第13章 Hibernate Search
13.1. Hibernate Search を初めて使う場合
13.1.1. Hibernate Search について
Hibernate Search は、Hibernate アプリケーションに全文検索機能を提供します。SQL ベースのソリューションが適切でない検索アプリケーションに特に適しています (全文、あいまい、および位置情報検索を含む)。Hibernate Search は全文検索エンジンとして Apache Lucene を使用しますが、メンテナンスオーバーヘッドを最小化するよう設計されています。設定後は、インデックス作成、クラスタリング、およびデータ同期化が透過的にメンテナンスされ、ユーザーはビジネス要件を満たすことに集中できます。
JBoss EAP の以前のリリースには Hibernate 4.2 と Hibernate Search 4.6 が含まれていました。JBoss EAP 7 には、Hibernate 5 と Hibernate Search 5.5 が含まれます。
Hibernate Search 5.5 は Java 7 と連携し、Lucene 5.3.x に基づいて構築されています。ネイティブ Lucene API を使用している場合は、このバージョンを使用してください。
13.1.2. 概要
Hibernate Search は、Apache Lucene によりサポートされるインデックス作成コンポーネントとインデックス検索コンポーネントから構成されます。データベースに対してエンティティーが挿入、更新、または削除されるたびに、Hibernate Search はこのイベントを (Hibernate イベントシステム経由で) 追跡し、インデックスアップデートをスケジュールします。これらすべてのアップデートは、Apache Lucene API を直接使用せずに処理されます。代わりに、基礎となる Lucene インデックスとの対話は IndexManager 経由で処理されます。デフォルトでは、IndexManager と Lucene インデックス間には 1 対 1 の関係があります。IndexManager は選択された back end、reader strategy、および DirectoryProvider を含む特定のインデックス設定を抽象化します。
インデックスが作成されると、基礎となる Lucene インフラストラクチャーを使用する代わりに、エンティティーを検索し、管理対象エンティティーのリストを返すことができます。同じ永続化コンテキストが Hibernate と Hibernate Search 間で共有されます。FullTextSession クラスは、アプリケーションコードが統一された org.hibernate.Query または javax.persistence.Query API を HQL、JPA-QL、またはネイティブクエリーとまったく同じように使用できるように Hibernate Session クラス上に構築されます。
JDBC ベースであるかどうかに関係なく、すべての操作にはトランザクション形式のバッチモードが推奨されます。
データベースと Hibernate Search の両方において、JDBC または JTA に関係なくトランザクションで操作を実行することが推奨されます。
Hibernate Search は、Hibernate または EntityManager の長い会話パターン (アトミック会話) で完全に動作します。
13.1.3. Directory Provider について
Hibernate Search インフラストラクチャーの一部である Apache Lucene には、インデックスを格納するディレクトリーという概念があります。Hibernate Search は、ディレクトリープロバイダー経由で Lucene ディレクトリーの初期化と設定を処理します。
directory_provider プロパティーは、インデックスを格納するために使用するディレクトリープロバイダーを指定します。デフォルトのファイルシステムディレクトリープロバイダーは、filesystem であり、インデックスを格納するローカルファイルシステムを使用します。
13.1.4. ワーカーについて
Lucene インデックスに対するアップデートは、Hibernate Search ワーカーによって処理されます。ワーカーはすべてのエンティティーの変更を受け取り、それらをコンテキスト別にキューに格納し、コンテキストが終了したら適用します。最も一般的なコンテキストはトランザクションですが、エンティティーの変更または他のアプリケーションイベントの数によって異なることがあります。
効率を向上させるために、対話はバッチ処理され、一般的にコンテキストの終了時に適用されます。トランザクション外部では、インデックスアップデート操作は、実際のデータベース操作の直後に実行されます。実行中のトランザクションの場合は、トランザクションコミットフェーズに対してインデックスアップデート操作がスケジュールされ、トランザクションロールバックの場合は、破棄されます。ワーカーには特定のバッチサイズ制限を設定できます。この制限を超えると、コンテキストに関係なくインデックス作成が実行されます。
インデックスアップデートのこの処理方法は以下の 2 つの利点があります。
- パフォーマンス: Lucene インデックス作成のパフォーマンスは、操作をバッチで実行した場合に向上します。
- ACIDity: 実行したワークは、データベーストランザクションにより実行されたワークと同じスコープを持ち、トランザクションがコミットされた場合にのみ実行されます。これは、厳密には ACID ではありませんが、ACID の動作は全文検索インデックスにほとんど役に立ちません。インデックスはいつでもソースから再構築できます。
2 つのバッチモード (スコープなしと従来のもの) の関係は、オートコミットと従来の動作の関係に似ています。パフォーマンスの観点からは、トランザクションモードが推奨されます。スコープの選択は透過的に行われます。Hibernate Search は、トランザクションの存在を検出し、スコープを調整します。
13.1.5. バックエンドセットアップおよび操作
13.1.5.1. バックエンド
Hibernate Search は、さまざまなバックエンドを使用してワークのバッチを処理します。バックエンドは設定オプション default.worker.backend に制限されません。このプロパティーは、バックエンド設定の一部である BackendQueueProcessor インターフェースの実装を指定します。バックエンドをセットアップするには、JMS バックエンドなどの追加の設定が必要です。
13.1.5.2. Lucene
Lucene モードでは、ノードのすべてのインデックスアップデートが、ディレクトリープロバイダーを使用した Lucene ディレクトリーに対する同じノードにより実行されます。このモードは、非クラスター環境または共有ディレクトリーストアがあるクラスター環境で使用します。
図13.1 Lucene バックエンド設定
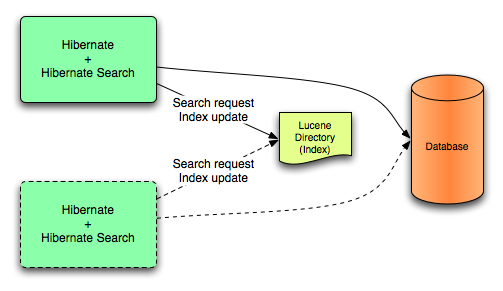
Lucene モードは、ディレクトリーでロックストラテジーを管理する非クラスターアプリケーションまたはクラスターアプリケーションを対象とします。Lucene モードの第一の利点は、Lucene クエリーの変更の単純化と即時的な可視性です。Near Real Time (NRT) バックエンドは非クラスターおよび非共有インデックス設定向けの代替バックエンドです。
13.1.5.3. JMS
ノードのインデックスアップデートは JMS キューに送信されます。特別なリーダーがキューを処理し、マスターインデックスをアップデートします。マスターおよびスレーブパターンを確立するために、マスターインデックスはスレーブコピーに定期的に複製されます。マスターは Lucene インデックスアップデートを行います。スレーブは読み書き操作を受け取りますが、読み取り操作をローカルインデックスコピーで処理します。Lucene インデックスを更新するのはマスターだけです。また、マスターのみがアップデート操作でローカル変更を適応できます。
図13.2 JMS バックエンド設定
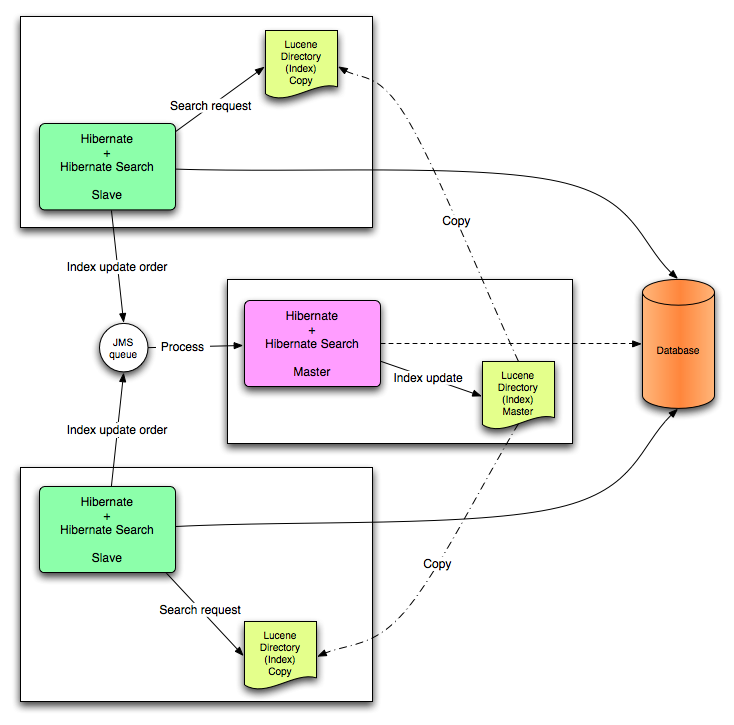
このモードは、スループットが重要であり、インデックスアップデートの遅延が許容されるクラスタ環境を対象とします。JMS プロバイダーにより、信頼性が保証され、ローカルインデックスコピーを変更するためにスレーブが使用されます。
13.1.6. リーダーストラテジー
クエリーを実行する場合は、Hibernate Search がリーダーストラテジーを使用して Apache Lucene インデックスを処理します。頻繁なアップデート、読み取りが大部分、非同期インデックスアップデートなどのアプリケーションのプロファイルに基づいてリーダーストラテジーを選択します。
13.1.6.3. カスタムリーダーストラテジー
カスタムリーダーストラテジーは、org.hibernate.search.reader.ReaderProvider の実装を使用して記述できます。実装はスレッドセーフである必要があります。
13.2. Configuration (設定)
13.2.1. 最小設定
Hibernate Search は、設定と操作に柔軟性を提供するよう設計されており、デフォルト値は大部分のユースケースに適合するよう慎重に選択されます。最低でも、Directory Provider とプロパティーを設定する必要があります。デフォルトの Directory Provider は filesystem であり、インデックスストレージにローカルファイルシステムが使用されます。利用可能な Directory Provider とその設定の詳細については、DirectoryProvider Configuration を参照してください。
Hibernate を直接使用している場合は、DirectoryProvider などの設定を設定ファイルの hibernate.properties または hibernate.cfg.xml で指定する必要があります。Hibernate を JPA で使用している場合、設定ファイルは persistence.xml になります。
13.2.2. IndexManager の設定
Hibernate Search は、このインターフェースに対して複数の実装を提供します。
-
directory-based: LuceneDirectory抽象化を使用してインデックスファイルを管理するデフォルトの実装。 -
near-real-time: 各コミット時にディスクへの書き込みのフラッシュを回避します。また、このインデックスマネージャーはDirectoryベースですが、Lucene の Near Real-Time (NRT) 機能を使用します。
デフォルト値以外の IndexManager を指定するには、以下のプロパティーを指定します。
hibernate.search.[default|<indexname>].indexmanager = near-real-time
13.2.2.1. Directory-based
Directory-based 実装は、デフォルトの IndexManager 実装です。高度な設定が可能であり、リーダーストラテジー、バックエンド、およびディレクトリープロバイダーに対して個別の設定を指定できます。
13.2.2.2. Near Real Time
NRTIndexManager は、デフォルトの IndexManager の拡張であり、レイテンシーの低いインデックス書き込みに Lucene NRT (Near Real Time) 機能を使用します。ただし、lucene 以外の別のバックエンドに対する設定は無視され、Directory に対する排他的な書き込みロックが取得されます。
IndexWriter は、低いレイテンシーを提供するために各変更をディスクにフラッシュしません。クエリーは、フラッシュされていないインデックスライターバッファーからアップデートされた状態を読み取ることができます。ただし、IndexWriter が終了した場合やアプリケーションがクラッシュした場合は、アップデートが失われ、インデックスを再構築する必要があることがあります。
記載された欠点が原因でデータが制限された非クラスタ Web サイトには Near Real Time 設定が推奨されます (パフォーマンスを向上させるためにマスターノードを個別に設定できます)。
13.2.2.3. Custom
カスタマイズ IndexManager をセットアップするにはカスタム実装に完全修飾クラス名を指定します。以下のように、実装に対して引数のないコンストラクターをセットアップします。
[default|<indexname>].indexmanager = my.corp.myapp.CustomIndexManager
カスタムインデックスマネージャー実装では、デフォルト実装と同じコンポーネントが必要ありません。たとえば、Directory インターフェースを公開しないリモートインデックスサービスに委任します。
13.2.3. DirectoryProvider 設定
DirectoryProvider は、Directory に対する Hibernate Search の抽象化であり、基礎となる Lucene リソースの設定と初期化を処理します。ディレクトリープロバイダーおよびプロパティーには、Hibernate Search で利用可能なディレクトリープロバイダーと対応するオプションが示されます。
各インデックスエンティティーは、Lucene インデックスに関連付けられます (複数のエンティティーが同じインデックスを共有する場合を除く)。インデックスの名前は、@Indexed アノテーションの index プロパティーにより提供されます。index プロパティーが指定されない場合は、インデックスクラスの完全修飾名が名前として使用されます (推奨)。
DirectoryProvider と追加のオプションは、接頭辞 hibernate.search.<indexname> を使用して設定できます。名前 default (hibernate.search.default) は予約され、すべてのインデックスに適用するプロパティーを定義するために使用できます。ディレクトリープロバイダーの設定には、hibernate.search.default.directory_provider を使用してデフォルトディレクトリープロバイダーをファイルシステムのものにどのように設定するかが示されています。hibernate.search.default.indexBase により、インデックス用のデフォルトベースディレクトリーが設定されます。結果として、エンティティー Status のインデックスが /usr/lucene/indexes/org.hibernate.example.Status に作成されます。
ただし、Rule エンティティーのインデックスはメモリ内ディレクトリーを使用します。これは、このエンティティーのデフォルトディレクトリープロバイダーがプロパティー hibernate.search.Rules.directory_provider によりオーバーライドされるためです。
最後に、Action エンティティーは、hibernate.search.Actions.directory_provider 経由で指定されたカスタムディレクトリープロバイダー CustomDirectoryProvider を使用します。
インデックス名の指定
package org.hibernate.example;
@Indexed
public class Status { ... }
@Indexed(index="Rules")
public class Rule { ... }
@Indexed(index="Actions")
public class Action { ... }
ディレクトリープロバイダーの設定
hibernate.search.default.directory_provider = filesystem hibernate.search.default.indexBase=/usr/lucene/indexes hibernate.search.Rules.directory_provider = ram hibernate.search.Actions.directory_provider = com.acme.hibernate.CustomDirectoryProvider
定義された設定スキームを使用して、ディレクトリープロバイダーやベースディレクトリーなどの共通のルールを簡単に定義したり、これらのデフォルト値をインデックスごとに後でオーバーライドしたりできます。
ディレクトリープロバイダーおよびプロパティー
- ram
- なし
- filesystem
ファイルシステムベースのディレクトリー。使用されるディレクトリーは <indexBase>/< indexName >
- indexBase : ベースディレクトリー
- indexName: @Indexed.index をオーバーライドする (共有インデックスの場合に有用)
- locking_strategy : オプション (LockFactory 設定を参照)
-
filesystem_access_type: この
DirectoryProviderにより使用されるFSDirectory実装のタイプを決定できます。許可される値は、auto(デフォルト値。Windows 以外のシステムではNIOFSDirectory、Windows ではSimpleFSDirectoryを選択)、simple (SimpleFSDirectory)、nio (NIOFSDirectory)、mmap (MMapDirectory)です。この設定を変更する前にこれらの Directory 実装の Javadocs を参照してください。NIOFSDirectoryまたはMMapDirectoryを使用するとパフォーマンスが大幅に向上することがありますが、問題も発生します。
filesystem-masterファイルシステムベースのディレクトリー (
filesystemなど)。通常は、インデックスもソースディレクトリー (コピーディレクトリー) にコピーされます。更新期間の推奨値は、情報をコピーする時間よりも 50% (以上) 大きい値です (デフォルトでは 3600 秒 - 60 分)。
コピーは増分コピーメカニズムに基づき、平均コピー時間が短縮されることに注意してください。
DirectoryProvider は、通常 JMS バックエンドクラスターのマスターノートで使用されます。
buffer_size_on_copyは、オペレーティングシステムと利用可能な RAM に依存します。最良の結果を得るには、16〜64MB の値を使用することが推奨されます。- indexBase: ベースディレクトリー
- indexName: @Indexed.index をオーバーライドする (共有インデックスの場合に有用)
- sourceBase: ソース (コピー) ベースディレクトリー
-
source: ソースディレクトリー接尾辞 (デフォルト値は
@Indexed.index)。実際のソースディレクトリー名は<sourceBase>/<source> - refresh: 秒単位の更新期間 (コピーは refresh 秒ごとに実行されます)。以下の refresh 期間が経過した時にまだコピーが実行中である場合は、2 番目のコピー操作が省略されます。
- buffer_size_on_copy: 単一の低レベルコピー命令で移動する MegaBytes のサイズ。デフォルト値は 16MB です。
- locking_strategy : オプション (LockFactory 設定を参照)
-
filesystem_access_type: この
DirectoryProviderにより使用されるFSDirectory実装のタイプを決定できます。許可される値は、auto(デフォルト値。Windows 以外のシステムではNIOFSDirectory、Windows ではSimpleFSDirectoryを選択)、simple (SimpleFSDirectory)、nio (NIOFSDirectory)、mmap (MMapDirectory)です。この設定を変更する前にこれらの Directory 実装の Javadocs を参照してください。NIOFSDirectoryまたはMMapDirectoryを使用するとパフォーマンスが大幅に向上することがありますが、問題も発生します。
filesystem-slaveファイルシステムベースのディレクトリー (
filesystemなど)。通常は、マスターバージョン (ソース) が取得されます。ロックや不整合な検索結果を避けるために、2 つのローカルコピーが保持されます。更新期間の推奨値は、情報をコピーする時間よりも 50% (以上) 大きい値です (デフォルトでは 3600 秒 - 60 分)。
コピーは増分コピーメカニズムに基づき、平均コピー時間が短縮されることに注意してください。refresh 期間が経過した時にまだコピーが実行中である場合は、2 番目のコピー操作が省略されます。
JMS バックエンドを使用してスレーブノードで一般的に使用される DirectoryProvider。
buffer_size_on_copyは、オペレーティングシステムと利用可能な RAM に依存します。最良の結果を得るには、16〜64MB の値を使用することが推奨されます。- indexBase: ベースディレクトリー
- indexName: @Indexed.index をオーバーライドする (共有インデックスの場合に有用)
- sourceBase: ソース (コピー) ベースディレクトリー
-
source: ソースディレクトリー接尾辞 (デフォルト値は
@Indexed.index)。実際のソースディレクトリー名は<sourceBase>/<source> - refresh: 秒単位の更新期間 (コピーは refresh 秒ごとに実行されます)。
- buffer_size_on_copy: 単一の低レベルコピー命令で移動する MegaBytes のサイズ。デフォルト値は 16MB です。
- locking_strategy : オプション (LockFactory 設定を参照)
- retry_marker_lookup: オプションであり、デフォルト値は 0 です。Hibernate Search がソースディレクトリーのマーカーファイルをチェックする回数を定義します。試行の間隔は 5 秒です。
-
retry_initialize_period: オプション。再試行初期化機能を有効にするために秒を整数値で設定します。スレーブがマスターインデックスを見つけることができない場合は、見つかるまでバックグラウンドで再試行され、アプリケーションの起動は阻止されません。インデックスが初期化される前に実行された fullText クエリーはブロックされませんが、空の結果を返します。オプションを有効にしない場合や、明示的にゼロに設定しない場合は、再試行タイマーのスケジュールの代わりに、失敗して例外が発生します。無効なインデックスなしでアプリケーションが起動しないようにし、初期化タイムアウトを制御する場合は、代わりに
retry_marker_lookupを参照してください。 -
filesystem_access_type: この
DirectoryProviderにより使用されるFSDirectory実装のタイプを決定できます。許可される値は、auto (デフォルト値。Windows 以外のシステムではNIOFSDirectory、Windows ではSimpleFSDirectoryを選択)、simple (SimpleFSDirectory)、nio (NIOFSDirectory)、mmap (MMapDirectory)です。この設定を変更する前にこれらの Directory 実装の Javadocs を参照してください。NIOFSDirectoryまたはMMapDirectoryを使用するとパフォーマンスが大幅に向上することがありますが、問題も発生します。
組み込みのディレクトリープロバイダーがニーズを満たさない場合は、org.hibernate.store.DirectoryProvider インターフェースを実装して独自のディレクトリープロバイダーを記述できます。この場合は、プロバイダーの完全修飾クラス名を directory_provider プロパティーに渡します。追加のプロパティーは、接頭辞 hibernate.search.<indexname> を使用して渡すことができます。
13.2.4. ワーカー設定
ワーカー設定を介して Hibernate Search がどのように Lucene と対話するかを定義できます。複数のアーキテクチャーコンポーネントと拡張が存在します。
ワーカー設定を使用して Infinispan クエリーが Lucene と対話する方法を定義します。この設定では、複数のアーキテクチャーコンポーネントと拡張が存在します。
最初に、Worker について説明します。Worker インターフェースの実装は、すべてのエンティティーの変更を受け取り、コンテキスト別にキューに格納し、コンテキストが終了したら適用します。最も直感的なコンテキスト (特に ORM との接続) はトランザクションです。このため、Hibernate Search は、トランザクションごとにすべての変更をスコープ指定するためにデフォルトで TransactionalWorker を使用します。ただし、コンテキストがエンティティーの変更や他のアプリケーション (ライフサイクル) イベントの数などに依存するシナリオが考えられます。
| プロパティー | 説明 |
|---|---|
|
|
使用する |
|
|
接頭辞が |
|
|
コンテキストごとにバッチ化されたインデックス作成操作の最大数を定義します。この制限に到達すると、コンテキストがまだ終了していなくてもインデックス作成がトリガーされます。このプロパティーは、 |
コンテキストが終了すると、インデックスの変更を準備し、適用します。これは、新しいスレッド内で同期的または非同期的に行えます。同期のアップデートの利点は、インデックスが常にデータベースと同期されることです。その一方で、非同期アップデートでは、ユーザー応答時間を最小化できます。非同期アップデートの欠点は、データベースとインデックスの状態が一致しない場合があることです。
以下のオプションはインデックスごとに異なることがあります。実際には、indexName 接頭辞または default を使用してすべてのインデックスのデフォルト値を設定します。
| プロパティー | 説明 |
|---|---|
|
|
|
|
|
バックエンドは、スレッドプールを使用して、同じトランザクションコンテキスト (またはバッチ) からアップデートを同時に適用できます。デフォルト値は 1 です。トランザクションごとに多くの操作がある場合は、大きい値を試行できます。 |
|
|
スレッドプールが枯渇した場合のワークキューの最大数を定義します。非同期実行の場合のみ役に立ちます。デフォルト値は無制限です。制限に達すると、メインスレッドによりワークが実行されます。 |
これまで、どの実行モードであるかに関係なく、すべてのワークは同じ仮想マシン (VM) 内で実行されました。1 つの VM に対してワークの合計量は変わりませんでした。問題に対処するために、委任という優れた方法があります。hibernate.search.default.worker.backend を設定することにより、インデックス作成ワークを別のサーバーに送信できます。繰り返しますが、このオプションは、各インデックスに対して個別に設定できます。
| プロパティー | 説明 |
|---|---|
|
|
また、 |
| プロパティー | 説明 |
|---|---|
|
|
InitialContext を初期化するために JNDI プロパティーを定義します (必要な場合)。JNDI は JMS バックエンドによってのみ使用されます。 |
|
|
JMS バックエンドに必要です。JMS 接続ファクトリーをルックアップする JNDI 名を定義します (Red Hat JBoss Enterprise Application Platform ではデフォルトで |
|
|
JMS バックエンドに必要です。JMS キューをルックアップする JNDI 名を定義します。キューはワークメッセージをポストするために使用されます。 |
お気づきになったかもしれませんが、示された一部のプロパティーは相互に影響を及ぼします。つまり、すべてのプロパティー値の組み合わせが有効であるとは限りません。実際には、機能しない設定を使用することがあります。これは、特に、示された一部のインターフェースの独自の実装を提供する場合に当てはまります。独自の Worker または BackendQueueProcessor 実装を記述する前に既存のコードを調べてください。
