Applications dans le domaine de la construction
Créer et gérer des applications sur OpenShift Container Platform
Résumé
Chapitre 1. Aperçu des applications dans le domaine de la construction
Avec OpenShift Container Platform, vous pouvez créer, modifier, supprimer et gérer des applications à l'aide de la console web ou de l'interface de ligne de commande (CLI).
1.1. Travailler sur un projet
Les projets permettent d'organiser et de gérer les applications de manière isolée. Vous pouvez gérer l'ensemble du cycle de vie du projet, y compris la création, la visualisation et la suppression d'un projet dans OpenShift Container Platform.
Après avoir créé le projet, vous pouvez accorder ou révoquer l'accès à un projet et gérer les rôles de cluster pour les utilisateurs à l'aide de la perspective du développeur. Vous pouvez également modifier la ressource de configuration du projet lors de la création d'un modèle de projet utilisé pour le provisionnement automatique de nouveaux projets.
En utilisant le CLI, vous pouvez créer un projet en tant qu'utilisateur différent en vous faisant passer pour un autre utilisateur lors d'une requête à l'API de OpenShift Container Platform. Lorsque vous demandez la création d'un nouveau projet, OpenShift Container Platform utilise un point de terminaison pour provisionner le projet selon un modèle personnalisable. En tant qu'administrateur de cluster, vous pouvez choisir d'empêcher un groupe d'utilisateurs authentifiés d'auto-approvisionner de nouveaux projets.
1.2. Travailler sur une application
1.2.1. Création d'une application
Pour créer des applications, vous devez avoir créé un projet ou avoir accès à un projet avec les rôles et permissions appropriés. Vous pouvez créer une application en utilisant la perspective développeur dans la console web, les opérateurs installés ou le CLI de OpenShift Container Platform. Les applications à ajouter au projet peuvent provenir de Git, de fichiers JAR, de devfiles ou du catalogue de développeurs.
Vous pouvez également utiliser des composants qui incluent du code source ou binaire, des images et des modèles pour créer une application à l'aide de la CLI d'OpenShift Container Platform. Avec la console web d'OpenShift Container Platform, vous pouvez créer une application à partir d'un Operator installé par un administrateur de cluster.
1.2.2. Gestion d'une application
Après avoir créé l'application, vous pouvez utiliser la console web pour surveiller les mesures de votre projet ou de votre application. Vous pouvez également modifier ou supprimer l'application à l'aide de la console web. Lorsque l'application est en cours d'exécution, toutes les ressources de l'application ne sont pas utilisées. En tant qu'administrateur de cluster, vous pouvez choisir d'inactiver ces ressources évolutives afin de réduire la consommation de ressources.
1.2.3. Connecter une application à des services
Une application utilise des services d'appui pour construire et connecter des charges de travail, qui varient en fonction du fournisseur de services. Grâce à l'opérateur de liaison de services, vous pouvez, en tant que développeur, lier des charges de travail avec des services d'appui gérés par l'opérateur, sans aucune procédure manuelle pour configurer la connexion de liaison. Vous pouvez également appliquer la liaison de services aux environnements IBM Power, IBM zSystems et IBM® LinuxONE.
1.2.4. Déploiement d'une application
Vous pouvez déployer votre application à l'aide des objets Deployment ou DeploymentConfig et les gérer à partir de la console web. Vous pouvez créer des stratégies de déploiement qui permettent de réduire les temps d'arrêt lors d'une modification ou d'une mise à niveau de l'application.
Vous pouvez également utiliser Helm, un gestionnaire de paquets logiciels qui simplifie le déploiement d'applications et de services sur les clusters OpenShift Container Platform.
1.3. Utilisation de Red Hat Marketplace
La place de marché Red Hat est une place de marché cloud ouverte où vous pouvez découvrir et accéder à des logiciels certifiés pour les environnements basés sur des conteneurs qui fonctionnent sur des clouds publics et sur site.
Chapitre 2. Projets
2.1. Travailler avec des projets
Le site project permet à une communauté d'utilisateurs d'organiser et de gérer son contenu indépendamment des autres communautés.
Les projets commençant par openshift- et kube- sont des projets par défaut. Ces projets hébergent des composants de cluster qui s'exécutent sous forme de pods et d'autres composants d'infrastructure. En tant que tel, OpenShift Container Platform ne vous permet pas de créer des projets commençant par openshift- ou kube- à l'aide de la commande oc new-project. Les administrateurs de clusters peuvent créer ces projets à l'aide de la commande oc adm new-project.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default kube-system , kube-public, openshift-node, openshift-infra et openshift. Vous ne pouvez pas utiliser ces espaces de noms pour exécuter des pods ou des services.
2.1.1. Création d'un projet à l'aide de la console web
Si l'administrateur de votre cluster l'autorise, vous pouvez créer un nouveau projet.
Les projets commençant par openshift- et kube- sont considérés comme critiques par OpenShift Container Platform. Ainsi, OpenShift Container Platform ne vous permet pas de créer des projets commençant par openshift- à l'aide de la console Web.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default kube-system , kube-public, openshift-node, openshift-infra et openshift. Vous ne pouvez pas utiliser ces espaces de noms pour exécuter des pods ou des services.
Procédure
- Naviguez jusqu'à Home → Projects.
- Cliquez sur Create Project.
- Entrez les détails de votre projet.
- Cliquez sur Create.
2.1.2. Création d'un projet à l'aide de la perspective du développeur dans la console web
Vous pouvez utiliser la perspective Developer dans la console web d'OpenShift Container Platform pour créer un projet dans votre cluster.
Les projets commençant par openshift- et kube- sont considérés comme critiques par OpenShift Container Platform. Ainsi, OpenShift Container Platform ne vous permet pas de créer des projets commençant par openshift- ou kube- à l'aide de la perspective Developer. Les administrateurs de cluster peuvent créer ces projets à l'aide de la commande oc adm new-project.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default kube-system , kube-public, openshift-node, openshift-infra et openshift. Vous ne pouvez pas utiliser ces espaces de noms pour exécuter des pods ou des services.
Conditions préalables
- Assurez-vous que vous disposez des rôles et autorisations appropriés pour créer des projets, des applications et d'autres charges de travail dans OpenShift Container Platform.
Procédure
Vous pouvez créer un projet en utilisant la perspective Developer, comme suit :
Cliquez sur le menu déroulant Project pour obtenir une liste de tous les projets disponibles. Sélectionnez Create Project.
Figure 2.1. Créer un projet
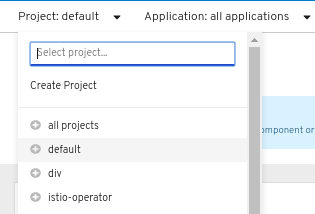
-
Dans la boîte de dialogue Create Project, saisissez un nom unique, tel que
myproject, dans le champ Name. - Optionnel : Ajoutez les détails Display Name et Description pour le projet.
- Cliquez sur Create.
- Utilisez le panneau de navigation de gauche pour accéder à la vue Project et voir le tableau de bord de votre projet.
En option :
- Utilisez le menu déroulant Project en haut de l'écran et sélectionnez all projects pour lister tous les projets de votre cluster.
- Utilisez l'onglet Details pour voir les détails du projet.
- Si vous disposez des autorisations adéquates pour un projet, vous pouvez utiliser l'onglet Project Access pour accorder ou révoquer les privilèges administrator, edit et view pour le projet.
2.1.3. Création d'un projet à l'aide de l'interface de programmation
Si l'administrateur de votre cluster l'autorise, vous pouvez créer un nouveau projet.
Les projets commençant par openshift- et kube- sont considérés comme critiques par OpenShift Container Platform. Ainsi, OpenShift Container Platform ne vous permet pas de créer des projets commençant par openshift- ou kube- à l'aide de la commande oc new-project. Les administrateurs de clusters peuvent créer ces projets à l'aide de la commande oc adm new-project.
Vous ne pouvez pas attribuer de SCC aux pods créés dans l'un des espaces de noms par défaut : default kube-system , kube-public, openshift-node, openshift-infra et openshift. Vous ne pouvez pas utiliser ces espaces de noms pour exécuter des pods ou des services.
Procédure
Exécutez :
$ oc new-project <project_name> \ --description="<description>" --display-name="<display_name>"Par exemple :
$ oc new-project hello-openshift \ --description="This is an example project" \ --display-name="Hello OpenShift"
Le nombre de projets que vous êtes autorisé à créer peut être limité par l'administrateur du système. Une fois la limite atteinte, il se peut que vous deviez supprimer un projet existant pour en créer un nouveau.
2.1.4. Visualiser un projet à l'aide de la console web
Procédure
- Naviguez jusqu'à Home → Projects.
Sélectionnez un projet à visualiser.
Sur cette page, cliquez sur Workloads pour voir les charges de travail du projet.
2.1.5. Visualisation d'un projet à l'aide de l'interface de programmation
Lorsque vous consultez des projets, vous ne pouvez voir que les projets auxquels vous avez accès en vertu de la politique d'autorisation.
Procédure
Pour afficher une liste de projets, exécutez :
$ oc get projectsVous pouvez passer du projet actuel à un autre projet pour les opérations de l'interface de programmation. Le projet spécifié est alors utilisé dans toutes les opérations ultérieures qui manipulent le contenu d'un projet :
oc project <nom_du_projet>
2.1.6. Fournir des autorisations d'accès à votre projet à l'aide de la perspective du développeur
Vous pouvez utiliser la vue Project dans la perspective Developer pour accorder ou révoquer des autorisations d'accès à votre projet.
Procédure
Pour ajouter des utilisateurs à votre projet et leur donner accès à Admin, Edit ou View:
- Dans la perspective Developer, accédez à la vue Project.
- Dans la page Project, sélectionnez l'onglet Project Access.
Cliquez sur Add Access pour ajouter une nouvelle ligne d'autorisations à celles qui sont définies par défaut.
Figure 2.2. Autorisations de projet
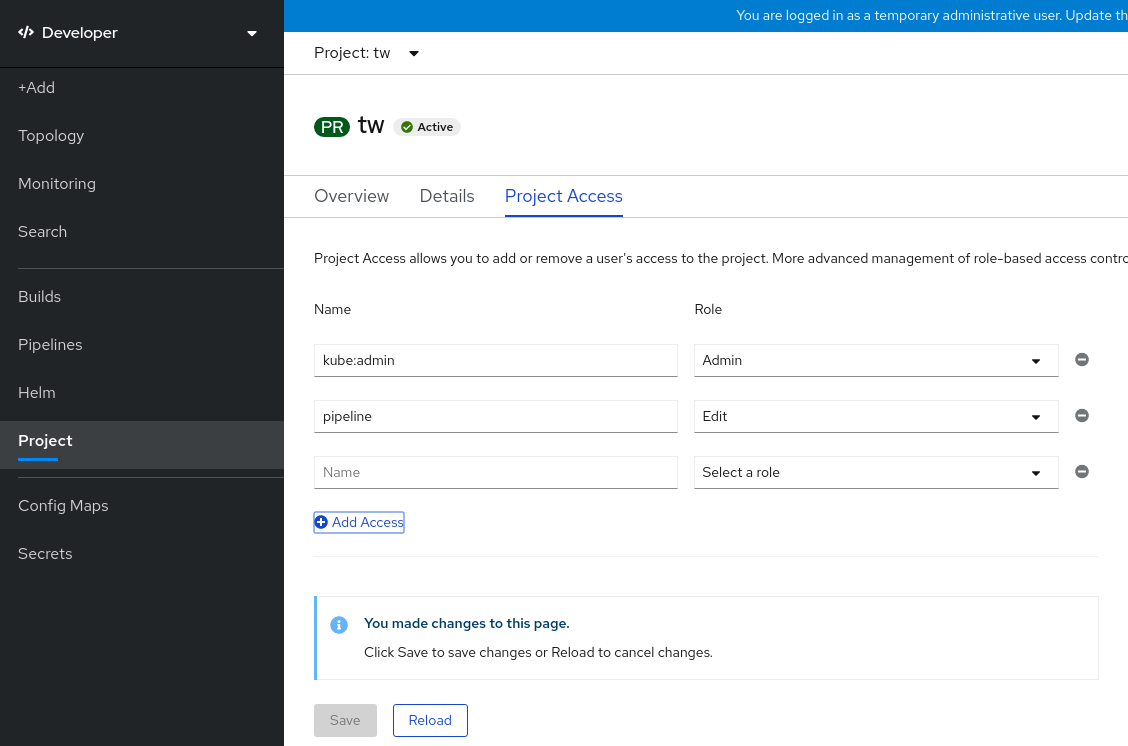
- Saisissez le nom de l'utilisateur, cliquez sur la liste déroulante Select a role et sélectionnez un rôle approprié.
- Cliquez sur Save pour ajouter les nouvelles autorisations.
Vous pouvez également utiliser :
- La liste déroulante Select a role, pour modifier les autorisations d'accès d'un utilisateur existant.
- L'icône Remove Access, pour supprimer complètement les autorisations d'accès d'un utilisateur existant au projet.
Le contrôle d'accès avancé basé sur les rôles est géré dans les vues Roles et Roles Binding de la perspective Administrator.
2.1.7. Personnaliser les rôles de cluster disponibles à l'aide de la perspective du développeur
Les utilisateurs d'un projet sont affectés à un rôle de groupe en fonction de leur contrôle d'accès. Vous pouvez accéder à ces rôles en vous rendant sur le site Project → Project access → Role. Par défaut, ces rôles sont Admin, Edit, et View.
Pour ajouter ou modifier les rôles du cluster pour un projet, vous pouvez personnaliser le code YAML du cluster.
Procédure
Pour personnaliser les différents rôles de cluster d'un projet :
-
Dans la vue Search, utilisez la liste déroulante Resources pour rechercher
Console. Parmi les options disponibles, sélectionnez l'option Console
operator.openshift.io/v1.Figure 2.3. Recherche d'une ressource de la console
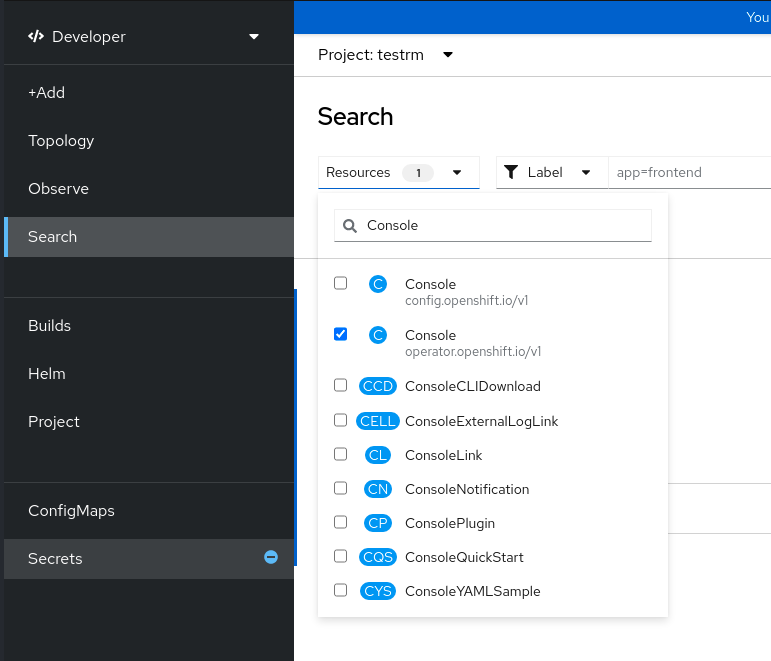
- Sélectionnez cluster dans la liste Name.
- Naviguez vers l'onglet YAML pour visualiser et modifier le code YAML.
Dans le code YAML sous
spec, ajoutez ou modifiez la liste deavailableClusterRoleset enregistrez vos modifications :spec: customization: projectAccess: availableClusterRoles: - admin - edit - view
2.1.8. Ajouter à un projet
Procédure
- Sélectionnez Developer dans le sélecteur de contexte en haut du menu de navigation de la console web.
- Cliquez sur Add
- En haut de la page, sélectionnez le nom du projet que vous souhaitez ajouter.
- Cliquez sur une méthode à ajouter à votre projet, puis suivez le flux de travail.
Vous pouvez également ajouter des composants à la topologie à l'aide de la recherche rapide.
2.1.9. Vérifier l'état d'un projet à l'aide de la console web
Procédure
- Naviguez jusqu'à Home → Projects.
- Sélectionnez un projet pour connaître son statut.
2.1.10. Vérifier l'état d'un projet à l'aide de l'interface de programmation
Procédure
Exécutez :
$ oc statusCette commande fournit une vue d'ensemble du projet en cours, avec ses composants et leurs relations.
2.1.11. Suppression d'un projet à l'aide de la console web
Vous pouvez supprimer un projet en utilisant la console web d'OpenShift Container Platform.
Si vous n'avez pas le droit de supprimer le projet, l'option Delete Project n'est pas disponible.
Procédure
- Naviguez jusqu'à Home → Projects.
- Localisez le projet que vous souhaitez supprimer dans la liste des projets.
-
À l'extrême droite de la liste des projets, sélectionnez Delete Project dans le menu Options
 .
.
- Lorsque le volet Delete Project s'ouvre, saisissez le nom du projet que vous souhaitez supprimer dans le champ.
- Cliquez sur Delete.
2.1.12. Suppression d'un projet à l'aide de l'interface de programmation
Lorsque vous supprimez un projet, le serveur met à jour l'état du projet en le faisant passer de Active à Terminating. Ensuite, le serveur efface tout le contenu d'un projet qui est dans l'état Terminating avant de supprimer définitivement le projet. Tant qu'un projet est dans l'état Terminating, vous ne pouvez pas ajouter de nouveau contenu au projet. Les projets peuvent être supprimés à partir du CLI ou de la console web.
Procédure
Exécutez :
oc delete project <project_name> $ oc delete project <project_name>
2.2. Créer un projet en tant qu'autre utilisateur
L'usurpation d'identité vous permet de créer un projet en tant qu'utilisateur différent.
2.2.1. L'usurpation d'identité de l'API
Vous pouvez configurer une requête à l'API OpenShift Container Platform pour qu'elle agisse comme si elle provenait d'un autre utilisateur. Pour plus d'informations, voir User impersonation dans la documentation Kubernetes.
2.2.2. Se faire passer pour un utilisateur lors de la création d'un projet
Vous pouvez vous faire passer pour un autre utilisateur lorsque vous créez une demande de projet. Comme system:authenticated:oauth est le seul groupe bootstrap à pouvoir créer des demandes de projet, vous devez vous faire passer pour ce groupe.
Procédure
Pour créer une demande de projet au nom d'un autre utilisateur :
$ oc new-project <project> --as=<user> \ --as-group=system:authenticated --as-group=system:authenticated:oauth
2.3. Configuration de la création de projets
Dans OpenShift Container Platform, projects est utilisé pour regrouper et isoler des objets liés. Lorsqu'une demande est faite pour créer un nouveau projet à l'aide de la console web ou de la commande oc new-project, un point de terminaison dans OpenShift Container Platform est utilisé pour provisionner le projet selon un modèle, qui peut être personnalisé.
En tant qu'administrateur de cluster, vous pouvez autoriser et configurer la façon dont les développeurs et les comptes de service peuvent créer, ou self-provision, leurs propres projets.
2.3.1. A propos de la création de projets
Le serveur API de OpenShift Container Platform fournit automatiquement de nouveaux projets basés sur le modèle de projet identifié par le paramètre projectRequestTemplate dans la ressource de configuration de projet du cluster. Si le paramètre n'est pas défini, le serveur API crée un modèle par défaut qui crée un projet avec le nom demandé et attribue à l'utilisateur demandeur le rôle admin pour ce projet.
Lorsqu'une demande de projet est soumise, l'API substitue les paramètres suivants dans le modèle :
| Paramètres | Description |
|---|---|
|
| Le nom du projet. Obligatoire. |
|
| Le nom d'affichage du projet. Peut être vide. |
|
| La description du projet. Peut être vide. |
|
| Le nom d'utilisateur de l'utilisateur administrateur. |
|
| Le nom d'utilisateur de l'utilisateur demandeur. |
L'accès à l'API est accordé aux développeurs ayant le rôle self-provisioner et le rôle de cluster self-provisioners. Ce rôle est disponible par défaut pour tous les développeurs authentifiés.
2.3.2. Modifier le modèle pour les nouveaux projets
En tant qu'administrateur de cluster, vous pouvez modifier le modèle de projet par défaut afin que les nouveaux projets soient créés en fonction de vos besoins.
Pour créer votre propre modèle de projet personnalisé :
Procédure
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. Générer le modèle de projet par défaut :
oc adm create-bootstrap-project-template -o yaml > template.yaml-
Utilisez un éditeur de texte pour modifier le fichier
template.yamlgénéré en ajoutant des objets ou en modifiant des objets existants. Le modèle de projet doit être créé dans l'espace de noms
openshift-config. Chargez votre modèle modifié :$ oc create -f template.yaml -n openshift-configModifiez la ressource de configuration du projet à l'aide de la console Web ou de la CLI.
En utilisant la console web :
- Naviguez jusqu'à la page Administration → Cluster Settings.
- Cliquez sur Configuration pour afficher toutes les ressources de configuration.
- Trouvez l'entrée pour Project et cliquez sur Edit YAML.
Utilisation de la CLI :
Modifier la ressource
project.config.openshift.io/cluster:$ oc edit project.config.openshift.io/cluster
Mettez à jour la section
specpour inclure les paramètresprojectRequestTemplateetname, et définissez le nom de votre modèle de projet téléchargé. Le nom par défaut estproject-request.Ressource de configuration de projet avec modèle de projet personnalisé
apiVersion: config.openshift.io/v1 kind: Project metadata: ... spec: projectRequestTemplate: name: <template_name>- Après avoir enregistré vos modifications, créez un nouveau projet pour vérifier que vos modifications ont bien été appliquées.
2.3.3. Désactiver l'auto-provisionnement des projets
Vous pouvez empêcher un groupe d'utilisateurs authentifiés d'auto-approvisionner de nouveaux projets.
Procédure
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. Affichez l'utilisation de la liaison de rôle du cluster
self-provisionersen exécutant la commande suivante :$ oc describe clusterrolebinding.rbac self-provisionersExemple de sortie
Name: self-provisioners Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: self-provisioner Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated:oauthPassez en revue les sujets de la section
self-provisioners.Supprimez le rôle de cluster
self-provisionerdu groupesystem:authenticated:oauth.Si la liaison des rôles du cluster
self-provisionerslie uniquement le rôleself-provisionerau groupesystem:authenticated:oauth, exécutez la commande suivante :$ oc patch clusterrolebinding.rbac self-provisioners -p '{"subjects": null}'Si la liaison du rôle de cluster
self-provisionerslie le rôleself-provisionerà plus d'utilisateurs, de groupes ou de comptes de service que le groupesystem:authenticated:oauth, exécutez la commande suivante :$ oc adm policy \ remove-cluster-role-from-group self-provisioner \ system:authenticated:oauth
Modifiez le lien du rôle de cluster
self-provisionerspour empêcher les mises à jour automatiques du rôle. Les mises à jour automatiques réinitialisent les rôles de cluster à l'état par défaut.Pour mettre à jour l'attribution des rôles à l'aide de l'interface de ligne de commande :
Exécutez la commande suivante :
$ oc edit clusterrolebinding.rbac self-provisionersDans la définition de rôle affichée, définissez la valeur du paramètre
rbac.authorization.kubernetes.io/autoupdatesurfalse, comme indiqué dans l'exemple suivant :apiVersion: authorization.openshift.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "false" ...
Pour mettre à jour l'attribution des rôles à l'aide d'une seule commande :
$ oc patch clusterrolebinding.rbac self-provisioners -p '{ "metadata": { "annotations": { "rbac.authorization.kubernetes.io/autoupdate": "false" } } }'
Connectez-vous en tant qu'utilisateur authentifié et vérifiez qu'il n'est plus possible d'auto-provisionner un projet :
$ oc new-project testExemple de sortie
Error from server (Forbidden): You may not request a new project via this API.Pensez à personnaliser ce message de demande de projet pour fournir des instructions plus utiles et spécifiques à votre organisation.
2.3.4. Personnalisation du message de demande de projet
Lorsqu'un développeur ou un compte de service qui n'est pas en mesure d'auto-provisionner des projets fait une demande de création de projet à l'aide de la console web ou de la CLI, le message d'erreur suivant est renvoyé par défaut :
You may not request a new project via this API.Les administrateurs de clusters peuvent personnaliser ce message. Envisagez de le mettre à jour pour fournir des instructions supplémentaires sur la manière de demander un nouveau projet spécifique à votre organisation. Par exemple :
-
Pour demander un projet, contactez votre administrateur système à l'adresse
projectname@example.com. -
Pour demander un nouveau projet, remplissez le formulaire de demande de projet situé à l'adresse
https://internal.example.com/openshift-project-request.
Pour personnaliser le message de demande de projet :
Procédure
Modifiez la ressource de configuration du projet à l'aide de la console Web ou de la CLI.
En utilisant la console web :
- Naviguez jusqu'à la page Administration → Cluster Settings.
- Cliquez sur Configuration pour afficher toutes les ressources de configuration.
- Trouvez l'entrée pour Project et cliquez sur Edit YAML.
Utilisation de la CLI :
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. Modifier la ressource
project.config.openshift.io/cluster:$ oc edit project.config.openshift.io/cluster
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
Mettez à jour la section
specpour inclure le paramètreprojectRequestMessageet définissez la valeur de votre message personnalisé :Ressource de configuration de projet avec message de demande de projet personnalisé
apiVersion: config.openshift.io/v1 kind: Project metadata: ... spec: projectRequestMessage: <message_string>Par exemple :
apiVersion: config.openshift.io/v1 kind: Project metadata: ... spec: projectRequestMessage: To request a project, contact your system administrator at projectname@example.com.- Après avoir enregistré vos modifications, essayez de créer un nouveau projet en tant que développeur ou compte de service qui n'est pas en mesure d'auto-provisionner des projets afin de vérifier que vos modifications ont été appliquées avec succès.
Chapitre 3. Création d'applications
3.1. Créer des applications à l'aide de la perspective du développeur
La perspective Developer de la console web vous offre les options suivantes à partir de la vue Add pour créer des applications et des services associés et les déployer sur OpenShift Container Platform :
Getting started resources: Utilisez ces ressources pour vous aider à démarrer avec la Developer Console. Vous pouvez choisir de masquer l'en-tête à l'aide du menu Options
.
- Creating applications using samples: Utiliser des échantillons de code existants pour commencer à créer des applications sur OpenShift Container Platform.
- Build with guided documentation: Suivez la documentation guidée pour créer des applications et vous familiariser avec les concepts et terminologies clés.
- Explore new developer features: Explorez les nouvelles fonctionnalités et ressources de la perspective Developer.
Developer catalog: Explorez le catalogue des développeurs pour sélectionner les applications, services ou sources nécessaires aux constructeurs d'images, puis ajoutez-les à votre projet.
- All Services: Parcourez le catalogue pour découvrir les services d'OpenShift Container Platform.
- Database: Sélectionnez le service de base de données requis et ajoutez-le à votre application.
- Operator Backed: Sélectionner et déployer le service géré par l'opérateur requis.
- Helm chart: Sélectionnez la carte Helm requise pour simplifier le déploiement des applications et des services.
- Devfile: Sélectionnez un fichier de développement sur le site Devfile registry pour définir de manière déclarative un environnement de développement.
Event Source: Sélectionner une source d'événements pour s'intéresser à une classe d'événements provenant d'un système particulier.
NoteL'option Services gérés est également disponible si le RHOAS Operator est installé.
- Git repository: Importez une base de code existante, un fichier Devfile ou un fichier Docker depuis votre dépôt Git en utilisant les options From Git, From Devfile, ou From Dockerfile respectivement, pour construire et déployer une application sur OpenShift Container Platform.
- Container images: Utiliser des images existantes à partir d'un flux d'images ou d'un registre pour les déployer sur OpenShift Container Platform.
- Pipelines: Utilisez Tekton pipeline pour créer des pipelines CI/CD pour votre processus de livraison de logiciels sur OpenShift Container Platform.
Serverless: Explorer les options Serverless pour créer, construire et déployer des applications sans état et sans serveur sur OpenShift Container Platform.
- Channel: Créer un canal Knative pour créer une couche de transmission et de persistance des événements avec des implémentations en mémoire et fiables.
- Samples: Explorer les exemples d'applications disponibles pour créer, construire et déployer rapidement une application.
- Quick Starts: Explorez les options de démarrage rapide pour créer, importer et exécuter des applications à l'aide d'instructions et de tâches étape par étape.
From Local Machine: Explorez la tuile From Local Machine pour importer ou télécharger des fichiers sur votre machine locale afin de créer et de déployer facilement des applications.
- Import YAML: Chargement d'un fichier YAML pour créer et définir des ressources pour la construction et le déploiement d'applications.
- Upload JAR file: Télécharger un fichier JAR pour créer et déployer des applications Java.
- Share my Project: Cette option permet d'ajouter ou de supprimer des utilisateurs à un projet et de leur fournir des options d'accessibilité.
- Helm Chart repositories: Cette option permet d'ajouter des référentiels Helm Chart dans un espace de noms.
- Re-ordering of resources: Utilisez ces ressources pour réorganiser les ressources épinglées ajoutées à votre volet de navigation. L'icône de glisser-déposer s'affiche sur le côté gauche de la ressource épinglée lorsque vous la survolez dans le volet de navigation. La ressource glissée ne peut être déposée que dans la section où elle se trouve.
Notez que certaines options, telles que Pipelines, Event Source, et Import Virtual Machines, ne sont affichées que lorsque OpenShift Pipelines Operator, OpenShift Serverless Operator, et OpenShift Virtualization Operator sont installés, respectivement.
3.1.1. Conditions préalables
Pour créer des applications à l'aide de la perspective Developer, il faut s'assurer que
- Vous vous êtes connecté à la console web.
- Vous avez créé un projet ou avez accès à un projet avec les rôles et autorisations appropriés pour créer des applications et d'autres charges de travail dans OpenShift Container Platform.
Pour créer des applications sans serveur, en plus des prérequis précédents, assurez-vous que :
3.1.2. Création d'exemples d'applications
Vous pouvez utiliser les exemples d'applications dans le flux Add de la perspective Developer pour créer, construire et déployer rapidement des applications.
Conditions préalables
- Vous vous êtes connecté à la console web de OpenShift Container Platform et vous êtes dans la perspective Developer.
Procédure
- Dans la vue Add, cliquez sur la tuile Samples pour afficher la page Samples.
- Sur la page Samples, sélectionnez l'un des exemples de candidature disponibles pour voir le formulaire Create Sample Application.
Sur le site Create Sample Application Form:
- Dans le champ Name, le nom du déploiement est affiché par défaut. Vous pouvez modifier ce nom si nécessaire.
- Dans le site Builder Image Version, une image de constructeur est sélectionnée par défaut. Vous pouvez modifier cette version de l'image en utilisant la liste déroulante Builder Image Version.
- Un exemple d'URL de dépôt Git est ajouté par défaut.
- Cliquez sur Create pour créer l'exemple d'application. L'état de construction de l'application d'exemple est affiché sur la vue Topology. Une fois l'application exemple créée, vous pouvez voir le déploiement ajouté à l'application.
3.1.3. Création d'applications à l'aide de Quick Starts
La page Quick Starts vous montre comment créer, importer et exécuter des applications sur OpenShift Container Platform, avec des instructions et des tâches étape par étape.
Conditions préalables
- Vous vous êtes connecté à la console web de OpenShift Container Platform et vous êtes dans la perspective Developer.
Procédure
- Dans la vue Add, cliquez sur le lien View all quick starts pour afficher la page Quick Starts.
- Dans la page Quick Starts, cliquez sur la tuile correspondant au démarrage rapide que vous souhaitez utiliser.
- Cliquez sur Start pour commencer le démarrage rapide.
3.1.4. Importer une base de code depuis Git pour créer une application
Vous pouvez utiliser la perspective Developer pour créer, construire et déployer une application sur OpenShift Container Platform en utilisant une base de code existante sur GitHub.
La procédure suivante vous guide à travers l'option From Git dans la perspective Developer pour créer une application.
Procédure
- Dans la vue Add, cliquez sur From Git dans la tuile Git Repository pour afficher le formulaire Import from git.
-
Dans la section Git, entrez l'URL du dépôt Git pour la base de code que vous souhaitez utiliser pour créer une application. Par exemple, entrez l'URL de cet exemple d'application Node.js
https://github.com/sclorg/nodejs-ex. L'URL est ensuite validée. Facultatif : vous pouvez cliquer sur Show Advanced Git Options pour ajouter des détails tels que
- Git Reference pour pointer vers le code d'une branche, d'une balise ou d'un commit spécifique à utiliser pour construire l'application.
- Context Dir pour spécifier le sous-répertoire du code source de l'application que vous voulez utiliser pour construire l'application.
- Source Secret pour créer un site Secret Name avec des informations d'identification permettant d'extraire votre code source d'un dépôt privé.
Facultatif : vous pouvez importer un fichier de développement, un fichier Docker ou une image de construction via votre dépôt Git pour personnaliser davantage votre déploiement.
- Si votre dépôt Git contient un fichier devfile, un fichier Docker ou une image builder, il est automatiquement détecté et renseigné dans les champs de chemin respectifs. Si un fichier devfile, un fichier Docker et une image builder sont détectés dans le même dépôt, le fichier devfile est sélectionné par défaut.
- Pour modifier le type d'importation de fichiers et sélectionner une stratégie différente, cliquez sur l'option Edit import strategy.
- Si plusieurs devfiles, Dockerfiles ou images de constructeur sont détectés, pour importer un devfile, un Dockerfile ou une image de constructeur spécifique, spécifiez les chemins respectifs relatifs au répertoire contextuel.
Une fois l'URL Git validée, l'image du constructeur recommandée est sélectionnée et marquée d'une étoile. Si l'image du constructeur n'est pas détectée automatiquement, sélectionnez-en une. Pour l'URL
https://github.com/sclorg/nodejs-exGit, l'image du constructeur Node.js est sélectionnée par défaut.- Facultatif : Utilisez la liste déroulante Builder Image Version pour spécifier une version.
- En outre, il est possible de choisir une stratégie différente en utilisant le site : Utilisez le site Edit import strategy pour sélectionner une autre stratégie.
- Facultatif : Pour l'image du constructeur Node.js, utilisez le champ Run command pour remplacer la commande d'exécution de l'application.
Dans la section General:
-
Dans le champ Application, saisissez un nom unique pour le groupe d'applications, par exemple
myapp. Assurez-vous que le nom de l'application est unique dans un espace de noms. Le champ Name pour identifier les ressources créées pour cette application est automatiquement rempli sur la base de l'URL du dépôt Git s'il n'y a pas d'applications existantes. S'il y a des applications existantes, vous pouvez choisir de déployer le composant dans une application existante, de créer une nouvelle application ou de garder le composant non assigné.
NoteLe nom de la ressource doit être unique dans un espace de noms. Modifiez le nom de la ressource si vous obtenez une erreur.
-
Dans le champ Application, saisissez un nom unique pour le groupe d'applications, par exemple
Dans la section Resources, sélectionnez :
- Deploymentil s'agit de créer une application à la manière de Kubernetes.
- Deployment Configl'objectif est de créer une application de type OpenShift Container Platform.
Serverless Deploymentpour créer un service Knative.
NoteVous pouvez définir la préférence de ressource par défaut pour l'importation en parcourant la page Préférences utilisateur et en cliquant sur Applications → champ Resource type. L'option Serverless Deployment s'affiche dans le formulaire Import from Git uniquement si l'opérateur OpenShift Serverless est installé dans votre cluster. Pour plus de détails, reportez-vous à la documentation d'OpenShift Serverless.
- Dans la section Pipelines, sélectionnez Add Pipeline, puis cliquez sur Show Pipeline Visualization pour voir le pipeline de l'application. Un pipeline par défaut est sélectionné, mais vous pouvez choisir le pipeline que vous souhaitez dans la liste des pipelines disponibles pour l'application.
Facultatif : dans la section Advanced Options, les adresses Target port et Create a route to the application sont sélectionnées par défaut afin que vous puissiez accéder à votre application à l'aide d'une URL publique.
Si votre application n'expose pas ses données sur le port public par défaut, 80, décochez la case et définissez le numéro du port cible que vous souhaitez exposer.
- Facultatif : Vous pouvez utiliser les options avancées suivantes pour personnaliser davantage votre application :
- Routage
En cliquant sur le lien Routing, vous pouvez effectuer les actions suivantes :
- Personnaliser le nom d'hôte de l'itinéraire.
- Spécifiez le chemin que le routeur surveille.
- Sélectionnez le port cible pour le trafic dans la liste déroulante.
Sécurisez votre itinéraire en cochant la case Secure Route. Sélectionnez le type de terminaison TLS requis et définissez une politique pour le trafic non sécurisé dans les listes déroulantes correspondantes.
NotePour les applications sans serveur, le service Knative gère toutes les options de routage ci-dessus. Cependant, vous pouvez personnaliser le port cible pour le trafic, si nécessaire. Si le port cible n'est pas spécifié, le port par défaut de
8080est utilisé.
- Cartographie du domaine
Si vous créez un site Serverless Deployment, vous pouvez ajouter un mappage de domaine personnalisé au service Knative lors de sa création.
Dans la section Advanced options, cliquez sur Show advanced Routing options.
- Si le CR de mappage de domaine que vous souhaitez mapper au service existe déjà, vous pouvez le sélectionner dans le menu déroulant Domain mapping.
-
Si vous voulez créer un nouveau CR de mappage de domaine, tapez le nom de domaine dans la case et sélectionnez l'option Create. Par exemple, si vous tapez
example.com, l'option Create est Create "example.com".
- Bilans de santé
Cliquez sur le lien Health Checks pour ajouter des sondes de préparation, d'activité et de démarrage à votre application. Toutes les sondes ont des données par défaut pré-remplies ; vous pouvez ajouter les sondes avec les données par défaut ou les personnaliser selon vos besoins.
Pour personnaliser les sondes de santé :
- Cliquez sur Add Readiness Probe, si nécessaire, modifiez les paramètres pour vérifier si le conteneur est prêt à traiter les demandes, et cochez la case pour ajouter la sonde.
- Cliquez sur Add Liveness Probe, si nécessaire, modifiez les paramètres pour vérifier si un conteneur est toujours en cours d'exécution, et cochez la case pour ajouter la sonde.
Cliquez sur Add Startup Probe, si nécessaire, modifiez les paramètres pour vérifier si l'application dans le conteneur a démarré, et cochez la case pour ajouter la sonde.
Pour chacune des sondes, vous pouvez spécifier le type de demande - HTTP GET, Container Command, ou TCP Socket, dans la liste déroulante. Le formulaire change en fonction du type de demande sélectionné. Vous pouvez ensuite modifier les valeurs par défaut des autres paramètres, tels que les seuils de réussite et d'échec de la sonde, le nombre de secondes avant d'effectuer la première sonde après le démarrage du conteneur, la fréquence de la sonde et la valeur du délai d'attente.
- Configuration et déploiement de la construction
Cliquez sur les liens Build Configuration et Deployment pour voir les options de configuration correspondantes. Certaines options sont sélectionnées par défaut ; vous pouvez les personnaliser davantage en ajoutant les déclencheurs et les variables d'environnement nécessaires.
Pour les applications sans serveur, l'option Deployment n'est pas affichée car la ressource de configuration Knative maintient l'état souhaité pour votre déploiement au lieu d'une ressource
DeploymentConfig.
- Mise à l'échelle
Cliquez sur le lien Scaling pour définir le nombre de pods ou d'instances de l'application que vous souhaitez déployer initialement.
Si vous créez un déploiement sans serveur, vous pouvez également configurer les paramètres suivants :
-
Min Pods détermine la limite inférieure du nombre de pods qui doivent fonctionner à tout moment pour un service Knative. Ce paramètre est également connu sous le nom de
minScale. -
Max Pods détermine la limite supérieure du nombre de pods qui peuvent être en cours d'exécution à tout moment pour un service Knative. Ce paramètre est également connu sous le nom de
maxScale. - Concurrency target détermine le nombre de requêtes simultanées souhaitées pour chaque instance de l'application à un moment donné.
- Concurrency limit détermine la limite du nombre de requêtes simultanées autorisées pour chaque instance de l'application à un moment donné.
- Concurrency utilization détermine le pourcentage de la limite de requêtes simultanées qui doit être atteint avant que Knative ne mette à l'échelle des pods supplémentaires pour gérer le trafic additionnel.
-
Autoscale window définit la fenêtre temporelle sur laquelle les métriques sont moyennées afin de fournir des informations pour les décisions de mise à l'échelle lorsque l'autoscaler n'est pas en mode panique. Un service est mis à l'échelle zéro si aucune demande n'est reçue pendant cette fenêtre. La durée par défaut de la fenêtre d'autoscale est
60s. Cette fenêtre est également connue sous le nom de fenêtre stable.
-
Min Pods détermine la limite inférieure du nombre de pods qui doivent fonctionner à tout moment pour un service Knative. Ce paramètre est également connu sous le nom de
- Limite des ressources
- Cliquez sur le lien Resource Limit pour définir la quantité de ressources CPU et Memory qu'un conteneur est garanti ou autorisé à utiliser lorsqu'il est en cours d'exécution.
- Étiquettes
Cliquez sur le lien Labels pour ajouter des étiquettes personnalisées à votre application.
- Cliquez sur Create pour créer l'application et une notification de réussite s'affiche. Vous pouvez voir l'état de la construction de l'application dans la vue Topology.
3.1.5. Téléchargement de fichiers JAR pour faciliter le déploiement d'applications Java
Vous pouvez utiliser les fichiers JAR dans la vue Topology de la perspective Developer pour déployer vos applications Java. Vous pouvez télécharger un fichier JAR à l'aide des options suivantes :
- Naviguez jusqu'à la vue Add de la perspective Developer et cliquez sur Upload JAR file dans la tuile From Local Machine. Parcourez et sélectionnez votre fichier JAR, ou glissez-déposez un fichier JAR pour déployer votre application.
- Naviguez jusqu'à la vue Topology et utilisez l'option Upload JAR file, ou glissez-déposez un fichier JAR pour déployer votre application.
- Utilisez le menu en contexte dans la vue Topology, puis utilisez l'option Upload JAR file pour télécharger votre fichier JAR afin de déployer votre application.
Suivez les instructions suivantes pour télécharger un fichier JAR dans la vue Topology afin de déployer une application Java :
Procédure
- Dans la vue Topology, cliquez avec le bouton droit de la souris n'importe où dans la vue Topology pour afficher le menu Add to Project.
- Survolez le menu Add to Project pour voir les options du menu, puis sélectionnez l'option Upload JAR file pour voir le formulaire Upload JAR file. Vous pouvez également faire glisser et déposer le fichier JAR dans la vue Topology.
- Dans le champ JAR file, recherchez le fichier JAR requis sur votre machine locale et téléchargez-le. Vous pouvez également glisser-déposer le fichier JAR dans le champ. Un message d'alerte s'affiche en haut à droite si un type de fichier incompatible est glissé-déposé dans la vue Topology. Une erreur de champ s'affiche si un type de fichier incompatible est déposé sur le champ dans le formulaire de téléchargement.
- Vous pouvez également spécifier des commandes Java optionnelles pour personnaliser votre application déployée. L'icône d'exécution et l'image du constructeur sont sélectionnées par défaut. Si une image de constructeur n'est pas détectée automatiquement, sélectionnez-en une. Si nécessaire, vous pouvez modifier la version à l'aide de la liste déroulante Builder Image Version.
- Dans le champ facultatif Application Name, saisissez un nom unique pour votre application d'étiquetage des ressources.
- Dans le champ Name, saisissez un nom de composant unique pour les ressources associées.
- Facultatif : Dans la liste déroulante Advanced options → Resource type, sélectionnez un autre type de ressource dans la liste des types de ressources par défaut.
- Dans le site Advanced options, cliquez sur Create a Route to the Application pour configurer une URL publique pour votre application déployée.
Cliquez sur Create pour déployer l'application. L'utilisateur voit une notification de toast l'informant que le fichier JAR est en train d'être téléchargé et que cela prend un certain temps. La notification de toast comprend également un lien permettant de consulter les journaux de construction.
NoteSi l'utilisateur tente de fermer l'onglet du navigateur pendant que la construction est en cours, une alerte web s'affiche pour demander à l'utilisateur s'il souhaite réellement quitter la page.
Une fois le fichier JAR téléchargé et l'application déployée, vous pouvez voir le déploiement dans la vue Topology.
3.1.6. Utilisation du registre Devfile pour accéder aux fichiers Devfile
Vous pouvez utiliser les devfiles dans le flux Add de la perspective Developer pour créer une application. Le flux Add offre une intégration complète avec le registre communautaire des devfiles. Un fichier devfile est un fichier YAML portable qui décrit votre environnement de développement sans qu'il soit nécessaire de le configurer à partir de zéro. En utilisant la perspective Devfile registry, vous pouvez utiliser un fichier devfile préconfiguré pour créer une application.
Procédure
- Naviguez vers Developer Perspective → Add → Developer Catalog → All Services. Une liste de tous les services disponibles sur le site Developer Catalog s'affiche.
- Sous All Services, sélectionnez Devfiles pour rechercher les fichiers de développement qui prennent en charge un langage ou un cadre particulier. Vous pouvez également utiliser le filtre par mot-clé pour rechercher un fichier de développement particulier à l'aide de son nom, de son étiquette ou de sa description.
- Cliquez sur le fichier de développement que vous souhaitez utiliser pour créer une application. La tuile devfile affiche les détails du devfile, y compris le nom, la description, le fournisseur et la documentation du devfile.
- Cliquez sur Create pour créer une application et la visualiser dans la vue Topology.
3.1.7. Utiliser le catalogue du développeur pour ajouter des services ou des composants à votre application
Vous utilisez le catalogue de développeurs pour déployer des applications et des services basés sur des services soutenus par l'opérateur, tels que les bases de données, les images de constructeurs et les diagrammes Helm. Le catalogue des développeurs contient une collection de composants d'application, de services, de sources d'événements ou de constructeurs source-image que vous pouvez ajouter à votre projet. Les administrateurs de clusters peuvent personnaliser le contenu mis à disposition dans le catalogue.
Procédure
- Dans la perspective Developer, naviguez jusqu'à la vue Add et, à partir de la tuile Developer Catalog, cliquez sur All Services pour afficher tous les services disponibles sur Developer Catalog.
- Sous All Services, sélectionnez le type de service ou le composant que vous devez ajouter à votre projet. Pour cet exemple, sélectionnez Databases pour obtenir la liste de tous les services de base de données, puis cliquez sur MariaDB pour afficher les détails du service.
Cliquez sur Instantiate Template pour afficher un modèle automatiquement rempli avec les détails du service MariaDB, puis cliquez sur Create pour créer et afficher le service MariaDB dans la vue Topology.
Figure 3.1. MariaDB dans la topologie

