6.3. Outils
De nombreux outils sont disponibles pour aider à diagnostiquer les problèmes de performance dans le sous-système des E/S. vmstat fournit un aperçu grossier des performances du système. Les colonnes suivantes concernent davantage les E/S :
si (swap in), so (swap out), bi (block in), bo (block out) et wa (temps d'attente des E/S). si et so sont utiles lorsque votre espace swap est situé sur le même périphérique que la partition de vos données et sont un indicateur de la pression mémoire générale. si et bi sont des opérations de lecture, tandis que so et bo sont des opérations d'écriture. Chacune de ces catégories est rapportée en kilo-octets. wa est le temps d'inactivité, il indique quelle portion de la file d'attente d'exécution est bloquée, en train d'attendre que les E/S soient terminées.
L'analayse de votre système avec vmstatvous indiquera si le sous-système des E/S pourrait être responsable des problèmes de performance ou non. Veuillez aussi prendre note des colonnes
free, buff et cache. L'augmentation de la valeur cache aux côtés de la valeur bo, suivie par une baisse de cache et une augmentation de free indique que le système est en train d'effectuer une ré-écriture et une invalidation du cache de la page.
Remarquez que les numéros des E/S rapportées par vmstat sont des agrégations de toutes les E/S sur tous les périphériques. Une fois que vous avez déterminé qu'il y a un écart de performance dans le sous-système des E/S, vous pouvez examiner le problème de plus près avec iostat, ce qui divisera les E/S rapportées par périphérique. Vous pouvez aussi récupérer des informations plus détaillées, comme la taille de requête moyenne, le nombre de lecture et écritures par seconde, ainsi que le nombre de fusions d'E/S en cours.
En vous aidant de la taille de requête moyenne et de la taille de file d'attente moyenne (
avgqu-sz), vous pourrez effectuer quelques estimations sur la manière par laquelle le stockage devrait fonctionner en utilisant les graphes générés lors de la caractérisation des performances de votre stockage. Certaines généralisations s'appliquent, par exemple : si la taille de requête moyenne est de 4 Ko et que la taille de file d'attente moyenne est de 1, il est improbable que le débit soit très performant.
Si les chiffres des performances ne correspondent pas aux performances auxquelles vous vous attendez, vous pouvez effectuer une analyse plus précise avec blktrace. L'ensemble d'utilitaires blktrace vous offre des informations précises sur le temps passé dans le sous-système des E/S. La sortie de blktrace est un ensemble de fichiers de suivi pouvant être traités après-coup par d'autres utilitaires comme blkparse.
blkparse est l'utilitaire complémentaire à blktrace. Il lit les sorties brutes du suivi est produit une courte version texte.
Ci-dessous figure un exemple de sortie de blktrace :
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
Comme vous pouvez le constater, la sortie est dense et difficile à lire. Vous pouvez voir quels processus sont responsables des E/S effectuées sur votre périphérique et lesquels sont utiles, mais dans son résumé, blkparse vous offre des informations supplémentaires sous un format plus facile à assimiler. Les informations du résumé de blkparse sont imprimées à la fin de sa sortie :
Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0
Le résumé affiche les taux d'E/S moyens, l'activité liée aux fusions et compare la charge de travail de lecture avec la charge de travail d'écriture. Néanmoins, la plupart du temps, la sortie de blkparse est trop volumineuse pour être utilisée en tant que telle. Fort heureusement, il existe plusieurs outils pour assister à la visualisation des données.
btt fournit une analyse du temps pris par les E/S dans les différentes zones de la pile d'E/S. Ces zones sont les suivantes :
- Q — une E/S de bloc est en attente
- G — obtenir une requêteUne nouvelle E/S de bloc en file d'attente n'était pas candidate pour une fusion avec toute requête existante, ainsi une requête pour une nouvelle couche de bloc est allouée.
- M — une E/S de bloc est fusionnée avec une requête existante.
- I — Une requête est insérée dans la file d'attente du périphérique.
- D — Une requête est délivrée au périphérique.
- C — Une requête est complétée par le pilote.
- P — La file d'attente du périphérique bloc est branchée (« Plugged ») afin d'autoriser l'agrégation des requêtes.
