Mise en réseau
Configuration et gestion de la mise en réseau des clusters
Résumé
Chapitre 1. About networking
Red Hat OpenShift Networking est un écosystème de fonctionnalités, de plugins et de capacités de mise en réseau avancées qui étendent la mise en réseau de Kubernetes avec les fonctionnalités avancées liées à la mise en réseau dont votre cluster a besoin pour gérer son trafic réseau pour un ou plusieurs clusters hybrides. Cet écosystème de capacités de mise en réseau intègre l'entrée, la sortie, l'équilibrage de charge, le débit haute performance, la sécurité, la gestion du trafic inter- et intra-cluster et fournit un outil d'observabilité basé sur les rôles pour réduire ses complexités naturelles.
La liste suivante met en évidence certaines des fonctionnalités de Red Hat OpenShift Networking les plus couramment utilisées et disponibles sur votre cluster :
Réseau primaire du cluster fourni par l'un des plugins Container Network Interface (CNI) suivants :
- Plugin réseau OVN-Kubernetes, le plugin par défaut est le plugin réseau OVN-Kubernetes
- Plugin réseau SDN OpenShift, une alternative optionnelle
- Plugins de réseaux primaires alternatifs certifiés par des tiers
- Opérateur de réseau en grappe pour la gestion des plugins de réseau
- Opérateur d'entrée pour le trafic web crypté TLS
- Opérateur DNS pour l'attribution des noms
- MetalLB Operator pour l'équilibrage de la charge de trafic sur les clusters bare metal
- Prise en charge du basculement IP pour une haute disponibilité
- Prise en charge supplémentaire des réseaux matériels grâce à plusieurs plugins CNI, notamment pour les réseaux matériels macvlan, ipvlan et SR-IOV
- IPv4, IPv6 et adressage double pile
- Clusters hybrides Linux-Windows pour les charges de travail basées sur Windows
- Red Hat OpenShift Service Mesh pour la découverte, l'équilibrage de charge, l'authentification de service à service, la reprise sur panne, les métriques et la surveillance des services
- OpenShift à nœud unique
- Opérateur d'observabilité du réseau pour le débogage et l'analyse du réseau
- Technologies Submariner et Red Hat Application Interconnect pour la mise en réseau entre clusters
Chapitre 2. Comprendre la mise en réseau
Les administrateurs de clusters disposent de plusieurs options pour exposer au trafic externe les applications qui s'exécutent au sein d'un cluster et pour sécuriser les connexions réseau :
- Types de services, tels que les ports de nœuds ou les équilibreurs de charge
-
Les ressources de l'API, telles que
IngressetRoute
Par défaut, Kubernetes attribue à chaque pod une adresse IP interne pour les applications qui s'exécutent dans le pod. Les pods et leurs conteneurs peuvent fonctionner en réseau, mais les clients extérieurs au cluster n'ont pas accès au réseau. Lorsque vous exposez votre application au trafic externe, le fait de donner à chaque module sa propre adresse IP signifie que les modules peuvent être traités comme des hôtes physiques ou des machines virtuelles en termes d'allocation de ports, de mise en réseau, de nommage, de découverte de services, d'équilibrage de charge, de configuration d'applications et de migration.
Certaines plateformes en nuage proposent des API de métadonnées qui écoutent l'adresse IP 169.254.169.254, une adresse IP locale dans le bloc CIDR d'IPv4 169.254.0.0/16.
Ce bloc CIDR n'est pas accessible depuis le réseau de pods. Les pods qui ont besoin d'accéder à ces adresses IP doivent recevoir un accès au réseau hôte en définissant le champ spec.hostNetwork dans la spécification du pod sur true.
Si vous autorisez un hôte pod à accéder au réseau, vous lui accordez un accès privilégié à l'infrastructure réseau sous-jacente.
2.1. OpenShift Container Platform DNS
Si vous exécutez plusieurs services, tels que des services front-end et back-end à utiliser avec plusieurs pods, des variables d'environnement sont créées pour les noms d'utilisateur, les IP de service, etc. afin que les pods front-end puissent communiquer avec les services back-end. Si le service est supprimé et recréé, une nouvelle adresse IP peut lui être attribuée, ce qui oblige à recréer les pods frontaux pour récupérer les valeurs mises à jour de la variable d'environnement IP du service. En outre, le service back-end doit être créé avant tous les pods front-end pour garantir que l'IP du service est générée correctement et qu'elle peut être fournie aux pods front-end en tant que variable d'environnement.
Pour cette raison, OpenShift Container Platform dispose d'un DNS intégré de sorte que les services peuvent être atteints par le DNS du service ainsi que par l'IP/port du service.
2.2. Opérateur Ingress de la plateforme de conteneurs OpenShift
Lorsque vous créez votre cluster OpenShift Container Platform, les pods et les services s'exécutant sur le cluster se voient attribuer chacun leur propre adresse IP. Les adresses IP sont accessibles aux autres pods et services fonctionnant à proximité, mais ne sont pas accessibles aux clients extérieurs. L'opérateur d'ingestion (Ingress Operator) met en œuvre l'API IngressController et est le composant responsable de l'activation de l'accès externe aux services de cluster d'OpenShift Container Platform.
L'opérateur d'ingestion permet aux clients externes d'accéder à votre service en déployant et en gérant un ou plusieurs contrôleurs d'ingestion basés sur HAProxy pour gérer le routage. Vous pouvez utiliser l'opérateur d'ingestion pour acheminer le trafic en spécifiant les ressources OpenShift Container Platform Route et Kubernetes Ingress. Les configurations au sein du contrôleur d'ingestion, telles que la possibilité de définir le type endpointPublishingStrategy et l'équilibrage de charge interne, fournissent des moyens de publier les points d'extrémité du contrôleur d'ingestion.
2.2.1. Comparaison des itinéraires et des entrées
La ressource Kubernetes Ingress dans OpenShift Container Platform met en œuvre le contrôleur Ingress avec un service de routeur partagé qui s'exécute en tant que pod dans le cluster. La façon la plus courante de gérer le trafic Ingress est d'utiliser le contrôleur Ingress. Vous pouvez faire évoluer et répliquer ce pod comme n'importe quel autre pod ordinaire. Ce service de routeur est basé sur HAProxy, qui est une solution d'équilibreur de charge open source.
La route OpenShift Container Platform fournit le trafic Ingress aux services dans le cluster. Les routes offrent des fonctionnalités avancées qui peuvent ne pas être prises en charge par les contrôleurs d'entrée Kubernetes standard, telles que le recryptage TLS, le passage TLS et le fractionnement du trafic pour les déploiements bleu-vert.
Le trafic entrant accède aux services du cluster par l'intermédiaire d'une route. Les routes et les entrées sont les principales ressources permettant de gérer le trafic entrant. Ingress offre des fonctionnalités similaires à celles d'une route, telles que l'acceptation de demandes externes et leur délégation en fonction de la route. Cependant, avec Ingress, vous ne pouvez autoriser que certains types de connexions : HTTP/2, HTTPS et identification du nom du serveur (SNI), et TLS avec certificat. Dans OpenShift Container Platform, les routes sont générées pour répondre aux conditions spécifiées par la ressource Ingress.
2.3. Glossaire des termes courants pour la mise en réseau de OpenShift Container Platform
Ce glossaire définit les termes courants utilisés dans le contenu des réseaux.
- l'authentification
- Pour contrôler l'accès à un cluster OpenShift Container Platform, un administrateur de cluster peut configurer l'authentification des utilisateurs et s'assurer que seuls les utilisateurs approuvés accèdent au cluster. Pour interagir avec un cluster OpenShift Container Platform, vous devez vous authentifier auprès de l'API OpenShift Container Platform. Vous pouvez vous authentifier en fournissant un jeton d'accès OAuth ou un certificat client X.509 dans vos demandes à l'API OpenShift Container Platform.
- Opérateur d'équilibreur de charge AWS
-
L'opérateur AWS Load Balancer (ALB) déploie et gère une instance de
aws-load-balancer-controller. - Opérateur de réseau en grappe
- L'opérateur de réseau de cluster (CNO) déploie et gère les composants du réseau de cluster dans un cluster OpenShift Container Platform. Cela inclut le déploiement du plugin réseau Container Network Interface (CNI) sélectionné pour le cluster lors de l'installation.
- carte de configuration
-
Une carte de configuration permet d'injecter des données de configuration dans les pods. Vous pouvez référencer les données stockées dans une carte de configuration dans un volume de type
ConfigMap. Les applications fonctionnant dans un pod peuvent utiliser ces données. - ressource personnalisée (CR)
- Un CR est une extension de l'API Kubernetes. Vous pouvez créer des ressources personnalisées.
- DNS
- Cluster DNS est un serveur DNS qui sert les enregistrements DNS pour les services Kubernetes. Les conteneurs démarrés par Kubernetes incluent automatiquement ce serveur DNS dans leurs recherches DNS.
- Opérateur DNS
- L'opérateur DNS déploie et gère CoreDNS pour fournir un service de résolution de noms aux pods. Cela permet la découverte de services Kubernetes basée sur le DNS dans OpenShift Container Platform.
- déploiement
- Un objet de ressource Kubernetes qui maintient le cycle de vie d'une application.
- domaine
- Le domaine est un nom DNS géré par le contrôleur d'entrée.
- évacuation
- Processus de partage de données vers l'extérieur par le biais du trafic sortant d'un réseau à partir d'un pod.
- Opérateur DNS externe
- L'opérateur DNS externe déploie et gère ExternalDNS pour fournir la résolution de nom pour les services et les routes du fournisseur DNS externe à OpenShift Container Platform.
- Itinéraire basé sur HTTP
- Une route basée sur HTTP est une route non sécurisée qui utilise le protocole de routage HTTP de base et expose un service sur un port d'application non sécurisé.
- Entrée
- La ressource Kubernetes Ingress dans OpenShift Container Platform met en œuvre le contrôleur Ingress avec un service de routeur partagé qui s'exécute en tant que pod dans le cluster.
- Contrôleur d'entrée
- L'opérateur d'ingestion gère les contrôleurs d'ingestion. L'utilisation d'un contrôleur d'ingestion est le moyen le plus courant d'autoriser l'accès externe à un cluster OpenShift Container Platform.
- l'infrastructure fournie par l'installateur
- Le programme d'installation déploie et configure l'infrastructure sur laquelle le cluster fonctionne.
- kubelet
- Un agent de nœud primaire qui s'exécute sur chaque nœud du cluster pour s'assurer que les conteneurs s'exécutent dans un pod.
- Opérateur NMState de Kubernetes
- L'opérateur Kubernetes NMState fournit une API Kubernetes pour effectuer une configuration réseau basée sur l'état à travers les nœuds du cluster OpenShift Container Platform avec NMState.
- kube-proxy
- Kube-proxy est un service proxy qui s'exécute sur chaque nœud et aide à mettre des services à la disposition de l'hôte externe. Il aide à transmettre les demandes aux bons conteneurs et est capable d'effectuer un équilibrage primitif de la charge.
- équilibreurs de charge
- OpenShift Container Platform utilise des répartiteurs de charge pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster.
- Opérateur MetalLB
-
En tant qu'administrateur de cluster, vous pouvez ajouter l'opérateur MetalLB à votre cluster afin que lorsqu'un service de type
LoadBalancerest ajouté au cluster, MetalLB puisse ajouter une adresse IP externe pour le service. - multidiffusion
- Avec la multidiffusion IP, les données sont diffusées simultanément à de nombreuses adresses IP.
- espaces nominatifs
- Un espace de noms isole des ressources système spécifiques qui sont visibles par tous les processus. À l'intérieur d'un espace de noms, seuls les processus membres de cet espace peuvent voir ces ressources.
- la mise en réseau
- Informations sur le réseau d'un cluster OpenShift Container Platform.
- nœud
- Une machine de travail dans le cluster OpenShift Container Platform. Un nœud est soit une machine virtuelle (VM), soit une machine physique.
- Opérateur Ingress de la plateforme de conteneurs OpenShift
-
L'opérateur d'ingestion met en œuvre l'API
IngressControlleret est le composant responsable de l'accès externe aux services d'OpenShift Container Platform. - nacelle
- Un ou plusieurs conteneurs avec des ressources partagées, telles que le volume et les adresses IP, fonctionnant dans votre cluster OpenShift Container Platform. Un pod est la plus petite unité de calcul définie, déployée et gérée.
- Opérateur PTP
-
L'opérateur PTP crée et gère les services
linuxptp. - itinéraire
- La route OpenShift Container Platform fournit le trafic Ingress aux services dans le cluster. Les routes offrent des fonctionnalités avancées qui peuvent ne pas être prises en charge par les contrôleurs d'entrée Kubernetes standard, telles que le recryptage TLS, le passage TLS et le fractionnement du trafic pour les déploiements bleu-vert.
- mise à l'échelle
- Augmentation ou diminution de la capacité des ressources.
- service
- Expose une application en cours d'exécution sur un ensemble de pods.
- Opérateur de réseau de virtualisation d'E/S à racine unique (SR-IOV)
- L'opérateur de réseau SR-IOV (Single Root I/O Virtualization) gère les périphériques réseau SR-IOV et les attachements réseau dans votre cluster.
- les réseaux définis par logiciel (SDN)
- OpenShift Container Platform utilise une approche de mise en réseau définie par logiciel (SDN) pour fournir un réseau de cluster unifié qui permet la communication entre les pods à travers le cluster OpenShift Container Platform.
- Protocole de transmission de contrôle de flux (SCTP)
- SCTP est un protocole fiable basé sur des messages qui fonctionne sur un réseau IP.
- souillure
- Les taches et les tolérances garantissent que les pods sont planifiés sur les nœuds appropriés. Vous pouvez appliquer un ou plusieurs taints à un nœud.
- tolérance
- Vous pouvez appliquer des tolérances aux modules. Les tolérances permettent à l'ordonnanceur de programmer des pods dont les taches correspondent.
- console web
- Une interface utilisateur (UI) pour gérer OpenShift Container Platform.
Chapitre 3. Accès aux hôtes
Apprenez à créer un hôte bastion pour accéder aux instances OpenShift Container Platform et aux nœuds du plan de contrôle à l'aide d'un accès shell sécurisé (SSH).
3.1. Accès aux hôtes sur Amazon Web Services dans un cluster d'infrastructure provisionné par l'installateur
Le programme d'installation d'OpenShift Container Platform ne crée pas d'adresses IP publiques pour les instances Amazon Elastic Compute Cloud (Amazon EC2) qu'il provisionne pour votre cluster OpenShift Container Platform. Pour pouvoir accéder par SSH à vos hôtes OpenShift Container Platform, vous devez suivre cette procédure.
Procédure
-
Créez un groupe de sécurité qui autorise l'accès SSH au nuage privé virtuel (VPC) créé par la commande
openshift-install. - Créez une instance Amazon EC2 sur l'un des sous-réseaux publics créés par le programme d'installation.
Associez une adresse IP publique à l'instance Amazon EC2 que vous avez créée.
Contrairement à l'installation d'OpenShift Container Platform, vous devez associer l'instance Amazon EC2 que vous avez créée à une paire de clés SSH. Le système d'exploitation que vous choisissez pour cette instance n'a pas d'importance, car elle servira simplement de bastion SSH pour relier l'internet au VPC de votre cluster OpenShift Container Platform. L'Amazon Machine Image (AMI) que vous utilisez a son importance. Avec Red Hat Enterprise Linux CoreOS (RHCOS), par exemple, vous pouvez fournir des clés via Ignition, comme le fait le programme d'installation.
Une fois que vous avez provisionné votre instance Amazon EC2 et que vous pouvez y accéder par SSH, vous devez ajouter la clé SSH que vous avez associée à votre installation d'OpenShift Container Platform. Cette clé peut être différente de la clé de l'instance bastion, mais ce n'est pas obligatoire.
NoteL'accès SSH direct n'est recommandé que pour la reprise après sinistre. Lorsque l'API Kubernetes est réactive, exécutez plutôt des pods privilégiés.
-
Exécutez
oc get nodes, inspectez la sortie et choisissez l'un des nœuds qui est un maître. Le nom d'hôte ressemble àip-10-0-1-163.ec2.internal. À partir de l'hôte SSH Bastion que vous avez déployé manuellement dans Amazon EC2, connectez-vous en SSH à l'hôte du plan de contrôle. Veillez à utiliser la même clé SSH que celle spécifiée lors de l'installation :
$ ssh -i <ssh-key-path> core@<master-hostname>
Chapitre 4. Aperçu des opérateurs de réseaux
OpenShift Container Platform prend en charge plusieurs types d'opérateurs de mise en réseau. Vous pouvez gérer la mise en réseau du cluster à l'aide de ces opérateurs de mise en réseau.
4.1. Opérateur de réseau en grappe
L'opérateur de réseau de cluster (CNO) déploie et gère les composants du réseau de cluster dans un cluster OpenShift Container Platform. Cela inclut le déploiement du plugin réseau Container Network Interface (CNI) sélectionné pour le cluster lors de l'installation. Pour plus d'informations, voir Cluster Network Operator dans OpenShift Container Platform.
4.2. Opérateur DNS
L'opérateur DNS déploie et gère CoreDNS pour fournir un service de résolution de noms aux pods. Cela permet la découverte de services Kubernetes basés sur le DNS dans OpenShift Container Platform. Pour plus d'informations, voir DNS Operator dans OpenShift Container Platform.
4.3. Opérateur d'entrée
Lorsque vous créez votre cluster OpenShift Container Platform, les pods et les services fonctionnant sur le cluster se voient attribuer des adresses IP. Les adresses IP sont accessibles à d'autres pods et services fonctionnant à proximité, mais ne sont pas accessibles aux clients externes. L'opérateur d'ingestion met en œuvre l'API du contrôleur d'ingestion et est responsable de l'activation de l'accès externe aux services du cluster OpenShift Container Platform. Pour plus d'informations, voir Ingress Operator dans OpenShift Container Platform.
4.4. Opérateur DNS externe
L'opérateur DNS externe déploie et gère ExternalDNS pour fournir la résolution de nom pour les services et les routes du fournisseur DNS externe à OpenShift Container Platform. Pour plus d'informations, voir Comprendre l'opérateur DNS externe.
4.5. Opérateur du pare-feu du nœud d'entrée
L'opérateur du pare-feu du nœud d'entrée utilise un filtre de paquets Berkley étendu (eBPF) et un plugin eXpress Data Path (XDP) pour traiter les règles du pare-feu du nœud, mettre à jour les statistiques et générer des événements pour le trafic abandonné. L'opérateur gère les ressources du pare-feu du nœud d'entrée, vérifie la configuration du pare-feu, n'autorise pas les règles mal configurées susceptibles d'empêcher l'accès au cluster et charge les programmes XDP du pare-feu du nœud d'entrée sur les interfaces sélectionnées dans l'objet ou les objets de la règle. Pour plus d'informations, voir Comprendre l'opérateur de pare-feu de nœud d'entrée
Chapitre 5. Opérateur de réseau de clusters dans OpenShift Container Platform
Le Cluster Network Operator (CNO) déploie et gère les composants du réseau de cluster sur un cluster OpenShift Container Platform, y compris le plugin réseau Container Network Interface (CNI) sélectionné pour le cluster lors de l'installation.
5.1. Opérateur de réseau en grappe
L'opérateur de réseau de cluster met en œuvre l'API network du groupe d'API operator.openshift.io. L'opérateur déploie le plugin réseau OVN-Kubernetes, ou le plugin de fournisseur de réseau que vous avez sélectionné lors de l'installation du cluster, à l'aide d'un ensemble de démons.
Procédure
L'opérateur de réseau de cluster est déployé lors de l'installation en tant que Kubernetes Deployment.
Exécutez la commande suivante pour afficher l'état du déploiement :
$ oc get -n openshift-network-operator deployment/network-operatorExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE network-operator 1/1 1 1 56mExécutez la commande suivante pour afficher l'état de l'opérateur de réseau de cluster :
$ oc get clusteroperator/networkExemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE network 4.5.4 True False False 50mLes champs suivants fournissent des informations sur l'état de l'opérateur :
AVAILABLE,PROGRESSING, etDEGRADED. Le champAVAILABLEestTruelorsque l'opérateur de réseau de groupe signale un état de disponibilité.
5.2. Visualisation de la configuration du réseau de la grappe
Chaque nouvelle installation d'OpenShift Container Platform possède un objet network.config nommé cluster.
Procédure
Utilisez la commande
oc describepour afficher la configuration du réseau de la grappe :$ oc describe network.config/clusterExemple de sortie
Name: cluster Namespace: Labels: <none> Annotations: <none> API Version: config.openshift.io/v1 Kind: Network Metadata: Self Link: /apis/config.openshift.io/v1/networks/cluster Spec:1 Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Network Type: OpenShiftSDN Service Network: 172.30.0.0/16 Status:2 Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Cluster Network MTU: 8951 Network Type: OpenShiftSDN Service Network: 172.30.0.0/16 Events: <none>
5.3. Visualisation du statut de l'opérateur de réseau de cluster
Vous pouvez inspecter l'état et afficher les détails de l'opérateur de réseau de cluster à l'aide de la commande oc describe.
Procédure
Exécutez la commande suivante pour afficher l'état de l'opérateur de réseau de cluster :
$ oc describe clusteroperators/network
5.4. Visualisation des journaux de l'opérateur de réseau de clusters
Vous pouvez consulter les journaux de l'opérateur de réseau de cluster à l'aide de la commande oc logs.
Procédure
Exécutez la commande suivante pour afficher les journaux de l'opérateur de réseau de cluster :
$ oc logs --namespace=openshift-network-operator deployment/network-operator
5.5. Cluster Network Operator configuration
The configuration for the cluster network is specified as part of the Cluster Network Operator (CNO) configuration and stored in a custom resource (CR) object that is named cluster. The CR specifies the fields for the Network API in the operator.openshift.io API group.
The CNO configuration inherits the following fields during cluster installation from the Network API in the Network.config.openshift.io API group and these fields cannot be changed:
clusterNetwork- IP address pools from which pod IP addresses are allocated.
serviceNetwork- IP address pool for services.
defaultNetwork.type- Cluster network plugin, such as OpenShift SDN or OVN-Kubernetes.
Après l'installation du cluster, vous ne pouvez pas modifier les champs énumérés dans la section précédente.
You can specify the cluster network plugin configuration for your cluster by setting the fields for the defaultNetwork object in the CNO object named cluster.
5.5.1. Cluster Network Operator configuration object
The fields for the Cluster Network Operator (CNO) are described in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
The name of the CNO object. This name is always |
|
|
| A list specifying the blocks of IP addresses from which pod IP addresses are allocated and the subnet prefix length assigned to each individual node in the cluster. For example:
Cette valeur est prête à l'emploi et héritée de l'objet |
|
|
| A block of IP addresses for services. The OpenShift SDN and OVN-Kubernetes network plugins support only a single IP address block for the service network. For example:
Cette valeur est prête à l'emploi et héritée de l'objet |
|
|
| Configures the network plugin for the cluster network. |
|
|
| The fields for this object specify the kube-proxy configuration. If you are using the OVN-Kubernetes cluster network plugin, the kube-proxy configuration has no effect. |
defaultNetwork object configuration
The values for the defaultNetwork object are defined in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
Either Note OpenShift Container Platform uses the OVN-Kubernetes network plugin by default. |
|
|
| This object is only valid for the OpenShift SDN network plugin. |
|
|
| This object is only valid for the OVN-Kubernetes network plugin. |
Configuration for the OpenShift SDN network plugin
The following table describes the configuration fields for the OpenShift SDN network plugin:
| Field | Type | Description |
|---|---|---|
|
|
| Le mode d'isolation du réseau pour OpenShift SDN. |
|
|
| L'unité de transmission maximale (MTU) pour le réseau superposé VXLAN. Cette valeur est normalement configurée automatiquement. |
|
|
|
Le port à utiliser pour tous les paquets VXLAN. La valeur par défaut est |
Vous ne pouvez modifier la configuration du plugin réseau de votre cluster que lors de l'installation du cluster.
Example OpenShift SDN configuration
defaultNetwork:
type: OpenShiftSDN
openshiftSDNConfig:
mode: NetworkPolicy
mtu: 1450
vxlanPort: 4789Configuration for the OVN-Kubernetes network plugin
The following table describes the configuration fields for the OVN-Kubernetes network plugin:
| Field | Type | Description |
|---|---|---|
|
|
| L'unité de transmission maximale (MTU) pour le réseau superposé Geneve (Generic Network Virtualization Encapsulation). Cette valeur est normalement configurée automatiquement. |
|
|
| Le port UDP pour le réseau superposé de Geneve. |
|
|
| Si le champ est présent, IPsec est activé pour le cluster. |
|
|
| Specify a configuration object for customizing network policy audit logging. If unset, the defaults audit log settings are used. |
|
|
| Optional: Specify a configuration object for customizing how egress traffic is sent to the node gateway. Note |
|
|
If your existing network infrastructure overlaps with the
For example, if the This field cannot be changed after installation. |
The default value is |
|
|
If your existing network infrastructure overlaps with the This field cannot be changed after installation. |
The default value is |
| Field | Type | Description |
|---|---|---|
|
| entier |
The maximum number of messages to generate every second per node. The default value is |
|
| entier |
The maximum size for the audit log in bytes. The default value is |
|
| chaîne de caractères | One of the following additional audit log targets:
|
|
| chaîne de caractères |
The syslog facility, such as |
| Field | Type | Description |
|---|---|---|
|
|
|
Set this field to
This field has an interaction with the Open vSwitch hardware offloading feature. If you set this field to |
Vous ne pouvez modifier la configuration de votre plugin de réseau de cluster que lors de l'installation du cluster, à l'exception du champ gatewayConfig qui peut être modifié lors de l'exécution en tant qu'activité post-installation.
Example OVN-Kubernetes configuration with IPSec enabled
defaultNetwork:
type: OVNKubernetes
ovnKubernetesConfig:
mtu: 1400
genevePort: 6081
ipsecConfig: {}kubeProxyConfig object configuration
The values for the kubeProxyConfig object are defined in the following table:
| Field | Type | Description |
|---|---|---|
|
|
|
The refresh period for Note
Because of performance improvements introduced in OpenShift Container Platform 4.3 and greater, adjusting the |
|
|
|
The minimum duration before refreshing |
5.5.2. Exemple de configuration de l'opérateur de réseau en grappe
Une configuration CNO complète est spécifiée dans l'exemple suivant :
Exemple d'objet Opérateur de réseau en grappe
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
serviceNetwork:
- 172.30.0.0/16
defaultNetwork:
type: OpenShiftSDN
openshiftSDNConfig:
mode: NetworkPolicy
mtu: 1450
vxlanPort: 4789
kubeProxyConfig:
iptablesSyncPeriod: 30s
proxyArguments:
iptables-min-sync-period:
- 0sChapitre 6. Opérateur DNS dans OpenShift Container Platform
L'opérateur DNS déploie et gère CoreDNS pour fournir un service de résolution de noms aux pods, permettant la découverte de services Kubernetes basés sur le DNS dans OpenShift Container Platform.
6.1. Opérateur DNS
L'opérateur DNS met en œuvre l'API dns du groupe d'API operator.openshift.io. L'opérateur déploie CoreDNS à l'aide d'un ensemble de démons, crée un service pour l'ensemble de démons et configure le kubelet pour demander aux pods d'utiliser l'adresse IP du service CoreDNS pour la résolution de noms.
Procédure
L'opérateur DNS est déployé lors de l'installation avec un objet Deployment.
Utilisez la commande
oc getpour afficher l'état du déploiement :$ oc get -n openshift-dns-operator deployment/dns-operatorExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE dns-operator 1/1 1 1 23hUtilisez la commande
oc getpour afficher l'état de l'opérateur DNS :$ oc get clusteroperator/dnsExemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE dns 4.1.0-0.11 True False False 92mAVAILABLEPROGRESSINGet fournissent des informations sur l'état de l'opérateur. est lorsqu'au moins un pod de l'ensemble de démons CoreDNS signale une condition d'état .DEGRADEDAVAILABLETrueAvailable
6.2. Modification de l'état de gestion de l'opérateur DNS
DNS gère le composant CoreDNS afin de fournir un service de résolution de noms pour les pods et les services dans le cluster. L'adresse managementState de l'opérateur DNS est définie par défaut sur Managed, ce qui signifie que l'opérateur DNS gère activement ses ressources. Vous pouvez le changer en Unmanaged, ce qui signifie que l'opérateur DNS ne gère pas ses ressources.
Les cas d'utilisation suivants concernent la modification de l'opérateur DNS managementState:
-
Vous êtes un développeur et vous voulez tester un changement de configuration pour voir s'il corrige un problème dans CoreDNS. Vous pouvez empêcher l'opérateur DNS d'écraser le correctif en définissant
managementStatesurUnmanaged. -
Vous êtes un administrateur de cluster et vous avez signalé un problème avec CoreDNS, mais vous devez appliquer une solution de contournement jusqu'à ce que le problème soit résolu. Vous pouvez définir le champ
managementStatede l'opérateur DNS surUnmanagedpour appliquer la solution de contournement.
Procédure
Changer
managementStateOpérateur DNS :oc patch dns.operator.openshift.io default --type merge --patch '{"spec":{"managementState":"Unmanaged"}}'
6.3. Contrôle du placement des pods DNS
L'opérateur DNS dispose de deux ensembles de démons : l'un pour CoreDNS et l'autre pour gérer le fichier /etc/hosts. Le jeu de démons pour /etc/hosts doit être exécuté sur chaque hôte de nœud afin d'ajouter une entrée au registre d'images de cluster pour prendre en charge l'extraction d'images. Les politiques de sécurité peuvent interdire la communication entre les paires de nœuds, ce qui empêche le jeu de démons pour CoreDNS de s'exécuter sur chaque nœud.
En tant qu'administrateur de cluster, vous pouvez utiliser un sélecteur de nœud personnalisé pour configurer le jeu de démons pour CoreDNS afin qu'il s'exécute ou non sur certains nœuds.
Conditions préalables
-
Vous avez installé le CLI
oc. -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour empêcher la communication entre certains nœuds, configurez le champ
spec.nodePlacement.nodeSelectorAPI :Modifier l'objet Opérateur DNS nommé
default:$ oc edit dns.operator/defaultSpécifiez un sélecteur de nœuds qui n'inclut que les nœuds du plan de contrôle dans le champ
spec.nodePlacement.nodeSelectorAPI :spec: nodePlacement: nodeSelector: node-role.kubernetes.io/worker: ""
Pour permettre au démon défini pour CoreDNS de fonctionner sur les nœuds, configurez une taint et une toleration :
Modifier l'objet Opérateur DNS nommé
default:$ oc edit dns.operator/defaultSpécifier une clé d'altération et une tolérance pour l'altération :
spec: nodePlacement: tolerations: - effect: NoExecute key: "dns-only" operators: Equal value: abc tolerationSeconds: 36001 - 1
- Si l'erreur est
dns-only, elle peut être tolérée indéfiniment. Vous pouvez omettretolerationSeconds.
6.4. Afficher le DNS par défaut
Chaque nouvelle installation d'OpenShift Container Platform possède un site dns.operator nommé default.
Procédure
Utilisez la commande
oc describepour afficher les paramètres par défautdns:$ oc describe dns.operator/defaultExemple de sortie
Name: default Namespace: Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: DNS ... Status: Cluster Domain: cluster.local1 Cluster IP: 172.30.0.102 ...Pour connaître le CIDR de service de votre cluster, utilisez la commande
oc get:$ oc get networks.config/cluster -o jsonpath='{$.status.serviceNetwork}'
Exemple de sortie
[172.30.0.0/16]6.5. Utilisation de la redirection DNS
Vous pouvez utiliser la redirection DNS pour remplacer la configuration de la redirection par défaut dans le fichier /etc/resolv.conf de la manière suivante :
- Spécifiez les serveurs de noms pour chaque zone. Si la zone transférée est le domaine Ingress géré par OpenShift Container Platform, le serveur de noms en amont doit être autorisé pour le domaine.
- Fournir une liste de serveurs DNS en amont.
- Modifier la politique de transfert par défaut.
Une configuration de transfert DNS pour le domaine par défaut peut comporter à la fois les serveurs par défaut spécifiés dans le fichier /etc/resolv.conf et les serveurs DNS en amont.
Procédure
Modifier l'objet Opérateur DNS nommé
default:$ oc edit dns.operator/defaultCela permet à l'opérateur de créer et de mettre à jour la carte de configuration nommée
dns-defaultavec des blocs de configuration de serveur supplémentaires basés surServer. Si aucun des serveurs ne dispose d'une zone correspondant à la requête, la résolution de noms revient aux serveurs DNS en amont.Configuration de la redirection DNS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: servers: - name: example-server1 zones:2 - example.com forwardPlugin: policy: Random3 upstreams:4 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers:5 policy: Random6 upstreams:7 - type: SystemResolvConf8 - type: Network address: 1.2.3.49 port: 5310 - 1
- Doit être conforme à la syntaxe du nom de service
rfc6335. - 2
- Doit être conforme à la définition d'un sous-domaine dans la syntaxe du nom de service
rfc1123. Le domaine de cluster,cluster.local, n'est pas un sous-domaine valide pour le champzones. - 3
- Définit la politique de sélection des résolveurs en amont. La valeur par défaut est
Random. Vous pouvez également utiliser les valeursRoundRobin, etSequential. - 4
- Un maximum de 15
upstreamsest autorisé parforwardPlugin. - 5
- Facultatif. Vous pouvez l'utiliser pour remplacer la stratégie par défaut et transmettre la résolution DNS aux résolveurs DNS spécifiés (résolveurs en amont) pour le domaine par défaut. Si vous ne fournissez pas de résolveurs en amont, les requêtes de nom DNS sont envoyées aux serveurs situés à l'adresse
/etc/resolv.conf. - 6
- Détermine l'ordre dans lequel les serveurs en amont sont sélectionnés pour l'interrogation. Vous pouvez spécifier l'une de ces valeurs :
RandomRoundRobin, ouSequential. La valeur par défaut estSequential. - 7
- Facultatif. Vous pouvez l'utiliser pour fournir des résolveurs en amont.
- 8
- Vous pouvez spécifier deux types de
upstreams-SystemResolvConfetNetwork.SystemResolvConfconfigure l'amont pour utiliser/etc/resolv.confetNetworkdéfinit unNetworkresolver. Vous pouvez spécifier l'un ou l'autre ou les deux. - 9
- Si le type spécifié est
Network, vous devez fournir une adresse IP. Le champaddressdoit être une adresse IPv4 ou IPv6 valide. - 10
- Si le type spécifié est
Network, vous pouvez éventuellement indiquer un port. Le champportdoit avoir une valeur comprise entre1et65535. Si vous ne spécifiez pas de port pour l'amont, le port 853 est utilisé par défaut.
Lorsque vous travaillez dans un environnement très réglementé, vous pouvez avoir besoin de sécuriser le trafic DNS lorsque vous transmettez des requêtes à des résolveurs en amont, afin de garantir un trafic DNS supplémentaire et la confidentialité des données. Les administrateurs de clusters peuvent configurer la sécurité de la couche transport (TLS) pour les requêtes DNS transmises.
Configuration du transfert DNS avec TLS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: servers: - name: example-server1 zones:2 - example.com forwardPlugin: transportConfig: transport: TLS3 tls: caBundle: name: mycacert serverName: dnstls.example.com4 policy: Random5 upstreams:6 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers:7 transportConfig: transport: TLS tls: caBundle: name: mycacert serverName: dnstls.example.com upstreams: - type: Network8 address: 1.2.3.49 port: 5310 - 1
- Doit être conforme à la syntaxe du nom de service
rfc6335. - 2
- Doit être conforme à la définition d'un sous-domaine dans la syntaxe du nom de service
rfc1123. Le domaine de cluster,cluster.local, n'est pas un sous-domaine valide pour le champzones. Le domaine de cluster,cluster.local, est unsubdomainnon valide pourzones. - 3
- Lors de la configuration de TLS pour les requêtes DNS transférées, le champ
transportdoit avoir la valeurTLS. Par défaut, CoreDNS met en cache les connexions transférées pendant 10 secondes. CoreDNS maintiendra une connexion TCP ouverte pendant ces 10 secondes si aucune requête n'est émise. Dans le cas de clusters importants, assurez-vous que votre serveur DNS est conscient du fait qu'il pourrait recevoir de nombreuses nouvelles connexions à maintenir ouvertes, car vous pouvez initier une connexion par nœud. Configurez votre hiérarchie DNS en conséquence pour éviter les problèmes de performance. - 4
- Lors de la configuration de TLS pour les requêtes DNS transmises, il s'agit d'un nom de serveur obligatoire utilisé dans le cadre de l'indication du nom du serveur (SNI) pour valider le certificat du serveur TLS en amont.
- 5
- Définit la politique de sélection des résolveurs en amont. La valeur par défaut est
Random. Vous pouvez également utiliser les valeursRoundRobin, etSequential. - 6
- Il est obligatoire. Vous pouvez l'utiliser pour fournir des résolveurs en amont. Un maximum de 15 entrées
upstreamsest autorisé par entréeforwardPlugin. - 7
- Facultatif. Vous pouvez l'utiliser pour remplacer la stratégie par défaut et transmettre la résolution DNS aux résolveurs DNS spécifiés (résolveurs en amont) pour le domaine par défaut. Si vous ne fournissez pas de résolveurs en amont, les requêtes de nom DNS sont envoyées aux serveurs situés à l'adresse
/etc/resolv.conf. - 8
Networkindique que ce résolveur en amont doit traiter les demandes transférées séparément des résolveurs en amont répertoriés dans/etc/resolv.conf. Seul le typeNetworkest autorisé en cas d'utilisation de TLS et vous devez fournir une adresse IP.- 9
- Le champ
addressdoit être une adresse IPv4 ou IPv6 valide. - 10
- Vous pouvez optionnellement fournir un port. La valeur de
portdoit être comprise entre1et65535. Si vous ne spécifiez pas de port pour l'amont, le port 853 est utilisé par défaut.
NoteSi
serversest indéfini ou invalide, la carte de configuration ne contient que le serveur par défaut.Afficher la carte de configuration :
$ oc get configmap/dns-default -n openshift-dns -o yamlExemple de ConfigMap DNS basé sur l'exemple précédent de DNS
apiVersion: v1 data: Corefile: | example.com:5353 { forward . 1.1.1.1 2.2.2.2:5353 } bar.com:5353 example.com:5353 { forward . 3.3.3.3 4.4.4.4:54541 } .:5353 { errors health kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure upstream fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf 1.2.3.4:53 { policy Random } cache 30 reload } kind: ConfigMap metadata: labels: dns.operator.openshift.io/owning-dns: default name: dns-default namespace: openshift-dns- 1
- Les modifications apportées au site
forwardPlugindéclenchent une mise à jour continue de l'ensemble des démons CoreDNS.
6.6. Statut de l'opérateur DNS
Vous pouvez inspecter l'état et afficher les détails de l'opérateur DNS à l'aide de la commande oc describe.
Procédure
Consulter l'état de l'opérateur DNS :
$ oc describe clusteroperators/dns6.7. Journaux de l'opérateur DNS
Vous pouvez consulter les journaux de l'opérateur DNS à l'aide de la commande oc logs.
Procédure
Consulter les journaux de l'opérateur DNS :
$ oc logs -n openshift-dns-operator deployment/dns-operator -c dns-operator6.8. Configuration du niveau de journalisation de CoreDNS
Vous pouvez configurer le niveau du journal CoreDNS pour déterminer la quantité de détails dans les messages d'erreur enregistrés. Les valeurs valides pour le niveau de journalisation du CoreDNS sont Normal, Debug, et Trace. La valeur par défaut logLevel est Normal.
Le plugin d'erreurs est toujours activé. Les paramètres suivants de logLevel donnent lieu à des réponses d'erreur différentes :
-
logLevel:Normalactive la classe "erreurs" :log . { class error }. -
logLevel:Debugactive la classe "denial" :log . { class denial error }. -
logLevel:Traceactive la classe "all" :log . { class all }.
Procédure
Pour remplacer
logLevelparDebug, entrez la commande suivante :$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Debug"}}' --type=mergePour remplacer
logLevelparTrace, entrez la commande suivante :$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Trace"}}' --type=merge
Vérification
Pour s'assurer que le niveau de journalisation souhaité a été défini, vérifiez la carte de configuration :
$ oc get configmap/dns-default -n openshift-dns -o yaml
6.9. Configuration du niveau de journalisation de l'opérateur CoreDNS
Les administrateurs de clusters peuvent configurer le niveau de journal de l'opérateur afin de localiser plus rapidement les problèmes DNS d'OpenShift. Les valeurs valides pour operatorLogLevel sont Normal, Debug, et Trace. Trace contient les informations les plus détaillées. La valeur par défaut de operatorlogLevel est Normal. Il existe sept niveaux de journalisation pour les problèmes : Trace, Debug, Info, Warning, Error, Fatal et Panic. Une fois le niveau de journalisation défini, les entrées de journal correspondant à ce niveau de gravité ou à un niveau supérieur seront enregistrées.
-
operatorLogLevel: "Normal"setlogrus.SetLogLevel("Info"). -
operatorLogLevel: "Debug"setlogrus.SetLogLevel("Debug"). -
operatorLogLevel: "Trace"setlogrus.SetLogLevel("Trace").
Procédure
Pour remplacer
operatorLogLevelparDebug, entrez la commande suivante :$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Debug"}}' --type=mergePour remplacer
operatorLogLevelparTrace, entrez la commande suivante :$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Trace"}}' --type=merge
6.10. Optimisation du cache CoreDNS
Vous pouvez configurer la durée maximale de la mise en cache réussie ou non, également connue sous le nom de mise en cache positive ou négative, effectuée par CoreDNS. Le réglage de la durée de la mise en cache des réponses aux requêtes DNS peut réduire la charge des résolveurs DNS en amont.
Procédure
Modifiez l'objet Opérateur DNS nommé
defaulten exécutant la commande suivante :$ oc edit dns.operator.openshift.io/defaultModifier les valeurs de mise en cache de la durée de vie (TTL) :
Configuration de la mise en cache DNS
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: positiveTTL: 1h1 negativeTTL: 0.5h10m2 - 1
- La valeur de la chaîne
1hest convertie en nombre de secondes par CoreDNS. Si ce champ est omis, la valeur est supposée être0set le cluster utilise la valeur interne par défaut de900scomme solution de repli. - 2
- La valeur de la chaîne peut être une combinaison d'unités telles que
0.5h10met est convertie en nombre de secondes par CoreDNS. Si ce champ est omis, la valeur est supposée être0set le cluster utilise la valeur interne par défaut de30scomme solution de repli.
AvertissementLa définition de champs TTL de faible valeur peut entraîner une augmentation de la charge sur le cluster, sur les résolveurs en amont, ou sur les deux.
Chapitre 7. Opérateur Ingress dans OpenShift Container Platform
7.1. Opérateur Ingress de la plateforme de conteneurs OpenShift
Lorsque vous créez votre cluster OpenShift Container Platform, les pods et les services s'exécutant sur le cluster se voient attribuer chacun leur propre adresse IP. Les adresses IP sont accessibles aux autres pods et services fonctionnant à proximité, mais ne sont pas accessibles aux clients extérieurs. L'opérateur d'ingestion (Ingress Operator) met en œuvre l'API IngressController et est le composant responsable de l'activation de l'accès externe aux services de cluster d'OpenShift Container Platform.
L'opérateur d'ingestion permet aux clients externes d'accéder à votre service en déployant et en gérant un ou plusieurs contrôleurs d'ingestion basés sur HAProxy pour gérer le routage. Vous pouvez utiliser l'opérateur d'ingestion pour acheminer le trafic en spécifiant les ressources OpenShift Container Platform Route et Kubernetes Ingress. Les configurations au sein du contrôleur d'ingestion, telles que la possibilité de définir le type endpointPublishingStrategy et l'équilibrage de charge interne, fournissent des moyens de publier les points d'extrémité du contrôleur d'ingestion.
7.2. L'actif de configuration Ingress
Le programme d'installation génère un bien avec une ressource Ingress dans le groupe API config.openshift.io, cluster-ingress-02-config.yml.
Définition YAML de la ressource Ingress
apiVersion: config.openshift.io/v1
kind: Ingress
metadata:
name: cluster
spec:
domain: apps.openshiftdemos.com
Le programme d'installation stocke cette ressource dans le fichier cluster-ingress-02-config.yml du répertoire manifests/. Cette ressource Ingress définit la configuration de l'ensemble du cluster pour Ingress. Cette configuration d'Ingress est utilisée comme suit :
- L'opérateur d'entrée utilise le domaine de la configuration d'entrée du cluster comme domaine pour le contrôleur d'entrée par défaut.
-
L'opérateur OpenShift API Server utilise le domaine de la configuration Ingress du cluster. Ce domaine est également utilisé lors de la génération d'un hôte par défaut pour une ressource
Routequi ne spécifie pas d'hôte explicite.
7.3. Paramètres de configuration du contrôleur d'entrée
La ressource ingresscontrollers.operator.openshift.io offre les paramètres de configuration suivants.
| Paramètres | Description |
|---|---|
|
|
La valeur
S'il est vide, la valeur par défaut est |
|
|
|
|
|
Sur GCP, AWS et Azure, vous pouvez configurer les champs
Si elle n'est pas définie, la valeur par défaut est basée sur
Pour la plupart des plateformes, la valeur
|
|
|
La valeur
The secret must contain the following keys and data: *
S'il n'est pas défini, un certificat générique est automatiquement généré et utilisé. Le certificat est valable pour le contrôleur d'entrée Le certificat en cours d'utilisation, qu'il soit généré ou spécifié par l'utilisateur, est automatiquement intégré au serveur OAuth intégré à OpenShift Container Platform. |
|
|
|
|
|
|
|
|
Si ce n'est pas le cas, les valeurs par défaut sont utilisées. Note
Le paramètre |
|
|
Si elle n'est pas définie, la valeur par défaut est basée sur la ressource
Lors de l'utilisation des types de profil
La version TLS minimale pour les contrôleurs d'entrée est Note
Les codes et la version TLS minimale du profil de sécurité configuré sont reflétés dans l'état Important
L'opérateur d'entrée convertit le TLS |
|
|
Le sous-champ |
|
|
|
|
|
|
|
|
En définissant
Par défaut, la politique est définie sur
En définissant Ces ajustements ne s'appliquent qu'aux itinéraires en clair, terminés par les bords et recryptés, et uniquement lors de l'utilisation du protocole HTTP/1.
Pour les en-têtes de requête, ces ajustements ne sont appliqués qu'aux itinéraires qui ont l'annotation |
|
|
|
|
|
|
|
|
Pour tout cookie que vous souhaitez capturer, les paramètres suivants doivent figurer dans votre configuration
Par exemple : |
|
|
|
|
|
|
|
|
Le type
|
|
|
Le type
Ces connexions proviennent de sondes de santé d'équilibreurs de charge ou de connexions spéculatives de navigateurs web (préconnexion) et peuvent être ignorées sans risque. Cependant, ces demandes peuvent être causées par des erreurs de réseau, de sorte que la définition de ce champ à |
Tous les paramètres sont facultatifs.
7.3.1. Profils de sécurité TLS du contrôleur d'entrée
Les profils de sécurité TLS permettent aux serveurs de déterminer les algorithmes de chiffrement qu'un client peut utiliser lorsqu'il se connecte au serveur.
7.3.1.1. Comprendre les profils de sécurité TLS
Vous pouvez utiliser un profil de sécurité TLS (Transport Layer Security) pour définir les algorithmes TLS requis par les différents composants d'OpenShift Container Platform. Les profils de sécurité TLS d'OpenShift Container Platform sont basés sur les configurations recommandées par Mozilla.
Vous pouvez spécifier l'un des profils de sécurité TLS suivants pour chaque composant :
| Profile | Description |
|---|---|
|
| Ce profil est destiné à être utilisé avec des clients ou des bibliothèques anciens. Il est basé sur l'ancienne configuration recommandée pour la rétrocompatibilité.
Le profil Note Pour le contrôleur d'entrée, la version minimale de TLS passe de 1.0 à 1.1. |
|
| Ce profil est la configuration recommandée pour la majorité des clients. Il s'agit du profil de sécurité TLS par défaut pour le contrôleur d'entrée, le kubelet et le plan de contrôle. Le profil est basé sur la configuration recommandée pour la compatibilité intermédiaire.
Le profil |
|
| Ce profil est destiné à être utilisé avec des clients modernes qui n'ont pas besoin de rétrocompatibilité. Ce profil est basé sur la configuration recommandée pour la compatibilité moderne.
Le profil |
|
| Ce profil permet de définir la version de TLS et les algorithmes de chiffrement à utiliser. Avertissement
Soyez prudent lorsque vous utilisez un profil |
Lorsque l'on utilise l'un des types de profil prédéfinis, la configuration effective du profil est susceptible d'être modifiée entre les versions. Par exemple, si l'on spécifie l'utilisation du profil intermédiaire déployé dans la version X.Y.Z, une mise à niveau vers la version X.Y.Z 1 peut entraîner l'application d'une nouvelle configuration de profil, ce qui se traduit par un déploiement.
7.3.1.2. Configuration du profil de sécurité TLS pour le contrôleur d'entrée
Pour configurer un profil de sécurité TLS pour un contrôleur d'entrée, modifiez la ressource personnalisée (CR) IngressController afin de spécifier un profil de sécurité TLS prédéfini ou personnalisé. Si aucun profil de sécurité TLS n'est configuré, la valeur par défaut est basée sur le profil de sécurité TLS défini pour le serveur API.
Exemple de CR IngressController qui configure le profil de sécurité TLS Old
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...Le profil de sécurité TLS définit la version minimale de TLS et les algorithmes de chiffrement TLS pour les connexions TLS des contrôleurs d'entrée.
Les chiffres et la version TLS minimale du profil de sécurité TLS configuré sont indiqués dans la ressource personnalisée (CR) IngressController sous Status.Tls Profile et dans le profil de sécurité TLS configuré sous Spec.Tls Security Profile. Pour le profil de sécurité TLS Custom, les algorithmes de chiffrement spécifiques et la version TLS minimale sont répertoriés sous les deux paramètres.
L'image du contrôleur d'entrée HAProxy prend en charge TLS 1.3 et le profil Modern.
L'opérateur d'entrée convertit également le TLS 1.0 d'un profil Old ou Custom en 1.1.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifiez le CR
IngressControllerdans le projetopenshift-ingress-operatorpour configurer le profil de sécurité TLS :$ oc edit IngressController default -n openshift-ingress-operatorAjouter le champ
spec.tlsSecurityProfile:Exemple de CR
IngressControllerpour un profilCustomapiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom1 custom:2 ciphers:3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- 1
- Spécifiez le type de profil de sécurité TLS (
Old,Intermediate, ouCustom). La valeur par défaut estIntermediate. - 2
- Spécifiez le champ approprié pour le type sélectionné :
-
old: {} -
intermediate: {} -
custom:
-
- 3
- Pour le type
custom, spécifiez une liste de chiffrements TLS et la version TLS minimale acceptée.
- Enregistrez le fichier pour appliquer les modifications.
Vérification
Vérifiez que le profil est défini dans le CR
IngressController:$ oc describe IngressController default -n openshift-ingress-operatorExemple de sortie
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
7.3.1.3. Configuration de l'authentification mutuelle TLS
Vous pouvez configurer le contrôleur d'entrée pour activer l'authentification mutuelle TLS (mTLS) en définissant une valeur spec.clientTLS. La valeur clientTLS configure le contrôleur d'entrée pour qu'il vérifie les certificats des clients. Cette configuration comprend la définition d'une valeur clientCA, qui est une référence à une carte de configuration. La carte de configuration contient le paquet de certificats CA codé PEM utilisé pour vérifier le certificat d'un client. En option, vous pouvez configurer une liste de filtres de sujet de certificat.
Si la valeur clientCA indique un point de distribution de liste de révocation de certificats (CRL) X509v3, l'opérateur d'entrée télécharge la CRL et configure le contrôleur d'entrée pour qu'il en prenne acte. Les demandes qui ne fournissent pas de certificats valides sont rejetées.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Créer une carte de configuration dans l'espace de noms
openshift-config:$ oc create configmap router-ca-certs-default --from-file=ca-bundle.pem=client-ca.crt -n openshift-configNoteLa clé de données de la carte de configuration doit être
ca-bundle.pem, et la valeur des données doit être un certificat d'autorité de certification au format PEM.Modifiez la ressource
IngressControllerdans le projetopenshift-ingress-operator:$ oc edit IngressController default -n openshift-ingress-operatorAjoutez le champ spec.clientTLS et ses sous-champs pour configurer le TLS mutuel :
Exemple de CR
IngressControllerpour un profilclientTLSqui spécifie des modèles de filtrageapiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: clientTLS: clientCertificatePolicy: Required clientCA: name: router-ca-certs-default allowedSubjectPatterns: - "^/CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift$"
7.4. Afficher le contrôleur d'entrée par défaut
L'opérateur d'ingestion est une fonctionnalité essentielle d'OpenShift Container Platform et est activé d'emblée.
Chaque nouvelle installation d'OpenShift Container Platform a un ingresscontroller nommé default. Il peut être complété par des contrôleurs d'ingestion supplémentaires. Si l'adresse ingresscontroller par défaut est supprimée, l'opérateur d'ingestion la recréera automatiquement dans la minute qui suit.
Procédure
Affichez le contrôleur d'entrée par défaut :
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/default
7.5. Visualiser l'état de l'opérateur d'entrée
Vous pouvez visualiser et contrôler l'état de votre opérateur d'entrée.
Procédure
Consultez votre statut d'opérateur d'entrée :
$ oc describe clusteroperators/ingress
7.6. Consulter les journaux du contrôleur d'entrée
Vous pouvez consulter les journaux du contrôleur d'ingérence.
Procédure
Consultez les journaux du contrôleur d'ingérence :
oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>
7.7. Afficher l'état du contrôleur d'entrée
Vous pouvez consulter l'état d'un contrôleur d'entrée particulier.
Procédure
Consulter l'état d'un contrôleur d'entrée :
oc describe --namespace=openshift-ingress-operator ingresscontroller/<name> $ oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
7.8. Configuration du contrôleur d'entrée
7.8.1. Définition d'un certificat personnalisé par défaut
En tant qu'administrateur, vous pouvez configurer un contrôleur d'entrée pour qu'il utilise un certificat personnalisé en créant une ressource Secret et en modifiant la ressource personnalisée (CR) IngressController.
Conditions préalables
- Vous devez disposer d'une paire certificat/clé dans des fichiers codés PEM, où le certificat est signé par une autorité de certification de confiance ou par une autorité de certification de confiance privée que vous avez configurée dans une infrastructure de clés publiques (PKI) personnalisée.
Votre certificat répond aux exigences suivantes :
- Le certificat est valable pour le domaine d'entrée.
-
Le certificat utilise l'extension
subjectAltNamepour spécifier un domaine de remplacement, tel que*.apps.ocp4.example.com.
Vous devez avoir un CR
IngressController. Vous pouvez utiliser le CR par défaut :$ oc --namespace openshift-ingress-operator get ingresscontrollersExemple de sortie
NAME AGE default 10m
Si vous avez des certificats intermédiaires, ils doivent être inclus dans le fichier tls.crt du secret contenant un certificat par défaut personnalisé. L'ordre est important lors de la spécification d'un certificat ; indiquez votre (vos) certificat(s) intermédiaire(s) après le(s) certificat(s) de serveur.
Procédure
Ce qui suit suppose que le certificat personnalisé et la paire de clés se trouvent dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Remplacez les noms de chemin réels par tls.crt et tls.key. Vous pouvez également remplacer custom-certs-default par un autre nom lorsque vous créez la ressource Secret et que vous y faites référence dans le CR IngressController.
Cette action entraînera le redéploiement du contrôleur d'entrée, à l'aide d'une stratégie de déploiement continu.
Créez une ressource Secret contenant le certificat personnalisé dans l'espace de noms
openshift-ingressà l'aide des fichierstls.crtettls.key.$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.keyMettre à jour la CR du contrôleur d'ingestion pour qu'elle fasse référence au nouveau secret du certificat :
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'Vérifier que la mise à jour a été effective :
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddateoù :
<domain>- Spécifie le nom de domaine de base pour votre cluster.
Exemple de sortie
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GMAstuceVous pouvez également appliquer le code YAML suivant pour définir un certificat par défaut personnalisé :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: defaultCertificate: name: custom-certs-defaultLe nom du secret du certificat doit correspondre à la valeur utilisée pour mettre à jour le CR.
Une fois que le CR du contrôleur d'ingestion a été modifié, l'opérateur d'ingestion met à jour le déploiement du contrôleur d'ingestion afin d'utiliser le certificat personnalisé.
7.8.2. Suppression d'un certificat personnalisé par défaut
En tant qu'administrateur, vous pouvez supprimer un certificat personnalisé pour lequel vous avez configuré un contrôleur d'entrée.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc). - Vous avez précédemment configuré un certificat par défaut personnalisé pour le contrôleur d'entrée.
Procédure
Pour supprimer le certificat personnalisé et restaurer le certificat fourni avec OpenShift Container Platform, entrez la commande suivante :
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'Il peut y avoir un délai pendant que le cluster réconcilie la nouvelle configuration du certificat.
Vérification
Pour confirmer que le certificat original du cluster est restauré, entrez la commande suivante :
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddateoù :
<domain>- Spécifie le nom de domaine de base pour votre cluster.
Exemple de sortie
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
7.8.3. Mise à l'échelle automatique d'un contrôleur d'entrée
Mettre automatiquement à l'échelle un contrôleur d'entrée pour répondre dynamiquement aux exigences de performance ou de disponibilité du routage, telles que l'exigence d'augmenter le débit. La procédure suivante fournit un exemple de mise à l'échelle du contrôleur par défaut IngressController.
Le Custom Metrics Autoscaler est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès à un cluster OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin. - L'opérateur Custom Metrics Autoscaler est installé.
Procédure
Créez un projet dans l'espace de noms
openshift-ingress-operatoren exécutant la commande suivante :$ oc project openshift-ingress-operatorActiver la surveillance d'OpenShift pour des projets définis par l'utilisateur en créant et en appliquant une carte de configuration :
Créez un nouvel objet
ConfigMap,cluster-monitoring-config.yaml:cluster-monitoring-config.yaml
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | enableUserWorkload: true1 - 1
- Lorsqu'il est défini sur
true, le paramètreenableUserWorkloadpermet la surveillance de projets définis par l'utilisateur dans un cluster.
Appliquez la carte de configuration en exécutant la commande suivante :
$ oc apply -f cluster-monitoring-config.yaml
Créez un compte de service pour vous authentifier auprès de Thanos en exécutant la commande suivante :
$ oc create serviceaccount thanos && oc describe serviceaccount thanosExemple de sortie
Name: thanos Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> Image pull secrets: thanos-dockercfg-b4l9s Mountable secrets: thanos-dockercfg-b4l9s Tokens: thanos-token-c422q Events: <none>Définir un objet
TriggerAuthenticationdans l'espace de nomsopenshift-ingress-operatoren utilisant le jeton du compte de service.Définissez la variable
secretqui contient le secret en exécutant la commande suivante :$ secret=$(oc get secret | grep thanos-token | head -n 1 | awk '{ print $1 }')Créez l'objet
TriggerAuthenticationet transmettez la valeur de la variablesecretau paramètreTOKEN:$ oc process TOKEN="$secret" -f - <<EOF | oc apply -f - apiVersion: template.openshift.io/v1 kind: Template parameters: - name: TOKEN objects: - apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-trigger-auth-prometheus spec: secretTargetRef: - parameter: bearerToken name: \${TOKEN} key: token - parameter: ca name: \${TOKEN} key: ca.crt EOF
Créer et appliquer un rôle pour la lecture des métriques de Thanos :
Créez un nouveau rôle,
thanos-metrics-reader.yaml, qui lit les métriques des pods et des nœuds :thanos-metrics-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader rules: - apiGroups: - "" resources: - pods - nodes verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - getAppliquez le nouveau rôle en exécutant la commande suivante :
$ oc apply -f thanos-metrics-reader.yaml
Ajoutez le nouveau rôle au compte de service en entrant les commandes suivantes :
$ oc adm policy add-role-to-user thanos-metrics-reader -z thanos --role=namespace=openshift-ingress-operator$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanosNoteL'argument
add-cluster-role-to-usern'est requis que si vous utilisez des requêtes inter-espaces de noms. L'étape suivante utilise une requête de l'espace de nomskube-metricsqui nécessite cet argument.Créez un nouveau fichier YAML
ScaledObject,ingress-autoscaler.yaml, qui cible le déploiement du contrôleur d'ingestion par défaut :Exemple
ScaledObjectdéfinitionapiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: ingress-scaler spec: scaleTargetRef:1 apiVersion: operator.openshift.io/v1 kind: IngressController name: default envSourceContainerName: ingress-operator minReplicaCount: 1 maxReplicaCount: 202 cooldownPeriod: 1 pollingInterval: 1 triggers: - type: prometheus metricType: AverageValue metadata: serverAddress: https://<example-cluster>:90913 namespace: openshift-ingress-operator4 metricName: 'kube-node-role' threshold: '1' query: 'sum(kube_node_role{role="worker",service="kube-state-metrics"})'5 authModes: "bearer" authenticationRef: name: keda-trigger-auth-prometheus- 1
- La ressource personnalisée que vous ciblez. Dans ce cas, il s'agit du contrôleur Ingress.
- 2
- Facultatif : Le nombre maximal de répliques. Si vous omettez ce champ, le maximum par défaut est fixé à 100 répliques.
- 3
- L'adresse et le port du cluster.
- 4
- L'espace de noms de l'opérateur d'entrée.
- 5
- Cette expression correspond au nombre de nœuds de travail présents dans la grappe déployée.
ImportantSi vous utilisez des requêtes inter-espace, vous devez cibler le port 9091 et non le port 9092 dans le champ
serverAddress. Vous devez également disposer de privilèges élevés pour lire les métriques à partir de ce port.Appliquez la définition de ressource personnalisée en exécutant la commande suivante :
$ oc apply -f ingress-autoscaler.yaml
Vérification
Vérifiez que le contrôleur d'entrée par défaut est mis à l'échelle pour correspondre à la valeur renvoyée par la requête
kube-state-metricsen exécutant les commandes suivantes :Utilisez la commande
greppour rechercher des répliques dans le fichier YAML du contrôleur d'entrée :$ oc get ingresscontroller/default -o yaml | grep replicas:Exemple de sortie
replicas: 3Obtenir les pods dans le projet
openshift-ingress:$ oc get pods -n openshift-ingressExemple de sortie
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
7.8.4. Mise à l'échelle d'un contrôleur d'entrée
Mettre à l'échelle manuellement un contrôleur d'entrée pour répondre aux exigences de performance de routage ou de disponibilité telles que l'exigence d'augmenter le débit. Les commandes oc sont utilisées pour mettre à l'échelle la ressource IngressController. La procédure suivante fournit un exemple de mise à l'échelle de la ressource par défaut IngressController.
La mise à l'échelle n'est pas une action immédiate, car il faut du temps pour créer le nombre souhaité de répliques.
Procédure
Affichez le nombre actuel de répliques disponibles pour le site par défaut
IngressController:$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Exemple de sortie
2Adaptez la version par défaut
IngressControllerau nombre de répliques souhaité à l'aide de la commandeoc patch. L'exemple suivant met à l'échelle le serveur par défautIngressControlleravec 3 réplicas :$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=mergeExemple de sortie
ingresscontroller.operator.openshift.io/default patchedVérifiez que la valeur par défaut de
IngressControllerest adaptée au nombre de répliques que vous avez spécifié :$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'Exemple de sortie
3AstuceVous pouvez également appliquer le fichier YAML suivant pour adapter un contrôleur d'ingestion à trois répliques :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 31 - 1
- Si vous avez besoin d'un nombre différent de répliques, modifiez la valeur de
replicas.
7.8.5. Configuration de la journalisation des accès d'entrée
Vous pouvez configurer le contrôleur d'entrée pour activer les journaux d'accès. Si vous avez des clusters qui ne reçoivent pas beaucoup de trafic, vous pouvez enregistrer les logs dans un sidecar. Si vous avez des clusters à fort trafic, pour éviter de dépasser la capacité de la pile de journalisation ou pour intégrer une infrastructure de journalisation en dehors d'OpenShift Container Platform, vous pouvez transmettre les journaux à un point d'extrémité syslog personnalisé. Vous pouvez également spécifier le format des journaux d'accès.
La journalisation des conteneurs est utile pour activer les journaux d'accès sur les clusters à faible trafic lorsqu'il n'y a pas d'infrastructure de journalisation Syslog existante, ou pour une utilisation à court terme lors du diagnostic de problèmes avec le contrôleur d'entrée.
Syslog est nécessaire pour les clusters à fort trafic où les logs d'accès pourraient dépasser la capacité de la pile OpenShift Logging, ou pour les environnements où toute solution de logging doit s'intégrer à une infrastructure de logging Syslog existante. Les cas d'utilisation de Syslog peuvent se chevaucher.
Conditions préalables
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Configurer l'enregistrement des accès entrants à un sidecar.
Pour configurer la journalisation des accès entrants, vous devez spécifier une destination à l'aide de
spec.logging.access.destination. Pour spécifier la journalisation vers un conteneur sidecar, vous devez spécifierContainerspec.logging.access.destination.type. L'exemple suivant est une définition de contrôleur d'entrée qui enregistre vers une destinationContainer:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: ContainerLorsque vous configurez le contrôleur d'entrée pour qu'il se connecte à un sidecar, l'opérateur crée un conteneur nommé
logsdans le pod du contrôleur d'entrée :$ oc -n openshift-ingress logs deployment.apps/router-default -c logsExemple de sortie
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
Configurer la journalisation de l'accès à l'entrée vers un point de terminaison Syslog.
Pour configurer la journalisation des accès d'entrée, vous devez spécifier une destination à l'aide de
spec.logging.access.destination. Pour spécifier la journalisation vers un point de terminaison Syslog, vous devez spécifierSyslogpourspec.logging.access.destination.type. Si le type de destination estSyslog, vous devez également spécifier un point d'extrémité de destination à l'aide despec.logging.access.destination.syslog.endpointet vous pouvez spécifier une installation à l'aide despec.logging.access.destination.syslog.facility. L'exemple suivant est une définition de contrôleur d'entrée qui enregistre vers une destinationSyslog:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514NoteLe port de destination de
syslogdoit être UDP.
Configurer l'enregistrement des accès d'entrée avec un format d'enregistrement spécifique.
Vous pouvez spécifier
spec.logging.access.httpLogFormatpour personnaliser le format du journal. L'exemple suivant est une définition de contrôleur d'entrée qui enregistre sur un point d'extrémitésyslogavec l'adresse IP 1.2.3.4 et le port 10514 :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514 httpLogFormat: '%ci:%cp [%t] %ft %b/%s %B %bq %HM %HU %HV'
Désactiver la journalisation des accès entrants.
Pour désactiver la journalisation des accès entrants, laissez
spec.loggingouspec.logging.accessvide :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: null
7.8.6. Réglage du nombre de fils du contrôleur d'ingérence
Un administrateur de cluster peut définir le nombre de threads afin d'augmenter le nombre de connexions entrantes qu'un cluster peut gérer. Vous pouvez corriger un contrôleur d'entrée existant pour augmenter le nombre de threads.
Conditions préalables
- La procédure suivante suppose que vous avez déjà créé un contrôleur d'entrée.
Procédure
Mettre à jour le contrôleur d'entrée pour augmenter le nombre de threads :
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'NoteSi vous disposez d'un nœud capable d'exécuter de grandes quantités de ressources, vous pouvez configurer
spec.nodePlacement.nodeSelectoravec des étiquettes correspondant à la capacité du nœud prévu et configurerspec.tuningOptions.threadCountavec une valeur élevée appropriée.
7.8.7. Configuration d'un contrôleur d'entrée pour utiliser un équilibreur de charge interne
Lors de la création d'un contrôleur d'ingestion sur des plateformes en nuage, le contrôleur d'ingestion est publié par un équilibreur de charge en nuage public par défaut. En tant qu'administrateur, vous pouvez créer un contrôleur d'entrée qui utilise un équilibreur de charge interne au nuage.
Si votre fournisseur de cloud est Microsoft Azure, vous devez avoir au moins un équilibreur de charge public qui pointe vers vos nœuds. Si ce n'est pas le cas, tous vos nœuds perdront la connectivité de sortie vers l'internet.
Si vous souhaitez modifier le paramètre scope pour une ressource IngressController, vous pouvez modifier le paramètre .spec.endpointPublishingStrategy.loadBalancer.scope après la création de la ressource personnalisée (CR).
Figure 7.1. Diagramme de LoadBalancer
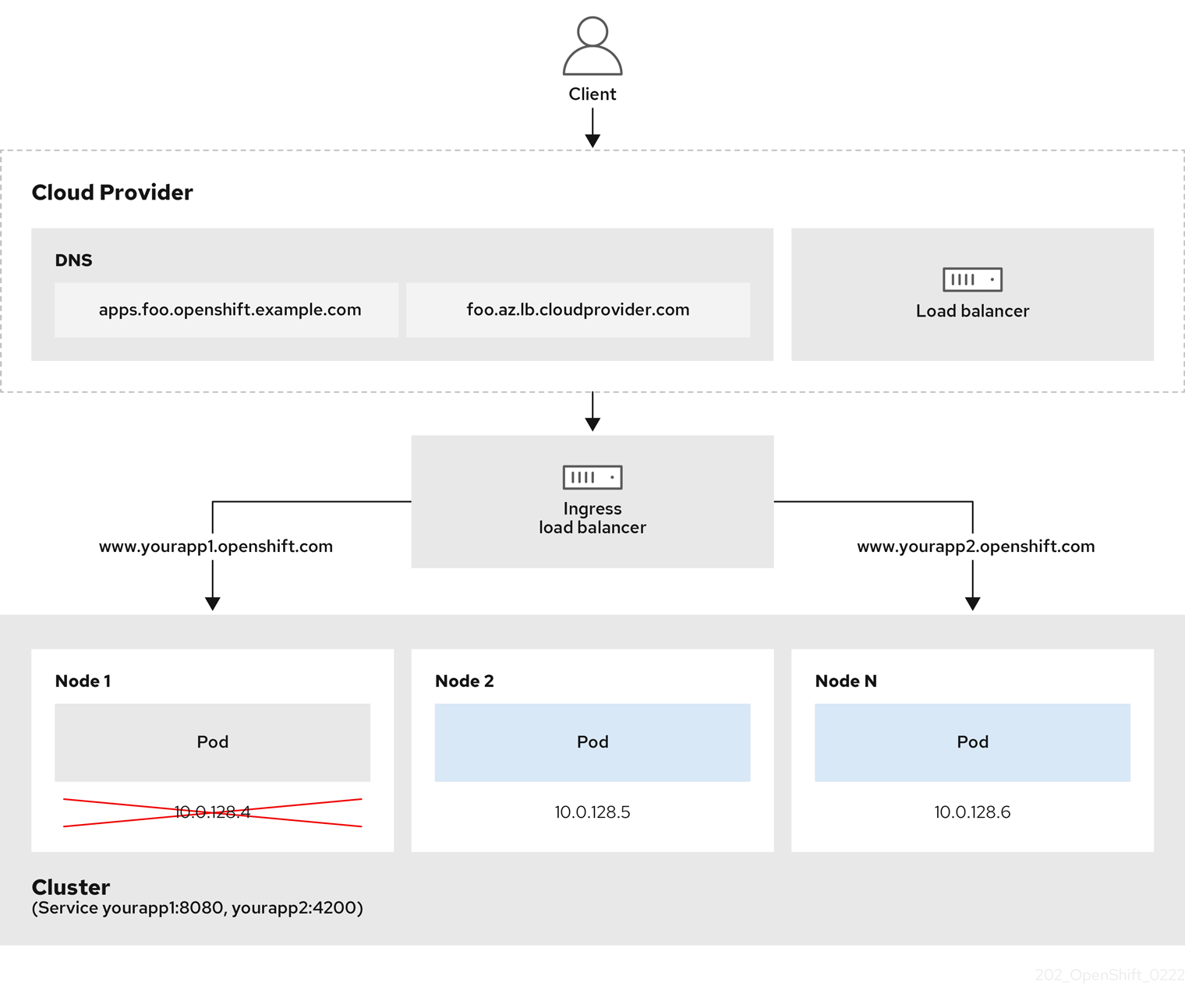
Le graphique précédent illustre les concepts suivants relatifs à la stratégie de publication des points d'extrémité de OpenShift Container Platform Ingress LoadBalancerService :
- Vous pouvez équilibrer la charge en externe, en utilisant l'équilibreur de charge du fournisseur de cloud, ou en interne, en utilisant l'équilibreur de charge du contrôleur d'ingestion OpenShift.
- Vous pouvez utiliser l'adresse IP unique de l'équilibreur de charge et des ports plus familiers, tels que 8080 et 4200, comme le montre le cluster illustré dans le graphique.
- Le trafic provenant de l'équilibreur de charge externe est dirigé vers les pods et géré par l'équilibreur de charge, comme le montre l'instance d'un nœud en panne. Voir la documentation de Kubernetes Services pour plus de détails sur la mise en œuvre.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez une ressource personnalisée (CR)
IngressControllerdans un fichier nommé<name>-ingress-controller.yaml, comme dans l'exemple suivant :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name>1 spec: domain: <domain>2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal3 Créez le contrôleur d'entrée défini à l'étape précédente en exécutant la commande suivante :
oc create -f <name>-ingress-controller.yaml1 - 1
- Remplacez
<name>par le nom de l'objetIngressController.
Facultatif : Confirmez que le contrôleur d'entrée a été créé en exécutant la commande suivante :
$ oc --all-namespaces=true get ingresscontrollers
7.8.8. Configuration de l'accès global pour un contrôleur d'entrée sur GCP
Un contrôleur d'entrée créé sur GCP avec un équilibreur de charge interne génère une adresse IP interne pour le service. Un administrateur de cluster peut spécifier l'option d'accès global, qui permet aux clients de n'importe quelle région du même réseau VPC et de la même région de calcul que l'équilibreur de charge, d'atteindre les charges de travail exécutées sur votre cluster.
Pour plus d'informations, voir la documentation GCP pour l'accès global.
Conditions préalables
- Vous avez déployé un cluster OpenShift Container Platform sur une infrastructure GCP.
- Vous avez configuré un contrôleur d'entrée pour utiliser un équilibreur de charge interne.
-
You installed the OpenShift CLI (
oc).
Procédure
Configurez la ressource Ingress Controller pour autoriser l'accès global.
NoteVous pouvez également créer un contrôleur d'entrée et spécifier l'option d'accès global.
Configurer la ressource Ingress Controller :
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultModifiez le fichier YAML :
Sample
clientAccessconfiguration toGlobalspec: endpointPublishingStrategy: loadBalancer: providerParameters: gcp: clientAccess: Global1 type: GCP scope: Internal type: LoadBalancerService- 1
- Set
gcp.clientAccesstoGlobal.
- Enregistrez le fichier pour appliquer les modifications.
Exécutez la commande suivante pour vérifier que le service autorise l'accès global :
$ oc -n openshift-ingress edit svc/router-default -o yamlLa sortie montre que l'accès global est activé pour GCP avec l'annotation
networking.gke.io/internal-load-balancer-allow-global-access.
7.8.9. Définition de l'intervalle de contrôle de santé du contrôleur d'entrée
L'administrateur d'un cluster peut définir l'intervalle de contrôle de santé afin de déterminer la durée d'attente du routeur entre deux contrôles de santé consécutifs. Cette valeur est appliquée globalement par défaut à toutes les routes. La valeur par défaut est de 5 secondes.
Conditions préalables
- La procédure suivante suppose que vous avez déjà créé un contrôleur d'entrée.
Procédure
Mettre à jour le contrôleur d'entrée afin de modifier l'intervalle entre les contrôles de santé du back-end :
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'NotePour remplacer le site
healthCheckIntervalpour un seul itinéraire, utilisez l'annotation d'itinérairerouter.openshift.io/haproxy.health.check.interval
7.8.10. Configurer le contrôleur d'entrée par défaut de votre cluster pour qu'il soit interne
Vous pouvez configurer le contrôleur d'entrée default de votre cluster pour qu'il soit interne en le supprimant et en le recréant.
Si votre fournisseur de cloud est Microsoft Azure, vous devez avoir au moins un équilibreur de charge public qui pointe vers vos nœuds. Si ce n'est pas le cas, tous vos nœuds perdront la connectivité de sortie vers l'internet.
Si vous souhaitez modifier le paramètre scope pour une ressource IngressController, vous pouvez modifier le paramètre .spec.endpointPublishingStrategy.loadBalancer.scope après la création de la ressource personnalisée (CR).
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Configurez le contrôleur d'entrée
defaultde votre cluster pour qu'il soit interne en le supprimant et en le recréant.$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF
7.8.11. Configuration de la politique d'admission des routes
Les administrateurs et les développeurs d'applications peuvent exécuter des applications dans plusieurs espaces de noms avec le même nom de domaine. Cela s'adresse aux organisations où plusieurs équipes développent des microservices qui sont exposés sur le même nom d'hôte.
L'autorisation des revendications à travers les espaces de noms ne devrait être activée que pour les clusters avec confiance entre les espaces de noms, sinon un utilisateur malveillant pourrait prendre le contrôle d'un nom d'hôte. Pour cette raison, la politique d'admission par défaut interdit les demandes de noms d'hôtes entre espaces de noms.
Conditions préalables
- Privilèges d'administrateur de cluster.
Procédure
Modifiez le champ
.spec.routeAdmissionde la variable de ressourceingresscontrollerà l'aide de la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeExemple de configuration du contrôleur d'entrée
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...AstuceVous pouvez également appliquer le langage YAML suivant pour configurer la politique d'admission des routes :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
7.8.12. Utilisation d'itinéraires génériques
Le contrôleur d'entrée HAProxy prend en charge les itinéraires génériques. L'opérateur d'entrée utilise wildcardPolicy pour configurer la variable d'environnement ROUTER_ALLOW_WILDCARD_ROUTES du contrôleur d'entrée.
Le comportement par défaut du contrôleur d'entrée est d'admettre les itinéraires avec une politique de caractères génériques de None, ce qui est rétrocompatible avec les ressources IngressController existantes.
Procédure
Configurer la politique des caractères génériques.
Utilisez la commande suivante pour modifier la ressource
IngressController:$ oc edit IngressControllerSous
spec, définissez le champwildcardPolicycommeWildcardsDisallowedouWildcardsAllowed:spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
7.8.13. Utilisation des en-têtes X-Forwarded
Vous configurez le contrôleur d'entrée HAProxy pour qu'il spécifie une stratégie de traitement des en-têtes HTTP, y compris Forwarded et X-Forwarded-For. L'opérateur d'entrée utilise le champ HTTPHeaders pour configurer la variable d'environnement ROUTER_SET_FORWARDED_HEADERS du contrôleur d'entrée.
Procédure
Configurez le champ
HTTPHeaderspour le contrôleur d'entrée.Utilisez la commande suivante pour modifier la ressource
IngressController:$ oc edit IngressControllerSous
spec, définissez le champ de politiqueHTTPHeaderssurAppend,Replace,IfNoneouNever:apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: forwardedHeaderPolicy: Append
Exemples de cas d'utilisation
As a cluster administrator, you can:
Configurez un proxy externe qui injecte l'en-tête
X-Forwarded-Fordans chaque requête avant de la transmettre à un contrôleur d'entrée.Pour configurer le contrôleur d'entrée afin qu'il transmette l'en-tête sans modification, vous devez spécifier la politique
never. Le contrôleur d'entrée ne définit alors jamais les en-têtes et les applications ne reçoivent que les en-têtes fournis par le proxy externe.Configurez le contrôleur d'entrée pour qu'il transmette sans modification l'en-tête
X-Forwarded-Forque votre proxy externe définit sur les requêtes de clusters externes.Pour configurer le contrôleur d'entrée afin qu'il définisse l'en-tête
X-Forwarded-Forsur les requêtes internes du cluster, qui ne passent pas par le proxy externe, spécifiez la stratégieif-none. Si l'en-tête d'une requête HTTP est déjà défini via le proxy externe, le contrôleur d'entrée le conserve. Si l'en-tête est absent parce que la requête n'est pas passée par le proxy, le contrôleur d'entrée ajoute l'en-tête.
As an application developer, you can:
Configurer un proxy externe spécifique à l'application qui injecte l'en-tête
X-Forwarded-For.Pour configurer un contrôleur d'entrée afin qu'il transmette l'en-tête sans modification pour la route d'une application, sans affecter la politique pour les autres routes, ajoutez une annotation
haproxy.router.openshift.io/set-forwarded-headers: if-noneouhaproxy.router.openshift.io/set-forwarded-headers: neversur la route de l'application.NoteVous pouvez définir l'annotation
haproxy.router.openshift.io/set-forwarded-headerspour chaque itinéraire, indépendamment de la valeur définie globalement pour le contrôleur d'entrée.
7.8.14. Activation de la connectivité HTTP/2 Ingress
Vous pouvez activer la connectivité HTTP/2 transparente de bout en bout dans HAProxy. Cela permet aux propriétaires d'applications d'utiliser les fonctionnalités du protocole HTTP/2, notamment la connexion unique, la compression des en-têtes, les flux binaires, etc.
Vous pouvez activer la connectivité HTTP/2 pour un contrôleur d'entrée individuel ou pour l'ensemble du cluster.
Pour permettre l'utilisation de HTTP/2 pour la connexion du client à HAProxy, un itinéraire doit spécifier un certificat personnalisé. Une route qui utilise le certificat par défaut ne peut pas utiliser HTTP/2. Cette restriction est nécessaire pour éviter les problèmes liés à la coalescence des connexions, lorsque le client réutilise une connexion pour différents itinéraires qui utilisent le même certificat.
La connexion entre HAProxy et le module d'application ne peut utiliser HTTP/2 que pour le recryptage des itinéraires et non pour les itinéraires terminés ou non sécurisés. Cette restriction est due au fait que HAProxy utilise la négociation de protocole au niveau de l'application (ALPN), qui est une extension TLS, pour négocier l'utilisation de HTTP/2 avec le back-end. Il en résulte que le protocole HTTP/2 de bout en bout est possible avec passthrough et re-encrypt, mais pas avec des itinéraires non sécurisés ou terminés par un bord.
L'utilisation de WebSockets avec une route de recryptage et avec HTTP/2 activé sur un contrôleur d'entrée nécessite la prise en charge de WebSocket sur HTTP/2. WebSockets sur HTTP/2 est une fonctionnalité de HAProxy 2.4, qui n'est pas supportée par OpenShift Container Platform pour le moment.
Pour les routes non passantes, le contrôleur d'entrée négocie sa connexion à l'application indépendamment de la connexion du client. Cela signifie qu'un client peut se connecter au contrôleur d'entrée et négocier HTTP/1.1, et que le contrôleur d'entrée peut ensuite se connecter à l'application, négocier HTTP/2, et transmettre la demande de la connexion HTTP/1.1 du client en utilisant la connexion HTTP/2 à l'application. Cela pose un problème si le client tente par la suite de faire passer sa connexion de HTTP/1.1 au protocole WebSocket, car le contrôleur d'entrée ne peut pas transmettre WebSocket à HTTP/2 et ne peut pas faire passer sa connexion HTTP/2 à WebSocket. Par conséquent, si vous avez une application destinée à accepter des connexions WebSocket, elle ne doit pas autoriser la négociation du protocole HTTP/2, sinon les clients ne parviendront pas à passer au protocole WebSocket.
Procédure
Activer HTTP/2 sur un seul contrôleur d'entrée.
Pour activer HTTP/2 sur un contrôleur d'entrée, entrez la commande
oc annotate:oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=trueRemplacer
<ingresscontroller_name>par le nom du contrôleur d'entrée à annoter.
Activer HTTP/2 sur l'ensemble du cluster.
Pour activer HTTP/2 pour l'ensemble du cluster, entrez la commande
oc annotate:$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=trueAstuceVous pouvez également appliquer le YAML suivant pour ajouter l'annotation :
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster annotations: ingress.operator.openshift.io/default-enable-http2: "true"
7.8.15. Configuration du protocole PROXY pour un contrôleur d'entrée
Un administrateur de cluster peut configurer le protocole PROXY lorsqu'un contrôleur d'entrée utilise les types de stratégie de publication des points d'extrémité HostNetwork ou NodePortService. Le protocole PROXY permet à l'équilibreur de charge de conserver les adresses client d'origine pour les connexions que le contrôleur d'entrée reçoit. Les adresses client d'origine sont utiles pour la journalisation, le filtrage et l'injection d'en-têtes HTTP. Dans la configuration par défaut, les connexions que le contrôleur d'entrée reçoit ne contiennent que l'adresse source associée à l'équilibreur de charge.
Cette fonctionnalité n'est pas prise en charge dans les déploiements en nuage. Cette restriction s'explique par le fait que lorsque OpenShift Container Platform fonctionne sur une plateforme cloud et qu'un IngressController spécifie qu'un service d'équilibrage de charge doit être utilisé, l'opérateur d'ingestion configure le service d'équilibrage de charge et active le protocole PROXY en fonction de l'exigence de la plateforme en matière de préservation des adresses source.
Vous devez configurer OpenShift Container Platform et l'équilibreur de charge externe pour qu'ils utilisent le protocole PROXY ou TCP.
Le protocole PROXY n'est pas pris en charge par le contrôleur d'entrée par défaut avec les clusters fournis par l'installateur sur des plates-formes non cloud qui utilisent un VIP d'entrée Keepalived.
Conditions préalables
- Vous avez créé un contrôleur d'entrée.
Procédure
Modifiez la ressource Ingress Controller :
$ oc -n openshift-ingress-operator edit ingresscontroller/defaultDéfinir la configuration PROXY :
Si votre contrôleur d'entrée utilise le type de stratégie de publication des points d'extrémité hostNetwork, définissez le sous-champ
spec.endpointPublishingStrategy.hostNetwork.protocolsurPROXY:Exemple de configuration de
hostNetworkpourPROXYspec: endpointPublishingStrategy: hostNetwork: protocol: PROXY type: HostNetworkSi votre contrôleur d'entrée utilise le type de stratégie de publication des points d'extrémité NodePortService, attribuez la valeur
PROXYau sous-champspec.endpointPublishingStrategy.nodePort.protocol:Exemple de configuration de
nodePortpourPROXYspec: endpointPublishingStrategy: nodePort: protocol: PROXY type: NodePortService
7.8.16. Spécification d'un domaine de cluster alternatif à l'aide de l'option appsDomain
En tant qu'administrateur de cluster, vous pouvez spécifier une alternative au domaine de cluster par défaut pour les routes créées par l'utilisateur en configurant le champ appsDomain. Le champ appsDomain est un domaine optionnel pour OpenShift Container Platform à utiliser à la place du domaine par défaut, qui est spécifié dans le champ domain. Si vous spécifiez un domaine alternatif, il remplace le domaine de cluster par défaut afin de déterminer l'hôte par défaut pour une nouvelle route.
Par exemple, vous pouvez utiliser le domaine DNS de votre entreprise comme domaine par défaut pour les routes et les entrées des applications fonctionnant sur votre cluster.
Conditions préalables
- You deployed an OpenShift Container Platform cluster.
-
Vous avez installé l'interface de ligne de commande
oc.
Procédure
Configurez le champ
appsDomainen spécifiant un autre domaine par défaut pour les itinéraires créés par l'utilisateur.Modifiez la ressource ingress
cluster:$ oc edit ingresses.config/cluster -o yamlModifiez le fichier YAML :
Exemple de configuration de
appsDomainpourtest.example.comapiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.example.com1 appsDomain: <test.example.com>2 - 1
- Spécifie le domaine par défaut. Vous ne pouvez pas modifier le domaine par défaut après l'installation.
- 2
- Facultatif : Domaine de l'infrastructure OpenShift Container Platform à utiliser pour les routes d'application. Au lieu du préfixe par défaut,
apps, vous pouvez utiliser un autre préfixe commetest.
Vérifiez qu'un itinéraire existant contient le nom de domaine spécifié dans le champ
appsDomainen exposant l'itinéraire et en vérifiant le changement de domaine de l'itinéraire :NoteAttendez que le site
openshift-apiserverfinisse de diffuser les mises à jour avant d'exposer l'itinéraire.Exposer l'itinéraire :
$ oc expose service hello-openshift route.route.openshift.io/hello-openshift exposedExemple de sortie :
$ oc get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
7.8.17. Conversion des en-têtes HTTP
HAProxy 2.2 met par défaut les noms d'en-tête HTTP en minuscules, par exemple en remplaçant Host: xyz.com par host: xyz.com. Si les applications existantes sont sensibles à la mise en majuscules des noms d'en-tête HTTP, utilisez le champ API spec.httpHeaders.headerNameCaseAdjustments du contrôleur d'entrée pour trouver une solution permettant d'accommoder les applications existantes jusqu'à ce qu'elles soient corrigées.
Comme OpenShift Container Platform inclut HAProxy 2.2, assurez-vous d'ajouter la configuration nécessaire à l'aide de spec.httpHeaders.headerNameCaseAdjustments avant de procéder à la mise à niveau.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
En tant qu'administrateur de cluster, vous pouvez convertir le cas de l'en-tête HTTP en entrant la commande oc patch ou en définissant le champ HeaderNameCaseAdjustments dans le fichier YAML du contrôleur d'entrée.
Spécifiez un en-tête HTTP à mettre en majuscules en entrant la commande
oc patch.Entrez la commande
oc patchpour remplacer l'en-tête HTTPhostparHost:$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'Annoter l'itinéraire de la demande :
$ oc annotate routes/my-application haproxy.router.openshift.io/h1-adjust-case=trueLe contrôleur d'entrée ajuste ensuite l'en-tête de demande
hostcomme spécifié.
Spécifiez les ajustements à l'aide du champ
HeaderNameCaseAdjustmentsen configurant le fichier YAML du contrôleur d'entrée.L'exemple suivant de contrôleur d'entrée YAML ajuste l'en-tête
hostàHostpour les requêtes HTTP/1 vers des itinéraires correctement annotés :Exemple de contrôleur d'entrée YAML
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: headerNameCaseAdjustments: - HostL'exemple de route suivant permet d'ajuster les cas de figure des en-têtes de réponse HTTP à l'aide de l'annotation
haproxy.router.openshift.io/h1-adjust-case:Exemple de route YAML
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true1 name: my-application namespace: my-application spec: to: kind: Service name: my-application- 1
- Fixer
haproxy.router.openshift.io/h1-adjust-caseà true (vrai).
7.8.18. Utilisation de la compression du routeur
Vous configurez le contrôleur d'entrée HAProxy pour spécifier globalement la compression du routeur pour des types MIME spécifiques. Vous pouvez utiliser la variable mimeTypes pour définir les formats des types MIME auxquels la compression est appliquée. Les types sont les suivants : application, image, message, multipart, texte, vidéo ou un type personnalisé précédé de "X-". Pour voir la notation complète des types et sous-types MIME, voir RFC1341.
La mémoire allouée à la compression peut affecter le nombre maximal de connexions. En outre, la compression de tampons volumineux peut entraîner une certaine latence, comme c'est le cas pour les expressions rationnelles lourdes ou les longues listes d'expressions rationnelles.
Tous les types MIME ne bénéficient pas de la compression, mais HAProxy utilise tout de même des ressources pour essayer de les compresser si on le lui demande. En général, les formats de texte, tels que html, css et js, bénéficient de la compression, mais les formats déjà compressés, tels que les images, l'audio et la vidéo, bénéficient peu en échange du temps et des ressources consacrés à la compression.
Procédure
Configurez le champ
httpCompressionpour le contrôleur d'entrée.Utilisez la commande suivante pour modifier la ressource
IngressController:$ oc edit -n openshift-ingress-operator ingresscontrollers/defaultSous
spec, définissez le champ de politiquehttpCompressionsurmimeTypeset indiquez une liste de types MIME pour lesquels la compression doit être appliquée :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpCompression: mimeTypes: - "text/html" - "text/css; charset=utf-8" - "application/json" ...
7.8.19. Personnalisation des pages de réponse au code d'erreur de HAProxy
En tant qu'administrateur de cluster, vous pouvez spécifier un code d'erreur personnalisé pour la page de réponse 503, 404 ou les deux pages d'erreur. Le routeur HAProxy sert une page d'erreur 503 lorsque le module d'application ne fonctionne pas ou une page d'erreur 404 lorsque l'URL demandée n'existe pas. Par exemple, si vous personnalisez la page de réponse au code d'erreur 503, la page est servie lorsque le module d'application n'est pas en cours d'exécution et la page de réponse HTTP au code d'erreur 404 par défaut est servie par le routeur HAProxy en cas d'itinéraire incorrect ou inexistant.
Les pages de réponse aux codes d'erreur personnalisés sont spécifiées dans une carte de configuration, puis patchées sur le contrôleur d'entrée. Les clés de la carte de configuration ont deux noms de fichier disponibles : error-page-503.http et error-page-404.http.
Les pages de réponse de code d'erreur HTTP personnalisées doivent respecter les directives de configuration de la page d'erreur HTTP de HAProxy. Voici un exemple de la page de réponse par défaut du code d'erreur http 503 du routeur HAProxy de OpenShift Container Platform. Vous pouvez utiliser le contenu par défaut comme modèle pour créer votre propre page personnalisée.
Par défaut, le routeur HAProxy ne sert qu'une page d'erreur 503 lorsque l'application n'est pas en cours d'exécution ou lorsque la route est incorrecte ou inexistante. Ce comportement par défaut est le même que le comportement sur OpenShift Container Platform 4.8 et antérieur. Si une carte de configuration pour la personnalisation d'une réponse de code d'erreur HTTP n'est pas fournie et que vous utilisez une page de réponse de code d'erreur HTTP personnalisée, le routeur sert une page de réponse de code d'erreur 404 ou 503 par défaut.
Si vous utilisez la page de code d'erreur 503 par défaut d'OpenShift Container Platform comme modèle pour vos personnalisations, les en-têtes du fichier nécessitent un éditeur qui peut utiliser les fins de ligne CRLF.
Procédure
Créez une carte de configuration nommée
my-custom-error-code-pagesdans l'espace de nomsopenshift-config:$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.httpImportantSi vous ne spécifiez pas le format correct pour la page de réponse du code d'erreur personnalisé, une panne du module de routeur se produit. Pour résoudre cette panne, vous devez supprimer ou corriger la carte de configuration et supprimer les router pods concernés afin qu'ils puissent être recréés avec les informations correctes.
Patch du contrôleur d'entrée pour référencer la carte de configuration
my-custom-error-code-pagespar son nom :$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeL'opérateur d'entrée copie la carte de configuration
my-custom-error-code-pagesde l'espace de nomsopenshift-configvers l'espace de nomsopenshift-ingress. L'opérateur nomme la carte de configuration selon le modèle<your_ingresscontroller_name>-errorpages, dans l'espace de nomsopenshift-ingress.Afficher la copie :
$ oc get cm default-errorpages -n openshift-ingressExemple de sortie
NAME DATA AGE default-errorpages 2 25s1 - 1
- L'exemple de nom de carte de configuration est
default-errorpagescar la ressource personnalisée (CR) du contrôleur d'entréedefaulta été corrigée.
Confirmez que la carte de configuration contenant la page de réponse d'erreur personnalisée est montée sur le volume du routeur, la clé de la carte de configuration étant le nom du fichier contenant la réponse du code d'erreur HTTP personnalisé :
Pour la réponse au code d'erreur personnalisé HTTP 503 :
oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.httpPour la réponse au code d'erreur HTTP personnalisé 404 :
oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
Vérification
Vérifiez votre code d'erreur personnalisé dans la réponse HTTP :
Créez un projet et une application de test :
$ oc new-project test-ingress$ oc new-app django-psql-examplePour la réponse au code d'erreur http personnalisé 503 :
- Arrêter tous les pods pour l'application.
Exécutez la commande curl suivante ou visitez le nom d'hôte de la route dans le navigateur :
$ curl -vk <route_hostname>
Pour la réponse au code d'erreur http personnalisé 404 :
- Visiter un itinéraire inexistant ou un itinéraire incorrect.
Exécutez la commande curl suivante ou visitez le nom d'hôte de la route dans le navigateur :
$ curl -vk <route_hostname>
Vérifier que l'attribut
errorfilefigure bien dans le fichierhaproxy.config:oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
7.8.20. Définition du nombre maximum de connexions du contrôleur d'entrée
Un administrateur de cluster peut définir le nombre maximum de connexions simultanées pour les déploiements de routeurs OpenShift. Vous pouvez corriger un contrôleur d'entrée existant pour augmenter le nombre maximum de connexions.
Conditions préalables
- La procédure suivante suppose que vous avez déjà créé un contrôleur d'entrée
Procédure
Mettez à jour le contrôleur d'entrée afin de modifier le nombre maximal de connexions pour HAProxy :
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'AvertissementSi la valeur de
spec.tuningOptions.maxConnectionsest supérieure à la limite actuelle du système d'exploitation, le processus HAProxy ne démarrera pas. Voir le tableau de la section "Paramètres de configuration du contrôleur d'entrée" pour plus d'informations sur ce paramètre.
Chapitre 8. Ingress sharding dans OpenShift Container Platform
Dans OpenShift Container Platform, un Ingress Controller peut servir toutes les routes ou un sous-ensemble de routes. Par défaut, le contrôleur d'ingestion sert toutes les routes créées dans n'importe quel espace de noms du cluster. Vous pouvez ajouter des contrôleurs d'entrée supplémentaires à votre cluster pour optimiser le routage en créant shards, qui sont des sous-ensembles d'itinéraires basés sur des caractéristiques sélectionnées. Pour marquer un itinéraire comme membre d'une grappe, utilisez des étiquettes dans le champ de l'itinéraire ou de l'espace de noms metadata. Le contrôleur d'entrée utilise selectors, également connu sous le nom de selection expression, pour sélectionner un sous-ensemble d'itinéraires à partir de l'ensemble des itinéraires à desservir.
La répartition des entrées est utile lorsque vous souhaitez équilibrer la charge du trafic entrant entre plusieurs contrôleurs d'entrée, lorsque vous souhaitez isoler le trafic à acheminer vers un contrôleur d'entrée spécifique, ou pour toute une série d'autres raisons décrites dans la section suivante.
Par défaut, chaque route utilise le domaine par défaut du cluster. Toutefois, les itinéraires peuvent être configurés pour utiliser le domaine du routeur à la place. Pour plus d'informations, voir Création d'un itinéraire pour le sharding de contrôleur d'entrée.
8.1. Regroupement des contrôleurs d'entrée
Vous pouvez utiliser le partage d'entrée, également connu sous le nom de partage de routeur, pour distribuer un ensemble d'itinéraires sur plusieurs routeurs en ajoutant des étiquettes aux itinéraires, aux espaces de noms ou aux deux. Le contrôleur d'entrée utilise un ensemble correspondant de sélecteurs pour n'admettre que les itinéraires dotés d'une étiquette spécifique. Chaque groupe d'entrée comprend les itinéraires filtrés à l'aide d'une expression de sélection donnée.
En tant que principal mécanisme d'entrée du trafic dans la grappe, le contrôleur d'entrée peut être fortement sollicité. En tant qu'administrateur de la grappe, vous pouvez répartir les routes pour :
- Équilibrer les contrôleurs d'entrée, ou routeurs, avec plusieurs itinéraires pour accélérer les réponses aux changements.
- Attribuer à certains itinéraires des garanties de fiabilité différentes de celles des autres itinéraires.
- Permettre à certains contrôleurs d'entrée de définir des politiques différentes.
- Ne permettre qu'à des itinéraires spécifiques d'utiliser des fonctionnalités supplémentaires.
- Exposer des itinéraires différents sur des adresses différentes afin que les utilisateurs internes et externes puissent voir des itinéraires différents, par exemple.
- Transférer le trafic d'une version d'une application à une autre lors d'un déploiement bleu-vert.
Lorsque les contrôleurs d'entrée sont groupés, une route donnée est admise par zéro ou plusieurs contrôleurs d'entrée du groupe. L'état d'une route indique si un contrôleur d'entrée l'a admise ou non. Un contrôleur d'entrée n'admettra une route que si elle est unique à son groupe.
Un contrôleur d'entrée peut utiliser trois méthodes de répartition :
- Ajout d'un sélecteur d'espace de noms au contrôleur d'ingestion, de sorte que tous les itinéraires d'un espace de noms dont les étiquettes correspondent au sélecteur d'espace de noms se trouvent dans la grappe d'ingestion.
- Ajout d'un sélecteur d'itinéraires au contrôleur d'entrée, de sorte que tous les itinéraires dont les étiquettes correspondent au sélecteur d'itinéraires se trouvent dans le groupe d'entrée.
- Ajout d'un sélecteur d'espace de noms et d'un sélecteur d'itinéraires au contrôleur d'ingestion, de sorte que les itinéraires dont les étiquettes correspondent au sélecteur d'itinéraires dans un espace de noms dont les étiquettes correspondent au sélecteur d'espace de noms se trouvent dans la grappe d'ingestion.
Avec la répartition, vous pouvez distribuer des sous-ensembles d'itinéraires sur plusieurs contrôleurs d'entrée. Ces sous-ensembles peuvent ne pas se chevaucher ( traditional sharding) ou se chevaucher ( overlapped sharding).
8.1.1. Exemple de partage traditionnel
Un contrôleur d'entrée finops-router est configuré avec le sélecteur d'étiquettes spec.namespaceSelector.matchLabels.name réglé sur finance et ops:
Exemple de définition YAML pour finops-router
apiVersion: v1
items:
- apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: finops-router
namespace: openshift-ingress-operator
spec:
namespaceSelector:
matchLabels:
name:
- finance
- ops
Un deuxième contrôleur d'entrée dev-router est configuré avec le sélecteur d'étiquettes spec.namespaceSelector.matchLabels.name réglé sur dev:
Exemple de définition YAML pour dev-router
apiVersion: v1
items:
- apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: dev-router
namespace: openshift-ingress-operator
spec:
namespaceSelector:
matchLabels:
name: dev
Si toutes les routes d'application sont dans des espaces de noms séparés, chacun étiqueté avec name:finance, name:ops, et name:dev respectivement, cette configuration distribue efficacement vos routes entre les deux contrôleurs d'entrée. Les routes de OpenShift Container Platform pour la console, l'authentification et d'autres objectifs ne doivent pas être gérées.
Dans le scénario ci-dessus, la répartition devient un cas particulier de partitionnement, sans que les sous-ensembles ne se chevauchent. Les routes sont réparties entre les routeurs.
Le contrôleur d'entrée default continue à servir toutes les routes à moins que les champs namespaceSelector ou routeSelector ne contiennent des routes à exclure. Consultez cette solution de la base de connaissances de Red Hat et la section "Sharding the default Ingress Controller" pour plus d'informations sur la manière d'exclure les itinéraires du contrôleur d'entrée par défaut.
8.1.2. Exemple de partage superposé
Outre finops-router et dev-router dans l'exemple ci-dessus, vous avez également devops-router, qui est configuré avec le sélecteur d'étiquettes spec.namespaceSelector.matchLabels.name défini sur dev et ops:
Exemple de définition YAML pour devops-router
apiVersion: v1
items:
- apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: devops-router
namespace: openshift-ingress-operator
spec:
namespaceSelector:
matchLabels:
name:
- dev
- ops
Les routes des espaces de noms intitulés name:dev et name:ops sont maintenant gérées par deux contrôleurs d'entrée différents. Avec cette configuration, les sous-ensembles d'itinéraires se chevauchent.
Le chevauchement de sous-ensembles d'itinéraires permet de créer des règles de routage plus complexes. Par exemple, vous pouvez détourner le trafic hautement prioritaire vers le site dédié finops-router tout en envoyant le trafic moins prioritaire vers devops-router.
8.1.3. Partage du contrôleur d'entrée par défaut
Après la création d'un nouveau shard d'ingestion, il se peut que des routes admises dans votre nouveau shard d'ingestion soient également admises par le contrôleur d'ingestion par défaut. En effet, le contrôleur d'entrée par défaut n'a pas de sélecteurs et admet tous les itinéraires par défaut.
Vous pouvez empêcher un contrôleur d'entrée de desservir des itinéraires avec des étiquettes spécifiques à l'aide de sélecteurs d'espace de noms ou de sélecteurs d'itinéraires. La procédure suivante empêche le contrôleur d'entrée par défaut de desservir les itinéraires finance, ops et dev, nouvellement partagés, à l'aide d'un sélecteur d'espace de noms. Cette procédure permet d'isoler davantage les groupes de serveurs d'entrée.
Vous devez conserver toutes les routes d'administration d'OpenShift Container Platform sur le même Ingress Controller. Par conséquent, évitez d'ajouter des sélecteurs supplémentaires au contrôleur d'ingestion par défaut qui excluent ces routes essentielles.
Conditions préalables
-
You installed the OpenShift CLI (
oc). - Vous êtes connecté en tant qu'administrateur de projet.
Procédure
Modifiez le contrôleur d'entrée par défaut en exécutant la commande suivante :
$ oc edit ingresscontroller -n openshift-ingress-operator defaultModifiez le contrôleur d'entrée pour qu'il contienne une adresse
namespaceSelectorqui exclut les itinéraires portant l'une des étiquettesfinance,opsetdev:apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: namespaceSelector: matchExpressions: - key: type operator: NotIn values: - finance - ops - dev
Le contrôleur d'entrée par défaut ne desservira plus les espaces de noms intitulés name:finance, name:ops, et name:dev.
8.1.4. Sharding d'entrée et DNS
L'administrateur de la grappe est chargé de créer une entrée DNS distincte pour chaque routeur d'un projet. Un routeur ne transmettra pas de routes inconnues à un autre routeur.
Prenons l'exemple suivant :
-
Le routeur A se trouve sur l'hôte 192.168.0.5 et a des routes avec
*.foo.com. -
Le routeur B se trouve sur l'hôte 192.168.1.9 et a des routes avec
*.example.com.
Des entrées DNS séparées doivent résoudre *.foo.com en nœud hébergeant le routeur A et *.example.com en nœud hébergeant le routeur B :
-
*.foo.com A IN 192.168.0.5 -
*.example.com A IN 192.168.1.9
8.1.5. Configuration de la répartition des contrôleurs d'entrée à l'aide d'étiquettes d'itinéraires
La répartition du contrôleur d'entrée à l'aide d'étiquettes d'itinéraires signifie que le contrôleur d'entrée dessert n'importe quel itinéraire dans n'importe quel espace de noms sélectionné par le sélecteur d'itinéraires.
Figure 8.1. Répartition des entrées à l'aide d'étiquettes d'itinéraires
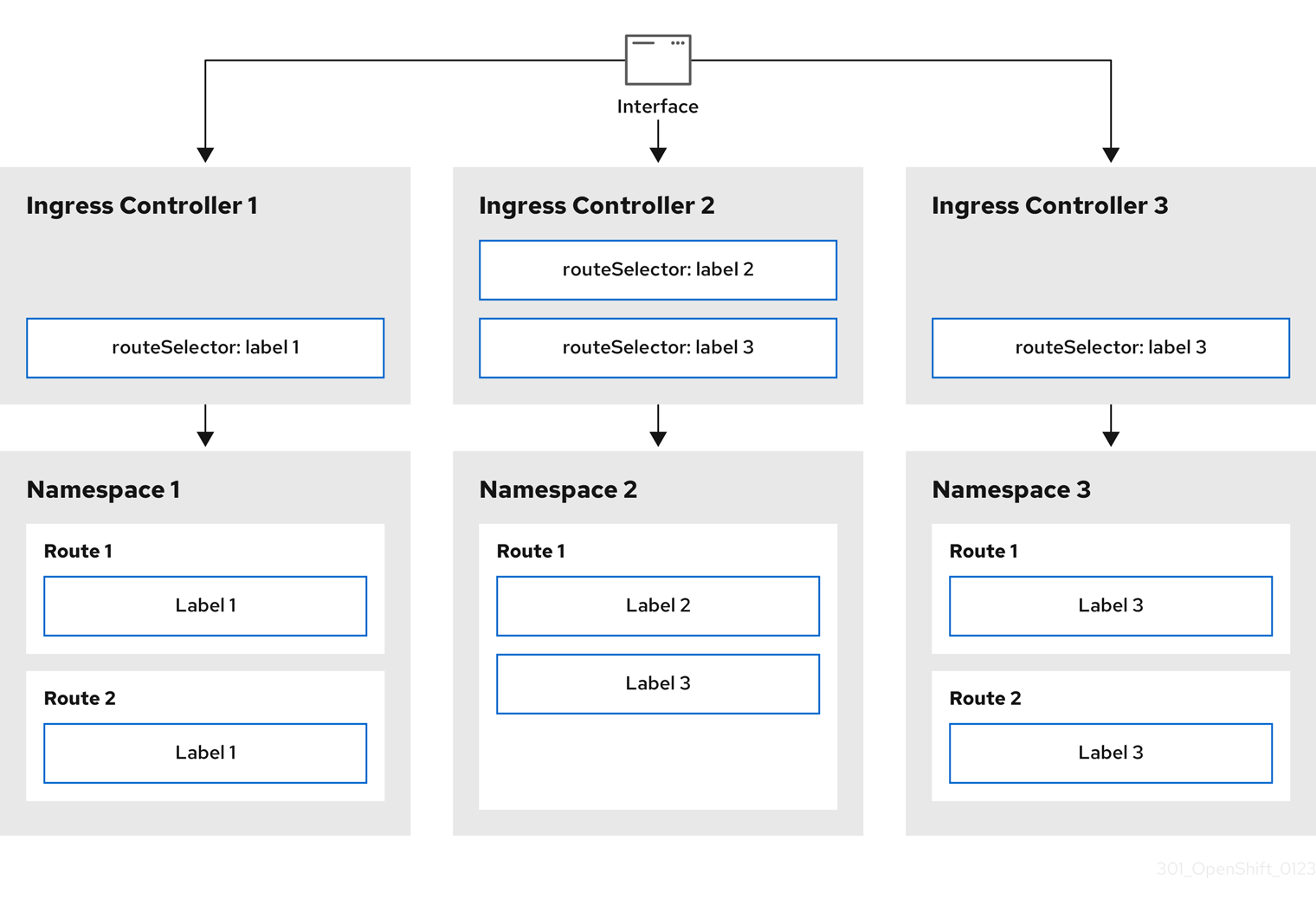
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Procédure
Modifiez le fichier
router-internal.yaml:# cat router-internal.yaml apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net>1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" routeSelector: matchLabels: type: sharded status: {} kind: List metadata: resourceVersion: "" selfLink: ""- 1
- Indiquez un domaine à utiliser par le contrôleur d'entrée. Ce domaine doit être différent du domaine par défaut du contrôleur d'entrée.
Appliquer le fichier du contrôleur d'entrée
router-internal.yaml:# oc apply -f router-internal.yamlLe contrôleur d'entrée sélectionne les routes dans n'importe quel espace de noms qui ont l'étiquette
type: sharded.Créez une nouvelle route en utilisant le domaine configuré dans le site
router-internal.yaml:oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
8.1.6. Configuration de la répartition des contrôleurs d'entrée à l'aide d'étiquettes d'espace de noms
La répartition du contrôleur d'entrée à l'aide d'étiquettes d'espace de noms signifie que le contrôleur d'entrée dessert n'importe quelle route dans n'importe quel espace de noms sélectionné par le sélecteur d'espace de noms.
Figure 8.2. La mise en commun à l'entrée à l'aide d'étiquettes d'espace de noms
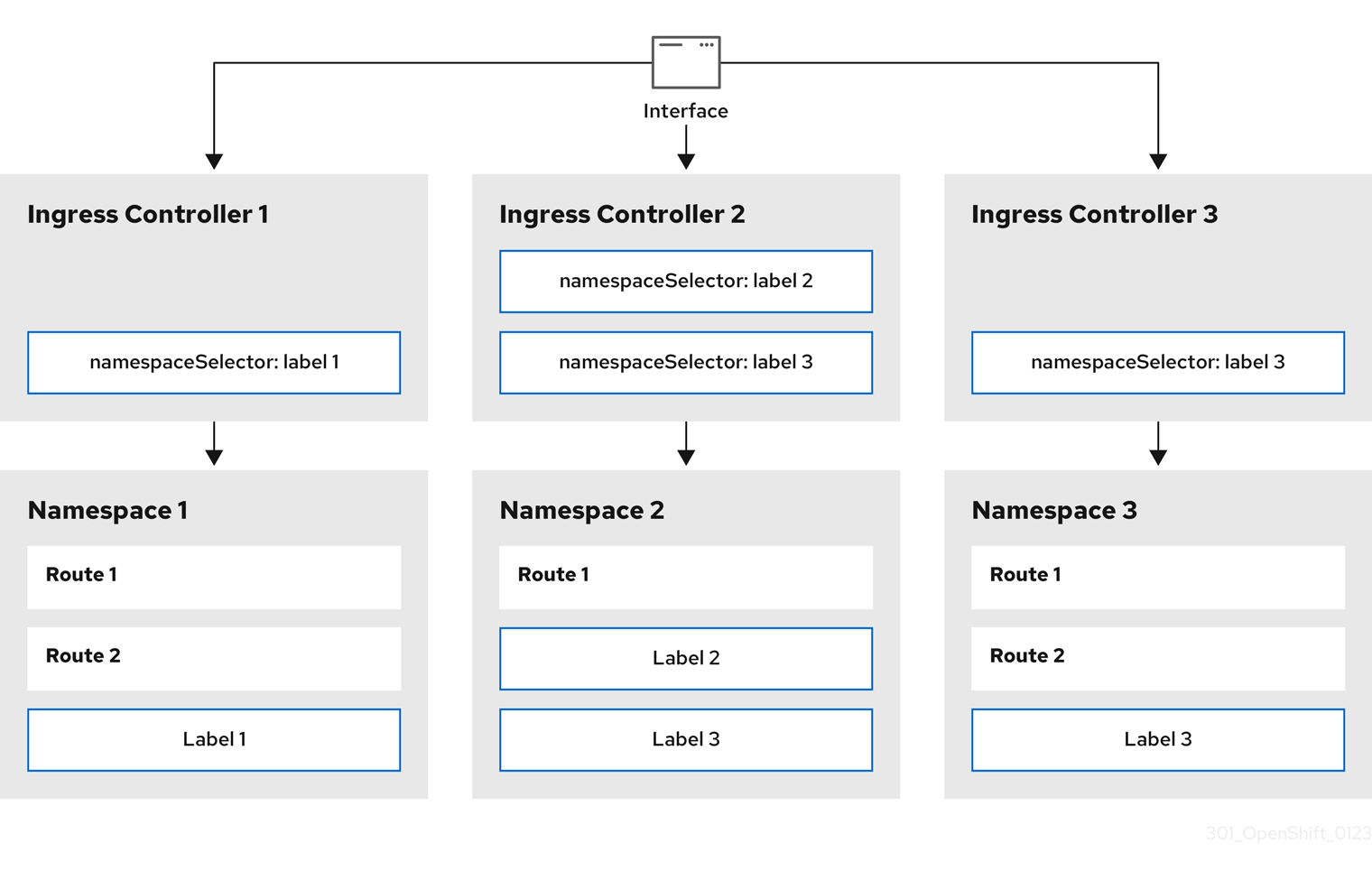
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Procédure
Modifiez le fichier
router-internal.yaml:# cat router-internal.yamlExemple de sortie
apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net>1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" namespaceSelector: matchLabels: type: sharded status: {} kind: List metadata: resourceVersion: "" selfLink: ""- 1
- Indiquez un domaine à utiliser par le contrôleur d'entrée. Ce domaine doit être différent du domaine par défaut du contrôleur d'entrée.
Appliquer le fichier du contrôleur d'entrée
router-internal.yaml:# oc apply -f router-internal.yamlLe contrôleur d'entrée sélectionne les itinéraires dans tout espace de noms sélectionné par le sélecteur d'espace de noms et portant l'étiquette
type: sharded.Créez une nouvelle route en utilisant le domaine configuré dans le site
router-internal.yaml:oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
8.2. Création d'une route pour le sharding du contrôleur d'entrée
Une route vous permet d'héberger votre application à une URL. Dans ce cas, le nom d'hôte n'est pas défini et la route utilise un sous-domaine à la place. Lorsque vous spécifiez un sous-domaine, vous utilisez automatiquement le domaine du contrôleur d'entrée qui expose l'itinéraire. Lorsqu'un itinéraire est exposé par plusieurs contrôleurs d'ingestion, l'itinéraire est hébergé sur plusieurs URL.
La procédure suivante décrit comment créer une route pour le sharding du contrôleur d'entrée, en utilisant l'application hello-openshift comme exemple.
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Conditions préalables
-
You installed the OpenShift CLI (
oc). - Vous êtes connecté en tant qu'administrateur de projet.
- Vous avez une application web qui expose un port et un point d'extrémité HTTP ou TLS qui écoute le trafic sur le port.
- Vous avez configuré le contrôleur d'entrée pour le partage.
Procédure
Créez un projet appelé
hello-openshiften exécutant la commande suivante :$ oc new-project hello-openshiftCréez un pod dans le projet en exécutant la commande suivante :
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.jsonCréez un service appelé
hello-openshiften exécutant la commande suivante :$ oc expose pod/hello-openshiftCréez une définition de route appelée
hello-openshift-route.yaml:Définition YAML de la route créée pour le sharding :
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded1 name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift2 tls: termination: edge to: kind: Service name: hello-openshift- 1
- La clé d'étiquette et la valeur d'étiquette correspondante doivent toutes deux correspondre à celles spécifiées dans le contrôleur d'entrée. Dans cet exemple, le contrôleur d'entrée a la clé et la valeur d'étiquette
type: sharded. - 2
- La route sera exposée en utilisant la valeur du champ
subdomain. Lorsque vous spécifiez le champsubdomain, vous devez laisser le nom d'hôte non défini. Si vous spécifiez à la fois les champshostetsubdomain, l'itinéraire utilisera la valeur du champhostet ignorera le champsubdomain.
Utilisez
hello-openshift-route.yamlpour créer une route vers l'applicationhello-openshiften exécutant la commande suivante :$ oc -n hello-openshift create -f hello-openshift-route.yaml
Vérification
Obtenez l'état de la route à l'aide de la commande suivante :
$ oc -n hello-openshift get routes/hello-openshift-edge -o yamlLa ressource
Routequi en résulte devrait ressembler à ce qui suit :Exemple de sortie
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift tls: termination: edge to: kind: Service name: hello-openshift status: ingress: - host: hello-openshift.<apps-sharded.basedomain.example.net>1 routerCanonicalHostname: router-sharded.<apps-sharded.basedomain.example.net>2 routerName: sharded3 - 1
- Le nom d'hôte que le contrôleur d'entrée, ou le routeur, utilise pour exposer l'itinéraire. La valeur du champ
hostest automatiquement déterminée par le contrôleur d'entrée et utilise son domaine. Dans cet exemple, le domaine du contrôleur d'entrée est<apps-sharded.basedomain.example.net>. - 2
- Le nom d'hôte du contrôleur d'entrée.
- 3
- Le nom du contrôleur d'entrée. Dans cet exemple, le contrôleur d'entrée porte le nom
sharded.
Ressources complémentaires
Chapitre 9. Opérateur de pare-feu Ingress Node dans OpenShift Container Platform
L'opérateur de pare-feu du nœud d'entrée permet aux administrateurs de gérer les configurations de pare-feu au niveau du nœud.
9.1. Installation de l'opérateur de pare-feu du nœud d'entrée
En tant qu'administrateur de cluster, vous pouvez installer l'opérateur de pare-feu du nœud d'entrée à l'aide de la CLI d'OpenShift Container Platform ou de la console Web.
9.1.1. Installation de l'opérateur de pare-feu du nœud d'entrée à l'aide de la CLI
En tant qu'administrateur de cluster, vous pouvez installer l'Opérateur à l'aide de la CLI.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous disposez d'un compte avec des privilèges d'administrateur.
Procédure
Pour créer l'espace de noms
openshift-ingress-node-firewall, entrez la commande suivante :$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: labels: pod-security.kubernetes.io/enforce: privileged pod-security.kubernetes.io/enforce-version: v1.24 name: openshift-ingress-node-firewall EOFPour créer un CR
OperatorGroup, entrez la commande suivante :$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ingress-node-firewall-operators namespace: openshift-ingress-node-firewall EOFS'abonner à l'opérateur de pare-feu du nœud d'entrée.
Pour créer un CR
Subscriptionpour l'opérateur de pare-feu du nœud d'entrée, entrez la commande suivante :$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ingress-node-firewall-sub namespace: openshift-ingress-node-firewall spec: name: ingress-node-firewall channel: stable source: redhat-operators sourceNamespace: openshift-marketplace EOF
Pour vérifier que l'opérateur est installé, entrez la commande suivante :
$ oc get ip -n openshift-ingress-node-firewallExemple de sortie
NAME CSV APPROVAL APPROVED install-5cvnz ingress-node-firewall.4.12.0-202211122336 Automatic truePour vérifier la version de l'opérateur, entrez la commande suivante :
$ oc get csv -n openshift-ingress-node-firewallExemple de sortie
NAME DISPLAY VERSION REPLACES PHASE ingress-node-firewall.4.12.0-202211122336 Ingress Node Firewall Operator 4.12.0-202211122336 ingress-node-firewall.4.12.0-202211102047 Succeeded
9.1.2. Installation de l'opérateur de pare-feu du nœud d'entrée à l'aide de la console web
En tant qu'administrateur de cluster, vous pouvez installer l'Opérateur à l'aide de la console web.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous disposez d'un compte avec des privilèges d'administrateur.
Procédure
Installer l'opérateur de pare-feu du nœud d'entrée :
- Dans la console Web OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Sélectionnez Ingress Node Firewall Operator dans la liste des opérateurs disponibles, puis cliquez sur Install.
- Sur la page Install Operator, sous Installed Namespace, sélectionnez Operator recommended Namespace.
- Cliquez sur Install.
Vérifiez que l'opérateur de pare-feu du nœud d'entrée a été installé avec succès :
- Naviguez jusqu'à la page Operators → Installed Operators.
Assurez-vous que Ingress Node Firewall Operator est listé dans le projet openshift-ingress-node-firewall avec un Status de InstallSucceeded.
NotePendant l'installation, un opérateur peut afficher un état Failed. Si l'installation réussit par la suite avec un message InstallSucceeded, vous pouvez ignorer le message Failed.
Si l'Opérateur n'a pas de Status de InstallSucceeded, dépanner en suivant les étapes suivantes :
- Inspectez les onglets Operator Subscriptions et Install Plans pour vérifier qu'il n'y a pas de défaillances ou d'erreurs sous Status.
-
Naviguez vers la page Workloads → Pods et vérifiez les journaux pour les pods dans le projet
openshift-ingress-node-firewall. Vérifiez l'espace de noms du fichier YAML. Si l'annotation est manquante, vous pouvez ajouter l'annotation
workload.openshift.io/allowed=managementà l'espace de noms de l'opérateur à l'aide de la commande suivante :$ oc annotate ns/openshift-ingress-node-firewall workload.openshift.io/allowed=managementNotePour les clusters OpenShift à nœud unique, l'espace de noms
openshift-ingress-node-firewallnécessite l'annotationworkload.openshift.io/allowed=management.
9.2. Opérateur du pare-feu du nœud d'entrée
L'opérateur de pare-feu de nœud d'entrée fournit des règles de pare-feu d'entrée au niveau d'un nœud en déployant l'ensemble de démons sur les nœuds que vous spécifiez et gérez dans les configurations de pare-feu. Pour déployer le jeu de démons, vous créez une ressource personnalisée (CR) IngressNodeFirewallConfig. L'opérateur applique la CR IngressNodeFirewallConfig pour créer l'ensemble de démons de pare-feu de nœuds d'entrée daemon, qui s'exécute sur tous les nœuds correspondant à la CR nodeSelector.
Vous configurez rules de la CR IngressNodeFirewall et les appliquez aux clusters en utilisant nodeSelector et en fixant les valeurs à "true".
L'opérateur de pare-feu du nœud d'entrée ne prend en charge que les règles de pare-feu sans état.
Le paramètre des unités de transmission maximale (MTU) est de 4Kb (kilo-octets) dans OpenShift Container Platform 4.12.
Les contrôleurs d'interface réseau (NIC) qui ne prennent pas en charge les pilotes XDP natifs fonctionneront à des performances moindres.
9.3. Déploiement de l'opérateur de pare-feu du nœud d'entrée
Prérequis
- L'opérateur de pare-feu du nœud d'entrée est installé.
Procédure
Pour déployer l'opérateur de pare-feu du nœud d'entrée, créez une ressource personnalisée IngressNodeFirewallConfig qui déploiera l'ensemble de démons de l'opérateur. Vous pouvez déployer un ou plusieurs CRD IngressNodeFirewall sur des nœuds en appliquant des règles de pare-feu.
-
Créez le site
IngressNodeFirewallConfigà l'intérieur de l'espace de nomsopenshift-ingress-node-firewallnomméingressnodefirewallconfig. Exécutez la commande suivante pour déployer les règles de l'opérateur de pare-feu du nœud d'entrée :
$ oc apply -f rule.yaml
9.3.1. Objet de configuration du pare-feu du nœud d'entrée
Les champs de l'objet de configuration Ingress Node Firewall sont décrits dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
|
Le nom de l'objet CR. Le nom de l'objet règles de pare-feu doit être |
|
|
|
Espace de noms pour l'objet CR de l'opérateur du pare-feu d'entrée. Le CR |
|
|
| Une contrainte de sélection de nœuds utilisée pour cibler les nœuds par le biais d'étiquettes de nœuds spécifiées. Par exemple : Note
L'une des étiquettes utilisées dans |
L'opérateur consomme le CR et crée un ensemble de démons de pare-feu de nœuds d'entrée sur tous les nœuds qui correspondent à nodeSelector.
Exemple de configuration de l'opérateur de pare-feu du nœud d'entrée
L'exemple suivant présente une configuration complète du pare-feu du nœud d'entrée :
Exemple d'objet de configuration du pare-feu du nœud d'entrée
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewallConfig
metadata:
name: ingressnodefirewallconfig
namespace: openshift-ingress-node-firewall
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
L'opérateur consomme le CR et crée un ensemble de démons de pare-feu de nœuds d'entrée sur tous les nœuds qui correspondent à nodeSelector.
9.3.2. Objet "règles de pare-feu" du nœud d'entrée
Les champs de l'objet Règles de pare-feu du nœud d'entrée sont décrits dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
| Le nom de l'objet CR. |
|
|
|
Les champs de cet objet spécifient les interfaces auxquelles appliquer les règles de pare-feu. Par exemple, |
|
|
|
Vous pouvez utiliser |
|
|
|
|
Configuration de l'objet d'entrée
Les valeurs de l'objet ingress sont définies dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
| Permet de définir le bloc CIDR. Vous pouvez configurer plusieurs CIDR de différentes familles d'adresses. Note
Des CIDR différents vous permettent d'utiliser la même règle d'ordre. S'il existe plusieurs objets |
|
|
|
Les objets du pare-feu d'entrée
Définissez Note Les règles de pare-feu en entrée sont vérifiées à l'aide d'un webhook de vérification qui bloque toute configuration invalide. Le webhook de vérification vous empêche de bloquer les services critiques du cluster tels que le serveur API ou SSH. |
Exemple d'objet de règles de pare-feu pour le nœud d'entrée
L'exemple suivant présente une configuration complète du pare-feu du nœud d'entrée :
Exemple de configuration du pare-feu du nœud d'entrée
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall
spec:
interfaces:
- eth0
nodeSelector:
matchLabels:
<do_node_ingress_firewall>: 'true'
ingress:
- sourceCIDRs:
- 172.16.0.0/12
rules:
- order: 10
protocolConfig:
protocol: ICMP
icmp:
icmpType: 8 #ICMP Echo request
action: Deny
- order: 20
protocolConfig:
protocol: TCP
tcp:
ports: "8000-9000"
action: Deny
- sourceCIDRs:
- fc00:f853:ccd:e793::0/64
rules:
- order: 10
protocolConfig:
protocol: ICMPv6
icmpv6:
icmpType: 128 #ICMPV6 Echo request
action: DenyExemple d'objet de règles de pare-feu de nœud d'entrée à confiance zéro
Les règles de pare-feu de nœud d'entrée à confiance zéro peuvent fournir une sécurité supplémentaire aux clusters à interfaces multiples. Par exemple, vous pouvez utiliser des règles de pare-feu de nœud d'entrée à confiance zéro pour supprimer tout le trafic sur une interface spécifique, à l'exception de SSH.
L'exemple suivant présente une configuration complète d'un ensemble de règles de pare-feu de nœud d'entrée à confiance zéro :
Les utilisateurs doivent ajouter tous les ports que leur application utilisera à leur liste d'autorisations dans le cas suivant afin de garantir un fonctionnement correct.
Exemple de règles de pare-feu de nœud d'entrée à confiance zéro
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall-zero-trust
spec:
interfaces:
- eth1
nodeSelector:
matchLabels:
<do_node_ingress_firewall>: 'true'
ingress:
- sourceCIDRs:
- 0.0.0.0/0
rules:
- order: 10
protocolConfig:
protocol: TCP
tcp:
ports: 22
action: Allow
- order: 20
action: Deny 9.4. Affichage des règles de l'opérateur de pare-feu du nœud d'entrée
Procédure
Exécutez la commande suivante pour afficher toutes les règles en vigueur :
$ oc get ingressnodefirewallChoisissez l'un des noms de
<resource>et exécutez la commande suivante pour afficher les règles ou les configurations :$ oc get <resource> <name> -o yaml
9.5. Dépannage de l'opérateur de pare-feu du nœud d'entrée
Exécutez la commande suivante pour répertorier les définitions de ressources personnalisées (CRD) installées sur le pare-feu du nœud d'entrée :
$ oc get crds | grep ingressnodefirewallExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE ingressnodefirewallconfigs.ingressnodefirewall.openshift.io 2022-08-25T10:03:01Z ingressnodefirewallnodestates.ingressnodefirewall.openshift.io 2022-08-25T10:03:00Z ingressnodefirewalls.ingressnodefirewall.openshift.io 2022-08-25T10:03:00ZExécutez la commande suivante pour afficher l'état de l'opérateur de pare-feu du nœud d'entrée :
$ oc get pods -n openshift-ingress-node-firewallExemple de sortie
NAME READY STATUS RESTARTS AGE ingress-node-firewall-controller-manager 2/2 Running 0 5d21h ingress-node-firewall-daemon-pqx56 3/3 Running 0 5d21hLes champs suivants fournissent des informations sur l'état de l'opérateur :
READY,STATUS,AGE, etRESTARTS. Le champSTATUSestRunninglorsque l'opérateur de pare-feu du nœud d'entrée déploie un ensemble de démons sur les nœuds attribués.Exécutez la commande suivante pour collecter tous les journaux des nœuds de pare-feu entrants :
$ oc adm must-gather – gather_ingress_node_firewallLes journaux sont disponibles dans le rapport du nœud sos contenant les sorties eBPF
bpftoolà l'adresse/sos_commands/ebpf. Ces rapports comprennent les tables de consultation utilisées ou mises à jour lorsque le pare-feu d'entrée XDP traite les paquets, met à jour les statistiques et émet des événements.
Chapitre 10. Configuration d'un contrôleur d'entrée pour la gestion manuelle du DNS
En tant qu'administrateur de cluster, lorsque vous créez un contrôleur d'entrée, l'opérateur gère automatiquement les enregistrements DNS. Cela présente certaines limites lorsque la zone DNS requise est différente de la zone DNS du cluster ou lorsque la zone DNS est hébergée en dehors du fournisseur de cloud.
En tant qu'administrateur de cluster, vous pouvez configurer un contrôleur d'entrée pour qu'il arrête la gestion automatique du DNS et démarre la gestion manuelle du DNS. Définissez dnsManagementPolicy pour spécifier quand il doit être géré automatiquement ou manuellement.
Lorsque vous modifiez un contrôleur d'entrée de Managed à Unmanaged, l'opérateur ne nettoie pas l'ancien enregistrement DNS wildcard provisionné sur le nuage. Lorsque vous modifiez un contrôleur d'entrée de Unmanaged à Managed, l'opérateur tente de créer l'enregistrement DNS sur le fournisseur de cloud s'il n'existe pas ou met à jour l'enregistrement DNS s'il existe déjà.
Lorsque vous remplacez dnsManagementPolicy par unmanaged, vous devez gérer manuellement le cycle de vie de l'enregistrement DNS générique sur le fournisseur de services en nuage.
10.1. Managed Politique de gestion du DNS
La politique de gestion DNS de Managed pour les contrôleurs d'entrée garantit que le cycle de vie de l'enregistrement DNS sauvage sur le fournisseur d'informatique en nuage est automatiquement géré par l'opérateur.
10.2. Unmanaged Politique de gestion du DNS
La politique de gestion DNS de Unmanaged pour les contrôleurs d'entrée garantit que le cycle de vie de l'enregistrement DNS wildcard sur le fournisseur de cloud n'est pas géré automatiquement, mais qu'il relève de la responsabilité de l'administrateur du cluster.
Sur la plateforme cloud AWS, si le domaine du contrôleur d'entrée ne correspond pas à dnsConfig.Spec.BaseDomain, la politique de gestion DNS est automatiquement définie sur Unmanaged.
10.3. Création d'un contrôleur d'entrée personnalisé avec la politique de gestion DNS Unmanaged
En tant qu'administrateur de cluster, vous pouvez créer un nouveau contrôleur d'entrée personnalisé avec la politique de gestion DNS Unmanaged.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un fichier de ressources personnalisées (CR) nommé
sample-ingress.yamlcontenant les éléments suivants :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name>1 spec: domain: <domain>2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: External3 dnsManagementPolicy: Unmanaged4 - 1
- Spécifiez l'objet
<name>avec un nom pour l'objetIngressController. - 2
- Spécifiez l'adresse
domainen fonction de l'enregistrement DNS qui a été créé en tant que condition préalable. - 3
- Spécifiez l'adresse
scopecommeExternalpour exposer l'équilibreur de charge à l'extérieur. - 4
dnsManagementPolicyindique si le contrôleur d'entrée gère le cycle de vie de l'enregistrement DNS générique associé à l'équilibreur de charge. Les valeurs valides sontManagedetUnmanaged. La valeur par défaut estManaged.
Enregistrez le fichier pour appliquer les modifications.
oc apply -f <name>.yaml1
10.4. Modification d'un contrôleur d'entrée existant
En tant qu'administrateur de cluster, vous pouvez modifier un contrôleur d'entrée existant pour gérer manuellement le cycle de vie des enregistrements DNS.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Modifiez le choix de
IngressControllerpour définirdnsManagementPolicy:SCOPE=$(oc -n openshift-ingress-operator get ingresscontroller <name> -o=jsonpath="{.status.endpointPublishingStrategy.loadBalancer.scope}") oc -n openshift-ingress-operator patch ingresscontrollers/<name> --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"dnsManagementPolicy":"Unmanaged", "scope":"${SCOPE}"}}}}'- Facultatif : vous pouvez supprimer l'enregistrement DNS associé dans le fournisseur de cloud.
Chapitre 11. Configuration de la stratégie de publication des points d'extrémité du contrôleur d'entrée
11.1. Stratégie de publication des points d'extrémité du contrôleur d'entrée
NodePortService endpoint publishing strategy
La stratégie de publication des points d'extrémité NodePortService publie le contrôleur d'ingestion à l'aide d'un service NodePort de Kubernetes.
Dans cette configuration, le déploiement du contrôleur d'entrée utilise un réseau de conteneurs. Un site NodePortService est créé pour publier le déploiement. Les ports de nœuds spécifiques sont alloués dynamiquement par OpenShift Container Platform ; toutefois, pour prendre en charge les allocations de ports statiques, les modifications apportées au champ node port du site NodePortService géré sont conservées.
Figure 11.1. Diagramme de NodePortService

Le graphique précédent illustre les concepts suivants relatifs à la stratégie de publication des points d'extrémité Ingress NodePort d'OpenShift Container Platform :
- Tous les nœuds disponibles dans la grappe ont leur propre adresse IP, accessible de l'extérieur. Le service fonctionnant dans la grappe est lié à l'unique NodePort de tous les nœuds.
-
Lorsque le client se connecte à un nœud en panne, par exemple en connectant l'adresse IP
10.0.128.4dans le graphique, le port du nœud connecte directement le client à un nœud disponible qui exécute le service. Dans ce scénario, aucun équilibrage de charge n'est nécessaire. Comme le montre l'image, l'adresse10.0.128.4est hors service et une autre adresse IP doit être utilisée à la place.
L'opérateur d'entrée ignore toute mise à jour des champs .spec.ports[].nodePort du service.
Par défaut, les ports sont attribués automatiquement et vous pouvez accéder aux attributions de ports pour les intégrations. Cependant, il est parfois nécessaire d'allouer des ports statiques pour s'intégrer à l'infrastructure existante, qui peut ne pas être facilement reconfigurée en réponse aux ports dynamiques. Pour réaliser des intégrations avec des ports de nœuds statiques, vous pouvez mettre à jour la ressource de service géré directement.
Pour plus d'informations, consultez la documentation sur les services Kubernetes à l'adresse NodePort.
HostNetwork endpoint publishing strategy
La stratégie de publication des points d'extrémité HostNetwork publie le contrôleur d'entrée sur les ports des nœuds où le contrôleur d'entrée est déployé.
Un contrôleur d'entrée doté de la stratégie de publication de points finaux HostNetwork ne peut avoir qu'une seule réplique de pod par nœud. Si vous voulez des répliques n, vous devez utiliser au moins des nœuds n où ces répliques peuvent être planifiées. Étant donné que chaque réplique de pod demande les ports 80 et 443 sur l'hôte du nœud où elle est planifiée, une réplique ne peut pas être planifiée sur un nœud si un autre pod sur le même nœud utilise ces ports.
11.1.1. Configuration de l'étendue de la publication du contrôleur d'entrée sur Interne
Lorsqu'un administrateur de cluster installe un nouveau cluster sans spécifier qu'il s'agit d'un cluster privé, le contrôleur d'entrée par défaut est créé avec un scope défini sur External. Les administrateurs de clusters peuvent modifier un contrôleur d'entrée à portée External en Internal.
Conditions préalables
-
Vous avez installé le CLI
oc.
Procédure
Pour modifier un contrôleur d'entrée à portée de
ExternalenInternal, entrez la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"scope":"Internal"}}}}'Pour vérifier l'état du contrôleur d'entrée, entrez la commande suivante :
$ oc -n openshift-ingress-operator get ingresscontrollers/default -o yamlLa condition d'état
Progressingindique si vous devez prendre d'autres mesures. Par exemple, la condition d'état peut indiquer que vous devez supprimer le service en entrant la commande suivante :$ oc -n openshift-ingress delete services/router-defaultSi vous supprimez le service, l'opérateur d'entrée le recrée en tant que
Internal.
11.1.2. Configuration de l'étendue de la publication du point d'extrémité du contrôleur d'entrée sur Externe
Lorsqu'un administrateur de cluster installe un nouveau cluster sans spécifier qu'il s'agit d'un cluster privé, le contrôleur d'entrée par défaut est créé avec une adresse scope définie sur External.
La portée du contrôleur d'entrée peut être configurée pour être Internal pendant l'installation ou après, et les administrateurs de clusters peuvent changer un contrôleur d'entrée Internal en External.
Sur certaines plateformes, il est nécessaire de supprimer et de recréer le service.
La modification de l'étendue peut perturber le trafic Ingress, potentiellement pendant plusieurs minutes. Cela s'applique aux plateformes où il est nécessaire de supprimer et de recréer le service, car la procédure peut amener OpenShift Container Platform à déprovisionner l'équilibreur de charge du service existant, à en provisionner un nouveau et à mettre à jour le DNS.
Conditions préalables
-
Vous avez installé le CLI
oc.
Procédure
Pour modifier un contrôleur d'entrée à portée de
InternalenExternal, entrez la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontrollers/private --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"scope":"External"}}}}'Pour vérifier l'état du contrôleur d'entrée, entrez la commande suivante :
$ oc -n openshift-ingress-operator get ingresscontrollers/default -o yamlLa condition d'état
Progressingindique si vous devez prendre d'autres mesures. Par exemple, la condition d'état peut indiquer que vous devez supprimer le service en entrant la commande suivante :$ oc -n openshift-ingress delete services/router-defaultSi vous supprimez le service, l'opérateur d'entrée le recrée en tant que
External.
Chapitre 12. Vérification de la connectivité à un point d'extrémité
L'opérateur de réseau de cluster (CNO) exécute un contrôleur, le contrôleur de contrôle de connectivité, qui effectue un contrôle de l'état des connexions entre les ressources de votre cluster. En examinant les résultats des contrôles de santé, vous pouvez diagnostiquer les problèmes de connexion ou éliminer la connectivité réseau comme cause d'un problème que vous étudiez.
12.1. Vérification de l'état des connexions
Pour vérifier que les ressources de la grappe sont accessibles, une connexion TCP est établie avec chacun des services API de grappe suivants :
- Service de serveur API Kubernetes
- Points d'extrémité du serveur API Kubernetes
- Service de serveur API OpenShift
- Points d'extrémité du serveur API OpenShift
- Équilibreurs de charge
Pour vérifier que les services et les points de terminaison des services sont accessibles sur chaque nœud de la grappe, une connexion TCP est établie avec chacune des cibles suivantes :
- Service cible de bilan de santé
- Points finaux cibles du bilan de santé
12.2. Mise en œuvre des bilans de santé des connexions
Le contrôleur de vérification de la connectivité orchestre les vérifications de connexion dans votre cluster. Les résultats des tests de connexion sont stockés dans les objets PodNetworkConnectivity de l'espace de noms openshift-network-diagnostics. Les tests de connexion sont effectués en parallèle toutes les minutes.
L'opérateur de réseau de grappe (CNO) déploie plusieurs ressources dans la grappe pour envoyer et recevoir des contrôles de santé de la connectivité :
- Bilan de santé source
-
Ce programme se déploie dans un seul ensemble de répliques de pods géré par un objet
Deployment. Le programme consomme des objetsPodNetworkConnectivityet se connecte au sitespec.targetEndpointspécifié dans chaque objet. - Objectif du bilan de santé
- Un module déployé dans le cadre d'un ensemble de démons sur chaque nœud du cluster. Ce module est à l'écoute des contrôles de santé entrants. La présence de ce module sur chaque nœud permet de tester la connectivité de chaque nœud.
12.3. Champs de l'objet PodNetworkConnectivityCheck
Les champs de l'objet PodNetworkConnectivityCheck sont décrits dans les tableaux suivants.
| Field | Type | Description |
|---|---|---|
|
|
|
Le nom de l'objet au format suivant :
|
|
|
|
L'espace de noms auquel l'objet est associé. Cette valeur est toujours |
|
|
|
Le nom du pod d'où provient le contrôle de connexion, par exemple |
|
|
|
La cible de la vérification de la connexion, telle que |
|
|
| Configuration du certificat TLS à utiliser. |
|
|
| Le nom du certificat TLS utilisé, le cas échéant. La valeur par défaut est une chaîne vide. |
|
|
| Un objet représentant l'état du test de connexion et les journaux des succès et échecs récents de la connexion. |
|
|
| Le dernier état de la vérification de la connexion et tous les états précédents. |
|
|
| Journaux des tests de connexion pour les tentatives infructueuses. |
|
|
| Connecter les journaux de tests couvrant les périodes de pannes éventuelles. |
|
|
| Journaux de tests de connexion pour les tentatives réussies. |
Le tableau suivant décrit les champs des objets du tableau status.conditions:
| Field | Type | Description |
|---|---|---|
|
|
| Moment où l'état de la connexion est passé d'un état à un autre. |
|
|
| Les détails de la dernière transition dans un format lisible par l'homme. |
|
|
| Le dernier état de la transition dans un format lisible par machine. |
|
|
| L'état de la condition. |
|
|
| Le type d'affection. |
Le tableau suivant décrit les champs des objets du tableau status.conditions:
| Field | Type | Description |
|---|---|---|
|
|
| Date à laquelle l'échec de la connexion a été résolu. |
|
|
| Entrées du journal de connexion, y compris l'entrée du journal relative à la fin réussie de la panne. |
|
|
| Un résumé des détails de la panne dans un format lisible par l'homme. |
|
|
| Date à laquelle l'échec de la connexion a été détecté pour la première fois. |
|
|
| Entrées du journal de connexion, y compris l'échec initial. |
Champs du journal des connexions
Les champs d'une entrée du journal des connexions sont décrits dans le tableau suivant. L'objet est utilisé dans les champs suivants :
-
status.failures[] -
status.successes[] -
status.outages[].startLogs[] -
status.outages[].endLogs[]
| Field | Type | Description |
|---|---|---|
|
|
| Enregistre la durée de l'action. |
|
|
| Fournit l'état dans un format lisible par l'homme. |
|
|
|
Fournit la raison de l'état dans un format lisible par la machine. La valeur est l'une des suivantes : |
|
|
| Indique si l'entrée du journal est un succès ou un échec. |
|
|
| Heure de début de la vérification de la connexion. |
12.4. Vérification de la connectivité réseau d'un terminal
En tant qu'administrateur de cluster, vous pouvez vérifier la connectivité d'un point d'extrémité, tel qu'un serveur API, un équilibreur de charge, un service ou un pod.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Pour dresser la liste des objets
PodNetworkConnectivityChecken cours, entrez la commande suivante :$ oc get podnetworkconnectivitycheck -n openshift-network-diagnosticsExemple de sortie
NAME AGE network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-1 73m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-2 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-service-cluster 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-default-service-cluster 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-load-balancer-api-external 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-load-balancer-api-internal 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-master-1 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-master-2 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-worker-c-n8mbf 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-worker-d-4hnrz 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-service-cluster 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-1 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-2 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-service-cluster 75mConsulter les journaux des tests de connexion :
- À partir de la sortie de la commande précédente, identifiez le point d'extrémité pour lequel vous souhaitez consulter les journaux de connectivité.
