Chapter 4. Deploying and testing a model
4.1. Preparing a model for deployment
After you train a model, you can deploy it by using the OpenShift AI model serving capabilities.
To prepare a model for deployment, you must move the model from your workbench to your S3-compatible object storage. You use the data connection that you created in the Storing data with data connections section and upload the model from a notebook. You also convert the model to the portable ONNX format. ONNX allows you to transfer models between frameworks with minimal preparation and without the need for rewriting the models.
Prerequisites
You created the data connection
My Storage.
You added the
My Storagedata connection to your workbench.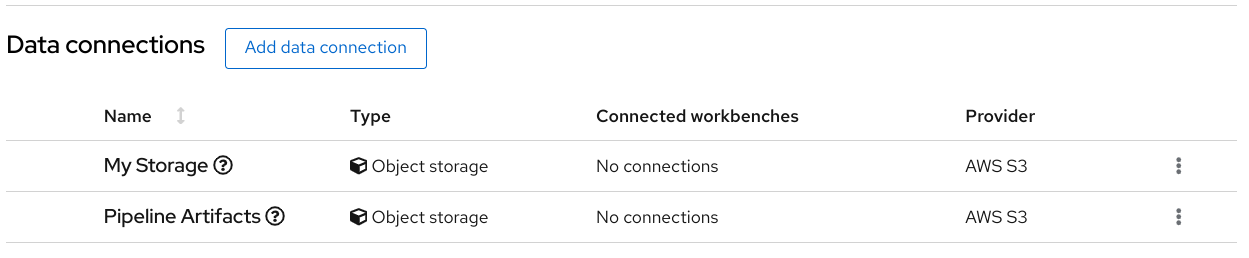
Procedure
-
In your Jupyter environment, open the
2_save_model.ipynbfile. - Follow the instructions in the notebook to make the model accessible in storage and save it in the portable ONNX format.
Verification
When you have completed the notebook instructions, the models/fraud/1/model.onnx file is in your object storage and it is ready for your model server to use.
Next step
4.2. Deploying a model
Now that the model is accessible in storage and saved in the portable ONNX format, you can use an OpenShift AI model server to deploy it as an API.
OpenShift AI offers two options for model serving:
- Single-model serving - Each model in the project is deployed on its own model server. This platform is suitable for large models or models that need dedicated resources.
- Multi-model serving - All models in the project are deployed on the same model server. This platform is suitable for sharing resources amongst deployed models. Multi-model serving is the only option offered in the Red Hat Developer Sandbox environment.
Note: For each project, you can specify only one model serving platform. If you want to change to the other model serving platform, you must create a new project.
For this tutorial, since you are only deploying only one model, you can select either serving type. The steps for deploying the fraud detection model depend on the type of model serving platform you select:
4.2.1. Deploying a model on a single-model server
OpenShift AI single-model servers host only one model. You create a new model server and deploy your model to it.
Note: If you are using the Red Hat Developer Sandbox environment, you must use multi-model serving.
Prerequiste
-
A user with
adminprivileges has enabled the single-model serving platform on your OpenShift cluster.
Procedure
In the OpenShift AI dashboard, navigate to the project details page and click the Models tab.
