Operator
OpenShift Container Platform의 Operator 작업
초록
1장. Operator 개요
Operator는 OpenShift Container Platform의 가장 중요한 구성 요소 중 하나입니다. Operator는 컨트롤 플레인에서 서비스를 패키징, 배포 및 관리하는 기본 방법입니다. 또한 사용자가 실행하는 애플리케이션에 이점을 제공할 수 있습니다.
Operator는 kubectl 및 oc 명령과 같은 CLI 툴 및 Kubernetes API와 통합됩니다. 애플리케이션 모니터링, 상태 점검 수행, OTA(Over-the-air) 업데이트 관리 및 애플리케이션이 지정된 상태로 유지되도록 하는 수단을 제공합니다.
두 가지 모두 유사한 Operator 개념과 목표를 따르지만 OpenShift Container Platform의 Operator는 목적에 따라 서로 다른 두 시스템에서 관리합니다.
- CVO(Cluster Version Operator)에서 관리하는 Platform Operator는 클러스터 기능을 수행하기 위해 기본적으로 설치됩니다.
- OLM(Operator Lifecycle Manager)에서 관리하는 선택적 추가 기능 Operator는 사용자가 애플리케이션에서 실행할 수 있도록 액세스할 수 있습니다.
Operator를 사용하면 클러스터에서 실행 중인 서비스를 모니터링할 수 있는 애플리케이션을 생성합니다. Operator는 애플리케이션을 위해 특별히 설계되었습니다. Operator는 설치 및 구성과 같은 일반적인 Day 1 작업과 자동 확장 및 축소 및 백업과 같은 Day 2 작업을 구현하고 자동화합니다. 이러한 모든 활동은 클러스터 내에서 실행되는 소프트웨어입니다.
1.1. 개발자의 경우
개발자는 다음 Operator 작업을 수행할 수 있습니다.
1.2. 관리자의 경우
클러스터 관리자는 다음 Operator 작업을 수행할 수 있습니다.
operator-sdk CLI에서 생성된 파일 및 디렉터리에 대한 자세한 내용은 Appendices를 참조하십시오.
Red Hat Operator에 대한 모든 정보를 알아보려면 Red Hat Operator를 참조하십시오.
1.3. 다음 단계
Operator에 대한 자세한 내용은 Operator를 참조하십시오. https://access.redhat.com/documentation/en-us/openshift_container_platform/4.6/html-single/operators/#olm-what-operators-are
2장. Operator 이해
2.1. Operator란 무엇인가?
개념적으로 Operator는 사람의 운영 지식을 소비자와 더 쉽게 공유할 수 있는 소프트웨어로 인코딩합니다.
Operator는 다른 소프트웨어를 실행하는 데 따르는 운영의 복잡성을 완화해주는 소프트웨어입니다. OpenShift Container Platform과 같은 Kubernetes 환경을 조사하고 현재 상태를 사용하여 실시간으로 의사 결정을 내리는 소프트웨어 벤더의 엔지니어링 팀의 확장 기능처럼 작동합니다. 고급 Operator는 업그레이드를 원활하게 처리하고 오류에 자동으로 대응하며 시간을 절약하기 위해 소프트웨어 백업 프로세스를 생략하는 등의 바로 가기를 실행하지 않습니다.
Operator는 Kubernetes 애플리케이션을 패키징, 배포, 관리하는 메서드입니다.
Kubernetes 애플리케이션은 Kubernetes API 및 kubectl 또는 oc 툴링을 사용하여 Kubernetes API에 배포하고 관리하는 앱입니다. Kubernetes를 최대한 활용하기 위해서는 Kubernetes에서 실행되는 앱을 제공하고 관리하기 위해 확장할 응집력 있는 일련의 API가 필요합니다. Operator는 Kubernetes에서 이러한 유형의 앱을 관리하는 런타임으로 생각할 수 있습니다.
2.1.1. Operator를 사용하는 이유는 무엇입니까?
Operator는 다음과 같은 기능을 제공합니다.
- 반복된 설치 및 업그레이드.
- 모든 시스템 구성 요소에 대한 지속적인 상태 점검.
- OpenShift 구성 요소 및 ISV 콘텐츠에 대한 OTA(Over-The-Air) 업데이트
- 필드 엔지니어의 지식을 캡슐화하여 한두 명이 아닌 모든 사용자에게 전파.
- Kubernetes에 배포하는 이유는 무엇입니까?
- Kubernetes(및 확장으로)에는 온프레미스 및 클라우드 공급자 전체에서 작동하는 복잡한 분산 시스템을 빌드하는 데 필요한 모든 기본 기능(비밀 처리, 로드 밸런싱, 서비스 검색, 자동 스케일링)이 포함되어 있습니다.
- Kubernetes API 및
kubectl툴링으로 앱을 관리하는 이유는 무엇입니까? -
이러한 API는 기능이 다양하고 모든 플랫폼에 대한 클라이언트가 있으며 클러스터의 액세스 제어/감사에 연결됩니다. Operator는 Kubernetes 확장 메커니즘인 CRD(사용자 정의 리소스 정의)를 사용하므로 사용자 정의 오브젝트(예:
MongoDB)가 기본 제공되는 네이티브 Kubernetes 오브젝트처럼 보이고 작동합니다. - Operator는 서비스 브로커와 어떻게 다릅니까?
- 서비스 브로커는 앱의 프로그래밍 방식 검색 및 배포를 위한 단계입니다. 그러나 오래 실행되는 프로세스가 아니므로 업그레이드, 장애 조치 또는 스케일링과 같은 2일 차 작업을 실행할 수 없습니다. 튜닝할 수 있는 항목에 대한 사용자 정의 및 매개변수화는 설치 시 제공되지만 Operator는 클러스터의 현재 상태를 지속적으로 관찰합니다. 클러스터 외부 서비스는 서비스 브로커에 적합하지만 해당 서비스를 위한 Operator도 있습니다.
2.1.2. Operator 프레임워크
Operator 프레임워크는 위에서 설명한 고객 경험을 제공하는 툴 및 기능 제품군입니다. 코드를 작성하는 데 그치지 않고 Operator를 테스트, 제공, 업데이트하는 것이 중요합니다. Operator 프레임워크 구성 요소는 이러한 문제를 해결하는 오픈 소스 툴로 구성됩니다.
- Operator SDK
- Operator SDK는 Operator 작성자가 Kubernetes API 복잡성에 대한 지식이 없어도 전문 지식을 기반으로 자체 Operator를 부트스트랩, 빌드, 테스트, 패키지할 수 있도록 지원합니다.
- Operator Lifecycle Manager
- OLM(Operator Lifecycle Manager)은 클러스터에서 Operator의 설치, 업그레이드, RBAC(역할 기반 액세스 제어)를 제어합니다. OpenShift Container Platform 4.6에 기본적으로 배포됩니다.
- Operator 레지스트리
- Operator 레지스트리는 CSV(클러스터 서비스 버전) 및 CRD(사용자 정의 리소스 정의)를 클러스터에 생성하기 위해 저장하고 패키지 및 채널에 대한 Operator 메타데이터를 저장합니다. 이 Operator 카탈로그 데이터를 OLM에 제공하기 위해 Kubernetes 또는 OpenShift 클러스터에서 실행됩니다.
- OperatorHub
- OperatorHub는 클러스터 관리자가 클러스터에 설치할 Operator를 검색하고 선택할 수 있는 웹 콘솔입니다. OpenShift Container Platform에 기본적으로 배포됩니다.
이러한 툴은 구성 가능하도록 설계되어 있어 유용한 툴을 모두 사용할 수 있습니다.
2.1.3. Operator 완성 모델
Operator 내에 캡슐화된 관리 논리의 세분화 수준은 다를 수 있습니다. 이 논리는 일반적으로 Operator에서 표시하는 서비스 유형에 따라 크게 달라집니다.
그러나 대부분의 Operator에 포함될 수 있는 특정 기능 세트의 경우 캡슐화된 Operator 작업의 완성 정도를 일반화할 수 있습니다. 이를 위해 다음 Operator 완성 모델에서는 Operator의 일반적인 2일 차 작업에 대해 5단계 완성도를 정의합니다.
그림 2.1. Operator 완성 모델
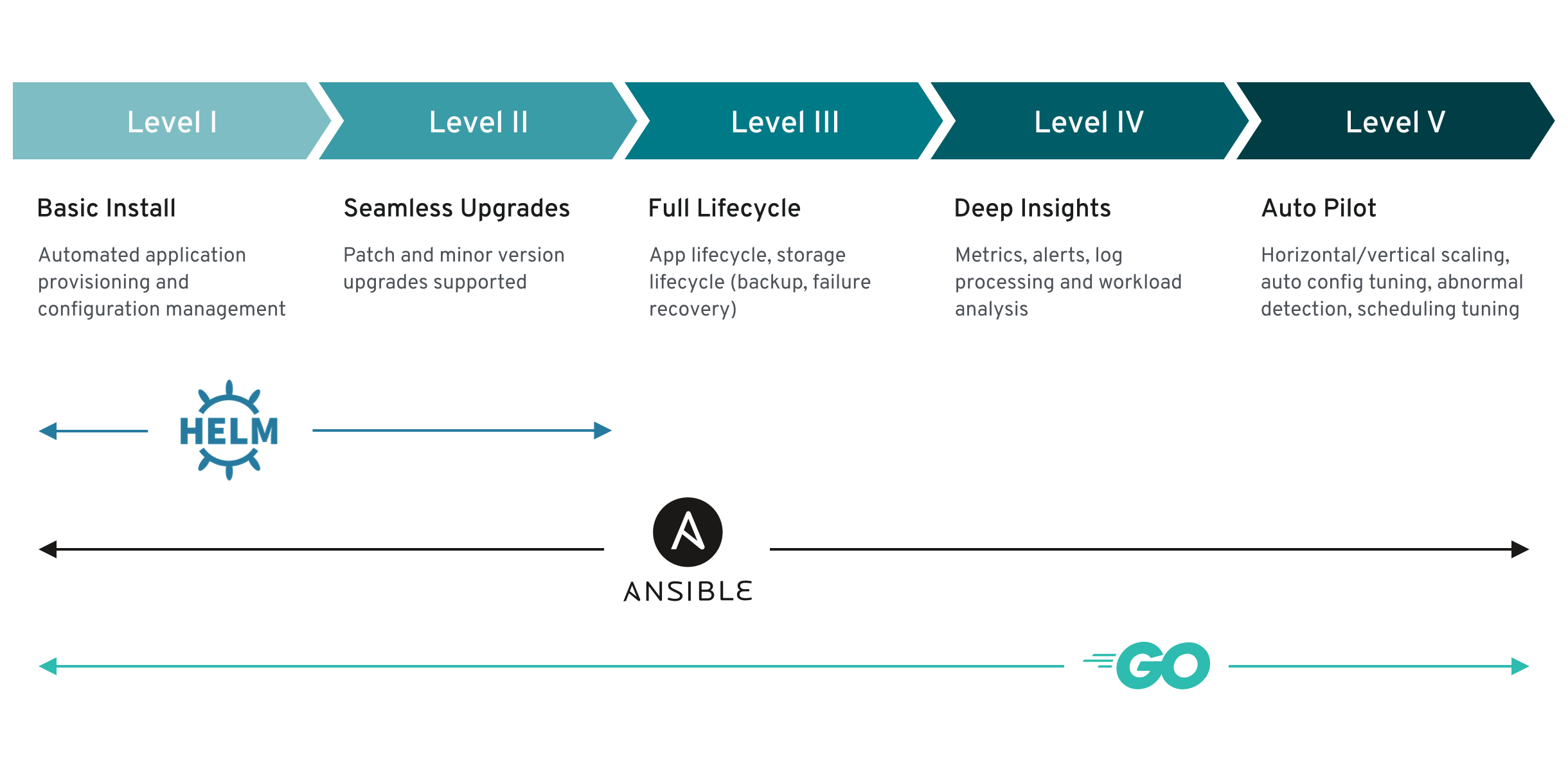
또한 위 모델은 Operator SDK의 Helm, Go, Ansible 기능을 통해 이러한 기능을 가장 잘 개발할 수 있는 방법을 보여줍니다.
2.2. Operator 프레임워크 일반 용어집
이 주제에서는 두 패키징 형식에 대해 OLM(Operator Lifecycle Manager) 및 Operator SDK를 포함하여 Operator 프레임워크와 관련된 일반 용어집을 제공합니다. 패키지 매니페스트 형식 및 번들 형식.
2.2.1. 일반 Operator 프레임워크 용어
2.2.1.1. 번들
번들 형식에서 번들은 Operator CSV, 매니페스트, 메타데이터로 이루어진 컬렉션입니다. 이러한 구성 요소가 모여 클러스터에 설치할 수 있는 고유한 버전의 Operator를 형성합니다.
2.2.1.2. 번들 이미지
번들 형식에서 번들 이미지는 Operator 매니페스트에서 빌드하고 하나의 번들을 포함하는 컨테이너 이미지입니다. 번들 이미지는 Quay.io 또는 DockerHub와 같은 OCI(Open Container Initiative) 사양 컨테이너 레지스트리에서 저장 및 배포합니다.
2.2.1.3. 카탈로그 소스
카탈로그 소스는 애플리케이션을 정의하는 CSV, CRD, 패키지의 리포지토리입니다.
2.2.1.4. 카탈로그 이미지
패키지 매니페스트 형식에서 카탈로그 이미지는 OLM을 사용하여 클러스터에 설치할 수 있는 Operator 메타데이터 및 업데이트 메타데이터 세트를 설명하는 컨테이너화된 데이터 저장소입니다.
2.2.1.5. 채널
채널은 Operator의 업데이트 스트림을 정의하고 구독자에게 업데이트를 배포하는 데 사용됩니다. 헤드는 해당 채널의 최신 버전을 가리킵니다. 예를 들어 stable 채널에는 Operator의 모든 안정적인 버전이 가장 오래된 것부터 최신 순으로 정렬되어 있습니다.
Operator에는 여러 개의 채널이 있을 수 있으며 특정 채널에 대한 서브스크립션 바인딩에서는 해당 채널의 업데이트만 찾습니다.
2.2.1.6. 채널 헤드
채널 헤드는 알려진 특정 채널의 최신 업데이트를 나타냅니다.
2.2.1.7. 클러스터 서비스 버전
CSV(클러스터 서비스 버전)는 Operator 메타데이터에서 생성하는 YAML 매니페스트로, OLM이 클러스터에서 Operator를 실행하는 것을 지원합니다. 로고, 설명, 버전과 같은 정보로 사용자 인터페이스를 채우는 데 사용되는 Operator 컨테이너 이미지와 함께 제공되는 메타데이터입니다.
또한 필요한 RBAC 규칙 및 관리하거나 사용하는 CR(사용자 정의 리소스)과 같이 Operator를 실행하는 데 필요한 기술 정보의 소스이기도 합니다.
2.2.1.8. 종속성
Operator는 클러스터에 있는 다른 Operator에 종속되어 있을 수 있습니다. 예를 들어 Vault Operator는 데이터 지속성 계층과 관련하여 etcd Operator에 종속됩니다.
OLM은 설치 단계 동안 지정된 모든 버전의 Operator 및 CRD가 클러스터에 설치되도록 하여 종속 항목을 해결합니다. 이러한 종속성은 필수 CRD API를 충족하고 패키지 또는 번들과 관련이 없는 카탈로그에서 Operator를 찾아 설치함으로써 해결할 수 있습니다.
2.2.1.9. 인덱스 이미지
번들 형식에서 인덱스 이미지는 모든 버전의 CSV 및 CRD를 포함하여 Operator 번들에 대한 정보를 포함하는 데이터베이스 이미지(데이터베이스 스냅샷)를 나타냅니다. 이 인덱스는 클러스터에서 Operator 기록을 호스팅하고 opm CLI 툴을 사용하여 Operator를 추가하거나 제거하는 방식으로 유지 관리할 수 있습니다.
2.2.1.10. 설치 계획
설치 계획은 CSV를 자동으로 설치하거나 업그레이드하기 위해 생성하는 계산된 리소스 목록입니다.
2.2.1.11. Operator group
Operator group은 동일한 네임스페이스에 배포된 모든 Operator를 OperatorGroup 오브젝트로 구성하여 네임스페이스 목록 또는 클러스터 수준에서 CR을 조사합니다.
2.2.1.12. 패키지
번들 형식에서 패키지는 각 버전과 함께 Operator의 모든 릴리스 내역을 포함하는 디렉터리입니다. 릴리스된 Operator 버전은 CRD와 함께 CSV 매니페스트에 설명되어 있습니다.
2.2.1.13. 레지스트리
레지스트리는 각각 모든 채널의 최신 버전 및 이전 버전이 모두 포함된 Operator의 번들 이미지를 저장하는 데이터베이스입니다.
2.2.1.14. Subscription
서브스크립션은 패키지의 채널을 추적하여 CSV를 최신 상태로 유지합니다.
2.2.1.15. 업데이트 그래프
업데이트 그래프는 패키지된 다른 소프트웨어의 업데이트 그래프와 유사하게 CSV 버전을 함께 연결합니다. Operator를 순서대로 설치하거나 특정 버전을 건너뛸 수 있습니다. 업데이트 그래프는 최신 버전이 추가됨에 따라 앞부분에서만 증가할 것으로 예상됩니다.
2.3. Operator 프레임워크 패키지 형식
이 가이드에서는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager)에서 지원하는 Operator의 패키지 형식에 대해 간단히 설명합니다.
2.3.1. 번들 형식
Operator의 번들 형식은 Operator 프레임워크에서 도입한 새로운 패키지 형식입니다. 번들 형식 사양에서는 확장성을 개선하고 자체 카탈로그를 호스팅하는 업스트림 사용자를 더 효과적으로 지원하기 위해 Operator 메타데이터의 배포를 단순화합니다.
Operator 번들은 단일 버전의 Operator를 나타냅니다. 디스크상의 번들 매니페스트는 컨테이너화되어 번들 이미지(Kubernetes 매니페스트와 Operator 메타데이터를 저장하는 실행 불가능한 컨테이너 이미지)로 제공됩니다. 그런 다음 podman 및 docker와 같은 기존 컨테이너 툴과 Quay와 같은 컨테이너 레지스트리를 사용하여 번들 이미지의 저장 및 배포를 관리합니다.
Operator 메타데이터에는 다음이 포함될 수 있습니다.
- Operator 확인 정보(예: 이름 및 버전)
- UI를 구동하는 추가 정보(예: 아이콘 및 일부 예제 CR(사용자 정의 리소스))
- 필요한 API 및 제공된 API.
- 관련 이미지.
Operator 레지스트리 데이터베이스에 매니페스트를 로드할 때 다음 요구 사항이 검증됩니다.
- 번들의 주석에 하나 이상의 채널이 정의되어 있어야 합니다.
- 모든 번들에 정확히 하나의 CSV(클러스터 서비스 버전)가 있습니다.
- CSV에 CRD(사용자 정의 리소스 정의)가 포함된 경우 해당 CRD가 번들에 있어야 합니다.
2.3.1.1. 매니페스트
번들 매니페스트는 Operator의 배포 및 RBAC 모델을 정의하는 Kubernetes 매니페스트 세트를 나타냅니다.
번들에는 디렉터리당 하나의 CSV와 일반적으로 /manifests 디렉터리에서 CSV의 고유 API를 정의하는 CRD가 포함됩니다.
Bundle 형식 레이아웃의 예
etcd
├── manifests
│ ├── etcdcluster.crd.yaml
│ └── etcdoperator.clusterserviceversion.yaml
│ └── secret.yaml
│ └── configmap.yaml
└── metadata
└── annotations.yaml
└── dependencies.yaml추가 지원 오브젝트
다음과 같은 오브젝트 유형도 번들의 /manifests 디렉터리에 선택적으로 포함될 수 있습니다.
지원되는 선택적 오브젝트 유형
-
ClusterRole -
ClusterRoleBinding -
ConfigMap -
PodDisruptionBudget -
PriorityClass -
PrometheusRule -
Role -
RoleBinding -
Secret -
Service -
ServiceAccount -
ServiceMonitor -
VerticalPodAutoscaler
이러한 선택적 오브젝트가 번들에 포함된 경우 OLM(Operator Lifecycle Manager)은 번들에서 해당 오브젝트를 생성하고 CSV와 함께 해당 라이프사이클을 관리할 수 있습니다.
선택적 오브젝트의 라이프사이클
- CSV가 삭제되면 OLM은 선택적 오브젝트를 삭제합니다.
CSV가 업그레이드되면 다음을 수행합니다.
- 선택적 오브젝트의 이름이 동일하면 OLM에서 해당 오브젝트를 대신 업데이트합니다.
- 버전 간 선택적 오브젝트의 이름이 변경된 경우 OLM은 해당 오브젝트를 삭제하고 다시 생성합니다.
2.3.1.2. 주석
번들의 /metadata 디렉터리에는 annotations.yaml 파일도 포함되어 있습니다. 이 파일에서는 번들을 번들 인덱스에 추가하는 방법에 대한 형식 및 패키지 정보를 설명하는 데 도움이 되는 고급 집계 데이터를 정의합니다.
예제 annotations.yaml
annotations:
operators.operatorframework.io.bundle.mediatype.v1: "registry+v1"
operators.operatorframework.io.bundle.manifests.v1: "manifests/"
operators.operatorframework.io.bundle.metadata.v1: "metadata/"
operators.operatorframework.io.bundle.package.v1: "test-operator"
operators.operatorframework.io.bundle.channels.v1: "beta,stable"
operators.operatorframework.io.bundle.channel.default.v1: "stable" - 1
- Operator 번들의 미디어 유형 또는 형식입니다.
registry+v1형식은 CSV 및 관련 Kubernetes 오브젝트가 포함됨을 나타냅니다. - 2
- Operator 매니페스트가 포함된 디렉터리의 이미지 경로입니다. 이 라벨은 나중에 사용할 수 있도록 예약되어 있으며 현재 기본값은
manifests/입니다. 값manifests.v1은 번들에 Operator 매니페스트가 포함되어 있음을 나타냅니다. - 3
- 번들에 대한 메타데이터 파일이 포함된 디렉터리의 이미지의 경로입니다. 이 라벨은 나중에 사용할 수 있도록 예약되어 있으며 현재 기본값은
metadata/입니다. 값metadata.v1은 이 번들에 Operator 메타데이터가 있음을 나타냅니다. - 4
- 번들의 패키지 이름입니다.
- 5
- Operator 레지스트리에 추가될 때 번들이 서브스크립션되는 채널 목록입니다.
- 6
- 레지스트리에서 설치할 때 Operator를 서브스크립션해야 하는 기본 채널입니다.
불일치하는 경우 이러한 주석을 사용하는 클러스터상의 Operator 레지스트리만 이 파일에 액세스할 수 있기 때문에 annotations.yaml 파일을 신뢰할 수 있습니다.
2.3.1.3. 종속 항목 파일
Operator의 종속 항목은 번들의 metadata/ 폴더에 있는 dependencies.yaml 파일에 나열되어 있습니다. 이 파일은 선택 사항이며 현재는 명시적인 Operator 버전 종속 항목을 지정하는 데만 사용됩니다.
종속성 목록에는 종속성의 유형을 지정하기 위해 각 항목에 대한 type 필드가 포함되어 있습니다. 지원되는 Operator 종속 항목에는 두 가지가 있습니다.
-
olm.package: 이 유형은 특정 Operator 버전에 대한 종속성을 나타냅니다. 종속 정보에는 패키지 이름과 패키지 버전이 semver 형식으로 포함되어야 합니다. 예를 들어0.5.2와 같은 정확한 버전이나>0.5.1과 같은 버전 범위를 지정할 수 있습니다. -
olm.gvk:gvk유형을 사용하면 작성자가 CSV의 기존 CRD 및 API 기반 사용과 유사하게 GVK(그룹/버전/종류) 정보로 종속성을 지정할 수 있습니다. 이 경로를 통해 Operator 작성자는 모든 종속 항목, API 또는 명시적 버전을 동일한 위치에 통합할 수 있습니다.
다음 예제에서는 Prometheus Operator 및 etcd CRD에 대한 종속 항목을 지정합니다.
dependencies.yaml 파일의 예
dependencies:
- type: olm.package
value:
packageName: prometheus
version: ">0.27.0"
- type: olm.gvk
value:
group: etcd.database.coreos.com
kind: EtcdCluster
version: v1beta22.3.1.4. opm 정보
opm CLI 툴은 Operator 번들 형식과 함께 사용할 수 있도록 Operator 프레임워크에서 제공합니다. 이 툴을 사용하면 소프트웨어 리포지토리와 유사한 인덱스라는 번들 목록에서 Operator 카탈로그를 생성하고 유지 관리할 수 있습니다. 결과적으로 인덱스 이미지라는 컨테이너 이미지를 컨테이너 레지스트리에 저장한 다음 클러스터에 설치할 수 있습니다.
인덱스에는 컨테이너 이미지 실행 시 제공된 포함 API를 통해 쿼리할 수 있는 Operator 매니페스트 콘텐츠에 대한 포인터 데이터베이스가 포함되어 있습니다. OpenShift Container Platform에서 OLM(Operator Lifecycle Manager)은 CatalogSource 오브젝트에서 인덱스 이미지를 카탈로그로 참조하여 사용할 수 있으며 주기적으로 이미지를 폴링하여 클러스터에 설치된 Operator를 자주 업데이트할 수 있습니다.
-
opmCLI 설치 단계는 CLI 툴을 참조하십시오.
2.3.2. 패키지 매니페스트 형식
Operator를 위한 패키지 매니페스트 형식은 Operator 프레임워크에서 도입한 레거시 패키지 형식입니다. 이 형식은 OpenShift Container Platform 4.5에서 더 이상 사용되지 않지만 계속 지원되며 Red Hat에서 제공하는 Operator는 현재 이 메서드를 사용하여 제공됩니다.
이 형식에서는 Operator 버전이 단일 CSV(클러스터 서비스 버전)와 일반적으로 CSV의 고유 API를 정의하는 CRD(사용자 정의 리소스 정의)로 표시되지만 추가 오브젝트가 포함될 수 있습니다.
모든 Operator 버전은 단일 디렉터리에 중첩됩니다.
패키지 매니페스트 형식 레이아웃 예제
etcd
├── 0.6.1
│ ├── etcdcluster.crd.yaml
│ └── etcdoperator.clusterserviceversion.yaml
├── 0.9.0
│ ├── etcdbackup.crd.yaml
│ ├── etcdcluster.crd.yaml
│ ├── etcdoperator.v0.9.0.clusterserviceversion.yaml
│ └── etcdrestore.crd.yaml
├── 0.9.2
│ ├── etcdbackup.crd.yaml
│ ├── etcdcluster.crd.yaml
│ ├── etcdoperator.v0.9.2.clusterserviceversion.yaml
│ └── etcdrestore.crd.yaml
└── etcd.package.yaml
또한 패키지 이름 및 채널 세부 정보를 정의하는 패키지 매니페스트인 <name>.package.yaml 파일도 포함합니다.
패키지 매니페스트 예제
packageName: etcd
channels:
- name: alpha
currentCSV: etcdoperator.v0.9.2
- name: beta
currentCSV: etcdoperator.v0.9.0
- name: stable
currentCSV: etcdoperator.v0.9.2
defaultChannel: alphaOperator 레지스트리 데이터베이스에 패키지 매니페스트를 로드할 때 다음 요구 사항이 검증됩니다.
- 모든 패키지에는 채널이 한 개 이상 있습니다.
- 패키지의 채널이 가리키는 모든 CSV가 존재합니다.
- Operator의 모든 버전에는 정확히 하나의 CSV가 있습니다.
- CSV에서 CRD를 보유하는 경우 해당 CRD는 Operator 버전의 디렉터리에 있어야 합니다.
- CSV가 교체되는 경우 기존 CSV와 새 CSV 둘 다 패키지에 있어야 합니다.
2.4. OLM(Operator Lifecycle Manager)
2.4.1. Operator Lifecycle Manager 개념 및 리소스
이 가이드에서는 OpenShift Container Platform에서 OLM(Operator Lifecycle Manager)을 구동하는 개념에 대한 개요를 제공합니다.
2.4.1.1. Operator Lifecycle Manager란?
OLM(Operator Lifecycle Manager)은 OpenShift Container Platform 클러스터에서 실행되는 Kubernetes 네이티브 애플리케이션(Operator) 및 관련 서비스의 라이프사이클을 설치, 업데이트, 관리하는 데 도움이 됩니다. Operator 프레임워크의 일부로, 효과적이고 자동화되었으며 확장 가능한 방식으로 Operator를 관리하도록 설계된 오픈 소스 툴킷입니다.
그림 2.2. Operator Lifecycle Manager 워크플로
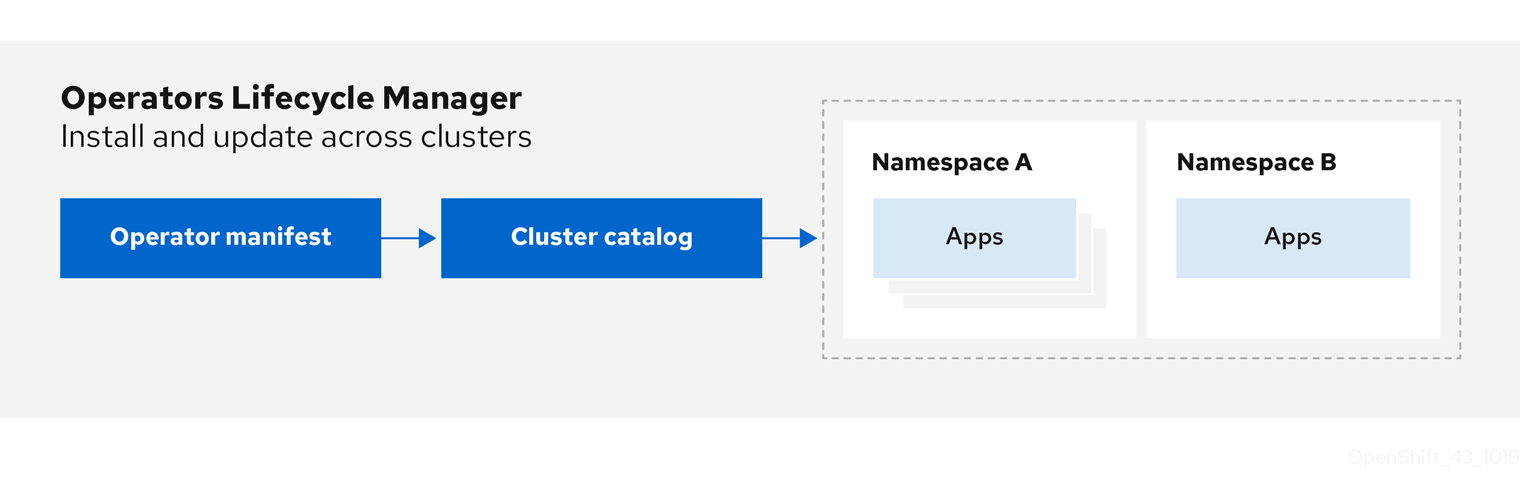
OLM은 OpenShift Container Platform 4.6에서 기본적으로 실행되므로 클러스터 관리자가 클러스터에서 실행되는 Operator를 설치, 업그레이드 및 부여할 수 있습니다. OpenShift Container Platform 웹 콘솔은 클러스터 관리자가 Operator를 설치할 수 있는 관리 화면을 제공하고, 클러스터에 제공되는 Operator 카탈로그를 사용할 수 있는 액세스 권한을 특정 프로젝트에 부여합니다.
개발자의 경우 분야별 전문가가 아니어도 셀프서비스 경험을 통해 데이터베이스, 모니터링, 빅 데이터 서비스의 인스턴스를 프로비저닝하고 구성할 수 있습니다. Operator에서 해당 지식을 제공하기 때문입니다.
2.4.1.2. OLM 리소스
다음 CRD(사용자 정의 리소스 정의)는 OLM(Operator Lifecycle Manager)에서 정의하고 관리합니다.
| 리소스 | 짧은 이름 | 설명 |
|---|---|---|
|
|
| 애플리케이션 메타데이터입니다. 예를 들면 이름, 버전, 아이콘, 필수 리소스입니다. |
|
|
| 애플리케이션을 정의하는 CSV, CRD, 패키지의 리포지토리입니다. |
|
|
| 패키지의 채널을 추적하여 CSV를 최신 상태로 유지합니다. |
|
|
| CSV를 자동으로 설치하거나 업그레이드하기 위해 생성하는 계산된 리소스 목록입니다. |
|
|
|
동일한 네임스페이스에 배포된 모든 Operator를 |
2.4.1.2.1. 클러스터 서비스 버전
CSV(클러스터 서비스 버전)는 OpenShift Container Platform 클러스터에서 실행 중인 특정 버전의 Operator를 나타냅니다. 클러스터에서 Operator를 실행할 때 OLM(Operator Lifecycle Manager)을 지원하는 Operator 메타데이터에서 생성한 YAML 매니페스트입니다.
이러한 Operator 관련 메타데이터는 OLM이 클러스터에서 Operator가 계속 안전하게 실행되도록 유지하고 새 버전의 Operator가 게시되면 업데이트 적용 방법에 대한 정보를 제공하는 데 필요합니다. 이는 기존 운영 체제의 패키징 소프트웨어와 유사합니다. OLM 패키징 단계를 rpm, deb 또는 apk 번들을 생성하는 단계로 고려해 보십시오.
CSV에는 Operator 컨테이너 이미지와 함께 제공되는 메타데이터가 포함되며 이러한 데이터는 이름, 버전, 설명, 라벨, 리포지토리 링크, 로고와 같은 정보로 사용자 인터페이스를 채우는 데 사용됩니다.
CSV는 Operator를 실행하는 데 필요한 기술 정보의 소스이기도 합니다(예: RBAC 규칙, 클러스터 요구 사항, 설치 전략을 관리하고 사용하는 CR(사용자 정의 리소스)). 이 정보는 OLM에 필요한 리소스를 생성하고 Operator를 배포로 설정하는 방법을 지정합니다.
2.4.1.2.2. 카탈로그 소스
카탈로그 소스는 일반적으로 컨테이너 레지스트리에 저장된 인덱스 이미지를 참조하여 메타데이터 저장소를 나타냅니다. OLM(Operator Lifecycle Manager)은 카탈로그 소스를 쿼리하여 Operator 및 해당 종속성을 검색하고 설치합니다. OpenShift Container Platform 웹 콘솔의 OperatorHub에는 카탈로그 소스에서 제공하는 Operator도 표시됩니다.
클러스터 관리자는 웹 콘솔의 관리 → 클러스터 설정 → 글로벌 구성 → OperatorHub 페이지를 사용하여 클러스터에서 활성화된 카탈로그 소스에서 제공하는 전체 Operator 목록을 볼 수 있습니다.
CatalogSource 오브젝트의 spec은 Pod를 구성하는 방법 또는 Operator Registry gRPC API를 제공하는 서비스와 통신하는 방법을 나타냅니다.
예 2.1. CatalogSource 오브젝트의 예
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
generation: 1
name: example-catalog
namespace: openshift-marketplace
spec:
displayName: Example Catalog
image: quay.io/example-org/example-catalog:v1
priority: -400
publisher: Example Org
sourceType: grpc
updateStrategy:
registryPoll:
interval: 30m0s
status:
connectionState:
address: example-catalog.openshift-marketplace.svc:50051
lastConnect: 2021-08-26T18:14:31Z
lastObservedState: READY
latestImageRegistryPoll: 2021-08-26T18:46:25Z
registryService:
createdAt: 2021-08-26T16:16:37Z
port: 50051
protocol: grpc
serviceName: example-catalog
serviceNamespace: openshift-marketplace- 1
CatalogSource오브젝트의 이름입니다. 이 값은 요청된 네임스페이스에 생성된 관련 Pod의 이름으로도 사용됩니다.- 2
- 사용 가능한 카탈로그를 만드는 네임스페이스입니다. 카탈로그를 모든 네임스페이스에서 클러스터 전체로 사용하려면 이 값을
openshift-marketplace로 설정합니다. 기본 Red Hat 제공 카탈로그 소스에서도openshift-marketplace네임스페이스를 사용합니다. 그러지 않으면 해당 네임스페이스에서만 Operator를 사용할 수 있도록 값을 특정 네임스페이스로 설정합니다. - 3
- 웹 콘솔 및 CLI에 있는 카탈로그의 표시 이름입니다.
- 4
- 카탈로그의 인덱스 이미지입니다.
- 5
- 카탈로그 소스의 가중치입니다. OLM은 종속성 확인 중에 가중치를 사용하여 우선순위를 지정합니다. 가중치가 높을수록 가중치가 낮은 카탈로그보다 카탈로그가 선호됨을 나타냅니다.
- 6
- 소스 유형에는 다음이 포함됩니다.
-
이미지참조가있는gRPC: OLM은 이미지를 가져와서 호환되는 API를 제공해야 하는 Pod를 실행합니다. -
address필드 -
configmap: OLM은 구성 맵 데이터를 구문 분석하고 이를 통해 gRPC API를 제공할 수 있는 Pod를 실행합니다.
-
- 7
- 지정된 간격으로 새 버전을 자동으로 확인하여 최신 상태를 유지합니다.
- 8
- 카탈로그 연결의 마지막으로 관찰된 상태입니다. 예를 들면 다음과 같습니다.
-
준비됨 : 연결이 성공적으로 설정되었습니다. -
연결 중 :연결이 설정하려고 시도하고 있습니다. -
TRANSIENT_FAILURE: 연결을 설정하려고 시도하는 동안 시간 제한과 같은 임시 문제가 발생했습니다. 상태는 결국CONNECTING으로 다시 전환되고 다시 연결 시도합니다.
자세한 내용은 gRPC 문서의 연결 상태를 참조하십시오.
-
- 9
- 카탈로그 이미지를 저장하는 컨테이너 레지스트리가 폴링되어 이미지가 최신 상태인지 확인할 수 있는 마지막 시간입니다.
- 10
- 카탈로그의 Operator 레지스트리 서비스의 상태 정보입니다.
서브스크립션의 CatalogSource 오브젝트 name을 참조하면 요청된 Operator를 찾기 위해 검색할 위치를 OLM에 지시합니다.
예 2.2. 카탈로그 소스를 참조하는 Subscription 오브젝트의 예
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: example-operator
namespace: example-namespace
spec:
channel: stable
name: example-operator
source: example-catalog
sourceNamespace: openshift-marketplace2.4.1.2.3. 서브스크립션
Subscription 오브젝트에서 정의하는 서브스크립션은 Operator를 설치하려는 의도를 나타냅니다. Operator와 카탈로그 소스를 연결하는 사용자 정의 리소스입니다.
서브스크립션은 Operator 패키지에서 구독할 채널과 업데이트를 자동 또는 수동으로 수행할지를 나타냅니다. 자동으로 설정된 경우 OLM(Operator Lifecycle Manager)은 서브스크립션을 통해 클러스터에서 항상 최신 버전의 Operator가 실행되도록 Operator를 관리하고 업그레이드합니다.
Subscription 개체 예
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: example-operator
namespace: example-namespace
spec:
channel: stable
name: example-operator
source: example-catalog
sourceNamespace: openshift-marketplace
이 Subscription 오브젝트는 Operator의 이름 및 네임스페이스, Operator 데이터를 확인할 수 있는 카탈로그를 정의합니다. alpha, beta 또는 stable과 같은 채널은 카탈로그 소스에서 설치해야 하는 Operator 스트림을 결정하는 데 도움이 됩니다.
서브스크립션에서 채널 이름은 Operator마다 다를 수 있지만 이름 지정 스키마는 지정된 Operator 내의 공통 규칙을 따라야 합니다. 예를 들어 채널 이름은 Operator(1.2, 1.3) 또는 릴리스 빈도(stable, fast)에서 제공하는 애플리케이션의 마이너 릴리스 업데이트 스트림을 따를 수 있습니다.
OpenShift Container Platform 웹 콘솔에서 쉽게 확인할 수 있을 뿐만 아니라 관련 서브스크립션의 상태를 검사하여 사용 가능한 최신 버전의 Operator가 있는 경우 이를 확인할 수 있습니다. currentCSV 필드와 연결된 값은 OLM에 알려진 최신 버전이고 installedCSV는 클러스터에 설치된 버전입니다.
2.4.1.2.4. 설치 계획
InstallPlan 오브젝트에서 정의하는 설치 계획은 OLM(Operator Lifecycle Manager)에서 특정 버전의 Operator로 설치 또는 업그레이드하기 위해 생성하는 리소스 세트를 설명합니다. 버전은 CSV(클러스터 서비스 버전)에서 정의합니다.
Operator, 클러스터 관리자 또는 Operator 설치 권한이 부여된 사용자를 설치하려면 먼저 Subscription 오브젝트를 생성해야 합니다. 서브스크립션은 카탈로그 소스에서 사용 가능한 Operator 버전의 스트림을 구독하려는 의도를 나타냅니다. 그런 다음 서브스크립션을 통해 Operator의 리소스를 쉽게 설치할 수 있도록 InstallPlan 오브젝트가 생성됩니다.
그런 다음 다음 승인 전략 중 하나에 따라 설치 계획을 승인해야 합니다.
-
서브스크립션의
spec.installPlanApproval필드가Automatic로 설정된 경우 설치 계획이 자동으로 승인됩니다. -
서브스크립션의
spec.installPlanApproval필드가Manual로 설정된 경우 클러스터 관리자 또는 적절한 권한이 있는 사용자가 설치 계획을 수동으로 승인해야 합니다.
설치 계획이 승인되면 OLM에서 지정된 리소스를 생성하고 서브스크립션에서 지정한 네임스페이스에 Operator를 설치합니다.
예 2.3. InstallPlan 오브젝트의 예
apiVersion: operators.coreos.com/v1alpha1
kind: InstallPlan
metadata:
name: install-abcde
namespace: operators
spec:
approval: Automatic
approved: true
clusterServiceVersionNames:
- my-operator.v1.0.1
generation: 1
status:
...
catalogSources: []
conditions:
- lastTransitionTime: '2021-01-01T20:17:27Z'
lastUpdateTime: '2021-01-01T20:17:27Z'
status: 'True'
type: Installed
phase: Complete
plan:
- resolving: my-operator.v1.0.1
resource:
group: operators.coreos.com
kind: ClusterServiceVersion
manifest: >-
...
name: my-operator.v1.0.1
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1alpha1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: apiextensions.k8s.io
kind: CustomResourceDefinition
manifest: >-
...
name: webservers.web.servers.org
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1beta1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: ''
kind: ServiceAccount
manifest: >-
...
name: my-operator
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: rbac.authorization.k8s.io
kind: Role
manifest: >-
...
name: my-operator.v1.0.1-my-operator-6d7cbc6f57
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
- resolving: my-operator.v1.0.1
resource:
group: rbac.authorization.k8s.io
kind: RoleBinding
manifest: >-
...
name: my-operator.v1.0.1-my-operator-6d7cbc6f57
sourceName: redhat-operators
sourceNamespace: openshift-marketplace
version: v1
status: Created
...2.4.1.2.5. Operator groups
OperatorGroup 리소스에서 정의하는 Operator group에서는 OLM에서 설치한 Operator에 다중 테넌트 구성을 제공합니다. Operator group은 멤버 Operator에 필요한 RBAC 액세스 권한을 생성할 대상 네임스페이스를 선택합니다.
대상 네임스페이스 세트는 쉼표로 구분된 문자열 형식으로 제공되며 CSV(클러스터 서비스 버전)의 olm.targetNamespaces 주석에 저장되어 있습니다. 이 주석은 멤버 Operator의 CSV 인스턴스에 적용되며 해당 배포에 프로젝션됩니다.
2.4.2. Operator Lifecycle Manager 아키텍처
이 가이드에서는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager) 구성 요소 아키텍처를 간략하게 설명합니다.
2.4.2.1. 구성 요소의 역할
OLM(Operator Lifecycle Manager)은 OLM Operator와 Catalog Operator의 두 Operator로 구성됩니다.
각 Operator는 OLM 프레임워크의 기반이 되는 CRD(사용자 정의 리소스 정의)를 관리합니다.
| 리소스 | 짧은 이름 | 소유자 | Description |
|---|---|---|---|
|
|
| OLM | 애플리케이션 메타데이터: 이름, 버전, 아이콘, 필수 리소스, 설치 등입니다. |
|
|
| 카탈로그 | CSV를 자동으로 설치하거나 업그레이드하기 위해 생성하는 계산된 리소스 목록입니다. |
|
|
| 카탈로그 | 애플리케이션을 정의하는 CSV, CRD, 패키지의 리포지토리입니다. |
|
|
| 카탈로그 | 패키지의 채널을 추적하여 CSV를 최신 상태로 유지하는 데 사용됩니다. |
|
|
| OLM |
동일한 네임스페이스에 배포된 모든 Operator를 |
또한 각 Operator는 다음 리소스를 생성합니다.
| 리소스 | 소유자 |
|---|---|
|
| OLM |
|
| |
|
| |
|
| |
|
CRD( | 카탈로그 |
|
|
2.4.2.2. OLM Operator
CSV에 지정된 필수 리소스가 클러스터에 제공되면 OLM Operator는 CSV 리소스에서 정의하는 애플리케이션을 배포합니다.
OLM Operator는 필수 리소스 생성과는 관련이 없습니다. CLI 또는 Catalog Operator를 사용하여 이러한 리소스를 수동으로 생성하도록 선택할 수 있습니다. 이와 같은 분리를 통해 사용자는 애플리케이션에 활용하기 위해 선택하는 OLM 프레임워크의 양을 점차 늘리며 구매할 수 있습니다.
OLM Operator에서는 다음 워크플로를 사용합니다.
- 네임스페이스에서 CSV(클러스터 서비스 버전)를 조사하고 해당 요구 사항이 충족되는지 확인합니다.
요구사항이 충족되면 CSV에 대한 설치 전략을 실행합니다.
참고설치 전략을 실행하기 위해서는 CSV가 Operator group의 활성 멤버여야 합니다.
2.4.2.3. Catalog Operator
Catalog Operator는 CSV(클러스터 서비스 버전) 및 CSV에서 지정하는 필수 리소스를 확인하고 설치합니다. 또한 채널에서 패키지 업데이트에 대한 카탈로그 소스를 조사하고 원하는 경우 사용 가능한 최신 버전으로 자동으로 업그레이드합니다.
채널에서 패키지를 추적하려면 원하는 패키지를 구성하는 Subscription 오브젝트, 채널, 업데이트를 가져오는 데 사용할 CatalogSource 오브젝트를 생성하면 됩니다. 업데이트가 확인되면 사용자를 대신하여 네임스페이스에 적절한 InstallPlan 오브젝트를 기록합니다.
Catalog Operator에서는 다음 워크플로를 사용합니다.
- 클러스터의 각 카탈로그 소스에 연결합니다.
사용자가 생성한 설치 계획 중 확인되지 않은 계획이 있는지 조사하고 있는 경우 다음을 수행합니다.
- 요청한 이름과 일치하는 CSV를 찾아 확인된 리소스로 추가합니다.
- 각 관리 또는 필수 CRD의 경우 CRD를 확인된 리소스로 추가합니다.
- 각 필수 CRD에 대해 이를 관리하는 CSV를 확인합니다.
- 확인된 설치 계획을 조사하고 사용자의 승인에 따라 또는 자동으로 해당 계획에 대해 검색된 리소스를 모두 생성합니다.
- 카탈로그 소스 및 서브스크립션을 조사하고 이에 따라 설치 계획을 생성합니다.
2.4.2.4. 카탈로그 레지스트리
Catalog 레지스트리는 클러스터에서 생성할 CSV 및 CRD를 저장하고 패키지 및 채널에 대한 메타데이터를 저장합니다.
패키지 매니페스트는 패키지 ID를 CSV 세트와 연결하는 카탈로그 레지스트리의 항목입니다. 패키지 내에서 채널은 특정 CSV를 가리킵니다. CSV는 교체하는 CSV를 명시적으로 참조하므로 패키지 매니페스트는 Catalog Operator에 각 중간 버전을 거쳐 CSV를 최신 버전으로 업데이트하는 데 필요한 모든 정보를 제공합니다.
2.4.3. Operator Lifecycle Manager 워크플로
이 가이드에서는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager)의 워크플로를 간략하게 설명합니다.
2.4.3.1. OLM의 Operator 설치 및 업그레이드 워크플로
OLM(Operator Lifecycle Manager) 에코시스템에서 다음 리소스를 사용하여 Operator 설치 및 업그레이드를 확인합니다.
-
ClusterServiceVersion(CSV) -
CatalogSource -
서브스크립션
CSV에 정의된 Operator 메타데이터는 카탈로그 소스라는 컬렉션에 저장할 수 있습니다. OLM은 Operator Registry API를 사용하는 카탈로그 소스를 통해 사용 가능한 Operator와 설치된 Operator의 업그레이드를 쿼리합니다.
그림 2.3. 카탈로그 소스 개요
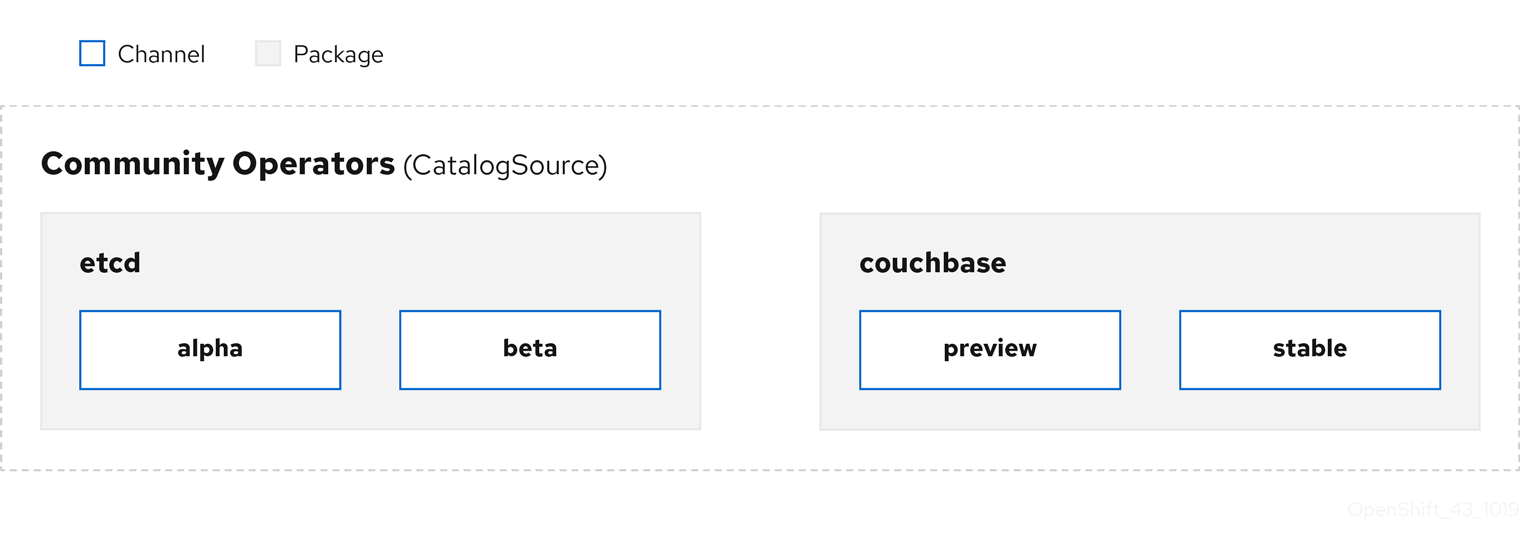
Operator는 카탈로그 소스 내에서 패키지와 채널이라는 업데이트 스트림으로 구성되는데, 채널은 웹 브라우저와 같이 연속 릴리스 주기에서 OpenShift Container Platform 또는 기타 소프트웨어에 친숙한 업데이트 패턴이어야 합니다.
그림 2.4. 카탈로그 소스의 패키지 및 채널
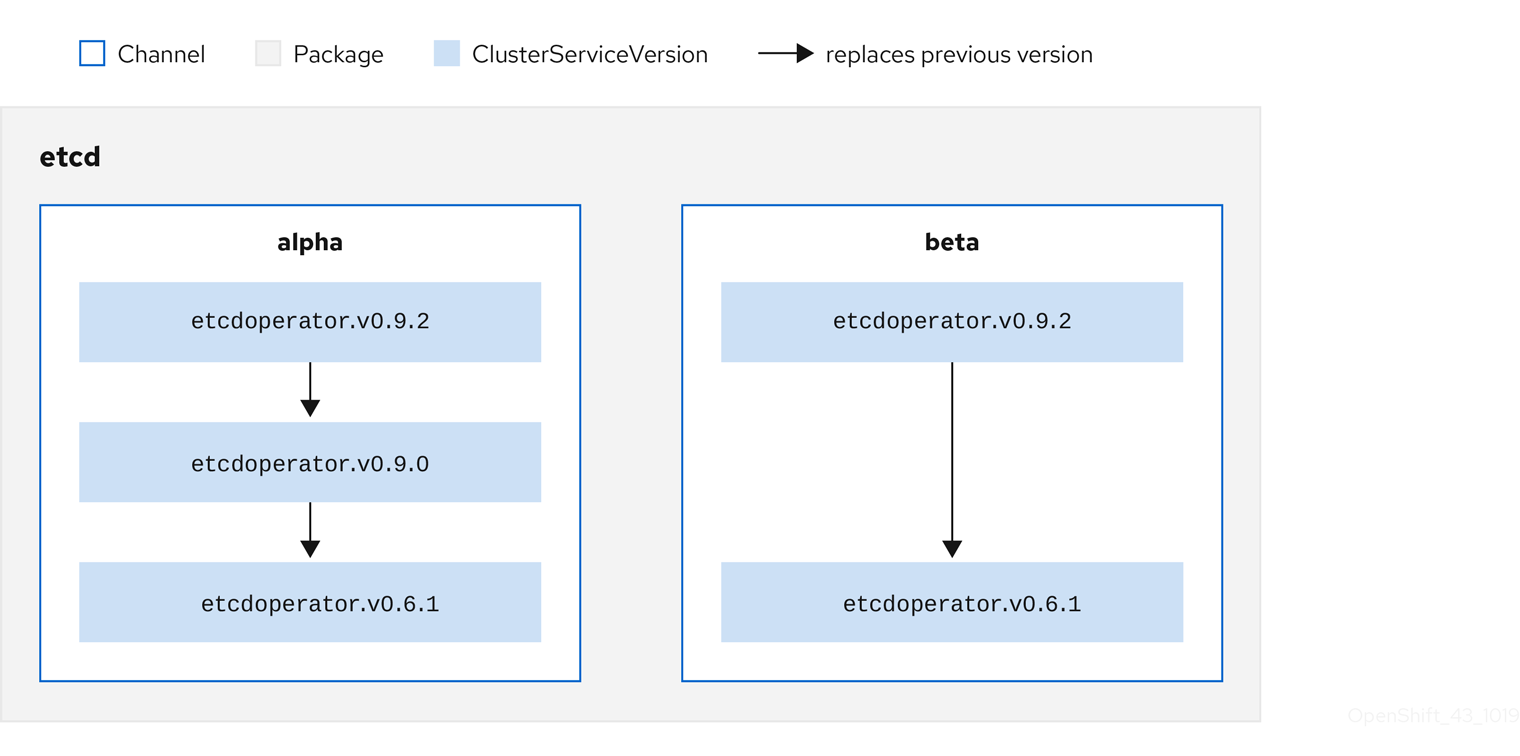
사용자는 서브스크립션의 특정 카탈로그 소스에서 특정 패키지 및 채널(예: etcd 패키지 및 해당 alpha 채널)을 나타냅니다. 네임스페이스에 아직 설치되지 않은 패키지에 서브스크립션이 생성되면 해당 패키지의 최신 Operator가 설치됩니다.
