에 저장됩니다. 백업 시간과 저장 용량을 줄이려면 이 레이블 선택기를 추가하여 백업에서 해당 PVC를 필터링할 수 있습니다.
- 3
- 이 필드와
datamover필드를 사용하면 CSIVolumeSnapshots를원격 클라우드 스토리지에 자동으로 업로드할 수 있습니다. - 4
- 이 필드와
snapshotMoveData필드를 사용하면 CSIVolumeSnapshots를원격 클라우드 스토리지에 자동으로 업로드할 수 있습니다. - 5
- 이 필드는 기본적으로 모든 볼륨에 대해 Pod 볼륨 파일 시스템 백업을 사용할지 여부를 나타냅니다. 원하는 PVC를 백업하려면 이 값을
false로 설정하세요.
다음 명령을 입력하여 YAML 파일에 변경 사항을 적용합니다.
$ oc apply -f <backup_file_name>.yaml<백업_파일_이름>을파일 이름으로 바꾸세요.백업 개체 상태와 Velero 로그에서 백업 프로세스를 모니터링합니다.
백업 개체 상태를 모니터링하려면 다음 명령을 입력하세요.
$ watch "oc get backups.velero.io -n openshift-adp <backup_file_name> -o jsonpath='{.status}' | jq"Velero 로그를 모니터링하려면 다음 명령을 입력하세요.
$ oc logs -n openshift-adp -ldeploy=velero -f
검증
-
status.phase필드가Completed이면 백업 프로세스가 완료된 것으로 간주됩니다.
9.5.2. OpenShift Virtualization에서 호스팅된 클러스터 복원
OpenShift Virtualization에서 호스팅된 클러스터를 백업한 후 백업을 복원할 수 있습니다.
복원 프로세스는 백업을 생성한 동일한 관리 클러스터에서만 완료할 수 있습니다.
프로세스
-
HostedControlPlane네임스페이스에서 실행 중인 포드나 영구 볼륨 클레임(PVC)이 없는지 확인합니다. 관리 클러스터에서 다음 객체를 삭제합니다.
-
HostedCluster -
NodePool - PVCs
-
다음 예와 유사한 복원 매니페스트 YAML 파일을 만듭니다.
apiVersion: velero.io/v1 kind: Restore metadata: name: hc-clusters-hosted-restore namespace: openshift-adp spec: backupName: hc-clusters-hosted-backup restorePVs: true1 existingResourcePolicy: update2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io다음 명령을 입력하여 YAML 파일에 변경 사항을 적용합니다.
$ oc apply -f <restore_resource_file_name>.yaml<restore_resource_file_name>을해당 파일 이름으로 바꾸세요.복원 상태 필드와 Velero 로그를 확인하여 복원 프로세스를 모니터링합니다.
복원 상태 필드를 확인하려면 다음 명령을 입력하세요.
$ watch "oc get restores.velero.io -n openshift-adp <backup_file_name> -o jsonpath='{.status}' | jq"Velero 로그를 확인하려면 다음 명령을 입력하세요.
$ oc logs -n openshift-adp -ldeploy=velero -f
검증
-
status.phase필드가Completed이면 복원 프로세스가 완료된 것으로 간주됩니다.
다음 단계
- 얼마 후, KubeVirt VM이 생성되고 호스팅된 클러스터에 컴퓨팅 노드로 가입합니다. 호스팅된 클러스터 워크로드가 예상대로 다시 실행되는지 확인하세요.
9.6. AWS에서 호스팅되는 클러스터에 대한 재해 복구
Amazon Web Services(AWS) 내에서 호스팅된 클러스터를 동일한 지역으로 복구할 수 있습니다. 예를 들어, 관리 클러스터의 업그레이드가 실패하고 호스팅된 클러스터가 읽기 전용 상태인 경우 재해 복구가 필요합니다.
재해 복구 프로세스에는 다음 단계가 포함됩니다.
- 소스 관리 클러스터에서 호스트된 클러스터 백업
- 대상 관리 클러스터에서 호스팅 클러스터 복원
- 소스 관리 클러스터에서 호스팅 클러스터 삭제
프로세스 중에 워크로드가 계속 실행됩니다. 기간 동안 클러스터 API를 사용할 수 없지만 이는 작업자 노드에서 실행 중인 서비스에는 영향을 미치지 않습니다.
API 서버 URL을 유지하려면 소스 관리 클러스터와 대상 관리 클러스터 모두에 --external-dns 플래그가 있어야 합니다. 이렇게 하면 서버 URL이 https://api-sample-hosted.sample-hosted.aws.openshift.com 로 끝납니다. 다음 예제를 참조하십시오.
예: 외부 DNS 플래그
--external-dns-provider=aws \
--external-dns-credentials=<path_to_aws_credentials_file> \
--external-dns-domain-filter=<basedomain>
API 서버 URL을 유지하기 위해 --external-dns 플래그를 포함하지 않으면 호스팅된 클러스터를 마이그레이션할 수 없습니다.
9.6.1. 백업 및 복원 프로세스 개요
백업 및 복원 프로세스는 다음과 같이 작동합니다.
관리 클러스터 1에서 소스 관리 클러스터로 간주할 수 있는 컨트롤 플레인 및 작업자는 외부 DNS API를 사용하여 상호 작용합니다. 외부 DNS API에 액세스할 수 있으며 로드 밸런서는 관리 클러스터 간에 위치합니다.

etcd, 컨트롤 플레인 및 작업자 노드가 포함된 호스팅 클러스터의 스냅샷을 생성합니다. 이 프로세스 중에 작업자 노드는 액세스할 수 없는 경우에도 외부 DNS API에 계속 액세스하려고 합니다. 워크로드가 실행 중이고 컨트롤 플레인은 로컬 매니페스트 파일에 저장되고 etcd는 S3 버킷으로 백업됩니다. 데이터 플레인이 활성 상태이고 컨트롤 플레인이 일시 중지되었습니다.

대상 관리 클러스터 2로 간주할 수 있는 관리 클러스터 2에서는 S3 버킷에서 etcd를 복원하고 로컬 매니페스트 파일에서 컨트롤 플레인을 복원합니다. 이 프로세스 중에 외부 DNS API가 중지되고 호스팅된 클러스터 API에 액세스할 수 없게 되고 API를 사용하는 모든 작업자는 매니페스트 파일을 업데이트할 수 없지만 워크로드는 여전히 실행 중입니다.

외부 DNS API에 다시 액세스할 수 있으며 작업자 노드는 이를 사용하여 관리 클러스터 2로 이동합니다. 외부 DNS API는 컨트롤 플레인을 가리키는 로드 밸런서에 액세스할 수 있습니다.

관리 클러스터 2에서 컨트롤 플레인 및 작업자 노드는 외부 DNS API를 사용하여 상호 작용합니다. etcd의 S3 백업을 제외하고 관리 클러스터 1에서 리소스가 삭제됩니다. 관리 클러스터 1에서 호스트 클러스터를 다시 설정하려고 하면 작동하지 않습니다.

9.6.2. AWS에서 호스팅된 클러스터 백업
대상 관리 클러스터에서 호스팅된 클러스터를 복구하려면 먼저 모든 관련 데이터를 백업해야 합니다.
프로세스
다음 명령을 입력하여 소스 관리 클러스터를 선언하는 구성 맵 파일을 만듭니다.
$ oc create configmap mgmt-parent-cluster -n default \ --from-literal=from=${MGMT_CLUSTER_NAME}다음 명령을 입력하여 호스팅된 클러스터 및 노드 풀에서 조정을 종료합니다.
$ PAUSED_UNTIL="true"$ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge$ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} \ -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator다음 bash 스크립트를 실행하여 etcd를 백업하고 S3 버킷에 데이터를 업로드합니다.
작은 정보이 스크립트를 함수로 래핑하고 기본 함수에서 호출합니다.
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd 백업에 대한 자세한 내용은 "호스트 클러스터에서 etcd 백업 및 복원"을 참조하십시오.
다음 명령을 입력하여 Kubernetes 및 OpenShift Container Platform 오브젝트를 백업합니다. 다음 오브젝트를 백업해야 합니다.
-
HostedCluster 네임스페이스의
HostedCluster및NodePool오브젝트 -
HostedCluster 네임스페이스의
HostedCluster시크릿 -
HostedControl Plane 네임 스페이스의
HostedControlPlane -
호스팅 컨트롤 플레인 네임스페이스의
Cluster -
호스팅된 컨트롤 플레인 네임스페이스에서
AWSCluster,AWSMachineTemplate,AWSMachine -
Hosted Control Plane 네임스페이스에서
MachineDeployments,MachineSets,Machines 호스팅된 컨트롤 플레인 네임스페이스의
ControlPlane시크릿다음 명령을 입력하세요:
$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ chmod 700 ${BACKUP_DIR}/namespaces/다음 명령을 입력하여
HostedCluster네임스페이스에서HostedCluster객체를 백업합니다.$ echo "Backing Up HostedCluster Objects:"$ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml$ echo "--> HostedCluster"$ sed -i '' -e '/^status:$/,$d' \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml다음 명령을 입력하여
HostedCluster네임스페이스에서NodePool객체를 백업합니다.$ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml$ echo "--> NodePool"$ sed -i '' -e '/^status:$/,$ d' \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml다음 셸 스크립트를 실행하여
HostedCluster네임스페이스의 비밀을 백업합니다.$ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done다음 셸 스크립트를 실행하여
HostedCluster제어 평면 네임스페이스의 비밀을 백업합니다.$ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done다음 명령을 입력하여 호스팅된 제어 평면을 백업합니다.
$ echo "--> HostedControlPlane:"$ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml다음 명령을 입력하여 클러스터를 백업합니다.
$ echo "--> Cluster:"$ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} \ -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME})$ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml다음 명령을 입력하여 AWS 클러스터를 백업합니다.
$ echo "--> AWS Cluster:"$ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml다음 명령을 입력하여 AWS
MachineTemplate객체를 백업합니다.$ echo "--> AWS Machine Template:"$ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml다음 셸 스크립트를 실행하여 AWS
Machines객체를 백업합니다.$ echo "--> AWS Machine:"$ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done다음 셸 스크립트를 실행하여
MachineDeployments객체를 백업합니다.$ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done다음 셸 스크립트를 실행하여
MachineSets객체를 백업합니다.$ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done다음 셸 스크립트를 실행하여 Hosted Control Plane 네임스페이스에서
Machines객체를 백업합니다.$ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
HostedCluster 네임스페이스의
다음 명령을 입력하여
ControlPlane경로를 정리합니다.$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all해당 명령을 입력하면 ExternalDNS Operator가 Route53 항목을 삭제할 수 있습니다.
다음 스크립트를 실행하여 Route53 항목이 깨끗한지 확인하세요.
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
검증
모든 OpenShift Container Platform 오브젝트 및 S3 버킷을 확인하여 모든 것이 예상대로 표시되는지 확인합니다.
다음 단계
호스팅된 클러스터를 복원합니다.
9.6.3. 호스팅된 클러스터 복원
백업한 모든 오브젝트를 수집하고 대상 관리 클러스터에 복원합니다.
사전 요구 사항
소스 관리 클러스터에서 데이터를 백업합니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되거나 스크립트를 사용하는 경우 MGMT2_KUBECONFIG 변수에 배치되었는지 확인합니다. export KUBECONFIG=<Kubeconfig FilePath>를 사용하거나 스크립트를 사용하는 경우 export KUBECONFIG=$MGMT2_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여 복원 중인 클러스터의 네임스페이스가 새 관리 클러스터에 포함되어 있지 않은지 확인합니다.
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup대상 관리 클러스터에서 네임스페이스 삭제
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true다음 명령을 입력하여 삭제된 네임스페이스를 다시 생성합니다.
네임스페이스 생성 명령
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}다음 명령을 입력하여 HC 네임스페이스에 보안을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*다음 명령을 입력하여
HostedCluster컨트롤 플레인 네임스페이스에서 오브젝트를 복원합니다.비밀 명령 복원
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*클러스터 복원 명령
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*노드와 노드 풀을 복구하여 AWS 인스턴스를 재사용하는 경우 다음 명령을 입력하여 HC 컨트롤 플레인 네임스페이스에서 오브젝트를 복원합니다.
AWS용 명령
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*기계에 대한 명령
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*이 bash 스크립트를 실행하여 etcd 데이터 및 호스팅 클러스터를 복원합니다.
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fi노드와 노드 풀을 복구하여 AWS 인스턴스를 재사용하는 경우 다음 명령을 입력하여 노드 풀을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
검증
노드가 완전히 복원되었는지 확인하려면 다음 기능을 사용합니다.
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
다음 단계
클러스터를 종료하고 삭제합니다.
9.6.4. 소스 관리 클러스터에서 호스트된 클러스터 삭제
호스팅된 클러스터를 백업하고 대상 관리 클러스터로 복원한 후 소스 관리 클러스터에서 호스팅된 클러스터를 종료하고 삭제합니다.
사전 요구 사항
데이터를 백업하고 소스 관리 클러스터에 복원했습니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되거나 스크립트를 사용하는 경우 MGMT_KUBECONFIG 변수에 배치되었는지 확인합니다. export KUBECONFIG=<Kubeconfig FilePath>를 사용하거나 스크립트를 사용하는 경우 export KUBECONFIG=$MGMT_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여
deployment및statefulset오브젝트를 확장합니다.중요spec.persistentVolumeClaimRetentionPolicy.whenScaled필드의 값이Delete로 설정된 경우 데이터 손실이 발생할 수 있으므로 상태 저장 세트를 스케일링하지 마십시오.이 문제를 해결하려면
spec.persistentVolumeClaimRetentionPolicy.whenScaled필드의 값을Retain으로 업데이트합니다. 상태 저장 세트를 조정하는 컨트롤러가 없는지 확인하고 값을Delete로 다시 반환하여 데이터가 손실될 수 있습니다.$ export KUBECONFIG=${MGMT_KUBECONFIG}배포 명령 축소
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15다음 명령을 입력하여
NodePool오브젝트를 삭제합니다.NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi다음 명령을 입력하여
machine및machineset오브젝트를 삭제합니다.# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true다음 명령을 입력하여 클러스터 오브젝트를 삭제합니다.
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all이러한 명령을 입력하여 AWS 머신(Kubernetes 오브젝트)을 삭제합니다. 실제 AWS 머신 삭제에 대해 우려하지 마십시오. 클라우드 인스턴스는 영향을 받지 않습니다.
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done다음 명령을 입력하여
HostedControlPlane및ControlPlaneHC 네임스페이스 오브젝트를 삭제합니다.HCP 및 ControlPlane HC NS 명령 삭제
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true다음 명령을 입력하여
HostedCluster및 HC 네임스페이스 오브젝트를 삭제합니다.HC 및 HC 네임스페이스 삭제 명령
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
검증
모든 것이 작동하는지 확인하려면 다음 명령을 입력합니다.
검증 명령
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 내부 명령
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
다음 단계
새 관리 클러스터에서 실행되는 새 OVN 컨트롤 플레인에 연결할 수 있도록 호스팅 클러스터에서 OVN Pod를 삭제합니다.
-
호스팅 클러스터의 kubeconfig 경로를 사용하여
KUBECONFIG환경 변수를 로드합니다. 다음 명령을 입력합니다.
$ oc delete pod -n openshift-ovn-kubernetes --all
9.7. OADP를 사용하여 호스트된 클러스터에 대한 재해 복구
OADP(OpenShift API for Data Protection) Operator를 사용하여 AWS(Amazon Web Services) 및 베어 메탈에서 재해 복구를 수행할 수 있습니다.
OADP(OpenShift API for Data Protection)의 재해 복구 프로세스에는 다음 단계가 포함됩니다.
- OADP를 사용하도록 Amazon Web Services 또는 베어 메탈과 같은 플랫폼 준비
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
- OADP를 사용하여 호스트 클러스터 복원
9.7.1. 사전 요구 사항
관리 클러스터에서 다음 사전 요구 사항을 충족해야 합니다.
- OADP Operator를 설치했습니다.
- 스토리지 클래스를 생성하셨습니다.
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - 카탈로그 소스를 통해 OADP 서브스크립션에 액세스할 수 있습니다.
- S3, Microsoft Azure, Google Cloud 또는 MinIO 등 OADP와 호환되는 클라우드 스토리지 공급자를 이용할 수 있습니다.
- 연결이 끊긴 환경에서는 OADP와 호환되는 자체 호스팅 스토리지 공급자(예: Red Hat OpenShift Data Foundation 또는 MinIO )에 액세스할 수 있습니다.
- 호스팅된 컨트롤 플레인 pod가 실행 중입니다.
9.7.2. OADP를 사용하도록 AWS 준비
호스트된 클러스터에 대한 재해 복구를 수행하려면 AWS(Amazon Web Services) S3 호환 스토리지에서 OADP(OpenShift API for Data Protection)를 사용할 수 있습니다. DataProtectionApplication 오브젝트를 생성하면 openshift-adp 네임스페이스에 새 velero 배포 및 node-agent Pod가 생성됩니다.
