Chapitre 4. CPU
Le terme CPU, de l'anglais Central Processing Unit, est un nom inapproprié pour la plupart des systèmes puisque le mot central sous-entend unique, alors que la plupart des systèmes modernes possèdent plus d'une unité de traitement, ou cœur. Physiquement, les CPU sont contenus dans un paquet attaché à une carte-mère dans un socket. Chaque socket sur la carte-mère possède plusieurs connexions : vers d'autres sockets de CPU, vers des contrôleurs mémoire, vers des contrôleurs d'interruptions, et autres périphériques. Un socket vers le système d'exploitation est un groupement logique de CPU et de ressources associées. Ce concept est central à la plupart des discussions sur l'optimisation des CPU.
Red Hat Enterprise Linux conserve une mine de statistiques sur les événements CPU de systèmes ; ces statistiques sont utiles à la planification d'une stratégie d'amélioration des performances des CPU. La Section 4.1.2, « Régler les performances CPU » discute de certaines des statistiques les plus utiles, où les trouver et comment les analyser pour optimiser les performances.
Topologie
Les ordinateurs plus anciens possèdent relativement moins de CPU par système, ce qui permettait une architecture connue sous le nom de SMP (de l'anglais, Symmetric Multi-Processor, « multiprocesseur symétrique »). Cela signifie que chaque CPU dans le système possède un accès similaire (ou symétrique) à la mémoire disponible. Ces dernières années, le nombre de CPU par socket a augmenté au point où tenter de donner un accès symétrique à toute la mémoire RAM dans un système est devenu très coûteux. De nos jours, la plupart des systèmes comptant de nombreux CPU possèdent une architecture appelée NUMA (de l'anglais, Non-Uniform Memory Access, « accès mémoire non-uniforme ») au lieu de SMP.
Les processeurs AMD ont possédé ce type d'architecture depuis quelques temps avec leurs interconnexions HT (de l'anglais, Hyper Transport), tandis qu'Intel a commencé à implémenter NUMA dans leurs designs QPI (de l'anglais, Quick Path Interconnect). NUMA et SMP sont optimisés de différentes manières, puisque vous devez fournir un acompte de la topologie du système lors de l'allocation de ressources d'une application.
Threads
À l'intérieur d'un système d'exploitation Linux, l'unité d'exécution est appelée un thread. Les threads possèdent un contexte de registre, une pile et un segment de code exécutable qu'ils exécutent sur un CPU. Le travail du système d'exploitation est de programmer ces threads sur les CPU disponibles.
Le système d'exploitation maximise l'utilisation du CPU en équilibrant les charges des threads sur les cœurs disponibles. Puisque le système d'exploitation est principalement intéressé à garder les CPU occupés, il peut ne pas prendre les décisions optimales quand aux performances des applications. Déplacer un thread d'application vers le CPU sur un autre socket peut être pire au niveau performance que simplement attendre que le CPU redevienne disponible, puisque les opérations d'accès mémoire peuvent ralentir de manière drastique sur les sockets. Pour des applications de haute performance, il est habituellement mieux que le créateur détermine où les threads devraient être placés. La Section 4.2, « Ordonnancement CPU » traite des meilleures manières d'allouer les CPU et la mémoire afin de mieux exécuter les threads d'application.
Interruptions
L'un des événements système moins évident (mais tout aussi important) pouvant avoir un impact sur les performances des applications sont les interruptions (aussi appelées des IRQ sous Linux). Ces événements sont gérés par le système d'exploitation et sont utilisés par des périphériques pour signaler l'arrivée de données ou l'achèvement d'une opération, comme une opération d'écriture réseau ou un événement d'horodatage.
La manière par laquelle le système d'exploitation ou le CPU qui exécute le code de l'application gère une interruption n'affecte pas le fonctionnement de l'application. Cependant, il peut y avoir un impact sur la performance de l'application. Ce chapitre discute fournit aussi des conseils sur comment empêcher les interruptions d'avoir un impact négatif sur les performances des applications.
