Chapter 5. Migrating virtual machine instances between Compute nodes
You sometimes need to migrate instances from one Compute node to another Compute node in the overcloud, to perform maintenance, rebalance the workload, or replace a failed or failing node.
- Compute node maintenance
- If you need to temporarily take a Compute node out of service, for instance, to perform hardware maintenance or repair, kernel upgrades and software updates, you can migrate instances running on the Compute node to another Compute node.
- Failing Compute node
- If a Compute node is about to fail and you need to service it or replace it, you can migrate instances from the failing Compute node to a healthy Compute node.
- Failed Compute nodes
- If a Compute node has already failed, you can evacuate the instances. You can rebuild instances from the original image on another Compute node, using the same name, UUID, network addresses, and any other allocated resources the instance had before the Compute node failed.
- Workload rebalancing
- You can migrate one or more instances to another Compute node to rebalance the workload. For example, you can consolidate instances on a Compute node to conserve power, migrate instances to a Compute node that is physically closer to other networked resources to reduce latency, or distribute instances across Compute nodes to avoid hot spots and increase resiliency.
Director configures all Compute nodes to provide secure migration. All Compute nodes also require a shared SSH key to provide the users of each host with access to other Compute nodes during the migration process. Director creates this key using the OS::TripleO::Services::NovaCompute composable service. This composable service is one of the main services included on all Compute roles by default. For more information, see Composable Services and Custom Roles in the Advanced Overcloud Customization guide.
If you have a functioning Compute node, and you want to make a copy of an instance for backup purposes, or to copy the instance to a different environment, follow the procedure in Importing virtual machines into the overcloud in the Director Installation and Usage guide.
5.1. Migration types
Red Hat OpenStack Platform (RHOSP) supports the following types of migration.
Cold migration
Cold migration, or non-live migration, involves shutting down a running instance before migrating it from the source Compute node to the destination Compute node.
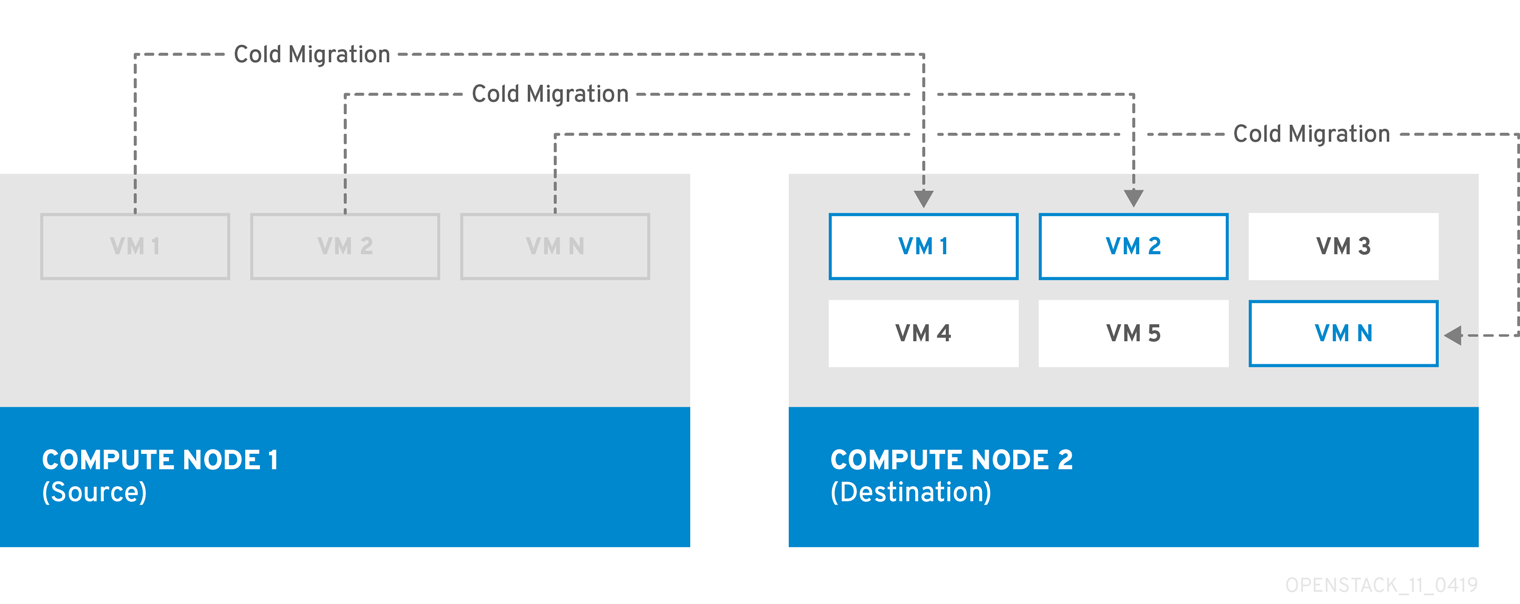
Cold migration involves some downtime for the instance. The migrated instance maintains access to the same volumes and IP addresses.
