6.3. Strumenti
Sono disponibili un certo numero di strumenti per la diagnosi dei problimi relativi alle prestazioni nei sottosistemi I/O. vmstat fornisce una breve panoramica sulle prestazioni del sistema. Le seguenti colonne riportano i parametri più importanti per I/O:
si (swap in), so (swap out), bi (block in), bo (block out), e wa (I/O wait time). si e so sono utili quando lo spazio di swap è sullo stesso dispositivo della partizione dati, e risulta indicativo della pressione generale della memoria. si e bi sono operazioni di lettura mentre so e bo sono operazioni di scrittura. Queste categorie sono riportate in kilobyte. wa è il tempo di inattività; Esso indica quale sezione della coda di esecuzione è stata bloccata in attesa del completamento dell'I/O.
Analizzando il sistema con vmstat potrete scoprire se il sottosistema I/O sia il responsabile per eventuali problemi di prestazione. A tal proposito vale la pena consultare anche le colonne
free, buff, e cache . L'aumento del valore cache insieme a bo seguito da una riduzione di cache ed un aumento di free, indica che il sistema esegue una operazione di write-back e di annullamento della cache della pagina.
Da notare come i numeri di I/O riportati da vmstat risultano essere aggregazioni di tutti gli I/O per tutti i dispositivi. Una volta determinata la presenza di un abbassamento delle prestazioni nel sottosistema I/O, sarà possibile esaminare il problema in dettaglio con iostat, il quale eseguirà una analisi dettagliata del riporto I/O in base al dispositivo. È possibile altresì ripristinare informazioni più dettagliate, come ad esempio la dimensione media della richiesta, il numero di processi di scrittura e scrittura per secondo e la quantità di operazioni Merge dell'I/O in corso.
Tramite la dimensione media della richiesta e la dimensione media della coda (
avgqu-sz), sarà possibile stimare le prestazioni dello storage usando i grafici generati durante l'analisi delle prestazioni. Sono applicate alcune generalizzazioni, se la dimensione media delle richieste è 4KB e quella della coda risulta essere 1, l'output netto non dovrebbe risultare performante.
Se i valori della prestazione non corrispondono alla prestazione prevista, sarà possibile eseguire una analisi più dettagliata con blktrace. La suite di utilità blktrace rende disponibili informazioni più dettagliate sul tempo trascorso nel sottosistema I/O. L'output di blktrace è un insieme di file di traccia binari che possono essere processati in un secondo momento da altre utilità come ad esempio blkparse.
blkparse è una utilità usata insieme a blktrace. Essa legge l'output dalla traccia e produce una breve versione di testo.
Il seguente è un esempio di output blktrace:
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark]
8,64 3 0 0.000012707 0 m N cfq4162S / alloced
8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark]
8,64 3 3 0.000015813 4162 P N [fs_mark]
8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark]
8,64 3 0 0.000018632 0 m N cfq4162S / insert_request
8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr
8,64 3 0 0.000021945 0 m N cfq4162S / idle=0
8,64 3 5 0.000023460 4162 U N [fs_mark] 1
8,64 3 0 0.000025761 0 m N cfq workload slice:300
8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2
8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null)
8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert
8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request
8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1
8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark]
8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
L'output è complesso e difficile da laggere. È possibile sapere i processi responsabili per l'I/O sul dispositivo, quale risulta essere utile, ma blkparse è in grado di rendere disponibili maggiori informazioni in un formato più semplice. Le informazioni di blkparse sono riportate nella parte finale di questo output:
Total (sde):
Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB
Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB
Reads Requeued: 0 Writes Requeued: 125
Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB
Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB
IO unplugs: 20,087 Timer unplugs: 0
Il sommario mostra il tasso di I/O medio, l'attività di merge e confronta i carichi di lavoro delle operazioni di lettura con quelle di scrittura. Per la maggior parte dei casi tuttavia l'output di blkparse è troppo ampio per essere utile da solo. Fortunatamente sono disponibili alcuni strumenti per la visualizzazione dei dati più importanti.
btt fornisce una analisi della quantità di tempo che l'I/O ha trascorso nelle diverse aree dello stack. Queste aree sono:
- Q — Un blocco I/O messo in coda
- G — Ottieni una richiestaUn blocco I/O appena messo in coda non è il condidato per una opearazione di Merge con una richiesta esistente, per questo motivo è stato assegnata una nuova richiesta del livello del blocco.
- M — Un blocco I/O è stato unito con una richiesta esistente.
