Chapter 5. Upgrading a Cluster
5.1. Overview
When new versions of OpenShift Container Platform are released, you can upgrade your existing cluster to apply the latest enhancements and bug fixes. This includes upgrading from previous minor versions, such as release 3.4 to 3.5, and applying asynchronous errata updates within a minor version (3.5.z releases). See the OpenShift Container Platform 3.5 Release Notes to review the latest changes.
Due to the core architectural changes between the major versions, OpenShift Enterprise 2 environments cannot be upgraded to OpenShift Container Platform 3 and require a fresh installation.
Unless noted otherwise, node and masters within a major version are forward and backward compatible across one minor version, so upgrading your cluster should go smoothly. However, you should not run mismatched versions longer than necessary to upgrade the entire cluster.
5.1.1. In-place or Blue-Green Upgrades
There are two methods for performing OpenShift Container Platform cluster upgrades. You can either do in-place upgrades (automated or manual), or upgrade using a blue-green deployment method.
In-place Upgrades
With in-place upgrades, the cluster upgrade is performed on all hosts in a single, running cluster: first masters and then nodes. Pods are evacuated off of nodes and recreated on other running nodes before a node upgrade begins; this helps reduce downtime of user applications.
If you installed using the quick or advanced installation and the ~/.config/openshift/installer.cfg.yml or inventory file that was used is available, you can perform an automated in-place upgrade. Alternatively, you can upgrade in-place manually.
Blue-green Deployments
The blue-green deployment upgrade method follows a similar flow to the in-place method: masters and etcd servers are still upgraded first, however a parallel environment is created for new nodes instead of upgrading them in-place.
This method allows administrators to switch traffic from the old set of nodes (e.g., the "blue" deployment) to the new set (e.g., the "green" deployment) after the new deployment has been verified. If a problem is detected, it is also then easy to rollback to the old deployment quickly.
5.2. Performing Automated In-place Cluster Upgrades
5.2.1. Overview
An etcd performance issue has been discovered on new and upgraded OpenShift Container Platform 3.5 clusters. See the following Knowledgebase Solution for further details:
If you installed using the advanced installation and the inventory file that was used is available, you can use the upgrade playbook to automate the OpenShift cluster upgrade process. If you installed using the quick installation method and a ~/.config/openshift/installer.cfg.yml file is available, you can use the installer to perform the automated upgrade.
The automated upgrade performs the following steps for you:
- Applies the latest configuration.
- Upgrades master and etcd components and restarts services.
- Upgrades node components and restarts services.
- Applies the latest cluster policies.
- Updates the default router if one exists.
- Updates the default registry if one exists.
- Updates default image streams and InstantApp templates.
Ensure that you have met all prerequisites before proceeding with an upgrade. Failure to do so can result in a failed upgrade.
Running Ansible playbooks with the --tags or --check options is not supported by Red Hat.
5.2.2. Preparing for an Automated Upgrade
Before upgrading your cluster to OpenShift Container Platform 3.5, the cluster must be already upgraded to the latest asynchronous release of version 3.4. Cluster upgrades cannot span more than one minor version at a time, so if your cluster is at a version earlier than 3.4, you must first upgrade incrementally (e.g., 3.2 to 3.3, then 3.3 to 3.4).
Before attempting the upgrade, follow the steps in Verifying the Upgrade to verify the cluster’s health. This will confirm that nodes are in the Ready state, running the expected starting version, and will ensure that there are no diagnostic errors or warnings.
To prepare for an automated upgrade:
If you are upgrading from OpenShift Container Platform 3.4 to 3.5, manually disable the 3.4 channel and enable the 3.5 channel on each master and node host:
# subscription-manager repos --disable="rhel-7-server-ose-3.4-rpms" \ --enable="rhel-7-server-ose-3.5-rpms" \ --enable="rhel-7-server-rpms" \ --enable="rhel-7-server-extras-rpms" \ --enable="rhel-7-fast-datapath-rpms" # yum clean allFor any upgrade path, always ensure that you have the latest version of the atomic-openshift-utils package on each RHEL 7 system, which also updates the openshift-ansible-* packages:
# yum update atomic-openshift-utilsInstall or update to the following latest available *-excluder packages on each RHEL 7 system, which helps ensure your systems stay on the correct versions of atomic-openshift and docker packages when you are not trying to upgrade, according to the OpenShift Container Platform version:
# yum install atomic-openshift-excluder atomic-openshift-docker-excluderThese packages add entries to the
excludedirective in the host’s /etc/yum.conf file.When installing or updating atomic-openshift-utils, /usr/share/openshift/examples/ does not get updated with the latest templates. To update the file:
# mkdir /usr/share/openshift/examples # cp -R /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v3.6/* /usr/share/openshift/examples/
To persist /usr/share/openshift/examples/ on all masters:
mkdir /usr/share/openshift/examples
scp -R /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v3.6/* user@masterx:/usr/share/openshift/examplesYou must be logged in as a cluster administrative user on the master host for the upgrade to succeed:
$ oc loginAfter satisfying these steps, there are two methods for running the automated upgrade:
Choose and follow one of these methods.
5.2.3. Using the Installer to Upgrade
If you installed OpenShift Container Platform using the quick installation method, you should have an installation configuration file located at ~/.config/openshift/installer.cfg.yml. The installer requires this file to start an upgrade.
The installer supports upgrading between minor versions of OpenShift Container Platform (one minor version at a time, e.g., 3.4 to 3.5) as well as between asynchronous errata updates within a minor version (e.g., 3.5.z).
If you have an older format installation configuration file in ~/.config/openshift/installer.cfg.yml from an installation of a previous cluster version, the installer will attempt to upgrade the file to the new supported format. If you do not have an installation configuration file of any format, you can create one manually.
To start an upgrade with the quick installer:
- Satisfy the steps in Preparing for an Automated Upgrade to ensure you are using the latest upgrade playbooks.
Run the installer with the
upgradesubcommand:# atomic-openshift-installer upgrade- Then, follow the on-screen instructions to upgrade to the latest release.
After all master and node upgrades have completed, a recommendation will be printed to reboot all hosts. After rebooting, if there are no additional features enabled, you can verify the upgrade. Otherwise, the next step depends on what additional features have you previously enabled.
Expand Feature Next Step Aggregated Logging
Cluster Metrics
5.2.4. Running Upgrade Playbooks Directly
You can run automated upgrade playbooks using Ansible directly, similar to the advanced installation method, if you have an inventory file. Playbooks can be run using the ansible-playbook command.
The same v3_5 upgrade playbooks can be used for either of the following scenarios:
- Upgrading existing OpenShift Container Platform 3.4 clusters to 3.5
- Upgrading existing OpenShift Container Platform 3.5 clusters to the latest asynchronous errata updates
5.2.4.1. Upgrading the Control Plane and Nodes in Separate Phases
An OpenShift Container Platform cluster can be upgraded in one or more phases. You can choose whether to upgrade all hosts in one phase by running a single Ansible playbook, or upgrade the control plane (master components) and nodes in multiple phases using separate playbooks.
Instructions on the full upgrade process and when to call these playbooks are described in Upgrading to the Latest OpenShift Container Platform 3.5 Release.
When upgrading in separate phases, the control plane phase includes upgrading:
- etcd
- master components
- node services running on masters
- Docker running on masters
- Docker running on any separate etcd hosts
When upgrading only the nodes, the control plane must already be upgraded. The node phase includes upgrading:
- node services running on stand-alone nodes
- Docker running on stand-alone nodes
Nodes running master components are not included during the node upgrade phase, even though they have node services and Docker running on them. Instead, they are upgraded as part of the control plane upgrade phase. This ensures node services and Docker on masters are not upgraded twice (once during the control plane phase and again during the node phase).
5.2.4.2. Customizing Node Upgrades
Whether upgrading in a single or multiple phases, you can customize how the node portion of the upgrade progresses by passing certain Ansible variables to an upgrade playbook using the -e option.
Instructions on the full upgrade process and when to call these playbooks are described in Upgrading to the Latest OpenShift Container Platform 3.5 Release.
The openshift_upgrade_nodes_serial variable can be set to an integer or percentage to control how many node hosts are upgraded at the same time. The default is 1, upgrading nodes one at a time.
For example, to upgrade 20 percent of the total number of detected nodes at a time:
$ ansible-playbook -i <path/to/inventory/file> \
</path/to/upgrade/playbook> \
-e openshift_upgrade_nodes_serial="20%"
The openshift_upgrade_nodes_label variable allows you to specify that only nodes with a certain label are upgraded. This can also be combined with the openshift_upgrade_nodes_serial variable.
For example, to only upgrade nodes in the group1 region, two at a time:
$ ansible-playbook -i <path/to/inventory/file> \
</path/to/upgrade/playbook> \
-e openshift_upgrade_nodes_serial="2" \
-e openshift_upgrade_nodes_label="region=group1"See Managing Nodes for more on node labels.
