7.4. Splitter
Overview
Copy linkLink copied to clipboard!
A splitter is a type of router that splits an incoming message into a series of outgoing messages. Each of the outgoing messages contains a piece of the original message. In Apache Camel, the splitter pattern, shown in Figure 7.4, “Splitter Pattern”, is implemented by the
split() Java DSL command.
Figure 7.4. Splitter Pattern
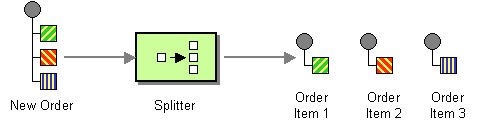
The Apache Camel splitter actually supports two patterns, as follows:
- Simple splitter—implements the splitter pattern on its own.
- Splitter/aggregator—combines the splitter pattern with the aggregator pattern, such that the pieces of the message are recombined after they have been processed.
Java DSL example
Copy linkLink copied to clipboard!
The following example defines a route from
seda:a to seda:b that splits messages by converting each line of an incoming message into a separate outgoing message:
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("seda:a")
.split(bodyAs(String.class).tokenize("\n"))
.to("seda:b");
}
};
The splitter can use any expression language, so you can split messages using any of the supported scripting languages, such as XPath, XQuery, or SQL (see Part II, “Routing Expression and Predicate Languages”). The following example extracts
bar elements from an incoming message and insert them into separate outgoing messages:
from("activemq:my.queue")
.split(xpath("//foo/bar"))
.to("file://some/directory")XML configuration example
Copy linkLink copied to clipboard!
The following example shows how to configure a splitter route in XML, using the XPath scripting language:
<camelContext id="buildSplitter" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="seda:a"/>
<split>
<xpath>//foo/bar</xpath>
<to uri="seda:b"/>
</split>
</route>
</camelContext>
You can use the tokenize expression in the XML DSL to split bodies or headers using a token, where the tokenize expression is defined using the
tokenize element. In the following example, the message body is tokenized using the \n separator character. To use a regular expression pattern, set regex=true in the tokenize element.
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<split>
<tokenize token="\n"/>
<to uri="mock:result"/>
</split>
</route>
</camelContext>Splitting into groups of lines
Copy linkLink copied to clipboard!
To split a big file into chunks of 1000 lines, you can define a splitter route as follows in the Java DSL:
from("file:inbox")
.split().tokenize("\n", 1000).streaming()
.to("activemq:queue:order");
The second argument to
tokenize specifies the number of lines that should be grouped into a single chunk. The streaming() clause directs the splitter not to read the whole file at once (resulting in much better performance if the file is large).
The same route can be defined in XML DSL as follows:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000"/>
<to uri="activemq:queue:order"/>
</split>
</route>
The output when using the
group option is always of java.lang.String type.
Splitter reply
Copy linkLink copied to clipboard!
If the exchange that enters the splitter has the InOut message-exchange pattern (that is, a reply is expected), the splitter returns a copy of the original input message as the reply message in the Out message slot. You can override this default behavior by implementing your own aggregation strategy.
Parallel execution
Copy linkLink copied to clipboard!
If you want to execute the resulting pieces of the message in parallel, you can enable the parallel processing option, which instantiates a thread pool to process the message pieces. For example:
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
from("activemq:my.queue").split(xPathBuilder).parallelProcessing().to("activemq:my.parts");
You can customize the underlying
ThreadPoolExecutor used in the parallel splitter. For example, you can specify a custom executor in the Java DSL as follows:
XPathBuilder xPathBuilder = new XPathBuilder("//foo/bar");
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
from("activemq:my.queue")
.split(xPathBuilder)
.parallelProcessing()
.executorService(threadPoolExecutor)
.to("activemq:my.parts");
You can specify a custom executor in the XML DSL as follows:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:parallel-custom-pool"/>
<split executorServiceRef="threadPoolExecutor">
<xpath>/invoice/lineItems</xpath>
<to uri="mock:result"/>
</split>
</route>
</camelContext>
<bean id="threadPoolExecutor" class="java.util.concurrent.ThreadPoolExecutor">
<constructor-arg index="0" value="8"/>
<constructor-arg index="1" value="16"/>
<constructor-arg index="2" value="0"/>
<constructor-arg index="3" value="MILLISECONDS"/>
<constructor-arg index="4"><bean class="java.util.concurrent.LinkedBlockingQueue"/></constructor-arg>
</bean>Using a bean to perform splitting
Copy linkLink copied to clipboard!
