Nodes
Red Hat OpenShift Service on AWS Nodes
Abstract
Chapter 1. Overview of nodes
1.1. About nodes
A node is a virtual or bare-metal machine in a Kubernetes cluster. Worker nodes host your application containers, grouped as pods. The control plane nodes run services that are required to control the Kubernetes cluster. In Red Hat OpenShift Service on AWS, the control plane nodes are hosted in a Red Hat-owned AWS account. Red Hat fully manages the control plane infrastructure for you.
Worker nodes are not guaranteed longevity, and may be replaced at any time as part of the normal operation and management of OpenShift. For more details, see Node lifecycle.
Having stable and healthy nodes in a cluster is fundamental to the smooth functioning of your hosted application. In Red Hat OpenShift Service on AWS, you can access, manage, and monitor a node through the Node object representing the node. Using the OpenShift CLI (oc) or the web console, you can perform the following operations on a node.
The following components of a node are responsible for maintaining the running of pods and providing the Kubernetes runtime environment.
- Container runtime
- The container runtime is responsible for running containers. Red Hat OpenShift Service on AWS deploys the CRI-O container runtime on each of the Red Hat Enterprise Linux CoreOS (RHCOS) nodes in your cluster. The Windows Machine Config Operator (WMCO) deploys the containerd runtime on its Windows nodes.
- Kubelet
- Kubelet runs on nodes and reads the container manifests. It ensures that the defined containers have started and are running. The kubelet process maintains the state of work and the node server. Kubelet manages network rules and port forwarding. The kubelet manages containers that are created by Kubernetes only.
- DNS
- Cluster DNS is a DNS server which serves DNS records for Kubernetes services. Containers started by Kubernetes automatically include this DNS server in their DNS searches.

1.1.1. Read operations
The read operations allow an administrator or a developer to get information about nodes in an Red Hat OpenShift Service on AWS cluster.
- List all the nodes in a cluster.
- Get information about a node, such as memory and CPU usage, health, status, and age.
- List pods running on a node.
1.1.2. Enhancement operations
Red Hat OpenShift Service on AWS allows you to do more than just access and manage nodes; as an administrator, you can perform the following tasks on nodes to make the cluster more efficient, application-friendly, and to provide a better environment for your developers.
- Manage node-level tuning for high-performance applications that require some level of kernel tuning by using the Node Tuning Operator.
- Run background tasks on nodes automatically with daemon sets. You can create and use daemon sets to create shared storage, run a logging pod on every node, or deploy a monitoring agent on all nodes.
1.2. About pods
A pod is one or more containers deployed together on a node. As a cluster administrator, you can define a pod, assign it to run on a healthy node that is ready for scheduling, and manage. A pod runs as long as the containers are running. You cannot change a pod once it is defined and is running. Some operations you can perform when working with pods are:
1.2.1. Read operations
As an administrator, you can get information about pods in a project through the following tasks:
- List pods associated with a project, including information such as the number of replicas and restarts, current status, and age.
- View pod usage statistics such as CPU, memory, and storage consumption.
1.2.2. Management operations
The following list of tasks provides an overview of how an administrator can manage pods in an Red Hat OpenShift Service on AWS cluster.
Control scheduling of pods using the advanced scheduling features available in Red Hat OpenShift Service on AWS:
- Node-to-pod binding rules such as pod affinity, node affinity, and anti-affinity.
- Node labels and selectors.
- Pod topology spread constraints.
- Configure how pods behave after a restart using pod controllers and restart policies.
- Limit both egress and ingress traffic on a pod.
- Add and remove volumes to and from any object that has a pod template. A volume is a mounted file system available to all the containers in a pod. Container storage is ephemeral; you can use volumes to persist container data.
1.2.3. Enhancement operations
You can work with pods more easily and efficiently with the help of various tools and features available in Red Hat OpenShift Service on AWS. The following operations involve using those tools and features to better manage pods.
-
Secrets: Some applications need sensitive information, such as passwords and usernames. An administrator can use the
Secretobject to provide sensitive data to pods using theSecretobject.
1.3. About containers
A container is the basic unit of an Red Hat OpenShift Service on AWS application, which comprises the application code packaged along with its dependencies, libraries, and binaries. Containers provide consistency across environments and multiple deployment targets: physical servers, virtual machines (VMs), and private or public cloud.
Linux container technologies are lightweight mechanisms for isolating running processes and limiting access to only designated resources. As an administrator, You can perform various tasks on a Linux container, such as:
Red Hat OpenShift Service on AWS provides specialized containers called Init containers. Init containers run before application containers and can contain utilities or setup scripts not present in an application image. You can use an Init container to perform tasks before the rest of a pod is deployed.
Apart from performing specific tasks on nodes, pods, and containers, you can work with the overall Red Hat OpenShift Service on AWS cluster to keep the cluster efficient and the application pods highly available.
1.4. Glossary of common terms for Red Hat OpenShift Service on AWS nodes
This glossary defines common terms that are used in the node content.
- Container
- It is a lightweight and executable image that comprises software and all its dependencies. Containers virtualize the operating system, as a result, you can run containers anywhere from a data center to a public or private cloud to even a developer’s laptop.
- Daemon set
- Ensures that a replica of the pod runs on eligible nodes in an Red Hat OpenShift Service on AWS cluster.
- egress
- The process of data sharing externally through a network’s outbound traffic from a pod.
- garbage collection
- The process of cleaning up cluster resources, such as terminated containers and images that are not referenced by any running pods.
- Ingress
- Incoming traffic to a pod.
- Job
- A process that runs to completion. A job creates one or more pod objects and ensures that the specified pods are successfully completed.
- Labels
- You can use labels, which are key-value pairs, to organise and select subsets of objects, such as a pod.
- Node
- A worker machine in the Red Hat OpenShift Service on AWS cluster. A node can be either be a virtual machine (VM) or a physical machine.
- Node Tuning Operator
- You can use the Node Tuning Operator to manage node-level tuning by using the TuneD daemon. It ensures custom tuning specifications are passed to all containerized TuneD daemons running in the cluster in the format that the daemons understand. The daemons run on all nodes in the cluster, one per node.
- Self Node Remediation Operator
- The Operator runs on the cluster nodes and identifies and reboots nodes that are unhealthy.
- Pod
- One or more containers with shared resources, such as volume and IP addresses, running in your Red Hat OpenShift Service on AWS cluster. A pod is the smallest compute unit defined, deployed, and managed.
- Toleration
- Indicates that the pod is allowed (but not required) to be scheduled on nodes or node groups with matching taints. You can use tolerations to enable the scheduler to schedule pods with matching taints.
- Taint
- A core object that comprises a key, value, and effect. Taints and tolerations work together to ensure that pods are not scheduled on irrelevant nodes.
Chapter 2. Working with pods
2.1. Using pods
A pod is one or more containers deployed together on one host, and the smallest compute unit that can be defined, deployed, and managed.
2.1.1. Understanding pods
Pods are the rough equivalent of a machine instance (physical or virtual) to a Container. Each pod is allocated its own internal IP address, therefore owning its entire port space, and containers within pods can share their local storage and networking.
Pods have a lifecycle; they are defined, then they are assigned to run on a node, then they run until their container(s) exit or they are removed for some other reason. Pods, depending on policy and exit code, might be removed after exiting, or can be retained to enable access to the logs of their containers.
Red Hat OpenShift Service on AWS treats pods as largely immutable; changes cannot be made to a pod definition while it is running. Red Hat OpenShift Service on AWS implements changes by terminating an existing pod and recreating it with modified configuration, base image(s), or both. Pods are also treated as expendable, and do not maintain state when recreated. Therefore pods should usually be managed by higher-level controllers, rather than directly by users.
Bare pods that are not managed by a replication controller will be not rescheduled upon node disruption.
2.1.2. Example pod configurations
Red Hat OpenShift Service on AWS leverages the Kubernetes concept of a pod, which is one or more containers deployed together on one host, and the smallest compute unit that can be defined, deployed, and managed.
The following is an example definition of a pod. It demonstrates many features of pods, most of which are discussed in other topics and thus only briefly mentioned here:
Pod object definition (YAML)
kind: Pod
apiVersion: v1
metadata:
name: example
labels:
environment: production
app: abc
spec:
restartPolicy: Always
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: abc
args:
- sleep
- "1000000"
volumeMounts:
- name: cache-volume
mountPath: /cache
image: registry.access.redhat.com/ubi7/ubi-init:latest
securityContext:
allowPrivilegeEscalation: false
runAsNonRoot: true
capabilities:
drop: ["ALL"]
resources:
limits:
memory: "100Mi"
cpu: "1"
requests:
memory: "100Mi"
cpu: "1"
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi- 1
- Pods can be "tagged" with one or more labels, which can then be used to select and manage groups of pods in a single operation. The labels are stored in key/value format in the
metadatahash. - 2
- The pod restart policy with possible values
Always,OnFailure, andNever. The default value isAlways. - 3
- Red Hat OpenShift Service on AWS defines a security context for containers which specifies whether they are allowed to run as privileged containers, run as a user of their choice, and more. The default context is very restrictive but administrators can modify this as needed.
- 4
containersspecifies an array of one or more container definitions.- 5
- The container specifies where external storage volumes are mounted within the container.
- 6
- Specify the volumes to provide for the pod. Volumes mount at the specified path. Do not mount to the container root,
/, or any path that is the same in the host and the container. This can corrupt your host system if the container is sufficiently privileged, such as the host/dev/ptsfiles. It is safe to mount the host by using/host. - 7
- Each container in the pod is instantiated from its own container image.
- 8
- The pod defines storage volumes that are available to its container(s) to use.
If you attach persistent volumes that have high file counts to pods, those pods can fail or can take a long time to start. For more information, see When using Persistent Volumes with high file counts in OpenShift, why do pods fail to start or take an excessive amount of time to achieve "Ready" state?.
This pod definition does not include attributes that are filled by Red Hat OpenShift Service on AWS automatically after the pod is created and its lifecycle begins. The Kubernetes pod documentation has details about the functionality and purpose of pods.
2.1.3. Understanding resource requests and limits
You can specify CPU and memory requests and limits for pods by using a pod spec, as shown in "Example pod configurations", or the specification for the controlling object of the pod.
CPU and memory requests specify the minimum amount of a resource that a pod needs to run, helping Red Hat OpenShift Service on AWS to schedule pods on nodes with sufficient resources.
CPU and memory limits define the maximum amount of a resource that a pod can consume, preventing the pod from consuming excessive resources and potentially impacting other pods on the same node.
CPU and memory requests and limits are processed by using the following principles:
CPU limits are enforced by using CPU throttling. When a container approaches its CPU limit, the kernel restricts access to the CPU specified as the container’s limit. As such, a CPU limit is a hard limit that the kernel enforces. Red Hat OpenShift Service on AWS can allow a container to exceed its CPU limit for extended periods of time. However, container runtimes do not terminate pods or containers for excessive CPU usage.
CPU limits and requests are measured in CPU units. One CPU unit is equivalent to 1 physical CPU core or 1 virtual core, depending on whether the node is a physical host or a virtual machine running inside a physical machine. Fractional requests are allowed. For example, when you define a container with a CPU request of
0.5, you are requesting half as much CPU time than if you asked for1.0CPU. For CPU units,0.1is equivalent to the100m, which can be read as one hundred millicpu or one hundred millicores. A CPU resource is always an absolute amount of resource, and is never a relative amount.NoteBy default, the smallest amount of CPU that can be allocated to a pod is 10 mCPU. You can request resource limits lower than 10 mCPU in a pod spec. However, the pod would still be allocated 10 mCPU.
Memory limits are enforced by the kernel by using out of memory (OOM) kills. When a container uses more than its memory limit, the kernel can terminate that container. However, terminations happen only when the kernel detects memory pressure. As such, a container that over allocates memory might not be immediately killed. This means memory limits are enforced reactively. A container can use more memory than its memory limit. If it does, the container can get killed.
You can express memory as a plain integer or as a fixed-point number by using one of these quantity suffixes:
E,P,T,G,M, ork. You can also use the power-of-two equivalents:Ei,Pi,Ti,Gi,Mi, orKi.
If the node where a pod is running has enough of a resource available, it is possible for a container to use more CPU or memory resources than it requested. However, the container cannot exceed the corresponding limit. For example, if you set a container memory request of 256 MiB, and that container is in a pod scheduled to a node with 8GiB of memory and no other pods, the container can try to use more memory than the requested 256 MiB.
This behavior does not apply to CPU and memory limits. These limits are applied by the kubelet and the container runtime, and are enforced by the kernel. On Linux nodes, the kernel enforces limits by using cgroups.
2.2. Viewing pods
As an administrator, you can view cluster pods, check their health, and evaluate the overall health of the cluster. You can also view a list of pods associated with a specific project or view usage statistics about pods. Regularly viewing pods can help you detect problems early, track resource usage, and ensure cluster stability.
2.2.1. Viewing pods in a project
You can display pod usage statistics, such as CPU, memory, and storage consumption, to monitor container runtime environments and ensure efficient resource use.
Procedure
Change to the project by entering the following command:
$ oc project <project_name>Obtain a list of pods by entering the following command:
$ oc get podsExample output
NAME READY STATUS RESTARTS AGE console-698d866b78-bnshf 1/1 Running 2 165m console-698d866b78-m87pm 1/1 Running 2 165mOptional: Add the
-o wideflags to view the pod IP address and the node where the pod is located. For example:$ oc get pods -o wideExample output
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE console-698d866b78-bnshf 1/1 Running 2 166m 10.128.0.24 ip-10-0-152-71.ec2.internal <none> console-698d866b78-m87pm 1/1 Running 2 166m 10.129.0.23 ip-10-0-173-237.ec2.internal <none>
2.2.2. Describing a pod
To troubleshoot pod issues and view detailed information about a pod in Red Hat OpenShift Service on AWS, you can describe a pod using the oc describe pod command. The Events section in the output provides detailed information about the pod and the containers inside of it.
Procedure
Describe a pod by running the following command:
$ oc describe pod -n <namespace> busybox-1Example output
Name: busybox-1 Namespace: busy Priority: 0 Service Account: default Node: worker-3/192.168.0.0 Start Time: Mon, 27 Nov 2023 14:41:25 -0500 Labels: app=busybox pod-template-hash=<hash> Annotations: k8s.ovn.org/pod-networks: … Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulled 41m (x170 over 7d1h) kubelet Container image "quay.io/quay/busybox:latest" already present on machine Normal Created 41m (x170 over 7d1h) kubelet Created container busybox Normal Started 41m (x170 over 7d1h) kubelet Started container busybox
2.2.3. Viewing pod usage statistics
You can display usage statistics about pods, which provide the runtime environments for containers. These usage statistics include CPU, memory, and storage consumption.
Prerequisites
-
You must have
cluster-readerpermission to view the usage statistics. - Metrics must be installed to view the usage statistics.
Procedure
View the usage statistics by entering the following command:
$ oc adm top pods -n <namespace>Example output
NAME CPU(cores) MEMORY(bytes) console-7f58c69899-q8c8k 0m 22Mi console-7f58c69899-xhbgg 0m 25Mi downloads-594fcccf94-bcxk8 3m 18Mi downloads-594fcccf94-kv4p6 2m 15MiOptional: Add the
--selector=''label to view usage statistics for pods with labels. Note that you must choose the label query to filter on, such as=,==, or!=. For example:$ oc adm top pod --selector='<pod_name>'
2.2.4. Viewing resource logs
You can view logs for resources in the OpenShift CLI (oc) or web console. Logs display from the end (or tail) by default. Viewing logs for resources can help you troubleshoot issues and monitor resource behavior.
2.2.4.1. Viewing resource logs by using the web console
Use the following procedure to view resource logs by using the Red Hat OpenShift Service on AWS web console.
Procedure
In the Red Hat OpenShift Service on AWS console, navigate to Workloads → Pods or navigate to the pod through the resource you want to investigate.
NoteSome resources, such as builds, do not have pods to query directly. In such instances, you can locate the Logs link on the Details page for the resource.
- Select a project from the drop-down menu.
- Click the name of the pod you want to investigate.
- Click Logs.
2.2.4.2. Viewing resource logs by using the CLI
Use the following procedure to view resource logs by using the command-line interface (CLI).
Prerequisites
-
Access to the OpenShift CLI (
oc).
Procedure
View the log for a specific pod by entering the following command:
$ oc logs -f <pod_name> -c <container_name>where:
-f- Optional: Specifies that the output follows what is being written into the logs.
<pod_name>- Specifies the name of the pod.
<container_name>- Optional: Specifies the name of a container. When a pod has more than one container, you must specify the container name.
For example:
$ oc logs -f ruby-57f7f4855b-znl92 -c rubyView the log for a specific resource by entering the following command:
$ oc logs <object_type>/<resource_name>For example:
$ oc logs deployment/ruby
2.3. Configuring an Red Hat OpenShift Service on AWS cluster for pods
As an administrator, you can create and maintain an efficient cluster for pods.
By keeping your cluster efficient, you can provide a better environment for your developers using such tools as what a pod does when it exits, ensuring that the required number of pods is always running, when to restart pods designed to run only once, limit the bandwidth available to pods, and how to keep pods running during disruptions.
2.3.1. Configuring how pods behave after restart
A pod restart policy determines how Red Hat OpenShift Service on AWS responds when Containers in that pod exit. The policy applies to all Containers in that pod.
The possible values are:
-
Always- Tries restarting a successfully exited Container on the pod continuously, with an exponential back-off delay (10s, 20s, 40s) capped at 5 minutes. The default isAlways. -
OnFailure- Tries restarting a failed Container on the pod with an exponential back-off delay (10s, 20s, 40s) capped at 5 minutes. -
Never- Does not try to restart exited or failed Containers on the pod. Pods immediately fail and exit.
After the pod is bound to a node, the pod will never be bound to another node. This means that a controller is necessary in order for a pod to survive node failure:
| Condition | Controller Type | Restart Policy |
|---|---|---|
| Pods that are expected to terminate (such as batch computations) | Job |
|
| Pods that are expected to not terminate (such as web servers) | Replication controller |
|
| Pods that must run one-per-machine | Daemon set | Any |
If a Container on a pod fails and the restart policy is set to OnFailure, the pod stays on the node and the Container is restarted. If you do not want the Container to restart, use a restart policy of Never.
If an entire pod fails, Red Hat OpenShift Service on AWS starts a new pod. Developers must address the possibility that applications might be restarted in a new pod. In particular, applications must handle temporary files, locks, incomplete output, and so forth caused by previous runs.
Kubernetes architecture expects reliable endpoints from cloud providers. When a cloud provider is down, the kubelet prevents Red Hat OpenShift Service on AWS from restarting.
If the underlying cloud provider endpoints are not reliable, do not install a cluster using cloud provider integration. Install the cluster as if it was in a no-cloud environment. It is not recommended to toggle cloud provider integration on or off in an installed cluster.
For details on how Red Hat OpenShift Service on AWS uses restart policy with failed Containers, see the Example States in the Kubernetes documentation.
2.3.2. Limiting the bandwidth available to pods
You can apply quality-of-service traffic shaping to a pod and effectively limit its available bandwidth. Egress traffic (from the pod) is handled by policing, which simply drops packets in excess of the configured rate. Ingress traffic (to the pod) is handled by shaping queued packets to effectively handle data. The limits you place on a pod do not affect the bandwidth of other pods.
Procedure
To limit the bandwidth on a pod:
Write an object definition JSON file, and specify the data traffic speed using
kubernetes.io/ingress-bandwidthandkubernetes.io/egress-bandwidthannotations. For example, to limit both pod egress and ingress bandwidth to 10M/s:Limited
Podobject definition{ "kind": "Pod", "spec": { "containers": [ { "image": "openshift/hello-openshift", "name": "hello-openshift" } ] }, "apiVersion": "v1", "metadata": { "name": "iperf-slow", "annotations": { "kubernetes.io/ingress-bandwidth": "10M", "kubernetes.io/egress-bandwidth": "10M" } } }Create the pod using the object definition:
$ oc create -f <file_or_dir_path>
2.3.3. Understanding how to use pod disruption budgets to specify the number of pods that must be up
A pod disruption budget allows the specification of safety constraints on pods during operations, such as draining a node for maintenance.
PodDisruptionBudget is an API object that specifies the minimum number or percentage of replicas that must be up at a time. Setting these in projects can be helpful during node maintenance (such as scaling a cluster down or a cluster upgrade) and is only honored on voluntary evictions (not on node failures).
A PodDisruptionBudget object’s configuration consists of the following key parts:
- A label selector, which is a label query over a set of pods.
An availability level, which specifies the minimum number of pods that must be available simultaneously, either:
-
minAvailableis the number of pods must always be available, even during a disruption. -
maxUnavailableis the number of pods can be unavailable during a disruption.
-
Available refers to the number of pods that has condition Ready=True. Ready=True refers to the pod that is able to serve requests and should be added to the load balancing pools of all matching services.
A maxUnavailable of 0% or 0 or a minAvailable of 100% or equal to the number of replicas is permitted but can block nodes from being drained.
The default setting for maxUnavailable is 1 for all the machine config pools in Red Hat OpenShift Service on AWS. It is recommended to not change this value and update one control plane node at a time. Do not change this value to 3 for the control plane pool.
You can check for pod disruption budgets across all projects with the following:
$ oc get poddisruptionbudget --all-namespacesThe following example contains some values that are specific to Red Hat OpenShift Service on AWS on AWS.
Example output
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
openshift-apiserver openshift-apiserver-pdb N/A 1 1 121m
openshift-cloud-controller-manager aws-cloud-controller-manager 1 N/A 1 125m
openshift-cloud-credential-operator pod-identity-webhook 1 N/A 1 117m
openshift-cluster-csi-drivers aws-ebs-csi-driver-controller-pdb N/A 1 1 121m
openshift-cluster-storage-operator csi-snapshot-controller-pdb N/A 1 1 122m
openshift-cluster-storage-operator csi-snapshot-webhook-pdb N/A 1 1 122m
openshift-console console N/A 1 1 116m
#...
The PodDisruptionBudget is considered healthy when there are at least minAvailable pods running in the system. Every pod above that limit can be evicted.
Depending on your pod priority and preemption settings, lower-priority pods might be removed despite their pod disruption budget requirements.
2.3.3.1. Specifying the number of pods that must be up with pod disruption budgets
You can use a PodDisruptionBudget object to specify the minimum number or percentage of replicas that must be up at a time.
Procedure
To configure a pod disruption budget:
Create a YAML file with the an object definition similar to the following:
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: minAvailable: 22 selector:3 matchLabels: name: my-pod- 1
PodDisruptionBudgetis part of thepolicy/v1API group.- 2
- The minimum number of pods that must be available simultaneously. This can be either an integer or a string specifying a percentage, for example,
20%. - 3
- A label query over a set of resources. The result of
matchLabelsandmatchExpressionsare logically conjoined. Leave this parameter blank, for exampleselector {}, to select all pods in the project.
Or:
apiVersion: policy/v11 kind: PodDisruptionBudget metadata: name: my-pdb spec: maxUnavailable: 25%2 selector:3 matchLabels: name: my-pod- 1
PodDisruptionBudgetis part of thepolicy/v1API group.- 2
- The maximum number of pods that can be unavailable simultaneously. This can be either an integer or a string specifying a percentage, for example,
20%. - 3
- A label query over a set of resources. The result of
matchLabelsandmatchExpressionsare logically conjoined. Leave this parameter blank, for exampleselector {}, to select all pods in the project.
Run the following command to add the object to project:
$ oc create -f </path/to/file> -n <project_name>
2.5. Creating and using config maps
The following sections define config maps and how to create and use them.
2.5.1. Understanding config maps
Many applications require configuration by using some combination of configuration files, command-line arguments, and environment variables. In Red Hat OpenShift Service on AWS, these configuration artifacts are decoupled from image content to keep containerized applications portable.
The ConfigMap object provides mechanisms to inject containers with configuration data while keeping containers agnostic of Red Hat OpenShift Service on AWS. A config map can be used to store fine-grained information like individual properties or coarse-grained information like entire configuration files or JSON blobs.
The ConfigMap object holds key-value pairs of configuration data that can be consumed in pods or used to store configuration data for system components such as controllers. For example:
ConfigMap Object Definition
kind: ConfigMap
apiVersion: v1
metadata:
creationTimestamp: 2016-02-18T19:14:38Z
name: example-config
namespace: my-namespace
data:
example.property.1: hello
example.property.2: world
example.property.file: |-
property.1=value-1
property.2=value-2
property.3=value-3
binaryData:
bar: L3Jvb3QvMTAw
You can use the binaryData field when you create a config map from a binary file, such as an image.
Configuration data can be consumed in pods in a variety of ways. A config map can be used to:
- Populate environment variable values in containers
- Set command-line arguments in a container
- Populate configuration files in a volume
Users and system components can store configuration data in a config map.
A config map is similar to a secret, but designed to more conveniently support working with strings that do not contain sensitive information.
2.5.1.1. Config map restrictions
A config map must be created before its contents can be consumed in pods.
Controllers can be written to tolerate missing configuration data. Consult individual components configured by using config maps on a case-by-case basis.
ConfigMap objects reside in a project.
They can only be referenced by pods in the same project.
The Kubelet only supports the use of a config map for pods it gets from the API server.
This includes any pods created by using the CLI, or indirectly from a replication controller. It does not include pods created by using the Red Hat OpenShift Service on AWS node’s --manifest-url flag, its --config flag, or its REST API because these are not common ways to create pods.
2.5.2. Creating a config map in the Red Hat OpenShift Service on AWS web console
You can create a config map in the Red Hat OpenShift Service on AWS web console.
Procedure
To create a config map as a cluster administrator:
-
In the Administrator perspective, select
Workloads→Config Maps. - At the top right side of the page, select Create Config Map.
- Enter the contents of your config map.
- Select Create.
-
In the Administrator perspective, select
To create a config map as a developer:
-
In the Developer perspective, select
Config Maps. - At the top right side of the page, select Create Config Map.
- Enter the contents of your config map.
- Select Create.
-
In the Developer perspective, select
2.5.3. Creating a config map by using the CLI
You can use the following command to create a config map from directories, specific files, or literal values.
Procedure
Create a config map:
$ oc create configmap <configmap_name> [options]
2.5.3.1. Creating a config map from a directory
You can create a config map from a directory by using the --from-file flag. This method allows you to use multiple files within a directory to create a config map.
Each file in the directory is used to populate a key in the config map, where the name of the key is the file name, and the value of the key is the content of the file.
For example, the following command creates a config map with the contents of the example-files directory:
$ oc create configmap game-config --from-file=example-files/View the keys in the config map:
$ oc describe configmaps game-configExample output
Name: game-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
game.properties: 158 bytes
ui.properties: 83 bytes
You can see that the two keys in the map are created from the file names in the directory specified in the command. The content of those keys might be large, so the output of oc describe only shows the names of the keys and their sizes.
Prerequisite
You must have a directory with files that contain the data you want to populate a config map with.
The following procedure uses these example files:
game.propertiesandui.properties:$ cat example-files/game.propertiesExample output
enemies=aliens lives=3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives=30$ cat example-files/ui.propertiesExample output
color.good=purple color.bad=yellow allow.textmode=true how.nice.to.look=fairlyNice
Procedure
Create a config map holding the content of each file in this directory by entering the following command:
$ oc create configmap game-config \ --from-file=example-files/
Verification
Enter the
oc getcommand for the object with the-ooption to see the values of the keys:$ oc get configmaps game-config -o yamlExample output
apiVersion: v1 data: game.properties: |- enemies=aliens lives=3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives=30 ui.properties: | color.good=purple color.bad=yellow allow.textmode=true how.nice.to.look=fairlyNice kind: ConfigMap metadata: creationTimestamp: 2016-02-18T18:34:05Z name: game-config namespace: default resourceVersion: "407" selflink: /api/v1/namespaces/default/configmaps/game-config uid: 30944725-d66e-11e5-8cd0-68f728db1985
2.5.3.2. Creating a config map from a file
You can create a config map from a file by using the --from-file flag. You can pass the --from-file option multiple times to the CLI.
You can also specify the key to set in a config map for content imported from a file by passing a key=value expression to the --from-file option. For example:
$ oc create configmap game-config-3 --from-file=game-special-key=example-files/game.properties
If you create a config map from a file, you can include files containing non-UTF8 data that are placed in this field without corrupting the non-UTF8 data. Red Hat OpenShift Service on AWS detects binary files and transparently encodes the file as MIME. On the server, the MIME payload is decoded and stored without corrupting the data.
Prerequisite
You must have a directory with files that contain the data you want to populate a config map with.
The following procedure uses these example files:
game.propertiesandui.properties:$ cat example-files/game.propertiesExample output
enemies=aliens lives=3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives=30$ cat example-files/ui.propertiesExample output
color.good=purple color.bad=yellow allow.textmode=true how.nice.to.look=fairlyNice
Procedure
Create a config map by specifying a specific file:
$ oc create configmap game-config-2 \ --from-file=example-files/game.properties \ --from-file=example-files/ui.propertiesCreate a config map by specifying a key-value pair:
$ oc create configmap game-config-3 \ --from-file=game-special-key=example-files/game.properties
Verification
Enter the
oc getcommand for the object with the-ooption to see the values of the keys from the file:$ oc get configmaps game-config-2 -o yamlExample output
apiVersion: v1 data: game.properties: |- enemies=aliens lives=3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives=30 ui.properties: | color.good=purple color.bad=yellow allow.textmode=true how.nice.to.look=fairlyNice kind: ConfigMap metadata: creationTimestamp: 2016-02-18T18:52:05Z name: game-config-2 namespace: default resourceVersion: "516" selflink: /api/v1/namespaces/default/configmaps/game-config-2 uid: b4952dc3-d670-11e5-8cd0-68f728db1985Enter the
oc getcommand for the object with the-ooption to see the values of the keys from the key-value pair:$ oc get configmaps game-config-3 -o yamlExample output
apiVersion: v1 data: game-special-key: |-1 enemies=aliens lives=3 enemies.cheat=true enemies.cheat.level=noGoodRotten secret.code.passphrase=UUDDLRLRBABAS secret.code.allowed=true secret.code.lives=30 kind: ConfigMap metadata: creationTimestamp: 2016-02-18T18:54:22Z name: game-config-3 namespace: default resourceVersion: "530" selflink: /api/v1/namespaces/default/configmaps/game-config-3 uid: 05f8da22-d671-11e5-8cd0-68f728db1985- 1
- This is the key that you set in the preceding step.
2.5.3.3. Creating a config map from literal values
You can supply literal values for a config map.
The --from-literal option takes a key=value syntax, which allows literal values to be supplied directly on the command line.
Procedure
Create a config map by specifying a literal value:
$ oc create configmap special-config \ --from-literal=special.how=very \ --from-literal=special.type=charm
Verification
Enter the
oc getcommand for the object with the-ooption to see the values of the keys:$ oc get configmaps special-config -o yamlExample output
apiVersion: v1 data: special.how: very special.type: charm kind: ConfigMap metadata: creationTimestamp: 2016-02-18T19:14:38Z name: special-config namespace: default resourceVersion: "651" selflink: /api/v1/namespaces/default/configmaps/special-config uid: dadce046-d673-11e5-8cd0-68f728db1985
2.5.4. Use cases: Consuming config maps in pods
The following sections describe some uses cases when consuming ConfigMap objects in pods.
2.5.4.1. Populating environment variables in containers by using config maps
You can use config maps to populate individual environment variables in containers or to populate environment variables in containers from all keys that form valid environment variable names.
As an example, consider the following config map:
ConfigMap with two environment variables
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm ConfigMap with one environment variable
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO Procedure
You can consume the keys of this
ConfigMapin a pod usingconfigMapKeyRefsections.Sample
Podspecification configured to inject specific environment variablesapiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env:1 - name: SPECIAL_LEVEL_KEY2 valueFrom: configMapKeyRef: name: special-config3 key: special.how4 - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config5 key: special.type6 optional: true7 envFrom:8 - configMapRef: name: env-config9 securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Never- 1
- Stanza to pull the specified environment variables from a
ConfigMap. - 2
- Name of a pod environment variable that you are injecting a key’s value into.
- 3 5
- Name of the
ConfigMapto pull specific environment variables from. - 4 6
- Environment variable to pull from the
ConfigMap. - 7
- Makes the environment variable optional. As optional, the pod will be started even if the specified
ConfigMapand keys do not exist. - 8
- Stanza to pull all environment variables from a
ConfigMap. - 9
- Name of the
ConfigMapto pull all environment variables from.
When this pod is run, the pod logs will include the following output:
SPECIAL_LEVEL_KEY=very log_level=INFO
SPECIAL_TYPE_KEY=charm is not listed in the example output because optional: true is set.
2.5.4.2. Setting command-line arguments for container commands with config maps
You can use a config map to set the value of the commands or arguments in a container by using the Kubernetes substitution syntax $(VAR_NAME).
As an example, consider the following config map:
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charmProcedure
To inject values into a command in a container, you must consume the keys you want to use as environment variables. Then you can refer to them in a container’s command using the
$(VAR_NAME)syntax.Sample pod specification configured to inject specific environment variables
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]1 env: - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: name: special-config key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config key: special.type securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Never- 1
- Inject the values into a command in a container using the keys you want to use as environment variables.
When this pod is run, the output from the echo command run in the test-container container is as follows:
very charm
2.5.4.3. Injecting content into a volume by using config maps
You can inject content into a volume by using config maps.
Example ConfigMap custom resource (CR)
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charmProcedure
You have a couple different options for injecting content into a volume by using config maps.
The most basic way to inject content into a volume by using a config map is to populate the volume with files where the key is the file name and the content of the file is the value of the key:
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "cat", "/etc/config/special.how" ] volumeMounts: - name: config-volume mountPath: /etc/config securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] volumes: - name: config-volume configMap: name: special-config1 restartPolicy: Never- 1
- File containing key.
When this pod is run, the output of the cat command will be:
veryYou can also control the paths within the volume where config map keys are projected:
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "cat", "/etc/config/path/to/special-key" ] volumeMounts: - name: config-volume mountPath: /etc/config securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] volumes: - name: config-volume configMap: name: special-config items: - key: special.how path: path/to/special-key1 restartPolicy: Never- 1
- Path to config map key.
When this pod is run, the output of the cat command will be:
very
2.6. Including pod priority in pod scheduling decisions
You can enable pod priority and preemption in your cluster. Pod priority indicates the importance of a pod relative to other pods and queues the pods based on that priority. pod preemption allows the cluster to evict, or preempt, lower-priority pods so that higher-priority pods can be scheduled if there is no available space on a suitable node pod priority also affects the scheduling order of pods and out-of-resource eviction ordering on the node.
To use priority and preemption, reference a priority class in the pod specification to apply that weight for scheduling.
2.6.1. Understanding pod priority
When you use the Pod Priority and Preemption feature, the scheduler orders pending pods by their priority, and a pending pod is placed ahead of other pending pods with lower priority in the scheduling queue. As a result, the higher priority pod might be scheduled sooner than pods with lower priority if its scheduling requirements are met. If a pod cannot be scheduled, scheduler continues to schedule other lower priority pods.
2.6.1.1. Pod priority classes
You can assign pods a priority class, which is a non-namespaced object that defines a mapping from a name to the integer value of the priority. The higher the value, the higher the priority.
A priority class object can take any 32-bit integer value smaller than or equal to 1000000000 (one billion). Reserve numbers larger than or equal to one billion for critical pods that must not be preempted or evicted. By default, Red Hat OpenShift Service on AWS has two reserved priority classes for critical system pods to have guaranteed scheduling.