5.2.4.3. Customizing Upgrades With Ansible Hooks
When upgrading OpenShift Container Platform, you can execute custom tasks during specific operations through a system called hooks. Hooks allow cluster administrators to provide files defining tasks to execute before and/or after specific areas during installations and upgrades. This can be very helpful to validate or modify custom infrastructure when installing or upgrading OpenShift Container Platform.
It is important to remember that when a hook fails, the operation fails. This means a good hook can run multiple times and provide the same results. A great hook is idempotent.
5.2.4.3.1. Limitations
- Hooks have no defined or versioned interface. They can use internal openshift-ansible variables, but there is no guarantee these will remain in future releases. In the future, hooks may be versioned, giving you advance warning that your hook needs to be updated to work with the latest openshift-ansible.
- Hooks have no error handling, so an error in a hook will halt the upgrade process. The problem will need to be addressed and the upgrade re-run.
5.2.4.3.2. Using Hooks
Hooks are defined in the hosts inventory file under the OSEv3:vars section.
Each hook must point to a YAML file which defines Ansible tasks. This file will be used as an include, meaning that the file cannot be a playbook, but a set of tasks. Best practice suggests using absolute paths to the hook file to avoid any ambiguity.
Example Hook Definitions in an Inventory File
[OSEv3:vars]
openshift_master_upgrade_pre_hook=/usr/share/custom/pre_master.yml
openshift_master_upgrade_hook=/usr/share/custom/master.yml
openshift_master_upgrade_post_hook=/usr/share/custom/post_master.ymlExample pre_master.yml Task
---
# Trivial example forcing an operator to ack the start of an upgrade
# file=/usr/share/custom/pre_master.yml
- name: note the start of a master upgrade
debug:
msg: "Master upgrade of {{ inventory_hostname }} is about to start"
- name: require an operator agree to start an upgrade
pause:
prompt: "Hit enter to start the master upgrade"5.2.4.3.3. Available Upgrade Hooks
openshift_master_upgrade_pre_hook- Runs before each master is upgraded.
- This hook runs against each master in serial.
-
If a task must run against a different host, said task must use
delegate_toorlocal_action.
openshift_master_upgrade_hook- Runs after each master is upgraded, but before its service or system restart.
- This hook runs against each master in serial.
-
If a task must run against a different host, said task must use
delegate_toorlocal_action.
openshift_master_upgrade_post_hook- Runs after each master is upgraded and has had its service or system restart.
- This hook runs against each master in serial.
-
If a task must run against a different host, said task must use
delegate_toorlocal_action.
5.2.4.4. Upgrading to the Latest OpenShift Container Platform 3.5 Release
To upgrade an existing OpenShift Container Platform 3.4 or 3.5 cluster to the latest 3.5 release:
- Satisfy the steps in Preparing for an Automated Upgrade to ensure you are using the latest upgrade playbooks.
-
Ensure the
deployment_typeparameter in your inventory file is set toopenshift-enterprise. -
If you have multiple masters configured and want to enable rolling, full system restarts of the hosts, you can set the
openshift_rolling_restart_modeparameter in your inventory file tosystem. Otherwise, the default valueservicesperforms rolling service restarts on HA masters, but does not reboot the systems. See Configuring Cluster Variables for details. At this point, you can choose to run the upgrade in a single or multiple phases. See Upgrading the Control Plane and Nodes in Separate Phases for more details which components are upgraded in each phase.
If your inventory file is located somewhere other than the default /etc/ansible/hosts, add the
-iflag to specify its location. If you previously used theatomic-openshift-installercommand to run your installation, you can check ~/.config/openshift/hosts for the last inventory file that was used, if needed.NoteYou can add
--tags pre_upgradeto the followingansible-playbookcommands to run the pre-upgrade checks for the playbook. This is a dry-run option that preforms all pre-upgrade checks without actually upgrading any hosts, and reports any problems found.Option A) Upgrade control plane and nodes in a single phase.
Run the upgrade.yml playbook to upgrade the cluster in a single phase using one playbook; the control plane is still upgraded first, then nodes in-place:
# ansible-playbook -i </path/to/inventory/file> \ /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/upgrades/v3_5/upgrade.yml \ [-e <customized_node_upgrade_variables>]1 - 1
- See Customizing Node Upgrades for any desired
<customized_node_upgrade_variables>.
Option B) Upgrade the control plane and nodes in separate phases.
To upgrade only the control plane, run the upgrade_control_plane.yaml playbook:
# ansible-playbook -i </path/to/inventory/file> \ /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/upgrades/v3_5/upgrade_control_plane.ymlTo upgrade only the nodes, run the upgrade_nodes.yaml playbook:
# ansible-playbook -i </path/to/inventory/file> \ /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/upgrades/v3_5/upgrade_nodes.yml \ [-e <customized_node_upgrade_variables>]1 - 1
- See Customizing Node Upgrades for any desired
<customized_node_upgrade_variables>.
If you are upgrading the nodes in groups as described in Customizing Node Upgrades, continue invoking the upgrade_nodes.yml playbook until all nodes have been successfully upgraded.
After all master and node upgrades have completed, a recommendation will be printed to reboot all hosts. After rebooting, if there are no additional features enabled, you can verify the upgrade. Otherwise, the next step depends on what additional features have you previously enabled.
Expand Feature Next Step Aggregated Logging
Cluster Metrics
5.2.5. Upgrading the EFK Logging Stack
To upgrade an existing EFK logging stack deployment, you must use the provided /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/openshift-logging.yml Ansible playbook. This is the playbook to use if you were deploying logging for the first time on an existing cluster, but is also used to upgrade existing logging deployments.
If you have not already done so, see Specifying Logging Ansible Variables in the Aggregating Container Logs topic and update your Ansible inventory file to at least set the following required variable within the
[OSEv3:vars]section:[OSEv3:vars] openshift_hosted_logging_deploy=true1 openshift_hosted_logging_deployer_prefix=registry.example.com:8888/openshift3/2 openshift_hosted_logging_deployer_version=3.5.03 Add any other
openshift_logging_*oropenshift_hosted_logging_*variables that you want to specify to override the defaults, as described in Specifying Logging Ansible Variables.+
See the OpenShift Container Platform example Ansible host file in the openshift/openshift-ansible repo for the full list of variables.
- When you have finished updating your inventory file, follow the instructions in Deploying the EFK Stack to run the openshift-logging.yml playbook and complete the logging deployment upgrade.
5.2.6. Upgrading Cluster Metrics
To upgrade an existing cluster metrics deployment, you must use the provided /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/openshift-metrics.yml Ansible playbook. This is the playbook to use if you were deploying metrics for the first time on an existing cluster, but is also used to upgrade existing metrics deployments.
If you have not already done so, see Specifying Metrics Ansible Variables in the Enabling Cluster Metrics topic and update your Ansible inventory file to at least set the following required variables within the
[OSEv3:vars]section:[OSEv3:vars] openshift_metrics_install_metrics=true1 openshift_metrics_image_version=<tag>2 openshift_metrics_hawkular_hostname=<fqdn>3 openshift_metrics_cassandra_storage_type=(emptydir|pv|dynamic)4 Add any other
openshift_metrics_*oropenshift_hosted_metrics_*variables that you want to specify to override the defaults, as described in Specifying Metrics Ansible Variables.+
See the OpenShift Container Platform example Ansible host file in the openshift/openshift-ansible repo for the full list of variables.
- When you have finished updating your inventory file, follow the instructions in Deploying the Metrics Deployment to run the openshift_metrics.yml playbook and complete the metrics deployment upgrade.
5.2.7. Verifying the Upgrade
To verify the upgrade:
If you are using a proxy, you must add the IP address of the etcd endpoints to the
openshift_no_proxycluster variable in your inventory file.NoteIf you are not using a proxy, you can skip this step.
In OpenShift Container Platform 3.4, the master connected to the etcd cluster using the host name of the etcd endpoints. In OpenShift Container Platform 3.5, the master now connects to etcd via IP address.