4.1. Topologie de CPU
Copier lienLien copié sur presse-papiers!
4.1.1. Topologie des CPU et de NUMA
Copier lienLien copié sur presse-papiers!
Les premiers processeurs d'ordinateurs étaient des monoprocesseurs, ce qui signifie que le système ne possédait qu'un seul CPU. L'illusion d'exécution des processus en parallèle était due au fait que le système d'exploitation faisait rapidement basculer l'unique CPU d'un thread d'exécution (ou processus) à un autre. En vue d'améliorer les performances du système, les concepteurs ont remarqué qu'augmenter la vitesse de l'horloge pour exécuter des instructions plus rapidement fonctionnait jusqu'à un certain point uniquement (correspondant habituellement aux limitations de la création d'une forme d'onde d'horloge stable avec la technologie actuelle). Dans un effort pour accomplir de meilleures performances générales du système, les concepteurs ont ajouté un autre CPU au système, permettant ainsi deux flux d'exécution parallèles. Cette tendance d'ajout de processeurs a continué au cours du temps.
La plupart des premiers systèmes à multiples processeurs étaient conçus de manière à ce que chaque CPU possédait le même chemin logique vers chaque emplacement mémoire (habituellement un bus parallèle). Ceci laisse autant de temps à chaque CPU dans le système pour accéder à tout emplacement dans la mémoire. Ce type d'architecture est connu sous le nom de système SMP (« Symmetric Multi-Processor »). SMP est convenable pour un petit nombre de CPU, mais lorsque le compte de CPU dépasse un certain seuil (8 ou 16), le nombre de traces parallèles requises pour permettre un accès égal à la mémoire utilise trop d'emplacements disponibles sur la carte, laissant moins d'espace aux périphériques.
Deux nouveaux concepts combinés pour autoriser un nombre de CPU élevé dans un système :
- Bus sériels
- Topologies NUMA
Un bus sériel est un chemin de communication unifilaire avec une très haute fréquence d'horloge, qui transfère les données en rafales de paquets. Les concepteurs de matériel ont commencé à utiliser les bus sériels en tant qu'interconnexions à haute vitesse entre les CPU, les contrôleurs mémoire et les autres périphériques. Cela signifie qu'au lieu de nécessiter entre 32 et 64 traces depuis la carte de chaque CPU vers le sous-système de la mémoire, il n'y a plus qu'une trace, réduisant la quantité d'espace requis sur la carte de manière substantielle.
Les concepteurs de matériel empaquetaient davantage de transistors dans le même espace en réduisant les tailles des dies. Au lieu de mettre les CPU individuels directement sur la carte-mère, ils se sont mis à les empaqueter dans des paquets (ou cartouches) de processeurs en tant que processeurs multi-cœurs. Puis, au lieu d'essayer de fournir un accès égal à la mémoire pour chaque paquet de processeurs, les concepteurs ont eu recours à la stratégie NUMA (accès mémoire non-uniforme, de l'anglais « Non-Uniform Memeroy Access »), avec laquelle chaque combinaison paquet/socket possède une ou plusieurs zone(s) de mémoire dédiée(s) pour un accès à grande vitesse. Chaque socket possède aussi une interconnexion vers d'autres sockets pour un accès plus lent vers la mémoire des autres sockets.
Prenez en considération ce simple exemple de NUMA ; supposons que nous disposons d'une carte-mère à deux sockets et que chaque socket contient un paquet quad-core. Cela signifie que le nombre total de CPU dans le système est de huit, quatre dans chaque socket. Chaque socket possède aussi une banque mémoire attachée avec quatre gigaoctets de mémoire vive (RAM), pour un total de huit gigaoctets de mémoire système. Dans cet exemple, les CPU 0 à 3 sont dans le socket 0 et les CPU 4 à 7 sont dans le socket 1. Chaque socket de cet exemple correspond aussi à un nœud NUMA.