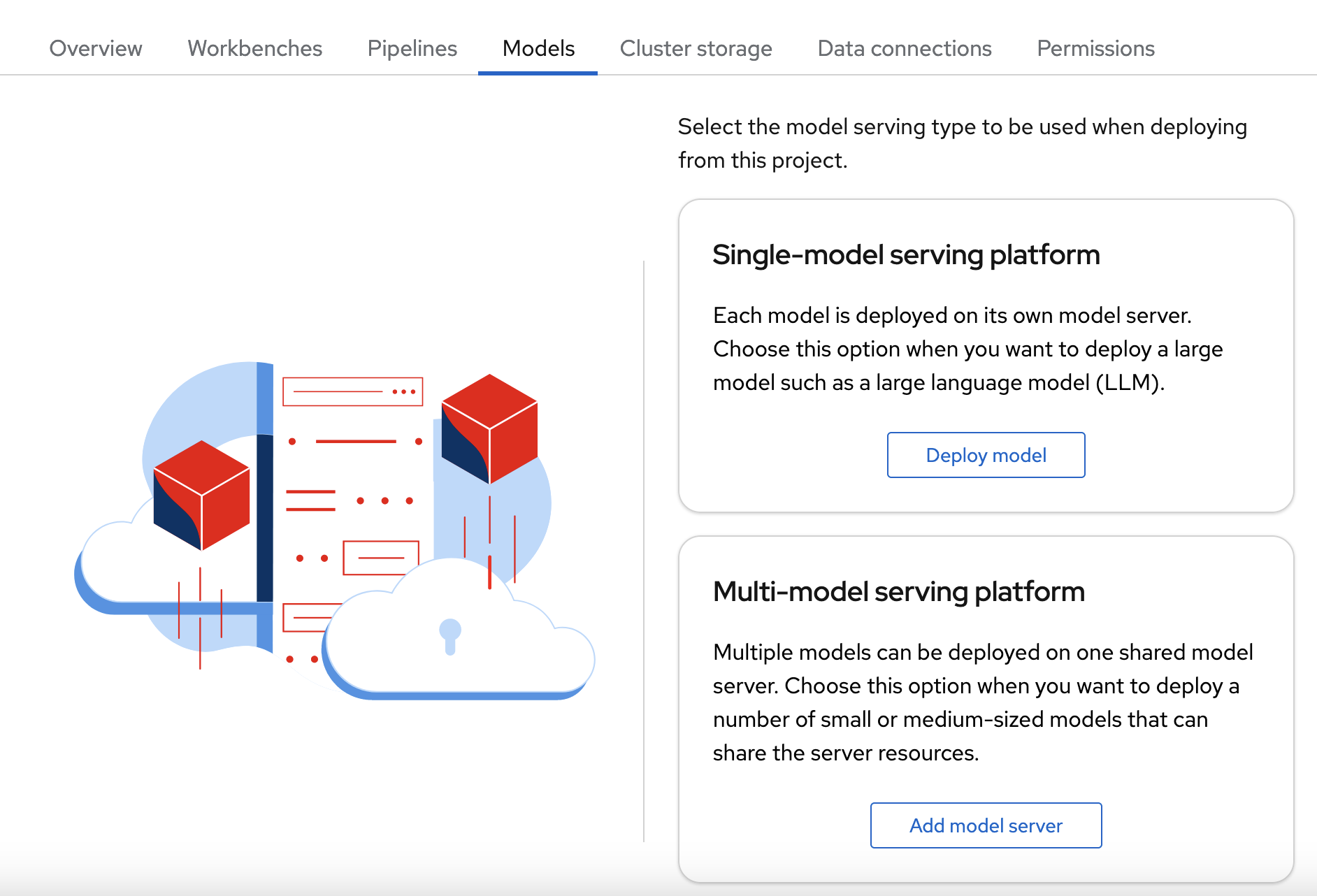
Note: Depending on how model serving has been configured on your cluster, you might see only one model serving platform option.
- In the Single-model serving platform tile, click Deploy model.
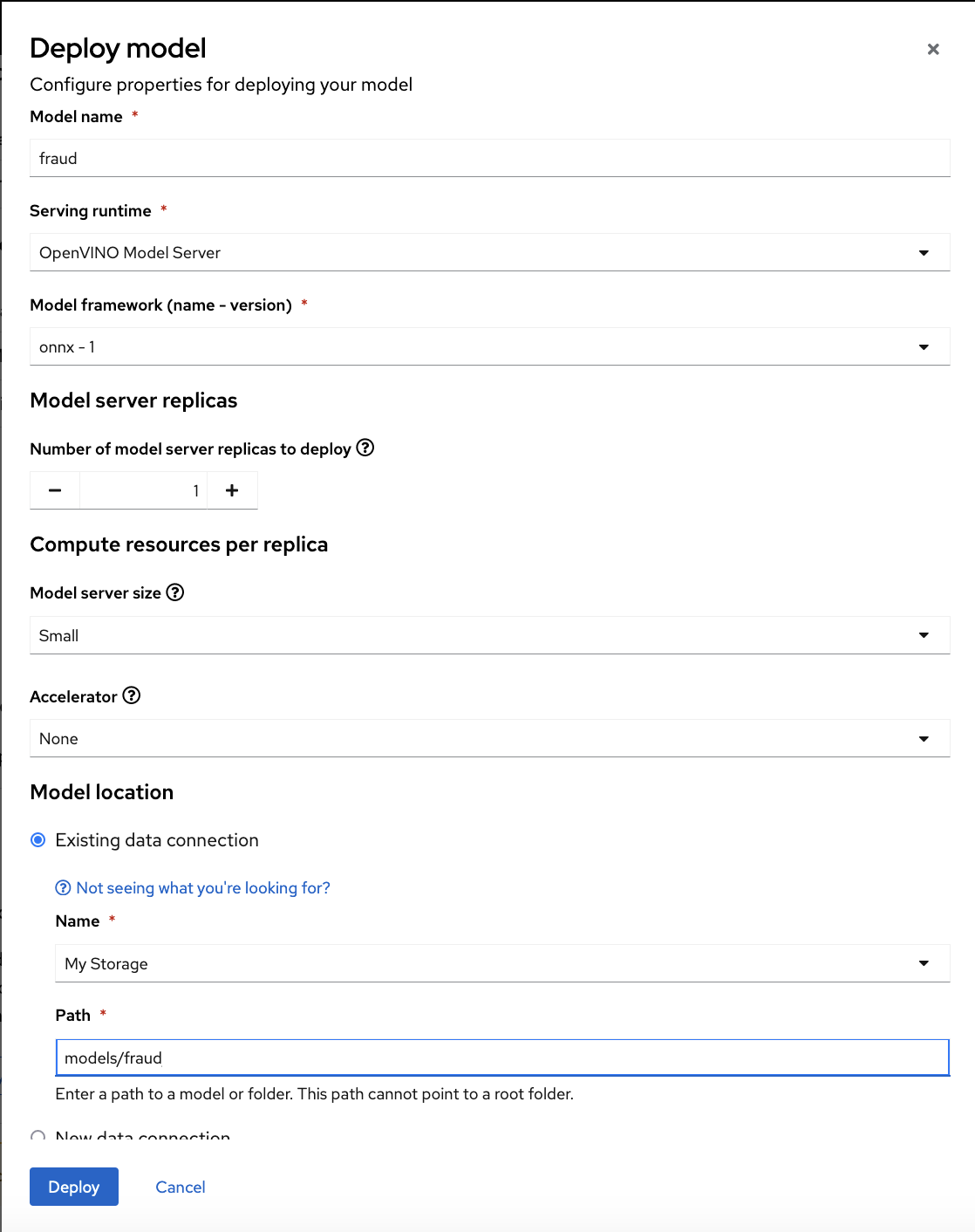
In the form, provide the following values:
-
For Model Name, type
fraud. -
For Serving runtime, select
OpenVINO Model Server. -