13.2.4.1. JMS マスター/スレーブバックエンド
本セクションでは、マスター/スレーブ Hibernate Search アーキテクチャーの設定方法について詳しく説明します。
図13.3 JMS バックエンド設定
13.2.4.2. スレーブノード
各インデックスアップデート操作は、JMS キューに送信されます。インデックスクエリー操作はローカルインデックスコピーで実行されます。
JMS スレーブ設定
### slave configuration ## DirectoryProvider # (remote) master location hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local copy location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-slave ## Back-end configuration hibernate.search.default.worker.backend = jms hibernate.search.default.worker.jms.connection_factory = /ConnectionFactory hibernate.search.default.worker.jms.queue = queue/hibernatesearch #optional jndi configuration (check your JMS provider for more information) ## Optional asynchronous execution strategy # hibernate.search.default.worker.execution = async # hibernate.search.default.worker.thread_pool.size = 2 # hibernate.search.default.worker.buffer_queue.max = 50
検索結果を高速化するには、ファイルシステムローカルコピーが推奨されます。
13.2.4.3. マスターノード
各インデックスアップデート操作は、JMS キューから取得され、実行されます。マスターインデックスは定期的にコピーされます。
JMS キュー内のインデックスアップデート操作が実行され、マスターインデックスが定期的にコピーされます。
JMS マスター設定
### master configuration ## DirectoryProvider # (remote) master location where information is copied to hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local master location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-master ## Back-end configuration #Back-end is the default for Lucene
JMS からインデックスワークキューを処理するために、Hibernate Search フレームワーク設定以外に、メッセージ駆動 Bean を記述して、セットアップする必要があります。
インデックス作成キューを処理するメッセージ駆動 Bean
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType",
propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination",
propertyValue="queue/hibernatesearch"),
@ActivationConfigProperty(propertyName="DLQMaxResent", propertyValue="1")
} )
public class MDBSearchController extends AbstractJMSHibernateSearchController
implements MessageListener {
@PersistenceContext EntityManager em;
//method retrieving the appropriate session
protected Session getSession() {
return (Session) em.getDelegate();
}
//potentially close the session opened in #getSession(), not needed here
protected void cleanSessionIfNeeded(Session session)
}
}
このサンプルは、Hibernate Search ソースコードで利用可能な抽象 JMS コントローラークラスから継承され、JavaEE MDB を実装します。この実装はサンプルとして提供され、Java EE メッセージ駆動 Bean 以外のものを使用するよう調整できます。
13.2.5. Lucene インデックス作成のチューニング
13.2.5.1. Lucene インデックス作成パフォーマンスのチューニング
Hibernate Search では、基礎となる Lucene IndexWriter に渡される mergeFactor、maxMergeDocs、maxBufferedDocs などのパラメーターセットを指定して、Lucene インデックス作成パフォーマンスをチューニングできます。これらのパラメーターは、インデックスまたはシャードごとにすべてのインデックスに適用するデフォルト値として指定します。
さまざまなユースケースに対してチューニングできる複数の低レベル IndexWriter 設定があります。これらのパラメーターは、以下のように indexwriter キーワードでグループ化されます。
hibernate.search.[default|<indexname>].indexwriter.<parameter_name>
特定のシャード設定の indexwriter 値に値が設定されていない場合は、Hibernate Search がインデックスセクションをチェックし、その後でデフォルトセクションをチェックします。
以下の表の設定では、次のように Animal インデックスの 2 番目のシャードで適用される設定になります。
-
max_merge_docs= 10 -
merge_factor= 20 -
ram_buffer_size= 64MB -
term_index_interval= Lucene default
他のすべての値は Lucene で定義されたデフォルト値を使用します。
すべての値のデフォルトでは、Lucene の独自のデフォルトになります。このため、インデックス作成パフォーマンスと動作プロパティーのリストにリストされた値は使用している Lucene のバージョンによって異なります。示された値はバージョン 2.4 に対して相対的になります。
Hibernate Search の以前のバージョンでは batch プロパティーと transaction プロパティーが使用されていました。これは、バックエンドが常に同じ設定を使用してワークを実行するため、現在該当しません。
| プロパティー | 説明 | デフォルト値 |
|---|---|---|
|
|
同じインデックスに書き込む必要がある他のプロセスがない場合は、 |
|
|
|
各インデックスには、インデックスに適用するアップデートを含む「パイプライン」が含まれます。このキューがいっぱいである場合は、キューに操作を追加すると、ブロック操作になります。 |
|
|
|
バッファされたメモリ内削除用語を適用およびフラッシュする前に必要な削除用語の最小数を決定します。メモリ内にバッファされたドキュメントがある場合、ドキュメントはマージされ、新しいセグメントが作成されます。 |
無効 (RAM 使用によりフラッシュ) |
|
|
インデックス作成中にメモリ内にバッファされるドキュメントの量を制御します。値が大きなると、より多くの RAM が消費されます。 |
無効 (RAM 使用によりフラッシュ) |
|
|
セグメントで許可されたドキュメントの最大数を定義します。頻繁にインデックスが変わる場合は、小さい値が適切です。インデックスが頻繁に変わらない場合は、値が大きいと、検索パフォーマンスが向上します。 |
無制限 (Integer.MAX_VALUE) |
|
|
セグメントマージの頻度とサイズを制御します。 挿入の実行時にセグメントインデックスをマージする頻度を決定します。値が小さいと、インデックス作成中の RAM の使用量が小さくなり、最適化されていないインデックスでの検索が高速になりますが、インデックス作成時間が長くなります。値が大きいと、インデックス作成中の RAM の使用量が大きくなり、最適化されていないインデックスでの検索が低速になりますが、インデックス作成時間は短くなります。したがって、大きい値 (> 10) はバッチインデックス作成に最適であり、小さい値 (< 10) は対話的に維持するインデックスに最適です。値は 2 よりも小さくしないでください。 |
10 |
|
|
セグメントマージの頻度とサイズを制御します。次のセグメントマージ操作でこのサイズ (MB 単位) よりも小さいセグメントが常に考慮されます。この値が大きすぎると、頻度が少ない場合であってもマージ操作のコストが高くなることがあります。 |
0 MB (実際には 1K 以下) |
|
|
セグメントマージの頻度とサイズを制御します。 このサイズ (MB 単位) よりも大きいセグメントは大きいセグメントでマージされません。 これにより、メモリーの要件が少なくなり、最適な検索速度が失われる一部のマージ操作を回避できます。インデックスの最適化時に、この値は無視されます。
|
無制限 |
|
|
セグメントマージの頻度とサイズを制御します。
インデックスの最適化時でも、このサイズ (MB 単位) よりも大きいセグメントは大きいセグメントでマージされません (
|
無制限 |
|
|
セグメントマージの頻度とサイズを制御します。
マージポリシーを推測する場合に削除されたドキュメントを考慮しない場合は、
|
|
|
|
ドキュメントバッファー専用の RAM の量 (MB 単位) を制御します。max_buffered_docs とともに使用すると、最初に発生したイベントに対してフラッシュが実行されます。 一般的に、インデックス作成パフォーマンスを向上させるには、ドキュメント数の代わりに RAM 使用量によりフラッシュし、できるだけ大きい RAM バッファーを使用することが推奨されます。 |
16 MB |
|
|
エキスパート: インデックス用語間の間隔を設定します。 値が大きいと、IndexReader が使用するメモリーが少なくなりますが、用語へのランダムアクセスは遅くなります。値が小さいと、IndexReader が使用するメモリーが多くなり、用語へのランダムアクセスが速くなります。詳細については、Lucene ドキュメンテーションを参照してください。 |
128 |
|
|
複合ファイル形式を使用する利点は、使用するファイル記述子が少なくなることです。欠点は、インデックスの作成時間が長くなり、一時ディスク容量が大きくなることです。インデックス作成時間を短縮するためにこのパラメーターを
ブール値パラメーター。“true” または “false” を使用します。このオプションのデフォルト値は |
true |
|
|
すべてのエンティティーの変更で Lucene インデックスのアップデートが必要になるわけではありません。アップデートされたすべてのエンティティープロパティー (ダーティープロパティー) のインデックスが作成されていない場合は、Hibernate Search によりインデックスの再作成プロセスが省略されます。
各アップデートイベントで呼び出す必要があるカスタム
この最適化は、
ブール値パラメーター。“true” または “false” を使用します。このオプションのデフォルト値は |
true |
blackhole バックエンドは、本番稼働で使用することを目的としません。インデックス作成のボトルネックを特定するツールとしてのみ使用してください。
13.2.5.2. Lucene IndexWriter
さまざまなユースケースに対してチューニングできる複数の低レベル IndexWriter 設定があります。これらのパラメーターは、以下のように indexwriter キーワードでグループ化されます。
default.<indexname>.indexwriter.<parameter_name>
シャード設定の indexwriter に値が設定されていない場合は、Hibernate Search がインデックスセクションをチェックし、その後でデフォルトセクションをチェックします。
13.2.5.3. パフォーマンスオプション設定
以下の設定では、次のように Animal インデックスの 2 番目のシャードで適用される設定になります。
パフォーマンスオプション設定例
default.Animals.2.indexwriter.max_merge_docs = 10 default.Animals.2.indexwriter.merge_factor = 20 default.Animals.2.indexwriter.term_index_interval = default default.indexwriter.max_merge_docs = 100 default.indexwriter.ram_buffer_size = 64
-
max_merge_docs= 10 -
merge_factor= 20 -
ram_buffer_size= 64MB -
term_index_interval= Lucene default
他のすべての値は Lucene で定義されたデフォルト値を使用します。
Lucene デフォルト値は、Hibernate Search のデフォルト設定です。したがって、以下の表にリストされた値は使用している Lucene のバージョンによって異なります。示された値はバージョン 2.4 に対して相対的になります。Lucene インデックス作成パフォーマンスの詳細については、Lucene ドキュメンテーションを参照してください。
バックエンドでは常に同じ設定を使用してワークが実行されます。
| プロパティー | 説明 | デフォルト値 |
|---|---|---|
|
|
同じインデックスに書き込む必要がある他のプロセスがない場合は、 |
|
|
|
各インデックスには、インデックスに適用するアップデートを含む「パイプライン」が含まれます。このキューがいっぱいである場合は、キューに操作を追加すると、ブロック操作になります。 |
|
|
|
バッファされたメモリ内削除用語を適用およびフラッシュする前に必要な削除用語の最小数を決定します。メモリ内にバッファされたドキュメントがある場合、ドキュメントはマージされ、新しいセグメントが作成されます。 |
無効 (RAM 使用によりフラッシュ) |
|
|
インデックス作成中にメモリ内にバッファされるドキュメントの量を制御します。値が大きなると、より多くの RAM が消費されます。 |
無効 (RAM 使用によりフラッシュ) |
|
|
セグメントで許可されたドキュメントの最大数を定義します。頻繁にインデックスが変わる場合は、小さい値が適切です。インデックスが頻繁に変わらない場合は、値が大きいと、検索パフォーマンスが向上します。 |
無制限 (Integer.MAX_VALUE) |
|
|
セグメントマージの頻度とサイズを制御します。 挿入の実行時にセグメントインデックスをマージする頻度を決定します。値が小さいと、インデックス作成中の RAM の使用量が小さくなり、最適化されていないインデックスでの検索が高速になりますが、インデックス作成時間が長くなります。値が大きいと、インデックス作成中の RAM の使用量が大きくなり、最適化されていないインデックスでの検索が低速になりますが、インデックス作成時間は短くなります。したがって、大きい値 (> 10) はバッチインデックス作成に最適であり、小さい値 (< 10) は対話的に維持するインデックスに最適です。値は 2 よりも小さくしないでください。 |
10 |
|
|
セグメントマージの頻度とサイズを制御します。 次のセグメントマージ操作でこのサイズ (MB 単位) よりも小さいセグメントが常に考慮されます。 この設定値が大きすぎると、コストがかかるマージ操作になる場合があります (頻度は少なくなります)。
|
0 MB (実際には 1K 以下) |
|
|
セグメントマージの頻度とサイズを制御します。 このサイズ (MB 単位) よりも大きいセグメントは大きいセグメントでマージされません。 これにより、メモリーの要件が少なくなり、最適な検索速度が失われる一部のマージ操作を回避できます。インデックスの最適化時に、この値は無視されます。
|
無制限 |
|
|
セグメントマージの頻度とサイズを制御します。
インデックスの最適化時でも、このサイズ (MB 単位) よりも大きいセグメントは大きいセグメントでマージされません (
|
無制限 |
|
|
セグメントマージの頻度とサイズを制御します。
マージポリシーを推測する場合に削除されたドキュメントを考慮しない場合は、
|
|
|
|
ドキュメントバッファー専用の RAM の量 (MB 単位) を制御します。max_buffered_docs とともに使用すると、最初に発生したイベントに対してフラッシュが実行されます。 一般的に、インデックス作成パフォーマンスを向上させるには、ドキュメント数の代わりに RAM 使用量によりフラッシュし、できるだけ大きい RAM バッファーを使用することが推奨されます。 |
16 MB |
|
|
エキスパート: インデックス用語間の間隔を設定します。 値が大きいと、IndexReader が使用するメモリーが少なくなりますが、用語へのランダムアクセスは遅くなります。値が小さいと、IndexReader が使用するメモリーが多くなり、用語へのランダムアクセスが速くなります。詳細については、Lucene ドキュメンテーションを参照してください。 |
128 |
|
|
複合ファイル形式を使用する利点は、使用するファイル記述子が少なくなることです。欠点は、インデックスの作成時間が長くなり、一時ディスク容量が大きくなることです。インデックス作成時間を短縮するためにこのパラメーターを
ブール値パラメーター。“true” または “false” を使用します。このオプションのデフォルト値は |
true |
|
|
すべてのエンティティーの変更で Lucene インデックスのアップデートが必要になるわけではありません。アップデートされたすべてのエンティティープロパティー (ダーティープロパティー) のインデックスが作成されていない場合は、Hibernate Search によりインデックスの再作成プロセスが省略されます。
各アップデートイベントで呼び出す必要があるカスタム
この最適化は、
ブール値パラメーター。“true” または “false” を使用します。このオプションのデフォルト値は |
true |
13.2.5.4. インデックス作成速度のチューニング
アーキテクチャーで許可される場合は、インデックス作成の効率を向上させるために default.exclusive_index_use=true を保持します。
インデックス作成速度をチューニングする場合は、最初にオブジェクトのロードを最適化し、インデックス作成プロセスをチューニングするベースラインとして実現するタイミングを使用することが推奨されます。ワーカーバックエンドとして blackhole を設定し、インデックス作成ルーチンを開始します。このバックエンドは Hibernate Search を無効にしません。インデックスに対して必要な変更セットが生成されますが、それらの変更セットはインデックスに対してフラッシュされるのではなく破棄されます。hibernate.search.indexing_strategy を manual に設定するのとは異なり、blackhole を使用すると、データベースからより多くのデータがロードされることがあります (関連付けられたエンティティーのインデックスが再び作成されるため)。
hibernate.search.[default|<indexname>].worker.backend blackhole
blackhole バックエンドは、本番稼働で使用することを目的としません。インデックス作成のボトルネックを特定する診断ツールとしてのみ使用してください。
13.2.5.5. セグメントサイズの制御
以下のオプションを使用すると、作成するセグメントの最大サイズを設定できます。
-
merge_max_size -
merge_max_optimize_size -
merge_calibrate_by_deletes
セグメントサイズの制御
//to be fairly confident no files grow above 15MB, use: hibernate.search.default.indexwriter.ram_buffer_size = 10 hibernate.search.default.indexwriter.merge_max_optimize_size = 7 hibernate.search.default.indexwriter.merge_max_size = 7
マージ操作に対して max_size をハード制限セグメントサイズの半分未満に設定します (セグメントのマージでは 2 つのセグメントが結合されるため)。
新しいセグメントは最初に期待したものよりも大きい場合がありますが、作成されるセグメントは ram_buffer_size よりも大幅に大きくなりません。このしきい値は推定値としてチェックされます。
13.2.6. LockFactory 設定
Lucene ディレクトリーは、Hibernate Search で管理された各インデックス用の LockingFactory 経由でカスタムロックストラテジーを使用して設定できます。
一部のロックストラテジーは、ファイルシステムレベルのロックを必要とし、RAM ベースのインデックスで使用できます。このストラテジーを使用する場合は、ロックマーカーファイルを格納するファイルシステムの場所を参照するよう IndexBase 設定オプションを指定する必要があります。
ロックファクトリーを選択するには、hibernate.search.<index>.locking_strategy オプションを以下のいずれかのオプションに設定します。
- simple
- native
- single
- none
| 名前 | クラス | 説明 |
|---|---|---|
|
LockFactory 設定 |
org.apache.lucene.store.SimpleFSLockFactory |
Java のファイル API に基づいた安全な実装。マーカーファイルを作成することによりインデックスの使用をマークします。 何らかの理由でアプリケーションを終了する必要がある場合はアプリケーションを再び起動する前にこのファイルを削除する必要があります。 |
|
|
org.apache.lucene.store.NativeFSLockFactory |
この実装には NFS の既知の問題があります。ネットワーク共有で使用しないでください。
|
|
|
org.apache.lucene.store.SingleInstanceLockFactory |
この LockFactory はファイルマーカーを使用しませんが、メモリーに保持される Java オブジェクトロックです。したがって、これは、インデックスが他のプロセスで共有されない場合のみ使用できます。
これは、 |
|
|
org.apache.lucene.store.NoLockFactory |
このインデックスへの変更はロックにより調整されません。 |
ロックストラテジー設定の例は以下のとおりです。
hibernate.search.default.locking_strategy = simple hibernate.search.Animals.locking_strategy = native hibernate.search.Books.locking_strategy = org.custom.components.MyLockingFactory
13.2.7. インデックス形式の互換性
Hibernate Search は、アプリケーションを新しいバージョンに移植するための後方互換性がある API またはツールを現在提供していません。API はインデックスの書き込みと検索に Apache Lucene を使用します。場合によっては、インデックス形式のアップデートが必要になることがあります。この場合は、データのインデックスを再び作成する必要があることがあります (Lucene が古い形式を読み取れないとき)。
インデックス形式をアップデートする前にインデックスをバックアップします。
Hibernate Search は、hibernate.search.lucene_version 設定プロパティーを公開します。このプロパティーによって、Analyzers と他の Lucene クラスが古いバージョンの Lucene で定義された動作に準拠するよう指示されます。lucene-core.jar に含まれる org.apache.lucene.util.Version も参照してください。オプションが指定されていない場合は、Hibernate Search によって、Lucene がデフォルトのバージョンを使用するよう指示されます。アップグレードの実行時に変更が自動的に行われないように、使用するバージョンを設定で明示的に定義することが推奨されます。アップグレード後に、必要に応じて設定値を明示的に更新できます。
Analyzers と Lucene 3.0 で作成されたインデックスとの互換性を維持する
hibernate.search.lucene_version = LUCENE_30
設定された SearchFactory はグローバルであり、該当するパラメーターを含むすべての Lucene API が影響を受けます。Lucene が使用され、Hibernate Search が省略された場合は、整合的な結果を得るために同じ値を適用してください。
13.3. アプリケーション用 Hibernate Search
13.3.1. Hibernate Seach の最初のステップ
アプリケーションに対して Hiberate 検索を初めて使用する場合は、以下のトピックを参照してください。
13.3.2. Maven を使用した Hibernate Seach の有効化
Maven プロジェクトで以下の設定を使用して、hibernate-search-orm 依存関係を追加します。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-orm</artifactId>
<version>5.5.1.Final-redhat-1</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-orm</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>13.3.3. アノテーションの追加
本項では、本の詳細が含まれるデータベースを保有していると仮定します。アプリケーションには Hibernate によって管理される example.Book および example.Author クラスが含まれ、アプリケーションにフリーテキスト検索機能を追加して本の検索を有効にします。
例: Hibernate Search 固有のアノテーションを追加する前の Book および Author エンティティー
package example;
...
@Entity
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
private String subtitle;
@ManyToMany
private Set<Author> authors = new HashSet<Author>();
private Date publicationDate;
public Book() {}
// standard getters/setters follow here
...
}package example;
...
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
public Author() {}
// standard getters/setters follow here
...