$ oc get priorityclassesExample output
NAME VALUE GLOBAL-DEFAULT AGE
system-node-critical 2000001000 false 72m
system-cluster-critical 2000000000 false 72m
openshift-user-critical 1000000000 false 3d13h
cluster-logging 1000000 false 29ssystem-node-critical - This priority class has a value of 2000001000 and is used for all pods that should never be evicted from a node. Examples of pods that have this priority class are
ovnkube-node, and so forth. A number of critical components include thesystem-node-criticalpriority class by default, for example:- master-api
- master-controller
- master-etcd
- ovn-kubernetes
- sync
system-cluster-critical - This priority class has a value of 2000000000 (two billion) and is used with pods that are important for the cluster. Pods with this priority class can be evicted from a node in certain circumstances. For example, pods configured with the
system-node-criticalpriority class can take priority. However, this priority class does ensure guaranteed scheduling. Examples of pods that can have this priority class are fluentd, add-on components like descheduler, and so forth. A number of critical components include thesystem-cluster-criticalpriority class by default, for example:- fluentd
- metrics-server
- descheduler
-
openshift-user-critical - You can use the
priorityClassNamefield with important pods that cannot bind their resource consumption and do not have predictable resource consumption behavior. Prometheus pods under theopenshift-monitoringandopenshift-user-workload-monitoringnamespaces use theopenshift-user-criticalpriorityClassName. Monitoring workloads usesystem-criticalas their firstpriorityClass, but this causes problems when monitoring uses excessive memory and the nodes cannot evict them. As a result, monitoring drops priority to give the scheduler flexibility, moving heavy workloads around to keep critical nodes operating. - cluster-logging - This priority is used by Fluentd to make sure Fluentd pods are scheduled to nodes over other apps.
2.6.1.2. Pod priority names
After you have one or more priority classes, you can create pods that specify a priority class name in a Pod spec. The priority admission controller uses the priority class name field to populate the integer value of the priority. If the named priority class is not found, the pod is rejected.
2.6.2. Understanding pod preemption
When a developer creates a pod, the pod goes into a queue. If the developer configured the pod for pod priority or preemption, the scheduler picks a pod from the queue and tries to schedule the pod on a node. If the scheduler cannot find space on an appropriate node that satisfies all the specified requirements of the pod, preemption logic is triggered for the pending pod.
When the scheduler preempts one or more pods on a node, the nominatedNodeName field of higher-priority Pod spec is set to the name of the node, along with the nodename field. The scheduler uses the nominatedNodeName field to keep track of the resources reserved for pods and also provides information to the user about preemptions in the clusters.
After the scheduler preempts a lower-priority pod, the scheduler honors the graceful termination period of the pod. If another node becomes available while scheduler is waiting for the lower-priority pod to terminate, the scheduler can schedule the higher-priority pod on that node. As a result, the nominatedNodeName field and nodeName field of the Pod spec might be different.
Also, if the scheduler preempts pods on a node and is waiting for termination, and a pod with a higher-priority pod than the pending pod needs to be scheduled, the scheduler can schedule the higher-priority pod instead. In such a case, the scheduler clears the nominatedNodeName of the pending pod, making the pod eligible for another node.
Preemption does not necessarily remove all lower-priority pods from a node. The scheduler can schedule a pending pod by removing a portion of the lower-priority pods.
The scheduler considers a node for pod preemption only if the pending pod can be scheduled on the node.
2.6.2.1. Non-preempting priority classes
Pods with the preemption policy set to Never are placed in the scheduling queue ahead of lower-priority pods, but they cannot preempt other pods. A non-preempting pod waiting to be scheduled stays in the scheduling queue until sufficient resources are free and it can be scheduled. Non-preempting pods, like other pods, are subject to scheduler back-off. This means that if the scheduler tries unsuccessfully to schedule these pods, they are retried with lower frequency, allowing other pods with lower priority to be scheduled before them.
Non-preempting pods can still be preempted by other, high-priority pods.
2.6.2.2. Pod preemption and other scheduler settings
If you enable pod priority and preemption, consider your other scheduler settings:
- Pod priority and pod disruption budget
- A pod disruption budget specifies the minimum number or percentage of replicas that must be up at a time. If you specify pod disruption budgets, Red Hat OpenShift Service on AWS respects them when preempting pods at a best effort level. The scheduler attempts to preempt pods without violating the pod disruption budget. If no such pods are found, lower-priority pods might be preempted despite their pod disruption budget requirements.
- Pod priority and pod affinity
- Pod affinity requires a new pod to be scheduled on the same node as other pods with the same label.
If a pending pod has inter-pod affinity with one or more of the lower-priority pods on a node, the scheduler cannot preempt the lower-priority pods without violating the affinity requirements. In this case, the scheduler looks for another node to schedule the pending pod. However, there is no guarantee that the scheduler can find an appropriate node and pending pod might not be scheduled.
To prevent this situation, carefully configure pod affinity with equal-priority pods.
2.6.2.3. Graceful termination of preempted pods
When preempting a pod, the scheduler waits for the pod graceful termination period to expire, allowing the pod to finish working and exit. If the pod does not exit after the period, the scheduler kills the pod. This graceful termination period creates a time gap between the point that the scheduler preempts the pod and the time when the pending pod can be scheduled on the node.
To minimize this gap, configure a small graceful termination period for lower-priority pods.
2.6.3. Configuring priority and preemption
You apply pod priority and preemption by creating a priority class object and associating pods to the priority by using the priorityClassName in your pod specs.
You cannot add a priority class directly to an existing scheduled pod.
Procedure
To configure your cluster to use priority and preemption:
Define a pod spec to include the name of a priority class by creating a YAML file similar to the following:
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent priorityClassName: system-cluster-critical1 - 1
- Specify the priority class to use with this pod.
Create the pod:
$ oc create -f <file-name>.yamlYou can add the priority name directly to the pod configuration or to a pod template.
2.7. Placing pods on specific nodes using node selectors
A node selector specifies a map of key-value pairs. The rules are defined using custom labels on nodes and selectors specified in pods.
For the pod to be eligible to run on a node, the pod must have the indicated key-value pairs as the label on the node.
If you are using node affinity and node selectors in the same pod configuration, see the important considerations below.
2.7.1. Using node selectors to control pod placement
You can use node selectors on pods and labels on nodes to control where the pod is scheduled. With node selectors, Red Hat OpenShift Service on AWS schedules the pods on nodes that contain matching labels.
You add labels to a node, a compute machine set, or a machine config. Adding the label to the compute machine set ensures that if the node or machine goes down, new nodes have the label. Labels added to a node or machine config do not persist if the node or machine goes down.
To add node selectors to an existing pod, add a node selector to the controlling object for that pod, such as a ReplicaSet object, DaemonSet object, StatefulSet object, Deployment object, or DeploymentConfig object. Any existing pods under that controlling object are recreated on a node with a matching label. If you are creating a new pod, you can add the node selector directly to the pod spec. If the pod does not have a controlling object, you must delete the pod, edit the pod spec, and recreate the pod.
You cannot add a node selector directly to an existing scheduled pod.
Prerequisites
To add a node selector to existing pods, determine the controlling object for that pod. For example, the router-default-66d5cf9464-m2g75 pod is controlled by the router-default-66d5cf9464 replica set:
$ oc describe pod router-default-66d5cf9464-7pwkcExample output
kind: Pod
apiVersion: v1
metadata:
# ...
Name: router-default-66d5cf9464-7pwkc
Namespace: openshift-ingress
# ...
Controlled By: ReplicaSet/router-default-66d5cf9464
# ...
The web console lists the controlling object under ownerReferences in the pod YAML:
apiVersion: v1
kind: Pod
metadata:
name: router-default-66d5cf9464-7pwkc
# ...
ownerReferences:
- apiVersion: apps/v1
kind: ReplicaSet
name: router-default-66d5cf9464
uid: d81dd094-da26-11e9-a48a-128e7edf0312
controller: true
blockOwnerDeletion: true
# ...Procedure
Add the matching node selector to a pod:
To add a node selector to existing and future pods, add a node selector to the controlling object for the pods:
Example
ReplicaSetobject with labelskind: ReplicaSet apiVersion: apps/v1 metadata: name: hello-node-6fbccf8d9 # ... spec: # ... template: metadata: creationTimestamp: null labels: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default pod-template-hash: 66d5cf9464 spec: nodeSelector: kubernetes.io/os: linux node-role.kubernetes.io/worker: '' type: user-node1 # ...- 1
- Add the node selector.
To add a node selector to a specific, new pod, add the selector to the
Podobject directly:Example
Podobject with a node selectorapiVersion: v1 kind: Pod metadata: name: hello-node-6fbccf8d9 # ... spec: nodeSelector: region: east type: user-node # ...NoteYou cannot add a node selector directly to an existing scheduled pod.
Chapter 3. Automatically scaling pods with the Custom Metrics Autoscaler Operator
3.1. Release notes
3.1.1. Custom Metrics Autoscaler Operator release notes
You can review the following release notes to learn about changes in the Custom Metrics Autoscaler Operator version 2.18.1-2. The release notes for the Custom Metrics Autoscaler Operator for Red Hat OpenShift describe new features and enhancements, deprecated features, and known issues.
The Custom Metrics Autoscaler Operator uses the Kubernetes-based Event Driven Autoscaler (KEDA) and is built on top of the Red Hat OpenShift Service on AWS horizontal pod autoscaler (HPA).
The Custom Metrics Autoscaler Operator for Red Hat OpenShift is provided as an installable component, with a distinct release cycle from the core Red Hat OpenShift Service on AWS. The Red Hat OpenShift Container Platform Life Cycle Policy outlines release compatibility.
3.1.1.1. Supported versions
The following table defines the Custom Metrics Autoscaler Operator versions for each Red Hat OpenShift Service on AWS version.
| Version | Red Hat OpenShift Service on AWS version | General availability |
|---|---|---|
| 2.18.1-2 | 4.21 | General availability |
| 2.18.1-2 | 4.20 | General availability |
| 2.18.1-2 | 4.19 | General availability |
| 2.18.1-2 | 4.18 | General availability |
| 2.18.1-2 | 4.17 | General availability |
| 2.18.1-2 | 4.16 | General availability |
| 2.18.1-2 | 4.15 | General availability |
| 2.18.1-2 | 4.14 | General availability |
| 2.18.1-2 | 4.13 | General availability |
| 2.18.1-2 | 4.12 | General availability |
3.1.1.2. Custom Metrics Autoscaler Operator 2.18.1-2 release notes
Issued: 09 February 2026
This release of the Custom Metrics Autoscaler Operator 2.18.1-2 addresses Common Vulnerabilities and Exposures (CVEs). The following advisory is available for the Custom Metrics Autoscaler Operator:
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2. Release notes for past releases of the Custom Metrics Autoscaler Operator
You can review the following release notes to learn about changes in previous versions of the Custom Metrics Autoscaler Operator.
For the current version, see Custom Metrics Autoscaler Operator release notes.
3.1.2.1. Custom Metrics Autoscaler Operator 2.18.1-1 release notes
Issued: 15 January 2026
This release of the Custom Metrics Autoscaler Operator 2.18.1-1 provides new features and enhancements, deprecated features, and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the Custom Metrics Autoscaler Operator:
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.1.1. New features and enhancements
3.1.2.1.1.1. Forced activation
You can now temporarily force the activation of a scale target by adding the autoscaling.keda.sh/force-activation: "true" annotation to the ScaledObject custom resource (CR). (KEDA issue 6903)
3.1.2.1.1.2. Excluding labels from being propagated to the HPA
You can now exclude specific labels from being propagated to a Horizontal Pod Autoscaler (HPA) by using the scaledobject.keda.sh/hpa-excluded-labels annotation to the ScaledObject or ScaledJob CR. (KEDA issue 6849)
3.1.2.1.1.3. Pause in scaling down
You can now pause the scaling down of an object without preventing the object from scaling up. (KEDA issue 6902)
3.1.2.1.1.4. Pause in scaling up
You can now pause the scaling up for an object without preventing the object from scaling down. (KEDA issue 7022)
3.1.2.1.1.5. Support for the s390x architecture
The Operator can now run on s390x architecture. Previously it ran on amd64, ppc64le, or arm64. (KEDA issue 6543)
3.1.2.1.1.6. Fallback for triggers of Value metric type
Fallback is now supported for triggers that use the Value metric type. Previously, fallback was supported for only the AverageValue metric type. (KEDA issue 6655)
3.1.2.1.1.7. Support for even distribution of Kafka partitions
You can now configure a Kafka scaler to scale Kafka consumers by partition count on the topic. This ensures that the partitions are evenly spread across all consumers. (KEDA issue 2581)
3.1.2.1.1.8. The Zap logger has replaced the Kubernetes logger
The Operator now uses the Zap logging library to emit logs. (KEDA issue 5732)
3.1.2.1.2. Deprecated and removed features
-
For the CPU and Memory triggers, the
typesetting, deprecated in an earlier version, is removed. You must usemetricTypeinstead. (KEDA bug 6698)
3.1.2.1.3. Bug fixes
- Before this update, a bug in the pending-pod-condition detection logic caused duplicate jobs to be created for scaled jobs that have slow-starting containers. This fix changes the logic to properly evaluate each pod individually and correctly identify when a job is no longer pending. (KEDA bug 6698)
-
Before this update, if a deployment object contained an
envFromparameter that included a prefix setting, the prefix was ignored and the environment variable keys were added to the scaler configuration without the prefix. With this fix, the prefix is now added to the environment variable key. (KEDA bug 6728) - Before this update, a scale client was not initialized when creating a new scale handler. This was due to a segmentation fault that occurred when accessing an uninitialized scale client in the scale handler during non-static fallback modes for specific scale target types. This fix corrects this issue. (KEDA bug 6992)
-
Before this update, if a user created a scaled object, the object had the
Pausedstatus condition ofUnknown. This fix properly sets thePausedcondition tofalse. (KEDA bug 7011) -
Before this update, after removing the
autoscaling.keda.sh/paused-replicasfrom a scaled object CR, the object could still have thePausedstatus condition oftrue. This issue has been resolved and the object reports the pause status correctly. (KEDA bug 6982) -
Before this update, when creating a scaled object with the
scaledobject.keda.sh/transfer-hpa-ownershipannotation, the object status might not list the name of the HPA that is taking ownership of the object. With this fix, the HPA name is reported correctly. (KEDA bug 6336) -
Before this update, a cron trigger incorrectly prevented scaling the replicas to 0 even if the cron schedule was inactive and the
minReplicaCountvalue is0. This happened because the trigger always reported a metric value of1during its inactive periods. With this fix, the cron trigger is now able to return a metric of0, allowing an object to scale to 0. (KEDA bug 6886) -
Before this update, in a Kafka trigger, specifying
sasl:noneresulted in an error, despitenonebeing the default value forsasl. With this fix, you can now configuresasl:nonein a Kafka trigger. (KEDA bug 7061) - Before this update, when scaling to 0, the Operator might not check if all scalers are not active. As a result, the Operator could scale an object to 0 even though there were active scalers. This fix corrects this issue. (KEDA issue 6986)
3.1.2.2. Custom Metrics Autoscaler Operator 2.17.2-2 release notes
Issued: 21 October 2025
This release of the Custom Metrics Autoscaler Operator 2.17.2-2 is a rebuild of the 2.17.2 version of the Custom Metrics Autoscaler Operator using a newer base image and Go compiler. There are no code changes to the Custom Metrics Autoscaler Operator. The following advisory is available for the Custom Metrics Autoscaler Operator:
3.1.2.3. Custom Metrics Autoscaler Operator 2.17.2 release notes
Issued: 25 September 2025
This release of the Custom Metrics Autoscaler Operator 2.17.2 addresses Common Vulnerabilities and Exposures (CVEs). The following advisory is available for the Custom Metrics Autoscaler Operator:
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.3.1. New features and enhancements
3.1.2.3.1.1. The KEDA controller is automatically created during installation
The KEDA controller is now automatically created when you install the Custom Metrics Autoscaler Operator. Previously, you needed to manually create the KEDA controller. You can edit the automatically-created KEDA controller, as needed.
3.1.2.3.1.2. Support for the Kubernetes workload trigger
The Cluster Metrics Autoscaler Operator now supports using the Kubernetes workload trigger to scale pods based on the number of pods matching a specific label selector.
3.1.2.3.1.3. Support for bound service account tokens
The Cluster Metrics Autoscaler Operator now supports bound service account tokens. Previously, the Operator supported only legacy service account tokens, which are being phased out in favor of bound service account tokens for security reasons.
3.1.2.3.2. Bug fixes
- Previously, the KEDA controller did not support volume mounts. As a result, you could not use Kerberos with the Kafka scaler. With this fix, the KEDA controller now supports volume mounts. (OCPBUGS-42559)
-
Previously, the KEDA version in the
keda-operatordeployment object log reported that the Custom Metrics Autoscaler Operator was based on an incorrect KEDA version. With this fix, the correct KEDA version is reported in the log. (OCPBUGS-58129)
3.1.2.4. Custom Metrics Autoscaler Operator 2.15.1-4 release notes
Issued: 31 March 2025
This release of the Custom Metrics Autoscaler Operator 2.15.1-4 addresses Common Vulnerabilities and Exposures (CVEs). The following advisory is available for the Custom Metrics Autoscaler Operator:
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.4.1. New features and enhancements
3.1.2.4.1.1. CMA multi-arch builds
With this version of the Custom Metrics Autoscaler Operator, you can now install and run the Operator on an ARM64 Red Hat OpenShift Service on AWS cluster.
3.1.2.5. Custom Metrics Autoscaler Operator 2.14.1-467 release notes
This release of the Custom Metrics Autoscaler Operator 2.14.1-467 provides a CVE and a bug fix for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHSA-2024:7348.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.5.1. Bug fixes
- Previously, the root file system of the Custom Metrics Autoscaler Operator pod was writable, which is unnecessary and could present security issues. This update makes the pod root file system read-only, which addresses the potential security issue. (OCPBUGS-37989)
3.1.2.6. Custom Metrics Autoscaler Operator 2.14.1-454 release notes
This release of the Custom Metrics Autoscaler Operator 2.14.1-454 provides a CVE, a new feature, and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHBA-2024:5865.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.6.1. New features and enhancements
3.1.2.6.1.1. Support for the Cron trigger with the Custom Metrics Autoscaler Operator
The Custom Metrics Autoscaler Operator can now use the Cron trigger to scale pods based on an hourly schedule. When your specified time frame starts, the Custom Metrics Autoscaler Operator scales pods to your desired amount. When the time frame ends, the Operator scales back down to the previous level.
For more information, see Understanding the Cron trigger.
3.1.2.6.2. Bug fixes
-
Previously, if you made changes to audit configuration parameters in the
KedaControllercustom resource, thekeda-metrics-server-audit-policyconfig map would not get updated. As a consequence, you could not change the audit configuration parameters after the initial deployment of the Custom Metrics Autoscaler. With this fix, changes to the audit configuration now render properly in the config map, allowing you to change the audit configuration any time after installation. (OCPBUGS-32521)
3.1.2.7. Custom Metrics Autoscaler Operator 2.13.1 release notes
This release of the Custom Metrics Autoscaler Operator 2.13.1-421 provides a new feature and a bug fix for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHBA-2024:4837.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.7.1. New features and enhancements
3.1.2.7.1.1. Support for custom certificates with the Custom Metrics Autoscaler Operator
The Custom Metrics Autoscaler Operator can now use custom service CA certificates to connect securely to TLS-enabled metrics sources, such as an external Kafka cluster or an external Prometheus service. By default, the Operator uses automatically-generated service certificates to connect to on-cluster services only. There is a new field in the KedaController object that allows you to load custom server CA certificates for connecting to external services by using config maps.
For more information, see Custom CA certificates for the Custom Metrics Autoscaler.
3.1.2.7.2. Bug fixes
-
Previously, the
custom-metrics-autoscalerandcustom-metrics-autoscaler-adapterimages were missing time zone information. As a consequence, scaled objects withcrontriggers failed to work because the controllers were unable to find time zone information. With this fix, the image builds are updated to include time zone information. As a result, scaled objects containingcrontriggers now function properly. Scaled objects containingcrontriggers are currently not supported for the custom metrics autoscaler. (OCPBUGS-34018)
3.1.2.8. Custom Metrics Autoscaler Operator 2.12.1-394 release notes
This release of the Custom Metrics Autoscaler Operator 2.12.1-394 provides a bug fix for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHSA-2024:2901.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of Kubernetes-based Event Driven Autoscaler (KEDA).
3.1.2.8.1. Bug fixes
-
Previously, the
protojson.Unmarshalfunction entered into an infinite loop when unmarshaling certain forms of invalid JSON. This condition could occur when unmarshaling into a message that contains agoogle.protobuf.Anyvalue or when theUnmarshalOptions.DiscardUnknownoption is set. This release fixes this issue. (OCPBUGS-30305) -
Previously, when parsing a multipart form, either explicitly with the
Request.ParseMultipartFormmethod or implicitly with theRequest.FormValue,Request.PostFormValue, orRequest.FormFilemethod, the limits on the total size of the parsed form were not applied to the memory consumed. This could cause memory exhaustion. With this fix, the parsing process now correctly limits the maximum size of form lines while reading a single form line. (OCPBUGS-30360) -
Previously, when following an HTTP redirect to a domain that is not on a matching subdomain or on an exact match of the initial domain, an HTTP client would not forward sensitive headers, such as
AuthorizationorCookie. For example, a redirect fromexample.comtowww.example.comwould forward theAuthorizationheader, but a redirect towww.example.orgwould not forward the header. This release fixes this issue. (OCPBUGS-30365) -
Previously, verifying a certificate chain that contains a certificate with an unknown public key algorithm caused the certificate verification process to panic. This condition affected all crypto and Transport Layer Security (TLS) clients and servers that set the
Config.ClientAuthparameter to theVerifyClientCertIfGivenorRequireAndVerifyClientCertvalue. The default behavior is for TLS servers to not verify client certificates. This release fixes this issue. (OCPBUGS-30370) -
Previously, if errors returned from the
MarshalJSONmethod contained user-controlled data, an attacker could have used the data to break the contextual auto-escaping behavior of the HTML template package. This condition would allow for subsequent actions to inject unexpected content into the templates. This release fixes this issue. (OCPBUGS-30397) -
Previously, the
net/httpandgolang.org/x/net/http2Go packages did not limit the number ofCONTINUATIONframes for an HTTP/2 request. This condition could result in excessive CPU consumption. This release fixes this issue. (OCPBUGS-30894)
3.1.2.9. Custom Metrics Autoscaler Operator 2.12.1-384 release notes
This release of the Custom Metrics Autoscaler Operator 2.12.1-384 provides a bug fix for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHBA-2024:2043.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
3.1.2.9.1. Bug fixes
-
Previously, the
custom-metrics-autoscalerandcustom-metrics-autoscaler-adapterimages were missing time zone information. As a consequence, scaled objects withcrontriggers failed to work because the controllers were unable to find time zone information. With this fix, the image builds are updated to include time zone information. As a result, scaled objects containingcrontriggers now function properly. (OCPBUGS-32395)
3.1.2.10. Custom Metrics Autoscaler Operator 2.12.1-376 release notes
This release of the Custom Metrics Autoscaler Operator 2.12.1-376 provides security updates and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHSA-2024:1812.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
3.1.2.10.1. Bug fixes
- Previously, if invalid values such as nonexistent namespaces were specified in scaled object metadata, the underlying scaler clients would not free, or close, their client descriptors, resulting in a slow memory leak. This fix properly closes the underlying client descriptors when there are errors, preventing memory from leaking. (OCPBUGS-30145)
-
Previously the
ServiceMonitorcustom resource (CR) for thekeda-metrics-apiserverpod was not functioning, because the CR referenced an incorrect metrics port name ofhttp. This fix corrects theServiceMonitorCR to reference the proper port name ofmetrics. As a result, the Service Monitor functions properly. (OCPBUGS-25806)
3.1.2.11. Custom Metrics Autoscaler Operator 2.11.2-322 release notes
This release of the Custom Metrics Autoscaler Operator 2.11.2-322 provides security updates and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The following advisory is available for the RHSA-2023:6144.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
3.1.2.11.1. Bug fixes
- Because the Custom Metrics Autoscaler Operator version 3.11.2-311 was released without a required volume mount in the Operator deployment, the Custom Metrics Autoscaler Operator pod would restart every 15 minutes. This fix adds the required volume mount to the Operator deployment. As a result, the Operator no longer restarts every 15 minutes. (OCPBUGS-22361)
3.1.2.12. Custom Metrics Autoscaler Operator 2.11.2-311 release notes
This release of the Custom Metrics Autoscaler Operator 2.11.2-311 provides new features and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The components of the Custom Metrics Autoscaler Operator 2.11.2-311 were released in RHBA-2023:5981.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
3.1.2.12.1. New features and enhancements
3.1.2.12.1.1. Red Hat OpenShift Service on AWS and OpenShift Dedicated are now supported
The Custom Metrics Autoscaler Operator 2.11.2-311 can be installed on Red Hat OpenShift Service on AWS and OpenShift Dedicated managed clusters. Previous versions of the Custom Metrics Autoscaler Operator could be installed only in the openshift-keda namespace. This prevented the Operator from being installed on Red Hat OpenShift Service on AWS and OpenShift Dedicated clusters. This version of Custom Metrics Autoscaler allows installation to other namespaces such as openshift-operators or keda, enabling installation into Red Hat OpenShift Service on AWS and OpenShift Dedicated clusters.
3.1.2.12.2. Bug fixes
-
Previously, if the Custom Metrics Autoscaler Operator was installed and configured, but not in use, the OpenShift CLI reported the
couldn’t get resource list for external.metrics.k8s.io/v1beta1: Got empty response for: external.metrics.k8s.io/v1beta1error after anyoccommand was entered. The message, although harmless, could have caused confusion. With this fix, theGot empty response for: external.metrics…error no longer appears inappropriately. (OCPBUGS-15779) - Previously, any annotation or label change to objects managed by the Custom Metrics Autoscaler were reverted by Custom Metrics Autoscaler Operator any time the Keda Controller was modified, for example after a configuration change. This caused continuous changing of labels in your objects. The Custom Metrics Autoscaler now uses its own annotation to manage labels and annotations, and annotation or label are no longer inappropriately reverted. (OCPBUGS-15590)
3.1.2.13. Custom Metrics Autoscaler Operator 2.10.1-267 release notes
This release of the Custom Metrics Autoscaler Operator 2.10.1-267 provides new features and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The components of the Custom Metrics Autoscaler Operator 2.10.1-267 were released in RHBA-2023:4089.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
3.1.2.13.1. Bug fixes
-
Previously, the
custom-metrics-autoscalerandcustom-metrics-autoscaler-adapterimages did not contain time zone information. Because of this, scaled objects with cron triggers failed to work because the controllers were unable to find time zone information. With this fix, the image builds now include time zone information. As a result, scaled objects containing cron triggers now function properly. (OCPBUGS-15264) -
Previously, the Custom Metrics Autoscaler Operator would attempt to take ownership of all managed objects, including objects in other namespaces and cluster-scoped objects. Because of this, the Custom Metrics Autoscaler Operator was unable to create the role binding for reading the credentials necessary to be an API server. This caused errors in the
kube-systemnamespace. With this fix, the Custom Metrics Autoscaler Operator skips adding theownerReferencefield to any object in another namespace or any cluster-scoped object. As a result, the role binding is now created without any errors. (OCPBUGS-15038) -
Previously, the Custom Metrics Autoscaler Operator added an
ownerReferencesfield to theopenshift-kedanamespace. While this did not cause functionality problems, the presence of this field could have caused confusion for cluster administrators. With this fix, the Custom Metrics Autoscaler Operator does not add theownerReferencefield to theopenshift-kedanamespace. As a result, theopenshift-kedanamespace no longer has a superfluousownerReferencefield. (OCPBUGS-15293) -
Previously, if you used a Prometheus trigger configured with authentication method other than pod identity, and the
podIdentityparameter was set tonone, the trigger would fail to scale. With this fix, the Custom Metrics Autoscaler for OpenShift now properly handles thenonepod identity provider type. As a result, a Prometheus trigger configured with authentication method other than pod identity, and thepodIdentityparameter sset tononenow properly scales. (OCPBUGS-15274)
3.1.2.14. Custom Metrics Autoscaler Operator 2.10.1 release notes
This release of the Custom Metrics Autoscaler Operator 2.10.1 provides new features and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The components of the Custom Metrics Autoscaler Operator 2.10.1 were released in RHEA-2023:3199.
Before installing this version of the Custom Metrics Autoscaler Operator, remove any previously installed Technology Preview versions or the community-supported version of KEDA.
3.1.2.14.1. New features and enhancements
3.1.2.14.1.1. Custom Metrics Autoscaler Operator general availability
The Custom Metrics Autoscaler Operator is now generally available as of Custom Metrics Autoscaler Operator version 2.10.1.
Scaling by using a scaled job is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process.
For more information about the support scope of Red Hat Technology Preview features, see Technology Preview Features Support Scope.
3.1.2.14.1.2. Performance metrics
You can now use the Prometheus Query Language (PromQL) to query metrics on the Custom Metrics Autoscaler Operator.
3.1.2.14.1.3. Pausing the custom metrics autoscaling for scaled objects
You can now pause the autoscaling of a scaled object, as needed, and resume autoscaling when ready.
3.1.2.14.1.4. Replica fall back for scaled objects
You can now specify the number of replicas to fall back to if a scaled object fails to get metrics from the source.
3.1.2.14.1.5. Customizable HPA naming for scaled objects
You can now specify a custom name for the horizontal pod autoscaler in scaled objects.
3.1.2.14.1.6. Activation and scaling thresholds
Because the horizontal pod autoscaler (HPA) cannot scale to or from 0 replicas, the Custom Metrics Autoscaler Operator does that scaling, after which the HPA performs the scaling. You can now specify when the HPA takes over autoscaling, based on the number of replicas. This allows for more flexibility with your scaling policies.
3.1.2.15. Custom Metrics Autoscaler Operator 2.8.2-174 release notes
This release of the Custom Metrics Autoscaler Operator 2.8.2-174 provides new features and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The components of the Custom Metrics Autoscaler Operator 2.8.2-174 were released in RHEA-2023:1683.
The Custom Metrics Autoscaler Operator version 2.8.2-174 is a Technology Preview feature.
3.1.2.15.1. New features and enhancements
3.1.2.15.1.1. Operator upgrade support
You can now upgrade from a prior version of the Custom Metrics Autoscaler Operator. See "Changing the update channel for an Operator" in the "Additional resources" for information on upgrading an Operator.
3.1.2.15.1.2. must-gather support
You can now collect data about the Custom Metrics Autoscaler Operator and its components by using the Red Hat OpenShift Service on AWS must-gather tool. Currently, the process for using the must-gather tool with the Custom Metrics Autoscaler is different than for other operators. See "Gathering debugging data in the "Additional resources" for more information.
3.1.2.16. Custom Metrics Autoscaler Operator 2.8.2 release notes
This release of the Custom Metrics Autoscaler Operator 2.8.2 provides new features and bug fixes for running the Operator in an Red Hat OpenShift Service on AWS cluster. The components of the Custom Metrics Autoscaler Operator 2.8.2 were released in RHSA-2023:1042.
The Custom Metrics Autoscaler Operator version 2.8.2 is a Technology Preview feature.
3.1.2.16.1. New features and enhancements
3.1.2.16.1.1. Audit Logging
You can now gather and view audit logs for the Custom Metrics Autoscaler Operator and its associated components. Audit logs are security-relevant chronological sets of records that document the sequence of activities that have affected the system by individual users, administrators, or other components of the system.
3.1.2.16.1.2. Scale applications based on Apache Kafka metrics
You can now use the KEDA Apache kafka trigger/scaler to scale deployments based on an Apache Kafka topic.
3.1.2.16.1.3. Scale applications based on CPU metrics
You can now use the KEDA CPU trigger/scaler to scale deployments based on CPU metrics.
3.1.2.16.1.4. Scale applications based on memory metrics
You can now use the KEDA memory trigger/scaler to scale deployments based on memory metrics.
3.2. Custom Metrics Autoscaler Operator overview
As a developer, you can use Custom Metrics Autoscaler Operator for Red Hat OpenShift to specify how Red Hat OpenShift Service on AWS should automatically increase or decrease the number of pods for a deployment, stateful set, custom resource, or job based on custom metrics that are not based only on CPU or memory.
The Custom Metrics Autoscaler Operator is an optional Operator, based on the Kubernetes Event Driven Autoscaler (KEDA), that allows workloads to be scaled using additional metrics sources other than pod metrics.
The custom metrics autoscaler currently supports only the Prometheus, CPU, memory, and Apache Kafka metrics.
The Custom Metrics Autoscaler Operator scales your pods up and down based on custom, external metrics from specific applications. Your other applications continue to use other scaling methods. You configure triggers, also known as scalers, which are the source of events and metrics that the custom metrics autoscaler uses to determine how to scale. The custom metrics autoscaler uses a metrics API to convert the external metrics to a form that Red Hat OpenShift Service on AWS can use. The custom metrics autoscaler creates a horizontal pod autoscaler (HPA) that performs the actual scaling.
To use the custom metrics autoscaler, you create a ScaledObject or ScaledJob object for a workload, which is a custom resource (CR) that defines the scaling metadata. You specify the deployment or job to scale, the source of the metrics to scale on (trigger), and other parameters such as the minimum and maximum replica counts allowed.
You can create only one scaled object or scaled job for each workload that you want to scale. Also, you cannot use a scaled object or scaled job and the horizontal pod autoscaler (HPA) on the same workload.
The custom metrics autoscaler, unlike the HPA, can scale to zero. If you set the minReplicaCount value in the custom metrics autoscaler CR to 0, the custom metrics autoscaler scales the workload down from 1 to 0 replicas to or up from 0 replicas to 1. This is known as the activation phase. After scaling up to 1 replica, the HPA takes control of the scaling. This is known as the scaling phase.
Some triggers allow you to change the number of replicas that are scaled by the cluster metrics autoscaler. In all cases, the parameter to configure the activation phase always uses the same phrase, prefixed with activation. For example, if the threshold parameter configures scaling, activationThreshold would configure activation. Configuring the activation and scaling phases allows you more flexibility with your scaling policies. For example, you can configure a higher activation phase to prevent scaling up or down if the metric is particularly low.
The activation value has more priority than the scaling value in case of different decisions for each. For example, if the threshold is set to 10, and the activationThreshold is 50, if the metric reports 40, the scaler is not active and the pods are scaled to zero even if the HPA requires 4 instances.