3.2. Création d'applications à partir d'opérateurs installés
Operators sont une méthode de conditionnement, de déploiement et de gestion d'une application Kubernetes. Vous pouvez créer des applications sur OpenShift Container Platform à l'aide d'opérateurs qui ont été installés par un administrateur de cluster.
Ce guide présente aux développeurs un exemple de création d'applications à partir d'un opérateur installé en utilisant la console web d'OpenShift Container Platform.
3.2.1. Création d'un cluster etcd à l'aide d'un opérateur
Cette procédure décrit la création d'un nouveau cluster etcd à l'aide de l'opérateur etcd, géré par Operator Lifecycle Manager (OLM).
Conditions préalables
- Accès à un cluster OpenShift Container Platform 4.12.
- L'opérateur etcd a déjà été installé par un administrateur sur l'ensemble du cluster.
Procédure
-
Créez un nouveau projet dans la console web d'OpenShift Container Platform pour cette procédure. Cet exemple utilise un projet appelé
my-etcd. Naviguez jusqu'à la page Operators → Installed Operators. Les opérateurs qui ont été installés sur la grappe par l'administrateur de la grappe et qui sont disponibles pour être utilisés sont affichés ici sous la forme d'une liste de versions de service de grappe (CSV). Les CSV sont utilisées pour lancer et gérer le logiciel fourni par l'opérateur.
AstuceVous pouvez obtenir cette liste à partir de l'interface de programmation en utilisant :
$ oc get csvSur la page Installed Operators, cliquez sur l'opérateur etcd pour obtenir plus de détails et connaître les actions disponibles.
Comme indiqué sous Provided APIs, cet opérateur met à disposition trois nouveaux types de ressources, dont un pour un etcd Cluster (la ressource
EtcdCluster). Ces objets fonctionnent de la même manière que les objets Kubernetes natifs intégrés, tels queDeploymentouReplicaSet, mais contiennent une logique spécifique à la gestion de etcd.Créer un nouveau cluster etcd :
- Dans la boîte API etcd Cluster, cliquez sur Create instance.
-
L'écran suivant vous permet d'apporter des modifications au modèle minimal de départ d'un objet
EtcdCluster, comme la taille de l'amas. Pour l'instant, cliquez sur Create pour finaliser. Cela déclenche le démarrage par l'opérateur des pods, des services et des autres composants du nouveau cluster etcd.
Cliquez sur le cluster etcd example, puis sur l'onglet Resources pour voir que votre projet contient maintenant un certain nombre de ressources créées et configurées automatiquement par l'Opérateur.
Vérifiez qu'un service Kubernetes a été créé pour vous permettre d'accéder à la base de données depuis d'autres pods de votre projet.
Tous les utilisateurs ayant le rôle
editdans un projet donné peuvent créer, gérer et supprimer des instances d'application (un cluster etcd, dans cet exemple) gérées par des opérateurs qui ont déjà été créés dans le projet, en libre-service, comme dans un service en nuage. Si vous souhaitez donner cette possibilité à d'autres utilisateurs, les administrateurs du projet peuvent ajouter le rôle à l'aide de la commande suivante :$ oc policy add-role-to-user edit <user> -n <target_project>
Vous disposez désormais d'un cluster etcd qui réagit aux pannes et rééquilibre les données lorsque les pods deviennent malsains ou sont migrés entre les nœuds du cluster. Plus important encore, les administrateurs de clusters ou les développeurs disposant d'un accès approprié peuvent désormais facilement utiliser la base de données avec leurs applications.
3.3. Création d'applications à l'aide de l'interface de programmation
Vous pouvez créer une application OpenShift Container Platform à partir de composants qui incluent du code source ou binaire, des images et des modèles en utilisant la CLI d'OpenShift Container Platform.
L'ensemble des objets créés par new-app dépend des artefacts transmis en entrée : référentiels de sources, images ou modèles.
3.3.1. Créer une application à partir du code source
La commande new-app permet de créer des applications à partir du code source d'un dépôt Git local ou distant.
La commande new-app crée une configuration de construction, qui elle-même crée une nouvelle image d'application à partir de votre code source. La commande new-app crée également un objet Deployment pour déployer la nouvelle image et un service pour fournir un accès équilibré au déploiement de votre image.
OpenShift Container Platform détecte automatiquement si la stratégie de construction pipeline, source ou docker doit être utilisée, et dans le cas de la construction source, détecte une image de constructeur de langage appropriée.
3.3.1.1. Locale
Pour créer une application à partir d'un dépôt Git dans un répertoire local :
oc new-app /<chemin d'accès au code source>
Si vous utilisez un dépôt Git local, le dépôt doit avoir un remote nommé origin qui pointe vers une URL accessible par le cluster OpenShift Container Platform. S'il n'y a pas de remote reconnu, l'exécution de la commande new-app créera un build binaire.
3.3.1.2. A distance
Pour créer une application à partir d'un dépôt Git distant :
$ oc new-app https://github.com/sclorg/cakephp-exPour créer une application à partir d'un dépôt Git privé et distant :
$ oc new-app https://github.com/youruser/yourprivaterepo --source-secret=yoursecret
Si vous utilisez un dépôt Git distant privé, vous pouvez utiliser l'option --source-secret pour spécifier un secret de clone source existant qui sera injecté dans votre configuration de construction pour accéder au dépôt.
Vous pouvez utiliser un sous-répertoire de votre dépôt de code source en spécifiant un drapeau --context-dir. Pour créer une application à partir d'un dépôt Git distant et d'un sous-répertoire contextuel :
$ oc new-app https://github.com/sclorg/s2i-ruby-container.git \
--context-dir=2.0/test/puma-test-app
De plus, lorsque vous spécifiez une URL distante, vous pouvez spécifier une branche Git à utiliser en ajoutant #<branch_name> à la fin de l'URL :
$ oc new-app https://github.com/openshift/ruby-hello-world.git#beta43.3.1.3. Détection de la stratégie de construction
OpenShift Container Platform détermine automatiquement la stratégie de construction à utiliser en détectant certains fichiers :
Si un fichier Jenkins existe dans le répertoire racine ou le répertoire contextuel spécifié du référentiel source lors de la création d'une nouvelle application, OpenShift Container Platform génère une stratégie de construction de pipeline.
NoteLa stratégie de construction
pipelineest obsolète ; envisagez d'utiliser Red Hat OpenShift Pipelines à la place.- Si un fichier Docker existe dans le répertoire racine ou le répertoire contextuel spécifié du référentiel source lors de la création d'une nouvelle application, OpenShift Container Platform génère une stratégie de construction Docker.
- Si aucun fichier Jenkins ou Docker n'est détecté, OpenShift Container Platform génère une stratégie de construction de source.
Ignorez la stratégie de construction détectée automatiquement en attribuant à l'indicateur --strategy la valeur docker, pipeline ou source.
$ oc new-app /home/user/code/myapp --strategy=docker
La commande oc nécessite que les fichiers contenant les sources de compilation soient disponibles dans un dépôt Git distant. Pour toutes les constructions de sources, vous devez utiliser git remote -v.
3.3.1.4. Détection des langues
Si vous utilisez la stratégie de construction des sources, new-app tente de déterminer le constructeur de langage à utiliser en fonction de la présence de certains fichiers dans le répertoire racine ou le répertoire contextuel spécifié du référentiel :
| Langue | Dossiers |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Après la détection d'une langue, new-app recherche sur le serveur OpenShift Container Platform des balises de flux d'images ayant une annotation supports correspondant à la langue détectée, ou un flux d'images correspondant au nom de la langue détectée. Si aucune correspondance n'est trouvée, new-app recherche dans le registre Docker Hub une image dont le nom correspond à la langue détectée.
Vous pouvez remplacer l'image que le constructeur utilise pour un référentiel source particulier en spécifiant l'image, soit un flux d'images ou une spécification de conteneur, et le référentiel avec un ~ comme séparateur. Notez que dans ce cas, la détection de la stratégie de construction et la détection de la langue ne sont pas effectuées.
Par exemple, pour utiliser le flux d'images myproject/my-ruby dont la source se trouve dans un dépôt distant :
$ oc new-app myproject/my-ruby~https://github.com/openshift/ruby-hello-world.git
Pour utiliser le flux d'images du conteneur openshift/ruby-20-centos7:latest avec la source dans un dépôt local :
$ oc new-app openshift/ruby-20-centos7:latest~/home/user/code/my-ruby-app
La détection de la langue nécessite que le client Git soit installé localement afin que votre dépôt puisse être cloné et inspecté. Si Git n'est pas disponible, vous pouvez éviter l'étape de détection de la langue en spécifiant l'image du constructeur à utiliser avec votre référentiel à l'aide de la syntaxe <image>~<repository>.
L'invocation de -i <image> <repository> nécessite que new-app tente de cloner repository afin de déterminer le type d'artefact, ce qui échouera si Git n'est pas disponible.
L'invocation -i <image> --code <repository> demande à new-app de cloner repository pour déterminer si image doit être utilisé comme constructeur du code source ou déployé séparément, comme dans le cas d'une image de base de données.
3.3.2. Créer une application à partir d'une image
Vous pouvez déployer une application à partir d'une image existante. Les images peuvent provenir de flux d'images dans le serveur OpenShift Container Platform, d'images dans un registre spécifique ou d'images dans le serveur Docker local.
La commande new-app tente de déterminer le type d'image spécifié dans les arguments qui lui sont transmis. Toutefois, vous pouvez indiquer explicitement à new-app s'il s'agit d'une image conteneur en utilisant l'argument --docker-image ou d'un flux d'images en utilisant l'argument -i|--image-stream.
Si vous spécifiez une image à partir de votre dépôt Docker local, vous devez vous assurer que la même image est disponible pour les nœuds du cluster OpenShift Container Platform.
3.3.2.1. Image Docker Hub MySQL
Créez une application à partir de l'image MySQL de Docker Hub, par exemple :
$ oc new-app mysql3.3.2.2. Image dans un registre privé
Créer une application en utilisant une image dans un registre privé, spécifier la spécification complète de l'image du conteneur :
$ oc new-app myregistry:5000/example/myimage3.3.2.3. Flux d'images existant et balise de flux d'images optionnelle
Créer une application à partir d'un flux d'images existant et d'une balise de flux d'images optionnelle :
$ oc new-app my-stream:v13.3.3. Créer une application à partir d'un modèle
Vous pouvez créer une application à partir d'un modèle précédemment stocké ou d'un fichier de modèle, en spécifiant le nom du modèle comme argument. Par exemple, vous pouvez stocker un modèle d'application et l'utiliser pour créer une application.
Téléchargez un modèle d'application dans la bibliothèque de modèles de votre projet actuel. L'exemple suivant télécharge un modèle d'application à partir d'un fichier appelé examples/sample-app/application-template-stibuild.json:
$ oc create -f examples/sample-app/application-template-stibuild.json
Créez ensuite une nouvelle application en faisant référence au modèle d'application. Dans cet exemple, le nom du modèle est ruby-helloworld-sample:
$ oc new-app ruby-helloworld-sample
Pour créer une nouvelle application en faisant référence à un fichier modèle dans votre système de fichiers local, sans le stocker au préalable dans OpenShift Container Platform, utilisez l'argument -f|--file. Par exemple :
$ oc new-app -f examples/sample-app/application-template-stibuild.json3.3.3.1. Paramètres du modèle
Lors de la création d'une application basée sur un modèle, utilisez l'argument -p|--param pour définir les valeurs des paramètres définis par le modèle :
$ oc new-app ruby-helloworld-sample \
-p ADMIN_USERNAME=admin -p ADMIN_PASSWORD=mypassword
Vous pouvez stocker vos paramètres dans un fichier, puis utiliser ce fichier avec --param-file lors de l'instanciation d'un modèle. Si vous souhaitez lire les paramètres à partir de l'entrée standard, utilisez --param-file=-. Voici un exemple de fichier appelé helloworld.params:
ADMIN_USERNAME=admin
ADMIN_PASSWORD=mypasswordFaire référence aux paramètres du fichier lors de l'instanciation d'un modèle :
$ oc new-app ruby-helloworld-sample --param-file=helloworld.params3.3.4. Modifier la création d'une application
La commande new-app génère des objets OpenShift Container Platform qui construisent, déploient et exécutent l'application créée. Normalement, ces objets sont créés dans le projet en cours et reçoivent des noms dérivés des dépôts de sources d'entrée ou des images d'entrée. Cependant, avec new-app, vous pouvez modifier ce comportement.
| Objet | Description |
|---|---|
|
|
Un objet |
|
|
Pour l'objet |
|
|
Un objet |
|
|
La commande |
| Autres | D'autres objets peuvent être générés lors de l'instanciation de modèles, en fonction du modèle. |
3.3.4.1. Spécification des variables d'environnement
Lorsque vous générez des applications à partir d'un modèle, d'une source ou d'une image, vous pouvez utiliser l'argument -e|--env pour transmettre des variables d'environnement au conteneur d'application au moment de l'exécution :
$ oc new-app openshift/postgresql-92-centos7 \
-e POSTGRESQL_USER=user \
-e POSTGRESQL_DATABASE=db \
-e POSTGRESQL_PASSWORD=password
Les variables peuvent également être lues à partir d'un fichier en utilisant l'argument --env-file. Voici un exemple de fichier appelé postgresql.env:
POSTGRESQL_USER=user
POSTGRESQL_DATABASE=db
POSTGRESQL_PASSWORD=passwordLire les variables du fichier :
$ oc new-app openshift/postgresql-92-centos7 --env-file=postgresql.env
En outre, les variables d'environnement peuvent être fournies sur l'entrée standard en utilisant --env-file=-:
$ cat postgresql.env | oc new-app openshift/postgresql-92-centos7 --env-file=-
Les objets BuildConfig créés dans le cadre du traitement new-app ne sont pas mis à jour avec les variables d'environnement transmises avec l'argument -e|--env ou --env-file.
3.3.4.2. Spécifier les variables de l'environnement de construction
Lorsque vous générez des applications à partir d'un modèle, d'une source ou d'une image, vous pouvez utiliser l'argument --build-env pour transmettre des variables d'environnement au conteneur de compilation au moment de l'exécution :
$ oc new-app openshift/ruby-23-centos7 \
--build-env HTTP_PROXY=http://myproxy.net:1337/ \
--build-env GEM_HOME=~/.gem
Les variables peuvent également être lues à partir d'un fichier en utilisant l'argument --build-env-file. Voici un exemple de fichier appelé ruby.env:
HTTP_PROXY=http://myproxy.net:1337/
GEM_HOME=~/.gemLire les variables du fichier :
$ oc new-app openshift/ruby-23-centos7 --build-env-file=ruby.env
En outre, les variables d'environnement peuvent être fournies sur l'entrée standard en utilisant --build-env-file=-:
$ cat ruby.env | oc new-app openshift/ruby-23-centos7 --build-env-file=-3.3.4.3. Spécification des étiquettes
Lorsque vous générez des applications à partir de sources, d'images ou de modèles, vous pouvez utiliser l'argument -l|--label pour ajouter des étiquettes aux objets créés. Les étiquettes facilitent la sélection collective, la configuration et la suppression des objets associés à l'application.
$ oc new-app https://github.com/openshift/ruby-hello-world -l name=hello-world3.3.4.4. Visualisation de la sortie sans création
Pour voir une simulation de l'exécution de la commande new-app, vous pouvez utiliser l'argument -o|--output avec une valeur yaml ou json. Vous pouvez ensuite utiliser la sortie pour prévisualiser les objets créés ou la rediriger vers un fichier que vous pouvez modifier. Lorsque vous êtes satisfait, vous pouvez utiliser oc create pour créer les objets OpenShift Container Platform.
Pour enregistrer les artefacts de new-app dans un fichier, procédez comme suit :
$ oc new-app https://github.com/openshift/ruby-hello-world \
-o yaml > myapp.yamlModifier le fichier :
$ vi myapp.yamlCréez une nouvelle application en faisant référence au fichier :
$ oc create -f myapp.yaml3.3.4.5. Création d'objets avec des noms différents
Les objets créés par new-app sont normalement nommés d'après le référentiel source ou l'image utilisée pour les générer. Vous pouvez définir le nom des objets produits en ajoutant le drapeau --name à la commande :
$ oc new-app https://github.com/openshift/ruby-hello-world --name=myapp3.3.4.6. Création d'objets dans un autre projet
Normalement, new-app crée des objets dans le projet en cours. Cependant, vous pouvez créer des objets dans un autre projet en utilisant l'argument -n|--namespace:
$ oc new-app https://github.com/openshift/ruby-hello-world -n myproject3.3.4.7. Création d'objets multiples
La commande new-app permet de créer plusieurs applications en spécifiant plusieurs paramètres à new-app. Les étiquettes spécifiées dans la ligne de commande s'appliquent à tous les objets créés par la commande unique. Les variables d'environnement s'appliquent à tous les composants créés à partir de la source ou des images.
Pour créer une application à partir d'un référentiel source et d'une image Docker Hub :
$ oc new-app https://github.com/openshift/ruby-hello-world mysql
Si un dépôt de code source et une image de constructeur sont spécifiés en tant qu'arguments séparés, new-app utilise l'image de constructeur comme constructeur pour le dépôt de code source. Si ce n'est pas le cas, spécifiez l'image du constructeur requise pour la source en utilisant le séparateur ~.
3.3.4.8. Regroupement d'images et de sources dans un même module
La commande new-app permet de déployer plusieurs images ensemble dans un seul pod. Pour spécifier les images à regrouper, utilisez le séparateur . L'argument de ligne de commande --group peut également être utilisé pour spécifier les images à regrouper. Pour regrouper l'image construite à partir d'un référentiel source avec d'autres images, spécifiez son image de construction dans le groupe :
$ oc new-app ruby+mysqlPour déployer une image construite à partir de la source et une image externe ensemble :
$ oc new-app \
ruby~https://github.com/openshift/ruby-hello-world \
mysql \
--group=ruby+mysql3.3.4.9. Recherche d'images, de modèles et d'autres données
Pour rechercher des images, des modèles et d'autres entrées pour la commande oc new-app, ajoutez les drapeaux --search et --list. Par exemple, pour trouver toutes les images ou tous les modèles qui incluent PHP :
$ oc new-app --search phpChapitre 4. Visualisation de la composition des applications à l'aide de la vue Topologie
La vue Topology dans la perspective Developer de la console web fournit une représentation visuelle de toutes les applications d'un projet, de leur état de construction, et des composants et services qui leur sont associés.
4.1. Conditions préalables
Pour afficher vos applications dans la vue Topology et interagir avec elles, assurez-vous que
- Vous vous êtes connecté à la console web.
- Vous disposez des rôles et autorisations appropriés dans un projet pour créer des applications et d'autres charges de travail dans OpenShift Container Platform.
- Vous avez créé et déployé une application sur OpenShift Container Platform en utilisant la perspective Developer .
- Vous êtes dans la perspective Developer .
4.2. Visualiser la topologie de votre application
Vous pouvez naviguer vers la vue Topology en utilisant le panneau de navigation de gauche dans la perspective Developer. Après avoir déployé une application, vous êtes automatiquement dirigé vers Graph view où vous pouvez voir l'état des pods d'application, accéder rapidement à l'application sur une URL publique, accéder au code source pour le modifier et voir l'état de votre dernier build. Vous pouvez faire un zoom avant et arrière pour voir plus de détails sur une application particulière.
La vue Topology vous permet de surveiller vos applications à l'aide de la vue List. Utilisez l'icône List view (
![]() ) pour afficher une liste de toutes vos applications et utilisez l'icône Graph view (
) pour afficher une liste de toutes vos applications et utilisez l'icône Graph view (
![]() ) pour revenir à la vue graphique.
) pour revenir à la vue graphique.
Vous pouvez personnaliser les vues comme vous le souhaitez à l'aide des éléments suivants :
- Utilisez le champ Find by name pour trouver les composants requis. Les résultats de la recherche peuvent apparaître en dehors de la zone visible ; cliquez sur Fit to Screen dans la barre d'outils en bas à gauche pour redimensionner la vue Topology afin d'afficher tous les composants.
La liste déroulante Display Options permet de configurer la vue Topology des différents groupes d'applications. Les options disponibles dépendent des types de composants déployés dans le projet :
Mode (Connectivity ou Consumption)
- Connectivité : Sélectionnez cette option pour afficher toutes les connexions entre les différents nœuds de la topologie.
- Consommation : Sélectionnez cette option pour afficher la consommation de ressources pour tous les nœuds de la topologie.
Expand groupe
- Machines virtuelles : Permet d'afficher ou de masquer les machines virtuelles.
- Groupes d'applications : Permet de condenser les groupes d'applications en cartes avec une vue d'ensemble d'un groupe d'applications et des alertes qui lui sont associées.
- Communiqués Helm : Clair pour condenser les composants déployés en tant que version Helm dans des cartes présentant une vue d'ensemble d'une version donnée.
- Services Knative : Clear to condense the Knative Service components into cards with an overview of a given component.
- Groupements d'opérateurs : Permet de condenser les composants déployés avec un opérateur dans des cartes présentant une vue d'ensemble du groupe donné.
Show sur la base de Pod Count ou Labels
- Nombre de pods : Sélectionnez cette option pour afficher le nombre de gousses d'un composant dans l'icône du composant.
- Étiquettes : Permet d'afficher ou de masquer les étiquettes des composants.
La vue Topology vous offre également l'option Export application pour télécharger votre application au format ZIP. Vous pouvez ensuite importer l'application téléchargée dans un autre projet ou un autre cluster. Pour plus de détails, voir Exporting an application to another project or cluster dans la section Additional resources.
4.3. Interagir avec les applications et les composants
La vue Topology dans la perspective Developer de la console web offre les options suivantes pour interagir avec les applications et les composants :
-
Cliquez sur Open URL (
 ) pour voir votre application exposée par la route sur une URL publique.
) pour voir votre application exposée par la route sur une URL publique.
Cliquez sur Edit Source code pour accéder à votre code source et le modifier.
NoteCette fonctionnalité n'est disponible que lorsque vous créez des applications à l'aide des options From Git, From Catalog et From Dockerfile.
-
Passez votre curseur sur l'icône en bas à gauche du pod pour voir le nom de la dernière version et son statut. L'état de la construction de l'application est indiqué par New (
 ), Pending (
), Pending (
 ), Running (
), Running (
 ), Completed (
), Completed (
 ), Failed (
), Failed (
 ), et Canceled (
), et Canceled (
 ).
).
L'état ou la phase du pod est indiqué par des couleurs et des infobulles différentes :
-
Running (
 ) : Le pod est lié à un nœud et tous les conteneurs sont créés. Au moins un conteneur est toujours en cours d'exécution ou est en train de démarrer ou de redémarrer.
) : Le pod est lié à un nœud et tous les conteneurs sont créés. Au moins un conteneur est toujours en cours d'exécution ou est en train de démarrer ou de redémarrer.
-
Not Ready (
 ) : Les pods qui exécutent plusieurs conteneurs ne sont pas tous prêts.
) : Les pods qui exécutent plusieurs conteneurs ne sont pas tous prêts.
-
Warning(
 ) : Les conteneurs dans les pods sont en train d'être terminés, mais la terminaison n'a pas réussi. Certains conteneurs peuvent être dans d'autres états.
) : Les conteneurs dans les pods sont en train d'être terminés, mais la terminaison n'a pas réussi. Certains conteneurs peuvent être dans d'autres états.
-
Failed(
 ) : Tous les conteneurs du pod se sont terminés, mais au moins un conteneur s'est terminé par un échec. C'est-à-dire que le conteneur est sorti avec un statut non nul ou a été interrompu par le système.
) : Tous les conteneurs du pod se sont terminés, mais au moins un conteneur s'est terminé par un échec. C'est-à-dire que le conteneur est sorti avec un statut non nul ou a été interrompu par le système.
-
Pending(
 ) : Le pod est accepté par le cluster Kubernetes, mais un ou plusieurs des conteneurs n'ont pas été configurés et rendus prêts à fonctionner. Cela inclut le temps qu'un pod passe à attendre d'être planifié ainsi que le temps passé à télécharger des images de conteneurs sur le réseau.
) : Le pod est accepté par le cluster Kubernetes, mais un ou plusieurs des conteneurs n'ont pas été configurés et rendus prêts à fonctionner. Cela inclut le temps qu'un pod passe à attendre d'être planifié ainsi que le temps passé à télécharger des images de conteneurs sur le réseau.
-
Succeeded(
 ) : Tous les conteneurs du pod se sont terminés avec succès et ne seront pas redémarrés.
) : Tous les conteneurs du pod se sont terminés avec succès et ne seront pas redémarrés.
-
Terminating(
 ) : Lorsqu'un pod est en cours de suppression, il est indiqué comme Terminating par certaines commandes kubectl. L'état Terminating n'est pas l'une des phases du pod. Un pod bénéficie d'une période de terminaison gracieuse, dont la valeur par défaut est de 30 secondes.
) : Lorsqu'un pod est en cours de suppression, il est indiqué comme Terminating par certaines commandes kubectl. L'état Terminating n'est pas l'une des phases du pod. Un pod bénéficie d'une période de terminaison gracieuse, dont la valeur par défaut est de 30 secondes.
-
Unknown(
 ) : L'état du module n'a pas pu être obtenu. Cette phase se produit généralement en raison d'une erreur de communication avec le nœud où le module devrait être exécuté.
) : L'état du module n'a pas pu être obtenu. Cette phase se produit généralement en raison d'une erreur de communication avec le nœud où le module devrait être exécuté.
-
Running (
Après la création d'une application et le déploiement d'une image, l'état s'affiche comme suit : Pending. Une fois que l'application est construite, elle est affichée sous la forme Running.
Figure 4.1. Topologie de l'application
Le nom de la ressource d'application est accompagné d'indicateurs pour les différents types d'objets de ressource, comme suit :
-
CJ:
CronJob -
D:
Deployment -
DC:
DeploymentConfig -
DS:
DaemonSet -
J:
Job -
P:
Pod -
SS:
StatefulSet  (Knative) : Une application sans serveur
Note
(Knative) : Une application sans serveur
NoteLes applications sans serveur prennent un certain temps pour se charger et s'afficher sur le site Graph view. Lorsque vous déployez une application sans serveur, elle crée d'abord une ressource de service, puis une révision. Ensuite, elle est déployée et affichée sur la page Graph view. S'il s'agit de la seule charge de travail, il se peut que vous soyez redirigé vers la page Add. Une fois la révision déployée, l'application sans serveur est affichée sur la page Graph view.
-
CJ:
4.4. Mise à l'échelle des pods d'application et vérification des builds et des routes
La vue Topology fournit les détails des composants déployés dans le panneau Overview. Vous pouvez utiliser les onglets Overview et Resources pour mettre à l'échelle les pods d'application, vérifier l'état de la construction, les services et les itinéraires comme suit :
Cliquez sur le nœud du composant pour afficher le panneau Overview à droite. Utilisez l'onglet Overview pour :
- Faites évoluer vos pods à l'aide des flèches vers le haut et vers le bas pour augmenter ou diminuer le nombre d'instances de l'application manuellement. Pour les applications sans serveur, les pods sont automatiquement réduits à zéro lorsqu'ils sont inactifs et augmentés en fonction du trafic du canal.
- Vérifiez les pages Labels, Annotations, et Status de la demande.
Cliquez sur l'onglet Resources pour
- Voir la liste de tous les pods, leur statut, les journaux d'accès, et cliquer sur le pod pour voir les détails du pod.
- Voir les builds, leur statut, les logs d'accès, et démarrer un nouveau build si nécessaire.
- Voir les services et les routes utilisés par le composant.
Pour les applications sans serveur, l'onglet Resources fournit des informations sur la révision, les routes et les configurations utilisées pour ce composant.
4.5. Ajouter des composants à un projet existant
Procédure
-
Cliquez sur Add to Project (
 ) à côté du volet de navigation gauche ou appuyez sur Ctrl+Espace
) à côté du volet de navigation gauche ou appuyez sur Ctrl+Espace
- Recherchez le composant et sélectionnez Create ou appuyez sur Entrée pour ajouter le composant au projet et le voir dans la topologie Graph view.
Figure 4.2. Ajout d'un composant via la recherche rapide
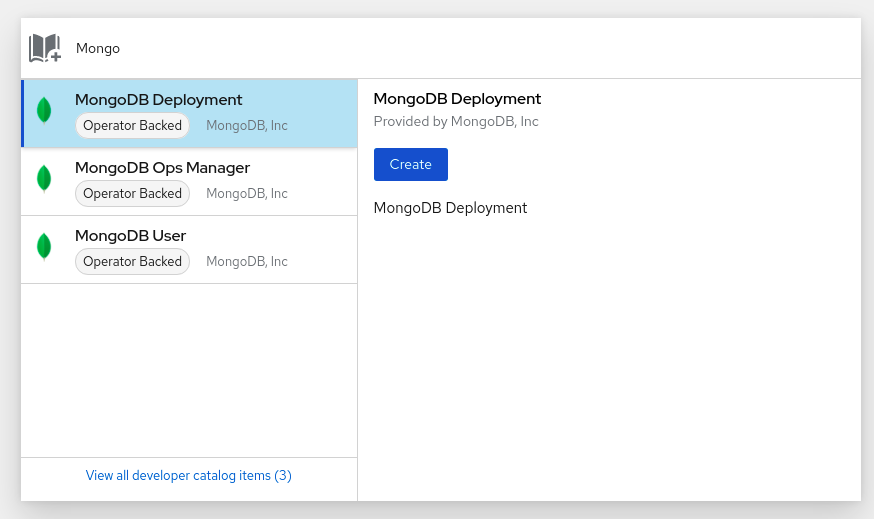
Vous pouvez également utiliser les options Import from Git, Container Image, Database, From Catalog, Operator Backed, Helm Charts, Samples, ou Upload JAR file dans le menu contextuel en cliquant avec le bouton droit de la souris dans la topologie Graph view pour ajouter un composant à votre projet.
Figure 4.3. Menu contextuel pour ajouter des services

4.6. Regroupement de plusieurs composants au sein d'une application
Vous pouvez utiliser la vue Add pour ajouter plusieurs composants ou services à votre projet et utiliser la topologie Graph view pour regrouper les applications et les ressources au sein d'un groupe d'applications.
Conditions préalables
- Vous avez créé et déployé au moins deux composants sur OpenShift Container Platform en utilisant la perspective Developer.
Procédure
Pour ajouter un service à un groupe d'applications existant, appuyez sur la touche Shift et faites-le glisser vers le groupe d'applications existant. Le fait de faire glisser un composant et de l'ajouter à un groupe d'application permet d'ajouter les étiquettes nécessaires au composant.
Figure 4.4. Regroupement d'applications

Vous pouvez également ajouter le composant à une application en procédant comme suit :
- Cliquez sur le module de service pour afficher le panneau Overview à droite.
- Cliquez sur le menu déroulant Actions et sélectionnez Edit Application Grouping.
- Dans la boîte de dialogue Edit Application Grouping, cliquez sur la liste déroulante Application et sélectionnez un groupe d'applications approprié.
- Cliquez sur Save pour ajouter le service au groupe d'applications.
Vous pouvez supprimer un composant d'un groupe d'applications en sélectionnant le composant et en le faisant glisser hors du groupe d'applications à l'aide de la touche Maj.
4.7. Ajouter des services à votre application
Pour ajouter un service à votre application, utilisez les actions Add en utilisant le menu contextuel dans la topologie Graph view.
Outre le menu contextuel, vous pouvez ajouter des services en utilisant la barre latérale ou en survolant et en faisant glisser la flèche pendante du groupe d'applications.
Procédure
Cliquez avec le bouton droit de la souris sur un groupe d'application dans la topologie Graph view pour afficher le menu contextuel.
Figure 4.5. Menu contextuel d'ajout de ressources
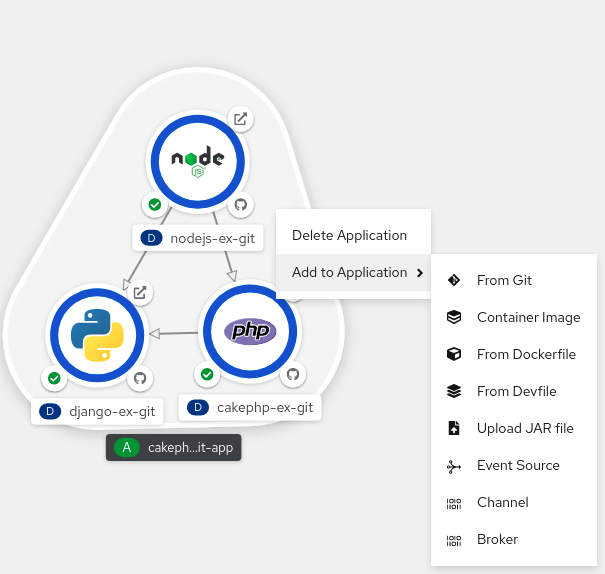
- Utilisez Add to Application pour sélectionner une méthode d'ajout d'un service au groupe d'application, telle que From Git, Container Image, From Dockerfile, From Devfile, Upload JAR file, Event Source, Channel, ou Broker.
- Remplissez le formulaire correspondant à la méthode choisie et cliquez sur Create. Par exemple, pour ajouter un service basé sur le code source de votre dépôt Git, choisissez la méthode From Git, remplissez le formulaire Import from Git et cliquez sur Create.
4.8. Supprimer des services de votre application
Dans la topologie Graph view, supprimez un service de votre application à l'aide du menu contextuel.
Procédure
- Cliquez avec le bouton droit de la souris sur un service d'un groupe d'applications dans la topologie Graph view pour afficher le menu contextuel.
Sélectionnez Delete Deployment pour supprimer le service.
Figure 4.6. Suppression de l'option de déploiement

4.9. Étiquettes et annotations utilisées pour la vue Topologie
La vue Topology utilise les étiquettes et les annotations suivantes :
- Icône affichée dans le nœud
-
Les icônes du nœud sont définies en recherchant les icônes correspondantes à l'aide de l'étiquette
app.openshift.io/runtime, suivie de l'étiquetteapp.kubernetes.io/name. Cette recherche est effectuée à l'aide d'un ensemble prédéfini d'icônes. - Lien vers l'éditeur de code source ou la source
-
L'annotation
app.openshift.io/vcs-uriest utilisée pour créer des liens vers l'éditeur de code source. - Connecteur de nœud
-
L'annotation
app.openshift.io/connects-toest utilisée pour relier les nœuds. - Regroupement d'applications
-
L'étiquette
app.kubernetes.io/part-of=<appname>est utilisée pour regrouper les applications, les services et les composants.
Pour des informations détaillées sur les étiquettes et les annotations que les applications OpenShift Container Platform doivent utiliser, voir Guidelines for labels and annotations for OpenShift applications.
Chapitre 5. Exporter des applications
En tant que développeur, vous pouvez exporter votre application au format ZIP. En fonction de vos besoins, importez l'application exportée vers un autre projet du même cluster ou d'un cluster différent en utilisant l'option Import YAML dans la vue Add. L'exportation de votre application vous permet de réutiliser les ressources de votre application et de gagner du temps.
5.1. Conditions préalables
Vous avez installé l'opérateur gitops-primer depuis le OperatorHub.
NoteL'option Export application est désactivée dans la vue Topology même après l'installation de l'opérateur gitops-primer.
- Vous avez créé une application dans la vue Topology pour permettre Export application.
5.2. Procédure
Dans la perspective du développeur, effectuez l'une des opérations suivantes :
- Naviguez jusqu'à la vue Add et cliquez sur Export application dans la tuile Application portability.
- Naviguez jusqu'à la vue Topology et cliquez sur Export application.
- Cliquez sur OK dans la boîte de dialogue Export Application. Une notification s'ouvre pour confirmer que l'exportation des ressources de votre projet a commencé.
Étapes facultatives que vous pouvez être amené à effectuer dans les scénarios suivants :
- Si vous avez commencé à exporter une application incorrecte, cliquez sur Export application → Cancel Export.
- Si votre exportation est déjà en cours et que vous souhaitez recommencer, cliquez sur Export application → Restart Export.
Si vous souhaitez consulter les journaux associés à l'exportation d'une application, cliquez sur Export application et sur le lien View Logs.

