5. Using High Availability and Agent Load Balancing
High availability with JBoss ON servers means that all JBoss ON servers which use the same, central database interact together in a cloud. This allows seamless failover between servers when a server has to be taken offline for maintenance, and it provides a natural method for load balancing agent and resource operations.
Having multiple JBoss ON servers in a cloud also allow agents to define a preference for which server they use for regular communications. This preference (affinity) is a way of load balancing agent-server communications for better overall performance.
5.1. About Agent-Server Communication and Server Availability
Copy linkLink copied to clipboard!
5.1.1. Agents and Server Communication
Copy linkLink copied to clipboard!
Part of planning whether to use high availability is understanding how agents and servers communicate with each other.
Agents and servers have two-way communication. Agents send current monitoring data, configuration settings, resources, and other current data to the server. The server sends configuration updates, alert definitions, drift definitions, and other settings to the agent.
When an agent is first installed, the agent configuration prompts for the hostname or IP address of a server to connect to. That is the registration server (which can be any server in the JBoss ON deployment). Then, as part of the agent registration, it receives a list of available JBoss ON servers. The first server in that list is the one that the agent attempts to communicate with most regularly, and it tries the other servers in the list in order (more on that in Section 5.1.5, “Agents and Server Failover”). That first server may be the registration server or it may be a different one; it does not matter.
While there are slight preferences in what server an agent connects to, there are no limits on what agents can connect to what servers and what servers can communicate with what agents. Any server can communicate with any agent at any given time, and vice versa.
Note
Because communication must be bidirectional, all servers must be accessible by all agents, and all agents must be accessible by all servers. Having resolvable hostnames and IP addresses for servers and agents — which are configured when the server or agent is installed — is critical.
However, servers never communicate with each other, so it is not necessary for servers to be able to resolve each other's hostnames or IP addresses.
5.1.2. Server Availability: Multiple Servers in a Single Cloud
Copy linkLink copied to clipboard!
In many deployments, there is a single JBoss ON server and all agents communicate with that server. However, there are a couple of environments where multiple servers are beneficial:
- There are problems processing the agent load, which can impact evaluating metrics, generating alerts or events, or reporting resource availability. This is not necessarily because of the number of agents; it could be related to network quality or other factors.
- You have a geographically distributed environment with multiple data centers or logical grouping of agents to servers.
Multiple JBoss ON servers in the same deployment are configured to use the same backend database. When a new JBoss ON server is added to the database, that server is automatically added to the JBoss ON server high availability cloud.
A high availability configuration does not necessarily imply a large number of JBoss ON agents. Having multiple servers does not affect the ultimate load on the central database, so it does not have a huge effect on performance. The purpose of high availability is that the overall JBoss ON deployment requires responsiveness and availability, as well as fault tolerance, so multiple servers are required. This can be true even with relatively few agents.
Important
Although JBoss ON servers can be added to the high availability server cloud with relative ease, it should be done cautiously due to the potential impact on the backend database. Each JBoss ON server limits its concurrent database connections, but there is no restriction on the total number of connections across the cloud. Adding a second server can double the potential database connections, even if the number of agents remains the same. The increase in connections is linear as servers are added.
Basically, high availability is a way of providing natural failover and redundancy for the entire JBoss ON deployment. Because all servers use the same database backend, they all have access to the same agents and inventory, monitoring data, resource histories, and other information. This means that all of the JBoss ON servers are essentially identical.
JBoss ON servers can be added to and removed from the high availability cloud easily. Servers can also be temporarily removed by being put into maintenance mode.
There are some things to required when planning high availability:
- All servers must be running the same version of JBoss ON.
- All servers must be uniquely named. This string is defined during server installation.
- Each server must define a unique endpoint (hostname or IP address) that is resolvable by all JBoss ON agents running against the high availability server cloud.
- Optional. Adjust the concurrency limits on the servers to prevent creating too much load on the database and damaging performance.
5.1.3. Agents and Server Partitions: Distributing Agent Load
Copy linkLink copied to clipboard!
When there is only a single server, the agent distribution is pretty simple: all agents communicate with that one server.
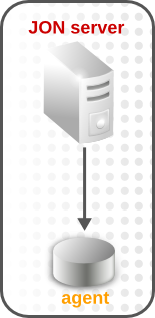
Figure 2. All on a Single Server
Once high availability is introduced, however, then agents have choices in what server to communicate with. All servers are on a list of available servers which is sent to the agent, but the agent always attempts to contact the first server in its list, its primary server.
The server list is slight different for each agent because the list is generated in a round-robin pattern. For example:
A1: S1, S2, S3
A2: S2, S3, S1
A3: S3, S1, S2
This creates a fairly even distribution of agents across the servers. The distribution is a partition.