OLM에서는 의도적으로 버전을 비교하지 않으므로 지정된 카탈로그 → 채널 → 패키지 경로에서 사용 가능한 "최신" Operator의 버전 번호가 가장 높은 버전 번호일 필요는 없습니다. Git 리포지토리와 유사하게 채널의 헤드 참조로 간주해야 합니다.
각 CSV에는 교체 대상 Operator를 나타내는 replaces 매개변수가 있습니다. 이 매개변수를 통해 OLM에서 쿼리할 수 있는 CSV 그래프가 빌드되고 업데이트를 채널 간에 공유할 수 있습니다. 채널은 업데이트 그래프의 진입점으로 간주할 수 있습니다.
그림 2.5. 사용 가능한 채널 업데이트의 OLM 그래프
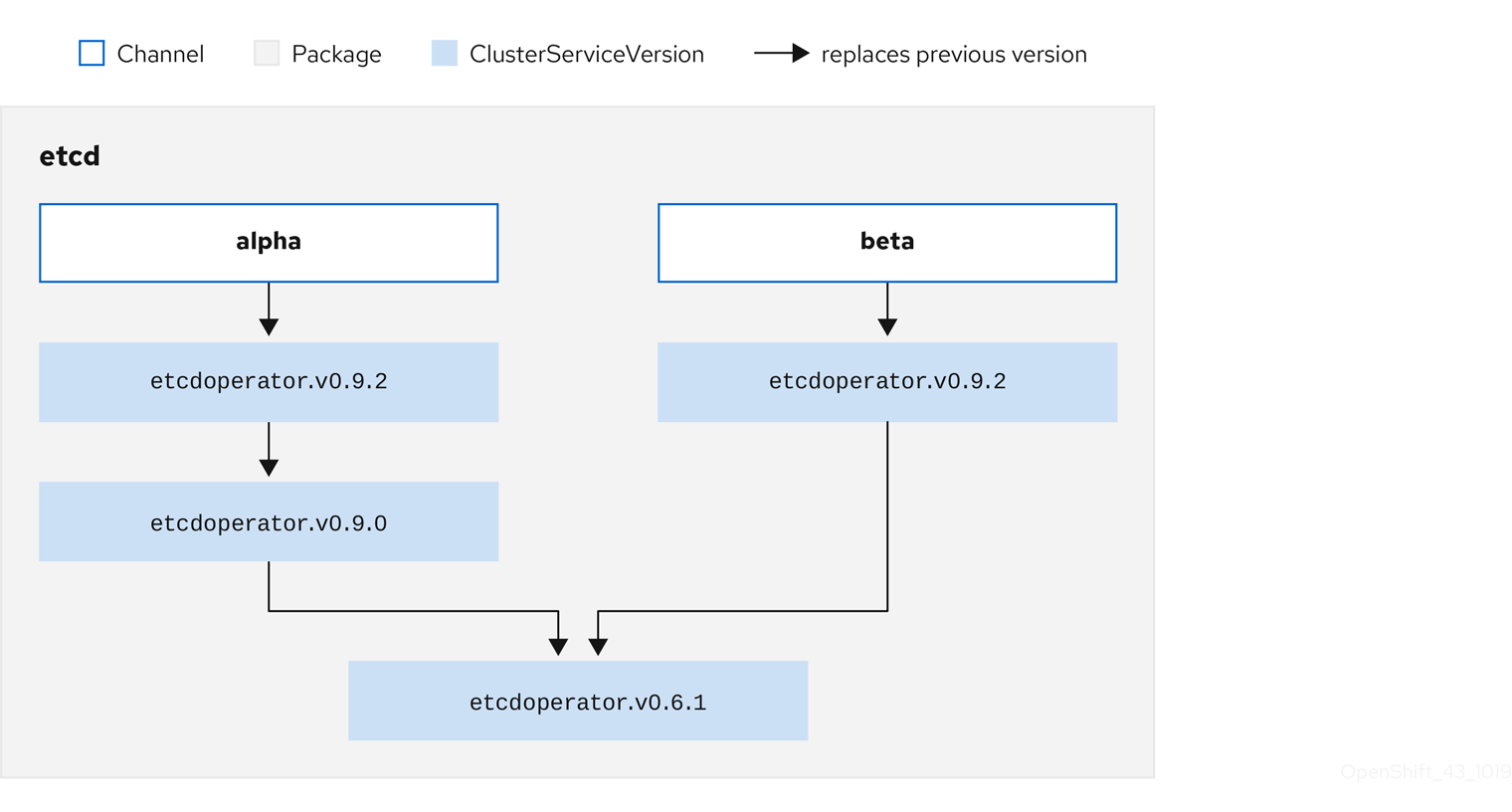
패키지에 포함된 채널의 예
packageName: example
channels:
- name: alpha
currentCSV: example.v0.1.2
- name: beta
currentCSV: example.v0.1.3
defaultChannel: alpha
OLM에서 카탈로그 소스, 패키지, 채널, CSV와 관련된 업데이트를 쿼리하려면 카탈로그에서 입력 CSV를 replaces하는 단일 CSV를 모호하지 않게 결정적으로 반환할 수 있어야 합니다.
2.4.3.1.1. 업그레이드 경로의 예
업그레이드 시나리오 예제에서는 CSV 버전 0.1.1에 해당하는 Operator가 설치되어 있는 것으로 간주합니다. OLM은 카탈로그 소스를 쿼리하고 구독 채널에서 이전 버전이지만 설치되지 않은 CSV 버전 0.1.2를 교체하는(결국 설치된 이전 CSV 버전 0.1.1을 교체함) 새 CSV 버전 0.1.3이 포함된 업그레이드를 탐지합니다.
OLM은 CSV에 지정된 replaces 필드를 통해 채널 헤드에서 이전 버전으로 돌아가 업그레이드 경로 0.1.3 → 0.1.2 → 0.1.1을 결정합니다. 화살표 방향은 전자가 후자를 대체함을 나타냅니다. OLM은 채널 헤드에 도달할 때까지 Operator 버전을 한 번에 하나씩 업그레이드합니다.
지정된 이 시나리오의 경우 OLM은 Operator 버전 0.1.2를 설치하여 기존 Operator 버전 0.1.1을 교체합니다. 그런 다음 Operator 버전 0.1.3을 설치하여 이전에 설치한 Operator 버전 0.1.2를 대체합니다. 이 시점에 설치한 Operator 버전 0.1.3이 채널 헤드와 일치하며 업그레이드가 완료됩니다.
2.4.3.1.2. 업그레이드 건너뛰기
OLM의 기본 업그레이드 경로는 다음과 같습니다.
- 카탈로그 소스는 Operator에 대한 하나 이상의 업데이트로 업데이트됩니다.
- OLM은 카탈로그 소스에 포함된 최신 버전에 도달할 때까지 Operator의 모든 버전을 트래버스합니다.
그러나 경우에 따라 이 작업을 수행하는 것이 안전하지 않을 수 있습니다. 게시된 버전의 Operator가 아직 설치되지 않은 경우 클러스터에 설치해서는 안 되는 경우가 있습니다. 예를 들면 버전에 심각한 취약성이 있기 때문입니다.
이러한 경우 OLM에서는 두 가지 클러스터 상태를 고려하여 다음을 둘 다 지원하는 업데이트 그래프를 제공해야 합니다.
- "잘못"된 중간 Operator가 클러스터에 표시되고 설치되었습니다.
- "잘못된" 중간 Operator가 클러스터에 아직 설치되지 않았습니다.
새 카탈로그를 제공하고 건너뛰기 릴리스를 추가하면 클러스터 상태 및 잘못된 업데이트가 있는지와 관계없이 OLM에서 항상 고유한 단일 업데이트를 가져올 수 있습니다.
릴리스를 건너뛰는 CSV의 예
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: etcdoperator.v0.9.2
namespace: placeholder
annotations:
spec:
displayName: etcd
description: Etcd Operator
replaces: etcdoperator.v0.9.0
skips:
- etcdoperator.v0.9.1기존 CatalogSource 및 새 CatalogSource의 다음 예제를 고려하십시오.
그림 2.6. 업데이트 건너뛰기
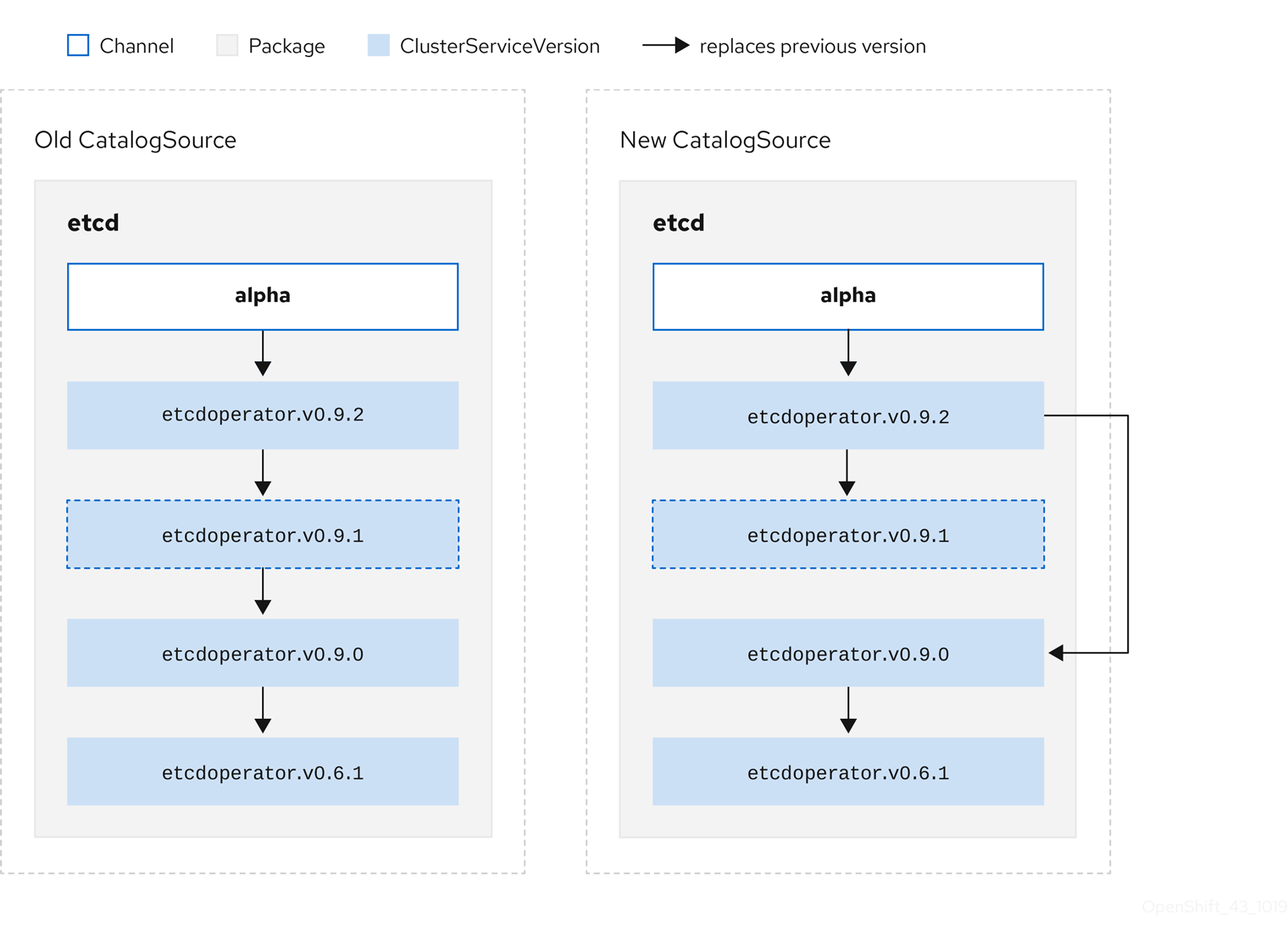
이 그래프에는 다음이 유지됩니다.
- 기존 CatalogSource에 있는 모든 Operator에는 새 CatalogSource에 단일 대체 항목이 있습니다.
- 새 CatalogSource에 있는 모든 Operator에는 새 CatalogSource에 단일 대체 항목이 있습니다.
- 잘못된 업데이트가 아직 설치되지 않은 경우 설치되지 않습니다.
2.4.3.1.3. 여러 Operator 교체
설명된 새 CatalogSource를 생성하려면 하나의 Operator를 replace하지만 여러 Operator를 건너뛸 수 있는 CSV를 게시해야 합니다. 이 작업은 skipRange 주석을 사용하여 수행할 수 있습니다.
olm.skipRange: <semver_range>
여기서 <semver_range>에는 semver 라이브러리에서 지원하는 버전 범위 형식이 있습니다.
카탈로그에서 업데이트를 검색할 때 채널 헤드에 skipRange 주석이 있고 현재 설치된 Operator에 범위에 해당하는 버전 필드가 있는 경우 OLM이 채널의 최신 항목으로 업데이트됩니다.
우선순위 순서는 다음과 같습니다.
-
기타 건너뛰기 기준이 충족되는 경우 서브스크립션의
sourceName에 지정된 소스의 채널 헤드 -
sourceName에 지정된 소스의 현재 Operator를 대체하는 다음 Operator - 기타 건너뛰기 조건이 충족되는 경우 서브스크립션에 표시되는 다른 소스의 채널 헤드.
- 서브스크립션에 표시되는 모든 소스의 현재 Operator를 대체하는 다음 Operator.
skipRange가 있는 CSV의 예
apiVersion: operators.coreos.com/v1alpha1
kind: ClusterServiceVersion
metadata:
name: elasticsearch-operator.v4.1.2
namespace: <namespace>
annotations:
olm.skipRange: '>=4.1.0 <4.1.2'2.4.3.1.4. z-stream 지원
마이너 버전이 동일한 경우 z-stream 또는 패치 릴리스로 이전 z-stream 릴리스를 모두 교체해야 합니다. OLM은 메이저, 마이너 또는 패치 버전을 구분하지 않으므로 카탈로그에 올바른 그래프만 빌드해야 합니다.
즉 OLM은 이전 CatalogSource에서와 같이 그래프를 가져올 수 있어야 하고 이전과 유사하게 새 CatalogSource에서와 같이 그래프를 생성할 수 있어야 합니다.
그림 2.7. 여러 Operator 교체
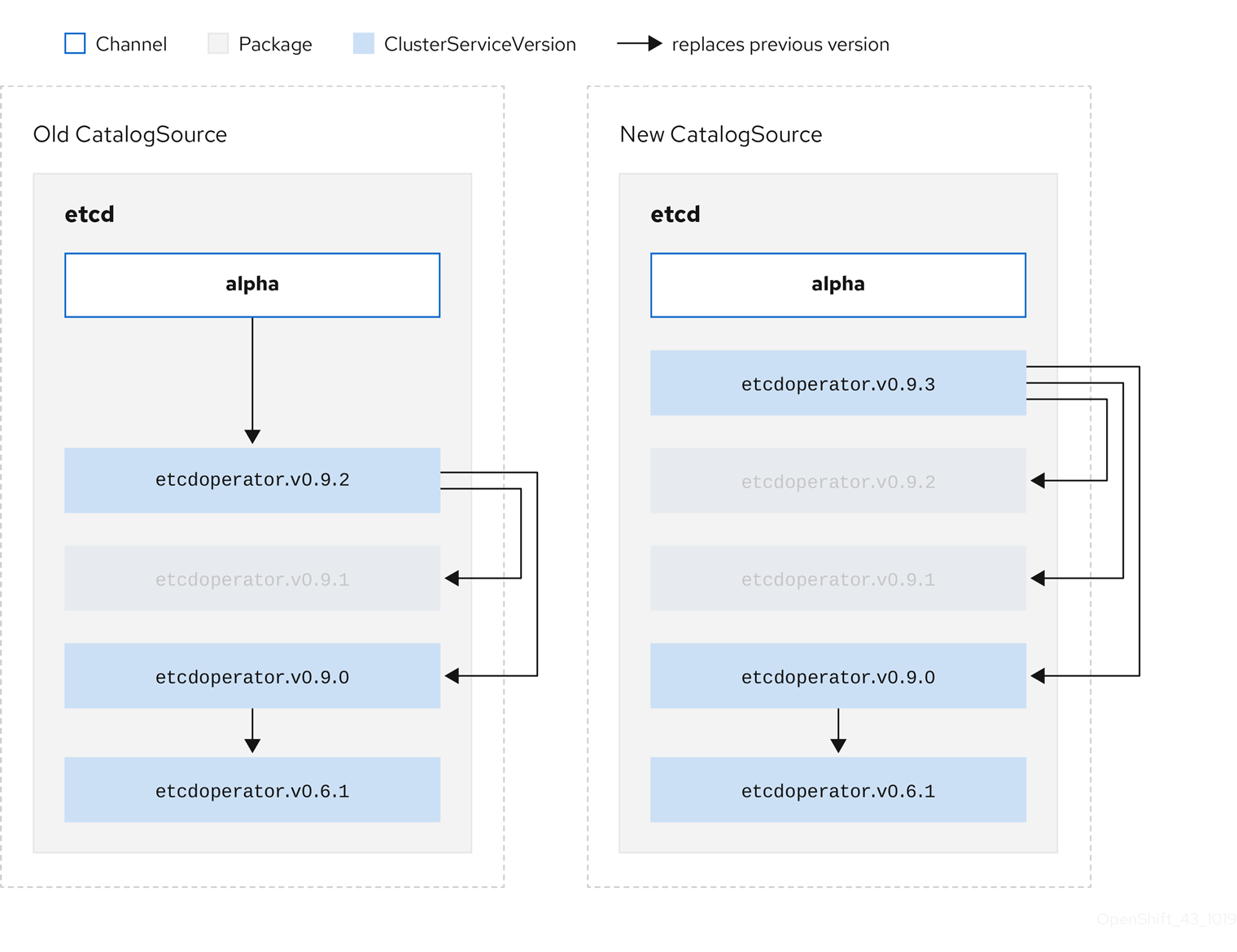
이 그래프에는 다음이 유지됩니다.
- 기존 CatalogSource에 있는 모든 Operator에는 새 CatalogSource에 단일 대체 항목이 있습니다.
- 새 CatalogSource에 있는 모든 Operator에는 새 CatalogSource에 단일 대체 항목이 있습니다.
- 이전 CatalogSource의 모든 z-stream 릴리스가 새 CatalogSource의 최신 z-stream 릴리스로 업데이트됩니다.
- 사용할 수 없는 릴리스는 "가상" 그래프 노드로 간주할 수 있습니다. 해당 콘텐츠가 존재할 필요는 없으며 그래프가 이와 같은 경우 레지스트리에서 응답하기만 하면 됩니다.
2.4.4. Operator Lifecycle Manager 종속성 확인
이 가이드에서는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager)을 사용한 종속성 해결 및 CRD(사용자 정의 리소스 정의) 업그레이드 라이프사이클에 대해 간단히 설명합니다.
2.4.4.1. 종속성 확인 정보
OLM은 실행 중인 Operator의 종속성 확인 및 업그레이드 라이프사이클을 관리합니다. OLM에서 발생하는 문제는 다양한 방식에서 yum 및 rpm과 같은 기타 운영 체제 패키지 관리자와 유사합니다.
그러나 OLM에는 유사한 시스템에는 일반적으로 해당하지 않는 한 가지 제약 조건이 있습니다. 즉 Operator가 항상 실행되고 있으므로 OLM에서 서로 함께 작동하지 않는 Operator 세트를 제공하지 않도록 합니다.
즉 OLM에서 다음을 수행하지 않아야 합니다.
- 제공할 수 없는 API가 필요한 Operator 세트를 설치합니다.
- Operator에 종속된 다른 Operator를 중단하는 방식으로 Operator를 업데이트합니다.
2.4.4.2. 종속 항목 파일
Operator의 종속 항목은 번들의 metadata/ 폴더에 있는 dependencies.yaml 파일에 나열되어 있습니다. 이 파일은 선택 사항이며 현재는 명시적인 Operator 버전 종속 항목을 지정하는 데만 사용됩니다.
종속성 목록에는 종속성의 유형을 지정하기 위해 각 항목에 대한 type 필드가 포함되어 있습니다. 지원되는 Operator 종속 항목에는 두 가지가 있습니다.
-
olm.package: 이 유형은 특정 Operator 버전에 대한 종속성을 나타냅니다. 종속 정보에는 패키지 이름과 패키지 버전이 semver 형식으로 포함되어야 합니다. 예를 들어0.5.2와 같은 정확한 버전이나>0.5.1과 같은 버전 범위를 지정할 수 있습니다. -
olm.gvk:gvk유형을 사용하면 작성자가 CSV의 기존 CRD 및 API 기반 사용과 유사하게 GVK(그룹/버전/종류) 정보로 종속성을 지정할 수 있습니다. 이 경로를 통해 Operator 작성자는 모든 종속 항목, API 또는 명시적 버전을 동일한 위치에 통합할 수 있습니다.
다음 예제에서는 Prometheus Operator 및 etcd CRD에 대한 종속 항목을 지정합니다.
dependencies.yaml 파일의 예
dependencies:
- type: olm.package
value:
packageName: prometheus
version: ">0.27.0"
- type: olm.gvk
value:
group: etcd.database.coreos.com
kind: EtcdCluster
version: v1beta22.4.4.3. 종속 기본 설정
Operator의 종속성을 동등하게 충족하는 옵션이 여러 개가 있을 수 있습니다. OLM(Operator Lifecycle Manager)의 종속성 확인자는 요청된 Operator의 요구 사항에 가장 적합한 옵션을 결정합니다. Operator 작성자 또는 사용자에게는 명확한 종속성 확인을 위해 이러한 선택이 어떻게 이루어지는지 이해하는 것이 중요할 수 있습니다.
2.4.4.3.1. 카탈로그 우선순위
OpenShift Container Platform 클러스터에서 OLM은 카탈로그 소스를 읽고 설치에 사용할 수 있는 Operator를 확인합니다.
CatalogSource 오브젝트의 예
apiVersion: "operators.coreos.com/v1alpha1"
kind: "CatalogSource"
metadata:
name: "my-operators"
namespace: "operators"
spec:
sourceType: grpc
image: example.com/my/operator-index:v1
displayName: "My Operators"
priority: 100
CatalogSource 오브젝트에는 priority 필드가 있으며 확인자는 이 필드를 통해 종속성에 대한 옵션의 우선순위를 부여하는 방법을 확인합니다.
카탈로그 기본 설정을 관리하는 규칙에는 다음 두 가지가 있습니다.
- 우선순위가 높은 카탈로그의 옵션이 우선순위가 낮은 카탈로그의 옵션보다 우선합니다.
- 종속 항목과 동일한 카탈로그의 옵션이 다른 카탈로그보다 우선합니다.
2.4.4.3.2. 채널 순서
카탈로그의 Operator 패키지는 사용자가 OpenShift Container Platform 클러스터에서 구독할 수 있는 업데이트 채널 컬렉션입니다. 채널은 마이너 릴리스(1.2, 1.3) 또는 릴리스 빈도(stable, fast)에 대해 특정 업데이트 스트림을 제공하는 데 사용할 수 있습니다.
동일한 패키지에 있지만 채널이 다른 Operator로 종속성을 충족할 수 있습니다. 예를 들어 버전 1.2의 Operator는 stable 및 fast 채널 모두에 존재할 수 있습니다.
각 패키지에는 기본이 채널이 있으며 항상 기본이 아닌 채널에 우선합니다. 기본 채널의 옵션으로 종속성을 충족할 수 없는 경우 남아 있는 채널의 옵션을 채널 이름의 사전 순으로 고려합니다.
2.4.4.3.3. 채널 내 순서
대부분의 경우 단일 채널 내에는 종속성을 충족하는 옵션이 여러 개 있습니다. 예를 들어 하나의 패키지 및 채널에 있는 Operator에서는 동일한 API 세트를 제공합니다.
이는 사용자가 서브스크립션을 생성할 때 업데이트를 수신하는 채널을 나타냅니다. 이를 통해 검색 범위가 이 하나의 채널로 즉시 줄어듭니다. 하지만 채널 내에서 다수의 Operator가 종속성을 충족할 수 있습니다.
채널 내에서는 업데이트 그래프에서 더 높이 있는 최신 Operator가 우선합니다. 채널 헤드에서 종속성을 충족하면 먼저 시도됩니다.
2.4.4.3.4. 기타 제약 조건
패키지 종속 항목에서 제공하는 제약 조건 외에도 OLM에는 필요한 사용자 상태를 나타내고 확인 불변성을 적용하는 추가 제약 조건이 포함됩니다.
2.4.4.3.4.1. 서브스크립션 제약 조건
서브스크립션 제약 조건은 서브스크립션을 충족할 수 있는 Operator 세트를 필터링합니다. 서브스크립션은 종속성 확인자에 대한 사용자 제공 제약 조건입니다. Operator가 클러스터에 없는 경우 새 Operator를 설치하거나 기존 Operator를 계속 업데이트할지를 선언합니다.
2.4.4.3.4.2. 패키지 제약 조건
하나의 네임스페이스 내에 동일한 패키지의 두 Operator가 제공되지 않을 수 있습니다.
2.4.4.4. CRD 업그레이드
OLM은 CRD(사용자 정의 리소스 정의)가 단수형 CSV(클러스터 서비스 버전)에 속하는 경우 CRD를 즉시 업그레이드합니다. CRD가 여러 CSV에 속하는 경우에는 다음과 같은 하위 호환 조건을 모두 충족할 때 CRD가 업그레이드됩니다.
- 현재 CRD의 기존 서비스 버전은 모두 새 CRD에 있습니다.
- CRD 제공 버전과 연결된 기존의 모든 인스턴스 또는 사용자 정의 리소스는 새 CRD의 검증 스키마에 대해 검증할 때 유효합니다.
2.4.4.5. 종속성 모범 사례
종속 항목을 지정할 때는 모범 사례를 고려해야 합니다.
- API 또는 특정 버전의 Operator 범위에 따라
-
Operator는 언제든지 API를 추가하거나 제거할 수 있습니다. 항상 Operator에서 요구하는 API에
olm.gvk종속성을 지정합니다. 이에 대한 예외는 대신olm.package제약 조건을 지정하는 경우입니다. - 최소 버전 설정
API 변경에 대한 Kubernetes 설명서에서는 Kubernetes 스타일 Operator에 허용되는 변경 사항을 설명합니다. 이러한 버전 관리 규칙을 사용하면 API가 이전 버전과 호환되는 경우 Operator에서 API 버전 충돌 없이 API를 업데이트할 수 있습니다.
Operator 종속 항목의 경우 이는 API 버전의 종속성을 확인하는 것으로는 종속 Operator가 의도한 대로 작동하는지 확인하는 데 충분하지 않을 수 있을 의미합니다.
예를 들면 다음과 같습니다.
-
TestOperator v1.0.0에서는 v1alpha1 API 버전의
MyObject리소스를 제공합니다. -
TestOperator v1.0.1에서는 새 필드
spec.newfield를MyObject에 추가하지만 여전히 v1alpha1입니다.
Operator에
spec.newfield를MyObject리소스에 쓰는 기능이 필요할 수 있습니다.olm.gvk제약 조건만으로는 OLM에서 TestOperator v1.0.0이 아닌 TestOperator v1.0.1이 필요한 것으로 판단하는 데 충분하지 않습니다.가능한 경우 API를 제공하는 특정 Operator를 미리 알고 있는 경우 추가
olm.package제약 조건을 지정하여 최솟값을 설정합니다.-
TestOperator v1.0.0에서는 v1alpha1 API 버전의
- 최대 버전 생략 또는 광범위한 범위 허용
Operator는 API 서비스 및 CRD와 같은 클러스터 범위의 리소스를 제공하기 때문에 짧은 종속성 기간을 지정하는 Operator는 해당 종속성의 다른 소비자에 대한 업데이트를 불필요하게 제한할 수 있습니다.
가능한 경우 최대 버전을 설정하지 마십시오. 또는 다른 Operator와 충돌하지 않도록 매우 광범위한 의미 범위를 설정하십시오. 예를 들면
>1.0.0 <2.0.0과 같습니다.기존 패키지 관리자와 달리 Operator 작성자는 OLM의 채널을 통해 업데이트가 안전함을 명시적으로 인코딩합니다. 기존 서브스크립션에 대한 업데이트가 제공되면 Operator 작성자가 이전 버전에서 업데이트할 수 있음을 나타내는 것으로 간주합니다. 종속성에 최대 버전을 설정하면 특정 상한에서 불필요하게 잘라 작성자의 업데이트 스트림을 덮어씁니다.
참고클러스터 관리자는 Operator 작성자가 설정한 종속 항목을 덮어쓸 수 없습니다.
그러나 피해야 하는 알려진 비호환성이 있는 경우 최대 버전을 설정할 수 있으며 설정해야 합니다. 버전 범위 구문을 사용하여 특정 버전을 생략할 수 있습니다(예:
> 1.0.0 !1.2.1).
2.4.4.6. 종속성 경고
종속성을 지정할 때 고려해야 할 경고 사항이 있습니다.
- 혼합 제약 조건(AND) 없음
현재 제약 조건 간 AND 관계를 지정할 수 있는 방법은 없습니다. 즉 하나의 Operator가 지정된 API를 제공하면서 버전이
>1.1.0인 다른 Operator에 종속되도록 지정할 수 없습니다.즉 다음과 같은 종속성을 지정할 때를 나타냅니다.
dependencies: - type: olm.package value: packageName: etcd version: ">3.1.0" - type: olm.gvk value: group: etcd.database.coreos.com kind: EtcdCluster version: v1beta2OLM은 EtcdCluster를 제공하는 Operator와 버전이
>3.1.0인 Operator를 사용하여 이러한 조건을 충족할 수 있습니다. 이러한 상황이 발생하는지 또는 두 제약 조건을 모두 충족하는 Operator가 선택되었는지는 잠재적 옵션을 방문하는 순서에 따라 다릅니다. 종속성 기본 설정 및 순서 지정 옵션은 잘 정의되어 있으며 추론할 수 있지만 주의를 기울이기 위해 Operator는 둘 중 하나의 메커니즘을 유지해야 합니다.- 네임스페이스 간 호환성
- OLM은 네임스페이스 범위에서 종속성 확인을 수행합니다. 한 네임스페이스의 Operator를 업데이트하면 다른 네임스페이스의 Operator에 문제가 되고 반대의 경우도 마찬가지인 경우 업데이트 교착 상태에 빠질 수 있습니다.
2.4.4.7. 종속성 확인 시나리오 예제
다음 예제에서 공급자는 CRD 또는 API 서비스를 "보유"한 Operator입니다.
예제: 종속 API 사용 중단
A 및 B는 다음과 같은 API입니다(CRD).
- A 공급자는 B에 의존합니다.
- B 공급자에는 서브스크립션이 있습니다.
- C를 제공하도록 B 공급자를 업데이트하지만 B를 더 이상 사용하지 않습니다.
결과는 다음과 같습니다.
- B에는 더 이상 공급자가 없습니다.
- A가 더 이상 작동하지 않습니다.
이는 OLM에서 업그레이드 전략으로 방지하는 사례입니다.
예제: 버전 교착 상태
A 및 B는 다음과 같은 API입니다.
- A 공급자에는 B가 필요합니다.
- B 공급자에는 A가 필요합니다.
- A 공급자를 업데이트(A2 제공, B2 요청)하고 A를 더 이상 사용하지 않습니다.
- B 공급자를 업데이트(A2 제공, B2 요청)하고 B를 더 이상 사용하지 않습니다.
OLM에서 B를 동시에 업데이트하지 않고 A를 업데이트하거나 반대 방향으로 시도하는 경우 새 호환 가능 세트가 있는 경우에도 새 버전의 Operator로 진행할 수 없습니다.
이는 OLM에서 업그레이드 전략으로 방지하는 또 다른 사례입니다.
2.4.5. Operator groups
이 가이드에서는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager)에서 Operator groups을 사용하는 방법을 간략하게 설명합니다.
2.4.5.1. Operator groups 정의
OperatorGroup 리소스에서 정의하는 Operator group에서는 OLM에서 설치한 Operator에 다중 테넌트 구성을 제공합니다. Operator group은 멤버 Operator에 필요한 RBAC 액세스 권한을 생성할 대상 네임스페이스를 선택합니다.
대상 네임스페이스 세트는 쉼표로 구분된 문자열 형식으로 제공되며 CSV(클러스터 서비스 버전)의 olm.targetNamespaces 주석에 저장되어 있습니다. 이 주석은 멤버 Operator의 CSV 인스턴스에 적용되며 해당 배포에 프로젝션됩니다.
2.4.5.2. Operator group 멤버십
다음 조건이 충족되면 Operator가 Operator group의 멤버로 간주됩니다.
- Operator의 CSV는 Operator group과 동일한 네임스페이스에 있습니다.
- Operator의 CSV 설치 모드에서는 Operator group이 대상으로 하는 네임스페이스 세트를 지원합니다.
CSV의 설치 모드는 InstallModeType 필드 및 부울 Supported 필드로 구성됩니다. CSV 사양에는 다음 네 가지 InstallModeTypes로 구성된 설치 모드 세트가 포함될 수 있습니다.
| InstallModeType | 설명 |
|---|---|
|
| Operator가 자체 네임스페이스를 선택하는 Operator group의 멤버일 수 있습니다. |
|
| Operator가 하나의 네임스페이스를 선택하는 Operator group의 멤버일 수 있습니다. |
|
| Operator가 네임스페이스를 두 개 이상 선택하는 Operator group의 멤버일 수 있습니다. |
|
|
Operator가 네임스페이스를 모두 선택하는 Operator group의 멤버일 수 있습니다(대상 네임스페이스 세트는 빈 문자열( |
CSV 사양에서 InstallModeType 항목이 생략되면 암시적으로 지원하는 기존 항목에서 지원을 유추할 수 있는 경우를 제외하고 해당 유형을 지원하지 않는 것으로 간주합니다.
2.4.5.3. 대상 네임스페이스 선택
spec.targetNamespaces 매개변수를 사용하여 Operator group의 대상 네임스페이스의 이름을 명시적으로 지정할 수 있습니다.
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
targetNamespaces:
- my-namespace
또는 라벨 선택기를 spec.selector 매개변수와 함께 사용하여 네임스페이스를 지정할 수도 있습니다.
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
spec:
selector:
cool.io/prod: "true"
spec.targetNamespaces를 통해 여러 네임스페이스를 나열하거나 spec.selector를 통해 라벨 선택기를 사용하는 것은 바람직하지 않습니다. Operator group의 대상 네임스페이스 두 개 이상에 대한 지원이 향후 릴리스에서 제거될 수 있습니다.
spec.targetNamespaces 및 spec.selector를 둘 다 정의하면 spec.selector가 무시됩니다. 또는 모든 네임스페이스를 선택하는 global Operator group을 지정하려면 spec.selector 및 spec.targetNamespaces를 둘 다 생략하면 됩니다.
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: my-group
namespace: my-namespace
선택된 네임스페이스의 확인된 세트는 Opeator group의 status.namespaces 매개변수에 표시됩니다. 글로벌 Operator group의 status.namespace에는 사용 중인 Operator에 모든 네임스페이스를 조사해야 함을 알리는 빈 문자열("")이 포함됩니다.
2.4.5.4. Operator group CSV 주석
Operator group의 멤버 CSV에는 다음과 같은 주석이 있습니다.
| 주석 | 설명 |
|---|---|
|
| Operator group의 이름을 포함합니다. |
|
| Operator group의 네임스페이스를 포함합니다. |
|
| Operator group의 대상 네임스페이스 선택 사항을 나열하는 쉼표로 구분된 문자열을 포함합니다. |
olm.targetNamespaces를 제외한 모든 주석은 CSV 복사본에 포함됩니다. CSV 복제본에서 olm.targetNamespaces 주석을 생략하면 테넌트 간에 대상 네임스페이스를 복제할 수 없습니다.
2.4.5.5. 제공된 API 주석
GVK(그룹/버전/종류)는 Kubernetes API의 고유 ID입니다. Operator group에서 제공하는 GVK에 대한 정보는 olm.providedAPIs 주석에 표시됩니다. 주석 값은 <kind>.<version>.<group>으로 구성된 문자열로, 쉼표로 구분됩니다. Operator group의 모든 활성 멤버 CSV에서 제공하는 CRD 및 API 서비스의 GVK가 포함됩니다.
PackageManifest 리소스를 제공하는 하나의 활성 멤버 CSV에서 OperatorGroup 오브젝트의 다음 예제를 검토합니다.
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
annotations:
olm.providedAPIs: PackageManifest.v1alpha1.packages.apps.redhat.com
name: olm-operators
namespace: local
...
spec:
selector: {}
serviceAccount:
metadata:
creationTimestamp: null
targetNamespaces:
- local
status:
lastUpdated: 2019-02-19T16:18:28Z
namespaces:
- local2.4.5.6. 역할 기반 액세스 제어
Operator v이 생성되면 세 개의 클러스터 역할이 생성됩니다. 각 역할에는 다음과 같이 라벨과 일치하도록 클러스터 역할 선택기가 설정된 단일 집계 규칙이 포함됩니다.
| 클러스터 역할 | 일치해야 하는 라벨 |
|---|---|
|
|
|
|
|
|
|
|
|
다음 RBAC 리소스는 CSV가 AllNamespaces 설치 모드로 모든 네임스페이스를 조사하고 이유가 InterOperatorGroupOwnerConflict인 실패 상태가 아닌 한 CSV가 Operator group의 활성 멤버가 될 때 생성됩니다.
- CRD의 각 API 리소스에 대한 클러스터 역할
- API 서비스의 각 API 리소스에 대한 클러스터 역할
- 추가 역할 및 역할 바인딩
| 클러스터 역할 | 설정 |
|---|---|
|
|
집계 라벨:
|
|
|
집계 라벨:
|
|
|
집계 라벨:
|
|
|
집계 라벨:
|
| 클러스터 역할 | 설정 |
|---|---|
|
|
집계 라벨:
|
|
|
집계 라벨:
|
|
|
집계 라벨:
|
추가 역할 및 역할 바인딩
-
CSV에서
*를 포함하는 정확히 하나의 대상 네임스페이스를 정의하는 경우 CSV의permissions필드에 정의된 각 권한에 대해 클러스터 역할 및 해당 클러스터 역할 바인딩이 생성됩니다. 생성된 모든 리소스에는olm.owner: <csv_name>및olm.owner.namespace: <csv_namespace>라벨이 지정됩니다. -
CSV에서
*를 포함하는 정확히 하나의 대상 네임스페이스를 정의하지 않는 경우에는olm.owner: <csv_name>및olm.owner.namespace: <csv_namespace>라벨이 있는 Operator 네임스페이스의 모든 역할 및 역할 바인딩이 대상 네임스페이스에 복사됩니다.
2.4.5.7. CSV 복사본
OLM은 해당 Operator group의 각 대상 네임스페이스에서 Operator group의 모든 활성 멤버에 대한 CSV 복사본을 생성합니다. CSV 복사본의 용도는 대상 네임스페이스의 사용자에게 특정 Operator가 그곳에서 생성된 리소스를 조사하도록 구성됨을 알리는 것입니다.
CSV 복사본은 상태 이유가 Copied이고 해당 소스 CSV의 상태와 일치하도록 업데이트됩니다. olm.targetNamespaces 주석은 해당 주석이 클러스터에서 생성되기 전에 CSV 복사본에서 제거됩니다. 대상 네임스페이스 선택 단계를 생략하면 테넌트 간 대상 네임스페이스가 중복되지 않습니다.
CSV 복사본은 복사본의 소스 CSV가 더 이상 존재하지 않거나 소스 CSV가 속한 Operator group이 더 이상 CSV 복사본의 네임스페이스를 대상으로 하지 않는 경우 삭제됩니다.
2.4.5.8. 정적 Operator groups
spec.staticProvidedAPIs 필드가 true로 설정된 경우 Operator group은 static입니다. 결과적으로 OLM은 Operator group의 olm.providedAPIs 주석을 수정하지 않으므로 사전에 설정할 수 있습니다. 이는 사용자가 Operator group을 사용하여 일련의 네임스페이스에서 리소스 경합을 방지하려고 하지만 해당 리소스에 대한 API를 제공하는 활성 멤버 CSV가 없는 경우 유용합니다.
다음은 something.cool.io/cluster-monitoring: "true" 주석을 사용하여 모든 네임스페이스에서 Prometheus 리소스를 보호하는 Operator group의 예입니다.
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-monitoring
namespace: cluster-monitoring
annotations:
olm.providedAPIs: Alertmanager.v1.monitoring.coreos.com,Prometheus.v1.monitoring.coreos.com,PrometheusRule.v1.monitoring.coreos.com,ServiceMonitor.v1.monitoring.coreos.com
spec:
staticProvidedAPIs: true
selector:
matchLabels:
something.cool.io/cluster-monitoring: "true"2.4.5.9. Operator group 교집합
대상 네임스페이스 세트의 교집합이 빈 세트가 아니고 olm.providedAPIs 주석으로 정의되어 제공된 API 세트의 교집합이 빈 세트가 아닌 경우 두 Operator groups을 교차 제공 API가 있다고 합니다.
잠재적인 문제는 교차 제공 API가 있는 Operator groups이 교차 네임스페이스 세트에서 동일한 리소스에 대해 경쟁할 수 있다는 점입니다.
교집합 규칙을 확인할 때는 Operator group 네임스페이스가 항상 선택한 대상 네임스페이스의 일부로 포함됩니다.
교집합 규칙
활성 멤버 CSV가 동기화될 때마다 OLM은 CSV의 Operator group 및 기타 모든 그룹 간에 교차 제공되는 API 세트에 대한 클러스터를 쿼리합니다. 그런 다음 OLM은 해당 세트가 빈 세트인지 확인합니다.
true및 CSV 제공 API가 Operator group의 서브 세트인 경우:- 계속 전환합니다.
true및 CSV 제공 API가 Operator group의 서브 세트가 아닌 경우:Operator group이 정적이면 다음을 수행합니다.
- CSV에 속하는 배포를 정리합니다.
-
상태 이유
CannotModifyStaticOperatorGroupProvidedAPIs와 함께 CSV를 실패 상태로 전환합니다.
Operator group이 정적이 아니면 다음을 수행합니다.
-
Operator group의
olm.providedAPIs주석을 주석 자체와 CSV 제공 API를 결합한 내용으로 교체합니다.
-
Operator group의
false및 CSV 제공 API가 Operator group의 서브 세트가 아닌 경우:- CSV에 속하는 배포를 정리합니다.
-
상태 이유
InterOperatorGroupOwnerConflict와 함께 CSV를 실패 상태로 전환합니다.
false및 CSV 제공 API가 Operator group의 서브 세트인 경우:Operator group이 정적이면 다음을 수행합니다.
- CSV에 속하는 배포를 정리합니다.
-
상태 이유
CannotModifyStaticOperatorGroupProvidedAPIs와 함께 CSV를 실패 상태로 전환합니다.
Operator group이 정적이 아니면 다음을 수행합니다.
-
Operator group의
olm.providedAPIs주석을 주석 자체와 CSV 제공 API 간의 차이로 교체합니다.
-
Operator group의
Operator group으로 인한 실패 상태는 터미널이 아닙니다.
Operator group이 동기화될 때마다 다음 작업이 수행됩니다.
- 활성 멤버 CSV에서 제공되는 API 세트는 클러스터에서 계산됩니다. CSV 복사본은 무시됩니다.
-
클러스터 세트는
olm.providedAPIs와 비교되며olm.providedAPIs에 추가 API가 포함된 경우 해당 API가 정리됩니다. - 모든 네임스페이스에서 동일한 API를 제공하는 모든 CSV가 다시 큐에 추가됩니다. 그러면 충돌하는 CSV의 크기 조정 또는 삭제를 통해 충돌이 해결되었을 수 있음을 교차 group의 충돌하는 CSV에 알립니다.
2.4.5.10. 멀티 테넌트 Operator 관리에 대한 제한 사항
OpenShift Container Platform은 클러스터에 다양한 Operator 변형을 동시에 설치할 수 있도록 제한된 지원을 제공합니다. Operator는 컨트롤 플레인 확장입니다. 모든 테넌트 또는 네임스페이스는 클러스터의 동일한 컨트롤 플레인을 공유합니다. 따라서 멀티 테넌트 환경의 테넌트도 Operator를 공유해야 합니다.
OLM(Operator Lifecycle Manager)은 다른 네임스페이스에 Operator를 여러 번 설치합니다. 이에 대한 한 가지 제한 사항은 Operator의 API 버전이 동일해야 한다는 것입니다.
Operator의 다른 주요 버전에는 종종 호환되지 않는 CRD(사용자 정의 리소스 정의)가 있습니다. 이렇게 하면 OLM을 신속하게 확인하기 어렵습니다.
2.4.5.11. Operator groups 문제 해결
멤버십
-
단일 네임스페이스에 두 개 이상의 Operator groups이 있는 경우 해당 네임스페이스에서 생성된 모든 CSV는
TooManyOperatorGroups이유와 함께 실패 상태로 전환됩니다. 이러한 이유로 실패한 상태의 CSV는 네임스페이스의 Operator groups 수가 1에 도달하면 보류 중으로 전환됩니다. -
CSV의 설치 모드가 해당 네임스페이스에서 Operator group의 대상 네임스페이스 선택을 지원하지 않는 경우 CSV는
UnsupportedOperatorGroup이유와 함께 실패 상태로 전환됩니다. 이러한 이유로 실패 상태에 있는 CSV는 Operator group의 대상 네임스페이스 선택이 지원되는 구성으로 변경된 후 보류 중으로 전환되거나 대상 네임스페이스 선택을 지원하도록 CSV의 설치 모드가 수정됩니다.
2.4.6. Operator Lifecycle Manager 지표
2.4.6.1. 표시되는 지표
OLM(Operator Lifecycle Manager)에서는 Prometheus 기반 OpenShift Container Platform 클러스터 모니터링 스택에서 사용할 특정 OLM 관련 리소스를 표시합니다.
| 이름 | 설명 |
|---|---|
|
| 카탈로그 소스 수입니다. |
|
|
CSV(클러스터 서비스 버전)를 조정할 때 CSV 버전이 |
|
| 성공적으로 등록된 CSV 수입니다. |
|
|
CSV를 재조정할 때 CSV 버전이 |
|
| CSV 업그레이드의 단조 수입니다. |
|
| 설치 계획 수입니다. |
|
| 서브스크립션 수입니다. |
|
|
서브스크립션 동기화의 단조 수입니다. |
2.4.7. Operator Lifecycle Manager의 Webhook 관리
Operator 작성자는 Webhook를 통해 리소스를 오브젝트 저장소에 저장하고 Operator 컨트롤러에서 이를 처리하기 전에 리소스를 가로채기, 수정, 수락 또는 거부할 수 있습니다. Operator와 함께 webhook 가 제공 될 때 OLM (Operator Lifecycle Manager)은 이러한 Webhook의 라이프 사이클을 관리할 수 있습니다.
Operator 개발자가 Operator의 Webhook 를 정의하는 방법과 OLM에서 실행할 때의 고려 사항에 대한 자세한 내용은 CSV(클러스터 서비스 버전) 생성.
2.5. OperatorHub 이해
2.5.1. OperatorHub 정보
OperatorHub는 클러스터 관리자가 Operator를 검색하고 설치하는 데 사용하는 OpenShift Container Platform의 웹 콘솔 인터페이스입니다. 한 번의 클릭으로 Operator를 클러스터 외부 소스에서 가져와서 클러스터에 설치 및 구독하고 엔지니어링 팀에서 OLM(Operator Lifecycle Manager)을 사용하여 배포 환경에서 제품을 셀프서비스로 관리할 수 있습니다.
클러스터 관리자는 다음 카테고리로 그룹화된 카탈로그에서 선택할 수 있습니다.
| 카테고리 | 설명 |
|---|---|
| Red Hat Operator | Red Hat에서 Red Hat 제품을 패키지 및 제공합니다. Red Hat에서 지원합니다. |
| 인증된 Operator | 선도적인 ISV(독립 소프트웨어 벤더)의 제품입니다. Red Hat은 패키지 및 제공을 위해 ISV와 협력합니다. ISV에서 지원합니다. |
| Red Hat Marketplace | Red Hat Marketplace에서 구매할 수 있는 인증 소프트웨어입니다. |
| 커뮤니티 Operator | operator-framework/community-operators GitHub 리포지토리의 관련 담당자가 유지 관리하는 선택적 표시 소프트웨어입니다. 공식적으로 지원되지 않습니다. |
| 사용자 정의 Operator | 클러스터에 직접 추가하는 Operator입니다. 사용자 정의 Operator를 추가하지 않은 경우 OperatorHub의 웹 콘솔에 사용자 정의 카테고리가 표시되지 않습니다. |
OperatorHub의 Operator는 OLM에서 실행되도록 패키지됩니다. 여기에는 Operator를 설치하고 안전하게 실행하는 데 필요한 모든 CRD, RBAC 규칙, 배포, 컨테이너 이미지가 포함된 CSV(클러스터 서비스 버전)라는 YAML 파일이 포함됩니다. 또한 해당 기능 및 지원되는 Kubernetes 버전에 대한 설명과 같이 사용자가 볼 수 있는 정보가 포함됩니다.
Operator SDK는 OLM 및 OperatorHub에서 사용하도록 Operator를 패키지하는 개발자를 지원하는 데 사용할 수 있습니다. 고객이 액세스할 수 있도록 설정할 상용 애플리케이션이 있는 경우 Red Hat Partner Connect 포털(connect.redhat.com)에 제공된 인증 워크플로를 사용하여 포함합니다.
2.5.2. OperatorHub 아키텍처
OperatorHub UI 구성 요소는 기본적으로 openshift-marketplace 네임스페이스의 OpenShift Container Platform에서 Marketplace Operator에 의해 구동됩니다.
2.5.2.1. OperatorHub 사용자 정의 리소스
Marketplace Operator는 OperatorHub와 함께 제공되는 기본 CatalogSource 오브젝트를 관리하는 cluster라는 OperatorHub CR(사용자 정의 리소스)을 관리합니다. 이 리소스를 수정하여 기본 카탈로그를 활성화하거나 비활성화할 수 있어 제한된 네트워크 환경에서 OpenShift Container Platform을 구성할 때 유용합니다.
OperatorHub 사용자 정의 리소스의 예
apiVersion: config.openshift.io/v1
kind: OperatorHub
metadata:
name: cluster
spec:
disableAllDefaultSources: true
sources: [
{
name: "community-operators",
disabled: false
}
]2.6. Red Hat 제공 Operator 카탈로그
2.6.1. Operator 카탈로그 정보
Operator 카탈로그는 OLM(Operator Lifecycle Manager)에서 쿼리하여 Operator 및 해당 종속성을 검색하고 설치할 수 있는 메타데이터 리포지토리입니다. OLM은 항상 최신 버전의 카탈로그에 있는 Operator를 설치합니다. OpenShift Container Platform 4.6부터는 인덱스 이미지를 사용하여 Red Hat에서 제공하는 카탈로그가 배포됩니다.
Operator 번들 형식을 기반으로 하는 인덱스 이미지는 컨테이너화된 카탈로그 스냅샷입니다. 일련의 Operator 매니페스트 콘텐츠에 대한 포인터의 데이터베이스를 포함하는 변경 불가능한 아티팩트입니다. 카탈로그는 인덱스 이미지를 참조하여 클러스터에서 OLM에 대한 콘텐츠를 소싱할 수 있습니다.
OpenShift Container Platform 4.6부터는 Red Hat에서 제공하는 인덱스 이미지가 더 이상 사용되지 않는 패키지 매니페스트 형식을 기반으로 이전 버전의 OpenShift Container Platform 4에 배포되는 앱 레지스트리 카탈로그 이미지를 대체합니다. 앱 레지스트리 카탈로그 이미지는 Red Hat for OpenShift Container Platform 4.6 이상에서 배포되지 않지만 패키지 매니페스트 형식을 기반으로 하는 사용자 정의 카탈로그 이미지는 계속 지원됩니다.
카탈로그가 업데이트되면 최신 버전의 Operator가 변경되고 이전 버전은 제거되거나 변경될 수 있습니다. 또한 OLM이 네트워크가 제한된 환경의 OpenShift Container Platform 클러스터에서 실행되면 최신 콘텐츠를 가져오기 위해 인터넷에서 카탈로그에 직접 액세스할 수 없습니다.
클러스터 관리자는 Red Hat에서 제공하는 카탈로그를 기반으로 또는 처음부터 자체 사용자 정의 인덱스 이미지를 생성할 수 있습니다. 이 이미지는 클러스터에서 카탈로그 콘텐츠를 소싱하는 데 사용할 수 있습니다. 자체 인덱스 이미지를 생성하고 업데이트하면 클러스터에서 사용 가능한 Operator 세트를 사용자 정의할 수 있을 뿐만 아니라 앞서 언급한 제한된 네트워크 환경 문제도 방지할 수 있습니다.
사용자 정의 카탈로그 이미지를 생성할 때 이전 버전의 OpenShift Container Platform 4에서는 여러 릴리스에서 더 이상 사용되지 않는 oc adm catalog build 명령을 사용해야 했습니다. OpenShift Container Platform 4.6부터는 Red Hat 제공 인덱스 이미지를 사용할 수 있으므로 카탈로그 빌더는 향후 릴리스에서 oc adm catalog build 명령이 제거되기 전에 인덱스 이미지를 관리하는 데 opm index 명령을 사용하도록 전환해야 합니다.