For Model framework, select
onnx-1. -
For Existing data connection, select
My Storage. -
Type the path that leads to the version folder that contains your model file:
models/fraud Leave the other fields with the default settings.
-
For Model Name, type
- Click Deploy.
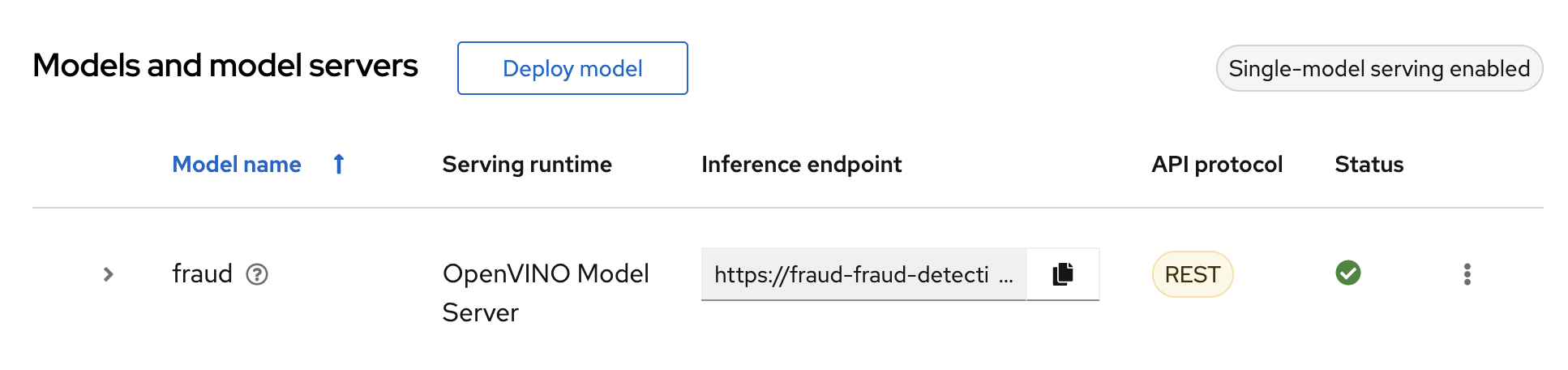
Verification
Wait for the model to deploy and for the Status to show a green checkmark.