L'accès mémoire de la banque 0 du CPU 0 peut prendre trois cycles d'horloge : un cycle pour présenter l'adresse au contrôleur mémoire, un cycle pour paramétrer l'accès à l'emplacement mémoire et un cycle pour lire ou écrire sur l'emplacement. Cependant, l'accès à la mémoire depuis le même emplacement par le CPU 4 peut prendre six cycles ; comme il se trouve sur un autre socket, il doit passer par deux contrôleurs mémoire : le contrôleur mémoire local sur le socket 1, puis le contrôleur mémoire distant sur le socket 0. Si la mémoire est contestée sur cet emplacement (c'est-à-dire si plus d'un CPU tente d'accéder au même emplacement simultanément), les contrôleurs mémoire devront arbitrer et sérialiser l'accès à la mémoire, l'accès mémoire prendra ainsi plus de temps. L'ajout de consistance de cache (s'assurer que les caches du CPU local contiennent bien les mêmes données pour le même emplacement mémoire) complique encore plus le processus.
Les plus récents processeurs hauts de gamme d'Intel (Xeon) et d'AMD (Opteron) possède des topologies NUMA. Les processeurs AMD utilisent une interconnexion appelée HyperTransport, ou HT, alors qu'Intel en utilise une nommée QuickPath Interconnect, ou QPI. Les interconnexions diffèrent dans la manière par laquelle elles se connectent aux autres interconnexions, à la mémoire, ou aux appareils périphériques, mais en réalité, elles sont un commutateur permettant un accès transparent vers un périphérique connecté depuis un autre périphérique connecté. Dans ce cas, transparent fait référence au fait qu'aucune API de programmation particulière n'est requise pour utiliser l'interconnexion.
Comme les architectures de systèmes sont très diverses, il n'est pas commode de caractériser de manière spécifique les pénalités de performance imposées par l'accès à la mémoire non-locale. Il peut être dit que chaque saut à travers une interconnexion impose au moins une pénalité de performance relativement constante. Ainsi, référencer un emplacement mémoire se trouvant à deux interconnexions du CPU actuel imposera au moins 2N + temps de cycle mémoire, où N est la pénalité par saut.
Au vu de cette pénalité de performance, les applications sensibles aux performances devraient éviter d'accéder à la mémoire distante de manière régulière dans un système avec une topologie NUMA. L'application devrait être paramétrée de manière à rester sur un nœud en particulier et alloue de la mémoire à partir de ce nœud.
Pour ce faire, les applications doivent connaître quelques choses :
- Quelle est la topologie du système ?
- Où se trouve l'application actuellement en cours d'exécution ?
- Où se trouve la banque mémoire la plus proche ?
4.1.2. Régler les performances CPU
Copier lienLien copié sur presse-papiers!
Veuillez lire cette section pour comprendre comment effectuer les réglages afin d'améliorer les performances CPU et pour une introduction à plusieurs outils pouvant assister dans ce processus.
À l'origine, NUMA était utilisé pour connecter un seul processeur à de multiples banques de mémoire. Comme les fabricants de CPU raffinaient leurs processus et que les tailles de die diminuaient, de multiples cœurs de CPU ont pu être inclus dans un seul paquetage. Ces cœurs de CPU ont été mis en grappe afin qu'ils aient tous un accès équitable à la banque de mémoire locale et que le cache puisse être partagé entre les cœurs ; cependant, chaque « saut » à travers une interconnexion entre le cœur, la mémoire et le cache implique une petite pénalité de performance.
L'exemple de système Figure 4.1, « Accès local et distant dans la topologie NUMA » contient deux nœuds NUMA. Chaque nœud possède quatre CPU, une banque de mémoire et un contrôleur de mémoire. Tout CPU sur un nœud a un accès direct à la banque de mémoire de ce nœud. En suivant les flèches sur le nœud 1 (« Node 1 »), les étapes sont comme suit :
- Un CPU (de 0 à 3) présente l'adresse mémoire au contrôleur de mémoire local.