Cold migration requires that both the source and destination Compute nodes are running.
Live migration
Live migration involves moving the instance from the source Compute node to the destination Compute node without shutting it down, and while maintaining state consistency.
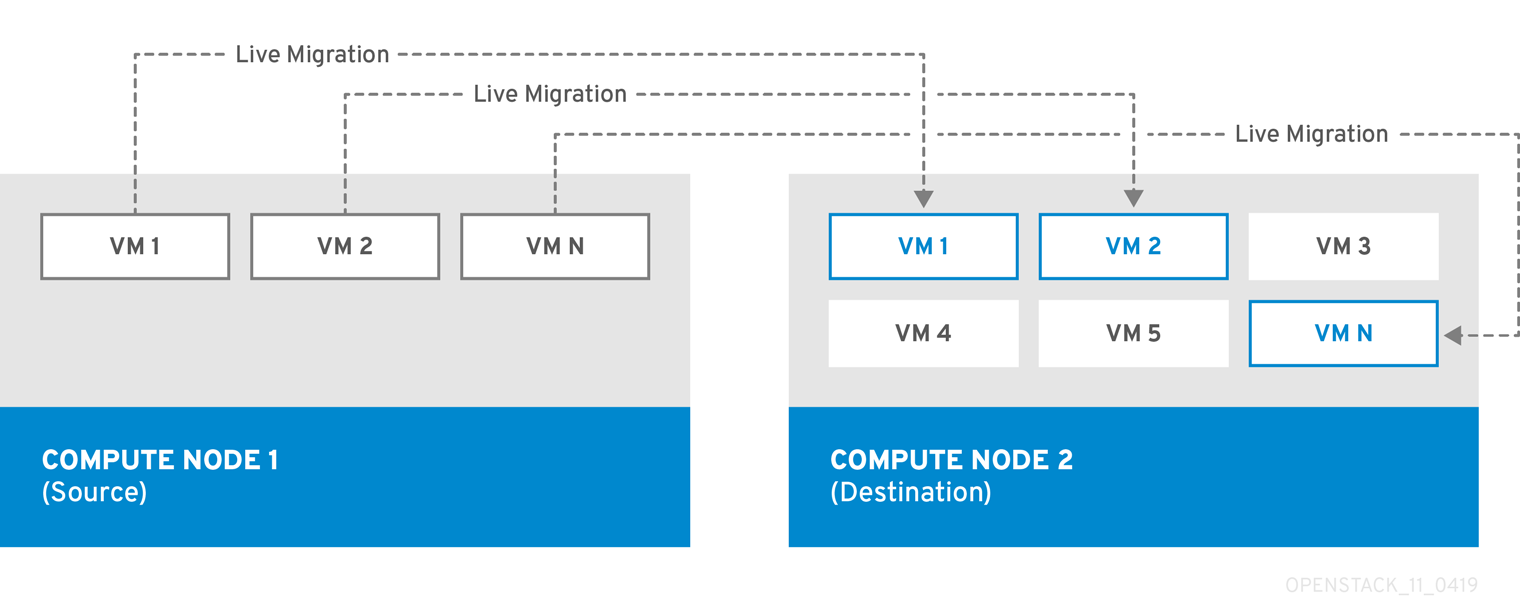
Live migrating an instance involves little or no perceptible downtime. However, live migration does impact performance for the duration of the migration operation. Therefore, instances should be taken out of the critical path while being migrated.