}
Book および Author クラスにいくつかのアノテーションを追加する必要があります。最初のアノテーション @Indexed は Book をインデックス可能とマーク付けします。設計上、Hibernate Search はトークン化されていない ID をインデックスに保存し、指定エンティティーのインデックスが単一になるようにします。@DocumentId はこのために使用するプロパティーをマーク付けし、ほとんどの場合でデータベースの主キーと同じになります。@Id アノテーションが存在する場合は、@DocumentId は任意のアノテーションになります。
次に、検索可能にしたいフィールドをそのようにマーク付けする必要があります。この例では、最初に title および subtitle の両方に @Field アノテーションを付けます。パラメーター index=Index.YES はテキストがインデックス化されるようにし、analyze=Analyze.YES はデフォルトの Lucene アナライザーを使用してテキストが分析されるようにします。通常、分析とは文を個別の単語にチャンク化し、「a」や「the」などの頻繁に使用される単語を潜在的に除外することを意味します。アナライザーの詳細は後で説明します。@Field 内に指定する 3 つ目のパラメーターは store=Store.NO であり、実際のデータがインデックスで保存されないようにします。このデーターがインデックスで保存されるかどうかは、検索の機能と関係ありません。Lucene の観点から見ると、インデックスが作成された後にデータを保持する必要はありません。データを保存する利点は、射影を用いて読み出しができることです。
射影を使用しない場合、Hibernate Search はクエリーの基準に一致するエンティティーのデータベース識別子を見つけるために、デフォルトどおりに Lucene クエリーを実行し、これらの識別子を使用してデータベースから管理対象オブジェクトを読み出します。射影を使用するかどうかは、ケースバイケースで決定します。デフォルトでは管理対象オブジェクトを返すのに対し、射影はオブジェクトアレイのみを返すため、デフォルトの動作が推奨されます。index=Index.YES、analyze=Analyze.YES 、および store=Store.NO は 3 つのパラメーターのデフォルト値であり、省略できます。
次に説明するアノテーションは @DateBridge です。このアノテーションは、Hibernate Search の組み込みフィールドブリッジの 1 つです。Lucene インデックスは完全に文字列ベースです。そのため、Hibernate Search はインデックス化されたフィールドのデータ型を文字列に変換し、文字列をインデックス化されたフィールドのデータ型に変換する必要があります。複数の事前定義済みブリッジが提供されますが、その 1 つが java.util.Date を指定の解決方法で String に変換する DateBridge です。詳細については、ブリッジを参照してください。
最後のアノテーションは @IndexedEmbedded です。このアノテーションは、関連するエンティティー (@ManyToMany、@*ToOne、@Embedded、および @ElementCollection) を所有するエンティティーの一部としてインデックス化するために使用されます。Lucene インデックスドキュメントはオブジェクトの関係を認識しないフラットなデータ構造であるため、これが必要になります。著者名を検索可能にするには、著者名が本の一部としてインデックス化される必要があります。@IndexedEmbedded の他にも、インデックスに含めたい関連エンティティーのすべてのフィールドを @Indexed でマーク付けする必要があります。詳細については、埋め込みオブジェクトおよび関連付けられたオブジェクトを参照してください。
エンティティーマッピングの詳細については、エンティティーのマッピングを参照してください。
例: Hibernate 検索アノテーションを追加した後のエンティティー
package example;
...
@Entity
public class Book {
@Id
@GeneratedValue
private Integer id;
private String title;
private String subtitle;
@Field(index = Index.YES, analyze=Analyze.NO, store = Store.YES)
@DateBridge(resolution = Resolution.DAY)
private Date publicationDate;
@ManyToMany
private Set<Author> authors = new HashSet<Author>();
public Book() {
}
// standard getters/setters follow here
...
}package example;
...
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
public Author() {
}
// standard getters/setters follow here
...
}13.3.4. インデックス化
Hibernate Search は、Hibernate Core から永続化、更新、または削除された各エンティティーを透過的にインデックス化します。しかし、データベースにすでに存在するデータに対して最初の Lucene インデックスを作成する必要があります。上記のプロパティーとアノテーションを追加したら、本の最初のバッチインデックスをトリガーします。これには、以下のコードスニペットの 1 つを使用します。
例: Hibernate セッションを使用したデータのインデックス化
FullTextSession fullTextSession = org.hibernate.search.Search.getFullTextSession(session); fullTextSession.createIndexer().startAndWait();
例: JPA を使用したデータのインデックス化
EntityManager em = entityManagerFactory.createEntityManager(); FullTextEntityManager fullTextEntityManager = org.hibernate.search.jpa.Search.getFullTextEntityManager(em); fullTextEntityManager.createIndexer().startAndWait();
上記のコードを実行した後、/var/lucene/indexes/example.Book 以下に Lucene インデックスが作成されるはずです。Luke でこのインデックスを確認してみてください。Hibernate Search がどのように機能するかがわかるはずです。
13.3.5. 検索
検索を実行するには、Lucene API または Hibernate Search クエリー DSL のいずれかを使用して Lucene クエリーを作成します。クエリーを org.hibernate.Query でラップして、Hibernate API から必要な機能を取得します。以下のコードは、インデックス化されたフィールドに対してクエリーを準備します。このコードを実行すると、Book のリストが返されます。
例: Hibernate Search セッションを使用した検索の作成および実行
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
// create native Lucene query using the query DSL
// alternatively you can write the Lucene query using the Lucene query parser
// or the Lucene programmatic API. The Hibernate Search DSL is recommended though
QueryBuilder qb = fullTextSession.getSearchFactory()
.buildQueryBuilder().forEntity( Book.class ).get();
org.apache.lucene.search.Query query = qb
.keyword()
.onFields("title", "subtitle", "authors.name", "publicationDate")
.matching("Java rocks!")
.createQuery();
// wrap Lucene query in a org.hibernate.Query
org.hibernate.Query hibQuery =
fullTextSession.createFullTextQuery(query, Book.class);
// execute search
List result = hibQuery.list();
tx.commit();
session.close();例: JPA を使用した検索の作成および実行
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
em.getTransaction().begin();
// create native Lucene query using the query DSL
// alternatively you can write the Lucene query using the Lucene query parser
// or the Lucene programmatic API. The Hibernate Search DSL is recommended though
QueryBuilder qb = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity( Book.class ).get();
org.apache.lucene.search.Query query = qb
.keyword()
.onFields("title", "subtitle", "authors.name", "publicationDate")
.matching("Java rocks!")
.createQuery();
// wrap Lucene query in a javax.persistence.Query
javax.persistence.Query persistenceQuery =
fullTextEntityManager.createFullTextQuery(query, Book.class);
// execute search
List result = persistenceQuery.getResultList();
em.getTransaction().commit();
em.close();13.3.6. アナライザー
インデックス化された本のエンティティーの題名が Refactoring: Improving the Design of Existing Code であり、refactor、refactors、refactored、および refactoring クエリーのヒットが必要であると仮定します。インデックス化と検索を行うときに、言葉のステミングを適用する Lucene のアナライザークラスを選択します。Hibernate Search はアナライザーを設定する方法を複数提供します (詳細については、デフォルトのアナライザーとクラスによるアナライザーを参照)。
-
設定ファイルで
analyzerプロパティーを設定します。指定されたクラスがデフォルトのアナライザーになります。 -
エンティティーレベルで
@Analyzerアノテーションを設定します。 -
フィールドレベルで
@Analyzerアノテーションを設定します。
完全修飾クラス名または使用するアナライザーを指定するか、@Analyzer アノテーションを使用して @AnalyzerDef アノテーションによって定義されたアナライザーを確認します。アナライザーを確認する場合はファクトリーを持つ Solr アナライザーフレームワークが使用されます。ファクトリークラスの詳細については、Solr JavaDoc または Solr Wiki (http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters) の対応する項を参照してください。
この例では StandardTokenizerFactory が LowerCaseFilterFactory と SnowballPorterFilterFactory の 2 つのフィルターファクトリーによって使用されます。トークナイザーは句読点とハイフンで言葉を分割しますが、メールアドレスとインターネットのホスト名は分割しません。この操作とその他の一般的な操作には、標準のトークナイザーが適しています。小文字フィルターはトークンのすべての文字を小文字に変換し、snowball フィルターは言語固有のステミングを適用します。
Solr フレームワークを使用する場合は、任意数のフィルターを用いてトークナイザーを使用します。
例: @AnalyzerDef および Solr フレームワークを使用したアナライザーの定義および使用
@Indexed
@AnalyzerDef(
name = "customanalyzer",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = SnowballPorterFilterFactory.class,
params = { @Parameter(name = "language", value = "English") })
})
public class Book implements Serializable {
@Field
@Analyzer(definition = "customanalyzer")
private String title;
@Field
@Analyzer(definition = "customanalyzer")
private String subtitle;
@IndexedEmbedded
private Set authors = new HashSet();
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.YES)
@DateBridge(resolution = Resolution.DAY)
private Date publicationDate;
public Book() {
}
// standard getters/setters follow here
...
}
@AnalyzerDef を使用してアナライザーを定義した後、@Analyzer を使用してエンティティーおよびプロパティーに適用します。この例では、customanalyzer は定義されていますが、エンティティーに適用されていません。アナライザーは title および subtitle プロパティーのみに適用されます。アナライザーの定義はグローバルです。エンティティーに対してアナライザーを定義し、必要に応じて他のエンティティーの定義を再使用します。
13.4. インデックス構造へのエンティティーのマッピング
13.4.1. エンティティーのマッピング
エンティティーをインデックス化するために必要なメタデータ情報はすべてアノテーションを用いて記述されるため、XML マッピングファイルは必要ありません。基本的な Hibernate 設定には Hibernate マッピングを使用できますが、Hibernate Search 固有の設定はアノテーションを用いて表現する必要があります。
13.4.1.1. 基本的なマッピング
最初に、エンティティーのマッピングで最も一般的に使用されるアノテーションについて説明します。
Lucene ベースの Query API は、以下の一般的なアノテーションを使用してエンティティーをマップします。
- @Indexed
- @Field
- @NumericField
- @Id
13.4.1.2. @Indexed
最初に、永続クラスをインデックス可能であると宣言する必要があります。これを行うには、クラスに @Indexed アノテーションを付けます (@Indexedアノテーションが付いていないエンティティーはインデックス化プロセスによって無視されます)。
@Entity
@Indexed
public class Essay {
...
}
また、任意で @Indexed アノテーションの index 属性を指定して、インデックスのデフォルト名を変更することもできます。
13.4.1.3. @Field
エンティティーの各プロパティー (または属性) に対して、インデックス化する方法を記述できます。デフォルト (アノテーションなし) では、プロパティーはインデックス化プロセスで無視されます。
Hibernate Search 5 よりも前のリリースでは、数値フィールドのエンコーディングは @NumericField で明示的に要求された場合のみ選択されました。Hibernate Search 5 では、このエンコーディングは数値の種類に応じて自動的に選択されます。数値のエンコーディングを回避するために、@Field.bridge または @FieldBridge を使用して非数値フィールドブリッジを明示的に指定できます。パッケージ org.hibernate.search.bridge.builtin には、数字を文字列としてエンコードする一連のブリッジ (org.hibernate.search.bridge.builtin.IntegerBridge など) が含まれます。
@Field はプロパティーをインデックス化されたプロパティーとして宣言します。また、以下の属性を 1 つまたは複数設定することにより、インデックス化プロセスの複数の側面を設定できます。
-
name: この名前でプロパティーが Lucene Document に保存されます。デフォルト値はプロパティー名 (JavaBeans 慣例に準拠する) になります。 -
store: プロパティーを Lucene インデックスに保存するかどうかを定義します。値を保存する場合はStore.YESを指定します (インデックス領域の消費が増えますが、射影は許可されます)。圧縮して保存する場合はStore.COMPRESSを指定します (CPU の消費が増えます)。保存しない場合はStore.NOを指定します (デフォルト値です)。プロパティーが保存されると、元の値を Lucene Document から取得できます。これは、要素のインデックス化の有無には関係しません。 index: プロパティーがインデックス化されるかどうかを示します。Index.NOを指定するとインデックス化されず、クエリーでは見つかりません。Index.YESを選択すると、要素がインデックス化され、検索可能になります。デフォルト値はIndex.YESです。Index.NOは、プロパティーを検索可能にする必要がなく、射影を利用できるようにする場合に便利です。注記analyzeおよびnormsはプロパティーのインデックス化が必要になるため、Index.NOをAnalyze.YESまたはNorms.YESとともに使用しても意味がありません。analyze: プロパティーが分析されるかどうかを決定します。Analyze.YESの場合は分析され、Analyze.NOの場合は分析されません。デフォルト値はAnalyze.YESです。注記プロパティーを分析するかどうかは、要素をそのまま検索するか、または要素に含まれる言葉を基に検索するかによって異なります。テキストフィールドを分析することは意味がありますが、データフィールドの分析はほとんど必要ないでしょう。
注記ソートに使用されるフィールドは分析しないでください。
-
norms: インデックス時間のブースティング情報を保存するかどうかを示します。保存する場合はNorms.YES、保存しない場合はNorms.NOを指定します。保存しないと大量のメモリーを節約できますが、インデックス時間のブースティング情報を使用できません。デフォルト値はNorms.YESです。 termVector: 単語 (term) と出現頻度 (frequency) のペアを示します。この属性を使用すると、インデックス化中にドキュメント内で term vector を保存できます。デフォルト値はTermVector.NOです。この属性の値は次のとおりです。
値 定義 TermVector.YES
各ドキュメントに term vector を保存します。これにより、同期された 2 つのアレイが生成されます (1 つのアレイには document term が含まれ、もう 1 つのアレイには term の頻度が含まれます)。
TermVector.NO
term vector を保存しません。
TermVector.WITH_OFFSETS
term vector およびトークンオフセット情報を保存します。これは、TermVector.YES と同じですが、言葉の開始および終了オフセット位置情報が含まれます。
TermVector.WITH_POSITIONS
term vector およびトークン位置情報を保存します。これは、TermVector.YES と同じですが、ドキュメントで言葉が発生する順序位置 (ordinal position) が含まれます。
TermVector.WITH_POSITION_OFFSETS
term vector、トークン位置、およびオフセット情報を保存します。これは、YES、WITH_OFFSETS、および WITH_POSITIONS の組み合わせです。
indexNullAs: デフォルトでは、null の値は無視されインデックス化されませんが、indexNullAsを使用するとnullの値のトークンとして挿入される文字列を指定できます。デフォルトでは、nullの値がインデックス化されないことを示すField.DO_NOT_INDEX_NULLに設定されます。Field.DEFAULT_NULL_TOKENに設定すると、デフォルトのnullトークンが使用されます。設定でデフォルトのnullトークンを指定するには、hibernate.search.default_null_tokenを使用します。このプロパティーが設定されず、Field.DEFAULT_NULL_TOKENが指定された場合は、デフォルトで文字列「null」が使用されます。注記indexNullAsパラメーターが使用される場合、検索で同じトークンを使用してnullの値を検索することが重要になります。また、分析されないフィールド (Analyze.NO) のみでこの機能を使用することが推奨されます。警告カスタムの FieldBridge または TwoWayFieldBridge を実装する場合、null 値のインデックス化の処理は開発者に委ねられます (LuceneOptions.indexNullAs() の JavaDocs を参照してください)。
13.4.1.4. @NumericField
@NumericField は @Field と同種のアノテーションで、@Field または @DocumentId と同じスコープで指定できます。このアノテーションは Integer、Long、Float、および Double プロパティーに指定できます。インデックス化するときに、トライ木の構造を使用して値がインデックス化されます。プロパティーが数値のフィールドとしてインデックス化されると、効率的に範囲クエリーおよびソートを実行でき、標準の @Field プロパティーで同じクエリーを実行するよりもかなり高速に順序付けできます。@NumericField アノテーションには以下のパラメーターを使用できます。
| 値 | 定義 |
|---|---|
|
forField |
(任意設定) 数値としてインデックス化される関連する @Field の名前を指定します。プロパティーに 1 つの @Field 宣言以外が含まれる場合のみ必須です。 |
|
precisionStep |
(任意設定) トライ木構造がインデックスに保存される方法を変更します。precisionSteps を小さくするとディスク使用量が増え、範囲およびソートクエリーが高速になります。値を大きくすると、使用される容量が少なくなり、範囲クエリーの速度が通常の @Fields で実行される範囲クエリーの速度に近くなります。デフォルト値は 4 です。 |
@NumericField は Double、Long、Integer、および Float のみをサポートします。他の数値型に対して Lucene の同様の機能を利用できません。そのため、他の型はデフォルトまたはカスタムの TwoWayFieldBridge を用いた文字列のエンコーディングを使用する必要があります。
型の変換中に近似に対応できるのであればカスタムの NumericFieldBridge を使用できます。
例: カスタム NumericFieldBridge の定義
public class BigDecimalNumericFieldBridge extends NumericFieldBridge {
private static final BigDecimal storeFactor = BigDecimal.valueOf(100);
@Override
public void set(String name, Object value, Document document, LuceneOptions luceneOptions) {
if ( value != null ) {
BigDecimal decimalValue = (BigDecimal) value;
Long indexedValue = Long.valueOf( decimalValue.multiply( storeFactor ).longValue() );
luceneOptions.addNumericFieldToDocument( name, indexedValue, document );
}
}
@Override
public Object get(String name, Document document) {
String fromLucene = document.get( name );
BigDecimal storedBigDecimal = new BigDecimal( fromLucene );
return storedBigDecimal.divide( storeFactor );
}
}13.4.1.5. @Id
エンティティーの id (識別子) プロパティーは、特定のエンティティーのインデックスを一意にするために Hibernate Search によって使用される特別なプロパティーです。設計上、id は保存する必要があり、トークン化できません。プロパティーをインデックス識別子としてマーク付けするには、@DocumentId アノテーションを使用します。JPA を使用し、@Id が指定済みである場合は、@DocumentId を省略できます。選択したエンティティー識別子はドキュメント識別子としても使用されます。
Infinispan クエリーはエンティティーの id プロパティーを使用してインデックスが一意に識別されるようにします。設計上、ID は保存され、トークンに変換しないようにする必要があります。プロパティーをインデックス ID としてマークするには、@DocumentId アノテーションを使用します。
例: インデックス化されたプロパティーの指定
@Entity
@Indexed
public class Essay {
...
@Id
@DocumentId
public Long getId() { return id; }
@Field(name="Abstract", store=Store.YES)
public String getSummary() { return summary; }
@Lob
@Field
public String getText() { return text; }
@Field @NumericField( precisionStep = 6)
public float getGrade() { return grade; }
}
上記の例では、id、Abstract、text、および grade の 4 つのフィールドでインデックスを定義します。デフォルトでは、JavaBean 仕様に従ってフィールド名に大文字が使用されていないことに注意してください。grade フィールドは、デフォルトよりも若干 precision step (精度ステップ) が大きく、数値としてアノテーションが付けられます。
13.4.1.6. プロパティーを複数回マッピングする
場合によっては、インデックスごとに若干異なるインデックス化ストラテジーでプロパティーを複数回マッピングする必要があることがあります。たとえば、フィールドでクエリーをソートするには、フィールドが分析されていない必要があります。このプロパティーで単語を基に検索し、ソートも行うには、インデックス化する必要があります (1 度分析し、1 度分析しません)。@Fields はこれを可能にします。
例: @Fields を使用してプロパティーを複数回マッピングする
@Entity
@Indexed(index = "Book" )
public class Book {
@Fields( {
@Field,
@Field(name = "summary_forSort", analyze = Analyze.NO, store = Store.YES)
} )
public String getSummary() {
return summary;
}
...
}
この例では、フィールド summary が 2 回インデックス化されます。summary としてトークン化される方法で 1 度インデックス化され、summary_forSort として非トークン化される方法でもう 1 度インデックス化されます。
13.4.1.7. 埋め込みオブジェクトおよび関連付けられたオブジェクト
関連付けられたオブジェクトおよび埋め込みオブジェクトは、ルートエンティティーインデックスの一部としてインデックス化できます。これは、関連付けられたオブジェクトのプロパティーを基にエンティティーを検索する場合に便利です。この目的は、関連付けられた市が Atlanta (Lucene クエリーパーサー言語では address.city:Atlanta に変換されます) である場所を返すことです。場所 (place) フィールドは Place インデックスでインデックス化されます。Place インデックスドキュメントには、クエリーが可能な address.id、address.street、および address.city フィールドも含まれます。
例: アソシエーションのインデックス化
@Entity
@Indexed
public class Place {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field
private String name;
@OneToOne( cascade = { CascadeType.PERSIST, CascadeType.REMOVE } )
@IndexedEmbedded
private Address address;
....
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
@Field
private String street;
@Field
private String city;
@ContainedIn
@OneToMany(mappedBy="address")
private Set<Place> places;
...
}
@IndexedEmbedded 技術を使用するときに Lucene インデックスでデータが非正規化されるため、Hibernate Search は Place オブジェクトと Address オブジェクトの変更を認識し、インデックスを最新の状態にする必要があります。Address の変更時に Lucene ドキュメントが確実に更新されるように、双方向の関係の逆側を @ContainedIn でマーク付けします。
@ContainedIn は、エンティティーを示すアソシエーションと埋め込みオブジェクト (コレクション) の両方に便利です。
これまでの説明を踏まえ、@IndexedEmbedded をネストする例を以下に示します。
例: @IndexedEmbedded と @ContainedIn のネストの使用
@Entity
@Indexed
public class Place {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field
private String name;
@OneToOne( cascade = { CascadeType.PERSIST, CascadeType.REMOVE } )
@IndexedEmbedded
private Address address;
....
}
@Entity
public class Address {
@Id
@GeneratedValue
private Long id;
@Field
private String street;
@Field
private String city;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_")
private Owner ownedBy;
@ContainedIn
@OneToMany(mappedBy="address")
private Set<Place> places;
...
}
@Embeddable
public class Owner {
@Field
private String name;
...