- Le contrôleur de mémoire paramètre l'accès à l'adresse mémoire.
- Le CPU effectue des opérations de lecture ou d'écriture sur cette adresse mémoire.
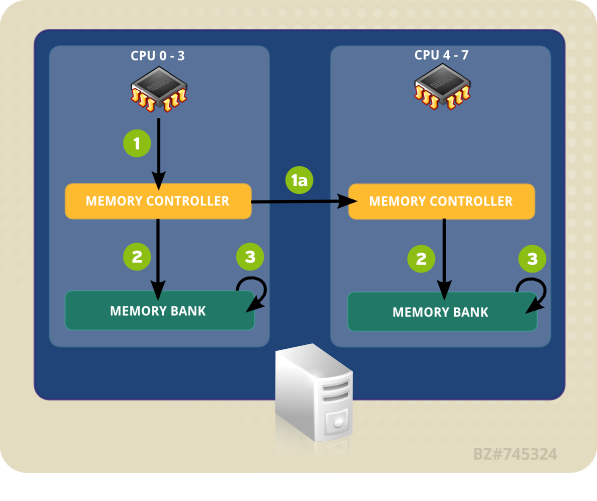
Figure 4.1. Accès local et distant dans la topologie NUMA
Cependant, si un CPU sur un nœud doit accéder au code résidant sur la banque mémoire d'un autre nœud NUMA, le chemin qu'il doit prendre sera moins direct :
- Un CPU (de 0 à 3) présente l'adresse mémoire distante au contrôleur de mémoire local.
- La requête du CPU pour cette adresse mémoire distante est passée à un contrôleur de mémoire distant, local au nœud contenant cette adresse mémoire.
- Le contrôleur de mémoire distant paramètre l'accès à l'adresse mémoire distante.
- Le CPU effectue des opérations de lecture ou d'écriture sur cette adresse mémoire distante.
Chaque action doit passer à travers de multiples contrôleurs de mémoire. Ainsi, l'accès peut prendre plus de deux fois plus longtemps lors de tentatives d'accès aux adresses mémoire distantes. Ainsi, la préoccupation principale en termes de performances dans un système multi-core est de s'assurer que les informations puissent circuler le plus efficacement possible, via la chemin le plus court ou le plus rapide.
Pour configurer une application pour des performances CPU optimales, vous devez connaître :
- la topologie du système (de quelle manière sont connectés ses composants),
- le cœur sur lequel l'application s'exécute et
- l'emplacement de la banque de mémoire la plus proche.
Red Hat Enterprise Linux 6 est fourni avec un certain nombre d'outils pour vous aider à trouver ces informations et régler votre système en conséquence. Les sections suivantes vous offrent un aperçu des outils utiles aux réglages des performances CPU.
4.1.2.1. Définir les affinités de CPU avec taskset
Copier lienLien copié sur presse-papiers!
taskset récupère et définit les affinités de CPU d'un processus en cours d'exécution (par ID de processus). Il peut aussi être utilisé pour lancer un processus avec une affinité de CPU donnée, ce qui lie le processus spécifié à un CPU ou à un ensemble de CPU spécifié. Cependant, taskset ne garantit pas l'allocation de mémoire locale. Si vous avez besoin des bénéfices de performance supplémentaires offerts par l'allocation de mémoire locale, nous recommandons numactl plutôt que taskset ; veuillez consulter la Section 4.1.2.2, « Contrôler la stratégie NUMA avec numactl » pour obtenir de détails supplémentaires.
Les affinités de CPU sont représentées en tant que masque de bits. Le bit d'ordre le plus bas correspond au premier CPU logique et le plus haut correspond au dernier CPU logique. ces masques sont habituellement donnés en valeurs hexadécimales, ainsi
0x00000001 représente le processeur 0 et 0x00000003 représente les processeurs 0 et 1.