OADP를 사용하도록 AWS를 준비하려면 "Multicloud Object Gateway로 데이터 보호를 위한 OpenShift API 구성"을 참조하십시오.
다음 단계
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
9.7.3. OADP를 사용하도록 베어 메탈 준비
호스트된 클러스터에 대한 재해 복구를 수행하려면 베어 메탈에서 OADP(OpenShift API for Data Protection)를 사용할 수 있습니다. DataProtectionApplication 오브젝트를 생성하면 openshift-adp 네임스페이스에 새 velero 배포 및 node-agent Pod가 생성됩니다.
OADP를 사용하도록 베어 메탈을 준비하려면 "AWS S3 호환 스토리지로 데이터 보호를 위한 OpenShift API 구성"을 참조하십시오.
다음 단계
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
9.7.4. 데이터 플레인 워크로드 백업
데이터 플레인 워크로드가 중요하지 않은 경우 이 절차를 건너뛸 수 있습니다. OADP Operator를 사용하여 데이터 플레인 워크로드를 백업하려면 "애플리케이션 백업"을 참조하십시오.
다음 단계
- OADP를 사용하여 호스트 클러스터 복원
9.7.5. 컨트롤 플레인 워크로드 백업
Backup CR(사용자 정의 리소스)을 생성하여 컨트롤 플레인 워크로드를 백업할 수 있습니다. 단계는 플랫폼이 AWS인지 베어메탈인지에 따라 다릅니다.
9.7.5.1. AWS에서 제어 평면 워크로드 백업
Backup CR(사용자 정의 리소스)을 생성하여 컨트롤 플레인 워크로드를 백업할 수 있습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
다음 명령을 실행하여
HostedCluster리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'다음 명령을 실행하여 호스팅된 클러스터의 인프라 ID를 가져옵니다.
$ oc get hostedcluster -n local-cluster <hosted_cluster_name> -o=jsonpath="{.spec.infraID}"다음 단계에서 사용할 인프라 ID를 기록해 두세요.
다음 명령을 실행하여
cluster.cluster.x-k8s.io리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch cluster.cluster.x-k8s.io \ -n local-cluster-<hosted_cluster_name> <hosted_cluster_infra_id> \ --type json -p '[{"op": "add", "path": "/spec/paused", "value": true}]'다음 명령을 실행하여
NodePool리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'다음 명령을 실행하여
HostedCluster리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'다음 명령을 실행하여
AgentMachine리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'다음 명령을 실행하여 호스팅된 제어 평면 네임스페이스가 삭제되지 않도록
HostedCluster리소스에 주석을 추가합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace=trueBackupCR을 정의하는 YAML 파일을 생성합니다.예 9.1.
backup-control-plane.yaml파일 예apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_resource_name>1 namespace: openshift-adp labels: velero.io/storage-location: default spec: hooks: {} includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 includedResources: - sa - role - rolebinding - pod - pvc - pv - bmh - configmap - infraenv5 - priorityclasses - pdb - agents - hostedcluster - nodepool - secrets - hostedcontrolplane - cluster - agentcluster - agentmachinetemplate - agentmachine - machinedeployment - machineset - machine excludedResources: [] storageLocation: default ttl: 2h0m0s snapshotMoveData: true6 datamover: "velero"7 defaultVolumesToFsBackup: true8 - 1
backup_resource_name을Backup리소스의 이름으로 교체합니다.- 2
- 특정 네임스페이스를 선택하여 오브젝트를 백업합니다. 호스팅 클러스터 네임스페이스와 호스팅된 컨트롤 플레인 네임스페이스를 포함해야 합니다.
- 3
<hosted_cluster_namespace>를 호스트된 클러스터 네임스페이스의 이름으로 바꿉니다(예:클러스터).- 4
<hosted_control_plane_namespace>를 호스트된 컨트롤 플레인 네임스페이스의 이름으로 바꿉니다(예:클러스터 호스팅).- 5
- 별도의 네임스페이스에
infraenv리소스를 생성해야 합니다. 백업 프로세스 중에infraenv리소스를 삭제하지 마십시오. - 6 7
- CSI 볼륨 스냅샷을 활성화하고 컨트롤 플레인 워크로드를 클라우드 스토리지에 자동으로 업로드합니다.
- 8
- PV(영구 볼륨)의
fs-backup방법을 기본값으로 설정합니다. 이 설정은 CSI(Container Storage Interface) 볼륨 스냅샷과fs-backup방법을 조합할 때 유용합니다.
참고CSI 볼륨 스냅샷을 사용하려면
backup.velero.io/backup-volumes-excludes=<pv_name>주석을 PV에 추가해야 합니다.다음 명령을 실행하여
BackupCR을 적용합니다.$ oc apply -f backup-control-plane.yaml
검증
다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get backups.velero.io <backup_resource_name> -n openshift-adp \ -o jsonpath='{.status.phase}'
다음 단계
- OADP를 사용하여 호스트 클러스터 복원
9.7.5.2. 베어 메탈 플랫폼에서 제어 평면 작업 부하 백업
Backup CR(사용자 정의 리소스)을 생성하여 컨트롤 플레인 워크로드를 백업할 수 있습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
다음 명령을 실행하여
HostedCluster리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'다음 명령을 실행하여 호스팅된 클러스터의 인프라 ID를 가져옵니다.
$ oc --kubeconfig <management_cluster_kubeconfig_file> \ get hostedcluster -n <hosted_cluster_namespace> \ <hosted_cluster_name> -o=jsonpath="{.spec.infraID}"- 다음 단계에서 사용할 인프라 ID를 기록해 두세요.
다음 명령을 실행하여
cluster.cluster.x-k8s.io리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate cluster -n <hosted_control_plane_namespace> \ <hosted_cluster_infra_id> cluster.x-k8s.io/paused=true다음 명령을 실행하여
NodePool리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'다음 명령을 실행하여
HostedCluster리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all다음 명령을 실행하여
AgentMachine리소스의 조정을 일시 중지합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all동일한 관리 클러스터에 백업하고 복원하는 경우 다음 명령을 실행하여 호스팅된 제어 평면 네임스페이스가 삭제되지 않도록
HostedCluster리소스에 주석을 추가합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace=trueBackupCR을 정의하는 YAML 파일을 생성합니다.예 9.2.
backup-control-plane.yaml파일 예apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_resource_name>1 namespace: openshift-adp labels: velero.io/storage-location: default spec: hooks: {} includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 - <agent_namespace>5 includedResources: - sa - role - rolebinding - pod - pvc - pv - bmh - configmap - infraenv - priorityclasses - pdb - agents - hostedcluster - nodepool - secrets - services - deployments - hostedcontrolplane - cluster - agentcluster - agentmachinetemplate - agentmachine - machinedeployment - machineset - machine excludedResources: [] storageLocation: default ttl: 2h0m0s snapshotMoveData: true6 datamover: "velero"7 defaultVolumesToFsBackup: true8 - 1
backup_resource_name을Backup리소스의 이름으로 교체합니다.- 2
- 특정 네임스페이스를 선택하여 오브젝트를 백업합니다. 호스팅 클러스터 네임스페이스와 호스팅된 컨트롤 플레인 네임스페이스를 포함해야 합니다.
- 3
<hosted_cluster_namespace>를 호스트된 클러스터 네임스페이스의 이름으로 바꿉니다(예:클러스터).- 4
<hosted_control_plane_namespace>를 호스트된 컨트롤 플레인 네임스페이스의 이름으로 바꿉니다(예:클러스터 호스팅).- 5
<agent_namespace>를Agent,BMH,InfraEnvCR이 있는 네임스페이스(예:agents )로 바꾸세요.- 6 7
- CSI 볼륨 스냅샷을 활성화하고 컨트롤 플레인 워크로드를 클라우드 스토리지에 자동으로 업로드합니다.
- 8
- PV(영구 볼륨)의
fs-backup방법을 기본값으로 설정합니다. 이 설정은 CSI(Container Storage Interface) 볼륨 스냅샷과fs-backup방법을 조합할 때 유용합니다.
참고CSI 볼륨 스냅샷을 사용하려면
backup.velero.io/backup-volumes-excludes=<pv_name>주석을 PV에 추가해야 합니다.다음 명령을 실행하여
BackupCR을 적용합니다.$ oc apply -f backup-control-plane.yaml
검증
다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get backups.velero.io <backup_resource_name> -n openshift-adp \ -o jsonpath='{.status.phase}'
다음 단계
- OADP를 사용하여 호스팅된 클러스터를 복원합니다.
9.7.6. OADP를 사용하여 호스트 클러스터 복원
호스팅된 클러스터를 동일한 관리 클러스터나 새로운 관리 클러스터로 복원할 수 있습니다.
9.7.6.1. OADP를 사용하여 호스팅된 클러스터를 동일한 관리 클러스터로 복원
Restore CR(사용자 정의 리소스)을 생성하여 호스팅된 클러스터를 복원할 수 있습니다.
- 인플레이스 업데이트를 사용하는 경우 InfraEnv에는 예비 노드가 필요하지 않습니다. 새 관리 클러스터에서 작업자 노드를 다시 프로비저닝해야 합니다.
- 교체 업데이트를 사용하는 경우 작업자 노드를 배포하려면 InfraEnv에 대한 예비 노드가 필요합니다.
호스트 클러스터를 백업한 후 이를 삭제하여 복원 프로세스를 시작해야 합니다. 노드 프로비저닝을 시작하려면 호스팅 클러스터를 삭제하기 전에 데이터 플레인의 워크로드를 백업해야 합니다.
사전 요구 사항
- 콘솔을 사용하여 호스팅된 클러스터를 삭제하여 클러스터 제거 단계를 완료했습니다.
- 클러스터를 제거한 후 나머지 리소스 제거 단계를 완료했습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
다음 명령을 실행하여 호스팅된 컨트롤 플레인 네임스페이스에 Pod 및 PVC(영구 볼륨 클레임)가 없는지 확인합니다.
$ oc get pod pvc -n <hosted_control_plane_namespace>예상 출력
No resources foundRestoreCR을 정의하는 YAML 파일을 생성합니다.restore-hosted-cluster.yaml파일의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_resource_name>1 namespace: openshift-adp spec: backupName: <backup_resource_name>2 restorePVs: true3 existingResourcePolicy: update4 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io중요별도의 네임스페이스에
infraenv리소스를 생성해야 합니다. 복원 프로세스 중에infraenv리소스를 삭제하지 마십시오. 새 노드를 다시 프로비저닝하려면infraenv리소스가 필요합니다.다음 명령을 실행하여
RestoreCR을 적용합니다.$ oc apply -f restore-hosted-cluster.yaml다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ -o jsonpath='{.status.phase}'복원 프로세스가 완료되면 컨트롤 플레인 워크로드를 백업하는 동안 일시 중지된
HostedCluster및NodePool리소스의 조정을 시작합니다.다음 명령을 실행하여
HostedCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json \ -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'다음 명령을 실행하여
NodePool리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json \ -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'
제어 평면 작업 부하를 백업하는 동안 일시 중지한 에이전트 공급자 리소스의 조정을 시작합니다.
다음 명령을 실행하여
HostedCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all다음 명령을 실행하여
AgentMachine리소스의 조정을 시작합니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all
다음 명령을 실행하여
HostedCluster리소스에서hypershift.openshift.io/skip-delete-hosted-controlplane-namespace-주석을 제거하면 호스팅된 제어 평면 네임스페이스를 수동으로 삭제하지 않아도 됩니다.$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace- \ --overwrite=true --all
9.7.6.2. OADP를 사용하여 호스팅된 클러스터를 새 관리 클러스터로 복원
복원 사용자 정의 리소스(CR)를 생성하여 호스팅된 클러스터를 새 관리 클러스터로 복원할 수 있습니다.
-
기존 업데이트를 사용하는 경우
InfraEnv리소스에 예비 노드가 필요하지 않습니다. 새 관리 클러스터에서 작업자 노드를 다시 프로비저닝해야 합니다. -
교체 업데이트를 사용하는 경우 작업자 노드를 배포하기 위해
InfraEnv리소스에 대한 예비 노드가 필요합니다.
사전 요구 사항
-
OADP(OpenShift API for Data Protection)를 사용하도록 새 관리 클러스터를 구성했습니다.
복원CR이 백업 저장소에 액세스할 수 있도록 새 관리 클러스터에는 백업한 관리 클러스터와 동일한 DPA(데이터 보호 애플리케이션)가 있어야 합니다. 호스팅된 클러스터의 DNS를 확인하기 위해 새 관리 클러스터의 네트워킹 설정을 구성했습니다.
- 호스트의 DNS는 새 관리 클러스터와 호스팅된 클러스터의 IP로 확인되어야 합니다.
- 호스팅된 클러스터는 새 관리 클러스터의 IP로 확인되어야 합니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
백업을 만든 관리 클러스터가 아닌, 호스팅된 클러스터를 복원할 새 관리 클러스터에서 다음 단계를 완료하세요.
프로세스
RestoreCR을 정의하는 YAML 파일을 생성합니다.restore-hosted-cluster.yaml파일의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_resource_name>1 namespace: openshift-adp spec: includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 - <agent_namespace>5 backupName: <backup_resource_name>6 cleanupBeforeRestore: CleanupRestored veleroManagedClustersBackupName: <managed_cluster_name>7 veleroCredentialsBackupName: <credentials_backup_name> veleroResourcesBackupName: <resources_backup_name> restorePVs: true8 preserveNodePorts: true existingResourcePolicy: update9 excludedResources: - pod - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io - pv - pvc- 1
<restore_resource_name>을Restore리소스의 이름으로 바꿉니다.- 2
- 특정 네임스페이스를 선택하여 오브젝트를 백업합니다. 호스팅 클러스터 네임스페이스와 호스팅된 컨트롤 플레인 네임스페이스를 포함해야 합니다.
- 3
<hosted_cluster_namespace>를 호스트된 클러스터 네임스페이스의 이름으로 바꿉니다(예:클러스터).- 4
<hosted_control_plane_namespace>를 호스트된 컨트롤 플레인 네임스페이스의 이름으로 바꿉니다(예:클러스터 호스팅).- 5
<agent_namespace>를Agent,BMH,InfraEnvCR이 있는 네임스페이스(예:agents )로 바꾸세요.- 6
<backup_resource_name>을Backup리소스의 이름으로 바꿉니다.- 7
- Red Hat Advanced Cluster Management를 사용하지 않는 경우 이 필드를 생략할 수 있습니다.
- 8
- PV(영구 볼륨) 및 해당 Pod의 복구를 시작합니다.
- 9
- 백업된 콘텐츠를 사용하여 기존 오브젝트를 덮어쓰는지 확인합니다.
다음 명령을 실행하여
RestoreCR을 적용합니다.$ oc --kubeconfig <restore_management_kubeconfig> apply -f restore-hosted-cluster.yaml다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc --kubeconfig <restore_management_kubeconfig> \ get restore.velero.io <restore_resource_name> \ -n openshift-adp -o jsonpath='{.status.phase}'다음 명령을 실행하여 모든 CR이 복원되었는지 확인하세요.
$ oc --kubeconfig <restore_management_kubeconfig> get infraenv -n <agent_namespace>$ oc --kubeconfig <restore_management_kubeconfig> get agent -n <agent_namespace>$ oc --kubeconfig <restore_management_kubeconfig> get bmh -n <agent_namespace>$ oc --kubeconfig <restore_management_kubeconfig> get hostedcluster -n <hosted_cluster_namespace>$ oc --kubeconfig <restore_management_kubeconfig> get nodepool -n <hosted_cluster_namespace>$ oc --kubeconfig <restore_management_kubeconfig> get agentmachine -n <hosted_controlplane_namespace>$ oc --kubeconfig <restore_management_kubeconfig> get agentcluster -n <hosted_controlplane_namespace>앞으로 새로운 관리 클러스터를 기본 관리 클러스터로 사용할 계획이라면 다음 단계를 완료하세요. 그렇지 않은 경우, 백업한 관리 클러스터를 기본 관리 클러스터로 사용하려는 경우 "OADP를 사용하여 호스팅된 클러스터를 동일한 관리 클러스터로 복원"의 5~8단계를 완료합니다.
다음 명령을 실행하여 백업한 관리 클러스터에서 클러스터 API 배포를 제거합니다.
$ oc --kubeconfig <backup_management_kubeconfig> delete deploy cluster-api \ -n <hosted_control_plane_namespace>한 번에 하나의 클러스터 API만 클러스터에 액세스할 수 있으므로 이 단계에서는 새 관리 클러스터에 대한 클러스터 API가 올바르게 작동하는지 확인합니다.
