第12章 Java 永続 API (JPA)
12.1. Java 永続 API (JPA) について
Java Persistence API (JPA) は、Java オブジェクトまたはクラスとリレーショナルデータベース間でデータのアクセス、永続化、および管理を行うための Java 仕様です。この JPA 仕様では、透過オブジェクトまたはリレーショナルマッピングのパラダイムが考慮されます。オブジェクトまたはリレーショナル永続化メカニズムに必要な基本的な API とメタデータが標準化されます。
JPA 自体は製品ではなく仕様にすぎません。それ自体では永続化やその他の処理を実行できません。JPA はインターフェースセットにすぎず、実装を必要とします。
12.2. Hibernate Core
Hibernate Core は、Java 言語のオブジェクトリレーショナルマッピングフレームワークです。これは、オブジェクト指向ドメインモデルをリレーショナルデータベースにマッピングするためのフレームワークを提供するため、アプリケーションはデータベースとの直接対話を回避できます。Hibernate では、直接的な永続データベースアクセスを高レベルオブジェクト処理関数に置き換えることにより、オブジェクトリレーショナルインピーダンスの不一致の問題が解決されます。
12.3. Hibernate EntityManager
Hibernate EntityManager を使用すると、Java Persistence 2.1 仕様で定義されたように、プラグラミングインターフェースとライフサイクルルールが実装されます。このラッパーを Hibernate Annotations とともに使用することにより、 成熟した Hibernate Core の上に完全な (およびスタンドアロンの) JPA 永続化ソリューションが実装されます。プロジェクトのビジネス上のニーズまたは技術的なニーズに応じて、これら 3 つすべて、JPA プログラミングインターフェースなしのアノテーション、または純粋なネイティブ Hibernate Core の組み合わせを使用できます。いつでも Hibernate ネイティブ API、または必要な場合はネイティブ JDBC および SQL を使用できます。また、JBoss EAP が完全な Java 永続化ソリューションとともに提供されます。
JBoss EAP は Java Persistence 2.1 仕様に完全準拠しています。また、Hibernate はこの仕様に追加機能を提供します。JPA と JBoss EAP を使用するには、JBoss EAP に同梱されている bean-validation、greeter、および kitchensink クイックスタートを参照してください。クイックスタートのダウンロードおよび実行方法については、クイックスタートサンプルの使用を参照してください。
JPA の永続化は EJB 3 またはより新しい CDI、Java Context and Dependency Injection などのコンテナーと特定のコンテナーの外部で実行されるスタンドアロン Java SE アプリケーションで利用できます。両方の環境で以下のプログラミングインターフェースとアーティファクトを利用できます。
- EntityManagerFactory
- エンティティーマネージャーファクトリーはエンティティーマネージャーインスタンスを提供し、すべてのインスタンスは、特定の実装などで定義されたのと同じデフォルト設定を使用するために同じデータベースに接続するよう設定されます。複数のエンティティーマネージャーファクトリーを準備して複数のデータストアにアクセスできます。このインターフェースはネイティブ Hibernate の SessionFactory に似ています。
- EntityManager
- EntityManager API は、特定の作業単位でデータベースにアクセスするために使用されます。また、永続エンティティーインスタンスを作成および削除してプライマリーキー ID でエンティティーを見つけたり、すべてのエンティティーに対してクエリーを実行したりするためにも使用されます。このインターフェースは、Hibernate のセッションに似ています。
- 永続コンテキスト
- 永続コンテキストは、永続エンティティー ID が一意のエンティティーインスタンスであるエンティティーインスタンスのセットです。永続コンテキスト内で、エンティティーインスタンスとそのライフサイクルは特定のエンティティーマネージャーによって管理されます。このコンテキストのスコープはトランザクションまたは拡張された作業単位のいずれかです。
- 永続ユニット
- 該当するエンティティーマネージャーで管理できるエンティティータイプのセットは、永続ユニットにより定義されます。永続ユニットは、アプリケーションで関連付けまたはグループ化され、単一データストアに対するマッピングで併置する必要があるすべてのクラスのセットを定義します。
- コンテナー管理エンティティーマネージャー
- ライフサイクルがコンテナーにより管理されるエンティティーマネージャー。
- アプリケーション管理エンティティーマネージャー
- ライフサイクルがアプリケーションにより管理されるエンティティーマネージャー。
- JTA エンティティーマネージャー
- JTA トランザクションに関与するエンティティーマネージャー。
- リソースローカルエンティティーマネージャー
- リソーストランザクション (JTA トランザクションではない) を使用するエンティティーマネージャー。
12.4. 単純な JPA アプリケーションの作成
Red Hat Developer Studio で単純な JPA アプリケーションを作成する場合は、以下の手順を実行します。
JBoss Developer Studio で JPA プロジェクトを作成します。
Red Hat JBoss Developer Studio で、File-→ New -→ Project をクリックします。リストで JPA を見つけ、展開し、JPA Project を選択します。以下のダイアログが表示されます。
図12.1 新規 JPA プロジェクトダイアログ
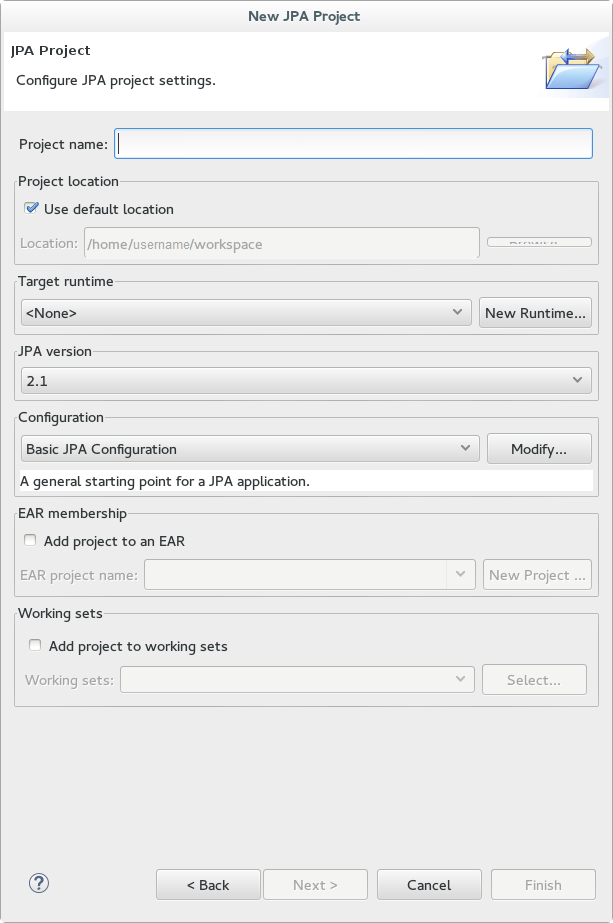
- プロジェクト名を入力します。
- ターゲットランタイムを選択します。ターゲットランタイムがない場合は、Define New Server を使用した JBoss EAP Server の追加 に記載された手順に従って新しいサーバーとランタイムを定義します。
- JPA version (JPA バージョン) de 2.1 が選択されていることを確認します。
- Configuration (設定) で Basic JPA Configuration (基本的な JPA 設定) を選択します。
- Finish をクリックします。
- 要求されたら、このタイプのプロジェクトを JPA パースペクティブウインドウに関連付けるかどうかを選択します。
新しい永続性設定ファイルを作成および設定します。
- Red Hat JBoss Developer Studio で EJB 3.x プロジェクトを開きます。
- Project Explorer (プロジェクトエクスプローラー) パネルでプロジェクトルートディレクトリーを右クリックします。
-
New (新規)
Other (その他)…. を選択します。 - XML フォルダーから XML File (XML ファイル) を選択し、Next (次へ) をクリックします。
-
親ディレクトリーとして
ejbModule/META-INF/フォルダーを選択します。 -
ファイルの名前を
persistence.xmlと指定し、Next (次へ) をクリックします。 - Create XML file from an XML schema file (XML スキーマファイルから XML ファイルを作成) を選択し、Next (次へ) をクリックします。
Select XML Catalog entry (XML カタログエントリーの選択) リストから http://java.sun.com/xml/ns/persistence/persistence_2.0.xsd を選択し、Next (次へ) をクリックします。
図12.2 永続 XML スキーマ
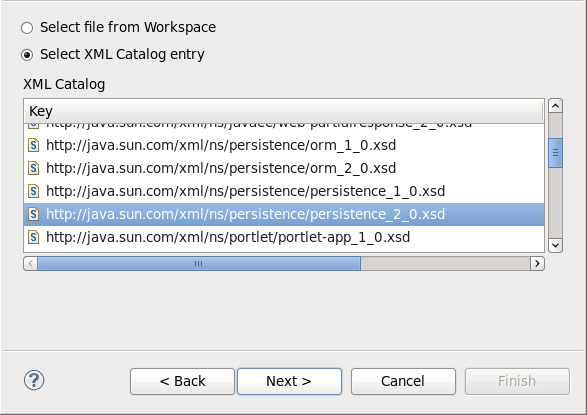
Finish (完了) をクリックしてファイルを作成します。
persistence.xmlがMETA-INF/フォルダーに作成され、設定可能な状態になります。永続設定ファイルの例
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd" version="2.0"> <persistence-unit name="example" transaction-type="JTA"> <provider>org.hibernate.ejb.HibernatePersistence</provider> <jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source> <mapping-file>ormap.xml</mapping-file> <jar-file>TestApp.jar</jar-file> <class>org.test.Test</class> <shared-cache-mode>NONE</shared-cache-mode> <validation-mode>CALLBACK</validation-mode> <properties> <property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/> <property name="hibernate.hbm2ddl.auto" value="create-drop"/> </properties> </persistence-unit> </persistence>
12.5. Configuration (設定)
12.5.1. Hibernate 設定プロパティー
| プロパティー名 | 説明 |
|---|---|
|
hibernate.dialect |
Hibernate の
ほとんどのケースで、Hibernate は、JDBC ドライバーにより返された JDBC メタデータに基づいて正しい |
|
hibernate.show_sql |
ブール変数。SQL ステートメントをすべてコンソールに書き込みます。これは、ログカテゴリー |
|
hibernate.format_sql |
ブール変数。SQL をログとコンソールにプリティプリントします。 |
|
hibernate.default_schema |
修飾されていないテーブル名を、生成された SQL の該当するスキーマ/テーブルスペースで修飾します。 |
|
hibernate.default_catalog |
修飾されていないテーブル名を、生成された SQL の該当するカタログで修飾します。 |
|
hibernate.session_factory_name |
org.hibernate.SessionFactory が、作成後に JNDI のこの名前に自動的にバインドされます。たとえば、 |