When configuring a cluster to use proxy settings (see Configuring Global Proxy Options), this change causes the master-to-etcd connection to be proxied as well, rather than being excluded by host name in each host’s
NO_PROXYsetting (see Working with HTTP Proxies for more aboutNO_PROXY).To workaround this issue, add the IP address of the etcd endpoint to the
NO_PROXYenvironment variable on each master host’s /etc/sysconfig/atomic-openshift-master-controllers file. For example:NO_PROXY=<ip_address>Use the IP address or host name that the master uses to contact the etcd cluster as the
<ip_address>. The<port>should be2379if you are using standalone etcd (clustered) or4001for embedded etcd (single master, non-clustered etcd). The installer will be updated in a future release to handle this scenario automatically during installation and upgrades (BZ#1466783).Restart the master service for the changes to take effect:
# systemctl restart atomic-openshift-master
Check that all nodes are marked as Ready:
# oc get nodes NAME STATUS AGE master.example.com Ready,SchedulingDisabled 165d node1.example.com Ready 165d node2.example.com Ready 165dThen, verify that you are running the expected versions of the docker-registry and router images, if deployed. Replace
<tag>withv3.5.5.31.66for the latest version.# oc get -n default dc/docker-registry -o json | grep \"image\" "image": "openshift3/ose-docker-registry:<tag>", # oc get -n default dc/router -o json | grep \"image\" "image": "openshift3/ose-haproxy-router:<tag>",You can use the diagnostics tool on the master to look for common issues:
# oc adm diagnostics ... [Note] Summary of diagnostics execution: [Note] Completed with no errors or warnings seen.
5.3. Performing Manual In-place Cluster Upgrades
5.3.1. Overview
An etcd performance issue has been discovered on new and upgraded OpenShift Container Platform 3.5 clusters. See the following Knowledgebase Solution for further details:
As an alternative to performing an automated upgrade, you can manually upgrade your OpenShift cluster. To manually upgrade without disruption, it is important to upgrade each component as documented in this topic.
Before you begin your upgrade, familiarize yourself now with the entire procedure. Specific releases may require additional steps to be performed at key points before or during the standard upgrade process.
Ensure that you have met all prerequisites before proceeding with an upgrade. Failure to do so can result in a failed upgrade.
5.3.2. Preparing for a Manual Upgrade
Before upgrading your cluster to OpenShift Container Platform 3.5, the cluster must be already upgraded to the latest asynchronous release of version 3.4. Cluster upgrades cannot span more than one minor version at a time, so if your cluster is at a version earlier than 3.4, you must first upgrade incrementally (e.g., 3.2 to 3.3, then 3.3 to 3.4).
Before attempting the upgrade, follow the steps in Verifying the Upgrade to verify the cluster’s health. This will confirm that nodes are in the Ready state, running the expected starting version, and will ensure that there are no diagnostic errors or warnings.
To prepare for a manual upgrade, follow these steps:
If you have any PetSet objects in your cluster, see Migrating PetSets to StatefulSets before continuing.
If you are upgrading from OpenShift Container Platform 3.4 to 3.5, manually disable the 3.4 channel and enable the 3.5 channel on each host:
# subscription-manager repos --disable="rhel-7-server-ose-3.4-rpms" \ --enable="rhel-7-server-ose-3.5-rpms" \ --enable="rhel-7-server-extras-rpms" \ --enable="rhel-7-fast-datapath-rpms"On RHEL 7 systems, also clear the yum cache:
# yum clean allInstall or update to the latest available version of the atomic-openshift-utils package on each RHEL 7 system, which provides files that will be used in later sections:
# yum install atomic-openshift-utilsWhen installing or updating atomic-openshift-utils, /usr/share/openshift/examples/ does not get updated with the latest templates. To update the file:
# mkdir /usr/share/openshift/examples # cp -R /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v3.6/* /usr/share/openshift/examples/
Install or update to the following latest available *-excluder packages on each RHEL 7 system, which helps ensure your systems stay on the correct versions of atomic-openshift and docker packages when you are not trying to upgrade, according to the OpenShift Container Platform version:
# yum install atomic-openshift-excluder atomic-openshift-docker-excluderThese packages add entries to the
excludedirective in the host’s /etc/yum.conf file.Create an etcd backup on each master. The etcd package is required, even if using embedded etcd, for access to the
etcdctlcommand to make the backup.NoteThe etcd package is installed by default for RHEL Atomic Host 7 systems. If the master is a RHEL 7 system and etcd is not already installed, install it now:
# yum install etcdTo create the backup, run:
# ETCD_DATA_DIR=/var/lib/origin/openshift.local.etcd1 # etcdctl backup \ --data-dir $ETCD_DATA_DIR \ --backup-dir $ETCD_DATA_DIR.bak.<date>2 For any upgrade path, ensure that you are running the latest kernel on each RHEL 7 system:
# yum update kernel
5.3.3. Upgrading Master Components
Before upgrading any stand-alone nodes, upgrade the master components (which provide the control plane for the cluster).
Run the following command on each master to remove the atomic-openshift packages from the list of yum excludes on the host:
# atomic-openshift-excluder unexcludeUpgrade etcd on all master hosts and any separate etcd hosts that are not also master hosts.
For RHEL 7 systems using the RPM-based method:
Upgrade the etcd package:
# yum update etcdRestart the etcd service and review the logs to ensure it restarts successfully:
# systemctl restart etcd # journalctl -r -u etcd
For RHEL Atomic Host 7 systems and RHEL 7 systems using the containerized method:
Pull the latest rhel7/etcd image:
# docker pull registry.access.redhat.com/rhel7/etcdRestart the etcd_container service and review the logs to ensure it restarts successfully:
# systemctl restart etcd_container # journalctl -r -u etcd_container
On each master host, upgrade the atomic-openshift packages or related images.
For masters using the RPM-based method on a RHEL 7 system, upgrade all installed atomic-openshift packages and the openvswitch package:
# yum upgrade atomic-openshift\* openvswitchFor masters using the containerized method on a RHEL 7 or RHEL Atomic Host 7 system, set the
IMAGE_VERSIONparameter to the version you are upgrading to in the following files:- /etc/sysconfig/atomic-openshift-master (single master clusters only)
- /etc/sysconfig/atomic-openshift-master-controllers (multi-master clusters only)
- /etc/sysconfig/atomic-openshift-master-api (multi-master clusters only)
- /etc/sysconfig/atomic-openshift-node
- /etc/sysconfig/atomic-openshift-openvswitch
For example:
IMAGE_VERSION=<tag>Replace
<tag>withv3.5.5.31.66for the latest version.
Restart the master service(s) on each master and review logs to ensure they restart successfully.
For single master clusters:
# systemctl restart atomic-openshift-master # journalctl -r -u atomic-openshift-masterFor multi-master clusters:
# systemctl restart atomic-openshift-master-controllers # systemctl restart atomic-openshift-master-api # journalctl -r -u atomic-openshift-master-controllers # journalctl -r -u atomic-openshift-master-apiBecause masters also have node components running on them in order to be configured as part of the OpenShift SDN, restart the atomic-openshift-node and openvswitch services:
# systemctl restart openvswitch # systemctl restart atomic-openshift-node # journalctl -r -u openvswitch # journalctl -r -u atomic-openshift-nodeIf you are performing a cluster upgrade that requires updating Docker to version 1.12, you must also perform the following steps if you are not already on Docker 1.12:
ImportantThe node component on masters is set by default to unschedulable status during initial installation, so that pods are not deployed to them. However, it is possible to set them schedulable during the initial installation or manually thereafter. If any of your masters are also configured as a schedulable node, skip the following Docker upgrade steps for those masters and instead run all steps described in Upgrading Nodes when you get to that section for those hosts as well.
Upgrade the docker package.
For RHEL 7 systems:
# yum update dockerThen, restart the docker service and review the logs to ensure it restarts successfully:
# systemctl restart docker # journalctl -r -u dockerFor RHEL Atomic Host 7 systems, upgrade to the latest Atomic tree if one is available:
NoteIf upgrading to RHEL Atomic Host 7.3.2, this upgrades Docker to version 1.12.
# atomic host upgrade
After the upgrade is completed and prepared for the next boot, reboot the host and ensure the docker service starts successfully:
# systemctl reboot # journalctl -r -u dockerRemove the following file, which is no longer required:
# rm /etc/systemd/system/docker.service.d/docker-sdn-ovs.conf
Run the following command on each master to add the atomic-openshift packages back to the list of yum excludes on the host:
# atomic-openshift-excluder exclude
During the cluster upgrade, it can sometimes be useful to take a master out of rotation since some DNS client libraries will not properly to the other masters for cluster DNS. In addition to stopping the master and controller services, you can remove the EndPoint from the Kubernetes service’s subsets.addresses.
$ oc edit ep/kubernetes -n defaultWhen the master is restarted, the Kubernetes service will be automatically updated.
5.3.4. Updating Policy Definitions
After a cluster upgrade, the recommended default cluster roles may be updated. To check if an update is recommended for your environment, you can run:
# oc adm policy reconcile-cluster-roles
If you have customized default cluster roles and want to ensure a role reconciliation does not modify those customized roles, annotate them with openshift.io/reconcile-protect set to true. Doing so means you are responsible for manually updating those roles with any new or required permissions during upgrades.
This command outputs a list of roles that are out of date and their new proposed values. For example:
# oc adm policy reconcile-cluster-roles
apiVersion: v1
items:
- apiVersion: v1
kind: ClusterRole
metadata:
creationTimestamp: null
name: admin
rules:
- attributeRestrictions: null
resources:
- builds/custom
...Your output will vary based on the OpenShift version and any local customizations you have made. Review the proposed policy carefully.