- Après une exportation réussie, cliquez sur Download dans la boîte de dialogue pour télécharger les ressources de l'application au format ZIP sur votre machine.
Chapitre 6. Connecter les applications aux services
6.1. Notes de mise à jour pour Service Binding Operator
L'opérateur de liaison de services se compose d'un contrôleur et d'une définition de ressource personnalisée (CRD) pour la liaison de services. Il gère le plan de données pour les charges de travail et les services d'appui. Le contrôleur de liaison de services lit les données mises à disposition par le plan de contrôle des services d'appui. Il projette ensuite ces données vers les charges de travail conformément aux règles spécifiées dans la ressource ServiceBinding.
Avec Service Binding Operator, vous pouvez :
- Liez vos charges de travail grâce à des services de sauvegarde gérés par l'opérateur.
- Automatiser la configuration des données de liaison.
- Fournir aux opérateurs de services une expérience administrative simple pour fournir et gérer l'accès aux services.
- Enrichir le cycle de développement avec une méthode de liaison de service cohérente et déclarative qui élimine les divergences dans les environnements en grappe.
La définition de ressource personnalisée (CRD) de l'opérateur de liaison de services prend en charge les API suivantes :
-
Service Binding avec le groupe API
binding.operators.coreos.com. -
Service Binding (Spec API) avec le groupe API
servicebinding.io.
6.1.1. Matrice de soutien
Certaines fonctionnalités du tableau suivant sont en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Dans le tableau, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Service Binding Operator | API Group and Support Status | OpenShift Versions | |
|---|---|---|---|
| Version |
|
| |
| 1.3.3 | GA | GA | 4.9-4.12 |
| 1.3.1 | GA | GA | 4.9-4.11 |
| 1.3 | GA | GA | 4.9-4.11 |
| 1.2 | GA | GA | 4.7-4.11 |
| 1.1.1 | GA | TP | 4.7-4.10 |
| 1.1 | GA | TP | 4.7-4.10 |
| 1.0.1 | GA | TP | 4.7-4.9 |
| 1.0 | GA | TP | 4.7-4.9 |
6.1.2. Rendre l'open source plus inclusif
Red Hat s'engage à remplacer les termes problématiques dans son code, sa documentation et ses propriétés Web. Nous commençons par ces quatre termes : master, slave, blacklist et whitelist. En raison de l'ampleur de cette entreprise, ces changements seront mis en œuvre progressivement au cours de plusieurs versions à venir. Pour plus de détails, consultez le message de Chris Wright, directeur technique de Red Hat.
6.1.3. Notes de version pour Service Binding Operator 1.3.3
Service Binding Operator 1.3.3 est maintenant disponible sur OpenShift Container Platform 4.9, 4.10, 4.11 et 4.12.
6.1.3.1. Problèmes corrigés
-
Avant cette mise à jour, une vulnérabilité de sécurité
CVE-2022-41717a été constatée pour Service Binding Operator. Cette mise à jour corrige l'erreurCVE-2022-41717et met à jour le paquetgolang.org/x/netde v0.0.0-20220906165146-f3363e06e74c à v0.4.0. APPSVC-1256 - Avant cette mise à jour, les services fournis n'étaient détectés que si la ressource concernée avait l'annotation \N "servicebinding.io/provisioned-service : true" définie, tandis que les autres services fournis n'étaient pas détectés. Avec cette mise à jour, le mécanisme de détection identifie correctement tous les services fournis en se basant sur l'attribut "status.binding.name". APPSVC-1204
6.1.4. Notes de version pour Service Binding Operator 1.3.1
Service Binding Operator 1.3.1 est maintenant disponible sur OpenShift Container Platform 4.9, 4.10, et 4.11.
6.1.4.1. Problèmes corrigés
-
Avant cette mise à jour, une vulnérabilité de sécurité
CVE-2022-32149a été notée pour Service Binding Operator. Cette mise à jour corrige l'erreurCVE-2022-32149et met à jour le paquetagegolang.org/x/textde v0.3.7 à v0.3.8. APPSVC-1220
6.1.5. Notes de version pour Service Binding Operator 1.3
Service Binding Operator 1.3 est maintenant disponible sur OpenShift Container Platform 4.9, 4.10, et 4.11.
6.1.5.1. Fonctionnalité supprimée
- Dans Service Binding Operator 1.3, la fonction de descripteur Operator Lifecycle Manager (OLM) a été supprimée afin d'améliorer l'utilisation des ressources. Au lieu des descripteurs OLM, vous pouvez utiliser les annotations CRD pour déclarer les données de liaison.
6.1.6. Notes de mise à jour pour Service Binding Operator 1.2
Service Binding Operator 1.2 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, 4.10, et 4.11.
6.1.6.1. Nouvelles fonctionnalités
Cette section présente les nouveautés de Service Binding Operator 1.2 :
-
Permettre à l'opérateur de liaison de services de prendre en compte les champs facultatifs dans les annotations en fixant la valeur de l'indicateur
optionalàtrue. -
Soutien aux ressources
servicebinding.io/v1beta1. - Amélioration de la découvrabilité des services liables en exposant le secret de liaison pertinent sans exiger la présence d'une charge de travail.
6.1.6.2. Problèmes connus
- Actuellement, lorsque vous installez Service Binding Operator sur OpenShift Container Platform 4.11, l'empreinte mémoire de Service Binding Operator augmente au-delà des limites prévues. Toutefois, en cas d'utilisation réduite, l'empreinte mémoire reste dans les limites prévues pour votre environnement ou vos scénarios. Par rapport à OpenShift Container Platform 4.10, en cas de stress, l'empreinte mémoire moyenne et maximale augmente considérablement. Ce problème est également évident dans les versions précédentes de Service Binding Operator. Il n'y a actuellement aucune solution à ce problème. APPSVC-1200
-
Par défaut, les fichiers projetés ont des permissions de 0644. Service Binding Operator ne peut pas définir de permissions spécifiques en raison d'un bogue dans Kubernetes qui cause des problèmes si le service attend des permissions spécifiques telles que
0600. Comme solution de contournement, vous pouvez modifier le code du programme ou de l'application qui s'exécute à l'intérieur d'une ressource de charge de travail pour copier le fichier dans le répertoire/tmpet définir les autorisations appropriées. APPSVC-1127 Il y a actuellement un problème connu avec l'installation de Service Binding Operator dans un mode d'installation à espace de noms unique. L'absence d'une règle de contrôle d'accès basé sur les rôles (RBAC) adaptée à l'espace de noms empêche la liaison d'une application à quelques services connus soutenus par l'opérateur que le Service Binding Operator peut automatiquement détecter et lier. Dans ce cas, un message d'erreur similaire à l'exemple suivant est généré :
Exemple de message d'erreur
`postgresclusters.postgres-operator.crunchydata.com "hippo" is forbidden: User "system:serviceaccount:my-petclinic:service-binding-operator" cannot get resource "postgresclusters" in API group "postgres-operator.crunchydata.com" in the namespace "my-petclinic"`Solution 1 : Installez le Service Binding Operator dans le mode d'installation
all namespaces. Par conséquent, la règle RBAC appropriée à l'échelle du cluster existe maintenant et la liaison réussit.Solution 2 : Si vous ne pouvez pas installer le Service Binding Operator dans le mode d'installation
all namespaces, installez la liaison de rôle suivante dans l'espace de noms où le Service Binding Operator est installé :Exemple : Liaison de rôles pour l'opérateur Crunchy Postgres
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: service-binding-crunchy-postgres-viewer subjects: - kind: ServiceAccount name: service-binding-operator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: service-binding-crunchy-postgres-viewer-roleSelon la spécification, lorsque vous modifiez les ressources
ClusterWorkloadResourceMapping, le Service Binding Operator doit utiliser la version précédente de la ressourceClusterWorkloadResourceMappingpour supprimer les données de liaison qui ont été projetées jusqu'à présent. Actuellement, lorsque vous modifiez les ressourcesClusterWorkloadResourceMapping, le Service Binding Operator utilise la dernière version de la ressourceClusterWorkloadResourceMappingpour supprimer les données de liaison. Par conséquent, {the servicebinding-title} peut supprimer les données de liaison de manière incorrecte. Pour contourner ce problème, procédez comme suit :-
Supprimer toutes les ressources
ServiceBindingqui utilisent la ressourceClusterWorkloadResourceMappingcorrespondante. -
Modifier la ressource
ClusterWorkloadResourceMapping. -
Appliquez à nouveau les ressources
ServiceBindingque vous avez retirées à l'étape 1.
-
Supprimer toutes les ressources
6.1.7. Notes de version pour Service Binding Operator 1.1.1
Service Binding Operator 1.1.1 est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
6.1.7.1. Problèmes corrigés
-
Avant cette mise à jour, une vulnérabilité de sécurité
CVE-2021-38561a été notée pour le diagramme Service Binding Operator Helm. Cette mise à jour corrige l'erreurCVE-2021-38561et met à jour le paquetagegolang.org/x/textde v0.3.6 à v0.3.7. APPSVC-1124 -
Avant cette mise à jour, les utilisateurs du Developer Sandbox ne disposaient pas d'autorisations suffisantes pour lire les ressources
ClusterWorkloadResourceMapping. Par conséquent, l'opérateur de liaison de services empêchait toutes les liaisons de services d'aboutir. Avec cette mise à jour, le Service Binding Operator inclut désormais les règles de contrôle d'accès basées sur les rôles (RBAC) appropriées pour tout sujet authentifié, y compris les utilisateurs de l'Environnement de développement. Ces règles RBAC permettent à l'opérateur de liaison de services deget,listetwatchles ressourcesClusterWorkloadResourceMappingpour les utilisateurs de l'Environnement de développement et de traiter les liaisons de services avec succès. APPSVC-1135
6.1.7.2. Problèmes connus
Il y a actuellement un problème connu avec l'installation de Service Binding Operator dans un mode d'installation à espace de noms unique. L'absence d'une règle de contrôle d'accès basé sur les rôles (RBAC) adaptée à l'espace de noms empêche la liaison d'une application à quelques services connus soutenus par l'opérateur que le Service Binding Operator peut automatiquement détecter et lier. Dans ce cas, un message d'erreur similaire à l'exemple suivant est généré :
Exemple de message d'erreur
`postgresclusters.postgres-operator.crunchydata.com "hippo" is forbidden: User "system:serviceaccount:my-petclinic:service-binding-operator" cannot get resource "postgresclusters" in API group "postgres-operator.crunchydata.com" in the namespace "my-petclinic"`Solution 1 : Installez le Service Binding Operator dans le mode d'installation
all namespaces. Par conséquent, la règle RBAC appropriée à l'échelle du cluster existe maintenant et la liaison réussit.Solution 2 : Si vous ne pouvez pas installer le Service Binding Operator dans le mode d'installation
all namespaces, installez la liaison de rôle suivante dans l'espace de noms où le Service Binding Operator est installé :Exemple : Liaison de rôles pour l'opérateur Crunchy Postgres
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: service-binding-crunchy-postgres-viewer subjects: - kind: ServiceAccount name: service-binding-operator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: service-binding-crunchy-postgres-viewer-roleActuellement, lorsque vous modifiez les ressources
ClusterWorkloadResourceMapping, l'opérateur de liaison de service n'applique pas le comportement correct. En guise de solution de contournement, procédez comme suit :-
Supprimer toutes les ressources
ServiceBindingqui utilisent la ressourceClusterWorkloadResourceMappingcorrespondante. -
Modifier la ressource
ClusterWorkloadResourceMapping. -
Appliquez à nouveau les ressources
ServiceBindingque vous avez retirées à l'étape 1.
-
Supprimer toutes les ressources
6.1.8. Notes de mise à jour pour Service Binding Operator 1.1
Service Binding Operator est maintenant disponible sur OpenShift Container Platform 4.7, 4.8, 4.9, et 4.10.
6.1.8.1. Nouvelles fonctionnalités
Cette section présente les nouveautés de Service Binding Operator 1.1 :
Options de liaison de service
- Cartographie des ressources de la charge de travail : Définir exactement où les données contraignantes doivent être projetées pour les charges de travail secondaires.
- Lier de nouvelles charges de travail à l'aide d'un sélecteur d'étiquettes.
6.1.8.2. Problèmes corrigés
- Avant cette mise à jour, les liaisons de services qui utilisaient des sélecteurs d'étiquettes pour sélectionner des charges de travail ne projetaient pas les données de liaison de services dans les nouvelles charges de travail qui correspondaient aux sélecteurs d'étiquettes donnés. Par conséquent, l'opérateur de liaison de services ne pouvait pas lier périodiquement ces nouvelles charges de travail. Avec cette mise à jour, les liaisons de service projettent désormais les données de liaison de service dans les nouvelles charges de travail qui correspondent au sélecteur d'étiquette donné. L'opérateur de liaison de services tente désormais périodiquement de trouver et de lier ces nouvelles charges de travail. APPSVC-1083
6.1.8.3. Problèmes connus
Il y a actuellement un problème connu avec l'installation de Service Binding Operator dans un mode d'installation à espace de noms unique. L'absence d'une règle de contrôle d'accès basé sur les rôles (RBAC) adaptée à l'espace de noms empêche la liaison d'une application à quelques services connus soutenus par l'opérateur que le Service Binding Operator peut automatiquement détecter et lier. Dans ce cas, un message d'erreur similaire à l'exemple suivant est généré :
Exemple de message d'erreur
`postgresclusters.postgres-operator.crunchydata.com "hippo" is forbidden: User "system:serviceaccount:my-petclinic:service-binding-operator" cannot get resource "postgresclusters" in API group "postgres-operator.crunchydata.com" in the namespace "my-petclinic"`Solution 1 : Installez le Service Binding Operator dans le mode d'installation
all namespaces. Par conséquent, la règle RBAC appropriée à l'échelle du cluster existe maintenant et la liaison réussit.Solution 2 : Si vous ne pouvez pas installer le Service Binding Operator dans le mode d'installation
all namespaces, installez la liaison de rôle suivante dans l'espace de noms où le Service Binding Operator est installé :Exemple : Liaison de rôles pour l'opérateur Crunchy Postgres
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: service-binding-crunchy-postgres-viewer subjects: - kind: ServiceAccount name: service-binding-operator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: service-binding-crunchy-postgres-viewer-roleActuellement, lorsque vous modifiez les ressources
ClusterWorkloadResourceMapping, l'opérateur de liaison de service n'applique pas le comportement correct. En guise de solution de contournement, procédez comme suit :-
Supprimer toutes les ressources
ServiceBindingqui utilisent la ressourceClusterWorkloadResourceMappingcorrespondante. -
Modifier la ressource
ClusterWorkloadResourceMapping. -
Appliquez à nouveau les ressources
ServiceBindingque vous avez retirées à l'étape 1.
-
Supprimer toutes les ressources
6.1.9. Notes de version pour Service Binding Operator 1.0.1
Service Binding Operator est désormais disponible sur OpenShift Container Platform 4.7, 4.8 et 4.9.
Service Binding Operator 1.0.1 prend en charge OpenShift Container Platform 4.9 et les versions ultérieures :
- IBM Power Systems
- IBM Z et LinuxONE
La définition des ressources personnalisées (CRD) de l'opérateur de liaison de services 1.0.1 prend en charge les API suivantes :
-
Service Binding avec le groupe API
binding.operators.coreos.com. Service Binding (Spec API Tech Preview) avec le groupe API
servicebinding.io.ImportantService Binding (Spec API Tech Preview) avec le groupe d'API
servicebinding.ioest une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
6.1.9.1. Matrice de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Aperçu de la technologie Fonctionnalités Support Champ d'application
Dans le tableau ci-dessous, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Opérateur de liaison de services 1.0.1 |
|---|---|
|
| GA |
|
| TP |
6.1.9.2. Problèmes corrigés
-
Avant cette mise à jour, la liaison des valeurs de données à partir d'une ressource personnalisée (CR)
Clusterde l'APIpostgresql.k8s.enterpriesedb.io/v1collectait la valeur de liaisonhostà partir du champ.metadata.namede la CR. La valeur de liaison collectée est un nom d'hôte incorrect et le nom d'hôte correct est disponible dans le champ.status.writeService. Avec cette mise à jour, les annotations que l'opérateur de liaison de service utilise pour exposer les valeurs des données de liaison à partir du CR du service d'appui sont maintenant modifiées pour collecter la valeur de liaisonhostà partir du champ.status.writeService. L'opérateur de liaison de service utilise ces annotations modifiées pour projeter le nom d'hôte correct dans les liaisonshostetprovider. APPSVC-1040 -
Avant cette mise à jour, lorsque vous liez un CR
PostgresClusterde l'APIpostgres-operator.crunchydata.com/v1beta1, les valeurs des données de liaison n'incluaient pas les valeurs des certificats de la base de données. Par conséquent, l'application ne parvenait pas à se connecter à la base de données. Avec cette mise à jour, les modifications apportées aux annotations que l'opérateur de liaison de services utilise pour exposer les données de liaison à partir du CR du service de soutien incluent désormais les certificats de la base de données. Le Service Binding Operator utilise ces annotations modifiées pour projeter les fichiers de certificats correctsca.crt,tls.crtettls.key. APPSVC-1045 -
Avant cette mise à jour, lorsque vous liez une ressource personnalisée (CR)
PerconaXtraDBClusterde l'APIpxc.percona.com, les valeurs des données de liaison n'incluaient pas les valeursportetdatabase. Ces valeurs de liaison, ainsi que les autres déjà projetées, sont nécessaires pour qu'une application puisse se connecter avec succès au service de base de données. Avec cette mise à jour, les annotations que l'opérateur de liaison de service utilise pour exposer les valeurs de données de liaison du service de soutien CR sont maintenant modifiées pour projeter les valeurs de liaison supplémentairesportetdatabase. L'opérateur de liaison de service utilise ces annotations modifiées pour projeter l'ensemble complet des valeurs de liaison que l'application peut utiliser pour se connecter avec succès au service de base de données. APPSVC-1073
6.1.9.3. Problèmes connus
Actuellement, lorsque vous installez l'opérateur de liaison de services dans le mode d'installation à espace de noms unique, l'absence d'une règle de contrôle d'accès basé sur les rôles (RBAC) adaptée à l'espace de noms empêche la liaison réussie d'une application à quelques services connus soutenus par l'opérateur, que l'opérateur de liaison de services peut automatiquement détecter et auxquels il peut se lier. En outre, le message d'erreur suivant est généré :
Exemple de message d'erreur
`postgresclusters.postgres-operator.crunchydata.com "hippo" is forbidden: User "system:serviceaccount:my-petclinic:service-binding-operator" cannot get resource "postgresclusters" in API group "postgres-operator.crunchydata.com" in the namespace "my-petclinic"`Solution 1 : Installez le Service Binding Operator dans le mode d'installation
all namespaces. Par conséquent, la règle RBAC appropriée à l'échelle du cluster existe maintenant et la liaison réussit.Solution 2 : Si vous ne pouvez pas installer le Service Binding Operator dans le mode d'installation
all namespaces, installez la liaison de rôle suivante dans l'espace de noms où le Service Binding Operator est installé :Exemple : Liaison de rôles pour l'opérateur Crunchy Postgres
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: service-binding-crunchy-postgres-viewer subjects: - kind: ServiceAccount name: service-binding-operator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: service-binding-crunchy-postgres-viewer-role
6.1.10. Notes de mise à jour pour Service Binding Operator 1.0
Service Binding Operator est désormais disponible sur OpenShift Container Platform 4.7, 4.8 et 4.9.
La définition des ressources personnalisées (CRD) de l'opérateur de liaison de services 1.0 prend en charge les API suivantes :
-
Service Binding avec le groupe API
binding.operators.coreos.com. Service Binding (Spec API Tech Preview) avec le groupe API
servicebinding.io.ImportantService Binding (Spec API Tech Preview) avec le groupe d'API
servicebinding.ioest une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
6.1.10.1. Matrice de soutien
Certaines fonctionnalités de cette version sont actuellement en avant-première technologique. Ces fonctionnalités expérimentales ne sont pas destinées à être utilisées en production.
Aperçu de la technologie Fonctionnalités Support Champ d'application
Dans le tableau ci-dessous, les caractéristiques sont marquées par les statuts suivants :
- TP: Technology Preview
- GA: General Availability
Notez l'étendue de l'assistance suivante sur le portail client de Red Hat pour ces fonctionnalités :
| Fonctionnalité | Opérateur de liaison de services 1.0 |
|---|---|
|
| GA |
|
| TP |
6.1.10.2. Nouvelles fonctionnalités
Service Binding Operator 1.0 prend en charge OpenShift Container Platform 4.9 et les versions ultérieures :
- IBM Power Systems
- IBM Z et LinuxONE
Cette section présente les nouveautés de Service Binding Operator 1.0 :
Exposition des données contraignantes des services
- Basé sur les annotations présentes dans le CRD, les ressources personnalisées (CR) ou les ressources.
- Basé sur les descripteurs présents dans les descripteurs OLM (Operator Lifecycle Manager).
- Soutien aux services fournis
Projection de la charge de travail
- Projection des données de reliure sous forme de fichiers, avec montage des volumes.
- Projection des données contraignantes sous forme de variables d'environnement.
Options de liaison de service
- Lier les services de soutien dans un espace de noms différent de l'espace de noms de la charge de travail.
- Projeter les données de liaison dans les charges de travail spécifiques des conteneurs.
- Détection automatique des données de liaison à partir des ressources appartenant au service d'appui CR.
- Composer des données de liaison personnalisées à partir des données de liaison exposées.
-
Prise en charge des ressources de charge de travail non conformes à
PodSpec.
Sécurité
- Prise en charge du contrôle d'accès basé sur les rôles (RBAC).
6.2. Comprendre l'opérateur de liaison de service
Les développeurs d'applications ont besoin d'accéder aux services d'appui pour créer et connecter des charges de travail. La connexion des charges de travail aux services d'appui constitue toujours un défi, car chaque fournisseur de services propose une manière différente d'accéder à ses secrets et de les consommer dans une charge de travail. En outre, la configuration et la maintenance manuelles de cette liaison entre les charges de travail et les services d'appui rendent le processus fastidieux, inefficace et sujet aux erreurs.
L'opérateur de liaison de services permet aux développeurs d'applications de lier facilement les charges de travail aux services de soutien gérés par l'opérateur, sans procédures manuelles pour configurer la connexion de liaison.
6.2.1. Terminologie du Service Binding
Cette section résume les termes de base utilisés dans la liaison de service.
| Liaison de service | La représentation de l'action de fournir des informations sur un service à une charge de travail. Les exemples incluent l'établissement d'un échange d'informations d'identification entre une application Java et une base de données dont elle a besoin. |
| Service de soutien | Tout service ou logiciel que l'application consomme sur le réseau dans le cadre de son fonctionnement normal. Il peut s'agir par exemple d'une base de données, d'un courtier en messages, d'une application avec des points d'extrémité REST, d'un flux d'événements, d'un moniteur de performance d'application (APM) ou d'un module de sécurité matériel (HSM). |
| Charge de travail (application) | Tout processus s'exécutant dans un conteneur. Les exemples incluent une application Spring Boot, une application NodeJS Express, ou une application Ruby on Rails. |
| Données contraignantes | Informations sur un service que vous utilisez pour configurer le comportement d'autres ressources au sein du cluster. Il peut s'agir par exemple d'informations d'identification, de détails de connexion, de montages de volumes ou de secrets. |
| Connexion contraignante | Toute connexion qui établit une interaction entre les composants connectés, tels qu'un service de soutien liant et une application nécessitant ce service de soutien. |
6.2.2. À propos de l'opérateur de reliure de service
L'opérateur de liaison de services se compose d'un contrôleur et d'une définition de ressource personnalisée (CRD) pour la liaison de services. Il gère le plan de données pour les charges de travail et les services d'appui. Le contrôleur de liaison de services lit les données mises à disposition par le plan de contrôle des services d'appui. Il projette ensuite ces données vers les charges de travail conformément aux règles spécifiées dans la ressource ServiceBinding.
Par conséquent, l'opérateur de liaison de services permet aux charges de travail d'utiliser des services d'appui ou des services externes en collectant et en partageant automatiquement les données de liaison avec les charges de travail. Le processus consiste à rendre le service d'appui liable et à lier la charge de travail et le service ensemble.
6.2.2.1. Rendre liant un service d'appui géré par un opérateur
Pour rendre un service liant, en tant que fournisseur d'un opérateur, vous devez exposer les données de liaison requises par les charges de travail pour se lier aux services fournis par l'opérateur. Vous pouvez fournir les données de liaison sous forme d'annotations ou de descripteurs dans le CRD de l'opérateur qui gère le service d'appui.
6.2.2.2. Lier une charge de travail à un service d'appui
En utilisant l'opérateur de liaison de service, en tant que développeur d'application, vous devez déclarer l'intention d'établir une connexion de liaison. Vous devez créer un CR ServiceBinding qui fait référence au service d'appui. Cette action déclenche l'opérateur de liaison de service pour projeter les données de liaison exposées dans la charge de travail. Le Service Binding Operator reçoit l'intention déclarée et lie la charge de travail au service d'appui.
Le CRD de l'opérateur de liaison de services prend en charge les API suivantes :
-
Service Binding avec le groupe API
binding.operators.coreos.com. -
Service Binding (Spec API) avec le groupe API
servicebinding.io.
Avec Service Binding Operator, vous pouvez :
- Liez vos charges de travail à des services de sauvegarde gérés par l'opérateur.
- Automatiser la configuration des données de liaison.
- Fournir aux opérateurs de services une expérience administrative simple pour fournir et gérer l'accès aux services.
- Enrichissez le cycle de développement avec une méthode de liaison de service cohérente et déclarative qui élimine les divergences dans les environnements en grappe.
6.2.3. Caractéristiques principales
Exposition des données contraignantes des services
- Basé sur les annotations présentes dans le CRD, les ressources personnalisées (CR) ou les ressources.
Projection de la charge de travail
- Projection des données de reliure sous forme de fichiers, avec montage des volumes.
- Projection des données contraignantes sous forme de variables d'environnement.
Options de liaison de service
- Lier les services de soutien dans un espace de noms différent de l'espace de noms de la charge de travail.
- Projeter les données de liaison dans les charges de travail spécifiques des conteneurs.
- Détection automatique des données de liaison à partir des ressources appartenant au service d'appui CR.
- Composer des données de liaison personnalisées à partir des données de liaison exposées.
-
Prise en charge des ressources de charge de travail non conformes à
PodSpec.
Sécurité
- Prise en charge du contrôle d'accès basé sur les rôles (RBAC).
6.2.4. Différences entre les API
Le CRD de l'opérateur de liaison de services prend en charge les API suivantes :
-
Service Binding avec le groupe API
binding.operators.coreos.com. -
Service Binding (Spec API) avec le groupe API
servicebinding.io.
Ces deux groupes d'API présentent des caractéristiques similaires, mais ne sont pas tout à fait identiques. Voici la liste complète des différences entre ces groupes d'API :
| Fonctionnalité | Soutenu par le groupe API binding.operators.coreos.com | Soutenu par le groupe API servicebinding.io | Notes |
|---|---|---|---|
| Liaison avec les services fournis | Oui | Oui | Non applicable (N/A) |
| Projection directe du secret | Oui | Oui | Non applicable (N/A) |
| Relier comme des fichiers | Oui | Oui |
|
| Lier en tant que variables d'environnement | Oui | Oui |
|
| Sélection de la charge de travail à l'aide d'un sélecteur d'étiquettes | Oui | Oui | Non applicable (N/A) |
|
Détection des ressources contraignantes ( | Oui | Non |
Le groupe API |
| Stratégies de dénomination | Oui | Non |
Il n'existe actuellement aucun mécanisme au sein du groupe API |
| Chemin d'accès au conteneur | Oui | Partiel |
Étant donné qu'une liaison de service du groupe d'API |
| Filtrage des noms de conteneurs | Non | Oui |
Le groupe API |
| Chemin secret | Oui | Non |
Le groupe API |
| Autres sources de liaison (par exemple, données de liaison provenant d'annotations) | Oui | Autorisé par l'opérateur de liaison de service | La spécification exige la prise en charge de l'obtention de données contraignantes à partir de services et de secrets fournis. Cependant, une lecture stricte de la spécification suggère que la prise en charge d'autres sources de données de liaison est autorisée. De ce fait, Service Binding Operator peut extraire les données de liaison de diverses sources (par exemple, extraire les données de liaison des annotations). Service Binding Operator prend en charge ces sources dans les deux groupes d'API. |
6.3. Installation de l'opérateur de liaison de service
Ce guide guide les administrateurs de cluster à travers le processus d'installation du Service Binding Operator sur un cluster OpenShift Container Platform.
Vous pouvez installer Service Binding Operator sur OpenShift Container Platform 4.7 et plus.
Conditions préalables
-
Vous avez accès à un cluster OpenShift Container Platform en utilisant un compte avec des permissions
cluster-admin. - Votre cluster a la capacité Marketplace activée ou la source du catalogue Red Hat Operator configurée manuellement.
6.3.1. Installation du Service Binding Operator à l'aide de la console web
Vous pouvez installer Service Binding Operator à l'aide de OpenShift Container Platform OperatorHub. Lorsque vous installez Service Binding Operator, les ressources personnalisées (CR) nécessaires à la configuration du service binding sont automatiquement installées avec l'Operator.
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Operators → OperatorHub.
-
Utilisez la boîte Filter by keyword pour rechercher
Service Binding Operatordans le catalogue. Cliquez sur la tuile Service Binding Operator. - Lisez la brève description de l'opérateur sur la page Service Binding Operator. Cliquez sur Install.
Sur la page Install Operator:
-
Sélectionnez All namespaces on the cluster (default) pour l'espace de noms Installation Mode. Ce mode installe l'opérateur dans l'espace de noms par défaut
openshift-operators, ce qui permet à l'opérateur de surveiller tous les espaces de noms du cluster et d'y avoir accès. - Sélectionnez Automatic pour la stratégie d'approbation Approval Strategy. Cela garantit que les futures mises à niveau de l'opérateur sont gérées automatiquement par le gestionnaire du cycle de vie de l'opérateur (OLM). Si vous sélectionnez la stratégie d'approbation Manual, OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement la demande de mise à jour OLM pour mettre à jour l'opérateur vers la nouvelle version.
Sélectionnez un site Update Channel.
- Par défaut, le canal stable permet l'installation de la dernière version stable et prise en charge de l'opérateur de liaison de services.
-
Sélectionnez All namespaces on the cluster (default) pour l'espace de noms Installation Mode. Ce mode installe l'opérateur dans l'espace de noms par défaut
Cliquez sur Install.
NoteL'opérateur est installé automatiquement dans l'espace de noms
openshift-operators.- Dans le volet Installed Operator — ready for use, cliquez sur View Operator. Vous verrez l'opérateur listé sur la page Installed Operators.
- Vérifiez que Status est défini sur Succeeded pour confirmer la réussite de l'installation de l'opérateur de reliure de service.
6.3.2. Ressources complémentaires
6.4. Premiers pas avec la liaison de service
Le Service Binding Operator gère le plan de données pour les charges de travail et les services d'appui. Ce guide fournit des instructions et des exemples pour vous aider à créer une instance de base de données, à déployer une application et à utiliser l'opérateur de liaison de services pour créer une connexion de liaison entre l'application et le service de base de données.
Conditions préalables
-
Vous avez accès à un cluster OpenShift Container Platform en utilisant un compte avec des permissions
cluster-admin. -
Vous avez installé le CLI
oc. - Vous avez installé Service Binding Operator depuis OperatorHub.
Vous avez installé la version 5.1.2 de l'Opérateur Crunchy Postgres pour Kubernetes depuis OperatorHub en utilisant le canal v5 Update. L'opérateur installé est disponible dans un espace de noms approprié, tel que l'espace de noms
my-petclinic.NoteVous pouvez créer l'espace de noms à l'aide de la commande
oc create namespace my-petclinic.
6.4.1. Création d'une instance de base de données PostgreSQL
Pour créer une instance de base de données PostgreSQL, vous devez créer une ressource personnalisée (CR) PostgresCluster et configurer la base de données.
Procédure
Créez le CR
PostgresClusterdans l'espace de nomsmy-petclinicen exécutant la commande suivante dans l'interpréteur de commandes :$ oc apply -n my-petclinic -f - << EOD --- apiVersion: postgres-operator.crunchydata.com/v1beta1 kind: PostgresCluster metadata: name: hippo spec: image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres:ubi8-14.4-0 postgresVersion: 14 instances: - name: instance1 dataVolumeClaimSpec: accessModes: - "ReadWriteOnce" resources: requests: storage: 1Gi backups: pgbackrest: image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.38-0 repos: - name: repo1 volume: volumeClaimSpec: accessModes: - "ReadWriteOnce" resources: requests: storage: 1Gi EODLes annotations ajoutées dans cette CR
PostgresClusteractivent la connexion de liaison de service et déclenchent le rapprochement de l'opérateur.La sortie vérifie que l'instance de la base de données est créée :
Exemple de sortie
postgrescluster.postgres-operator.crunchydata.com/hippo createdAprès avoir créé l'instance de la base de données, assurez-vous que tous les pods de l'espace de noms
my-petclinicsont en cours d'exécution :$ oc get pods -n my-petclinicLa sortie, qui prend quelques minutes à s'afficher, vérifie que la base de données est créée et configurée :
Exemple de sortie
NAME READY STATUS RESTARTS AGE hippo-backup-9rxm-88rzq 0/1 Completed 0 2m2s hippo-instance1-6psd-0 4/4 Running 0 3m28s hippo-repo-host-0 2/2 Running 0 3m28sUne fois la base de données configurée, vous pouvez déployer l'application d'exemple et la connecter au service de base de données.
6.4.2. Déploiement de l'exemple d'application Spring PetClinic
Pour déployer l'application d'exemple Spring PetClinic sur un cluster OpenShift Container Platform, vous devez utiliser une configuration de déploiement et configurer votre environnement local pour pouvoir tester l'application.
Procédure
Déployez l'application
spring-petclinicavec la ressource personnalisée (CR)PostgresClusteren exécutant la commande suivante dans le shell :$ oc apply -n my-petclinic -f - << EOD --- apiVersion: apps/v1 kind: Deployment metadata: name: spring-petclinic labels: app: spring-petclinic spec: replicas: 1 selector: matchLabels: app: spring-petclinic template: metadata: labels: app: spring-petclinic spec: containers: - name: app image: quay.io/service-binding/spring-petclinic:latest imagePullPolicy: Always env: - name: SPRING_PROFILES_ACTIVE value: postgres ports: - name: http containerPort: 8080 --- apiVersion: v1 kind: Service metadata: labels: app: spring-petclinic name: spring-petclinic spec: type: NodePort ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: spring-petclinic EODLa sortie vérifie que l'exemple d'application Spring PetClinic est créé et déployé :
Exemple de sortie
deployment.apps/spring-petclinic created service/spring-petclinic createdNoteSi vous déployez l'application à l'aide de Container images dans la perspective Developer de la console web, vous devez entrer les variables d'environnement suivantes dans la section Deployment de la page Advanced options:
- Nom : SPRING_PROFILES_ACTIVE
- Valeur : postgres
Vérifiez que l'application n'est pas encore connectée au service de base de données en exécutant la commande suivante :
$ oc get pods -n my-petclinicLa sortie prend quelques minutes pour afficher l'état de
CrashLoopBackOff:Exemple de sortie
NAME READY STATUS RESTARTS AGE spring-petclinic-5b4c7999d4-wzdtz 0/1 CrashLoopBackOff 4 (13s ago) 2m25sÀ ce stade, le pod ne démarre pas. Si vous essayez d'interagir avec l'application, elle renvoie des erreurs.
Exposez le service pour créer une route pour votre application :
$ oc expose service spring-petclinic -n my-petclinicLa sortie vérifie que le service
spring-petclinicest exposé et qu'une route pour l'exemple d'application Spring PetClinic est créée :Exemple de sortie
route.route.openshift.io/spring-petclinic exposed
Vous pouvez maintenant utiliser l'opérateur de liaison de service pour connecter l'application au service de base de données.
6.4.3. Connexion de l'application d'exemple Spring PetClinic au service de base de données PostgreSQL
Pour connecter l'exemple d'application au service de base de données, vous devez créer une ressource personnalisée (CR) ServiceBinding qui déclenche le Service Binding Operator pour projeter les données de liaison dans l'application.
Procédure
Créez un CR
ServiceBindingpour projeter les données de la reliure :$ oc apply -n my-petclinic -f - << EOD --- apiVersion: binding.operators.coreos.com/v1alpha1 kind: ServiceBinding metadata: name: spring-petclinic-pgcluster spec: services:1 - group: postgres-operator.crunchydata.com version: v1beta1 kind: PostgresCluster2 name: hippo application:3 name: spring-petclinic group: apps version: v1 resource: deployments EODLa sortie vérifie que le CR
ServiceBindingest créé pour projeter les données de reliure dans l'exemple d'application.Exemple de sortie
servicebinding.binding.operators.coreos.com/spring-petclinic createdVérifier que la demande de liaison de service a abouti :
$ oc get servicebindings -n my-petclinicExemple de sortie
NAME READY REASON AGE spring-petclinic-pgcluster True ApplicationsBound 7sPar défaut, les valeurs des données de liaison du service de base de données sont projetées sous forme de fichiers dans le conteneur de charge de travail qui exécute l'exemple d'application. Par exemple, toutes les valeurs de la ressource Secret sont projetées dans le répertoire
bindings/spring-petclinic-pgcluster.NoteEn option, vous pouvez également vérifier que les fichiers de l'application contiennent les données de reliure projetées, en imprimant le contenu du répertoire :
$ for i in username password host port type; do oc exec -it deploy/spring-petclinic -n my-petclinic -- /bin/bash -c 'cd /tmp; find /bindings/*/'$i' -exec echo -n {}:" " \; -exec cat {} \;'; echo; doneExemple de résultat : Avec toutes les valeurs de la ressource secrète
/bindings/spring-petclinic-pgcluster/username: hippo /bindings/spring-petclinic-pgcluster/password: KXKF{nAI,I-J6zLt:W+FKnze /bindings/spring-petclinic-pgcluster/host: hippo-primary.my-petclinic.svc /bindings/spring-petclinic-pgcluster/port: 5432 /bindings/spring-petclinic-pgcluster/type: postgresqlConfigurez le transfert de port à partir du port d'application pour accéder à l'exemple d'application à partir de votre environnement local :
$ oc port-forward --address 0.0.0.0 svc/spring-petclinic 8080:80 -n my-petclinicExemple de sortie
Forwarding from 0.0.0.0:8080 -> 8080 Handling connection for 8080Accès http://localhost:8080/petclinic.
Vous pouvez maintenant accéder à distance à l'application d'exemple Spring PetClinic sur localhost:8080 et constater que l'application est désormais connectée au service de base de données.
6.5. Démarrer avec le service binding sur IBM Power, IBM zSystems et IBM(R) LinuxONE
Le Service Binding Operator gère le plan de données pour les charges de travail et les services d'appui. Ce guide fournit des instructions et des exemples pour vous aider à créer une instance de base de données, à déployer une application et à utiliser l'opérateur de liaison de services pour créer une connexion de liaison entre l'application et le service de base de données.
Conditions préalables
-
Vous avez accès à un cluster OpenShift Container Platform en utilisant un compte avec des permissions
cluster-admin. -
Vous avez installé le CLI
oc. - Vous avez installé le Service Binding Operator depuis OperatorHub.
6.5.1. Déployer un opérateur PostgreSQL
Procédure
-
Pour déployer l'opérateur PostgreSQL de Dev4Devs dans l'espace de noms
my-petclinic, exécutez la commande suivante dans l'interpréteur de commandes :
$ oc apply -f - << EOD
---
apiVersion: v1
kind: Namespace
metadata:
name: my-petclinic
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: postgres-operator-group
namespace: my-petclinic
---
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: ibm-multiarch-catalog
namespace: openshift-marketplace
spec:
sourceType: grpc
image: quay.io/ibm/operator-registry-<architecture>
imagePullPolicy: IfNotPresent
displayName: ibm-multiarch-catalog
updateStrategy:
registryPoll:
interval: 30m
---
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: postgresql-operator-dev4devs-com
namespace: openshift-operators
spec:
channel: alpha
installPlanApproval: Automatic
name: postgresql-operator-dev4devs-com
source: ibm-multiarch-catalog
sourceNamespace: openshift-marketplace
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: database-view
labels:
servicebinding.io/controller: "true"
rules:
- apiGroups:
- postgresql.dev4devs.com
resources:
- databases
verbs:
- get
- list
EOD- 1
- L'image de l'opérateur.
-
Pour IBM Power :
quay.io/ibm/operator-registry-ppc64le:release-4.9 -
Pour IBM zSystems et IBM® LinuxONE :
quay.io/ibm/operator-registry-s390x:release-4.8
-
Pour IBM Power :
Vérification
Une fois l'opérateur installé, dressez la liste des abonnements à l'opérateur dans l'espace de noms
openshift-operators:$ oc get subs -n openshift-operatorsExemple de sortie
NAME PACKAGE SOURCE CHANNEL postgresql-operator-dev4devs-com postgresql-operator-dev4devs-com ibm-multiarch-catalog alpha rh-service-binding-operator rh-service-binding-operator redhat-operators stable
6.5.2. Création d'une instance de base de données PostgreSQL
Pour créer une instance de base de données PostgreSQL, vous devez créer une ressource personnalisée (CR) Database et configurer la base de données.
Procédure
Créez le CR
Databasedans l'espace de nomsmy-petclinicen exécutant la commande suivante dans l'interpréteur de commandes :$ oc apply -f - << EOD apiVersion: postgresql.dev4devs.com/v1alpha1 kind: Database metadata: name: sampledatabase namespace: my-petclinic annotations: host: sampledatabase type: postgresql port: "5432" service.binding/database: 'path={.spec.databaseName}' service.binding/port: 'path={.metadata.annotations.port}' service.binding/password: 'path={.spec.databasePassword}' service.binding/username: 'path={.spec.databaseUser}' service.binding/type: 'path={.metadata.annotations.type}' service.binding/host: 'path={.metadata.annotations.host}' spec: databaseCpu: 30m databaseCpuLimit: 60m databaseMemoryLimit: 512Mi databaseMemoryRequest: 128Mi databaseName: "sampledb" databaseNameKeyEnvVar: POSTGRESQL_DATABASE databasePassword: "samplepwd" databasePasswordKeyEnvVar: POSTGRESQL_PASSWORD databaseStorageRequest: 1Gi databaseUser: "sampleuser" databaseUserKeyEnvVar: POSTGRESQL_USER image: registry.redhat.io/rhel8/postgresql-13:latest databaseStorageClassName: nfs-storage-provisioner size: 1 EODLes annotations ajoutées dans cette CR
Databaseactivent la connexion de liaison de service et déclenchent le rapprochement de l'opérateur.La sortie vérifie que l'instance de la base de données est créée :
Exemple de sortie
database.postgresql.dev4devs.com/sampledatabase createdAprès avoir créé l'instance de la base de données, assurez-vous que tous les pods de l'espace de noms
my-petclinicsont en cours d'exécution :$ oc get pods -n my-petclinicLa sortie, qui prend quelques minutes à s'afficher, vérifie que la base de données est créée et configurée :
Exemple de sortie
NAME READY STATUS RESTARTS AGE sampledatabase-cbc655488-74kss 0/1 Running 0 32s
Une fois la base de données configurée, vous pouvez déployer l'application d'exemple et la connecter au service de base de données.
6.5.3. Déploiement de l'exemple d'application Spring PetClinic
Pour déployer l'application d'exemple Spring PetClinic sur un cluster OpenShift Container Platform, vous devez utiliser une configuration de déploiement et configurer votre environnement local pour pouvoir tester l'application.
Procédure
Déployez l'application
spring-petclinicavec la ressource personnalisée (CR)PostgresClusteren exécutant la commande suivante dans le shell :$ oc apply -n my-petclinic -f - << EOD --- apiVersion: apps/v1 kind: Deployment metadata: name: spring-petclinic labels: app: spring-petclinic spec: replicas: 1 selector: matchLabels: app: spring-petclinic template: metadata: labels: app: spring-petclinic spec: containers: - name: app image: quay.io/service-binding/spring-petclinic:latest imagePullPolicy: Always env: - name: SPRING_PROFILES_ACTIVE value: postgres - name: org.springframework.cloud.bindings.boot.enable value: "true" ports: - name: http containerPort: 8080 --- apiVersion: v1 kind: Service metadata: labels: app: spring-petclinic name: spring-petclinic spec: type: NodePort ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: spring-petclinic EODLa sortie vérifie que l'exemple d'application Spring PetClinic est créé et déployé :
Exemple de sortie
deployment.apps/spring-petclinic created service/spring-petclinic createdNoteSi vous déployez l'application à l'aide de Container images dans la perspective Developer de la console web, vous devez entrer les variables d'environnement suivantes dans la section Deployment de la page Advanced options:
- Nom : SPRING_PROFILES_ACTIVE
- Valeur : postgres
Vérifiez que l'application n'est pas encore connectée au service de base de données en exécutant la commande suivante :
$ oc get pods -n my-petclinicIl faut quelques minutes pour que l'état de
CrashLoopBackOffs'affiche :Exemple de sortie
NAME READY STATUS RESTARTS AGE spring-petclinic-5b4c7999d4-wzdtz 0/1 CrashLoopBackOff 4 (13s ago) 2m25sÀ ce stade, le pod ne démarre pas. Si vous essayez d'interagir avec l'application, elle renvoie des erreurs.
Vous pouvez maintenant utiliser l'opérateur de liaison de service pour connecter l'application au service de base de données.
6.5.4. Connexion de l'application d'exemple Spring PetClinic au service de base de données PostgreSQL
Pour connecter l'exemple d'application au service de base de données, vous devez créer une ressource personnalisée (CR) ServiceBinding qui déclenche le Service Binding Operator pour projeter les données de liaison dans l'application.
Procédure
Créez un CR
ServiceBindingpour projeter les données de la reliure :$ oc apply -n my-petclinic -f - << EOD --- apiVersion: binding.operators.coreos.com/v1alpha1 kind: ServiceBinding metadata: name: spring-petclinic-pgcluster spec: services:1 - group: postgresql.dev4devs.com kind: Database2 name: sampledatabase version: v1alpha1 application:3 name: spring-petclinic group: apps version: v1 resource: deployments EODLa sortie vérifie que le CR
ServiceBindingest créé pour projeter les données de reliure dans l'exemple d'application.Exemple de sortie
servicebinding.binding.operators.coreos.com/spring-petclinic createdVérifier que la demande de liaison de service a abouti :
$ oc get servicebindings -n my-petclinicExemple de sortie
NAME READY REASON AGE spring-petclinic-postgresql True ApplicationsBound 47mPar défaut, les valeurs des données de liaison du service de base de données sont projetées sous forme de fichiers dans le conteneur de charge de travail qui exécute l'exemple d'application. Par exemple, toutes les valeurs de la ressource Secret sont projetées dans le répertoire
bindings/spring-petclinic-pgcluster.Une fois la connexion créée, vous pouvez accéder à la topologie pour voir la connexion visuelle.
Figure 6.1. Connexion de spring-petclinic à une base de données d'échantillons
Configurez le transfert de port à partir du port d'application pour accéder à l'exemple d'application à partir de votre environnement local :
$ oc port-forward --address 0.0.0.0 svc/spring-petclinic 8080:80 -n my-petclinicExemple de sortie
Forwarding from 0.0.0.0:8080 -> 8080 Handling connection for 8080Accès http://localhost:8080.
Vous pouvez maintenant accéder à distance à l'application d'exemple Spring PetClinic sur localhost:8080 et constater que l'application est désormais connectée au service de base de données.
6.6. Exposer des données contraignantes à partir d'un service
Les développeurs d'applications ont besoin d'accéder aux services d'appui pour créer et connecter des charges de travail. La connexion des charges de travail aux services d'appui constitue toujours un défi, car chaque fournisseur de services exige une manière différente d'accéder à ses secrets et de les consommer dans une charge de travail.
L'opérateur de liaison de services permet aux développeurs d'applications de lier facilement des charges de travail avec des services d'appui gérés par l'opérateur, sans procédures manuelles pour configurer la connexion de liaison. Pour que le Service Binding Operator fournisse les données de liaison, vous devez, en tant que fournisseur d'opérateur ou utilisateur qui crée des services d'appui, exposer les données de liaison afin qu'elles soient automatiquement détectées par le Service Binding Operator. Ensuite, l'opérateur de liaison de services collecte automatiquement les données de liaison auprès du service d'appui et les partage avec une charge de travail afin de fournir une expérience cohérente et prévisible.
6.6.1. Méthodes d'exposition des données contraignantes
Cette section décrit les méthodes que vous pouvez utiliser pour exposer les données de liaison.
Assurez-vous de connaître et de comprendre les exigences et l'environnement de votre charge de travail, ainsi que la manière dont elle fonctionne avec les services fournis.
Les données contraignantes sont exposées dans les circonstances suivantes :
Le service de sauvegarde est disponible en tant que ressource de service provisionnée.
Le service auquel vous souhaitez vous connecter est conforme à la spécification Service Binding. Vous devez créer une ressource
Secretavec toutes les valeurs de données de liaison requises et la référencer dans la ressource personnalisée (CR) du service d'appui. La détection de toutes les valeurs de données de liaison est automatique.Le service de sauvegarde n'est pas disponible en tant que ressource de service provisionné.
Vous devez exposer les données de liaison à partir du service de soutien. En fonction des exigences de votre charge de travail et de votre environnement, vous pouvez choisir l'une des méthodes suivantes pour exposer les données de liaison :
- Référence secrète directe
- Déclaration des données de liaison par le biais de définitions de ressources personnalisées (CRD) ou d'annotations CR
- Détection des données contraignantes par le biais des ressources détenues
6.6.1.1. Service fourni
Le service fourni représente un CR de service d'appui avec une référence à une ressource Secret placée dans le champ .status.binding.name du CR de service d'appui.
En tant que fournisseur d'opérateurs ou utilisateur qui crée des services d'appui, vous pouvez utiliser cette méthode pour vous conformer à la spécification Service Binding, en créant une ressource Secret et en la référençant dans la section .status.binding.name du CR du service d'appui. Cette ressource Secret doit fournir toutes les valeurs de données de liaison nécessaires pour qu'une charge de travail se connecte au service d'appui.
Les exemples suivants montrent une CR AccountService qui représente un service d'appui et une ressource Secret référencée à partir de la CR.
Exemple : AccountService CR
apiVersion: example.com/v1alpha1
kind: AccountService
name: prod-account-service
spec:
...
status:
binding:
name: hippo-pguser-hippoExemple : Ressource référencée Secret
apiVersion: v1
kind: Secret
metadata:
name: hippo-pguser-hippo
data:
password: "MTBz"
user: "Z3Vlc3Q="
...
Lors de la création d'une ressource de liaison de service, vous pouvez directement donner les détails de la ressource AccountService dans la spécification ServiceBinding comme suit :
Exemple : ServiceBinding ressource
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: account-service
spec:
...
services:
- group: "example.com"
version: v1alpha1
kind: AccountService
name: prod-account-service
application:
name: spring-petclinic
group: apps
version: v1
resource: deploymentsExemple : ServiceBinding ressource dans Specification API
apiVersion: servicebinding.io/v1beta1
kind: ServiceBinding
metadata:
name: account-service
spec:
...
service:
apiVersion: example.com/v1alpha1
kind: AccountService
name: prod-account-service
workload:
apiVersion: apps/v1
kind: Deployment
name: spring-petclinic
Cette méthode expose toutes les clés de la ressource hippo-pguser-hippo référencée Secret en tant que données de liaison à projeter dans la charge de travail.
6.6.1.2. Référence secrète directe
Vous pouvez utiliser cette méthode si toutes les valeurs de données de liaison requises sont disponibles dans une ressource Secret que vous pouvez référencer dans votre définition de liaison de service. Dans cette méthode, une ressource ServiceBinding fait directement référence à une ressource Secret pour se connecter à un service. Toutes les clés de la ressource Secret sont exposées en tant que données de liaison.
Exemple : Spécification avec l'API binding.operators.coreos.com
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: account-service
spec:
...
services:
- group: ""
version: v1
kind: Secret
name: hippo-pguser-hippoExemple : Spécification conforme à l'API servicebinding.io
apiVersion: servicebinding.io/v1beta1
kind: ServiceBinding
metadata:
name: account-service
spec:
...
service:
apiVersion: v1
kind: Secret
name: hippo-pguser-hippo6.6.1.3. Déclarer des données contraignantes par le biais d'annotations CRD ou CR
Vous pouvez utiliser cette méthode pour annoter les ressources du service d'appui afin d'exposer les données de liaison avec des annotations spécifiques. L'ajout d'annotations dans la section metadata modifie les CR et CRD des services d'appui. Service Binding Operator détecte les annotations ajoutées aux CR et CRD et crée ensuite une ressource Secret avec les valeurs extraites sur la base des annotations.
Les exemples suivants montrent les annotations qui sont ajoutées sous la section metadata et un objet ConfigMap référencé à partir d'une ressource :
Exemple : Exposer les données de liaison d'un objet Secret défini dans les annotations CR
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
service.binding: 'path={.metadata.name}-pguser-{.metadata.name},objectType=Secret'
...
L'exemple précédent place le nom du nom secret dans le modèle {.metadata.name}-pguser-{.metadata.name} qui se résout en hippo-pguser-hippo. Le modèle peut contenir plusieurs expressions JSONPath.
Exemple : Objet référencé Secret à partir d'une ressource
apiVersion: v1
kind: Secret
metadata:
name: hippo-pguser-hippo
data:
password: "MTBz"
user: "Z3Vlc3Q="Exemple : Exposer les données de liaison d'un objet ConfigMap défini dans les annotations CR
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
service.binding: 'path={.metadata.name}-config,objectType=ConfigMap'
...
L'exemple précédent place le nom de la carte de configuration dans le modèle {.metadata.name}-config qui se résout en hippo-config. Le modèle peut contenir plusieurs expressions JSONPath.
Exemple : Objet référencé ConfigMap à partir d'une ressource
apiVersion: v1
kind: ConfigMap
metadata:
name: hippo-config
data:
db_timeout: "10s"
user: "hippo"6.6.1.4. Détection des données contraignantes par le biais des ressources détenues
Vous pouvez utiliser cette méthode si votre service d'appui possède une ou plusieurs ressources Kubernetes telles que la route, le service, la carte de configuration ou le secret que vous pouvez utiliser pour détecter les données de liaison. Dans cette méthode, l'opérateur de liaison de service détecte les données de liaison à partir des ressources appartenant au service de soutien CR.
Les exemples suivants montrent que l'option de l'API detectBindingResources est définie sur true dans le CR ServiceBinding:
Exemple
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-detect-all
namespace: my-petclinic
spec:
detectBindingResources: true
services:
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster
name: hippo
application:
name: spring-petclinic
group: apps
version: v1
resource: deployments
Dans l'exemple précédent, PostgresCluster custom service resource possède une ou plusieurs ressources Kubernetes telles que route, service, config map ou secret.
L'opérateur de liaison de services détecte automatiquement les données de liaison exposées sur chacune des ressources possédées.
6.6.2. Modèle de données
Le modèle de données utilisé dans les annotations suit des conventions spécifiques.
Les annotations de liaison de service doivent utiliser la convention suivante :
service.binding(/<NAME>)?:
"<VALUE>|(path=<JSONPATH_TEMPLATE>(,objectType=<OBJECT_TYPE>)?(,elementType=<ELEMENT_TYPE>)?(,sourceKey=<SOURCE_KEY>)?(,sourceValue=<SOURCE_VALUE>)?)"où :
|
|
Spécifie le nom sous lequel la valeur de liaison doit être exposée. Vous ne pouvez l'exclure que si le paramètre |
|
|
Spécifie la valeur constante exposée lorsqu'aucun |
Le modèle de données fournit des détails sur les valeurs autorisées et la sémantique des paramètres path, elementType, objectType, sourceKey, et sourceValue.
| Paramètres | Description | Valeur par défaut |
|---|---|---|
|
| Modèle JSONPath composé d'expressions JSONPath entourées d'accolades {}. | N/A |
|
|
Indique si la valeur de l'élément référencé dans le paramètre
|
|
|
|
Indique si la valeur de l'élément indiqué dans le paramètre |
|
|
|
Spécifie la clé de la ressource Remarque :
| N/A |
|
|
Spécifie la clé dans la tranche de cartes. Remarque :
| N/A |
Les paramètres sourceKey et sourceValue ne sont applicables que si l'élément indiqué dans le paramètre path fait référence à une ressource ConfigMap ou Secret.
6.6.3. Définition du mappage des annotations comme étant facultatif
Les annotations peuvent contenir des champs facultatifs. Par exemple, un chemin vers les informations d'identification peut ne pas être présent si le point de terminaison du service ne nécessite pas d'authentification. Dans ce cas, un champ peut ne pas exister dans le chemin cible des annotations. Par conséquent, Service Binding Operator génère une erreur par défaut.
En tant que fournisseur de services, pour indiquer si vous avez besoin d'un mappage d'annotations, vous pouvez définir une valeur pour le drapeau optional dans vos annotations lors de l'activation des services. Le Service Binding Operator ne fournit le mappage des annotations que si le chemin cible est disponible. Lorsque le chemin cible n'est pas disponible, le Service Binding Operator ignore le mappage optionnel et poursuit la projection des mappages existants sans générer d'erreur.
Procédure
Pour rendre un champ des annotations facultatif, définissez la valeur de l'indicateur
optionalsurtrue:Exemple
apiVersion: apps.example.org/v1beta1 kind: Database metadata: name: my-db namespace: my-petclinic annotations: service.binding/username: path={.spec.name},optional=true ...
-
Si vous attribuez la valeur
falseà l'indicateuroptionalet que l'opérateur de liaison de services ne parvient pas à trouver le chemin cible, l'opérateur échoue dans le mappage des annotations. -
Si l'indicateur
optionaln'a pas de valeur définie, l'opérateur de liaison de services considère que la valeur estfalsepar défaut et échoue dans le mappage des annotations.
6.6.4. Exigences RBAC
Pour exposer les données de liaison du service d'appui à l'aide de l'opérateur de liaison de service, vous devez disposer de certaines autorisations de contrôle d'accès basé sur les rôles (RBAC). Spécifiez certains verbes dans le champ rules de la ressource ClusterRole pour accorder les autorisations RBAC pour les ressources du service d'appui. Lorsque vous définissez ces rules, vous permettez à l'opérateur de liaison de services de lire les données de liaison des ressources de service de soutien dans l'ensemble du cluster. Si les utilisateurs n'ont pas le droit de lire les données de liaison ou de modifier les ressources de l'application, le Service Binding Operator les empêche de lier les services à l'application. Le respect des exigences RBAC permet d'éviter une élévation inutile des autorisations pour l'utilisateur et empêche l'accès à des services ou à des applications non autorisés.
L'opérateur de liaison de services effectue des demandes auprès de l'API Kubernetes à l'aide d'un compte de service dédié. Par défaut, ce compte dispose d'autorisations pour lier des services à des charges de travail, toutes deux représentées par les objets Kubernetes ou OpenShift standard suivants :
-
Deployments -
DaemonSets -
ReplicaSets -
StatefulSets -
DeploymentConfigs
Le compte de service Operator est lié à un rôle de cluster agrégé, ce qui permet aux fournisseurs Operator ou aux administrateurs de cluster de lier des ressources de service personnalisées aux charges de travail. Pour accorder les permissions requises au sein d'un ClusterRole, marquez-le avec l'indicateur servicebinding.io/controller et définissez la valeur de l'indicateur à true. L'exemple suivant montre comment autoriser l'opérateur de liaison de service à get, watch, et list les ressources personnalisées (CR) de l'opérateur Crunchy PostgreSQL :
Exemple : Activer la liaison avec les instances de base de données PostgreSQL provisionnées par l'opérateur Crunchy PostgreSQL
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: postgrescluster-reader
labels:
servicebinding.io/controller: "true"
rules:
- apiGroups:
- postgres-operator.crunchydata.com
resources:
- postgresclusters
verbs:
- get
- watch
- list
...Ce rôle de cluster peut être déployé lors de l'installation du service de sauvegarde Operator.
6.6.5. Catégories de données contraignantes exposables
L'opérateur de liaison de service vous permet d'exposer les valeurs des données de liaison des ressources de service d'appui et des définitions de ressources personnalisées (CRD).
Cette section fournit des exemples montrant comment vous pouvez utiliser les différentes catégories de données exposables. Vous devez modifier ces exemples pour les adapter à votre environnement de travail et à vos besoins.
6.6.5.1. Exposer une chaîne de caractères à partir d'une ressource
L'exemple suivant montre comment exposer la chaîne du champ metadata.name de la ressource personnalisée (CR) PostgresCluster en tant que nom d'utilisateur :
Exemple
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
service.binding/username: path={.metadata.name}
...6.6.5.2. Exposition d'une valeur constante en tant qu'élément de liaison
Les exemples suivants montrent comment exposer une valeur constante à partir de la ressource personnalisée (CR) PostgresCluster:
Exemple : Exposition d'une valeur constante
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
"service.binding/type": "postgresql" - 1
- La liaison
typedoit être exposée avec la valeurpostgresql.
6.6.5.3. Exposer l'intégralité d'une carte de configuration ou d'un secret référencé à partir d'une ressource
Les exemples suivants montrent comment exposer un secret entier par le biais d'annotations :
Exemple : Exposer un secret entier par le biais d'annotations
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
service.binding: 'path={.metadata.name}-pguser-{.metadata.name},objectType=Secret'Exemple : Le secret référencé de la ressource du service d'appui
apiVersion: v1
kind: Secret
metadata:
name: hippo-pguser-hippo
data:
password: "MTBz"
user: "Z3Vlc3Q="6.6.5.4. Exposer une entrée spécifique d'une carte de configuration ou d'un secret référencé à partir d'une ressource
Les exemples suivants montrent comment exposer une entrée spécifique d'une carte de configuration par le biais d'annotations :
Exemple : Exposer une entrée d'une carte de configuration par le biais d'annotations
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
service.binding: 'path={.metadata.name}-config,objectType=ConfigMap,sourceKey=user'Exemple : La carte de configuration référencée de la ressource de service d'appui
Les données de liaison doivent avoir une clé dont le nom est db_timeout et la valeur 10s:
apiVersion: v1
kind: ConfigMap
metadata:
name: hippo-config
data:
db_timeout: "10s"
user: "hippo"6.6.5.5. Exposer une valeur de définition de ressource
L'exemple suivant montre comment exposer une valeur de définition de ressource par le biais d'annotations :
Exemple : Exposer une valeur de définition de ressource par le biais d'annotations
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
service.binding/username: path={.metadata.name}
...6.6.5.6. Exposer les entrées d'une collection avec la clé et la valeur de chaque entrée
L'exemple suivant montre comment exposer les entrées d'une collection avec la clé et la valeur de chaque entrée par le biais d'annotations :
Exemple : Exposer les entrées d'une collection par le biais d'annotations
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
"service.binding/uri": "path={.status.connections},elementType=sliceOfMaps,sourceKey=type,sourceValue=url"
spec:
...
status:
connections:
- type: primary
url: primary.example.com
- type: secondary
url: secondary.example.com
- type: '404'
url: black-hole.example.comL'exemple suivant montre comment les entrées précédentes d'une collection d'annotations sont projetées dans l'application liée.
Exemple : Lier des fichiers de données
/bindings/<binding-name>/uri_primary => primary.example.com
/bindings/<binding-name>/uri_secondary => secondary.example.com
/bindings/<binding-name>/uri_404 => black-hole.example.comExemple : Configuration à partir d'une ressource de service d'appui
status:
connections:
- type: primary
url: primary.example.com
- type: secondary
url: secondary.example.com
- type: '404'
url: black-hole.example.com
L'exemple précédent vous aide à projeter toutes ces valeurs avec des clés telles que primary, secondary, etc.
6.6.5.7. Exposer les éléments d'une collection avec une clé par élément
L'exemple suivant montre comment exposer les éléments d'une collection avec une clé par élément au moyen d'annotations :
Exemple : Exposer les éléments d'une collection par le biais d'annotations
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
"service.binding/tags": "path={.spec.tags},elementType=sliceOfStrings"
spec:
tags:
- knowledge
- is
- powerL'exemple suivant montre comment les éléments précédents d'une collection d'annotations sont projetés dans l'application liée.
Exemple : Lier des fichiers de données
/bindings/<binding-name>/tags_0 => knowledge
/bindings/<binding-name>/tags_1 => is
/bindings/<binding-name>/tags_2 => powerExemple : Configuration à partir d'une ressource de service d'appui
spec:
tags:
- knowledge
- is
- power6.6.5.8. Exposer les valeurs des entrées d'une collection avec une clé par valeur d'entrée
L'exemple suivant montre comment exposer les valeurs des entrées d'une collection avec une clé par valeur d'entrée par le biais d'annotations :
Exemple : Exposer les valeurs des entrées d'une collection par le biais d'annotations
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
namespace: my-petclinic
annotations:
"service.binding/url": "path={.spec.connections},elementType=sliceOfStrings,sourceValue=url"
spec:
connections:
- type: primary
url: primary.example.com
- type: secondary
url: secondary.example.com
- type: '404'
url: black-hole.example.comL'exemple suivant montre comment les valeurs précédentes d'une collection dans les annotations sont projetées dans l'application liée.
Exemple : Lier des fichiers de données
/bindings/<binding-name>/url_0 => primary.example.com
/bindings/<binding-name>/url_1 => secondary.example.com
/bindings/<binding-name>/url_2 => black-hole.example.com6.7. Projeter des données contraignantes
Cette section fournit des informations sur la manière dont vous pouvez consommer les données de liaison.
6.7.1. Consommation de données contraignantes
Une fois que le service de soutien expose les données de liaison, pour qu'une charge de travail accède à ces données et les consomme, vous devez les projeter dans la charge de travail à partir d'un service de soutien. Service Binding Operator projette automatiquement cet ensemble de données dans la charge de travail selon les méthodes suivantes :
- Par défaut, sous forme de fichiers.
-
En tant que variables d'environnement, après avoir configuré le paramètre
.spec.bindAsFilesà partir de la ressourceServiceBinding.
6.7.2. Configuration du chemin d'accès au répertoire pour projeter les données de liaison à l'intérieur du conteneur de charge de travail
Par défaut, Service Binding Operator monte les données de liaison sous forme de fichiers dans un répertoire spécifique de votre ressource de charge de travail. Vous pouvez configurer le chemin d'accès au répertoire à l'aide de la variable d'environnement SERVICE_BINDING_ROOT dans le conteneur où s'exécute votre charge de travail.
Exemple : Liaison de données montées sous forme de fichiers
$SERVICE_BINDING_ROOT
├── account-database
│ ├── type
│ ├── provider
│ ├── uri
│ ├── username
│ └── password
└── transaction-event-stream
├── type
├── connection-count
├── uri
├── certificates
└── private-key- 1
- Répertoire racine.
- 2 5
- Répertoire qui stocke les données de liaison.
- 3
- Identifiant obligatoire qui identifie le type de données de reliure projetées dans le répertoire correspondant.
- 4
- Facultatif : Identifiant permettant d'identifier le fournisseur afin que l'application puisse identifier le type de service de soutien auquel elle peut se connecter.
Pour consommer les données de liaison en tant que variables d'environnement, utilisez la fonction de langage intégrée du langage de programmation de votre choix qui peut lire les variables d'environnement.
Exemple : Utilisation du client Python
import os
username = os.getenv("USERNAME")
password = os.getenv("PASSWORD")Pour utiliser le nom du répertoire des données contraignantes pour rechercher les données contraignantes
Service Binding Operator utilise le nom de la ressource ServiceBinding (.metadata.name) comme nom du répertoire des données de liaison. La spécification fournit également un moyen de remplacer ce nom par le champ .spec.name. Par conséquent, il existe un risque de collision entre les noms des données de liaison s'il y a plusieurs ressources ServiceBinding dans l'espace de noms. Cependant, en raison de la nature du montage de volume dans Kubernetes, le répertoire de données de liaison contiendra des valeurs provenant d'une seule des ressources Secret.
6.7.2.1. Calcul du chemin final pour la projection des données de liaison sous forme de fichiers
Le tableau suivant résume la configuration du calcul du chemin final pour la projection des données de reliure lorsque les fichiers sont montés dans un répertoire spécifique :
SERVICE_BINDING_ROOT | Chemin final |
|---|---|
| Non disponible |
|
|
|
|
Dans le tableau précédent, l'entrée <ServiceBinding_ResourceName> indique le nom de la ressource ServiceBinding que vous configurez dans la section .metadata.name de la ressource personnalisée (CR).
Par défaut, les fichiers projetés ont des permissions de 0644. Service Binding Operator ne peut pas définir de permissions spécifiques en raison d'un bogue dans Kubernetes qui cause des problèmes si le service attend des permissions spécifiques telles que 0600. Comme solution de contournement, vous pouvez modifier le code du programme ou de l'application qui s'exécute à l'intérieur d'une ressource de charge de travail pour copier le fichier dans le répertoire /tmp et définir les autorisations appropriées.
Pour accéder aux données de liaison et les utiliser dans la variable d'environnement existante SERVICE_BINDING_ROOT, utilisez la fonction de langage intégrée du langage de programmation de votre choix qui peut lire les variables d'environnement.
Exemple : Utilisation du client Python
from pyservicebinding import binding
try:
sb = binding.ServiceBinding()
except binding.ServiceBindingRootMissingError as msg:
# log the error message and retry/exit
print("SERVICE_BINDING_ROOT env var not set")
sb = binding.ServiceBinding()
bindings_list = sb.bindings("postgresql")
Dans l'exemple précédent, la variable bindings_list contient les données de liaison pour le type de service de base de données postgresql.
6.7.3. Projeter les données contraignantes
En fonction des exigences de votre charge de travail et de votre environnement, vous pouvez choisir de projeter les données de liaison sous forme de fichiers ou de variables d'environnement.
Conditions préalables
Vous comprenez les concepts suivants :
- L'environnement et les exigences de votre charge de travail, et la manière dont elle fonctionne avec les services fournis.
- Consommation des données de liaison dans votre ressource de charge de travail.
- Configuration de la manière dont le chemin final pour la projection des données est calculé pour la méthode par défaut.
- Les données de liaison sont exposées à partir du service d'appui.
Procédure
-
Pour projeter les données de liaison sous forme de fichiers, déterminez le dossier de destination en vous assurant que la variable d'environnement
SERVICE_BINDING_ROOTest présente dans le conteneur où s'exécute votre charge de travail. -
Pour projeter les données de liaison en tant que variables d'environnement, définissez la valeur du paramètre
.spec.bindAsFilessurfalseà partir de la ressourceServiceBindingdans la ressource personnalisée (CR).
6.8. Lier les charges de travail à l'aide de l'opérateur de liaison de services
Les développeurs d'applications doivent lier une charge de travail à un ou plusieurs services d'appui en utilisant un secret de liaison. Ce secret est généré dans le but de stocker des informations qui seront consommées par la charge de travail.
Prenons l'exemple d'un service auquel vous souhaitez vous connecter et qui expose déjà les données de liaison. Dans ce cas, vous aurez également besoin d'une charge de travail à utiliser avec la ressource personnalisée (CR) ServiceBinding. En utilisant cette CR ServiceBinding, la charge de travail envoie une demande de liaison avec les détails des services à lier.
Exemple de ServiceBinding CR
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-pgcluster
namespace: my-petclinic
spec:
services:
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster
name: hippo
application:
name: spring-petclinic
group: apps
version: v1
resource: deployments
Comme le montre l'exemple précédent, vous pouvez également utiliser directement un site ConfigMap ou un site Secret en tant que ressource de service à utiliser comme source de données de liaison.
6.8.1. Stratégies de dénomination
Les stratégies de dénomination ne sont disponibles que pour le groupe binding.operators.coreos.com API.
Les stratégies de nommage utilisent les modèles Go pour vous aider à définir des noms de liaison personnalisés par le biais de la demande de liaison de service. Les stratégies de dénomination s'appliquent à tous les attributs, y compris les correspondances dans la ressource personnalisée (CR) ServiceBinding.
Un service d'appui projette les noms de liaison sous forme de fichiers ou de variables d'environnement dans la charge de travail. Si une charge de travail attend les noms de liaison projetés dans un format particulier, mais que les noms de liaison à projeter à partir du service d'appui ne sont pas disponibles dans ce format, vous pouvez modifier les noms de liaison à l'aide de stratégies d'attribution de noms.
Fonctions de post-traitement prédéfinies
Lors de l'utilisation des stratégies de dénomination, en fonction des attentes ou des exigences de votre charge de travail, vous pouvez utiliser les fonctions de post-traitement prédéfinies suivantes, dans n'importe quelle combinaison, pour convertir les chaînes de caractères :
-
upper: Convertit les chaînes de caractères en lettres capitales ou majuscules. -
lower: Convertit les chaînes de caractères en lettres minuscules. -
title: Convertit les chaînes de caractères où la première lettre de chaque mot est en majuscule, à l'exception de certains mots mineurs.
Stratégies de dénomination prédéfinies
Les noms de liens déclarés par le biais d'annotations sont traités pour leur changement de nom avant leur projection dans la charge de travail selon les stratégies de dénomination prédéfinies suivantes :
none: Lorsqu'il est appliqué, il n'y a pas de changement dans les noms des liaisons.Exemple
Après la compilation du modèle, les noms de la liaison prennent la forme
{{ .name }}.host: hippo-pgbouncer port: 5432upper: Appliqué lorsqu'aucunnamingStrategyn'est défini. Lorsqu'il est appliqué, il convertit toutes les chaînes de caractères de la clé du nom de la liaison en lettres capitales ou majuscules.Exemple
Après la compilation du modèle, les noms des liens prennent la forme
{{ .service.kind | upper}}_{{ .name | upper }}.DATABASE_HOST: hippo-pgbouncer DATABASE_PORT: 5432Si votre charge de travail nécessite un format différent, vous pouvez définir une stratégie de dénomination personnalisée et modifier le nom de la liaison à l'aide d'un préfixe et d'un séparateur, par exemple
PORT_DATABASE.
-
Lorsque les noms des liens sont projetés sous forme de fichiers, la stratégie de dénomination prédéfinie
noneest appliquée par défaut et les noms des liens ne changent pas. -
Lorsque les noms des liens sont projetés en tant que variables d'environnement et qu'aucun
namingStrategyn'est défini, la stratégie de dénomination prédéfinieuppercaseest appliquée par défaut. - Vous pouvez remplacer les stratégies de dénomination prédéfinies en définissant des stratégies de dénomination personnalisées utilisant différentes combinaisons de noms de liaison personnalisés et de fonctions de post-traitement prédéfinies.
6.8.2. Options de reliure avancées
Vous pouvez définir la ressource personnalisée (CR) ServiceBinding pour qu'elle utilise les options de liaison avancées suivantes :
-
Modifier les noms des liens : Cette option n'est disponible que pour le groupe
binding.operators.coreos.comAPI. -
Composer des données de liaison personnalisées : Cette option n'est disponible que pour le groupe
binding.operators.coreos.comAPI. -
Lier les charges de travail à l'aide de sélecteurs d'étiquettes : Cette option est disponible pour les groupes d'API
binding.operators.coreos.cometservicebinding.io.
6.8.2.1. Modifier les noms des liaisons avant de les projeter dans la charge de travail
Vous pouvez spécifier les règles de modification des noms de liaison dans l'attribut .spec.namingStrategy du CR ServiceBinding. Par exemple, considérons un exemple d'application Spring PetClinic qui se connecte à la base de données PostgreSQL. Dans ce cas, le service de base de données PostgreSQL expose les champs host et port de la base de données à utiliser pour la liaison. L'exemple d'application Spring PetClinic peut accéder à ces données de liaison exposées par le biais des noms de liaison.
Exemple : Exemple d'application Spring PetClinic sur le site ServiceBinding CR
...
application:
name: spring-petclinic
group: apps
version: v1
resource: deployments
...Exemple : Service de base de données PostgreSQL dans le CR ServiceBinding
...
services:
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster
name: hippo
...
Si namingStrategy n'est pas défini et que les noms des liens sont projetés en tant que variables d'environnement, la valeur host: hippo-pgbouncer dans le service d'appui et la variable d'environnement projetée apparaîtront comme indiqué dans l'exemple suivant :
Exemple
DATABASE_HOST: hippo-pgbounceroù :
|
|
Spécifie le service backend |
|
| Spécifie le nom de la liaison. |
Après avoir appliqué la stratégie de nommage POSTGRESQL_{{ .service.kind | upper }}_{{ .name | upper }}_ENV, la liste des noms de liaison personnalisés préparée par la demande de liaison de service apparaît comme le montre l'exemple suivant :
Exemple
POSTGRESQL_DATABASE_HOST_ENV: hippo-pgbouncer
POSTGRESQL_DATABASE_PORT_ENV: 5432
Les éléments suivants décrivent les expressions définies dans la stratégie de dénomination POSTGRESQL_{{ .service.kind | upper }}_{{ .name | upper }}_ENV:
-
.name: Fait référence au nom de la liaison exposée par le service d'appui. Dans l'exemple précédent, les noms de liaison sontHOSTetPORT. -
.service.kind: Désigne le type de ressource de service dont les noms de liaison sont modifiés par la stratégie de dénomination. -
upper: Fonction de chaîne utilisée pour post-traiter la chaîne de caractères lors de la compilation de la chaîne du modèle Go. -
POSTGRESQL: Préfixe du nom de la liaison personnalisée. -
ENV: Suffixe du nom de la liaison personnalisée.
Comme dans l'exemple précédent, vous pouvez définir les modèles de chaînes dans namingStrategy pour définir comment chaque clé des noms de liaison doit être préparée par la demande de liaison de service.
6.8.2.2. Composer des données de liaison personnalisées
En tant que développeur d'applications, vous pouvez composer des données de liaison personnalisées dans les circonstances suivantes :
- Le service de soutien n'expose pas les données de liaison.
- Les valeurs exposées ne sont pas disponibles dans le format requis par la charge de travail.
Par exemple, considérons un cas où le service de soutien CR expose l'hôte, le port et l'utilisateur de la base de données en tant que données de liaison, mais la charge de travail exige que les données de liaison soient consommées en tant que chaîne de connexion. Vous pouvez composer des données de liaison personnalisées à l'aide d'attributs dans la ressource Kubernetes représentant le service d'appui.
Exemple
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-pgcluster
namespace: my-petclinic
spec:
services:
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster
name: hippo
id: postgresDB
- group: ""
version: v1
kind: Secret
name: hippo-pguser-hippo
id: postgresSecret
application:
name: spring-petclinic
group: apps
version: v1
resource: deployments
mappings:
## From the database service
- name: JDBC_URL
value: 'jdbc:postgresql://{{ .postgresDB.metadata.annotations.proxy }}:{{ .postgresDB.spec.port }}/{{ .postgresDB.metadata.name }}'
## From both the services!
- name: CREDENTIALS
value: '{{ .postgresDB.metadata.name }}{{ translationService.postgresSecret.data.password }}'
## Generate JSON
- name: DB_JSON
value: {{ json .postgresDB.status }} - 1
- Nom de la ressource du service de soutien.
- 2
- Identifiant facultatif.
- 3
- Nom JSON généré par le Service Binding Operator. Le Service Binding Operator projette ce nom JSON comme le nom d'un fichier ou d'une variable d'environnement.
- 4
- Valeur JSON générée par l'opérateur de liaison de services. Le Service Binding Operator projette cette valeur JSON dans un fichier ou une variable d'environnement. La valeur JSON contient les attributs du champ spécifié de la ressource personnalisée du service d'appui.
6.8.2.3. Lier les charges de travail à l'aide d'un sélecteur d'étiquettes
Vous pouvez utiliser un sélecteur d'étiquettes pour spécifier la charge de travail à lier. Si vous déclarez une liaison de service en utilisant les sélecteurs d'étiquettes pour récupérer des charges de travail, l'opérateur de liaison de service tente périodiquement de trouver et de lier de nouvelles charges de travail qui correspondent au sélecteur d'étiquettes donné.
Par exemple, en tant qu'administrateur de cluster, vous pouvez lier un service à chaque Deployment dans un espace de noms avec l'étiquette environment: production en définissant un champ labelSelector approprié dans le CR ServiceBinding. Cela permet à l'opérateur de liaison de services de lier chacune de ces charges de travail à un CR ServiceBinding.
Exemple ServiceBinding CR dans l'API binding.operators.coreos.com/v1alpha1
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: multi-application-binding
namespace: service-binding-demo
spec:
application:
labelSelector:
matchLabels:
environment: production
group: apps
version: v1
resource: deployments
services:
group: ""
version: v1
kind: Secret
name: super-secret-data- 1
- Spécifie la charge de travail qui est liée.
Exemple ServiceBinding CR dans l'API servicebinding.io
apiVersion: servicebindings.io/v1beta1
kind: ServiceBinding
metadata:
name: multi-application-binding
namespace: service-binding-demo
spec:
workload:
selector:
matchLabels:
environment: production
apiVersion: app/v1
kind: Deployment
service:
apiVersion: v1
kind: Secret
name: super-secret-data- 1
- Spécifie la charge de travail qui est liée.
Si vous définissez les paires de champs suivantes, Service Binding Operator refuse l'opération de liaison et génère une erreur :
-
Les champs
nameetlabelSelectordans l'APIbinding.operators.coreos.com/v1alpha1. -
Les champs
nameetselectordans l'APIservicebinding.io(Spec API).
Comprendre le comportement du rebinding
Prenons le cas où, après une liaison réussie, vous utilisez le champ name pour identifier une charge de travail. Si vous supprimez et recréez cette charge de travail, l'outil de réconciliation ServiceBinding ne lie pas à nouveau la charge de travail et l'opérateur ne peut pas projeter les données de liaison sur la charge de travail. Toutefois, si vous utilisez le champ labelSelector pour identifier une charge de travail, le programme de rapprochement ServiceBinding lie à nouveau la charge de travail et l'opérateur projette les données de liaison.
6.8.3. Lier des charges de travail secondaires qui ne sont pas conformes à PodSpec
Un scénario typique de liaison de service implique la configuration du service de soutien, de la charge de travail (déploiement) et de l'opérateur de liaison de service. Considérons un scénario impliquant une charge de travail secondaire (qui peut également être un opérateur d'application) qui n'est pas conforme à PodSpec et qui se trouve entre la charge de travail principale (déploiement) et l'opérateur de liaison de service.
Pour ces ressources de charge de travail secondaire, l'emplacement du chemin d'accès au conteneur est arbitraire. Pour la liaison de service, si la charge de travail secondaire d'une CR n'est pas conforme à la PodSpec, vous devez spécifier l'emplacement du chemin du conteneur. Cela permet de projeter les données de liaison dans le chemin du conteneur spécifié dans la charge de travail secondaire de la ressource personnalisée (CR) ServiceBinding, par exemple lorsque vous ne voulez pas que les données de liaison se trouvent dans un pod.
Dans Service Binding Operator, vous pouvez configurer le chemin d'accès des conteneurs ou des secrets au sein d'une charge de travail et lier ces chemins d'accès à un emplacement personnalisé.
6.8.3.1. Configuration de l'emplacement personnalisé du chemin d'accès au conteneur
Cet emplacement personnalisé est disponible pour le groupe API binding.operators.coreos.com lorsque Service Binding Operator projette les données de liaison en tant que variables d'environnement.
Considérons une charge de travail secondaire CR, qui n'est pas conforme à la PodSpec et dont les conteneurs sont situés sur le chemin spec.containers:
Exemple : Charge de travail secondaire CR
apiVersion: "operator.sbo.com/v1"
kind: SecondaryWorkload
metadata:
name: secondary-workload
spec:
containers:
- name: hello-world
image: quay.io/baijum/secondary-workload:latest
ports:
- containerPort: 8080Procédure
Configurez le chemin d'accès
spec.containersen spécifiant une valeur dans le CRServiceBindinget liez ce chemin d'accès à un emplacement personnaliséspec.application.bindingPath.containersPath:Exemple :
ServiceBindingCR avec le chemin d'accèsspec.containersdans un emplacement personnaliséapiVersion: binding.operators.coreos.com/v1alpha1 kind: ServiceBinding metadata: name: spring-petclinic-pgcluster spec: services: - group: postgres-operator.crunchydata.com version: v1beta1 kind: PostgresCluster name: hippo id: postgresDB - group: "" version: v1 kind: Secret name: hippo-pguser-hippo id: postgresSecret application:1 name: spring-petclinic group: apps version: v1 resource: deployments application:2 name: secondary-workload group: operator.sbo.com version: v1 resource: secondaryworkloads bindingPath: containersPath: spec.containers3
Après avoir spécifié l'emplacement du chemin du conteneur, Service Binding Operator génère les données de liaison, qui deviennent disponibles dans le chemin du conteneur spécifié dans la charge de travail secondaire de la CR ServiceBinding.
L'exemple suivant montre le chemin spec.containers avec les champs envFrom et secretRef:
Exemple : Charge de travail secondaire CR avec les champs envFrom et secretRef
apiVersion: "operator.sbo.com/v1"
kind: SecondaryWorkload
metadata:
name: secondary-workload
spec:
containers:
- env:
- name: ServiceBindingOperatorChangeTriggerEnvVar
value: "31793"
envFrom:
- secretRef:
name: secret-resource-name
image: quay.io/baijum/secondary-workload:latest
name: hello-world
ports:
- containerPort: 8080
resources: {}6.8.3.2. Configuration de l'emplacement personnalisé du chemin d'accès secret
Cet emplacement personnalisé est disponible pour le groupe API binding.operators.coreos.com lorsque Service Binding Operator projette les données de liaison en tant que variables d'environnement.
Considérons une charge de travail secondaire CR, qui n'est pas conforme à la PodSpec, avec seulement le secret sur le chemin spec.secret:
Exemple : Charge de travail secondaire CR
apiVersion: "operator.sbo.com/v1"
kind: SecondaryWorkload
metadata:
name: secondary-workload
spec:
secret: ""Procédure
Configurer le chemin d'accès
spec.secreten spécifiant une valeur dans le CRServiceBindinget lier ce chemin d'accès à un emplacement personnaliséspec.application.bindingPath.secretPath:Exemple :
ServiceBindingCR avec le chemin d'accèsspec.secretdans un emplacement personnaliséapiVersion: binding.operators.coreos.com/v1alpha1 kind: ServiceBinding metadata: name: spring-petclinic-pgcluster spec: ... application:1 name: secondary-workload group: operator.sbo.com version: v1 resource: secondaryworkloads bindingPath: secretPath: spec.secret2 ...
Après avoir spécifié l'emplacement du chemin secret, Service Binding Operator génère les données de liaison, qui deviennent disponibles dans le chemin secret spécifié dans la charge de travail secondaire du CR ServiceBinding.
L'exemple suivant montre le chemin spec.secret avec la valeur binding-request:
Exemple : Charge de travail secondaire CR avec la valeur binding-request
...
apiVersion: "operator.sbo.com/v1"
kind: SecondaryWorkload
metadata:
name: secondary-workload
spec:
secret: binding-request-72ddc0c540ab3a290e138726940591debf14c581
...- 1
- Nom unique de la ressource
Secretgénérée par le Service Binding Operator.
6.8.3.3. Cartographie des ressources de la charge de travail
-
Le mappage des ressources de charge de travail est disponible pour les charges de travail secondaires de la ressource personnalisée (CR)
ServiceBindingpour les deux groupes API :binding.operators.coreos.cometservicebinding.io. -
Vous devez définir les ressources
ClusterWorkloadResourceMappinguniquement dans le groupe d'APIservicebinding.io. Cependant, les ressourcesClusterWorkloadResourceMappinginteragissent avec les ressourcesServiceBindingsous les groupes d'APIbinding.operators.coreos.cometservicebinding.io.
Si vous ne pouvez pas configurer des emplacements de chemin d'accès personnalisés en utilisant la méthode de configuration du chemin d'accès du conteneur, vous pouvez définir exactement où les données de liaison doivent être projetées. Spécifiez où projeter les données de liaison pour un type de charge de travail donné en définissant les ressources ClusterWorkloadResourceMapping dans le groupe API servicebinding.io.
L'exemple suivant montre comment définir un mappage pour les ressources CronJob.batch/v1.
Exemple : Cartographie des ressources CronJob.batch/v1
apiVersion: servicebinding.io/v1beta1
kind: ClusterWorkloadResourceMapping
metadata:
name: cronjobs.batch
spec:
versions:
- version: "v1"
annotations: .spec.jobTemplate.spec.template.metadata.annotations
containers:
- path: .spec.jobTemplate.spec.template.spec.containers[*]
- path: .spec.jobTemplate.spec.template.spec.initContainers[*]
name: .name
env: .env
volumeMounts: .volumeMounts
volumes: .spec.jobTemplate.spec.template.spec.volumes - 1
- Nom de la ressource
ClusterWorkloadResourceMapping, qui doit être qualifié deplural.groupde la ressource de charge de travail mappée. - 2
- Version de la ressource en cours de mappage. Toute version non spécifiée peut être remplacée par le caractère générique "*".
- 3
- Facultatif : Identifiant du champ
.annotationsdans un pod, spécifié avec un JSONPath fixe. La valeur par défaut est.spec.template.spec.annotations. - 4
- Identifiant des champs
.containerset.initContainersdans un module, spécifié par un chemin JSONPath. Si aucune entrée sous le champcontainersn'est définie, l'opérateur de liaison de services utilise par défaut deux chemins :.spec.template.spec.containers[*]et.spec.template.spec.initContainers[\*], tous les autres champs étant définis par défaut. Toutefois, si vous spécifiez une entrée, vous devez définir le champ.path. - 5
- Facultatif : Identifiant du champ
.namedans un conteneur, spécifié avec un chemin JSONPath fixe. La valeur par défaut est.name. - 6
- Facultatif : Identifiant du champ
.envdans un conteneur, spécifié avec un chemin JSONPath fixe. La valeur par défaut est.env. - 7
- Facultatif : Identifiant du champ
.volumeMountsdans un conteneur, spécifié avec un chemin JSONPath fixe. La valeur par défaut est.volumeMounts. - 8
- Facultatif : Identifiant du champ
.volumesdans un pod, spécifié avec un JSONPath fixe. La valeur par défaut est.spec.template.spec.volumes.
Dans ce contexte, un chemin JSONPath fixe est un sous-ensemble de la grammaire JSONPath qui n'accepte que les opérations suivantes :
-
Recherche de champ :
.spec.template -
Indexation des tableaux :
.spec['template']
Toutes les autres opérations ne sont pas acceptées.
-
Recherche de champ :
-
La plupart de ces champs sont facultatifs. Lorsqu'ils ne sont pas spécifiés, l'opérateur de liaison de services prend des valeurs par défaut compatibles avec les ressources
PodSpec. -
L'opérateur de liaison de services exige que chacun de ces champs soit structurellement équivalent au champ correspondant dans un déploiement de pods. Par exemple, le contenu du champ
.envdans une ressource de charge de travail doit pouvoir accepter la même structure de données que le champ.envdans une ressource Pod. Dans le cas contraire, la projection de données de liaison dans une telle charge de travail pourrait entraîner un comportement inattendu de la part de l'opérateur de liaison de services.
Comportement spécifique au groupe d'API binding.operators.coreos.com
Vous pouvez vous attendre aux comportements suivants lorsque les ressources ClusterWorkloadResourceMapping interagissent avec les ressources ServiceBinding dans le cadre du groupe API binding.operators.coreos.com:
-
Si une ressource
ServiceBindingavec la valeur de l'indicateurbindAsFiles: falseest créée avec l'un de ces mappages, les variables d'environnement sont projetées dans le champ.envFromsous chaque champpathspécifié dans la ressourceClusterWorkloadResourceMappingcorrespondante. En tant qu'administrateur de cluster, vous pouvez spécifier à la fois une ressource
ClusterWorkloadResourceMappinget le champ.spec.application.bindingPath.containersPathdans une ressourceServiceBinding.bindings.coreos.comà des fins de liaison.L'opérateur de liaison de services tente de projeter les données de liaison dans les emplacements spécifiés à la fois dans une ressource
ClusterWorkloadResourceMappinget dans le champ.spec.application.bindingPath.containersPath. Ce comportement équivaut à l'ajout d'une entrée de conteneur à la ressourceClusterWorkloadResourceMappingcorrespondante avec l'attributpath: $containersPath, toutes les autres valeurs prenant leur valeur par défaut.
6.8.4. Délier les charges de travail d'un service d'appui
Vous pouvez délier une charge de travail d'un service de soutien à l'aide de l'outil oc.
Pour délier une charge de travail d'un service d'appui, supprimez la ressource personnalisée (CR)
ServiceBindingqui lui est liée :oc delete ServiceBinding <.metadata.name> $ oc delete ServiceBinding <.metadata.name>Exemple
$ oc delete ServiceBinding spring-petclinic-pgclusteroù :
spring-petclinic-pgclusterSpécifie le nom du CR
ServiceBinding.
6.9. Connecter une application à un service en utilisant la perspective du développeur
Outre le regroupement de plusieurs composants au sein d'une application, vous pouvez également utiliser la vue Topology pour relier les composants entre eux. Vous pouvez utiliser un connecteur contraignant ou visuel pour relier les composants.
Une connexion contraignante entre les composants ne peut être établie que si le nœud cible est un service soutenu par l'opérateur. Ceci est indiqué par l'info-bulle Create a binding connector qui apparaît lorsque vous faites glisser une flèche vers un tel nœud cible. Lorsqu'une application est connectée à un service à l'aide d'un connecteur de liaison, une ressource ServiceBinding est créée. Ensuite, le contrôleur Service Binding Operator projette les données de liaison nécessaires dans le déploiement de l'application. Une fois que la demande a abouti, l'application est redéployée en établissant une interaction entre les composants connectés.
Un connecteur visuel établit uniquement une connexion visuelle entre les composants, décrivant une intention de connexion. Aucune interaction n'est établie entre les composants. Si le nœud cible n'est pas un service soutenu par un opérateur, l'info-bulle Create a visual connector s'affiche lorsque vous faites glisser une flèche vers un nœud cible.
6.9.1. Découverte et identification des services liables soutenus par l'opérateur
En tant qu'utilisateur, si vous souhaitez créer un service liant, vous devez savoir quels sont les services liants. Les services liables sont des services que les applications peuvent consommer facilement parce qu'ils exposent leurs données de liaison telles que les informations d'identification, les détails de connexion, les montages de volume, les secrets et d'autres données de liaison de manière standard. La perspective Developer vous aide à découvrir et à identifier ces services liables.
Procédure
Pour découvrir et identifier les services liables soutenus par l'opérateur, il convient d'envisager les approches alternatives suivantes :
- Cliquez sur Add → Developer Catalog → Operator Backed pour voir les tuiles soutenues par l'opérateur. Les services soutenus par l'opérateur qui prennent en charge les fonctions de liaison de service ont un badge Bindable sur les tuiles.
Dans le volet gauche de la page Operator Backed, cochez la case Bindable.
AstuceCliquez sur l'icône d'aide à côté de Service binding pour obtenir plus d'informations sur les services de reliure.
- Cliquez sur Add → Add et recherchez les services soutenus par l'opérateur. Lorsque vous cliquez sur le service liant, vous pouvez voir le badge Bindable dans le panneau latéral à droite.
6.9.2. Créer une connexion visuelle entre les composants
Vous pouvez représenter une intention de connecter des composants d'application en utilisant le connecteur visuel.
Cette procédure vous présente un exemple de création d'une connexion visuelle entre un service de base de données PostgreSQL et un exemple d'application Spring PetClinic.
Conditions préalables
- Vous avez créé et déployé un exemple d'application Spring PetClinic en utilisant la perspective Developer.
-
Vous avez créé et déployé une instance de base de données Crunchy PostgreSQL en utilisant la perspective Developer. Cette instance possède les composants suivants :
hippo-backup,hippo-instance,hippo-repo-host, ethippo-pgbouncer.
Procédure
Survolez l'exemple d'application Spring PetClinic pour voir une flèche pendante sur le nœud.
Figure 6.2. Connecteur visuel
-
Cliquez et faites glisser la flèche vers le déploiement
hippo-pgbouncerpour y connecter l'exemple d'application Spring PetClinic. -
Cliquez sur le déploiement
spring-petclinicpour afficher le panneau Overview. Sous l'onglet Details, cliquez sur l'icône d'édition dans la section Annotations pour voir les onglets Key =app.openshift.io/connects-toet Value =[{"apiVersion":"apps/v1","kind":"Deployment","name":"hippo-pgbouncer"}]ajoutée au déploiement. Facultatif : vous pouvez répéter ces étapes pour établir des connexions visuelles entre d'autres applications et composants que vous créez.
Figure 6.3. Connecter plusieurs applications
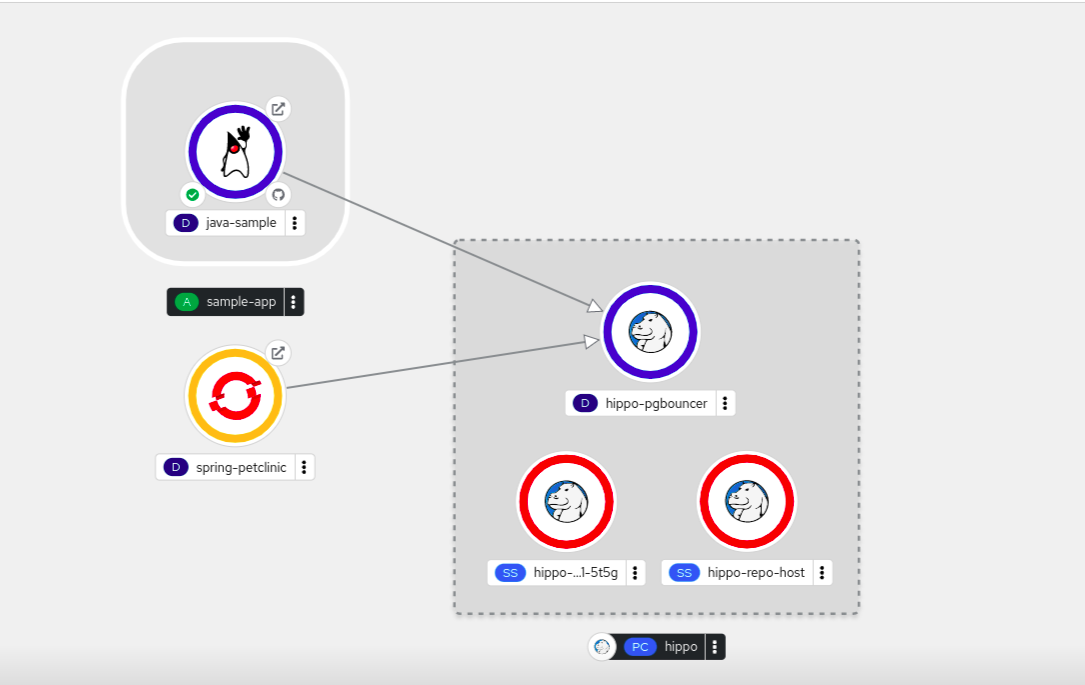
6.9.3. Création d'une liaison entre les composants
Vous pouvez créer une connexion de liaison avec des composants soutenus par l'opérateur, comme le montre l'exemple suivant, qui utilise un service de base de données PostgreSQL et un exemple d'application Spring PetClinic. Pour créer une connexion de liaison avec un service soutenu par l'Opérateur de base de données PostgreSQL, vous devez d'abord ajouter l'Opérateur de base de données PostgreSQL fourni par Red Hat à OperatorHub, puis installer l'Opérateur. L'Opérateur de base de données PostgreSQL crée et gère ensuite la ressource Base de données, qui expose les données de liaison dans les secrets, les cartes de configuration, l'état et les attributs de spécification.
Conditions préalables
- Vous avez créé et déployé un exemple d'application Spring PetClinic dans la perspective Developer.
- Vous avez installé Service Binding Operator sur le site OperatorHub.
-
Vous avez installé l'Opérateur Crunchy Postgres for Kubernetes à partir du OperatorHub dans le canal
v5Update . -
Vous avez créé une ressource PostgresCluster dans la perspective Developer, ce qui a donné lieu à une instance de base de données Crunchy PostgreSQL avec les composants suivants :
hippo-backup,hippo-instance,hippo-repo-host, ethippo-pgbouncer.
Procédure
-
Dans la perspective Developer, passez au projet concerné, par exemple
my-petclinic. - Dans la vue Topology, survolez l'exemple d'application Spring PetClinic pour voir une flèche pendante sur le nœud.
- Faites glisser la flèche sur l'icône de la base de données hippo dans le cluster Postgres pour établir une connexion contraignante avec l'exemple d'application Spring PetClinic.
Dans la boîte de dialogue Create Service Binding, conservez le nom par défaut ou ajoutez un nom différent pour la liaison de service, puis cliquez sur Create.
Figure 6.4. Boîte de dialogue Service Binding
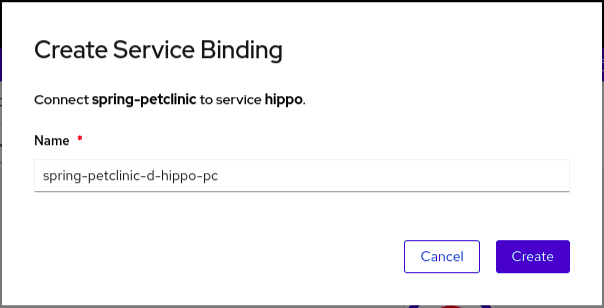
- Facultatif : si vous avez des difficultés à établir une connexion de liaison à l'aide de la vue Topologie, allez à Add → YAML → Import YAML.
Facultatif : dans l'éditeur YAML, ajoutez la ressource
ServiceBinding:apiVersion: binding.operators.coreos.com/v1alpha1 kind: ServiceBinding metadata: name: spring-petclinic-pgcluster namespace: my-petclinic spec: services: - group: postgres-operator.crunchydata.com version: v1beta1 kind: PostgresCluster name: hippo application: name: spring-petclinic group: apps version: v1 resource: deploymentsUne demande de liaison de service est créée et une connexion de liaison est créée par l'intermédiaire d'une ressource
ServiceBinding. Lorsque la demande de connexion au service de base de données aboutit, l'application est redéployée et la connexion est établie.Figure 6.5. Connecteur de liaison
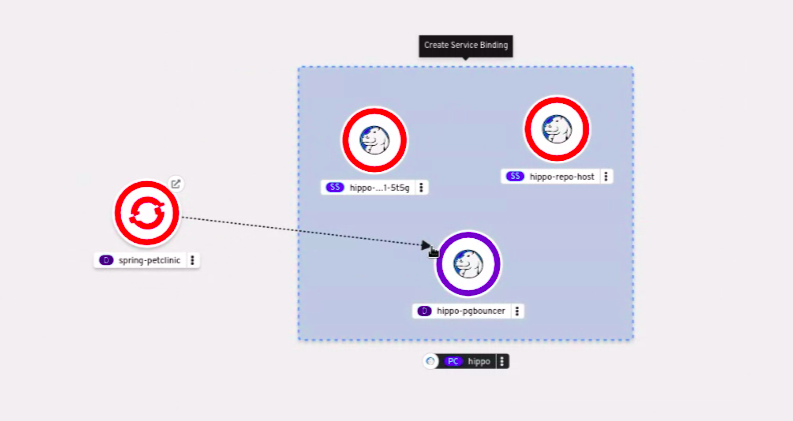 Astuce
AstuceVous pouvez également utiliser le menu contextuel en faisant glisser la flèche pendante pour ajouter et créer une connexion contraignante à un service soutenu par l'opérateur.
Figure 6.6. Menu contextuel pour créer une connexion contraignante