2.6.2. Red Hat 제공 Operator 카탈로그 정보
다음은 Red Hat에서 제공하는 Operator 카탈로그입니다.
| 카탈로그 | 인덱스 이미지 | 설명 |
|---|---|---|
|
|
| Red Hat에서 Red Hat 제품을 패키지 및 제공합니다. Red Hat에서 지원합니다. |
|
|
| 선도적인 ISV(독립 소프트웨어 벤더)의 제품입니다. Red Hat은 패키지 및 제공을 위해 ISV와 협력합니다. ISV에서 지원합니다. |
|
|
| Red Hat Marketplace에서 구매할 수 있는 인증 소프트웨어입니다. |
|
|
| operator-framework/community-operators GitHub 리포지토리의 관련 담당자가 유지 관리하는 소프트웨어입니다. 공식적으로 지원되지 않습니다. |
2.7. CRD
2.7.1. 사용자 정의 리소스 정의를 사용하여 Kubernetes API 확장
이 가이드에서는 클러스터 관리자가 CRD(사용자 정의 리소스 정의)를 생성하고 관리하여 OpenShift Container Platform 클러스터를 확장할 수 있는 방법을 설명합니다.
2.7.1.1. 사용자 정의 리소스 정의
Kubernetes API에서 리소스는 특정 종류의 API 오브젝트 컬렉션을 저장하는 끝점입니다. 예를 들어 기본 제공 Pod 리소스에는 Pod 오브젝트의 컬렉션이 포함됩니다.
CRD(사용자 정의 리소스 정의) 오브젝트는 클러스터에서 종류라는 새로운 고유한 오브젝트 유형을 정의하고 Kubernetes API 서버에서 전체 라이프사이클을 처리하도록 합니다.
CR(사용자 정의 리소스) 오브젝트는 클러스터 관리자가 클러스터에 추가한 CRD에서 생성하므로 모든 클러스터 사용자가 새 리소스 유형을 프로젝트에 추가할 수 있습니다.
클러스터 관리자가 새 CRD를 클러스터에 추가하면 Kubernetes API 서버는 전체 클러스터 또는 단일 프로젝트(네임스페이스)에서 액세스할 수 있는 새 RESTful 리소스 경로를 생성하여 반응하고 지정된 CR을 제공하기 시작합니다.
클러스터 관리자가 다른 사용자에게 CRD에 대한 액세스 권한을 부여하려면 클러스터 역할 집계를 사용하여 admin, edit 또는 view 기본 클러스터 역할이 있는 사용자에게 액세스 권한을 부여할 수 있습니다. 클러스터 역할 집계를 사용하면 이러한 클러스터 역할에 사용자 정의 정책 규칙을 삽입할 수 있습니다. 이 동작은 새 리소스를 기본 제공 리소스인 것처럼 클러스터의 RBAC 정책에 통합합니다.
특히 운영자는 CRD를 필수 RBAC 정책 및 기타 소프트웨어별 논리와 함께 패키지로 제공하는 방식으로 CRD를 사용합니다. 또한 클러스터 관리자는 Operator의 라이프사이클 외부에서 클러스터에 CRD를 수동으로 추가하여 모든 사용자에게 제공할 수 있습니다.
클러스터 관리자만 CRD를 생성할 수 있지만 기존 CRD에 대한 읽기 및 쓰기 권한이 있는 개발자의 경우 기존 CRD에서 CR을 생성할 수 있습니다.
2.7.1.2. 사용자 정의 리소스 정의 생성
사용자 정의 리소스(CR) 오브젝트를 생성하려면 클러스터 관리자가 먼저 CRD(사용자 정의 리소스 정의)를 생성해야 합니다.
사전 요구 사항
-
cluster-admin사용자 권한을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
프로세스
CRD를 생성하려면 다음을 수행합니다.
다음 필드 유형을 포함하는 YAML 파일을 생성합니다.
CRD에 대한 YAML 파일의 예
apiVersion: apiextensions.k8s.io/v11 kind: CustomResourceDefinition metadata: name: crontabs.stable.example.com2 spec: group: stable.example.com3 versions: name: v14 scope: Namespaced5 names: plural: crontabs6 singular: crontab7 kind: CronTab8 shortNames: - ct9 - 1
apiextensions.k8s.io/v1API를 사용합니다.- 2
- 정의의 이름을 지정합니다.
group및plural필드의 값을 사용하는<plural-name>.<group>형식이어야 합니다. - 3
- API의 그룹 이름을 지정합니다. API 그룹은 논리적으로 관련된 오브젝트의 컬렉션입니다. 예를 들어
Job또는ScheduledJob과 같은 배치 오브젝트는 모두 배치 API 그룹(예:batch.api.example.com)에 있을 수 있습니다. 조직의 FQDN(정규화된 도메인 이름)을 사용하는 것이 좋습니다. - 4
- URL에 사용할 버전 이름을 지정합니다. 각 API 그룹은 여러 버전(예:
v1alpha,v1beta,v1)에 있을 수 있습니다. - 5
- 특정 프로젝트(
Namespaced) 또는 클러스터의 모든 프로젝트(Cluster)에서 사용자 정의 오브젝트를 사용할 수 있는지 지정합니다. - 6
- URL에서 사용할 복수형 이름을 지정합니다.
plural필드는 API URL의 리소스와 동일합니다. - 7
- CLI 및 디스플레이에서 별칭으로 사용할 단수형 이름을 지정합니다.
- 8
- 생성할 수 있는 오브젝트의 종류를 지정합니다. 유형은 CamelCase에 있을 수 있습니다.
- 9
- CLI의 리소스와 일치하는 짧은 문자열을 지정합니다.
참고기본적으로 CRD는 클러스터 범위이며 모든 프로젝트에서 사용할 수 있습니다.
CRD 오브젝트를 생성합니다.
$ oc create -f <file_name>.yaml다음에 새 RESTful API 끝점이 생성됩니다.
/apis/<spec:group>/<spec:version>/<scope>/*/<names-plural>/...예를 들어 예제 파일을 사용하면 다음 끝점이 생성됩니다.
/apis/stable.example.com/v1/namespaces/*/crontabs/...이 끝점 URL을 사용하여 CR을 생성하고 관리할 수 있습니다. 오브젝트 종류는 생성한 CRD 오브젝트의
spec.kind필드를 기반으로 합니다.
2.7.1.3. 사용자 정의 리소스 정의에 대한 클러스터 역할 생성
클러스터 관리자는 기존 클러스터 범위의 CRD(사용자 정의 리소스 정의)에 권한을 부여할 수 있습니다. admin, edit, view 기본 클러스터 역할을 사용하는 경우 해당 규칙에 클러스터 역할 집계를 활용할 수 있습니다.
이러한 각 역할에 대한 권한을 명시적으로 할당해야 합니다. 권한이 더 많은 역할은 권한이 더 적은 역할의 규칙을 상속하지 않습니다. 역할에 규칙을 할당하는 경우 권한이 더 많은 역할에 해당 동사를 할당해야 합니다. 예를 들어 보기 역할에 get crontabs 권한을 부여하는 경우 edit 및 admin 역할에도 부여해야 합니다. admin 또는 edit 역할은 일반적으로 프로젝트 템플릿을 통해 프로젝트를 생성한 사용자에게 할당됩니다.
사전 요구 사항
- CRD를 생성합니다.
프로세스
CRD의 클러스터 역할 정의 파일을 생성합니다. 클러스터 역할 정의는 각 클러스터 역할에 적용되는 규칙이 포함된 YAML 파일입니다. OpenShift Container Platform 컨트롤러는 사용자가 지정하는 규칙을 기본 클러스터 역할에 추가합니다.
클러스터 역할 정의에 대한 YAML 파일의 예
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v11 metadata: name: aggregate-cron-tabs-admin-edit2 labels: rbac.authorization.k8s.io/aggregate-to-admin: "true"3 rbac.authorization.k8s.io/aggregate-to-edit: "true"4 rules: - apiGroups: ["stable.example.com"]5 resources: ["crontabs"]6 verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"]7 --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: aggregate-cron-tabs-view8 labels: # Add these permissions to the "view" default role. rbac.authorization.k8s.io/aggregate-to-view: "true"9 rbac.authorization.k8s.io/aggregate-to-cluster-reader: "true"10 rules: - apiGroups: ["stable.example.com"]11 resources: ["crontabs"]12 verbs: ["get", "list", "watch"]13 - 1
rbac.authorization.k8s.io/v1API를 사용합니다.- 2 8
- 정의의 이름을 지정합니다.
- 3
- 관리 기본 역할에 권한을 부여하려면 이 라벨을 지정합니다.
- 4
- 편집 기본 역할에 권한을 부여하려면 이 라벨을 지정합니다.
- 5 11
- CRD의 그룹 이름을 지정합니다.
- 6 12
- 이러한 규칙이 적용되는 CRD의 복수형 이름을 지정합니다.
- 7 13
- 역할에 부여된 권한을 나타내는 동사를 지정합니다. 예를 들어
admin및edit역할에는 읽기 및 쓰기 권한을 적용하고view역할에는 읽기 권한만 적용합니다. - 9
view기본 역할에 권한을 부여하려면 이 라벨을 지정합니다.- 10
cluster-reader기본 역할에 권한을 부여하려면 이 라벨을 지정합니다.
클러스터 역할을 생성합니다.
$ oc create -f <file_name>.yaml
2.7.1.4. 파일에서 사용자 정의 리소스 생성
CRD(사용자 정의 리소스 정의)가 클러스터에 추가되면 CR 사양을 사용하여 파일에서 CLI를 통해 CR(사용자 정의 리소스)을 생성할 수 있습니다.
사전 요구 사항
- 클러스터 관리자가 클러스터에 CRD를 추가했습니다.
프로세스
CR에 대한 YAML 파일을 생성합니다. 다음 예제 정의에서
cronSpec및image사용자 정의 필드는Kind CR에 설정됩니다. CronTab.Kind는 CRD 오브젝트의spec.kind필드에서 제공합니다.CR에 대한 YAML 파일의 예
apiVersion: "stable.example.com/v1"1 kind: CronTab2 metadata: name: my-new-cron-object3 finalizers:4 - finalizer.stable.example.com spec:5 cronSpec: "* * * * /5" image: my-awesome-cron-image파일을 생성한 후 오브젝트를 생성합니다.
$ oc create -f <file_name>.yaml
2.7.1.5. 사용자 정의 리소스 검사
CLI를 사용하여 클러스터에 존재하는 CR(사용자 정의 리소스) 오브젝트를 검사할 수 있습니다.
사전 요구 사항
- CR 오브젝트는 액세스할 수 있는 네임스페이스에 있습니다.
프로세스
특정 종류의 CR에 대한 정보를 얻으려면 다음을 실행합니다.
$ oc get <kind>예를 들면 다음과 같습니다.
$ oc get crontab출력 예
NAME KIND my-new-cron-object CronTab.v1.stable.example.com리소스 이름은 대소문자를 구분하지 않으며 CRD에 정의된 단수형 또는 복수형 양식이나 짧은 이름을 사용할 수 있습니다. 예를 들면 다음과 같습니다.
$ oc get crontabs$ oc get crontab$ oc get ctCR의 원시 YAML 데이터를 볼 수도 있습니다.
$ oc get <kind> -o yaml예를 들면 다음과 같습니다.
$ oc get ct -o yaml출력 예
apiVersion: v1 items: - apiVersion: stable.example.com/v1 kind: CronTab metadata: clusterName: "" creationTimestamp: 2017-05-31T12:56:35Z deletionGracePeriodSeconds: null deletionTimestamp: null name: my-new-cron-object namespace: default resourceVersion: "285" selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object uid: 9423255b-4600-11e7-af6a-28d2447dc82b spec: cronSpec: '* * * * /5'1 image: my-awesome-cron-image2
2.7.2. 사용자 정의 리소스 정의에서 리소스 관리
이 가이드에서는 개발자가 CRD(사용자 정의 리소스 정의)에서 제공하는 CR(사용자 정의 리소스)을 관리하는 방법을 설명합니다.
2.7.2.1. 사용자 정의 리소스 정의
Kubernetes API에서 리소스는 특정 종류의 API 오브젝트 컬렉션을 저장하는 끝점입니다. 예를 들어 기본 제공 Pod 리소스에는 Pod 오브젝트의 컬렉션이 포함됩니다.
CRD(사용자 정의 리소스 정의) 오브젝트는 클러스터에서 종류라는 새로운 고유한 오브젝트 유형을 정의하고 Kubernetes API 서버에서 전체 라이프사이클을 처리하도록 합니다.
CR(사용자 정의 리소스) 오브젝트는 클러스터 관리자가 클러스터에 추가한 CRD에서 생성하므로 모든 클러스터 사용자가 새 리소스 유형을 프로젝트에 추가할 수 있습니다.
특히 운영자는 CRD를 필수 RBAC 정책 및 기타 소프트웨어별 논리와 함께 패키지로 제공하는 방식으로 CRD를 사용합니다. 또한 클러스터 관리자는 Operator의 라이프사이클 외부에서 클러스터에 CRD를 수동으로 추가하여 모든 사용자에게 제공할 수 있습니다.
클러스터 관리자만 CRD를 생성할 수 있지만 기존 CRD에 대한 읽기 및 쓰기 권한이 있는 개발자의 경우 기존 CRD에서 CR을 생성할 수 있습니다.
2.7.2.2. 파일에서 사용자 정의 리소스 생성
CRD(사용자 정의 리소스 정의)가 클러스터에 추가되면 CR 사양을 사용하여 파일에서 CLI를 통해 CR(사용자 정의 리소스)을 생성할 수 있습니다.
사전 요구 사항
- 클러스터 관리자가 클러스터에 CRD를 추가했습니다.
프로세스
CR에 대한 YAML 파일을 생성합니다. 다음 예제 정의에서
cronSpec및image사용자 정의 필드는Kind CR에 설정됩니다. CronTab.Kind는 CRD 오브젝트의spec.kind필드에서 제공합니다.CR에 대한 YAML 파일의 예
apiVersion: "stable.example.com/v1"1 kind: CronTab2 metadata: name: my-new-cron-object3 finalizers:4 - finalizer.stable.example.com spec:5 cronSpec: "* * * * /5" image: my-awesome-cron-image파일을 생성한 후 오브젝트를 생성합니다.
$ oc create -f <file_name>.yaml
2.7.2.3. 사용자 정의 리소스 검사
CLI를 사용하여 클러스터에 존재하는 CR(사용자 정의 리소스) 오브젝트를 검사할 수 있습니다.
사전 요구 사항
- CR 오브젝트는 액세스할 수 있는 네임스페이스에 있습니다.
프로세스
특정 종류의 CR에 대한 정보를 얻으려면 다음을 실행합니다.
$ oc get <kind>예를 들면 다음과 같습니다.
$ oc get crontab출력 예
NAME KIND my-new-cron-object CronTab.v1.stable.example.com리소스 이름은 대소문자를 구분하지 않으며 CRD에 정의된 단수형 또는 복수형 양식이나 짧은 이름을 사용할 수 있습니다. 예를 들면 다음과 같습니다.
$ oc get crontabs$ oc get crontab$ oc get ctCR의 원시 YAML 데이터를 볼 수도 있습니다.
$ oc get <kind> -o yaml예를 들면 다음과 같습니다.
$ oc get ct -o yaml출력 예
apiVersion: v1 items: - apiVersion: stable.example.com/v1 kind: CronTab metadata: clusterName: "" creationTimestamp: 2017-05-31T12:56:35Z deletionGracePeriodSeconds: null deletionTimestamp: null name: my-new-cron-object namespace: default resourceVersion: "285" selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object uid: 9423255b-4600-11e7-af6a-28d2447dc82b spec: cronSpec: '* * * * /5'1 image: my-awesome-cron-image2
3장. 사용자 작업
3.1. 설치된 Operator에서 애플리케이션 생성
이 가이드에서는 개발자에게 OpenShift Container Platform 웹 콘솔을 사용하여 설치한 Operator에서 애플리케이션을 생성하는 예제를 안내합니다.
3.1.1. Operator를 사용하여 etcd 클러스터 생성
이 절차에서는 OLM(Operator Lifecycle Manager)에서 관리하는 etcd Operator를 사용하여 새 etcd 클러스터를 생성하는 과정을 안내합니다.
사전 요구 사항
- OpenShift Container Platform 4.6 클러스터에 액세스할 수 있습니다.
- 관리자가 클러스터 수준에 etcd Operator를 이미 설치했습니다.
프로세스
-
이 절차를 위해 OpenShift Container Platform 웹 콘솔에 새 프로젝트를 생성합니다. 이 예제에서는
my-etcd라는 프로젝트를 사용합니다. Operator → 설치된 Operator 페이지로 이동합니다. 이 페이지에는 클러스터 관리자가 클러스터에 설치하여 사용할 수 있는 Operator가 CSV(클러스터 서비스 버전) 목록으로 표시됩니다. CSV는 Operator에서 제공하는 소프트웨어를 시작하고 관리하는 데 사용됩니다.
작은 정보다음을 사용하여 CLI에서 이 목록을 가져올 수 있습니다.
$ oc get csv자세한 내용과 사용 가능한 작업을 확인하려면 설치된 Operator 페이지에서 etcd Operator를 클릭합니다.
이 Operator에서는 제공된 API 아래에 표시된 것과 같이 etcd 클러스터(
EtcdCluster리소스)용 하나를 포함하여 새로운 리소스 유형 세 가지를 사용할 수 있습니다. 이러한 오브젝트는 내장된 네이티브 Kubernetes 오브젝트(예:Deployment또는ReplicaSet)와 비슷하게 작동하지만 etcd 관리와 관련된 논리가 포함됩니다.새 etcd 클러스터를 생성합니다.
- etcd 클러스터 API 상자에서 인스턴스 생성을 클릭합니다.
-
다음 화면을 사용하면 클러스터 크기와 같은
EtcdCluster오브젝트의 최소 시작 템플릿을 수정할 수 있습니다. 지금은 생성을 클릭하여 종료하십시오. 그러면 Operator에서 새 etcd 클러스터의 Pod, 서비스 및 기타 구성 요소를 가동합니다.
예제 etcd 클러스터를 클릭한 다음 리소스 탭을 클릭하여 Operator에서 자동으로 생성 및 구성한 리소스 수가 프로젝트에 포함되는지 확인합니다.
프로젝트의 다른 Pod에서 데이터베이스에 액세스할 수 있도록 Kubernetes 서비스가 생성되었는지 확인합니다.
지정된 프로젝트에서
edit역할을 가진 모든 사용자는 클라우드 서비스와 마찬가지로 셀프 서비스 방식으로 프로젝트에 이미 생성된 Operator에서 관리하는 애플리케이션 인스턴스(이 예제의 etcd 클러스터)를 생성, 관리, 삭제할 수 있습니다. 이 기능을 사용하여 추가 사용자를 활성화하려면 프로젝트 관리자가 다음 명령을 사용하여 역할을 추가하면 됩니다.$ oc policy add-role-to-user edit <user> -n <target_project>
이제 Pod가 비정상적인 상태가 되거나 클러스터의 다른 노드로 마이그레이션되면 오류에 반응하고 데이터를 재조정할 etcd 클러스터가 생성되었습니다. 가장 중요한 점은 적절한 액세스 권한이 있는 클러스터 관리자 또는 개발자가 애플리케이션과 함께 데이터베이스를 쉽게 사용할 수 있다는 점입니다.
3.2. 네임스페이스에 Operator 설치
클러스터 관리자가 계정에 Operator 설치 권한을 위임한 경우 셀프서비스 방식으로 Operator를 설치하고 네임스페이스에 등록할 수 있습니다.
3.2.1. 사전 요구 사항
- 클러스터 관리자는 셀프서비스 Operator를 네임스페이스에 설치할 수 있도록 OpenShift Container Platform 사용자 계정에 특정 권한을 추가해야 합니다. 자세한 내용은 비 클러스터 관리자가 Operator를 설치하도록 허용을 참조하십시오.
3.2.2. OperatorHub를 통한 Operator 설치
OperatorHub는 Operator를 검색하는 사용자 인터페이스입니다. 이는 클러스터에 Operator를 설치하고 관리하는 OLM(Operator Lifecycle Manager)과 함께 작동합니다.
적절한 권한이 있는 클러스터 관리자는 OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OperatorHub에서 Operator를 설치할 수 있습니다.
설치하는 동안 Operator의 다음 초기 설정을 결정해야합니다.
- 설치 모드
- Operator를 설치할 특정 네임스페이스를 선택합니다.
- 업데이트 채널
- 여러 채널을 통해 Operator를 사용할 수있는 경우 구독할 채널을 선택할 수 있습니다. 예를 들어, stable 채널에서 배치하려면 (사용 가능한 경우) 목록에서 해당 채널을 선택합니다.
- 승인 전략
자동 또는 수동 업데이트를 선택할 수 있습니다.
설치된 Operator에 대해 자동 업데이트를 선택하는 경우 선택한 채널에 해당 Operator의 새 버전이 제공되면 OLM(Operator Lifecycle Manager)에서 Operator의 실행 중인 인스턴스를 개입 없이 자동으로 업그레이드합니다.
수동 업데이트를 선택하면 최신 버전의 Operator가 사용 가능할 때 OLM이 업데이트 요청을 작성합니다. 클러스터 관리자는 Operator를 새 버전으로 업데이트하려면 OLM 업데이트 요청을 수동으로 승인해야 합니다.
3.2.3. 웹 콘솔을 사용하여 OperatorHub에서 설치
OpenShift Container Platform 웹 콘솔을 사용하여 OperatorHub에서 Operator를 설치하고 구독할 수 있습니다.
사전 요구 사항
- Operator 설치 권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → OperatorHub 페이지로 이동합니다.
원하는 Operator를 찾으려면 키워드를 Filter by keyword 상자에 입력하거나 스크롤합니다. 예를 들어 Kubernetes Operator의 고급 클러스터 관리 기능을 찾으려면
advanced를 입력합니다.인프라 기능에서 옵션을 필터링할 수 있습니다. 예를 들어, 연결이 끊긴 환경 (제한된 네트워크 환경이라고도 함)에서 작업하는 Operator를 표시하려면 Disconnected를 선택합니다.
Operator를 선택하여 추가 정보를 표시합니다.
참고커뮤니티 Operator를 선택하면 Red Hat이 커뮤니티 Operator를 인증하지 않는다고 경고합니다. 계속하기 전에 경고를 확인해야합니다.
- Operator에 대한 정보를 확인하고 Install을 클릭합니다.
Operator 설치 페이지에서 다음을 수행합니다.
- Operator를 설치할 특정 단일 네임스페이스를 선택합니다. Operator는 이 단일 네임 스페이스에서만 모니터링 및 사용할 수 있게 됩니다.
- Update Channe을 선택합니다 (하나 이상이 사용 가능한 경우).
- 앞에서 설명한 대로 자동 또는 수동 승인 전략을 선택합니다.
이 OpenShift Container Platform 클러스터에서 선택한 네임스페이스에서 Operator를 사용할 수 있도록 하려면 설치를 클릭합니다.
수동 승인 전략을 선택한 경우 설치 계획을 검토하고 승인할 때까지 서브스크립션의 업그레이드 상태가 업그레이드 중으로 유지됩니다.
Install Plan 페이지에서 승인 한 후 subscription 업그레이드 상태가 Up to date로 이동합니다.
- 자동 승인 전략을 선택한 경우 업그레이드 상태가 개입 없이 최신 상태로 확인되어야 합니다.
서브스크립션의 업그레이드 상태가 최신이면 Operator → 설치된 Operator를 선택하여 설치된 Operator의 CSV(클러스터 서비스 버전)가 최종적으로 표시되는지 확인합니다. 상태는 최종적으로 관련 네임스페이스에서 InstallSucceeded로 확인되어야 합니다.
참고모든 네임 스페이스… 설치 모드에서는
openshift-operators네임스페이스에서 상태가 InstallSucceeded 로 확인 되지만 다른 네임스페이스에서 확인하면 상태가 복사됩니다.그러지 않은 경우 다음을 수행합니다.
-
openshift-operators프로젝트(또는 A 특정 네임 스페이스… 워크로드 → Pod 페이지에서 추가 문제 해결을 위해 문제를 보고하는 설치 모드가 선택되었습니다.
-
3.2.4. CLI를 사용하여 OperatorHub에서 설치
OpenShift Container Platform 웹 콘솔을 사용하는 대신 CLI를 사용하여 OperatorHub에서 Operator를 설치할 수 있습니다. oc 명령을 사용하여 Subscription 개체를 만들거나 업데이트합니다.
사전 요구 사항
- Operator 설치 권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
-
로컬 시스템에
oc명령을 설치합니다.
프로세스
OperatorHub에서 클러스터에 사용 가능한 Operator의 목록을 표시합니다.
$ oc get packagemanifests -n openshift-marketplace출력 예
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m ...필요한 Operator의 카탈로그를 기록해 둡니다.
필요한 Operator를 검사하여 지원되는 설치 모드 및 사용 가능한 채널을 확인합니다.
$ oc describe packagemanifests <operator_name> -n openshift-marketplaceOperatorGroup오브젝트로 정의되는 Operator group에서 Operator group과 동일한 네임스페이스에 있는 모든 Operator에 대해 필요한 RBAC 액세스 권한을 생성할 대상 네임스페이스를 선택합니다.Operator를 서브스크립션하는 네임스페이스에는 Operator의 설치 모드, 즉
AllNamespaces또는SingleNamespace모드와 일치하는 Operator group이 있어야 합니다. 설치하려는 Operator에서AllNamespaces를 사용하는 경우openshift-operators네임스페이스에 적절한 Operator group이 이미 있습니다.그러나 Operator에서
SingleNamespace모드를 사용하고 적절한 Operator group이 없는 경우 이를 생성해야 합니다.참고이 프로세스의 웹 콘솔 버전에서는
SingleNamespace모드를 선택할 때 자동으로OperatorGroup및Subscription개체 생성을 자동으로 처리합니다.OperatorGroup개체 YAML 파일을 만듭니다 (예:operatorgroup.yaml).OperatorGroup오브젝트의 예apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace> spec: targetNamespaces: - <namespace>OperatorGroup개체를 생성합니다.$ oc apply -f operatorgroup.yaml
Subscription개체 YAML 파일을 생성하여 OpenShift Pipelines Operator에 네임스페이스를 등록합니다(예:sub.yaml).Subscription개체 예apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: openshift-operators1 spec: channel: <channel_name>2 name: <operator_name>3 source: redhat-operators4 sourceNamespace: openshift-marketplace5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
AllNamespaces설치 모드를 사용하려면openshift-operators네임스페이스를 지정합니다. 그 외에는SingleNamespace설치 모드를 사용하도록 관련 단일 네임스페이스를 지정합니다.- 2
- 등록할 채널의 이름입니다.
- 3
- 등록할 Operator의 이름입니다.
- 4
- Operator를 제공하는 카탈로그 소스의 이름입니다.
- 5
- 카탈로그 소스의 네임스페이스입니다. 기본 OperatorHub 카탈로그 소스에는
openshift-marketplace를 사용합니다. - 6
env매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 존재해야 하는 환경 변수 목록을 정의합니다.- 7
envFrom매개 변수는 컨테이너에 환경 변수를 채울 소스 목록을 정의합니다.- 8
volumes매개변수는 OLM에서 생성한 Pod에 있어야 하는 볼륨 목록을 정의합니다.- 9
volumeMounts매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 존재해야 하는 VolumeMounts 목록을 정의합니다.volumeMount가 존재하지 않는볼륨을참조하는 경우 OLM에서 Operator를 배포하지 못합니다.- 10
tolerations매개변수는 OLM에서 생성한 Pod의 허용 오차 목록을 정의합니다.- 11
resources매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 대한 리소스 제약 조건을 정의합니다.- 12
nodeSelector매개변수는 OLM에서 생성한 Pod에 대한NodeSelector를 정의합니다.
Subscription오브젝트를 생성합니다.$ oc apply -f sub.yaml이 시점에서 OLM은 이제 선택한 Operator를 인식합니다. Operator의 CSV(클러스터 서비스 버전)가 대상 네임스페이스에 표시되고 Operator에서 제공하는 API를 생성에 사용할 수 있어야 합니다.
3.2.5. 특정 버전의 Operator 설치
Subscription 오브젝트에 CSV(클러스터 서비스 버전)를 설정하면 특정 버전의 Operator를 설치할 수 있습니다.
사전 요구 사항
- Operator 설치 권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치됨
프로세스
startingCSV필드를 설정하여 특정 버전의 Operator에 네임스페이스를 서브스크립션하는Subscription오브젝트 YAML 파일을 생성합니다. 카탈로그에 이후 버전이 있는 경우 Operator가 자동으로 업그레이드되지 않도록installPlanApproval필드를Manual로 설정합니다.예를 들어 다음
sub.yaml파일을 사용하여 특별히 3.4.0 버전에 Red Hat Quay Operator를 설치할 수 있습니다.특정 시작 Operator 버전이 있는 서브스크립션
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: quay-operator namespace: quay spec: channel: quay-v3.4 installPlanApproval: Manual1 name: quay-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: quay-operator.v3.4.02 Subscription오브젝트를 생성합니다.$ oc apply -f sub.yaml- 보류 중인 설치 계획을 수동으로 승인하여 Operator 설치를 완료합니다.
4장. 관리자 작업
4.1. 클러스터에 Operator 추가
클러스터 관리자는 OperatorHub가 있는 네임스페이스에 Operator를 등록하여 OpenShift Container Platform 클러스터에 Operator를 설치할 수 있습니다.
4.1.1. OperatorHub를 통한 Operator 설치
OperatorHub는 Operator를 검색하는 사용자 인터페이스입니다. 이는 클러스터에 Operator를 설치하고 관리하는 OLM(Operator Lifecycle Manager)과 함께 작동합니다.
적절한 권한이 있는 클러스터 관리자는 OpenShift Container Platform 웹 콘솔 또는 CLI를 사용하여 OperatorHub에서 Operator를 설치할 수 있습니다.
설치하는 동안 Operator의 다음 초기 설정을 결정해야합니다.
- 설치 모드
- Operator를 설치할 특정 네임스페이스를 선택합니다.
- 업데이트 채널
- 여러 채널을 통해 Operator를 사용할 수있는 경우 구독할 채널을 선택할 수 있습니다. 예를 들어, stable 채널에서 배치하려면 (사용 가능한 경우) 목록에서 해당 채널을 선택합니다.
- 승인 전략
자동 또는 수동 업데이트를 선택할 수 있습니다.
설치된 Operator에 대해 자동 업데이트를 선택하는 경우 선택한 채널에 해당 Operator의 새 버전이 제공되면 OLM(Operator Lifecycle Manager)에서 Operator의 실행 중인 인스턴스를 개입 없이 자동으로 업그레이드합니다.
수동 업데이트를 선택하면 최신 버전의 Operator가 사용 가능할 때 OLM이 업데이트 요청을 작성합니다. 클러스터 관리자는 Operator를 새 버전으로 업데이트하려면 OLM 업데이트 요청을 수동으로 승인해야 합니다.
4.1.2. 웹 콘솔을 사용하여 OperatorHub에서 설치
OpenShift Container Platform 웹 콘솔을 사용하여 OperatorHub에서 Operator를 설치하고 구독할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. - Operator 설치 권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → OperatorHub 페이지로 이동합니다.
원하는 Operator를 찾으려면 키워드를 Filter by keyword 상자에 입력하거나 스크롤합니다. 예를 들어 Kubernetes Operator의 고급 클러스터 관리 기능을 찾으려면
advanced를 입력합니다.인프라 기능에서 옵션을 필터링할 수 있습니다. 예를 들어, 연결이 끊긴 환경 (제한된 네트워크 환경이라고도 함)에서 작업하는 Operator를 표시하려면 Disconnected를 선택합니다.
Operator를 선택하여 추가 정보를 표시합니다.
참고커뮤니티 Operator를 선택하면 Red Hat이 커뮤니티 Operator를 인증하지 않는다고 경고합니다. 계속하기 전에 경고를 확인해야합니다.
- Operator에 대한 정보를 확인하고 Install을 클릭합니다.
Operator 설치 페이지에서 다음을 수행합니다.
다음 명령 중 하나를 선택합니다.
-
All namespaces on the cluster (default)에서는 기본
openshift-operators네임스페이스에 Operator가 설치되므로 Operator가 클러스터의 모든 네임스페이스를 모니터링하고 사용할 수 있습니다. 이 옵션을 항상 사용할 수있는 것은 아닙니다. - A specific namespace on the cluster를 사용하면 Operator를 설치할 특정 단일 네임 스페이스를 선택할 수 있습니다. Operator는 이 단일 네임 스페이스에서만 모니터링 및 사용할 수 있게 됩니다.
-
All namespaces on the cluster (default)에서는 기본
- Operator를 설치할 특정 단일 네임스페이스를 선택합니다. Operator는 이 단일 네임 스페이스에서만 모니터링 및 사용할 수 있게 됩니다.
- Update Channe을 선택합니다 (하나 이상이 사용 가능한 경우).
- 앞에서 설명한 대로 자동 또는 수동 승인 전략을 선택합니다.
이 OpenShift Container Platform 클러스터에서 선택한 네임스페이스에서 Operator를 사용할 수 있도록 하려면 설치를 클릭합니다.
수동 승인 전략을 선택한 경우 설치 계획을 검토하고 승인할 때까지 서브스크립션의 업그레이드 상태가 업그레이드 중으로 유지됩니다.
Install Plan 페이지에서 승인 한 후 subscription 업그레이드 상태가 Up to date로 이동합니다.
- 자동 승인 전략을 선택한 경우 업그레이드 상태가 개입 없이 최신 상태로 확인되어야 합니다.
서브스크립션의 업그레이드 상태가 최신이면 Operator → 설치된 Operator를 선택하여 설치된 Operator의 CSV(클러스터 서비스 버전)가 최종적으로 표시되는지 확인합니다. 상태는 최종적으로 관련 네임스페이스에서 InstallSucceeded로 확인되어야 합니다.
참고모든 네임 스페이스… 설치 모드에서는
openshift-operators네임스페이스에서 상태가 InstallSucceeded 로 확인 되지만 다른 네임스페이스에서 확인하면 상태가 복사됩니다.그러지 않은 경우 다음을 수행합니다.
-
openshift-operators프로젝트(또는 A 특정 네임 스페이스… 워크로드 → Pod 페이지에서 추가 문제 해결을 위해 문제를 보고하는 설치 모드가 선택되었습니다.
-
4.1.3. CLI를 사용하여 OperatorHub에서 설치
OpenShift Container Platform 웹 콘솔을 사용하는 대신 CLI를 사용하여 OperatorHub에서 Operator를 설치할 수 있습니다. oc 명령을 사용하여 Subscription 개체를 만들거나 업데이트합니다.
사전 요구 사항
- Operator 설치 권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
-
로컬 시스템에
oc명령을 설치합니다.
프로세스
OperatorHub에서 클러스터에 사용 가능한 Operator의 목록을 표시합니다.
$ oc get packagemanifests -n openshift-marketplace출력 예
NAME CATALOG AGE 3scale-operator Red Hat Operators 91m advanced-cluster-management Red Hat Operators 91m amq7-cert-manager Red Hat Operators 91m ... couchbase-enterprise-certified Certified Operators 91m crunchy-postgres-operator Certified Operators 91m mongodb-enterprise Certified Operators 91m ... etcd Community Operators 91m jaeger Community Operators 91m kubefed Community Operators 91m ...필요한 Operator의 카탈로그를 기록해 둡니다.
필요한 Operator를 검사하여 지원되는 설치 모드 및 사용 가능한 채널을 확인합니다.
$ oc describe packagemanifests <operator_name> -n openshift-marketplaceOperatorGroup오브젝트로 정의되는 Operator group에서 Operator group과 동일한 네임스페이스에 있는 모든 Operator에 대해 필요한 RBAC 액세스 권한을 생성할 대상 네임스페이스를 선택합니다.Operator를 서브스크립션하는 네임스페이스에는 Operator의 설치 모드, 즉
AllNamespaces또는SingleNamespace모드와 일치하는 Operator group이 있어야 합니다. 설치하려는 Operator에서AllNamespaces를 사용하는 경우openshift-operators네임스페이스에 적절한 Operator group이 이미 있습니다.그러나 Operator에서
SingleNamespace모드를 사용하고 적절한 Operator group이 없는 경우 이를 생성해야 합니다.참고이 프로세스의 웹 콘솔 버전에서는
SingleNamespace모드를 선택할 때 자동으로OperatorGroup및Subscription개체 생성을 자동으로 처리합니다.OperatorGroup개체 YAML 파일을 만듭니다 (예:operatorgroup.yaml).OperatorGroup오브젝트의 예apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: <operatorgroup_name> namespace: <namespace> spec: targetNamespaces: - <namespace>OperatorGroup개체를 생성합니다.$ oc apply -f operatorgroup.yaml
Subscription개체 YAML 파일을 생성하여 OpenShift Pipelines Operator에 네임스페이스를 등록합니다(예:sub.yaml).Subscription개체 예apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: <subscription_name> namespace: openshift-operators1 spec: channel: <channel_name>2 name: <operator_name>3 source: redhat-operators4 sourceNamespace: openshift-marketplace5 config: env:6 - name: ARGS value: "-v=10" envFrom:7 - secretRef: name: license-secret volumes:8 - name: <volume_name> configMap: name: <configmap_name> volumeMounts:9 - mountPath: <directory_name> name: <volume_name> tolerations:10 - operator: "Exists" resources:11 requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" nodeSelector:12 foo: bar- 1
AllNamespaces설치 모드를 사용하려면openshift-operators네임스페이스를 지정합니다. 그 외에는SingleNamespace설치 모드를 사용하도록 관련 단일 네임스페이스를 지정합니다.- 2
- 등록할 채널의 이름입니다.
- 3
- 등록할 Operator의 이름입니다.
- 4
- Operator를 제공하는 카탈로그 소스의 이름입니다.
- 5
- 카탈로그 소스의 네임스페이스입니다. 기본 OperatorHub 카탈로그 소스에는
openshift-marketplace를 사용합니다. - 6
env매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 존재해야 하는 환경 변수 목록을 정의합니다.- 7
envFrom매개 변수는 컨테이너에 환경 변수를 채울 소스 목록을 정의합니다.- 8
volumes매개변수는 OLM에서 생성한 Pod에 있어야 하는 볼륨 목록을 정의합니다.- 9
volumeMounts매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 존재해야 하는 VolumeMounts 목록을 정의합니다.volumeMount가 존재하지 않는볼륨을참조하는 경우 OLM에서 Operator를 배포하지 못합니다.- 10
tolerations매개변수는 OLM에서 생성한 Pod의 허용 오차 목록을 정의합니다.- 11
resources매개변수는 OLM에서 생성한 Pod의 모든 컨테이너에 대한 리소스 제약 조건을 정의합니다.- 12
nodeSelector매개변수는 OLM에서 생성한 Pod에 대한NodeSelector를 정의합니다.
Subscription오브젝트를 생성합니다.$ oc apply -f sub.yaml이 시점에서 OLM은 이제 선택한 Operator를 인식합니다. Operator의 CSV(클러스터 서비스 버전)가 대상 네임스페이스에 표시되고 Operator에서 제공하는 API를 생성에 사용할 수 있어야 합니다.
4.1.4. 특정 버전의 Operator 설치
Subscription 오브젝트에 CSV(클러스터 서비스 버전)를 설정하면 특정 버전의 Operator를 설치할 수 있습니다.
사전 요구 사항
- Operator 설치 권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
-
OpenShift CLI(
oc)가 설치됨
프로세스
startingCSV필드를 설정하여 특정 버전의 Operator에 네임스페이스를 서브스크립션하는Subscription오브젝트 YAML 파일을 생성합니다. 카탈로그에 이후 버전이 있는 경우 Operator가 자동으로 업그레이드되지 않도록installPlanApproval필드를Manual로 설정합니다.예를 들어 다음
sub.yaml파일을 사용하여 특별히 3.4.0 버전에 Red Hat Quay Operator를 설치할 수 있습니다.특정 시작 Operator 버전이 있는 서브스크립션
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: quay-operator namespace: quay spec: channel: quay-v3.4 installPlanApproval: Manual1 name: quay-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: quay-operator.v3.4.02 Subscription오브젝트를 생성합니다.$ oc apply -f sub.yaml- 보류 중인 설치 계획을 수동으로 승인하여 Operator 설치를 완료합니다.
4.2. 설치된 Operator 업그레이드
클러스터 관리자는 OpenShift Container Platform 클러스터에서 OLM(Operator Lifecycle Manager)을 사용하여 이전에 설치한 Operator를 업그레이드할 수 있습니다.
4.2.1. Operator의 업데이트 채널 변경
설치된 Operator의 서브스크립션은 Operator의 업데이트를 추적하고 수신하는 데 사용되는 업데이트 채널을 지정합니다. Operator를 업그레이드하여 추적을 시작하고 최신 채널에서 업데이트를 수신하려면 서브스크립션의 업데이트 채널을 변경하면 됩니다.
서브스크립션의 업데이트 채널 이름은 Operator마다 다를 수 있지만 이름 지정 스키마는 지정된 Operator 내의 공통 규칙을 따라야 합니다. 예를 들어 채널 이름은 Operator(1.2, 1.3) 또는 릴리스 빈도(stable, fast)에서 제공하는 애플리케이션의 마이너 릴리스 업데이트 스트림을 따를 수 있습니다.
설치된 Operator는 현재 채널보다 오래된 채널로 변경할 수 없습니다.
서브스크립션의 승인 전략이 자동으로 설정되어 있으면 선택한 채널에서 새 Operator 버전을 사용할 수 있게 되는 즉시 업그레이드 프로세스가 시작됩니다. 승인 전략이 수동으로 설정된 경우 보류 중인 업그레이드를 수동으로 승인해야 합니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 이전에 설치한 Operator입니다.
절차
- OpenShift Container Platform 웹 콘솔의 관리자 관점에서 Operator → 설치된 Operator로 이동합니다.
- 업데이트 채널을 변경할 Operator 이름을 클릭합니다.
- 서브스크립션 탭을 클릭합니다.
- 채널에서 업데이트 채널의 이름을 클릭합니다.
- 변경할 최신 업데이트 채널을 클릭한 다음 저장을 클릭합니다.
자동 승인 전략이 있는 서브스크립션의 경우 업그레이드가 자동으로 시작됩니다. Operator → 설치된 Operator 페이지로 이동하여 업그레이드 진행 상황을 모니터링합니다. 완료되면 상태가 성공 및 최신으로 변경됩니다.
수동 승인 전략이 있는 서브스크립션의 경우 서브스크립션 탭에서 업그레이드를 수동으로 승인할 수 있습니다.
4.2.2. 보류 중인 Operator 업그레이드 수동 승인
설치된 Operator의 서브스크립션에 있는 승인 전략이 수동으로 설정된 경우 새 업데이트가 현재 업데이트 채널에 릴리스될 때 업데이트를 수동으로 승인해야 설치가 시작됩니다.
사전 요구 사항
- OLM(Operator Lifecycle Manager)을 사용하여 이전에 설치한 Operator입니다.
절차
- OpenShift Container Platform 웹 콘솔의 관리자 관점에서 Operator → 설치된 Operator로 이동합니다.
- 보류 중인 업그레이드가 있는 Operator에 업그레이드 사용 가능 상태가 표시됩니다. 업그레이드할 Operator 이름을 클릭합니다.
- 서브스크립션 탭을 클릭합니다. 승인이 필요한 업그레이드는 업그레이드 상태 옆에 표시됩니다. 예를 들어 1 승인 필요가 표시될 수 있습니다.
- 1 승인 필요를 클릭한 다음 설치 계획 프리뷰를 클릭합니다.
- 업그레이드할 수 있는 것으로 나열된 리소스를 검토합니다. 문제가 없는 경우 승인을 클릭합니다.
- Operator → 설치된 Operator 페이지로 이동하여 업그레이드 진행 상황을 모니터링합니다. 완료되면 상태가 성공 및 최신으로 변경됩니다.
4.3. 클러스터에서 Operator 삭제
다음에서는 OpenShift Container Platform 클러스터에서 OLM(Operator Lifecycle Manager)을 사용하여 이전에 설치한 Operator를 삭제하는 방법을 설명합니다.
4.3.1. 웹 콘솔을 사용하여 클러스터에서 Operator 삭제
클러스터 관리자는 웹 콘솔을 사용하여 선택한 네임스페이스에서 설치된 Operator를 삭제할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터 웹 콘솔에 액세스할 수 있습니다.
프로세스
- Operator → 설치된 Operator 페이지에서 스크롤하거나 이름별 필터링에 키워드를 입력하여 원하는 Operator를 찾습니다. 그런 다음 해당 Operator를 클릭합니다.
Operator 세부 정보 페이지 오른쪽에 있는 작업 목록에서 Operator 제거를 선택합니다.
Operator를 설치 제거하시겠습니까? 대화 상자가 표시되고 다음 메시지가 표시됩니다.
Operator를 제거해도 사용자 정의 리소스 정의 또는 관리형 리소스는 제거되지 않습니다. Operator에서 클러스터에 애플리케이션을 배포하거나 클러스터 외부 리소스를 구성한 경우 해당 리소스는 계속 실행되며 수동으로 정리해야 합니다.
이 작업은 Operator 및 Operator 배포 및 Pod(있는 경우)를 제거합니다. CRD 및 CR을 포함하여 Operator에서 관리하는 Operand 및 리소스는 제거되지 않습니다. 웹 콘솔에서는 일부 Operator의 대시보드 및 탐색 항목을 활성화합니다. Operator를 설치 제거한 후 해당 항목을 제거하려면 Operator CRD를 수동으로 삭제해야 할 수 있습니다.
- 설치 제거를 선택합니다. 이 Operator는 실행을 중지하고 더 이상 업데이트를 수신하지 않습니다.
4.3.2. CLI를 사용하여 클러스터에서 Operator 삭제
클러스터 관리자는 CLI를 사용하여 선택한 네임스페이스에서 설치된 Operator를 삭제할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. -
oc명령이 워크스테이션에 설치되어 있습니다.
프로세스
currentCSV필드에서 구독한 Operator(예:jaeger)의 현재 버전을 확인합니다.$ oc get subscription jaeger -n openshift-operators -o yaml | grep currentCSV출력 예
currentCSV: jaeger-operator.v1.8.2서브스크립션을 삭제합니다(예:
jaeger).$ oc delete subscription jaeger -n openshift-operators출력 예
subscription.operators.coreos.com "jaeger" deleted이전 단계의
currentCSV값을 사용하여 대상 네임스페이스에서 Operator의 CSV를 삭제합니다.$ oc delete clusterserviceversion jaeger-operator.v1.8.2 -n openshift-operators출력 예
clusterserviceversion.operators.coreos.com "jaeger-operator.v1.8.2" deleted
4.3.3. 실패한 서브스크립션 새로 고침
OLM(Operator Lifecycle Manager)에서는 네트워크상에서 액세스할 수 없는 이미지를 참조하는 Operator를 구독하는 경우 openshift-marketplace 네임스페이스에 다음 오류로 인해 실패하는 작업을 확인할 수 있습니다.
출력 예
ImagePullBackOff for
Back-off pulling image "example.com/openshift4/ose-elasticsearch-operator-bundle@sha256:6d2587129c846ec28d384540322b40b05833e7e00b25cca584e004af9a1d292e"출력 예
rpc error: code = Unknown desc = error pinging docker registry example.com: Get "https://example.com/v2/": dial tcp: lookup example.com on 10.0.0.1:53: no such host결과적으로 서브스크립션이 이러한 장애 상태에 고착되어 Operator를 설치하거나 업그레이드할 수 없습니다.
서브스크립션, CSV(클러스터 서비스 버전) 및 기타 관련 오브젝트를 삭제하여 실패한 서브스크립션을 새로 고칠 수 있습니다. 서브스크립션을 다시 생성하면 OLM에서 올바른 버전의 Operator를 다시 설치합니다.
사전 요구 사항
- 액세스할 수 없는 번들 이미지를 가져올 수 없는 실패한 서브스크립션이 있습니다.
- 올바른 번들 이미지에 액세스할 수 있는지 확인했습니다.
프로세스
Operator가 설치된 네임스페이스에서
Subscription및ClusterServiceVersion오브젝트의 이름을 가져옵니다.$ oc get sub,csv -n <namespace>출력 예
NAME PACKAGE SOURCE CHANNEL subscription.operators.coreos.com/elasticsearch-operator elasticsearch-operator redhat-operators 5.0 NAME DISPLAY VERSION REPLACES PHASE clusterserviceversion.operators.coreos.com/elasticsearch-operator.5.0.0-65 OpenShift Elasticsearch Operator 5.0.0-65 Succeeded서브스크립션을 삭제합니다.
$ oc delete subscription <subscription_name> -n <namespace>클러스터 서비스 버전을 삭제합니다.
$ oc delete csv <csv_name> -n <namespace>openshift-marketplace네임스페이스에서 실패한 모든 작업 및 관련 구성 맵의 이름을 가져옵니다.$ oc get job,configmap -n openshift-marketplace출력 예
NAME COMPLETIONS DURATION AGE job.batch/1de9443b6324e629ddf31fed0a853a121275806170e34c926d69e53a7fcbccb 1/1 26s 9m30s NAME DATA AGE configmap/1de9443b6324e629ddf31fed0a853a121275806170e34c926d69e53a7fcbccb 3 9m30s작업을 삭제합니다.
$ oc delete job <job_name> -n openshift-marketplace이렇게 하면 액세스할 수 없는 이미지를 가져오려는 Pod가 다시 생성되지 않습니다.
구성 맵을 삭제합니다.
$ oc delete configmap <configmap_name> -n openshift-marketplace- 웹 콘솔에서 OperatorHub를 사용하여 Operator를 다시 설치합니다.
검증
Operator가 제대로 다시 설치되었는지 확인합니다.
$ oc get sub,csv,installplan -n <namespace>
4.4. Operator Lifecycle Manager에서 프록시 지원 구성
OpenShift Container Platform 클러스터에 글로벌 프록시가 구성된 경우 OLM(Operator Lifecycle Manager)은 클러스터 수준 프록시를 사용하여 관리하는 Operator를 자동으로 구성합니다. 그러나 설치된 Operator를 글로벌 프록시를 덮어쓰거나 사용자 정의 CA 인증서를 삽입하도록 구성할 수도 있습니다.
4.4.1. Operator의 프록시 설정 덮어쓰기
클러스터 수준 송신 프록시가 구성된 경우 OLM(Operator Lifecycle Manager)에서 실행되는 Operator는 배포 시 클러스터 수준 프록시 설정을 상속합니다. 클러스터 관리자는 Operator 서브스크립션을 구성하여 이러한 프록시 설정을 덮어쓸 수도 있습니다.
Operator에서는 관리형 Operand에 대해 Pod의 프록시 설정을 위한 환경 변수 설정을 처리해야 합니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
프로세스
- 웹 콘솔에서 Operators → OperatorHub 페이지로 이동합니다.
- Operator를 선택하고 설치를 클릭합니다.
Operator 설치 페이지에서
spec섹션에 다음 환경 변수를 하나 이상 포함하도록Subscription오브젝트를 수정합니다.-
HTTP_PROXY -
HTTPS_PROXY -
NO_PROXY
예를 들면 다음과 같습니다.
프록시 설정 덮어쓰기가 포함된
Subscription오브젝트apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: etcd-config-test namespace: openshift-operators spec: config: env: - name: HTTP_PROXY value: test_http - name: HTTPS_PROXY value: test_https - name: NO_PROXY value: test channel: clusterwide-alpha installPlanApproval: Automatic name: etcd source: community-operators sourceNamespace: openshift-marketplace startingCSV: etcdoperator.v0.9.4-clusterwide참고이러한 환경 변수는 이전에 설정한 클러스터 수준 또는 사용자 정의 프록시 설정을 제거하기 위해 빈 값을 사용하여 설정을 해제할 수도 있습니다.
OLM에서는 이러한 환경 변수를 단위로 처리합니다. 환경 변수가 한 개 이상 설정되어 있으면 세 개 모두 덮어쓰는 것으로 간주하며 구독한 Operator의 배포에 클러스터 수준 기본값이 사용되지 않습니다.
-
- 선택한 네임스페이스에서 Operator를 사용할 수 있도록 설치를 클릭합니다.
Operator의 CSV가 관련 네임스페이스에 표시되면 사용자 정의 프록시 환경 변수가 배포에 설정되어 있는지 확인할 수 있습니다. 예를 들면 CLI를 사용합니다.
$ oc get deployment -n openshift-operators \ etcd-operator -o yaml \ | grep -i "PROXY" -A 2출력 예
- name: HTTP_PROXY value: test_http - name: HTTPS_PROXY value: test_https - name: NO_PROXY value: test image: quay.io/coreos/etcd-operator@sha256:66a37fd61a06a43969854ee6d3e21088a98b93838e284a6086b13917f96b0d9c ...
4.4.2. 사용자 정의 CA 인증서 삽입
클러스터 관리자가 구성 맵을 사용하여 클러스터에 사용자 정의 CA 인증서를 추가하면 Cluster Network Operator는 사용자 제공 인증서와 시스템 CA 인증서를 단일 번들로 병합합니다. 이 병합된 번들은 OLM(Operator Lifecycle Manager)에서 실행 중인 Operator에 삽입할 수 있는데 이러한 작업은 중간자 HTTPS 프록시를 사용하는 경우 유용합니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. - 구성 맵을 사용하여 사용자 정의 CA 인증서를 클러스터에 추가했습니다.
- 필요한 Operator가 OLM에 설치되어 실행되고 있습니다.
프로세스
Operator의 서브스크립션이 존재하고 다음 라벨을 포함하는 네임스페이스에 빈 구성 맵을 생성합니다.
apiVersion: v1 kind: ConfigMap metadata: name: trusted-ca1 labels: config.openshift.io/inject-trusted-cabundle: "true"2 이 구성 맵이 생성되면 병합된 번들의 인증서 콘텐츠로 즉시 채워집니다.
Subscription오브젝트를 업데이트하여 사용자 정의 CA가 필요한 Pod 내의 각 컨테이너에trusted-ca구성 맵을 볼륨으로 마운트하는spec.config섹션을 포함합니다.apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: my-operator spec: package: etcd channel: alpha config:1 selector: matchLabels: <labels_for_pods>2 volumes:3 - name: trusted-ca configMap: name: trusted-ca items: - key: ca-bundle.crt4 path: tls-ca-bundle.pem5 volumeMounts:6 - name: trusted-ca mountPath: /etc/pki/ca-trust/extracted/pem readOnly: true
4.5. Operator 상태 보기
OLM(Operator Lifecycle Manager)의 시스템 상태를 이해하는 것은 설치된 Operator와 관련된 결정을 내리고 문제를 디버깅하는 데 중요합니다. OLM에서는 서브스크립션 및 관련 카탈로그 소스의 상태 및 수행된 작업과 관련된 통찰력을 제공합니다. 이를 통해 사용자는 Operator의 상태를 더 잘 이해할 수 있습니다.