}
@*ToMany、@*ToOne、および @Embedded 属性には @IndexedEmbedded アノテーションを付けることができます。その後、関連付けられたクラスの属性は主要なエンティティーインデックスへ追加されます。インデックスに以下のフィールドが含まれます。
- id
- name
- address.street
- address.city
- address.ownedBy_name
デフォルトの接頭辞は propertyName. で、従来のオブジェクトナビゲーションの慣例に従います。これをオーバーライドするには ownedBy プロパティーで示されたように prefix 属性を使用します。
空の文字列には接頭辞を設定できません。
オブジェクトグラフにクラス (インスタンスではない) の循環依存関係が含まれる場合は、depth プロパティーが必要になります。Owner が Place を参照する場合がこの例になります。Hibernate Search では、想定された深さに達すると (またはオブジェクトグラフの境界に達すると)、インデックス化された埋め込み属性が含まれなくなります。自己参照を持つクラスが循環依存関係の例になります。この例では、depth が 1 に設定されているため、Owner (存在する場合) の @IndexedEmbedded 属性は無視されます。
オブジェクトアソシエーションに @IndexedEmbedded を使用すると、以下のように Lucene のクエリー構文を使用してクエリーを表現できます。
名前に JBoss が含まれ、住所の市が Atlanta である場所を返す場合、Lucene クエリーでは次のようになります。
+name:jboss +address.city:atlanta
名前に JBoss が含まれ、所有者の名前に Joe が含まれる場所を返す場合、Lucene クエリーでは次のようになります。
+name:jboss +address.ownedBy_name:joe
この挙動は、関係結合操作をより効率的に模擬しますが、データが重複されます。そのままの状態では Lucene インデックスにはアソシエーションの観念がなく、結合操作は存在しないことに注意してください。完全テキストのインデックス速度や機能充実の利点を活かしながらリレーショナルモデルの正規化を維持するのに役立つ可能性があります。
関連付けされたオブジェクト自体が @Indexed である場合があります。
@IndexedEmbedded がエンティティーを参照する場合、関連付けは指向性を持つ必要があり、前述の例のように逆側には @ContainedIn アノテーションを付ける必要があります。このアノテーションを付けないと、関連付けられたエンティティーが更新されたときに Hibernate Search はルートインデックスを更新できません (前述の例では、関連付けられた Address インスタンスが更新されたときに Place インデックスドキュメントを更新する必要があります)。
場合によっては、@IndexedEmbedded アノテーションが付けられたオブジェクト型が Hibernate および Hibernate Search が対象とするオブジェクト型でないことがあります。これは、実装の代わりにインターフェースが使用される場合に特に当てはまります。このため、targetElement パラメーターを使用して Hibernate Search が対象とするオブジェクト型をオーバーライドできます。
例: @IndexedEmbedded の targetElement プロパティーの使用
@Entity
@Indexed
public class Address {
@Id
@GeneratedValue
@DocumentId
private Long id;
@Field
private String street;
@IndexedEmbedded(depth = 1, prefix = "ownedBy_", )
@Target(Owner.class)
private Person ownedBy;
...
}
@Embeddable
public class Owner implements Person { ... }
13.4.1.8. 特定パスへ埋め込むオブジェクトの制限
@IndexedEmbedded アノテーションは、depth の代わりとして使用でき、depth とともに使用できる includePaths 属性も提供します。
depth のみを使用すると、埋め込まれた型のインデックス化されたフィールドすべてが同じ深さで再帰的に追加されます。このため、必要でない可能性がある他のすべてのフィールドを追加せずに特定のパスのみを選択することが難しくなります。
不必要なエンティティーのロードおよびインデックス化を回避するために、必要なパスのみを指定できます。通常のアプリケーションにはパスごとに異なる深さが必要になることがあり、以下の例で示されたようにパスを明示的に指定する必要があることがあります。
例: @IndexedEmbedded の includePaths プロパティーの使用
@Entity
@Indexed
public class Person {
@Id
public int getId() {
return id;
}
@Field
public String getName() {
return name;
}
@Field
public String getSurname() {
return surname;
}
@OneToMany
@IndexedEmbedded(includePaths = { "name" })
public Set<Person> getParents() {
return parents;
}
@ContainedIn
@ManyToOne
public Human getChild() {
return child;
}
...//other fields omitted
上記の例のようにマッピングを使用すると、name、surname、親の name、またはこれらの組み合わせで Person を検索できます。親の surname はインデックス化されないため、親の surname では検索ができませんが、インデックス化の速度が速くなり、スペースを節約でき、全体的なパフォーマンスが向上します。
@IndexedEmbeddedincludePaths には、指定されたパスと、depth の制限された値を指定して通常インデックス化するものが含まれます。includePaths を使用するときに depth を未定義にすると、depth`=0` を設定した場合と同様の挙動になり、含まれたパスのみがインデックス化されます。
例: @IndexedEmbedded の includePaths プロパティーの使用
@Entity
@Indexed
public class Human {
@Id
public int getId() {
return id;
}
@Field
public String getName() {
return name;
}
@Field
public String getSurname() {
return surname;
}
@OneToMany
@IndexedEmbedded(depth = 2, includePaths = { "parents.parents.name" })
public Set<Human> getParents() {
return parents;
}
@ContainedIn
@ManyToOne
public Human getChild() {
return child;
}
...//other fields omitted上記の例では、各 Human の name および surname 属性がインデックス化されます。depth 属性により、親の name と surname は再帰的に 2 つ目の行までインデックス化されます。Person、Person の親、または祖父母の name または surname を使用して検索できます。第 2 レベルを越えると、もう 1 つのレベルをインデックス化しますが、name のみで surname は対象になりません。
この結果、インデックスには以下のフィールドが含まれます。
-
id: 主キーとして -
_hibernate_class: エンティティータイプを保存します -
name: 直接フィールドとして -
surname: 直接フィールドとして -
parents.name: depth 1 の埋め込まれたフィールドとして -
parents.surname: depth 1 の埋め込まれたフィールドとして -
parents.parents.name: depth 2 の埋め込まれたフィールドとして -
parents.parents.surname: depth 2 の埋め込まれたフィールドとして -
parents.parents.parents.name: includePaths によって指定された追加パスとして。最初のparents.はフィールド名から推測され、残りのパスは includePaths の属性になります。
必要なクエリーを最初に定義してアプリケーションを設計すると、その時点でユースケースの実装に必要なフィールドや不必要なフィールドが分かるため、インデックス化されたパスの明示的な制御が簡単になります。
13.4.2. ブースティング
Lucene は、特定のドキュメントやフィールドに異なる重要度を与えることができるブースティング (boosting) という概念を持ちます。Lucene はインデックス時ブースティング (Index time boosting) と検索時ブースティング (Search time boosting) を区別します。今後の項では、Hibernate Search を使用してインデックス時ブースティングを実現する方法を説明します。
13.4.2.1. 静的なインデックス時ブースティング
インデックス化されたクラスやプロパティーの静的なブースト値を定義するには、@Boost アノテーションを使用します。このアノテーションを @Field 内で使用するか、メソッドまたはクラスレベルで直接指定します。
例: @Boost の異なる使用方法
@Entity
@Indexed
public class Essay {
...
@Id
@DocumentId
public Long getId() { return id; }
@Field(name="Abstract", store=Store.YES, boost=@Boost(2f))
@Boost(1.5f)
public String getSummary() { return summary; }
@Lob
@Field(boost=@Boost(1.2f))
public String getText() { return text; }
@Field
public String getISBN() { return isbn; }
}上記の例では、Essay が検索リストの最上部に達する可能性は 1.7 倍になります。summary フィールドは isbn フィールドよりも 3.0 倍重要になります (プロパティーの @Field.boost と @Boost は累積的であるため、2 x 1.5 になります)。text フィールドは isbn フィールドよりも 1.2 倍重要になります。この説明は厳密には正しくありませんが、わかりやすく実際の感覚では現実とほぼ同じになります。
13.4.2.2. 動的なインデックス時ブースティング
静的なインデックス時ブースティングで使用された @Boost アノテーションは静的ブースト係数を定義します。この係数は、実行時のインデックス化済みエンティティーのの状態とは関係ありません。ただし、ブースト係数がエンティティーの実際の状態に依存する可能性があるユースケースがあります。この場合は、@DynamicBoost アノテーションをカスタム BoostStrategy とともに使用できます。
例: 動的なブーストの例
public enum PersonType {
NORMAL,
VIP
}
@Entity
@Indexed
@DynamicBoost(impl = VIPBoostStrategy.class)
public class Person {
private PersonType type;
// ....
}
public class VIPBoostStrategy implements BoostStrategy {
public float defineBoost(Object value) {
Person person = ( Person ) value;
if ( person.getType().equals( PersonType.VIP ) ) {
return 2.0f;
}
else {
return 1.0f;
}
}
}
上記の例では、VIPBoostStrategy を、インデックス化するときに使用される BoostStrategy インターフェースの実装として指定することにより、動的ブーストがクラスレベルで定義されています。@DynamicBoost はクラスまたはフィールドレベルに配置できます。エンティティー全体が defineBoost メソッドに渡されるか、またはアノテーションが付けられたフィールド/プロパティーの値のみが渡されるかはアノテーションの配置によります。渡されたオブジェクトを正しい型にキャストするのはユーザーに任されています。この例では、VIP の person のインデックス化された値はすべて普通の person の値よりも重要度が 2 倍になります。
指定された BoostStrategy 実装は、パブリックの引数のないコンストラクターを定義する必要があります。
エンティティーで @Boostアノテーションと @DynamicBoost アノテーションを組み合わせることができます。定義されたブースト係数はすべて累積的です。
13.4.3. 分析
Analysis とはテキストを 1 つの言葉 (単語) に変換するプロセスのことであり、フルテキスト検索エンジンの主要機能の 1 つです。Lucene は Analyzer の概念を使用してこのプロセスを制御します。以下の項では、Hibernate Search が提供するアナライザーの設定方法を複数取り上げます。
13.4.3.1. デフォルトのアナライザーとクラスによるアナライザー
トークン化されたフィールドをインデックス化するために使用されるデフォルトのアナライザークラスは、hibernate.search.analyzer プロパティーから設定可能です。このプロパティーのデフォルト値は org.apache.lucene.analysis.standard.StandardAnalyzer です。
また、エンティティー、プロパティーおよび @Field ごとにアナライザークラスを定義することもできます。@Field ごとの定義は、単一のプロパティーから複数のフィールドをインデックス化するときに便利です。
Example: Different ways of using @Analyzer
@Entity
@Indexed
@Analyzer(impl = EntityAnalyzer.class)
public class MyEntity {
@Id
@GeneratedValue
@DocumentId
private Integer id;
@Field
private String name;
@Field
@Analyzer(impl = PropertyAnalyzer.class)
private String summary;
@Field(analyzer = @Analyzer(impl = FieldAnalyzer.class)
private String body;
...
}
この例では、トークン化されたプロパティー (name) をインデックス化するために EntityAnalyzer が使用されます。例外は summary と body であり、これらはそれぞれ PropertyAnalyzer と FieldAnalyzer によってインデックス化されます。
通常、同じエンティティーで異なるアナライザーを使用することは推奨されません。特に、クエリー全体で同じアナライザーを使用する QueryParser を使用する場合、クエリーの構築がより複雑になり、初心者にとって結果の予測がより困難になります。原則的に、フィールドではインデックス化とクエリーに同じアナライザーを使用します。
13.4.3.2. 名前付きのアナライザー
アナライザーの使用は非常に複雑になることがあります。そのため、Hibernate Search にはアナライザー定義の概念が導入されています。アナライザー定義は多くの @Analyzer 宣言による再使用が可能であり、以下のもので構成されます。
- 名前: 定義を参照するために使用される一意の文字列。
- 文字フィルターのリスト: 各文字フィルターはトークン化の前に入力文字を事前処理します。文字フィルターは文字を追加、変更、または削除できます。一般的な使用例の 1 つが文字の正規化です。
- トークナイザー: 入力ストリームを個別の単語にトークン化します。
- フィルターのリスト: 各フィルターは単語を削除または変更します。また、トークナイザーによって提供されたストリームに単語を追加することもあります。
文字フィルターのリスト、トークナイザー、およびそれに続くフィルターのリストによってタスクが分離され、各コンポーネントの再使用が容易になり、非常に柔軟にカスタマイズされたアナライザーを構築できます (レゴブロックのように)。通常、文字フィルターが文字入力の事前処理を行った後、Tokenizer が文字入力をトークンに変換してトークン化プロセスを開始します。その後、TokenFilter によってトークンがさらに処理されます。Hibernate Search は Solr アナライザーフレームワークを使用してこのインフラストラクチャーをサポートします。
ここで、以下に示された具体的な例を確認してみましょう。最初に、文字フィルターはそのファクトリーによって定義されます。例ではマッピング文字フィルターが使用され、マッピングファイルに指定されたルールを基にして入力の文字を置き換えます。次にトークナイザーが定義されます。この例では標準のトークナイザーが使用されます。最後にフィルターのリストがファクトリーによって定義されます。この例では、専用の単語プロパティーファイルを読み取って StopFilter フィルターが構築されます。また、フィルターは大文字と小文字を区別しないことが想定されます。
例: @AnalyzerDef および Solr フレームワーク
@AnalyzerDef(name="customanalyzer",
charFilters = {
@CharFilterDef(factory = MappingCharFilterFactory.class, params = {
@Parameter(name = "mapping",
value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties")
})
},
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class, params = {
@Parameter(name="words",
value= "org/hibernate/search/test/analyzer/solr/stoplist.properties" ),
@Parameter(name="ignoreCase", value="true")
})
})
public class Team {
...
}フィルターと文字フィルターは、@AnalyzerDef アノテーションに定義された順序で適用されます。順序が関係することに注意してください。
トークナイザー、トークンフィルター、または文字フィルターの一部には設定またはメタデータファイルなどのリソースをロードするものがあります。これには停止フィルターと類義語フィルターが該当します。リソース文字セットが VM のデフォルトを使用しない場合、resource_charset パラメーターを追加して明示的に指定できます。
例: 特定の文字セットを使用したプロパティーファイルのロード
@AnalyzerDef(name="customanalyzer",
charFilters = {
@CharFilterDef(factory = MappingCharFilterFactory.class, params = {
@Parameter(name = "mapping",
value = "org/hibernate/search/test/analyzer/solr/mapping-chars.properties")
})
},
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = ISOLatin1AccentFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class, params = {
@Parameter(name="words",
value= "org/hibernate/search/test/analyzer/solr/stoplist.properties" ),
@Parameter(name="resource_charset", value = "UTF-16BE"),
@Parameter(name="ignoreCase", value="true")
})
})
public class Team {
...
}以下の例で示されているように、アナライザー定義は定義後に @Analyzer 宣言で再使用できます。
例: 名前によるアナライザーの参照
@Entity
@Indexed
@AnalyzerDef(name="customanalyzer", ... )
public class Team {
@Id
@DocumentId
@GeneratedValue
private Integer id;
@Field
private String name;
@Field
private String location;
@Field
@Analyzer(definition = "customanalyzer")
private String description;
}@AnalyzerDef によって宣言されたアナライザーインスタンスは、SearchFactory で名前を用いて使用することもできます。これはクエリーの構築時に役に立ちます。
Analyzer analyzer = fullTextSession.getSearchFactory().getAnalyzer("customanalyzer");クエリーのフィールドは、共通の「言語」を話すよう、フィールドをインデックス化するために使用したのと同じアナライザーで分析する必要があります。クエリーとインデックス化プロセスの間では同じトークンが再使用されます。このルールには例外もありますが、ほとんどの場合に当てはまります。完全に理解して作業を行っている場合以外はこのルールに従ってください。
13.4.3.3. 使用可能なアナライザー
Solr および Lucene には便利なデフォルトの文字フィルター、トークナイザー、およびフィルターが多く含まれています。文字フィルターファクトリー、トークナイザーファクトリー、およびフィルターファクトリーの完全なリストについては、http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters を参照してください。この一部を以下に示します。
| ファクトリー | 説明 | パラメーター |
|---|---|---|
|
MappingCharFilterFactory |
リソースファイルに指定されたマッピングを基に、1 つ以上の文字を置き換えます。 |
|
|
HTMLStripCharFilterFactory |
標準の HTML タグを削除し、テキストは保持します。 |
none |
| ファクトリー | 説明 | パラメーター |
|---|---|---|
|
StandardTokenizerFactory |
Lucene の標準トークナイザーを使用します。 |
none |
|
HTMLStripCharFilterFactory |
標準の HTML タグを削除してテキストは保持し、StandardTokenizer へ渡します。 |
none |
|
PatternTokenizerFactory |
指定の正規表現パターンでテキストを改行します。 |
pattern: トークン化に使用する正規表現。 group: トークンに抽出するパターングループを示します。 |
| ファクトリー | 説明 | パラメーター |
|---|---|---|
|
StandardFilterFactory |
頭字語からピリオドを削除し、単語からアポストロフィー (') を削除します。 |
none |
|
LowerCaseFilterFactory |
すべての言葉を小文字にします。 |
none |
|
StopFilterFactory |
ストップワードのリストと一致する言葉 (トークン) を削除します。 |
words: ストップワードが含まれるリソースファイルを示します。 ignoreCase: ストップワードを比較するときに case を無視する場合は true、無視しない場合は false。 |
|
SnowballPorterFilterFactory |
単語を指定言語の語根にします。たとえば、protect、protects、および protection はすべて同じ語根を持ちます。このようなフィルターを使用すると、関連する単語に一致する検索を実行できます。 |
|
IDEの org.apache.lucene.analysis.TokenizerFactory および org.apache.lucene.analysis.TokenFilterFactory の実装をすべてチェックし、利用できる実装を確認することが推奨されます。
13.4.3.4. 動的アナライザーの選択
これまでの説明では、アナライザーを指定する方法はすべて静的でした。しかし、多言語のアプリケーションなど、インデックス化されるエンティティーの現在の状態に応じてアナライザーを選択すると便利なユースケースもあります。たとえば、BlogEntry クラスの場合、アナライザーはエントリーの言語プロパティーに依存できます。このプロパティーに応じて、実際のテキストをインデックス化するために適切な言語固有のステマーを選択する必要があります。
動的なアナライザー選択を有効にするために、Hibernate Search では AnalyzerDiscriminator アノテーションが導入されました。以下の例は、このアノテーションの使用方法を示しています。
例: @AnalyzerDiscriminator の使用方法
@Entity
@Indexed
@AnalyzerDefs({
@AnalyzerDef(name = "en",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = EnglishPorterFilterFactory.class
)
}),
@AnalyzerDef(name = "de",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class),
filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = GermanStemFilterFactory.class)
})
})
public class BlogEntry {
@Id
@GeneratedValue
@DocumentId
private Integer id;
@Field
@AnalyzerDiscriminator(impl = LanguageDiscriminator.class)
private String language;
@Field
private String text;
private Set<BlogEntry> references;
// standard getter/setter
...
}public class LanguageDiscriminator implements Discriminator {
public String getAnalyzerDefinitionName(Object value, Object entity, String field) {
if ( value == null || !( entity instanceof BlogEntry ) ) {
return null;
}
return (String) value;
}
}
@AnalyzerDiscriminator を使用する前に、動的に使用されるすべてのアナライザーを @AnalyzerDef 定義で事前に定義する必要があります。この場合は、アナライザーを動的に選択するためのクラスまたはエンティティーの特定のプロパティーに @AnalyzerDiscriminator アノテーションを配置します。AnalyzerDiscriminator の impl パラメーターを使用して、Discriminator インターフェースの具体的な実装を指定します。このインターフェースに実装を提供することはユーザーに任されています。実装しなければならない唯一のメソッドは getAnalyzerDefinitionName() であり、このメソッドは Lucene ドキュメントにフィールドが追加されるたびに呼び出されます。インデックス化されるエンティティーもインターフェースメソッドへ渡されます。AnalyzerDiscriminator がクラスレベルではなくプロパティーレベルに配置された場合のみ value パラメーターが設定されます。この場合、値はこのプロパティーの現在の値を表します。
Discriminator インターフェースの実装は、既存アナライザー定義の名前を返す必要がありますが、デフォルトのアナライザーをオーバーライドしない場合は null を返す必要があります。上記の例では、言語パラメーターが @AnalyzerDefs で指定された名前に一致する「de」または「en」のどちらかであることを仮定します。
13.4.3.5. アナライザーの読み出し
ステミングや音声的近似などを活用するために、ドメインモデルで複数のアナライザーが使用された場合にアナライザーを読み出すことができます。この場合、同じアナライザーを使用してクエリーを構築します。この代わりに、正しいアナライザーを自動的に選択する Hibernate Search クエリー DSL を使用することもできます。
Lucene プログラム API または Lucene クエリーパーサーのいずれを使用する場合でも、指定のエンティティーのスコープ指定されたアナライザーを読み出しできます。スコープ指定されたアナライザーは、インデックス化されたフィールドに応じて適切なアナライザーを適用するアナライザーです。各フィールドで動作する各エンティティーには複数のアナライザーを定義できます。スコープ指定されたアナライザーはすべてのアナライザーをコンテキストを意識したアナライザーに統合します。この理論は若干複雑ですが、クエリーで正しいアナライザーを使用することは簡単です。
子エンティティーにプログラムを用いたマッピングを使用する場合、子エンティティーによって定義されたフィールドのみが表示されます。親エンティティーから継承されたフィールドやメソッドは設定できません。親エンティティーから継承されたプロパティーを設定するには、子エンティティーでプロパティーをオーバーライドするか、親エンティティーに対してプログラムを用いたマッピングを作成します。これは、子エンティティーで再定義しないと親エンティティーのフィールドまたはメソッドにアノテーションをつけられない場合にアノテーションの使用を模擬します。
例: フルテキストのクエリー構築時におけるスコープ指定されたアナライザーの使用
org.apache.lucene.queryParser.QueryParser parser = new QueryParser(
"title",
fullTextSession.getSearchFactory().getAnalyzer( Song.class )
);
org.apache.lucene.search.Query luceneQuery =
parser.parse( "title:sky Or title_stemmed:diamond" );
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Song.class );
List result = fullTextQuery.list(); //return a list of managed objects
上記の例では、歌のタイトルが 2 つのフィールドでインデックス化されます。標準のアナライザーは title フィールドで使用され、ステミングアナライザーは title_stemmed フィールドで使用されます。検索ファクトリーによって提供されたアナライザーを使用して、クエリーは目的のフィールドに応じて適切なアナライザーを使用します。
@AnalyzerDef によって定義されたアナライザーは、searchFactory.getAnalyzer(String) を使用して定義名で取得することもできます。
13.4.4. ブリッジ
これまでの説明では、エンティティーの基本的なマッピングで重要な条件の 1 つが無視されていました。Lucene では、すべてのインデックスフィールドを文字列として表す必要があります。インデックス化するには @Field アノテーションが付けられたエンティティープロパティーをすべて文字列に変換する必要があります。これまでの説明で取り上げなかった理由は、Hibernate Search のビルトインブリッジによってほとんどのプロパティーが変換されるためです。しかし、場合によっては変換プロセスでさらに細かい制御が必要になることがあります。
13.4.4.1. ビルトインブリッジ
Hibernate Search には、Java プロパティー型とそのフルテキスト表現との間のビルドインブリッジが含まれています。
- null
-
デフォルトでは
null要素はインデックス化されません。 Lucene は null 要素をサポートしませんが、場合によってはnullの値を表すカスタムトークンを挿入すると便利なことがあります。 - java.lang.String
- 文字列は short、Short、integer、Integer、long、Long、float、Float、double と同様にインデックス化されます。
- Double、BigInteger、BigDecimal
数字は文字列の表現に変換されます。Lucene はそのままでは数字を比較できず (範囲指定のクエリーで使用)、パディングを行う必要があることに注意してください。
注記Range クエリーの使用には欠点があるため、代わりに結果クエリーを適切な範囲にフィルターする Filter クエリーを使用できます。Hibernate Search では、カスタム StringBridge の使用もサポートされています (カスタムブリッジを参照)。
- java.util.Date
日付はグリニッジ標準時 (GMT) で yyyyMMddHHmmssSSS の形式で保存されます。たとえば、アメリカ東部標準時 (EST) の 2006 年 11 月 7 日午後 4 時 3 分 12 秒は 200611072203012 になります。内部の形式は気にする必要はありません。TermRangeQuery を使用するときに重要なのは、日付がグリニッジ標準時で表されることを認識することです。
通常、日付をミリ秒まで保存する必要はありません。
@DateBridgeはインデックスに保存するのに適切な精度 (resolution) を定義します (@DateBridge(resolution=Resolution.DAY))。日付パターンはこの定義に従って省略されます。
@Entity
@Indexed
public class Meeting {
@Field(analyze=Analyze.NO)
private Date date;
...