Next step
4.2.2. Deploying a model on a multi-model server
OpenShift AI multi-model servers can host several models at once. You create a new model server and deploy your model to it.
Prerequiste
-
A user with
adminprivileges has enabled the multi-model serving platform on your OpenShift cluster.
Procedure
In the OpenShift AI dashboard, navigate to the project details page and click the Models tab.
Note: Depending on how model serving has been configured on your cluster, you might see only one model serving platform option.
- In the Multi-model serving platform tile, click Add model server.
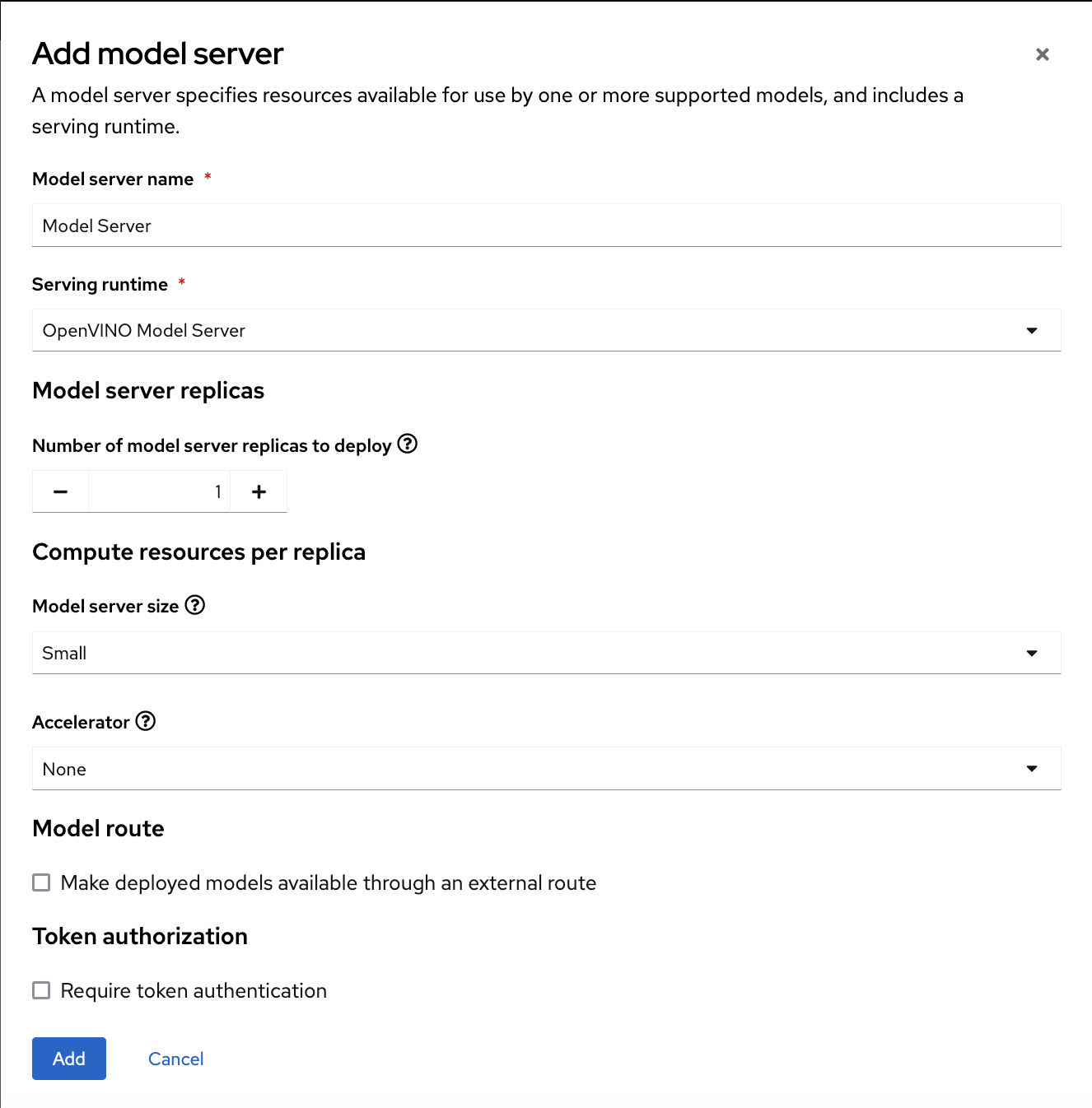
In the form, provide the following values:
-
For Model server name, type a name, for example
Model Server. -
For Serving runtime, select
OpenVINO Model Server. Leave the other fields with the default settings.