|
hibernate.max_fetch_depth |
シングルエンドのアソシエーション (1 対 1 や多対 1 など) に対して外部結合フェッチツリーの最大の深さを設定します。 |
|
hibernate.default_batch_fetch_size |
関連付けの Hibernate 一括フェッチに対するデフォルトサイズを設定します。推奨値は、 |
|
hibernate.default_entity_mode |
この |
|
hibernate.order_updates |
ブール変数。Hibernate で、更新されるアイテムの主キー値で SQL 更新の順番付けを行います。これにより、高度な並列システムにおけるトランザクションデッドロックが軽減されます。 |
|
hibernate.generate_statistics |
ブール変数。有効にすると、Hibernate がパフォーマンスのチューニングに役に立つ統計情報を収集します。 |
|
hibernate.use_identifier_rollback |
ブール変数。有効にすると、オブジェクトが削除されたときに、生成された識別子プロパティーがデフォルト値にリセットされます。 |
|
hibernate.use_sql_comments |
ブール変数。有効にすると、デバッグを簡単にするために Hibernate が SQL 内にコメントを生成します。デフォルト値は |
|
hibernate.id.new_generator_mappings |
ブール値。@GeneratedValue を使用する場合に関係するプロパティーです。新しい IdentifierGenerator 実装が javax.persistence.GenerationType.AUTO、javax.persistence.GenerationType.TABLE、または javax.persistence.GenerationType.SEQUENCE に対して使用されるかどうかを示します。デフォルト値は |
|
hibernate.ejb.naming_strategy |
Hibernate EntityManager を使用している場合は、org.hibernate.cfg.NamingStrategy 実装を選択します。Hibernate 5.0 では アプリケーションが EntityManager を使用しない場合は、Hibernate Reference Documentation - Naming Strategies の手順に従って NamingStrategy を設定します。
MetadataBuilder を使用し、暗黙的なネーミングストラテジーを適用するネイティブブートストラップの例については、Hibernate 5.0 ドキュメンテーションの http://docs.jboss.org/hibernate/orm/5.0/userguide/html_single/Hibernate_User_Guide.html#bootstrap-native-metadata を参照してください。物理的なネーミングストラテジーは |
|
hibernate.implicit_naming_strategy |
使用する
デフォルト設定は、 |
|
hibernate.physical_naming_strategy |
データベースオブジェクト名に物理的なネーミングルールを適用するプラグ可能なストラテジーコントラクト。使用する PhysicalNamingStrategy クラスを指定します。デフォルトでは |
新しいアプリケーションでは、hibernate.id.new_generator_mappings のデフォルト値を true のままにする必要があります。Hibernate 3.3.x を使用した既存のアプリケーションが継続してシーケンスオブジェクトやテーブルベースのジェネレーターを使用し、後方互換性を維持する場合は、デフォルト値を false に変更する必要がある場合があります。
12.5.2. Hibernate JDBC と接続プロパティー
| プロパティー名 | 説明 |
|---|---|
|
hibernate.jdbc.fetch_size |
JDBC のフェッチサイズを判断するゼロでない値です ( |
|
hibernate.jdbc.batch_size |
Hibernate による JDBC2 バッチ更新の使用を有効にするゼロでない値です。推奨値は、 |
|
hibernate.jdbc.batch_versioned_data |
ブール変数。JDBC ドライバーが |
|
hibernate.jdbc.factory_class |
カスタム org.hibernate.jdbc.Batcher を選択します。ほとんどのアプリケーションにはこの設定プロパティーは必要ありません。 |
|
hibernate.jdbc.use_scrollable_resultset |
ブール変数。Hibernate による JDBC2 のスクロール可能な結果セットの使用を有効にします。このプロパティーはユーザーが提供した JDBC 接続を使用する場合にのみ必要です。その他の場合、Hibernate は接続メタデータを使用します。 |
|
hibernate.jdbc.use_streams_for_binary |
ブール変数。システムレベルのプロパティーです。 |
|
hibernate.jdbc.use_get_generated_keys |
ブール変数。JDBC3 |
|
hibernate.connection.provider_class |
JDBC 接続を Hibernate に提供するカスタム org.hibernate.connection.ConnectionProvider のクラス名です。 |
|
hibernate.connection.isolation |
JDBC トランザクションの分離レベルを設定します。java.sql.Connection で意味のある値をチェックしますが、ほとんどのデータベースはすべての分離レベルをサポートするとは限らず、一部のデータベースは標準的でない分離を追加的に定義します。標準的な値は |
|
hibernate.connection.autocommit |
ブール変数。このプロパティーの使用は推奨されません。JDBC でプールされた接続に対して自動コミットを有効にします。 |
|
hibernate.connection.release_mode |
Hibernate が JDBC 接続を解放するタイミングを指定します。デフォルトでは、セッションが明示的に閉じられるか切断されるまで JDBC 接続が保持されます。デフォルト値である auto では、JTA および CMT トランザクションストラテジーに対して
利用可能な値は auto (デフォルト)、on_close、
この設定により、 |
|
hibernate.connection.<propertyName> |
JDBC プロパティー <propertyName> を |
|
hibernate.jndi.<propertyName> |
プロパティー <propertyName> を JNDI |
12.5.3. Hibernate キャッシュプロパティー
| プロパティー名 | 説明 |
|---|---|
|
|
カスタム |
|
|
ブール変数です。2 次キャッシュの操作を最適化し、読み取りを増やして書き込みを最小限にします。これはクラスター化されたキャッシュで最も便利な設定であり、Hibernate 3 ではクラスター化されたキャッシュの実装に対してデフォルトで有効になっています。 |
|
|
ブール変数です。クエリーキャッシュを有効にします。各クエリーをキャッシュ可能に設定する必要があります。 |
|
|
ブール変数です。 |
|
|
カスタム |
|
|
2 次キャッシュのリージョン名に使用する接頭辞です。 |
|
|
ブール変数です。人間が解読可能な形式でデータを 2 次キャッシュに保存するよう Hibernate を設定します。 |
|
|
@Cacheable または @Cache が使用される場合に使用するデフォルトの org.hibernate.annotations.CacheConcurrencyStrategy の名前を付与するため使用される設定です。このデフォルト値を上書するには、 |
12.5.4. Hibernate トランザクションプロパティー
| プロパティー名 | 説明 |
|---|---|
|
|
Hibernate |
|
|
アプリケーションサーバーから JTA |
|
|
|
|
|
ブール変数。有効な場合、トランザクションの完了前フェーズの間にセッションが自動的にフラッシュされます。ビルトインおよび自動セッションコンテキスト管理が推奨されます。 |
|
|
ブール変数。有効な場合、トランザクションの完了後フェーズの間にセッションが自動的に閉じられます。ビルトインおよび自動セッションコンテキスト管理が推奨されます。 |
12.5.5. その他の Hibernate プロパティー
| プロパティー名 | 説明 |
|---|---|
|
|
「現在」の |
|
|
|
|
|
Hibernate クエリーのトークンと SQL トークンとのマッピングに使用します (トークンは関数名またはリテラル名である場合があります)。たとえば、 |
|
|
|
|
|
SessionFactory の作成中に実行される SQL DML ステートメントが含まれる任意のファイルの名前 (コンマ区切り)。テストやデモに便利です。たとえば、INSERT ステートメントを追加すると、デプロイ時に最小限のデータセットがデータベースに入力されます。値の例としては、
特定ファイルのステートメントは後続ファイルのステートメントの前に実行されるため、ファイルの順番に注意する必要があります。これらのステートメントはスキーマが作成された場合のみ実行されます ( |
|
|
カスタム ImportSqlCommandExtractor のクラス名。デフォルト値は組み込みの SingleLineSqlCommandExtractor です。各インポートファイルから単一の SQL ステートメントを抽出する専用のパーサーを実装する時に便利です。Hibernate は、複数行にまたがる命令/コメントおよび引用符で囲まれた文字列をサポートする MultipleLinesSqlCommandExtractor も提供します (各ステートメントの最後にセミコロンが必要です)。 |
|
|
ブール値。 |
|
|
javassist または cglib をバイト操作エンジンとして使用することができます。デフォルトでは |
12.5.6. Hibernate SQL 方言
hibernate.dialect プロパティーをアプリケーションデータベースの適切な org.hibernate.dialect.Dialect サブクラスに設定する必要があります。方言が指定されている場合、Hibernate は他のプロパティーの一部に実用的なデフォルトを使用します。そのため、これらのプロパティーを手作業で指定する必要はありません。
| RDBMS | 方言 |
|---|---|
|
DB2 |
|
|
DB2 AS/400 |
|
|
DB2 OS390 |
|
|