복원 프로세스가 완료되면 컨트롤 플레인 워크로드를 백업하는 동안 일시 중지된
HostedCluster및NodePool리소스의 조정을 시작합니다.다음 명령을 실행하여
HostedCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <restore_management_kubeconfig> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json \ -p '[{"op": "replace", "path": "/spec/pausedUntil", "value": "false"}]'다음 명령을 실행하여
NodePool리소스의 조정을 시작합니다.$ oc --kubeconfig <restore_management_kubeconfig> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json \ -p '[{"op": "replace", "path": "/spec/pausedUntil", "value": "false"}]'다음 명령을 실행하여 호스팅된 클러스터가 호스팅된 제어 평면을 사용할 수 있다고 보고하는지 확인하세요.
$ oc --kubeconfig <restore_management_kubeconfig> get hostedcluster다음 명령을 실행하여 호스팅된 클러스터가 클러스터 운영자를 사용할 수 있다고 보고하는지 확인하세요.
$ oc get co --kubeconfig <hosted_cluster_kubeconfig>
제어 평면 작업 부하를 백업하는 동안 일시 중지한 에이전트 공급자 리소스의 조정을 시작합니다.
다음 명령을 실행하여
HostedCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <restore_management_kubeconfig> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all다음 명령을 실행하여
AgentMachine리소스의 조정을 시작합니다.$ oc --kubeconfig <restore_management_kubeconfig> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all다음 명령을 실행하여
HostedCluster리소스의 조정을 시작합니다.$ oc --kubeconfig <restore_management_kubeconfig> \ annotate cluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all
다음 명령을 실행하여 노드 풀이 예상대로 작동하는지 확인하세요.
$ oc --kubeconfig <restore_management_kubeconfig> \ get nodepool -n <hosted_cluster_namespace>출력 예
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE hosted-0 hosted-0 3 3 False False 4.17.11 False False선택 사항: 충돌이 발생하지 않고 새 관리 클러스터가 계속 작동하도록 하려면 다음 단계를 완료하여 백업 관리 클러스터에서
HostedCluster리소스를 제거합니다.백업한 관리 클러스터의
ClusterDeployment리소스에서 다음 명령을 실행하여spec.preserveOnDelete매개변수를true로 설정합니다.$ oc --kubeconfig <backup_management_kubeconfig> patch \ -n <hosted_control_plane_namespace> \ ClusterDeployment/<hosted_cluster_name> -p \ '{"spec":{"preserveOnDelete":'true'}}' \ --type=merge이 단계에서는 호스트의 프로비저닝이 해제되지 않도록 보장합니다.
다음 명령을 실행하여 머신을 삭제합니다.
$ oc --kubeconfig <backup_management_kubeconfig> patch \ <machine_name> -n <hosted_control_plane_namespace> -p \ '[{"op":"remove","path":"/metadata/finalizers"}]' \ --type=merge$ oc --kubeconfig <backup_management_kubeconfig> \ delete machine <machine_name> \ -n <hosted_control_plane_namespace>다음 명령을 실행하여
AgentCluster및Cluster리소스를 삭제합니다.$ oc --kubeconfig <backup_management_kubeconfig> \ delete agentcluster <hosted_cluster_name> \ -n <hosted_control_plane_namespace>$ oc --kubeconfig <backup_management_kubeconfig> \ patch cluster <cluster_name> \ -n <hosted_control_plane_namespace> \ -p '[{"op":"remove","path":"/metadata/finalizers"}]' \ --type=json$ oc --kubeconfig <backup_management_kubeconfig> \ delete cluster <cluster_name> \ -n <hosted_control_plane_namespace>Red Hat Advanced Cluster Management를 사용하는 경우 다음 명령을 실행하여 관리되는 클러스터를 삭제합니다.
$ oc --kubeconfig <backup_management_kubeconfig> \ patch managedcluster <hosted_cluster_name> \ -n <hosted_cluster_namespace> \ -p '[{"op":"remove","path":"/metadata/finalizers"}]' \ --type=json$ oc --kubeconfig <backup_management_kubeconfig> \ delete managedcluster <hosted_cluster_name> \ -n <hosted_cluster_namespace>다음 명령을 실행하여
HostedCluster리소스를 삭제합니다.$ oc --kubeconfig <backup_management_kubeconfig> \ delete hostedcluster \ -n <hosted_cluster_namespace> <hosted_cluster_name>
9.7.7. 백업 및 복원 프로세스 관찰
OADP(OpenShift API for Data Protection)를 사용하여 호스팅된 클러스터를 백업하고 복원할 때 프로세스를 모니터링하고 관찰할 수 있습니다.
프로세스
다음 명령을 실행하여 백업 프로세스를 관찰합니다.
$ watch "oc get backups.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"다음 명령을 실행하여 복원 프로세스를 관찰합니다.
$ watch "oc get restores.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"다음 명령을 실행하여 Velero 로그를 관찰합니다.
$ oc logs -n openshift-adp -ldeploy=velero -f다음 명령을 실행하여 모든 OADP 오브젝트의 진행 상황을 확인합니다.
$ watch "echo BackupRepositories:;echo;oc get backuprepositories.velero.io -A;echo; echo BackupStorageLocations: ;echo; oc get backupstoragelocations.velero.io -A;echo;echo DataUploads: ;echo;oc get datauploads.velero.io -A;echo;echo DataDownloads: ;echo;oc get datadownloads.velero.io -n openshift-adp; echo;echo VolumeSnapshotLocations: ;echo;oc get volumesnapshotlocations.velero.io -A;echo;echo Backups:;echo;oc get backup -A; echo;echo Restores:;echo;oc get restore -A"
9.7.8. velero CLI를 사용하여 백업 및 복원 리소스 설명
데이터 보호를 위한 OpenShift API를 사용하는 경우 velero CLI(명령줄 인터페이스)를 사용하여 Backup 및 Restore 리소스에 대한 자세한 정보를 얻을 수 있습니다.
프로세스
다음 명령을 실행하여 컨테이너에서
veleroCLI를 사용하도록 별칭을 생성합니다.$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'다음 명령을 실행하여
RestoreCR(사용자 정의 리소스)에 대한 세부 정보를 가져옵니다.$ velero restore describe <restore_resource_name> --details1 - 1
<restore_resource_name>을Restore리소스의 이름으로 바꿉니다.
다음 명령을 실행하여
BackupCR에 대한 세부 정보를 가져옵니다.$ velero restore describe <backup_resource_name> --details1 - 1
<backup_resource_name>을Backup리소스의 이름으로 바꿉니다.
9.8. OADP를 사용하여 호스팅된 클러스터에 대한 자동 재해 복구
베어 메탈 또는 Amazon Web Services(AWS) 플랫폼의 호스팅 클러스터에서 OADP(OpenShift API for Data Protection) Operator를 사용하여 일부 백업 및 복원 단계를 자동화할 수 있습니다.
이 과정에는 다음 단계가 포함됩니다.
- OADP 구성
- 데이터 보호 애플리케이션(DPA) 정의
- 데이터 플레인 워크로드 백업
- 컨트롤 플레인 워크로드 백업
- OADP를 사용하여 호스트 클러스터 복원
9.8.1. 사전 요구 사항
관리 클러스터에서 다음 사전 요구 사항을 충족해야 합니다.
- OADP Operator를 설치했습니다.
- 스토리지 클래스를 생성하셨습니다.
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - 카탈로그 소스를 통해 OADP 서브스크립션에 액세스할 수 있습니다.
- S3, Microsoft Azure, Google Cloud 또는 MinIO 등 OADP와 호환되는 클라우드 스토리지 공급자를 이용할 수 있습니다.
- 연결이 끊긴 환경에서는 OADP와 호환되는 자체 호스팅 스토리지 공급자(예: Red Hat OpenShift Data Foundation 또는 MinIO )에 액세스할 수 있습니다.
- 호스팅된 컨트롤 플레인 pod가 실행 중입니다.
9.8.2. OADP 구성
호스팅된 클러스터가 AWS에 있는 경우 "Multicloud Object Gateway를 사용하여 데이터 보호를 위한 OpenShift API 구성"의 단계에 따라 OADP를 구성합니다.
호스팅된 클러스터가 베어 메탈 플랫폼에 있는 경우 "AWS S3 호환 스토리지를 사용하여 데이터 보호를 위한 OpenShift API 구성"의 단계에 따라 OADP를 구성합니다.
9.8.3. DPA를 사용하여 백업 및 복원 프로세스 자동화
데이터 보호 애플리케이션(DPA)을 사용하면 백업 및 복원 프로세스의 일부를 자동화할 수 있습니다. DPA를 사용하면 리소스 조정을 일시 중지하고 다시 시작하는 단계가 자동화됩니다. DPA는 백업 위치와 Velero Pod 구성을 포함한 정보를 정의합니다.
DataProtectionApplication 객체를 정의하여 DPA를 만들 수 있습니다.
프로세스
베어메탈 플랫폼을 사용하는 경우 다음 단계를 완료하여 DPA를 만들 수 있습니다.
다음 예와 유사한 매니페스트 파일을 만듭니다.
예 9.3.
dpa.yaml파일 예시apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: dpa-sample namespace: openshift-adp spec: backupLocations: - name: default velero: provider: aws1 default: true objectStorage: bucket: <bucket_name>2 prefix: <bucket_prefix>3 config: region: minio4 profile: "default" s3ForcePathStyle: "true" s3Url: "<bucket_url>"5 insecureSkipTLSVerify: "true" credential: key: cloud name: cloud-credentials default: true snapshotLocations: - velero: provider: aws6 config: region: minio7 profile: "default" credential: key: cloud name: cloud-credentials configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - openshift - aws - csi - hypershift resourceTimeout: 2h다음 명령을 실행하여 CR 오브젝트를 생성합니다.
$ oc create -f dpa.yamlDataProtectionApplication오브젝트를 생성하면openshift-adp네임스페이스에 새velero배포 및node-agentPod가 생성됩니다.
Amazon Web Services(AWS)를 사용하는 경우 다음 단계를 완료하여 DPA를 생성할 수 있습니다.
다음 예와 유사한 매니페스트 파일을 만듭니다.
예 9.4.
dpa.yaml파일 예시apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: dpa-sample namespace: openshift-adp spec: backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name>1 prefix: <bucket_prefix>2 config: region: minio3 profile: "backupStorage" credential: key: cloud name: cloud-credentials snapshotLocations: - velero: provider: aws config: region: minio4 profile: "volumeSnapshot" credential: key: cloud name: cloud-credentials configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - openshift - aws - csi - hypershift resourceTimeout: 2h다음 명령을 실행하여 리소스를 생성합니다.
$ oc create -f dpa.yamlDataProtectionApplication오브젝트를 생성하면openshift-adp네임스페이스에 새velero배포 및node-agentPod가 생성됩니다.
다음 단계
- 데이터 플레인 작업 부하를 백업합니다.
9.8.4. 데이터 플레인 워크로드 백업
OADP Operator를 사용하여 데이터 플레인 워크로드를 백업하려면 "애플리케이션 백업"을 참조하십시오. 데이터 플레인 워크로드가 중요하지 않은 경우 이 절차를 건너뛸 수 있습니다.
9.8.5. 컨트롤 플레인 워크로드 백업
Backup CR(사용자 정의 리소스)을 생성하여 컨트롤 플레인 워크로드를 백업할 수 있습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
BackupCR을 정의하는 YAML 파일을 생성합니다.예 9.5.
backup-control-plane.yaml파일 예apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_resource_name>1 namespace: openshift-adp labels: velero.io/storage-location: default spec: hooks: {} includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 includedResources: - sa - role - rolebinding - pod - pvc - pv - bmh - configmap - infraenv5 - priorityclasses - pdb - agents - hostedcluster - nodepool - secrets - services - deployments - hostedcontrolplane - cluster - agentcluster - agentmachinetemplate - agentmachine - machinedeployment - machineset - machine - route - clusterdeployment excludedResources: [] storageLocation: default ttl: 2h0m0s snapshotMoveData: true6 datamover: "velero"7 defaultVolumesToFsBackup: true8 - 1
backup_resource_name을백업리소스의 이름으로 바꾸세요.- 2
- 특정 네임스페이스를 선택하여 오브젝트를 백업합니다. 호스팅 클러스터 네임스페이스와 호스팅된 컨트롤 플레인 네임스페이스를 포함해야 합니다.
- 3
<hosted_cluster_namespace>를 호스트된 클러스터 네임스페이스의 이름으로 바꿉니다(예:클러스터).- 4
<hosted_control_plane_namespace>를 호스트된 컨트롤 플레인 네임스페이스의 이름으로 바꿉니다(예:클러스터 호스팅).- 5
- 별도의 네임스페이스에
infraenv리소스를 생성해야 합니다. 백업 프로세스 중에infraenv리소스를 삭제하지 마십시오. - 6 7
- CSI 볼륨 스냅샷을 활성화하고 컨트롤 플레인 워크로드를 클라우드 스토리지에 자동으로 업로드합니다.
- 8
- PV(영구 볼륨)의
fs-backup방법을 기본값으로 설정합니다. 이 설정은 CSI(Container Storage Interface) 볼륨 스냅샷과fs-backup방법을 조합할 때 유용합니다.
참고CSI 볼륨 스냅샷을 사용하려면
backup.velero.io/backup-volumes-excludes=<pv_name>주석을 PV에 추가해야 합니다.다음 명령을 실행하여
BackupCR을 적용합니다.$ oc apply -f backup-control-plane.yaml
검증
다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get backups.velero.io <backup_resource_name> -n openshift-adp \ -o jsonpath='{.status.phase}'
다음 단계
- OADP를 사용하여 호스팅된 클러스터를 복원합니다.
9.8.6. OADP를 사용하여 호스트 클러스터 복원
Restore CR(사용자 정의 리소스)을 생성하여 호스팅된 클러스터를 복원할 수 있습니다.
-
기존 업데이트를 사용하는 경우
InfraEnv리소스에 예비 노드가 필요하지 않습니다. 새 관리 클러스터에서 작업자 노드를 다시 프로비저닝해야 합니다. -
교체 업데이트를 사용하는 경우 작업자 노드를 배포하기 위해
InfraEnv리소스에 대한 예비 노드가 필요합니다.
호스트 클러스터를 백업한 후 이를 삭제하여 복원 프로세스를 시작해야 합니다. 노드 프로비저닝을 시작하려면 호스팅 클러스터를 삭제하기 전에 데이터 플레인의 워크로드를 백업해야 합니다.
사전 요구 사항
- 콘솔을 사용하여 클러스터 제거 (RHACM 문서)의 단계를 완료하여 호스팅된 클러스터를 삭제했습니다.
- 클러스터를 제거한 후 남아 있는 리소스 제거 (RHACM 문서)의 단계를 완료했습니다.
백업 프로세스를 모니터링하고 관찰하려면 "백업 및 복원 프로세스 예약"을 참조하십시오.
프로세스
다음 명령을 실행하여 호스팅된 컨트롤 플레인 네임스페이스에 Pod 및 PVC(영구 볼륨 클레임)가 없는지 확인합니다.
$ oc get pod pvc -n <hosted_control_plane_namespace>예상 출력
No resources foundRestoreCR을 정의하는 YAML 파일을 생성합니다.restore-hosted-cluster.yaml파일의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_resource_name>1 namespace: openshift-adp spec: backupName: <backup_resource_name>2 restorePVs: true3 existingResourcePolicy: update4 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io중요별도의 네임스페이스에
infraenv리소스를 생성해야 합니다. 복원 프로세스 중에 infraenv 리소스를 삭제하지 마십시오. 새 노드를 다시 프로비저닝하려면 infraenv 리소스가 필요합니다.다음 명령을 실행하여
RestoreCR을 적용합니다.$ oc apply -f restore-hosted-cluster.yaml다음 명령을 실행하여
status.phase의 값이완료되었는지 확인합니다.$ oc get hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ -o jsonpath='{.status.phase}'
9.8.7. 백업 및 복원 프로세스 관찰
OADP(OpenShift API for Data Protection)를 사용하여 호스팅된 클러스터를 백업하고 복원할 때 프로세스를 모니터링하고 관찰할 수 있습니다.
프로세스
다음 명령을 실행하여 백업 프로세스를 관찰합니다.
$ watch "oc get backups.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"다음 명령을 실행하여 복원 프로세스를 관찰합니다.
$ watch "oc get restores.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"다음 명령을 실행하여 Velero 로그를 관찰합니다.
$ oc logs -n openshift-adp -ldeploy=velero -f다음 명령을 실행하여 모든 OADP 오브젝트의 진행 상황을 확인합니다.