Live migration requires that both the source and destination Compute nodes are running.
In some cases, instances cannot use live migration. For more information, see Migration Constraints.
Evacuation
If you need to migrate instances because the source Compute node has already failed, you can evacuate the instances.
5.2. Migration constraints
Migration constraints typically arise with block migration, configuration disks, or when one or more instances access physical hardware on the Compute node.
CPU constraints
The source and destination Compute nodes must have the same CPU architecture. For example, Red Hat does not support migrating an instance from an x86_64 CPU to a ppc64le CPU. In some cases, the CPU of the source and destination Compute node must match exactly, such as instances that use CPU host passthrough. In all cases, the CPU features of the destination node must be a superset of the CPU features on the source node.
Memory constraints
The destination Compute node must have sufficient available RAM. Memory oversubscription can cause migration to fail.
Block migration constraints
Migrating instances that use disks that are stored locally on a Compute node takes significantly longer than migrating volume-backed instances that use shared storage, such as Red Hat Ceph Storage. This latency arises because OpenStack Compute (nova) migrates local disks block-by-block between the Compute nodes over the control plane network by default. By contrast, volume-backed instances that use shared storage, such as Red Hat Ceph Storage, do not have to migrate the volumes, because each Compute node already has access to the shared storage.
Network congestion in the control plane network caused by migrating local disks or instances that consume large amounts of RAM might impact the performance of other systems that use the control plane network, such as RabbitMQ.
Read-only drive migration constraints
Migrating a drive is supported only if the drive has both read and write capabilities. For example, OpenStack Compute (nova) cannot migrate a CD-ROM drive or a read-only config drive. However, OpenStack Compute (nova) can migrate a drive with both read and write capabilities, including a config drive with a drive format such as vfat.
Live migration constraints
In some cases, live migrating instances involves additional constraints.
- No new operations during migration
- To achieve state consistency between the copies of the instance on the source and destination nodes, RHOSP must prevent new operations during live migration. Otherwise, live migration might take a long time or potentially never end if writes to memory occur faster than live migration can replicate the state of the memory.
- CPU pinning with NUMA
-
NovaSchedulerDefaultFiltersparameter in the Compute configuration must include the valuesAggregateInstanceExtraSpecsFilterandNUMATopologyFilter. - Multi-cell clouds
- In a multi-cell cloud, instances can be live migrated to a different host in the same cell, but not across cells.
- Floating instances
-
When live migrating floating instances, if the configuration of
NovaComputeCpuSharedSeton the destination Compute node is different from the configuration ofNovaComputeCpuSharedSeton the source Compute node, the instances will not be allocated to the CPUs configured for shared (unpinned) instances on the destination Compute node. Therefore, if you need to live migrate floating instances, you must configure all the Compute nodes with the same CPU mappings for dedicated (pinned) and shared (unpinned) instances, or use a host aggregate for the shared instances. - Destination Compute node capacity
- The destination Compute node must have sufficient capacity to host the instance that you want to migrate.
- SR-IOV live migration
- Instances with SR-IOV-based network interfaces can be live migrated. Live migrating instances with direct mode SR-IOV network interfaces attached incurs network downtime while the direct mode interfaces are being detached and re-attached.
Constraints that preclude live migration
You cannot live migrate an instance that uses the following features.
- PCI passthrough
- QEMU/KVM hypervisors support attaching PCI devices on the Compute node to an instance. Use PCI passthrough to give an instance exclusive access to PCI devices, which appear and behave as if they are physically attached to the operating system of the instance. However, because PCI passthrough involves physical addresses, OpenStack Compute does not support live migration of instances using PCI passthrough.