Pour visualiser l'objet, entrez la commande suivante :
$ oc get podnetworkconnectivitycheck <name> \ -n openshift-network-diagnostics -o yamloù
<name>indique le nom de l'objetPodNetworkConnectivityCheck.Exemple de sortie
apiVersion: controlplane.operator.openshift.io/v1alpha1 kind: PodNetworkConnectivityCheck metadata: name: network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 namespace: openshift-network-diagnostics ... spec: sourcePod: network-check-source-7c88f6d9f-hmg2f targetEndpoint: 10.0.0.4:6443 tlsClientCert: name: "" status: conditions: - lastTransitionTime: "2021-01-13T20:11:34Z" message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnectSuccess status: "True" type: Reachable failures: - latency: 2.241775ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:10:34Z" - latency: 2.582129ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:09:34Z" - latency: 3.483578ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:08:34Z" outages: - end: "2021-01-13T20:11:34Z" endLogs: - latency: 2.032018ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T20:11:34Z" - latency: 2.241775ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:10:34Z" - latency: 2.582129ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:09:34Z" - latency: 3.483578ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:08:34Z" message: Connectivity restored after 2m59.999789186s start: "2021-01-13T20:08:34Z" startLogs: - latency: 3.483578ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:08:34Z" successes: - latency: 2.845865ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:14:34Z" - latency: 2.926345ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:13:34Z" - latency: 2.895796ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:12:34Z" - latency: 2.696844ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:11:34Z" - latency: 1.502064ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:10:34Z" - latency: 1.388857ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:09:34Z" - latency: 1.906383ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:08:34Z" - latency: 2.089073ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:07:34Z" - latency: 2.156994ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:06:34Z" - latency: 1.777043ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:05:34Z"
Chapitre 13. Modification du MTU pour le réseau de la grappe
En tant qu'administrateur de grappe, vous pouvez modifier le MTU du réseau de la grappe après l'installation de la grappe. Ce changement est perturbant car les nœuds du cluster doivent être redémarrés pour finaliser le changement de MTU. Vous ne pouvez modifier le MTU que pour les clusters utilisant les plugins réseau OVN-Kubernetes ou OpenShift SDN.
13.1. À propos du MTU du cluster
Lors de l'installation, l'unité de transmission maximale (MTU) du réseau de la grappe est détectée automatiquement sur la base du MTU de l'interface réseau primaire des nœuds de la grappe. Normalement, il n'est pas nécessaire de remplacer le MTU détecté.
Il est possible que vous souhaitiez modifier le MTU du réseau de la grappe pour plusieurs raisons :
- Le MTU détecté lors de l'installation du cluster n'est pas correct pour votre infrastructure
- L'infrastructure de votre cluster nécessite désormais un MTU différent, par exemple suite à l'ajout de nœuds nécessitant un MTU différent pour des performances optimales
Vous pouvez modifier le MTU du cluster uniquement pour les plugins de réseau de cluster OVN-Kubernetes et OpenShift SDN.
13.1.1. Considérations relatives à l'interruption de service
Lorsque vous initiez un changement de MTU sur votre cluster, les effets suivants peuvent avoir un impact sur la disponibilité du service :
- Au moins deux redémarrages en continu sont nécessaires pour achever la migration vers un nouveau MTU. Pendant cette période, certains nœuds ne sont pas disponibles car ils redémarrent.
- Les applications spécifiques déployées sur le cluster avec des intervalles de temporisation plus courts que l'intervalle de temporisation TCP absolu peuvent subir des perturbations pendant le changement de MTU.
13.1.2. Sélection de la valeur MTU
Lorsque vous planifiez votre migration MTU, il y a deux valeurs MTU liées mais distinctes à prendre en compte.
- Hardware MTU: Cette valeur MTU est définie en fonction des spécificités de votre infrastructure réseau.
Cluster network MTU: Cette valeur MTU est toujours inférieure à la valeur MTU de votre matériel pour tenir compte de l'overlay du réseau cluster. L'overhead spécifique est déterminé par votre plugin réseau :
-
OVN-Kubernetes:
100octets -
OpenShift SDN:
50octets
-
OVN-Kubernetes:
Si votre cluster requiert des valeurs MTU différentes pour les différents nœuds, vous devez soustraire la valeur overhead de votre plugin réseau de la valeur MTU la plus basse utilisée par n'importe quel nœud de votre cluster. Par exemple, si certains nœuds de votre grappe ont un MTU de 9001, et d'autres de 1500, vous devez fixer cette valeur à 1400.
13.1.3. Comment fonctionne le processus de migration
Le tableau suivant résume le processus de migration en distinguant les étapes du processus initiées par l'utilisateur et les actions que la migration exécute en réponse.
| Étapes initiées par l'utilisateur | Activité OpenShift Container Platform |
|---|---|
| Définissez les valeurs suivantes dans la configuration de l'opérateur de réseau de cluster :
| Cluster Network Operator (CNO): Confirme que chaque champ a une valeur valide.
Si les valeurs fournies sont valides, le CNO écrit une nouvelle configuration temporaire avec le MTU pour le réseau cluster fixé à la valeur du champ Machine Config Operator (MCO): Effectue un redémarrage progressif de chaque nœud de la grappe. |
| Reconfigurez le MTU de l'interface réseau principale pour les nœuds de la grappe. Pour ce faire, vous pouvez utiliser différentes méthodes, notamment
| N/A |
|
Définissez la valeur | Machine Config Operator (MCO): Effectue un redémarrage progressif de chaque nœud du cluster avec la nouvelle configuration MTU. |
13.2. Modifier le MTU du cluster
En tant qu'administrateur de cluster, vous pouvez modifier l'unité de transmission maximale (MTU) de votre cluster. La migration est perturbatrice et les nœuds de votre cluster peuvent être temporairement indisponibles pendant la mise à jour du MTU.
La procédure suivante décrit comment modifier le MTU de la grappe en utilisant les configurations de machine, le DHCP ou une ISO. Si vous utilisez l'approche DHCP ou ISO, vous devez vous référer aux artefacts de configuration que vous avez conservés après l'installation de votre cluster pour compléter la procédure.
Conditions préalables
-
You installed the OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. Vous avez identifié le MTU cible pour votre cluster. Le MTU correct varie en fonction du plugin réseau utilisé par votre cluster :
-
OVN-Kubernetes: Le MTU du cluster doit être défini à
100de moins que la valeur MTU matérielle la plus basse de votre cluster. -
OpenShift SDN: Le MTU du cluster doit être défini à
50de moins que la valeur MTU matérielle la plus basse de votre cluster.
-
OVN-Kubernetes: Le MTU du cluster doit être défini à
Procédure
Pour augmenter ou diminuer le MTU pour le réseau cluster, suivez la procédure suivante.
Pour obtenir le MTU actuel du réseau de la grappe, entrez la commande suivante :
$ oc describe network.config clusterExemple de sortie
... Status: Cluster Network: Cidr: 10.217.0.0/22 Host Prefix: 23 Cluster Network MTU: 1400 Network Type: OpenShiftSDN Service Network: 10.217.4.0/23 ...Préparez votre configuration pour le MTU matériel :
Si votre MTU matériel est spécifié avec DHCP, mettez à jour votre configuration DHCP, par exemple avec la configuration dnsmasq suivante :
dhcp-option-force=26,<mtu>où :
<mtu>- Spécifie le MTU matériel que le serveur DHCP doit annoncer.
- Si le MTU de votre matériel est spécifié par une ligne de commande du noyau avec PXE, mettez à jour cette configuration en conséquence.
Si votre MTU matériel est spécifié dans une configuration de connexion NetworkManager, effectuez les étapes suivantes. Cette approche est la valeur par défaut d'OpenShift Container Platform si vous ne spécifiez pas explicitement votre configuration réseau avec DHCP, une ligne de commande du noyau ou une autre méthode. Vos nœuds de cluster doivent tous utiliser la même configuration réseau sous-jacente pour que la procédure suivante fonctionne sans modification.
Recherchez l'interface réseau principale :
Si vous utilisez le plugin réseau OpenShift SDN, entrez la commande suivante :
$ oc debug node/<node_name> -- chroot /host ip route list match 0.0.0.0/0 | awk '{print $5 }'où :
<node_name>- Spécifie le nom d'un nœud dans votre cluster.
Si vous utilisez le plugin réseau OVN-Kubernetes, entrez la commande suivante :
oc debug node/<node_name> -- chroot /host nmcli -g connection.interface-name c show ovs-if-phys0où :
<node_name>- Spécifie le nom d'un nœud dans votre cluster.
Créez la configuration NetworkManager suivante dans le fichier
<interface>-mtu.conf:Exemple de configuration de la connexion NetworkManager
[connection-<interface>-mtu] match-device=interface-name:<interface> ethernet.mtu=<mtu>où :
<mtu>- Spécifie la nouvelle valeur du MTU matériel.
<interface>- Spécifie le nom de l'interface réseau primaire.
Créez deux objets
MachineConfig, l'un pour les nœuds du plan de contrôle et l'autre pour les nœuds de travail de votre cluster :Créez la configuration Butane suivante dans le fichier
control-plane-interface.bu:variant: openshift version: 4.12.0 metadata: name: 01-control-plane-interface labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/NetworkManager/conf.d/99-<interface>-mtu.conf1 contents: local: <interface>-mtu.conf2 mode: 0600Créez la configuration Butane suivante dans le fichier
worker-interface.bu:variant: openshift version: 4.12.0 metadata: name: 01-worker-interface labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/NetworkManager/conf.d/99-<interface>-mtu.conf1 contents: local: <interface>-mtu.conf2 mode: 0600Créez des objets
MachineConfigà partir des configurations Butane en exécutant la commande suivante :$ for manifest in control-plane-interface worker-interface; do butane --files-dir . $manifest.bu > $manifest.yaml done
Pour commencer la migration du MTU, spécifiez la configuration de la migration en entrant la commande suivante. L'opérateur Machine Config effectue un redémarrage progressif des nœuds de la grappe pour préparer le changement de MTU.
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": { "mtu": { "network": { "from": <overlay_from>, "to": <overlay_to> } , "machine": { "to" : <machine_to> } } } } }'où :
<overlay_from>- Spécifie la valeur actuelle du MTU du réseau cluster.
<overlay_to>-
Spécifie le MTU cible pour le réseau du cluster. Cette valeur est définie par rapport à la valeur de
<machine_to>et pour OVN-Kubernetes doit être100moins et pour OpenShift SDN doit être50moins. <machine_to>- Spécifie le MTU pour l'interface réseau primaire sur le réseau hôte sous-jacent.
Exemple d'augmentation du MTU du cluster
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": { "mtu": { "network": { "from": 1400, "to": 9000 } , "machine": { "to" : 9100} } } } }'Lorsque le MCO met à jour les machines de chaque pool de configuration, il redémarre chaque nœud un par un. Vous devez attendre que tous les nœuds soient mis à jour. Vérifiez l'état du pool de configuration des machines en entrant la commande suivante :
$ oc get mcpUn nœud mis à jour avec succès a le statut suivant :
UPDATED=true,UPDATING=false,DEGRADED=false.NotePar défaut, le MCO met à jour une machine par pool à la fois, ce qui fait que la durée totale de la migration augmente avec la taille du cluster.
Confirmer l'état de la configuration de la nouvelle machine sur les hôtes :
Pour répertorier l'état de la configuration de la machine et le nom de la configuration de la machine appliquée, entrez la commande suivante :
$ oc describe node | egrep "hostname|machineconfig"Exemple de sortie
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: DoneVérifiez que les affirmations suivantes sont vraies :
-
La valeur du champ
machineconfiguration.openshift.io/stateestDone. -
La valeur du champ
machineconfiguration.openshift.io/currentConfigest égale à la valeur du champmachineconfiguration.openshift.io/desiredConfig.
-
La valeur du champ
Pour confirmer que la configuration de la machine est correcte, entrez la commande suivante :
oc get machineconfig <config_name> -o yaml | grep ExecStartoù
<config_name>est le nom de la machine configurée dans le champmachineconfiguration.openshift.io/currentConfig.La configuration de la machine doit inclure la mise à jour suivante de la configuration de systemd :
ExecStart=/usr/local/bin/mtu-migration.sh
Mettre à jour la valeur MTU de l'interface réseau sous-jacente :
Si vous spécifiez le nouveau MTU avec une configuration de connexion NetworkManager, entrez la commande suivante. L'opérateur MachineConfig effectue automatiquement un redémarrage des nœuds de votre cluster.
$ for manifest in control-plane-interface worker-interface; do oc create -f $manifest.yaml done- Si vous spécifiez le nouveau MTU avec une option de serveur DHCP ou une ligne de commande du noyau et PXE, apportez les modifications nécessaires à votre infrastructure.
Lorsque le MCO met à jour les machines de chaque pool de configuration, il redémarre chaque nœud un par un. Vous devez attendre que tous les nœuds soient mis à jour. Vérifiez l'état du pool de configuration des machines en entrant la commande suivante :
$ oc get mcpUn nœud mis à jour avec succès a le statut suivant :
UPDATED=true,UPDATING=false,DEGRADED=false.NotePar défaut, le MCO met à jour une machine par pool à la fois, ce qui fait que la durée totale de la migration augmente avec la taille du cluster.
Confirmer l'état de la configuration de la nouvelle machine sur les hôtes :
Pour répertorier l'état de la configuration de la machine et le nom de la configuration de la machine appliquée, entrez la commande suivante :
$ oc describe node | egrep "hostname|machineconfig"Exemple de sortie
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: DoneVérifiez que les affirmations suivantes sont vraies :
-
La valeur du champ
machineconfiguration.openshift.io/stateestDone. -
La valeur du champ
machineconfiguration.openshift.io/currentConfigest égale à la valeur du champmachineconfiguration.openshift.io/desiredConfig.
-
La valeur du champ
Pour confirmer que la configuration de la machine est correcte, entrez la commande suivante :
oc get machineconfig <config_name> -o yaml | grep path :où
<config_name>est le nom de la machine configurée dans le champmachineconfiguration.openshift.io/currentConfig.Si la configuration de la machine est déployée avec succès, la sortie précédente contient le chemin d'accès au fichier
/etc/NetworkManager/system-connections/<connection_name>.La configuration de la machine ne doit pas contenir la ligne
ExecStart=/usr/local/bin/mtu-migration.sh.
Pour finaliser la migration du MTU, entrez l'une des commandes suivantes :
Si vous utilisez le plugin réseau OVN-Kubernetes :
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": null, "defaultNetwork":{ "ovnKubernetesConfig": { "mtu": <mtu> }}}}'où :
<mtu>-
Spécifie le nouveau MTU du réseau cluster que vous avez spécifié avec
<overlay_to>.
Si vous utilisez le plugin réseau OpenShift SDN :
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": null, "defaultNetwork":{ "openshiftSDNConfig": { "mtu": <mtu> }}}}'où :
<mtu>-
Spécifie le nouveau MTU du réseau cluster que vous avez spécifié avec
<overlay_to>.
Vérification
Vous pouvez vérifier qu'un nœud de votre cluster utilise un MTU que vous avez spécifié dans la procédure précédente.
Pour obtenir le MTU actuel du réseau de la grappe, entrez la commande suivante :
$ oc describe network.config clusterObtenir le MTU actuel de l'interface réseau principale d'un nœud.
Pour dresser la liste des nœuds de votre cluster, entrez la commande suivante :
$ oc get nodesPour obtenir le paramètre MTU actuel de l'interface réseau principale d'un nœud, entrez la commande suivante :
$ oc debug node/<node> -- chroot /host ip address show <interface>où :
<node>- Spécifie un nœud à partir de la sortie de l'étape précédente.
<interface>- Spécifie le nom de l'interface réseau primaire pour le nœud.
Exemple de sortie
ens3 : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8051
Chapitre 14. Configuration de la plage de service du port de nœud
En tant qu'administrateur de grappe, vous pouvez étendre la plage de ports de nœuds disponibles. Si votre grappe utilise un grand nombre de ports de nœuds, vous devrez peut-être augmenter le nombre de ports disponibles.
La plage de ports par défaut est 30000-32767. Vous ne pouvez jamais réduire la plage de ports, même si vous l'étendez d'abord au-delà de la plage par défaut.
14.1. Conditions préalables
-
Votre infrastructure de cluster doit autoriser l'accès aux ports que vous spécifiez dans la plage étendue. Par exemple, si vous étendez la plage de ports du nœud à
30000-32900, la plage de ports inclusive de32768-32900doit être autorisée par votre pare-feu ou votre configuration de filtrage de paquets.
14.2. Extension de la plage de ports du nœud
Vous pouvez étendre la plage de ports du nœud pour le cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour étendre la plage de ports du nœud, entrez la commande suivante. Remplacez
<port>par le plus grand numéro de port de la nouvelle plage.$ oc patch network.config.openshift.io cluster --type=merge -p \ '{ "spec": { "serviceNodePortRange": "30000-<port>" } }'AstuceVous pouvez également appliquer le fichier YAML suivant pour mettre à jour la plage de ports du nœud :
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNodePortRange: "30000-<port>"Exemple de sortie
network.config.openshift.io/cluster patchedPour confirmer que la configuration est active, entrez la commande suivante. L'application de la mise à jour peut prendre plusieurs minutes.
$ oc get configmaps -n openshift-kube-apiserver config \ -o jsonpath="{.data['config\.yaml']}" | \ grep -Eo '"service-node-port-range":["[[:digit:]]+-[[:digit:]]+"]'Exemple de sortie
"service-node-port-range":["30000-33000"]
Chapitre 15. Configuration du basculement IP
Cette rubrique décrit la configuration du basculement IP pour les pods et les services sur votre cluster OpenShift Container Platform.
Le basculement IP gère un pool d'adresses IP virtuelles (VIP) sur un ensemble de nœuds. Chaque adresse VIP de l'ensemble est desservie par un nœud sélectionné dans l'ensemble. Tant qu'un seul nœud est disponible, les VIP sont desservis. Il n'existe aucun moyen de répartir explicitement les adresses VIP entre les nœuds, de sorte qu'il peut y avoir des nœuds sans adresses VIP et d'autres nœuds avec de nombreuses adresses VIP. S'il n'y a qu'un seul nœud, tous les VIP s'y trouvent.
Les VIP doivent être routables depuis l'extérieur du cluster.
Le basculement IP surveille un port sur chaque VIP afin de déterminer si le port est accessible sur le nœud. Si le port n'est pas accessible, le VIP n'est pas affecté au nœud. Si le port est défini sur 0, cette vérification est supprimée. Le script de contrôle effectue les tests nécessaires.
Le basculement IP utilise Keepalived pour héberger un ensemble d'adresses VIP accessibles de l'extérieur sur un ensemble d'hôtes. Chaque VIP n'est desservi que par un seul hôte à la fois. Keepalived utilise le protocole VRRP (Virtual Router Redundancy Protocol) pour déterminer quel hôte, parmi l'ensemble des hôtes, dessert quel VIP. Si un hôte devient indisponible, ou si le service que Keepalived surveille ne répond pas, le VIP est basculé sur un autre hôte de l'ensemble. Cela signifie qu'un VIP est toujours servi tant qu'un hôte est disponible.
Lorsqu'un nœud exécutant Keepalived passe le script de contrôle, le VIP sur ce nœud peut entrer dans l'état master en fonction de sa priorité et de la priorité du maître actuel et selon la stratégie de préemption.
Un administrateur de cluster peut fournir un script via la variable OPENSHIFT_HA_NOTIFY_SCRIPT, et ce script est appelé chaque fois que l'état du VIP sur le nœud change. Keepalived utilise l'état master lorsqu'il gère le VIP, l'état backup lorsqu'un autre noeud gère le VIP, ou l'état fault lorsque le script de vérification échoue. Le script de notification est appelé avec le nouvel état à chaque fois que l'état change.
Vous pouvez créer une configuration de déploiement de basculement IP sur OpenShift Container Platform. La configuration de déploiement de basculement IP spécifie l'ensemble des adresses VIP et l'ensemble des nœuds sur lesquels ils sont gérés. Un cluster peut avoir plusieurs configurations de déploiement de basculement IP, chacune gérant son propre ensemble d'adresses VIP uniques. Chaque nœud de la configuration de basculement IP exécute un pod de basculement IP, et ce pod exécute Keepalived.
Lorsque l'on utilise des VIP pour accéder à un pod avec un réseau hôte, le pod d'application s'exécute sur tous les nœuds qui exécutent les pods de basculement IP. Cela permet à n'importe quel nœud de basculement IP de devenir le maître et de desservir les VIP en cas de besoin. Si les modules d'application ne sont pas exécutés sur tous les nœuds avec basculement IP, certains nœuds de basculement IP ne desservent jamais les VIP ou certains modules d'application ne reçoivent jamais de trafic. Utilisez le même sélecteur et le même nombre de réplications, à la fois pour le basculement IP et pour les modules d'application, afin d'éviter cette incohérence.
Lorsque l'on utilise des VIP pour accéder à un service, n'importe quel nœud peut faire partie de l'ensemble de nœuds de basculement IP, puisque le service est accessible sur tous les nœuds, quel que soit l'endroit où s'exécute le module d'application. N'importe lequel des nœuds de basculement IP peut devenir maître à tout moment. Le service peut soit utiliser des IP externes et un port de service, soit utiliser une adresse NodePort.
Lors de l'utilisation d'IP externes dans la définition du service, les VIP sont définis sur les IP externes et le port de surveillance du basculement d'IP est défini sur le port du service. Lors de l'utilisation d'un port de nœud, le port est ouvert sur chaque nœud du cluster et le service équilibre le trafic à partir du nœud qui dessert actuellement le VIP. Dans ce cas, le port de surveillance du basculement IP est défini sur NodePort dans la définition du service.
La mise en place d'un site NodePort est une opération privilégiée.
Même si un service VIP est hautement disponible, les performances peuvent encore être affectées. Keepalived s'assure que chaque VIP est desservi par un nœud de la configuration, et plusieurs VIP peuvent se retrouver sur le même nœud même si d'autres nœuds n'en ont pas. Les stratégies qui équilibrent la charge de manière externe sur un ensemble de VIP peuvent être contrecarrées lorsque le basculement IP place plusieurs VIP sur le même nœud.
Lorsque vous utilisez ingressIP, vous pouvez configurer le basculement IP pour avoir la même plage VIP que la plage ingressIP. Vous pouvez également désactiver le port de surveillance. Dans ce cas, tous les VIP apparaissent sur le même nœud du cluster. Tout utilisateur peut configurer un service avec ingressIP et le rendre hautement disponible.
Il y a un maximum de 254 VIP dans le cluster.
15.1. Variables d'environnement pour le basculement IP
Le tableau suivant contient les variables utilisées pour configurer le basculement IP.
| Nom de la variable | Défaut | Description |
|---|---|---|
|
|
|
Le module de basculement IP tente d'ouvrir une connexion TCP à ce port sur chaque IP virtuelle (VIP). Si la connexion est établie, le service est considéré comme étant en cours d'exécution. Si ce port est défini sur |
|
|
Nom de l'interface que le basculement IP utilise pour envoyer le trafic VRRP (Virtual Router Redundancy Protocol). La valeur par défaut est | |
|
|
|
Le nombre de répliques à créer. Il doit correspondre à la valeur |
|
|
La liste des plages d'adresses IP à répliquer. Elle doit être fournie. Par exemple, | |
|
|
|
La valeur de décalage utilisée pour définir les ID des routeurs virtuels. L'utilisation de différentes valeurs de décalage permet à plusieurs configurations de basculement IP d'exister au sein d'un même cluster. Le décalage par défaut est |
|
|
Le nombre de groupes à créer pour VRRP. S'il n'est pas défini, un groupe est créé pour chaque plage IP virtuelle spécifiée avec la variable | |
|
| ENTRÉE |
Le nom de la chaîne iptables, pour ajouter automatiquement une règle |
|
| Le nom du chemin complet dans le système de fichiers pod d'un script qui est périodiquement exécuté pour vérifier que l'application fonctionne. | |
|
|
| Période, en secondes, pendant laquelle le script de contrôle est exécuté. |
|
| Le nom du chemin complet dans le système de fichiers pod d'un script qui est exécuté chaque fois que l'état change. | |
|
|
|
La stratégie de gestion d'un nouvel hôte de priorité supérieure. La stratégie |
15.2. Configuration du basculement IP
En tant qu'administrateur de grappe, vous pouvez configurer le basculement IP sur une grappe entière ou sur un sous-ensemble de nœuds, comme défini par le sélecteur d'étiquettes. Vous pouvez également configurer plusieurs configurations de déploiement du basculement IP dans votre grappe, chacune étant indépendante des autres.
La configuration du déploiement du basculement IP garantit qu'un pod de basculement s'exécute sur chacun des nœuds correspondant aux contraintes ou à l'étiquette utilisée.
Ce pod exécute Keepalived, qui peut surveiller un point d'extrémité et utiliser le protocole VRRP (Virtual Router Redundancy Protocol) pour basculer l'IP virtuelle (VIP) d'un nœud à l'autre si le premier nœud ne peut pas atteindre le service ou le point d'extrémité.
Pour une utilisation en production, définissez un selector qui sélectionne au moins deux nœuds, et définissez replicas égal au nombre de nœuds sélectionnés.
Conditions préalables
-
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous avez créé un secret de fabrication.
Procédure
Créez un compte de service de basculement IP :
$ oc create sa ipfailoverMise à jour des contraintes de contexte de sécurité (SCC) pour
hostNetwork:$ oc adm policy add-scc-to-user privileged -z ipfailover $ oc adm policy add-scc-to-user hostnetwork -z ipfailoverCréer un fichier YAML de déploiement pour configurer le basculement IP :
Exemple de déploiement YAML pour la configuration du basculement IP
apiVersion: apps/v1 kind: Deployment metadata: name: ipfailover-keepalived1 labels: ipfailover: hello-openshift spec: strategy: type: Recreate replicas: 2 selector: matchLabels: ipfailover: hello-openshift template: metadata: labels: ipfailover: hello-openshift spec: serviceAccountName: ipfailover privileged: true hostNetwork: true nodeSelector: node-role.kubernetes.io/worker: "" containers: - name: openshift-ipfailover image: quay.io/openshift/origin-keepalived-ipfailover ports: - containerPort: 63000 hostPort: 63000 imagePullPolicy: IfNotPresent securityContext: privileged: true volumeMounts: - name: lib-modules mountPath: /lib/modules readOnly: true - name: host-slash mountPath: /host readOnly: true mountPropagation: HostToContainer - name: etc-sysconfig mountPath: /etc/sysconfig readOnly: true - name: config-volume mountPath: /etc/keepalive env: - name: OPENSHIFT_HA_CONFIG_NAME value: "ipfailover" - name: OPENSHIFT_HA_VIRTUAL_IPS2 value: "1.1.1.1-2" - name: OPENSHIFT_HA_VIP_GROUPS3 value: "10" - name: OPENSHIFT_HA_NETWORK_INTERFACE4 value: "ens3" #The host interface to assign the VIPs - name: OPENSHIFT_HA_MONITOR_PORT5 value: "30060" - name: OPENSHIFT_HA_VRRP_ID_OFFSET6 value: "0" - name: OPENSHIFT_HA_REPLICA_COUNT7 value: "2" #Must match the number of replicas in the deployment - name: OPENSHIFT_HA_USE_UNICAST value: "false" #- name: OPENSHIFT_HA_UNICAST_PEERS #value: "10.0.148.40,10.0.160.234,10.0.199.110" - name: OPENSHIFT_HA_IPTABLES_CHAIN8 value: "INPUT" #- name: OPENSHIFT_HA_NOTIFY_SCRIPT9 # value: /etc/keepalive/mynotifyscript.sh - name: OPENSHIFT_HA_CHECK_SCRIPT10 value: "/etc/keepalive/mycheckscript.sh" - name: OPENSHIFT_HA_PREEMPTION11 value: "preempt_delay 300" - name: OPENSHIFT_HA_CHECK_INTERVAL12 value: "2" livenessProbe: initialDelaySeconds: 10 exec: command: - pgrep - keepalived volumes: - name: lib-modules hostPath: path: /lib/modules - name: host-slash hostPath: path: / - name: etc-sysconfig hostPath: path: /etc/sysconfig # config-volume contains the check script # created with `oc create configmap keepalived-checkscript --from-file=mycheckscript.sh` - configMap: defaultMode: 0755 name: keepalived-checkscript name: config-volume imagePullSecrets: - name: openshift-pull-secret13 - 1
- Le nom du déploiement du basculement IP.
- 2
- La liste des plages d'adresses IP à répliquer. Elle doit être fournie. Par exemple,
1.2.3.4-6,1.2.3.9. - 3
- Le nombre de groupes à créer pour VRRP. S'il n'est pas défini, un groupe est créé pour chaque plage IP virtuelle spécifiée avec la variable
OPENSHIFT_HA_VIP_GROUPS. - 4
- Nom de l'interface que le basculement IP utilise pour envoyer le trafic VRRP. Par défaut,
eth0est utilisé. - 5
- Le module de basculement IP tente d'ouvrir une connexion TCP à ce port sur chaque VIP. Si la connexion est établie, le service est considéré comme étant en cours d'exécution. Si ce port est défini sur
0, le test est toujours réussi. La valeur par défaut est80. - 6
- La valeur de décalage utilisée pour définir les ID des routeurs virtuels. L'utilisation de différentes valeurs de décalage permet à plusieurs configurations de basculement IP d'exister au sein d'un même cluster. Le décalage par défaut est
0, et la plage autorisée va de0à255. - 7
- Le nombre de répliques à créer. Il doit correspondre à la valeur
spec.replicasdans la configuration du déploiement du basculement IP. La valeur par défaut est2. - 8
- Le nom de la chaîne
iptablespour ajouter automatiquement une règleiptablesafin d'autoriser le trafic VRRP. Si la valeur n'est pas définie, une règleiptablesn'est pas ajoutée. Si la chaîne n'existe pas, elle n'est pas créée et Keepalived fonctionne en mode unicast. La valeur par défaut estINPUT. - 9
- Le nom du chemin complet dans le système de fichiers pod d'un script qui est exécuté chaque fois que l'état change.
- 10
- Le nom du chemin complet dans le système de fichiers pod d'un script qui est périodiquement exécuté pour vérifier que l'application fonctionne.
- 11
- La stratégie de gestion d'un nouvel hôte de priorité supérieure. La valeur par défaut est
preempt_delay 300, ce qui fait qu'une instance Keepalived prend en charge un VIP après 5 minutes si un maître de priorité inférieure détient le VIP. - 12
- Période, en secondes, pendant laquelle le script de vérification est exécuté. La valeur par défaut est
2. - 13
- Créez le secret d'extraction avant de créer le déploiement, sinon vous obtiendrez une erreur lors de la création du déploiement.
15.3. À propos des adresses IP virtuelles
Keepalived gère un ensemble d'adresses IP virtuelles (VIP). L'administrateur doit s'assurer que toutes ces adresses :
- Sont accessibles sur les hôtes configurés depuis l'extérieur du cluster.
- Ne sont pas utilisés à d'autres fins au sein du groupe.
Keepalived sur chaque nœud détermine si le service nécessaire est en cours d'exécution. Si c'est le cas, les VIP sont pris en charge et Keepalived participe à la négociation pour déterminer quel nœud dessert le VIP. Pour qu'un nœud puisse participer, le service doit être à l'écoute sur le port de surveillance d'un VIP ou le contrôle doit être désactivé.
Chaque VIP de l'ensemble peut être desservi par un nœud différent.
15.4. Configuration des scripts de contrôle et de notification
Keepalived surveille la santé de l'application en exécutant périodiquement un script de vérification optionnel fourni par l'utilisateur. Par exemple, le script peut tester un serveur web en émettant une requête et en vérifiant la réponse.
Lorsqu'un script de contrôle n'est pas fourni, un simple script par défaut est exécuté pour tester la connexion TCP. Ce test par défaut est supprimé lorsque le port du moniteur est 0.
Chaque module de basculement IP gère un démon Keepalived qui gère une ou plusieurs IP virtuelles (VIP) sur le nœud où le module est exécuté. Le démon Keepalived conserve l'état de chaque VIP pour ce nœud. Un VIP particulier sur un nœud particulier peut être dans l'état master, backup ou fault.
Lorsque le script de vérification de ce VIP sur le nœud qui est dans l'état master échoue, le VIP sur ce nœud entre dans l'état fault, ce qui déclenche une renégociation. Au cours de la renégociation, tous les VIP d'un nœud qui ne sont pas dans l'état fault participent au choix du nœud qui prendra en charge le VIP. En fin de compte, le VIP entre dans l'état master sur un nœud, et le VIP reste dans l'état backup sur les autres nœuds.
Lorsqu'un nœud avec un VIP dans l'état backup échoue, le VIP sur ce nœud entre dans l'état fault. Lorsque le script de contrôle réussit à nouveau pour un VIP sur un nœud dans l'état fault, le VIP sur ce nœud quitte l'état fault et négocie pour entrer dans l'état master. Le VIP sur ce nœud peut alors entrer dans l'état master ou backup.
En tant qu'administrateur du cluster, vous pouvez fournir un script de notification optionnel, qui est appelé chaque fois que l'état change. Keepalived transmet les trois paramètres suivants au script :
-
$1-groupouinstance -
$2- Nom du sitegroupouinstance -
$3- Le nouvel État :master,backup, oufault
Les scripts de vérification et de notification s'exécutent dans le module de basculement IP et utilisent le système de fichiers du module, et non le système de fichiers de l'hôte. Toutefois, le module de basculement IP rend le système de fichiers hôte disponible sous le chemin de montage /hosts. Lors de la configuration d'un script de contrôle ou de notification, vous devez fournir le chemin d'accès complet au script. L'approche recommandée pour fournir les scripts est d'utiliser une carte de configuration.
Les noms des chemins complets des scripts de vérification et de notification sont ajoutés au fichier de configuration de Keepalived, _/etc/keepalived/keepalived.conf, qui est chargé à chaque démarrage de Keepalived. Les scripts peuvent être ajoutés au pod avec une carte de configuration comme suit.
Conditions préalables
-
You installed the OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez le script souhaité et créez une carte de configuration pour le contenir. Le script n'a pas d'arguments d'entrée et doit renvoyer
0pourOKet1pourfail.Le script de vérification,
mycheckscript.sh:#!/bin/bash # Whatever tests are needed # E.g., send request and verify response exit 0Créer la carte de configuration :
$ oc create configmap mycustomcheck --from-file=mycheckscript.shAjouter le script au pod. L'adresse
defaultModepour les fichiers de configuration montés doit pouvoir être exécutée à l'aide des commandesocou en modifiant la configuration du déploiement. Une valeur de0755,493décimal, est typique :$ oc set env deploy/ipfailover-keepalived \ OPENSHIFT_HA_CHECK_SCRIPT=/etc/keepalive/mycheckscript.sh$ oc set volume deploy/ipfailover-keepalived --add --overwrite \ --name=config-volume \ --mount-path=/etc/keepalive \ --source='{"configMap": { "name": "mycustomcheck", "defaultMode": 493}}'NoteLa commande
oc set envest sensible aux espaces blancs. Il ne doit pas y avoir d'espace de part et d'autre du signe=.AstuceVous pouvez également modifier la configuration du déploiement de
ipfailover-keepalived:$ oc edit deploy ipfailover-keepalivedspec: containers: - env: - name: OPENSHIFT_HA_CHECK_SCRIPT1 value: /etc/keepalive/mycheckscript.sh ... volumeMounts:2 - mountPath: /etc/keepalive name: config-volume dnsPolicy: ClusterFirst ... volumes:3 - configMap: defaultMode: 07554 name: customrouter name: config-volume ...- 1
- Dans le champ
spec.container.env, ajoutez la variable d'environnementOPENSHIFT_HA_CHECK_SCRIPTpour qu'elle pointe vers le fichier de script monté. - 2
- Ajoutez le champ
spec.container.volumeMountspour créer le point de montage. - 3
- Ajouter un nouveau champ
spec.volumespour mentionner la carte de configuration. - 4
- Cela permet de définir l'autorisation d'exécution des fichiers. Lors de la relecture, elle est affichée en décimal,
493.
Enregistrez les modifications et quittez l'éditeur. Cette opération redémarre
ipfailover-keepalived.
15.5. Configuration de la préemption VRRP
Lorsqu'une IP virtuelle (VIP) sur un nœud quitte l'état fault en passant le script de contrôle, la VIP sur le nœud entre dans l'état backup si elle a une priorité inférieure à celle de la VIP sur le nœud qui est actuellement dans l'état master. Toutefois, si le VIP du nœud qui quitte l'état fault a une priorité plus élevée, la stratégie de préemption détermine son rôle dans le cluster.
La stratégie nopreempt ne déplace pas master du VIP de priorité inférieure sur l'hôte vers le VIP de priorité supérieure sur l'hôte. Avec preempt_delay 300, la valeur par défaut, Keepalived attend les 300 secondes spécifiées et déplace master vers le VIP de plus haute priorité sur l'hôte.
Conditions préalables
-
You installed the OpenShift CLI (
oc).
Procédure
Pour spécifier la préemption, entrez dans
oc edit deploy ipfailover-keepalivedpour modifier la configuration du déploiement du routeur :$ oc edit deploy ipfailover-keepalived... spec: containers: - env: - name: OPENSHIFT_HA_PREEMPTION1 value: preempt_delay 300 ...- 1
- Définir la valeur de
OPENSHIFT_HA_PREEMPTION:-
preempt_delay 300: Keepalived attend les 300 secondes spécifiées et déplacemastervers le VIP de priorité supérieure sur l'hôte. Il s'agit de la valeur par défaut. -
nopreempt: ne déplace pasmasterdu VIP de priorité inférieure sur l'hôte vers le VIP de priorité supérieure sur l'hôte.
-
15.6. À propos du décalage de l'ID VRRP
Chaque module de basculement IP géré par la configuration de déploiement de basculement IP, 1 module par nœud ou réplique, exécute un démon Keepalived. Au fur et à mesure que des configurations de déploiement de basculement IP sont configurées, d'autres modules sont créés et d'autres démons participent à la négociation commune du protocole VRRP (Virtual Router Redundancy Protocol). Cette négociation est effectuée par tous les démons Keepalived et détermine quels nœuds gèrent quelles IP virtuelles (VIP).
En interne, Keepalived attribue un vrrp-id unique à chaque VIP. La négociation utilise cet ensemble de vrrp-ids, lorsqu'une décision est prise, le VIP correspondant au vrrp-id gagnant est pris en charge sur le nœud gagnant.
Par conséquent, pour chaque VIP défini dans la configuration du déploiement du basculement IP, le pod de basculement IP doit attribuer un vrrp-id correspondant. Pour ce faire, il commence par OPENSHIFT_HA_VRRP_ID_OFFSET et attribue séquentiellement vrrp-ids à la liste des VIP. Les valeurs de vrrp-ids peuvent être comprises dans l'intervalle 1..255.
Lorsqu'il existe plusieurs configurations de déploiement de basculement IP, vous devez spécifier OPENSHIFT_HA_VRRP_ID_OFFSET pour qu'il soit possible d'augmenter le nombre de VIP dans la configuration de déploiement et qu'aucune des plages vrrp-id ne se chevauche.
15.7. Configuration du basculement IP pour plus de 254 adresses
La gestion du basculement IP est limitée à 254 groupes d'adresses IP virtuelles (VIP). Par défaut, OpenShift Container Platform attribue une adresse IP à chaque groupe. Vous pouvez utiliser la variable OPENSHIFT_HA_VIP_GROUPS pour changer cela afin que plusieurs adresses IP soient dans chaque groupe et définir le nombre de groupes VIP disponibles pour chaque instance VRRP (Virtual Router Redundancy Protocol) lors de la configuration du basculement IP.
Le regroupement des VIP permet d'élargir la gamme d'attribution des VIP par VRRP dans le cas d'événements de basculement VRRP, et est utile lorsque tous les hôtes du cluster ont accès à un service localement. Par exemple, lorsqu'un service est exposé avec un ExternalIP.
En règle générale, pour le basculement, ne limitez pas les services, tels que le routeur, à un hôte spécifique. Au contraire, les services doivent être répliqués sur chaque hôte de sorte qu'en cas de basculement IP, les services ne doivent pas être recréés sur le nouvel hôte.
Si vous utilisez les contrôles de santé d'OpenShift Container Platform, la nature du basculement IP et des groupes signifie que toutes les instances du groupe ne sont pas contrôlées. Pour cette raison, les contrôles de santé de Kubernetes doivent être utilisés pour s'assurer que les services sont actifs.
Conditions préalables
-
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour modifier le nombre d'adresses IP attribuées à chaque groupe, modifiez la valeur de la variable
OPENSHIFT_HA_VIP_GROUPS, par exemple :Exemple
DeploymentYAML pour la configuration du basculement IP... spec: env: - name: OPENSHIFT_HA_VIP_GROUPS1 value: "3" ...- 1
- Si
OPENSHIFT_HA_VIP_GROUPSest défini sur3dans un environnement comportant sept VIP, il crée trois groupes, assignant trois VIP au premier groupe et deux VIP aux deux groupes restants.
Si le nombre de groupes défini par OPENSHIFT_HA_VIP_GROUPS est inférieur au nombre d'adresses IP définies pour le basculement, le groupe contient plus d'une adresse IP et toutes les adresses sont déplacées en tant qu'unité unique.
15.8. Haute disponibilité Pour ingressIP
Dans les clusters non-cloud, il est possible de combiner le basculement IP et ingressIP vers un service. Il en résulte des services à haute disponibilité pour les utilisateurs qui créent des services à l'aide de ingressIP.
L'approche consiste à spécifier une plage ingressIPNetworkCIDR et à utiliser la même plage lors de la création de la configuration ipfailover.
Étant donné que le basculement IP peut prendre en charge un maximum de 255 VIP pour l'ensemble du cluster, le site ingressIPNetworkCIDR doit être /24 ou plus petit.
15.9. Suppression du basculement IP
Lors de la configuration initiale du basculement IP, les nœuds de travail du cluster sont modifiés avec une règle iptables qui autorise explicitement les paquets multicast sur 224.0.0.18 pour Keepalived. En raison de la modification des nœuds, la suppression du basculement IP nécessite l'exécution d'un travail pour supprimer la règle iptables et supprimer les adresses IP virtuelles utilisées par Keepalived.
Procédure
Facultatif : identifiez et supprimez tous les scripts de contrôle et de notification qui sont stockés sous forme de cartes de configuration :
Identifier si des pods pour le basculement IP utilisent une carte de configuration comme volume :
$ oc get pod -l ipfailover \ -o jsonpath="\ {range .items[?(@.spec.volumes[*].configMap)]} {'Namespace: '}{.metadata.namespace} {'Pod: '}{.metadata.name} {'Volumes that use config maps:'} {range .spec.volumes[?(@.configMap)]} {'volume: '}{.name} {'configMap: '}{.configMap.name}{'\n'}{end} {end}"Exemple de sortie
Namespace: default Pod: keepalived-worker-59df45db9c-2x9mn Volumes that use config maps: volume: config-volume configMap: mycustomcheckSi l'étape précédente a fourni les noms des cartes de configuration utilisées comme volumes, supprimez les cartes de configuration :
oc delete configmap <configmap_name> $ oc delete configmap <configmap_name>
Identifier un déploiement existant pour le basculement IP :
$ oc get deployment -l ipfailoverExemple de sortie
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE default ipfailover 2/2 2 2 105dSupprimer le déploiement :
oc delete deployment <ipfailover_deployment_name>Supprimez le compte de service
ipfailover:$ oc delete sa ipfailoverExécutez un travail qui supprime la règle des tables IP ajoutée lors de la configuration initiale du basculement IP :
Créez un fichier tel que
remove-ipfailover-job.yamldont le contenu est similaire à l'exemple suivant :apiVersion: batch/v1 kind: Job metadata: generateName: remove-ipfailover- labels: app: remove-ipfailover spec: template: metadata: name: remove-ipfailover spec: containers: - name: remove-ipfailover image: quay.io/openshift/origin-keepalived-ipfailover:4.12 command: ["/var/lib/ipfailover/keepalived/remove-failover.sh"] nodeSelector: kubernetes.io/hostname: <host_name> <.> restartPolicy: Never<.> Exécutez la tâche pour chaque nœud de votre cluster qui a été configuré pour le basculement IP et remplacez le nom d'hôte à chaque fois.
Exécuter le travail :
$ oc create -f remove-ipfailover-job.yamlExemple de sortie
job.batch/remove-ipfailover-2h8dm created
Vérification
Confirmez que le travail a supprimé la configuration initiale du basculement IP.
$ oc logs job/remove-ipfailover-2h8dmExemple de sortie
remove-failover.sh: OpenShift IP Failover service terminating. - Removing ip_vs module ... - Cleaning up ... - Releasing VIPs (interface eth0) ...
Chapitre 16. Configuration des sysctl de réseau au niveau de l'interface
Sous Linux, sysctl permet à un administrateur de modifier les paramètres du noyau au moment de l'exécution. Vous pouvez modifier les sysctls réseau au niveau de l'interface en utilisant le méta plugin tuning Container Network Interface (CNI). Le méta plugin CNI de réglage fonctionne en chaîne avec un plugin CNI principal, comme illustré.
Le plugin CNI principal attribue l'interface et la transmet au méta plugin CNI de réglage au moment de l'exécution. Vous pouvez modifier certains sysctls et plusieurs attributs d'interface (mode promiscuous, mode all-multicast, MTU et adresse MAC) dans l'espace de noms du réseau en utilisant le méta plugin CNI tuning. Dans la configuration du méta plugin CNI tuning, le nom de l'interface est représenté par le jeton IFNAME, et est remplacé par le nom réel de l'interface au moment de l'exécution.
Dans OpenShift Container Platform, le méta plugin CNI tuning ne prend en charge que la modification des sysctls réseau au niveau de l'interface.
16.1. Configuration du CNI d'accord
La procédure suivante configure le CNI de réglage pour modifier le réseau au niveau de l'interface net.ipv4.conf.IFNAME.accept_redirects sysctl. Cet exemple permet d'accepter et d'envoyer des paquets ICMP redirigés.
Procédure
Créez une définition de pièce jointe au réseau, telle que
tuning-example.yaml, avec le contenu suivant :apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: <name>1 namespace: default2 spec: config: '{ "cniVersion": "0.4.0",3 "name": "<name>",4 "plugins": [{ "type": "<main_CNI_plugin>"5 }, { "type": "tuning",6 "sysctl": { "net.ipv4.conf.IFNAME.accept_redirects": "1"7 } } ] }- 1
- Spécifie le nom de la pièce jointe réseau supplémentaire à créer. Le nom doit être unique dans l'espace de noms spécifié.
- 2
- Spécifie l'espace de noms auquel l'objet est associé.
- 3
- Spécifie la version de la spécification CNI.
- 4
- Spécifie le nom de la configuration. Il est recommandé de faire correspondre le nom de la configuration à la valeur du nom de la définition de l'attachement au réseau.
- 5
- Spécifie le nom du plugin CNI principal à configurer.
- 6
- Spécifie le nom du méta plugin CNI.
- 7
- Spécifie le sysctl à définir.
Un exemple de fichier yaml est présenté ici :
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: tuningnad namespace: default spec: config: '{ "cniVersion": "0.4.0", "name": "tuningnad", "plugins": [{ "type": "bridge" }, { "type": "tuning", "sysctl": { "net.ipv4.conf.IFNAME.accept_redirects": "1" } } ] }'Appliquez le fichier yaml en exécutant la commande suivante :
$ oc apply -f tuning-example.yamlExemple de sortie
networkattachmentdefinition.k8.cni.cncf.io/tuningnad createdCréez un pod tel que
examplepod.yamlavec la définition de l'attachement réseau similaire à ce qui suit :apiVersion: v1 kind: Pod metadata: name: tunepod namespace: default annotations: k8s.v1.cni.cncf.io/networks: tuningnad1 spec: containers: - name: podexample image: centos command: ["/bin/bash", "-c", "sleep INF"] securityContext: runAsUser: 20002 runAsGroup: 30003 allowPrivilegeEscalation: false4 capabilities:5 drop: ["ALL"] securityContext: runAsNonRoot: true6 seccompProfile:7 type: RuntimeDefault- 1
- Spécifiez le nom du site configuré
NetworkAttachmentDefinition. - 2
runAsUsercontrôle l'identifiant de l'utilisateur avec lequel le conteneur est exécuté.- 3
runAsGroupcontrôle l'identifiant du groupe primaire avec lequel les conteneurs sont exécutés.- 4
allowPrivilegeEscalationdétermine si un pod peut demander à autoriser l'escalade des privilèges. S'il n'est pas spécifié, la valeur par défaut est true. Ce booléen contrôle directement si le drapeauno_new_privsest activé sur le processus du conteneur.- 5
capabilitiespermettent des actions privilégiées sans donner un accès complet à la racine. Cette politique permet de s'assurer que toutes les capacités sont supprimées du pod.- 6
runAsNonRoot: trueexige que le conteneur fonctionne avec un utilisateur dont l'UID est différent de 0.- 7
RuntimeDefaultactive le profil seccomp par défaut pour un pod ou une charge de travail de conteneur.
Appliquez le fichier yaml en exécutant la commande suivante :
$ oc apply -f examplepod.yamlVérifiez que le module est créé en exécutant la commande suivante :
$ oc get podExemple de sortie
NAME READY STATUS RESTARTS AGE tunepod 1/1 Running 0 47sConnectez-vous au module en exécutant la commande suivante :
$ oc rsh tunepodVérifiez les valeurs des drapeaux sysctl configurés. Par exemple, trouvez la valeur
net.ipv4.conf.net1.accept_redirectsen exécutant la commande suivante :sh-4.4# sysctl net.ipv4.conf.net1.accept_redirectsRésultats attendus
net.ipv4.conf.net1.accept_redirects = 1
Chapitre 17. Utilisation du protocole SCTP (Stream Control Transmission Protocol) sur un cluster bare metal
En tant qu'administrateur de cluster, vous pouvez utiliser le protocole SCTP (Stream Control Transmission Protocol) sur un cluster.
17.1. Prise en charge du protocole de transmission de contrôle de flux (SCTP) sur OpenShift Container Platform
En tant qu'administrateur de cluster, vous pouvez activer SCTP sur les hôtes du cluster. Sur Red Hat Enterprise Linux CoreOS (RHCOS), le module SCTP est désactivé par défaut.
SCTP est un protocole fiable basé sur des messages qui fonctionne sur un réseau IP.
Lorsque cette option est activée, vous pouvez utiliser SCTP comme protocole avec les pods, les services et la stratégie réseau. Un objet Service doit être défini avec le paramètre type réglé sur la valeur ClusterIP ou NodePort.
17.1.1. Exemple de configurations utilisant le protocole SCTP
Vous pouvez configurer un pod ou un service pour qu'il utilise le protocole SCTP en attribuant au paramètre protocol la valeur SCTP dans l'objet pod ou service.
Dans l'exemple suivant, un pod est configuré pour utiliser SCTP :
apiVersion: v1
kind: Pod
metadata:
namespace: project1
name: example-pod
spec:
containers:
- name: example-pod
...
ports:
- containerPort: 30100
name: sctpserver
protocol: SCTPDans l'exemple suivant, un service est configuré pour utiliser SCTP :
apiVersion: v1
kind: Service
metadata:
namespace: project1
name: sctpserver
spec:
...
ports:
- name: sctpserver
protocol: SCTP
port: 30100
targetPort: 30100
type: ClusterIP
Dans l'exemple suivant, un objet NetworkPolicy est configuré pour s'appliquer au trafic réseau SCTP sur le port 80 à partir de n'importe quel pod doté d'une étiquette spécifique :
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-sctp-on-http
spec:
podSelector:
matchLabels:
role: web
ingress:
- ports:
- protocol: SCTP
port: 8017.2. Activation du protocole de transmission par contrôle de flux (SCTP)
En tant qu'administrateur de cluster, vous pouvez charger et activer le module noyau SCTP figurant sur la liste noire sur les nœuds de travail de votre cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Créez un fichier nommé
load-sctp-module.yamlqui contient la définition YAML suivante :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: load-sctp-module labels: machineconfiguration.openshift.io/role: worker spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/modprobe.d/sctp-blacklist.conf mode: 0644 overwrite: true contents: source: data:, - path: /etc/modules-load.d/sctp-load.conf mode: 0644 overwrite: true contents: source: data:,sctpPour créer l'objet
MachineConfig, entrez la commande suivante :$ oc create -f load-sctp-module.yamlEn option : Pour observer l'état des nœuds pendant que l'opérateur MachineConfig applique le changement de configuration, entrez la commande suivante. Lorsque l'état d'un nœud passe à
Ready, la mise à jour de la configuration est appliquée.$ oc get nodes
17.3. Vérification de l'activation du protocole de transmission par contrôle de flux (SCTP)
Vous pouvez vérifier que le SCTP fonctionne sur un cluster en créant un pod avec une application qui écoute le trafic SCTP, en l'associant à un service, puis en vous connectant au service exposé.
Conditions préalables
-
Accès à l'internet depuis le cluster pour installer le paquet
nc. -
Installez le CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
La création d'un pod démarre un listener SCTP :
Créer un fichier nommé
sctp-server.yamlqui définit un pod avec le YAML suivant :apiVersion: v1 kind: Pod metadata: name: sctpserver labels: app: sctpserver spec: containers: - name: sctpserver image: registry.access.redhat.com/ubi8/ubi command: ["/bin/sh", "-c"] args: ["dnf install -y nc && sleep inf"] ports: - containerPort: 30102 name: sctpserver protocol: SCTPCréez le pod en entrant la commande suivante :
$ oc create -f sctp-server.yaml
Créer un service pour le pod d'écoute SCTP.
Créez un fichier nommé
sctp-service.yamlqui définit un service avec le YAML suivant :apiVersion: v1 kind: Service metadata: name: sctpservice labels: app: sctpserver spec: type: NodePort selector: app: sctpserver ports: - name: sctpserver protocol: SCTP port: 30102 targetPort: 30102Pour créer le service, entrez la commande suivante :
$ oc create -f sctp-service.yaml
Créer un pod pour le client SCTP.
Créez un fichier nommé
sctp-client.yamlavec le langage YAML suivant :apiVersion: v1 kind: Pod metadata: name: sctpclient labels: app: sctpclient spec: containers: - name: sctpclient image: registry.access.redhat.com/ubi8/ubi command: ["/bin/sh", "-c"] args: ["dnf install -y nc && sleep inf"]Pour créer l'objet
Pod, entrez la commande suivante :$ oc apply -f sctp-client.yaml
Exécutez une liste d'écoute SCTP sur le serveur.
Pour vous connecter au module serveur, entrez la commande suivante :
$ oc rsh sctpserverPour démarrer l'auditeur SCTP, entrez la commande suivante :
$ nc -l 30102 --sctp
Se connecter à l'auditeur SCTP sur le serveur.
- Ouvrez une nouvelle fenêtre ou un nouvel onglet dans votre programme de terminal.
Obtenez l'adresse IP du service
sctpservice. Entrez la commande suivante :$ oc get services sctpservice -o go-template='{{.spec.clusterIP}}{{"\n"}}'Pour se connecter au pod client, entrez la commande suivante :
$ oc rsh sctpclientPour démarrer le client SCTP, entrez la commande suivante. Remplacez
<cluster_IP>par l'adresse IP du cluster du servicesctpservice.# nc <cluster_IP> 30102 --sctp
Chapitre 18. Utilisation du matériel PTP
Vous pouvez configurer les services linuxptp et utiliser du matériel compatible PTP dans les nœuds de cluster d'OpenShift Container Platform.
18.1. À propos du matériel PTP
Vous pouvez utiliser la console OpenShift Container Platform ou OpenShift CLI (oc) pour installer PTP en déployant le PTP Operator. L'opérateur PTP crée et gère les services linuxptp et fournit les fonctionnalités suivantes :
- Découverte des appareils compatibles PTP dans le cluster.
-
Gestion de la configuration des services
linuxptp. -
Notification des événements d'horloge PTP qui affectent négativement les performances et la fiabilité de votre application avec le sidecar PTP Operator
cloud-event-proxy.
L'opérateur PTP travaille avec des appareils compatibles PTP sur des clusters approvisionnés uniquement sur une infrastructure bare-metal.
18.2. À propos de PTP
Le Precision Time Protocol (PTP) est utilisé pour synchroniser les horloges d'un réseau. Lorsqu'il est utilisé en conjonction avec un support matériel, le PTP est capable d'une précision inférieure à la microseconde et est plus précis que le Network Time Protocol (NTP).
Le paquet linuxptp comprend les programmes ptp4l et phc2sys pour la synchronisation des horloges. ptp4l implémente l'horloge frontière PTP et l'horloge ordinaire. ptp4l synchronise l'horloge matérielle PTP avec l'horloge source avec un horodatage matériel et synchronise l'horloge système avec l'horloge source avec un horodatage logiciel. phc2sys est utilisé pour l'horodatage matériel afin de synchroniser l'horloge système avec l'horloge matérielle PTP sur le contrôleur d'interface de réseau (NIC).
18.2.1. Éléments d'un domaine PTP
Le protocole PTP est utilisé pour synchroniser plusieurs nœuds connectés dans un réseau, avec des horloges pour chaque nœud. Les horloges synchronisées par PTP sont organisées dans une hiérarchie source-destination. La hiérarchie est créée et mise à jour automatiquement par l'algorithme de la meilleure horloge maîtresse (BMC), qui s'exécute sur chaque horloge. Les horloges de destination sont synchronisées avec les horloges sources, et les horloges de destination peuvent elles-mêmes être la source d'autres horloges en aval. Les types d'horloges suivants peuvent être inclus dans les configurations :
- Horloge du grand maître
- L'horloge grand maître fournit des informations horaires standard aux autres horloges du réseau et assure une synchronisation précise et stable. Elle écrit des horodatages et répond aux demandes de temps des autres horloges. Les horloges grand maître peuvent être synchronisées avec une source de temps GPS (Global Positioning System).
- Horloge ordinaire
- L'horloge ordinaire dispose d'une connexion à port unique qui peut jouer le rôle d'horloge source ou de destination, en fonction de sa position dans le réseau. L'horloge ordinaire peut lire et écrire des horodatages.
- Horloge frontière
- L'horloge périphérique possède des ports dans deux ou plusieurs voies de communication et peut être à la fois une source et une destination pour d'autres horloges de destination. L'horloge périphérique fonctionne comme une horloge de destination en amont. L'horloge de destination reçoit le message de synchronisation, corrige le retard, puis crée un nouveau signal temporel source à transmettre sur le réseau. L'horloge périphérique produit un nouveau paquet de données temporelles qui reste correctement synchronisé avec l'horloge source et peut réduire le nombre de dispositifs connectés qui se rapportent directement à l'horloge source.
18.2.2. Avantages du PTP par rapport au NTP
L'un des principaux avantages du PTP par rapport au NTP est le support matériel présent dans divers contrôleurs d'interface réseau (NIC) et commutateurs de réseau. Le matériel spécialisé permet au PTP de tenir compte des retards dans le transfert des messages et d'améliorer la précision de la synchronisation du temps. Pour obtenir la meilleure précision possible, il est recommandé que tous les composants de réseau entre les horloges PTP soient compatibles avec le matériel PTP.
Le PTP matériel offre une précision optimale, car la carte d'interface réseau peut horodater les paquets PTP au moment exact où ils sont envoyés et reçus. Comparé au PTP logiciel, qui nécessite un traitement supplémentaire des paquets PTP par le système d'exploitation, le PTP matériel offre une précision optimale.
Avant d'activer le PTP, assurez-vous que NTP est désactivé pour les nœuds requis. Vous pouvez désactiver le service chronologique (chronyd) à l'aide d'une ressource personnalisée MachineConfig. Pour plus d'informations, voir Désactivation du service chronologique.
18.2.3. Utilisation de PTP avec un matériel à double NIC
OpenShift Container Platform prend en charge le matériel NIC simple et double pour une synchronisation PTP précise dans le cluster.
Pour les réseaux télécoms 5G qui offrent une couverture du spectre à bande moyenne, chaque unité virtuelle distribuée (vDU) nécessite des connexions à 6 unités radio (RU). Pour établir ces connexions, chaque hôte vDU a besoin de deux cartes d'interface réseau configurées en tant qu'horloges limites.
Le matériel Dual NIC vous permet de connecter chaque NIC à la même horloge leader en amont, avec des instances ptp4l distinctes pour chaque NIC alimentant les horloges en aval.
18.3. Installation de l'opérateur PTP à l'aide du CLI
En tant qu'administrateur de cluster, vous pouvez installer l'Opérateur à l'aide de la CLI.
Conditions préalables
- Un cluster installé sur du matériel bare-metal avec des nœuds dont le matériel prend en charge le protocole PTP.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un espace de noms pour l'opérateur PTP.
Enregistrez le YAML suivant dans le fichier
ptp-namespace.yaml:apiVersion: v1 kind: Namespace metadata: name: openshift-ptp annotations: workload.openshift.io/allowed: management labels: name: openshift-ptp openshift.io/cluster-monitoring: "true"Créer le CR
Namespace:$ oc create -f ptp-namespace.yaml
Créez un groupe d'opérateurs pour l'opérateur PTP.
Enregistrez le YAML suivant dans le fichier
ptp-operatorgroup.yaml:apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ptp-operators namespace: openshift-ptp spec: targetNamespaces: - openshift-ptpCréer le CR
OperatorGroup:$ oc create -f ptp-operatorgroup.yaml
S'abonner à l'opérateur PTP.
Enregistrez le YAML suivant dans le fichier
ptp-sub.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ptp-operator-subscription namespace: openshift-ptp spec: channel: "stable" name: ptp-operator source: redhat-operators sourceNamespace: openshift-marketplaceCréer le CR
Subscription:$ oc create -f ptp-sub.yaml
Pour vérifier que l'opérateur est installé, entrez la commande suivante :
$ oc get csv -n openshift-ptp -o custom-columns=Name:.metadata.name,Phase:.status.phaseExemple de sortie
Name Phase 4.12.0-202301261535 Succeeded
18.4. Installation de l'opérateur PTP à l'aide de la console web
En tant qu'administrateur de cluster, vous pouvez installer l'opérateur PTP à l'aide de la console web.
Vous devez créer l'espace de noms et le groupe d'opérateurs comme indiqué dans la section précédente.
Procédure
Installez l'opérateur PTP à l'aide de la console web d'OpenShift Container Platform :
- Dans la console Web OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Choisissez PTP Operator dans la liste des opérateurs disponibles, puis cliquez sur Install.
- Sur la page Install Operator, sous A specific namespace on the cluster, sélectionnez openshift-ptp. Cliquez ensuite sur Install.
En option, vérifier que l'installation de l'opérateur PTP a réussi : Vérifiez que l'opérateur PTP a été installé avec succès :
- Passez à la page Operators → Installed Operators.
Assurez-vous que PTP Operator est listé dans le projet openshift-ptp avec un Status de InstallSucceeded.
NotePendant l'installation, un opérateur peut afficher un état Failed. Si l'installation réussit par la suite avec un message InstallSucceeded, vous pouvez ignorer le message Failed.
Si l'opérateur n'apparaît pas tel qu'il a été installé, il convient de poursuivre le dépannage :
- Allez à la page Operators → Installed Operators et inspectez les onglets Operator Subscriptions et Install Plans pour voir s'il y a des défaillances ou des erreurs sous Status.
-
Allez sur la page Workloads → Pods et vérifiez les journaux pour les pods dans le projet
openshift-ptp.
18.5. Configuration des dispositifs PTP
L'opérateur PTP ajoute la définition de ressource personnalisée (CRD) NodePtpDevice.ptp.openshift.io à OpenShift Container Platform.
Une fois installé, l'opérateur PTP recherche dans votre grappe des périphériques réseau compatibles PTP sur chaque nœud. Il crée et met à jour un objet de ressource personnalisée (CR) NodePtpDevice pour chaque nœud qui fournit un périphérique réseau compatible PTP.
18.5.1. Découverte des périphériques réseau compatibles avec le protocole PTP dans votre cluster
Pour obtenir une liste complète des périphériques réseau compatibles avec le protocole PTP dans votre cluster, exécutez la commande suivante :
$ oc get NodePtpDevice -n openshift-ptp -o yamlExemple de sortie
apiVersion: v1 items: - apiVersion: ptp.openshift.io/v1 kind: NodePtpDevice metadata: creationTimestamp: "2022-01-27T15:16:28Z" generation: 1 name: dev-worker-01 namespace: openshift-ptp resourceVersion: "6538103" uid: d42fc9ad-bcbf-4590-b6d8-b676c642781a spec: {} status: devices:2 - name: eno1 - name: eno2 - name: eno3 - name: eno4 - name: enp5s0f0 - name: enp5s0f1 ...
18.5.2. Configuration des services linuxptp en tant qu'horloge ordinaire
Vous pouvez configurer les services linuxptp (ptp4l, phc2sys) comme des horloges ordinaires en créant un objet PtpConfig custom resource (CR).
Utilisez l'exemple suivant PtpConfig CR comme base pour configurer les services linuxptp en tant qu'horloge ordinaire pour votre matériel et votre environnement particuliers. Cet exemple CR ne configure pas les événements rapides PTP. Pour configurer les événements rapides PTP, définissez les valeurs appropriées pour ptp4lOpts, ptp4lConf, et ptpClockThreshold. ptpClockThreshold n'est nécessaire que lorsque les événements sont activés. Voir "Configuring the PTP fast event notifications publisher" (Configuration de l'éditeur de notifications d'événements rapides PTP) pour plus d'informations.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur PTP.
Procédure
Créez le CR
PtpConfigsuivant, puis enregistrez le YAML dans le fichierordinary-clock-ptp-config.yaml.Configuration recommandée de l'horloge ordinaire PTP
apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: ordinary-clock-ptp-config namespace: openshift-ptp spec: profile: - name: ordinary-clock interface: "<interface_name>" phc2sysOpts: "-a -r -n 24" ptp4lOpts: "-2 -s" ptpSchedulingPolicy: SCHED_FIFO ptpSchedulingPriority: 10 ptp4lConf: | [global] # # Default Data Set # twoStepFlag 1 slaveOnly 1 priority1 128 priority2 128 domainNumber 24 clockClass 255 clockAccuracy 0xFE offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison G.8275.x G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval -4 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval 4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval 0 kernel_leap 1 check_fup_sync 0 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 max_frequency 900000000 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type OC network_transport L2 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0xA0 recommend: - profile: ordinary-clock priority: 4 match: - nodeLabel: "node-role.kubernetes.io/worker" nodeName: "<node_name>"Expand Tableau 18.1. Options de configuration de l'horloge ordinaire PTP CR Champ de ressource personnalisé Description nameLe nom du CR
PtpConfig.profileSpécifier un tableau d'un ou plusieurs objets
profile. Chaque profil doit être nommé de manière unique.interfaceIndiquez l'interface réseau à utiliser par le service
ptp4l, par exempleens787f1.ptp4lOptsSpécifiez les options de configuration du système pour le service
ptp4l, par exemple-2pour sélectionner le transport réseau IEEE 802.3. Les options ne doivent pas inclure le nom de l'interface réseau-i <interface>et le fichier de configuration du service-f /etc/ptp4l.conf, car le nom de l'interface réseau et le fichier de configuration du service sont automatiquement ajoutés. Ajoutez--summary_interval -4pour utiliser les événements rapides PTP avec cette interface.phc2sysOptsSpécifier les options de configuration du système pour le service
phc2sys. Si ce champ est vide, l'opérateur PTP ne démarre pas le servicephc2sys. Pour les cartes réseau Intel Columbiaville 800 Series, définissez les options dephc2sysOptssur-a -r -m -n 24 -N 8 -R 16.-mimprime les messages surstdout.linuxptp-daemonDaemonSetanalyse les journaux et génère des métriques Prometheus.ptp4lConfIndiquez une chaîne contenant la configuration qui remplacera le fichier par défaut
/etc/ptp4l.conf. Pour utiliser la configuration par défaut, laissez le champ vide.tx_timestamp_timeoutPour les cartes réseau de la série 800 d'Intel Columbiaville, définissez
tx_timestamp_timeoutsur50.boundary_clock_jbodPour les cartes réseau de la série 800 d'Intel Columbiaville, définissez
boundary_clock_jbodsur0.ptpSchedulingPolicyPolitique d'ordonnancement des processus
ptp4letphc2sys. La valeur par défaut estSCHED_OTHER. UtilisezSCHED_FIFOsur les systèmes qui prennent en charge l'ordonnancement FIFO.ptpSchedulingPriorityValeur entière de 1 à 65 utilisée pour définir la priorité FIFO pour les processus
ptp4letphc2syslorsqueptpSchedulingPolicyest défini surSCHED_FIFO. Le champptpSchedulingPriorityn'est pas utilisé lorsqueptpSchedulingPolicyest défini surSCHED_OTHER.ptpClockThresholdFacultatif. Si
ptpClockThresholdn'est pas présent, les valeurs par défaut sont utilisées pour les champsptpClockThreshold.ptpClockThresholdconfigure le délai de déconnexion de l'horloge maître PTP avant le déclenchement des événements PTP.holdOverTimeoutest la valeur temporelle en secondes avant que l'état de l'événement de l'horloge PTP ne passe àFREERUNlorsque l'horloge maître PTP est déconnectée. Les paramètresmaxOffsetThresholdetminOffsetThresholdconfigurent les valeurs de décalage en nanosecondes qui se comparent aux valeurs deCLOCK_REALTIME(phc2sys) ou au décalage du maître (ptp4l). Lorsque la valeur de décalageptp4louphc2sysest en dehors de cette plage, l'état de l'horloge PTP est réglé surFREERUN. Lorsque la valeur de décalage est comprise dans cette plage, l'état de l'horloge PTP est réglé surLOCKED.recommendSpécifier un tableau d'un ou plusieurs objets
recommendqui définissent les règles d'application deprofileaux nœuds..recommend.profileIndiquez le nom de l'objet
.recommend.profiledéfini dans la sectionprofile..recommend.priorityRéglez
.recommend.prioritysur0pour une horloge ordinaire..recommend.matchSpécifiez les règles
.recommend.matchavecnodeLabelounodeName..recommend.match.nodeLabelMettez à jour
nodeLabelavec lekeydenode.Labelsà partir de l'objet nœud en utilisant la commandeoc get nodes --show-labels. Par exemple :node-role.kubernetes.io/worker..recommend.match.nodeLabelMettez à jour
nodeNameavec la valeur denode.Namede l'objet nœud en utilisant la commandeoc get nodes. Par exemple :compute-0.example.com.Créez le CR
PtpConfigen exécutant la commande suivante :$ oc create -f ordinary-clock-ptp-config.yaml
Vérification
Vérifiez que le profil
PtpConfigest appliqué au nœud.Obtenez la liste des pods dans l'espace de noms
openshift-ptpen exécutant la commande suivante :$ oc get pods -n openshift-ptp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-4xkbb 1/1 Running 0 43m 10.1.196.24 compute-0.example.com linuxptp-daemon-tdspf 1/1 Running 0 43m 10.1.196.25 compute-1.example.com ptp-operator-657bbb64c8-2f8sj 1/1 Running 0 43m 10.129.0.61 control-plane-1.example.comVérifiez que le profil est correct. Examinez les journaux du démon
linuxptpqui correspond au nœud spécifié dans le profilPtpConfig. Exécutez la commande suivante :$ oc logs linuxptp-daemon-4xkbb -n openshift-ptp -c linuxptp-daemon-containerExemple de sortie
I1115 09:41:17.117596 4143292 daemon.go:107] in applyNodePTPProfile I1115 09:41:17.117604 4143292 daemon.go:109] updating NodePTPProfile to: I1115 09:41:17.117607 4143292 daemon.go:110] ------------------------------------ I1115 09:41:17.117612 4143292 daemon.go:102] Profile Name: profile1 I1115 09:41:17.117616 4143292 daemon.go:102] Interface: ens787f1 I1115 09:41:17.117620 4143292 daemon.go:102] Ptp4lOpts: -2 -s I1115 09:41:17.117623 4143292 daemon.go:102] Phc2sysOpts: -a -r -n 24 I1115 09:41:17.117626 4143292 daemon.go:116] ------------------------------------
18.5.3. Configuration des services linuxptp en tant qu'horloge frontière
Vous pouvez configurer les services linuxptp (ptp4l, phc2sys) en tant qu'horloge frontière en créant un objet PtpConfig custom resource (CR).
Utilisez l'exemple suivant PtpConfig CR comme base pour configurer les services linuxptp en tant qu'horloge frontière pour votre matériel et votre environnement particuliers. Cet exemple CR ne configure pas les événements rapides PTP. Pour configurer les événements rapides PTP, définissez les valeurs appropriées pour ptp4lOpts, ptp4lConf et ptpClockThreshold. ptpClockThreshold n'est utilisé que lorsque les événements sont activés. Voir "Configuring the PTP fast event notifications publisher" (Configuration de l'éditeur de notifications d'événements rapides PTP) pour plus d'informations.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur PTP.
Procédure
Créez le CR
PtpConfigsuivant, puis enregistrez le YAML dans le fichierboundary-clock-ptp-config.yaml.Configuration recommandée de l'horloge limite PTP
--- apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: boundary-clock-ptp-config namespace: openshift-ptp spec: profile: - name: boundary-clock phc2sysOpts: "-a -r -n 24" ptp4lOpts: "-2" ptpSchedulingPolicy: SCHED_FIFO ptpSchedulingPriority: 10 ptp4lConf: | [<interface_1>] masterOnly 0 [<interface_2>] masterOnly 1 [<interface_3>] masterOnly 1 [<interface_4>] masterOnly 1 [global] # # Default Data Set # twoStepFlag 1 slaveOnly 0 priority1 128 priority2 128 domainNumber 24 clockClass 248 clockAccuracy 0xFE offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison G.8275.x G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval -4 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval 4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval 0 kernel_leap 1 check_fup_sync 0 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 max_frequency 900000000 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type BC network_transport L2 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0xA0 recommend: - profile: boundary-clock priority: 4 match: - nodeLabel: node-role.kubernetes.io/master nodeName: <nodename>Expand Tableau 18.2. Options de configuration de l'horloge boundary CR du PTP Champ de ressource personnalisé Description nameLe nom du CR
PtpConfig.profileSpécifier un tableau d'un ou plusieurs objets
profile.nameSpécifiez le nom d'un objet de profil qui identifie de manière unique un objet de profil.
ptp4lOptsSpécifiez les options de configuration du système pour le service
ptp4l. Les options ne doivent pas inclure le nom de l'interface réseau-i <interface>et le fichier de configuration du service-f /etc/ptp4l.confcar le nom de l'interface réseau et le fichier de configuration du service sont automatiquement ajoutés.ptp4lConfSpécifiez la configuration requise pour démarrer
ptp4len tant qu'horloge périphérique. Par exemple,ens1f0se synchronise à partir d'une horloge grand maître etens1f3synchronise les périphériques connectés.<interface_1>L'interface qui reçoit l'horloge de synchronisation.
<interface_2>L'interface qui envoie l'horloge de synchronisation.
tx_timestamp_timeoutPour les cartes réseau de la série 800 d'Intel Columbiaville, définissez
tx_timestamp_timeoutsur50.boundary_clock_jbodPour les cartes d'interface réseau de la série Intel Columbiaville 800, assurez-vous que
boundary_clock_jbodest défini sur0. Pour les cartes d'interface réseau de la série Intel Fortville X710, assurez-vous queboundary_clock_jbodest défini sur1.phc2sysOptsSpécifier les options de configuration du système pour le service
phc2sys. Si ce champ est vide, l'opérateur PTP ne démarre pas le servicephc2sys.ptpSchedulingPolicyPolitique d'ordonnancement pour les processus ptp4l et phc2sys. La valeur par défaut est
SCHED_OTHER. UtilisezSCHED_FIFOsur les systèmes qui prennent en charge l'ordonnancement FIFO.ptpSchedulingPriorityValeur entière de 1 à 65 utilisée pour définir la priorité FIFO pour les processus
ptp4letphc2syslorsqueptpSchedulingPolicyest défini surSCHED_FIFO. Le champptpSchedulingPriorityn'est pas utilisé lorsqueptpSchedulingPolicyest défini surSCHED_OTHER.ptpClockThresholdFacultatif. Si
ptpClockThresholdn'est pas présent, les valeurs par défaut sont utilisées pour les champsptpClockThreshold.ptpClockThresholdconfigure le délai de déconnexion de l'horloge maître PTP avant le déclenchement des événements PTP.holdOverTimeoutest la valeur temporelle en secondes avant que l'état de l'événement de l'horloge PTP ne passe àFREERUNlorsque l'horloge maître PTP est déconnectée. Les paramètresmaxOffsetThresholdetminOffsetThresholdconfigurent les valeurs de décalage en nanosecondes qui se comparent aux valeurs deCLOCK_REALTIME(phc2sys) ou au décalage du maître (ptp4l). Lorsque la valeur de décalageptp4louphc2sysest en dehors de cette plage, l'état de l'horloge PTP est réglé surFREERUN. Lorsque la valeur de décalage est comprise dans cette plage, l'état de l'horloge PTP est réglé surLOCKED.recommendSpécifier un tableau d'un ou plusieurs objets
recommendqui définissent les règles d'application deprofileaux nœuds..recommend.profileIndiquez le nom de l'objet
.recommend.profiledéfini dans la sectionprofile..recommend.prioritySpécifiez le champ
priorityavec une valeur entière comprise entre0et99. Un nombre plus élevé est moins prioritaire, de sorte qu'une priorité de99est inférieure à une priorité de10. Si un nœud peut être associé à plusieurs profils conformément aux règles définies dans le champmatch, le profil ayant la priorité la plus élevée est appliqué à ce nœud..recommend.matchSpécifiez les règles
.recommend.matchavecnodeLabelounodeName..recommend.match.nodeLabelMettez à jour
nodeLabelavec lekeydenode.Labelsà partir de l'objet nœud en utilisant la commandeoc get nodes --show-labels. Par exemple :node-role.kubernetes.io/worker..recommend.match.nodeLabelMettez à jour
nodeNameavec la valeur denode.Namede l'objet nœud en utilisant la commandeoc get nodes. Par exemple :compute-0.example.com.Créez le CR en exécutant la commande suivante :
$ oc create -f boundary-clock-ptp-config.yaml
Vérification
Vérifiez que le profil
PtpConfigest appliqué au nœud.Obtenez la liste des pods dans l'espace de noms
openshift-ptpen exécutant la commande suivante :$ oc get pods -n openshift-ptp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-4xkbb 1/1 Running 0 43m 10.1.196.24 compute-0.example.com linuxptp-daemon-tdspf 1/1 Running 0 43m 10.1.196.25 compute-1.example.com ptp-operator-657bbb64c8-2f8sj 1/1 Running 0 43m 10.129.0.61 control-plane-1.example.comVérifiez que le profil est correct. Examinez les journaux du démon
linuxptpqui correspond au nœud spécifié dans le profilPtpConfig. Exécutez la commande suivante :$ oc logs linuxptp-daemon-4xkbb -n openshift-ptp -c linuxptp-daemon-containerExemple de sortie
I1115 09:41:17.117596 4143292 daemon.go:107] in applyNodePTPProfile I1115 09:41:17.117604 4143292 daemon.go:109] updating NodePTPProfile to: I1115 09:41:17.117607 4143292 daemon.go:110] ------------------------------------ I1115 09:41:17.117612 4143292 daemon.go:102] Profile Name: profile1 I1115 09:41:17.117616 4143292 daemon.go:102] Interface: I1115 09:41:17.117620 4143292 daemon.go:102] Ptp4lOpts: -2 I1115 09:41:17.117623 4143292 daemon.go:102] Phc2sysOpts: -a -r -n 24 I1115 09:41:17.117626 4143292 daemon.go:116] ------------------------------------
18.5.4. Configuration des services linuxptp en tant qu'horloges limites pour le matériel à double carte réseau
Le matériel Precision Time Protocol (PTP) avec deux NIC configurés en tant qu'horloges limites est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes d'un point de vue fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Vous pouvez configurer les services linuxptp (ptp4l, phc2sys) en tant qu'horloges limites pour le matériel à deux NIC en créant un objet de ressource personnalisée (CR) PtpConfig pour chaque NIC.
Le matériel Dual NIC vous permet de connecter chaque NIC à la même horloge leader en amont, avec des instances ptp4l distinctes pour chaque NIC alimentant les horloges en aval.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur PTP.
Procédure
Créez deux CR
PtpConfigdistincts, un pour chaque NIC, en utilisant le CR de référence dans "Configuring linuxptp services as a boundary clock" comme base pour chaque CR. Par exemple :Créez
boundary-clock-ptp-config-nic1.yaml, en spécifiant des valeurs pourphc2sysOpts:apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: boundary-clock-ptp-config-nic1 namespace: openshift-ptp spec: profile: - name: "profile1" ptp4lOpts: "-2 --summary_interval -4" ptp4lConf: |1 [ens5f1] masterOnly 1 [ens5f0] masterOnly 0 ... phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"2 - 1
- Spécifiez les interfaces requises pour démarrer
ptp4len tant qu'horloge périphérique. Par exemple,ens5f0se synchronise à partir d'une horloge grand maître etens5f1synchronise les périphériques connectés. - 2
- Valeurs requises
phc2sysOpts.-mimprime des messages àstdout.linuxptp-daemonDaemonSetanalyse les journaux et génère des métriques Prometheus.
Créez
boundary-clock-ptp-config-nic2.yaml, en supprimant complètement le champphc2sysOptspour désactiver le servicephc2syspour le deuxième NIC :apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: boundary-clock-ptp-config-nic2 namespace: openshift-ptp spec: profile: - name: "profile2" ptp4lOpts: "-2 --summary_interval -4" ptp4lConf: |1 [ens7f1] masterOnly 1 [ens7f0] masterOnly 0 ...- 1
- Spécifiez les interfaces requises pour démarrer
ptp4len tant qu'horloge périphérique sur le second NIC.
NoteVous devez supprimer complètement le champ
phc2sysOptsdu deuxième CRPtpConfigpour désactiver le servicephc2syssur le deuxième NIC.
Créez les CR double NIC
PtpConfigen exécutant les commandes suivantes :Créez le CR qui configure le PTP pour le premier NIC :
$ oc create -f boundary-clock-ptp-config-nic1.yamlCréez le CR qui configure le PTP pour le second NIC :
$ oc create -f boundary-clock-ptp-config-nic2.yaml
Vérification
Vérifiez que l'opérateur PTP a appliqué les CR
PtpConfigpour les deux NIC. Examinez les journaux du démonlinuxptpcorrespondant au nœud sur lequel est installé le matériel à double carte d'interface réseau. Par exemple, exécutez la commande suivante :$ oc logs linuxptp-daemon-cvgr6 -n openshift-ptp -c linuxptp-daemon-containerExemple de sortie
ptp4l[80828.335]: [ptp4l.1.config] master offset 5 s2 freq -5727 path delay 519 ptp4l[80828.343]: [ptp4l.0.config] master offset -5 s2 freq -10607 path delay 533 phc2sys[80828.390]: [ptp4l.0.config] CLOCK_REALTIME phc offset 1 s2 freq -87239 delay 539
18.5.5. Intel Columbiaville E800 series NIC comme référence d'horloge ordinaire PTP
Le tableau suivant décrit les modifications que vous devez apporter à la configuration PTP de référence afin d'utiliser les cartes d'interface réseau de la série Intel Columbiaville E800 comme horloges ordinaires. Apportez les modifications dans une ressource personnalisée (CR) PtpConfig que vous appliquez au cluster.
| Configuration PTP | Réglage recommandé |
|---|---|
|
|
|
|
|
|
|
|
|
Pour phc2sysOpts, -m imprime des messages à stdout. linuxptp-daemon DaemonSet analyse les journaux et génère des métriques Prometheus.
18.5.6. Configuration de l'ordonnancement des priorités FIFO pour le matériel PTP
Dans les télécoms ou autres configurations de déploiement nécessitant une faible latence, les threads du démon PTP s'exécutent dans un espace CPU restreint, aux côtés du reste des composants de l'infrastructure. Par défaut, les threads PTP s'exécutent avec la stratégie SCHED_OTHER. En cas de forte charge, ces threads risquent de ne pas bénéficier de la latence de planification dont ils ont besoin pour fonctionner sans erreur.
Pour atténuer les erreurs potentielles de latence d'ordonnancement, vous pouvez configurer les services linuxptp de l'opérateur PTP pour permettre aux threads de s'exécuter avec une politique SCHED_FIFO. Si SCHED_FIFO est défini pour un CR PtpConfig, alors ptp4l et phc2sys s'exécuteront dans le conteneur parent sous chrt avec une priorité définie par le champ ptpSchedulingPriority du CR PtpConfig.
Le réglage de ptpSchedulingPolicy est facultatif et n'est nécessaire que si vous rencontrez des erreurs de latence.
Procédure
Modifier le profil
PtpConfigCR :$ oc edit PtpConfig -n openshift-ptpModifiez les champs
ptpSchedulingPolicyetptpSchedulingPriority:apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: <ptp_config_name> namespace: openshift-ptp ... spec: profile: - name: "profile1" ... ptpSchedulingPolicy: SCHED_FIFO1 ptpSchedulingPriority: 102 -
Sauvegardez et quittez pour appliquer les changements à
PtpConfigCR.
Vérification
Obtenir le nom du pod
linuxptp-daemonet du nœud correspondant où la CRPtpConfiga été appliquée :$ oc get pods -n openshift-ptp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-gmv2n 3/3 Running 0 1d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-lgm55 3/3 Running 0 1d17h 10.1.196.25 compute-1.example.com ptp-operator-3r4dcvf7f4-zndk7 1/1 Running 0 1d7h 10.129.0.61 control-plane-1.example.comVérifier que le processus
ptp4ls'exécute avec la priorité FIFO mise à jour dechrt:$ oc -n openshift-ptp logs linuxptp-daemon-lgm55 -c linuxptp-daemon-container|grep chrtExemple de sortie
I1216 19:24:57.091872 1600715 daemon.go:285] /bin/chrt -f 65 /usr/sbin/ptp4l -f /var/run/ptp4l.0.config -2 --summary_interval -4 -m
18.5.7. Configuration du filtrage des journaux pour les services linuxptp
Le démon linuxptp génère des journaux que vous pouvez utiliser à des fins de débogage. Dans les télécoms ou d'autres configurations de déploiement qui disposent d'une capacité de stockage limitée, ces journaux peuvent augmenter la demande de stockage.
Pour réduire le nombre de messages de journalisation, vous pouvez configurer la ressource personnalisée (CR) PtpConfig afin d'exclure les messages de journalisation qui indiquent la valeur master offset. Le message master offset indique la différence entre l'horloge du nœud actuel et l'horloge principale en nanosecondes.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur PTP.
Procédure
Modifier le CR
PtpConfig:$ oc edit PtpConfig -n openshift-ptpDans
spec.profile, ajoutez la spécificationptpSettings.logReduceet fixez la valeur àtrue:apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: <ptp_config_name> namespace: openshift-ptp ... spec: profile: - name: "profile1" ... ptpSettings: logReduce: "true"NoteÀ des fins de débogage, vous pouvez renvoyer cette spécification à
Falsepour inclure les messages de décalage du maître.-
Sauvegardez et quittez pour appliquer les changements à
PtpConfigCR.
Vérification
Obtenir le nom du pod
linuxptp-daemonet du nœud correspondant où la CRPtpConfiga été appliquée :$ oc get pods -n openshift-ptp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-gmv2n 3/3 Running 0 1d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-lgm55 3/3 Running 0 1d17h 10.1.196.25 compute-1.example.com ptp-operator-3r4dcvf7f4-zndk7 1/1 Running 0 1d7h 10.129.0.61 control-plane-1.example.comVérifiez que les messages de décalage du maître sont exclus des journaux en exécutant la commande suivante :
$ oc -n openshift-ptp logs <linux_daemon_container> -c linuxptp-daemon-container | grep "master offset"1 - 1
- <linux_daemon_container> est le nom du pod
linuxptp-daemon, par exemplelinuxptp-daemon-gmv2n.
Lorsque vous configurez la spécification
logReduce, cette commande ne signale aucune instance demaster offsetdans les journaux du démonlinuxptp.
18.6. Dépannage des problèmes courants de l'opérateur PTP
Dépannez les problèmes courants de l'opérateur PTP en procédant comme suit.
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installez l'opérateur PTP sur un cluster bare-metal avec des hôtes qui prennent en charge PTP.
Procédure
Vérifiez que l'opérateur et les opérandes ont bien été déployés dans le cluster pour les nœuds configurés.
$ oc get pods -n openshift-ptp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-lmvgn 3/3 Running 0 4d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-qhfg7 3/3 Running 0 4d17h 10.1.196.25 compute-1.example.com ptp-operator-6b8dcbf7f4-zndk7 1/1 Running 0 5d7h 10.129.0.61 control-plane-1.example.comNoteLorsque le bus d'événements rapides PTP est activé, le nombre de pods
linuxptp-daemonprêts est3/3. Si le bus d'événements rapides PTP n'est pas activé,2/2est affiché.Vérifiez que le matériel pris en charge est présent dans le cluster.
$ oc -n openshift-ptp get nodeptpdevices.ptp.openshift.ioExemple de sortie
NAME AGE control-plane-0.example.com 10d control-plane-1.example.com 10d compute-0.example.com 10d compute-1.example.com 10d compute-2.example.com 10dVérifiez les interfaces réseau PTP disponibles pour un nœud :
oc -n openshift-ptp get nodeptpdevices.ptp.openshift.io <node_name> -o yamloù :
- <node_name>
Spécifie le nœud que vous souhaitez interroger, par exemple,
compute-0.example.com.Exemple de sortie
apiVersion: ptp.openshift.io/v1 kind: NodePtpDevice metadata: creationTimestamp: "2021-09-14T16:52:33Z" generation: 1 name: compute-0.example.com namespace: openshift-ptp resourceVersion: "177400" uid: 30413db0-4d8d-46da-9bef-737bacd548fd spec: {} status: devices: - name: eno1 - name: eno2 - name: eno3 - name: eno4 - name: enp5s0f0 - name: enp5s0f1
Vérifiez que l'interface PTP est bien synchronisée avec l'horloge primaire en accédant au pod
linuxptp-daemonpour le nœud correspondant.Obtenez le nom du pod
linuxptp-daemonet du nœud correspondant que vous souhaitez dépanner en exécutant la commande suivante :$ oc get pods -n openshift-ptp -o wideExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-lmvgn 3/3 Running 0 4d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-qhfg7 3/3 Running 0 4d17h 10.1.196.25 compute-1.example.com ptp-operator-6b8dcbf7f4-zndk7 1/1 Running 0 5d7h 10.129.0.61 control-plane-1.example.comRemote shell dans le conteneur
linuxptp-daemonrequis :oc rsh -n openshift-ptp -c linuxptp-daemon-container <linux_daemon_container>où :
- <linux_daemon_container>
-
est le conteneur que vous voulez diagnostiquer, par exemple
linuxptp-daemon-lmvgn.
Dans la connexion shell à distance au conteneur
linuxptp-daemon, utilisez l'outil PTP Management Client (pmc) pour diagnostiquer l'interface réseau. Exécutez la commande suivantepmcpour vérifier l'état de synchronisation du dispositif PTP, par exempleptp4l.# pmc -u -f /var/run/ptp4l.0.config -b 0 'GET PORT_DATA_SET'Exemple de sortie lorsque le nœud est synchronisé avec succès sur l'horloge primaire
sending: GET PORT_DATA_SET 40a6b7.fffe.166ef0-1 seq 0 RESPONSE MANAGEMENT PORT_DATA_SET portIdentity 40a6b7.fffe.166ef0-1 portState SLAVE logMinDelayReqInterval -4 peerMeanPathDelay 0 logAnnounceInterval -3 announceReceiptTimeout 3 logSyncInterval -4 delayMechanism 1 logMinPdelayReqInterval -4 versionNumber 2
18.7. Cadre de notification des événements rapides du matériel PTP
18.7.1. A propos du PTP et des erreurs de synchronisation d'horloge
Les applications natives de l'informatique en nuage, telles que le RAN virtuel, nécessitent l'accès à des notifications sur les événements de synchronisation du matériel qui sont essentiels au fonctionnement de l'ensemble du réseau. Les notifications d'événements rapides sont des signaux d'alerte précoce concernant des événements de synchronisation d'horloge PTP (Precision Time Protocol) imminents et en temps réel. Les erreurs de synchronisation d'horloge PTP peuvent affecter négativement la performance et la fiabilité de votre application à faible latence, par exemple, une application vRAN fonctionnant dans une unité distribuée (DU).
La perte de synchronisation PTP est une erreur critique pour un réseau RAN. Si la synchronisation est perdue sur un nœud, la radio peut être arrêtée et le trafic OTA (Over the Air) du réseau peut être déplacé vers un autre nœud du réseau sans fil. Les notifications d'événements rapides atténuent les erreurs de charge de travail en permettant aux nœuds de cluster de communiquer l'état de la synchronisation de l'horloge PTP à l'application vRAN exécutée dans l'unité centrale.
Les notifications d'événements sont disponibles pour les applications RAN fonctionnant sur le même nœud DU. Une API REST de type "publish/subscribe" transmet les notifications d'événements au bus de messagerie. La messagerie par publication/abonnement, ou messagerie pub/sub, est une architecture de communication asynchrone de service à service dans laquelle tout message publié sur un sujet est immédiatement reçu par tous les abonnés au sujet.
Des notifications d'événements rapides sont générées par l'opérateur PTP dans OpenShift Container Platform pour chaque interface réseau compatible PTP. Les événements sont mis à disposition à l'aide d'un conteneur sidecar cloud-event-proxy sur un bus de messages AMQP (Advanced Message Queuing Protocol). Le bus de messages AMQP est fourni par l'opérateur d'interconnexion AMQ.
Les notifications d'événements rapides PTP sont disponibles pour les interfaces réseau configurées pour utiliser des horloges ordinaires PTP ou des horloges limites PTP.
18.7.2. À propos du cadre de notifications d'événements rapides PTP
Vous pouvez abonner des applications d'unités distribuées (DU) aux notifications d'événements rapides du protocole Precision Time Protocol (PTP) générées par OpenShift Container Platform avec le conteneur PTP Operator et cloud-event-proxy sidecar. Vous activez le conteneur sidecar cloud-event-proxy en définissant le champ enableEventPublisher sur true dans la ressource personnalisée (CR) ptpOperatorConfig et en spécifiant une adresse AMQP (Advanced Message Queuing Protocol) transportHost. Les événements rapides PTP utilisent un bus de notification d'événements AMQP fourni par l'opérateur AMQ Interconnect. AMQ Interconnect est un composant de Red Hat AMQ, un routeur de messagerie qui fournit un routage flexible des messages entre tous les points d'extrémité compatibles avec AMQP. Une vue d'ensemble du cadre des événements rapides PTP est présentée ci-dessous :
Figure 18.1. Vue d'ensemble des événements rapides PTP
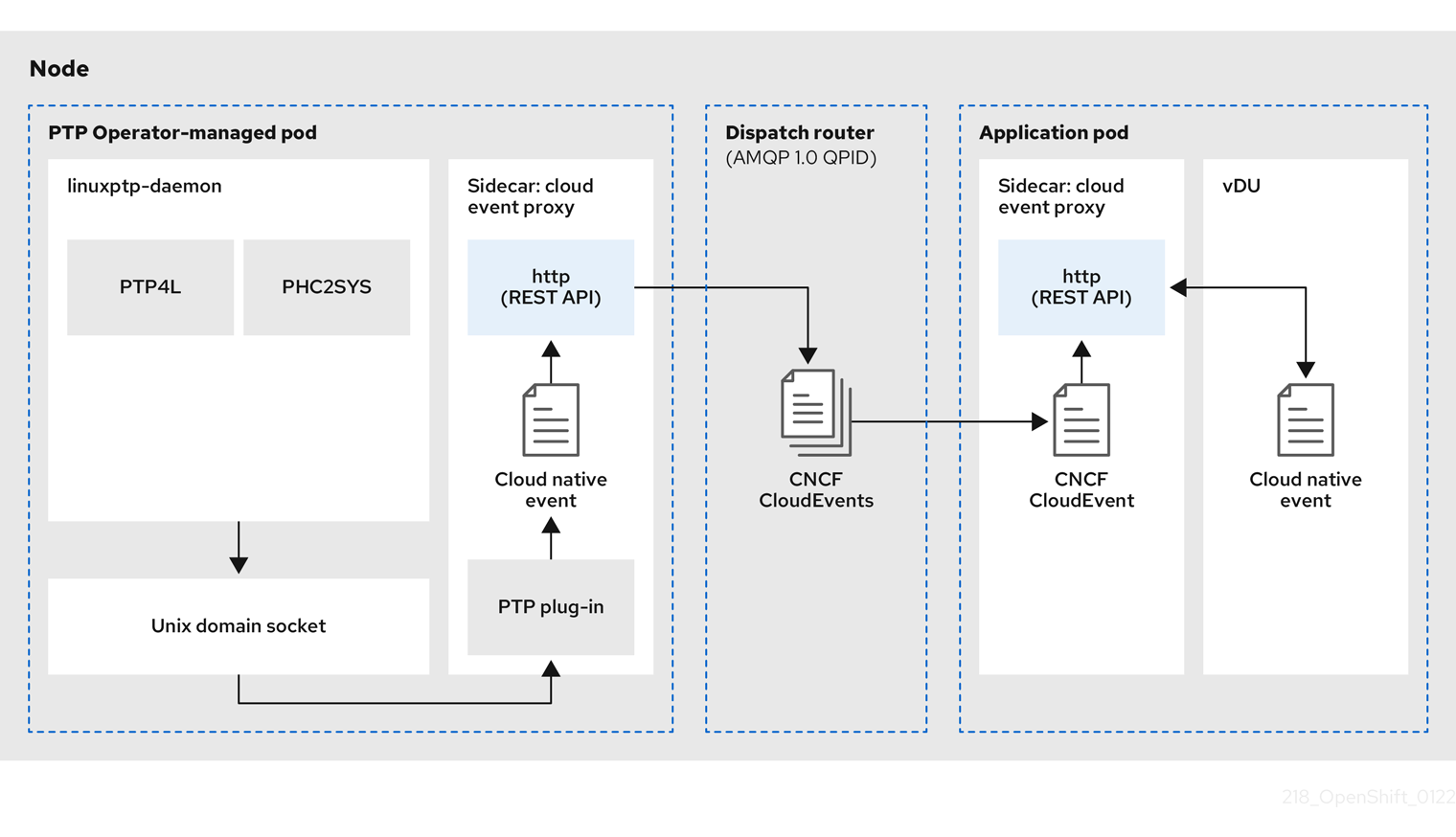
Le conteneur sidecar cloud-event-proxy peut accéder aux mêmes ressources que l'application vRAN principale sans utiliser aucune des ressources de l'application principale et sans latence significative.
Le cadre de notifications d'événements rapides utilise une API REST pour la communication et est basé sur la spécification de l'API REST O-RAN. Le cadre se compose d'un éditeur, d'un abonné et d'un bus de messagerie AMQ pour gérer les communications entre les applications de l'éditeur et de l'abonné. Le sidecar cloud-event-proxy est un conteneur utilitaire qui s'exécute dans un pod faiblement couplé au conteneur d'application DU principal sur le nœud DU. Il fournit un cadre de publication d'événements qui vous permet d'abonner les applications DU aux événements PTP publiés.
Les applications DU exécutent le conteneur cloud-event-proxy dans un modèle de sidecar pour s'abonner aux événements PTP. Le flux de travail suivant décrit comment une application DU utilise les événements rapides PTP :
-
DU application requests a subscription: Le DU envoie une requête API au sidecar
cloud-event-proxypour créer un abonnement aux événements PTP. Le sidecarcloud-event-proxycrée une ressource d'abonnement. -
cloud-event-proxy sidecar creates the subscription: La ressource d'événement est conservée par le sidecar
cloud-event-proxy. Le conteneur sidecarcloud-event-proxyenvoie un accusé de réception avec un ID et une URL permettant d'accéder à la ressource d'abonnement stockée. Le sidecar crée un protocole d'écoute de messagerie AMQ pour la ressource spécifiée dans l'abonnement. -
DU application receives the PTP event notification: Le conteneur sidecar
cloud-event-proxyécoute l'adresse spécifiée dans le qualificateur de ressource. Le consommateur d'événements DU traite le message et le transmet à l'URL de retour spécifiée dans l'abonnement. -
cloud-event-proxy sidecar validates the PTP event and posts it to the DU application: Le sidecar
cloud-event-proxyreçoit l'événement, déballe l'objet "cloud events" pour récupérer les données et récupère l'URL de retour pour renvoyer l'événement à l'application consommateur de l'UA. - DU application uses the PTP event: Le consommateur d'événements de l'application DU reçoit et traite l'événement PTP.
18.7.3. Installation du bus de messagerie AMQ
Pour transmettre des notifications d'événements rapides PTP entre l'éditeur et l'abonné sur un nœud, vous devez installer et configurer un bus de messagerie AMQ pour qu'il fonctionne localement sur le nœud. Pour ce faire, vous devez installer l'opérateur d'interconnexion AMQ à utiliser dans le cluster.
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
-
Installez l'opérateur d'interconnexion AMQ dans son propre espace de noms
amq-interconnect. Voir Ajouter l'intégration Red Hat - Opérateur d'interconnexion AMQ.
Vérification
Vérifiez que l'opérateur d'interconnexion AMQ est disponible et que les pods requis sont en cours d'exécution :
$ oc get pods -n amq-interconnectExemple de sortie
NAME READY STATUS RESTARTS AGE amq-interconnect-645db76c76-k8ghs 1/1 Running 0 23h interconnect-operator-5cb5fc7cc-4v7qm 1/1 Running 0 23hVérifiez que les pods producteurs d'événements
linuxptp-daemonPTP requis sont exécutés dans l'espace de nomsopenshift-ptp.$ oc get pods -n openshift-ptpExemple de sortie
NAME READY STATUS RESTARTS AGE linuxptp-daemon-2t78p 3/3 Running 0 12h linuxptp-daemon-k8n88 3/3 Running 0 12h
18.7.4. Configuration de l'éditeur de notifications d'événements rapides PTP
Pour commencer à utiliser les notifications d'événements rapides PTP pour une interface réseau dans votre cluster, vous devez activer l'éditeur d'événements rapides dans la ressource personnalisée (CR) PTP Operator PtpOperatorConfig et configurer les valeurs ptpClockThreshold dans une CR PtpConfig que vous créez.
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur PTP et l'opérateur d'interconnexion AMQ.
Procédure
Modifier la configuration par défaut de l'opérateur PTP pour activer les événements rapides PTP.
Enregistrez le YAML suivant dans le fichier
ptp-operatorconfig.yaml:apiVersion: ptp.openshift.io/v1 kind: PtpOperatorConfig metadata: name: default namespace: openshift-ptp spec: daemonNodeSelector: node-role.kubernetes.io/worker: "" ptpEventConfig: enableEventPublisher: true1 transportHost: amqp://<instance_name>.<namespace>.svc.cluster.local2 - 1
- Réglez
enableEventPublishersurtruepour activer les notifications d'événements rapides PTP. - 2
- Définissez
transportHostcomme étant le routeur AMQ que vous avez configuré, où<instance_name>et<namespace>correspondent au nom de l'instance du routeur AMQ Interconnect et à l'espace de noms, par exemple,amqp://amq-interconnect.amq-interconnect.svc.cluster.local
Mettre à jour le CR
PtpOperatorConfig:$ oc apply -f ptp-operatorconfig.yaml
Créez une ressource personnalisée (CR)
PtpConfigpour l'interface activée par PTP et définissez les valeurs requises pourptpClockThresholdetptp4lOpts. Le fichier YAML suivant illustre les valeurs requises que vous devez définir dans la CRPtpConfig:spec: profile: - name: "profile1" interface: "enp5s0f0" ptp4lOpts: "-2 -s --summary_interval -4"1 phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16"2 ptp4lConf: ""3 ptpClockThreshold:4 holdOverTimeout: 5 maxOffsetThreshold: 100 minOffsetThreshold: -100- 1
- Ajouter
--summary_interval -4pour utiliser les événements rapides PTP. - 2
- Valeurs requises
phc2sysOpts.-mimprime des messages àstdout.linuxptp-daemonDaemonSetanalyse les journaux et génère des métriques Prometheus. - 3
- Spécifiez une chaîne contenant la configuration qui remplacera le fichier /etc/ptp4l.conf par défaut. Pour utiliser la configuration par défaut, laissez le champ vide.
- 4
- Facultatif. Si la strophe
ptpClockThresholdn'est pas présente, des valeurs par défaut sont utilisées pour les champsptpClockThreshold. La strophe indique les valeurs par défaut deptpClockThreshold. Les valeurs deptpClockThresholdconfigurent le délai de déclenchement des événements PTP après la déconnexion de l'horloge maître PTP.holdOverTimeoutest la valeur de temps en secondes avant que l'état de l'événement de l'horloge PTP ne passe àFREERUNlorsque l'horloge maître PTP est déconnectée. Les paramètresmaxOffsetThresholdetminOffsetThresholdconfigurent des valeurs de décalage en nanosecondes qui se comparent aux valeurs deCLOCK_REALTIME(phc2sys) ou au décalage du maître (ptp4l). Lorsque la valeur de décalageptp4louphc2sysest en dehors de cette plage, l'état de l'horloge PTP est réglé surFREERUN. Lorsque la valeur de décalage est comprise dans cette plage, l'état de l'horloge PTP est réglé surLOCKED.
18.7.5. Abonnement des applications DU aux événements PTP Référence de l'API REST
Utilisez l'API REST de notifications d'événements PTP pour abonner une application d'unité distribuée (UD) aux événements PTP générés sur le nœud parent.
Abonner les applications aux événements PTP en utilisant l'adresse de ressource /cluster/node/<node_name>/ptp, où <node_name> est le nœud de cluster qui exécute l'application DU.
Déployez votre conteneur d'application DU cloud-event-consumer et votre conteneur sidecar cloud-event-proxy dans un pod d'application DU séparé. L'application DU cloud-event-consumer s'abonne au conteneur cloud-event-proxy dans le module d'application.
Utilisez les points d'extrémité API suivants pour abonner l'application DU cloud-event-consumer aux événements PTP publiés par le conteneur cloud-event-proxy à http://localhost:8089/api/ocloudNotifications/v1/ dans le pod d'application DU :
/api/ocloudNotifications/v1/subscriptions-
POST: Crée un nouvel abonnement -
GET: Récupère une liste d'abonnements
-
/api/ocloudNotifications/v1/subscriptions/<subscription_id>-
GET: Renvoie les détails de l'identifiant d'abonnement spécifié
-
api/ocloudNotifications/v1/subscriptions/status/<subscription_id>-
PUT: Crée une nouvelle demande de ping d'état pour l'identifiant d'abonnement spécifié
-
/api/ocloudNotifications/v1/health-
GET: Renvoie l'état de santé deocloudNotificationsAPI
-
api/ocloudNotifications/v1/publishers-
GET: Renvoie un tableau de messagesos-clock-sync-state,ptp-clock-class-change, etlock-statepour le nœud de la grappe
-
/api/ocloudnotifications/v1/<resource_address>/CurrentState-
GET: Renvoie l'état actuel de l'un des types d'événements suivants :os-clock-sync-stateptp-clock-class-change, oulock-state
-
9089 est le port par défaut du conteneur cloud-event-consumer déployé dans le pod d'application. Vous pouvez configurer un port différent pour votre application DU si nécessaire.
18.7.5.1. api/ocloudNotifications/v1/subscriptions
Méthode HTTP
GET api/ocloudNotifications/v1/subscriptions
Description
Renvoie une liste d'abonnements. Si des abonnements existent, un code d'état 200 OK est renvoyé avec la liste des abonnements.
Exemple de réponse API
[
{
"id": "75b1ad8f-c807-4c23-acf5-56f4b7ee3826",
"endpointUri": "http://localhost:9089/event",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/75b1ad8f-c807-4c23-acf5-56f4b7ee3826",
"resource": "/cluster/node/compute-1.example.com/ptp"
}
]Méthode HTTP
POST api/ocloudNotifications/v1/subscriptions
Description
Crée un nouvel abonnement. Si un abonnement est créé avec succès, ou s'il existe déjà, un code d'état 201 Created est renvoyé.
| Paramètres | Type |
|---|---|
| abonnement | données |
Exemple de charge utile
{
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions",
"resource": "/cluster/node/compute-1.example.com/ptp"
}18.7.5.2. api/ocloudNotifications/v1/abonnements/
Méthode HTTP
GET api/ocloudNotifications/v1/subscriptions/<subscription_id>
Description
Renvoie les détails de l'abonnement avec l'ID <subscription_id>
| Paramètres | Type |
|---|---|
|
| chaîne de caractères |
Exemple de réponse API
{
"id":"48210fb3-45be-4ce0-aa9b-41a0e58730ab",
"endpointUri": "http://localhost:9089/event",
"uriLocation":"http://localhost:8089/api/ocloudNotifications/v1/subscriptions/48210fb3-45be-4ce0-aa9b-41a0e58730ab",
"resource":"/cluster/node/compute-1.example.com/ptp"
}18.7.5.3. api/ocloudNotifications/v1/abonnements/status/
Méthode HTTP
PUT api/ocloudNotifications/v1/subscriptions/status/<subscription_id>
Description
Crée une nouvelle demande de ping d'état pour l'abonnement avec l'ID <subscription_id>. Si un abonnement est présent, la demande d'état est réussie et le code d'état 202 Accepted est renvoyé.
| Paramètres | Type |
|---|---|
|
| chaîne de caractères |
Exemple de réponse API
{"status":"ping sent"}18.7.5.4. api/ocloudNotifications/v1/santé/
Méthode HTTP
GET api/ocloudNotifications/v1/health/
Description
Renvoie l'état de santé de l'API REST ocloudNotifications.
Exemple de réponse API
OK18.7.5.5. api/ocloudNotifications/v1/publishers
Méthode HTTP
GET api/ocloudNotifications/v1/publishers
Description
Renvoie un tableau de détails os-clock-sync-state, ptp-clock-class-change, et lock-state pour le nœud de cluster. Le système génère des notifications lorsque l'état de l'équipement concerné change.
-
os-clock-sync-stateles notifications décrivent l'état de synchronisation de l'horloge du système d'exploitation hôte. Peut être dans l'étatLOCKEDouFREERUN. -
ptp-clock-class-changedécrivent l'état actuel de la classe d'horloge PTP. -
lock-stateles notifications décrivent l'état actuel du verrouillage de l'équipement PTP. Il peut s'agir de l'étatLOCKED,HOLDOVERouFREERUN.
Exemple de réponse API
[
{
"id": "0fa415ae-a3cf-4299-876a-589438bacf75",
"endpointUri": "http://localhost:9085/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:9085/api/ocloudNotifications/v1/publishers/0fa415ae-a3cf-4299-876a-589438bacf75",
"resource": "/cluster/node/compute-1.example.com/sync/sync-status/os-clock-sync-state"
},
{
"id": "28cd82df-8436-4f50-bbd9-7a9742828a71",
"endpointUri": "http://localhost:9085/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:9085/api/ocloudNotifications/v1/publishers/28cd82df-8436-4f50-bbd9-7a9742828a71",
"resource": "/cluster/node/compute-1.example.com/sync/ptp-status/ptp-clock-class-change"
},
{
"id": "44aa480d-7347-48b0-a5b0-e0af01fa9677",
"endpointUri": "http://localhost:9085/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:9085/api/ocloudNotifications/v1/publishers/44aa480d-7347-48b0-a5b0-e0af01fa9677",
"resource": "/cluster/node/compute-1.example.com/sync/ptp-status/lock-state"
}
]
Vous pouvez trouver les événements os-clock-sync-state, ptp-clock-class-change et lock-state dans les journaux du conteneur cloud-event-proxy. Par exemple :
$ oc logs -f linuxptp-daemon-cvgr6 -n openshift-ptp -c cloud-event-proxyExemple d'événement os-clock-sync-state
{
"id":"c8a784d1-5f4a-4c16-9a81-a3b4313affe5",
"type":"event.sync.sync-status.os-clock-sync-state-change",
"source":"/cluster/compute-1.example.com/ptp/CLOCK_REALTIME",
"dataContentType":"application/json",
"time":"2022-05-06T15:31:23.906277159Z",
"data":{
"version":"v1",
"values":[
{
"resource":"/sync/sync-status/os-clock-sync-state",
"dataType":"notification",
"valueType":"enumeration",
"value":"LOCKED"
},
{
"resource":"/sync/sync-status/os-clock-sync-state",
"dataType":"metric",
"valueType":"decimal64.3",
"value":"-53"
}
]
}
}Exemple d'événement ptp-clock-class-change
{
"id":"69eddb52-1650-4e56-b325-86d44688d02b",
"type":"event.sync.ptp-status.ptp-clock-class-change",
"source":"/cluster/compute-1.example.com/ptp/ens2fx/master",
"dataContentType":"application/json",
"time":"2022-05-06T15:31:23.147100033Z",
"data":{
"version":"v1",
"values":[
{
"resource":"/sync/ptp-status/ptp-clock-class-change",
"dataType":"metric",
"valueType":"decimal64.3",
"value":"135"
}
]
}
}Exemple d'événement d'état de blocage
{
"id":"305ec18b-1472-47b3-aadd-8f37933249a9",
"type":"event.sync.ptp-status.ptp-state-change",
"source":"/cluster/compute-1.example.com/ptp/ens2fx/master",
"dataContentType":"application/json",
"time":"2022-05-06T15:31:23.467684081Z",
"data":{
"version":"v1",
"values":[
{
"resource":"/sync/ptp-status/lock-state",
"dataType":"notification",
"valueType":"enumeration",
"value":"LOCKED"
},
{
"resource":"/sync/ptp-status/lock-state",
"dataType":"metric",
"valueType":"decimal64.3",
"value":"62"
}
]
}
}18.7.5.6. /api/ocloudnotifications/v1//CurrentState
Méthode HTTP
GET api/ocloudNotifications/v1/cluster/node/<node_name>/sync/ptp-status/lock-state/CurrentState
GET api/ocloudNotifications/v1/cluster/node/<node_name>/sync/sync-status/os-clock-sync-state/CurrentState
GET api/ocloudNotifications/v1/cluster/node/<node_name>/sync/ptp-status/ptp-clock-class-change/CurrentState
Description
Configurez le point de terminaison de l'API CurrentState pour qu'il renvoie l'état actuel des événements os-clock-sync-state, ptp-clock-class-change ou lock-state pour le nœud de cluster.
-
os-clock-sync-stateles notifications décrivent l'état de synchronisation de l'horloge du système d'exploitation hôte. Peut être dans l'étatLOCKEDouFREERUN. -
ptp-clock-class-changedécrivent l'état actuel de la classe d'horloge PTP. -
lock-stateles notifications décrivent l'état actuel du verrouillage de l'équipement PTP. Il peut s'agir de l'étatLOCKED,HOLDOVERouFREERUN.
| Paramètres | Type |
|---|---|
|
| chaîne de caractères |
Exemple de réponse de l'API sur l'état de verrouillage
{
"id": "c1ac3aa5-1195-4786-84f8-da0ea4462921",
"type": "event.sync.ptp-status.ptp-state-change",
"source": "/cluster/node/compute-1.example.com/sync/ptp-status/lock-state",
"dataContentType": "application/json",
"time": "2023-01-10T02:41:57.094981478Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "notification",
"valueType": "enumeration",
"value": "LOCKED"
},
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "29"
}
]
}
}Exemple de réponse de l'API os-clock-sync-state
{
"specversion": "0.3",
"id": "4f51fe99-feaa-4e66-9112-66c5c9b9afcb",
"source": "/cluster/node/compute-1.example.com/sync/sync-status/os-clock-sync-state",
"type": "event.sync.sync-status.os-clock-sync-state-change",
"subject": "/cluster/node/compute-1.example.com/sync/sync-status/os-clock-sync-state",
"datacontenttype": "application/json",
"time": "2022-11-29T17:44:22.202Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/CLOCK_REALTIME",
"dataType": "notification",
"valueType": "enumeration",
"value": "LOCKED"
},
{
"resource": "/cluster/node/compute-1.example.com/CLOCK_REALTIME",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "27"
}
]
}
}Exemple de réponse API ptp-clock-class-change
{
"id": "064c9e67-5ad4-4afb-98ff-189c6aa9c205",
"type": "event.sync.ptp-status.ptp-clock-class-change",
"source": "/cluster/node/compute-1.example.com/sync/ptp-status/ptp-clock-class-change",
"dataContentType": "application/json",
"time": "2023-01-10T02:41:56.785673989Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "165"
}
]
}
}18.7.6. Surveillance des mesures d'événements rapides PTP à l'aide du CLI
Vous pouvez surveiller les métriques du bus d'événements rapides directement à partir des conteneurs cloud-event-proxy à l'aide du CLI oc.
Les mesures de notification des événements rapides PTP sont également disponibles dans la console web d'OpenShift Container Platform.
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer et configurer l'opérateur PTP.
Procédure
Obtenir la liste des pods
linuxptp-daemonactifs.$ oc get pods -n openshift-ptpExemple de sortie
NAME READY STATUS RESTARTS AGE linuxptp-daemon-2t78p 3/3 Running 0 8h linuxptp-daemon-k8n88 3/3 Running 0 8hAccédez aux métriques du conteneur
cloud-event-proxyrequis en exécutant la commande suivante :oc exec -it <linuxptp-daemon> -n openshift-ptp -c cloud-event-proxy -- curl 127.0.0.1:9091/metricsoù :
- <linuxptp-daemon>
Spécifie le pod que vous voulez interroger, par exemple,
linuxptp-daemon-2t78p.Exemple de sortie
# HELP cne_amqp_events_published Metric to get number of events published by the transport # TYPE cne_amqp_events_published gauge cne_amqp_events_published{address="/cluster/node/compute-1.example.com/ptp/status",status="success"} 1041 # HELP cne_amqp_events_received Metric to get number of events received by the transport # TYPE cne_amqp_events_received gauge cne_amqp_events_received{address="/cluster/node/compute-1.example.com/ptp",status="success"} 1019 # HELP cne_amqp_receiver Metric to get number of receiver created # TYPE cne_amqp_receiver gauge cne_amqp_receiver{address="/cluster/node/mock",status="active"} 1 cne_amqp_receiver{address="/cluster/node/compute-1.example.com/ptp",status="active"} 1 cne_amqp_receiver{address="/cluster/node/compute-1.example.com/redfish/event",status="active"} ...
18.7.7. Surveillance des mesures d'événements rapides PTP dans la console web
Vous pouvez surveiller les métriques d'événements rapides PTP dans la console web OpenShift Container Platform en utilisant la pile de surveillance Prometheus préconfigurée et auto-actualisée.
Conditions préalables
-
Install the OpenShift Container Platform CLI
oc. -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Entrez la commande suivante pour renvoyer la liste des mesures PTP disponibles à partir du conteneur sidecar
cloud-event-proxy:oc exec -it <linuxptp_daemon_pod> -n openshift-ptp -c cloud-event-proxy -- curl 127.0.0.1:9091/metricsoù :
- <linuxptp_daemon_pod>
-
Spécifie le pod que vous voulez interroger, par exemple,
linuxptp-daemon-2t78p.
-
Copiez le nom de la métrique PTP que vous souhaitez interroger dans la liste des métriques renvoyées, par exemple,
cne_amqp_events_received. - Dans la console Web OpenShift Container Platform, cliquez sur Observe → Metrics.
- Collez la métrique PTP dans le champ Expression et cliquez sur Run queries.
Chapitre 19. Opérateur DNS externe
19.1. Opérateur DNS externe dans OpenShift Container Platform
L'opérateur DNS externe déploie et gère ExternalDNS pour fournir la résolution de nom pour les services et les routes du fournisseur DNS externe à OpenShift Container Platform.
19.1.1. Opérateur DNS externe
L'opérateur DNS externe met en œuvre l'API DNS externe du groupe d'API olm.openshift.io. L'opérateur DNS externe déploie le site ExternalDNS à l'aide d'une ressource de déploiement. Le déploiement ExternalDNS surveille les ressources telles que les services et les routes dans le cluster et met à jour les fournisseurs DNS externes.
Procédure
Vous pouvez déployer l'opérateur ExternalDNS à la demande depuis l'OperatorHub, ce qui crée un objet Subscription.
Vérifier le nom d'un plan d'installation :
$ oc -n external-dns-operator get sub external-dns-operator -o yaml | yq '.status.installplan.name'Exemple de sortie
install-zcvlrVérifier le statut d'un plan d'installation, le statut d'un plan d'installation doit être
Complete:$ oc -n external-dns-operator get ip <install_plan_name> -o yaml | yq .status.phase'Exemple de sortie
CompleteUtilisez la commande
oc getpour visualiser l'état deDeployment:$ oc get -n external-dns-operator deployment/external-dns-operatorExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE external-dns-operator 1/1 1 1 23h
19.1.2. Journaux de l'opérateur DNS externe
Vous pouvez consulter les journaux de l'opérateur DNS externe à l'aide de la commande oc logs.
Procédure
Consulter les journaux de l'opérateur DNS externe :
$ oc logs -n external-dns-operator deployment/external-dns-operator -c external-dns-operator
19.1.2.1. Limitations du nom de domaine de l'opérateur DNS externe
L'opérateur DNS externe utilise le registre TXT, qui suit le nouveau format et ajoute le préfixe pour les enregistrements TXT. Cela réduit la longueur maximale du nom de domaine pour les enregistrements TXT. Un enregistrement DNS ne peut être présent sans un enregistrement TXT correspondant, de sorte que le nom de domaine de l'enregistrement DNS doit respecter la même limite que les enregistrements TXT. Par exemple, l'enregistrement DNS est <domain-name-from-source> et l'enregistrement TXT est external-dns-<record-type>-<domain-name-from-source>.
Le nom de domaine des enregistrements DNS générés par l'Opérateur DNS externe est soumis aux limitations suivantes :
| Type d'enregistrement | Nombre de caractères |
|---|---|
| CNAME | 44 |
| Enregistrements CNAME Wildcard sur AzureDNS | 42 |
| A | 48 |
| Enregistrements A Wildcard sur AzureDNS | 46 |
Si le nom de domaine généré par le DNS externe dépasse la limite de nom de domaine, l'instance DNS externe affiche l'erreur suivante :
oc -n external-dns-operator logs external-dns-aws-7ddbd9c7f8-2jqjh - 1
- Le paramètre
external-dns-aws-7ddbd9c7f8-2jqjhspécifie le nom du module DNS externe.
Exemple de sortie
time="2022-09-02T08:53:57Z" level=info msg="Desired change: CREATE external-dns-cname-hello-openshift-aaaaaaaaaa-bbbbbbbbbb-ccccccc.test.example.io TXT [Id: /hostedzone/Z06988883Q0H0RL6UMXXX]"
time="2022-09-02T08:53:57Z" level=info msg="Desired change: CREATE external-dns-hello-openshift-aaaaaaaaaa-bbbbbbbbbb-ccccccc.test.example.io TXT [Id: /hostedzone/Z06988883Q0H0RL6UMXXX]"
time="2022-09-02T08:53:57Z" level=info msg="Desired change: CREATE hello-openshift-aaaaaaaaaa-bbbbbbbbbb-ccccccc.test.example.io A [Id: /hostedzone/Z06988883Q0H0RL6UMXXX]"
time="2022-09-02T08:53:57Z" level=error msg="Failure in zone test.example.io. [Id: /hostedzone/Z06988883Q0H0RL6UMXXX]"
time="2022-09-02T08:53:57Z" level=error msg="InvalidChangeBatch: [FATAL problem: DomainLabelTooLong (Domain label is too long) encountered with 'external-dns-a-hello-openshift-aaaaaaaaaa-bbbbbbbbbb-ccccccc']\n\tstatus code: 400, request id: e54dfd5a-06c6-47b0-bcb9-a4f7c3a4e0c6"19.2. Installation d'un opérateur DNS externe sur les fournisseurs de services en nuage
Vous pouvez installer External DNS Operator sur des fournisseurs de cloud tels que AWS, Azure et GCP.
19.2.1. Installation de l'opérateur DNS externe
Vous pouvez installer l'Opérateur DNS Externe en utilisant le OperatorHub de OpenShift Container Platform.
Procédure
- Cliquez sur Operators → OperatorHub dans la console Web d'OpenShift Container Platform.
- Cliquez sur External DNS Operator. Vous pouvez utiliser la zone de texte Filter by keyword ou la liste de filtres pour rechercher un opérateur DNS externe dans la liste des opérateurs.
-
Sélectionnez l'espace de noms
external-dns-operator. - Sur la page Opérateur DNS externe, cliquez sur Install.
Sur la page Install Operator, assurez-vous que vous avez sélectionné les options suivantes :
- Mettre à jour le canal à l'adresse stable-v1.
- Mode d'installation comme A specific name on the cluster.
-
L'espace de noms installé est
external-dns-operator. Si l'espace de nomsexternal-dns-operatorn'existe pas, il est créé lors de l'installation de l'opérateur. - Sélectionnez Approval Strategy comme Automatic ou Manual. La stratégie d'approbation est définie par défaut sur Automatic.
- Cliquez sur Install.
Si vous sélectionnez Automatic updates, Operator Lifecycle Manager (OLM) met automatiquement à jour l'instance en cours d'exécution de votre opérateur sans aucune intervention.
Si vous sélectionnez Manual updates, l'OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement cette demande de mise à jour pour que l'opérateur soit mis à jour avec la nouvelle version.
Vérification
Vérifiez que l'opérateur DNS externe affiche le site Status comme Succeeded sur le tableau de bord des opérateurs installés.
19.3. Paramètres de configuration de l'opérateur DNS externe
Les opérateurs DNS externes comprennent les paramètres de configuration suivants :
19.3.1. Paramètres de configuration de l'opérateur DNS externe
L'opérateur DNS externe comprend les paramètres de configuration suivants :
| Paramètres | Description |
|---|---|
|
| Permet d'activer le type de fournisseur de nuages. |
|
|
Permet de spécifier les zones DNS par leurs domaines. Si vous ne spécifiez pas de zones,
|
|
|
Permet de spécifier les zones AWS en fonction de leur domaine. Si vous ne spécifiez pas de domaines,
|
|
|
Permet de spécifier la source des enregistrements DNS,
|
19.4. Création d'enregistrements DNS sur AWS
Vous pouvez créer des enregistrements DNS sur AWS et AWS GovCloud en utilisant l'opérateur DNS externe.
19.4.1. Création d'enregistrements DNS sur une zone publique hébergée pour AWS à l'aide de l'Opérateur DNS Externe de Red Hat
Vous pouvez créer des enregistrements DNS sur une zone hébergée publique pour AWS en utilisant l'Opérateur DNS externe de Red Hat. Vous pouvez utiliser les mêmes instructions pour créer des enregistrements DNS sur une zone hébergée pour AWS GovCloud.
Procédure
Vérifiez l'utilisateur. L'utilisateur doit avoir accès à l'espace de noms
kube-system. Si vous n'avez pas les informations d'identification, vous pouvez les récupérer dans l'espace de nomskube-systempour utiliser le client du fournisseur de cloud :$ oc whoamiExemple de sortie
system:adminRécupérer les valeurs du secret aws-creds présent dans l'espace de noms
kube-system.$ export AWS_ACCESS_KEY_ID=$(oc get secrets aws-creds -n kube-system --template={{.data.aws_access_key_id}} | base64 -d) $ export AWS_SECRET_ACCESS_KEY=$(oc get secrets aws-creds -n kube-system --template={{.data.aws_secret_access_key}} | base64 -d)Obtenir les itinéraires pour vérifier le domaine :
$ oc get routes --all-namespaces | grep consoleExemple de sortie
openshift-console console console-openshift-console.apps.testextdnsoperator.apacshift.support console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.testextdnsoperator.apacshift.support downloads http edge/Redirect NoneObtenir la liste des zones DNS pour trouver celle qui correspond au domaine de la route trouvée précédemment :
$ aws route53 list-hosted-zones | grep testextdnsoperator.apacshift.supportExemple de sortie
HOSTEDZONES terraform /hostedzone/Z02355203TNN1XXXX1J6O testextdnsoperator.apacshift.support. 5Créer une ressource
ExternalDNSpour une sourceroute:$ cat <<EOF | oc create -f - apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-aws1 spec: domains: - filterType: Include2 matchType: Exact3 name: testextdnsoperator.apacshift.support4 provider: type: AWS5 source:6 type: OpenShiftRoute7 openshiftRouteOptions: routerName: default8 EOF- 1
- Définit le nom de la ressource DNS externe.
- 2
- Par défaut, toutes les zones hébergées sont sélectionnées comme cibles potentielles. Vous pouvez inclure une zone hébergée dont vous avez besoin.
- 3
- La correspondance du domaine de la zone cible doit être exacte (par opposition à une correspondance par expression régulière).
- 4
- Indiquez le domaine exact de la zone que vous souhaitez mettre à jour. Les noms d'hôte des routes doivent être des sous-domaines du domaine spécifié.
- 5
- Définit le fournisseur DNS
AWS Route53. - 6
- Définit les options pour la source des enregistrements DNS.
- 7
- Définit la ressource OpenShift
routecomme source pour les enregistrements DNS qui sont créés dans le fournisseur DNS spécifié précédemment. - 8
- Si la source est
OpenShiftRoute, alors vous pouvez passer le nom du contrôleur d'entrée d'OpenShift. L'opérateur DNS externe sélectionne le nom d'hôte canonique de ce routeur comme cible lors de la création de l'enregistrement CNAME.
Vérifiez les enregistrements créés pour les routes OCP à l'aide de la commande suivante :
$ aws route53 list-resource-record-sets --hosted-zone-id Z02355203TNN1XXXX1J6O --query "ResourceRecordSets[?Type == 'CNAME']" | grep console
19.5. Création d'enregistrements DNS sur Azure
Vous pouvez créer des enregistrements DNS sur Azure à l'aide de l'opérateur DNS externe.
19.5.1. Création d'enregistrements DNS sur une zone DNS publique pour Azure à l'aide de Red Hat External DNS Operator
Vous pouvez créer des enregistrements DNS sur une zone DNS publique pour Azure en utilisant Red Hat External DNS Operator.
Procédure
Vérifiez l'utilisateur. L'utilisateur doit avoir accès à l'espace de noms
kube-system. Si vous n'avez pas les informations d'identification, vous pouvez les récupérer dans l'espace de nomskube-systempour utiliser le client du fournisseur de cloud :$ oc whoamiExemple de sortie
system:adminRécupère les valeurs du secret azure-credentials présent dans l'espace de noms
kube-system.$ CLIENT_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_client_id}} | base64 -d) $ CLIENT_SECRET=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_client_secret}} | base64 -d) $ RESOURCE_GROUP=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_resourcegroup}} | base64 -d) $ SUBSCRIPTION_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_subscription_id}} | base64 -d) $ TENANT_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_tenant_id}} | base64 -d)Se connecter à azure avec des valeurs décodées en base64 :
$ az login --service-principal -u "${CLIENT_ID}" -p "${CLIENT_SECRET}" --tenant "${TENANT_ID}"Obtenir les itinéraires pour vérifier le domaine :
$ oc get routes --all-namespaces | grep consoleExemple de sortie
openshift-console console console-openshift-console.apps.test.azure.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.azure.example.com downloads http edge/Redirect NoneObtenir la liste des zones DNS pour trouver celle qui correspond au domaine de la route trouvée précédemment :
$ az network dns zone list --resource-group "${RESOURCE_GROUP}"Créer une ressource
ExternalDNSpour une sourceroute:apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-azure1 spec: zones: - "/subscriptions/1234567890/resourceGroups/test-azure-xxxxx-rg/providers/Microsoft.Network/dnszones/test.azure.example.com"2 provider: type: Azure3 source: openshiftRouteOptions:4 routerName: default5 type: OpenShiftRoute6 EOF- 1
- Spécifie le nom du DNS CR externe.
- 2
- Définir l'ID de la zone.
- 3
- Définit le fournisseur Azure DNS.
- 4
- Vous pouvez définir des options pour la source des enregistrements DNS.
- 5
- Si la source est
OpenShiftRoute, vous pouvez passer le nom du contrôleur d'entrée d'OpenShift. Le DNS externe sélectionne le nom d'hôte canonique de ce routeur comme cible lors de la création de l'enregistrement CNAME. - 6
- Définit la ressource OpenShift
routecomme source pour les enregistrements DNS qui sont créés dans le fournisseur DNS spécifié précédemment.
Vérifiez les enregistrements créés pour les routes OCP à l'aide de la commande suivante :
$ az network dns record-set list -g "${RESOURCE_GROUP}" -z test.azure.example.com | grep consoleNotePour créer des enregistrements sur des zones hébergées privées sur des dns Azure privés, vous devez spécifier la zone privée sous
zonesqui remplit le type de fournisseur àazure-private-dnsdans les args du conteneurExternalDNS.
19.6. Création d'enregistrements DNS sur GCP
Vous pouvez créer des enregistrements DNS sur GCP à l'aide de l'opérateur DNS externe.
19.6.1. Création d'enregistrements DNS sur une zone publique gérée pour GCP à l'aide de Red Hat External DNS Operator
Vous pouvez créer des enregistrements DNS sur une zone publique gérée pour GCP en utilisant Red Hat External DNS Operator.
Procédure
Vérifiez l'utilisateur. L'utilisateur doit avoir accès à l'espace de noms
kube-system. Si vous n'avez pas les informations d'identification, vous pouvez les récupérer dans l'espace de nomskube-systempour utiliser le client du fournisseur de cloud :$ oc whoamiExemple de sortie
system:adminCopiez la valeur de service_account.json dans gcp-credentials secret dans un fichier encoded-gcloud.json en exécutant la commande suivante :
$ oc get secret gcp-credentials -n kube-system --template='{{$v := index .data "service_account.json"}}{{$v}}' | base64 -d - > decoded-gcloud.jsonExporter les informations d'identification Google :
$ export GOOGLE_CREDENTIALS=decoded-gcloud.jsonActivez votre compte en utilisant la commande suivante :
$ gcloud auth activate-service-account <client_email as per decoded-gcloud.json> --key-file=decoded-gcloud.jsonDéfinissez votre projet :
$ gcloud config set project <project_id as per decoded-gcloud.json>Obtenir les itinéraires pour vérifier le domaine :
$ oc get routes --all-namespaces | grep consoleExemple de sortie
openshift-console console console-openshift-console.apps.test.gcp.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.gcp.example.com downloads http edge/Redirect NoneObtenir la liste des zones gérées pour trouver la zone qui correspond au domaine de la route trouvée précédemment :
$ gcloud dns managed-zones list | grep test.gcp.example.com qe-cvs4g-private-zone test.gcp.example.comCréer une ressource
ExternalDNSpour une sourceroute:apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-gcp1 spec: domains: - filterType: Include2 matchType: Exact3 name: test.gcp.example.com4 provider: type: GCP5 source: openshiftRouteOptions:6 routerName: default7 type: OpenShiftRoute8 EOF- 1
- Spécifie le nom du DNS CR externe.
- 2
- Par défaut, toutes les zones hébergées sont sélectionnées comme cibles potentielles. Vous pouvez inclure une zone hébergée dont vous avez besoin.
- 3
- La correspondance du domaine de la zone cible doit être exacte (par opposition à une correspondance par expression régulière).
- 4
- Indiquez le domaine exact de la zone que vous souhaitez mettre à jour. Les noms d'hôte des routes doivent être des sous-domaines du domaine spécifié.
- 5
- Définit le fournisseur de Google Cloud DNS.
- 6
- Vous pouvez définir des options pour la source des enregistrements DNS.
- 7
- Si la source est
OpenShiftRoute, vous pouvez passer le nom du contrôleur d'entrée d'OpenShift. Le DNS externe sélectionne le nom d'hôte canonique de ce routeur comme cible lors de la création de l'enregistrement CNAME. - 8
- Définit la ressource OpenShift
routecomme source pour les enregistrements DNS qui sont créés dans le fournisseur DNS spécifié précédemment.
Vérifiez les enregistrements créés pour les routes OCP à l'aide de la commande suivante :
$ gcloud dns record-sets list --zone=qe-cvs4g-private-zone | grep console
19.7. Création d'enregistrements DNS sur Infoblox
Vous pouvez créer des enregistrements DNS sur Infoblox à l'aide de l'opérateur DNS externe de Red Hat.
19.7.1. Création d'enregistrements DNS sur une zone DNS publique sur Infoblox
Vous pouvez créer des enregistrements DNS sur une zone DNS publique sur Infoblox en utilisant l'opérateur DNS externe de Red Hat.
Conditions préalables
-
Vous avez accès au CLI OpenShift (
oc). - Vous avez accès à l'interface utilisateur d'Infoblox.
Procédure
Créez un objet
secretavec les informations d'identification Infoblox en exécutant la commande suivante :$ oc -n external-dns-operator create secret generic infoblox-credentials --from-literal=EXTERNAL_DNS_INFOBLOX_WAPI_USERNAME=<infoblox_username> --from-literal=EXTERNAL_DNS_INFOBLOX_WAPI_PASSWORD=<infoblox_password>Obtenez les objets routes pour vérifier votre domaine de cluster en exécutant la commande suivante :
$ oc get routes --all-namespaces | grep consoleExample Output
openshift-console console console-openshift-console.apps.test.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.example.com downloads http edge/Redirect NoneCréez un fichier YAML de ressource
ExternalDNS, par exemple, sample-infoblox.yaml, comme suit :apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-infoblox spec: provider: type: Infoblox infoblox: credentials: name: infoblox-credentials gridHost: ${INFOBLOX_GRID_PUBLIC_IP} wapiPort: 443 wapiVersion: "2.3.1" domains: - filterType: Include matchType: Exact name: test.example.com source: type: OpenShiftRoute openshiftRouteOptions: routerName: defaultCréez une ressource
ExternalDNSsur Infoblox en exécutant la commande suivante :$ oc create -f sample-infoblox.yamlDepuis l'interface Infoblox, vérifiez les enregistrements DNS créés pour les itinéraires
console:- Cliquez sur Data Management → DNS → Zones.
- Sélectionnez le nom de la zone.
19.8. Configuration du proxy à l'échelle du cluster sur l'opérateur DNS externe
Vous pouvez configurer le proxy à l'échelle du cluster dans l'Opérateur DNS externe. Après avoir configuré le proxy en grappe dans l'opérateur DNS externe, Operator Lifecycle Manager (OLM) met automatiquement à jour tous les déploiements des opérateurs avec les variables d'environnement telles que HTTP_PROXY, HTTPS_PROXY, et NO_PROXY.
19.8.1. Configuration de l'opérateur DNS externe pour qu'il fasse confiance à l'autorité de certification du proxy à l'échelle du cluster
Vous pouvez configurer l'opérateur DNS externe pour qu'il fasse confiance à l'autorité de certification du proxy à l'échelle du cluster.
Procédure
Créez la carte de configuration pour contenir le bundle CA dans l'espace de noms
external-dns-operatoren exécutant la commande suivante :$ oc -n external-dns-operator create configmap trusted-caPour injecter le paquet d'AC de confiance dans la carte de configuration, ajoutez l'étiquette
config.openshift.io/inject-trusted-cabundle=trueà la carte de configuration en exécutant la commande suivante :$ oc -n external-dns-operator label cm trusted-ca config.openshift.io/inject-trusted-cabundle=trueMettez à jour l'abonnement de l'opérateur DNS externe en exécutant la commande suivante :
$ oc -n external-dns-operator patch subscription external-dns-operator --type='json' -p='[{"op": "add", "path": "/spec/config", "value":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}]}}]'
Vérification
Une fois le déploiement de l'opérateur DNS externe terminé, vérifiez que la variable d'environnement de l'autorité de certification approuvée est ajoutée au déploiement
external-dns-operatoren exécutant la commande suivante :$ oc -n external-dns-operator exec deploy/external-dns-operator -c external-dns-operator -- printenv TRUSTED_CA_CONFIGMAP_NAMEExemple de sortie
trusted-ca
Chapitre 20. Politique des réseaux
20.1. A propos de la politique de réseau
En tant qu'administrateur de cluster, vous pouvez définir des politiques de réseau qui restreignent le trafic vers les pods de votre cluster.
Les politiques de réseau configurées sont ignorées dans les réseaux IPv6.
20.1.1. A propos de la politique de réseau
Dans un cluster utilisant un plugin réseau qui prend en charge la politique réseau de Kubernetes, l'isolation du réseau est entièrement contrôlée par les objets NetworkPolicy. Dans OpenShift Container Platform 4.12, OpenShift SDN prend en charge l'utilisation de la politique réseau dans son mode d'isolation réseau par défaut.
La politique de réseau ne s'applique pas à l'espace de noms du réseau hôte. Les pods dont le réseau d'hôtes est activé ne sont pas affectés par les règles de la politique de réseau.
Par défaut, tous les modules d'un projet sont accessibles aux autres modules et aux points d'extrémité du réseau. Pour isoler un ou plusieurs pods dans un projet, vous pouvez créer des objets NetworkPolicy dans ce projet pour indiquer les connexions entrantes autorisées. Les administrateurs de projet peuvent créer et supprimer des objets NetworkPolicy dans leur propre projet.
Si un pod est associé à des sélecteurs dans un ou plusieurs objets NetworkPolicy, il n'acceptera que les connexions autorisées par au moins un de ces objets NetworkPolicy. Un module qui n'est sélectionné par aucun objet NetworkPolicy est entièrement accessible.
Les exemples suivants d'objets NetworkPolicy illustrent la prise en charge de différents scénarios :
Refuser tout le trafic :
Pour qu'un projet soit refusé par défaut, ajoutez un objet
NetworkPolicyqui correspond à tous les pods mais n'accepte aucun trafic :kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} ingress: []N'autoriser que les connexions provenant du contrôleur d'entrée de la plate-forme OpenShift Container :
Pour qu'un projet n'autorise que les connexions provenant du contrôleur d'ingestion de la plate-forme OpenShift Container, ajoutez l'objet
NetworkPolicysuivant.apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - IngressN'accepte que les connexions provenant de pods au sein d'un projet :
Pour que les pods acceptent les connexions d'autres pods du même projet, mais rejettent toutes les autres connexions de pods d'autres projets, ajoutez l'objet suivant
NetworkPolicy:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {}N'autoriser le trafic HTTP et HTTPS qu'en fonction des étiquettes de pods :
Pour permettre uniquement l'accès HTTP et HTTPS aux pods avec un label spécifique (
role=frontenddans l'exemple suivant), ajoutez un objetNetworkPolicysimilaire à ce qui suit :kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-http-and-https spec: podSelector: matchLabels: role: frontend ingress: - ports: - protocol: TCP port: 80 - protocol: TCP port: 443Accepter les connexions en utilisant des sélecteurs d'espace de noms et de pods :
Pour faire correspondre le trafic réseau en combinant les sélecteurs d'espace de noms et de pods, vous pouvez utiliser un objet
NetworkPolicysimilaire à ce qui suit :kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-pod-and-namespace-both spec: podSelector: matchLabels: name: test-pods ingress: - from: - namespaceSelector: matchLabels: project: project_name podSelector: matchLabels: name: test-pods
NetworkPolicy sont additifs, ce qui signifie que vous pouvez combiner plusieurs objets NetworkPolicy pour répondre à des exigences complexes en matière de réseau.