$ watch "echo BackupRepositories:;echo;oc get backuprepositories.velero.io -A;echo; echo BackupStorageLocations: ;echo; oc get backupstoragelocations.velero.io -A;echo;echo DataUploads: ;echo;oc get datauploads.velero.io -A;echo;echo DataDownloads: ;echo;oc get datadownloads.velero.io -n openshift-adp; echo;echo VolumeSnapshotLocations: ;echo;oc get volumesnapshotlocations.velero.io -A;echo;echo Backups:;echo;oc get backup -A; echo;echo Restores:;echo;oc get restore -A"
9.8.8. velero CLI를 사용하여 백업 및 복원 리소스 설명
데이터 보호를 위한 OpenShift API를 사용하는 경우 velero CLI(명령줄 인터페이스)를 사용하여 Backup 및 Restore 리소스에 대한 자세한 정보를 얻을 수 있습니다.
프로세스
다음 명령을 실행하여 컨테이너에서
veleroCLI를 사용하도록 별칭을 생성합니다.$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'다음 명령을 실행하여
RestoreCR(사용자 정의 리소스)에 대한 세부 정보를 가져옵니다.$ velero restore describe <restore_resource_name> --details1 - 1
<restore_resource_name>을Restore리소스의 이름으로 바꿉니다.
다음 명령을 실행하여
BackupCR에 대한 세부 정보를 가져옵니다.$ velero restore describe <backup_resource_name> --details1 - 1
<backup_resource_name>을Backup리소스의 이름으로 바꿉니다.
10장. 호스팅된 제어 평면에 대한 인증 및 권한 부여
OpenShift Container Platform 컨트롤 플레인에는 내장 OAuth 서버가 포함되어 있습니다. OpenShift Container Platform API에 인증하기 위해 OAuth 액세스 토큰을 얻을 수 있습니다. 호스팅 클러스터를 생성한 후 ID 공급자를 지정하여 OAuth를 구성할 수 있습니다.
10.1. CLI를 사용하여 호스팅된 클러스터에 대한 OAuth 서버 구성
CLI를 사용하여 호스팅된 클러스터에 대한 내부 OAuth 서버를 구성할 수 있습니다.
다음 지원되는 ID 공급자에 대해 OAuth를 구성할 수 있습니다.
-
oidc -
htpasswd -
Keystone -
ldap -
기본 인증 -
request-header -
github -
gitlab -
google
OAuth 구성에 ID 공급자를 추가하면 기본 kubeadmin 사용자 공급자가 제거됩니다.
ID 공급자를 구성할 때는 호스팅된 클러스터에 최소한 하나의 NodePool 복제본을 미리 구성해야 합니다. DNS 확인을 위한 트래픽은 워커 노드를 통해 전송됩니다. htpasswd 및 request-header ID 공급자의 경우 NodePool 복제본을 미리 구성할 필요가 없습니다.
사전 요구 사항
- 호스팅 클러스터를 생성했습니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에서
HostedCluster사용자 정의 리소스(CR)를 편집합니다.$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>다음 예를 사용하여
HostedClusterCR에 OAuth 구성을 추가합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: oauth: identityProviders: - openID:3 claims: email:4 - <email_address> name:5 - <display_name> preferredUsername:6 - <preferred_username> clientID: <client_id>7 clientSecret: name: <client_id_secret_name>8 issuer: https://example.com/identity9 mappingMethod: lookup10 name: IAM type: OpenID- 1
- 호스팅된 클러스터 이름을 지정합니다.
- 2
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 3
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 제공자 이름은 리디렉션 URL을 작성하는 데에도 사용됩니다.
- 4
- 이메일 주소로 사용할 속성 목록을 정의합니다.
- 5
- 표시 이름으로 사용할 속성 목록을 정의합니다.
- 6
- 기본 사용자 이름으로 사용할 속성 목록을 정의합니다.
- 7
- OpenID 제공자에 등록된 클라이언트의 ID를 정의합니다. 클라이언트가
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>URL로 리디렉션하도록 허용해야 합니다. - 8
- OpenID 공급자에 등록된 클라이언트의 비밀을 정의합니다.
- 9
- OpenID 사양에 설명된 Issuer Identifier 입니다. 쿼리 또는 조각 구성 요소 없이 https를 사용해야 합니다.
- 10
- 이 공급자의 ID와
사용자개체 간의 매핑이 설정되는 방식을 제어하는 매핑 방법을 정의합니다.
- 파일을 저장하여 변경 사항을 적용합니다.
10.2. 웹 콘솔을 사용하여 호스팅된 클러스터에 대한 OAuth 서버 구성
OpenShift Container Platform 웹 콘솔을 사용하여 호스팅된 클러스터에 대한 내부 OAuth 서버를 구성할 수 있습니다.
다음 지원되는 ID 공급자에 대해 OAuth를 구성할 수 있습니다.
-
oidc -
htpasswd -
Keystone -
ldap -
기본 인증 -
request-header -
github -
gitlab -
google
OAuth 구성에 ID 공급자를 추가하면 기본 kubeadmin 사용자 공급자가 제거됩니다.
ID 공급자를 구성할 때는 호스팅된 클러스터에 최소한 하나의 NodePool 복제본을 미리 구성해야 합니다. DNS 확인을 위한 트래픽은 워커 노드를 통해 전송됩니다. htpasswd 및 request-header ID 공급자의 경우 NodePool 복제본을 미리 구성할 필요가 없습니다.
사전 요구 사항
-
cluster-admin권한이 있는 사용자로 로그인했습니다. - 호스팅 클러스터를 생성했습니다.
프로세스
- 홈 → API 탐색기 로 이동합니다.
-
HostedCluster리소스를 검색하려면 종류별 필터링 상자를 사용하세요. -
편집하려는
HostedCluster리소스를 클릭합니다. - 인스턴스 탭을 클릭합니다.
-
옵션 메뉴를 클릭하세요
 호스팅 클러스터 이름 항목 옆에 있는 Edit HostedCluster를 클릭합니다.
호스팅 클러스터 이름 항목 옆에 있는 Edit HostedCluster를 클릭합니다.
YAML 파일에 OAuth 구성을 추가합니다.
spec: configuration: oauth: identityProviders: - openID:1 claims: email:2 - <email_address> name:3 - <display_name> preferredUsername:4 - <preferred_username> clientID: <client_id>5 clientSecret: name: <client_id_secret_name>6 issuer: https://example.com/identity7 mappingMethod: lookup8 name: IAM type: OpenID- 1
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 제공자 이름은 리디렉션 URL을 작성하는 데에도 사용됩니다.
- 2
- 이메일 주소로 사용할 속성 목록을 정의합니다.
- 3
- 표시 이름으로 사용할 속성 목록을 정의합니다.
- 4
- 기본 사용자 이름으로 사용할 속성 목록을 정의합니다.
- 5
- OpenID 제공자에 등록된 클라이언트의 ID를 정의합니다. 클라이언트가
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>URL로 리디렉션하도록 허용해야 합니다. - 6
- OpenID 공급자에 등록된 클라이언트의 비밀을 정의합니다.
- 7
- OpenID 사양에 설명된 Issuer Identifier 입니다. 쿼리 또는 조각 구성 요소 없이 https를 사용해야 합니다.
- 8
- 이 공급자의 ID와
사용자개체 간의 매핑이 설정되는 방식을 제어하는 매핑 방법을 정의합니다.
- 저장을 클릭합니다.
10.3. AWS의 호스팅 클러스터에서 CCO를 사용하여 구성 요소 IAM 역할 할당
Amazon Web Services(AWS)의 호스팅 클러스터에서 Cloud Credential Operator(CCO)를 사용하여 단기적이고 제한된 권한의 보안 자격 증명을 제공하는 IAM 역할을 구성 요소에 할당할 수 있습니다. 기본적으로 CCO는 호스팅된 제어 평면에서 실행됩니다.
CCO는 AWS에서 호스팅되는 클러스터에 대해서만 수동 모드를 지원합니다. 기본적으로 호스팅 클러스터는 수동 모드로 구성됩니다. 관리 클러스터는 수동 이외의 모드를 사용할 수 있습니다.
10.4. AWS에서 호스팅되는 클러스터에 CCO 설치 확인
호스팅된 제어 평면에서 CCO(Cloud Credential Operator)가 올바르게 실행되고 있는지 확인할 수 있습니다.
사전 요구 사항
- Amazon Web Services(AWS)에서 호스팅 클러스터를 구성했습니다.
프로세스
다음 명령을 실행하여 호스팅된 클러스터에서 CCO가 수동 모드로 구성되었는지 확인하세요.
$ oc get cloudcredentials <hosted_cluster_name> \ -n <hosted_cluster_namespace> \ -o=jsonpath={.spec.credentialsMode}예상 출력
Manual다음 명령을 실행하여
serviceAccountIssuer리소스의 값이 비어 있지 않은지 확인하세요.$ oc get authentication cluster --kubeconfig <hosted_cluster_name>.kubeconfig \ -o jsonpath --template '{.spec.serviceAccountIssuer }'출력 예
https://aos-hypershift-ci-oidc-29999.s3.us-east-2.amazonaws.com/hypershift-ci-29999
10.5. AWS STS를 사용하여 운영자가 CCO 기반 워크플로를 지원하도록 지원
프로젝트를 Operator Lifecycle Manager(OLM)에서 실행하도록 설계하는 Operator 작성자는 프로젝트를 사용자 지정하여 Cloud Credential Operator(CCO)를 지원함으로써 STS 지원 OpenShift Container Platform 클러스터에서 AWS에 대해 Operator가 인증하도록 할 수 있습니다.
이 방법을 사용하면 운영자는 CredentialsRequest 객체를 생성하고 결과 Secret 객체를 읽기 위한 RBAC 권한이 필요하며 이에 대한 책임이 있습니다.
기본적으로 Operator 배포와 관련된 Pod는 serviceAccountToken 볼륨을 마운트하여 서비스 계정 토큰을 결과 Secret 객체에서 참조할 수 있도록 합니다.
필수 조건
- OpenShift Container Platform 4.14 이상
- STS 모드의 클러스터
- OLM 기반 운영자 프로젝트
프로세스
Operator 프로젝트의
ClusterServiceVersion(CSV) 객체를 업데이트하세요.운영자가
CredentialsRequests객체를 생성할 수 있는 RBAC 권한이 있는지 확인하세요.예 10.1.
clusterPermissions목록 예시# ... install: spec: clusterPermissions: - rules: - apiGroups: - "cloudcredential.openshift.io" resources: - credentialsrequests verbs: - create - delete - get - list - patch - update - watchAWS STS를 사용하여 CCO 기반 워크플로우 방식에 대한 지원을 요청하려면 다음 주석을 추가하세요.
# ... metadata: annotations: features.operators.openshift.io/token-auth-aws: "true"
Operator 프로젝트 코드를 업데이트하세요.
Subscription객체에 의해 Pod에 설정된 환경 변수에서 역할 ARN을 가져옵니다. 예를 들면 다음과 같습니다.// Get ENV var roleARN := os.Getenv("ROLEARN") setupLog.Info("getting role ARN", "role ARN = ", roleARN) webIdentityTokenPath := "/var/run/secrets/openshift/serviceaccount/token"패치 및 적용할
CredentialsRequest개체가 준비되었는지 확인하세요. 예를 들면 다음과 같습니다.예 10.2.
CredentialsRequest객체 생성 예제import ( minterv1 "github.com/openshift/cloud-credential-operator/pkg/apis/cloudcredential/v1" corev1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) var in = minterv1.AWSProviderSpec{ StatementEntries: []minterv1.StatementEntry{ { Action: []string{ "s3:*", }, Effect: "Allow", Resource: "arn:aws:s3:*:*:*", }, }, STSIAMRoleARN: "<role_arn>", } var codec = minterv1.Codec var ProviderSpec, _ = codec.EncodeProviderSpec(in.DeepCopyObject()) const ( name = "<credential_request_name>" namespace = "<namespace_name>" ) var CredentialsRequestTemplate = &minterv1.CredentialsRequest{ ObjectMeta: metav1.ObjectMeta{ Name: name, Namespace: "openshift-cloud-credential-operator", }, Spec: minterv1.CredentialsRequestSpec{ ProviderSpec: ProviderSpec, SecretRef: corev1.ObjectReference{ Name: "<secret_name>", Namespace: namespace, }, ServiceAccountNames: []string{ "<service_account_name>", }, CloudTokenPath: "", }, }또는 YAML 형식의
CredentialsRequest객체에서 시작하는 경우(예: Operator 프로젝트 코드의 일부로) 다음과 같이 다르게 처리할 수 있습니다.예 10.3. YAML 형식의
CredentialsRequest객체 생성 예시// CredentialsRequest is a struct that represents a request for credentials type CredentialsRequest struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` Metadata struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"metadata"` Spec struct { SecretRef struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"secretRef"` ProviderSpec struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` StatementEntries []struct { Effect string `yaml:"effect"` Action []string `yaml:"action"` Resource string `yaml:"resource"` } `yaml:"statementEntries"` STSIAMRoleARN string `yaml:"stsIAMRoleARN"` } `yaml:"providerSpec"` // added new field CloudTokenPath string `yaml:"cloudTokenPath"` } `yaml:"spec"` } // ConsumeCredsRequestAddingTokenInfo is a function that takes a YAML filename and two strings as arguments // It unmarshals the YAML file to a CredentialsRequest object and adds the token information. func ConsumeCredsRequestAddingTokenInfo(fileName, tokenString, tokenPath string) (*CredentialsRequest, error) { // open a file containing YAML form of a CredentialsRequest file, err := os.Open(fileName) if err != nil { return nil, err } defer file.Close() // create a new CredentialsRequest object cr := &CredentialsRequest{} // decode the yaml file to the object decoder := yaml.NewDecoder(file) err = decoder.Decode(cr) if err != nil { return nil, err } // assign the string to the existing field in the object cr.Spec.CloudTokenPath = tokenPath // return the modified object return cr, nil }참고현재 Operator 번들에
CredentialsRequest객체를 추가하는 것은 지원되지 않습니다.자격 증명 요청에 역할 ARN과 웹 ID 토큰 경로를 추가하고 운영자 초기화 중에 적용합니다.
예 10.4. Operator 초기화 중
CredentialsRequest객체 적용 예제// apply CredentialsRequest on install credReq := credreq.CredentialsRequestTemplate credReq.Spec.CloudTokenPath = webIdentityTokenPath c := mgr.GetClient() if err := c.Create(context.TODO(), credReq); err != nil { if !errors.IsAlreadyExists(err) { setupLog.Error(err, "unable to create CredRequest") os.Exit(1) } }다음 예에서 보듯이, Operator가 CCO에서
Secret객체가 나타날 때까지 기다릴 수 있는지 확인하세요. 이 객체는 Operator에서 조정 중인 다른 항목과 함께 호출됩니다.예 10.5.
Secret객체를 기다리는 예제// WaitForSecret is a function that takes a Kubernetes client, a namespace, and a v1 "k8s.io/api/core/v1" name as arguments // It waits until the secret object with the given name exists in the given namespace // It returns the secret object or an error if the timeout is exceeded func WaitForSecret(client kubernetes.Interface, namespace, name string) (*v1.Secret, error) { // set a timeout of 10 minutes timeout := time.After(10 * time.Minute)1 // set a polling interval of 10 seconds ticker := time.NewTicker(10 * time.Second) // loop until the timeout or the secret is found for { select { case <-timeout: // timeout is exceeded, return an error return nil, fmt.Errorf("timed out waiting for secret %s in namespace %s", name, namespace) // add to this error with a pointer to instructions for following a manual path to a Secret that will work on STS case <-ticker.C: // polling interval is reached, try to get the secret secret, err := client.CoreV1().Secrets(namespace).Get(context.Background(), name, metav1.GetOptions{}) if err != nil { if errors.IsNotFound(err) { // secret does not exist yet, continue waiting continue } else { // some other error occurred, return it return nil, err } } else { // secret is found, return it return secret, nil } } } }- 1
시간 초과값은 CCO가 추가된CredentialsRequest객체를 얼마나 빨리 감지하고Secret객체를 생성하는지에 대한 추정치에 따라 결정됩니다. 운영자가 아직 클라우드 리소스에 액세스하지 못하는 이유가 무엇인지 궁금해하는 클러스터 관리자를 위해 시간을 줄이거나 맞춤형 피드백을 만드는 것을 고려해 볼 수 있습니다.
CCO가 자격 증명 요청에서 생성한 비밀을 읽고 해당 비밀의 데이터가 포함된 AWS 구성 파일을 만들어 AWS 구성을 설정합니다.
예 10.6. AWS 구성 생성 예시
func SharedCredentialsFileFromSecret(secret *corev1.Secret) (string, error) { var data []byte switch { case len(secret.Data["credentials"]) > 0: data = secret.Data["credentials"] default: return "", errors.New("invalid secret for aws credentials") } f, err := ioutil.TempFile("", "aws-shared-credentials") if err != nil { return "", errors.Wrap(err, "failed to create file for shared credentials") } defer f.Close() if _, err := f.Write(data); err != nil { return "", errors.Wrapf(err, "failed to write credentials to %s", f.Name()) } return f.Name(), nil }중요비밀은 존재한다고 가정하지만, 이 비밀을 사용할 때는 운영자 코드가 기다렸다가 다시 시도해야 CCO가 비밀을 생성할 시간을 얻을 수 있습니다.