-
For Model server name, type a name, for example
- Click Add.
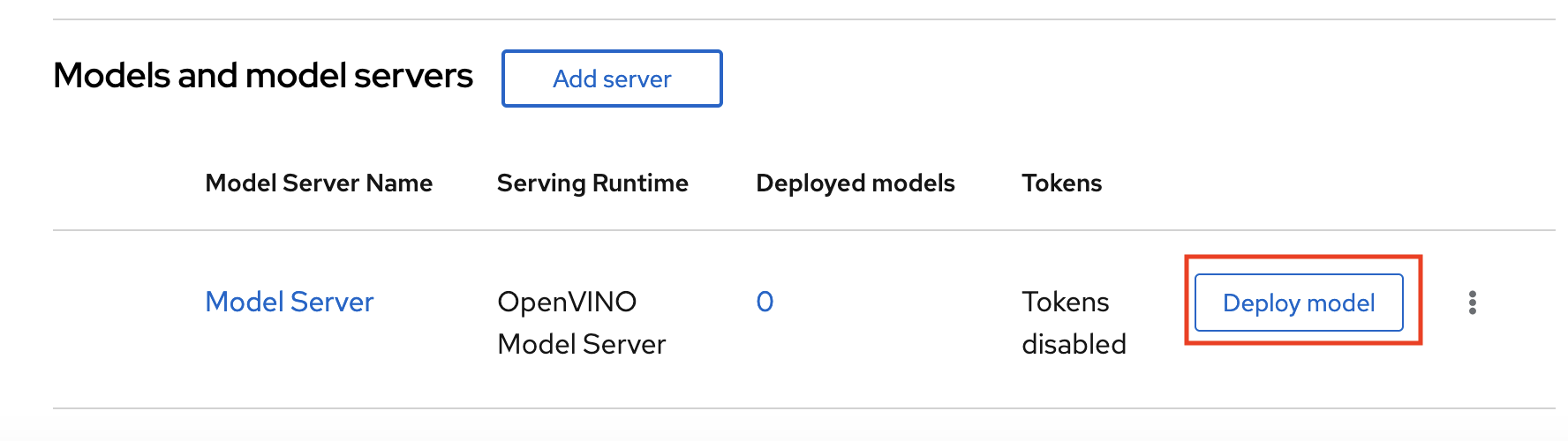
In the Models and model servers list, next to the new model server, click Deploy model.