You can either modify this output to re-apply any local policy changes you have made, or you can automatically apply the new policy using the following process:
Reconcile the cluster roles:
# oc adm policy reconcile-cluster-roles \ --additive-only=true \ --confirmReconcile the cluster role bindings:
# oc adm policy reconcile-cluster-role-bindings \ --exclude-groups=system:authenticated \ --exclude-groups=system:authenticated:oauth \ --exclude-groups=system:unauthenticated \ --exclude-users=system:anonymous \ --additive-only=true \ --confirmAlso run:
# oc adm policy reconcile-cluster-role-bindings \ system:build-strategy-jenkinspipeline \ --confirm \ -o nameReconcile security context constraints:
# oc adm policy reconcile-sccs \ --additive-only=true \ --confirm
5.3.5. Upgrading Nodes
After upgrading your masters, you can upgrade your nodes. When restarting the atomic-openshift-node service, there will be a brief disruption of outbound network connectivity from running pods to services while the service proxy is restarted. The length of this disruption should be very short and scales based on the number of services in the entire cluster.
You can alternatively use the blue-green deployment method at this point to create a parallel environment for new nodes instead of upgrading them in place.
One at at time for each node that is not also a master, you must disable scheduling and evacuate its pods to other nodes, then upgrade packages and restart services.
Run the following command on each node to remove the atomic-openshift packages from the list of yum excludes on the host:
# atomic-openshift-excluder unexcludeAs a user with cluster-admin privileges, disable scheduling for the node:
# oc adm manage-node <node> --schedulable=falseEvacuate pods on the node to other nodes:
ImportantThe
--forceoption deletes any pods that are not backed by a replication controller.# oc adm drain <node> --force --delete-local-data --ignore-daemonsetsUpgrade the node component packages or related images.
For nodes using the RPM-based method on a RHEL 7 system, upgrade all installed atomic-openshift packages and the openvswitch package:
# yum upgrade atomic-openshift\* openvswitchFor nodes using the containerized method on a RHEL 7 or RHEL Atomic Host 7 system, set the
IMAGE_VERSIONparameter in the /etc/sysconfig/atomic-openshift-node and /etc/sysconfig/openvswitch files to the version you are upgrading to. For example:IMAGE_VERSION=<tag>Replace
<tag>withv3.5.5.31.66for the latest version.
Restart the atomic-openshift-node and openvswitch services and review the logs to ensure they restart successfully:
# systemctl restart openvswitch # systemctl restart atomic-openshift-node # journalctl -r -u atomic-openshift-node # journalctl -r -u openvswitchIf you are performing a cluster upgrade that requires updating Docker to version 1.12, you must also perform the following steps if you are not already on Docker 1.12:
Upgrade the docker package.
For RHEL 7 systems:
# yum update dockerThen, restart the docker service and review the logs to ensure it restarts successfully:
# systemctl restart docker # journalctl -r -u dockerAfter Docker is restarted, restart the atomic-openshift-node service again and review the logs to ensure it restarts successfully:
# systemctl restart atomic-openshift-node # journalctl -r -u atomic-openshift-nodeFor RHEL Atomic Host 7 systems, upgrade to the latest Atomic tree if one is available:
NoteIf upgrading to RHEL Atomic Host 7.3.2, this upgrades Docker to version 1.12.
# atomic host upgradeAfter the upgrade is completed and prepared for the next boot, reboot the host and ensure the docker service starts successfully:
# systemctl reboot # journalctl -r -u docker
Remove the following file, which is no longer required:
# rm /etc/systemd/system/docker.service.d/docker-sdn-ovs.conf
Re-enable scheduling for the node:
# oc adm manage-node <node> --schedulableRun the following command on each node to add the atomic-openshift packages back to the list of yum excludes on the host:
# atomic-openshift-excluder exclude- Repeat the previous steps on the next node, and continue repeating these steps until all nodes have been upgraded.
After all nodes have been upgraded, as a user with cluster-admin privileges, verify that all nodes are showing as Ready:
# oc get nodes NAME STATUS AGE master.example.com Ready,SchedulingDisabled 165d node1.example.com Ready 165d node2.example.com Ready 165d
5.3.6. Upgrading the Router
If you have previously deployed a router, the router deployment configuration must be upgraded to apply updates contained in the router image. To upgrade your router without disrupting services, you must have previously deployed a highly-available routing service.
Edit your router’s deployment configuration. For example, if it has the default router name:
# oc edit dc/routerApply the following changes:
...
spec:
template:
spec:
containers:
- env:
...
image: registry.access.redhat.com/openshift3/ose-haproxy-router:<tag>
imagePullPolicy: IfNotPresent
...- 1
- Adjust
<tag>to match the version you are upgrading to (usev3.5.5.31.66for the latest version).
You should see one router pod updated and then the next.
5.3.7. Upgrading the Registry
The registry must also be upgraded for changes to take effect in the registry image. If you have used a PersistentVolumeClaim or a host mount point, you may restart the registry without losing the contents of your registry. Storage for the Registry details how to configure persistent storage for the registry.
Edit your registry’s deployment configuration:
# oc edit dc/docker-registryApply the following changes:
...
spec:
template:
spec:
containers:
- env:
...
image: registry.access.redhat.com/openshift3/ose-docker-registry:<tag>
imagePullPolicy: IfNotPresent
...- 1
- Adjust
<tag>to match the version you are upgrading to (usev3.5.5.31.66for the latest version).
Images that are being pushed or pulled from the internal registry at the time of upgrade will fail and should be restarted automatically. This will not disrupt pods that are already running.
5.3.8. Updating the Default Image Streams and Templates
By default, the quick and advanced installation methods automatically create default image streams, InstantApp templates, and database service templates in the openshift project, which is a default project to which all users have view access. These objects were created during installation from the JSON files located under the /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/ directory.
Because RHEL Atomic Host 7 cannot use yum to update packages, the following steps must take place on a RHEL 7 system.
Update the packages that provide the example JSON files. On a subscribed Red Hat Enterprise Linux 7 system where you can run the CLI as a user with cluster-admin permissions, install or update to the latest version of the atomic-openshift-utils package, which should also update the openshift-ansible- packages:
# yum update atomic-openshift-utilsTo persist /usr/share/openshift/examples/ on the first master:
scp -R /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v3.6/* user@master1:/usr/share/openshift/examples/To persist /usr/share/openshift/examples/ on all masters:
mkdir /usr/share/openshift/examples
scp -R /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v3.6/* user@masterx:/usr/share/openshift/examplesThe openshift-ansible-roles package provides the latest example JSON files.
After a manual upgrade, get the latest templates from openshift-ansible-roles:
rpm -ql openshift-ansible-roles | grep examples | grep v1.5In this example, /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/image-streams/image-streams-rhel7.json is the latest file that you want in the latest openshift-ansible-roles package.
/usr/share/openshift/examples/image-streams/image-streams-rhel7.json is not owned by a package, but is updated by Ansible. If you are upgrading outside of Ansible. you need to get the latest .json files on the system where you are running
oc, which can run anywhere that has access to the master.Install atomic-openshift-utils and its dependencies to install the new content into /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/.:
$ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/image-streams/image-streams-rhel7.json $ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/image-streams/dotnet_imagestreams.json $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/image-streams/image-streams-rhel7.json $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/image-streams/dotnet_imagestreams.jsonUpdate the templates:
$ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/ $ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/db-templates/ $ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/infrastructure-templates/ $ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/xpaas-templates/ $ oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/xpaas-streams/ $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/ $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/db-templates/ $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/infrastructure-templates/ $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/xpaas-templates/ $ oc replace -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/xpaas-streams/Errors are generated for items that already exist. This is expected behavior:
# oc create -n openshift -f /usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/ Error from server: error when creating "/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/cakephp-mysql.json": templates "cakephp-mysql-example" already exists Error from server: error when creating "/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/cakephp.json": templates "cakephp-example" already exists Error from server: error when creating "/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/dancer-mysql.json": templates "dancer-mysql-example" already exists Error from server: error when creating "/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/dancer.json": templates "dancer-example" already exists Error from server: error when creating "/usr/share/ansible/openshift-ansible/roles/openshift_examples/files/examples/v1.5/quickstart-templates/django-postgresql.json": templates "django-psql-example" already exists
Now, content can be updated. Without running the automated upgrade playbooks, the content is not updated in /usr/share/openshift/.
5.3.9. Importing the Latest Images
After updating the default image streams, you may also want to ensure that the images within those streams are updated. For each image stream in the default openshift project, you can run:
# oc import-image -n openshift <imagestream>For example, get the list of all image streams in the default openshift project:
# oc get is -n openshift
NAME DOCKER REPO TAGS UPDATED
mongodb registry.access.redhat.com/openshift3/mongodb-24-rhel7 2.4,latest,v3.1.1.6 16 hours ago
mysql registry.access.redhat.com/openshift3/mysql-55-rhel7 5.5,latest,v3.1.1.6 16 hours ago
nodejs registry.access.redhat.com/openshift3/nodejs-010-rhel7 0.10,latest,v3.1.1.6 16 hours ago
...Update each image stream one at a time:
# oc import-image -n openshift nodejs
The import completed successfully.