Par exemple, pour les objets NetworkPolicy définis dans les exemples précédents, vous pouvez définir les politiques allow-same-namespace et allow-http-and-https dans le même projet. Cela permet aux pods portant l'étiquette role=frontend d'accepter toutes les connexions autorisées par chaque politique. C'est-à-dire des connexions sur n'importe quel port à partir de pods dans le même espace de noms, et des connexions sur les ports 80 et 443 à partir de pods dans n'importe quel espace de noms.
20.1.1.1. Utilisation de la stratégie réseau allow-from-router
Utilisez l'adresse NetworkPolicy pour autoriser le trafic externe quelle que soit la configuration du routeur :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-router
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/ingress:""
podSelector: {}
policyTypes:
- Ingress- 1
policy-group.network.openshift.io/ingress:""prend en charge à la fois Openshift-SDN et OVN-Kubernetes.
20.1.1.2. Utilisation de la stratégie réseau allow-from-hostnetwork
Ajoutez l'objet suivant allow-from-hostnetwork NetworkPolicy pour diriger le trafic des pods du réseau hôte :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-hostnetwork
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/host-network:""
podSelector: {}
policyTypes:
- Ingress20.1.2. Optimisations de la politique réseau avec OpenShift SDN
Utilisez une stratégie de réseau pour isoler les pods qui sont différenciés les uns des autres par des étiquettes au sein d'un espace de noms.
Il est inefficace d'appliquer les objets NetworkPolicy à un grand nombre de pods individuels dans un seul espace de noms. Les étiquettes de pods n'existent pas au niveau de l'adresse IP, de sorte qu'une stratégie de réseau génère une règle de flux Open vSwitch (OVS) distincte pour chaque lien possible entre chaque pod sélectionné à l'aide d'une adresse podSelector.
Par exemple, si la spécification podSelector et l'entrée podSelector dans un objet NetworkPolicy correspondent chacune à 200 pods, 40 000 (200*200) règles de flux OVS sont générées. Cela peut ralentir un nœud.
Lors de l'élaboration de votre politique de réseau, reportez-vous aux lignes directrices suivantes :
Réduisez le nombre de règles de flux OVS en utilisant des espaces de noms pour contenir des groupes de pods qui doivent être isolés.
NetworkPolicyles objets qui sélectionnent un espace de noms entier, en utilisant le sitenamespaceSelectorou un site videpodSelector, ne génèrent qu'une seule règle de flux OVS correspondant à l'ID de réseau virtuel VXLAN (VNID) de l'espace de noms.- Conservez les modules qui n'ont pas besoin d'être isolés dans leur espace de noms d'origine et déplacez les modules qui ont besoin d'être isolés dans un ou plusieurs espaces de noms différents.
- Créez des stratégies réseau supplémentaires ciblées pour l'espace de nommage afin d'autoriser le trafic spécifique que vous souhaitez autoriser à partir des modules isolés.
20.1.3. Optimisations de la politique réseau avec OpenShift OVN
Lors de l'élaboration de votre politique de réseau, reportez-vous aux lignes directrices suivantes :
-
Pour les politiques de réseau ayant la même spécification
spec.podSelector, il est plus efficace d'utiliser une politique de réseau avec plusieurs règlesingressouegressque plusieurs politiques de réseau avec des sous-ensembles de règlesingressouegress. Chaque règle
ingressouegressbasée sur les spécificationspodSelectorounamespaceSelectorgénère un nombre de flux OVS proportionnel ànumber of pods selected by network policy number of pods selected by ingress or egress rule. Il est donc préférable d'utiliser les spécificationspodSelectorounamespaceSelectorqui permettent de sélectionner autant de pods que nécessaire dans une règle, plutôt que de créer des règles individuelles pour chaque pod.Par exemple, la politique suivante contient deux règles :
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchLabels: role: frontend - from: - podSelector: matchLabels: role: backendLa politique suivante exprime ces deux règles en une seule :
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchExpressions: - {key: role, operator: In, values: [frontend, backend]}La même règle s'applique à la spécification
spec.podSelector. Si vous avez les mêmes règlesingressouegresspour différentes politiques de réseau, il peut être plus efficace de créer une politique de réseau avec une spécificationspec.podSelectorcommune. Par exemple, les deux politiques suivantes ont des règles différentes :metadata: name: policy1 spec: podSelector: matchLabels: role: db ingress: - from: - podSelector: matchLabels: role: frontend metadata: name: policy2 spec: podSelector: matchLabels: role: client ingress: - from: - podSelector: matchLabels: role: frontendLa politique de réseau suivante exprime ces deux règles en une seule :
metadata: name: policy3 spec: podSelector: matchExpressions: - {key: role, operator: In, values: [db, client]} ingress: - from: - podSelector: matchLabels: role: frontendVous pouvez appliquer cette optimisation lorsque seuls plusieurs sélecteurs sont exprimés comme un seul. Dans les cas où les sélecteurs sont basés sur des étiquettes différentes, il peut être impossible d'appliquer cette optimisation. Dans ce cas, envisagez d'appliquer de nouvelles étiquettes pour l'optimisation de la politique de réseau en particulier.
20.1.4. Prochaines étapes
20.2. Création d'une politique de réseau
En tant qu'utilisateur ayant le rôle admin, vous pouvez créer une stratégie de réseau pour un espace de noms.
20.2.1. Exemple d'objet NetworkPolicy
Un exemple d'objet NetworkPolicy est annoté ci-dessous :
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 27017- 1
- Le nom de l'objet NetworkPolicy.
- 2
- Un sélecteur qui décrit les pods auxquels la politique s'applique. L'objet de politique ne peut sélectionner que des pods dans le projet qui définit l'objet NetworkPolicy.
- 3
- Un sélecteur qui correspond aux pods à partir desquels l'objet de politique autorise le trafic entrant. Le sélecteur correspond aux pods situés dans le même espace de noms que la NetworkPolicy.
- 4
- Liste d'un ou plusieurs ports de destination sur lesquels le trafic doit être accepté.
20.2.2. Création d'une politique de réseau à l'aide de l'interface de ligne de commande
Pour définir des règles granulaires décrivant le trafic réseau entrant ou sortant autorisé pour les espaces de noms de votre cluster, vous pouvez créer une stratégie réseau.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique de réseau.
Procédure
Créer une règle de politique :
Créer un fichier
<policy_name>.yaml:$ touch <policy_name>.yamloù :
<policy_name>- Spécifie le nom du fichier de stratégie réseau.
Définissez une politique de réseau dans le fichier que vous venez de créer, comme dans les exemples suivants :
Refuser l'entrée de tous les pods dans tous les espaces de noms
Il s'agit d'une politique fondamentale, qui bloque tout réseau inter-pods autre que le trafic inter-pods autorisé par la configuration d'autres politiques de réseau.
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: ingress: []Autoriser l'entrée de tous les pods dans le même espace de noms
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {}Autoriser le trafic entrant vers un pod à partir d'un espace de noms particulier
Cette politique autorise le trafic vers les pods étiquetés
pod-aà partir des pods fonctionnant surnamespace-y.kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-traffic-pod spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-y
Pour créer l'objet de stratégie de réseau, entrez la commande suivante :
oc apply -f <policy_name>.yaml -n <namespace>où :
<policy_name>- Spécifie le nom du fichier de stratégie réseau.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Exemple de sortie
networkpolicy.networking.k8s.io/deny-by-default created
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix de créer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir d'un formulaire dans la console web.
20.2.3. Création d'une stratégie réseau de refus de tout par défaut
Il s'agit d'une politique fondamentale, qui bloque tout réseau inter-pods autre que le trafic réseau autorisé par la configuration d'autres politiques de réseau déployées. Cette procédure applique une politique par défaut : deny-by-default.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique de réseau.
Procédure
Créez le fichier YAML suivant qui définit une politique
deny-by-defaultpour refuser l'entrée de tous les pods dans tous les espaces de noms. Enregistrez le YAML dans le fichierdeny-by-default.yaml:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default namespace: default1 spec: podSelector: {}2 ingress: []3 - 1
namespace: defaultdéploie cette politique dans l'espace de nomsdefault.- 2
podSelector:est vide, cela signifie qu'elle correspond à tous les pods. Par conséquent, la politique s'applique à tous les modules de l'espace de noms par défaut.- 3
- Aucune règle
ingressn'est spécifiée. Le trafic entrant est donc supprimé pour tous les pods.
Appliquez la politique en entrant la commande suivante :
$ oc apply -f deny-by-default.yamlExemple de sortie
networkpolicy.networking.k8s.io/deny-by-default created
20.2.4. Création d'une politique de réseau pour autoriser le trafic en provenance de clients externes
La politique deny-by-default étant en place, vous pouvez configurer une politique qui autorise le trafic des clients externes vers un pod portant l'étiquette app=web.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Suivez cette procédure pour configurer une politique qui autorise un service externe à partir de l'Internet public directement ou en utilisant un équilibreur de charge pour accéder au module. Le trafic n'est autorisé que vers un pod portant l'étiquette app=web.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique de réseau.
Procédure
Créez une politique qui autorise le trafic provenant de l'Internet public directement ou en utilisant un équilibreur de charge pour accéder au pod. Enregistrez le YAML dans le fichier
web-allow-external.yaml:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-external namespace: default spec: policyTypes: - Ingress podSelector: matchLabels: app: web ingress: - {}Appliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-external.yamlExemple de sortie
networkpolicy.networking.k8s.io/web-allow-external created
Cette politique autorise le trafic en provenance de toutes les ressources, y compris le trafic externe, comme l'illustre le diagramme suivant :
20.2.5. Création d'une politique de réseau autorisant le trafic vers une application à partir de tous les espaces de noms
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Suivez cette procédure pour configurer une stratégie qui autorise le trafic de tous les pods de tous les espaces de noms vers une application particulière.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique de réseau.
Procédure
Créez une politique qui autorise le trafic de tous les pods dans tous les espaces de noms vers une application particulière. Enregistrez le YAML dans le fichier
web-allow-all-namespaces.yaml:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-all-namespaces namespace: default spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: {}2 NotePar défaut, si vous ne précisez pas
namespaceSelector, aucun espace de noms n'est sélectionné, ce qui signifie que la stratégie n'autorise que le trafic provenant de l'espace de noms dans lequel la stratégie de réseau est déployée.Appliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-all-namespaces.yamlExemple de sortie
networkpolicy.networking.k8s.io/web-allow-all-namespaces created
Vérification
Démarrez un service web dans l'espace de noms
defaulten entrant la commande suivante :$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour déployer une image
alpinedans l'espace de nomssecondaryet pour démarrer un shell :$ oc run test-$RANDOM --namespace=secondary --rm -i -t --image=alpine -- shExécutez la commande suivante dans l'interpréteur de commandes et observez que la demande est autorisée :
# wget -qO- --timeout=2 http://web.defaultRésultats attendus
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
20.2.6. Création d'une politique de réseau autorisant le trafic vers une application à partir d'un espace de noms
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Suivez cette procédure pour configurer une politique qui autorise le trafic vers un pod avec l'étiquette app=web à partir d'un espace de noms particulier. Vous pourriez vouloir faire ceci pour :
- Restreindre le trafic vers une base de données de production aux seuls espaces de noms dans lesquels des charges de travail de production sont déployées.
- Permet aux outils de surveillance déployés dans un espace de noms particulier de récupérer les mesures de l'espace de noms actuel.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique de réseau.
Procédure
Créez une politique qui autorise le trafic de tous les pods dans un espace de noms particulier avec un label
purpose=production. Sauvegardez le YAML dans le fichierweb-allow-prod.yaml:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-prod namespace: default spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production2 Appliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-prod.yamlExemple de sortie
networkpolicy.networking.k8s.io/web-allow-prod created
Vérification
Démarrez un service web dans l'espace de noms
defaulten entrant la commande suivante :$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour créer l'espace de noms
prod:$ oc create namespace prodExécutez la commande suivante pour étiqueter l'espace de noms
prod:$ oc label namespace/prod purpose=productionExécutez la commande suivante pour créer l'espace de noms
dev:$ oc create namespace devExécutez la commande suivante pour étiqueter l'espace de noms
dev:$ oc label namespace/dev purpose=testingExécutez la commande suivante pour déployer une image
alpinedans l'espace de nomsdevet pour démarrer un shell :$ oc run test-$RANDOM --namespace=dev --rm -i -t --image=alpine -- shExécutez la commande suivante dans l'interpréteur de commandes et observez que la demande est bloquée :
# wget -qO- --timeout=2 http://web.defaultRésultats attendus
wget: download timed outExécutez la commande suivante pour déployer une image
alpinedans l'espace de nomsprodet démarrer un shell :$ oc run test-$RANDOM --namespace=prod --rm -i -t --image=alpine -- shExécutez la commande suivante dans l'interpréteur de commandes et observez que la demande est autorisée :
# wget -qO- --timeout=2 http://web.defaultRésultats attendus
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
20.3. Visualisation d'une politique de réseau
En tant qu'utilisateur ayant le rôle admin, vous pouvez afficher une stratégie de réseau pour un espace de noms.
20.3.1. Exemple d'objet NetworkPolicy
Un exemple d'objet NetworkPolicy est annoté ci-dessous :
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 27017- 1
- Le nom de l'objet NetworkPolicy.
- 2
- Un sélecteur qui décrit les pods auxquels la politique s'applique. L'objet de politique ne peut sélectionner que des pods dans le projet qui définit l'objet NetworkPolicy.
- 3
- Un sélecteur qui correspond aux pods à partir desquels l'objet de politique autorise le trafic entrant. Le sélecteur correspond aux pods situés dans le même espace de noms que la NetworkPolicy.
- 4
- Liste d'un ou plusieurs ports de destination sur lesquels le trafic doit être accepté.
20.3.2. Visualisation des stratégies de réseau à l'aide de l'interface de ligne de commande
Vous pouvez examiner les politiques de réseau dans un espace de noms.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez visualiser n'importe quelle stratégie de réseau dans le cluster.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms où la politique de réseau existe.
Procédure
Liste des politiques de réseau dans un espace de noms :
Pour afficher les objets de stratégie de réseau définis dans un espace de noms, entrez la commande suivante :
$ oc get networkpolicyFacultatif : Pour examiner une politique de réseau spécifique, entrez la commande suivante :
oc describe networkpolicy <nom_de_la_politique> -n <espace_de_noms>où :
<policy_name>- Spécifie le nom de la stratégie de réseau à inspecter.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Par exemple :
$ oc describe networkpolicy allow-same-namespaceSortie de la commande
oc describeName: allow-same-namespace Namespace: ns1 Created on: 2021-05-24 22:28:56 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: PodSelector: <none> Not affecting egress traffic Policy Types: Ingress
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix d'afficher une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir d'un formulaire dans la console web.
20.4. Modification d'une politique de réseau
En tant qu'utilisateur ayant le rôle admin, vous pouvez modifier une stratégie réseau existante pour un espace de noms.
20.4.1. Modification d'une politique de réseau
Vous pouvez modifier une stratégie de réseau dans un espace de noms.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez modifier une stratégie réseau dans n'importe quel espace de noms du cluster.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms où la politique de réseau existe.
Procédure
Facultatif : Pour répertorier les objets de stratégie de réseau dans un espace de noms, entrez la commande suivante :
$ oc get networkpolicyoù :
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Modifiez l'objet de politique de réseau.
Si vous avez enregistré la définition de la stratégie réseau dans un fichier, éditez le fichier et apportez les modifications nécessaires, puis entrez la commande suivante.
$ oc apply -n <namespace> -f <policy_file>.yamloù :
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
<policy_file>- Spécifie le nom du fichier contenant la politique de réseau.
Si vous devez mettre à jour l'objet de stratégie de réseau directement, entrez la commande suivante :
oc edit networkpolicy <policy_name> -n <namespace> $ oc edit networkpolicy <policy_name> -n <namespace>où :
<policy_name>- Spécifie le nom de la politique de réseau.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Confirmez la mise à jour de l'objet de stratégie de réseau.
oc describe networkpolicy <nom_de_la_politique> -n <espace_de_noms>où :
<policy_name>- Spécifie le nom de la politique de réseau.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix entre éditer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir de la politique dans la console web via le menu Actions.
20.4.2. Exemple d'objet NetworkPolicy
Un exemple d'objet NetworkPolicy est annoté ci-dessous :
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-27107
spec:
podSelector:
matchLabels:
app: mongodb
ingress:
- from:
- podSelector:
matchLabels:
app: app
ports:
- protocol: TCP
port: 27017- 1
- Le nom de l'objet NetworkPolicy.
- 2
- Un sélecteur qui décrit les pods auxquels la politique s'applique. L'objet de politique ne peut sélectionner que des pods dans le projet qui définit l'objet NetworkPolicy.
- 3
- Un sélecteur qui correspond aux pods à partir desquels l'objet de politique autorise le trafic entrant. Le sélecteur correspond aux pods situés dans le même espace de noms que la NetworkPolicy.
- 4
- Liste d'un ou plusieurs ports de destination sur lesquels le trafic doit être accepté.
20.5. Suppression d'une politique de réseau
En tant qu'utilisateur ayant le rôle admin, vous pouvez supprimer une stratégie de réseau d'un espace de noms.
20.5.1. Suppression d'une stratégie de réseau à l'aide de l'interface de ligne de commande
Vous pouvez supprimer une stratégie de réseau dans un espace de noms.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez supprimer n'importe quelle stratégie de réseau dans le cluster.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin. - Vous travaillez dans l'espace de noms où la politique de réseau existe.
Procédure
Pour supprimer un objet de stratégie de réseau, entrez la commande suivante :
oc delete networkpolicy <policy_name> -n <namespace>où :
<policy_name>- Spécifie le nom de la politique de réseau.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Exemple de sortie
networkpolicy.networking.k8s.io/default-deny deleted
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix entre supprimer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir de la politique dans la console web via le menu Actions.
20.6. Définir une politique de réseau par défaut pour les projets
En tant qu'administrateur de cluster, vous pouvez modifier le modèle de nouveau projet pour inclure automatiquement les stratégies de réseau lorsque vous créez un nouveau projet. Si vous n'avez pas encore de modèle personnalisé pour les nouveaux projets, vous devez d'abord en créer un.
20.6.1. Modifier le modèle pour les nouveaux projets
En tant qu'administrateur de cluster, vous pouvez modifier le modèle de projet par défaut afin que les nouveaux projets soient créés en fonction de vos besoins.
Pour créer votre propre modèle de projet personnalisé :
Procédure
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. Générer le modèle de projet par défaut :
oc adm create-bootstrap-project-template -o yaml > template.yaml-
Utilisez un éditeur de texte pour modifier le fichier
template.yamlgénéré en ajoutant des objets ou en modifiant des objets existants. Le modèle de projet doit être créé dans l'espace de noms
openshift-config. Chargez votre modèle modifié :$ oc create -f template.yaml -n openshift-configModifiez la ressource de configuration du projet à l'aide de la console Web ou de la CLI.
En utilisant la console web :
- Naviguez jusqu'à la page Administration → Cluster Settings.
- Cliquez sur Configuration pour afficher toutes les ressources de configuration.
- Trouvez l'entrée pour Project et cliquez sur Edit YAML.
Utilisation de la CLI :
Modifier la ressource
project.config.openshift.io/cluster:$ oc edit project.config.openshift.io/cluster
Mettez à jour la section
specpour inclure les paramètresprojectRequestTemplateetname, et définissez le nom de votre modèle de projet téléchargé. Le nom par défaut estproject-request.Ressource de configuration de projet avec modèle de projet personnalisé
apiVersion: config.openshift.io/v1 kind: Project metadata: ... spec: projectRequestTemplate: name: <template_name>- Après avoir enregistré vos modifications, créez un nouveau projet pour vérifier que vos modifications ont bien été appliquées.
20.6.2. Ajouter des politiques de réseau au nouveau modèle de projet
En tant qu'administrateur de cluster, vous pouvez ajouter des politiques de réseau au modèle par défaut pour les nouveaux projets. OpenShift Container Platform créera automatiquement tous les objets NetworkPolicy spécifiés dans le modèle du projet.
Conditions préalables
-
Votre cluster utilise un fournisseur de réseau CNI par défaut qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avec l'optionmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
You installed the OpenShift CLI (
oc). -
Vous devez vous connecter au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous devez avoir créé un modèle de projet personnalisé par défaut pour les nouveaux projets.
Procédure
Modifiez le modèle par défaut pour un nouveau projet en exécutant la commande suivante :
$ oc edit template <project_template> -n openshift-configRemplacez
<project_template>par le nom du modèle par défaut que vous avez configuré pour votre cluster. Le nom du modèle par défaut estproject-request.Dans le modèle, ajoutez chaque objet
NetworkPolicyen tant qu'élément du paramètreobjects. Le paramètreobjectsaccepte une collection d'un ou plusieurs objets.Dans l'exemple suivant, la collection de paramètres
objectscomprend plusieurs objetsNetworkPolicy.objects: - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - Ingress - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress ...Facultatif : Créez un nouveau projet pour confirmer que vos objets de stratégie de réseau ont été créés avec succès en exécutant les commandes suivantes :
Créer un nouveau projet :
oc new-project <projet> $ oc new-project <projet>1 - 1
- Remplacez
<project>par le nom du projet que vous créez.
Confirmez que les objets de stratégie de réseau du nouveau modèle de projet existent dans le nouveau projet :
$ oc get networkpolicy NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
20.7. Configuration de l'isolation des multitenants à l'aide d'une stratégie de réseau
En tant qu'administrateur de cluster, vous pouvez configurer vos stratégies réseau pour assurer l'isolation du réseau multitenant.
Si vous utilisez le plugin réseau OpenShift SDN, la configuration des politiques réseau comme décrit dans cette section fournit une isolation réseau similaire au mode multitenant mais avec un mode de politique réseau défini.
20.7.1. Configuration de l'isolation des multitenants à l'aide d'une stratégie de réseau
Vous pouvez configurer votre projet pour l'isoler des pods et des services dans d'autres espaces de noms de projets.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
You installed the OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
admin.
Procédure
Créez les objets
NetworkPolicysuivants :Une police nommée
allow-from-openshift-ingress.$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: "" podSelector: {} policyTypes: - Ingress EOFNotepolicy-group.network.openshift.io/ingress: ""est l'étiquette de sélecteur d'espace de noms préférée pour OpenShift SDN. Vous pouvez utiliser l'étiquette de sélecteur d'espace de nomsnetwork.openshift.io/policy-group: ingress, mais il s'agit d'une étiquette héritée.Une police nommée
allow-from-openshift-monitoring:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-monitoring spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: monitoring podSelector: {} policyTypes: - Ingress EOFUne police nommée
allow-same-namespace:$ cat << EOF| oc create -f - kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {} EOFUne police nommée
allow-from-kube-apiserver-operator:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress EOFPour plus de détails, voir Nouveau contrôleur de webhook
kube-apiserver-operatorvalidant l'état de santé du webhook.
Facultatif : Pour confirmer que les politiques de réseau existent dans votre projet actuel, entrez la commande suivante :
$ oc describe networkpolicyExemple de sortie
Name: allow-from-openshift-ingress Namespace: example1 Created on: 2020-06-09 00:28:17 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: ingress Not affecting egress traffic Policy Types: Ingress Name: allow-from-openshift-monitoring Namespace: example1 Created on: 2020-06-09 00:29:57 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: monitoring Not affecting egress traffic Policy Types: Ingress
20.7.2. Prochaines étapes
Chapitre 21. Opérateur d'équilibreur de charge AWS
21.1. Notes de mise à jour de AWS Load Balancer Operator
L'opérateur AWS Load Balancer (ALB) déploie et gère une instance de la ressource AWSLoadBalancerController.
Ces notes de version suivent le développement de l'opérateur AWS Load Balancer dans OpenShift Container Platform.
Pour une vue d'ensemble de l'AWS Load Balancer Operator, voir AWS Load Balancer Operator dans OpenShift Container Platform.
21.1.1. AWS Load Balancer Operator 1.0.0
L'avis suivant est disponible pour la version 1.0.0 d'AWS Load Balancer Operator :
21.1.1.1. Changements notables
-
Cette version utilise la nouvelle version de l'API
v1.
21.1.1.2. Bug fixes
- Auparavant, le contrôleur provisionné par AWS Load Balancer Operator n'utilisait pas correctement la configuration du proxy cluster-wide. Ces paramètres sont désormais appliqués de manière appropriée au contrôleur. (OCPBUGS-4052, OCPBUGS-5295)
21.1.2. Versions antérieures
Les deux premières versions de l'AWS Load Balancer Operator sont disponibles en tant qu'aperçu technologique. Ces versions ne doivent pas être utilisées dans un cluster de production. Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
L'avis suivant est disponible pour la version 0.2.0 d'AWS Load Balancer Operator :
L'avis suivant est disponible pour la version 0.0.1 d'AWS Load Balancer Operator :
21.2. Opérateur AWS Load Balancer dans OpenShift Container Platform
L'opérateur AWS Load Balancer (ALB) déploie et gère une instance de aws-load-balancer-controller. Vous pouvez installer l'opérateur ALB à partir de l'OperatorHub en utilisant la console web ou le CLI d'OpenShift Container Platform.
21.2.1. Opérateur d'équilibreur de charge AWS
L'opérateur de l'équilibreur de charge AWS peut marquer les sous-réseaux publics si la balise kubernetes.io/role/elb est manquante. En outre, l'opérateur de l'équilibreur de charge AWS détecte les éléments suivants dans le nuage AWS sous-jacent :
- L'ID du nuage privé virtuel (VPC) sur lequel le cluster hébergeant l'opérateur est déployé.
- Sous-réseaux publics et privés du VPC découvert.
L'opérateur AWS Load Balancer prend en charge la ressource de service Kubernetes de type LoadBalancer en utilisant l'équilibreur de charge réseau (NLB) avec le type de cible instance uniquement.
Conditions préalables
- Vous devez disposer des informations d'identification AWS secrètes. Les informations d'identification sont utilisées pour le marquage des sous-réseaux et la découverte des VPC.
Procédure
Vous pouvez déployer l'opérateur AWS Load Balancer à la demande depuis OperatorHub, en créant un objet
Subscription:$ oc -n aws-load-balancer-operator get sub aws-load-balancer-operator --template='{{.status.installplan.name}}{{"\n"}}'Exemple de sortie
install-zlfbtVérifier le statut d'un plan d'installation. Le statut d'un plan d'installation doit être
Complete:$ oc -n aws-load-balancer-operator get ip <install_plan_name> --template='{{.status.phase}}{{{\N-"\N\N"}}''Exemple de sortie
CompleteUtilisez la commande
oc getpour visualiser l'état deDeployment:$ oc get -n aws-load-balancer-operator deployment/aws-load-balancer-operator-controller-managerExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE aws-load-balancer-operator-controller-manager 1/1 1 1 23h
21.2.2. Journaux de l'opérateur de l'équilibreur de charge AWS
Utilisez la commande oc logs pour afficher les journaux de l'opérateur AWS Load Balancer.
Procédure
Consulter les journaux de l'opérateur AWS Load Balancer :
$ oc logs -n aws-load-balancer-operator deployment/aws-load-balancer-operator-controller-manager -c manager
21.3. Comprendre l'opérateur d'équilibreur de charge AWS
L'opérateur AWS Load Balancer (ALB) déploie et gère une instance de la ressource aws-load-balancer-controller. Vous pouvez installer l'AWS Load Balancer Operator depuis l'OperatorHub en utilisant la console web ou le CLI d'OpenShift Container Platform.
Le déploiement d'AWS Load Balancer Operator est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
21.3.1. Installation de l'opérateur AWS Load Balancer
Vous pouvez installer l'opérateur AWS Load Balancer depuis OperatorHub en utilisant la console web d'OpenShift Container Platform.
Conditions préalables
-
Vous vous êtes connecté à la console web de OpenShift Container Platform en tant qu'utilisateur avec les permissions
cluster-admin. - Votre cluster est configuré avec AWS comme type de plateforme et fournisseur de cloud.
Procédure
- Naviguez vers Operators → OperatorHub dans la console web de OpenShift Container Platform.
- Sélectionnez le site AWS Load Balancer Operator. Vous pouvez utiliser la zone de texte Filter by keyword ou la liste de filtres pour rechercher l'opérateur AWS Load Balancer dans la liste des opérateurs.
-
Sélectionnez l'espace de noms
aws-load-balancer-operator. - Suivez les instructions pour préparer l'opérateur à l'installation.
- Sur la page AWS Load Balancer Operator, cliquez sur Install.
Sur la page Install Operator, sélectionnez les options suivantes :
- Update the channel comme stable-v1.
- Installation mode comme A specific namespace on the cluster.
-
Installed Namespace comme
aws-load-balancer-operator. Si l'espace de nomsaws-load-balancer-operatorn'existe pas, il est créé lors de l'installation de l'opérateur. - Sélectionnez Update approval comme Automatic ou Manual. Par défaut, Update approval est défini sur Automatic. Si vous sélectionnez les mises à jour automatiques, l'Operator Lifecycle Manager (OLM) met automatiquement à niveau l'instance en cours d'exécution de votre opérateur sans aucune intervention. Si vous sélectionnez les mises à jour manuelles, l'OLM crée une demande de mise à jour. En tant qu'administrateur de cluster, vous devez ensuite approuver manuellement cette demande de mise à jour pour mettre à jour l'opérateur vers la nouvelle version.
- Cliquez sur Install.
Vérification
- Vérifiez que l'opérateur AWS Load Balancer affiche le site Status comme Succeeded sur le tableau de bord des opérateurs installés.
21.4. Installation d'AWS Load Balancer Operator sur un cluster Security Token Service
Vous pouvez installer l'opérateur AWS Load Balancer sur un cluster Security Token Service (STS).
L'opérateur de l'équilibreur de charge AWS s'appuie sur CredentialsRequest pour démarrer l'opérateur et chaque instance AWSLoadBalancerController. L'opérateur d'équilibreur de charge AWS attend que les secrets requis soient créés et disponibles. Le Cloud Credential Operator ne fournit pas les secrets automatiquement dans le cluster STS. Vous devez définir les secrets d'identification manuellement à l'aide du binaire ccoctl.
Si vous ne souhaitez pas fournir de secret d'identification à l'aide de Cloud Credential Operator, vous pouvez configurer l'instance AWSLoadBalancerController sur le cluster STS en spécifiant le secret d'identification dans la ressource personnalisée (CR) du contrôleur d'équilibre de charge AWS.
21.4.1. Bootstrapping AWS Load Balancer Operator on Security Token Service cluster
Conditions préalables
-
Vous devez extraire et préparer le binaire
ccoctl.
Procédure
Créez l'espace de noms
aws-load-balancer-operatoren exécutant la commande suivante :$ oc create namespace aws-load-balancer-operatorTéléchargez la ressource personnalisée (CR)
CredentialsRequestde l'opérateur AWS Load Balancer et créez un répertoire pour la stocker en exécutant la commande suivante :$ curl --create-dirs -o <path-to-credrequests-dir>/cr.yaml https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/operator-credentials-request.yamlUtilisez l'outil
ccoctlpour traiter les objetsCredentialsRequestde l'opérateur AWS Load Balancer, en exécutant la commande suivante :$ ccoctl aws create-iam-roles \ --name <name> --region=<aws_region> \ --credentials-requests-dir=<path-to-credrequests-dir> \ --identity-provider-arn <oidc-arn>Appliquez les secrets générés dans le répertoire manifests de votre cluster en exécutant la commande suivante :
$ ls manifests/*-credentials.yaml | xargs -I{} oc apply -f {}Vérifiez que le secret d'identification de l'opérateur AWS Load Balancer est créé en exécutant la commande suivante :
$ oc -n aws-load-balancer-operator get secret aws-load-balancer-operator --template='{{index .data "credentials"}}' | base64 -dExemple de sortie
[default] sts_regional_endpoints = regional role_arn = arn:aws:iam::999999999999:role/aws-load-balancer-operator-aws-load-balancer-operator web_identity_token_file = /var/run/secrets/openshift/serviceaccount/token
21.4.2. Configuration de l'opérateur AWS Load Balancer sur le cluster Security Token Service à l'aide des objets gérés CredentialsRequest
Conditions préalables
-
Vous devez extraire et préparer le binaire
ccoctl.
Procédure
L'opérateur AWS Load Balancer crée l'objet
CredentialsRequestdans l'espace de nomsopenshift-cloud-credential-operatorpour chaque ressource personnalisée (CR)AWSLoadBalancerController. Vous pouvez extraire et enregistrer l'objetCredentialsRequestcréé dans un répertoire en exécutant la commande suivante :$ oc get credentialsrequest -n openshift-cloud-credential-operator \ aws-load-balancer-controller-<cr-name> -o yaml > <path-to-credrequests-dir>/cr.yaml1 - 1
- Le paramètre
aws-load-balancer-controller-<cr-name>indique le nom de la demande d'informations d'identification créée par l'opérateur de l'équilibreur de charge AWS. Le paramètrecr-nameindique le nom de l'instance du contrôleur AWS Load Balancer.
Utilisez l'outil
ccoctlpour traiter tous les objetsCredentialsRequestdans le répertoirecredrequestsen exécutant la commande suivante :$ ccoctl aws create-iam-roles \ --name <name> --region=<aws_region> \ --credentials-requests-dir=<path-to-credrequests-dir> \ --identity-provider-arn <oidc-arn>Appliquez les secrets générés dans le répertoire manifests à votre cluster, en exécutant la commande suivante :
$ ls manifests/*-credentials.yaml | xargs -I{} oc apply -f {}Vérifiez que le pod
aws-load-balancer-controllerest créé :$ oc -n aws-load-balancer-operator get pods NAME READY STATUS RESTARTS AGE aws-load-balancer-controller-cluster-9b766d6-gg82c 1/1 Running 0 137m aws-load-balancer-operator-controller-manager-b55ff68cc-85jzg 2/2 Running 0 3h26m
21.4.3. Configuration de l'opérateur AWS Load Balancer sur le cluster Security Token Service à l'aide d'informations d'identification spécifiques
Vous pouvez spécifier le secret d'authentification en utilisant le champ spec.credentials dans la ressource personnalisée (CR) du contrôleur AWS Load Balancer. Vous pouvez utiliser l'objet prédéfini CredentialsRequest du contrôleur pour savoir quels rôles sont requis.
Conditions préalables
-
Vous devez extraire et préparer le binaire
ccoctl.
Procédure
Téléchargez la ressource personnalisée CredentialsRequest (CR) du contrôleur AWS Load Balancer et créez un répertoire pour la stocker en exécutant la commande suivante :
$ curl --create-dirs -o <path-to-credrequests-dir>/cr.yaml https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/controller/controller-credentials-request.yamlUtilisez l'outil
ccoctlpour traiter l'objetCredentialsRequestdu contrôleur :$ ccoctl aws create-iam-roles \ --name <name> --region=<aws_region> \ --credentials-requests-dir=<path-to-credrequests-dir> \ --identity-provider-arn <oidc-arn>Appliquez les secrets à votre cluster :
$ ls manifests/*-credentials.yaml | xargs -I{} oc apply -f {}Vérifiez que le secret d'identification a été créé pour être utilisé par le contrôleur :
$ oc -n aws-load-balancer-operator get secret aws-load-balancer-controller-manual-cluster --template='{{index .data "credentials"}}' | base64 -dExemple de sortie
[default] sts_regional_endpoints = regional role_arn = arn:aws:iam::999999999999:role/aws-load-balancer-operator-aws-load-balancer-controller web_identity_token_file = /var/run/secrets/openshift/serviceaccount/tokenCréez le fichier YAML de la ressource
AWSLoadBalancerController, par exemplesample-aws-lb-manual-creds.yaml, comme suit :apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController1 metadata: name: cluster2 spec: credentials: name: <secret-name>3
21.5. Création d'une instance de AWS Load Balancer Controller
Après avoir installé l'opérateur, vous pouvez créer une instance du contrôleur AWS Load Balancer.
21.5.1. Création d'une instance du contrôleur AWS Load Balancer à l'aide d'AWS Load Balancer Operator
Vous ne pouvez installer qu'une seule instance de aws-load-balancer-controller dans un cluster. Vous pouvez créer le contrôleur AWS Load Balancer en utilisant le CLI. L'opérateur AWS Load Balancer (ALB) ne réconcilie que la ressource portant le nom cluster.
Conditions préalables
-
Vous avez créé l'espace de noms
echoserver. -
Vous avez accès au CLI OpenShift (
oc).
Procédure
Créez un fichier YAML de la ressource
aws-load-balancer-controller, par exemplesample-aws-lb.yaml, comme suit :apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController1 metadata: name: cluster2 spec: subnetTagging: Auto3 additionalResourceTags:4 - key: example.org/security-scope value: staging ingressClass: cloud5 config: replicas: 26 enabledAddons:7 - AWSWAFv28 - 1
- Définit la ressource
aws-load-balancer-controller. - 2
- Définit le nom de l'instance du contrôleur AWS Load Balancer. Ce nom d'instance est ajouté comme suffixe à toutes les ressources connexes.
- 3
- Les options valides sont
AutoetManual. Lorsque la valeur est définie surAuto, l'opérateur tente de déterminer les sous-réseaux qui appartiennent à la grappe et les marque de manière appropriée. L'opérateur ne peut pas déterminer le rôle correctement si les balises de sous-réseau interne ne sont pas présentes sur le sous-réseau interne. Si vous avez installé votre cluster sur une infrastructure fournie par l'utilisateur, vous pouvez marquer manuellement les sous-réseaux avec les balises de rôle appropriées et définir la stratégie de marquage des sous-réseaux surManual. - 4
- Définit les balises utilisées par le contrôleur lorsqu'il approvisionne les ressources AWS.
- 5
- La valeur par défaut de ce champ est
alb. L'opérateur fournit une ressourceIngressClassportant le même nom si elle n'existe pas. - 6
- Spécifie le nombre de répliques du contrôleur.
- 7
- Spécifie les modules complémentaires pour les équilibreurs de charge AWS, qui sont spécifiés par le biais d'annotations.
- 8
- Active l'annotation
alb.ingress.kubernetes.io/wafv2-acl-arn.
Créez une ressource
aws-load-balancer-controlleren exécutant la commande suivante :$ oc create -f sample-aws-lb.yamlUne fois le contrôleur AWS Load Balancer lancé, créez une ressource
deployment:apiVersion: apps/v1 kind: Deployment1 metadata: name: <echoserver>2 namespace: echoserver spec: selector: matchLabels: app: echoserver replicas: 33 template: metadata: labels: app: echoserver spec: containers: - image: openshift/origin-node command: - "/bin/socat" args: - TCP4-LISTEN:8080,reuseaddr,fork - EXEC:'/bin/bash -c \"printf \\\"HTTP/1.0 200 OK\r\n\r\n\\\"; sed -e \\\"/^\r/q\\\"\"' imagePullPolicy: Always name: echoserver ports: - containerPort: 8080Créer une ressource
service:apiVersion: v1 kind: Service1 metadata: name: <echoserver>2 namespace: echoserver spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector: app: echoserverDéployer une ressource
Ingresssoutenue par l'ALB :apiVersion: networking.k8s.io/v1 kind: Ingress1 metadata: name: <echoserver>2 namespace: echoserver annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Exact backend: service: name: <echoserver>3 port: number: 80
Vérification
Vérifiez l'état de la ressource
Ingresspour afficher l'hôte de l'équilibreur de charge AWS (ALB) provisionné en exécutant la commande suivante :$ HOST=$(oc get ingress -n echoserver echoserver --template='{{(index .status.loadBalancer.ingress 0).hostname}}')Vérifiez l'état de l'hôte AWS Load Balancer (ALB) provisionné en exécutant la commande suivante :
$ curl $HOST
21.6. Création de plusieurs entrées
Vous pouvez acheminer le trafic vers différents services faisant partie d'un même domaine par le biais d'un seul équilibreur de charge AWS (ALB). Chaque ressource d'entrée fournit différents points d'extrémité du domaine.
21.6.1. Création de plusieurs entrées via un seul équilibreur de charge AWS
Vous pouvez acheminer le trafic vers plusieurs entrées via un seul équilibreur de charge AWS (ALB) à l'aide de la CLI.
Conditions préalables
-
Vous avez un accès au CLI OpenShift (
oc).
Procédure
Créez un fichier YAML de la ressource
IngressClassParams, par exemplesample-single-lb-params.yaml, comme suit :apiVersion: elbv2.k8s.aws/v1beta11 kind: IngressClassParams metadata: name: <single-lb-params>2 spec: group: name: single-lb3 Créez une ressource
IngressClassParamsen exécutant la commande suivante :$ oc create -f sample-single-lb-params.yamlCréez un fichier YAML de la ressource
IngressClass, par exemplesample-single-lb.yaml, comme suit :apiVersion: networking.k8s.io/v11 kind: IngressClass metadata: name: <single-lb>2 spec: controller: ingress.k8s.aws/alb3 parameters: apiGroup: elbv2.k8s.aws4 kind: IngressClassParams5 name: single-lb6 - 1
- Définit le groupe API et la version de la ressource
IngressClass. - 2
- Spécifie le nom du site
IngressClass. - 3
- Définit le nom du contrôleur, commun à tous les
IngressClasses. Le siteaws-load-balancer-controllerréconcilie le contrôleur. - 4
- Définit le groupe API de la ressource
IngressClassParams. - 5
- Définit le type de ressource de la ressource
IngressClassParams. - 6
- Définit le nom de la ressource
IngressClassParams.
Créez une ressource
IngressClassen exécutant la commande suivante :$ oc create -f sample-single-lb.yamlCréez un fichier YAML de la ressource
Ingress, par exemplesample-multiple-ingress.yaml, comme suit :apiVersion: networking.k8s.io/v11 kind: Ingress metadata: name: <example-1>2 annotations: alb.ingress.kubernetes.io/scheme: internet-facing3 alb.ingress.kubernetes.io/group.order: "1"4 spec: ingressClass: alb5 rules: - host: example.com6 http: paths: - path: /blog7 backend: service: name: <example-1>8 port: number: 809 kind: Ingress metadata: name: <example-2> annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/group.order: "2" spec: ingressClass: alb rules: - host: example.com http: paths: - path: /store backend: service: name: <example-2> port: number: 80 kind: Ingress metadata: name: <example-3> annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/group.order: "3" spec: ingressClass: alb rules: - host: example.com http: paths: - path: / backend: service: name: <example-3> port: number: 80- 1 2
- Spécifie le nom d'une entrée.
- 3
- Indique que l'équilibreur de charge doit être placé dans le sous-réseau public et le rend accessible sur l'internet.
- 4
- Spécifie l'ordre dans lequel les règles des entrées sont appliquées lorsque la demande est reçue par l'équilibreur de charge.
- 5
- Spécifie la classe d'entrée qui appartient à cette entrée.
- 6
- Définit le nom d'un domaine utilisé pour l'acheminement des demandes.
- 7
- Définit le chemin qui doit mener au service.
- 8
- Définit le nom du service qui dessert le point de terminaison configuré dans l'entrée.
- 9
- Définit le port du service qui dessert le point d'extrémité.
Créez les ressources
Ingressen exécutant la commande suivante :$ oc create -f sample-multiple-ingress.yaml
21.7. Ajout de la terminaison TLS
Vous pouvez ajouter une terminaison TLS sur l'équilibreur de charge AWS.
21.7.1. Ajout d'une terminaison TLS sur l'équilibreur de charge AWS
Vous pouvez acheminer le trafic du domaine vers les pods d'un service et ajouter une terminaison TLS sur l'équilibreur de charge AWS.
Conditions préalables
-
Vous avez un accès au CLI OpenShift (
oc).
Procédure
Installez l'opérateur et créez une instance de la ressource
aws-load-balancer-controller:apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController metadata: name: cluster1 spec: subnetTagging: auto ingressClass: tls-termination2 - 1
- Définit l'instance
aws-load-balancer-controller. - 2
- Définit le nom d'une ressource
ingressClassréconciliée par le contrôleur AWS Load Balancer. Cette ressourceingressClassest créée si elle n'existe pas. Vous pouvez ajouter des valeursingressClasssupplémentaires. Le contrôleur réconcilie les valeursingressClasssi la ressourcespec.controllerest définie suringress.k8s.aws/alb.
Créer une ressource
Ingress:apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: <example>1 annotations: alb.ingress.kubernetes.io/scheme: internet-facing2 alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-west-2:xxxxx3 spec: ingressClassName: tls-termination4 rules: - host: <example.com>5 http: paths: - path: / pathType: Exact backend: service: name: <example-service>6 port: number: 80- 1
- Spécifie le nom d'une entrée.
- 2
- Le contrôleur fournit l'équilibreur de charge pour cette ressource
Ingressdans un sous-réseau public de sorte que l'équilibreur de charge soit accessible sur l'internet. - 3
- Le nom de ressource Amazon du certificat que vous attachez à l'équilibreur de charge.
- 4
- Définit le nom de la classe d'entrée.
- 5
- Définit le domaine pour l'acheminement du trafic.
- 6
- Définit le service d'acheminement du trafic.
21.8. Configuration d'un proxy à l'échelle d'un cluster
Vous pouvez configurer le proxy à l'échelle du cluster dans l'opérateur AWS Load Balancer. Après avoir configuré le proxy en grappe dans l'opérateur AWS Load Balancer, Operator Lifecycle Manager (OLM) met automatiquement à jour tous les déploiements des opérateurs avec les variables d'environnement telles que HTTP_PROXY, HTTPS_PROXY, et NO_PROXY. Ces variables sont ajoutées au contrôleur géré par l'opérateur d'équilibreur de charge AWS.
21.8.1. Configurer l'opérateur AWS Load Balancer pour qu'il fasse confiance à l'autorité de certification du proxy à l'échelle du cluster
Créez la carte de configuration pour contenir le bundle de l'autorité de certification (CA) dans l'espace de noms
aws-load-balancer-operatoret injectez un bundle CA qui est approuvé par OpenShift Container Platform dans une carte de configuration en exécutant la commande suivante :$ oc -n aws-load-balancer-operator create configmap trusted-caPour injecter le paquet d'AC de confiance dans la carte de configuration, ajoutez l'étiquette
config.openshift.io/inject-trusted-cabundle=trueà la carte de configuration en exécutant la commande suivante :$ oc -n aws-load-balancer-operator label cm trusted-ca config.openshift.io/inject-trusted-cabundle=trueMettez à jour l'abonnement de l'AWS Load Balancer Operator pour accéder à la carte de configuration dans le déploiement de l'AWS Load Balancer Operator en exécutant la commande suivante :
$ oc -n aws-load-balancer-operator patch subscription aws-load-balancer-operator --type='merge' -p '{"spec":{"config":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}],"volumes":[{"name":"trusted-ca","configMap":{"name":"trusted-ca"}}],"volumeMounts":[{"name":"trusted-ca","mountPath":"/etc/pki/tls/certs/albo-tls-ca-bundle.crt","subPath":"ca-bundle.crt"}]}}}'Une fois le déploiement de l'opérateur AWS Load Balancer terminé, vérifiez que le bundle CA est ajouté au déploiement
aws-load-balancer-operator-controller-manageren exécutant la commande suivante :$ oc -n aws-load-balancer-operator exec deploy/aws-load-balancer-operator-controller-manager -c manager -- bash -c "ls -l /etc/pki/tls/certs/albo-tls-ca-bundle.crt; printenv TRUSTED_CA_CONFIGMAP_NAME"Exemple de sortie
-rw-r--r--. 1 root 1000690000 5875 Jan 11 12:25 /etc/pki/tls/certs/albo-tls-ca-bundle.crt trusted-caFacultatif : Redémarrez le déploiement de l'opérateur AWS Load Balancer chaque fois que la carte de configuration est modifiée en exécutant la commande suivante :
$ oc -n aws-load-balancer-operator rollout restart deployment/aws-load-balancer-operator-controller-manager
Chapitre 22. Réseaux multiples
22.1. Comprendre les réseaux multiples
Dans Kubernetes, la mise en réseau des conteneurs est déléguée à des plugins de mise en réseau qui mettent en œuvre l'interface de réseau de conteneurs (CNI).
OpenShift Container Platform utilise le plugin CNI Multus pour permettre le chaînage des plugins CNI. Lors de l'installation du cluster, vous configurez votre réseau de pods default. Le réseau par défaut gère tout le trafic réseau ordinaire pour le cluster. Vous pouvez définir un additional network basé sur les plugins CNI disponibles et attacher un ou plusieurs de ces réseaux à vos pods. Vous pouvez définir plusieurs réseaux supplémentaires pour votre cluster, en fonction de vos besoins. Cela vous donne de la flexibilité lorsque vous configurez des pods qui fournissent des fonctionnalités réseau, telles que la commutation ou le routage.
22.1.1. Scénarios d'utilisation d'un réseau supplémentaire
Vous pouvez utiliser un réseau supplémentaire dans les situations où l'isolation du réseau est nécessaire, y compris la séparation du plan de données et du plan de contrôle. L'isolation du trafic réseau est utile pour les raisons de performance et de sécurité suivantes :
- Performances
- Vous pouvez envoyer du trafic sur deux plans différents afin de gérer la quantité de trafic sur chaque plan.
- Sécurité
- Vous pouvez envoyer le trafic sensible sur un plan de réseau géré spécifiquement pour des considérations de sécurité, et vous pouvez séparer les données privées qui ne doivent pas être partagées entre les locataires ou les clients.
Tous les pods du cluster utilisent toujours le réseau par défaut du cluster pour maintenir la connectivité à travers le cluster. Chaque module dispose d'une interface eth0 qui est attachée au réseau du module à l'échelle du cluster. Vous pouvez afficher les interfaces d'un module à l'aide de la commande oc exec -it <pod_name> -- ip a. Si vous ajoutez des interfaces réseau supplémentaires qui utilisent Multus CNI, elles sont nommées net1, net2, ..., netN.
Pour attacher des interfaces réseau supplémentaires à un pod, vous devez créer des configurations qui définissent la manière dont les interfaces sont attachées. Vous spécifiez chaque interface en utilisant une ressource personnalisée (CR) NetworkAttachmentDefinition. Une configuration CNI à l'intérieur de chacune de ces CR définit la manière dont cette interface est créée.
22.1.2. Réseaux supplémentaires dans OpenShift Container Platform
OpenShift Container Platform fournit les plugins CNI suivants pour créer des réseaux supplémentaires dans votre cluster :
- bridge: Configurez un réseau supplémentaire basé sur un pont pour permettre aux pods sur le même hôte de communiquer entre eux et avec l'hôte.
- host-device: Configurer un réseau supplémentaire hôte-dispositif pour permettre aux pods d'accéder à un périphérique de réseau Ethernet physique sur le système hôte.
- ipvlan: Configurer un réseau supplémentaire basé sur ipvlan pour permettre aux pods d'un hôte de communiquer avec d'autres hôtes et pods sur ces hôtes, de manière similaire à un réseau supplémentaire basé sur macvlan. Contrairement à un réseau supplémentaire basé sur macvlan, chaque pod partage la même adresse MAC que l'interface réseau physique parent.
- macvlan: Configurer un réseau supplémentaire basé sur macvlan pour permettre aux pods sur un hôte de communiquer avec d'autres hôtes et pods sur ces hôtes en utilisant une interface réseau physique. Chaque pod attaché à un réseau supplémentaire basé sur macvlan reçoit une adresse MAC unique.
- SR-IOV: Configurer un réseau supplémentaire basé sur SR-IOV pour permettre aux pods de s'attacher à une interface de fonction virtuelle (VF) sur un matériel compatible SR-IOV sur le système hôte.
22.2. Configuration d'un réseau supplémentaire
En tant qu'administrateur de cluster, vous pouvez configurer un réseau supplémentaire pour votre cluster. Les types de réseaux suivants sont pris en charge :
22.2.1. Approches de la gestion d'un réseau supplémentaire
Vous pouvez gérer le cycle de vie d'un réseau supplémentaire selon deux approches. Chaque approche est mutuellement exclusive et vous ne pouvez utiliser qu'une seule approche à la fois pour gérer un réseau supplémentaire. Dans les deux cas, le réseau supplémentaire est géré par un plugin CNI (Container Network Interface) que vous configurez.
Pour un réseau supplémentaire, les adresses IP sont fournies par un plugin CNI de gestion des adresses IP (IPAM) que vous configurez dans le cadre du réseau supplémentaire. Le plugin IPAM prend en charge une variété d'approches d'attribution d'adresses IP, y compris l'attribution DHCP et l'attribution statique.
-
Modifier la configuration du Cluster Network Operator (CNO) : Le CNO crée et gère automatiquement l'objet
NetworkAttachmentDefinition. En plus de gérer le cycle de vie de l'objet, le CNO s'assure qu'un DHCP est disponible pour un réseau supplémentaire qui utilise une adresse IP attribuée par DHCP. -
Appliquer un manifeste YAML : Vous pouvez gérer le réseau supplémentaire directement en créant un objet
NetworkAttachmentDefinition. Cette approche permet le chaînage des plugins CNI.
Lors du déploiement de nœuds OpenShift Container Platform avec plusieurs interfaces réseau sur Red Hat OpenStack Platform (RHOSP) avec OVN SDN, la configuration DNS de l'interface secondaire peut être prioritaire sur la configuration DNS de l'interface primaire. Dans ce cas, supprimez les serveurs de noms DNS pour l'identifiant de sous-réseau qui est attaché à l'interface secondaire :
$ openstack subnet set --dns-nameserver 0.0.0.0 <subnet_id>22.2.2. Configuration pour une connexion réseau supplémentaire
Un réseau supplémentaire est configuré en utilisant l'API NetworkAttachmentDefinition dans le groupe d'API k8s.cni.cncf.io.
Ne stockez pas d'informations sensibles ou secrètes dans l'objet NetworkAttachmentDefinition car ces informations sont accessibles à l'utilisateur de l'administration du projet.
La configuration de l'API est décrite dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
| Nom du réseau supplémentaire. |
|
|
| L'espace de noms auquel l'objet est associé. |
|
|
| La configuration du plugin CNI au format JSON. |
22.2.2.1. Configuration d'un réseau supplémentaire par l'intermédiaire de l'opérateur de réseau du cluster
La configuration d'une connexion réseau supplémentaire est spécifiée dans le cadre de la configuration de l'opérateur de réseau de cluster (CNO).
Le fichier YAML suivant décrit les paramètres de configuration pour la gestion d'un réseau supplémentaire avec le CNO :
Cluster Network Operator configuration
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
# ...
additionalNetworks:
- name: <name>
namespace: <namespace>
rawCNIConfig: |-
{
...
}
type: Raw- 1
- Un tableau d'une ou plusieurs configurations de réseau supplémentaires.
- 2
- Le nom de la pièce jointe réseau supplémentaire que vous créez. Le nom doit être unique au sein de l'adresse
namespace. - 3
- L'espace de noms dans lequel l'attachement au réseau doit être créé. Si vous ne spécifiez pas de valeur, l'espace de noms
defaultest utilisé. - 4
- Une configuration du plugin CNI au format JSON.
22.2.2.2. Configuration d'un réseau supplémentaire à partir d'un manifeste YAML
La configuration d'un réseau supplémentaire est spécifiée dans un fichier de configuration YAML, comme dans l'exemple suivant :
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: <name>
spec:
config: |-
{
...
}22.2.3. Configurations pour des types de réseaux supplémentaires
Les champs de configuration spécifiques aux réseaux supplémentaires sont décrits dans les sections suivantes.
22.2.3.1. Configuration d'un réseau supplémentaire de ponts
L'objet suivant décrit les paramètres de configuration du plugin CNI bridge :
| Field | Type | Description |
|---|---|---|
|
|
|
La version de la spécification CNI. La valeur |
|
|
|
La valeur du paramètre |
|
|
| |
|
|
|
Indiquez le nom du pont virtuel à utiliser. Si l'interface du pont n'existe pas sur l'hôte, elle est créée. La valeur par défaut est |
|
|
| L'objet de configuration pour le plugin IPAM CNI. Le plugin gère l'attribution des adresses IP pour la définition des pièces jointes. |
|
|
|
La valeur |
|
|
|
La valeur |
|
|
|
La valeur |
|
|
|
Défini sur |
|
|
|
La valeur |
|
|
|
La valeur |
|
|
| Spécifiez une balise de réseau local virtuel (VLAN) sous la forme d'une valeur entière. Par défaut, aucune balise VLAN n'est attribuée. |
|
|
| Fixe l'unité de transmission maximale (MTU) à la valeur spécifiée. La valeur par défaut est définie automatiquement par le noyau. |
22.2.3.1.1. exemple de configuration de pont
L'exemple suivant configure un réseau supplémentaire nommé bridge-net:
{
"cniVersion": "0.3.1",
"name": "work-network",
"type": "bridge",
"isGateway": true,
"vlan": 2,
"ipam": {
"type": "dhcp"
}
}22.2.3.2. Configuration d'un périphérique hôte réseau supplémentaire
Spécifiez votre périphérique réseau en définissant un seul des paramètres suivants : device, hwaddr, kernelpath, ou pciBusID.
L'objet suivant décrit les paramètres de configuration du plugin CNI hôte-dispositif :
| Field | Type | Description |
|---|---|---|
|
|
|
La version de la spécification CNI. La valeur |
|
|
|
La valeur du paramètre |
|
|
|
Le nom du plugin CNI à configurer : |
|
|
|
Facultatif : Le nom de l'appareil, par exemple |
|
|
| Facultatif : L'adresse MAC du matériel de l'appareil. |
|
|
|
Facultatif : Le chemin d'accès au périphérique du noyau Linux, tel que |
|
|
|
Facultatif : L'adresse PCI du périphérique réseau, par exemple |
22.2.3.2.1. exemple de configuration d'un dispositif hôte
L'exemple suivant configure un réseau supplémentaire nommé hostdev-net:
{
"cniVersion": "0.3.1",
"name": "work-network",
"type": "host-device",
"device": "eth1"
}22.2.3.3. Configuration d'un réseau supplémentaire IPVLAN
L'objet suivant décrit les paramètres de configuration du plugin IPVLAN CNI :
| Field | Type | Description |
|---|---|---|
|
|
|
La version de la spécification CNI. La valeur |
|
|
|
La valeur du paramètre |
|
|
|
Le nom du plugin CNI à configurer : |
|
|
|
Le mode de fonctionnement du réseau virtuel. La valeur doit être |
|
|
|
L'interface Ethernet à associer à l'attachement réseau. Si l'adresse |
|
|
| Fixe l'unité de transmission maximale (MTU) à la valeur spécifiée. La valeur par défaut est définie automatiquement par le noyau. |
|
|
| L'objet de configuration pour le plugin IPAM CNI. Le plugin gère l'attribution des adresses IP pour la définition des pièces jointes.
Ne pas spécifier |
22.2.3.3.1. exemple de configuration ipvlan
L'exemple suivant configure un réseau supplémentaire nommé ipvlan-net:
{
"cniVersion": "0.3.1",
"name": "work-network",
"type": "ipvlan",
"master": "eth1",
"mode": "l3",
"ipam": {
"type": "static",
"addresses": [
{
"address": "192.168.10.10/24"
}
]
}
}22.2.3.4. Configuration d'un réseau supplémentaire MACVLAN
L'objet suivant décrit les paramètres de configuration du plugin CNI macvlan :
| Field | Type | Description |
|---|---|---|
|
|
|
La version de la spécification CNI. La valeur |
|
|
|
La valeur du paramètre |
|
|
|
Le nom du plugin CNI à configurer : |
|
|
|
Configure la visibilité du trafic sur le réseau virtuel. Doit être soit |
|
|
| L'interface réseau de l'hôte à associer à l'interface macvlan nouvellement créée. Si aucune valeur n'est spécifiée, l'interface de la route par défaut est utilisée. |
|
|
| L'unité de transmission maximale (MTU) à la valeur spécifiée. La valeur par défaut est définie automatiquement par le noyau. |
|
|
| L'objet de configuration pour le plugin IPAM CNI. Le plugin gère l'attribution des adresses IP pour la définition des pièces jointes. |
Si vous spécifiez la clé master pour la configuration du plugin, utilisez une interface réseau physique différente de celle qui est associée à votre plugin réseau principal afin d'éviter tout conflit éventuel.
22.2.3.4.1. exemple de configuration macvlan
L'exemple suivant configure un réseau supplémentaire nommé macvlan-net:
{
"cniVersion": "0.3.1",
"name": "macvlan-net",
"type": "macvlan",
"master": "eth1",
"mode": "bridge",
"ipam": {
"type": "dhcp"
}
}22.2.4. Configuration de l'attribution d'adresses IP pour un réseau supplémentaire
Le module de gestion des adresses IP (IPAM) Container Network Interface (CNI) fournit des adresses IP aux autres modules CNI.
Vous pouvez utiliser les types d'attribution d'adresses IP suivants :
- Affectation statique.
- Attribution dynamique par le biais d'un serveur DHCP. Le serveur DHCP que vous spécifiez doit être accessible depuis le réseau supplémentaire.
- Affectation dynamique via le plugin CNI de Whereabouts IPAM.
22.2.4.1. Configuration de l'attribution d'une adresse IP statique
Le tableau suivant décrit la configuration pour l'attribution d'une adresse IP statique :
| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
|
|
| Un tableau d'objets spécifiant les adresses IP à attribuer à l'interface virtuelle. Les adresses IPv4 et IPv6 sont prises en charge. |
|
|
| Un tableau d'objets spécifiant les routes à configurer dans le pod. |
|
|
| Facultatif : Un tableau d'objets spécifiant la configuration DNS. |
Le tableau addresses nécessite des objets avec les champs suivants :
| Field | Type | Description |
|---|---|---|
|
|
|
Une adresse IP et un préfixe de réseau que vous spécifiez. Par exemple, si vous spécifiez |
|
|
| Passerelle par défaut vers laquelle acheminer le trafic réseau sortant. |
| Field | Type | Description |
|---|---|---|
|
|
|
La plage d'adresses IP au format CIDR, par exemple |
|
|
| La passerelle où le trafic réseau est acheminé. |
| Field | Type | Description |
|---|---|---|
|
|
| Un tableau d'une ou plusieurs adresses IP auxquelles envoyer les requêtes DNS. |
|
|
|
Le domaine par défaut à ajouter à un nom d'hôte. Par exemple, si le domaine est défini sur |
|
|
|
Un tableau de noms de domaine à ajouter à un nom d'hôte non qualifié, tel que |
Exemple de configuration de l'attribution d'une adresse IP statique
{
"ipam": {
"type": "static",
"addresses": [
{
"address": "191.168.1.7/24"
}
]
}
}22.2.4.2. Configuration de l'attribution dynamique d'adresses IP (DHCP)
Le JSON suivant décrit la configuration pour l'attribution dynamique d'adresses IP avec DHCP.
Un pod obtient son bail DHCP d'origine lors de sa création. Le bail doit être renouvelé périodiquement par un serveur DHCP minimal déployé sur le cluster.
Pour déclencher le déploiement du serveur DHCP, vous devez créer un attachement réseau shim en modifiant la configuration de l'opérateur réseau du cluster, comme dans l'exemple suivant :
Exemple de définition de l'attachement au réseau de cales
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: dhcp-shim
namespace: default
type: Raw
rawCNIConfig: |-
{
"name": "dhcp-shim",
"cniVersion": "0.3.1",
"type": "bridge",
"ipam": {
"type": "dhcp"
}
}
# ...| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
Exemple de configuration de l'attribution dynamique d'une adresse IP (DHCP)
{
"ipam": {
"type": "dhcp"
}
}22.2.4.3. Configuration de l'attribution dynamique d'adresses IP avec Whereabouts
Le plugin Whereabouts CNI permet l'attribution dynamique d'une adresse IP à un réseau supplémentaire sans utiliser de serveur DHCP.
Le tableau suivant décrit la configuration pour l'attribution dynamique d'adresses IP avec Whereabouts :
| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
|
|
| Une adresse IP et une plage d'adresses en notation CIDR. Les adresses IP sont attribuées à partir de cette plage d'adresses. |
|
|
| Facultatif : Une liste de zéro ou plusieurs adresses IP et plages d'adresses en notation CIDR. Les adresses IP situées dans une plage d'adresses exclue ne sont pas attribuées. |
Exemple de configuration de l'attribution dynamique d'adresses IP à l'aide de Whereabouts
{
"ipam": {
"type": "whereabouts",
"range": "192.0.2.192/27",
"exclude": [
"192.0.2.192/30",
"192.0.2.196/32"
]
}
}22.2.5. Création d'un rattachement réseau supplémentaire avec l'opérateur de réseau de cluster
Le Cluster Network Operator (CNO) gère les définitions de réseaux supplémentaires. Lorsque vous spécifiez un réseau supplémentaire à créer, le CNO crée automatiquement l'objet NetworkAttachmentDefinition.
Ne modifiez pas les objets NetworkAttachmentDefinition gérés par le Cluster Network Operator. Cela risquerait de perturber le trafic sur votre réseau supplémentaire.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Facultatif : Créez l'espace de noms pour les réseaux supplémentaires :
oc create namespace <namespace_name> $ oc create namespace <namespace_name>Pour modifier la configuration du CNO, entrez la commande suivante :
$ oc edit networks.operator.openshift.io clusterModifiez le CR que vous êtes en train de créer en ajoutant la configuration pour le réseau supplémentaire que vous êtes en train de créer, comme dans l'exemple de CR suivant.
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: # ... additionalNetworks: - name: tertiary-net namespace: namespace2 type: Raw rawCNIConfig: |- { "cniVersion": "0.3.1", "name": "tertiary-net", "type": "ipvlan", "master": "eth1", "mode": "l2", "ipam": { "type": "static", "addresses": [ { "address": "192.168.1.23/24" } ] } }- Enregistrez vos modifications et quittez l'éditeur de texte pour valider vos modifications.
Vérification
Confirmez que le CNO a créé l'objet
NetworkAttachmentDefinitionen exécutant la commande suivante. Il peut y avoir un délai avant que le CNO ne crée l'objet.oc get network-attachment-definitions -n <namespace>où :
<namespace>- Spécifie l'espace de noms pour l'attachement réseau que vous avez ajouté à la configuration CNO.
Exemple de sortie
NAME AGE test-network-1 14m
22.2.6. Création d'une pièce jointe réseau supplémentaire par l'application d'un manifeste YAML
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un fichier YAML avec votre configuration réseau supplémentaire, comme dans l'exemple suivant :
apiVersion: k8s.cni.cncf.io/v1 kind: NetworkAttachmentDefinition metadata: name: next-net spec: config: |- { "cniVersion": "0.3.1", "name": "work-network", "type": "host-device", "device": "eth1", "ipam": { "type": "dhcp" } }Pour créer le réseau supplémentaire, entrez la commande suivante :
oc apply -f <file>.yamloù :
<file>- Spécifie le nom du fichier contenant le manifeste YAML.
22.3. À propos du routage et du transfert virtuels
22.3.1. À propos du routage et du transfert virtuels
Les dispositifs de routage et de transfert virtuels (VRF) combinés aux règles IP permettent de créer des domaines de routage et de transfert virtuels. La VRF réduit le nombre d'autorisations nécessaires à la CNF et offre une meilleure visibilité de la topologie des réseaux secondaires. La VRF est utilisée pour fournir une fonctionnalité multi-locataires, par exemple, lorsque chaque locataire a ses propres tables de routage et nécessite des passerelles par défaut différentes.
Les processus peuvent lier une socket au périphérique VRF. Les paquets passant par la socket liée utilisent la table de routage associée au périphérique VRF. Une caractéristique importante de la VRF est qu'elle n'affecte que le trafic de la couche 3 du modèle OSI et des couches supérieures, de sorte que les outils L2, tels que LLDP, ne sont pas concernés. Cela permet à des règles IP plus prioritaires, telles que le routage basé sur une politique, d'avoir la priorité sur les règles du dispositif VRF qui dirigent un trafic spécifique.
22.3.1.1. Avantages des réseaux secondaires pour les opérateurs de télécommunications
Dans les cas d'utilisation des télécommunications, chaque CNF peut potentiellement être connecté à plusieurs réseaux différents partageant le même espace d'adressage. Ces réseaux secondaires peuvent potentiellement entrer en conflit avec le CIDR du réseau principal du cluster. Grâce au plugin VRF de CNI, les fonctions réseau peuvent être connectées à l'infrastructure de différents clients en utilisant la même adresse IP, ce qui permet d'isoler les différents clients. Les adresses IP sont superposées à l'espace IP d'OpenShift Container Platform. Le plugin CNI VRF réduit également le nombre de permissions nécessaires à CNF et augmente la visibilité des topologies des réseaux secondaires.
22.4. Configuration de la politique multi-réseaux
En tant qu'administrateur de cluster, vous pouvez configurer le multi-réseau pour les réseaux supplémentaires. Vous pouvez spécifier une politique multi-réseaux pour les réseaux supplémentaires SR-IOV et macvlan. Les réseaux supplémentaires macvlan sont entièrement pris en charge. Les autres types de réseaux supplémentaires, tels que ipvlan, ne sont pas pris en charge.
La prise en charge de la configuration de politiques multi-réseaux pour les réseaux supplémentaires SR-IOV est une fonctionnalité de l'aperçu technologique et n'est prise en charge qu'avec les cartes d'interface réseau (NIC) du noyau. SR-IOV n'est pas pris en charge pour les applications du kit de développement du plan de données (DPDK).
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Les politiques de réseau configurées sont ignorées dans les réseaux IPv6.
22.4.1. Différences entre la politique multi-réseaux et la politique des réseaux
Bien que l'API MultiNetworkPolicy mette en œuvre l'API NetworkPolicy, il existe plusieurs différences importantes :
Vous devez utiliser l'API
MultiNetworkPolicy:apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy-
Vous devez utiliser le nom de la ressource
multi-networkpolicylorsque vous utilisez le CLI pour interagir avec les politiques multi-réseaux. Par exemple, vous pouvez afficher un objet de politique multi-réseaux avec la commandeoc get multi-networkpolicy <name>où<name>est le nom d'une politique multi-réseaux. Vous devez spécifier une annotation avec le nom de la définition de l'attachement au réseau qui définit le réseau supplémentaire macvlan ou SR-IOV :
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: annotations: k8s.v1.cni.cncf.io/policy-for: <network_name>où :
<network_name>- Spécifie le nom d'une définition de pièce jointe au réseau.
22.4.2. Activation de la politique multi-réseaux pour le cluster
En tant qu'administrateur de cluster, vous pouvez activer la prise en charge des politiques multi-réseaux sur votre cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez le fichier
multinetwork-enable-patch.yamlavec le YAML suivant :apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: useMultiNetworkPolicy: trueConfigurer le cluster pour activer la politique multi-réseaux :
$ oc patch network.operator.openshift.io cluster --type=merge --patch-file=multinetwork-enable-patch.yamlExemple de sortie
network.operator.openshift.io/cluster patched
22.4.3. Travailler avec une politique multi-réseaux
En tant qu'administrateur de cluster, vous pouvez créer, modifier, afficher et supprimer des politiques multi-réseaux.
22.4.3.1. Conditions préalables
- Vous avez activé la prise en charge des stratégies multi-réseaux pour votre cluster.
22.4.3.2. Création d'une politique multi-réseaux à l'aide de l'interface CLI
Pour définir des règles granulaires décrivant le trafic réseau entrant ou sortant autorisé pour les espaces de noms de votre cluster, vous pouvez créer une stratégie multi-réseaux.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique multi-réseaux.
Procédure
Créer une règle de politique :
Créer un fichier
<policy_name>.yaml:$ touch <policy_name>.yamloù :
<policy_name>- Spécifie le nom du fichier de stratégie multi-réseaux.
Définissez une politique multi-réseaux dans le fichier que vous venez de créer, comme dans les exemples suivants :
Refuser l'entrée de tous les pods dans tous les espaces de noms
Il s'agit d'une politique fondamentale, qui bloque tout réseau inter-pods autre que le trafic inter-pods autorisé par la configuration d'autres politiques de réseau.
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: deny-by-default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: ingress: []où :
<network_name>- Spécifie le nom d'une définition de pièce jointe au réseau.
Autoriser l'entrée de tous les pods dans le même espace de noms
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: allow-same-namespace annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: ingress: - from: - podSelector: {}où :
<network_name>- Spécifie le nom d'une définition de pièce jointe au réseau.
Autoriser le trafic entrant vers un pod à partir d'un espace de noms particulier
Cette politique autorise le trafic vers les pods étiquetés
pod-aà partir des pods fonctionnant surnamespace-y.apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: allow-traffic-pod annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-yoù :
<network_name>- Spécifie le nom d'une définition de pièce jointe au réseau.
Restreindre le trafic vers un service
Cette politique, lorsqu'elle est appliquée, garantit que tous les pods portant les étiquettes
app=bookstoreetrole=apine sont accessibles qu'aux pods portant l'étiquetteapp=bookstore. Dans cet exemple, l'application pourrait être un serveur d'API REST, marqué par les étiquettesapp=bookstoreetrole=api.Cet exemple traite des cas d'utilisation suivants :
- Restreindre le trafic d'un service aux seuls autres microservices qui doivent l'utiliser.
Restreindre les connexions à une base de données pour n'autoriser que l'application qui l'utilise.
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: api-allow annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: app: bookstore role: api ingress: - from: - podSelector: matchLabels: app: bookstoreoù :
<network_name>- Spécifie le nom d'une définition de pièce jointe au réseau.
Pour créer l'objet de politique multiréseau, entrez la commande suivante :
oc apply -f <policy_name>.yaml -n <namespace>où :
<policy_name>- Spécifie le nom du fichier de stratégie multi-réseaux.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Exemple de sortie
multinetworkpolicy.k8s.cni.cncf.io/deny-by-default created
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix de créer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir d'un formulaire dans la console web.
22.4.3.3. Modification d'une politique multi-réseaux
Vous pouvez modifier une politique multi-réseaux dans un espace de noms.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms où la politique multi-réseaux existe.
Procédure
Facultatif : Pour répertorier les objets de stratégie multi-réseaux d'un espace de noms, entrez la commande suivante :
$ oc get multi-networkpolicyoù :
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Modifier l'objet de politique multi-réseaux.
Si vous avez enregistré la définition de la stratégie multi-réseaux dans un fichier, éditez le fichier et apportez les modifications nécessaires, puis entrez la commande suivante.
$ oc apply -n <namespace> -f <policy_file>.yamloù :
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
<policy_file>- Spécifie le nom du fichier contenant la politique de réseau.
Si vous devez mettre à jour l'objet de stratégie multi-réseau directement, entrez la commande suivante :
oc edit multi-networkpolicy <nom_de_la_politique> -n <espace_de_noms>où :
<policy_name>- Spécifie le nom de la politique de réseau.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Confirmez la mise à jour de l'objet de stratégie multi-réseaux.
oc describe multi-networkpolicy <nom_de_la_politique> -n <espace_de_noms>où :
<policy_name>- Spécifie le nom de la politique multi-réseaux.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix entre éditer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir de la politique dans la console web via le menu Actions.
22.4.3.4. Visualisation des politiques multi-réseaux à l'aide de la CLI
Vous pouvez examiner les politiques multi-réseaux dans un espace de noms.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms où la politique multi-réseaux existe.
Procédure
Liste des politiques multi-réseaux dans un espace de noms :
Pour afficher les objets de stratégie multi-réseaux définis dans un espace de noms, entrez la commande suivante :
$ oc get multi-networkpolicyEn outre, il est possible d'examiner une politique multi-réseaux spécifique : Pour examiner une politique multi-réseaux spécifique, entrez la commande suivante :
oc describe multi-networkpolicy <nom_de_la_politique> -n <espace_de_noms>où :
<policy_name>- Spécifie le nom de la politique multi-réseaux à inspecter.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix d'afficher une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir d'un formulaire dans la console web.
22.4.3.5. Suppression d'une politique multi-réseaux à l'aide de la CLI
Vous pouvez supprimer une politique multi-réseaux dans un espace de noms.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms où la politique multi-réseaux existe.
Procédure
Pour supprimer un objet de stratégie multi-réseaux, entrez la commande suivante :
oc delete multi-networkpolicy <nom_de_la_politique> -n <espace_de_noms>où :
<policy_name>- Spécifie le nom de la politique multi-réseaux.
<namespace>- Facultatif : Spécifie l'espace de noms si l'objet est défini dans un espace de noms différent de l'espace de noms actuel.
Exemple de sortie
multinetworkpolicy.k8s.cni.cncf.io/default-deny deleted
Si vous vous connectez à la console web avec les privilèges cluster-admin, vous avez le choix entre supprimer une politique de réseau dans n'importe quel espace de noms du cluster directement dans YAML ou à partir de la politique dans la console web via le menu Actions.
22.4.3.6. Création d'une politique de refus de tout par défaut pour les réseaux multiples
Il s'agit d'une politique fondamentale, qui bloque tout réseau inter-pods autre que le trafic réseau autorisé par la configuration d'autres politiques de réseau déployées. Cette procédure applique une politique par défaut : deny-by-default.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique multi-réseaux.
Procédure
Créez le fichier YAML suivant qui définit une politique
deny-by-defaultpour refuser l'entrée de tous les pods dans tous les espaces de noms. Enregistrez le YAML dans le fichierdeny-by-default.yaml:apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: deny-by-default namespace: default1 annotations: k8s.v1.cni.cncf.io/policy-for: <network_name>2 spec: podSelector: {}3 ingress: []4 - 1
namespace: defaultdéploie cette politique dans l'espace de nomsdefault.- 2
podSelector:est vide, cela signifie qu'elle correspond à tous les pods. Par conséquent, la politique s'applique à tous les modules de l'espace de noms par défaut.- 3
network_name: spécifie le nom d'une définition de pièce jointe au réseau.- 4
- Aucune règle
ingressn'est spécifiée. Le trafic entrant est donc supprimé pour tous les pods.
Appliquez la politique en entrant la commande suivante :
$ oc apply -f deny-by-default.yamlExemple de sortie
multinetworkpolicy.k8s.cni.cncf.io/deny-by-default created
22.4.3.7. Création d'une stratégie multi-réseaux pour autoriser le trafic provenant de clients externes
La politique deny-by-default étant en place, vous pouvez configurer une politique qui autorise le trafic des clients externes vers un pod portant l'étiquette app=web.
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Suivez cette procédure pour configurer une politique qui autorise un service externe à partir de l'Internet public directement ou en utilisant un équilibreur de charge pour accéder au module. Le trafic n'est autorisé que vers un pod portant l'étiquette app=web.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique multi-réseaux.
Procédure
Créez une politique qui autorise le trafic provenant de l'Internet public directement ou en utilisant un équilibreur de charge pour accéder au pod. Enregistrez le YAML dans le fichier
web-allow-external.yaml:apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: web-allow-external namespace: default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: policyTypes: - Ingress podSelector: matchLabels: app: web ingress: - {}Appliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-external.yamlExemple de sortie
multinetworkpolicy.k8s.cni.cncf.io/web-allow-external created
Cette politique autorise le trafic en provenance de toutes les ressources, y compris le trafic externe, comme l'illustre le diagramme suivant :
22.4.3.8. Création d'une politique multi-réseaux autorisant le trafic vers une application à partir de tous les espaces de noms
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Suivez cette procédure pour configurer une stratégie qui autorise le trafic de tous les pods de tous les espaces de noms vers une application particulière.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique multi-réseaux.
Procédure
Créez une politique qui autorise le trafic de tous les pods dans tous les espaces de noms vers une application particulière. Enregistrez le YAML dans le fichier
web-allow-all-namespaces.yaml:apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: web-allow-all-namespaces namespace: default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: {}2 NotePar défaut, si vous ne précisez pas
namespaceSelector, aucun espace de noms n'est sélectionné, ce qui signifie que la stratégie n'autorise que le trafic provenant de l'espace de noms dans lequel la stratégie de réseau est déployée.Appliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-all-namespaces.yamlExemple de sortie
multinetworkpolicy.k8s.cni.cncf.io/web-allow-all-namespaces created
Vérification
Démarrez un service web dans l'espace de noms
defaulten entrant la commande suivante :$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour déployer une image
alpinedans l'espace de nomssecondaryet pour démarrer un shell :$ oc run test-$RANDOM --namespace=secondary --rm -i -t --image=alpine -- shExécutez la commande suivante dans l'interpréteur de commandes et observez que la demande est autorisée :
# wget -qO- --timeout=2 http://web.defaultRésultats attendus
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
22.4.3.9. Création d'une politique multi-réseaux autorisant le trafic vers une application à partir d'un espace de noms
Si vous vous connectez avec un utilisateur ayant le rôle cluster-admin, vous pouvez créer une stratégie de réseau dans n'importe quel espace de noms du cluster.
Suivez cette procédure pour configurer une politique qui autorise le trafic vers un pod avec l'étiquette app=web à partir d'un espace de noms particulier. Vous pourriez vouloir faire ceci pour :
- Restreindre le trafic vers une base de données de production aux seuls espaces de noms dans lesquels des charges de travail de production sont déployées.
- Permet aux outils de surveillance déployés dans un espace de noms particulier de récupérer les mesures de l'espace de noms actuel.
Conditions préalables
-
Votre cluster utilise un plugin réseau qui prend en charge les objets
NetworkPolicy, tel que le fournisseur de réseau OpenShift SDN avecmode: NetworkPolicy. Ce mode est le mode par défaut pour OpenShift SDN. -
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous travaillez dans l'espace de noms auquel s'applique la politique multi-réseaux.
Procédure
Créez une politique qui autorise le trafic de tous les pods dans un espace de noms particulier avec un label
purpose=production. Sauvegardez le YAML dans le fichierweb-allow-prod.yaml:apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: web-allow-prod namespace: default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: app: web1 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production2 Appliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-prod.yamlExemple de sortie
multinetworkpolicy.k8s.cni.cncf.io/web-allow-prod created
Vérification
Démarrez un service web dans l'espace de noms
defaulten entrant la commande suivante :$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour créer l'espace de noms
prod:$ oc create namespace prodExécutez la commande suivante pour étiqueter l'espace de noms
prod:$ oc label namespace/prod purpose=productionExécutez la commande suivante pour créer l'espace de noms
dev:$ oc create namespace devExécutez la commande suivante pour étiqueter l'espace de noms
dev:$ oc label namespace/dev purpose=testingExécutez la commande suivante pour déployer une image
alpinedans l'espace de nomsdevet pour démarrer un shell :$ oc run test-$RANDOM --namespace=dev --rm -i -t --image=alpine -- shExécutez la commande suivante dans l'interpréteur de commandes et observez que la demande est bloquée :
# wget -qO- --timeout=2 http://web.defaultRésultats attendus
wget: download timed outExécutez la commande suivante pour déployer une image
alpinedans l'espace de nomsprodet démarrer un shell :$ oc run test-$RANDOM --namespace=prod --rm -i -t --image=alpine -- shExécutez la commande suivante dans l'interpréteur de commandes et observez que la demande est autorisée :
# wget -qO- --timeout=2 http://web.defaultRésultats attendus
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
22.5. Attacher un pod à un réseau supplémentaire
En tant qu'utilisateur du cluster, vous pouvez attacher un pod à un réseau supplémentaire.
22.5.1. Ajouter un pod à un réseau supplémentaire
Vous pouvez ajouter un module à un réseau supplémentaire. Le pod continue à envoyer le trafic réseau normal lié au cluster sur le réseau par défaut.
Lorsqu'un module est créé, des réseaux supplémentaires lui sont rattachés. Toutefois, si un module existe déjà, il n'est pas possible d'y attacher des réseaux supplémentaires.
Le pod doit se trouver dans le même espace de noms que le réseau supplémentaire.
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Connectez-vous au cluster.
Procédure
Ajouter une annotation à l'objet
Pod. Un seul des formats d'annotation suivants peut être utilisé :Pour attacher un réseau supplémentaire sans aucune personnalisation, ajoutez une annotation avec le format suivant. Remplacez
<network>par le nom du réseau supplémentaire à associer au pod :metadata: annotations: k8s.v1.cni.cncf.io/networks: <network>[,<network>,...]1 - 1
- Pour spécifier plus d'un réseau supplémentaire, séparez chaque réseau par une virgule. N'incluez pas d'espace entre les virgules. Si vous spécifiez plusieurs fois le même réseau supplémentaire, plusieurs interfaces réseau seront attachées à ce pod.
Pour joindre un réseau supplémentaire avec des personnalisations, ajoutez une annotation avec le format suivant :
metadata: annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "<network>",1 "namespace": "<namespace>",2 "default-route": ["<default-route>"]3 } ]
Pour créer le module, entrez la commande suivante. Remplacez
<name>par le nom du module.$ oc create -f <name>.yamlFacultatif : Pour confirmer que l'annotation existe dans le CR
Pod, entrez la commande suivante, en remplaçant<name>par le nom du module.$ oc get pod <name> -o yamlDans l'exemple suivant, le pod
example-podest rattaché au réseau supplémentairenet1:$ oc get pod example-pod -o yaml apiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/networks: macvlan-bridge k8s.v1.cni.cncf.io/networks-status: |-1 [{ "name": "openshift-sdn", "interface": "eth0", "ips": [ "10.128.2.14" ], "default": true, "dns": {} },{ "name": "macvlan-bridge", "interface": "net1", "ips": [ "20.2.2.100" ], "mac": "22:2f:60:a5:f8:00", "dns": {} }] name: example-pod namespace: default spec: ... status: ...- 1
- Le paramètre
k8s.v1.cni.cncf.io/networks-statusest un tableau JSON d'objets. Chaque objet décrit l'état d'un réseau supplémentaire attaché au pod. La valeur de l'annotation est stockée sous forme de texte brut.
22.5.1.1. Spécification des options d'adressage et de routage spécifiques au pod
Lorsque vous attachez un module à un réseau supplémentaire, vous pouvez vouloir spécifier d'autres propriétés de ce réseau dans un module particulier. Cela vous permet de modifier certains aspects du routage, ainsi que de spécifier des adresses IP et des adresses MAC statiques. Pour ce faire, vous pouvez utiliser les annotations au format JSON.
Conditions préalables
- Le pod doit se trouver dans le même espace de noms que le réseau supplémentaire.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster.
Procédure
Pour ajouter un pod à un réseau supplémentaire tout en spécifiant des options d'adressage et/ou de routage, procédez comme suit :
Modifiez la définition de la ressource
Pod. Si vous modifiez une ressourcePodexistante, exécutez la commande suivante pour modifier sa définition dans l'éditeur par défaut. Remplacez<name>par le nom de la ressourcePodà modifier.oc edit pod <name> $ oc edit pod <name>Dans la définition de la ressource
Pod, ajoutez le paramètrek8s.v1.cni.cncf.io/networksau mappage du podmetadata. Le paramètrek8s.v1.cni.cncf.io/networksaccepte une chaîne JSON d'une liste d'objets référençant le nom des ressources personnalisées (CR)NetworkAttachmentDefinitionen plus de spécifier des propriétés supplémentaires.metadata: annotations: k8s.v1.cni.cncf.io/networks: '[<network>[,<network>,...]]'1 - 1
- Remplacez
<network>par un objet JSON comme indiqué dans les exemples suivants. Les guillemets simples sont obligatoires.
Dans l'exemple suivant, l'annotation spécifie l'attachement réseau qui aura la route par défaut, en utilisant le paramètre
default-route.apiVersion: v1 kind: Pod metadata: name: example-pod annotations: k8s.v1.cni.cncf.io/networks: ' { "name": "net1" }, { "name": "net2",1 "default-route": ["192.0.2.1"]2 }' spec: containers: - name: example-pod command: ["/bin/bash", "-c", "sleep 2000000000000"] image: centos/tools- 1
- La clé
nameest le nom du réseau supplémentaire à associer au pod. - 2
- La clé
default-routespécifie la valeur d'une passerelle sur laquelle le trafic doit être acheminé si aucune autre entrée de routage n'est présente dans la table de routage. Si plus d'une clédefault-routeest spécifiée, le pod ne sera pas activé.
La route par défaut permet d'acheminer vers la passerelle tout le trafic qui n'est pas spécifié dans d'autres routes.
La définition de la route par défaut sur une interface autre que l'interface réseau par défaut pour OpenShift Container Platform peut faire en sorte que le trafic prévu pour le trafic pod-to-pod soit acheminé sur une autre interface.
Pour vérifier les propriétés de routage d'un pod, la commande oc peut être utilisée pour exécuter la commande ip à l'intérieur d'un pod.
oc exec -it <nom_du_pod> -- ip route
Vous pouvez également consulter le site k8s.v1.cni.cncf.io/networks-status du pod pour savoir quel réseau supplémentaire s'est vu attribuer la route par défaut, grâce à la présence de la clé default-route dans la liste d'objets au format JSON.
Pour définir une adresse IP statique ou une adresse MAC pour un pod, vous pouvez utiliser les annotations au format JSON. Pour ce faire, vous devez créer des réseaux qui autorisent spécifiquement cette fonctionnalité. Ceci peut être spécifié dans un rawCNIConfig pour le CNO.
Modifiez le CR CNO en exécutant la commande suivante :
$ oc edit networks.operator.openshift.io cluster
Le fichier YAML suivant décrit les paramètres de configuration du CNO :
Configuration YAML de l'opérateur de réseau de cluster
name: <name>
namespace: <namespace>
rawCNIConfig: '{
...
}'
type: Raw- 1
- Indiquez un nom pour la pièce jointe réseau supplémentaire que vous créez. Le nom doit être unique au sein de l'adresse
namespace. - 2
- Indiquez l'espace de noms dans lequel créer la pièce jointe au réseau. Si vous ne spécifiez pas de valeur, l'espace de noms
defaultest utilisé. - 3
- Spécifiez la configuration du plugin CNI au format JSON, qui est basé sur le modèle suivant.
L'objet suivant décrit les paramètres de configuration pour l'utilisation d'une adresse MAC statique et d'une adresse IP à l'aide du plugin CNI macvlan :
macvlan Objet de configuration JSON du plugin CNI utilisant une adresse IP et MAC statique
{
"cniVersion": "0.3.1",
"name": "<name>",
"plugins": [{
"type": "macvlan",
"capabilities": { "ips": true },
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "static"
}
}, {
"capabilities": { "mac": true },
"type": "tuning"
}]
}- 1
- Spécifie le nom de la pièce jointe réseau supplémentaire à créer. Le nom doit être unique au sein de l'adresse
namespace. - 2
- Spécifie un tableau de configurations de plugins CNI. Le premier objet spécifie une configuration de plugin macvlan et le second objet spécifie une configuration de plugin tuning.
- 3
- Spécifie qu'une demande est faite pour activer la fonctionnalité d'adresse IP statique des capacités de configuration d'exécution du plugin CNI.
- 4
- Spécifie l'interface utilisée par le plugin macvlan.
- 5
- Spécifie qu'une demande est faite pour activer la fonctionnalité d'adresse MAC statique d'un plugin CNI.
L'attachement réseau ci-dessus peut être référencé dans une annotation au format JSON, avec des clés permettant de spécifier l'adresse IP statique et l'adresse MAC qui seront attribuées à un pod donné.
Modifier le pod avec :
oc edit pod <name> $ oc edit pod <name>macvlan Objet de configuration JSON du plugin CNI utilisant une adresse IP et MAC statique
apiVersion: v1
kind: Pod
metadata:
name: example-pod
annotations:
k8s.v1.cni.cncf.io/networks: '[
{
"name": "<name>",
"ips": [ "192.0.2.205/24" ],
"mac": "CA:FE:C0:FF:EE:00"
}
]'Les adresses IP statiques et les adresses MAC ne doivent pas nécessairement être utilisées en même temps ; vous pouvez les utiliser séparément ou ensemble.
Pour vérifier l'adresse IP et les propriétés MAC d'un module avec des réseaux supplémentaires, utilisez la commande oc pour exécuter la commande ip dans un module.
oc exec -it <nom_du_pod> -- ip a22.6. Retrait d'un pod d'un réseau supplémentaire
En tant qu'utilisateur du cluster, vous pouvez retirer un pod d'un réseau supplémentaire.
22.6.1. Retrait d'un pod d'un réseau supplémentaire
Vous ne pouvez retirer un pod d'un réseau supplémentaire qu'en supprimant le pod.
Conditions préalables
- Un réseau supplémentaire est rattaché au pod.
-
Installez le CLI OpenShift (
oc). - Connectez-vous au cluster.
Procédure
Pour supprimer le module, entrez la commande suivante :
oc delete pod <name> -n <namespace> $ oc delete pod <name> -n <namespace>-
<name>est le nom du module. -
<namespace>est l'espace de noms qui contient le pod.
-
22.7. Modification d'un réseau supplémentaire
En tant qu'administrateur de cluster, vous pouvez modifier la configuration d'un réseau supplémentaire existant.
22.7.1. Modification d'une définition supplémentaire de pièce jointe au réseau
En tant qu'administrateur de cluster, vous pouvez apporter des modifications à un réseau supplémentaire existant. Les pods existants attachés au réseau supplémentaire ne seront pas mis à jour.
Conditions préalables
- Vous avez configuré un réseau supplémentaire pour votre cluster.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour modifier un réseau supplémentaire pour votre cluster, suivez les étapes suivantes :
Exécutez la commande suivante pour modifier le CR de l'opérateur de réseau de cluster (CNO) dans votre éditeur de texte par défaut :
$ oc edit networks.operator.openshift.io cluster-
Dans la collection
additionalNetworks, mettez à jour le réseau supplémentaire avec vos modifications. - Enregistrez vos modifications et quittez l'éditeur de texte pour valider vos modifications.
Optionnel : Confirmez que le CNO a mis à jour l'objet
NetworkAttachmentDefinitionen exécutant la commande suivante. Remplacez<network-name>par le nom du réseau supplémentaire à afficher. Il peut y avoir un délai avant que le CNO ne mette à jour l'objetNetworkAttachmentDefinitionpour refléter vos changements.oc get network-attachment-definitions <networkame> -o yamlPar exemple, la sortie de console suivante affiche un objet
NetworkAttachmentDefinitionnomménet1:$ oc get network-attachment-definitions net1 -o go-template='{{printf "%s\n" .spec.config}}' { "cniVersion": "0.3.1", "type": "macvlan", "master": "ens5", "mode": "bridge", "ipam": {"type":"static","routes":[{"dst":"0.0.0.0/0","gw":"10.128.2.1"}],"addresses":[{"address":"10.128.2.100/23","gateway":"10.128.2.1"}],"dns":{"nameservers":["172.30.0.10"],"domain":"us-west-2.compute.internal","search":["us-west-2.compute.internal"]}} }
22.8. Suppression d'un réseau supplémentaire
En tant qu'administrateur de cluster, vous pouvez supprimer une pièce jointe réseau supplémentaire.
22.8.1. Suppression d'une définition supplémentaire de pièce jointe au réseau
En tant qu'administrateur de cluster, vous pouvez supprimer un réseau supplémentaire de votre cluster OpenShift Container Platform. Le réseau supplémentaire n'est pas supprimé des pods auxquels il est attaché.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour supprimer un réseau supplémentaire de votre cluster, procédez comme suit :
Modifiez le Cluster Network Operator (CNO) dans votre éditeur de texte par défaut en exécutant la commande suivante :
$ oc edit networks.operator.openshift.io clusterModifiez la CR en supprimant la configuration de la collection
additionalNetworkspour la définition de l'attachement réseau que vous supprimez.apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: additionalNetworks: []1 - 1
- Si vous supprimez le mappage de configuration pour la seule définition de pièce jointe réseau supplémentaire dans la collection
additionalNetworks, vous devez spécifier une collection vide.
- Enregistrez vos modifications et quittez l'éditeur de texte pour valider vos modifications.
Facultatif : Confirmez que le réseau supplémentaire CR a été supprimé en exécutant la commande suivante :
$ oc get network-attachment-definition --all-namespaces
22.9. Affectation d'un réseau secondaire à un VRF
22.9.1. Affectation d'un réseau secondaire à un VRF
En tant qu'administrateur de cluster, vous pouvez configurer un réseau supplémentaire pour votre domaine VRF en utilisant le plugin CNI VRF. Le réseau virtuel créé par ce plugin est associé à une interface physique que vous spécifiez.
Les applications qui utilisent les VRF doivent se lier à un périphérique spécifique. L'usage courant est d'utiliser l'option SO_BINDTODEVICE pour une socket. SO_BINDTODEVICE lie la socket à un périphérique spécifié dans le nom de l'interface passée, par exemple, eth1. Pour utiliser SO_BINDTODEVICE, l'application doit avoir les capacités de CAP_NET_RAW.
L'utilisation d'une VRF via la commande ip vrf exec n'est pas prise en charge dans les pods OpenShift Container Platform. Pour utiliser la VRF, liez les applications directement à l'interface VRF.
22.9.1.1. Création d'un attachement réseau supplémentaire avec le plugin CNI VRF
L'opérateur de réseau de cluster (CNO) gère les définitions de réseaux supplémentaires. Lorsque vous spécifiez un réseau supplémentaire à créer, le CNO crée automatiquement la ressource personnalisée (CR) NetworkAttachmentDefinition.
Ne modifiez pas les CR NetworkAttachmentDefinition gérés par l'opérateur du réseau en grappe. Cela risquerait de perturber le trafic sur votre réseau supplémentaire.
Pour créer un attachement réseau supplémentaire avec le plugin CNI VRF, suivez la procédure suivante.
Conditions préalables
- Installez le CLI (oc) de OpenShift Container Platform.
- Connectez-vous au cluster OpenShift en tant qu'utilisateur disposant des privilèges cluster-admin.
Procédure
Créez la ressource personnalisée (CR)
Networkpour l'attachement au réseau supplémentaire et insérez la configurationrawCNIConfigpour le réseau supplémentaire, comme dans l'exemple de CR suivant. Enregistrez le YAML dans le fichieradditional-network-attachment.yaml.apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: additionalNetworks: - name: test-network-1 namespace: additional-network-1 type: Raw rawCNIConfig: '{ "cniVersion": "0.3.1", "name": "macvlan-vrf", "plugins": [1 { "type": "macvlan",2 "master": "eth1", "ipam": { "type": "static", "addresses": [ { "address": "191.168.1.23/24" } ] } }, { "type": "vrf", "vrfname": "example-vrf-name",3 "table": 10014 }] }'- 1
pluginsdoit être une liste. Le premier élément de la liste doit être le réseau secondaire qui sous-tend le réseau VRF. Le deuxième élément de la liste est la configuration du plugin VRF.- 2
typedoit être réglé survrf.- 3
vrfnameest le nom du VRF auquel l'interface est assignée. S'il n'existe pas dans le pod, il est créé.- 4
- Facultatif.
tableest l'ID de la table de routage. Par défaut, le paramètretableidest utilisé. S'il n'est pas spécifié, le CNI attribue un ID de table de routage libre au VRF.
NoteVRF ne fonctionne correctement que si la ressource est de type
netdevice.Créer la ressource
Network:$ oc create -f additional-network-attachment.yamlConfirmez que le CNO a créé le CR
NetworkAttachmentDefinitionen exécutant la commande suivante. Remplacez<namespace>par l'espace de noms que vous avez spécifié lors de la configuration de l'attachement au réseau, par exempleadditional-network-1.oc get network-attachment-definitions -n <namespace>Exemple de sortie
NAME AGE additional-network-1 14mNoteIl peut y avoir un délai avant que le CNO ne crée le CR.
Vérification de la réussite de l'attachement au réseau VRF supplémentaire
Pour vérifier que le VRF CNI est correctement configuré et que l'attachement réseau supplémentaire est attaché, procédez comme suit :
- Créez un réseau qui utilise le VRF CNI.
- Attribuer le réseau à un pod.
Vérifiez que l'attachement réseau du pod est connecté au réseau supplémentaire VRF. Connectez-vous à distance au pod et exécutez la commande suivante :
$ ip vrf showExemple de sortie
Name Table ----------------------- red 10Confirmez que l'interface VRF est maître de l'interface secondaire :
$ ip linkExemple de sortie
5 : net1 : <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master red state UP mode
Chapitre 23. Réseaux matériels
23.1. À propos des réseaux matériels de virtualisation des E/S à racine unique (SR-IOV)
La spécification SR-IOV (Single Root I/O Virtualization) est une norme pour un type d'affectation de périphérique PCI qui peut partager un périphérique unique avec plusieurs pods.
SR-IOV peut segmenter un dispositif de réseau conforme, reconnu sur le nœud hôte comme une fonction physique (PF), en plusieurs fonctions virtuelles (VF). La VF est utilisée comme n'importe quel autre périphérique réseau. Le pilote de périphérique réseau SR-IOV pour le périphérique détermine comment la VF est exposée dans le conteneur :
-
netdevicepilote : Un périphérique réseau normal du noyau dans le sitenetnsdu conteneur -
vfio-pciconducteur : Un dispositif de caractère monté dans le conteneur
Vous pouvez utiliser les périphériques réseau SR-IOV avec des réseaux supplémentaires sur votre cluster OpenShift Container Platform installé sur une infrastructure bare metal ou Red Hat OpenStack Platform (RHOSP) pour les applications qui nécessitent une bande passante élevée ou une faible latence.
Vous pouvez configurer des politiques multi-réseaux pour les réseaux SR-IOV. Il s'agit d'un aperçu technologique et les réseaux supplémentaires SR-IOV ne sont pris en charge qu'avec les cartes réseau du noyau. Ils ne sont pas pris en charge pour les applications du kit de développement du plan de données (DPDK).
La création de politiques multi-réseaux sur les réseaux SR-IOV risque de ne pas offrir les mêmes performances aux applications que les réseaux SR-IOV sur lesquels aucune politique multi-réseaux n'est configurée.
Les politiques multi-réseaux pour le réseau SR-IOV sont une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Vous pouvez activer le SR-IOV sur un nœud à l'aide de la commande suivante :
$ oc label node <node_name> feature.node.kubernetes.io/network-sriov.capable="true"23.1.1. Composants qui gèrent les périphériques de réseau SR-IOV
L'opérateur de réseau SR-IOV crée et gère les composants de la pile SR-IOV. Il remplit les fonctions suivantes :
- Orchestrer la découverte et la gestion des périphériques de réseau SR-IOV
-
Génère
NetworkAttachmentDefinitiondes ressources personnalisées pour l'interface de réseau de conteneurs SR-IOV (CNI) - Crée et met à jour la configuration du plugin de l'appareil réseau SR-IOV
-
Crée des ressources personnalisées spécifiques au nœud
SriovNetworkNodeState -
Met à jour le champ
spec.interfacesdans chaque ressource personnaliséeSriovNetworkNodeState
L'opérateur fournit les éléments suivants :
- Démon de configuration du réseau SR-IOV
- Ensemble de démons déployés sur les nœuds de travail lors du démarrage de l'opérateur de réseau SR-IOV. Le démon est responsable de la découverte et de l'initialisation des périphériques réseau SR-IOV dans le cluster.
- Webhook de l'opérateur de réseau SR-IOV
- Un webhook de contrôleur d'admission dynamique qui valide la ressource personnalisée de l'opérateur et définit les valeurs par défaut appropriées pour les champs non définis.
- SR-IOV Injecteur de ressources réseau
-
Un webhook de contrôleur d'admission dynamique qui fournit une fonctionnalité pour patcher les spécifications des pods Kubernetes avec des demandes et des limites pour les ressources réseau personnalisées telles que les VF SR-IOV. L'injecteur de ressources réseau SR-IOV ajoute automatiquement le champ
resourceau premier conteneur d'un pod. - Plugin de périphérique de réseau SR-IOV
- Un plugin de périphérique qui découvre, annonce et alloue des ressources de fonction virtuelle (VF) de réseau SR-IOV. Les plugins de périphérique sont utilisés dans Kubernetes pour permettre l'utilisation de ressources limitées, généralement dans des dispositifs physiques. Les plugins de périphérique permettent au planificateur de Kubernetes de connaître la disponibilité des ressources, de sorte que le planificateur peut programmer des pods sur des nœuds disposant de ressources suffisantes.
- SR-IOV Plugin CNI
- Un plugin CNI qui attache les interfaces VF allouées par le plugin de périphérique réseau SR-IOV directement à un pod.
- SR-IOV InfiniBand CNI plugin
- Un plugin CNI qui attache les interfaces InfiniBand (IB) VF allouées par le plugin de périphérique réseau SR-IOV directement dans un pod.
L'injecteur de ressources du réseau SR-IOV et le webhook de l'opérateur du réseau SR-IOV sont activés par défaut et peuvent être désactivés en modifiant le site default SriovOperatorConfig CR. Soyez prudent lorsque vous désactivez le webhook du contrôleur d'admission de l'opérateur de réseau SR-IOV. Vous pouvez désactiver le webhook dans des circonstances spécifiques, telles que le dépannage, ou si vous souhaitez utiliser des périphériques non pris en charge.
23.1.1.1. Plates-formes prises en charge
L'opérateur de réseau SR-IOV est pris en charge sur les plates-formes suivantes :
- Métal nu
- Plate-forme Red Hat OpenStack (RHOSP)
23.1.1.2. Dispositifs pris en charge
OpenShift Container Platform prend en charge les contrôleurs d'interface réseau suivants :
| Fabricant | Model | ID du vendeur | ID de l'appareil |
|---|---|---|---|
| Broadcom | BCM57414 | 14e4 | 16d7 |
| Broadcom | BCM57508 | 14e4 | 1750 |
| Intel | X710 | 8086 | 1572 |
| Intel | XL710 | 8086 | 1583 |
| Intel | XXV710 | 8086 | 158b |
| Intel | E810-CQDA2 | 8086 | 1592 |
| Intel | E810-2CQDA2 | 8086 | 1592 |
| Intel | E810-XXVDA2 | 8086 | 159b |
| Intel | E810-XXVDA4 | 8086 | 1593 |
| Mellanox | Famille MT27700 [ConnectX-4] | 15b3 | 1013 |
| Mellanox | Famille MT27710 [ConnectX-4 Lx] | 15b3 | 1015 |
| Mellanox | Famille MT27800 [ConnectX-5] | 15b3 | 1017 |
| Mellanox | Famille MT28880 [ConnectX-5 Ex] | 15b3 | 1019 |
| Mellanox | Famille MT28908 [ConnectX-6] | 15b3 | 101b |
| Mellanox | Famille MT2892 [ConnectX-6 Dx] | 15b3 | 101d |
| Mellanox | Famille MT2894 [ConnectX-6 Lx] | 15b3 | 101f |
| Mellanox | MT42822 BlueField-2 en mode NIC ConnectX-6 | 15b3 | a2d6 |
| Pensando [1] | DSC-25 carte de services distribués 25G à double port pour pilote ionique | 0x1dd8 | 0x1002 |
| Pensando [1] | DSC-100 carte de services distribués 100G à double port pour pilote ionique | 0x1dd8 | 0x1003 |
| Silicom | Famille STS | 8086 | 1591 |
- OpenShift SR-IOV est pris en charge, mais vous devez définir une adresse MAC (media access control) statique, Virtual Function (VF), à l'aide du fichier de configuration CNI SR-IOV lorsque vous utilisez SR-IOV.
Pour obtenir la liste la plus récente des cartes prises en charge et des versions compatibles d'OpenShift Container Platform, consultez la matrice de prise en charge des réseaux matériels SR-IOV (Single Root I/O Virtualization) et PTP d'OpenShift.
23.1.1.3. Découverte automatisée des dispositifs de réseau SR-IOV
L'opérateur de réseau SR-IOV recherche dans votre cluster les périphériques réseau compatibles SR-IOV sur les nœuds de travail. L'opérateur crée et met à jour une ressource personnalisée (CR) SriovNetworkNodeState pour chaque nœud de travailleur qui fournit un périphérique réseau SR-IOV compatible.
Le CR porte le même nom que le nœud de travail. La liste status.interfaces fournit des informations sur les périphériques réseau d'un nœud.
Ne pas modifier un objet SriovNetworkNodeState. L'Opérateur crée et gère ces ressources automatiquement.
23.1.1.3.1. Exemple d'objet SriovNetworkNodeState
Le fichier YAML suivant est un exemple d'objet SriovNetworkNodeState créé par l'opérateur de réseau SR-IOV :
Un objet SriovNetworkNodeState
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodeState
metadata:
name: node-25
namespace: openshift-sriov-network-operator
ownerReferences:
- apiVersion: sriovnetwork.openshift.io/v1
blockOwnerDeletion: true
controller: true
kind: SriovNetworkNodePolicy
name: default
spec:
dpConfigVersion: "39824"
status:
interfaces:
- deviceID: "1017"
driver: mlx5_core
mtu: 1500
name: ens785f0
pciAddress: "0000:18:00.0"
totalvfs: 8
vendor: 15b3
- deviceID: "1017"
driver: mlx5_core
mtu: 1500
name: ens785f1
pciAddress: "0000:18:00.1"
totalvfs: 8
vendor: 15b3
- deviceID: 158b
driver: i40e
mtu: 1500
name: ens817f0
pciAddress: 0000:81:00.0
totalvfs: 64
vendor: "8086"
- deviceID: 158b
driver: i40e
mtu: 1500
name: ens817f1
pciAddress: 0000:81:00.1
totalvfs: 64
vendor: "8086"
- deviceID: 158b
driver: i40e
mtu: 1500
name: ens803f0
pciAddress: 0000:86:00.0
totalvfs: 64
vendor: "8086"
syncStatus: Succeeded23.1.1.4. Exemple d'utilisation d'une fonction virtuelle dans un pod
Vous pouvez exécuter une application d'accès direct à la mémoire à distance (RDMA) ou un kit de développement du plan de données (DPDK) dans un pod auquel est attaché un SR-IOV VF.
Cet exemple montre un pod utilisant une fonction virtuelle (VF) en mode RDMA :
Pod qui utilise le mode RDMA
apiVersion: v1
kind: Pod
metadata:
name: rdma-app
annotations:
k8s.v1.cni.cncf.io/networks: sriov-rdma-mlnx
spec:
containers:
- name: testpmd
image: <RDMA_image>
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 0
capabilities:
add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]
command: ["sleep", "infinity"]L'exemple suivant montre un pod avec un VF en mode DPDK :
Pod spec qui utilise le mode DPDK
apiVersion: v1
kind: Pod
metadata:
name: dpdk-app
annotations:
k8s.v1.cni.cncf.io/networks: sriov-dpdk-net
spec:
containers:
- name: testpmd
image: <DPDK_image>
securityContext:
runAsUser: 0
capabilities:
add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
memory: "1Gi"
cpu: "2"
hugepages-1Gi: "4Gi"
requests:
memory: "1Gi"
cpu: "2"
hugepages-1Gi: "4Gi"
command: ["sleep", "infinity"]
volumes:
- name: hugepage
emptyDir:
medium: HugePages23.1.1.5. Bibliothèque DPDK à utiliser avec les applications de conteneurs
Une bibliothèque optionnelle, app-netutil, fournit plusieurs méthodes API pour collecter des informations réseau sur un pod à partir d'un conteneur s'exécutant dans ce pod.
Cette bibliothèque peut aider à intégrer les fonctions virtuelles SR-IOV (VF) en mode DPDK (Data Plane Development Kit) dans le conteneur. La bibliothèque fournit à la fois une API Golang et une API C.
Actuellement, trois méthodes API sont mises en œuvre :
GetCPUInfo()- Cette fonction détermine quels sont les processeurs disponibles pour le conteneur et renvoie la liste.
GetHugepages()-
Cette fonction détermine la quantité de mémoire de page énorme demandée dans la spécification
Podpour chaque conteneur et renvoie les valeurs. GetInterfaces()- Cette fonction détermine l'ensemble des interfaces du conteneur et renvoie la liste. La valeur de retour comprend le type d'interface et les données spécifiques à chaque interface.
Le dépôt de la bibliothèque comprend un exemple de fichier Docker pour construire une image de conteneur, dpdk-app-centos. L'image de conteneur peut exécuter l'un des exemples d'applications DPDK suivants, en fonction d'une variable d'environnement dans la spécification du pod : l2fwd l3wd testpmd l'image de conteneur fournit un exemple d'intégration de la bibliothèque app-netutil dans l'image de conteneur elle-même. La bibliothèque peut également être intégrée dans un conteneur d'initialisation. Ce dernier peut collecter les données requises et les transmettre à une charge de travail DPDK existante.
23.1.1.6. Injection de ressources dans des pages volumineuses pour l'API descendante
Lorsqu'une spécification de pod inclut une demande de ressources ou une limite pour les pages volumineuses, l'injecteur de ressources réseau ajoute automatiquement des champs API descendants à la spécification de pod afin de fournir les informations sur les pages volumineuses au conteneur.
L'injecteur de ressources réseau ajoute un volume nommé podnetinfo et monté sur /etc/podnetinfo pour chaque conteneur du module. Le volume utilise l'API Downward et inclut un fichier pour les demandes de pages énormes et les limites. La convention de dénomination des fichiers est la suivante :
-
/etc/podnetinfo/hugepages_1G_request_<container-name> -
/etc/podnetinfo/hugepages_1G_limit_<container-name> -
/etc/podnetinfo/hugepages_2M_request_<container-name> -
/etc/podnetinfo/hugepages_2M_limit_<container-name>
Les chemins spécifiés dans la liste précédente sont compatibles avec la bibliothèque app-netutil. Par défaut, la bibliothèque est configurée pour rechercher des informations sur les ressources dans le répertoire /etc/podnetinfo. Si vous choisissez de spécifier manuellement les éléments du chemin d'accès à l'API descendante, la bibliothèque app-netutil recherche les chemins d'accès suivants en plus des chemins d'accès de la liste précédente.
-
/etc/podnetinfo/hugepages_request -
/etc/podnetinfo/hugepages_limit -
/etc/podnetinfo/hugepages_1G_request -
/etc/podnetinfo/hugepages_1G_limit -
/etc/podnetinfo/hugepages_2M_request -
/etc/podnetinfo/hugepages_2M_limit
Comme pour les chemins que l'injecteur de ressources réseau peut créer, les chemins de la liste précédente peuvent éventuellement se terminer par un suffixe _<container-name>.
23.1.3. Prochaines étapes
- Installation de l'opérateur de réseau SR-IOV
- Optionnel : Configuration de l'opérateur de réseau SR-IOV
- Configuration d'un périphérique de réseau SR-IOV
- Si vous utilisez OpenShift Virtualization : Connexion d'une machine virtuelle à un réseau SR-IOV
- Configuration de l'attachement à un réseau SR-IOV
- Ajout d'un pod à un réseau supplémentaire SR-IOV
23.2. Installation de l'opérateur de réseau SR-IOV
Vous pouvez installer l'opérateur de réseau SR-IOV (Single Root I/O Virtualization) sur votre cluster pour gérer les périphériques et les pièces jointes du réseau SR-IOV.
23.2.1. Installation de l'opérateur de réseau SR-IOV
En tant qu'administrateur de cluster, vous pouvez installer l'opérateur de réseau SR-IOV en utilisant la CLI d'OpenShift Container Platform ou la console web.
23.2.1.1. CLI : Installation de l'opérateur de réseau SR-IOV
En tant qu'administrateur de cluster, vous pouvez installer l'Opérateur à l'aide de la CLI.
Conditions préalables
- Un cluster installé sur du matériel bare-metal avec des nœuds dont le matériel prend en charge le SR-IOV.
-
Installez le CLI OpenShift (
oc). -
Un compte avec des privilèges
cluster-admin.
Procédure
Pour créer l'espace de noms
openshift-sriov-network-operator, entrez la commande suivante :$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator annotations: workload.openshift.io/allowed: management EOFPour créer un OperatorGroup CR, entrez la commande suivante :
$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator EOFS'abonner à l'opérateur du réseau SR-IOV.
Exécutez la commande suivante pour obtenir la version majeure et mineure d'OpenShift Container Platform. Cette information est nécessaire pour la valeur
channeldans l'étape suivante.$ OC_VERSION=$(oc version -o yaml | grep openshiftVersion | \ grep -o '[0-9]*[.][0-9]*' | head -1)Pour créer un CR d'abonnement pour l'opérateur de réseau SR-IOV, entrez la commande suivante :
$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subscription namespace: openshift-sriov-network-operator spec: channel: "${OC_VERSION}" name: sriov-network-operator source: redhat-operators sourceNamespace: openshift-marketplace EOF
Pour vérifier que l'opérateur est installé, entrez la commande suivante :
$ oc get csv -n openshift-sriov-network-operator \ -o custom-columns=Name:.metadata.name,Phase:.status.phaseExemple de sortie
Name Phase sriov-network-operator.4.12.0-202310121402 Succeeded
23.2.1.2. Console Web : Installation de l'opérateur de réseau SR-IOV
En tant qu'administrateur de cluster, vous pouvez installer l'Opérateur à l'aide de la console web.
Conditions préalables
- Un cluster installé sur du matériel bare-metal avec des nœuds dont le matériel prend en charge le SR-IOV.
-
Installez le CLI OpenShift (
oc). -
Un compte avec des privilèges
cluster-admin.
Procédure
Installer l'opérateur de réseau SR-IOV :
- Dans la console web d'OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Sélectionnez SR-IOV Network Operator dans la liste des opérateurs disponibles, puis cliquez sur Install.
- Sur la page Install Operator page, sous Installed Namespacesélectionnez Operator recommended Namespace.
- Cliquez Install.
Vérifiez que l'opérateur de réseau SR-IOV a été installé avec succès :
- Naviguez jusqu'à l'écran Operators → Installed Operators page.
Veiller à ce que SR-IOV Network Operator soit listé dans le projet openshift-sriov-network-operator avec un Status de InstallSucceeded.
NotePendant l'installation, un opérateur peut afficher un Failed un état d'erreur. Si l'installation réussit par la suite avec un InstallSucceeded vous pouvez ignorer le message Failed message.
Si l'opérateur n'apparaît pas tel qu'il a été installé, il convient de poursuivre le dépannage :
- Inspecter les Operator Subscriptions et Install Plans et les onglets pour détecter toute défaillance ou erreur dans le cadre de la Status.
-
Naviguez jusqu'à l'écran Workloads → Pods et vérifiez les journaux des pods du projet
openshift-sriov-network-operator. Vérifiez l'espace de noms du fichier YAML. Si l'annotation est manquante, vous pouvez ajouter l'annotation
workload.openshift.io/allowed=managementà l'espace de noms de l'opérateur à l'aide de la commande suivante :$ oc annotate ns/openshift-sriov-network-operator workload.openshift.io/allowed=managementNotePour les clusters OpenShift à nœud unique, l'annotation
workload.openshift.io/allowed=managementest requise pour l'espace de noms.
23.2.2. Prochaines étapes
- Optionnel : Configuration de l'opérateur de réseau SR-IOV
23.3. Configuration de l'opérateur de réseau SR-IOV
L'opérateur de réseau SR-IOV (Single Root I/O Virtualization) gère les périphériques réseau SR-IOV et les attachements réseau dans votre cluster.
23.3.1. Configuration de l'opérateur de réseau SR-IOV
Il n'est normalement pas nécessaire de modifier la configuration de l'opérateur de réseau SR-IOV. La configuration par défaut est recommandée pour la plupart des cas d'utilisation. Ne procédez à la modification de la configuration que si le comportement par défaut de l'opérateur n'est pas compatible avec votre cas d'utilisation.
L'opérateur du réseau SR-IOV ajoute la ressource SriovOperatorConfig.sriovnetwork.openshift.io CustomResourceDefinition. L'opérateur crée automatiquement une ressource personnalisée SriovOperatorConfig (CR) nommée default dans l'espace de noms openshift-sriov-network-operator.
Le CR default contient la configuration de l'opérateur du réseau SR-IOV pour votre cluster. Pour modifier la configuration de l'opérateur, vous devez modifier ce CR.
23.3.1.1. SR-IOV Network Operator config custom resource (ressource personnalisée de configuration de l'opérateur de réseau)
Les champs de la ressource personnalisée sriovoperatorconfig sont décrits dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
|
Spécifie le nom de l'instance de l'opérateur de réseau SR-IOV. La valeur par défaut est |
|
|
|
Spécifie l'espace de noms de l'instance de l'opérateur de réseau SR-IOV. La valeur par défaut est |
|
|
| Spécifie la sélection de nœuds pour contrôler la planification du démon de configuration du réseau SR-IOV sur les nœuds sélectionnés. Par défaut, ce champ n'est pas défini et l'opérateur déploie le daemon SR-IOV Network Config sur les nœuds de travail. |
|
|
|
Indique s'il faut désactiver ou activer le processus de vidange du nœud lorsque vous appliquez une nouvelle stratégie pour configurer la carte d'interface réseau sur un nœud. La définition de ce champ sur
Pour les clusters à un seul nœud, définissez ce champ sur |
|
|
|
Indique s'il faut activer ou désactiver le jeu de démons Network Resources Injector. Par défaut, ce champ est défini sur |
|
|
|
Indique s'il faut activer ou désactiver le jeu de démons webhook du contrôleur d'admission de l'opérateur. Par défaut, ce champ est défini sur |
|
|
|
Spécifie le niveau de verbosité des journaux de l'opérateur. La valeur |
23.3.1.2. À propos de l'injecteur de ressources réseau
L'injecteur de ressources réseau est une application de contrôleur d'admission dynamique Kubernetes. Il fournit les capacités suivantes :
- Mutation des demandes et des limites de ressources dans une spécification de pod pour ajouter un nom de ressource SR-IOV conformément à une annotation de définition d'attachement au réseau SR-IOV.
-
Mutation d'une spécification de pod avec un volume d'API descendant pour exposer les annotations de pod, les étiquettes et les demandes et limites de pages énormes. Les conteneurs qui s'exécutent dans le pod peuvent accéder aux informations exposées en tant que fichiers sous le chemin
/etc/podnetinfo.
Par défaut, l'injecteur de ressources réseau est activé par l'opérateur de réseau SR-IOV et s'exécute en tant que démon sur tous les nœuds du plan de contrôle. Voici un exemple de pods d'injecteur de ressources réseau fonctionnant dans un cluster avec trois nœuds de plan de contrôle :
$ oc get pods -n openshift-sriov-network-operatorExemple de sortie
NAME READY STATUS RESTARTS AGE
network-resources-injector-5cz5p 1/1 Running 0 10m
network-resources-injector-dwqpx 1/1 Running 0 10m
network-resources-injector-lktz5 1/1 Running 0 10m23.3.1.3. À propos du webhook du contrôleur d'admission de l'opérateur de réseau SR-IOV
Le webhook du contrôleur d'admission de l'opérateur de réseau SR-IOV est une application de contrôleur d'admission dynamique Kubernetes. Il fournit les capacités suivantes :
-
Validation du CR
SriovNetworkNodePolicylors de sa création ou de sa mise à jour. -
Mutation du CR
SriovNetworkNodePolicyen fixant la valeur par défaut des champspriorityetdeviceTypelors de la création ou de la mise à jour du CR.
Par défaut, le webhook du contrôleur d'admission de l'opérateur de réseau SR-IOV est activé par l'opérateur et s'exécute en tant que démon sur tous les nœuds du plan de contrôle.
Soyez prudent lorsque vous désactivez le webhook du contrôleur d'admission de l'opérateur de réseau SR-IOV. Vous pouvez désactiver le webhook dans des circonstances spécifiques, telles que le dépannage, ou si vous souhaitez utiliser des périphériques non pris en charge.
Voici un exemple de pods de webhooks du contrôleur d'admission de l'opérateur fonctionnant dans un cluster avec trois nœuds de plan de contrôle :
$ oc get pods -n openshift-sriov-network-operatorExemple de sortie
NAME READY STATUS RESTARTS AGE
operator-webhook-9jkw6 1/1 Running 0 16m
operator-webhook-kbr5p 1/1 Running 0 16m
operator-webhook-rpfrl 1/1 Running 0 16m23.3.1.4. À propos des sélecteurs de nœuds personnalisés
Le démon SR-IOV Network Config découvre et configure les périphériques réseau SR-IOV sur les nœuds de la grappe. Par défaut, il est déployé sur tous les nœuds worker du cluster. Vous pouvez utiliser des étiquettes de nœuds pour spécifier sur quels nœuds le démon SR-IOV Network Config s'exécute.
23.3.1.5. Désactivation ou activation de l'injecteur de ressources réseau
Pour désactiver ou activer l'injecteur de ressources réseau, qui est activé par défaut, suivez la procédure suivante.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Vous devez avoir installé l'opérateur de réseau SR-IOV.
Procédure
Définissez le champ
enableInjector. Remplacez<value>parfalsepour désactiver la fonctionnalité ou partruepour l'activer.$ oc patch sriovoperatorconfig default \ --type=merge -n openshift-sriov-network-operator \ --patch '{ "spec": { "enableInjector": <value> } }'AstuceVous pouvez également appliquer le YAML suivant pour mettre à jour l'opérateur :
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableInjector: <value>
23.3.1.6. Désactivation ou activation du webhook du contrôleur d'admission de l'opérateur de réseau SR-IOV
Pour désactiver ou activer le webhook du contrôleur d'admission, qui est activé par défaut, suivez la procédure suivante.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Vous devez avoir installé l'opérateur de réseau SR-IOV.
Procédure
Définissez le champ
enableOperatorWebhook. Remplacez<value>parfalsepour désactiver la fonctionnalité ou partruepour l'activer :$ oc patch sriovoperatorconfig default --type=merge \ -n openshift-sriov-network-operator \ --patch '{ "spec": { "enableOperatorWebhook": <value> } }'AstuceVous pouvez également appliquer le YAML suivant pour mettre à jour l'opérateur :
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableOperatorWebhook: <value>
23.3.1.7. Configuration d'un NodeSelector personnalisé pour le démon SR-IOV Network Config
Le démon SR-IOV Network Config découvre et configure les périphériques réseau SR-IOV sur les nœuds de la grappe. Par défaut, il est déployé sur tous les nœuds worker du cluster. Vous pouvez utiliser des étiquettes de nœuds pour spécifier sur quels nœuds le démon SR-IOV Network Config s'exécute.
Pour spécifier les nœuds où le démon SR-IOV Network Config est déployé, suivez la procédure suivante.
Lorsque vous mettez à jour le champ configDaemonNodeSelector, le démon SR-IOV Network Config est recréé sur chaque nœud sélectionné. Pendant que le démon est recréé, les utilisateurs du cluster ne peuvent pas appliquer de nouvelle politique de nœuds SR-IOV Network ni créer de nouveaux pods SR-IOV.
Procédure
Pour mettre à jour le sélecteur de nœuds de l'opérateur, entrez la commande suivante :
$ oc patch sriovoperatorconfig default --type=json \ -n openshift-sriov-network-operator \ --patch '[{ "op": "replace", "path": "/spec/configDaemonNodeSelector", "value": {<node_label>} }]'Remplacez
<node_label>par une étiquette à appliquer comme dans l'exemple suivant :"node-role.kubernetes.io/worker": "".AstuceVous pouvez également appliquer le YAML suivant pour mettre à jour l'opérateur :
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: configDaemonNodeSelector: <node_label>
23.3.1.8. Configuration de l'opérateur de réseau SR-IOV pour les installations à nœud unique
Par défaut, l'opérateur de réseau SR-IOV draine les charges de travail d'un nœud avant chaque changement de politique. L'opérateur effectue cette action pour s'assurer qu'aucune charge de travail n'utilise les fonctions virtuelles avant la reconfiguration.
Pour les installations sur un seul nœud, il n'y a pas d'autres nœuds pour recevoir les charges de travail. Par conséquent, l'opérateur doit être configuré pour ne pas drainer les charges de travail du nœud unique.
Après avoir exécuté la procédure suivante pour désactiver les charges de travail drainantes, vous devez supprimer toute charge de travail utilisant une interface réseau SR-IOV avant de modifier toute stratégie de nœud de réseau SR-IOV.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Vous devez avoir installé l'opérateur de réseau SR-IOV.
Procédure
Pour attribuer la valeur
trueau champdisableDrain, entrez la commande suivante :$ oc patch sriovoperatorconfig default --type=merge \ -n openshift-sriov-network-operator \ --patch '{ "spec": { "disableDrain": true } }'AstuceVous pouvez également appliquer le YAML suivant pour mettre à jour l'opérateur :
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: disableDrain: true
23.3.1.9. Déploiement de l'opérateur SR-IOV pour les plans de contrôle hébergés
Les plans de contrôle hébergés sont une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Après avoir configuré et déployé votre cluster de services d'hébergement, vous pouvez créer un abonnement à l'opérateur SR-IOV sur un cluster hébergé. Le pod SR-IOV s'exécute sur les machines de travail plutôt que sur le plan de contrôle.
Conditions préalables
Vous avez configuré et déployé le cluster hébergé.
Procédure
Créer un espace de noms et un groupe d'opérateurs :
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operatorCréer un abonnement à l'opérateur SR-IOV :
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: "4.12" name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: s/qe-app-registry/redhat-operators sourceNamespace: openshift-marketplace
Vérification
Pour vérifier que l'opérateur SR-IOV est prêt, exécutez la commande suivante et affichez le résultat :
$ oc get csv -n openshift-sriov-network-operatorExemple de sortie
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.12.0-202211021237 SR-IOV Network Operator 4.12.0-202211021237 sriov-network-operator.4.12.0-202210290517 SucceededPour vérifier que les pods SR-IOV sont déployés, exécutez la commande suivante :
$ oc get pods -n openshift-sriov-network-operator
23.3.2. Prochaines étapes
23.4. Configuration d'un périphérique de réseau SR-IOV
Vous pouvez configurer un dispositif de virtualisation d'E/S à racine unique (SR-IOV) dans votre cluster.
23.4.1. Objet de configuration du nœud de réseau SR-IOV
Vous spécifiez la configuration du dispositif de réseau SR-IOV pour un nœud en créant une stratégie de nœud de réseau SR-IOV. L'objet API de la stratégie fait partie du groupe API sriovnetwork.openshift.io.
Le fichier YAML suivant décrit une politique de nœuds de réseau SR-IOV :
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: <name>
namespace: openshift-sriov-network-operator
spec:
resourceName: <sriov_resource_name>
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
priority: <priority>
mtu: <mtu>
needVhostNet: false
numVfs: <num>
nicSelector:
vendor: "<vendor_code>"
deviceID: "<device_id>"
pfNames: ["<pf_name>", ...]
rootDevices: ["<pci_bus_id>", ...]
netFilter: "<filter_string>"
deviceType: <device_type>
isRdma: false
linkType: <link_type>
eSwitchMode: "switchdev" - 1
- Nom de l'objet ressource personnalisé.
- 2
- L'espace de noms dans lequel l'opérateur de réseau SR-IOV est installé.
- 3
- Le nom de la ressource du plugin de périphérique réseau SR-IOV. Vous pouvez créer plusieurs stratégies de nœuds de réseau SR-IOV pour un nom de ressource.
Lorsque vous spécifiez un nom, veillez à utiliser l'expression syntaxique acceptée
^[a-zA-Z0-9_] $dans le formulaireresourceName. - 4
- Le sélecteur de nœuds indique les nœuds à configurer. Seuls les périphériques de réseau SR-IOV sur les nœuds sélectionnés sont configurés. Le plugin SR-IOV Container Network Interface (CNI) et le plugin de périphérique sont déployés sur les nœuds sélectionnés uniquement.
- 5
- Facultatif : La priorité est une valeur entière comprise entre
0et99. Plus la valeur est petite, plus la priorité est élevée. Par exemple, une priorité de10est plus élevée que celle de99. La valeur par défaut est99. - 6
- Facultatif : L'unité de transmission maximale (MTU) de la fonction virtuelle. La valeur maximale du MTU peut varier selon les modèles de contrôleurs d'interface réseau (NIC).
- 7
- Facultatif : Définissez
needVhostNetsurtruepour monter le périphérique/dev/vhost-netdans le pod. Utilisez le périphérique/dev/vhost-netmonté avec le kit de développement du plan de données (DPDK) pour transmettre le trafic à la pile réseau du noyau. - 8
- Le nombre de fonctions virtuelles (VF) à créer pour le périphérique de réseau physique SR-IOV. Pour un contrôleur d'interface réseau (NIC) Intel, le nombre de VF ne peut pas être supérieur au nombre total de VF pris en charge par le périphérique. Pour un NIC Mellanox, le nombre de VF ne peut pas être supérieur à
128. - 9
- Le sélecteur NIC identifie le dispositif à configurer par l'opérateur. Il n'est pas nécessaire de spécifier des valeurs pour tous les paramètres. Il est recommandé d'identifier le périphérique réseau avec suffisamment de précision pour éviter de sélectionner un périphérique par inadvertance.
Si vous spécifiez
rootDevices, vous devez également spécifier une valeur pourvendor,deviceIDoupfNames. Si vous spécifiezpfNamesetrootDevicesen même temps, assurez-vous qu'ils se réfèrent au même appareil. Si vous spécifiez une valeur pournetFilter, il n'est pas nécessaire de spécifier d'autres paramètres car un ID de réseau est unique. - 10
- Facultatif : Le code hexadécimal du fournisseur de l'appareil de réseau SR-IOV. Les seules valeurs autorisées sont
8086et15b3. - 11
- Facultatif : Le code hexadécimal du périphérique du réseau SR-IOV. Par exemple,
101best l'ID d'un périphérique Mellanox ConnectX-6. - 12
- Facultatif : Un tableau d'un ou plusieurs noms de fonctions physiques (PF) pour l'appareil.
- 13
- Facultatif : Un tableau d'une ou plusieurs adresses de bus PCI pour le PF de l'appareil. Indiquer l'adresse au format suivant :
0000:02:00.1. - 14
- Facultatif : Le filtre réseau spécifique à la plateforme. La seule plateforme prise en charge est Red Hat OpenStack Platform (RHOSP). Les valeurs acceptables utilisent le format suivant :
openstack/NetworkID:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx. Remplacezxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxpar la valeur du fichier de métadonnées/var/config/openstack/latest/network_data.json. - 15
- Facultatif : Le type de pilote pour les fonctions virtuelles. Les seules valeurs autorisées sont
netdeviceetvfio-pci. La valeur par défaut estnetdevice.Pour qu'une carte d'interface réseau Mellanox fonctionne en mode DPDK sur des nœuds métalliques nus, utilisez le type de pilote
netdeviceet définissezisRdmacommetrue. - 16
- Facultatif : Permet d'activer ou non le mode d'accès direct à la mémoire à distance (RDMA). La valeur par défaut est
false.Si le paramètre
isRdmaest réglé surtrue, vous pouvez continuer à utiliser le VF compatible RDMA comme un périphérique réseau normal. Un périphérique peut être utilisé dans l'un ou l'autre mode.Définissez
isRdmasurtrueetneedVhostNetsurtruepour configurer une carte d'interface réseau Mellanox à utiliser avec les applications Fast Datapath DPDK. - 17
- Optionnel : Le type de lien pour les VF. La valeur par défaut est
ethpour Ethernet. Remplacez cette valeur par "ib" pour InfiniBand.Lorsque
linkTypeest défini surib,isRdmaest automatiquement défini surtruepar le webhook de l'opérateur de réseau SR-IOV. LorsquelinkTypeest défini surib,deviceTypene doit pas être défini survfio-pci.Ne pas définir linkType sur 'eth' pour SriovNetworkNodePolicy, car cela peut conduire à un nombre incorrect de périphériques disponibles rapportés par le plugin de périphérique.
- 18
- Facultatif : Pour activer le délestage matériel, le champ "eSwitchMode" doit être défini sur
"switchdev".
23.4.1.1. Exemples de configuration de nœuds de réseau SR-IOV
L'exemple suivant décrit la configuration d'un dispositif InfiniBand :
Exemple de configuration d'un dispositif InfiniBand
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-ib-net-1
namespace: openshift-sriov-network-operator
spec:
resourceName: ibnic1
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 4
nicSelector:
vendor: "15b3"
deviceID: "101b"
rootDevices:
- "0000:19:00.0"
linkType: ib
isRdma: trueL'exemple suivant décrit la configuration d'un périphérique réseau SR-IOV dans une machine virtuelle RHOSP :
Exemple de configuration d'un dispositif SR-IOV dans une machine virtuelle
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-sriov-net-openstack-1
namespace: openshift-sriov-network-operator
spec:
resourceName: sriovnic1
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 1
nicSelector:
vendor: "15b3"
deviceID: "101b"
netFilter: "openstack/NetworkID:ea24bd04-8674-4f69-b0ee-fa0b3bd20509" - 1
- Le champ
numVfsest toujours défini sur1lors de la configuration de la stratégie de réseau de nœuds pour une machine virtuelle. - 2
- Le champ
netFilterdoit faire référence à un ID de réseau lorsque la machine virtuelle est déployée sur RHOSP. Les valeurs valides pournetFiltersont disponibles à partir d'un objetSriovNetworkNodeState.
23.4.1.2. Partitionnement des fonctions virtuelles (VF) pour les dispositifs SR-IOV
Dans certains cas, vous pouvez souhaiter répartir les fonctions virtuelles (VF) d'une même fonction physique (PF) dans plusieurs pools de ressources. Par exemple, vous pouvez vouloir que certaines fonctions virtuelles se chargent avec le pilote par défaut et que les autres se chargent avec le pilote vfio-pci. Dans un tel déploiement, le sélecteur pfNames de votre ressource personnalisée (CR) SriovNetworkNodePolicy peut être utilisé pour spécifier une plage de VF pour un pool en utilisant le format suivant : <pfname>#<first_vf>-<last_vf>.
Par exemple, le YAML suivant montre le sélecteur pour une interface nommée netpf0 avec les VF 2 et 7:
pfNames: ["netpf0#2-7"]-
netpf0est le nom de l'interface PF. -
2est le premier indice VF (basé sur 0) qui est inclus dans la plage. -
7est le dernier indice VF (basé sur 0) qui est inclus dans la plage.
Il est possible de sélectionner des VF dans la même CP en utilisant des CR de polices différentes si les conditions suivantes sont remplies :
-
La valeur
numVfsdoit être identique pour les polices qui sélectionnent la même CP. -
L'indice VF doit être compris entre
0et<numVfs>-1. Par exemple, si vous avez une police dont la valeurnumVfsest définie sur8, la valeur<first_vf>ne doit pas être inférieure à0, et la valeur<last_vf>ne doit pas être supérieure à7. - Les fourchettes de valeurs des différentes politiques ne doivent pas se chevaucher.
-
L'adresse
<first_vf>ne doit pas être plus grande que l'adresse<last_vf>.
L'exemple suivant illustre le partitionnement des cartes réseau pour un périphérique SR-IOV.
La politique policy-net-1 définit un pool de ressources net-1 qui contient le VF 0 de PF netpf0 avec le pilote VF par défaut. La politique policy-net-1-dpdk définit un pool de ressources net-1-dpdk qui contient les VF 8 à 15 de la PF netpf0 avec le pilote VF vfio.
Politique policy-net-1:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-net-1
namespace: openshift-sriov-network-operator
spec:
resourceName: net1
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 16
nicSelector:
pfNames: ["netpf0#0-0"]
deviceType: netdevice
Politique policy-net-1-dpdk:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-net-1-dpdk
namespace: openshift-sriov-network-operator
spec:
resourceName: net1dpdk
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 16
nicSelector:
pfNames: ["netpf0#8-15"]
deviceType: vfio-pciVérification de la réussite du partitionnement de l'interface
Confirmez que l'interface est partitionnée en fonctions virtuelles (VF) pour le périphérique SR-IOV en exécutant la commande suivante.
ip link show <interface> - 1
- Remplacez
<interface>par l'interface que vous avez spécifiée lors du partitionnement en VF pour le périphérique SR-IOV, par exemple,ens3f1.
Exemple de sortie
5: ens3f1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 3c:fd:fe:d1:bc:01 brd ff:ff:ff:ff:ff:ff
vf 0 link/ether 5a:e7:88:25:ea:a0 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 1 link/ether 3e:1d:36:d7:3d:49 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 2 link/ether ce:09:56:97:df:f9 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 3 link/ether 5e:91:cf:88:d1:38 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
vf 4 link/ether e6:06:a1:96:2f:de brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off23.4.2. Configuration des périphériques de réseau SR-IOV
L'opérateur de réseau SR-IOV ajoute la ressource SriovNetworkNodePolicy.sriovnetwork.openshift.io CustomResourceDefinition à OpenShift Container Platform. Vous pouvez configurer un périphérique réseau SR-IOV en créant une ressource personnalisée (CR) SriovNetworkNodePolicy.
Lors de l'application de la configuration spécifiée dans un objet SriovNetworkNodePolicy, l'opérateur SR-IOV peut vidanger les nœuds et, dans certains cas, les redémarrer.
L'application d'une modification de configuration peut prendre plusieurs minutes.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Vous avez installé l'opérateur de réseau SR-IOV.
- Vous avez suffisamment de nœuds disponibles dans votre cluster pour gérer la charge de travail expulsée des nœuds épuisés.
- Vous n'avez sélectionné aucun nœud du plan de contrôle pour la configuration des équipements du réseau SR-IOV.
Procédure
-
Créez un objet
SriovNetworkNodePolicy, puis enregistrez le YAML dans le fichier<name>-sriov-node-network.yaml. Remplacez<name>par le nom de cette configuration. -
Facultatif : Étiqueter les nœuds de cluster compatibles SR-IOV avec
SriovNetworkNodePolicy.Spec.NodeSelectors'ils ne le sont pas déjà. Pour plus d'informations sur l'étiquetage des nœuds, voir "Understanding how to update labels on nodes". Créer l'objet
SriovNetworkNodePolicy:oc create -f <name>-sriov-node-network.yamloù
<name>spécifie le nom de cette configuration.Après l'application de la mise à jour de la configuration, tous les pods de l'espace de noms
sriov-network-operatorpassent à l'étatRunning.Pour vérifier que le dispositif de réseau SR-IOV est configuré, entrez la commande suivante. Remplacez
<node_name>par le nom d'un nœud avec le dispositif de réseau SR-IOV que vous venez de configurer.oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'
23.4.3. Dépannage de la configuration SR-IOV
Après avoir suivi la procédure de configuration d'un périphérique de réseau SR-IOV, les sections suivantes traitent de certaines conditions d'erreur.
Pour afficher l'état des nœuds, exécutez la commande suivante :
oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name>
où : <node_name> indique le nom d'un nœud doté d'un dispositif de réseau SR-IOV.
Sortie d'erreur : Impossible d'allouer de la mémoire
"lastSyncError": "write /sys/bus/pci/devices/0000:3b:00.1/sriov_numvfs: cannot allocate memory"Lorsqu'un nœud indique qu'il ne peut pas allouer de mémoire, vérifiez les éléments suivants :
- Confirmez que les paramètres SR-IOV globaux sont activés dans le BIOS du nœud.
- Confirmez que VT-d est activé dans le BIOS du nœud.
23.4.4. Affectation d'un réseau SR-IOV à un VRF
En tant qu'administrateur de cluster, vous pouvez affecter une interface réseau SR-IOV à votre domaine VRF en utilisant le plugin CNI VRF.
Pour ce faire, ajoutez la configuration VRF au paramètre facultatif metaPlugins de la ressource SriovNetwork.
Les applications qui utilisent les VRF doivent se lier à un périphérique spécifique. L'usage courant est d'utiliser l'option SO_BINDTODEVICE pour une socket. SO_BINDTODEVICE lie la socket à un périphérique spécifié dans le nom de l'interface passée, par exemple, eth1. Pour utiliser SO_BINDTODEVICE, l'application doit avoir les capacités de CAP_NET_RAW.
L'utilisation d'une VRF via la commande ip vrf exec n'est pas prise en charge dans les pods OpenShift Container Platform. Pour utiliser la VRF, liez les applications directement à l'interface VRF.
23.4.4.1. Création d'un attachement réseau SR-IOV supplémentaire avec le plugin CNI VRF
L'opérateur de réseau SR-IOV gère les définitions de réseaux supplémentaires. Lorsque vous indiquez un réseau SR-IOV supplémentaire à créer, l'opérateur de réseau SR-IOV crée automatiquement la ressource personnalisée (CR) NetworkAttachmentDefinition.
