7.5. Aggregator
Overview
Copy linkLink copied to clipboard!
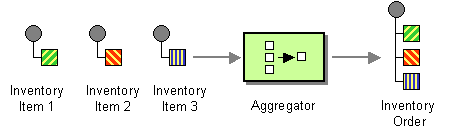
The aggregator pattern, shown in Figure 7.5, “Aggregator Pattern”, enables you to combine a batch of related messages into a single message.
Figure 7.5. Aggregator Pattern
To control the aggregator's behavior, Apache Camel allows you to specify the properties described in Enterprise Integration Patterns, as follows:
- Correlation expression — Determines which messages should be aggregated together. The correlation expression is evaluated on each incoming message to produce a correlation key. Incoming messages with the same correlation key are then grouped into the same batch. For example, if you want to aggregate all incoming messages into a single message, you can use a constant expression.
- Completeness condition — Determines when a batch of messages is complete. You can specify this either as a simple size limit or, more generally, you can specify a predicate condition that flags when the batch is complete.
- Aggregation algorithm — Combines the message exchanges for a single correlation key into a single message exchange.
For example, consider a stock market data system that receives 30,000 messages per second. You might want to throttle down the message flow if your GUI tool cannot cope with such a massive update rate. The incoming stock quotes can be aggregated together simply by choosing the latest quote and discarding the older prices. (You can apply a delta processing algorithm, if you prefer to capture some of the history.)
How the aggregator works
Copy linkLink copied to clipboard!
Figure 7.6, “Aggregator Implementation” shows an overview of how the aggregator works, assuming it is fed with a stream of exchanges that have correlation keys such as A, B, C, or D.
Figure 7.6. Aggregator Implementation
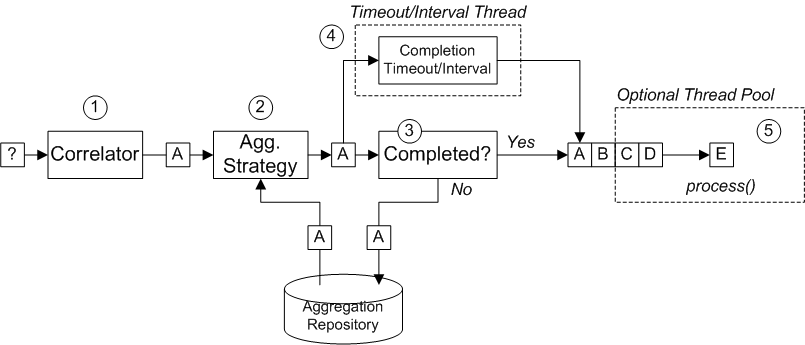
The incoming stream of exchanges shown in Figure 7.6, “Aggregator Implementation” is processed as follows:
- The correlator is responsible for sorting exchanges based on the correlation key. For each incoming exchange, the correlation expression is evaluated, yielding the correlation key. For example, for the exchange shown in Figure 7.6, “Aggregator Implementation”, the correlation key evaluates to A.
- The aggregation strategy is responsible for merging exchanges with the same correlation key. When a new exchange, A, comes in, the aggregator looks up the corresponding aggregate exchange, A', in the aggregation repository and combines it with the new exchange.Until a particular aggregation cycle is completed, incoming exchanges are continuously aggregated with the corresponding aggregate exchange. An aggregation cycle lasts until terminated by one of the completion mechanisms.
- If a completion predicate is specified on the aggregator, the aggregate exchange is tested to determine whether it is ready to be sent to the next processor in the route. Processing continues as follows:
- If complete, the aggregate exchange is processed by the latter part of the route. There are two alternative models for this: synchronous (the default), which causes the calling thread to block, or asynchronous (if parallel processing is enabled), where the aggregate exchange is submitted to an executor thread pool (as shown in Figure 7.6, “Aggregator Implementation”).
- If not complete, the aggregate exchange is saved back to the aggregation repository.
- In parallel with the synchronous completion tests, it is possible to enable an asynchronous completion test by enabling either the
completionTimeoutoption or thecompletionIntervaloption. These completion tests run in a separate thread and, whenever the completion test is satisfied, the corresponding exchange is marked as complete and starts to be processed by the latter part of the route (either synchronously or asynchronously, depending on whether parallel processing is enabled or not). - If parallel processing is enabled, a thread pool is responsible for processing exchanges in the latter part of the route. By default, this thread pool contains ten threads, but you have the option of customizing the pool (the section called “Threading options”).