또한 대기 기간은 결국 시간 초과되어 사용자에게 OpenShift Container Platform 클러스터 버전과 CCO가 STS 감지를 통한
CredentialsRequest개체 워크플로를 지원하지 않는 이전 버전일 수 있다는 경고를 보냅니다. 이런 경우에는 사용자에게 다른 방법을 사용하여 비밀번호를 추가해야 한다고 알려주십시오.AWS SDK 세션을 구성합니다(예:
예 10.7. AWS SDK 세션 구성 예시
sharedCredentialsFile, err := SharedCredentialsFileFromSecret(secret) if err != nil { // handle error } options := session.Options{ SharedConfigState: session.SharedConfigEnable, SharedConfigFiles: []string{sharedCredentialsFile}, }
11장. 호스팅된 제어 평면에 대한 처리 기계 구성
독립형 OpenShift Container Platform 클러스터에서 머신 구성 풀은 노드 세트를 관리합니다. MachineConfigPool 사용자 정의 리소스(CR)를 사용하여 머신 구성을 처리할 수 있습니다.
NodePool CR의 nodepool.spec.config 필드에서 모든 machineconfiguration.openshift.io 리소스를 참조할 수 있습니다.
호스팅된 제어 평면에는 MachineConfigPool CR이 존재하지 않습니다. 노드 풀에는 컴퓨팅 노드 세트가 포함되어 있습니다. 노드 풀을 사용하여 머신 구성을 처리할 수 있습니다.
OpenShift Container Platform 4.18 이상에서는 워커 노드의 기본 컨테이너 런타임이 runC에서 crun으로 변경되었습니다.
11.1. 호스팅된 컨트롤 플레인의 노드 풀 구성
호스팅된 컨트롤 플레인에서는 관리 클러스터의 구성 맵 내에 MachineConfig 오브젝트를 생성하여 노드 풀을 구성할 수 있습니다.
절차
관리 클러스터의 구성 맵 내에
MachineConfig오브젝트를 생성하려면 다음 정보를 입력합니다.apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: ${PATH}1 - 1
MachineConfig오브젝트가 저장된 노드의 경로를 설정합니다.
구성 맵에 오브젝트를 추가한 후 다음과 같이 구성 맵을 노드 풀에 적용할 수 있습니다.
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- &
lt;configmap_name>을 구성 맵 이름으로 바꿉니다.
11.2. 노드 풀의 kubelet 구성 참조
노드 풀에서 kubelet 구성을 참조하려면 구성 맵에 kubelet 구성을 추가한 다음 NodePool 리소스에 구성 맵을 적용합니다.
프로세스
다음 정보를 입력하여 관리 클러스터의 구성 맵 내부에 kubelet 구성을 추가합니다.
kubelet 구성이 있는
ConfigMap오브젝트의 예apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name>1 namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: <kubeletconfig_name>2 spec: kubeletConfig: registerWithTaints: - key: "example.sh/unregistered" value: "true" effect: "NoExecute"다음 명령을 입력하여 노드 풀에 구성 맵을 적용합니다.
$ oc edit nodepool <nodepool_name> --namespace clusters1 - 1
- &
lt;nodepool_name>을 노드 풀 이름으로 바꿉니다.
NodePool리소스 구성의 예apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- &
lt;configmap_name>을 구성 맵 이름으로 바꿉니다.
11.3. 호스트 클러스터에서 노드 튜닝 구성
호스팅된 클러스터의 노드에 노드 수준 튜닝을 설정하려면 Node Tuning Operator를 사용할 수 있습니다. 호스팅된 컨트롤 플레인에서는 Tuned 오브젝트가 포함된 구성 맵을 생성하고 노드 풀에 해당 구성 맵을 참조하여 노드 튜닝을 구성할 수 있습니다.
절차
유효한 tuned 매니페스트가 포함된 구성 맵을 생성하고 노드 풀에서 매니페스트를 참조합니다. 다음 예에서
Tuned매니페스트는tuned-1-node-label노드 라벨이 임의의 값이 포함된 노드에서vm.dirty_ratio를 55로 설정하는 프로필을 정의합니다.tuned-1.yaml이라는 파일에 다음ConfigMap매니페스트를 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile참고Tuned 사양의
spec.recommend섹션에 있는 항목에 라벨을 추가하지 않으면 node-pool 기반 일치로 간주되므로spec.recommend섹션에서 가장 높은 우선 순위 프로필이 풀의 노드에 적용됩니다. Tuned.spec.recommend.match섹션에서 레이블 값을 설정하여 보다 세분화된 노드 레이블 기반 일치를 수행할 수 있지만 노드 레이블은 노드 풀의.spec.management.upgradeType값을InPlace로 설정하지 않는 한 업그레이드 중에 유지되지 않습니다.관리 클러스터에
ConfigMap오브젝트를 생성합니다.$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml노드 풀을 편집하거나 하나를 생성하여 노드 풀의
spec.tuningConfig필드에서ConfigMap오브젝트를 참조합니다. 이 예에서는 2개의 노드가 포함된nodepool-1이라는NodePool이 하나만 있다고 가정합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...참고여러 노드 풀에서 동일한 구성 맵을 참조할 수 있습니다. 호스팅된 컨트롤 플레인에서 Node Tuning Operator는 노드 풀 이름과 네임스페이스의 해시를 Tuned CR 이름에 추가하여 구별합니다. 이 경우 동일한 호스트 클러스터에 대해 다른 Tuned CR에 동일한 이름의 여러 TuneD 프로필을 생성하지 마십시오.
검증
이제 Tuned 매니페스트가 포함된 ConfigMap 오브젝트를 생성하여 NodePool 에서 참조하므로 Node Tuning Operator가 Tuned 오브젝트를 호스팅된 클러스터에 동기화합니다. 정의된 Tuned 오브젝트와 각 노드에 적용되는 TuneD 프로필을 확인할 수 있습니다.
호스트 클러스터에서
Tuned오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator출력 예
NAME AGE default 7m36s rendered 7m36s tuned-1 65s호스팅된 클러스터의
Profile오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator출력 예
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s참고사용자 지정 프로필이 생성되지 않으면 기본적으로
openshift-node프로필이 적용됩니다.튜닝이 올바르게 적용되었는지 확인하려면 노드에서 디버그 쉘을 시작하고 sysctl 값을 확인합니다.
$ oc --kubeconfig="$HC_KUBECONFIG" \ debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio출력 예
vm.dirty_ratio = 55
11.4. 호스트된 컨트롤 플레인을 위한 SR-IOV Operator 배포
호스팅 서비스 클러스터를 구성하고 배포한 후 호스팅된 클러스터에서 SR-IOV Operator에 대한 서브스크립션을 생성할 수 있습니다. SR-IOV Pod는 컨트롤 플레인이 아닌 작업자 머신에서 실행됩니다.
사전 요구 사항
AWS에 호스팅 클러스터를 구성하고 배포해야 합니다.
프로세스
네임스페이스 및 Operator 그룹을 생성합니다.
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operatorSR-IOV Operator에 대한 서브스크립션을 생성합니다.
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: stable name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: redhat-operators sourceNamespace: openshift-marketplace
검증
SR-IOV Operator가 준비되었는지 확인하려면 다음 명령을 실행하고 결과 출력을 확인합니다.
$ oc get csv -n openshift-sriov-network-operator출력 예
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.19.0-202211021237 SR-IOV Network Operator 4.19.0-202211021237 sriov-network-operator.4.19.0-202210290517 SucceededSR-IOV Pod가 배포되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get pods -n openshift-sriov-network-operator
11.5. 호스팅된 클러스터의 NTP 서버 구성
Butane을 사용하여 호스팅된 클러스터에 대한 NTP(Network Time Protocol) 서버를 구성할 수 있습니다.
프로세스
chrony.conf파일의 내용을 포함하는 Butane 구성 파일99-worker-chrony.bu를 만듭니다. Butane에 대한 자세한 내용은 " Butane을 사용하여 머신 구성 생성"을 참조하십시오.99-worker-chrony.bu구성 예# ... variant: openshift version: 4.19.0 metadata: name: 99-worker-chrony labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 06441 overwrite: true contents: inline: | pool 0.rhel.pool.ntp.org iburst2 driftfile /var/lib/chrony/drift makestep 1.0 3 rtcsync logdir /var/log/chrony # ...참고머신 간 통신의 경우 UDP(User Datagram Protocol) 포트의 NTP는
123입니다. 외부 NTP 시간 서버를 구성한 경우 UDP 포트123을 열어야 합니다.Butane을 사용하여 Butane이 노드에 전송하는 구성이 포함된
MachineConfig파일99-worker-chrony.yaml을 생성합니다. 다음 명령을 실행합니다.$ butane 99-worker-chrony.bu -o 99-worker-chrony.yaml예:
99-worker-chrony.yaml구성# Generated by Butane; do not edit apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path관리 클러스터의 구성 맵 내에
99-worker-chrony.yaml파일의 내용을 추가합니다.구성 맵 예
apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: <namespace>1 data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path # ...- 1
- &
lt;namespace>를클러스터와같이 노드 풀을 생성한 네임스페이스 이름으로 바꿉니다.
다음 명령을 실행하여 노드 풀에 구성 맵을 적용합니다.
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>NodePool구성의 예apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- &
lt;configmap_name>을 구성 맵 이름으로 바꿉니다.
InfraEnvCR(사용자 정의 리소스)을 정의하는infra-env.yaml파일에 NTP 서버 목록을 추가합니다.infra-env.yaml파일 예apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv # ... spec: additionalNTPSources: - <ntp_server>1 - <ntp_server1> - <ntp_server2> # ...- 1
- &
lt;ntp_server>를 NTP 서버의 이름으로 바꿉니다. 호스트 인벤토리 및InfraEnvCR 생성에 대한 자세한 내용은 "호스트 인벤토리 생성"을 참조하십시오.
다음 명령을 실행하여
InfraEnvCR을 적용합니다.$ oc apply -f infra-env.yaml
검증
다음 필드를 확인하여 호스트 인벤토리의 상태를 확인합니다.
-
conditions: 이미지가 성공적으로 생성되었는지를 나타내는 표준 Kubernetes 상태입니다. -
isoDownloadURL: Discovery Image를 다운로드할 URL입니다. createdTime: 이미지가 마지막으로 생성된 시간입니다.InfraEnvCR을 수정하는 경우 새 이미지를 다운로드하기 전에 타임스탬프를 업데이트했는지 확인합니다.다음 명령을 실행하여 호스트 인벤토리가 생성되었는지 확인합니다.
$ oc describe infraenv <infraenv_resource_name> -n <infraenv_namespace>참고InfraEnvCR을 수정하는 경우InfraEnvCR이createdTime필드를 확인하여 새 검색 이미지를 생성했는지 확인합니다. 이미 호스트를 부팅한 경우 최신 Discovery Image를 사용하여 다시 부팅합니다.
-
12장. 호스트 클러스터에서 기능 게이트 사용
호스트 클러스터에서 기능 게이트를 사용하여 기본 기능 세트의 일부가 아닌 기능을 활성화할 수 있습니다. 호스팅된 클러스터에서 기능 게이트를 사용하여 TechPreviewNoUpgrade 기능을 활성화할 수 있습니다.
12.1. 기능 게이트를 사용하여 기능 세트 활성화
OpenShift CLI로 HostedCluster CR(사용자 정의 리소스)을 편집하여 호스트 클러스터에서 TechPreviewNoUpgrade 기능을 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에서 편집할
HostedClusterCR을 엽니다.$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>featureSet필드에 값을 입력하여 기능 세트를 정의합니다. 예를 들면 다음과 같습니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: featureGate: featureSet: TechPreviewNoUpgrade3 주의클러스터에서
TechPreviewNoUpgrade기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 이 기능 세트를 사용하면 테스트 클러스터에서 이러한 기술 프리뷰 기능을 완전히 테스트할 수 있습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화하지 마십시오.- 파일을 저장하여 변경 사항을 적용합니다.
검증
다음 명령을 실행하여 호스트 클러스터에서
TechPreviewNoUpgrade기능 게이트가 활성화되어 있는지 확인합니다.$ oc get featuregate cluster -o yaml
13장. 호스트된 컨트롤 플레인에 대한 가시성
메트릭 세트를 구성하여 호스팅되는 컨트롤 플레인의 메트릭을 수집할 수 있습니다. HyperShift Operator는 관리하는 각 호스팅 클러스터의 관리 클러스터에서 모니터링 대시보드를 생성하거나 삭제할 수 있습니다.
13.1. 호스팅된 컨트롤 플레인에 대한 메트릭 세트 구성
Red Hat OpenShift Container Platform의 호스트된 컨트롤 플레인은 각 컨트롤 플레인 네임스페이스에서 ServiceMonitor 리소스를 생성하여 Prometheus 스택이 컨트롤 플레인에서 지표를 수집할 수 있습니다. ServiceMonitor 리소스는 메트릭 재레이블을 사용하여 etcd 또는 Kubernetes API 서버와 같은 특정 구성 요소에서 포함되거나 제외되는 메트릭을 정의합니다. 컨트롤 플레인에서 생성하는 메트릭 수는 이를 수집하는 모니터링 스택의 리소스 요구 사항에 직접적인 영향을 미칩니다.
모든 상황에 적용되는 고정된 수의 메트릭을 생성하는 대신 각 컨트롤 플레인에 생성할 메트릭 세트를 식별하는 메트릭 세트를 구성할 수 있습니다. 다음 메트릭 세트가 지원됩니다.
-
Telemetry: 이러한 메트릭은 Telemetry에 필요합니다. 이 세트는 기본 세트이며 가장 작은 메트릭 세트입니다. -
SRE: 이 세트에는 알림을 생성하고 제어 평면 구성 요소의 문제를 해결하는 데 필요한 측정 항목이 포함되어 있습니다. -
All: 이 세트에는 독립 실행형 OpenShift Container Platform 컨트롤 플레인 구성 요소에서 생성하는 모든 메트릭이 포함됩니다.
메트릭 세트를 구성하려면 다음 명령을 입력하여 HyperShift Operator 배포에서 METRICS_SET 환경 변수를 설정합니다.
$ oc set env -n hypershift deployment/operator METRICS_SET=All13.1.1. SRE 메트릭 세트 구성
SRE 메트릭 집합을 지정하면 HyperShift Operator는 단일 키( config) 를 가진 sre-metric-set 이라는 구성 맵을 찾습니다. config 키 값에는 컨트롤 플레인 구성 요소로 구성된 RelabelConfigs 세트가 포함되어야 합니다.
다음 구성 요소를 지정할 수 있습니다.
-
etcd -
kubeAPIServer -
kubeControllerManager -
openshiftAPIServer -
openshiftControllerManager -
openshiftRouteControllerManager -
cvo - OLM
-
catalogOperator -
registryOperator -
nodeTuningOperator -
controlPlaneOperator -
hostedClusterConfigOperator
다음 예에서는 SRE 메트릭 세트의 구성을 보여줍니다.
kubeAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "transformation_(transformation_latencies_microseconds|failures_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "network_plugin_operations_latency_microseconds|sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
kubeControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "rest_client_request_latency_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "root_ca_cert_publisher_sync_duration_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
openshiftAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
openshiftControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
openshiftRouteControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
olm:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
catalogOperator:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
cvo:
- action: drop
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]13.2. 호스팅된 클러스터에서 모니터링 대시보드 활성화
호스팅된 클러스터에서 구성 맵을 생성하여 모니터링 대시보드를 활성화할 수 있습니다.
프로세스
로컬 클러스터네임스페이스에hypershift-operator-install-flags구성 맵을 만듭니다. 다음 예제 구성을 참조하세요.kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "--monitoring-dashboards --metrics-set=All"1 installFlagsToRemove: ""- 1
--monitoring-dashboards --metrics-set=All플래그는 모든 메트릭에 대한 모니터링 대시보드를 추가합니다.
다음 환경 변수를 포함하도록
hypershift네임스페이스에서 HyperShift Operator 배포를 업데이트할 때까지 몇 분 정도 기다립니다.- name: MONITORING_DASHBOARDS value: "1"모니터링 대시보드가 활성화된 경우 HyperShift Operator가 관리하는 각 호스팅 클러스터에 대해 Operator는
openshift-config-managed네임스페이스에cp-<hosted_cluster_namespace>-<hosted_cluster_name>이라는 구성 맵을 생성합니다. 여기서 <hosted_cluster_namespace>는 호스팅된 클러스터의 네임스페이스이고 <hosted_cluster_name>은 호스트된 클러스터의 이름입니다. 결과적으로 관리 클러스터의 관리 콘솔에 새 대시보드가 추가됩니다.- 대시보드를 보려면 관리 클러스터 콘솔에 로그인하고 모니터링 → 대시보드를 클릭하여 호스트 클러스터의 대시보드로 이동합니다.