Figure 3.1. Custom metrics autoscaler workflow
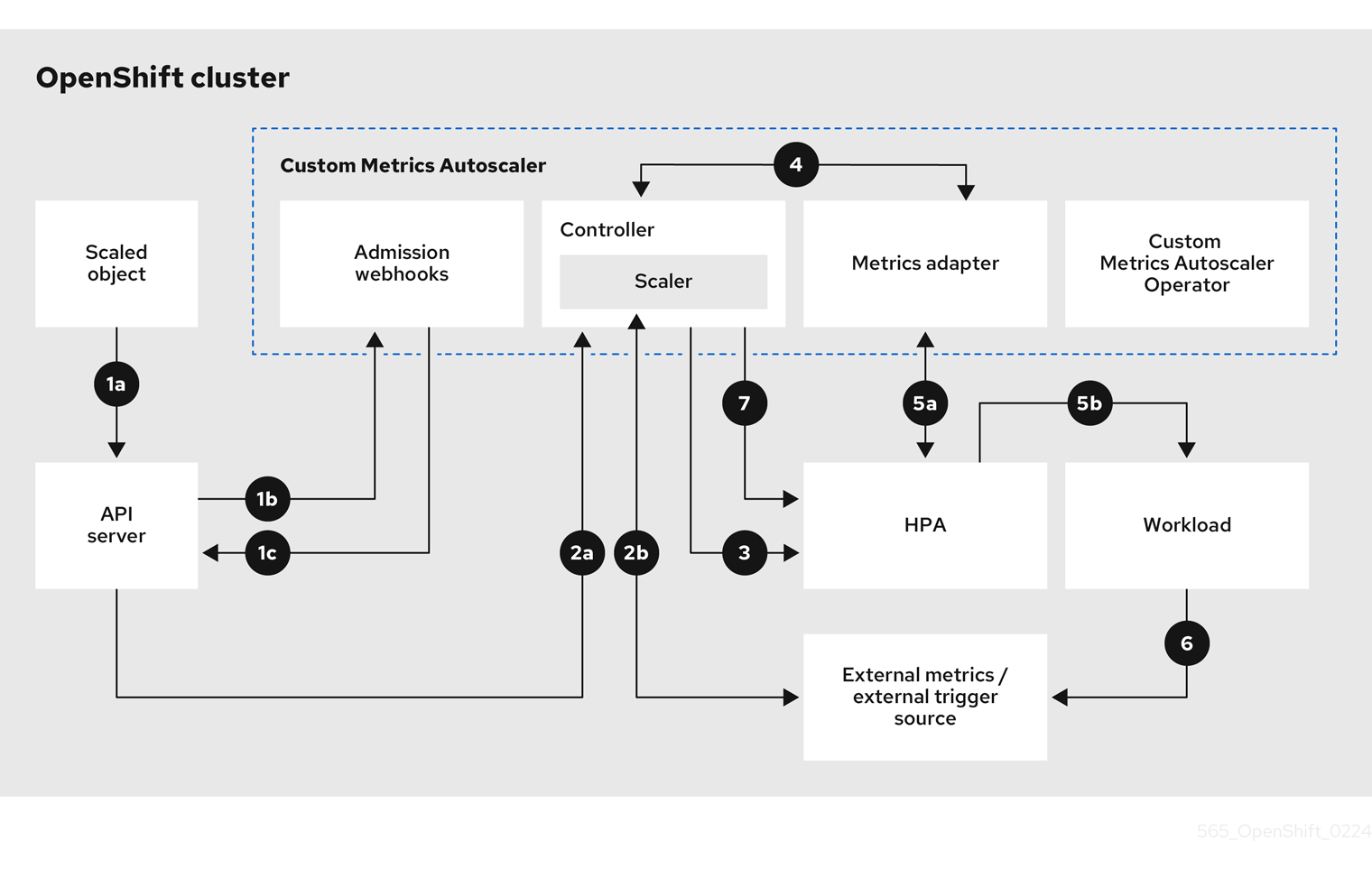
- You create or modify a scaled object custom resource for a workload on a cluster. The object contains the scaling configuration for that workload. Prior to accepting the new object, the OpenShift API server sends it to the custom metrics autoscaler admission webhooks process to ensure that the object is valid. If validation succeeds, the API server persists the object.
- The custom metrics autoscaler controller watches for new or modified scaled objects. When the OpenShift API server notifies the controller of a change, the controller monitors any external trigger sources, also known as data sources, that are specified in the object for changes to the metrics data. One or more scalers request scaling data from the external trigger source. For example, for a Kafka trigger type, the controller uses the Kafka scaler to communicate with a Kafka instance to obtain the data requested by the trigger.
- The controller creates a horizontal pod autoscaler object for the scaled object. As a result, the Horizontal Pod Autoscaler (HPA) Operator starts monitoring the scaling data associated with the trigger. The HPA requests scaling data from the cluster OpenShift API server endpoint.
- The OpenShift API server endpoint is served by the custom metrics autoscaler metrics adapter. When the metrics adapter receives a request for custom metrics, it uses a GRPC connection to the controller to request it for the most recent trigger data received from the scaler.
- The HPA makes scaling decisions based upon the data received from the metrics adapter and scales the workload up or down by increasing or decreasing the replicas.
- As a it operates, a workload can affect the scaling metrics. For example, if a workload is scaled up to handle work in a Kafka queue, the queue size decreases after the workload processes all the work. As a result, the workload is scaled down.
-
If the metrics are in a range specified by the
minReplicaCountvalue, the custom metrics autoscaler controller disables all scaling, and leaves the replica count at a fixed level. If the metrics exceed that range, the custom metrics autoscaler controller enables scaling and allows the HPA to scale the workload. While scaling is disabled, the HPA does not take any action.
3.2.1. Custom CA certificates for the Custom Metrics Autoscaler
By default, the Custom Metrics Autoscaler Operator uses automatically-generated service CA certificates to connect to on-cluster services.
If you want to use off-cluster services that require custom CA certificates, you can add the required certificates to a config map. Then, add the config map to the KedaController custom resource as described in Installing the custom metrics autoscaler. The Operator loads those certificates on start-up and registers them as trusted by the Operator.
The config maps can contain one or more certificate files that contain one or more PEM-encoded CA certificates. Or, you can use separate config maps for each certificate file.
If you later update the config map to add additional certificates, you must restart the keda-operator-* pod for the changes to take effect.
3.3. Installing the custom metrics autoscaler
You can use the Red Hat OpenShift Service on AWS web console to install the Custom Metrics Autoscaler Operator.
The installation creates the following five CRDs:
-
ClusterTriggerAuthentication -
KedaController -
ScaledJob -
ScaledObject -
TriggerAuthentication
The installation process also creates the KedaController custom resource (CR). You can modify the default KedaController CR, if needed. For more information, see "Editing the Keda Controller CR".
If you are installing a Custom Metrics Autoscaler Operator version lower than 2.17.2, you must manually create the Keda Controller CR. You can use the procedure described in "Editing the Keda Controller CR" to create the CR.
3.3.1. Installing the custom metrics autoscaler
You can use the following procedure to install the Custom Metrics Autoscaler Operator.
Prerequisites
-
You have access to the cluster as a user with the
cluster-adminrole. - Remove any previously-installed Technology Preview versions of the Cluster Metrics Autoscaler Operator.
Remove any versions of the community-based KEDA.
Also, remove the KEDA 1.x custom resource definitions by running the following commands:
$ oc delete crd scaledobjects.keda.k8s.io$ oc delete crd triggerauthentications.keda.k8s.io-
Ensure that the
kedanamespace exists. If not, you must manaully create thekedanamespace. Optional: If you need the Custom Metrics Autoscaler Operator to connect to off-cluster services, such as an external Kafka cluster or an external Prometheus service, put any required service CA certificates into a config map. The config map must exist in the same namespace where the Operator is installed. For example:
$ oc create configmap -n openshift-keda thanos-cert --from-file=ca-cert.pem
Procedure
- In the Red Hat OpenShift Service on AWS web console, click Ecosystem → Software Catalog.
- Choose Custom Metrics Autoscaler from the list of available Operators, and click Install.
- On the Install Operator page, ensure that the A specific namespace on the cluster option is selected for Installation Mode.
- For Installed Namespace, click Select a namespace.
Click Select Project:
-
If the
kedanamespace exists, select keda from the list. If the
kedanamespace does not exist:- Select Create Project to open the Create Project window.
-
In the Name field, enter
keda. -
In the Display Name field, enter a descriptive name, such as
keda. - Optional: In the Display Name field, add a description for the namespace.
- Click Create.
-
If the
- Click Install.
Verify the installation by listing the Custom Metrics Autoscaler Operator components:
- Navigate to Workloads → Pods.
-
Select the
kedaproject from the drop-down menu and verify that thecustom-metrics-autoscaler-operator-*pod is running. -
Navigate to Workloads → Deployments to verify that the
custom-metrics-autoscaler-operatordeployment is running.
Optional: Verify the installation in the OpenShift CLI using the following command:
$ oc get all -n kedaThe output appears similar to the following:
Example output
NAME READY STATUS RESTARTS AGE pod/custom-metrics-autoscaler-operator-5fd8d9ffd8-xt4xp 1/1 Running 0 18m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/custom-metrics-autoscaler-operator 1/1 1 1 18m NAME DESIRED CURRENT READY AGE replicaset.apps/custom-metrics-autoscaler-operator-5fd8d9ffd8 1 1 1 18m
3.3.2. Editing the Keda Controller CR
You can use the following procedure to modify the KedaController custom resource (CR), which is automatically installed during the installation of the Custom Metrics Autoscaler Operator.
Procedure
- In the Red Hat OpenShift Service on AWS web console, click Ecosystem → Installed Operators.
- Click Custom Metrics Autoscaler.
- On the Operator Details page, click the KedaController tab.
On the KedaController tab, click Create KedaController and edit the file.
kind: KedaController apiVersion: keda.sh/v1alpha1 metadata: name: keda namespace: openshift-keda spec: watchNamespace: ''1 operator: logLevel: info2 logEncoder: console3 caConfigMaps:4 - thanos-cert - kafka-cert volumeMounts:5 - mountPath: /<path_to_directory> name: <name> volumes:6 - name: <volume_name> emptyDir: medium: Memory metricsServer: logLevel: '0'7 auditConfig:8 logFormat: "json" logOutputVolumeClaim: "persistentVolumeClaimName" policy: rules: - level: Metadata omitStages: ["RequestReceived"] omitManagedFields: false lifetime: maxAge: "2" maxBackup: "1" maxSize: "50" serviceAccount: {}- 1
- Specifies a single namespace in which the Custom Metrics Autoscaler Operator scales applications. Leave it blank or leave it empty to scale applications in all namespaces. This field should have a namespace or be empty. The default value is empty.
- 2
- Specifies the level of verbosity for the Custom Metrics Autoscaler Operator log messages. The allowed values are
debug,info,error. The default isinfo. - 3
- Specifies the logging format for the Custom Metrics Autoscaler Operator log messages. The allowed values are
consoleorjson. The default isconsole. - 4
- Optional: Specifies one or more config maps with CA certificates, which the Custom Metrics Autoscaler Operator can use to connect securely to TLS-enabled metrics sources.
- 5
- Optional: Add the container mount path.
- 6
- Optional: Add a
volumesblock to list each projected volume source. - 7
- Specifies the logging level for the Custom Metrics Autoscaler Metrics Server. The allowed values are
0forinfoand4fordebug. The default is0. - 8
- Activates audit logging for the Custom Metrics Autoscaler Operator and specifies the audit policy to use, as described in the "Configuring audit logging" section.
- Click Save to save the changes.
3.4. Understanding custom metrics autoscaler triggers
Triggers, also known as scalers, provide the metrics that the Custom Metrics Autoscaler Operator uses to scale your pods.
The custom metrics autoscaler currently supports the Prometheus, CPU, memory, Apache Kafka, and cron triggers.
You use a ScaledObject or ScaledJob custom resource to configure triggers for specific objects, as described in the sections that follow.
You can configure a certificate authority to use with your scaled objects or for all scalers in the cluster.
3.4.1. Understanding the Prometheus trigger
You can scale pods based on Prometheus metrics, which can use the installed Red Hat OpenShift Service on AWS monitoring or an external Prometheus server as the metrics source. See "Configuring the custom metrics autoscaler to use Red Hat OpenShift Service on AWS monitoring" for information on the configurations required to use the Red Hat OpenShift Service on AWS monitoring as a source for metrics.
If Prometheus is collecting metrics from the application that the custom metrics autoscaler is scaling, do not set the minimum replicas to 0 in the custom resource. If there are no application pods, the custom metrics autoscaler does not have any metrics to scale on.
Example scaled object with a Prometheus target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prom-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: prometheus
metadata:
serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092
namespace: kedatest
metricName: http_requests_total
threshold: '5'
query: sum(rate(http_requests_total{job="test-app"}[1m]))
authModes: basic
cortexOrgID: my-org
ignoreNullValues: "false"
unsafeSsl: "false"
timeout: 1000 - 1
- Specifies Prometheus as the trigger type.
- 2
- Specifies the address of the Prometheus server. This example uses Red Hat OpenShift Service on AWS monitoring.
- 3
- Optional: Specifies the namespace of the object you want to scale. This parameter is mandatory if using Red Hat OpenShift Service on AWS monitoring as a source for the metrics.
- 4
- Specifies the name to identify the metric in the
external.metrics.k8s.ioAPI. If you are using more than one trigger, all metric names must be unique. - 5
- Specifies the value that triggers scaling. Must be specified as a quoted string value.
- 6
- Specifies the Prometheus query to use.
- 7
- Specifies the authentication method to use. Prometheus scalers support bearer authentication (
bearer), basic authentication (basic), or TLS authentication (tls). You configure the specific authentication parameters in a trigger authentication, as discussed in a following section. As needed, you can also use a secret. - 8
- 9
- Optional: Specifies how the trigger should proceed if the Prometheus target is lost.
-
If
true, the trigger continues to operate if the Prometheus target is lost. This is the default behavior. -
If
false, the trigger returns an error if the Prometheus target is lost.
-
If
- 10
- Optional: Specifies whether the certificate check should be skipped. For example, you might skip the check if you are running in a test environment and using self-signed certificates at the Prometheus endpoint.
-
If
false, the certificate check is performed. This is the default behavior. If
true, the certificate check is not performed.ImportantSkipping the check is not recommended.
-
If
- 11
- Optional: Specifies an HTTP request timeout in milliseconds for the HTTP client used by this Prometheus trigger. This value overrides any global timeout setting.
3.4.1.1. Configuring GPU-based autoscaling with Prometheus and DCGM metrics
You can use the Custom Metrics Autoscaler with NVIDIA Data Center GPU Manager (DCGM) metrics to scale workloads based on GPU utilization. This is particularly useful for AI and machine learning workloads that require GPU resources.
Example scaled object with a Prometheus target for GPU-based autoscaling
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: gpu-scaledobject
namespace: my-namespace
spec:
scaleTargetRef:
kind: Deployment
name: gpu-deployment
minReplicaCount: 1
maxReplicaCount: 5
triggers:
- type: prometheus
metadata:
serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092
namespace: my-namespace
metricName: gpu_utilization
threshold: '90'
query: SUM(DCGM_FI_DEV_GPU_UTIL{instance=~".+", gpu=~".+"})
authModes: bearer
authenticationRef:
name: keda-trigger-auth-prometheus- 1
- Specifies the minimum number of replicas to maintain. For GPU workloads, this should not be set to
0to ensure that metrics continue to be collected. - 2
- Specifies the maximum number of replicas allowed during scale-up operations.
- 3
- Specifies the GPU utilization percentage threshold that triggers scaling. When the average GPU utilization exceeds 90%, the autoscaler scales up the deployment.
- 4
- Specifies a Prometheus query using NVIDIA DCGM metrics to monitor GPU utilization across all GPU devices. The
DCGM_FI_DEV_GPU_UTILmetric provides GPU utilization percentages.
3.4.1.2. Configuring the custom metrics autoscaler to use Red Hat OpenShift Service on AWS monitoring
You can use the installed Red Hat OpenShift Service on AWS Prometheus monitoring as a source for the metrics used by the custom metrics autoscaler. However, there are some additional configurations you must perform.
For your scaled objects to be able to read the Red Hat OpenShift Service on AWS Prometheus metrics, you must use a trigger authentication or a cluster trigger authentication in order to provide the authentication information required. The following procedure differs depending on which trigger authentication method you use. For more information on trigger authentications, see "Understanding custom metrics autoscaler trigger authentications".
These steps are not required for an external Prometheus source.
You must perform the following tasks, as described in this section:
- Create a service account.
- Create the trigger authentication.
- Create a role.
- Add that role to the service account.
- Reference the token in the trigger authentication object used by Prometheus.
Prerequisites
- Red Hat OpenShift Service on AWS monitoring must be installed.
- Monitoring of user-defined workloads must be enabled in Red Hat OpenShift Service on AWS monitoring, as described in the Creating a user-defined workload monitoring config map section.
- The Custom Metrics Autoscaler Operator must be installed.
Procedure
Change to the appropriate project:
$ oc project <project_name>1 - 1
- Specifies one of the following projects:
- If you are using a trigger authentication, specify the project with the object you want to scale.
-
If you are using a cluster trigger authentication, specify the
openshift-kedaproject.
Create a service account if your cluster does not have one:
Create a
service accountobject by using the following command:$ oc create serviceaccount thanos1 - 1
- Specifies the name of the service account.
Create a trigger authentication with the service account token:
Create a YAML file similar to the following:
apiVersion: keda.sh/v1alpha1 kind: <authentication_method>1 metadata: name: keda-trigger-auth-prometheus spec: boundServiceAccountToken:2 - parameter: bearerToken3 serviceAccountName: thanos4 - 1
- Specifies one of the following trigger authentication methods:
-
If you are using a trigger authentication, specify
TriggerAuthentication. This example configures a trigger authentication. -
If you are using a cluster trigger authentication, specify
ClusterTriggerAuthentication.
-
If you are using a trigger authentication, specify
- 2
- Specifies that this trigger authentication uses a bound service account token for authorization when connecting to the metrics endpoint.
- 3
- Specifies the authentication parameter to supply by using the token. Here, the example uses bearer authentication.
- 4
- Specifies the name of the service account to use.
Create the CR object:
$ oc create -f <file-name>.yaml
Create a role for reading Thanos metrics:
Create a YAML file with the following parameters:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watchCreate the CR object:
$ oc create -f <file-name>.yaml
Create a role binding for reading Thanos metrics:
Create a YAML file similar to the following:
apiVersion: rbac.authorization.k8s.io/v1 kind: <binding_type>1 metadata: name: thanos-metrics-reader2 namespace: my-project3 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: thanos-metrics-reader subjects: - kind: ServiceAccount name: thanos4 namespace: <namespace_name>5 - 1
- Specifies one of the following object types:
-
If you are using a trigger authentication, specify
RoleBinding. -
If you are using a cluster trigger authentication, specify
ClusterRoleBinding.
-
If you are using a trigger authentication, specify
- 2
- Specifies the name of the role you created.
- 3
- Specifies one of the following projects:
- If you are using a trigger authentication, specify the project with the object you want to scale.
-
If you are using a cluster trigger authentication, specify the
openshift-kedaproject.
- 4
- Specifies the name of the service account to bind to the role.
- 5
- Specifies the project where you previously created the service account.
Create the CR object:
$ oc create -f <file-name>.yaml
You can now deploy a scaled object or scaled job to enable autoscaling for your application, as described in "Understanding how to add custom metrics autoscalers". To use Red Hat OpenShift Service on AWS monitoring as the source, in the trigger, or scaler, you must include the following parameters:
-
triggers.typemust beprometheus -
triggers.metadata.serverAddressmust behttps://thanos-querier.openshift-monitoring.svc.cluster.local:9092 -
triggers.metadata.authModesmust bebearer -
triggers.metadata.namespacemust be set to the namespace of the object to scale -
triggers.authenticationRefmust point to the trigger authentication resource specified in the previous step
3.4.2. Understanding the CPU trigger
You can scale pods based on CPU metrics. This trigger uses cluster metrics as the source for metrics.
The custom metrics autoscaler scales the pods associated with an object to maintain the CPU usage that you specify. The autoscaler increases or decreases the number of replicas between the minimum and maximum numbers to maintain the specified CPU utilization across all pods. The memory trigger considers the memory utilization of the entire pod. If the pod has multiple containers, the memory trigger considers the total memory utilization of all containers in the pod.
-
This trigger cannot be used with the
ScaledJobcustom resource. -
When using a memory trigger to scale an object, the object does not scale to
0, even if you are using multiple triggers.
Example scaled object with a CPU target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: cpu
metricType: Utilization
metadata:
value: '60'
minReplicaCount: 1 - 1
- Specifies CPU as the trigger type.
- 2
- Specifies the type of metric to use, either
UtilizationorAverageValue. - 3
- Specifies the value that triggers scaling. Must be specified as a quoted string value.
-
When using
Utilization, the target value is the average of the resource metrics across all relevant pods, represented as a percentage of the requested value of the resource for the pods. -
When using
AverageValue, the target value is the average of the metrics across all relevant pods.
-
When using
- 4
- Specifies the minimum number of replicas when scaling down. For a CPU trigger, enter a value of
1or greater, because the HPA cannot scale to zero if you are using only CPU metrics.
3.4.3. Understanding the memory trigger
You can scale pods based on memory metrics. This trigger uses cluster metrics as the source for metrics.
The custom metrics autoscaler scales the pods associated with an object to maintain the average memory usage that you specify. The autoscaler increases and decreases the number of replicas between the minimum and maximum numbers to maintain the specified memory utilization across all pods. The memory trigger considers the memory utilization of entire pod. If the pod has multiple containers, the memory utilization is the sum of all of the containers.
-
This trigger cannot be used with the
ScaledJobcustom resource. -
When using a memory trigger to scale an object, the object does not scale to
0, even if you are using multiple triggers.
Example scaled object with a memory target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: memory-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: memory
metricType: Utilization
metadata:
value: '60'
containerName: api - 1
- Specifies memory as the trigger type.
- 2
- Specifies the type of metric to use, either
UtilizationorAverageValue. - 3
- Specifies the value that triggers scaling. Must be specified as a quoted string value.
-
When using
Utilization, the target value is the average of the resource metrics across all relevant pods, represented as a percentage of the requested value of the resource for the pods. -
When using
AverageValue, the target value is the average of the metrics across all relevant pods.
-
When using
- 4
- Optional: Specifies an individual container to scale, based on the memory utilization of only that container, rather than the entire pod. In this example, only the container named
apiis to be scaled.
3.4.4. Understanding the Kafka trigger
You can scale pods based on an Apache Kafka topic or other services that support the Kafka protocol. The custom metrics autoscaler does not scale higher than the number of Kafka partitions, unless you set the allowIdleConsumers parameter to true in the scaled object or scaled job.
If the number of consumer groups exceeds the number of partitions in a topic, the extra consumer groups remain idle. To avoid this, by default the number of replicas does not exceed:
- The number of partitions on a topic, if a topic is specified
- The number of partitions of all topics in the consumer group, if no topic is specified
-
The
maxReplicaCountspecified in scaled object or scaled job CR
You can use the allowIdleConsumers parameter to disable these default behaviors.
Example scaled object with a Kafka target
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: my-namespace
spec:
# ...
triggers:
- type: kafka
metadata:
topic: my-topic
bootstrapServers: my-cluster-kafka-bootstrap.openshift-operators.svc:9092
consumerGroup: my-group
lagThreshold: '10'
activationLagThreshold: '5'
offsetResetPolicy: latest
allowIdleConsumers: true
scaleToZeroOnInvalidOffset: false
excludePersistentLag: false
version: '1.0.0'
partitionLimitation: '1,2,10-20,31'
tls: enable - 1
- Specifies Kafka as the trigger type.
- 2
- Specifies the name of the Kafka topic on which Kafka is processing the offset lag.
- 3
- Specifies a comma-separated list of Kafka brokers to connect to.
- 4
- Specifies the name of the Kafka consumer group used for checking the offset on the topic and processing the related lag.
- 5
- Optional: Specifies the average target value that triggers scaling. Must be specified as a quoted string value. The default is
5. - 6
- Optional: Specifies the target value for the activation phase. Must be specified as a quoted string value.
- 7
- Optional: Specifies the Kafka offset reset policy for the Kafka consumer. The available values are:
latestandearliest. The default islatest. - 8
- Optional: Specifies whether the number of Kafka replicas can exceed the number of partitions on a topic.
-
If
true, the number of Kafka replicas can exceed the number of partitions on a topic. This allows for idle Kafka consumers. -
If
false, the number of Kafka replicas cannot exceed the number of partitions on a topic. This is the default.
-
If
- 9
- Specifies how the trigger behaves when a Kafka partition does not have a valid offset.
-
If
true, the consumers are scaled to zero for that partition. -
If
false, the scaler keeps a single consumer for that partition. This is the default.
-
If
- 10
- Optional: Specifies whether the trigger includes or excludes partition lag for partitions whose current offset is the same as the current offset of the previous polling cycle.
-
If
true, the scaler excludes partition lag in these partitions. -
If
false, the trigger includes all consumer lag in all partitions. This is the default.
-
If
- 11
- Optional: Specifies the version of your Kafka brokers. Must be specified as a quoted string value. The default is
1.0.0. - 12
- Optional: Specifies a comma-separated list of partition IDs to scope the scaling on. If set, only the listed IDs are considered when calculating lag. Must be specified as a quoted string value. The default is to consider all partitions.
- 13
- Optional: Specifies whether to use TSL client authentication for Kafka. The default is
disable. For information on configuring TLS, see "Understanding custom metrics autoscaler trigger authentications".
3.4.5. Understanding the Cron trigger
You can scale pods based on a time range.
When the time range starts, the custom metrics autoscaler scales the pods associated with an object from the configured minimum number of pods to the specified number of desired pods. At the end of the time range, the pods are scaled back to the configured minimum. The time period must be configured in cron format.
The following example scales the pods associated with this scaled object from 0 to 100 from 6:00 AM to 6:30 PM India Standard Time.
Example scaled object with a Cron trigger
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
scaleTargetRef:
name: my-deployment
minReplicaCount: 0
maxReplicaCount: 100
cooldownPeriod: 300
triggers:
- type: cron
metadata:
timezone: Asia/Kolkata
start: "0 6 * * *"
end: "30 18 * * *"
desiredReplicas: "100" - 1
- Specifies the minimum number of pods to scale down to at the end of the time frame.
- 2
- Specifies the maximum number of replicas when scaling up. This value should be the same as
desiredReplicas. The default is100. - 3
- Specifies a Cron trigger.
- 4
- Specifies the timezone for the time frame. This value must be from the IANA Time Zone Database.
- 5
- Specifies the start of the time frame.
- 6
- Specifies the end of the time frame.
- 7
- Specifies the number of pods to scale to between the start and end of the time frame. This value should be the same as
maxReplicaCount.
3.4.6. Understanding the Kubernetes workload trigger
You can scale pods based on the number of pods matching a specific label selector.
The Custom Metrics Autoscaler Operator tracks the number of pods with a specific label that are in the same namespace, then calculates a relation based on the number of labeled pods to the pods for the scaled object. Using this relation, the Custom Metrics Autoscaler Operator scales the object according to the scaling policy in the ScaledObject or ScaledJob specification.
The pod counts includes pods with a Succeeded or Failed phase.
For example, if you have a frontend deployment and a backend deployment. You can use a kubernetes-workload trigger to scale the backend deployment based on the number of frontend pods. If number of frontend pods goes up, the Operator would scale the backend pods to maintain the specified ratio. In this example, if there are 10 pods with the app=frontend pod selector, the Operator scales the backend pods to 5 in order to maintain the 0.5 ratio set in the scaled object.
Example scaled object with a Kubernetes workload trigger
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: workload-scaledobject
namespace: my-namespace
spec:
triggers:
- type: kubernetes-workload
metadata:
podSelector: 'app=frontend'
value: '0.5'
activationValue: '3.1' - 1
- Specifies a Kubernetes workload trigger.
- 2
- Specifies one or more pod selectors and/or set-based selectors, separated with commas, to use to get the pod count.
- 3
- Specifies the target relation between the scaled workload and the number of pods that match the selector. The relation is calculated following the following formula:
relation = (pods that match the selector) / (scaled workload pods) - 4
- Optional: Specifies the target value for scaler activation phase. The default is
0.
3.5. Understanding custom metrics autoscaler trigger authentications
A trigger authentication allows you to include authentication information in a scaled object or a scaled job that can be used by the associated containers. You can use trigger authentications to pass Red Hat OpenShift Service on AWS secrets, platform-native pod authentication mechanisms, environment variables, and so on.
You define a TriggerAuthentication object in the same namespace as the object that you want to scale. That trigger authentication can be used only by objects in that namespace.
Alternatively, to share credentials between objects in multiple namespaces, you can create a ClusterTriggerAuthentication object that can be used across all namespaces.
Trigger authentications and cluster trigger authentication use the same configuration. However, a cluster trigger authentication requires an additional kind parameter in the authentication reference of the scaled object.
Example trigger authentication that uses a bound service account token
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: secret-triggerauthentication
namespace: my-namespace
spec:
boundServiceAccountToken:
- parameter: bearerToken
serviceAccountName: thanos Example cluster trigger authentication that uses a bound service account token
kind: ClusterTriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: bound-service-account-token-triggerauthentication
spec:
boundServiceAccountToken:
- parameter: bearerToken
serviceAccountName: thanos Example trigger authentication that uses a secret for Basic authentication
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: secret-triggerauthentication
namespace: my-namespace
spec:
secretTargetRef:
- parameter: username
name: my-basic-secret
key: username
- parameter: password
name: my-basic-secret
key: password- 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses a secret for authorization when connecting to the metrics endpoint.
- 3
- Specifies the authentication parameter to supply by using the secret.
- 4
- Specifies the name of the secret to use. See the following example secret for Basic authentication.
- 5
- Specifies the key in the secret to use with the specified parameter.
Example secret for Basic authentication
apiVersion: v1
kind: Secret
metadata:
name: my-basic-secret
namespace: default
data:
username: "dXNlcm5hbWU="
password: "cGFzc3dvcmQ="- 1
- User name and password to supply to the trigger authentication. The values in the
datastanza must be base-64 encoded.
Example trigger authentication that uses a secret for CA details
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: secret-triggerauthentication
namespace: my-namespace
spec:
secretTargetRef:
- parameter: key
name: my-secret
key: client-key.pem
- parameter: ca
name: my-secret
key: ca-cert.pem - 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses a secret for authorization when connecting to the metrics endpoint.
- 3
- Specifies the type of authentication to use.
- 4
- Specifies the name of the secret to use.
- 5
- Specifies the key in the secret to use with the specified parameter.
- 6
- Specifies the authentication parameter for a custom CA when connecting to the metrics endpoint.
- 7
- Specifies the name of the secret to use. See the following example secret with certificate authority (CA) details.
- 8
- Specifies the key in the secret to use with the specified parameter.
Example secret with certificate authority (CA) details
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: my-namespace
data:
ca-cert.pem: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0...
client-cert.pem: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0...
client-key.pem: LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0t...Example trigger authentication that uses a bearer token
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: token-triggerauthentication
namespace: my-namespace
spec:
secretTargetRef:
- parameter: bearerToken
name: my-secret
key: bearerToken - 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses a secret for authorization when connecting to the metrics endpoint.
- 3
- Specifies the type of authentication to use.
- 4
- Specifies the name of the secret to use. See the following example secret for a bearer token.
- 5
- Specifies the key in the token to use with the specified parameter.
Example secret for a bearer token
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: my-namespace
data:
bearerToken: "<bearer_token>" - 1
- Specifies a bearer token to use with bearer authentication. The value must be base-64 encoded.
Example trigger authentication that uses an environment variable
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: env-var-triggerauthentication
namespace: my-namespace
spec:
env:
- parameter: access_key
name: ACCESS_KEY
containerName: my-container - 1
- Specifies the namespace of the object you want to scale.
- 2
- Specifies that this trigger authentication uses environment variables for authorization when connecting to the metrics endpoint.
- 3
- Specify the parameter to set with this variable.
- 4
- Specify the name of the environment variable.
- 5
- Optional: Specify a container that requires authentication. The container must be in the same resource as referenced by
scaleTargetRefin the scaled object.
Example trigger authentication that uses pod authentication providers
kind: TriggerAuthentication
apiVersion: keda.sh/v1alpha1
metadata:
name: pod-id-triggerauthentication
namespace: my-namespace
spec:
podIdentity:
provider: aws-eks Additional resources
3.5.1. Using trigger authentications
You use trigger authentications and cluster trigger authentications by using a custom resource to create the authentication, then add a reference to a scaled object or scaled job.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
- If you are using a bound service account token, the service account must exist.
If you are using a bound service account token, a role-based access control (RBAC) object that enables the Custom Metrics Autoscaler Operator to request service account tokens from the service account must exist.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: keda-operator-token-creator namespace: <namespace_name>1 rules: - apiGroups: - "" resources: - serviceaccounts/token verbs: - create resourceNames: - thanos2 --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: keda-operator-token-creator-binding namespace: <namespace_name>3 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: keda-operator-token-creator subjects: - kind: ServiceAccount name: keda-operator namespace: openshift-keda-
If you are using a secret, the
Secretobject must exist.
Procedure
Create the
TriggerAuthenticationorClusterTriggerAuthenticationobject.Create a YAML file that defines the object:
Example trigger authentication with a bound service account token
kind: TriggerAuthentication apiVersion: keda.sh/v1alpha1 metadata: name: prom-triggerauthentication namespace: my-namespace1 spec: boundServiceAccountToken:2 - parameter: token serviceAccountName: thanos3 Create the
TriggerAuthenticationobject:$ oc create -f <filename>.yaml
Create or edit a
ScaledObjectYAML file that uses the trigger authentication:Create a YAML file that defines the object by running the following command:
Example scaled object with a trigger authentication
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: scaledobject namespace: my-namespace spec: scaleTargetRef: name: example-deployment maxReplicaCount: 100 minReplicaCount: 0 pollingInterval: 30 triggers: - type: prometheus metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092 namespace: kedatest # replace <NAMESPACE> metricName: http_requests_total threshold: '5' query: sum(rate(http_requests_total{job="test-app"}[1m])) authModes: "basic" authenticationRef: name: prom-triggerauthentication1 kind: TriggerAuthentication2 Example scaled object with a cluster trigger authentication
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: scaledobject namespace: my-namespace spec: scaleTargetRef: name: example-deployment maxReplicaCount: 100 minReplicaCount: 0 pollingInterval: 30 triggers: - type: prometheus metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092 namespace: kedatest # replace <NAMESPACE> metricName: http_requests_total threshold: '5' query: sum(rate(http_requests_total{job="test-app"}[1m])) authModes: "basic" authenticationRef: name: prom-cluster-triggerauthentication1 kind: ClusterTriggerAuthentication2 Create the scaled object by running the following command:
$ oc apply -f <filename>
3.6. Understanding how to add custom metrics autoscalers
To add a custom metrics autoscaler, create a ScaledObject custom resource for a deployment, stateful set, or custom resource. Create a ScaledJob custom resource for a job.
You can create only one scaled object for each workload that you want to scale. Also, you cannot use a scaled object and the horizontal pod autoscaler (HPA) on the same workload.
3.6.1. Adding a custom metrics autoscaler to a workload
You can create a custom metrics autoscaler for a workload that is created by a Deployment, StatefulSet, or custom resource object.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
If you use a custom metrics autoscaler for scaling based on CPU or memory:
Your cluster administrator must have properly configured cluster metrics. You can use the
oc describe PodMetrics <pod-name>command to determine if metrics are configured. If metrics are configured, the output appears similar to the following, with CPU and Memory displayed under Usage.$ oc describe PodMetrics openshift-kube-scheduler-ip-10-0-135-131.ec2.internalExample output
Name: openshift-kube-scheduler-ip-10-0-135-131.ec2.internal Namespace: openshift-kube-scheduler Labels: <none> Annotations: <none> API Version: metrics.k8s.io/v1beta1 Containers: Name: wait-for-host-port Usage: Memory: 0 Name: scheduler Usage: Cpu: 8m Memory: 45440Ki Kind: PodMetrics Metadata: Creation Timestamp: 2019-05-23T18:47:56Z Self Link: /apis/metrics.k8s.io/v1beta1/namespaces/openshift-kube-scheduler/pods/openshift-kube-scheduler-ip-10-0-135-131.ec2.internal Timestamp: 2019-05-23T18:47:56Z Window: 1m0s Events: <none>The pods associated with the object you want to scale must include specified memory and CPU limits. For example:
Example pod spec
apiVersion: v1 kind: Pod # ... spec: containers: - name: app image: images.my-company.example/app:v4 resources: limits: memory: "128Mi" cpu: "500m" # ...
Procedure
Create a YAML file similar to the following. Only the name
<2>, object name<4>, and object kind<5>are required:Example scaled object
apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: annotations: autoscaling.keda.sh/paused-replicas: "0"1 name: scaledobject2 namespace: my-namespace spec: scaleTargetRef: apiVersion: apps/v13 name: example-deployment4 kind: Deployment5 envSourceContainerName: .spec.template.spec.containers[0]6 cooldownPeriod: 2007 maxReplicaCount: 1008 minReplicaCount: 09 metricsServer:10 auditConfig: logFormat: "json" logOutputVolumeClaim: "persistentVolumeClaimName" policy: rules: - level: Metadata omitStages: "RequestReceived" omitManagedFields: false lifetime: maxAge: "2" maxBackup: "1" maxSize: "50" fallback:11 failureThreshold: 3 replicas: 6 behavior: static12 pollingInterval: 3013 advanced: restoreToOriginalReplicaCount: false14 horizontalPodAutoscalerConfig: name: keda-hpa-scale-down15 behavior:16 scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 100 periodSeconds: 15 triggers: - type: prometheus17 metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092 namespace: kedatest metricName: http_requests_total threshold: '5' query: sum(rate(http_requests_total{job="test-app"}[1m])) authModes: basic authenticationRef:18 name: prom-triggerauthentication kind: TriggerAuthentication- 1
- Optional: Specifies that the Custom Metrics Autoscaler Operator is to scale the replicas to the specified value and stop autoscaling, as described in the "Pausing the custom metrics autoscaler for a workload" section.