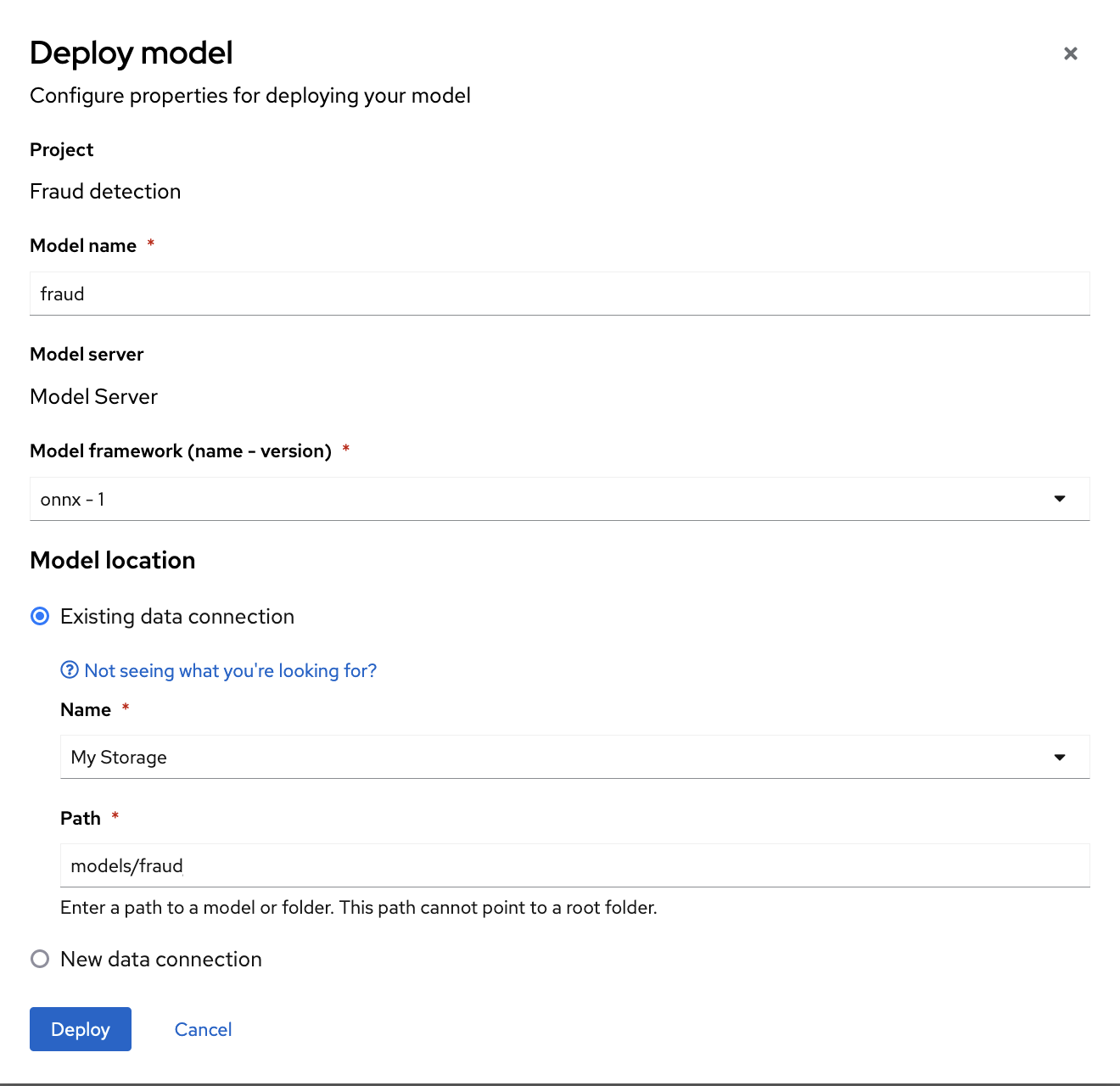
In the form, provide the following values:
-
For Model Name, type
fraud. -
For Model framework, select
onnx-1. -
For Existing data connection, select
My Storage. -
Type the path that leads to the version folder that contains your model file:
models/fraud Leave the other fields with the default settings.
-
For Model Name, type
- Click Deploy.