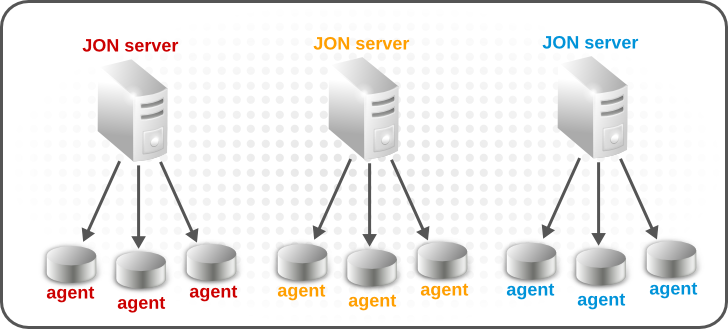
Figure 3. Partitions: Agent Load Distributed Among Multiple Servers
As servers are added to the high availability cloud, the agent-server lists are updated. Changing the agent load distribution is called a partition event.
5.1.4. Agents and Preferred Servers: Affinity and Load Balancing
Copy linkLink copied to clipboard!
The natural distribution of the agent load is fairly random and creates an even distribution. However, in some network environments, a randome distribution doesn't really make sense or provide the best efficiency. For example, servers and agents in the same region or facility can communicate faster than servers and agents that are much further away. In that case, an administrator would prefer an explicit, sensible server-agent relationship instead of a random one.
JBoss ON has the concept of server-agent affinity. An affinity is a defined preference for what server an agent communicates with. An affinity group is essentially a manual partition. It is a group of servers and agents, and the agents selectively communicate with servers in their affinity group first.
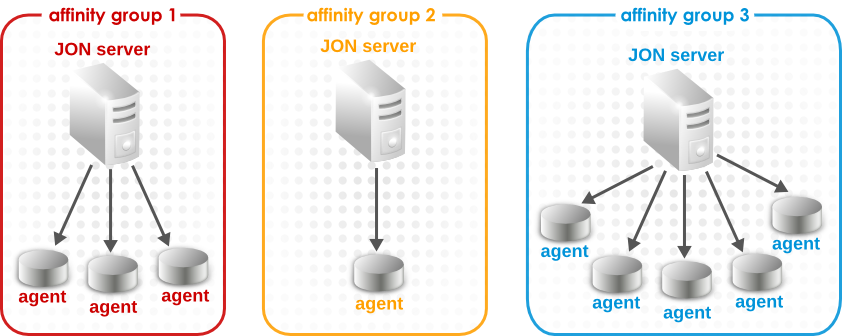
Figure 4. Affinity Preferences for Agent Load
An affinity group creates a loose preference for an agent on what servers it communicates with — it does not create a hard rule or restrict what servers the agent can communicate with.
Note
An affinity group defines a one-way preference, from the agent to the server. Any server can contact any agent in the JBoss ON topology, regardless of any affinity preference.
When an agent's primary server is unavailable, the agent attempts to round-robin through the other servers in its affinity group. If none of those servers are available or there are no other servers in the affinity group, then it iterates through all of the servers in the JBoss ON high availability cloud, according to its failover list. That is true for all of the agents in the affinity group, so eventually any agents in one group would be evenly distributed among other JBoss ON servers.
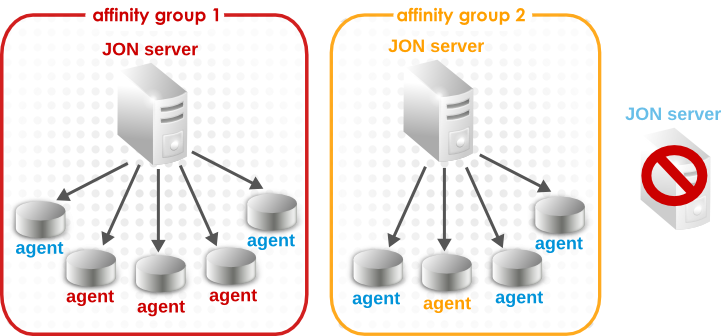
Figure 5. Failover with Affinity
Affinity groups provide (at least) three potential advantages:
- Physical or network efficiency. Generally, if certain agent-server connections clearly run more efficiently than others, then defining affinity to prefer those connections makes sense. This could include servers and agents co-located in the same data center, geographic grouping, or network topology.
- Logical organization. There may be organizational reasons, apart from operating efficiency, to group specific agents and servers together, such as administrative responsibilities or business unit assignments.
- Warm backup. It may be the case that certain machines should not be assigned agent load unless specifically needed for failover purposes. In this case, all agents should be assigned affinity to a subset of available servers, leaving some servers without any associated agents in normal operation.
5.1.5. Agents and Server Failover
Copy linkLink copied to clipboard!
There is a central list of servers which is provided to each agent to identify what servers are available to that agent. This is the failover list. When a new server joins the cloud, it is added to the list and the list is updated to the agent.
Whatever server is first in the list for the agent is the server it most frequently communicates with — its primary server. If the agent cannot connect to that server, then it attempts to connect to the next server in the list, until it finds an available server.
The agent checks back periodically (every hour) to see when its primary server is back online and switches back to that server as soon as it is back.
For a regular distribution of agents, the agent runs through all available servers in a (relatively) random order, according to whatever failover list it was provided. If the agent belongs to an affinity group, it first tries all of the servers in that affinity group, and then moves on to servers outside the affinity group in whatever order is set in its failover list.