Java DSL example
Copy linkLink copied to clipboard!
The following example aggregates exchanges with the same
StockSymbol header value, using the UseLatestAggregationStrategy aggregation strategy. For a given StockSymbol value, if more than three seconds elapse since the last exchange with that correlation key was received, the aggregated exchange is deemed to be complete and is sent to the mock endpoint.
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");XML DSL example
Copy linkLink copied to clipboard!
The following example shows how to configure the same route in XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>Specifying the correlation expression
Copy linkLink copied to clipboard!
In the Java DSL, the correlation expression is always passed as the first argument to the
aggregate() DSL command. You are not limited to using the Simple expression language here. You can specify a correlation expression using any of the expression languages or scripting languages, such as XPath, XQuery, SQL, and so on.
For exampe, to correlate exchanges using an XPath expression, you could use the following Java DSL route:
from("direct:start")
.aggregate(xpath("/stockQuote/@symbol"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
If the correlation expression cannot be evaluated on a particular incoming exchange, the aggregator throws a
CamelExchangeException by default. You can suppress this exception by setting the ignoreInvalidCorrelationKeys option. For example, in the Java DSL:
from(...).aggregate(...).ignoreInvalidCorrelationKeys()
In the XML DSL, you can set the
ignoreInvalidCorrelationKeys option is set as an attribute, as follows:
<aggregate strategyRef="aggregatorStrategy"
ignoreInvalidCorrelationKeys="true"
...>
...
</aggregate>Specifying the aggregation strategy
Copy linkLink copied to clipboard!
In Java DSL, you can either pass the aggregation strategy as the second argument to the
aggregate() DSL command or specify it using the aggregationStrategy() clause. For example, you can use the aggregationStrategy() clause as follows:
from("direct:start")
.aggregate(header("id"))
.aggregationStrategy(new UseLatestAggregationStrategy())
.completionTimeout(3000)
.to("mock:aggregated");
Apache Camel provides the following basic aggregation strategies (where the classes belong to the
org.apache.camel.processor.aggregate Java package):
UseLatestAggregationStrategy- Return the last exchange for a given correlation key, discarding all earlier exchanges with this key. For example, this strategy could be useful for throttling the feed from a stock exchange, where you just want to know the latest price of a particular stock symbol.
UseOriginalAggregationStrategy- Return the first exchange for a given correlation key, discarding all later exchanges with this key. You must set the first exchange by calling
UseOriginalAggregationStrategy.setOriginal()before you can use this strategy. GroupedExchangeAggregationStrategy- Concatenates all of the exchanges for a given correlation key into a list, which is stored in the
Exchange.GROUPED_EXCHANGEexchange property. See the section called “Grouped exchanges”.
Implementing a custom aggregation strategy
Copy linkLink copied to clipboard!
If you want to apply a different aggregation strategy, you can implement one of the following aggregation strategy base interfaces:
org.apache.camel.processor.aggregate.AggregationStrategy- The basic aggregation strategy interface.
org.apache.camel.processor.aggregate.TimeoutAwareAggregationStrategy- Implement this interface, if you want your implementation to receive a notification when an aggregation cycle times out. The
timeoutnotification method has the following signature:void timeout(Exchange oldExchange, int index, int total, long timeout) org.apache.camel.processor.aggregate.CompletionAwareAggregationStrategy- Implement this interface, if you want your implementation to receive a notification when an aggregation cycle completes normally. The notification method has the following signature:
void onCompletion(Exchange exchange)
For example, the following code shows two different custom aggregation strategies,
StringAggregationStrategy and ArrayListAggregationStrategy::
//simply combines Exchange String body values using '+' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "+" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
}Note
Since Apache Camel 2.0, the
AggregationStrategy.aggregate() callback method is also invoked for the very first exchange. On the first invocation of the aggregate method, the oldExchange parameter is null and the newExchange parameter contains the first incoming exchange.
To aggregate messages using the custom strategy class,
ArrayListAggregationStrategy, define a route like the following:
from("direct:start")
.aggregate(header("StockSymbol"), new ArrayListAggregationStrategy())
.completionTimeout(3000)
.to("mock:result");
You can also configure a route with a custom aggregation strategy in XML, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
completionTimeout="3000">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy" class="com.my_package_name.ArrayListAggregationStrategy"/>Controlling the lifecycle of a custom aggregation strategy
Copy linkLink copied to clipboard!