- Dans le menu de navigation, cliquez sur Topology. Le déploiement spring-petclinic dans la vue Topologie comprend un lien Open URL pour afficher sa page web.
- Cliquez sur le lien Open URL.
Vous pouvez maintenant visualiser à distance l'exemple d'application Spring PetClinic pour confirmer que l'application est maintenant connectée au service de base de données et que les données ont été projetées avec succès vers l'application à partir du service de base de données Crunchy PostgreSQL.
L'opérateur de liaison de service a réussi à créer une connexion fonctionnelle entre l'application et le service de base de données.
6.9.4. Vérification de l'état de votre liaison de service à partir de la vue Topologie
La perspective Developer vous aide à vérifier l'état de votre liaison de service par le biais de la vue Topology.
Procédure
Si la liaison de service a réussi, cliquez sur le connecteur de liaison. Un panneau latéral apparaît et affiche l'état de Connected sous l'onglet Details.
En option, vous pouvez consulter l'état de Connected dans les pages suivantes, du point de vue de Developer:
- La page ServiceBindings.
- La page ServiceBinding details. En outre, le titre de la page affiche un badge Connected.
Si la liaison de service n'a pas abouti, le connecteur de liaison affiche une pointe de flèche rouge et une croix rouge au milieu de la connexion. Cliquez sur ce connecteur pour afficher l'état de Error dans le panneau latéral sous l'onglet Details. Si vous le souhaitez, cliquez sur l'état Error pour obtenir des informations spécifiques sur le problème sous-jacent.
Vous pouvez également consulter l'état de Error et une infobulle sur les pages suivantes à partir de la perspective Developer:
- La page ServiceBindings.
- La page ServiceBinding details. En outre, le titre de la page affiche un badge Error.
Dans la page ServiceBindings, utilisez le menu déroulant Filter pour dresser la liste des liaisons de service en fonction de leur statut.
Chapitre 7. Travailler avec les tableaux de bord
7.1. Comprendre la barre
Helm est un gestionnaire de paquets logiciels qui simplifie le déploiement d'applications et de services sur les clusters d'OpenShift Container Platform.
Helm utilise un format d'emballage appelé charts. Un diagramme Helm est un ensemble de fichiers décrivant les ressources de OpenShift Container Platform.
Une instance en cours d'exécution de la carte dans un cluster est appelée release. Une nouvelle version est créée chaque fois qu'une carte est installée sur le cluster.
Chaque fois qu'un graphique est installé, ou qu'une version est mise à jour ou annulée, une révision incrémentielle est créée.
7.1.1. Caractéristiques principales
Helm permet de :
- Recherche dans une vaste collection de graphiques stockés dans le référentiel de graphiques.
- Modifier les graphiques existants.
- Créez vos propres graphiques avec les ressources d'OpenShift Container Platform ou de Kubernetes.
- Regroupez et partagez vos applications sous forme de graphiques.
7.1.2. Certification Red Hat des cartes Helm pour OpenShift
Vous pouvez choisir de vérifier et de certifier vos diagrammes Helm par Red Hat pour tous les composants que vous allez déployer sur Red Hat OpenShift Container Platform. Les cartes passent par un flux de certification automatisé Red Hat OpenShift qui garantit la conformité en matière de sécurité ainsi qu'une intégration et une expérience optimales avec la plateforme. La certification assure l'intégrité de la carte et garantit que la carte Helm fonctionne de manière transparente sur les clusters Red Hat OpenShift.
7.2. Installation du Helm
La section suivante décrit comment installer Helm sur différentes plateformes à l'aide de la CLI.
Vous pouvez également trouver l'URL des derniers binaires à partir de la console web d'OpenShift Container Platform en cliquant sur l'icône ? dans le coin supérieur droit et en sélectionnant Command Line Tools.
Conditions préalables
- Vous avez installé Go, version 1.13 ou supérieure.
7.2.1. Sous Linux
Téléchargez le binaire Helm et ajoutez-le à votre chemin d'accès :
Linux (x86_64, amd64)
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-amd64 -o /usr/local/bin/helmLinux sur IBM zSystems et IBM® LinuxONE (s390x)
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-s390x -o /usr/local/bin/helmLinux sur IBM Power (ppc64le)
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-ppc64le -o /usr/local/bin/helm
Rendre le fichier binaire exécutable :
# chmod +x /usr/local/bin/helmVérifier la version installée :
$ helm versionExemple de sortie
version.BuildInfo{Version:"v3.0", GitCommit:"b31719aab7963acf4887a1c1e6d5e53378e34d93", GitTreeState:"clean", GoVersion:"go1.13.4"}
7.2.2. Sous Windows 7/8
-
Téléchargez le dernier fichier
.exeet placez-le dans un répertoire de votre choix. - Cliquez avec le bouton droit de la souris sur Start et cliquez sur Control Panel.
- Sélectionnez System and Security puis cliquez sur System.
- Dans le menu de gauche, sélectionnez Advanced systems settings et cliquez sur Environment Variables en bas.
- Sélectionnez Path dans la section Variable et cliquez sur Edit.
-
Cliquez sur New et saisissez le chemin d'accès au dossier contenant le fichier
.exedans le champ ou cliquez sur Browse et sélectionnez le répertoire, puis cliquez sur OK.
7.2.3. Sur Windows 10
-
Téléchargez le dernier fichier
.exeet placez-le dans un répertoire de votre choix. -
Cliquez sur Search et tapez
envouenvironment. - Sélectionnez Edit environment variables for your account.
- Sélectionnez Path dans la section Variable et cliquez sur Edit.
- Cliquez sur New et saisissez le chemin d'accès au répertoire contenant le fichier exe dans le champ ou cliquez sur Browse et sélectionnez le répertoire, puis cliquez sur OK.
7.2.4. Sur MacOS
Téléchargez le binaire Helm et ajoutez-le à votre chemin d'accès :
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-darwin-amd64 -o /usr/local/bin/helmRendre le fichier binaire exécutable :
# chmod +x /usr/local/bin/helmVérifier la version installée :
$ helm versionExemple de sortie
version.BuildInfo{Version:"v3.0", GitCommit:"b31719aab7963acf4887a1c1e6d5e53378e34d93", GitTreeState:"clean", GoVersion:"go1.13.4"}
7.3. Configurer des dépôts de cartes Helm personnalisés
Vous pouvez installer les graphiques Helm sur un cluster OpenShift Container Platform en utilisant les méthodes suivantes :
- Le CLI.
- La perspective Developer de la console web.
Le site Developer Catalog, dans la perspective Developer de la console Web, affiche les graphiques Helm disponibles dans le cluster. Par défaut, il répertorie les graphiques Helm du dépôt de graphiques Helm de Red Hat OpenShift. Pour obtenir une liste des graphiques, consultez le fichier Red Hat Helm index .
En tant qu'administrateur de cluster, vous pouvez ajouter plusieurs référentiels de diagrammes Helm adaptés au cluster et à l'espace de noms, distincts du référentiel Helm par défaut adapté au cluster, et afficher les diagrammes Helm de ces référentiels sur le site Developer Catalog.
En tant qu'utilisateur normal ou membre d'un projet disposant des autorisations de contrôle d'accès basé sur les rôles (RBAC) appropriées, vous pouvez ajouter plusieurs référentiels de diagrammes Helm dans l'espace de noms, en plus du référentiel Helm par défaut dans le cluster, et afficher les diagrammes Helm de ces référentiels dans le site Developer Catalog.
Dans la perspective Developer de la console web, vous pouvez utiliser la page Helm pour :
- Créez des versions et des dépôts Helm en utilisant le bouton Create.
- Créer, mettre à jour ou supprimer un référentiel graphique Helm à l'échelle d'un cluster ou d'un espace de noms.
- Consultez la liste des référentiels graphiques Helm existants dans l'onglet Référentiels, qui peuvent également être facilement distingués en tant que référentiels de cluster ou d'espace de noms.
7.3.1. Installation d'un diagramme Helm sur un cluster OpenShift Container Platform
Conditions préalables
- Vous avez un cluster OpenShift Container Platform en cours d'exécution et vous vous y êtes connecté.
- Vous avez installé Helm.
Procédure
Créer un nouveau projet :
$ oc new-project vaultAjouter un référentiel de cartes Helm à votre client Helm local :
$ helm repo add openshift-helm-charts https://charts.openshift.io/Exemple de sortie
"openshift-helm-charts" has been added to your repositoriesMettre à jour le référentiel :
$ helm repo updateInstaller un exemple de chambre forte HashiCorp :
$ helm install example-vault openshift-helm-charts/hashicorp-vaultExemple de sortie
NAME: example-vault LAST DEPLOYED: Fri Mar 11 12:02:12 2022 NAMESPACE: vault STATUS: deployed REVISION: 1 NOTES: Thank you for installing HashiCorp Vault!Vérifiez que la carte a été installée avec succès :
$ helm listExemple de sortie
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION example-vault vault 1 2022-03-11 12:02:12.296226673 +0530 IST deployed vault-0.19.0 1.9.2
7.3.2. Installer les cartes Helm en utilisant la perspective du développeur
Vous pouvez utiliser la perspective Developer de la console Web ou le CLI pour sélectionner et installer un graphique parmi les graphiques Helm répertoriés dans la perspective Developer Catalog. Vous pouvez créer des versions Helm en installant des graphiques Helm et les voir dans la perspective Developer de la console Web.
Conditions préalables
- Vous vous êtes connecté à la console web et avez basculé dans la perspective Developer .
Procédure
Pour créer des versions de Helm à partir des cartes de Helm fournies dans le site Developer Catalog:
- Dans la perspective Developer, accédez à la vue Add et sélectionnez un projet. Cliquez ensuite sur l'option Helm Chart pour voir tous les diagrammes de barre dans la vue Developer Catalog.
- Sélectionnez un graphique et lisez la description, le README et d'autres détails concernant le graphique.
Cliquez sur Install Helm Chart.
Figure 7.1. Fiches de pilotage dans le catalogue des développeurs