MILLISECOND よりも小さい精度を持つ日付を @DocumentId にすることはできません。
デフォルトの Date ブリッジは Lucene の DateTools を使用して String からの変換と String への変換を行います。つまり、すべての日付は GMT 時間で表されます。日付を固定の時間帯で保存することが要件である場合は、カスタムの日付ブリッジを実装する必要があります。日付のインデックス化および検索に関するアプリケーションの要件を理解するようにしてください。
- java.net.URI、java.net.URL
- URI および URL は文字列の表現に変換されます。
- java.lang.Class
- クラスは完全修飾クラス名に変換されます。クラスがリハイドレートされる場合は、スレッドコンテキストクラスローダーが使用されます。
13.4.4.2. カスタムブリッジ
場合によっては Hibernate Search のビルトインブリッジが一部のプロパティータイプに対応しなかったり、ブリッジによって使用される String 表現が要件に合わなかったりすることがあります。この問題に対応する方法を以下に説明します。
13.4.4.2.1. StringBridge
最も簡単な方法は、想定される Object から String へのブリッジの実装を Hibernate Search に提供することです。これを行うには、org.hibernate.search.bridge.StringBridge インターフェースを実装する必要があります。同時に使用されるため、すべての実装はスレッドセーフである必要があります。
例: カスタムの StringBridge 実装
/**
* Padding Integer bridge.
* All numbers will be padded with 0 to match 5 digits
*
* @author Emmanuel Bernard
*/
public class PaddedIntegerBridge implements StringBridge {
private int PADDING = 5;
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > PADDING)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < PADDING ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
}
前の例で定義された文字列ブリッジの場合、@FieldBridge アノテーションによってすべてのプロパティーおよびフィールドでこのブリッジを使用できます。
@FieldBridge(impl = PaddedIntegerBridge.class) private Integer length;
13.4.4.2.2. パラメーター化されたブリッジ
ブリッジ実装をより柔軟にするために、パラメーターをブリッジ実装に渡すこともできます。以下の例では、ParameterizedBridge インターフェースが実装され、パラメーターは @FieldBridge アノテーションを介して渡されます。
例: ブリッジ実装へパラメーターを渡す
public class PaddedIntegerBridge implements StringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map<String,String> parameters) {
String padding = parameters.get( PADDING_PROPERTY );
if (padding != null) this.padding = Integer.parseInt( padding );
}
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
}
//property
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name="padding", value="10")
)
private Integer length;
ParameterizedBridge インターフェースは、StringBridge、TwoWayStringBridge、FieldBridge 実装によって実装できます。
すべての実装はスレッドセーフである必要がありますが、パラメーターは初期化時に設定され、この段階では特別な措置は必要ありません。
13.4.4.2.3. 型対応ブリッジ
以下に適用されているブリッジの型を取得すると便利な場合があります。
- フィールド/ゲッターレベルのブリッジに対するプロパティーの戻り値の型。
- クラスレベルのブリッジに対するクラス型。
例としては、独自の方法で列挙を処理し、実際の列挙型にアクセスする必要があるブリッジが挙げられます。AppliedOnTypeAwareBridge を実装するすべてのブリッジは、ブリッジが適用されている型をインジェクトします。パラメーターと同様に、インジェクトされた型はスレッドセーフに関しては特別な注意が必要ありません。
13.4.4.2.4. 双方向ブリッジ
@DocumentId アノテーションが付けられた ID プロパティーでブリッジ実装を使用することが想定される場合、TwoWayStringBridge を使用する必要があります。これは StringBridge が若干拡張されたものです。Hibernate Search は識別子の文字列表現を読み取り、オブジェクトを生成する必要があります。@FieldBridge アノテーションの使用方法は同じです。
例: ID プロパティーに使用できる TwoWayStringBridge の実装
public class PaddedIntegerBridge implements TwoWayStringBridge, ParameterizedBridge {
public static String PADDING_PROPERTY = "padding";
private int padding = 5; //default
public void setParameterValues(Map parameters) {
Object padding = parameters.get( PADDING_PROPERTY );
if (padding != null) this.padding = (Integer) padding;
}
public String objectToString(Object object) {
String rawInteger = ( (Integer) object ).toString();
if (rawInteger.length() > padding)
throw new IllegalArgumentException( "Try to pad on a number too big" );
StringBuilder paddedInteger = new StringBuilder( );
for ( int padIndex = rawInteger.length() ; padIndex < padding ; padIndex++ ) {
paddedInteger.append('0');
}
return paddedInteger.append( rawInteger ).toString();
}
public Object stringToObject(String stringValue) {
return new Integer(stringValue);
}
}
//id property
@DocumentId
@FieldBridge(impl = PaddedIntegerBridge.class,
params = @Parameter(name="padding", value="10")
private Integer id;「object = stringToObject( objectToString( object ) )」のように、双方向処理をべき等にすることが重要になります。
13.4.4.2.5. FieldBridge
一部のユースケースでは、プロパティーを Lucene インデックスにマップするときにオブジェクトから文字列への単純な変換以上のものが必要になることがあります。柔軟性を最大化にするために、ブリッジを FieldBridge として実装することもできます。このインターフェースはプロパティー値を提供し、その値を Lucene Document で自由にマップできるようにします。たとえば、1 つのプロパティーを 2 つの異なるドキュメントフィールドに保存できます。インターフェースは Hibernate UserType の概念と非常に似ています。
例: FieldBridge インターフェースの実装
/**
* Store the date in 3 different fields - year, month, day - to ease Range Query per
* year, month or day (eg get all the elements of December for the last 5 years).
* @author Emmanuel Bernard
*/
public class DateSplitBridge implements FieldBridge {
private final static TimeZone GMT = TimeZone.getTimeZone("GMT");
public void set(String name, Object value, Document document, LuceneOptions luceneOptions) {
Date date = (Date) value;
Calendar cal = GregorianCalendar.getInstance(GMT);
cal.setTime(date);
int year = cal.get(Calendar.YEAR);
int month = cal.get(Calendar.MONTH) + 1;
int day = cal.get(Calendar.DAY_OF_MONTH);
// set year
luceneOptions.addFieldToDocument(
name + ".year",
String.valueOf( year ),
document );
// set month and pad it if needed
luceneOptions.addFieldToDocument(
name + ".month",
month < 10 ? "0" : "" + String.valueOf( month ),
document );
// set day and pad it if needed
luceneOptions.addFieldToDocument(
name + ".day",
day < 10 ? "0" : "" + String.valueOf( day ),
document );
}
}
//property
@FieldBridge(impl = DateSplitBridge.class)
private Date date;
上記の例では、フィールドは直接 Document へ追加されていません。追加は LuceneOptions ヘルパーに委譲されています。このヘルパーは Store や TermVector などの @Field で選択されたオプションを適用したり、選択された @Boost の値を適用したりします。特に、COMPRESS 実装の複雑さをカプセル化するのに便利です。LuceneOptions に委譲して Document にフィールドを追加することが推奨されますが、必要な場合は Document を直接編集し、LuceneOptions を無視することも可能です。
LuceneOptions のようなクラスは、Lucene API の変更からアプリケーションを守り、コードを簡単にするために作成されます。可能な場合はこのようなクラスを使用してください。ただし、柔軟性がさらに必要な場合、使用は強制されません。
13.4.4.2.6. ClassBridge
場合によっては、エンティティーのプロパティーを複数組み合わせ、特定の方法で Lucene インデックスへインデックス化すると便利です。@ClassBridge および @ClassBridges アノテーションは、プロパティーレベルではなくクラスレベルで定義できます。この場合、カスタムフィールドブリッジ実装は特定のプロパティーでなく値パラメーターとしてエンティティーインスタンスを受け取ります。以下の例では示されていませんが、@ClassBridge は項基本的なマッピングで説明されている termVector 属性をサポートします。
例: クラスブリッジの実装
@Entity
@Indexed
(name="branchnetwork",
store=Store.YES,
impl = CatFieldsClassBridge.class,
params = @Parameter( name="sepChar", value=" " ) )
public class Department {
private int id;
private String network;
private String branchHead;
private String branch;
private Integer maxEmployees
...
}
public class CatFieldsClassBridge implements FieldBridge, ParameterizedBridge {
private String sepChar;
public void setParameterValues(Map parameters) {
this.sepChar = (String) parameters.get( "sepChar" );
}
public void set( String name, Object value, Document document, LuceneOptions luceneOptions) {
// In this particular class the name of the new field was passed
// from the name field of the ClassBridge Annotation. This is not
// a requirement. It just works that way in this instance. The
// actual name could be supplied by hard coding it below.
Department dep = (Department) value;
String fieldValue1 = dep.getBranch();
if ( fieldValue1 == null ) {
fieldValue1 = "";
}
String fieldValue2 = dep.getNetwork();
if ( fieldValue2 == null ) {
fieldValue2 = "";
}
String fieldValue = fieldValue1 + sepChar + fieldValue2;
Field field = new Field( name, fieldValue, luceneOptions.getStore(),
luceneOptions.getIndex(), luceneOptions.getTermVector() );
field.setBoost( luceneOptions.getBoost() );
document.add( field );
}
}
この例では、特定の CatFieldsClassBridge が department インスタンスへ適用され、フィールドブリッジによってブランチとネットワークの両方が連結され、連結がインデックス化されます。
13.5. クエリー
Hibernate SearchHibernate Search は Lucene クエリーを実行し、InfinispanHibernate セッションによって管理されるドメインオブジェクトを読み出しできます。検索は Hibernate パラダイムの範囲で Lucene の機能を提供し、Hibernate の従来の検索メカニズム (HQL、Criteria クエリー、ネイティブ SQL クエリー) に他の可能性を提供します。
クエリーの準備および実行は、以下の 4 つの段階で構成されます。
- FullTextSession の作成
- Hibernate QueryHibernate Search クエリー DSL (推奨) または Lucene Query API を使用した Lucene クエリーの作成
- org.hibernate.Query を使用した Lucene クエリーのラッピング
- サンプル list() または scroll() の呼び出しによる検索の実行
クエリー機能にアクセスするには、FullTextSession を使用します。この検索固有のセッションはクエリーおよびインデックス化の機能を提供するために正規の org.hibernate.Session をラップします。
例: FullTextSession の作成
Session session = sessionFactory.openSession(); ... FullTextSession fullTextSession = Search.getFullTextSession(session);
FullTextSession を使用して、Hibernate SearchHibernate Search クエリー DSL またはネイティブ Lucene クエリーを使用したフルテキストクエリーを構築します。
Hibernate SearchHibernate Search クエリー DSL を使用する場合は以下のコードを使用します。
final QueryBuilder b = fullTextSession.getSearchFactory().buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
List result = fullTextQuery.list(); //return a list of managed objectsこの代わりに、Lucene クエリーパーサーまたは Lucene プログラム API のいずれかを使用して Lucene クエリーを記述します。
例: QueryParser を用いた Lucene クエリーの作成
SearchFactory searchFactory = fullTextSession.getSearchFactory();
org.apache.lucene.queryParser.QueryParser parser =
new QueryParser("title", searchFactory.getAnalyzer(Myth.class) );
try {
org.apache.lucene.search.Query luceneQuery = parser.parse( "history:storm^3" );
}
catch (ParseException e) {
//handle parsing failure
}
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery(luceneQuery);
List result = fullTextQuery.list(); //return a list of managed objectsLucene クエリー上に構築された Hibernate クエリーは org.hibernate.Query です。このクエリーは HQL (Hibernate Query Language)、Native、Criteria などの他の Hibernate クエリー機能と同じパラダイム内に留まります。クエリーには list()、uniqueResult()、iterate() and scroll() などのメソッドを使用します。
Hibernate Java Persistence API では同じ拡張を使用できます。
例: JPA API を使用した Search クエリーの作成
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
...
final QueryBuilder b = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
javax.persistence.Query fullTextQuery = fullTextEntityManager.createFullTextQuery( luceneQuery );
List result = fullTextQuery.getResultList(); //return a list of managed objects以下の例では Hibernate API を使用しますが、FullTextQuery が読み出される方法を調整するだけで Java Persistence API を使用して同じ例を簡単に書き直すことができます。
13.5.1. クエリーの構築
Hibernate Search クエリーは Lucene クエリー上で構築されるため、ユーザーはすべての Lucene クエリータイプを使用できます。クエリーが構築されると、Hibernate Search は org.hibernate.Query をクエリー操作 API として使用してさらにクエリー処理を行います。
13.5.1.1. Lucene API を使用した Lucene クエリーの構築
Lucene API では、クエリーパーサー (簡単なクエリー) または Lucene プログラム API (複雑なクエリー) を使用します。Lucene クエリーの構築は、Hibernate Search ドキュメントの範囲外になります。詳細については、オンラインの Lucene ドキュメント、Lucene in Action、または Hibernate Search in Action を参照してください。
13.5.1.2. Lucene クエリーの構築
Lucene プログラム API はフルテキストクエリーを有効にします。しかし、Lucene プログラム API を使用する場合はパラメーターを同等の文字列に変換し、さらに正しいアナライザーを適切なフィールドに適用する必要があります。たとえば、N-gram アナライザーは複数の N-gram を指定の言葉のトークンとして使用し、そのように検索する必要があります。この作業には QueryBuilder の使用が推奨されます。
Hibernate Search クエリー API は以下の特徴を持ちます。
- メソッド名は英語になります。そのため、API 操作は一連の英語のフレーズや指示として読み取りおよび理解されます。
- 現在入力した接頭辞の補完を可能にし、ユーザーが適切なオプションを選択できる IDE 自動補完を使用します。
- チェイニングメソッドパターンを頻繁に使用します。
- API 操作の使用および読み取りは簡単です。
API を使用するには、最初に指定の indexedentitytype にアタッチされるクエリービルダーを作成します。この QueryBuilder は、使用するアナライザーと適用するフィールドブリッジを認識します。複数の QueryBuilder を作成できます (クエリーのルートに関係する各エンティティー型ごと)。QueryBuilder は SearchFactory から派生します。
QueryBuilder mythQB = searchFactory.buildQueryBuilder().forEntity( Myth.class ).get();
指定のフィールドに使用するアナライザーをオーバーライドすることもできます。
QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity( Myth.class )
.overridesForField("history","stem_analyzer_definition")
.get();クエリービルダーは Lucene クエリーの構築に使用されるようになりました。Lucene のクエリーパーサーを使用して生成されたカスタマイズ済みクエリーまたは Lucene プログラム API を使用してアセンブルされた Query オブジェクトは、Hibernate Search DSL とともに使用されます。
13.5.1.3. キーワードクエリー
以下の例は特定の単語を検索する方法を示しています。
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();| パラメーター | 説明 |
|---|---|
|
keyword() |
このパラメーターを使用して特定の単語を見つけます。 |
|
onField() |
このパラメーターを使用して単語を検索する Lucene フィールドを指定します。 |
|
matching() |
このパラメーターを使用して検索する文字列の一致を指定します。 |
|
createQuery() |
Lucene クエリーオブジェクトを作成します。 |
-
値「storm」は
historyFieldBridge から渡されます。これは、数字や日付が関係する場合に便利です。 -
その後、フィールドブリッジの値はフィールド
historyをインデックス化するために使用されるアナライザーへ渡されます。これにより、クエリーがインデックス化と同じ用語変換を使用するようにします (小文字、N-gram、ステミングなど)。分析プロセスが指定の単語に対して複数の用語を生成する場合、ブール値クエリーはSHOULDロジック (おおよそORロジックと同様) とともに使用されます。
文字列型でないプロパティーを検索します。
@Indexed
public class Myth {
@Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
public Date getCreationDate() { return creationDate; }
public Date setCreationDate(Date creationDate) { this.creationDate = creationDate; }
private Date creationDate;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("creationDate").matching(birthdate).createQuery();プレーンな Lucene では、Date オブジェクトは文字列の表現に変換する必要がありました (この例では年)。
FieldBridge に objectToString メソッドがある場合 (および組み込みのすべての FieldBridge 実装にこのメソッドがある場合)、この変換はどのオブジェクトに対しても実行できます。
次の例は、N-gram アナライザーを使用するフィールドを検索します。N-gram アナライザーは単語の N-gram の連続をインデックス化します。これは、ユーザーによる誤字を防ぐのに役立ちます。たとえば、単語 hibernate の 3-gram は hib、ibe、ber、ern、rna、nat、ate になります。
@AnalyzerDef(name = "ngram",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class ),
filters = {
@TokenFilterDef(factory = StandardFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class),
@TokenFilterDef(factory = NGramFilterFactory.class,
params = {
@Parameter(name = "minGramSize", value = "3"),
@Parameter(name = "maxGramSize", value = "3") } )
}
)
public class Myth {
@Field(analyzer=@Analyzer(definition="ngram")
public String getName() { return name; }
public String setName(String name) { this.name = name; }
private String name;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("name").matching("Sisiphus")
.createQuery();
一致する単語「Sisiphus」は小文字に変換され、3-gram (sis、isi、sip、iph、phu、hus) に分割されます。各 N-gram はクエリーの一部になります。その後、ユーザーは Sysiphus (i ではなく y) myth (シーシュポスの神話) を検索できます。ユーザーに対してすべてが透過的に行われます。
特定のフィールドがフィールドブリッジまたはアナライザーを使用しないようにするには、ignoreAnalyzer() または ignoreFieldBridge() 関数を呼び出すことができます。
同じフィールドで可能な単語を複数検索し、すべてを一致する句に追加します。
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();複数のフィールドで同じ単語を検索するには、onFields メソッドを使用します。
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();同じ用語を検索する場合でも、あるフィールドに対して他のフィールドとは異なる処理をする必要があることがあります。このような場合は andField() メソッドを使用します。
Query luceneQuery = mythQB.keyword()
.onField("history")
.andField("name")
.boostedTo(5)
.andField("description")
.matching("storm")
.createQuery();前述の例では、フィールド名のみが 5 にブーストされます。
13.5.1.4. ファジークエリー
レーベンシュタイン距離 (Levenshtein Distance) アルゴリズムを基にしてファジークエリーを実行するには、keyword クエリーで開始して fuzzy フラグを追加します。
Query luceneQuery = mythQB
.keyword()
.fuzzy()
.withThreshold( .8f )
.withPrefixLength( 1 )
.onField("history")
.matching("starm")
.createQuery();
threshold を越えると 2 つの用語の一致を考慮します。これは、0 から 1 の間の小数であり、デフォルト値は 0.5 になります。prefixLength は「ファジーの度合い」によって無視される接頭辞の長さになります。デフォルト値は 0 ですが、大量の異なる用語が含まれるインデックスではゼロ以外の値を指定することが推奨されます。
13.5.1.5. ワイルドカードクエリー
ワイルドカードクエリーは、単語の一部のみがわかる場合に便利です。? は単一の文字を表し、* は複数の文字を表します。パフォーマンス上の理由で、クエリーの最初に ? または * を使用しないことが推奨されます。
Query luceneQuery = mythQB
.keyword()
.wildcard()
.onField("history")
.matching("sto*")
.createQuery();
ワイルドカードクエリーは、アナライザーを一致する用語に適用しません。* または ? が適切に処理されないリスクが大変高くなります。
13.5.1.6. フレーズクエリー
これまでは、単語または単語のセットを検索しましたが、完全一致の文または近似の文を検索することも可能です。文の検索には phrase() を使用します。
Query luceneQuery = mythQB
.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();おおよその文はスロップ (slop) 係数を追加すると検索可能になります。スロップ係数は、その文で許可される別の単語の数を表します。これは、within または near 演算子と同様に動作します。
Query luceneQuery = mythQB
.phrase()
.withSlop(3)
.onField("history")
.sentence("Thou kill")
.createQuery();13.5.1.7. 範囲クエリー
範囲クエリーは指定の境界の間、上、または下で値を検索します。
//look for 0 <= starred < 3
Query luceneQuery = mythQB
.range()
.onField("starred")
.from(0).to(3).excludeLimit()
.createQuery();
//look for myths strictly BC
Date beforeChrist = ...;
Query luceneQuery = mythQB
.range()
.onField("creationDate")
.below(beforeChrist).excludeLimit()
.createQuery();13.5.1.8. クエリーの組み合わせ
クエリーを集合 (組み合わせ) するとさらに複雑なクエリーを作成できます。以下の集合演算子を使用できます。
-
SHOULD: クエリーにはサブクエリーの一致要素が含まれるはずです。 -
MUST: クエリーにはサブクエリーの一致要素が含まれていなければなりません。 -
MUST NOT: クエリーにはサブクエリーの一致要素が含まれていてはなりません。
サブクエリーはブール値クエリー自体を含む Lucene クエリーです。
例: SHOULD クエリー
//look for popular myths that are preferably urban
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();例: MUST クエリー
//look for popular urban myths
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();例: MUST NOT クエリー
//look for popular modern myths that are not urban
Date twentiethCentury = ...;
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.not()
.must( mythQB.range().onField("starred").above(4).createQuery() )
.must( mythQB
.range()
.onField("creationDate")
.above(twentiethCentury)
.createQuery() )
.createQuery();13.5.1.9. クエリーオプション
Hibernate Search クエリー DSL は簡単に使用および読み取りできるクエリー API です。Lucene クエリーを許可および作成すると、DSL によってサポートされていないクエリー型を取り入れることができます。
クエリー型およびフィールドのクエリーオプションの概要は次のとおりです。
- boostedTo (クエリー型およびフィールド上) はクエリー全体または特定のフィールドを指定の係数にブーストします。
- withConstantScore (クエリー上) は、定数スコア (constant score) がブーストと等しいクエリーに一致するすべての結果を返します。
- filteredBy(Filter) (クエリー上) は Filter インスタンスを使用してクエリー結果をフィルターします。
- ignoreAnalyzer (フィールド上) は、このフィールドの処理時にアナライザーを無視します。
- ignoreFieldBridge (フィールド上) は、このフィールドの処理時にフィールドブリッジを無視します。
例: クエリーオプションの組み合わせ
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.should( mythQB
.keyword()
.onField("name")
.boostedTo(3)
.ignoreAnalyzer()
.matching("urban").createQuery() )
.must( mythQB
.range()
.boostedTo(5).withConstantScore()
.onField("starred").above(4).createQuery() )