- Port resource requests
You cannot live migrate an instance that uses a port that has resource requests, such as a guaranteed minimum bandwidth QoS policy. Use the following command to check if a port has resource requests:
$ openstack port show <port_name/port_id>
5.3. Preparing to migrate
Before you migrate one or more instances, you need to determine the Compute node names and the IDs of the instances to migrate.
Procedure
Identify the source Compute node host name and the destination Compute node host name:
(undercloud) $ source ~/overcloudrc (overcloud) $ openstack compute service listList the instances on the source Compute node and locate the ID of the instance or instances that you want to migrate:
(overcloud) $ openstack server list --host <source> --all-projectsReplace
<source>with the name or ID of the source Compute node.Optional: If you are migrating instances from a source Compute node to perform maintenance on the node, you must disable the node to prevent the scheduler from assigning new instances to the node during maintenance:
(overcloud) $ source ~/stackrc (undercloud) $ openstack compute service set <source> nova-compute --disableReplace
<source>with the name or ID of the source Compute node.
You are now ready to perform the migration. Follow the required procedure detailed in Cold migrating an instance or Live migrating an instance.
5.4. Cold migrating an instance
Cold migrating an instance involves stopping the instance and moving it to another Compute node. Cold migration facilitates migration scenarios that live migrating cannot facilitate, such as migrating instances that use PCI passthrough. The scheduler automatically selects the destination Compute node. For more information, see Migration Constraints.
Procedure
To cold migrate an instance, enter the following command to power off and move the instance:
(overcloud) $ openstack server migrate <vm> --wait-
Replace
<vm>with the name or ID of the instance to migrate. -
Specify the
--block-migrationflag if migrating a locally stored volume.
-
Replace
- Wait for migration to complete. While you wait for the instance migration to complete, you can check the migration status. For more information, see Checking migration status.
Check the status of the instance:
(overcloud) $ openstack server list --all-projectsA status of "VERIFY_RESIZE" indicates you need to confirm or revert the migration:
If the migration worked as expected, confirm it:
(overcloud) $ openstack server resize --confirm <vm>`Replace
<vm>with the name or ID of the instance to migrate. A status of "ACTIVE" indicates that the instance is ready to use.If the migration did not work as expected, revert it:
(overcloud) $ openstack server resize --revert <vm>`Replace
<vm>with the name or ID of the instance.
Restart the instance:
(overcloud) $ openstack server start <vm>Replace
<vm>with the name or ID of the instance.Optional: If you disabled the source Compute node for maintenance, you must re-enable the node so that new instances can be assigned to it:
(overcloud) $ source ~/stackrc (undercloud) $ openstack compute service set <source> nova-compute --enableReplace
<source>with the host name of the source Compute node.
5.5. Live migrating an instance
Live migration moves an instance from a source Compute node to a destination Compute node with a minimal amount of downtime. Live migration might not be appropriate for all instances. For more information, see Migration Constraints.
Procedure
To live migrate an instance, specify the instance and the destination Compute node:
(overcloud) $ openstack server migrate <vm> --live-migration [--host <dest>] --wait-
Replace
<vm>with the name or ID of the instance. Replace
<dest>with the name or ID of the destination Compute node.NoteThe
openstack server migratecommand covers migrating instances with shared storage, which is the default. Specify the--block-migrationflag to migrate a locally stored volume:(overcloud) $ openstack server migrate <vm> --live-migration [--host <dest>] --wait --block-migration
-
Replace
Confirm that the instance is migrating:
(overloud) $ openstack server show <vm> +----------------------+--------------------------------------+ | Field | Value | +----------------------+--------------------------------------+ | ... | ... | | status | MIGRATING | | ... | ... | +----------------------+--------------------------------------+- Wait for migration to complete. While you wait for the instance migration to complete, you can check the migration status. For more information, see Checking migration status.
Check the status of the instance to confirm if the migration was successful:
(overcloud) $ openstack server list --host <dest> --all-projectsReplace
<dest>with the name or ID of the destination Compute node.Optional: If you disabled the source Compute node for maintenance, you must re-enable the node so that new instances can be assigned to it:
(overcloud) $ source ~/stackrc (undercloud) $ openstack compute service set <source> nova-compute --enableReplace
<source>with the host name of the source Compute node.