- 2
- Specifies a name for this custom metrics autoscaler.
- 3
- Optional: Specifies the API version of the target resource. The default is
apps/v1. - 4
- Specifies the name of the object that you want to scale.
- 5
- Specifies the
kindasDeployment,StatefulSetorCustomResource. - 6
- Optional: Specifies the name of the container in the target resource, from which the custom metrics autoscaler gets environment variables holding secrets and so forth. The default is
.spec.template.spec.containers[0]. - 7
- Optional. Specifies the period in seconds to wait after the last trigger is reported before scaling the deployment back to
0if theminReplicaCountis set to0. The default is300. - 8
- Optional: Specifies the maximum number of replicas when scaling up. The default is
100. - 9
- Optional: Specifies the minimum number of replicas when scaling down.
- 10
- Optional: Specifies the parameters for audit logs. as described in the "Configuring audit logging" section.
- 11
- Optional: Specifies the number of replicas to fall back to if a scaler fails to get metrics from the source for the number of times defined by the
failureThresholdparameter. For more information on fallback behavior, see the KEDA documentation. - 12
- Optional: Specifies the replica count to be used if a fallback occurs. Enter one of the following options or omit the parameter:
-
Enter
staticto use the number of replicas specified by thefallback.replicasparameter. This is the default. -
Enter
currentReplicasto maintain the current number of replicas. -
Enter
currentReplicasIfHigherto maintain the current number of replicas, if that number is higher than thefallback.replicasparameter. If the current number of replicas is lower than thefallback.replicasparameter, use thefallback.replicasvalue. -
Enter
currentReplicasIfLowerto maintain the current number of replicas, if that number is lower than thefallback.replicasparameter. If the current number of replicas is higher than thefallback.replicasparameter, use thefallback.replicasvalue.
-
Enter
- 13
- Optional: Specifies the interval in seconds to check each trigger on. The default is
30. - 14
- Optional: Specifies whether to scale back the target resource to the original replica count after the scaled object is deleted. The default is
false, which keeps the replica count as it is when the scaled object is deleted. - 15
- Optional: Specifies a name for the horizontal pod autoscaler. The default is
keda-hpa-{scaled-object-name}. - 16
- Optional: Specifies a scaling policy to use to control the rate to scale pods up or down, as described in the "Scaling policies" section.
- 17
- Specifies the trigger to use as the basis for scaling, as described in the "Understanding the custom metrics autoscaler triggers" section. This example uses Red Hat OpenShift Service on AWS monitoring.
- 18
- Optional: Specifies a trigger authentication or a cluster trigger authentication. For more information, see Understanding the custom metrics autoscaler trigger authentication in the Additional resources section.
-
Enter
TriggerAuthenticationto use a trigger authentication. This is the default. -
Enter
ClusterTriggerAuthenticationto use a cluster trigger authentication.
-
Enter
Create the custom metrics autoscaler by running the following command:
$ oc create -f <filename>.yaml
Verification
View the command output to verify that the custom metrics autoscaler was created:
$ oc get scaledobject <scaled_object_name>Example output
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK AGE scaledobject apps/v1.Deployment example-deployment 0 50 prometheus prom-triggerauthentication True True True 17sNote the following fields in the output:
-
TRIGGERS: Indicates the trigger, or scaler, that is being used. -
AUTHENTICATION: Indicates the name of any trigger authentication being used. READY: Indicates whether the scaled object is ready to start scaling:-
If
True, the scaled object is ready. -
If
False, the scaled object is not ready because of a problem in one or more of the objects you created.
-
If
ACTIVE: Indicates whether scaling is taking place:-
If
True, scaling is taking place. -
If
False, scaling is not taking place because there are no metrics or there is a problem in one or more of the objects you created.
-
If
FALLBACK: Indicates whether the custom metrics autoscaler is able to get metrics from the source-
If
False, the custom metrics autoscaler is getting metrics. -
If
True, the custom metrics autoscaler is getting metrics because there are no metrics or there is a problem in one or more of the objects you created.
-
If
-
3.7. Pausing the custom metrics autoscaler for a scaled object
You can pause and restart the autoscaling of a workload, as needed.
For example, you might want to pause autoscaling before performing cluster maintenance or to avoid resource starvation by removing non-mission-critical workloads.
3.7.1. Pausing a custom metrics autoscaler
You can pause the autoscaling of a scaled object by adding the autoscaling.keda.sh/paused-replicas annotation to the custom metrics autoscaler for that scaled object. The custom metrics autoscaler scales the replicas for that workload to the specified value and pauses autoscaling until the annotation is removed.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
annotations:
autoscaling.keda.sh/paused-replicas: "4"
# ...Procedure
Use the following command to edit the
ScaledObjectCR for your workload:$ oc edit ScaledObject scaledobjectAdd the
autoscaling.keda.sh/paused-replicasannotation with any value:apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: annotations: autoscaling.keda.sh/paused-replicas: "4"1 creationTimestamp: "2023-02-08T14:41:01Z" generation: 1 name: scaledobject namespace: my-project resourceVersion: '65729' uid: f5aec682-acdf-4232-a783-58b5b82f5dd0- 1
- Specifies that the Custom Metrics Autoscaler Operator is to scale the replicas to the specified value and stop autoscaling.
3.7.2. Restarting the custom metrics autoscaler for a scaled object
You can restart a paused custom metrics autoscaler by removing the autoscaling.keda.sh/paused-replicas annotation for that ScaledObject.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
annotations:
autoscaling.keda.sh/paused-replicas: "4"
# ...Procedure
Use the following command to edit the
ScaledObjectCR for your workload:$ oc edit ScaledObject scaledobjectRemove the
autoscaling.keda.sh/paused-replicasannotation.apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: annotations: autoscaling.keda.sh/paused-replicas: "4"1 creationTimestamp: "2023-02-08T14:41:01Z" generation: 1 name: scaledobject namespace: my-project resourceVersion: '65729' uid: f5aec682-acdf-4232-a783-58b5b82f5dd0- 1
- Remove this annotation to restart a paused custom metrics autoscaler.
3.8. Gathering audit logs
You can gather audit logs, which are a security-relevant chronological set of records documenting the sequence of activities that have affected the system by individual users, administrators, or other components of the system.
For example, audit logs can help you understand where an autoscaling request is coming from. This is key information when backends are getting overloaded by autoscaling requests made by user applications and you need to determine which is the troublesome application.
3.8.1. Configuring audit logging
You can configure auditing for the Custom Metrics Autoscaler Operator by editing the KedaController custom resource. The logs are sent to an audit log file on a volume that is secured by using a persistent volume claim in the KedaController CR.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
Procedure
Edit the
KedaControllercustom resource to add theauditConfigstanza:kind: KedaController apiVersion: keda.sh/v1alpha1 metadata: name: keda namespace: keda spec: # ... metricsServer: # ... auditConfig: logFormat: "json"1 logOutputVolumeClaim: "pvc-audit-log"2 policy: rules:3 - level: Metadata omitStages: "RequestReceived"4 omitManagedFields: false5 lifetime:6 maxAge: "2" maxBackup: "1" maxSize: "50"- 1
- Specifies the output format of the audit log, either
legacyorjson. - 2
- Specifies an existing persistent volume claim for storing the log data. All requests coming to the API server are logged to this persistent volume claim. If you leave this field empty, the log data is sent to stdout.
- 3
- Specifies which events should be recorded and what data they should include:
-
None: Do not log events. -
Metadata: Log only the metadata for the request, such as user, timestamp, and so forth. Do not log the request text and the response text. This is the default. -
Request: Log only the metadata and the request text but not the response text. This option does not apply for non-resource requests. -
RequestResponse: Log event metadata, request text, and response text. This option does not apply for non-resource requests.
-
- 4
- Specifies stages for which no event is created.
- 5
- Specifies whether to omit the managed fields of the request and response bodies from being written to the API audit log, either
trueto omit the fields orfalseto include the fields. - 6
- Specifies the size and lifespan of the audit logs.
-
maxAge: The maximum number of days to retain audit log files, based on the timestamp encoded in their filename. -
maxBackup: The maximum number of audit log files to retain. Set to0to retain all audit log files. -
maxSize: The maximum size in megabytes of an audit log file before it gets rotated.
-
Verification
View the audit log file directly:
Obtain the name of the
keda-metrics-apiserver-*pod:oc get pod -n kedaExample output
NAME READY STATUS RESTARTS AGE custom-metrics-autoscaler-operator-5cb44cd75d-9v4lv 1/1 Running 0 8m20s keda-metrics-apiserver-65c7cc44fd-rrl4r 1/1 Running 0 2m55s keda-operator-776cbb6768-zpj5b 1/1 Running 0 2m55sView the log data by using a command similar to the following:
$ oc logs keda-metrics-apiserver-<hash>|grep -i metadata1 - 1
- Optional: You can use the
grepcommand to specify the log level to display:Metadata,Request,RequestResponse.
For example:
$ oc logs keda-metrics-apiserver-65c7cc44fd-rrl4r|grep -i metadataExample output
... {"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"4c81d41b-3dab-4675-90ce-20b87ce24013","stage":"ResponseComplete","requestURI":"/healthz","verb":"get","user":{"username":"system:anonymous","groups":["system:unauthenticated"]},"sourceIPs":["10.131.0.1"],"userAgent":"kube-probe/1.28","responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2023-02-16T13:00:03.554567Z","stageTimestamp":"2023-02-16T13:00:03.555032Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":""}} ...
Alternatively, you can view a specific log:
Use a command similar to the following to log into the
keda-metrics-apiserver-*pod:$ oc rsh pod/keda-metrics-apiserver-<hash> -n kedaFor example:
$ oc rsh pod/keda-metrics-apiserver-65c7cc44fd-rrl4r -n kedaChange to the
/var/audit-policy/directory:sh-4.4$ cd /var/audit-policy/List the available logs:
sh-4.4$ lsExample output
log-2023.02.17-14:50 policy.yamlView the log, as needed:
sh-4.4$ cat <log_name>/<pvc_name>|grep -i <log_level>1 - 1
- Optional: You can use the
grepcommand to specify the log level to display:Metadata,Request,RequestResponse.
For example:
sh-4.4$ cat log-2023.02.17-14:50/pvc-audit-log|grep -i RequestExample output
... {"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Request","auditID":"63e7f68c-04ec-4f4d-8749-bf1656572a41","stage":"ResponseComplete","requestURI":"/openapi/v2","verb":"get","user":{"username":"system:aggregator","groups":["system:authenticated"]},"sourceIPs":["10.128.0.1"],"responseStatus":{"metadata":{},"code":304},"requestReceivedTimestamp":"2023-02-17T13:12:55.035478Z","stageTimestamp":"2023-02-17T13:12:55.038346Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:discovery\" of ClusterRole \"system:discovery\" to Group \"system:authenticated\""}} ...
3.9. Gathering debugging data
When opening a support case, it is helpful to provide debugging information about your cluster to Red Hat Support.
To help troubleshoot your issue, provide the following information:
-
Data gathered using the
must-gathertool. - The unique cluster ID.
You can use the must-gather tool to collect data about the Custom Metrics Autoscaler Operator and its components, including the following items:
-
The
kedanamespace and its child objects. - The Custom Metric Autoscaler Operator installation objects.
- The Custom Metric Autoscaler Operator CRD objects.
3.9.1. Gathering debugging data
The following command runs the must-gather tool for the Custom Metrics Autoscaler Operator:
$ oc adm must-gather --image="$(oc get packagemanifests openshift-custom-metrics-autoscaler-operator \
-n openshift-marketplace \
-o jsonpath='{.status.channels[?(@.name=="stable")].currentCSVDesc.annotations.containerImage}')"
The standard Red Hat OpenShift Service on AWS must-gather command, oc adm must-gather, does not collect Custom Metrics Autoscaler Operator data.
Prerequisites
-
You are logged in to Red Hat OpenShift Service on AWS as a user with the
dedicated-adminrole. -
The Red Hat OpenShift Service on AWS CLI (
oc) installed.
Procedure
-
Navigate to the directory where you want to store the
must-gatherdata. Perform one of the following:
To get only the Custom Metrics Autoscaler Operator
must-gatherdata, use the following command:$ oc adm must-gather --image="$(oc get packagemanifests openshift-custom-metrics-autoscaler-operator \ -n openshift-marketplace \ -o jsonpath='{.status.channels[?(@.name=="stable")].currentCSVDesc.annotations.containerImage}')"The custom image for the
must-gathercommand is pulled directly from the Operator package manifests, so that it works on any cluster where the Custom Metric Autoscaler Operator is available.To gather the default
must-gatherdata in addition to the Custom Metric Autoscaler Operator information:Use the following command to obtain the Custom Metrics Autoscaler Operator image and set it as an environment variable:
$ IMAGE="$(oc get packagemanifests openshift-custom-metrics-autoscaler-operator \ -n openshift-marketplace \ -o jsonpath='{.status.channels[?(@.name=="stable")].currentCSVDesc.annotations.containerImage}')"Use the
oc adm must-gatherwith the Custom Metrics Autoscaler Operator image:$ oc adm must-gather --image-stream=openshift/must-gather --image=${IMAGE}
Example 3.1. Example must-gather output for the Custom Metric Autoscaler
└── keda ├── apps │ ├── daemonsets.yaml │ ├── deployments.yaml │ ├── replicasets.yaml │ └── statefulsets.yaml ├── apps.openshift.io │ └── deploymentconfigs.yaml ├── autoscaling │ └── horizontalpodautoscalers.yaml ├── batch │ ├── cronjobs.yaml │ └── jobs.yaml ├── build.openshift.io │ ├── buildconfigs.yaml │ └── builds.yaml ├── core │ ├── configmaps.yaml │ ├── endpoints.yaml │ ├── events.yaml │ ├── persistentvolumeclaims.yaml │ ├── pods.yaml │ ├── replicationcontrollers.yaml │ ├── secrets.yaml │ └── services.yaml ├── discovery.k8s.io │ └── endpointslices.yaml ├── image.openshift.io │ └── imagestreams.yaml ├── k8s.ovn.org │ ├── egressfirewalls.yaml │ └── egressqoses.yaml ├── keda.sh │ ├── kedacontrollers │ │ └── keda.yaml │ ├── scaledobjects │ │ └── example-scaledobject.yaml │ └── triggerauthentications │ └── example-triggerauthentication.yaml ├── monitoring.coreos.com │ └── servicemonitors.yaml ├── networking.k8s.io │ └── networkpolicies.yaml ├── keda.yaml ├── pods │ ├── custom-metrics-autoscaler-operator-58bd9f458-ptgwx │ │ ├── custom-metrics-autoscaler-operator │ │ │ └── custom-metrics-autoscaler-operator │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ └── custom-metrics-autoscaler-operator-58bd9f458-ptgwx.yaml │ ├── custom-metrics-autoscaler-operator-58bd9f458-thbsh │ │ └── custom-metrics-autoscaler-operator │ │ └── custom-metrics-autoscaler-operator │ │ └── logs │ ├── keda-metrics-apiserver-65c7cc44fd-6wq4g │ │ ├── keda-metrics-apiserver │ │ │ └── keda-metrics-apiserver │ │ │ └── logs │ │ │ ├── current.log │ │ │ ├── previous.insecure.log │ │ │ └── previous.log │ │ └── keda-metrics-apiserver-65c7cc44fd-6wq4g.yaml │ └── keda-operator-776cbb6768-fb6m5 │ ├── keda-operator │ │ └── keda-operator │ │ └── logs │ │ ├── current.log │ │ ├── previous.insecure.log │ │ └── previous.log │ └── keda-operator-776cbb6768-fb6m5.yaml ├── policy │ └── poddisruptionbudgets.yaml └── route.openshift.io └── routes.yamlCreate a compressed file from the
must-gatherdirectory that was created in your working directory. For example, on a computer that uses a Linux operating system, run the following command:$ tar cvaf must-gather.tar.gz must-gather.local.5421342344627712289/1 - 1
- Replace
must-gather-local.5421342344627712289/with the actual directory name.
- Attach the compressed file to your support case on the Red Hat Customer Portal.
3.10. Viewing Operator metrics
The Custom Metrics Autoscaler Operator exposes ready-to-use metrics that it pulls from the on-cluster monitoring component. You can query the metrics by using the Prometheus Query Language (PromQL) to analyze and diagnose issues. All metrics are reset when the controller pod restarts.
3.10.1. Accessing performance metrics
You can access the metrics and run queries by using the Red Hat OpenShift Service on AWS web console.
Procedure
- Select the Administrator perspective in the Red Hat OpenShift Service on AWS web console.
- Select Observe → Metrics.
- To create a custom query, add your PromQL query to the Expression field.
- To add multiple queries, select Add Query.
3.10.1.1. Provided Operator metrics
The Custom Metrics Autoscaler Operator exposes the following metrics, which you can view by using the Red Hat OpenShift Service on AWS web console.
| Metric name | Description |
|---|---|
|
|
Whether the particular scaler is active or inactive. A value of |
|
| The current value for each scaler’s metric, which is used by the Horizontal Pod Autoscaler (HPA) in computing the target average. |
|
| The latency of retrieving the current metric from each scaler. |
|
| The number of errors that have occurred for each scaler. |
|
| The total number of errors encountered for all scalers. |
|
| The number of errors that have occurred for each scaled obejct. |
|
| The total number of Custom Metrics Autoscaler custom resources in each namespace for each custom resource type. |
|
| The total number of triggers by trigger type. |
Custom Metrics Autoscaler Admission webhook metrics
The Custom Metrics Autoscaler Admission webhook also exposes the following Prometheus metrics.
| Metric name | Description |
|---|---|
|
| The number of scaled object validations. |
|
| The number of validation errors. |
3.11. Removing the Custom Metrics Autoscaler Operator
You can remove the custom metrics autoscaler from your Red Hat OpenShift Service on AWS cluster. After removing the Custom Metrics Autoscaler Operator, remove other components associated with the Operator to avoid potential issues.
Delete the KedaController custom resource (CR) first. If you do not delete the KedaController CR, Red Hat OpenShift Service on AWS can hang when you delete the keda project. If you delete the Custom Metrics Autoscaler Operator before deleting the CR, you are not able to delete the CR.
3.11.1. Uninstalling the Custom Metrics Autoscaler Operator
Use the following procedure to remove the custom metrics autoscaler from your Red Hat OpenShift Service on AWS cluster.
Prerequisites
- The Custom Metrics Autoscaler Operator must be installed.
Procedure
- In the Red Hat OpenShift Service on AWS web console, click Ecosystem → Installed Operators.
- Switch to the keda project.
Remove the
KedaControllercustom resource.- Find the CustomMetricsAutoscaler Operator and click the KedaController tab.
- Find the custom resource, and then click Delete KedaController.
- Click Uninstall.
Remove the Custom Metrics Autoscaler Operator:
- Click Ecosystem → Installed Operators.
-
Find the CustomMetricsAutoscaler Operator and click the Options menu
 and select Uninstall Operator.
and select Uninstall Operator.
- Click Uninstall.
Optional: Use the OpenShift CLI to remove the custom metrics autoscaler components:
Delete the custom metrics autoscaler CRDs:
-
clustertriggerauthentications.keda.sh -
kedacontrollers.keda.sh -
scaledjobs.keda.sh -
scaledobjects.keda.sh -
triggerauthentications.keda.sh
$ oc delete crd clustertriggerauthentications.keda.sh kedacontrollers.keda.sh scaledjobs.keda.sh scaledobjects.keda.sh triggerauthentications.keda.shDeleting the CRDs removes the associated roles, cluster roles, and role bindings. However, there might be a few cluster roles that must be manually deleted.
-
List any custom metrics autoscaler cluster roles:
$ oc get clusterrole | grep keda.shDelete the listed custom metrics autoscaler cluster roles. For example:
$ oc delete clusterrole.keda.sh-v1alpha1-adminList any custom metrics autoscaler cluster role bindings:
$ oc get clusterrolebinding | grep keda.shDelete the listed custom metrics autoscaler cluster role bindings. For example:
$ oc delete clusterrolebinding.keda.sh-v1alpha1-admin
Delete the custom metrics autoscaler project:
$ oc delete project kedaDelete the Cluster Metric Autoscaler Operator:
$ oc delete operator/openshift-custom-metrics-autoscaler-operator.keda
Chapter 4. Controlling pod placement onto nodes (scheduling)
4.1. Controlling pod placement using the scheduler
Pod scheduling is an internal process that determines placement of new pods onto nodes within the cluster.
The scheduler code has a clean separation that watches new pods as they get created and identifies the most suitable node to host them. It then creates bindings (pod to node bindings) for the pods using the master API.
- Default pod scheduling
- Red Hat OpenShift Service on AWS comes with a default scheduler that serves the needs of most users. The default scheduler uses both inherent and customization tools to determine the best fit for a pod.
- Advanced pod scheduling
In situations where you might want more control over where new pods are placed, the Red Hat OpenShift Service on AWS advanced scheduling features allow you to configure a pod so that the pod is required or has a preference to run on a particular node or alongside a specific pod.
You can control pod placement by using the following scheduling features:
4.1.1. About the default scheduler
The default Red Hat OpenShift Service on AWS pod scheduler is responsible for determining the placement of new pods onto nodes within the cluster. It reads data from the pod and finds a node that is a good fit based on configured profiles. It is completely independent and exists as a standalone solution. It does not modify the pod; it creates a binding for the pod that ties the pod to the particular node.
4.1.1.1. Understanding default scheduling
The existing generic scheduler is the default platform-provided scheduler engine that selects a node to host the pod in a three-step operation:
- Filters the nodes
- The available nodes are filtered based on the constraints or requirements specified. This is done by running each node through the list of filter functions called predicates, or filters.
- Prioritizes the filtered list of nodes
- This is achieved by passing each node through a series of priority, or scoring, functions that assign it a score between 0 - 10, with 0 indicating a bad fit and 10 indicating a good fit to host the pod. The scheduler configuration can also take in a simple weight (positive numeric value) for each scoring function. The node score provided by each scoring function is multiplied by the weight (default weight for most scores is 1) and then combined by adding the scores for each node provided by all the scores. This weight attribute can be used by administrators to give higher importance to some scores.
- Selects the best fit node
- The nodes are sorted based on their scores and the node with the highest score is selected to host the pod. If multiple nodes have the same high score, then one of them is selected at random.
4.1.2. Scheduler use cases
One of the important use cases for scheduling within Red Hat OpenShift Service on AWS is to support flexible affinity and anti-affinity policies.
4.1.2.1. Affinity
Administrators should be able to configure the scheduler to specify affinity at any topological level, or even at multiple levels. Affinity at a particular level indicates that all pods that belong to the same service are scheduled onto nodes that belong to the same level. This handles any latency requirements of applications by allowing administrators to ensure that peer pods do not end up being too geographically separated. If no node is available within the same affinity group to host the pod, then the pod is not scheduled.
If you need greater control over where the pods are scheduled, see Controlling pod placement on nodes using node affinity rules and Placing pods relative to other pods using affinity and anti-affinity rules.
These advanced scheduling features allow administrators to specify which node a pod can be scheduled on and to force or reject scheduling relative to other pods.
4.1.2.2. Anti-affinity
Administrators should be able to configure the scheduler to specify anti-affinity at any topological level, or even at multiple levels. Anti-affinity (or 'spread') at a particular level indicates that all pods that belong to the same service are spread across nodes that belong to that level. This ensures that the application is well spread for high availability purposes. The scheduler tries to balance the service pods across all applicable nodes as evenly as possible.
If you need greater control over where the pods are scheduled, see Controlling pod placement on nodes using node affinity rules and Placing pods relative to other pods using affinity and anti-affinity rules.
These advanced scheduling features allow administrators to specify which node a pod can be scheduled on and to force or reject scheduling relative to other pods.
4.2. Placing pods relative to other pods using affinity and anti-affinity rules
Affinity is a property of pods that controls the nodes on which they prefer to be scheduled. Anti-affinity is a property of pods that prevents a pod from being scheduled on a node.
In Red Hat OpenShift Service on AWS, pod affinity and pod anti-affinity allow you to constrain which nodes your pod is eligible to be scheduled on based on the key-value labels on other pods.
4.2.1. Understanding pod affinity
Pod affinity and pod anti-affinity allow you to constrain which nodes your pod is eligible to be scheduled on based on the key/value labels on other pods.
- Pod affinity can tell the scheduler to locate a new pod on the same node as other pods if the label selector on the new pod matches the label on the current pod.
- Pod anti-affinity can prevent the scheduler from locating a new pod on the same node as pods with the same labels if the label selector on the new pod matches the label on the current pod.
For example, using affinity rules, you could spread or pack pods within a service or relative to pods in other services. Anti-affinity rules allow you to prevent pods of a particular service from scheduling on the same nodes as pods of another service that are known to interfere with the performance of the pods of the first service. Or, you could spread the pods of a service across nodes, availability zones, or availability sets to reduce correlated failures.
A label selector might match pods with multiple pod deployments. Use unique combinations of labels when configuring anti-affinity rules to avoid matching pods.
There are two types of pod affinity rules: required and preferred.
Required rules must be met before a pod can be scheduled on a node. Preferred rules specify that, if the rule is met, the scheduler tries to enforce the rules, but does not guarantee enforcement.
Depending on your pod priority and preemption settings, the scheduler might not be able to find an appropriate node for a pod without violating affinity requirements. If so, a pod might not be scheduled.
To prevent this situation, carefully configure pod affinity with equal-priority pods.
You configure pod affinity/anti-affinity through the Pod spec files. You can specify a required rule, a preferred rule, or both. If you specify both, the node must first meet the required rule, then attempts to meet the preferred rule.
The following example shows a Pod spec configured for pod affinity and anti-affinity.
In this example, the pod affinity rule indicates that the pod can schedule onto a node only if that node has at least one already-running pod with a label that has the key security and value S1. The pod anti-affinity rule says that the pod prefers to not schedule onto a node if that node is already running a pod with label having key security and value S2.
Sample Pod config file with pod affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: docker.io/ocpqe/hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]- 1
- Stanza to configure pod affinity.
- 2
- Defines a required rule.
- 3 5
- The key and value (label) that must be matched to apply the rule.
- 4
- The operator represents the relationship between the label on the existing pod and the set of values in the
matchExpressionparameters in the specification for the new pod. Can beIn,NotIn,Exists, orDoesNotExist.
Sample Pod config file with pod anti-affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-antiaffinity
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: docker.io/ocpqe/hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]- 1
- Stanza to configure pod anti-affinity.
- 2
- Defines a preferred rule.
- 3
- Specifies a weight for a preferred rule. The node with the highest weight is preferred.
- 4
- Description of the pod label that determines when the anti-affinity rule applies. Specify a key and value for the label.
- 5
- The operator represents the relationship between the label on the existing pod and the set of values in the
matchExpressionparameters in the specification for the new pod. Can beIn,NotIn,Exists, orDoesNotExist.
If labels on a node change at runtime such that the affinity rules on a pod are no longer met, the pod continues to run on the node.
4.2.2. Configuring a pod affinity rule
The following steps demonstrate a simple two-pod configuration that creates pod with a label and a pod that uses affinity to allow scheduling with that pod.
You cannot add an affinity directly to a scheduled pod.
Procedure
Create a pod with a specific label in the pod spec:
Create a YAML file with the following content:
apiVersion: v1 kind: Pod metadata: name: security-s1 labels: security: S1 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: security-s1 image: docker.io/ocpqe/hello-pod securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefaultCreate the pod.
$ oc create -f <pod-spec>.yaml
When creating other pods, configure the following parameters to add the affinity:
Create a YAML file with the following content:
apiVersion: v1 kind: Pod metadata: name: security-s1-east # ... spec: affinity:1 podAffinity: requiredDuringSchedulingIgnoredDuringExecution:2 - labelSelector: matchExpressions: - key: security3 values: - S1 operator: In4 topologyKey: topology.kubernetes.io/zone5 # ...- 1
- Adds a pod affinity.
- 2
- Configures the
requiredDuringSchedulingIgnoredDuringExecutionparameter or thepreferredDuringSchedulingIgnoredDuringExecutionparameter. - 3
- Specifies the
keyandvaluesthat must be met. If you want the new pod to be scheduled with the other pod, use the samekeyandvaluesparameters as the label on the first pod. - 4
- Specifies an
operator. The operator can beIn,NotIn,Exists, orDoesNotExist. For example, use the operatorInto require the label to be in the node. - 5
- Specify a
topologyKey, which is a prepopulated Kubernetes label that the system uses to denote such a topology domain.
Create the pod.
$ oc create -f <pod-spec>.yaml
4.2.3. Configuring a pod anti-affinity rule
The following steps demonstrate a simple two-pod configuration that creates pod with a label and a pod that uses an anti-affinity preferred rule to attempt to prevent scheduling with that pod.
You cannot add an affinity directly to a scheduled pod.
Procedure
Create a pod with a specific label in the pod spec:
Create a YAML file with the following content:
apiVersion: v1 kind: Pod metadata: name: security-s1 labels: security: S1 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: security-s1 image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]Create the pod.
$ oc create -f <pod-spec>.yaml
When creating other pods, configure the following parameters:
Create a YAML file with the following content:
apiVersion: v1 kind: Pod metadata: name: security-s2-east # ... spec: # ... affinity:1 podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution:2 - weight: 1003 podAffinityTerm: labelSelector: matchExpressions: - key: security4 values: - S1 operator: In5 topologyKey: kubernetes.io/hostname6 # ...- 1
- Adds a pod anti-affinity.
- 2
- Configures the
requiredDuringSchedulingIgnoredDuringExecutionparameter or thepreferredDuringSchedulingIgnoredDuringExecutionparameter. - 3
- For a preferred rule, specifies a weight for the node, 1-100. The node that with highest weight is preferred.
- 4
- Specifies the
keyandvaluesthat must be met. If you want the new pod to not be scheduled with the other pod, use the samekeyandvaluesparameters as the label on the first pod. - 5
- Specifies an
operator. The operator can beIn,NotIn,Exists, orDoesNotExist. For example, use the operatorInto require the label to be in the node. - 6
- Specifies a
topologyKey, which is a prepopulated Kubernetes label that the system uses to denote such a topology domain.
Create the pod.
$ oc create -f <pod-spec>.yaml
4.2.4. Sample pod affinity and anti-affinity rules
The following examples demonstrate pod affinity and pod anti-affinity.
4.2.4.1. Pod Affinity
The following example demonstrates pod affinity for pods with matching labels and label selectors.
The pod team4 has the label
team:4.apiVersion: v1 kind: Pod metadata: name: team4 labels: team: "4" # ... spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: ocp image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] # ...The pod team4a has the label selector
team:4underpodAffinity.apiVersion: v1 kind: Pod metadata: name: team4a # ... spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: team operator: In values: - "4" topologyKey: kubernetes.io/hostname containers: - name: pod-affinity image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] # ...- The team4a pod is scheduled on the same node as the team4 pod.
4.2.4.2. Pod Anti-affinity
The following example demonstrates pod anti-affinity for pods with matching labels and label selectors.
The pod pod-s1 has the label
security:s1.apiVersion: v1 kind: Pod metadata: name: pod-s1 labels: security: s1 # ... spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: ocp image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] # ...The pod pod-s2 has the label selector
security:s1underpodAntiAffinity.apiVersion: v1 kind: Pod metadata: name: pod-s2 # ... spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - s1 topologyKey: kubernetes.io/hostname containers: - name: pod-antiaffinity image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] # ...-
The pod pod-s2 cannot be scheduled on the same node as
pod-s1.
4.2.4.3. Pod Affinity with no Matching Labels
The following example demonstrates pod affinity for pods without matching labels and label selectors.
The pod pod-s1 has the label
security:s1.apiVersion: v1 kind: Pod metadata: name: pod-s1 labels: security: s1 # ... spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: ocp image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] # ...The pod pod-s2 has the label selector
security:s2.apiVersion: v1 kind: Pod metadata: name: pod-s2 # ... spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - s2 topologyKey: kubernetes.io/hostname containers: - name: pod-affinity image: docker.io/ocpqe/hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] # ...The pod pod-s2 is not scheduled unless there is a node with a pod that has the
security:s2label. If there is no other pod with that label, the new pod remains in a pending state:Example output
NAME READY STATUS RESTARTS AGE IP NODE pod-s2 0/1 Pending 0 32s <none>
4.3. Controlling pod placement on nodes using node affinity rules
Affinity is a property of pods that controls the nodes on which they prefer to be scheduled.
In Red Hat OpenShift Service on AWS node affinity is a set of rules used by the scheduler to determine where a pod can be placed. The rules are defined using custom labels on the nodes and label selectors specified in pods.
4.3.1. Understanding node affinity
Node affinity allows a pod to specify an affinity towards a group of nodes it can be placed on. The node does not have control over the placement.
For example, you could configure a pod to only run on a node with a specific CPU or in a specific availability zone.
There are two types of node affinity rules: required and preferred.
Required rules must be met before a pod can be scheduled on a node. Preferred rules specify that, if the rule is met, the scheduler tries to enforce the rules, but does not guarantee enforcement.
If labels on a node change at runtime that results in an node affinity rule on a pod no longer being met, the pod continues to run on the node.
You configure node affinity through the Pod spec file. You can specify a required rule, a preferred rule, or both. If you specify both, the node must first meet the required rule, then attempts to meet the preferred rule.
The following example is a Pod spec with a rule that requires the pod be placed on a node with a label whose key is e2e-az-NorthSouth and whose value is either e2e-az-North or e2e-az-South:
Example pod configuration file with a node affinity required rule
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: e2e-az-NorthSouth
operator: In
values:
- e2e-az-North
- e2e-az-South
containers:
- name: with-node-affinity
image: docker.io/ocpqe/hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
# ...- 1
- The stanza to configure node affinity.
- 2
- Defines a required rule.
- 3 5 6
- The key/value pair (label) that must be matched to apply the rule.
- 4
- The operator represents the relationship between the label on the node and the set of values in the
matchExpressionparameters in thePodspec. This value can beIn,NotIn,Exists, orDoesNotExist,Lt, orGt.
The following example is a node specification with a preferred rule that a node with a label whose key is e2e-az-EastWest and whose value is either e2e-az-East or e2e-az-West is preferred for the pod:
Example pod configuration file with a node affinity preferred rule
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: e2e-az-EastWest
operator: In
values:
- e2e-az-East
- e2e-az-West
containers:
- name: with-node-affinity
image: docker.io/ocpqe/hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
# ...- 1
- The stanza to configure node affinity.
- 2
- Defines a preferred rule.
- 3
- Specifies a weight for a preferred rule. The node with highest weight is preferred.
- 4 6 7
- The key/value pair (label) that must be matched to apply the rule.
- 5
- The operator represents the relationship between the label on the node and the set of values in the
matchExpressionparameters in thePodspec. This value can beIn,NotIn,Exists, orDoesNotExist,Lt, orGt.
There is no explicit node anti-affinity concept, but using the NotIn or DoesNotExist operator replicates that behavior.
If you are using node affinity and node selectors in the same pod configuration, note the following:
-
If you configure both
nodeSelectorandnodeAffinity, both conditions must be satisfied for the pod to be scheduled onto a candidate node. -
If you specify multiple
nodeSelectorTermsassociated withnodeAffinitytypes, then the pod can be scheduled onto a node if one of thenodeSelectorTermsis satisfied. -
If you specify multiple
matchExpressionsassociated withnodeSelectorTerms, then the pod can be scheduled onto a node only if allmatchExpressionsare satisfied.
4.3.2. Configuring a required node affinity rule
Required rules must be met before a pod can be scheduled on a node.