You can implement a custom aggregation strategy so that its lifecycle is aligned with the lifecycle of the enterprise integration pattern that is controlling it. This can be useful for ensuring that the aggregation strategy can shut down gracefully.
To implement an aggregation strategy with lifecycle support, you must implement the
org.apache.camel.Service interface (in addition to the AggregationStrategy interface) and provide implementations of the start() and stop() lifecycle methods. For example, the following code example shows an outline of an aggregation strategy with lifecycle support:
// Java
import org.apache.camel.processor.aggregate.AggregationStrategy;
import org.apache.camel.Service;
import java.lang.Exception;
...
class MyAggStrategyWithLifecycleControl
implements AggregationStrategy, Service {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// Implementation not shown...
...
}
public void start() throws Exception {
// Actions to perform when the enclosing EIP starts up
...
}
public void stop() throws Exception {
// Actions to perform when the enclosing EIP is stopping
...
}
}Exchange properties
Copy linkLink copied to clipboard!
The following properties are set on each aggregated exchange:
| Header | Type | Description |
|---|---|---|
Exchange.AGGREGATED_SIZE
|
int
|
The total number of exchanges aggregated into this exchange. |
Exchange.AGGREGATED_COMPLETED_BY
|
String
|
Indicates the mechanism responsible for completing the aggregate exchange. Possible values are: predicate, size, timeout, interval, or consumer.
|
The following properties are set on exchanges redelivered by the HawtDB aggregation repository (see the section called “Persistent aggregation repository”):
| Header | Type | Description |
|---|---|---|
Exchange.REDELIVERY_COUNTER
|
int
|
Sequence number of the current redelivery attempt (starting at 1).
|
Specifying a completion condition
Copy linkLink copied to clipboard!
It is mandatory to specify at least one completion condition, which determines when an aggregate exchange leaves the aggregator and proceeds to the next node on the route. The following completion conditions can be specified:
completionPredicate- Evaluates a predicate after each exchange is aggregated in order to determine completeness. A value of
trueindicates that the aggregate exchange is complete. completionSize- Completes the aggregate exchange after the specified number of incoming exchanges are aggregated.
completionTimeout- (Incompatible with
completionInterval) Completes the aggregate exchange, if no incoming exchanges are aggregated within the specified timeout.In other words, the timeout mechanism keeps track of a timeout for each correlation key value. The clock starts ticking after the latest exchange with a particular key value is received. If another exchange with the same key value is not received within the specified timeout, the corresponding aggregate exchange is marked complete and sent to the next node on the route. completionInterval- (Incompatible with
completionTimeout) Completes all outstanding aggregate exchanges, after each time interval (of specified length) has elapsed.The time interval is not tailored to each aggregate exchange. This mechanism forces simultaneous completion of all outstanding aggregate exchanges. Hence, in some cases, this mechanism could complete an aggregate exchange immediately after it started aggregating. completionFromBatchConsumer- When used in combination with a consumer endpoint that supports the batch consumer mechanism, this completion option automatically figures out when the current batch of exchanges is complete, based on information it receives from the consumer endpoint. See the section called “Batch consumer”.
forceCompletionOnStop- When this option is enabled, it forces completion of all outstanding aggregate exchanges when the current route context is stopped.
The preceding completion conditions can be combined arbitrarily, except for the
completionTimeout and completionInterval conditions, which cannot be simultaneously enabled. When conditions are used in combination, the general rule is that the first completion condition to trigger is the effective completion condition.
Specifying the completion predicate
Copy linkLink copied to clipboard!
You can specify an arbitrary predicate expression that determines when an aggregated exchange is complete. There are two possible ways of evaluating the predicate expression:
- On the latest aggregate exchange—this is the default behavior.
- On the latest incoming exchange—this behavior is selected when you enable the
eagerCheckCompletionoption.
For example, if you want to terminate a stream of stock quotes every time you receive an
ALERT message (as indicated by the value of a MsgType header in the latest incoming exchange), you can define a route like the following:
from("direct:start")
.aggregate(
header("id"),
new UseLatestAggregationStrategy()
)
.completionPredicate(
header("MsgType").isEqualTo("ALERT")
)
.eagerCheckCompletion()
.to("mock:result");
The following example shows how to configure the same route using XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy"
eagerCheckCompletion="true">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionPredicate>
<simple>$MsgType = 'ALERT'</simple>
</completionPredicate>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.aggregate.UseLatestAggregationStrategy"/>Specifying a dynamic completion timeout
Copy linkLink copied to clipboard!