Dans la page Install Helm Chart:
- Saisissez un nom unique pour la version dans le champ Release Name.
- Sélectionnez la version de la carte requise dans la liste déroulante Chart Version.
Configurez votre carte Helm en utilisant le site Form View ou le site YAML View.
NoteLorsque cela est possible, vous pouvez passer de la vue YAML View à la vue Form View. Les données sont conservées lors du passage d'une vue à l'autre.
- Cliquez sur Install pour créer un communiqué de presse Helm. Vous serez redirigé vers la vue Topology où la version est affichée. Si le tableau Helm contient des notes de mise à jour, le tableau est présélectionné et le panneau de droite affiche les notes de mise à jour pour cette version.
- Voir la nouvelle version de Helm sur la page Helm Releases.
Vous pouvez mettre à niveau, revenir en arrière ou désinstaller une version de Helm en utilisant le bouton Actions sur le panneau latéral ou en cliquant avec le bouton droit de la souris sur une version de Helm.
7.3.3. Utilisation de Helm dans le terminal web
Vous pouvez utiliser Helm en initialisant le terminal Web dans la perspective Developer de la console Web. Pour plus d'informations, voir Utilisation du terminal web.
7.3.4. Créer un graphique Helm personnalisé sur OpenShift Container Platform
Procédure
Créer un nouveau projet :
$ oc new-project nodejs-ex-kTéléchargez un exemple de graphique Node.js contenant des objets OpenShift Container Platform :
$ git clone https://github.com/redhat-developer/redhat-helm-chartsAllez dans le répertoire contenant l'exemple de tableau :
$ cd redhat-helm-charts/alpha/nodejs-ex-k/Modifiez le fichier
Chart.yamlet ajoutez une description de votre graphique :apiVersion: v21 name: nodejs-ex-k2 description: A Helm chart for OpenShift3 icon: https://static.redhat.com/libs/redhat/brand-assets/latest/corp/logo.svg4 version: 0.2.15 - 1
- La version de l'API de la carte. Il devrait être
v2pour les cartes Helm qui nécessitent au moins Helm 3. - 2
- Le nom de votre graphique.
- 3
- La description de votre carte.
- 4
- L'URL d'une image à utiliser comme icône.
- 5
- La version de votre graphique selon la spécification Semantic Versioning (SemVer) 2.0.0.
Vérifiez que le graphique est correctement formaté :
$ helm lintExemple de sortie
[INFO] Chart.yaml: icon is recommended 1 chart(s) linted, 0 chart(s) failedNaviguer vers le niveau de répertoire précédent :
$ cd ..Installer la carte :
$ helm install nodejs-chart nodejs-ex-kVérifiez que la carte a été installée avec succès :
$ helm listExemple de sortie
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION nodejs-chart nodejs-ex-k 1 2019-12-05 15:06:51.379134163 -0500 EST deployed nodejs-0.1.0 1.16.0
7.3.5. Ajouter des dépôts de cartes Helm personnalisés
En tant qu'administrateur de cluster, vous pouvez ajouter des référentiels de graphiques Helm personnalisés à votre cluster et activer l'accès aux graphiques Helm à partir de ces référentiels dans le site Developer Catalog.
Procédure
Pour ajouter un nouveau dépôt de cartes Helm, vous devez ajouter la ressource personnalisée (CR) Helm Chart Repository à votre cluster.
Exemple de dépôt de cartes de barre CR
apiVersion: helm.openshift.io/v1beta1 kind: HelmChartRepository metadata: name: <name> spec: # optional name that might be used by console # name: <chart-display-name> connectionConfig: url: <helm-chart-repository-url>Par exemple, pour ajouter un référentiel d'échantillons graphiques Azure, exécutez :
$ cat <<EOF | oc apply -f - apiVersion: helm.openshift.io/v1beta1 kind: HelmChartRepository metadata: name: azure-sample-repo spec: name: azure-sample-repo connectionConfig: url: https://raw.githubusercontent.com/Azure-Samples/helm-charts/master/docs EOFNaviguez sur le site Developer Catalog dans la console Web pour vérifier que les cartes Helm du référentiel de cartes sont affichées.
Par exemple, utilisez le filtre Chart repositories pour rechercher un graphique Helm dans le référentiel.
Figure 7.2. Filtre sur les référentiels graphiques
 Note
NoteSi un administrateur de cluster supprime tous les référentiels de cartes, vous ne pouvez pas afficher l'option Helm dans la vue Add, Developer Catalog et dans le panneau de navigation gauche.
7.3.6. Ajout de dépôts de graphiques Helm personnalisés dans l'espace de noms
La définition de ressource personnalisée (CRD) HelmChartRepository pour le référentiel Helm permet aux administrateurs d'ajouter des référentiels Helm en tant que ressources personnalisées. La définition de ressource personnalisée ProjectHelmChartRepository (namespace-scoped) permet aux membres du projet disposant des autorisations de contrôle d'accès basé sur les rôles (RBAC) appropriées de créer des ressources de référentiel Helm de leur choix, mais limitées à leur espace de noms. Ces membres du projet peuvent consulter des graphiques provenant de ressources de dépôt Helm à la fois à l'échelle du cluster et à l'échelle de l'espace de noms.
- Les administrateurs peuvent empêcher les utilisateurs de créer des ressources de référentiel Helm dans un espace de noms. En limitant les utilisateurs, les administrateurs ont la possibilité de contrôler le RBAC par le biais d'un rôle d'espace de noms au lieu d'un rôle de cluster. Cela évite d'élever inutilement les autorisations pour l'utilisateur et empêche l'accès à des services ou des applications non autorisés.
- L'ajout du référentiel Helm à l'échelle de l'espace de noms n'a pas d'impact sur le comportement du référentiel Helm à l'échelle du cluster existant.
En tant qu'utilisateur régulier ou membre de projet disposant des autorisations RBAC appropriées, vous pouvez ajouter à votre cluster des référentiels de diagrammes Helm personnalisés dans l'espace de noms et activer l'accès aux diagrammes Helm à partir de ces référentiels dans le site Developer Catalog.
Procédure
Pour ajouter un nouveau référentiel Helm Chart dans l'espace de noms, vous devez ajouter la ressource personnalisée (CR) Helm Chart Repository à votre espace de noms.
Exemple de référentiel de diagramme de Helm dans l'espace de nommage (Namespace-scoped) CR
apiVersion: helm.openshift.io/v1beta1 kind: ProjectHelmChartRepository metadata: name: <name> spec: url: https://my.chart-repo.org/stable # optional name that might be used by console name: <chart-repo-display-name> # optional and only needed for UI purposes description: <My private chart repo> # required: chart repository URL connectionConfig: url: <helm-chart-repository-url>Par exemple, pour ajouter un référentiel de graphiques Azure scoped à votre espace de noms
my-namespace, exécutez :$ cat <<EOF | oc apply --namespace my-namespace -f - apiVersion: helm.openshift.io/v1beta1 kind: ProjectHelmChartRepository metadata: name: azure-sample-repo spec: name: azure-sample-repo connectionConfig: url: https://raw.githubusercontent.com/Azure-Samples/helm-charts/master/docs EOFLa sortie vérifie que le référentiel de diagrammes Helm est créé dans l'espace de noms :
Exemple de sortie
projecthelmchartrepository.helm.openshift.io/azure-sample-repo createdNaviguez vers Developer Catalog dans la console web pour vérifier que les graphiques Helm du référentiel de graphiques sont affichés dans votre espace de noms
my-namespace.Par exemple, utilisez le filtre Chart repositories pour rechercher un graphique Helm dans le référentiel.
Figure 7.3. Filtre des référentiels graphiques dans votre espace de noms

Il est également possible d'exécuter :
$ oc get projecthelmchartrepositories --namespace my-namespaceExemple de sortie
NAME AGE azure-sample-repo 1mNoteSi un administrateur de cluster ou un utilisateur normal disposant des autorisations RBAC appropriées supprime tous les référentiels graphiques d'un espace de noms spécifique, vous ne pouvez pas afficher l'option Helm dans la vue Add, Developer Catalog et dans le panneau de navigation de gauche pour cet espace de noms spécifique.
7.3.7. Création d'informations d'identification et de certificats CA pour ajouter des référentiels graphiques Helm
Certains référentiels graphiques Helm ont besoin d'informations d'identification et de certificats d'autorité de certification (CA) personnalisés pour s'y connecter. Vous pouvez utiliser la console web ainsi que le CLI pour ajouter des informations d'identification et des certificats.
Procédure
Pour configurer les informations d'identification et les certificats, puis ajouter un référentiel graphique Helm à l'aide de l'interface de programmation :
Dans l'espace de noms
openshift-config, créez un objetConfigMapavec un certificat d'autorité de certification personnalisé au format encodé PEM, et stockez-le sous la cléca-bundle.crtdans la carte de configuration :$ oc create configmap helm-ca-cert \ --from-file=ca-bundle.crt=/path/to/certs/ca.crt \ -n openshift-configDans l'espace de noms
openshift-config, créez un objetSecretpour ajouter les configurations TLS du client :$ oc create secret tls helm-tls-configs \ --cert=/path/to/certs/client.crt \ --key=/path/to/certs/client.key \ -n openshift-configNotez que le certificat et la clé du client doivent être au format codé PEM et stockés sous les clés
tls.crtettls.key, respectivement.Ajoutez le référentiel Helm comme suit :
$ cat <<EOF | oc apply -f - apiVersion: helm.openshift.io/v1beta1 kind: HelmChartRepository metadata: name: <helm-repository> spec: name: <helm-repository> connectionConfig: url: <URL for the Helm repository> tlsConfig: name: helm-tls-configs ca: name: helm-ca-cert EOFLes certificats
ConfigMapetSecretsont consommés dans le CR HelmChartRepository à l'aide des champstlsConfigetca. Ces certificats sont utilisés pour se connecter à l'URL du référentiel Helm.Par défaut, tous les utilisateurs authentifiés ont accès à tous les graphiques configurés. Toutefois, pour les référentiels graphiques nécessitant des certificats, vous devez fournir aux utilisateurs un accès en lecture à la carte de configuration
helm-ca-certet au secrethelm-tls-configsdans l'espace de nomsopenshift-config, comme suit :$ cat <<EOF | kubectl apply -f - apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: openshift-config name: helm-chartrepos-tls-conf-viewer rules: - apiGroups: [""] resources: ["configmaps"] resourceNames: ["helm-ca-cert"] verbs: ["get"] - apiGroups: [""] resources: ["secrets"] resourceNames: ["helm-tls-configs"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: openshift-config name: helm-chartrepos-tls-conf-viewer subjects: - kind: Group apiGroup: rbac.authorization.k8s.io name: 'system:authenticated' roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: helm-chartrepos-tls-conf-viewer EOF
7.3.8. Filtrer les tableaux de bord en fonction de leur niveau de certification
Vous pouvez filtrer les graphiques de Helm en fonction de leur niveau de certification sur le site Developer Catalog.
Procédure
- Dans le site Developer perspective, accédez à la vue Add et sélectionnez un projet.
- Dans la tuile Developer Catalog, sélectionnez l'option Helm Chart pour voir toutes les cartes de Helm dans Developer Catalog.
Utilisez les filtres à gauche de la liste des graphiques Helm pour filtrer les graphiques requis :
- Utilisez le filtre Chart Repositories pour filtrer les graphiques fournis par Red Hat Certification Charts ou OpenShift Helm Charts.
-
Utilisez le filtre Source pour filtrer les graphiques provenant de Partners, Community ou Red Hat. Les graphiques certifiés sont indiqués par l'icône (
 ).
).
Le filtre Source n'est pas visible lorsqu'il n'y a qu'un seul type de fournisseur.
Vous pouvez maintenant sélectionner la carte requise et l'installer.
7.3.9. Désactivation des dépôts de Helm Chart
Vous pouvez désactiver les cartes Helm d'un référentiel de cartes Helm particulier dans le catalogue en définissant la propriété disabled de la ressource personnalisée HelmChartRepository sur true.
Procédure
Pour désactiver un référentiel graphique Helm à l'aide de l'interface de programmation, ajoutez l'indicateur
disabled: trueà la ressource personnalisée. Par exemple, pour supprimer un référentiel graphique d'un échantillon Azure, exécutez :$ cat <<EOF | oc apply -f - apiVersion: helm.openshift.io/v1beta1 kind: HelmChartRepository metadata: name: azure-sample-repo spec: connectionConfig: url:https://raw.githubusercontent.com/Azure-Samples/helm-charts/master/docs disabled: true EOFPour désactiver un référentiel Helm Chart récemment ajouté à l'aide de la console Web :
-
Allez sur Custom Resource Definitions et recherchez la ressource personnalisée
HelmChartRepository. - Allez sur Instances, trouvez le référentiel que vous voulez désactiver et cliquez sur son nom.
Allez dans l'onglet YAML, ajoutez le drapeau
disabled: truedans la sectionspecet cliquez surSave.Exemple
spec: connectionConfig: url: <url-of-the-repositoru-to-be-disabled> disabled: trueLe dépôt est maintenant désactivé et n'apparaîtra pas dans le catalogue.
-
Allez sur Custom Resource Definitions et recherchez la ressource personnalisée
7.4. Travailler avec les versions de Helm
Vous pouvez utiliser la perspective Developer dans la console web pour mettre à jour, revenir en arrière ou désinstaller une version de Helm.
7.4.1. Conditions préalables
- Vous vous êtes connecté à la console web et avez basculé dans la perspective Developer .
7.4.2. Mise à jour d'une version de Helm
Vous pouvez mettre à jour une version de Helm pour passer à une nouvelle version de graphique ou mettre à jour votre configuration de version.
Procédure
- Dans la vue Topology, sélectionnez la commande de barre pour afficher le panneau latéral.
- Cliquez sur Actions → Upgrade Helm Release.
- Dans la page Upgrade Helm Release, sélectionnez la version Chart Version vers laquelle vous souhaitez vous mettre à niveau, puis cliquez sur Upgrade pour créer une autre version de Helm. La page Helm Releases affiche les deux révisions.
7.4.3. Revenir sur une version de Helm
Si une version échoue, vous pouvez revenir à une version antérieure de Helm.
Procédure
Pour revenir sur une version à l'aide de la vue Helm:
- Dans la perspective Developer, naviguez jusqu'à la vue Helm pour voir le Helm Releases dans l'espace de noms.
-
Cliquez sur le menu Options
à côté de la liste des communiqués, et sélectionnez Rollback.
- Dans la page Rollback Helm Release, sélectionnez le site Revision sur lequel vous souhaitez revenir et cliquez sur Rollback.
- Dans la page Helm Releases, cliquez sur le graphique pour voir les détails et les ressources de cette version.
Allez sur l'onglet Revision History pour voir toutes les révisions de la carte.
Figure 7.4. Historique des révisions de Helm

-
Si vous le souhaitez, vous pouvez également utiliser le menu Options
adjacent à une révision particulière et sélectionner la révision sur laquelle revenir.
7.4.4. Désinstallation d'une version de Helm
Procédure
- Dans la vue Topology, cliquez avec le bouton droit de la souris sur la version de Helm et sélectionnez Uninstall Helm Release.
- Dans la demande de confirmation, entrez le nom du graphique et cliquez sur Uninstall.
Chapitre 8. Déploiements
8.1. Comprendre les objets Deployment et DeploymentConfig
Les objets API Deployment et DeploymentConfig dans OpenShift Container Platform fournissent deux méthodes similaires mais différentes pour une gestion fine des applications utilisateur courantes. Ils sont composés des objets API distincts suivants :
-
Un objet
DeploymentConfigouDeployment, qui décrit l'état souhaité d'un composant particulier de l'application en tant que modèle de pod. -
DeploymentConfigimpliquent un ou plusieurs objets replication controllers, qui contiennent un enregistrement ponctuel de l'état d'un déploiement en tant que modèle de pod. De même, les objetsDeploymentimpliquent un ou plusieurs replica sets, un successeur des contrôleurs de réplication. - Un ou plusieurs pods, qui représentent une instance d'une version particulière d'une application.
8.1.1. Les éléments constitutifs d'un déploiement
Les déploiements et les configurations de déploiement sont activés par l'utilisation d'objets API Kubernetes natifs ReplicaSet et ReplicationController, respectivement, en tant qu'éléments constitutifs.
Les utilisateurs n'ont pas à manipuler les contrôleurs de réplication, les ensembles de répliques ou les pods appartenant aux objets ou aux déploiements DeploymentConfig. Les systèmes de déploiement garantissent que les changements sont propagés de manière appropriée.
Si les stratégies de déploiement existantes ne sont pas adaptées à votre cas d'utilisation et que vous devez exécuter des étapes manuelles pendant le cycle de vie de votre déploiement, vous devriez envisager de créer une stratégie de déploiement personnalisée.
Les sections suivantes fournissent plus de détails sur ces objets.
8.1.1.1. Contrôleurs de réplication
Un contrôleur de réplication veille à ce qu'un nombre déterminé de répliques d'un module soient en cours d'exécution à tout moment. Si des pods sortent ou sont supprimés, le contrôleur de réplication agit pour en instancier d'autres jusqu'au nombre défini. De même, s'il y a plus de pods en cours d'exécution que souhaité, il en supprime autant que nécessaire pour atteindre le nombre défini.
La configuration d'un contrôleur de réplication comprend
- Le nombre de répliques souhaitées, qui peut être ajusté au moment de l'exécution.
-
Une définition de
Podà utiliser lors de la création d'un pod répliqué. - Un sélecteur pour identifier les modules gérés.
Un sélecteur est un ensemble d'étiquettes attribuées aux pods gérés par le contrôleur de réplication. Ces étiquettes sont incluses dans la définition de Pod que le contrôleur de réplication instancie. Le contrôleur de réplication utilise le sélecteur pour déterminer combien d'instances du pod sont déjà en cours d'exécution afin de procéder aux ajustements nécessaires.
Le contrôleur de réplication n'effectue pas de mise à l'échelle automatique en fonction de la charge ou du trafic, car il ne suit ni l'un ni l'autre. Il faut donc que le nombre de répliques soit ajusté par un système de mise à l'échelle automatique externe.
Voici un exemple de définition d'un contrôleur de réplication :
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend-1
spec:
replicas: 1
selector:
name: frontend
template:
metadata:
labels:
name: frontend
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always- 1
- Le nombre de copies du module à exécuter.
- 2
- Le sélecteur d'étiquettes du module à exécuter.
- 3
- Un modèle pour le module que le contrôleur crée.
- 4
- Les étiquettes sur le pod doivent inclure celles du sélecteur d'étiquettes.
- 5
- La longueur maximale du nom après expansion des paramètres est de 63 caractères.
8.1.1.2. Jeux de répliques
Similaire à un contrôleur de réplication, un ReplicaSet est un objet natif de l'API Kubernetes qui garantit qu'un nombre spécifié de répliques de pods est en cours d'exécution à tout moment. La différence entre un ensemble de répliques et un contrôleur de réplication est qu'un ensemble de répliques prend en charge les exigences de sélecteur basées sur l'ensemble alors qu'un contrôleur de réplication ne prend en charge que les exigences de sélecteur basées sur l'égalité.
N'utilisez les ensembles de répliques que si vous avez besoin d'une orchestration personnalisée des mises à jour ou si vous n'avez pas besoin de mises à jour du tout. Dans le cas contraire, utilisez les déploiements. Les ensembles de répliques peuvent être utilisés indépendamment, mais ils sont utilisés par les déploiements pour orchestrer la création, la suppression et les mises à jour des modules. Les déploiements gèrent automatiquement leurs ensembles de répliques, fournissent des mises à jour déclaratives aux pods et n'ont pas à gérer manuellement les ensembles de répliques qu'ils créent.
Voici un exemple de définition de ReplicaSet:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend-1
labels:
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
tier: frontend
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always- 1
- Une requête d'étiquette sur un ensemble de ressources. Les résultats de
matchLabelsetmatchExpressionssont logiquement joints. - 2
- Sélecteur basé sur l'égalité pour spécifier les ressources dont les étiquettes correspondent au sélecteur.
- 3
- Sélecteur basé sur un ensemble pour filtrer les clés. Cela permet de sélectionner toutes les ressources dont la clé est égale à
tieret la valeur àfrontend.
8.1.2. Objets DeploymentConfig
S'appuyant sur les contrôleurs de réplication, OpenShift Container Platform ajoute une prise en charge étendue du cycle de vie du développement et du déploiement de logiciels grâce au concept d'objets DeploymentConfig. Dans le cas le plus simple, un objet DeploymentConfig crée un nouveau contrôleur de réplication et lui permet de démarrer des pods.
Cependant, les déploiements d'OpenShift Container Platform à partir d'objets DeploymentConfig offrent également la possibilité de passer d'un déploiement existant d'une image à un nouveau déploiement et de définir des crochets à exécuter avant ou après la création du contrôleur de réplication.
Le système de déploiement DeploymentConfig offre les possibilités suivantes :
-
Un objet
DeploymentConfig, qui est un modèle pour les applications en cours d'exécution. - Déclencheurs de déploiements automatisés en réponse à des événements.
- Stratégies de déploiement personnalisables par l'utilisateur pour passer de la version précédente à la nouvelle version. Une stratégie s'exécute à l'intérieur d'un pod, communément appelé processus de déploiement.
- Un ensemble de crochets (crochets de cycle de vie) pour exécuter un comportement personnalisé à différents moments du cycle de vie d'un déploiement.
- Versionnement de votre application pour permettre des retours en arrière soit manuellement, soit automatiquement en cas d'échec du déploiement.
- Mise à l'échelle manuelle de la réplication et mise à l'échelle automatique.
Lorsque vous créez un objet DeploymentConfig, un contrôleur de réplication est créé pour représenter le modèle de pod de l'objet DeploymentConfig. Si le déploiement change, un nouveau contrôleur de réplication est créé avec le dernier modèle de pod et un processus de déploiement s'exécute pour réduire l'ancien contrôleur de réplication et augmenter le nouveau.
Les instances de votre application sont automatiquement ajoutées et supprimées des équilibreurs de charge et des routeurs au fur et à mesure de leur création. Tant que votre application prend en charge l'arrêt progressif lorsqu'elle reçoit le signal TERM, vous pouvez vous assurer que les connexions utilisateur en cours ont une chance de se terminer normalement.
L'objet OpenShift Container Platform DeploymentConfig définit les détails suivants :
-
Les éléments d'une définition
ReplicationController. - Déclencheurs pour la création automatique d'un nouveau déploiement.
- La stratégie de transition entre les déploiements.
- Crochets du cycle de vie.
Chaque fois qu'un déploiement est déclenché, que ce soit manuellement ou automatiquement, un module de déploiement gère le déploiement (y compris la réduction de l'ancien contrôleur de réplication, l'augmentation du nouveau et l'exécution des crochets). Le module de déploiement reste en place pendant une durée indéterminée après l'achèvement du déploiement afin de conserver les journaux du déploiement. Lorsqu'un déploiement est remplacé par un autre, le contrôleur de réplication précédent est conservé pour permettre un retour en arrière facile si nécessaire.
Exemple DeploymentConfig définition
apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: frontend
spec:
replicas: 5
selector:
name: frontend
template: { ... }
triggers:
- type: ConfigChange
- imageChangeParams:
automatic: true
containerNames:
- helloworld
from:
kind: ImageStreamTag
name: hello-openshift:latest
type: ImageChange
strategy:
type: Rolling - 1
- Un déclencheur de changement de configuration entraîne la création d'un nouveau contrôleur de réplication lorsque des changements sont détectés dans le modèle de pod de la configuration de déploiement.
- 2
- Un déclencheur de changement d'image entraîne la création d'un nouveau déploiement chaque fois qu'une nouvelle version de l'image de référence est disponible dans le flux d'images nommé.
- 3
- La stratégie par défaut
Rollingpermet une transition sans temps d'arrêt entre les déploiements.
8.1.3. Déploiements
Kubernetes fournit un type d'objet API natif de première classe dans OpenShift Container Platform appelé Deployment. Les objets Deployment sont des descendants de l'objet DeploymentConfig spécifique à OpenShift Container Platform.
Comme les objets DeploymentConfig, les objets Deployment décrivent l'état souhaité d'un composant particulier d'une application en tant que modèle de pod. Les déploiements créent des ensembles de répliques qui orchestrent les cycles de vie des pods.
Par exemple, la définition de déploiement suivante crée un ensemble de répliques pour mettre en place un pod hello-openshift:
Définition du déploiement
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-openshift
spec:
replicas: 1
selector:
matchLabels:
app: hello-openshift
template:
metadata:
labels:
app: hello-openshift
spec:
containers:
- name: hello-openshift
image: openshift/hello-openshift:latest
ports:
- containerPort: 808.1.4. Comparaison des objets Deployment et DeploymentConfig
Les objets Deployment de Kubernetes et les objets DeploymentConfig fournis par OpenShift Container Platform sont tous deux pris en charge dans OpenShift Container Platform ; cependant, il est recommandé d'utiliser les objets Deployment à moins que vous n'ayez besoin d'une fonctionnalité ou d'un comportement spécifique fourni par les objets DeploymentConfig.
Les sections suivantes décrivent plus en détail les différences entre les deux types d'objets afin de vous aider à choisir le type d'objet à utiliser.
8.1.4.1. Conception
Une différence importante entre les objets Deployment et DeploymentConfig réside dans les propriétés du théorème CAP que chaque conception a choisi pour le processus de déploiement. Les objets DeploymentConfig préfèrent la cohérence, tandis que les objets Deployments privilégient la disponibilité à la cohérence.
Pour les objets DeploymentConfig, si un nœud exécutant un pod de déploiement tombe en panne, il n'est pas remplacé. Le processus attend que le nœud revienne en ligne ou qu'il soit supprimé manuellement. La suppression manuelle du nœud supprime également le module correspondant. Cela signifie que vous ne pouvez pas supprimer le pod pour décoller le rollout, car le kubelet est responsable de la suppression du pod associé.
Cependant, les déploiements sont pilotés par un gestionnaire de contrôleur. Le gestionnaire de contrôleur fonctionne en mode haute disponibilité sur les maîtres et utilise des algorithmes d'élection de leader pour privilégier la disponibilité par rapport à la cohérence. Lors d'une panne, il est possible que d'autres maîtres agissent en même temps sur le même déploiement, mais ce problème sera résolu peu de temps après la panne.
8.1.4.2. Fonctionnalités spécifiques à l'objet DeploymentConfig
Recouvrements automatiques
Actuellement, les déploiements ne permettent pas de revenir automatiquement au dernier jeu de répliques déployé avec succès en cas d'échec.
Déclencheurs
Les déploiements ont un déclencheur implicite de changement de configuration en ce sens que chaque changement dans le modèle de pod d'un déploiement déclenche automatiquement un nouveau déploiement. Si vous ne souhaitez pas de nouveaux déploiements en cas de modification du modèle de pod, mettez le déploiement en pause :
oc rollout pause deployments/<name>Crochets du cycle de vie
Les déploiements ne prennent pas encore en charge les crochets de cycle de vie.
Stratégies personnalisées
Les déploiements ne prennent pas encore en charge les stratégies de déploiement personnalisées spécifiées par l'utilisateur.
8.1.4.3. Fonctionnalités spécifiques au déploiement
Renversement
Le processus de déploiement des objets Deployment est piloté par une boucle de contrôleur, contrairement aux objets DeploymentConfig qui utilisent des pods de déploiement pour chaque nouveau déploiement. Cela signifie que l'objet Deployment peut avoir autant d'ensembles de répliques actives que possible, et que le contrôleur de déploiement finira par réduire tous les anciens ensembles de répliques et par augmenter le plus récent.
DeploymentConfig ne peuvent avoir qu'un seul pod de déploiement en cours d'exécution, sinon plusieurs déployeurs entrent en conflit en essayant de mettre à l'échelle ce qu'ils pensent être le contrôleur de réplication le plus récent. De ce fait, seuls deux contrôleurs de réplication peuvent être actifs à un moment donné. En fin de compte, cela se traduit par des déploiements plus rapides pour les objets Deployment.
Mise à l'échelle proportionnelle
Le contrôleur de déploiement étant la seule source de vérité concernant la taille des nouveaux et des anciens ensembles de répliques appartenant à un objet Deployment, il est en mesure d'adapter les déploiements en cours. Les répliques supplémentaires sont distribuées proportionnellement à la taille de chaque ensemble de répliques.
DeploymentConfig ne peuvent pas être mis à l'échelle lorsqu'un déploiement est en cours, car le contrôleur finira par avoir des problèmes avec le processus de déploiement concernant la taille du nouveau contrôleur de réplication.
Pause à mi-parcours
Les déploiements peuvent être mis en pause à tout moment, ce qui signifie que vous pouvez également mettre en pause les déploiements en cours. En revanche, il n'est pas possible de mettre en pause les pods de déploiement actuellement, donc si vous essayez de mettre en pause un déploiement au milieu d'un déploiement, le processus de déploiement ne sera pas affecté et continuera jusqu'à ce qu'il se termine.
8.2. Gestion des processus de déploiement
8.2.1. Gestion des objets DeploymentConfig
DeploymentConfig peuvent être gérés depuis la page Workloads de la console web d'OpenShift Container Platform ou en utilisant le CLI oc. Les procédures suivantes montrent l'utilisation de la CLI, sauf indication contraire.
8.2.1.1. Démarrer un déploiement
Vous pouvez lancer un rollout pour commencer le processus de déploiement de votre application.
Procédure
Pour lancer un nouveau processus de déploiement à partir d'un objet
DeploymentConfigexistant, exécutez la commande suivante :oc rollout latest dc/<name>NoteSi un processus de déploiement est déjà en cours, la commande affiche un message et un nouveau contrôleur de réplication ne sera pas déployé.
8.2.1.2. Visualisation d'un déploiement
Vous pouvez visualiser un déploiement pour obtenir des informations de base sur toutes les révisions disponibles de votre application.
Procédure
Pour afficher les détails de tous les contrôleurs de réplication récemment créés pour l'objet
DeploymentConfigfourni, y compris tout processus de déploiement en cours, exécutez la commande suivante :oc rollout history dc/<name>Pour afficher les détails spécifiques à une révision, ajoutez le drapeau
--revision:$ oc rollout history dc/<name> --revision=1Pour obtenir des informations plus détaillées sur un objet
DeploymentConfiget sa dernière révision, utilisez la commandeoc describe:oc describe dc <name> $ oc describe dc <name>
8.2.1.3. Réessayer un déploiement
Si la révision actuelle de votre objet DeploymentConfig n'a pas été déployée, vous pouvez relancer le processus de déploiement.
Procédure
Pour redémarrer un processus de déploiement qui a échoué :
oc rollout retry dc/<name>Si la dernière révision a été déployée avec succès, la commande affiche un message et le processus de déploiement n'est pas réessayé.
NoteUne nouvelle tentative de déploiement redémarre le processus de déploiement et ne crée pas de nouvelle révision de déploiement. Le contrôleur de réplication redémarré a la même configuration que celle qu'il avait au moment de l'échec.
8.2.1.4. Revenir en arrière dans un déploiement
Les retours en arrière permettent de revenir à une révision précédente et peuvent être effectués à l'aide de l'API REST, de l'interface de programmation ou de la console web.
Procédure
Pour revenir à la dernière révision déployée avec succès de votre configuration :
oc rollout undo dc/<name>Le modèle de l'objet
DeploymentConfigest inversé pour correspondre à la révision de déploiement spécifiée dans la commande undo, et un nouveau contrôleur de réplication est démarré. Si aucune révision n'est spécifiée avec--to-revision, la dernière révision déployée avec succès est utilisée.Les déclencheurs de changement d'image sur l'objet
DeploymentConfigsont désactivés dans le cadre du retour en arrière afin d'éviter de lancer accidentellement un nouveau processus de déploiement peu après la fin du retour en arrière.Pour réactiver les déclencheurs de changement d'image :
oc set triggers dc/<name> --auto
Les configurations de déploiement permettent également de revenir automatiquement à la dernière révision réussie de la configuration en cas d'échec du dernier processus de déploiement. Dans ce cas, le dernier modèle dont le déploiement a échoué reste intact dans le système et c'est aux utilisateurs de corriger leurs configurations.
8.2.1.5. Exécuter des commandes dans un conteneur
Vous pouvez ajouter une commande à un conteneur, qui modifie le comportement de démarrage du conteneur en remplaçant l'image ENTRYPOINT. Ceci est différent d'un crochet de cycle de vie, qui peut être exécuté une fois par déploiement à un moment spécifié.
Procédure
Ajoutez les paramètres
commandau champspecde l'objetDeploymentConfig. Vous pouvez également ajouter un champargs, qui modifie le champcommand(ouENTRYPOINTsicommandn'existe pas).spec: containers: - name: <container_name> image: 'image' command: - '<command>' args: - '<argument_1>' - '<argument_2>' - '<argument_3>'Par exemple, pour exécuter la commande
javaavec les arguments-jaret/opt/app-root/springboots2idemo.jar:spec: containers: - name: example-spring-boot image: 'image' command: - java args: - '-jar' - /opt/app-root/springboots2idemo.jar
8.2.1.6. Visualisation des journaux de déploiement
Procédure
Pour diffuser les journaux de la dernière révision d'un objet
DeploymentConfigdonné :$ oc logs -f dc/<name>Si la dernière révision est en cours ou a échoué, la commande renvoie les journaux du processus responsable du déploiement de vos pods. En cas de succès, elle renvoie les journaux d'un pod de votre application.
Vous pouvez également consulter les journaux des anciens processus de déploiement qui ont échoué, si et seulement si ces processus (anciens contrôleurs de réplication et leurs pods de déploiement) existent et n'ont pas été élagués ou supprimés manuellement :
oc logs --version=1 dc/<name>
8.2.1.7. Déclencheurs de déploiement
Un objet DeploymentConfig peut contenir des déclencheurs, qui entraînent la création de nouveaux processus de déploiement en réponse à des événements survenant dans le cluster.
Si aucun déclencheur n'est défini sur un objet DeploymentConfig, un déclencheur de changement de configuration est ajouté par défaut. Si les déclencheurs sont définis comme un champ vide, les déploiements doivent être lancés manuellement.
Déclencheurs de déploiement des changements de configuration
Le déclencheur de changement de configuration entraîne la création d'un nouveau contrôleur de réplication lorsque des changements de configuration sont détectés dans le modèle de pod de l'objet DeploymentConfig.
Si un déclencheur de changement de configuration est défini sur un objet DeploymentConfig, le premier contrôleur de réplication est automatiquement créé peu après la création de l'objet DeploymentConfig lui-même et il n'est pas mis en pause.
Déclenchement du déploiement des changements de configuration
triggers:
- type: "ConfigChange"Déclencheurs de déploiement de changement d'image
Le déclencheur de changement d'image entraîne la création d'un nouveau contrôleur de réplication chaque fois que le contenu d'une balise de flux d'images change (lorsqu'une nouvelle version de l'image est poussée).
Déclencheur de déploiement de changement d'image
triggers:
- type: "ImageChange"
imageChangeParams:
automatic: true
from:
kind: "ImageStreamTag"
name: "origin-ruby-sample:latest"
namespace: "myproject"
containerNames:
- "helloworld"- 1
- Si le champ
imageChangeParams.automaticest défini surfalse, le déclencheur est désactivé.
Dans l'exemple ci-dessus, lorsque la valeur de la balise latest du flux d'images origin-ruby-sample change et que la nouvelle valeur de l'image diffère de l'image actuelle spécifiée dans le conteneur helloworld de l'objet DeploymentConfig, un nouveau contrôleur de réplication est créé à l'aide de la nouvelle image pour le conteneur helloworld.
Si un déclencheur de changement d'image est défini sur un objet DeploymentConfig (avec un déclencheur de changement de configuration et automatic=false, ou avec automatic=true) et que la balise de flux d'images pointée par le déclencheur de changement d'images n'existe pas encore, le processus de déploiement initial démarrera automatiquement dès qu'une image sera importée ou poussée par une construction vers la balise de flux d'images.
8.2.1.7.1. Définition des déclencheurs de déploiement
Procédure
Vous pouvez définir des déclencheurs de déploiement pour un objet
DeploymentConfigà l'aide de la commandeoc set triggers. Par exemple, pour définir un déclencheur de changement d'image, utilisez la commande suivante :$ oc set triggers dc/<dc_name> \ --from-image=<project>/<image>:<tag> -c <container_name>
8.2.1.8. Définition des ressources de déploiement
Un déploiement est complété par un module qui consomme des ressources (mémoire, CPU et stockage éphémère) sur un nœud. Par défaut, les modules consomment des ressources illimitées sur le nœud. Toutefois, si un projet spécifie des limites de conteneurs par défaut, les modules consomment des ressources jusqu'à ces limites.
La limite minimale de mémoire pour un déploiement est de 12 Mo. Si un conteneur ne démarre pas en raison d'un événement pod Cannot allocate memory, la limite de mémoire est trop basse. Augmentez ou supprimez la limite de mémoire. La suppression de la limite permet aux pods de consommer des ressources de nœuds illimitées.
Vous pouvez également limiter l'utilisation des ressources en spécifiant des limites de ressources dans le cadre de la stratégie de déploiement. Les ressources de déploiement peuvent être utilisées avec les stratégies de recréation, de roulement ou de déploiement personnalisé.
Procédure
Dans l'exemple suivant, chacun des éléments suivants :
resources,cpu,memoryetephemeral-storageest facultatif :type: "Recreate" resources: limits: cpu: "100m"1 memory: "256Mi"2 ephemeral-storage: "1Gi"3 Toutefois, si un quota a été défini pour votre projet, l'un des deux éléments suivants est nécessaire :
Un ensemble de sections
resourcesavec unrequestsexplicite :type: "Recreate" resources: requests:1 cpu: "100m" memory: "256Mi" ephemeral-storage: "1Gi"- 1
- L'objet
requestscontient la liste des ressources correspondant à la liste des ressources du quota.
-
Une plage de limites définie dans votre projet, où les valeurs par défaut de l'objet
LimitRanges'appliquent aux pods créés au cours du processus de déploiement.
Pour définir les ressources de déploiement, choisissez l'une des options ci-dessus. Dans le cas contraire, la création d'un pod de déploiement échoue, en raison d'un quota non atteint.
8.2.1.9. Mise à l'échelle manuelle
Outre les retours en arrière, vous pouvez exercer un contrôle fin sur le nombre de répliques en les échelonnant manuellement.
Les pods peuvent également être mis à l'échelle automatiquement à l'aide de la commande oc autoscale.
Procédure
Pour mettre à l'échelle manuellement un objet
DeploymentConfig, utilisez la commandeoc scale. Par exemple, la commande suivante définit les répliques de l'objetfrontendDeploymentConfigsur3.$ oc scale dc frontend --replicas=3Le nombre de répliques se propage finalement à l'état souhaité et actuel du déploiement configuré par l'objet
DeploymentConfigfrontend.
8.2.1.10. Accès aux dépôts privés à partir d'objets DeploymentConfig
Vous pouvez ajouter un secret à votre objet DeploymentConfig afin qu'il puisse accéder aux images d'un dépôt privé. Cette procédure présente la méthode de la console web d'OpenShift Container Platform.
Procédure
- Créer un nouveau projet.
- Sur la page Workloads, créez un secret contenant les informations d'identification permettant d'accéder à un dépôt d'images privé.
-
Créer un objet
DeploymentConfig. -
Sur la page de l'éditeur d'objets
DeploymentConfig, définissez l'objet Pull Secret et enregistrez vos modifications.
8.2.1.11. Affectation de pods à des nœuds spécifiques
Vous pouvez utiliser des sélecteurs de nœuds en conjonction avec des nœuds étiquetés pour contrôler le placement des pods.
Les administrateurs de clusters peuvent définir le sélecteur de nœuds par défaut pour un projet afin de restreindre le placement des pods à des nœuds spécifiques. En tant que développeur, vous pouvez définir un sélecteur de nœuds sur une configuration Pod afin de restreindre encore davantage les nœuds.
Procédure
Pour ajouter un sélecteur de nœud lors de la création d'un module, modifiez la configuration
Podet ajoutez la valeurnodeSelector. Cette valeur peut être ajoutée à une seule configurationPodou à un modèlePod:apiVersion: v1 kind: Pod spec: nodeSelector: disktype: ssd ...Les pods créés lorsque le sélecteur de nœuds est en place sont assignés aux nœuds avec les étiquettes spécifiées. Les étiquettes spécifiées ici sont utilisées conjointement avec les étiquettes ajoutées par un administrateur de cluster.
Par exemple, si l'administrateur du cluster a ajouté les labels
type=user-nodeetregion=eastà un projet et que vous ajoutez le labeldisktype: ssdci-dessus à un module, ce dernier n'est jamais planifié que sur les nœuds qui ont les trois labels.NoteLes étiquettes ne peuvent être définies que sur une seule valeur, de sorte que la définition d'un sélecteur de nœud de
region=westdans une configurationPodqui aregion=eastcomme valeur par défaut définie par l'administrateur, entraîne la création d'un module qui ne sera jamais programmé.
8.2.1.12. Exécuter un pod avec un compte de service différent
Vous pouvez exécuter un pod avec un compte de service autre que celui par défaut.
Procédure
Modifiez l'objet
DeploymentConfig:oc edit dc/<deployment_config>Ajoutez les paramètres
serviceAccountetserviceAccountNameau champspecet indiquez le compte de service que vous souhaitez utiliser :spec: securityContext: {} serviceAccount: <service_account> serviceAccountName: <service_account>
8.3. Utiliser des stratégies de déploiement
Un site deployment strategy est un moyen de modifier ou de mettre à niveau une application. L'objectif est d'effectuer le changement sans interruption de service, de manière à ce que l'utilisateur remarque à peine les améliorations.
Comme l'utilisateur final accède généralement à l'application par une route gérée par un routeur, la stratégie de déploiement peut se concentrer sur les caractéristiques de l'objet DeploymentConfig ou sur les caractéristiques de routage. Les stratégies axées sur le déploiement ont un impact sur toutes les routes qui utilisent l'application. Les stratégies qui utilisent les fonctions de routage ciblent des routes individuelles.
De nombreuses stratégies de déploiement sont prises en charge par l'objet DeploymentConfig, et certaines stratégies supplémentaires sont prises en charge par les fonctionnalités du routeur. Les stratégies de déploiement sont abordées dans cette section.
Choosing a deployment strategy
Lors du choix d'une stratégie de déploiement, il convient de tenir compte des éléments suivants :
- Les connexions de longue durée doivent être gérées avec élégance.
- Les conversions de bases de données peuvent être complexes et doivent être effectuées et reconduites en même temps que l'application.
- Si l'application est un hybride de microservices et de composants traditionnels, un temps d'arrêt peut être nécessaire pour effectuer la transition.
- Vous devez disposer de l'infrastructure nécessaire.
- Si vous disposez d'un environnement de test non isolé, vous pouvez casser à la fois les nouvelles et les anciennes versions.
Une stratégie de déploiement utilise des contrôles de disponibilité pour déterminer si un nouveau module est prêt à être utilisé. Si un contrôle de disponibilité échoue, l'objet DeploymentConfig tente à nouveau d'exécuter le module jusqu'à ce qu'il s'arrête. Le délai d'attente par défaut est de 10m, une valeur définie dans TimeoutSeconds dans dc.spec.strategy.*params.
8.3.1. Stratégie de roulement
Un déploiement continu remplace lentement les instances de la version précédente d'une application par des instances de la nouvelle version de l'application. La stratégie de déploiement continu est la stratégie de déploiement par défaut utilisée si aucune stratégie n'est spécifiée sur un objet DeploymentConfig.
Un déploiement continu attend généralement que les nouveaux pods deviennent ready par le biais d'un contrôle de disponibilité avant de réduire les anciens composants. En cas de problème important, le déploiement continu peut être interrompu.
When to use a rolling deployment:
- Lorsque vous souhaitez éviter toute interruption de service lors de la mise à jour d'une application.
- Lorsque votre application permet l'exécution simultanée d'un ancien et d'un nouveau code.
Un déploiement continu signifie que vous avez à la fois d'anciennes et de nouvelles versions de votre code qui tournent en même temps. Cela nécessite généralement que votre application gère la compatibilité N-1.
Exemple de définition d'une stratégie de roulement
strategy:
type: Rolling
rollingParams:
updatePeriodSeconds: 1
intervalSeconds: 1
timeoutSeconds: 120
maxSurge: "20%"
maxUnavailable: "10%"
pre: {}
post: {}- 1
- Le temps d'attente entre les mises à jour individuelles des pods. Si elle n'est pas spécifiée, la valeur par défaut est
1. - 2
- Le temps d'attente entre l'interrogation de l'état de déploiement après la mise à jour. Si elle n'est pas spécifiée, la valeur par défaut est
1. - 3
- Le temps d'attente d'un événement de mise à l'échelle avant d'abandonner. Facultatif ; la valeur par défaut est
600. Ici, giving up signifie un retour automatique au déploiement complet précédent. - 4
maxSurgeest facultatif et prend par défaut la valeur25%s'il n'est pas spécifié. Voir les informations sous la procédure suivante.- 5
maxUnavailableest facultatif et prend par défaut la valeur25%s'il n'est pas spécifié. Voir les informations sous la procédure suivante.- 6
preetpostsont tous deux des crochets de cycle de vie.
La stratégie de roulement :
-
Exécute n'importe quel crochet de cycle de vie de
pre. - Augmente la capacité du nouveau contrôleur de réplication en fonction du nombre de poussées.
- Réduit l'ancien contrôleur de réplication en fonction du nombre maximum d'indisponibilités.
- Répéter cette mise à l'échelle jusqu'à ce que le nouveau contrôleur de réplication ait atteint le nombre de répliques souhaité et que l'ancien contrôleur de réplication ait été mis à l'échelle.
-
Exécute n'importe quel crochet de cycle de vie de
post.
Lors de la réduction d'échelle, la stratégie de roulement attend que les modules soient prêts pour décider si la poursuite de la mise à l'échelle affecterait la disponibilité. Si les modules mis à l'échelle ne sont jamais prêts, le processus de déploiement finira par s'interrompre et entraînera un échec du déploiement.
Le paramètre maxUnavailable est le nombre maximum de modules qui peuvent être indisponibles pendant la mise à jour. Le paramètre maxSurge est le nombre maximum de modules qui peuvent être planifiés en plus du nombre initial de modules. Les deux paramètres peuvent être définis en pourcentage (par exemple, 10%) ou en valeur absolue (par exemple, 2). La valeur par défaut est 25%.
Ces paramètres permettent d'ajuster le déploiement en termes de disponibilité et de rapidité. Ces paramètres permettent d'ajuster le déploiement en fonction de la disponibilité et de la vitesse :
-
maxUnavailable*=0etmaxSurge*=20%garantit le maintien de la pleine capacité pendant la mise à jour et l'augmentation rapide de la capacité. -
maxUnavailable*=10%etmaxSurge*=0effectue une mise à jour sans utiliser de capacité supplémentaire (mise à jour sur place). -
maxUnavailable*=10%etmaxSurge*=10%évolue rapidement avec un risque de perte de capacité.
En règle générale, si vous souhaitez des déploiements rapides, utilisez maxSurge. Si vous devez tenir compte d'un quota de ressources et que vous pouvez accepter une indisponibilité partielle, utilisez maxUnavailable.
8.3.1.1. Déploiement de Canary
Tous les déploiements roulants dans OpenShift Container Platform sont canary deployments; une nouvelle version (le canari) est testée avant que toutes les anciennes instances ne soient remplacées. Si la vérification de l'état de préparation ne réussit pas, l'instance canari est supprimée et l'objet DeploymentConfig est automatiquement reconduit.
Le contrôle de l'état de préparation fait partie du code de l'application et peut être aussi sophistiqué que nécessaire pour garantir que la nouvelle instance est prête à être utilisée. Si vous devez mettre en œuvre des contrôles plus complexes de l'application (tels que l'envoi de charges de travail d'utilisateurs réels à la nouvelle instance), envisagez de mettre en œuvre un déploiement personnalisé ou d'utiliser une stratégie de déploiement "bleu-vert".
8.3.1.2. Création d'un déploiement continu
Les déploiements continus sont le type de déploiement par défaut dans OpenShift Container Platform. Vous pouvez créer un déploiement continu à l'aide de la CLI.
Procédure
Créez une application basée sur les exemples d'images de déploiement trouvées sur Quay.io:
$ oc new-app quay.io/openshifttest/deployment-example:latestSi le routeur est installé, rendez l'application disponible via une route ou utilisez directement l'IP du service.
$ oc expose svc/deployment-example-
Accédez à l'application à l'adresse
deployment-example.<project>.<router_domain>pour vérifier que vous voyez l'imagev1. Faire évoluer l'objet
DeploymentConfigjusqu'à trois répliques :$ oc scale dc/deployment-example --replicas=3Déclencher automatiquement un nouveau déploiement en étiquetant une nouvelle version de l'exemple avec l'étiquette
latest:$ oc tag deployment-example:v2 deployment-example:latest-
Dans votre navigateur, actualisez la page jusqu'à ce que vous voyiez l'image
v2. Lorsque vous utilisez la CLI, la commande suivante montre combien de pods sont sur la version 1 et combien sont sur la version 2. Dans la console web, les pods sont progressivement ajoutés à la version 2 et retirés de la version 1 :
$ oc describe dc deployment-example
Au cours du processus de déploiement, le nouveau contrôleur de réplication est mis à l'échelle de façon incrémentielle. Une fois que les nouveaux pods sont marqués comme ready (en passant leur contrôle de préparation), le processus de déploiement se poursuit.
Si les pods ne sont pas prêts, le processus est interrompu et le déploiement revient à sa version précédente.
8.3.1.3. Démarrer un déploiement continu à l'aide de la perspective du développeur
Conditions préalables
- Assurez-vous que vous êtes dans la perspective Developer de la console web.
- Assurez-vous que vous avez créé une application à l'aide de la vue Add et que vous la voyez déployée dans la vue Topology.
Procédure
Pour lancer un déploiement continu afin de mettre à niveau une application :
- Dans la vue Topology de la perspective Developer, cliquez sur le nœud d'application pour voir l'onglet Overview dans le panneau latéral. Notez que la stratégie Update Strategy est définie sur la stratégie par défaut Rolling.
Dans le menu déroulant Actions, sélectionnez Start Rollout pour lancer une mise à jour continue. Le déploiement continu démarre la nouvelle version de l'application et met fin à l'ancienne.
Figure 8.1. Mise à jour en continu