4.5.1. Operator 서브스크립션 상태 유형
서브스크립션은 다음 상태 유형을 보고할 수 있습니다.
| 상태 | 설명 |
|---|---|
|
| 해결에 사용되는 일부 또는 모든 카탈로그 소스가 정상 상태가 아닙니다. |
|
| 서브스크립션 설치 계획이 없습니다. |
|
| 서브스크립션 설치 계획이 설치 대기 중입니다. |
|
| 서브스크립션 설치 계획이 실패했습니다. |
기본 OpenShift Container Platform 클러스터 Operator는 CVO(Cluster Version Operator)에서 관리하며 Subscription 오브젝트가 없습니다. 애플리케이션 Operator는 OLM(Operator Lifecycle Manager)에서 관리하며 Subscription 오브젝트가 있습니다.
4.5.2. CLI를 사용하여 Operator 서브스크립션 상태 보기
CLI를 사용하여 Operator 서브스크립션 상태를 볼 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
Operator 서브스크립션을 나열합니다.
$ oc get subs -n <operator_namespace>oc describe명령을 사용하여Subscription리소스를 검사합니다.$ oc describe sub <subscription_name> -n <operator_namespace>명령 출력에서 Operator 서브스크립션 조건 유형의 상태에 대한
Conditions섹션을 확인합니다. 다음 예에서 사용 가능한 모든 카탈로그 소스가 정상이므로CatalogSourcesUnhealthy조건 유형의 상태가false입니다.출력 예
Conditions: Last Transition Time: 2019-07-29T13:42:57Z Message: all available catalogsources are healthy Reason: AllCatalogSourcesHealthy Status: False Type: CatalogSourcesUnhealthy
기본 OpenShift Container Platform 클러스터 Operator는 CVO(Cluster Version Operator)에서 관리하며 Subscription 오브젝트가 없습니다. 애플리케이션 Operator는 OLM(Operator Lifecycle Manager)에서 관리하며 Subscription 오브젝트가 있습니다.
4.5.3. CLI를 사용하여 Operator 카탈로그 소스 상태 보기
CLI를 사용하여 Operator 카탈로그 소스의 상태를 볼 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
절차
네임스페이스의 카탈로그 소스를 나열합니다. 예를 들어 클러스터 전체 카탈로그 소스에 사용되는
openshift-marketplace네임스페이스를 확인할 수 있습니다.$ oc get catalogsources -n openshift-marketplace출력 예
NAME DISPLAY TYPE PUBLISHER AGE certified-operators Certified Operators grpc Red Hat 55m community-operators Community Operators grpc Red Hat 55m example-catalog Example Catalog grpc Example Org 2m25s redhat-marketplace Red Hat Marketplace grpc Red Hat 55m redhat-operators Red Hat Operators grpc Red Hat 55moc describe명령을 사용하여 카탈로그 소스에 대한 자세한 내용 및 상태를 가져옵니다.$ oc describe catalogsource example-catalog -n openshift-marketplace출력 예
Name: example-catalog Namespace: openshift-marketplace ... Status: Connection State: Address: example-catalog.openshift-marketplace.svc:50051 Last Connect: 2021-09-09T17:07:35Z Last Observed State: TRANSIENT_FAILURE Registry Service: Created At: 2021-09-09T17:05:45Z Port: 50051 Protocol: grpc Service Name: example-catalog Service Namespace: openshift-marketplace앞의 예제 출력에서 마지막으로 관찰된 상태는
TRANSIENT_FAILURE입니다. 이 상태는 카탈로그 소스에 대한 연결을 설정하는 데 문제가 있음을 나타냅니다.카탈로그 소스가 생성된 네임스페이스의 Pod를 나열합니다.
$ oc get pods -n openshift-marketplace출력 예
NAME READY STATUS RESTARTS AGE certified-operators-cv9nn 1/1 Running 0 36m community-operators-6v8lp 1/1 Running 0 36m marketplace-operator-86bfc75f9b-jkgbc 1/1 Running 0 42m example-catalog-bwt8z 0/1 ImagePullBackOff 0 3m55s redhat-marketplace-57p8c 1/1 Running 0 36m redhat-operators-smxx8 1/1 Running 0 36m카탈로그 소스가 네임스페이스에 생성되면 해당 네임스페이스에 카탈로그 소스의 Pod가 생성됩니다. 위 예제 출력에서
example-catalog-bwt8zpod의 상태는ImagePullBackOff입니다. 이 상태는 카탈로그 소스의 인덱스 이미지를 가져오는 데 문제가 있음을 나타냅니다.자세한 정보는
oc describe명령을 사용하여 Pod를 검사합니다.$ oc describe pod example-catalog-bwt8z -n openshift-marketplace출력 예
Name: example-catalog-bwt8z Namespace: openshift-marketplace Priority: 0 Node: ci-ln-jyryyg2-f76d1-ggdbq-worker-b-vsxjd/10.0.128.2 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 48s default-scheduler Successfully assigned openshift-marketplace/example-catalog-bwt8z to ci-ln-jyryyf2-f76d1-fgdbq-worker-b-vsxjd Normal AddedInterface 47s multus Add eth0 [10.131.0.40/23] from openshift-sdn Normal BackOff 20s (x2 over 46s) kubelet Back-off pulling image "quay.io/example-org/example-catalog:v1" Warning Failed 20s (x2 over 46s) kubelet Error: ImagePullBackOff Normal Pulling 8s (x3 over 47s) kubelet Pulling image "quay.io/example-org/example-catalog:v1" Warning Failed 8s (x3 over 47s) kubelet Failed to pull image "quay.io/example-org/example-catalog:v1": rpc error: code = Unknown desc = reading manifest v1 in quay.io/example-org/example-catalog: unauthorized: access to the requested resource is not authorized Warning Failed 8s (x3 over 47s) kubelet Error: ErrImagePull앞의 예제 출력에서 오류 메시지는 권한 부여 문제로 인해 카탈로그 소스의 인덱스 이미지를 성공적으로 가져오지 못한 것으로 표시됩니다. 예를 들어 인덱스 이미지는 로그인 인증 정보가 필요한 레지스트리에 저장할 수 있습니다.
4.6. 비 클러스터 관리자가 Operator를 설치하도록 허용
Operator를 실행하는 데 광범위한 권한이 필요할 수 있으며 필요한 권한이 버전에 따라 다를 수 있습니다. OLM(Operator Lifecycle Manager)은 cluster-admin 권한으로 실행됩니다. 기본적으로 Operator 작성자는 CSV(클러스터 서비스 버전)의 권한 세트를 지정할 수 있으며 OLM은 이에 따라 해당 권한 세트를 Operator에 부여합니다.
클러스터 관리자는 Operator가 클러스터 범위 권한을 얻을 수 없고 사용자가 OLM을 사용하여 권한을 에스컬레이션할 수 없도록 조치를 취해야 합니다. 이러한 작동을 잠글 수 있는 한 가지 방법은 Operator를 클러스터에 추가하기 전에 클러스터 관리자가 Operator를 감사하는 것입니다. 클러스터 관리자에게는 서비스 계정을 사용하여 Operator를 설치 또는 업그레이드하는 동안 수행할 수 있는 작업을 결정하고 제한하는 툴도 제공됩니다.
클러스터 관리자는 Operator group을 일련의 권한이 부여된 서비스 계정과 연결함으로써 RBAC 규칙을 사용하여 사전에 정해진 범위 내에서만 작동하도록 Operator에 정책을 설정할 수 있습니다. Operator는 해당 규칙에서 명시적으로 허용하지 않는 작업은 수행할 수 없습니다.
이처럼 비 클러스터 관리자에 의해 범위가 제한되는 자급식 Operator 설치에서는 더 많은 사용자가 더 많은 Operator 프레임워크 툴을 안전하게 사용할 수 있어 Operator를 통해 애플리케이션을 빌드하는 경험을 더 다양하게 제공할 수 있습니다.
4.6.1. Operator 설치 정책 이해
OLM(Operator Lifecycle Manager)을 사용하면 클러스터 관리자가 Operator group룹에 서비스 계정을 지정하여 해당 그룹에 연결된 모든 Operator를 배포하고 서비스 계정에 부여된 권한에 따라 실행할 수 있습니다.
APIService 및 CustomResourceDefinition 리소스는 항상 cluster-admin 역할을 사용하여 OLM에 의해 생성됩니다. Operator group과 연결된 서비스 계정에는 이러한 리소스를 작성할 수 있는 권한을 부여해서는 안 됩니다.
지정된 서비스 계정에 설치 또는 업그레이드 중인 Operator에 대한 적절한 권한이 없는 경우 클러스터 관리자가 문제를 쉽게 해결할 수 있도록 각 리소스 상태에 유용한 정보 및 컨텍스트 정보가 추가됩니다.
이제 Operator group에 연결된 모든 Operator의 권한이 지정된 서비스 계정에 부여된 권한으로 제한됩니다. Operator에서 서비스 계정 범위를 벗어나는 권한을 요청하면 설치가 실패하고 해당 오류 메시지가 표시됩니다.
4.6.1.1. 설치 시나리오
Operator를 클러스터에서 설치하거나 업그레이드할 수 있는지 결정하는 경우 OLM(Operator Lifecycle Manager)은 다음 시나리오를 고려합니다.
- 클러스터 관리자가 새 Operator group을 생성하고 서비스 계정을 지정합니다. 이 Operator group과 연결된 모든 Operator가 설치되고 서비스 계정에 부여된 권한에 따라 실행됩니다.
- 클러스터 관리자가 새 Operator group을 생성하고 서비스 계정을 지정하지 않습니다. OpenShift Container Platform은 이전 버전과의 호환성을 유지하므로 기본 동작은 그대로 유지되면서 Operator 설치 및 업그레이드가 허용됩니다.
- 서비스 계정을 지정하지 않는 기존 Operator group의 경우 기본 동작은 그대로 유지되면서 Operator 설치 및 업그레이드가 허용됩니다.
- 클러스터 관리자가 기존 Operator group을 업데이트하고 서비스 계정을 지정합니다. OLM을 사용하면 현재 권한을 사용하여 기존 Operator를 계속 실행될 수 있습니다. 이러한 기존 Operator에서 업그레이드를 수행하면 기존 Operator가 새 Operator와 같이 서비스 계정에 부여된 권한에 따라 다시 설치되어 실행됩니다.
- 권한을 추가하거나 제거함으로써 Operator group에서 지정하는 서비스 계정이 변경되거나 기존 서비스 계정을 새 서비스 계정과 교체합니다. 기존 Operator에서 업그레이드를 수행하면 기존 Operator가 새 Operator와 같이 업데이트된 서비스 계정에 부여된 권한에 따라 다시 설치되어 실행됩니다.
- 클러스터 관리자는 Operator group에서 서비스 계정을 제거합니다. 기본 동작은 유지되고 Operator 설치 및 업그레이드는 허용됩니다.
4.6.1.2. 설치 워크플로
Operator group이 서비스 계정에 연결되고 Operator가 설치 또는 업그레이드되면 OLM(Operator Lifecycle Manager)에서 다음과 같은 워크플로를 사용합니다.
-
OLM에서 지정된
Subscription오브젝트를 선택합니다. - OLM에서 이 서브스크립션에 연결된 Operator group을 가져옵니다.
- OLM에서 Operator group에 서비스 계정이 지정되었는지 확인합니다.
- OLM에서 서비스 계정에 대한 클라이언트 범위를 생성하고 범위가 지정된 클라이언트를 사용하여 Operator를 설치합니다. 이렇게 하면 Operator에서 요청한 모든 권한이 항상 Operator group 서비스 계정의 권한으로 제한됩니다.
- OLM은 CSV에 지정된 권한 세트를 사용하여 새 서비스 계정을 생성하고 Operator에 할당합니다. Operator는 할당된 서비스 계정으로 실행됩니다.
4.6.2. Operator 설치 범위 지정
OLM(Operator Lifecycle Manager)의 Operator 설치 및 업그레이드에 대한 범위 지정 규칙을 제공하려면 서비스 계정을 Operator group에 연결합니다.
클러스터 관리자는 다음 예제를 통해 일련의 Operator를 지정된 네임스페이스로 제한할 수 있습니다.
프로세스
새 네임스페이스를 생성합니다.
$ cat <<EOF | oc create -f - apiVersion: v1 kind: Namespace metadata: name: scoped EOFOperator를 제한할 권한을 할당합니다. 이를 위해서는 새 서비스 계정, 관련 역할, 역할 바인딩을 생성해야 합니다.
$ cat <<EOF | oc create -f - apiVersion: v1 kind: ServiceAccount metadata: name: scoped namespace: scoped EOF다음 예제에서는 간소화를 위해 지정된 네임스페이스에서 모든 작업을 수행할 수 있는 서비스 계정 권한을 부여합니다. 프로덕션 환경에서는 더 세분화된 권한 세트를 생성해야 합니다.
$ cat <<EOF | oc create -f - apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: scoped namespace: scoped rules: - apiGroups: ["*"] resources: ["*"] verbs: ["*"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: scoped-bindings namespace: scoped roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: scoped subjects: - kind: ServiceAccount name: scoped namespace: scoped EOF지정된 네임스페이스에
OperatorGroup오브젝트를 생성합니다. 이 Operator group은 지정된 네임스페이스를 대상으로 하여 테넌시가 제한되도록 합니다.또한 Operator group에서는 사용자가 서비스 계정을 지정할 수 있습니다. 이전 단계에서 생성한 서비스 계정을 지정합니다.
$ cat <<EOF | oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: scoped namespace: scoped spec: serviceAccountName: scoped targetNamespaces: - scoped EOF지정된 네임스페이스에 설치된 Operator는 모두 이 Operator group 및 지정된 서비스 계정에 연결됩니다.
지정된 네임스페이스에
Subscription오브젝트를 생성하여 Operator를 설치합니다.$ cat <<EOF | oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: etcd namespace: scoped spec: channel: singlenamespace-alpha name: etcd source: <catalog_source_name>1 sourceNamespace: <catalog_source_namespace>2 EOFOperator group에 연결된 모든 Operator의 권한이 지정된 서비스 계정에 부여된 권한으로 제한됩니다. Operator에서 서비스 계정 외부에 있는 권한을 요청하는 경우 설치가 실패하고 관련 오류가 표시됩니다.
4.6.2.1. 세분화된 권한
OLM(Operator Lifecycle Manager)은 Operator group에 지정된 서비스 계정을 사용하여 설치 중인 Operator와 관련하여 다음 리소스를 생성하거나 업데이트합니다.
-
ClusterServiceVersion -
서브스크립션 -
Secret -
ServiceAccount -
Service -
ClusterRole및ClusterRoleBinding -
Role및RoleBinding
Operator를 지정된 네임스페이스로 제한하려면 클러스터 관리자가 서비스 계정에 다음 권한을 부여하여 시작하면 됩니다.
다음 역할은 일반적인 예이며 특정 Operator를 기반으로 추가 규칙이 필요할 수 있습니다.
kind: Role
rules:
- apiGroups: ["operators.coreos.com"]
resources: ["subscriptions", "clusterserviceversions"]
verbs: ["get", "create", "update", "patch"]
- apiGroups: [""]
resources: ["services", "serviceaccounts"]
verbs: ["get", "create", "update", "patch"]
- apiGroups: ["rbac.authorization.k8s.io"]
resources: ["roles", "rolebindings"]
verbs: ["get", "create", "update", "patch"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["list", "watch", "get", "create", "update", "patch", "delete"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["list", "watch", "get", "create", "update", "patch", "delete"]또한 Operator에서 가져오기 보안을 지정하는 경우 다음 권한도 추가해야 합니다.
kind: ClusterRole
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
kind: Role
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["create", "update", "patch"]- 1
- OLM 네임스페이스에서 보안을 가져오는 데 필요합니다.
4.6.3. 권한 장애 문제 해결
권한 부족으로 인해 Operator 설치가 실패하는 경우 다음 절차를 사용하여 오류를 확인합니다.
프로세스
Subscription오브젝트를 검토합니다. 해당 상태에는 Operator에 필요한[Cluster]Role[Binding]오브젝트를 생성하는InstallPlan오브젝트를 가리키는 오브젝트 참조installPlanRef가 있습니다.apiVersion: operators.coreos.com/v1 kind: Subscription metadata: name: etcd namespace: scoped status: installPlanRef: apiVersion: operators.coreos.com/v1 kind: InstallPlan name: install-4plp8 namespace: scoped resourceVersion: "117359" uid: 2c1df80e-afea-11e9-bce3-5254009c9c23InstallPlan오브젝트의 상태에 오류가 있는지 확인합니다.apiVersion: operators.coreos.com/v1 kind: InstallPlan status: conditions: - lastTransitionTime: "2019-07-26T21:13:10Z" lastUpdateTime: "2019-07-26T21:13:10Z" message: 'error creating clusterrole etcdoperator.v0.9.4-clusterwide-dsfx4: clusterroles.rbac.authorization.k8s.io is forbidden: User "system:serviceaccount:scoped:scoped" cannot create resource "clusterroles" in API group "rbac.authorization.k8s.io" at the cluster scope' reason: InstallComponentFailed status: "False" type: Installed phase: Failed오류 메시지에는 다음이 표시됩니다.
-
리소스의 API 그룹을 포함하여 생성할 수 없는 리소스 유형. 이 경우
rbac.authorization.k8s.io그룹의clusterroles입니다. - 리소스의 이름.
-
오류 유형
is forbidden은 사용자에게 작업을 수행할 수 있는 권한이 충분하지 않음을 나타냅니다. - 리소스를 생성하거나 업데이트하려고 시도한 사용자의 이름. 이 경우 Operator group에 지정된 서비스 계정을 나타냅니다.
작업 범위:
cluster scope여부사용자는 서비스 계정에 누락된 권한을 추가한 다음 다시 수행할 수 있습니다.
참고OLM(Operator Lifecycle Manager)은 현재 첫 번째 시도에서 전체 오류 목록을 제공하지 않습니다.
-
리소스의 API 그룹을 포함하여 생성할 수 없는 리소스 유형. 이 경우
4.7. 사용자 정의 카탈로그 관리
이 가이드에서는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager)에서 번들 형식 또는 레거시 패키지 매니페스트 형식을 사용하여 패키지로 제공되는 Operator용 사용자 정의 카탈로그 사용 방법을 설명합니다.
4.7.1. 번들 형식을 사용하는 사용자 정의 카탈로그
4.7.1.1. 사전 요구 사항
-
opmCLI를 설치합니다.
4.7.1.2. 인덱스 이미지 생성
opm CLI를 사용하여 인덱스 이미지를 생성할 수 있습니다.
사전 요구 사항
-
opm버전 1.12.3 이상 -
podman버전 1.9.3+ 번들 이미지를 빌드하여 Docker v2-2를 지원하는 레지스트리로 내보냄
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
절차
새 인덱스를 시작합니다.
$ opm index add \ --bundles <registry>/<namespace>/<bundle_image_name>:<tag> \1 --tag <registry>/<namespace>/<index_image_name>:<tag> \2 [--binary-image <registry_base_image>]3 인덱스 이미지를 레지스트리로 내보냅니다.
필요한 경우 대상 레지스트리로 인증합니다.
$ podman login <registry>인덱스 이미지를 내보냅니다.
$ podman push <registry>/<namespace>/test-catalog:latest
4.7.1.3. 인덱스 이미지에서 카탈로그 생성
인덱스 이미지에서 Operator 카탈로그를 생성하고 OLM(Operator Lifecycle Manager)과 함께 사용하도록 OpenShift Container Platform 클러스터에 적용할 수 있습니다.
사전 요구 사항
- 인덱스 이미지를 빌드하여 레지스트리로 내보냈습니다.
프로세스
인덱스 이미지를 참조하는
CatalogSource오브젝트를 생성합니다.다음을 사양에 맞게 수정하고
catalogsource.yaml파일로 저장합니다.apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace1 spec: sourceType: grpc image: <registry>:<port>/<namespace>/redhat-operator-index:v4.62 displayName: My Operator Catalog publisher: <publisher_name>3 updateStrategy: registryPoll:4 interval: 30m파일을 사용하여
CatalogSource오브젝트를 생성합니다.$ oc apply -f catalogSource.yaml
다음 리소스가 성공적으로 생성되었는지 확인합니다.
Pod를 확인합니다.
$ oc get pods -n openshift-marketplace출력 예
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26h카탈로그 소스를 확인합니다.
$ oc get catalogsource -n openshift-marketplace출력 예
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5s패키지 매니페스트 확인합니다.
$ oc get packagemanifest -n openshift-marketplace출력 예
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
이제 OpenShift Container Platform 웹 콘솔의 OperatorHub 페이지에서 Operator를 설치할 수 있습니다.
4.7.1.4. 인덱스 이미지 업데이트
사용자 정의 인덱스 이미지를 참조하는 카탈로그 소스를 사용하도록 OperatorHub를 구성하면 클러스터 관리자가 인덱스 이미지에 번들 이미지를 추가하여 클러스터에 사용 가능한 Operator를 최신 상태로 유지할 수 있습니다.
opm index add 명령을 사용하여 기존 인덱스 이미지를 업데이트할 수 있습니다.
사전 요구 사항
-
opm버전 1.12.3 이상 -
podman버전 1.9.3+ - 인덱스 이미지를 빌드하여 레지스트리로 내보냈습니다.
- 기존 카탈로그 소스에서 인덱스 이미지를 참조합니다.
프로세스
번들 이미지를 추가하여 기존 인덱스를 업데이트합니다.
$ opm index add \ --bundles <registry>/<namespace>/<new_bundle_image>@sha256:<digest> \1 --from-index <registry>/<namespace>/<existing_index_image>:<existing_tag> \2 --tag <registry>/<namespace>/<existing_index_image>:<updated_tag> \3 --pull-tool podman4 다음과 같습니다.
<registry>-
quay.io 또는과 같은 레지스트리의 호스트 이름을 지정합니다.mirror.example.com <namespace>-
ocs-dev또는abc와 같은 레지스트리의 네임스페이스를 지정합니다. <new_bundle_image>-
ocs-operator와 같이 레지스트리에 추가할 새 번들 이미지를 지정합니다. <digest>-
번들 이미지의 SHA 이미지 ID 또는 다이제스트를 지정합니다(예:
c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41). <existing_index_image>-
이전에 내보낸 이미지를 지정합니다(예:
abc-redhat-operator-index). <existing_tag>-
4.6과 같이 이전에 푸시된 이미지 태그를 지정합니다. <updated_tag>-
4.6.1과 같이 업데이트된 인덱스 이미지에 적용할 이미지 태그를 지정합니다.
명령 예
$ opm index add \ --bundles quay.io/ocs-dev/ocs-operator@sha256:c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41 \ --from-index mirror.example.com/abc/abc-redhat-operator-index:4.6 \ --tag mirror.example.com/abc/abc-redhat-operator-index:4.6.1 \ --pull-tool podman업데이트된 인덱스 이미지를 내보냅니다.
$ podman push <registry>/<namespace>/<existing_index_image>:<updated_tag>OLM(Operator Lifecycle Manager)이 정기적으로 카탈로그 소스에서 참조하는 인덱스 이미지를 자동으로 폴링하면 새 패키지가 성공적으로 추가되었는지 확인합니다.
$ oc get packagemanifests -n openshift-marketplace
4.7.1.5. 인덱스 이미지 정리
Operator 번들 포맷을 기반으로 하는 인덱스 이미지는 Operator 카탈로그의 컨테이너화된 스냅샷입니다. 지정된 패키지 목록을 제외한 인덱스를 모두 정리하여 원하는 Operator만 포함하는 소스 인덱스 복사본을 생성할 수 있습니다.
사전 요구 사항
-
podman버전 1.9.3+ -
grpcurl(타사 명령줄 도구) -
opm버전 1.18.0 이상 Docker v2-2를 지원하는 레지스트리에 액세스
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
절차
대상 레지스트리로 인증합니다.
$ podman login <target_registry>정리된 인덱스에 포함하려는 패키지 목록을 결정합니다.
컨테이너에서 정리하려는 소스 인덱스 이미지를 실행합니다. 예를 들면 다음과 같습니다.
$ podman run -p50051:50051 \ -it registry.redhat.io/redhat/redhat-operator-index:v4.6출력 예
Trying to pull registry.redhat.io/redhat/redhat-operator-index:v4.6... Getting image source signatures Copying blob ae8a0c23f5b1 done ... INFO[0000] serving registry database=/database/index.db port=50051별도의 터미널 세션에서
grpcurl명령을 사용하여 인덱스에서 제공하는 패키지 목록을 가져옵니다.$ grpcurl -plaintext localhost:50051 api.Registry/ListPackages > packages.outpackages.out파일을 검사하고 정리된 인덱스에 보관할 이 목록에 있는 패키지 이름을 확인합니다. 예를 들면 다음과 같습니다.패키지 목록 조각의 예
... { "name": "advanced-cluster-management" } ... { "name": "jaeger-product" } ... { { "name": "quay-operator" } ...-
podman run명령을 실행한 터미널 세션에서 Ctrl 및 C를 눌러 컨테이너 프로세스를 중지합니다.
다음 명령을 실행하여 지정된 패키지를 제외한 소스 인덱스를 모두 정리합니다.
$ opm index prune \ -f registry.redhat.io/redhat/redhat-operator-index:v4.6 \1 -p advanced-cluster-management,jaeger-product,quay-operator \2 [-i registry.redhat.io/openshift4/ose-operator-registry:v4.6] \3 -t <target_registry>:<port>/<namespace>/redhat-operator-index:v4.64 다음 명령을 실행하여 새 인덱스 이미지를 대상 레지스트리로 내보냅니다.
$ podman push <target_registry>:<port>/<namespace>/redhat-operator-index:v4.6<namespace>는 레지스트리의 기존 네임스페이스입니다.
4.7.2. 패키지 매니페스트 형식을 사용하는 사용자 정의 카탈로그
4.7.2.1. 패키지 매니페스트 형식 카탈로그 이미지 빌드
클러스터 관리자는 OLM(Operator Lifecycle Manager)에서 사용할 Package Manifest Format에 따라 사용자 정의 Operator 카탈로그 이미지를 빌드할 수 있습니다. 카탈로그 이미지는 Docker v2-2를 지원하는 컨테이너 이미지 레지스트리로 내보낼 수 있습니다. 제한된 네트워크에 있는 클러스터의 경우 이 레지스트리는 제한된 네트워크 클러스터 설치 중에 작성된 미러 레지스트리와 같이 클러스터에 네트워크 액세스 권한이 있는 레지스트리일 수 있습니다.
OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
이 예제의 절차에서는 네트워크 및 인터넷에 둘 다 액세스할 수 있는 미러 레지스트리를 사용한다고 가정합니다.
Windows 및 macOS 버전은 oc adm catalog build 명령을 제공하지 않으므로 이 프로세스에는 Linux 버전의 oc 클라이언트만 사용할 수 있습니다.
사전 요구 사항
- 무제한 네트워크 액세스가 가능한 워크스테이션
-
oc버전 4.3.5 이상 Linux 클라이언트 -
podman버전 1.9.3+ - Docker v2-2를 지원하는 미러 레지스트리에 액세스
프라이빗 레지스트리로 작업 중인 경우
REG_CREDS환경 변수를 이후 단계에서 사용하기 위해 레지스트리 자격 증명의 파일 경로로 설정합니다. 예를 들어podmanCLI의 경우:$ REG_CREDS=${XDG_RUNTIME_DIR}/containers/auth.jsonquay.io 계정에서 액세스할 수 있는 비공개 네임스페이스로 작업하는 경우 Quay 인증 토큰을 설정해야 합니다. quay.io 자격 증명을 사용하여 로그인 API에 대해 요청하여
--auth-token플래그와 함께 사용할AUTH_TOKEN환경 변수를 설정합니다.$ AUTH_TOKEN=$(curl -sH "Content-Type: application/json" \ -XPOST https://quay.io/cnr/api/v1/users/login -d ' { "user": { "username": "'"<quay_username>"'", "password": "'"<quay_password>"'" } }' | jq -r '.token')
프로세스
무제한 네트워크 액세스가 가능한 워크스테이션에서 대상 미러 레지스트리를 사용하여 인증합니다.
$ podman login <registry_host_name>빌드 중 기본 이미지를 가져올 수 있도록
registry.redhat.io로 인증합니다.$ podman login registry.redhat.ioQuay.io에서
redhat-operators카탈로그를 기반으로 카탈로그 이미지를 빌드하고 태그를 지정한 후 미러 레지스트리로 내보냅니다.$ oc adm catalog build \ --appregistry-org redhat-operators \1 --from=registry.redhat.io/openshift4/ose-operator-registry:v4.6 \2 --filter-by-os="linux/amd64" \3 --to=<registry_host_name>:<port>/olm/redhat-operators:v1 \4 [-a ${REG_CREDS}] \5 [--insecure] \6 [--auth-token "${AUTH_TOKEN}"]7 - 1
- App Registry 인스턴스에서 가져올 조직(네임스페이스).
- 2
- 대상 OpenShift Container Platform 클러스터 주 버전 및 부 버전과 일치하는 태그를 사용하여
--from을 Operator 레지스트리 기본 이미지로 설정합니다. - 3
- 기본 이미지에 사용할 운영 체제 및 아키텍처로
--filter-by-os를 설정합니다. 대상 OpenShift Container Platform 클러스터와 일치해야 합니다. 유효한 값은linux/amd64,linux/ppc64le및linux/s390x입니다. - 4
- 카탈로그 이미지 이름을 지정하고 태그를 포함합니다(예:
v1). - 5
- 선택 사항: 필요한 경우 레지스트리 자격 증명 파일의 위치를 지정합니다.
- 6
- 선택 사항: 대상 레지스트리에 대한 신뢰성을 구성하지 않으려면
--insecure플래그를 추가합니다. - 7
- 선택 사항: 공용이 아닌 다른 애플리케이션 레지스트리 카탈로그가 사용되는 경우 Quay 인증 토큰을 지정합니다.
출력 예
INFO[0013] loading Bundles dir=/var/folders/st/9cskxqs53ll3wdn434vw4cd80000gn/T/300666084/manifests-829192605 ... Pushed sha256:f73d42950021f9240389f99ddc5b0c7f1b533c054ba344654ff1edaf6bf827e3 to example_registry:5000/olm/redhat-operators:v1간혹 유효하지 않은 매니페스트가 Red Hat에서 제공하는 카탈로그에 실수로 포함될 때가 있습니다. 이 경우 다음과 같은 몇 가지 오류가 표시될 수 있습니다.
오류가 있는 출력 예
... INFO[0014] directory dir=/var/folders/st/9cskxqs53ll3wdn434vw4cd80000gn/T/300666084/manifests-829192605 file=4.2 load=package W1114 19:42:37.876180 34665 builder.go:141] error building database: error loading package into db: fuse-camel-k-operator.v7.5.0 specifies replacement that couldn't be found Uploading ... 244.9kB/s이러한 오류는 일반적으로 치명적이지 않으며 언급 된 Operator 패키지에 설치하려는 Operator 또는 해당 종속성이 없는 경우 무시할 수 있습니다.
4.7.2.2. 패키지 매니페스트 형식 카탈로그 이미지 미러링
클러스터 관리자는 패키지 매니페스트 형식을 기반으로 사용자 정의 Operator 카탈로그 이미지를 레지스트리에 미러링하고 카탈로그 소스를 사용하여 클러스터에 콘텐츠를 로드할 수 있습니다. 이 예의 절차에서는 이전에 빌드되어 지원되는 레지스트리로 푸시된 사용자 정의 redhat-operators 카탈로그 이미지를 사용합니다.
사전 요구 사항
- 무제한 네트워크 액세스가 가능한 워크스테이션
- 패키지 매니페스트 형식을 기반으로 하는 사용자 정의 Operator 카탈로그 이미지를 지원되는 레지스트리로 내보냄
-
oc버전 4.3.5+ -
podman버전 1.9.3+ Docker v2-2를 지원하는 미러 레지스트리에 액세스
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
프라이빗 레지스트리로 작업 중인 경우
REG_CREDS환경 변수를 이후 단계에서 사용하기 위해 레지스트리 자격 증명의 파일 경로로 설정합니다. 예를 들어podmanCLI의 경우:$ REG_CREDS=${XDG_RUNTIME_DIR}/containers/auth.json
프로세스
oc adm catalog mirror명령은 사용자 정의 Operator 카탈로그 이미지의 내용을 추출하여 미러링에 필요한 매니페스트를 생성합니다. 다음 중 하나를 선택할 수 있습니다.- 명령의 기본 동작이 매니페스트를 생성한 후 모든 이미지 콘텐츠를 미러 레지스트리에 자동으로 미러링하도록 허용합니다.
-
미러링에 필요한 매니페스트만 생성하고 이미지 컨텐츠를 레지스트리에 실제로 미러링하지는 않으려면
--manifests-only플래그를 추가합니다. 이 방법은 미러링할 항목을 검토하는 데 유용할 수 있으며 컨텐츠의 하위 집합만 필요한 경우 매핑 목록을 변경할 수 있습니다. 그런 다음oc image mirror명령과 함께 해당 파일을 사용하여 이후 단계에서 수정된 이미지 목록을 미러링할 수 있습니다.
무제한 네트워크 액세스 권한이 있는 워크스테이션에서 다음 명령을 실행합니다.
$ oc adm catalog mirror \ <registry_host_name>:<port>/olm/redhat-operators:v1 \1 <registry_host_name>:<port> \2 [-a ${REG_CREDS}] \3 [--insecure] \4 [--index-filter-by-os='<platform>/<arch>'] \5 [--manifests-only]6 - 1
- Operator 카탈로그 이미지를 지정합니다.
- 2
- 대상 레지스트리의 정규화된 도메인 이름(FQDN)을 지정합니다.
- 3
- 선택 사항: 필요한 경우 레지스트리 자격 증명 파일의 위치를 지정합니다.
- 4
- 선택 사항: 대상 레지스트리에 대한 신뢰성을 구성하지 않으려면
--insecure플래그를 추가합니다. - 5
- 선택 사항: 여러 변형을 사용할 수 있을 때 선택할 카탈로그 이미지의 플랫폼 및 아키텍처를 지정합니다. 이미지는
'<platform>/<arch>[/<variant>]’로 전달됩니다. 이는 카탈로그 이미지에서 참조하는 이미지에는 적용되지 않습니다. 유효한 값은linux/amd64,linux/ppc64le및linux/s390x입니다. - 6
- 선택 사항: 미러링에 필요한 매니페스트만 생성하고 실제로 이미지 콘텐츠를 레지스트리에 미러링하지 않습니다.
출력 예
using database path mapping: /:/tmp/190214037 wrote database to /tmp/190214037 using database at: /tmp/190214037/bundles.db1 ...- 1
- 명령으로 생성된 임시 데이터베이스.
명령을 실행하면 현재 디렉터리에
manifests-<index_image_name>-<random_number>/디렉터리가 생성되고 다음 파일이 생성됩니다.-
catalogSource.yaml파일은 카탈로그 이미지 태그 및 기타 관련 메타데이터로 미리 채워진CatalogSource오브젝트에 대한 기본 정의입니다. 이 파일은 있는 그대로 사용하거나 카탈로그 소스를 클러스터에 추가하도록 수정할 수 있습니다. imageContentSourcePolicy.yaml파일은 Operator 매니페스트에 저장된 이미지 참조와 미러링된 레지스트리 간에 변환하도록 노드를 구성할 수 있는ImageContentSourcePolicy오브젝트를 정의합니다.참고클러스터에서
ImageContentSourcePolicy오브젝트를 사용하여 저장소 미러링을 구성하는 경우 미러링된 레지스트리에 대한 글로벌 풀 시크릿만 사용할 수 있습니다. 프로젝트에 풀 시크릿을 추가할 수 없습니다.-
mapping.txt파일에는 모든 소스 이미지와 대상 레지스트리에서 매핑할 위치가 포함되어 있습니다. 이 파일은oc image mirror명령과 호환되며 미러링 구성을 추가로 사용자 정의하는 데 사용할 수 있습니다.
이전 단계에서
--manifests-only플래그를 사용했고 컨텐츠의 하위 집합만 미러링하려는 경우:mapping.txt파일의 이미지 목록을 사양에 맞게 수정합니다. 미러링할 이미지 하위 집합의 정확한 이름과 버전을 모를 경우 다음 단계를 사용하여 찾습니다.oc adm catalog mirror명령으로 생성된 임시 데이터베이스에 대해sqlite3도구를 실행하여 일반 검색 쿼리와 일치하는 이미지 목록을 검색합니다. 출력은 나중에mapping.txt파일을 편집하는 방법을 알려주는 데 도움이 됩니다.예를 들어
clusterlogging.4.3문자열과 유사한 이미지 목록을 검색하려면 다음을 수행합니다.$ echo "select * from related_image \ where operatorbundle_name like 'clusterlogging.4.3%';" \ | sqlite3 -line /tmp/190214037/bundles.db1 - 1
- 데이터베이스 파일의 경로를 찾으려면
oc adm catalog mirror명령의 이전 출력을 참조하십시오.
출력 예
image = registry.redhat.io/openshift4/ose-logging-kibana5@sha256:aa4a8b2a00836d0e28aa6497ad90a3c116f135f382d8211e3c55f34fb36dfe61 operatorbundle_name = clusterlogging.4.3.33-202008111029.p0 image = registry.redhat.io/openshift4/ose-oauth-proxy@sha256:6b4db07f6e6c962fc96473d86c44532c93b146bbefe311d0c348117bf759c506 operatorbundle_name = clusterlogging.4.3.33-202008111029.p0 ...이전 단계의 결과를 사용하여 미러링할 이미지의 하위 집합만 포함하도록
mapping.txt파일을 편집합니다.예를 들어 이전 예제 출력의
image값을 사용하여mapping.txt파일에 다음과 같은 일치하는 줄이 있는지 찾을 수 있습니다.mapping.txt에서 일치하는 이미지 매핑registry.redhat.io/openshift4/ose-logging-kibana5@sha256:aa4a8b2a00836d0e28aa6497ad90a3c116f135f382d8211e3c55f34fb36dfe61=<registry_host_name>:<port>/openshift4-ose-logging-kibana5:a767c8f0 registry.redhat.io/openshift4/ose-oauth-proxy@sha256:6b4db07f6e6c962fc96473d86c44532c93b146bbefe311d0c348117bf759c506=<registry_host_name>:<port>/openshift4-ose-oauth-proxy:3754ea2b이 예에서 이러한 이미지만 미러링하려는 경우
mapping.txt파일에서 다른 모든 항목을 제거하고 위의 두 줄만 남겨 둡니다.
네트워크 액세스가 제한되지 않은 워크스테이션에서 수정된
mapping.txt파일을 사용하여oc image mirror명령을 사용하여 레지스트리에 이미지를 미러링합니다.$ oc image mirror \ [-a ${REG_CREDS}] \ --filter-by-os='.*' \ -f ./manifests-redhat-operators-<random_number>/mapping.txt주의--filter-by-os플래그가 설정되지 않았거나.*이외의 값으로 설정된 경우 명령에서 다른 아키텍처를 필터링하여 매니페스트 목록의 다이제스트( 다중 아키텍처 이미지 라고도 함)를 변경합니다. 잘못된 다이제스트로 인해 연결이 끊긴 클러스터에 해당 이미지와 Operator가 배포되지 않습니다.
새
ImageContentSourcePolicy오브젝트를 생성합니다.$ oc create -f ./manifests-redhat-operators-<random_number>/imageContentSourcePolicy.yaml
이제 CatalogSource 오브젝트를 생성하여 미러링된 콘텐츠를 참조할 수 있습니다.
4.7.2.3. 패키지 매니페스트 형식 카탈로그 이미지 업데이트
클러스터 관리자가 사용자 정의 Operator 카탈로그 이미지를 사용하도록 OperatorHub를 구성하면 관리자는 Red Hat에서 제공하는 앱 레지스트리 카탈로그에 수행된 업데이트를 캡처하여 최신 Operator에서 OpenShift Container Platform 클러스터를 최신 상태로 유지할 수 있습니다. 이러한 작업은 새 Operator 카탈로그 이미지를 빌드하고 내보낸 다음 CatalogSource 오브젝트의 기존 spec.image 매개변수를 새 이미지 다이제스트로 교체하여 수행됩니다.
이 예제의 절차에서는 OperatorHub에 사용할 사용자 정의 redhat-operators 카탈로그 이미지를 이미 구성한 것으로 가정합니다.
Windows 및 macOS 버전은 oc adm catalog build 명령을 제공하지 않으므로 이 프로세스에는 Linux 버전의 oc 클라이언트만 사용할 수 있습니다.
사전 요구 사항
- 무제한 네트워크 액세스가 가능한 워크스테이션
-
oc버전 4.3.5 이상 Linux 클라이언트 -
podman버전 1.9.3+ Docker v2-2를 지원하는 미러 레지스트리에 액세스
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
- 사용자 정의 카탈로그 이미지를 사용하도록 OperatorHub 구성
프라이빗 레지스트리로 작업 중인 경우
REG_CREDS환경 변수를 이후 단계에서 사용하기 위해 레지스트리 자격 증명의 파일 경로로 설정합니다. 예를 들어podmanCLI의 경우:$ REG_CREDS=${XDG_RUNTIME_DIR}/containers/auth.jsonquay.io 계정에서 액세스할 수 있는 비공개 네임스페이스로 작업하는 경우 Quay 인증 토큰을 설정해야 합니다. quay.io 자격 증명을 사용하여 로그인 API에 대해 요청하여
--auth-token플래그와 함께 사용할AUTH_TOKEN환경 변수를 설정합니다.$ AUTH_TOKEN=$(curl -sH "Content-Type: application/json" \ -XPOST https://quay.io/cnr/api/v1/users/login -d ' { "user": { "username": "'"<quay_username>"'", "password": "'"<quay_password>"'" } }' | jq -r '.token')
프로세스
무제한 네트워크 액세스가 가능한 워크스테이션에서 대상 미러 레지스트리를 사용하여 인증합니다.
$ podman login <registry_host_name>빌드 중 기본 이미지를 가져올 수 있도록
registry.redhat.io로 인증합니다.$ podman login registry.redhat.ioQuay.io에서
redhat-operators카탈로그를 기반으로 새 카탈로그 이미지를 빌드하고 태그를 지정한 후 미러 레지스트리로 내보냅니다.$ oc adm catalog build \ --appregistry-org redhat-operators \1 --from=registry.redhat.io/openshift4/ose-operator-registry:v4.6 \2 --filter-by-os="linux/amd64" \3 --to=<registry_host_name>:<port>/olm/redhat-operators:v2 \4 [-a ${REG_CREDS}] \5 [--insecure] \6 [--auth-token "${AUTH_TOKEN}"]7 - 1
- App Registry 인스턴스에서 가져올 조직(네임스페이스).
- 2
- 대상 OpenShift Container Platform 클러스터 주 버전 및 부 버전과 일치하는 태그를 사용하여
--from을 Operator 레지스트리 기본 이미지로 설정합니다. - 3
- 기본 이미지에 사용할 운영 체제 및 아키텍처로
--filter-by-os를 설정합니다. 대상 OpenShift Container Platform 클러스터와 일치해야 합니다. 유효한 값은linux/amd64,linux/ppc64le및linux/s390x입니다. - 4
- 카탈로그 이미지 이름을 지정하고 태그를 포함합니다. 예를 들면 업데이트된 카탈로그이므로
v2입니다. - 5
- 선택 사항: 필요한 경우 레지스트리 자격 증명 파일의 위치를 지정합니다.
- 6
- 선택 사항: 대상 레지스트리에 대한 신뢰성을 구성하지 않으려면
--insecure플래그를 추가합니다. - 7
- 선택 사항: 공용이 아닌 다른 애플리케이션 레지스트리 카탈로그가 사용되는 경우 Quay 인증 토큰을 지정합니다.
출력 예
INFO[0013] loading Bundles dir=/var/folders/st/9cskxqs53ll3wdn434vw4cd80000gn/T/300666084/manifests-829192605 ... Pushed sha256:f73d42950021f9240389f99ddc5b0c7f1b533c054ba344654ff1edaf6bf827e3 to example_registry:5000/olm/redhat-operators:v2카탈로그의 콘텐츠를 대상 레지스트리에 미러링합니다. 다음의
oc adm catalog mirror명령은 사용자 정의 Operator 카탈로그 이미지의 콘텐츠를 추출하여 미러링에 필요한 매니페스트를 생성하고 레지스트리에 이미지를 미러링합니다.$ oc adm catalog mirror \ <registry_host_name>:<port>/olm/redhat-operators:v2 \1 <registry_host_name>:<port> \2 [-a ${REG_CREDS}] \3 [--insecure] \4 [--index-filter-by-os='<platform>/<arch>']5 - 1
- 새 Operator 카탈로그 이미지를 지정합니다.
- 2
- 대상 레지스트리의 정규화된 도메인 이름(FQDN)을 지정합니다.
- 3
- 선택 사항: 필요한 경우 레지스트리 자격 증명 파일의 위치를 지정합니다.
- 4
- 선택 사항: 대상 레지스트리에 대한 신뢰성을 구성하지 않으려면
--insecure플래그를 추가합니다. - 5
- 선택 사항: 여러 변형을 사용할 수 있을 때 선택할 카탈로그 이미지의 플랫폼 및 아키텍처를 지정합니다. 이미지는
'<platform>/<arch>[/<variant>]’로 전달됩니다. 이는 카탈로그 이미지에서 참조하는 이미지에는 적용되지 않습니다. 유효한 값은linux/amd64,linux/ppc64le및linux/s390x입니다.
새로 생성한 매니페스트를 적용합니다.
$ oc replace -f ./manifests-redhat-operators-<random_number>중요imageContentSourcePolicy.yaml매니페스트를 적용하지 않아도 될 수 있습니다. 변경이 필요한지 확인하려면 파일의diff를 완료합니다.카탈로그 이미지를 참조하는
CatalogSource오브젝트를 업데이트합니다.이
CatalogSource오브젝트에 대한 원본catalogsource.yaml파일이 있는 경우 다음을 수행합니다.catalogsource.yaml파일을 편집하여spec.image필드의 새 카탈로그 이미지를 참조합니다.apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog namespace: openshift-marketplace spec: sourceType: grpc image: <registry_host_name>:<port>/olm/redhat-operators:v21 displayName: My Operator Catalog publisher: grpc- 1
- 새 Operator 카탈로그 이미지를 지정합니다.
업데이트된 파일을 사용하여
CatalogSource오브젝트를 교체합니다.$ oc replace -f catalogsource.yaml
또는 다음 명령을 사용하여 카탈로그 소스를 편집하고
spec.image매개변수에서 새 카탈로그 이미지를 참조합니다.$ oc edit catalogsource <catalog_source_name> -n openshift-marketplace
업데이트된 Operator는 OpenShift Container Platform 클러스터의 OperatorHub 페이지에서 사용할 수 있어야 합니다.
4.7.2.4. 패키지 매니페스트 형식 카탈로그 이미지 테스트
Operator 카탈로그 이미지 콘텐츠를 컨테이너로 실행하고 gRPC API를 쿼리하여 검증할 수 있습니다. 그런 다음 이미지를 추가로 테스트하려면 카탈로그 소스의 이미지를 참조하여 OLM(Operator Lifecycle Manager)에서 서브스크립션을 확인할 수 있습니다. 이 예의 절차에서는 이전에 빌드되어 지원되는 레지스트리로 푸시된 사용자 정의 redhat-operators 카탈로그 이미지를 사용합니다.
사전 요구 사항
- 지원되는 레지스트리에 내보낸 사용자 정의 패키지 매니페스트 형식 카탈로그 이미지
-
podman버전 1.9.3+ -
oc버전 4.3.5+ Docker v2-2를 지원하는 미러 레지스트리에 액세스
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
-
grpcurl
프로세스
Operator 카탈로그 이미지를 가져옵니다.
$ podman pull <registry_host_name>:<port>/olm/redhat-operators:v1이미지를 실행합니다.
$ podman run -p 50051:50051 \ -it <registry_host_name>:<port>/olm/redhat-operators:v1grpcurl을 사용하여 사용 가능한 패키지에 대해 실행 중인 이미지를 쿼리합니다.$ grpcurl -plaintext localhost:50051 api.Registry/ListPackages출력 예
{ "name": "3scale-operator" } { "name": "amq-broker" } { "name": "amq-online" }채널에서 최신 Operator 번들을 가져옵니다.
$ grpcurl -plaintext -d '{"pkgName":"kiali-ossm","channelName":"stable"}' localhost:50051 api.Registry/GetBundleForChannel출력 예
{ "csvName": "kiali-operator.v1.0.7", "packageName": "kiali-ossm", "channelName": "stable", ...이미지의 다이제스트를 가져옵니다.
$ podman inspect \ --format='{{index .RepoDigests 0}}' \ <registry_host_name>:<port>/olm/redhat-operators:v1출력 예
example_registry:5000/olm/redhat-operators@sha256:f73d42950021f9240389f99ddc5b0c7f1b533c054ba344654ff1edaf6bf827e3Operator 및 해당 종속성을 지원하는 네임스페이스
my-ns에 Operator group이 있다고 가정하고 이미지 다이제스트를 사용하여CatalogSource오브젝트를 생성합니다. 예를 들면 다음과 같습니다.apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: custom-redhat-operators namespace: my-ns spec: sourceType: grpc image: example_registry:5000/olm/redhat-operators@sha256:f73d42950021f9240389f99ddc5b0c7f1b533c054ba344654ff1edaf6bf827e3 displayName: Red Hat Operators카탈로그 이미지에서 사용 가능한 최신
servicemeshoperator및 해당 종속성을 확인하는 서브스크립션을 생성합니다.apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: servicemeshoperator namespace: my-ns spec: source: custom-redhat-operators sourceNamespace: my-ns name: servicemeshoperator channel: "1.0"
4.7.3. 기본 OperatorHub 소스 비활성화
Red Hat 및 커뮤니티 프로젝트에서 제공하는 콘텐츠를 소싱하는 Operator 카탈로그는 OpenShift Container Platform을 설치하는 동안 기본적으로 OperatorHub용으로 구성됩니다. 클러스터 관리자는 기본 카탈로그 세트를 비활성화할 수 있습니다.
절차
OperatorHub오브젝트에disableAllDefaultSources: true를 추가하여 기본 카탈로그의 소스를 비활성화합니다.$ oc patch OperatorHub cluster --type json \ -p '[{"op": "add", "path": "/spec/disableAllDefaultSources", "value": true}]'
또는 웹 콘솔을 사용하여 카탈로그 소스를 관리할 수 있습니다. 관리자 → 클러스터 설정 → 글로벌 구성 → OperatorHub 페이지에서 개별 소스를 생성, 삭제, 비활성화, 활성화할 수 있는 소스 탭을 클릭합니다.
4.7.4. 사용자 정의 카탈로그 제거
클러스터 관리자는 관련 카탈로그 소스를 삭제하여 이전에 클러스터에 추가된 사용자 정의 Operator 카탈로그를 제거할 수 있습니다.
절차
- 웹 콘솔의 관리자 화면에서 관리자 → 클러스터 설정으로 이동합니다.
- 글로벌 구성 탭을 클릭한 다음 OperatorHub를 클릭합니다.
- 소스 탭을 클릭합니다.
-
제거할 카탈로그의 옵션 메뉴
 를 선택한 다음 카탈로그 소스 삭제를 클릭합니다.
를 선택한 다음 카탈로그 소스 삭제를 클릭합니다.
4.8. 제한된 네트워크에서 Operator Lifecycle Manager 사용
제한된 네트워크(연결이 끊긴 클러스터)에 설치된 OpenShift Container Platform 클러스터의 경우 OLM(Operator Lifecycle Manager)은 기본적으로 원격 레지스트리에서 호스팅되는 Red Hat 제공 OperatorHub 소스에 액세스할 수 없습니다. 이러한 원격 소스에는 완전한 인터넷 연결이 필요하기 때문입니다.
그러나 클러스터 관리자는 워크스테이션에 완전한 인터넷 액세스 권한이 있는 경우 제한된 네트워크에서 OLM을 사용하도록 클러스터를 활성화할 수 있습니다. 원격 OperatorHub 콘텐츠를 가져오는 데 완전한 인터넷 액세스 권한이 필요한 워크스테이션은 원격 소스의 로컬 미러를 준비하고 콘텐츠를 미러 레지스트리로 내보내는 데 사용됩니다.
미러 레지스트리는 워크스테이션 및 연결이 끊긴 클러스터 모두에 연결해야 하는 베스천 호스트에 있거나 미러링된 콘텐츠를 연결이 끊긴 환경에 물리적으로 이동하기 위해 이동식 미디어가 필요한 완전히 연결이 끊긴 호스트 또는 에어갭(Airgap) 호스트에 있을 수 있습니다.
이 가이드에서는 제한된 네트워크에서 OLM을 활성화하는 데 필요한 다음 프로세스를 설명합니다.
- OLM의 기본 원격 OperatorHub 소스를 비활성화합니다.
- 완전한 인터넷 액세스가 가능한 워크스테이션을 사용하여 OperatorHub 콘텐츠의 로컬 미러를 생성하고 미러 레지스트리로 내보냅니다.
- 기본 원격 소스가 아닌 미러 레지스트리의 로컬 소스에서 Operator를 설치하고 관리하도록 OLM을 구성합니다.
제한된 네트워크에서 OLM을 활성화한 후에는 제한되지 않은 워크스테이션을 계속 사용하여 최신 버전의 Operator가 출시될 때 로컬 OperatorHub 소스를 업데이트할 수 있습니다.
OLM은 로컬 소스에서 Operator를 관리할 수 있지만 지정된 Operator를 제한된 네트워크에서 실행할 수 있는지는 Operator에 따라 다릅니다. Operator는 다음을 수행해야 합니다.
-
Operator에서 기능을 수행하는 데 필요할 수 있는 관련 이미지 또는 기타 컨테이너 이미지를 CSV(
ClusterServiceVersion) 오브젝트의relatedImages매개변수에 나열합니다. - 태그가 아닌 다이제스트(SHA)를 통해 지정된 모든 이미지를 참조합니다.
연결이 끊긴 모드에서 실행을 지원하는 Red Hat Operator 목록은 다음 Red Hat Knowledgebase 문서를 참조하십시오.