5.6. Checking migration status
Migration involves several state transitions before migration is complete. During a healthy migration, the migration state typically transitions as follows:
- Queued: The Compute service has accepted the request to migrate an instance, and migration is pending.
- Preparing: The Compute service is preparing to migrate the instance.
- Running: The Compute service is migrating the instance.
- Post-migrating: The Compute service has built the instance on the destination Compute node and is releasing resources on the source Compute node.
- Completed: The Compute service has completed migrating the instance and finished releasing resources on the source Compute node.
Procedure
Retrieve the list of migration IDs for the instance:
$ nova server-migration-list <vm> +----+-------------+----------- (...) | Id | Source Node | Dest Node | (...) +----+-------------+-----------+ (...) | 2 | - | - | (...) +----+-------------+-----------+ (...)Replace
<vm>with the name or ID of the instance.Show the status of the migration:
$ <vm> <migration-id>-
Replace
<vm>with the name or ID of the instance. Replace
<migration-id>with the ID of the migration.Running the
nova server-migration-showcommand returns the following example output:+------------------------+--------------------------------------+ | Property | Value | +------------------------+--------------------------------------+ | created_at | 2017-03-08T02:53:06.000000 | | dest_compute | controller | | dest_host | - | | dest_node | - | | disk_processed_bytes | 0 | | disk_remaining_bytes | 0 | | disk_total_bytes | 0 | | id | 2 | | memory_processed_bytes | 65502513 | | memory_remaining_bytes | 786427904 | | memory_total_bytes | 1091379200 | | server_uuid | d1df1b5a-70c4-4fed-98b7-423362f2c47c | | source_compute | compute2 | | source_node | - | | status | running | | updated_at | 2017-03-08T02:53:47.000000 | +------------------------+--------------------------------------+TipThe OpenStack Compute service measures progress of the migration by the number of remaining memory bytes to copy. If this number does not decrease over time, the migration might be unable to complete, and the Compute service might abort it.
-
Replace
Sometimes instance migration can take a long time or encounter errors. For more information, see Troubleshooting migration.
5.7. Evacuating an instance
If you want to move an instance from a dead or shut-down Compute node to a new host in the same environment, you can evacuate it.
The evacuate process destroys the original instance and rebuilds it on another Compute node using the original image, instance name, UUID, network addresses, and any other resources the original instance had allocated to it.
If the instance uses shared storage, the instance root disk is not rebuilt during the evacuate process, as the disk remains accessible by the destination Compute node. If the instance does not use shared storage, then the instance root disk is also rebuilt on the destination Compute node.
-
You can only perform an evacuation when the Compute node is fenced, and the API reports that the state of the Compute node is "down" or "forced-down". If the Compute node is not reported as "down" or "forced-down", the
evacuatecommand fails. - To perform an evacuation, you must be a cloud administrator.
5.7.1. Evacuating one instance
You can evacuate instances one at a time.
Procedure
- Log onto the failed Compute node as an administrator.
Disable the Compute node:
(overcloud) [stack@director ~]$ openstack compute service set \ <host> <service> --disable-
Replace
<host>with the name of the Compute node to evacuate the instance from. -
Replace
<service>with the name of the service to disable, for examplenova-compute.
-
Replace
To evacuate an instance, enter the following command:
(overcloud) [stack@director ~]$ nova evacuate [--password <pass>] <vm> [<dest>]-
Replace
<pass>with the admin password to set for the evacuated instance. If a password is not specified, a random password is generated and output when the evacuation is complete. -
Replace
<vm>with the name or ID of the instance to evacuate. Replace
<dest>with the name of the Compute node to evacuate the instance to. If you do not specify the destination Compute node, the Compute scheduler selects one for you. You can find possible Compute nodes by using the following command:(overcloud) [stack@director ~]$ openstack hypervisor list
-
Replace
5.7.2. Evacuating all instances on a host
You can evacuate all instances on a specified Compute node.