Procedure
The following steps demonstrate a simple configuration that creates a node and a pod that the scheduler is required to place on the node.
Create a pod with a specific label in the pod spec:
Create a YAML file with the following content:
NoteYou cannot add an affinity directly to a scheduled pod.
Example output
apiVersion: v1 kind: Pod metadata: name: s1 spec: affinity:1 nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution:2 nodeSelectorTerms: - matchExpressions: - key: e2e-az-name3 values: - e2e-az1 - e2e-az2 operator: In4 #...- 1
- Adds a pod affinity.
- 2
- Configures the
requiredDuringSchedulingIgnoredDuringExecutionparameter. - 3
- Specifies the
keyandvaluesthat must be met. If you want the new pod to be scheduled on the node you edited, use the samekeyandvaluesparameters as the label in the node. - 4
- Specifies an
operator. The operator can beIn,NotIn,Exists, orDoesNotExist. For example, use the operatorInto require the label to be in the node.
Create the pod:
$ oc create -f <file-name>.yaml
4.3.3. Configuring a preferred node affinity rule
Preferred rules specify that, if the rule is met, the scheduler tries to enforce the rules, but does not guarantee enforcement.
Procedure
The following steps demonstrate a simple configuration that creates a node and a pod that the scheduler tries to place on the node.
Create a pod with a specific label:
Create a YAML file with the following content:
NoteYou cannot add an affinity directly to a scheduled pod.
apiVersion: v1 kind: Pod metadata: name: s1 spec: affinity:1 nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution:2 - weight:3 preference: matchExpressions: - key: e2e-az-name4 values: - e2e-az3 operator: In5 #...- 1
- Adds a pod affinity.
- 2
- Configures the
preferredDuringSchedulingIgnoredDuringExecutionparameter. - 3
- Specifies a weight for the node, as a number 1-100. The node with highest weight is preferred.
- 4
- Specifies the
keyandvaluesthat must be met. If you want the new pod to be scheduled on the node you edited, use the samekeyandvaluesparameters as the label in the node. - 5
- Specifies an
operator. The operator can beIn,NotIn,Exists, orDoesNotExist. For example, use the operatorInto require the label to be in the node.
Create the pod.
$ oc create -f <file-name>.yaml
4.3.4. Sample node affinity rules
The following examples demonstrate node affinity.
4.3.4.1. Node affinity with matching labels
The following example demonstrates node affinity for a node and pod with matching labels:
The Node1 node has the label
zone:us:$ oc label node node1 zone=usTipYou can alternatively apply the following YAML to add the label:
kind: Node apiVersion: v1 metadata: name: <node_name> labels: zone: us #...The pod-s1 pod has the
zoneanduskey/value pair under a required node affinity rule:$ cat pod-s1.yamlExample output
apiVersion: v1 kind: Pod metadata: name: pod-s1 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - image: "docker.io/ocpqe/hello-pod" name: hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: "zone" operator: In values: - us #...The pod-s1 pod can be scheduled on Node1:
$ oc get pod -o wideExample output
NAME READY STATUS RESTARTS AGE IP NODE pod-s1 1/1 Running 0 4m IP1 node1
4.3.4.2. Node affinity with no matching labels
The following example demonstrates node affinity for a node and pod without matching labels:
The Node1 node has the label
zone:emea:$ oc label node node1 zone=emeaTipYou can alternatively apply the following YAML to add the label:
kind: Node apiVersion: v1 metadata: name: <node_name> labels: zone: emea #...The pod-s1 pod has the
zoneanduskey/value pair under a required node affinity rule:$ cat pod-s1.yamlExample output
apiVersion: v1 kind: Pod metadata: name: pod-s1 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - image: "docker.io/ocpqe/hello-pod" name: hello-pod securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: "zone" operator: In values: - us #...The pod-s1 pod cannot be scheduled on Node1:
$ oc describe pod pod-s1Example output
... Events: FirstSeen LastSeen Count From SubObjectPath Type Reason --------- -------- ----- ---- ------------- -------- ------ 1m 33s 8 default-scheduler Warning FailedScheduling No nodes are available that match all of the following predicates:: MatchNodeSelector (1).
4.4. Placing pods onto overcommited nodes
In an overcommited state, the sum of the container compute resource requests and limits exceeds the resources available on the system. Overcommitment might be desirable in development environments where a trade-off of guaranteed performance for capacity is acceptable.
Requests and limits enable administrators to allow and manage the overcommitment of resources on a node. The scheduler uses requests for scheduling your container and providing a minimum service guarantee. Limits constrain the amount of compute resource that may be consumed on your node.
4.4.1. Understanding overcommitment
Requests and limits enable administrators to allow and manage the overcommitment of resources on a node. The scheduler uses requests for scheduling your container and providing a minimum service guarantee. Limits constrain the amount of compute resource that may be consumed on your node.
Red Hat OpenShift Service on AWS administrators can control the level of overcommit and manage container density on nodes by configuring masters to override the ratio between request and limit set on developer containers. In conjunction with a per-project LimitRange object specifying limits and defaults, this adjusts the container limit and request to achieve the desired level of overcommit.
That these overrides have no effect if no limits have been set on containers. Create a LimitRange object with default limits, per individual project, or in the project template, to ensure that the overrides apply.
After these overrides, the container limits and requests must still be validated by any LimitRange object in the project. It is possible, for example, for developers to specify a limit close to the minimum limit, and have the request then be overridden below the minimum limit, causing the pod to be forbidden. This unfortunate user experience should be addressed with future work, but for now, configure this capability and LimitRange objects with caution.
4.4.2. Understanding nodes overcommitment
To maintain optimal system performance and stability in an overcommitted environment in Red Hat OpenShift Service on AWS, configure your nodes to manage resource contention effectively.
When the node starts, it ensures that the kernel tunable flags for memory management are set properly. The kernel should never fail memory allocations unless it runs out of physical memory.
To ensure this behavior, Red Hat OpenShift Service on AWS configures the kernel to always overcommit memory by setting the vm.overcommit_memory parameter to 1, overriding the default operating system setting.
Red Hat OpenShift Service on AWS also configures the kernel to not panic when it runs out of memory by setting the vm.panic_on_oom parameter to 0. A setting of 0 instructs the kernel to call the OOM killer in an Out of Memory (OOM) condition, which kills processes based on priority.
You can view the current setting by running the following commands on your nodes:
$ sysctl -a |grep commitExample output
#...
vm.overcommit_memory = 0
#...$ sysctl -a |grep panicExample output
#...
vm.panic_on_oom = 0
#...The previous commands should already be set on nodes, so no further action is required.
You can also perform the following configurations for each node:
- Disable or enforce CPU limits using CPU CFS quotas
- Reserve resources for system processes
- Reserve memory across quality of service tiers
4.5. Placing pods on specific nodes using node selectors
A node selector specifies a map of key/value pairs that are defined using custom labels on nodes and selectors specified in pods.
For the pod to be eligible to run on a node, the pod must have the same key/value node selector as the label on the node.
4.5.1. About node selectors
You can use node selectors on pods and labels on nodes to control where the pod is scheduled. With node selectors, Red Hat OpenShift Service on AWS schedules the pods on nodes that contain matching labels.
You can use a node selector to place specific pods on specific nodes, cluster-wide node selectors to place new pods on specific nodes anywhere in the cluster, and project node selectors to place new pods in a project on specific nodes.
For example, as a cluster administrator, you can create an infrastructure where application developers can deploy pods only onto the nodes closest to their geographical location by including a node selector in every pod they create. In this example, the cluster consists of five data centers spread across two regions. In the U.S., label the nodes as us-east, us-central, or us-west. In the Asia-Pacific region (APAC), label the nodes as apac-east or apac-west. The developers can add a node selector to the pods they create to ensure the pods get scheduled on those nodes.
A pod is not scheduled if the Pod object contains a node selector, but no node has a matching label.
If you are using node selectors and node affinity in the same pod configuration, the following rules control pod placement onto nodes:
-
If you configure both
nodeSelectorandnodeAffinity, both conditions must be satisfied for the pod to be scheduled onto a candidate node. -
If you specify multiple
nodeSelectorTermsassociated withnodeAffinitytypes, then the pod can be scheduled onto a node if one of thenodeSelectorTermsis satisfied. -
If you specify multiple
matchExpressionsassociated withnodeSelectorTerms, then the pod can be scheduled onto a node only if allmatchExpressionsare satisfied.
- Node selectors on specific pods and nodes
You can control which node a specific pod is scheduled on by using node selectors and labels.
To use node selectors and labels, first label the node to avoid pods being descheduled, then add the node selector to the pod.
NoteYou cannot add a node selector directly to an existing scheduled pod. You must label the object that controls the pod, such as deployment config.
For example, the following
Nodeobject has theregion: eastlabel:Sample
Nodeobject with a labelkind: Node apiVersion: v1 metadata: name: ip-10-0-131-14.ec2.internal selfLink: /api/v1/nodes/ip-10-0-131-14.ec2.internal uid: 7bc2580a-8b8e-11e9-8e01-021ab4174c74 resourceVersion: '478704' creationTimestamp: '2019-06-10T14:46:08Z' labels: kubernetes.io/os: linux topology.kubernetes.io/zone: us-east-1a node.openshift.io/os_version: '4.5' node-role.kubernetes.io/worker: '' topology.kubernetes.io/region: us-east-1 node.openshift.io/os_id: rhcos node.kubernetes.io/instance-type: m4.large kubernetes.io/hostname: ip-10-0-131-14 kubernetes.io/arch: amd64 region: east1 type: user-node #...- 1
- Labels to match the pod node selector.
A pod has the
type: user-node,region: eastnode selector:Sample
Podobject with node selectorsapiVersion: v1 kind: Pod metadata: name: s1 #... spec: nodeSelector:1 region: east type: user-node #...- 1
- Node selectors to match the node label. The node must have a label for each node selector.
When you create the pod using the example pod spec, it can be scheduled on the example node.
- Default cluster-wide node selectors
With default cluster-wide node selectors, when you create a pod in that cluster, Red Hat OpenShift Service on AWS adds the default node selectors to the pod and schedules the pod on nodes with matching labels.
For example, the following
Schedulerobject has the default cluster-wideregion=eastandtype=user-nodenode selectors:Example Scheduler Operator Custom Resource
apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster #... spec: defaultNodeSelector: type=user-node,region=east #...A node in that cluster has the
type=user-node,region=eastlabels:Example
NodeobjectapiVersion: v1 kind: Node metadata: name: ci-ln-qg1il3k-f76d1-hlmhl-worker-b-df2s4 #... labels: region: east type: user-node #...Example
Podobject with a node selectorapiVersion: v1 kind: Pod metadata: name: s1 #... spec: nodeSelector: region: east #...When you create the pod using the example pod spec in the example cluster, the pod is created with the cluster-wide node selector and is scheduled on the labeled node:
Example pod list with the pod on the labeled node
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-s1 1/1 Running 0 20s 10.131.2.6 ci-ln-qg1il3k-f76d1-hlmhl-worker-b-df2s4 <none> <none>NoteIf the project where you create the pod has a project node selector, that selector takes preference over a cluster-wide node selector. Your pod is not created or scheduled if the pod does not have the project node selector.
- Project node selectors
With project node selectors, when you create a pod in this project, Red Hat OpenShift Service on AWS adds the node selectors to the pod and schedules the pods on a node with matching labels. If there is a cluster-wide default node selector, a project node selector takes preference.
For example, the following project has the
region=eastnode selector:Example
NamespaceobjectapiVersion: v1 kind: Namespace metadata: name: east-region annotations: openshift.io/node-selector: "region=east" #...The following node has the
type=user-node,region=eastlabels:Example
NodeobjectapiVersion: v1 kind: Node metadata: name: ci-ln-qg1il3k-f76d1-hlmhl-worker-b-df2s4 #... labels: region: east type: user-node #...When you create the pod using the example pod spec in this example project, the pod is created with the project node selectors and is scheduled on the labeled node:
Example
PodobjectapiVersion: v1 kind: Pod metadata: namespace: east-region #... spec: nodeSelector: region: east type: user-node #...Example pod list with the pod on the labeled node
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-s1 1/1 Running 0 20s 10.131.2.6 ci-ln-qg1il3k-f76d1-hlmhl-worker-b-df2s4 <none> <none>A pod in the project is not created or scheduled if the pod contains different node selectors. For example, if you deploy the following pod into the example project, it is not created:
Example
Podobject with an invalid node selectorapiVersion: v1 kind: Pod metadata: name: west-region #... spec: nodeSelector: region: west #...
4.5.2. Using node selectors to control pod placement
You can use node selectors on pods and labels on nodes to control where the pod is scheduled. With node selectors, Red Hat OpenShift Service on AWS schedules the pods on nodes that contain matching labels.
You add labels to a node, a compute machine set, or a machine config. Adding the label to the compute machine set ensures that if the node or machine goes down, new nodes have the label. Labels added to a node or machine config do not persist if the node or machine goes down.
To add node selectors to an existing pod, add a node selector to the controlling object for that pod, such as a ReplicaSet object, DaemonSet object, StatefulSet object, Deployment object, or DeploymentConfig object. Any existing pods under that controlling object are recreated on a node with a matching label. If you are creating a new pod, you can add the node selector directly to the pod spec. If the pod does not have a controlling object, you must delete the pod, edit the pod spec, and recreate the pod.
You cannot add a node selector directly to an existing scheduled pod.
Prerequisites
To add a node selector to existing pods, determine the controlling object for that pod. For example, the router-default-66d5cf9464-m2g75 pod is controlled by the router-default-66d5cf9464 replica set:
$ oc describe pod router-default-66d5cf9464-7pwkcExample output
kind: Pod
apiVersion: v1
metadata:
# ...
Name: router-default-66d5cf9464-7pwkc
Namespace: openshift-ingress
# ...
Controlled By: ReplicaSet/router-default-66d5cf9464
# ...
The web console lists the controlling object under ownerReferences in the pod YAML:
apiVersion: v1
kind: Pod
metadata:
name: router-default-66d5cf9464-7pwkc
# ...
ownerReferences:
- apiVersion: apps/v1
kind: ReplicaSet
name: router-default-66d5cf9464
uid: d81dd094-da26-11e9-a48a-128e7edf0312
controller: true
blockOwnerDeletion: true
# ...Procedure
Add the matching node selector to a pod:
To add a node selector to existing and future pods, add a node selector to the controlling object for the pods:
Example
ReplicaSetobject with labelskind: ReplicaSet apiVersion: apps/v1 metadata: name: hello-node-6fbccf8d9 # ... spec: # ... template: metadata: creationTimestamp: null labels: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default pod-template-hash: 66d5cf9464 spec: nodeSelector: kubernetes.io/os: linux node-role.kubernetes.io/worker: '' type: user-node1 # ...- 1
- Add the node selector.
To add a node selector to a specific, new pod, add the selector to the
Podobject directly:Example
Podobject with a node selectorapiVersion: v1 kind: Pod metadata: name: hello-node-6fbccf8d9 # ... spec: nodeSelector: region: east type: user-node # ...NoteYou cannot add a node selector directly to an existing scheduled pod.
4.6. Controlling pod placement by using pod topology spread constraints
You can use pod topology spread constraints to provide fine-grained control over the placement of your pods across nodes, zones, regions, or other user-defined topology domains. Distributing pods across failure domains can help to achieve high availability and more efficient resource utilization.
4.6.1. Example use cases
- As an administrator, I want my workload to automatically scale between two to fifteen pods. I want to ensure that when there are only two pods, they are not placed on the same node, to avoid a single point of failure.
- As an administrator, I want to distribute my pods evenly across multiple infrastructure zones to reduce latency and network costs. I want to ensure that my cluster can self-heal if issues arise.
4.6.2. Important considerations
- Pods in an Red Hat OpenShift Service on AWS cluster are managed by workload controllers such as deployments, stateful sets, or daemon sets. These controllers define the desired state for a group of pods, including how they are distributed and scaled across the nodes in the cluster. You should set the same pod topology spread constraints on all pods in a group to avoid confusion. When using a workload controller, such as a deployment, the pod template typically handles this for you.
-
Mixing different pod topology spread constraints can make Red Hat OpenShift Service on AWS behavior confusing and troubleshooting more difficult. You can avoid this by ensuring that all nodes in a topology domain are consistently labeled. Red Hat OpenShift Service on AWS automatically populates well-known labels, such as
kubernetes.io/hostname. This helps avoid the need for manual labeling of nodes. These labels provide essential topology information, ensuring consistent node labeling across the cluster. - Only pods within the same namespace are matched and grouped together when spreading due to a constraint.
- You can specify multiple pod topology spread constraints, but you must ensure that they do not conflict with each other. All pod topology spread constraints must be satisfied for a pod to be placed.
4.6.3. Understanding skew and maxSkew
Skew refers to the difference in the number of pods that match a specified label selector across different topology domains, such as zones or nodes.
The skew is calculated for each domain by taking the absolute difference between the number of pods in that domain and the number of pods in the domain with the lowest amount of pods scheduled. Setting a maxSkew value guides the scheduler to maintain a balanced pod distribution.
4.6.3.1. Example skew calculation
You have three zones (A, B, and C), and you want to distribute your pods evenly across these zones. If zone A has 5 pods, zone B has 3 pods, and zone C has 2 pods, to find the skew, you can subtract the number of pods in the domain with the lowest amount of pods scheduled from the number of pods currently in each zone. This means that the skew for zone A is 3, the skew for zone B is 1, and the skew for zone C is 0.
4.6.3.2. The maxSkew parameter
The maxSkew parameter defines the maximum allowable difference, or skew, in the number of pods between any two topology domains. If maxSkew is set to 1, the number of pods in any topology domain should not differ by more than 1 from any other domain. If the skew exceeds maxSkew, the scheduler attempts to place new pods in a way that reduces the skew, adhering to the constraints.
Using the previous example skew calculation, the skew values exceed the default maxSkew value of 1. The scheduler places new pods in zone B and zone C to reduce the skew and achieve a more balanced distribution, ensuring that no topology domain exceeds the skew of 1.
4.6.4. Example configurations for pod topology spread constraints
You can specify which pods to group together, which topology domains they are spread among, and the acceptable skew.
The following examples demonstrate pod topology spread constraint configurations.
Example to distribute pods that match the specified labels based on their zone
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
region: us-east
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
region: us-east
matchLabelKeys:
- my-pod-label
containers:
- image: "docker.io/ocpqe/hello-pod"
name: hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]- 1
- The maximum difference in number of pods between any two topology domains. The default is
1, and you cannot specify a value of0. - 2
- The key of a node label. Nodes with this key and identical value are considered to be in the same topology.
- 3
- How to handle a pod if it does not satisfy the spread constraint. The default is
DoNotSchedule, which tells the scheduler not to schedule the pod. Set toScheduleAnywayto still schedule the pod, but the scheduler prioritizes honoring the skew to not make the cluster more imbalanced. - 4
- Pods that match this label selector are counted and recognized as a group when spreading to satisfy the constraint. Be sure to specify a label selector, otherwise no pods can be matched.
- 5
- Be sure that this
Podspec also sets its labels to match this label selector if you want it to be counted properly in the future. - 6
- A list of pod label keys to select which pods to calculate spreading over.
Example demonstrating a single pod topology spread constraint
kind: Pod
apiVersion: v1
metadata:
name: my-pod
labels:
region: us-east
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
region: us-east
containers:
- image: "docker.io/ocpqe/hello-pod"
name: hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
The previous example defines a Pod spec with a one pod topology spread constraint. It matches on pods labeled region: us-east, distributes among zones, specifies a skew of 1, and does not schedule the pod if it does not meet these requirements.
Example demonstrating multiple pod topology spread constraints
kind: Pod
apiVersion: v1
metadata:
name: my-pod-2
labels:
region: us-east
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
topologySpreadConstraints:
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
region: us-east
- maxSkew: 1
topologyKey: rack
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
region: us-east
containers:
- image: "docker.io/ocpqe/hello-pod"
name: hello-pod
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
The previous example defines a Pod spec with two pod topology spread constraints. Both match on pods labeled region: us-east, specify a skew of 1, and do not schedule the pod if it does not meet these requirements.
The first constraint distributes pods based on a user-defined label node, and the second constraint distributes pods based on a user-defined label rack. Both constraints must be met for the pod to be scheduled.
Chapter 5. Using jobs and daemon sets
5.1. Running background tasks on nodes automatically with daemon sets
As an administrator, you can create and use daemon sets to run replicas of a pod on specific or all nodes in a Red Hat OpenShift Service on AWS cluster.
A daemon set ensures that all (or some) nodes run a copy of a pod. As nodes are added to the cluster, pods are added to the cluster. As nodes are removed from the cluster, those pods are removed through garbage collection. Deleting a daemon set will clean up the pods it created.
You can use daemon sets to create shared storage, run a logging pod on every node in your cluster, or deploy a monitoring agent on every node.
For security reasons, the cluster administrators and the project administrators can create daemon sets.
For more information on daemon sets, see the Kubernetes documentation.
Daemon set scheduling is incompatible with project’s default node selector. If you fail to disable it, the daemon set gets restricted by merging with the default node selector. This results in frequent pod recreates on the nodes that got unselected by the merged node selector, which in turn puts unwanted load on the cluster.
5.1.1. Scheduled by default scheduler
A daemon set ensures that all eligible nodes run a copy of a pod. Normally, the node that a pod runs on is selected by the Kubernetes scheduler. However, daemon set pods are created and scheduled by the daemon set controller. That introduces the following issues:
-
Inconsistent pod behavior: Normal pods waiting to be scheduled are created and in Pending state, but daemon set pods are not created in
Pendingstate. This is confusing to the user. - Pod preemption is handled by default scheduler. When preemption is enabled, the daemon set controller will make scheduling decisions without considering pod priority and preemption.
The ScheduleDaemonSetPods feature, enabled by default in Red Hat OpenShift Service on AWS, lets you schedule daemon sets using the default scheduler instead of the daemon set controller, by adding the NodeAffinity term to the daemon set pods, instead of the spec.nodeName term. The default scheduler is then used to bind the pod to the target host. If node affinity of the daemon set pod already exists, it is replaced. The daemon set controller only performs these operations when creating or modifying daemon set pods, and no changes are made to the spec.template of the daemon set.
kind: Pod
apiVersion: v1
metadata:
name: hello-node-6fbccf8d9-9tmzr
#...
spec:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- target-host-name
#...
In addition, a node.kubernetes.io/unschedulable:NoSchedule toleration is added automatically to daemon set pods. The default scheduler ignores unschedulable Nodes when scheduling daemon set pods.
5.1.2. Creating daemonsets
When creating daemon sets, the nodeSelector field is used to indicate the nodes on which the daemon set should deploy replicas.
Prerequisites
Before you start using daemon sets, disable the default project-wide node selector in your namespace, by setting the namespace annotation
openshift.io/node-selectorto an empty string:$ oc patch namespace myproject -p \ '{"metadata": {"annotations": {"openshift.io/node-selector": ""}}}'TipYou can alternatively apply the following YAML to disable the default project-wide node selector for a namespace:
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: openshift.io/node-selector: '' #...
Procedure
To create a daemon set:
Define the daemon set yaml file:
apiVersion: apps/v1 kind: DaemonSet metadata: name: hello-daemonset spec: selector: matchLabels: name: hello-daemonset1 template: metadata: labels: name: hello-daemonset2 spec: nodeSelector:3 role: worker containers: - image: openshift/hello-openshift imagePullPolicy: Always name: registry ports: - containerPort: 80 protocol: TCP resources: {} terminationMessagePath: /dev/termination-log serviceAccount: default terminationGracePeriodSeconds: 10 #...Create the daemon set object:
$ oc create -f daemonset.yamlTo verify that the pods were created, and that each node has a pod replica:
Find the daemonset pods:
$ oc get podsExample output
hello-daemonset-cx6md 1/1 Running 0 2m hello-daemonset-e3md9 1/1 Running 0 2mView the pods to verify the pod has been placed onto the node:
$ oc describe pod/hello-daemonset-cx6md|grep NodeExample output
Node: openshift-node01.hostname.com/10.14.20.134$ oc describe pod/hello-daemonset-e3md9|grep NodeExample output
Node: openshift-node02.hostname.com/10.14.20.137
- If you update a daemon set pod template, the existing pod replicas are not affected.
- If you delete a daemon set and then create a new daemon set with a different template but the same label selector, it recognizes any existing pod replicas as having matching labels and thus does not update them or create new replicas despite a mismatch in the pod template.
- If you change node labels, the daemon set adds pods to nodes that match the new labels and deletes pods from nodes that do not match the new labels.
To update a daemon set, force new pod replicas to be created by deleting the old replicas or nodes.
5.2. Running tasks in pods using jobs
A job executes a task in your Red Hat OpenShift Service on AWS cluster.
A job tracks the overall progress of a task and updates its status with information about active, succeeded, and failed pods. Deleting a job will clean up any pod replicas it created. Jobs are part of the Kubernetes API, which can be managed with oc commands like other object types.
Sample Job specification
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 1
completions: 1
activeDeadlineSeconds: 1800
backoffLimit: 6
ttlSecondsAfterFinished: 100
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure
#...- 1
- The pod replicas a job should run in parallel.
- 2
- Successful pod completions are needed to mark a job completed.
- 3
- The maximum duration the job can run.
- 4
- The number of retries for a job.
- 5
- The period of time in seconds after which the job should be automatically deleted upon completion.
- 6
- The template for the pod the controller creates.
- 7
- The restart policy of the pod.
Additional resources
5.2.1. Understanding jobs and cron jobs
A job tracks the overall progress of a task and updates its status with information about active, succeeded, and failed pods. Deleting a job cleans up any pods it created. Jobs are part of the Kubernetes API, which can be managed with oc commands like other object types.
There are two possible resource types that allow creating run-once objects in Red Hat OpenShift Service on AWS:
- Job
A regular job is a run-once object that creates a task and ensures the job finishes.
There are three main types of task suitable to run as a job:
Non-parallel jobs:
- A job that starts only one pod, unless the pod fails.
- The job is complete as soon as its pod terminates successfully.
Parallel jobs with a fixed completion count:
- a job that starts multiple pods.
-
The job represents the overall task and is complete when there is one successful pod for each value in the range
1to thecompletionsvalue.
Parallel jobs with a work queue:
- A job with multiple parallel worker processes in a given pod.
- Red Hat OpenShift Service on AWS coordinates pods to determine what each should work on or use an external queue service.
- Each pod is independently capable of determining whether or not all peer pods are complete and that the entire job is done.
- When any pod from the job terminates with success, no new pods are created.
- When at least one pod has terminated with success and all pods are terminated, the job is successfully completed.
When any pod has exited with success, no other pod should be doing any work for this task or writing any output. Pods should all be in the process of exiting.
For more information about how to make use of the different types of job, see Job Patterns in the Kubernetes documentation.
- Cron job
A job can be scheduled to run multiple times, using a cron job.
A cron job builds on a regular job by allowing you to specify how the job should be run. Cron jobs are part of the Kubernetes API, which can be managed with
occommands like other object types.Cron jobs are useful for creating periodic and recurring tasks, like running backups or sending emails. Cron jobs can also schedule individual tasks for a specific time, such as if you want to schedule a job for a low activity period. A cron job creates a
Jobobject based on the timezone configured on the control plane node that runs the cronjob controller.WarningA cron job creates a
Jobobject approximately once per execution time of its schedule, but there are circumstances in which it fails to create a job or two jobs might be created. Therefore, jobs must be idempotent and you must configure history limits.
5.2.1.1. Understanding how to create jobs
Both resource types require a job configuration that consists of the following key parts:
- A pod template, which describes the pod that Red Hat OpenShift Service on AWS creates.
The
parallelismparameter, which specifies how many pods running in parallel at any point in time should execute a job.-
For non-parallel jobs, leave unset. When unset, defaults to
1.
-
For non-parallel jobs, leave unset. When unset, defaults to
The
completionsparameter, specifying how many successful pod completions are needed to finish a job.-
For non-parallel jobs, leave unset. When unset, defaults to
1. - For parallel jobs with a fixed completion count, specify a value.
-
For parallel jobs with a work queue, leave unset. When unset defaults to the
parallelismvalue.
-
For non-parallel jobs, leave unset. When unset, defaults to
5.2.1.2. Understanding how to set a maximum duration for jobs
When defining a job, you can define its maximum duration by setting the activeDeadlineSeconds field. It is specified in seconds and is not set by default. When not set, there is no maximum duration enforced.
The maximum duration is counted from the time when a first pod gets scheduled in the system, and defines how long a job can be active. It tracks overall time of an execution. After reaching the specified timeout, the job is terminated by Red Hat OpenShift Service on AWS.
5.2.1.3. Understanding how to set a job back off policy for pod failure
A job can be considered failed, after a set amount of retries due to a logical error in configuration or other similar reasons. Failed pods associated with the job are recreated by the controller with an exponential back off delay (10s, 20s, 40s …) capped at six minutes. The limit is reset if no new failed pods appear between controller checks.
Use the spec.backoffLimit parameter to set the number of retries for a job.
5.2.1.4. Understanding how to configure a cron job to remove artifacts
Cron jobs can leave behind artifact resources such as jobs or pods. As a user it is important to configure history limits so that old jobs and their pods are properly cleaned. There are two fields within cron job’s spec responsible for that:
-
.spec.successfulJobsHistoryLimit. The number of successful finished jobs to retain (defaults to 3). -
.spec.failedJobsHistoryLimit. The number of failed finished jobs to retain (defaults to 1).
5.2.1.5. Understanding how to automatically remove completed jobs
You can specify that Red Hat OpenShift Service on AWS should delete jobs when they are finished, either Complete or Failed, in order to limit the number of objects in your cluster.
By default, for jobs that are not associated with a cron job or other controlling object, Red Hat OpenShift Service on AWS does not delete the job or its related pods when the job is finished. If you keep these artifacts in your cluster, you can view the status of finished jobs or view job logs for errors, warnings, or other diagnostic output.
However, having too many of these objects in the cluster can lead to etcd issues, latency issues, performance degradation, and other problems.
You can configure a time-to-live (TTL) duration for jobs without a controlling object by setting the ttlSecondsAfterFinished parameter in the job spec. When set, Red Hat OpenShift Service on AWS deletes the jobs and any related pods immediately after the job is finished or after a specified period of time in seconds.
5.2.1.6. Known limitations
The job specification restart policy only applies to the pods, and not the job controller. However, the job controller is hard-coded to keep retrying jobs to completion.
As such, restartPolicy: Never or --restart=Never results in the same behavior as restartPolicy: OnFailure or --restart=OnFailure. That is, when a job fails it is restarted automatically until it succeeds (or is manually discarded). The policy only sets which subsystem performs the restart.
With the Never policy, the job controller performs the restart. With each attempt, the job controller increments the number of failures in the job status and create new pods. This means that with each failed attempt, the number of pods increases.
With the OnFailure policy, kubelet performs the restart. Each attempt does not increment the number of failures in the job status. In addition, kubelet will retry failed jobs starting pods on the same nodes.
5.2.2. Creating jobs
You create a job in Red Hat OpenShift Service on AWS by creating a job object.
Procedure
To create a job:
Create a YAML file similar to the following:
apiVersion: batch/v1 kind: Job metadata: name: pi spec: parallelism: 11 completions: 12 activeDeadlineSeconds: 18003 backoffLimit: 64 ttlSecondsAfterFinished: 1005 template:6 metadata: name: pi spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: OnFailure7 #...- 1
- Optional: Specify how many pod replicas a job should run in parallel; defaults to
1.-
For non-parallel jobs, leave unset. When unset, defaults to
1.
-
For non-parallel jobs, leave unset. When unset, defaults to
- 2
- Optional: Specify how many successful pod completions are needed to mark a job completed.
-
For non-parallel jobs, leave unset. When unset, defaults to
1. - For parallel jobs with a fixed completion count, specify the number of completions.
-
For parallel jobs with a work queue, leave unset. When unset defaults to the
parallelismvalue.
-
For non-parallel jobs, leave unset. When unset, defaults to
- 3
- Optional: Specify the maximum duration the job can run.
- 4
- Optional: Specify the number of retries for a job. This field defaults to six.
- 5
- Optional: Specify the period of time in seconds after which the job should be automatically deleted upon completion. If set to '0', the job is immediately deleted after completion. If this field is not included, the job is not automatically deleted.
- 6
- Specify the template for the pod the controller creates.
- 7
- Specify the restart policy of the pod:
-
Never. Do not restart the job. -
OnFailure. Restart the job only if it fails. Always. Always restart the job.For details on how Red Hat OpenShift Service on AWS uses restart policy with failed containers, see the Example States in the Kubernetes documentation.
-
Create the job:
$ oc create -f <file-name>.yaml
You can also create and launch a job from a single command using oc create job. The following command creates and launches a job similar to the one specified in the previous example:
$ oc create job pi --image=perl -- perl -Mbignum=bpi -wle 'print bpi(2000)'5.2.3. Creating cron jobs
You create a cron job in Red Hat OpenShift Service on AWS by creating a job object.
Procedure
To create a cron job:
Create a YAML file similar to the following:
apiVersion: batch/v1 kind: CronJob metadata: name: pi spec: schedule: "*/1 * * * *"1 concurrencyPolicy: "Replace"2 startingDeadlineSeconds: 2003 suspend: true4 successfulJobsHistoryLimit: 35 failedJobsHistoryLimit: 16 jobTemplate:7 spec: template: metadata: labels:8 parent: "cronjobpi" spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: OnFailure9 - 1
- Schedule for the job specified in cron format. In this example, the job will run every minute.
- 2
- An optional concurrency policy, specifying how to treat concurrent jobs within a cron job. Only one of the following concurrent policies may be specified. If not specified, this defaults to allowing concurrent executions.
-
Allowallows cron jobs to run concurrently. -
Forbidforbids concurrent runs, skipping the next run if the previous has not finished yet. -
Replacecancels the currently running job and replaces it with a new one.
-
- 3
- An optional deadline (in seconds) for starting the job if it misses its scheduled time for any reason. Missed jobs executions will be counted as failed ones. If not specified, there is no deadline.
- 4
- An optional flag allowing the suspension of a cron job. If set to
true, all subsequent executions will be suspended. - 5
- The number of successful finished jobs to retain (defaults to 3).
- 6
- The number of failed finished jobs to retain (defaults to 1).
- 7
- Job template. This is similar to the job example.
- 8
- Sets a label for jobs spawned by this cron job.
- 9
- The restart policy of the pod. This does not apply to the job controller.Note
The
.spec.successfulJobsHistoryLimitand.spec.failedJobsHistoryLimitfields are optional. These fields specify how many completed and failed jobs should be kept. By default, they are set to3and1respectively. Setting a limit to0corresponds to keeping none of the corresponding kind of jobs after they finish.
Create the cron job:
$ oc create -f <file-name>.yaml
You can also create and launch a cron job from a single command using oc create cronjob. The following command creates and launches a cron job similar to the one specified in the previous example:
$ oc create cronjob pi --image=perl --schedule='*/1 * * * *' -- perl -Mbignum=bpi -wle 'print bpi(2000)'
With oc create cronjob, the --schedule option accepts schedules in cron format.
Chapter 6. Working with nodes
6.1. Viewing and listing the nodes in your Red Hat OpenShift Service on AWS cluster
You can list all the nodes in your cluster to obtain information such as status, age, memory usage, and details about the nodes.
When you perform node management operations, the CLI interacts with node objects that are representations of actual node hosts. The master uses the information from node objects to validate nodes with health checks.
Worker nodes are not guaranteed longevity, and may be replaced at any time as part of the normal operation and management of OpenShift. For more details about the node lifecycle, refer to additional resources.
6.1.1. About listing all the nodes in a cluster
You can get detailed information about the nodes in the cluster, which can help you understand the state of the nodes in your cluster.