.createQuery();13.5.1.10. Hibernate Search クエリーの構築
13.5.1.10.1. 一般論
Lucene クエリーを構築したら、Hibernate クエリー内でラップします。クエリーは、インデックス化されたエンティティーをすべて検索し、インデックス化されたクラスのすべての型を返します。この挙動を変更するには、明示的に設定する必要があります。
例: Hibernate クエリー内の Lucene クエリーのラッピング
FullTextSession fullTextSession = Search.getFullTextSession( session ); org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
パフォーマンスを向上するには、以下のように戻り値の型を制限します。
例: エンティティー型での検索結果のフィルター
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Customer.class );
// or
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Item.class, Actor.class );2 つ目の例の最初の部分は、一致する Customer のみを返します。同じ例の 2 つ目の部分は一致する Actor および Item を返します。型制限は多形です。このため、ベースクラス Person の 2 つのサブクラスである Salesman および Customer が返される場合は、Person.class を指定して結果の型に基づいてフィルターします。
13.5.1.10.2. ページネーション
パフォーマンスの劣化を防ぐため、クエリーごとに返されるオブジェクトの数を制限することが推奨されます。ユーザーがあるページから別のページへ移動するユースケースは大変一般的です。ページネーションを定義する方法は、プレーン HQL または Criteria クエリーでページネーションを定義する方法に似ています。
例: 検索クエリーに対するページネーションの定義
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Customer.class );
fullTextQuery.setFirstResult(15); //start from the 15th element
fullTextQuery.setMaxResults(10); //return 10 elements
fulltextQuery.getResultSize() を用いたページネーションに関係なく、一致する要素の合計数を取得できます。
13.5.1.10.3. 並び順
Apache Lucene には、柔軟で強力な結果ソートメカニズムが含まれています。デフォルトでは関連性でソートされます。他のプロパティーでソートするようソートメカニズムを変更するには、Lucene Sort オブジェクトを使用して Lucene ソートストラテジーを適用します。
例: Lucene Sort の指定
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( query, Book.class );
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
List results = query.list();ソートに使用されるフィールドはトークン化しないでください。トークン化に関する詳細については、@Fieldを参照してください。
13.5.1.10.4. フェッチングストラテジー
戻り値の型が 1 つのクラスに制限される場合、Hibernate SearchHibernate Search は単一のクエリーを使用してオブジェクトをロードします。Hibernate SearchHibernate Search は、ドメインモデルに定義された静的なフェッチングストラテジーによって制限されます。以下のように、特定のユースケースに対してフェッチングストラテジーを絞り込むと便利です。
例: クエリーでの FetchMode の指定
Criteria criteria =
s.createCriteria( Book.class ).setFetchMode( "authors", FetchMode.JOIN );
s.createFullTextQuery( luceneQuery ).setCriteriaQuery( criteria );この例では、クエリーは LuceneQuery に一致するすべての Book を返します。authors のコレクションは SQL の外部結合を使用して同じクエリーからロードされます。
Criteria クエリーの定義では、提供された Criteria クエリーを基に型が推測されます。そのため、戻り値のエンティティー型を制限する必要はありません。
フェッチモードのみが調整可能なプロパティーです。Criteria とともに制限を使用すると、getResultSize() によって SearchException が発生するため、Criteria クエリーで制限 (where 句) を使用しないでください。
複数のエンティティーが想定される場合は、setCriteriaQuery を使用しないでください。
13.5.1.10.5. 射影 (Projection)
プロパティーの小さなサブセットのみが必要になることがあります。以下のように、Hibernate Search を使用してプロパティーのサブセットを返します。
Hibernate Search は Lucene インデックスからプロパティーを抽出し、オブジェクトの表現に変換して Object[] のリストを返します。射影により、時間がかかるデータベースラウンドトリップは回避されますが、以下の制約があります。
-
射影されたプロパティーはインデックス (
@Field(store=Store.YES)) に保存される必要があります。これにより、インデックスのサイズが大きくなります。 射影されたプロパティーは org.hibernate.search.bridge.TwoWayFieldBridge または
org.hibernate.search.bridge.TwoWayStringBridge(より単純なバージョン) を実装するFieldBridgeを使用する必要があります。注記Hibernate Search の組み込み型はすべて双方向です。
- インデックス化されたエンティティーのシンプルなプロパティーまたは埋め込みされた関連のみを射影できます。埋め込みエンティティー全体は射影できません。
- 射影は、@IndexedEmbedded を用いてインデックス化されたコレクションまたはマップでは動作しません。
Lucene はクエリー結果のメタデータ情報を提供します。射影定数を使用してメタデータを読み出します。
例: 射影を使用したメタデータの読み出し
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.;
List results = query.list();
Object[] firstResult = (Object[]) results.get(0);
float score = firstResult[0];
Book book = firstResult[1];
String authorName = firstResult[2];フィールドは、以下の射影定数と組み合わせることができます。
- FullTextQuery.THIS:: 初期化された管理対象エンティティーを返します (射影されていないクエリーが行うとおり)。
- FullTextQuery.DOCUMENT:: 射影されたオブジェクトに関連する Lucene Document を返します。
- FullTextQuery.OBJECT_CLASS: インデックス化されたエンティティーのクラスを返します。
- FullTextQuery.SCORE: クエリーのドキュメントスコアを返します。スコアはある 1 つのクエリーの結果を特定のクエリーの別の結果と比較するのに便利ですが、さまざまなクエリーの結果を比較する場合は役に立ちません。
- FullTextQuery.ID: 射影されたオブジェクトの ID プロパティー値。
- FullTextQuery.DOCUMENT_ID: Lucene ドキュメント ID。Lucene のドキュメント ID は 2 つの異なる IndexReader が開かれる間に変更される可能性があるため、この値を使用する場合は注意してください。
- FullTextQuery.EXPLANATION: 該当するクエリーのオブジェクト/ドキュメントに一致する Lucene Explanation オブジェクトを返します。これは、大量のデータの読み出しには適していません。通常、Explanation の実行で使用するリソースの量は、一致する要素ごとに Lucene クエリー全体を実行する場合に匹敵します。そのため、射影が推奨されます。
13.5.1.10.6. オブジェクト初期化ストラテジーのカスタマイズ
デフォルトでは、Hibernate SearchHibernate Search は最も適切なストラテジーを使用してフルテキストクエリーに一致するエンティティーを初期化します。1 つまたは複数のクエリーを実行して、必要なエンティティーを読み出します。この方法により、永続コンテキスト (セッション) または 2 次キャッシュに読み出されたエンティティーがほとんど存在しない場合にデータベーストリップが最小化されます。
2 次キャッシュにエンティティーが存在する場合は、データベースオブジェクトを読み出す前にキャッシュをチェックするよう Hibernate SearchHibernate Search を強制します。
例: クエリー使用前の 2 次キャッシュのチェック
FullTextQuery query = session.createFullTextQuery(luceneQuery, User.class);
query.initializeObjectWith(
ObjectLookupMethod.SECOND_LEVEL_CACHE,
DatabaseRetrievalMethod.QUERY
);
ObjectLookupMethod は、オブジェクトに簡単に (データベースからフェッチせずに) アクセスできるかどうかをチェックするストラテジーを定義します。他のオプションは次のとおりです。
-
ObjectLookupMethod.PERSISTENCE_CONTEXTは、一致するエンティティーの多くがすでに永続コンテキストにロードされている場合に使用されます (Session または EntityManager にロードされます)。 -
ObjectLookupMethod.SECOND_LEVEL_CACHEは永続コンテキストをチェックし、その後に 2 次キャッシュをチェックします。
以下を設定して 2 次キャッシュを検索します。
- 2 次キャッシュを適切に設定および有効にします。
- 関連するエンティティーに対して 2 次キャッシュを有効にします。これは、@Cacheable などのアノテーションを使用して行われます。
-
Session、EntityManager、または Query に対する 2 次キャッシュの読み取りアクセスを有効にします。Hibernate ネイティブ API では
CacheMode.NORMALを使用し、Java Persistence API ではCacheRetrieveMode.USEを使用します。
2 次キャッシュの実装が EHCache または Infinispan でない場合は、 ObjectLookupMethod.SECOND_LEVEL_CACHE を使用しないでください。他の 2 次キャッシュプロバイダーはこの操作を効率的に実装しません。
次のように DatabaseRetrievalMethod を使用して、データベースからオブジェクトがロードされる方法をカスタマイズします。
- QUERY (デフォルト値) はクエリーのセットを使用してバッチごとに複数のオブジェクトをロードします。この方法が推奨されます。
-
FIND_BY_ID は
Session.getまたはEntityManager.findセマンティックを使用して 1 度に 1 つずつオブジェクトをロードします。これは、Hibernate Core がバッチでエンティティーをロードできるようにバッチサイズがエンティティー用に設定されている場合に推奨されます。
13.5.1.10.7. クエリーの時間制限
次のように、Hibernate Guide でクエリーが要する時間を制限します。
- 制限に達したら例外を発生させます。
- 時間制限に達したら読み出された結果の数を制限します。
13.5.1.10.8. 時間制限での例外の発生
定義された時間を越えてクエリーが実行された場合、QueryTimeoutException が発生します (プログラム API に応じて org.hibernate.QueryTimeoutException または javax.persistence.QueryTimeoutException が発生します)。
ネイティブ Hibernate API を使用して制限を定義するには、以下の方法の 1 つを使用します。
例: クエリー例外でのタイムアウトの定義
Query luceneQuery = ...;
FullTextQuery query = fullTextSession.createFullTextQuery(luceneQuery, User.class);
//define the timeout in seconds
query.setTimeout(5);
//alternatively, define the timeout in any given time unit
query.setTimeout(450, TimeUnit.MILLISECONDS);
try {
query.list();
}
catch (org.hibernate.QueryTimeoutException e) {
//do something, too slow
}getResultSize(), iterate()、iterate()、および scroll() はメソッド呼び出しが終わるまでタイムアウトを考慮します。そのため、Iterable または ScrollableResults はタイムアウトを無視します。さらに explain() はこのタイムアウト期間に従いません。このメソッドはデバッグや、クエリーのパフォーマンスが遅い理由をチェックするために使用されます。
Java Persistence API (JPA) を使用して実行時間を制限する標準的な方法は次のとおりです。
例: クエリー例外でのタイムアウトの定義
Query luceneQuery = ...;
FullTextQuery query = fullTextEM.createFullTextQuery(luceneQuery, User.class);
//define the timeout in milliseconds
query.setHint( "javax.persistence.query.timeout", 450 );
try {
query.getResultList();
}
catch (javax.persistence.QueryTimeoutException e) {
//do something, too slow
}サンプルコードは、クエリーが指定された結果の値で停止することを保証しません。
13.5.2. 結果の読み出し
Hibernate クエリーは構築後に HQL または Criteria クエリーと同じように実行されます。同じパラダイムとオブジェクトセマンティックが Lucene Query クエリーに適用され、list()、uniqueResult()、iterate()、scroll() などの一般的な操作を使用できます。
13.5.2.1. パフォーマンスに関する注意点
妥当な数の結果が予期され (ページネーションを使用する場合など)、すべての結果で作業を行うことが想定される場合、list() または uniqueResult() の使用が推奨されます。list() はエンティティー batch-size が適切に設定されている場合に最適です。list()、uniqueResult()、および iterate() を使用する場合は Hibernate Search がすべての Lucene Hits 要素 (ページネーション内) を処理する必要があることに注意してください。
Lucene ドキュメントのローディングを最小限にしたい場合は、scroll() の使用が適しています。ScrollableResults オブジェクトは Lucene リソースを保持するため、終了後はこのオブジェクトを閉じるようにしてください。scroll の使用が想定される場合にオブジェクトを一括してロードするには、query.setFetchSize() を使用できます。ロードされていないオブジェクトがアクセスされた場合、Hibernate Search は次の fetchSize オブジェクトを 1 度にロードします。
スクローリングよりもページネーションの使用が推奨されます。
13.5.2.2. 結果サイズ
以下のような場合、一致するドキュメントの合計数が分かると便利です。
- Google 検索による検索結果の合計を表す機能を提供する場合 (例:「検索結果約 888,000,000 件中 1 - 10 件を表示」)
- 高速なページネーションのナビゲーションを実装する場合
- 制限されたクエリーがゼロを返すか、十分な結果を返さないときに近似値を追加する、複数ステップの検索エンジンを実装する場合
一致するドキュメントをすべて読み出すには大量のリソースを消費します。Hibernate Search では、ページネーションパラメーターに関係なく、一致するドキュメントの合計数を読み出しできます。さらに、オブジェクトのロードを発生させずに一致する要素の数を読み出しすることもできます。
例: クエリーの結果サイズの決定
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
//return the number of matching books without loading a single one
assert 3245 == ;
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setMaxResult(10);
List results = query.list();
//return the total number of matching books regardless of pagination
assert 3245 == ;Google と同様に、インデックスがデータベースに対して完全に最新の状態になっていない場合は (非同期クラスターなど)、結果の数は近似値になります。
13.5.2.3. ResultTransformer
射影の結果は Object 配列として返されます。オブジェクトに使用されたデータ構造がアプリケーションの要件と一致しない場合は、ResultTransformer を適用します。ResultTransformer はクエリーの実行後に必要なデータ構造を構築します。
射影の結果は Object 配列として返されます。オブジェクトに使用されたデータ構造がアプリケーションの要件と一致しない場合は、ResultTransformer を適用します。ResultTransformer はクエリーの実行後に必要なデータ構造を構築します。
例: 射影への ResultTransformer の使用
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( "title", "mainAuthor.name" );
query.setResultTransformer( new StaticAliasToBeanResultTransformer( BookView.class, "title", "author" ) );
List<BookView> results = (List<BookView>) query.list();
for(BookView view : results) {
log.info( "Book: " + view.getTitle() + ", " + view.getAuthor() );
}
ResultTransformer 実装の例は、Hibernate Core のコードベースにあります。
13.5.2.4. 結果の理解
クエリーの結果が想定外であった場合、結果を理解するには Luke ツールを使用すると便利です。しかし、 Hibernate Search では (特定クエリーの) 結果の Lucene Explanation オブジェクトへアクセスすることもできます。このクラスは、Lucene ユーザーにとっては非常に高度なクラスですが、オブジェクトのスコアを理解するのに便利です。特定の結果の Explanation オブジェクトへアクセスする方法は 2 つあります。
-
fullTextQuery.explain(int)メソッドの使用 - 射影の使用
最初の方法は、ドキュメント ID をパラメーターとして取り、Explanation オブジェクトを返します。ドキュメント ID は射影および FullTextQuery.DOCUMENT_ID 定数を使用して読み出しできます。
ドキュメント ID はエンティティー ID とは関係ありません。これらを混同しないようにしてください。
2 つ目の方法は、FullTextQuery.EXPLANATION 定数を使用して Explanation オブジェクトを射影します。
例: 射影を使用した Lucene Explanation オブジェクトの読み出し
FullTextQuery ftQuery = s.createFullTextQuery( luceneQuery, Dvd.class )
.setProjection(
FullTextQuery.DOCUMENT_ID,
,
FullTextQuery.THIS );
@SuppressWarnings("unchecked") List<Object[]> results = ftQuery.list();
for (Object[] result : results) {
Explanation e = (Explanation) result[1];
display( e.toString() );
}Explanation オブジェクトの使用で消費するリソースは Lucene クエリーを再実行するのとほぼ同じため、必要な場合のみ使用してください。
13.5.2.5. Filters
Apache Lucene には、カスタムのフィルター処理に従ってクエリーの結果をフィルターできる強力な機能が含まれています。これは、フィルターをキャッシュおよび再使用できるため、データの制限を追加で適用する大変強力な方法です。ユースケースには以下が含まれます。
- security
- 一時データ (例: 閲覧専用の先月のデータ)
- 入力 (population) フィルター (例: 指定のカテゴリーに限定される検索)
Hibernate Search では、さらに、透過的にキャッシュされるパラメーター化可能な名前付きフィルターの概念が導入されます。Hibernate Core フィルターの概念を知っている場合、その API は非常に似ています
例: クエリーに対するフルテキストフィルターの有効化
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("bestDriver");
fullTextQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
fullTextQuery.list(); //returns only best drivers where andre has credentialsこの例では、クエリー上で 2 つのフィルターが有効になっています。フィルターは好きなだけ (有効または無効) にできます。
フィルターの宣言は、@FullTextFilterDef アノテーションから行われます。このアノテーションは、フィルターが後で適用されるクエリーに関係なく、 @Indexed エンティティーである場合があります。これは、暗黙的に、フィルター定義がグローバルであり、その名前が一意である必要があることを示します。SearchException は、同じ名前で 2 つの異なる @FullTextFilterDef アノテーションが定義された場合にスローされます。各名前付きフィルターは実際のフィルター実装を指定する必要があります。
例: フィルターの定義および実装
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }public class BestDriversFilter extends org.apache.lucene.search.Filter {
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
OpenBitSet bitSet = new OpenBitSet( reader.maxDoc() );
TermDocs termDocs = reader.termDocs( new Term( "score", "5" ) );
while ( termDocs.next() ) {
bitSet.set( termDocs.doc() );
}
return bitSet;
}
}
BestDriversFilter は、スコアが 5 のドライバーに結果セットを削減する単純な Lucene フィルターの例です。この例では、指定されたフィルターは org.apache.lucene.search.Filter を直接実装し、引数がないコンストラクターを含みます。
フィルターの作成で追加の手順が必要な場合、または使用するフィルターに引数がないコンストラクターが含まれない場合は、ファクトリーパターンを使用できます。
例: ファクトリーパターンを使用したフィルターの作成
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilterFactory.class)
public class Driver { ... }
public class BestDriversFilterFactory {
@Factory
public Filter getFilter() {
//some additional steps to cache the filter results per IndexReader
Filter bestDriversFilter = new BestDriversFilter();
return new CachingWrapperFilter(bestDriversFilter);
}
}
Hibernate Search は、@Factory アノテーションが付いたメソッドを探し、そのメソッドを使用してフィルターインスタンスを構築します。ファクトリーには引数がないコンストラクターが含まれる必要があります。
Infinispan クエリーは @Factory アノテーションが付いたメソッドを使用してフィルターインスタンスを構築します。ファクトリーには引数がないコンストラクターが含まれる必要があります。
名前付きフィルターは、パラメーターをフィルターに渡す必要がある場合に便利です。たとえば、セキュリティーフィルターが、適用するセキュリティーレベルを認識する場合を考えてみます。
例: 定義されたフィルターにパラメーターを渡す
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("security").setParameter( "level", 5 );各パラメーター名では、対象となる名前付きフィルター定義のフィルターまたはフィルターファクトリーのいずれかでセッターが関連付けられているとします。例: 実際のフィルター実装でのパラメーターの使用
public class SecurityFilterFactory {
private Integer level;
/**
* injected parameter
*/
public void setLevel(Integer level) {
this.level = level;
}
@Key public FilterKey getKey() {
StandardFilterKey key = new StandardFilterKey();
key.addParameter( level );
return key;
}
@Factory
public Filter getFilter() {
Query query = new TermQuery( new Term("level", level.toString() ) );
return new CachingWrapperFilter( new QueryWrapperFilter(query) );
}
}@Key アノテーションが付いたメソッドは FilterKey オブジェクトを返すことに注意してください。返されたオブジェクトには特別なコントラクトがあります (キーオブジェクトは equals() / hashCode() を実装して、特定のフィルタータイプが同じであり、パラメーターセットが同じである場合のみ 2 つのキーが同じになるようにします)。つまり、2 つのフィルターキーは、キーが生成されるフィルターが交換可能である場合のみ同じになります。キーオブジェクトはキャッシュメカニズムでキーとして使用されます。
@Key メソッドは以下の場合のみ必要です。
- フィルターキャッシュシステムが有効である (デフォルトで有効)
- フィルターにパラメーターが含まれる
ほとんどの場合、StandardFilterKey 実装を使用するだけで十分です。これにより、equals() / hashCode() 実装はパラメーターの各 equals および hashcode メソッドに委譲されます。
これまでに説明したように、定義されたフィルターはデフォルトでキャッシュされ、キャッシュはハード参照とソフト参照の組み合わせを使用して必要な場合にメモリーの破棄を許可します。ハード参照キャッシュは最後に使用されたフィルターを追跡し、使用頻度が最も低いフィルターを必要に応じて SoftReferences に変換します。ハード参照キャッシュのサイズを調整するには、hibernate.search.filter.cache_strategy.size (デフォルト値は 128) を使用します。フィルターキャッシュの高度な使用については、独自の FilterCachingStrategy を実装してください。クラス名は hibernate.search.filter.cache_strategy によって定義されます。
このフィルターキャッシュメカニズムを実際のフィルター結果と混同しないでください。Lucene では、CachingWrapperFilter に IndexReader を使用してフィルターをラップすることが一般的です。このラッパーは、コストがかかる再計算を回避するために getDocIdSet(IndexReader リーダー) メソッドから返された DocIdSet をキャッシュします。リーダーは開いたときのインデックスの状態を表すため、計算される DocIdSet は同じ IndexReader インスタンスに対してのみキャッシュできることに注意してください。ドキュメントリストは開いた IndexReader 内で変更できません。ただし、別の/新しい IndexReader インスタンスがドキュメントの別のセット (別のインデックスのもの、またはインデックスが変更されたため) で動作することがあります。この場合、キャッシュされた DocIdSet は再計算する必要があります。
Hibernate Search は、キャッシュのこの側面でも役に立ちます。デフォルトでは、@FullTextFilterDef の cache フラグは FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS に設定され、フィルターインスタンスが自動的にキャッシュされ、指定されたフィルターが CachingWrapperFilter の Hibernate 固有の実装にラップされます。このクラスの Lucene のバージョンとは異なり、SoftReferences はハード参照数 (フィルターキャッシュに関する説明を参照) とともに使用されます。ハード参照数は、hibernate.search.filter.cache_docidresults.size (デフォルト値は 5) を使用して調整できます。ラップの動作は @FullTextFilterDef.cache パラメーターを使用して制御できます。このパラメーターには以下の 3 つの異なる値があります。
| 値 | 定義 |
|---|---|
|
FilterCacheModeType.NONE |
フィルターインスタンスなしと結果なしは Hibernate Search によってキャッシュされます。フィルターの呼び出しごとに、新しいフィルターインスタンスが作成されます。この設定は、頻繁に変更するデータやメモリーの制約が大きい環境に役に立つことがあります。 |
|
FilterCacheModeType.INSTANCE_ONLY |
フィルターインスタンスはキャッシュされ、同時 Filter.getDocIdSet() 呼び出しで再使用されます。この設定は、フィルターが独自のキャッシュメカニズムを使用する場合、またはフィルター結果が動的に変更される場合に役に立ちます (アプリケーション固有のイベントにより両方のケースで DocIdSet キャッシュが不必要になることが原因)。 |
|
FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS |
フィルターインスタンスの結果と DocIdSet の結果の両方がキャッシュされます。これはデフォルト値です。 |
最後に、フィルターをキャッシュする理由について説明します。フィルターのキャッシュが必要になる状況は 2 つあります。
その状況は以下のとおりです。
- システムが対象となるエンティティーインデックスを頻繁に更新しない (つまり、IndexReader が頻繁に再利用される)
- フィルターの DocIdSet の計算のコストが高い (クエリーを実行するのにかかる時間と比較して)
13.5.2.6. シャード化された環境におけるフィルターの使用
シャード化された環境では、使用できるシャードのサブセットでクエリーを実行できます。これは、2 つのステップで行われます。
インデックスシャードのサブセットをクエリーする
- フィルター設定に応じて、IndexManagers のサブセットを選択するシャードストラテジーを作成します。
- クエリーの実行時にフィルターを有効にします。
例: インデックスシャードのサブセットをクエリーする
この例では、customer フィルターが有効になるとクエリーが特定のカスタマーシャードに対して実行されます。
public class CustomerShardingStrategy implements IndexShardingStrategy {
// stored IndexManagers in an array indexed by customerID
private IndexManager[] indexManagers;
public void initialize(Properties properties, IndexManager[] indexManagers) {
this.indexManagers = indexManagers;
}
public IndexManager[] getIndexManagersForAllShards() {
return indexManagers;
}
public IndexManager getIndexManagerForAddition(
Class<?> entity, Serializable id, String idInString, Document document) {
Integer customerID = Integer.parseInt(document.getFieldable("customerID").stringValue());
return indexManagers[customerID];
}
public IndexManager[] getIndexManagersForDeletion(
Class<?> entity, Serializable id, String idInString) {
return getIndexManagersForAllShards();
}
/**
* Optimization; don't search ALL shards and union the results; in this case, we
* can be certain that all the data for a particular customer Filter is in a single
* shard; simply return that shard by customerID.