Firebird |
|
|
FrontBase |
|
|
H2 Database |
|
|
HypersonicSQL |
|
|
Informix |
|
|
Ingres |
|
|
Interbase |
|
|
MariaDB 10 |
|
|
Mckoi SQL |
|
|
Microsoft SQL Server 2000 |
|
|
Microsoft SQL Server 2005 |
|
|
Microsoft SQL Server 2008 |
|
|
Microsoft SQL Server 2012 |
|
|
Microsoft SQL Server 2014 |
|
|
MySQL5 |
|
|
MySQL5.7 |
|
|
InnoDB を用いる MYSQL5 |
|
|
MyISAM を用いる MySQL |
|
|
Oracle (全バージョン) |
|
|
Oracle 9i |
|
|
Oracle 10g |
|
|
Oracle 11g |
|
|
Oracle 12c |
|
|
Pointbase |
|
|
PostgreSQL |
|
|
PostgreSQL 9.2 |
|
|
PostgreSQL 9.3 |
|
|
PostgreSQL 9.4 |
|
|
Postgres Plus Advanced Server |
|
|
Progress |
|
|
SAP DB |
|
|
Sybase |
|
|
Sybase 15.7 |
|
|
Sybase Anywhere |
|
12.6. 2 次キャッシュ
12.6.1. 2 次キャッシュ
2 次キャッシュとは、アプリケーションセッション以外で永続的に情報を保持するローカルのデータストアのことです。このキャッシュは永続プロバイダーにより管理されており、アプリケーションとデータを分けることでランタイム効率の改善をはかることができます。
JBoss EAP では、以下の目的のためにキャッシュがサポートされます。
- Web セッションのクラスタリング
- ステートフルセッション Bean のクラスタリング
- SSO クラスタリング
- Hibernate 2 次キャッシュ
各キャッシュコンテナーは 「repl」 と 「dist」 キャッシュを定義します。これらのキャッシュは、ユーザーアプリケーションで直接使用しないでください。
12.6.2. Hibernate 用 2 次キャッシュの設定
Hibernate 向けの 2 次レベルキャッシュとして動作する Infinispan の設定は、以下の 2 つの方法で行なえます。
-
Hibernate ネイティブアプリケーション経由 (
hibernate.cfg.xmlを使用) -
JPA アプリケーション経由 (
persistence.xmlを使用)
Hibernate ネイティブアプリケーションを使用した Hibernate 用 2 次キャッシュの設定
-
デプロイメントのクラスパスに
hibernate.cfg.xmlを作成します。 以下の XML を
hibernate.cfg.xmlに追加します。XML は<session-factory>タグ内に存在する必要があります。<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property> <property name="hibernate.cache.region.factory_class">org.jboss.as.jpa.hibernate5.infinispan.InfinispanRegionFactory</property>
JPA ネイティブアプリケーションを使用した Hibernate 用 2 次キャッシュの設定
- Red Hat JBoss Developer Studio で Hibernate 設定ファイルを作成する方法については、単純な JPA アプリケーションの作成を参照してください。
以下の内容を
persistence.xmlファイルに追加します。<persistence-unit name="..."> (...) <!-- other configuration --> <shared-cache-mode>$SHARED_CACHE_MODE</shared-cache-mode> <properties> <property name="hibernate.cache.use_second_level_cache" value="true" /> <property name="hibernate.cache.use_query_cache" value="true" /> </properties> </persistence-unit>注記$SHARED_CACHE_MODEの値には以下のものがあります。- ALL - すべてのエンティティーがキャッシュ可能である見なされます。
- ENABLE_SELECTIVE - キャッシュ可能とマークされたエンティティーのみがキャッシュ可能であると見なされます。
- DISABLE_SELECTIVE - キャッシュ不可と明示的に示されたものを除くすべてのエンティティーはキャッシュ可能と見なされます。
12.7. Hibernate アノテーション
org.hibernate.annotations パッケージには、標準的な JPA アノテーション以外に Hibernate により提供される一部のアノテーションが含まれます。
| アノテーション | 説明 |
|---|---|
|
|
クラス、プロパティー、コレクションのいずれかのレベルで定義できる任意の SQL チェック制約です。 |
|
|
エンティティーまたはコレクションを不変としてマーク付けします。アノテーションがない場合、要素は可変となります。 不変のエンティティーはアプリケーションによって更新されないことがあります。不変エンティティーへの更新は無視されますが、例外は発生しません。
|
| アノテーション | 説明 |
|---|---|
|
|
ルートエンティティーまたはコレクションにキャッシングストラテジーを追加します。 |
| アノテーション | 説明 |
|---|---|
|
|
永続マップのキータイプを定義します。 |
|
|
異なるエンティティータイプを参照する |
|
|
SQL の順序付け (HQL の順序付けではない) を使用してコレクションの順序を付けます。 |
|
|
コレクションやアレイ、結合されたサブクラスの削除に使用されるストラテジーです。 |
|
|
カスタムパーシスターを指定します。 |
|
|
コレクションのソート (Java レベルのソート)。 |
|
|
要素エンティティーまたはコレクションのターゲットエンティティーへ追加する where 節。この節は SQL で書かれます。 |
|
|
コレクション結合テーブルへ追加する where 節。この節は SQL で書かれます。 |
| アノテーション | 説明 |
|---|---|
|
|
Hibernate のデフォルトである |
|
|
Hibernate のデフォルトである |
|
|
Hibernate のデフォルトである |
|
|
Hibernate のデフォルトである |
|
|
Hibernate のデフォルトである |
|
|
不変の読み取り専用エンティティーを指定のサブセレクト表現へマッピングします。 |
|
|
自動フラッシュが適切に行われ、派生したエンティティーに対するクエリーが古いデータを返さないようにします。ほとんどの場合、 |
| アノテーション | 説明 |
|---|---|
|
|
アソシエーションにカスケードストラテジーを適用します。 |
|
|
標準的な
|
|
|
Hibernate がエンティティーの階層に適用する多様性タイプを定義するために使用されます。 |
|
|
特定クラスのレイジーおよびプロキシ設定。 |
|
|
1 次または 2 次テーブルへの補足情報。 |
|
|
Table の複数アノテーション。 |
|
|
明示的なターゲットを定義し、リフレクションやジェネリクスで解決しないようにします。 |
|
|
1 つのエンティティーまたはコンポーネントに対して単一の tuplizer を定義します。 |
|
|
1 つのエンティティーまたはコンポーネントに対して tuplizer のセットを定義します。 |
| アノテーション | 説明 |
|---|---|
|
|
SQL ローディングのバッチサイズ。 |
|
|
フェッチングストラテジープロファイルを定義します。 |
|
|
|
| アノテーション | 説明 |
|---|---|
|
|
エンティティーまたはコレクションのターゲットエンティティーにフィルターを追加します。 |
|
|
フィルター定義。 |
|
|
フィルター定義のアレイ。 |
|
|
結合テーブルのコレクションへフィルターを追加します。 |
|
|
複数の |
|
|
複数の |
|
|
パラメーターの定義。 |
| アノテーション | 説明 |
|---|---|
|
|
このアノテーション付けされたプロパティーはデータベースによって生成されます。 |
|
|
Hibernate ジェネレーターをデタイプ (detyped) で記述するジェネレーターアノテーションです。 |
|
|
汎用ジェネレーター定義のアレイ。 |
|
|
プロパティーがエンティティーのナチュラル ID の一部であることを指定します。 |
|
|
キーと値のパターン。 |
|
|
Hibernate の |
| アノテーション | 説明 |
|---|---|
|
|
ルートエントリーに置かれる識別子の公式です。 |
|
|
Hibernate 固有の識別子プロパティーを表現する任意のアノテーションです。 |
|
|
該当する識別子の値を対応するエンティティータイプにマッピングします。 |
| アノテーション | 説明 |
|---|---|
|
|
Hibernate NamedNativeQuery オブジェクトを保持するよう |
|
|
|
|
|
|
|
|
Hibernate の機能で |
| アノテーション | 説明 |
|---|---|
|
|
プロパティーのアクセスタイプ。 |
|
|
カラムのアレイをサポートします。コンポーネントユーザータイプのマッピングに便利です。 |
|
|
カラムからの値の読み取りやカラムへの値の書き込みに使用されるカスタム SQL 表現です。直接的なオブジェクトのロードや保存、クエリーに使用されます。write 表現には必ず値に対して 1 つの 「?」 プレースホルダーが含まれなければなりません。 |
|
|
|
| アノテーション | 説明 |
|---|---|
|
|
ほとんどの場所で |
|
|
データベースのインデックスを定義します。 |
|
|
ほとんどの場所で |
|
|
所有者 (通常は所有するエンティティー) へのポインターとしてプロパティーを参照します。 |
|
|
Hibernate のタイプ。 |
|
|
Hibernate タイプの定義。 |
|
|
Hibernate タイプ定義のアレイ。 |
| アノテーション | 説明 |
|---|---|
|
|
複数のエンティティータイプを参照する ToOne を定義します。対応するエンティティータイプの照合は、メタデータ識別子カラムを介して行われます。このようなマッピングは最低限行う必要があります。 |
|
|
|
|
|