Procedure
- Log onto the failed Compute node as an administrator.
Disable the Compute node:
(overcloud) [stack@director ~]$ openstack compute service set \ <host> <service> --disable-
Replace
<host>with the name of the Compute node to evacuate the instances from. -
Replace
<service>with the name of the service to disable, for examplenova-compute.
-
Replace
Evacuate all instances on a specified Compute node:
(overcloud) [stack@director ~]$ nova host-evacuate [--target_host <dest>] [--force] <host>Replace
<dest>with the name of the destination Compute node to evacuate the instances to. If you do not specify the destination, the Compute scheduler selects one for you. You can find possible Compute nodes by using the following command:(overcloud) [stack@director ~]$ openstack hypervisor list-
Replace
<host>with the name of the Compute node to evacuate the instances from.
5.8. Troubleshooting migration
The following issues can arise during instance migration:
- The migration process encounters errors.
- The migration process never ends.
- Performance of the instance degrades after migration.
5.8.1. Errors during migration
The following issues can send the migration operation into an error state:
- Running a cluster with different versions of Red Hat OpenStack Platform (RHOSP).
- Specifying an instance ID that cannot be found.
-
The instance you are trying to migrate is in an
errorstate. - The Compute service is shutting down.
- A race condition occurs.
-
Live migration enters a
failedstate.
When live migration enters a failed state, it is typically followed by an error state. The following common issues can cause a failed state:
- A destination Compute host is not available.
- A scheduler exception occurs.
- The rebuild process fails due to insufficient computing resources.
- A server group check fails.
- The instance on the source Compute node gets deleted before migration to the destination Compute node is complete.
5.8.2. Never-ending live migration
Live migration can fail to complete, which leaves migration in a perpetual running state. A common reason for a live migration that never completes is that client requests to the instance running on the source Compute node create changes that occur faster than the Compute service can replicate them to the destination Compute node.
Use one of the following methods to address this situation:
- Abort the live migration.
- Force the live migration to complete.
Aborting live migration
If the instance state changes faster than the migration procedure can copy it to the destination node, and you do not want to temporarily suspend the instance operations, you can abort the live migration.
Procedure
Retrieve the list of migrations for the instance:
$ nova server-migration-list <vm>Replace
<vm>with the name or ID of the instance.Abort the live migration:
$ nova live-migration-abort <vm> <migration-id>-
Replace
<vm>with the name or ID of the instance. -
Replace
<migration-id>with the ID of the migration.
-
Replace
Forcing live migration to complete
If the instance state changes faster than the migration procedure can copy it to the destination node, and you want to temporarily suspend the instance operations to force migration to complete, you can force the live migration procedure to complete.
Forcing live migration to complete might lead to perceptible downtime.
Procedure
Retrieve the list of migrations for the instance:
$ nova server-migration-list <vm>Replace
<vm>with the name or ID of the instance.Force the live migration to complete:
$ nova live-migration-force-complete <vm> <migration-id>-
Replace
<vm>with the name or ID of the instance. -
Replace
<migration-id>with the ID of the migration.
-
Replace
5.8.3. Instance performance degrades after migration
For instances that use a NUMA topology, the source and destination Compute nodes must have the same NUMA topology and configuration. The NUMA topology of the destination Compute node must have sufficient resources available. If the NUMA configuration between the source and destination Compute nodes is not the same, it is possible that live migration succeeds while the instance performance degrades. For example, if the source Compute node maps NIC 1 to NUMA node 0, but the destination Compute node maps NIC 1 to NUMA node 5, after migration the instance might route network traffic from a first CPU across the bus to a second CPU with NUMA node 5 to route traffic to NIC 1. This can result in expected behavior, but degraded performance. Similarly, if NUMA node 0 on the source Compute node has sufficient available CPU and RAM, but NUMA node 0 on the destination Compute node already has instances using some of the resources, the instance might run correctly but suffer performance degradation. For more information, see Migration constraints.