-
선택 사항: 호스트 클러스터에서 모니터링 대시보드를 비활성화하려면
hypershift-operator-install-flags구성 맵에서--monitoring-dashboards --metrics-set=All플래그를 제거합니다. 호스트 클러스터를 삭제하면 해당 대시보드도 삭제됩니다.
13.2.1. 대시보드 사용자 정의
HyperShift Operator는 호스트된 각 클러스터에 대한 대시보드를 생성하기 위해 Operator 네임스페이스(hypershift)의 monitoring-dashboard-template 구성 맵에 저장된 템플릿을 사용합니다. 이 템플릿에는 대시보드에 대한 메트릭이 포함된 Grafana 패널 세트가 포함되어 있습니다. 구성 맵의 콘텐츠를 편집하여 대시보드를 사용자 지정할 수 있습니다.
대시보드가 생성되면 다음 문자열이 특정 호스팅 클러스터에 해당하는 값으로 교체됩니다.
| 이름 | 설명 |
|---|---|
|
| 호스트된 클러스터의 이름 |
|
| 호스팅된 클러스터의 네임스페이스 |
|
| 호스팅된 클러스터의 컨트롤 플레인 Pod가 배치되는 네임스페이스 |
|
|
호스팅된 클러스터 메트릭의 |
14장. 호스트된 컨트롤 플레인 네트워킹
독립 실행형 OpenShift Container Platform의 경우 프록시 지원은 기본적으로 클러스터의 워크로드가 HTTP 또는 HTTPS 프록시를 사용하여 외부 서비스에 액세스하도록 구성되어 있는지 확인하고, 구성된 경우 NO_PROXY 설정을 준수하고 프록시용으로 구성된 신뢰 번들을 수락하는 것입니다.
호스팅된 컨트롤 플레인의 경우 프록시 지원에 다음과 같은 추가 사용 사례가 포함됩니다.
14.1. 외부 서비스에 액세스해야 하는 컨트롤 플레인 워크로드
컨트롤 플레인에서 실행되는 Operator는 호스팅된 클러스터에 대해 구성된 프록시를 통해 외부 서비스에 액세스해야 합니다. 프록시는 일반적으로 데이터 플레인을 통해서만 액세스할 수 있습니다. 컨트롤 플레인 워크로드는 다음과 같습니다.
- Control Plane Operator는 OAuth 서버 구성을 생성할 때 특정 ID 공급자에서 끝점을 검증하고 가져와야 합니다.
- OAuth 서버에는 LDAP가 아닌 ID 공급자 액세스 권한이 필요합니다.
- OpenShift API 서버는 이미지 레지스트리 메타데이터 가져오기를 처리합니다.
- Ingress Operator는 외부 카나리아 경로를 검증하려면 액세스할 수 있어야 합니다.
-
도메인 이름 서비스(DNS) 프로토콜이 예상대로 작동하려면 전송 제어 프로토콜(TCP)과 사용자 데이터그램 프로토콜(UDP)에서 방화벽 포트
53을열어야 합니다.
호스팅된 클러스터에서는 컨트롤 플레인 Operator, Ingress Operator, OAuth 서버 및 OpenShift API 서버 Pod에서 시작된 트래픽을 데이터 플레인을 통해 구성된 프록시로 보낸 다음 최종 대상으로 보내야 합니다.
예를 들어 프록시 액세스가 필요한 레지스트리에서 OpenShift 이미지 스트림을 가져오는 경우와 같이 호스팅된 클러스터가 제로 컴퓨팅 노드로 감소하면 일부 작업을 수행할 수 없습니다.
14.2. Ignition 엔드포인트에 액세스해야 하는 컴퓨팅 노드
컴퓨팅 노드에 ignition 엔드포인트에 액세스하는 데 프록시가 필요한 경우 컴퓨팅 노드에 구성된 user-data stub에서 프록시를 구성해야 합니다. 시스템이 Ignition URL에 액세스하는 데 프록시가 필요한 경우 프록시 구성이 스텁에 포함됩니다.
스텁은 다음 예와 유사합니다.
---
{"ignition":{"config":{"merge":[{"httpHeaders":[{"name":"Authorization","value":"Bearer ..."},{"name":"TargetConfigVersionHash","value":"a4c1b0dd"}],"source":"https://ignition.controlplanehost.example.com/ignition","verification":{}}],"replace":{"verification":{}}},"proxy":{"httpProxy":"http://proxy.example.org:3128", "httpsProxy":"https://proxy.example.org:3129", "noProxy":"host.example.org"},"security":{"tls":{"certificateAuthorities":[{"source":"...","verification":{}}]}},"timeouts":{},"version":"3.2.0"},"passwd":{},"storage":{},"systemd":{}}
---14.3. API 서버에 액세스해야 하는 컴퓨팅 노드
이 사용 사례는 호스팅되는 컨트롤 플레인이 있는 AWS의 Red Hat OpenShift Service가 아닌 자체 관리형 호스팅 컨트롤 플레인과 관련이 있습니다.
컨트롤 플레인과의 통신을 위해 호스팅되는 컨트롤 플레인은 IP 주소 172.20.0.1에서 수신 대기하는 모든 컴퓨팅 노드의 로컬 프록시를 사용하고 트래픽을 API 서버로 전달합니다. API 서버에 액세스하는 데 외부 프록시가 필요한 경우 해당 로컬 프록시에서 외부 프록시를 사용하여 트래픽을 보내야 합니다. 프록시가 필요하지 않은 경우 호스팅되는 컨트롤 플레인은 TCP를 통해서만 패킷을 전달하는 로컬 프록시에 haproxy 를 사용합니다. 프록시가 필요한 경우 호스팅되는 컨트롤 플레인은 사용자 정의 프록시, control-plane-operator-kubernetes-default-proxy 를 사용하여 외부 프록시를 통해 트래픽을 보냅니다.
14.4. 외부 액세스가 필요한 관리 클러스터
HyperShift Operator에는 관리 클러스터의 OpenShift 글로벌 프록시 구성을 모니터링하고 자체 배포에서 프록시 환경 변수를 설정하는 컨트롤러가 있습니다. 외부 액세스가 필요한 컨트롤 플레인 배포는 관리 클러스터의 프록시 환경 변수를 사용하여 구성됩니다.
14.5. 보조 네트워크가 있고 기본 pod 네트워크가 없는 프록시 및 호스팅 클러스터를 사용하는 관리 클러스터
관리 클러스터가 프록시 구성을 사용하고 보조 네트워크를 사용하여 호스팅된 클러스터를 구성하지만 기본 pod 네트워크를 연결하지 않는 경우 보조 네트워크의 CIDR을 프록시 구성에 추가합니다. 특히 관리 클러스터의 프록시 구성의 noProxy 섹션에 보조 네트워크의 CIDR을 추가해야 합니다. 그렇지 않으면 Kubernetes API 서버가 프록시를 통해 일부 API 요청을 라우팅합니다. 호스팅된 클러스터 구성에서 보조 네트워크의 CIDR이 noProxy 섹션에 자동으로 추가됩니다.
15장. 호스트된 컨트롤 플레인 문제 해결
호스팅된 제어 평면에 문제가 발생하면 다음 정보를 참조하여 문제 해결을 안내받으세요.
15.1. 호스팅된 제어 평면의 문제를 해결하기 위한 정보 수집
호스팅된 클러스터의 문제를 해결해야 하는 경우 must-gather 명령을 실행하여 정보를 수집할 수 있습니다. 이 명령은 관리 클러스터와 호스팅 클러스터에 대한 출력을 생성합니다.
관리 클러스터의 출력에는 다음과 같은 내용이 포함됩니다.
- 클러스터 범위 리소스: 이러한 리소스는 관리 클러스터의 노드 정의입니다.
-
하이퍼시프트 덤프압축 파일: 이 파일은 다른 사람들과 콘텐츠를 공유해야 할 때 유용합니다. - 네임스페이스 리소스: 이 리소스에는 구성 맵, 서비스, 이벤트, 로그 등 관련 네임스페이스의 모든 개체가 포함됩니다.
- 네트워크 로그: 이 로그에는 OVN 북쪽 및 남쪽 데이터베이스와 각 데이터베이스의 상태가 포함됩니다.
- 호스팅된 클러스터: 이 수준의 출력에는 호스팅된 클러스터 내부의 모든 리소스가 포함됩니다.
호스팅된 클러스터의 출력에는 다음과 같은 내용이 포함됩니다.
- 클러스터 범위 리소스: 이 리소스에는 노드 및 CRD와 같은 모든 클러스터 범위 개체가 포함됩니다.
- 네임스페이스 리소스: 이 리소스에는 구성 맵, 서비스, 이벤트, 로그 등 관련 네임스페이스의 모든 개체가 포함됩니다.
출력에는 클러스터의 비밀 개체가 포함되지 않지만 비밀 이름에 대한 참조가 포함될 수 있습니다.
사전 요구 사항
-
관리 클러스터에 대한
클러스터 관리자액세스 권한이 있어야 합니다. -
HostedCluster리소스의name값과 CR이 배포된 네임스페이스가 필요합니다. -
hcp명령줄 인터페이스가 설치되어 있어야 합니다. 자세한 내용은 "호스트 제어 플레인 명령줄 인터페이스 설치"를 참조하세요. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
kubeconfig파일이 로드되어 관리 클러스터를 가리키는지 확인해야 합니다.
프로세스
문제 해결을 위해 출력을 수집하려면 다음 명령을 입력하세요.
$ oc adm must-gather \ --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:v<mce_version> \ /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE \ hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=NAME ; tar -cvzf NAME.tgz NAME다음과 같습니다.
-
<mce_version>을현재 사용 중인 멀티클러스터 엔진 Operator 버전으로 바꾸세요. 예:2.6. -
hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE매개변수는 선택 사항입니다. 이를 포함하지 않으면 호스팅된 클러스터가 기본 네임스페이스인clusters에 있는 것처럼 명령이 실행됩니다. -
명령 결과를 압축 파일로 저장하려면
--dest-dir=NAME매개변수를 지정하고NAME을결과를 저장할 디렉토리 이름으로 바꾸세요.
-
15.2. 호스팅된 클러스터에 대한 OpenShift 컨테이너 플랫폼 데이터 수집
멀티클러스터 엔진 Operator 웹 콘솔이나 CLI를 사용하여 호스팅된 클러스터에 대한 OpenShift Container Platform 디버깅 정보를 수집할 수 있습니다.
15.2.1. CLI를 사용하여 호스팅된 클러스터에 대한 데이터 수집
CLI를 사용하여 호스팅된 클러스터에 대한 OpenShift Container Platform 디버깅 정보를 수집할 수 있습니다.
사전 요구 사항
-
관리 클러스터에 대한
클러스터 관리자액세스 권한이 있어야 합니다. -
HostedCluster리소스의name값과 CR이 배포된 네임스페이스가 필요합니다. -
hcp명령줄 인터페이스가 설치되어 있어야 합니다. 자세한 내용은 "호스트 제어 플레인 명령줄 인터페이스 설치"를 참조하세요. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
kubeconfig파일이 로드되어 관리 클러스터를 가리키는지 확인해야 합니다.
프로세스
다음 명령을 입력하여
kubeconfig파일을 생성합니다.$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfig파일을 저장한 후 다음 예제 명령을 입력하여 호스팅된 클러스터에 액세스할 수 있습니다.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes. 다음 명령을 입력하여 반드시 수집해야 할 정보를 수집하세요.
$ oc adm must-gather
15.2.2. 웹 콘솔을 사용하여 호스팅된 클러스터에 대한 데이터 수집
멀티클러스터 엔진 Operator 웹 콘솔을 사용하여 호스팅된 클러스터에 대한 OpenShift Container Platform 디버깅 정보를 수집할 수 있습니다.
사전 요구 사항
-
관리 클러스터에 대한
클러스터 관리자액세스 권한이 있어야 합니다. -
HostedCluster리소스의name값과 CR이 배포된 네임스페이스가 필요합니다. -
hcp명령줄 인터페이스가 설치되어 있어야 합니다. 자세한 내용은 "호스트 제어 플레인 명령줄 인터페이스 설치"를 참조하세요. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
kubeconfig파일이 로드되어 관리 클러스터를 가리키는지 확인해야 합니다.
프로세스
- 웹 콘솔에서 모든 클러스터를 선택하고 문제를 해결하려는 클러스터를 선택합니다.
- 오른쪽 상단 모서리에서 kubeconfig 다운로드를 선택합니다.
-
다운로드한
kubeconfig파일을 내보냅니다. 다음 명령을 입력하여 반드시 수집해야 할 정보를 수집하세요.
$ oc adm must-gather
15.3. 연결이 끊긴 환경에서 must-gather 명령 입력
연결이 끊긴 환경에서 must-gather 명령을 실행하려면 다음 단계를 완료하세요.
프로세스
- 연결이 끊긴 환경에서 Red Hat 운영자 카탈로그 이미지를 해당 미러 레지스트리로 미러링합니다. 자세한 내용은 연결이 끊긴 네트워크에 설치를 참조하세요.
다음 명령을 실행하여 미러 레지스트리의 이미지를 참조하는 로그를 추출합니다.
REGISTRY=registry.example.com:5000 IMAGE=$REGISTRY/multicluster-engine/must-gather-rhel8@sha256:ff9f37eb400dc1f7d07a9b6f2da9064992934b69847d17f59e385783c071b9d8 $ oc adm must-gather \ --image=$IMAGE /usr/bin/gather \ hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE \ hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=./data
15.4. OpenShift Virtualization에서 호스팅된 클러스터 문제 해결
OpenShift Virtualization에서 호스팅된 클러스터의 문제를 해결할 때는 최상위 HostedCluster 및 NodePool 리소스부터 시작한 다음 근본 원인을 찾을 때까지 스택을 따라 작업합니다. 다음 단계를 따르면 일반적인 문제의 근본 원인을 발견하는 데 도움이 됩니다.
15.4.1. HostedCluster 리소스가 부분 상태에 갇혔습니다.
호스팅된 제어 평면이 HostedCluster 리소스가 보류 중이어서 완전히 온라인 상태가 되지 않는 경우, 필수 구성 요소, 리소스 조건, 노드 및 운영자 상태를 확인하여 문제를 파악합니다.
프로세스
- OpenShift Virtualization에서 호스팅된 클러스터에 대한 모든 전제 조건을 충족하는지 확인하세요.
-
진행을 방해하는 검증 오류에 대한
HostedCluster및NodePool리소스의 조건을 확인합니다. 호스팅된 클러스터의
kubeconfig파일을 사용하여 호스팅된 클러스터의 상태를 검사합니다.-
oc get clusteroperators명령의 출력을 보고 보류 중인 클러스터 운영자가 무엇인지 확인하세요. -
oc get nodes명령의 출력을 보고 작업자 노드가 준비되었는지 확인하세요.
-
15.4.2. 등록된 작업자 노드가 없습니다.
호스팅된 제어 평면에 등록된 작업자 노드가 없어 호스팅된 제어 평면이 완전히 온라인 상태가 되지 않는 경우, 호스팅된 제어 평면의 다양한 부분의 상태를 확인하여 문제를 파악합니다.
프로세스
-
문제가 무엇인지 알려주는
HostedCluster및NodePool조건을 확인하세요. NodePool리소스에 대한 KubeVirt 워커 노드 가상 머신(VM) 상태를 보려면 다음 명령을 입력하세요.$ oc get vm -n <namespace>VM이 프로비저닝 상태에 갇힌 경우 다음 명령을 입력하여 VM 네임스페이스 내의 CDI 가져오기 포드를 보고 가져오기 포드가 완료되지 않은 이유에 대한 단서를 확인하세요.
$ oc get pods -n <namespace> | grep "import"VM이 시작 상태에 멈춘 경우 다음 명령을 입력하여 virt-launcher 포드의 상태를 확인하세요.
$ oc get pods -n <namespace> -l kubevirt.io=virt-launchervirt-launcher 포드가 보류 상태인 경우 포드가 예약되지 않는 이유를 조사하세요. 예를 들어, virt-launcher 포드를 실행하기에 충분한 리소스가 없을 수 있습니다.
- VM이 실행 중이지만 작업자 노드로 등록되지 않은 경우 웹 콘솔을 사용하여 영향을 받는 VM 중 하나에 VNC 액세스 권한을 얻으세요. VNC 출력은 점화 구성이 적용되었는지 여부를 나타냅니다. VM이 시작 시 호스팅된 제어 평면 점화 서버에 액세스할 수 없는 경우 VM을 올바르게 프로비저닝할 수 없습니다.
- 점화 구성이 적용되었지만 VM이 여전히 노드로 등록되지 않는 경우 문제 식별: VM 콘솔 로그에 액세스를 참조하여 시작 중에 VM 콘솔 로그에 액세스하는 방법을 알아보세요.