Name: nodejs
Created: 10 seconds ago
Labels: <none>
Annotations: openshift.io/image.dockerRepositoryCheck=2016-07-05T19:20:30Z
Docker Pull Spec: 172.30.204.22:5000/openshift/nodejs
Tag Spec Created PullSpec Image
latest 4 9 seconds ago registry.access.redhat.com/rhscl/nodejs-4-rhel7:latest 570ad8ed927fd5c2c9554ef4d9534cef808dfa05df31ec491c0969c3bd372b05
4 registry.access.redhat.com/rhscl/nodejs-4-rhel7:latest 9 seconds ago <same> 570ad8ed927fd5c2c9554ef4d9534cef808dfa05df31ec491c0969c3bd372b05
0.10 registry.access.redhat.com/openshift3/nodejs-010-rhel7:latest 9 seconds ago <same> a1ef33be788a28ec2bdd48a9a5d174ebcfbe11c8e986d2996b77f5bccaaa4774
In order to update your S2I-based applications, you must manually trigger a new build of those applications after importing the new images using oc start-build <app-name>.
5.3.10. Upgrading the EFK Logging Stack
Manual upgrade steps for logging deployments are no longer available starting in OpenShift Container Platform 3.5.
To upgrade an existing EFK logging stack deployment, you must use the provided /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/openshift-logging.yml Ansible playbook. This is the playbook to use if you were deploying logging for the first time on an existing cluster, but is also used to upgrade existing logging deployments.
If you have not already done so, see Specifying Logging Ansible Variables in the Aggregating Container Logs topic and update your Ansible inventory file to at least set the following required variable within the
[OSEv3:vars]section:[OSEv3:vars] openshift_hosted_logging_deploy=true1 openshift_hosted_logging_deployer_prefix=registry.example.com:8888/openshift3/2 openshift_hosted_logging_deployer_version=3.5.03 Add any other
openshift_logging_*oropenshift_hosted_logging_*variables that you want to specify to override the defaults, as described in Specifying Logging Ansible Variables.+
See the OpenShift Container Platform example Ansible host file in the openshift/openshift-ansible repo for the full list of variables.
- When you have finished updating your inventory file, follow the instructions in Deploying the EFK Stack to run the openshift-logging.yml playbook and complete the logging deployment upgrade.
5.3.11. Upgrading Cluster Metrics
Manual upgrade steps for metrics deployments are no longer available starting in OpenShift Container Platform 3.5.
To upgrade an existing cluster metrics deployment, you must use the provided /usr/share/ansible/openshift-ansible/playbooks/byo/openshift-cluster/openshift-metrics.yml Ansible playbook. This is the playbook to use if you were deploying metrics for the first time on an existing cluster, but is also used to upgrade existing metrics deployments.
If you have not already done so, see Specifying Metrics Ansible Variables in the Enabling Cluster Metrics topic and update your Ansible inventory file to at least set the following required variables within the
[OSEv3:vars]section:[OSEv3:vars] openshift_metrics_install_metrics=true1 openshift_metrics_image_version=<tag>2 openshift_metrics_hawkular_hostname=<fqdn>3 openshift_metrics_cassandra_storage_type=(emptydir|pv|dynamic)4 Add any other
openshift_metrics_*oropenshift_hosted_metrics_*variables that you want to specify to override the defaults, as described in Specifying Metrics Ansible Variables.+
See the OpenShift Container Platform example Ansible host file in the openshift/openshift-ansible repo for the full list of variables.
- When you have finished updating your inventory file, follow the instructions in Deploying the Metrics Deployment to run the openshift_metrics.yml playbook and complete the metrics deployment upgrade.
5.3.12. Additional Manual Steps Per Release
Some OpenShift Container Platform releases may have additional instructions specific to that release that must be performed to fully apply the updates across the cluster. This section will be updated over time as new asynchronous updates are released for OpenShift Container Platform 3.5.
See the OpenShift Container Platform 3.5 Release Notes to review the latest release notes.
5.3.12.1. OpenShift Container Platform 3.5.5.5
Migrating PetSets to StatefulSets
PetSet obects are an Alpha feature in upstream Kubernetes 1.4 and are not supported by Red Hat. In Kubernetes 1.5, they are replaced by the Beta feature StatefulSets. Red Hat currently does not offer support for either PetSets or StatefulSets.
If you have any existing PetSets in your cluster, they MUST be removed before upgrading to OpenShift Container Platform 3.5. Automatically migrating PetSets to StatefulSets in OpenShift Container Platform 3.5 is not supported. See the Kubernetes "Upgrading from PetSets to StatefulSets" documentation for additional information:
https://kubernetes.io/docs/tasks/manage-stateful-set/upgrade-pet-set-to-stateful-set/
Red Hat strongly recommends reading the above referenced documentation in its entirety before taking any destructive actions.
If you want to simply remove all PetSets without manually migrating to StatefulSets, run this command as a user with cluster-admin privileges:
$ oc get petsets --all-namespaces -o yaml | oc delete -f - --cascade=falseMigrating Jobs
With deprecation of the extensions/v1beta1.Job resource, you must migrate all Job resources to use the batch/v1.Job instead. To verify which objects will be migrated, run:
$ oc adm migrate storage --include=jobs
You can also increase the log level using the --loglevel flag. When you are ready to perform the actual migration, add the --confirm option:
$ oc adm migrate storage --include=jobs --confirm5.3.12.2. OpenShift Container Platform 3.5.5.8
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.8 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.3. OpenShift Container Platform 3.5.5.24
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.24 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.4. OpenShift Container Platform 3.5.5.26
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.26 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.5. OpenShift Container Platform 3.5.5.31
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.31 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.6. OpenShift Container Platform 3.5.5.31.36
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.31.36 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.7. OpenShift Container Platform 3.5.5.31.48
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.31.48 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.8. OpenShift Container Platform 3.5.5.31.48-10
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.31.48-10 that are not already mentioned inline during the standard manual upgrade process.
5.3.12.9. OpenShift Container Platform 3.5.5.31.66
There are no additional manual steps for the upgrade to OpenShift Container Platform 3.5.5.31.66 that are not already mentioned inline during the standard manual upgrade process.
5.3.13. Verifying the Upgrade
To verify the upgrade:
If you are using a proxy, you must add the IP address of the etcd endpoints to the
openshift_no_proxycluster variable in your inventory file.NoteIf you are not using a proxy, you can skip this step.
In OpenShift Container Platform 3.4, the master connected to the etcd cluster using the host name of the etcd endpoints. In OpenShift Container Platform 3.5, the master now connects to etcd via IP address.
When configuring a cluster to use proxy settings (see Configuring Global Proxy Options), this change causes the master-to-etcd connection to be proxied as well, rather than being excluded by host name in each host’s
NO_PROXYsetting (see Working with HTTP Proxies for more aboutNO_PROXY).To workaround this issue, add the IP address of the etcd endpoint to the
NO_PROXYenvironment variable on each master host’s /etc/sysconfig/atomic-openshift-master-controllers file. For example:NO_PROXY=<ip_address>Use the IP address or host name that the master uses to contact the etcd cluster as the
<ip_address>. The<port>should be2379if you are using standalone etcd (clustered) or4001for embedded etcd (single master, non-clustered etcd). The installer will be updated in a future release to handle this scenario automatically during installation and upgrades (BZ#1466783).Restart the master service for the changes to take effect:
# systemctl restart atomic-openshift-master
Check that all nodes are marked as Ready:
# oc get nodes NAME STATUS AGE master.example.com Ready,SchedulingDisabled 165d node1.example.com Ready 165d node2.example.com Ready 165dVerify that you are running the expected versions of the docker-registry and router images, if deployed. Replace
<tag>withv3.5.5.31.66for the latest version.# oc get -n default dc/docker-registry -o json | grep \"image\" "image": "openshift3/ose-docker-registry:<tag>", # oc get -n default dc/router -o json | grep \"image\" "image": "openshift3/ose-haproxy-router:<tag>",Use the diagnostics tool on the master to look for common issues:
# oc adm diagnostics ... [Note] Summary of diagnostics execution: [Note] Completed with no errors or warnings seen.
5.4. Blue-Green Deployments
5.4.1. Overview
An etcd performance issue has been discovered on new and upgraded OpenShift Container Platform 3.5 clusters. See the following Knowledgebase Solution for further details:
This topic serves as an alternative approach for node host upgrades to the in-place upgrade method.
The blue-green deployment upgrade method follows a similar flow to the in-place method: masters and etcd servers are still upgraded first, however a parallel environment is created for new node hosts instead of upgrading them in-place.
This method allows administrators to switch traffic from the old set of node hosts (e.g., the blue deployment) to the new set (e.g., the green deployment) after the new deployment has been verified. If a problem is detected, it is also then easy to rollback to the old deployment quickly.