As the splitter can use any expression to do the splitting, we can use a bean to perform splitting, by invoking the
method() expression. The bean should return an iterable value such as: java.util.Collection, java.util.Iterator, or an array.
The following route defines a
method() expression that calls a method on the mySplitterBean bean instance:
from("direct:body")
// here we use a POJO bean mySplitterBean to do the split of the payload
.split()
.method("mySplitterBean", "splitBody")
.to("mock:result");
from("direct:message")
// here we use a POJO bean mySplitterBean to do the split of the message
// with a certain header value
.split()
.method("mySplitterBean", "splitMessage")
.to("mock:result");
Where
mySplitterBean is an instance of the MySplitterBean class, which is defined as follows:
public class MySplitterBean {
/**
* The split body method returns something that is iteratable such as a java.util.List.
*
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<String> splitBody(String body) {
// since this is based on an unit test you can of couse
// use different logic for splitting as Apache Camel have out
// of the box support for splitting a String based on comma
// but this is for show and tell, since this is java code
// you have the full power how you like to split your messages
List<String> answer = new ArrayList<String>();
String[] parts = body.split(",");
for (String part : parts) {
answer.add(part);
}
return answer;
}
/**
* The split message method returns something that is iteratable such as a java.util.List.
*
* @param header the header of the incoming message with the name user
* @param body the payload of the incoming message
* @return a list containing each part split
*/
public List<Message> splitMessage(@Header(value = "user") String header, @Body String body) {
// we can leverage the Parameter Binding Annotations
// http://camel.apache.org/parameter-binding-annotations.html
// to access the message header and body at same time,
// then create the message that we want, splitter will
// take care rest of them.
// *NOTE* this feature requires Apache Camel version >= 1.6.1
List<Message> answer = new ArrayList<Message>();
String[] parts = header.split(",");
for (String part : parts) {
DefaultMessage message = new DefaultMessage();
message.setHeader("user", part);
message.setBody(body);
answer.add(message);
}
return answer;
}
}
Exchange properties
Copy linkLink copied to clipboard!
The following properties are set on each split exchange:
| header | type | description |
|---|---|---|
CamelSplitIndex
|
int
|
Apache Camel 2.0: A split counter that increases for each Exchange being split. The counter starts from 0. |
CamelSplitSize
|
int
|
Apache Camel 2.0: The total number of Exchanges that was split. This header is not applied for stream based splitting. |
CamelSplitComplete
|
boolean
|
Apache Camel 2.4: Whether or not this Exchange is the last. |
Splitter/aggregator pattern
Copy linkLink copied to clipboard!
It is a common pattern for the message pieces to be aggregated back into a single exchange, after processing of the individual pieces has completed. To support this pattern, the
split() DSL command lets you provide an AggregationStrategy object as the second argument.
Java DSL example
Copy linkLink copied to clipboard!
The following example shows how to use a custom aggregation strategy to recombine a split message after all of the message pieces have been processed:
from("direct:start")
.split(body().tokenize("@"), new MyOrderStrategy())
// each split message is then send to this bean where we can process it
.to("bean:MyOrderService?method=handleOrder")
// this is important to end the splitter route as we do not want to do more routing
// on each split message
.end()
// after we have split and handled each message we want to send a single combined
// response back to the original caller, so we let this bean build it for us
// this bean will receive the result of the aggregate strategy: MyOrderStrategy
.to("bean:MyOrderService?method=buildCombinedResponse")
AggregationStrategy implementation
Copy linkLink copied to clipboard!