Pour définir les affinités de CPU d'un processus en cours d'exécution, veuillez exécuter la commande suivante, en remplaçant mask par le masque du ou des processeurs auxquels vous souhaitez voir le processus lié et remplacez pid par l'ID de processus du processus pour lequel vous souhaitez modifier les affinités.
# taskset -p mask pid
Pour lancer un processus avec une affinité en particulier, exécutez la commande suivante en remplaçant mask par le masque du ou des processeurs auxquels vous souhaitez voir le processus lié et program par le programme, les options et les arguments du programme que vous souhaitez exécuter.
# taskset mask -- program
Au lieu de spécifier les processeurs en tant que masque de bits, vous pouvez aussi utiliser l'option
-c pour fournir une liste séparée par des virgules de différents processeurs, ou une gamme de processeurs, de la manière suivante :
# taskset -c 0,5,7-9 -- myprogram
Des informations supplémentaires sur taskset sont disponibles sur la page man :
man taskset.
4.1.2.2. Contrôler la stratégie NUMA avec numactl
Copier lienLien copié sur presse-papiers!
numactl exécute les processus avec une stratégie d'ordonnancement ou de placement de mémoire spécifiée. La stratégie sélectionnée est définie pour ce processus et tous ses enfants. numactl peut aussi définir une stratégie persistante pour des segments de mémoire ou des fichiers partagés et les affinités CPU de la mémoire d'un processus. Il utilise le système de fichiers /sys pour déterminer la topologie du système.
Le système de fichiers
/sys contient des informations sur la manière par laquelle les CPU, la mémoire et les appareils périphériques sont connectés via des interconnexions NUMA. Plus spécifiquement, le répertoire /sys/devices/system/cpu contient des informations sur la manière par laquelle les CPU d'un système sont connectés les uns aux autres. Le répertoire /sys/devices/system/node contient des informations sur les nœuds NUMA dans le système et les distances relatives entre ces nœuds.
Dans un système NUMA, plus la distance est grande entre un processeur et banque de mémoire, plus l'accès de ce processeur à cette banque de mémoire sera lent. Ainsi, les applications dépendantes des performances devraient donc être configurées de manière à allouer de la mémoire depuis la banque de mémoire la plus proche possible.
Les applications dépendantes des performances doivent aussi être configurées de manière à s'exécuter sur un nombre de cœurs défini, particulièrement dans le cas d'applications à multiples threads. Comme les caches de premier niveau sont habituellement petits, si de multiples threads sont exécutés sur un seul cœur, chaque thread pourrait potentiellement supprimer les données mises en cache accédées par thread précédent. Lorsque le système d'exploitation tente d'effectuer plusieurs tâches à la fois (« multitask ») sur ces threads et que les threads continuent de supprimer les données mises en cache des uns et des autres, un grand pourcentage de leur temps d'exécution est passé à remplacer les lignes du cache. Ce problème est appelé le trashing de cache. Il est ainsi recommandé de lier une application à multiples threads à un nœud plutôt qu'à un seul cœur, puisque cela permet aux threads de partager des lignes de cache sur de multiples niveaux (premier, second et dernier niveau de cache) et minimise le besoin d'opérations de remplissage des caches. Cependant, lier une application à un seul cœur peut être performant si tous les threads accèdent aux mêmes données mises en cache.
numactl vous permet de lier une application à un cœur ou à un nœud NUMA en particulier, ainsi que d'allouer la mémoire associée à un cœur ou à un ensemble de cœurs à cette application. Voici quelques options utiles offertes par numactl :
--show- Affiche les paramètres de la stratégie NUMA du processus actuel. Ce paramètre ne requiert pas de paramètres supplémentaires et peut être utilisé comme ceci :
numactl --show. --hardware- Affiche un inventaire des nœuds disponibles sur le système.