It is possible to specify a dynamic completion timeout, where the timeout value is recalculated for every incoming exchange. For example, to set the timeout value from the
timeout header in each incoming exchange, you could define a route as follows:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionTimeout(header("timeout"))
.to("mock:aggregated");
You can configure the same route in the XML DSL, as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionTimeout>
<header>timeout</header>
</completionTimeout>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
Note
You can also add a fixed timeout value and Apache Camel will fall back to use this value, if the dynamic value is
null or 0.
Specifying a dynamic completion size
Copy linkLink copied to clipboard!
It is possible to specify a dynamic completion size, where the completion size is recalculated for every incoming exchange. For example, to set the completion size from the
mySize header in each incoming exchange, you could define a route as follows:
from("direct:start")
.aggregate(header("StockSymbol"), new UseLatestAggregationStrategy())
.completionSize(header("mySize"))
.to("mock:aggregated");
And the same example using Spring XML:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate strategyRef="aggregatorStrategy">
<correlationExpression>
<simple>header.StockSymbol</simple>
</correlationExpression>
<completionSize>
<header>mySize</header>
</completionSize>
<to uri="mock:aggregated"/>
</aggregate>
</route>
</camelContext>
<bean id="aggregatorStrategy"
class="org.apache.camel.processor.UseLatestAggregationStrategy"/>
Note
You can also add a fixed size value and Apache Camel will fall back to use this value, if the dynamic value is
null or 0.
Forcing completion with a special message
Copy linkLink copied to clipboard!
It is possible to force completion of all outstanding aggregate messages, by sending a message with a special header to the route. There are two alternative header settings you can use to force completion:
Exchange.AGGREGATION_COMPLETE_ALL_GROUPS- Set to
true, to force completion of the current aggregation cycle. This message acts purely as a signal and is not included in any aggregation cycle. After processing this signal message, the content of the message is discarded. Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE- Set to
true, to force completion of the current aggregation cycle. This message is included in the current aggregation cycle.
Enforcing unique correlation keys
Copy linkLink copied to clipboard!
In some aggregation scenarios, you might want to enforce the condition that the correlation key is unique for each batch of exchanges. In other words, when the aggregate exchange for a particular correlation key completes, you want to make sure that no further aggregate exchanges with that correlation key are allowed to proceed. For example, you might want to enforce this condition, if the latter part of the route expects to process exchanges with unique correlation key values.
Depending on how the completion conditions are configured, there might be a risk of more than one aggregate exchange being generated with a particular correlation key. For example, although you might define a completion predicate that is designed to wait until all the exchanges with a particular correlation key are received, you might also define a completion timeout, which could fire before all of the exchanges with that key have arrived. In this case, the late-arriving exchanges could give rise to a second aggregate exchange with the same correlation key value.
For such scenarios, you can configure the aggregator to suppress aggregate exchanges that duplicate previous correlation key values, by setting the
closeCorrelationKeyOnCompletion option. In order to suppress duplicate correlation key values, it is necessary for the aggregator to record previous correlation key values in a cache. The size of this cache (the number of cached correlation keys) is specified as an argument to the closeCorrelationKeyOnCompletion() DSL command. To specify a cache of unlimited size, you can pass a value of zero or a negative integer. For example, to specify a cache size of 10000 key values:
from("direct:start")
.aggregate(header("UniqueBatchID"), new MyConcatenateStrategy())
.completionSize(header("mySize"))
.closeCorrelationKeyOnCompletion(10000)
.to("mock:aggregated");
If an aggregate exchange completes with a duplicate correlation key value, the aggregator throws a
ClosedCorrelationKeyException exception.
Grouped exchanges
Copy linkLink copied to clipboard!
You can combine all of the aggregated exchanges in an outgoing batch into a single
org.apache.camel.impl.GroupedExchange holder class. To enable grouped exchanges, specify the groupExchanges() option, as shown in the following Java DSL route:
from("direct:start")
.aggregate(header("StockSymbol"))
.completionTimeout(3000)
.groupExchanges()
.to("mock:result");
The grouped exchange that is sent to
mock:result contains the list of aggregated exchanges stored in the exchange property, Exchange.GROUPED_EXCHANGE. The following line of code shows how a subsequent processor can access the contents of the grouped exchange in the form of a list:
// Java
List<Exchange> grouped = ex.getProperty(Exchange.GROUPED_EXCHANGE, List.class);Note
When you enable the grouped exchanges feature, you must not configure an aggregation strategy (the grouped exchanges feature is itself an aggregation strategy).