15.4.3. 작업자 노드가 NotReady 상태에 갇혔습니다.
클러스터를 생성하는 동안, 네트워킹 스택이 롤아웃되는 동안 노드는 일시적으로 NotReady 상태로 전환됩니다. 이 과정의 일부는 정상적입니다. 하지만 이 프로세스의 이 부분이 15분 이상 걸리는 경우 노드 객체와 포드를 조사하여 문제를 파악하세요.
프로세스
다음 명령을 입력하여 노드 개체의 조건을 보고 노드가 준비되지 않은 이유를 확인하세요.
$ oc get nodes -o yaml클러스터 내에서 실패한 포드를 찾으려면 다음 명령을 입력하세요.
$ oc get pods -A --field-selector=status.phase!=Running,status,phase!=Succeeded
15.4.4. Ingress 및 콘솔 클러스터 운영자가 온라인 상태가 되지 않습니다.
Ingress 및 콘솔 클러스터 운영자가 온라인 상태가 아니어서 호스팅된 제어 평면이 완전히 온라인 상태가 되지 않는 경우 와일드카드 DNS 경로와 로드 밸런서를 확인하세요.
프로세스
클러스터가 기본 Ingress 동작을 사용하는 경우 다음 명령을 입력하여 가상 머신(VM)이 호스팅되는 OpenShift Container Platform 클러스터에서 와일드카드 DNS 경로가 활성화되었는지 확인하세요.
$ oc patch ingresscontroller -n openshift-ingress-operator \ default --type=json -p \ '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'호스팅된 제어 평면에 사용자 지정 기본 도메인을 사용하는 경우 다음 단계를 완료하세요.
- 로드 밸런서가 VM 포드를 올바르게 타겟팅하고 있는지 확인하세요.
- 와일드카드 DNS 항목이 로드 밸런서 IP 주소를 대상으로 하는지 확인하세요.
15.4.5. 호스팅된 클러스터에 대한 로드 밸런서 서비스를 사용할 수 없습니다.
로드 밸런서 서비스를 사용할 수 없게 되어 호스팅된 제어 평면이 완전히 온라인 상태가 되지 않는 경우 이벤트, 세부 정보 및 Kubernetes 클러스터 구성 관리자(KCCM) 포드를 확인하세요.
프로세스
- 호스팅된 클러스터 내의 로드 밸런서 서비스와 관련된 이벤트와 세부 정보를 찾아보세요.
기본적으로 호스팅된 클러스터의 로드 밸런서는 호스팅된 제어 평면 네임스페이스 내의 kubevirt-cloud-controller-manager에 의해 처리됩니다. KCCM Pod가 온라인 상태인지 확인하고 오류나 경고가 있는지 로그를 확인하세요. 호스팅된 제어 평면 네임스페이스에서 KCCM Pod를 식별하려면 다음 명령을 입력하세요.
$ oc get pods -n <hosted_control_plane_namespace> \ -l app=cloud-controller-manager
15.4.6. 호스팅된 클러스터 PVC를 사용할 수 없습니다.
호스팅된 클러스터의 영구 볼륨 클레임(PVC)을 사용할 수 없어 호스팅된 제어 평면이 완전히 온라인 상태가 되지 않는 경우 PVC 이벤트와 세부 정보, 구성 요소 로그를 확인하세요.
프로세스
- PVC와 관련된 이벤트와 세부 정보를 찾아 어떤 오류가 발생하고 있는지 파악하세요.
PVC가 포드에 연결되지 않는 경우 호스팅된 클러스터 내의 kubevirt-csi-node
데몬셋구성 요소에 대한 로그를 확인하여 문제를 자세히 조사하세요. 각 노드의 kubevirt-csi-node 포드를 식별하려면 다음 명령을 입력하세요.$ oc get pods -n openshift-cluster-csi-drivers -o wide \ -l app=kubevirt-csi-driverPVC가 영구 볼륨(PV)에 바인딩할 수 없는 경우 호스팅된 제어 평면 네임스페이스 내의 kubevirt-csi-controller 구성 요소의 로그를 확인합니다. 호스팅된 제어 평면 네임스페이스 내에서 kubevirt-csi-controller 포드를 식별하려면 다음 명령을 입력하세요.
$ oc get pods -n <hcp namespace> -l app=kubevirt-csi-driver
15.4.7. VM 노드가 클러스터에 올바르게 가입하지 않습니다.
VM 노드가 클러스터에 올바르게 가입하지 않아 호스팅된 제어 평면이 완전히 온라인 상태가 되지 않는 경우 VM 콘솔 로그에 액세스하세요.
프로세스
- VM 콘솔 로그에 액세스하려면 OpenShift Virtualization 호스팅 제어 평면 클러스터의 일부인 VM에 대한 직렬 콘솔 로그를 가져오는 방법 의 단계를 완료하세요.
15.4.8. RHCOS 이미지 미러링 실패
연결이 끊긴 환경에서 OpenShift Virtualization의 호스팅된 제어 평면의 경우, oc-mirror는 Red Hat Enterprise Linux CoreOS(RHCOS) 이미지를 내부 레지스트리에 자동으로 미러링하지 못합니다. 처음으로 호스팅 클러스터를 만들면 Kubevirt 가상 머신이 부팅되지 않습니다. 이는 내부 레지스트리에서 부팅 이미지를 사용할 수 없기 때문입니다.
이 문제를 해결하려면 RHCOS 이미지를 수동으로 내부 레지스트리에 미러링합니다.
프로세스
다음 명령을 실행하여 내부 레지스트리 이름을 가져옵니다.
$ oc get imagecontentsourcepolicy -o json \ | jq -r '.items[].spec.repositoryDigestMirrors[0].mirrors[0]'다음 명령을 실행하여 페이로드 이미지를 가져옵니다.
$ oc get clusterversion version -ojsonpath='{.status.desired.image}'호스팅된 클러스터의 페이로드 이미지에서 부트 이미지가 포함된
0000_50_installer_coreos-bootimages.yaml파일을 추출합니다.<payload_image>를페이로드 이미지의 이름으로 바꾸세요. 다음 명령을 실행합니다.$ oc image extract \ --file /release-manifests/0000_50_installer_coreos-bootimages.yaml \ <payload_image> --confirm다음 명령을 실행하여 RHCOS 이미지를 가져옵니다.
$ cat 0000_50_installer_coreos-bootimages.yaml | yq -r .data.stream \ | jq -r '.architectures.x86_64.images.kubevirt."digest-ref"'RHCOS 이미지를 내부 레지스트리로 미러링합니다.
<rhcos_image>를RHCOS 이미지로 바꾸세요. 예:quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:d9643ead36b1c026be664c9c65c11433c6cdf71bfd93ba229141d134a4a6dd94.<internal_registry>를내부 레지스트리 이름으로 바꾸세요. 예:virthost.ostest.test.metalkube.org:5000/localimages/ocp-v4.0-art-dev. 다음 명령을 실행합니다.$ oc image mirror <rhcos_image> <internal_registry>ImageDigestMirrorSet객체를 정의하는rhcos-boot-kubevirt.yaml이라는 YAML 파일을 만듭니다. 다음 예제 구성을 참조하세요.apiVersion: config.openshift.io/v1 kind: ImageDigestMirrorSet metadata: name: rhcos-boot-kubevirt spec: repositoryDigestMirrors: - mirrors: - virthost.ostest.test.metalkube.org:5000/localimages/ocp-v4.0-art-dev1 source: quay.io/openshift-release-dev/ocp-v4.0-art-dev2 다음 명령을 실행하여
rhcos-boot-kubevirt.yaml파일을 적용하여ImageDigestMirrorSet객체를 생성합니다.$ oc apply -f rhcos-boot-kubevirt.yaml
15.4.9. 베어메탈이 아닌 클러스터를 늦은 바인딩 풀로 반환합니다.
BareMetalHosts 없이 후기 바인딩 관리 클러스터를 사용하는 경우 후기 바인딩 클러스터를 삭제하고 노드를 Discovery ISO로 다시 반환하기 위해 추가 수동 단계를 완료해야 합니다.
BareMetalHosts가 없는 늦은 바인딩 관리 클러스터의 경우 클러스터 정보를 제거해도 모든 노드가 Discovery ISO로 자동으로 반환되지 않습니다.
프로세스
늦은 바인딩을 사용하여 베어메탈이 아닌 노드의 바인딩을 해제하려면 다음 단계를 완료하세요.
- 클러스터 정보를 제거합니다. 자세한 내용은 관리에서 클러스터 제거를 참조하세요.
- 루트 디스크를 정리합니다.
- Discovery ISO로 수동으로 재부팅합니다.
15.5. 베어 메탈에서 호스팅된 클러스터 문제 해결
다음 정보는 베어 메탈에서 호스팅된 제어 평면의 문제를 해결하는 데 적용됩니다.
15.5.1. 베어 메탈의 호스팅된 제어 평면에 노드를 추가하는 데 실패했습니다.
Assisted Installer를 사용하여 프로비저닝된 노드로 호스팅된 제어 평면 클러스터를 확장하는 경우 호스트는 포트 22642가 포함된 URL로 시동을 걸지 못합니다. 해당 URL은 호스팅된 제어 평면에 유효하지 않으며 클러스터에 문제가 있음을 나타냅니다.
프로세스
문제를 확인하려면 지원 서비스 로그를 검토하세요.
$ oc logs -n multicluster-engine <assisted_service_pod_name>1 - 1
- 지원 서비스 포드 이름을 지정합니다.
로그에서 다음 예와 유사한 오류를 찾으세요.
error="failed to get pull secret for update: invalid pull secret data in secret pull-secret"pull secret must contain auth for \"registry.redhat.io\"이 문제를 해결하려면 Kubernetes Operator 설명서의 멀티클러스터 엔진에서 "네임스페이스에 풀 시크릿 추가"를 참조하세요.
참고호스팅된 제어 플레인을 사용하려면 독립 실행형 운영자 또는 Red Hat Advanced Cluster Management의 일부로 멀티클러스터 엔진 운영자를 설치해야 합니다. 운영자는 Red Hat Advanced Cluster Management와 긴밀한 관계를 맺고 있으므로 운영자에 대한 설명서는 해당 제품 설명서 내에 게시됩니다. Red Hat Advanced Cluster Management를 사용하지 않더라도 멀티클러스터 엔진 운영자를 다루는 설명서의 일부는 호스팅된 제어 평면과 관련이 있습니다.
15.6. 호스팅된 제어 평면 구성 요소 다시 시작
호스팅된 제어 평면의 관리자인 경우 hypershift.openshift.io/restart-date 주석을 사용하여 특정 HostedCluster 리소스에 대한 모든 제어 평면 구성 요소를 다시 시작할 수 있습니다. 예를 들어, 인증서 순환을 위해 제어 평면 구성 요소를 다시 시작해야 할 수도 있습니다.
프로세스
제어 평면을 다시 시작하려면 다음 명령을 입력하여
HostedCluster리소스에 주석을 추가합니다.$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> \ <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)1 - 1
- 주석 값이 변경될 때마다 제어 평면이 다시 시작됩니다.
date명령은 고유한 문자열의 소스 역할을 합니다. 주석은 타임스탬프가 아닌 문자열로 처리됩니다.
검증
제어 평면을 다시 시작하면 일반적으로 다음과 같은 호스팅된 제어 평면 구성 요소가 다시 시작됩니다.
다른 구성 요소에서 구현한 변경 사항의 부작용으로 일부 추가 구성 요소가 다시 시작되는 것을 볼 수 있습니다.
- Catalog Operator
- certified-operators-catalog
- cluster-api
- cluster-autoscaler
- cluster-policy-controller
- cluster-version-operator
- community-operators-catalog
- control-plane-operator
- hosted-cluster-config-operator
- ignition-server
- Ingress Operator
- konnectivity-agent
- konnectivity-server
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- machine-approver
- oauth-openshift
- OLM Operator
- openshift-apiserver
- openshift-controller-manager
- openshift-oauth-apiserver
- packageserver
- redhat-marketplace-catalog
- redhat-operators-catalog
15.7. 호스팅된 클러스터와 호스팅된 제어 평면의 조정 일시 중지
클러스터 인스턴스 관리자인 경우 호스팅된 클러스터와 호스팅된 제어 평면의 조정을 일시 중지할 수 있습니다. etcd 데이터베이스를 백업하고 복원할 때나 호스팅된 클러스터나 호스팅된 제어 평면의 문제를 디버깅해야 할 때 조정을 일시 중지할 수 있습니다.
프로세스
호스팅된 클러스터와 호스팅된 제어 평면에 대한 조정을 일시 중지하려면
HostedCluster리소스의pausedUntil필드를 채웁니다.특정 시간까지 조정을 일시 중지하려면 다음 명령을 입력하세요.
$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"<timestamp>"}}' \ --type=merge1 - 1
- RFC339 형식으로 타임스탬프를 지정합니다(예:
2024-03-03T03:28:48Z). 지정된 시간이 지날 때까지 조정이 일시 중지됩니다.
조정을 무기한 일시 중지하려면 다음 명령을 입력하세요.
$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"true"}}' \ --type=mergeHostedCluster리소스에서 필드를 제거할 때까지 조정이 일시 중지됩니다.HostedCluster리소스에 대한 일시 중지 조정 필드가 채워지면 해당 필드가 연결된HostedControlPlane리소스에 자동으로 추가됩니다.
pausedUntil필드를 제거하려면 다음 패치 명령을 입력하세요.$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":null}}' \ --type=merge
15.8. 데이터 플레인을 0으로 축소
호스팅된 컨트롤 플레인을 사용하지 않는 경우 리소스 및 비용을 절약하기 위해 데이터 플레인을 0으로 축소할 수 있습니다.
데이터 플레인을 0으로 축소할 준비가 되었는지 확인합니다. 축소 후에는 작업자 노드의 작업 부하가 사라지기 때문입니다.
프로세스
다음 명령을 실행하여 호스팅된 클러스터에 액세스하도록
kubeconfig파일을 설정합니다.$ export KUBECONFIG=<install_directory>/auth/kubeconfig다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 축소합니다.$ oc get nodepool --namespace <hosted_cluster_namespace>선택 사항: 포드가 비워지는 것을 방지하려면 다음 명령을 실행하여
NodePool리소스에nodeDrainTimeout필드를 추가합니다.$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>출력 예
apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: arch: amd64 clusterName: clustername1 management: autoRepair: false replace: rollingUpdate: maxSurge: 1 maxUnavailable: 0 strategy: RollingUpdate upgradeType: Replace nodeDrainTimeout: 0s2 # ...참고노드 드레이닝 프로세스가 일정 기간 동안 계속되도록 하려면
nodeDrainTimeout필드 값을 적절하게 설정할 수 있습니다(예:nodeDrainTimeout: 1m).다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 축소합니다.$ oc scale nodepool/<nodepool_name> --namespace <hosted_cluster_namespace> \ --replicas=0참고데이터 계획을 0으로 축소한 후 컨트롤 플레인의 일부 Pod는
Pending상태를 유지하고 호스팅된 컨트롤 플레인은 계속 실행 중입니다. 필요한 경우NodePool리소스를 확장할 수 있습니다.다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 축소합니다.$ oc scale nodepool/<nodepool_name> --namespace <hosted_cluster_namespace> --replicas=1NodePool리소스의 크기를 조정한 후NodePool리소스가준비상태로 사용 가능해질 때까지 몇 분간 기다립니다.
검증
다음 명령을 실행하여
nodeDrainTimeout필드의 값이0보다 큰지 확인하세요.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -ojsonpath='{.spec.nodeDrainTimeout}'
15.9. 에이전트 서비스 오류 및 에이전트가 클러스터에 가입하지 않음
어떤 경우에는 에이전트가 부트 아티팩트가 있는 머신을 부팅한 후 클러스터에 가입하지 못할 수 있습니다. 다음 오류가 있는지 agent.service 로그를 확인하여 이 문제를 확인할 수 있습니다.
Error: copying system image from manifest list: Source image rejected: A signature was required, but no signature exists이 문제는 서명이 없으면 이미지 서명 검증이 실패하기 때문에 발생합니다. 해결 방법으로 컨테이너 정책을 수정하여 서명 확인을 비활성화할 수 있습니다.