*/
public IndexManager[] getIndexManagersForQuery(
FullTextFilterImplementor[] filters) {
FullTextFilter filter = getCustomerFilter(filters, "customer");
if (filter == null) {
return getIndexManagersForAllShards();
}
else {
return new IndexManager[] { indexManagers[Integer.parseInt(
filter.getParameter("customerID").toString())] };
}
}
private FullTextFilter getCustomerFilter(FullTextFilterImplementor[] filters, String name) {
for (FullTextFilterImplementor filter: filters) {
if (filter.getName().equals(name)) return filter;
}
return null;
}
}
この例では、customer という名前のフィルターが存在する場合はこのカスタマー専用のシャードのみがクエリーされます。存在しない場合はすべてのシャードが返されます。指定のシャードストラテジーはパラメーターに応じて 1 つ以上のフィルターに反応します。
2 つ目の手順では、クエリー実行時にフィルターを有効にします。クエリーの後に Lucene の結果もフィルターする通常のフィルターですが、シャードストラテジーのみへ渡される特別なフィルターを使用できます (シャードストラテジーへ渡されないと無視されます)。
この機能を使用するには、フィルターの宣言時に ShardSensitiveOnlyFilter クラスを指定します。
@Indexed
@FullTextFilterDef(name="customer", impl=ShardSensitiveOnlyFilter.class)
public class Customer {
...
}
FullTextQuery query = ftEm.createFullTextQuery(luceneQuery, Customer.class);
query.enableFulltextFilter("customer").setParameter("CustomerID", 5);
@SuppressWarnings("unchecked")
List<Customer> results = query.getResultList();ShardSensitiveOnlyFilter を使用する場合、Lacene フィルターを実装する必要はありません。シャード化された環境でクエリーの実行を迅速にするために、フィルターおよびこれらにフィルターに反応するシャードストラテジーの使用が推奨されます。
13.5.3. ファセット
ファセット検索 (faceted search) は、クエリーの結果を複数のカテゴリーに分割できるテクニックです。このカテゴリー化には、各カテゴリーのヒット数の計算や、ファセット (カテゴリー) を基にして検索結果をさらに制限する機能が含まれます。以下の例はファセットの例を示しています。検索結果のヒット数は 15 であり、ページの主要部分に表示されます。左側のナビゲーションバーには Computers & Internet カテゴリーと、サブカテゴリーの Programming、Computer Science、Databases、Software、Web Development、Networking、および Home Computing が表示されます。各サブカテゴリーには、メインの検索基準に一致し、それぞれのサブカテゴリーに属する本の数が表示されます。カテゴリー Computers & Internet のこのような分割は、具体的な検索ファセットの 1 つです。別のファセットの例としては、カスタマーレビューの平均が挙げられます。
ファセット検索では、クエリーの結果がカテゴリーに分割されます。カテゴリー化には、各カテゴリーのヒット数の計算が含まれ、これらのファセット (カテゴリー) に基づいて検索結果がさらに制限されます。以下の例では、主要なページにファセット検索の結果の 15 件が表示されています。
左側のナビゲーションバーは、カテゴリーとサブカテゴリーを示しています。各サブカテゴリーに対して、本の数は主要な検索基準に一致し、各サブカテゴリーに属します。カテゴリー Computers & Internet のこのような分割は具体的な検索ファセットの 1 つです。別のファセットの例としては、カスタマーレビューの平均が挙げられます。
例: Amazon での Hibernate Search の検索
Hibernate Search では、QueryBuilder および FullTextQuery クラスがファセット API へのエントリーポイントになります。QueryBuilder はファセットリクエストを作成し、FullTextQuery は FacetManager へアクセスします。FacetManager はファセットリクエストをクエリーに適用し、検索結果を絞り込むために既存のクエリーへ追加されるファセットを選択します。例では、以下の例で示されたようにエンティティー Cd が使用されます。
例: エンティティー Cd
@Indexed
public class Cd {
private int id;
@Fields( {
@Field,
@Field(name = "name_un_analyzed", analyze = Analyze.NO)
})
private String name;
@Field(analyze = Analyze.NO)
@NumericField
private int price;
Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
private Date releaseYear;
@Field(analyze = Analyze.NO)
private String label;
// setter/getter
...Hibernate Search 5.2 よりも前は、@Facet アノテーションを明示的に使用する必要がありませんでした。Hibernate Search 5.2 では、Lucene のネイティブファセット API を使用するために、@Facet アノテーションを明示的に使用することが必要になりました。
13.5.3.1. ファセットリクエストの作成
ファセット検索を行うための最初の手順は FacetingRequest を作成することです。現在、離散ファセット (discrete faceting) と範囲ファセット (range faceting) の 2 つの種類のファセットリクエストがサポートされています。離散ファセットリクエストの場合、ファセット (カテゴリー化) を使用したいインデックスフィールドと、適用するファセットオプションを指定します。離散ファセットリクエストの例を以下に示します。
例: 離散ファセットリクエストの作成
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest labelFacetingRequest = builder.facet()
.name( "labelFaceting" )
.onField( "label")
.discrete()
.orderedBy( FacetSortOrder.COUNT_DESC )
.includeZeroCounts( false )
.maxFacetCount( 1 )
.createFacetingRequest();
このファセットリクエストを実行すると、インデックス化されたフィールド label の各離散値に対して Facet インスタンスが作成されます。Facet インスタンスは実際のフィールド値を記録します。この値には、元のクエリー結果内でこの特定のフィールド値が発生する頻度が含まれます。orderedBy、includeZeroCounts、および maxFacetCount はすべてのファセットリクエストに適用できる任意のパラメーターです。orderedBy を使用すると、作成されたファセットが返される順序を指定できます。デフォルト値は FacetSortOrder.COUNT_DESC ですが、フィールド値と範囲が指定された順番をソートすることもできます。includeZeroCount はカウント数が 0 のファセットが結果に含まれるかどうかを決定します (デフォルトでは含まれます)。maxFacetCount を使用すると返されるファセットの最大数を制限できます。
現時点では、インデックス化されたフィールドにファセットを適用するにはそのフィールドが複数の事前条件を満たしている必要があります。インデックス化されたプロパティーは String 型、Date 型、または Number のサブタイプでなければなりません。null 値は使用しないようにしてください。さらに、プロパティーは Analyze.NO でインデックス化する必要があり、数値のプロパティーの場合は @NumericField を指定する必要があります。
範囲ファセットリクエストの作成は離散ファセットリクエストの作成と非常に似ていますが、ファセットを使用するフィールド値の範囲を指定する必要があります。3 つの異なる価格範囲が指定されている、範囲ファセットリクエストの例を以下に示します。below および above は 1 度だけ指定できますが、from - to の範囲は何度でも指定できます。範囲の境界に excludeLimit を使用して、範囲に含まれるかどうかを指定することもできます。
例: 範囲ファセットリクエストの作成
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest priceFacetingRequest = builder.facet()
.name( "priceFaceting" )
.onField( "price" )
.range()
.below( 1000 )
.from( 1001 ).to( 1500 )
.above( 1500 ).excludeLimit()
.createFacetingRequest();
13.5.3.2. ファセットリクエストの適用
ファセットリクエストは、FullTextQuery クラスを用いて読み出しできる FacetManager クラスを使用して、クエリーに適用されます。
ファセットリクエストはいくつでも有効にでき、ファセットリクエスト名を指定して getFacets() で読み出しできます。ファセットリクエスト名を指定してそのファセットを無効にできる disableFaceting() メソッドもあります。
ファセットリクエストは、FullTextQuery を用いて読み出しできる FacetManager を使用して、クエリーに適用できます。
例: ファセットリクエストの適用
// create a fulltext query Query luceneQuery = builder.all().createQuery(); // match all query FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Cd.class ); // retrieve facet manager and apply faceting request FacetManager facetManager = fullTextQuery.getFacetManager(); facetManager.enableFaceting( priceFacetingRequest ); // get the list of Cds List<Cd> cds = fullTextQuery.list(); ... // retrieve the faceting results List<Facet> facets = facetManager.getFacets( "priceFaceting" ); ...
複数のファセットリクエストは getFacets() を使用し、ファセットリクエスト名を指定することにより読み出しできます。
disableFaceting() メソッドは、ファセットリクエスト名を指定してファセットリクエストを無効にします。
13.5.3.3. クエリー結果の制限
最後に、「ドリルダウン」機能を実装するために、返された Facet のいずれかを元のクエリーの追加基準として適用できます。この場合は、FacetSelection を使用できます。FacetSelection は FacetManager から利用できます。これにより、クエリー基準としてのファセットの選択 (selectFacets)、単一のファセット制限の削除 (deselectFacets)、すべてのファセット制限の消去 (clearSelectedFacets)、および現在選択されているすべてのファセットの読み出し (getSelectedFacets) が可能になります。以下にコード例を示します。
// create a fulltext query Query luceneQuery = builder.all().createQuery(); // match all query FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, clazz ); // retrieve facet manager and apply faceting request FacetManager facetManager = fullTextQuery.getFacetManager(); facetManager.enableFaceting( priceFacetingRequest ); // get the list of Cd List<Cd> cds = fullTextQuery.list(); assertTrue(cds.size() == 10); // retrieve the faceting results List<Facet> facets = facetManager.getFacets( "priceFaceting" ); assertTrue(facets.get(0).getCount() == 2) // apply first facet as additional search criteria facetManager.getFacetGroup( "priceFaceting" ).selectFacets( facets.get( 0 ) ); // re-execute the query cds = fullTextQuery.list(); assertTrue(cds.size() == 2);
13.5.4. クエリー処理の最適化
クエリーのパフォーマンスは複数の基準に依存します。
- Lucene クエリー。
- ロードされたオブジェクトの数: ページネーション (常に使用) またはインデックス射影 (必要な場合) の使用。
- Hibernate Search が Lucene リーダーと対話する方法: 適切なリーダーストラテジーの定義。
- インデックスから頻繁に抽出される値のキャッシュ: インデックス値のキャッシュ: FieldCacheを参照。
13.5.4.1. インデックス値のキャッシュ: FieldCache
Lucene インデックスの主な機能はクエリーの一致を特定することです。クエリーが実行された後、有用な情報を抽出するために結果を分析する必要があります。通常、Hibernate Search は Class タイプと主キーを抽出する必要があります。
インデックスから必要な値を抽出すると、パフォーマンスに負担がかかります。負担が大変小さくて気がつかないこともありますが、キャッシュした方がよい場合もあります。
要件は使用される射影の種類によって異なります。クエリーコンテキストなどから推測できる場合、Class 型は必要ありません。
@CacheFromIndex アノテーションを使用すると、Hibernate Search が必要とする主なメタデータフィールドの異なるキャッシュ方法を試すことができます。
import static org.hibernate.search.annotations.FieldCacheType.CLASS;
import static org.hibernate.search.annotations.FieldCacheType.ID;
@Indexed
@CacheFromIndex( { CLASS, ID } )
public class Essay {
...このアノテーションを使用して Class 型および ID をキャッシュすることはできません。
CLASS: Hibernate Search は Lucene FieldCache を使用して、インデックスから Class 型を抽出するパフォーマンスを向上します。この値はデフォルトでは有効になっています。@CacheFromIndex アノテーションを指定しないと、この値が Hibernate Search によって適用されます。
-
ID: 主識別子を抽出するとキャッシュが使用されます。パフォーマンスが最も優れたクエリーが提供されるはずですが、メモリーを大量に消費するため、パフォーマンスが低下する可能性があります。
ウォームアップの後 (一部のクエリーを実行した後) に、パフォーマンスとメモリー消費の影響を計測します。フィールドキャッシュを有効にするとパフォーマンスが向上する可能性がありますが、向上しないこともあります。
FieldCache を使用するデメリットは 2 つあります。
- メモリーの使用量: これらのキャッシュはメモリーを大量に使用します。通常、CLASS キャッシュの要件は ID キャッシュよりも少なくなります。
- インデックスのウォームアップ: フィールドキャッシュを使用する場合、新しいインデックスまたはセグメントの最初のクエリーはキャッシュが有効になっていない場合よりも遅くなります。
クエリーによっては、クラス型が必要でない場合があります。このような場合、CLASS フィールドキャッシュを有効にしても使用されないことがあります。たとえば、単一のクラスを対象とする場合、戻り値はすべてその型になります (クエリーの実行ごとに評価されます)。
ID FieldCache を使用する場合、対象エンティティーの ID は (構築するすべてのブリッジとして) TwoWayFieldBridge を使用する必要があります。特定のクエリーにロードされるすべての型は ID にフィールド名を使用し、同じ型の ID を持つ必要があります (クエリーの実行ごとに評価されます)。
13.6. 手動によるインデックスの変更
Hibernate Core はデータベースに変更を適用するため、Hibernate Search はこのような変更を検出し、インデックスを自動的に更新します (EventListeners が無効になっている場合を除く)。バックアップをリストアしないとデータに影響するときなど、場合によっては Hibernate を使用せずにデータベースに変更が加えられることがあります。このような場合、Hibernate Search は手動インデックス API を公開して明示的にインデックスから単一のエンティティーを更新または削除します。さらに、データベース全体に対してインデックスを再構築したり、特定の型への参照をすべて削除したりします。
これらのメソッドは Lucene インデックスのみに影響し、変更はデータベースには適用されません。
13.6.1. インデックスへのインスタンスの追加
FullTextSession.index(T entity) を使用すると、特定のオブジェクトインスタンスを直接インデックスへ追加したり、更新したりできます。このエンティティーがすでにインデックス化されている場合は、インデックスが更新されます。インデックスへの変更は、トランザクションのコミット時のみに適用されます。
FullTextSession.index(T entity) を使用してオブジェクトまたはインスタンスをインデックスに直接追加します。インデックスは、エンティティーがインデックス化されるときに更新されます。Infinispan Query は、トランザクションのコミット時にインデックスに変更を適用します。
例: FullTextSession.index(T entity) を用いたエンティティーのインデックス化
FullTextSession fullTextSession = Search.getFullTextSession(session); Transaction tx = fullTextSession.beginTransaction(); Object customer = fullTextSession.load( Customer.class, 8 ); fullTextSession.index(customer); tx.commit(); //index only updated at commit time
1 つの型またはインデックス化されたすべての型のすべてのインスタンスを追加したい場合は、MassIndexer を使用する方法が推奨されます。
MassIndexer を使用して 1 つの型 (またはインデックス化されたすべての型) を追加します。詳細については、MassIndexer の使用を参照してください。
13.6.2. インデックスからのインスタンスの削除
データベースから物理的に削除しなくても、指定の型の 1 つまたはすべてのエンティティーを Lucene インデックスから削除できます。この操作はパージと呼ばれ、FullTextSession を使用して実行されます。
パージ操作により、Lucene インデックスからある型の 1 つのエンティティーまたはすべてのエンティティーを削除できます (データベースから物理的に削除する必要はありません)。この操作は FullTextSession を使用して実行されます。
例: インデックスから 1 つのエンティティーの特定インスタンスをパージする
FullTextSession fullTextSession = Search.getFullTextSession(session);
Transaction tx = fullTextSession.beginTransaction();
for (Customer customer : customers) {
fullTextSession.purgeAll( Customer.class );
//optionally optimize the index
//fullTextSession.getSearchFactory().optimize( Customer.class );
tx.commit(); //index is updated at commit timeこのような操作の後にインデックスを最適化することが推奨されます。
FullTextEntityManager では index、purge、および purgeAll メソッドも利用できます。
すべての手動インデックス化メソッド (index、purge、および purgeAll) はインデックスのみに影響し、データベースには影響しませんが、トランザクションに対応するためトランザクションが正常にコミットされるまで (または flushToIndexes が使用されるまで) 適用されません。
13.6.3. インデックスの再構築
インデックスへのエンティティーマッピングを変更するとき、ほとんどの場合でインデックス全体を更新する必要があります。たとえば、異なるアナライザーを使用して既存のフィールドをインデックス化する場合は、影響のある型のインデックスを再構築する必要があります。また、データベースが置き換えられた場合 (バックアップからリストアされたり、レガシーシステムからインポートされた場合など) は、既存データからインデックスを再構築できるようにしたいことがあります。Hibernate Search には 2 つのメインストラテジーがあります。
インデクサーのエンティティーマッピングを変更するには、インデックス全体を更新する必要がある場合があります。異なるアナライザーを使用して既存のフィールドをインデックス化する場合は、影響を受ける型に対してインデックスを再構築する必要があります。
また、バックアップから復元するか、レガシーシステムからインポートすることによりデータベースが置き換えられた場合は、既存のデータからインデックスを再構築する必要があります。Infinispan Query は 2 つの主要なストラテジーを提供します。
-
すべてのエンティティーで
FullTextSession.index()を使用し、FullTextSession.flushToIndexes()を定期的に使用する。 -
MassIndexerを使用する。
13.6.3.1. flushToIndexes() の使用
このストラテジーでは、既存のインデックスを削除した後、FullTextSession.purgeAll() および FullTextSession.index() を使用してすべてのエンティティーをインデックスに戻しますが、メモリーと効率性の制約があります。効率性を最大化にするために、Hibernate Search はインデックスの操作を一括してコミット時に実行します。大量のデータをインデックス化することが想定される場合は、トラザクションがコミットされるまですべてのドキュメントがキューに保持されるため、メモリーの消費に注意する必要があります。キューを周期的に空にしないと OutOfMemoryException が発生する可能性があります。キューを空にするには、fullTextSession.flushToIndexes() を使用します。fullTextSession.flushToIndexes() が呼び出されるたびに (またはトランザクションがコミットされると) バッチキューが処理され、インデックスのすべての変更が適用されます。1 度フラッシュすると変更をロールバックできないことに注意してください。
例: index() および flushToIndexes() を使用したインデックスの再構築
fullTextSession.setFlushMode(FlushMode.MANUAL);
fullTextSession.setCacheMode(CacheMode.IGNORE);
transaction = fullTextSession.beginTransaction();
//Scrollable results will avoid loading too many objects in memory
ScrollableResults results = fullTextSession.createCriteria( Email.class )
.setFetchSize(BATCH_SIZE)
.scroll( ScrollMode.FORWARD_ONLY );
int index = 0;
while( results.next() ) {
index++;
fullTextSession.index( results.get(0) ); //index each element
if (index % BATCH_SIZE == 0) {
fullTextSession.flushToIndexes(); //apply changes to indexes
fullTextSession.clear(); //free memory since the queue is processed
}
}
transaction.commit();
この明示的な API はより優れた制御機能を提供するため、hibernate.search.default.worker.batch_size は廃止されました。
アプリケーションがメモリー不足にならないバッチサイズを使用するようにしてください。バッチサイズを大きくするとデータベースからオブジェクトをフェッチする速度が速くなりますが、より多くのメモリーが必要になります。
13.6.3.2. MassIndexer の使用
Hibernate Search の MassIndexer は複数の平行スレッドを使用してインデックスを再構築します。オプションで、リロードが必要なエンティティーを選択したり、すべてのエンティティーを再インデックス化したりできます。この方法はパフォーマンスを最大化するために最適化されますが、アプリケーションをメンテナンスモードに設定する必要があります。MassIndexer がビジー状態のときはインデックスのクエリーは推奨されません。
例: MassIndexer を使用したインデックスの再構築
fullTextSession.createIndexer().startAndWait();
これは、インデックスを再構築して削除し、データベースからすべてのエンティティーをリロードします。これは簡単に使用できますが、プロセスを迅速にするために多少の調整を行うことが推奨されます。
MassIndexer の実行中はインデックスの内容が未定義になります。MassIndexer の動作中にクエリーが実行されると、結果の一部が失われる可能性があります。
例: 調整された MassIndexer の使用