Ne modifiez pas les ressources personnalisées NetworkAttachmentDefinition gérées par l'opérateur de réseau SR-IOV. Cela pourrait perturber le trafic sur votre réseau supplémentaire.
Pour créer un attachement réseau SR-IOV supplémentaire avec le plugin CNI VRF, suivez la procédure suivante.
Conditions préalables
- Installez le CLI (oc) de OpenShift Container Platform.
- Connectez-vous au cluster OpenShift Container Platform en tant qu'utilisateur disposant des privilèges cluster-admin.
Procédure
Créez la ressource personnalisée (CR)
SriovNetworkpour l'attachement supplémentaire au réseau SR-IOV et insérez la configurationmetaPlugins, comme dans l'exemple de CR suivant. Enregistrez le YAML dans le fichiersriov-network-attachment.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: example-network namespace: additional-sriov-network-1 spec: ipam: | { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "routes": [{ "dst": "0.0.0.0/0" }], "gateway": "10.56.217.1" } vlan: 0 resourceName: intelnics metaPlugins : | { "type": "vrf",1 "vrfname": "example-vrf-name"2 }Créer la ressource
SriovNetwork:$ oc create -f sriov-network-attachment.yaml
Vérification de la création de la CR NetworkAttachmentDefinition
Confirmez que l'opérateur du réseau SR-IOV a créé le CR
NetworkAttachmentDefinitionen exécutant la commande suivante.oc get network-attachment-definitions -n <namespace>1 - 1
- Remplacez
<namespace>par l'espace de noms que vous avez spécifié lors de la configuration de l'attachement au réseau, par exemple,additional-sriov-network-1.
Exemple de sortie
NAME AGE additional-sriov-network-1 14mNoteIl peut y avoir un délai avant que l'opérateur du réseau SR-IOV ne crée le CR.
Vérification de la réussite de l'attachement au réseau SR-IOV supplémentaire
Pour vérifier que le VRF CNI est correctement configuré et que l'attachement réseau SR-IOV supplémentaire est attaché, procédez comme suit :
- Créer un réseau SR-IOV qui utilise la VRF CNI.
- Attribuer le réseau à un pod.
Vérifiez que l'attachement réseau du pod est connecté au réseau supplémentaire SR-IOV. Connectez-vous à distance au pod et exécutez la commande suivante :
$ ip vrf showExemple de sortie
Name Table ----------------------- red 10Confirmez que l'interface VRF est maître de l'interface secondaire :
$ ip linkExemple de sortie
... 5: net1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master red state UP mode ...
23.4.5. Prochaines étapes
23.5. Configuration d'une connexion au réseau Ethernet SR-IOV
Vous pouvez configurer une connexion réseau Ethernet pour un périphérique de virtualisation d'E/S à racine unique (SR-IOV) dans le cluster.
23.5.1. Objet de configuration de l'appareil Ethernet
Vous pouvez configurer un périphérique de réseau Ethernet en définissant un objet SriovNetwork.
Le fichier YAML suivant décrit un objet SriovNetwork:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: <name>
namespace: openshift-sriov-network-operator
spec:
resourceName: <sriov_resource_name>
networkNamespace: <target_namespace>
vlan: <vlan>
spoofChk: "<spoof_check>"
ipam: |-
{}
linkState: <link_state>
maxTxRate: <max_tx_rate>
minTxRate: <min_tx_rate>
vlanQoS: <vlan_qos>
trust: "<trust_vf>"
capabilities: <capabilities> - 1
- Un nom pour l'objet. L'opérateur de réseau SR-IOV crée un objet
NetworkAttachmentDefinitionportant le même nom. - 2
- L'espace de noms dans lequel l'opérateur de réseau SR-IOV est installé.
- 3
- La valeur du paramètre
spec.resourceNamede l'objetSriovNetworkNodePolicyqui définit le matériel SR-IOV pour ce réseau supplémentaire. - 4
- L'espace de noms cible pour l'objet
SriovNetwork. Seuls les pods de l'espace de noms cible peuvent s'attacher au réseau supplémentaire. - 5
- Facultatif : Un ID de réseau local virtuel (VLAN) pour le réseau supplémentaire. La valeur entière doit être comprise entre
0et4095. La valeur par défaut est0. - 6
- Facultatif : Le mode de vérification de l'usurpation d'identité du VF. Les valeurs autorisées sont les chaînes
"on"et"off".ImportantVous devez mettre la valeur que vous indiquez entre guillemets, sinon l'objet est rejeté par l'opérateur de réseau SR-IOV.
- 7
- Un objet de configuration pour le plugin IPAM CNI sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition de l'attachement.
- 8
- Facultatif : L'état de la liaison de la fonction virtuelle (VF). Les valeurs autorisées sont
enable,disableetauto. - 9
- Facultatif : Vitesse de transmission maximale, en Mbps, pour le VF.
- 10
- Facultatif : Un taux de transmission minimum, en Mbps, pour le VF. Cette valeur doit être inférieure ou égale à la vitesse de transmission maximale.Note
Les cartes réseau Intel ne prennent pas en charge le paramètre
minTxRate. Pour plus d'informations, voir BZ#1772847. - 11
- Facultatif : Un niveau de priorité IEEE 802.1p pour le VF. La valeur par défaut est
0. - 12
- Facultatif : Le mode de confiance du VF. Les valeurs autorisées sont les chaînes
"on"et"off".ImportantVous devez mettre la valeur que vous indiquez entre guillemets, sinon l'opérateur de réseau SR-IOV rejette l'objet.
- 13
- Facultatif : Les capacités à configurer pour ce réseau supplémentaire. Vous pouvez spécifier
"{ "ips": true }"pour activer la prise en charge des adresses IP ou"{ "mac": true }"pour activer la prise en charge des adresses MAC.
23.5.1.1. Configuration de l'attribution d'adresses IP pour un réseau supplémentaire
Le module de gestion des adresses IP (IPAM) Container Network Interface (CNI) fournit des adresses IP aux autres modules CNI.
Vous pouvez utiliser les types d'attribution d'adresses IP suivants :
- Affectation statique.
- Attribution dynamique par le biais d'un serveur DHCP. Le serveur DHCP que vous spécifiez doit être accessible depuis le réseau supplémentaire.
- Affectation dynamique via le plugin CNI de Whereabouts IPAM.
23.5.1.1.1. Configuration de l'attribution d'une adresse IP statique
Le tableau suivant décrit la configuration pour l'attribution d'une adresse IP statique :
| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
|
|
| Un tableau d'objets spécifiant les adresses IP à attribuer à l'interface virtuelle. Les adresses IPv4 et IPv6 sont prises en charge. |
|
|
| Un tableau d'objets spécifiant les routes à configurer dans le pod. |
|
|
| Facultatif : Un tableau d'objets spécifiant la configuration DNS. |
Le tableau addresses nécessite des objets avec les champs suivants :
| Field | Type | Description |
|---|---|---|
|
|
|
Une adresse IP et un préfixe de réseau que vous spécifiez. Par exemple, si vous spécifiez |
|
|
| Passerelle par défaut vers laquelle acheminer le trafic réseau sortant. |
| Field | Type | Description |
|---|---|---|
|
|
|
La plage d'adresses IP au format CIDR, par exemple |
|
|
| La passerelle où le trafic réseau est acheminé. |
| Field | Type | Description |
|---|---|---|
|
|
| Un tableau d'une ou plusieurs adresses IP auxquelles envoyer les requêtes DNS. |
|
|
|
Le domaine par défaut à ajouter à un nom d'hôte. Par exemple, si le domaine est défini sur |
|
|
|
Un tableau de noms de domaine à ajouter à un nom d'hôte non qualifié, tel que |
Exemple de configuration de l'attribution d'une adresse IP statique
{
"ipam": {
"type": "static",
"addresses": [
{
"address": "191.168.1.7/24"
}
]
}
}23.5.1.1.2. Configuration de l'attribution dynamique d'adresses IP (DHCP)
Le JSON suivant décrit la configuration pour l'attribution dynamique d'adresses IP avec DHCP.
Un pod obtient son bail DHCP d'origine lors de sa création. Le bail doit être renouvelé périodiquement par un serveur DHCP minimal déployé sur le cluster.
L'opérateur réseau SR-IOV ne crée pas de déploiement de serveur DHCP ; l'opérateur réseau du cluster est responsable de la création du déploiement minimal de serveur DHCP.
Pour déclencher le déploiement du serveur DHCP, vous devez créer un attachement réseau shim en modifiant la configuration de l'opérateur réseau du cluster, comme dans l'exemple suivant :
Exemple de définition de l'attachement au réseau de cales
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: dhcp-shim
namespace: default
type: Raw
rawCNIConfig: |-
{
"name": "dhcp-shim",
"cniVersion": "0.3.1",
"type": "bridge",
"ipam": {
"type": "dhcp"
}
}
# ...| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
Exemple de configuration de l'attribution dynamique d'une adresse IP (DHCP)
{
"ipam": {
"type": "dhcp"
}
}23.5.1.1.3. Configuration de l'attribution dynamique d'adresses IP avec Whereabouts
Le plugin Whereabouts CNI permet l'attribution dynamique d'une adresse IP à un réseau supplémentaire sans utiliser de serveur DHCP.
Le tableau suivant décrit la configuration pour l'attribution dynamique d'adresses IP avec Whereabouts :
| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
|
|
| Une adresse IP et une plage d'adresses en notation CIDR. Les adresses IP sont attribuées à partir de cette plage d'adresses. |
|
|
| Facultatif : Une liste de zéro ou plusieurs adresses IP et plages d'adresses en notation CIDR. Les adresses IP situées dans une plage d'adresses exclue ne sont pas attribuées. |
Exemple de configuration de l'attribution dynamique d'adresses IP à l'aide de Whereabouts
{
"ipam": {
"type": "whereabouts",
"range": "192.0.2.192/27",
"exclude": [
"192.0.2.192/30",
"192.0.2.196/32"
]
}
}23.5.2. Configuration du réseau supplémentaire SR-IOV
Vous pouvez configurer un réseau supplémentaire qui utilise le matériel SR-IOV en créant un objet SriovNetwork. Lorsque vous créez un objet SriovNetwork, l'opérateur de réseau SR-IOV crée automatiquement un objet NetworkAttachmentDefinition.
Ne pas modifier ou supprimer un objet SriovNetwork s'il est rattaché à un pod en état running.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un objet
SriovNetwork, puis enregistrez le fichier YAML dans le fichier<name>.yaml, où<name>est le nom de ce réseau supplémentaire. La spécification de l'objet peut ressembler à l'exemple suivant :apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: attach1 namespace: openshift-sriov-network-operator spec: resourceName: net1 networkNamespace: project2 ipam: |- { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "gateway": "10.56.217.1" }Pour créer l'objet, entrez la commande suivante :
$ oc create -f <name>.yamloù
<name>indique le nom du réseau supplémentaire.Facultatif : Pour confirmer l'existence de l'objet
NetworkAttachmentDefinitionassocié à l'objetSriovNetworkcréé à l'étape précédente, entrez la commande suivante. Remplacez<namespace>par le networkNamespace que vous avez spécifié dans l'objetSriovNetwork.oc get net-attach-def -n <namespace>
23.5.3. Prochaines étapes
23.6. Configuration d'une connexion au réseau InfiniBand SR-IOV
Vous pouvez configurer une connexion réseau InfiniBand (IB) pour un périphérique de virtualisation d'E/S à racine unique (SR-IOV) dans le cluster.
23.6.1. Objet de configuration du dispositif InfiniBand
Vous pouvez configurer un périphérique réseau InfiniBand (IB) en définissant un objet SriovIBNetwork.
Le fichier YAML suivant décrit un objet SriovIBNetwork:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovIBNetwork
metadata:
name: <name>
namespace: openshift-sriov-network-operator
spec:
resourceName: <sriov_resource_name>
networkNamespace: <target_namespace>
ipam: |-
{}
linkState: <link_state>
capabilities: <capabilities> - 1
- Un nom pour l'objet. L'opérateur de réseau SR-IOV crée un objet
NetworkAttachmentDefinitionportant le même nom. - 2
- L'espace de noms dans lequel l'opérateur SR-IOV est installé.
- 3
- La valeur du paramètre
spec.resourceNamede l'objetSriovNetworkNodePolicyqui définit le matériel SR-IOV pour ce réseau supplémentaire. - 4
- L'espace de noms cible pour l'objet
SriovIBNetwork. Seuls les pods de l'espace de noms cible peuvent s'attacher au périphérique réseau. - 5
- Facultatif : Un objet de configuration pour le plugin IPAM CNI sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition de l'attachement.
- 6
- Facultatif : L'état de la liaison de la fonction virtuelle (VF). Les valeurs autorisées sont
enable,disableetauto. - 7
- Facultatif : Les capacités à configurer pour ce réseau. Vous pouvez spécifier
"{ "ips": true }"pour activer la prise en charge des adresses IP ou"{ "infinibandGUID": true }"pour activer la prise en charge des identificateurs uniques globaux (GUID) de l'IB.
23.6.1.1. Configuration de l'attribution d'adresses IP pour un réseau supplémentaire
Le module de gestion des adresses IP (IPAM) Container Network Interface (CNI) fournit des adresses IP aux autres modules CNI.
Vous pouvez utiliser les types d'attribution d'adresses IP suivants :
- Affectation statique.
- Attribution dynamique par le biais d'un serveur DHCP. Le serveur DHCP que vous spécifiez doit être accessible depuis le réseau supplémentaire.
- Affectation dynamique via le plugin CNI de Whereabouts IPAM.
23.6.1.1.1. Configuration de l'attribution d'une adresse IP statique
Le tableau suivant décrit la configuration pour l'attribution d'une adresse IP statique :
| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
|
|
| Un tableau d'objets spécifiant les adresses IP à attribuer à l'interface virtuelle. Les adresses IPv4 et IPv6 sont prises en charge. |
|
|
| Un tableau d'objets spécifiant les routes à configurer dans le pod. |
|
|
| Facultatif : Un tableau d'objets spécifiant la configuration DNS. |
Le tableau addresses nécessite des objets avec les champs suivants :
| Field | Type | Description |
|---|---|---|
|
|
|
Une adresse IP et un préfixe de réseau que vous spécifiez. Par exemple, si vous spécifiez |
|
|
| Passerelle par défaut vers laquelle acheminer le trafic réseau sortant. |
| Field | Type | Description |
|---|---|---|
|
|
|
La plage d'adresses IP au format CIDR, par exemple |
|
|
| La passerelle où le trafic réseau est acheminé. |
| Field | Type | Description |
|---|---|---|
|
|
| Un tableau d'une ou plusieurs adresses IP auxquelles envoyer les requêtes DNS. |
|
|
|
Le domaine par défaut à ajouter à un nom d'hôte. Par exemple, si le domaine est défini sur |
|
|
|
Un tableau de noms de domaine à ajouter à un nom d'hôte non qualifié, tel que |
Exemple de configuration de l'attribution d'une adresse IP statique
{
"ipam": {
"type": "static",
"addresses": [
{
"address": "191.168.1.7/24"
}
]
}
}23.6.1.1.2. Configuration de l'attribution dynamique d'adresses IP (DHCP)
Le JSON suivant décrit la configuration pour l'attribution dynamique d'adresses IP avec DHCP.
Un pod obtient son bail DHCP d'origine lors de sa création. Le bail doit être renouvelé périodiquement par un serveur DHCP minimal déployé sur le cluster.
Pour déclencher le déploiement du serveur DHCP, vous devez créer un attachement réseau shim en modifiant la configuration de l'opérateur réseau du cluster, comme dans l'exemple suivant :
Exemple de définition de l'attachement au réseau de cales
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: dhcp-shim
namespace: default
type: Raw
rawCNIConfig: |-
{
"name": "dhcp-shim",
"cniVersion": "0.3.1",
"type": "bridge",
"ipam": {
"type": "dhcp"
}
}
# ...| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
Exemple de configuration de l'attribution dynamique d'une adresse IP (DHCP)
{
"ipam": {
"type": "dhcp"
}
}23.6.1.1.3. Configuration de l'attribution dynamique d'adresses IP avec Whereabouts
Le plugin Whereabouts CNI permet l'attribution dynamique d'une adresse IP à un réseau supplémentaire sans utiliser de serveur DHCP.
Le tableau suivant décrit la configuration pour l'attribution dynamique d'adresses IP avec Whereabouts :
| Field | Type | Description |
|---|---|---|
|
|
|
Le type d'adresse IPAM. La valeur |
|
|
| Une adresse IP et une plage d'adresses en notation CIDR. Les adresses IP sont attribuées à partir de cette plage d'adresses. |
|
|
| Facultatif : Une liste de zéro ou plusieurs adresses IP et plages d'adresses en notation CIDR. Les adresses IP situées dans une plage d'adresses exclue ne sont pas attribuées. |
Exemple de configuration de l'attribution dynamique d'adresses IP à l'aide de Whereabouts
{
"ipam": {
"type": "whereabouts",
"range": "192.0.2.192/27",
"exclude": [
"192.0.2.192/30",
"192.0.2.196/32"
]
}
}23.6.2. Configuration du réseau supplémentaire SR-IOV
Vous pouvez configurer un réseau supplémentaire qui utilise le matériel SR-IOV en créant un objet SriovIBNetwork. Lorsque vous créez un objet SriovIBNetwork, l'opérateur de réseau SR-IOV crée automatiquement un objet NetworkAttachmentDefinition.
Ne pas modifier ou supprimer un objet SriovIBNetwork s'il est rattaché à un pod en état running.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un objet
SriovIBNetwork, puis enregistrez le fichier YAML dans le fichier<name>.yaml, où<name>est le nom de ce réseau supplémentaire. La spécification de l'objet peut ressembler à l'exemple suivant :apiVersion: sriovnetwork.openshift.io/v1 kind: SriovIBNetwork metadata: name: attach1 namespace: openshift-sriov-network-operator spec: resourceName: net1 networkNamespace: project2 ipam: |- { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "gateway": "10.56.217.1" }Pour créer l'objet, entrez la commande suivante :
$ oc create -f <name>.yamloù
<name>indique le nom du réseau supplémentaire.Facultatif : Pour confirmer l'existence de l'objet
NetworkAttachmentDefinitionassocié à l'objetSriovIBNetworkcréé à l'étape précédente, entrez la commande suivante. Remplacez<namespace>par le networkNamespace que vous avez spécifié dans l'objetSriovIBNetwork.oc get net-attach-def -n <namespace>
23.6.3. Prochaines étapes
23.7. Ajout d'un pod à un réseau supplémentaire SR-IOV
Vous pouvez ajouter un pod à un réseau existant de virtualisation d'E/S à racine unique (SR-IOV).
23.7.1. Configuration de l'exécution pour une pièce jointe au réseau
Lors de l'attachement d'un module à un réseau supplémentaire, vous pouvez spécifier une configuration d'exécution afin d'effectuer des personnalisations spécifiques pour le module. Par exemple, vous pouvez demander une adresse matérielle MAC spécifique.
Vous spécifiez la configuration d'exécution en définissant une annotation dans la spécification du pod. La clé de l'annotation est k8s.v1.cni.cncf.io/networks, et elle accepte un objet JSON qui décrit la configuration d'exécution.
23.7.1.1. Configuration de l'exécution pour un attachement SR-IOV basé sur Ethernet
Le JSON suivant décrit les options de configuration de la durée d'exécution pour un accessoire de réseau SR-IOV basé sur Ethernet.
[
{
"name": "<name>",
"mac": "<mac_address>",
"ips": ["<cidr_range>"]
}
]- 1
- Le nom du CR de définition de l'attachement au réseau SR-IOV.
- 2
- Facultatif : L'adresse MAC de l'appareil SR-IOV qui est allouée à partir du type de ressource défini dans le CR de définition de l'attachement au réseau SR-IOV. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "mac": true }dans l'objetSriovNetwork. - 3
- Facultatif : adresses IP pour le périphérique SR-IOV allouées à partir du type de ressource défini dans la CR de définition de l'attachement au réseau SR-IOV. Les adresses IPv4 et IPv6 sont prises en charge. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "ips": true }dans l'objetSriovNetwork.
Exemple de configuration d'exécution
apiVersion: v1
kind: Pod
metadata:
name: sample-pod
annotations:
k8s.v1.cni.cncf.io/networks: |-
[
{
"name": "net1",
"mac": "20:04:0f:f1:88:01",
"ips": ["192.168.10.1/24", "2001::1/64"]
}
]
spec:
containers:
- name: sample-container
image: <image>
imagePullPolicy: IfNotPresent
command: ["sleep", "infinity"]23.7.1.2. Configuration de l'exécution pour un attachement SR-IOV basé sur InfiniBand
Le JSON suivant décrit les options de configuration de la durée d'exécution pour un attachement réseau SR-IOV basé sur InfiniBand.
[
{
"name": "<network_attachment>",
"infiniband-guid": "<guid>",
"ips": ["<cidr_range>"]
}
]- 1
- Le nom du CR de définition de l'attachement au réseau SR-IOV.
- 2
- Le GUID InfiniBand pour le périphérique SR-IOV. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "infinibandGUID": true }dans l'objetSriovIBNetwork. - 3
- Les adresses IP pour le dispositif SR-IOV qui est alloué à partir du type de ressource défini dans le CR de définition de l'attachement au réseau SR-IOV. Les adresses IPv4 et IPv6 sont prises en charge. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "ips": true }dans l'objetSriovIBNetwork.
Exemple de configuration d'exécution
apiVersion: v1
kind: Pod
metadata:
name: sample-pod
annotations:
k8s.v1.cni.cncf.io/networks: |-
[
{
"name": "ib1",
"infiniband-guid": "c2:11:22:33:44:55:66:77",
"ips": ["192.168.10.1/24", "2001::1/64"]
}
]
spec:
containers:
- name: sample-container
image: <image>
imagePullPolicy: IfNotPresent
command: ["sleep", "infinity"]23.7.2. Ajouter un pod à un réseau supplémentaire
Vous pouvez ajouter un module à un réseau supplémentaire. Le pod continue à envoyer le trafic réseau normal lié au cluster sur le réseau par défaut.
Lorsqu'un module est créé, des réseaux supplémentaires lui sont rattachés. Toutefois, si un module existe déjà, il n'est pas possible d'y attacher des réseaux supplémentaires.
Le pod doit se trouver dans le même espace de noms que le réseau supplémentaire.
L'injecteur de ressources réseau SR-IOV ajoute automatiquement le champ resource au premier conteneur d'un module.
Si vous utilisez un contrôleur d'interface réseau (NIC) Intel en mode DPDK (Data Plane Development Kit), seul le premier conteneur de votre pod est configuré pour accéder au NIC. Votre réseau supplémentaire SR-IOV est configuré pour le mode DPDK si deviceType est défini sur vfio-pci dans l'objet SriovNetworkNodePolicy.
Vous pouvez contourner ce problème en vous assurant que le conteneur qui a besoin d'accéder au NIC est le premier conteneur défini dans l'objet Pod ou en désactivant l'injecteur de ressources réseau. Pour plus d'informations, voir BZ#1990953.
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Connectez-vous au cluster.
- Installer l'opérateur SR-IOV.
-
Créez un objet
SriovNetworkou un objetSriovIBNetworkpour y attacher le pod.
Procédure
Ajouter une annotation à l'objet
Pod. Un seul des formats d'annotation suivants peut être utilisé :Pour attacher un réseau supplémentaire sans aucune personnalisation, ajoutez une annotation avec le format suivant. Remplacez
<network>par le nom du réseau supplémentaire à associer au pod :metadata: annotations: k8s.v1.cni.cncf.io/networks: <network>[,<network>,...]1 - 1
- Pour spécifier plus d'un réseau supplémentaire, séparez chaque réseau par une virgule. N'incluez pas d'espace entre les virgules. Si vous spécifiez plusieurs fois le même réseau supplémentaire, plusieurs interfaces réseau seront attachées à ce pod.
Pour joindre un réseau supplémentaire avec des personnalisations, ajoutez une annotation avec le format suivant :
metadata: annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "<network>",1 "namespace": "<namespace>",2 "default-route": ["<default-route>"]3 } ]
Pour créer le module, entrez la commande suivante. Remplacez
<name>par le nom du module.$ oc create -f <name>.yamlFacultatif : Pour confirmer que l'annotation existe dans le CR
Pod, entrez la commande suivante, en remplaçant<name>par le nom du module.$ oc get pod <name> -o yamlDans l'exemple suivant, le pod
example-podest rattaché au réseau supplémentairenet1:$ oc get pod example-pod -o yaml apiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/networks: macvlan-bridge k8s.v1.cni.cncf.io/networks-status: |-1 [{ "name": "openshift-sdn", "interface": "eth0", "ips": [ "10.128.2.14" ], "default": true, "dns": {} },{ "name": "macvlan-bridge", "interface": "net1", "ips": [ "20.2.2.100" ], "mac": "22:2f:60:a5:f8:00", "dns": {} }] name: example-pod namespace: default spec: ... status: ...- 1
- Le paramètre
k8s.v1.cni.cncf.io/networks-statusest un tableau JSON d'objets. Chaque objet décrit l'état d'un réseau supplémentaire attaché au pod. La valeur de l'annotation est stockée sous forme de texte brut.
23.7.3. Création d'un pod SR-IOV aligné sur un accès mémoire non uniforme (NUMA)
Vous pouvez créer un pod SR-IOV aligné NUMA en limitant le SR-IOV et les ressources CPU allouées à partir du même nœud NUMA avec restricted ou single-numa-node Topology Manager polices.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez configuré la politique du Gestionnaire de CPU sur
static. Pour plus d'informations sur le gestionnaire de CPU, voir la section "Ressources supplémentaires". Vous avez configuré la politique de Topology Manager sur
single-numa-node.NoteLorsque
single-numa-noden'est pas en mesure de satisfaire la demande, vous pouvez configurer la politique du gestionnaire de topologie pourrestricted.
Procédure
Créez la spécification de pod SR-IOV suivante, puis enregistrez le YAML dans le fichier
<name>-sriov-pod.yaml. Remplacez<name>par un nom pour ce pod.L'exemple suivant montre une spécification de pod SR-IOV :
apiVersion: v1 kind: Pod metadata: name: sample-pod annotations: k8s.v1.cni.cncf.io/networks: <name>1 spec: containers: - name: sample-container image: <image>2 command: ["sleep", "infinity"] resources: limits: memory: "1Gi"3 cpu: "2"4 requests: memory: "1Gi" cpu: "2"- 1
- Remplacer
<name>par le nom de la définition de l'attachement au réseau SR-IOV CR. - 2
- Remplacez
<image>par le nom de l'imagesample-pod. - 3
- Pour créer le pod SR-IOV avec une garantie de qualité de service, définissez
memory limitségal àmemory requests. - 4
- Pour créer le pod SR-IOV avec une qualité de service garantie, définissez
cpu limitségal àcpu requests.
Créez l'exemple de pod SR-IOV en exécutant la commande suivante :
$ oc create -f <filename>1 - 1
- Remplacez
<filename>par le nom du fichier que vous avez créé à l'étape précédente.
Confirmez que le site
sample-podest configuré avec une qualité de service garantie.$ oc describe pod sample-podConfirmez que le site
sample-podest doté d'unités centrales exclusives.$ oc exec sample-pod -- cat /sys/fs/cgroup/cpuset/cpuset.cpusConfirmez que le dispositif SR-IOV et les CPU alloués à l'adresse
sample-podse trouvent sur le même nœud NUMA.$ oc exec sample-pod -- cat /sys/fs/cgroup/cpuset/cpuset.cpus
23.7.4. Un modèle de pod de test pour les clusters qui utilisent SR-IOV sur OpenStack
Le pod testpmd suivant illustre la création d'un conteneur avec des pages énormes, des unités centrales réservées et le port SR-IOV.
Un exemple de pod testpmd
apiVersion: v1
kind: Pod
metadata:
name: testpmd-sriov
namespace: mynamespace
annotations:
cpu-load-balancing.crio.io: "disable"
cpu-quota.crio.io: "disable"
# ...
spec:
containers:
- name: testpmd
command: ["sleep", "99999"]
image: registry.redhat.io/openshift4/dpdk-base-rhel8:v4.9
securityContext:
capabilities:
add: ["IPC_LOCK","SYS_ADMIN"]
privileged: true
runAsUser: 0
resources:
requests:
memory: 1000Mi
hugepages-1Gi: 1Gi
cpu: '2'
openshift.io/sriov1: 1
limits:
hugepages-1Gi: 1Gi
cpu: '2'
memory: 1000Mi
openshift.io/sriov1: 1
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
readOnly: False
runtimeClassName: performance-cnf-performanceprofile
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
- Cet exemple suppose que le nom du profil de performance est
cnf-performance profile.
23.8. Configuration des paramètres sysctl du réseau au niveau de l'interface pour les réseaux SR-IOV
En tant qu'administrateur de cluster, vous pouvez modifier les sysctls de réseau au niveau de l'interface à l'aide du méta plugin Tuning Container Network Interface (CNI) pour un pod connecté à un périphérique réseau SR-IOV.
23.8.1. Étiquetage des nœuds dotés d'une carte d'interface réseau compatible SR-IOV
Si vous souhaitez activer SR-IOV uniquement sur les nœuds capables de le faire, il existe plusieurs façons de procéder :
-
Installez l'opérateur NFD (Node Feature Discovery). NFD détecte la présence de cartes d'interface réseau compatibles SR-IOV et étiquette les nœuds avec
node.alpha.kubernetes-incubator.io/nfd-network-sriov.capable = true. Examinez le CR
SriovNetworkNodeStatepour chaque nœud. La stropheinterfacescomprend une liste de tous les dispositifs SR-IOV découverts par l'opérateur de réseau SR-IOV sur le nœud de travail. Étiquetez chaque nœud avecfeature.node.kubernetes.io/network-sriov.capable: "true"à l'aide de la commande suivante :$ oc label node <node_name> feature.node.kubernetes.io/network-sriov.capable="true"NoteVous pouvez donner aux nœuds le nom que vous souhaitez.
23.8.2. Définition d'un drapeau sysctl
Vous pouvez définir les paramètres du réseau sysctl au niveau de l'interface pour un pod connecté à un périphérique réseau SR-IOV.
Dans cet exemple, net.ipv4.conf.IFNAME.accept_redirects est défini sur 1 sur les interfaces virtuelles créées.
Le site sysctl-tuning-test est un espace de noms utilisé dans cet exemple.
Utilisez la commande suivante pour créer l'espace de noms
sysctl-tuning-test:$ oc create namespace sysctl-tuning-test
23.8.2.1. Définition d'un drapeau sysctl sur les nœuds dotés de périphériques réseau SR-IOV
L'opérateur de réseau SR-IOV ajoute la définition de ressource personnalisée (CRD) SriovNetworkNodePolicy.sriovnetwork.openshift.io à OpenShift Container Platform. Vous pouvez configurer un périphérique réseau SR-IOV en créant une ressource personnalisée (CR) SriovNetworkNodePolicy.
Lors de l'application de la configuration spécifiée dans un objet SriovNetworkNodePolicy, l'opérateur SR-IOV peut vidanger et redémarrer les nœuds.
L'application d'une modification de configuration peut prendre plusieurs minutes.
Suivez cette procédure pour créer une ressource personnalisée (CR) SriovNetworkNodePolicy.
Procédure
Créez une ressource personnalisée (CR)
SriovNetworkNodePolicy. Par exemple, enregistrez le YAML suivant dans le fichierpolicyoneflag-sriov-node-network.yaml:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policyoneflag1 namespace: openshift-sriov-network-operator2 spec: resourceName: policyoneflag3 nodeSelector:4 feature.node.kubernetes.io/network-sriov.capable="true" priority: 105 numVfs: 56 nicSelector:7 pfNames: ["ens5"]8 deviceType: "netdevice"9 isRdma: false10 - 1
- Nom de l'objet ressource personnalisé.
- 2
- L'espace de noms dans lequel l'opérateur de réseau SR-IOV est installé.
- 3
- Le nom de la ressource du plugin de périphérique réseau SR-IOV. Vous pouvez créer plusieurs stratégies de nœuds de réseau SR-IOV pour un nom de ressource.
- 4
- Le sélecteur de nœuds indique les nœuds à configurer. Seuls les périphériques de réseau SR-IOV sur les nœuds sélectionnés sont configurés. Le plugin SR-IOV Container Network Interface (CNI) et le plugin de périphérique sont déployés sur les nœuds sélectionnés uniquement.
- 5
- Facultatif : La priorité est une valeur entière comprise entre
0et99. Plus la valeur est petite, plus la priorité est élevée. Par exemple, une priorité de10est plus élevée que celle de99. La valeur par défaut est99. - 6
- Le nombre de fonctions virtuelles (VF) à créer pour le périphérique de réseau physique SR-IOV. Pour un contrôleur d'interface réseau (NIC) Intel, le nombre de VF ne peut pas être supérieur au nombre total de VF pris en charge par le périphérique. Pour un NIC Mellanox, le nombre de VF ne peut pas être supérieur à
128. - 7
- Le sélecteur NIC identifie le dispositif à configurer par l'opérateur. Il n'est pas nécessaire de spécifier des valeurs pour tous les paramètres. Il est recommandé d'identifier le périphérique réseau avec suffisamment de précision pour éviter de sélectionner un périphérique par inadvertance. Si vous spécifiez
rootDevices, vous devez également spécifier une valeur pourvendor,deviceIDoupfNames. Si vous spécifiezpfNamesetrootDevicesen même temps, assurez-vous qu'ils se réfèrent au même dispositif. Si vous spécifiez une valeur pournetFilter, il n'est pas nécessaire de spécifier d'autres paramètres car un ID de réseau est unique. - 8
- Facultatif : Un tableau d'un ou plusieurs noms de fonctions physiques (PF) pour l'appareil.
- 9
- Facultatif : Le type de pilote pour les fonctions virtuelles. La seule valeur autorisée est
netdevice. Pour qu'une carte d'interface réseau Mellanox fonctionne en mode DPDK sur des nœuds métalliques nus, définissezisRdmasurtrue. - 10
- Facultatif : Permet d'activer ou non le mode d'accès direct à la mémoire à distance (RDMA). La valeur par défaut est
false. Si le paramètreisRdmaest défini surtrue, vous pouvez continuer à utiliser le VF compatible RDMA comme un périphérique réseau normal. Un périphérique peut être utilisé dans l'un ou l'autre mode. DéfinissezisRdmasurtrueetneedVhostNetsurtruepour configurer une carte d'interface réseau Mellanox à utiliser avec les applications Fast Datapath DPDK.
NoteLe type de pilote
vfio-pcin'est pas pris en charge.Créer l'objet
SriovNetworkNodePolicy:$ oc create -f policyoneflag-sriov-node-network.yamlAprès avoir appliqué la mise à jour de la configuration, tous les pods de l'espace de noms
sriov-network-operatorpassent à l'étatRunning.Pour vérifier que le dispositif de réseau SR-IOV est configuré, entrez la commande suivante. Remplacez
<node_name>par le nom d'un nœud avec le dispositif de réseau SR-IOV que vous venez de configurer.oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'Exemple de sortie
Succeeded
23.8.2.2. Configuration de sysctl sur un réseau SR-IOV
Vous pouvez définir des paramètres sysctl spécifiques à l'interface sur les interfaces virtuelles créées par SR-IOV en ajoutant la configuration de réglage au paramètre facultatif metaPlugins de la ressource SriovNetwork.
L'opérateur de réseau SR-IOV gère les définitions de réseaux supplémentaires. Lorsque vous indiquez un réseau SR-IOV supplémentaire à créer, l'opérateur de réseau SR-IOV crée automatiquement la ressource personnalisée (CR) NetworkAttachmentDefinition.
Ne modifiez pas les ressources personnalisées NetworkAttachmentDefinition gérées par l'opérateur de réseau SR-IOV. Cela pourrait perturber le trafic sur votre réseau supplémentaire.
Pour modifier les paramètres du réseau au niveau de l'interface net.ipv4.conf.IFNAME.accept_redirects sysctl , créez un réseau SR-IOV supplémentaire avec le plugin de réglage Container Network Interface (CNI).
Conditions préalables
- Installez le CLI (oc) de OpenShift Container Platform.
- Connectez-vous au cluster OpenShift Container Platform en tant qu'utilisateur disposant des privilèges cluster-admin.
Procédure
Créez la ressource personnalisée (CR)
SriovNetworkpour l'attachement supplémentaire au réseau SR-IOV et insérez la configurationmetaPlugins, comme dans l'exemple de CR suivant. Enregistrez le YAML dans le fichiersriov-network-interface-sysctl.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: onevalidflag1 namespace: openshift-sriov-network-operator2 spec: resourceName: policyoneflag3 networkNamespace: sysctl-tuning-test4 ipam: '{ "type": "static" }'5 capabilities: '{ "mac": true, "ips": true }'6 metaPlugins : |7 { "type": "tuning", "capabilities":{ "mac":true }, "sysctl":{ "net.ipv4.conf.IFNAME.accept_redirects": "1" } }- 1
- Un nom pour l'objet. L'opérateur de réseau SR-IOV crée un objet NetworkAttachmentDefinition portant le même nom.
- 2
- L'espace de noms dans lequel l'opérateur de réseau SR-IOV est installé.
- 3
- La valeur du paramètre
spec.resourceNamede l'objetSriovNetworkNodePolicyqui définit le matériel SR-IOV pour ce réseau supplémentaire. - 4
- L'espace de noms cible pour l'objet
SriovNetwork. Seuls les pods de l'espace de noms cible peuvent s'attacher au réseau supplémentaire. - 5
- Un objet de configuration pour le plugin IPAM CNI sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition de l'attachement.
- 6
- Optionnel : Définissez les capacités du réseau supplémentaire. Vous pouvez spécifier
"{ "ips": true }"pour activer la prise en charge des adresses IP ou"{ "mac": true }"pour activer la prise en charge des adresses MAC. - 7
- Facultatif : Le paramètre metaPlugins est utilisé pour ajouter des capacités supplémentaires à l'appareil. Dans ce cas d'utilisation, réglez le champ
typesurtuning. Spécifiez le réseau au niveau de l'interfacesysctlque vous souhaitez définir dans le champsysctl.
Créer la ressource
SriovNetwork:$ oc create -f sriov-network-interface-sysctl.yaml
Vérification de la création de la CR NetworkAttachmentDefinition
Confirmez que l'opérateur du réseau SR-IOV a créé le CR
NetworkAttachmentDefinitionen exécutant la commande suivante :oc get network-attachment-definitions -n <namespace>1 - 1
- Remplacez
<namespace>par la valeur denetworkNamespaceque vous avez spécifiée dans l'objetSriovNetwork. Par exemple,sysctl-tuning-test.
Exemple de sortie
NAME AGE onevalidflag 14mNoteIl peut y avoir un délai avant que l'opérateur du réseau SR-IOV ne crée le CR.
Vérification de la réussite de l'attachement au réseau SR-IOV supplémentaire
Pour vérifier que le CNI d'accord est correctement configuré et que l'attachement réseau SR-IOV supplémentaire est attaché, procédez comme suit :
Créez un CR
Pod. Enregistrez le YAML suivant dans le fichierexamplepod.yaml:apiVersion: v1 kind: Pod metadata: name: tunepod namespace: sysctl-tuning-test annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "onevalidflag",1 "mac": "0a:56:0a:83:04:0c",2 "ips": ["10.100.100.200/24"]3 } ] spec: containers: - name: podexample image: centos command: ["/bin/bash", "-c", "sleep INF"] securityContext: runAsUser: 2000 runAsGroup: 3000 allowPrivilegeEscalation: false capabilities: drop: ["ALL"] securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault- 1
- Le nom du CR de définition de l'attachement au réseau SR-IOV.
- 2
- Facultatif : L'adresse MAC de l'appareil SR-IOV qui est allouée à partir du type de ressource défini dans la définition de l'attachement au réseau SR-IOV CR. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "mac": true }dans l'objet SriovNetwork. - 3
- Facultatif : adresses IP pour le périphérique SR-IOV qui sont allouées à partir du type de ressource défini dans le CR de définition de l'attachement au réseau SR-IOV. Les adresses IPv4 et IPv6 sont prises en charge. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "ips": true }dans l'objetSriovNetwork.
Créer le CR
Pod:$ oc apply -f examplepod.yamlVérifiez que le module est créé en exécutant la commande suivante :
$ oc get pod -n sysctl-tuning-testExemple de sortie
NAME READY STATUS RESTARTS AGE tunepod 1/1 Running 0 47sConnectez-vous au module en exécutant la commande suivante :
$ oc rsh -n sysctl-tuning-test tunepodVérifiez les valeurs de l'indicateur sysctl configuré. Trouvez la valeur
net.ipv4.conf.IFNAME.accept_redirectsen exécutant la commande suivante: :$ sysctl net.ipv4.conf.net1.accept_redirectsExemple de sortie
net.ipv4.conf.net1.accept_redirects = 1
23.8.3. Configuration des paramètres sysctl pour les pods associés au drapeau d'interface SR-IOV lié
Vous pouvez définir les paramètres du réseau sysctl au niveau de l'interface pour un pod connecté à un périphérique réseau SR-IOV lié.
Dans cet exemple, les paramètres spécifiques au niveau de l'interface réseau sysctl qui peuvent être configurés sont définis sur l'interface liée.
Le site sysctl-tuning-test est un espace de noms utilisé dans cet exemple.
Utilisez la commande suivante pour créer l'espace de noms
sysctl-tuning-test:$ oc create namespace sysctl-tuning-test
23.8.3.1. Définition de tous les drapeaux sysctl sur les nœuds avec des périphériques de réseau SR-IOV liés
L'opérateur de réseau SR-IOV ajoute la définition de ressource personnalisée (CRD) SriovNetworkNodePolicy.sriovnetwork.openshift.io à OpenShift Container Platform. Vous pouvez configurer un périphérique réseau SR-IOV en créant une ressource personnalisée (CR) SriovNetworkNodePolicy.
Lors de l'application de la configuration spécifiée dans un objet SriovNetworkNodePolicy, l'opérateur SR-IOV peut vidanger les nœuds et, dans certains cas, les redémarrer.
L'application d'une modification de configuration peut prendre plusieurs minutes.
Suivez cette procédure pour créer une ressource personnalisée (CR) SriovNetworkNodePolicy.
Procédure
Créez une ressource personnalisée (CR)
SriovNetworkNodePolicy. Enregistrez le YAML suivant dans le fichierpolicyallflags-sriov-node-network.yaml. Remplacezpolicyallflagspar le nom de la configuration.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policyallflags1 namespace: openshift-sriov-network-operator2 spec: resourceName: policyallflags3 nodeSelector:4 node.alpha.kubernetes-incubator.io/nfd-network-sriov.capable = `true` priority: 105 numVfs: 56 nicSelector:7 pfNames: ["ens1f0"]8 deviceType: "netdevice"9 isRdma: false10 - 1
- Nom de l'objet ressource personnalisé.
- 2
- L'espace de noms dans lequel l'opérateur de réseau SR-IOV est installé.
- 3
- Le nom de la ressource du plugin de périphérique réseau SR-IOV. Vous pouvez créer plusieurs stratégies de nœuds de réseau SR-IOV pour un nom de ressource.
- 4
- Le sélecteur de nœuds indique les nœuds à configurer. Seuls les périphériques de réseau SR-IOV sur les nœuds sélectionnés sont configurés. Le plugin SR-IOV Container Network Interface (CNI) et le plugin de périphérique sont déployés sur les nœuds sélectionnés uniquement.
- 5
- Facultatif : La priorité est une valeur entière comprise entre
0et99. Plus la valeur est petite, plus la priorité est élevée. Par exemple, une priorité de10est plus élevée que celle de99. La valeur par défaut est99. - 6
- Nombre de fonctions virtuelles (VF) à créer pour le périphérique réseau physique SR-IOV. Pour un contrôleur d'interface réseau (NIC) Intel, le nombre de VF ne peut pas être supérieur au nombre total de VF pris en charge par le périphérique. Pour un NIC Mellanox, le nombre de VF ne peut pas être supérieur à
128. - 7
- Le sélecteur NIC identifie le dispositif à configurer par l'opérateur. Il n'est pas nécessaire de spécifier des valeurs pour tous les paramètres. Il est recommandé d'identifier le périphérique réseau avec suffisamment de précision pour éviter de sélectionner un périphérique par inadvertance. Si vous spécifiez
rootDevices, vous devez également spécifier une valeur pourvendor,deviceIDoupfNames. Si vous spécifiezpfNamesetrootDevicesen même temps, assurez-vous qu'ils se réfèrent au même dispositif. Si vous spécifiez une valeur pournetFilter, il n'est pas nécessaire de spécifier d'autres paramètres car un ID de réseau est unique. - 8
- Facultatif : Un tableau d'un ou plusieurs noms de fonctions physiques (PF) pour l'appareil.
- 9
- Facultatif : Le type de pilote pour les fonctions virtuelles. La seule valeur autorisée est
netdevice. Pour qu'une carte d'interface réseau Mellanox fonctionne en mode DPDK sur des nœuds métalliques nus, définissezisRdmasurtrue. - 10
- Facultatif : Permet d'activer ou non le mode d'accès direct à la mémoire à distance (RDMA). La valeur par défaut est
false. Si le paramètreisRdmaest défini surtrue, vous pouvez continuer à utiliser le VF compatible RDMA comme un périphérique réseau normal. Un périphérique peut être utilisé dans l'un ou l'autre mode. DéfinissezisRdmasurtrueetneedVhostNetsurtruepour configurer une carte d'interface réseau Mellanox à utiliser avec les applications Fast Datapath DPDK.
NoteLe type de pilote
vfio-pcin'est pas pris en charge.Créer l'objet SriovNetworkNodePolicy :
$ oc create -f policyallflags-sriov-node-network.yamlAprès avoir appliqué la mise à jour de la configuration, tous les pods de l'espace de noms sriov-network-operator passent à l'état
Running.Pour vérifier que le dispositif de réseau SR-IOV est configuré, entrez la commande suivante. Remplacez
<node_name>par le nom d'un nœud avec le dispositif de réseau SR-IOV que vous venez de configurer.oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'Exemple de sortie
Succeeded
23.8.3.2. Configuration de sysctl sur un réseau SR-IOV lié
Vous pouvez définir des paramètres sysctl spécifiques à l'interface sur une interface liée créée à partir de deux interfaces SR-IOV. Pour ce faire, ajoutez la configuration de réglage au paramètre facultatif Plugins de la définition de l'attachement au réseau de liaison.
Ne modifiez pas les ressources personnalisées NetworkAttachmentDefinition gérées par l'opérateur de réseau SR-IOV. Cela pourrait perturber le trafic sur votre réseau supplémentaire.
Pour modifier des paramètres réseau spécifiques au niveau de l'interface sysctl, créez la ressource personnalisée (CR) SriovNetwork avec le plugin de réglage Container Network Interface (CNI) en suivant la procédure suivante.
Conditions préalables
- Installez le CLI (oc) de OpenShift Container Platform.
- Connectez-vous au cluster OpenShift Container Platform en tant qu'utilisateur disposant des privilèges cluster-admin.
Procédure
Créez la ressource personnalisée (CR)
SriovNetworkpour l'interface liée, comme dans l'exemple de CR suivant. Enregistrez le YAML dans le fichiersriov-network-attachment.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: allvalidflags1 namespace: openshift-sriov-network-operator2 spec: resourceName: policyallflags3 networkNamespace: sysctl-tuning-test4 capabilities: '{ "mac": true, "ips": true }'5 - 1
- Un nom pour l'objet. L'opérateur de réseau SR-IOV crée un objet NetworkAttachmentDefinition portant le même nom.
- 2
- L'espace de noms dans lequel l'opérateur de réseau SR-IOV est installé.
- 3
- La valeur du paramètre
spec.resourceNamede l'objetSriovNetworkNodePolicyqui définit le matériel SR-IOV pour ce réseau supplémentaire. - 4
- L'espace de noms cible pour l'objet
SriovNetwork. Seuls les pods de l'espace de noms cible peuvent s'attacher au réseau supplémentaire. - 5
- Facultatif : Les capacités à configurer pour ce réseau supplémentaire. Vous pouvez spécifier
"{ "ips": true }"pour activer la prise en charge des adresses IP ou"{ "mac": true }"pour activer la prise en charge des adresses MAC.
Créer la ressource
SriovNetwork:$ oc create -f sriov-network-attachment.yamlCréez une définition d'attachement au réseau de liens comme dans l'exemple suivant CR. Enregistrez le YAML dans le fichier
sriov-bond-network-interface.yaml.apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: bond-sysctl-network namespace: sysctl-tuning-test spec: config: '{ "cniVersion":"0.4.0", "name":"bound-net", "plugins":[ { "type":"bond",1 "mode": "active-backup",2 "failOverMac": 1,3 "linksInContainer": true,4 "miimon": "100", "links": [5 {"name": "net1"}, {"name": "net2"} ], "ipam":{6 "type":"static" } }, { "type":"tuning",7 "capabilities":{ "mac":true }, "sysctl":{ "net.ipv4.conf.IFNAME.accept_redirects": "0", "net.ipv4.conf.IFNAME.accept_source_route": "0", "net.ipv4.conf.IFNAME.disable_policy": "1", "net.ipv4.conf.IFNAME.secure_redirects": "0", "net.ipv4.conf.IFNAME.send_redirects": "0", "net.ipv6.conf.IFNAME.accept_redirects": "0", "net.ipv6.conf.IFNAME.accept_source_route": "1", "net.ipv6.neigh.IFNAME.base_reachable_time_ms": "20000", "net.ipv6.neigh.IFNAME.retrans_time_ms": "2000" } } ] }'- 1
- Le type est
bond. - 2
- L'attribut
modespécifie le mode de liaison. Les modes de liaison pris en charge sont les suivants :-
balance-rr- 0 -
active-backup- 1 balance-xor- 2Pour les modes
balance-rroubalance-xor, vous devez définir le modetrustsuronpour la fonction virtuelle SR-IOV.
-
- 3
- L'attribut
failoverest obligatoire pour le mode de sauvegarde active. - 4
- Le drapeau
linksInContainer=trueinforme le Bond CNI que les interfaces requises doivent être trouvées à l'intérieur du conteneur. Par défaut, Bond CNI recherche ces interfaces sur l'hôte, ce qui ne fonctionne pas pour l'intégration avec SRIOV et Multus. - 5
- La section
linksdéfinit les interfaces qui seront utilisées pour créer le lien. Par défaut, Multus nomme les interfaces attachées comme suit : \N "net\N", plus un nombre consécutif, en commençant par un. - 6
- Un objet de configuration pour le plugin IPAM CNI sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition de l'attachement. Dans cet exemple de pod, les adresses IP sont configurées manuellement, donc dans ce cas,
ipamest défini comme statique. - 7
- Ajoutez des capacités supplémentaires à l'appareil. Par exemple, définissez le champ
typesurtuning. Spécifiez le réseau au niveau de l'interfacesysctlque vous souhaitez définir dans le champ sysctl. Cet exemple définit tous les paramètres de réseau au niveau de l'interfacesysctlqui peuvent être définis.
Créer la ressource de rattachement au réseau de liens :
$ oc create -f sriov-bond-network-interface.yaml
Vérification de la création de la CR NetworkAttachmentDefinition
Confirmez que l'opérateur du réseau SR-IOV a créé le CR
NetworkAttachmentDefinitionen exécutant la commande suivante :oc get network-attachment-definitions -n <namespace>1 - 1
- Remplacez
<namespace>par le networkNamespace que vous avez spécifié lors de la configuration de l'attachement au réseau, par exemple,sysctl-tuning-test.
Exemple de sortie
NAME AGE bond-sysctl-network 22m allvalidflags 47mNoteIl peut y avoir un délai avant que l'opérateur du réseau SR-IOV ne crée le CR.
Vérification du succès de la ressource réseau SR-IOV supplémentaire
Pour vérifier que le CNI d'accord est correctement configuré et que l'attachement réseau SR-IOV supplémentaire est attaché, procédez comme suit :
Créez un CR
Pod. Par exemple, enregistrez le YAML suivant dans le fichierexamplepod.yaml:apiVersion: v1 kind: Pod metadata: name: tunepod namespace: sysctl-tuning-test annotations: k8s.v1.cni.cncf.io/networks: |- [ {"name": "allvalidflags"},1 {"name": "allvalidflags"}, { "name": "bond-sysctl-network", "interface": "bond0", "mac": "0a:56:0a:83:04:0c",2 "ips": ["10.100.100.200/24"]3 } ] spec: containers: - name: podexample image: centos command: ["/bin/bash", "-c", "sleep INF"] securityContext: runAsUser: 2000 runAsGroup: 3000 allowPrivilegeEscalation: false capabilities: drop: ["ALL"] securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault- 1
- Le nom du CR de définition de l'attachement au réseau SR-IOV.
- 2
- Facultatif : L'adresse MAC de l'appareil SR-IOV qui est allouée à partir du type de ressource défini dans la définition de l'attachement au réseau SR-IOV CR. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "mac": true }dans l'objet SriovNetwork. - 3
- Facultatif : adresses IP pour le périphérique SR-IOV qui sont allouées à partir du type de ressource défini dans le CR de définition de l'attachement au réseau SR-IOV. Les adresses IPv4 et IPv6 sont prises en charge. Pour utiliser cette fonctionnalité, vous devez également spécifier
{ "ips": true }dans l'objetSriovNetwork.
Appliquer le YAML :
$ oc apply -f examplepod.yamlVérifiez que le module est créé en exécutant la commande suivante :
$ oc get pod -n sysctl-tuning-testExemple de sortie
NAME READY STATUS RESTARTS AGE tunepod 1/1 Running 0 47sConnectez-vous au module en exécutant la commande suivante :
$ oc rsh -n sysctl-tuning-test tunepodVérifiez les valeurs de l'indicateur
sysctlconfiguré. Trouvez la valeurnet.ipv6.neigh.IFNAME.base_reachable_time_msen exécutant la commande suivante: :$ sysctl net.ipv6.neigh.bond0.base_reachable_time_msExemple de sortie
net.ipv6.neigh.bond0.base_reachable_time_ms = 20000
23.9. Utilisation de la multidiffusion haute performance
Vous pouvez utiliser le multicast sur votre réseau matériel de virtualisation d'E/S à racine unique (SR-IOV).
23.9.1. Multidiffusion haute performance
Le plugin réseau OpenShift SDN supporte le multicast entre les pods sur le réseau par défaut. Il est préférable de l'utiliser pour la coordination ou la découverte de services à faible bande passante, et non pour des applications à large bande passante. Pour les applications telles que le streaming média, comme la télévision sur protocole Internet (IPTV) et la vidéoconférence multipoint, vous pouvez utiliser du matériel de virtualisation d'E/S à racine unique (SR-IOV) pour fournir des performances quasi natives.
Lors de l'utilisation d'interfaces SR-IOV supplémentaires pour le multicast :
- Les paquets de multidiffusion doivent être envoyés ou reçus par un pod via l'interface SR-IOV supplémentaire.
- Le réseau physique qui connecte les interfaces SR-IOV décide du routage et de la topologie multicast, qui n'est pas contrôlée par OpenShift Container Platform.
23.9.2. Configuration d'une interface SR-IOV pour la multidiffusion
La procédure suivante crée un exemple d'interface SR-IOV pour le multicast.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Créer un objet
SriovNetworkNodePolicy:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policy-example namespace: openshift-sriov-network-operator spec: resourceName: example nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" numVfs: 4 nicSelector: vendor: "8086" pfNames: ['ens803f0'] rootDevices: ['0000:86:00.0']Créer un objet
SriovNetwork:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: net-example namespace: openshift-sriov-network-operator spec: networkNamespace: default ipam: |1 { "type": "host-local",2 "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "routes": [ {"dst": "224.0.0.0/5"}, {"dst": "232.0.0.0/5"} ], "gateway": "10.56.217.1" } resourceName: exampleCréer un pod avec une application multicast :
apiVersion: v1 kind: Pod metadata: name: testpmd namespace: default annotations: k8s.v1.cni.cncf.io/networks: nic1 spec: containers: - name: example image: rhel7:latest securityContext: capabilities: add: ["NET_ADMIN"]1 command: [ "sleep", "infinity"]- 1
- La capacité
NET_ADMINn'est requise que si votre application doit attribuer l'adresse IP multicast à l'interface SR-IOV. Dans le cas contraire, elle peut être omise.
23.10. Utilisation de DPDK et RDMA
L'application conteneurisée Data Plane Development Kit (DPDK) est prise en charge sur OpenShift Container Platform. Vous pouvez utiliser du matériel réseau de virtualisation d'E/S à racine unique (SR-IOV) avec le kit de développement du plan de données (DPDK) et avec l'accès direct à la mémoire à distance (RDMA).
Pour plus d'informations sur les appareils pris en charge, reportez-vous à la section Appareils pris en charge.
23.10.1. Utilisation d'une fonction virtuelle en mode DPDK avec un NIC Intel
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Installer l'opérateur de réseau SR-IOV.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez l'objet
SriovNetworkNodePolicysuivant, puis enregistrez le YAML dans le fichierintel-dpdk-node-policy.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: intel-dpdk-node-policy namespace: openshift-sriov-network-operator spec: resourceName: intelnics nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" priority: <priority> numVfs: <num> nicSelector: vendor: "8086" deviceID: "158b" pfNames: ["<pf_name>", ...] rootDevices: ["<pci_bus_id>", "..."] deviceType: vfio-pci1 - 1
- Spécifiez le type de pilote pour les fonctions virtuelles à
vfio-pci.
NoteVoir la section
Configuring SR-IOV network devicespour une explication détaillée de chaque option deSriovNetworkNodePolicy.Lors de l'application de la configuration spécifiée dans un objet
SriovNetworkNodePolicy, l'opérateur SR-IOV peut vidanger les nœuds et, dans certains cas, les redémarrer. L'application d'une modification de configuration peut prendre plusieurs minutes. Assurez-vous au préalable qu'il y a suffisamment de nœuds disponibles dans votre cluster pour gérer la charge de travail expulsée.Après l'application de la mise à jour de la configuration, tous les pods de l'espace de noms
openshift-sriov-network-operatorpasseront à l'étatRunning.Créez l'objet
SriovNetworkNodePolicyen exécutant la commande suivante :$ oc create -f intel-dpdk-node-policy.yamlCréez l'objet
SriovNetworksuivant, puis enregistrez le YAML dans le fichierintel-dpdk-network.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: intel-dpdk-network namespace: openshift-sriov-network-operator spec: networkNamespace: <target_namespace> ipam: |- # ...1 vlan: <vlan> resourceName: intelnics- 1
- Spécifier un objet de configuration pour le plugin CNI ipam sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition des pièces jointes.
NoteVoir la section "Configuration du réseau supplémentaire SR-IOV" pour une explication détaillée de chaque option sur
SriovNetwork.Une bibliothèque optionnelle, app-netutil, fournit plusieurs méthodes API pour collecter des informations réseau sur le pod parent d'un conteneur.
Créez l'objet
SriovNetworken exécutant la commande suivante :$ oc create -f intel-dpdk-network.yamlCréez la spécification
Podsuivante, puis enregistrez le YAML dans le fichierintel-dpdk-pod.yaml.apiVersion: v1 kind: Pod metadata: name: dpdk-app namespace: <target_namespace>1 annotations: k8s.v1.cni.cncf.io/networks: intel-dpdk-network spec: containers: - name: testpmd image: <DPDK_image>2 securityContext: runAsUser: 0 capabilities: add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]3 volumeMounts: - mountPath: /dev/hugepages4 name: hugepage resources: limits: openshift.io/intelnics: "1"5 memory: "1Gi" cpu: "4"6 hugepages-1Gi: "4Gi"7 requests: openshift.io/intelnics: "1" memory: "1Gi" cpu: "4" hugepages-1Gi: "4Gi" command: ["sleep", "infinity"] volumes: - name: hugepage emptyDir: medium: HugePages- 1
- Spécifiez le même
target_namespaceoù l'objetSriovNetworkintel-dpdk-networkest créé. Si vous souhaitez créer le pod dans un espace de noms différent, modifieztarget_namespaceà la fois dans la spécificationPodet dans l'objetSriovNetowrk. - 2
- Spécifiez l'image DPDK qui inclut votre application et la bibliothèque DPDK utilisée par l'application.
- 3
- Spécifier les capacités supplémentaires requises par l'application à l'intérieur du conteneur pour l'allocation de pages énormes, l'allocation de ressources système et l'accès à l'interface réseau.
- 4
- Monter un volume hugepage sur le pod DPDK sous
/dev/hugepages. Le volume hugepage est soutenu par le type de volume emptyDir, le support étantHugepages. - 5
- Facultatif : Spécifiez le nombre de dispositifs DPDK alloués au pod DPDK. Cette demande de ressource et cette limite, si elles ne sont pas explicitement spécifiées, seront automatiquement ajoutées par l'injecteur de ressources du réseau SR-IOV. L'injecteur de ressources réseau SR-IOV est un composant du contrôleur d'admission géré par l'opérateur SR-IOV. Il est activé par défaut et peut être désactivé en définissant l'option
enableInjectorsurfalsedans le CRSriovOperatorConfigpar défaut. - 6
- Spécifiez le nombre d'unités centrales. Le pod DPDK nécessite généralement que des CPU exclusifs soient alloués par le kubelet. Pour ce faire, définissez la politique du gestionnaire de CPU sur
staticet créez un pod avecGuaranteedQoS. - 7
- Spécifiez la taille de la page d'accueil
hugepages-1Giouhugepages-2Miet la quantité de pages d'accueil qui seront allouées au module DPDK. Configurez2Miet1Gihugepages séparément. La configuration de la page d'accueil1Ginécessite l'ajout d'arguments de noyau aux nœuds. Par exemple, l'ajout des arguments du noyaudefault_hugepagesz=1GB,hugepagesz=1Gethugepages=16aura pour effet d'allouer16*1Gihugepages lors du démarrage du système.
Créez le module DPDK en exécutant la commande suivante :
$ oc create -f intel-dpdk-pod.yaml
23.10.2. Utilisation d'une fonction virtuelle en mode DPDK avec un NIC Mellanox
Vous pouvez créer une stratégie de nœud de réseau et créer un pod Data Plane Development Kit (DPDK) à l'aide d'une fonction virtuelle en mode DPDK avec un NIC Mellanox.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous avez installé l'opérateur de réseau SR-IOV (Single Root I/O Virtualization).
-
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
SriovNetworkNodePolicyEnregistrez la configuration YAML suivante dans un fichiermlx-dpdk-node-policy.yaml:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: mlx-dpdk-node-policy namespace: openshift-sriov-network-operator spec: resourceName: mlxnics nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" priority: <priority> numVfs: <num> nicSelector: vendor: "15b3" deviceID: "1015"1 pfNames: ["<pf_name>", ...] rootDevices: ["<pci_bus_id>", "..."] deviceType: netdevice2 isRdma: true3 - 1
- Indiquez le code hexadécimal du périphérique du réseau SR-IOV.
- 2
- Spécifiez le type de pilote pour les fonctions virtuelles à
netdevice. Une fonction virtuelle (VF) Mellanox SR-IOV peut fonctionner en mode DPDK sans utiliser le type de périphériquevfio-pci. Le périphérique VF apparaît comme une interface réseau du noyau à l'intérieur d'un conteneur. - 3
- Activer le mode RDMA (Remote Direct Memory Access). Ceci est nécessaire pour que les cartes Mellanox fonctionnent en mode DPDK.
NoteVoir Configuring an SR-IOV network device pour une explication détaillée de chaque option de l'objet
SriovNetworkNodePolicy.Lors de l'application de la configuration spécifiée dans un objet
SriovNetworkNodePolicy, l'opérateur SR-IOV peut vidanger les nœuds et, dans certains cas, les redémarrer. L'application d'une modification de configuration peut prendre plusieurs minutes. Assurez-vous au préalable qu'il y a suffisamment de nœuds disponibles dans votre cluster pour gérer la charge de travail expulsée.Après l'application de la mise à jour de la configuration, tous les pods de l'espace de noms
openshift-sriov-network-operatorpasseront à l'étatRunning.Créez l'objet
SriovNetworkNodePolicyen exécutant la commande suivante :$ oc create -f mlx-dpdk-node-policy.yamlSriovNetworkEnregistrez la configuration YAML suivante dans un fichiermlx-dpdk-network.yaml:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: mlx-dpdk-network namespace: openshift-sriov-network-operator spec: networkNamespace: <target_namespace> ipam: |-1 ... vlan: <vlan> resourceName: mlxnics- 1
- Spécifier un objet de configuration pour le plugin IPAM (gestion des adresses IP) Container Network Interface (CNI) sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition de l'attachement.
NoteVoir Configuring an SR-IOV network device pour une explication détaillée de chaque option de l'objet
SriovNetwork.La bibliothèque d'options
app-netutilfournit plusieurs méthodes API pour collecter des informations réseau sur le module parent d'un conteneur.Créez l'objet
SriovNetworken exécutant la commande suivante :$ oc create -f mlx-dpdk-network.yamlPodEnregistrez la configuration YAML suivante dans un fichiermlx-dpdk-pod.yaml:apiVersion: v1 kind: Pod metadata: name: dpdk-app namespace: <target_namespace>1 annotations: k8s.v1.cni.cncf.io/networks: mlx-dpdk-network spec: containers: - name: testpmd image: <DPDK_image>2 securityContext: runAsUser: 0 capabilities: add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]3 volumeMounts: - mountPath: /dev/hugepages4 name: hugepage resources: limits: openshift.io/mlxnics: "1"5 memory: "1Gi" cpu: "4"6 hugepages-1Gi: "4Gi"7 requests: openshift.io/mlxnics: "1" memory: "1Gi" cpu: "4" hugepages-1Gi: "4Gi" command: ["sleep", "infinity"] volumes: - name: hugepage emptyDir: medium: HugePages- 1
- Spécifiez le même
target_namespaceoù l'objetSriovNetworkmlx-dpdk-networkest créé. Pour créer le pod dans un espace de noms différent, modifieztarget_namespaceà la fois dans la spécificationPodet dans l'objetSriovNetwork. - 2
- Spécifiez l'image DPDK qui inclut votre application et la bibliothèque DPDK utilisée par l'application.
- 3
- Spécifier les capacités supplémentaires requises par l'application à l'intérieur du conteneur pour l'allocation de pages énormes, l'allocation de ressources système et l'accès à l'interface réseau.
- 4
- Montez le volume hugepage sur le pod DPDK sous
/dev/hugepages. Le volume hugepage est soutenu par le type de volumeemptyDir, le support étantHugepages. - 5
- Facultatif : Spécifiez le nombre de périphériques DPDK alloués pour le module DPDK. Si elle n'est pas explicitement spécifiée, cette demande de ressource et cette limite sont automatiquement ajoutées par l'injecteur de ressources du réseau SR-IOV. L'injecteur de ressources réseau SR-IOV est un composant du contrôleur d'admission géré par l'opérateur SR-IOV. Il est activé par défaut et peut être désactivé en définissant l'option
enableInjectorsurfalsedans le CRSriovOperatorConfigpar défaut. - 6
- Spécifiez le nombre d'unités centrales. Le pod DPDK nécessite généralement que des CPU exclusifs soient alloués à partir du kubelet. Pour ce faire, définissez la politique du gestionnaire de CPU sur
staticet créez un pod avecGuaranteedQuality of Service (QoS). - 7
- Spécifiez la taille de la page d'accueil
hugepages-1Giouhugepages-2Miet la quantité de pages d'accueil qui seront allouées au module DPDK. Configurez séparément2Miet1Gihugepages. La configuration de1Gihugepages nécessite l'ajout d'arguments de noyau à Nodes.
Créez le module DPDK en exécutant la commande suivante :
$ oc create -f mlx-dpdk-pod.yaml
23.10.3. Vue d'ensemble de l'obtention d'un débit de ligne DPDK spécifique
Pour atteindre un débit de ligne spécifique du kit de développement du plan de données (DPDK), déployez un opérateur de réglage de nœud et configurez la virtualisation d'E/S à racine unique (SR-IOV). Vous devez également régler les paramètres du DPDK pour les ressources suivantes :
- CPU isolés
- Hugepages
- Le planificateur de topologie
Dans les versions précédentes d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift Container Platform. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
Environnement de test DPDK
Le diagramme suivant montre les composants d'un environnement de test de trafic :
- Traffic generator: Une application qui peut générer un trafic de paquets important.
- SR-IOV-supporting NIC: Carte d'interface réseau compatible avec SR-IOV. La carte exécute un certain nombre de fonctions virtuelles sur une interface physique.
- Physical Function (PF): Fonction PCI Express (PCIe) d'un adaptateur réseau qui prend en charge l'interface SR-IOV.
- Virtual Function (VF): Une fonction PCIe légère sur un adaptateur de réseau qui prend en charge le SR-IOV. Le VF est associé à la PF PCIe de l'adaptateur réseau. Le VF représente une instance virtualisée de l'adaptateur réseau.
- Switch: Un commutateur de réseau. Les nœuds peuvent également être connectés dos à dos.
-
testpmd: Une application d'exemple incluse dans le DPDK. L'applicationtestpmdpeut être utilisée pour tester le DPDK dans un mode de transmission de paquets. L'applicationtestpmdest également un exemple de construction d'une application complète à l'aide du kit de développement logiciel (SDK) DPDK. - worker 0 et worker 1: Nœuds OpenShift Container Platform.
23.10.4. Utilisation du SR-IOV et du Node Tuning Operator pour atteindre un débit de ligne DPDK
Vous pouvez utiliser le Node Tuning Operator pour configurer des CPU isolés, des hugepages et un planificateur de topologie. Vous pouvez ensuite utiliser l'opérateur de réglage de nœud avec la virtualisation d'E/S à racine unique (SR-IOV) pour atteindre un débit de ligne spécifique du kit de développement du plan de données (DPDK).
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous avez installé l'opérateur de réseau SR-IOV.
-
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin. Vous avez déployé un Node Tuning Operator autonome.
NoteDans les versions précédentes d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
Procédure
Créez un objet
PerformanceProfileen vous inspirant de l'exemple suivant :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: globallyDisableIrqLoadBalancing: true cpu: isolated: 21-51,73-1031 reserved: 0-20,52-722 hugepages: defaultHugepagesSize: 1G3 pages: - count: 32 size: 1G net: userLevelNetworking: true numa: topologyPolicy: "single-numa-node" nodeSelector: node-role.kubernetes.io/worker-cnf: ""- 1
- Si l'hyperthreading est activé sur le système, allouez les liens symboliques appropriés aux groupes de CPU
isolatedetreserved. Si le système contient plusieurs nœuds d'accès à la mémoire non uniforme (NUMA), allouez les CPU des deux NUMA aux deux groupes. Vous pouvez également utiliser le Créateur de profil de performance pour cette tâche. Pour plus d'informations, voir Creating a performance profile. - 2
- Vous pouvez également spécifier une liste de périphériques dont les files d'attente seront définies en fonction du nombre d'unités centrales réservées. Pour plus d'informations, voir Reducing NIC queues using the Node Tuning Operator.
- 3
- Allouer le nombre et la taille des hugepages nécessaires. Vous pouvez spécifier la configuration NUMA pour les hugepages. Par défaut, le système alloue un nombre pair à chaque nœud NUMA du système. Si nécessaire, vous pouvez demander l'utilisation d'un noyau en temps réel pour les nœuds. Pour plus d'informations, voir Provisioning a worker with real-time capabilities pour plus d'informations.
-
Enregistrez le fichier
yamlsousmlx-dpdk-perfprofile-policy.yaml. Appliquez le profil de performance à l'aide de la commande suivante :
$ oc create -f mlx-dpdk-perfprofile-policy.yaml
23.10.4.1. Exemple d'opérateur de réseau SR-IOV pour les fonctions virtuelles
Vous pouvez utiliser l'opérateur de réseau de virtualisation d'E/S à racine unique (SR-IOV) pour allouer et configurer des fonctions virtuelles (VF) à partir de cartes d'interface réseau de fonctions physiques supportant la SR-IOV sur les nœuds.
Pour plus d'informations sur le déploiement de l'opérateur, voir Installing the SR-IOV Network Operator. Pour plus d'informations sur la configuration d'un périphérique réseau SR-IOV, voir Configuring an SR-IOV network device.
Il existe quelques différences entre l'exécution des charges de travail du kit de développement du plan de données (DPDK) sur les VF Intel et les VF Mellanox. Cette section fournit des exemples de configuration d'objets pour les deux types de VF. Voici un exemple d'objet sriovNetworkNodePolicy utilisé pour exécuter des applications DPDK sur des cartes réseau Intel :
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: dpdk-nic-1
namespace: openshift-sriov-network-operator
spec:
deviceType: vfio-pci
needVhostNet: true
nicSelector:
pfNames: ["ens3f0"]
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numVfs: 10
priority: 99
resourceName: dpdk_nic_1
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: dpdk-nic-1
namespace: openshift-sriov-network-operator
spec:
deviceType: vfio-pci
needVhostNet: true
nicSelector:
pfNames: ["ens3f1"]
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numVfs: 10
priority: 99
resourceName: dpdk_nic_2- 1
- Pour les NIC d'Intel,
deviceTypedoit êtrevfio-pci. - 2
- Si la communication du noyau avec les charges de travail DPDK est nécessaire, ajoutez
needVhostNet: true. Cela permet de monter les périphériques/dev/net/tunet/dev/vhost-netdans le conteneur afin que l'application puisse créer un périphérique de prise et connecter le périphérique de prise à la charge de travail DPDK.
Voici un exemple d'objet sriovNetworkNodePolicy pour les cartes d'interface réseau Mellanox :
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: dpdk-nic-1
namespace: openshift-sriov-network-operator
spec:
deviceType: netdevice
isRdma: true
nicSelector:
rootDevices:
- "0000:5e:00.1"
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numVfs: 5
priority: 99
resourceName: dpdk_nic_1
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: dpdk-nic-2
namespace: openshift-sriov-network-operator
spec:
deviceType: netdevice
isRdma: true
nicSelector:
rootDevices:
- "0000:5e:00.0"
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numVfs: 5
priority: 99
resourceName: dpdk_nic_2- 1
- Pour les dispositifs Mellanox, le site
deviceTypedoit êtrenetdevice. - 2
- Pour les dispositifs Mellanox,
isRdmadoit êtretrue. Les cartes Mellanox sont connectées aux applications DPDK en utilisant la bifurcation de flux. Ce mécanisme divise le trafic entre l'espace utilisateur Linux et l'espace noyau, et peut améliorer la capacité de traitement du débit de ligne.
23.10.4.2. Exemple d'opérateur de réseau SR-IOV
Voici un exemple de définition d'un objet sriovNetwork. Dans ce cas, les configurations Intel et Mellanox sont identiques :
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: dpdk-network-1
namespace: openshift-sriov-network-operator
spec:
ipam: '{"type": "host-local","ranges": [[{"subnet": "10.0.1.0/24"}]],"dataDir":
"/run/my-orchestrator/container-ipam-state-1"}'
networkNamespace: dpdk-test
spoofChk: "off"
trust: "on"
resourceName: dpdk_nic_1
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: dpdk-network-2
namespace: openshift-sriov-network-operator
spec:
ipam: '{"type": "host-local","ranges": [[{"subnet": "10.0.2.0/24"}]],"dataDir":
"/run/my-orchestrator/container-ipam-state-1"}'
networkNamespace: dpdk-test
spoofChk: "off"
trust: "on"
resourceName: dpdk_nic_2- 1
- Vous pouvez utiliser une implémentation différente de la gestion des adresses IP (IPAM), telle que Whereabouts. Pour plus d'informations, voir Dynamic IP address assignment configuration with Whereabouts.
- 2
- Vous devez demander l'adresse
networkNamespaceoù la définition de la pièce jointe au réseau sera créée. Vous devez créer le CRsriovNetworksous l'espace de nomsopenshift-sriov-network-operator. - 3
- La valeur de
resourceNamedoit correspondre à celle deresourceNamecréée soussriovNetworkNodePolicy.
23.10.4.3. Exemple de charge de travail de base DPDK
Voici un exemple de conteneur du kit de développement du plan de données (DPDK) :
apiVersion: v1
kind: Namespace
metadata:
name: dpdk-test
---
apiVersion: v1
kind: Pod
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: '[
{
"name": "dpdk-network-1",
"namespace": "dpdk-test"
},
{
"name": "dpdk-network-2",
"namespace": "dpdk-test"
}
]'
irq-load-balancing.crio.io: "disable"
cpu-load-balancing.crio.io: "disable"
cpu-quota.crio.io: "disable"
labels:
app: dpdk
name: testpmd
namespace: dpdk-test
spec:
runtimeClassName: performance-performance
containers:
- command:
- /bin/bash
- -c
- sleep INF
image: registry.redhat.io/openshift4/dpdk-base-rhel8
imagePullPolicy: Always
name: dpdk
resources:
limits:
cpu: "16"
hugepages-1Gi: 8Gi
memory: 2Gi
requests:
cpu: "16"
hugepages-1Gi: 8Gi
memory: 2Gi
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
- NET_RAW
- NET_ADMIN
runAsUser: 0
volumeMounts:
- mountPath: /mnt/huge
name: hugepages
terminationGracePeriodSeconds: 5
volumes:
- emptyDir:
medium: HugePages
name: hugepages- 1
- Demandez les réseaux SR-IOV dont vous avez besoin. Les ressources pour les appareils seront injectées automatiquement.
- 2
- Désactiver la base d'équilibrage de charge du CPU et de l'IRQ. Pour plus d'informations, voir Disabling interrupt processing for individual pods pour plus d'informations.
- 3
- Réglez le
runtimeClasssur leperformance-performance. Ne définissez pasruntimeClasssurHostNetworkouprivileged. - 4
- Demander un nombre égal de ressources pour les demandes et les limites afin de démarrer le pod avec
GuaranteedQualité de service (QoS).
Ne démarrez pas le pod avec SLEEP puis exécutez dans le pod pour démarrer le testpmd ou la charge de travail DPDK. Cela peut ajouter des interruptions supplémentaires car le processus exec n'est rattaché à aucun processeur.
23.10.4.4. Exemple de script testpmd
Voici un exemple de script pour l'exécution de testpmd:
#!/bin/bash
set -ex
export CPU=$(cat /sys/fs/cgroup/cpuset/cpuset.cpus)
echo ${CPU}
dpdk-testpmd -l ${CPU} -a ${PCIDEVICE_OPENSHIFT_IO_DPDK_NIC_1} -a ${PCIDEVICE_OPENSHIFT_IO_DPDK_NIC_2} -n 4 -- -i --nb-cores=15 --rxd=4096 --txd=4096 --rxq=7 --txq=7 --forward-mode=mac --eth-peer=0,50:00:00:00:00:01 --eth-peer=1,50:00:00:00:00:02
Cet exemple utilise deux CR sriovNetwork différents. La variable d'environnement contient l'adresse PCI de la fonction virtuelle (VF) qui a été allouée au module. Si vous utilisez le même réseau dans la définition du pod, vous devez diviser le pciAddress. Il est important de configurer les adresses MAC correctes du générateur de trafic. Cet exemple utilise des adresses MAC personnalisées.
23.10.5. Utilisation d'une fonction virtuelle en mode RDMA avec un NIC Mellanox
RDMA over Converged Ethernet (RoCE) est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes d'un point de vue fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
RDMA over Converged Ethernet (RoCE) est le seul mode pris en charge lors de l'utilisation de RDMA sur OpenShift Container Platform.
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Installer l'opérateur de réseau SR-IOV.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez l'objet
SriovNetworkNodePolicysuivant, puis enregistrez le YAML dans le fichiermlx-rdma-node-policy.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: mlx-rdma-node-policy namespace: openshift-sriov-network-operator spec: resourceName: mlxnics nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" priority: <priority> numVfs: <num> nicSelector: vendor: "15b3" deviceID: "1015"1 pfNames: ["<pf_name>", ...] rootDevices: ["<pci_bus_id>", "..."] deviceType: netdevice2 isRdma: true3 NoteVoir la section
Configuring SR-IOV network devicespour une explication détaillée de chaque option deSriovNetworkNodePolicy.Lors de l'application de la configuration spécifiée dans un objet
SriovNetworkNodePolicy, l'opérateur SR-IOV peut vidanger les nœuds et, dans certains cas, les redémarrer. L'application d'une modification de configuration peut prendre plusieurs minutes. Assurez-vous au préalable qu'il y a suffisamment de nœuds disponibles dans votre cluster pour gérer la charge de travail expulsée.Après l'application de la mise à jour de la configuration, tous les pods de l'espace de noms
openshift-sriov-network-operatorpasseront à l'étatRunning.Créez l'objet
SriovNetworkNodePolicyen exécutant la commande suivante :$ oc create -f mlx-rdma-node-policy.yamlCréez l'objet
SriovNetworksuivant, puis enregistrez le YAML dans le fichiermlx-rdma-network.yaml.apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: mlx-rdma-network namespace: openshift-sriov-network-operator spec: networkNamespace: <target_namespace> ipam: |-1 # ... vlan: <vlan> resourceName: mlxnics- 1
- Spécifier un objet de configuration pour le plugin CNI ipam sous la forme d'un bloc YAML scalaire. Le plugin gère l'attribution des adresses IP pour la définition des pièces jointes.
NoteVoir la section "Configuration du réseau supplémentaire SR-IOV" pour une explication détaillée de chaque option sur
SriovNetwork.Une bibliothèque optionnelle, app-netutil, fournit plusieurs méthodes API pour collecter des informations réseau sur le pod parent d'un conteneur.
Créez l'objet
SriovNetworkNodePolicyen exécutant la commande suivante :$ oc create -f mlx-rdma-network.yamlCréez la spécification
Podsuivante, puis enregistrez le YAML dans le fichiermlx-rdma-pod.yaml.apiVersion: v1 kind: Pod metadata: name: rdma-app namespace: <target_namespace>1 annotations: k8s.v1.cni.cncf.io/networks: mlx-rdma-network spec: containers: - name: testpmd image: <RDMA_image>2 securityContext: runAsUser: 0 capabilities: add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]3 volumeMounts: - mountPath: /dev/hugepages4 name: hugepage resources: limits: memory: "1Gi" cpu: "4"5 hugepages-1Gi: "4Gi"6 requests: memory: "1Gi" cpu: "4" hugepages-1Gi: "4Gi" command: ["sleep", "infinity"] volumes: - name: hugepage emptyDir: medium: HugePages- 1
- Spécifiez le même
target_namespaceoù l'objetSriovNetworkmlx-rdma-networkest créé. Si vous souhaitez créer le pod dans un espace de noms différent, modifieztarget_namespacedans la spécificationPodet dans l'objetSriovNetowrk. - 2
- Spécifiez l'image RDMA qui inclut votre application et la bibliothèque RDMA utilisée par l'application.
- 3
- Spécifier les capacités supplémentaires requises par l'application à l'intérieur du conteneur pour l'allocation de pages énormes, l'allocation de ressources système et l'accès à l'interface réseau.
- 4
- Monter le volume hugepage sur le pod RDMA sous
/dev/hugepages. Le volume hugepage est sauvegardé par le type de volume emptyDir, le support étantHugepages. - 5
- Spécifiez le nombre de CPU. Le pod RDMA nécessite généralement que des CPU exclusifs soient alloués par le kubelet. Pour ce faire, définissez la politique du gestionnaire de CPU sur
staticet créez un pod avecGuaranteedQoS. - 6
- Spécifiez la taille de la page d'accueil
hugepages-1Giouhugepages-2Miet la quantité de pages d'accueil qui seront allouées au pod RDMA. Configurez2Miet1Gihugepages séparément. La configuration de1Gihugepage nécessite l'ajout d'arguments de noyau à Nodes.
Créez le pod RDMA en exécutant la commande suivante :
$ oc create -f mlx-rdma-pod.yaml
23.10.6. Un modèle de pod de test pour les clusters qui utilisent OVS-DPDK sur OpenStack
Le pod testpmd suivant illustre la création d'un conteneur avec des pages énormes, des unités centrales réservées et le port SR-IOV.
Un exemple de pod testpmd
apiVersion: v1
kind: Pod
metadata:
name: testpmd-dpdk
namespace: mynamespace
annotations:
cpu-load-balancing.crio.io: "disable"
cpu-quota.crio.io: "disable"
# ...
spec:
containers:
- name: testpmd
command: ["sleep", "99999"]
image: registry.redhat.io/openshift4/dpdk-base-rhel8:v4.9
securityContext:
capabilities:
add: ["IPC_LOCK","SYS_ADMIN"]
privileged: true
runAsUser: 0
resources:
requests:
memory: 1000Mi
hugepages-1Gi: 1Gi
cpu: '2'
openshift.io/dpdk1: 1
limits:
hugepages-1Gi: 1Gi
cpu: '2'
memory: 1000Mi
openshift.io/dpdk1: 1
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
readOnly: False
runtimeClassName: performance-cnf-performanceprofile
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
- Le nom
dpdk1dans cet exemple correspond à une ressourceSriovNetworkNodePolicycréée par l'utilisateur. Vous pouvez remplacer ce nom par celui d'une ressource que vous créez. - 2
- Si votre profil de performance ne s'appelle pas
cnf-performance profile, remplacez cette chaîne par le nom correct du profil de performance.
23.10.7. Un modèle de pod de test pour les clusters qui utilisent le déchargement matériel OVS sur OpenStack
Le pod testpmd suivant démontre le déchargement matériel d'Open vSwitch (OVS) sur Red Hat OpenStack Platform (RHOSP).
Un exemple de pod testpmd
apiVersion: v1
kind: Pod
metadata:
name: testpmd-sriov
namespace: mynamespace
annotations:
k8s.v1.cni.cncf.io/networks: hwoffload1
spec:
runtimeClassName: performance-cnf-performanceprofile
containers:
- name: testpmd
command: ["sleep", "99999"]
image: registry.redhat.io/openshift4/dpdk-base-rhel8:v4.9
securityContext:
capabilities:
add: ["IPC_LOCK","SYS_ADMIN"]
privileged: true
runAsUser: 0
resources:
requests:
memory: 1000Mi
hugepages-1Gi: 1Gi
cpu: '2'
limits:
hugepages-1Gi: 1Gi
cpu: '2'
memory: 1000Mi
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
readOnly: False
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
- Si votre profil de performance ne s'appelle pas
cnf-performance profile, remplacez cette chaîne par le nom correct du profil de performance.
23.11. Utiliser la liaison au niveau du pod
Le bonding au niveau du pod est essentiel pour permettre aux charges de travail à l'intérieur des pods de bénéficier d'une haute disponibilité et d'un débit plus élevé. Avec le bonding au niveau du pod, vous pouvez créer une interface de bonding à partir de plusieurs interfaces de fonctions virtuelles de virtualisation d'E/S à racine unique (SR-IOV) dans une interface en mode noyau. Les fonctions virtuelles SR-IOV sont transférées dans le pod et attachées à un pilote de noyau.
Un scénario dans lequel le bonding au niveau du pod est nécessaire est la création d'une interface de bonding à partir de plusieurs fonctions virtuelles SR-IOV sur différentes fonctions physiques. La création d'une interface de liaison à partir de deux fonctions physiques différentes sur l'hôte peut être utilisée pour obtenir une haute disponibilité et un débit élevé au niveau du pod.
Pour obtenir des conseils sur des tâches telles que la création d'un réseau SR-IOV, les politiques de réseau, les définitions d'attachement au réseau et les pods, voir Configuration d'un dispositif de réseau SR-IOV.
23.11.1. Configuration d'une interface de liaison à partir de deux interfaces SR-IOV
Le bonding permet d'agréger plusieurs interfaces réseau en une seule interface logique. L'interface Bond Container Network Interface (Bond-CNI) intègre la capacité de liaison dans les conteneurs.
Bond-CNI peut être créé en utilisant des fonctions virtuelles SR-IOV (Single Root I/O Virtualization) et en les plaçant dans l'espace de noms du réseau de conteneurs.
OpenShift Container Platform ne supporte que Bond-CNI en utilisant les fonctions virtuelles SR-IOV. L'opérateur de réseau SR-IOV fournit le plugin CNI SR-IOV nécessaire pour gérer les fonctions virtuelles. D'autres CNI ou types d'interfaces ne sont pas pris en charge.
Conditions préalables
- L'opérateur de réseau SR-IOV doit être installé et configuré pour obtenir des fonctions virtuelles dans un conteneur.
- Pour configurer les interfaces SR-IOV, un réseau et une politique SR-IOV doivent être créés pour chaque interface.
- L'opérateur de réseau SR-IOV crée une définition de l'attachement au réseau pour chaque interface SR-IOV, sur la base du réseau SR-IOV et de la politique définie.
-
Le site
linkStateest réglé sur la valeur par défautautopour la fonction virtuelle SR-IOV.
23.11.1.1. Création d'une définition d'attachement à un réseau de liens
Maintenant que les fonctions virtuelles SR-IOV sont disponibles, vous pouvez créer une définition d'attachement au réseau de liaison.
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: bond-net1
namespace: demo
spec:
config: '{
"type": "bond",
"cniVersion": "0.3.1",
"name": "bond-net1",
"mode": "active-backup",
"failOverMac": 1,
"linksInContainer": true,
"miimon": "100",
"mtu": 1500,
"links": [
{"name": "net1"},
{"name": "net2"}
],
"ipam": {
"type": "host-local",
"subnet": "10.56.217.0/24",
"routes": [{
"dst": "0.0.0.0/0"
}],
"gateway": "10.56.217.1"
}
}'- 1
- Le type cni- est toujours défini sur
bond. - 2
- L'attribut
modespécifie le mode de liaison.NoteLes modes de liaison pris en charge sont les suivants :
-
balance-rr- 0 -
active-backup- 1 -
balance-xor- 2
Pour les modes
balance-rroubalance-xor, vous devez définir le modetrustsuronpour la fonction virtuelle SR-IOV. -
- 3
- L'attribut
failoverest obligatoire pour le mode de sauvegarde active et doit être défini sur 1. - 4
- Le drapeau
linksInContainer=trueinforme le Bond CNI que les interfaces requises doivent être trouvées à l'intérieur du conteneur. Par défaut, Bond CNI recherche ces interfaces sur l'hôte, ce qui ne fonctionne pas pour l'intégration avec SRIOV et Multus. - 5
- La section
linksdéfinit les interfaces qui seront utilisées pour créer le lien. Par défaut, Multus nomme les interfaces attachées comme suit : \N "net\N", plus un nombre consécutif, en commençant par un.
23.11.1.2. Création d'un pod à l'aide d'une interface de liaison
Testez la configuration en créant un pod avec un fichier YAML nommé par exemple
podbonding.yamlavec un contenu similaire à ce qui suit :apiVersion: v1 kind: Pod metadata: name: bondpod1 namespace: demo annotations: k8s.v1.cni.cncf.io/networks: demo/sriovnet1, demo/sriovnet2, demo/bond-net11 spec: containers: - name: podexample image: quay.io/openshift/origin-network-interface-bond-cni:4.11.0 command: ["/bin/bash", "-c", "sleep INF"]- 1
- Notez l'annotation du réseau : il contient deux attachements de réseau SR-IOV et un attachement de réseau de liaison. L'attachement de liaison utilise les deux interfaces SR-IOV comme interfaces de port liées.
Appliquez le fichier yaml en exécutant la commande suivante :
$ oc apply -f podbonding.yamlInspectez les interfaces du pod à l'aide de la commande suivante :
$ oc rsh -n demo bondpod1 sh-4.4# sh-4.4# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 3: eth0@if150: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP link/ether 62:b1:b5:c8:fb:7a brd ff:ff:ff:ff:ff:ff inet 10.244.1.122/24 brd 10.244.1.255 scope global eth0 valid_lft forever preferred_lft forever 4: net3: <BROADCAST,MULTICAST,UP,LOWER_UP400> mtu 1500 qdisc noqueue state UP qlen 1000 link/ether 9e:23:69:42:fb:8a brd ff:ff:ff:ff:ff:ff1 inet 10.56.217.66/24 scope global bond0 valid_lft forever preferred_lft forever 43: net1: <BROADCAST,MULTICAST,UP,LOWER_UP800> mtu 1500 qdisc mq master bond0 state UP qlen 1000 link/ether 9e:23:69:42:fb:8a brd ff:ff:ff:ff:ff:ff2 44: net2: <BROADCAST,MULTICAST,UP,LOWER_UP800> mtu 1500 qdisc mq master bond0 state UP qlen 1000 link/ether 9e:23:69:42:fb:8a brd ff:ff:ff:ff:ff:ff3 - 1
- L'interface de liaison est automatiquement nommée
net3. Pour définir un nom d'interface spécifique, ajoutez le suffixe@nameà l'annotationk8s.v1.cni.cncf.io/networksdu pod. - 2
- L'interface
net1est basée sur une fonction virtuelle SR-IOV. - 3
- L'interface
net2est basée sur une fonction virtuelle SR-IOV.
NoteSi aucun nom d'interface n'est configuré dans l'annotation du pod, les noms d'interface sont attribués automatiquement sous la forme
net<n>,<n>commençant par1.Facultatif : si vous souhaitez définir un nom d'interface spécifique, par exemple
bond0, modifiez l'annotationk8s.v1.cni.cncf.io/networkset définissezbond0comme nom d'interface comme suit :annotations: k8s.v1.cni.cncf.io/networks: demo/sriovnet1, demo/sriovnet2, demo/bond-net1@bond0
23.12. Configuration du délestage matériel
En tant qu'administrateur de cluster, vous pouvez configurer le délestage matériel sur les nœuds compatibles afin d'augmenter les performances de traitement des données et de réduire la charge sur les processeurs hôtes.
23.12.1. À propos du délestage matériel
Le déchargement matériel Open vSwitch est une méthode de traitement des tâches réseau qui consiste à les détourner de l'unité centrale et à les décharger sur un processeur dédié sur un contrôleur d'interface réseau. Les clusters peuvent ainsi bénéficier de vitesses de transfert de données plus rapides, d'une réduction de la charge de travail de l'unité centrale et d'une baisse des coûts informatiques.
L'élément clé de cette fonctionnalité est une classe moderne de contrôleurs d'interface réseau connus sous le nom de SmartNIC. Un SmartNIC est un contrôleur d'interface réseau capable de gérer des tâches de traitement réseau lourdes en termes de calcul. De la même manière qu'une carte graphique dédiée peut améliorer les performances graphiques, un SmartNIC peut améliorer les performances du réseau. Dans chaque cas, un processeur dédié améliore les performances pour un type spécifique de tâche de traitement.
Dans OpenShift Container Platform, vous pouvez configurer le délestage matériel pour les nœuds bare metal qui ont un SmartNIC compatible. Le délestage matériel est configuré et activé par l'opérateur du réseau SR-IOV.
Le délestage matériel n'est pas compatible avec toutes les charges de travail ou tous les types d'application. Seuls les deux types de communication suivants sont pris en charge :
- de pod à pod
- pod-to-service, où le service est un service ClusterIP soutenu par un pod régulier
Dans tous les cas, le délestage matériel n'a lieu que lorsque les pods et les services sont affectés à des nœuds dotés d'un SmartNIC compatible. Supposons, par exemple, qu'un module sur un nœud avec délestage matériel essaie de communiquer avec un service sur un nœud normal. Sur le nœud normal, tout le traitement a lieu dans le noyau, de sorte que les performances globales de la communication entre le pod et le service sont limitées aux performances maximales de ce nœud normal. Le déchargement matériel n'est pas compatible avec les applications DPDK.
Le fait d'activer le délestage matériel sur un nœud, mais de ne pas configurer les pods pour qu'ils l'utilisent, peut entraîner une diminution des performances de débit pour le trafic des pods. Vous ne pouvez pas configurer le délestage matériel pour les pods qui sont gérés par OpenShift Container Platform.
23.12.2. Dispositifs pris en charge
Le délestage matériel est pris en charge par les contrôleurs d'interface réseau suivants :
| Fabricant | Model | ID du vendeur | ID de l'appareil |
|---|---|---|---|
| Mellanox | Famille MT27800 [ConnectX-5] | 15b3 | 1017 |
| Mellanox | Famille MT28880 [ConnectX-5 Ex] | 15b3 | 1019 |
| Fabricant | Model | ID du vendeur | ID de l'appareil |
|---|---|---|---|
| Mellanox | Famille MT2892 [ConnectX-6 Dx] | 15b3 | 101d |
| Mellanox | Famille MT2894 [ConnectX-6 Lx] | 15b3 | 101f |
| Mellanox | MT42822 BlueField-2 en mode NIC ConnectX-6 | 15b3 | a2d6 |
L'utilisation d'un périphérique ConnectX-6 Lx ou BlueField-2 en mode ConnectX-6 NIC est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
23.12.3. Conditions préalables
- Votre cluster possède au moins une machine bare metal avec un contrôleur d'interface réseau pris en charge pour le délestage matériel.
- Vous avez installé l'opérateur de réseau SR-IOV.
- Votre cluster utilise le plugin réseau OVN-Kubernetes.
-
Dans la configuration de votre plugin réseau OVN-Kubernetes, le champ
gatewayConfig.routingViaHostest défini surfalse.
23.12.4. Configuration d'un pool de configuration de machines pour le délestage matériel
Pour activer le délestage matériel, vous devez d'abord créer un pool de configuration machine dédié et le configurer pour qu'il fonctionne avec l'opérateur de réseau SR-IOV.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Créez un pool de configuration pour les machines sur lesquelles vous souhaitez utiliser le délestage matériel.
Créez un fichier, tel que
mcp-offloading.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: mcp-offloading1 spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,mcp-offloading]}2 nodeSelector: matchLabels: node-role.kubernetes.io/mcp-offloading: ""3 Appliquer la configuration pour le pool de configuration de la machine :
$ oc create -f mcp-offloading.yaml
Ajoutez des nœuds au pool de configuration de machines. Étiqueter chaque nœud avec l'étiquette de rôle de nœud de votre pool :
$ oc label node worker-2 node-role.kubernetes.io/mcp-offloading=""Facultatif : Pour vérifier que le nouveau pool est créé, exécutez la commande suivante :
$ oc get nodesExemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 2d v1.25.0 master-1 Ready master 2d v1.25.0 master-2 Ready master 2d v1.25.0 worker-0 Ready worker 2d v1.25.0 worker-1 Ready worker 2d v1.25.0 worker-2 Ready mcp-offloading,worker 47h v1.25.0 worker-3 Ready mcp-offloading,worker 47h v1.25.0Ajouter ce pool de configuration machine à la ressource personnalisée
SriovNetworkPoolConfig:Créez un fichier, tel que
sriov-pool-config.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkPoolConfig metadata: name: sriovnetworkpoolconfig-offload namespace: openshift-sriov-network-operator spec: ovsHardwareOffloadConfig: name: mcp-offloading1 - 1
- Le nom du pool de configuration de la machine pour le délestage matériel.
Appliquer la configuration :
oc create -f <SriovNetworkPoolConfig_name>.yamlNoteLorsque vous appliquez la configuration spécifiée dans un objet
SriovNetworkPoolConfig, l'opérateur SR-IOV vide et redémarre les nœuds du pool de configuration de la machine.L'application des changements de configuration peut prendre plusieurs minutes.
23.12.5. Configuration de la politique des nœuds de réseau SR-IOV
Vous pouvez créer une configuration de dispositif de réseau SR-IOV pour un nœud en créant une stratégie de nœud de réseau SR-IOV. Pour activer le délestage matériel, vous devez définir le champ .spec.eSwitchMode avec la valeur "switchdev".
La procédure suivante permet de créer une interface SR-IOV pour un contrôleur d'interface réseau avec délestage matériel.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Créez un fichier, tel que
sriov-node-policy.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: sriov-node-policy <.> namespace: openshift-sriov-network-operator spec: deviceType: netdevice <.> eSwitchMode: "switchdev" <.> nicSelector: deviceID: "1019" rootDevices: - 0000:d8:00.0 vendor: "15b3" pfNames: - ens8f0 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" numVfs: 6 priority: 5 resourceName: mlxnics<.> Nom de l'objet ressource personnalisé. <.> Requis. Le délestage matériel n'est pas pris en charge par
vfio-pci<.> Requis.Appliquer la configuration de la politique :
$ oc create -f sriov-node-policy.yamlNoteLorsque vous appliquez la configuration spécifiée dans un objet
SriovNetworkPoolConfig, l'opérateur SR-IOV vide et redémarre les nœuds du pool de configuration de la machine.L'application d'une modification de configuration peut prendre plusieurs minutes.
23.12.5.1. Exemple de politique de nœuds de réseau SR-IOV pour OpenStack
L'exemple suivant décrit une interface SR-IOV pour un contrôleur d'interface réseau (NIC) avec déchargement matériel sur Red Hat OpenStack Platform (RHOSP).
Une interface SR-IOV pour une carte d'interface réseau avec délestage matériel sur RHOSP
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: ${name}
namespace: openshift-sriov-network-operator
spec:
deviceType: switchdev
isRdma: true
nicSelector:
netFilter: openstack/NetworkID:${net_id}
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: 'true'
numVfs: 1
priority: 99
resourceName: ${name}23.12.6. Création d'une définition de pièce jointe au réseau
Après avoir défini le pool de configuration machine et la stratégie de nœuds de réseau SR-IOV, vous pouvez créer une définition d'attachement réseau pour la carte d'interface réseau que vous avez spécifiée.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Créez un fichier, tel que
net-attach-def.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: net-attach-def <.> namespace: net-attach-def <.> annotations: k8s.v1.cni.cncf.io/resourceName: openshift.io/mlxnics <.> spec: config: '{"cniVersion":"0.3.1","name":"ovn-kubernetes","type":"ovn-k8s-cni-overlay","ipam":{},"dns":{}}'<.> Le nom de la définition de la pièce jointe au réseau. <.> L'espace de noms pour votre définition de pièce jointe au réseau. <.> Il s'agit de la valeur du champ
spec.resourceNameque vous avez spécifiée dans l'objetSriovNetworkNodePolicy.Appliquer la configuration pour la définition de l'attachement au réseau :
$ oc create -f net-attach-def.yaml
Vérification
Exécutez la commande suivante pour vérifier si la nouvelle définition est présente :
$ oc get net-attach-def -AExemple de sortie
NAMESPACE NAME AGE net-attach-def net-attach-def 43h
23.12.7. Ajouter la définition de l'attachement réseau à vos pods
Après avoir créé le pool de configuration machine, les ressources personnalisées SriovNetworkPoolConfig et SriovNetworkNodePolicy et la définition de l'attachement au réseau, vous pouvez appliquer ces configurations à vos modules en ajoutant la définition de l'attachement au réseau aux spécifications de votre module.
Procédure
Dans la spécification du pod, ajoutez le champ
.metadata.annotations.k8s.v1.cni.cncf.io/networkset indiquez la définition de l'attachement réseau que vous avez créée pour le déchargement matériel :.... metadata: annotations: v1.multus-cni.io/default-network: net-attach-def/net-attach-def <.><.> La valeur doit être le nom et l'espace de noms de la définition de l'attachement réseau que vous avez créée pour le déchargement matériel.
23.13. Passage de Bluefield-2 de DPU à NIC
Vous pouvez faire passer le périphérique réseau Bluefield-2 du mode unité de traitement des données (DPU) au mode contrôleur d'interface réseau (NIC).
Le passage de Bluefield-2 du mode unité de traitement des données (DPU) au mode contrôleur d'interface réseau (NIC) est une fonctionnalité de l'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
23.13.1. Passage de Bluefield-2 du mode DPU au mode NIC
Utilisez la procédure suivante pour faire passer Bluefield-2 du mode unités de traitement des données (DPU) au mode contrôleur d'interface réseau (NIC).
Actuellement, seul le passage de Bluefield-2 du mode DPU au mode NIC est pris en charge. Le passage du mode NIC au mode DPU n'est pas pris en charge.
Conditions préalables
- Vous avez installé l'opérateur de réseau SR-IOV. Pour plus d'informations, voir "Installation de l'opérateur de réseau SR-IOV".
- Vous avez mis à jour Bluefield-2 avec le dernier firmware. Pour plus d'informations, voir Firmware for NVIDIA BlueField-2.
Procédure
Ajoutez les étiquettes suivantes à chacun de vos nœuds de travail en entrant les commandes suivantes :
$ oc label node <example_node_name_one> node-role.kubernetes.io/sriov=oc label node <example_nom_du_node_deux> node-role.kubernetes.io/sriov= $ oc label node <example_nom_du_node_deux> rôleCréez un pool de configuration de machines pour l'opérateur SR-IOV, par exemple :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: sriov spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,sriov]} nodeSelector: matchLabels: node-role.kubernetes.io/sriov: ""Appliquez le fichier
machineconfig.yamlsuivant aux nœuds de travail :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: sriov name: 99-bf2-dpu spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,ZmluZF9jb250YWluZXIoKSB7CiAgY3JpY3RsIHBzIC1vIGpzb24gfCBqcSAtciAnLmNvbnRhaW5lcnNbXSB8IHNlbGVjdCgubWV0YWRhdGEubmFtZT09InNyaW92LW5ldHdvcmstY29uZmlnLWRhZW1vbiIpIHwgLmlkJwp9CnVudGlsIG91dHB1dD0kKGZpbmRfY29udGFpbmVyKTsgW1sgLW4gIiRvdXRwdXQiIF1dOyBkbwogIGVjaG8gIndhaXRpbmcgZm9yIGNvbnRhaW5lciB0byBjb21lIHVwIgogIHNsZWVwIDE7CmRvbmUKISBzdWRvIGNyaWN0bCBleGVjICRvdXRwdXQgL2JpbmRhdGEvc2NyaXB0cy9iZjItc3dpdGNoLW1vZGUuc2ggIiRAIgo= mode: 0755 overwrite: true path: /etc/default/switch_in_sriov_config_daemon.sh systemd: units: - name: dpu-switch.service enabled: true contents: | [Unit] Description=Switch BlueField2 card to NIC/DPU mode RequiresMountsFor=%t/containers Wants=network.target After=network-online.target kubelet.service [Service] SuccessExitStatus=0 120 RemainAfterExit=True ExecStart=/bin/bash -c '/etc/default/switch_in_sriov_config_daemon.sh nic || shutdown -r now'1 Type=oneshot [Install] WantedBy=multi-user.target- 1
- Optionnel : L'adresse PCI d'une carte spécifique peut être spécifiée en option, par exemple
ExecStart=/bin/bash -c '/etc/default/switch_in_sriov_config_daemon.sh nic 0000:5e:00.0 || echo done'. Par défaut, le premier appareil est sélectionné. S'il y a plus d'un périphérique, vous devez spécifier l'adresse PCI à utiliser. L'adresse PCI doit être la même sur tous les nœuds qui font passer Bluefield-2 du mode DPU au mode NIC.
- Attendez que les nœuds de travail redémarrent. Après le redémarrage, le périphérique réseau Bluefield-2 sur les nœuds de travailleur passe en mode NIC.
23.14. Désinstallation de l'opérateur de réseau SR-IOV
Pour désinstaller l'opérateur de réseau SR-IOV, vous devez supprimer toutes les charges de travail SR-IOV en cours d'exécution, désinstaller l'opérateur et supprimer les webhooks utilisés par l'opérateur.
23.14.1. Désinstallation de l'opérateur de réseau SR-IOV
En tant qu'administrateur de cluster, vous pouvez désinstaller l'opérateur de réseau SR-IOV.
Conditions préalables
-
Vous avez accès à un cluster OpenShift Container Platform en utilisant un compte avec des permissions
cluster-admin. - Vous avez installé l'opérateur de réseau SR-IOV.
Procédure
Supprimer toutes les ressources personnalisées (CR) SR-IOV :
$ oc delete sriovnetwork -n openshift-sriov-network-operator --all$ oc delete sriovnetworknodepolicy -n openshift-sriov-network-operator --all$ oc delete sriovibnetwork -n openshift-sriov-network-operator --all- Suivez les instructions de la section "Suppression des opérateurs d'une grappe" pour supprimer l'opérateur de réseau SR-IOV de votre grappe.
Supprimer les définitions de ressources personnalisées SR-IOV qui restent dans le cluster après la désinstallation de l'opérateur de réseau SR-IOV :
$ oc delete crd sriovibnetworks.sriovnetwork.openshift.io$ oc delete crd sriovnetworknodepolicies.sriovnetwork.openshift.io$ oc delete crd sriovnetworknodestates.sriovnetwork.openshift.io$ oc delete crd sriovnetworkpoolconfigs.sriovnetwork.openshift.io$ oc delete crd sriovnetworks.sriovnetwork.openshift.io$ oc delete crd sriovoperatorconfigs.sriovnetwork.openshift.ioSupprimer les webhooks SR-IOV :
$ oc delete mutatingwebhookconfigurations network-resources-injector-config$ oc delete MutatingWebhookConfiguration sriov-operator-webhook-config$ oc delete ValidatingWebhookConfiguration sriov-operator-webhook-configSupprimer l'espace de noms de l'opérateur de réseau SR-IOV :
$ oc delete namespace openshift-sriov-network-operator
Chapitre 24. Plugin réseau OVN-Kubernetes
24.1. À propos du plugin réseau OVN-Kubernetes
Le cluster OpenShift Container Platform utilise un réseau virtualisé pour les réseaux de pods et de services.
Faisant partie de Red Hat OpenShift Networking, le plugin réseau OVN-Kubernetes est le fournisseur de réseau par défaut pour OpenShift Container Platform. OVN-Kubernetes est basé sur Open Virtual Network (OVN) et fournit une implémentation de réseau basée sur la superposition. Un cluster qui utilise le plugin OVN-Kubernetes exécute également Open vSwitch (OVS) sur chaque nœud. OVN configure OVS sur chaque nœud pour mettre en œuvre la configuration réseau déclarée.
OVN-Kubernetes est la solution de mise en réseau par défaut pour OpenShift Container Platform et les déploiements OpenShift à nœud unique.
OVN-Kubernetes, issu du projet OVS, utilise un grand nombre des mêmes constructions, telles que les règles de flux ouvertes, pour déterminer comment les paquets voyagent à travers le réseau. Pour plus d'informations, consultez le site web de l'Open Virtual Network.
OVN-Kubernetes est une série de démons pour OVS qui traduisent les configurations de réseaux virtuels en règles OpenFlow. OpenFlow est un protocole de communication avec les commutateurs et les routeurs de réseau, fournissant un moyen de contrôler à distance le flux du trafic réseau sur un périphérique de réseau, permettant aux administrateurs de réseau de configurer, de gérer et de surveiller le flux du trafic réseau.
OVN-Kubernetes offre davantage de fonctionnalités avancées qui ne sont pas disponibles sur OpenFlow. OVN prend en charge le routage virtuel distribué, les commutateurs logiques distribués, le contrôle d'accès, le DHCP et le DNS. OVN met en œuvre le routage virtuel distribué dans des flux logiques qui équivalent à des flux ouverts. Par exemple, si vous avez un pod qui envoie une requête DHCP sur le réseau, il envoie une diffusion à la recherche d'une adresse DHCP, il y aura une règle de flux logique qui correspondra à ce paquet et qui répondra en lui donnant une passerelle, un serveur DNS, une adresse IP et ainsi de suite.
OVN-Kubernetes exécute un démon sur chaque nœud. Il existe des ensembles de démons pour les bases de données et pour le contrôleur OVN qui s'exécutent sur chaque nœud. Le contrôleur OVN programme le démon Open vSwitch sur les nœuds pour prendre en charge les fonctionnalités du fournisseur de réseau : IP de sortie, pare-feu, routeurs, réseau hybride, cryptage IPSEC, IPv6, politique de réseau, journaux de politique de réseau, délestage matériel et multidiffusion.
24.1.1. Objectif OVN-Kubernetes
Le plugin réseau OVN-Kubnernetes est un plugin CNI Kubernetes open-source et entièrement fonctionnel qui utilise Open Virtual Network (OVN) pour gérer les flux de trafic réseau. OVN est une solution de virtualisation de réseau développée par la communauté et agnostique vis-à-vis des fournisseurs. Le plugin réseau OVN-Kubnernetes :
- Utilise OVN (Open Virtual Network) pour gérer les flux de trafic du réseau. OVN est une solution de virtualisation de réseau développée par la communauté et indépendante des fournisseurs.
- Met en œuvre la prise en charge de la politique réseau de Kubernetes, y compris les règles d'entrée et de sortie.
- Utilise le protocole Geneve (Generic Network Virtualization Encapsulation) plutôt que VXLAN pour créer un réseau superposé entre les nœuds.
Le plugin réseau OVN-Kubernetes présente les avantages suivants par rapport à OpenShift SDN.
- Prise en charge complète des réseaux IPv6 à pile unique et IPv4/IPv6 à double pile sur les plates-formes prises en charge
- Prise en charge des clusters hybrides avec des charges de travail Linux et Microsoft Windows
- Cryptage IPsec facultatif des communications à l'intérieur du cluster
- Déchargement du traitement des données réseau de l'unité centrale vers des cartes réseau et des unités de traitement des données (DPU) compatibles
24.1.2. Matrice des caractéristiques des plugins réseau pris en charge
Red Hat OpenShift Networking offre deux options pour le plugin réseau, OpenShift SDN et OVN-Kubernetes, pour le plugin réseau. Le tableau suivant résume la prise en charge actuelle des fonctionnalités pour les deux plugins réseau :
| Fonctionnalité | OVN-Kubernetes | OpenShift SDN |
|---|---|---|
| IP de sortie | Soutenu | Soutenu |
| Pare-feu de sortie [1] | Soutenu | Soutenu |
| Routeur de sortie | Soutenu [2] | Soutenu |
| Réseau hybride | Soutenu | Non pris en charge |
| Cryptage IPsec pour les communications à l'intérieur du cluster | Soutenu | Non pris en charge |
| IPv6 | Soutenu [3] | Non pris en charge |
| Politique de réseau Kubernetes | Soutenu | Soutenu |
| Journaux de la politique réseau de Kubernetes | Soutenu | Non pris en charge |
| Déchargement du matériel | Soutenu | Non pris en charge |
| Multidiffusion | Soutenu | Soutenu |
- Le pare-feu de sortie est également connu sous le nom de politique de réseau de sortie dans OpenShift SDN. Ce n'est pas la même chose que la politique de réseau de sortie.
- Le routeur de sortie pour OVN-Kubernetes ne prend en charge que le mode de redirection.
- IPv6 n'est pris en charge que sur les clusters bare metal, IBM Power et IBM zSystems.
24.1.3. OVN-Kubernetes IPv6 et limitations de la double pile
Le plugin réseau OVN-Kubernetes a les limitations suivantes :
Pour les clusters configurés pour un réseau à double pile, le trafic IPv4 et IPv6 doit utiliser la même interface réseau comme passerelle par défaut. Si cette condition n'est pas remplie, les modules sur l'hôte dans l'ensemble de démons
ovnkube-nodeentrent dans l'étatCrashLoopBackOff. Si vous affichez un pod avec une commande telle queoc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yaml, le champstatuscontient plus d'un message sur la passerelle par défaut, comme le montre la sortie suivante :I1006 16:09:50.985852 60651 helper_linux.go:73] Found default gateway interface br-ex 192.168.127.1 I1006 16:09:50.985923 60651 helper_linux.go:73] Found default gateway interface ens4 fe80::5054:ff:febe:bcd4 F1006 16:09:50.985939 60651 ovnkube.go:130] multiple gateway interfaces detected: br-ex ens4La seule solution consiste à reconfigurer le réseau de l'hôte de manière à ce que les deux familles IP utilisent la même interface réseau pour la passerelle par défaut.
Pour les clusters configurés pour un réseau à double pile, les tables de routage IPv4 et IPv6 doivent contenir la passerelle par défaut. Si cette condition n'est pas remplie, les modules sur l'hôte dans l'ensemble de démons
ovnkube-nodeentrent dans l'étatCrashLoopBackOff. Si vous affichez un pod avec une commande telle queoc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yaml, le champstatuscontient plus d'un message sur la passerelle par défaut, comme le montre la sortie suivante :I0512 19:07:17.589083 108432 helper_linux.go:74] Found default gateway interface br-ex 192.168.123.1 F0512 19:07:17.589141 108432 ovnkube.go:133] failed to get default gateway interfaceLa seule solution consiste à reconfigurer le réseau de l'hôte de manière à ce que les deux familles IP contiennent la passerelle par défaut.
24.1.4. Affinité de session
L'affinité de session est une fonctionnalité qui s'applique aux objets Kubernetes Service. Vous pouvez utiliser session affinity si vous voulez vous assurer qu'à chaque fois que vous vous connectez à un <service_VIP>:<Port>, le trafic est toujours équilibré en charge vers le même back-end. Pour plus d'informations, notamment sur la manière de définir l'affinité de session en fonction de l'adresse IP d'un client, voir Affinité de session.
Délai d'attente pour l'affinité de session
Le plugin réseau OVN-Kubernetes pour OpenShift Container Platform calcule le délai d'attente pour une session à partir d'un client sur la base du dernier paquet. Par exemple, si vous exécutez la commande curl 10 fois, le délai de la session collante commence à partir du dixième paquet et non du premier. Par conséquent, si le client contacte continuellement le service, la session n'est jamais interrompue. Le délai d'attente démarre lorsque le service n'a pas reçu de paquet pendant la durée définie par le paramètre timeoutSeconds paramètre.
24.2. Architecture OVN-Kubernetes
24.2.1. Introduction à l'architecture OVN-Kubernetes
Le schéma suivant présente l'architecture OVN-Kubernetes.
Figure 24.1. Architecture OVK-Kubernetes
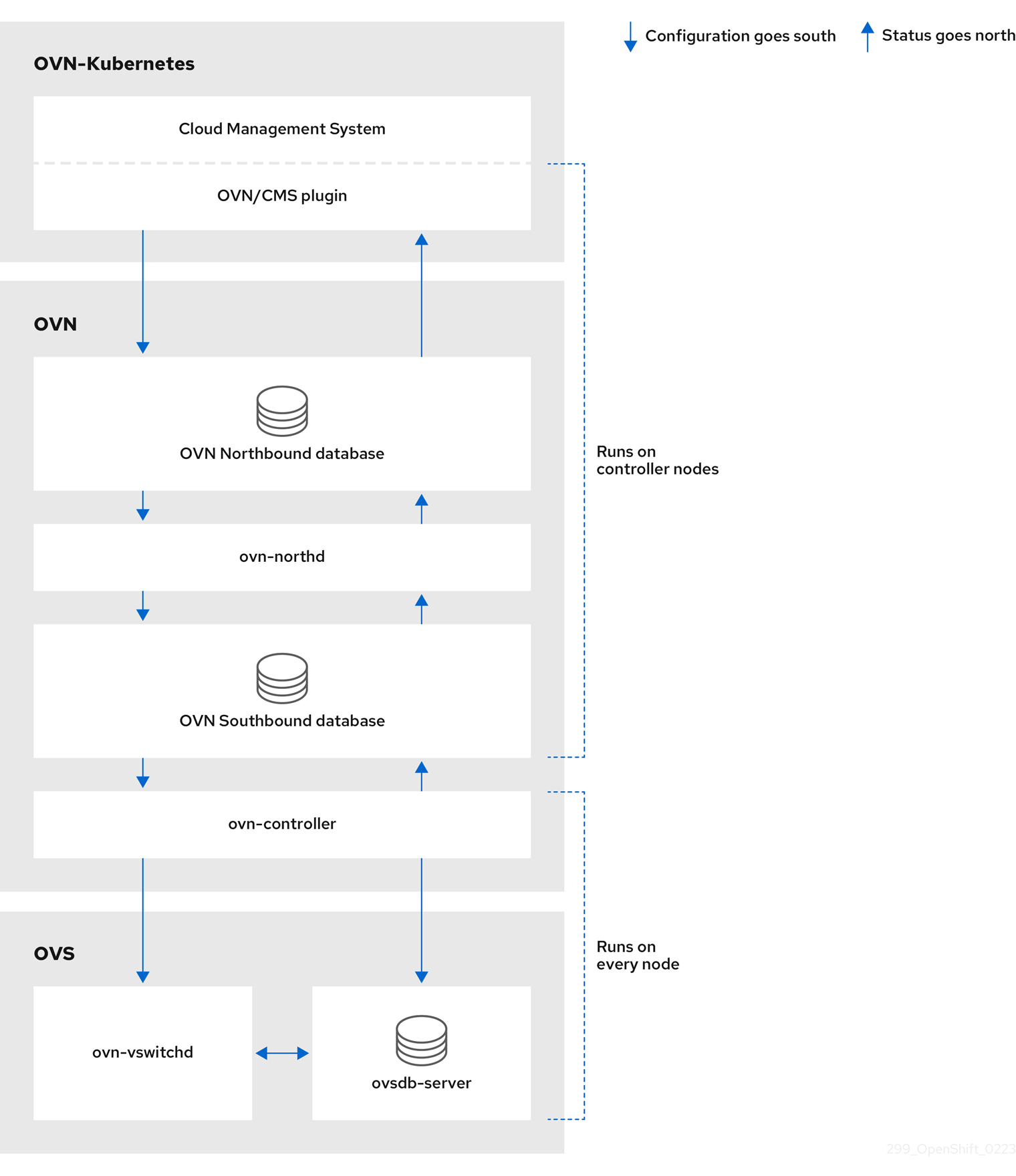
Les éléments clés sont les suivants :
- Cloud Management System (CMS) - Un client spécifique à la plateforme pour OVN qui fournit un plugin spécifique au CMS pour l'intégration d'OVN. Le plugin traduit le concept de configuration logique du réseau du système de gestion en nuage, stocké dans la base de données de configuration du CMS dans un format spécifique au CMS, en une représentation intermédiaire comprise par OVN.
-
OVN Northbound database (
nbdb) - Stocke la configuration logique du réseau transmise par le plugin CMS. -
OVN Southbound database (
sbdb) - Stocke l'état de la configuration physique et logique du réseau pour le système OpenVswitch (OVS) sur chaque nœud, y compris les tables qui les lient. -
ovn-northd - Il s'agit du client intermédiaire entre
nbdbetsbdb. Il traduit la configuration logique du réseau en termes de concepts de réseau conventionnels, tirés denbdb, en flux de chemins de données logiques danssbdben dessous de lui. Le nom du conteneur estnorthdet il fonctionne dans les podsovnkube-master. -
ovn-controller - Il s'agit de l'agent OVN qui interagit avec OVS et les hyperviseurs pour toute information ou mise à jour nécessaire à
sbdb. Leovn-controllerlit les flux logiques depuis lesbdb, les traduit en fluxOpenFlowet les envoie au démon OVS du nœud. Le nom du conteneur estovn-controlleret il s'exécute dans les podsovnkube-node.
La base de données OVN northbound possède la configuration logique du réseau qui lui a été transmise par le système de gestion des nuages (CMS). La base de données OVN northbound contient l'état actuel souhaité du réseau, présenté comme une collection de ports logiques, de commutateurs logiques, de routeurs logiques, etc. Le ovn-northd (conteneurnorthd ) se connecte à la base de données OVN northbound et à la base de données OVN southbound. Il traduit la configuration logique du réseau en termes de concepts de réseau conventionnels, tirés de la base de données OVN northbound, en flux de chemins de données logiques dans la base de données OVN southbound.
La base de données southbound d'OVN contient des représentations physiques et logiques du réseau et des tables de liaison qui les relient. Chaque nœud du cluster est représenté dans la base de données southbound, et vous pouvez voir les ports qui y sont connectés. Elle contient également tous les flux logiques, qui sont partagés avec le processus ovn-controller qui s'exécute sur chaque nœud et que ovn-controller transforme en règles OpenFlow pour programmer Open vSwitch.
Les nœuds du plan de contrôle Kubernetes contiennent chacun un pod ovnkube-master qui héberge des conteneurs pour les bases de données OVN northbound et southbound. Toutes les bases de données OVN en direction du nord forment un cluster Raft et toutes les bases de données en direction du sud forment un cluster Raft distinct. À tout moment, un seul ovnkube-master est le leader et les autres pods ovnkube-master sont des suiveurs.
24.2.2. Liste de toutes les ressources du projet OVN-Kubernetes
Il est important de trouver les ressources et les conteneurs qui fonctionnent dans le projet OVN-Kubernetes pour vous aider à comprendre la mise en œuvre du réseau OVN-Kubernetes.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
L'OpenShift CLI (
oc) est installé.
Procédure
Exécutez la commande suivante pour obtenir toutes les ressources, les points de terminaison et
ConfigMapsdans le projet OVN-Kubernetes :$ oc get all,ep,cm -n openshift-ovn-kubernetesExemple de sortie
NAME READY STATUS RESTARTS AGE pod/ovnkube-master-9g7zt 6/6 Running 1 (48m ago) 57m pod/ovnkube-master-lqs4v 6/6 Running 0 57m pod/ovnkube-master-vxhtq 6/6 Running 0 57m pod/ovnkube-node-9k9kc 5/5 Running 0 57m pod/ovnkube-node-jg52r 5/5 Running 0 51m pod/ovnkube-node-k8wf7 5/5 Running 0 57m pod/ovnkube-node-tlwk6 5/5 Running 0 47m pod/ovnkube-node-xsvnk 5/5 Running 0 57m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/ovn-kubernetes-master ClusterIP None <none> 9102/TCP 57m service/ovn-kubernetes-node ClusterIP None <none> 9103/TCP,9105/TCP 57m service/ovnkube-db ClusterIP None <none> 9641/TCP,9642/TCP 57m NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/ovnkube-master 3 3 3 3 3 beta.kubernetes.io/os=linux,node-role.kubernetes.io/master= 57m daemonset.apps/ovnkube-node 5 5 5 5 5 beta.kubernetes.io/os=linux 57m NAME ENDPOINTS AGE endpoints/ovn-kubernetes-master 10.0.132.11:9102,10.0.151.18:9102,10.0.192.45:9102 57m endpoints/ovn-kubernetes-node 10.0.132.11:9105,10.0.143.72:9105,10.0.151.18:9105 + 7 more... 57m endpoints/ovnkube-db 10.0.132.11:9642,10.0.151.18:9642,10.0.192.45:9642 + 3 more... 57m NAME DATA AGE configmap/control-plane-status 1 55m configmap/kube-root-ca.crt 1 57m configmap/openshift-service-ca.crt 1 57m configmap/ovn-ca 1 57m configmap/ovn-kubernetes-master 0 55m configmap/ovnkube-config 1 57m configmap/signer-ca 1 57mTrois sites
ovnkube-masterssont exécutés sur les nœuds du plan de contrôle, et deux ensembles de démons sont utilisés pour déployer les modulesovnkube-masteretovnkube-node. Il y a un podovnkube-nodepour chaque nœud du cluster. Dans cet exemple, il y en a 5, et comme il y a unovnkube-nodepar nœud dans le cluster, il y a cinq nœuds dans le cluster. Le podovnkube-configConfigMapcontient les configurations OpenShift Container Platform OVN-Kubernetes démarrées par online-master etovnkube-node. Le siteovn-kubernetes-masterConfigMapcontient les informations sur le maître en ligne actuel.Listez tous les conteneurs dans les pods
ovnkube-masteren exécutant la commande suivante :$ oc get pods ovnkube-master-9g7zt \ -o jsonpath='{.spec.containers[*].name}' -n openshift-ovn-kubernetesRésultats attendus
northd nbdb kube-rbac-proxy sbdb ovnkube-master ovn-dbcheckerLe pod
ovnkube-masterest composé de plusieurs conteneurs. Il est responsable de l'hébergement de la base de données nord (conteneurnbdb), de la base de données sud (conteneursbdb), de la surveillance des événements du cluster pour les pods, egressIP, namespaces, services, endpoints, egress firewall et network policy et de leur écriture dans la base de données nord (podovnkube-master), ainsi que de la gestion de l'allocation des sous-réseaux des pods aux nœuds.Listez tous les conteneurs dans les pods
ovnkube-nodeen exécutant la commande suivante :$ oc get pods ovnkube-node-jg52r \ -o jsonpath='{.spec.containers[*].name}' -n openshift-ovn-kubernetesRésultats attendus
ovn-controller ovn-acl-logging kube-rbac-proxy kube-rbac-proxy-ovn-metrics ovnkube-nodeLe pod
ovnkube-nodea un conteneur (ovn-controller) qui réside sur chaque nœud d'OpenShift Container Platform. Le siteovn-controllerde chaque nœud connecte la base de données OVN northbound à la base de données OVN southbound pour connaître la configuration OVN. Leovn-controllerse connecte au sud auovs-vswitchden tant que contrôleur OpenFlow, pour contrôler le trafic réseau, et auovsdb-serverlocal pour lui permettre de surveiller et de contrôler la configuration de l'Open vSwitch.
24.2.3. Liste du contenu de la base de données OVN-Kubernetes northbound
Pour comprendre les règles de flux logique, il faut examiner la base de données de la connexion nord et comprendre quels objets s'y trouvent pour voir comment ils sont traduits en règles de flux logique. L'information à jour est présente sur l'OVN Raft leader et cette procédure décrit comment trouver le Raft leader et ensuite l'interroger pour lister le contenu de la base de données de la liaison nord de l'OVN.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
L'OpenShift CLI (
oc) est installé.
Procédure
Trouver le chef de file du radeau OVN pour la base de données en direction du nord.
NoteLe chef de file du radeau stocke les informations les plus récentes.
Dressez la liste des pods en exécutant la commande suivante :
$ oc get po -n openshift-ovn-kubernetesExemple de sortie
NAME READY STATUS RESTARTS AGE ovnkube-master-7j97q 6/6 Running 2 (148m ago) 149m ovnkube-master-gt4ms 6/6 Running 1 (140m ago) 147m ovnkube-master-mk6p6 6/6 Running 0 148m ovnkube-node-8qvtr 5/5 Running 0 149m ovnkube-node-fqdc9 5/5 Running 0 149m ovnkube-node-tlfwv 5/5 Running 0 149m ovnkube-node-wlwkn 5/5 Running 0 142mChoisissez au hasard l'un des pods maîtres et exécutez la commande suivante :
$ oc exec -n openshift-ovn-kubernetes ovnkube-master-7j97q \ -- /usr/bin/ovn-appctl -t /var/run/ovn/ovnnb_db.ctl \ --timeout=3 cluster/status OVN_NorthboundExemple de sortie
Defaulted container "northd" out of: northd, nbdb, kube-rbac-proxy, sbdb, ovnkube-master, ovn-dbchecker 1c57 Name: OVN_Northbound Cluster ID: c48a (c48aa5c0-a704-4c77-a066-24fe99d9b338) Server ID: 1c57 (1c57b6fc-2849-49b7-8679-fbf18bafe339) Address: ssl:10.0.147.219:9643 Status: cluster member Role: follower1 Term: 5 Leader: 2b4f2 Vote: unknown Election timer: 10000 Log: [2, 3018] Entries not yet committed: 0 Entries not yet applied: 0 Connections: ->0000 ->0000 <-8844 <-2b4f Disconnections: 0 Servers: 1c57 (1c57 at ssl:10.0.147.219:9643) (self) 8844 (8844 at ssl:10.0.163.212:9643) last msg 8928047 ms ago 2b4f (2b4f at ssl:10.0.242.240:9643) last msg 620 ms ago3 Recherchez le pod
ovnkube-masterfonctionnant sur l'adresse IP10.0.242.240à l'aide de la commande suivante :$ oc get po -o wide -n openshift-ovn-kubernetes | grep 10.0.242.240 | grep -v ovnkube-nodeExemple de sortie
ovnkube-master-gt4ms 6/6 Running 1 (143m ago) 150m 10.0.242.240 ip-10-0-242-240.ec2.internal <none> <none>Le pod
ovnkube-master-gt4msfonctionne sur l'adresse IP 10.0.242.240.
Exécutez la commande suivante pour afficher tous les objets de la base de données northbound :
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl showLe résultat est trop long pour être énuméré ici. La liste comprend les règles NAT, les commutateurs logiques, les équilibreurs de charge, etc.
Exécutez la commande suivante pour afficher les options disponibles avec la commande
ovn-nbctl:$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-mk6p6 \ -c northd ovn-nbctl --helpVous pouvez vous concentrer sur des composants spécifiques en utilisant certaines des commandes suivantes :
Exécutez la commande suivante pour afficher la liste des routeurs logiques :
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl lr-listExemple de sortie
f971f1f3-5112-402f-9d1e-48f1d091ff04 (GR_ip-10-0-145-205.ec2.internal) 69c992d8-a4cf-429e-81a3-5361209ffe44 (GR_ip-10-0-147-219.ec2.internal) 7d164271-af9e-4283-b84a-48f2a44851cd (GR_ip-10-0-163-212.ec2.internal) 111052e3-c395-408b-97b2-8dd0a20a29a5 (GR_ip-10-0-165-9.ec2.internal) ed50ce33-df5d-48e8-8862-2df6a59169a0 (GR_ip-10-0-209-170.ec2.internal) f44e2a96-8d1e-4a4d-abae-ed8728ac6851 (GR_ip-10-0-242-240.ec2.internal) ef3d0057-e557-4b1a-b3c6-fcc3463790b0 (ovn_cluster_router)NoteCette sortie montre qu'il y a un routeur sur chaque nœud et un
ovn_cluster_router.Exécutez la commande suivante pour afficher la liste des commutateurs logiques :
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl ls-listExemple de sortie
82808c5c-b3bc-414a-bb59-8fec4b07eb14 (ext_ip-10-0-145-205.ec2.internal) 3d22444f-0272-4c51-afc6-de9e03db3291 (ext_ip-10-0-147-219.ec2.internal) bf73b9df-59ab-4c58-a456-ce8205b34ac5 (ext_ip-10-0-163-212.ec2.internal) bee1e8d0-ec87-45eb-b98b-63f9ec213e5e (ext_ip-10-0-165-9.ec2.internal) 812f08f2-6476-4abf-9a78-635f8516f95e (ext_ip-10-0-209-170.ec2.internal) f65e710b-32f9-482b-8eab-8d96a44799c1 (ext_ip-10-0-242-240.ec2.internal) 84dad700-afb8-4129-86f9-923a1ddeace9 (ip-10-0-145-205.ec2.internal) 1b7b448b-e36c-4ca3-9f38-4a2cf6814bfd (ip-10-0-147-219.ec2.internal) d92d1f56-2606-4f23-8b6a-4396a78951de (ip-10-0-163-212.ec2.internal) 6864a6b2-de15-4de3-92d8-f95014b6f28f (ip-10-0-165-9.ec2.internal) c26bf618-4d7e-4afd-804f-1a2cbc96ec6d (ip-10-0-209-170.ec2.internal) ab9a4526-44ed-4f82-ae1c-e20da04947d9 (ip-10-0-242-240.ec2.internal) a8588aba-21da-4276-ba0f-9d68e88911f0 (join)NoteCette sortie montre qu'il y a un commutateur ext pour chaque nœud, des commutateurs avec le nom du nœud lui-même et un commutateur join.
Exécutez la commande suivante pour afficher la liste des équilibreurs de charge :
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl lb-listExemple de sortie
UUID LB PROTO VIP IPs f0fb50f9-4968-4b55-908c-616bae4db0a2 Service_default/ tcp 172.30.0.1:443 10.0.147.219:6443,10.0.163.212:6443,169.254.169.2:6443 0dc42012-4f5b-432e-ae01-2cc4bfe81b00 Service_default/ tcp 172.30.0.1:443 10.0.147.219:6443,169.254.169.2:6443,10.0.242.240:6443 f7fff5d5-5eff-4a40-98b1-3a4ba8f7f69c Service_default/ tcp 172.30.0.1:443 169.254.169.2:6443,10.0.163.212:6443,10.0.242.240:6443 12fe57a0-50a4-4a1b-ac10-5f288badee07 Service_default/ tcp 172.30.0.1:443 10.0.147.219:6443,10.0.163.212:6443,10.0.242.240:6443 3f137fbf-0b78-4875-ba44-fbf89f254cf7 Service_openshif tcp 172.30.23.153:443 10.130.0.14:8443 174199fe-0562-4141-b410-12094db922a7 Service_openshif tcp 172.30.69.51:50051 10.130.0.84:50051 5ee2d4bd-c9e2-4d16-a6df-f54cd17c9ac3 Service_openshif tcp 172.30.143.87:9001 10.0.145.205:9001,10.0.147.219:9001,10.0.163.212:9001,10.0.165.9:9001,10.0.209.170:9001,10.0.242.240:9001 a056ae3d-83f8-45bc-9c80-ef89bce7b162 Service_openshif tcp 172.30.164.74:443 10.0.147.219:6443,10.0.163.212:6443,10.0.242.240:6443 bac51f3d-9a6f-4f5e-ac02-28fd343a332a Service_openshif tcp 172.30.0.10:53 10.131.0.6:5353 tcp 172.30.0.10:9154 10.131.0.6:9154 48105bbc-51d7-4178-b975-417433f9c20a Service_openshif tcp 172.30.26.159:2379 10.0.147.219:2379,169.254.169.2:2379,10.0.242.240:2379 tcp 172.30.26.159:9979 10.0.147.219:9979,169.254.169.2:9979,10.0.242.240:9979 7de2b8fc-342a-415f-ac13-1a493f4e39c0 Service_openshif tcp 172.30.53.219:443 10.128.0.7:8443 tcp 172.30.53.219:9192 10.128.0.7:9192 2cef36bc-d720-4afb-8d95-9350eff1d27a Service_openshif tcp 172.30.81.66:443 10.128.0.23:8443 365cb6fb-e15e-45a4-a55b-21868b3cf513 Service_openshif tcp 172.30.96.51:50051 10.130.0.19:50051 41691cbb-ec55-4cdb-8431-afce679c5e8d Service_openshif tcp 172.30.98.218:9099 169.254.169.2:9099 82df10ba-8143-400b-977a-8f5f416a4541 Service_openshif tcp 172.30.26.159:2379 10.0.147.219:2379,10.0.163.212:2379,169.254.169.2:2379 tcp 172.30.26.159:9979 10.0.147.219:9979,10.0.163.212:9979,169.254.169.2:9979 debe7f3a-39a8-490e-bc0a-ebbfafdffb16 Service_openshif tcp 172.30.23.244:443 10.128.0.48:8443,10.129.0.27:8443,10.130.0.45:8443 8a749239-02d9-4dc2-8737-716528e0da7b Service_openshif tcp 172.30.124.255:8443 10.128.0.14:8443 880c7c78-c790-403d-a3cb-9f06592717a3 Service_openshif tcp 172.30.0.10:53 10.130.0.20:5353 tcp 172.30.0.10:9154 10.130.0.20:9154 d2f39078-6751-4311-a161-815bbaf7f9c7 Service_openshif tcp 172.30.26.159:2379 169.254.169.2:2379,10.0.163.212:2379,10.0.242.240:2379 tcp 172.30.26.159:9979 169.254.169.2:9979,10.0.163.212:9979,10.0.242.240:9979 30948278-602b-455c-934a-28e64c46de12 Service_openshif tcp 172.30.157.35:9443 10.130.0.43:9443 2cc7e376-7c02-4a82-89e8-dfa1e23fb003 Service_openshif tcp 172.30.159.212:17698 10.128.0.48:17698,10.129.0.27:17698,10.130.0.45:17698 e7d22d35-61c2-40c2-bc30-265cff8ed18d Service_openshif tcp 172.30.143.87:9001 10.0.145.205:9001,10.0.147.219:9001,10.0.163.212:9001,10.0.165.9:9001,10.0.209.170:9001,169.254.169.2:9001 75164e75-e0c5-40fb-9636-bfdbf4223a02 Service_openshif tcp 172.30.150.68:1936 10.129.4.8:1936,10.131.0.10:1936 tcp 172.30.150.68:443 10.129.4.8:443,10.131.0.10:443 tcp 172.30.150.68:80 10.129.4.8:80,10.131.0.10:80 7bc4ee74-dccf-47e9-9149-b011f09aff39 Service_openshif tcp 172.30.164.74:443 10.0.147.219:6443,10.0.163.212:6443,169.254.169.2:6443 0db59e74-1cc6-470c-bf44-57c520e0aa8f Service_openshif tcp 10.0.163.212:31460 tcp 10.0.163.212:32361 c300e134-018c-49af-9f84-9deb1d0715f8 Service_openshif tcp 172.30.42.244:50051 10.130.0.47:50051 5e352773-429b-4881-afb3-a13b7ba8b081 Service_openshif tcp 172.30.244.66:443 10.129.0.8:8443,10.130.0.8:8443 54b82d32-1939-4465-a87d-f26321442a7a Service_openshif tcp 172.30.12.9:8443 10.128.0.35:8443NoteA partir de cette sortie tronquée, vous pouvez voir qu'il y a beaucoup de répartiteurs de charge OVN-Kubernetes. Les équilibreurs de charge dans OVN-Kubernetes sont des représentations de services.
24.2.4. Arguments de ligne de commande pour ovn-nbctl afin d'examiner le contenu de la base de données de la liaison descendante
Le tableau suivant décrit les arguments de ligne de commande qui peuvent être utilisés avec ovn-nbctl pour examiner le contenu de la base de données northbound.
| Argument | Description |
|---|---|
|
| Une vue d'ensemble du contenu de la base de données pour le trafic nord. |
|
| Affiche les détails associés au commutateur ou au routeur spécifié. |
|
| Afficher les routeurs logiques. |
|
|
Utilisation des informations du routeur à partir de |
|
| Affiche les détails de la traduction d'adresses réseau pour le routeur spécifié. |
|
| Afficher les commutateurs logiques |
|
|
Utilisation des informations sur le commutateur à partir de |
|
| Obtenir le type du port logique. |
|
| Montrer les équilibreurs de charge. |
24.2.5. Liste du contenu de la base de données OVN-Kubernetes en direction du sud
Les règles de flux logiques sont stockées dans la base de données southbound qui est une représentation de votre infrastructure. L'information à jour est présente sur le Raft leader OVN et cette procédure décrit comment trouver le Raft leader et l'interroger pour lister le contenu de la base de données OVN southbound.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
L'OpenShift CLI (
oc) est installé.
Procédure
Trouver le chef de file du radeau OVN pour la base de données en direction du sud.
NoteLe chef de file du radeau stocke les informations les plus récentes.
Dressez la liste des pods en exécutant la commande suivante :
$ oc get po -n openshift-ovn-kubernetesExemple de sortie
NAME READY STATUS RESTARTS AGE ovnkube-master-7j97q 6/6 Running 2 (134m ago) 135m ovnkube-master-gt4ms 6/6 Running 1 (126m ago) 133m ovnkube-master-mk6p6 6/6 Running 0 134m ovnkube-node-8qvtr 5/5 Running 0 135m ovnkube-node-bqztb 5/5 Running 0 117m ovnkube-node-fqdc9 5/5 Running 0 135m ovnkube-node-tlfwv 5/5 Running 0 135m ovnkube-node-wlwkn 5/5 Running 0 128mChoisissez au hasard l'un des pods principaux et exécutez la commande suivante pour trouver le chef de file du radeau OVN en direction du sud :
$ oc exec -n openshift-ovn-kubernetes ovnkube-master-7j97q \ -- /usr/bin/ovn-appctl -t /var/run/ovn/ovnsb_db.ctl \ --timeout=3 cluster/status OVN_SouthboundExemple de sortie
Defaulted container "northd" out of: northd, nbdb, kube-rbac-proxy, sbdb, ovnkube-master, ovn-dbchecker 1930 Name: OVN_Southbound Cluster ID: f772 (f77273c0-7986-42dd-bd3c-a9f18e25701f) Server ID: 1930 (1930f4b7-314b-406f-9dcb-b81fe2729ae1) Address: ssl:10.0.147.219:9644 Status: cluster member Role: follower1 Term: 3 Leader: 70812 Vote: unknown Election timer: 16000 Log: [2, 2423] Entries not yet committed: 0 Entries not yet applied: 0 Connections: ->0000 ->7145 <-7081 <-7145 Disconnections: 0 Servers: 7081 (7081 at ssl:10.0.163.212:9644) last msg 59 ms ago3 1930 (1930 at ssl:10.0.147.219:9644) (self) 7145 (7145 at ssl:10.0.242.240:9644) last msg 7871735 ms agoRecherchez le pod
ovnkube-masterfonctionnant sur l'adresse IP10.0.163.212à l'aide de la commande suivante :$ oc get po -o wide -n openshift-ovn-kubernetes | grep 10.0.163.212 | grep -v ovnkube-nodeExemple de sortie
ovnkube-master-mk6p6 6/6 Running 0 136m 10.0.163.212 ip-10-0-163-212.ec2.internal <none> <none>Le pod
ovnkube-master-mk6p6fonctionne sur l'adresse IP 10.0.163.212.