8.3.2. Recréer une stratégie
La stratégie recréer a un comportement de déploiement de base et prend en charge les crochets de cycle de vie pour injecter du code dans le processus de déploiement.
Exemple de définition de la stratégie de recréation
strategy:
type: Recreate
recreateParams:
pre: {}
mid: {}
post: {}La stratégie de recréation :
-
Exécute n'importe quel crochet de cycle de vie de
pre. - Ramène le déploiement précédent à zéro.
-
Exécute n'importe quel crochet de cycle de vie de
mid. - Augmentation de la taille du nouveau déploiement.
-
Exécute n'importe quel crochet de cycle de vie de
post.
Lors de la mise à l'échelle, si le nombre de répliques du déploiement est supérieur à un, la première réplique du déploiement est validée avant la mise à l'échelle complète du déploiement. Si la validation de la première réplique échoue, le déploiement est considéré comme un échec.
When to use a recreate deployment:
- Lorsque vous devez exécuter des migrations ou d'autres transformations de données avant que votre nouveau code ne démarre.
- Lorsque vous ne souhaitez pas que des versions anciennes et nouvelles du code de votre application soient exécutées en même temps.
- Lorsque vous souhaitez utiliser un volume RWO, qui n'est pas pris en charge pour être partagé entre plusieurs répliques.
Un déploiement par recréation entraîne des temps d'arrêt car, pendant une brève période, aucune instance de votre application ne s'exécute. Cependant, l'ancien et le nouveau code ne s'exécutent pas en même temps.
8.3.3. Démarrer un déploiement recréé à l'aide de la perspective du développeur
Vous pouvez changer la stratégie de déploiement de la mise à jour continue par défaut à une mise à jour de recréation en utilisant la perspective Developer dans la console web.
Conditions préalables
- Assurez-vous que vous êtes dans la perspective Developer de la console web.
- Assurez-vous que vous avez créé une application à l'aide de la vue Add et que vous la voyez déployée dans la vue Topology.
Procédure
Pour passer à une stratégie de mise à jour par recréation et pour mettre à niveau une application :
- Dans le menu déroulant Actions, sélectionnez Edit Deployment Config pour voir les détails de la configuration du déploiement de l'application.
-
Dans l'éditeur YAML, remplacez
spec.strategy.typeparRecreateet cliquez sur Save. - Dans la vue Topology, sélectionnez le nœud pour afficher l'onglet Overview dans le panneau latéral. Le site Update Strategy est désormais défini sur Recreate.
Utilisez le menu déroulant Actions pour sélectionner Start Rollout afin de lancer une mise à jour à l'aide de la stratégie de recréation. La stratégie recréer met d'abord fin aux pods de l'ancienne version de l'application, puis lance les pods de la nouvelle version.
Figure 8.2. Recréer la mise à jour

8.3.4. Stratégie personnalisée
La stratégie personnalisée vous permet de fournir votre propre comportement de déploiement.
Exemple de définition d'une stratégie personnalisée
strategy:
type: Custom
customParams:
image: organization/strategy
command: [ "command", "arg1" ]
environment:
- name: ENV_1
value: VALUE_1
Dans l'exemple ci-dessus, l'image du conteneur organization/strategy fournit le comportement de déploiement. Le tableau facultatif command remplace toute directive CMD spécifiée dans l'image Dockerfile. Les variables d'environnement facultatives fournies sont ajoutées à l'environnement d'exécution du processus de stratégie.
En outre, OpenShift Container Platform fournit les variables d'environnement suivantes au processus de déploiement :
| Variable d'environnement | Description |
|---|---|
|
| Le nom du nouveau déploiement, un contrôleur de réplication. |
|
| L'espace de noms du nouveau déploiement. |
Le nombre de répliques du nouveau déploiement sera initialement égal à zéro. La responsabilité de la stratégie est de rendre le nouveau déploiement actif en utilisant la logique qui répond le mieux aux besoins de l'utilisateur.
Vous pouvez également utiliser l'objet customParams pour injecter la logique de déploiement personnalisée dans les stratégies de déploiement existantes. Fournir une logique de script shell personnalisée et appeler le binaire openshift-deploy. Les utilisateurs ne doivent pas fournir leur image de conteneur de déploiement personnalisé ; dans ce cas, l'image de déploiement par défaut d'OpenShift Container Platform est utilisée à la place :
strategy:
type: Rolling
customParams:
command:
- /bin/sh
- -c
- |
set -e
openshift-deploy --until=50%
echo Halfway there
openshift-deploy
echo CompleteIl en résulte le déploiement suivant :
Started deployment #2
--> Scaling up custom-deployment-2 from 0 to 2, scaling down custom-deployment-1 from 2 to 0 (keep 2 pods available, don't exceed 3 pods)
Scaling custom-deployment-2 up to 1
--> Reached 50% (currently 50%)
Halfway there
--> Scaling up custom-deployment-2 from 1 to 2, scaling down custom-deployment-1 from 2 to 0 (keep 2 pods available, don't exceed 3 pods)
Scaling custom-deployment-1 down to 1
Scaling custom-deployment-2 up to 2
Scaling custom-deployment-1 down to 0
--> Success
CompleteSi le processus de stratégie de déploiement personnalisé nécessite un accès à l'API OpenShift Container Platform ou à l'API Kubernetes, le conteneur qui exécute la stratégie peut utiliser le jeton de compte de service disponible dans le conteneur pour l'authentification.
8.3.5. Crochets du cycle de vie
Les stratégies rolling et recreate prennent en charge lifecycle hooks, ou crochets de déploiement, qui permettent d'injecter un comportement dans le processus de déploiement à des points prédéfinis de la stratégie :
Exemple pre crochet de cycle de vie
pre:
failurePolicy: Abort
execNewPod: {} - 1
execNewPodest un crochet de cycle de vie basé sur les pods.
Chaque crochet a un failure policy, qui définit l'action que la stratégie doit entreprendre en cas d'échec du crochet :
|
| Le processus de déploiement sera considéré comme un échec si le crochet échoue. |
|
| L'exécution du crochet doit être répétée jusqu'à ce qu'elle réussisse. |
|
| Tout échec du crochet doit être ignoré et le déploiement doit se poursuivre. |
Les crochets ont un champ spécifique au type qui décrit comment exécuter le crochet. Actuellement, les crochets basés sur les pods sont le seul type de crochet pris en charge, spécifié par le champ execNewPod.
Crochet de cycle de vie basé sur les pods
Les crochets de cycle de vie basés sur les pods exécutent le code du crochet dans un nouveau pod dérivé du modèle dans un objet DeploymentConfig.
L'exemple de déploiement simplifié suivant utilise la stratégie de roulement. Les déclencheurs et d'autres détails mineurs sont omis par souci de concision :
kind: DeploymentConfig
apiVersion: apps.openshift.io/v1
metadata:
name: frontend
spec:
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: helloworld
image: openshift/origin-ruby-sample
replicas: 5
selector:
name: frontend
strategy:
type: Rolling
rollingParams:
pre:
failurePolicy: Abort
execNewPod:
containerName: helloworld
command: [ "/usr/bin/command", "arg1", "arg2" ]
env:
- name: CUSTOM_VAR1
value: custom_value1
volumes:
- data - 1
- Le nom
helloworldfait référence àspec.template.spec.containers[0].name. - 2
- Ce site
commandremplace tout siteENTRYPOINTdéfini par l'imageopenshift/origin-ruby-sample. - 3
envest un ensemble optionnel de variables d'environnement pour le conteneur de crochets.- 4
volumesest un ensemble facultatif de références de volume pour le conteneur de crochets.
Dans cet exemple, le hook pre sera exécuté dans un nouveau pod utilisant l'image openshift/origin-ruby-sample du conteneur helloworld. Le pod de crochet a les propriétés suivantes :
-
La commande de crochet est
/usr/bin/command arg1 arg2. -
Le conteneur de crochets possède la variable d'environnement
CUSTOM_VAR1=custom_value1. -
La politique d'échec du crochet est
Abort, ce qui signifie que le processus de déploiement échoue si le crochet échoue. -
Le module de crochet hérite du volume
datadu module d'objetDeploymentConfig.
8.3.5.1. Mise en place de crochets de cycle de vie
Vous pouvez définir des crochets de cycle de vie, ou crochets de déploiement, pour un déploiement à l'aide de l'interface utilisateur.
Procédure
Utilisez la commande
oc set deployment-hookpour définir le type de crochet que vous souhaitez :--pre,--mid, ou--post. Par exemple, pour définir un crochet de pré-déploiement :$ oc set deployment-hook dc/frontend \ --pre -c helloworld -e CUSTOM_VAR1=custom_value1 \ --volumes data --failure-policy=abort -- /usr/bin/command arg1 arg2
8.4. Utilisation de stratégies de déploiement basées sur les itinéraires
Les stratégies de déploiement permettent à l'application d'évoluer. Certaines stratégies utilisent les objets Deployment pour apporter des changements qui sont vus par les utilisateurs de toutes les routes qui aboutissent à l'application. D'autres stratégies avancées, telles que celles décrites dans cette section, utilisent les fonctions du routeur en conjonction avec les objets Deployment pour avoir un impact sur des routes spécifiques.
La stratégie la plus courante en matière d'itinéraires consiste à utiliser un site blue-green deployment. La nouvelle version (la version verte) est mise en place à des fins de test et d'évaluation, tandis que les utilisateurs continuent d'utiliser la version stable (la version bleue). Lorsqu'ils sont prêts, les utilisateurs passent à la version verte. En cas de problème, vous pouvez revenir à la version bleue.
Une stratégie alternative courante consiste à utiliser A/B versions qui sont tous deux actifs en même temps et dont certains utilisateurs utilisent une version et d'autres l'autre. Cette méthode peut être utilisée pour expérimenter des modifications de l'interface utilisateur et d'autres fonctionnalités afin d'obtenir l'avis des utilisateurs. Elle peut également servir à vérifier le bon fonctionnement dans un contexte de production où les problèmes n'affectent qu'un nombre limité d'utilisateurs.
Le déploiement d'un canari permet de tester la nouvelle version, mais lorsqu'un problème est détecté, il revient rapidement à la version précédente. Cela peut se faire avec les deux stratégies ci-dessus.
Les stratégies de déploiement basées sur les itinéraires ne permettent pas de faire évoluer le nombre de pods dans les services. Pour maintenir les caractéristiques de performance souhaitées, il peut être nécessaire de modifier les configurations de déploiement.
8.4.1. Proxy shards et fractionnement du trafic
Dans les environnements de production, vous pouvez contrôler avec précision la distribution du trafic qui arrive sur un shard particulier. Lorsqu'il s'agit d'un grand nombre d'instances, vous pouvez utiliser l'échelle relative des différents serveurs pour mettre en œuvre un trafic basé sur le pourcentage. Cela se combine bien avec proxy shard, qui transfère ou divise le trafic qu'il reçoit vers un service ou une application distinct(e) fonctionnant ailleurs.
Dans la configuration la plus simple, le proxy transmet les demandes sans les modifier. Dans des configurations plus complexes, vous pouvez dupliquer les requêtes entrantes et les envoyer à la fois à un cluster séparé et à une instance locale de l'application, et comparer le résultat. D'autres modèles consistent à garder les caches d'une installation DR au chaud ou à échantillonner le trafic entrant à des fins d'analyse.
N'importe quel proxy TCP (ou UDP) peut être exécuté sous le shard souhaité. Utilisez la commande oc scale pour modifier le nombre relatif d'instances servant les requêtes sous le proxy shard. Pour une gestion plus complexe du trafic, envisagez de personnaliser le routeur OpenShift Container Platform avec des capacités d'équilibrage proportionnel.
8.4.2. Compatibilité N-1
Les applications dans lesquelles un nouveau code et un ancien code sont exécutés en même temps doivent veiller à ce que les données écrites par le nouveau code puissent être lues et traitées (ou ignorées de manière élégante) par l'ancienne version du code. C'est ce qu'on appelle parfois schema evolution et c'est un problème complexe.
Ces données peuvent prendre plusieurs formes : données stockées sur un disque, dans une base de données, dans un cache temporaire ou faisant partie de la session du navigateur de l'utilisateur. Bien que la plupart des applications web puissent prendre en charge les déploiements continus, il est important de tester et de concevoir votre application en conséquence.
Pour certaines applications, la période pendant laquelle l'ancien et le nouveau code fonctionnent côte à côte est courte, de sorte que les bogues ou quelques transactions d'utilisateurs qui échouent sont acceptables. Pour d'autres, le modèle de défaillance peut aboutir à ce que l'ensemble de l'application devienne non fonctionnelle.
Une façon de valider la compatibilité N-1 est de procéder à un déploiement A/B : exécuter l'ancien et le nouveau code en même temps, de façon contrôlée, dans un environnement de test, et vérifier que le trafic qui circule vers le nouveau déploiement ne provoque pas de défaillances dans l'ancien déploiement.
8.4.3. Fin gracieuse
OpenShift Container Platform et Kubernetes donnent aux instances d'applications le temps de s'arrêter avant de les retirer des rotations d'équilibrage de charge. Cependant, les applications doivent s'assurer qu'elles terminent proprement les connexions des utilisateurs avant de quitter l'instance.
Lors de l'arrêt, OpenShift Container Platform envoie un signal TERM aux processus du conteneur. Le code de l'application, lorsqu'il reçoit SIGTERM, cesse d'accepter de nouvelles connexions. Cela permet de s'assurer que les équilibreurs de charge acheminent le trafic vers d'autres instances actives. Le code de l'application attend ensuite que toutes les connexions ouvertes soient fermées, ou met fin de manière gracieuse aux connexions individuelles à la prochaine occasion, avant de quitter.
À l'expiration de la période d'arrêt en douceur, un processus qui n'a pas été arrêté reçoit le signal KILL, ce qui met immédiatement fin au processus. L'attribut terminationGracePeriodSeconds d'un pod ou d'un modèle de pod contrôle la période de terminaison gracieuse (30 secondes par défaut) et peut être personnalisé par application si nécessaire.
8.4.4. Déploiements "bleu-vert
Les déploiements bleu-vert impliquent l'exécution simultanée de deux versions d'une application et le transfert du trafic de la version en production (la version bleue) vers la version la plus récente (la version verte). Vous pouvez utiliser une stratégie de roulement ou changer de service dans un itinéraire.
Étant donné que de nombreuses applications dépendent de données persistantes, vous devez disposer d'une application prenant en charge N-1 compatibility, ce qui signifie qu'elle partage des données et met en œuvre la migration en direct entre la base de données, le magasin ou le disque en créant deux copies de la couche de données.
Tenez compte des données utilisées pour tester la nouvelle version. S'il s'agit des données de production, un bogue dans la nouvelle version peut endommager la version de production.
8.4.4.1. Mise en place d'un déploiement bleu-vert
Les déploiements bleu-vert utilisent deux objets Deployment. Les deux sont en cours d'exécution et celui qui est en production dépend du service spécifié par l'itinéraire, chaque objet Deployment étant exposé à un service différent.
Les routes sont destinées au trafic web (HTTP et HTTPS), cette technique est donc mieux adaptée aux applications web.
Vous pouvez créer une nouvelle route vers la nouvelle version et la tester. Lorsque vous êtes prêt, modifiez le service dans l'itinéraire de production pour qu'il pointe vers le nouveau service et la nouvelle version (verte) est en ligne.
Si nécessaire, vous pouvez revenir à l'ancienne version (bleue) en rebasculant le service sur la version précédente.
Procédure
Créer deux composants d'application indépendants.
Créez une copie de l'application d'exemple exécutant l'image
v1sous le serviceexample-blue:$ oc new-app openshift/deployment-example:v1 --name=example-blueCréez une deuxième copie qui utilise l'image
v2sous le serviceexample-green:$ oc new-app openshift/deployment-example:v2 --name=example-green
Créez un itinéraire qui pointe vers l'ancien service :
$ oc expose svc/example-blue --name=bluegreen-example-
Accédez à l'application à l'adresse
bluegreen-example-<project>.<router_domain>pour vérifier que vous voyez l'imagev1. Modifiez l'itinéraire et changez le nom du service en
example-green:$ oc patch route/bluegreen-example -p '{"spec":{"to":{"name":"example-green"}}}'-
Pour vérifier que l'itinéraire a changé, actualisez le navigateur jusqu'à ce que vous voyiez l'image
v2.
8.4.5. Déploiements A/B
La stratégie de déploiement A/B vous permet d'essayer une nouvelle version de l'application de manière limitée dans l'environnement de production. Vous pouvez spécifier que la version de production reçoit la plupart des demandes des utilisateurs, tandis qu'une fraction limitée des demandes va à la nouvelle version.
Étant donné que vous contrôlez la part des requêtes adressées à chaque version, vous pouvez, au fur et à mesure des tests, augmenter la part des requêtes adressées à la nouvelle version et, en fin de compte, cesser d'utiliser la version précédente. En ajustant la charge des requêtes sur chaque version, il se peut que le nombre de pods dans chaque service doive également être ajusté pour fournir les performances attendues.
Outre la mise à niveau du logiciel, vous pouvez utiliser cette fonction pour expérimenter des versions de l'interface utilisateur. Étant donné que certains utilisateurs reçoivent l'ancienne version et d'autres la nouvelle, vous pouvez évaluer la réaction de l'utilisateur aux différentes versions afin d'éclairer les décisions en matière de conception.
Pour que cela soit efficace, l'ancienne et la nouvelle version doivent être suffisamment similaires pour pouvoir fonctionner en même temps. C'est souvent le cas lors de la publication de corrections de bogues et lorsque les nouvelles fonctionnalités n'interfèrent pas avec les anciennes. Les versions doivent être compatibles N-1 pour fonctionner correctement ensemble.
OpenShift Container Platform prend en charge la compatibilité N-1 via la console web et le CLI.
8.4.5.1. Équilibrage de la charge pour les tests A/B
L'utilisateur établit une route avec plusieurs services. Chaque service gère une version de l'application.
Chaque service se voit attribuer une adresse weight et la part des demandes adressées à chaque service correspond à l'adresse service_weight divisée par l'adresse sum_of_weights. L'adresse weight de chaque service est distribuée aux points d'extrémité du service de manière à ce que la somme des adresses weights des points d'extrémité corresponde à l'adresse weight du service.
La ligne peut comporter jusqu'à quatre services. L'adresse weight du service peut être comprise entre 0 et 256. Lorsque weight est 0, le service ne participe pas à l'équilibrage de charge mais continue à servir les connexions persistantes existantes. Lorsque le service weight n'est pas 0, chaque point d'extrémité a un minimum de weight de 1. Pour cette raison, un service avec beaucoup de points d'extrémité peut se retrouver avec un weight plus élevé que prévu. Dans ce cas, réduisez le nombre de pods pour obtenir l'équilibre de charge attendu weight.
Procédure
Pour configurer l'environnement A/B :
Créez les deux applications et donnez-leur des noms différents. Chacune crée un objet
Deployment. Les applications sont des versions du même programme ; l'une est généralement la version de production actuelle et l'autre la nouvelle version proposée.Créer la première application. L'exemple suivant crée une application appelée
ab-example-a:$ oc new-app openshift/deployment-example --name=ab-example-aCréez la deuxième application :
$ oc new-app openshift/deployment-example:v2 --name=ab-example-bLes deux applications sont déployées et les services sont créés.
Rendre l'application accessible à l'extérieur par le biais d'une route. À ce stade, vous pouvez exposer l'une ou l'autre version. Il peut être pratique d'exposer d'abord la version de production actuelle et de modifier ensuite la route pour ajouter la nouvelle version.
$ oc expose svc/ab-example-aNaviguez jusqu'à l'application à l'adresse
ab-example-a.<project>.<router_domain>pour vérifier que vous voyez la version attendue.Lorsque vous déployez la route, le routeur équilibre le trafic en fonction des
weightsspécifiés pour les services. À ce stade, il n'y a qu'un seul service avecweight=1par défaut, de sorte que toutes les requêtes lui sont adressées. L'ajout de l'autre service en tant quealternateBackendset l'ajustement deweightsdonnent vie à la configuration A/B. Cette opération peut être effectuée à l'aide de la commande . Cela peut être fait par la commandeoc set route-backendsou en modifiant la route.En fixant la valeur de
oc set route-backendà0, le service ne participe pas à l'équilibrage de la charge, mais continue à servir les connexions persistantes existantes.NoteLes modifications apportées à l'itinéraire ne font que changer la portion de trafic vers les différents services. Il se peut que vous deviez faire évoluer le déploiement pour ajuster le nombre de pods afin de gérer les charges prévues.
Pour modifier l'itinéraire, exécutez :
oc edit route <route_name> $ oc edit route <route_name>Exemple de sortie
... metadata: name: route-alternate-service annotations: haproxy.router.openshift.io/balance: roundrobin spec: host: ab-example.my-project.my-domain to: kind: Service name: ab-example-a weight: 10 alternateBackends: - kind: Service name: ab-example-b weight: 15 ...
8.4.5.1.1. Gestion des poids d'une route existante à l'aide de la console web
Procédure
- Naviguez jusqu'à la page Networking → Routes.
-
Cliquez sur le menu Actions
à côté de l'itinéraire que vous souhaitez modifier et sélectionnez Edit Route.
-
Modifiez le fichier YAML. Mettez à jour la valeur
weightpour qu'elle soit un nombre entier entre0et256qui spécifie le poids relatif de la cible par rapport à d'autres objets de référence de la cible. La valeur0supprime les demandes adressées à ce back-end. La valeur par défaut est100. Exécutezoc explain routes.spec.alternateBackendspour plus d'informations sur les options. - Cliquez sur Save.
8.4.5.1.2. Gestion des poids d'une nouvelle route à l'aide de la console web
- Naviguez jusqu'à la page Networking → Routes.
- Cliquez sur Create Route.
- Saisissez l'itinéraire Name.
- Sélectionnez le site Service.
- Cliquez sur Add Alternate Service.
-
Saisissez une valeur pour Weight et Alternate Service Weight. Entrez un nombre entre
0et255qui représente le poids relatif par rapport aux autres cibles. La valeur par défaut est100. - Sélectionnez le site Target Port.
- Cliquez sur Create.
8.4.5.1.3. Gestion des poids à l'aide du CLI
Procédure
Pour gérer les services et les poids correspondants équilibrés par la route, utilisez la commande
oc set route-backends:$ oc set route-backends ROUTENAME \ [--zero|--equal] [--adjust] SERVICE=WEIGHT[%] [...] [options]Par exemple, le texte suivant définit
ab-example-acomme le service principal avecweight=198etab-example-bcomme le premier service de remplacement avecweight=2:$ oc set route-backends ab-example ab-example-a=198 ab-example-b=2Cela signifie que 99 % du trafic est envoyé au service
ab-example-aet 1 % au serviceab-example-b.Cette commande ne met pas le déploiement à l'échelle. Il se peut que vous deviez le faire pour avoir suffisamment de pods pour gérer la charge de la demande.
Exécutez la commande sans drapeaux pour vérifier la configuration actuelle :
$ oc set route-backends ab-exampleExemple de sortie
NAME KIND TO WEIGHT routes/ab-example Service ab-example-a 198 (99%) routes/ab-example Service ab-example-b 2 (1%)Pour modifier le poids d'un service individuel par rapport à lui-même ou au service principal, utilisez l'option
--adjust. La spécification d'un pourcentage ajuste le service par rapport au service principal ou au premier service de remplacement (si vous spécifiez le service principal). S'il y a d'autres backends, leur poids reste proportionnel à celui qui a été modifié.L'exemple suivant modifie le poids des services
ab-example-aetab-example-b:$ oc set route-backends ab-example --adjust ab-example-a=200 ab-example-b=10Il est également possible de modifier le poids d'un service en spécifiant un pourcentage :
$ oc set route-backends ab-example --adjust ab-example-b=5%En spécifiant
$ oc set route-backends ab-example --adjust ab-example-b=+15%L'indicateur
--equalfixe l'adresseweightde tous les services à100:$ oc set route-backends ab-example --equalLe drapeau
--zerofixe l'adresseweightde tous les services à0. Toutes les requêtes renvoient alors une erreur 503.NoteTous les routeurs ne peuvent pas prendre en charge des backends multiples ou pondérés.
8.4.5.1.4. Un service, plusieurs objets Deployment
Procédure
Créez une nouvelle application, en ajoutant un label
ab-example=truequi sera commun à tous les tessons :$ oc new-app openshift/deployment-example --name=ab-example-a --as-deployment-config=true --labels=ab-example=true --env=SUBTITLE\=shardA $ oc delete svc/ab-example-aL'application est déployée et un service est créé. Il s'agit du premier shard.
Rendre l'application disponible via une route ou utiliser directement l'IP du service :
$ oc expose deployment ab-example-a --name=ab-example --selector=ab-example\=true $ oc expose service ab-example-
Accédez à l'application à l'adresse
ab-example-<project_name>.<router_domain>pour vérifier que vous voyez l'imagev1. Créer un deuxième dépôt basé sur la même image source et le même label que le premier dépôt, mais avec une version étiquetée différente et des variables d'environnement uniques :
$ oc new-app openshift/deployment-example:v2 \ --name=ab-example-b --labels=ab-example=true \ SUBTITLE="shard B" COLOR="red" --as-deployment-config=true $ oc delete svc/ab-example-bÀ ce stade, les deux ensembles de pods sont desservis par la route. Cependant, comme les navigateurs (en laissant une connexion ouverte) et le routeur (par défaut, par l'intermédiaire d'un cookie) tentent de préserver votre connexion à un serveur dorsal, il se peut que les deux ensembles ne vous soient pas renvoyés.
Pour forcer votre navigateur vers l'un ou l'autre shard :
Utilisez la commande
oc scalepour réduire les répliques deab-example-aà0.$ oc scale dc/ab-example-a --replicas=0Rafraîchissez votre navigateur pour afficher
v2etshard B(en rouge).Faites passer
ab-example-aà la réplique de1etab-example-bà0:$ oc scale dc/ab-example-a --replicas=1; oc scale dc/ab-example-b --replicas=0Rafraîchissez votre navigateur pour afficher
v1etshard A(en bleu).
Si vous déclenchez un déploiement sur l'un ou l'autre shard, seuls les pods de ce shard sont affectés. Vous pouvez déclencher un déploiement en modifiant la variable d'environnement
SUBTITLEdans l'un des objetsDeployment:$ oc edit dc/ab-example-aou
$ oc edit dc/ab-example-b
Chapitre 9. Quotas
9.1. Quotas de ressources par projet
Un resource quota, défini par un objet ResourceQuota, fournit des contraintes qui limitent la consommation globale de ressources par projet. Il peut limiter la quantité d'objets pouvant être créés dans un projet par type, ainsi que la quantité totale de ressources de calcul et de stockage susceptibles d'être consommées par les ressources de ce projet.
Ce guide décrit le fonctionnement des quotas de ressources, la manière dont les administrateurs de clusters peuvent définir et gérer les quotas de ressources par projet, et la manière dont les développeurs et les administrateurs de clusters peuvent les visualiser.
9.1.1. Ressources gérées par quotas
Les paragraphes suivants décrivent l'ensemble des ressources de calcul et des types d'objets qui peuvent être gérés par un quota.
Un pod est dans un état terminal si status.phase in (Failed, Succeeded) est vrai.
| Nom de la ressource | Description |
|---|---|
|
|
La somme des demandes de CPU de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
|
La somme des demandes de mémoire de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
|
La somme des demandes de CPU de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
|
La somme des demandes de mémoire de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
| La somme des limites de CPU de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
| La somme des limites de mémoire de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
| Nom de la ressource | Description |
|---|---|
|
| La somme des demandes de stockage sur l'ensemble des réclamations de volumes persistants dans n'importe quel état ne peut pas dépasser cette valeur. |
|
| Le nombre total de réclamations de volumes persistants qui peuvent exister dans le projet. |
|
| La somme des demandes de stockage sur l'ensemble des réclamations de volumes persistants dans n'importe quel état qui ont une classe de stockage correspondante, ne peut pas dépasser cette valeur. |
|
| Le nombre total de réclamations de volumes persistants avec une classe de stockage correspondante qui peuvent exister dans le projet. |
|
|
La somme des demandes de stockage éphémère local pour tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
|
La somme des demandes de stockage éphémère pour tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
|
| La somme des limites de stockage éphémère de tous les pods dans un état non terminal ne peut pas dépasser cette valeur. |
| Nom de la ressource | Description |
|---|---|
|
| Le nombre total de pods dans un état non terminal qui peuvent exister dans le projet. |
|
| Le nombre total de contrôleurs de réplication qui peuvent exister dans le projet. |
|
| Nombre total de quotas de ressources pouvant exister dans le projet. |
|
| Le nombre total de services qui peuvent exister dans le projet. |
|
|
Le nombre total de services de type |
|
|
Le nombre total de services de type |
|
| Le nombre total de secrets qui peuvent exister dans le projet. |
|
|
Le nombre total d'objets |
|
| Le nombre total de réclamations de volumes persistants qui peuvent exister dans le projet. |
|
| Le nombre total de flux d'images qui peuvent exister dans le projet. |
9.1.2. Périmètre des quotas
Chaque quota peut être associé à un ensemble de scopes. Un quota ne mesure l'utilisation d'une ressource que si elle correspond à l'intersection des champs d'application énumérés.
L'ajout d'un champ d'application à un quota restreint l'ensemble des ressources auxquelles ce quota peut s'appliquer. La spécification d'une ressource en dehors de l'ensemble autorisé entraîne une erreur de validation.
| Champ d'application | Description |
|
|
Faire correspondre les pods qui ont la meilleure qualité de service pour |
|
|
Les pods qui n'ont pas la meilleure qualité de service pour |
Un champ d'application BestEffort limite un quota aux ressources suivantes :
-
pods
Un champ d'application NotBestEffort limite un quota au suivi des ressources suivantes :
-
pods -
memory -
requests.memory -
limits.memory -
cpu -
requests.cpu -
limits.cpu
9.1.3. Application des quotas
Après la création d'un quota de ressources pour un projet, le projet limite la possibilité de créer de nouvelles ressources susceptibles d'enfreindre la contrainte de quota jusqu'à ce qu'il ait calculé des statistiques d'utilisation mises à jour.
Après la création d'un quota et la mise à jour des statistiques d'utilisation, le projet accepte la création de nouveaux contenus. Lorsque vous créez ou modifiez des ressources, votre quota d'utilisation est incrémenté dès la demande de création ou de modification de la ressource.
Lorsque vous supprimez une ressource, l'utilisation de votre quota est décrémentée lors du prochain recalcul complet des statistiques de quota pour le projet. Un délai configurable détermine le temps nécessaire pour ramener les statistiques d'utilisation des quotas à la valeur observée actuellement dans le système.
Si les modifications du projet dépassent une limite de quota d'utilisation, le serveur refuse l'action et un message d'erreur approprié est renvoyé à l'utilisateur expliquant la contrainte de quota violée et les statistiques d'utilisation actuellement observées dans le système.
9.1.4. Demandes et limites
Lors de l'allocation des ressources informatiques, chaque conteneur peut spécifier une demande et une valeur limite pour le processeur, la mémoire et le stockage éphémère. Les quotas peuvent restreindre n'importe laquelle de ces valeurs.
Si le quota a une valeur spécifiée pour requests.cpu ou requests.memory, il faut que chaque conteneur entrant fasse une demande explicite pour ces ressources. Si le quota a une valeur spécifiée pour limits.cpu ou limits.memory, il faut que chaque conteneur entrant spécifie une limite explicite pour ces ressources.
9.1.5. Exemples de définitions de quotas de ressources
core-object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: core-object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2" - 1
- Le nombre total d'objets
ConfigMapqui peuvent exister dans le projet. - 2
- Le nombre total de réclamations de volume persistantes (PVC) qui peuvent exister dans le projet.
- 3
- Le nombre total de contrôleurs de réplication qui peuvent exister dans le projet.
- 4
- Le nombre total de secrets qui peuvent exister dans le projet.
- 5
- Le nombre total de services qui peuvent exister dans le projet.
- 6
- Le nombre total de services de type
LoadBalancerqui peuvent exister dans le projet.
openshift-object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: openshift-object-counts
spec:
hard:
openshift.io/imagestreams: "10" - 1
- Nombre total de flux d'images pouvant exister dans le projet.
compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "4"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi - 1
- Le nombre total de pods dans un état non terminal qui peuvent exister dans le projet.
- 2
- Sur l'ensemble des pods dans un état non terminal, la somme des demandes de CPU ne peut pas dépasser 1 cœur.
- 3
- Sur l'ensemble des pods dans un état non terminal, la somme des demandes de mémoire ne peut pas dépasser 1Gi.
- 4
- Pour tous les pods dans un état non terminal, la somme des limites de CPU ne peut pas dépasser 2 cœurs.
- 5
- Pour tous les pods dans un état non terminal, la somme des limites de mémoire ne peut pas dépasser 2Gi.
besteffort.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort
spec:
hard:
pods: "1"
scopes:
- BestEffort compute-resources-long-running.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-long-running
spec:
hard:
pods: "4"
limits.cpu: "4"
limits.memory: "2Gi"
scopes:
- NotTerminating - 1
- Le nombre total de pods dans un état non terminal.
- 2
- Pour tous les pods dans un état non terminal, la somme des limites de CPU ne peut pas dépasser cette valeur.
- 3
- La somme des limites de mémoire de tous les pods dans un état non terminal ne peut pas dépasser cette valeur.
- 4
- Restreint le quota aux seuls pods correspondants pour lesquels
spec.activeDeadlineSecondsest défini surnil. Les pods de construction relèvent deNotTerminatingà moins que la politiqueRestartNeverne soit appliquée.
compute-resources-time-bound.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-time-bound
spec:
hard:
pods: "2"
limits.cpu: "1"
limits.memory: "1Gi"
scopes:
- Terminating - 1
- Le nombre total de pods dans un état de terminaison.
- 2
- Pour tous les pods en état de terminaison, la somme des limites de CPU ne peut pas dépasser cette valeur.
- 3
- La somme des limites de mémoire ne peut pas dépasser cette valeur pour tous les pods en état de terminaison.
- 4
- Restreint le quota aux seuls pods correspondants où
spec.activeDeadlineSeconds >=0. Par exemple, ce quota s'applique aux pods de construction ou de déploiement, mais pas aux pods de longue durée comme un serveur web ou une base de données.
storage-consumption.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-consumption
spec:
hard:
persistentvolumeclaims: "10"
requests.storage: "50Gi"
gold.storageclass.storage.k8s.io/requests.storage: "10Gi"
silver.storageclass.storage.k8s.io/requests.storage: "20Gi"
silver.storageclass.storage.k8s.io/persistentvolumeclaims: "5"
bronze.storageclass.storage.k8s.io/requests.storage: "0"
bronze.storageclass.storage.k8s.io/persistentvolumeclaims: "0"
requests.ephemeral-storage: 2Gi
limits.ephemeral-storage: 4Gi - 1
- Le nombre total de demandes de volumes persistants dans un projet
- 2
- Pour toutes les demandes de volume persistant d'un projet, la somme de l'espace de stockage demandé ne peut dépasser cette valeur.
- 3
- Pour toutes les demandes de volumes persistants d'un projet, la somme du stockage demandé dans la classe de stockage or ne peut pas dépasser cette valeur.
- 4
- Pour toutes les demandes de volumes persistants d'un projet, la somme du stockage demandé dans la classe de stockage argent ne peut pas dépasser cette valeur.
- 5
- Pour toutes les demandes de volumes persistants d'un projet, le nombre total de demandes dans la classe de stockage Silver ne peut pas dépasser cette valeur.
- 6
- Sur l'ensemble des demandes de volumes persistants d'un projet, la somme des espaces de stockage demandés dans la classe de stockage bronze ne peut pas dépasser cette valeur. Lorsque cette valeur est fixée à
0, cela signifie que la classe de stockage bronze ne peut pas demander de stockage. - 7
- Pour toutes les demandes de volumes persistants d'un projet, la somme du stockage demandé dans la classe de stockage bronze ne peut pas dépasser cette valeur. Lorsque cette valeur est fixée à
0, cela signifie que la classe de stockage bronze ne peut pas créer de demandes. - 8
- Sur l'ensemble des pods dans un état non terminal, la somme des demandes de stockage éphémère ne peut pas dépasser 2Gi.
- 9
- La somme des limites de stockage éphémère de tous les pods dans un état non terminal ne peut pas dépasser 4Gi.
9.1.6. Création d'un quota
Vous pouvez créer un quota pour limiter l'utilisation des ressources dans un projet donné.
Procédure
- Définir le quota dans un fichier.
Utilisez le fichier pour créer le quota et l'appliquer à un projet :
$ oc create -f <file> [-n <project_name>]Par exemple :
$ oc create -f core-object-counts.yaml -n demoproject
9.1.6.1. Création de quotas de nombre d'objets
Vous pouvez créer un quota de comptage d'objets pour tous les types de ressources standard à espace de noms sur OpenShift Container Platform, tels que les objets BuildConfig et DeploymentConfig. Un quota de comptage d'objets place un quota défini sur tous les types de ressources standard à espace de noms.
Lors de l'utilisation d'un quota de ressources, un objet est imputé au quota lors de sa création. Ces types de quotas sont utiles pour se protéger contre l'épuisement des ressources. Le quota ne peut être créé que s'il y a suffisamment de ressources disponibles dans le projet.
Procédure
Pour configurer un quota de comptage d'objets pour une ressource :
Exécutez la commande suivante :
$ oc create quota <name> \ --hard=count/<resource>.<group>=<quota>,count/<resource>.<group>=<quota>1 - 1
- La variable
<resource>est le nom de la ressource et<group>est le groupe API, le cas échéant. Utilisez la commandeoc api-resourcespour obtenir une liste des ressources et des groupes d'API qui leur sont associés.
Par exemple :
$ oc create quota test \ --hard=count/deployments.extensions=2,count/replicasets.extensions=4,count/pods=3,count/secrets=4Exemple de sortie
resourcequota "test" createdCet exemple limite les ressources répertoriées à la limite stricte de chaque projet du cluster.
Vérifiez que le quota a été créé :
$ oc describe quota testExemple de sortie
Name: test Namespace: quota Resource Used Hard -------- ---- ---- count/deployments.extensions 0 2 count/pods 0 3 count/replicasets.extensions 0 4 count/secrets 0 4
9.1.6.2. Définition d'un quota de ressources pour les ressources étendues
Le surengagement des ressources n'est pas autorisé pour les ressources étendues, vous devez donc spécifier requests et limits pour la même ressource étendue dans un quota. Actuellement, seuls les éléments de quota avec le préfixe requests. sont autorisés pour les ressources étendues. Voici un exemple de scénario permettant de définir un quota de ressources pour la ressource GPU nvidia.com/gpu.
Procédure
Déterminez le nombre de GPU disponibles sur un nœud de votre cluster. Par exemple, le nombre de GPU disponibles sur un nœud de votre cluster :
# oc describe node ip-172-31-27-209.us-west-2.compute.internal | egrep 'Capacity|Allocatable|gpu'Exemple de sortie
openshift.com/gpu-accelerator=true Capacity: nvidia.com/gpu: 2 Allocatable: nvidia.com/gpu: 2 nvidia.com/gpu 0 0Dans cet exemple, 2 GPU sont disponibles.
Fixer un quota dans l'espace de noms
nvidia. Dans cet exemple, le quota est de1:# cat gpu-quota.yamlExemple de sortie
apiVersion: v1 kind: ResourceQuota metadata: name: gpu-quota namespace: nvidia spec: hard: requests.nvidia.com/gpu: 1Créer le quota :
# oc create -f gpu-quota.yamlExemple de sortie
resourcequota/gpu-quota createdVérifiez que le quota de l'espace de noms est correct :
# oc describe quota gpu-quota -n nvidiaExemple de sortie
Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 0 1Définir un pod qui demande un seul GPU. L'exemple de fichier de définition suivant s'appelle
gpu-pod.yaml:apiVersion: v1 kind: Pod metadata: generateName: gpu-pod- namespace: nvidia spec: restartPolicy: OnFailure containers: - name: rhel7-gpu-pod image: rhel7 env: - name: NVIDIA_VISIBLE_DEVICES value: all - name: NVIDIA_DRIVER_CAPABILITIES value: "compute,utility" - name: NVIDIA_REQUIRE_CUDA value: "cuda>=5.0" command: ["sleep"] args: ["infinity"] resources: limits: nvidia.com/gpu: 1Créer la capsule :
# oc create -f gpu-pod.yamlVérifiez que le module est en cours d'exécution :
# oc get podsExemple de sortie
NAME READY STATUS RESTARTS AGE gpu-pod-s46h7 1/1 Running 0 1mVérifiez que le compteur du quota
Usedest correct :# oc describe quota gpu-quota -n nvidiaExemple de sortie
Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 1 1Tentative de création d'un second pod GPU dans l'espace de noms
nvidia. Celui-ci est techniquement disponible sur le nœud car il possède 2 GPU :# oc create -f gpu-pod.yamlExemple de sortie
Error from server (Forbidden): error when creating "gpu-pod.yaml": pods "gpu-pod-f7z2w" is forbidden: exceeded quota: gpu-quota, requested: requests.nvidia.com/gpu=1, used: requests.nvidia.com/gpu=1, limited: requests.nvidia.com/gpu=1Ce message d'erreur Forbidden est attendu parce que vous avez un quota de 1 GPU et que ce pod a essayé d'allouer un deuxième GPU, qui dépasse son quota.
9.1.7. Consultation d'un quota
Vous pouvez consulter les statistiques d'utilisation liées aux limites définies dans le quota d'un projet en naviguant dans la console web jusqu'à la page Quota du projet.
Vous pouvez également utiliser l'interface de gestion pour afficher les détails des quotas.
Procédure
Obtenir la liste des quotas définis dans le projet. Par exemple, pour un projet appelé
demoproject:$ oc get quota -n demoprojectExemple de sortie
NAME AGE besteffort 11m compute-resources 2m core-object-counts 29mDécrivez le quota qui vous intéresse, par exemple le quota
core-object-counts:$ oc describe quota core-object-counts -n demoprojectExemple de sortie
Name: core-object-counts Namespace: demoproject Resource Used Hard -------- ---- ---- configmaps 3 10 persistentvolumeclaims 0 4 replicationcontrollers 3 20 secrets 9 10 services 2 10
9.1.8. Configuration de quotas de ressources explicites
Configurer des quotas de ressources explicites dans un modèle de demande de projet pour appliquer des quotas de ressources spécifiques dans les nouveaux projets.
Conditions préalables
- Accès au cluster en tant qu'utilisateur ayant le rôle d'administrateur de cluster.
-
Installez le CLI OpenShift (
oc).
Procédure
Ajouter une définition de quota de ressources à un modèle de demande de projet :
Si un modèle de demande de projet n'existe pas dans un cluster :
Créez un modèle de projet bootstrap et produisez-le dans un fichier appelé
template.yaml:oc adm create-bootstrap-project-template -o yaml > template.yamlAjoutez une définition de quota de ressources à
template.yaml. L'exemple suivant définit un quota de ressources nommé "consommation de stockage". La définition doit être ajoutée avant la sectionparameters:dans le modèle :- apiVersion: v1 kind: ResourceQuota metadata: name: storage-consumption namespace: ${PROJECT_NAME} spec: hard: persistentvolumeclaims: "10"1 requests.storage: "50Gi"2 gold.storageclass.storage.k8s.io/requests.storage: "10Gi"3 silver.storageclass.storage.k8s.io/requests.storage: "20Gi"4 silver.storageclass.storage.k8s.io/persistentvolumeclaims: "5"5 bronze.storageclass.storage.k8s.io/requests.storage: "0"6 bronze.storageclass.storage.k8s.io/persistentvolumeclaims: "0"7 - 1
- Le nombre total de demandes de volumes persistants dans un projet.
- 2
- Pour toutes les demandes de volume persistant d'un projet, la somme de l'espace de stockage demandé ne peut dépasser cette valeur.
- 3
- Pour toutes les demandes de volumes persistants d'un projet, la somme du stockage demandé dans la classe de stockage or ne peut pas dépasser cette valeur.
- 4
- Pour toutes les demandes de volumes persistants d'un projet, la somme du stockage demandé dans la classe de stockage argent ne peut pas dépasser cette valeur.
- 5
- Pour toutes les demandes de volumes persistants d'un projet, le nombre total de demandes dans la classe de stockage Silver ne peut pas dépasser cette valeur.
- 6
- Sur l'ensemble des demandes de volumes persistants d'un projet, la somme des espaces de stockage demandés dans la classe de stockage bronze ne peut pas dépasser cette valeur. Lorsque cette valeur est fixée à
0, la classe de stockage bronze ne peut pas demander de stockage. - 7
- Sur l'ensemble des demandes de volumes persistants d'un projet, la somme du stockage demandé dans la classe de stockage bronze ne peut pas dépasser cette valeur. Lorsque cette valeur est définie sur
0, la classe de stockage bronze ne peut pas créer de demandes.
Créer un modèle de demande de projet à partir du fichier
template.yamlmodifié dans l'espace de nomsopenshift-config:$ oc create -f template.yaml -n openshift-configNotePour inclure la configuration en tant qu'annotation
kubectl.kubernetes.io/last-applied-configuration, ajoutez l'option--save-configà la commandeoc create.Par défaut, le modèle s'appelle
project-request.
Si un modèle de demande de projet existe déjà dans un cluster :
NoteSi vous gérez des objets de manière déclarative ou impérative au sein de votre cluster à l'aide de fichiers de configuration, modifiez le modèle de demande de projet existant à l'aide de ces fichiers.
Liste des modèles dans l'espace de noms
openshift-config:$ oc get templates -n openshift-configModifier un modèle de demande de projet existant :
oc edit template <project_request_template> -n openshift-config-
Ajoutez une définition de quota de ressources, telle que l'exemple précédent
storage-consumption, dans le modèle existant. La définition doit être ajoutée avant la sectionparameters:du modèle.
Si vous avez créé un modèle de demande de projet, faites-y référence dans la ressource de configuration du projet du cluster :
Accéder à la ressource de configuration du projet pour l'éditer :
En utilisant la console web :
- Naviguez jusqu'à la page Administration → Cluster Settings.
- Cliquez sur Configuration pour afficher toutes les ressources de configuration.
- Trouvez l'entrée pour Project et cliquez sur Edit YAML.
En utilisant le CLI :
Modifier la ressource
project.config.openshift.io/cluster:$ oc edit project.config.openshift.io/cluster
Mettez à jour la section
specde la ressource de configuration du projet pour inclure les paramètresprojectRequestTemplateetname. L'exemple suivant fait référence au nom du modèle de demande de projet par défautproject-request:apiVersion: config.openshift.io/v1 kind: Project metadata: ... spec: projectRequestTemplate: name: project-request
Vérifier que le quota de ressources est appliqué lors de la création des projets :
Créer un projet :
oc new-project <nom_du_projet>Liste des quotas de ressources du projet :
$ oc get resourcequotasDécrivez en détail le quota de ressources :
oc describe resourcequotas <resource_quota_name>
9.2. Quotas de ressources pour plusieurs projets
Un quota multi-projets, défini par un objet ClusterResourceQuota, permet de partager les quotas entre plusieurs projets. Les ressources utilisées dans chaque projet sélectionné sont agrégées et cet agrégat est utilisé pour limiter les ressources dans tous les projets sélectionnés.
Ce guide décrit comment les administrateurs de clusters peuvent définir et gérer des quotas de ressources pour plusieurs projets.
9.2.1. Sélection de plusieurs projets lors de la création de quotas
Lors de la création de quotas, vous pouvez sélectionner plusieurs projets sur la base d'une sélection d'annotations, d'une sélection d'étiquettes ou des deux.
Procédure
Pour sélectionner des projets en fonction des annotations, exécutez la commande suivante :
$ oc create clusterquota for-user \ --project-annotation-selector openshift.io/requester=<user_name> \ --hard pods=10 \ --hard secrets=20Cela crée l'objet
ClusterResourceQuotasuivant :apiVersion: quota.openshift.io/v1 kind: ClusterResourceQuota metadata: name: for-user spec: quota:1 hard: pods: "10" secrets: "20" selector: annotations:2 openshift.io/requester: <user_name> labels: null3 status: namespaces:4 - namespace: ns-one status: hard: pods: "10" secrets: "20" used: pods: "1" secrets: "9" total:5 hard: pods: "10" secrets: "20" used: pods: "1" secrets: "9"- 1
- L'objet
ResourceQuotaSpecqui sera appliqué aux projets sélectionnés. - 2
- Un simple sélecteur clé-valeur pour les annotations.
- 3
- Un sélecteur d'étiquettes qui peut être utilisé pour sélectionner des projets.
- 4
- Une carte par espace de nommage qui décrit l'utilisation actuelle des quotas dans chaque projet sélectionné.
- 5
- L'utilisation globale de tous les projets sélectionnés.
Ce document de quota multi-projets contrôle tous les projets demandés par
<user_name>en utilisant le point de terminaison de demande de projet par défaut. Vous êtes limité à 10 pods et 20 secrets.De même, pour sélectionner des projets en fonction des étiquettes, exécutez la commande suivante :
$ oc create clusterresourcequota for-name \1 --project-label-selector=name=frontend \2 --hard=pods=10 --hard=secrets=20Cela crée la définition d'objet suivante :
ClusterResourceQuota:apiVersion: quota.openshift.io/v1 kind: ClusterResourceQuota metadata: creationTimestamp: null name: for-name spec: quota: hard: pods: "10" secrets: "20" selector: annotations: null labels: matchLabels: name: frontend
9.2.2. Affichage des quotas de ressources applicables aux clusters
Un administrateur de projet n'est pas autorisé à créer ou à modifier le quota multi-projets qui limite son projet, mais il est autorisé à consulter les documents relatifs au quota multi-projets qui sont appliqués à son projet. L'administrateur de projet peut le faire via la ressource AppliedClusterResourceQuota.
Procédure
Pour afficher les quotas appliqués à un projet, exécutez :
$ oc describe AppliedClusterResourceQuotaExemple de sortie
Name: for-user Namespace: <none> Created: 19 hours ago Labels: <none> Annotations: <none> Label Selector: <null> AnnotationSelector: map[openshift.io/requester:<user-name>] Resource Used Hard -------- ---- ---- pods 1 10 secrets 9 20
9.2.3. Granularité de la sélection
Le nombre de projets actifs sélectionnés par un quota multiprojets est un élément important en raison des considérations de verrouillage lors de la demande d'attribution de quotas. La sélection de plus de 100 projets dans le cadre d'un quota multiprojets unique peut avoir des effets néfastes sur la réactivité du serveur API dans ces projets.
Chapitre 10. Utiliser des cartes de configuration avec des applications
Les cartes de configuration vous permettent de dissocier les artefacts de configuration du contenu de l'image afin de maintenir la portabilité des applications conteneurisées.
Les sections suivantes définissent les cartes de configuration et expliquent comment les créer et les utiliser.
Pour plus d'informations sur la création de cartes de configuration, voir Création et utilisation de cartes de configuration.
10.1. Comprendre les cartes de configuration
De nombreuses applications doivent être configurées à l'aide d'une combinaison de fichiers de configuration, d'arguments de ligne de commande et de variables d'environnement. Dans OpenShift Container Platform, ces artefacts de configuration sont découplés du contenu de l'image afin de maintenir la portabilité des applications conteneurisées.
L'objet ConfigMap fournit des mécanismes pour injecter des conteneurs avec des données de configuration tout en gardant les conteneurs agnostiques de OpenShift Container Platform. Une carte de configuration peut être utilisée pour stocker des informations fines comme des propriétés individuelles ou des informations grossières comme des fichiers de configuration entiers ou des blobs JSON.
L'objet API ConfigMap contient des paires clé-valeur de données de configuration qui peuvent être consommées dans des pods ou utilisées pour stocker des données de configuration pour des composants système tels que des contrôleurs. Par exemple, l'objet
ConfigMap Définition de l'objet
kind: ConfigMap
apiVersion: v1
metadata:
creationTimestamp: 2016-02-18T19:14:38Z
name: example-config
namespace: default
data:
example.property.1: hello
example.property.2: world
example.property.file: |-
property.1=value-1
property.2=value-2
property.3=value-3
binaryData:
bar: L3Jvb3QvMTAw
Vous pouvez utiliser le champ binaryData lorsque vous créez une carte de configuration à partir d'un fichier binaire, tel qu'une image.
Les données de configuration peuvent être consommées dans les pods de différentes manières. Une carte de configuration peut être utilisée pour :
- Remplir les valeurs des variables d'environnement dans les conteneurs
- Définir les arguments de la ligne de commande dans un conteneur
- Remplir les fichiers de configuration d'un volume
Les utilisateurs et les composants du système peuvent stocker des données de configuration dans une carte de configuration.
Une carte de configuration est similaire à un secret, mais elle est conçue pour faciliter le travail avec des chaînes de caractères qui ne contiennent pas d'informations sensibles.
Restrictions de la carte de configuration
A config map must be created before its contents can be consumed in pods.
Les contrôleurs peuvent être écrits de manière à tolérer les données de configuration manquantes. Consultez les composants individuels configurés à l'aide de cartes de configuration au cas par cas.
ConfigMap objects reside in a project.
Ils ne peuvent être référencés que par les pods du même projet.
The Kubelet only supports the use of a config map for pods it gets from the API server.
Cela inclut tous les pods créés en utilisant le CLI, ou indirectement à partir d'un contrôleur de réplication. Cela n'inclut pas les pods créés en utilisant le drapeau --manifest-url, le drapeau --config ou l'API REST du nœud OpenShift Container Platform, car ce ne sont pas des moyens courants de créer des pods.
10.2. Cas d'utilisation : Consommer des cartes de configuration dans les pods
Les sections suivantes décrivent quelques cas d'utilisation des objets ConfigMap dans les pods.
10.2.1. Remplir les variables d'environnement dans les conteneurs à l'aide de cartes de configuration
Les cartes de configuration peuvent être utilisées pour remplir des variables d'environnement individuelles dans des conteneurs ou pour remplir des variables d'environnement dans des conteneurs à partir de toutes les clés qui forment des noms de variables d'environnement valides.
Prenons l'exemple de la carte de configuration suivante :
ConfigMap avec deux variables d'environnement
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charm ConfigMap avec une variable d'environnement
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO Procédure
Vous pouvez consommer les clés de ce
ConfigMapdans un pod en utilisant les sectionsconfigMapKeyRef.Exemple de spécification
Podconfigurée pour injecter des variables d'environnement spécifiquesapiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "env" ] env:1 - name: SPECIAL_LEVEL_KEY2 valueFrom: configMapKeyRef: name: special-config3 key: special.how4 - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config5 key: special.type6 optional: true7 envFrom:8 - configMapRef: name: env-config9 restartPolicy: Never- 1
- Stanza pour extraire les variables d'environnement spécifiées d'un site
ConfigMap. - 2
- Nom de la variable d'environnement du pod dans laquelle vous injectez la valeur de la clé.
- 3 5
- Nom de l'adresse
ConfigMapà partir de laquelle des variables d'environnement spécifiques doivent être extraites. - 4 6
- Variable d'environnement à extraire de
ConfigMap. - 7
- Rend la variable d'environnement facultative. En tant qu'optionnel, le pod sera démarré même si les
ConfigMapet les clés spécifiés n'existent pas. - 8
- Stanza pour extraire toutes les variables d'environnement d'un site
ConfigMap. - 9
- Nom de l'adresse
ConfigMapà partir de laquelle toutes les variables d'environnement doivent être extraites.
Lorsque ce module est exécuté, les journaux du module incluent la sortie suivante :
SPECIAL_LEVEL_KEY=very log_level=INFO
SPECIAL_TYPE_KEY=charm n'est pas listé dans l'exemple de sortie car optional: true est activé.
10.2.2. Définition des arguments de ligne de commande pour les commandes de conteneurs avec les cartes de configuration
Une carte de configuration peut également être utilisée pour définir la valeur des commandes ou des arguments dans un conteneur. Pour ce faire, on utilise la syntaxe de substitution de Kubernetes $(VAR_NAME). Considérons la carte de configuration suivante :
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charmProcédure
Pour injecter des valeurs dans une commande dans un conteneur, vous devez consommer les clés que vous souhaitez utiliser comme variables d'environnement, comme dans le cas d'utilisation de ConfigMaps dans des variables d'environnement. Vous pouvez ensuite y faire référence dans la commande d'un conteneur à l'aide de la syntaxe
$(VAR_NAME).Exemple de spécification
Podconfigurée pour injecter des variables d'environnement spécifiquesapiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "-c", "echo $(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]1 env: - name: SPECIAL_LEVEL_KEY valueFrom: configMapKeyRef: name: special-config key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-config key: special.type restartPolicy: Never- 1
- Injectez les valeurs dans une commande dans un conteneur en utilisant les clés que vous souhaitez utiliser comme variables d'environnement.
Lorsque ce module est exécuté, la sortie de la commande echo exécutée dans le conteneur test-container est la suivante :
very charm
10.2.3. Injecter du contenu dans un volume en utilisant des cartes de configuration
Vous pouvez injecter du contenu dans un volume en utilisant des cartes de configuration.
Exemple ConfigMap ressource personnalisée (CR)
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.type: charmProcédure
Vous disposez de plusieurs options pour injecter du contenu dans un volume à l'aide de cartes de configuration.
La façon la plus simple d'injecter du contenu dans un volume à l'aide d'une carte de configuration consiste à remplir le volume avec des fichiers dont la clé est le nom et le contenu la valeur de la clé :
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "cat", "/etc/config/special.how" ] volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-config1 restartPolicy: Never- 1
- Fichier contenant la clé.
Lorsque ce pod est exécuté, la sortie de la commande cat sera la suivante :
veryVous pouvez également contrôler les chemins à l'intérieur du volume où les clés de configuration sont projetées :
apiVersion: v1 kind: Pod metadata: name: dapi-test-pod spec: containers: - name: test-container image: gcr.io/google_containers/busybox command: [ "/bin/sh", "cat", "/etc/config/path/to/special-key" ] volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-config items: - key: special.how path: path/to/special-key1 restartPolicy: Never- 1
- Chemin d'accès à la clé de la carte de configuration.
Lorsque ce pod est exécuté, la sortie de la commande cat sera la suivante :
very
Chapitre 11. Suivi des métriques du projet et de l'application à l'aide de la perspective du développeur
La vue Observe de la perspective Developer offre des options pour surveiller les mesures de votre projet ou de votre application, telles que l'utilisation de l'unité centrale, de la mémoire et de la bande passante, ainsi que des informations relatives au réseau.
11.1. Conditions préalables
- Vous avez créé et déployé des applications sur OpenShift Container Platform.
- Vous vous êtes connecté à la console web et avez basculé dans la perspective Developer .
11.2. Contrôler les paramètres de votre projet
Après avoir créé des applications dans votre projet et les avoir déployées, vous pouvez utiliser la perspective Developer dans la console web pour voir les métriques de votre projet.
Procédure
- Dans le panneau de navigation gauche de la perspective Developer, cliquez sur Observe pour voir les Dashboard, Metrics, Alerts et Events de votre projet.
Facultatif : L'onglet Dashboard permet d'afficher des graphiques décrivant les mesures d'application suivantes :
- Utilisation de l'unité centrale
- Utilisation de la mémoire
- Consommation de bande passante
- Informations relatives au réseau, telles que le taux de paquets transmis et reçus et le taux de paquets abandonnés.
Dans l'onglet Dashboard, vous pouvez accéder aux tableaux de bord des ressources de calcul Kubernetes.
Figure 11.1. Observer le tableau de bord
 Note
NoteDans la liste Dashboard, le tableau de bord Kubernetes / Compute Resources / Namespace (Pods) est sélectionné par défaut.
Les options suivantes permettent d'obtenir plus de détails :
- Sélectionnez un tableau de bord dans la liste Dashboard pour afficher les mesures filtrées. Tous les tableaux de bord produisent des sous-menus supplémentaires lorsqu'ils sont sélectionnés, à l'exception de Kubernetes / Compute Resources / Namespace (Pods).
- Sélectionnez une option dans la liste Time Range pour déterminer la période de temps pour les données capturées.
- Définissez une plage horaire personnalisée en sélectionnant Custom time range dans la liste Time Range. Vous pouvez saisir ou sélectionner les dates et heures From et To. Cliquez sur Save pour enregistrer la plage horaire personnalisée.
- Sélectionnez une option dans la liste Refresh Interval pour déterminer la période de temps après laquelle les données sont rafraîchies.
- Passez votre curseur sur les graphiques pour voir les détails spécifiques de votre pod.
- Cliquez sur Inspect situé dans le coin supérieur droit de chaque graphique pour voir les détails d'un graphique particulier. Les détails du graphique apparaissent dans l'onglet Metrics.
Facultatif : Utilisez l'onglet Metrics pour rechercher l'indicateur de projet requis.
Figure 11.2. Suivi des métriques