メタデータの |
|
|
特定のアソシエーションに使用されるフェッチングストラテジーを定義します。 |
|
|
コレクションのレイジー状態を定義します。 |
|
|
ToOne アソシエーション (つまり、 |
|
|
アソシエーション上で要素が見つからなかった時に実行するアクションです。 |
| アノテーション | 説明 |
|---|---|
|
|
アノテーション付けされたプロパティーの変更によってエンティティーのバージョン番号が増加するかどうか。アノテーション付けされていない場合、プロパティーは楽観的ロックストラテジー (デフォルト) に関与します。 |
|
|
エンティティーに適用される楽観的ロックのスタイルを定義するために使用されます。階層ではルートエンティティーのみに有効です。 |
|
|
バージョンおよびタイムスタンプバージョンプロパティーと併用するのに最適なアノテーションです。アノテーション値はタイムスタンプが生成される場所を決定します。 |
12.8. Hibernate クエリー言語
12.8.1. Hibernate クエリー言語
JPQL の概要
Java Persistence Query Language (JPQL) は、Java Persistence API (JPA) 仕様の一部として定義されたプラットフォーム非依存のオブジェクト指向クエリー言語です。JPQL は、リレーショナルデータベースに格納されたエンティティーに対してクエリーを実行するために使用されます。この言語は SQL から大きな影響を受けており、クエリーの構文は SQL クエリーに類似しますが、データベーステーブルと直接動作するのではなく JPA エンティティーオブジェクトに対して動作します。
HQL の概要
Hibernate Query Language (HQL) は、強力なクエリー言語であり、見た目は SQL に似ています。ただし、SQL と比較して、HQL は完全なオブジェクト指向であり、継承、ポリモーフィズム、アソシエーションなどの概念を理解します。
HQL は JPQL のスーパーセットです。HQL クエリーは有効な JPQL クエリーでないこともありますが、JPQL クエリーは常に有効な HQL クエリーになります。
HQL と JPQL は共にタイプセーフでないクエリー操作を実行します。基準 (criteria) クエリーがタイプセーフなクエリーを提供します。
12.8.2. HQL ステートメントについて
HQL と JPQL では、SELECT、UPDATE、および DELETE ステートメントを使用できます。HQL では、SQL の INSERT-SELECT に似た形式で INSERT ステートメントも使用できます。
更新操作または削除操作を一括で実行する場合は、アクティブな永続コンテキストでデータベースとエンティティーとの間に不整合が発生することがあるため、注意が必要です。一般的に、一括の更新操作または削除操作は、新しい永続コンテキストのトランザクション内、またはこのような操作により状態が影響を受ける可能性があるエンティティーを取得する前またはアクセスする前にのみ実行します。
| ステートメント | 説明 |
|---|---|
|
|
HQL での SELECT ステートメントの BNF は以下のとおりです。 select_statement :: =
[select_clause]
from_clause
[where_clause]
[groupby_clause]
[having_clause]
[orderby_clause]
|
|
|
HQL の UPDATE ステートメントの BNF は JPQL と同じです。 |
|
|
HQL の DELETE ステートメントの BNF は JPQL と同じです。 |
12.8.3. INSERT ステートメント
HQL は INSERT ステートメントを定義する機能を追加します。これに相当するステートメントは JPQL にはありません。HQL の INSERT ステートメントの BNF は次のとおりです。
insert_statement ::= insert_clause select_statement insert_clause ::= INSERT INTO entity_name (attribute_list) attribute_list ::= state_field[, state_field ]*
attribute_list は、SQL INSERT ステートメントの column specification と似ています。マップされた継承に関係するエンティティーでは、名前付きエンティティー上で直接定義された属性のみを attribute_list で使用することが可能です。スーパークラスプロパティーは許可されず、サブクラスプロパティーは意味がありません。よって、 INSERT ステートメントは本質的に非多形となります。
The select_statement can be any valid HQL select query, with the caveat that the return types must match the types expected by the insert. Currently, this is checked during query compilation rather than allowing the check to relegate to the database. This can cause problems with Hibernate Types that are equivalent as opposed to equal. For example, this might cause mismatch issues between an attribute mapped as an org.hibernate.type.DateType and an attribute defined as a org.hibernate.type.TimestampType, even though the database might not make a distinction or might be able to handle the conversion.
insert ステートメントは id 属性に対して 2 つのオプションを提供します。1 つ目は、id 属性を attribute_list に明示的に指定するオプションです。この場合、値は対応する select 式から取得されます。2 つ目は attribute_list に指定しないオプションであり、この場合生成された値が使用されます。2 つ目のオプションは、「データベース内」で動作する id ジェネレーターを使用する場合のみ選択可能です。このオプションを「インメモリ」タイプのジェネレーターで使用しようとすると、構文解析中に例外が生じます。
insert ステートメントは楽観的ロックの属性に対しても 2 つのオプションを提供します。1 つ目は attribute_list に属性を指定するオプションです。この場合、値は対応する select 式から取得されます。2 つ目は attribute_list に指定しないオプションです。この場合、対応する org.hibernate.type.VersionType によって定義される seed value が使用されます。
例: INSERT クエリーステートメント
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ..."; int createdEntities = s.createQuery( hqlInsert ).executeUpdate();
12.8.4. FROM 節
FROM 節の役割は、他のクエリーが使用できるオブジェクトモデルタイプの範囲を定義することです。また、他のクエリーが使用できる「ID 変数」もすべて定義します。
12.8.5. WITH 節
HQL は WITH 節を定義し、結合条件を限定します。これは HQL に固有の機能で、JPQL はこの機能を定義しません。
例: With 句
select distinct c
from Customer c
left join c.orders o
with o.value > 5000.00
生成された SQL では、with clause の条件が生成された SQL の on clause の一部となりますが、本項の他のクエリーでは HQL/JPQL の条件が生成された SQL の where clause の一部となることが重要な違いです。この例に特有の違いは重要ではないでしょう。さらに複雑なクエリーでは、with clause が必要になることがあります。
明示的な結合は、アソシエーションまたはコンポーネント/埋め込み属性を参照することがあります。コンポーネント/埋め込み属性では、結合は論理的であり、物理 (SQL) 結合に関連しません。
12.8.6. HQL の順序付け
クエリーの結果を順序付けすることも可能です。ORDER BY 節を使用して、結果を順序付けするために使用される選択値を指定します。order-by 節の一部として有効な式タイプには以下が含まれます。
- ステートフィールド
- コンポーネント/埋め込み可能属性
- 算術演算や関数などのスカラー式
- 前述の式タイプのいずれかに対する select 節に宣言された ID 変数
HQL は、order-by 節で参照されたすべての値が select 節で名付けされることを強制しませんが、JPQL では必要となります。データベースの移植性を要求するアプリケーションは、select 節で参照されない order-by 節の参照値をサポートしないデータベースがあることを認識する必要があります。
order-by の各式は、ASC (昇順) または DESC (降順) で希望の順序を示すよう修飾することができます。
例: Order-by
// legal because p.name is implicitly part of p
select p
from Person p
order by p.name
select c.id, sum( o.total ) as t
from Order o
inner join o.customer c
group by c.id
order by t12.8.7. 一括更新、一括送信、および一括削除
Hibernate では、Data Manipulation Language (DML) を使用して、マップ済みデータベースのデータを直接、一括挿入、一括更新、および一括削除できます (Hibernate Query Language を使用)。
DML を使用すると、オブジェクト/リレーショナルマッピングに違反し、オブジェクトの状態に影響が出ることがあります。オブジェクトの状態はメモリーでは変わりません。DML を使用することにより、基礎となるデータベースで実行された操作に応じて、メモリー内オブジェクトの状態は影響を受けません。DML を使用する場合、メモリー内データは注意を払って使用する必要があります。
UPDATE ステートメントと DELETE ステートメントの擬似構文:
( UPDATE | DELETE ) FROM? EntityName (WHERE where_conditions)?.