Exécutez la commande suivante pour afficher toutes les informations stockées dans la base de données "southbound" :
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-mk6p6 \ -c northd -- ovn-sbctl showExemple de sortie
Chassis "8ca57b28-9834-45f0-99b0-96486c22e1be" hostname: ip-10-0-156-16.ec2.internal Encap geneve ip: "10.0.156.16" options: {csum="true"} Port_Binding k8s-ip-10-0-156-16.ec2.internal Port_Binding etor-GR_ip-10-0-156-16.ec2.internal Port_Binding jtor-GR_ip-10-0-156-16.ec2.internal Port_Binding openshift-ingress-canary_ingress-canary-hsblx Port_Binding rtoj-GR_ip-10-0-156-16.ec2.internal Port_Binding openshift-monitoring_prometheus-adapter-658fc5967-9l46x Port_Binding rtoe-GR_ip-10-0-156-16.ec2.internal Port_Binding openshift-multus_network-metrics-daemon-77nvz Port_Binding openshift-ingress_router-default-64fd8c67c7-df598 Port_Binding openshift-dns_dns-default-ttpcq Port_Binding openshift-monitoring_alertmanager-main-0 Port_Binding openshift-e2e-loki_loki-promtail-g2pbh Port_Binding openshift-network-diagnostics_network-check-target-m6tn4 Port_Binding openshift-monitoring_thanos-querier-75b5cf8dcb-qf8qj Port_Binding cr-rtos-ip-10-0-156-16.ec2.internal Port_Binding openshift-image-registry_image-registry-7b7bc44566-mp9b8Cette sortie détaillée montre le châssis et les ports qui sont attachés au châssis qui, dans ce cas, sont tous les ports du routeur et tout ce qui fonctionne comme un réseau hôte. Tous les pods communiquent avec le réseau plus large en utilisant la traduction d'adresse du réseau source (SNAT). Leur adresse IP est traduite en adresse IP du nœud sur lequel le module fonctionne, puis envoyée sur le réseau.
Outre les informations relatives au châssis, la base de données de la sortie sud contient tous les flux logiques, qui sont ensuite envoyés à
ovn-controller, qui fonctionne sur chacun des nœuds.ovn-controllertraduit les flux logiques en règles de flux ouvert et programme finalementOpenvSwitchafin que vos pods puissent suivre les règles de flux ouvert et sortir du réseau.Exécutez la commande suivante pour afficher les options disponibles avec la commande
ovn-sbctl:$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-mk6p6 \ -c northd -- ovn-sbctl --help
24.2.6. Arguments de ligne de commande pour ovn-sbctl afin d'examiner le contenu de la base de données de la liaison descendante
Le tableau suivant décrit les arguments de ligne de commande qui peuvent être utilisés avec ovn-sbctl pour examiner le contenu de la base de données de la liaison descendante.
| Argument | Description |
|---|---|
|
| Vue d'ensemble du contenu de la base de données de la direction sud. |
|
| Répertorie le contenu de la base de données de la sortie sud pour le port spécifié. |
|
| Dresser la liste des flux logiques. |
24.2.7. Architecture logique OVN-Kubernetes
OVN est une solution de virtualisation du réseau. Il crée des commutateurs et des routeurs logiques. Ces commutateurs et routeurs sont interconnectés pour créer n'importe quelle topologie de réseau. Lorsque vous exécutez ovnkube-trace avec le niveau de journal défini sur 2 ou 5, les composants logiques OVN-Kubernetes sont exposés. Le diagramme suivant montre comment les routeurs et les commutateurs sont connectés dans OpenShift Container Platform.
Figure 24.2. Composants du routeur et du commutateur OVN-Kubernetes
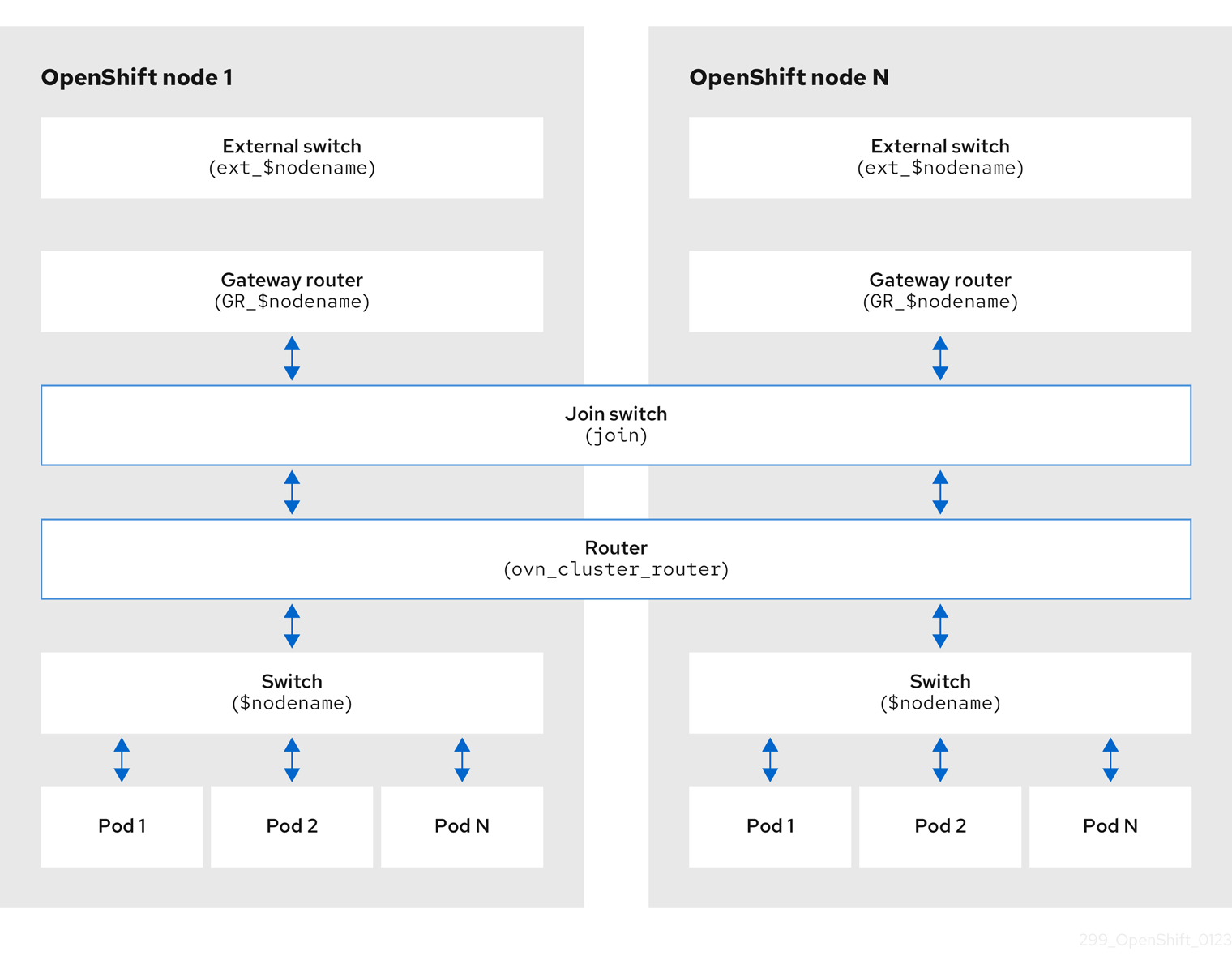
Les principaux composants impliqués dans le traitement des paquets sont les suivants :
- Routeurs de passerelle
-
Les routeurs passerelle, parfois appelés routeurs passerelle L3, sont généralement utilisés entre les routeurs distribués et le réseau physique. Les routeurs passerelle, y compris leurs ports de connexion logiques, sont liés à un emplacement physique (non distribué) ou à un châssis. Les ports de raccordement de ce routeur sont appelés ports l3gateway dans la base de données ovn-southbound (
ovn-sbdb). - Routeurs logiques distribués
- Les routeurs logiques distribués et les commutateurs logiques derrière eux, auxquels les machines virtuelles et les conteneurs s'attachent, résident effectivement sur chaque hyperviseur.
- Rejoindre le commutateur local
- Les commutateurs locaux Join sont utilisés pour connecter le routeur distribué et les routeurs de passerelle. Ils réduisent le nombre d'adresses IP nécessaires sur le routeur distribué.
- Commutateurs logiques avec ports de brassage
- Les commutateurs logiques avec ports de connexion sont utilisés pour virtualiser la pile du réseau. Ils connectent des ports logiques distants par le biais de tunnels.
- Commutateurs logiques avec ports localnet
- Les commutateurs logiques dotés de ports localnet sont utilisés pour connecter l'OVN au réseau physique. Ils relient les ports logiques distants en pontant les paquets vers les segments L2 physiques directement connectés à l'aide des ports localnet.
- Ports de brassage
- Les ports de brassage représentent la connectivité entre les commutateurs logiques et les routeurs logiques, ainsi qu'entre les routeurs logiques homologues. Une connexion unique possède une paire de ports de brassage à chacun de ces points de connectivité, un de chaque côté.
- ports l3gateway
-
les ports l3gateway sont les entrées de liaison de port dans le site
ovn-sbdbpour les ports de connexion logiques utilisés dans les routeurs passerelle. Ils sont appelés ports l3gateway plutôt que ports patch pour illustrer le fait que ces ports sont liés à un châssis tout comme le routeur gateway lui-même. - ports localnet
-
des ports localnet sont présents sur les commutateurs logiques pontés qui permettent une connexion à un réseau accessible localement à partir de chaque instance
ovn-controller. Cela permet de modéliser la connectivité directe au réseau physique à partir des commutateurs logiques. Un commutateur logique ne peut être relié qu'à un seul port localnet.
24.2.7.1. Installation de network-tools sur l'hôte local
Installez network-tools sur votre hôte local pour disposer d'une collection d'outils permettant de déboguer les problèmes de réseau des clusters OpenShift Container Platform.
Procédure
Clonez le dépôt
network-toolssur votre station de travail avec la commande suivante :$ git clone git@github.com:openshift/network-tools.gitAllez dans le répertoire du dépôt que vous venez de cloner :
$ cd network-toolsFacultatif : Liste de toutes les commandes disponibles :
$ ./debug-scripts/network-tools -h
24.2.7.2. Exécution de network-tools
Obtenez des informations sur les commutateurs logiques et les routeurs en exécutant network-tools.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster en tant qu'utilisateur disposant des privilèges
cluster-admin. -
Vous avez installé
network-toolssur l'hôte local.
Procédure
Dressez la liste des routeurs en exécutant la commande suivante :
$ ./debug-scripts/network-tools ovn-db-run-command ovn-nbctl lr-listExemple de sortie
Leader pod is ovnkube-master-vslqm 5351ddd1-f181-4e77-afc6-b48b0a9df953 (GR_helix13.lab.eng.tlv2.redhat.com) ccf9349e-1948-4df8-954e-39fb0c2d4d06 (GR_helix14.lab.eng.tlv2.redhat.com) e426b918-75a8-4220-9e76-20b7758f92b7 (GR_hlxcl7-master-0.hlxcl7.lab.eng.tlv2.redhat.com) dded77c8-0cc3-4b99-8420-56cd2ae6a840 (GR_hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com) 4f6747e6-e7ba-4e0c-8dcd-94c8efa51798 (GR_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com) 52232654-336e-4952-98b9-0b8601e370b4 (ovn_cluster_router)Dressez la liste des ports localnet en exécutant la commande suivante :
$ ./debug-scripts/network-tools ovn-db-run-command \ ovn-sbctl find Port_Binding type=localnetExemple de sortie
Leader pod is ovnkube-master-vslqm _uuid : 3de79191-cca8-4c28-be5a-a228f0f9ebfc additional_chassis : [] additional_encap : [] chassis : [] datapath : 3f1a4928-7ff5-471f-9092-fe5f5c67d15c encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : br-ex_helix13.lab.eng.tlv2.redhat.com mac : [unknown] nat_addresses : [] options : {network_name=physnet} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 2 type : localnet up : false virtual_parent : [] _uuid : dbe21daf-9594-4849-b8f0-5efbfa09a455 additional_chassis : [] additional_encap : [] chassis : [] datapath : db2a6067-fe7c-4d11-95a7-ff2321329e11 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : br-ex_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com mac : [unknown] nat_addresses : [] options : {network_name=physnet} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 2 type : localnet up : false virtual_parent : [] [...]Dressez la liste des ports
l3gatewayen exécutant la commande suivante :$ ./debug-scripts/network-tools ovn-db-run-command \ ovn-sbctl find Port_Binding type=l3gatewayExemple de sortie
Leader pod is ovnkube-master-vslqm _uuid : 9314dc80-39e1-4af7-9cc0-ae8a9708ed59 additional_chassis : [] additional_encap : [] chassis : 336a923d-99e8-4e71-89a6-12564fde5760 datapath : db2a6067-fe7c-4d11-95a7-ff2321329e11 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : etor-GR_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com mac : ["52:54:00:3e:95:d3"] nat_addresses : ["52:54:00:3e:95:d3 10.46.56.77"] options : {l3gateway-chassis="7eb1f1c3-87c2-4f68-8e89-60f5ca810971", peer=rtoe-GR_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 1 type : l3gateway up : true virtual_parent : [] _uuid : ad7eb303-b411-4e9f-8d36-d07f1f268e27 additional_chassis : [] additional_encap : [] chassis : f41453b8-29c5-4f39-b86b-e82cf344bce4 datapath : 082e7a60-d9c7-464b-b6ec-117d3426645a encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : etor-GR_helix14.lab.eng.tlv2.redhat.com mac : ["34:48:ed:f3:e2:2c"] nat_addresses : ["34:48:ed:f3:e2:2c 10.46.56.14"] options : {l3gateway-chassis="2e8abe3a-cb94-4593-9037-f5f9596325e2", peer=rtoe-GR_helix14.lab.eng.tlv2.redhat.com} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 1 type : l3gateway up : true virtual_parent : [] [...]Dressez la liste des ports de correctifs en exécutant la commande suivante :
$ ./debug-scripts/network-tools ovn-db-run-command \ ovn-sbctl find Port_Binding type=patchExemple de sortie
Leader pod is ovnkube-master-vslqm _uuid : c48b1380-ff26-4965-a644-6bd5b5946c61 additional_chassis : [] additional_encap : [] chassis : [] datapath : 72734d65-fae1-4bd9-a1ee-1bf4e085a060 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : jtor-ovn_cluster_router mac : [router] nat_addresses : [] options : {peer=rtoj-ovn_cluster_router} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 4 type : patch up : false virtual_parent : [] _uuid : 5df51302-f3cd-415b-a059-ac24389938f7 additional_chassis : [] additional_encap : [] chassis : [] datapath : 0551c90f-e891-4909-8e9e-acc7909e06d0 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : rtos-hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com mac : ["0a:58:0a:82:00:01 10.130.0.1/23"] nat_addresses : [] options : {chassis-redirect-port=cr-rtos-hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com, peer=stor-hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 4 type : patch up : false virtual_parent : [] [...]
24.3. Dépannage d'OVN-Kubernetes
OVN-Kubernetes dispose de nombreuses sources de contrôles de santé et de journaux intégrés.
24.3.1. Surveillance de l'état de santé d'OVN-Kubernetes à l'aide de sondes d'état de préparation
Les pods ovnkube-master et ovnkube-node ont des conteneurs configurés avec des sondes de préparation.
Conditions préalables
-
Accès à la CLI OpenShift (
oc). -
Vous avez accès au cluster avec les privilèges
cluster-admin. -
Vous avez installé
jq.
Procédure
Examinez les détails de la sonde de préparation
ovnkube-masteren exécutant la commande suivante :$ oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-master \ -o json | jq '.items[0].spec.containers[] | .name,.readinessProbe'La sonde de préparation des conteneurs de base de données nord et sud du pod
ovnkube-mastervérifie l'état de santé du cluster Raft qui héberge les bases de données.Examinez les détails de la sonde de préparation
ovnkube-nodeen exécutant la commande suivante :$ oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-master \ -o json | jq '.items[0].spec.containers[] | .name,.readinessProbe'Le conteneur
ovnkube-nodedans le podovnkube-nodedispose d'une sonde de préparation pour vérifier la présence du fichier de configuration CNI ovn-kubernetes, dont l'absence indiquerait que le pod ne fonctionne pas ou n'est pas prêt à accepter des demandes de configuration de pods.Affichez tous les événements, y compris les échecs des sondes, pour l'espace de noms à l'aide de la commande suivante :
$ oc get events -n openshift-ovn-kubernetesAfficher les événements pour ce seul pod :
$ oc describe pod ovnkube-master-tp2z8 -n openshift-ovn-kubernetesAffiche les messages et les statuts de l'opérateur du réseau de clusters :
$ oc get co/network -o json | jq '.status.conditions[]'Affichez le statut
readyde chaque conteneur dans les podsovnkube-masteren exécutant le script suivant :$ for p in $(oc get pods --selector app=ovnkube-master -n openshift-ovn-kubernetes \ -o jsonpath='{range.items[*]}{" "}{.metadata.name}'); do echo === $p ===; \ oc get pods -n openshift-ovn-kubernetes $p -o json | jq '.status.containerStatuses[] | .name, .ready'; \ doneNoteOn s'attend à ce que tous les états des conteneurs soient signalés comme étant
true. L'échec d'une enquête sur l'état de préparation fait passer le statut àfalse.
24.3.2. Visualisation des alertes OVN-Kubernetes dans la console
L'interface utilisateur des alertes fournit des informations détaillées sur les alertes ainsi que sur les règles d'alerte et les silences qui les régissent.
Conditions préalables
- Vous avez accès au cluster en tant que développeur ou en tant qu'utilisateur disposant d'autorisations de visualisation pour le projet dont vous consultez les métriques.
Procédure (UI)
- Dans la Administrator sélectionnez Observe → Alerting. Les trois pages principales de l'interface utilisateur d'alerte dans cette perspective sont les suivantes Alerts, Silences, et Alerting Rules sont les trois pages principales de l'interface utilisateur des alertes dans cette perspective.
- Consultez les règles pour les alertes OVN-Kubernetes en sélectionnant Observe → Alerting → Alerting Rules.
24.3.3. Visualisation des alertes OVN-Kubernetes dans le CLI
Vous pouvez obtenir des informations sur les alertes et les règles d'alerte et de silence qui les régissent à partir de la ligne de commande.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
L'OpenShift CLI (
oc) est installé. -
Vous avez installé
jq.
Procédure
Pour visualiser les alertes actives ou en cours de déclenchement, exécutez les commandes suivantes.
Définissez la variable d'environnement alert manager route en exécutant la commande suivante :
$ ALERT_MANAGER=$(oc get route alertmanager-main -n openshift-monitoring \ -o jsonpath='{@.spec.host}')Emettez une requête
curlà l'API de route du gestionnaire d'alertes avec les détails d'autorisation corrects demandant des champs spécifiques en exécutant la commande suivante :$ curl -s -k -H "Authorization: Bearer \ $(oc create token prometheus-k8s -n openshift-monitoring)" \ https://$ALERT_MANAGER/api/v1/alerts \ | jq '.data[] | "\(.labels.severity) \(.labels.alertname) \(.labels.pod) \(.labels.container) \(.labels.endpoint) \(.labels.instance)"'
Affichez les règles d'alerte en exécutant la commande suivante :
$ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -s 'http://localhost:9090/api/v1/rules' | jq '.data.groups[].rules[] | select(((.name|contains("ovn")) or (.name|contains("OVN")) or (.name|contains("Ovn")) or (.name|contains("North")) or (.name|contains("South"))) and .type=="alerting")'
24.3.4. Visualisation des journaux OVN-Kubernetes à l'aide de la CLI
Vous pouvez consulter les journaux de chaque pod dans les pods ovnkube-master et ovnkube-node à l'aide de la CLI OpenShift (oc).
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Accès à la CLI OpenShift (
oc). -
Vous avez installé
jq.
Procédure
Visualiser le journal d'un pod spécifique :
$ oc logs -f <nom_du_pod> -c <nom_du_conteneur> -n <espace_de_noms>où :
-f- Facultatif : Spécifie que la sortie suit ce qui est écrit dans les journaux.
<pod_name>- Spécifie le nom du module.
<container_name>- Facultatif : Spécifie le nom d'un conteneur. Lorsqu'un module a plus d'un conteneur, vous devez spécifier le nom du conteneur.
<namespace>- Spécifie l'espace de noms dans lequel le module est exécuté.
Par exemple :
$ oc logs ovnkube-master-7h4q7 -n openshift-ovn-kubernetes$ oc logs -f ovnkube-master-7h4q7 -n openshift-ovn-kubernetes -c ovn-dbcheckerLe contenu des fichiers journaux est imprimé.
Examinez les entrées les plus récentes dans tous les conteneurs des modules
ovnkube-master:$ for p in $(oc get pods --selector app=ovnkube-master -n openshift-ovn-kubernetes \ -o jsonpath='{range.items[*]}{" "}{.metadata.name}'); \ do echo === $p ===; for container in $(oc get pods -n openshift-ovn-kubernetes $p \ -o json | jq -r '.status.containerStatuses[] | .name');do echo ---$container---; \ oc logs -c $container $p -n openshift-ovn-kubernetes --tail=5; done; doneAffichez les 5 dernières lignes de chaque journal dans chaque conteneur d'un pod
ovnkube-masterà l'aide de la commande suivante :$ oc logs -l app=ovnkube-master -n openshift-ovn-kubernetes --all-containers --tail 5
24.3.5. Visualisation des journaux OVN-Kubernetes à l'aide de la console web
Vous pouvez consulter les journaux de chaque pod dans les pods ovnkube-master et ovnkube-node dans la console web.
Conditions préalables
-
Accès à la CLI OpenShift (
oc).
Procédure
- Dans la console OpenShift Container Platform, naviguez vers Workloads → Pods ou naviguez vers le pod par le biais de la ressource que vous souhaitez étudier.
-
Sélectionnez le projet
openshift-ovn-kubernetesdans le menu déroulant. - Cliquez sur le nom du module que vous souhaitez examiner.
-
Cliquez Logs. Par défaut, pour le site
ovnkube-master, les journaux associés au conteneurnorthdsont affichés. - Utilisez le menu déroulant pour sélectionner les journaux pour chaque conteneur à tour de rôle.
24.3.5.1. Modifier les niveaux de journalisation d'OVN-Kubernetes
Le niveau de log par défaut d'OVN-Kubernetes est 2. Pour déboguer OVN-Kubernetes, réglez le niveau de log à 5. Suivez cette procédure pour augmenter le niveau de journalisation d'OVN-Kubernetes afin de vous aider à déboguer un problème.
Conditions préalables
-
Vous avez accès au cluster avec les privilèges
cluster-admin. - Vous avez accès à la console web de OpenShift Container Platform.
Procédure
Exécutez la commande suivante pour obtenir des informations détaillées sur tous les pods du projet OVN-Kubernetes :
$ oc get po -o wide -n openshift-ovn-kubernetesExemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ovnkube-master-84nc9 6/6 Running 0 50m 10.0.134.156 ip-10-0-134-156.ec2.internal <none> <none> ovnkube-master-gmlqv 6/6 Running 0 50m 10.0.209.180 ip-10-0-209-180.ec2.internal <none> <none> ovnkube-master-nhts2 6/6 Running 1 (48m ago) 50m 10.0.147.31 ip-10-0-147-31.ec2.internal <none> <none> ovnkube-node-2cbh8 5/5 Running 0 43m 10.0.217.114 ip-10-0-217-114.ec2.internal <none> <none> ovnkube-node-6fvzl 5/5 Running 0 50m 10.0.147.31 ip-10-0-147-31.ec2.internal <none> <none> ovnkube-node-f4lzz 5/5 Running 0 24m 10.0.146.76 ip-10-0-146-76.ec2.internal <none> <none> ovnkube-node-jf67d 5/5 Running 0 50m 10.0.209.180 ip-10-0-209-180.ec2.internal <none> <none> ovnkube-node-np9mf 5/5 Running 0 40m 10.0.165.191 ip-10-0-165-191.ec2.internal <none> <none> ovnkube-node-qjldg 5/5 Running 0 50m 10.0.134.156 ip-10-0-134-156.ec2.internal <none> <none>Créez un fichier
ConfigMapsimilaire à l'exemple suivant et utilisez un nom de fichier tel queenv-overrides.yaml:Exemple de fichier
ConfigMapkind: ConfigMap apiVersion: v1 metadata: name: env-overrides namespace: openshift-ovn-kubernetes data: ip-10-0-217-114.ec2.internal: |1 # This sets the log level for the ovn-kubernetes node process: OVN_KUBE_LOG_LEVEL=5 # You might also/instead want to enable debug logging for ovn-controller: OVN_LOG_LEVEL=dbg ip-10-0-209-180.ec2.internal: | # This sets the log level for the ovn-kubernetes node process: OVN_KUBE_LOG_LEVEL=5 # You might also/instead want to enable debug logging for ovn-controller: OVN_LOG_LEVEL=dbg _master: |2 # This sets the log level for the ovn-kubernetes master process as well as the ovn-dbchecker: OVN_KUBE_LOG_LEVEL=5 # You might also/instead want to enable debug logging for northd, nbdb and sbdb on all masters: OVN_LOG_LEVEL=dbgAppliquez le fichier
ConfigMapà l'aide de la commande suivante :$ oc create configmap env-overrides.yaml -n openshift-ovn-kubernetesExemple de sortie
configmap/env-overrides.yaml createdRedémarrez les pods
ovnkubepour appliquer le nouveau niveau de journalisation à l'aide des commandes suivantes :$ oc delete pod -n openshift-ovn-kubernetes \ --field-selector spec.nodeName=ip-10-0-217-114.ec2.internal -l app=ovnkube-node$ oc delete pod -n openshift-ovn-kubernetes \ --field-selector spec.nodeName=ip-10-0-209-180.ec2.internal -l app=ovnkube-node$ oc delete pod -n openshift-ovn-kubernetes -l app=ovnkube-master
24.3.6. Vérification de la connectivité réseau du pod OVN-Kubernetes
Le contrôleur de vérification de la connectivité, dans OpenShift Container Platform 4.10 et plus, orchestre les vérifications de connexion dans votre cluster. Celles-ci incluent l'API Kubernetes, l'API OpenShift et les nœuds individuels. Les résultats des tests de connexion sont stockés dans les objets PodNetworkConnectivity de l'espace de noms openshift-network-diagnostics. Les tests de connexion sont effectués toutes les minutes en parallèle.
Conditions préalables
-
Accès à la CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé
jq.
Procédure
Pour dresser la liste des objets
PodNetworkConnectivityChecken cours, entrez la commande suivante :$ oc get podnetworkconnectivitychecks -n openshift-network-diagnosticsAffichez le succès le plus récent pour chaque objet de connexion à l'aide de la commande suivante :
$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics \ -o json | jq '.items[]| .spec.targetEndpoint,.status.successes[0]'Affichez les échecs les plus récents pour chaque objet de connexion à l'aide de la commande suivante :
$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics \ -o json | jq '.items[]| .spec.targetEndpoint,.status.failures[0]'Affichez les pannes les plus récentes pour chaque objet de connexion à l'aide de la commande suivante :
$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics \ -o json | jq '.items[]| .spec.targetEndpoint,.status.outages[0]'Le contrôleur de vérification de la connectivité enregistre également les mesures de ces vérifications dans Prometheus.
Affichez toutes les mesures en exécutant la commande suivante :
$ oc exec prometheus-k8s-0 -n openshift-monitoring -- \ promtool query instant http://localhost:9090 \ '{component="openshift-network-diagnostics"}'Voir la latence entre le pod source et le service openshift api pour les 5 dernières minutes :
$ oc exec prometheus-k8s-0 -n openshift-monitoring -- \ promtool query instant http://localhost:9090 \ '{component="openshift-network-diagnostics"}'
24.4. Tracer Openflow avec ovnkube-trace
Les flux de trafic OVN et OVS peuvent être simulés dans un seul utilitaire appelé ovnkube-trace. L'utilitaire ovnkube-trace exécute ovn-trace, ovs-appctl ofproto/trace et ovn-detrace et met en corrélation ces informations dans un seul résultat.
Vous pouvez exécuter le binaire ovnkube-trace à partir d'un conteneur dédié. Pour les versions postérieures à OpenShift Container Platform 4.7, vous pouvez également copier le binaire sur un hôte local et l'exécuter à partir de cet hôte.
Les binaires des images Quay ne fonctionnent pas actuellement pour les environnements à double pile IP ou IPv6 uniquement. Pour ces environnements, vous devez compiler à partir des sources.
24.4.1. Installation de ovnkube-trace sur l'hôte local
L'outil ovnkube-trace trace des simulations de paquets pour un trafic UDP ou TCP arbitraire entre des points d'un cluster OpenShift Container Platform piloté par OVN-Kubernetes. Copiez le binaire ovnkube-trace sur votre hôte local pour qu'il puisse être exécuté sur le cluster.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez une variable pod en utilisant la commande suivante :
$ POD=$(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-master -o name | head -1 | awk -F '/' '{print $NF}')Exécutez la commande suivante sur votre hôte local pour copier le binaire des pods
ovnkube-master:$ oc cp -n openshift-ovn-kubernetes $POD:/usr/bin/ovnkube-trace ovnkube-traceRendez
ovnkube-traceexécutable en exécutant la commande suivante :$ chmod +x ovnkube-traceAffichez les options disponibles sur
ovnkube-traceen exécutant la commande suivante :$ ./ovnkube-trace -helpRésultats attendus
I0111 15:05:27.973305 204872 ovs.go:90] Maximum command line arguments set to: 191102 Usage of ./ovnkube-trace: -dst string dest: destination pod name -dst-ip string destination IP address (meant for tests to external targets) -dst-namespace string k8s namespace of dest pod (default "default") -dst-port string dst-port: destination port (default "80") -kubeconfig string absolute path to the kubeconfig file -loglevel string loglevel: klog level (default "0") -ovn-config-namespace string namespace used by ovn-config itself -service string service: destination service name -skip-detrace skip ovn-detrace command -src string src: source pod name -src-namespace string k8s namespace of source pod (default "default") -tcp use tcp transport protocol -udp use udp transport protocolLes arguments de ligne de commande pris en charge sont des constructions Kubernetes familières, telles que les espaces de noms, les pods, les services, de sorte que vous n'avez pas besoin de trouver l'adresse MAC, l'adresse IP des nœuds de destination ou le type ICMP.
Les niveaux d'enregistrement sont les suivants :
- 0 (production minimale)
- 2 (plus d'informations sur les résultats des commandes de suivi)
- 5 (sortie de débogage)
24.4.2. Exécution de ovnkube-trace
Lancer ovn-trace pour simuler la transmission de paquets au sein d'un réseau logique OVN.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. -
Vous avez installé
ovnkube-tracesur l'hôte local
Exemple : Test du fonctionnement de la résolution DNS à partir d'un module déployé
Cet exemple illustre comment tester la résolution DNS d'un module déployé vers le module DNS central qui fonctionne dans le cluster.
Procédure
Démarrez un service web dans l'espace de noms par défaut en entrant la commande suivante :
$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Liste des pods fonctionnant dans l'espace de noms
openshift-dns:oc get pods -n openshift-dnsExemple de sortie
NAME READY STATUS RESTARTS AGE dns-default-467qw 2/2 Running 0 49m dns-default-6prvx 2/2 Running 0 53m dns-default-fkqr8 2/2 Running 0 53m dns-default-qv2rg 2/2 Running 0 49m dns-default-s29vr 2/2 Running 0 49m dns-default-vdsbn 2/2 Running 0 53m node-resolver-6thtt 1/1 Running 0 53m node-resolver-7ksdn 1/1 Running 0 49m node-resolver-8sthh 1/1 Running 0 53m node-resolver-c5ksw 1/1 Running 0 50m node-resolver-gbvdp 1/1 Running 0 53m node-resolver-sxhkd 1/1 Running 0 50mExécutez la commande suivante
ovn-kube-tracepour vérifier que la résolution DNS fonctionne :$ ./ovnkube-trace \ -src-namespace default \1 -src web \2 -dst-namespace openshift-dns \3 -dst dns-default-467qw \4 -udp -dst-port 53 \5 -loglevel 06 - 1
- Espace de noms du pod source
- 2
- Nom du pod source
- 3
- Espace de noms du pod de destination
- 4
- Nom du pod de destination
- 5
- Utilisez le protocole de transport
udp. Le port 53 est le port utilisé par le service DNS. - 6
- Définir le niveau de journalisation à 1 (0 est le niveau minimal et 5 est le niveau de débogage)
Résultats attendus
I0116 10:19:35.601303 17900 ovs.go:90] Maximum command line arguments set to: 191102 ovn-trace source pod to destination pod indicates success from web to dns-default-467qw ovn-trace destination pod to source pod indicates success from dns-default-467qw to web ovs-appctl ofproto/trace source pod to destination pod indicates success from web to dns-default-467qw ovs-appctl ofproto/trace destination pod to source pod indicates success from dns-default-467qw to web ovn-detrace source pod to destination pod indicates success from web to dns-default-467qw ovn-detrace destination pod to source pod indicates success from dns-default-467qw to webLa sortie indique le succès du pod déployé vers le port DNS et indique également qu'il est réussi dans l'autre sens. Vous savez donc que le trafic bidirectionnel est supporté sur le port UDP 53 si mon pod web veut faire de la résolution DNS à partir du core DNS.
Si, par exemple, cela n'a pas fonctionné et que vous souhaitiez obtenir ovn-trace, ovs-appctl ofproto/trace et ovn-detrace, ainsi que d'autres informations de type débogage, augmentez le niveau du journal à 2 et exécutez à nouveau la commande de la manière suivante :
$ ./ovnkube-trace \
-src-namespace default \
-src web \
-dst-namespace openshift-dns \
-dst dns-default-467qw \
-udp -dst-port 53 \
-loglevel 2Les résultats de cette augmentation du niveau de journalisation sont trop nombreux pour être énumérés ici. En cas d'échec, la sortie de cette commande montre quel flux laisse tomber ce trafic. Par exemple, une politique de réseau d'entrée ou de sortie peut être configurée sur le cluster qui n'autorise pas ce trafic.
Exemple : Vérification à l'aide de la sortie debug d'un refus par défaut configuré
Cet exemple montre comment identifier, à l'aide de la sortie de débogage, qu'une stratégie de refus par défaut à l'entrée bloque le trafic.
Procédure
Créez le fichier YAML suivant qui définit une politique
deny-by-defaultpour refuser l'entrée de tous les pods dans tous les espaces de noms. Enregistrez le YAML dans le fichierdeny-by-default.yaml:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default namespace: default spec: podSelector: {} ingress: []Appliquez la politique en entrant la commande suivante :
$ oc apply -f deny-by-default.yamlExemple de sortie
networkpolicy.networking.k8s.io/deny-by-default createdDémarrez un service web dans l'espace de noms
defaulten entrant la commande suivante :$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80Exécutez la commande suivante pour créer l'espace de noms
prod:$ oc create namespace prodExécutez la commande suivante pour étiqueter l'espace de noms
prod:$ oc label namespace/prod purpose=productionExécutez la commande suivante pour déployer une image
alpinedans l'espace de nomsprodet démarrer un shell :$ oc run test-6459 --namespace=prod --rm -i -t --image=alpine -- sh- Ouvrez une autre session de terminal.
Dans cette nouvelle session de terminal, exécutez
ovn-tracepour vérifier l'échec de la communication entre le pod sourcetest-6459fonctionnant dans l'espace de nomsprodet le pod de destination fonctionnant dans l'espace de nomsdefault:$ ./ovnkube-trace \ -src-namespace prod \ -src test-6459 \ -dst-namespace default \ -dst web \ -tcp -dst-port 80 \ -loglevel 0Résultats attendus
I0116 14:20:47.380775 50822 ovs.go:90] Maximum command line arguments set to: 191102 ovn-trace source pod to destination pod indicates failure from test-6459 to webAugmentez le niveau de journalisation à 2 pour révéler la raison de l'échec en exécutant la commande suivante :
$ ./ovnkube-trace \ -src-namespace prod \ -src test-6459 \ -dst-namespace default \ -dst web \ -tcp -dst-port 80 \ -loglevel 2Résultats attendus
ct_lb_mark /* default (use --ct to customize) */ ------------------------------------------------ 3. ls_out_acl_hint (northd.c:6092): !ct.new && ct.est && !ct.rpl && ct_mark.blocked == 0, priority 4, uuid 32d45ad4 reg0[8] = 1; reg0[10] = 1; next; 4. ls_out_acl (northd.c:6435): reg0[10] == 1 && (outport == @a16982411286042166782_ingressDefaultDeny), priority 2000, uuid f730a8871 ct_commit { ct_mark.blocked = 1; };- 1
- Le trafic entrant est bloqué en raison de la politique de refus par défaut en place
Créez une politique qui autorise le trafic de tous les pods dans un espace de noms particulier avec un label
purpose=production. Sauvegardez le YAML dans le fichierweb-allow-prod.yaml:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-prod namespace: default spec: podSelector: matchLabels: app: web policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: productionAppliquez la politique en entrant la commande suivante :
$ oc apply -f web-allow-prod.yamlExécutez
ovnkube-tracepour vérifier que le trafic est maintenant autorisé en entrant la commande suivante :$ ./ovnkube-trace \ -src-namespace prod \ -src test-6459 \ -dst-namespace default \ -dst web \ -tcp -dst-port 80 \ -loglevel 0Résultats attendus
I0116 14:25:44.055207 51695 ovs.go:90] Maximum command line arguments set to: 191102 ovn-trace source pod to destination pod indicates success from test-6459 to web ovn-trace destination pod to source pod indicates success from web to test-6459 ovs-appctl ofproto/trace source pod to destination pod indicates success from test-6459 to web ovs-appctl ofproto/trace destination pod to source pod indicates success from web to test-6459 ovn-detrace source pod to destination pod indicates success from test-6459 to web ovn-detrace destination pod to source pod indicates success from web to test-6459Dans le shell ouvert, exécutez la commande suivante :
wget -qO- --timeout=2 http://web.defaultRésultats attendus
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
24.5. Migrer du plugin réseau SDN d'OpenShift
En tant qu'administrateur de cluster, vous pouvez migrer vers le plugin réseau OVN-Kubernetes à partir du plugin réseau OpenShift SDN.
Pour en savoir plus sur OVN-Kubernetes, lisez À propos du plugin réseau OVN-Kubernetes.
24.5.1. Migration vers le plugin réseau OVN-Kubernetes
La migration vers le plugin réseau OVN-Kubernetes est un processus manuel qui comprend un certain temps d'arrêt pendant lequel votre cluster est inaccessible. Bien qu'une procédure de retour en arrière soit fournie, la migration est conçue pour être un processus à sens unique.
Une migration vers le plugin réseau OVN-Kubernetes est prise en charge sur les plateformes suivantes :
- Matériel métallique nu
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- IBM Cloud
- Microsoft Azure
- Plate-forme Red Hat OpenStack (RHOSP)
- Red Hat Virtualization (RHV)
- VMware vSphere
La migration vers ou depuis le plugin réseau OVN-Kubernetes n'est pas prise en charge pour les services cloud OpenShift gérés tels que OpenShift Dedicated et Red Hat OpenShift Service on AWS (ROSA).
24.5.1.1. Considérations pour la migration vers le plugin réseau OVN-Kubernetes
Si vous avez plus de 150 nœuds dans votre cluster OpenShift Container Platform, ouvrez un dossier de support pour obtenir des conseils sur votre migration vers le plugin réseau OVN-Kubernetes.
Les sous-réseaux attribués aux nœuds et les adresses IP attribuées aux pods individuels ne sont pas conservés pendant la migration.
Bien que le plugin réseau OVN-Kubernetes mette en œuvre de nombreuses fonctionnalités présentes dans le plugin réseau SDN d'OpenShift, la configuration n'est pas la même.
Si votre cluster utilise l'une des capacités suivantes du plugin réseau OpenShift SDN, vous devez configurer manuellement la même capacité dans le plugin réseau OVN-Kubernetes :
- Isolation de l'espace de noms
- Pods de routeurs de sortie
-
Si votre cluster ou le réseau environnant utilise une partie de la plage d'adresses
100.64.0.0/16, vous devez choisir une autre plage d'adresses IP inutilisée en spécifiant la spécificationv4InternalSubnetsous la définition de l'objetspec.defaultNetwork.ovnKubernetesConfig. OVN-Kubernetes utilise par défaut la plage d'adresses IP100.64.0.0/16en interne.
Les sections suivantes mettent en évidence les différences de configuration entre les capacités susmentionnées dans les plugins réseau OVN-Kubernetes et OpenShift SDN.
Isolation de l'espace de noms
OVN-Kubernetes ne prend en charge que le mode d'isolation de la politique de réseau.
Si votre cluster utilise OpenShift SDN configuré en mode multitenant ou en mode d'isolation de sous-réseau, vous ne pouvez pas migrer vers le plugin réseau OVN-Kubernetes.
Adresses IP de sortie
OpenShift SDN prend en charge deux modes IP de sortie différents :
- Dans cette approche, une plage d'adresses IP de sortie est attribuée à un nœud automatically assigned une plage d'adresses IP de sortie est attribuée à un nœud.
- Dans cette approche, une liste d'une ou plusieurs adresses IP de sortie est attribuée à un nœud manually assigned une liste d'une ou plusieurs adresses IP de sortie est attribuée à un nœud.
Le processus de migration prend en charge la migration des configurations IP de sortie qui utilisent le mode d'attribution automatique.
Les différences dans la configuration d'une adresse IP egress entre OVN-Kubernetes et OpenShift SDN sont décrites dans le tableau suivant :
| OVN-Kubernetes | OpenShift SDN |
|---|---|
|
|
Pour plus d'informations sur l'utilisation des adresses IP de sortie dans OVN-Kubernetes, voir "Configuration d'une adresse IP de sortie".
Politiques du réseau de sortie
La différence de configuration d'une politique de réseau egress, également connue sous le nom de pare-feu egress, entre OVN-Kubernetes et OpenShift SDN est décrite dans le tableau suivant :
| OVN-Kubernetes | OpenShift SDN |
|---|---|
|
|
Comme le nom d'un objet EgressFirewall ne peut être défini que sur default, après la migration, tous les objets EgressNetworkPolicy migrés sont nommés default, quel que soit le nom qu'ils portaient sous OpenShift SDN.
Si vous revenez ensuite à OpenShift SDN, tous les objets EgressNetworkPolicy sont nommés default car le nom précédent est perdu.
Pour plus d'informations sur l'utilisation d'un pare-feu de sortie dans OVN-Kubernetes, voir "Configuration d'un pare-feu de sortie pour un projet".
Pods de routeurs de sortie
OVN-Kubernetes supporte les egress router pods en mode redirect. OVN-Kubernetes ne supporte pas les egress router pods en mode proxy HTTP ou DNS.
Lorsque vous déployez un routeur de sortie avec l'opérateur de réseau de cluster, vous ne pouvez pas spécifier de sélecteur de nœud pour contrôler le nœud utilisé pour héberger le module de routeur de sortie.
Multidiffusion
La différence entre l'activation du trafic multicast sur OVN-Kubernetes et OpenShift SDN est décrite dans le tableau suivant :
| OVN-Kubernetes | OpenShift SDN |
|---|---|
|
|
Pour plus d'informations sur l'utilisation de la multidiffusion dans OVN-Kubernetes, voir "Activation de la multidiffusion pour un projet".
Politiques de réseau
OVN-Kubernetes supporte entièrement l'API Kubernetes NetworkPolicy dans le groupe d'API networking.k8s.io/v1. Aucun changement n'est nécessaire dans vos politiques de réseau lors de la migration depuis OpenShift SDN.
24.5.1.2. Comment fonctionne le processus de migration
Le tableau suivant résume le processus de migration en distinguant les étapes du processus initiées par l'utilisateur et les actions que la migration exécute en réponse.
| Étapes initiées par l'utilisateur | Activité de migration |
|---|---|
|
Définissez le champ |
|
|
Mettre à jour le champ |
|
| Redémarrez chaque nœud du cluster. |
|
Si un retour en arrière vers OpenShift SDN est nécessaire, le tableau suivant décrit le processus.
| Étapes initiées par l'utilisateur | Activité de migration |
|---|---|
| Suspendre le MCO pour s'assurer qu'il n'interrompt pas la migration. | Le MCO s'arrête. |
|
Définissez le champ |
|
|
Mettre à jour le champ |
|
| Redémarrez chaque nœud du cluster. |
|
| Activer le MCO après le redémarrage de tous les nœuds de la grappe. |
|
24.5.2. Migration vers le plugin réseau OVN-Kubernetes
En tant qu'administrateur de cluster, vous pouvez changer le plugin réseau de votre cluster pour OVN-Kubernetes. Pendant la migration, vous devez redémarrer chaque nœud de votre cluster.
Pendant la migration, votre cluster est indisponible et les charges de travail peuvent être interrompues. N'effectuez la migration que si une interruption de service est acceptable.
Conditions préalables
- Un cluster configuré avec le plugin réseau OpenShift SDN CNI en mode d'isolation de la politique réseau.
-
Installez le CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Une sauvegarde récente de la base de données etcd est disponible.
- Un redémarrage peut être déclenché manuellement pour chaque nœud.
- Le cluster est dans un état connu, sans aucune erreur.
Procédure
Pour sauvegarder la configuration du réseau de clusters, entrez la commande suivante :
oc get Network.config.openshift.io cluster -o yaml > cluster-openshift-sdn.yamlPour préparer tous les nœuds à la migration, définissez le champ
migrationsur l'objet de configuration Cluster Network Operator en entrant la commande suivante :$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes" } } }'NoteCette étape ne déploie pas OVN-Kubernetes immédiatement. Au lieu de cela, la spécification du champ
migrationdéclenche le Machine Config Operator (MCO) pour appliquer de nouvelles configurations de machine à tous les nœuds du cluster en préparation du déploiement d'OVN-Kubernetes.Facultatif : vous pouvez désactiver la migration automatique de plusieurs fonctionnalités OpenShift SDN vers les équivalents OVN-Kubernetes :
- IP de sortie
- Pare-feu de sortie
- Multidiffusion
Pour désactiver la migration automatique de la configuration pour l'une des fonctionnalités OpenShift SDN mentionnées précédemment, spécifiez les clés suivantes :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes", "features": { "egressIP": <bool>, "egressFirewall": <bool>, "multicast": <bool> } } } }'où :
bool: Spécifie si la migration de la fonctionnalité doit être activée. La valeur par défaut esttrue.Facultatif : vous pouvez personnaliser les paramètres suivants pour OVN-Kubernetes afin de répondre aux exigences de votre infrastructure réseau :
- Unité de transmission maximale (MTU)
- Geneve (Generic Network Virtualization Encapsulation) port de réseau superposé
- Sous-réseau interne IPv4 d'OVN-Kubernetes
- Sous-réseau interne IPv6 d'OVN-Kubernetes
Pour personnaliser l'un ou l'autre des paramètres susmentionnés, entrez et personnalisez la commande suivante. Si vous n'avez pas besoin de modifier la valeur par défaut, omettez la clé du correctif.
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":<mtu>, "genevePort":<port>, "v4InternalSubnet":"<ipv4_subnet>", "v6InternalSubnet":"<ipv6_subnet>" }}}}'où :
mtu-
Le MTU pour le réseau superposé de Geneve. Cette valeur est normalement configurée automatiquement, mais si les nœuds de votre cluster n'utilisent pas tous le même MTU, vous devez la définir explicitement à
100moins que la valeur du MTU du plus petit nœud. port-
Le port UDP pour le réseau superposé de Geneve. Si aucune valeur n'est spécifiée, la valeur par défaut est
6081. Le port ne peut pas être le même que le port VXLAN utilisé par OpenShift SDN. La valeur par défaut du port VXLAN est4789. ipv4_subnet-
Une plage d'adresses IPv4 à usage interne pour OVN-Kubernetes. Vous devez vous assurer que la plage d'adresses IP ne chevauche pas un autre sous-réseau utilisé par votre installation OpenShift Container Platform. La plage d'adresses IP doit être supérieure au nombre maximum de nœuds pouvant être ajoutés au cluster. La valeur par défaut est
100.64.0.0/16. ipv6_subnet-
Une plage d'adresses IPv6 à usage interne pour OVN-Kubernetes. Vous devez vous assurer que la plage d'adresses IP ne chevauche pas un autre sous-réseau utilisé par votre installation OpenShift Container Platform. La plage d'adresses IP doit être supérieure au nombre maximum de nœuds pouvant être ajoutés au cluster. La valeur par défaut est
fd98::/48.
Exemple de commande de patch pour mettre à jour le champ
mtu$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":1200 }}}}'Lorsque le MCO met à jour les machines de chaque pool de configuration, il redémarre chaque nœud un par un. Vous devez attendre que tous les nœuds soient mis à jour. Vérifiez l'état du pool de configuration des machines en entrant la commande suivante :
$ oc get mcpUn nœud mis à jour avec succès a le statut suivant :
UPDATED=true,UPDATING=false,DEGRADED=false.NotePar défaut, le MCO met à jour une machine par pool à la fois, ce qui fait que la durée totale de la migration augmente avec la taille du cluster.
Confirmer l'état de la configuration de la nouvelle machine sur les hôtes :
Pour répertorier l'état de la configuration de la machine et le nom de la configuration de la machine appliquée, entrez la commande suivante :
$ oc describe node | egrep "hostname|machineconfig"Exemple de sortie
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: DoneVérifiez que les affirmations suivantes sont vraies :
-
La valeur du champ
machineconfiguration.openshift.io/stateestDone. -
La valeur du champ
machineconfiguration.openshift.io/currentConfigest égale à la valeur du champmachineconfiguration.openshift.io/desiredConfig.
-
La valeur du champ
Pour confirmer que la configuration de la machine est correcte, entrez la commande suivante :
oc get machineconfig <config_name> -o yaml | grep ExecStartoù
<config_name>est le nom de la machine configurée dans le champmachineconfiguration.openshift.io/currentConfig.La configuration de la machine doit inclure la mise à jour suivante de la configuration de systemd :
ExecStart=/usr/local/bin/configure-ovs.sh OVNKubernetesSi un nœud est bloqué à l'état
NotReady, examinez les journaux de pods du démon de configuration de la machine et résolvez les erreurs éventuelles.Pour dresser la liste des pods, entrez la commande suivante :
$ oc get pod -n openshift-machine-config-operatorExemple de sortie
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43hLes noms des modules de démon de configuration sont au format suivant :
machine-config-daemon-<seq>. La valeur<seq>est une séquence alphanumérique aléatoire de cinq caractères.Affichez le journal du pod pour le premier pod de démon de configuration de machine montré dans la sortie précédente en entrant la commande suivante :
$ oc logs <pod> -n openshift-machine-config-operatoroù
podest le nom d'un pod de démon de configuration de machine.- Résoudre les erreurs éventuelles dans les journaux affichés par la sortie de la commande précédente.
Pour démarrer la migration, configurez le plugin réseau OVN-Kubernetes à l'aide d'une des commandes suivantes :
Pour spécifier le fournisseur de réseau sans modifier le bloc d'adresses IP du réseau de la grappe, entrez la commande suivante :
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "networkType": "OVNKubernetes" } }'Pour spécifier un autre bloc d'adresses IP du réseau cluster, entrez la commande suivante :
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "clusterNetwork": [ { "cidr": "<cidr>", "hostPrefix": <prefix> } ], "networkType": "OVNKubernetes" } }'où
cidrest un bloc CIDR etprefixest la tranche du bloc CIDR attribuée à chaque nœud de votre cluster. Vous ne pouvez pas utiliser un bloc CIDR qui chevauche le bloc CIDR100.64.0.0/16car le fournisseur de réseau OVN-Kubernetes utilise ce bloc en interne.ImportantVous ne pouvez pas modifier le bloc d'adresses du réseau de service pendant la migration.
Vérifiez que le déploiement du jeu de démons Multus est terminé avant de passer aux étapes suivantes :
$ oc -n openshift-multus rollout status daemonset/multusLe nom des nacelles Multus se présente sous la forme
multus-<xxxxx>, où<xxxxx>est une séquence aléatoire de lettres. Le redémarrage des pods peut prendre quelques instants.Exemple de sortie
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled outPour terminer la migration, redémarrez chaque nœud de votre cluster. Par exemple, vous pouvez utiliser un script bash similaire à l'exemple suivant. Le script suppose que vous pouvez vous connecter à chaque hôte en utilisant
sshet que vous avez configurésudopour ne pas demander de mot de passe.#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 doneSi l'accès ssh n'est pas disponible, vous pourrez peut-être redémarrer chaque nœud via le portail de gestion de votre fournisseur d'infrastructure.
Confirmez que la migration a réussi :
Pour confirmer que le plugin réseau est OVN-Kubernetes, entrez la commande suivante. La valeur de
status.networkTypedoit êtreOVNKubernetes.$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'Pour confirmer que les nœuds du cluster sont dans l'état
Ready, entrez la commande suivante :$ oc get nodesPour confirmer que vos pods ne sont pas dans un état d'erreur, entrez la commande suivante :
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'Si les pods d'un nœud sont dans un état d'erreur, redémarrez ce nœud.
Pour confirmer que tous les opérateurs du cluster ne sont pas dans un état anormal, entrez la commande suivante :
$ oc get coL'état de chaque opérateur de cluster doit être le suivant :
AVAILABLE="True",PROGRESSING="False",DEGRADED="False". Si un opérateur de cluster n'est pas disponible ou est dégradé, vérifiez les journaux de l'opérateur de cluster pour plus d'informations.
N'effectuez les étapes suivantes que si la migration a réussi et que votre cluster est en bon état :
Pour supprimer la configuration de la migration de l'objet de configuration CNO, entrez la commande suivante :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'Pour supprimer la configuration personnalisée du fournisseur de réseau OpenShift SDN, entrez la commande suivante :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "defaultNetwork": { "openshiftSDNConfig": null } } }'Pour supprimer l'espace de noms du fournisseur de réseau OpenShift SDN, entrez la commande suivante :
$ oc delete namespace openshift-sdn
24.6. Revenir au fournisseur de réseau SDN OpenShift
En tant qu'administrateur de cluster, vous pouvez revenir au plugin réseau OpenShift SDN à partir du plugin réseau OVN-Kubernetes si la migration vers OVN-Kubernetes échoue.
24.6.1. Repousser le plugin réseau vers OpenShift SDN
En tant qu'administrateur de cluster, vous pouvez revenir sur votre cluster avec le plugin réseau OpenShift SDN Container Network Interface (CNI). Pendant le rollback, vous devez redémarrer chaque nœud de votre cluster.
Ne revenir à OpenShift SDN que si la migration vers OVN-Kubernetes échoue.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Un cluster installé sur une infrastructure configurée avec le plugin réseau OVN-Kubernetes.
Procédure
Arrêter tous les pools de configuration de machines gérés par le MCO (Machine Config Operator) :
Arrêter le pool de configuration maître :
$ oc patch MachineConfigPool master --type='merge' --patch \ '{ "spec": { "paused": true } }'Arrêter le pool de configuration de la machine de travail :
$ oc patch MachineConfigPool worker --type='merge' --patch \ '{ "spec":{ "paused" :true } }'
Pour commencer la migration, réinitialisez le plugin réseau à OpenShift SDN en entrant les commandes suivantes :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OpenShiftSDN" } } }' $ oc patch Network.config.openshift.io cluster --type='merge' \ --patch '{ "spec": { "networkType": "OpenShiftSDN" } }'Facultatif : Vous pouvez désactiver la migration automatique de plusieurs capacités OVN-Kubernetes vers les équivalents SDN d'OpenShift :
- IP de sortie
- Pare-feu de sortie
- Multidiffusion
Pour désactiver la migration automatique de la configuration pour l'une des fonctionnalités OpenShift SDN mentionnées précédemment, spécifiez les clés suivantes :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OpenShiftSDN", "features": { "egressIP": <bool>, "egressFirewall": <bool>, "multicast": <bool> } } } }'où :
bool: Spécifie si la migration de la fonctionnalité doit être activée. La valeur par défaut esttrue.Facultatif : vous pouvez personnaliser les paramètres suivants pour OpenShift SDN afin de répondre aux exigences de votre infrastructure réseau :
- Unité de transmission maximale (MTU)
- Port VXLAN
Pour personnaliser l'un ou l'autre des paramètres susmentionnés, ou les deux, personnalisez et entrez la commande suivante. Si vous n'avez pas besoin de modifier la valeur par défaut, omettez la clé du correctif.
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "openshiftSDNConfig":{ "mtu":<mtu>, "vxlanPort":<port> }}}}'mtu-
Le MTU pour le réseau superposé VXLAN. Cette valeur est normalement configurée automatiquement, mais si les nœuds de votre cluster n'utilisent pas tous le même MTU, vous devez la définir explicitement à
50moins que la plus petite valeur MTU du nœud. port-
Le port UDP pour le réseau superposé VXLAN. Si aucune valeur n'est spécifiée, la valeur par défaut est
4789. Le port ne peut pas être le même que le port Geneve utilisé par OVN-Kubernetes. La valeur par défaut du port Geneve est6081.
Exemple de commande patch
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "openshiftSDNConfig":{ "mtu":1200 }}}}'Attendez que le déploiement du jeu de démons Multus soit terminé.
$ oc -n openshift-multus rollout status daemonset/multusLe nom des nacelles Multus se présente sous la forme
multus-<xxxxx>où<xxxxx>est une séquence aléatoire de lettres. Le redémarrage des pods peut prendre quelques instants.Exemple de sortie
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled outPour terminer le retour en arrière, redémarrez chaque nœud de votre cluster. Par exemple, vous pouvez utiliser un script bash similaire au suivant. Le script suppose que vous pouvez vous connecter à chaque hôte en utilisant
sshet que vous avez configurésudopour ne pas demander de mot de passe.#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 doneSi l'accès ssh n'est pas disponible, vous pourrez peut-être redémarrer chaque nœud via le portail de gestion de votre fournisseur d'infrastructure.
Une fois que les nœuds de votre cluster ont redémarré, démarrez tous les pools de configuration des machines :
Démarrer le pool de configuration maître :
$ oc patch MachineConfigPool master --type='merge' --patch \ '{ "spec": { "paused": false } }'Démarrer le pool de configuration du travailleur :
$ oc patch MachineConfigPool worker --type='merge' --patch \ '{ "spec": { "paused": false } }'
Lorsque le MCO met à jour les machines de chaque pool de configuration, il redémarre chaque nœud.
Par défaut, le MCO ne met à jour qu'une seule machine par pool à la fois, de sorte que le temps nécessaire à la migration augmente avec la taille du cluster.
Confirmer l'état de la configuration de la nouvelle machine sur les hôtes :
Pour répertorier l'état de la configuration de la machine et le nom de la configuration de la machine appliquée, entrez la commande suivante :
$ oc describe node | egrep "hostname|machineconfig"Exemple de sortie
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: DoneVérifiez que les affirmations suivantes sont vraies :
-
La valeur du champ
machineconfiguration.openshift.io/stateestDone. -
La valeur du champ
machineconfiguration.openshift.io/currentConfigest égale à la valeur du champmachineconfiguration.openshift.io/desiredConfig.
-
La valeur du champ
Pour confirmer que la configuration de la machine est correcte, entrez la commande suivante :
oc get machineconfig <config_name> -o yamloù
<config_name>est le nom de la machine configurée dans le champmachineconfiguration.openshift.io/currentConfig.
Confirmez que la migration a réussi :
Pour confirmer que le plugin réseau est OpenShift SDN, entrez la commande suivante. La valeur de
status.networkTypedoit êtreOpenShiftSDN.$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'Pour confirmer que les nœuds du cluster sont dans l'état
Ready, entrez la commande suivante :$ oc get nodesSi un nœud est bloqué à l'état
NotReady, examinez les journaux de pods du démon de configuration de la machine et résolvez les erreurs éventuelles.Pour dresser la liste des pods, entrez la commande suivante :
$ oc get pod -n openshift-machine-config-operatorExemple de sortie
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43hLes noms des modules de démon de configuration sont au format suivant :
machine-config-daemon-<seq>. La valeur<seq>est une séquence alphanumérique aléatoire de cinq caractères.Pour afficher le journal des pods pour chaque pod de démon de configuration de machine présenté dans la sortie précédente, entrez la commande suivante :
$ oc logs <pod> -n openshift-machine-config-operatoroù
podest le nom d'un pod de démon de configuration de machine.- Résoudre les erreurs éventuelles dans les journaux affichés par la sortie de la commande précédente.
Pour confirmer que vos pods ne sont pas dans un état d'erreur, entrez la commande suivante :
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'Si les pods d'un nœud sont dans un état d'erreur, redémarrez ce nœud.
N'effectuez les étapes suivantes que si la migration a réussi et que votre cluster est en bon état :
Pour supprimer la configuration de la migration de l'objet de configuration Opérateur de réseau de cluster, entrez la commande suivante :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'Pour supprimer la configuration OVN-Kubernetes, entrez la commande suivante :
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "defaultNetwork": { "ovnKubernetesConfig":null } } }'Pour supprimer l'espace de noms du fournisseur de réseau OVN-Kubernetes, entrez la commande suivante :
$ oc delete namespace openshift-ovn-kubernetes
24.7. Passage à un réseau à double pile IPv4/IPv6
En tant qu'administrateur de cluster, vous pouvez convertir votre cluster IPv4 à pile unique en un cluster à double réseau prenant en charge les familles d'adresses IPv4 et IPv6. Après la conversion, tous les pods nouvellement créés sont activés pour la double pile.
Un réseau à double pile est pris en charge sur les clusters provisionnés sur du bare metal, IBM Power, l'infrastructure IBM zSystems et les clusters OpenShift à nœud unique.
24.7.1. Conversion vers un réseau en grappe à double pile
En tant qu'administrateur de cluster, vous pouvez convertir votre réseau de cluster à pile unique en réseau de cluster à double pile.
Après la conversion au réseau à double pile, seuls les nouveaux modules créés se voient attribuer des adresses IPv6. Tout pod créé avant la conversion doit être recréé pour recevoir une adresse IPv6.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Votre cluster utilise le plugin réseau OVN-Kubernetes.
- Les nœuds du cluster ont des adresses IPv6.
- Vous avez configuré un routeur IPv6 en fonction de votre infrastructure.
Procédure
Pour spécifier les blocs d'adresses IPv6 pour le cluster et les réseaux de service, créez un fichier contenant le YAML suivant :
- op: add path: /spec/clusterNetwork/- value:1 cidr: fd01::/48 hostPrefix: 64 - op: add path: /spec/serviceNetwork/- value: fd02::/1122 - 1
- Spécifiez un objet avec les champs
cidrethostPrefix. Le préfixe d'hôte doit être égal ou supérieur à64. Le préfixe CIDR IPv6 doit être suffisamment grand pour contenir le préfixe d'hôte spécifié. - 2
- Spécifiez un CIDR IPv6 avec un préfixe de
112. Kubernetes n'utilise que les 16 bits les plus bas. Pour un préfixe de112, les adresses IP sont attribuées de112à128bits.
Pour corriger la configuration du réseau de la grappe, entrez la commande suivante :
$ oc patch network.config.openshift.io cluster \ --type='json' --patch-file <file>.yamloù :
file- Indique le nom du fichier que vous avez créé à l'étape précédente.
Exemple de sortie
network.config.openshift.io/cluster patched
Vérification
Effectuez l'étape suivante pour vérifier que le réseau cluster reconnaît les blocs d'adresses IPv6 que vous avez spécifiés dans la procédure précédente.
Affiche la configuration du réseau :
$ oc describe networkExemple de sortie
Status: Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Cidr: fd01::/48 Host Prefix: 64 Cluster Network MTU: 1400 Network Type: OVNKubernetes Service Network: 172.30.0.0/16 fd02::/112
24.7.2. Conversion vers un réseau en grappe à pile unique
En tant qu'administrateur de cluster, vous pouvez convertir votre réseau de cluster à double pile en un réseau de cluster à pile unique.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Votre cluster utilise le plugin réseau OVN-Kubernetes.
- Les nœuds du cluster ont des adresses IPv6.
- Vous avez activé la mise en réseau à double pile.
Procédure
Modifiez la ressource personnalisée (CR)
networks.config.openshift.ioen exécutant la commande suivante :$ oc edit networks.config.openshift.io-
Supprimez la configuration spécifique à IPv6 que vous avez ajoutée aux champs
cidrethostPrefixdans la procédure précédente.
24.8. Journalisation des règles de pare-feu et de stratégie de réseau de sortie
En tant qu'administrateur de cluster, vous pouvez configurer la journalisation d'audit pour votre cluster et activer la journalisation pour un ou plusieurs espaces de noms. OpenShift Container Platform produit des journaux d'audit pour les pare-feu de sortie et les stratégies réseau.
La journalisation des audits n'est disponible que pour le plugin réseau OVN-Kubernetes.
24.8.1. Journalisation des audits
Le plugin réseau OVN-Kubernetes utilise les ACL de l'Open Virtual Network (OVN) pour gérer les pare-feu de sortie et les politiques de réseau. La journalisation d'audit expose les événements d'autorisation et de refus des ACL.
Vous pouvez configurer la destination des journaux d'audit, comme un serveur syslog ou un socket de domaine UNIX. Indépendamment de toute configuration supplémentaire, un journal d'audit est toujours enregistré sur /var/log/ovn/acl-audit-log.log sur chaque pod OVN-Kubernetes dans le cluster.
L'enregistrement des audits est activé par espace de noms en annotant l'espace de noms avec la clé k8s.ovn.org/acl-logging comme dans l'exemple suivant :
Exemple d'annotation d'un espace de noms
kind: Namespace
apiVersion: v1
metadata:
name: example1
annotations:
k8s.ovn.org/acl-logging: |-
{
"deny": "info",
"allow": "info"
}
Le format de journalisation est compatible avec syslog tel que défini par RFC5424. L'option syslog est configurable et est définie par défaut sur local0. Un exemple d'entrée de journal peut ressembler à ce qui suit :
Exemple d'entrée de journal de refus d'ACL pour une stratégie de réseau
2021-06-13T19:33:11.590Z|00005|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_deny-all", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0Le tableau suivant décrit les valeurs d'annotation de l'espace de noms :
| Annotation | Valeur |
|---|---|
|
|
Vous devez spécifier au moins l'un des éléments suivants :
|
24.8.2. Configuration de l'audit
La configuration de la journalisation des audits est spécifiée dans le cadre de la configuration du fournisseur de réseau du cluster OVN-Kubernetes. Le fichier YAML suivant illustre les valeurs par défaut pour la journalisation des audits :
Configuration de la journalisation des audits
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
defaultNetwork:
ovnKubernetesConfig:
policyAuditConfig:
destination: "null"
maxFileSize: 50
rateLimit: 20
syslogFacility: local0Le tableau suivant décrit les champs de configuration de la journalisation des audits.
| Field | Type | Description |
|---|---|---|
|
| entier |
Nombre maximal de messages à générer chaque seconde par nœud. La valeur par défaut est |
|
| entier |
Taille maximale du journal d'audit en octets. La valeur par défaut est |
|
| chaîne de caractères | One of the following additional audit log targets:
|
|
| chaîne de caractères |
L'installation syslog, telle que |
24.8.3. Configuration de l'audit du pare-feu de sortie et de la stratégie réseau pour un cluster
En tant qu'administrateur de cluster, vous pouvez personnaliser la journalisation des audits pour votre cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour personnaliser la configuration de la journalisation des audits, entrez la commande suivante :
$ oc edit network.operator.openshift.io/clusterAstuceVous pouvez également personnaliser et appliquer le fichier YAML suivant pour configurer l'enregistrement des audits :
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: defaultNetwork: ovnKubernetesConfig: policyAuditConfig: destination: "null" maxFileSize: 50 rateLimit: 20 syslogFacility: local0
Vérification
Pour créer un espace de noms avec des stratégies de réseau, procédez comme suit :
Créer un espace de noms pour la vérification :
$ cat <<EOF| oc create -f - kind: Namespace apiVersion: v1 metadata: name: verify-audit-logging annotations: k8s.ovn.org/acl-logging: '{ "deny": "alert", "allow": "alert" }' EOFExemple de sortie
namespace/verify-audit-logging createdActiver la journalisation des audits :
$ oc annotate namespace verify-audit-logging k8s.ovn.org/acl-logging='{ "deny": "alert", "allow": "alert" }'namespace/verify-audit-logging annotatedCréer des politiques de réseau pour l'espace de noms :
$ cat <<EOF| oc create -n verify-audit-logging -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-all spec: podSelector: matchLabels: policyTypes: - Ingress - Egress --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} policyTypes: - Ingress - Egress ingress: - from: - podSelector: {} egress: - to: - namespaceSelector: matchLabels: namespace: verify-audit-logging EOFExemple de sortie
networkpolicy.networking.k8s.io/deny-all created networkpolicy.networking.k8s.io/allow-from-same-namespace created
Créer un pod pour le trafic source dans l'espace de noms
default:$ cat <<EOF| oc create -n default -f - apiVersion: v1 kind: Pod metadata: name: client spec: containers: - name: client image: registry.access.redhat.com/rhel7/rhel-tools command: ["/bin/sh", "-c"] args: ["sleep inf"] EOFCréer deux pods dans l'espace de noms
verify-audit-logging:$ for name in client server; do cat <<EOF| oc create -n verify-audit-logging -f - apiVersion: v1 kind: Pod metadata: name: ${name} spec: containers: - name: ${name} image: registry.access.redhat.com/rhel7/rhel-tools command: ["/bin/sh", "-c"] args: ["sleep inf"] EOF doneExemple de sortie
pod/client created pod/server createdPour générer du trafic et produire des entrées de journal d'audit de stratégie de réseau, procédez comme suit :
Obtenir l'adresse IP du pod nommé
serverdans l'espace de nomsverify-audit-logging:$ POD_IP=$(oc get pods server -n verify-audit-logging -o jsonpath='{.status.podIP}')Effectuez un ping de l'adresse IP de la commande précédente à partir du pod nommé
clientdans l'espace de nomsdefaultet confirmez que tous les paquets sont abandonnés :$ oc exec -it client -n default -- /bin/ping -c 2 $POD_IPExemple de sortie
PING 10.128.2.55 (10.128.2.55) 56(84) bytes of data. --- 10.128.2.55 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 2041msEffectuez un ping de l'adresse IP enregistrée dans la variable d'environnement du shell
POD_IPà partir du pod nomméclientdans l'espace de nomsverify-audit-logginget confirmez que tous les paquets sont autorisés :$ oc exec -it client -n verify-audit-logging -- /bin/ping -c 2 $POD_IPExemple de sortie
PING 10.128.0.86 (10.128.0.86) 56(84) bytes of data. 64 bytes from 10.128.0.86: icmp_seq=1 ttl=64 time=2.21 ms 64 bytes from 10.128.0.86: icmp_seq=2 ttl=64 time=0.440 ms --- 10.128.0.86 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.440/1.329/2.219/0.890 ms
Affiche les dernières entrées du journal d'audit de la stratégie de réseau :
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node --no-headers=true | awk '{ print $1 }') ; do oc exec -it $pod -n openshift-ovn-kubernetes -- tail -4 /var/log/ovn/acl-audit-log.log doneExemple de sortie
Defaulting container name to ovn-controller. Use 'oc describe pod/ovnkube-node-hdb8v -n openshift-ovn-kubernetes' to see all of the containers in this pod. 2021-06-13T19:33:11.590Z|00005|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_deny-all", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:33:12.614Z|00006|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_deny-all", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:10.037Z|00007|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:11.037Z|00008|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0
24.8.4. Activation de la journalisation d'audit du pare-feu de sortie et de la stratégie de réseau pour un espace de noms
En tant qu'administrateur de cluster, vous pouvez activer la journalisation d'audit pour un espace de noms.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour activer la journalisation des audits pour un espace de noms, entrez la commande suivante :
$ oc annotate namespace <namespace> \ k8s.ovn.org/acl-logging='{ "deny": "alert", "allow": "notice" }'où :
<namespace>- Spécifie le nom de l'espace de noms.
AstuceVous pouvez également appliquer le code YAML suivant pour activer l'enregistrement des audits :
kind: Namespace apiVersion: v1 metadata: name: <namespace> annotations: k8s.ovn.org/acl-logging: |- { "deny": "alert", "allow": "notice" }Exemple de sortie
namespace/verify-audit-logging annotated
Vérification
Affiche les dernières entrées du journal d'audit :
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node --no-headers=true | awk '{ print $1 }') ; do oc exec -it $pod -n openshift-ovn-kubernetes -- tail -4 /var/log/ovn/acl-audit-log.log doneExemple de sortie
2021-06-13T19:33:11.590Z|00005|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_deny-all", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0
24.8.5. Désactivation de la journalisation d'audit du pare-feu de sortie et de la stratégie de réseau pour un espace de noms
En tant qu'administrateur de cluster, vous pouvez désactiver la journalisation d'audit pour un espace de noms.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour désactiver la journalisation des audits pour un espace de noms, entrez la commande suivante :
oc annotate --overwrite namespace <namespace> k8s.ovn.org/acl-logging-où :
<namespace>- Spécifie le nom de l'espace de noms.
AstuceVous pouvez également appliquer le code YAML suivant pour désactiver la journalisation des audits :
kind: Namespace apiVersion: v1 metadata: name: <namespace> annotations: k8s.ovn.org/acl-logging: nullExemple de sortie
namespace/verify-audit-logging annotated
24.9. Configuration du cryptage IPsec
Lorsque l'option IPsec est activée, tout le trafic réseau entre les nœuds du cluster OVN-Kubernetes est crypté avec IPsec Transport mode.
IPsec est désactivé par défaut. Il peut être activé pendant ou après l'installation du cluster. Pour plus d'informations sur l'installation d'un cluster, voir OpenShift Container Platform installation overview. Si vous devez activer IPsec après l'installation du cluster, vous devez d'abord redimensionner le MTU de votre cluster pour prendre en compte la surcharge de l'en-tête IPsec ESP.
La documentation suivante décrit comment activer et désactiver IPSec après l'installation du cluster.
24.9.1. Conditions préalables
-
Vous avez diminué la taille du MTU de la grappe de
46octets pour tenir compte de la surcharge supplémentaire de l'en-tête ESP IPsec. Pour plus d'informations sur le redimensionnement du MTU utilisé par votre cluster, reportez-vous à la section Modification du MTU pour le réseau du cluster.
24.9.2. Types de flux de trafic réseau cryptés par IPsec
Lorsque le protocole IPsec est activé, seuls les flux de trafic réseau suivants entre les pods sont cryptés :
- Trafic entre pods sur différents nœuds du réseau de la grappe
- Trafic d'un pod sur le réseau hôte vers un pod sur le réseau cluster
Les flux de trafic suivants ne sont pas cryptés :
- Trafic entre les pods situés sur le même nœud du réseau de la grappe
- Trafic entre les pods sur le réseau hôte
- Trafic d'un pod sur le réseau cluster vers un pod sur le réseau hôte
Les flux cryptés et non cryptés sont illustrés dans le diagramme suivant :
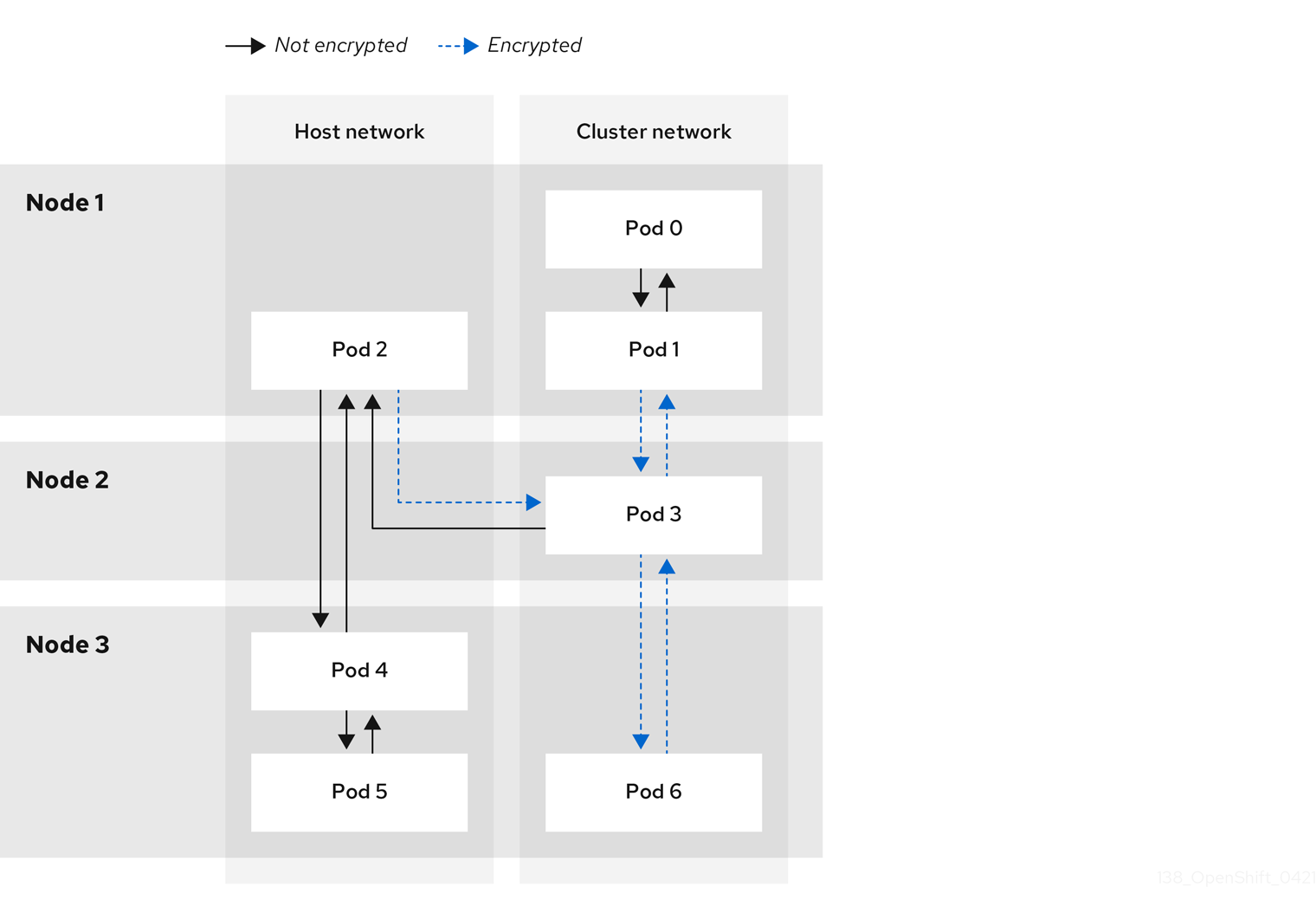
24.9.2.1. Exigences en matière de connectivité réseau lorsque IPsec est activé
You must configure the network connectivity between machines to allow OpenShift Container Platform cluster components to communicate. Each machine must be able to resolve the hostnames of all other machines in the cluster.
| Protocol | Port | Description |
|---|---|---|
| UDP |
| IPsec IKE packets |
|
| IPsec NAT-T packets | |
| ESP | N/A | IPsec Encapsulating Security Payload (ESP) |
24.9.3. Protocole de cryptage et mode IPsec
Le cryptogramme utilisé est AES-GCM-16-256. La valeur de contrôle d'intégrité (ICV) est de 16 octets. La longueur de la clé est de 256 bits.
Le mode IPsec utilisé est Transport modeiPsec est un mode qui crypte les communications de bout en bout en ajoutant un en-tête ESP (Encapsulated Security Payload) à l'en-tête IP du paquet d'origine et en cryptant les données du paquet. OpenShift Container Platform n'utilise ni ne prend actuellement en charge IPsec Tunnel mode pour les communications de pod à pod.
24.9.4. Génération et rotation des certificats de sécurité
L'opérateur du réseau de cluster (CNO) génère une autorité de certification (CA) X.509 auto-signée qui est utilisée par IPsec pour le cryptage. Les demandes de signature de certificat (CSR) de chaque nœud sont automatiquement satisfaites par le CNO.
La validité de l'autorité de certification est de 10 ans. Les certificats individuels des nœuds sont valables 5 ans et sont automatiquement remplacés après 4 ans et demi.
24.9.5. Activation du cryptage IPsec
En tant qu'administrateur de cluster, vous pouvez activer le cryptage IPsec après l'installation du cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin. -
Vous avez réduit la taille du MTU de votre cluster de
46octets pour tenir compte de la surcharge de l'en-tête IPsec ESP.
Procédure
Pour activer le cryptage IPsec, entrez la commande suivante :
$ oc patch networks.operator.openshift.io cluster --type=merge \ -p '{"spec":{"defaultNetwork":{"ovnKubernetesConfig":{"ipsecConfig":{ }}}}}'
24.9.6. Vérification de l'activation d'IPsec
En tant qu'administrateur de cluster, vous pouvez vérifier que le protocole IPsec est activé.
Vérification
Pour trouver les noms des pods du plan de contrôle OVN-Kubernetes, entrez la commande suivante :
$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-masterExemple de sortie
ovnkube-master-4496s 1/1 Running 0 6h39m ovnkube-master-d6cht 1/1 Running 0 6h42m ovnkube-master-skblc 1/1 Running 0 6h51m ovnkube-master-vf8rf 1/1 Running 0 6h51m ovnkube-master-w7hjr 1/1 Running 0 6h51m ovnkube-master-zsk7x 1/1 Running 0 6h42mVérifiez que le protocole IPsec est activé sur votre cluster :
$ oc -n openshift-ovn-kubernetes -c nbdb rsh ovnkube-master-<XXXXX> \ ovn-nbctl --no-leader-only get nb_global . ipsecoù :
<XXXXX>- Spécifie la séquence aléatoire de lettres pour un pod de l'étape précédente.
Exemple de sortie
true
24.9.7. Désactivation du cryptage IPsec
En tant qu'administrateur de cluster, vous ne pouvez désactiver le cryptage IPsec que si vous avez activé IPsec après l'installation du cluster.
Si vous avez activé IPsec lors de l'installation de votre cluster, vous ne pouvez pas désactiver IPsec avec cette procédure.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Pour désactiver le cryptage IPsec, entrez la commande suivante :
$ oc patch networks.operator.openshift.io/cluster --type=json \ -p='[{"op":"remove", "path":"/spec/defaultNetwork/ovnKubernetesConfig/ipsecConfig"}]'-
Facultatif : vous pouvez augmenter la taille du MTU de votre cluster de
46octets car il n'y a plus de surcharge due à l'en-tête ESP IPsec dans les paquets IP.
24.9.8. Ressources supplémentaires
24.10. Configuration d'un pare-feu de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez créer un pare-feu de sortie pour un projet qui restreint le trafic de sortie de votre cluster OpenShift Container Platform.
24.10.1. Fonctionnement d'un pare-feu de sortie dans un projet
En tant qu'administrateur de cluster, vous pouvez utiliser un egress firewall pour limiter les hôtes externes auxquels certains ou tous les pods peuvent accéder depuis le cluster. Un pare-feu de sortie prend en charge les scénarios suivants :
- Un pod ne peut se connecter qu'à des hôtes internes et ne peut pas établir de connexions avec l'internet public.
- Un pod ne peut se connecter qu'à l'internet public et ne peut pas initier de connexions vers des hôtes internes qui sont en dehors du cluster OpenShift Container Platform.
- Un pod ne peut pas atteindre les sous-réseaux internes spécifiés ou les hôtes en dehors du cluster OpenShift Container Platform.
- Un pod ne peut se connecter qu'à des hôtes externes spécifiques.
Par exemple, vous pouvez autoriser un projet à accéder à une plage d'adresses IP donnée, mais refuser le même accès à un autre projet. Vous pouvez également empêcher les développeurs d'applications d'effectuer des mises à jour à partir des miroirs de Python Pip et exiger que les mises à jour proviennent uniquement de sources approuvées.
Le pare-feu de sortie ne s'applique pas à l'espace de noms du réseau hôte. Les pods dont le réseau d'hôtes est activé ne sont pas affectés par les règles de pare-feu de sortie.
Vous configurez une stratégie de pare-feu de sortie en créant un objet de ressource personnalisée (CR) EgressFirewall. Le pare-feu de sortie correspond au trafic réseau qui répond à l'un des critères suivants :
- Une plage d'adresses IP au format CIDR
- Un nom DNS qui se résout en une adresse IP
- Un numéro de port
- Un protocole qui est l'un des protocoles suivants : TCP, UDP et SCTP
Si votre pare-feu de sortie comprend une règle de refus pour 0.0.0.0/0, l'accès à vos serveurs API OpenShift Container Platform est bloqué. Vous devez soit ajouter des règles d'autorisation pour chaque adresse IP, soit utiliser la règle d'autorisation de type nodeSelector dans vos règles de stratégie de sortie pour vous connecter aux serveurs API.
L'exemple suivant illustre l'ordre des règles de pare-feu de sortie nécessaires pour garantir l'accès au serveur API :
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: default
namespace: <namespace>
spec:
egress:
- to:
cidrSelector: <api_server_address_range>
type: Allow
# ...
- to:
cidrSelector: 0.0.0.0/0
type: Deny
Pour trouver l'adresse IP de vos serveurs API, exécutez oc get ep kubernetes -n default.
Pour plus d'informations, voir BZ#1988324.
Les règles de pare-feu de sortie ne s'appliquent pas au trafic qui passe par les routeurs. Tout utilisateur autorisé à créer un objet Route CR peut contourner les règles du pare-feu de sortie en créant une route qui pointe vers une destination interdite.
24.10.1.1. Limites d'un pare-feu de sortie
Un pare-feu de sortie présente les limitations suivantes :
- Aucun projet ne peut avoir plus d'un objet EgressFirewall.
- Un maximum d'un objet EgressFirewall avec un maximum de 8 000 règles peut être défini par projet.
- Si vous utilisez le plugin réseau OVN-Kubernetes avec le mode passerelle partagée dans Red Hat OpenShift Networking, les réponses de retour d'entrée sont affectées par les règles de pare-feu de sortie. Si les règles de pare-feu de sortie éliminent l'IP de destination de la réponse d'entrée, le trafic est éliminé.
La violation de l'une ou l'autre de ces restrictions a pour effet de briser le pare-feu de sortie du projet et peut entraîner l'interruption de tout le trafic du réseau externe.
Une ressource Egress Firewall peut être créée dans les projets kube-node-lease, kube-public, kube-system, openshift et openshift-.
24.10.1.2. Ordre de correspondance pour les règles de politique de pare-feu de sortie
Les règles de pare-feu de sortie sont évaluées dans l'ordre où elles sont définies, de la première à la dernière. La première règle qui correspond à une connexion de sortie d'un pod s'applique. Les règles suivantes sont ignorées pour cette connexion.
24.10.1.3. Fonctionnement de la résolution des serveurs de noms de domaine (DNS)
Si vous utilisez des noms DNS dans l'une de vos règles de stratégie de pare-feu de sortie, la résolution correcte des noms de domaine est soumise aux restrictions suivantes :
- Les mises à jour de noms de domaine sont interrogées sur la base d'une durée de vie (TTL). Par défaut, cette durée est de 30 minutes. Lorsque le contrôleur du pare-feu de sortie interroge les serveurs de noms locaux pour un nom de domaine, si la réponse inclut un TTL et que celui-ci est inférieur à 30 minutes, le contrôleur définit la durée pour ce nom DNS à la valeur renvoyée. Chaque nom DNS est interrogé après l'expiration du TTL de l'enregistrement DNS.
- Le pod doit résoudre le domaine à partir des mêmes serveurs de noms locaux si nécessaire. Sinon, les adresses IP du domaine connues par le contrôleur du pare-feu de sortie et le module peuvent être différentes. Si les adresses IP d'un nom d'hôte diffèrent, le pare-feu de sortie risque de ne pas être appliqué de manière cohérente.
- Étant donné que le contrôleur de pare-feu de sortie et les modules interrogent de manière asynchrone le même serveur de noms local, le module peut obtenir l'adresse IP mise à jour avant le contrôleur de sortie, ce qui provoque une situation de course. En raison de cette limitation actuelle, l'utilisation de noms de domaine dans les objets EgressFirewall n'est recommandée que pour les domaines dont les changements d'adresse IP sont peu fréquents.
Le pare-feu de sortie permet toujours aux pods d'accéder à l'interface externe du nœud sur lequel le pod se trouve pour la résolution DNS.
Si vous utilisez des noms de domaine dans votre stratégie de pare-feu de sortie et que votre résolution DNS n'est pas gérée par un serveur DNS sur le nœud local, vous devez ajouter des règles de pare-feu de sortie qui autorisent l'accès aux adresses IP de votre serveur DNS. si vous utilisez des noms de domaine dans vos modules.
24.10.2. Objet de ressource personnalisée (CR) EgressFirewall
Vous pouvez définir une ou plusieurs règles pour un pare-feu de sortie. Une règle est soit une règle Allow, soit une règle Deny, avec une spécification du trafic auquel la règle s'applique.
Le fichier YAML suivant décrit un objet CR EgressFirewall :
Objet EgressFirewall
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: <name>
spec:
egress:
...24.10.2.1. Règles EgressFirewall
Le fichier YAML suivant décrit un objet de règle de pare-feu de sortie. L'utilisateur peut sélectionner une plage d'adresses IP au format CIDR, un nom de domaine ou utiliser nodeSelector pour autoriser ou refuser le trafic de sortie. La strophe egress attend un tableau d'un ou plusieurs objets.
Règles de politique de sortie (Egress policy rule stanza)
egress:
- type: <type>
to:
cidrSelector: <cidr>
dnsName: <dns_name>
nodeSelector: <label_name>: <label_value>
ports:
...- 1
- Le type de règle. La valeur doit être
AllowouDeny. - 2
- Une strophe décrivant une règle de correspondance du trafic de sortie qui spécifie le champ
cidrSelectorou le champdnsName. Vous ne pouvez pas utiliser les deux champs dans la même règle. - 3
- Une plage d'adresses IP au format CIDR.
- 4
- Un nom de domaine DNS.
- 5
- Les étiquettes sont des paires clé/valeur définies par l'utilisateur. Les étiquettes sont attachées à des objets, tels que les nacelles. Le site
nodeSelectorpermet de sélectionner un ou plusieurs labels de nœuds et de les attacher aux nacelles. - 6
- Facultatif : Une strophe décrivant une collection de ports réseau et de protocoles pour la règle.
Strophe portuaire
ports:
- port: <port>
protocol: <protocol> 24.10.2.2. Exemple d'objets CR EgressFirewall
L'exemple suivant définit plusieurs règles de stratégie de pare-feu de sortie :
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: default
spec:
egress:
- type: Allow
to:
cidrSelector: 1.2.3.0/24
- type: Deny
to:
cidrSelector: 0.0.0.0/0- 1
- Une collection d'objets de règles de stratégie de pare-feu de sortie.
L'exemple suivant définit une règle de stratégie qui refuse le trafic vers l'hôte à l'adresse IP 172.16.1.1, si le trafic utilise le protocole TCP et le port de destination 80 ou n'importe quel protocole et le port de destination 443.
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: default
spec:
egress:
- type: Deny
to:
cidrSelector: 172.16.1.1
ports:
- port: 80
protocol: TCP
- port: 44324.10.2.3. Exemple de nodeSelector pour EgressFirewall
En tant qu'administrateur de cluster, vous pouvez autoriser ou refuser le trafic de sortie vers les nœuds de votre cluster en spécifiant une étiquette à l'aide de nodeSelector. Les étiquettes peuvent être appliquées à un ou plusieurs nœuds. Voici un exemple avec l'étiquette region=east:
apiVersion: v1
kind: Pod
metadata:
name: default
spec:
egress:
- to:
nodeSelector:
matchLabels:
region: east
type: AllowAu lieu d'ajouter des règles manuelles par adresse IP de nœud, utilisez les sélecteurs de nœuds pour créer une étiquette qui permet aux pods situés derrière un pare-feu de sortie d'accéder aux pods du réseau hôte.
24.10.3. Création d'un objet de stratégie de pare-feu de sortie
En tant qu'administrateur de cluster, vous pouvez créer un objet de stratégie de pare-feu de sortie pour un projet.
Si le projet a déjà un objet EgressFirewall défini, vous devez modifier la stratégie existante pour apporter des changements aux règles du pare-feu de sortie.
Conditions préalables
- Un cluster qui utilise le plugin réseau OVN-Kubernetes.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster en tant qu'administrateur du cluster.
Procédure
Créer une règle de politique :
-
Créez un fichier
<policy_name>.yamldans lequel<policy_name>décrit les règles de la politique de sortie. - Dans le fichier que vous avez créé, définissez un objet de politique de sortie.
-
Créez un fichier
Entrez la commande suivante pour créer l'objet de politique. Remplacez
<policy_name>par le nom de la politique et<project>par le projet auquel la règle s'applique.oc create -f <policy_name>.yaml -n <project>Dans l'exemple suivant, un nouvel objet EgressFirewall est créé dans un projet nommé
project1:$ oc create -f default.yaml -n project1Exemple de sortie
egressfirewall.k8s.ovn.org/v1 created-
Facultatif : Enregistrez le fichier
<policy_name>.yamlpour pouvoir le modifier ultérieurement.
24.11. Visualisation d'un pare-feu de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez dresser la liste des noms de tous les pare-feux de sortie existants et afficher les règles de trafic pour un pare-feu de sortie spécifique.
24.11.1. Visualisation d'un objet EgressFirewall
Vous pouvez visualiser un objet EgressFirewall dans votre cluster.
Conditions préalables
- Un cluster utilisant le plugin réseau OVN-Kubernetes.
-
Installer l'interface de ligne de commande (CLI) d'OpenShift, communément appelée
oc. - Vous devez vous connecter au cluster.
Procédure
Facultatif : Pour afficher les noms des objets EgressFirewall définis dans votre cluster, entrez la commande suivante :
$ oc get egressfirewall --all-namespacesPour inspecter une politique, entrez la commande suivante. Remplacez
<policy_name>par le nom de la stratégie à inspecter.$ oc describe egressfirewall <nom_de_la_politique>Exemple de sortie
Name: default Namespace: project1 Created: 20 minutes ago Labels: <none> Annotations: <none> Rule: Allow to 1.2.3.0/24 Rule: Allow to www.example.com Rule: Deny to 0.0.0.0/0
24.12. Modification d'un pare-feu de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez modifier les règles de trafic réseau d'un pare-feu de sortie existant.
24.12.1. Modification d'un objet EgressFirewall
En tant qu'administrateur de cluster, vous pouvez mettre à jour le pare-feu de sortie pour un projet.
Conditions préalables
- Un cluster utilisant le plugin réseau OVN-Kubernetes.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster en tant qu'administrateur du cluster.
Procédure
Trouvez le nom de l'objet EgressFirewall pour le projet. Remplacez
<project>par le nom du projet.$ oc get -n <projet> egressfirewallFacultatif : si vous n'avez pas enregistré une copie de l'objet EgressFirewall lors de la création du pare-feu de réseau de sortie, entrez la commande suivante pour créer une copie.
$ oc get -n <project> egressfirewall <name> -o yaml > <filename>.yamlRemplacer
<project>par le nom du projet. Remplacez<name>par le nom de l'objet. Remplacer<filename>par le nom du fichier dans lequel enregistrer le YAML.Après avoir modifié les règles de stratégie, entrez la commande suivante pour remplacer l'objet EgressFirewall. Remplacez
<filename>par le nom du fichier contenant l'objet EgressFirewall mis à jour.$ oc replace -f <filename>.yaml
24.13. Suppression d'un pare-feu de sortie d'un projet
En tant qu'administrateur de cluster, vous pouvez supprimer un pare-feu de sortie d'un projet pour supprimer toutes les restrictions sur le trafic réseau du projet qui quitte le cluster OpenShift Container Platform.
24.13.1. Suppression d'un objet EgressFirewall
En tant qu'administrateur de cluster, vous pouvez supprimer un pare-feu de sortie d'un projet.
Conditions préalables
- Un cluster utilisant le plugin réseau OVN-Kubernetes.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster en tant qu'administrateur du cluster.
Procédure
Trouvez le nom de l'objet EgressFirewall pour le projet. Remplacez
<project>par le nom du projet.$ oc get -n <projet> egressfirewallEntrez la commande suivante pour supprimer l'objet EgressFirewall. Remplacez
<project>par le nom du projet et<name>par le nom de l'objet.oc delete -n <project> egressfirewall <name> $ oc delete -n <project> egressfirewall <name>
24.14. Configuration d'une adresse IP de sortie
En tant qu'administrateur de cluster, vous pouvez configurer le plugin réseau OVN-Kubernetes Container Network Interface (CNI) pour attribuer une ou plusieurs adresses IP de sortie à un espace de noms, ou à des pods spécifiques dans un espace de noms.
24.14.1. Conception architecturale et mise en œuvre de l'adresse IP de sortie
La fonctionnalité d'adresse IP de sortie d'OpenShift Container Platform vous permet de vous assurer que le trafic d'un ou plusieurs pods dans un ou plusieurs espaces de noms a une adresse IP source cohérente pour les services en dehors du réseau du cluster.
Par exemple, vous pouvez avoir un pod qui interroge périodiquement une base de données hébergée sur un serveur extérieur à votre cluster. Pour appliquer les conditions d'accès au serveur, un dispositif de filtrage des paquets est configuré pour n'autoriser le trafic qu'à partir d'adresses IP spécifiques. Pour garantir la fiabilité de l'accès au serveur à partir de ce module spécifique, vous pouvez configurer une adresse IP de sortie spécifique pour le module qui envoie les requêtes au serveur.
Une adresse IP de sortie attribuée à un espace de noms est différente d'un routeur de sortie, qui est utilisé pour envoyer le trafic vers des destinations spécifiques.
Dans certaines configurations de cluster, les pods d'application et les pods de routeur d'entrée fonctionnent sur le même nœud. Si vous configurez une adresse IP de sortie pour un projet d'application dans ce scénario, l'adresse IP n'est pas utilisée lorsque vous envoyez une requête à une route à partir du projet d'application.
Les adresses IP de sortie ne doivent pas être configurées dans les fichiers de configuration du réseau Linux, tels que ifcfg-eth0.
24.14.1.1. Soutien à la plate-forme
La prise en charge de la fonctionnalité d'adresse IP de sortie sur diverses plates-formes est résumée dans le tableau suivant :
| Plate-forme | Soutenu |
|---|---|
| Métal nu | Oui |
| VMware vSphere | Oui |
| Plate-forme Red Hat OpenStack (RHOSP) | Oui |
| Amazon Web Services (AWS) | Oui |
| Google Cloud Platform (GCP) | Oui |
| Microsoft Azure | Oui |
L'attribution d'adresses IP de sortie aux nœuds du plan de contrôle avec la fonctionnalité EgressIP n'est pas prise en charge sur un cluster provisionné sur Amazon Web Services (AWS). (BZ#2039656)
24.14.1.2. Considérations relatives à la plateforme de cloud public
Pour les clusters provisionnés sur une infrastructure de cloud public, il existe une contrainte sur le nombre absolu d'adresses IP assignables par nœud. Le nombre maximal d'adresses IP assignables par nœud, ou le IP capacitypeut être décrit par la formule suivante :
IP capacity = public cloud default capacity - sum(current IP assignments)Bien que la fonction Egress IPs gère la capacité d'adresses IP par nœud, il est important de tenir compte de cette contrainte dans vos déploiements. Par exemple, pour un cluster installé sur une infrastructure bare-metal avec 8 nœuds, vous pouvez configurer 150 adresses IP de sortie. Toutefois, si un fournisseur de cloud public limite la capacité d'adresses IP à 10 adresses IP par nœud, le nombre total d'adresses IP assignables n'est que de 80. Pour obtenir la même capacité d'adresses IP dans cet exemple de fournisseur de cloud, il faudrait allouer 7 nœuds supplémentaires.
Pour confirmer la capacité IP et les sous-réseaux de n'importe quel nœud de votre environnement de cloud public, vous pouvez entrer la commande oc get node <node_name> -o yaml. L'annotation cloud.network.openshift.io/egress-ipconfig comprend des informations sur la capacité et les sous-réseaux du nœud.
La valeur d'annotation est un tableau contenant un objet unique dont les champs fournissent les informations suivantes pour l'interface réseau primaire :
-
interface: Spécifie l'ID de l'interface sur AWS et Azure et le nom de l'interface sur GCP. -
ifaddr: Spécifie le masque de sous-réseau pour une ou les deux familles d'adresses IP. -
capacity: Spécifie la capacité d'adresses IP pour le nœud. Sur AWS, la capacité d'adresses IP est fournie par famille d'adresses IP. Sur Azure et GCP, la capacité d'adresses IP comprend les adresses IPv4 et IPv6.
L'attachement et le détachement automatiques des adresses IP de sortie pour le trafic entre les nœuds sont disponibles. Cela permet au trafic de nombreux pods dans les espaces de noms d'avoir une adresse IP source cohérente vers des emplacements en dehors du cluster. Cela prend également en charge OpenShift SDN et OVN-Kubernetes, qui est le plugin de mise en réseau par défaut dans Red Hat OpenShift Networking dans OpenShift Container Platform 4.12.
La fonctionnalité RHOSP egress IP address crée un port de réservation Neutron appelé egressip-<IP address>. En utilisant le même utilisateur RHOSP que celui utilisé pour l'installation du cluster OpenShift Container Platform, vous pouvez attribuer une adresse IP flottante à ce port de réservation afin de disposer d'une adresse SNAT prévisible pour le trafic de sortie. Lorsqu'une adresse IP de sortie sur un réseau RHOSP est déplacée d'un nœud à un autre, en raison d'un basculement de nœud, par exemple, le port de réservation Neutron est supprimé et recréé. Cela signifie que l'association IP flottante est perdue et que vous devez réassigner manuellement l'adresse IP flottante au nouveau port de réservation.
Lorsqu'un administrateur de cluster RHOSP assigne une IP flottante au port de réservation, OpenShift Container Platform ne peut pas supprimer le port de réservation. L'objet CloudPrivateIPConfig ne peut pas effectuer d'opérations de suppression et de déplacement jusqu'à ce qu'un administrateur de cluster RHOSP désassigne l'IP flottante du port de réservation.
Les exemples suivants illustrent l'annotation des nœuds de plusieurs fournisseurs de nuages publics. Les annotations sont en retrait pour faciliter la lecture.
Exemple d'annotation cloud.network.openshift.io/egress-ipconfig sur AWS
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"eni-078d267045138e436",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ipv4":14,"ipv6":15}
}
]Exemple cloud.network.openshift.io/egress-ipconfig annotation sur GCP
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"nic0",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ip":14}
}
]Les sections suivantes décrivent la capacité d'adresses IP pour les environnements de cloud public pris en charge, à utiliser dans votre calcul de capacité.
24.14.1.2.1. Limites de capacité des adresses IP d'Amazon Web Services (AWS)
Sur AWS, les contraintes d'attribution des adresses IP dépendent du type d'instance configuré. Pour plus d'informations, voir Adresses IP par interface réseau par type d'instance
24.14.1.2.2. Limites de capacité des adresses IP de Google Cloud Platform (GCP)
Sur le GCP, le modèle de réseau met en œuvre des adresses IP de nœuds supplémentaires par le biais de l'alias d'adresses IP, plutôt que par l'attribution d'adresses IP. Toutefois, la capacité d'adresses IP est directement liée à la capacité d'alias d'adresses IP.
Les limites de capacité suivantes s'appliquent à l'attribution de l'alias IP :
- Le nombre maximum d'alias IP, tant IPv4 qu'IPv6, est de 10 par nœud.
- Par VPC, le nombre maximum d'alias IP n'est pas spécifié, mais les tests d'évolutivité d'OpenShift Container Platform révèlent que le maximum est d'environ 15 000.
Pour plus d'informations, voir Quotas par instance et Aperçu des plages d'adresses IP alias.
24.14.1.2.3. Limites de capacité des adresses IP de Microsoft Azure
Sur Azure, les limites de capacité suivantes existent pour l'attribution d'adresses IP :
- Par NIC, le nombre maximum d'adresses IP assignables, tant pour IPv4 que pour IPv6, est de 256.
- Par réseau virtuel, le nombre maximum d'adresses IP attribuées ne peut dépasser 65 536.
Pour plus d'informations, voir Limites de mise en réseau.
24.14.1.3. Attribution d'IP de sortie aux pods
Pour attribuer une ou plusieurs IP de sortie à un espace de noms ou à des modules spécifiques d'un espace de noms, les conditions suivantes doivent être remplies :
-
Au moins un nœud de votre cluster doit avoir le label
k8s.ovn.org/egress-assignable: "". -
Il existe un objet
EgressIPqui définit une ou plusieurs adresses IP de sortie à utiliser comme adresse IP source pour le trafic quittant le cluster à partir des pods d'un espace de noms.
Si vous créez des objets EgressIP avant d'étiqueter les nœuds de votre cluster pour l'attribution d'IP de sortie, OpenShift Container Platform risque d'attribuer chaque adresse IP de sortie au premier nœud avec l'étiquette k8s.ovn.org/egress-assignable: "".
Pour garantir que les adresses IP de sortie sont largement réparties entre les nœuds du cluster, appliquez toujours l'étiquette aux nœuds destinés à héberger les adresses IP de sortie avant de créer des objets EgressIP.
24.14.1.4. Attribution des adresses IP de sortie aux nœuds
Lors de la création d'un objet EgressIP, les conditions suivantes s'appliquent aux nœuds portant l'étiquette k8s.ovn.org/egress-assignable: "":
- Une adresse IP de sortie n'est jamais attribuée à plus d'un nœud à la fois.
- Une adresse IP de sortie est répartie équitablement entre les nœuds disponibles qui peuvent héberger l'adresse IP de sortie.
Si le tableau
spec.EgressIPsd'un objetEgressIPspécifie plus d'une adresse IP, les conditions suivantes s'appliquent :- Aucun nœud n'hébergera jamais plus d'une des adresses IP spécifiées.
- Le trafic est réparti de manière à peu près égale entre les adresses IP spécifiées pour un espace de noms donné.
- Si un nœud devient indisponible, les adresses IP de sortie qui lui sont attribuées sont automatiquement réattribuées, sous réserve des conditions décrites précédemment.
Lorsqu'un pod correspond au sélecteur de plusieurs objets EgressIP, il n'est pas garanti que l'adresse IP de sortie spécifiée dans les objets EgressIP soit attribuée en tant qu'adresse IP de sortie pour le pod.
En outre, si un objet EgressIP spécifie plusieurs adresses IP de sortie, il n'y a aucune garantie quant à l'adresse IP de sortie qui sera utilisée. Par exemple, si un pod correspond à un sélecteur pour un objet EgressIP avec deux adresses IP de sortie, 10.10.20.1 et 10.10.20.2, l'une ou l'autre peut être utilisée pour chaque connexion TCP ou conversation UDP.
24.14.1.5. Schéma architectural d'une configuration d'adresses IP de sortie
Le diagramme suivant illustre une configuration d'adresses IP de sortie. Il décrit quatre pods dans deux espaces de noms différents fonctionnant sur trois nœuds d'un cluster. Les nœuds se voient attribuer des adresses IP à partir du bloc CIDR 192.168.126.0/18 sur le réseau hôte.
Le nœud 1 et le nœud 3 sont tous deux étiquetés avec k8s.ovn.org/egress-assignable: "" et sont donc disponibles pour l'attribution d'adresses IP de sortie.
Les lignes en pointillé du diagramme représentent le flux de trafic provenant de pod1, pod2 et pod3 et transitant par le réseau de pods pour sortir de la grappe à partir du nœud 1 et du nœud 3. Lorsqu'un service externe reçoit du trafic de l'un des pods sélectionnés par l'objet EgressIP, l'adresse IP source est soit 192.168.126.10, soit 192.168.126.102. Le trafic est réparti de manière à peu près égale entre ces deux nœuds.
Les ressources suivantes du diagramme sont illustrées en détail :
NamespaceobjetsLes espaces de noms sont définis dans le manifeste suivant :
Objets de l'espace de noms
apiVersion: v1 kind: Namespace metadata: name: namespace1 labels: env: prod --- apiVersion: v1 kind: Namespace metadata: name: namespace2 labels: env: prodEgressIPobjetL'objet
EgressIPsuivant décrit une configuration qui sélectionne tous les modules dans n'importe quel espace de noms avec l'étiquetteenvdéfinie surprod. Les adresses IP de sortie pour les modules sélectionnés sont192.168.126.10et192.168.126.102.EgressIPobjetapiVersion: k8s.ovn.org/v1 kind: EgressIP metadata: name: egressips-prod spec: egressIPs: - 192.168.126.10 - 192.168.126.102 namespaceSelector: matchLabels: env: prod status: items: - node: node1 egressIP: 192.168.126.10 - node: node3 egressIP: 192.168.126.102Pour la configuration de l'exemple précédent, OpenShift Container Platform attribue les deux adresses IP egress aux nœuds disponibles. Le champ
statusindique si et où les adresses IP de sortie sont attribuées.
24.14.2. Objet EgressIP
Le fichier YAML suivant décrit l'API de l'objet EgressIP. La portée de l'objet est à l'échelle du cluster ; il n'est pas créé dans un espace de noms.
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: <name>
spec:
egressIPs:
- <ip_address>
namespaceSelector:
...
podSelector:
...- 1
- Nom de l'objet
EgressIPs. - 2
- Un tableau d'une ou plusieurs adresses IP.
- 3
- Un ou plusieurs sélecteurs pour les espaces de noms auxquels associer les adresses IP de sortie.
- 4
- Facultatif : Un ou plusieurs sélecteurs de modules dans les espaces de noms spécifiés auxquels associer les adresses IP de sortie. L'application de ces sélecteurs permet de sélectionner un sous-ensemble de modules dans un espace de noms.
Le fichier YAML suivant décrit la strophe du sélecteur d'espace de noms :
Strophe de sélecteur d'espace de noms
namespaceSelector:
matchLabels:
<label_name>: <label_value>- 1
- Une ou plusieurs règles de correspondance pour les espaces de noms. Si plusieurs règles de correspondance sont fournies, tous les espaces de noms correspondants sont sélectionnés.
Le YAML suivant décrit la strophe optionnelle pour le sélecteur de pods :
Stance de sélection de pods
podSelector:
matchLabels:
<label_name>: <label_value>- 1
- Facultatif : Une ou plusieurs règles de correspondance pour les pods dans les espaces de noms qui correspondent aux règles
namespaceSelectorspécifiées. Si cette option est spécifiée, seuls les pods qui correspondent aux règles sont sélectionnés. Les autres pods de l'espace de noms ne sont pas sélectionnés.
Dans l'exemple suivant, l'objet EgressIP associe les adresses IP de sortie 192.168.126.11 et 192.168.126.102 aux pods dont l'étiquette app est définie sur web et qui se trouvent dans les espaces de noms dont l'étiquette env est définie sur prod:
Exemple d'objet EgressIP
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: egress-group1
spec:
egressIPs:
- 192.168.126.11
- 192.168.126.102
podSelector:
matchLabels:
app: web
namespaceSelector:
matchLabels:
env: prod
Dans l'exemple suivant, l'objet EgressIP associe les adresses IP de sortie 192.168.127.30 et 192.168.127.40 à tous les pods dont l'étiquette environment n'est pas réglée sur development:
Exemple d'objet EgressIP
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: egress-group2
spec:
egressIPs:
- 192.168.127.30
- 192.168.127.40
namespaceSelector:
matchExpressions:
- key: environment
operator: NotIn
values:
- development24.14.3. Étiquetage d'un nœud pour l'hébergement des adresses IP de sortie
Vous pouvez appliquer le label k8s.ovn.org/egress-assignable="" à un nœud de votre cluster afin qu'OpenShift Container Platform puisse attribuer une ou plusieurs adresses IP de sortie au nœud.
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Connectez-vous au cluster en tant qu'administrateur du cluster.
Procédure
Pour étiqueter un nœud afin qu'il puisse héberger une ou plusieurs adresses IP de sortie, entrez la commande suivante :
$ oc label nodes <node_name> k8s.ovn.org/egress-assignable=""1 - 1
- Le nom du nœud à étiqueter.
AstuceVous pouvez également appliquer le langage YAML suivant pour ajouter l'étiquette à un nœud :
apiVersion: v1 kind: Node metadata: labels: k8s.ovn.org/egress-assignable: "" name: <node_name>
24.14.4. Prochaines étapes
24.15. Attribution d'une adresse IP de sortie
En tant qu'administrateur de cluster, vous pouvez attribuer une adresse IP de sortie au trafic quittant le cluster à partir d'un espace de noms ou de pods spécifiques dans un espace de noms.
24.15.1. Attribution d'une adresse IP de sortie à un espace de noms
Vous pouvez attribuer une ou plusieurs adresses IP de sortie à un espace de noms ou à des modules spécifiques d'un espace de noms.
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Connectez-vous au cluster en tant qu'administrateur du cluster.
- Configurez au moins un nœud pour qu'il héberge une adresse IP de sortie.
Procédure
Créer un objet
EgressIP:-
Créer un fichier
<egressips_name>.yamloù<egressips_name>est le nom de l'objet. Dans le fichier que vous avez créé, définissez un objet
EgressIP, comme dans l'exemple suivant :apiVersion: k8s.ovn.org/v1 kind: EgressIP metadata: name: egress-project1 spec: egressIPs: - 192.168.127.10 - 192.168.127.11 namespaceSelector: matchLabels: env: qa
-
Créer un fichier
Pour créer l'objet, entrez la commande suivante.
oc apply -f <egressips_name>.yaml1 - 1
- Remplacer
<egressips_name>par le nom de l'objet.
Exemple de sortie
egressips.k8s.ovn.org/<egressips_name> créé-
Facultatif : Enregistrez le fichier
<egressips_name>.yamlpour pouvoir le modifier ultérieurement. Ajoutez des étiquettes à l'espace de noms qui nécessite des adresses IP de sortie. Pour ajouter une étiquette à l'espace de noms d'un objet
EgressIPdéfini à l'étape 1, exécutez la commande suivante :oc label ns <namespace> env=qa1 - 1
- Remplacer
<namespace>par l'espace de noms qui nécessite des adresses IP de sortie.
24.16. Considérations relatives à l'utilisation d'un module de routeur de sortie
24.16.1. À propos d'un pod de routeur de sortie
Le pod routeur egress d'OpenShift Container Platform redirige le trafic vers un serveur distant spécifié à partir d'une adresse IP source privée qui n'est pas utilisée à d'autres fins. Un pod routeur egress peut envoyer du trafic réseau à des serveurs qui sont configurés pour n'autoriser l'accès qu'à partir d'adresses IP spécifiques.
Le module de routeur de sortie n'est pas destiné à chaque connexion sortante. La création d'un grand nombre de modules de routeur de sortie peut dépasser les limites de votre matériel réseau. Par exemple, la création d'un module de routeur de sortie pour chaque projet ou application pourrait dépasser le nombre d'adresses MAC locales que l'interface réseau peut gérer avant de revenir au filtrage des adresses MAC dans le logiciel.
L'image du routeur de sortie n'est pas compatible avec Amazon AWS, Azure Cloud ou toute autre plateforme cloud qui ne prend pas en charge les manipulations de la couche 2 en raison de leur incompatibilité avec le trafic macvlan.
24.16.1.1. Modes du routeur de sortie
En redirect modeun pod routeur de sortie configure les règles iptables pour rediriger le trafic de sa propre adresse IP vers une ou plusieurs adresses IP de destination. Les modules clients qui doivent utiliser l'adresse IP source réservée doivent être modifiés pour se connecter au routeur de sortie plutôt que de se connecter directement à l'adresse IP de destination.
Le plugin CNI egress router supporte uniquement le mode redirect. Il s'agit d'une différence avec l'implémentation du routeur egress que vous pouvez déployer avec OpenShift SDN. Contrairement au routeur de sortie pour OpenShift SDN, le plugin CNI du routeur de sortie ne prend pas en charge le mode proxy HTTP ou le mode proxy DNS.
24.16.1.2. Mise en œuvre d'un pod de routeur de sortie
L'implémentation du routeur de sortie utilise le plugin Container Network Interface (CNI) du routeur de sortie. Le plugin ajoute une interface réseau secondaire à un pod.
Un routeur de sortie est un module qui possède deux interfaces réseau. Par exemple, le module peut avoir des interfaces réseau eth0 et net1. L'interface eth0 se trouve sur le réseau du cluster et le pod continue à l'utiliser pour le trafic réseau ordinaire lié au cluster. L'interface net1 est sur un réseau secondaire et possède une adresse IP et une passerelle pour ce réseau. D'autres pods dans le cluster OpenShift Container Platform peuvent accéder au service de routeur de sortie et le service permet aux pods d'accéder à des services externes. Le routeur egress agit comme un pont entre les pods et un système externe.
Le trafic qui quitte le routeur de sortie passe par un nœud, mais les paquets ont l'adresse MAC de l'interface net1 du pod du routeur de sortie.
Lorsque vous ajoutez une ressource personnalisée de routeur de sortie, l'opérateur de réseau de cluster crée les objets suivants :
-
La définition de l'attachement réseau pour l'interface réseau secondaire
net1du pod. - Un déploiement pour le routeur de sortie.
Si vous supprimez une ressource personnalisée de routeur de sortie, l'opérateur supprime les deux objets de la liste précédente qui sont associés au routeur de sortie.
24.16.1.3. Considérations relatives au déploiement
Un pod routeur de sortie ajoute une adresse IP et une adresse MAC supplémentaires à l'interface réseau principale du nœud. Par conséquent, il se peut que vous deviez configurer votre hyperviseur ou votre fournisseur de cloud pour autoriser l'adresse supplémentaire.
- Plate-forme Red Hat OpenStack (RHOSP)
Si vous déployez OpenShift Container Platform sur RHOSP, vous devez autoriser le trafic à partir des adresses IP et MAC du pod routeur egress sur votre environnement OpenStack. Si vous n'autorisez pas le trafic, la communication échouera:
$ openstack port set --allowed-address \ ip_address=<ip_address>,mac_address=<mac_address> <neutron_port_uuid>- Red Hat Virtualization (RHV)
- Si vous utilisez RHV, vous devez sélectionner No Network Filter pour le contrôleur d'interface réseau virtuel (vNIC).
- VMware vSphere
- Si vous utilisez VMware vSphere, consultez la documentation VMware pour sécuriser les commutateurs standard vSphere. Affichez et modifiez les paramètres par défaut de VMware vSphere en sélectionnant le commutateur virtuel de l'hôte dans le client Web vSphere.
En particulier, assurez-vous que les éléments suivants sont activés :
24.16.1.4. Configuration du basculement
Pour éviter les temps d'arrêt, l'opérateur du réseau de cluster déploie le module de routeur de sortie en tant que ressource de déploiement. Le nom du déploiement est egress-router-cni-deployment. Le module correspondant au déploiement a une étiquette app=egress-router-cni.
Pour créer un nouveau service pour le déploiement, utilisez la commande oc expose deployment/egress-router-cni-deployment --port <port_number> ou créez un fichier comme dans l'exemple suivant :
apiVersion: v1
kind: Service
metadata:
name: app-egress
spec:
ports:
- name: tcp-8080
protocol: TCP
port: 8080
- name: tcp-8443
protocol: TCP
port: 8443
- name: udp-80
protocol: UDP
port: 80
type: ClusterIP
selector:
app: egress-router-cni24.17. Déploiement d'un pod routeur de sortie en mode redirection
En tant qu'administrateur de cluster, vous pouvez déployer un pod routeur de sortie pour rediriger le trafic vers des adresses IP de destination spécifiées à partir d'une adresse IP source réservée.
L'implémentation du routeur de sortie utilise le plugin CNI (Container Network Interface) du routeur de sortie.
24.17.1. Ressource personnalisée du routeur de sortie
Définir la configuration d'un module de routeur de sortie dans une ressource personnalisée de routeur de sortie. Le fichier YAML suivant décrit les champs de configuration d'un routeur de sortie en mode redirection :
apiVersion: network.operator.openshift.io/v1
kind: EgressRouter
metadata:
name: <egress_router_name>
namespace: <namespace> <.>
spec:
addresses: [ <.>
{
ip: "<egress_router>", <.>
gateway: "<egress_gateway>" <.>
}
]
mode: Redirect
redirect: {
redirectRules: [ <.>
{
destinationIP: "<egress_destination>",
port: <egress_router_port>,
targetPort: <target_port>, <.>
protocol: <network_protocol> <.>
},
...
],
fallbackIP: "<egress_destination>" <.>
}
<.> Facultatif : Le champ namespace indique l'espace de noms dans lequel le routeur de sortie doit être créé. Si vous ne spécifiez pas de valeur dans le fichier ou sur la ligne de commande, l'espace de noms default est utilisé.
<.> Le champ addresses spécifie les adresses IP à configurer sur l'interface réseau secondaire.
<.> Le champ ip spécifie l'adresse IP source réservée et le masque de réseau du réseau physique sur lequel se trouve le nœud à utiliser avec le pod du routeur de sortie. Utilisez la notation CIDR pour spécifier l'adresse IP et le masque de réseau.
<.> Le champ gateway indique l'adresse IP de la passerelle réseau.
<.> Facultatif : Le champ redirectRules spécifie une combinaison d'adresse IP de destination de sortie, de port de routeur de sortie et de protocole. Les connexions entrantes au routeur de sortie sur le port et le protocole spécifiés sont acheminées vers l'adresse IP de destination.
<.> Facultatif : Le champ targetPort indique le port réseau de l'adresse IP de destination. Si ce champ n'est pas spécifié, le trafic est acheminé vers le même port réseau que celui par lequel il est arrivé.
<.> Le champ protocol prend en charge TCP, UDP ou SCTP.
<.> Facultatif : Le champ fallbackIP spécifie une adresse IP de destination. Si vous ne spécifiez aucune règle de redirection, le routeur de sortie envoie tout le trafic à cette adresse IP de repli. Si vous spécifiez des règles de redirection, toutes les connexions aux ports réseau qui ne sont pas définies dans les règles sont envoyées par le routeur de sortie à cette adresse IP de repli. Si vous ne spécifiez pas ce champ, le routeur de sortie rejette les connexions aux ports réseau qui ne sont pas définis dans les règles.
Exemple de spécification d'un routeur de sortie
apiVersion: network.operator.openshift.io/v1
kind: EgressRouter
metadata:
name: egress-router-redirect
spec:
networkInterface: {
macvlan: {
mode: "Bridge"
}
}
addresses: [
{
ip: "192.168.12.99/24",
gateway: "192.168.12.1"
}
]
mode: Redirect
redirect: {
redirectRules: [
{
destinationIP: "10.0.0.99",
port: 80,
protocol: UDP
},
{
destinationIP: "203.0.113.26",
port: 8080,
targetPort: 80,
protocol: TCP
},
{
destinationIP: "203.0.113.27",
port: 8443,
targetPort: 443,
protocol: TCP
}
]
}24.17.2. Déploiement d'un routeur de sortie en mode redirection
Vous pouvez déployer un routeur de sortie pour rediriger le trafic de sa propre adresse IP source réservée vers une ou plusieurs adresses IP de destination.
Après l'ajout d'un routeur de sortie, les modules clients qui doivent utiliser l'adresse IP source réservée doivent être modifiés pour se connecter au routeur de sortie plutôt que de se connecter directement à l'adresse IP de destination.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Créer une définition de routeur de sortie.
Pour que les autres modules puissent trouver l'adresse IP du module de routeur de sortie, créez un service qui utilise le routeur de sortie, comme dans l'exemple suivant :
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: web-app protocol: TCP port: 8080 type: ClusterIP selector: app: egress-router-cni <.><.> Spécifier l'étiquette pour le routeur de sortie. La valeur indiquée est ajoutée par l'opérateur du réseau de cluster et n'est pas configurable.
Après avoir créé le service, vos pods peuvent se connecter au service. Le pod routeur de sortie redirige le trafic vers le port correspondant de l'adresse IP de destination. Les connexions proviennent de l'adresse IP source réservée.
Vérification
Pour vérifier que l'opérateur du réseau de clusters a démarré le routeur de sortie, suivez la procédure suivante :
Affichez la définition de l'attachement au réseau que l'opérateur a créée pour le routeur de sortie :
$ oc get network-attachment-definition egress-router-cni-nadLe nom de la définition de l'attachement réseau n'est pas configurable.
Exemple de sortie
NAME AGE egress-router-cni-nad 18mAffichez le déploiement du module de routeur de sortie :
$ oc get deployment egress-router-cni-deploymentLe nom du déploiement n'est pas configurable.
Exemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE egress-router-cni-deployment 1/1 1 1 18mAffichez l'état du pod du routeur de sortie :
$ oc get pods -l app=egress-router-cniExemple de sortie
NAME READY STATUS RESTARTS AGE egress-router-cni-deployment-575465c75c-qkq6m 1/1 Running 0 18m- Affichez les journaux et la table de routage pour le pod du routeur de sortie.
Obtenir le nom du nœud pour le pod du routeur de sortie :
$ POD_NODENAME=$(oc get pod -l app=egress-router-cni -o jsonpath="{.items[0].spec.nodeName}")Entrez dans une session de débogage sur le nœud cible. Cette étape instancie un pod de débogage appelé
<node_name>-debug:$ oc debug node/$POD_NODENAMEDéfinissez
/hostcomme répertoire racine dans le shell de débogage. Le pod de débogage monte le système de fichiers racine de l'hôte dans/hostau sein du pod. En changeant le répertoire racine en/host, vous pouvez exécuter des binaires à partir des chemins d'exécution de l'hôte :# chroot /hostDans la console de l'environnement
chroot, affichez les journaux du routeur de sortie :# cat /tmp/egress-router-logExemple de sortie
2021-04-26T12:27:20Z [debug] Called CNI ADD 2021-04-26T12:27:20Z [debug] Gateway: 192.168.12.1 2021-04-26T12:27:20Z [debug] IP Source Addresses: [192.168.12.99/24] 2021-04-26T12:27:20Z [debug] IP Destinations: [80 UDP 10.0.0.99/30 8080 TCP 203.0.113.26/30 80 8443 TCP 203.0.113.27/30 443] 2021-04-26T12:27:20Z [debug] Created macvlan interface 2021-04-26T12:27:20Z [debug] Renamed macvlan to "net1" 2021-04-26T12:27:20Z [debug] Adding route to gateway 192.168.12.1 on macvlan interface 2021-04-26T12:27:20Z [debug] deleted default route {Ifindex: 3 Dst: <nil> Src: <nil> Gw: 10.128.10.1 Flags: [] Table: 254} 2021-04-26T12:27:20Z [debug] Added new default route with gateway 192.168.12.1 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat PREROUTING -i eth0 -p UDP --dport 80 -j DNAT --to-destination 10.0.0.99 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat PREROUTING -i eth0 -p TCP --dport 8080 -j DNAT --to-destination 203.0.113.26:80 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat PREROUTING -i eth0 -p TCP --dport 8443 -j DNAT --to-destination 203.0.113.27:443 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat -o net1 -j SNAT --to-source 192.168.12.99L'emplacement du fichier de journalisation et le niveau de journalisation ne sont pas configurables lorsque vous démarrez le routeur de sortie en créant un objet
EgressRoutercomme décrit dans cette procédure.Dans la console de l'environnement
chroot, récupérez l'identifiant du conteneur :# crictl ps --name egress-router-cni-pod | awk '{print $1}'Exemple de sortie
CONTAINER bac9fae69ddb6Déterminer l'ID du processus du conteneur. Dans cet exemple, l'ID du conteneur est
bac9fae69ddb6:# crictl inspect -o yaml bac9fae69ddb6 | grep 'pid:' | awk '{print $2}'Exemple de sortie
68857Entrez l'espace de noms du réseau du conteneur :
# nsenter -n -t 68857Afficher la table de routage :
# ip routeDans l'exemple suivant, l'interface réseau
net1est la route par défaut. Le trafic pour le réseau cluster utilise l'interface réseaueth0. Le trafic destiné au réseau192.168.12.0/24utilise l'interface réseaunet1et provient de l'adresse IP source réservée192.168.12.99. Le pod achemine tout le reste du trafic vers la passerelle à l'adresse IP192.168.12.1. Le routage pour le réseau de service n'est pas montré.Exemple de sortie
default via 192.168.12.1 dev net1 10.128.10.0/23 dev eth0 proto kernel scope link src 10.128.10.18 192.168.12.0/24 dev net1 proto kernel scope link src 192.168.12.99 192.168.12.1 dev net1
24.18. Activation de la multidiffusion pour un projet
24.18.1. À propos de la multidiffusion
Avec la multidiffusion IP, les données sont diffusées simultanément à de nombreuses adresses IP.
À l'heure actuelle, le multicast est utilisé de préférence pour la coordination ou la découverte de services à faible bande passante et non comme une solution à large bande passante.
Le trafic multicast entre les pods d'OpenShift Container Platform est désactivé par défaut. Si vous utilisez le plugin réseau OVN-Kubernetes, vous pouvez activer le multicast par projet.
24.18.2. Activation de la multidiffusion entre les pods
Vous pouvez activer le multicast entre les pods de votre projet.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Exécutez la commande suivante pour activer la multidiffusion pour un projet. Remplacez
<namespace>par l'espace de noms du projet pour lequel vous souhaitez activer la multidiffusion.$ oc annotate namespace <namespace> \ k8s.ovn.org/multicast-enabled=trueAstuceVous pouvez également appliquer le YAML suivant pour ajouter l'annotation :
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: k8s.ovn.org/multicast-enabled: "true"
Vérification
Pour vérifier que la multidiffusion est activée pour un projet, suivez la procédure suivante :
Remplacez votre projet actuel par le projet pour lequel vous avez activé la multidiffusion. Remplacez
<project>par le nom du projet.$ oc project <projet>Créez un pod qui servira de récepteur multicast :
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: mlistener labels: app: multicast-verify spec: containers: - name: mlistener image: registry.access.redhat.com/ubi8 command: ["/bin/sh", "-c"] args: ["dnf -y install socat hostname && sleep inf"] ports: - containerPort: 30102 name: mlistener protocol: UDP EOFCréez un pod qui servira d'émetteur multicast :
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: msender labels: app: multicast-verify spec: containers: - name: msender image: registry.access.redhat.com/ubi8 command: ["/bin/sh", "-c"] args: ["dnf -y install socat && sleep inf"] EOFDans une nouvelle fenêtre ou un nouvel onglet de terminal, démarrez l'auditeur de multidiffusion.
Obtenir l'adresse IP du pod :
$ POD_IP=$(oc get pods mlistener -o jsonpath='{.status.podIP}')Démarrez l'auditeur de multidiffusion en entrant la commande suivante :
$ oc exec mlistener -i -t -- \ socat UDP4-RECVFROM:30102,ip-add-membership=224.1.0.1:$POD_IP,fork EXEC:hostname
Démarrer l'émetteur de multidiffusion.
Obtenir la plage d'adresses IP du réseau de pods :
$ CIDR=$(oc get Network.config.openshift.io cluster \ -o jsonpath='{.status.clusterNetwork[0].cidr}')Pour envoyer un message multicast, entrez la commande suivante :
$ oc exec msender -i -t -- \ /bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"Si la multidiffusion fonctionne, la commande précédente renvoie le résultat suivant :
mlistener
24.19. Désactiver la multidiffusion pour un projet
24.19.1. Désactivation de la multidiffusion entre les pods
Vous pouvez désactiver le multicast entre les pods de votre projet.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Désactivez la multidiffusion en exécutant la commande suivante :
$ oc annotate namespace <namespace> \1 k8s.ovn.org/multicast-enabled-- 1
- Le site
namespacedu projet pour lequel vous souhaitez désactiver la multidiffusion.
AstuceVous pouvez également appliquer le YAML suivant pour supprimer l'annotation :
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: k8s.ovn.org/multicast-enabled: null
24.20. Suivi des flux du réseau
En tant qu'administrateur de cluster, vous pouvez collecter des informations sur les flux de réseaux de pods de votre cluster pour vous aider dans les domaines suivants :
- Surveiller le trafic d'entrée et de sortie sur le réseau de pods.
- Dépanner les problèmes de performance.
- Recueillir des données pour la planification des capacités et les audits de sécurité.
Lorsque vous activez la collecte des flux réseau, seules les métadonnées relatives au trafic sont collectées. Par exemple, les données des paquets ne sont pas collectées, mais le protocole, l'adresse source, l'adresse de destination, les numéros de port, le nombre d'octets et d'autres informations au niveau des paquets sont collectés.
Les données sont collectées dans un ou plusieurs des formats d'enregistrement suivants :
- NetFlow
- sFlow
- IPFIX
Lorsque vous configurez l'opérateur réseau du cluster (CNO) avec une ou plusieurs adresses IP et numéros de port de collecteurs, l'opérateur configure Open vSwitch (OVS) sur chaque nœud pour envoyer les enregistrements de flux réseau à chaque collecteur.
Vous pouvez configurer l'opérateur pour qu'il envoie des enregistrements à plusieurs types de collecteurs de flux réseau. Par exemple, vous pouvez envoyer des enregistrements aux collecteurs NetFlow et également aux collecteurs sFlow.
Lorsqu'OVS envoie des données aux collecteurs, chaque type de collecteur reçoit des enregistrements identiques. Par exemple, si vous configurez deux collecteurs NetFlow, OVS sur un nœud envoie des enregistrements identiques aux deux collecteurs. Si vous configurez également deux collecteurs sFlow, les deux collecteurs sFlow reçoivent des enregistrements identiques. Cependant, chaque type de collecteur a un format d'enregistrement unique.
La collecte des données sur les flux du réseau et l'envoi des enregistrements aux collecteurs affectent les performances. Les nœuds traitent les paquets plus lentement. Si l'impact sur les performances est trop important, vous pouvez supprimer les destinations des collecteurs pour désactiver la collecte des données de flux réseau et rétablir les performances.
L'activation des collecteurs de flux réseau peut avoir un impact sur les performances globales du réseau de la grappe.
24.20.1. Configuration d'objets de réseau pour le suivi des flux de réseau
Les champs de configuration des collecteurs de flux réseau dans le Cluster Network Operator (CNO) sont présentés dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
|
Le nom de l'objet CNO. Ce nom est toujours |
|
|
|
Un ou plusieurs des sites suivants : |
|
|
| Une liste de paires d'adresses IP et de ports réseau pour un maximum de 10 collecteurs. |
|
|
| Une liste de paires d'adresses IP et de ports réseau pour un maximum de 10 collecteurs. |
|
|
| Une liste de paires d'adresses IP et de ports réseau pour un maximum de 10 collecteurs. |
Après avoir appliqué le manifeste suivant au CNO, l'Opérateur configure Open vSwitch (OVS) sur chaque nœud du cluster pour envoyer des enregistrements de flux réseau au collecteur NetFlow qui écoute à l'adresse 192.168.1.99:2056.
Exemple de configuration pour le suivi des flux du réseau
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
exportNetworkFlows:
netFlow:
collectors:
- 192.168.1.99:205624.20.2. Ajout de destinations pour les collecteurs de flux réseau
En tant qu'administrateur de cluster, vous pouvez configurer l'opérateur de réseau de cluster (CNO) pour qu'il envoie des métadonnées de flux réseau sur le réseau de pods à un collecteur de flux réseau.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin. - Vous disposez d'un collecteur de flux réseau et vous connaissez l'adresse IP et le port sur lesquels il écoute.
Procédure
Créez un fichier patch qui spécifie le type de collecteur de flux réseau ainsi que l'adresse IP et les informations de port des collecteurs :
spec: exportNetworkFlows: netFlow: collectors: - 192.168.1.99:2056Configurer le CNO avec les collecteurs de flux du réseau :
$ oc patch network.operator cluster --type merge -p "$(cat <nom_du_fichier>.yaml)"Exemple de sortie
network.operator.openshift.io/cluster patched
Vérification
La vérification n'est généralement pas nécessaire. Vous pouvez exécuter la commande suivante pour confirmer qu'Open vSwitch (OVS) sur chaque nœud est configuré pour envoyer des enregistrements de flux réseau à un ou plusieurs collecteurs.
Consultez la configuration de l'opérateur pour confirmer que le champ
exportNetworkFlowsest configuré :$ oc get network.operator cluster -o jsonpath="{.spec.exportNetworkFlows}"Exemple de sortie
{"netFlow":{"collectors":["192.168.1.99:2056"]}}Visualiser la configuration des flux réseau dans OVS à partir de chaque nœud :
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node -o jsonpath='{range@.items[*]}{.metadata.name}{"\n"}{end}'); do ; echo; echo $pod; oc -n openshift-ovn-kubernetes exec -c ovnkube-node $pod \ -- bash -c 'for type in ipfix sflow netflow ; do ovs-vsctl find $type ; done'; doneExemple de sortie
ovnkube-node-xrn4p _uuid : a4d2aaca-5023-4f3d-9400-7275f92611f9 active_timeout : 60 add_id_to_interface : false engine_id : [] engine_type : [] external_ids : {} targets : ["192.168.1.99:2056"] ovnkube-node-z4vq9 _uuid : 61d02fdb-9228-4993-8ff5-b27f01a29bd6 active_timeout : 60 add_id_to_interface : false engine_id : [] engine_type : [] external_ids : {} targets : ["192.168.1.99:2056"]- ...
24.20.3. Suppression de toutes les destinations pour les collecteurs de flux réseau
En tant qu'administrateur de cluster, vous pouvez configurer l'opérateur de réseau de cluster (CNO) pour qu'il cesse d'envoyer des métadonnées de flux réseau à un collecteur de flux réseau.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté au cluster avec un utilisateur disposant des privilèges
cluster-admin.
Procédure
Supprimer tous les collecteurs de flux réseau :
$ oc patch network.operator cluster --type='json' \ -p='[{"op":"remove", "path":"/spec/exportNetworkFlows"}]'Exemple de sortie
network.operator.openshift.io/cluster patched
24.21. Configuration d'un réseau hybride
En tant qu'administrateur de cluster, vous pouvez configurer le plugin réseau Red Hat OpenShift Networking OVN-Kubernetes pour permettre aux nœuds Linux et Windows d'héberger des charges de travail Linux et Windows, respectivement.
24.21.1. Configuring hybrid networking with OVN-Kubernetes
You can configure your cluster to use hybrid networking with OVN-Kubernetes. This allows a hybrid cluster that supports different node networking configurations. For example, this is necessary to run both Linux and Windows nodes in a cluster.
You must configure hybrid networking with OVN-Kubernetes during the installation of your cluster. You cannot switch to hybrid networking after the installation process.
Conditions préalables
-
Vous avez défini
OVNKubernetespour le paramètrenetworking.networkTypedans le fichierinstall-config.yaml. Pour plus d'informations, consultez la documentation d'installation pour configurer les personnalisations du réseau OpenShift Container Platform sur le fournisseur de cloud que vous avez choisi.
Procédure
Change to the directory that contains the installation program and create the manifests:
$ ./openshift-install create manifests --dir <installation_directory>où :
<installation_directory>-
Spécifie le nom du répertoire qui contient le fichier
install-config.yamlpour votre cluster.
Créez un fichier manifeste (stub manifest file) pour la configuration réseau avancée, nommé
cluster-network-03-config.ymldans le répertoire<installation_directory>/manifests/:$ cat <<EOF > <installation_directory>/manifests/cluster-network-03-config.yml apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: EOFoù :
<installation_directory>-
Spécifie le nom du répertoire qui contient le répertoire
manifests/pour votre cluster.
Ouvrez le fichier
cluster-network-03-config.ymldans un éditeur et configurez OVN-Kubernetes avec un réseau hybride, comme dans l'exemple suivant :Specify a hybrid networking configuration
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: defaultNetwork: ovnKubernetesConfig: hybridOverlayConfig: hybridClusterNetwork:1 - cidr: 10.132.0.0/14 hostPrefix: 23 hybridOverlayVXLANPort: 98982 - 1
- Indiquez la configuration CIDR utilisée pour les nœuds du réseau superposé supplémentaire. Le CIDR
hybridClusterNetworkne peut pas chevaucher le CIDRclusterNetwork. - 2
- Spécifiez un port VXLAN personnalisé pour le réseau superposé supplémentaire. Ceci est nécessaire pour l'exécution de nœuds Windows dans un cluster installé sur vSphere, et ne doit pas être configuré pour un autre fournisseur de cloud. Le port personnalisé peut être n'importe quel port ouvert, à l'exception du port par défaut
4789. Pour plus d'informations sur cette exigence, voir la documentation Microsoft sur la connectivité Pod-to-pod entre les hôtes est rompue.
NoteWindows Server Long-Term Servicing Channel (LTSC) : Windows Server 2019 n'est pas pris en charge sur les clusters avec une valeur
hybridOverlayVXLANPortpersonnalisée car cette version du serveur Windows ne prend pas en charge la sélection d'un port VXLAN personnalisé.-
Enregistrez le fichier
cluster-network-03-config.ymlet quittez l'éditeur de texte. -
Facultatif : Sauvegardez le fichier
manifests/cluster-network-03-config.yml. Le programme d'installation supprime le répertoiremanifests/lors de la création du cluster.
Complétez toutes les autres configurations d'installation, puis créez votre cluster. La mise en réseau hybride est activée lorsque le processus d'installation est terminé.
Chapitre 25. Plugin réseau SDN OpenShift
25.1. À propos du plugin réseau OpenShift SDN
Faisant partie de Red Hat OpenShift Networking, OpenShift SDN est un plugin réseau qui utilise une approche de réseau défini par logiciel (SDN) pour fournir un réseau de cluster unifié qui permet la communication entre les pods à travers le cluster OpenShift Container Platform. Ce réseau de pods est établi et maintenu par OpenShift SDN, qui configure un réseau superposé à l'aide d'Open vSwitch (OVS).
25.1.1. Modes d'isolation du réseau OpenShift SDN
OpenShift SDN propose trois modes SDN pour configurer le réseau de pods :
-
Network policy permet aux administrateurs de projets de configurer leurs propres politiques d'isolation en utilisant les objets
NetworkPolicy. La politique de réseau est le mode par défaut dans OpenShift Container Platform 4.12. - Multitenant permet d'isoler les pods et les services au niveau du projet. Les pods de différents projets ne peuvent pas envoyer de paquets aux pods et aux services d'un autre projet, ni en recevoir de leur part. Vous pouvez désactiver l'isolation d'un projet, ce qui lui permet d'envoyer du trafic réseau à tous les pods et services de l'ensemble du cluster et de recevoir du trafic réseau de ces pods et services.
- Subnet fournit un réseau de pods plat où chaque pod peut communiquer avec tous les autres pods et services. Le mode "politique de réseau" offre les mêmes fonctionnalités que le mode "sous-réseau".
25.1.2. Matrice des caractéristiques des plugins réseau pris en charge
Red Hat OpenShift Networking offre deux options pour le plugin réseau, OpenShift SDN et OVN-Kubernetes, pour le plugin réseau. Le tableau suivant résume la prise en charge actuelle des fonctionnalités pour les deux plugins réseau :
| Fonctionnalité | OpenShift SDN | OVN-Kubernetes |
|---|---|---|
| IP de sortie | Soutenu | Soutenu |
| Pare-feu de sortie [1] | Soutenu | Soutenu |
| Routeur de sortie | Soutenu | Soutenu [2] |
| Réseau hybride | Non pris en charge | Soutenu |
| Cryptage IPsec | Non pris en charge | Soutenu |
| IPv6 | Non pris en charge | Soutenu [3] |
| Politique de réseau Kubernetes | Soutenu | Soutenu |
| Journaux de la politique réseau de Kubernetes | Non pris en charge | Soutenu |
| Multidiffusion | Soutenu | Soutenu |
| Déchargement du matériel | Non pris en charge | Soutenu |
- Le pare-feu de sortie est également connu sous le nom de politique de réseau de sortie dans OpenShift SDN. Ce n'est pas la même chose que la politique de réseau de sortie.
- Le routeur de sortie pour OVN-Kubernetes ne prend en charge que le mode de redirection.
- IPv6 n'est pris en charge que sur les clusters bare metal, IBM Power et IBM zSystems.
25.2. Configuration des IP de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez configurer le plugin réseau OpenShift SDN Container Network Interface (CNI) pour attribuer une ou plusieurs adresses IP de sortie à un projet.
25.2.1. Conception architecturale et mise en œuvre de l'adresse IP de sortie
La fonctionnalité d'adresse IP de sortie d'OpenShift Container Platform vous permet de vous assurer que le trafic d'un ou plusieurs pods dans un ou plusieurs espaces de noms a une adresse IP source cohérente pour les services en dehors du réseau du cluster.