4.8.1. 사전 요구 사항
-
cluster-admin권한이 있는 사용자로 OpenShift Container Platform 클러스터에 로그인합니다. -
기본 카탈로그를 정리하고 선택한 Operator 서브 세트만 미러링하려면
opmCLI를 설치합니다.
IBM Z의 제한된 네트워크에서 OLM을 사용하는 경우 레지스트리를 배치하는 디렉터리에 12GB 이상을 할당해야 합니다.
4.8.2. 기본 OperatorHub 소스 비활성화
Red Hat 및 커뮤니티 프로젝트에서 제공하는 콘텐츠를 소싱하는 Operator 카탈로그는 OpenShift Container Platform을 설치하는 동안 기본적으로 OperatorHub용으로 구성됩니다. 제한된 네트워크 환경에서는 클러스터 관리자로서 기본 카탈로그를 비활성화해야 합니다. 그런 다음 로컬 카탈로그 소스를 사용하도록 OperatorHub를 구성할 수 있습니다.
절차
OperatorHub오브젝트에disableAllDefaultSources: true를 추가하여 기본 카탈로그의 소스를 비활성화합니다.$ oc patch OperatorHub cluster --type json \ -p '[{"op": "add", "path": "/spec/disableAllDefaultSources", "value": true}]'
또는 웹 콘솔을 사용하여 카탈로그 소스를 관리할 수 있습니다. 관리자 → 클러스터 설정 → 글로벌 구성 → OperatorHub 페이지에서 개별 소스를 생성, 삭제, 비활성화, 활성화할 수 있는 소스 탭을 클릭합니다.
4.8.3. 인덱스 이미지 정리
Operator 번들 포맷을 기반으로 하는 인덱스 이미지는 Operator 카탈로그의 컨테이너화된 스냅샷입니다. 지정된 패키지 목록을 제외한 인덱스를 모두 정리하여 원하는 Operator만 포함하는 소스 인덱스 복사본을 생성할 수 있습니다.
제한된 네트워크 OpenShift Container Platform 클러스터에서 미러링된 콘텐츠를 사용하도록 OLM(Operator Lifecycle Manager)을 구성할 때는 기본 카탈로그에서 Operator 서브 세트만 미러링하려면 이 정리 방법을 사용하십시오.
이 절차의 단계에서 대상 레지스트리는 무제한 네트워크 액세스 권한을 사용하여 워크스테이션에서 액세스할 수 있는 기존 미러 레지스트리입니다. 이 예제에서는 기본 redhat-operators 카탈로그의 인덱스 이미지를 정리하는 방법도 보여주지만 프로세스는 모든 인덱스 이미지에서 동일합니다.
사전 요구 사항
- 무제한 네트워크 액세스가 가능한 워크스테이션
-
podman버전 1.9.3+ -
grpcurl(타사 명령줄 도구) -
opm버전 1.18.0 이상 Docker v2-2를 지원하는 레지스트리에 액세스
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
절차
registry.redhat.io로 인증합니다.$ podman login registry.redhat.io대상 레지스트리로 인증합니다.
$ podman login <target_registry>정리된 인덱스에 포함하려는 패키지 목록을 결정합니다.
컨테이너에서 정리하려는 소스 인덱스 이미지를 실행합니다. 예를 들면 다음과 같습니다.
$ podman run -p50051:50051 \ -it registry.redhat.io/redhat/redhat-operator-index:v4.6출력 예
Trying to pull registry.redhat.io/redhat/redhat-operator-index:v4.6... Getting image source signatures Copying blob ae8a0c23f5b1 done ... INFO[0000] serving registry database=/database/index.db port=50051별도의 터미널 세션에서
grpcurl명령을 사용하여 인덱스에서 제공하는 패키지 목록을 가져옵니다.$ grpcurl -plaintext localhost:50051 api.Registry/ListPackages > packages.outpackages.out파일을 검사하고 정리된 인덱스에 보관할 이 목록에 있는 패키지 이름을 확인합니다. 예를 들면 다음과 같습니다.패키지 목록 조각의 예
... { "name": "advanced-cluster-management" } ... { "name": "jaeger-product" } ... { { "name": "quay-operator" } ...-
podman run명령을 실행한 터미널 세션에서 Ctrl 및 C를 눌러 컨테이너 프로세스를 중지합니다.
다음 명령을 실행하여 지정된 패키지를 제외한 소스 인덱스를 모두 정리합니다.
$ opm index prune \ -f registry.redhat.io/redhat/redhat-operator-index:v4.6 \1 -p advanced-cluster-management,jaeger-product,quay-operator \2 [-i registry.redhat.io/openshift4/ose-operator-registry:v4.6] \3 -t <target_registry>:<port>/<namespace>/redhat-operator-index:v4.64 다음 명령을 실행하여 새 인덱스 이미지를 대상 레지스트리로 내보냅니다.
$ podman push <target_registry>:<port>/<namespace>/redhat-operator-index:v4.6<namespace>는 레지스트리의 기존 네임스페이스입니다. 예를 들어 미러링된 콘텐츠를 모두 내보내기 위해olm-mirror네임스페이스를 생성할 수 있습니다.
4.8.4. Operator 카탈로그 미러링
oc adm catalog mirror 명령을 사용하여 Red Hat 제공 카탈로그 또는 사용자 정의 카탈로그의 Operator 콘텐츠를 컨테이너 이미지 레지스트리에 미러링할 수 있습니다. 대상 레지스트리는 Docker v2-2를 지원해야 합니다. 제한된 네트워크에 있는 클러스터의 경우 이 레지스트리는 제한된 네트워크 클러스터 설치 중 생성된 미러 레지스트리와 같이 클러스터에 네트워크 액세스 권한이 있는 레지스트리일 수 있습니다.
OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
oc adm catalog mirror 명령은 또한 Red Hat 제공 인덱스 이미지이든 자체 사용자 정의 빌드 인덱스 이미지이든 미러링 프로세스 중에 지정하는 인덱스 이미지를 대상 레지스트리에 자동으로 미러링합니다. 그러면 미러링된 인덱스 이미지를 사용하여 OLM(Operator Lifecycle Manager)이 OpenShift Container Platform 클러스터에 미러링된 카탈로그를 로드할 수 있는 카탈로그 소스를 생성할 수 있습니다.
사전 요구 사항
- 워크스테이션에서 무제한 네트워크 액세스가 가능합니다.
-
podman버전이 1.9.3 이상입니다. - Docker v2-2를 지원하는 미러 레지스트리에 액세스할 수 있습니다.
-
미러 레지스트리에서 미러링된 Operator 콘텐츠를 저장하는 데 사용할 네임스페이스를 결정합니다. 예를 들어
olm-mirror네임스페이스를 생성할 수 있습니다. - 미러 레지스트리가 인터넷에 액세스할 수 없는 경우 이동식 미디어를 무제한 네트워크 액세스 권한이 있는 워크스테이션에 연결합니다.
registry.redhat.io를 포함한 프라이빗 레지스트리로작업하는 경우REG_CREDS환경 변수를 이후 단계에서 사용할 레지스트리 자격 증명의 파일 경로로 설정합니다. 예를 들어podmanCLI의 경우:$ REG_CREDS=${XDG_RUNTIME_DIR}/containers/auth.json
프로세스
Red Hat 제공 카탈로그를 미러링하려면 무제한 네트워크 액세스 권한이 있는 워크스테이션에서 다음 명령을 실행하여
registry.redhat.io로 인증합니다.$ podman login registry.redhat.iooc adm catalog mirror명령은 인덱스 이미지의 콘텐츠를 추출하여 미러링에 필요한 매니페스트를 생성합니다. 명령의 기본 동작은 매니페스트를 생성한 다음 인덱스 이미지 자체뿐만 아니라 인덱스 이미지의 모든 이미지 콘텐츠를 미러 레지스트리에 자동으로 미러링합니다. 또는 미러 레지스트리가 완전히 연결이 끊긴 호스트 또는 에어갭(Airgap) 호스트에 있는 경우 먼저 콘텐츠를 이동식 미디어로 미러링하고 미디어를 연결이 끊긴 환경으로 이동한 다음 미디어에서 레지스트리로 해당 콘텐츠를 미러링할 수 있습니다.옵션 A: 미러 레지스트리가 무제한 네트워크 액세스 권한이 있는 워크스테이션과 동일한 네트워크에 있는 경우 워크스테이션에서 다음 작업을 수행합니다.
미러 레지스트리에 인증이 필요한 경우 다음 명령을 실행하여 레지스트리에 로그인합니다.
$ podman login <mirror_registry>다음 명령을 실행하여 콘텐츠를 미러링합니다.
$ oc adm catalog mirror \ <index_image> \1 <mirror_registry>:<port>/<namespace> \2 [-a ${REG_CREDS}] \3 [--insecure] \4 [--index-filter-by-os='<platform>/<arch>'] \5 [--manifests-only]6 - 1
- 미러링할 카탈로그의 인덱스 이미지를 지정합니다. 예를 들어 이전에 생성한 정리된 인덱스 이미지 또는
registry.redhat.io/redhat/redhat-operator-index:v4.6과 같은 기본 카탈로그의 소스 인덱스 이미지 중 하나일 수 있습니다. - 2
- Operator 콘텐츠를 미러링할 대상 레지스트리 및 네임스페이스의 정규화된 도메인 이름(FQDN)을 지정합니다. 여기서
<namespace>는 레지스트리의 기존 네임스페이스입니다. 예를 들어 미러링된 콘텐츠를 모두 내보내기 위해olm-mirror네임스페이스를 생성할 수 있습니다. - 3
- 선택 사항: 필요한 경우 registry.
redhat.io에{REG_CREDS}가 필요합니다. - 4
- 선택 사항: 대상 레지스트리에 대한 신뢰성을 구성하지 않으려면
--insecure플래그를 추가합니다. - 5
- 선택 사항: 여러 변형을 사용할 수 있을 때 선택할 인덱스 이미지의 플랫폼 및 아키텍처를 지정합니다. 이미지는
'<platform>/<arch>[/<variant>]’로 전달됩니다. 이는 인덱스에서 참조하는 이미지에는 적용되지 않습니다. 유효한 값은linux/amd64,linux/ppc64le및linux/s390x입니다. - 6
- 선택 사항: 미러링에 필요한 매니페스트만 생성하고 실제로 이미지 콘텐츠를 레지스트리에 미러링하지 않습니다. 이 선택 사항은 미러링할 항목을 검토하는 데 유용할 수 있으며 패키지의 서브 세트만 필요한 경우 매핑 목록을 변경할 수 있습니다. 그런 다음
oc image mirror명령과 함께mapping.txt파일을 사용하여 이후 단계에서 수정된 이미지 목록을 미러링할 수 있습니다. 이 플래그는 카탈로그에서 콘텐츠의 고급 선택적 미러링에만 사용됩니다. 이전에 인덱스 이미지를 정리하기 위해 사용한 경우opm index prune명령은 대부분의 카탈로그 관리 사용 사례에 적합합니다.
출력 예
src image has index label for database path: /database/index.db using database path mapping: /database/index.db:/tmp/153048078 wrote database to /tmp/1530480781 ... wrote mirroring manifests to manifests-redhat-operator-index-16142116422 참고Red Hat Quay는 중첩 리포지토리를 지원하지 않습니다. 결과적으로
oc adm catalog mirror명령을 실행하면401무단 오류와 함께 실패합니다. 이 문제를 해결하려면oc adm catalog mirror명령을 실행할 때--max-components=2옵션을 사용하여 중첩된 리포지토리 생성을 비활성화할 수 있습니다. 이 해결 방법에 대한 자세한 내용은 Quay 레지스트리 Knowledgebase 솔루션과 함께 catalog mirror 명령을 사용하는 동안 인가되지 않은 오류가 발생한 것을 참조하십시오.
옵션 B: 미러 레지스트리가 연결이 끊긴 호스트에 있는 경우 다음 작업을 수행합니다.
무제한 네트워크 액세스 권한이 있는 워크스테이션에서 다음 명령을 실행하여 콘텐츠를 로컬 파일에 미러링합니다.
$ oc adm catalog mirror \ <index_image> \1 file:///local/index \2 [-a ${REG_CREDS}] \ [--insecure]출력 예
... info: Mirroring completed in 5.93s (5.915MB/s) wrote mirroring manifests to manifests-my-index-16149855281 To upload local images to a registry, run: oc adm catalog mirror file://local/index/myrepo/my-index:v1 REGISTRY/REPOSITORY2 -
현재 디렉터리에 생성된
v2/디렉터리를 이동식 미디어로 복사합니다. - 물리적으로 미디어를 제거하고 연결이 끊긴 환경의 호스트에 연결하여 미러 레지스트리에 액세스할 수 있습니다.
미러 레지스트리에 인증이 필요한 경우 연결이 끊긴 환경의 호스트에서 다음 명령을 실행하여 레지스트리에 로그인합니다.
$ podman login <mirror_registry>v2/디렉터리가 포함된 상위 디렉터리에서 다음 명령을 실행하여 로컬 파일에서 미러 레지스트리로 이미지를 업로드합니다.$ oc adm catalog mirror \ file://local/index/<repo>/<index_image>:<tag> \1 <mirror_registry>:<port>/<namespace> \2 [-a ${REG_CREDS}] \ [--insecure]참고Red Hat Quay는 중첩 리포지토리를 지원하지 않습니다. 결과적으로
oc adm catalog mirror명령을 실행하면401무단 오류와 함께 실패합니다. 이 문제를 해결하려면oc adm catalog mirror명령을 실행할 때--max-components=2옵션을 사용하여 중첩된 리포지토리 생성을 비활성화할 수 있습니다. 이 해결 방법에 대한 자세한 내용은 Quay 레지스트리 Knowledgebase 솔루션과 함께 catalog mirror 명령을 사용하는 동안 인가되지 않은 오류가 발생한 것을 참조하십시오.
콘텐츠를 레지스트리에 미러링한 후 현재 디렉터리에 생성된 매니페스트 디렉터리를 검사합니다.
참고매니페스트 디렉터리 이름은 이후 단계에서 사용됩니다.
이전 단계에서 동일한 네트워크의 레지스트리에 콘텐츠를 미러링한 경우 디렉터리 이름은 다음 형식을 취합니다.
manifests-<index_image_name>-<random_number>이전 단계에서 연결이 끊긴 호스트의 레지스트리에 콘텐츠를 미러링한 경우 디렉터리 이름은 다음 형식을 취합니다.
manifests-index/<namespace>/<index_image_name>-<random_number>매니페스트 디렉터리에는 다음 파일이 포함되어 있으며, 이 중 일부는 추가 수정이 필요할 수 있습니다.
catalogSource.yaml파일은 인덱스 이미지 태그 및 기타 관련 메타데이터로 미리 채워진CatalogSource오브젝트에 대한 기본 정의입니다. 이 파일은 있는 그대로 사용하거나 카탈로그 소스를 클러스터에 추가하도록 수정할 수 있습니다.중요콘텐츠를 로컬 파일에 미러링한 경우
metadata.name필드에서 .name 필드에서 백슬래시(/) 문자를 제거하려면catalogSource.yaml파일을 수정해야 합니다. 그러지 않으면 오브젝트 생성을 시도할 때 "잘못된 리소스 이름" 오류로 인해 실패합니다.imageContentSourcePolicy.yaml파일은 Operator 매니페스트에 저장된 이미지 참조와 미러링된 레지스트리 간에 변환하도록 노드를 구성할 수 있는ImageContentSourcePolicy오브젝트를 정의합니다.참고클러스터에서
ImageContentSourcePolicy오브젝트를 사용하여 저장소 미러링을 구성하는 경우 미러링된 레지스트리에 대한 글로벌 풀 시크릿만 사용할 수 있습니다. 프로젝트에 풀 시크릿을 추가할 수 없습니다.mapping.txt파일에는 모든 소스 이미지와 대상 레지스트리에서 매핑할 위치가 포함되어 있습니다. 이 파일은oc image mirror명령과 호환되며 미러링 구성을 추가로 사용자 정의하는 데 사용할 수 있습니다.중요미러링 프로세스 중
--manifests-only플래그를 사용한 후 미러링할 패키지의 서브 세트를 추가로 트리밍하려면mapping.txt파일을 수정하고oc image mirror명령으로 파일을 사용하는 데 대한 “패키지 매니페스트 형식 카탈로그 이미지 미러링” 절차의 단계를 참조하십시오. 추가 조치를 수행한 후 이 프로세스를 계속할 수 있습니다.
연결 해제된 클러스터에 액세스할 수 있는 호스트에서 매니페스트 디렉터리에
imageContentSourcePolicy.yaml파일을 지정하도록 다음 명령을 실행하여ImageContentSourcePolicy오브젝트를 생성합니다.$ oc create -f <path/to/manifests/dir>/imageContentSourcePolicy.yaml여기서
<path/to/manifests/dir>은 미러링된 콘텐츠의 매니페스트 디렉터리 경로입니다.
이제 미러링된 인덱스 이미지 및 Operator 콘텐츠를 참조하도록 CatalogSource 오브젝트를 생성할 수 있습니다.
4.8.5. 인덱스 이미지에서 카탈로그 생성
인덱스 이미지에서 Operator 카탈로그를 생성하고 OLM(Operator Lifecycle Manager)과 함께 사용하도록 OpenShift Container Platform 클러스터에 적용할 수 있습니다.
사전 요구 사항
- 인덱스 이미지를 빌드하여 레지스트리로 내보냈습니다.
프로세스
인덱스 이미지를 참조하는
CatalogSource오브젝트를 생성합니다.oc adm catalog mirror명령을 사용하여 카탈로그를 대상 레지스트리에 미러링하는 경우 생성된catalogSource.yaml파일을 시작점으로 사용할 수 있습니다.다음을 사양에 맞게 수정하고
catalogsource.yaml파일로 저장합니다.apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: my-operator-catalog1 namespace: openshift-marketplace2 spec: sourceType: grpc image: <registry>:<port>/<namespace>/redhat-operator-index:v4.63 displayName: My Operator Catalog publisher: <publisher_name>4 updateStrategy: registryPoll:5 interval: 30m- 1
- 레지스트리에 업로드하기 전에 콘텐츠를 로컬 파일에 미러링한 경우 오브젝트를 생성할 때 "잘못된 리소스 이름" 오류가 발생하지 않도록
metadata.name필드에서 백슬래시(/) 문자를 제거합니다. - 2
- 카탈로그 소스를 모든 네임스페이스의 사용자가 전역적으로 사용할 수 있도록 하려면
openshift-marketplace네임스페이스를 지정합니다. 그러지 않으면 카탈로그의 범위가 지정되고 해당 네임스페이스에 대해서만 사용할 수 있도록 다른 네임스페이스를 지정할 수 있습니다. - 3
- 인덱스 이미지를 지정합니다.
- 4
- 카탈로그를 게시하는 이름 또는 조직 이름을 지정합니다.
- 5
- 카탈로그 소스는 새 버전을 자동으로 확인하여 최신 상태를 유지할 수 있습니다.
파일을 사용하여
CatalogSource오브젝트를 생성합니다.$ oc apply -f catalogSource.yaml
다음 리소스가 성공적으로 생성되었는지 확인합니다.
Pod를 확인합니다.
$ oc get pods -n openshift-marketplace출력 예
NAME READY STATUS RESTARTS AGE my-operator-catalog-6njx6 1/1 Running 0 28s marketplace-operator-d9f549946-96sgr 1/1 Running 0 26h카탈로그 소스를 확인합니다.
$ oc get catalogsource -n openshift-marketplace출력 예
NAME DISPLAY TYPE PUBLISHER AGE my-operator-catalog My Operator Catalog grpc 5s패키지 매니페스트 확인합니다.
$ oc get packagemanifest -n openshift-marketplace출력 예
NAME CATALOG AGE jaeger-product My Operator Catalog 93s
이제 OpenShift Container Platform 웹 콘솔의 OperatorHub 페이지에서 Operator를 설치할 수 있습니다.
4.8.6. 인덱스 이미지 업데이트
사용자 정의 인덱스 이미지를 참조하는 카탈로그 소스를 사용하도록 OperatorHub를 구성하면 클러스터 관리자가 인덱스 이미지에 번들 이미지를 추가하여 클러스터에 사용 가능한 Operator를 최신 상태로 유지할 수 있습니다.
opm index add 명령을 사용하여 기존 인덱스 이미지를 업데이트할 수 있습니다. 제한된 네트워크의 경우 업데이트된 콘텐츠도 클러스터에 다시 미러링해야 합니다.
사전 요구 사항
-
opm버전 1.12.3 이상 -
podman버전 1.9.3+ - 인덱스 이미지를 빌드하여 레지스트리로 내보냈습니다.
- 기존 카탈로그 소스에서 인덱스 이미지를 참조합니다.
프로세스
번들 이미지를 추가하여 기존 인덱스를 업데이트합니다.
$ opm index add \ --bundles <registry>/<namespace>/<new_bundle_image>@sha256:<digest> \1 --from-index <registry>/<namespace>/<existing_index_image>:<existing_tag> \2 --tag <registry>/<namespace>/<existing_index_image>:<updated_tag> \3 --pull-tool podman4 다음과 같습니다.
<registry>-
quay.io 또는과 같은 레지스트리의 호스트 이름을 지정합니다.mirror.example.com <namespace>-
ocs-dev또는abc와 같은 레지스트리의 네임스페이스를 지정합니다. <new_bundle_image>-
ocs-operator와 같이 레지스트리에 추가할 새 번들 이미지를 지정합니다. <digest>-
번들 이미지의 SHA 이미지 ID 또는 다이제스트를 지정합니다(예:
c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41). <existing_index_image>-
이전에 내보낸 이미지를 지정합니다(예:
abc-redhat-operator-index). <existing_tag>-
4.6과 같이 이전에 푸시된 이미지 태그를 지정합니다. <updated_tag>-
4.6.1과 같이 업데이트된 인덱스 이미지에 적용할 이미지 태그를 지정합니다.
명령 예
$ opm index add \ --bundles quay.io/ocs-dev/ocs-operator@sha256:c7f11097a628f092d8bad148406aa0e0951094a03445fd4bc0775431ef683a41 \ --from-index mirror.example.com/abc/abc-redhat-operator-index:4.6 \ --tag mirror.example.com/abc/abc-redhat-operator-index:4.6.1 \ --pull-tool podman업데이트된 인덱스 이미지를 내보냅니다.
$ podman push <registry>/<namespace>/<existing_index_image>:<updated_tag>Operator 카탈로그 미러링 절차에 있는 단계를 다시 수행하여 업데이트된 콘텐츠를 미러링합니다. 그러나 ICSP(
ImageContentSourcePolicy) 오브젝트 생성에 대한 단계에 도달하면oc create명령 대신oc replace명령을 사용합니다. 예를 들면 다음과 같습니다.$ oc replace -f ./manifests-redhat-operator-index-<random_number>/imageContentSourcePolicy.yaml이 변경 사항은 오브젝트가 이미 존재하고 업데이트해야 하므로 필요합니다.
참고일반적으로
oc apply명령을 사용하여 이전에oc apply를 사용하여 생성한 기존 오브젝트를 업데이트할 수 있습니다. 그러나 ICSP 오브젝트의metadata.annotations필드 크기와 관련하여 알려진 문제로 인해 현재 이 단계에oc replace명령을 사용해야 합니다.OLM(Operator Lifecycle Manager)이 정기적으로 카탈로그 소스에서 참조하는 인덱스 이미지를 자동으로 폴링하면 새 패키지가 성공적으로 추가되었는지 확인합니다.
$ oc get packagemanifests -n openshift-marketplace
5장. Operator 개발
5.1. Operator SDK 정보
Operator 프레임워크는 Operator라는 Kubernetes 네이티브 애플리케이션을 효율적이고 확장 가능하며 자동화된 방식으로 관리하는 오픈 소스 툴킷입니다. Operator는 Kubernetes 확장성을 활용하여 클라우드 서비스(예: 프로비저닝, 스케일링, 백업, 복원) 자동화의 이점을 제공하는 동시에 Kubernetes를 실행할 수 있는 모든 위치에서 실행할 수 있습니다.
Operator를 사용하면 Kubernetes 상의 복잡한 상태 저장 애플리케이션을 쉽게 관리할 수 있습니다. 그러나 현재는 하위 API 사용, 상용구 작성, 중복으로 이어지는 모듈성 부족과 같은 문제로 인해 Operator를 작성하기 어려울 수 있습니다.
Operator 프레임워크의 구성 요소인 Operator SDK는 Operator 개발자가 Operator를 빌드, 테스트, 배포하는 데 사용할 수 있는 CLI(명령줄 인터페이스) 툴을 제공합니다.
Operator SDK를 사용하는 이유는 무엇입니까?
Operator SDK는 Kubernetes 네이티브 애플리케이션 구축 프로세스를 간소화하는데 이를 위해서는 애플리케이션별 운영 지식이 필요할 수 있습니다. Operator SDK를 사용하면 이러한 문제가 완화될 뿐만 아니라 미터링 또는 모니터링과 같이 다수의 공통 관리 기능에 필요한 상용구 코드의 양을 줄이는 데 도움이 됩니다.
Operator SDK는 controller-runtime 라이브러리를 사용하여 다음과 같은 기능을 제공함으로써 Operator를 더 쉽게 작성할 수 있는 프레임워크입니다.
- 운영 논리를 더 직관적으로 작성할 수 있는 고급 API 및 추상화
- 새 프로젝트를 신속하게 부트스트랩하기 위한 스캐폴드 및 코드 생성 툴
- OLM(Operator Lifecycle Manager) 통합을 통해 클러스터에서 수행되는 Operator 패키지, 설치, 실행 작업 간소화
- 일반적인 Operator 사용 사례를 포함하는 확장 기능
- Prometheus Operator가 배포된 클러스터에서 사용할 수 있도록 생성되는 모든 Go 기반 Operator에 자동으로 설정된 지표
OpenShift Container Platform과 같은 Kubernetes 기반 클러스터에 대한 클러스터 관리자 액세스 권한이 있는 Operator 작성자는 Operator SDK CLI를 사용하여 Go, Ansible 또는 Helm을 기반으로 자체 Operator를 개발할 수 있습니다. Kubebuilder는 Go 기반 Operator의 스캐폴드 솔루션으로 Operator SDK에 포함되어 있습니다. 즉 기존 Kubebuilder 프로젝트를 그대로 Operator SDK와 함께 사용할 수 있으며 계속 작업할 수 있습니다.
OpenShift Container Platform 4.6에서는 Operator SDK v0.19.4를 지원합니다.
5.1.1. Operator란 무엇인가?
기본 Operator 개념 및 용어에 대한 개요는 Operator 이해를 참조하십시오.
5.1.2. 개발 워크플로
Operator SDK는 다음 워크플로를 제공하여 새 Operator를 개발합니다.
- Operator SDK CLI(명령줄 인터페이스)를 사용하여 Operator 프로젝트를 생성합니다.
- CRD(사용자 정의 리소스 정의)를 추가하여 새 리소스 API를 정의합니다.
- Operator SDK API를 사용하여 조사할 리소스를 지정합니다.
- 지정된 핸들러에서 Operator 조정 논리를 정의하고 Operator SDK API를 사용하여 리소스와 상호 작용합니다.
- Operator SDK CLI를 사용하여 Operator 배포 매니페스트를 빌드하고 생성합니다.
그림 5.1. Operator SDK 워크플로
Operator SDK를 사용하는 Operator는 Operator 작성자가 정의한 핸들러에서 조사하는 리소스에 대한 이벤트를 처리하고 애플리케이션 상태를 조정하는 작업을 수행합니다.
5.2. Operator SDK CLI 설치
Operator SDK는 Operator 개발자가 Operator를 빌드, 테스트, 배포하는 데 사용할 수 있는 CLI(명령줄 인터페이스) 툴을 제공합니다. 워크스테이션에 Operator SDK CLI를 설치하여 자체 Operator를 작성할 준비를 할 수 있습니다.
OpenShift Container Platform 4.6은 업스트림 소스에서 설치할 수 있는 Operator SDK v0.19.4를 지원합니다.
OpenShift Container Platform 4.7부터 Operator SDK는 완전히 지원되며 공식 Red Hat 제품 소스에서 사용할 수 있습니다. 자세한 내용은 OpenShift Container Platform 4.7 릴리스 노트 를 참조하십시오.
5.2.1. GitHub 릴리스에서 Operator SDK CLI 설치
GitHub의 프로젝트에서 Operator SDK CLI의 사전 빌드된 릴리스 바이너리를 다운로드하여 설치할 수 있습니다.
사전 요구 사항
- Go v1.13 이상
-
dockerv17.03 이상,podmanv1.9.3 이상 또는buildahv1.7 이상 -
OpenShift CLI (
oc) v4.6 이상이 설치됨 - Kubernetes v1.12.0+를 기반으로 클러스터에 액세스
- 컨테이너 레지스트리에 대한 액세스
프로세스
릴리스 버전 변수를 설정합니다.
$ RELEASE_VERSION=v0.19.4릴리스 바이너리를 다운로드합니다.
Linux의 경우:
$ curl -OJL https://github.com/operator-framework/operator-sdk/releases/download/${RELEASE_VERSION}/operator-sdk-${RELEASE_VERSION}-x86_64-linux-gnumacOS의 경우:
$ curl -OJL https://github.com/operator-framework/operator-sdk/releases/download/${RELEASE_VERSION}/operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin
다운로드한 릴리스 바이너리를 확인합니다.
제공된
.asc파일을 다운로드합니다.Linux의 경우:
$ curl -OJL https://github.com/operator-framework/operator-sdk/releases/download/${RELEASE_VERSION}/operator-sdk-${RELEASE_VERSION}-x86_64-linux-gnu.ascmacOS의 경우:
$ curl -OJL https://github.com/operator-framework/operator-sdk/releases/download/${RELEASE_VERSION}/operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin.asc
바이너리 및 해당
.asc파일을 동일한 디렉터리에 배치하고 다음 명령을 실행하여 바이너리를 확인합니다.Linux의 경우:
$ gpg --verify operator-sdk-${RELEASE_VERSION}-x86_64-linux-gnu.ascmacOS의 경우:
$ gpg --verify operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin.asc
워크스테이션에 관리자의 공개 키가 없는 경우 다음과 같은 오류가 발생합니다.
오류가 있는 출력 예
$ gpg: assuming signed data in 'operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin' $ gpg: Signature made Fri Apr 5 20:03:22 2019 CEST $ gpg: using RSA key <key_id>1 $ gpg: Can't check signature: No public key- 1
- RSA 키 문자열.
키를 다운로드하려면 다음 명령을 실행하여
<key_id>를 이전 명령의 출력에 제공된 RSA 키 문자열로 바꿉니다.$ gpg [--keyserver keys.gnupg.net] --recv-key "<key_id>"1 - 1
- 키 서버가 구성되지 않은 경우
--keyserver옵션을 사용하여 하나를 지정합니다.
PATH에 릴리스 바이너리를 설치합니다.Linux의 경우:
$ chmod +x operator-sdk-${RELEASE_VERSION}-x86_64-linux-gnu$ sudo cp operator-sdk-${RELEASE_VERSION}-x86_64-linux-gnu /usr/local/bin/operator-sdk$ rm operator-sdk-${RELEASE_VERSION}-x86_64-linux-gnumacOS의 경우:
$ chmod +x operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin$ sudo cp operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin /usr/local/bin/operator-sdk$ rm operator-sdk-${RELEASE_VERSION}-x86_64-apple-darwin
CLI 도구가 올바르게 설치되었는지 확인합니다.
$ operator-sdk version
5.2.2. Homebrew에서 Operator SDK CLI 설치
Homebrew를 사용하여 SDK CLI를 설치할 수 있습니다.
사전 요구 사항
- Homebrew
-
dockerv17.03 이상,podmanv1.9.3 이상 또는buildahv1.7 이상 -
OpenShift CLI (
oc) v4.6 이상이 설치됨 - Kubernetes v1.12.0+를 기반으로 클러스터에 액세스
- 컨테이너 레지스트리에 대한 액세스
프로세스
tag 명령을 사용하여 SDK CLI
를설치합니다.$ brew install operator-sdkCLI 도구가 올바르게 설치되었는지 확인합니다.
$ operator-sdk version
5.2.3. 소스에서 Operator SDK CLI 컴파일 및 설치
Operator SDK 소스 코드를 가져와 SDK CLI를 컴파일하고 설치할 수 있습니다.
사전 요구 사항
프로세스
operator-sdk리포지토리를 복제합니다.$ git clone https://github.com/operator-framework/operator-sdk복제된 리포지토리의 디렉터리로 변경합니다.
$ cd operator-sdkv0.19.4 릴리스를 확인합니다.
$ git checkout tags/v0.19.4 -b v0.19.4종속성을 업데이트합니다.
$ make tidySDK CLI를 컴파일하고 설치합니다.
$ make install그러면
$GOPATH/bin/디렉터리에 CLI 바이너리operator-sdk가 설치됩니다.CLI 도구가 올바르게 설치되었는지 확인합니다.
$ operator-sdk version
5.3. Go 기반 Operator 생성
Operator 개발자는 Operator SDK의 Go 프로그래밍 언어 지원을 활용하여 분산형 키-값 저장소인 Memcached에 대한 Go 기반 Operator 예제를 빌드하고 라이프사이클을 관리할 수 있습니다.
Kubebuilder 는 Go 기반 Operator의 스캐폴딩 솔루션으로 Operator SDK에 포함되어 있습니다.
5.3.1. Operator SDK를 사용하여 Go 기반 Operator 생성
Operator SDK를 사용하면 Kubernetes 네이티브 애플리케이션을 더 쉽게 빌드할 수 있으며 애플리케이션별 운영 지식이 필요할 수 있습니다. SDK는 이러한 장벽을 낮출 뿐만 아니라 미터링 또는 모니터링과 같은 많은 공통 관리 기능에 필요한 상용구 코드의 양을 줄이는 데 도움이 됩니다.
이 절차에서는 SDK에서 제공하는 툴과 라이브러리를 사용하여 간단한 Memcached Operator를 생성하는 예를 설명합니다.
사전 요구 사항
- 개발 워크스테이션에 Operator SDK v0.19.4 CLI가 설치되어 있습니다.
-
Kubernetes 기반 클러스터에 설치된 OLM(Operator Lifecycle Manager) (애플리케이션
/v1beta2API 그룹을 지원하기 위해 v1.8 이상) (예: OpenShift Container Platform 4.6 -
cluster
-admin 권한이 있는 계정을 사용하여 클러스터에대한 액세스 -
OpenShift CLI (
oc) v4.6 이상이 설치됨
절차
Operator 프로젝트를 생성합니다.
프로젝트에 사용할 디렉터리를 생성합니다.
$ mkdir -p $HOME/projects/memcached-operator디렉터리로 변경합니다.
$ cd $HOME/projects/memcached-operatorGo 모듈에 대한 지원을 활성화합니다.
$ export GO111MODULE=onoperator-sdk init명령을 실행하여 프로젝트를 초기화합니다.$ operator-sdk init \ --domain=example.com \ --repo=github.com/example-inc/memcached-operator참고operator-sdk init명령은 기본적으로go.kubebuilder.io/v2플러그인을 사용합니다.
지원되는 이미지를 사용하도록 Operator를 업데이트합니다.
프로젝트 루트 수준 Dockerfile에서 기본 러너 이미지 참조를 에서 변경합니다.
FROM gcr.io/distroless/static:nonroot다음으로 변경합니다.
FROM registry.access.redhat.com/ubi8/ubi-minimal:latest-
Go 프로젝트 버전에 따라 Dockerfile에
USER 65532:65532또는USER nonroot:nonroot지시문이 포함될 수 있습니다. 두 경우 모두 지원되는 실행기 이미지에 행이 필요하지 않으므로 행을 제거합니다. config/default/manager_auth_proxy_patch.yaml파일에서image값을 변경합니다.gcr.io/kubebuilder/kube-rbac-proxy:<tag>지원되는 이미지를 사용하려면 다음을 실행합니다.
registry.redhat.io/openshift4/ose-kube-rbac-proxy:v4.6
다음 행을 대체하여 이후 빌드 중에 필요한 종속성을 설치하도록 Makefile에서
테스트대상을 업데이트합니다.예 5.1. 기존
테스트대상test: generate fmt vet manifests go test ./... -coverprofile cover.out다음 행을 사용하여 다음을 수행합니다.
예 5.2. 업데이트된
테스트대상ENVTEST_ASSETS_DIR=$(shell pwd)/testbin test: manifests generate fmt vet ## Run tests. mkdir -p ${ENVTEST_ASSETS_DIR} test -f ${ENVTEST_ASSETS_DIR}/setup-envtest.sh || curl -sSLo ${ENVTEST_ASSETS_DIR}/setup-envtest.sh https://raw.githubusercontent.com/kubernetes-sigs/controller-runtime/v0.7.2/hack/setup-envtest.sh source ${ENVTEST_ASSETS_DIR}/setup-envtest.sh; fetch_envtest_tools $(ENVTEST_ASSETS_DIR); setup_envtest_env $(ENVTEST_ASSETS_DIR); go test ./... -coverprofile cover.outCRD(사용자 정의 리소스 정의) API 및 컨트롤러를 생성합니다.
다음 명령을 실행하여
캐시버전v1및 종류의Memcached그룹이 있는 API를 생성합니다.$ operator-sdk create api \ --group=cache \ --version=v1 \ --kind=Memcached메시지가 표시되면 리소스 및 컨트롤러 모두 생성하도록
y를 입력합니다.Create Resource [y/n] y Create Controller [y/n] y출력 예
Writing scaffold for you to edit... api/v1/memcached_types.go controllers/memcached_controller.go ...이 프로세스는
api/v1/memcached_types.go에 Memcached 리소스 API를 생성하고controllers/memcached_controller.go에 컨트롤러를 생성합니다.spec및status가 다음과 같도록api/v1/memcached_types.go에서 Go 유형 정의를 수정합니다.// MemcachedSpec defines the desired state of Memcached type MemcachedSpec struct { // +kubebuilder:validation:Minimum=0 // Size is the size of the memcached deployment Size int32 `json:"size"` } // MemcachedStatus defines the observed state of Memcached type MemcachedStatus struct { // Nodes are the names of the memcached pods Nodes []string `json:"nodes"` }+kubebuilder:subresource:status마커를 추가하여 CRD 매니페스트에status하위 리소스를 추가합니다.// Memcached is the Schema for the memcacheds API // +kubebuilder:subresource:status1 type Memcached struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty"` Spec MemcachedSpec `json:"spec,omitempty"` Status MemcachedStatus `json:"status,omitempty"` }- 1
- 이 행을 추가합니다.
그러면 컨트롤러에서 CR 오브젝트의 나머지 부분을 변경하지 않고도 CR 상태를 업데이트할 수 있습니다.
리소스 유형에 대해 생성된 코드를 업데이트합니다.
$ make generate작은 정보*_types.go파일을 수정한 후에는make generate명령을 실행하여 해당 리소스 유형에 대해 생성된 코드를 업데이트해야 합니다.위의 Makefile 대상은
controller-gen유틸리티를 호출하여api/v1/zz_generated.deepcopy.go파일을 업데이트합니다. 이렇게 하면 API Go 유형 정의에서 모든종류의유형에서 구현해야 하는runtime.Object인터페이스를 구현할 수 있습니다.
CRD 매니페스트를 생성하고 업데이트합니다.
$ make manifests이 Makefile 대상은
controller-gen유틸리티를 호출하여config/crd/bases/cache.example.com_memcacheds.yaml파일에서 CRD 매니페스트를 생성합니다.선택 사항: CRD에 사용자 지정 검증을 추가합니다.
매니페스트가 생성될 때
spec.validation블록의 CRD 매니페스트에 OpenAPI v3.0 스키마가 추가됩니다. 이 검증 블록을 사용하면 Kubernetes가 생성 또는 업데이트될 때MemcachedCR(사용자 정의 리소스)의 속성을 검증할 수 있습니다.Operator 작성자는 Kubebuilder 마커 라는 주석과 같은 단일 줄 주석을 사용하여 API에 대한 사용자 정의 검증을 구성할 수 있습니다. 이러한 마커에는 항상
+kubebuilder:validation접두사가 있어야 합니다. 예를 들어 열거형 사양을 추가하는 작업은 다음 마커를 추가하여 수행할 수 있습니다.// +kubebuilder:validation:Enum=Lion;Wolf;Dragon type Alias stringAPI 코드의 마커 사용은 Kubebuilder Generating CRD 및 Markers for Config/Code Generation 설명서에서 설명합니다. 전체 OpenAPIv3 검증 마커 목록은 Kubebuilder CRD 검증 설명서에서도 사용할 수 있습니다.
사용자 정의 검증을 추가하는 경우 다음 명령을 실행하여 CRD에 대한 OpenAPI 검증 섹션을 업데이트합니다.
$ make manifests
새 API 및 컨트롤러를 생성하면 컨트롤러 논리를 구현할 수 있습니다. 이 예제에서는 생성된 컨트롤러 파일
controllers/memcached_controller.go를 다음 예제 구현으로 교체합니다.예 5.3.
memcached_controller.go의 예/* Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */ package controllers import ( "context" "reflect" "github.com/go-logr/logr" appsv1 "k8s.io/api/apps/v1" corev1 "k8s.io/api/core/v1" "k8s.io/apimachinery/pkg/api/errors" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" "k8s.io/apimachinery/pkg/runtime" "k8s.io/apimachinery/pkg/types" ctrl "sigs.k8s.io/controller-runtime" "sigs.k8s.io/controller-runtime/pkg/client" cachev1 "github.com/example-inc/memcached-operator/api/v1" ) // MemcachedReconciler reconciles a Memcached object type MemcachedReconciler struct { client.Client Log logr.Logger Scheme *runtime.Scheme } // +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups=cache.example.com,resources=memcacheds/status,verbs=get;update;patch // +kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete // +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list; func (r *MemcachedReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) { ctx := context.Background() log := r.Log.WithValues("memcached", req.NamespacedName) // Fetch the Memcached instance memcached := &cachev1.Memcached{} err := r.Get(ctx, req.NamespacedName, memcached) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue log.Info("Memcached resource not found. Ignoring since object must be deleted") return ctrl.Result{}, nil } // Error reading the object - requeue the request. log.Error(err, "Failed to get Memcached") return ctrl.Result{}, err } // Check if the deployment already exists, if not create a new one found := &appsv1.Deployment{} err = r.Get(ctx, types.NamespacedName{Name: memcached.Name, Namespace: memcached.Namespace}, found) if err != nil && errors.IsNotFound(err) { // Define a new deployment dep := r.deploymentForMemcached(memcached) log.Info("Creating a new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name) err = r.Create(ctx, dep) if err != nil { log.Error(err, "Failed to create new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name) return ctrl.Result{}, err } // Deployment created successfully - return and requeue return ctrl.Result{Requeue: true}, nil } else if err != nil { log.Error(err, "Failed to get Deployment") return ctrl.Result{}, err } // Ensure the deployment size is the same as the spec size := memcached.Spec.Size if *found.Spec.Replicas != size { found.Spec.Replicas = &size err = r.Update(ctx, found) if err != nil { log.Error(err, "Failed to update Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name) return ctrl.Result{}, err } // Spec updated - return and requeue return ctrl.Result{Requeue: true}, nil } // Update the Memcached status with the pod names // List the pods for this memcached's deployment podList := &corev1.PodList{} listOpts := []client.ListOption{ client.InNamespace(memcached.Namespace), client.MatchingLabels(labelsForMemcached(memcached.Name)), } if err = r.List(ctx, podList, listOpts...); err != nil { log.Error(err, "Failed to list pods", "Memcached.Namespace", memcached.Namespace, "Memcached.Name", memcached.Name) return ctrl.Result{}, err } podNames := getPodNames(podList.Items) // Update status.Nodes if needed if !reflect.DeepEqual(podNames, memcached.Status.Nodes) { memcached.Status.Nodes = podNames err := r.Status().Update(ctx, memcached) if err != nil { log.Error(err, "Failed to update Memcached status") return ctrl.Result{}, err } } return ctrl.Result{}, nil } // deploymentForMemcached returns a memcached Deployment object func (r *MemcachedReconciler) deploymentForMemcached(m *cachev1.Memcached) *appsv1.Deployment { ls := labelsForMemcached(m.Name) replicas := m.Spec.Size dep := &appsv1.Deployment{ ObjectMeta: metav1.ObjectMeta{ Name: m.Name, Namespace: m.Namespace, }, Spec: appsv1.DeploymentSpec{ Replicas: &replicas, Selector: &metav1.LabelSelector{ MatchLabels: ls, }, Template: corev1.PodTemplateSpec{ ObjectMeta: metav1.ObjectMeta{ Labels: ls, }, Spec: corev1.PodSpec{ Containers: []corev1.Container{{ Image: "memcached:1.4.36-alpine", Name: "memcached", Command: []string{"memcached", "-m=64", "-o", "modern", "-v"}, Ports: []corev1.ContainerPort{{ ContainerPort: 11211, Name: "memcached", }}, }}, }, }, }, } // Set Memcached instance as the owner and controller ctrl.SetControllerReference(m, dep, r.Scheme) return dep } // labelsForMemcached returns the labels for selecting the resources // belonging to the given memcached CR name. func labelsForMemcached(name string) map[string]string { return map[string]string{"app": "memcached", "memcached_cr": name} } // getPodNames returns the pod names of the array of pods passed in func getPodNames(pods []corev1.Pod) []string { var podNames []string for _, pod := range pods { podNames = append(podNames, pod.Name) } return podNames } func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&cachev1.Memcached{}). Owns(&appsv1.Deployment{}). Complete(r) }예제 컨트롤러는 각
MemcachedCR에 대해 다음 조정 논리를 실행합니다.- Memcached 배포가 없는 경우 생성합니다.
-
배포 크기가
MemcachedCR 사양에 지정된 것과 같은지 확인합니다. -
MemcachedCR 상태를memcachedPod의 이름으로 업데이트합니다.
다음 두 하위 단계에서는 컨트롤러에서 리소스를 감시하는 방법과 조정 반복문이 트리거되는 방법을 검사합니다. 이러한 단계를 건너뛰어 Operator를 직접 빌드하고 실행할 수 있습니다.
controllers/memcached_controller.go파일에서 컨트롤러 구현을 검사하여 컨트롤러에서 리소스를 감시하는 방법을 확인합니다.SetupWithManager()함수는 해당 컨트롤러가 소유하고 관리하는 CR 및 기타 리소스를 조사하기 위해 컨트롤러가 빌드되는 방법을 지정합니다.예 5.4.
SetupWithManager()함수import ( ... appsv1 "k8s.io/api/apps/v1" ... ) func (r *MemcachedReconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr). For(&cachev1.Memcached{}). Owns(&appsv1.Deployment{}). Complete(r) }NewControllerManagedBy()에서는 다양한 컨트롤러 구성을 허용하는 컨트롤러 빌더를 제공합니다.For(&cachev1.Memcached{})는 조사할 기본 리소스로Memcached유형을 지정합니다.Memcached유형에 대한 각 추가, 업데이트 또는 삭제 이벤트의 경우 조정 반복문은 해당Memcached오브젝트의 조정Request인수(네임스페이스 및 이름 키로 구성됨)로 전송됩니다.Owns(&appsv1.Deployment{})는 조사할 보조 리소스로Deployment유형을 지정합니다. 이벤트 핸들러는Deployment유형, 즉 추가, 업데이트 또는 삭제 이벤트가 발생할 때마다 각 이벤트를 배포 소유자의 조정 요청에 매핑합니다. 이 경우 소유자는 배포가 생성된Memcached오브젝트입니다.모든 컨트롤러에는 조정 반복문을 구현하는
Reconcile()메서드가 포함된 조정기 오브젝트가 있습니다. 조정 반복문에는 캐시에서 기본 리소스 오브젝트인Memcached를 찾는 데 사용되는 네임스페이스 및 이름 키인Request인수가 전달됩니다.예 5.5. 조정 반복문
import ( ctrl "sigs.k8s.io/controller-runtime" cachev1 "github.com/example-inc/memcached-operator/api/v1" ... ) func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { // Lookup the Memcached instance for this reconcile request memcached := &cachev1.Memcached{} err := r.Get(ctx, req.NamespacedName, memcached) ... }Reconcile()함수의 반환 값에 따라 조정요청이다시 큐에 추가될 수 있으며 루프가 다시 트리거될 수 있습니다.예 5.6. 대기열 논리 재지정
// Reconcile successful - don't requeue return reconcile.Result{}, nil // Reconcile failed due to error - requeue return reconcile.Result{}, err // Requeue for any reason other than error return reconcile.Result{Requeue: true}, nil유예 기간 후 요청을 다시 큐에 추가하도록
Result.RequeueAfter를 설정할 수 있습니다.예 5.7. 유예 기간 후 다시 큐에 추가
import "time" // Reconcile for any reason other than an error after 5 seconds return ctrl.Result{RequeueAfter: time.Second*5}, nil참고주기적으로 CR을 조정하도록
RequeueAfter를 설정하여Result를 반환할 수 있습니다.조정기, 클라이언트, 리소스 이벤트와의 상호 작용에 대한 자세한 내용은 Controller Runtime Client API 설명서를 참조하십시오.
5.3.2. Operator 실행
Operator SDK CLI를 사용하여 Operator를 빌드하고 실행할 수 있는 방법은 두 가지가 있습니다.
- Go 프로그램으로 클러스터 외부에서 로컬로 실행합니다.
- 클러스터에서 배포로 실행합니다.
사전 요구 사항
5.3.2.1. 클러스터 외부에서 로컬로 실행
Operator 프로젝트를 클러스터 외부의 Go 프로그램으로 실행할 수 있습니다. 이 방법은 배포 및 테스트 속도를 높이기 위한 개발 목적에 유용합니다.
절차
다음 명령을 실행하여
~/.kube/config파일에 구성된 클러스터에 CRD(사용자 정의 리소스 정의)를 설치하고 Operator를 Go 프로그램으로 로컬에서 실행합니다.$ make install run예 5.8. 출력 예
... 2021-01-10T21:09:29.016-0700 INFO controller-runtime.metrics metrics server is starting to listen {"addr": ":8080"} 2021-01-10T21:09:29.017-0700 INFO setup starting manager 2021-01-10T21:09:29.017-0700 INFO controller-runtime.manager starting metrics server {"path": "/metrics"} 2021-01-10T21:09:29.018-0700 INFO controller-runtime.manager.controller.memcached Starting EventSource {"reconciler group": "cache.example.com", "reconciler kind": "Memcached", "source": "kind source: /, Kind="} 2021-01-10T21:09:29.218-0700 INFO controller-runtime.manager.controller.memcached Starting Controller {"reconciler group": "cache.example.com", "reconciler kind": "Memcached"} 2021-01-10T21:09:29.218-0700 INFO controller-runtime.manager.controller.memcached Starting workers {"reconciler group": "cache.example.com", "reconciler kind": "Memcached", "worker count": 1}
5.3.2.2. 배포로 실행
Go 기반 Operator 프로젝트를 생성한 후 클러스터 내에서 Operator를 빌드하고 실행할 수 있습니다.
절차
다음
make명령을 실행하여 Operator 이미지를 빌드하고 내보냅니다. 액세스할 수 있는 리포지토리를 참조하려면 다음 단계에서IMG인수를 수정합니다. Quay.io와 같은 리포지토리 사이트에 컨테이너를 저장하기 위해 계정을 받을 수 있습니다.이미지를 빌드합니다.
$ make docker-build IMG=<registry>/<user>/<image_name>:<tag>참고Operator에 대해 SDK에서 생성한 Dockerfile은
Go 빌드를 위해GOARCH=amd64를 명시적으로 참조합니다. 이는AMD64 이외의 아키텍처의 경우GOARCH=$CACHEGETARCH에 수정될 수 있습니다. Docker는 환경 변수를-platform에서 지정한 값으로 자동 설정합니다. Buildah를 사용하면-build-arg를 목적으로 사용해야 합니다. 자세한 내용은 여러 아키텍처를 참조하십시오.이미지를 리포지토리로 내보냅니다.
$ make docker-push IMG=<registry>/<user>/<image_name>:<tag>참고두 명령 모두 이미지의 이름과 태그(예:
IMG=<registry>/<user>/<image_name>:<tag>)를 Makefile에 설정할 수 있습니다. 기본 이미지 이름을 설정하려면IMG ?= controller:latest값을 수정합니다.
다음 명령을 실행하여 Operator를 배포합니다.
$ make deploy IMG=<registry>/<user>/<image_name>:<tag>기본적으로 이 명령은
<project_name>-system형식으로 된 Operator 프로젝트 이름을 사용하여 네임스페이스를 생성하고 배포에 사용됩니다. 이 명령은 또한config/rbac에서 RBAC 매니페스트를 설치합니다.Operator가 실행 중인지 확인합니다.
$ oc get deployment -n <project_name>-system출력 예
NAME READY UP-TO-DATE AVAILABLE AGE <project_name>-controller-manager 1/1 1 1 8m
5.3.3. 사용자 정의 리소스 생성
Operator가 설치되면 Operator에서 현재 클러스터에 제공하는 CR(사용자 정의 리소스)을 생성하여 Operator를 테스트할 수 있습니다.
사전 요구 사항
-
MemcachedCR을 제공하는 Memcached Operator의 예가 클러스터에 설치됨
프로세스
Operator가 설치된 네임스페이스로 변경합니다. 예를 들어
make deploy명령을 사용하여 Operator를 배포한 경우 다음을 실행합니다.$ oc project memcached-operator-system다음 사양을 포함하도록
config/samples/cache_v1_memcached.yaml의 샘플MemcachedCR 매니페스트를 편집합니다.apiVersion: cache.example.com/v1 kind: Memcached metadata: name: memcached-sample ... spec: ... size: 3CR을 생성합니다.
$ oc apply -f config/samples/cache_v1_memcached.yamlMemcachedOperator에서 샘플 CR에 대한 배포를 올바른 크기로 생성하는지 확인합니다.$ oc get deployments출력 예
NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 8m memcached-sample 3/3 3 3 1mPod 및 CR 상태를 확인하여 상태가 Memcached Pod 이름으로 업데이트되었는지 확인합니다.
Pod를 확인합니다.