Batch consumer
Copy linkLink copied to clipboard!
The aggregator can work together with the batch consumer pattern to aggregate the total number of messages reported by the batch consumer (a batch consumer endpoint sets the
CamelBatchSize, CamelBatchIndex , and CamelBatchComplete properties on the incoming exchange). For example, to aggregate all of the files found by a File consumer endpoint, you could use a route like the following:
from("file://inbox")
.aggregate(xpath("//order/@customerId"), new AggregateCustomerOrderStrategy())
.completionFromBatchConsumer()
.to("bean:processOrder");
Currently, the following endpoints support the batch consumer mechanism: File, FTP, Mail, iBatis, and JPA.
Persistent aggregation repository
Copy linkLink copied to clipboard!
If you want pending aggregated exchanges to be stored persistently, you can use either the HawtDB component or the SQL Component for persistence support as a persistent aggregation repository. For example, if using HawtDB, you need to include a dependency on the
camel-hawtdb component in your Maven POM. You can then configure a route to use the HawtDB aggregation repository as follows:
public void configure() throws Exception {
HawtDBAggregationRepository repo = new AggregationRepository("repo1", "target/data/hawtdb.dat");
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.aggregationRepository(repo)
.to("mock:aggregated");
}
The HawtDB aggregation repository has a feature that enables it to recover and retry any failed exchanges (that is, any exchange that raised an exception while it was being processed by the latter part of the route). Figure 7.7, “Recoverable Aggregation Repository” shows an overview of the recovery mechanism.
Figure 7.7. Recoverable Aggregation Repository
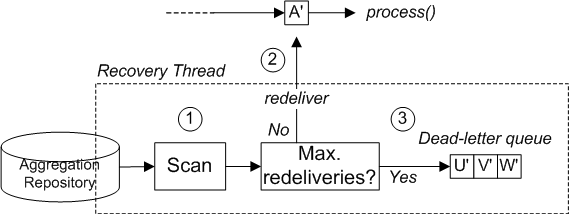
The recovery mechanism works as follows:
- The aggregator creates a dedicated recovery thread, which runs in the background, scanning the aggregation repository to find any failed exchanges.
- Each failed exchange is checked to see whether its current redelivery count exceeds the maximum redelivery limit. If it is under the limit, the recovery task resubmits the exchange for processing in the latter part of the route.
- If the current redelivery count is over the limit, the failed exchange is passed to the dead letter queue.
Threading options
Copy linkLink copied to clipboard!
As shown in Figure 7.6, “Aggregator Implementation”, the aggregator is dsecoupled from the latter part of the route, where the exchanges sent to the latter part of the route are processed by a dedicated thread pool. By default, this pool contains just a single thread. If you want to specify a pool with multiple threads, enable the
parallelProcessing option, as follows:
from("direct:start")
.aggregate(header("id"), new UseLatestAggregationStrategy())
.completionTimeout(3000)
.parallelProcessing()
.to("mock:aggregated");
By default, this creates a pool with 10 worker threads.
If you want to exercise more control over the created thread pool, specify a custom
java.util.concurrent.ExecutorService instance using the executorService option (in which case it is unnecessary to enable the parallelProcessing option).
Aggregating into a List
Copy linkLink copied to clipboard!
A common aggregation scenario involves aggregating a series of incoming message bodies into a
List object. To facilitate this scenario, Apache Camel provides the AbstractListAggregationStrategy abstract class, which you can quickly extend to create an aggregation strategy for this case. Incoming message bodies of type, T, are aggregated into a completed exchange, with a message body of type List<T>.
For example, to aggregate a series of
Integer message bodies into a List<Integer> object, you could use an aggregation strategy defined as follows:
import org.apache.camel.processor.aggregate.AbstractListAggregationStrategy;
...
/**
* Strategy to aggregate integers into a List<Integer>.
*/
public final class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so just return that as-is
return exchange.getIn().getBody(Integer.class);
}
}Aggregator options
Copy linkLink copied to clipboard!