While blue-green is a proven and valid strategy for deploying just about any software, there are always trade-offs. Not all environments have the same uptime requirements or the resources to properly perform blue-green deployments.
In an OpenShift Container Platform environment, the most suitable candidate for blue-green deployments are the node hosts. All user processes run on these systems and even critical pieces of OpenShift Container Platform infrastructure are self-hosted on these resources. Uptime is most important for these workloads and the additional complexity of blue-green deployments can be justified.
The exact implementation of this approach varies based on your requirements. Often the main challenge is having the excess capacity to facilitate such an approach.
Figure 5.1. Blue-Green Deployment
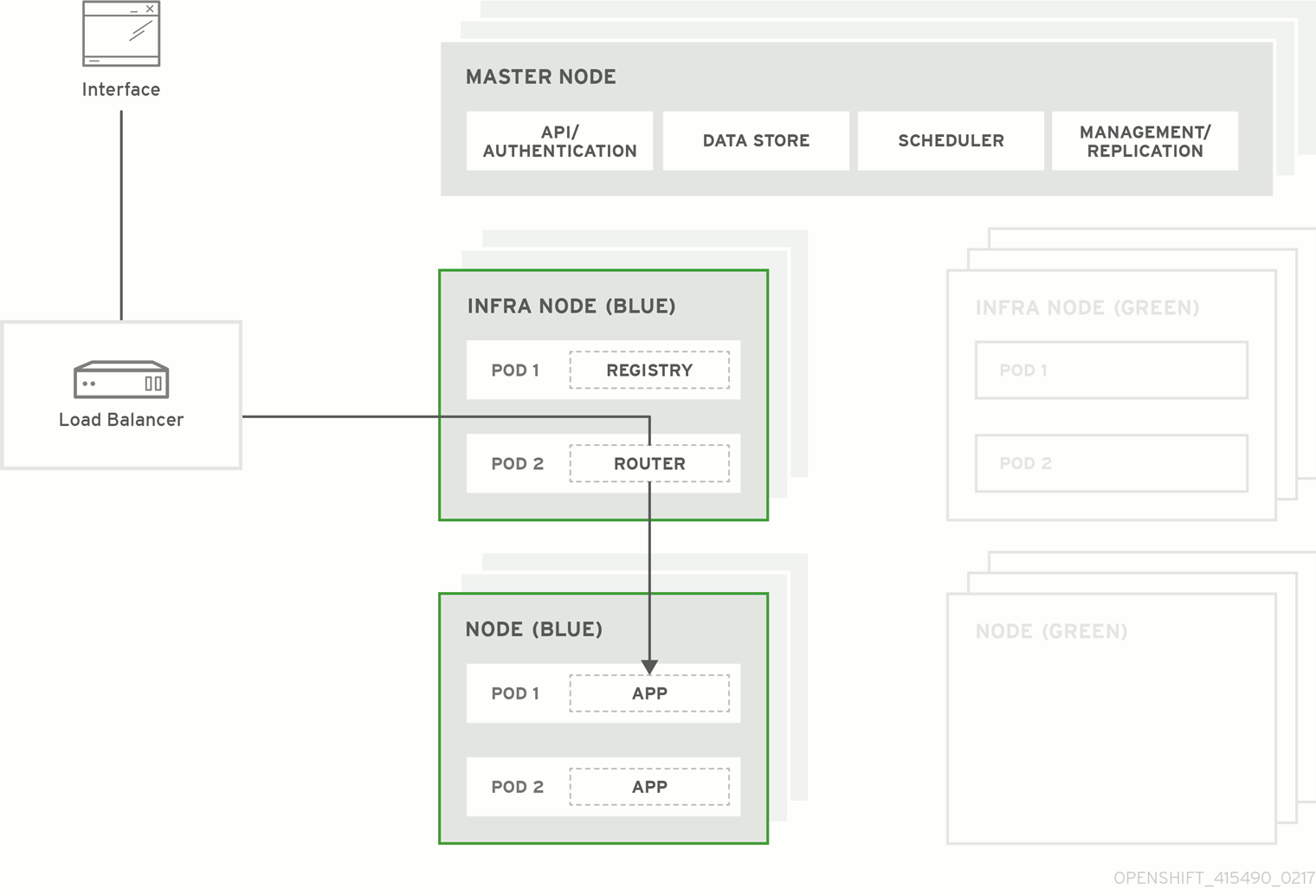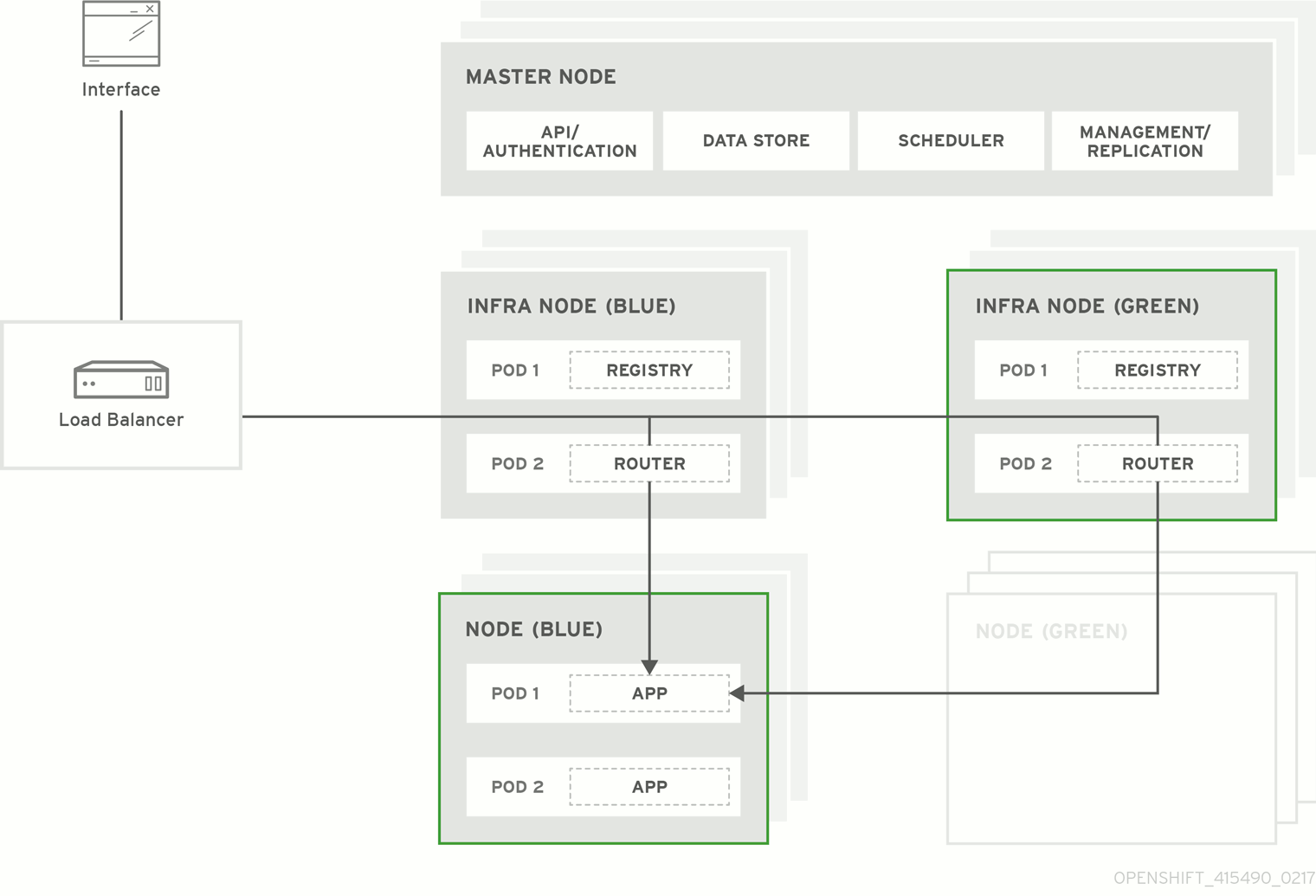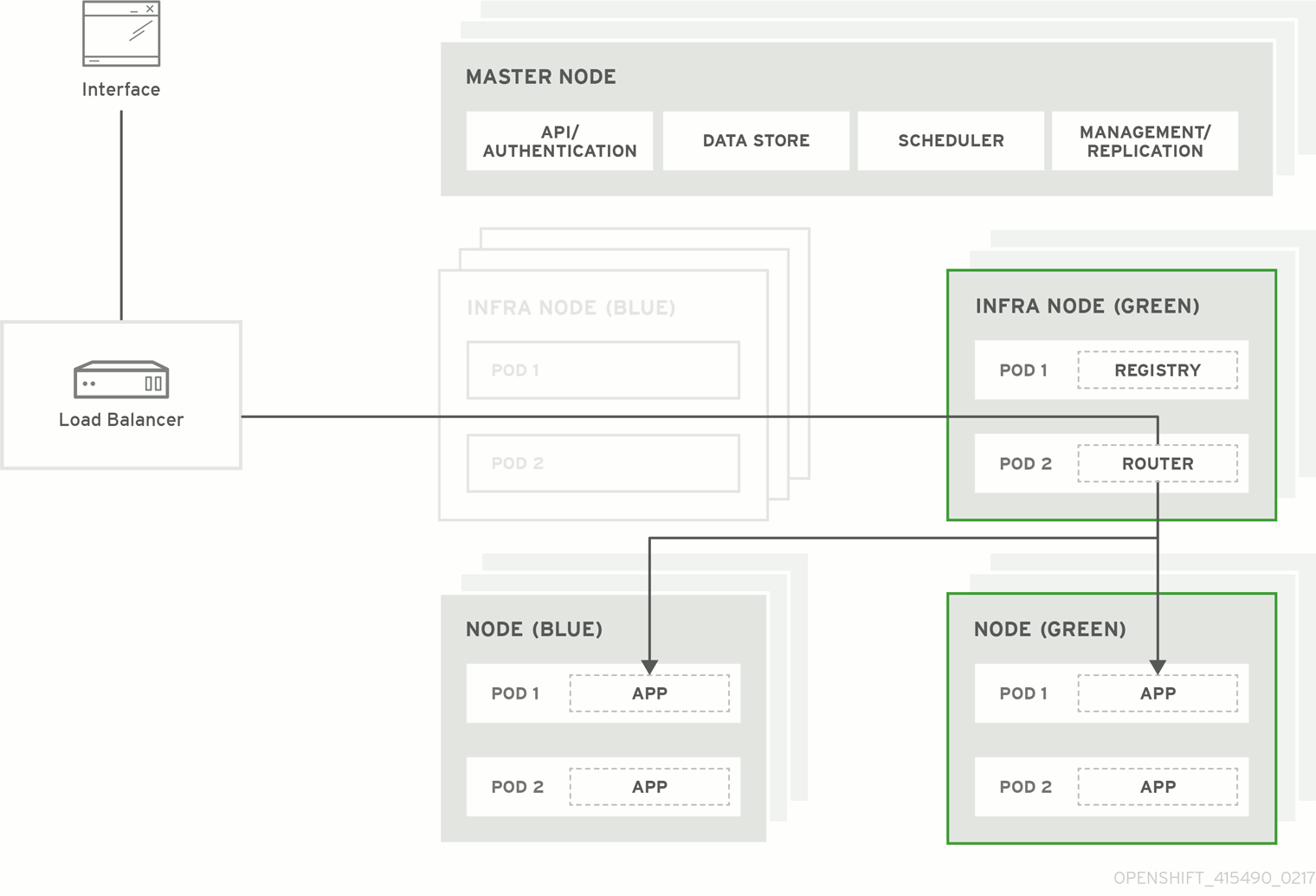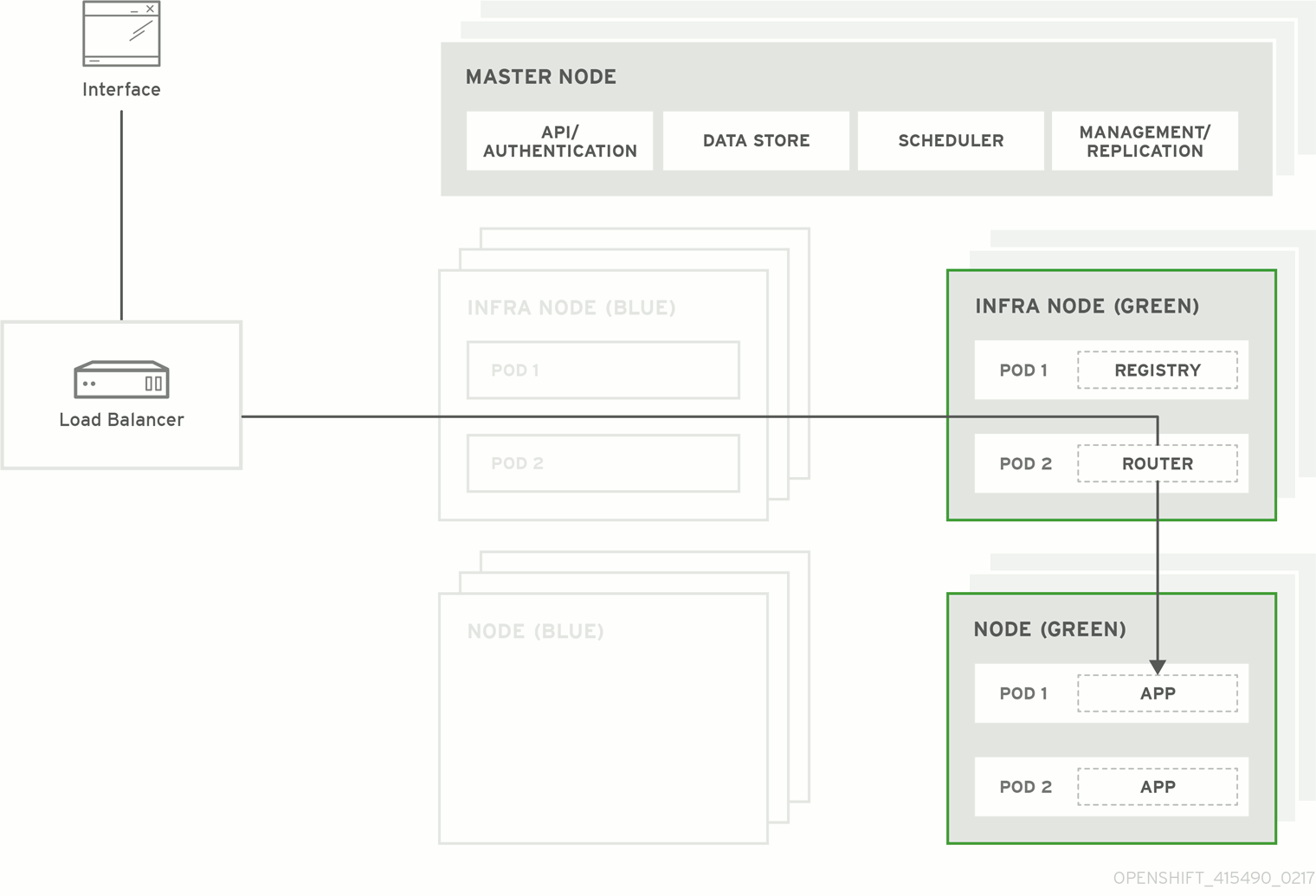
5.4.2. Preparing for a Blue-Green Upgrade
After you have upgraded your master and etcd hosts using method described for In-place Upgrades, use the following sections to prepare your environment for a blue-green upgrade of the remaining node hosts.
5.4.2.1. Sharing Software Entitlements
Administrators must temporarily share the Red Hat software entitlements between the blue-green deployments or provide access to the installation content by means of a system such as Red Hat Satellite. This can be accomplished by sharing the consumer ID from the previous node host:
On each old node host that will be upgraded, note its
system identityvalue, which is the consumer ID:# subscription-manager identity | grep system system identity: 6699375b-06db-48c4-941e-689efd6ce3aaOn each new RHEL 7 or RHEL Atomic Host 7 system that is going to replace an old node host, register using the respective consumer ID from the previous step:
# subscription-manager register --consumerid=6699375b-06db-48c4-941e-689efd6ce3aa
After a successful deployment, remember to unregister the old host with subscription-manager clean to prevent the environment from being out of compliance.
5.4.2.2. Labeling Blue Nodes
You must ensure that your current node hosts in production are labeled either blue or green. In this example, the current production environment will be blue and the new environment will be green.
Get the current list of node names known to the cluster:
$ oc get nodesEnsure that all hosts have appropriate node labels. Consider that by default, all master hosts are also configured as unschedulable node hosts (so that they are joined to the pod network). To improve cluster management, add a label to each host that describes its type, such as
type=masterortype=node.For example, to label node hosts that are also masters as
type=master, run the following for each relevant<node_name>:$ oc label node <node_name> type=masterTo label non-master node hosts as
type=node, run the following for each relevant<node_name>:$ oc label node <node_name> type=nodeAlternatively, if you have already finished labeling certain nodes with
type=masterand just want to label all remaining nodes astype=node, you can use the--alloption and any hosts that already had atype=set will not be overwritten:$ oc label node --all type=nodeLabel all non-master node hosts in your current production environment to
color=blue. For example, using the labels described in the previous step:$ oc label node -l type=node color=blueIn the above command, the
-lflag is used to match a subset of the environment using the selectortype=node, and all matches are labeled withcolor=blue.
5.4.2.3. Creating and Labeling Green Nodes
Create the new green environment for any node hosts that are to be replaced by adding an equal number of new node hosts to the existing cluster. You can use either the quick installer or advanced install method as described in Adding Hosts to an Existing Cluster.