--membind- Alloue la mémoire des nœuds spécifiés uniquement. Lorsque ceci est en cours d'utilisation, l'allocation échouera si la mémoire sur ces nœuds est insuffisante. L'utilisation de ce paramètre se fait ainsi :
numactl --membind=nodes program, où nodes est la liste des nœuds à partir desquels vous souhaitez allouer de la mémoire et program est le programme dont les conditions nécessaires de mémoire devraient être allouées à partir de ce nœud. Le nombre de nœuds peut être donné en tant que liste séparée par des virgules, en tant que gamme, ou avec une combinaison des deux. Des détails supplémentaires sont disponibles sur la page man numactl :man numactl. --cpunodebind- Exécute une commande (et ses processus enfants) sur les CPU appartenant au(x) nœud(s) spécifié(s) uniquement. L'utilisation de ce paramètre se fait ainsi :
numactl --cpunodebind=nodes program, où nodes est la liste des nœuds dont les CPU devraient être liés au programme spécifié (program). Les numéros des nœuds peuvent être donnés en tant que liste séparée par des virgules, en tant que gamme, ou avec une combinaison des deux. Des détails supplémentaires sont disponibles sur la page man numactl :man numactl. --physcpubind- Exécute une commande (et ses processus enfants) sur les CPU spécifiés uniquement. L'utilisation de ce paramètre se fait ainsi :
numactl --physcpubind=cpu program, où cpu est la liste séparée par des virgules des numéros des CPU physiques comme affichés dans les champs du processeur de/proc/cpuinfoet program est le programme qui doit uniquement effectuer des exécutions sur ces CPU. Les CPU peuvent aussi être spécifiés de manière relative aucpusetactuel. Veuillez consulter la page man numactl pour obtenir des informations supplémentaires :man numactl. --localalloc- Spécifie que la mémoire devrait toujours être allouée sur le nœud actuel.
--preferred- Lorsque possible, la mémoire est allouée sur le nœud spécifié. Si la mémoire ne peut pas être allouée sur le nœud spécifié, elle le sera sur d'autres nœuds. Cette option prend uniquement un seul numéro de nœud, comme suit :
numactl --preferred=node. Veuillez consulter la page man numactl pour obtenir des informations supplémentaires :man numactl.
La bibliothèque libnuma incluse dans le paquetage numactl offre une simple interface de programmation à la stratégie NUMA prise en charge par le noyau. Elle est utile pour effectuer des réglages à granularité plus fine que l'utilitaire numactl. Des informations supplémentaires sont disponibles sur la page man :
man numa(3).
4.1.3. numastat
Copier lienLien copié sur presse-papiers!
Important
Auparavant, l'outil numastat était un script Perl écrit par Andi Kleen. Il a été réécrit de manière significative pour Red Hat Enterprise Linux 6.4.
Même si la commande par défaut (
numastat, sans options ni paramètres) maintient une stricte compatibilité avec la version précédente de l'outil, remarquez que fournir des options ou des paramètres à cette commande modifiera le contenu et le format de sa sortie de manière significative.
numastat affiche des statistiques de mémoire (comme les allocations réussies et manquées) pour les processus et le système d'exploitation sur une base « par nœud NUMA ». Par défaut, exécuter
numastat affiche combien de pages de mémoire sont occupées par les catégories d'événements suivantes sur chaque nœud.
Les performances optimales du CPU sont indiquées par des valeurs
numa_miss et numa_foreign basses.
Cette version mise à jour de numastat affiche aussi si la mémoire du processus est étendue à travers un système ou centralisée sur des nœuds spécifiques à l'aide de numactl.
Recoupez la sortie numastat avec la sortie top par CPU pour vérifier que les threads de processus sont exécutés sur les mêmes nœuds que ceux auxquels la mémoire est allouée.
Catégories de suivi par défaut
- numa_hit
- Nombre d'allocations tentées sur ce nœud ayant réussi.