FROM キーワードと WHERE Clause はオプションです。
UPDATE ステートメントまたは DELETE ステートメントの実行結果は、実際に影響 (更新または削除) を受けた行の数です。
例: 一括更新ステートメント
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlUpdate = "update Company set name = :newName where name = :oldName";
int updatedEntities = s.createQuery( hqlUpdate )
.setString( "newName", newName )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();例: 一括削除ステートメント
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlDelete = "delete Company where name = :oldName";
int deletedEntities = s.createQuery( hqlDelete )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
Query.executeUpdate() メソッドにより返された int 値は、操作で影響を受けたデータベース内のエンティティー数を示します。
内部的に、データベースは複数の SQL ステートメントを使用して DML 更新または削除の要求に対する操作を実行することがあります。多くの場合、これは、更新または削除する必要があるテーブルと結合テーブル間に存在する関係のためです。
たとえば、上記の例のように削除ステートメントを発行すると、oldName で指定された会社用の Company テーブルだけでなく、結合テーブルに対しても削除が実行されることがあります。したがって、Employee テーブルとの関係が BiDirectional ManyToMany である Company テーブルで、以前の例の正常な実行結果として、対応する結合テーブル Company_Employee から複数の行が失われます。
上記の int deletedEntries 値には、この操作により影響を受けたすべての行 (結合テーブルの行を含む) の数が含まれます。
INSERT ステートメントの擬似構文は INSERT INTO EntityName properties_list select_statement です。
INSERT INTO … SELECT … という形式のみサポートされ、INSERT INTO … VALUES … という形式はサポートされません。
例: 一括挿入ステートメント
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlInsert = "insert into Account (id, name) select c.id, c.name from Customer c where ...";
int createdEntities = s.createQuery( hqlInsert )
.executeUpdate();
tx.commit();
session.close();
SELECT ステートメントを介して id 属性の値を提供しない場合は、基礎となるデータベースが自動生成されたキーをサポートする限り、ユーザーに対して ID が生成されます。この一括挿入操作の戻り値は、データベースで実際に作成されたエントリーの数です。
12.8.8. コレクションメンバーの参照
コレクション値 (collection-valued) アソシエーションへの参照は、実際はコレクションの値を参照します。
例: コレクションの参照
select c
from Customer c
join c.orders o
join o.lineItems l
join l.product p
where o.status = 'pending'
and p.status = 'backorder'
// alternate syntax
select c
from Customer c,
in(c.orders) o,
in(o.lineItems) l
join l.product p
where o.status = 'pending'
and p.status = 'backorder'
この例では、ID 変数 o が、Customer#orders アソシエーションの要素の型であるオブジェクトモデル型 Order を実際に参照します。
更にこの例には、IN 構文を使用してコレクションアソシエーション結合を指定する代替の構文があります。構文は両方同等です。アプリケーションが使用する構文は任意に選択できます。
12.8.9. 修飾パス式
コレクション値 (collection-valued) のアソシエーションは、実際にはそのコレクションの値を参照すると前項で説明しました。コレクションのタイプを基に、明示的な修飾式のセットも使用可能です。
| 表現 | 説明 |
|---|---|
|
|
コレクション値を参照します。修飾子を指定しないことと同じです。目的を明示的に表す場合に便利です。コレクション値 (collection-valued) の参照のすべてのタイプに対して有効です。 |
|
|
HQL ルールに基づき、マップキーまたはリストの場所 (OrderColumn の値) を参照するよう javax.persistence.OrderColumn アノテーションを指定するマップとリストに対して有効です。ただし、JPQL ではリストでの使用に対して確保され、マップに対して |
|
|
マップに対してのみ有効です。マップのキーを参照します。キー自体がエンティティーである場合は、さらにナビゲートすることが可能です。 |
|
|
マップに対してのみ有効です。マップの論理 java.util.Map.Entry タプル (キーと値の組み合わせ) を参照します。 |
例: 修飾されたコレクションの参照
// Product.images is a Map<String,String> : key = a name, value = file path
// select all the image file paths (the map value) for Product#123
select i
from Product p
join p.images i
where p.id = 123
// same as above
select value(i)
from Product p
join p.images i
where p.id = 123
// select all the image names (the map key) for Product#123
select key(i)
from Product p
join p.images i
where p.id = 123
// select all the image names and file paths (the 'Map.Entry') for Product#123
select entry(i)
from Product p
join p.images i
where p.id = 123
// total the value of the initial line items for all orders for a customer
select sum( li.amount )
from Customer c
join c.orders o
join o.lineItems li
where c.id = 123
and index(li) = 112.8.10. スカラー関数
HQL は、使用される基盤のデータに関係なく使用できる一部の標準的な機能を定義します。また、HQL は方言やアプリケーションによって定義された追加の機能も理解することができます。
12.8.11. HQL の標準化された関数について
使用される基盤のデータベースに関係なく HQL で使用できる関数は次のとおりです。
| 機能 | 説明 |
|---|---|
|
|
バイナリーデータの長さを返します。 |
|
|
SQL キャストを実行します。キャストターゲットは使用する Hibernate マッピングタイプを命名する必要があります。 |
|
|
datetime 値で SQL の抽出を実行します。抽出により、datetime 値の一部が抽出されます (年など)。以下の省略形を参照してください。 |
|
|
秒を抽出する抽出の省略形。 |
|
|
分を抽出する抽出の省略形。 |
|
|
時間を抽出する抽出の省略形。 |
|
|
日を抽出する抽出の省略形。 |
|
|
月を抽出する抽出の省略形。 |
|
|
年を抽出する抽出の省略形。 |
|
|
値を文字データとしてキャストする省略形。 |
アプリケーション開発者は独自の関数セットを提供することもできます。通常、カスタム SQL 関数か SQL スニペットのエイリアスで表します。このような関数は、org.hibernate.cfg.Configuration の addSqlFunction メソッドを使用して宣言します。
12.8.12. 連結演算
HQL は、連結 (CONCAT) 関数をサポートするだけでなく、連結演算子も定義します。連結演算子は JPQL によっては定義されないため、移植可能なアプリケーションでは使用しないでください。連結演算子は SQL の連結演算子である || を使用します。
例: 連結操作
select 'Mr. ' || c.name.first || ' ' || c.name.last from Customer c where c.gender = Gender.MALE
12.8.13. 動的インスタンス化
select 節でのみ有効な特別な式タイプがありますが、Hibernate では「動的インスタンス化」と呼びます。JPQL はこの機能の一部をサポートし、「コンストラクター式」と呼びます。
例: 動的インスタンス化 - コンストラクター
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offsprObject[] に対処せずに、クエリーの結果として返されるタイプセーフの Java オブジェクトで値をラッピングします。クラス参照は完全修飾する必要があり、一致するコンストラクターがなければなりません。
ここでは、クラスをマッピングする必要はありません。エンティティーを表す場合、結果となるインスタンスは NEW 状態で返されます (管理されません)。
この部分は JPQL もサポートします。HQL は他の「動的インスタンス化」もサポートします。最初に、スカラーの結果に対して Object[] ではなくリストを返すよう、クエリーで指定できます。
例: 動的インスタンス化 - リスト
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offsprこのクエリーの結果は List<Object[]> ではなく List<List>
また、HQL はマップにおけるスカラーの結果のラッピングもサポートします。
例: 動的インスタンス化 - マップ
select new map( mother as mother, offspr as offspr, mate as mate )
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
select new map( max(c.bodyWeight) as max, min(c.bodyWeight) as min, count(*) as n )
from Cat cxtこのクエリーの結果は List<Object[]> ではなく List<Map<String,Object>> になります。マップのキーは select 式へ提供されたエイリアスによって定義されます。
12.8.14. HQL 述語
述語は where 句、having 句、および検索 case 式の基盤を形成します。これらは通常は TRUE または FALSE の真理値に解決される式ですが、一般的に NULL 値が関係するブール値の比較は UNKNOWN に解決されます。
HQL 述語
Null 述語
NULL の値をチェックします。基本的な属性参照、エンティティー参照、およびパラメーターへ適用できます。HQL では、コンポーネント/埋め込み可能タイプにも適用できます。
Null チェックの例
// select everyone with an associated address select p from Person p where p.address is not null // select everyone without an associated address select p from Person p where p.address is null
LIKE 述語
文字列値で LIKE 比較を実行します。構文は次のとおりです。
like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]セマンティックは SQL の LIKE 式に従います。
pattern_valueは、string_expressionで一致を試みるパターンです。SQL と同様に、pattern_valueには_(アンダースコア) と%(パーセント) をワイルドカードとして使用できます。意味も同じであり、_はあらゆる 1 つの文字と一致し、%はあらゆる数の文字と一致します。任意の
escape_characterは、pattern_valueの_や%をエスケープするために使用するエスケープ文字を指定するために使用されます。これは_や%が含まれるパターンを検索する必要がある場合に役立ちます。Like 述語の例
select p from Person p where p.name like '%Schmidt' select p from Person p where p.name not like 'Jingleheimmer%' // find any with name starting with "sp_" select sp from StoredProcedureMetadata sp where sp.name like 'sp|_%' escape '|'
BETWEEN 述語
SQL の
BETWEEN式と同様です。値が他の 2 つの値の間にあることを評価するために実行します。演算対象はすべて比較可能な型を持つ必要があります。Between 述語の例
select p from Customer c join c.paymentHistory p where c.id = 123 and index(p) between 0 and 9 select c from Customer c where c.president.dateOfBirth between {d '1945-01-01'} and {d '1965-01-01'} select o from Order o where o.total between 500 and 5000 select p from Person p where p.name between 'A' and 'E'IN 述語