$ oc get pods출력 예
NAME READY STATUS RESTARTS AGE memcached-sample-6fd7c98d8-7dqdr 1/1 Running 0 1m memcached-sample-6fd7c98d8-g5k7v 1/1 Running 0 1m memcached-sample-6fd7c98d8-m7vn7 1/1 Running 0 1mCR 상태 확인:
$ oc get memcached/memcached-sample -o yaml출력 예
apiVersion: cache.example.com/v1 kind: Memcached metadata: ... name: memcached-sample ... spec: size: 3 status: nodes: - memcached-sample-6fd7c98d8-7dqdr - memcached-sample-6fd7c98d8-g5k7v - memcached-sample-6fd7c98d8-m7vn7
배포 크기를 업데이트합니다.
config/samples/cache_v1_memcached.yaml파일을 업데이트하여MemcachedCR의spec.size필드를3에서5로 변경합니다.$ oc patch memcached memcached-sample \ -p '{"spec":{"size": 5}}' \ --type=mergeOperator에서 배포 크기를 변경하는지 확인합니다.
$ oc get deployments출력 예
NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 10m memcached-sample 5/5 5 5 3m
5.4. Ansible 기반 Operator 생성
이 가이드에서는 Operator SDK의 Ansible 지원을 간략하게 설명하고 Ansible 플레이북 및 모듈을 사용하는 operator-sdk CLI 툴을 사용하여 Ansible 기반 Operator를 빌드하고 실행하는 예제를 안내합니다.
5.4.1. Operator SDK의 Ansible 지원
Operator 프레임워크는 Operator라는 Kubernetes 네이티브 애플리케이션을 효율적이고 확장 가능하며 자동화된 방식으로 관리하는 오픈 소스 툴킷입니다. 이 프레임워크에는 개발자가 Kubernetes API 복잡성에 대한 지식이 없어도 전문 지식을 기반으로 Operator를 부트스트래핑하고 빌드할 수 있도록 지원하는 Operator SDK가 포함되어 있습니다.
Operator 프로젝트를 생성하기 위한 Operator SDK 옵션 중 하나는 Go 코드를 작성하지 않고도 기존 Ansible 플레이북 및 모듈을 활용하여 Kubernetes 리소스를 통합 애플리케이션으로 배포하는 것입니다.
5.4.1.1. 사용자 정의 리소스 파일
Operator는 Kubernetes 확장 메커니즘인 CRD(사용자 정의 리소스 정의)를 사용하므로 CR(사용자 정의 리소스)이 기본 제공되는 네이티브 Kubernetes 오브젝트처럼 보이고 작동합니다.
CR 파일 형식은 Kubernetes 리소스 파일입니다. 오브젝트에는 필수 및 선택적 필드가 있습니다.
| 필드 | 설명 |
|---|---|
|
| 생성할 CR의 버전입니다. |
|
| 생성할 CR의 종류입니다. |
|
| 생성할 Kubernetes별 메타데이터입니다. |
|
| Ansible에 전달되는 변수의 키-값 목록입니다. 이 필드는 기본적으로 비어 있습니다. |
|
|
오브젝트의 현재 상태를 요약합니다. Ansible 기반 Operator의 경우 CRD에 대해 |
|
| CR에 추가할 Kubernetes별 주석입니다. |
다음 CR 주석 목록은 Operator의 동작을 수정합니다.
| 주석 | 설명 |
|---|---|
|
|
CR 조정 간격을 지정합니다. 이 값은 표준 Golang 패키지 |
Ansible 기반 Operator 주석의 예
apiVersion: "test1.example.com/v1alpha1"
kind: "Test1"
metadata:
name: "example"
annotations:
ansible.operator-sdk/reconcile-period: "30s"5.4.1.2. watches.yaml 파일
GVK(그룹/버전/종류)는 Kubernetes API의 고유 ID입니다. watches.yaml 파일에는 GVK로 확인하는 CR(사용자 정의 리소스)에서 Ansible 역할 또는 플레이북으로의 매핑 목록이 포함됩니다. Operator는 이 매핑 파일이 미리 정의된 위치(/opt/ansible/watches.yaml)에 있을 것으로 예상합니다.
| 필드 | 설명 |
|---|---|
|
| 조사할 CR 그룹입니다. |
|
| 조사할 CR 버전입니다. |
|
| 조사할 CR의 종류입니다. |
|
|
컨테이너에 추가된 Ansible 역할의 경로입니다. 예를 들어 |
|
|
컨테이너에 추가된 Ansible 플레이북의 경로입니다. 이 플레이북은 역할을 호출하는 방법이 될 것으로 예상됩니다. 이 필드는 |
|
| 지정된 CR에 대한 조정 간격, 즉 역할 또는 플레이북이 실행되는 간격입니다. |
|
|
|
watches.yaml 파일의 예
- version: v1alpha1
group: test1.example.com
kind: Test1
role: /opt/ansible/roles/Test1
- version: v1alpha1
group: test2.example.com
kind: Test2
playbook: /opt/ansible/playbook.yml
- version: v1alpha1
group: test3.example.com
kind: Test3
playbook: /opt/ansible/test3.yml
reconcilePeriod: 0
manageStatus: false5.4.1.2.1. 고급 옵션
GVK별 watches.yaml 파일에 고급 기능을 추가하여 사용할 수 있습니다. 해당 기능은 group, version, kind, playbook 또는 role 필드로 이동할 수 있습니다.
일부 기능은 해당 CR의 주석을 사용하여 리소스별로 덮어쓸 수 있습니다. 덮어쓸 수 있는 옵션에는 아래에 지정된 주석이 있습니다.
| 기능 | YAML 키 | 설명 | 덮어쓸 주석 | 기본값 |
|---|---|---|---|---|
| 기간 조정 |
| 특정 CR에 대한 조정 실행 간격입니다. |
|
|
| 상태 관리 |
|
Operator에서 각 CR |
| |
| 종속 리소스 조사 |
| Operator에서 Ansible을 통해 생성한 리소스를 동적으로 조사할 수 있습니다. |
| |
| 클러스터 범위 리소스 조사 |
| Operator에서 Ansible을 통해 생성한 클러스터 범위 리소스를 조사할 수 있습니다. |
| |
| 최대 실행기 아티팩트 수 |
| Ansible Runner에서 각 개별 리소스에 대해 Operator 컨테이너에 보관하는 아티팩트 디렉터리의 수를 관리합니다. |
|
|
고급 옵션이 있는 watches.yml 파일의 예
- version: v1alpha1
group: app.example.com
kind: AppService
playbook: /opt/ansible/playbook.yml
maxRunnerArtifacts: 30
reconcilePeriod: 5s
manageStatus: False
watchDependentResources: False5.4.1.3. Ansible로 전송된 추가 변수
추가 변수는 Ansible로 보낸 다음 Operator에서 관리할 수 있습니다. CR(사용자 정의 리소스)의 spec 섹션은 키-값 쌍을 추가 변수로 전달합니다. 이는 ansible-playbook 명령에 전달된 추가 변수와 동일합니다.
또한 Operator는 CR 이름 및 CR 네임스페이스에 대한 meta 필드에 추가 변수를 전달합니다.
다음 CR 예제의 경우
apiVersion: "app.example.com/v1alpha1"
kind: "Database"
metadata:
name: "example"
spec:
message: "Hello world 2"
newParameter: "newParam"Ansible에 추가 변수로 전달되는 구조는 다음과 같습니다.
{ "meta": {
"name": "<cr_name>",
"namespace": "<cr_namespace>",
},
"message": "Hello world 2",
"new_parameter": "newParam",
"_app_example_com_database": {
<full_crd>
},
}
message 및 newParameter 필드는 최상위 레벨에서 추가 변수로 설정되며, meta는 Operator에 정의된 CR에 대한 관련 메타데이터를 제공합니다. meta 필드는 Ansible의 점 표기법을 사용하여 액세스할 수 있습니다. 예를 들면 다음과 같습니다.
- debug:
msg: "name: {{ meta.name }}, {{ meta.namespace }}"5.4.1.4. Ansible Runner 디렉터리
Ansible Runner는 컨테이너에서 실행되는 Ansible에 대한 정보를 보관합니다. 해당 정보는 /tmp/ansible-operator/runner/<group>/<version>/<kind>/<namespace>/<name>에 있습니다.
5.4.2. Operator SDK를 사용하여 Ansible 기반 Operator 빌드
이 절차에서는 Operator SDK에서 제공하는 툴 및 라이브러리를 사용하여 Ansible 플레이북 및 모듈에서 제공하는 간단한 Memcached Operator를 구축하는 예제를 설명합니다.
사전 요구 사항
- 개발 워크스테이션에 Operator SDK v0.19.4 CLI가 설치되어 있습니다.
-
cluster
-admin권한이 있는 계정을 사용하여 Kubernetes 기반 클러스터 v1.11.3 이상(예: OpenShift Container Platform 4.6)에 대한 액세스 -
OpenShift CLI (
oc) v4.6 이상이 설치됨 -
ansiblev2.9.0+ -
ansible-runnerv1.1.0+ -
ansible-runner-httpv1.0.0+
프로세스
새 Operator 프로젝트를 생성합니다. 네임스페이스 범위의 Operator는 단일 네임스페이스에서 리소스를 감시하고 관리합니다. 유연성으로 인해 네임스페이스 범위의 Operator가 선호됩니다. 이를 통해 분리된 업그레이드, 장애 및 모니터링을 위한 네임스페이스 격리, 다양한 API 정의를 사용할 수 있습니다.
새 Ansible 기반 네임스페이스 범위의
memcached-operator프로젝트를 생성하고 새 디렉터리로 변경하려면 다음 명령을 사용합니다.$ operator-sdk new memcached-operator \ --api-version=cache.example.com/v1alpha1 \ --kind=Memcached \ --type=ansible$ cd memcached-operator이렇게 하면 API 버전
example.com/v1apha1및 종류Memcached가 있는 Memcached리소스를 조사하기 위해memcached-operator프로젝트가 생성됩니다.Operator 논리를 사용자 지정합니다.
이 예에서는
memcached-operator에서 각MemcachedCR(사용자 정의 리소스)에 대해 다음 조정 논리를 실행합니다.-
memcached배포가 없는 경우 해당 배포를 생성합니다. -
배포 크기가
MemcachedCR에서 지정한 것과 같은지 확인합니다.
기본적으로
memcached-operator는watches.yaml파일에 표시된 대로Memcached리소스 이벤트를 감시하고 Ansible 역할Memcached를 실행합니다.- version: v1alpha1 group: cache.example.com kind: Memcached선택적으로
watches.yaml 파일에서 다음 논리를 사용자 지정할 수 있습니다.역할옵션을 지정하면 Ansible 역할로ansible-runner를 시작할 때 이 지정된 경로를 사용하도록 Operator가 구성됩니다. 기본적으로operator-sdk new명령은 역할이 이동해야 하는 절대 경로를 채웁니다.- version: v1alpha1 group: cache.example.com kind: Memcached role: /opt/ansible/roles/memcachedwatches.yaml파일에서플레이북옵션을 지정하면 Ansible 플레이북으로ansible-runner를 시작할 때 이 지정된 경로를 사용하도록 Operator가 구성됩니다.- version: v1alpha1 group: cache.example.com kind: Memcached playbook: /opt/ansible/playbook.yaml
-
Memcached Ansible 역할을 빌드합니다.
roles/memcached/디렉터리에서 생성된 Ansible 역할을 수정합니다. 이 Ansible 역할은 리소스를 수정할 때 실행되는 논리를 제어합니다.Memcached사양을 정의합니다.Ansible 기반 Operator에 대한 사양 정의는 Ansible에서 완전히 수행할 수 있습니다. Ansible Operator는 CR 사양 필드에 나열된 모든 키-값 쌍을 Ansible에 변수로 전달합니다. spec 필드에 있는 모든 변수의 이름은 Ansible을 실행하기 전에 Operator에서 snake 케이스(하위 코어의 소문자)로 변환됩니다. 예를 들어 사양의
serviceAccount는 Ansible에서service_account로 변환됩니다.작은 정보애플리케이션에 예상되는 입력을 수신하려면 변수에 대해 Ansible에서 일부 유형 검증을 수행해야 합니다.
사용자가
spec필드를 설정하지 않는 경우roles/memcached/defaults/main.yml 파일을 수정하여 기본값을 설정합니다.size: 1Memcached배포를 정의합니다.Memcached사양을 정의하면 리소스 변경 시 Ansible이 실제로 실행되는 것을 정의할 수 있습니다. Ansible 역할이므로 기본 동작은roles/memcached/tasks/main.yml파일의 작업을 실행합니다.목표는
memcached:1.4.36-alpine이미지를 실행하는 경우 Ansible에서 배포를 생성하는 것입니다. Ansible 2.7+는 배포 정의를 제어하는 데 이 예제를 활용하는 k8s Ansible 모듈을 지원합니다.roles/memcached/tasks/main.yml을 다음과 일치하도록 수정합니다.- name: start memcached k8s: definition: kind: Deployment apiVersion: apps/v1 metadata: name: '{{ meta.name }}-memcached' namespace: '{{ meta.namespace }}' spec: replicas: "{{size}}" selector: matchLabels: app: memcached template: metadata: labels: app: memcached spec: containers: - name: memcached command: - memcached - -m=64 - -o - modern - -v image: "docker.io/memcached:1.4.36-alpine" ports: - containerPort: 11211참고이 예제에서는
size변수를 사용하여Memcached배포의 복제본 수를 제어합니다. 이 예제에서는 기본값을1로 설정하지만 모든 사용자는 기본값을 덮어쓰는 CR을 생성할 수 있습니다.
CRD를 배포합니다.
Operator를 실행하기 전에 Kubernetes는 Operator가 모니터링할 새 CRD(사용자 정의 리소스 정의)를 알아야 합니다.
MemcachedCRD를 배포합니다.$ oc create -f deploy/crds/cache.example.com_memcacheds_crd.yamlOperator를 빌드하고 실행합니다.
Operator를 빌드하고 실행하는 방법은 다음 두 가지가 있습니다.
- Kubernetes 클러스터 내부의 포드로 사용됩니다.
-
operator-sdk up명령을 사용하여 클러스터 외부의 Go 프로그램으로.
다음 방법 중 하나를 선택합니다.
Kubernetes 클러스터 내에서 포드로 실행합니다. 이 방법이 프로덕션에 사용하는 데 선호되는 방법입니다.
memcached-operator이미지를 빌드하여 레지스트리로 내보냅니다.$ operator-sdk build quay.io/example/memcached-operator:v0.0.1$ podman push quay.io/example/memcached-operator:v0.0.1배포 매니페스트는
deploy/operator.yaml파일에 생성됩니다. 이 파일의 배포 이미지는 플레이스 홀더REPLACE_IMAGE에서 이전 빌드 이미지로 수정해야 합니다. 이를 수행하려면 다음을 실행합니다.$ sed -i 's|REPLACE_IMAGE|quay.io/example/memcached-operator:v0.0.1|g' deploy/operator.yamlmemcached-operator매니페스트를 배포합니다.$ oc create -f deploy/service_account.yaml$ oc create -f deploy/role.yaml$ oc create -f deploy/role_binding.yaml$ oc create -f deploy/operator.yamlmemcached-operator배포가 시작되어 실행 중인지 확인합니다.$ oc get deploymentNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE memcached-operator 1 1 1 1 1m
클러스터 외부에서 실행합니다. 이 방법은 배포 및 테스트 속도를 높이기 위해 개발 주기 동안 선호됩니다.
Ansible Runner 및 Ansible Runner HTTP 플러그인이 설치되어 있는지 확인합니다. 그렇지 않으면 CR이 생성될 때 Ansible Runner에서 예기치 않은 오류가 발생합니다.
또한
watches.yaml파일에서 참조되는 역할 경로가 시스템에 있어야 합니다. 일반적으로 컨테이너가 디스크에 배치되는 위치이므로 이 역할을 구성된 Ansible 역할 경로(예:/etc/ansible/roles)에 수동으로 복사해야 합니다.$HOME/.kube/config에 있는 기본 Kubernetes 구성 파일을 사용하여 Operator를 로컬로 실행하려면 다음을 수행합니다.$ operator-sdk run --local제공된 Kubernetes 구성 파일을 사용하여 Operator를 로컬로 실행하려면 다음을 수행합니다.
$ operator-sdk run --local --kubeconfig=config
MemcachedCR을 생성합니다.표시된 대로
deploy/crds/cache_v1alpha1_memcached_cr.yaml파일을 수정하고MemcachedCR을 생성합니다.$ cat deploy/crds/cache_v1alpha1_memcached_cr.yaml출력 예
apiVersion: "cache.example.com/v1alpha1" kind: "Memcached" metadata: name: "example-memcached" spec: size: 3$ oc apply -f deploy/crds/cache_v1alpha1_memcached_cr.yamlmemcached-operator가 CR에 대한 배포를 생성하는지 확인합니다.$ oc get deployment출력 예
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE memcached-operator 1 1 1 1 2m example-memcached 3 3 3 3 1mPod에서 세 개의 복제본이 생성되었는지 확인합니다.
$ oc get podsNAME READY STATUS RESTARTS AGE example-memcached-6fd7c98d8-7dqdr 1/1 Running 0 1m example-memcached-6fd7c98d8-g5k7v 1/1 Running 0 1m example-memcached-6fd7c98d8-m7vn7 1/1 Running 0 1m memcached-operator-7cc7cfdf86-vvjqk 1/1 Running 0 2m
크기를 업데이트합니다.
memcachedCR의spec.size필드를3에서4로 변경하고 변경 사항을 적용합니다.$ cat deploy/crds/cache_v1alpha1_memcached_cr.yaml출력 예
apiVersion: "cache.example.com/v1alpha1" kind: "Memcached" metadata: name: "example-memcached" spec: size: 4$ oc apply -f deploy/crds/cache_v1alpha1_memcached_cr.yamlOperator에서 배포 크기를 변경하는지 확인합니다.
$ oc get deployment출력 예
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE example-memcached 4 4 4 4 5m
리소스를 정리합니다.
$ oc delete -f deploy/crds/cache_v1alpha1_memcached_cr.yaml$ oc delete -f deploy/operator.yaml$ oc delete -f deploy/role_binding.yaml$ oc delete -f deploy/role.yaml$ oc delete -f deploy/service_account.yaml$ oc delete -f deploy/crds/cache_v1alpha1_memcached_crd.yaml
5.4.3. k8s Ansible 모듈을 사용하여 애플리케이션 라이프사이클 관리
Ansible을 사용하여 Kubernetes에서 애플리케이션의 라이프사이클을 관리하려면 k8s Ansible 모듈을 사용할 수 있습니다. 이 Ansible 모듈을 사용하면 개발자가 기존 Kubernetes 리소스 파일(YAML으로 작성된)을 활용하거나 기본 Ansible에서 라이프사이클 관리를 표시할 수 있습니다.
기존 Kubernetes 리소스 파일과 함께 Ansible을 사용할 때의 가장 큰 이점 중 하나는 Jinja 템플릿을 사용할 수 있다는 점입니다. 그러면 Ansible의 몇 가지 간단한 변수를 사용하여 리소스를 사용자 정의할 수 있습니다.
이 섹션에서는 k8s Ansible 모듈 사용에 대해 자세히 설명합니다. 시작하려면 로컬 워크스테이션에 모듈을 설치하고 플레이북을 사용하여 테스트한 후 Operator 내에서 사용하십시오.
5.4.3.1. k8s Ansible 모듈 설치
로컬 워크스테이션에 k8s Ansible 모듈을 설치하려면 다음을 수행합니다.
프로세스
Ansible 2.9 이상을 설치합니다.
$ sudo yum install ansiblepip를 사용하여 OpenShift python 클라이언트 패키지를 설치합니다.$ sudo pip install openshift$ sudo pip install kubernetes
5.4.3.2. k8s Ansible 모듈 로컬 테스트
경우에 따라 개발자가 매번 Operator를 실행하고 다시 빌드하는 대신 로컬 시스템에서 Ansible 코드를 실행하는 것이 좋습니다.
프로세스
community.kubernetes컬렉션을 설치합니다.$ ansible-galaxy collection install community.kubernetes새 Ansible 기반 Operator 프로젝트를 초기화합니다.
$ operator-sdk new --type ansible \ --kind Test1 \ --api-version test1.example.com/v1alpha1 test1-operator출력 예
Create test1-operator/tmp/init/galaxy-init.sh Create test1-operator/tmp/build/Dockerfile Create test1-operator/tmp/build/test-framework/Dockerfile Create test1-operator/tmp/build/go-test.sh Rendering Ansible Galaxy role [test1-operator/roles/test1]... Cleaning up test1-operator/tmp/init Create test1-operator/watches.yaml Create test1-operator/deploy/rbac.yaml Create test1-operator/deploy/crd.yaml Create test1-operator/deploy/cr.yaml Create test1-operator/deploy/operator.yaml Run git init ... Initialized empty Git repository in /home/user/go/src/github.com/user/opsdk/test1-operator/.git/ Run git init done$ cd test1-operator원하는 Ansible 논리로
roles/test1/tasks/main.yml파일을 수정합니다. 이 예제에서는 변수의 스위치로 네임스페이스를 생성하고 삭제합니다.- name: set test namespace to "{{ state }}" community.kubernetes.k8s: api_version: v1 kind: Namespace state: "{{ state }}" name: test ignore_errors: true1 - 1
ignore_errors: true를 설정하면 존재하지 않는 프로젝트를 삭제하는 데 실패하지 않습니다.
roles/test1/defaults/main.yml파일을 수정하여state를 기본적으로present로 설정합니다.state: presenttest1역할을 포함하는 최상위 디렉터리에 Ansible플레이북 playbook.yml을 생성합니다.- hosts: localhost roles: - test1플레이북을 실행합니다.
$ ansible-playbook playbook.yml출력 예
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match 'all' PLAY [localhost] *************************************************************************** PROCEDURE [Gathering Facts] ********************************************************************* ok: [localhost] Task [test1 : set test namespace to present] changed: [localhost] PLAY RECAP ********************************************************************************* localhost : ok=2 changed=1 unreachable=0 failed=0네임스페이스가 생성되었는지 확인합니다.
$ oc get namespace출력 예
NAME STATUS AGE default Active 28d kube-public Active 28d kube-system Active 28d test Active 3sstate를absent로 설정하여 플레이북을 재실행합니다.$ ansible-playbook playbook.yml --extra-vars state=absent출력 예
[WARNING]: provided hosts list is empty, only localhost is available. Note that the implicit localhost does not match 'all' PLAY [localhost] *************************************************************************** PROCEDURE [Gathering Facts] ********************************************************************* ok: [localhost] Task [test1 : set test namespace to absent] changed: [localhost] PLAY RECAP ********************************************************************************* localhost : ok=2 changed=1 unreachable=0 failed=0네임스페이스가 삭제되었는지 확인합니다.
$ oc get namespace출력 예
NAME STATUS AGE default Active 28d kube-public Active 28d kube-system Active 28d
5.4.3.3. Operator 내에서 k8s Ansible 모듈 테스트
로컬에서 k8s Ansible 모듈을 사용하는 방법을 익히면 CR(사용자 정의 리소스)이 변경될 때 Operator 내부에서 동일한 Ansible 논리를 트리거할 수 있습니다. 이 예제에서는 Operator에서 조사하는 특정 Kubernetes 리소스에 Ansible 역할을 매핑합니다. 이 매핑은 watches.yaml 파일에서 수행됩니다.
5.4.3.3.1. Ansible 기반 Operator를 로컬에서 테스트
Ansible 워크플로를 로컬에서 테스트한 후 로컬에서 실행되는 Ansible 기반 Operator 내부의 논리를 테스트할 수 있습니다.
이를 위해 Operator 프로젝트의 최상위 디렉터리에서 operator-sdk run --local 명령을 사용합니다. 이 명령은 watches.yaml 파일에서 읽고 ~/.kube/config 파일을 사용하여 k8s Ansible 모듈처럼 Kubernetes 클러스터와 통신합니다.
절차
run --local명령은watches.yaml파일에서 읽기 때문에 Operator 작성자가 사용할 수 있는 옵션이 있습니다.역할이단독으로 남아 있는 경우(기본적으로/opt/ansible/roles/<name>) Operator의/opt/ansible/roles/디렉터리에 역할을 복사해야 합니다.이는 변경 사항이 현재 디렉터리에서 반영되지 않기 때문에 번거로울 수 있습니다. 대신 현재 디렉터리를 가리키도록
역할필드를 변경하고 기존 행을 주석 처리합니다.- version: v1alpha1 group: test1.example.com kind: Test1 # role: /opt/ansible/roles/Test1 role: /home/user/test1-operator/Test1CR(사용자 정의 리소스)
Test1에 대한 CRD(사용자 정의 리소스 정의) 및 적절한 RBAC(역할 기반 액세스 제어) 정의를 생성합니다.operator-sdk명령은deploy/디렉토리 내에서 이러한 파일을 자동으로 생성합니다.$ oc create -f deploy/crds/test1_v1alpha1_test1_crd.yaml$ oc create -f deploy/service_account.yaml$ oc create -f deploy/role.yaml$ oc create -f deploy/role_binding.yamlrun --local명령을 실행합니다.$ operator-sdk run --local출력 예
[...] INFO[0000] Starting to serve on 127.0.0.1:8888 INFO[0000] Watching test1.example.com/v1alpha1, Test1, defaultOperator에서 이벤트의 리소스
Test1을 모니터링하므로 CR을 생성하면 실행할 Ansible 역할이 트리거됩니다.deploy/cr.yaml파일을 확인합니다.apiVersion: "test1.example.com/v1alpha1" kind: "Test1" metadata: name: "example"spec필드가 설정되지 않았기 때문에 추가 변수 없이 Ansible이 호출됩니다. 다음 섹션에서는 CR에서 Ansible로 추가 변수를 전달하는 방법을 설명합니다. 따라서 Operator에 적절한 기본값을 설정하는 것이 중요합니다.기본 변수
state를present로 설정하여Test1의 CR 인스턴스를 생성합니다.$ oc create -f deploy/cr.yaml네임스페이스
테스트가생성되었는지 확인합니다.$ oc get namespace출력 예
NAME STATUS AGE default Active 28d kube-public Active 28d kube-system Active 28d test Active 3sdeploy/cr.yaml파일을 수정하여state필드를absent로 설정합니다.apiVersion: "test1.example.com/v1alpha1" kind: "Test1" metadata: name: "example" spec: state: "absent"변경 사항을 적용하고 네임스페이스가 삭제되었는지 확인합니다.
$ oc apply -f deploy/cr.yaml$ oc get namespace출력 예
NAME STATUS AGE default Active 28d kube-public Active 28d kube-system Active 28d
5.4.3.3.2. 클러스터에서 Ansible 기반 Operator 테스트
Ansible 기반 Operator 내부에서 로컬로 Ansible 논리를 실행하는 방법을 익히면 OpenShift Container Platform과 같은 Kubernetes 클러스터의 Pod 내부에서 Operator를 테스트할 수 있습니다. 프로덕션 환경에서는 클러스터에서 포드로 실행하는 것이 좋습니다.
절차
test1-operator이미지를 빌드하여 레지스트리로 내보냅니다.$ operator-sdk build quay.io/example/test1-operator:v0.0.1$ podman push quay.io/example/test1-operator:v0.0.1배포 매니페스트는
deploy/operator.yaml파일에 생성됩니다. 이 파일의 배포 이미지는 플레이스 홀더REPLACE_IMAGE에서 이전에 빌드된 이미지로 수정해야 합니다. 이를 수행하려면 다음 명령을 실행합니다.$ sed -i 's|REPLACE_IMAGE|quay.io/example/test1-operator:v0.0.1|g' deploy/operator.yamlmacOS에서 이러한 단계를 수행하는 경우 대신 다음 명령을 사용합니다.
$ sed -i "" 's|REPLACE_IMAGE|quay.io/example/test1-operator:v0.0.1|g' deploy/operator.yamltest1-operator를 배포합니다.$ oc create -f deploy/crds/test1_v1alpha1_test1_crd.yaml1 - 1
- CRD가 아직 없는 경우에만 필요합니다.
$ oc create -f deploy/service_account.yaml$ oc create -f deploy/role.yaml$ oc create -f deploy/role_binding.yaml$ oc create -f deploy/operator.yamltest1-operator가 실행 중인지 확인합니다.$ oc get deployment출력 예
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE test1-operator 1 1 1 1 1m이제
test1-operator에 대한 Ansible 로그를 볼 수 있습니다.$ oc logs deployment/test1-operator
5.4.4. operator_sdk.util Ansible 컬렉션을 사용하여 사용자 정의 리소스 상태 관리
Ansible 기반 Operator는 이전 Ansible 실행에 대한 일반적인 정보를 사용하여 CR(사용자 정의 리소스) status 하위 리소스를 자동으로 업데이트합니다. 여기에는 다음과 같이 성공 및 실패한 작업의 수와 관련 오류 메시지가 포함됩니다.
status:
conditions:
- ansibleResult:
changed: 3
completion: 2018-12-03T13:45:57.13329
failures: 1
ok: 6
skipped: 0
lastTransitionTime: 2018-12-03T13:45:57Z
message: 'Status code was -1 and not [200]: Request failed: <urlopen error [Errno
113] No route to host>'
reason: Failed
status: "True"
type: Failure
- lastTransitionTime: 2018-12-03T13:46:13Z
message: Running reconciliation
reason: Running
status: "True"
type: Running
Ansible 기반 Operator를 사용하면 Operator 작성자가 operator_sdk.util 컬렉션에 포함된 k8s_status Ansible 모듈로 사용자 정의 상태 값을 제공할 수 있습니다. 그러면 작성자는 원하는 키-값 쌍을 사용하여 Ansible 내에서 status를 업데이트할 수 있습니다.
기본적으로 Ansible 기반 Operator에는 항상 위에 표시된 것처럼 일반 Ansible 실행 출력이 포함됩니다. 애플리케이션에서 Ansible 출력을 통해 상태를 업데이트하지 않도록 하려면 애플리케이션에서 수동으로 상태를 추적하면 됩니다.
절차
애플리케이션에서 CR 상태를 수동으로 추적하려면
manageStatus필드를false로 설정하여watches.yaml파일을 업데이트합니다.- version: v1 group: api.example.com kind: Test1 role: Test1 manageStatus: falseoperator_sdk.util.k8s_statusAnsible 모듈을 사용하여 하위 리소스를 업데이트합니다. 예를 들어test1 및 test2값을 사용하여 업데이트하려면operator_sdk.util을 다음과 같이 사용할 수 있습니다.- operator_sdk.util.k8s_status: api_version: app.example.com/v1 kind: Test1 name: "{{ meta.name }}" namespace: "{{ meta.namespace }}" status: test1: test2새 Ansible Operator에 포함된 역할의
meta/main.yml에서도 컬렉션을 선언할 수 있습니다.collections: - operator_sdk.util역할 메타에 컬렉션을 선언하면
k8s_status모듈을 직접 호출할 수 있습니다.k8s_status: <snip> status: test1: test2
5.5. Helm 기반 Operator 생성
이 가이드에서는 Operator SDK의 Helm 차트 지원을 간략하게 설명하고 기존 Helm 차트를 사용하는 operator-sdk CLI 툴을 사용하여 Nginx Operator를 빌드하고 실행하는 예를 보여줍니다.
5.5.1. Operator SDK의 Helm 차트 지원
Operator 프레임워크는 Operator라는 Kubernetes 네이티브 애플리케이션을 효율적이고 확장 가능하며 자동화된 방식으로 관리하는 오픈 소스 툴킷입니다. 이 프레임워크에는 개발자가 Kubernetes API 복잡성에 대한 지식이 없어도 전문 지식을 기반으로 Operator를 부트스트래핑하고 빌드할 수 있도록 지원하는 Operator SDK가 포함되어 있습니다.
Operator 프로젝트를 생성하기 위한 Operator SDK 옵션 중 하나는 Go 코드를 작성하지 않고 Kubernetes 리소스를 통합 애플리케이션으로 배포하기 위해 기존 Helm 차트를 활용하는 것입니다. 이러한 Helm 기반 Operator는 차트의 일부로 생성되는 Kubernetes 오브젝트에 변경 사항을 적용해야 하기 때문에 롤아웃 시 논리가 거의 필요하지 않은 상태 비저장 애플리케이션에서 잘 작동하도록 설계되었습니다. 이는 제한적으로 들릴 수 있지만 Kubernetes 커뮤니티에서 빌드한 Helm 차트의 확산으로 알 수 있듯이 대용량 사용 사례에도 충분할 수 있습니다.
Operator의 주요 기능은 애플리케이션 인스턴스를 표시하는 사용자 정의 오브젝트에서 읽고 원하는 상태가 실행 중인 것과 일치하도록 하는 것입니다. Helm 기반 Operator의 경우 오브젝트의 spec 필드는 일반적으로 Helm values.yaml 파일에 설명된 구성 옵션의 목록입니다. Helm CLI(예: helm install -f values.yaml)를 사용하여 이러한 값을 플래그로 설정하는 대신 CR(사용자 정의 리소스) 내에 표시할 수 있습니다. 그러면 네이티브 Kubernetes 개체로서 여기에 적용된 RBAC 및 감사 추적의 이점을 활용할 수 있습니다.
Tomcat이라는 간단한 CR 예제를 살펴보겠습니다.
apiVersion: apache.org/v1alpha1
kind: Tomcat
metadata:
name: example-app
spec:
replicaCount: 2
이 경우 replicaCount 값인 2가 다음이 사용되는 차트의 템플릿으로 전파됩니다.
{{ .Values.replicaCount }}
Operator를 빌드하고 배포한 후에는 CR 인스턴스를 새로 생성하여 앱의 새 인스턴스를 배포하거나 oc 명령을 사용하여 모든 환경에서 실행 중인 다른 인스턴스를 나열할 수 있습니다.
$ oc get Tomcats --all-namespacesHelm CLI를 사용하거나 Tiller를 설치할 필요가 없습니다. Helm 기반 Operator는 Helm 프로젝트에서 코드를 가져옵니다. Operator의 인스턴스를 실행하고 CRD(사용자 정의 리소스 정의)를 사용하여 CR을 등록하기만 하면 됩니다. RBAC를 준수하기 때문에 프로덕션이 변경되는 것을 더 쉽게 방지할 수 있습니다.
5.5.2. Operator SDK를 사용하여 Helm 기반 Operator 빌드
이 절차에서는 Operator SDK에서 제공하는 툴 및 라이브러리를 사용하여 Helm 차트에 의해 구동되는 간단한 Nginx Operator를 빌드하는 예를 설명합니다.
각 차트에 대해 새 Operator를 빌드하는 것이 좋습니다. 이를 통해 Go에 완전히 확장된 Operator를 작성하여 Helm 기반 Operator에서 마이그레이션하려는 경우 더 많은 기본 제공 Kubernetes API(예: oc get Nginx) 및 유연성을 허용할 수 있습니다.
사전 요구 사항
- 개발 워크스테이션에 Operator SDK v0.19.4 CLI가 설치되어 있습니다.
-
cluster
-admin권한이 있는 계정을 사용하여 Kubernetes 기반 클러스터 v1.11.3 이상(예: OpenShift Container Platform 4.6)에 대한 액세스 -
OpenShift CLI (
oc) v4.6 이상이 설치됨
절차
새 Operator 프로젝트를 생성합니다. 네임스페이스 범위의 Operator는 단일 네임스페이스에서 리소스를 감시하고 관리합니다. 유연성으로 인해 네임스페이스 범위의 Operator가 선호됩니다. 이를 통해 분리된 업그레이드, 장애 및 모니터링을 위한 네임스페이스 격리, 다양한 API 정의를 사용할 수 있습니다.
새 Helm 기반 네임스페이스 범위
nginx-operator프로젝트를 생성하려면 다음 명령을 사용합니다.$ operator-sdk new nginx-operator \ --api-version=example.com/v1alpha1 \ --kind=Nginx \ --type=helm$ cd nginx-operator그러면 API 버전
example.com/v1apha1및 종류 Nginx를 사용하여 Nginx 리소스를 조사하기 위해 특별히nginx-operator프로젝트가 생성됩니다.Operator 논리를 사용자 지정합니다.
이 예에서
nginx-operator는 각NginxCR(사용자 정의 리소스)에 대해 다음 조정 논리를 실행합니다.- Nginx 배포가 없는 경우 해당 배포를 생성합니다.
- Nginx 서비스가 없는 경우 해당 서비스를 생성합니다.
- Nginx 수신이 활성화되어 있지만 없는 경우 해당 수신을 생성합니다.
- 배포, 서비스 및 선택적 수신이 Nginx CR에 지정된 대로 원하는 구성(예: 복제본 수, 이미지, 서비스 유형)과 일치하는지 확인합니다.
기본적으로
nginx-operator는watches.yaml파일에 표시된Nginx리소스 이벤트를 감시하고 지정된 차트를 사용하여 Helm 릴리스를 실행합니다.- version: v1alpha1 group: example.com kind: Nginx chart: /opt/helm/helm-charts/nginxNginx Helm 차트를 검토합니다.
Helm Operator 프로젝트가 생성되면 Operator SDK는 간단한 Nginx 릴리스에 대한 템플릿 세트가 포함된 Helm 차트 예제를 생성합니다.
이 예제에서는 Helm 차트 개발자가 릴리스에 대한 유용한 정보를 전달하는 데 사용하는
NOTES.txt템플릿과 함께 배포, 서비스, 수신 리소스에 대해 템플릿을 사용할 수 있습니다.Helm 차트에 익숙하지 않은 경우 Helm 차트 개발자 설명서 를 검토하십시오.
Nginx CR 사양을 이해합니다.
Helm은 값이라는 개념을 사용하여
values.yaml파일에 정의된 Helm 차트 기본값에 대한 사용자 정의 기능을 제공합니다.CR 사양에 원하는 값을 설정하여 이러한 기본값을 재정의합니다. 예를 들어 복제본 수를 사용할 수 있습니다.
먼저
helm-charts/nginx/values.yaml파일을 검사하여 차트에replicaCount라는 값이 있으며 기본적으로1로 설정되어 있는지 확인합니다. 배포에 Nginx 인스턴스 2개가 있으려면 CR 사양에replicaCount가 포함되어야 합니다. 2.deploy/crds/example.com_v1alpha1_nginx_cr.yaml파일을 다음과 같이 업데이트합니다.apiVersion: example.com/v1alpha1 kind: Nginx metadata: name: example-nginx spec: replicaCount: 2마찬가지로 기본 서비스 포트는
80으로 설정됩니다.8080을 대신 사용하려면 서비스 포트 덮어쓰기를 추가하여deploy/crds/example.com_v1alpha1_nginx_cr.yaml파일을 다시 업데이트합니다.apiVersion: example.com/v1alpha1 kind: Nginx metadata: name: example-nginx spec: replicaCount: 2 service: port: 8080Helm Operator는
helm install -f ./overrides.yaml명령과 마찬가지로 값 파일의 콘텐츠인 것처럼 전체 사양을 적용합니다.
CRD를 배포합니다.
Operator를 실행하기 전에 Kubernetes는 Operator가 모니터링할 새 CRD(사용자 정의 리소스 정의)에 대해 알아야 합니다. 다음 CRD를 배포합니다.
$ oc create -f deploy/crds/example_v1alpha1_nginx_crd.yamlOperator를 빌드하고 실행합니다.
Operator를 빌드하고 실행하는 방법은 다음 두 가지가 있습니다.
- Kubernetes 클러스터 내부의 포드로 사용됩니다.
-
operator-sdk up명령을 사용하여 클러스터 외부의 Go 프로그램으로.
다음 방법 중 하나를 선택합니다.
Kubernetes 클러스터 내에서 포드로 실행합니다. 이 방법이 프로덕션에 사용하는 데 선호되는 방법입니다.
nginx-operator이미지를 빌드하여 레지스트리로 내보냅니다.$ operator-sdk build quay.io/example/nginx-operator:v0.0.1$ podman push quay.io/example/nginx-operator:v0.0.1배포 매니페스트는
deploy/operator.yaml파일에 생성됩니다. 이 파일의 배포 이미지는 플레이스 홀더REPLACE_IMAGE에서 이전 빌드 이미지로 수정해야 합니다. 이를 수행하려면 다음을 실행합니다.$ sed -i 's|REPLACE_IMAGE|quay.io/example/nginx-operator:v0.0.1|g' deploy/operator.yamlnginx-operator매니페스트를 배포합니다.$ oc create -f deploy/service_account.yaml$ oc create -f deploy/role.yaml$ oc create -f deploy/role_binding.yaml$ oc create -f deploy/operator.yamlnginx-operator배포가 실행 중인지 확인합니다.$ oc get deployment출력 예
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-operator 1 1 1 1 1m
클러스터 외부에서 실행합니다. 이 방법은 배포 및 테스트 속도를 높이기 위해 개발 주기 동안 선호됩니다.
watches.yaml파일에서 참조되는 차트 경로가 시스템에 있어야 합니다. 기본적으로watches.yaml파일은operator-sdk build 명령으로 빌드된 Operator 이미지를 사용하도록 스캐폴드됩니다.operator-sdk run --local명령을 사용하여 Operator를 개발하고 테스트할 때 SDK는 이 경로를 위해 로컬 파일 시스템에서 찾습니다.Helm 차트 경로를 가리키도록 이 위치에 심볼릭 링크를 생성합니다.
$ sudo mkdir -p /opt/helm/helm-charts$ sudo ln -s $PWD/helm-charts/nginx /opt/helm/helm-charts/nginx$HOME/.kube/config에 있는 기본 Kubernetes 구성 파일을 사용하여 Operator를 로컬로 실행하려면 다음을 수행합니다.$ operator-sdk run --local제공된 Kubernetes 구성 파일을 사용하여 Operator를 로컬로 실행하려면 다음을 수행합니다.
$ operator-sdk run --local --kubeconfig=<path_to_config>
NginxCR을 배포합니다.이전에 수정한
NginxCR을 적용합니다.$ oc apply -f deploy/crds/example.com_v1alpha1_nginx_cr.yamlnginx-operator가 CR에 대한 배포를 생성하는지 확인합니다.$ oc get deployment출력 예
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE example-nginx-b9phnoz9spckcrua7ihrbkrt1 2 2 2 2 1mPod에서 두 개의 복제본이 생성되었는지 확인합니다.
$ oc get pods출력 예
NAME READY STATUS RESTARTS AGE example-nginx-b9phnoz9spckcrua7ihrbkrt1-f8f9c875d-fjcr9 1/1 Running 0 1m example-nginx-b9phnoz9spckcrua7ihrbkrt1-f8f9c875d-ljbzl 1/1 Running 0 1m서비스 포트가
8080으로 설정되어 있는지 확인합니다.$ oc get service출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE example-nginx-b9phnoz9spckcrua7ihrbkrt1 ClusterIP 10.96.26.3 <none> 8080/TCP 1mreplicaCount를 업데이트하고 포트를 제거합니다.spec.replicaCount필드를2에서3으로 변경하고,spec.service필드를 제거한 다음, 변경 사항을 적용합니다.$ cat deploy/crds/example.com_v1alpha1_nginx_cr.yaml출력 예
apiVersion: "example.com/v1alpha1" kind: "Nginx" metadata: name: "example-nginx" spec: replicaCount: 3$ oc apply -f deploy/crds/example.com_v1alpha1_nginx_cr.yamlOperator에서 배포 크기를 변경하는지 확인합니다.
$ oc get deployment출력 예
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE example-nginx-b9phnoz9spckcrua7ihrbkrt1 3 3 3 3 1m서비스 포트가 기본
80으로 설정되어 있는지 확인합니다.$ oc get service출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE example-nginx-b9phnoz9spckcrua7ihrbkrt1 ClusterIP 10.96.26.3 <none> 80/TCP 1m리소스를 정리합니다.
$ oc delete -f deploy/crds/example.com_v1alpha1_nginx_cr.yaml$ oc delete -f deploy/operator.yaml$ oc delete -f deploy/role_binding.yaml$ oc delete -f deploy/role.yaml$ oc delete -f deploy/service_account.yaml$ oc delete -f deploy/crds/example_v1alpha1_nginx_crd.yaml
5.6. CSV(클러스터 서비스 버전) 생성
ClusterServiceVersion 오브젝트에서 정의하는 CSV(클러스터 서비스 버전)는 클러스터에서 Operator를 실행할 때 OLM(Operator Lifecycle Manager)을 지원하는 Operator 메타데이터에서 생성되는 YAML 매니페스트입니다. 로고, 설명, 버전과 같은 정보로 사용자 인터페이스를 채우는 데 사용되는 Operator 컨테이너 이미지와 함께 제공되는 메타데이터입니다. 또한 필요한 RBAC 규칙 및 관리하거나 사용하는 CR(사용자 정의 리소스)과 같이 Operator를 실행하는 데 필요한 기술 정보의 소스이기도 합니다.
Operator SDK에는 수동 정의 YAML 매니페스트 및 Operator 소스 파일에 포함된 정보를 사용하여 사용자 지정된 현재 Operator 프로젝트의 CSV를 생성하는 generate csv 하위 명령이 포함되어 있습니다.
CSV 생성 명령을 사용하면 Operator에서 OLM과 상호 작용하거나 메타데이터를 카탈로그 레지스트리에 게시하는 데 전문적인 OLM 지식을 보유한 Operator 작성자가 필요하지 않습니다. 또한 새로운 Kubernetes 및 OLM 기능이 구현되면서 시간이 지남에 따라 CSV 사양이 변경될 수 있으므로 Operator SDK는 앞으로의 새로운 CSV 기능을 처리할 수 있도록 업데이트 시스템을 쉽게 확장할 수 있습니다.
CSV 버전은 Operator 버전과 동일하며 Operator 버전을 업그레이드하면 새 CSV가 생성됩니다. Operator 작성자는 --csv-version 플래그를 사용하여 제공된 의미 체계 버전이 있는 CSV에 Operator 상태를 캡슐화할 수 있습니다.
$ operator-sdk generate csv --csv-version <version>
이 작업은 멱등이며 새 버전이 제공되거나 YAML 매니페스트 또는 소스 파일이 변경된 경우에만 CSV 파일을 업데이트합니다. Operator 작성자는 CSV 매니페스트의 대부분의 필드를 직접 수정할 필요가 없습니다. 수정이 필요한 사항은 이 가이드에 정의되어 있습니다. 예를 들어 CSV 버전은 metadata.name 에 포함되어야 합니다.
5.6.1. CSV 생성 작동 방식
Operator 프로젝트의 deploy/ 디렉터리는 Operator 배포에 필요한 모든 매니페스트의 표준 위치입니다. Operator SDK는 deploy/ 의 매니페스트의 데이터를 사용하여 CSV(클러스터 서비스 버전)를 작성할 수 있습니다.
다음 명령은 다음과 같습니다.
$ operator-sdk generate csv --csv-version <version>
기본적으로 CSV YAML 파일을 deploy/olm-catalog/ 디렉터리에 작성합니다.
CSV를 생성하려면 정확히 세 가지 유형의 매니페스트가 필요합니다.
-
operator.yaml -
*_{crd,cr}.yaml -
RBAC 역할 파일(예:
role.yaml)
Operator 작성자는 이러한 파일에 대한 다양한 버전 지정 요구 사항을 가질 수 있으며 deploy/olm-catalog/csv-config.yaml 파일에 포함된 특정 파일을 구성할 수 있습니다.
워크플로
기존 CSV가 감지되고 모든 구성 기본값이 사용되는지 여부에 따라 다음 중 csv 하위 명령을 생성합니다.
YAML 매니페스트 및 소스 파일에서 사용 가능한 데이터를 사용하여 현재와 동일한 위치 및 명명 규칙을 사용하여 새 CSV를 생성합니다.
-
업데이트 메커니즘은
deploy/에서 기존 CSV를 확인합니다. 찾을 수 없는 경우 여기에서 캐시 라고 하는ClusterServiceVersion오브젝트를 생성하고 Kubernetes APIObjectMeta와 같은 Operator 메타데이터에서 쉽게 파생된 필드를 채웁니다. -
업데이트 메커니즘은
Deployment리소스와 같이 CSV에서 사용하는 데이터가 포함된 매니페스트를 위해deploy/를 검색하고 이 데이터와 함께 캐시에 적절한 CSV 필드를 설정합니다. - 검색이 완료되면 채워진 모든 캐시 필드가 CSV YAML 파일에 다시 작성됩니다.
-
업데이트 메커니즘은
또는 다음을 수행합니다.
YAML 매니페스트 및 소스 파일에서 사용 가능한 데이터를 사용하여 현재 사전 정의된 위치에서 기존 CSV를 업데이트합니다.
-
업데이트 메커니즘은
deploy/에서 기존 CSV를 확인합니다. 하나의 파일이 발견되면 CSV YAML 파일 콘텐츠가 CSV 캐시로 마샬링됩니다. -
업데이트 메커니즘은
Deployment리소스와 같이 CSV에서 사용하는 데이터가 포함된 매니페스트를 위해deploy/를 검색하고 이 데이터와 함께 캐시에 적절한 CSV 필드를 설정합니다. - 검색이 완료되면 채워진 모든 캐시 필드가 CSV YAML 파일에 다시 작성됩니다.
-
업데이트 메커니즘은
CSV의 설명 및 생성되지 않은 기타 CSV 부분은 유지해야 하므로 개별 YAML 필드가 전체 파일이 아닌 덮어쓰기됩니다.
5.6.2. CSV 구성 구성
Operator 작성자는 deploy/olm-catalog/csv-config.yaml 파일에서 여러 필드를 채워 CSV 구성을 구성할 수 있습니다.
| 필드 | 설명 |
|---|---|
|
|
Operator 리소스 매니페스트 파일 경로입니다. 기본값: |
|
|
CRD 및 CR 매니페스트 파일 경로 목록입니다. 기본값: |
|
|
RBAC 역할 매니페스트 파일 경로 목록입니다. 기본값: |
5.6.3. 수동으로 정의한 CSV 필드
대부분의 CSV 필드는 Operator SDK와 관련 없이 생성된 일반 매니페스트를 사용하여 채울 수 없습니다. 이러한 필드는 대부분 Operator 및 다양한 CRD(사용자 정의 리소스 정의)에 대해 사람이 작성한 메타데이터입니다.
Operator 작성자는 CSV(클러스터 서비스 버전) YAML 파일을 직접 수정하여 다음과 같은 필수 필드에 개인화된 데이터를 추가해야 합니다. Operator SDK는 필수 필드에서 데이터 부족이 탐지되는 경우 CSV 생성 중 경고를 표시합니다.
다음 테이블에는 필수 또는 선택적인 수동 정의 CSV 필드가 자세히 설명되어 있습니다.
| 필드 | 설명 |
|---|---|
|
|
이 CSV의 고유 이름입니다. 고유성을 유지하도록 이름에 Operator 버전이 포함되어야 합니다(예: |
|
|
Operator 완성 모델에 따른 기능 수준입니다. 옵션에는 |
|
| Operator를 확인하는 공용 이름입니다. |
|
| Operator 기능에 대한 간단한 설명입니다. |
|
| Operator를 설명하는 키워드입니다. |
|
|
|
|
|
|
|
| Operator 내부에서 사용할 키-값 쌍입니다. |
|
|
Operator의 의미 체계 버전입니다(예: |
|
|
Operator에서 사용하는 모든 CRD입니다. CRD YAML 파일이
|
| 필드 | 설명 |
|---|---|
|
| CSV 이름이 이 CSV로 교체됩니다. |
|
|
Operator 또는 애플리케이션과 관련된 URL(예: 웹 사이트 및 문서)을 각각 |
|
| Operator에서 클러스터의 리소스와 연결할 수 있는 선택기입니다. |
|
|
Operator 고유의 base64로 인코딩된 아이콘으로, |
|
|
이 버전의 소프트웨어에서 달성한 완성 수준입니다. 옵션에는 |
위의 각 필드에 보관해야 하는 데이터에 대한 자세한 내용은 CSV 사양에서 확인할 수 있습니다.
현재 사용자 개입이 필요한 여러 YAML 필드를 Operator 코드에서 구문 분석할 수 있습니다.
5.6.3.1. Operator 메타데이터 주석
Operator 개발자는 CSV(클러스터 서비스 버전) 메타데이터에 특정 주석을 수동으로 정의하여 OperatorHub와 같은 UI의 기능을 활성화하거나 성능을 강조할 수 있습니다.
다음 테이블에는 metadata.annotations 필드를 사용하여 수동으로 정의할 수 있는 Operator 메타데이터 주석이 나열되어 있습니다.
| 필드 | 설명 |
|---|---|
|
| CRD(사용자 정의 리소스 정의) 템플릿에 최소 구성 세트를 제공합니다. 사용자가 추가로 사용자 정의할 수 있도록 호환되는 UI가 이 템플릿에 미리 채워집니다. |
|
| Operator를 설치할 때 생성해야 하는 단일 필수 사용자 정의 리소스를 지정합니다. 전체 YAML 정의를 포함하는 템플릿을 포함해야 합니다. |
|
| Operator를 배포해야 하는 제안된 네임스페이스를 설정합니다. |
|
| Operator에서 지원하는 인프라 기능입니다. 사용자는 웹 콘솔에서 OperatorHub를 통해 Operator를 검색할 때 이러한 기능을 확인하고 필터링할 수 있습니다. 유효한 대소문자를 구분하는 값은 다음과 같습니다.
중요
FIPS 검증 / 진행중인 모듈 암호화 라이브러리 사용은
|
|
|
Operator를 사용하는 데 필요한 특정 서브스크립션을 나열하기 위한 자유 양식 어레이입니다. 예를 들면 |
|
| UI에서 사용자 조작용이 아닌 CRD를 숨깁니다. |
사용 사례 예
Operator에서 연결이 끊긴 및 프록시 인식 지원
operators.openshift.io/infrastructure-features: '["disconnected", "proxy-aware"]'Operator에는 OpenShift Container Platform 라이센스가 필요합니다.
operators.openshift.io/valid-subscription: '["OpenShift Container Platform"]'Operator에는 3scale 라이센스가 필요합니다.
operators.openshift.io/valid-subscription: '["3Scale Commercial License", "Red Hat Managed Integration"]'Operator는 연결이 끊긴 프록시 인식을 지원하며 OpenShift Container Platform 라이센스가 필요합니다.
operators.openshift.io/infrastructure-features: '["disconnected", "proxy-aware"]'
operators.openshift.io/valid-subscription: '["OpenShift Container Platform"]'5.6.4. CSV 생성
사전 요구 사항
- Operator SDK를 사용하여 생성된 Operator 프로젝트
프로세스
-
Operator 프로젝트에서 필요한 경우
deploy/olm-catalog/csv-config.yaml파일을 수정하여 CSV 구성을 구성합니다. CSV를 생성합니다.
$ operator-sdk generate csv --csv-version <version>-
deploy/olm-catalog/디렉터리에 생성된 새 CSV에서 필요한 모든 수동 정의 필드가 적절하게 설정되었는지 확인합니다.
5.6.5. 제한된 네트워크 환경에 대한 Operator 활성화
사용 중인 Operator는 Operator 작성자로서 제한된 네트워크 또는 연결이 끊긴 환경에서 제대로 실행하려면 추가 요구 사항을 충족해야 합니다.