Par exemple, vous pouvez avoir un pod qui interroge périodiquement une base de données hébergée sur un serveur extérieur à votre cluster. Pour appliquer les conditions d'accès au serveur, un dispositif de filtrage des paquets est configuré pour n'autoriser le trafic qu'à partir d'adresses IP spécifiques. Pour garantir la fiabilité de l'accès au serveur à partir de ce module spécifique, vous pouvez configurer une adresse IP de sortie spécifique pour le module qui envoie les requêtes au serveur.
Une adresse IP de sortie attribuée à un espace de noms est différente d'un routeur de sortie, qui est utilisé pour envoyer le trafic vers des destinations spécifiques.
Dans certaines configurations de cluster, les pods d'application et les pods de routeur d'entrée fonctionnent sur le même nœud. Si vous configurez une adresse IP de sortie pour un projet d'application dans ce scénario, l'adresse IP n'est pas utilisée lorsque vous envoyez une requête à une route à partir du projet d'application.
Une adresse IP de sortie est mise en œuvre sous la forme d'une adresse IP supplémentaire sur l'interface réseau principale d'un nœud et doit se trouver dans le même sous-réseau que l'adresse IP principale du nœud. L'adresse IP supplémentaire ne doit être attribuée à aucun autre nœud de la grappe.
Les adresses IP de sortie ne doivent pas être configurées dans les fichiers de configuration du réseau Linux, tels que ifcfg-eth0.
25.2.1.1. Soutien à la plate-forme
La prise en charge de la fonctionnalité d'adresse IP de sortie sur diverses plates-formes est résumée dans le tableau suivant :
| Plate-forme | Soutenu |
|---|---|
| Métal nu | Oui |
| VMware vSphere | Oui |
| Plate-forme Red Hat OpenStack (RHOSP) | Oui |
| Amazon Web Services (AWS) | Oui |
| Google Cloud Platform (GCP) | Oui |
| Microsoft Azure | Oui |
L'attribution d'adresses IP de sortie aux nœuds du plan de contrôle avec la fonctionnalité EgressIP n'est pas prise en charge sur un cluster provisionné sur Amazon Web Services (AWS). (BZ#2039656)
25.2.1.2. Considérations relatives à la plateforme de cloud public
Pour les clusters provisionnés sur une infrastructure de cloud public, il existe une contrainte sur le nombre absolu d'adresses IP assignables par nœud. Le nombre maximal d'adresses IP assignables par nœud, ou le IP capacitypeut être décrit par la formule suivante :
IP capacity = public cloud default capacity - sum(current IP assignments)Bien que la fonction Egress IPs gère la capacité d'adresses IP par nœud, il est important de tenir compte de cette contrainte dans vos déploiements. Par exemple, pour un cluster installé sur une infrastructure bare-metal avec 8 nœuds, vous pouvez configurer 150 adresses IP de sortie. Toutefois, si un fournisseur de cloud public limite la capacité d'adresses IP à 10 adresses IP par nœud, le nombre total d'adresses IP assignables n'est que de 80. Pour obtenir la même capacité d'adresses IP dans cet exemple de fournisseur de cloud, il faudrait allouer 7 nœuds supplémentaires.
Pour confirmer la capacité IP et les sous-réseaux de n'importe quel nœud de votre environnement de cloud public, vous pouvez entrer la commande oc get node <node_name> -o yaml. L'annotation cloud.network.openshift.io/egress-ipconfig comprend des informations sur la capacité et les sous-réseaux du nœud.
La valeur d'annotation est un tableau contenant un objet unique dont les champs fournissent les informations suivantes pour l'interface réseau primaire :
-
interface: Spécifie l'ID de l'interface sur AWS et Azure et le nom de l'interface sur GCP. -
ifaddr: Spécifie le masque de sous-réseau pour une ou les deux familles d'adresses IP. -
capacity: Spécifie la capacité d'adresses IP pour le nœud. Sur AWS, la capacité d'adresses IP est fournie par famille d'adresses IP. Sur Azure et GCP, la capacité d'adresses IP comprend les adresses IPv4 et IPv6.
L'attachement et le détachement automatiques des adresses IP de sortie pour le trafic entre les nœuds sont disponibles. Cela permet au trafic de nombreux pods dans les espaces de noms d'avoir une adresse IP source cohérente vers des emplacements en dehors du cluster. Cela prend également en charge OpenShift SDN et OVN-Kubernetes, qui est le plugin de mise en réseau par défaut dans Red Hat OpenShift Networking dans OpenShift Container Platform 4.12.
La fonctionnalité RHOSP egress IP address crée un port de réservation Neutron appelé egressip-<IP address>. En utilisant le même utilisateur RHOSP que celui utilisé pour l'installation du cluster OpenShift Container Platform, vous pouvez attribuer une adresse IP flottante à ce port de réservation afin de disposer d'une adresse SNAT prévisible pour le trafic de sortie. Lorsqu'une adresse IP de sortie sur un réseau RHOSP est déplacée d'un nœud à un autre, en raison d'un basculement de nœud, par exemple, le port de réservation Neutron est supprimé et recréé. Cela signifie que l'association IP flottante est perdue et que vous devez réassigner manuellement l'adresse IP flottante au nouveau port de réservation.
Lorsqu'un administrateur de cluster RHOSP assigne une IP flottante au port de réservation, OpenShift Container Platform ne peut pas supprimer le port de réservation. L'objet CloudPrivateIPConfig ne peut pas effectuer d'opérations de suppression et de déplacement jusqu'à ce qu'un administrateur de cluster RHOSP désassigne l'IP flottante du port de réservation.
Les exemples suivants illustrent l'annotation des nœuds de plusieurs fournisseurs de nuages publics. Les annotations sont en retrait pour faciliter la lecture.
Exemple d'annotation cloud.network.openshift.io/egress-ipconfig sur AWS
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"eni-078d267045138e436",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ipv4":14,"ipv6":15}
}
]Exemple cloud.network.openshift.io/egress-ipconfig annotation sur GCP
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"nic0",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ip":14}
}
]Les sections suivantes décrivent la capacité d'adresses IP pour les environnements de cloud public pris en charge, à utiliser dans votre calcul de capacité.
25.2.1.2.1. Limites de capacité des adresses IP d'Amazon Web Services (AWS)
Sur AWS, les contraintes d'attribution des adresses IP dépendent du type d'instance configuré. Pour plus d'informations, voir Adresses IP par interface réseau par type d'instance
25.2.1.2.2. Limites de capacité des adresses IP de Google Cloud Platform (GCP)
Sur le GCP, le modèle de réseau met en œuvre des adresses IP de nœuds supplémentaires par le biais de l'alias d'adresses IP, plutôt que par l'attribution d'adresses IP. Toutefois, la capacité d'adresses IP est directement liée à la capacité d'alias d'adresses IP.
Les limites de capacité suivantes s'appliquent à l'attribution de l'alias IP :
- Le nombre maximum d'alias IP, tant IPv4 qu'IPv6, est de 10 par nœud.
- Par VPC, le nombre maximum d'alias IP n'est pas spécifié, mais les tests d'évolutivité d'OpenShift Container Platform révèlent que le maximum est d'environ 15 000.
Pour plus d'informations, voir Quotas par instance et Aperçu des plages d'adresses IP alias.
25.2.1.2.3. Limites de capacité des adresses IP de Microsoft Azure
Sur Azure, les limites de capacité suivantes existent pour l'attribution d'adresses IP :
- Par NIC, le nombre maximum d'adresses IP assignables, tant pour IPv4 que pour IPv6, est de 256.
- Par réseau virtuel, le nombre maximum d'adresses IP attribuées ne peut dépasser 65 536.
Pour plus d'informations, voir Limites de mise en réseau.
25.2.1.3. Limites
Les limitations suivantes s'appliquent lors de l'utilisation d'adresses IP de sortie avec le plugin réseau SDN OpenShift :
- Vous ne pouvez pas utiliser des adresses IP de sortie attribuées manuellement et automatiquement sur les mêmes nœuds.
- Si vous attribuez manuellement des adresses IP de sortie à partir d'une plage d'adresses IP, vous ne devez pas rendre cette plage disponible pour l'attribution automatique d'adresses IP.
- Vous ne pouvez pas partager les adresses IP de sortie entre plusieurs espaces de noms en utilisant l'implémentation de l'adresse IP de sortie d'OpenShift SDN.
Si vous devez partager des adresses IP entre plusieurs espaces de noms, l'implémentation de l'adresse IP de sortie du plugin réseau OVN-Kubernetes vous permet de répartir les adresses IP entre plusieurs espaces de noms.
Si vous utilisez OpenShift SDN en mode multitenant, vous ne pouvez pas utiliser d'adresses IP de sortie avec un espace de noms qui est joint à un autre espace de noms par les projets qui leur sont associés. Par exemple, si project1 et project2 sont joints en exécutant la commande oc adm pod-network join-projects --to=project1 project2, aucun des deux projets ne peut utiliser d'adresse IP de sortie. Pour plus d'informations, voir BZ#1645577.
25.2.1.4. Méthodes d'attribution des adresses IP
Vous pouvez attribuer des adresses IP de sortie à des espaces de noms en définissant le paramètre egressIPs de l'objet NetNamespace. Une fois qu'une adresse IP de sortie est associée à un projet, OpenShift SDN vous permet d'attribuer des adresses IP de sortie à des hôtes de deux manières :
- Dans cette approche, une plage d'adresses IP de sortie est attribuée à un nœud automatically assigned une plage d'adresses IP de sortie est attribuée à un nœud.
- Dans cette approche, une liste d'une ou plusieurs adresses IP de sortie est attribuée à un nœud manually assigned une liste d'une ou plusieurs adresses IP de sortie est attribuée à un nœud.
Les espaces de noms qui demandent une adresse IP de sortie sont mis en correspondance avec les nœuds qui peuvent héberger ces adresses IP de sortie, puis les adresses IP de sortie sont attribuées à ces nœuds. Si le paramètre egressIPs est défini sur un objet NetNamespace, mais qu'aucun nœud n'héberge cette adresse IP de sortie, le trafic de sortie de l'espace de noms sera abandonné.
La haute disponibilité des nœuds est automatique. Si un nœud hébergeant une adresse IP de sortie est inaccessible et qu'il existe des nœuds capables d'héberger cette adresse IP de sortie, l'adresse IP de sortie est déplacée vers un nouveau nœud. Lorsque le nœud inaccessible revient en ligne, l'adresse IP de sortie est automatiquement déplacée afin d'équilibrer les adresses IP de sortie entre les nœuds.
25.2.1.4.1. Points à prendre en compte lors de l'utilisation d'adresses IP de sortie attribuées automatiquement
Les considérations suivantes s'appliquent lors de l'utilisation de l'approche d'attribution automatique pour les adresses IP de sortie :
-
Vous définissez le paramètre
egressCIDRsde la ressourceHostSubnetde chaque nœud pour indiquer la plage d'adresses IP de sortie pouvant être hébergées par un nœud. OpenShift Container Platform définit le paramètreegressIPsde la ressourceHostSubneten fonction de la plage d'adresses IP spécifiée.
Si le nœud hébergeant l'adresse IP de sortie de l'espace de noms est inaccessible, OpenShift Container Platform réattribuera l'adresse IP de sortie à un autre nœud avec une plage d'adresses IP de sortie compatible. L'approche d'attribution automatique fonctionne mieux pour les clusters installés dans des environnements offrant une certaine flexibilité dans l'association d'adresses IP supplémentaires aux nœuds.
25.2.1.4.2. Points à prendre en considération lors de l'utilisation d'adresses IP de sortie attribuées manuellement
Cette approche permet de contrôler quels nœuds peuvent héberger une adresse IP de sortie.
Si votre cluster est installé sur une infrastructure de cloud public, vous devez vous assurer que chaque nœud auquel vous attribuez des adresses IP de sortie dispose d'une capacité de réserve suffisante pour héberger les adresses IP. Pour plus d'informations, voir "Considérations sur la plate-forme" dans une section précédente.
Les considérations suivantes s'appliquent à l'attribution manuelle des adresses IP de sortie :
-
Le paramètre
egressIPsde la ressourceHostSubnetde chaque nœud indique les adresses IP qui peuvent être hébergées par un nœud. - Plusieurs adresses IP de sortie par espace de noms sont prises en charge.
Si un espace de noms possède plusieurs adresses IP de sortie et que ces adresses sont hébergées sur plusieurs nœuds, les considérations supplémentaires suivantes s'appliquent :
- Si un pod se trouve sur un nœud hébergeant une adresse IP de sortie, ce pod utilise toujours l'adresse IP de sortie du nœud.
- Si un pod ne se trouve pas sur un nœud hébergeant une adresse IP de sortie, il utilise une adresse IP de sortie aléatoire.
25.2.2. Configuration des adresses IP de sortie attribuées automatiquement à un espace de noms
Dans OpenShift Container Platform, vous pouvez activer l'attribution automatique d'une adresse IP de sortie pour un espace de noms spécifique sur un ou plusieurs nœuds.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Mettez à jour l'objet
NetNamespaceavec l'adresse IP de sortie en utilisant le JSON suivant :$ oc patch netnamespace <project_name> --type=merge -p \ '{ "egressIPs": [ "<ip_address>" ] }'où :
<project_name>- Spécifie le nom du projet.
<ip_address>-
Spécifie une ou plusieurs adresses IP de sortie pour le réseau
egressIPs.
Par exemple, pour attribuer à
project1une adresse IP de 192.168.1.100 et àproject2une adresse IP de 192.168.1.101 :$ oc patch netnamespace project1 --type=merge -p \ '{"egressIPs": ["192.168.1.100"]}' $ oc patch netnamespace project2 --type=merge -p \ '{"egressIPs": ["192.168.1.101"]}'NoteComme OpenShift SDN gère l'objet
NetNamespace, vous ne pouvez effectuer des changements qu'en modifiant l'objetNetNamespaceexistant. Ne créez pas de nouvel objetNetNamespace.Indiquez quels nœuds peuvent héberger des adresses IP de sortie en définissant le paramètre
egressCIDRspour chaque hôte à l'aide du JSON suivant :$ oc patch hostsubnet <node_name> --type=merge -p \ '{ "egressCIDRs": [ "<ip_address_range>", "<ip_address_range>" ] }'où :
<node_name>- Spécifie un nom de nœud.
<ip_address_range>-
Spécifie une plage d'adresses IP au format CIDR. Vous pouvez spécifier plusieurs plages d'adresses pour le réseau
egressCIDRs.
Par exemple, pour configurer
node1etnode2afin qu'ils hébergent des adresses IP de sortie dans la plage 192.168.1.0 à 192.168.1.255 :$ oc patch hostsubnet node1 --type=merge -p \ '{"egressCIDRs": ["192.168.1.0/24"]}' $ oc patch hostsubnet node2 --type=merge -p \ '{"egressCIDRs": ["192.168.1.0/24"]}'OpenShift Container Platform attribue automatiquement des adresses IP de sortie spécifiques aux nœuds disponibles de manière équilibrée. Dans ce cas, elle attribue l'adresse IP de sortie 192.168.1.100 à
node1et l'adresse IP de sortie 192.168.1.101 ànode2ou vice versa.
25.2.3. Configuration des adresses IP de sortie attribuées manuellement pour un espace de noms
Dans OpenShift Container Platform, vous pouvez associer une ou plusieurs adresses IP de sortie à un espace de noms.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Mettez à jour l'objet
NetNamespaceen spécifiant l'objet JSON suivant avec les adresses IP souhaitées :$ oc patch netnamespace <project_name> --type=merge -p \ '{ "egressIPs": [ "<ip_address>" ] }'où :
<project_name>- Spécifie le nom du projet.
<ip_address>-
Spécifie une ou plusieurs adresses IP de sortie pour le réseau
egressIPs.
Par exemple, pour attribuer le projet
project1aux adresses IP192.168.1.100et192.168.1.101:$ oc patch netnamespace project1 --type=merge \ -p '{"egressIPs": ["192.168.1.100","192.168.1.101"]}'Pour assurer une haute disponibilité, définissez la valeur
egressIPssur deux adresses IP ou plus sur des nœuds différents. Si plusieurs adresses IP de sortie sont définies, les pods utilisent toutes les adresses IP de sortie de manière à peu près égale.NoteComme OpenShift SDN gère l'objet
NetNamespace, vous ne pouvez effectuer des changements qu'en modifiant l'objetNetNamespaceexistant. Ne créez pas de nouvel objetNetNamespace.Attribuer manuellement l'adresse IP de sortie aux hôtes du nœud.
Si votre cluster est installé sur une infrastructure de cloud public, vous devez confirmer que le nœud dispose d'une capacité d'adresses IP disponible.
Définissez le paramètre
egressIPssur l'objetHostSubnetde l'hôte du nœud. En utilisant le JSON suivant, incluez autant d'adresses IP que vous souhaitez attribuer à cet hôte de nœud :$ oc patch hostsubnet <node_name> --type=merge -p \ '{ "egressIPs": [ "<ip_address>", "<ip_address>" ] }'où :
<node_name>- Spécifie un nom de nœud.
<ip_address>-
Spécifie une adresse IP. Vous pouvez spécifier plusieurs adresses IP pour la matrice
egressIPs.
Par exemple, pour spécifier que
node1doit avoir les IP de sortie192.168.1.100,192.168.1.101et192.168.1.102:$ oc patch hostsubnet node1 --type=merge -p \ '{"egressIPs": ["192.168.1.100", "192.168.1.101", "192.168.1.102"]}'Dans l'exemple précédent, tout le trafic de sortie pour
project1sera acheminé vers le nœud hébergeant l'adresse IP de sortie spécifiée, puis connecté à cette adresse IP via la traduction d'adresses de réseau (NAT).
25.2.4. Ressources supplémentaires
- Si vous configurez l'attribution manuelle d'adresses IP de sortie, reportez-vous à la section Considérations relatives à la plate-forme pour obtenir des informations sur la planification de la capacité IP.
25.3. Configuration d'un pare-feu de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez créer un pare-feu de sortie pour un projet qui restreint le trafic de sortie de votre cluster OpenShift Container Platform.
25.3.1. Fonctionnement d'un pare-feu de sortie dans un projet
En tant qu'administrateur de cluster, vous pouvez utiliser un egress firewall pour limiter les hôtes externes auxquels certains ou tous les pods peuvent accéder depuis le cluster. Un pare-feu de sortie prend en charge les scénarios suivants :
- Un pod ne peut se connecter qu'à des hôtes internes et ne peut pas établir de connexions avec l'internet public.
- Un pod ne peut se connecter qu'à l'internet public et ne peut pas initier de connexions vers des hôtes internes qui sont en dehors du cluster OpenShift Container Platform.
- Un pod ne peut pas atteindre les sous-réseaux internes spécifiés ou les hôtes en dehors du cluster OpenShift Container Platform.
- Un pod ne peut se connecter qu'à des hôtes externes spécifiques.
Par exemple, vous pouvez autoriser un projet à accéder à une plage d'adresses IP donnée, mais refuser le même accès à un autre projet. Vous pouvez également empêcher les développeurs d'applications d'effectuer des mises à jour à partir des miroirs de Python Pip et exiger que les mises à jour proviennent uniquement de sources approuvées.
Le pare-feu de sortie ne s'applique pas à l'espace de noms du réseau hôte. Les pods dont le réseau d'hôtes est activé ne sont pas affectés par les règles de pare-feu de sortie.
Vous configurez une stratégie de pare-feu de sortie en créant un objet de ressource personnalisée (CR) EgressNetworkPolicy. Le pare-feu de sortie correspond au trafic réseau qui répond à l'un des critères suivants :
- Une plage d'adresses IP au format CIDR
- Un nom DNS qui se résout en une adresse IP
Si votre pare-feu de sortie comprend une règle de refus pour 0.0.0.0/0, l'accès à vos serveurs API OpenShift Container Platform est bloqué. Vous devez soit ajouter des règles d'autorisation pour chaque adresse IP, soit utiliser la règle d'autorisation de type nodeSelector dans vos règles de stratégie de sortie pour vous connecter aux serveurs API.
L'exemple suivant illustre l'ordre des règles de pare-feu de sortie nécessaires pour garantir l'accès au serveur API :
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: default
namespace: <namespace>
spec:
egress:
- to:
cidrSelector: <api_server_address_range>
type: Allow
# ...
- to:
cidrSelector: 0.0.0.0/0
type: Deny
Pour trouver l'adresse IP de vos serveurs API, exécutez oc get ep kubernetes -n default.
Pour plus d'informations, voir BZ#1988324.
Vous devez avoir OpenShift SDN configuré pour utiliser soit la politique de réseau, soit le mode multitenant pour configurer un pare-feu de sortie.
Si vous utilisez le mode stratégie réseau, un pare-feu de sortie n'est compatible qu'avec une seule stratégie par espace de noms et ne fonctionnera pas avec les projets qui partagent un réseau, tels que les projets globaux.
Les règles de pare-feu de sortie ne s'appliquent pas au trafic qui passe par les routeurs. Tout utilisateur autorisé à créer un objet Route CR peut contourner les règles du pare-feu de sortie en créant une route qui pointe vers une destination interdite.
25.3.1.1. Limites d'un pare-feu de sortie
Un pare-feu de sortie présente les limitations suivantes :
- Aucun projet ne peut avoir plus d'un objet EgressNetworkPolicy.
- Un maximum d'un objet EgressNetworkPolicy avec un maximum de 1 000 règles peut être défini par projet.
-
Le projet
defaultne peut pas utiliser de pare-feu de sortie. Lors de l'utilisation du plugin réseau OpenShift SDN en mode multitenant, les limitations suivantes s'appliquent :
-
Les projets globaux ne peuvent pas utiliser de pare-feu de sortie. Vous pouvez rendre un projet global en utilisant la commande
oc adm pod-network make-projects-global. -
Les projets fusionnés à l'aide de la commande
oc adm pod-network join-projectsne peuvent utiliser un pare-feu de sortie dans aucun des projets fusionnés.
-
Les projets globaux ne peuvent pas utiliser de pare-feu de sortie. Vous pouvez rendre un projet global en utilisant la commande
La violation de l'une ou l'autre de ces restrictions a pour effet de briser le pare-feu de sortie du projet et peut entraîner l'interruption de tout le trafic du réseau externe.
Une ressource Egress Firewall peut être créée dans les projets kube-node-lease, kube-public, kube-system, openshift et openshift-.
25.3.1.2. Ordre de correspondance pour les règles de politique de pare-feu de sortie
Les règles de pare-feu de sortie sont évaluées dans l'ordre où elles sont définies, de la première à la dernière. La première règle qui correspond à une connexion de sortie d'un pod s'applique. Les règles suivantes sont ignorées pour cette connexion.
25.3.1.3. Fonctionnement de la résolution des serveurs de noms de domaine (DNS)
Si vous utilisez des noms DNS dans l'une de vos règles de stratégie de pare-feu de sortie, la résolution correcte des noms de domaine est soumise aux restrictions suivantes :
- Les mises à jour de noms de domaine sont interrogées sur la base d'une durée de vie (TTL). Par défaut, cette durée est de 30 secondes. Lorsque le contrôleur du pare-feu de sortie interroge les serveurs de noms locaux pour un nom de domaine, si la réponse comprend un TTL inférieur à 30 secondes, le contrôleur définit la durée sur la valeur renvoyée. Si le TTL de la réponse est supérieur à 30 minutes, le contrôleur fixe la durée à 30 minutes. Si le TTL est compris entre 30 secondes et 30 minutes, le contrôleur ignore la valeur et fixe la durée à 30 secondes.
- Le pod doit résoudre le domaine à partir des mêmes serveurs de noms locaux si nécessaire. Sinon, les adresses IP du domaine connues par le contrôleur du pare-feu de sortie et le module peuvent être différentes. Si les adresses IP d'un nom d'hôte diffèrent, le pare-feu de sortie risque de ne pas être appliqué de manière cohérente.
- Étant donné que le contrôleur de pare-feu de sortie et les modules interrogent de manière asynchrone le même serveur de noms local, le module peut obtenir l'adresse IP mise à jour avant le contrôleur de sortie, ce qui provoque une situation de course. En raison de cette limitation actuelle, l'utilisation de noms de domaine dans les objets EgressNetworkPolicy n'est recommandée que pour les domaines dont les changements d'adresse IP sont peu fréquents.
Le pare-feu de sortie permet toujours aux pods d'accéder à l'interface externe du nœud sur lequel le pod se trouve pour la résolution DNS.
Si vous utilisez des noms de domaine dans votre stratégie de pare-feu de sortie et que votre résolution DNS n'est pas gérée par un serveur DNS sur le nœud local, vous devez ajouter des règles de pare-feu de sortie qui autorisent l'accès aux adresses IP de votre serveur DNS. si vous utilisez des noms de domaine dans vos modules.
25.3.2. Objet de ressource personnalisée (CR) EgressNetworkPolicy
Vous pouvez définir une ou plusieurs règles pour un pare-feu de sortie. Une règle est soit une règle Allow, soit une règle Deny, avec une spécification du trafic auquel la règle s'applique.
Le fichier YAML suivant décrit un objet CR EgressNetworkPolicy :
Objet EgressNetworkPolicy
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: <name>
spec:
egress:
...25.3.2.1. Règles de politique de réseau de sortie (EgressNetworkPolicy)
Le fichier YAML suivant décrit un objet de règle de pare-feu de sortie. L'utilisateur peut sélectionner une plage d'adresses IP au format CIDR, un nom de domaine ou utiliser nodeSelector pour autoriser ou refuser le trafic de sortie. La strophe egress attend un tableau d'un ou plusieurs objets.
Règles de politique de sortie (Egress policy rule stanza)
egress:
- type: <type>
to:
cidrSelector: <cidr>
dnsName: <dns_name> - 1
- Le type de règle. La valeur doit être
AllowouDeny. - 2
- Une strophe décrivant une règle de correspondance du trafic de sortie. Une valeur pour le champ
cidrSelectorou le champdnsNamede la règle. Vous ne pouvez pas utiliser les deux champs dans la même règle. - 3
- Une plage d'adresses IP au format CIDR.
- 4
- Un nom de domaine.
25.3.2.2. Exemple d'objets CR EgressNetworkPolicy
L'exemple suivant définit plusieurs règles de stratégie de pare-feu de sortie :
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: default
spec:
egress:
- type: Allow
to:
cidrSelector: 1.2.3.0/24
- type: Allow
to:
dnsName: www.example.com
- type: Deny
to:
cidrSelector: 0.0.0.0/0- 1
- Une collection d'objets de règles de stratégie de pare-feu de sortie.
25.3.3. Création d'un objet de stratégie de pare-feu de sortie
En tant qu'administrateur de cluster, vous pouvez créer un objet de stratégie de pare-feu de sortie pour un projet.
Si le projet a déjà un objet EgressNetworkPolicy défini, vous devez modifier la stratégie existante pour apporter des changements aux règles du pare-feu de sortie.
Conditions préalables
- Un cluster qui utilise le plugin réseau OpenShift SDN.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster en tant qu'administrateur du cluster.
Procédure
Créer une règle de politique :
-
Créez un fichier
<policy_name>.yamldans lequel<policy_name>décrit les règles de la politique de sortie. - Dans le fichier que vous avez créé, définissez un objet de politique de sortie.
-
Créez un fichier
Entrez la commande suivante pour créer l'objet de politique. Remplacez
<policy_name>par le nom de la politique et<project>par le projet auquel la règle s'applique.oc create -f <policy_name>.yaml -n <project>Dans l'exemple suivant, un nouvel objet EgressNetworkPolicy est créé dans un projet nommé
project1:$ oc create -f default.yaml -n project1Exemple de sortie
egressnetworkpolicy.network.openshift.io/v1 created-
Facultatif : Enregistrez le fichier
<policy_name>.yamlpour pouvoir le modifier ultérieurement.
25.4. Modification d'un pare-feu de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez modifier les règles de trafic réseau d'un pare-feu de sortie existant.
25.4.1. Visualisation d'un objet EgressNetworkPolicy
Vous pouvez visualiser un objet EgressNetworkPolicy dans votre cluster.
Conditions préalables
- Un cluster utilisant le plugin réseau OpenShift SDN.
-
Installer l'interface de ligne de commande (CLI) d'OpenShift, communément appelée
oc. - Vous devez vous connecter au cluster.
Procédure
Facultatif : Pour afficher les noms des objets EgressNetworkPolicy définis dans votre cluster, entrez la commande suivante :
$ oc get egressnetworkpolicy --all-namespacesPour inspecter une politique, entrez la commande suivante. Remplacez
<policy_name>par le nom de la stratégie à inspecter.$ oc describe egressnetworkpolicy <nom_de_la_politique>Exemple de sortie
Name: default Namespace: project1 Created: 20 minutes ago Labels: <none> Annotations: <none> Rule: Allow to 1.2.3.0/24 Rule: Allow to www.example.com Rule: Deny to 0.0.0.0/0
25.5. Modification d'un pare-feu de sortie pour un projet
En tant qu'administrateur de cluster, vous pouvez modifier les règles de trafic réseau d'un pare-feu de sortie existant.
25.5.1. Modification d'un objet EgressNetworkPolicy
En tant qu'administrateur de cluster, vous pouvez mettre à jour le pare-feu de sortie pour un projet.
Conditions préalables
- Un cluster utilisant le plugin réseau OpenShift SDN.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster en tant qu'administrateur du cluster.
Procédure
Trouvez le nom de l'objet EgressNetworkPolicy pour le projet. Remplacez
<project>par le nom du projet.oc get -n <project> egressnetworkpolicyFacultatif : si vous n'avez pas enregistré une copie de l'objet EgressNetworkPolicy lors de la création du pare-feu de réseau de sortie, entrez la commande suivante pour créer une copie.
$ oc get -n <project> egressnetworkpolicy <name> -o yaml > <filename>.yamlRemplacer
<project>par le nom du projet. Remplacez<name>par le nom de l'objet. Remplacer<filename>par le nom du fichier dans lequel enregistrer le YAML.Après avoir modifié les règles de stratégie, entrez la commande suivante pour remplacer l'objet EgressNetworkPolicy. Remplacez
<filename>par le nom du fichier contenant l'objet EgressNetworkPolicy mis à jour.$ oc replace -f <filename>.yaml
25.6. Suppression d'un pare-feu de sortie d'un projet
En tant qu'administrateur de cluster, vous pouvez supprimer un pare-feu de sortie d'un projet pour supprimer toutes les restrictions sur le trafic réseau du projet qui quitte le cluster OpenShift Container Platform.
25.6.1. Suppression d'un objet EgressNetworkPolicy
En tant qu'administrateur de cluster, vous pouvez supprimer un pare-feu de sortie d'un projet.
Conditions préalables
- Un cluster utilisant le plugin réseau OpenShift SDN.
-
Installez le CLI OpenShift (
oc). - Vous devez vous connecter au cluster en tant qu'administrateur du cluster.
Procédure
Trouvez le nom de l'objet EgressNetworkPolicy pour le projet. Remplacez
<project>par le nom du projet.oc get -n <project> egressnetworkpolicyEntrez la commande suivante pour supprimer l'objet EgressNetworkPolicy. Remplacez
<project>par le nom du projet et<name>par le nom de l'objet.oc delete -n <project> egressnetworkpolicy <name>
25.7. Considérations relatives à l'utilisation d'un module de routeur de sortie
25.7.1. À propos d'un pod de routeur de sortie
Le pod routeur egress d'OpenShift Container Platform redirige le trafic vers un serveur distant spécifié à partir d'une adresse IP source privée qui n'est pas utilisée à d'autres fins. Un pod routeur egress peut envoyer du trafic réseau à des serveurs qui sont configurés pour n'autoriser l'accès qu'à partir d'adresses IP spécifiques.
Le module de routeur de sortie n'est pas destiné à chaque connexion sortante. La création d'un grand nombre de modules de routeur de sortie peut dépasser les limites de votre matériel réseau. Par exemple, la création d'un module de routeur de sortie pour chaque projet ou application pourrait dépasser le nombre d'adresses MAC locales que l'interface réseau peut gérer avant de revenir au filtrage des adresses MAC dans le logiciel.
L'image du routeur de sortie n'est pas compatible avec Amazon AWS, Azure Cloud ou toute autre plateforme cloud qui ne prend pas en charge les manipulations de la couche 2 en raison de leur incompatibilité avec le trafic macvlan.
25.7.1.1. Modes du routeur de sortie
En redirect modeun pod routeur de sortie configure les règles iptables pour rediriger le trafic de sa propre adresse IP vers une ou plusieurs adresses IP de destination. Les modules clients qui doivent utiliser l'adresse IP source réservée doivent être modifiés pour se connecter au routeur de sortie plutôt que de se connecter directement à l'adresse IP de destination.
En HTTP proxy modeun pod de routeur de sortie fonctionne comme un proxy HTTP sur le port 8080. Ce mode ne fonctionne que pour les clients qui se connectent à des services basés sur HTTP ou HTTPS, mais il nécessite généralement moins de modifications des pods clients pour les faire fonctionner. Il est possible de demander à de nombreux programmes d'utiliser un proxy HTTP en définissant une variable d'environnement.
En DNS proxy modeun pod routeur de sortie fonctionne comme un proxy DNS pour les services basés sur TCP depuis sa propre adresse IP vers une ou plusieurs adresses IP de destination. Pour utiliser l'adresse IP source réservée, les modules clients doivent être modifiés pour se connecter au module de routeur de sortie plutôt que de se connecter directement à l'adresse IP de destination. Cette modification garantit que les destinations externes traitent le trafic comme s'il provenait d'une source connue.
Le mode de redirection fonctionne pour tous les services, à l'exception des services HTTP et HTTPS. Pour les services HTTP et HTTPS, utilisez le mode proxy HTTP. Pour les services basés sur TCP avec des adresses IP ou des noms de domaine, utilisez le mode proxy DNS.
25.7.1.2. Mise en œuvre d'un pod de routeur de sortie
La configuration du pod du routeur de sortie est effectuée par un conteneur d'initialisation. Ce conteneur s'exécute dans un contexte privilégié afin de pouvoir configurer l'interface macvlan et définir les règles iptables. Une fois que le conteneur d'initialisation a fini de configurer les règles iptables, il se termine. Ensuite, le module routeur de sortie exécute le conteneur pour gérer le trafic du routeur de sortie. L'image utilisée varie en fonction du mode du routeur de sortie.
Les variables d'environnement déterminent les adresses utilisées par l'image egress-router. L'image configure l'interface macvlan pour qu'elle utilise EGRESS_SOURCE comme adresse IP, avec EGRESS_GATEWAY comme adresse IP pour la passerelle.
Des règles de traduction d'adresses réseau (NAT) sont mises en place pour que les connexions à l'adresse IP du cluster du pod sur n'importe quel port TCP ou UDP soient redirigées vers le même port sur l'adresse IP spécifiée par la variable EGRESS_DESTINATION.
Si seuls certains nœuds de votre cluster sont capables de revendiquer l'adresse IP source spécifiée et d'utiliser la passerelle spécifiée, vous pouvez spécifier nodeName ou nodeSelector pour identifier les nœuds acceptables.
25.7.1.3. Considérations relatives au déploiement
Un pod routeur de sortie ajoute une adresse IP et une adresse MAC supplémentaires à l'interface réseau principale du nœud. Par conséquent, il se peut que vous deviez configurer votre hyperviseur ou votre fournisseur de cloud pour autoriser l'adresse supplémentaire.
- Plate-forme Red Hat OpenStack (RHOSP)
Si vous déployez OpenShift Container Platform sur RHOSP, vous devez autoriser le trafic à partir des adresses IP et MAC du pod routeur egress sur votre environnement OpenStack. Si vous n'autorisez pas le trafic, la communication échouera:
$ openstack port set --allowed-address \ ip_address=<ip_address>,mac_address=<mac_address> <neutron_port_uuid>- Red Hat Virtualization (RHV)
- Si vous utilisez RHV, vous devez sélectionner No Network Filter pour le contrôleur d'interface réseau virtuel (vNIC).
- VMware vSphere
- Si vous utilisez VMware vSphere, consultez la documentation VMware pour sécuriser les commutateurs standard vSphere. Affichez et modifiez les paramètres par défaut de VMware vSphere en sélectionnant le commutateur virtuel de l'hôte dans le client Web vSphere.
En particulier, assurez-vous que les éléments suivants sont activés :
25.7.1.4. Configuration du basculement
Pour éviter les temps d'arrêt, vous pouvez déployer un module de routeur de sortie avec une ressource Deployment, comme dans l'exemple suivant. Pour créer un nouvel objet Service pour l'exemple de déploiement, utilisez la commande oc expose deployment/egress-demo-controller.
apiVersion: apps/v1
kind: Deployment
metadata:
name: egress-demo-controller
spec:
replicas: 1
selector:
matchLabels:
name: egress-router
template:
metadata:
name: egress-router
labels:
name: egress-router
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
...
containers:
...25.8. Déploiement d'un pod routeur de sortie en mode redirection
En tant qu'administrateur de cluster, vous pouvez déployer un module de routeur de sortie configuré pour rediriger le trafic vers des adresses IP de destination spécifiées.
25.8.1. Spécification du pod du routeur de sortie pour le mode redirection
Définir la configuration d'un module de routeur de sortie dans l'objet Pod. Le fichier YAML suivant décrit les champs pour la configuration d'un module de routeur de sortie en mode redirection :
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE
value: <egress_router>
- name: EGRESS_GATEWAY
value: <egress_gateway>
- name: EGRESS_DESTINATION
value: <egress_destination>
- name: EGRESS_ROUTER_MODE
value: init
containers:
- name: egress-router-wait
image: registry.redhat.io/openshift4/ose-pod- 1
- L'annotation indique à OpenShift Container Platform de créer une interface réseau macvlan sur le contrôleur d'interface réseau (NIC) primaire et de déplacer cette interface macvlan dans l'espace de noms réseau du pod. Vous devez inclure les guillemets autour de la valeur
"true". Pour qu'OpenShift Container Platform crée l'interface macvlan sur une interface NIC différente, définissez la valeur d'annotation au nom de cette interface. Par exemple,eth1. - 2
- Adresse IP du réseau physique sur lequel se trouve le nœud, réservée à l'usage du routeur de sortie. Facultatif : vous pouvez inclure la longueur du sous-réseau, le suffixe
/24, afin qu'une route appropriée vers le sous-réseau local soit définie. Si vous ne spécifiez pas de longueur de sous-réseau, le routeur de sortie ne peut accéder qu'à l'hôte spécifié par la variableEGRESS_GATEWAYet à aucun autre hôte du sous-réseau. - 3
- Même valeur que la passerelle par défaut utilisée par le nœud.
- 4
- Serveur externe vers lequel diriger le trafic. Dans cet exemple, les connexions au pod sont redirigées vers
203.0.113.25, avec une adresse IP source de192.168.12.99.
Exemple de spécification de pod de routeur de sortie
apiVersion: v1
kind: Pod
metadata:
name: egress-multi
labels:
name: egress-multi
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE
value: 192.168.12.99/24
- name: EGRESS_GATEWAY
value: 192.168.12.1
- name: EGRESS_DESTINATION
value: |
80 tcp 203.0.113.25
8080 tcp 203.0.113.26 80
8443 tcp 203.0.113.26 443
203.0.113.27
- name: EGRESS_ROUTER_MODE
value: init
containers:
- name: egress-router-wait
image: registry.redhat.io/openshift4/ose-pod25.8.2. Format de configuration de la destination de sortie
Lorsqu'un module de routeur de sortie est déployé en mode redirection, vous pouvez spécifier des règles de redirection en utilisant un ou plusieurs des formats suivants :
-
<port> <protocol> <ip_address>- Les connexions entrantes vers le site<port>doivent être redirigées vers le même port sur le site<ip_address>.<protocol>est soittcpsoitudp. -
<port> <protocol> <ip_address> <remote_port>- Comme ci-dessus, sauf que la connexion est redirigée vers un autre<remote_port>sur<ip_address>. -
<ip_address>- Si la dernière ligne est une adresse IP unique, toute connexion sur un autre port sera redirigée vers le port correspondant à cette adresse IP. S'il n'y a pas d'adresse IP de repli, les connexions sur les autres ports sont rejetées.
Dans l'exemple qui suit, plusieurs règles sont définies :
-
La première ligne redirige le trafic du port local
80vers le port80sur203.0.113.25. -
Les deuxième et troisième lignes redirigent les ports locaux
8080et8443vers les ports distants80et443sur203.0.113.26. - La dernière ligne correspond au trafic pour tous les ports non spécifiés dans les règles précédentes.
Exemple de configuration
80 tcp 203.0.113.25
8080 tcp 203.0.113.26 80
8443 tcp 203.0.113.26 443
203.0.113.2725.8.3. Déploiement d'un pod routeur de sortie en mode redirection
En redirect modeun pod routeur de sortie configure des règles iptables pour rediriger le trafic de sa propre adresse IP vers une ou plusieurs adresses IP de destination. Les modules clients qui doivent utiliser l'adresse IP source réservée doivent être modifiés pour se connecter au routeur de sortie plutôt que de se connecter directement à l'adresse IP de destination.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Créer un module de routeur de sortie.
Pour que les autres modules puissent trouver l'adresse IP du module de routeur de sortie, créez un service qui pointe vers le module de routeur de sortie, comme dans l'exemple suivant :
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: http port: 80 - name: https port: 443 type: ClusterIP selector: name: egress-1Vos pods peuvent maintenant se connecter à ce service. Leurs connexions sont redirigées vers les ports correspondants sur le serveur externe, en utilisant l'adresse IP de sortie réservée.
25.9. Déploiement d'un pod routeur de sortie en mode proxy HTTP
En tant qu'administrateur de cluster, vous pouvez déployer un pod de routeur de sortie configuré pour acheminer le trafic vers les services HTTP et HTTPS spécifiés.
25.9.1. Spécification du pod du routeur de sortie pour le mode HTTP
Définir la configuration d'un module de routeur de sortie dans l'objet Pod. Le fichier YAML suivant décrit les champs pour la configuration d'un module de routeur de sortie en mode HTTP :
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE
value: <egress-router>
- name: EGRESS_GATEWAY
value: <egress-gateway>
- name: EGRESS_ROUTER_MODE
value: http-proxy
containers:
- name: egress-router-pod
image: registry.redhat.io/openshift4/ose-egress-http-proxy
env:
- name: EGRESS_HTTP_PROXY_DESTINATION
value: |-
...
...- 1
- L'annotation indique à OpenShift Container Platform de créer une interface réseau macvlan sur le contrôleur d'interface réseau (NIC) primaire et de déplacer cette interface macvlan dans l'espace de noms réseau du pod. Vous devez inclure les guillemets autour de la valeur
"true". Pour qu'OpenShift Container Platform crée l'interface macvlan sur une interface NIC différente, définissez la valeur d'annotation au nom de cette interface. Par exemple,eth1. - 2
- Adresse IP du réseau physique sur lequel se trouve le nœud, réservée à l'usage du routeur de sortie. Facultatif : vous pouvez inclure la longueur du sous-réseau, le suffixe
/24, afin qu'une route appropriée vers le sous-réseau local soit définie. Si vous ne spécifiez pas de longueur de sous-réseau, le routeur de sortie ne peut accéder qu'à l'hôte spécifié par la variableEGRESS_GATEWAYet à aucun autre hôte du sous-réseau. - 3
- Même valeur que la passerelle par défaut utilisée par le nœud.
- 4
- Une chaîne ou une chaîne de plusieurs lignes YAML spécifiant comment configurer le proxy. Notez que ceci est spécifié en tant que variable d'environnement dans le conteneur de proxy HTTP, et non avec les autres variables d'environnement dans le conteneur init.
25.9.2. Format de configuration de la destination de sortie
Lorsqu'un module de routeur de sortie est déployé en mode proxy HTTP, vous pouvez spécifier des règles de redirection en utilisant un ou plusieurs des formats suivants. Chaque ligne de la configuration spécifie un groupe de connexions à autoriser ou à refuser :
-
Une adresse IP autorise les connexions à cette adresse IP, par exemple
192.168.1.1. -
Une plage CIDR autorise les connexions à cette plage CIDR, par exemple
192.168.1.0/24. -
Un nom d'hôte permet d'accéder à cet hôte par procuration, par exemple
www.example.com. -
Un nom de domaine précédé de
*.permet d'accéder par procuration à ce domaine et à tous ses sous-domaines, comme*.example.com. -
Une adresse
!suivie de l'une des expressions de correspondance précédentes refuse la connexion. -
Si la dernière ligne est
*, tout ce qui n'est pas explicitement refusé est autorisé. Sinon, tout ce qui n'est pas autorisé est refusé.
Vous pouvez également utiliser * pour autoriser les connexions vers toutes les destinations distantes.
Exemple de configuration
!*.example.com
!192.168.1.0/24
192.168.2.1
*25.9.3. Déploiement d'un pod routeur de sortie en mode proxy HTTP
En HTTP proxy modeun pod de routeur de sortie fonctionne comme un proxy HTTP sur le port 8080. Ce mode ne fonctionne que pour les clients qui se connectent à des services basés sur HTTP ou HTTPS, mais il nécessite généralement moins de modifications des pods clients pour les faire fonctionner. Il est possible de demander à de nombreux programmes d'utiliser un proxy HTTP en définissant une variable d'environnement.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Créer un module de routeur de sortie.
Pour que les autres modules puissent trouver l'adresse IP du module de routeur de sortie, créez un service qui pointe vers le module de routeur de sortie, comme dans l'exemple suivant :
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: http-proxy port: 80801 type: ClusterIP selector: name: egress-1- 1
- Assurez-vous que le port
httpest défini sur8080.
Pour configurer le pod client (et non le pod proxy egress) afin qu'il utilise le proxy HTTP, définissez les variables
http_proxyouhttps_proxy:apiVersion: v1 kind: Pod metadata: name: app-1 labels: name: app-1 spec: containers: env: - name: http_proxy value: http://egress-1:8080/1 - name: https_proxy value: http://egress-1:8080/ ...- 1
- Le service créé à l'étape précédente.
NoteL'utilisation des variables d'environnement
http_proxyethttps_proxyn'est pas nécessaire pour toutes les configurations. Si vous ne parvenez pas à créer une configuration fonctionnelle, consultez la documentation de l'outil ou du logiciel que vous utilisez dans le module.
25.10. Déploiement d'un pod routeur egress en mode proxy DNS
En tant qu'administrateur de cluster, vous pouvez déployer un pod routeur de sortie configuré pour acheminer le trafic vers des noms DNS et des adresses IP spécifiques.
25.10.1. Spécification du pod du routeur de sortie pour le mode DNS
Définir la configuration d'un module de routeur de sortie dans l'objet Pod. Le fichier YAML suivant décrit les champs pour la configuration d'un module de routeur de sortie en mode DNS :
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE
value: <egress-router>
- name: EGRESS_GATEWAY
value: <egress-gateway>
- name: EGRESS_ROUTER_MODE
value: dns-proxy
containers:
- name: egress-router-pod
image: registry.redhat.io/openshift4/ose-egress-dns-proxy
securityContext:
privileged: true
env:
- name: EGRESS_DNS_PROXY_DESTINATION
value: |-
...
- name: EGRESS_DNS_PROXY_DEBUG
value: "1"
...- 1
- L'annotation indique à OpenShift Container Platform de créer une interface réseau macvlan sur le contrôleur d'interface réseau (NIC) primaire et de déplacer cette interface macvlan dans l'espace de noms réseau du pod. Vous devez inclure les guillemets autour de la valeur
"true". Pour qu'OpenShift Container Platform crée l'interface macvlan sur une interface NIC différente, définissez la valeur d'annotation au nom de cette interface. Par exemple,eth1. - 2
- Adresse IP du réseau physique sur lequel se trouve le nœud, réservée à l'usage du routeur de sortie. Facultatif : vous pouvez inclure la longueur du sous-réseau, le suffixe
/24, afin qu'une route appropriée vers le sous-réseau local soit définie. Si vous ne spécifiez pas de longueur de sous-réseau, le routeur de sortie ne peut accéder qu'à l'hôte spécifié par la variableEGRESS_GATEWAYet à aucun autre hôte du sous-réseau. - 3
- Même valeur que la passerelle par défaut utilisée par le nœud.
- 4
- Spécifiez une liste d'une ou plusieurs destinations proxy.
- 5
- En option, spécifiez la sortie du journal du proxy DNS vers : Spécifiez la sortie du journal du proxy DNS sur
stdout.
25.10.2. Format de configuration de la destination de sortie
Lorsque le routeur est déployé en mode proxy DNS, vous spécifiez une liste de mappages de ports et de destinations. Une destination peut être une adresse IP ou un nom DNS.
Un pod de routeur de sortie prend en charge les formats suivants pour spécifier les mappages de port et de destination :
- Port et adresse distante
-
Vous pouvez spécifier un port source et un hôte de destination en utilisant le format à deux champs :
<port> <remote_address>.
L'hôte peut être une adresse IP ou un nom DNS. Si un nom DNS est fourni, la résolution DNS se fait au moment de l'exécution. Pour un hôte donné, le proxy se connecte au port source spécifié sur l'hôte de destination lorsqu'il se connecte à l'adresse IP de l'hôte de destination.
Exemple de paire de ports et d'adresses distantes
80 172.16.12.11
100 example.com- Port, adresse distante et port distant
-
Vous pouvez spécifier un port source, un hôte de destination et un port de destination en utilisant le format à trois champs :
<port> <remote_address> <remote_port>.
Le format à trois champs se comporte de la même manière que la version à deux champs, à l'exception du fait que le port de destination peut être différent du port source.
Exemple de port, d'adresse distante et de port distant
8080 192.168.60.252 80
8443 web.example.com 44325.10.3. Déploiement d'un pod routeur egress en mode proxy DNS
En DNS proxy modeun pod routeur de sortie agit comme un proxy DNS pour les services basés sur TCP de sa propre adresse IP vers une ou plusieurs adresses IP de destination.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Créer un module de routeur de sortie.
Créer un service pour le pod du routeur de sortie :
Créez un fichier nommé
egress-router-service.yamlqui contient le YAML suivant. Attribuez àspec.portsla liste des ports que vous avez définie précédemment pour la variable d'environnementEGRESS_DNS_PROXY_DESTINATION.apiVersion: v1 kind: Service metadata: name: egress-dns-svc spec: ports: ... type: ClusterIP selector: name: egress-dns-proxyPar exemple :
apiVersion: v1 kind: Service metadata: name: egress-dns-svc spec: ports: - name: con1 protocol: TCP port: 80 targetPort: 80 - name: con2 protocol: TCP port: 100 targetPort: 100 type: ClusterIP selector: name: egress-dns-proxyPour créer le service, entrez la commande suivante :
$ oc create -f egress-router-service.yamlLes pods peuvent maintenant se connecter à ce service. Les connexions sont dirigées vers les ports correspondants du serveur externe, en utilisant l'adresse IP de sortie réservée.
25.11. Configuration d'une liste de destination de pods de routeur de sortie à partir d'une carte de configuration
En tant qu'administrateur de cluster, vous pouvez définir un objet ConfigMap qui spécifie les mappages de destination pour un module de routeur de sortie. Le format spécifique de la configuration dépend du type de module de routeur de sortie. Pour plus de détails sur le format, reportez-vous à la documentation du module de routeur de sortie spécifique.
25.11.1. Configuration des mappages de destination d'un routeur de sortie à l'aide d'une carte de configuration
Pour un ensemble de mappages de destination important ou changeant fréquemment, vous pouvez utiliser une carte de configuration pour gérer la liste de manière externe. L'avantage de cette approche est que l'autorisation de modifier la carte de configuration peut être déléguée à des utilisateurs ne disposant pas des privilèges cluster-admin. Le pod de routeur de sortie nécessitant un conteneur privilégié, les utilisateurs ne disposant pas des privilèges cluster-admin ne peuvent pas modifier directement la définition du pod.
Le module de routeur de sortie n'est pas automatiquement mis à jour lorsque la carte de configuration est modifiée. Vous devez redémarrer le module de routeur de sortie pour obtenir les mises à jour.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un fichier contenant les données de mappage pour le pod du routeur de sortie, comme dans l'exemple suivant :
# Egress routes for Project "Test", version 3 80 tcp 203.0.113.25 8080 tcp 203.0.113.26 80 8443 tcp 203.0.113.26 443 # Fallback 203.0.113.27Vous pouvez insérer des lignes vierges et des commentaires dans ce fichier.
Créer un objet
ConfigMapà partir du fichier :$ oc delete configmap egress-routes --ignore-not-found$ oc create configmap egress-routes \ --from-file=destination=my-egress-destination.txtDans la commande précédente, la valeur
egress-routesest le nom de l'objetConfigMapà créer etmy-egress-destination.txtest le nom du fichier à partir duquel les données sont lues.AstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
apiVersion: v1 kind: ConfigMap metadata: name: egress-routes data: destination: | # Egress routes for Project "Test", version 3 80 tcp 203.0.113.25 8080 tcp 203.0.113.26 80 8443 tcp 203.0.113.26 443 # Fallback 203.0.113.27Créez une définition de pod de routeur de sortie et spécifiez la strophe
configMapKeyRefpour le champEGRESS_DESTINATIONdans la strophe d'environnement :... env: - name: EGRESS_DESTINATION valueFrom: configMapKeyRef: name: egress-routes key: destination ...
25.12. Activation de la multidiffusion pour un projet
25.12.1. À propos de la multidiffusion
Avec la multidiffusion IP, les données sont diffusées simultanément à de nombreuses adresses IP.
À l'heure actuelle, le multicast est utilisé de préférence pour la coordination ou la découverte de services à faible bande passante et non comme une solution à large bande passante.
Le trafic multicast entre les pods de OpenShift Container Platform est désactivé par défaut. Si vous utilisez le plugin réseau OpenShift SDN, vous pouvez activer le multicast par projet.
Lors de l'utilisation du plugin réseau OpenShift SDN en mode d'isolation networkpolicy:
-
Les paquets de multidiffusion envoyés par un pod seront distribués à tous les autres pods du projet, indépendamment des objets
NetworkPolicy. Les modules peuvent être en mesure de communiquer par multidiffusion même s'ils ne peuvent pas communiquer par monodiffusion. -
Les paquets de multidiffusion envoyés par un pod dans un projet ne seront jamais transmis aux pods d'un autre projet, même s'il existe des objets
NetworkPolicyqui permettent la communication entre les projets.
Lors de l'utilisation du plugin réseau OpenShift SDN en mode d'isolation multitenant:
- Les paquets de multidiffusion envoyés par un pod seront distribués à tous les autres pods du projet.
- Les paquets multicast envoyés par un pod dans un projet seront délivrés aux pods dans d'autres projets seulement si chaque projet est joint et que le multicast est activé dans chaque projet joint.
25.12.2. Activation de la multidiffusion entre les pods
Vous pouvez activer le multicast entre les pods de votre projet.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Exécutez la commande suivante pour activer la multidiffusion pour un projet. Remplacez
<namespace>par l'espace de noms du projet pour lequel vous souhaitez activer la multidiffusion.$ oc annotate netnamespace <namespace> \ netnamespace.network.openshift.io/multicast-enabled=true
Vérification
Pour vérifier que la multidiffusion est activée pour un projet, suivez la procédure suivante :
Remplacez votre projet actuel par le projet pour lequel vous avez activé la multidiffusion. Remplacez
<project>par le nom du projet.$ oc project <projet>Créez un pod qui servira de récepteur multicast :
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: mlistener labels: app: multicast-verify spec: containers: - name: mlistener image: registry.access.redhat.com/ubi8 command: ["/bin/sh", "-c"] args: ["dnf -y install socat hostname && sleep inf"] ports: - containerPort: 30102 name: mlistener protocol: UDP EOFCréez un pod qui servira d'émetteur multicast :
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: msender labels: app: multicast-verify spec: containers: - name: msender image: registry.access.redhat.com/ubi8 command: ["/bin/sh", "-c"] args: ["dnf -y install socat && sleep inf"] EOFDans une nouvelle fenêtre ou un nouvel onglet de terminal, démarrez l'auditeur de multidiffusion.
Obtenir l'adresse IP du pod :
$ POD_IP=$(oc get pods mlistener -o jsonpath='{.status.podIP}')Démarrez l'auditeur de multidiffusion en entrant la commande suivante :
$ oc exec mlistener -i -t -- \ socat UDP4-RECVFROM:30102,ip-add-membership=224.1.0.1:$POD_IP,fork EXEC:hostname
Démarrer l'émetteur de multidiffusion.
Obtenir la plage d'adresses IP du réseau de pods :
$ CIDR=$(oc get Network.config.openshift.io cluster \ -o jsonpath='{.status.clusterNetwork[0].cidr}')Pour envoyer un message multicast, entrez la commande suivante :
$ oc exec msender -i -t -- \ /bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"Si la multidiffusion fonctionne, la commande précédente renvoie le résultat suivant :
mlistener
25.13. Désactiver la multidiffusion pour un projet
25.13.1. Désactivation de la multidiffusion entre les pods
Vous pouvez désactiver le multicast entre les pods de votre projet.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Désactivez la multidiffusion en exécutant la commande suivante :
$ oc annotate netnamespace <namespace> \1 netnamespace.network.openshift.io/multicast-enabled-- 1
- Le site
namespacedu projet pour lequel vous souhaitez désactiver la multidiffusion.
25.14. Configurer l'isolation du réseau à l'aide d'OpenShift SDN
Lorsque votre cluster est configuré pour utiliser le mode d'isolation multitenant pour le plugin réseau OpenShift SDN, chaque projet est isolé par défaut. Le trafic réseau n'est pas autorisé entre les pods ou les services de différents projets en mode d'isolation multitenant.
Vous pouvez modifier le comportement de l'isolation multitenant pour un projet de deux manières :
- Vous pouvez rejoindre un ou plusieurs projets, ce qui permet le trafic réseau entre les pods et les services de différents projets.
- Vous pouvez désactiver l'isolation du réseau pour un projet. Il sera globalement accessible et acceptera le trafic réseau des pods et des services de tous les autres projets. Un projet globalement accessible peut accéder aux pods et aux services de tous les autres projets.
25.14.1. Conditions préalables
- Vous devez avoir un cluster configuré pour utiliser le plugin réseau OpenShift SDN en mode d'isolation multitenant.
25.14.2. Rejoindre des projets
Vous pouvez joindre deux projets ou plus pour permettre le trafic réseau entre les pods et les services dans différents projets.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Utilisez la commande suivante pour joindre des projets à un réseau de projets existant :
$ oc adm pod-network join-projects --to=<projet1> <projet2> <projet3>Au lieu de spécifier des noms de projets spécifiques, vous pouvez utiliser l'option
--selector=<project_selector>pour spécifier des projets sur la base d'une étiquette associée.Facultatif : Exécutez la commande suivante pour afficher les réseaux de pods que vous avez réunis :
$ oc get netnamespacesLes projets du même réseau de pods ont le même ID de réseau dans la colonne NETID dans la colonne
25.14.3. Isoler un projet
Vous pouvez isoler un projet de sorte que les pods et les services d'autres projets ne puissent pas accéder à ses pods et à ses services.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Pour isoler les projets dans le cluster, exécutez la commande suivante :
oc adm pod-network isolate-projects <projet1> <projet2> $ oc adm pod-network isolate-projects <projet2>Au lieu de spécifier des noms de projets spécifiques, vous pouvez utiliser l'option
--selector=<project_selector>pour spécifier des projets sur la base d'une étiquette associée.
25.14.4. Désactiver l'isolation du réseau pour un projet
Vous pouvez désactiver l'isolation du réseau pour un projet.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Vous devez vous connecter au cluster avec un utilisateur ayant le rôle
cluster-admin.
Procédure
Exécutez la commande suivante pour le projet :
oc adm pod-network make-projects-global <projet1> <projet2> $ oc adm pod-network make-projects-global <projet2>Au lieu de spécifier des noms de projets spécifiques, vous pouvez utiliser l'option
--selector=<project_selector>pour spécifier des projets sur la base d'une étiquette associée.
25.15. Configuration de kube-proxy
Le proxy réseau Kubernetes (kube-proxy) s'exécute sur chaque nœud et est géré par le Cluster Network Operator (CNO). kube-proxy maintient les règles réseau pour transférer les connexions pour les points d'extrémité associés aux services.
25.15.1. À propos de la synchronisation des règles d'iptables
La période de synchronisation détermine la fréquence à laquelle le proxy réseau Kubernetes (kube-proxy) synchronise les règles iptables sur un nœud.
Une synchronisation commence lorsque l'un des événements suivants se produit :
- Un événement se produit, tel que l'ajout ou la suppression d'un service ou d'un point d'extrémité dans le cluster.
- Le temps écoulé depuis la dernière synchronisation dépasse la période de synchronisation définie pour kube-proxy.
25.15.2. paramètres de configuration de kube-proxy
Vous pouvez modifier les paramètres suivants kubeProxyConfig.
En raison des améliorations de performance introduites dans OpenShift Container Platform 4.3 et plus, l'ajustement du paramètre iptablesSyncPeriod n'est plus nécessaire.
| Paramètres | Description | Valeurs | Défaut |
|---|---|---|---|
|
|
La période de rafraîchissement des règles |
Un intervalle de temps, tel que |
|
|
|
Durée minimale avant l'actualisation des règles |
Un intervalle de temps, tel que |
|
25.15.3. Modifier la configuration de kube-proxy
Vous pouvez modifier la configuration du proxy réseau Kubernetes pour votre cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à un cluster en cours d'exécution avec le rôle
cluster-admin.
Procédure
Modifiez la ressource personnalisée (CR)
Network.operator.openshift.ioen exécutant la commande suivante :$ oc edit network.operator.openshift.io clusterModifiez le paramètre
kubeProxyConfigdans le CR avec les changements apportés à la configuration de kube-proxy, comme dans l'exemple de CR suivant :apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: kubeProxyConfig: iptablesSyncPeriod: 30s proxyArguments: iptables-min-sync-period: ["30s"]Enregistrez le fichier et quittez l'éditeur de texte.
La syntaxe est validée par la commande
oclorsque vous enregistrez le fichier et quittez l'éditeur. Si vos modifications contiennent une erreur de syntaxe, l'éditeur ouvre le fichier et affiche un message d'erreur.Entrez la commande suivante pour confirmer la mise à jour de la configuration :
$ oc get networks.operator.openshift.io -o yamlExemple de sortie
apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 defaultNetwork: type: OpenShiftSDN kubeProxyConfig: iptablesSyncPeriod: 30s proxyArguments: iptables-min-sync-period: - 30s serviceNetwork: - 172.30.0.0/16 status: {} kind: ListEn option : Entrez la commande suivante pour confirmer que l'opérateur du réseau de clusters a accepté la modification de la configuration :
$ oc get clusteroperator networkExemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE network 4.1.0-0.9 True False False 1mLe champ
AVAILABLEestTruelorsque la mise à jour de la configuration est appliquée avec succès.
Chapitre 26. Configuration des itinéraires
26.1. Configuration des itinéraires
26.1.1. Création d'un itinéraire basé sur HTTP
Une route vous permet d'héberger votre application à une URL publique. Elle peut être sécurisée ou non, en fonction de la configuration de sécurité du réseau de votre application. Une route basée sur HTTP est une route non sécurisée qui utilise le protocole de routage HTTP de base et expose un service sur un port d'application non sécurisé.
La procédure suivante décrit comment créer une route simple basée sur le protocole HTTP vers une application web, en utilisant l'application hello-openshift comme exemple.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous êtes connecté en tant qu'administrateur.
- Vous avez une application web qui expose un port et un point de terminaison TCP qui écoute le trafic sur le port.
Procédure
Créez un projet appelé
hello-openshiften exécutant la commande suivante :$ oc new-project hello-openshiftCréez un pod dans le projet en exécutant la commande suivante :
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.jsonCréez un service appelé
hello-openshiften exécutant la commande suivante :$ oc expose pod/hello-openshiftCréez une route non sécurisée vers l'application
hello-openshiften exécutant la commande suivante :$ oc expose svc hello-openshift
Vérification
Pour vérifier que la ressource
routeque vous avez créée fonctionne, exécutez la commande suivante :$ oc get routes -o yaml <name of resource>1 - 1
- Dans cet exemple, la route est nommée
hello-openshift.
Exemple de définition YAML de la route non sécurisée créée :
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: hello-openshift
spec:
host: hello-openshift-hello-openshift.<Ingress_Domain>
port:
targetPort: 8080
to:
kind: Service
name: hello-openshift- 1
<Ingress_Domain>est le nom de domaine d'entrée par défaut. L'objetingresses.config/clusterest créé lors de l'installation et ne peut pas être modifié. Si vous souhaitez spécifier un domaine différent, vous pouvez spécifier un autre domaine de cluster à l'aide de l'optionappsDomain.- 2
targetPortest le port cible sur les pods qui est sélectionné par le service vers lequel cette route pointe.NotePour afficher votre domaine d'entrée par défaut, exécutez la commande suivante :
$ oc get ingresses.config/cluster -o jsonpath={.spec.domain}
26.1.2. Création d'une route pour le sharding du contrôleur d'entrée
Une route vous permet d'héberger votre application à une URL. Dans ce cas, le nom d'hôte n'est pas défini et la route utilise un sous-domaine à la place. Lorsque vous spécifiez un sous-domaine, vous utilisez automatiquement le domaine du contrôleur d'entrée qui expose l'itinéraire. Lorsqu'un itinéraire est exposé par plusieurs contrôleurs d'ingestion, l'itinéraire est hébergé sur plusieurs URL.
La procédure suivante décrit comment créer une route pour le sharding du contrôleur d'entrée, en utilisant l'application hello-openshift comme exemple.
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous êtes connecté en tant qu'administrateur de projet.
- Vous avez une application web qui expose un port et un point d'extrémité HTTP ou TLS qui écoute le trafic sur le port.
- Vous avez configuré le contrôleur d'entrée pour le partage.
Procédure
Créez un projet appelé
hello-openshiften exécutant la commande suivante :$ oc new-project hello-openshiftCréez un pod dans le projet en exécutant la commande suivante :
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.jsonCréez un service appelé
hello-openshiften exécutant la commande suivante :$ oc expose pod/hello-openshiftCréez une définition de route appelée
hello-openshift-route.yaml:Définition YAML de la route créée pour le sharding :
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded1 name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift2 tls: termination: edge to: kind: Service name: hello-openshift- 1
- La clé d'étiquette et la valeur d'étiquette correspondante doivent toutes deux correspondre à celles spécifiées dans le contrôleur d'entrée. Dans cet exemple, le contrôleur d'entrée a la clé et la valeur d'étiquette
type: sharded. - 2
- La route sera exposée en utilisant la valeur du champ
subdomain. Lorsque vous spécifiez le champsubdomain, vous devez laisser le nom d'hôte non défini. Si vous spécifiez à la fois les champshostetsubdomain, l'itinéraire utilisera la valeur du champhostet ignorera le champsubdomain.
Utilisez
hello-openshift-route.yamlpour créer une route vers l'applicationhello-openshiften exécutant la commande suivante :$ oc -n hello-openshift create -f hello-openshift-route.yaml
Vérification
Obtenez l'état de la route à l'aide de la commande suivante :
$ oc -n hello-openshift get routes/hello-openshift-edge -o yamlLa ressource
Routequi en résulte devrait ressembler à ce qui suit :Exemple de sortie
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift tls: termination: edge to: kind: Service name: hello-openshift status: ingress: - host: hello-openshift.<apps-sharded.basedomain.example.net>1 routerCanonicalHostname: router-sharded.<apps-sharded.basedomain.example.net>2 routerName: sharded3 - 1
- Le nom d'hôte que le contrôleur d'entrée, ou le routeur, utilise pour exposer l'itinéraire. La valeur du champ
hostest automatiquement déterminée par le contrôleur d'entrée et utilise son domaine. Dans cet exemple, le domaine du contrôleur d'entrée est<apps-sharded.basedomain.example.net>. - 2
- Le nom d'hôte du contrôleur d'entrée.
- 3
- Le nom du contrôleur d'entrée. Dans cet exemple, le contrôleur d'entrée porte le nom
sharded.
26.1.3. Configuration des délais d'attente pour les itinéraires
Vous pouvez configurer les délais d'attente par défaut pour une route existante lorsque vous avez des services qui ont besoin d'un délai d'attente faible, qui est nécessaire pour la disponibilité du niveau de service (SLA), ou d'un délai d'attente élevé, pour les cas où le back-end est lent.
Conditions préalables
- Vous avez besoin d'un contrôleur d'ingestion déployé sur un cluster en cours d'exécution.
Procédure
À l'aide de la commande
oc annotate, ajoutez le délai d'attente à l'itinéraire :$ oc annotate route <route_name> \ --overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit>1 - 1
- Les unités de temps prises en charge sont les microsecondes (us), les millisecondes (ms), les secondes (s), les minutes (m), les heures (h) ou les jours (d).
L'exemple suivant définit un délai d'attente de deux secondes sur une route nommée
myroute:$ oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s
26.1.4. Sécurité stricte du transport HTTP
La politique HTTP Strict Transport Security (HSTS) est une amélioration de la sécurité qui signale au client du navigateur que seul le trafic HTTPS est autorisé sur l'hôte de la route. HSTS optimise également le trafic web en signalant que le transport HTTPS est nécessaire, sans utiliser de redirections HTTP. HSTS est utile pour accélérer les interactions avec les sites web.
Lorsque la politique HSTS est appliquée, elle ajoute un en-tête Strict Transport Security aux réponses HTTP et HTTPS du site. Vous pouvez utiliser la valeur insecureEdgeTerminationPolicy dans une route pour rediriger HTTP vers HTTPS. Lorsque la politique HSTS est appliquée, le client modifie toutes les requêtes de l'URL HTTP en HTTPS avant l'envoi de la requête, ce qui élimine la nécessité d'une redirection.
Les administrateurs de clusters peuvent configurer HSTS de la manière suivante :
- Activer HSTS par itinéraire
- Désactiver HSTS par itinéraire
- Appliquer HSTS par domaine, pour un ensemble de domaines, ou utiliser des étiquettes d'espace de noms en combinaison avec des domaines
HSTS ne fonctionne qu'avec les routes sécurisées, qu'elles soient terminées en périphérie ou réencryptées. La configuration est inefficace sur les routes HTTP ou passthrough.
26.1.4.1. Activation de HTTP Strict Transport Security par itinéraire
HTTP strict transport security (HSTS) est mis en œuvre dans le modèle HAProxy et appliqué aux itinéraires de bordure et de recryptage qui ont l'annotation haproxy.router.openshift.io/hsts_header.
Conditions préalables
- Vous êtes connecté au cluster avec un utilisateur disposant de privilèges d'administrateur pour le projet.
-
Vous avez installé le CLI
oc.
Procédure
Pour activer HSTS sur une route, ajoutez la valeur
haproxy.router.openshift.io/hsts_headerà la route de terminaison ou de recryptage. Pour ce faire, vous pouvez utiliser l'outiloc annotateen exécutant la commande suivante :$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=31536000;\1 includeSubDomains;preload"- 1
- Dans cet exemple, l'âge maximum est fixé à
31536000ms, soit environ huit heures et demie.
NoteDans cet exemple, le signe égal (
=) est entre guillemets. Cela est nécessaire pour exécuter correctement la commande annoter.Exemple de route configurée avec une annotation
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=31536000;includeSubDomains;preload1 2 3 ... spec: host: def.abc.com tls: termination: "reencrypt" ... wildcardPolicy: "Subdomain"- 1
- Requis.
max-agemesure la durée, en secondes, pendant laquelle la politique HSTS est en vigueur. Si la valeur est0, la politique est annulée. - 2
- Facultatif. Lorsqu'il est inclus,
includeSubDomainsindique au client que tous les sous-domaines de l'hôte doivent avoir la même politique HSTS que l'hôte. - 3
- Facultatif. Lorsque
max-ageest supérieur à 0, vous pouvez ajouterpreloaddanshaproxy.router.openshift.io/hsts_headerpour permettre aux services externes d'inclure ce site dans leurs listes de préchargement HSTS. Par exemple, des sites tels que Google peuvent établir une liste de sites pour lesquelspreloadest défini. Les navigateurs peuvent alors utiliser ces listes pour déterminer les sites avec lesquels ils peuvent communiquer via HTTPS, avant même d'avoir interagi avec le site. Sanspreload, les navigateurs doivent avoir interagi avec le site via HTTPS, au moins une fois, pour obtenir l'en-tête.
26.1.4.2. Désactivation de HTTP Strict Transport Security par itinéraire
Pour désactiver HTTP strict transport security (HSTS) par itinéraire, vous pouvez définir la valeur max-age dans l'annotation de l'itinéraire sur 0.
Conditions préalables
- Vous êtes connecté au cluster avec un utilisateur disposant de privilèges d'administrateur pour le projet.
-
Vous avez installé le CLI
oc.
Procédure
Pour désactiver HSTS, définissez la valeur
max-agedans l'annotation de l'itinéraire sur0, en entrant la commande suivante :$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"AstuceVous pouvez également appliquer le YAML suivant pour créer la carte de configuration :
Exemple de désactivation de HSTS par itinéraire
metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=0Pour désactiver HSTS pour chaque route d'un espace de noms, entrez la commande suivante :
$ oc annotate route --all -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"
Vérification
Pour demander l'annotation de tous les itinéraires, entrez la commande suivante :
$ oc get route --all-namespaces -o go-template='{{range .items}}{{if .metadata.annotations}}{{$a := index .metadata.annotations "haproxy.router.openshift.io/hsts_header"}}{{$n := .metadata.name}}{{with $a}}Name: {{$n}} HSTS: {{$a}}{{"\n"}}{{else}}{{""}}{{end}}{{end}}{{end}}'Exemple de sortie
Name: routename HSTS: max-age=0
26.1.4.3. Renforcer la sécurité stricte du transport HTTP par domaine
Pour appliquer HTTP Strict Transport Security (HSTS) par domaine pour les itinéraires sécurisés, ajoutez un enregistrement requiredHSTSPolicies à la spécification d'entrée pour capturer la configuration de la politique HSTS.
Si vous configurez un site requiredHSTSPolicy pour qu'il applique HSTS, tout itinéraire nouvellement créé doit être configuré avec une annotation de politique HSTS conforme.
Pour gérer les clusters mis à niveau avec des routes HSTS non conformes, vous pouvez mettre à jour les manifestes à la source et appliquer les mises à jour.
Vous ne pouvez pas utiliser les commandes oc expose route ou oc create route pour ajouter un itinéraire dans un domaine qui applique HSTS, car l'API de ces commandes n'accepte pas les annotations.
HSTS ne peut pas être appliqué aux routes non sécurisées ou non TLS, même si HSTS est demandé pour toutes les routes au niveau mondial.
Conditions préalables
- Vous êtes connecté au cluster avec un utilisateur disposant de privilèges d'administrateur pour le projet.
-
Vous avez installé le CLI
oc.
Procédure
Modifiez le fichier de configuration de l'entrée :
$ oc edit ingresses.config.openshift.io/clusterExemple de politique HSTS
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: 'hello-openshift-default.apps.username.devcluster.openshift.com' requiredHSTSPolicies:1 - domainPatterns:2 - '*hello-openshift-default.apps.username.devcluster.openshift.com' - '*hello-openshift-default2.apps.username.devcluster.openshift.com' namespaceSelector:3 matchLabels: myPolicy: strict maxAge:4 smallestMaxAge: 1 largestMaxAge: 31536000 preloadPolicy: RequirePreload5 includeSubDomainsPolicy: RequireIncludeSubDomains6 - domainPatterns:7 - 'abc.example.com' - '*xyz.example.com' namespaceSelector: matchLabels: {} maxAge: {} preloadPolicy: NoOpinion includeSubDomainsPolicy: RequireNoIncludeSubDomains- 1
- Obligatoire.
requiredHSTSPoliciesest validé dans l'ordre et le premierdomainPatternscorrespondant s'applique. - 2 7
- Obligatoire. Vous devez indiquer au moins un nom d'hôte
domainPatterns. Un nombre quelconque de domaines peut être listé. Vous pouvez inclure plusieurs sections d'options d'application pour différentesdomainPatterns. - 3
- Facultatif. Si vous incluez
namespaceSelector, il doit correspondre aux étiquettes du projet où résident les itinéraires, afin d'appliquer la politique HSTS sur les itinéraires. Les itinéraires qui ne correspondent qu'ànamespaceSelectoret non àdomainPatternsne sont pas validés. - 4
- Requis.
max-agemesure la durée, en secondes, pendant laquelle la politique HSTS est en vigueur. Ce paramètre de la politique permet d'appliquer une valeur minimale et une valeur maximale àmax-age.-
La valeur de
largestMaxAgedoit être comprise entre0et2147483647. Elle peut ne pas être spécifiée, ce qui signifie qu'aucune limite supérieure n'est imposée. -
La valeur
smallestMaxAgedoit être comprise entre0et2147483647. Entrez0pour désactiver HSTS pour le dépannage, sinon entrez1si vous ne voulez jamais que HSTS soit désactivé. Il est possible de ne pas spécifier de valeur, ce qui signifie qu'aucune limite inférieure n'est appliquée.
-
La valeur de
- 5
- Facultatif. L'inclusion de
preloaddanshaproxy.router.openshift.io/hsts_headerpermet aux services externes d'inclure ce site dans leurs listes de préchargement HSTS. Les navigateurs peuvent alors utiliser ces listes pour déterminer les sites avec lesquels ils peuvent communiquer via HTTPS, avant même d'avoir interagi avec le site. Sipreloadn'est pas défini, les navigateurs doivent interagir au moins une fois avec le site pour obtenir l'en-tête.preloadpeut être défini avec l'une des options suivantes :-
RequirePreloadle sitepreloadest requis par le siteRequiredHSTSPolicy. -
RequireNoPreloadle sitepreloadest interdit par le siteRequiredHSTSPolicy. -
NoOpinionl'article 2 de la loi sur la protection de l'environnement prévoit que :preloadn'a pas d'importance pourRequiredHSTSPolicy.
-
- 6
- Facultatif.
includeSubDomainsPolicypeut être défini avec l'une des options suivantes :-
RequireIncludeSubDomainsle siteincludeSubDomainsest requis par le siteRequiredHSTSPolicy. -
RequireNoIncludeSubDomainsle siteincludeSubDomainsest interdit par le siteRequiredHSTSPolicy. -
NoOpinionl'article 2 de la loi sur la protection de l'environnement prévoit que :includeSubDomainsn'a pas d'importance pourRequiredHSTSPolicy.
-
Vous pouvez appliquer HSTS à toutes les routes du cluster ou d'un espace de noms particulier en entrant l'adresse
oc annotate command.Pour appliquer HSTS à toutes les routes de la grappe, entrez l'adresse
oc annotate command. Par exemple :$ oc annotate route --all --all-namespaces --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=31536000"Pour appliquer HSTS à toutes les routes d'un espace de noms particulier, entrez l'adresse
oc annotate command. Par exemple :$ oc annotate route --all -n my-namespace --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=31536000"
Vérification
Vous pouvez revoir la politique HSTS que vous avez configurée. Par exemple :
Pour vérifier l'ensemble
maxAgepour les politiques HSTS requises, entrez la commande suivante :$ oc get clusteroperator/ingress -n openshift-ingress-operator -o jsonpath='{range .spec.requiredHSTSPolicies[*]}{.spec.requiredHSTSPolicies.maxAgePolicy.largestMaxAge}{"\n"}{end}'Pour examiner les annotations HSTS sur tous les itinéraires, entrez la commande suivante :
$ oc get route --all-namespaces -o go-template='{{range .items}}{{if .metadata.annotations}}{{$a := index .metadata.annotations "haproxy.router.openshift.io/hsts_header"}}{{$n := .metadata.name}}{{with $a}}Name: {{$n}} HSTS: {{$a}}{{"\n"}}{{else}}{{""}}{{end}}{{end}}{{end}}'Exemple de sortie
Nom : <_routename_> HSTS : max-age=31536000;preload;includeSubDomains
26.1.5. Méthodes de résolution des problèmes de débit
Parfois, les applications déployées à l'aide d'OpenShift Container Platform peuvent causer des problèmes de débit réseau, tels qu'une latence anormalement élevée entre des services spécifiques.
Si les fichiers journaux ne révèlent aucune cause du problème, utilisez les méthodes suivantes pour analyser les problèmes de performance :
Utilisez un analyseur de paquets, tel que
pingoutcpdump, pour analyser le trafic entre un pod et son nœud.Par exemple, exécutez l'outil
tcpdumpsur chaque module tout en reproduisant le comportement à l'origine du problème. Examinez les captures des deux côtés pour comparer les horodatages d'envoi et de réception afin d'analyser la latence du trafic vers et depuis un module. La latence peut se produire dans OpenShift Container Platform si l'interface d'un nœud est surchargée par le trafic provenant d'autres pods, de périphériques de stockage ou du plan de données.$ tcpdump -s 0 -i any -w /tmp/dump.pcap host <podip 1> && host <podip 2>1 - 1
podipest l'adresse IP du module. Exécutez la commandeoc get pod <pod_name> -o widepour obtenir l'adresse IP d'un module.
La commande
tcpdumpgénère un fichier à l'adresse/tmp/dump.pcapcontenant tout le trafic entre ces deux pods. Vous pouvez lancer l'analyseur peu avant que le problème ne se reproduise et l'arrêter peu après la fin de la reproduction du problème pour minimiser la taille du fichier. Vous pouvez également exécuter un analyseur de paquets entre les nœuds (en éliminant le SDN de l'équation) avec :$ tcpdump -s 0 -i any -w /tmp/dump.pcap port 4789Utilisez un outil de mesure de la bande passante, tel que
iperfpour mesurer le débit de streaming et le débit UDP. Localisez les éventuels goulets d'étranglement en exécutant l'outil d'abord à partir des pods, puis à partir des nœuds.-
Pour plus d'informations sur l'installation et l'utilisation de
iperf, consultez cette solution Red Hat.
-
Pour plus d'informations sur l'installation et l'utilisation de
- Dans certains cas, la grappe peut marquer le nœud avec le pod de routeur comme malsain en raison de problèmes de latence. Utilisez les profils de latence des travailleurs pour ajuster la fréquence à laquelle la grappe attend une mise à jour de l'état du nœud avant d'agir.
-
Si votre cluster comporte des nœuds à faible et à forte latence, configurez le champ
spec.nodePlacementdans le contrôleur d'entrée pour contrôler l'emplacement du module de routeur.
26.1.6. Utilisation de cookies pour conserver l'état des routes
OpenShift Container Platform fournit des sessions collantes, qui permettent un trafic d'application avec état en s'assurant que tout le trafic atteint le même point de terminaison. Cependant, si le pod d'extrémité se termine, que ce soit à la suite d'un redémarrage, d'une mise à l'échelle ou d'un changement de configuration, cet état peut disparaître.
OpenShift Container Platform peut utiliser des cookies pour configurer la persistance de la session. Le contrôleur Ingress sélectionne un point de terminaison pour traiter les demandes des utilisateurs et crée un cookie pour la session. Le cookie est renvoyé dans la réponse à la demande et l'utilisateur renvoie le cookie lors de la prochaine demande de la session. Le cookie indique au contrôleur d'entrée quel point d'accès gère la session, ce qui garantit que les demandes des clients utilisent le cookie et qu'elles sont acheminées vers le même module.
Les cookies ne peuvent pas être installés sur les routes passthrough, car le trafic HTTP ne peut pas être vu. Au lieu de cela, un nombre est calculé sur la base de l'adresse IP source, qui détermine le backend.
Si les backends changent, le trafic peut être dirigé vers le mauvais serveur, ce qui le rend moins collant. Si vous utilisez un équilibreur de charge, qui masque l'IP source, le même numéro est défini pour toutes les connexions et le trafic est envoyé au même pod.
26.1.6.1. Annoter un itinéraire avec un cookie
Vous pouvez définir un nom de cookie qui remplacera le nom par défaut généré automatiquement pour l'itinéraire. Cela permet à l'application qui reçoit le trafic de la route de connaître le nom du cookie. En supprimant le cookie, elle peut forcer la prochaine demande à choisir à nouveau un point de terminaison. Ainsi, si un serveur est surchargé, il tente de retirer les demandes du client et de les redistribuer.
Procédure
Annote l'itinéraire avec le nom du cookie spécifié :
$ oc annotate route <route_name> router.openshift.io/cookie_name="<cookie_name>"où :
<route_name>- Spécifie le nom de l'itinéraire.
<cookie_name>- Spécifie le nom du cookie.
Par exemple, pour annoter la route
my_routeavec le nom de cookiemy_cookie:$ oc annotate route my_route router.openshift.io/cookie_name="my_cookie"Saisir le nom d'hôte de la route dans une variable :
rOUTE_NAME=$(oc get route <route_name> -o jsonpath='{.spec.host}')où :
<route_name>- Spécifie le nom de l'itinéraire.
Enregistrez le cookie, puis accédez à l'itinéraire :
$ curl $ROUTE_NAME -k -c /tmp/cookie_jarUtiliser le cookie sauvegardé par la commande précédente lors de la connexion à la route :
$ curl $ROUTE_NAME -k -b /tmp/cookie_jar
26.1.7. Routes basées sur le chemin
Les itinéraires basés sur un chemin d'accès spécifient un composant de chemin d'accès qui peut être comparé à une URL, ce qui exige que le trafic de l'itinéraire soit basé sur HTTP. Ainsi, plusieurs itinéraires peuvent être servis en utilisant le même nom d'hôte, chacun avec un chemin d'accès différent. Les routeurs doivent faire correspondre les itinéraires en fonction du chemin le plus spécifique au moins spécifique. Cependant, cela dépend de l'implémentation du routeur.
Le tableau suivant présente des exemples d'itinéraires et leur accessibilité :
| Itinéraire | Par rapport à | Accessible |
|---|---|---|
| www.example.com/test | www.example.com/test | Oui |
| www.example.com | Non | |
| www.example.com/test et www.example.com | www.example.com/test | Oui |
| www.example.com | Oui | |
| www.example.com | www.example.com/text | Oui (Correspondance avec l'hôte, pas avec l'itinéraire) |
| www.example.com | Oui |
Un itinéraire non sécurisé avec un chemin
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: route-unsecured
spec:
host: www.example.com
path: "/test"
to:
kind: Service
name: service-name- 1
- Le chemin est le seul attribut ajouté pour un itinéraire basé sur le chemin.
Le routage basé sur le chemin n'est pas disponible lors de l'utilisation de TLS passthrough, car le routeur ne termine pas TLS dans ce cas et ne peut pas lire le contenu de la requête.
26.1.8. Annotations spécifiques à l'itinéraire
Le contrôleur d'entrée peut définir les options par défaut pour toutes les routes qu'il expose. Un itinéraire individuel peut remplacer certaines de ces options par défaut en fournissant des configurations spécifiques dans ses annotations. Red Hat ne prend pas en charge l'ajout d'une annotation d'itinéraire à un itinéraire géré par un opérateur.
Pour créer une liste blanche avec plusieurs IP ou sous-réseaux sources, utilisez une liste délimitée par des espaces. Tout autre type de délimiteur entraîne l'ignorance de la liste sans message d'avertissement ou d'erreur.
| Variable | Description | Variable d'environnement utilisée par défaut |
|---|---|---|
|
|
Définit l'algorithme d'équilibrage de la charge. Les options disponibles sont |
|
|
|
Désactive l'utilisation de cookies pour suivre les connexions liées. Si la valeur est | |
|
| Spécifie un cookie facultatif à utiliser pour cet itinéraire. Le nom doit être composé d'une combinaison de lettres majuscules et minuscules, de chiffres, de "_" et de "-". La valeur par défaut est le nom de la clé interne hachée de l'itinéraire. | |
|
|
Définit le nombre maximum de connexions autorisées vers un pod de soutien à partir d'un routeur. | |
|
|
Le réglage de | |
|
|
Limite le nombre de connexions TCP simultanées établies à partir de la même adresse IP source. Il accepte une valeur numérique. | |
|
|
Limite la vitesse à laquelle un client ayant la même adresse IP source peut effectuer des requêtes HTTP. Elle accepte une valeur numérique. | |
|
|
Limite la vitesse à laquelle un client ayant la même adresse IP source peut établir des connexions TCP. Il accepte une valeur numérique. | |
|
| Définit un délai d'attente côté serveur pour la route. (Unités de temps) |
|
|
| Ce délai s'applique à une connexion tunnel, par exemple, WebSocket sur des routes en texte clair, en bordure, réencryptées ou passthrough. Avec les types d'itinéraires cleartext, edge ou reencrypt, cette annotation est appliquée en tant que tunnel timeout avec la valeur timeout existante. Pour les types de routes passthrough, l'annotation est prioritaire sur toute valeur de timeout existante. |
|
|
|
Vous pouvez définir un IngressController ou la configuration ingress . Cette annotation redéploie le routeur et configure le proxy HA pour qu'il émette l'option globale haproxy |
|
|
| Définit l'intervalle pour les contrôles de santé du back-end. (Unités de temps) |
|
|
| Définit une liste blanche pour l'itinéraire. La liste blanche est une liste d'adresses IP et de plages CIDR séparées par des espaces pour les adresses sources approuvées. Les demandes provenant d'adresses IP qui ne figurent pas dans la liste blanche sont rejetées. Le nombre maximum d'adresses IP et de plages CIDR autorisées dans une liste blanche est de 61. | |
|
| Définit un en-tête Strict-Transport-Security pour la route terminée ou recryptée. | |
|
|
Définit le champ | |
|
| Définit le chemin de réécriture de la requête sur le backend. | |
|
| Définit une valeur pour restreindre les cookies. Les valeurs possibles sont les suivantes :
Cette valeur ne s'applique qu'aux itinéraires de recryptage et aux itinéraires de périphérie. Pour plus d'informations, voir la documentation sur les cookies SameSite. | |
|
|
Définit la politique de traitement des en-têtes HTTP
|
|
Les variables d'environnement ne peuvent pas être modifiées.
Variables de délai d'attente du routeur
TimeUnits sont représentés par un nombre suivi de l'unité : us *(microsecondes), ms (millisecondes, par défaut), s (secondes), m (minutes), h *(heures), d (jours).
L'expression régulière est : [1-9][0-9]*(us\|ms\|s\|m\|h\|d).
| Variable | Défaut | Description |
|---|---|---|
|
|
| Temps écoulé entre les vérifications ultérieures de l'état de conservation sur les extrémités arrière. |
|
|
| Contrôle le délai d'attente TCP FIN pour le client qui se connecte à la route. Si le FIN envoyé pour fermer la connexion ne répond pas dans le délai imparti, HAProxy ferme la connexion. Ce délai est inoffensif s'il est fixé à une valeur faible et utilise moins de ressources sur le routeur. |
|
|
| Durée pendant laquelle un client doit accuser réception ou envoyer des données. |
|
|
| Le temps de connexion maximum. |
|
|
| Contrôle le délai TCP FIN entre le routeur et le pod qui soutient la route. |
|
|
| Durée pendant laquelle un serveur doit accuser réception ou envoyer des données. |
|
|
| Durée pendant laquelle les connexions TCP ou WebSocket restent ouvertes. Ce délai est réinitialisé à chaque rechargement de HAProxy. |
|
|
|
Définit le temps d'attente maximum pour l'apparition d'une nouvelle requête HTTP. Si ce délai est trop court, il peut causer des problèmes avec les navigateurs et les applications qui ne s'attendent pas à une petite valeur
Certaines valeurs de délai d'attente effectif peuvent correspondre à la somme de certaines variables, plutôt qu'au délai d'attente spécifique prévu. Par exemple, |
|
|
| Durée de la transmission d'une requête HTTP. |
|
|
| Indique la fréquence minimale à laquelle le routeur doit se recharger et accepter de nouvelles modifications. |
|
|
| Délai d'attente pour la collecte des données métriques de HAProxy. |
Un itinéraire définissant un délai d'attente personnalisé
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/timeout: 5500ms
...- 1
- Spécifie le nouveau délai d'attente avec les unités supportées par HAProxy (
us,ms,s,m,h,d). Si l'unité n'est pas fournie,msest l'unité par défaut.
Si la valeur du délai d'attente côté serveur pour les routes passthrough est trop faible, les connexions WebSocket risquent d'expirer fréquemment sur cette route.
Un itinéraire qui n'autorise qu'une seule adresse IP spécifique
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10Une route qui autorise plusieurs adresses IP
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10 192.168.1.11 192.168.1.12Une route qui permet à une adresse IP d'accéder à un réseau CIDR
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.0/24Une route qui autorise à la fois une adresse IP et des réseaux CIDR d'adresses IP
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 180.5.61.153 192.168.1.0/24 10.0.0.0/8Une route spécifiant une cible de réécriture
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/rewrite-target: /
...- 1
- Définit
/comme chemin de réécriture de la requête sur le backend.
La définition de l'annotation haproxy.router.openshift.io/rewrite-target sur un itinéraire spécifie que le contrôleur d'entrée doit réécrire les chemins dans les requêtes HTTP utilisant cet itinéraire avant de transmettre les requêtes à l'application dorsale. La partie du chemin de la requête qui correspond au chemin spécifié dans spec.path est remplacée par la cible de réécriture spécifiée dans l'annotation.
Le tableau suivant donne des exemples du comportement de réécriture du chemin pour diverses combinaisons de spec.path, de chemin de requête et de cible de réécriture.
| Route.spec.path | Chemin de la demande | Réécriture de l'objectif | Chemin de la demande transmise |
|---|---|---|---|
| /foo | /foo | / | / |
| /foo | /foo/ | / | / |
| /foo | /foo/bar | / | /bar |
| /foo | /foo/bar/ | / | /bar/ |
| /foo | /foo | /bar | /bar |
| /foo | /foo/ | /bar | /bar/ |
| /foo | /foo/bar | /baz | /baz/bar |
| /foo | /foo/bar/ | /baz | /baz/bar/ |
| /foo/ | /foo | / | N/A (le chemin de la demande ne correspond pas au chemin de l'itinéraire) |
| /foo/ | /foo/ | / | / |
| /foo/ | /foo/bar | / | /bar |
26.1.9. Configuration de la politique d'admission des routes
Les administrateurs et les développeurs d'applications peuvent exécuter des applications dans plusieurs espaces de noms avec le même nom de domaine. Cela s'adresse aux organisations où plusieurs équipes développent des microservices qui sont exposés sur le même nom d'hôte.
L'autorisation des revendications à travers les espaces de noms ne devrait être activée que pour les clusters avec confiance entre les espaces de noms, sinon un utilisateur malveillant pourrait prendre le contrôle d'un nom d'hôte. Pour cette raison, la politique d'admission par défaut interdit les demandes de noms d'hôtes entre espaces de noms.
Conditions préalables
- Privilèges d'administrateur de cluster.
Procédure
Modifiez le champ
.spec.routeAdmissionde la variable de ressourceingresscontrollerà l'aide de la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeExemple de configuration du contrôleur d'entrée
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...AstuceVous pouvez également appliquer le langage YAML suivant pour configurer la politique d'admission des routes :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
26.1.10. Création d'un itinéraire à travers un objet d'entrée
Certains composants de l'écosystème ont une intégration avec les ressources Ingress mais pas avec les ressources route. Pour couvrir ce cas, OpenShift Container Platform crée automatiquement des objets route gérés lorsqu'un objet Ingress est créé. Ces objets route sont supprimés lorsque les objets Ingress correspondants sont supprimés.
Procédure
Définir un objet Ingress dans la console OpenShift Container Platform ou en entrant la commande
oc create:Définition YAML d'une entrée
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend annotations: route.openshift.io/termination: "reencrypt"1 route.openshift.io/destination-ca-certificate-secret: secret-ca-cert2 spec: rules: - host: www.example.com3 http: paths: - backend: service: name: frontend port: number: 443 path: / pathType: Prefix tls: - hosts: - www.example.com secretName: example-com-tls-certificate- 1
- L'annotation
route.openshift.io/terminationpeut être utilisée pour configurer le champspec.tls.terminationdeRoute, carIngressn'a pas de champ pour cela. Les valeurs acceptées sontedge,passthroughetreencrypt. Toutes les autres valeurs sont ignorées. Lorsque la valeur de l'annotation n'est pas définie,edgeest l'itinéraire par défaut. Les détails du certificat TLS doivent être définis dans le fichier modèle pour mettre en œuvre l'itinéraire périphérique par défaut. - 3
- Lorsque vous travaillez avec un objet
Ingress, vous devez spécifier un nom d'hôte explicite, contrairement à ce qui se passe avec les routes. Vous pouvez utiliser la syntaxe<host_name>.<cluster_ingress_domain>, par exempleapps.openshiftdemos.com, pour tirer parti de l'enregistrement DNS générique*.<cluster_ingress_domain>et du certificat de service pour le cluster. Sinon, vous devez vous assurer qu'il existe un enregistrement DNS pour le nom d'hôte choisi.Si vous spécifiez la valeur
passthroughdans l'annotationroute.openshift.io/termination, définissezpathà''etpathTypeàImplementationSpecificdans la spécification :spec: rules: - host: www.example.com http: paths: - path: '' pathType: ImplementationSpecific backend: service: name: frontend port: number: 443$ oc apply -f ingress.yaml
- 2
- L'adresse
route.openshift.io/destination-ca-certificate-secretpeut être utilisée sur un objet Ingress pour définir un itinéraire avec un certificat de destination (CA) personnalisé. L'annotation fait référence à un secret kubernetes,secret-ca-cert, qui sera inséré dans l'itinéraire généré.-
Pour spécifier un objet route avec une autorité de certification de destination à partir d'un objet d'entrée, vous devez créer un secret de type
kubernetes.io/tlsouOpaqueavec un certificat au format PEM dans le spécificateurdata.tls.crtdu secret.
-
Pour spécifier un objet route avec une autorité de certification de destination à partir d'un objet d'entrée, vous devez créer un secret de type
Dressez la liste de vos itinéraires :
$ oc get routesLe résultat comprend une route autogénérée dont le nom commence par
frontend-:NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD frontend-gnztq www.example.com frontend 443 reencrypt/Redirect NoneSi vous inspectez cet itinéraire, il se présente comme suit :
YAML Définition d'un itinéraire autogénéré
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend-gnztq ownerReferences: - apiVersion: networking.k8s.io/v1 controller: true kind: Ingress name: frontend uid: 4e6c59cc-704d-4f44-b390-617d879033b6 spec: host: www.example.com path: / port: targetPort: https tls: certificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- insecureEdgeTerminationPolicy: Redirect key: | -----BEGIN RSA PRIVATE KEY----- [...] -----END RSA PRIVATE KEY----- termination: reencrypt destinationCACertificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- to: kind: Service name: frontend
26.1.11. Création d'une route à l'aide du certificat par défaut par le biais d'un objet d'entrée
Si vous créez un objet Ingress sans spécifier de configuration TLS, OpenShift Container Platform génère une route non sécurisée. Pour créer un objet Ingress qui génère un itinéraire sécurisé à terminaison périphérique à l'aide du certificat d'entrée par défaut, vous pouvez spécifier une configuration TLS vide comme suit.
Conditions préalables
- Vous avez un service que vous voulez exposer.
-
Vous avez accès au CLI OpenShift (
oc).
Procédure
Créez un fichier YAML pour l'objet Ingress. Dans cet exemple, le fichier s'appelle
example-ingress.yaml:Définition YAML d'un objet Ingress
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend ... spec: rules: ... tls: - {}1 - 1
- Utilisez cette syntaxe exacte pour spécifier TLS sans spécifier de certificat personnalisé.
Créez l'objet Ingress en exécutant la commande suivante :
$ oc create -f example-ingress.yaml
Vérification
Vérifiez que OpenShift Container Platform a créé la route attendue pour l'objet Ingress en exécutant la commande suivante :
$ oc get routes -o yamlExemple de sortie
apiVersion: v1 items: - apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend-j9sdd1 ... spec: ... tls:2 insecureEdgeTerminationPolicy: Redirect termination: edge3 ...
26.1.12. Création d'un itinéraire à l'aide du certificat de l'autorité de certification de destination dans l'annotation Ingress
L'annotation route.openshift.io/destination-ca-certificate-secret peut être utilisée sur un objet Ingress pour définir un itinéraire avec un certificat CA de destination personnalisé.
Conditions préalables
- Vous pouvez disposer d'une paire certificat/clé dans des fichiers codés PEM, où le certificat est valable pour l'hôte de la route.
- Il se peut que vous disposiez d'un certificat d'autorité de certification distinct dans un fichier codé PEM qui complète la chaîne de certificats.
- Vous devez disposer d'un certificat d'autorité de certification de destination distinct dans un fichier codé en PEM.
- Vous devez avoir un service que vous souhaitez exposer.
Procédure
Ajouter le site
route.openshift.io/destination-ca-certificate-secretaux annotations d'entrée :apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend annotations: route.openshift.io/termination: "reencrypt" route.openshift.io/destination-ca-certificate-secret: secret-ca-cert1 ...- 1
- L'annotation fait référence à un secret kubernetes.
Le secret référencé dans cette annotation sera inséré dans l'itinéraire généré.
Exemple de sortie
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend annotations: route.openshift.io/termination: reencrypt route.openshift.io/destination-ca-certificate-secret: secret-ca-cert spec: ... tls: insecureEdgeTerminationPolicy: Redirect termination: reencrypt destinationCACertificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- ...
26.1.13. Configurer le contrôleur d'entrée de la plateforme OpenShift Container pour un réseau à double pile
Si votre cluster OpenShift Container Platform est configuré pour un réseau à double pile IPv4 et IPv6, votre cluster est accessible de l'extérieur par les routes OpenShift Container Platform.
Le contrôleur d'entrée dessert automatiquement les services qui ont des points d'extrémité IPv4 et IPv6, mais vous pouvez configurer le contrôleur d'entrée pour des services à pile unique ou à double pile.
Conditions préalables
- Vous avez déployé un cluster OpenShift Container Platform sur du métal nu.
-
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Pour que le contrôleur d'entrée serve le trafic sur IPv4/IPv6 à une charge de travail, vous pouvez créer un fichier YAML de service ou modifier un fichier YAML de service existant en définissant les champs
ipFamiliesetipFamilyPolicy. Par exemple :Exemple de fichier YAML de service
apiVersion: v1 kind: Service metadata: creationTimestamp: yyyy-mm-ddT00:00:00Z labels: name: <service_name> manager: kubectl-create operation: Update time: yyyy-mm-ddT00:00:00Z name: <service_name> namespace: <namespace_name> resourceVersion: "<resource_version_number>" selfLink: "/api/v1/namespaces/<namespace_name>/services/<service_name>" uid: <uid_number> spec: clusterIP: 172.30.0.0/16 clusterIPs:1 - 172.30.0.0/16 - <second_IP_address> ipFamilies:2 - IPv4 - IPv6 ipFamilyPolicy: RequireDualStack3 ports: - port: 8080 protocol: TCP targetport: 8080 selector: name: <namespace_name> sessionAffinity: None type: ClusterIP status: loadbalancer: {}- 1
- Dans une instance à double pile, deux sites différents sont fournis :
clusterIPs. - 2
- Pour une instance à pile unique, entrez
IPv4ouIPv6. Pour une instance à double pile, entrez à la foisIPv4etIPv6. - 3
- Pour une instance à pile unique, entrez
SingleStack. Pour une instance à double pile, entrezRequireDualStack.
Ces ressources génèrent des
endpointscorrespondants. Le contrôleur d'entrée surveille maintenantendpointslices.Pour afficher
endpoints, entrez la commande suivante :$ oc get endpointsPour afficher
endpointslices, entrez la commande suivante :$ oc get endpointslices
26.2. Itinéraires sécurisés
Les itinéraires sécurisés permettent d'utiliser plusieurs types de terminaisons TLS pour fournir des certificats au client. Les sections suivantes décrivent comment créer des itinéraires de recryptage, de bordure et de passage avec des certificats personnalisés.
Si vous créez des itinéraires dans Microsoft Azure via des points de terminaison publics, les noms des ressources sont soumis à des restrictions. Vous ne pouvez pas créer de ressources qui utilisent certains termes. Pour obtenir une liste des termes restreints par Azure, voir Résoudre les erreurs de noms de ressources réservées dans la documentation Azure.
26.2.1. Création d'une route de recryptage avec un certificat personnalisé
Vous pouvez configurer une route sécurisée en utilisant la terminaison TLS reencrypt avec un certificat personnalisé à l'aide de la commande oc create route.
Conditions préalables
- Vous devez disposer d'une paire certificat/clé dans des fichiers codés PEM, où le certificat est valide pour l'hôte de la route.
- Il se peut que vous disposiez d'un certificat d'autorité de certification distinct dans un fichier codé PEM qui complète la chaîne de certificats.
- Vous devez disposer d'un certificat d'autorité de certification de destination distinct dans un fichier codé en PEM.
- Vous devez avoir un service que vous souhaitez exposer.
Les fichiers clés protégés par un mot de passe ne sont pas pris en charge. Pour supprimer une phrase de passe d'un fichier clé, utilisez la commande suivante :
$ openssl rsa -in password_protected_tls.key -out tls.keyProcédure
Cette procédure permet de créer une ressource Route avec un certificat personnalisé et de recrypter la terminaison TLS. La procédure suivante suppose que la paire certificat/clé se trouve dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Vous devez également spécifier un certificat d'autorité de certification de destination pour permettre au contrôleur d'entrée de faire confiance au certificat du service. Vous pouvez également spécifier un certificat d'autorité de certification si nécessaire pour compléter la chaîne de certificats. Remplacez les noms de chemin réels pour tls.crt, tls.key, cacert.crt, et (éventuellement) ca.crt. Remplacez frontend par le nom de la ressource Service que vous souhaitez exposer. Remplacez le nom d'hôte approprié par www.example.com.
Créer une ressource
Routesécurisée en utilisant la terminaison TLS reencrypt et un certificat personnalisé :$ oc create route reencrypt --service=frontend --cert=tls.crt --key=tls.key --dest-ca-cert=destca.crt --ca-cert=ca.crt --hostname=www.example.comSi vous examinez la ressource
Routequi en résulte, elle devrait ressembler à ce qui suit :Définition YAML de la route sécurisée
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: reencrypt key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- destinationCACertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----Voir
oc create route reencrypt --helppour plus d'options.
26.2.2. Création d'une route périphérique avec un certificat personnalisé
Vous pouvez configurer un itinéraire sécurisé utilisant la terminaison TLS en périphérie avec un certificat personnalisé à l'aide de la commande oc create route. Avec un itinéraire périphérique, le contrôleur d'entrée met fin au cryptage TLS avant de transmettre le trafic au pod de destination. L'itinéraire spécifie le certificat et la clé TLS que le contrôleur d'entrée utilise pour l'itinéraire.
Conditions préalables
- Vous devez disposer d'une paire certificat/clé dans des fichiers codés PEM, où le certificat est valide pour l'hôte de la route.
- Il se peut que vous disposiez d'un certificat d'autorité de certification distinct dans un fichier codé PEM qui complète la chaîne de certificats.
- Vous devez avoir un service que vous souhaitez exposer.
Les fichiers clés protégés par un mot de passe ne sont pas pris en charge. Pour supprimer une phrase de passe d'un fichier clé, utilisez la commande suivante :
$ openssl rsa -in password_protected_tls.key -out tls.keyProcédure
Cette procédure crée une ressource Route avec un certificat personnalisé et une terminaison TLS. La procédure suivante suppose que la paire certificat/clé se trouve dans les fichiers tls.crt et tls.key dans le répertoire de travail actuel. Vous pouvez également spécifier un certificat CA si nécessaire pour compléter la chaîne de certificats. Remplacez les noms de chemin réels par tls.crt, tls.key et (éventuellement) ca.crt. Remplacez le nom du service que vous souhaitez exposer par frontend. Remplacez le nom d'hôte approprié par www.example.com.
Créer une ressource
Routesécurisée en utilisant la terminaison TLS et un certificat personnalisé.$ oc create route edge --service=frontend --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=www.example.comSi vous examinez la ressource
Routequi en résulte, elle devrait ressembler à ce qui suit :Définition YAML de la route sécurisée
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: edge key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----Voir
oc create route edge --helppour plus d'options.
26.2.3. Création d'une route passante
Vous pouvez configurer une route sécurisée utilisant la terminaison passthrough à l'aide de la commande oc create route. Avec la terminaison passthrough, le trafic crypté est envoyé directement à la destination sans que le routeur n'assure la terminaison TLS. Par conséquent, aucune clé ni aucun certificat n'est nécessaire sur l'itinéraire.
Conditions préalables
- Vous devez avoir un service que vous souhaitez exposer.
Procédure
Créer une ressource
Route:$ oc create route passthrough route-passthrough-secured --service=frontend --port=8080Si vous examinez la ressource
Routequi en résulte, elle devrait ressembler à ce qui suit :Une route sécurisée à l'aide de la terminaison Passthrough
apiVersion: route.openshift.io/v1 kind: Route metadata: name: route-passthrough-secured1 spec: host: www.example.com port: targetPort: 8080 tls: termination: passthrough2 insecureEdgeTerminationPolicy: None3 to: kind: Service name: frontendLe module de destination est chargé de fournir des certificats pour le trafic au point final. Il s'agit actuellement de la seule méthode permettant d'exiger des certificats de clients, également connus sous le nom d'authentification bidirectionnelle.
Chapitre 27. Configuration du trafic entrant dans le cluster
27.1. Configuration du trafic d'entrée du cluster
OpenShift Container Platform propose les méthodes suivantes pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster.
Les méthodes sont recommandées, par ordre de préférence :
- Si vous disposez de HTTP/HTTPS, utilisez un contrôleur d'entrée.
- Si vous avez un protocole TLS crypté autre que HTTPS. Par exemple, pour TLS avec l'en-tête SNI, utilisez un contrôleur d'entrée.
-
Sinon, utilisez un équilibreur de charge, une adresse IP externe ou une adresse
NodePort.
| Méthode | Objectif |
|---|---|
| Permet d'accéder au trafic HTTP/HTTPS et aux protocoles cryptés TLS autres que HTTPS (par exemple, TLS avec l'en-tête SNI). | |
| Attribution automatique d'une IP externe à l'aide d'un service d'équilibrage de charge | Permet le trafic vers des ports non standard par le biais d'une adresse IP attribuée à partir d'un pool. La plupart des plateformes en nuage offrent une méthode pour démarrer un service avec une adresse IP d'équilibreur de charge. |
| Autorise le trafic vers une adresse IP spécifique ou une adresse d'un pool sur le réseau de la machine. Pour les installations bare-metal ou les plates-formes qui ressemblent à bare-metal, MetalLB permet de démarrer un service avec une adresse IP d'équilibreur de charge. | |
| Autorise le trafic vers des ports non standard via une adresse IP spécifique. | |
| Exposer un service sur tous les nœuds de la grappe. |
27.1.1. Comparaison : Accès tolérant aux adresses IP externes
Pour les méthodes de communication qui permettent d'accéder à une adresse IP externe, l'accès tolérant aux pannes à l'adresse IP est un autre élément à prendre en considération. Les caractéristiques suivantes permettent un accès tolérant aux pannes à une adresse IP externe.
- Basculement IP
- Le basculement IP gère un pool d'adresses IP virtuelles pour un ensemble de nœuds. Il est mis en œuvre avec Keepalived et Virtual Router Redundancy Protocol (VRRP). Le basculement IP est un mécanisme de couche 2 uniquement et repose sur la multidiffusion. La multidiffusion peut présenter des inconvénients pour certains réseaux.
- MetalLB
- MetalLB dispose d'un mode couche 2, mais n'utilise pas le multicast. Le mode couche 2 présente l'inconvénient de transférer tout le trafic pour une adresse IP externe via un seul nœud.
- Attribution manuelle d'adresses IP externes
- Vous pouvez configurer votre cluster avec un bloc d'adresses IP qui est utilisé pour attribuer des adresses IP externes aux services. Par défaut, cette fonctionnalité est désactivée. Cette fonctionnalité est flexible, mais c'est sur l'administrateur de la grappe ou du réseau que pèse la plus lourde charge. La grappe est prête à recevoir le trafic destiné à l'adresse IP externe, mais chaque client doit décider de la manière dont il souhaite acheminer le trafic vers les nœuds.
27.2. Configuration des IP externes pour les services
En tant qu'administrateur de cluster, vous pouvez désigner un bloc d'adresses IP externe au cluster qui peut envoyer du trafic aux services du cluster.
Cette fonctionnalité est généralement plus utile pour les clusters installés sur du matériel "bare-metal".
27.2.1. Conditions préalables
- Votre infrastructure réseau doit acheminer le trafic des adresses IP externes vers votre cluster.
27.2.2. À propos d'ExternalIP
Pour les environnements non cloud, OpenShift Container Platform prend en charge l'attribution d'adresses IP externes à un champ d'objet Service spec.externalIPs[] par l'intermédiaire de la fonction ExternalIP (adresse IP virtuelle). En définissant ce champ, OpenShift Container Platform attribue une adresse IP virtuelle supplémentaire au service. L'adresse IP peut être en dehors du réseau de service défini pour le cluster. Un service configuré avec un ExternalIP fonctionne de la même manière qu'un service avec type=NodePort, ce qui vous permet de diriger le trafic vers un nœud local pour l'équilibrage de la charge.
Vous devez configurer votre infrastructure réseau pour vous assurer que les blocs d'adresses IP externes que vous définissez sont acheminés vers le cluster.
OpenShift Container Platform étend la fonctionnalité ExternalIP de Kubernetes en ajoutant les capacités suivantes :
- Restrictions sur l'utilisation d'adresses IP externes par les utilisateurs au moyen d'une politique configurable
- Attribution automatique d'une adresse IP externe à un service sur demande
Désactivée par défaut, l'utilisation de la fonctionnalité ExternalIP peut présenter un risque pour la sécurité, car le trafic interne à la grappe vers une adresse IP externe est dirigé vers ce service. Cela pourrait permettre aux utilisateurs de la grappe d'intercepter le trafic sensible destiné aux ressources externes.
Cette fonctionnalité n'est prise en charge que dans les déploiements non cloud. Pour les déploiements dans le nuage, utilisez les services d'équilibreur de charge pour le déploiement automatique d'un équilibreur de charge dans le nuage afin de cibler les points d'extrémité d'un service.
Vous pouvez attribuer une adresse IP externe de la manière suivante :
- Attribution automatique d'une IP externe
-
OpenShift Container Platform attribue automatiquement une adresse IP du bloc CIDR
autoAssignCIDRsau tableauspec.externalIPs[]lorsque vous créez un objetServiceavecspec.type=LoadBalancerdéfini. Dans ce cas, OpenShift Container Platform met en œuvre une version non cloud du type de service d'équilibreur de charge et attribue des adresses IP aux services. L'attribution automatique est désactivée par défaut et doit être configurée par un administrateur de cluster comme décrit dans la section suivante. - Attribution manuelle d'une IP externe
-
OpenShift Container Platform utilise les adresses IP attribuées au tableau
spec.externalIPs[]lorsque vous créez un objetService. Vous ne pouvez pas spécifier une adresse IP qui est déjà utilisée par un autre service.
27.2.2.1. Configuration pour ExternalIP
L'utilisation d'une adresse IP externe dans OpenShift Container Platform est régie par les champs suivants dans la CR Network.config.openshift.io nommée cluster:
-
spec.externalIP.autoAssignCIDRsdéfinit un bloc d'adresses IP utilisé par l'équilibreur de charge lorsqu'il choisit une adresse IP externe pour le service. OpenShift Container Platform ne supporte qu'un seul bloc d'adresses IP pour l'attribution automatique. Cela peut être plus simple que d'avoir à gérer l'espace de port d'un nombre limité d'adresses IP partagées lors de l'attribution manuelle d'ExternalIPs aux services. Si l'attribution automatique est activée, un objetServiceavecspec.type=LoadBalancerse voit attribuer une adresse IP externe. -
spec.externalIP.policydéfinit les blocs d'adresses IP autorisés lors de la spécification manuelle d'une adresse IP. OpenShift Container Platform n'applique pas de règles de politique aux blocs d'adresses IP définis parspec.externalIP.autoAssignCIDRs.
S'il est correctement acheminé, le trafic externe provenant du bloc d'adresses IP externes configuré peut atteindre les points d'extrémité du service via n'importe quel port TCP ou UDP auquel le service est exposé.
En tant qu'administrateur de cluster, vous devez configurer le routage vers les IP externes sur les types de réseau OpenShiftSDN et OVN-Kubernetes. Vous devez également vous assurer que le bloc d'adresses IP que vous attribuez se termine sur un ou plusieurs nœuds de votre cluster. Pour plus d'informations, voir Kubernetes External IPs.
OpenShift Container Platform prend en charge l'attribution automatique et manuelle des adresses IP, et chaque adresse est garantie pour être attribuée à un service au maximum. Cela garantit que chaque service peut exposer les ports qu'il a choisis, quels que soient les ports exposés par d'autres services.
Pour utiliser les blocs d'adresses IP définis par autoAssignCIDRs dans OpenShift Container Platform, vous devez configurer l'attribution d'adresses IP et le routage nécessaires pour votre réseau hôte.
Le fichier YAML suivant décrit un service pour lequel une adresse IP externe a été configurée :
Exemple d'objet Service avec spec.externalIPs[] set
apiVersion: v1
kind: Service
metadata:
name: http-service
spec:
clusterIP: 172.30.163.110
externalIPs:
- 192.168.132.253
externalTrafficPolicy: Cluster
ports:
- name: highport
nodePort: 31903
port: 30102
protocol: TCP
targetPort: 30102
selector:
app: web
sessionAffinity: None
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.168.132.25327.2.2.2. Restrictions concernant l'attribution d'une adresse IP externe
En tant qu'administrateur de cluster, vous pouvez spécifier des blocs d'adresses IP à autoriser et à rejeter.
Les restrictions ne s'appliquent qu'aux utilisateurs qui n'ont pas les privilèges cluster-admin. Un administrateur de cluster peut toujours définir le champ service spec.externalIPs[] sur n'importe quelle adresse IP.
Vous configurez la politique d'adresse IP avec un objet policy défini en spécifiant le champ spec.ExternalIP.policy. L'objet de stratégie a la forme suivante :
{
"policy": {
"allowedCIDRs": [],
"rejectedCIDRs": []
}
}Les règles suivantes s'appliquent lors de la configuration des restrictions de politique :
-
Si
policy={}est défini, la création d'un objetServiceavecspec.ExternalIPs[]défini échouera. C'est la valeur par défaut pour OpenShift Container Platform. Le comportement lorsquepolicy=nullest défini est identique. Si
policyest défini et quepolicy.allowedCIDRs[]oupolicy.rejectedCIDRs[]est défini, les règles suivantes s'appliquent :-
Si
allowedCIDRs[]etrejectedCIDRs[]sont tous deux définis,rejectedCIDRs[]a la priorité surallowedCIDRs[]. -
Si
allowedCIDRs[]est défini, la création d'un objetServiceavecspec.ExternalIPs[]ne réussira que si les adresses IP spécifiées sont autorisées. -
Si
rejectedCIDRs[]est défini, la création d'un objetServiceavecspec.ExternalIPs[]ne réussira que si les adresses IP spécifiées ne sont pas rejetées.
-
Si
27.2.2.3. Exemples d'objets de politique
Les exemples qui suivent présentent plusieurs configurations de politiques différentes.
Dans l'exemple suivant, la politique empêche OpenShift Container Platform de créer un service avec une adresse IP externe spécifiée :
Exemple de politique de rejet de toute valeur spécifiée pour l'objet
Servicespec.externalIPs[]apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: externalIP: policy: {} ...Dans l'exemple suivant, les champs
allowedCIDRsetrejectedCIDRssont tous deux définis.Exemple de politique incluant des blocs CIDR autorisés et rejetés
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: externalIP: policy: allowedCIDRs: - 172.16.66.10/23 rejectedCIDRs: - 172.16.66.10/24 ...Dans l'exemple suivant,
policyest défini surnull. S'il est défini surnull, le champpolicyn'apparaîtra pas dans le résultat de l'inspection de l'objet de configuration en entrantoc get networks.config.openshift.io -o yaml.Exemple de politique autorisant toute valeur spécifiée pour l'objet
Servicespec.externalIPs[]apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: externalIP: policy: null ...
27.2.3. Configuration du bloc d'adresses IP externes
La configuration des blocs d'adresses ExternalIP est définie par une ressource personnalisée (CR) Réseau nommée cluster. La CR Réseau fait partie du groupe d'API config.openshift.io.
Lors de l'installation d'un cluster, l'opérateur de version de cluster (CVO) crée automatiquement un CR de réseau nommé cluster. La création d'autres objets CR de ce type n'est pas prise en charge.
Le fichier YAML suivant décrit la configuration ExternalIP :
Network.config.openshift.io CR named cluster
apiVersion: config.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
externalIP:
autoAssignCIDRs: []
policy:
...- 1
- Définit le bloc d'adresses IP au format CIDR disponible pour l'attribution automatique d'adresses IP externes à un service. Une seule plage d'adresses IP est autorisée.
- 2
- Définit les restrictions relatives à l'attribution manuelle d'une adresse IP à un service. Si aucune restriction n'est définie, la spécification du champ
spec.externalIPdans un objetServicen'est pas autorisée. Par défaut, aucune restriction n'est définie.
Le fichier YAML suivant décrit les champs de la strophe policy:
Réseau.config.openshift.io policy stanza
policy:
allowedCIDRs: []
rejectedCIDRs: [] Exemple de configurations IP externes
Plusieurs configurations possibles pour les pools d'adresses IP externes sont présentées dans les exemples suivants :
Le fichier YAML suivant décrit une configuration qui permet d'attribuer automatiquement des adresses IP externes :
Exemple de configuration avec
spec.externalIP.autoAssignCIDRssetapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: ... externalIP: autoAssignCIDRs: - 192.168.132.254/29Le fichier YAML suivant configure les règles de stratégie pour les plages CIDR autorisées et rejetées :
Exemple de configuration avec
spec.externalIP.policysetapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: ... externalIP: policy: allowedCIDRs: - 192.168.132.0/29 - 192.168.132.8/29 rejectedCIDRs: - 192.168.132.7/32
27.2.4. Configurer des blocs d'adresses IP externes pour votre cluster
En tant qu'administrateur de cluster, vous pouvez configurer les paramètres ExternalIP suivants :
-
Un bloc d'adresses ExternalIP utilisé par OpenShift Container Platform pour remplir automatiquement le champ
spec.clusterIPpour un objetService. -
Objet de stratégie permettant de restreindre les adresses IP pouvant être attribuées manuellement au tableau
spec.clusterIPd'un objetService.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
En option : Pour afficher la configuration IP externe actuelle, entrez la commande suivante :
$ oc describe networks.config clusterPour modifier la configuration, entrez la commande suivante :
$ oc edit networks.config clusterModifiez la configuration ExternalIP, comme dans l'exemple suivant :
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: ... externalIP:1 ...- 1
- Spécifiez la configuration de la strophe
externalIP.
Pour confirmer la mise à jour de la configuration ExternalIP, entrez la commande suivante :
$ oc get networks.config cluster -o go-template='{{.spec.externalIP}}{{"\n"}}'
27.2.5. Prochaines étapes
27.3. Configuration du trafic d'entrée du cluster à l'aide d'un contrôleur d'entrée
OpenShift Container Platform fournit des méthodes pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster. Cette méthode utilise un contrôleur d'entrée (Ingress Controller).
27.3.1. Utilisation de contrôleurs d'entrée et d'itinéraires
L'opérateur d'entrée gère les contrôleurs d'entrée et les DNS de type "wildcard".
L'utilisation d'un contrôleur d'ingestion est le moyen le plus courant d'autoriser l'accès externe à un cluster OpenShift Container Platform.
Un contrôleur d'entrée est configuré pour accepter les demandes externes et les transmettre par proxy sur la base des itinéraires configurés. Ceci est limité à HTTP, HTTPS utilisant SNI, et TLS utilisant SNI, ce qui est suffisant pour les applications et services web qui fonctionnent sur TLS avec SNI.
Travaillez avec votre administrateur pour configurer un contrôleur d'entrée qui acceptera les demandes externes et les transmettra par proxy en fonction des itinéraires configurés.
L'administrateur peut créer une entrée DNS générique et configurer ensuite un contrôleur d'entrée. Vous pouvez alors travailler avec le contrôleur d'entrée périphérique sans avoir à contacter les administrateurs.
Par défaut, chaque contrôleur d'entrée du cluster peut admettre n'importe quelle route créée dans n'importe quel projet du cluster.
Le contrôleur d'entrée :
- Possède deux répliques par défaut, ce qui signifie qu'il doit être exécuté sur deux nœuds de travail.
- Peut être étendu pour avoir plus de répliques sur plus de nœuds.
Les procédures de cette section requièrent des conditions préalables effectuées par l'administrateur du cluster.
27.3.2. Conditions préalables
Avant de commencer les procédures suivantes, l'administrateur doit
- Configurez le port externe de l'environnement réseau de la grappe pour que les demandes puissent atteindre la grappe.
Assurez-vous qu'il existe au moins un utilisateur ayant le rôle d'administrateur de cluster. Pour ajouter ce rôle à un utilisateur, exécutez la commande suivante :
$ oc adm policy add-cluster-role-to-user cluster-admin username- Disposer d'un cluster OpenShift Container Platform avec au moins un maître et au moins un nœud et un système extérieur au cluster qui a un accès réseau au cluster. Cette procédure suppose que le système externe se trouve sur le même sous-réseau que le cluster. La mise en réseau supplémentaire requise pour les systèmes externes sur un sous-réseau différent n'entre pas dans le cadre de cette rubrique.
27.3.3. Création d'un projet et d'un service
Si le projet et le service que vous souhaitez exposer n'existent pas, créez d'abord le projet, puis le service.
Si le projet et le service existent déjà, passez à la procédure d'exposition du service pour créer une route.
Conditions préalables
-
Installez le CLI
ocet connectez-vous en tant qu'administrateur de cluster.
Procédure
Créez un nouveau projet pour votre service en exécutant la commande
oc new-project:$ oc new-project myprojectUtilisez la commande
oc new-apppour créer votre service :$ oc new-app nodejs:12~https://github.com/sclorg/nodejs-ex.gitPour vérifier que le service a été créé, exécutez la commande suivante :
$ oc get svc -n myprojectExemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.197.157 <none> 8080/TCP 70sPar défaut, le nouveau service n'a pas d'adresse IP externe.
27.3.4. Exposer le service en créant une route
Vous pouvez exposer le service en tant que route en utilisant la commande oc expose.
Procédure
Pour exposer le service :
- Connectez-vous à OpenShift Container Platform.
Connectez-vous au projet dans lequel se trouve le service que vous souhaitez exposer :
$ oc project myprojectExécutez la commande
oc expose servicepour exposer la route :$ oc expose service nodejs-exExemple de sortie
route.route.openshift.io/nodejs-ex exposedPour vérifier que le service est exposé, vous pouvez utiliser un outil, tel que cURL, pour vous assurer que le service est accessible depuis l'extérieur du cluster.
Utilisez la commande
oc get routepour trouver le nom d'hôte de la route :$ oc get routeExemple de sortie
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD nodejs-ex nodejs-ex-myproject.example.com nodejs-ex 8080-tcp NoneUtilisez cURL pour vérifier que l'hôte répond à une requête GET :
$ curl --head nodejs-ex-myproject.example.comExemple de sortie
HTTP/1.1 200 OK ...
27.3.5. Configuration de la répartition des contrôleurs d'entrée à l'aide d'étiquettes d'itinéraires
La répartition du contrôleur d'entrée à l'aide d'étiquettes d'itinéraires signifie que le contrôleur d'entrée dessert n'importe quel itinéraire dans n'importe quel espace de noms sélectionné par le sélecteur d'itinéraires.
Figure 27.1. Répartition des entrées à l'aide d'étiquettes d'itinéraires
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Procédure
Modifiez le fichier
router-internal.yaml:# cat router-internal.yaml apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net>1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" routeSelector: matchLabels: type: sharded status: {} kind: List metadata: resourceVersion: "" selfLink: ""- 1
- Indiquez un domaine à utiliser par le contrôleur d'entrée. Ce domaine doit être différent du domaine par défaut du contrôleur d'entrée.
Appliquer le fichier du contrôleur d'entrée
router-internal.yaml:# oc apply -f router-internal.yamlLe contrôleur d'entrée sélectionne les routes dans n'importe quel espace de noms qui ont l'étiquette
type: sharded.Créez une nouvelle route en utilisant le domaine configuré dans le site
router-internal.yaml:oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
27.3.6. Configuration de la répartition des contrôleurs d'entrée à l'aide d'étiquettes d'espace de noms
La répartition du contrôleur d'entrée à l'aide d'étiquettes d'espace de noms signifie que le contrôleur d'entrée dessert n'importe quelle route dans n'importe quel espace de noms sélectionné par le sélecteur d'espace de noms.
Figure 27.2. La mise en commun à l'entrée à l'aide d'étiquettes d'espace de noms
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Procédure
Modifiez le fichier
router-internal.yaml:# cat router-internal.yamlExemple de sortie
apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net>1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" namespaceSelector: matchLabels: type: sharded status: {} kind: List metadata: resourceVersion: "" selfLink: ""- 1
- Indiquez un domaine à utiliser par le contrôleur d'entrée. Ce domaine doit être différent du domaine par défaut du contrôleur d'entrée.
Appliquer le fichier du contrôleur d'entrée
router-internal.yaml:# oc apply -f router-internal.yamlLe contrôleur d'entrée sélectionne les itinéraires dans tout espace de noms sélectionné par le sélecteur d'espace de noms et portant l'étiquette
type: sharded.Créez une nouvelle route en utilisant le domaine configuré dans le site
router-internal.yaml:oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
27.3.7. Création d'une route pour le sharding du contrôleur d'entrée
Une route vous permet d'héberger votre application à une URL. Dans ce cas, le nom d'hôte n'est pas défini et la route utilise un sous-domaine à la place. Lorsque vous spécifiez un sous-domaine, vous utilisez automatiquement le domaine du contrôleur d'entrée qui expose l'itinéraire. Lorsqu'un itinéraire est exposé par plusieurs contrôleurs d'ingestion, l'itinéraire est hébergé sur plusieurs URL.
La procédure suivante décrit comment créer une route pour le sharding du contrôleur d'entrée, en utilisant l'application hello-openshift comme exemple.
La répartition des contrôleurs d'entrée est utile pour équilibrer la charge du trafic entrant entre un ensemble de contrôleurs d'entrée et pour isoler le trafic vers un contrôleur d'entrée spécifique. Par exemple, l'entreprise A s'adresse à un contrôleur d'entrée et l'entreprise B à un autre.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). - Vous êtes connecté en tant qu'administrateur de projet.
- Vous avez une application web qui expose un port et un point d'extrémité HTTP ou TLS qui écoute le trafic sur le port.
- Vous avez configuré le contrôleur d'entrée pour le partage.
Procédure
Créez un projet appelé
hello-openshiften exécutant la commande suivante :$ oc new-project hello-openshiftCréez un pod dans le projet en exécutant la commande suivante :
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.jsonCréez un service appelé
hello-openshiften exécutant la commande suivante :$ oc expose pod/hello-openshiftCréez une définition de route appelée
hello-openshift-route.yaml:Définition YAML de la route créée pour le sharding :
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded1 name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift2 tls: termination: edge to: kind: Service name: hello-openshift- 1
- La clé d'étiquette et la valeur d'étiquette correspondante doivent toutes deux correspondre à celles spécifiées dans le contrôleur d'entrée. Dans cet exemple, le contrôleur d'entrée a la clé et la valeur d'étiquette
type: sharded. - 2
- La route sera exposée en utilisant la valeur du champ
subdomain. Lorsque vous spécifiez le champsubdomain, vous devez laisser le nom d'hôte non défini. Si vous spécifiez à la fois les champshostetsubdomain, l'itinéraire utilisera la valeur du champhostet ignorera le champsubdomain.
Utilisez
hello-openshift-route.yamlpour créer une route vers l'applicationhello-openshiften exécutant la commande suivante :$ oc -n hello-openshift create -f hello-openshift-route.yaml
Vérification
Obtenez l'état de la route à l'aide de la commande suivante :
$ oc -n hello-openshift get routes/hello-openshift-edge -o yamlLa ressource
Routequi en résulte devrait ressembler à ce qui suit :Exemple de sortie
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift tls: termination: edge to: kind: Service name: hello-openshift status: ingress: - host: hello-openshift.<apps-sharded.basedomain.example.net>1 routerCanonicalHostname: router-sharded.<apps-sharded.basedomain.example.net>2 routerName: sharded3 - 1
- Le nom d'hôte que le contrôleur d'entrée, ou le routeur, utilise pour exposer l'itinéraire. La valeur du champ
hostest automatiquement déterminée par le contrôleur d'entrée et utilise son domaine. Dans cet exemple, le domaine du contrôleur d'entrée est<apps-sharded.basedomain.example.net>. - 2
- Le nom d'hôte du contrôleur d'entrée.
- 3
- Le nom du contrôleur d'entrée. Dans cet exemple, le contrôleur d'entrée porte le nom
sharded.
27.4. Configuration du trafic entrant dans le cluster à l'aide d'un équilibreur de charge
OpenShift Container Platform fournit des méthodes pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster. Cette méthode utilise un équilibreur de charge.
27.4.1. Utilisation d'un équilibreur de charge pour acheminer le trafic vers le cluster
Si vous n'avez pas besoin d'une adresse IP externe spécifique, vous pouvez configurer un service d'équilibreur de charge pour permettre l'accès externe à un cluster OpenShift Container Platform.
Un service d'équilibrage de charge attribue une IP unique. L'équilibreur de charge a une seule IP de routeur de périphérie, qui peut être une IP virtuelle (VIP), mais qui reste une machine unique pour l'équilibrage initial de la charge.
Si un pool est configuré, il l'est au niveau de l'infrastructure, et non par un administrateur de cluster.
Les procédures de cette section requièrent des conditions préalables effectuées par l'administrateur du cluster.
27.4.2. Conditions préalables
Avant de commencer les procédures suivantes, l'administrateur doit
- Configurez le port externe de l'environnement réseau de la grappe pour que les demandes puissent atteindre la grappe.
Assurez-vous qu'il existe au moins un utilisateur ayant le rôle d'administrateur de cluster. Pour ajouter ce rôle à un utilisateur, exécutez la commande suivante :
$ oc adm policy add-cluster-role-to-user cluster-admin username- Disposer d'un cluster OpenShift Container Platform avec au moins un maître et au moins un nœud et un système extérieur au cluster qui a un accès réseau au cluster. Cette procédure suppose que le système externe se trouve sur le même sous-réseau que le cluster. La mise en réseau supplémentaire requise pour les systèmes externes sur un sous-réseau différent n'entre pas dans le cadre de cette rubrique.
27.4.3. Création d'un projet et d'un service
Si le projet et le service que vous souhaitez exposer n'existent pas, créez d'abord le projet, puis le service.
Si le projet et le service existent déjà, passez à la procédure d'exposition du service pour créer une route.
Conditions préalables
-
Installez le CLI
ocet connectez-vous en tant qu'administrateur de cluster.
Procédure
Créez un nouveau projet pour votre service en exécutant la commande
oc new-project:$ oc new-project myprojectUtilisez la commande
oc new-apppour créer votre service :$ oc new-app nodejs:12~https://github.com/sclorg/nodejs-ex.gitPour vérifier que le service a été créé, exécutez la commande suivante :
$ oc get svc -n myprojectExemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.197.157 <none> 8080/TCP 70sPar défaut, le nouveau service n'a pas d'adresse IP externe.
27.4.4. Exposer le service en créant une route
Vous pouvez exposer le service en tant que route en utilisant la commande oc expose.
Procédure
Pour exposer le service :
- Connectez-vous à OpenShift Container Platform.
Connectez-vous au projet dans lequel se trouve le service que vous souhaitez exposer :
$ oc project myprojectExécutez la commande
oc expose servicepour exposer la route :$ oc expose service nodejs-exExemple de sortie
route.route.openshift.io/nodejs-ex exposedPour vérifier que le service est exposé, vous pouvez utiliser un outil, tel que cURL, pour vous assurer que le service est accessible depuis l'extérieur du cluster.
Utilisez la commande
oc get routepour trouver le nom d'hôte de la route :$ oc get routeExemple de sortie
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD nodejs-ex nodejs-ex-myproject.example.com nodejs-ex 8080-tcp NoneUtilisez cURL pour vérifier que l'hôte répond à une requête GET :
$ curl --head nodejs-ex-myproject.example.comExemple de sortie
HTTP/1.1 200 OK ...
27.4.5. Création d'un service d'équilibreur de charge
La procédure suivante permet de créer un service d'équilibreur de charge.
Conditions préalables
- Assurez-vous que le projet et le service que vous souhaitez exposer existent.
Procédure
Pour créer un service d'équilibreur de charge :
- Connectez-vous à OpenShift Container Platform.
Chargez le projet dans lequel se trouve le service que vous souhaitez exposer.
$ oc project project1Ouvrez un fichier texte sur le nœud du plan de contrôle et collez le texte suivant, en modifiant le fichier si nécessaire :
Exemple de fichier de configuration d'un équilibreur de charge
apiVersion: v1 kind: Service metadata: name: egress-21 spec: ports: - name: db port: 33062 loadBalancerIP: loadBalancerSourceRanges:3 - 10.0.0.0/8 - 192.168.0.0/16 type: LoadBalancer4 selector: name: mysql5 - 1
- Entrez un nom descriptif pour le service d'équilibreur de charge.
- 2
- Saisissez le même port que celui sur lequel le service que vous souhaitez exposer écoute.
- 3
- Entrez une liste d'adresses IP spécifiques pour restreindre le trafic via l'équilibreur de charge. Ce champ est ignoré si le fournisseur de cloud computing ne prend pas en charge cette fonctionnalité.
- 4
- Saisissez
Loadbalancercomme type. - 5
- Saisissez le nom du service.
NotePour limiter le trafic via l'équilibreur de charge à des adresses IP spécifiques, il est recommandé d'utiliser le champ Ingress Controller (contrôleur d'entrée)
spec.endpointPublishingStrategy.loadBalancer.allowedSourceRanges. Ne définissez pas le champloadBalancerSourceRanges.- Save and exit the file.
Exécutez la commande suivante pour créer le service :
$ oc create -f <nom-de-fichier>Par exemple :
$ oc create -f mysql-lb.yamlExécutez la commande suivante pour afficher le nouveau service :
$ oc get svcExemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE egress-2 LoadBalancer 172.30.22.226 ad42f5d8b303045-487804948.example.com 3306:30357/TCP 15mLe service dispose d'une adresse IP externe automatiquement attribuée si un fournisseur de cloud est activé.
Sur le maître, utilisez un outil, tel que cURL, pour vous assurer que vous pouvez atteindre le service en utilisant l'adresse IP publique :
$ curl <public-ip>:<port>Par exemple :
$ curl 172.29.121.74:3306Les exemples de cette section utilisent un service MySQL, qui nécessite une application client. Si vous obtenez une chaîne de caractères avec le message
Got packets out of order, vous êtes en train de vous connecter au service :Si vous disposez d'un client MySQL, connectez-vous à l'aide de la commande CLI standard :
$ mysql -h 172.30.131.89 -u admin -pExemple de sortie
Enter password: Welcome to the MariaDB monitor. Commands end with ; or \g. MySQL [(none)]>
27.5. Configuration du trafic d'entrée des clusters sur AWS
OpenShift Container Platform fournit des méthodes pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster. Cette méthode utilise des répartiteurs de charge sur AWS, en particulier un répartiteur de charge réseau (NLB) ou un répartiteur de charge classique (CLB). Les deux types d'équilibreurs de charge peuvent transmettre l'adresse IP du client au nœud, mais un CLB nécessite la prise en charge du protocole proxy, qu'OpenShift Container Platform active automatiquement.
Il existe deux façons de configurer un contrôleur d'entrée pour qu'il utilise un NLB :
-
En remplaçant de force le contrôleur d'entrée qui utilise actuellement un CLB. Cette opération supprime l'objet
IngressControlleret une panne se produira pendant que les nouveaux enregistrements DNS se propagent et que le NLB est approvisionné. -
En modifiant un contrôleur d'entrée existant qui utilise un CLB pour utiliser un NLB. Cela permet de modifier l'équilibreur de charge sans avoir à supprimer et à recréer l'objet
IngressController.
Les deux méthodes peuvent être utilisées pour passer d'un NLB à un CLB.
Vous pouvez configurer ces équilibreurs de charge sur un cluster AWS nouveau ou existant.
27.5.1. Configuration des délais d'attente de l'équilibreur de charge classique sur AWS
OpenShift Container Platform fournit une méthode pour définir un délai d'attente personnalisé pour une route ou un contrôleur d'entrée spécifique. En outre, un AWS Classic Load Balancer (CLB) dispose de son propre délai d'attente, dont la durée par défaut est de 60 secondes.
Si le délai d'attente du CLB est plus court que le délai d'attente de l'itinéraire ou le délai d'attente du contrôleur d'entrée, l'équilibreur de charge peut mettre fin prématurément à la connexion. Vous pouvez éviter ce problème en augmentant le délai d'expiration de l'itinéraire et du CLB.
27.5.1.1. Configuration des délais d'attente pour les itinéraires
Vous pouvez configurer les délais d'attente par défaut pour une route existante lorsque vous avez des services qui ont besoin d'un délai d'attente faible, qui est nécessaire pour la disponibilité du niveau de service (SLA), ou d'un délai d'attente élevé, pour les cas où le back-end est lent.
Conditions préalables
- Vous avez besoin d'un contrôleur d'ingestion déployé sur un cluster en cours d'exécution.
Procédure
À l'aide de la commande
oc annotate, ajoutez le délai d'attente à l'itinéraire :$ oc annotate route <route_name> \ --overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit>1 - 1
- Les unités de temps prises en charge sont les microsecondes (us), les millisecondes (ms), les secondes (s), les minutes (m), les heures (h) ou les jours (d).
L'exemple suivant définit un délai d'attente de deux secondes sur une route nommée
myroute:$ oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s
27.5.1.2. Configuration des délais d'attente de l'équilibreur de charge classique
Vous pouvez configurer les délais par défaut d'un équilibreur de charge classique (CLB) pour prolonger les connexions inactives.
Conditions préalables
- Vous devez disposer d'un contrôleur d'ingestion déployé sur un cluster en cours d'exécution.
Procédure
Définissez un délai d'inactivité de connexion AWS de cinq minutes pour la valeur par défaut
ingresscontrolleren exécutant la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"type":"LoadBalancerService", "loadBalancer": \ {"scope":"External", "providerParameters":{"type":"AWS", "aws": \ {"type":"Classic", "classicLoadBalancer": \ {"connectionIdleTimeout":"5m"}}}}}}}'Facultatif : Rétablissez la valeur par défaut du délai d'attente en exécutant la commande suivante :
$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"loadBalancer":{"providerParameters":{"aws":{"classicLoadBalancer": \ {"connectionIdleTimeout":null}}}}}}}'
Vous devez spécifier le champ scope lorsque vous modifiez la valeur du délai de connexion, sauf si l'étendue actuelle est déjà définie. Lorsque vous définissez le champ scope, il n'est pas nécessaire de le faire à nouveau si vous rétablissez la valeur par défaut du délai d'attente.
27.5.2. Configuration du trafic d'entrée des clusters sur AWS à l'aide d'un équilibreur de charge réseau
OpenShift Container Platform fournit des méthodes pour communiquer depuis l'extérieur du cluster avec les services qui s'exécutent dans le cluster. L'une de ces méthodes utilise un équilibreur de charge réseau (NLB). Vous pouvez configurer un NLB sur un cluster AWS nouveau ou existant.
27.5.2.1. Passage du contrôleur d'entrée d'un équilibreur de charge classique à un équilibreur de charge réseau
Vous pouvez remplacer le contrôleur d'entrée qui utilise un équilibreur de charge classique (CLB) par un équilibreur de charge réseau (NLB) sur AWS.
Le passage d'un équilibreur de charge à l'autre ne supprime pas l'objet IngressController.
Cette procédure peut entraîner les problèmes suivants :
- Une panne qui peut durer plusieurs minutes en raison de la propagation de nouveaux enregistrements DNS, du provisionnement de nouveaux équilibreurs de charge et d'autres facteurs. Les adresses IP et les noms canoniques de l'équilibreur de charge du contrôleur d'entrée peuvent changer après l'application de cette procédure.
- Fuite de ressources de l'équilibreur de charge en raison d'un changement dans l'annotation du service.