The following command lists all nodes:
$ oc get nodesThe following example is a cluster with healthy nodes:
$ oc get nodesExample output
NAME STATUS ROLES AGE VERSION master.example.com Ready master 7h v1.34.2 node1.example.com Ready worker 7h v1.34.2 node2.example.com Ready worker 7h v1.34.2The following example is a cluster with one unhealthy node:
$ oc get nodesExample output
NAME STATUS ROLES AGE VERSION master.example.com Ready master 7h v1.34.2 node1.example.com NotReady,SchedulingDisabled worker 7h v1.34.2 node2.example.com Ready worker 7h v1.34.2The conditions that trigger a
NotReadystatus are shown later in this section.The
-o wideoption provides additional information on nodes.$ oc get nodes -o wideExample output
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME master.example.com Ready master 171m v1.34.2 10.0.129.108 <none> Red Hat Enterprise Linux CoreOS 48.83.202103210901-0 (Ootpa) 4.21.0-240.15.1.el8_3.x86_64 cri-o://1.34.2-30.rhaos4.10.gitf2f339d.el8-dev node1.example.com Ready worker 72m v1.34.2 10.0.129.222 <none> Red Hat Enterprise Linux CoreOS 48.83.202103210901-0 (Ootpa) 4.21.0-240.15.1.el8_3.x86_64 cri-o://1.34.2-30.rhaos4.10.gitf2f339d.el8-dev node2.example.com Ready worker 164m v1.34.2 10.0.142.150 <none> Red Hat Enterprise Linux CoreOS 48.83.202103210901-0 (Ootpa) 4.21.0-240.15.1.el8_3.x86_64 cri-o://1.34.2-30.rhaos4.10.gitf2f339d.el8-devThe following command lists information about a single node:
$ oc get node <node>For example:
$ oc get node node1.example.comExample output
NAME STATUS ROLES AGE VERSION node1.example.com Ready worker 7h v1.34.2The following command provides more detailed information about a specific node, including the reason for the current condition:
$ oc describe node <node>For example:
$ oc describe node node1.example.comNoteThe following example contains some values that are specific to Red Hat OpenShift Service on AWS on AWS.
Example output
Name: node1.example.com Roles: worker Labels: kubernetes.io/os=linux kubernetes.io/hostname=ip-10-0-131-14 kubernetes.io/arch=amd64 node-role.kubernetes.io/worker= node.kubernetes.io/instance-type=m4.large node.openshift.io/os_id=rhcos node.openshift.io/os_version=4.5 region=east topology.kubernetes.io/region=us-east-1 topology.kubernetes.io/zone=us-east-1a Annotations: cluster.k8s.io/machine: openshift-machine-api/ahardin-worker-us-east-2a-q5dzc machineconfiguration.openshift.io/currentConfig: worker-309c228e8b3a92e2235edd544c62fea8 machineconfiguration.openshift.io/desiredConfig: worker-309c228e8b3a92e2235edd544c62fea8 machineconfiguration.openshift.io/state: Done volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Wed, 13 Feb 2019 11:05:57 -0500 Taints: <none> Unschedulable: false Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- OutOfDisk False Wed, 13 Feb 2019 15:09:42 -0500 Wed, 13 Feb 2019 11:05:57 -0500 KubeletHasSufficientDisk kubelet has sufficient disk space available MemoryPressure False Wed, 13 Feb 2019 15:09:42 -0500 Wed, 13 Feb 2019 11:05:57 -0500 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Wed, 13 Feb 2019 15:09:42 -0500 Wed, 13 Feb 2019 11:05:57 -0500 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Wed, 13 Feb 2019 15:09:42 -0500 Wed, 13 Feb 2019 11:05:57 -0500 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Wed, 13 Feb 2019 15:09:42 -0500 Wed, 13 Feb 2019 11:07:09 -0500 KubeletReady kubelet is posting ready status Addresses: InternalIP: 10.0.140.16 InternalDNS: ip-10-0-140-16.us-east-2.compute.internal Hostname: ip-10-0-140-16.us-east-2.compute.internal Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8172516Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7558116Ki pods: 250 System Info: Machine ID: 63787c9534c24fde9a0cde35c13f1f66 System UUID: EC22BF97-A006-4A58-6AF8-0A38DEEA122A Boot ID: f24ad37d-2594-46b4-8830-7f7555918325 Kernel Version: 3.10.0-957.5.1.el7.x86_64 OS Image: Red Hat Enterprise Linux CoreOS 410.8.20190520.0 (Ootpa) Operating System: linux Architecture: amd64 Container Runtime Version: cri-o://1.34.2-0.6.dev.rhaos4.3.git9ad059b.el8-rc2 Kubelet Version: v1.34.2 Kube-Proxy Version: v1.34.2 PodCIDR: 10.128.4.0/24 ProviderID: aws:///us-east-2a/i-04e87b31dc6b3e171 Non-terminated Pods: (12 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits --------- ---- ------------ ---------- --------------- ------------- openshift-cluster-node-tuning-operator tuned-hdl5q 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-dns dns-default-l69zr 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-image-registry node-ca-9hmcg 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-ingress router-default-76455c45c-c5ptv 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-machine-config-operator machine-config-daemon-cvqw9 20m (1%) 0 (0%) 50Mi (0%) 0 (0%) openshift-marketplace community-operators-f67fh 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-monitoring alertmanager-main-0 50m (3%) 50m (3%) 210Mi (2%) 10Mi (0%) openshift-monitoring node-exporter-l7q8d 10m (0%) 20m (1%) 20Mi (0%) 40Mi (0%) openshift-monitoring prometheus-adapter-75d769c874-hvb85 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-multus multus-kw8w5 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-ovn-kubernetes ovnkube-node-t4dsn 80m (0%) 0 (0%) 1630Mi (0%) 0 (0%) Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 380m (25%) 270m (18%) memory 880Mi (11%) 250Mi (3%) attachable-volumes-aws-ebs 0 0 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal NodeHasSufficientPID 6d (x5 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 6d kubelet, m01.example.com Updated Node Allocatable limit across pods Normal NodeHasSufficientMemory 6d (x6 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 6d (x6 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasNoDiskPressure Normal NodeHasSufficientDisk 6d (x6 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientDisk Normal NodeHasSufficientPID 6d kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientPID Normal Starting 6d kubelet, m01.example.com Starting kubelet. #...where:
Names- Specifies the name of the node.
Roles-
Specifies the role of the node, either
masterorworker. Labels- Specifies the labels applied to the node.
Annotations- Specifies the annotations applied to the node.
Taints- Specifies the taints applied to the node.
Conditions-
Specifies the node conditions and status. The
conditionsstanza lists theReady,PIDPressure,MemoryPressure,DiskPressureandOutOfDiskstatus. These condition are described later in this section. Addresses- Specifies the IP address and hostname of the node.
Capacity- Specifies the pod resources and allocatable resources.
Information- Specifies information about the node host.
Non-terminated Pods- Specifies the pods on the node.
Events- Specifies the events reported by the node.
Among the information shown for nodes, the following node conditions appear in the output of the commands shown in this section:
| Condition | Description |
|---|---|
|
|
If |
|
|
If |
|
|
If |
|
|
If |
|
|
If |
|
|
If |
|
|
If |
|
| Pods cannot be scheduled for placement on the node. |
6.1.2. Listing pods on a node in your cluster
You can list all of the pods on a node by using the oc get pods command along with specific flags. This command shows the number of pods on that node, the state of the pods, number of pod restarts, and the age of the pods.
Procedure
To list all or selected pods on selected nodes:
$ oc get pod --selector=<nodeSelector>$ oc get pod --selector=kubernetes.io/osOr:
$ oc get pod -l=<nodeSelector>$ oc get pod -l kubernetes.io/os=linuxTo list all pods on a specific node, including terminated pods:
$ oc get pod --all-namespaces --field-selector=spec.nodeName=<nodename>
6.1.3. Viewing memory and CPU usage statistics on your nodes
You can display usage statistics about nodes, including CPU, memory, and storage consumption. These statistics can help you ensure your cluster is running efficiently.
Prerequisites
-
You must have
cluster-readerpermission to view the usage statistics. - Metrics must be installed to view the usage statistics.
Procedure
To view the usage statistics:
$ oc adm top nodesExample output
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-12-143.ec2.compute.internal 1503m 100% 4533Mi 61% ip-10-0-132-16.ec2.compute.internal 76m 5% 1391Mi 18% ip-10-0-140-137.ec2.compute.internal 398m 26% 2473Mi 33% ip-10-0-142-44.ec2.compute.internal 656m 43% 6119Mi 82% ip-10-0-146-165.ec2.compute.internal 188m 12% 3367Mi 45% ip-10-0-19-62.ec2.compute.internal 896m 59% 5754Mi 77% ip-10-0-44-193.ec2.compute.internal 632m 42% 5349Mi 72%To view the usage statistics for nodes with labels:
$ oc adm top node --selector=''You must choose the selector (label query) to filter on. Supports
=,==, and!=.
6.2. Working with nodes
As an administrator, you can perform several tasks to make your clusters more efficient. You can use the oc adm command to cordon, uncordon, and drain a specific node.
Cordoning and draining are only allowed on worker nodes that are part of Red Hat OpenShift Cluster Manager machine pools.
6.2.1. Evacuating pods on nodes
You can remove, or evacuate, pods from a given node or nodes. Evacuating pods allows you to migrate all or selected pods to other nodes.
You can evacuate only pods that are backed by a replication controller. The replication controller creates new pods on other nodes and removes the existing pods from the specified node(s).
Bare pods, meaning those not backed by a replication controller, are unaffected by default. You can evacuate a subset of pods by specifying a pod selector. Because pod selectors are based on labels, all of the pods with the specified label are evacuated.
Procedure
Mark the nodes as unschedulable before performing the pod evacuation.
Mark the node as unschedulable by running the following command:
$ oc adm cordon <node1>Example output
node/<node1> cordonedCheck that the node status is
Ready,SchedulingDisabledby running the following command:$ oc get node <node1>Example output
NAME STATUS ROLES AGE VERSION <node1> Ready,SchedulingDisabled worker 1d v1.34.2
Evacuate the pods by using one of the following methods:
Evacuate all or selected pods on one or more nodes by running the
oc adm draincommand:$ oc adm drain <node1> <node2> [--pod-selector=<pod_selector>]Force the deletion of bare pods by using the
--forceoption with theoc adm draincommand. When set totrue, deletion continues even if there are pods not managed by a replication controller, replica set, job, daemon set, or stateful set.$ oc adm drain <node1> <node2> --force=trueSet a period of time in seconds for each pod to terminate gracefully by using the
--grace-periodoption with theoc adm draincommand. If negative, the default value specified in the pod will be used:$ oc adm drain <node1> <node2> --grace-period=-1Ignore pods managed by daemon sets by using the
--ignore-daemonsets=trueoption with theoc adm draincommand:$ oc adm drain <node1> <node2> --ignore-daemonsets=trueSet the length of time to wait before giving up using the
--timeoutoption with theoc adm draincommand. A value of0sets an infinite length of time.$ oc adm drain <node1> <node2> --timeout=5sDelete pods even if there are pods using
emptyDirvolumes by setting the--delete-emptydir-data=trueoption with theoc adm draincommand. Local data is deleted when the node is drained.$ oc adm drain <node1> <node2> --delete-emptydir-data=trueList objects that would be migrated without actually performing the evacuation, by using the
--dry-run=trueoption with theoc adm draincommand:$ oc adm drain <node1> <node2> --dry-run=trueInstead of specifying specific node names (for example,
<node1> <node2>), you can use the--selector=<node_selector>option with theoc adm draincommand to evacuate pods on selected nodes.
Mark the node as schedulable when done by using the following command.
$ oc adm uncordon <node1>
6.3. Using the Node Tuning Operator
Red Hat OpenShift Service on AWS supports the Node Tuning Operator to improve performance of your nodes on your clusters. The Node Tuning Operator in Red Hat OpenShift Service on AWS helps you manage node-level tuning by orchestrating the TuneD daemon. You can use this unified interface to apply custom tuning specifications and achieve low latency performance for high-performance applications.
Before creating a node tuning configuration, you must create a custom tuning specification.
The Node Tuning Operator helps you manage node-level tuning by orchestrating the TuneD daemon and achieves low latency performance by using the Performance Profile controller. The majority of high-performance applications require some level of kernel tuning. The Node Tuning Operator provides a unified management interface to users of node-level sysctls and more flexibility to add custom tuning specified by user needs.
The Operator manages the containerized TuneD daemon for Red Hat OpenShift Service on AWS as a Kubernetes daemon set. It ensures the custom tuning specification is passed to all containerized TuneD daemons running in the cluster in the format that the daemons understand. The daemons run on all nodes in the cluster, one per node.
Node-level settings applied by the containerized TuneD daemon are rolled back on an event that triggers a profile change or when the containerized TuneD daemon is terminated gracefully by receiving and handling a termination signal.
The Node Tuning Operator uses the Performance Profile controller to implement automatic tuning to achieve low latency performance for Red Hat OpenShift Service on AWS applications.
The cluster administrator configures a performance profile to define node-level settings such as the following:
- Updating the kernel to kernel-rt.
- Choosing CPUs for housekeeping.
- Choosing CPUs for running workloads.
The Node Tuning Operator is part of a standard Red Hat OpenShift Service on AWS installation in version 4.1 and later.
In earlier versions of Red Hat OpenShift Service on AWS, the Performance Addon Operator was used to implement automatic tuning to achieve low latency performance for OpenShift applications. In Red Hat OpenShift Service on AWS 4.11 and later, this functionality is part of the Node Tuning Operator.
6.3.1. Custom tuning specification
The custom resource (CR) for the Operator has two major sections. The first section, profile:, is a list of TuneD profiles and their names. The second, recommend:, defines the profile selection logic.
Multiple custom tuning specifications can co-exist as multiple CRs in the Operator’s namespace. The existence of new CRs or the deletion of old CRs is detected by the Operator. All existing custom tuning specifications are merged and appropriate objects for the containerized TuneD daemons are updated.
Management state
The Operator Management state is set by adjusting the default Tuned CR. By default, the Operator is in the Managed state and the spec.managementState field is not present in the default Tuned CR. Valid values for the Operator Management state are as follows:
- Managed: the Operator will update its operands as configuration resources are updated
- Unmanaged: the Operator will ignore changes to the configuration resources
- Removed: the Operator will remove its operands and resources the Operator provisioned
Profile data
The profile: section lists TuneD profiles and their names.
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settingsRecommended profiles
The profile: selection logic is defined by the recommend: section of the CR. The recommend: section is a list of items to recommend the profiles based on a selection criteria.
recommend:
<recommend-item-1>
# ...
<recommend-item-n>The individual items of the list:
- machineConfigLabels:
<mcLabels>
match:
<match>
priority: <priority>
profile: <tuned_profile_name>
operand:
debug: <bool>
tunedConfig:
reapply_sysctl: <bool> - 1
- Optional.
- 2
- A dictionary of key/value
MachineConfiglabels. The keys must be unique. - 3
- If omitted, profile match is assumed unless a profile with a higher priority matches first or
machineConfigLabelsis set. - 4
- An optional list.
- 5
- Profile ordering priority. Lower numbers mean higher priority (
0is the highest priority). - 6
- A TuneD profile to apply on a match. For example
tuned_profile_1. - 7
- Optional operand configuration.
- 8
- Turn debugging on or off for the TuneD daemon. Options are
truefor on orfalsefor off. The default isfalse. - 9
- Turn
reapply_sysctlfunctionality on or off for the TuneD daemon. Options aretruefor on andfalsefor off.
<match> is an optional list recursively defined as follows:
- label: <label_name>
value: <label_value>
type: <label_type>
<match>
If <match> is not omitted, all nested <match> sections must also evaluate to true. Otherwise, false is assumed and the profile with the respective <match> section will not be applied or recommended. Therefore, the nesting (child <match> sections) works as logical AND operator. Conversely, if any item of the <match> list matches, the entire <match> list evaluates to true. Therefore, the list acts as logical OR operator.
If machineConfigLabels is defined, machine config pool based matching is turned on for the given recommend: list item. <mcLabels> specifies the labels for a machine config. The machine config is created automatically to apply host settings, such as kernel boot parameters, for the profile <tuned_profile_name>. This involves finding all machine config pools with machine config selector matching <mcLabels> and setting the profile <tuned_profile_name> on all nodes that are assigned the found machine config pools. To target nodes that have both master and worker roles, you must use the master role.
The list items match and machineConfigLabels are connected by the logical OR operator. The match item is evaluated first in a short-circuit manner. Therefore, if it evaluates to true, the machineConfigLabels item is not considered.
When using machine config pool based matching, it is advised to group nodes with the same hardware configuration into the same machine config pool. Not following this practice might result in TuneD operands calculating conflicting kernel parameters for two or more nodes sharing the same machine config pool.
Example: Node or pod label based matching
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
The CR above is translated for the containerized TuneD daemon into its recommend.conf file based on the profile priorities. The profile with the highest priority (10) is openshift-control-plane-es and, therefore, it is considered first. The containerized TuneD daemon running on a given node looks to see if there is a pod running on the same node with the tuned.openshift.io/elasticsearch label set. If not, the entire <match> section evaluates as false. If there is such a pod with the label, in order for the <match> section to evaluate to true, the node label also needs to be node-role.kubernetes.io/master or node-role.kubernetes.io/infra.
If the labels for the profile with priority 10 matched, openshift-control-plane-es profile is applied and no other profile is considered. If the node/pod label combination did not match, the second highest priority profile (openshift-control-plane) is considered. This profile is applied if the containerized TuneD pod runs on a node with labels node-role.kubernetes.io/master or node-role.kubernetes.io/infra.
Finally, the profile openshift-node has the lowest priority of 30. It lacks the <match> section and, therefore, will always match. It acts as a profile catch-all to set openshift-node profile, if no other profile with higher priority matches on a given node.
Example: Machine config pool based matching
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-customTo minimize node reboots, label the target nodes with a label the machine config pool’s node selector will match, then create the Tuned CR above and finally create the custom machine config pool itself.
Cloud provider-specific TuneD profiles
With this functionality, all Cloud provider-specific nodes can conveniently be assigned a TuneD profile specifically tailored to a given Cloud provider on a Red Hat OpenShift Service on AWS cluster. This can be accomplished without adding additional node labels or grouping nodes into machine config pools.
This functionality takes advantage of spec.providerID node object values in the form of <cloud-provider>://<cloud-provider-specific-id> and writes the file /var/lib/ocp-tuned/provider with the value <cloud-provider> in NTO operand containers. The content of this file is then used by TuneD to load provider-<cloud-provider> profile if such profile exists.
The openshift profile that both openshift-control-plane and openshift-node profiles inherit settings from is now updated to use this functionality through the use of conditional profile loading. Neither NTO nor TuneD currently include any Cloud provider-specific profiles. However, it is possible to create a custom profile provider-<cloud-provider> that will be applied to all Cloud provider-specific cluster nodes.
Example GCE Cloud provider profile
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
Due to profile inheritance, any setting specified in the provider-<cloud-provider> profile will be overwritten by the openshift profile and its child profiles.
6.3.2. Creating node tuning configurations
You can create tuning configurations by using the Red Hat OpenShift Service on AWS (ROSA) CLI, rosa.
Prerequisites
- You have downloaded the latest version of the ROSA CLI.
- You have a cluster on the latest version.
- You have a specification file configured for node tuning.
Procedure
Run the following command to create your tuning configuration:
$ rosa create tuning-config -c <cluster_id> --name <name_of_tuning> --spec-path <path_to_spec_file>You must supply the path to the
spec.jsonfile or the command returns an error.$ I: Tuning config 'sample-tuning' has been created on cluster 'cluster-example'.$ I: To view all tuning configs, run 'rosa list tuning-configs -c cluster-example'
Verification
You can verify the existing tuning configurations that are applied by your account with the following command:
$ rosa list tuning-configs -c <cluster_name> [-o json]You can specify the type of output you want for the configuration list.
Without specifying the output type, you see the ID and name of the tuning configuration:
Example output without specifying output type
ID NAME 20468b8e-edc7-11ed-b0e4-0a580a800298 sample-tuningIf you specify an output type, such as
json, you receive the tuning configuration as JSON text:NoteThe following JSON output has hard line-returns for the sake of reading clarity. This JSON output is invalid unless you remove the newlines in the JSON strings.
Example output specifying JSON output
[ { "kind": "TuningConfig", "id": "20468b8e-edc7-11ed-b0e4-0a580a800298", "href": "/api/clusters_mgmt/v1/clusters/23jbsevqb22l0m58ps39ua4trff9179e/tuning_configs/20468b8e-edc7-11ed-b0e4-0a580a800298", "name": "sample-tuning", "spec": { "profile": [ { "data": "[main]\nsummary=Custom OpenShift profile\ninclude=openshift-node\n\n[sysctl]\nvm.dirty_ratio=\"55\"\n", "name": "tuned-1-profile" } ], "recommend": [ { "priority": 20, "profile": "tuned-1-profile" } ] } } ]
6.3.3. Modifying your node tuning configurations
You can view and update the node tuning configurations by using the Red Hat OpenShift Service on AWS (ROSA) CLI, rosa.
Prerequisites
- You have downloaded the latest version of the ROSA CLI.
- You have a cluster on the latest version
- Your cluster has a node tuning configuration added to it
Procedure
You view the tuning configurations with the
rosa describecommand:$ rosa describe tuning-config -c <cluster_id> \ --name <name_of_tuning> \ [-o json]where:
<cluster_id>- Specifies the cluster ID for the cluster that you own that you want to apply a node tuning configuration.
<name_of_tuning>- Specifies the name of your tuning configuration.
-o json- Specifies the output type. This parameter is optional. If you do not specify any outputs, you see only the ID and name of the tuning configuration.
Example output without specifying output type
Name: sample-tuning ID: 20468b8e-edc7-11ed-b0e4-0a580a800298 Spec: { "profile": [ { "data": "[main]\nsummary=Custom OpenShift profile\ninclude=openshift-node\n\n[sysctl]\nvm.dirty_ratio=\"55\"\n", "name": "tuned-1-profile" } ], "recommend": [ { "priority": 20, "profile": "tuned-1-profile" } ] }Example output specifying JSON output
{ "kind": "TuningConfig", "id": "20468b8e-edc7-11ed-b0e4-0a580a800298", "href": "/api/clusters_mgmt/v1/clusters/23jbsevqb22l0m58ps39ua4trff9179e/tuning_configs/20468b8e-edc7-11ed-b0e4-0a580a800298", "name": "sample-tuning", "spec": { "profile": [ { "data": "[main]\nsummary=Custom OpenShift profile\ninclude=openshift-node\n\n[sysctl]\nvm.dirty_ratio=\"55\"\n", "name": "tuned-1-profile" } ], "recommend": [ { "priority": 20, "profile": "tuned-1-profile" } ] } }After verifying the tuning configuration, you edit the existing configurations with the
rosa editcommand:$ rosa edit tuning-config -c <cluster_id> --name <name_of_tuning> --spec-path <path_to_spec_file>In this command, you use the
spec.jsonfile to edit your configurations.
Verification
Run the
rosa describecommand again, to see that the changes you made to thespec.jsonfile are updated in the tuning configurations:$ rosa describe tuning-config -c <cluster_id> --name <name_of_tuning>Example output
Name: sample-tuning ID: 20468b8e-edc7-11ed-b0e4-0a580a800298 Spec: { "profile": [ { "data": "[main]\nsummary=Custom OpenShift profile\ninclude=openshift-node\n\n[sysctl]\nvm.dirty_ratio=\"55\"\n", "name": "tuned-2-profile" } ], "recommend": [ { "priority": 10, "profile": "tuned-2-profile" } ] }
6.3.4. Deleting node tuning configurations
You can delete tuning configurations if you no longer need them by using the Red Hat OpenShift Service on AWS (ROSA) CLI, rosa.
You cannot delete a tuning configuration referenced in a machine pool. You must first remove the tuning configuration from all machine pools before you can delete it.
Prerequisites
- You have downloaded the latest version of the ROSA CLI.
- You have a cluster on the latest version .
- Your cluster has a node tuning configuration that you want delete.
Procedure
To delete the tuning configurations, run the following command:
$ rosa delete tuning-config -c <cluster_id> <name_of_tuning>The tuning configuration on the cluster is deleted
Example output
? Are you sure you want to delete tuning config sample-tuning on cluster sample-cluster? Yes I: Successfully deleted tuning config 'sample-tuning' from cluster 'sample-cluster'
Chapter 7. Working with containers
7.1. Understanding Containers
Containers are the basic units of Red Hat OpenShift Service on AWS applications that isolate processes to provide portable micro-services. To maintain cluster stability, you must understand how container runtimes manage workloads and how kernel memory allocation impacts resource limits on your nodes.
Linux container technologies are lightweight mechanisms for isolating running processes so that they are limited to interacting with only their designated resources.
Many application instances can be running in containers on a single host without visibility into each others' processes, files, network, and so on. Typically, each container provides a single service (often called a "micro-service"), such as a web server or a database, though containers can be used for arbitrary workloads.
The Linux kernel has been incorporating capabilities for container technologies for years. Red Hat OpenShift Service on AWS and Kubernetes add the ability to orchestrate containers across multi-host installations.
7.1.1. About containers and RHEL kernel memory
Due to Red Hat Enterprise Linux (RHEL) behavior, a container on a node with high CPU usage might seem to consume more memory than expected. The higher memory consumption could be caused by the kmem_cache in the RHEL kernel. The RHEL kernel creates a kmem_cache for each cgroup. For added performance, the kmem_cache contains a cpu_cache, and a node cache for any NUMA nodes. These caches all consume kernel memory.
The amount of memory stored in those caches is proportional to the number of CPUs that the system uses. As a result, a higher number of CPUs results in a greater amount of kernel memory being held in these caches. Higher amounts of kernel memory in these caches can cause Red Hat OpenShift Service on AWS containers to exceed the configured memory limits, resulting in the container being killed.
To avoid losing containers due to kernel memory issues, ensure that the containers request sufficient memory. You can use the following formula to estimate the amount of memory consumed by the kmem_cache, where nproc is the number of processing units available that are reported by the nproc command. The lower limit of container requests should be this value plus the container memory requirements:
$(nproc) X 1/2 MiB7.1.2. About the container engine and container runtime
A container engine is a piece of software that processes user requests, including command-line options and image pulls. The container engine uses a container runtime, also called a lower-level container runtime, to run and manage the components required to deploy and operate containers. You likely will not need to interact with the container engine or container runtime.
The Red Hat OpenShift Service on AWS documentation uses the term container runtime to refer to the lower-level container runtime. Other documentation can refer to the container engine as the container runtime.
Red Hat OpenShift Service on AWS uses CRI-O as the container engine and crun or runC as the container runtime. The default container runtime is crun.
7.2. Using Init Containers to perform tasks before a pod is deployed
You can use init containers, which are specialized containers that run before application containers and can contain utilities or setup scripts not present in an app image.
7.2.1. Understanding init containers
You can use an init container to perform tasks before the rest of a pod is deployed. You can use init containers to perform setup tasks that should be completed before the main application logic begins, such as environment preparation, dependency checks, or configuration generation.
A pod can have init containers in addition to application containers. Init containers allow you to reorganize setup scripts and binding code.
An init container can:
- Contain and run utilities that are not desirable to include in the app container image for security reasons.
- Contain utilities or custom code for setup that is not present in an app image. For example, there is no requirement to make an image FROM another image just to use a tool like sed, awk, python, or dig during setup.
- Use Linux namespaces so that they have different filesystem views from app containers, such as access to secrets that application containers are not able to access.
Because each init container must complete successfully before the next one is started, they provide an easy way to block or delay the startup of app containers until some set of preconditions are met.
For example, the following are some ways you can use init containers:
Wait for a service to be created by using a shell command similar to the following:
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; done; exit 1Register this pod with a remote server from the Downward API by using a command similar to the following:
$ curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register -d ‘instance=$()&ip=$()’-
Delay starting the app container by using a command such as
sleep 60. - Clone a git repository into a volume.
-
Place values into a configuration file and run a template tool to dynamically generate a configuration file for the main app container. For example, place the
POD_IPvalue in a configuration and generate the main app configuration file using Jinja.
7.2.2. Creating Init Containers
You create an init container by creating a pod spec that contains an initContainers configuration.
The following example outlines a simple pod which has two init containers. The first init continer waits for the myservice service to complete. After that, the second waits for mydb service to complete. After both init containers complete, the pod begins.
Procedure
Create the pod for the Init Container:
Create a YAML file similar to the following:
apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: myapp-container image: registry.access.redhat.com/ubi9/ubi:latest command: ['sh', '-c', 'echo The app is running! && sleep 3600'] securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] initContainers: - name: init-myservice image: registry.access.redhat.com/ubi9/ubi:latest command: ['sh', '-c', 'until getent hosts myservice; do echo waiting for myservice; sleep 2; done;'] securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] - name: init-mydb image: registry.access.redhat.com/ubi9/ubi:latest command: ['sh', '-c', 'until getent hosts mydb; do echo waiting for mydb; sleep 2; done;'] securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]Create the pod by using the following command:
$ oc create -f myapp.yamlView the status of the pod by using the following command:
$ oc get podsExample output
NAME READY STATUS RESTARTS AGE myapp-pod 0/1 Init:0/2 0 5sThe pod status,
Init:0/2, indicates it is waiting for the two services.
Create the
myserviceservice.Create a YAML file similar to the following:
kind: Service apiVersion: v1 metadata: name: myservice spec: ports: - protocol: TCP port: 80 targetPort: 9376Create the pod by using the following command:
$ oc create -f myservice.yamlView the status of the pod by using the following command:
$ oc get podsExample output
NAME READY STATUS RESTARTS AGE myapp-pod 0/1 Init:1/2 0 5sThe pod status,
Init:1/2, indicates it is waiting for one service, in this case themydbservice.
Create the
mydbservice:Create a YAML file similar to the following:
kind: Service apiVersion: v1 metadata: name: mydb spec: ports: - protocol: TCP port: 80 targetPort: 9377Create the pod by using the following command:
$ oc create -f mydb.yamlView the status of the pod by using the following command:
$ oc get podsExample output
NAME READY STATUS RESTARTS AGE myapp-pod 1/1 Running 0 2mThe pod status,
Running, indicates that it is no longer waiting for the services and is running.
7.3. Using volumes to persist container data
Files in a container are ephemeral. As such, when a container crashes or stops, the data is lost. You can use volumes to persist the data used by the containers in a pod. A volume is directory, accessible to the Containers in a pod, where data is stored for the life of the pod.
7.3.1. Understanding volumes
Volumes are mounted file systems available to pods and their containers which may be backed by a number of host-local or network attached storage endpoints. Containers are not persistent by default; on restart, their contents are cleared.
To ensure that the file system on the volume contains no errors and, if errors are present, to repair them when possible, Red Hat OpenShift Service on AWS invokes the fsck utility prior to the mount utility. This occurs when either adding a volume or updating an existing volume.
The simplest volume type is emptyDir, which is a temporary directory on a single machine. Administrators may also allow you to request a persistent volume that is automatically attached to your pods.
emptyDir volume storage may be restricted by a quota based on the pod’s FSGroup, if the FSGroup parameter is enabled by your cluster administrator.
7.3.2. Working with volumes using the Red Hat OpenShift Service on AWS CLI
You can use the CLI command oc set volume to add and remove volumes and volume mounts for any object that has a pod template like replication controllers or deployment configs. You can also list volumes in pods or any object that has a pod template.
The oc set volume command uses the following general syntax:
$ oc set volume <object_selection> <operation> <mandatory_parameters> <options>- Object selection
-
Specify one of the following for the
object_selectionparameter in theoc set volumecommand:
| Syntax | Description | Example |
|---|---|---|
|
|
Selects |
|
|
|
Selects |
|
|
|
Selects resources of type |
|
|
|
Selects all resources of type |
|
|
| File name, directory, or URL to file to use to edit the resource. |
|
- Operation
-
Specify
--addor--removefor theoperationparameter in theoc set volumecommand. - Mandatory parameters
- Any mandatory parameters are specific to the selected operation and are discussed in later sections.
- Options
- Any options are specific to the selected operation and are discussed in later sections.
7.3.3. Listing volumes and volume mounts in a pod
You can list volumes and volume mounts in pods or pod templates:
Procedure
To list volumes:
$ oc set volume <object_type>/<name> [options]List volume supported options:
| Option | Description | Default |
|---|---|---|
|
| Name of the volume. | |
|
|
Select containers by name. It can also take wildcard |
|
For example:
To list all volumes for pod p1:
$ oc set volume pod/p1To list volume v1 defined on all deployment configs:
$ oc set volume dc --all --name=v1
7.3.4. Adding volumes to a pod
You can add volumes and volume mounts to a pod.
Procedure
To add a volume, a volume mount, or both to pod templates:
$ oc set volume <object_type>/<name> --add [options]| Option | Description | Default |
|---|---|---|
|
| Name of the volume. | Automatically generated, if not specified. |
|
|
Name of the volume source. Supported values: |
|
|
|
Select containers by name. It can also take wildcard |
|
|
|
Mount path inside the selected containers. Do not mount to the container root, | |
|
|
Host path. Mandatory parameter for | |
|
|
Name of the secret. Mandatory parameter for | |
|
|
Name of the configmap. Mandatory parameter for | |
|
|
Name of the persistent volume claim. Mandatory parameter for | |
|
|
Details of volume source as a JSON string. Recommended if the desired volume source is not supported by | |
|
|
Display the modified objects instead of updating them on the server. Supported values: | |
|
| Output the modified objects with the given version. |
|
For example:
To add a new volume source emptyDir to the registry
DeploymentConfigobject:$ oc set volume dc/registry --addTipYou can alternatively apply the following YAML to add the volume:
Example 7.1. Sample deployment config with an added volume
kind: DeploymentConfig apiVersion: apps.openshift.io/v1 metadata: name: registry namespace: registry spec: replicas: 3 selector: app: httpd template: metadata: labels: app: httpd spec: volumes:1 - name: volume-pppsw emptyDir: {} containers: - name: httpd image: >- image-registry.openshift-image-registry.svc:5000/openshift/httpd:latest ports: - containerPort: 8080 protocol: TCP- 1
- Add the volume source emptyDir.
To add volume v1 with secret secret1 for replication controller r1 and mount inside the containers at /data:
$ oc set volume rc/r1 --add --name=v1 --type=secret --secret-name='secret1' --mount-path=/dataTipYou can alternatively apply the following YAML to add the volume:
Example 7.2. Sample replication controller with added volume and secret
kind: ReplicationController apiVersion: v1 metadata: name: example-1 namespace: example spec: replicas: 0 selector: app: httpd deployment: example-1 deploymentconfig: example template: metadata: creationTimestamp: null labels: app: httpd deployment: example-1 deploymentconfig: example spec: volumes:1 - name: v1 secret: secretName: secret1 defaultMode: 420 containers: - name: httpd image: >- image-registry.openshift-image-registry.svc:5000/openshift/httpd:latest volumeMounts:2 - name: v1 mountPath: /dataTo add existing persistent volume v1 with claim name pvc1 to deployment configuration dc.json on disk, mount the volume on container c1 at /data, and update the
DeploymentConfigobject on the server:$ oc set volume -f dc.json --add --name=v1 --type=persistentVolumeClaim \ --claim-name=pvc1 --mount-path=/data --containers=c1TipYou can alternatively apply the following YAML to add the volume:
Example 7.3. Sample deployment config with persistent volume added
kind: DeploymentConfig apiVersion: apps.openshift.io/v1 metadata: name: example namespace: example spec: replicas: 3 selector: app: httpd template: metadata: labels: app: httpd spec: volumes: - name: volume-pppsw emptyDir: {} - name: v11 persistentVolumeClaim: claimName: pvc1 containers: - name: httpd image: >- image-registry.openshift-image-registry.svc:5000/openshift/httpd:latest ports: - containerPort: 8080 protocol: TCP volumeMounts:2 - name: v1 mountPath: /dataTo add a volume v1 based on Git repository https://github.com/namespace1/project1 with revision 5125c45f9f563 for all replication controllers:
$ oc set volume rc --all --add --name=v1 \ --source='{"gitRepo": { "repository": "https://github.com/namespace1/project1", "revision": "5125c45f9f563" }}'
7.3.5. Updating volumes and volume mounts in a pod
You can modify the volumes and volume mounts in a pod.