연결이 끊긴 모드를 지원하는 Operator 요구 사항
Operator의 CSV(클러스터 서비스 버전)에서 다음을 수행합니다.
- Operator에서 기능을 수행하는 데 필요할 수 있는 관련 이미지 또는 기타 컨테이너 이미지를 나열합니다.
- 태그가 아닌 다이제스트(SHA)를 통해 지정된 모든 이미지를 참조합니다.
- Operator의 모든 종속 항목은 연결이 끊긴 모드에서 실행할 수 있어야 합니다.
- Operator에 클러스터 외부 리소스가 필요하지 않아야 합니다.
CSV 요구 사항의 경우 Operator 작성자는 다음과 같은 변경을 수행할 수 있습니다.
사전 요구 사항
- Operator 프로젝트에 CSV가 포함되어 있습니다.
프로세스
사용 중인 Operator에 대한 CSV의 두 위치에서 관련 이미지에 대한 SHA 참조를 사용합니다.
spec.relatedImages를 업데이트합니다.... spec: relatedImages:1 - name: etcd-operator2 image: quay.io/etcd-operator/operator@sha256:d134a9865524c29fcf75bbc4469013bc38d8a15cb5f41acfddb6b9e492f556e43 - name: etcd-image image: quay.io/etcd-operator/etcd@sha256:13348c15263bd8838ec1d5fc4550ede9860fcbb0f843e48cbccec07810eebb68 ...Operator에서 사용할 이미지를 삽입하는 환경 변수를 선언할 때 배포의
env섹션을 업데이트합니다.spec: install: spec: deployments: - name: etcd-operator-v3.1.1 spec: replicas: 1 selector: matchLabels: name: etcd-operator strategy: type: Recreate template: metadata: labels: name: etcd-operator spec: containers: - args: - /opt/etcd/bin/etcd_operator_run.sh env: - name: WATCH_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.annotations['olm.targetNamespaces'] - name: ETCD_OPERATOR_DEFAULT_ETCD_IMAGE1 value: quay.io/etcd-operator/etcd@sha256:13348c15263bd8838ec1d5fc4550ede9860fcbb0f843e48cbccec07810eebb682 - name: ETCD_LOG_LEVEL value: INFO image: quay.io/etcd-operator/operator@sha256:d134a9865524c29fcf75bbc4469013bc38d8a15cb5f41acfddb6b9e492f556e43 imagePullPolicy: IfNotPresent livenessProbe: httpGet: path: /healthy port: 8080 initialDelaySeconds: 10 periodSeconds: 30 name: etcd-operator readinessProbe: httpGet: path: /ready port: 8080 initialDelaySeconds: 10 periodSeconds: 30 resources: {} serviceAccountName: etcd-operator strategy: deployment참고프로브를 구성할 때
timeoutSeconds값은periodSeconds값보다 작아야 합니다.timeoutSeconds기본값은1입니다.periodSeconds의 기본값은10입니다.
연결이 끊긴 환경에서도 Operator가 작동함을 나타내는
Disconnected주석을 추가합니다.metadata: annotations: operators.openshift.io/infrastructure-features: '["disconnected"]'이 인프라 기능을 통해 OperatorHub에서 Operator를 필터링할 수 있습니다.
5.6.6. 여러 아키텍처 및 운영 체제의 Operator 활성화
OLM(Operator Lifecycle Manager)은 모든 Operator가 Linux 호스트에서 실행되는 것으로 가정합니다. 그러나 Operator 작성자는 OpenShift Container Platform 클러스터에서 작업자 노드를 사용할 수 있는 경우 Operator가 다른 아키텍처에서 워크로드 관리를 지원하는지를 지정할 수 있습니다.
Operator가 AMD64 및 Linux 이외의 변형을 지원하는 경우 Operator에 지원되는 변형 목록을 제공하는 라벨을 CSV(클러스터 서비스 버전)에 추가할 수 있습니다. 지원되는 아키텍처 및 운영 체제를 나타내는 라벨은 다음과 같이 정의합니다.
labels:
operatorframework.io/arch.<arch>: supported
operatorframework.io/os.<os>: supported
패키지 매니페스트를 라벨별로 필터링하는 경우 기본 채널의 채널 헤드에 있는 라벨만 사용됩니다. 예를 들어 기본이 아닌 채널에서 Operator에 추가 아키텍처를 제공할 수는 있지만 이러한 아키텍처는 PackageManifest API에서 필터링하는 데는 사용할 수 없습니다.
CSV에 os 라벨이 포함되지 않은 경우 기본적으로 다음 Linux 지원 라벨이 있는 것처럼 처리됩니다.
labels:
operatorframework.io/os.linux: supported
CSV에 arch 라벨이 포함되지 않은 경우 기본적으로 다음 AMD64 지원 라벨이 있는 것처럼 처리됩니다.
labels:
operatorframework.io/arch.amd64: supportedOperator에서 여러 개의 노드 아키텍처 또는 운영 체제를 지원하는 경우 라벨을 여러 개 추가할 수 있습니다.
사전 요구 사항
- Operator 프로젝트에 CSV가 포함되어 있습니다.
- 여러 아키텍처 및 운영 체제를 나열하기 위해서는 CSV에서 참조하는 Operator 이미지가 매니페스트 목록 이미지여야 합니다.
- Operator가 제한된 네트워크 또는 연결이 끊긴 환경에서 제대로 작동하려면 참조하는 이미지도 태그가 아닌 다이제스트(SHA)를 사용하여 지정해야 합니다.
프로세스
Operator에서 지원하는 각 지원 아키텍처 및 운영 체제에 대해 CSV의
metadata.labels에 라벨을 추가합니다.labels: operatorframework.io/arch.s390x: supported operatorframework.io/os.zos: supported operatorframework.io/os.linux: supported1 operatorframework.io/arch.amd64: supported2
5.6.6.1. Operator에 대한 아키텍처 및 운영 체제 지원
여러 아키텍처 및 운영 체제를 지원하는 Operator에 라벨을 지정하거나 해당 Operator를 필터링할 때는 OpenShift Container Platform의 OLM(Operator Lifecycle Manager)에서 다음 문자열이 지원됩니다.
| 아키텍처 | 문자열 |
|---|---|
| AMD64 |
|
| 64비트 PowerPC little-endian |
|
| IBM Z |
|
| 운영 체제 | 문자열 |
|---|---|
| Linux |
|
| z/OS |
|
다른 버전의 OpenShift Container Platform 및 기타 Kubernetes 기반 배포에서는 다른 아키텍처 및 운영 체제를 지원할 수 있습니다.
5.6.7. 제안된 네임스페이스 설정
일부 Operator는 특정 네임스페이스에 배포하거나 특정 네임스페이스에 보조 리소스가 있어야 제대로 작동합니다. 서브스크립션에서 확인된 경우 OLM(Operator Lifecycle Manager)은 기본적으로 Operator의 네임스페이스 리소스를 해당 서브스크립션의 네임스페이스로 설정합니다.
Operator 작성자는 원하는 대상 네임스페이스를 CSV(클러스터 서비스 버전)의 일부로 표시하여 Operator용으로 설치된 리소스의 최종 네임스페이스를 제어할 수 있습니다. OperatorHub를 사용하여 클러스터에 Operator를 추가하면 설치 프로세스 중 웹 콘솔에서 클러스터 관리자에게 제안된 네임스페이스를 자동으로 채울 수 있습니다.
프로세스
CSV에서
operatorframework.io/suggested-namespace주석을 제안된 네임스페이스로 설정합니다.metadata: annotations: operatorframework.io/suggested-namespace: <namespace>1 - 1
- 제안된 네임스페이스를 설정합니다.
5.6.8. Webhook 정의
Operator 작성자는 Webhook를 통해 리소스를 오브젝트 저장소에 저장하고 Operator 컨트롤러에서 이를 처리하기 전에 리소스를 가로채기, 수정, 수락 또는 거부할 수 있습니다. Operator와 함께 webhook 가 제공 될 때 OLM (Operator Lifecycle Manager)은 이러한 Webhook의 라이프 사이클을 관리할 수 있습니다.
Operator의 CSV(클러스터 서비스 버전) 리소스에는 다음 유형의 Webhook를 정의하는 webhookdefinitions 섹션을 포함할 수 있습니다.
- 승인 Webhook(검증 및 변경)
- 변환 Webhook
프로세스
Operator CSV의
spec섹션에webhookdefinitions섹션을 추가하고ValidatingAdmissionWebhook,MutatingAdmissionWebhook또는ConversionWebhooktype을 사용하여 Webhook 정의를 포함합니다. 다음 예제에는 세 가지 유형의 Webhook가 모두 포함되어 있습니다.Webhook를 포함하는 CSV
apiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: name: webhook-operator.v0.0.1 spec: customresourcedefinitions: owned: - kind: WebhookTest name: webhooktests.webhook.operators.coreos.io1 version: v1 install: spec: deployments: - name: webhook-operator-webhook ... ... ... strategy: deployment installModes: - supported: false type: OwnNamespace - supported: false type: SingleNamespace - supported: false type: MultiNamespace - supported: true type: AllNamespaces webhookdefinitions: - type: ValidatingAdmissionWebhook2 admissionReviewVersions: - v1beta1 - v1 containerPort: 443 targetPort: 4343 deploymentName: webhook-operator-webhook failurePolicy: Fail generateName: vwebhooktest.kb.io rules: - apiGroups: - webhook.operators.coreos.io apiVersions: - v1 operations: - CREATE - UPDATE resources: - webhooktests sideEffects: None webhookPath: /validate-webhook-operators-coreos-io-v1-webhooktest - type: MutatingAdmissionWebhook3 admissionReviewVersions: - v1beta1 - v1 containerPort: 443 targetPort: 4343 deploymentName: webhook-operator-webhook failurePolicy: Fail generateName: mwebhooktest.kb.io rules: - apiGroups: - webhook.operators.coreos.io apiVersions: - v1 operations: - CREATE - UPDATE resources: - webhooktests sideEffects: None webhookPath: /mutate-webhook-operators-coreos-io-v1-webhooktest - type: ConversionWebhook4 admissionReviewVersions: - v1beta1 - v1 containerPort: 443 targetPort: 4343 deploymentName: webhook-operator-webhook generateName: cwebhooktest.kb.io sideEffects: None webhookPath: /convert conversionCRDs: - webhooktests.webhook.operators.coreos.io5 ...
5.6.8.1. OLM의 Webhook 고려 사항
OLM(Operator Lifecycle Manager)을 사용하여 Operator를 Webhook와 함께 배포할 때는 다음을 정의해야 합니다.
-
type필드는ValidatingAdmissionWebhook,MutatingAdmissionWebhook또는ConversionWebhook중 하나로 설정해야 합니다. 그러지 않으면 CSV가 실패한 단계에 배치됩니다. -
CSV에는
webhookdefinition의deploymentName필드에 제공된 값과 이름이 같은 배포가 포함되어야 합니다.
Webhook가 생성되면 OLM은 Operator가 배포된 Operator group과 일치하는 네임스페이스에서만 Webhook가 작동하는지 확인합니다.
인증 기관 제약 조건
OLM은 각 배포에 하나의 CA(인증 기관)를 제공하도록 구성되어 있습니다. 배포에 CA를 생성하고 마운트하는 논리는 원래 API 서비스 라이프사이클 논리에 사용되었습니다. 결과는 다음과 같습니다.
-
TLS 인증서 파일이 배포에 마운트됩니다(
/apiserver.local.config/certificates/apiserver.crt). -
TLS 키 파일이 배포에 마운트됩니다(
/apiserver.local.config/certificates/apiserver.key).
승인 Webhook 규칙 제약 조건
Operator에서 클러스터를 복구할 수 없는 상태로 구성하는 것을 방지하기 위해 OLM은 승인 Webhook에 정의된 규칙에서 다음 요청을 가로채는 경우 CSV를 실패한 단계에 배치합니다.
- 모든 그룹을 대상으로 하는 요청
-
operators.coreos.com그룹을 대상으로 하는 요청 -
ValidatingWebhookConfigurations또는MutatingWebhookConfigurations리소스를 대상으로 하는 요청
변환 Webhook 제약 조건
OLM은 변환 Webhook 정의가 다음 제약 조건을 준수하지 않는 경우 CSV를 실패한 단계에 배치합니다.
-
변환 Webhook가 있는 CSV는
AllNamespaces설치 모드만 지원할 수 있습니다. -
변환 Webhook에서 대상으로 하는 CRD는
spec.preserveUnknownFields필드가false또는nil로 설정되어 있어야 합니다. - CSV에 정의된 변환 Webhook는 고유한 CRD를 대상으로 해야 합니다.
- 지정된 CRD의 전체 클러스터에는 하나의 변환 Webhook만 있을 수 있습니다.
5.6.9. CRD(사용자 정의 리소스 정의) 이해
Operator에서 사용할 수 있는 CRD(사용자 정의 리소스 정의)에는 두 가지 유형이 있습니다. 하나는 보유 CRD이고 다른 하나는 의존하는 필수 CRD입니다.
5.6.9.1. 보유 CRD
Operator가 보유한 CRD(사용자 정의 리소스 정의)는 CSV에서 가장 중요한 부분입니다. 이를 통해 Operator와 필수 RBAC 규칙, 종속성 관리 및 기타 Kubernetes 개념 간 관계가 설정됩니다.
Operator는 여러 CRD를 사용하여 개념을 함께 연결하는 것이 일반적입니다(한 오브젝트의 최상위 데이터베이스 구성 및 다른 오브젝트의 복제본 세트 표현 등). 각각은 CSV 파일에 나열되어야 합니다.
| 필드 | Description | 필수/선택 사항 |
|---|---|---|
|
| CRD의 전체 이름입니다. | 필수 항목 |
|
| 해당 오브젝트 API의 버전입니다. | 필수 항목 |
|
| 머신에서 읽을 수 있는 CRD 이름입니다. | 필수 항목 |
|
|
사람이 읽을 수 있는 버전의 CRD 이름입니다(예: | 필수 항목 |
|
| Operator에서 이 CRD를 사용하는 방법에 대한 간단한 설명 또는 CRD에서 제공하는 기능에 대한 설명입니다. | 필수 항목 |
|
|
이 CRD가 속하는 API 그룹입니다(예: | 선택 사항 |
|
|
CRD에는 하나 이상의 Kubernetes 오브젝트 유형이 있습니다. 이러한 항목은 오케스트레이션하는 모든 항목의 전체 목록이 아닌, 사용자에게 중요한 오브젝트만 나열하는 것이 좋습니다. 예를 들어 사용자가 수정할 수 없는 내부 상태를 저장하는 구성 맵은 나열하지 않도록 합니다. | 선택 사항 |
|
| 이러한 설명자는 Operator의 특정 입력 또는 출력에서 최종 사용자에게 가장 중요한 UI를 나타내는 방법입니다. CRD에 사용자가 제공해야 하는 보안 또는 구성 맵의 이름이 있는 경우 여기에서 지정할 수 있습니다. 이러한 항목은 호환되는 UI에서 연결되고 강조됩니다. 설명자에는 세 가지 유형이 있습니다.
모든 설명자에는 다음 필드를 사용할 수 있습니다.
일반적으로 설명자에 대한 자세한 내용은 openshift/console 프로젝트를 참조하십시오. | 선택 사항 |
다음 예제에서는 보안 및 구성 맵의 형태로 일부 사용자 입력이 필요하고 서비스, 상태 저장 세트, Pod, 구성 맵을 오케스트레이션하는 MongoDB Standalone CRD를 보여줍니다.
보유 CRD의 예
- displayName: MongoDB Standalone
group: mongodb.com
kind: MongoDbStandalone
name: mongodbstandalones.mongodb.com
resources:
- kind: Service
name: ''
version: v1
- kind: StatefulSet
name: ''
version: v1beta2
- kind: Pod
name: ''
version: v1
- kind: ConfigMap
name: ''
version: v1
specDescriptors:
- description: Credentials for Ops Manager or Cloud Manager.
displayName: Credentials
path: credentials
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:selector:core:v1:Secret'
- description: Project this deployment belongs to.
displayName: Project
path: project
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:selector:core:v1:ConfigMap'
- description: MongoDB version to be installed.
displayName: Version
path: version
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:label'
statusDescriptors:
- description: The status of each of the pods for the MongoDB cluster.
displayName: Pod Status
path: pods
x-descriptors:
- 'urn:alm:descriptor:com.tectonic.ui:podStatuses'
version: v1
description: >-
MongoDB Deployment consisting of only one host. No replication of
data.5.6.9.2. 필수 CRD
기타 필수 CRD에 의존하는 것은 전적으로 선택 사항이며 개별 Operator의 범위를 줄이고 여러 Operator를 함께 구성하여 종단 간 사용 사례를 해결하는 방법을 제공하기 위해서만 존재합니다.
이에 대한 예로는 애플리케이션을 설정하고 (etcd Operator에서) 분산형 잠금에 사용할 etcd 클러스터를 설치하고, 데이터 저장을 위해 (Postgres Operator에서) Postgres 데이터베이스를 설치할 수 있는 Operator가 있습니다.
OLM(Operator Lifecycle Manager)은 이러한 요구 사항을 충족하기 위해 클러스터에서 사용 가능한 CRD 및 Operator를 점검합니다. 적합한 버전이 있는 경우 Operator는 원하는 네임스페이스 내에서 시작되고 각 Operator에서 필요한 Kubernetes 리소스를 생성, 조사, 수정할 수 있도록 서비스 계정이 생성됩니다.
| 필드 | Description | 필수/선택 사항 |
|---|---|---|
|
| 필요한 CRD의 전체 이름입니다. | 필수 항목 |
|
| 해당 오브젝트 API의 버전입니다. | 필수 항목 |
|
| Kubernetes 오브젝트 종류입니다. | 필수 항목 |
|
| 사람이 읽을 수 있는 CRD 버전입니다. | 필수 항목 |
|
| 구성 요소가 더 큰 아키텍처에 어떻게 적용되는지 요약합니다. | 필수 항목 |
필수 CRD 예제
required:
- name: etcdclusters.etcd.database.coreos.com
version: v1beta2
kind: EtcdCluster
displayName: etcd Cluster
description: Represents a cluster of etcd nodes.5.6.9.3. CRD 업그레이드
OLM은 CRD(사용자 정의 리소스 정의)가 단수형 CSV(클러스터 서비스 버전)에 속하는 경우 CRD를 즉시 업그레이드합니다. CRD가 여러 CSV에 속하는 경우에는 다음과 같은 하위 호환 조건을 모두 충족할 때 CRD가 업그레이드됩니다.
- 현재 CRD의 기존 서비스 버전은 모두 새 CRD에 있습니다.
- CRD 제공 버전과 연결된 기존의 모든 인스턴스 또는 사용자 정의 리소스는 새 CRD의 검증 스키마에 대해 검증할 때 유효합니다.
5.6.9.3.1. 새 CRD 버전 추가
프로세스
Operator에 새 버전의 CRD를 추가하려면 다음을 수행합니다.
CSV의
versions섹션에서 CRD 리소스에 새 항목을 추가합니다.예를 들어 현재 CRD에 버전
v1alpha1이 있고, 새 버전v1beta1을 추가한 후 새 스토리지 버전으로 표시하려면v1beta1에 새 항목을 추가합니다.versions: - name: v1alpha1 served: true storage: false - name: v1beta11 served: true storage: true- 1
- 새 항목입니다.
CSV에서 새 버전을 사용하려고 하는 경우 CSV의
owned섹션에 있는 CRD의 참조 버전이 업데이트되었는지 확인합니다.customresourcedefinitions: owned: - name: cluster.example.com version: v1beta11 kind: cluster displayName: Cluster- 1
version을 업데이트합니다.
- 업데이트된 CRD 및 CSV를 번들로 내보냅니다.
5.6.9.3.2. CRD 버전 사용 중단 또는 제거
OLM(Operator Lifecycle Manager)에서는 CRD(사용자 정의 리소스 정의)의 제공 버전을 즉시 제거하는 것을 허용하지 않습니다. 대신 CRD의 served 필드를 false로 설정하여 더 이상 사용되지 않는 CRD 버전을 먼저 비활성화해야 합니다. 그러면 후속 CRD 업그레이드에서 제공되지 않는 버전을 제거할 수 있습니다.
프로세스
특정 버전의 CRD를 사용 중단하고 제거하려면 다음을 수행합니다.
이 버전이 더 이상 사용되지 않으며 후속 업그레이드에서 제거될 수 있음을 나타내려면 더 이상 사용되지 않는 버전을 제공되지 않음으로 표시합니다. 예를 들면 다음과 같습니다.
versions: - name: v1alpha1 served: false1 storage: true- 1
false로 설정합니다.
사용을 중단할 버전이 현재
storage버전인 경우storage버전을 제공 버전으로 전환합니다. 예를 들면 다음과 같습니다.versions: - name: v1alpha1 served: false storage: false1 - name: v1beta1 served: true storage: true2 참고CRD에서
storage버전이거나 이 버전이었던 특정 버전을 제거하려면 CRD 상태의storedVersion에서 해당 버전을 제거해야 합니다. OLM은 저장된 버전이 새 CRD에 더 이상 존재하지 않는 것으로 탐지하면 이 작업을 수행합니다.- 위 변경 사항으로 CRD를 업그레이드합니다.
이어지는 업그레이드 주기에서는 서비스되지 않는 버전을 CRD에서 완전히 제거할 수 있습니다. 예를 들면 다음과 같습니다.
versions: - name: v1beta1 served: true storage: true-
CSV의
owned섹션에서 참조하는 CRD 버전이 CRD에서 제거된 경우 적절하게 업데이트되었는지 확인합니다.
5.6.9.4. CRD 템플릿
Operator 사용자는 필수 옵션과 선택 옵션을 알고 있어야 합니다. 각 CRD(사용자 정의 리소스 정의)에 대한 템플릿에 alm-examples라는 주석으로 최소 구성 세트를 제공할 수 있습니다. 사용자가 추가로 사용자 정의할 수 있도록 호환되는 UI가 이 템플릿에 미리 채워집니다.
주석은 종류 목록으로 구성되며, 예를 들면 CRD 이름 및 Kubernetes 오브젝트의 해당 metadata 및 spec입니다.
다음 전체 예제에서는 EtcdCluster, EtcdBackup, EtcdRestore에 대한 템플릿을 제공합니다.
metadata:
annotations:
alm-examples: >-
[{"apiVersion":"etcd.database.coreos.com/v1beta2","kind":"EtcdCluster","metadata":{"name":"example","namespace":"default"},"spec":{"size":3,"version":"3.2.13"}},{"apiVersion":"etcd.database.coreos.com/v1beta2","kind":"EtcdRestore","metadata":{"name":"example-etcd-cluster"},"spec":{"etcdCluster":{"name":"example-etcd-cluster"},"backupStorageType":"S3","s3":{"path":"<full-s3-path>","awsSecret":"<aws-secret>"}}},{"apiVersion":"etcd.database.coreos.com/v1beta2","kind":"EtcdBackup","metadata":{"name":"example-etcd-cluster-backup"},"spec":{"etcdEndpoints":["<etcd-cluster-endpoints>"],"storageType":"S3","s3":{"path":"<full-s3-path>","awsSecret":"<aws-secret>"}}}]5.6.9.5. 내부 오브젝트 숨기기
Operator는 작업을 수행하기 위해 내부적으로 CRD(사용자 정의 리소스 정의)를 사용하는 것이 일반적입니다. 이러한 오브젝트는 사용자 조작용이 아니며 Operator 사용자에게 혼동을 줄 수 있습니다. 예를 들어 데이터베이스 Operator에는 사용자가 replication: true를 사용하여 데이터베이스 오브젝트를 생성할 때마다 생성되는 Replication CRD가 있을 수 있습니다.
Operator 작성자는 operators.operatorframework.io/internal-objects 주석을 Operator의 CSV(클러스터 서비스 버전)에 추가하여 사용자 조작용이 아닌 사용자 인터페이스에서 CRD를 숨길 수 있습니다.
프로세스
-
CRD 중 하나를 내부로 표시하기 전에 애플리케이션을 관리하는 데 필요할 수 있는 디버깅 정보 또는 구성이 CR의 상태 또는
spec블록에 반영되는지 확인합니다(Operator에 적용 가능한 경우). operators.operatorframework.io/internal-objects주석을 Operator의 CSV에 추가하여 사용자 인터페이스에서 숨길 내부 오브젝트를 지정합니다.내부 오브젝트 주석
apiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: name: my-operator-v1.2.3 annotations: operators.operatorframework.io/internal-objects: '["my.internal.crd1.io","my.internal.crd2.io"]'1 ...- 1
- 내부 CRD를 문자열 배열로 설정합니다.
5.6.9.6. 필수 사용자 정의 리소스 초기화
Operator가 완전히 작동하기 위해서는 사용자가 사용자 정의 리소스를 인스턴스화해야 할 수 있습니다. 그러나 사용자가 필요한 내용과 리소스를 정의하는 방법을 결정하는 것이 어려울 수 있습니다.
Operator 개발자는 CSV(클러스터 서비스 버전)에 operatorframework.io/initialization-resource 주석을 추가하여 Operator를 설치할 때 생성해야 하는 단일 필수 사용자 정의 리소스를 지정할 수 있습니다. 주석에는 설치 중 리소스를 초기화하는 데 필요한 전체 YAML 정의가 포함된 템플릿이 포함되어야 합니다.
OpenShift Container Platform 웹 콘솔에서 Operator를 설치한 후 이 주석을 정의한 경우 사용자에게 CSV에 제공된 템플릿을 사용하여 리소스를 생성하라는 메시지가 표시됩니다.
프로세스
Operator의 CSV에
operatorframework.io/initialization-resource주석을 추가하여 필요한 사용자 정의 리소스를 지정합니다. 예를 들어 다음 주석은StorageCluster리소스 생성이 필요하고 전체 YAML 정의를 제공합니다.초기화 리소스 주석
apiVersion: operators.coreos.com/v1alpha1 kind: ClusterServiceVersion metadata: name: my-operator-v1.2.3 annotations: operatorframework.io/initialization-resource: |- { "apiVersion": "ocs.openshift.io/v1", "kind": "StorageCluster", "metadata": { "name": "example-storagecluster" }, "spec": { "manageNodes": false, "monPVCTemplate": { "spec": { "accessModes": [ "ReadWriteOnce" ], "resources": { "requests": { "storage": "10Gi" } }, "storageClassName": "gp2" } }, "storageDeviceSets": [ { "count": 3, "dataPVCTemplate": { "spec": { "accessModes": [ "ReadWriteOnce" ], "resources": { "requests": { "storage": "1Ti" } }, "storageClassName": "gp2", "volumeMode": "Block" } }, "name": "example-deviceset", "placement": {}, "portable": true, "resources": {} } ] } } ...
5.6.10. API 서비스 이해
CRD와 마찬가지로 Operator에서 사용할 수 있는 API 서비스에는 두 가지 유형, 즉 보유 및 필수가 있습니다.
5.6.10.1. 보유 API 서비스
API 서비스가 CSV에 속하는 경우 CSV는 해당 서비스를 지원하는 확장 api-server 및 해당 서비스에서 제공하는 GVK(그룹/버전/종류)의 배포에 대해 설명해야 합니다.
API 서비스는 제공하는 그룹/버전별로 고유하게 식별되며 제공할 것으로 예상되는 다양한 종류를 나타내기 위해 여러 번 나열될 수 있습니다.
| 필드 | Description | 필수/선택 사항 |
|---|---|---|
|
|
API 서비스에서 제공하는 그룹입니다(예: | 필수 항목 |
|
|
API 서비스의 버전입니다(예: | 필수 항목 |
|
| API 서비스에서 제공해야 하는 종류입니다. | 필수 항목 |
|
| 제공되는 API 서비스의 복수형 이름입니다. | 필수 항목 |
|
|
CSV에서 정의한 배포 이름으로, API 서비스에 해당합니다(보유 API 서비스의 경우 필수). OLM Operator는 CSV 보류 단계 동안 CSV의 | 필수 항목 |
|
|
사람이 읽을 수 있는 버전의 API 서비스 이름입니다(예: | 필수 항목 |
|
| Operator에서 이 API 서비스를 사용하는 방법에 대한 간단한 설명 또는 API 서비스에서 제공하는 기능에 대한 설명입니다. | 필수 항목 |
|
| 사용 중인 API 서비스에서 Kubernetes 오브젝트 유형을 한 개 이상 보유하고 있습니다. 이러한 항목은 resources 섹션에 나열되어 문제 해결에 필요할 수 있는 오브젝트 또는 애플리케이션에 연결하는 방법을 사용자에게 알립니다(예: 데이터베이스를 표시하는 서비스 또는 수신 규칙). 오케스트레이션하는 모든 항목의 전체 목록이 아닌, 사용자에게 중요한 오브젝트만 나열하는 것이 좋습니다. 예를 들어 사용자가 수정할 수 없는 내부 상태를 저장하는 구성 맵은 나열하지 않도록 합니다. | 선택 사항 |
|
| 본질적으로 보유 CRD와 동일합니다. | 선택 사항 |
5.6.10.1.1. API 서비스 리소스 생성
OLM(Operator Lifecycle Manager)은 각각의 고유한 보유 API 서비스에 대해 서비스 및 API 서비스 리소스를 생성하거나 교체합니다.
-
서비스 Pod 선택기는 API 서비스 설명의
DeploymentName필드와 일치하는 CSV 배포에서 복사합니다. - 각 설치에 대해 새 CA 키/인증서 쌍이 생성되고 base64로 인코딩된 CA 번들이 각 API 서비스 리소스에 포함됩니다.
5.6.10.1.2. API 서비스 제공 인증서
OLM은 보유 API 서비스가 설치될 때마다 제공 키/인증서 쌍을 생성합니다. 제공 인증서에는 생성된 Service 리소스의 호스트 이름을 포함하는 CN(일반 이름)이 있으며 해당 API 서비스 리소스에 포함된 CA 번들의 개인 키로 서명합니다.
인증서는 배포 네임스페이스에 유형 kubernetes.io/tls의 보안으로 저장되고 API 서비스 설명의 DeploymentName 필드와 일치하는 CSV의 배포 볼륨 섹션에 apiservice-cert라는 볼륨이 자동으로 추가됩니다.
아직 존재하지 않는 경우 이름이 일치하는 볼륨 마운트도 해당 배포의 모든 컨테이너에 추가됩니다. 그러면 사용자가 필요한 이름으로 볼륨 마운트를 정의하여 모든 사용자 정의 경로 요구 사항을 충족할 수 있습니다. 생성된 볼륨 마운트의 경로는 기본적으로 /apiserver.local.config/certificates이며 동일한 경로의 기존 볼륨 마운트는 교체됩니다.
5.6.10.2. 필수 API 서비스
OLM은 설치를 시도하기 전에 모든 필수 CSV에 사용 가능한 API 서비스가 있고 필요한 GVK를 모두 검색할 수 있는지 확인합니다. 이를 통해 CSV는 보유하지 않는 API 서비스에서 제공하는 특정 종류에 의존할 수 있습니다.
| 필드 | Description | 필수/선택 사항 |
|---|---|---|
|
|
API 서비스에서 제공하는 그룹입니다(예: | 필수 항목 |
|
|
API 서비스의 버전입니다(예: | 필수 항목 |
|
| API 서비스에서 제공해야 하는 종류입니다. | 필수 항목 |
|
|
사람이 읽을 수 있는 버전의 API 서비스 이름입니다(예: | 필수 항목 |
|
| Operator에서 이 API 서비스를 사용하는 방법에 대한 간단한 설명 또는 API 서비스에서 제공하는 기능에 대한 설명입니다. | 필수 항목 |
5.7. 번들 이미지 작업
Operator SDK를 사용하여 번들 형식을 사용하여 Operator를 패키징할 수 있습니다.
5.7.1. 번들 이미지 빌드
Operator SDK를 사용하여 Operator 번들 이미지를 빌드, 푸시 및 검증할 수 있습니다.
사전 요구 사항
- Operator SDK 버전 0.19.4
-
podman버전 1.9.3+ - Operator SDK를 사용하여 생성된 Operator 프로젝트
Docker v2-2를 지원하는 레지스트리에 액세스
중요OpenShift Container Platform 클러스터의 내부 레지스트리는 미러링 프로세스 중에 필요한 태그 없이 푸시를 지원하지 않으므로 대상 레지스트리로 사용할 수 없습니다.
절차
Operator 프로젝트 디렉터리에서 다음
make명령을 실행하여 Operator 이미지를 빌드하고 내보냅니다. 액세스할 수 있는 리포지토리를 참조하려면 다음 단계에서IMG인수를 수정합니다. Quay.io와 같은 리포지토리 사이트에 컨테이너를 저장하기 위해 계정을 받을 수 있습니다.이미지를 빌드합니다.
$ make docker-build IMG=<registry>/<user>/<operator_image_name>:<tag>참고Operator에 대해 SDK에서 생성한 Dockerfile은
Go 빌드를 위해GOARCH=amd64를 명시적으로 참조합니다. 이는AMD64 이외의 아키텍처의 경우GOARCH=$CACHEGETARCH에 수정될 수 있습니다. Docker는 환경 변수를-platform에서 지정한 값으로 자동 설정합니다. Buildah를 사용하면-build-arg를 목적으로 사용해야 합니다. 자세한 내용은 여러 아키텍처를 참조하십시오.이미지를 리포지토리로 내보냅니다.
$ make docker-push IMG=<registry>/<user>/<operator_image_name>:<tag>
IMGURL을 내보낸 Operator 이미지 이름 및 태그로 설정하여Makefile을 업데이트합니다.$ # Image URL to use all building/pushing image targets IMG ?= <registry>/<user>/<operator_image_name>:<tag>이 값은 후속 작업에 사용됩니다.
Operator SDK
generate bundle및bundle validate명령을 비롯한 다양한 명령을 호출하는make bundle명령을 실행하여 Operator 번들 매니페스트를 생성합니다.$ make bundleOperator의 번들 매니페스트는 애플리케이션을 표시, 생성, 관리하는 방법을 설명합니다.
make bundle명령은 Operator 프로젝트에서 다음 파일 및 디렉터리를 생성합니다.-
ClusterServiceVersion오브젝트를 포함하는bundle/manifests라는 번들 매니페스트 디렉터리 -
bundle/metadata라는 번들 메타데이터 디렉터리 -
config/crd디렉터리의 모든 CRD(사용자 정의 리소스 정의) -
Dockerfile
bundle.Dockerfile
그런 다음
operator-sdk bundle validate를 사용하여 이러한 파일을 자동으로 검증하고 디스크상의 번들 표현이 올바른지 확인합니다.-
다음 명령을 실행하여 번들 이미지를 빌드하고 내보냅니다. OLM에서는 하나 이상의 번들 이미지를 참조하는 인덱스 이미지를 통해 Operator 번들을 사용합니다.
번들 이미지를 빌드합니다. 이미지를 내보낼 레지스트리, 사용자 네임스페이스, 이미지 태그에 대한 세부 정보를 사용하여
BUNDLE_IMG를 설정합니다.$ make bundle-build BUNDLE_IMG=<registry>/<user>/<bundle_image_name>:<tag>번들 이미지를 내보냅니다.
$ docker push <registry>/<user>/<bundle_image_name>:<tag>
5.8. 스코어 카드를 사용하여 Operator 검증
Operator 작성자는 Operator가 올바르게 패키지화되고 구문 오류가 없는지 확인해야 합니다. Operator 작성자는 Operator SDK 스코어 카드 툴을 사용하여 Operator 패키징을 검증하고 테스트를 실행할 수 있습니다.
OpenShift Container Platform 4.6에서는 Operator SDK v0.19.4를 지원합니다.
5.8.1. 스코어 카드 툴 정보
Operator를 검증하기 위해 Operator SDK에서 제공하는 스코어 카드 툴은 관련 CR(사용자 정의 리소스) 및 Operator에 필요한 모든 리소스를 생성하여 시작합니다. 그런 다음 스코어 카드는 API 서버에 대한 호출을 기록하고 일부 테스트를 실행하는 데 사용되는 Operator 배포에 프록시 컨테이너를 생성합니다. 수행되는 테스트에서는 CR에서 일부 매개변수도 검사합니다.
5.8.2. 스코어 카드 구성
스코어 카드 툴에서는 내부 플러그인과 여러 글로벌 구성 옵션을 구성할 수 있는 구성 파일을 사용합니다.
5.8.2.1. 설정 파일
스코어 카드 도구 구성의 기본 위치는 <project_dir>/.osdk-scorecard.* 입니다. 다음은 YAML 형식의 구성 파일의 예입니다.
스코어 카드 구성 파일
scorecard:
output: json
plugins:
- basic:
cr-manifest:
- "deploy/crds/cache.example.com_v1alpha1_memcached_cr.yaml"
- "deploy/crds/cache.example.com_v1alpha1_memcachedrs_cr.yaml"
- olm:
cr-manifest:
- "deploy/crds/cache.example.com_v1alpha1_memcached_cr.yaml"
- "deploy/crds/cache.example.com_v1alpha1_memcachedrs_cr.yaml"
csv-path: "deploy/olm-catalog/memcached-operator/0.0.3/memcached-operator.v0.0.3.clusterserviceversion.yaml"글로벌 옵션에 대한 구성 방법은 가장 높은 우선 순위에서 가장 낮은 우선 순위를 사용합니다.
명령 인수 (사용 가능한 경우) → 설정 파일 → 기본값
구성 파일은 YAML 형식이어야 합니다. 향후 모든 operator-sdk 하위 명령의 구성을 허용하도록 구성 파일을 확장할 수 있으므로 스코어 카드 구성은 스코어 카드 하위 섹션 아래 있어야 합니다.
구성 파일 지원은 viper 패키지에서 제공합니다. viper 설정의 작동 방식에 대한 자세한 내용은 README 를 참조하십시오.
5.8.2.2. 명령 인수
대부분의 스코어 카드 도구 구성은 구성 파일을 사용하여 수행되지만 다음 인수를 사용할 수도 있습니다.
| 플래그 | 유형 | 설명 |
|---|---|---|
|
| string | 번들 검증 테스트에 사용되는 번들 디렉터리의 경로입니다. |
|
| string |
스코어 카드 구성 파일의 경로입니다. 기본값은 |
|
| string |
출력 형식. 유효한 옵션은 |
|
| string |
|
|
| string |
실행할 스코어 카드의 버전입니다. default 및 only valid 옵션은 |
|
| string | 테스트를 필터링할 레이블 선택기입니다. |
|
| 부울 |
|
5.8.2.3. 구성 파일 옵션
스코어 카드 구성 파일은 다음과 같은 옵션을 제공합니다.
| 옵션 | 유형 | 설명 |
|---|---|---|
|
| string |
|
|
| string |
|
|
| string |
|
|
| array | 플러그인 이름의 배열입니다. |
5.8.2.3.1. 기본 및 OLM 플러그인
스코어 카드는 구성 파일의 plugins 섹션에서 구성한 내부 기본 및 olm 플러그인을 지원합니다.
| 옵션 | 유형 | 설명 |
|---|---|---|
|
| []string |
테스트 중인 CR의 경로입니다. |
|
| string |
Operator의 CSV(클러스터 서비스 버전) 경로입니다. OLM 테스트에 필요하거나 |
|
| 부울 | OLM에서 CSV 및 관련 CRD가 클러스터에 배포되었음을 나타냅니다. |
|
| string |
|
|
| string |
플러그인을 실행할 네임스페이스입니다. 설정되지 않으면 |
|
| int | Operator를 초기화하는 동안 시간 초과될 때까지의 시간(초)입니다. |
|
| string | 클러스터에 배포해야 하는 CRD가 포함된 디렉터리의 경로입니다. |
|
| string |
네임스페이스 내에서 실행되는 모든 리소스가 포함된 매니페스트 파일입니다. 기본적으로 스코어 카드는 |
|
| string |
전역적으로 실행되는 필수 리소스(네임스페이스가 아님)가 포함된 매니페스트. 기본적으로 스코어 카드는 |
현재 CSV와 함께 스코어 카드를 사용하면 CLI, 구성 파일 또는 CSV 주석을 통해 여러 CR 매니페스트를 설정할 수 없습니다. 클러스터에서 Operator를 종료하고, 테스트한 각 CR에 대한 스코어 카드를 다시 배포해야 합니다.
5.8.3. 수행된 테스트
기본적으로 스코어 카드 도구에는 두 개의 내부 플러그인에서 사용할 수 있는 내부 테스트 세트가 있습니다. 플러그인에 대해 여러 CR을 지정하면 각 CR 후에 테스트 환경이 완전히 정리되므로 각 CR에 테스트 환경이 정리됩니다.
각 테스트에는 테스트를 고유하게 식별하는 짧은 이름이 있습니다. 이 기능은 실행할 특정 테스트 또는 테스트를 선택할 때 유용합니다. 예를 들면 다음과 같습니다.
$ operator-sdk scorecard -o text --selector=test=checkspectest$ operator-sdk scorecard -o text --selector='test in (checkspectest,checkstatustest)'5.8.3.1. 기본 플러그인
다음 기본 Operator 테스트는 기본 플러그인에서 사용할 수 있습니다.
| 테스트 | Description | 짧은 이름 |
|---|---|---|
| Spec Block Exists |
이 테스트는 클러스터에서 생성된 CR(사용자 정의 리소스)을 확인하여 모든 CR에 |
|
| 상태 블록이 있음 |
이 테스트는 클러스터에서 생성된 CR을 확인하여 모든 CR에 |
|
| Into CR에 문제가 있습니다 |
이 테스트에서는 스코어 카드 프록시 로그를 읽어 Operator가 |
|
5.8.3.2. OLM 플러그인
olm 플러그인에서 다음 OLM(Operator Lifecycle Manager) 통합 테스트를 사용할 수 있습니다.
| 테스트 | Description | 짧은 이름 |
|---|---|---|
| OLM 번들 유효성 검사 | 이 테스트에서는 bundle 플래그에 지정된 대로 bundle 디렉터리에 있는 OLM 번들 매니페스트의 유효성을 검사합니다. 번들 콘텐츠에 오류가 포함된 경우 테스트 결과 출력에 검증기 로그 및 검증 라이브러리의 오류 메시지가 포함됩니다. |
|
| Provided APIs Have Validation |
이 테스트에서는 제공된 CR의 CRD에 검증 섹션이 포함되어 있고 CR에서 감지된 각 |
|
| Owned CRDs Have Resources Listed |
이 테스트에서는 |
|
| Spec Fields With Descriptors |
이 테스트에서는 사용자 정의 리소스의 |
|
| Status Fields With Descriptors |
이 테스트에서는 사용자 정의 리소스의 |
|
5.8.4. 스코어 카드 실행
사전 요구 사항
스코어 카드 툴에서 Operator 프로젝트에 대한 다음 사전 요구 사항을 확인합니다.
- Kubernetes 1.11.3 이상을 실행하는 클러스터에 액세스할 수 있습니다.
-
스코어 카드를 사용하여 OLM(Operator Lifecycle Manager)과 Operator 프로젝트의 통합을 확인하려면 CSV(클러스터 서비스 버전) 파일도 필요합니다. 이는
olm-deployed옵션을 사용하는 경우 필요합니다. Operator SDK(SDK 이외의 Operator)를 사용하여 생성되지 않은 Operator의 경우 다음을 수행합니다.
- Operator 및 CR(사용자 정의 리소스)을 설치하고 구성하는 리소스 매니페스트입니다.
-
clientcmd또는controller-runtime구성 getter와 같은KUBECONFIG환경 변수에서 읽기를 지원하는 구성 getter입니다. 스코어 카드 프록시가 올바르게 작동하려면 이 작업이 필요합니다.
프로세스
-
Operator 프로젝트에
.osdk-scorecard.yaml구성 파일을 정의합니다. -
RBAC 파일에 정의된 네임스페이스(role
_binding)를 생성합니다. Operator 프로젝트의 루트 디렉터리에서 스코어 카드를 실행합니다.
$ operator-sdk scorecard실행된 텍스트 중 하나라도 통과하지 않은 경우 스코어 카드 반환 코드는
1이고 선택한 모든 테스트가 통과된 경우0입니다.
5.8.5. OLM 관리 Operator를 사용하여 스코어 카드 실행
CSV(클러스터 서비스 버전)를 사용하여 스코어 카드를 실행하여 클러스터 지원 및 비Operator SDK Operator를 테스트할 수 있습니다.
절차
스코어 카드에는 Operator의 배포 Pod에 있는 프록시 컨테이너가 Operator 로그를 읽어야 합니다. CSV를 수정하고 한 개의 추가 오브젝트를 생성해야 OLM(Operator Lifecycle Manager)을 사용하여 Operator를 배포하기 전에 프록시를 실행해야 합니다.
이 단계는 bash 함수를 사용하여 수동으로 또는 자동화할 수 있습니다. 다음 방법 중 하나를 선택합니다.
수동 방법:
local
kubeconfig파일 을 포함하는 프록시 서버 보안을 생성합니다.스코어 카드 프록시의 네임스페이스 소유자 참조를 사용하여 사용자 이름을 생성합니다.
$ echo '{"apiVersion":"","kind":"","name":"scorecard","uid":"","Namespace":"'<namespace>'"}' | base64 -w 01 - 1
<namespace>를 Operator가 배포할 네임스페이스로 바꿉니다.
다음 템플릿을 사용하여
구성매니페스트scorecard-config.yaml을 작성하고<username>을 이전 단계에서 생성한 base64 사용자 이름으로 바꿉니다.apiVersion: v1 kind: Config clusters: - cluster: insecure-skip-tls-verify: true server: http://<username>@localhost:8889 name: proxy-server contexts: - context: cluster: proxy-server user: admin/proxy-server name: <namespace>/proxy-server current-context: <namespace>/proxy-server preferences: {} users: - name: admin/proxy-server user: username: <username> password: unusedConfig를 base64로 인코딩합니다.$ cat scorecard-config.yaml | base64 -w 0시크릿매니페스트scorecard-secret.yaml을 생성합니다.apiVersion: v1 kind: Secret metadata: name: scorecard-kubeconfig namespace: <namespace>1 data: kubeconfig: <kubeconfig_base64>2 보안을 적용합니다.
$ oc apply -f scorecard-secret.yaml보안을 참조하는 볼륨을 Operator의 배포에 삽입합니다.
spec: install: spec: deployments: - name: memcached-operator spec: ... template: ... spec: containers: ... volumes: - name: scorecard-kubeconfig1 secret: secretName: scorecard-kubeconfig items: - key: kubeconfig path: config- 1
- Scorecard
kubeconfig볼륨.
Operator 배포에 있는 각 컨테이너에 볼륨 마운트 및
KUBECONFIG환경 변수를 삽입합니다.spec: install: spec: deployments: - name: memcached-operator spec: ... template: ... spec: containers: - name: container1 ... volumeMounts: - name: scorecard-kubeconfig1 mountPath: /scorecard-secret env: - name: KUBECONFIG2 value: /scorecard-secret/config - name: container23 ...Operator 배포에 스코어 카드 프록시 컨테이너를 삽입합니다.
spec: install: spec: deployments: - name: memcached-operator spec: ... template: ... spec: containers: ... - name: scorecard-proxy1 command: - scorecard-proxy env: - name: WATCH_NAMESPACE valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.namespace image: quay.io/operator-framework/scorecard-proxy:master imagePullPolicy: Always ports: - name: proxy containerPort: 8889- 1
- 스코어 카드 프록시 컨테이너.
자동화된 방법:
community-operators리포지토리에는 프로세스의 이전 단계를 수행할 수 있는 여러 bash 함수가 있습니다.다음
curl명령을 실행합니다.$ curl -Lo csv-manifest-modifiers.sh \ https://raw.githubusercontent.com/operator-framework/community-operators/master/scripts/lib/filecsv-manifest-modifiers.sh파일을 가져옵니다.$ . ./csv-manifest-modifiers.shkubeconfig시크릿 파일을 생성합니다.$ create_kubeconfig_secret_file scorecard-secret.yaml "<namespace>"1 - 1
<namespace>를 Operator가 배포할 네임스페이스로 바꿉니다.
보안을 적용합니다.
$ oc apply -f scorecard-secret.yamlkubeconfig볼륨을 삽입합니다.$ insert_kubeconfig_volume "<csv_file>"1 - 1
<csv_file>을 CSV 매니페스트 경로로 바꿉니다.
kubeconfig보안 마운트를 삽입합니다.$ insert_kubeconfig_secret_mount "<csv_file>"프록시 컨테이너를 삽입합니다.
$ insert_proxy_container "<csv_file>" "quay.io/operator-framework/scorecard-proxy:master"
- 프록시 컨테이너를 삽입한 후 Operator SDK 가이드로 시작하기의 단계를 수행하여 CSV 및 CRD(사용자 정의 리소스 정의)를 번들하고 OLM에 Operator를 배포합니다.
-
OLM에 Operator가 배포된 후 Operator 프로젝트에
.osdk-scorecard.yaml구성 파일을 정의하고csv-path: <csv_manifest_path>및olm-deployed옵션이 설정되었는지 확인합니다. csv-path: <csv_manifest_path>및olm-deployed옵션이 스코어 카드 구성 파일에 설정된 스코어 카드를 실행합니다.$ operator-sdk scorecard
5.9. Prometheus를 사용하여 기본 제공 모니터링 구성
이 가이드에서는 Prometheus Operator 및 Operator 작성자 세부 정보를 사용하여 Operator SDK에서 제공하는 기본 제공 모니터링 지원에 대해 설명합니다.
5.9.1. Prometheus Operator 지원
Prometheus는 오픈 소스 시스템 모니터링 및 경고 툴킷입니다. Prometheus Operator는 OpenShift Container Platform과 같은 Kubernetes 기반 클러스터에서 실행되는 Prometheus 클러스터를 생성, 구성, 관리합니다.
Helper 함수는 기본적으로 Operator SDK에 있으며 Prometheus Operator가 배포된 클러스터에서 사용하기 위해 생성한 Go 기반 Operator의 지표를 자동으로 설정합니다.
5.9.2. 지표 도우미
Operator SDK를 사용하여 생성한 Go 기반 Operator에서 다음 함수는 실행 중인 프로그램에 대한 일반 지표를 표시합니다.
func ExposeMetricsPort(ctx context.Context, port int32) (*v1.Service, error)
이러한 지표는 controller-runtime 라이브러리 API에서 상속됩니다. 기본적으로 지표는 0.0.0.0:8383/metrics에서 제공됩니다.
표시된 지표 포트를 사용하여 Service 오브젝트가 생성되고 Prometheus에서 액세스할 수 있습니다. 리더 Pod의 root 소유자가 삭제되면 Service 오브젝트가 가비지 수집됩니다.
다음 예제는 Operator SDK를 사용하여 생성한 모든 Operator의 cmd/manager/main.go 파일에 있습니다.
import(
"github.com/operator-framework/operator-sdk/pkg/metrics"
"machine.openshift.io/controller-runtime/pkg/manager"
)
var (
// Change the below variables to serve metrics on a different host or port.
metricsHost = "0.0.0.0"
metricsPort int32 = 8383
)
...
func main() {
...
// Pass metrics address to controller-runtime manager
mgr, err := manager.New(cfg, manager.Options{
Namespace: namespace,
MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort),
})
...
// Create Service object to expose the metrics port.
_, err = metrics.ExposeMetricsPort(ctx, metricsPort)
if err != nil {
// handle error
log.Info(err.Error())
}
...
}5.9.2.1. 지표 포트 수정
Operator 작성자는 지표가 표시되는 포트를 수정할 수 있습니다.
사전 요구 사항
- Operator SDK를 사용하여 Go 기반 Operator가 생성됨
- Kubernetes 기반 클러스터에 Prometheus Operator가 배포됨
프로세스
생성된 Operator의
cmd/manager/main.go파일에서 다음 줄에 있는metricsPort값을 변경합니다.var metricsPort int32 = 8383
5.9.3. 서비스 모니터
ServiceMonitor는 Service 오브젝트에서 Endpoints를 검색하고 해당 Pod를 모니터링하도록 Prometheus를 구성하는 Prometheus Operator에서 제공하는 사용자 정의 리소스입니다.
Operator SDK를 사용하여 생성한 Go 기반 Operator에서는 GenerateServiceMonitor() 도우미 함수에서 Service 오브젝트를 가져와서 이를 기반으로 ServiceMonitor 오브젝트를 생성할 수 있습니다.
5.9.3.1. 서비스 모니터 생성
Operator 작성자는 metrics.CreateServiceMonitor() 도우미 함수를 사용하여 생성한 모니터링 서비스에 대한 서비스 대상 검색 기능을 추가하여 새로 생성한 서비스를 허용할 수 있습니다.
사전 요구 사항
- Operator SDK를 사용하여 Go 기반 Operator가 생성됨
- Kubernetes 기반 클러스터에 Prometheus Operator가 배포됨
프로세스
Operator 코드에
metrics.CreateServiceMonitor()도우미 함수를 추가합니다.import( "k8s.io/api/core/v1" "github.com/operator-framework/operator-sdk/pkg/metrics" "machine.openshift.io/controller-runtime/pkg/client/config" ) func main() { ... // Populate below with the Service(s) for which you want to create ServiceMonitors. services := []*v1.Service{} // Create one ServiceMonitor per application per namespace. // Change the below value to name of the Namespace you want the ServiceMonitor to be created in. ns := "default" // restConfig is used for talking to the Kubernetes apiserver restConfig := config.GetConfig() // Pass the Service(s) to the helper function, which in turn returns the array of ServiceMonitor objects. serviceMonitors, err := metrics.CreateServiceMonitors(restConfig, ns, services) if err != nil { // Handle errors here. } ... }
5.10. 리더 선택 방식 구성
Operator의 라이프사이클 동안, 예를 들어 Operator에 대한 업그레이드를 롤아웃할 때 언제든지 여러 개의 인스턴스를 실행할 수 있습니다. 이러한 시나리오에서는 리더를 선택하여 여러 Operator 인스턴스 간 경합을 방지해야 합니다. 그러면 하나의 리더 인스턴스에서만 조정을 처리하고 다른 인스턴스는 비활성화되지만 리더가 아래로 내려가면 이어서 작업을 수행할 수 있습니다.
두 가지 리더 선택 구현 방법 중 선택할 수 있으며 각각 고유한 장단점이 있습니다.