- I — Inserita una richiesta nella coda del dispositivo.
- D — Emessa una richiesta al dispositivo.
- C — Richiesta completata dall'unità.
- P — La coda del dispositivo è bloccata "Plugged" e permette la raccolta di richieste.
- U — La coda del dispositivo è sbloccata "Unplugged", e permette l'emissione delle richieste per il dispositivo.
btt suddivide in modo dettagliato il tempo trascorso in ogni area e quello usato durante la transizione tra le aree, ad esempio:
- Q2Q — tempo trascorso tra richieste inviate al livello blocco
- Q2G — il tempo trascorso quando un blocco I/O viene messo in coda ed il tempo nel quale riceve una richiesta
- Q2I — il tempo trascorso da quando una richiesta è stata assegnata a quando la stessa viene inserita nella coda del dispositivo
- Q2M — il tempo trascorso quando un blocco I/O viene messo in coda ed il tempo entro il quale viene unito con una richiesta esistente
- Q2I — tempo trascorso quando una richiesta viene inserita nella coda del dispositivo ed il tempo entro il quale la richiesta viene inviata al dispositivo
- Q2D — il tempo trascorso entro il quale un blocco I/O viene unito con una richiesta esistente fino a quando la richiesta viene emessa al dispositivo
- D2C — tempo di servizio della richiesta per il dispositivo
- Q2C — tempo totale trascorso nel blocco per un richiesta
Da questa tabella è possibile avere numerose informazioni sul carico di lavoro. Per esempio se Q2Q è più grande di Q2C, ciò significa che l'applicazione non emette alcun I/O in rapida successione. Quindi qualsiasi problema relativo alle prestazioni potrebbe non avere alcuna relazione con il sottosistema I/O. Se D2C è molto alto il dispositivo necessita di un tempo più lungo per rispondere alle richieste. Tale comportamente potrebbe indicare che il dispositivo è semplicemente sovraccarico (ciò potrebbe derivare dal fatto che esso risulta essere una risorsa condivisa), oppure poichè il carico di lavoro inviato al dispositivo non è ottimale. Se Q2G è molto elevato ciò indicherà un numero molto grande di richieste messe in coda contemporaneamente. Ciò indicherà che lo storage non è in grado di gestire il carico I/O.
Per finire seekwatcher utilizza dati binari blktrace e genera un insieme di grafici, incluso Logical Block Address (LBA), output netti, ricerche per secondo, e I/Os Per Second (IOPS).
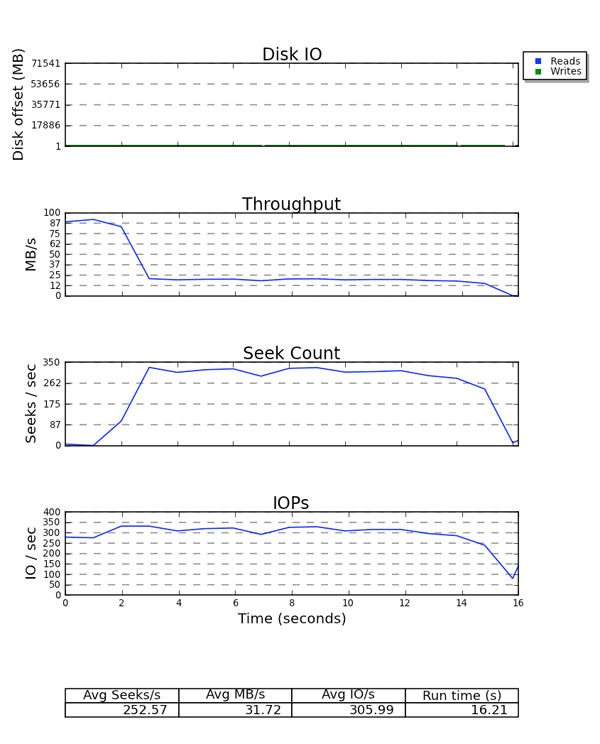
Figura 6.2. Esempio di output di seekwatcher
Tutti i grafici riportano il tempo con l'asse X. Il grafico LBA mostra i processi di lettura e scrittura in diversi colori. Da notare la relazione che intercorre tra i grafici dell'output netto e di ricerca/sec. Per uno storage sensibile alle ricerche, vi è una relazione inversa tra i due grafici. Il grafico IOPS è utile se per esempio non ricevete l'output netto previsto da un dispositivo, ma al tempo stesso raggiungete i limiti IOPS.