IN述語は、値のリストに特定の値があることを確認するチェックを行います。構文は次のとおりです。in_expression ::= single_valued_expression [NOT] IN single_valued_list single_valued_list ::= constructor_expression | (subquery) | collection_valued_input_parameter constructor_expression ::= (expression[, expression]*)single_valued_expressionのタイプとsingle_valued_listの各値は一致しなければなりません。JPQL は有効なタイプを文字列、数字、日付、時間、タイムスタンプ、列挙型に限定します。JPQL では、single_valued_expressionは下記のみを参照できます。- 簡単な属性を表す「ステートフィールド」。アソシエーションとコンポーネント/埋め込み属性を明確に除外します。
エンティティータイプの式。
HQL では、
single_valued_expressionはさらに広範囲の式タイプを参照することが可能です。単一値のアソシエーションは許可されます。コンポーネント/埋め込み属性も許可されますが、この機能は、基礎となるデータベースのタプルまたは「行値コンストラクター構文」へのサポートのレベルに依存します。また、HQL は値タイプを制限しませんが、基礎となるデータベースのべンダーによってはサポートが制限されるタイプがあることをアプリケーション開発者は認識しておいたほうがよいでしょう。これが JPQL の制限の主な原因となります。値のリストは複数の異なるソースより取得することが可能です。
constructor_expressionとcollection_valued_input_parameterでは、空の値のリストは許可されず、最低でも 1 つの値が含まれなければなりません。In 述語の例
select p from Payment p where type(p) in (CreditCardPayment, WireTransferPayment) select c from Customer c where c.hqAddress.state in ('TX', 'OK', 'LA', 'NM') select c from Customer c where c.hqAddress.state in ? select c from Customer c where c.hqAddress.state in ( select dm.state from DeliveryMetadata dm where dm.salesTax is not null ) // Not JPQL compliant! select c from Customer c where c.name in ( ('John','Doe'), ('Jane','Doe') ) // Not JPQL compliant! select c from Customer c where c.chiefExecutive in ( select p from Person p where ... )
12.8.15. 関係比較
比較には比較演算子 (=、>、>=、<、⇐、<>) の 1 つが関与します。また、HQL によって != は <>. と同義の比較演算子として定義されます。オペランドは同じ型でなければなりません。
例: 相対比較
// numeric comparison
select c
from Customer c
where c.chiefExecutive.age < 30
// string comparison
select c
from Customer c
where c.name = 'Acme'
// datetime comparison
select c
from Customer c
where c.inceptionDate < {d '2000-01-01'}
// enum comparison
select c
from Customer c
where c.chiefExecutive.gender = com.acme.Gender.MALE
// boolean comparison
select c
from Customer c
where c.sendEmail = true
// entity type comparison
select p
from Payment p
where type(p) = WireTransferPayment
// entity value comparison
select c
from Customer c
where c.chiefExecutive = c.chiefTechnologist
比較には、サブクエリー修飾子である ALL、 ANY、 SOME も関与します。SOME と ANY は同義です。
サブクエリーの結果にあるすべての値に対して比較が true である場合、ALL 修飾子は true に解決されます。サブクエリーの結果が空の場合は false に解決されます。
例: ALL サブクエリー比較修飾子
// select all players that scored at least 3 points // in every game. select p from Player p where 3 > all ( select spg.points from StatsPerGame spg where spg.player = p )
サブクエリーの結果にある値の一部 (最低でも 1 つ) に対して比較が true の場合、ANY または SOME 修飾子は true に解決されます。サブクエリーの結果が空である場合、false に解決されます。
12.9. Hibernate サービス
12.9.1. Hibernate サービス
サービスは、さまざまな機能タイプのプラグ可能な実装を Hibernate に提供するクラスです。サービスは特定のサービスコントラクトインターフェースの実装です。インターフェースはサービスロールとして知られ、実装クラスはサービス実装として知られています。通常、ユーザーはすべての標準的なサービスロールの代替実装へプラグインできます (オーバーライド)。また、サービスロールのベースセットを越えた追加サービスを定義できます (拡張)。
12.9.2. サービスコントラクト
マーカーインターフェース org.hibernate.service.Service を実装することがサービスの基本的な要件になります。Hibernate は基本的なタイプセーフのために内部でこのインターフェースを使用します。
起動と停止の通知を受け取るために、サービスは org.hibernate.service.spi.Startable および org.hibernate.service.spi.Stoppable インターフェースを任意で実装することもできます。その他に、JMX 統合が有効になっている場合に JMX でサービスを管理可能としてマーク付けする org.hibernate.service.spi.Manageable という任意のサービスコントラクトがあります。
12.9.3. サービス依存関係のタイプ
サービスは、以下の 2 つの方法のいずれかを使用して、他のサービスに依存関係を宣言できます。
- @org.hibernate.service.spi.InjectService
-
単一のパラメーターを受け取るサービス実装クラスのメソッドと
@InjectServiceアノテーションが付けられているメソッドは、他のサービスのインジェクションを要求していると見なされます。 -
デフォルトでは、メソッドパラメーターのタイプは、インジェクトされるサービスロールであると想定されます。パラメータータイプがサービスロールではない場合は、
InjectServiceのserviceRole属性を使用してロールを明示的に指定する必要があります。 -
デフォルトでは、インジェクトされたサービスは必須のサービスであると見なされます。そのため、名前付けされた依存サービスがない場合は、起動に失敗します。インジェクトされるサービスが任意のサービスである場合は、
InjectServiceの required 属性をfalse(デフォルト値はtrue) として宣言する必要があります。 - org.hibernate.service.spi.ServiceRegistryAwareService
-
2 つ目の方法は、単一の
injectServicesメソッドを宣言する任意のサービスインターフェースorg.hibernate.service.spi.ServiceRegistryAwareServiceをサービスが実装する方法です。 -
起動中、Hibernate は
org.hibernate.service.ServiceRegistry自体をこのインターフェースを実装するサービスにインジェクトします。その後、サービスはServiceRegistry参照を使用して、必要な他のサービスを見つけることができます。
12.9.4. サービスレジストリー
12.9.4.1. ServiceRegistry
サービス自体以外の中央サービス API は org.hibernate.service.ServiceRegistry インターフェースです。サービスレジストリーの主な目的は、サービスを保持および管理し、サービスへのアクセスを提供することです。
サービスレジストリーは階層的です。レジストリーのサービスは、同じレジストリーおよび親レジストリーにあるサービスへの依存や利用が可能です。
org.hibernate.service.ServiceRegistryBuilder を使用して org.hibernate.service.ServiceRegistry インスタンスをビルドします。
例: ServiceRegistryBuilder を使用した ServiceRegistry の作成
ServiceRegistryBuilder registryBuilder = new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();12.9.5. カスタムサービス
12.9.5.1. カスタムサービス
org.hibernate.service.ServiceRegistry がビルドされると、不変であると見なされます。サービス自体は再設定を許可することもありますが、ここで言う不変とはサービスの追加や置換を意味します。そのため org.hibernate.service.ServiceRegistryBuilder によって提供される別のロールにより、生成された org.hibernate.service.ServiceRegistry に格納されるサービスを微調整できるようになります。
カスタムサービスについて org.hibernate.service.ServiceRegistryBuilder に通知する方法は 2 つあります。
- org.hibernate.service.spi.BasicServiceInitiator クラスを実装してサービスクラスの要求に応じた構築を制御し、addInitiator メソッドを介して org.hibernate.service.ServiceRegistryBuilder へ追加します。
- サービスクラスをインスタンス化し、addService メソッドを介して org.hibernate.service.ServiceRegistryBuilder へ追加します。
サービスを追加する方法とイニシエーターを追加する方法はいずれも、レジストリーの拡張 (新しいサービスロールの追加) やサービスのオーバーライド (サービス実装の置換) に対して有効です。
例: ServiceRegistryBuilder を用いた既存サービスのカスタマーサービスへの置き換え
ServiceRegistryBuilder registryBuilder = new ServiceRegistryBuilder( bootstrapServiceRegistry );
registryBuilder.addService( JdbcServices.class, new FakeJdbcService() );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
public class FakeJdbcService implements JdbcServices{
@Override
public ConnectionProvider getConnectionProvider() {
return null;
}
@Override
public Dialect getDialect() {
return null;
}
@Override
public SqlStatementLogger getSqlStatementLogger() {
return null;
}
@Override
public SqlExceptionHelper getSqlExceptionHelper() {
return null;
}
@Override
public ExtractedDatabaseMetaData getExtractedMetaDataSupport() {
return null;
}
@Override
public LobCreator getLobCreator(LobCreationContext lobCreationContext) {
return null;
}
@Override
public ResultSetWrapper getResultSetWrapper() {
return null;
}
}12.9.6. ブートストラップレジストリー
12.9.6.1. ブートストラップレジストリー
ブートストラップレジストリーは、ほとんどの操作を行うために必ず必要になるサービスを保持します。主なサービスは ClassLoaderService (代表的な例) です。設定ファイルの解決にもクラスローディングサービス (リソースのルックアップ) へのアクセスが必要になります。通常の使用では、これがルートレジストリー (親なし) になります。
ブートストラップレジストリーのインスタンスは org.hibernate.service.BootstrapServiceRegistryBuilder クラスを使用してビルドされます。
12.9.6.2. BootstrapServiceRegistryBuilder の使用
例: BootstrapServiceRegistryBuilder の使用
BootstrapServiceRegistry bootstrapServiceRegistry = new BootstrapServiceRegistryBuilder()
// pass in org.hibernate.integrator.spi.Integrator instances which are not
// auto-discovered (for whatever reason) but which should be included
.with( anExplicitIntegrator )
// pass in a class loader that Hibernate should use to load application classes
.with( anExplicitClassLoaderForApplicationClasses )
// pass in a class loader that Hibernate should use to load resources
.with( anExplicitClassLoaderForResources )
// see BootstrapServiceRegistryBuilder for rest of available methods
...