Procédure
Modifiez le contrôleur d'entrée existant pour lequel vous souhaitez passer à l'utilisation d'un NLB. Cet exemple suppose que votre contrôleur d'entrée par défaut dispose d'une portée
Externalet d'aucune autre personnalisation :Exemple de fichier
ingresscontroller.yamlapiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB type: LoadBalancerServiceNoteSi vous ne spécifiez pas de valeur pour le champ
spec.endpointPublishingStrategy.loadBalancer.providerParameters.aws.type, le contrôleur d'entrée utilise la valeurspec.loadBalancer.platform.aws.typede la configuration du clusterIngressdéfinie lors de l'installation.AstuceSi votre contrôleur d'ingestion comporte d'autres personnalisations que vous souhaitez mettre à jour, telles que la modification du domaine, envisagez plutôt de remplacer de force le fichier de définition du contrôleur d'ingestion.
Appliquez les modifications au fichier YAML du contrôleur d'entrée en exécutant la commande :
$ oc apply -f ingresscontroller.yamlIl faut s'attendre à des interruptions de plusieurs minutes pendant la mise à jour du contrôleur d'entrée.
27.5.2.2. Passage du contrôleur d'entrée d'un équilibreur de charge réseau à un équilibreur de charge classique
Vous pouvez remplacer le contrôleur d'entrée qui utilise un équilibreur de charge réseau (NLB) par un équilibreur de charge classique (CLB) sur AWS.
Le passage d'un équilibreur de charge à l'autre ne supprime pas l'objet IngressController.
Cette procédure peut provoquer une panne qui peut durer plusieurs minutes en raison de la propagation de nouveaux enregistrements DNS, du provisionnement de nouveaux équilibreurs de charge et d'autres facteurs. Les adresses IP et les noms canoniques de l'équilibreur de charge du contrôleur d'entrée peuvent changer après l'application de cette procédure.
Procédure
Modifiez le contrôleur d'entrée existant pour lequel vous souhaitez passer à l'utilisation d'un CLB. Cet exemple suppose que votre contrôleur d'entrée par défaut dispose d'une portée
Externalet d'aucune autre personnalisation :Exemple de fichier
ingresscontroller.yamlapiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: Classic type: LoadBalancerServiceNoteSi vous ne spécifiez pas de valeur pour le champ
spec.endpointPublishingStrategy.loadBalancer.providerParameters.aws.type, le contrôleur d'entrée utilise la valeurspec.loadBalancer.platform.aws.typede la configuration du clusterIngressdéfinie lors de l'installation.AstuceSi votre contrôleur d'ingestion comporte d'autres personnalisations que vous souhaitez mettre à jour, telles que la modification du domaine, envisagez plutôt de remplacer de force le fichier de définition du contrôleur d'ingestion.
Appliquez les modifications au fichier YAML du contrôleur d'entrée en exécutant la commande :
$ oc apply -f ingresscontroller.yamlIl faut s'attendre à des interruptions de plusieurs minutes pendant la mise à jour du contrôleur d'entrée.
27.5.2.3. Remplacement du contrôleur d'entrée, de l'équilibreur de charge classique par un équilibreur de charge réseau
Vous pouvez remplacer un contrôleur d'entrée qui utilise un équilibreur de charge classique (CLB) par un contrôleur qui utilise un équilibreur de charge réseau (NLB) sur AWS.
Cette procédure peut entraîner les problèmes suivants :
- Une panne qui peut durer plusieurs minutes en raison de la propagation de nouveaux enregistrements DNS, du provisionnement de nouveaux équilibreurs de charge et d'autres facteurs. Les adresses IP et les noms canoniques de l'équilibreur de charge du contrôleur d'entrée peuvent changer après l'application de cette procédure.
- Fuite de ressources de l'équilibreur de charge en raison d'un changement dans l'annotation du service.
Procédure
Créez un fichier avec un nouveau contrôleur d'ingérence par défaut. L'exemple suivant suppose que votre contrôleur d'entrée par défaut possède une portée
Externalet aucune autre personnalisation :Exemple de fichier
ingresscontroller.ymlapiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB type: LoadBalancerServiceSi votre contrôleur d'ingestion par défaut présente d'autres personnalisations, veillez à modifier le fichier en conséquence.
AstuceSi votre contrôleur d'entrée n'a pas d'autres personnalisations et que vous ne mettez à jour que le type d'équilibreur de charge, envisagez de suivre la procédure décrite dans le document " Switching the Ingress Controller from using a Classic Load Balancer to a Network Load Balancer " (Passage du contrôleur d'entrée d'un équilibreur de charge classique à un équilibreur de charge réseau).
Forcez le remplacement du fichier YAML du contrôleur d'entrée :
$ oc replace --force --wait -f ingresscontroller.ymlAttendez que le contrôleur d'entrée soit remplacé. Attendez-vous à plusieurs minutes d'interruption.
27.5.2.4. Configuration d'un contrôleur d'entrée Network Load Balancer sur un cluster AWS existant
Vous pouvez créer un contrôleur d'entrée soutenu par un équilibreur de charge réseau AWS (NLB) sur un cluster existant.
Conditions préalables
- Un cluster AWS doit être installé.
PlatformStatusde la ressource d'infrastructure doit être AWS.Pour vérifier que le site
PlatformStatusest bien AWS, exécutez la commande :$ oc get infrastructure/cluster -o jsonpath='{.status.platformStatus.type}' AWS
Procédure
Créer un contrôleur d'entrée soutenu par AWS NLB sur un cluster existant.
Créer le manifeste du contrôleur d'entrée :
$ cat ingresscontroller-aws-nlb.yamlExemple de sortie
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: $my_ingress_controller1 namespace: openshift-ingress-operator spec: domain: $my_unique_ingress_domain2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: External3 providerParameters: type: AWS aws: type: NLB- 1
- Remplacez
$my_ingress_controllerpar un nom unique pour le contrôleur d'entrée. - 2
- Remplacez
$my_unique_ingress_domainpar un nom de domaine unique pour tous les contrôleurs d'entrée du cluster. Cette variable doit être un sous-domaine du nom DNS<clustername>.<domain>. - 3
- Vous pouvez remplacer
ExternalparInternalpour utiliser un NLB interne.
Créer la ressource dans le cluster :
$ oc create -f ingresscontroller-aws-nlb.yaml
Avant de pouvoir configurer un contrôleur d'entrée NLB sur un nouveau cluster AWS, vous devez suivre la procédure de création du fichier de configuration de l'installation.
27.5.2.5. Configuring an Ingress Controller Network Load Balancer on a new AWS cluster
You can create an Ingress Controller backed by an AWS Network Load Balancer (NLB) on a new cluster.
Conditions préalables
-
Créer le fichier
install-config.yamlet y apporter les modifications nécessaires.
Procédure
Create an Ingress Controller backed by an AWS NLB on a new cluster.
Change to the directory that contains the installation program and create the manifests:
./openshift-install create manifests --dir <installation_directory> $ ./openshift-install create manifests --dir <installation_directory>1 - 1
- Pour
<installation_directory>, indiquez le nom du répertoire qui contient le fichierinstall-config.yamlpour votre cluster.
Créez un fichier nommé
cluster-ingress-default-ingresscontroller.yamldans le répertoire<installation_directory>/manifests/:touch <installation_directory>/manifests/cluster-ingress-default-ingresscontroller.yaml1 - 1
- Pour
<installation_directory>, indiquez le nom du répertoire qui contient le répertoiremanifests/de votre cluster.
Après la création du fichier, plusieurs fichiers de configuration du réseau se trouvent dans le répertoire
manifests/, comme indiqué :$ ls <installation_directory>/manifests/cluster-ingress-default-ingresscontroller.yamlExemple de sortie
cluster-ingress-default-ingresscontroller.yamlOuvrez le fichier
cluster-ingress-default-ingresscontroller.yamldans un éditeur et saisissez une ressource personnalisée (CR) qui décrit la configuration de l'opérateur que vous souhaitez :apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB type: LoadBalancerService-
Enregistrez le fichier
cluster-ingress-default-ingresscontroller.yamlet quittez l'éditeur de texte. -
Facultatif : Sauvegardez le fichier
manifests/cluster-ingress-default-ingresscontroller.yaml. Le programme d'installation supprime le répertoiremanifests/lors de la création du cluster.
27.6. Configuration du trafic entrant du cluster pour un service IP externe
Vous pouvez attacher une adresse IP externe à un service afin qu'il soit disponible pour le trafic en dehors du cluster. Ceci n'est généralement utile que pour un cluster installé sur du matériel bare metal. L'infrastructure réseau externe doit être configurée correctement pour acheminer le trafic vers le service.
27.6.1. Conditions préalables
Votre cluster est configuré avec ExternalIPs activé. Pour plus d'informations, lisez Configuration des ExternalIPs pour les services.
NoteN'utilisez pas le même ExternalIP pour l'IP de sortie.
27.6.2. Attacher un ExternalIP à un service
Vous pouvez attacher un ExternalIP à un service. Si votre cluster est configuré pour allouer un ExternalIP automatiquement, vous n'aurez peut-être pas besoin d'attacher manuellement un ExternalIP au service.
Procédure
En outre, il est possible de confirmer les plages d'adresses IP configurées pour l'utilisation de ExternalIP : Pour confirmer quelles plages d'adresses IP sont configurées pour être utilisées avec ExternalIP, entrez la commande suivante :
$ oc get networks.config cluster -o jsonpath='{.spec.externalIP}{"\n"}'Si
autoAssignCIDRsest défini, OpenShift Container Platform attribue automatiquement un ExternalIP à un nouvel objetServicesi le champspec.externalIPsn'est pas spécifié.Attacher un ExternalIP au service.
Si vous créez un nouveau service, indiquez le champ
spec.externalIPset fournissez un tableau d'une ou plusieurs adresses IP valides. Par exemple :apiVersion: v1 kind: Service metadata: name: svc-with-externalip spec: ... externalIPs: - 192.174.120.10Si vous attachez un ExternalIP à un service existant, entrez la commande suivante. Remplacez
<name>par le nom du service. Remplacez<ip_address>par une adresse ExternalIP valide. Vous pouvez fournir plusieurs adresses IP séparées par des virgules.$ oc patch svc <name> -p \ '{ "spec": { "externalIPs": [ "<ip_address>" ] } }'Par exemple :
$ oc patch svc mysql-55-rhel7 -p '{"spec":{"externalIPs":["192.174.120.10"]}}'Exemple de sortie
"mysql-55-rhel7" patched
Pour confirmer qu'une adresse ExternalIP est attachée au service, entrez la commande suivante. Si vous avez spécifié une adresse ExternalIP pour un nouveau service, vous devez d'abord créer le service.
$ oc get svcExemple de sortie
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE mysql-55-rhel7 172.30.131.89 192.174.120.10 3306/TCP 13m
27.7. Configuration du trafic entrant de la grappe à l'aide d'un NodePort
OpenShift Container Platform fournit des méthodes pour communiquer depuis l'extérieur du cluster avec les services s'exécutant dans le cluster. Cette méthode utilise une adresse NodePort.
27.7.1. Utilisation d'un NodePort pour acheminer le trafic vers le cluster
Utilisez une ressource NodePort-type Service pour exposer un service sur un port spécifique sur tous les nœuds du cluster. Le port est spécifié dans le champ .spec.ports[*].nodePort de la ressource Service.
L'utilisation d'un port de nœud nécessite des ressources portuaires supplémentaires.
Un NodePort expose le service sur un port statique de l'adresse IP du nœud. Les NodePortse situent par défaut entre 30000 et 32767, ce qui signifie qu'un NodePort a peu de chances de correspondre au port prévu d'un service. Par exemple, le port 8080 peut être exposé en tant que port 31020 sur le nœud.
L'administrateur doit s'assurer que les adresses IP externes sont acheminées vers les nœuds.
NodePortet les IP externes sont indépendantes et peuvent être utilisées simultanément.
Les procédures de cette section requièrent des conditions préalables effectuées par l'administrateur du cluster.
27.7.2. Conditions préalables
Avant de commencer les procédures suivantes, l'administrateur doit
- Configurez le port externe de l'environnement réseau de la grappe pour que les demandes puissent atteindre la grappe.
Assurez-vous qu'il existe au moins un utilisateur ayant le rôle d'administrateur de cluster. Pour ajouter ce rôle à un utilisateur, exécutez la commande suivante :
oc adm policy add-cluster-role-to-user cluster-admin <user_name>- Disposer d'un cluster OpenShift Container Platform avec au moins un maître et au moins un nœud et un système extérieur au cluster qui a un accès réseau au cluster. Cette procédure suppose que le système externe se trouve sur le même sous-réseau que le cluster. La mise en réseau supplémentaire requise pour les systèmes externes sur un sous-réseau différent n'entre pas dans le cadre de cette rubrique.
27.7.3. Création d'un projet et d'un service
Si le projet et le service que vous souhaitez exposer n'existent pas, créez d'abord le projet, puis le service.
Si le projet et le service existent déjà, passez à la procédure d'exposition du service pour créer une route.
Conditions préalables
-
Installez le CLI
ocet connectez-vous en tant qu'administrateur de cluster.
Procédure
Créez un nouveau projet pour votre service en exécutant la commande
oc new-project:$ oc new-project myprojectUtilisez la commande
oc new-apppour créer votre service :$ oc new-app nodejs:12~https://github.com/sclorg/nodejs-ex.gitPour vérifier que le service a été créé, exécutez la commande suivante :
$ oc get svc -n myprojectExemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.197.157 <none> 8080/TCP 70sPar défaut, le nouveau service n'a pas d'adresse IP externe.
27.7.4. Exposer le service en créant une route
Vous pouvez exposer le service en tant que route en utilisant la commande oc expose.
Procédure
Pour exposer le service :
- Connectez-vous à OpenShift Container Platform.
Connectez-vous au projet dans lequel se trouve le service que vous souhaitez exposer :
$ oc project myprojectPour exposer un port de nœud pour l'application, modifiez la définition de ressource personnalisée (CRD) d'un service en entrant la commande suivante :
$ oc edit svc <service_name>Exemple de sortie
spec: ports: - name: 8443-tcp nodePort: 303271 port: 8443 protocol: TCP targetPort: 8443 sessionAffinity: None type: NodePort2 Facultatif : Pour confirmer que le service est disponible avec un port de nœud exposé, entrez la commande suivante :
$ oc get svc -n myprojectExemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.217.127 <none> 3306/TCP 9m44s nodejs-ex-ingress NodePort 172.30.107.72 <none> 3306:31345/TCP 39sEn option : Pour supprimer le service créé automatiquement par la commande
oc new-app, entrez la commande suivante :$ oc delete svc nodejs-ex
Vérification
Pour vérifier que le port du nœud de service est mis à jour avec un port de la plage
30000-32767, entrez la commande suivante :$ oc get svcDans l'exemple suivant, le port mis à jour est
30327:Exemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE httpd NodePort 172.xx.xx.xx <none> 8443:30327/TCP 109s
27.8. Configuration du trafic entrant dans le cluster à l'aide des plages de sources autorisées de l'équilibreur de charge
Vous pouvez spécifier une liste de plages d'adresses IP pour le serveur IngressController, ce qui limite l'accès au service d'équilibrage de charge lorsque le serveur endpointPublishingStrategy est LoadBalancerService.
27.8.1. Configuration des plages de sources autorisées de l'équilibreur de charge
Vous pouvez activer et configurer le champ spec.endpointPublishingStrategy.loadBalancer.allowedSourceRanges. En configurant les plages de sources autorisées de l'équilibreur de charge, vous pouvez limiter l'accès à l'équilibreur de charge pour le contrôleur d'entrée à une liste spécifiée de plages d'adresses IP. L'opérateur d'entrée rapproche le service d'équilibreur de charge et définit le champ spec.loadBalancerSourceRanges en fonction de AllowedSourceRanges.
Si vous avez déjà défini le champ spec.loadBalancerSourceRanges ou l'anotation du service d'équilibreur de charge service.beta.kubernetes.io/load-balancer-source-ranges dans une version précédente d'OpenShift Container Platform, Ingress Controller commence à signaler Progressing=True après une mise à niveau. Pour résoudre ce problème, définissez AllowedSourceRanges qui écrase le champ spec.loadBalancerSourceRanges et efface l'annotation service.beta.kubernetes.io/load-balancer-source-ranges. Ingress Controller recommence à signaler Progressing=False.
Conditions préalables
- Vous avez déployé un contrôleur d'ingestion sur un cluster en cours d'exécution.
Procédure
Définissez l'API des plages de sources autorisées pour le contrôleur d'entrée en exécutant la commande suivante :
$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"loadBalancer":{"allowedSourceRanges":["0.0.0.0/0"]}}}}'1 - 1
- La valeur de l'exemple
0.0.0.0/0spécifie la plage de sources autorisée.
27.8.2. Migration vers des plages de sources autorisées par l'équilibreur de charge
Si vous avez déjà défini l'annotation service.beta.kubernetes.io/load-balancer-source-ranges, vous pouvez migrer vers les plages de sources autorisées de l'équilibreur de charge. Lorsque vous définissez l'annotation AllowedSourceRanges, le contrôleur d'entrée définit le champ spec.loadBalancerSourceRanges en fonction de la valeur AllowedSourceRanges et désactive l'annotation service.beta.kubernetes.io/load-balancer-source-ranges.
Si vous avez déjà défini le champ spec.loadBalancerSourceRanges ou l'anotation du service d'équilibreur de charge service.beta.kubernetes.io/load-balancer-source-ranges dans une version précédente d'OpenShift Container Platform, le contrôleur d'ingestion commence à signaler Progressing=True après une mise à niveau. Pour remédier à ce problème, définissez AllowedSourceRanges qui écrase le champ spec.loadBalancerSourceRanges et efface l'annotation service.beta.kubernetes.io/load-balancer-source-ranges. Le contrôleur d'ingestion recommence à signaler Progressing=False.
Conditions préalables
-
Vous avez défini l'annotation
service.beta.kubernetes.io/load-balancer-source-ranges.
Procédure
Assurez-vous que l'adresse
service.beta.kubernetes.io/load-balancer-source-rangesest réglée :$ oc get svc router-default -n openshift-ingress -o yamlExemple de sortie
apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/load-balancer-source-ranges: 192.168.0.1/32Assurez-vous que le champ
spec.loadBalancerSourceRangesest désactivé :$ oc get svc router-default -n openshift-ingress -o yamlExemple de sortie
... spec: loadBalancerSourceRanges: - 0.0.0.0/0 ...- Mettez à jour votre cluster vers OpenShift Container Platform 4.12.
Définissez les plages de sources API autorisées pour le site
ingresscontrolleren exécutant la commande suivante :$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"loadBalancer":{"allowedSourceRanges":["0.0.0.0/0"]}}}}'1 - 1
- La valeur de l'exemple
0.0.0.0/0spécifie la plage de sources autorisée.
Chapitre 28. Kubernetes NMState
28.1. À propos de l'opérateur NMState de Kubernetes
L'opérateur Kubernetes NMState fournit une API Kubernetes pour effectuer une configuration réseau basée sur l'état à travers les nœuds du cluster OpenShift Container Platform avec NMState. L'opérateur Kubernetes NMState offre aux utilisateurs des fonctionnalités permettant de configurer divers types d'interfaces réseau, le DNS et le routage sur les nœuds du cluster. En outre, les démons sur les nœuds du cluster rapportent périodiquement l'état des interfaces réseau de chaque nœud au serveur API.
Red Hat prend en charge l'opérateur NMState de Kubernetes dans des environnements de production sur des installations bare-metal, IBM Power, IBM zSystems, IBM® LinuxONE, VMware vSphere et OpenStack.
Avant de pouvoir utiliser NMState avec OpenShift Container Platform, vous devez installer l'opérateur Kubernetes NMState.
28.1.1. Installation de l'opérateur NMState de Kubernetes
Vous pouvez installer l'opérateur Kubernetes NMState en utilisant la console web ou le CLI.
28.1.1.1. Installation de l'opérateur NMState de Kubernetes à l'aide de la console Web
Vous pouvez installer l'opérateur Kubernetes NMState à l'aide de la console web. Une fois installé, l'opérateur peut déployer le contrôleur d'état NMState en tant qu'ensemble de démons sur tous les nœuds du cluster.
Conditions préalables
-
Vous êtes connecté en tant qu'utilisateur avec des privilèges
cluster-admin.
Procédure
- Sélectionner Operators → OperatorHub.
-
Dans le champ de recherche ci-dessous All Itemsentrez
nmstateet cliquez sur Enter pour rechercher l'opérateur NMState de Kubernetes. - Cliquez sur le résultat de la recherche de l'opérateur NMState de Kubernetes.
- Cliquez sur Install pour ouvrir la fenêtre Install Operator fenêtre.
- Cliquez sur Install pour installer l'opérateur.
- Une fois l'installation de l'opérateur terminée, cliquez sur View Operator.
-
Sous Provided APIscliquez sur Create Instance pour ouvrir la boîte de dialogue de création d'une instance de
kubernetes-nmstate. Dans le champ Name de la boîte de dialogue, assurez-vous que le nom de l'instance est bien
nmstate.NoteLa restriction de nom est un problème connu. L'instance est un singleton pour l'ensemble du cluster.
- Acceptez les paramètres par défaut et cliquez sur Create pour créer l'instance.
Résumé
Une fois cette opération terminée, l'opérateur a déployé le contrôleur d'état NMState comme un ensemble de démons sur tous les nœuds du cluster.
28.1.1.2. Installation de l'opérateur NMState de Kubernetes à l'aide de la CLI
Vous pouvez installer l'opérateur NMState Kubernetes en utilisant le CLI OpenShift (oc). Une fois installé, l'opérateur peut déployer le contrôleur d'état NMState en tant qu'ensemble de démons sur tous les nœuds du cluster.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté en tant qu'utilisateur avec des privilèges
cluster-admin.
Procédure
Créez l'espace de noms
nmstateOperator :$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: labels: kubernetes.io/metadata.name: openshift-nmstate name: openshift-nmstate name: openshift-nmstate spec: finalizers: - kubernetes EOFCréer le site
OperatorGroup:$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: annotations: olm.providedAPIs: NMState.v1.nmstate.io generateName: openshift-nmstate- name: openshift-nmstate-tn6k8 namespace: openshift-nmstate spec: targetNamespaces: - openshift-nmstate EOFS'abonner à l'opérateur
nmstate:$ cat << EOF| oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: labels: operators.coreos.com/kubernetes-nmstate-operator.openshift-nmstate: "" name: kubernetes-nmstate-operator namespace: openshift-nmstate spec: channel: stable installPlanApproval: Automatic name: kubernetes-nmstate-operator source: redhat-operators sourceNamespace: openshift-marketplace EOFCréation d'une instance de l'opérateur
nmstate:$ cat << EOF | oc apply -f - apiVersion: nmstate.io/v1 kind: NMState metadata: name: nmstate EOF
Vérification
Confirmez que le déploiement de l'opérateur
nmstateest en cours :oc get clusterserviceversion -n openshift-nmstate \ -o custom-columns=Name:.metadata.name,Phase:.status.phaseExemple de sortie
Name Phase kubernetes-nmstate-operator.4.12.0-202210210157 Succeeded
28.2. Observation de l'état du réseau de nœuds
L'état du réseau des nœuds est la configuration du réseau pour tous les nœuds de la grappe.
28.2.1. À propos de l'état-major
OpenShift Container Platform utilise nmstate pour signaler et configurer l'état du réseau des nœuds. Cela permet de modifier la configuration de la politique réseau, par exemple en créant un pont Linux sur tous les nœuds, en appliquant un seul manifeste de configuration au cluster.
La mise en réseau des nœuds est surveillée et mise à jour par les objets suivants :
NodeNetworkState- Indique l'état du réseau sur ce nœud.
NodeNetworkConfigurationPolicy-
Décrit la configuration réseau requise sur les nœuds. Vous mettez à jour la configuration du réseau des nœuds, notamment en ajoutant ou en supprimant des interfaces, en appliquant un manifeste
NodeNetworkConfigurationPolicyà la grappe. NodeNetworkConfigurationEnactment- Signale les politiques de réseau appliquées à chaque nœud.
OpenShift Container Platform prend en charge l'utilisation des types d'interface nmstate suivants :
- Pont Linux
- VLAN
- Obligation
- Ethernet
Si votre cluster OpenShift Container Platform utilise OVN-Kubernetes comme plugin réseau, vous ne pouvez pas attacher un pont Linux ou un bonding à l'interface par défaut d'un hôte en raison d'un changement dans la topologie du réseau hôte d'OVN-Kubernetes. Comme solution de contournement, utilisez une interface réseau secondaire connectée à votre hôte ou basculez vers le plugin réseau OpenShift SDN.
28.2.2. Visualisation de l'état du réseau d'un nœud
Un objet NodeNetworkState existe sur chaque nœud de la grappe. Cet objet est périodiquement mis à jour et capture l'état du réseau pour ce nœud.
Procédure
Liste de tous les objets
NodeNetworkStatedans le cluster :$ oc get nnsInspecter un objet
NodeNetworkStatepour visualiser le réseau sur ce nœud. La sortie de cet exemple a été expurgée pour plus de clarté :$ oc get nns node01 -o yamlExemple de sortie
apiVersion: nmstate.io/v1 kind: NodeNetworkState metadata: name: node011 status: currentState:2 dns-resolver: ... interfaces: ... route-rules: ... routes: ... lastSuccessfulUpdateTime: "2020-01-31T12:14:00Z"3 - 1
- Le nom de l'objet
NodeNetworkStateest tiré du nœud. - 2
- Le site
currentStatecontient la configuration réseau complète du nœud, y compris les DNS, les interfaces et les itinéraires. - 3
- Date de la dernière mise à jour réussie. Elle est mise à jour périodiquement tant que le nœud est accessible et peut être utilisée pour évaluer la fraîcheur du rapport.
28.3. Mise à jour de la configuration du réseau de nœuds
Vous pouvez mettre à jour la configuration du réseau de nœuds, par exemple en ajoutant ou en supprimant des interfaces sur les nœuds, en appliquant les manifestes NodeNetworkConfigurationPolicy au cluster.
28.3.1. À propos de l'état-major
OpenShift Container Platform utilise nmstate pour signaler et configurer l'état du réseau des nœuds. Cela permet de modifier la configuration de la politique réseau, par exemple en créant un pont Linux sur tous les nœuds, en appliquant un seul manifeste de configuration au cluster.
La mise en réseau des nœuds est surveillée et mise à jour par les objets suivants :
NodeNetworkState- Indique l'état du réseau sur ce nœud.
NodeNetworkConfigurationPolicy-
Décrit la configuration réseau requise sur les nœuds. Vous mettez à jour la configuration du réseau des nœuds, notamment en ajoutant ou en supprimant des interfaces, en appliquant un manifeste
NodeNetworkConfigurationPolicyà la grappe. NodeNetworkConfigurationEnactment- Signale les politiques de réseau appliquées à chaque nœud.
OpenShift Container Platform prend en charge l'utilisation des types d'interface nmstate suivants :
- Pont Linux
- VLAN
- Obligation
- Ethernet
Si votre cluster OpenShift Container Platform utilise OVN-Kubernetes comme plugin réseau, vous ne pouvez pas attacher un pont Linux ou un bonding à l'interface par défaut d'un hôte en raison d'un changement dans la topologie du réseau hôte d'OVN-Kubernetes. Comme solution de contournement, utilisez une interface réseau secondaire connectée à votre hôte ou basculez vers le plugin réseau OpenShift SDN.
28.3.2. Création d'une interface sur les nœuds
Créez une interface sur les nœuds de la grappe en appliquant un manifeste NodeNetworkConfigurationPolicy à la grappe. Le manifeste détaille la configuration requise pour l'interface.
Par défaut, le manifeste s'applique à tous les nœuds du cluster. Pour ajouter l'interface à des nœuds spécifiques, ajoutez le paramètre spec: nodeSelector et le <key>:<value> approprié pour votre sélecteur de nœud.
Vous pouvez configurer simultanément plusieurs nœuds compatibles avec nmstate. La configuration s'applique à 50 % des nœuds en parallèle. Cette stratégie permet d'éviter que l'ensemble de la grappe ne soit indisponible en cas de défaillance de la connexion réseau. Pour appliquer la configuration de la stratégie en parallèle à une partie spécifique du cluster, utilisez le champ maxUnavailable.
Procédure
Créez le manifeste
NodeNetworkConfigurationPolicy. L'exemple suivant configure un pont Linux sur tous les nœuds de travail et configure le résolveur DNS :apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy1 spec: nodeSelector:2 node-role.kubernetes.io/worker: ""3 maxUnavailable: 34 desiredState: interfaces: - name: br1 description: Linux bridge with eth1 as a port5 type: linux-bridge state: up ipv4: dhcp: true enabled: true auto-dns: false bridge: options: stp: enabled: false port: - name: eth1 dns-resolver:6 config: search: - example.com - example.org server: - 8.8.8.8- 1
- Nom de la politique.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. - 3
- Cet exemple utilise le sélecteur de nœuds
node-role.kubernetes.io/worker: ""pour sélectionner tous les nœuds de travail dans le cluster. - 4
- Facultatif : Spécifie le nombre maximum de nœuds compatibles avec nmstate auxquels la configuration de la stratégie peut être appliquée simultanément. Ce paramètre peut prendre la forme d'un pourcentage (chaîne), par exemple
"10%", ou d'une valeur absolue (nombre), par exemple3. - 5
- Facultatif : description lisible par l'homme de l'interface.
- 6
- Optional: Specifies the search and server settings for the DNS server.
Créez la politique de réseau de nœuds :
oc apply -f br1-eth1-policy.yaml1 - 1
- Nom de fichier du manifeste de la stratégie de configuration du réseau de nœuds.
Ressources supplémentaires
28.3.3. Confirmation des mises à jour de la stratégie de réseau de nœuds sur les nœuds
Un manifeste NodeNetworkConfigurationPolicy décrit la configuration réseau demandée pour les nœuds de la grappe. La politique de réseau de nœuds comprend la configuration de réseau demandée et l'état d'exécution de la politique sur l'ensemble de la grappe.
Lorsque vous appliquez une stratégie de réseau de nœuds, un objet NodeNetworkConfigurationEnactment est créé pour chaque nœud du cluster. La mise en œuvre de la configuration du réseau de nœuds est un objet en lecture seule qui représente l'état de l'exécution de la stratégie sur ce nœud. Si la stratégie n'est pas appliquée sur le nœud, l'acte pour ce nœud inclut une trace de retour pour le dépannage.
Procédure
Pour confirmer qu'une politique a été appliquée au cluster, dressez la liste des politiques et de leur état :
$ oc get nncpFacultatif : si la configuration d'une politique prend plus de temps que prévu, vous pouvez inspecter l'état demandé et les conditions d'état d'une politique particulière :
$ oc get nncp <policy> -o yamlFacultatif : si la configuration d'une stratégie sur tous les nœuds prend plus de temps que prévu, vous pouvez répertorier l'état des mises en œuvre sur le cluster :
$ oc get nnceFacultatif : Pour afficher la configuration d'un texte particulier, y compris les rapports d'erreur en cas d'échec de la configuration :
$ oc get nnce <node>.<policy> -o yaml
28.3.4. Suppression d'une interface des nœuds
Vous pouvez supprimer une interface d'un ou de plusieurs nœuds de la grappe en modifiant l'objet NodeNetworkConfigurationPolicy et en définissant l'objet state de l'interface sur absent.
La suppression d'une interface d'un nœud ne rétablit pas automatiquement la configuration du réseau du nœud à un état antérieur. Si vous souhaitez rétablir l'état précédent, vous devez définir la configuration du réseau du nœud dans la stratégie.
Si vous supprimez un pont ou une interface de liaison, toutes les cartes d'interface réseau de nœuds du cluster qui étaient précédemment attachées ou subordonnées à ce pont ou à cette interface de liaison sont placées dans l'état down et deviennent inaccessibles. Pour éviter de perdre la connectivité, configurez la carte réseau du nœud dans la même stratégie de manière à ce qu'elle ait un état up et une adresse IP DHCP ou statique.
La suppression de la stratégie de réseau du nœud qui a ajouté une interface ne modifie pas la configuration de la stratégie sur le nœud. Bien qu'un site NodeNetworkConfigurationPolicy soit un objet dans le cluster, il ne représente que la configuration demandée.
De même, la suppression d'une interface ne supprime pas la stratégie.
Procédure
Mettez à jour le manifeste
NodeNetworkConfigurationPolicyutilisé pour créer l'interface. L'exemple suivant supprime un pont Linux et configure la carte réseaueth1avec DHCP pour éviter de perdre la connectivité :apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: <br1-eth1-policy>1 spec: nodeSelector:2 node-role.kubernetes.io/worker: ""3 desiredState: interfaces: - name: br1 type: linux-bridge state: absent4 - name: eth15 type: ethernet6 state: up7 ipv4: dhcp: true8 enabled: true9 - 1
- Nom de la politique.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. - 3
- Cet exemple utilise le sélecteur de nœuds
node-role.kubernetes.io/worker: ""pour sélectionner tous les nœuds de travail dans le cluster. - 4
- La modification de l'état à
absentsupprime l'interface. - 5
- Le nom de l'interface qui doit être détachée de l'interface du pont.
- 6
- Le type d'interface. Cet exemple crée une interface réseau Ethernet.
- 7
- L'état demandé pour l'interface.
- 8
- Facultatif : Si vous n'utilisez pas
dhcp, vous pouvez définir une adresse IP statique ou laisser l'interface sans adresse IP. - 9
- Active
ipv4dans cet exemple.
Mettez à jour la stratégie sur le nœud et supprimez l'interface :
oc apply -f <br1-eth1-policy.yaml>1 - 1
- Nom de fichier du manifeste de la politique.
28.3.5. Exemples de configurations de politiques pour différentes interfaces
28.3.5.1. Exemple : Politique de configuration du réseau du nœud de l'interface de pont Linux
Créez une interface de pont Linux sur les nœuds de la grappe en appliquant un manifeste NodeNetworkConfigurationPolicy à la grappe.
Le fichier YAML suivant est un exemple de manifeste pour une interface de pont Linux. Il contient des exemples de valeurs que vous devez remplacer par vos propres informations.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: br1-eth1-policy
spec:
nodeSelector:
kubernetes.io/hostname: <node01>
desiredState:
interfaces:
- name: br1
description: Linux bridge with eth1 as a port
type: linux-bridge
state: up
ipv4:
dhcp: true
enabled: true
bridge:
options:
stp:
enabled: false
port:
- name: eth1 - 1
- Nom de la politique.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. - 3
- Cet exemple utilise un sélecteur de nœuds
hostname. - 4
- Name of the interface.
- 5
- Facultatif : description lisible par l'homme de l'interface.
- 6
- Le type d'interface. Cet exemple crée un pont.
- 7
- L'état demandé pour l'interface après sa création.
- 8
- Facultatif : Si vous n'utilisez pas
dhcp, vous pouvez définir une adresse IP statique ou laisser l'interface sans adresse IP. - 9
- Active
ipv4dans cet exemple. - 10
- Désactive
stpdans cet exemple. - 11
- Le NIC du nœud auquel le pont s'attache.
28.3.5.2. Exemple : Politique de configuration du réseau du nœud de l'interface VLAN
Créez une interface VLAN sur les nœuds de la grappe en appliquant un manifeste NodeNetworkConfigurationPolicy à la grappe.
Le fichier YAML suivant est un exemple de manifeste pour une interface VLAN. Il contient des exemples de valeurs que vous devez remplacer par vos propres informations.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: vlan-eth1-policy
spec:
nodeSelector:
kubernetes.io/hostname: <node01>
desiredState:
interfaces:
- name: eth1.102
description: VLAN using eth1
type: vlan
state: up
vlan:
base-iface: eth1
id: 102 - 1
- Nom de la politique.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. - 3
- Cet exemple utilise un sélecteur de nœuds
hostname. - 4
- Name of the interface.
- 5
- Facultatif : description lisible par l'homme de l'interface.
- 6
- The type of interface. This example creates a VLAN.
- 7
- L'état demandé pour l'interface après sa création.
- 8
- Le NIC du nœud auquel le VLAN est attaché.
- 9
- La balise VLAN.
28.3.5.3. Exemple : Politique de configuration du réseau des nœuds d'interface de liaison
Créez une interface de liaison sur les nœuds de la grappe en appliquant un manifeste NodeNetworkConfigurationPolicy à la grappe.
OpenShift Container Platform ne prend en charge que les modes de liaison suivants :
-
mode=1 active-backup
-
mode=2 balance-xor
-
mode=4 802.3ad
-
mode=5 balance-tlb
- mode=6 balance-alb
Le fichier YAML suivant est un exemple de manifeste pour une interface de liaison. Il contient des exemples de valeurs que vous devez remplacer par vos propres informations.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: bond0-eth1-eth2-policy
spec:
nodeSelector:
kubernetes.io/hostname: <node01>
desiredState:
interfaces:
- name: bond0
description: Bond with ports eth1 and eth2
type: bond
state: up
ipv4:
dhcp: true
enabled: true
link-aggregation:
mode: active-backup
options:
miimon: '140'
port:
- eth1
- eth2
mtu: 1450 - 1
- Nom de la politique.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. - 3
- Cet exemple utilise un sélecteur de nœuds
hostname. - 4
- Name of the interface.
- 5
- Facultatif : description lisible par l'homme de l'interface.
- 6
- The type of interface. This example creates a bond.
- 7
- L'état demandé pour l'interface après sa création.
- 8
- Facultatif : Si vous n'utilisez pas
dhcp, vous pouvez définir une adresse IP statique ou laisser l'interface sans adresse IP. - 9
- Active
ipv4dans cet exemple. - 10
- Le mode de pilotage de la liaison. Cet exemple utilise un mode de sauvegarde actif.
- 11
- Facultatif : Cet exemple utilise miimon pour inspecter le lien de liaison toutes les 140 ms.
- 12
- Les NIC des nœuds subordonnés dans le lien.
- 13
- Facultatif : L'unité de transmission maximale (MTU) pour la liaison. Si elle n'est pas spécifiée, cette valeur est fixée par défaut à
1500.
28.3.5.4. Exemple : Politique de configuration du réseau du nœud d'interface Ethernet
Configurez une interface Ethernet sur les nœuds de la grappe en appliquant un manifeste NodeNetworkConfigurationPolicy à la grappe.
Le fichier YAML suivant est un exemple de manifeste pour une interface Ethernet. Il contient des valeurs types que vous devez remplacer par vos propres informations.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: eth1-policy
spec:
nodeSelector:
kubernetes.io/hostname: <node01>
desiredState:
interfaces:
- name: eth1
description: Configuring eth1 on node01
type: ethernet
state: up
ipv4:
dhcp: true
enabled: true - 1
- Nom de la politique.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. - 3
- Cet exemple utilise un sélecteur de nœuds
hostname. - 4
- Name of the interface.
- 5
- Facultatif : description lisible par l'homme de l'interface.
- 6
- Le type d'interface. Cet exemple crée une interface réseau Ethernet.
- 7
- L'état demandé pour l'interface après sa création.
- 8
- Facultatif : Si vous n'utilisez pas
dhcp, vous pouvez définir une adresse IP statique ou laisser l'interface sans adresse IP. - 9
- Active
ipv4dans cet exemple.
28.3.5.5. Exemple : Interfaces multiples dans la politique de configuration du réseau du même nœud
Vous pouvez créer plusieurs interfaces dans la même politique de configuration de réseau de nœuds. Ces interfaces peuvent se référencer les unes les autres, ce qui vous permet de construire et de déployer une configuration de réseau à l'aide d'un seul manifeste de stratégie.
L'exemple suivant crée un lien nommé bond10 entre deux cartes d'interface réseau et un pont Linux nommé br1 qui se connecte au lien.
#...
interfaces:
- name: bond10
description: Bonding eth2 and eth3 for Linux bridge
type: bond
state: up
link-aggregation:
port:
- eth2
- eth3
- name: br1
description: Linux bridge on bond
type: linux-bridge
state: up
bridge:
port:
- name: bond10
#...28.3.6. Capturer l'IP statique d'une carte réseau attachée à un pont
La capture de l'IP statique d'un NIC est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information au cours du processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Créez une interface de pont Linux sur les nœuds du cluster et transférez la configuration IP statique du NIC vers le pont en appliquant un seul manifeste NodeNetworkConfigurationPolicy au cluster.
Le fichier YAML suivant est un exemple de manifeste pour une interface de pont Linux. Il contient des valeurs types que vous devez remplacer par vos propres informations.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: br1-eth1-copy-ipv4-policy
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
capture:
eth1-nic: interfaces.name=="eth1"
eth1-routes: routes.running.next-hop-interface=="eth1"
br1-routes: capture.eth1-routes | routes.running.next-hop-interface := "br1"
desiredState:
interfaces:
- name: br1
description: Linux bridge with eth1 as a port
type: linux-bridge
state: up
ipv4: "{{ capture.eth1-nic.interfaces.0.ipv4 }}"
bridge:
options:
stp:
enabled: false
port:
- name: eth1
routes:
config: "{{ capture.br1-routes.routes.running }}"- 1
- Le nom de la police.
- 2
- Facultatif : si vous n'incluez pas le paramètre
nodeSelector, la stratégie s'applique à tous les nœuds du cluster. Cet exemple utilise le sélecteur de nœudsnode-role.kubernetes.io/worker: ""pour sélectionner tous les nœuds de travail du cluster. - 3
- La référence au NIC du nœud auquel le pont s'attache.
- 4
- Le type d'interface. Cet exemple crée un pont.
- 5
- L'adresse IP de l'interface du pont. Cette valeur correspond à l'adresse IP du NIC référencé par l'entrée
spec.capture.eth1-nic. - 6
- Le NIC du nœud auquel le pont s'attache.
28.3.7. Exemples : Gestion de l'IP
Les exemples de configuration suivants illustrent différentes méthodes de gestion des adresses IP.
Ces exemples utilisent le type d'interface ethernet pour simplifier l'exemple tout en montrant le contexte lié à la configuration de la politique. Ces exemples de gestion IP peuvent être utilisés avec les autres types d'interface.
28.3.7.1. Statique
L'extrait suivant configure statiquement une adresse IP sur l'interface Ethernet :
...
interfaces:
- name: eth1
description: static IP on eth1
type: ethernet
state: up
ipv4:
dhcp: false
address:
- ip: 192.168.122.250
prefix-length: 24
enabled: true
...- 1
- Remplacez cette valeur par l'adresse IP statique de l'interface.
28.3.7.2. Pas d'adresse IP
L'extrait suivant garantit que l'interface n'a pas d'adresse IP :
...
interfaces:
- name: eth1
description: No IP on eth1
type: ethernet
state: up
ipv4:
enabled: false
...28.3.7.3. Configuration dynamique de l'hôte
L'extrait suivant configure une interface Ethernet qui utilise une adresse IP, une adresse de passerelle et un DNS dynamiques :
...
interfaces:
- name: eth1
description: DHCP on eth1
type: ethernet
state: up
ipv4:
dhcp: true
enabled: true
...L'extrait suivant configure une interface Ethernet qui utilise une adresse IP dynamique mais pas d'adresse de passerelle dynamique ni de DNS :
...
interfaces:
- name: eth1
description: DHCP without gateway or DNS on eth1
type: ethernet
state: up
ipv4:
dhcp: true
auto-gateway: false
auto-dns: false
enabled: true
...28.3.7.4. DNS
Définir la configuration DNS est analogue à la modification du fichier /etc/resolv.conf. L'extrait suivant définit la configuration DNS sur l'hôte.
...
interfaces:
...
ipv4:
...
auto-dns: false
...
dns-resolver:
config:
search:
- example.com
- example.org
server:
- 8.8.8.8
...- 1
- Vous devez configurer une interface avec
auto-dns: falseou utiliser une configuration IP statique sur une interface pour que Kubernetes NMState stocke les paramètres DNS personnalisés.
Vous ne pouvez pas utiliser br-ex, un pont Open vSwitch géré par OVNKubernetes, comme interface lors de la configuration des résolveurs DNS.
28.3.7.5. Routage statique
L'extrait suivant configure une route statique et une IP statique sur l'interface eth1.
...
interfaces:
- name: eth1
description: Static routing on eth1
type: ethernet
state: up
ipv4:
dhcp: false
address:
- ip: 192.0.2.251
prefix-length: 24
enabled: true
routes:
config:
- destination: 198.51.100.0/24
metric: 150
next-hop-address: 192.0.2.1
next-hop-interface: eth1
table-id: 254
...28.4. Dépannage de la configuration du réseau de nœuds
Si la configuration du réseau de nœuds rencontre un problème, la politique est automatiquement annulée et les actes signalent un échec. Il s'agit notamment des problèmes suivants
- La configuration n'est pas appliquée sur l'hôte.
- L'hôte perd la connexion à la passerelle par défaut.
- L'hôte perd la connexion avec le serveur API.
28.4.1. Dépannage d'une configuration incorrecte de la politique de configuration du réseau de nœuds
Vous pouvez appliquer des modifications à la configuration du réseau de nœuds à l'ensemble de votre cluster en appliquant une stratégie de configuration du réseau de nœuds. Si vous appliquez une configuration incorrecte, vous pouvez utiliser l'exemple suivant pour dépanner et corriger la stratégie de réseau de nœuds défaillante.
Dans cet exemple, une stratégie de pont Linux est appliquée à un exemple de cluster comprenant trois nœuds de plan de contrôle et trois nœuds de calcul. La stratégie n'est pas appliquée car elle fait référence à une interface incorrecte. Pour trouver l'erreur, examinez les ressources NMState disponibles. Vous pouvez ensuite mettre à jour la stratégie avec la configuration correcte.
Procédure
Créez une politique et appliquez-la à votre cluster. L'exemple suivant crée un pont simple sur l'interface
ens01:apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: ens01-bridge-testfail spec: desiredState: interfaces: - name: br1 description: Linux bridge with the wrong port type: linux-bridge state: up ipv4: dhcp: true enabled: true bridge: options: stp: enabled: false port: - name: ens01$ oc apply -f ens01-bridge-testfail.yamlExemple de sortie
nodenetworkconfigurationpolicy.nmstate.io/ens01-bridge-testfail createdVérifiez l'état de la politique en exécutant la commande suivante :
$ oc get nncpLe résultat montre que la politique a échoué :
Exemple de sortie
NAME STATUS ens01-bridge-testfail FailedToConfigureToutefois, l'état de la politique n'indique pas à lui seul si elle a échoué sur tous les nœuds ou sur un sous-ensemble de nœuds.
Répertoriez les éléments de configuration du réseau des nœuds pour voir si la stratégie a réussi sur l'un d'entre eux. Si la stratégie n'a échoué que pour un sous-ensemble de nœuds, cela signifie que le problème est lié à une configuration de nœud spécifique. Si la stratégie a échoué sur tous les nœuds, cela suggère que le problème est lié à la stratégie.
$ oc get nnceLe résultat montre que la politique a échoué sur tous les nœuds :
Exemple de sortie
NAME STATUS control-plane-1.ens01-bridge-testfail FailedToConfigure control-plane-2.ens01-bridge-testfail FailedToConfigure control-plane-3.ens01-bridge-testfail FailedToConfigure compute-1.ens01-bridge-testfail FailedToConfigure compute-2.ens01-bridge-testfail FailedToConfigure compute-3.ens01-bridge-testfail FailedToConfigureAffichez l'une des exécutions qui a échoué et regardez la traceback. La commande suivante utilise l'outil de sortie
jsonpathpour filtrer la sortie :$ oc get nnce compute-1.ens01-bridge-testfail -o jsonpath='{.status.conditions[?(@.type=="Failing")].message}'Cette commande renvoie une large traceback qui a été éditée pour des raisons de concision :
Exemple de sortie
error reconciling NodeNetworkConfigurationPolicy at desired state apply: , failed to execute nmstatectl set --no-commit --timeout 480: 'exit status 1' '' ... libnmstate.error.NmstateVerificationError: desired ======= --- name: br1 type: linux-bridge state: up bridge: options: group-forward-mask: 0 mac-ageing-time: 300 multicast-snooping: true stp: enabled: false forward-delay: 15 hello-time: 2 max-age: 20 priority: 32768 port: - name: ens01 description: Linux bridge with the wrong port ipv4: address: [] auto-dns: true auto-gateway: true auto-routes: true dhcp: true enabled: true ipv6: enabled: false mac-address: 01-23-45-67-89-AB mtu: 1500 current ======= --- name: br1 type: linux-bridge state: up bridge: options: group-forward-mask: 0 mac-ageing-time: 300 multicast-snooping: true stp: enabled: false forward-delay: 15 hello-time: 2 max-age: 20 priority: 32768 port: [] description: Linux bridge with the wrong port ipv4: address: [] auto-dns: true auto-gateway: true auto-routes: true dhcp: true enabled: true ipv6: enabled: false mac-address: 01-23-45-67-89-AB mtu: 1500 difference ========== --- desired +++ current @@ -13,8 +13,7 @@ hello-time: 2 max-age: 20 priority: 32768 - port: - - name: ens01 + port: [] description: Linux bridge with the wrong port ipv4: address: [] line 651, in _assert_interfaces_equal\n current_state.interfaces[ifname],\nlibnmstate.error.NmstateVerificationError:Le site
NmstateVerificationErrorrépertorie la configuration de la politiquedesired, la configurationcurrentde la politique sur le nœud, et le sitedifferencemet en évidence les paramètres qui ne correspondent pas. Dans cet exemple, leportest inclus dans ledifference, ce qui suggère que le problème vient de la configuration du port dans la politique.Pour vous assurer que la stratégie est correctement configurée, affichez la configuration du réseau pour un ou tous les nœuds en demandant l'objet
NodeNetworkState. La commande suivante renvoie la configuration du réseau pour le nœudcontrol-plane-1:$ oc get nns control-plane-1 -o yamlLa sortie montre que le nom de l'interface sur les nœuds est
ens1mais que la stratégie qui a échoué utilise incorrectementens01:Exemple de sortie
- ipv4: ... name: ens1 state: up type: ethernetCorrigez l'erreur en modifiant la politique existante :
$ oc edit nncp ens01-bridge-testfail... port: - name: ens1Enregistrez la politique pour appliquer la correction.
Vérifiez l'état de la politique pour vous assurer qu'elle a été mise à jour avec succès :
$ oc get nncpExemple de sortie
NAME STATUS ens01-bridge-testfail SuccessfullyConfigured
La politique mise à jour est configurée avec succès sur tous les nœuds du cluster.
Chapitre 29. Configuration du proxy à l'échelle du cluster
Les environnements de production peuvent refuser l'accès direct à Internet et disposer d'un proxy HTTP ou HTTPS. Vous pouvez configurer OpenShift Container Platform pour utiliser un proxy en modifiant l'objet Proxy pour les clusters existants ou en configurant les paramètres du proxy dans le fichier install-config.yaml pour les nouveaux clusters.
29.1. Conditions préalables
Examinez les sites auxquels votre cluster doit accéder et déterminez si l'un d'entre eux doit contourner le proxy. Par défaut, tout le trafic de sortie du système de la grappe est protégé par proxy, y compris les appels à l'API du fournisseur de cloud pour le cloud qui héberge votre grappe. Le proxy à l'échelle du système n'affecte que les composants du système, et non les charges de travail des utilisateurs. Ajoutez des sites au champ
spec.noProxyde l'objet Proxy pour contourner le proxy si nécessaire.NoteLe champ de l'objet Proxy
status.noProxyest rempli avec les valeurs des champsnetworking.machineNetwork[].cidr,networking.clusterNetwork[].cidr, etnetworking.serviceNetwork[]de votre configuration d'installation.Pour les installations sur Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure et Red Hat OpenStack Platform (RHOSP), le champ de l'objet
Proxystatus.noProxyest également renseigné avec le point de terminaison des métadonnées de l'instance (169.254.169.254).
29.2. Activation du proxy à l'échelle du cluster
L'objet Proxy est utilisé pour gérer le proxy egress à l'échelle du cluster. Lorsqu'un cluster est installé ou mis à niveau sans que le proxy soit configuré, un objet Proxy est toujours généré, mais il aura une valeur nulle spec. Par exemple :
apiVersion: config.openshift.io/v1
kind: Proxy
metadata:
name: cluster
spec:
trustedCA:
name: ""
status:
Un administrateur de cluster peut configurer le proxy pour OpenShift Container Platform en modifiant cet objet cluster Proxy .
Seul l'objet Proxy nommé cluster est pris en charge et aucune autre procuration ne peut être créée.
Conditions préalables
- Autorisations de l'administrateur du cluster
-
L'outil CLI d'OpenShift Container Platform
ocest installé
Procédure
Créez une carte de configuration contenant tous les certificats d'autorité de certification supplémentaires requis pour les connexions HTTPS.
NoteVous pouvez sauter cette étape si le certificat d'identité du proxy est signé par une autorité du groupe de confiance RHCOS.
Créez un fichier appelé
user-ca-bundle.yamlavec le contenu suivant, et fournissez les valeurs de vos certificats encodés PEM :apiVersion: v1 data: ca-bundle.crt: |1 <MY_PEM_ENCODED_CERTS>2 kind: ConfigMap metadata: name: user-ca-bundle3 namespace: openshift-config4 - 1
- Cette clé de données doit être nommée
ca-bundle.crt. - 2
- Un ou plusieurs certificats X.509 encodés PEM utilisés pour signer le certificat d'identité du proxy.
- 3
- Le nom de la carte de configuration qui sera référencée dans l'objet
Proxy. - 4
- La carte de configuration doit se trouver dans l'espace de noms
openshift-config.
Créez la carte de configuration à partir de ce fichier :
$ oc create -f user-ca-bundle.yaml
Utilisez la commande
oc editpour modifier l'objetProxy:$ oc edit proxy/clusterConfigurez les champs nécessaires pour le proxy :
apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: httpProxy: http://<username>:<pswd>@<ip>:<port>1 httpsProxy: https://<username>:<pswd>@<ip>:<port>2 noProxy: example.com3 readinessEndpoints: - http://www.google.com4 - https://www.google.com trustedCA: name: user-ca-bundle5 - 1
- URL proxy à utiliser pour créer des connexions HTTP en dehors du cluster. Le schéma de l'URL doit être
http. - 2
- URL de proxy à utiliser pour créer des connexions HTTPS en dehors du cluster. Le schéma d'URL doit être
httpouhttps. Spécifiez une URL pour le proxy qui prend en charge le schéma d'URL. Par exemple, la plupart des mandataires signaleront une erreur s'ils sont configurés pour utiliserhttpsalors qu'ils ne prennent en charge quehttp. Ce message d'erreur peut ne pas se propager dans les journaux et peut apparaître comme une défaillance de la connexion réseau. Si vous utilisez un proxy qui écoute les connexionshttpsdu cluster, vous devrez peut-être configurer le cluster pour qu'il accepte les autorités de certification et les certificats utilisés par le proxy. - 3
- Une liste de noms de domaines de destination, de domaines, d'adresses IP ou d'autres CIDR de réseau, séparés par des virgules, pour exclure le proxys.
Faites précéder un domaine de
.pour qu'il corresponde uniquement aux sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour contourner le proxy pour toutes les destinations. Si vous mettez à l'échelle des travailleurs qui ne sont pas inclus dans le réseau défini par le champnetworking.machineNetwork[].cidrde la configuration d'installation, vous devez les ajouter à cette liste pour éviter les problèmes de connexion.Ce champ est ignoré si les champs
httpProxyethttpsProxyne sont pas renseignés. - 4
- Une ou plusieurs URL externes au cluster à utiliser pour effectuer un contrôle de disponibilité avant d'écrire les valeurs
httpProxyethttpsProxydans l'état. - 5
- Une référence à la carte de configuration dans l'espace de noms
openshift-configqui contient des certificats d'autorité de certification supplémentaires requis pour les connexions HTTPS par procuration. Notez que la carte de configuration doit déjà exister avant d'être référencée ici. Ce champ est obligatoire sauf si le certificat d'identité du proxy est signé par une autorité du groupe de confiance RHCOS.
- Enregistrez le fichier pour appliquer les modifications.
29.3. Suppression du proxy à l'échelle du cluster
L'objet Proxy cluster ne peut pas être supprimé. Pour supprimer le proxy d'un cluster, supprimez tous les champs spec de l'objet Proxy.
Conditions préalables
- Autorisations de l'administrateur du cluster
-
L'outil CLI d'OpenShift Container Platform
ocest installé
Procédure
Utilisez la commande
oc editpour modifier le proxy :$ oc edit proxy/clusterSupprimez tous les champs
specde l'objet Proxy. Par exemple :apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: {}- Enregistrez le fichier pour appliquer les modifications.
Ressources supplémentaires
Chapitre 30. Configuration d'une ICP personnalisée
Certains composants de la plate-forme, tels que la console Web, utilisent des routes pour communiquer et doivent faire confiance aux certificats des autres composants pour interagir avec eux. Si vous utilisez une infrastructure de clés publiques (PKI) personnalisée, vous devez la configurer de manière à ce que ses certificats d'autorité de certification signés de manière privée soient reconnus dans l'ensemble du cluster.
Vous pouvez utiliser l'API Proxy pour ajouter des certificats d'autorité de certification approuvés à l'échelle du cluster. Vous devez effectuer cette opération soit lors de l'installation, soit lors de l'exécution.
Pendant installation, configurez le proxy de la grappe. Vous devez définir vos certificats CA signés de manière privée dans le paramètre
additionalTrustBundledu fichierinstall-config.yaml.Le programme d'installation génère un ConfigMap nommé
user-ca-bundlequi contient les certificats CA supplémentaires que vous avez définis. L'opérateur de réseau de cluster crée ensuite un ConfigMaptrusted-ca-bundlequi fusionne ces certificats CA avec l'ensemble de confiance Red Hat Enterprise Linux CoreOS (RHCOS) ; ce ConfigMap est référencé dans le champtrustedCAde l'objet Proxy.-
À runtimemodifiez l'objet Proxy par défaut pour y inclure vos certificats d'autorité de certification signés de manière privée (dans le cadre du processus d'activation du proxy du cluster). Cela implique la création d'un ConfigMap contenant les certificats d'autorité de certification signés de manière privée qui doivent être approuvés par le cluster, puis la modification de la ressource proxy avec le site
trustedCAfaisant référence au ConfigMap des certificats signés de manière privée.
Le champ additionalTrustBundle de la configuration de l'installateur et le champ trustedCA de la ressource proxy sont utilisés pour gérer le faisceau de confiance à l'échelle du cluster ; additionalTrustBundle est utilisé au moment de l'installation et trustedCA au moment de l'exécution.
Le champ trustedCA est une référence à un site ConfigMap contenant le certificat personnalisé et la paire de clés utilisés par le composant cluster.
30.1. Configuring the cluster-wide proxy during installation
Les environnements de production peuvent refuser l'accès direct à Internet et disposer à la place d'un proxy HTTP ou HTTPS. Vous pouvez configurer un nouveau cluster OpenShift Container Platform pour utiliser un proxy en configurant les paramètres du proxy dans le fichier install-config.yaml.
Conditions préalables
-
Vous avez un fichier
install-config.yamlexistant. Vous avez examiné les sites auxquels votre cluster doit accéder et déterminé si l'un d'entre eux doit contourner le proxy. Par défaut, tout le trafic de sortie du cluster est proxyé, y compris les appels aux API des fournisseurs de clouds d'hébergement. Vous avez ajouté des sites au champ
spec.noProxyde l'objetProxypour contourner le proxy si nécessaire.NoteLe champ de l'objet
Proxystatus.noProxyest rempli avec les valeurs des champsnetworking.machineNetwork[].cidr,networking.clusterNetwork[].cidretnetworking.serviceNetwork[]de votre configuration d'installation.Pour les installations sur Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure et Red Hat OpenStack Platform (RHOSP), le champ de l'objet
Proxystatus.noProxyest également renseigné avec le point de terminaison des métadonnées de l'instance (169.254.169.254).
Procédure
Modifiez votre fichier
install-config.yamlet ajoutez les paramètres du proxy. Par exemple :apiVersion: v1 baseDomain: my.domain.com proxy: httpProxy: http://<username>:<pswd>@<ip>:<port>1 httpsProxy: https://<username>:<pswd>@<ip>:<port>2 noProxy: ec2.<aws_region>.amazonaws.com,elasticloadbalancing.<aws_region>.amazonaws.com,s3.<aws_region>.amazonaws.com3 additionalTrustBundle: |4 -----BEGIN CERTIFICATE----- <MY_TRUSTED_CA_CERT> -----END CERTIFICATE----- additionalTrustBundlePolicy: <policy_to_add_additionalTrustBundle>5 - 1
- URL proxy à utiliser pour créer des connexions HTTP en dehors du cluster. Le schéma de l'URL doit être
http. - 2
- A proxy URL to use for creating HTTPS connections outside the cluster.
- 3
- Une liste de noms de domaine, d'adresses IP ou d'autres CIDR du réseau de destination, séparés par des virgules, à exclure du proxy. Faites précéder un domaine de
.pour qu'il corresponde uniquement aux sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour contourner le proxy pour toutes les destinations. Si vous avez ajouté les points d'extrémité AmazonEC2,Elastic Load Balancing, etS3VPC à votre VPC, vous devez ajouter ces points d'extrémité au champnoProxy. - 4
- S'il est fourni, le programme d'installation génère une carte de configuration nommée
user-ca-bundledans l'espace de nomsopenshift-configqui contient un ou plusieurs certificats CA supplémentaires requis pour les connexions HTTPS par proxy. L'opérateur de réseau de cluster crée ensuite une carte de configurationtrusted-ca-bundlequi fusionne ces contenus avec l'ensemble de confiance Red Hat Enterprise Linux CoreOS (RHCOS), et cette carte de configuration est référencée dans le champtrustedCAde l'objetProxy. Le champadditionalTrustBundleest requis à moins que le certificat d'identité du proxy ne soit signé par une autorité de l'ensemble de confiance RHCOS. - 5
- Facultatif : La politique qui détermine la configuration de l'objet
Proxypour référencer la carte de configurationuser-ca-bundledans le champtrustedCA. Les valeurs autorisées sontProxyonlyetAlways. UtilisezProxyonlypour référencer la carte de configurationuser-ca-bundleuniquement lorsque le proxyhttp/httpsest configuré. UtilisezAlwayspour toujours référencer la carte de configurationuser-ca-bundle. La valeur par défaut estProxyonly.
NoteLe programme d'installation ne prend pas en charge le champ proxy
readinessEndpoints.NoteSi le programme d'installation s'arrête, redémarrez et terminez le déploiement en utilisant la commande
wait-fordu programme d'installation. Par exemple :$ ./openshift-install wait-for install-complete --log-level debug- Save the file and reference it when installing OpenShift Container Platform.
Le programme d'installation crée un proxy à l'échelle de la grappe nommé cluster qui utilise les paramètres du proxy dans le fichier install-config.yaml fourni. Si aucun paramètre de proxy n'est fourni, un objet cluster Proxy est tout de même créé, mais il aura un spec nul.
Seul l'objet Proxy nommé cluster est pris en charge et aucune autre procuration ne peut être créée.
30.2. Activation du proxy à l'échelle du cluster
L'objet Proxy est utilisé pour gérer le proxy egress à l'échelle du cluster. Lorsqu'un cluster est installé ou mis à niveau sans que le proxy soit configuré, un objet Proxy est toujours généré, mais il aura une valeur nulle spec. Par exemple :
apiVersion: config.openshift.io/v1
kind: Proxy
metadata:
name: cluster
spec:
trustedCA:
name: ""
status:
Un administrateur de cluster peut configurer le proxy pour OpenShift Container Platform en modifiant cet objet cluster Proxy .
Seul l'objet Proxy nommé cluster est pris en charge et aucune autre procuration ne peut être créée.
Conditions préalables
- Autorisations de l'administrateur du cluster
-
L'outil CLI d'OpenShift Container Platform
ocest installé
Procédure
Créez une carte de configuration contenant tous les certificats d'autorité de certification supplémentaires requis pour les connexions HTTPS.
NoteVous pouvez sauter cette étape si le certificat d'identité du proxy est signé par une autorité du groupe de confiance RHCOS.
Créez un fichier appelé
user-ca-bundle.yamlavec le contenu suivant, et fournissez les valeurs de vos certificats encodés PEM :apiVersion: v1 data: ca-bundle.crt: |1 <MY_PEM_ENCODED_CERTS>2 kind: ConfigMap metadata: name: user-ca-bundle3 namespace: openshift-config4 - 1
- Cette clé de données doit être nommée
ca-bundle.crt. - 2
- Un ou plusieurs certificats X.509 encodés PEM utilisés pour signer le certificat d'identité du proxy.
- 3
- Le nom de la carte de configuration qui sera référencée dans l'objet
Proxy. - 4
- La carte de configuration doit se trouver dans l'espace de noms
openshift-config.
Créez la carte de configuration à partir de ce fichier :
$ oc create -f user-ca-bundle.yaml
Utilisez la commande
oc editpour modifier l'objetProxy:$ oc edit proxy/clusterConfigurez les champs nécessaires pour le proxy :
apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: httpProxy: http://<username>:<pswd>@<ip>:<port>1 httpsProxy: https://<username>:<pswd>@<ip>:<port>2 noProxy: example.com3 readinessEndpoints: - http://www.google.com4 - https://www.google.com trustedCA: name: user-ca-bundle5 - 1
- URL proxy à utiliser pour créer des connexions HTTP en dehors du cluster. Le schéma de l'URL doit être
http. - 2
- URL de proxy à utiliser pour créer des connexions HTTPS en dehors du cluster. Le schéma d'URL doit être
httpouhttps. Spécifiez une URL pour le proxy qui prend en charge le schéma d'URL. Par exemple, la plupart des mandataires signaleront une erreur s'ils sont configurés pour utiliserhttpsalors qu'ils ne prennent en charge quehttp. Ce message d'erreur peut ne pas se propager dans les journaux et peut apparaître comme une défaillance de la connexion réseau. Si vous utilisez un proxy qui écoute les connexionshttpsdu cluster, vous devrez peut-être configurer le cluster pour qu'il accepte les autorités de certification et les certificats utilisés par le proxy. - 3
- Une liste de noms de domaines de destination, de domaines, d'adresses IP ou d'autres CIDR de réseau, séparés par des virgules, pour exclure le proxys.
Faites précéder un domaine de
.pour qu'il corresponde uniquement aux sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour contourner le proxy pour toutes les destinations. Si vous mettez à l'échelle des travailleurs qui ne sont pas inclus dans le réseau défini par le champnetworking.machineNetwork[].cidrde la configuration d'installation, vous devez les ajouter à cette liste pour éviter les problèmes de connexion.Ce champ est ignoré si les champs
httpProxyethttpsProxyne sont pas renseignés. - 4
- Une ou plusieurs URL externes au cluster à utiliser pour effectuer un contrôle de disponibilité avant d'écrire les valeurs
httpProxyethttpsProxydans l'état. - 5
- Une référence à la carte de configuration dans l'espace de noms
openshift-configqui contient des certificats d'autorité de certification supplémentaires requis pour les connexions HTTPS par procuration. Notez que la carte de configuration doit déjà exister avant d'être référencée ici. Ce champ est obligatoire sauf si le certificat d'identité du proxy est signé par une autorité du groupe de confiance RHCOS.
- Enregistrez le fichier pour appliquer les modifications.
30.3. Injection de certificats à l'aide d'opérateurs
Une fois que votre certificat d'autorité de certification personnalisé est ajouté au cluster via ConfigMap, l'opérateur du réseau de clusters fusionne les certificats d'autorité de certification fournis par l'utilisateur et les certificats d'autorité de certification du système en un seul paquet et injecte le paquet fusionné dans l'opérateur qui demande l'injection du paquet de confiance.
Après l'ajout d'un label config.openshift.io/inject-trusted-cabundle="true" à la carte de configuration, les données existantes sont supprimées. L'opérateur du réseau de clusters devient propriétaire d'une carte de configuration et n'accepte que ca-bundle comme données. Vous devez utiliser une carte de configuration séparée pour stocker service-ca.crt en utilisant l'annotation service.beta.openshift.io/inject-cabundle=true ou une configuration similaire. L'ajout d'un label config.openshift.io/inject-trusted-cabundle="true" et d'une annotation service.beta.openshift.io/inject-cabundle=true sur la même carte de configuration peut entraîner des problèmes.
Les opérateurs demandent cette injection en créant un ConfigMap vide avec l'étiquette suivante :
config.openshift.io/inject-trusted-cabundle="true"Exemple de ConfigMap vide :
apiVersion: v1
data: {}
kind: ConfigMap
metadata:
labels:
config.openshift.io/inject-trusted-cabundle: "true"
name: ca-inject
namespace: apache- 1
- Spécifie le nom du ConfigMap vide.
L'opérateur monte cette ConfigMap dans le magasin de confiance local du conteneur.
L'ajout d'un certificat d'autorité de certification de confiance n'est nécessaire que si le certificat n'est pas inclus dans l'ensemble de confiance de Red Hat Enterprise Linux CoreOS (RHCOS).
L'injection de certificats n'est pas limitée aux opérateurs. L'opérateur de réseau en grappe injecte des certificats dans n'importe quel espace de noms lorsqu'un ConfigMap vide est créé avec l'étiquette config.openshift.io/inject-trusted-cabundle=true.
Le ConfigMap peut résider dans n'importe quel espace de noms, mais il doit être monté en tant que volume sur chaque conteneur d'un pod nécessitant une autorité de certification personnalisée. Par exemple, le ConfigMap peut se trouver dans n'importe quel espace de noms :
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-example-custom-ca-deployment
namespace: my-example-custom-ca-ns
spec:
...
spec:
...
containers:
- name: my-container-that-needs-custom-ca
volumeMounts:
- name: trusted-ca
mountPath: /etc/pki/ca-trust/extracted/pem
readOnly: true
volumes:
- name: trusted-ca
configMap:
name: trusted-ca
items:
- key: ca-bundle.crt
path: tls-ca-bundle.pem Chapitre 31. Répartition de la charge sur RHOSP
31.1. Limites des services d'équilibrage de charge
Les clusters OpenShift Container Platform sur Red Hat OpenStack Platform (RHOSP) utilisent Octavia pour gérer les services d'équilibreur de charge. En raison de ce choix, ces clusters présentent un certain nombre de limitations fonctionnelles.
RHOSP Octavia a deux fournisseurs supportés : Amphora et OVN. Ces fournisseurs diffèrent en termes de fonctionnalités disponibles et de détails d'implémentation. Ces distinctions affectent les services d'équilibrage de charge qui sont créés sur votre cluster.
31.1.1. Politiques locales en matière de trafic externe
Vous pouvez définir le paramètre de politique de trafic externe (ETP), .spec.externalTrafficPolicy, sur un service d'équilibreur de charge pour préserver l'adresse IP source du trafic entrant lorsqu'il atteint les pods d'extrémité du service. Cependant, si votre cluster utilise le fournisseur Amphora Octavia, l'adresse IP source du trafic est remplacée par l'adresse IP de la VM Amphora. Ce comportement ne se produit pas si votre cluster utilise le fournisseur OVN Octavia.
Si l'option ETP est définie sur Local, des moniteurs de santé doivent être créés pour l'équilibreur de charge. En l'absence de moniteurs de santé, le trafic peut être acheminé vers un nœud qui n'a pas de point d'extrémité fonctionnel, ce qui entraîne l'interruption de la connexion. Pour forcer Cloud Provider OpenStack à créer des moniteurs de santé, vous devez définir la valeur de l'option create-monitor dans la configuration du fournisseur de cloud à true.
Dans RHOSP 16.1 et 16.2, le fournisseur OVN Octavia ne prend pas en charge les moniteurs de santé. Par conséquent, la définition de l'ETP en local n'est pas supportée.
Dans RHOSP 16.1 et 16.2, le fournisseur Amphora Octavia ne prend pas en charge les moniteurs HTTP sur les pools UDP. Par conséquent, les services d'équilibrage de charge UDP ont des moniteurs UDP-CONNECT créés à la place. En raison de détails d'implémentation, cette configuration ne fonctionne correctement qu'avec le plugin CNI OVN-Kubernetes. Lorsque le plugin CNI OpenShift SDN est utilisé, les nœuds vivants des services UDP sont détectés de manière non fiable.
31.1.2. Plages de sources de l'équilibreur de charge
Utilisez la propriété .spec.loadBalancerSourceRanges pour restreindre le trafic qui peut passer par l'équilibreur de charge en fonction de l'IP source. Cette propriété ne peut être utilisée qu'avec le fournisseur Amphora Octavia. Si votre cluster utilise le fournisseur OVN Octavia, l'option est ignorée et le trafic n'est pas limité.
31.2. Utilisation du pilote Octavia OVN load balancer provider avec Kuryr SDN
Kuryr is a deprecated feature. Deprecated functionality is still included in OpenShift Container Platform and continues to be supported; however, it will be removed in a future release of this product and is not recommended for new deployments.
Pour la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, reportez-vous à la section Deprecated and removed features des notes de mise à jour d'OpenShift Container Platform.
Si votre cluster OpenShift Container Platform utilise Kuryr et a été installé sur un cloud Red Hat OpenStack Platform (RHOSP) 13 qui a ensuite été mis à niveau vers RHOSP 16, vous pouvez le configurer pour utiliser le pilote fournisseur Octavia OVN.
Kuryr remplace les équilibreurs de charge existants lorsque vous changez les pilotes des fournisseurs. Ce processus entraîne un certain temps d'arrêt.
Conditions préalables
-
Installer le CLI RHOSP,
openstack. -
Installer le CLI de OpenShift Container Platform,
oc. Vérifiez que le pilote Octavia OVN sur RHOSP est activé.
AstucePour afficher la liste des pilotes Octavia disponibles, sur une ligne de commande, entrez
openstack loadbalancer provider list.Le pilote
ovnest affiché dans la sortie de la commande.
Procédure
Pour passer du pilote du fournisseur Octavia Amphora à Octavia OVN :
Ouvrez le ConfigMap à l'adresse
kuryr-config. Sur une ligne de commande, entrez :$ oc -n openshift-kuryr edit cm kuryr-configDans le ConfigMap, supprimez la ligne qui contient
kuryr-octavia-provider: default. Par exemple :... kind: ConfigMap metadata: annotations: networkoperator.openshift.io/kuryr-octavia-provider: default1 ...- 1
- Supprimez cette ligne. Le cluster la régénérera avec la valeur
ovn.
Attendez que l'opérateur du réseau de cluster détecte la modification et redéploie les modules
kuryr-controlleretkuryr-cni. Ce processus peut prendre plusieurs minutes.Vérifiez que l'annotation
kuryr-configConfigMap est présente avecovncomme valeur. Sur une ligne de commande, entrez$ oc -n openshift-kuryr edit cm kuryr-configLa valeur du fournisseur
ovnest affichée dans la sortie :... kind: ConfigMap metadata: annotations: networkoperator.openshift.io/kuryr-octavia-provider: ovn ...Vérifiez que RHOSP a recréé ses équilibreurs de charge.
On a command line, enter:
$ openstack loadbalancer list | grep amphoraUn seul équilibreur de charge Amphora est affiché. Par exemple, l'écran affiche un seul équilibreur de charge Amphora :
a4db683b-2b7b-4988-a582-c39daaad7981 | ostest-7mbj6-kuryr-api-loadbalancer | 84c99c906edd475ba19478a9a6690efd | 172.30.0.1 | ACTIVE | amphoraRecherchez les équilibreurs de charge
ovnen entrant :$ openstack loadbalancer list | grep ovnLes autres équilibreurs de charge du type
ovnsont affichés. Par exemple :2dffe783-98ae-4048-98d0-32aa684664cc | openshift-apiserver-operator/metrics | 84c99c906edd475ba19478a9a6690efd | 172.30.167.119 | ACTIVE | ovn 0b1b2193-251f-4243-af39-2f99b29d18c5 | openshift-etcd/etcd | 84c99c906edd475ba19478a9a6690efd | 172.30.143.226 | ACTIVE | ovn f05b07fc-01b7-4673-bd4d-adaa4391458e | openshift-dns-operator/metrics | 84c99c906edd475ba19478a9a6690efd | 172.30.152.27 | ACTIVE | ovn
31.3. Mise à l'échelle des clusters pour le trafic d'applications à l'aide d'Octavia
Les clusters OpenShift Container Platform qui s'exécutent sur Red Hat OpenStack Platform (RHOSP) peuvent utiliser le service d'équilibrage de charge Octavia pour distribuer le trafic sur plusieurs machines virtuelles (VM) ou adresses IP flottantes. Cette fonctionnalité atténue le goulot d'étranglement que des machines ou des adresses uniques créent.
Si votre cluster utilise Kuryr, le Cluster Network Operator a créé un équilibreur de charge interne Octavia lors du déploiement. Vous pouvez utiliser cet équilibreur de charge pour la mise à l'échelle du réseau d'applications.
Si votre cluster n'utilise pas Kuryr, vous devez créer votre propre équilibreur de charge Octavia afin de l'utiliser pour la mise à l'échelle du réseau d'applications.
31.3.1. Mise à l'échelle des clusters à l'aide d'Octavia
Si vous souhaitez utiliser plusieurs équilibreurs de charge API, ou si votre cluster n'utilise pas Kuryr, créez un équilibreur de charge Octavia et configurez ensuite votre cluster pour qu'il l'utilise.
Conditions préalables
- Octavia est disponible sur votre déploiement de la plateforme Red Hat OpenStack (RHOSP).
Procédure
À partir d'une ligne de commande, créez un équilibreur de charge Octavia qui utilise le pilote Amphora :
openstack loadbalancer create --name API_OCP_CLUSTER --vip-subnet-id <id_of_worker_vms_subnet>Vous pouvez utiliser un nom de votre choix à la place de
API_OCP_CLUSTER.Une fois l'équilibreur de charge activé, créez des récepteurs :
$ openstack loadbalancer listener create --name API_OCP_CLUSTER_6443 --protocol HTTPS--protocol-port 6443 API_OCP_CLUSTERNotePour afficher l'état de l'équilibreur de charge, entrez
openstack loadbalancer list.Créez un pool qui utilise l'algorithme round robin et dont la persistance des sessions est activée :
openstack loadbalancer pool create --name API_OCP_CLUSTER_pool_6443 --lb-algorithm ROUND_ROBIN --session-persistence type=<source_IP_address> --listener API_OCP_CLUSTER_6443 --protocol HTTPSPour s'assurer que les machines du plan de contrôle sont disponibles, créez un moniteur de santé :
$ openstack loadbalancer healthmonitor create --delay 5 --max-retries 4 --timeout 10 --type TCP API_OCP_CLUSTER_pool_6443Ajoutez les machines du plan de contrôle en tant que membres du pool d'équilibreurs de charge :
$ for SERVER in $(MASTER-0-IP MASTER-1-IP MASTER-2-IP) do openstack loadbalancer member create --address $SERVER --protocol-port 6443 API_OCP_CLUSTER_pool_6443 doneFacultatif : Pour réutiliser l'adresse IP flottante de l'API de cluster, désactivez-la :
$ openstack floating ip unset $API_FIPAjoutez soit l'adresse
API_FIPnon paramétrée, soit une nouvelle adresse au VIP d'équilibreur de charge créé :$ openstack floating ip set --port $(openstack loadbalancer show -c <vip_port_id> -f value API_OCP_CLUSTER) $API_FIP
Votre cluster utilise maintenant Octavia pour l'équilibrage de charge.
Si Kuryr utilise le pilote Octavia Amphora, tout le trafic est acheminé via une seule machine virtuelle Amphora (VM).
Vous pouvez répéter cette procédure pour créer des équilibreurs de charge supplémentaires, ce qui peut atténuer le goulot d'étranglement.
31.3.2. Mise à l'échelle des grappes utilisant Kuryr à l'aide d'Octavia
Kuryr is a deprecated feature. Deprecated functionality is still included in OpenShift Container Platform and continues to be supported; however, it will be removed in a future release of this product and is not recommended for new deployments.
Pour la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, reportez-vous à la section Deprecated and removed features des notes de mise à jour d'OpenShift Container Platform.
Si votre cluster utilise Kuryr, associez l'adresse IP flottante API de votre cluster à l'équilibreur de charge Octavia préexistant.
Conditions préalables
- Votre cluster OpenShift Container Platform utilise Kuryr.
- Octavia est disponible sur votre déploiement de la plateforme Red Hat OpenStack (RHOSP).
Procédure
Facultatif : Pour réutiliser l'adresse IP flottante de l'API du cluster, désactivez-la à partir d'une ligne de commande :
$ openstack floating ip unset $API_FIPAjoutez soit l'adresse
API_FIPnon paramétrée, soit une nouvelle adresse au VIP d'équilibreur de charge créé :$ openstack floating ip set --port $(openstack loadbalancer show -c <vip_port_id> -f value ${OCP_CLUSTER}-kuryr-api-loadbalancer) $API_FIP
Votre cluster utilise maintenant Octavia pour l'équilibrage de charge.
Si Kuryr utilise le pilote Octavia Amphora, tout le trafic est acheminé via une seule machine virtuelle Amphora (VM).
Vous pouvez répéter cette procédure pour créer des équilibreurs de charge supplémentaires, ce qui peut atténuer le goulot d'étranglement.
31.4. Mise à l'échelle du trafic entrant en utilisant RHOSP Octavia
Kuryr is a deprecated feature. Deprecated functionality is still included in OpenShift Container Platform and continues to be supported; however, it will be removed in a future release of this product and is not recommended for new deployments.
Pour la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, reportez-vous à la section Deprecated and removed features des notes de mise à jour d'OpenShift Container Platform.
Vous pouvez utiliser les équilibreurs de charge Octavia pour mettre à l'échelle les contrôleurs Ingress sur les clusters qui utilisent Kuryr.
Conditions préalables
- Votre cluster OpenShift Container Platform utilise Kuryr.
- Octavia est disponible sur votre déploiement RHOSP.
Procédure
Pour copier le service interne actuel du routeur, sur une ligne de commande, entrez :
oc -n openshift-ingress get svc router-internal-default -o yaml > external_router.yamlDans le fichier
external_router.yaml, remplacez les valeurs demetadata.nameetspec.typeparLoadBalancer.Exemple de fichier de routeur
apiVersion: v1 kind: Service metadata: labels: ingresscontroller.operator.openshift.io/owning-ingresscontroller: default name: router-external-default1 namespace: openshift-ingress spec: ports: - name: http port: 80 protocol: TCP targetPort: http - name: https port: 443 protocol: TCP targetPort: https - name: metrics port: 1936 protocol: TCP targetPort: 1936 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default sessionAffinity: None type: LoadBalancer2
Vous pouvez supprimer les horodatages et autres informations non pertinentes pour l'équilibrage de la charge.
À partir d'une ligne de commande, créez un service à partir du fichier
external_router.yaml:$ oc apply -f external_router.yamlVérifiez que l'adresse IP externe du service est la même que celle qui est associée à l'équilibreur de charge :
Sur une ligne de commande, récupérez l'adresse IP externe du service :
$ oc -n openshift-ingress get svcExemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE router-external-default LoadBalancer 172.30.235.33 10.46.22.161 80:30112/TCP,443:32359/TCP,1936:30317/TCP 3m38s router-internal-default ClusterIP 172.30.115.123 <none> 80/TCP,443/TCP,1936/TCP 22hRécupérer l'adresse IP de l'équilibreur de charge :
$ openstack loadbalancer list | grep router-externalExemple de sortie
| 21bf6afe-b498-4a16-a958-3229e83c002c | openshift-ingress/router-external-default | 66f3816acf1b431691b8d132cc9d793c | 172.30.235.33 | ACTIVE | octavia |Vérifiez que les adresses que vous avez récupérées dans les étapes précédentes sont associées les unes aux autres dans la liste des adresses IP flottantes :
$ openstack floating ip list | grep 172.30.235.33Exemple de sortie
| e2f80e97-8266-4b69-8636-e58bacf1879e | 10.46.22.161 | 172.30.235.33 | 655e7122-806a-4e0a-a104-220c6e17bda6 | a565e55a-99e7-4d15-b4df-f9d7ee8c9deb | 66f3816acf1b431691b8d132cc9d793c |
Vous pouvez maintenant utiliser la valeur de EXTERNAL-IP comme nouvelle adresse d'entrée.
Si Kuryr utilise le pilote Octavia Amphora, tout le trafic est acheminé via une seule machine virtuelle Amphora (VM).
Vous pouvez répéter cette procédure pour créer des équilibreurs de charge supplémentaires, ce qui peut atténuer le goulot d'étranglement.
31.5. Configuring an external load balancer
Vous pouvez configurer un cluster OpenShift Container Platform sur Red Hat OpenStack Platform (RHOSP) pour utiliser un équilibreur de charge externe à la place de l'équilibreur de charge par défaut.
Conditions préalables
- On your load balancer, TCP over ports 6443, 443, and 80 must be available to any users of your system.
- Load balance the API port, 6443, between each of the control plane nodes.
- Load balance the application ports, 443 and 80, between all of the compute nodes.
- On your load balancer, port 22623, which is used to serve ignition startup configurations to nodes, is not exposed outside of the cluster.
Your load balancer must be able to access every machine in your cluster. Methods to allow this access include:
- Attaching the load balancer to the cluster’s machine subnet.
- Attaching floating IP addresses to machines that use the load balancer.
External load balancing services and the control plane nodes must run on the same L2 network, and on the same VLAN when using VLANs to route traffic between the load balancing services and the control plane nodes.
Procédure
Enable access to the cluster from your load balancer on ports 6443, 443, and 80.
As an example, note this HAProxy configuration:
A section of a sample HAProxy configuration
... listen my-cluster-api-6443 bind 0.0.0.0:6443 mode tcp balance roundrobin server my-cluster-master-2 192.0.2.2:6443 check server my-cluster-master-0 192.0.2.3:6443 check server my-cluster-master-1 192.0.2.1:6443 check listen my-cluster-apps-443 bind 0.0.0.0:443 mode tcp balance roundrobin server my-cluster-worker-0 192.0.2.6:443 check server my-cluster-worker-1 192.0.2.5:443 check server my-cluster-worker-2 192.0.2.4:443 check listen my-cluster-apps-80 bind 0.0.0.0:80 mode tcp balance roundrobin server my-cluster-worker-0 192.0.2.7:80 check server my-cluster-worker-1 192.0.2.9:80 check server my-cluster-worker-2 192.0.2.8:80 checkAdd records to your DNS server for the cluster API and apps over the load balancer. For example:
<load_balancer_ip_address> api.<cluster_name>.<base_domain> <load_balancer_ip_address> apps.<cluster_name>.<base_domain>À partir d'une ligne de commande, utilisez
curlpour vérifier que l'équilibreur de charge externe et la configuration DNS sont opérationnels.Verify that the cluster API is accessible:
$ curl https://<loadbalancer_ip_address>:6443/version --insecureIf the configuration is correct, you receive a JSON object in response:
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }Verify that cluster applications are accessible:
NoteYou can also verify application accessibility by opening the OpenShift Container Platform console in a web browser.
$ curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecureIf the configuration is correct, you receive an HTTP response:
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.<cluster-name>.<base domain>/ cache-control: no-cacheHTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=39HoZgztDnzjJkq/JuLJMeoKNXlfiVv2YgZc09c3TBOBU4NI6kDXaJH1LdicNhN1UsQWzon4Dor9GWGfopaTEQ==; Path=/; Secure x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Tue, 17 Nov 2020 08:42:10 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=9b714eb87e93cf34853e87a92d6894be; path=/; HttpOnly; Secure; SameSite=None cache-control: private
Chapitre 32. Équilibrage de charge avec MetalLB
32.1. A propos de MetalLB et de l'opérateur MetalLB
En tant qu'administrateur de cluster, vous pouvez ajouter l'opérateur MetalLB à votre cluster afin que lorsqu'un service de type LoadBalancer est ajouté au cluster, MetalLB puisse ajouter une adresse IP externe pour le service. L'adresse IP externe est ajoutée au réseau hôte de votre cluster.
32.1.1. Quand utiliser MetalLB
L'utilisation de MetalLB est intéressante lorsque vous disposez d'un cluster bare-metal, ou d'une infrastructure qui ressemble à du bare-metal, et que vous souhaitez un accès tolérant aux pannes à une application par le biais d'une adresse IP externe.
Vous devez configurer votre infrastructure réseau de manière à ce que le trafic réseau pour l'adresse IP externe soit acheminé des clients vers le réseau hôte du cluster.
Après avoir déployé MetalLB avec l'opérateur MetalLB, lorsque vous ajoutez un service de type LoadBalancer, MetalLB fournit un équilibreur de charge natif de la plateforme.
La MetalLB fonctionnant en mode couche 2 prend en charge le basculement en utilisant un mécanisme similaire au basculement IP. Toutefois, au lieu de s'appuyer sur le protocole de redondance des routeurs virtuels (VRRP) et sur keepalived, MetalLB s'appuie sur un protocole basé sur les commérages pour identifier les cas de défaillance des nœuds. Lorsqu'une défaillance est détectée, un autre nœud assume le rôle de nœud leader et un message ARP gratuit est envoyé pour diffuser ce changement.
La MetalLB fonctionnant en mode layer3 ou border gateway protocol (BGP) délègue la détection des défaillances au réseau. Le ou les routeurs BGP avec lesquels les nœuds d'OpenShift Container Platform ont établi une connexion identifieront toute défaillance de nœud et mettront fin aux routes vers ce nœud.
Il est préférable d'utiliser MetalLB plutôt que le basculement IP pour garantir la haute disponibilité des pods et des services.
32.1.2. Ressources personnalisées de l'opérateur MetalLB
L'opérateur MetalLB surveille son propre espace de noms pour les ressources personnalisées suivantes :
MetalLB-
Lorsque vous ajoutez une ressource personnalisée
MetalLBau cluster, l'opérateur MetalLB déploie MetalLB sur le cluster. L'opérateur ne prend en charge qu'une seule instance de la ressource personnalisée. Si l'instance est supprimée, l'opérateur supprime MetalLB du cluster. IPAddressPoolLa MetalLB a besoin d'un ou plusieurs pools d'adresses IP qu'elle peut attribuer à un service lorsque vous ajoutez un service de type
LoadBalancer. UnIPAddressPoolcomprend une liste d'adresses IP. La liste peut être une adresse IP unique définie à l'aide d'une plage, telle que 1.1.1.1-1.1.1.1, une plage spécifiée en notation CIDR, une plage spécifiée en tant qu'adresse de début et de fin séparée par un trait d'union, ou une combinaison des trois. UnIPAddressPoolnécessite un nom. La documentation utilise des noms tels quedoc-example,doc-example-reserved, etdoc-example-ipv6. Une ressourceIPAddressPoolattribue des adresses IP à partir du pool. Les ressources personnaliséesL2AdvertisementetBGPAdvertisementpermettent d'annoncer une IP donnée à partir d'un pool donné.NoteUn seul site
IPAddressPoolpeut être référencé par une annonce L2 et une annonce BGP.BGPPeer- La ressource BGP peer custom identifie le routeur BGP avec lequel MetalLB doit communiquer, le numéro d'AS du routeur, le numéro d'AS de MetalLB et les personnalisations pour l'annonce des routes. MetalLB annonce les routes pour les adresses IP du service load-balancer à un ou plusieurs pairs BGP.
BFDProfile- La ressource personnalisée BFD profile configure Bidirectional Forwarding Detection (BFD) pour un pair BGP. BFD permet de détecter les défaillances de chemin plus rapidement que BGP seul.
L2Advertisement-
La ressource personnalisée L2Advertisement annonce une IP provenant d'un site
IPAddressPoolà l'aide du protocole L2. BGPAdvertisement-
La ressource personnalisée BGPAdvertisement annonce une IP provenant d'un site
IPAddressPoolà l'aide du protocole BGP.
Une fois que vous avez ajouté la ressource personnalisée MetalLB au cluster et que l'opérateur a déployé MetalLB, les composants logiciels controller et speaker MetalLB commencent à fonctionner.
MetalLB valide toutes les ressources personnalisées pertinentes.
32.1.3. Composants du logiciel MetalLB
Lorsque vous installez l'Opérateur MetalLB, le déploiement metallb-operator-controller-manager démarre un pod. Le pod est l'implémentation de l'Opérateur. Le pod surveille les modifications apportées à toutes les ressources pertinentes.
Lorsque l'opérateur démarre une instance de MetalLB, il démarre un déploiement controller et un ensemble de démons speaker.
Vous pouvez configurer les spécifications de déploiement dans la ressource personnalisée MetalLB pour gérer le déploiement et l'exécution des pods controller et speaker dans votre cluster. Pour plus d'informations sur ces spécifications de déploiement, voir la section Additional Resources section.
controllerL'opérateur démarre le déploiement et un pod unique. Lorsque vous ajoutez un service de type
LoadBalancer, Kubernetes utilise le servicecontrollerpour allouer une adresse IP à partir d'un pool d'adresses. En cas de défaillance d'un service, vérifiez que vous avez l'entrée suivante dans vos journaux de podscontroller:Exemple de sortie
"event":"ipAllocated","ip":"172.22.0.201","msg":"IP address assigned by controllerspeakerL'opérateur démarre un ensemble de démons pour
speakerpods. Par défaut, un pod est démarré sur chaque nœud de votre cluster. Vous pouvez limiter les pods à des nœuds spécifiques en spécifiant un sélecteur de nœud dans la ressource personnaliséeMetalLBlorsque vous démarrez MetalLB. Sicontrollera alloué l'adresse IP au service et que le service n'est toujours pas disponible, lisez les journaux du podspeaker. Si le podspeakerest indisponible, exécutez la commandeoc describe pod -n.Pour le mode couche 2, après que le site
controllera attribué une adresse IP pour le service, les podsspeakerutilisent un algorithme pour déterminer quel podspeakersur quel nœud annoncera l'adresse IP de l'équilibreur de charge. L'algorithme consiste à hacher le nom du nœud et l'adresse IP de l'équilibreur de charge. Pour plus d'informations, voir "MetalLB and external traffic policy". Le sitespeakerutilise le protocole de résolution d'adresses (ARP) pour annoncer les adresses IPv4 et le protocole de découverte de voisins (NDP) pour annoncer les adresses IPv6.
En mode Border Gateway Protocol (BGP), après que controller a attribué une adresse IP au service, chaque pod speaker annonce l'adresse IP de l'équilibreur de charge à ses pairs BGP. Vous pouvez configurer les nœuds qui démarrent des sessions BGP avec des pairs BGP.
Les demandes concernant l'adresse IP de l'équilibreur de charge sont acheminées vers le nœud dont l'adresse speaker annonce l'adresse IP. Une fois que le nœud a reçu les paquets, le proxy de service les achemine vers un point de terminaison du service. Le point de terminaison peut se trouver sur le même nœud dans le cas optimal ou sur un autre nœud. Le proxy de service choisit un point de terminaison chaque fois qu'une connexion est établie.
32.1.4. MetalLB et politique de trafic externe
En mode couche 2, un nœud de votre cluster reçoit tout le trafic pour l'adresse IP de service. En mode BGP, un routeur du réseau hôte ouvre une connexion à l'un des nœuds de la grappe pour une nouvelle connexion client. La manière dont votre grappe gère le trafic après son entrée dans le nœud est affectée par la stratégie de trafic externe.
clusterIl s'agit de la valeur par défaut de
spec.externalTrafficPolicy.Avec la stratégie de trafic
cluster, une fois que le nœud a reçu le trafic, le proxy de service distribue le trafic à tous les pods de votre service. Cette stratégie assure une distribution uniforme du trafic dans les modules, mais elle masque l'adresse IP du client et l'application de vos modules peut avoir l'impression que le trafic provient du nœud plutôt que du client.localAvec la politique de trafic
local, après que le nœud a reçu le trafic, le proxy de service n'envoie le trafic qu'aux pods du même nœud. Par exemple, si le podspeakersur le nœud A annonce l'IP du service externe, tout le trafic est envoyé au nœud A. Une fois que le trafic entre dans le nœud A, le proxy de service n'envoie le trafic qu'aux modules du service qui se trouvent également sur le nœud A. Les modules du service qui se trouvent sur d'autres nœuds ne reçoivent aucun trafic du nœud A. Les modules du service situés sur d'autres nœuds servent de répliques en cas de basculement.Cette politique n'affecte pas l'adresse IP du client. Les modules d'application peuvent déterminer l'adresse IP du client à partir des connexions entrantes.
Les informations suivantes sont importantes lors de la configuration de la politique de trafic externe en mode BGP.
Bien que MetalLB annonce l'adresse IP de l'équilibreur de charge à partir de tous les nœuds éligibles, le nombre de nœuds équilibrant le service peut être limité par la capacité du routeur à établir des routes ECMP (equal-cost multipath). Si le nombre de nœuds annonçant l'adresse IP est supérieur à la limite du groupe ECMP du routeur, ce dernier utilisera moins de nœuds que ceux qui annoncent l'adresse IP.
Par exemple, si la politique de trafic externe est définie sur local et que le routeur a une limite de groupe ECMP définie sur 16 et que les pods implémentant un service LoadBalancer sont déployés sur 30 nœuds, les pods déployés sur 14 nœuds ne recevront pas de trafic. Dans cette situation, il serait préférable de définir la politique de trafic externe pour le service sur cluster.
32.1.5. Concepts MetalLB pour le mode couche 2
En mode couche 2, le pod speaker d'un nœud annonce l'adresse IP externe d'un service au réseau hôte. Du point de vue du réseau, le nœud semble avoir plusieurs adresses IP attribuées à une interface réseau.
Comme le mode couche 2 repose sur ARP et NDP, le client doit se trouver sur le même sous-réseau que les nœuds annonçant le service pour que la MetalLB fonctionne. En outre, l'adresse IP attribuée au service doit se trouver sur le même sous-réseau que le réseau utilisé par le client pour accéder au service.
Le pod speaker répond aux demandes ARP pour les services IPv4 et aux demandes NDP pour IPv6.
En mode couche 2, tout le trafic pour une adresse IP de service est acheminé via un seul nœud. Une fois le trafic entré dans le nœud, le proxy de service du fournisseur de réseau CNI distribue le trafic à tous les pods du service.
Comme tout le trafic d'un service passe par un seul nœud en mode couche 2, MetalLB n'implémente pas, au sens strict, d'équilibreur de charge pour la couche 2. MetalLB met plutôt en œuvre un mécanisme de basculement pour la couche 2 de sorte que lorsqu'un pod speaker devient indisponible, un pod speaker sur un autre nœud peut annoncer l'adresse IP du service.
Lorsqu'un nœud devient indisponible, le basculement est automatique. Les pods speaker sur les autres nœuds détectent qu'un nœud est indisponible et un nouveau pod speaker et un nouveau nœud prennent possession de l'adresse IP de service du nœud défaillant.
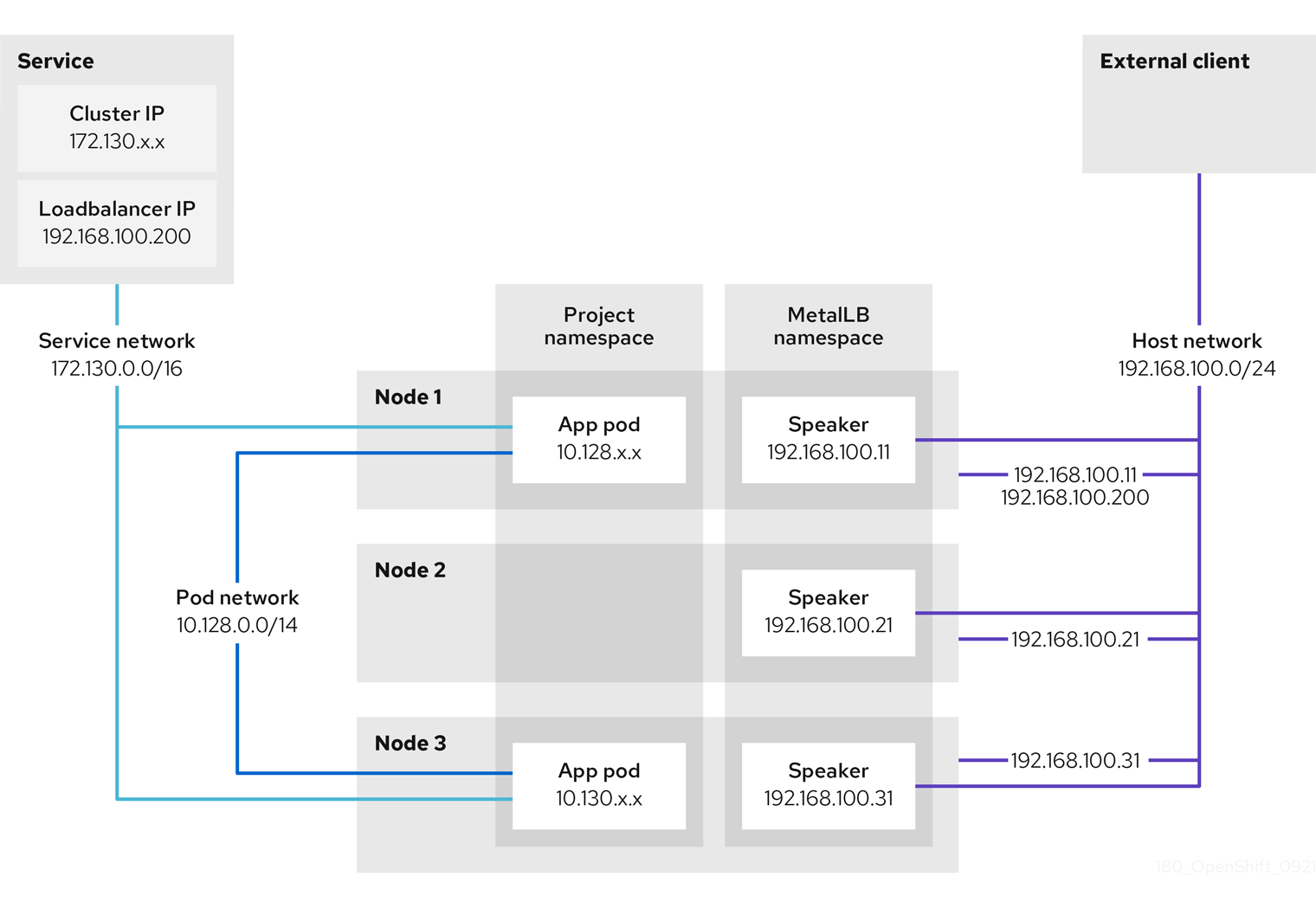
Le graphique précédent illustre les concepts suivants liés à la MetalLB :
-
Une application est disponible par le biais d'un service qui possède une adresse IP de cluster sur le sous-réseau
172.130.0.0/16. Cette adresse IP est accessible depuis l'intérieur du cluster. Le service dispose également d'une adresse IP externe que MetalLB lui a attribuée,192.168.100.200. - Les nœuds 1 et 3 disposent d'un pod pour l'application.
-
Le jeu de démons
speakerexécute un pod sur chaque nœud. L'opérateur MetalLB démarre ces pods. -
Chaque module
speakerest un module en réseau hôte. L'adresse IP du module est identique à l'adresse IP du nœud sur le réseau hôte. -
Le pod
speakersur le nœud 1 utilise ARP pour annoncer l'adresse IP externe du service,192.168.100.200. Le modulespeakerqui annonce l'adresse IP externe doit se trouver sur le même nœud qu'un point de terminaison du service et le point de terminaison doit être dans l'étatReady. Le trafic du client est acheminé vers le réseau hôte et se connecte à l'adresse IP
192.168.100.200. Une fois que le trafic entre dans le nœud, le proxy de service envoie le trafic au module d'application sur le même nœud ou sur un autre nœud, conformément à la stratégie de trafic externe que vous avez définie pour le service.-
Si la stratégie de trafic externe pour le service est définie sur
cluster, le nœud qui annonce l'adresse IP de l'équilibreur de charge192.168.100.200est sélectionné parmi les nœuds où un podspeakerest en cours d'exécution. Seul ce nœud peut recevoir du trafic pour le service. -
Si la politique de trafic externe pour le service est définie sur
local, le nœud qui annonce l'adresse IP de l'équilibreur de charge192.168.100.200est sélectionné parmi les nœuds où un podspeakerest en cours d'exécution et au moins un point d'extrémité du service. Seul ce nœud peut recevoir du trafic pour le service. Dans le graphique précédent, le nœud 1 ou 3 annoncerait192.168.100.200.
-
Si la stratégie de trafic externe pour le service est définie sur
-
Si le nœud 1 devient indisponible, l'adresse IP externe bascule sur un autre nœud. Sur un autre nœud disposant d'une instance du module d'application et du point de terminaison du service, le module
speakercommence à annoncer l'adresse IP externe,192.168.100.200, et le nouveau nœud reçoit le trafic du client. Dans le diagramme, le seul candidat est le nœud 3.
32.1.6. Concepts MetalLB pour le mode BGP
En mode BGP, par défaut, chaque pod speaker annonce l'adresse IP de l'équilibreur de charge pour un service à chaque pair BGP. Il est également possible d'annoncer les IP provenant d'un pool donné à un ensemble spécifique de pairs en ajoutant une liste optionnelle de pairs BGP. Les homologues BGP sont généralement des routeurs de réseau configurés pour utiliser le protocole BGP. Lorsqu'un routeur reçoit du trafic pour l'adresse IP de l'équilibreur de charge, il choisit l'un des nœuds avec un pod speaker qui a annoncé l'adresse IP. Le routeur envoie le trafic à ce nœud. Une fois le trafic entré dans le nœud, le proxy de service pour le plugin de réseau CNI distribue le trafic à tous les pods du service.
Le routeur directement connecté sur le même segment de réseau de couche 2 que les nœuds de cluster peut être configuré en tant qu'homologue BGP. Si le routeur directement connecté n'est pas configuré comme homologue BGP, vous devez configurer votre réseau de manière à ce que les paquets destinés aux adresses IP de l'équilibreur de charge soient acheminés entre les homologues BGP et les nœuds de cluster qui exécutent les pods speaker.
Chaque fois qu'un routeur reçoit un nouveau trafic pour l'adresse IP de l'équilibreur de charge, il crée une nouvelle connexion avec un nœud. Chaque fabricant de routeurs dispose d'un algorithme spécifique pour choisir le nœud avec lequel établir la connexion. Toutefois, les algorithmes sont généralement conçus pour répartir le trafic entre les nœuds disponibles afin d'équilibrer la charge du réseau.
Si un nœud devient indisponible, le routeur établit une nouvelle connexion avec un autre nœud doté d'un pod speaker qui annonce l'adresse IP de l'équilibreur de charge.
Figure 32.1. Schéma topologique de la MetalLB en mode BGP
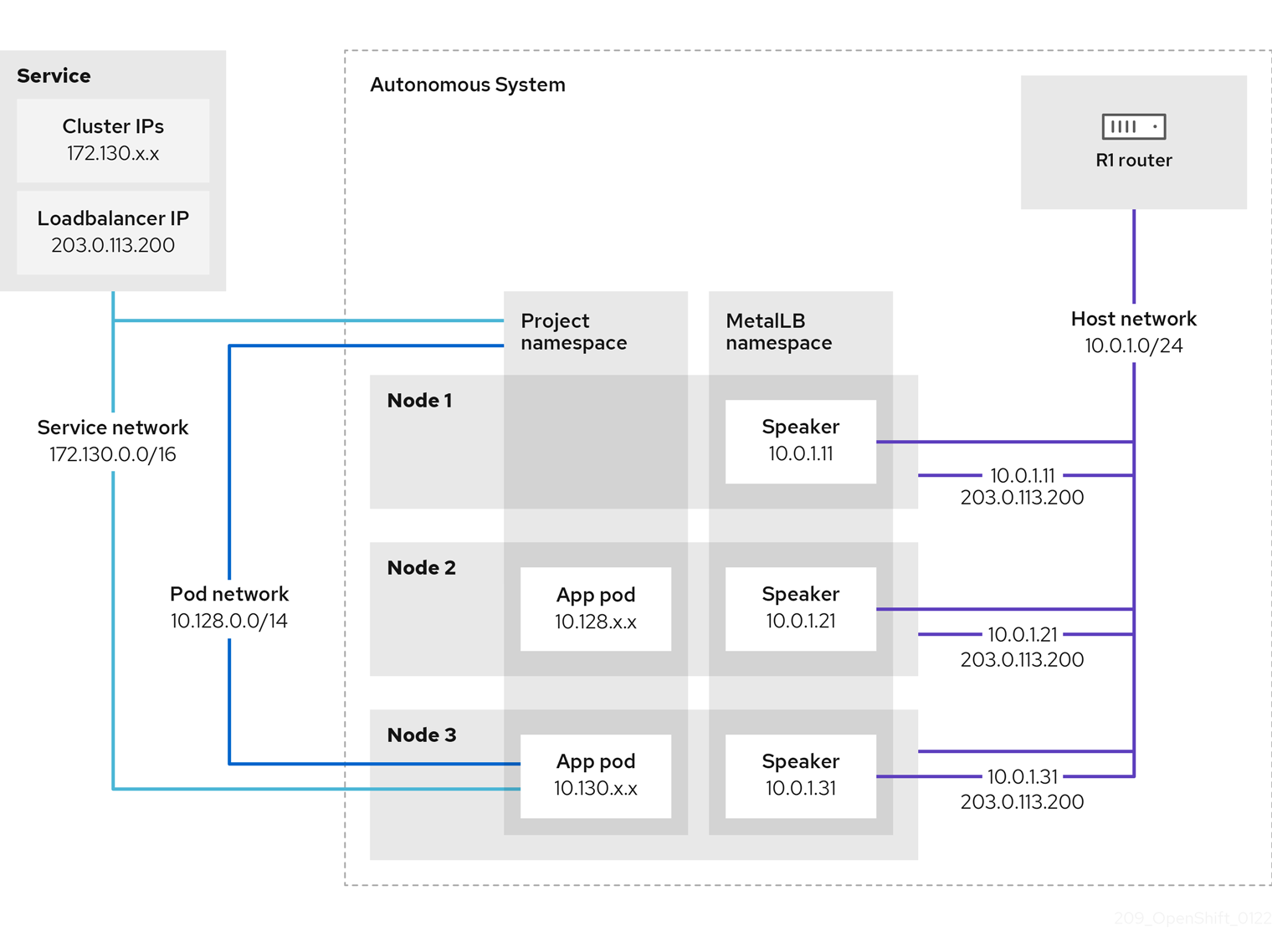
Le graphique précédent illustre les concepts suivants liés à la MetalLB :
-
Une application est disponible par l'intermédiaire d'un service qui possède une adresse IP IPv4 sur le sous-réseau
172.130.0.0/16. Cette adresse IP est accessible depuis l'intérieur du cluster. Le service dispose également d'une adresse IP externe que MetalLB lui a attribuée,203.0.113.200. - Les nœuds 2 et 3 disposent d'un pod pour l'application.
-
Le jeu de démons
speakerexécute un pod sur chaque nœud. L'opérateur MetalLB démarre ces pods. Vous pouvez configurer MetalLB pour spécifier les nœuds qui exécutent les podsspeaker. -
Chaque module
speakerest un module en réseau hôte. L'adresse IP du module est identique à l'adresse IP du nœud sur le réseau hôte. -
Chaque pod
speakerdémarre une session BGP avec tous les pairs BGP et annonce les adresses IP de l'équilibreur de charge ou les routes agrégées aux pairs BGP. Les modulesspeakerannoncent qu'ils font partie du système autonome 65010. Le diagramme montre un routeur, R1, en tant que pair BGP au sein du même système autonome. Cependant, vous pouvez configurer MetalLB pour démarrer des sessions BGP avec des pairs appartenant à d'autres systèmes autonomes. Tous les nœuds dotés d'un pod
speakerqui annonce l'adresse IP de l'équilibreur de charge peuvent recevoir du trafic pour le service.-
Si la stratégie de trafic externe pour le service est définie sur
cluster, tous les nœuds où un pod de haut-parleur est en cours d'exécution annoncent l'adresse IP de l'équilibreur de charge203.0.113.200et tous les nœuds avec un podspeakerpeuvent recevoir du trafic pour le service. Le préfixe de l'hôte n'est annoncé au routeur pair que si la stratégie de trafic externe est définie sur cluster. -
Si la stratégie de trafic externe pour le service est définie sur
local, tous les nœuds où un podspeakerest en cours d'exécution et où au moins un point d'extrémité du service est en cours d'exécution peuvent annoncer l'adresse IP de l'équilibreur de charge203.0.113.200. Seuls ces nœuds peuvent recevoir du trafic pour le service. Dans le graphique précédent, les nœuds 2 et 3 annonceraient203.0.113.200.
-
Si la stratégie de trafic externe pour le service est définie sur
-
Vous pouvez configurer MetalLB pour contrôler les pods
speakerqui démarrent des sessions BGP avec des pairs BGP spécifiques en spécifiant un sélecteur de nœud lorsque vous ajoutez une ressource personnalisée de pair BGP. - Tous les routeurs, tels que R1, qui sont configurés pour utiliser BGP peuvent être définis comme homologues BGP.
- Le trafic du client est acheminé vers l'un des nœuds du réseau hôte. Une fois que le trafic entre dans le nœud, le proxy de service envoie le trafic au module d'application sur le même nœud ou sur un autre nœud en fonction de la stratégie de trafic externe que vous avez définie pour le service.
- Si un nœud devient indisponible, le routeur détecte la défaillance et établit une nouvelle connexion avec un autre nœud. Vous pouvez configurer MetalLB pour qu'il utilise un profil BFD (Bidirectional Forwarding Detection) pour les pairs BGP. BFD permet une détection plus rapide des défaillances de liaison, de sorte que les routeurs peuvent initier de nouvelles connexions plus tôt que sans BFD.
32.1.7. Limites et restrictions
32.1.7.1. Considérations relatives à l'infrastructure pour MetalLB
MetalLB est principalement utile pour les installations sur site, bare metal, car ces installations n'incluent pas de capacité native de load-balancer. En plus des installations bare metal, les installations d'OpenShift Container Platform sur certaines infrastructures peuvent ne pas inclure une capacité native de load-balancer. Par exemple, les infrastructures suivantes peuvent bénéficier de l'ajout de l'opérateur MetalLB :
- Métal nu
- VMware vSphere
MetalLB Operator et MetalLB sont pris en charge par les fournisseurs de réseaux OpenShift SDN et OVN-Kubernetes.
32.1.7.2. Limites du mode couche 2
32.1.7.2.1. Goulot d'étranglement à nœud unique
MetalLB achemine tout le trafic d'un service via un seul nœud, qui peut devenir un goulot d'étranglement et limiter les performances.
Le mode couche 2 limite la bande passante d'entrée de votre service à la bande passante d'un seul nœud. Il s'agit d'une limitation fondamentale de l'utilisation de l'ARP et du NDP pour diriger le trafic.
32.1.7.2.2. Lenteur du basculement
Le basculement entre les nœuds dépend de la coopération des clients. Lorsqu'un basculement se produit, MetalLB envoie des paquets ARP gratuits pour notifier aux clients que l'adresse MAC associée à l'IP de service a changé.
La plupart des systèmes d'exploitation clients traitent correctement les paquets ARP gratuits et mettent rapidement à jour leurs caches de voisins. Lorsque les clients mettent à jour leurs caches rapidement, le basculement s'effectue en quelques secondes. Les clients basculent généralement vers un nouveau nœud en moins de 10 secondes. Toutefois, certains systèmes d'exploitation clients ne traitent pas du tout les paquets ARP gratuits ou ont des implémentations obsolètes qui retardent la mise à jour du cache.
Les versions récentes des systèmes d'exploitation courants tels que Windows, macOS et Linux implémentent correctement le basculement de couche 2. Il ne faut pas s'attendre à des problèmes de basculement lent, sauf pour les systèmes d'exploitation clients plus anciens et moins courants.
Pour minimiser l'impact d'un basculement planifié sur les clients obsolètes, laissez l'ancien nœud fonctionner pendant quelques minutes après le basculement de la direction. L'ancien nœud peut continuer à transmettre le trafic des clients obsolètes jusqu'à ce que leurs caches soient rafraîchis.
Lors d'un basculement non planifié, les IP de service sont inaccessibles jusqu'à ce que les clients obsolètes rafraîchissent leurs entrées de cache.
32.1.7.3. Limitations du mode BGP
32.1.7.3.1. La défaillance d'un nœud peut interrompre toutes les connexions actives
MetalLB partage une limitation commune à l'équilibrage de charge basé sur BGP. Lorsqu'une session BGP se termine, par exemple en cas de défaillance d'un nœud ou de redémarrage d'un pod speaker, la fin de la session peut entraîner la réinitialisation de toutes les connexions actives. Les utilisateurs finaux peuvent recevoir un message Connection reset by peer.
La conséquence d'une session BGP terminée est spécifique à l'implémentation de chaque fabricant de routeurs. Cependant, vous pouvez prévoir qu'un changement dans le nombre de pods speaker affecte le nombre de sessions BGP et que les connexions actives avec les pairs BGP seront interrompues.
Pour éviter ou réduire la probabilité d'une interruption de service, vous pouvez spécifier un sélecteur de nœud lorsque vous ajoutez un homologue BGP. En limitant le nombre de nœuds qui démarrent des sessions BGP, une défaillance sur un nœud qui n'a pas de session BGP n'a pas d'incidence sur les connexions au service.
32.1.7.3.2. Prise en charge d'un seul ASN et d'un seul ID de routeur uniquement
Lorsque vous ajoutez une ressource personnalisée BGP peer, vous spécifiez le champ spec.myASN pour identifier le numéro de système autonome (ASN) auquel MetalLB appartient. OpenShift Container Platform utilise une implémentation de BGP avec MetalLB qui exige que MetalLB appartienne à un seul ASN. Si vous tentez d'ajouter un pair BGP et que vous spécifiez une valeur différente pour spec.myASN par rapport à une ressource personnalisée de pair BGP existante, vous recevez une erreur.
De même, lorsque vous ajoutez une ressource personnalisée d'homologue BGP, le champ spec.routerID est facultatif. Si vous spécifiez une valeur pour ce champ, vous devez spécifier la même valeur pour toutes les autres ressources personnalisées d'homologue BGP que vous ajoutez.
La limitation à la prise en charge d'un seul ASN et d'un seul ID de routeur est une différence par rapport à la mise en œuvre de MetalLB soutenue par la communauté.
32.2. Installation de l'opérateur MetalLB
En tant qu'administrateur de cluster, vous pouvez ajouter l'Opérateur MetallB afin qu'il puisse gérer le cycle de vie d'une instance de MetalLB sur votre cluster.
La MetalLB et le basculement IP sont incompatibles. Si vous avez configuré le basculement IP pour votre cluster, effectuez les étapes pour supprimer le basculement IP avant d'installer l'Opérateur.
32.2.1. Installer l'Opérateur MetalLB à partir de l'OperatorHub en utilisant la console web
En tant qu'administrateur de cluster, vous pouvez installer l'opérateur MetalLB en utilisant la console web d'OpenShift Container Platform.
Conditions préalables
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Dans la console web d'OpenShift Container Platform, naviguez vers Operators → OperatorHub.
Tapez un mot-clé dans la case Filter by keyword ou faites défiler l'écran pour trouver l'opérateur souhaité. Par exemple, tapez
metallbpour trouver l'opérateur MetalLB.Vous pouvez également filtrer les options par Infrastructure Features. Par exemple, sélectionnez Disconnected si vous voulez voir les opérateurs qui travaillent dans des environnements déconnectés, également connus sous le nom d'environnements réseau restreints.
- Sur la page Install Operator acceptez les valeurs par défaut et cliquez sur Install.
Vérification
Pour confirmer que l'installation a réussi :
- Naviguez jusqu'à l'écran Operators → Installed Operators page.
-
Vérifiez que l'Opérateur est installé dans l'espace de noms
openshift-operatorset que son statut estSucceeded.
Si l'opérateur n'est pas installé correctement, vérifiez l'état de l'opérateur et consultez les journaux :
-
Naviguez jusqu'à l'écran Operators → Installed Operators et vérifiez que la colonne
Statusne présente pas d'erreurs ou de défaillances. -
Naviguez jusqu'à l'écran Workloads → Pods et vérifiez les journaux de tous les pods du projet
openshift-operatorsqui signalent des problèmes.
-
Naviguez jusqu'à l'écran Operators → Installed Operators et vérifiez que la colonne
32.2.2. Installation à partir d'OperatorHub en utilisant le CLI
Au lieu d'utiliser la console web d'OpenShift Container Platform, vous pouvez installer un Operator depuis OperatorHub en utilisant le CLI. Vous pouvez utiliser l'OpenShift CLI (oc) pour installer l'opérateur MetalLB.
Il est recommandé d'installer l'opérateur dans l'espace de noms metallb-system lors de l'utilisation de l'interface de programmation.
Conditions préalables
- Un cluster installé sur du matériel bare-metal.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un espace de noms pour l'opérateur MetalLB en entrant la commande suivante :
$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: metallb-system EOFCréer une ressource personnalisée (CR) de groupe d'opérateurs dans l'espace de noms :
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system EOFConfirmez que le groupe Operator est installé dans l'espace de noms :
$ oc get operatorgroup -n metallb-systemExemple de sortie
NAME AGE metallb-operator 14mCréer un CR
Subscription:Définissez le CR
Subscriptionet enregistrez le fichier YAML, par exemplemetallb-sub.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator-sub namespace: metallb-system spec: channel: stable name: metallb-operator source: redhat-operators1 sourceNamespace: openshift-marketplace- 1
- Vous devez spécifier la valeur
redhat-operators.
Pour créer le CR
Subscription, exécutez la commande suivante :$ oc create -f metallb-sub.yaml
Facultatif : Pour que les mesures BGP et BFD apparaissent dans Prometheus, vous pouvez étiqueter l'espace de noms comme dans la commande suivante :
$ oc label ns metallb-system "openshift.io/cluster-monitoring=true"
Vérification
Les étapes de vérification supposent que l'opérateur MetalLB est installé dans l'espace de noms metallb-system.
Confirmer que le plan d'installation se trouve dans l'espace de noms :
$ oc get installplan -n metallb-systemExemple de sortie
NAME CSV APPROVAL APPROVED install-wzg94 metallb-operator.4.12.0-nnnnnnnnnnnn Automatic trueNoteL'installation de l'opérateur peut prendre quelques secondes.
Pour vérifier que l'opérateur est installé, entrez la commande suivante :
$ oc get clusterserviceversion -n metallb-system \ -o custom-columns=Name:.metadata.name,Phase:.status.phaseExemple de sortie
Name Phase metallb-operator.4.12.0-nnnnnnnnnnnn Succeeded
32.2.3. Démarrer MetalLB sur votre cluster
Après avoir installé l'Opérateur, vous devez configurer une instance unique d'une ressource personnalisée MetalLB. Après avoir configuré la ressource personnalisée, l'Opérateur démarre MetalLB sur votre cluster.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur MetalLB.
Procédure
Cette procédure suppose que le MetalLB Operator est installé dans l'espace de noms metallb-system. Si vous avez effectué l'installation à l'aide de la console web, remplacez l'espace de noms par openshift-operators.
Créer une instance unique d'une ressource personnalisée MetalLB :
$ cat << EOF | oc apply -f - apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system EOF
Vérification
Confirmez que le déploiement du contrôleur MetalLB et le jeu de démons pour l'enceinte MetalLB sont en cours d'exécution.
Vérifiez que le déploiement du contrôleur est en cours :
$ oc get deployment -n metallb-system controllerExemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE controller 1/1 1 1 11mVérifiez que le démon défini pour l'orateur est en cours d'exécution :
$ oc get daemonset -n metallb-system speakerExemple de sortie
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE speaker 6 6 6 6 6 kubernetes.io/os=linux 18mL'exemple indique 6 enceintes. Le nombre de modules de haut-parleurs dans votre cluster peut être différent de celui indiqué dans l'exemple. Assurez-vous que la sortie indique un module pour chaque nœud de votre cluster.
32.2.4. Spécifications de déploiement pour MetalLB
Lorsque vous démarrez une instance de MetalLB à l'aide de la ressource personnalisée MetalLB, vous pouvez configurer des spécifications de déploiement dans la ressource personnalisée MetalLB pour gérer le déploiement et l'exécution des pods controller ou speaker dans votre cluster. Utilisez ces spécifications de déploiement pour gérer les tâches suivantes :
- Sélectionner les nœuds pour le déploiement des pods MetalLB.
- Gérer la programmation en utilisant la priorité et l'affinité des pods.
- Attribuer des limites de CPU pour les pods MetalLB.
- Attribuer une classe d'exécution de conteneur pour les pods MetalLB.
- Attribuer des métadonnées aux pods MetalLB.
32.2.4.1. Limiter les pods d'orateurs à des nœuds spécifiques
Par défaut, lorsque vous démarrez MetalLB avec l'Opérateur MetalLB, l'Opérateur démarre une instance d'un pod speaker sur chaque nœud du cluster. Seuls les nœuds avec un pod speaker peuvent annoncer une adresse IP d'équilibreur de charge. Vous pouvez configurer la ressource personnalisée MetalLB avec un sélecteur de nœud pour spécifier quels nœuds exécutent les pods speaker.
La raison la plus courante de limiter les pods speaker à des nœuds spécifiques est de s'assurer que seuls les nœuds disposant d'interfaces réseau sur des réseaux spécifiques annoncent les adresses IP de l'équilibreur de charge. Seuls les nœuds disposant d'un pod speaker en cours d'exécution sont annoncés comme destinations de l'adresse IP de l'équilibreur de charge.
Si vous limitez les pods speaker à des nœuds spécifiques et que vous spécifiez local pour la stratégie de trafic externe d'un service, vous devez vous assurer que les pods d'application du service sont déployés sur les mêmes nœuds.
Exemple de configuration pour limiter les pods de haut-parleurs aux nœuds de travail
apiVersion: metallb.io/v1beta1
kind: MetalLB
metadata:
name: metallb
namespace: metallb-system
spec:
nodeSelector: <.>
node-role.kubernetes.io/worker: ""
speakerTolerations: <.>
- key: "Example"
operator: "Exists"
effect: "NoExecute"
<.> L'exemple de configuration spécifie d'affecter les modules de haut-parleurs aux nœuds de travailleurs, mais vous pouvez spécifier les étiquettes que vous avez affectées aux nœuds ou tout sélecteur de nœud valide. <.> Dans cet exemple de configuration, le module auquel cette tolérance est attachée tolère toute souillure correspondant à la valeur key et à la valeur effect à l'aide de l'option operator.
Après avoir appliqué un manifeste avec le champ spec.nodeSelector, vous pouvez vérifier le nombre de pods que l'opérateur a déployés avec la commande oc get daemonset -n metallb-system speaker. De même, vous pouvez afficher les nœuds qui correspondent à vos étiquettes à l'aide d'une commande telle que oc get nodes -l node-role.kubernetes.io/worker=.
Vous pouvez éventuellement autoriser le nœud à contrôler les modules de haut-parleurs qui doivent ou ne doivent pas être programmés sur lui à l'aide de règles d'affinité. Vous pouvez également limiter ces modules en appliquant une liste de tolérances. Pour plus d'informations sur les règles d'affinité, les taches et les tolérances, consultez les ressources supplémentaires.
32.2.4.2. Configurer la priorité et l'affinité des pods dans un déploiement MetalLB
Vous pouvez éventuellement attribuer des règles de priorité et d'affinité aux modules controller et speaker en configurant la ressource personnalisée MetalLB. La priorité du pod indique l'importance relative d'un pod sur un nœud et planifie le pod en fonction de cette priorité. Définissez une priorité élevée pour votre module controller ou speaker afin de garantir la priorité de planification par rapport aux autres modules sur le nœud.
L'affinité de pod gère les relations entre les pods. Attribuez une affinité de pod à controller ou speaker pods pour contrôler le nœud sur lequel l'ordonnanceur place le pod dans le contexte des relations entre les pods. Par exemple, vous pouvez autoriser des modules avec des charges de travail logiquement liées sur le même nœud, ou vous assurer que les modules avec des charges de travail conflictuelles sont sur des nœuds séparés.
Conditions préalables
-
Vous êtes connecté en tant qu'utilisateur avec des privilèges
cluster-admin. - Vous avez installé l'opérateur MetalLB.
Procédure
Créez une ressource personnalisée
PriorityClass, telle quemyPriorityClass.yaml, pour configurer le niveau de priorité. Cet exemple utilise une classe de haute priorité :apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000Appliquer la configuration des ressources personnalisées
PriorityClass:$ oc apply -f myPriorityClass.yamlCréez une ressource personnalisée
MetalLB, telle queMetalLBPodConfig.yaml, pour spécifier les valeurspriorityClassNameetpodAffinity:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: priorityClassName: high-priority runtimeClassName: myclass speakerConfig: priorityClassName: high-priority runtimeClassName: myclass affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchLabels: app: metallb topologyKey: kubernetes.io/hostnameAppliquer la configuration des ressources personnalisées
MetalLB:$ oc apply -f MetalLBPodConfig.yaml
Vérification
Pour afficher la classe de priorité que vous avez attribuée aux pods dans un espace de noms, exécutez la commande suivante, en remplaçant
<namespace>par votre espace de noms cible :$ oc get pods -n <namespace> -o custom-columns=NAME :.metadata.name,PRIORITY :.spec.priorityClassNamePour vérifier que le planificateur a placé les pods conformément aux règles d'affinité des pods, affichez les métadonnées du nœud du pod en exécutant la commande suivante, en remplaçant
<namespace>par votre espace de noms cible :$ oc get pod -o=custom-columns=NODE :.spec.nodeName,NAME :.metadata.name -n <namespace>
32.2.4.3. Configurer les limites de CPU des pods dans un déploiement MetalLB
Vous pouvez optionnellement assigner des limites de CPU aux pods controller et speaker en configurant la ressource personnalisée MetalLB. La définition de limites de CPU pour les modules controller ou speaker vous aide à gérer les ressources de calcul sur le nœud. Cela permet de s'assurer que tous les modules du nœud disposent des ressources de calcul nécessaires pour gérer les charges de travail et l'entretien du cluster.
Conditions préalables
-
Vous êtes connecté en tant qu'utilisateur avec des privilèges
cluster-admin. - Vous avez installé l'opérateur MetalLB.
Procédure
Créez un fichier de ressources personnalisé
MetalLB, tel queCPULimits.yaml, afin de spécifier la valeurcpupour les modulescontrolleretspeaker:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: resources: limits: cpu: "200m" speakerConfig: resources: limits: cpu: "300m"Appliquer la configuration des ressources personnalisées
MetalLB:$ oc apply -f CPULimits.yaml
Vérification
Pour afficher les ressources informatiques d'un module, exécutez la commande suivante, en remplaçant
<pod_name>par votre module cible :oc describe pod <nom_du_pod>
32.2.4.4. Configurer une classe d'exécution de conteneur dans un déploiement MetalLB
Vous pouvez éventuellement affecter une classe d'exécution de conteneur aux modules controller et speaker en configurant la ressource personnalisée MetalLB. Par exemple, pour les charges de travail Windows, vous pouvez affecter une classe d'exécution Windows au module, qui utilise cette classe d'exécution pour tous les conteneurs du module.
Conditions préalables
-
Vous êtes connecté en tant qu'utilisateur avec des privilèges
cluster-admin. - Vous avez installé l'opérateur MetalLB.
Procédure
Créez une ressource personnalisée
RuntimeClass, telle quemyRuntimeClass.yaml, pour définir votre classe d'exécution :apiVersion: node.k8s.io/v1 kind: RuntimeClass metadata: name: myclass handler: myconfigurationAppliquer la configuration des ressources personnalisées
RuntimeClass:$ oc apply -f myRuntimeClass.yamlCréez une ressource personnalisée
MetalLB, telle queMetalLBRuntime.yaml, pour spécifier la valeurruntimeClassName:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: runtimeClassName: myclass annotations:1 controller: demo speakerConfig: runtimeClassName: myclass annotations:2 speaker: demo- 1 2
- Cet exemple utilise
annotationspour ajouter des métadonnées telles que des informations sur la version de construction ou des informations sur les demandes d'extraction GitHub. Les annotations peuvent contenir des caractères non autorisés dans les étiquettes. Cependant, vous ne pouvez pas utiliser les annotations pour identifier ou sélectionner des objets.
Appliquer la configuration des ressources personnalisées
MetalLB:$ oc apply -f MetalLBRuntime.yaml
Vérification
Pour afficher la durée d'exécution d'un conteneur pour un module, exécutez la commande suivante :
$ oc get pod -o custom-columns=NAME:metadata.name,STATUS:.status.phase,RUNTIME_CLASS:.spec.runtimeClassName
32.2.6. Prochaines étapes
32.3. Mise à jour de la MetalLB
Si vous utilisez actuellement la version 4.10 ou une version antérieure du MetalLB Operator, veuillez noter que les mises à jour automatiques vers une version postérieure à 4.10 ne fonctionnent pas. La mise à niveau vers une version plus récente à partir de n'importe quelle version de MetalLB Operator 4.11 ou plus récente est réussie. Par exemple, la mise à niveau de la version 4.12 à la version 4.13 se fera sans problème.
Voici un résumé de la procédure de mise à jour pour le MetalLB Operator à partir de la version 4.10 et des versions antérieures :
-
Supprimer la version de MetalLB Operator installée, par exemple 4.10. Assurez-vous que l'espace de noms et la ressource personnalisée
metallbne sont pas supprimés. - A l'aide du CLI, installez le MetalLB Operator 4.12 dans le même espace de noms que celui où la version précédente du MetalLB Operator était installée.
Cette procédure ne s'applique pas aux mises à jour automatiques du flux z de l'Opérateur MetalLB, qui suivent la méthode standard simple.
Pour connaître les étapes détaillées de la mise à niveau du MetalLB Operator à partir de la version 4.10 et des versions antérieures, consultez les instructions suivantes.
32.3.1. Suppression de l'opérateur MetalLB d'un cluster à l'aide de la console web
Les administrateurs de cluster peuvent supprimer les opérateurs installés dans un espace de noms sélectionné à l'aide de la console web.
Conditions préalables
-
Accès à la console web d'un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin.
Procédure
- Naviguez jusqu'à l'écran Operators → Installed Operators page.
- Recherchez l'opérateur MetalLB. Cliquez ensuite dessus.
Dans la partie droite de la page Operator Details sélectionnez Uninstall Operator dans le menu déroulant Actions dans le menu déroulant.
La boîte de dialogue Uninstall Operator? s'affiche.
Sélectionnez Uninstall pour supprimer l'opérateur, les déploiements de l'opérateur et les pods. Suite à cette action, l'opérateur cesse de fonctionner et ne reçoit plus de mises à jour.
NoteCette action ne supprime pas les ressources gérées par l'opérateur, y compris les définitions de ressources personnalisées (CRD) et les ressources personnalisées (CR). Les tableaux de bord et les éléments de navigation activés par la console Web et les ressources hors cluster qui continuent de fonctionner peuvent nécessiter un nettoyage manuel. Pour les supprimer après la désinstallation de l'opérateur, vous devrez peut-être supprimer manuellement les CRD de l'opérateur.
32.3.2. Suppression de MetalLB Operator d'un cluster à l'aide du CLI
Les administrateurs de clusters peuvent supprimer les opérateurs installés dans un espace de noms sélectionné à l'aide de l'interface de ligne de commande.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. -
ocinstallée sur le poste de travail.
Procédure
Vérifiez la version actuelle de l'opérateur MetalLB abonné dans le champ
currentCSV:$ oc get subscription metallb-operator -n metallb-system -o yaml | grep currentCSVExemple de sortie
currentCSV: metallb-operator.4.10.0-202207051316Supprimer l'abonnement :
$ oc delete subscription metallb-operator -n metallb-systemExemple de sortie
subscription.operators.coreos.com "metallb-operator" deletedSupprimez le CSV de l'opérateur dans l'espace de noms cible en utilisant la valeur
currentCSVde l'étape précédente :$ oc delete clusterserviceversion metallb-operator.4.10.0-202207051316 -n metallb-systemExemple de sortie
clusterserviceversion.operators.coreos.com "metallb-operator.4.10.0-202207051316" deleted
32.3.3. Mise à jour de l'opérateur MetalLB
Conditions préalables
-
Accédez au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Vérifiez que l'espace de noms
metallb-systemexiste toujours :$ oc get namespaces | grep metallb-systemExemple de sortie
metallb-system Active 31mVérifiez que la ressource personnalisée
metallbexiste toujours :$ oc get metallb -n metallb-systemExemple de sortie
NAME AGE metallb 33mSuivez les instructions données dans le document "Installing from OperatorHub using the CLI" pour installer la dernière version 4.12 de MetalLB Operator.
NoteLors de l'installation de la dernière version 4.12 de l'Opérateur MetalLB, vous devez installer l'Opérateur dans le même espace de noms que celui dans lequel il a été installé précédemment.
Vérifiez que la version mise à jour de l'opérateur est bien la version 4.12.
$ oc get csv -n metallb-systemExemple de sortie
NAME DISPLAY VERSION REPLACES PHASE metallb-operator.4.4.12.0-202207051316 MetalLB Operator 4.4.12.0-202207051316 Succeeded
32.3.4. Ressources supplémentaires
32.4. Configuration des pools d'adresses MetalLB
En tant qu'administrateur de cluster, vous pouvez ajouter, modifier et supprimer des pools d'adresses. L'opérateur MetalLB utilise les ressources personnalisées du pool d'adresses pour définir les adresses IP que MetalLB peut attribuer aux services. L'espace de noms utilisé dans les exemples suppose que l'espace de noms est metallb-system.
32.4.1. À propos de la ressource personnalisée IPAddressPool
La définition de ressource personnalisée du pool d'adresses (CRD) et l'API documentées dans "Load balancing with MetalLB" dans OpenShift Container Platform 4.10 peuvent toujours être utilisées dans 4.12. Cependant, la fonctionnalité améliorée associée à la publicité de IPAddressPools avec la couche 2 ou le protocole BGP n'est pas prise en charge lors de l'utilisation de la CRD du pool d'adresses.
Les champs de la ressource personnalisée IPAddressPool sont décrits dans le tableau suivant.
| Field | Type | Description |
|---|---|---|
|
|
|
Spécifie le nom du pool d'adresses. Lorsque vous ajoutez un service, vous pouvez spécifier ce nom de pool dans l'annotation |
|
|
| Spécifie l'espace de noms pour le pool d'adresses. Spécifier le même espace de noms que celui utilisé par l'opérateur MetalLB. |
|
|
|
Facultatif : Spécifie la paire clé-valeur attribuée à |
|
|
| Spécifie une liste d'adresses IP que MetalLB Operator attribuera aux services. Vous pouvez spécifier plusieurs plages dans un seul pool ; elles partageront toutes les mêmes paramètres. Spécifiez chaque plage en notation CIDR ou sous forme d'adresses IP de début et de fin séparées par un trait d'union. |
|
|
|
Facultatif : Spécifie si MetalLB attribue automatiquement les adresses IP de ce pool. Spécifiez |
32.4.2. Configuration d'un pool d'adresses
En tant qu'administrateur de cluster, vous pouvez ajouter des pools d'adresses à votre cluster pour contrôler les adresses IP que MetalLB peut attribuer aux services de load-balancer.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un fichier, tel que
ipaddresspool.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example labels:1 zone: east spec: addresses: - 203.0.113.1-203.0.113.10 - 203.0.113.65-203.0.113.75- 1
- Cette étiquette attribuée à
IPAddressPoolpeut être référencée paripAddressPoolSelectorsdans le CRDBGPAdvertisementpour associerIPAddressPoolà l'annonce.
Appliquer la configuration du pool d'adresses IP :
$ oc apply -f ipaddresspool.yaml
Vérification
Afficher le pool d'adresses :
$ oc describe -n metallb-system IPAddressPool doc-exampleExemple de sortie
Name: doc-example Namespace: metallb-system Labels: zone=east Annotations: <none> API Version: metallb.io/v1beta1 Kind: IPAddressPool Metadata: ... Spec: Addresses: 203.0.113.1-203.0.113.10 203.0.113.65-203.0.113.75 Auto Assign: true Events: <none>
Confirmez que le nom du pool d'adresses, tel que doc-example, et les plages d'adresses IP apparaissent dans la sortie.
32.4.3. Exemples de configurations de pools d'adresses
32.4.3.1. Exemple : Plages IPv4 et CIDR
Vous pouvez spécifier une plage d'adresses IP en notation CIDR. Vous pouvez combiner la notation CIDR avec la notation qui utilise un trait d'union pour séparer les limites inférieures et supérieures.
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: doc-example-cidr
namespace: metallb-system
spec:
addresses:
- 192.168.100.0/24
- 192.168.200.0/24
- 192.168.255.1-192.168.255.532.4.3.2. Exemple : Réserver des adresses IP
Vous pouvez définir le champ autoAssign sur false pour empêcher MetalLB d'attribuer automatiquement les adresses IP du pool. Lorsque vous ajoutez un service, vous pouvez demander une adresse IP spécifique du pool ou vous pouvez spécifier le nom du pool dans une annotation pour demander n'importe quelle adresse IP du pool.
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: doc-example-reserved
namespace: metallb-system
spec:
addresses:
- 10.0.100.0/28
autoAssign: false32.4.3.3. Exemple : Adresses IPv4 et IPv6
Vous pouvez ajouter des pools d'adresses qui utilisent IPv4 et IPv6. Vous pouvez spécifier plusieurs plages dans la liste addresses, comme dans plusieurs exemples IPv4.
L'attribution d'une adresse IPv4 unique, d'une adresse IPv6 unique ou des deux est déterminée par la façon dont vous ajoutez le service. Les champs spec.ipFamilies et spec.ipFamilyPolicy contrôlent la manière dont les adresses IP sont attribuées au service.
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: doc-example-combined
namespace: metallb-system
spec:
addresses:
- 10.0.100.0/28
- 2002:2:2::1-2002:2:2::10032.4.5. Prochaines étapes
- Pour le mode BGP, voir Configuration des pairs BGP MetalLB.
- Configuration des services pour l'utilisation de MetalLB.
32.5. A propos de la publicité pour les pools d'adresses IP
Vous pouvez configurer la MetalLB pour que l'adresse IP soit annoncée par les protocoles de la couche 2, le protocole BGP ou les deux. Avec la couche 2, MetalLB fournit une adresse IP externe tolérante aux pannes. Avec le protocole BGP, MetalLB fournit une tolérance aux pannes pour l'adresse IP externe et l'équilibrage de la charge.
MetalLB prend en charge la publicité par L2 et BGP pour le même ensemble d'adresses IP.
MetalLB offre la possibilité d'attribuer des pools d'adresses à des pairs BGP spécifiques, c'est-à-dire à un sous-ensemble de nœuds sur le réseau. Cela permet des configurations plus complexes, par exemple en facilitant l'isolation des nœuds ou la segmentation du réseau.
32.5.1. A propos de la ressource personnalisée BGPAdvertisement
Les champs de l'objet BGPAdvertisements sont définis dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
| Spécifie le nom de l'annonce BGP. |
|
|
| Spécifie l'espace de noms pour l'annonce BGP. Spécifiez le même espace de noms que celui utilisé par l'opérateur MetalLB. |
|
|
|
Facultatif : Spécifie le nombre de bits à inclure dans un masque CIDR de 32 bits. Pour agréger les routes que l'orateur annonce aux homologues BGP, le masque est appliqué aux routes pour plusieurs adresses IP de service et l'orateur annonce la route agrégée. Par exemple, avec une longueur d'agrégation de |
|
|
|
Facultatif : Spécifie le nombre de bits à inclure dans un masque CIDR de 128 bits. Par exemple, avec une longueur d'agrégation de |
|
|
| Facultatif : Spécifie une ou plusieurs communautés BGP. Chaque communauté est spécifiée sous la forme de deux valeurs de 16 bits séparées par le caractère deux-points. Les communautés connues doivent être spécifiées sous forme de valeurs de 16 bits :
|
|
|
| Facultatif : Spécifie la préférence locale pour cette annonce. Cet attribut BGP s'applique aux sessions BGP au sein du système autonome. |
|
|
|
Facultatif : La liste de |
|
|
|
Facultatif : Un sélecteur pour le |
|
|
|
Facultatif : |
|
|
| Facultatif : Peers (pairs) limite le pair BGP auquel annoncer les IP des pools sélectionnés. Lorsqu'elle est vide, l'IP de l'équilibreur de charge est annoncée à tous les pairs BGP configurés. |
32.5.2. Configurer MetalLB avec une annonce BGP et un cas d'utilisation de base
Configurez MetalLB comme suit pour que les routeurs BGP homologues reçoivent une route 203.0.113.200/32 et une route fc00:f853:ccd:e799::1/128 pour chaque adresse IP d'équilibreur de charge que MetalLB attribue à un service. Les champs localPref et communities n'étant pas spécifiés, les routes sont annoncées avec localPref à zéro et aucune communauté BGP.