The aggregator supports the following options:
| Option | Default | Description |
|---|---|---|
correlationExpression | Mandatory Expression which evaluates the correlation key to use for aggregation. The Exchange which has the same correlation key is aggregated together. If the correlation key could not be evaluated an Exception is thrown. You can disable this by using the ignoreBadCorrelationKeys option. | |
aggregationStrategy | Mandatory AggregationStrategy which is used to merge the incoming Exchange with the existing already merged exchanges. At first call the oldExchange parameter is null. On subsequent invocations the oldExchange contains the merged exchanges and newExchange is of course the new incoming Exchange. From Camel 2.9.2 onwards, the strategy can optionally be a TimeoutAwareAggregationStrategy implementation, which supports a timeout callback | |
strategyRef | A reference to lookup the AggregationStrategy in the Registry. | |
completionSize | Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a size dynamically - will use Integer as result. If both are set Camel will fallback to use the fixed value if the Expression result was null or 0. | |
completionTimeout | Time in millis that an aggregated exchange should be inactive before its complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a timeout dynamically - will use Long as result. If both are set Camel will fallback to use the fixed value if the Expression result was null or 0. You cannot use this option together with completionInterval, only one of the two can be used. | |
completionInterval | A repeating period in millis by which the aggregator will complete all current aggregated exchanges. Camel has a background task which is triggered every period. You cannot use this option together with completionTimeout, only one of them can be used. | |
completionPredicate | A Predicate to indicate when an aggregated exchange is complete. | |
completionFromBatchConsumer | false | This option is if the exchanges are coming from a Batch Consumer. Then when enabled the Aggregator will use the batch size determined by the Batch Consumer in the message header CamelBatchSize. See more details at Batch Consumer. This can be used to aggregate all files consumed from a File endpoint in that given poll. |
eagerCheckCompletion | false | Whether or not to eager check for completion when a new incoming Exchange has been received. This option influences the behavior of the completionPredicate option as the Exchange being passed in changes accordingly. When false the Exchange passed in the Predicate is the aggregated Exchange which means any information you may store on the aggregated Exchange from the AggregationStrategy is available for the Predicate. When true the Exchange passed in the Predicate is the incoming Exchange, which means you can access data from the incoming Exchange. |
forceCompletionOnStop | false | If true, complete all aggregated exchanges when the current route context is stopped. |
groupExchanges | false | If enabled then Camel will group all aggregated Exchanges into a single combined org.apache.camel.impl.GroupedExchange holder class that holds all the aggregated Exchanges. And as a result only one Exchange is being sent out from the aggregator. Can be used to combine many incoming Exchanges into a single output Exchange without coding a custom AggregationStrategy yourself. |
ignoreInvalidCorrelationKeys | false | Whether or not to ignore correlation keys which could not be evaluated to a value. By default Camel will throw an Exception, but you can enable this option and ignore the situation instead. |
closeCorrelationKeyOnCompletion | Whether or not late Exchanges should be accepted or not. You can enable this to indicate that if a correlation key has already been completed, then any new exchanges with the same correlation key be denied. Camel will then throw a closedCorrelationKeyException exception. When using this option you pass in a integer which is a number for a LRUCache which keeps that last X number of closed correlation keys. You can pass in 0 or a negative value to indicate a unbounded cache. By passing in a number you are ensured that cache wont grown too big if you use a log of different correlation keys. | |
discardOnCompletionTimeout | false | Camel 2.5: Whether or not exchanges which complete due to a timeout should be discarded. If enabled, then when a timeout occurs the aggregated message will not be sent out but dropped (discarded). |
aggregationRepository | Allows you to plug in you own implementation of org.apache.camel.spi.AggregationRepository which keeps track of the current inflight aggregated exchanges. Camel uses by default a memory based implementation. | |
aggregationRepositoryRef | Reference to lookup a aggregationRepository in the Registry. | |
parallelProcessing | false | When aggregated are completed they are being send out of the aggregator. This option indicates whether or not Camel should use a thread pool with multiple threads for concurrency. If no custom thread pool has been specified then Camel creates a default pool with 10 concurrent threads. |
executorService | If using parallelProcessing you can specify a custom thread pool to be used. In fact also if you are not using parallelProcessing this custom thread pool is used to send out aggregated exchanges as well. | |
executorServiceRef | Reference to lookup a executorService in the Registry | |
timeoutCheckerExecutorService | If using one of the completionTimeout, completionTimeoutExpression, or completionInterval options, a background thread is created to check for the completion for every aggregator. Set this option to provide a custom thread pool to be used rather than creating a new thread for every aggregator. | |
timeoutCheckerExecutorServiceRef | Reference to look up a timeoutCheckerExecutorService in the registry. | |
optimisticLocking | false | Turns on optimistic locking, which can be used in combination with an aggregation repository. |
optimisticLockRetryPolicy | Configures the retry policy for optimistic locking. |