The custom aggregation strategy,
MyOrderStrategy, used in the preceding route is implemented as follows:
/**
* This is our own order aggregation strategy where we can control
* how each split message should be combined. As we do not want to
* lose any message, we copy from the new to the old to preserve the
* order lines as long we process them
*/
public static class MyOrderStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// put order together in old exchange by adding the order from new exchange
if (oldExchange == null) {
// the first time we aggregate we only have the new exchange,
// so we just return it
return newExchange;
}
String orders = oldExchange.getIn().getBody(String.class);
String newLine = newExchange.getIn().getBody(String.class);
LOG.debug("Aggregate old orders: " + orders);
LOG.debug("Aggregate new order: " + newLine);
// put orders together separating by semi colon
orders = orders + ";" + newLine;
// put combined order back on old to preserve it
oldExchange.getIn().setBody(orders);
// return old as this is the one that has all the orders gathered until now
return oldExchange;
}
}
Stream based processing
Copy linkLink copied to clipboard!
When parallel processing is enabled, it is theoretically possible for a later message piece to be ready for aggregation before an earlier piece. In other words, the message pieces might arrive at the aggregator out of order. By default, this does not happen, because the splitter implementation rearranges the message pieces back into their original order before passing them into the aggregator.
If you would prefer to aggregate the message pieces as soon as they are ready (and possibly out of order), you can enable the streaming option, as follows:
from("direct:streaming")
.split(body().tokenize(","), new MyOrderStrategy())
.parallelProcessing()
.streaming()
.to("activemq:my.parts")
.end()
.to("activemq:all.parts");
You can also supply a custom iterator to use with streaming, as follows:
// Java
import static org.apache.camel.builder.ExpressionBuilder.beanExpression;
...
from("direct:streaming")
.split(beanExpression(new MyCustomIteratorFactory(), "iterator"))
.streaming().to("activemq:my.parts")Streaming and XPath
You cannot use streaming mode in conjunction with XPath. XPath requires the complete DOM XML document in memory.
Stream based processing with XML
Copy linkLink copied to clipboard!
If an incoming messages is a very large XML file, you can process the message most efficiently using the
tokenizeXML sub-command in streaming mode.
For example, given a large XML file that contains a sequence of
order elements, you can split the file into order elements using a route like the following:
from("file:inbox")
.split().tokenizeXML("order").streaming()
.to("activemq:queue:order");
You can do the same thing in XML, by defining a route like the following:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>
It is often the case that you need access to namespaces that are defined in one of the enclosing (ancestor) elements of the token elements. You can copy namespace definitions from one of the ancestor elements into the token element, by specifing which element you want to inherit namespace definitions from.
In the Java DSL, you specify the ancestor element as the second argument of
tokenizeXML. For example, to inherit namespace definitions from the enclosing orders element:
from("file:inbox")
.split().tokenizeXML("order", "orders").streaming()
.to("activemq:queue:order");
In the XML DSL, you specify the ancestor element using the
inheritNamespaceTagName attribute. For example:
<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order"
xml="true"
inheritNamespaceTagName="orders"/>
<to uri="activemq:queue:order"/>
</split>
</route>Options
Copy linkLink copied to clipboard!
The
split DSL command supports the following options:
| Name | Default Value | Description |
|---|---|---|
strategyRef
|
Refers to an AggregationStrategy to be used to assemble the replies from the sub-messages, into a single outgoing message from the Splitter. See the section titled What does the splitter return below for whats used by default. | |
parallelProcessing
|
false
|
If enables then processing the sub-messages occurs concurrently. Note the caller thread will still wait until all sub-messages has been fully processed, before it continues. |
executorServiceRef
|
Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
stopOnException
|
false
|
Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel continue splitting and process the sub-messages regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. |
streaming
|
false
|
If enabled then Camel will split in a streaming fashion, which means it will split the input message in chunks. This reduces the memory overhead. For example if you split big messages its recommended to enable streaming. If streaming is enabled then the sub-message replies will be aggregated out-of-order, eg in the order they come back. If disabled, Camel will process sub-message replies in the same order as they where splitted. |
timeout
|
Camel 2.5: Sets a total timeout specified in millis. If the Recipient List hasn't been able to split and process all replies within the given timeframe, then the timeout triggers and the Splitter breaks out and continues. Notice if you provide a TimeoutAwareAggregationStrategy then the timeout method is invoked before breaking out.
|
|
onPrepareRef
|
Camel 2.8: Refers to a custom Processor to prepare the sub-message of the Exchange, before its processed. This allows you to do any custom logic, such as deep-cloning the message payload if that's needed etc. | |
shareUnitOfWork
|
false
|
Camel 2.8: Whether the unit of work should be shared. See further below for more details. |