- Dans la liste Select Query, sélectionnez une option pour filtrer les détails requis pour votre projet. Les mesures filtrées pour tous les modules d'application de votre projet sont affichées dans le graphique. Les pods de votre projet sont également listés ci-dessous.
- À partir de la liste des nacelles, effacez les cases carrées colorées pour supprimer les mesures de nacelles spécifiques et filtrer davantage les résultats de votre recherche.
- Cliquez sur Show PromQL pour afficher la requête Prometheus. Vous pouvez modifier cette requête à l'aide des invites afin de la personnaliser et de filtrer les mesures que vous souhaitez voir pour cet espace de noms.
- Utilisez la liste déroulante pour définir un intervalle de temps pour les données affichées. Vous pouvez cliquer sur Reset Zoom pour rétablir la plage horaire par défaut.
- Facultatif : Dans la liste Select Query, sélectionnez Custom Query pour créer une requête Prometheus personnalisée et filtrer les mesures pertinentes.
En option, vous pouvez utiliser l'onglet pour effectuer les tâches suivantes : Utilisez l'onglet Alerts pour effectuer les tâches suivantes :
- Voir les règles qui déclenchent des alertes pour les applications de votre projet.
- Identifier les alertes de tir dans le projet.
- Le cas échéant, il est possible de désactiver ces alertes.
Figure 11.3. Suivi des alertes

Les options suivantes permettent d'obtenir plus de détails :
- Utilisez la liste Filter pour filtrer les alertes en fonction de leur Alert State et Severity.
- Cliquez sur une alerte pour accéder à la page de détails de cette alerte. Dans la page Alerts Details, vous pouvez cliquer sur View Metrics pour voir les paramètres de l'alerte.
- Utilisez la bascule Notifications à côté d'une règle d'alerte pour faire taire toutes les alertes de cette règle, puis sélectionnez la durée pendant laquelle les alertes seront réduites au silence dans la liste Silence for. Vous devez être autorisé à modifier les alertes pour voir la bascule Notifications.
-
Utilisez le menu Options
adjacent à une règle d'alerte pour voir les détails de la règle d'alerte.
Optionnel : Utilisez l'onglet Events pour voir les événements de votre projet.
Figure 11.4. Suivi des événements

Vous pouvez filtrer les événements affichés à l'aide des options suivantes :
- Dans la liste Resources, sélectionnez une ressource pour afficher les événements qui la concernent.
- Dans la liste All Types, sélectionnez un type d'événement pour afficher les événements correspondant à ce type.
- Recherchez des événements spécifiques à l'aide du champ Filter events by names or messages.
11.3. Contrôler les paramètres de votre application
Après avoir créé des applications dans votre projet et les avoir déployées, vous pouvez utiliser la vue Topology dans la perspective Developer pour voir les alertes et les mesures de votre application. Les alertes critiques et d'avertissement pour votre application sont indiquées sur le nœud de charge de travail dans la vue Topology.
Procédure
Pour consulter les alertes relatives à votre charge de travail :
- Dans la vue Topology, cliquez sur la charge de travail pour voir les détails de la charge de travail dans le panneau de droite.
Cliquez sur l'onglet Observe pour afficher les alertes critiques et d'avertissement pour l'application, les graphiques des mesures, telles que l'utilisation du processeur, de la mémoire et de la bande passante, ainsi que tous les événements pour l'application.
NoteSeules les alertes critiques et d'avertissement de l'état Firing sont affichées dans la vue Topology. Les alertes dans les états Silenced, Pending et Not Firing ne sont pas affichées.
Figure 11.5. Surveillance des paramètres de l'application

- Cliquez sur l'alerte répertoriée dans le panneau de droite pour voir les détails de l'alerte dans la page Alert Details.
- Cliquez sur l'un des graphiques pour accéder à l'onglet Metrics et voir les mesures détaillées de l'application.
- Cliquez sur View monitoring dashboard pour afficher le tableau de bord de surveillance de cette application.
11.4. Ventilation des vulnérabilités des images
Dans la perspective du développeur, le tableau de bord du projet affiche le lien Image Vulnerabilities dans la section Status. En utilisant ce lien, vous pouvez afficher la fenêtre Image Vulnerabilities breakdown, qui comprend des détails concernant les images de conteneurs vulnérables et les images de conteneurs corrigibles. La couleur de l'icône indique la gravité :
- Rouge : Haute priorité. Corriger immédiatement.
- Orange : Priorité moyenne. Peut être corrigé après les vulnérabilités de haute priorité.
- Jaune : Faible priorité. Peut être corrigé après les vulnérabilités de priorité élevée et moyenne.
En fonction du niveau de gravité, vous pouvez classer les vulnérabilités par ordre de priorité et les corriger de manière organisée.
Figure 11.6. Visualisation des vulnérabilités des images

11.5. Surveillance des métriques de vulnérabilité de vos applications et de vos images
Après avoir créé des applications dans votre projet et les avoir déployées, utilisez la perspective Developer dans la console web pour voir les métriques des vulnérabilités des dépendances de votre application dans votre cluster. Les métriques vous aident à analyser en détail les vulnérabilités des images suivantes :
- Nombre total d'images vulnérables dans un projet sélectionné
- Comptage par gravité de toutes les images vulnérables d'un projet sélectionné
- L'analyse de la gravité permet d'obtenir des informations détaillées, telles que le nombre de vulnérabilités, le nombre de vulnérabilités corrigibles et le nombre de modules affectés pour chaque image vulnérable
Conditions préalables
Vous avez installé l'opérateur Red Hat Quay Container Security à partir du Operator Hub.
NoteL'opérateur Red Hat Quay Container Security détecte les vulnérabilités en analysant les images qui se trouvent dans le registre quay.
Procédure
- Pour un aperçu général des vulnérabilités des images, dans le panneau de navigation de la perspective Developer, cliquez sur Project pour voir le tableau de bord du projet.
- Cliquez sur Image Vulnerabilities dans la section Status. La fenêtre qui s'ouvre affiche des détails tels que Vulnerable Container Images et Fixable Container Images.
Pour obtenir un aperçu détaillé des vulnérabilités, cliquez sur l'onglet Vulnerabilities dans le tableau de bord du projet.
- Pour obtenir plus de détails sur une image, cliquez sur son nom.
- Affichez le graphique par défaut avec tous les types de vulnérabilités dans l'onglet Details.
- Facultatif : Cliquez sur le bouton de basculement pour afficher un type spécifique de vulnérabilité. Par exemple, cliquez sur App dependency pour afficher les vulnérabilités liées à la dépendance d'une application.
- Facultatif : vous pouvez filtrer la liste des vulnérabilités en fonction de leur Severity et Type ou les trier par Severity, Package, Type, Source, Current Version, et Fixed in Version.
Cliquez sur un site Vulnerability pour obtenir les détails qui lui sont associés :
- Base image affichent des informations provenant d'un avis de sécurité de Red Hat (RHSA).
- App dependency les vulnérabilités affichent des informations provenant de l'application de sécurité Snyk.
Chapitre 12. Contrôler l'état de santé des applications à l'aide de bilans de santé
Dans les systèmes logiciels, les composants peuvent devenir malsains en raison de problèmes transitoires tels qu'une perte de connectivité temporaire, des erreurs de configuration ou des problèmes avec des dépendances externes. Les applications OpenShift Container Platform disposent d'un certain nombre d'options pour détecter et gérer les conteneurs malsains.
12.1. Comprendre les bilans de santé
Un contrôle de santé effectue périodiquement des diagnostics sur un conteneur en cours d'exécution à l'aide de n'importe quelle combinaison des contrôles de disponibilité, d'état de marche et de démarrage.
Vous pouvez inclure une ou plusieurs sondes dans la spécification du module qui contient le conteneur que vous souhaitez contrôler.
Si vous souhaitez ajouter ou modifier des contrôles de santé dans un pod existant, vous devez éditer l'objet pod DeploymentConfig ou utiliser la perspective Developer dans la console web. Vous ne pouvez pas utiliser l'interface de commande pour ajouter ou modifier les contrôles de santé d'un module existant.
- Sondage sur l'état de préparation
Un readiness probe détermine si un conteneur est prêt à accepter des demandes de service. Si la sonde de préparation échoue pour un conteneur, le kubelet supprime le pod de la liste des points de terminaison de service disponibles.
Après un échec, la sonde continue d'examiner le module. Si le pod devient disponible, le kubelet l'ajoute à la liste des points d'extrémité de service disponibles.
- Bilan de santé du caractère vivant
Un liveness probe détermine si un conteneur est toujours en cours d'exécution. Si la sonde d'intégrité échoue en raison d'une condition telle qu'un blocage, le kubelet tue le conteneur. Le pod répond alors en fonction de sa politique de redémarrage.
Par exemple, une sonde de vivacité sur un pod avec un
restartPolicydeAlwaysouOnFailuretue et redémarre le conteneur.- Sonde de démarrage
Une adresse startup probe indique si l'application au sein d'un conteneur est démarrée. Toutes les autres sondes sont désactivées jusqu'à ce que le démarrage réussisse. Si la sonde de démarrage ne réussit pas dans un délai spécifié, le kubelet tue le conteneur, et le conteneur est soumis au pod
restartPolicy.Certaines applications peuvent nécessiter un temps de démarrage supplémentaire lors de leur première initialisation. Vous pouvez utiliser une sonde de démarrage avec une sonde de disponibilité ou de préparation pour retarder cette sonde suffisamment longtemps pour gérer un temps de démarrage prolongé à l'aide des paramètres
failureThresholdetperiodSeconds.For example, you can add a startup probe, with a
failureThresholdof 30 failures and aperiodSecondsof 10 seconds (30 * 10s = 300s) for a maximum of 5 minutes, to a liveness probe. After the startup probe succeeds the first time, the liveness probe takes over.
Vous pouvez configurer des sondes de disponibilité, d'état de préparation et de démarrage avec l'un des types de tests suivants :
HTTP
GET: Lors de l'utilisation d'un test HTTPGET, le test détermine l'état de santé du conteneur à l'aide d'un crochet web. Le test est réussi si le code de réponse HTTP est compris entre200et399.Vous pouvez utiliser un test HTTP
GETavec des applications qui renvoient des codes d'état HTTP lorsqu'elles sont complètement initialisées.-
Commande de conteneur : Lors d'un test de commande de conteneur, la sonde exécute une commande à l'intérieur du conteneur. La sonde est réussie si le test se termine avec un état
0. - Socket TCP : Lors de l'utilisation d'un test de socket TCP, la sonde tente d'ouvrir un socket vers le conteneur. Le conteneur n'est considéré comme sain que si la sonde peut établir une connexion. Vous pouvez utiliser un test de socket TCP avec des applications qui ne commencent à écouter qu'une fois l'initialisation terminée.
Vous pouvez configurer plusieurs champs pour contrôler le comportement d'une sonde :
-
initialDelaySeconds: Le temps, en secondes, après le démarrage du conteneur avant que la sonde puisse être programmée. La valeur par défaut est 0. -
periodSeconds: Délai, en secondes, entre l'exécution des sondes. La valeur par défaut est10. Cette valeur doit être supérieure àtimeoutSeconds. -
timeoutSeconds: Le nombre de secondes d'inactivité après lesquelles la sonde s'arrête et le conteneur est considéré comme ayant échoué. La valeur par défaut est1. Cette valeur doit être inférieure àperiodSeconds. -
successThreshold: Nombre de fois où la sonde doit signaler un succès après un échec pour que l'état du conteneur soit rétabli. La valeur doit être1pour une sonde d'intégrité. La valeur par défaut est1. failureThreshold: Le nombre de fois que la sonde est autorisée à échouer. La valeur par défaut est 3. Après les tentatives spécifiées :- pour une enquête sur l'état de conservation, le conteneur est redémarré
-
pour une sonde de disponibilité, le pod est marqué
Unready -
pour une sonde de démarrage, le conteneur est tué et est soumis à l'autorité de contrôle du pod
restartPolicy
Exemples de sondes
Voici des exemples de sondes différentes telles qu'elles apparaîtraient dans une spécification d'objet.
Échantillon de sonde de préparation avec un conteneur commande sonde de préparation dans un pod spec
apiVersion: v1
kind: Pod
metadata:
labels:
test: health-check
name: my-application
...
spec:
containers:
- name: goproxy-app
args:
image: registry.k8s.io/goproxy:0.1
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
...Exemple de sonde de démarrage de commande de conteneur et de sonde de vivacité avec des tests de commande de conteneur dans une spécification de pod
apiVersion: v1
kind: Pod
metadata:
labels:
test: health-check
name: my-application
...
spec:
containers:
- name: goproxy-app
args:
image: registry.k8s.io/goproxy:0.1
livenessProbe:
httpGet:
scheme: HTTPS
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
...- 1
- Le nom du conteneur.
- 2
- Spécifiez l'image du conteneur à déployer.
- 3
- Une enquête sur l'état d'avancement des travaux.
- 4
- Un test HTTP
GET. - 5
- Le schéma internet :
HTTPouHTTPS. La valeur par défaut estHTTP. - 6
- Le port sur lequel le conteneur écoute.
- 7
- Une sonde de démarrage.
- 8
- Un test HTTP
GET. - 9
- Le port sur lequel le conteneur écoute.
- 10
- Le nombre de fois où la sonde doit être réessayée après un échec.
- 11
- Le nombre de secondes nécessaires pour exécuter la sonde.
Exemple de sonde de vivacité avec un test de commande de conteneur qui utilise un délai d'attente dans une spécification de pod
apiVersion: v1
kind: Pod
metadata:
labels:
test: health-check
name: my-application
...
spec:
containers:
- name: goproxy-app
args:
image: registry.k8s.io/goproxy:0.1
livenessProbe:
exec:
command:
- /bin/bash
- '-c'
- timeout 60 /opt/eap/bin/livenessProbe.sh
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
...- 1
- Le nom du conteneur.
- 2
- Spécifiez l'image du conteneur à déployer.
- 3
- La sonde d'intégrité.
- 4
- Le type de sonde, ici une sonde de commande de conteneur.
- 5
- La ligne de commande à exécuter dans le conteneur.
- 6
- Fréquence en secondes de l'exécution de la sonde.
- 7
- Le nombre de succès consécutifs nécessaires pour montrer un succès après un échec.
- 8
- Le nombre de fois où la sonde doit être réessayée après un échec.
Exemple de sonde d'état de préparation et de sonde d'état de disponibilité avec un test de socket TCP dans un déploiement
kind: Deployment
apiVersion: apps/v1
...
spec:
...
template:
spec:
containers:
- resources: {}
readinessProbe:
tcpSocket:
port: 8080
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
terminationMessagePath: /dev/termination-log
name: ruby-ex
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
...12.2. Configuration des contrôles de santé à l'aide de l'interface de ligne de commande
Pour configurer les sondes de disponibilité, de vivacité et de démarrage, ajoutez une ou plusieurs sondes à la spécification du module qui contient le conteneur pour lequel vous souhaitez effectuer des contrôles de santé
Si vous souhaitez ajouter ou modifier des contrôles de santé dans un pod existant, vous devez éditer l'objet pod DeploymentConfig ou utiliser la perspective Developer dans la console web. Vous ne pouvez pas utiliser l'interface de commande pour ajouter ou modifier les contrôles de santé d'un module existant.
Procédure
Pour ajouter des sondes à un conteneur :
Créez un objet
Podpour ajouter une ou plusieurs sondes :apiVersion: v1 kind: Pod metadata: labels: test: health-check name: my-application spec: containers: - name: my-container1 args: image: registry.k8s.io/goproxy:0.12 livenessProbe:3 tcpSocket:4 port: 80805 initialDelaySeconds: 156 periodSeconds: 207 timeoutSeconds: 108 readinessProbe:9 httpGet:10 host: my-host11 scheme: HTTPS12 path: /healthz port: 808013 startupProbe:14 exec:15 command:16 - cat - /tmp/healthy failureThreshold: 3017 periodSeconds: 2018 timeoutSeconds: 1019 - 1
- Indiquez le nom du conteneur.
- 2
- Spécifiez l'image du conteneur à déployer.
- 3
- Facultatif : Créez une sonde de réactivité.
- 4
- Spécifiez un test à effectuer, ici un test de socket TCP.
- 5
- Indiquez le port sur lequel le conteneur écoute.
- 6
- Indiquez le délai, en secondes, après le démarrage du conteneur avant que la sonde puisse être programmée.
- 7
- Indiquez le nombre de secondes nécessaires à l'exécution de la sonde. La valeur par défaut est
10. Cette valeur doit être supérieure àtimeoutSeconds. - 8
- Spécifiez le nombre de secondes d'inactivité après lesquelles la sonde est considérée comme ayant échoué. La valeur par défaut est
1. Cette valeur doit être inférieure àperiodSeconds. - 9
- Facultatif : Créez une sonde de préparation.
- 10
- Spécifiez le type de test à effectuer, ici un test HTTP.
- 11
- Spécifiez l'adresse IP de l'hôte. Si
hostn'est pas défini,PodIPest utilisé. - 12
- Spécifiez
HTTPouHTTPS. Sischemen'est pas défini, c'est le schémaHTTPqui est utilisé. - 13
- Indiquez le port sur lequel le conteneur écoute.
- 14
- Facultatif : Créer une sonde de démarrage.
- 15
- Indiquez le type de test à effectuer, ici une sonde d'exécution de conteneur.
- 16
- Spécifiez les commandes à exécuter sur le conteneur.
- 17
- Spécifiez le nombre de tentatives de la sonde après un échec.
- 18
- Indiquez le nombre de secondes nécessaires à l'exécution de la sonde. La valeur par défaut est
10. Cette valeur doit être supérieure àtimeoutSeconds. - 19
- Spécifiez le nombre de secondes d'inactivité après lesquelles la sonde est considérée comme ayant échoué. La valeur par défaut est
1. Cette valeur doit être inférieure àperiodSeconds.
NoteSi la valeur de
initialDelaySecondsest inférieure à celle deperiodSeconds, la première sonde de préparation se produit à un moment donné entre les deux périodes, en raison d'un problème de temporisation.La valeur
timeoutSecondsdoit être inférieure à la valeurperiodSeconds.Créer l'objet
Pod:oc create -f <nom-de-fichier>.yamlVérifier l'état du module de contrôle de santé :
$ oc describe pod health-checkExemple de sortie
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 9s default-scheduler Successfully assigned openshift-logging/liveness-exec to ip-10-0-143-40.ec2.internal Normal Pulling 2s kubelet, ip-10-0-143-40.ec2.internal pulling image "registry.k8s.io/liveness" Normal Pulled 1s kubelet, ip-10-0-143-40.ec2.internal Successfully pulled image "registry.k8s.io/liveness" Normal Created 1s kubelet, ip-10-0-143-40.ec2.internal Created container Normal Started 1s kubelet, ip-10-0-143-40.ec2.internal Started containerVoici le résultat d'une sonde qui a échoué et qui a redémarré un conteneur :
Exemple de résultat de vérification de l'état de conservation d'un conteneur malsain
$ oc describe pod pod1Exemple de sortie
.... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> Successfully assigned aaa/liveness-http to ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Normal AddedInterface 47s multus Add eth0 [10.129.2.11/23] Normal Pulled 46s kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Successfully pulled image "registry.k8s.io/liveness" in 773.406244ms Normal Pulled 28s kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Successfully pulled image "registry.k8s.io/liveness" in 233.328564ms Normal Created 10s (x3 over 46s) kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Created container liveness Normal Started 10s (x3 over 46s) kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Started container liveness Warning Unhealthy 10s (x6 over 34s) kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Liveness probe failed: HTTP probe failed with statuscode: 500 Normal Killing 10s (x2 over 28s) kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Container liveness failed liveness probe, will be restarted Normal Pulling 10s (x3 over 47s) kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Pulling image "registry.k8s.io/liveness" Normal Pulled 10s kubelet, ci-ln-37hz77b-f76d1-wdpjv-worker-b-snzrj Successfully pulled image "registry.k8s.io/liveness" in 244.116568ms
12.3. Contrôler la santé des applications en utilisant la perspective du développeur
Vous pouvez utiliser la perspective Developer pour ajouter trois types de sondes de santé à votre conteneur afin de vous assurer que votre application est saine :
- Utilisez la sonde Readiness pour vérifier si le conteneur est prêt à traiter les demandes.
- Utilisez la sonde Liveness pour vérifier si le conteneur est en cours d'exécution.
- Utilisez la sonde de démarrage pour vérifier si l'application contenue dans le conteneur a démarré.
Vous pouvez ajouter des contrôles de santé soit pendant la création et le déploiement d'une application, soit après avoir déployé une application.
12.4. Ajout de contrôles de santé dans la perspective du développeur
Vous pouvez utiliser la vue Topology pour ajouter des contrôles de santé à votre application déployée.
Prérequis :
- Vous avez basculé vers la perspective Developer dans la console web.
- Vous avez créé et déployé une application sur OpenShift Container Platform en utilisant la perspective Developer.
Procédure
- Dans la vue Topology, cliquez sur le nœud de l'application pour afficher le panneau latéral. Si le conteneur n'a pas de contrôles de santé ajoutés pour assurer le bon fonctionnement de votre application, une notification Health Checks s'affiche avec un lien pour ajouter des contrôles de santé.
- Dans la notification affichée, cliquez sur le lien Add Health Checks.
- Vous pouvez également cliquer sur la liste déroulante Actions et sélectionner Add Health Checks. Notez que si le conteneur a déjà des contrôles de santé, vous verrez l'option Edit Health Checks au lieu de l'option add.
- Dans le formulaire Add Health Checks, si vous avez déployé plusieurs conteneurs, utilisez la liste déroulante Container pour vous assurer que le conteneur approprié est sélectionné.
Cliquez sur les liens des bilans de santé requis pour les ajouter au conteneur. Les données par défaut des bilans de santé sont préremplies. Vous pouvez ajouter les sondes avec les données par défaut ou personnaliser davantage les valeurs, puis les ajouter. Par exemple, pour ajouter une sonde de préparation qui vérifie si votre conteneur est prêt à traiter des requêtes, procédez comme suit
- Cliquez sur Add Readiness Probe, pour afficher un formulaire contenant les paramètres de la sonde.
- Cliquez sur la liste déroulante Type pour sélectionner le type de requête que vous souhaitez ajouter. Par exemple, dans ce cas, sélectionnez Container Command pour sélectionner la commande qui sera exécutée à l'intérieur du conteneur.
-
Dans le champ Command, ajoutez un argument
cat, de même, vous pouvez ajouter plusieurs arguments pour le contrôle, par exemple, ajoutez un autre argument/tmp/healthy. Conservez ou modifiez les valeurs par défaut des autres paramètres selon les besoins.
NoteLa valeur
Timeoutdoit être inférieure à la valeurPeriod. La valeur par défaut deTimeoutest1. La valeur par défaut dePeriodest10.- Cliquez sur la coche en bas du formulaire. Le message Readiness Probe Added s'affiche.
- Cliquez sur Add pour ajouter le bilan de santé. Vous êtes redirigé vers la vue Topology et le conteneur est redémarré.
- Dans le panneau latéral, vérifiez que les sondes ont été ajoutées en cliquant sur le module déployé dans la section Pods.
- Dans la page Pod Details, cliquez sur le conteneur listé dans la section Containers.
-
Dans la page Container Details, vérifiez que la sonde de préparation - Exec Command
cat/tmp/healthya été ajoutée au conteneur.
12.5. Modification des bilans de santé dans la perspective du développeur
La vue Topology vous permet d'éditer les contrôles de santé ajoutés à votre application, de les modifier ou d'en ajouter d'autres.
Prérequis :
- Vous avez basculé vers la perspective Developer dans la console web.
- Vous avez créé et déployé une application sur OpenShift Container Platform en utilisant la perspective Developer.
- Vous avez ajouté des contrôles de santé à votre application.
Procédure
- Dans la vue Topology, cliquez avec le bouton droit de la souris sur votre application et sélectionnez Edit Health Checks. Sinon, dans le panneau latéral, cliquez sur la liste déroulante Actions et sélectionnez Edit Health Checks.
Dans la page Edit Health Checks:
- Pour supprimer une sonde de santé précédemment ajoutée, cliquez sur le signe moins qui lui est accolé.
Pour modifier les paramètres d'une sonde existante :
- Cliquez sur le lien Edit Probe à côté d'une sonde précédemment ajoutée pour afficher les paramètres de la sonde.
- Modifiez les paramètres selon vos besoins et cliquez sur la coche pour enregistrer vos modifications.
Pour ajouter une nouvelle sonde de santé, en plus des contrôles de santé existants, cliquez sur les liens d'ajout de sonde. Par exemple, pour ajouter une sonde d'activité qui vérifie si votre conteneur est en cours d'exécution :
- Cliquez sur Add Liveness Probe, pour afficher un formulaire contenant les paramètres de la sonde.
Modifiez les paramètres de la sonde si nécessaire.
NoteLa valeur
Timeoutdoit être inférieure à la valeurPeriod. La valeur par défaut deTimeoutest1. La valeur par défaut dePeriodest10.- Cliquez sur la coche en bas du formulaire. Le message Liveness Probe Added s'affiche.
- Cliquez sur Save pour enregistrer vos modifications et ajouter les sondes supplémentaires à votre conteneur. Vous êtes redirigé vers la vue Topology.
- Dans le panneau latéral, vérifiez que les sondes ont été ajoutées en cliquant sur le module déployé dans la section Pods.
- Dans la page Pod Details, cliquez sur le conteneur listé dans la section Containers.
-
Dans la page Container Details, vérifiez que la sonde Liveness -
HTTP Get 10.129.4.65:8080/a été ajoutée au conteneur, en plus des sondes existantes précédentes.
12.6. Suivi des échecs du bilan de santé à l'aide de la perspective du développeur
En cas d'échec du contrôle de santé d'une application, vous pouvez utiliser la vue Topology pour surveiller les violations du contrôle de santé.
Prérequis :
- Vous avez basculé vers la perspective Developer dans la console web.
- Vous avez créé et déployé une application sur OpenShift Container Platform en utilisant la perspective Developer.
- Vous avez ajouté des contrôles de santé à votre application.
Procédure
- Dans la vue Topology, cliquez sur le nœud de l'application pour afficher le panneau latéral.
- Cliquez sur l'onglet Observe pour voir les échecs du contrôle de santé dans la section Events (Warning).
- Cliquez sur la flèche vers le bas à côté de Events (Warning) pour voir les détails de l'échec du bilan de santé.
Chapitre 13. Applications d'édition
Vous pouvez modifier la configuration et le code source de l'application que vous créez à l'aide de la vue Topology.
13.1. Conditions préalables
- Vous disposez des rôles et autorisations appropriés dans un projet pour créer et modifier des applications dans OpenShift Container Platform.
- Vous avez créé et déployé une application sur OpenShift Container Platform en utilisant la perspective Developer .
- Vous vous êtes connecté à la console web et avez basculé dans la perspective Developer .
13.2. Modifier le code source d'une application à l'aide de la perspective du développeur
Vous pouvez utiliser la vue Topology dans la perspective Developer pour éditer le code source de votre application.
Procédure
Dans la vue Topology, cliquez sur l'icône Edit Source code, affichée en bas à droite de l'application déployée, pour accéder à votre code source et le modifier.
NoteCette fonctionnalité n'est disponible que lorsque vous créez des applications à l'aide des options From Git, From Catalog et From Dockerfile.
Si l'opérateur Eclipse Che est installé dans votre cluster, un espace de travail Che (
 ) est créé et vous êtes dirigé vers l'espace de travail pour éditer votre code source. S'il n'est pas installé, vous serez dirigé vers le dépôt Git (
) est créé et vous êtes dirigé vers l'espace de travail pour éditer votre code source. S'il n'est pas installé, vous serez dirigé vers le dépôt Git (
 ) dans lequel votre code source est hébergé.
) dans lequel votre code source est hébergé.
13.3. Modifier la configuration de l'application à l'aide de la perspective du développeur
Vous pouvez utiliser la vue Topology dans la perspective Developer pour modifier la configuration de votre application.
Actuellement, seules les configurations des applications créées à l'aide des options From Git, Container Image, From Catalog, ou From Dockerfile dans le flux de travail Add de la perspective Developer peuvent être modifiées. Les configurations des applications créées à l'aide du CLI ou de l'option YAML du flux de travail Add ne peuvent pas être modifiées.
Conditions préalables
Assurez-vous que vous avez créé une application à l'aide des options From Git, Container Image, From Catalog, ou From Dockerfile dans le flux de travail Add.
Procédure
Une fois que vous avez créé une application et qu'elle est affichée dans la vue Topology, cliquez avec le bouton droit de la souris sur l'application pour voir les options de modification disponibles.
Figure 13.1. Modifier l'application