- numa_miss
- Nombre de tentatives d'allocations sur un autre nœud qui ont été allouées à ce nœud en raison de la faible mémoire sur le nœud souhaité. Chaque événement
numa_misspossède un événementsnuma_foreigncorrespondant sur un autre nœud. - numa_foreign
- Nombre d'allocations initialement souhaitées pour ce nœud qui ont été allouées à un autre nœud. Chaque événement
numa_foreignpossède un événementnuma_misscorrespondant sur un autre nœud. - interleave_hit
- Nombre d'allocations de stratégie d'entrelacement réussies sur ce nœud.
- local_node
- Nombre de fois qu'un processus sur ce nœud a effectivement réussi à allouer de la mémoire sur ce nœud.
- other_node
- Nombre de fois qu'un processus sur un autre nœud a alloué de la mémoire sur ce nœud.
Fournir l'une des options suivantes change les unités affichées en mégaoctets de mémoire, arrondis à deux décimales) et modifie d'autres comportements numastat spécifiques, comme décrit ci-dessous.
-c- Condense horizontalement la table d'informations affichée. Ceci est utile sur des systèmes comportant un grand nombre de nœuds NUMA, mais la largeur des colonnes et l'espacement entre colonnes reste quelque peu imprévisible. Lorsque cette option est utilisée, la quantité de mémoire est arrondie au mégaoctet le plus proche.
-m- Affiche les informations d'utilisation de la mémoire du système global sur une base « par nœud », de manière similaire aux informations trouvées dans
/proc/meminfo. -n- Affiche les mêmes informationa que la commande d'origine
numastat(numa_hit, numa_miss, numa_foreign, interleave_hit, local_node et other_node), avec un format mis à jour utilisant les mégaoctets comme unité de mesure. -p pattern- Affiche des informations de mémoire par nœud pour le schéma spécifié. Si la valeur de pattern comprend des chiffres, numastat suppose qu'il s'agit un identifiant de processus numérique. Sinon, numastat recherche le schéma spécifié dans les lignes de commande des processus.Les arguments de ligne de commande saisis après la valeur de l'option
-psont supposées être des schémas supplémentaires avec lesquels filtrer. Les schémas supplémentaires agrandissent le filtre, plutôt que le réduire. -s- Arrange les données en ordre descendant de manière à ce que les plus gros consommateurs de mémoire (selon la colonne
total) soient répertoriés en premier.Optionnellement, vous pouvez spécifier un nœud et le tableau sera ordonné selon la colonne nœuds. Lors de l'utilisation de cette option, la valeur nœud doit suivre l'option-simmédiatement, comme décrit ici :numastat -s2N'incluez pas d'espace blanc entre l'option et sa valeur. -v- Affiche des informations plus détaillées (« verbose information »). C'est-à-dire des informations de processus sur de multiples processus afficheront des informations détaillées sur chaque processus.
-V- Affiche les informations de version de numastat.
-z- Omet les lignes et colonnes du tableau ne comportant que la valeur zéro du reste des informations affichées. Remarquez que les valeurs proches de zéro qui sont arrondies à zéro pour des raisons d'affichage ne seront pas omises de la sortie affichée.
4.1.4. numad (« NUMA Affinity Management Daemon »)
Copier lienLien copié sur presse-papiers!
numad est un démon de gestion des affinités NUMA automatique. Il contrôle la topologie NUMA et l'utilisation des ressources dans un système afin de dynamiquement améliorer l'allocation et la gestion des ressources NUMA (et donc les performances système).