// finally, build the bootstrap registry with all the above options
.build();12.9.6.3. BootstrapRegistry サービス
org.hibernate.service.classloading.spi.ClassLoaderService
Hibernate はクラスローダーと対話する必要がありますが、Hibernate (またはライブラリー) がクラスローダーと対話する方法は、アプリケーションをホストするランタイム環境によって異なります。クラスローディングの要件は、アプリケーションサーバー、OSGi コンテナー、およびその他のモジュラークラスローディングシステムによって限定されます。このサービスは、このような環境の複雑性の抽象化を Hibernate に提供しますが、単一のスワップ可能なコンポーネントを用いることも重要な点になります。
クラスローダーとの対話では、Hibernate に以下の機能が必要になります。
- アプリケーションクラスを見つける機能
- 統合クラスを見つける機能
- リソース (プロパティーファイル、xml ファイルなど) を見つける機能
- java.util.ServiceLoader をロードする機能
現在、アプリケーションクラスをロードする機能と統合クラスをロードする機能は、サービス上の 1 つの「ロードクラス」機能として組み合わされていますが、今後のリリースで変更になる可能性があります。
org.hibernate.integrator.spi.IntegratorService
アプリケーション、アドオン、およびその他のモジュールは Hibernate と統合する必要があります。以前の方法では、各モジュールの登録を調整するためにコンポーネント (通常はアプリケーション) が必要でした。この登録は各モジュールのインタグレーターの代わりに実行されました。
このサービスはディスカバリーに重点を置きます。org.hibernate.service.classloading.spi.ClassLoaderService によって提供される標準の Java java.util.ServiceLoader 機能を使用して、org.hibernate.integrator.spi.Integrator コントラクトの実装を検出します。
インテグレーターは /META-INF/services/org.hibernate.integrator.spi.Integrator という名前のファイルを定義し、クラスパス上で使用できるようにします。
このファイルは java.util.ServiceLoader メカニズムによって使用され、org.hibernate.integrator.spi.Integrator インターフェースを実装するクラスの完全修飾名を 1 行に 1 つずつリストします。
12.9.7. SessionFactory レジストリー
12.9.7.1. SessionFactory レジストリー
すべてのレジストリータイプのインスタンスを指定の org.hibernate.SessionFactory のターゲットとして扱うことが最良の方法ですが、このグループのサービスのインスタンスは明示的に 1 つの org.hibernate.SessionFactory に属します。
違いは開始する必要があるタイミングになります。一般的に開始する org.hibernate.SessionFactory にアクセスする必要があります。この特別なレジストリーは org.hibernate.service.spi.SessionFactoryServiceRegistry です。
12.9.7.2. SessionFactory サービス
org.hibernate.event.service.spi.EventListenerRegistry
- 説明
- イベントリスナーを管理するサービス。
- イニシエーター
-
org.hibernate.event.service.internal.EventListenerServiceInitiator - 実装
-
org.hibernate.event.service.internal.EventListenerRegistryImpl
12.9.8. インテグレーター
12.9.8.1. インテグレーター
org.hibernate.integrator.spi.Integrator の目的は、機能する SessionFactory のビルドプロセスに開発者がフックできるようにする簡単な手段を提供することです。org.hibernate.integrator.spi.Integrator インターフェースは、ビルドプロセスにフックできるようにする integrate と、終了する SessionFactory にフックできるようにする disintegrate の 2 つのメソッドを定義します。
org.hibernate.cfg.Configuration の代わりに org.hibernate.metamodel.source.MetadataImplementor を受け入れるオーバーロード形式の integrate は、org.hibernate.integrator.spi.Integrator で定義される 3 つ目のメソッドになります。この形式は 5.0 で完了予定であった新しいメタモデルコードでの使用向けです。
IntegratorService によって提供されるディスカバリー以外に、BootstrapServiceRegistry のビルド時にアプリケーションはインテグレーターを手動で登録することができます。
12.9.8.2. インテグレーターのユースケース
現在、org.hibernate.integrator.spi.Integrator の主なユースケースは、イベントリスナーの登録とサービスの提供です (org.hibernate.integrator.spi.ServiceContributingIntegrator を参照)。5.0 では、オブジェクトとリレーショナルモデルとの間のマッピングを定義するメタモデルを変更できるようにするための拡張を計画しています。
例: イベントリスナーの登録
public class MyIntegrator implements org.hibernate.integrator.spi.Integrator {
public void integrate(
Configuration configuration,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// As you might expect, an EventListenerRegistry is the thing with which event listeners are registered It is a
// service so we look it up using the service registry
final EventListenerRegistry eventListenerRegistry = serviceRegistry.getService( EventListenerRegistry.class );
// If you wish to have custom determination and handling of "duplicate" listeners, you would have to add an
// implementation of the org.hibernate.event.service.spi.DuplicationStrategy contract like this
eventListenerRegistry.addDuplicationStrategy( myDuplicationStrategy );
// EventListenerRegistry defines 3 ways to register listeners:
// 1) This form overrides any existing registrations with
eventListenerRegistry.setListeners( EventType.AUTO_FLUSH, myCompleteSetOfListeners );
// 2) This form adds the specified listener(s) to the beginning of the listener chain
eventListenerRegistry.prependListeners( EventType.AUTO_FLUSH, myListenersToBeCalledFirst );
// 3) This form adds the specified listener(s) to the end of the listener chain
eventListenerRegistry.appendListeners( EventType.AUTO_FLUSH, myListenersToBeCalledLast );
}
}12.10. Envers
12.10.1. Hibernate Envers
Hibernate Envers は監査およびバージョニングシステムであり、永続クラスへの変更履歴を追跡する方法を JBoss EAP に提供します。エンティティーに対する変更履歴を保存する @Audited アノテーションが付けられたエンティティーに対して監査テーブルが作成されます。その後、データの取得と問い合わせが可能になります。
Envers により開発者は次の作業を行うことが可能になります。
- JPA 仕様によって定義されるすべてのマッピングの監査
- JPA 仕様を拡張するすべての Hibernate マッピングの監査
- ネイティブ Hibernate API によりマッピングされた監査エンティティー
- リビジョンエンティティーを用いて各リビジョンのデータをログに記録
- 履歴データのクエリー
12.10.2. 永続クラスの監査
JBoss EAP では、Hibernate Envers と @Audited アノテーションを使用して永続クラスの監査を行います。アノテーションがクラスに適用されると、エンティティーのリビジョン履歴が保存されるテーブルが作成されます。
クラスに変更が加えられるたびに監査テーブルにエントリーが追加されます。エントリーにはクラスへの変更が含まれ、リビジョン番号が付けられます。そのため、変更をロールバックしたり、以前のリビジョンを表示したりすることが可能です。
12.10.3. 監査ストラテジー
12.10.3.1. 監査ストラテジー
監査ストラテジーは、監査情報の永続化、クエリー、および格納の方法を定義します。Hibernate Envers には、現在 2 つの監査ストラテジーが存在します。
- デフォルトの監査ストラテジー
- このストラテジーは監査データと開始リビジョンを共に永続化します。監査テーブルで挿入、更新、削除された各行については、開始リビジョンの有効性と合わせて、1 つ以上の行が監査テーブルに挿入されます。
- 監査テーブルの行は挿入後には更新されません。監査情報のクエリーはサブクエリーを使い監査テーブルの該当行を選択します (これは時間がかかり、インデックス化が困難です)。
- 妥当性監査ストラテジー
- このストラテジーは監査情報の開始リビジョンと最終リビジョンの両方を格納します。監査テーブルで挿入、更新、または削除された各行については、開始リビジョンの有効性とあわせて、1 つ以上の行が監査テーブルに挿入されます。
- 同時に、以前の監査行 (利用可能な場合) の最終リビジョンフィールドがこのリビジョンに設定されます。監査情報に対するクエリーは、サブクエリーの代わりに開始と最終リビジョンのいずれかを使用します。つまり、更新の数が増えるため監査情報の永続化には今までより少し時間がかかりますが、監査情報の取得は非常に早くなります。
- インデックスを増やすことで改善することも可能です。
監査の詳細については、永続クラスの監査を参照してください。アプリケーションの監査ストラテジーを設定するには、 監査ストラテジーの設定を参照してください。
12.10.3.2. 監査ストラテジーの設定
JBoss EAP では、2 つの監査ストラテジーがサポートされます。
- デフォルトの監査ストラテジー
- 妥当性監査ストラテジー
監査ストラテジーの定義
アプリケーションの persistence.xml ファイルで org.hibernate.envers.audit_strategy プロパティーを設定します。このプロパティーが persistence.xml ファイルで設定されていない場合は、デフォルトの監査ストラテジーが使用されます。
デフォルトの監査ストラテジーの設定
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>
妥当性監査ストラテジーの設定
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>
12.10.4. JPA エンティティーへの監査サポートの追加
JBoss EAP は、エンティティーの監査を使用して (Hibernate Envers を参照)、永続クラスの変更履歴を追跡します。本トピックでは、JPA エンティティーに対する監査サポートを追加する方法について説明します。
JPA エンティティーへの監査サポートの追加
- デプロイメントに適した使用可能な監査パラメーターを設定します (Envers パラメーターの設定を参照)。
- 監査対象となる JPA エンティティーを開きます。
-
org.hibernate.envers.Auditedインターフェースをインポートします。 監査対象となる各フィールドまたはプロパティーに
@Auditedアノテーションを付けます。または、1 度にクラス全体へアノテーションを付けます。例: 2 つのフィールドの監査
import org.hibernate.envers.Audited; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.GeneratedValue; import javax.persistence.Column; @Entity public class Person { @Id @GeneratedValue private int id; @Audited private String name; private String surname; @ManyToOne @Audited private Address address; // add getters, setters, constructors, equals and hashCode here }例: クラス全体の監査