- Cliquez sur Edit application-name pour voir le flux de travail Add que vous avez utilisé pour créer l'application. Le formulaire est pré-rempli avec les valeurs que vous avez ajoutées lors de la création de la demande.
Modifiez les valeurs nécessaires pour l'application.
NoteVous ne pouvez pas modifier le champ Name dans la section General, les pipelines CI/CD ou le champ Create a route to the application dans la section Advanced Options.
Cliquez sur Save pour redémarrer la construction et déployer une nouvelle image.
Figure 13.2. Modifier et redéployer l'application

Chapitre 14. Élaguer les objets pour récupérer des ressources
Au fil du temps, les objets API créés dans OpenShift Container Platform peuvent s'accumuler dans le magasin de données etcd du cluster par le biais d'opérations utilisateur normales, telles que la création et le déploiement d'applications.
Les administrateurs de clusters peuvent périodiquement élaguer les anciennes versions des objets du cluster qui ne sont plus nécessaires. Par exemple, l'élagage des images permet de supprimer d'anciennes images et couches qui ne sont plus utilisées, mais qui occupent encore de l'espace disque.
14.1. Opérations de taille de base
La CLI regroupe les opérations d'élagage sous une commande parent commune :
oc adm prune <object_type> <options> $ oc adm prune <object_type> <options>Ceci spécifie :
-
Le site
<object_type>sur lequel l'action doit être effectuée, tel quegroups,builds,deployments, ouimages. -
Le site
<options>pris en charge pour l'élagage de ce type d'objet.
14.2. Groupes de taille
Pour élaguer les enregistrements de groupes provenant d'un fournisseur externe, les administrateurs peuvent exécuter la commande suivante :
$ oc adm prune groups \
--sync-config=path/to/sync/config [<options>]| Options | Description |
|---|---|
|
| Indiquer qu'il faut tailler au lieu d'effectuer une marche à blanc. |
|
| Chemin d'accès au fichier de la liste noire des groupes. |
|
| Chemin d'accès au fichier de liste blanche des groupes. |
|
| Chemin d'accès au fichier de configuration de la synchronisation. |
Procédure
Pour voir les groupes que la commande prune supprime, exécutez la commande suivante :
$ oc adm prune groups --sync-config=ldap-sync-config.yamlPour effectuer l'opération d'élagage, ajoutez l'indicateur
--confirm:$ oc adm prune groups --sync-config=ldap-sync-config.yaml --confirm
14.3. Élaguer les ressources de déploiement
Vous pouvez élaguer les ressources associées aux déploiements qui ne sont plus nécessaires au système en raison de leur âge et de leur statut.
La commande suivante permet de supprimer les contrôleurs de réplication associés aux objets DeploymentConfig:
oc adm prune deployments [<options>]]
Pour élaguer également les ensembles de réplicas associés aux objets Deployment, utilisez l'indicateur --replica-sets. Cet indicateur est actuellement une fonctionnalité de l'aperçu technologique.
| Option | Description |
|---|---|
|
| Indiquer qu'il faut tailler au lieu d'effectuer une marche à blanc. |
|
|
Pour l'objet |
|
|
Pour l'objet |
|
|
N'élaguez pas un contrôleur de réplication qui est plus jeune que |
|
|
Élaguer tous les contrôleurs de réplication qui n'ont plus d'objet |
|
|
Si Important Ce drapeau est une fonctionnalité de l'aperçu technologique. |
Procédure
Pour voir ce qu'une opération d'élagage supprimerait, exécutez la commande suivante :
$ oc adm prune deployments --orphans --keep-complete=5 --keep-failed=1 \ --keep-younger-than=60mPour effectuer l'opération d'élagage, ajoutez le drapeau
--confirm:$ oc adm prune deployments --orphans --keep-complete=5 --keep-failed=1 \ --keep-younger-than=60m --confirm
14.4. Taille des constructions
Pour élaguer les builds qui ne sont plus nécessaires au système en raison de leur âge et de leur statut, les administrateurs peuvent exécuter la commande suivante :
$ oc adm prune builds [<options>]| Option | Description |
|---|---|
|
| Indiquer qu'il faut tailler au lieu d'effectuer une marche à blanc. |
|
| Élaguer toutes les constructions dont la configuration de construction n'existe plus, dont l'état est complet, en échec, en erreur ou annulé. |
|
|
Par configuration de construction, conserver les dernières constructions |
|
|
Par configuration de construction, conserver les dernières constructions |
|
|
Ne pas élaguer les objets qui sont plus jeunes que |
Procédure
Pour voir ce qu'une opération d'élagage supprimerait, exécutez la commande suivante :
$ oc adm prune builds --orphans --keep-complete=5 --keep-failed=1 \ --keep-younger-than=60mPour effectuer l'opération d'élagage, ajoutez le drapeau
--confirm:$ oc adm prune builds --orphans --keep-complete=5 --keep-failed=1 \ --keep-younger-than=60m --confirm
Les développeurs peuvent activer l'élagage automatique en modifiant leur configuration.
14.5. Élagage automatique des images
Les images du registre d'images OpenShift qui ne sont plus requises par le système en raison de leur âge, de leur statut ou qui dépassent les limites sont automatiquement élaguées. Les administrateurs de cluster peuvent configurer la ressource personnalisée d'élagage ou la suspendre.
Conditions préalables
- Permissions de l'administrateur du cluster.
-
Installez le CLI
oc.
Procédure
-
Vérifiez que l'objet nommé
imagepruners.imageregistry.operator.openshift.io/clustercontient les champsspecetstatussuivants :
spec:
schedule: 0 0 * * *
suspend: false
keepTagRevisions: 3
keepYoungerThanDuration: 60m
keepYoungerThan: 3600000000000
resources: {}
affinity: {}
nodeSelector: {}
tolerations: []
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 3
status:
observedGeneration: 2
conditions:
- type: Available
status: "True"
lastTransitionTime: 2019-10-09T03:13:45
reason: Ready
message: "Periodic image pruner has been created."
- type: Scheduled
status: "True"
lastTransitionTime: 2019-10-09T03:13:45
reason: Scheduled
message: "Image pruner job has been scheduled."
- type: Failed
staus: "False"
lastTransitionTime: 2019-10-09T03:13:45
reason: Succeeded
message: "Most recent image pruning job succeeded."- 1
schedule:CronJobcalendrier formaté. Ce champ est facultatif, la valeur par défaut est quotidienne à minuit.- 2
suspend: Si la valeur esttrue, l'élagage en coursCronJobest suspendu. Il s'agit d'un champ facultatif, la valeur par défaut étantfalse. La valeur initiale pour les nouveaux clusters estfalse.- 3
keepTagRevisions: Le nombre de révisions par balise à conserver. Ce champ est facultatif, la valeur par défaut est3. La valeur initiale est3.- 4
keepYoungerThanDuration: Conserver les images plus jeunes que cette durée. Ce champ est facultatif. Si aucune valeur n'est spécifiée, c'estkeepYoungerThanou la valeur par défaut60m(60 minutes) qui est utilisée.- 5
keepYoungerThan: Obsolète. Identique àkeepYoungerThanDuration, mais la durée est spécifiée sous la forme d'un entier en nanosecondes. Ce champ est facultatif. LorsquekeepYoungerThanDurationest défini, ce champ est ignoré.- 6
resources: Demandes et limites de ressources standard pour les pods. Ce champ est facultatif.- 7
affinity: Affinité standard du pod. Ce champ est facultatif.- 8
nodeSelector: Sélecteur de nœud de pod standard. Ce champ est facultatif.- 9
tolerations: Tolérances standard du pod. Ce champ est facultatif.- 10
successfulJobsHistoryLimit: Le nombre maximum de travaux réussis à conserver. Doit être>= 1pour que les métriques soient rapportées. Ce champ est facultatif ; la valeur par défaut est3. La valeur initiale est3.- 11
failedJobsHistoryLimit: Le nombre maximum de travaux échoués à conserver. Doit être>= 1pour que les métriques soient rapportées. Ce champ est facultatif ; la valeur par défaut est3. La valeur initiale est3.- 12
observedGeneration: La génération observée par l'opérateur.- 13
conditions: Les objets de la condition standard avec les types suivants :-
Available: Indique si la tâche d'élagage a été créée. Les raisons peuvent être Prêt ou Erreur. -
Scheduled: Indique si le prochain travail d'élagage a été programmé. Les raisons peuvent être Planifié, Suspendu ou Erreur. -
Failed: Indique si le dernier travail d'élagage a échoué.
-
Le comportement de l'opérateur de registre d'images pour la gestion de l'élagueur est orthogonal au managementState spécifié sur l'objet ClusterOperator de l'opérateur de registre d'images. Si l'opérateur de registre d'images n'est pas dans l'état Managed, l'élagueur d'images peut toujours être configuré et géré par la ressource personnalisée d'élagage.
Cependant, le site managementState de l'opérateur de registre d'images modifie le comportement de la tâche d'élagage d'images déployée :
-
Managedle code--prune-registrypour l'élagueur d'images est défini surtrue. -
Removedle drapeau--prune-registryde l'élagueur d'images est fixé àfalse, ce qui signifie qu'il n'élague que les métadonnées d'images dans etcd. -
Unmanagedle code--prune-registrypour l'élagueur d'images est défini surfalse.
14.6. Élagage manuel des images
La ressource personnalisée pruning permet l'élagage automatique des images du registre d'images OpenShift. Cependant, les administrateurs peuvent manuellement élaguer les images qui ne sont plus nécessaires au système en raison de leur âge, de leur statut ou de leur dépassement des limites. Il existe deux méthodes pour élaguer manuellement les images :
-
Exécution de l'élagage des images en tant que
JobouCronJobsur le cluster. -
Exécution de la commande
oc adm prune images.
Conditions préalables
-
Pour élaguer les images, vous devez d'abord vous connecter à l'interface CLI en tant qu'utilisateur disposant d'un jeton d'accès. L'utilisateur doit également avoir le rôle de cluster
system:image-prunerou un rôle supérieur (par exemple,cluster-admin). - Exposer le registre des images.
Procédure
Pour élaguer manuellement les images dont le système n'a plus besoin en raison de leur ancienneté, de leur état ou de leur dépassement, utilisez l'une des méthodes suivantes :
Exécutez l'élagage des images en tant que
JobouCronJobsur le cluster en créant un fichier YAML pour le compte de servicepruner, par exemple :$ oc create -f <filename>.yamlExemple de sortie
kind: List apiVersion: v1 items: - apiVersion: v1 kind: ServiceAccount metadata: name: pruner namespace: openshift-image-registry - apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: openshift-image-registry-pruner roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:image-pruner subjects: - kind: ServiceAccount name: pruner namespace: openshift-image-registry - apiVersion: batch/v1 kind: CronJob metadata: name: image-pruner namespace: openshift-image-registry spec: schedule: "0 0 * * *" concurrencyPolicy: Forbid successfulJobsHistoryLimit: 1 failedJobsHistoryLimit: 3 jobTemplate: spec: template: spec: restartPolicy: OnFailure containers: - image: "quay.io/openshift/origin-cli:4.1" resources: requests: cpu: 1 memory: 1Gi terminationMessagePolicy: FallbackToLogsOnError command: - oc args: - adm - prune - images - --certificate-authority=/var/run/secrets/kubernetes.io/serviceaccount/service-ca.crt - --keep-tag-revisions=5 - --keep-younger-than=96h - --confirm=true name: image-pruner serviceAccountName: prunerExécutez la commande
oc adm prune images [<options>]:$ oc adm prune images [<options>]L'élagage des images supprime les données du registre intégré, sauf si
--prune-registry=falseest utilisé.L'élagage des images avec l'option
--namespacene supprime pas les images, mais uniquement les flux d'images. Les images sont des ressources sans espace de noms. Par conséquent, en limitant l'élagage à un espace de noms particulier, il est impossible de calculer son utilisation actuelle.Par défaut, le registre intégré met en cache les métadonnées des blobs afin de réduire le nombre de demandes de stockage et d'augmenter la vitesse de traitement des demandes. L'élagage ne met pas à jour le cache du registre intégré. Les images qui contiennent encore des couches élaguées après l'élagage seront cassées car les couches élaguées qui ont des métadonnées dans le cache ne seront pas poussées. Par conséquent, vous devez redéployer le registre pour effacer le cache après l'élagage :
$ oc rollout restart deployment/image-registry -n openshift-image-registrySi le registre intégré utilise un cache Redis, vous devez nettoyer la base de données manuellement.
Si le redéploiement du registre après l'élagage n'est pas envisageable, vous devez désactiver le cache de façon permanente.
oc adm prune imagesnécessitent une route pour votre registre. Les routes de registre ne sont pas créées par défaut.Le tableau Prune images CLI configuration options décrit les options que vous pouvez utiliser avec la commande
oc adm prune images <options>.Expand Tableau 14.4. Options de configuration du CLI pour l'élagage des images Option Description --allInclure les images qui n'ont pas été poussées dans le registre, mais qui ont été mises en miroir par pullthrough. Cette option est activée par défaut. Pour limiter l'élagage aux images qui ont été poussées dans le registre intégré, passez
--all=false.--certificate-authorityLe chemin d'accès à un fichier d'autorité de certification à utiliser lors de la communication avec les registres gérés par OpenShift Container Platform. Par défaut, il s'agit des données de l'autorité de certification du fichier de configuration de l'utilisateur actuel. Si elle est fournie, une connexion sécurisée est initiée.
--confirmIndiquer que l'élagage doit avoir lieu, au lieu d'effectuer un test. Cette commande nécessite une route valide vers le registre intégré des images de conteneurs. Si cette commande est exécutée en dehors du réseau du cluster, l'itinéraire doit être fourni à l'aide de
--registry-url.--force-insecureCette option doit être utilisée avec précaution. Autoriser une connexion non sécurisée au registre de conteneurs hébergé via HTTP ou dont le certificat HTTPS n'est pas valide.
--keep-tag-revisions=<N>Pour chaque flux d'images, conserver au maximum
Nrévisions d'images par balise (par défaut3).--keep-younger-than=<duration>Ne pas élaguer les images plus récentes que
<duration>par rapport à l'heure actuelle. Alternativement, n'élaguer aucune image référencée par un autre objet plus récent que<duration>par rapport à l'heure actuelle (par défaut60m).--prune-over-size-limitÉlaguer chaque image qui dépasse la plus petite limite définie dans le même projet. Cet indicateur ne peut pas être combiné avec
--keep-tag-revisionsou--keep-younger-than.--registry-urlAdresse à utiliser pour contacter le registre. La commande tente d'utiliser une URL interne au cluster déterminée à partir des images gérées et des flux d'images. En cas d'échec (le registre ne peut pas être résolu ou atteint), un itinéraire alternatif qui fonctionne doit être fourni à l'aide de cet indicateur. Le nom d'hôte du registre peut être préfixé par
https://ouhttp://, ce qui met en œuvre un protocole de connexion particulier.--prune-registryEn conjonction avec les conditions stipulées par les autres options, cette option contrôle si les données dans le registre correspondant à l'objet API image d'OpenShift Container Platform sont élaguées. Par défaut, l'élagage des images traite à la fois les objets API d'image et les données correspondantes dans le registre.
Cette option est utile lorsque vous souhaitez uniquement supprimer le contenu d'etcd, afin de réduire le nombre d'objets image, mais que vous ne souhaitez pas nettoyer le stockage du registre, ou si vous avez l'intention de le faire séparément en élaguant le registre au cours d'une fenêtre de maintenance appropriée pour le registre.
14.6.1. Image conditions de taille
Vous pouvez appliquer des conditions à vos images élaguées manuellement.
Pour supprimer toute image gérée par OpenShift Container Platform, ou les images avec l'annotation
openshift.io/image.managed:Créés il y a au moins
--keep-younger-thanminutes et qui ne sont actuellement référencés par aucun :-
Pods créés il y a moins de
--keep-younger-thanminutes -
Flux d'images créés il y a moins de
--keep-younger-thanminutes - Nacelles de course à pied
- Dossiers en attente
- Contrôleurs de réplication
- Déploiements
- Configurations de déploiement
- Jeux de répliques
- Construire des configurations
- Constructions
-
--keep-tag-revisionsles éléments les plus récents dansstream.status.tags[].items
-
Pods créés il y a moins de
Qui dépassent la plus petite limite définie dans le même projet et qui ne sont actuellement référencées par aucune :
- Nacelles de course à pied
- Dossiers en attente
- Contrôleurs de réplication
- Déploiements
- Configurations de déploiement
- Jeux de répliques
- Construire des configurations
- Constructions
- Il n'y a pas de support pour l'élagage à partir de registres externes.
-
Lorsqu'une image est élaguée, toutes les références à l'image sont supprimées de tous les flux d'images qui contiennent une référence à l'image dans
status.tags. - Les calques d'image qui ne sont plus référencés par des images sont supprimés.
L'indicateur --prune-over-size-limit ne peut pas être combiné avec l'indicateur --keep-tag-revisions ni avec l'indicateur --keep-younger-than. Le cas échéant, le système renvoie une information indiquant que cette opération n'est pas autorisée.
La séparation de la suppression des objets API d'image OpenShift Container Platform et des données d'image du registre à l'aide de --prune-registry=false, suivie de l'élagage du registre, peut réduire les fenêtres temporelles et est plus sûre que la tentative d'élagage des deux à l'aide d'une seule commande. Toutefois, les fenêtres temporelles ne sont pas complètement supprimées.
Par exemple, vous pouvez toujours créer un pod faisant référence à une image lorsque l'élagage identifie cette image pour l'élagage. Vous devez toujours assurer le suivi d'un objet API créé au cours des opérations d'élagage et pouvant faire référence à des images, afin de limiter les références au contenu supprimé.
Refaire l'élagage sans l'option --prune-registry ou avec --prune-registry=true n'entraîne pas l'élagage du stockage associé dans le registre d'images pour les images précédemment élaguées par --prune-registry=false. Toutes les images qui ont été élaguées avec --prune-registry=false ne peuvent être supprimées du stockage du registre que par un élagage en profondeur du registre.
14.6.2. Exécution de l'opération d'élagage de l'image
Procédure
Pour voir ce qu'une opération d'élagage supprimerait :
Conserver jusqu'à trois révisions de balises et conserver les ressources (images, flux d'images et pods) à moins de 60 minutes :
$ oc adm prune images --keep-tag-revisions=3 --keep-younger-than=60mÉlagage de toutes les images qui dépassent les limites définies :
$ oc adm prune images --prune-over-size-limit
Pour effectuer l'opération d'élagage avec les options de l'étape précédente :
$ oc adm prune images --keep-tag-revisions=3 --keep-younger-than=60m --confirm$ oc adm prune images --prune-over-size-limit --confirm
14.6.3. Utilisation de connexions sécurisées ou non
La connexion sécurisée est l'approche préférée et recommandée. Elle s'effectue via le protocole HTTPS avec une vérification obligatoire du certificat. La commande prune tente toujours de l'utiliser si possible. Si ce n'est pas possible, elle peut dans certains cas se rabattre sur une connexion non sécurisée, ce qui est dangereux. Dans ce cas, soit la vérification du certificat est ignorée, soit le protocole HTTP simple est utilisé.
Le retour à une connexion non sécurisée est autorisé dans les cas suivants, sauf si --certificate-authority est spécifié :
-
La commande
pruneest exécutée avec l'option--force-insecure. -
Le site
registry-urlest préfixé par le schémahttp://. -
L'adresse fournie
registry-urlest une adresse de lien local oulocalhost. -
La configuration de l'utilisateur actuel permet une connexion non sécurisée. Cela peut être dû au fait que l'utilisateur se connecte à l'aide de
--insecure-skip-tls-verifyou choisit une connexion non sécurisée lorsqu'il y est invité.
Si le registre est sécurisé par une autorité de certification différente de celle utilisée par OpenShift Container Platform, elle doit être spécifiée à l'aide du drapeau --certificate-authority. Dans le cas contraire, la commande prune génère une erreur.
14.6.4. Problèmes d'élagage des images
Images non élaguées
Si vos images continuent de s'accumuler et que la commande prune ne supprime qu'une petite partie de ce que vous attendez, assurez-vous de bien comprendre les conditions d'élagage des images qui doivent s'appliquer pour qu'une image soit considérée comme candidate à l'élagage.
Assurez-vous que les images que vous souhaitez supprimer se trouvent à des positions plus élevées dans l'historique de chaque balise que le seuil de révision des balises que vous avez choisi. Prenons l'exemple d'une image ancienne et obsolète nommée sha:abz. En exécutant la commande suivante dans l'espace de noms N, où l'image est balisée, l'image est balisée trois fois dans un flux d'images unique nommé myapp:
$ oc get is -n N -o go-template='{{range $isi, $is := .items}}{{range $ti, $tag := $is.status.tags}}'\
'{{range $ii, $item := $tag.items}}{{if eq $item.image "'"sha:abz"\
$'"}}{{$is.metadata.name}}:{{$tag.tag}} at position {{$ii}} out of {{len $tag.items}}\n'\
'{{end}}{{end}}{{end}}{{end}}'Exemple de sortie
myapp:v2 at position 4 out of 5
myapp:v2.1 at position 2 out of 2
myapp:v2.1-may-2016 at position 0 out of 1
Lorsque les options par défaut sont utilisées, l'image n'est jamais élaguée parce qu'elle se trouve à la position 0 dans un historique de la balise myapp:v2.1-may-2016. Pour qu'une image soit prise en compte pour l'élagage, l'administrateur doit soit
Spécifiez
--keep-tag-revisions=0avec la commandeoc adm prune images.AvertissementCette action supprime toutes les balises de tous les espaces de noms avec les images sous-jacentes, à moins qu'elles ne soient plus jeunes ou qu'elles soient référencées par des objets plus jeunes que le seuil spécifié.
-
Supprimer tous les
istagsdont la position est inférieure au seuil de révision, c'est-à-diremyapp:v2.1etmyapp:v2.1-may-2016. -
Déplacer l'image plus loin dans l'historique, soit en lançant de nouvelles versions qui poussent vers le même
istag, soit en étiquetant d'autres images. Cela n'est pas toujours souhaitable pour les anciennes versions.
Les balises dont le nom contient la date ou l'heure de création d'une image particulière sont à éviter, sauf si l'image doit être conservée pendant une durée indéterminée. Ces balises ont tendance à n'avoir qu'une seule image dans leur historique, ce qui les empêche d'être élaguées.
Utilisation d'une connexion sécurisée contre un registre non sécurisé
Si vous voyez un message similaire au suivant dans la sortie de la commande oc adm prune images, c'est que votre registre n'est pas sécurisé et que le client oc adm prune images tente d'utiliser une connexion sécurisée :
error: error communicating with registry: Get https://172.30.30.30:5000/healthz: http: server gave HTTP response to HTTPS client-
La solution recommandée est de sécuriser le registre. Sinon, vous pouvez forcer le client à utiliser une connexion non sécurisée en ajoutant
--force-insecureà la commande ; cette solution n'est toutefois pas recommandée.
Utilisation d'une connexion non sécurisée contre un registre sécurisé
Si l'une des erreurs suivantes apparaît dans le résultat de la commande oc adm prune images, cela signifie que votre registre est sécurisé par un certificat signé par une autorité de certification autre que celle utilisée par le client oc adm prune images pour la vérification de la connexion :
error: error communicating with registry: Get http://172.30.30.30:5000/healthz: malformed HTTP response "\x15\x03\x01\x00\x02\x02"
error: error communicating with registry: [Get https://172.30.30.30:5000/healthz: x509: certificate signed by unknown authority, Get http://172.30.30.30:5000/healthz: malformed HTTP response "\x15\x03\x01\x00\x02\x02"]Par défaut, les données de l'autorité de certification stockées dans les fichiers de configuration de l'utilisateur sont utilisées ; il en va de même pour la communication avec l'API maître.
Utilisez l'option --certificate-authority pour fournir l'autorité de certification appropriée pour le serveur de registre d'images de conteneurs.
Utilisation d'une mauvaise autorité de certification
L'erreur suivante signifie que l'autorité de certification utilisée pour signer le certificat du registre d'images de conteneurs sécurisés est différente de l'autorité utilisée par le client :
error: error communicating with registry: Get https://172.30.30.30:5000/: x509: certificate signed by unknown authority
Veillez à fournir le bon drapeau à --certificate-authority.
En guise de solution de contournement, le drapeau --force-insecure peut être ajouté à la place. Cette solution n'est toutefois pas recommandée.
14.7. L'élagage du registre
Le registre OpenShift Container Registry peut accumuler des blobs qui ne sont pas référencés par le etcd du cluster OpenShift Container Platform. La procédure de base d'élagage des images ne peut donc pas les traiter. Ces images sont appelées orphaned blobs.
Les blobs orphelins peuvent se produire dans les cas suivants :
-
Suppression manuelle d'une image avec la commande
oc delete image <sha256:image-id>, qui supprime uniquement l'image de etcd, mais pas du registre. - La poussée vers le registre est initiée par des défaillances du démon, ce qui fait que certains blobs sont téléchargés, mais pas le manifeste de l'image (qui est téléchargé en tant que tout dernier composant). Toutes les images uniques deviennent orphelines.
- OpenShift Container Platform refuse une image en raison de restrictions de quotas.
- L'élagueur d'images standard supprime un manifeste d'image, mais il est interrompu avant de supprimer les blocs correspondants.
- Un bogue dans l'élagueur de registre, qui ne parvient pas à supprimer les blobs prévus, ce qui entraîne la suppression des objets images qui y font référence et rend les blobs orphelins.
Hard pruning le registre, une procédure distincte de l'élagage de l'image de base, permet aux administrateurs de cluster de supprimer les blobs orphelins. Vous devriez procéder à un hard prune si vous manquez d'espace de stockage dans votre OpenShift Container Registry et que vous pensez avoir des blobs orphelins.
Cette opération doit être peu fréquente et n'est nécessaire que si vous avez la preuve qu'un nombre important de nouveaux orphelins a été créé. Sinon, vous pouvez procéder à un élagage standard des images à intervalles réguliers, par exemple une fois par jour (en fonction du nombre d'images créées).
Procédure
Pour éliminer les blobs orphelins du registre :
Log in.
Connectez-vous au cluster avec le CLI en tant que
kubeadminou un autre utilisateur privilégié ayant accès à l'espace de nomsopenshift-image-registry.Run a basic image prune.
L'élagage de base des images supprime les images supplémentaires qui ne sont plus nécessaires. L'élagage dur ne supprime pas les images en soi. Il ne supprime que les blobs stockés dans le registre. Par conséquent, vous devez exécuter cette opération juste avant l'élagage en profondeur.
Switch the registry to read-only mode.
Si le registre n'est pas en mode lecture seule, les poussées qui se produisent en même temps que l'élagage ne le seront pas non plus :
- échouer et provoquer de nouveaux orphelins, ou
- réussit bien que les images ne puissent pas être extraites (parce que certains des blobs référencés ont été supprimés).
Les poussées n'aboutiront pas tant que le registre ne sera pas repassé en mode lecture-écriture. Par conséquent, l'élagage doit être programmé avec soin.
Pour passer le registre en mode lecture seule :
Sur le site
configs.imageregistry.operator.openshift.io/cluster, l'adressespec.readOnlyest remplacée par l'adressetrue:$ oc patch configs.imageregistry.operator.openshift.io/cluster -p '{"spec":{"readOnly":true}}' --type=merge
Add the
system:image-prunerrole.Le compte de service utilisé pour exécuter les instances du registre nécessite des autorisations supplémentaires pour répertorier certaines ressources.
Obtenir le nom du compte de service :
$ service_account=$(oc get -n openshift-image-registry \ -o jsonpath='{.spec.template.spec.serviceAccountName}' deploy/image-registry)Ajoutez le rôle de cluster
system:image-prunerau compte de service :$ oc adm policy add-cluster-role-to-user \ system:image-pruner -z \ ${service_account} -n openshift-image-registry
Optional: Run the pruner in dry-run mode.
Pour voir combien de blobs seraient supprimés, exécutez l'élagueur en mode "dry-run". Aucune modification n'est alors effectuée. L'exemple suivant fait référence à un pod de registre d'images appelé
image-registry-3-vhndw:$ oc -n openshift-image-registry exec pod/image-registry-3-vhndw -- /bin/sh -c '/usr/bin/dockerregistry -prune=check'Pour obtenir les chemins exacts des candidats à l'élagage, vous pouvez également augmenter le niveau de journalisation :
$ oc -n openshift-image-registry exec pod/image-registry-3-vhndw -- /bin/sh -c 'REGISTRY_LOG_LEVEL=info /usr/bin/dockerregistry -prune=check'Exemple de sortie
time="2017-06-22T11:50:25.066156047Z" level=info msg="start prune (dry-run mode)" distribution_version="v2.4.1+unknown" kubernetes_version=v1.6.1+$Format:%h$ openshift_version=unknown time="2017-06-22T11:50:25.092257421Z" level=info msg="Would delete blob: sha256:00043a2a5e384f6b59ab17e2c3d3a3d0a7de01b2cabeb606243e468acc663fa5" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:25.092395621Z" level=info msg="Would delete blob: sha256:0022d49612807cb348cabc562c072ef34d756adfe0100a61952cbcb87ee6578a" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:25.092492183Z" level=info msg="Would delete blob: sha256:0029dd4228961086707e53b881e25eba0564fa80033fbbb2e27847a28d16a37c" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:26.673946639Z" level=info msg="Would delete blob: sha256:ff7664dfc213d6cc60fd5c5f5bb00a7bf4a687e18e1df12d349a1d07b2cf7663" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:26.674024531Z" level=info msg="Would delete blob: sha256:ff7a933178ccd931f4b5f40f9f19a65be5eeeec207e4fad2a5bafd28afbef57e" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:26.674675469Z" level=info msg="Would delete blob: sha256:ff9b8956794b426cc80bb49a604a0b24a1553aae96b930c6919a6675db3d5e06" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 ... Would delete 13374 blobs Would free up 2.835 GiB of disk space Use -prune=delete to actually delete the dataRun the hard prune.
Exécutez la commande suivante à l'intérieur d'une instance en cours d'exécution d'un pod
image-registrypour exécuter le hard prune. L'exemple suivant fait référence à un module de registre d'images appeléimage-registry-3-vhndw:$ oc -n openshift-image-registry exec pod/image-registry-3-vhndw -- /bin/sh -c '/usr/bin/dockerregistry -prune=delete'Exemple de sortie
Deleted 13374 blobs Freed up 2.835 GiB of disk spaceSwitch the registry back to read-write mode.
Une fois l'élagage terminé, le registre peut être remis en mode lecture-écriture. Dans
configs.imageregistry.operator.openshift.io/cluster, définissezspec.readOnlysurfalse:$ oc patch configs.imageregistry.operator.openshift.io/cluster -p '{"spec":{"readOnly":false}}' --type=merge
14.8. Élaguer les tâches cron
Les tâches Cron permettent d'élaguer les tâches réussies, mais risquent de ne pas gérer correctement les tâches échouées. C'est pourquoi l'administrateur du cluster doit procéder à un nettoyage régulier des tâches manuellement. Il doit également limiter l'accès aux tâches cron à un petit groupe d'utilisateurs de confiance et définir des quotas appropriés pour empêcher la tâche cron de créer un trop grand nombre de tâches et de pods.
Chapitre 15. Applications de la marche au ralenti
Les administrateurs de clusters peuvent mettre les applications en veille pour réduire la consommation de ressources. Ceci est utile lorsque le cluster est déployé sur un nuage public où le coût est lié à la consommation de ressources.
Si des ressources évolutives ne sont pas utilisées, OpenShift Container Platform les découvre et les désactive en mettant à l'échelle leurs répliques à l'adresse 0. La prochaine fois que le trafic réseau est dirigé vers les ressources, celles-ci sont désidentifiées en mettant à l'échelle les répliques, et le fonctionnement normal se poursuit.
Les applications sont constituées de services, ainsi que d'autres ressources évolutives, telles que les configurations de déploiement. La mise en veille d'une application implique la mise en veille de toutes les ressources associées.
15.1. Applications de la marche au ralenti
La mise en veille d'une application consiste à trouver les ressources évolutives (configurations de déploiement, contrôleurs de réplication et autres) associées à un service. La mise en veille d'une application trouve le service et le marque comme étant en veille, en réduisant les ressources à zéro réplique.
Vous pouvez utiliser la commande oc idle pour mettre en veille un seul service ou utiliser l'option --resource-names-file pour mettre en veille plusieurs services.
15.1.1. Marche au ralenti d'un seul service
Procédure
Pour ralentir un seul service, exécutez :
$ oc idle <service>
15.1.2. Fonctionnement au ralenti de plusieurs services
La mise en veille de plusieurs services est utile si une application s'étend sur un ensemble de services au sein d'un projet, ou lorsque la mise en veille de plusieurs services est associée à un script permettant de mettre en veille plusieurs applications en vrac au sein d'un même projet.
Procédure
- Créez un fichier contenant la liste des services, chacun sur sa propre ligne.
Mettez les services au repos en utilisant l'option
--resource-names-file:$ oc idle --resource-names-file <filename>
La commande idle est limitée à un seul projet. Pour faire tourner les applications au ralenti dans une grappe, exécutez la commande idle pour chaque projet individuellement.
15.2. Applications de la marche au ralenti
Les services d'application redeviennent actifs lorsqu'ils reçoivent du trafic réseau et sont ramenés à leur état antérieur. Cela comprend à la fois le trafic vers les services et le trafic passant par les routes.
Les applications peuvent également être débridées manuellement en augmentant les ressources.
Procédure
Pour mettre à l'échelle une DeploymentConfig, exécutez :
oc scale --replicas=1 dc <dc_name> $ oc scale --replicas=1 dc <dc_name>
Le déverrouillage automatique par un routeur n'est actuellement pris en charge que par le routeur HAProxy par défaut.
Les services ne supportent pas le désidentification automatique si vous configurez Kuryr-Kubernetes comme un SDN.
Chapitre 16. Suppression d'applications
Vous pouvez supprimer les applications créées dans votre projet.
16.1. Suppression d'applications à l'aide de la perspective du développeur
Vous pouvez supprimer une application et tous ses composants associés en utilisant la vue Topology dans la perspective Developer:
- Cliquez sur l'application que vous souhaitez supprimer pour afficher le panneau latéral contenant les détails des ressources de l'application.
- Cliquez sur le menu déroulant Actions affiché en haut à droite du tableau de bord et sélectionnez Delete Application pour afficher une boîte de dialogue de confirmation.
- Saisissez le nom de l'application et cliquez sur Delete pour la supprimer.
Vous pouvez également cliquer avec le bouton droit de la souris sur l'application que vous souhaitez supprimer et cliquer sur Delete Application pour la supprimer.
Chapitre 17. Utilisation de Red Hat Marketplace
Red Hat Marketplace est une place de marché ouverte pour le cloud qui facilite la découverte et l'accès à des logiciels certifiés pour les environnements basés sur des conteneurs qui fonctionnent sur des clouds publics et sur site.
17.1. Fonctionnalités de Red Hat Marketplace
Les administrateurs de clusters peuvent utiliser Red Hat Marketplace pour gérer les logiciels sur OpenShift Container Platform, donner aux développeurs un accès en libre-service pour déployer des instances d'applications et corréler l'utilisation des applications par rapport à un quota.
17.1.1. Connecter les clusters OpenShift Container Platform à la place de marché
Les administrateurs de clusters peuvent installer un ensemble commun d'applications sur les clusters OpenShift Container Platform qui se connectent à la Marketplace. Ils peuvent également utiliser la place de marché pour suivre l'utilisation des clusters par rapport aux abonnements ou aux quotas. Les utilisateurs qu'ils ajoutent en utilisant la place de marché voient leur utilisation du produit suivie et facturée à leur organisation.
Au cours du processus de connexion au cluster, un opérateur Marketplace est installé pour mettre à jour le secret du registre des images, gérer le catalogue et rendre compte de l'utilisation de l'application.
17.1.2. Installer des applications
Les administrateurs de cluster peuvent installer les applications Marketplace depuis OperatorHub dans OpenShift Container Platform, ou depuis l'application web Marketplace.
Vous pouvez accéder aux applications installées à partir de la console web en cliquant sur Operators > Installed Operators.
17.1.3. Déployer des applications selon différentes perspectives
Vous pouvez déployer les applications Marketplace à partir des perspectives Administrateur et Développeur de la console web.
Le point de vue du développeur
Les développeurs peuvent accéder aux capacités nouvellement installées en utilisant la perspective du développeur.
Par exemple, après l'installation d'un opérateur de base de données, un développeur peut créer une instance à partir du catalogue dans son projet. L'utilisation de la base de données est agrégée et communiquée à l'administrateur du cluster.
Cette perspective n'inclut pas l'installation de l'opérateur et le suivi de l'utilisation de l'application.
Le point de vue de l'administrateur
Les administrateurs de clusters peuvent accéder à l'installation de l'opérateur et aux informations sur l'utilisation de l'application à partir de la perspective de l'administrateur.
Ils peuvent également lancer des instances d'application en parcourant les définitions de ressources personnalisées (CRD) dans la liste Installed Operators.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.