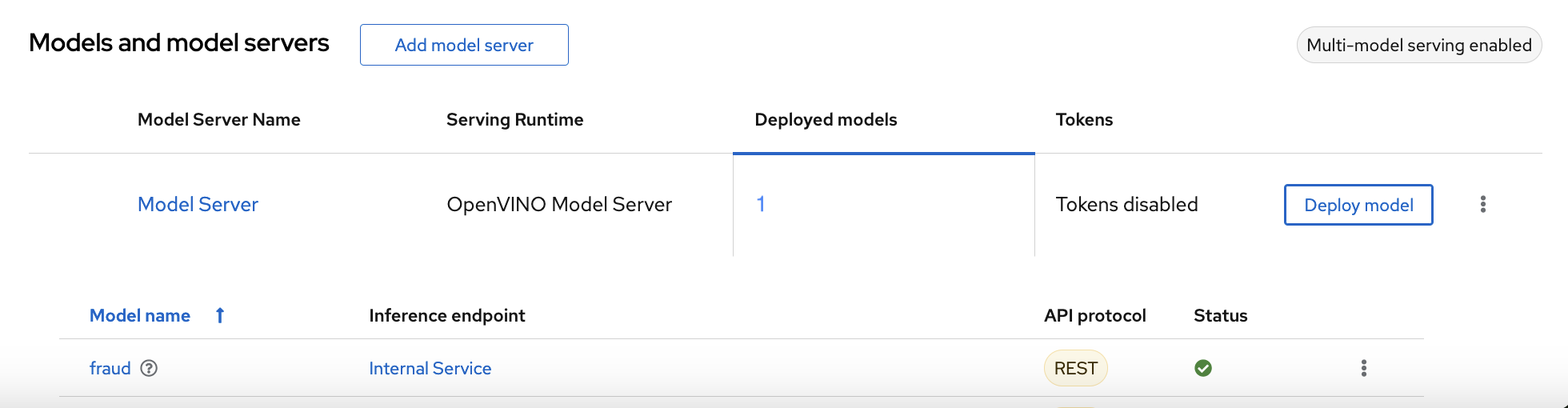
Verification
Wait for the model to deploy and for the Status to show a green checkmark.
Next step
4.3. Testing the model API
Now that you’ve deployed the model, you can test its API endpoints.
Procedure
- In the OpenShift AI dashboard, navigate to the project details page and click the Models tab.
Take note of the model’s Inference endpoint. You need this information when you test the model API.
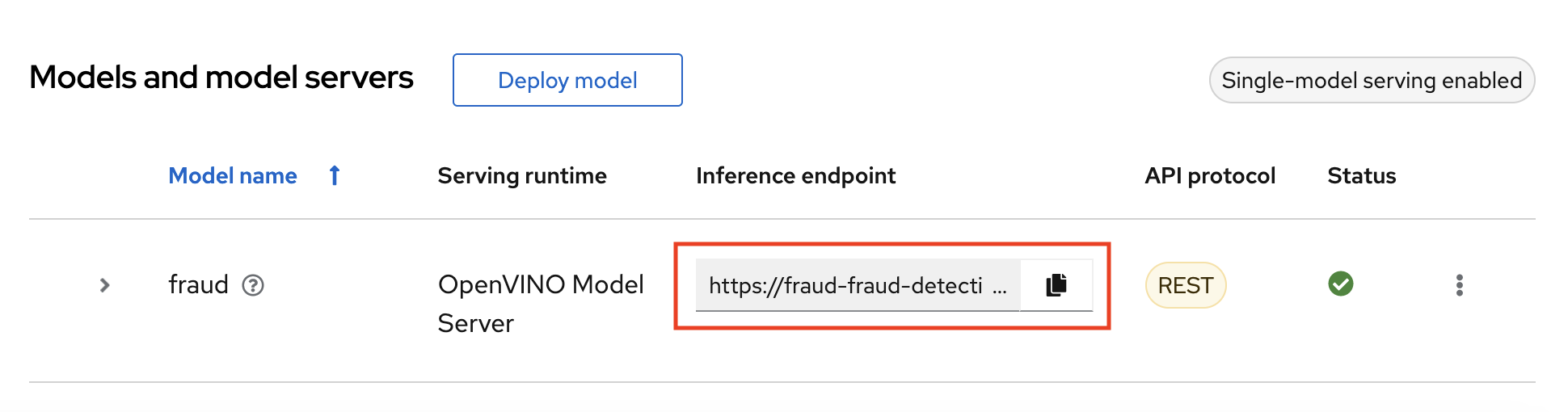
Return to the Jupyter environment and try out your new endpoint.
If you deployed your model with multi-model serving, follow the directions in
3_rest_requests_multi_model.ipynbto try a REST API call and4_grpc_requests_multi_model.ipynbto try a gRPC API call.If you deployed your model with single-model serving, follow the directions in
5_rest_requests_single_model.ipynbto try a REST API call.