프로세스
-
InfraEnv매니페스트에ignitionConfigOverride필드를 추가하여/etc/containers/policy.json파일을 재정의합니다. 이렇게 하면 컨테이너 이미지에 대한 서명 확인이 비활성화됩니다. 이미지 레지스트리에 따라
ignitionConfigOverride의 base64로 인코딩된 내용을 필요한/etc/containers/policy.json구성으로 바꿉니다.예
{ "default": [ { "type": "insecureAcceptAnything" } ], "transports": { "docker": { "<REGISTRY1>": [ { "type": "insecureAcceptAnything" } ], "REGISTRY2": [ { "type": "insecureAcceptAnything" } ] }, "docker-daemon": { "": [ { "type": "insecureAcceptAnything" } ] } } }ignitionConfigOverride를사용한 InfraEnv 매니페스트 예시apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_control_plane_namespace> spec: cpuArchitecture: s390x pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key> ignitionConfigOverride: '{"ignition":{"version":"3.2.0"},"storage":{"files":[{"path":"/etc/containers/policy.json","mode":420,"overwrite":true,"contents":{"source":"data:text/plain;charset=utf-8;base64,ewogICAgImRlZmF1bHQiOiBbCiAgICAgICAgewogICAgICAgICAgICAidHlwZSI6ICJpbnNlY3VyZUFjY2VwdEFueXRoaW5nIgogICAgICAgIH0KICAgIF0sCiAgICAidHJhbnNwb3J0cyI6CiAgICAgICAgewogICAgICAgICAgICAiZG9ja2VyLWRhZW1vbiI6CiAgICAgICAgICAgICAgICB7CiAgICAgICAgICAgICAgICAgICAgIiI6IFt7InR5cGUiOiJpbnNlY3VyZUFjY2VwdEFueXRoaW5nIn1dCiAgICAgICAgICAgICAgICB9CiAgICAgICAgfQp9"}}]}}'
16장. 호스팅된 클러스터 파괴
16.1. AWS에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 Amazon Web Services(AWS)에서 호스팅된 클러스터와 관리되는 클러스터 리소스를 삭제할 수 있습니다.
16.1.1. CLI를 사용하여 AWS에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 Amazon Web Services(AWS)에 호스팅된 클러스터를 파괴할 수 있습니다.
프로세스
다음 명령을 실행하여 멀티클러스터 엔진 Operator에서 관리되는 클러스터 리소스를 삭제합니다.
$ oc delete managedcluster <hosted_cluster_name>1 - 1
<hosted_cluster_name>을클러스터 이름으로 바꾸세요.
다음 명령을 실행하여 호스팅된 클러스터와 백엔드 리소스를 삭제합니다.
$ hcp destroy cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --role-arn <arn_role> \3 --sts-creds <path_to_sts_credential_file> \4 --base-domain <basedomain>5 중요AWS 보안 토큰 서비스(STS)의 세션 토큰이 만료된 경우 다음 명령을 실행하여
sts-creds.json이라는 JSON 파일에서 STS 자격 증명을 검색합니다.$ aws sts get-session-token --output json > sts-creds.json
16.2. 베어 메탈에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)나 멀티클러스터 엔진 Operator 웹 콘솔을 사용하여 베어 메탈에서 호스팅된 클러스터를 삭제할 수 있습니다.
16.2.1. CLI를 사용하여 베어 메탈에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 호스팅 클러스터를 만든 경우 명령을 실행하여 해당 호스팅 클러스터와 백엔드 리소스를 삭제할 수 있습니다.
프로세스
다음 명령을 실행하여 호스팅된 클러스터와 백엔드 리소스를 삭제합니다.
$ oc delete -f <hosted_cluster_config>.yaml1 - 1
- 호스팅된 클러스터를 생성할 때 렌더링된 구성 YAML 파일의 이름을 지정합니다.
참고구성 파일에서
--render및--render-sensitive플래그를 지정하지 않고 호스팅된 클러스터를 만든 경우 백엔드 리소스를 수동으로 제거해야 합니다.
16.2.2. 웹 콘솔을 사용하여 베어 메탈에서 호스팅된 클러스터 파괴
멀티클러스터 엔진 Operator 웹 콘솔을 사용하여 베어 메탈에서 호스팅된 클러스터를 삭제할 수 있습니다.
프로세스
- 콘솔에서 인프라 → 클러스터를 클릭합니다.
- 클러스터 페이지에서 삭제하려는 클러스터를 선택합니다.
- 클러스터를 제거하려면 작업 메뉴에서 클러스터 삭제를 선택합니다.
16.3. OpenShift Virtualization에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 OpenShift Virtualization에서 호스팅된 클러스터와 관리되는 클러스터 리소스를 삭제할 수 있습니다.
16.3.1. CLI를 사용하여 OpenShift Virtualization에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 OpenShift Virtualization에서 호스팅된 클러스터와 관리되는 클러스터 리소스를 삭제할 수 있습니다.
프로세스
다음 명령을 실행하여 멀티클러스터 엔진 Operator에서 관리되는 클러스터 리소스를 삭제합니다.
$ oc delete managedcluster <hosted_cluster_name>다음 명령을 실행하여 호스팅된 클러스터와 백엔드 리소스를 삭제합니다.
$ hcp destroy cluster kubevirt --name <hosted_cluster_name>
16.4. IBM Z에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 IBM Z 컴퓨트 노드와 관리형 클러스터 리소스가 있는 x86 베어 메탈에서 호스팅된 클러스터를 삭제할 수 있습니다.
16.4.1. IBM Z 컴퓨트 노드를 사용하여 x86 베어 메탈에서 호스팅된 클러스터 파괴
IBM Z® 컴퓨트 노드를 사용하여 x86 베어 메탈에서 호스팅된 클러스터와 관리되는 클러스터를 파괴하려면 명령줄 인터페이스(CLI)를 사용할 수 있습니다.
프로세스
다음 명령을 실행하여
NodePool개체의 노드 수를0개로 조정합니다.$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> \ --replicas 0NodePool객체가0으로 축소되면 컴퓨팅 노드가 호스팅된 클러스터에서 분리됩니다. OpenShift Container Platform 버전 4.17에서는 이 기능이 KVM이 있는 IBM Z에만 적용됩니다. z/VM 및 LPAR의 경우 컴퓨팅 노드를 수동으로 삭제해야 합니다.클러스터에 컴퓨팅 노드를 다시 연결하려면 원하는 컴퓨팅 노드 수만큼
NodePool객체를 확장할 수 있습니다. z/VM과 LPAR이 에이전트를 재사용하려면Discovery이미지를 사용하여 에이전트를 다시 만들어야 합니다.중요컴퓨팅 노드가 호스팅된 클러스터에서 분리되지 않았거나
준비되지 않음상태에 갇힌 경우 다음 명령을 실행하여 컴퓨팅 노드를 수동으로 삭제하세요.$ oc --kubeconfig <hosted_cluster_name>.kubeconfig delete \ node <compute_node_name>PR/SM(Processor Resource/Systems Manager) 모드에서 OSA 네트워크 장치를 사용하는 경우 자동 크기 조정이 지원되지 않습니다. 축소 프로세스 중에 새 에이전트가 합류하므로 기존 에이전트를 수동으로 삭제하고 노드 풀을 확장해야 합니다.
다음 명령을 입력하여 컴퓨팅 노드의 상태를 확인하세요.
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes컴퓨팅 노드가 호스팅된 클러스터에서 분리되면 에이전트의 상태가
자동 할당으로 변경됩니다.다음 명령을 실행하여 클러스터에서 에이전트를 삭제합니다.
$ oc -n <hosted_control_plane_namespace> delete agent <agent_name>참고클러스터에서 에이전트를 삭제한 후 에이전트로 생성한 가상 머신을 삭제할 수 있습니다.
다음 명령을 실행하여 호스팅된 클러스터를 삭제합니다.
$ hcp destroy cluster agent --name <hosted_cluster_name> \ --namespace <hosted_cluster_namespace>
16.5. IBM Power에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)를 사용하여 IBM Power에 호스팅된 클러스터를 삭제할 수 있습니다.
16.5.1. CLI를 사용하여 IBM Power에서 호스팅된 클러스터 파괴
IBM Power에서 호스팅된 클러스터를 파괴하려면 hcp 명령줄 인터페이스(CLI)를 사용할 수 있습니다.
프로세스
다음 명령을 실행하여 호스팅된 클러스터를 삭제합니다.
$ hcp destroy cluster agent --name=<hosted_cluster_name> \1 --namespace=<hosted_cluster_namespace> \2 --cluster-grace-period <duration>3
16.6. OpenStack에서 호스팅된 제어 평면 파괴
16.6.1. CLI를 사용하여 호스팅된 클러스터 파괴
hcp CLI 도구를 사용하여 Red Hat OpenStack Platform(RHOSP)에서 호스팅된 클러스터와 관련 리소스를 삭제할 수 있습니다.
사전 요구 사항
-
호스팅된 제어 평면 CLI인
hcp를설치했습니다.
프로세스
클러스터와 관련 리소스를 삭제하려면 다음 명령을 실행하세요.
$ hcp destroy cluster openstack --name=<cluster_name>다음과 같습니다.
<cluster_name>- 호스팅된 클러스터의 이름입니다.
프로세스가 완료되면 모든 클러스터와 해당 클러스터에 연결된 모든 리소스가 삭제됩니다.
16.7. 베어메탈이 아닌 에이전트 머신에서 호스팅된 클러스터 파괴
명령줄 인터페이스(CLI)나 멀티클러스터 엔진 Operator 웹 콘솔을 사용하여 베어메탈이 아닌 에이전트 머신에서 호스팅된 클러스터를 삭제할 수 있습니다.
16.7.1. 베어 메탈이 아닌 에이전트 시스템에서 호스트 클러스터 제거
hcp CLI(명령줄 인터페이스)를 사용하여 비bare-metal 에이전트 시스템에서 호스팅된 클러스터를 제거할 수 있습니다.
프로세스
다음 명령을 실행하여 호스팅된 클러스터 및 해당 백엔드 리소스를 삭제합니다.
$ hcp destroy cluster agent --name <hosted_cluster_name>1 - 1
- &
lt;hosted_cluster_name>을 호스트된 클러스터 이름으로 바꿉니다.
16.7.2. 웹 콘솔을 사용하여 베어 메탈이 아닌 에이전트 시스템에서 호스트 클러스터 제거
다중 클러스터 엔진 Operator 웹 콘솔을 사용하여 베어 메탈이 아닌 에이전트 머신에서 호스트된 클러스터를 제거할 수 있습니다.
프로세스
- 콘솔에서 인프라 → 클러스터를 클릭합니다.
- 클러스터 페이지에서 삭제할 클러스터를 선택합니다.
- 작업 메뉴에서 클러스터 삭제 를 선택하여 클러스터를 제거합니다.
17장. 수동으로 호스트 클러스터 가져오기
호스팅된 컨트롤 플레인을 사용할 수 있게 되면 호스팅된 클러스터는 멀티 클러스터 엔진 Operator로 자동으로 가져옵니다.
17.1. 가져온 호스팅 클러스터를 관리하는 데 대한 제한 사항
호스팅된 클러스터는 독립 실행형 OpenShift Container Platform 또는 타사 클러스터와 달리 Kubernetes Operator의 로컬 멀티 클러스터 엔진으로 자동으로 가져옵니다. 호스팅된 클러스터는 에이전트에서 클러스터의 리소스를 사용하지 않도록 호스팅 모드에서 일부 에이전트를 실행합니다.
호스팅된 클러스터를 자동으로 가져오는 경우 관리 클러스터에서 HostedCluster 리소스를 사용하여 호스팅된 클러스터에서 노드 풀과 컨트롤 플레인을 업데이트할 수 있습니다. 노드 풀과 컨트롤 플레인을 업데이트하려면 "호스트 클러스터에서 노드 풀 업그레이드" 및 "호스팅 클러스터에서 컨트롤 플레인 업그레이드"를 참조하십시오.
RHACM(Red Hat Advanced Cluster Management)을 사용하여 호스팅된 클러스터를 로컬 다중 클러스터 엔진 Operator 이외의 위치로 가져올 수 있습니다. 자세한 내용은 "Red Hat Advanced Cluster Management에서 Kubernetes Operator가 호스팅하는 클러스터에 대한 멀티클러스터 엔진 검색"을 참조하세요.
이 토폴로지에서는 클러스터가 호스팅되는 Kubernetes Operator의 로컬 멀티클러스터 엔진의 명령줄 인터페이스나 콘솔을 사용하여 호스팅된 클러스터를 업데이트해야 합니다. RHACM 허브 클러스터를 통해 호스팅된 클러스터를 업데이트할 수 없습니다.
17.3. 호스팅된 클러스터를 수동으로 가져오기
호스팅된 클러스터를 수동으로 가져오려면 다음 단계를 완료하세요.
프로세스
- 콘솔에서 인프라 → 클러스터를 클릭하고 가져오려는 호스팅 클러스터를 선택합니다.
호스팅된 클러스터 가져오기를 클릭합니다.
참고검색된 호스팅 클러스터의 경우 콘솔에서 가져올 수도 있지만, 클러스터가 업그레이드 가능한 상태여야 합니다. 호스팅된 제어 평면을 사용할 수 없어 호스팅된 클러스터가 업그레이드 가능한 상태가 아닌 경우 클러스터에서 가져오기가 비활성화됩니다. 가져오기를 클릭하여 프로세스를 시작하세요. 클러스터가 업데이트를 수신하는 동안은 상태가
'가져오기'이고, 그런 다음'준비'로 변경됩니다.
17.4. AWS에서 호스팅된 클러스터를 수동으로 가져오기
명령줄 인터페이스를 사용하여 Amazon Web Services(AWS)에 호스팅된 클러스터를 가져올 수도 있습니다.
프로세스
다음 샘플 YAML 파일을 사용하여
ManagedCluster리소스를 만듭니다.apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: import.open-cluster-management.io/hosting-cluster-name: local-cluster import.open-cluster-management.io/klusterlet-deploy-mode: Hosted open-cluster-management/created-via: hypershift labels: cloud: auto-detect cluster.open-cluster-management.io/clusterset: default name: <hosted_cluster_name>1 vendor: OpenShift name: <hosted_cluster_name> spec: hubAcceptsClient: true leaseDurationSeconds: 60- 1
<hosted_cluster_name>을호스팅 클러스터의 이름으로 바꾸세요.
다음 명령을 실행하여 리소스를 적용합니다.
$ oc apply -f <file_name>1 - 1
<file_name>을이전 단계에서 만든 YAML 파일 이름으로 바꾸세요.
Red Hat Advanced Cluster Management가 설치되어 있는 경우 다음 샘플 YAML 파일을 사용하여
KlusterletAddonConfig리소스를 만듭니다. 멀티클러스터 엔진 오퍼레이터만 설치한 경우 이 단계를 건너뜁니다.apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: clusterName: <hosted_cluster_name> clusterNamespace: <hosted_cluster_namespace> clusterLabels: cloud: auto-detect vendor: auto-detect applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: false다음 명령을 실행하여 리소스를 적용합니다.
$ oc apply -f <file_name>1 - 1
<file_name>을이전 단계에서 만든 YAML 파일 이름으로 바꾸세요.
가져오기 프로세스가 완료되면 호스팅된 클러스터가 콘솔에 표시됩니다. 다음 명령을 실행하여 호스팅된 클러스터의 상태를 확인할 수도 있습니다.
$ oc get managedcluster <hosted_cluster_name>
17.5. 호스팅된 클러스터를 멀티클러스터 엔진 운영자로 자동 가져오기 비활성화
제어 평면이 사용 가능해지면 호스팅된 클러스터가 자동으로 멀티클러스터 엔진 운영자로 가져옵니다. 필요한 경우 호스팅된 클러스터의 자동 가져오기를 비활성화할 수 있습니다.
자동 가져오기를 비활성화하더라도 이전에 가져온 호스팅된 클러스터는 영향을 받지 않습니다. 멀티클러스터 엔진 Operator 2.5로 업그레이드하고 자동 가져오기가 활성화된 경우, 제어 평면을 사용할 수 있는 경우 가져오지 않은 모든 호스팅 클러스터가 자동으로 가져옵니다.
Red Hat Advanced Cluster Management가 설치된 경우 모든 Red Hat Advanced Cluster Management 애드온도 활성화됩니다.
자동 가져오기가 비활성화된 경우 새로 생성된 호스팅 클러스터만 자동으로 가져오지 않습니다. 이미 가져온 호스팅 클러스터는 영향을 받지 않습니다. 콘솔을 사용하거나 ManagedCluster 및 KlusterletAddonConfig 사용자 정의 리소스를 만들어 클러스터를 수동으로 가져올 수 있습니다.
프로세스
호스팅된 클러스터의 자동 가져오기를 비활성화하려면 다음 단계를 완료하세요.
허브 클러스터에서 다음 명령을 입력하여 multicluster engine Operator가 설치된 네임스페이스의
AddonDeploymentConfig리소스에 있는hypershift-addon-deploy-config사양을 엽니다.$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine다음 예제와 같이
spec.customizedVariables섹션에서 값이"true"인autoImportDisabled변수를 추가합니다.apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: autoImportDisabled value: "true"-
자동 가져오기를 다시 활성화하려면
autoImportDisabled변수의 값을"false"로 설정하거나AddonDeploymentConfig리소스에서 해당 변수를 제거하세요.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.