When adding these new nodes, use the following Ansible variables:
-
Apply the
color=greenlabel automatically during the installation of these hosts by setting theopenshift_node_labelsvariable for each node host. You can always adjust the labels after installation as well, if needed, using theoc label nodecommand. -
In order to delay workload scheduling until the nodes are deemed healthy (which you will verify in later steps), set the
openshift_schedulable=Falsevariable for each node host to ensure they are unschedulable initially.
Example new_nodes Host Group
Add the following to your existing inventory. Everything that was in your inventory previously should remain.
[new_nodes]
node4.example.com openshift_node_labels="{'region': 'primary', 'color':'green'}" openshift_schedulable=False
node5.example.com openshift_node_labels="{'region': 'primary', 'color':'green'}" openshift_schedulable=False
node6.example.com openshift_node_labels="{'region': 'primary', 'color':'green'}" openshift_schedulable=False
infra-node3.example.com openshift_node_labels="{'region': 'infra', 'color':'green'}" openshift_schedulable=False
infra-node4.example.com openshift_node_labels="{'region': 'infra', 'color':'green'}" openshift_schedulable=False5.4.2.4. Verifying Green Nodes
Verify that your new green nodes are in a healthy state. Perform the following checklist:
Verify that new nodes are detected in the cluster and are in Ready state:
$ oc get nodes ip-172-31-49-10.ec2.internal Ready 3dVerify that the green nodes have proper labels:
$ oc get nodes -o wide --show-labels ip-172-31-49-10.ec2.internal Ready 4d beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=m4.large,beta.kubernetes.io/os=linux,color=green,failure-domain.beta.kubernetes.io/region=us-east-1,failure-domain.beta.kubernetes.io/zone=us-east-1c,hostname=openshift-cluster-1d005,kubernetes.io/hostname=ip-172-31-49-10.ec2.internal,region=us-east-1,type=infraPerform a diagnostic check for the cluster:
$ oc adm diagnostics [Note] Determining if client configuration exists for client/cluster diagnostics Info: Successfully read a client config file at '/root/.kube/config' Info: Using context for cluster-admin access: 'default/internal-api-upgradetest-openshift-com:443/system:admin' [Note] Performing systemd discovery [Note] Running diagnostic: ConfigContexts[default/api-upgradetest-openshift-com:443/system:admin] Description: Validate client config context is complete and has connectivity ... [Note] Running diagnostic: CheckExternalNetwork Description: Check that external network is accessible within a pod [Note] Running diagnostic: CheckNodeNetwork Description: Check that pods in the cluster can access its own node. [Note] Running diagnostic: CheckPodNetwork Description: Check pod to pod communication in the cluster. In case of ovs-subnet network plugin, all pods should be able to communicate with each other and in case of multitenant network plugin, pods in non-global projects should be isolated and pods in global projects should be able to access any pod in the cluster and vice versa. [Note] Running diagnostic: CheckServiceNetwork Description: Check pod to service communication in the cluster. In case of ovs-subnet network plugin, all pods should be able to communicate with all services and in case of multitenant network plugin, services in non-global projects should be isolated and pods in global projects should be able to access any service in the cluster. ...
5.4.3. Registry and Router Canary Deployments
A common practice is to scale the registry and router pods until they are migrated to new (green) infrastructure node hosts. For these pods, a canary deployment approach is commonly used.
Scaling these pods up will make them immediately active on the new infrastructure nodes. Pointing their deployment configuration to the new image initiates a rolling update. However, because of node anti-affinity, and the fact that the blue nodes are still unschedulable, the deployments to the old nodes will fail.
At this point, the registry and router deployments can be scaled down to the original number of pods. At any given point, the original number of pods is still available so no capacity is lost and downtime should be avoided.
5.4.4. Warming the Green Nodes
In order for pods to be migrated from the blue environment to the green, the required container images must be pulled. Network latency and load on the registry can cause delays if there is not sufficient capacity built in to the environment.
Often, the best way to minimize impact to the running system is to trigger new pod deployments that will land on the new nodes. Accomplish this by importing new image streams.
Major releases of OpenShift Container Platform (and sometimes asynchronous errata updates) introduce new image streams for builder images for users of Source-to-Image (S2I). Upon import, any builds or deployments configured with image change triggers are automatically created.
Another benefit of triggering the builds is that it does a fairly good job of fetching the majority of the ancillary images to all node hosts such as the various builder images, the pod infrastructure image, and deployers. Everything else can be moved over using node evacuation in a later step and will proceed more quickly as a result.
When you are ready to continue with the upgrade process, follow these steps to warm the green nodes:
Disable the blue nodes so that no new pods are run on them by setting them unschedulable:
$ oc adm manage-node --schedulable=false --selector=color=blueSet the green nodes to schedulable so that new pods only land on them:
$ oc adm manage-node --schedulable=true --selector=color=green- Update the default image streams and templates as described in Manual In-place Upgrades.
Import the latest images as described in Manual In-place Upgrades.
It is important to realize that this process can trigger a large number of builds. The good news is that the builds are performed on the green nodes and, therefore, do not impact any traffic on the blue deployment.
To monitor build progress across all namespaces (projects) in the cluster:
$ oc get events -w --all-namespacesIn large environments, builds rarely completely stop. However, you should see a large increase and decrease caused by the administrative image import.
5.4.5. Evacuating and Decommissioning Blue Nodes
For larger deployments, it is possible to have other labels that help determine how evacuation can be coordinated. The most conservative approach for avoiding downtime is to evacuate one node host at a time.
If services are composed of pods using zone anti-affinity, then an entire zone can be evacuated at once. It is important to ensure that the storage volumes used are available in the new zone as this detail can vary among cloud providers.
In OpenShift Container Platform 3.2 and later, a node host evacuation is triggered whenever the node service is stopped. Node labeling is very important and can cause issues if nodes are mislabeled or commands are run on nodes with generalized labels. Exercise caution if master hosts are also labeled with color=blue.
When you are ready to continue with the upgrade process, follow these steps.
Evacuate and delete all blue nodes by following one of the following options:
Option A Manually evacuate then delete all the
color=bluenodes with the following commands:$ oc adm manage-node --selector=color=blue --evacuate $ oc delete node --selector=color=blueOption B Filter out the masters before running the
deletecommand:Verify the list of blue node hosts to delete by running the following command. The output of this command includes a list of all node hosts that have the
color=bluelabel but do not have thetype=masterlabel. All of the hosts in your cluster must be assigned both thecolorandtypelabels. You can change the command to apply more filters if you need to further limit the list of nodes.$ oc get nodes -o go-template='{{ range .items }}{{ if (eq .metadata.labels.color "blue") and (ne .metadata.labels.type "master") }}{{ .metadata.name }}{{ "\n" }}{{end}}{{ end }}'After you confirm the list of blue nodes to delete, run this command to delete that list of nodes:
$ for i in $(oc get nodes -o \ go-template='{{ range .items }}{{ if (eq .metadata.labels.color "blue") and (ne .metadata.labels.type "master") }}{{ .metadata.name }}{{ "\n" }}{{end}}{{ end }}'); \ do oc delete node $i done
- After the blue node hosts no longer contain pods and have been removed from OpenShift Container Platform they are safe to power off. As a safety precaution, leaving the hosts around for a short period of time can prove beneficial if the upgrade has issues.
- Ensure that any desired scripts or files are captured before terminating these hosts. After a determined time period and capacity is not an issue, remove these hosts.
5.5. Operating System Updates and Upgrades
5.5.1. Updating and Upgrading the Operating System
Updating or upgrading your operating system (OS), by either changing OS versions or updating the system software, can impact the OpenShift Container Platform software running on those machines. In particular, these updates can affect the iptables rules or ovs flows that OpenShift Container Platform requires to operate.
Use the following to safely upgrade the OS on a host:
Ensure the host is unschedulable, meaning that no new pods will be placed onto the host:
$ oc adm manage-node <node_name> --schedulable=falseMigrate the pods from the host:
$ oc adm drain <node_name> --force --delete-local-data --ignore-daemonsetsInstall or update the *-excluder packages on each host with the following. This ensures the hosts stay on the correct versions of OpenShift Container Platform, as per the atomic-openshift and docker packages, instead of the most current versions:
# yum install atomic-openshift-excluder atomic-openshift-docker-excluderThis adds entries to the
excludedirective in the host’s /etc/yum.conf file.Update or upgrade the host packages, and reboot the host. A reboot ensures that the host is running the newest versions, and means that the
dockerand OpenShift Container Platform processes have been restarted, which will force them to check that all of the rules in other services are correct.However, instead of rebooting a node host, you can restart the services that are affected, or preserve the
iptablesstate. Both processes are described in the OpenShift Container Platform IPtables topic. Theovsflow rules do not need to be saved, but restarting the OpenShift Container Platform node software will fix the flow rules.Configure the host to be schedulable again:
$ oc adm manage-node <node_name> --schedulable=true