fullTextSession .createIndexer( User.class ) .batchSizeToLoadObjects( 25 ) .cacheMode( CacheMode.NORMAL ) .threadsToLoadObjects( 12 ) .idFetchSize( 150 ) .progressMonitor( monitor ) //a MassIndexerProgressMonitor implementation .startAndWait();
この例では、すべての User インスタンス (およびサブタイプ) のインデックスが再構築され、クエリーごとに 25 個のオブジェクトのバッチを使用して User インスタンスをロードするために 12 個の平行スレッドが作成されます。Lucene ドキュメントを出力するために、これらの 12 個のスレッドは、インデックス化された埋め込み関係と、カスタムの FieldBridges または ClassBridges を処理する必要もあります。スレッドによって、変換の処理中に追加属性のレイジーローディングがトリガーされます。そのため、平行して動作するスレッドが大量に必要になります。実際のインデックスの書き込みを行うスレッドの数は、各インデックスのバックエンド設定によって定義されます。
インデックス化を行うほとんどの場合で、キャッシュは不必要なオーバーヘッドになるため、cacheMode を CacheMode.IGNORE (デフォルト) のままにしておくことが推奨されます。メインエントリーがインデックスに含まれる列挙に似たデータである場合は、データに応じて他の CacheMode の一部を有効にするとパフォーマンスが向上する可能性があります。
最良のパフォーマンスを実現するスレッド数は、全体のアーキテクチャー、データベースの設計、およびデータの値に大きく依存します。内部スレッドグループの名前はすべて意味があるため、threaddumps などの解析ツールを使用すれば簡単に特定できるはずです。
MassIndexer はトランザクションを認識しないため、トランザクションを開始したりコミットする必要はありません。トランザクションではないため、処理中にユーザーによるシステムの使用を許可しないことが推奨されます。処理中にユーザーが結果を見つけられる可能性は低く、システムの負荷が大変高くなる可能性があります。
インデックス化の時間やメモリーの消費に影響するその他のパラメーターは次のとおりです。
-
hibernate.search.[default|<indexname>].exclusive_index_use -
hibernate.search.[default|<indexname>].indexwriter.max_buffered_docs -
hibernate.search.[default|<indexname>].indexwriter.max_merge_docs -
hibernate.search.[default|<indexname>].indexwriter.merge_factor -
hibernate.search.[default|<indexname>].indexwriter.merge_min_size -
hibernate.search.[default|<indexname>].indexwriter.merge_max_size -
hibernate.search.[default|<indexname>].indexwriter.merge_max_optimize_size -
hibernate.search.[default|<indexname>].indexwriter.merge_calibrate_by_deletes -
hibernate.search.[default|<indexname>].indexwriter.ram_buffer_size -
hibernate.search.[default|<indexname>].indexwriter.term_index_interval
以前のバージョンでは max_field_length を使用できましたが、これは Lucene から削除されました。LimitTokenCountAnalyzer を使用すると同様の効果を得ることができます。
.indexwriter はすべて Lucene 固有のパラメーターで、Hibernate Search はこれらのパラメーターを渡します。
MassIndexer は、前方のみスクロール可能な結果を使用して、ロードされる主キーで反復処理を行いますが、MySQL の JDBC ドライバーはメモリーのすべての値をロードします。この「最適化」が実行されないようにするには、idFetchSize を Integer.MIN_VALUE に設定します。
13.7. インデックスの最適化
Lucene インデックスは時々最適化する必要があります。基本的にデフラグメンテーションを行います。最適化がトリガーされるまで、Lucene は削除されたドキュメントのみをマーク付けするため、物理的な削除は適用されません。最適化処理中に削除が適用され、Lucene Directory のファイル数にも影響します。
Lucene インデックスの最適化により検索速度は向上しますが、インデックス化 (更新) のパフォーマンスには影響ありません。最適化中に検索を実行できますが、ほとんどの場合、検索速度が遅くなります。インデックスの更新はすべて停止されます。以下の場合に最適化をスケジュールすることが推奨されます。
Lucene インデックスの最適化により検索は短縮化されますが、インデックス更新のパフォーマンスには影響ありません。最適化中に検索を実行できますが、検索の処理は遅くなります。最適化中にインデックスの更新はすべて停止されます。したがって、以下の場合に最適化をスケジュールすることが推奨されます。
- アイドルシステム上、または検索の頻度が最も低い場合。
- インデックスに多くの変更が加えられた後。
MassIndexer (MassIndexer の使用を参照) はデフォルトで処理の最初と最後にインデックスを最適化します。このデフォルトの挙動を変更するには、MassIndexer.optimizeAfterPurge および MassIndexer.optimizeOnFinish を使用します。
13.7.1. 自動最適化
Hibernate Search は、以下のいずれかを行った後にインデックスを自動的に最適化します。
以下の実行後に、Infinispan Query によりインデックスが自動的に最適化されます。
- 一定量の操作 (挿入または削除)。
- 一定量のトランザクション。
インデックスの自動最適化の設定は、グローバルまたはインデックスごとに定義できます。
定義: 自動最適化パラメーターの定義
hibernate.search.default.optimizer.operation_limit.max = 1000 hibernate.search.default.optimizer.transaction_limit.max = 100 hibernate.search.Animal.optimizer.transaction_limit.max = 50
以下のいずれかが発生すると、即座に最適化が Animal インデックスへトリガーされます。
-
追加または削除の数が
1000に達した場合。 -
トランザクションの数が
50に達した場合 (hibernate.search.Animal.optimizer.transaction_limit.maxはhibernate.search.default.optimizer.transaction_limit.maxよりも優先されます)。
これらのパラメーターがすべて未定義であると、最適化は自動的に処理されません。
OptimizerStrategy のデフォルト実装をオーバーライドするには、org.hibernate.search.store.optimization.OptimizerStrategy を実装し、optimizer.implementation プロパティーを実装の完全修飾名に設定します。この実装はインターフェースを実装する必要があります。またパブリッククラスである必要があり、引数を取らないパブリックコンストラクターを持つ必要があります。
例: カスタム OptimizerStrategy のロード
hibernate.search.default.optimizer.implementation = com.acme.worlddomination.SmartOptimizer hibernate.search.default.optimizer.SomeOption = CustomConfigurationValue hibernate.search.humans.optimizer.implementation = default
キーワード default を使用して Hibernate Search のデフォルト実装を選択できます。.optimizer キーセパレーターの後のすべてのプロパティーは、最初に実装の initialize メソッドへ渡されます。
13.7.2. 手動の最適化
SearchFactory を用いると、プログラミングによって Hibernate Search から Lucene インデックスを最適化 (デフラグメンテーション) できます。
例: プログラミングによるインデックスの最適化
FullTextSession fullTextSession = Search.getFullTextSession(regularSession); SearchFactory searchFactory = fullTextSession.getSearchFactory(); searchFactory.optimize(Order.class); // or searchFactory.optimize();
最初の例は Orders を保持する Lucene インデックスを最適化し、2 番目の例はすべてのインデックスを最適化します。
searchFactory.optimize() は JMS バックエンドには影響しません。最適化操作はマスターノードに適用する必要があります。
searchFactory.optimize() は、JMC バックエンドに影響を与えないため、マスターノードに適用されます。
13.7.3. 最適化の調整
Apache Lucene には最適化が実行される方法に影響するパラメーターが含まれています。Hibernate Search はこれらのパラメーターを公開します。
その他のインデックス最適化のパラメーターには以下が含まれます。
-
hibernate.search.[default|<indexname>].indexwriter.max_buffered_docs -
hibernate.search.[default|<indexname>].indexwriter.max_merge_docs -
hibernate.search.[default|<indexname>].indexwriter.merge_factor -
hibernate.search.[default|<indexname>].indexwriter.ram_buffer_size -
hibernate.search.[default|<indexname>].indexwriter.term_index_interval
13.8. 高度な機能
13.8.1. SearchFactory へのアクセス
SearchFactory オブジェクトは、Hibernate Search の基礎となる Lucene リソースを追跡します。これは、ネイティブで Lucene へアクセスするのに便利な方法です。SearchFactory は FullTextSession からアクセスできます。
例: SearchFactory へのアクセス
FullTextSession fullTextSession = Search.getFullTextSession(regularSession); SearchFactory searchFactory = fullTextSession.getSearchFactory();
13.8.2. IndexReader の使用
Lucene のクエリーは IndexReader 上で実行されます。Hibernate Search はパフォーマンスを最大限にするためにインデックスリーダーをキャッシュしたり、 更新された IndexReader を最小化する I/O 操作を読み出す効率的な他のストラテジーを提供したりできます。コードはこのようなキャッシュされたリソースへアクセスできますが、複数の要件があります。
例: IndexReader へのアクセス
IndexReader reader = searchFactory.getIndexReaderAccessor().open(Order.class);
try {
//perform read-only operations on the reader
}
finally {
searchFactory.getIndexReaderAccessor().close(reader);
}
この例では、SearchFactory はこのエンティティーをクエリーするために必要なインデックスを決定します (シャードストラテジーを考慮します)。設定された ReaderProvider を各インデックスで使用すると、関係するすべてのインデックスの他に複合の IndexReader が返されます。この IndexReader は複数のクライアントで共有されるため、以下のルールに従う必要があります。
- indexReader.close() は呼び出さないでください。必要な場合は readerProvider.closeReader(reader) を使用しますが、finally ブロックで使用することが推奨されます。
- この IndexReader は変更操作では使用しないでください (読み取り専用の IndexReader で、変更操作での使用を試みると例外が発生します)。
これらのルールを守れば、IndexReader を自由に使用できます (特にネイティブ Lucene クエリーを実行する場合)。シャード化された IndexReaders を使用すると、ほとんどのクエリーはファイルシステムなどから直接開くよりも効率的になります。
open(Class… types) メソッドの代わりに、open(String… indexNames) を使用すると 1 つ以上のインデックス名を渡すことができます。このストラテジーを使用すると、シャードが使用されている場合にインデックス化された型のインデックスのサブセットも選択できます。
例: インデックス名による IndexReader へのアクセス
IndexReader reader = searchFactory.getIndexReaderAccessor().open("Products.1", "Products.3");13.8.3. Lucene Directory へのアクセス
Directory は、インデックスのストレージを表すために Lucene によって使用される最も一般的な抽象です。Hibernate Search は直接 Lucene Directory と対話しませんが、IndexManager を使用してこれらの対話を抽象化します。インデックスは Directory によって実装する必要はありません。
インデックスが Directory として表されていることを認識している場合にそのインデックスにアクセスするには、IndexManager を使用して Directory への参照を取得します。IndexManager を DirectoryBasedIndexManager へキャストし、getDirectoryProvider().getDirectory() を使用して基盤の Directory への参照を取得します。 IndexReader の使用が推奨され、この方法は推奨されません。
13.8.4. インデックスのシャード化
場合によっては、該当するエンティティーのインデックスデータを複数の Lucene インデックスに分割 (シャード化) することが役に立つことがあります。
シャード化は、利点の方が欠点よりも多い場合にのみ実行してください。各検索に対してすべてのシャードをオープンにする必要があるため、通常、シャード化されたインデックスの検索には時間がかかります。
シャード化のユースケースは以下のとおりです。
- 単一のインデックスは非常に大きいため、インデックスの更新に時間がかかり、アプリケーションが低速になります。
- 通常の検索では、インデックスのサブセットのみがヒットされます (データが顧客、地域、またはアプリケーションにより、自然にセグメント化された場合など)。
デフォルトでは、シャード化はシャードの数が設定されていない限り有効になりません。これを行う場合は、hibernate.search.<indexName>.sharding_strategy.nbr_of_shards プロパティーを使用してください。
例: インデックスのシャード化の有効化 この例では、5 つのシャードが有効になります。
hibernate.search.<indexName>.sharding_strategy.nbr_of_shards = 5
データをサブインデックスに分割するには IndexShardingStrategy を使用します。デフォルトのシャード化ストラテジーでは、ID 文字列表現のハッシュ値 (FieldBridge により生成されます) に従ってデータが分割されます。これにより、調整されたシャード化が保証されます。デフォルトストラテジーは、カスタム IndexShardingStrategy を実装することにより置き換えることができます。カスタムストラテジーを使用するには、hibernate.search.<indexName>.sharding_strategy プロパティーを設定する必要があります。
例: カスタムシャード化ストラテジーの指定
hibernate.search.<indexName>.sharding_strategy = my.shardingstrategy.Implementation
IndexShardingStrategy プロパティーを使用すると、クエリーを実行するシャードを選択して、検索を最適化することもできます。フィルターをアクティブ化することにより、シャード化ストラテジーでクエリー (IndexShardingStrategy.getIndexManagersForQuery) の応答に使用するシャードのサブセットを選択し、クエリーの実行を高速化できます。
各シャードには独立した IndexManager が存在し、異なるディレクトリープロバイダーおよびバックエンド設定を使用するよう設定できます。以下の例の Animal エンティティーの IndexManager インデックス名は Animal.0 から Animal.4 です。つまり、各シャードの独自のインデックスの名前の後に . (ドット) とインデックス番号が続きます。
例: エンティティー Animal のシャード化設定
hibernate.search.default.indexBase = /usr/lucene/indexes hibernate.search.Animal.sharding_strategy.nbr_of_shards = 5 hibernate.search.Animal.directory_provider = filesystem hibernate.search.Animal.0.indexName = Animal00 hibernate.search.Animal.3.indexBase = /usr/lucene/sharded hibernate.search.Animal.3.indexName = Animal03
上記の例では、デフォルトの id 文字列ハッシュストラテジーが使用され、Animal インデックスが 5 サブインデックスにシャード化されます。すべてのサブインデックスはファイルシステムインスタンスであり、各サブインデックスが格納されるディレクトリーは以下のようになります。
-
サブインデックス 0 の場合:
/usr/lucene/indexes/Animal00(共有された indexBase、オーバーライドされた indexName) -
サブインデックス 1 の場合:
/usr/lucene/indexes/Animal.1(共有された indexBase、デフォルトの indexName) -
サブインデックス 2 の場合:
/usr/lucene/indexes/Animal.2(共有された indexBase、デフォルトの indexName) -
サブインデックス 3 の場合:
/usr/lucene/shared/Animal03(オーバーライドされた indexBase、オーバーライドされた indexName) -
サブインデックス 4 の場合:
/usr/lucene/indexes/Animal.4(共有された indexBase、デフォルトの indexName)
IndexShardingStrategy を実装する場合は、任意のフィールドを使用してシャード化の選択を決定できます。削除を処理するために (purge および purgeAll 操作)、実装がすべてのフィールド値またはプライマリー ID を読み取らずに 1 つまたは複数のインデックスを返す必要があることがあります。この場合は、単一のインデックスを取得するのに十分な情報が存在せず、すべてのインデックスを返す必要があります。この結果、削除操作が、削除するドキュメントを含むすべてのインデックスに伝播されます。
13.8.5. Lucene のスコア計算式のカスタマイズ
org.apache.lucene.search.Similarity を拡張すると Lucene のスコア計算式をカスタマイズできます。このクラスに定義される抽象メソッドは、ドキュメント d に対してクエリー q のスコアを算出する以下の計算式の係数に一致します。
org.apache.lucene.search.Similarity を拡張して Lucene のスコア計算式をカスタマイズします。以下のように、抽象メソッドは、ドキュメント d に対してクエリー q のスコアを算出するのに使用される計算式に一致します。
*score(q,d) = coord(q,d) · queryNorm(q) · ∑ ~t in q~ ( tf(t in d) · idf(t) ^2^ · t.getBoost() · norm(t,d) )*
| 係数 | 説明 |
|---|---|
|
tf(t ind) |
文書 (d) の単語 (t) に対する単語頻度係数 (term frequency factor)。 |
|
idf(t) |
単語の逆文書頻度 (inverse document frequency)。 |
|
coord(q,d) |
指定の文書で見つかったクエリー対象の単語の数を基にしたスコア係数。 |
|
queryNorm(q) |
クエリー間のスコアを比較できるようにするため使用される正規化係数 (normalizing factor)。 |
|
t.getBoost() |
フィールドブースト。 |
|
norm(t,d) |
一部の (インデックス化時間) ブースト係数と長さ係数をカプセル化します。 |
この計算式の詳細な説明は本書の範囲外になります。詳細については、Similarity の Javadoc を参照してください。
Hibernate Search では、Lucene の類似度計算を変更する方法は 3 つあります。
プロパティー hibernate.search.similarity を使用して Similarity 実装の完全指定されたクラス名を指定すると、デフォルトの類似度を設定できます。デフォルト値は org.apache.lucene.search.DefaultSimilarity です。
similarity プロパティーを設定して、特定のインデックスに使用される類似度をオーバーライドすることもできます。
hibernate.search.default.similarity = my.custom.Similarity
@Similarity アノテーションを使用して、クラスレベルでデフォルトの類似度をオーバーライドすることもできます。
@Entity
@Indexed
@Similarity(impl = DummySimilarity.class)
public class Book {
...
}例として、文書で言葉が出現する頻度は重要でないと仮定しましょう。言葉が 1 度だけ出現する文書のスコアは、言葉が複数回出現する文書と同じになります。この場合、tf(float freq) メソッドのカスタム実装は 1.0 を返す必要があります。
2 つのエンティティーが同じインデックスを共有する場合は、同じ Similarity 実装を宣言する必要があります。同じクラス階層のクラスは常にインデックスを共有するため、サブタイプの Similarity 実装をオーバーライドできません。
同様に、インデックス設定とクラスレベルの設定は競合するため、これらの設定で類似度を設定しても意味がなく、拒否されます。
13.8.6. 例外処理の設定
Hibernate Search では、インデックスの作成中に例外をどのように処理するかを設定できます。設定が提供されない場合は、デフォルトで例外がログ出力に記録されます。以下のように、例外ロギングメカニズムを明示的に宣言できます。
hibernate.search.error_handler = log
デフォルトの例外処理は、同期と非同期のインデックス作成両方で実行されます。Hibernate Search は、デフォルトのエラー処理実装をオーバーライドする簡単なメカニズムを提供します。
独自の実装を提供するには、handle(ErrorContext context) メソッドを提供する ErrorHandler インターフェースを実装する必要があります。ErrorContext は、プライマリー LuceneWork インスタンス、基礎となる例外、およびプライマリー例外が原因で処理できなかった後続の LuceneWork インスタンスへの参照を提供します。
public interface ErrorContext {
List<LuceneWork> getFailingOperations();
LuceneWork getOperationAtFault();
Throwable getThrowable();
boolean hasErrors();
}Hibernate Search でこのエラー処理を登録するには、設定プロパティーで ErrorHandler 実装の完全修飾クラス名を宣言する必要があります。
hibernate.search.error_handler = CustomerErrorHandler
13.8.7. Hibernate Search の無効化
Hibernate Search は、必要に応じて部分的または完全に無効にできます。インデックスが読み取り専用の場合、またはインデックス作成を自動的ではなく手動で実行する場合は、Hibernate Search のインデックス作成を無効にできます。また、Hibernate Search を完全に無効にしてインデックス作成と検索を回避することもできます。
- インデックス作成の無効化
Hibernate Search インデックス作成を無効にするには、
indexing_strategy設定オプションをmanualに変更し、JBoss EAP を再起動します。hibernate.search.indexing_strategy = manual
- Hibernate Search の完全な無効化
Hibernate Search を完全に無効にするには、
autoregister_listeners設定オプションをfalseに変更してすべてのリスナーを無効にし、JBoss EAP を再起動します。hibernate.search.autoregister_listeners = false
13.9. モニタリング
Hibernate Search は、SearchFactory.getStatistics() を介して Statistics オブジェクトへのアクセスを提供します。たとえば、インデックスを作成するクラスやインデックスの格納するエントリーの数を決定できます。この情報は常に利用可能です。ただし、設定で hibernate.search.generate_statistics プロパティーを指定することにより、Lucene クエリーおよびオブジェクトのロードのタイミングの合計と平均を収集することもできます。
JMX を介した統計へのアクセス
JMX を介した統計へのアクセスを有効にするには、プロパティー hibernate.search.jmx_enabled を true に設定します。これにより、StatisticsInfoMBean Bean が自動的に登録され、Statistics オブジェクトを介した統計へのアクセスが提供されます。設定に応じて、IndexingProgressMonitorMBean Bean を登録することもできます。
インデックス作成の監視
一括インデクサー API が使用されている場合は、IndexingProgressMonitorMBean Beanを介してインデックス作成の進捗を監視できます。インデックスの作成中、この Bean は JMX にのみバインドされます。
JMX Bean は、システムプロパティー com.sun.management.jmxremote を true に設定することにより JConsole を使用してリモートでアクセスできます。