32.5.2.1. Exemple : Annonce d'une configuration de base d'un pool d'adresses avec BGP
Configurez MetalLB comme suit pour que le site IPAddressPool soit annoncé par le protocole BGP.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses IP.
Créez un fichier, tel que
ipaddresspool.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-bgp-basic spec: addresses: - 203.0.113.200/30 - fc00:f853:ccd:e799::/124Appliquer la configuration du pool d'adresses IP :
$ oc apply -f ipaddresspool.yaml
Créer une annonce BGP.
Créez un fichier, tel que
bgpadvertisement.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-basic namespace: metallb-system spec: ipAddressPools: - doc-example-bgp-basicAppliquer la configuration :
$ oc apply -f bgpadvertisement.yaml
32.5.3. Configurer MetalLB avec une annonce BGP et un cas d'utilisation avancé
Configurez MetalLB comme suit pour que MetalLB attribue des adresses IP aux services de load-balancer dans les plages entre 203.0.113.200 et 203.0.113.203 et entre fc00:f853:ccd:e799::0 et fc00:f853:ccd:e799::f.
Pour expliquer les deux annonces BGP, considérons un cas où MetalLB attribue l'adresse IP 203.0.113.200 à un service. Avec cette adresse IP comme exemple, l'orateur annonce deux routes aux pairs BGP :
-
203.0.113.200/32aveclocalPrefdéfini sur100et la communauté définie sur la valeur numérique de la communautéNO_ADVERTISE. Cette spécification indique aux routeurs homologues qu'ils peuvent utiliser cette route mais qu'ils ne doivent pas propager les informations relatives à cette route aux homologues BGP. -
203.0.113.200/30l'adresse IP de l'équilibreur de charge est agrégée par MetalLB en une seule route. MetalLB annonce la route agrégée aux pairs BGP avec l'attribut community défini sur8000:800. Les pairs BGP propagent la route203.0.113.200/30à d'autres pairs BGP. Lorsque le trafic est acheminé vers un nœud doté d'un haut-parleur, la route203.0.113.200/32est utilisée pour transférer le trafic dans le cluster et vers un pod associé au service.
Au fur et à mesure que vous ajoutez des services et que MetalLB attribue des adresses IP d'équilibreur de charge à partir du pool, les routeurs pairs reçoivent une route locale, 203.0.113.20x/32, pour chaque service, ainsi que la route agrégée 203.0.113.200/30. Chaque service ajouté génère la route /30, mais MetalLB déduplique les routes en une annonce BGP avant de communiquer avec les routeurs pairs.
32.5.3.1. Exemple : Annonce d'une configuration avancée d'un pool d'adresses avec BGP
Configurez MetalLB comme suit pour que le site IPAddressPool soit annoncé par le protocole BGP.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses IP.
Créez un fichier, tel que
ipaddresspool.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-bgp-adv labels: zone: east spec: addresses: - 203.0.113.200/30 - fc00:f853:ccd:e799::/124 autoAssign: falseAppliquer la configuration du pool d'adresses IP :
$ oc apply -f ipaddresspool.yaml
Créer une annonce BGP.
Créez un fichier, tel que
bgpadvertisement1.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-adv-1 namespace: metallb-system spec: ipAddressPools: - doc-example-bgp-adv communities: - 65535:65282 aggregationLength: 32 localPref: 100Appliquer la configuration :
$ oc apply -f bgpadvertisement1.yamlCréez un fichier, tel que
bgpadvertisement2.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-adv-2 namespace: metallb-system spec: ipAddressPools: - doc-example-bgp-adv communities: - 8000:800 aggregationLength: 30 aggregationLengthV6: 124Appliquer la configuration :
$ oc apply -f bgpadvertisement2.yaml
32.5.4. Publicité d'un groupe d'adresses IP à partir d'un sous-ensemble de nœuds
Pour annoncer une adresse IP à partir d'un pool d'adresses IP, uniquement à partir d'un ensemble spécifique de nœuds, utilisez la spécification .spec.nodeSelector dans la ressource personnalisée BGPAdvertisement. Cette spécification associe un pool d'adresses IP à un ensemble de nœuds dans le cluster. Ceci est utile lorsque vous avez des nœuds sur différents sous-réseaux dans un cluster et que vous voulez annoncer une adresse IP à partir d'un pool d'adresses à partir d'un sous-réseau spécifique, par exemple un sous-réseau public uniquement.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses IP en utilisant une ressource personnalisée :
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: pool1 spec: addresses: - 4.4.4.100-4.4.4.200 - 2001:100:4::200-2001:100:4::400Contrôlez les nœuds du cluster à partir desquels l'adresse IP de
pool1est annoncée en définissant la valeur.spec.nodeSelectordans la ressource personnalisée BGPAdvertisement :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: example spec: ipAddressPools: - pool1 nodeSelector: - matchLabels: kubernetes.io/hostname: NodeA - matchLabels: kubernetes.io/hostname: NodeB
Dans cet exemple, l'adresse IP de pool1 ne fait de la publicité que pour NodeA et NodeB.
32.5.5. À propos de la ressource personnalisée L2Advertisement
Les champs de l'objet l2Advertisements sont définis dans le tableau suivant :
| Field | Type | Description |
|---|---|---|
|
|
| Spécifie le nom de l'annonce L2. |
|
|
| Spécifie l'espace de noms pour l'annonce L2. Spécifiez le même espace de noms que celui utilisé par l'opérateur MetalLB. |
|
|
|
Facultatif : La liste de |
|
|
|
Facultatif : Un sélecteur pour le |
|
|
|
Facultatif : Important La limitation des nœuds à annoncer en tant que sauts suivants est une fonctionnalité de l'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement. Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique. |
32.5.6. Configuration de MetalLB avec une annonce L2
Configurez MetalLB comme suit pour que le site IPAddressPool soit annoncé avec le protocole L2.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses IP.
Créez un fichier, tel que
ipaddresspool.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-l2 spec: addresses: - 4.4.4.0/24 autoAssign: falseAppliquer la configuration du pool d'adresses IP :
$ oc apply -f ipaddresspool.yaml
Créer une publicité L2.
Créez un fichier, tel que
l2advertisement.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - doc-example-l2Appliquer la configuration :
$ oc apply -f l2advertisement.yaml
32.5.7. Configuration de MetalLB avec une annonce et une étiquette L2
Le champ ipAddressPoolSelectors dans les définitions des ressources personnalisées BGPAdvertisement et L2Advertisement est utilisé pour associer IPAddressPool à l'annonce sur la base de l'étiquette attribuée à IPAddressPool au lieu du nom lui-même.
Cet exemple montre comment configurer MetalLB pour que le site IPAddressPool soit annoncé avec le protocole L2 en configurant le champ ipAddressPoolSelectors.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses IP.
Créez un fichier, tel que
ipaddresspool.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-l2-label labels: zone: east spec: addresses: - 172.31.249.87/32Appliquer la configuration du pool d'adresses IP :
$ oc apply -f ipaddresspool.yaml
Créer une publicité L2 annonçant l'IP en utilisant
ipAddressPoolSelectors.Créez un fichier, tel que
l2advertisement.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement-label namespace: metallb-system spec: ipAddressPoolSelectors: - matchExpressions: - key: zone operator: In values: - eastAppliquer la configuration :
$ oc apply -f l2advertisement.yaml
32.6. Configuration des pairs BGP de la MetalLB
En tant qu'administrateur de cluster, vous pouvez ajouter, modifier et supprimer des pairs BGP (Border Gateway Protocol). L'opérateur MetalLB utilise les ressources personnalisées des pairs BGP pour identifier les pairs que les pods MetalLB speaker contactent pour démarrer des sessions BGP. Les pairs reçoivent les annonces de routes pour les adresses IP des répartiteurs de charge que MetalLB attribue aux services.
32.6.1. A propos de la ressource personnalisée BGP peer
Les champs de la ressource personnalisée BGP peer sont décrits dans le tableau suivant.
| Field | Type | Description |
|---|---|---|
|
|
| Spécifie le nom de la ressource personnalisée de l'homologue BGP. |
|
|
| Spécifie l'espace de noms pour la ressource personnalisée de l'homologue BGP. |
|
|
|
Spécifie le numéro du système autonome pour l'extrémité locale de la session BGP. Spécifiez la même valeur dans toutes les ressources personnalisées de l'homologue BGP que vous ajoutez. La plage est comprise entre |
|
|
|
Spécifie le numéro du système autonome pour l'extrémité distante de la session BGP. La plage est comprise entre |
|
|
| Spécifie l'adresse IP de l'homologue à contacter pour établir la session BGP. |
|
|
| Facultatif : Spécifie l'adresse IP à utiliser lors de l'établissement de la session BGP. La valeur doit être une adresse IPv4. |
|
|
|
Facultatif : Spécifie le port réseau de l'homologue à contacter pour établir la session BGP. La plage est comprise entre |
|
|
|
Facultatif : Spécifie la durée du temps de maintien à proposer à l'homologue BGP. La valeur minimale est de 3 secondes ( |
|
|
|
Facultatif : Spécifie l'intervalle maximum entre l'envoi de messages keep-alive à l'homologue BGP. Si vous spécifiez ce champ, vous devez également spécifier une valeur pour le champ |
|
|
| Facultatif : Spécifie l'ID du routeur à annoncer à l'homologue BGP. Si vous spécifiez ce champ, vous devez indiquer la même valeur dans chaque ressource personnalisée d'homologue BGP que vous ajoutez. |
|
|
| Facultatif : Spécifie le mot de passe MD5 à envoyer à l'homologue pour les routeurs qui appliquent les sessions BGP authentifiées par TCP MD5. |
|
|
|
Facultatif : Spécifie le nom du secret d'authentification pour le pair BGP. Le secret doit se trouver dans l'espace de noms |
|
|
| Facultatif : Spécifie le nom d'un profil BFD. |
|
|
| Facultatif : Spécifie un sélecteur, à l'aide d'expressions et d'étiquettes de correspondance, pour contrôler quels nœuds peuvent se connecter à l'homologue BGP. |
|
|
|
Facultatif : Spécifie que l'homologue BGP se trouve à plusieurs sauts de réseau. Si l'homologue BGP n'est pas directement connecté au même réseau, l'orateur ne peut pas établir de session BGP à moins que ce champ ne soit défini sur |
Le champ passwordSecret est mutuellement exclusif avec le champ password et contient une référence à un secret contenant le mot de passe à utiliser. La définition des deux champs entraîne l'échec de l'analyse.
32.6.2. Configuration d'un pair BGP
En tant qu'administrateur de cluster, vous pouvez ajouter une ressource personnalisée BGP peer pour échanger des informations de routage avec les routeurs du réseau et annoncer les adresses IP des services.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Configurer MetalLB avec une annonce BGP.
Procédure
Créez un fichier, tel que
bgppeer.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: doc-example-peer spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10Appliquer la configuration pour l'homologue BGP :
$ oc apply -f bgppeer.yaml
32.6.3. Configurer un ensemble spécifique de pairs BGP pour un pool d'adresses donné
Cette procédure illustre comment :
-
Configurez un ensemble de pools d'adresses (
pool1etpool2). -
Configurez un ensemble de pairs BGP (
peer1etpeer2). -
Configurer l'annonce BGP pour assigner
pool1àpeer1etpool2àpeer2.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses
pool1.Créez un fichier, tel que
ipaddresspool1.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: pool1 spec: addresses: - 4.4.4.100-4.4.4.200 - 2001:100:4::200-2001:100:4::400Appliquer la configuration du pool d'adresses IP
pool1:$ oc apply -f ipaddresspool1.yaml
Créer un pool d'adresses
pool2.Créez un fichier, tel que
ipaddresspool2.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: pool2 spec: addresses: - 5.5.5.100-5.5.5.200 - 2001:100:5::200-2001:100:5::400Appliquer la configuration du pool d'adresses IP
pool2:$ oc apply -f ipaddresspool2.yaml
Créer BGP
peer1.Créez un fichier, tel que
bgppeer1.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: peer1 spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10Appliquer la configuration pour l'homologue BGP :
$ oc apply -f bgppeer1.yaml
Créer BGP
peer2.Créez un fichier, tel que
bgppeer2.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: peer2 spec: peerAddress: 10.0.0.2 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10Appliquer la configuration pour le pair BGP2 :
$ oc apply -f bgppeer2.yaml
Créer une annonce BGP 1.
Créez un fichier, tel que
bgpadvertisement1.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-1 namespace: metallb-system spec: ipAddressPools: - pool1 peers: - peer1 communities: - 65535:65282 aggregationLength: 32 aggregationLengthV6: 128 localPref: 100Appliquer la configuration :
$ oc apply -f bgpadvertisement1.yaml
Créer une annonce BGP 2.
Créez un fichier, tel que
bgpadvertisement2.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-2 namespace: metallb-system spec: ipAddressPools: - pool2 peers: - peer2 communities: - 65535:65282 aggregationLength: 32 aggregationLengthV6: 128 localPref: 100Appliquer la configuration :
$ oc apply -f bgpadvertisement2.yaml
32.6.4. Exemple de configurations de pairs BGP
32.6.4.1. Exemple : Limiter les nœuds qui se connectent à un pair BGP
Vous pouvez spécifier le champ sélecteurs de nœuds pour contrôler quels nœuds peuvent se connecter à un homologue BGP.
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: doc-example-nodesel
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64501
myASN: 64500
nodeSelectors:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values: [compute-1.example.com, compute-2.example.com]32.6.4.2. Exemple : Spécifier un profil BFD pour un pair BGP
Vous pouvez spécifier un profil BFD à associer aux pairs BGP. BFD complète BGP en fournissant une détection plus rapide des échecs de communication entre les pairs que BGP seul.
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: doc-example-peer-bfd
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64501
myASN: 64500
holdTime: "10s"
bfdProfile: doc-example-bfd-profile-full
La suppression du profil de détection de transfert bidirectionnel (BFD) et de l'adresse bfdProfile ajoutée à la ressource homologue du protocole de passerelle frontalière (BGP) ne désactive pas le BFD. Au lieu de cela, le pair BGP commence à utiliser le profil BFD par défaut. Pour désactiver le BFD à partir d'une ressource homologue BGP, supprimez la configuration de l'homologue BGP et recréez-la sans profil BFD. Pour plus d'informations, voir BZ#2050824.
32.6.4.3. Exemple : Spécifier les pairs BGP pour un réseau à double pile
Pour prendre en charge les réseaux à double pile, ajoutez une ressource personnalisée BGP pour IPv4 et une ressource personnalisée BGP pour IPv6.
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: doc-example-dual-stack-ipv4
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64500
myASN: 64500
---
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: doc-example-dual-stack-ipv6
namespace: metallb-system
spec:
peerAddress: 2620:52:0:88::104
peerASN: 64500
myASN: 6450032.6.5. Prochaines étapes
32.7. Configuration de l'alias de communauté
En tant qu'administrateur de cluster, vous pouvez configurer un alias de communauté et l'utiliser pour différentes annonces.
32.7.1. À propos de la ressource communautaire personnalisée
La ressource personnalisée community est une collection d'alias pour les communautés. Les utilisateurs peuvent définir des alias nommés à utiliser pour annoncer ipAddressPools à l'aide de la ressource personnalisée BGPAdvertisement. Les champs de la ressource personnalisée community sont décrits dans le tableau suivant.
Le CRD community ne s'applique qu'à BGPAdvertisement.
| Field | Type | Description |
|---|---|---|
|
|
|
Spécifie le nom du site |
|
|
|
Spécifie l'espace de noms pour |
|
|
|
Spécifie une liste d'alias de communauté BGP qui peuvent être utilisés dans les annonces BGPA. Un alias de communauté se compose d'une paire de noms (alias) et de valeurs (nombre:nombre). Lier l'annonce BGPA à un alias de communauté en se référant au nom de l'alias dans le champ |
| Field | Type | Description |
|---|---|---|
|
|
|
Le nom de l'alias pour le site |
|
|
|
La valeur BGP |
32.7.2. Configurer MetalLB avec une annonce BGP et un alias de communauté
Configurez MetalLB comme suit pour que le site IPAddressPool soit annoncé avec le protocole BGP et l'alias de communauté défini sur la valeur numérique de la communauté NO_ADVERTISE.
Dans l'exemple suivant, le routeur BGP homologue doc-example-peer-community reçoit une route 203.0.113.200/32 et une route fc00:f853:ccd:e799::1/128 pour chaque adresse IP d'équilibreur de charge que MetalLB attribue à un service. Un alias de communauté est configuré avec la communauté NO_ADVERTISE.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un pool d'adresses IP.
Créez un fichier, tel que
ipaddresspool.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-bgp-community spec: addresses: - 203.0.113.200/30 - fc00:f853:ccd:e799::/124Appliquer la configuration du pool d'adresses IP :
$ oc apply -f ipaddresspool.yaml
Créez un alias de communauté nommé
community1.apiVersion: metallb.io/v1beta1 kind: Community metadata: name: community1 namespace: metallb-system spec: communities: - name: NO_ADVERTISE value: '65535:65282'Créer un pair BGP nommé
doc-example-bgp-peer.Créez un fichier, tel que
bgppeer.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: doc-example-bgp-peer spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10Appliquer la configuration pour l'homologue BGP :
$ oc apply -f bgppeer.yaml
Créer une annonce BGP avec l'alias de communauté.
Créez un fichier, tel que
bgpadvertisement.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgp-community-sample namespace: metallb-system spec: aggregationLength: 32 aggregationLengthV6: 128 communities: - NO_ADVERTISE1 ipAddressPools: - doc-example-bgp-community peers: - doc-example-peer- 1
- Indiquez ici le site
CommunityAlias.nameet non le nom de la ressource personnalisée (CR) de la communauté.
Appliquer la configuration :
$ oc apply -f bgpadvertisement.yaml
32.8. Configuration des profils MetalLB BFD
En tant qu'administrateur de cluster, vous pouvez ajouter, modifier et supprimer des profils BFD (Bidirectional Forwarding Detection). L'opérateur MetalLB utilise les ressources personnalisées du profil BFD pour identifier les sessions BGP qui utilisent BFD pour fournir une détection de défaillance de chemin plus rapide que celle fournie par BGP seul.
32.8.1. À propos de la ressource personnalisée du profil BFD
Les champs de la ressource personnalisée du profil BFD sont décrits dans le tableau suivant.
| Field | Type | Description |
|---|---|---|
|
|
| Spécifie le nom de la ressource personnalisée du profil BFD. |
|
|
| Spécifie l'espace de noms pour la ressource personnalisée du profil BFD. |
|
|
| Spécifie le multiplicateur de détection pour déterminer la perte de paquets. L'intervalle de transmission à distance est multiplié par cette valeur pour déterminer le délai de détection de la perte de connexion.
Par exemple, lorsque le multiplicateur de détection du système local est fixé à
La plage de valeurs est comprise entre |
|
|
|
Spécifie le mode de transmission de l'écho. Si vous n'utilisez pas de BFD distribué, le mode de transmission de l'écho ne fonctionne que si l'homologue est également FRR. La valeur par défaut est
Lorsque le mode de transmission en écho est activé, envisagez d'augmenter l'intervalle de transmission des paquets de contrôle afin de réduire l'utilisation de la bande passante. Par exemple, envisagez d'augmenter l'intervalle de transmission à |
|
|
|
Spécifie l'intervalle de transmission minimum, moins la gigue, que ce système utilise pour envoyer et recevoir des paquets d'écho. La plage est comprise entre |
|
|
| Indique le TTL minimum attendu pour un paquet de contrôle entrant. Ce champ s'applique uniquement aux sessions multi-sauts. La fixation d'un TTL minimum a pour but de rendre les exigences de validation des paquets plus strictes et d'éviter de recevoir des paquets de contrôle d'autres sessions.
La valeur par défaut est |
|
|
| Indique si une session est marquée comme active ou passive. Une session passive ne tente pas de démarrer la connexion. Au lieu de cela, elle attend les paquets de contrôle d'un homologue avant de commencer à répondre. Marquer une session comme passive est utile lorsque vous avez un routeur qui agit comme nœud central d'un réseau en étoile et que vous voulez éviter d'envoyer des paquets de contrôle que vous n'avez pas besoin que le système envoie.
La valeur par défaut est |
|
|
|
Spécifie l'intervalle minimum de réception des paquets de contrôle par ce système. La plage est comprise entre |
|
|
|
Spécifie l'intervalle de transmission minimum, moins la gigue, que ce système utilise pour envoyer des paquets de contrôle. La plage est comprise entre |
32.8.2. Configuration d'un profil BFD
En tant qu'administrateur de cluster, vous pouvez ajouter un profil BFD et configurer un pair BGP pour qu'il utilise le profil. Le BFD permet de détecter plus rapidement les défaillances de chemin que le BGP seul.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créez un fichier, tel que
bfdprofile.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: BFDProfile metadata: name: doc-example-bfd-profile-full namespace: metallb-system spec: receiveInterval: 300 transmitInterval: 300 detectMultiplier: 3 echoMode: false passiveMode: true minimumTtl: 254Appliquer la configuration du profil BFD :
$ oc apply -f bfdprofile.yaml
32.8.3. Prochaines étapes
- Configurer un pair BGP pour utiliser le profil BFD.
32.9. Configuration des services pour l'utilisation de MetalLB
En tant qu'administrateur de cluster, lorsque vous ajoutez un service de type LoadBalancer, vous pouvez contrôler la manière dont MetalLB attribue une adresse IP.
32.9.1. Demander une adresse IP spécifique
Comme d'autres implémentations de load-balancer, MetalLB accepte le champ spec.loadBalancerIP dans la spécification du service.
Si l'adresse IP demandée se trouve dans une plage d'un pool d'adresses, MetalLB attribue l'adresse IP demandée. Si l'adresse IP demandée ne se trouve dans aucune plage, MetalLB signale un avertissement.
Exemple de service YAML pour une adresse IP spécifique
apiVersion: v1
kind: Service
metadata:
name: <service_name>
annotations:
metallb.universe.tf/address-pool: <address_pool_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
loadBalancerIP: <ip_address>
Si la MetalLB ne peut pas attribuer l'adresse IP demandée, le site EXTERNAL-IP pour les rapports de service <pending> et l'exécution de oc describe service <service_name> comprend un événement comme dans l'exemple suivant.
Exemple d'événement lorsque MetalLB ne peut pas attribuer une adresse IP demandée
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning AllocationFailed 3m16s metallb-controller Failed to allocate IP for "default/invalid-request": "4.3.2.1" is not allowed in config32.9.2. Demande d'une adresse IP à partir d'un pool spécifique
Pour attribuer une adresse IP à partir d'une plage spécifique, mais sans vous préoccuper de l'adresse IP en question, vous pouvez utiliser l'annotation metallb.universe.tf/address-pool pour demander une adresse IP à partir du pool d'adresses spécifié.
Exemple de service YAML pour une adresse IP d'un pool spécifique
apiVersion: v1
kind: Service
metadata:
name: <service_name>
annotations:
metallb.universe.tf/address-pool: <address_pool_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
Si le pool d'adresses que vous spécifiez pour <address_pool_name> n'existe pas, MetalLB tente d'attribuer une adresse IP à partir de n'importe quel pool autorisant l'attribution automatique.
32.9.3. Accepter n'importe quelle adresse IP
Par défaut, les pools d'adresses sont configurés pour permettre une attribution automatique. MetalLB attribue une adresse IP à partir de ces pools d'adresses.
Pour accepter n'importe quelle adresse IP de n'importe quel pool configuré pour l'attribution automatique, aucune annotation ou configuration spéciale n'est nécessaire.
Exemple de service YAML pour l'acceptation de n'importe quelle adresse IP
apiVersion: v1
kind: Service
metadata:
name: <service_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer32.9.5. Configurer un service avec MetalLB
Vous pouvez configurer un service de répartition de charge pour qu'il utilise une adresse IP externe provenant d'un pool d'adresses.
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Installez l'opérateur MetalLB et démarrez MetalLB.
- Configurez au moins un pool d'adresses.
- Configurez votre réseau pour acheminer le trafic des clients vers le réseau hôte du cluster.
Procédure
Créez un fichier
<service_name>.yaml. Dans le fichier, assurez-vous que le champspec.typeest défini surLoadBalancer.Reportez-vous aux exemples pour savoir comment demander l'adresse IP externe que MetalLB attribue au service.
Créer le service :
oc apply -f <service_name>.yamlExemple de sortie
service/-YRFFGUNA nom_du_service> créé
Vérification
Décrivez le service :
oc describe service <service_name> $ oc describe service <service_name>Exemple de sortie
Name: <service_name> Namespace: default Labels: <none> Annotations: metallb.universe.tf/address-pool: doc-example <.> Selector: app=service_name Type: LoadBalancer <.> IP Family Policy: SingleStack IP Families: IPv4 IP: 10.105.237.254 IPs: 10.105.237.254 LoadBalancer Ingress: 192.168.100.5 <.> Port: <unset> 80/TCP TargetPort: 8080/TCP NodePort: <unset> 30550/TCP Endpoints: 10.244.0.50:8080 Session Affinity: None External Traffic Policy: Cluster Events: <.> Type Reason Age From Message ---- ------ ---- ---- ------- Normal nodeAssigned 32m (x2 over 32m) metallb-speaker announcing from node "<node_name>"<.> L'annotation est présente si vous demandez une adresse IP à partir d'un pool spécifique. <.> Le type de service doit indiquer
LoadBalancer. <.> Le champ d'entrée de l'équilibreur de charge indique l'adresse IP externe si le service est correctement attribué. <.> Le champ des événements indique le nom du nœud affecté à l'annonce de l'adresse IP externe. En cas d'erreur, le champ events indique la raison de l'erreur.
32.10. Journalisation, dépannage et support de la MetalLB
Si vous avez besoin de dépanner la configuration de MetalLB, reportez-vous aux sections suivantes pour les commandes les plus couramment utilisées.
32.10.1. Définir les niveaux de journalisation de la MetalLB
MetalLB utilise FRRouting (FRR) dans un conteneur avec le paramètre par défaut de info, ce qui génère beaucoup de logs. Vous pouvez contrôler la verbosité des journaux générés en paramétrant logLevel comme illustré dans cet exemple.
Pour en savoir plus sur MetalLB, configurez le site logLevel à l'adresse debug comme suit :
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Créez un fichier, tel que
setdebugloglevel.yaml, dont le contenu ressemble à l'exemple suivant :apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug nodeSelector: node-role.kubernetes.io/worker: ""Appliquer la configuration :
$ oc replace -f setdebugloglevel.yamlNoteUtilisez
oc replacecar le CRmetallbest déjà créé et vous modifiez ici le niveau du journal.Affiche les noms des pods
speaker:$ oc get -n metallb-system pods -l component=speakerExemple de sortie
NAME READY STATUS RESTARTS AGE speaker-2m9pm 4/4 Running 0 9m19s speaker-7m4qw 3/4 Running 0 19s speaker-szlmx 4/4 Running 0 9m19sNoteLes pods Speaker et Controller sont recréés pour s'assurer que le niveau de journalisation mis à jour est appliqué. Le niveau de journalisation est modifié pour tous les composants de MetalLB.
Consultez les journaux de
speaker:$ oc logs -n metallb-system speaker-7m4qw -c speakerExemple de sortie
{"branch":"main","caller":"main.go:92","commit":"3d052535","goversion":"gc / go1.17.1 / amd64","level":"info","msg":"MetalLB speaker starting (commit 3d052535, branch main)","ts":"2022-05-17T09:55:05Z","version":""} {"caller":"announcer.go:110","event":"createARPResponder","interface":"ens4","level":"info","msg":"created ARP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:119","event":"createNDPResponder","interface":"ens4","level":"info","msg":"created NDP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:110","event":"createARPResponder","interface":"tun0","level":"info","msg":"created ARP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:119","event":"createNDPResponder","interface":"tun0","level":"info","msg":"created NDP responder for interface","ts":"2022-05-17T09:55:05Z"} I0517 09:55:06.515686 95 request.go:665] Waited for 1.026500832s due to client-side throttling, not priority and fairness, request: GET:https://172.30.0.1:443/apis/operators.coreos.com/v1alpha1?timeout=32s {"Starting Manager":"(MISSING)","caller":"k8s.go:389","level":"info","ts":"2022-05-17T09:55:08Z"} {"caller":"speakerlist.go:310","level":"info","msg":"node event - forcing sync","node addr":"10.0.128.4","node event":"NodeJoin","node name":"ci-ln-qb8t3mb-72292-7s7rh-worker-a-vvznj","ts":"2022-05-17T09:55:08Z"} {"caller":"service_controller.go:113","controller":"ServiceReconciler","enqueueing":"openshift-kube-controller-manager-operator/metrics","epslice":"{\"metadata\":{\"name\":\"metrics-xtsxr\",\"generateName\":\"metrics-\",\"namespace\":\"openshift-kube-controller-manager-operator\",\"uid\":\"ac6766d7-8504-492c-9d1e-4ae8897990ad\",\"resourceVersion\":\"9041\",\"generation\":4,\"creationTimestamp\":\"2022-05-17T07:16:53Z\",\"labels\":{\"app\":\"kube-controller-manager-operator\",\"endpointslice.kubernetes.io/managed-by\":\"endpointslice-controller.k8s.io\",\"kubernetes.io/service-name\":\"metrics\"},\"annotations\":{\"endpoints.kubernetes.io/last-change-trigger-time\":\"2022-05-17T07:21:34Z\"},\"ownerReferences\":[{\"apiVersion\":\"v1\",\"kind\":\"Service\",\"name\":\"metrics\",\"uid\":\"0518eed3-6152-42be-b566-0bd00a60faf8\",\"controller\":true,\"blockOwnerDeletion\":true}],\"managedFields\":[{\"manager\":\"kube-controller-manager\",\"operation\":\"Update\",\"apiVersion\":\"discovery.k8s.io/v1\",\"time\":\"2022-05-17T07:20:02Z\",\"fieldsType\":\"FieldsV1\",\"fieldsV1\":{\"f:addressType\":{},\"f:endpoints\":{},\"f:metadata\":{\"f:annotations\":{\".\":{},\"f:endpoints.kubernetes.io/last-change-trigger-time\":{}},\"f:generateName\":{},\"f:labels\":{\".\":{},\"f:app\":{},\"f:endpointslice.kubernetes.io/managed-by\":{},\"f:kubernetes.io/service-name\":{}},\"f:ownerReferences\":{\".\":{},\"k:{\\\"uid\\\":\\\"0518eed3-6152-42be-b566-0bd00a60faf8\\\"}\":{}}},\"f:ports\":{}}}]},\"addressType\":\"IPv4\",\"endpoints\":[{\"addresses\":[\"10.129.0.7\"],\"conditions\":{\"ready\":true,\"serving\":true,\"terminating\":false},\"targetRef\":{\"kind\":\"Pod\",\"namespace\":\"openshift-kube-controller-manager-operator\",\"name\":\"kube-controller-manager-operator-6b98b89ddd-8d4nf\",\"uid\":\"dd5139b8-e41c-4946-a31b-1a629314e844\",\"resourceVersion\":\"9038\"},\"nodeName\":\"ci-ln-qb8t3mb-72292-7s7rh-master-0\",\"zone\":\"us-central1-a\"}],\"ports\":[{\"name\":\"https\",\"protocol\":\"TCP\",\"port\":8443}]}","level":"debug","ts":"2022-05-17T09:55:08Z"}Consulter les journaux FRR :
$ oc logs -n metallb-system speaker-7m4qw -c frrExemple de sortie
Started watchfrr 2022/05/17 09:55:05 ZEBRA: client 16 says hello and bids fair to announce only bgp routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 31 says hello and bids fair to announce only vnc routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 38 says hello and bids fair to announce only static routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 43 says hello and bids fair to announce only bfd routes vrf=0 2022/05/17 09:57:25.089 BGP: Creating Default VRF, AS 64500 2022/05/17 09:57:25.090 BGP: dup addr detect enable max_moves 5 time 180 freeze disable freeze_time 0 2022/05/17 09:57:25.090 BGP: bgp_get: Registering BGP instance (null) to zebra 2022/05/17 09:57:25.090 BGP: Registering VRF 0 2022/05/17 09:57:25.091 BGP: Rx Router Id update VRF 0 Id 10.131.0.1/32 2022/05/17 09:57:25.091 BGP: RID change : vrf VRF default(0), RTR ID 10.131.0.1 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF br0 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF ens4 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF ens4 addr 10.0.128.4/32 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF ens4 addr fe80::c9d:84da:4d86:5618/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF lo 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF ovs-system 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF tun0 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF tun0 addr 10.131.0.1/23 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF tun0 addr fe80::40f1:d1ff:feb6:5322/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth2da49fed 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth2da49fed addr fe80::24bd:d1ff:fec1:d88/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth2fa08c8c 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth2fa08c8c addr fe80::6870:ff:fe96:efc8/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth41e356b7 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth41e356b7 addr fe80::48ff:37ff:fede:eb4b/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth1295c6e2 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth1295c6e2 addr fe80::b827:a2ff:feed:637/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth9733c6dc 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth9733c6dc addr fe80::3cf4:15ff:fe11:e541/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth336680ea 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth336680ea addr fe80::94b1:8bff:fe7e:488c/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vetha0a907b7 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vetha0a907b7 addr fe80::3855:a6ff:fe73:46c3/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vethf35a4398 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vethf35a4398 addr fe80::40ef:2fff:fe57:4c4d/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vethf831b7f4 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vethf831b7f4 addr fe80::f0d9:89ff:fe7c:1d32/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vxlan_sys_4789 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vxlan_sys_4789 addr fe80::80c1:82ff:fe4b:f078/64 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] Timer (start timer expire). 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] BGP_Start (Idle->Connect), fd -1 2022/05/17 09:57:26.094 BGP: Allocated bnc 10.0.0.1/32(0)(VRF default) peer 0x7f807f7631a0 2022/05/17 09:57:26.094 BGP: sendmsg_zebra_rnh: sending cmd ZEBRA_NEXTHOP_REGISTER for 10.0.0.1/32 (vrf VRF default) 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] Waiting for NHT 2022/05/17 09:57:26.094 BGP: bgp_fsm_change_status : vrf default(0), Status: Connect established_peers 0 2022/05/17 09:57:26.094 BGP: 10.0.0.1 went from Idle to Connect 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] TCP_connection_open_failed (Connect->Active), fd -1 2022/05/17 09:57:26.094 BGP: bgp_fsm_change_status : vrf default(0), Status: Active established_peers 0 2022/05/17 09:57:26.094 BGP: 10.0.0.1 went from Connect to Active 2022/05/17 09:57:26.094 ZEBRA: rnh_register msg from client bgp: hdr->length=8, type=nexthop vrf=0 2022/05/17 09:57:26.094 ZEBRA: 0: Add RNH 10.0.0.1/32 type Nexthop 2022/05/17 09:57:26.094 ZEBRA: 0:10.0.0.1/32: Evaluate RNH, type Nexthop (force) 2022/05/17 09:57:26.094 ZEBRA: 0:10.0.0.1/32: NH has become unresolved 2022/05/17 09:57:26.094 ZEBRA: 0: Client bgp registers for RNH 10.0.0.1/32 type Nexthop 2022/05/17 09:57:26.094 BGP: VRF default(0): Rcvd NH update 10.0.0.1/32(0) - metric 0/0 #nhops 0/0 flags 0x6 2022/05/17 09:57:26.094 BGP: NH update for 10.0.0.1/32(0)(VRF default) - flags 0x6 chgflags 0x0 - evaluate paths 2022/05/17 09:57:26.094 BGP: evaluate_paths: Updating peer (10.0.0.1(VRF default)) status with NHT 2022/05/17 09:57:30.081 ZEBRA: Event driven route-map update triggered 2022/05/17 09:57:30.081 ZEBRA: Event handler for route-map: 10.0.0.1-out 2022/05/17 09:57:30.081 ZEBRA: Event handler for route-map: 10.0.0.1-in 2022/05/17 09:57:31.104 ZEBRA: netlink_parse_info: netlink-listen (NS 0) type RTM_NEWNEIGH(28), len=76, seq=0, pid=0 2022/05/17 09:57:31.104 ZEBRA: Neighbor Entry received is not on a VLAN or a BRIDGE, ignoring 2022/05/17 09:57:31.105 ZEBRA: netlink_parse_info: netlink-listen (NS 0) type RTM_NEWNEIGH(28), len=76, seq=0, pid=0 2022/05/17 09:57:31.105 ZEBRA: Neighbor Entry received is not on a VLAN or a BRIDGE, ignoring
32.10.1.1. Niveaux de journalisation du FRRouting (FRR)
Le tableau suivant décrit les niveaux de journalisation FRR.
| Niveau d'enregistrement | Description |
|---|---|
|
| Fournit toutes les informations de journalisation pour tous les niveaux de journalisation. |
|
|
Informations utiles au diagnostic. Réglé sur |
|
| Fournit des informations qui doivent toujours être enregistrées mais qui, dans des circonstances normales, ne nécessitent pas d'intervention de la part de l'utilisateur. Il s'agit du niveau de journalisation par défaut. |
|
|
Tout ce qui peut potentiellement provoquer un comportement incohérent de |
|
|
Toute erreur fatale au fonctionnement de |
|
| Désactiver la journalisation. |
32.10.2. Dépannage des problèmes BGP
L'implémentation BGP prise en charge par Red Hat utilise FRRouting (FRR) dans un conteneur dans les pods speaker. En tant qu'administrateur de cluster, si vous devez résoudre des problèmes de configuration BGP, vous devez exécuter des commandes dans le conteneur FRR.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Affiche les noms des pods
speaker:$ oc get -n metallb-system pods -l component=speakerExemple de sortie
NAME READY STATUS RESTARTS AGE speaker-66bth 4/4 Running 0 56m speaker-gvfnf 4/4 Running 0 56m ...Affichez la configuration en cours pour FRR :
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show running-config"Exemple de sortie
Building configuration... Current configuration: ! frr version 7.5.1_git frr defaults traditional hostname some-hostname log file /etc/frr/frr.log informational log timestamp precision 3 service integrated-vtysh-config ! router bgp 645001 bgp router-id 10.0.1.2 no bgp ebgp-requires-policy no bgp default ipv4-unicast no bgp network import-check neighbor 10.0.2.3 remote-as 645002 neighbor 10.0.2.3 bfd profile doc-example-bfd-profile-full3 neighbor 10.0.2.3 timers 5 15 neighbor 10.0.2.4 remote-as 645004 neighbor 10.0.2.4 bfd profile doc-example-bfd-profile-full5 neighbor 10.0.2.4 timers 5 15 ! address-family ipv4 unicast network 203.0.113.200/306 neighbor 10.0.2.3 activate neighbor 10.0.2.3 route-map 10.0.2.3-in in neighbor 10.0.2.4 activate neighbor 10.0.2.4 route-map 10.0.2.4-in in exit-address-family ! address-family ipv6 unicast network fc00:f853:ccd:e799::/1247 neighbor 10.0.2.3 activate neighbor 10.0.2.3 route-map 10.0.2.3-in in neighbor 10.0.2.4 activate neighbor 10.0.2.4 route-map 10.0.2.4-in in exit-address-family ! route-map 10.0.2.3-in deny 20 ! route-map 10.0.2.4-in deny 20 ! ip nht resolve-via-default ! ipv6 nht resolve-via-default ! line vty ! bfd profile doc-example-bfd-profile-full8 transmit-interval 35 receive-interval 35 passive-mode echo-mode echo-interval 35 minimum-ttl 10 ! ! end<.> La section
router bgpindique l'ASN pour MetalLB. <.> Confirmez qu'une ligneneighbor <ip-address> remote-as <peer-ASN>existe pour chaque ressource personnalisée de pair BGP que vous avez ajoutée. <.> Si vous avez configuré BFD, confirmez que le profil BFD est associé au pair BGP correct et que le profil BFD apparaît dans la sortie de la commande. <.> Confirmez que les lignesnetwork <ip-address-range>correspondent aux plages d'adresses IP que vous avez spécifiées dans les ressources personnalisées du pool d'adresses que vous avez ajoutées.Affiche le résumé BGP :
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bgp summary"Exemple de sortie
IPv4 Unicast Summary: BGP router identifier 10.0.1.2, local AS number 64500 vrf-id 0 BGP table version 1 RIB entries 1, using 192 bytes of memory Peers 2, using 29 KiB of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt 10.0.2.3 4 64500 387 389 0 0 0 00:32:02 0 11 10.0.2.4 4 64500 0 0 0 0 0 never Active 02 Total number of neighbors 2 IPv6 Unicast Summary: BGP router identifier 10.0.1.2, local AS number 64500 vrf-id 0 BGP table version 1 RIB entries 1, using 192 bytes of memory Peers 2, using 29 KiB of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt 10.0.2.3 4 64500 387 389 0 0 0 00:32:02 NoNeg3 10.0.2.4 4 64500 0 0 0 0 0 never Active 04 Total number of neighbors 2- 1 1 3
- Confirmez que la sortie comprend une ligne pour chaque ressource personnalisée d'homologue BGP que vous avez ajoutée.
- 2 4 2 4
- La sortie qui montre
0messages reçus et messages envoyés indique un homologue BGP qui n'a pas de session BGP. Vérifiez la connectivité du réseau et la configuration BGP de l'homologue BGP.
Afficher les pairs BGP qui ont reçu un pool d'adresses :
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bgp ipv4 unicast 203.0.113.200/30"Remplacez
ipv4paripv6pour afficher les homologues BGP qui ont reçu un pool d'adresses IPv6. Remplacez203.0.113.200/30par une plage d'adresses IPv4 ou IPv6 provenant d'un pool d'adresses.Exemple de sortie
BGP routing table entry for 203.0.113.200/30 Paths: (1 available, best #1, table default) Advertised to non peer-group peers: 10.0.2.3 <.> Local 0.0.0.0 from 0.0.0.0 (10.0.1.2) Origin IGP, metric 0, weight 32768, valid, sourced, local, best (First path received) Last update: Mon Jan 10 19:49:07 2022<.> Confirmez que la sortie comprend une adresse IP pour un homologue BGP.
32.10.3. Dépannage des problèmes BFD
L'implémentation de Bidirectional Forwarding Detection (BFD) prise en charge par Red Hat utilise FRRouting (FRR) dans un conteneur dans les pods speaker. L'implémentation BFD repose sur le fait que les pairs BFD sont également configurés en tant que pairs BGP avec une session BGP établie. En tant qu'administrateur de cluster, si vous devez résoudre des problèmes de configuration BFD, vous devez exécuter des commandes dans le conteneur FRR.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé l'OpenShift CLI (
oc).
Procédure
Affiche les noms des pods
speaker:$ oc get -n metallb-system pods -l component=speakerExemple de sortie
NAME READY STATUS RESTARTS AGE speaker-66bth 4/4 Running 0 26m speaker-gvfnf 4/4 Running 0 26m ...Affichez les pairs BFD :
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bfd peers brief"Exemple de sortie
Session count: 2 SessionId LocalAddress PeerAddress Status ========= ============ =========== ====== 3909139637 10.0.1.2 10.0.2.3 up <.><.> Confirmez que la colonne
PeerAddressinclut chaque pair BFD. Si la sortie ne répertorie pas l'adresse IP d'un homologue BFD que vous vous attendiez à voir figurer dans la sortie, dépannez la connectivité BGP avec l'homologue. Si le champ d'état indiquedown, vérifiez la connectivité des liens et de l'équipement entre le nœud et l'homologue. Vous pouvez déterminer le nom du nœud du module de haut-parleurs à l'aide d'une commande telle queoc get pods -n metallb-system speaker-66bth -o jsonpath='{.spec.nodeName}'.
32.10.4. Métriques MetalLB pour BGP et BFD
OpenShift Container Platform capture les métriques suivantes qui sont liées à MetalLB, aux pairs BGP et aux profils BFD :
-
metallb_bfd_control_packet_inputcompte le nombre de paquets de contrôle BFD reçus de chaque pair BFD. -
metallb_bfd_control_packet_outputcompte le nombre de paquets de contrôle BFD envoyés à chaque pair BFD. -
metallb_bfd_echo_packet_inputcompte le nombre de paquets d'écho BFD reçus de chaque pair BFD. -
metallb_bfd_echo_packet_outputcompte le nombre de paquets d'écho BFD envoyés à chaque pair BFD. -
metallb_bfd_session_down_eventscompte le nombre de fois où la session BFD avec un pair est entrée dans l'étatdown. -
metallb_bfd_session_upindique l'état de la connexion avec un pair BFD.1indique que la session estupet0indique que la session estdown. -
metallb_bfd_session_up_eventscompte le nombre de fois où la session BFD avec un pair est entrée dans l'étatup. -
metallb_bfd_zebra_notificationscompte le nombre de notifications BFD Zebra pour chaque pair BFD. -
metallb_bgp_announced_prefixes_totalcompte le nombre de préfixes d'adresses IP de l'équilibreur de charge qui sont annoncés aux pairs BGP. Les termes prefix et aggregated route ont la même signification. -
metallb_bgp_session_upindique l'état de la connexion avec un pair BGP.1indique que la session estupet0indique que la session estdown. -
metallb_bgp_updates_totalcompte le nombre de messages BGPupdateenvoyés à un homologue BGP.
Ressources supplémentaires
- Pour plus d'informations sur l'utilisation du tableau de bord de surveillance, reportez-vous à la section Interrogation des mesures.
32.10.5. A propos de la collecte des données MetalLB
Vous pouvez utiliser la commande CLI oc adm must-gather pour collecter des informations sur votre cluster, votre configuration MetalLB et le MetalLB Operator. Les fonctionnalités et objets suivants sont associés à MetalLB et à MetalLB Operator :
- L'espace de noms et les objets enfants dans lesquels l'opérateur MetalLB est déployé
- Toutes les définitions de ressources personnalisées (CRD) de l'opérateur MetalLB
La commande CLI oc adm must-gather collecte les informations suivantes à partir de FRRouting (FRR) que Red Hat utilise pour implémenter BGP et BFD :
-
/etc/frr/frr.conf -
/etc/frr/frr.log -
/etc/frr/daemonsfichier de configuration -
/etc/frr/vtysh.conf
Les fichiers de log et de configuration de la liste précédente sont collectés à partir du conteneur frr dans chaque pod speaker.
Outre les fichiers journaux et les fichiers de configuration, la commande CLI oc adm must-gather recueille les résultats des commandes vtysh suivantes :
-
show running-config -
show bgp ipv4 -
show bgp ipv6 -
show bgp neighbor -
show bfd peer
Aucune configuration supplémentaire n'est requise lorsque vous exécutez la commande CLI oc adm must-gather.
Ressources supplémentaires
Chapitre 33. Associer des métriques d'interfaces secondaires à des pièces jointes du réseau
33.1. Extension des mesures secondaires du réseau pour la surveillance
Les dispositifs secondaires, ou interfaces, sont utilisés à des fins différentes. Il est important d'avoir un moyen de les classer afin de pouvoir agréger les mesures pour les dispositifs secondaires ayant la même classification.
Les métriques exposées contiennent l'interface mais ne précisent pas son origine. Cela est possible lorsqu'il n'y a pas d'interfaces supplémentaires. Cependant, si des interfaces secondaires sont ajoutées, il peut être difficile d'utiliser les métriques car il est difficile d'identifier les interfaces en utilisant uniquement les noms d'interface.
Lors de l'ajout d'interfaces secondaires, leurs noms dépendent de l'ordre dans lequel elles sont ajoutées, et différentes interfaces secondaires peuvent appartenir à différents réseaux et être utilisées à des fins différentes.
Avec pod_network_name_info, il est possible d'étendre les mesures actuelles avec des informations supplémentaires qui identifient le type d'interface. De cette manière, il est possible d'agréger les mesures et d'ajouter des alarmes spécifiques à des types d'interface spécifiques.
Le type de réseau est généré à l'aide du nom du site NetworkAttachmentDefinition, qui est à son tour utilisé pour différencier différentes classes de réseaux secondaires. Par exemple, des interfaces appartenant à des réseaux différents ou utilisant des CNI différents utilisent des noms de définition d'attachement au réseau différents.
33.1.1. Démon de mesure du réseau
Le Network Metrics Daemon est un composant démon qui collecte et publie des mesures relatives au réseau.
Le kubelet publie déjà des métriques relatives au réseau que vous pouvez observer. Ces métriques sont les suivantes :
-
container_network_receive_bytes_total -
container_network_receive_errors_total -
container_network_receive_packets_total -
container_network_receive_packets_dropped_total -
container_network_transmit_bytes_total -
container_network_transmit_errors_total -
container_network_transmit_packets_total -
container_network_transmit_packets_dropped_total
Les étiquettes de ces métriques contiennent, entre autres, les éléments suivants
- Nom du pod
- Espace de noms Pod
-
Nom de l'interface (tel que
eth0)
Ces mesures fonctionnent bien jusqu'à ce que de nouvelles interfaces soient ajoutées au pod, par exemple via Multus, car il n'est pas clair à quoi les noms d'interface font référence.
L'étiquette de l'interface fait référence au nom de l'interface, mais on ne sait pas exactement à quoi cette interface est destinée. S'il existe de nombreuses interfaces différentes, il est impossible de comprendre à quel réseau se réfèrent les mesures que vous surveillez.
Ce problème est résolu par l'introduction du nouveau site pod_network_name_info décrit dans la section suivante.
33.1.2. Mesures avec nom de réseau
Ce daemonset publie une mesure de la jauge pod_network_name_info, avec une valeur fixe de 0:
pod_network_name_info{interface="net0",namespace="namespacename",network_name="nadnamespace/firstNAD",pod="podname"} 0L'étiquette du nom du réseau est produite à l'aide de l'annotation ajoutée par Multus. Il s'agit de la concaténation de l'espace de noms auquel appartient la définition de l'attachement au réseau et du nom de la définition de l'attachement au réseau.
Cette nouvelle mesure n'est pas très utile en soi, mais combinée aux mesures du réseau container_network_*, elle offre un meilleur soutien pour la surveillance des réseaux secondaires.
En utilisant une requête promql comme les suivantes, il est possible d'obtenir une nouvelle métrique contenant la valeur et le nom du réseau récupéré dans l'annotation k8s.v1.cni.cncf.io/networks-status:
(container_network_receive_bytes_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_receive_errors_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_receive_packets_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_receive_packets_dropped_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_transmit_bytes_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_transmit_errors_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_transmit_packets_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info )
(container_network_transmit_packets_dropped_total) + on(namespace,pod,interface) group_left(network_name)Chapitre 34. Observabilité du réseau
34.1. Notes de mise à jour de l'opérateur d'observabilité du réseau
L'opérateur d'observabilité du réseau permet aux administrateurs d'observer et d'analyser les flux de trafic réseau pour les clusters OpenShift Container Platform.
Ces notes de version suivent le développement de l'opérateur d'observabilité du réseau dans la plateforme OpenShift Container.
Pour une présentation de l'opérateur d'observabilité du réseau, voir À propos de l'opérateur d'observabilité du réseau.
34.1.1. Opérateur d'observabilité du réseau 1.2.0
L'avis suivant est disponible pour le Network Observability Operator 1.2.0 :
34.1.1.1. Préparation de la prochaine mise à jour
L'abonnement d'un opérateur installé spécifie un canal de mise à jour qui suit et reçoit les mises à jour pour l'opérateur. Jusqu'à la version 1.2 de Network Observability Operator, le seul canal disponible était v1.0.x. La version 1.2 de Network Observability Operator introduit le canal de mise à jour stable pour le suivi et la réception des mises à jour. Vous devez changer votre canal de v1.0.x à stable pour recevoir les futures mises à jour de l'opérateur. Le canal v1.0.x est obsolète et il est prévu de le supprimer dans une prochaine version.
34.1.1.2. Nouvelles fonctionnalités et améliorations
34.1.1.2.1. Histogramme dans la vue Flux de trafic
- Vous pouvez maintenant choisir d'afficher un histogramme des flux dans le temps. L'histogramme vous permet de visualiser l'historique des flux sans dépasser la limite de requêtes de Loki. Pour plus d'informations, voir Utilisation de l'histogramme.
34.1.1.2.2. Suivi des conversations
- Vous pouvez désormais interroger les flux par Log Typece qui permet de regrouper les flux réseau qui font partie de la même conversation. Pour plus d'informations, voir Travailler avec des conversations.
34.1.1.2.3. Alertes de santé relatives à l'observabilité du réseau
-
L'opérateur d'observabilité du réseau crée désormais des alertes automatiques si le site
flowlogs-pipelineabandonne des flux en raison d'erreurs à l'étape d'écriture ou si la limite du taux d'ingestion de Loki a été atteinte. Pour plus d'informations, voir Visualisation des informations de santé.
34.1.1.3. Bug fixes
-
Auparavant, après avoir modifié la valeur
namespacedans la spécification FlowCollector, les pods de l'agent eBPF fonctionnant dans l'espace de noms précédent n'étaient pas supprimés de manière appropriée. Désormais, les pods fonctionnant dans l'espace de noms précédent sont supprimés de manière appropriée. (NETOBSERV-774) -
Auparavant, après avoir modifié la valeur
caCert.namedans la spécification FlowCollector (comme dans la section Loki), les pods FlowLogs-Pipeline et les pods du plug-in Console n'étaient pas redémarrés, et n'étaient donc pas au courant du changement de configuration. Maintenant, les pods sont redémarrés, donc ils reçoivent le changement de configuration. (NETOBSERV-772) - Auparavant, les flux réseau entre les pods fonctionnant sur différents nœuds n'étaient parfois pas correctement identifiés comme étant des doublons parce qu'ils étaient capturés par différentes interfaces réseau. Cela entraînait une surestimation des mesures affichées dans le plug-in de la console. Désormais, les flux sont correctement identifiés comme étant des doublons et le plug-in de la console affiche des mesures précises. (NETOBSERV-755)
- L'option "reporter" du plug-in de la console permet de filtrer les flux en fonction du point d'observation du nœud source ou du nœud de destination. Auparavant, cette option mélangeait les flux indépendamment du point d'observation du nœud. Cela était dû au fait que les flux réseau étaient incorrectement signalés comme entrant ou sortant au niveau du nœud. Désormais, le signalement de la direction du flux réseau est correct. L'option "reporter" filtre le point d'observation source ou le point d'observation destination, comme prévu. (NETOBSERV-696)
- Auparavant, pour les agents configurés pour envoyer des flux directement au processeur en tant que requêtes protobuf gRPC, la charge utile soumise pouvait être trop importante et était rejetée par le serveur GRPC du processeur. Cela se produisait dans des scénarios de très forte charge et avec seulement certaines configurations de l'agent. L'agent enregistrait un message d'erreur, tel que : grpc: received message larger than max. En conséquence, il y a eu une perte d'informations sur ces flux. Désormais, la charge utile gRPC est divisée en plusieurs messages lorsque sa taille dépasse un certain seuil. Par conséquent, le serveur maintient la connectivité. (NETOBSERV-617)
34.1.1.4. Problème connu
-
Dans la version 1.2.0 du Network Observability Operator, utilisant Loki Operator 5.6, une transition de certificat Loki affecte périodiquement les pods
flowlogs-pipelineet résulte en des flux abandonnés plutôt qu'en des flux écrits dans Loki. Le problème se corrige de lui-même après un certain temps, mais il provoque toujours une perte temporaire de données de flux pendant la transition du certificat Loki. (NETOBSERV-980)
34.1.1.5. Changements techniques notables
-
Auparavant, vous pouviez installer le Network Observability Operator en utilisant un espace de noms personnalisé. Cette version introduit l'espace de noms
conversion webhookqui modifie l'espace de nomsClusterServiceVersion. En raison de cette modification, tous les espaces de noms disponibles ne sont plus répertoriés. De plus, pour permettre la collecte des métriques de l'opérateur, les espaces de noms partagés avec d'autres opérateurs, comme l'espace de nomsopenshift-operators, ne peuvent pas être utilisés. Désormais, l'opérateur doit être installé dans l'espace de nomsopenshift-netobserv-operator. Vous ne pouvez pas passer automatiquement à la nouvelle version de l'opérateur si vous avez précédemment installé l'opérateur d'observabilité du réseau en utilisant un espace de noms personnalisé. Si vous avez précédemment installé l'opérateur en utilisant un espace de noms personnalisé, vous devez supprimer l'instance de l'opérateur qui a été installée et réinstaller votre opérateur dans l'espace de nomsopenshift-netobserv-operator. Il est important de noter que les espaces de noms personnalisés, tels que l'espace de nomsnetobservcouramment utilisé, sont toujours possibles pourFlowCollector, Loki, Kafka et d'autres plug-ins. (NETOBSERV-907)(NETOBSERV-956)
34.1.2. Opérateur d'observabilité du réseau 1.1.0
L'avis suivant est disponible pour le Network Observability Operator 1.1.0 :
L'opérateur d'observabilité du réseau est maintenant stable et le canal de publication est mis à jour à v1.1.0.
34.1.2.1. Correction d'un bug
-
Auparavant, si la configuration de Loki
authTokenn'était pas en modeFORWARD, l'authentification n'était plus appliquée, ce qui permettait à tout utilisateur pouvant se connecter à la console OpenShift Container Platform dans un cluster OpenShift Container Platform de récupérer des flux sans authentification. Désormais, quel que soit le mode de LokiauthToken, seuls les administrateurs du cluster peuvent récupérer les flux. (BZ#2169468)
34.2. À propos de l'observabilité des réseaux
Red Hat propose aux administrateurs de clusters l'opérateur Network Observability pour observer le trafic réseau des clusters OpenShift Container Platform. L'observabilité du réseau utilise la technologie eBPF pour créer des flux réseau. Les flux réseau sont ensuite enrichis avec les informations d'OpenShift Container Platform et stockés dans Loki. Vous pouvez visualiser et analyser les informations de flux réseau stockées dans la console OpenShift Container Platform pour une meilleure compréhension et un dépannage plus approfondi.
34.2.1. Dépendance de l'opérateur d'observabilité du réseau
L'opérateur d'observabilité du réseau a besoin des opérateurs suivants :
- Loki : Vous devez installer Loki. Loki est le backend utilisé pour stocker tous les flux collectés. Il est recommandé d'installer Loki en installant le Red Hat Loki Operator pour l'installation de Network Observability Operator.
34.2.2. Dépendances optionnelles de l'opérateur d'observabilité du réseau
- Grafana : Vous pouvez installer Grafana pour utiliser des tableaux de bord personnalisés et des capacités d'interrogation, en utilisant l'opérateur Grafana. Red Hat ne prend pas en charge l'opérateur Grafana.
- Kafka : Il fournit l'évolutivité, la résilience et la haute disponibilité dans le cluster OpenShift Container Platform. Il est recommandé d'installer Kafka en utilisant l'opérateur AMQ Streams pour les déploiements à grande échelle.
34.2.3. Opérateur de l'observabilité du réseau
Le Network Observability Operator fournit la définition des ressources personnalisées de l'API Flow Collector. Une instance de Flow Collector est créée lors de l'installation et permet de configurer la collecte des flux réseau. L'instance de Flow Collector déploie des pods et des services qui forment un pipeline de surveillance où les flux réseau sont ensuite collectés et enrichis avec les métadonnées Kubernetes avant d'être stockés dans Loki. L'agent eBPF, qui est déployé en tant qu'objet daemonset, crée les flux réseau.
34.2.4. Intégration de la console OpenShift Container Platform
L'intégration de la console OpenShift Container Platform offre une vue d'ensemble, une vue de la topologie et des tableaux de flux de trafic.
34.2.4.1. Mesures d'observabilité du réseau
La console OpenShift Container Platform propose l'onglet Overview qui affiche les métriques globales agrégées du flux de trafic réseau sur le cluster. Les informations peuvent être affichées par nœud, espace de noms, propriétaire, pod et service. Des filtres et des options d'affichage permettent d'affiner davantage les métriques.
34.2.4.2. Vues de la topologie de l'observabilité du réseau
La console OpenShift Container Platform propose l'onglet Topology qui affiche une représentation graphique des flux réseau et de la quantité de trafic. La vue topologique représente le trafic entre les composants d'OpenShift Container Platform sous la forme d'un graphique de réseau. Vous pouvez affiner le graphique en utilisant les filtres et les options d'affichage. Vous pouvez accéder aux informations pour le nœud, l'espace de noms, le propriétaire, le pod et le service.
34.2.4.3. Tableaux des flux de trafic
La vue du tableau des flux de trafic fournit une vue des flux bruts, des options de filtrage non agrégées et des colonnes configurables. La console OpenShift Container Platform propose l'onglet Traffic flows qui affiche les données des flux réseau et la quantité de trafic.
34.3. Installation de l'opérateur d'observabilité du réseau
L'installation de Loki est une condition préalable à l'utilisation de l'opérateur d'observabilité du réseau. Il est recommandé d'installer Loki à l'aide de l'opérateur Loki ; par conséquent, ces étapes sont documentées ci-dessous avant l'installation de l'opérateur d'observabilité du réseau.
L'opérateur Loki intègre une passerelle qui met en œuvre l'authentification multi-tenant & avec Loki pour le stockage des flux de données. La ressource LokiStack ressource gère Lokiqui est un système d'agrégation de logs évolutif, hautement disponible et multitenant, et un proxy web avec l'authentification OpenShift Container Platform. Le proxy LokiStack utilise l'authentification OpenShift Container Platform pour renforcer le multi-tenant et faciliter l'enregistrement et l'indexation des données dans les magasins de logs Loki magasins de logs.
L'opérateur Loki peut également être utilisé pour la journalisation avec la LokiStack. L'opérateur d'observabilité du réseau nécessite une LokiStack dédiée, séparée de la journalisation.
34.3.1. Installation de l'opérateur Loki
Il est recommandé d'installer Loki en utilisant la version 5.6 de Loki Operator. Cette version permet de créer une instance de LokiStack en utilisant le mode de configuration openshift-network tennant. Elle fournit également un support d'authentification et d'autorisation entièrement automatique au sein du cluster pour Network Observability.
Conditions préalables
- Log Store pris en charge (AWS S3, Google Cloud Storage, Azure, Swift, Minio, OpenShift Data Foundation)
- OpenShift Container Platform 4.10 .
- Noyau Linux 4.18 .
Il y a plusieurs façons d'installer Loki. L'une des façons d'installer l'opérateur Loki est d'utiliser la console web Operator Hub de OpenShift Container Platform.
Procédure
Installer l'opérateur
Loki Operator:- Dans la console web d'OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Choisissez Loki Operator dans la liste des opérateurs disponibles, et cliquez sur Install.
- Sous Installation Modesélectionner All namespaces on the cluster.
- Vérifiez que vous avez installé l'opérateur Loki. Visitez le site Operators → Installed Operators et cherchez Loki Operator.
- Vérifiez que Loki Operator est listé avec Status comme Succeeded dans tous les projets.
Créez un fichier YAML
Secret. Vous pouvez créer ce secret dans la console web ou dans le CLI.-
À l'aide de la console web, naviguez jusqu'à l'écran Project → All Projects et sélectionnez Create Project. Nommez le projet
netobservet cliquez sur Create. -
Naviguez jusqu'à l'icône d'importation , dans le coin supérieur droit. Déposez votre fichier YAML dans l'éditeur. Il est important de créer ce fichier YAML dans l'espace de noms
netobservqui utiliseaccess_key_idetaccess_key_secretpour spécifier vos informations d'identification. Une fois le secret créé, vous devriez le voir apparaître sous la rubrique Workloads → Secrets dans la console web.
Voici un exemple de fichier YAML secret :
-
À l'aide de la console web, naviguez jusqu'à l'écran Project → All Projects et sélectionnez Create Project. Nommez le projet
apiVersion: v1
kind: Secret
metadata:
name: loki-s3
namespace: netobserv
stringData:
access_key_id: QUtJQUlPU0ZPRE5ON0VYQU1QTEUK
access_key_secret: d0phbHJYVXRuRkVNSS9LN01ERU5HL2JQeFJmaUNZRVhBTVBMRUtFWQo=
bucketnames: s3-bucket-name
endpoint: https://s3.eu-central-1.amazonaws.com
region: eu-central-1
Pour désinstaller Loki, reportez-vous à la procédure de désinstallation correspondant à la méthode que vous avez utilisée pour installer Loki. Il se peut que vous ayez encore ClusterRoles et ClusterRoleBindings, des données stockées dans le magasin d'objets et des volumes persistants qui doivent être supprimés.
34.3.1.1. Créer une ressource personnalisée LokiStack
Il est recommandé de déployer la LokiStack dans le même espace de noms que celui référencé par la spécification FlowCollector, spec.namespace. Vous pouvez utiliser la console web ou le CLI pour créer un espace de noms, ou un nouveau projet.
Procédure
- Naviguer vers Operators → Installed Operators.
-
Dans les détails, sous Provided APIssélectionnez
LokiStacket cliquez sur Create LokiStack. Veillez à ce que les champs suivants soient spécifiés soit dans Form View ou YAML view:
apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv spec: size: 1x.small storage: schemas: - version: v12 effectiveDate: '2022-06-01' secret: name: loki-s3 type: s3 storageClassName: gp31 tenants: mode: openshift-network- 1
- Utilisez un nom de classe de stockage disponible sur le cluster pour le mode d'accès
ReadWriteOnce. Vous pouvez utiliseroc get storageclassespour voir ce qui est disponible sur votre cluster.
ImportantVous ne devez pas réutiliser la même LokiStack que celle utilisée pour la journalisation des clusters.
34.3.1.1.1. Dimensionnement du déploiement
Le dimensionnement de Loki suit le format suivant N<x>.<size> où la valeur <N> est le nombre d'instances et <size> spécifie les capacités de performance.
1x.extra-small est utilisé à des fins de démonstration uniquement et n'est pas pris en charge.
| 1x.extra-petit | 1x.petit | 1x.moyen | |
|---|---|---|---|
| Data transfer | Utilisation à des fins de démonstration uniquement. | 500GB/jour | 2TB/jour |
| Queries per second (QPS) | Utilisation à des fins de démonstration uniquement. | 25-50 QPS à 200ms | 25-75 QPS à 200ms |
| Replication factor | Aucun | 2 | 3 |
| Total CPU requests | 5 vCPU | 36 vCPUs | 54 vCPUs |
| Total Memory requests | 7.5Gi | 63Gi | 139Gi |
| Total Disk requests | 150Gi | 300Gi | 450Gi |
34.3.1.2. Limites d'ingestion et alertes sanitaires de LokiStack
L'instance de LokiStack est livrée avec des paramètres par défaut en fonction de la taille configurée. Il est possible de remplacer certains de ces paramètres, tels que les limites d'ingestion et de requête. Vous pourriez vouloir les mettre à jour si vous obtenez des erreurs Loki dans le plugin Console, ou dans les journaux flowlogs-pipeline. Une alerte automatique dans la console web vous notifie lorsque ces limites sont atteintes.
Voici un exemple de limites configurées :
spec:
limits:
global:
ingestion:
ingestionBurstSize: 40
ingestionRate: 20
maxGlobalStreamsPerTenant: 25000
queries:
maxChunksPerQuery: 2000000
maxEntriesLimitPerQuery: 10000
maxQuerySeries: 3000Pour plus d'informations sur ces paramètres, voir la référence de l'API LokiStack.
34.3.2. Créer des rôles pour l'authentification et l'autorisation
Spécifiez les configurations d'authentification et d'autorisation en définissant ClusterRole et ClusterRoleBinding. Vous pouvez créer un fichier YAML pour définir ces rôles.
Procédure
- Dans la console web, cliquez sur l'icône d'importation, .
Déposez votre fichier YAML dans l'éditeur et cliquez sur Create:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: loki-netobserv-tenant rules: - apiGroups: - 'loki.grafana.com' resources: - network resourceNames: - logs verbs: - 'get' - 'create' --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: loki-netobserv-tenant roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: loki-netobserv-tenant subjects: - kind: ServiceAccount name: flowlogs-pipeline1 namespace: netobserv- 1
- Le site
flowlogs-pipelineécrit à Loki. Si vous utilisez Kafka, cette valeur estflowlogs-pipeline-transformer.
34.3.3. Installation de Kafka (optionnel)
L'Opérateur Kafka est pris en charge pour les environnements à grande échelle. Vous pouvez installer l'Opérateur Kafka en tant que Red Hat AMQ Streams à partir de l'Operator Hub, tout comme l'Opérateur Loki et l'Opérateur Network Observability ont été installés.
Pour désinstaller Kafka, reportez-vous à la procédure de désinstallation correspondant à la méthode utilisée pour l'installation.
34.3.4. Installation de l'opérateur d'observabilité du réseau
Vous pouvez installer l'opérateur d'observabilité réseau à l'aide de la console web Operator Hub de OpenShift Container Platform. Lorsque vous installez l'opérateur, il fournit la définition de ressource personnalisée (CRD) FlowCollector. Vous pouvez définir des spécifications dans la console web lorsque vous créez le FlowCollector.
Conditions préalables
- Installation de Loki. Il est recommandé d'installer Loki en utilisant la version 5.6 de l'Opérateur Loki.
Cette documentation part du principe que le nom de votre instance LokiStack est loki. L'utilisation d'un nom différent nécessite une configuration supplémentaire.
Procédure
- Dans la console web d'OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Choisissez Network Observability Operator dans la liste des opérateurs disponibles dans la fenêtre OperatorHubet cliquez sur Install.
-
Cochez la case
Enable Operator recommended cluster monitoring on this Namespace. Naviguer vers Operators → Installed Operators. Sous Provided APIs for Network Observability, sélectionnez le lien Flow Collector lien.
Naviguez jusqu'à l'onglet Flow Collector et cliquez sur Create FlowCollector. Effectuez les sélections suivantes dans la vue du formulaire :
-
spec.agent.ebpf.Sampling taille d'échantillonnage : Spécifier une taille d'échantillonnage pour les flux. Des tailles d'échantillonnage plus faibles auront un impact plus important sur l'utilisation des ressources. Pour plus d'informations, voir la référence de l'API
FlowCollector, sous spec.agent.ebpf. - spec.deploymentModel: Si vous utilisez Kafka, vérifiez que Kafka est sélectionné.
spec.exporters: Si vous utilisez Kafka, vous pouvez éventuellement envoyer des flux de réseau à Kafka, afin qu'ils puissent être consommés par tout processeur ou stockage prenant en charge l'entrée Kafka, comme Splunk, Elasticsearch ou Fluentd. Pour ce faire, définissez les spécifications suivantes :
-
Réglez le type sur
KAFKA. -
Régler le address comme
kafka-cluster-kafka-bootstrap.netobserv. -
Régler le topic comme
netobserv-flows-export. L'opérateur exporte tous les flux vers le sujet Kafka configuré. Définir les spécifications suivantes tls les spécifications :
certFile:
service-ca.crt, name:kafka-gateway-ca-bundle, et type:configmap.Vous pouvez également configurer cette option ultérieurement en modifiant directement le fichier YAML. Pour plus d'informations, voir Export enriched network flow data.
-
Réglez le type sur
-
loki.url: L'authentification étant spécifiée séparément, cette URL doit être mise à jour comme suit
https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network. La première partie de l'URL, "loki", doit correspondre au nom de votre LokiStack. -
loki.statusUrl: Réglez cette valeur sur
https://loki-query-frontend-http.netobserv.svc:3100/. La première partie de l'URL, "loki", doit correspondre au nom de votre LokiStack. -
loki.authToken: Sélectionnez la valeur
FORWARD. - tls.enable: Vérifiez que la case est cochée et qu'elle est donc activée.
statusTls: La valeur
enableest fausse par défaut.Pour la première partie du certificat, les noms de référence :
loki-gateway-ca-bundle,loki-ca-bundle, etloki-query-frontend-http,loki, doivent correspondre au nom de votreLokiStack.
-
spec.agent.ebpf.Sampling taille d'échantillonnage : Spécifier une taille d'échantillonnage pour les flux. Des tailles d'échantillonnage plus faibles auront un impact plus important sur l'utilisation des ressources. Pour plus d'informations, voir la référence de l'API
- Cliquez Create.
Vérification
Pour confirmer que l'opération s'est déroulée correctement, lorsque vous naviguez vers Observe vous devriez voir Network Traffic dans les options.
En l'absence de Application Traffic dans le cluster OpenShift Container Platform, les filtres par défaut peuvent indiquer qu'il n'y a pas de résultats, ce qui ne permet pas de visualiser le flux. À côté des sélections de filtres, sélectionnez Clear all filters pour voir le flux.
Si vous avez installé Loki en utilisant l'Opérateur Loki, il est conseillé de ne pas utiliser querierUrl, car cela peut casser l'accès à la console de Loki. Si vous avez installé Loki en utilisant un autre type d'installation de Loki, ceci ne s'applique pas.
34.3.5. Désinstallation de l'opérateur d'observabilité du réseau
Vous pouvez désinstaller l'opérateur d'observabilité réseau à l'aide de la console web Operator Hub d'OpenShift Container Platform, en travaillant dans l'espace de travail Operators → Installed Operators zone.
Procédure
Supprimer la ressource personnalisée
FlowCollector.- Cliquez Flow Collectorqui se trouve à côté de l'icône Network Observability Operator dans la colonne Provided APIs colonne.
-
Cliquez sur le menu des options
 pour l'option cluster et sélectionnez Delete FlowCollector.
pour l'option cluster et sélectionnez Delete FlowCollector.
Désinstaller l'opérateur d'observabilité du réseau.
- Retournez à la page Operators → Installed Operators dans l'espace.
-
Cliquez sur le menu des options
à côté de l'icône Network Observability Operator et sélectionnez Uninstall Operator.
-
Home → Projects et sélectionner
openshift-netobserv-operator - Naviguez jusqu'à Actions et sélectionnez Delete Project
Supprimez la définition de ressource personnalisée (CRD) de
FlowCollector.- Naviguer vers Administration → CustomResourceDefinitions.
-
Cherchez FlowCollector et cliquez sur le menu des options
.
Sélectionner Delete CustomResourceDefinition.
ImportantL'opérateur Loki et Kafka restent en place s'ils ont été installés et doivent être supprimés séparément. En outre, vous pouvez avoir des données restantes stockées dans un magasin d'objets et un volume persistant qui doivent être supprimés.
34.4. Opérateur de l'observabilité du réseau dans OpenShift Container Platform
Network Observability est un opérateur OpenShift qui déploie un pipeline de surveillance pour collecter et enrichir les flux de trafic réseau qui sont produits par l'agent eBPF de Network Observability.
34.4.1. Visualisation des statuts
L'opérateur d'observabilité réseau fournit l'API Flow Collector. Lorsqu'une ressource Flow Collector est créée, elle déploie des pods et des services pour créer et stocker des flux réseau dans le magasin de logs Loki, ainsi que pour afficher des tableaux de bord, des métriques et des flux dans la console web d'OpenShift Container Platform.
Procédure
Exécutez la commande suivante pour afficher l'état de
FlowCollector:$ oc get flowcollector/clusterExemple de sortie
NAME AGENT SAMPLING (EBPF) DEPLOYMENT MODEL STATUS cluster EBPF 50 DIRECT ReadyVérifiez l'état des pods fonctionnant dans l'espace de noms
netobserven entrant la commande suivante :$ oc get pods -n netobservExemple de sortie
NAME READY STATUS RESTARTS AGE flowlogs-pipeline-56hbp 1/1 Running 0 147m flowlogs-pipeline-9plvv 1/1 Running 0 147m flowlogs-pipeline-h5gkb 1/1 Running 0 147m flowlogs-pipeline-hh6kf 1/1 Running 0 147m flowlogs-pipeline-w7vv5 1/1 Running 0 147m netobserv-plugin-cdd7dc6c-j8ggp 1/1 Running 0 147m
flowlogs-pipeline les pods collectent les flux, enrichissent les flux collectés, puis envoient les flux vers le stockage Loki. Les pods netobserv-plugin créent un plugin de visualisation pour la console OpenShift Container Platform.
Vérifiez l'état des pods fonctionnant dans l'espace de noms
netobserv-privilegeden entrant la commande suivante :$ oc get pods -n netobserv-privilegedExemple de sortie
NAME READY STATUS RESTARTS AGE netobserv-ebpf-agent-4lpp6 1/1 Running 0 151m netobserv-ebpf-agent-6gbrk 1/1 Running 0 151m netobserv-ebpf-agent-klpl9 1/1 Running 0 151m netobserv-ebpf-agent-vrcnf 1/1 Running 0 151m netobserv-ebpf-agent-xf5jh 1/1 Running 0 151m
netobserv-ebpf-agent surveillent les interfaces réseau des nœuds pour obtenir des flux et les envoyer aux pods flowlogs-pipeline.
Si vous utilisez un opérateur Loki, vérifiez l'état des pods fonctionnant dans l'espace de noms
openshift-operators-redhaten entrant la commande suivante :$ oc get pods -n openshift-operators-redhatExemple de sortie
NAME READY STATUS RESTARTS AGE loki-operator-controller-manager-5f6cff4f9d-jq25h 2/2 Running 0 18h lokistack-compactor-0 1/1 Running 0 18h lokistack-distributor-654f87c5bc-qhkhv 1/1 Running 0 18h lokistack-distributor-654f87c5bc-skxgm 1/1 Running 0 18h lokistack-gateway-796dc6ff7-c54gz 2/2 Running 0 18h lokistack-index-gateway-0 1/1 Running 0 18h lokistack-index-gateway-1 1/1 Running 0 18h lokistack-ingester-0 1/1 Running 0 18h lokistack-ingester-1 1/1 Running 0 18h lokistack-ingester-2 1/1 Running 0 18h lokistack-querier-66747dc666-6vh5x 1/1 Running 0 18h lokistack-querier-66747dc666-cjr45 1/1 Running 0 18h lokistack-querier-66747dc666-xh8rq 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-b2xfb 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-jm94f 1/1 Running 0 18h
34.4.2. Visualisation de l'état et de la configuration de l'opérateur d'observabilité du réseau
Vous pouvez inspecter l'état et visualiser les détails du site FlowCollector à l'aide de la commande oc describe.
Procédure
Exécutez la commande suivante pour afficher l'état et la configuration de l'opérateur d'observabilité du réseau :
$ oc describe flowcollector/cluster
34.5. Configuration de l'opérateur d'observabilité du réseau
Vous pouvez mettre à jour la ressource API Flow Collector pour configurer le Network Observability Operator et ses composants gérés. Le collecteur de flux est explicitement créé lors de l'installation. Étant donné que cette ressource fonctionne à l'échelle du cluster, un seul FlowCollector est autorisé et il doit être nommé cluster.
34.5.1. Voir la ressource FlowCollector
Vous pouvez visualiser et éditer YAML directement dans la console web d'OpenShift Container Platform.
Procédure
- Dans la console web, naviguez vers Operators → Installed Operators.
- Sous la rubrique Provided APIs de la rubrique NetObserv Operatorsélectionnez Flow Collector.
-
Sélectionner cluster puis sélectionnez l'onglet YAML onglet. Là, vous pouvez modifier la ressource
FlowCollectorpour configurer l'opérateur Network Observability.
L'exemple suivant montre un exemple de ressource FlowCollector pour l'opérateur OpenShift Container Platform Network Observability :
Exemple de ressource FlowCollector
apiVersion: flows.netobserv.io/v1beta1
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: DIRECT
agent:
type: EBPF
ebpf:
sampling: 50
logLevel: info
privileged: false
resources:
requests:
memory: 50Mi
cpu: 100m
limits:
memory: 800Mi
processor:
logLevel: info
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 800Mi
conversationEndTimeout: 10s
logTypes: FLOW
conversationHeartbeatInterval: 30s
loki:
url: 'http://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network'
statusUrl: 'https://loki-query-frontend-http.netobserv.svc:3100/'
authToken: FORWARD
tls:
enable: true
caCert:
type: configmap
name: loki-gateway-ca-bundle
certFile: service-ca.crt
consolePlugin:
register: true
logLevel: info
portNaming:
enable: true
portNames:
"3100": loki
quickFilters:
- name: Applications
filter:
src_namespace!: 'openshift-,netobserv'
dst_namespace!: 'openshift-,netobserv'
default: true
- name: Infrastructure
filter:
src_namespace: 'openshift-,netobserv'
dst_namespace: 'openshift-,netobserv'
- name: Pods network
filter:
src_kind: 'Pod'
dst_kind: 'Pod'
default: true
- name: Services network
filter:
dst_kind: 'Service'- 1
- La spécification de l'agent,
spec.agent.type, doit êtreEBPF. eBPF est la seule option prise en charge par OpenShift Container Platform. - 2
- Vous pouvez définir la spécification d'échantillonnage,
spec.agent.ebpf.sampling, pour gérer les ressources. Des valeurs d'échantillonnage plus faibles peuvent consommer une grande quantité de ressources de calcul, de mémoire et de stockage. Vous pouvez atténuer ce phénomène en spécifiant une valeur de ratio d'échantillonnage. Une valeur de 100 signifie qu'un flux sur 100 est échantillonné. Une valeur de 0 ou 1 signifie que tous les flux sont capturés. Plus la valeur est faible, plus le nombre de flux renvoyés et la précision des mesures dérivées augmentent. Par défaut, l'échantillonnage eBPF est fixé à une valeur de 50, ce qui signifie qu'un flux est échantillonné tous les 50. Il est à noter qu'un plus grand nombre de flux échantillonnés signifie également un plus grand besoin de stockage. Il est recommandé de commencer par les valeurs par défaut et de les affiner de manière empirique, afin de déterminer les paramètres que votre cluster peut gérer. - 3
- Les spécifications facultatives
spec.processor.logTypes,spec.processor.conversationHeartbeatInterval, etspec.processor.conversationEndTimeoutpeuvent être définies pour activer le suivi des conversations. Lorsque cette option est activée, les événements de conversation peuvent être consultés dans la console web. Les valeurs pourspec.processor.logTypessont les suivantes : ou :FLOWSCONVERSATIONSENDED_CONVERSATIONSALLles exigences en matière de stockage sont les plus élevées pourALLet les plus faibles pourENDED_CONVERSATIONS. - 4
- La spécification Loki,
spec.loki, spécifie le client Loki. Les valeurs par défaut correspondent aux chemins d'installation de Loki mentionnés dans la section Installation de l'opérateur Loki. Si vous avez utilisé une autre méthode d'installation pour Loki, indiquez les informations client appropriées pour votre installation. - 5
- La spécification
spec.quickFiltersdéfinit les filtres qui s'affichent dans la console web. Les clés du filtreApplication,src_namespaceetdst_namespace, sont inversées (!), de sorte que le filtreApplicationaffiche tout le trafic provenant ou à destination de l'un des espaces de noms ou does not qui provient de, ou a une destination vers, n'importe quel espace de nomsopenshift-ounetobserv. Pour plus d'informations, voir Configuration des filtres rapides ci-dessous.
34.5.2. Configuration de la ressource Flow Collector avec Kafka
Vous pouvez configurer la ressource FlowCollector pour utiliser Kafka. Une instance Kafka doit être en cours d'exécution, et un sujet Kafka dédié à OpenShift Container Platform Network Observability doit être créé dans cette instance. Pour plus d'informations, reportez-vous à la documentation Kafka, telle que la documentation Kafka avec AMQ Streams.
L'exemple suivant montre comment modifier la ressource FlowCollector pour l'opérateur OpenShift Container Platform Network Observability afin d'utiliser Kafka :
Exemple de configuration Kafka dans la ressource FlowCollector
deploymentModel: KAFKA
kafka:
address: "kafka-cluster-kafka-bootstrap.netobserv"
topic: network-flows
tls:
enable: false - 1
- Définissez
spec.deploymentModelàKAFKAau lieu deDIRECTpour activer le modèle de déploiement Kafka. - 2
spec.kafka.addressfait référence à l'adresse du serveur d'amorçage Kafka. Vous pouvez spécifier un port si nécessaire, par exemplekafka-cluster-kafka-bootstrap.netobserv:9093pour utiliser TLS sur le port 9093.- 3
spec.kafka.topicdoit correspondre au nom d'un sujet créé dans Kafka.- 4
spec.kafka.tlspeut être utilisé pour chiffrer toutes les communications vers et depuis Kafka avec TLS ou mTLS. Lorsqu'il est activé, le certificat de l'autorité de certification Kafka doit être disponible en tant que ConfigMap ou Secret, à la fois dans l'espace de noms où le composant du processeurflowlogs-pipelineest déployé (par défaut :netobserv) et dans celui où les agents eBPF sont déployés (par défaut :netobserv-privileged). Il doit être référencé avecspec.kafka.tls.caCert. Lors de l'utilisation de mTLS, les secrets clients doivent également être disponibles dans ces espaces de noms (ils peuvent être générés, par exemple, à l'aide de l'opérateur utilisateur AMQ Streams) et référencés avecspec.kafka.tls.userCert.
34.5.3. Exporter des données de flux de réseau enrichies
Vous pouvez envoyer des flux réseau à Kafka, afin qu'ils puissent être consommés par n'importe quel processeur ou stockage prenant en charge l'entrée Kafka, comme Splunk, Elasticsearch ou Fluentd.
Conditions préalables
- Kafka installé
Procédure
- Dans la console web, naviguez vers Operators → Installed Operators.
- Sous la rubrique Provided APIs de la rubrique NetObserv Operatorsélectionnez Flow Collector.
- Sélectionnez cluster puis sélectionnez l'onglet YAML l'onglet
Modifiez le site
FlowCollectorpour configurerspec.exporterscomme suit :apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: exporters: - type: KAFKA kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" topic: netobserv-flows-export1 tls: enable: false2 - 1
- L'opérateur d'observabilité du réseau exporte tous les flux vers le sujet Kafka configuré.
- 2
- Vous pouvez chiffrer toutes les communications vers et depuis Kafka avec SSL/TLS ou mTLS. Lorsqu'il est activé, le certificat de l'autorité de certification Kafka doit être disponible en tant que ConfigMap ou Secret, dans l'espace de noms où le composant du processeur
flowlogs-pipelineest déployé (par défaut : netobserv). Il doit être référencé avecspec.exporters.tls.caCert. Lors de l'utilisation de mTLS, les secrets des clients doivent également être disponibles dans ces espaces de noms (ils peuvent être générés, par exemple, à l'aide de l'opérateur utilisateur AMQ Streams) et référencés avecspec.exporters.tls.userCert.
- Après configuration, les données de flux réseau peuvent être envoyées vers une sortie disponible au format JSON. Pour plus d'informations, voir Network flows format reference
34.5.4. Mise à jour de la ressource Collecteur de flux
Au lieu d'éditer YAML dans la console web d'OpenShift Container Platform, vous pouvez configurer les spécifications, telles que l'échantillonnage eBPF, en corrigeant la ressource personnalisée (CR) flowcollector:
Procédure
Exécutez la commande suivante pour corriger le CR
flowcollectoret mettre à jour la valeurspec.agent.ebpf.sampling:$ oc patch flowcollector cluster --type=json -p \N-[{"op\N" : \N "replace\N", \N "path\N" : \N"/spec/agent/ebpf/sampling\N", \N "value\N" : <nouvelle valeur>}] -n netobserv"
34.5.5. Configuration des filtres rapides
Vous pouvez modifier les filtres dans la ressource FlowCollector. Des correspondances exactes sont possibles en utilisant des guillemets doubles autour des valeurs. Sinon, des correspondances partielles sont utilisées pour les valeurs textuelles. Le caractère bang ( !), placé à la fin d'une clé, signifie la négation. Voir l'exemple de ressource FlowCollector pour plus de détails sur la modification du YAML.
Le filtre correspondant aux types "tous" ou "n'importe lequel" est un paramètre de l'interface utilisateur que les utilisateurs peuvent modifier à partir des options de la requête. Il ne fait pas partie de la configuration de cette ressource.
Voici une liste de toutes les clés de filtrage disponibles :
| Universelle* | Source | Destination | Description |
|---|---|---|---|
| espace de noms |
|
| Filtrer le trafic lié à un espace de noms spécifique. |
| nom |
|
| Filtrer le trafic lié à un nom de ressource leaf donné, tel qu'un pod, un service ou un nœud spécifique (pour le trafic hôte-réseau). |
| kind |
|
| Filtre le trafic lié à un type de ressource donné. Les types de ressources comprennent la ressource feuille (Pod, Service ou Node) ou la ressource propriétaire (Deployment et StatefulSet). |
| nom_du_propriétaire |
|
| Filtrer le trafic lié à un propriétaire de ressource donné, c'est-à-dire une charge de travail ou un ensemble de pods. Par exemple, il peut s'agir d'un nom de déploiement, d'un nom de StatefulSet, etc. |
| ressource |
|
|
Filtrer le trafic lié à une ressource spécifique désignée par son nom canonique, qui l'identifie de manière unique. La notation canonique est |
| adresse |
|
| Filtre le trafic lié à une adresse IP. Les protocoles IPv4 et IPv6 sont pris en charge. Les plages CIDR sont également prises en charge. |
| mac |
|
| Filtrer le trafic lié à une adresse MAC. |
| port |
|
| Filtrer le trafic lié à un port spécifique. |
| adresse_hôte |
|
| Filtre le trafic lié à l'adresse IP de l'hôte où les pods fonctionnent. |
| protocole | N/A | N/A | Filtrer le trafic lié à un protocole, tel que TCP ou UDP. |
-
Les clés universelles filtrent pour n'importe quelle source ou destination. Par exemple, le filtrage de
name: 'my-pod'signifie tout le trafic en provenance demy-podet tout le trafic à destination demy-pod, quel que soit le type de correspondance utilisé, qu'il s'agisse de Match all ou Match any.
34.6. Observer le trafic sur le réseau
En tant qu'administrateur, vous pouvez observer le trafic réseau dans la console OpenShift Container Platform pour un dépannage et une analyse détaillés. Cette fonctionnalité vous aide à obtenir des informations à partir de différentes représentations graphiques du flux de trafic. Plusieurs vues sont disponibles pour observer le trafic réseau.
34.6.1. Observer le trafic réseau à partir de la vue d'ensemble
La vue Overview affiche les métriques globales agrégées du flux de trafic réseau sur le cluster. En tant qu'administrateur, vous pouvez surveiller les statistiques à l'aide des options d'affichage disponibles.
34.6.1.1. Travailler avec la vue d'ensemble
En tant qu'administrateur, vous pouvez accéder à la vue Overview pour voir la représentation graphique des statistiques de débit.
Procédure
- Naviguer vers Observe → Network Traffic.
- Dans la page Network Traffic cliquez sur l'onglet Overview l'onglet
Vous pouvez configurer l'étendue de chaque donnée de débit en cliquant sur l'icône de menu.
34.6.1.2. Configuration des options avancées pour la vue d'ensemble
Vous pouvez personnaliser la vue graphique en utilisant les options avancées. Pour accéder aux options avancées, cliquez sur Show advanced optionsvous pouvez configurer les détails du graphique à l'aide du menu déroulant Display options dans le menu déroulant. Les options disponibles sont les suivantes :
- Metric type: Les métriques à afficher dans Bytes ou Packets. La valeur par défaut est Bytes.
- Scope: Pour sélectionner le détail des composants entre lesquels le trafic réseau circule. Vous pouvez définir l'étendue sur Node, Namespace, Ownerou Resource. Owner est une agrégation de ressources. Resource peut être un pod, un service, un nœud, dans le cas d'un trafic hôte-réseau, ou une adresse IP inconnue. La valeur par défaut est Namespace.
- Truncate labels: Sélectionnez la largeur requise de l'étiquette dans la liste déroulante. La valeur par défaut est M.
34.6.1.2.1. Gestion des panels
Vous pouvez sélectionner les statistiques à afficher et les réorganiser. Pour gérer les colonnes, cliquez sur Manage panels.
34.6.2. Observer le trafic réseau à partir de la vue Flux de trafic
La vue Traffic flows affiche les données des flux réseau et la quantité de trafic dans un tableau. En tant qu'administrateur, vous pouvez surveiller la quantité de trafic à travers l'application en utilisant le tableau des flux de trafic.
34.6.2.1. Travailler avec la vue des flux de trafic
En tant qu'administrateur, vous pouvez naviguer dans le tableau Traffic flows pour consulter les informations sur le flux du réseau.
Procédure
- Naviguer vers Observe → Network Traffic.
- Dans la page Network Traffic cliquez sur l'onglet Traffic flows l'onglet
Vous pouvez cliquer sur chaque ligne pour obtenir les informations correspondantes sur les flux.
34.6.2.2. Configuration des options avancées pour la vue Flux de trafic
Vous pouvez personnaliser et exporter la vue à l'aide de la fonction Show advanced options. Vous pouvez définir la taille des lignes à l'aide du menu déroulant Display options dans le menu déroulant. La valeur par défaut est Normal.
34.6.2.2.1. Gestion des colonnes
Vous pouvez sélectionner les colonnes à afficher et les réorganiser. Pour gérer les colonnes, cliquez sur Manage columns.
34.6.2.2.2. Exportation des données relatives au flux de trafic
Vous pouvez exporter des données à partir de la vue Traffic flows vue.
Procédure
- Cliquez Export data.
- Dans la fenêtre contextuelle, vous pouvez cocher la case Export all data pour exporter toutes les données, et décocher la case pour sélectionner les champs obligatoires à exporter.
- Cliquez Export.
34.6.2.3. Travailler avec le suivi des conversations
En tant qu'administrateur, vous pouvez regrouper les flux réseau qui font partie de la même conversation. Une conversation est définie comme un regroupement de pairs identifiés par leurs adresses IP, leurs ports et leurs protocoles, ce qui permet d'obtenir un numéro de téléphone unique Conversation Id. Vous pouvez interroger les événements de conversation dans la console web. Ces événements sont représentés dans la console web comme suit :
- Conversation start: Cet événement se produit lorsqu'une connexion démarre ou qu'un drapeau TCP est intercepté
-
Conversation tick: Cet événement se produit à chaque intervalle défini dans le paramètre
FlowCollectorspec.processor.conversationHeartbeatIntervallorsque la connexion est active. -
Conversation end: Cet événement se produit lorsque le paramètre
FlowCollectorspec.processor.conversationEndTimeoutest atteint ou que le drapeau TCP est intercepté. - Flow: Il s'agit du flux de trafic réseau qui se produit dans l'intervalle spécifié.
Procédure
- Dans la console web, naviguez vers Operators → Installed Operators.
- Sous la rubrique Provided APIs de la rubrique NetObserv Operatorsélectionnez Flow Collector.
- Sélectionner cluster puis sélectionnez l'onglet YAML l'onglet
Configurez la ressource personnalisée
FlowCollectorde manière à ce que les paramètresspec.processor.logTypes,conversationEndTimeoutetconversationHeartbeatIntervalsoient définis en fonction de vos besoins d'observation. Voici un exemple de configuration :Configurer
FlowCollectorpour le suivi des conversationsapiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: processor: conversationEndTimeout: 10s1 logTypes: FLOWS2 conversationHeartbeatInterval: 30s3 - 1
- L'événement Conversation end représente le moment où le site
conversationEndTimeoutest atteint ou le drapeau TCP est intercepté. - 2
- Lorsque
logTypesest défini surFLOWS, seul l'événement est exporté Flow est exporté. Si la valeur estALL, les événements de conversation et de flux sont exportés et visibles dans la page Network Traffic et sont visibles dans la page d'accueil. Pour vous concentrer uniquement sur les événements de conversation, vous pouvez spécifierCONVERSATIONSqui exporte les événements de conversation et de flux Conversation start, Conversation tick et Conversation end ouENDED_CONVERSATIONSqui exporte uniquement les événements Conversation end événements. Les besoins en stockage sont les plus élevés pourALLet les plus faibles pourENDED_CONVERSATIONS. - 3
- L'événement Conversation tick représente chaque intervalle défini dans le paramètre
FlowCollectorconversationHeartbeatIntervalpendant que la connexion réseau est active.
NoteSi vous mettez à jour l'option
logType, les flux de la sélection précédente ne disparaissent pas du module d'extension de la console. Par exemple, si vous définissez initialementlogTypesurCONVERSATIONSpour une période allant jusqu'à 10 heures du matin et que vous passez ensuite àENDED_CONVERSATIONS, le plugin de la console affiche tous les événements de conversation avant 10 heures du matin et uniquement les conversations terminées après 10 heures du matin.-
Rafraîchir la page Network Traffic dans l'onglet Traffic flows . Vous remarquerez qu'il y a deux nouvelles colonnes, Event/Type et Conversation Id. Tous les champs Event/Type sont
Flowlorsque Flow est l'option de requête sélectionnée. - Sélectionnez Query Options et choisissez l'option Log Type, Conversation. L'écran Event/Type affiche tous les événements de conversation souhaités.
- Vous pouvez ensuite filtrer sur un identifiant de conversation spécifique ou passer de l'identifiant de conversation à l'identifiant de conversation Conversation et Flow dans le panneau latéral.
34.6.2.3.1. Utilisation de l'histogramme
Vous pouvez cliquer sur Show histogram pour afficher une barre d'outils permettant de visualiser l'historique des flux sous la forme d'un histogramme. L'histogramme montre le nombre de journaux au fil du temps. Vous pouvez sélectionner une partie de l'histogramme pour filtrer les données de flux du réseau dans le tableau qui suit la barre d'outils.
34.6.3. Observer le trafic réseau à partir de la vue Topologie
La vue Topology fournit une représentation graphique des flux du réseau et de la quantité de trafic. En tant qu'administrateur, vous pouvez surveiller les données relatives au trafic dans l'application à l'aide de la vue Topology vue.
34.6.3.1. Travailler avec la vue Topologie
En tant qu'administrateur, vous pouvez accéder à la vue Topology pour voir les détails et les métriques du composant.
Procédure
- Naviguer vers Observe → Network Traffic.
- Dans la page Network Traffic cliquez sur l'onglet Topology l'onglet
Vous pouvez cliquer sur chaque composant dans le Topology pour afficher les détails et les mesures du composant.
34.6.3.2. Configuration des options avancées de la vue Topologie
Vous pouvez personnaliser et exporter la vue à l'aide de la fonction Show advanced options. La vue des options avancées présente les caractéristiques suivantes :
- Find in view: Pour rechercher les composants requis dans la vue.
Display options: Pour configurer les options suivantes :
- Layout: Permet de sélectionner la disposition de la représentation graphique. La valeur par défaut est ColaNoForce.
- Scope: Pour sélectionner l'étendue des composants entre lesquels le trafic réseau circule. La valeur par défaut est Namespace.
- Groups: Pour améliorer la compréhension de la propriété en regroupant les composants. La valeur par défaut est None.
- Collapse groups: Pour développer ou réduire les groupes. Les groupes sont développés par défaut. Cette option est désactivée si Groups a la valeur None.
- Show: Pour sélectionner les détails qui doivent être affichés. Toutes les options sont cochées par défaut. Les options disponibles sont les suivantes : Edges, Edges label, et Badges.
- Truncate labels: Pour sélectionner la largeur requise de l'étiquette dans la liste déroulante. La valeur par défaut est M.
34.6.3.2.1. Exportation de la vue topologique
Pour exporter la vue, cliquez sur Export topology view. La vue est téléchargée au format PNG.
34.6.4. Filtrage du trafic réseau
Par défaut, la page Trafic réseau affiche les données du flux de trafic dans le cluster en fonction des filtres par défaut configurés dans l'instance FlowCollector. Vous pouvez utiliser les options de filtrage pour observer les données requises en modifiant le filtre prédéfini.
- Options d'interrogation
Vous pouvez utiliser Query Options pour optimiser les résultats de la recherche, comme indiqué ci-dessous :
- Log Type: Les options disponibles Conversation et Flows permettent d'interroger les flux par type de journal, comme le journal des flux, les nouvelles conversations, les conversations terminées et les battements de cœur, qui sont des enregistrements périodiques avec des mises à jour pour les longues conversations. Une conversation est une agrégation de flux entre les mêmes pairs.
- Reporter Node: Chaque flux peut être signalé à la fois par le nœud source et le nœud de destination. Pour l'entrée dans le cluster, le flux est signalé à partir du nœud de destination et pour la sortie du cluster, le flux est signalé à partir du nœud source. Vous pouvez sélectionner l'une ou l'autre des options suivantes Source ou Destination. L'option Both est désactivée pour les options Overview et Topology l'option est désactivée. La valeur sélectionnée par défaut est Destination.
- Match filters: Vous pouvez déterminer la relation entre les différents paramètres de filtrage sélectionnés dans le filtre avancé. Les options disponibles sont Match all et Match any. Match all fournit des résultats qui correspondent à toutes les valeurs, et Match any fournit des résultats qui correspondent à n'importe laquelle des valeurs saisies. La valeur par défaut est Match all.
- Limit: Limite de données pour les requêtes internes. En fonction des paramètres de correspondance et de filtrage, le nombre de données sur les flux de trafic est affiché dans la limite spécifiée.
- Filtres rapides
-
Les valeurs par défaut du menu déroulant Quick filters sont définies dans la configuration de
FlowCollector. Vous pouvez modifier les options à partir de la console. - Filtres avancés
- Vous pouvez définir les filtres avancés en indiquant le paramètre à filtrer et sa valeur textuelle correspondante. La section Common dans la liste déroulante des paramètres permet de filtrer les résultats qui correspondent soit à Source ou Destination. Pour activer ou désactiver le filtre appliqué, vous pouvez cliquer sur le filtre appliqué répertorié sous les options de filtrage.
Pour comprendre les règles de spécification de la valeur du texte, cliquez sur Learn More.
Vous pouvez cliquer sur Reset default filter pour supprimer les filtres existants et appliquer le filtre défini dans la configuration de FlowCollector.
Vous pouvez également accéder aux données sur les flux de trafic dans l'onglet Network Traffic de l'onglet Namespaces, Services, Routes, Nodes, et Workloads qui fournissent les données filtrées des agrégations correspondantes.
34.7. Contrôle de l'opérateur d'observabilité du réseau
Vous pouvez utiliser la console web pour surveiller les alertes relatives à l'état de l'opérateur Network Observability.
34.7.1. Consultation d'informations sur la santé
Vous pouvez accéder aux mesures concernant l'état et l'utilisation des ressources de l'opérateur d'observabilité du réseau à partir de la page Dashboards de la console web. Une bannière d'alerte de santé qui vous dirige vers le tableau de bord peut apparaître sur les écrans Network Traffic et Home en cas de déclenchement d'une alerte. Les alertes sont générées dans les cas suivants :
-
L'alerte NetObservLokiError se produit si la charge de travail
flowlogs-pipelineabandonne des flux en raison d'erreurs de Loki, par exemple si la limite du taux d'ingestion de Loki a été atteinte. - L'alerte NetObservNoFlows l'alerte se produit si aucun flux n'est ingéré pendant un certain temps..Conditions préalables
- Vous avez installé le Network Observability Operator.
-
Vous avez accès au cluster en tant qu'utilisateur avec le rôle
cluster-adminou avec des permissions de visualisation pour tous les projets.
Procédure
- Dans la perspective Administrator dans la console web, naviguez vers Observe → Dashboards.
- Dans la liste déroulante Dashboards sélectionnez Netobserv/Health. Des mesures concernant la santé de l'opérateur sont affichées sur la page.
34.7.1.1. Désactivation des alertes sanitaires
Vous pouvez refuser les alertes sanitaires en modifiant la ressource FlowCollector:
- Dans la console web, naviguez vers Operators → Installed Operators.
- Sous la rubrique Provided APIs de la rubrique NetObserv Operatorsélectionnez Flow Collector.
- Sélectionner cluster puis sélectionnez l'onglet YAML l'onglet
-
Ajoutez
spec.processor.metrics.disableAlertspour désactiver les alertes de santé, comme dans l'exemple YAML suivant :
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowCollector
metadata:
name: cluster
spec:
processor:
metrics:
disableAlerts: [NetObservLokiError, NetObservNoFlows] - 1
- Vous pouvez spécifier une alerte ou une liste avec les deux types d'alertes à désactiver.
34.8. Paramètres de configuration de FlowCollector
FlowCollector est le schéma de l'API flowcollectors, qui pilote et configure la collecte des flux nets.
34.8.1. Spécifications de l'API FlowCollector
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| APIVersion définit le schéma versionné de cette représentation d'un objet. Les serveurs doivent convertir les schémas reconnus à la dernière valeur interne et peuvent rejeter les valeurs non reconnues. Plus d'informations : https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| Kind est une chaîne de caractères représentant la ressource REST que cet objet représente. Les serveurs peuvent en déduire le point d'accès auquel le client soumet ses requêtes. Dans CamelCase. Plus d'informations : https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| Métadonnées de l'objet standard. Plus d'informations : https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
| FlowCollectorSpec définit l'état souhaité du FlowCollector |
|
|
| FlowCollectorStatus définit l'état observé du collecteur de flux |
34.8.1.1. .spec
- Description
- FlowCollectorSpec définit l'état souhaité du FlowCollector
- Type
-
object - Exigée
-
agent -
deploymentModel
-
| Propriété | Type | Description |
|---|---|---|
|
|
| agent d'extraction des flux. |
|
|
| consolePlugin définit les paramètres liés au plugin OpenShift Container Platform Console, lorsqu'il est disponible. |
|
|
| deploymentModel définit le type de déploiement souhaité pour le traitement des flux. Les valeurs possibles sont "DIRECT" (par défaut) pour que le processeur de flux écoute directement les agents, ou "KAFKA" pour que les flux soient envoyés à un pipeline Kafka avant d'être consommés par le processeur. Kafka peut offrir une meilleure évolutivité, résilience et haute disponibilité (pour plus de détails, voir https://www.redhat.com/en/topics/integration/what-is-apache-kafka). |
|
|
| exporters définit des exportateurs optionnels supplémentaires pour une consommation ou un stockage personnalisé. Il s'agit d'une fonctionnalité expérimentale. Actuellement, seul l'exportateur KAFKA est disponible. |
|
|
| FlowCollectorExporter définit un exportateur supplémentaire pour envoyer les flux enrichis à |
|
|
| Configuration Kafka, permettant d'utiliser Kafka comme courtier dans le cadre du pipeline de collecte de flux. Disponible lorsque le \N "spec.deploymentModel" est \N "KAFKA". |
|
|
| Loki, le magasin de flux, les paramètres du client. |
|
|
| espace de noms dans lequel les pods NetObserv sont déployés. S'il est vide, c'est l'espace de noms de l'opérateur qui sera utilisé. |
|
|
| définit les paramètres du composant qui reçoit les flux de l'agent, les enrichit et les transmet à la couche de persistance de Loki. |
34.8.1.2. .spec.agent
- Description
- agent d'extraction des flux.
- Type
-
object - Exigée
-
type
-
| Propriété | Type | Description |
|---|---|---|
|
|
| ebpf décrit les paramètres liés au rapporteur de flux basé sur eBPF lorsque la propriété "agent.type" est définie sur "EBPF". |
|
|
| ipfix décrit les paramètres relatifs au rapporteur de flux basé sur IPFIX lorsque la propriété "agent.type" est définie sur "IPFIX". |
|
|
| type sélectionne l'agent de traçage des flux. Les valeurs possibles sont : "EBPF" (par défaut) pour utiliser l'agent NetObserv eBPF, "IPFIX" pour utiliser l'ancien collecteur IPFIX. "EBPF" est recommandé dans la plupart des cas car il offre de meilleures performances et devrait fonctionner quelle que soit la CNI installée sur le cluster. \N "IPFIX\N" fonctionne avec la CNI OVN-Kubernetes (d'autres CNI pourraient fonctionner si elles prennent en charge l'exportation d'IPFIX, mais elles nécessiteraient une configuration manuelle). |
34.8.1.2.1. .spec.agent.ebpf
- Description
- ebpf décrit les paramètres liés au rapporteur de flux basé sur eBPF lorsque la propriété "agent.type" est définie sur "EBPF".
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
|
cacheActiveTimeout est la période maximale pendant laquelle le reporter agrégera les flux avant de les envoyer. L'augmentation de |
|
|
|
cacheMaxFlows est le nombre maximum de flux dans un agrégat ; lorsqu'il est atteint, le rapporteur envoie les flux. L'augmentation de |
|
|
| Debug permet de définir certains aspects de la configuration interne de l'agent eBPF. Cette section est exclusivement destinée au débogage et à l'optimisation fine des performances, comme les variables env GOGC et GOMAXPROCS. Les utilisateurs qui définissent ses valeurs le font à leurs propres risques. |
|
|
|
excludeInterfaces contient les noms des interfaces qui seront exclues du suivi des flux. Si une entrée est entourée de barres obliques, telle que |
|
|
| imagePullPolicy est la politique d'extraction de Kubernetes pour l'image définie ci-dessus |
|
|
|
interfaces contient les noms des interfaces à partir desquelles les flux seront collectés. S'il est vide, l'agent récupérera toutes les interfaces du système, à l'exception de celles énumérées dans ExcludeInterfaces. Si une entrée est entourée de barres obliques, par exemple |
|
|
| kafkaBatchSize limite la taille maximale d'une requête en octets avant d'être envoyée à une partition. Ignoré si Kafka n'est pas utilisé. Valeur par défaut : 10 Mo. |
|
|
| logLevel définit le niveau de journalisation de l'agent NetObserv eBPF |
|
|
| mode privilégié pour le conteneur de l'agent eBPF. En général, ce paramètre peut être ignoré ou mis à faux : dans ce cas, l'opérateur définira des capacités granulaires (BPF, PERFMON, NET_ADMIN, SYS_RESOURCE) pour le conteneur, afin de permettre son fonctionnement correct. Si, pour une raison quelconque, ces capacités ne peuvent pas être définies, par exemple si une ancienne version du noyau ne connaissant pas CAP_BPF est utilisée, vous pouvez activer ce mode pour obtenir des privilèges plus globaux. |
|
|
| sont les ressources informatiques requises par ce conteneur. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| le taux d'échantillonnage du rapporteur de flux. 100 signifie qu'un flux sur 100 est envoyé. 0 ou 1 signifie que tous les flux sont échantillonnés. |
34.8.1.2.2. .spec.agent.ebpf.debug
- Description
- Debug permet de définir certains aspects de la configuration interne de l'agent eBPF. Cette section est exclusivement destinée au débogage et à l'optimisation fine des performances, comme les variables env GOGC et GOMAXPROCS. Les utilisateurs qui définissent ses valeurs le font à leurs propres risques.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| env permet de passer des variables d'environnement personnalisées à l'agent NetObserv. Utile pour passer des options très concrètes de réglage des performances, telles que GOGC, GOMAXPROCS, qui ne devraient pas être exposées publiquement dans le cadre du descripteur FlowCollector, car elles ne sont utiles que dans des scénarios de débogage ou d'assistance. |
34.8.1.2.3. .spec.agent.ebpf.resources
- Description
- sont les ressources informatiques requises par ce conteneur. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| Les limites décrivent la quantité maximale de ressources de calcul autorisée. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests décrit la quantité minimale de ressources informatiques requises. Si Requests est omis pour un conteneur, il prend par défaut la valeur Limits si elle est explicitement spécifiée, sinon il prend une valeur définie par l'implémentation. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
34.8.1.2.4. .spec.agent.ipfix
- Description
- ipfix décrit les paramètres relatifs au rapporteur de flux basé sur IPFIX lorsque la propriété "agent.type" est définie sur "IPFIX".
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| cacheActiveTimeout est la période maximale pendant laquelle le reporter agrégera les flux avant d'envoyer |
|
|
| cacheMaxFlows est le nombre maximum de flux dans un agrégat ; lorsqu'il est atteint, le rapporteur envoie les flux |
|
|
| clusterNetworkOperator définit les paramètres liés à l'opérateur de réseau de cluster de OpenShift Container Platform, le cas échéant. |
|
|
| forceSampleAll permet de désactiver l'échantillonnage dans le rapporteur de flux basé sur IPFIX. Il n'est pas recommandé d'échantillonner tout le trafic avec IPFIX, car cela pourrait entraîner une instabilité du cluster. Si vous voulez VRAIMENT le faire, mettez ce drapeau à true. Utilisez-le à vos risques et périls. Lorsqu'il est positionné à true, la valeur de "sampling" est ignorée. |
|
|
|
ovnKubernetes définit les paramètres de la CNI OVN-Kubernetes, lorsqu'elle est disponible. Cette configuration est utilisée lors de l'utilisation des exportations IPFIX d'OVN, sans OpenShift Container Platform. En cas d'utilisation d'OpenShift Container Platform, il faut se référer à la propriété |
|
|
| sampling est le taux d'échantillonnage du rapporteur. 100 signifie qu'un flux sur 100 est envoyé. Pour garantir la stabilité de la grappe, il n'est pas possible de définir une valeur inférieure à 2. Si vous souhaitez vraiment échantillonner chaque paquet, ce qui pourrait avoir un impact sur la stabilité de la grappe, reportez-vous à "forceSampleAll". Vous pouvez également utiliser l'agent eBPF au lieu d'IPFIX. |
34.8.1.2.5. .spec.agent.ipfix.clusterNetworkOperator
- Description
- clusterNetworkOperator définit les paramètres liés à l'opérateur de réseau de cluster de OpenShift Container Platform, le cas échéant.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| où la carte de configuration sera déployée. |
34.8.1.2.6. .spec.agent.ipfix.ovnKubernetes
- Description
-
ovnKubernetes définit les paramètres de la CNI OVN-Kubernetes, lorsqu'elle est disponible. Cette configuration est utilisée lors de l'utilisation des exportations IPFIX d'OVN, sans OpenShift Container Platform. En cas d'utilisation d'OpenShift Container Platform, il faut se référer à la propriété
clusterNetworkOperator. - Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| containerName définit le nom du conteneur à configurer pour IPFIX. |
|
|
| daemonSetName définit le nom du DaemonSet contrôlant les pods OVN-Kubernetes. |
|
|
| où les pods OVN-Kubernetes sont déployés. |
34.8.1.3. .spec.consolePlugin
- Description
- consolePlugin définit les paramètres liés au plugin OpenShift Container Platform Console, lorsqu'il est disponible.
- Type
-
object - Exigée
-
register
-
| Propriété | Type | Description |
|---|---|---|
|
|
| autoscaler spec d'un pod autoscaler horizontal à mettre en place pour le déploiement du plugin. |
|
|
| imagePullPolicy est la politique d'extraction de Kubernetes pour l'image définie ci-dessus |
|
|
| logLevel pour le backend du plugin de la console |
|
|
| port est le port de service du plugin |
|
|
| portNaming définit la configuration de la traduction du nom du port en nom de service |
|
|
| quickFilters configure les préréglages de filtres rapides pour le plugin Console |
|
|
| QuickFilter définit une configuration prédéfinie pour les filtres rapides de la console |
|
|
|
register permet, lorsqu'il vaut true, d'enregistrer automatiquement le plugin de console fourni avec l'opérateur OpenShift Container Platform Console. Lorsqu'il est défini à false, vous pouvez toujours l'enregistrer manuellement en éditant console.operator.OpenShift Container Platform.io/cluster avec la commande suivante : |
|
|
| replicas définit le nombre de répliques (pods) à démarrer. |
|
|
| ressources, en termes de ressources informatiques, requises par ce conteneur. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
34.8.1.3.1. .spec.consolePlugin.autoscaler
- Description
- autoscaler spécification d'un autoscaler de pods horizontaux à mettre en place pour le déploiement du plugin. Veuillez vous référer à la documentation HorizontalPodAutoscaler (autoscaling/v2)
34.8.1.3.2. .spec.consolePlugin.portNaming
- Description
- portNaming définit la configuration de la traduction du nom du port en nom de service
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| activer la traduction du nom du port vers le service du plugin de la console |
|
|
| portNames définit des noms de ports supplémentaires à utiliser dans la console, par exemple, portNames : {"3100" : \N- "loki\N"} |
34.8.1.3.3. .spec.consolePlugin.quickFilters
- Description
- quickFilters configure les préréglages de filtres rapides pour le plugin Console
- Type
-
array
34.8.1.3.4. .spec.consolePlugin.quickFilters[]
- Description
- QuickFilter définit une configuration prédéfinie pour les filtres rapides de la console
- Type
-
object - Exigée
-
filter -
name
-
| Propriété | Type | Description |
|---|---|---|
|
|
| default définit si ce filtre doit être actif par défaut ou non |
|
|
| est un ensemble de clés et de valeurs à définir lorsque ce filtre est sélectionné. Chaque clé peut être associée à une liste de valeurs à l'aide d'une chaîne de caractères séparée par des virgules, par exemple : filter : {"src_namespace" : \N "namespace1,namespace2"} |
|
|
| nom du filtre qui sera affiché dans la console |
34.8.1.3.5. .spec.consolePlugin.resources
- Description
- ressources, en termes de ressources informatiques, requises par ce conteneur. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| Les limites décrivent la quantité maximale de ressources de calcul autorisée. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests décrit la quantité minimale de ressources informatiques requises. Si Requests est omis pour un conteneur, il prend par défaut la valeur Limits si elle est explicitement spécifiée, sinon il prend une valeur définie par l'implémentation. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
34.8.1.4. .spec.exportateurs
- Description
- exporters définit des exportateurs optionnels supplémentaires pour une consommation ou un stockage personnalisé. Il s'agit d'une fonctionnalité expérimentale. Actuellement, seul l'exportateur KAFKA est disponible.
- Type
-
array
34.8.1.4.1. .spec.exporters[]
- Description
- FlowCollectorExporter définit un exportateur supplémentaire pour envoyer les flux enrichis à
- Type
-
object - Exigée
-
type
-
| Propriété | Type | Description |
|---|---|---|
|
|
| kafka décrit la configuration de kafka (adresse, sujet...) vers laquelle envoyer les flux enrichis. |
|
|
| type sélectionne le type d'exportateur. Seul "KAFKA" est disponible pour le moment. |
34.8.1.4.2. .spec.exporters[].kafka
- Description
- décrit la configuration kafka, telle que l'adresse ou le sujet, pour envoyer les flux enrichis.
- Type
-
object - Exigée
-
address -
topic
-
| Propriété | Type | Description |
|---|---|---|
|
|
| adresse du serveur Kafka |
|
|
| configuration du client tls. Si vous utilisez TLS, vérifiez que l'adresse correspond au port Kafka utilisé pour TLS, généralement 9093. Notez que, lorsque des agents eBPF sont utilisés, le certificat Kafka doit être copié dans l'espace de noms de l'agent (par défaut, il s'agit de netobserv-privileged). |
|
|
| sujet kafka à utiliser. Il doit exister, NetObserv ne le créera pas. |
34.8.1.4.3. .spec.exporters[].kafka.tls
- Description
- configuration du client tls. Si vous utilisez TLS, vérifiez que l'adresse correspond au port Kafka utilisé pour TLS, généralement 9093. Notez que, lorsque des agents eBPF sont utilisés, le certificat Kafka doit être copié dans l'espace de noms de l'agent (par défaut, il s'agit de netobserv-privileged).
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| caCert définit la référence du certificat pour l'autorité de certification |
|
|
| activer TLS |
|
|
| insecureSkipVerify permet d'ignorer la vérification côté client du certificat du serveur Si cette valeur est fixée à true, le champ CACert sera ignoré |
|
|
| userCert définit la référence du certificat utilisateur, utilisé pour mTLS (vous pouvez l'ignorer si vous utilisez TLS normal, à sens unique) |
34.8.1.4.4. .spec.exporters[].kafka.tls.caCert
- Description
- caCert définit la référence du certificat pour l'autorité de certification
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.4.5. .spec.exporters[].kafka.tls.userCert
- Description
- userCert définit la référence du certificat utilisateur, utilisé pour mTLS (vous pouvez l'ignorer si vous utilisez TLS normal, à sens unique)
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.5. .spec.kafka
- Description
- configuration kafka, permettant d'utiliser Kafka comme courtier dans le cadre du pipeline de collecte de flux. Disponible lorsque le \N "spec.deploymentModel" est \N "KAFKA".
- Type
-
object - Exigée
-
address -
topic
-
| Propriété | Type | Description |
|---|---|---|
|
|
| adresse du serveur Kafka |
|
|
| configuration du client tls. Si vous utilisez TLS, vérifiez que l'adresse correspond au port Kafka utilisé pour TLS, généralement 9093. Notez que, lorsque des agents eBPF sont utilisés, le certificat Kafka doit être copié dans l'espace de noms de l'agent (par défaut, il s'agit de netobserv-privileged). |
|
|
| sujet kafka à utiliser. Il doit exister, NetObserv ne le créera pas. |
34.8.1.5.1. .spec.kafka.tls
- Description
- configuration du client tls. Si vous utilisez TLS, vérifiez que l'adresse correspond au port Kafka utilisé pour TLS, généralement 9093. Notez que, lorsque des agents eBPF sont utilisés, le certificat Kafka doit être copié dans l'espace de noms de l'agent (par défaut, il s'agit de netobserv-privileged).
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| caCert définit la référence du certificat pour l'autorité de certification |
|
|
| activer TLS |
|
|
| insecureSkipVerify permet d'ignorer la vérification côté client du certificat du serveur Si cette valeur est fixée à true, le champ CACert sera ignoré |
|
|
| userCert définit la référence du certificat utilisateur, utilisé pour mTLS (vous pouvez l'ignorer si vous utilisez TLS normal, à sens unique) |
34.8.1.5.2. .spec.kafka.tls.caCert
- Description
- caCert définit la référence du certificat pour l'autorité de certification
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.5.3. .spec.kafka.tls.userCert
- Description
- userCert définit la référence du certificat utilisateur, utilisé pour mTLS (vous pouvez l'ignorer si vous utilisez TLS normal, à sens unique)
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.6. .spec.loki
- Description
- loki, le magasin de flux, les paramètres du client.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| AuthToken décrit la façon d'obtenir un jeton pour s'authentifier auprès de Loki DISABLED n'envoie aucun jeton avec la demande HOST utilise le compte de service du pod local pour s'authentifier auprès de Loki FORWARD transmet le jeton de l'utilisateur, dans ce mode, le pod qui ne reçoit pas de demande de l'utilisateur comme le processeur utilise le compte de service du pod local. Similaire au mode HOST. |
|
|
| batchSize est la taille maximale (en octets) du lot de journaux à accumuler avant l'envoi |
|
|
| batchWait est le temps d'attente maximum avant l'envoi d'un lot |
|
|
| maxBackoff est le délai maximum entre deux tentatives pour la connexion du client |
|
|
| maxRetries est le nombre maximum de tentatives de connexion pour les clients |
|
|
| minBackoff est le délai initial d'attente pour la connexion du client entre les tentatives |
|
|
|
querierURL spécifie l'adresse du service Loki querier, au cas où elle serait différente de l'URL de Loki ingester. Si elle est vide, la valeur de l'URL sera utilisée (en supposant que l'ingester et le querier de Loki se trouvent sur le même serveur). [IMPORTANT] ==== Si vous avez installé Loki à l'aide de Loki Operator, il est conseillé de ne pas utiliser |
|
|
| staticLabels est une carte des étiquettes communes à définir pour chaque flux |
|
|
| statusURL spécifie l'adresse des terminaux Loki /ready /metrics /config, dans le cas où elle est différente de l'URL du querier Loki. Si elle est vide, la valeur QuerierURL sera utilisée. Ceci est utile pour afficher les messages d'erreur et le contexte dans le frontend |
|
|
| tenantID est le Loki X-Scope-OrgID qui identifie le locataire pour chaque demande. Il sera ignoré si instanceSpec est spécifié |
|
|
| timeout est la limite de temps maximale de la connexion / de la demande Un timeout de zéro signifie qu'il n'y a pas de timeout. |
|
|
| configuration du client tls. |
|
|
| url est l'adresse d'un service Loki existant vers lequel envoyer les flux. |
34.8.1.6.1. .spec.loki.tls
- Description
- configuration du client tls.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| caCert définit la référence du certificat pour l'autorité de certification |
|
|
| activer TLS |
|
|
| insecureSkipVerify permet d'ignorer la vérification côté client du certificat du serveur Si cette valeur est fixée à true, le champ CACert sera ignoré |
|
|
| userCert définit la référence du certificat utilisateur, utilisé pour mTLS (vous pouvez l'ignorer si vous utilisez TLS normal, à sens unique) |
34.8.1.6.2. .spec.loki.tls.caCert
- Description
- caCert définit la référence du certificat pour l'autorité de certification
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.6.3. .spec.loki.tls.userCert
- Description
- userCert définit la référence du certificat utilisateur, utilisé pour mTLS (vous pouvez l'ignorer si vous utilisez TLS normal, à sens unique)
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.7. .spec.processeur
- Description
- définit les paramètres du composant qui reçoit les flux de l'agent, les enrichit et les transmet à la couche de persistance de Loki.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| le délai de fin de conversation est la durée d'attente à partir du dernier journal de flux pour mettre fin à une conversation |
|
|
| l'intervalle de battement de cœur de la conversation est la durée d'attente entre les rapports de battement de cœur d'une conversation |
|
|
| Debug permet de définir certains aspects de la configuration interne du processeur de flux. Cette section est exclusivement destinée au débogage et à l'optimisation fine des performances, comme les variables env GOGC et GOMAXPROCS. Les utilisateurs qui définissent ses valeurs le font à leurs propres risques. |
|
|
| dropUnusedFields permet, lorsqu'il est défini sur true, de supprimer les champs dont on sait qu'ils ne sont pas utilisés par OVS, afin d'économiser de l'espace de stockage. |
|
|
| enableKubeProbes est un drapeau qui permet d'activer ou de désactiver les sondes de disponibilité et d'état de préparation de Kubernetes |
|
|
| healthPort est un port HTTP collecteur dans le pod qui expose l'API de contrôle de santé |
|
|
| imagePullPolicy est la politique d'extraction de Kubernetes pour l'image définie ci-dessus |
|
|
| kafkaConsumerAutoscaler spec of a horizontal pod autoscaler to set up for flowlogs-pipeline-transformer, which consumes Kafka messages. Ce paramètre est ignoré lorsque Kafka est désactivé. |
|
|
| kafkaConsumerBatchSize indique au courtier la taille maximale du lot, en octets, que le consommateur acceptera. Ignoré si Kafka n'est pas utilisé. Valeur par défaut : 10MB. |
|
|
| kafkaConsumerQueueCapacity définit la capacité de la file d'attente interne utilisée par le client consommateur Kafka. Ignoré si Kafka n'est pas utilisé. |
|
|
| kafkaConsumerReplicas définit le nombre de répliques (pods) à démarrer pour flowlogs-pipeline-transformer, qui consomme des messages Kafka. Ce paramètre est ignoré lorsque Kafka est désactivé. |
|
|
| niveau d'enregistrement du collecteur en cours d'exécution |
|
|
| logTypes définit les types d'enregistrements à générer. Les valeurs possibles sont : \N "FLOWS\N" (par défaut) pour exporter les journaux de flux, \N "CONVERSATIONS\N" pour générer les événements newConnection, heartbeat, endConnection, \N "ENDED_CONVERSATIONS\N" pour générer uniquement les événements endConnection ou \N "ALL\N" pour générer à la fois les journaux de flux et les événements de conversations |
|
|
| Les métriques définissent la configuration du processeur en ce qui concerne les métriques |
|
|
| port du collecteur de flux (port hôte) Par conventions, certaines valeurs ne sont pas autorisées le port ne doit pas être inférieur à 1024 et ne doit pas être égal à ces valeurs : 4789,6081,500, et 4500 |
|
|
| profilePort permet de mettre en place un profileur Go pprof écoutant sur ce port |
|
|
| sont les ressources informatiques requises par ce conteneur. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
34.8.1.7.1. .spec.processor.debug
- Description
- Debug permet de définir certains aspects de la configuration interne du processeur de flux. Cette section est exclusivement destinée au débogage et à l'optimisation fine des performances, comme les variables env GOGC et GOMAXPROCS. Les utilisateurs qui définissent ses valeurs le font à leurs propres risques.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| env permet de passer des variables d'environnement personnalisées à l'agent NetObserv. Utile pour passer des options très concrètes de réglage des performances, telles que GOGC et GOMAXPROCS, qui ne devraient pas être exposées publiquement dans le cadre du descripteur FlowCollector, car elles ne sont utiles que dans les scénarios de débogage et d'assistance. |
34.8.1.7.2. .spec.processor.kafkaConsumerAutoscaler
- Description
- kafkaConsumerAutoscaler spec of a horizontal pod autoscaler to set up for flowlogs-pipeline-transformer, which consumes Kafka messages. Ce paramètre est ignoré lorsque Kafka est désactivé. Veuillez vous référer à la documentation de HorizontalPodAutoscaler (autoscaling/v2)
34.8.1.7.3. .spec.processor.metrics
- Description
- Les métriques définissent la configuration du processeur en ce qui concerne les métriques
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
|
disableAlerts est une liste d'alertes à désactiver. Les valeurs possibles sont les suivantes : |
|
|
| ignoreTags est une liste de tags permettant de spécifier les métriques à ignorer |
|
|
| configuration du point de terminaison metricsServer pour le scraper Prometheus |
34.8.1.7.4. .spec.processor.metrics.server
- Description
- configuration du point de terminaison metricsServer pour le scraper Prometheus
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| le port HTTP de prometheus |
|
|
| Configuration TLS. |
34.8.1.7.5. .spec.processor.metrics.server.tls
- Description
- Configuration TLS.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| Configuration TLS. |
|
|
| Sélectionnez le type de configuration TLS : "DISABLED" (par défaut) pour ne pas configurer TLS pour le point de terminaison, "PROVIDED" pour fournir manuellement un fichier cert et un fichier clé, et "AUTO" pour utiliser le certificat généré automatiquement par OpenShift Container Platform à l'aide d'annotations |
34.8.1.7.6. .spec.processor.metrics.server.tls.provided
- Description
- Configuration TLS.
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| certFile définit le chemin d'accès au nom du fichier de certificat dans la carte de configuration / Secret |
|
|
| certKey définit le chemin d'accès au fichier de la clé privée du certificat dans la carte de configuration / Secret. Omettre si la clé n'est pas nécessaire. |
|
|
| nom de la carte de configuration ou du secret contenant les certificats |
|
|
| type de référence du certificat : config map ou secret |
34.8.1.7.7. .spec.processor.resources
- Description
- sont les ressources informatiques requises par ce conteneur. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- Type
-
object
| Propriété | Type | Description |
|---|---|---|
|
|
| Les limites décrivent la quantité maximale de ressources de calcul autorisée. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests décrit la quantité minimale de ressources informatiques requises. Si Requests est omis pour un conteneur, il prend par défaut la valeur Limits si elle est explicitement spécifiée, sinon il prend une valeur définie par l'implémentation. Plus d'informations : https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
34.8.1.8. .statut
- Description
- FlowCollectorStatus définit l'état observé du collecteur de flux
- Type
-
object - Exigée
-
conditions
-
| Propriété | Type | Description |
|---|---|---|
|
|
| les conditions représentent les dernières observations disponibles de l'état d'un objet |
|
|
|
Condition contient des détails sur un aspect de l'état actuel de cette ressource API. --- Cette structure est destinée à être utilisée directement comme un tableau dans le chemin de champ .status.conditions. Par exemple, type FooStatus struct{ // Représente les observations de l'état actuel d'un foo. // Les types .status.conditions.connus sont les suivants : \N "Disponible", \N "En progression" et \N "Dégradé" // patchMergeKey=type // patchStrategy=merge // listType=map // listMapKey=type Conditions []metav1.Condition |
|
|
| où le plugin console et flowlogs-pipeline ont été déployés. |
34.8.1.8.1. .status.conditions
- Description
- les conditions représentent les dernières observations disponibles de l'état d'un objet
- Type
-
array
34.8.1.8.2. .status.conditions[]
- Description
-
Condition contient des détails sur un aspect de l'état actuel de cette ressource API. --- Cette structure est destinée à être utilisée directement comme un tableau dans le chemin de champ .status.conditions. Par exemple, type FooStatus struct{ // Représente les observations de l'état actuel d'un foo. // Les types .status.conditions.connus sont les suivants : \N "Disponible", \N "En progression" et \N "Dégradé" // patchMergeKey=type // patchStrategy=merge // listType=map // listMapKey=type Conditions []metav1.Condition
json:"conditions,omitempty" patchStrategy:"merge" patchMergeKey:"type" protobuf:"bytes,1,rep,name=conditions"// autres champs } - Type
-
object - Exigée
-
lastTransitionTime -
message -
reason -
status -
type
-
| Propriété | Type | Description |
|---|---|---|
|
|
| lastTransitionTime est la dernière fois que la condition est passée d'un état à un autre. Il doit s'agir du moment où la condition sous-jacente a changé. Si cette date n'est pas connue, il est possible d'utiliser le moment où le champ de l'API a changé. |
|
|
| message est un message lisible par l'homme indiquant les détails de la transition. Il peut s'agir d'une chaîne vide. |
|
|
| observedGeneration représente la .metadata.generation sur laquelle la condition a été définie. Par exemple, si .metadata.generation est actuellement 12, mais que .status.conditions[x].observedGeneration est 9, la condition est obsolète par rapport à l'état actuel de l'instance. |
|
|
| reason contient un identifiant programmatique indiquant la raison de la dernière transition de la condition. Les producteurs de types de conditions spécifiques peuvent définir les valeurs attendues et la signification de ce champ, et préciser si les valeurs sont considérées comme une API garantie. La valeur doit être une chaîne CamelCase. Ce champ ne peut pas être vide. |
|
|
| l'état de la condition, entre True, False, Unknown (vrai, faux, inconnu). |
|
|
| type de condition dans CamelCase ou dans foo.example.com/CamelCase. --- De nombreuses valeurs de .condition.type sont cohérentes dans des ressources comme Available, mais comme des conditions arbitraires peuvent être utiles (voir .node.status.conditions), la capacité de désescalade est importante. L'expression rationnelle à laquelle il correspond est (dns1123SubdomainFmt/) ?(qualifiedNameFmt) |
34.9. Référence du format des flux de réseau
Il s'agit des spécifications du format des flux réseau, utilisées à la fois en interne et lors de l'exportation des flux vers Kafka.
34.9.1. Référence du format des flux de réseau
Le document est organisé en deux catégories principales : Labels et régulière Fields. Cette distinction n'a d'importance que lors de l'interrogation de Loki. En effet Labelscontrairement à Fieldsdoit être utilisé dans les sélecteurs de flux.
Si vous lisez cette spécification comme une référence pour la fonction d'exportation de Kafka, vous devez traiter tous les éléments suivants Labels et Fields comme des champs ordinaires et ignorer les distinctions entre eux qui sont spécifiques à Loki.
34.9.1.1. Étiquettes
- Espace de noms SrcK8S
-
OptionalSrcK8S_Namespace:string
-
Espace de noms source
- DstK8S_Namespace
-
OptionalDstK8S_Namespace:string
-
Espace de noms de destination
- SrcK8S_OwnerName
-
OptionalSrcK8S_OwnerName:string
-
Propriétaire de la source, tel que Deployment, StatefulSet, etc.
- DstK8S_OwnerName
-
OptionalDstK8S_OwnerName:string
-
Propriétaire de la destination, tel que Deployment, StatefulSet, etc.
- Direction du flux
- FlowDirection: voir la section suivante, Enumeration: FlowDirection pour plus de détails.
Direction du flux à partir du point d'observation du nœud
- type d'enregistrement
-
Optional_RecordType:RecordType
-
Type d'enregistrement : "flowLog" pour les enregistrements de flux réguliers, ou "allConnections", "newConnection", "heartbeat", "endConnection" pour le suivi des conversations
34.9.1.2. Domaines
- SrcAddr
-
SrcAddr:
string
-
SrcAddr:
Adresse IP source (ipv4 ou ipv6)
- DstAddr
-
DstAddr:
string
-
DstAddr:
Adresse IP de destination (ipv4 ou ipv6)
- SrcMac
-
SrcMac:
string
-
SrcMac:
Adresse MAC de la source
- DstMac
-
DstMac:
string
-
DstMac:
Adresse MAC de destination
- SrcK8S_Name
-
OptionalSrcK8S_Name:string
-
Nom de l'objet Kubernetes correspondant à la source, tel que le nom du pod, le nom du service, etc.
- DstK8S_Name
-
OptionalDstK8S_Name:string
-
Nom de l'objet Kubernetes correspondant à la destination, tel que le nom du pod, le nom du service, etc.
- SrcK8S_Type
-
OptionalSrcK8S_Type:string
-
Type d'objet Kubernetes correspondant à la source, tel que Pod, Service, etc.
- DstK8S_Type
-
OptionalDstK8S_Type:string
-
Type d'objet Kubernetes correspondant à la destination, tel que le nom du pod, le nom du service, etc.
- SrcPort
-
SrcPort:
number
-
SrcPort:
Port source
- DstPort
-
DstPort:
number
-
DstPort:
Port de destination
- SrcK8S_OwnerType
-
OptionalSrcK8S_OwnerType:string
-
Type de propriétaire Kubernetes source, tel que Deployment, StatefulSet, etc.
- DstK8S_OwnerType
-
OptionalDstK8S_OwnerType:string
-
Type de propriétaire Kubernetes de destination, tel que Deployment, StatefulSet, etc.
- SrcK8S_HostIP
-
OptionalSrcK8S_HostIP:string
-
IP du nœud source
- DstK8S_HostIP
-
OptionalDstK8S_HostIP:string
-
IP du nœud de destination
- Nom de l'hôte SrcK8S
-
OptionalSrcK8S_HostName:string
-
Nom du nœud source
- DstK8S_HostName
-
OptionalDstK8S_HostName:string
-
Nom du nœud de destination
- Proto
-
Proto:
number
-
Proto:
Protocole L4
- Interface
-
OptionalInterface:string
-
Interface réseau
- Paquets
-
Packets:
number
-
Packets:
Nombre de paquets dans ce flux
- Paquets_AB
-
OptionalPackets_AB:number
-
Dans le suivi des conversations, compteur de paquets A à B par conversation
- Paquets_BA
-
OptionalPackets_BA:number
-
Dans le suivi des conversations, compteur de paquets B to A par conversation
- Octets
-
Bytes:
number
-
Bytes:
Nombre d'octets dans ce flux
- Octets_AB
-
OptionalBytes_AB:number
-
Dans le suivi des conversations, compteur d'octets A à B par conversation
- Octets_BA
-
OptionalBytes_BA:number
-
Dans le suivi des conversations, compteur d'octets de B à A par conversation
- Début du flux temporel (TimeFlowStartMs)
-
TimeFlowStartMs:
number
-
TimeFlowStartMs:
Heure de début de ce flux, en millisecondes
- TimeFlowEndMs
-
TimeFlowEndMs:
number
-
TimeFlowEndMs:
Horodatage de fin de ce flux, en millisecondes
- Heure de réception
-
TimeReceived:
number
-
TimeReceived:
Date à laquelle ce flux a été reçu et traité par le collecteur de flux, en secondes
- _HashId
-
Optional_HashId:string
-
Dans le suivi des conversations, l'identificateur de conversation
- isFirst
-
Optional_IsFirst:string
-
Dans le suivi des conversations, un drapeau identifiant le premier flux
- numFlowLogs
-
OptionalnumFlowLogs:number
-
Dans le suivi des conversations, un compteur de journaux de flux par conversation
34.9.1.3. Enumération : FlowDirection
- Entrée
-
Ingress =
"0"
-
Ingress =
Trafic entrant, à partir du point d'observation du nœud
- Sortie
-
Egress =
"1"
-
Egress =
Trafic sortant, à partir du point d'observation du nœud
34.10. Dépannage de l'observabilité des réseaux
Pour faciliter la résolution des problèmes liés à l'observabilité du réseau, vous pouvez effectuer certaines actions de dépannage.
34.10.1. Configuration du trafic réseau dans la console OpenShift Container Platform
Configurer manuellement l'entrée de menu du trafic réseau dans la console OpenShift Container Platform lorsque l'entrée de menu du trafic réseau n'est pas listée dans le menu de la console OpenShift Container Platform Observe l'entrée de menu trafic réseau n'est pas listée dans la console OpenShift Container Platform.
Conditions préalables
- Vous avez installé OpenShift Container Platform version 4.10 ou plus récente.
Procédure
Vérifiez si le champ
spec.consolePlugin.registerest défini surtrueen exécutant la commande suivante :$ oc -n netobserv get flowcollector cluster -o yamlExemple de sortie
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: falseFacultatif : Ajoutez le plugin
netobserv-pluginen modifiant manuellement la configuration de l'opérateur de console :$ oc edit console.operator.openshift.io clusterExemple de sortie
... spec: plugins: - netobserv-plugin ...Facultatif : Définissez le champ
spec.consolePlugin.registersurtrueen exécutant la commande suivante :$ oc -n netobserv edit flowcollector cluster -o yamlExemple de sortie
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: trueAssurez-vous que le statut des pods de console est
runningen exécutant la commande suivante :$ oc get pods -n openshift-console -l app=consoleRedémarrez les pods de la console en exécutant la commande suivante :
$ oc delete pods -n openshift-console -l app=console- Effacez le cache et l'historique de votre navigateur.
Vérifiez l'état des pods du plugin Network Observability en exécutant la commande suivante :
$ oc get pods -n netobserv -l app=netobserv-pluginExemple de sortie
NAME READY STATUS RESTARTS AGE netobserv-plugin-68c7bbb9bb-b69q6 1/1 Running 0 21sVérifiez les journaux des pods du plugin Network Observability en exécutant la commande suivante :
$ oc logs -n netobserv -l app=netobserv-pluginExemple de sortie
time="2022-12-13T12:06:49Z" level=info msg="Starting netobserv-console-plugin [build version: , build date: 2022-10-21 15:15] at log level info" module=main time="2022-12-13T12:06:49Z" level=info msg="listening on https://:9001" module=server
34.10.2. Flowlogs-Pipeline ne consomme pas les flux réseau après l'installation de Kafka
Si vous avez d'abord déployé le collecteur de flux avec deploymentModel: KAFKA, puis déployé Kafka, il se peut que le collecteur de flux ne se connecte pas correctement à Kafka. Redémarrez manuellement les pods flow-pipeline dans lesquels Flowlogs-pipeline ne consomme pas de flux réseau depuis Kafka.
Procédure
Supprimez les pods flow-pipeline pour les redémarrer en exécutant la commande suivante :
$ oc delete pods -n netobserv -l app=flowlogs-pipeline-transformer
34.10.3. Ne pas voir les flux de réseau provenant des interfaces br-int et br-ex
br-ex` et br-int sont des ponts virtuels fonctionnant à la couche 2 de l'OSI. L'agent eBPF travaille aux niveaux IP et TCP, respectivement aux couches 3 et 4. Vous pouvez vous attendre à ce que l'agent eBPF capture le trafic réseau passant par br-ex et br-int, lorsque le trafic réseau est traité par d'autres interfaces telles que des interfaces d'hôtes physiques ou de pods virtuels. Si vous limitez les interfaces réseau de l'agent eBPF à br-ex et br-int, vous ne verrez aucun flux réseau.
Supprimez manuellement la partie de interfaces ou excludeInterfaces qui restreint les interfaces réseau à br-int et br-ex.
Procédure
Supprimez le champ
interfaces: [ 'br-int', 'br-ex' ]. Cela permet à l'agent d'obtenir des informations de toutes les interfaces. Vous pouvez également spécifier l'interface de couche 3, par exempleeth0. Exécutez la commande suivante :$ oc edit -n netobserv flowcollector.yaml -o yamlExemple de sortie
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: agent: type: EBPF ebpf: interfaces: [ 'br-int', 'br-ex' ]1 - 1
- Spécifie les interfaces réseau.
34.10.4. Le pod de gestion du contrôleur de l'observabilité du réseau manque de mémoire
Vous pouvez augmenter les limites de mémoire pour l'opérateur Network Observability en corrigeant la version du service de cluster (CSV), où le pod du gestionnaire du contrôleur Network Observability manque de mémoire.
Procédure
Exécutez la commande suivante pour patcher le CSV :
$ oc -n netobserv patch csv network-observability-operator.v1.0.0 --type='json' -p='[{"op": "replace", "path":"/spec/install/spec/deployments/0/spec/template/spec/containers/0/resources/limits/memory", value: "1Gi"}]'Exemple de sortie
clusterserviceversion.operators.coreos.com/network-observability-operator.v1.0.0 patchedExécutez la commande suivante pour afficher le fichier CSV mis à jour :
$ oc -n netobserv get csv network-observability-operator.v1.0.0 -o jsonpath='{.spec.install.spec.deployments[0].spec.template.spec.containers[0].resources.limits.memory}' 1Gi
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.