Selon la charge de travail du système, numad peut fournir une amélioration des performances de référence allant jusqu'à 50%. pour réaliser ces gains de performance, numad accède périodiquement aux informations du système de fichiers
/proc pour contrôler les ressources système disponibles sur une base « par nœud ». Le démon tente ensuite de placer des processus significatifs sur les nœuds NUMA possédant suffisamment de mémoire alignée et de ressources CPU pour des performances NUMA optimales. Les limites actuelles pour la gestion des processus sont d'au moins 50% d'un CPU et au moins 300 Mo de mémoire.numad tente de maintenir un niveau d'utilisation des ressources et ré-équilibre les allocations lorsque nécessaire en déplaçant les processus entre les nœuds NUMA.
numad offre aussi un service de conseils pré-placement pouvant être interrogé par divers systèmes de gestion de tâches pour fournir une certaine assistance avec la liaison initiale des ressources CPU et de mémoire pour leurs processus. Ce service de conseils pré-placement est disponible que numad soit exécuté en tant que démon sur le système ou non. Veuillez vous reporter à la page man pour obtenir des détails supplémentaires sur l'utilisation de l'option
-w pour les conseils pré-placement : man numad.
4.1.4.1. Bénéfices de numad
Copier lienLien copié sur presse-papiers!
numad bénéficie principalement aux systèmes possédant des processus de longue durée qui consomment des quantités de ressources significatives, particulièrement lorsque ces processus sont contenus dans un sous-ensemble de la totalité des ressources système.
numad peut aussi être bénéfique à des applications consommant une quantité de ressources correspondant à de multiples nœuds NUMA. Cependant, plus le pourcentage de ressources consommées sur un système augmente, plus les bénéfices offerts par numad diminuent.
Il est improbable que numad puisse améliorer les performances lorsque les processus sont exécutés depuis quelques minutes uniquement ou lorsqu'ils ne consomment que peu de ressources. Il est aussi improbable que des systèmes avec des schémas d'accès mémoire continuellement imprévisibles, comme les bases de données intégrées de grande taille, puissent bénéficier de l'utilisation de numad.
4.1.4.2. Modes d'opération
Copier lienLien copié sur presse-papiers!
Note
Les statistiques de comptabilité de la mémoire du noyau peuvent se contredire après des fusions de grande taille. Ainsi, numad peut être confondu lorsque le démon KSM fusionne de grandes quantités de mémoire. Le démon KSM sera davantage conscient de NUMA dans le futur. Cependant, si votre système possède actuellement une grande quantité de mémoire libre, vous pourriez obtenir de meilleures performances en éteignant et désactivant le démon KSM.
numad peut être utilisé de deux manières :
- en tant que service
- en tant qu'exécutable
4.1.4.2.1. Utiliser numad en tant que service
Copier lienLien copié sur presse-papiers!
Pendant que le service numad est en cours d'exécution, il tentera de régler le système dynamiquement en se basant sur sa charge de travail.
Pour lancer le service, veuillez exécuter :
# service numad start
Pour rendre le service persistant à travers les redémarrages, veuillez exécuter :
# chkconfig numad on4.1.4.2.2. Utiliser numad en tant qu'exécutable
Copier lienLien copié sur presse-papiers!
Pour utiliser numad en tant qu'exécutable, veuillez exécuter :
# numad
numad sera exécuté jusqu'à ce qu'il soit arrêté. Lorsqu'il est exécuté, ses activités sont journalisées dans
/var/log/numad.log.
Pour restreindre la gestion numad à un processus spécifique, veuillez le démarrer avec les options suivantes.
# numad -S 0 -p pid-p pid- Ajoute le pid spécifié sur une liste d'inclusions spécifiques. Le processus spécifié ne sera pas géré jusqu'à ce qu'il atteigne la limite d'importance de processus numad.
-S mode- Le paramètre
-Sspécifie le type de scan de processus. Le définir sur0comme suit limite la gestion numad aux processus explicitement inclus.
Pour arrêter numad, veuillez exécuter :
# numad -i 0
Arrêter numad ne supprime pas les changements effectués pour améliorer les affinités NUMA. Si l'utilisation du système change de manière significative, exécuter numad à nouveau ajustera les affinités pour améliorer les performances sous les nouvelles conditions.
Pour obtenir des informations supplémentaires sur les options numad disponibles, veuillez consulter la page man numad :
man numad.