Procedure
Updating existing volumes using the --overwrite option:
$ oc set volume <object_type>/<name> --add --overwrite [options]For example:
To replace existing volume v1 for replication controller r1 with existing persistent volume claim pvc1:
$ oc set volume rc/r1 --add --overwrite --name=v1 --type=persistentVolumeClaim --claim-name=pvc1TipYou can alternatively apply the following YAML to replace the volume:
Example 7.4. Sample replication controller with persistent volume claim named
pvc1kind: ReplicationController apiVersion: v1 metadata: name: example-1 namespace: example spec: replicas: 0 selector: app: httpd deployment: example-1 deploymentconfig: example template: metadata: labels: app: httpd deployment: example-1 deploymentconfig: example spec: volumes: - name: v11 persistentVolumeClaim: claimName: pvc1 containers: - name: httpd image: >- image-registry.openshift-image-registry.svc:5000/openshift/httpd:latest ports: - containerPort: 8080 protocol: TCP volumeMounts: - name: v1 mountPath: /data- 1
- Set persistent volume claim to
pvc1.
To change the
DeploymentConfigobject d1 mount point to /opt for volume v1:$ oc set volume dc/d1 --add --overwrite --name=v1 --mount-path=/optTipYou can alternatively apply the following YAML to change the mount point:
Example 7.5. Sample deployment config with mount point set to
opt.kind: DeploymentConfig apiVersion: apps.openshift.io/v1 metadata: name: example namespace: example spec: replicas: 3 selector: app: httpd template: metadata: labels: app: httpd spec: volumes: - name: volume-pppsw emptyDir: {} - name: v2 persistentVolumeClaim: claimName: pvc1 - name: v1 persistentVolumeClaim: claimName: pvc1 containers: - name: httpd image: >- image-registry.openshift-image-registry.svc:5000/openshift/httpd:latest ports: - containerPort: 8080 protocol: TCP volumeMounts:1 - name: v1 mountPath: /opt- 1
- Set the mount point to
/opt.
7.3.6. Removing volumes and volume mounts from a pod
You can remove a volume or volume mount from a pod.
Procedure
To remove a volume from pod templates:
$ oc set volume <object_type>/<name> --remove [options]| Option | Description | Default |
|---|---|---|
|
| Name of the volume. | |
|
|
Select containers by name. It can also take wildcard |
|
|
| Indicate that you want to remove multiple volumes at once. | |
|
|
Display the modified objects instead of updating them on the server. Supported values: | |
|
| Output the modified objects with the given version. |
|
For example:
To remove a volume v1 from the
DeploymentConfigobject d1:$ oc set volume dc/d1 --remove --name=v1To unmount volume v1 from container c1 for the
DeploymentConfigobject d1 and remove the volume v1 if it is not referenced by any containers on d1:$ oc set volume dc/d1 --remove --name=v1 --containers=c1To remove all volumes for replication controller r1:
$ oc set volume rc/r1 --remove --confirm
7.3.7. Configuring volumes for multiple uses in a pod
You can configure a volume to share one volume for multiple uses in a single pod using the volumeMounts.subPath property to specify a subPath value inside a volume instead of the volume’s root.
You cannot add a subPath parameter to an existing scheduled pod.
Procedure
To view the list of files in the volume, run the
oc rshcommand:$ oc rsh <pod>Example output
sh-4.2$ ls /path/to/volume/subpath/mount example_file1 example_file2 example_file3Specify the
subPath:Example
Podspec withsubPathparameterapiVersion: v1 kind: Pod metadata: name: my-site spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: mysql image: mysql volumeMounts: - mountPath: /var/lib/mysql name: site-data subPath: mysql1 securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] - name: php image: php volumeMounts: - mountPath: /var/www/html name: site-data subPath: html2 securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] volumes: - name: site-data persistentVolumeClaim: claimName: my-site-data
7.4. Mapping volumes using projected volumes
A projected volume maps several existing volume sources into the same directory.
The following types of volume sources can be projected:
- Secrets
- Config Maps
- Downward API
All sources are required to be in the same namespace as the pod.
7.4.1. Understanding projected volumes
Projected volumes can map any combination of these volume sources into a single directory, allowing the user to:
- automatically populate a single volume with the keys from multiple secrets, config maps, and with downward API information, so that I can synthesize a single directory with various sources of information;
- populate a single volume with the keys from multiple secrets, config maps, and with downward API information, explicitly specifying paths for each item, so that I can have full control over the contents of that volume.
When the RunAsUser permission is set in the security context of a Linux-based pod, the projected files have the correct permissions set, including container user ownership. However, when the Windows equivalent RunAsUsername permission is set in a Windows pod, the kubelet is unable to correctly set ownership on the files in the projected volume.
Therefore, the RunAsUsername permission set in the security context of a Windows pod is not honored for Windows projected volumes running in Red Hat OpenShift Service on AWS.
The following general scenarios show how you can use projected volumes.
- Config map, secrets, Downward API.
-
Projected volumes allow you to deploy containers with configuration data that includes passwords. An application using these resources could be deploying Red Hat OpenStack Platform (RHOSP) on Kubernetes. The configuration data might have to be assembled differently depending on if the services are going to be used for production or for testing. If a pod is labeled with production or testing, the downward API selector
metadata.labelscan be used to produce the correct RHOSP configs. - Config map + secrets.
- Projected volumes allow you to deploy containers involving configuration data and passwords. For example, you might execute a config map with some sensitive encrypted tasks that are decrypted using a vault password file.
- ConfigMap + Downward API.
-
Projected volumes allow you to generate a config including the pod name (available via the
metadata.nameselector). This application can then pass the pod name along with requests to easily determine the source without using IP tracking. - Secrets + Downward API.
-
Projected volumes allow you to use a secret as a public key to encrypt the namespace of the pod (available via the
metadata.namespaceselector). This example allows the Operator to use the application to deliver the namespace information securely without using an encrypted transport.
7.4.1.1. Example Pod specs
The following are examples of Pod specs for creating projected volumes.
Pod with a secret, a Downward API, and a config map
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: container-test
image: busybox
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
volumes:
- name: all-in-one
projected:
defaultMode: 0400
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "cpu_limit"
resourceFieldRef:
containerName: container-test
resource: limits.cpu
- configMap:
name: myconfigmap
items:
- key: config
path: my-group/my-config
mode: 0777 - 1
- Add a
volumeMountssection for each container that needs the secret. - 2
- Specify a path to an unused directory where the secret will appear.
- 3
- Set
readOnlytotrue. - 4
- Add a
volumesblock to list each projected volume source. - 5
- Specify any name for the volume.
- 6
- Set the execute permission on the files.
- 7
- Add a secret. Enter the name of the secret object. Each secret you want to use must be listed.
- 8
- Specify the path to the secrets file under the
mountPath. Here, the secrets file is in /projected-volume/my-group/my-username. - 9
- Add a Downward API source.
- 10
- Add a ConfigMap source.
- 11
- Set the mode for the specific projection
If there are multiple containers in the pod, each container needs a volumeMounts section, but only one volumes section is needed.
Pod with multiple secrets with a non-default permission mode set
apiVersion: v1
kind: Pod
metadata:
name: volume-test
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: container-test
image: busybox
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
volumes:
- name: all-in-one
projected:
defaultMode: 0755
sources:
- secret:
name: mysecret
items:
- key: username
path: my-group/my-username
- secret:
name: mysecret2
items:
- key: password
path: my-group/my-password
mode: 511
The defaultMode can only be specified at the projected level and not for each volume source. However, as illustrated above, you can explicitly set the mode for each individual projection.
7.4.1.2. Pathing Considerations
- Collisions Between Keys when Configured Paths are Identical
If you configure any keys with the same path, the pod spec will not be accepted as valid. In the following example, the specified path for
mysecretandmyconfigmapare the same:apiVersion: v1 kind: Pod metadata: name: volume-test spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: container-test image: busybox volumeMounts: - name: all-in-one mountPath: "/projected-volume" readOnly: true securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] volumes: - name: all-in-one projected: sources: - secret: name: mysecret items: - key: username path: my-group/data - configMap: name: myconfigmap items: - key: config path: my-group/data
Consider the following situations related to the volume file paths.
- Collisions Between Keys without Configured Paths
- The only run-time validation that can occur is when all the paths are known at pod creation, similar to the above scenario. Otherwise, when a conflict occurs the most recent specified resource will overwrite anything preceding it (this is true for resources that are updated after pod creation as well).
- Collisions when One Path is Explicit and the Other is Automatically Projected
- In the event that there is a collision due to a user specified path matching data that is automatically projected, the latter resource will overwrite anything preceding it as before
7.4.2. Configuring a Projected Volume for a Pod
When creating projected volumes, consider the volume file path situations described in Understanding projected volumes.
The following example shows how to use a projected volume to mount an existing secret volume source. The steps can be used to create a user name and password secrets from local files. You then create a pod that runs one container, using a projected volume to mount the secrets into the same shared directory.
The user name and password values can be any valid string that is base64 encoded.
The following example shows admin in base64:
$ echo -n "admin" | base64Example output
YWRtaW4=
The following example shows the password 1f2d1e2e67df in base64:
$ echo -n "1f2d1e2e67df" | base64Example output
MWYyZDFlMmU2N2RmProcedure
To use a projected volume to mount an existing secret volume source.
Create the secret:
Create a YAML file similar to the following, replacing the password and user information as appropriate:
apiVersion: v1 kind: Secret metadata: name: mysecret type: Opaque data: pass: MWYyZDFlMmU2N2Rm user: YWRtaW4=Use the following command to create the secret:
$ oc create -f <secrets-filename>For example:
$ oc create -f secret.yamlExample output
secret "mysecret" createdYou can check that the secret was created using the following commands:
$ oc get secret <secret-name>For example:
$ oc get secret mysecretExample output
NAME TYPE DATA AGE mysecret Opaque 2 17h$ oc get secret <secret-name> -o yamlFor example:
$ oc get secret mysecret -o yamlapiVersion: v1 data: pass: MWYyZDFlMmU2N2Rm user: YWRtaW4= kind: Secret metadata: creationTimestamp: 2017-05-30T20:21:38Z name: mysecret namespace: default resourceVersion: "2107" selfLink: /api/v1/namespaces/default/secrets/mysecret uid: 959e0424-4575-11e7-9f97-fa163e4bd54c type: Opaque
Create a pod with a projected volume.
Create a YAML file similar to the following, including a
volumessection:kind: Pod metadata: name: test-projected-volume spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: test-projected-volume image: busybox args: - sleep - "86400" volumeMounts: - name: all-in-one mountPath: "/projected-volume" readOnly: true securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] volumes: - name: all-in-one projected: sources: - secret: name: mysecret1 - 1
- The name of the secret you created.
Create the pod from the configuration file:
$ oc create -f <your_yaml_file>.yamlFor example:
$ oc create -f secret-pod.yamlExample output
pod "test-projected-volume" created
Verify that the pod container is running, and then watch for changes to the pod:
$ oc get pod <name>For example:
$ oc get pod test-projected-volumeThe output should appear similar to the following:
Example output
NAME READY STATUS RESTARTS AGE test-projected-volume 1/1 Running 0 14sIn another terminal, use the
oc execcommand to open a shell to the running container:$ oc exec -it <pod> <command>For example:
$ oc exec -it test-projected-volume -- /bin/shIn your shell, verify that the
projected-volumesdirectory contains your projected sources:/ # lsExample output
bin home root tmp dev proc run usr etc projected-volume sys var
7.5. Allowing containers to consume API objects
You can use the Downward API to allow containers to consume information about API objects, such as the pod’s name, namespace, and resource values, without coupling to Red Hat OpenShift Service on AWS by using environment variables or a volume plugin.
7.5.1. Expose pod information to Containers using the Downward API
You can review the following tables to learn what information the Downward API contains, including the pod’s name, project, and resource values. Your containers can consume this information by using environment variables or a volume plugin.
Fields within the pod are selected using the FieldRef API type. FieldRef has two fields:
| Field | Description |
|---|---|
|
| The path of the field to select, relative to the pod. |
|
|
The API version to interpret the |
Currently, the valid selectors in the v1 API include:
| Selector | Description |
|---|---|
|
| The pod’s name. This is supported in both environment variables and volumes. |
|
| The pod’s namespace.This is supported in both environment variables and volumes. |
|
| The pod’s labels. This is only supported in volumes and not in environment variables. |
|
| The pod’s annotations. This is only supported in volumes and not in environment variables. |
|
| The pod’s IP. This is only supported in environment variables and not volumes. |
The apiVersion field, if not specified, defaults to the API version of the enclosing pod template.
7.5.2. Understanding how to consume container values using the downward API
Your containers can consume API values by using environment variables or a volume plugin.
Depending on the method you choose, containers can consume:
- Pod name
- Pod project/namespace
- Pod annotations
- Pod labels
Annotations and labels are available using only a volume plugin.
7.5.2.1. Consuming container values using environment variables
When using environment variables in a container, you can specify that the variable’s value should come from a FieldRef source instead of the literal value specified.
Only constant attributes of the pod can be consumed this way, because environment variables cannot be updated after a process is started in a way that allows the process to be notified that the value of a variable has changed. The following fields are supported for using with environment variables:
- Pod name
- Pod project/namespace
Procedure
Create a new pod spec that contains the environment variables you want the container to consume:
Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: env-test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env: - name: MY_POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Never # ...where:
spec.containers.env.valueFrom.fieldRef.fieldPath-
Specifies that the environment variable gets its value from the specified pod value, either
metadata.namefor the pod name ormetadata.namespacefor the pod namespace, instead of a literal value specified by avaluefield.
Create the pod from the
pod.yamlfile by using the following command:$ oc create -f pod.yaml
Verification
Check the container logs for the
MY_POD_NAMEandMY_POD_NAMESPACEvalues:$ oc logs -p dapi-env-test-pod
7.5.2.2. Consuming container values using a volume plugin
Your containers can consume Downward API values by using a volume plugin.
Containers can consume the following values:
- Pod name
- Pod project/namespace
- Pod annotations
- Pod labels
The following procedure show how to use the volume plugin.
Procedure
Create a new pod spec that contains the environment variables you want the container to consume:
Create a
volume-pod.yamlfile similar to the following:kind: Pod apiVersion: v1 metadata: labels: zone: us-east-coast cluster: downward-api-test-cluster1 rack: rack-123 name: dapi-volume-test-pod annotations: annotation1: "345" annotation2: "456" spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: volume-test-container image: gcr.io/google_containers/busybox command: ["sh", "-c", "cat /tmp/etc/pod_labels /tmp/etc/pod_annotations"] volumeMounts: - name: podinfo mountPath: /tmp/etc readOnly: false securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] volumes: - name: podinfo downwardAPI: defaultMode: 420 items: - fieldRef: fieldPath: metadata.name path: pod_name - fieldRef: fieldPath: metadata.namespace path: pod_namespace - fieldRef: fieldPath: metadata.labels path: pod_labels - fieldRef: fieldPath: metadata.annotations path: pod_annotations restartPolicy: Never # ...Create the pod from the
volume-pod.yamlfile by using the following command:$ oc create -f volume-pod.yaml
Verification
Check the container logs and verify the presence of the configured fields by using the following command:
$ oc logs -p dapi-volume-test-podExample output
cluster=downward-api-test-cluster1 rack=rack-123 zone=us-east-coast annotation1=345 annotation2=456 kubernetes.io/config.source=api
7.5.3. Understanding how to consume container resources using the Downward API
When creating pods, you can use the Downward API to inject information about computing resource requests and limits so that image and application authors can correctly create an image for specific environments.
You can do this using environment variable or a volume plugin.
7.5.3.1. Consuming container resources using environment variables
When creating pods, you can use the Downward API to inject information about computing resource requests and limits by using environment variables that correspond to the contents of the resources field in the spec.container field.
If the resource limits are not included in the container configuration, the downward API defaults to the node’s CPU and memory allocatable values.
Procedure
Create a new pod spec that contains the resources you want to inject:
Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: containers: - name: test-container image: gcr.io/google_containers/busybox:1.24 command: [ "/bin/sh", "-c", "env" ] resources: requests: memory: "32Mi" cpu: "125m" limits: memory: "64Mi" cpu: "250m" env: - name: MY_CPU_REQUEST valueFrom: resourceFieldRef: resource: requests.cpu - name: MY_CPU_LIMIT valueFrom: resourceFieldRef: resource: limits.cpu - name: MY_MEM_REQUEST valueFrom: resourceFieldRef: resource: requests.memory - name: MY_MEM_LIMIT valueFrom: resourceFieldRef: resource: limits.memory # ...Create the pod from the
pod.yamlfile by using the following command:$ oc create -f pod.yaml
7.5.3.2. Consuming container resources using a volume plugin
When creating pods, you can use the Downward API to inject information about computing resource requests and limits by using a volume plugin to describe the desired resources that correspond to the spec.resources field.
If the resource limits are not included in the container configuration, the Downward API defaults to the node’s CPU and memory allocatable values.
Procedure
Create a new pod spec that contains the resources you want to inject:
Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: containers: - name: client-container image: gcr.io/google_containers/busybox:1.24 command: ["sh", "-c", "while true; do echo; if [[ -e /etc/cpu_limit ]]; then cat /etc/cpu_limit; fi; if [[ -e /etc/cpu_request ]]; then cat /etc/cpu_request; fi; if [[ -e /etc/mem_limit ]]; then cat /etc/mem_limit; fi; if [[ -e /etc/mem_request ]]; then cat /etc/mem_request; fi; sleep 5; done"] resources: requests: memory: "32Mi" cpu: "125m" limits: memory: "64Mi" cpu: "250m" volumeMounts: - name: podinfo mountPath: /etc readOnly: false volumes: - name: podinfo downwardAPI: items: - path: "cpu_limit" resourceFieldRef: containerName: client-container resource: limits.cpu - path: "cpu_request" resourceFieldRef: containerName: client-container resource: requests.cpu - path: "mem_limit" resourceFieldRef: containerName: client-container resource: limits.memory - path: "mem_request" resourceFieldRef: containerName: client-container resource: requests.memory # ...Create the pod from the
volume-pod.yamlfile by using the following command:$ oc create -f volume-pod.yaml
7.5.4. Consuming secrets using the Downward API
When creating pods, you can use the downward API to inject secrets so image and application authors can create an image for specific environments.
Procedure
Create a secret to inject:
Create a
secret.yamlfile similar to the following:apiVersion: v1 kind: Secret metadata: name: mysecret data: password: <password> username: <username> type: kubernetes.io/basic-authCreate the secret object from the
secret.yamlfile by using the following command:$ oc create -f secret.yaml
Create a pod that references the
usernamefield from the aboveSecretobject:Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: env-test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env: - name: MY_SECRET_USERNAME valueFrom: secretKeyRef: name: mysecret key: username securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Never # ...Create the pod from the
pod.yamlfile by using the following command:$ oc create -f pod.yaml
Verification
Check the container logs for the
MY_SECRET_USERNAMEvalue by using the following command:$ oc logs -p dapi-env-test-pod
7.5.5. Consuming configuration maps using the Downward API
When creating pods, you can use the Downward API to inject configuration map values so that image and application authors can create an image for specific environments.
Procedure
Create a config map with the values to inject:
Create a
configmap.yamlfile similar to the following:apiVersion: v1 kind: ConfigMap metadata: name: myconfigmap data: mykey: myvalueCreate the config map from the
configmap.yamlfile by using the following command:$ oc create -f configmap.yaml
Create a pod that references the above config map:
Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: env-test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env: - name: MY_CONFIGMAP_VALUE valueFrom: configMapKeyRef: name: myconfigmap key: mykey securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Always # ...Create the pod from the
pod.yamlfile by using the following command:$ oc create -f pod.yaml
Verification
Check the container’s logs for the
MY_CONFIGMAP_VALUEvalue by using the following command:$ oc logs -p dapi-env-test-pod
7.5.6. Referencing environment variables
When creating pods, you can reference the value of a previously defined environment variable by using the $() syntax. By using this syntax, you can reference variables that you define within a pod configuration elsewhere in that configuration.
If the environment variable reference cannot be resolved, the value will be left as the provided string.
Procedure
Create a pod that references an existing environment variable:
Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: env-test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env: - name: MY_EXISTING_ENV value: my_value - name: MY_ENV_VAR_REF_ENV value: $(MY_EXISTING_ENV) securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Never # ...Create the pod from the
pod.yamlfile by using the following command:$ oc create -f pod.yaml
Verification
Check the container’s logs for the
MY_ENV_VAR_REF_ENVvalue by using the following command:$ oc logs -p dapi-env-test-pod
7.5.7. Escaping environment variable references
When creating a pod, you can escape an environment variable reference by using a double dollar sign. The value will then be set to a single dollar sign version of the provided value.
Procedure
Create a pod that references an existing environment variable:
Create a
pod.yamlfile similar to the following:apiVersion: v1 kind: Pod metadata: name: dapi-env-test-pod spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: env-test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env: - name: MY_NEW_ENV value: $$(SOME_OTHER_ENV) securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] restartPolicy: Never # ...Create the pod from the
pod.yamlfile by using the following command:$ oc create -f pod.yaml
Verification
Check the container’s logs for the
MY_NEW_ENVvalue by using the following command:$ oc logs -p dapi-env-test-pod
7.6. Copying files to or from Red Hat OpenShift Service on AWS containers
You can use the oc rsync command, or remote sync, to copy local files to or from a remote directory in a Red Hat OpenShift Service on AWS container.
The oc rsync command leverages the local Rsync tool on the client machine and the remote container for tasks such as copying database archives to and from your pods for backup and restore purposes, or copying source code changes into a running pod for development debugging.
If the Rsync tool is not found locally or in the remote container, a tar archive is created locally and sent to the container where the tar utility is used to extract the files. If tar is not available in the remote container, the copy fails.
7.6.1. Understanding how to copy files
You can use the oc rsync command, or remote sync, for copying database archives to and from your pods for backup and restore purposes. You can also use oc rsync to copy source code changes into a running pod for development debugging, when the running pod supports hot reload of source files.
$ oc rsync <source> <destination> [-c <container>]
When using the oc rysnc command, note the following requirements.
- Specifying the Copy Source
The source argument of the
oc rsynccommand must point to either a local directory or a pod directory. Individual files are not supported.When specifying a pod directory, the directory name must be prefixed with the pod name:
<pod name>:<dir>If the directory name ends in a path separator (
/), only the contents of the directory are copied to the destination. Otherwise, the directory and its contents are copied to the destination.- Specifying the Copy Destination
-
The destination argument of the
oc rsynccommand must point to a directory. If the directory does not exist, butrsyncis used for copy, the directory is created for you. - Deleting Files at the Destination
-
The
--deleteflag can be used to delete any files in the remote directory that are not in the local directory. - Continuous Syncing on File Change
Using the
--watchoption causes the command to monitor the source path for any file system changes, and synchronizes changes when they occur. With this argument, the command runs continuously.Synchronization occurs after short quiet periods to ensure a rapidly changing file system does not result in continuous synchronization calls.
When using the
--watchoption, the behavior is effectively the same as manually invokingoc rsyncrepeatedly, including any arguments normally passed tooc rsync. Therefore, you can control the behavior via the same flags used with manual invocations ofoc rsync, such as--delete.
7.6.2. Copying files to and from containers
You can use the oc rsync command for copying local files to or from a container.
Prerequisites
rsync must be installed. The
oc rsynccommand uses the localrsynctool, if present on the client machine and the remote container.If
rsyncis not found locally or in the remote container, a tar archive is created locally and sent to the container where the tar utility is used to extract the files. If tar is not available in the remote container, the copy will fail.The tar copy method does not provide the same functionality as
oc rsync. For example,oc rsynccreates the destination directory if it does not exist and only sends files that are different between the source and the destination.NoteIn Windows, the
cwRsyncclient should be installed and added to the PATH for use with theoc rsynccommand.
Procedure
To copy a local directory to a pod directory:
$ oc rsync <local-dir> <pod-name>:/<remote-dir> -c <container-name>For example:
$ oc rsync /home/user/source devpod1234:/src -c user-containerTo copy a pod directory to a local directory:
$ oc rsync devpod1234:/src /home/user/sourceExample output
$ oc rsync devpod1234:/src/status.txt /home/user/
7.6.3. Using advanced Rsync features
You can use the additional command-line options that are available with the standard rsync command if needed.
The oc rsync command exposes fewer command-line options than standard rsync command. In the case that you want to use a standard rsync command-line option that is not available with the oc rsync command, for example the --exclude-from=FILE option, it might be possible to use standard rsync with the --rsh (-e) option or RSYNC_RSH environment variable as a workaround, as shown in the following examples:
$ rsync --rsh='oc rsh' --exclude-from=<file_name> <local-dir> <pod-name>:/<remote-dir>or:
Export the RSYNC_RSH variable:
$ export RSYNC_RSH='oc rsh'Then, run the rsync command:
$ rsync --exclude-from=<file_name> <local-dir> <pod-name>:/<remote-dir>
Both of the above examples configure the standard rsync command to use oc rsh as its remote shell program to enable it to connect to the remote pod, and are an alternative to running oc rsync.
7.7. Executing remote commands in an Red Hat OpenShift Service on AWS container
You can use the oc exec command to execute remote commands in Red Hat OpenShift Service on AWS containers from your local machine.
7.7.1. Executing remote commands in containers
You can use the OpenShift CLI (oc) to execute remote commands in Red Hat OpenShift Service on AWS containers. By running commands in a container, you can perform troubleshooting, inspect logs, run scripts, and other tasks.
Procedure
Use a command similar to the following to run a command in a container:
$ oc exec <pod> [-c <container>] -- <command> [<arg_1> ... <arg_n>]For example:
$ oc exec mypod dateExample output
Thu Apr 9 02:21:53 UTC 2015ImportantFor security purposes, the
oc execcommand does not work when accessing privileged containers except when the command is executed by acluster-adminuser.
7.7.2. Protocol for initiating a remote command from a client
A client resource in your cluster can initiate the execution of a remote command in a container by issuing a request to the Kubernetes API server.
The following example is the format for a typical request to a Kubernetes API server:
/proxy/nodes/<node_name>/exec/<namespace>/<pod>/<container>?command=<command>where:
<node_name>- Specifies the FQDN of the node.
<namespace>- Specifies the project of the target pod.
<pod>- Specifies the name of the target pod.
<container>- Specifies the name of the target container.
<command>- Specifies the desired command to be executed.
Example request
/proxy/nodes/node123.openshift.com/exec/myns/mypod/mycontainer?command=dateAdditionally, the client can add parameters to the request to indicate any of the following conditions:
- The client should send input to the remote container’s command (stdin).
- The client’s terminal is a TTY.
- The remote container’s command should send output from stdout to the client.
- The remote container’s command should send output from stderr to the client.
After sending an exec request to the API server, the client upgrades the connection to one that supports multiplexed streams; the current implementation uses HTTP/2.
The client creates one stream each for stdin, stdout, and stderr. To distinguish among the streams, the client sets the streamType header on the stream to one of stdin, stdout, or stderr.
The client closes all streams, the upgraded connection, and the underlying connection when it is finished with the remote command execution request.
7.8. Using port forwarding to access applications in a container
You can configure port forwarding to pods, which expose services in your cluster to clients outside of the cluster.
7.8.1. Understanding port forwarding
You can use the OpenShift CLI (oc) to forward one or more local ports to a pod. This allows you to listen on a given or random port locally, and have data forwarded to and from given ports in the pod.
You can use a command similar to the following to forward one or more local ports to a pod.
$ oc port-forward <pod> [<local_port>:]<remote_port> [...[<local_port_n>:]<remote_port_n>]
The OpenShift CLI (oc) listens on each local port specified by the user, forwarding using the protocol described below.
You can specify ports by using the following formats:
|
| The client listens on port 5000 locally and forwards to 5000 in the pod. |
|
| The client listens on port 6000 locally and forwards to 5000 in the pod. |
|
| The client selects a free local port and forwards to 5000 in the pod. |
Red Hat OpenShift Service on AWS handles port-forward requests from clients. Upon receiving a request, Red Hat OpenShift Service on AWS upgrades the response and waits for the client to create port-forwarding streams. When Red Hat OpenShift Service on AWS receives a new stream, it copies data between the stream and the pod’s port.
Architecturally, there are options for forwarding to a pod’s port. The supported Red Hat OpenShift Service on AWS implementation invokes nsenter directly on the node host to enter the pod’s network namespace, then invokes socat to copy data between the stream and the pod’s port. However, a custom implementation could include running a helper pod that then runs nsenter and socat, so that those binaries are not required to be installed on the host.
7.8.2. Using port forwarding
You can use the OpenShift CLI (oc) to port-forward one or more local ports to a pod.
Procedure
Use a command similar to the following to listen on the specified port in a pod:
$ oc port-forward <pod> [<local_port>:]<remote_port> [...[<local_port_n>:]<remote_port_n>]For example, use the following command to listen on ports
5000and6000locally and forward data to and from ports5000and6000in the pod:$ oc port-forward <pod> 5000 6000Example output
Forwarding from 127.0.0.1:5000 -> 5000 Forwarding from [::1]:5000 -> 5000 Forwarding from 127.0.0.1:6000 -> 6000 Forwarding from [::1]:6000 -> 6000For example, use the following command to listen on port
8888locally and forward to5000in the pod:$ oc port-forward <pod> 8888:5000Example output
Forwarding from 127.0.0.1:8888 -> 5000 Forwarding from [::1]:8888 -> 5000For example, use the following command to listen on a free port locally and forward to
5000in the pod:$ oc port-forward <pod> :5000Example output
Forwarding from 127.0.0.1:42390 -> 5000 Forwarding from [::1]:42390 -> 5000Alternatively, use the following command to listen on a free port locally and forward to
5000in the pod:$ oc port-forward <pod> 0:5000
7.8.3. Protocol for initiating port forwarding from a client
A client resource in your cluster can initiate port forwarding to a pod by issuing a request to the Kubernetes API server.
Use a request in the following format:
/proxy/nodes/<node_name>/portForward/<namespace>/<pod>where:
<node_name>- Specifies the FQDN of the node.
<namespace>- Specifies the namespace of the target pod.
<pod>- Specifies the name of the target pod.
Example request
/proxy/nodes/node123.openshift.com/portForward/myns/mypodAfter sending a port forward request to the API server, the client upgrades the connection to one that supports multiplexed streams; the current implementation uses Hyptertext Transfer Protocol Version 2 (HTTP/2).
The client creates a stream with the port header containing the target port in the pod. All data written to the stream is delivered via the kubelet to the target pod and port. Similarly, all data sent from the pod for that forwarded connection is delivered back to the same stream in the client.
The client closes all streams, the upgraded connection, and the underlying connection when it is finished with the port forwarding request.
Chapter 8. Working with clusters
8.1. Viewing system event information in Red Hat OpenShift Service on AWS clusters
You can view events in Red Hat OpenShift Service on AWS, which are based on events that happen to API objects in an Red Hat OpenShift Service on AWS cluster.
8.1.1. Understanding events
Review the following information to learn how Red Hat OpenShift Service on AWS uses events to record information about real-world events in a resource-agnostic manner. Events also allow developers and administrators to consume information about system components in a unified way.
8.1.2. Viewing events using the CLI
You can get a list of events in a given project by using the CLI.
Procedure
View events in a project by using a command similar to the following:
$ oc get events [-n <project>]where:
project- Specifies the name of the project.
For example:
$ oc get events -n openshift-configExample output
LAST SEEN TYPE REASON OBJECT MESSAGE 97m Normal Scheduled pod/dapi-env-test-pod Successfully assigned openshift-config/dapi-env-test-pod to ip-10-0-171-202.ec2.internal 97m Normal Pulling pod/dapi-env-test-pod pulling image "gcr.io/google_containers/busybox" 97m Normal Pulled pod/dapi-env-test-pod Successfully pulled image "gcr.io/google_containers/busybox" 97m Normal Created pod/dapi-env-test-pod Created container 9m5s Warning FailedCreatePodSandBox pod/dapi-volume-test-pod Failed create pod sandbox: rpc error: code = Unknown desc = failed to create pod network sandbox k8s_dapi-volume-test-pod_openshift-config_6bc60c1f-452e-11e9-9140-0eec59c23068_0(748c7a40db3d08c07fb4f9eba774bd5effe5f0d5090a242432a73eee66ba9e22): Multus: Err adding pod to network "ovn-kubernetes": cannot set "ovn-kubernetes" ifname to "eth0": no netns: failed to Statfs "/proc/33366/ns/net": no such file or directory 8m31s Normal Scheduled pod/dapi-volume-test-pod Successfully assigned openshift-config/dapi-volume-test-pod to ip-10-0-171-202.ec2.internal #...View events in your project from the Red Hat OpenShift Service on AWS console:
- Launch the Red Hat OpenShift Service on AWS console.
- Click Home → Events and select your project.
Move to resource that you want to see events. For example: Home → Projects → <project-name> → <resource-name>.
Many objects, such as pods and deployments, also have an Events tab, which shows events related to that object.
8.1.3. List of events
Review the information in this section to learn about Red Hat OpenShift Service on AWS events.
| Name | Description |
|---|---|
|
| Failed pod configuration validation. |
| Name | Description |
|---|---|
|
| Back-off restarting failed the container. |
|
| Container created. |
|
| Pull/Create/Start failed. |
|
| Killing the container. |
|
| Container started. |
|
| Preempting other pods. |
|
| Container runtime did not stop the pod within specified grace period. |
| Name | Description |
|---|---|
|
| Container is unhealthy. |
| Name | Description |
|---|---|
|
| Back off Ctr Start, image pull. |
|
| The image’s NeverPull Policy is violated. |
|
| Failed to pull the image. |
|
| Failed to inspect the image. |
|
| Successfully pulled the image or the container image is already present on the machine. |
|
| Pulling the image. |
| Name | Description |
|---|---|
|
| Free disk space failed. |
|
| Invalid disk capacity. |
| Name | Description |
|---|---|
|
| Volume mount failed. |
|
| Host network not supported. |
|
| Host/port conflict. |
|
| Kubelet setup failed. |
|
| Undefined shaper. |
|
| Node is not ready. |
|
| Node is not schedulable. |
|
| Node is ready. |
|
| Node is schedulable. |
|
| Node selector mismatch. |
|
| Out of disk. |
|
| Node rebooted. |
|
| Starting kubelet. |
|
| Failed to attach volume. |
|
| Failed to detach volume. |
|
| Failed to expand/reduce volume. |
|
| Successfully expanded/reduced volume. |
|
| Failed to expand/reduce file system. |
|
| Successfully expanded/reduced file system. |
|
| Failed to unmount volume. |
|
| Failed to map a volume. |
|
| Failed unmaped device. |
|
| Volume is already mounted. |
|
| Volume is successfully detached. |
|
| Volume is successfully mounted. |
|
| Volume is successfully unmounted. |
|
| Container garbage collection failed. |
|
| Image garbage collection failed. |
|
| Failed to enforce System Reserved Cgroup limit. |
|
| Enforced System Reserved Cgroup limit. |
|
| Unsupported mount option. |
|
| Pod sandbox changed. |
|
| Failed to create pod sandbox. |
|
| Failed pod sandbox status. |
| Name | Description |
|---|---|
|
| Pod sync failed. |
| Name | Description |
|---|---|
|
| There is an OOM (out of memory) situation on the cluster. |
| Name | Description |
|---|---|
|
| Failed to stop a pod. |
|
| Failed to create a pod container. |
|
| Failed to make pod data directories. |
|
| Network is not ready. |
|
|
Error creating: |
|
|
Created pod: |
|
|
Error deleting: |
|
|
Deleted pod: |
| Name | Description |
|---|---|
| SelectorRequired | Selector is required. |
|
| Could not convert selector into a corresponding internal selector object. |
|
| HPA was unable to compute the replica count. |
|
| Unknown metric source type. |
|
| HPA was able to successfully calculate a replica count. |
|
| Failed to convert the given HPA. |
|
| HPA controller was unable to get the target’s current scale. |
|
| HPA controller was able to get the target’s current scale. |
|
| Failed to compute desired number of replicas based on listed metrics. |
|
|
New size: |
|
|
New size: |
|
| Failed to update status. |
| Name | Description |
|---|---|
|
| There are no persistent volumes available and no storage class is set. |
|
| Volume size or class is different from what is requested in claim. |
|
| Error creating recycler pod. |
|
| Occurs when volume is recycled. |
|
| Occurs when pod is recycled. |
|
| Occurs when volume is deleted. |
|
| Error when deleting the volume. |
|
| Occurs when volume for the claim is provisioned either manually or via external software. |
|
| Failed to provision volume. |
|
| Error cleaning provisioned volume. |
|
| Occurs when the volume is provisioned successfully. |
|
| Delay binding until pod scheduling. |
| Name | Description |
|---|---|
|
| Handler failed for pod start. |
|
| Handler failed for pre-stop. |
|
| Pre-stop hook unfinished. |
| Name | Description |
|---|---|
|
| Failed to cancel deployment. |
|
| Canceled deployment. |
|
| Created new replication controller. |
|
| No available Ingress IP to allocate to service. |
| Name | Description |
|---|---|
|
|
Failed to schedule pod: |
|
|
By |
|
|
Successfully assigned |
| Name | Description |
|---|---|
|
| This daemon set is selecting all pods. A non-empty selector is required. |
|
|
Failed to place pod on |
|
|
Found failed daemon pod |
| Name | Description |
|---|---|
|
| Error creating load balancer. |
|
| Deleting load balancer. |
|
| Ensuring load balancer. |
|
| Ensured load balancer. |
|
|
There are no available nodes for |
|
|
Lists the new |
|
|
Lists the new IP address. For example, |
|
|
Lists external IP address. For example, |
|
|
Lists the new UID. For example, |
|
|
Lists the new |
|
|
Lists the new |
|
| Updated load balancer with new hosts. |
|
| Error updating load balancer with new hosts. |
|
| Deleting load balancer. |
|
| Error deleting load balancer. |
|
| Deleted load balancer. |
8.2. Estimating the number of pods your Red Hat OpenShift Service on AWS nodes can hold
As a cluster administrator, you can use the OpenShift Cluster Capacity Tool to view the number of pods that can be scheduled in your cluster. This allows you to increase the current resources before they become exhausted and to ensure any future pods can be scheduled. This capacity comes from an individual node host in a cluster, and includes CPU, memory, disk space, and others.