- U — La file d'attente du périphérique est débranchée (« Unplugged »), autorisant ainsi aux requêtes agrégées d'être délivrées au périphérique.
btt divise le temps pris par chacune de ces zones ainsi que le temps pris pour effectuer les transitions entre celles-ci, comme suit :
- Q2Q — temps écoulé entre les requêtes envoyées à la couche du bloc.
- Q2G — temps écoulé entre le moment où une E/S de bloc est mise en file d'attente et le moment où une requête y est allouée.
- G2I — temps écoulé entre le moment où une requête est allouée et le moment où elle est insérée à la file d'attente du périphérique.
- Q2M — temps écoulé entre le moment où une E/S de bloc est mise en file d'attente et le moment où elle est fusionnée avec une requête existante.
- I2D — temps écoulé entre le moment où une requête est insérée à la file d'attente du périphérique et le moment où elle est réellement délivrée au périphérique.
- M2D — temps écoulé à partir du moment où une E/S de bloc est fusionnée avec une requête sortante jusqu'au moment où la requête est délivrée au périphérique
- D2C — temps de service de la requête par le périphérique.
- Q2C — temps total écoulé dans la couche du bloc par une requête.
Vous pouvez déduire de nombreuses choses sur une charge de travail à partir du tableau ci-dessus. Par exemple, si Q2Q est de bien plus grande taille que Q2C, cela signifie que l'application ne délivre pas d'E/S en rapides successions. Ainsi, tout problème de performance n'est pas forcément lié au sous-système des E/S. Si D2C est très élevé, alors le périphérique prend trop de temps à répondre aux requêtes. Ceci peut indiquer que le périphérique est tout simplement surchargé (ce qui peut être dû au fait qu'il est une ressource partagée), ou que la charge de travail envoyée au périphérique est sous-optimale. Si Q2G est très élevé, cela signifie que de nombreuses requêtes sont en file d'attente en même temps. Ceci pourrait indiquer que le stockage n'est pas en mesure de supporter la charge des E/S.
Finalement, seekwatcher consomme les données binaires de blktrace et génère un ensemble de graphiques, y compris pour l'adresse LBA (« Logical Block Address »), le débit, les recherches par seconde et les IOPS (« I/O Per Second », ou E/S par seconde).
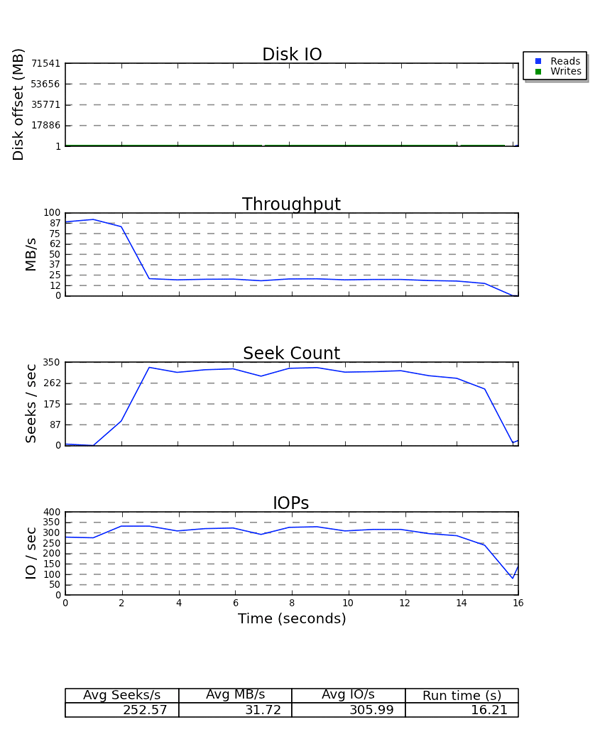
Figure 6.2. Exemple de sortie de « seekwatcher »
Sur tous les graphiques, l'axe X représente le temps. Le graphique LBA affiche les lectures et écritures de différentes couleurs. Il est intéressant de remarquer la relation entre les graphes du débit et des recherches par seconde. Pour un stockage sensible aux opérations de recherches, il existe une relation inverse entre les deux graphiques. Par exemple, le graphe IOPS est utile si vous n'obtenez pas le débit auquel vous vous attendiez d'un périphérique, mais que vous atteigniez les limitations de ses IOPS.