- Leader-for-life
-
리더 Pod는 삭제되는 경우에만 가비지 컬렉션을 사용하여 리더십을 포기합니다. 이 구현에서는 실수로 두 개의 인스턴스가 리더로 실행될 가능성을 방지합니다. 이러한 상태를 스플릿 브레인이라고 합니다. 그러나 이 방법을 사용하면 새 리더 선택이 지연될 수 있습니다. 예를 들어 리더 Pod가 응답하지 않거나 분할된 노드에 있는 경우
pod-eviction-timeout은 리더 Pod가 노드에서 삭제되고 아래로 내려가는 데 걸리는 시간을 지정하는데 기본값은5m입니다. 자세한 내용은 leader-for-life Go 설명서를 참조하십시오. - Leader-with-lease
- 리더 Pod는 주기적으로 리더 리스를 갱신하고 리스를 갱신할 수 없는 경우 리더십을 포기합니다. 이 구현에서는 기존 리더가 격리되었을 때 새 리더로 더 빠르게 전환할 수 있지만 특정 상황에서 스플릿 브레인이 발생할 가능성이 있습니다. 자세한 내용은 Leader-with-lease Go 설명서를 참조하십시오.
Operator SDK에서는 기본적으로 Leader-for-life 구현을 사용합니다. 두 가지 접근 방식에 대한 관련 Go 설명서를 참조하여 사용 사례에 적합한 장단점을 고려하도록 합니다.
5.10.1. Operator 리더 선택 예
다음 예제에서는 Operator에 대한 두 개의 리더 선택 옵션인 Leader-for-life 및 Leader-with-lease를 사용하는 방법을 보여줍니다.
5.10.1.1. Leader-for-life 선택
Leader-for-life 선택 방식을 구현하면 leader.Become() 호출 시 memcached-operator-lock이라는 구성 맵을 생성하여 Operator에서 리더가 될 때까지 재시도하지 못하도록 합니다.
import (
...
"github.com/operator-framework/operator-sdk/pkg/leader"
)
func main() {
...
err = leader.Become(context.TODO(), "memcached-operator-lock")
if err != nil {
log.Error(err, "Failed to retry for leader lock")
os.Exit(1)
}
...
}
Operator가 클러스터 내에서 실행되지 않는 경우 leader.Become()은 Operator의 이름을 탐지할 수 없기 때문에 리더 선택을 건너뛰기 위해 오류 없이 단순히 반환됩니다.
5.10.1.2. Leader-with-lease 선택
리더 선택을 위해 Manager 옵션을 사용하여 Leader-with-lease 구현을 활성화할 수 있습니다.
import (
...
"sigs.k8s.io/controller-runtime/pkg/manager"
)
func main() {
...
opts := manager.Options{
...
LeaderElection: true,
LeaderElectionID: "memcached-operator-lock"
}
mgr, err := manager.New(cfg, opts)
...
}
Operator가 클러스터에서 실행되지 않으면 Manager에서 리더 선택을 위한 구성 맵을 생성하기 위해 Operator의 네임스페이스를 탐지할 수 없기 때문에 시작 시 오류를 반환합니다. Manager에 LeaderElectionNamespace 옵션을 설정하여 이 네임스페이스를 덮어쓸 수 있습니다.
5.11. Operator SDK CLI 참조
이 가이드에서는 Operator SDK CLI 명령 및 해당 구문을 설명합니다.
$ operator-sdk <command> [<subcommand>] [<argument>] [<flags>]5.11.1. alpha
operator-sdk alpha 명령은 alpha 하위 명령을 실행하는 데 사용됩니다.
5.11.1.1. scorecard
alpha scorecard 하위 명령은 스코어 카드 툴을 실행하여 Operator 번들을 검증하고 개선을 위한 제안을 제공합니다. 이 명령은 하나의 인수를 사용하며, 인수는 번들 이미지이거나 매니페스트 및 메타데이터가 포함된 디렉터리입니다. 인수에 이미지 태그가 있으면 이미지가 원격으로 존재해야 합니다.
| 플래그 | Description |
|---|---|
|
| 스코어 카드 구성 파일 경로입니다. |
|
|
|
|
|
|
|
| 실행할 수 있는 테스트를 나열합니다. |
|
|
테스트 이미지를 실행할 네임스페이스입니다. 기본값: |
|
|
결과 출력 형식입니다. 사용 가능한 값은 |
|
| 실행할 테스트를 결정하는 라벨 선택기입니다. |
|
|
테스트에 사용할 서비스 계정입니다. 기본값: |
|
| 테스트가 실행된 후 리소스 정리를 비활성화합니다. |
|
|
테스트가 완료될 때까지 대기할 시간(초)입니다(예: |
5.11.2. Build
operator-sdk build 명령은 코드를 컴파일하고 실행 파일을 빌드합니다. 빌드가 완료되면 로컬 컨테이너 엔진을 사용하여 이미지가 빌드됩니다. 그런 다음 원격 레지스트리로 푸시해야 합니다.
| 인수 | 설명 |
|---|---|
|
|
빌드할 컨테이너 이미지(예: |
| 플래그 | 설명 |
|---|---|
|
| 추가 Go 빌드 인수. |
|
| 하나의 문자열로 추가 이미지 빌드 인수. |
|
|
OCI 이미지를 빌드하는 툴. 사용 가능한 옵션은 |
|
| 사용법 도움말 출력입니다. |
5.11.3. 번들
operator-sdk bundle 명령은 Operator 번들 메타데이터를 관리합니다.
5.11.3.1. 검증
bundle validate 하위 명령은 Operator 번들을 검증합니다.
| 플래그 | Description |
|---|---|
|
|
|
|
|
번들 이미지를 가져오고 압축 해제하는 툴입니다. 번들 이미지를 검증할 때만 사용됩니다. 사용 가능한 옵션은 |
5.11.4. cleanup
operator-sdk cleanup 명령은 run 명령을 사용하여 배포한 Operator용으로 생성된 리소스를 삭제하고 제거합니다.
5.11.4.1. PackageManifests
cleanup packagemanifests 하위 명령은 run packagemanifests 명령을 사용하여 OLM과 함께 배포된 Operator를 삭제합니다.
| 인수 | 설명 |
|---|---|
|
|
역할 및 서브스크립션 오브젝트와 같은 Kubernetes 리소스 매니페스트의 파일 경로입니다. 이러한 보충을 제공하거나 |
|
|
|
|
|
Kubernetes 구성 파일의 파일 경로입니다. 기본값: |
|
|
OLM이 설치된 네임스페이스입니다. 기본값: |
|
|
Operator 리소스가 생성되는 네임스페이스입니다. 네임스페이스는 클러스터에 이미 있거나 |
|
| 배포할 Operator의 버전입니다. |
|
|
명령이 실패하기 전에 명령이 완료될 때까지 기다리는 시간입니다. 기본값: |
|
| 사용법 도움말 출력입니다. |
5.11.5. 완료
operator-sdk completion 명령은 CLI 명령을 더 신속하고 쉽게 실행할 수 있도록 쉘 완료를 생성합니다.
| 하위 명령 | Description |
|---|---|
|
| bash 완료를 생성합니다. |
|
| zsh 완료를 생성합니다. |
| 플래그 | Description |
|---|---|
|
| 사용법 도움말 출력입니다. |
예를 들면 다음과 같습니다.
$ operator-sdk completion bash출력 예
# bash completion for operator-sdk -*- shell-script -*-
...
# ex: ts=4 sw=4 et filetype=sh5.11.6. create
operator-sdk create 명령은 Kubernetes API를 생성하거나 스캐폴드하는 데 사용됩니다.
5.11.6.1. api
create api 하위 명령은 Kubernetes API를 스캐폴드합니다. 하위 명령은 init 명령을 사용하여 초기화한 프로젝트에서 실행해야 합니다.
| 플래그 | Description |
|---|---|
|
|
|
5.11.6.2. Webhook
create webhook 하위 명령은 API 리소스의 Webhook를 스캐폴드합니다. 하위 명령은 init 명령을 사용하여 초기화한 프로젝트에서 실행해야 합니다.
| 플래그 | Description |
|---|---|
|
|
|
5.11.7. generate
필요에 따라 operator-sdk generate 명령은 특정 생성기를 호출하여 코드를 생성합니다.
5.11.7.1. 번들
generate bundle 하위 명령은 Operator 프로젝트에 대해 일련의 번들 매니페스트, 메타데이터, bundle.Dockerfile 파일을 생성합니다.
일반적으로 generate kustomize manifests 하위 명령을 먼저 실행하여 generate bundle 하위 명령에 사용되는 입력 Kustomize 베이스를 생성합니다. 그러나 초기화된 프로젝트에서 make bundle 명령을 사용하여 이러한 명령을 순서대로 실행하도록 자동화할 수 있습니다.
| 플래그 | Description |
|---|---|
|
|
번들이 속한 채널의 쉼표로 구분된 목록입니다. 기본값은 |
|
|
|
|
| 번들의 기본 채널입니다. |
|
|
배포 및 RBAC와 같은 Operator 매니페스트용 루트 디렉터리입니다. 이 디렉터리는 |
|
|
|
|
|
기존 번들을 읽을 디렉터리입니다. 이 디렉터리는 번들 |
|
|
번들 매니페스트용 Kustomize 베이스 및 |
|
| 번들 매니페스트를 생성합니다. |
|
| 번들 메타데이터 및 Dockerfile을 생성합니다. |
|
| 번들의 Operator 이름입니다. |
|
| 번들을 작성할 디렉터리입니다. |
|
|
번들 메타데이터 및 Dockerfile이 있는 경우 덮어씁니다. 기본값은 |
|
| 자동 모드로 실행됩니다. |
|
| 번들 매니페스트를 표준 출력에 작성합니다. |
|
| 생성된 번들에 있는 Operator의 의미 체계 버전입니다. 새 번들을 생성하거나 Operator를 업그레이드하는 경우에만 설정됩니다. |
5.11.7.2. kustomize
generate kustomize 하위 명령에는 Operator에 대한 Kustomize 데이터를 생성하는 하위 명령이 포함되어 있습니다.
5.11.7.2.1. 매니페스트
generate kustomize manifests 하위 명령은 다른 Operator SDK 명령에서 번들 매니페스트를 빌드하는 데 사용하는 Kustomize 베이스 및 kustomization.yaml 파일을 config/manifests 디렉터리에 생성하거나 다시 생성합니다. 베이스가 존재하지 않거나 --interactive=false 플래그를 설정하지 않은 경우 이 명령은 기본적으로 매니페스트 베이스의 중요한 구성 요소인 UI 메타데이터를 대화형으로 요청합니다.
| 플래그 | Description |
|---|---|
|
| API 유형 정의를 위한 루트 디렉터리입니다. |
|
|
|
|
| 기존 Kustomize 파일이 있는 디렉터리입니다. |
|
|
|
|
| Operator의 이름입니다. |
|
| Kustomize 파일을 작성할 디렉터리입니다. |
|
| 자동 모드로 실행됩니다. |
5.11.7.3. PackageManifests
generate packagemanifests 하위 명령 실행은 Operator를 카탈로그에 게시하여 OLM 또는 둘 다 사용하여 배포하는 첫 번째 단계입니다. 이 명령은 버전이 지정된 디렉터리에 매니페스트 세트를 생성하고 Operator용 패키지 매니페스트 파일을 생성합니다. 이 명령에서 사용하는 K ustomize 기반을 다시 생성하려면 generate kustomize manifests를 먼저 실행해야 합니다.
| 플래그 | 설명 |
|---|---|
|
| 생성된 패키지의 채널 이름입니다. |
|
| CRD(사용자 정의 리소스 정의) 매니페스트의 루트 디렉터리입니다. |
|
|
패키지 매니페스트 파일의 기본 채널로 |
|
|
배포 및 RBAC와 같은 Operator 매니페스트의 루트 디렉터리(예: |
|
| 업그레이드 중인 Operator의 의미 체계 버전입니다. |
|
|
|
|
|
기존 패키지 매니페스트를 읽을 디렉터리입니다. 이 디렉터리는 버전이 지정된 개별 패키지 디렉터리의 부모이며 |
|
|
|
|
| 패키지된 Operator의 이름입니다. |
|
| 패키지 매니페스트를 작성할 디렉터리입니다. |
|
| 자동 모드로 실행됩니다. |
|
|
패키지를 |
|
|
이 패키지에서 CRD(사용자 정의 리소스 정의) 매니페스트를 업데이트합니다. 기본값: |
|
| 패키지된 Operator의 의미 체계 버전입니다. |
5.11.8. init
operator-sdk init 명령은 Operator 프로젝트를 초기화하고 지정된 플러그인 의 기본 프로젝트 디렉터리 레이아웃을 생성하거나 스캐폴드 합니다.
이 명령은 다음 파일을 작성합니다.
- 상용구 라이센스 파일
-
도메인 및 리포지토리가 있는
PROJECT파일 -
프로젝트를 빌드할
Makefile -
프로젝트 종속 항목이 있는
go.mod파일 -
매니페스트를 사용자 정의하는
kustomization.yaml파일 - 관리자 매니페스트용 이미지를 사용자 정의하는 패치 파일
- Prometheus 지표를 활성화하는 패치 파일
-
실행할
main.go파일
| 플래그 | Description |
|---|---|
|
|
|
|
|
프로젝트를 초기화할 플러그인의 이름 및 버전(선택 사항)입니다. 사용 가능한 플러그인은 |
|
|
프로젝트 버전입니다. 사용 가능한 값은 |
5.11.9. new
operator-sdk new 명령은 새 Operator 애플리케이션을 생성하고 입력 <project_name> 을 기반으로 기본 프로젝트 디렉터리 레이아웃을 생성(또는 스캐폴드)합니다.
| 인수 | 설명 |
|---|---|
|
| 새 프로젝트의 이름입니다. |
| 플래그 | 설명 |
|---|---|
|
|
|
|
|
생성할 CRD 버전입니다. 기본값: |
|
|
Ansible 플레이북 스켈레톤을 생성합니다. |
|
|
기존 Helm 차트 |
|
| 요청된 Helm 차트의 차트 리포지터리 URL입니다. |
|
|
특정 버전의 Helm 차트입니다. |
|
| 사용법 및 도움말 출력. |
|
|
CRD 종류(예: |
|
| 심층 복사 및 OpenAPI 코드 및 OpenAPI CRD 사양 생성을 건너뜁니다. |
|
|
초기화할 Operator 유형: |
Operator SDK v0.12.0부터 --dep-manager 플래그 및 dep기반 프로젝트에 대한 지원이 제거되었습니다. Go 모듈은 이제 Go 프로젝트를 스캐폴드합니다.
Go 프로젝트의 사용 예
$ mkdir $GOPATH/src/github.com/example.com/$ cd $GOPATH/src/github.com/example.com/$ operator-sdk new app-operatorAnsible 프로젝트의 사용 예
$ operator-sdk new app-operator \
--type=ansible \
--api-version=app.example.com/v1alpha1 \
--kind=AppService5.11.10. OLM
operator-sdk olm 명령은 클러스터의 OLM(Operator Lifecycle Manager) 설치를 관리합니다.
5.11.10.1. 설치
OLM 설치 하위 명령은 클러스터에 OLM을 설치합니다.
| 인수 | 설명 |
|---|---|
|
|
OLM이 설치된 네임스페이스입니다. 기본값: |
|
|
명령이 실패하기 전에 명령이 완료될 때까지 기다리는 시간입니다. 기본값: |
|
|
설치할 OLM 리소스의 버전입니다. 기본값: |
|
| 사용법 도움말 출력입니다. |
5.11.10.2. status
OLM status 하위 명령은 클러스터에서 OLM(Operator Lifecycle Manager) 설치 상태를 가져옵니다.
| 인수 | 설명 |
|---|---|
|
|
OLM이 설치된 네임스페이스입니다. 기본값: |
|
|
명령이 실패하기 전에 명령이 완료될 때까지 기다리는 시간입니다. 기본값: |
|
|
클러스터에 설치된 OLM의 버전입니다. 설정되지 않으면 |
|
| 사용법 도움말 출력입니다. |
5.11.10.3. 제거
OLM uninstall 하위 명령은 클러스터에서 OLM을 제거합니다.
| 인수 | 설명 |
|---|---|
|
|
OLM을 제거할 네임스페이스입니다. 기본값: |
|
|
명령이 실패하기 전에 명령이 완료될 때까지 기다리는 시간입니다. 기본값: |
|
| 제거할 OLM 리소스의 버전입니다. |
|
| 사용법 도움말 출력입니다. |
5.11.11. run
operator-sdk run 명령은 다양한 환경에서 Operator를 시작할 수 있는 옵션을 제공합니다.
5.11.11.1. PackageManifests
run packagemanifests 하위 명령은 OLM(Operator Lifecycle Manager)을 사용하여 Operator의 패키지 매니페스트를 배포합니다. command 인수를 유효한 패키지 매니페스트 루트 디렉터리(예: <project_root>/packagemanifests )로 설정해야 합니다.
| 인수 | 설명 |
|---|---|
|
|
역할 및 서브스크립션 오브젝트와 같은 Kubernetes 리소스 매니페스트의 파일 경로입니다. 이러한 보충을 제공하거나 |
|
|
|
|
|
Kubernetes 구성 파일의 파일 경로입니다. 기본값: 환경 변수가 설정되지 않은 경우 |
|
|
OLM이 설치된 네임스페이스입니다. 기본값: |
|
|
Operator 리소스가 생성되는 네임스페이스입니다. 네임스페이스는 클러스터에 이미 있거나 |
|
| 배포할 Operator의 버전입니다. |
|
|
명령이 실패하기 전에 명령이 완료될 때까지 기다리는 시간입니다. 기본값: |
|
| 사용법 도움말 출력입니다. |
5.12. 부록
5.12.1. Operator 프로젝트 스캐폴딩 레이아웃
operator-sdk CLI는 각 Operator 프로젝트에 대해 여러 패키지를 생성합니다. 다음 섹션에서는 생성된 각 파일 및 디렉터리의 기본 실행에 대해 설명합니다.
5.12.1.1. Ansible 기반 프로젝트
operator-sdk new --type ansible 명령을 사용하여 생성된 Ansible 기반 Operator 프로젝트에는 다음 디렉터리 및 파일이 포함되어 있습니다.
| 파일/폴더 | 목적 |
|---|---|
|
| Ansible 역할을 테스트하는 데 사용되는 파일을 포함합니다. |
|
| 프로젝트를 생성하는 동안 사용되는 Helm 차트를 포함합니다. |
|
| Operator를 빌드하는 데 사용되는 Dockerfile 및 빌드 스크립트를 포함합니다. |
|
| CRD 등록, RBAC 설정, Operator를 배포로 배포하기 위한 다양한 YAML 매니페스트가 포함되어 있습니다. |
|
| 설치해야 하는 Ansible 콘텐츠를 포함합니다. |
|
| 그룹, 버전, 종류 및 역할을 포함합니다. |
5.12.1.2. Helm 기반 프로젝트
operator-sdk new --type helm 명령을 사용하여 생성된 Helm 기반 Operator 프로젝트에는 다음 디렉터리 및 파일이 포함됩니다.
| 파일/폴더 | 목적 |
|---|---|
|
| CRD 등록, RBAC 설정, Operator를 Deployment로 배포하기 위한 다양한 YAML 매니페스트가 포함되어 있습니다. |
|
|
|
|
| Operator를 빌드하는 데 사용되는 Dockerfile 및 빌드 스크립트를 포함합니다. |
|
| 그룹, 버전, 종류 및 Helm 차트 위치가 포함되어 있습니다. |
6장. Red Hat Operator
6.1. Cloud Credential Operator
목적
CCO(Cloud Credential Operator)는 클라우드 공급자 자격 증명을 Kubernetes CRD(사용자 지정 리소스 정의)로 관리합니다. CCO는 credentialsRequest CR(사용자 정의 리소스)에서 동기화되어 OpenShift Container Platform 구성 요소가 클러스터를 실행하는 데 필요한 특정 권한으로 클라우드 공급자 인증 정보를 요청할 수 있습니다.
install-config.yaml 파일에서 credentialsMode 매개변수에 다양한 값을 설정하면 CCO를 여러 모드에서 작동하도록 구성할 수 있습니다. 모드를 지정하지 않거나 credentialsMode 매개변수를 빈 문자열("")로 설정하면 CCO가 기본 모드에서 작동합니다.
기본 동작
여러 모드가 지원되는 플랫폼의 경우(AWS, Azure 및 GCP) CCO가 기본 모드에서 작동하는 경우 credentialsRequest CR을 처리할 수 있는 모드를 결정하기 위해 제공된 인증 정보를 동적으로 확인합니다.
기본적으로 CCO는 인증 정보가 기본 작동 모드인 mint 모드에 충분한지 결정하고 해당 인증 정보를 사용하여 클러스터의 구성 요소에 적절한 인증 정보를 생성합니다. 인증 정보가 Mint 모드에 충분하지 않으면 passthrough 모드에 충분한지 여부를 결정합니다. 인증 정보가 passthrough 모드에 충분하지 않으면 CCO에서 credentialsRequest CR을 적절하게 처리할 수 없습니다.
CCO는 Azure 인증 정보가 passthrough 모드에 충분한지 여부를 확인할 수 없습니다. Azure 인증 정보가 Mint 모드에 충분하지 않으면 CCO는 인증 정보가 passthrough 모드에 충분하다는 가정으로 작동합니다.
설치 중에 제공된 인증 정보가 충분하지 않다고 판단되면 설치에 실패합니다. AWS의 경우 설치 프로그램은 프로세스 초기에 실패하고 필요한 권한이 누락된 것을 나타냅니다. 다른 공급자는 오류가 발생할 때까지 오류 발생 원인에 대한 구체적인 정보를 제공하지 않을 수 있습니다.
설치에 성공하고 CCO에서 새 인증 정보가 충분하지 않은 것으로 판단되면 CCO는 새 credentialsRequest CR에 조건을 배치하여 충분하지 않은 인증 정보로 인해 이를 처리할 수 없음을 나타냅니다.
충분하지 않은 인증 정보 문제를 해결하려면 충분한 권한이 있는 인증 정보를 제공하십시오. 설치 중에 오류가 발생한 경우 다시 설치해보십시오. 새 credentialsRequest CR 문제의 경우 CCO가 CR을 다시 처리할 때까지 기다립니다. 또는 AWS, Azure 또는 GCP의 IAM을 수동으로 생성할 수 있습니다. 자세한 내용은 AWS, Azure 또는 GCP에 대한 설치 콘텐츠의 IAM 수동 생성 섹션을 참조하십시오.
모드
install-config.yaml 파일에서 credentialsMode 매개변수의 다른 값을 설정하면 mint, passthrough 또는 manual 모드에서 CCO를 작동하도록 구성할 수 있습니다. 이러한 옵션은 CCO가 클라우드 인증 정보를 사용하여 클러스터의 credentialsRequest CR을 처리하는 방법에 투명성과 유연성을 제공하며 조직의 보안 요구 사항에 맞게 CCO를 구성할 수 있습니다. 모든 클라우드 공급자에서 모든 CCO 모드가 지원되는 것은 아닙니다.
Mint 모드
Mint 모드는 AWS, Azure 및 GCP에서 지원됩니다.
Mint 모드는 CCO가 사용할 기본 및 권장 모범 사례 설정입니다. 이 모드에서 CCO는 제공된 관리자 수준 클라우드 인증 정보를 사용하여 클러스터를 실행합니다.
설치 후 인증 정보를 제거하지 않으면 CCO에서 저장하고 사용하여 클러스터의 구성 요소에 대한 credentialsRequest CR을 처리하고 필요한 특정 권한으로 각각에 대한 새 인증 정보를 생성합니다. mint 모드에서 클라우드 인증 정보의 지속적인 조정을 통해 업그레이드 등을 진행하기 위해 추가 인증 정보 또는 권한이 필요한 작업을 수행할 수 있습니다.
Mint 모드가 클러스터 kube-system 네임스페이스에 admin 수준 인증 정보를 저장해야 하는 요구 사항이 모든 조직의 보안 요구 사항에 맞지 않을 수 있습니다.
Mint 모드에서 CCO를 사용하는 경우 제공한 인증 정보가 OpenShift Container Platform을 실행 중이거나 설치하는 클라우드의 요구 사항을 충족하는지 확인하십시오. 제공된 인증 정보가 mint 모드에 충분하지 않으면 CCO에서 IAM 사용자를 생성할 수 없습니다.
| 클라우드 | 권한 |
|---|---|
| AWS |
|
| Azure | Azure 계정 콘텐츠 구성의 서비스 주체 생성 섹션에 지정된 권한이 있는 서비스 주체입니다. |
| GCP |
|
관리자 수준 인증 정보를 제거하거나 교체하는 Mint 모드
관리자 수준 인증 정보를 제거하거나 교체하는 Mint 모드는 OpenShift Container Platform 버전 4.4 이상의 AWS에서 지원됩니다.
이 옵션을 사용하려면 설치 중에 관리자 수준(admin-level) 인증 정보가 필요하지만 인증 정보는 클러스터에 영구적으로 저장되지 않으며 오래 유지할 필요가 없습니다.
mint 모드에서 OpenShift Container Platform을 설치한 후 클러스터에서 관리자 수준 인증 정보 시크릿을 제거할 수 있습니다. 보안을 제거하면 CCO는 이전에 기록된 읽기 전용 인증 정보를 사용하여 모든 credentialsRequest CR에 필요한 권한이 있는지 확인할 수 있습니다. 제거되고 나면 필요한 경우 기본 클라우드에서 관련 인증 정보를 삭제할 수 있습니다.
예를 들어 업그레이드 중에 관리자 수준 인증 정보를 변경해야 하는 경우가 아니면 관리자 수준 인증 정보가 필요하지 않습니다. 업그레이드하기 전에 관리자 수준 인증 정보를 사용하여 인증 정보 시크릿을 복원해야 합니다. 인증 정보가 없으면 업그레이드가 차단될 수 있습니다.
passthrough 모드
AWS, Azure, GCP, RHOSP(Red Hat OpenStack Platform), RHV(Red Hat Virtualization) 및 VMware vSphere에서 Passthrough 모드가 지원됩니다.
passthrough 모드에서 CCO는 제공된 클라우드 인증 정보를 클라우드 인증 정보를 요청하는 구성 요소에 전달합니다. 인증 정보에는 설치를 수행하고 클러스터의 구성 요소에 필요한 작업을 완료할 수 있는 권한이 있어야 하지만 새 인증 정보를 생성할 필요가 없습니다. CCO는 passthrough 모드로 추가 제한된 범위 인증 정보를 생성하지 않습니다.
Passthrough 모드 권한 요구사항
Passthrough 모드에서 CCO를 사용하는 경우 제공한 인증 정보가 OpenShift Container Platform을 실행 중이거나 설치하는 클라우드의 요구 사항을 충족하는지 확인하십시오. 제공된 인증 정보에서 CCO가 credentialsRequest CR을 생성하는 구성 요소에 충분하지 않으면 구성 요소가 권한이 없는 API를 호출하려고 할 때 오류를 보고합니다.
AWS, Azure 또는 GCP에서 passthrough 모드에 제공하는 인증 정보에는 실행 중 또는 설치 중인 OpenShift Container Platform 버전에 필요한 모든 credentialsRequest CR에 대한 요청된 권한이 있어야 합니다. 클라우드 공급자에 필요한 credentialsRequest CR을 찾으려면 AWS, Azure 또는 GCP에 대한 설치 콘텐츠의 IAM 수동 생성 섹션을 참조하십시오.
RHOSP(Red Hat OpenStack Platform)에 OpenShift Container Platform 클러스터를 설치하려면 CCO에 member 사용자 역할 권한이 있는 인증 정보가 필요합니다.
RHV(Red Hat Virtualization)에 OpenShift Container Platform 클러스터를 설치하려면 CCO에 다음 권한이 있는 인증 정보가 필요합니다.
-
DiskOperator -
DiskCreator -
UserTemplateBasedVm -
TemplateOwner -
TemplateCreator -
OpenShift Container Platform 배포를 대상으로 하는 특정 클러스터의
ClusterAdmin
VMware vSphere에 OpenShift Container Platform 클러스터를 설치하려면 CCO에 다음 vSphere 권한이 있는 인증 정보가 필요합니다.
| 카테고리 | 권한 |
|---|---|
| 데이터 저장소 | 공간 할당 |
| 폴더 | 폴더 생성, 폴더 삭제 |
| vSphere 태그 지정 | 모든 권한 |
| 네트워크 | 네트워크 할당 |
| 리소스 이름 | 리소스 풀에 가상 머신 할당 |
| 프로필 중심 스토리지 | 모든 권한 |
| vApp | 모든 권한 |
| 가상 머신 | 모든 권한 |
Passthrough 모드 인증 정보 유지 관리
클러스터가 업그레이드되어 Credential Request CR이 시간이 지남에 따라 변경되는 경우 요구 사항을 충족하도록 passthrough 모드 인증 정보를 수동으로 업데이트해야 합니다. 업그레이드 중 인증 정보 문제를 방지하려면 업그레이드하기 전에 새 버전의 OpenShift Container Platform에 대해 릴리스 이미지의 credentialsRequest CR을 확인하십시오. 클라우드 공급자에 필요한 credentialsRequest CR을 찾으려면 AWS, Azure 또는 GCP에 대한 설치 콘텐츠의 IAM 수동 생성 섹션을 참조하십시오.
설치 후 권한 감소
passthrough 모드를 사용할 때 각 구성 요소에는 다른 모든 구성 요소가 사용하는 것과 동일한 권한이 있습니다. 설치 후 권한을 줄이지 않으면 모든 구성 요소에 설치 프로그램 실행에 필요한 광범위한 권한이 있습니다.
설치 후 사용 중인 OpenShift Container Platform 버전의 릴리스 이미지의 credentialsRequest CR에 정의된 대로 인증 정보에 대한 권한을 클러스터를 실행하는 데 필요한 권한으로 줄일 수 있습니다.
AWS, Azure 또는 GCP에 필요한 credentialsRequest CR을 찾고 CCO에서 사용하는 권한을 변경하는 방법을 알아보려면 AWS, Azure 또는 GCP에 대한 설치 콘텐츠의 IAM 수동 생성 섹션을 참조하십시오.
수동 모드
수동 모드는 AWS에서 지원됩니다.
수동 모드에서 사용자는 CCO 대신 클라우드 인증 정보를 관리합니다. 이 모드를 사용하려면 실행 또는 설치 중인 OpenShift Container Platform 버전의 릴리스 이미지에서 credentialsRequest CR을 검사하고 기본 클라우드 공급자에 해당 인증 정보를 생성하고, 클러스터 클라우드 공급자에 대한 모든 credentialsRequest CR을 충족하기 위해 올바른 네임스페이스에 Kubernetes 보안을 생성해야 합니다.
수동 모드를 사용하면 각 클러스터 구성 요소에 클러스터에 관리자 수준 인증 정보를 저장하지 않고도 필요한 권한만 보유할 수 있습니다. 이 모드에서도 AWS 공용 IAM 끝점에 연결할 필요가 없습니다. 그러나 업그레이드할 때마다 새 릴리스 이미지로 권한을 수동으로 조정해야 합니다.
수동 모드를 사용하도록 AWS를 구성하는 방법에 대한 자세한 내용은 AWS의 IAM 수동 생성을 참조하십시오.
비활성화된 CCO
비활성화된 CCO는 Azure 및 GCP에서 지원됩니다.
Azure 또는 GCP의 인증 정보를 수동으로 관리하려면 CCO를 비활성화해야 합니다. CCO를 비활성화하면 수동 모드에서 CCO를 실행하는 것과 동일한 구성 및 유지 관리 요구 사항이 많지만 다른 프로세스에 의해 수행됩니다. 자세한 내용은 Azure 또는 GCP 에 대한 설치 콘텐츠의 IAM 수동 생성 섹션을 참조하십시오.
프로젝트
openshift-cloud-credential-operator
CRD
credentialsrequests.cloudcredential.openshift.io- 범위: 네임 스페이스
-
CR:
credentialsrequest - 검증: 있음
구성 오브젝트
구성이 필요하지 않습니다.
6.2. Cluster Authentication Operator
목적
Cluster Authentication Operator는 클러스터에서 Authentication 사용자 정의 리소스를 설치 및 유지 관리하고 다음을 실행하여 확인할 수 있습니다.
$ oc get clusteroperator authentication -o yaml프로젝트
6.3. Cluster Autoscaler Operator
목적
Cluster Autoscaler Operator는 cluster-api 공급자를 사용하여 OpenShift Cluster Autoscaler 배포를 관리합니다.
프로젝트
CRD
-
ClusterAutoscaler: 이는 클러스터에 대한 구성 자동 확장기 인스턴스를 제어하는 Singleton 리소스입니다. Operator는 관리형 네임스페이스에서WATCH_NAMESPACE환경 변수의 값인default라는ClusterAutoscaler리소스에만 응답합니다. -
MachineAutoscaler: 이 리소스는 노드 그룹을 대상으로 하며 해당 그룹,min및 max 크기에 대한 자동 확장을 활성화하고 구성하는 주석을 관리합니다.현재는MachineSet오브젝트만 대상으로 할 수 있습니다.
6.4. Cluster Image Registry Operator
목적
Cluster Image Registry Operator는 OpenShift Container Platform 레지스트리의 단일 인스턴스를 관리합니다. 스토리지 생성을 포함하여 레지스트리의 모든 구성을 관리합니다.
처음 시작 시 Operator는 클러스터에서 탐지된 구성에 따라 기본 image-registry 리소스 인스턴스를 생성합니다. 이는 클라우드 공급자를 기반으로 사용할 클라우드 스토리지 유형을 나타냅니다.
완전한 image-registry 리소스를 정의하는 데 사용할 수 있는 정보가 충분하지 않으면 불완전한 리소스가 정의되고 Operator는 누락된 항목에 대한 정보를 사용하여 리소스 상태를 업데이트합니다.
Cluster Image Registry Operator는 openshift-image-registry 네임스페이스에서 실행되며 해당 위치의 레지스트리 인스턴스도 관리합니다. 레지스트리의 모든 설정 및 워크로드 리소스는 해당 네임 스페이스에 있습니다.
프로젝트
6.5. Cluster Monitoring Operator
목적
Cluster Monitoring Operator는 OpenShift Container Platform 상단에 배포된 Prometheus 기반 클러스터 모니터링 스택을 관리하고 업데이트합니다.
프로젝트
CRD
alertmanagers.monitoring.coreos.com- 범위: 네임 스페이스
-
CR:
alertmanager - 검증: 있음
prometheuses.monitoring.coreos.com- 범위: 네임 스페이스
-
CR:
prometheus - 검증: 있음
prometheusrules.monitoring.coreos.com- 범위: 네임 스페이스
-
CR:
prometheusrule - 검증: 있음
servicemonitors.monitoring.coreos.com- 범위: 네임 스페이스
-
CR:
servicemonitor - 검증: 있음
구성 오브젝트
$ oc -n openshift-monitoring edit cm cluster-monitoring-config6.6. CNO(Cluster Network Operator)
목적
Cluster Network Operator는 OpenShift Container Platform 클러스터에 네트워킹 구성 요소를 설치 및 업그레이드합니다.
6.7. OpenShift Controller Manager Operator
목적
OpenShift Controller Manager Operator는 클러스터에서 OpenShiftControllerManager 사용자 정의 리소스를 설치하고 유지 관리하며 다음을 실행하여 확인할 수 있습니다.
$ oc get clusteroperator openshift-controller-manager -o yaml
CRD(사용자 정의 리소스 정의) openshiftcontrollermanagers.operator.openshift.io는 다음을 실행하여 클러스터에서 확인할 수 있습니다.
$ oc get crd openshiftcontrollermanagers.operator.openshift.io -o yaml프로젝트
6.8. Cluster Samples Operator
목적
Cluster Samples Operator는 openshift 네임스페이스에 저장된 샘플 이미지 스트림 및 템플릿을 관리합니다.
처음 시작 시 Operator는 기본 샘플 구성 리소스를 생성하여 이미지 스트림 및 템플릿을 생성하기 시작합니다. 구성 오브젝트는 키가 cluster이고 유형이 configs.samples인 클러스터 범위 지정 오브젝트입니다.
이미지 스트림은 registry.redhat.io의 이미지를 가리키는 RHCOS(Red Hat Enterprise Linux CoreOS) 기반 OpenShift Container Platform 이미지 스트림입니다. 마찬가지로 템플릿은 OpenShift Container Platform 템플릿으로 분류된 템플릿입니다.
Cluster Samples Operator 배포는 openshift-cluster-samples-operator 네임스페이스에 포함됩니다. 시작 시 내부 레지스트리 및 API 서버의 이미지 스트림 가져오기 논리에서 registry.redhat.io를 통해 인증하는 데 설치 가져오기 보안이 사용됩니다. 관리자는 샘플 이미지 스트림에 사용된 레지스트리를 변경하는 경우 openshift 네임스페이스에 추가 보안을 생성할 수 있습니다. 생성한 경우 이러한 보안에는 이미지를 손쉽게 가져오는 데 필요한 docker의 config.json 콘텐츠가 포함됩니다.
Cluster Samples Operator 이미지에는 관련 OpenShift Container Platform 릴리스의 이미지 스트림 및 템플릿 정의가 포함되어 있습니다. Cluster Samples Operator는 샘플을 생성한 후 호환되는 OpenShift Container Platform 버전을 나타내는 주석을 추가합니다. Operator는 이 주석을 사용하여 각 샘플이 호환되는 릴리스 버전과 일치하는지 확인합니다. 인벤토리 외부 샘플은 건너뛰기한 샘플과 마찬가지로 무시됩니다.
Operator에서 관리하는 모든 샘플에 대한 수정은 버전 주석을 수정하거나 삭제하지 않는 한 허용됩니다. 그러나 업그레이드 시 버전 주석이 변경되면 샘플이 최신 버전으로 업데이트되므로 이러한 수정 사항이 대체될 수 있습니다. Jenkins 이미지는 설치의 이미지 페이로드에 포함되어 있으며 이미지 스트림에 직접 태그가 지정됩니다.
샘플 리소스에는 삭제 시 다음을 정리하는 종료자가 포함됩니다.
- Operator에서 관리하는 이미지 스트림
- Operator에서 관리하는 템플릿
- Operator에서 생성하는 구성 리소스
- 클러스터 상태 리소스
샘플 리소스를 삭제하면 Cluster Samples Operator에서 기본 구성을 사용하여 리소스를 다시 생성합니다.
프로젝트
6.9. Cluster Storage Operator
목적
Cluster Storage Operator는 OpenShift Container Platform 클러스터 수준 스토리지 기본값을 설정합니다. 이를 통해 OpenShift Container Platform 클러스터에 기본 스토리지 클래스가 있는지 확인합니다.
프로젝트
설정
구성이 필요하지 않습니다.
참고
- Cluster Storage Operator는 AWS(Amazon Web Services) 및 RHOSP(Red Hat OpenStack Platform)를 지원합니다.
- 생성한 스토리지 클래스는 주석을 편집하여 기본이 아닌 상태로 설정할 수 있지만 Operator에서 실행하는 동안에는 스토리지 클래스를 삭제할 수 없습니다.
6.10. Cluster Version Operator
목적
클러스터 Operator는 특정 클러스터 기능 영역을 관리합니다. CVO(Cluster Version Operator)는 기본적으로 OpenShift Container Platform에 설치된 클러스터 Operator의 라이프사이클을 관리합니다.
CVO도 OpenShift Update Service를 통해 현재 구성 요소 버전 및 그래프의 정보를 기반으로 유효한 업데이트 및 업데이트 경로를 확인합니다.
프로젝트
추가 리소스
6.11. Console Operator
목적
Console Operator에서 클러스터에 OpenShift Container Platform 웹 콘솔을 설치하고 유지 관리합니다.
프로젝트
6.12. DNS Operator
목적
DNS Operator는 CoreDNS를 배포 및 관리하고 Pod에 이름 확인 서비스를 제공하여 OpenShift Container Platform에서 DNS 기반 Kubernetes 서비스 검색을 사용할 수 있도록 합니다.
Operator는 클러스터 구성을 기반으로 작동하는 기본 배포를 생성합니다.
-
기본 클러스터 도메인은
cluster.local입니다. - CoreDNS Corefile 또는 Kubernetes 플러그인 구성은 아직 지원되지 않습니다.
DNS Operator는 고정 IP를 사용하여 서비스로 노출되는 Kubernetes 데몬 세트로 CoreDNS를 관리합니다. CoreDNS는 클러스터의 모든 노드에서 실행됩니다.
프로젝트
6.13. etcd 클러스터 Operator
목적
etcd 클러스터 Operator는 etcd 클러스터 스케일링을 자동화하고 etcd 모니터링 및 지표를 활성화하여 재해 복구 절차를 간소화합니다.
프로젝트
CRD
etcds.operator.openshift.io- 범위: Cluster
-
CR:
etcd - 검증: 있음
구성 오브젝트
$ oc edit etcd cluster6.14. Ingress Operator
목적
Ingress Operator는 OpenShift Container Platform 라우터를 구성하고 관리합니다.
프로젝트
CRD
clusteringresses.ingress.openshift.io- 범위: 네임 스페이스
-
CR:
clusteringresses - 검증: 없음
구성 오브젝트
클러스터 구성
-
유형 이름:
clusteringresses.ingress.openshift.io -
인스턴스 이름:
default 보기 명령:
$ oc get clusteringresses.ingress.openshift.io -n openshift-ingress-operator default -o yaml
-
유형 이름:
참고
Ingress Operator는 openshift-ingress 프로젝트에서 라우터를 설정하고 라우터용 배포를 생성합니다.
$ oc get deployment -n openshift-ingress
Ingress Operator는 network/cluster 상태의 clusterNetwork[].cidr을 사용하여 관리형 수신 컨트롤러(라우터)를 작동하는 데 사용할 모드(IPv4, IPv6 또는 이중 스택)를 결정합니다. 예를 들어 clusterNetwork에 v6 cidr만 포함된 경우 수신 컨트롤러는 IPv6 전용 모드에서 작동합니다.
다음 예제에서는 클러스터 네트워크가 하나뿐이고 해당 네트워크가 IPv4 cidr이므로 Ingress Operator에서 관리하는 수신 컨트롤러가 IPv4 전용 모드에서 실행됩니다.
$ oc get network/cluster -o jsonpath='{.status.clusterNetwork[*]}'출력 예
map[cidr:10.128.0.0/14 hostPrefix:23]6.15. Kubernetes API Server Operator
목적
Kubernetes API Server Operator는 OpenShift Container Platform 상단에 배포된 Kubernetes API 서버를 관리하고 업데이트합니다. 이 Operator는 OpenShift library-go 프레임워크를 기반으로 하며 CVO(Cluster Version Operator)를 사용하여 설치됩니다.
프로젝트
openshift-kube-apiserver-operator
CRD
kubeapiservers.operator.openshift.io- 범위: Cluster
-
CR:
kubeapiserver - 검증: 있음
구성 오브젝트
$ oc edit kubeapiserver6.16. Kubernetes Controller Manager Operator
목적
Kubernetes Controller Manager Operator는 OpenShift Container Platform 상단에 배포된 Kubernetes Controller Manager를 관리하고 업데이트합니다. 이 Operator는 OpenShift library-go 프레임워크를 기반으로 하며 CVO(Cluster Version Operator)를 통해 설치됩니다.
여기에는 다음 구성 요소가 포함됩니다.
- Operator
- 부트스트랩 매니페스트 렌더러
- 정적 Pod 기반 설치
- 구성 관찰자
기본적으로 Operator는 metrics 서비스를 통해 Prometheus 지표를 표시합니다.
프로젝트
6.17. Kubernetes Scheduler Operator
목적
Kubernetes Scheduler Operator는 OpenShift Container Platform 상단에 배포된 Kubernetes Scheduler를 관리하고 업데이트합니다. 이 Operator는 OpenShift Container Platform library-go 프레임워크를 기반으로 하며 CVO(Cluster Version Operator)를 사용하여 설치됩니다.
Kubernetes Scheduler Operator에는 다음 구성 요소가 포함됩니다.
- Operator
- 부트스트랩 매니페스트 렌더러
- 정적 Pod 기반 설치
- 구성 관찰자
기본적으로 Operator는 metrics 서비스를 통해 Prometheus 지표를 표시합니다.
프로젝트
cluster-kube-scheduler-operator
설정
Kubernetes Scheduler의 구성은 다음을 병합한 결과입니다.
- 기본 구성.
-
사양
schedulers.config.openshift.io에서 관찰된 구성
이러한 구성은 모두 스파스 구성으로, 마지막에 유효한 구성을 형성하기 위해 병합된, 무효화된 JSON 조각입니다.
6.18. Machine API Operator
목적
Machine API Operator는 Kubernetes API를 확장하는 특정 용도의 CRD(사용자 정의 리소스 정의), 컨트롤러, RBAC 오브젝트의 라이프사이클을 관리합니다. 이를 통해 클러스터에서 원하는 머신 상태를 선언합니다.
프로젝트
CRD
-
MachineSet -
Machine -
MachineHealthCheck
6.19. Machine Config Operator
목적
Machine Config Operator는 커널과 kubelet 사이의 모든 것을 포함하여 기본 운영 체제 및 컨테이너 런타임의 구성 및 업데이트를 관리하고 적용합니다.
다음의 네 가지 구성 요소가 있습니다.
-
machine-config-server: 클러스터에 가입하는 새 머신에 Ignition 구성을 제공합니다. -
machine-config-controller:MachineConfig오브젝트에서 정의한 구성으로 머신 업그레이드를 조정합니다. 머신 세트의 업그레이드를 개별적으로 제어하는 옵션이 제공됩니다. -
machine-config-daemon: 업데이트 중에 새 머신 설정을 적용합니다. 머신 상태를 요청한 머신 구성에 대해 검증하고 확인합니다. -
machine-config: 먼저 머신을 설치, 시작 및 업데이트하는 완벽한 시스템 구성 소스를 제공합니다.
프로젝트
6.20. Marketplace Operator
목적
Marketplace Operator는 클러스터 외부 Operator를 클러스터로 가져오는 통로입니다.
프로젝트
6.21. Node Tuning Operator
목적
Node Tuning Operator는 Tuned 데몬을 오케스트레이션하여 노드 수준 튜닝을 관리하는 데 도움이 됩니다. 대부분의 고성능 애플리케이션에는 일정 수준의 커널 튜닝이 필요합니다. Node Tuning Operator는 노드 수준 sysctls 사용자에게 통합 관리 인터페이스를 제공하며 사용자의 필요에 따라 지정되는 사용자 정의 튜닝을 추가할 수 있는 유연성을 제공합니다.
Operator는 OpenShift Container Platform의 컨테이너화된 Tuned 데몬을 Kubernetes 데몬 세트로 관리합니다. 클러스터에서 실행되는 모든 컨테이너화된 Tuned 데몬에 사용자 정의 튜닝 사양이 데몬이 이해할 수 있는 형식으로 전달되도록 합니다. 데몬은 클러스터의 모든 노드에서 노드당 하나씩 실행됩니다.
컨테이너화된 Tuned 데몬을 통해 적용되는 노드 수준 설정은 프로필 변경을 트리거하는 이벤트 시 또는 컨테이너화된 Tuned 데몬이 종료 신호를 수신하고 처리하여 정상적으로 종료될 때 롤백됩니다.
버전 4.1 이상에서는 Node Tuning Operator가 표준 OpenShift Container Platform 설치에 포함되어 있습니다.
프로젝트
6.22. Operator Lifecycle Manager Operator
목적
OLM(Operator Lifecycle Manager)은 OpenShift Container Platform 클러스터에서 실행되는 Kubernetes 네이티브 애플리케이션(Operator) 및 관련 서비스의 라이프사이클을 설치, 업데이트, 관리하는 데 도움이 됩니다. Operator 프레임워크의 일부로, 효과적이고 자동화되었으며 확장 가능한 방식으로 Operator를 관리하도록 설계된 오픈 소스 툴킷입니다.
그림 6.1. Operator Lifecycle Manager 워크플로
OLM은 OpenShift Container Platform 4.6에서 기본적으로 실행되므로 클러스터 관리자가 클러스터에서 실행되는 Operator를 설치, 업그레이드 및 부여할 수 있습니다. OpenShift Container Platform 웹 콘솔은 클러스터 관리자가 Operator를 설치할 수 있는 관리 화면을 제공하고, 클러스터에 제공되는 Operator 카탈로그를 사용할 수 있는 액세스 권한을 특정 프로젝트에 부여합니다.
개발자의 경우 분야별 전문가가 아니어도 셀프서비스 경험을 통해 데이터베이스, 모니터링, 빅 데이터 서비스의 인스턴스를 프로비저닝하고 구성할 수 있습니다. Operator에서 해당 지식을 제공하기 때문입니다.
CRD
OLM(Operator Lifecycle Manager)은 OLM Operator와 Catalog Operator의 두 Operator로 구성됩니다.
각 Operator는 OLM 프레임워크의 기반이 되는 CRD(사용자 정의 리소스 정의)를 관리합니다.
| 리소스 | 짧은 이름 | 소유자 | Description |
|---|---|---|---|
|
|
| OLM | 애플리케이션 메타데이터: 이름, 버전, 아이콘, 필수 리소스, 설치 등입니다. |
|
|
| 카탈로그 | CSV를 자동으로 설치하거나 업그레이드하기 위해 생성하는 계산된 리소스 목록입니다. |
|
|
| 카탈로그 | 애플리케이션을 정의하는 CSV, CRD, 패키지의 리포지토리입니다. |
|
|
| 카탈로그 | 패키지의 채널을 추적하여 CSV를 최신 상태로 유지하는 데 사용됩니다. |
|
|
| OLM |
동일한 네임스페이스에 배포된 모든 Operator를 |
또한 각 Operator는 다음 리소스를 생성합니다.
| 리소스 | 소유자 |
|---|---|
|
| OLM |
|
| |
|
| |
|
| |
|
CRD( | 카탈로그 |
|
|
OLM Operator
CSV에 지정된 필수 리소스가 클러스터에 제공되면 OLM Operator는 CSV 리소스에서 정의하는 애플리케이션을 배포합니다.
OLM Operator는 필수 리소스 생성과는 관련이 없습니다. CLI 또는 Catalog Operator를 사용하여 이러한 리소스를 수동으로 생성하도록 선택할 수 있습니다. 이와 같은 분리를 통해 사용자는 애플리케이션에 활용하기 위해 선택하는 OLM 프레임워크의 양을 점차 늘리며 구매할 수 있습니다.
OLM Operator에서는 다음 워크플로를 사용합니다.
- 네임스페이스에서 CSV(클러스터 서비스 버전)를 조사하고 해당 요구 사항이 충족되는지 확인합니다.
요구사항이 충족되면 CSV에 대한 설치 전략을 실행합니다.
참고설치 전략을 실행하기 위해서는 CSV가 Operator group의 활성 멤버여야 합니다.
Catalog Operator
Catalog Operator는 CSV(클러스터 서비스 버전) 및 CSV에서 지정하는 필수 리소스를 확인하고 설치합니다. 또한 채널에서 패키지 업데이트에 대한 카탈로그 소스를 조사하고 원하는 경우 사용 가능한 최신 버전으로 자동으로 업그레이드합니다.
채널에서 패키지를 추적하려면 원하는 패키지를 구성하는 Subscription 오브젝트, 채널, 업데이트를 가져오는 데 사용할 CatalogSource 오브젝트를 생성하면 됩니다. 업데이트가 확인되면 사용자를 대신하여 네임스페이스에 적절한 InstallPlan 오브젝트를 기록합니다.
Catalog Operator에서는 다음 워크플로를 사용합니다.
- 클러스터의 각 카탈로그 소스에 연결합니다.
사용자가 생성한 설치 계획 중 확인되지 않은 계획이 있는지 조사하고 있는 경우 다음을 수행합니다.
- 요청한 이름과 일치하는 CSV를 찾아 확인된 리소스로 추가합니다.
- 각 관리 또는 필수 CRD의 경우 CRD를 확인된 리소스로 추가합니다.
- 각 필수 CRD에 대해 이를 관리하는 CSV를 확인합니다.
- 확인된 설치 계획을 조사하고 사용자의 승인에 따라 또는 자동으로 해당 계획에 대해 검색된 리소스를 모두 생성합니다.
- 카탈로그 소스 및 서브스크립션을 조사하고 이에 따라 설치 계획을 생성합니다.
카탈로그 레지스트리
Catalog 레지스트리는 클러스터에서 생성할 CSV 및 CRD를 저장하고 패키지 및 채널에 대한 메타데이터를 저장합니다.
패키지 매니페스트는 패키지 ID를 CSV 세트와 연결하는 카탈로그 레지스트리의 항목입니다. 패키지 내에서 채널은 특정 CSV를 가리킵니다. CSV는 교체하는 CSV를 명시적으로 참조하므로 패키지 매니페스트는 Catalog Operator에 각 중간 버전을 거쳐 CSV를 최신 버전으로 업데이트하는 데 필요한 모든 정보를 제공합니다.
추가 리소스
6.23. OpenShift API Server Operator
목적
OpenShift API Server Operator는 클러스터에서 openshift-apiserver를 설치하고 유지 관리합니다.
프로젝트
CRD
openshiftapiservers.operator.openshift.io- 범위: Cluster
-
CR:
openshiftapiserver - 검증: 있음
6.24. Prometheus Operator
목적
Kubernetes용 Prometheus Operator는 Kubernetes 서비스에 대한 간편한 모니터링 정의와 Prometheus 인스턴스 배포 및 관리 기능을 제공합니다.
설치가 완료되면 Prometheus Operator는 다음 기능을 제공합니다.
- 생성 및 삭제: Operator를 사용하여 Kubernetes 네임스페이스, 특정 애플리케이션 또는 팀에 대한 Prometheus 인스턴스를 쉽게 시작합니다.
- 간단한 설정: 네이티브 Kubernetes 리소스에서 Prometheus의 기본 사항(예: 버전, 지속성, 보존 정책 및 복제본)을 구성합니다.
- 라벨을 통한 대상 서비스: 익숙한 Kubernetes 레이블 쿼리를 기반으로 모니터링 대상 구성을 자동으로 생성합니다. Prometheus 특정 구성 언어를 배울 필요가 없습니다.
프로젝트
6.25. Windows Machine Config Operator
목적
WMCO(Windows Machine Config Operator)는 클러스터에 Windows 워크로드를 배포 및 관리하는 프로세스를 오케스트레이션합니다. WMCO는 Windows 컨테이너 워크로드를 OpenShift Container Platform 클러스터에서 실행할 수 있도록 Windows 머신을 컴퓨팅 노드로 구성합니다. 이 작업은 Docker 형식의 컨테이너 런타임이 설치된 Windows 이미지를 사용하는 머신 세트를 생성하여 수행됩니다. WMCO는 클러스터에 컴퓨팅 노드로 참여할 수 있도록 기본 Windows VM을 구성하는 데 필요한 모든 단계를 완료합니다.