8.2.1. Understanding the OpenShift Cluster Capacity Tool
Review the following information to learn how to use the OpenShift Cluster Capacity Tool to simulate a sequence of scheduling decisions that determine how many instances of an input pod can be scheduled on the cluster before the cluster is exhausted of resources.
The remaining allocatable capacity is a rough estimation, because it does not count all of the resources being distributed among nodes. It analyzes only the remaining resources and estimates the available capacity that is still consumable in terms of the number of instances of a pod with given requirements that can be scheduled in a cluster.
Also, pods might only have scheduling support on particular sets of nodes based on its selection and affinity criteria. As a result, the estimation of which remaining pods a cluster can schedule can be difficult.
You can run the OpenShift Cluster Capacity Tool as a stand-alone utility from the command line, or as a job in a pod inside an Red Hat OpenShift Service on AWS cluster. Running the tool as job inside of a pod enables you to run it multiple times without intervention.
8.2.2. Running the OpenShift Cluster Capacity Tool on the command line
You can run the OpenShift Cluster Capacity Tool from the command line to estimate the number of pods that can be scheduled onto your cluster.
You create a sample pod spec file, which the tool uses for estimating resource usage. The pod spec specifies its resource requirements as limits or requests. The cluster capacity tool takes the pod’s resource requirements into account for its estimation analysis.
Prerequisites
- Run the OpenShift Cluster Capacity Tool, which is available as a container image from the Red Hat Ecosystem Catalog. See the link in the "Additional resources" section.
Create a sample pod spec file:
Create a YAML file similar to the following:
apiVersion: v1 kind: Pod metadata: name: small-pod labels: app: guestbook tier: frontend spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: php-redis image: gcr.io/google-samples/gb-frontend:v4 imagePullPolicy: Always resources: limits: cpu: 150m memory: 100Mi requests: cpu: 150m memory: 100Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]Create the cluster role:
$ oc create -f <file_name>.yamlFor example:
$ oc create -f pod-spec.yaml
Procedure
From the terminal, log in to the Red Hat Registry:
$ podman login registry.redhat.ioPull the cluster capacity tool image:
$ podman pull registry.redhat.io/openshift4/ose-cluster-capacityRun the cluster capacity tool:
$ podman run -v $HOME/.kube:/kube:Z -v $(pwd):/cc:Z ose-cluster-capacity \ /bin/cluster-capacity --kubeconfig /kube/config --<pod_spec>.yaml /cc/<pod_spec>.yaml \ --verbosewhere:
- <pod_spec>.yaml
- Specifies the pod spec to use.
- verbose
- Outputs a detailed description of how many pods can be scheduled on each node in the cluster.
Example output
small-pod pod requirements: - CPU: 150m - Memory: 100Mi The cluster can schedule 88 instance(s) of the pod small-pod. Termination reason: Unschedulable: 0/5 nodes are available: 2 Insufficient cpu, 3 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate. Pod distribution among nodes: small-pod - 192.168.124.214: 45 instance(s) - 192.168.124.120: 43 instance(s)In the above example, the number of estimated pods that can be scheduled onto the cluster is 88.
8.2.3. Running the OpenShift Cluster Capacity Tool as a job inside a pod
You can run the OpenShift Cluster Capacity Tool as a job inside of a pod by using a ConfigMap object. This allows you to run the tool multiple times without needing user intervention.
Prerequisites
-
Download and install the OpenShift Cluster Capacity Tool from the
cluster-capacityrepository. See the link in the "Additional resources" section.
Procedure
Create the cluster role:
Create a YAML file similar to the following:
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cluster-capacity-role rules: - apiGroups: [""] resources: ["pods", "nodes", "persistentvolumeclaims", "persistentvolumes", "services", "replicationcontrollers"] verbs: ["get", "watch", "list"] - apiGroups: ["apps"] resources: ["replicasets", "statefulsets"] verbs: ["get", "watch", "list"] - apiGroups: ["policy"] resources: ["poddisruptionbudgets"] verbs: ["get", "watch", "list"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "watch", "list"]Create the cluster role by running the following command:
$ oc create -f <file_name>.yamlFor example:
$ oc create sa cluster-capacity-sa
Create the service account:
$ oc create sa cluster-capacity-sa -n defaultAdd the role to the service account:
$ oc adm policy add-cluster-role-to-user cluster-capacity-role \ system:serviceaccount:<namespace>:cluster-capacity-sawhere:
- <namespace>
- Specifies the namespace where the pod is located.
Define and create the pod spec:
Create a YAML file similar to the following:
apiVersion: v1 kind: Pod metadata: name: small-pod labels: app: guestbook tier: frontend spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: php-redis image: gcr.io/google-samples/gb-frontend:v4 imagePullPolicy: Always resources: limits: cpu: 150m memory: 100Mi requests: cpu: 150m memory: 100Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]Create the pod by running the following command:
$ oc create -f <file_name>.yamlFor example:
$ oc create -f pod.yaml
Created a config map object by running the following command:
$ oc create configmap cluster-capacity-configmap \ --from-file=pod.yaml=pod.yamlThe cluster capacity analysis is mounted in a volume using a config map object named
cluster-capacity-configmapto mount the input pod spec filepod.yamlinto a volumetest-volumeat the path/test-pod.Create the job using the below example of a job specification file:
Create a YAML file similar to the following:
apiVersion: batch/v1 kind: Job metadata: name: cluster-capacity-job spec: parallelism: 1 completions: 1 template: metadata: name: cluster-capacity-pod spec: containers: - name: cluster-capacity image: openshift/origin-cluster-capacity imagePullPolicy: "Always" volumeMounts: - mountPath: /test-pod name: test-volume env: - name: CC_INCLUSTER value: "true" command: - "/bin/sh" - "-ec" - | /bin/cluster-capacity --podspec=/test-pod/pod.yaml --verbose restartPolicy: "Never" serviceAccountName: cluster-capacity-sa volumes: - name: test-volume configMap: name: cluster-capacity-configmapwhere:
spec.template.spec.containers.env-
Specifies a required environment variable that indicates the Cluster Capacity Tool is running inside a cluster as a pod.
Thepod.yamlkey of theConfigMapobject is the same as thePodspec file name, though it is not required. By doing this, the input pod spec file can be accessed inside the pod as/test-pod/pod.yaml.
Run the cluster capacity image as a job in a pod by running the following command:
$ oc create -f cluster-capacity-job.yaml
Verification
Check the job logs to find the number of pods that can be scheduled in the cluster:
$ oc logs jobs/cluster-capacity-jobExample output
small-pod pod requirements: - CPU: 150m - Memory: 100Mi The cluster can schedule 52 instance(s) of the pod small-pod. Termination reason: Unschedulable: No nodes are available that match all of the following predicates:: Insufficient cpu (2). Pod distribution among nodes: small-pod - 192.168.124.214: 26 instance(s) - 192.168.124.120: 26 instance(s)
8.3. Restrict resource consumption with limit ranges
You can use limit ranges to restrict resource consumption for specific objects in a project.
By default, containers run with unbounded compute resources on an Red Hat OpenShift Service on AWS cluster.
You can configure resource consumption for the following objects:
- pods and containers: You can set minimum and maximum requirements for CPU and memory for pods and their containers.
-
Image streams: You can set limits on the number of images and tags in an
ImageStreamobject. - Images: You can limit the size of images that can be pushed to an internal registry.
- Persistent volume claims (PVC): You can restrict the size of the PVCs that can be requested.
If a pod does not meet the constraints imposed by the limit range, the pod cannot be created in the namespace.
8.3.1. About limit ranges
You can set specific resource limits for a pod, container, image, image stream, or persistent volume claim (PVC) in a specific project by defining a LimitRange object. A limit range allows you to restrict resource consumption in that project.
All requests to create and modify resources are evaluated against each LimitRange object in the project. If the resource violates any of the enumerated constraints, the resource is rejected.
The following shows a limit range object for all components: pod, container, image, image stream, or PVC. You can configure limits for any or all of these components in the same object. You create a different limit range object for each project where you want to control resources.
Sample limit range object for a container
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "resource-limits"
spec:
limits:
- type: "Container"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "100m"
memory: "4Mi"
default:
cpu: "300m"
memory: "200Mi"
defaultRequest:
cpu: "200m"
memory: "100Mi"
maxLimitRequestRatio:
cpu: "10"8.3.2. About component limits
Review the following examples to learn the limit range parameters for each component for when you create or edit a LimitRange object.
The examples are broken out for clarity. You can create a single LimitRange object for any or all components as necessary.
- Container limits
A limit range allows you to specify the minimum and maximum CPU and memory that each container in a pod can request for a specific project. If a container is created in the project, the container CPU and memory requests in the
Podspec must comply with the values set in theLimitRangeobject. If not, the pod does not get created. The following requirements must hold true:-
The container CPU or memory request and limit must be greater than or equal to the
minresource constraint for containers that are specified in theLimitRangeobject. -
The container CPU or memory request and limit must be less than or equal to the
maxresource constraint for containers that are specified in theLimitRangeobject.
If the
LimitRangeobject defines amaxCPU, you do not need to define a CPUrequestvalue in thePodspec. But you must specify a CPUlimitvalue that satisfies the maximum CPU constraint specified in the limit range. The following requirements must hold true:The ratio of the container limits to requests must be less than or equal to the
maxLimitRequestRatiovalue for containers that is specified in theLimitRangeobject.If the
LimitRangeobject defines amaxLimitRequestRatioconstraint, any new containers must have both arequestand alimitvalue. Red Hat OpenShift Service on AWS calculates the limit-to-request ratio by dividing thelimitby therequest. This value should be a non-negative integer greater than 1.For example, if a container has
cpu: 500in thelimitvalue, andcpu: 100in therequestvalue, the limit-to-request ratio forcpuis5. This ratio must be less than or equal to themaxLimitRequestRatio.
If the
Podspec does not specify a container resource memory or limit, thedefaultordefaultRequestCPU and memory values for containers specified in the limit range object are assigned to the container.Container
LimitRangeobject definitionapiVersion: "v1" kind: "LimitRange" metadata: name: "resource-limits" spec: limits: - type: "Container" max: cpu: "2" memory: "1Gi" min: cpu: "100m" memory: "4Mi" default: cpu: "300m" memory: "200Mi" defaultRequest: cpu: "200m" memory: "100Mi" maxLimitRequestRatio: cpu: "10"where:
metadata.name- Specifies the name of the limit range object.
spec.limit.max.cpu- Specifies the maximum amount of CPU that a single container in a pod can request.
spec.limit.max.memory- Specifies the maximum amount of memory that a single container in a pod can request.
spec.limit.min.cpu- Specifies the minimum amount of CPU that a single container in a pod can request.
spec.limit.min.memory- Specifies the minimum amount of memory that a single container in a pod can request.
spec.limit.default.cpu-
Specifies the default amount of CPU that a container can use if not specified in the
Podspec. spec.limit.default.memory-
Specifies the default amount of memory that a container can use if not specified in the
Podspec. spec.limit.defaultRequest.cpu-
Specifies the default amount of CPU that a container can request if not specified in the
Podspec. spec.limit.defaultRequest.memory-
Specifies the default amount of memory that a container can request if not specified in the
Podspec. spec.limit.maxLimitRequestRatio.cpu- Specifies the maximum limit-to-request ratio for a container.
-
The container CPU or memory request and limit must be greater than or equal to the
- Pod limits
A limit range allows you to specify the minimum and maximum CPU and memory limits for all containers across a pod in a given project. To create a container in the project, the container CPU and memory requests in the
Podspec must comply with the values set in theLimitRangeobject. If not, the pod does not get created.If the
Podspec does not specify a container resource memory or limit, thedefaultordefaultRequestCPU and memory values for containers specified in the limit range object are assigned to the container.Across all containers in a pod, the following requirements must hold true:
-
The container CPU or memory request and limit must be greater than or equal to the
minresource constraints for pods that are specified in theLimitRangeobject. -
The container CPU or memory request and limit must be less than or equal to the
maxresource constraints for pods that are specified in theLimitRangeobject. -
The ratio of the container limits to requests must be less than or equal to the
maxLimitRequestRatioconstraint specified in theLimitRangeobject.
Pod
LimitRangeobject definitionapiVersion: "v1" kind: "LimitRange" metadata: name: "resource-limits" spec: limits: - type: "Pod" max: cpu: "2" memory: "1Gi" min: cpu: "200m" memory: "6Mi" maxLimitRequestRatio: cpu: "10"where:
metadata.name- Specifies the name of the limit range object.
spec.limit.max.cpu- Specifies the maximum amount of CPU that a pod can request across all containers.
spec.limit.max.memory- Specifies the maximum amount of memory that a pod can request across all containers.
spec.limit.min.cpu- Specifies the minimum amount of CPU that a pod can request across all containers.
spec.limit.min.memory- Specifies the minimum amount of memory that a pod can request across all containers.
spec.limit.maxLimitRequestRatio.cpu- Specifies the maximum limit-to-request ratio for a container.
-
The container CPU or memory request and limit must be greater than or equal to the
- Image limits
A limit range allows you to specify the maximum size of an image that can be pushed to an OpenShift image registry.
When pushing images to an OpenShift image registry, the following requirement must hold true:
-
The size of the image must be less than or equal to the
maxsize for images that is specified in theLimitRangeobject.
Image
LimitRangeobject definitionapiVersion: "v1" kind: "LimitRange" metadata: name: "resource-limits" spec: limits: - type: openshift.io/Image max: storage: 1Giwhere:
metadata.name- Specifies the name of the limit range object.
spec.limit.max.storage- Specifies the maximum size of an image that can be pushed to an OpenShift image registry.
WarningThe image size is not always available in the manifest of an uploaded image. This is especially the case for images built with Docker 1.10 or higher and pushed to a v2 registry. If such an image is pulled with an older Docker daemon, the image manifest is converted by the registry to schema v1 lacking all the size information. No storage limit set on images prevent it from being uploaded.
-
The size of the image must be less than or equal to the
- Image stream limits
A limit range allows you to specify limits for image streams.
For each image stream, the following requirements must hold true:
-
The number of image tags in an
ImageStreamspecification must be less than or equal to theopenshift.io/image-tagsconstraint in theLimitRangeobject. -
The number of unique references to images in an
ImageStreamspecification must be less than or equal to theopenshift.io/imagesconstraint in the limit range object.
Imagestream
LimitRangeobject definitionapiVersion: "v1" kind: "LimitRange" metadata: name: "resource-limits" spec: limits: - type: openshift.io/ImageStream max: openshift.io/image-tags: 20 openshift.io/images: 30where
metadata.name-
Specifies the name of the
LimitRangeobject. spec.limit.max.openshift.io/image-tags-
Specifies the maximum number of unique image tags in the
imagestream.spec.tagsparameter in imagestream spec. spec.limit.max.openshift.io/images-
Specifies the maximum number of unique image references in the
imagestream.status.tagsparameter in theimagestreamspec.
The
openshift.io/image-tagsresource represents unique image references. Possible references are anImageStreamTag, anImageStreamImageand aDockerImage. Tags can be created using theoc tagandoc import-imagecommands. No distinction is made between internal and external references. However, each unique reference tagged in anImageStreamspecification is counted just once. It does not restrict pushes to an internal container image registry in any way, but is useful for tag restriction.The
openshift.io/imagesresource represents unique image names recorded in image stream status. It allows for restriction of a specific number of images that can be pushed to the OpenShift image registry. Internal and external references are not distinguished.-
The number of image tags in an
- Persistent volume claim limits
A limit range allows you to restrict the storage requested in a persistent volume claim (PVC).
Across all persistent volume claims in a project, the following requirements must hold true:
-
The resource request in a persistent volume claim (PVC) must be greater than or equal the
minconstraint for PVCs that is specified in theLimitRangeobject. -
The resource request in a persistent volume claim (PVC) must be less than or equal the
maxconstraint for PVCs that is specified in theLimitRangeobject.
PVC
LimitRangeobject definitionapiVersion: "v1" kind: "LimitRange" metadata: name: "resource-limits" spec: limits: - type: "PersistentVolumeClaim" min: storage: "2Gi" max: storage: "50Gi"where:
metadata.name-
Specifies the name of the
LimitRangeobject. spec.limit.min.storage- Specifies the minimum amount of storage that can be requested in a persistent volume claim.
spec.limit.max.storage- Specifies the maximum amount of storage that can be requested in a persistent volume claim.
-
The resource request in a persistent volume claim (PVC) must be greater than or equal the
8.3.3. Creating a Limit Range
You can define LimitRange objects to set specific resource limits for a pod, container, image, image stream, or persistent volume claim (PVC) in a specific project. A limit range allows you to restrict resource consumption in that project.
Procedure
Create a
LimitRangeobject with your required specifications:apiVersion: "v1" kind: "LimitRange" metadata: name: "resource-limits" spec: limits: - type: "Pod" max: cpu: "2" memory: "1Gi" min: cpu: "200m" memory: "6Mi" - type: "Container" max: cpu: "2" memory: "1Gi" min: cpu: "100m" memory: "4Mi" default: cpu: "300m" memory: "200Mi" defaultRequest: cpu: "200m" memory: "100Mi" maxLimitRequestRatio: cpu: "10" - type: openshift.io/Image max: storage: 1Gi - type: openshift.io/ImageStream max: openshift.io/image-tags: 20 openshift.io/images: 30 - type: "PersistentVolumeClaim" min: storage: "2Gi" max: storage: "50Gi"where:
metadata.name-
Specifies a name for the
LimitRangeobject. spec.limit.type.Pod- Specifies limits for a pod, specify the minimum and maximum CPU and memory requests as needed.
spec.limit.type.Container- Specifies limits for a container, specify the minimum and maximum CPU and memory requests as needed.
spec.limit.type.default-
For a container, specifies the default amount of CPU or memory that a container can use, if not specified in the
Podspec. This parameter is optional. spec.limit.type.defaultRequest-
For a container, specifies the default amount of CPU or memory that a container can request, if not specified in the
Podspec. This parameter is optional. spec.limit.type.maxLimitRequestRatio-
For a container, specifies the maximum limit-to-request ratio that can be specified in the
Podspec. This parameter is optional. spec.limit.type.openshift.io/Image- Specifies limits for an image object. Set the maximum size of an image that can be pushed to an OpenShift image registry.
spec.limit.type.openshift.io/ImageStream-
Specifies limits for an image stream. Set the maximum number of image tags and references that can be in the
ImageStreamobject file, as needed. spec.limit.type.openshift.io/PersistentVolueClaim- Specifies limits for a persistent volume claim. Set the minimum and maximum amount of storage that can be requested.
Create the object:
$ oc create -f <limit_range_file> -n <project>where:
<limit_range_file>- Specifies the name of the YAML file you created.
<project>- Specifies the project where you want the limits to apply.
8.3.4. Viewing a limit
You can view the limits defined in a project by navigating in the web console to the project’s Quota page. This allows you to see details about each of the limit ranges in a project.
You can also use the CLI to view limit range details:
Procedure
Get the list of
LimitRangeobjects defined in the project. For example, for a project called demoproject:$ oc get limits -n demoprojectNAME CREATED AT resource-limits 2020-07-15T17:14:23ZDescribe the
LimitRangeobject you are interested in, for example theresource-limitslimit range:$ oc describe limits resource-limits -n demoprojectName: resource-limits Namespace: demoproject Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio ---- -------- --- --- --------------- ------------- ----------------------- Pod cpu 200m 2 - - - Pod memory 6Mi 1Gi - - - Container cpu 100m 2 200m 300m 10 Container memory 4Mi 1Gi 100Mi 200Mi - openshift.io/Image storage - 1Gi - - - openshift.io/ImageStream openshift.io/image - 12 - - - openshift.io/ImageStream openshift.io/image-tags - 10 - - - PersistentVolumeClaim storage - 50Gi - - -
8.3.5. Deleting a Limit Range
You can remove any active LimitRange object so that it no longer enforces the limits in a project.
Procedure
Run the following command:
$ oc delete limits <limit_name>
8.4. Configuring cluster memory to meet container memory and risk requirements
As a cluster administrator, you can manage application memory usage to help your clusters operate more efficiently.
You can perform any of the following tasks to manage application memory:
- Determine the memory and risk requirements of a containerized application component and configuring the container memory parameters to suit those requirements.
- Configure containerized application runtimes (for example, OpenJDK) to adhere optimally to the configured container memory parameters.
- Diagnose and resolve memory-related error conditions associated with running in a container.
8.4.1. Understanding how to manage application memory
You can review the following concepts to learn how Red Hat OpenShift Service on AWS manages compute resources so that you can lean how to keep your cluster running efficiently.
For each kind of resource (memory, CPU, storage), Red Hat OpenShift Service on AWS allows optional request and limit values to be placed on each container in a pod.
Note the following information about memory requests and memory limits:
Memory request
- The memory request value, if specified, influences the Red Hat OpenShift Service on AWS scheduler. The scheduler considers the memory request when scheduling a container to a node, then fences off the requested memory on the chosen node for the use of the container.
- If a node’s memory is exhausted, Red Hat OpenShift Service on AWS prioritizes evicting its containers whose memory usage most exceeds their memory request. In serious cases of memory exhaustion, the node OOM killer might select and kill a process in a container based on a similar metric.
- The cluster administrator can assign quota or assign default values for the memory request value.
- The cluster administrator can override the memory request values that a developer specifies, to manage cluster overcommit.
Memory limit
- The memory limit value, if specified, provides a hard limit on the memory that can be allocated across all the processes in a container.
- If the memory allocated by all of the processes in a container exceeds the memory limit, the node Out of Memory (OOM) killer immediately selects and kills a process in the container.
- If both memory request and limit are specified, the memory limit value must be greater than or equal to the memory request.
- The cluster administrator can assign quota or assign default values for the memory limit value.
-
The minimum memory limit is 12 MB. If a container fails to start due to a
Cannot allocate memorypod event, the memory limit is too low. Either increase or remove the memory limit. Removing the limit allows pods to consume unbounded node resources.
The steps for sizing application memory on Red Hat OpenShift Service on AWS are as follows:
Determine expected container memory usage
Determine expected mean and peak container memory usage. For example, you could perform separate load testing. Remember to consider all the processes that could potentially run in parallel in the container, such as any ancillary scripts that might be spawned by the main application.
Determine risk appetite
Determine risk appetite for eviction. If the risk appetite is low, the container should request memory according to the expected peak usage plus a percentage safety margin. If the risk appetite is higher, it might be more appropriate to request memory according to the expected mean usage.
Set container memory request
Set the container memory request based on the above. The request should represent the application memory usage as accurately as possible. If the request is too high, cluster and quota usage will be inefficient. If the request is too low, the chances of application eviction increase.
Set container memory limit, if required
Set the container memory limit, if required. Setting a limit has the effect of immediately killing a container process if the combined memory usage of all processes in the container exceeds the limit. Setting a limit might make unanticipated excess memory usage obvious early (fail fast). However, setting a limit also terminates processes abruptly.
Note that some Red Hat OpenShift Service on AWS clusters might require a limit value to be set; some might override the request based on the limit; and some application images rely on a limit value being set as this is easier to detect than a request value.
If the memory limit is set, it should not be set to less than the expected peak container memory usage plus a percentage safety margin.
Ensure applications are tuned
Ensure your applications are tuned with respect to configured request and limit values, if appropriate. This step is particularly relevant to applications which pool memory, such as the JVM. The rest of this page discusses this.
8.4.2. Understanding OpenJDK settings for Red Hat OpenShift Service on AWS
You can review the following concepts to learn about how to deploy OpenJDK applications in your cluster effectively.
The default OpenJDK settings do not work well with containerized environments. As a result, some additional Java memory settings must always be provided whenever running the OpenJDK in a container.
The JVM memory layout is complex, version dependent, and describing it in detail is beyond the scope of this documentation. However, as a starting point for running OpenJDK in a container, at least the following three memory-related tasks are key:
- Overriding the JVM maximum heap size
OpenJDK defaults to using a maximum of 25% of available memory (recognizing any container memory limits in place) for heap memory. This default value is conservative, and, in a properly-configured container environment, would result in 75% of the memory assigned to a container being mostly unused. A much higher percentage for the JVM to use for heap memory, such as 80%, is more suitable in a container context where memory limits are imposed on the container level.
Most of the Red Hat containers include a startup script that replaces the OpenJDK default by setting updated values when the JVM launches.
For example, the Red Hat build of OpenJDK containers have a default value of 80%. This value can be set to a different percentage by defining the
JAVA_MAX_RAM_RATIOenvironment variable.For other OpenJDK deployements, the default value of 25% can be changed using the following command:
Example
$ java -XX:MaxRAMPercentage=80.0- Encouraging the JVM to release unused memory to the operating system, if appropriate
By default, the OpenJDK does not aggressively return unused memory to the operating system. This could be appropriate for many containerized Java workloads, but notable exceptions include workloads where additional active processes co-exist with a JVM within a container, whether those additional processes are native, additional JVMs, or a combination of the two.
Java-based agents can use the following JVM arguments to encourage the JVM to release unused memory to the operating system:
-XX:+UseParallelGC -XX:MinHeapFreeRatio=5 -XX:MaxHeapFreeRatio=10 -XX:GCTimeRatio=4 -XX:AdaptiveSizePolicyWeight=90These arguments are intended to return heap memory to the operating system whenever allocated memory exceeds 110% of in-use memory (
-XX:MaxHeapFreeRatio), spending up to 20% of CPU time in the garbage collector (-XX:GCTimeRatio). At no time will the application heap allocation be less than the initial heap allocation (overridden by-XX:InitialHeapSize/-Xms). Detailed additional information is available Tuning Java’s footprint in OpenShift (Part 1), Tuning Java’s footprint in OpenShift (Part 2), and at OpenJDK and Containers.- Ensuring all JVM processes within a container are appropriately configured
In the case that multiple JVMs run in the same container, it is essential to ensure that they are all configured appropriately. For many workloads it will be necessary to grant each JVM a percentage memory budget, leaving a perhaps substantial additional safety margin.
Many Java tools use different environment variables (
JAVA_OPTS,GRADLE_OPTS, and so on) to configure their JVMs and it can be challenging to ensure that the right settings are being passed to the right JVM.The
JAVA_TOOL_OPTIONSenvironment variable is always respected by the OpenJDK, and values specified inJAVA_TOOL_OPTIONSwill be overridden by other options specified on the JVM command line. By default, to ensure that these options are used by default for all JVM workloads run in the Java-based agent image, the Red Hat OpenShift Service on AWS Jenkins Maven agent image sets the following variable:JAVA_TOOL_OPTIONS="-Dsun.zip.disableMemoryMapping=true"
This does not guarantee that additional options are not required, but is intended to be a helpful starting point. Optimally tuning JVM workloads for running in a container is beyond the scope of this documentation, and may involve setting multiple additional JVM options.
8.4.3. Finding the memory request and limit from within a pod
You can configure your container to use the Downward API to dynamically discover its memory request and limit from within a pod. This allows your applications to better manage these resources without needing to use the API server.
Procedure
Configure the pod to add the
MEMORY_REQUESTandMEMORY_LIMITstanzas:Create a YAML file similar to the following:
apiVersion: v1 kind: Pod metadata: name: test spec: securityContext: runAsNonRoot: false seccompProfile: type: RuntimeDefault containers: - name: test image: fedora:latest command: - sleep - "3600" env: - name: MEMORY_REQUEST valueFrom: resourceFieldRef: containerName: test resource: requests.memory - name: MEMORY_LIMIT valueFrom: resourceFieldRef: containerName: test resource: limits.memory resources: requests: memory: 384Mi limits: memory: 512Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]where:
spec.consinters.env.name.MEMORY_REQUEST- This stanza discovers the application memory request value.
spec.consinters.env.name.MEMORY_LIMIT- This stanza discovers the application memory limit value.
Create the pod by running the following command:
$ oc create -f <file_name>.yaml
Verification
Access the pod using a remote shell:
$ oc rsh testCheck that the requested values were applied:
$ env | grep MEMORY | sortExample output
MEMORY_LIMIT=536870912 MEMORY_REQUEST=402653184
The memory limit value can also be read from inside the container by the /sys/fs/cgroup/memory/memory.limit_in_bytes file.
8.4.4. Understanding OOM kill policy
Red Hat OpenShift Service on AWS can kill a process in a container if the total memory usage of all the processes in the container exceeds the memory limit, or in serious cases of node memory exhaustion.
If a process is Out of Memory (OOM) killed, the container could exit immediately. If the container PID 1 process receives the SIGKILL, the container does exit immediately. Otherwise, the container behavior is dependent on the behavior of the other processes.
For example, a container process exited with code 137, indicating it received a SIGKILL signal.
If the container does not exit immediately, use the following stepts to detect if an OOM kill occurred.
Procedure
Access the pod using a remote shell:
# oc rsh <pod name>Run the following command to see the current OOM kill count in
/sys/fs/cgroup/memory/memory.oom_control:$ grep '^oom_kill ' /sys/fs/cgroup/memory/memory.oom_controlExample output
oom_kill 0Run the following command to provoke an OOM kill:
$ sed -e '' </dev/zeroExample output
KilledRun the following command to see that the OOM kill counter in
/sys/fs/cgroup/memory/memory.oom_controlincremented:$ grep '^oom_kill ' /sys/fs/cgroup/memory/memory.oom_controlExample output
oom_kill 1If one or more processes in a pod are OOM killed, when the pod subsequently exits, whether immediately or not, it will have phase Failed and reason OOMKilled. An OOM-killed pod might be restarted depending on the value of
restartPolicy. If not restarted, controllers such as the replication controller will notice the pod’s failed status and create a new pod to replace the old one.Use the following command to get the pod status:
$ oc get pod testExample output
NAME READY STATUS RESTARTS AGE test 0/1 OOMKilled 0 1mIf the pod has not restarted, run the following command to view the pod:
$ oc get pod test -o yamlExample output
apiVersion: v1 kind: Pod metadata: name: test # ... status: containerStatuses: - name: test ready: false restartCount: 0 state: terminated: exitCode: 137 reason: OOMKilled phase: FailedIf restarted, run the following command to view the pod:
$ oc get pod test -o yamlExample output
apiVersion: v1 kind: Pod metadata: name: test # ... status: containerStatuses: - name: test ready: true restartCount: 1 lastState: terminated: exitCode: 137 reason: OOMKilled state: running: phase: Running
8.4.5. Understanding pod eviction
You can review the following concepts to learn the Red Hat OpenShift Service on AWS pod eviction policy.
Red Hat OpenShift Service on AWS can evict a pod from its node when the node’s memory is exhausted. Depending on the extent of memory exhaustion, the eviction might or might not be graceful. Graceful eviction implies the main process (PID 1) of each container receiving a SIGTERM signal, then some time later a SIGKILL signal if the process has not exited already. Non-graceful eviction implies the main process of each container immediately receiving a SIGKILL signal.
An evicted pod has phase Failed and reason Evicted. It is not restarted, regardless of the value of restartPolicy. However, controllers such as the replication controller will notice the pod’s failed status and create a new pod to replace the old one.
$ oc get pod testExample output
NAME READY STATUS RESTARTS AGE
test 0/1 Evicted 0 1m$ oc get pod test -o yamlExample output
apiVersion: v1
kind: Pod
metadata:
name: test
...
status:
message: 'Pod The node was low on resource: [MemoryPressure].'
phase: Failed
reason: Evicted8.5. Configuring your cluster to place pods on overcommitted nodes
Red Hat OpenShift Service on AWS administrators can manage container density on nodes by configuring pod placement behavior and per-project resource limits that overcommit cannot exceed.
Alternatively, administrators can disable project-level resource overcommitment on customer-created namespaces that are not managed by Red Hat.
For more information about container resource management, see Additional resources.
In an overcommitted state, the sum of the container compute resource requestsand limits exceeds the resources available on the system. For example, you might want to use overcommitment in development environments where a trade-off of guaranteed performance for capacity is acceptable.
Containers can specify compute resource requests and limits. Requests are used for scheduling your container and provide a minimum service guarantee. Limits constrain the amount of compute resource that can be consumed on your node.
The scheduler attempts to optimize the compute resource use across all nodes in your cluster. It places pods onto specific nodes, taking the pods' compute resource requests and nodes' available capacity into consideration.
8.5.1. Project-level limits
In Red Hat OpenShift Service on AWS, because overcommitment of project-level resources is enabled by default, if required by your use case, you can disable overcommitment on projects that are not managed by Red Hat.
For the list of projects that are managed by Red Hat and cannot be modified, see "Red Hat Managed resources" in Support.
8.5.1.1. Disabling overcommitment for a project
If required by your use case, you can disable overcommitment on any project that is not managed by Red Hat. For a list of projects that cannot be modified, see "Red Hat Managed resources" in Support.
Prerequisites
- You are logged in to the cluster using an account with cluster administrator or cluster editor permissions.
Procedure
Edit the namespace object file:
If you are using the web console:
- Click Administration → Namespaces and click the namespace for the project.
- In the Annotations section, click the Edit button.
-
Click Add more and enter a new annotation that uses a Key of
quota.openshift.io/cluster-resource-override-enabledand a Value offalse. - Click Save.
If you are using the ROSA CLI (
rosa):Edit the namespace:
$ rosa edit namespace/<project_name>Add the following annotation:
apiVersion: v1 kind: Namespace metadata: annotations: quota.openshift.io/cluster-resource-override-enabled: "false" # ...where:
metadata.annotations.quota.openshift.io/cluster-resource-override-enabled.false- Specifies that overcommit is disabled for this namespace.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.