import org.hibernate.envers.Audited; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.GeneratedValue; import javax.persistence.Column; @Entity @Audited public class Person { @Id @GeneratedValue private int id; private String name; private String surname; @ManyToOne private Address address; // add getters, setters, constructors, equals and hashCode here }
JPA エンティティーの監査が設定されると、変更履歴を保存するために _AUD という名前のテーブルが作成されます。
12.10.5. Configuration (設定)
12.10.5.1. Envers パラメーターの設定
JBoss EAP は、Hibernate Envers からエンティティーの監査を使用して、永続クラスの変更履歴を追跡します。
利用可能な Envers パラメーターの設定
-
アプリケーションの
persistence.xmlファイルを開きます。 必要に応じて Envers プロパティーを追加、削除、または設定します。使用可能なプロパティーの一覧については、Envers の設定プロパティーを参照してください。
例: Envers パラメーター
<persistence-unit name="mypc"> <description>Persistence Unit.</description> <jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source> <shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode> <properties> <property name="hibernate.hbm2ddl.auto" value="create-drop" /> <property name="hibernate.show_sql" value="true" /> <property name="hibernate.cache.use_second_level_cache" value="true" /> <property name="hibernate.cache.use_query_cache" value="true" /> <property name="hibernate.generate_statistics" value="true" /> <property name="org.hibernate.envers.versionsTableSuffix" value="_V" /> <property name="org.hibernate.envers.revisionFieldName" value="ver_rev" /> </properties> </persistence-unit>
12.10.5.2. ランタイム時に監査を有効または無効にする
ランタイム時にエンティティーバージョン監査を有効または無効にする
-
AuditEventListenerクラスをサブクラス化します。 Hibernate イベント上で呼び出される次のメソッドを上書きします。
-
onPostInsert -
onPostUpdate -
onPostDelete -
onPreUpdateCollection -
onPreRemoveCollection -
onPostRecreateCollection
-
- イベントのリスナーとしてサブクラスを指定します。
- 変更を監査すべきであるか判断します。
- 変更を監査する必要がある場合は、呼び出しをスーパークラスへ渡します。
12.10.5.3. 条件付き監査の設定
Hibernate Envers は一連のイベントリスナーを使用して、さまざまな Hibernate イベントに対して監査データを永続化します。Envers jar がクラスパスにある場合、これらのリスナーは自動的に登録されます。
条件付き監査の実装
-
persistence.xmlファイルでhibernate.listeners.envers.autoRegisterの Hibernate プロパティーを false に設定します。 - 上書きする各イベントリスナーをサブクラス化します。条件付き監査の論理をサブクラスに置き、監査の実行が必要な場合はスーパーメソッドを呼び出します。
-
org.hibernate.envers.event.EnversIntegratorと似ているorg.hibernate.integrator.spi.Integratorのカスタム実装を作成します。デフォルトのクラスではなく、手順 2 で作成したイベントリスナーサブクラスを使用します。 -
jar に
META-INF/services/org.hibernate.integrator.spi.Integratorファイルを追加します。このファイルにはインターフェースを実装するクラスの完全修飾名を含める必要があります。
12.10.5.4. Envers の設定プロパティー
| プロパティー名 | デフォルト値 | 説明 |
|---|---|---|
|
|
デフォルト値なし |
監査エンティティーの名前の前に付けられた文字列。監査情報を保持するエンティティーの名前を作成します。 |
|
|
_AUD |
監査情報を保持するエンティティーの名前を作成する監査エンティティーの名前に追加された文字列。たとえば、 |
|
|
REV |
改訂番号を保持する監査エンティティーのフィールド名。 |
|
|
REVTYPE |
リビジョンタイプを保持する監査エンティティーのフィールド名。挿入、変更、または削除のための現在のリビジョンタイプは、それぞれ |
|
|
true |
このプロパティーは、所有されていない関係フィールドが変更された場合にリビジョンを生成するかどうかを決定します。これは、一対多関係のコレクションまたは一対一関係の |
|
|
true |
true の場合、オプティミスティックロッキングに使用したプロパティー ( |
|
|
false |
このプロパティーは、ID のみではなく、他の全プロパティーが null とマークされたエンティティーが削除される場合にエンティティーデータをリビジョンに保存すべきかどうかを定義します。このデータは最終リビジョンに存在するため、これは通常必要ありません。最終リビジョンのデータにアクセスする方が簡単で効率的ですが、この場合、削除前にエンティティーに含まれたデータが 2 回保存されることになります。 |
|
|
null (通常のテーブルと同じ) |
監査テーブルに使用されるデフォルトのスキーマ名。 |
|
|
null (通常のテーブルと同じ) |
監査テーブルに使用するデフォルトのカタログ名。 |
|
|
|
このプロパティーは、監査データを永続化する際に使用する監査ストラテジーを定義します。デフォルトでは、エンティティーが変更されたリビジョンのみが保存されます。あるいは、 |
|
|
REVEND |
監査エンティティーのリビジョン番号を保持するカラムの名前。このプロパティーは、妥当性監査ストラテジーが使用されている場合のみ有効です。 |
|
|
false |
このプロパティーは、データが最後に有効だった最終リビジョンのタイムスタンプを最終リビジョンとともに格納するかどうかを定義します。これは、テーブルパーティショニングを使用することにより、関係データベースから以前の監査レコードを削除する場合に役に立ちます。パーティショニングには、テーブル内に存在する列が必要です。このプロパティーは、 |
|
|
REVEND_TSTMP |
データが有効であった最終リビジョンのタイムスタンプの列名。 |
12.10.6. クエリーを介した監査情報の読み出し
Hibernate Envers は、クエリーから監査情報を読み出しする機能を提供します。
監査されたデータのクエリーは相関サブセレクトが関与するため、多くの場合で live データの対応するクエリーよりも大幅に処理が遅くなります。
特定のリビジョンでクラスのエンティティーをクエリーする
このようなクエリーのエントリーポイントは次のとおりです。
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);
AuditEntity ファクトリクラスを使用して制約を指定することができます。以下のクエリーは、name プロパティーが John と同等である場合のみエンティティーを選択します。
query.add(AuditEntity.property("name").eq("John"));以下のクエリーは特定のエンティティーと関連するエンティティーのみを選択します。
query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));結果を順序付けや制限付けしたり、凝集 (aggregations) および射影 (projections) のセット (グループ化を除く) を持つことが可能です。以下はフルクエリーの例になります。
List personsAtAddress = getAuditReader().createQuery()
.forEntitiesAtRevision(Person.class, 12)
.addOrder(AuditEntity.property("surname").desc())
.add(AuditEntity.relatedId("address").eq(addressId))
.setFirstResult(4)
.setMaxResults(2)
.getResultList();特定クラスのエンティティーが変更された場合のクエリーリビジョン
このようなクエリーのエントリーポイントは次のとおりです。
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);前の例と同様に、このクエリーへ制約を追加することが可能です。このクエリーに以下を追加することも可能です。
AuditEntity.revisionNumber()- 監査されたエンティティーが修正されたリビジョン番号の制約や射影、順序付けを指定します。
AuditEntity.revisionProperty(propertyName)- 監査されたエンティティーが修正されたリビジョンに対応するリビジョンエンティティーのプロパティーの制約や射影、順序付けを指定します。
AuditEntity.revisionType()- リビジョンのタイプ (ADD、MOD、DEL) へのアクセスを提供します。
クエリー結果を必要に応じて調整することが可能です。次のクエリーは、リビジョン番号 42 の後に entityId ID を持つ MyEntity クラスのエンティティーが変更された最小のリビジョン番号を選択します。
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.setProjection(AuditEntity.revisionNumber().min())
.add(AuditEntity.id().eq(entityId))
.add(AuditEntity.revisionNumber().gt(42))
.getSingleResult();
リビジョンのクエリーはプロパティーを最小化および最大化することも可能です。次のクエリーは、特定エンティティーの actualDate 値が指定の値よりは大きく、可能な限り小さいリビジョンを選択します。
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
// We are only interested in the first revision
.setProjection(AuditEntity.revisionNumber().min())
.add(AuditEntity.property("actualDate").minimize()
.add(AuditEntity.property("actualDate").ge(givenDate))
.add(AuditEntity.id().eq(givenEntityId)))
.getSingleResult();
minimize() および maximize() メソッドは制約を追加できる基準を返します。最大化または最小化されたプロパティーを持つエンティティーはこの基準を満たさなければなりません。
クエリー作成時に渡されるブール変数パラメーターは 2 つあります。
selectEntitiesOnly-
このパラメーターは、明示的なプロジェクションが設定されていない場合のみ有効です。
trueの場合、クエリーの結果は指定された制約を満たすリビジョンで変更されたエンティティーのリストです。
falseの場合、結果は 3 つの要素アレイのリストです。最初の要素は変更されたエンティティーインスタンスです。2 つ目の要素はリビジョンデータを含むエンティティーです。カスタムエンティティーが使用されない場合、これはDefaultRevisionEntityのインスタンスです。3 つ目の要素アレイはリビジョンの種類 (ADD、MOD、DEL) です。 selectDeletedEntities-
このパラメーターは、エンティティーが削除されたリビジョンが結果に含まれなければならない場合に指定されます。true の場合、エンティティーのリビジョンタイプが
DELになり、id 以外のすべてのフィールドの値がnullになります。
特定のプロパティーを修正したエンティティーのクエリーリビジョン
下記のクエリーは、actualDate プロパティーが変更された、指定の ID を持つ MyEntity のすべてのリビジョンを返します。
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())
hasChanged 条件は他の基準と組み合わせることができます。次のクエリーは、revisionNumber の生成時に MyEntity の水平スライスを返します。これは、prop2 ではなく prop1 を変更したリビジョンに限定されます。
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
結果セットには revisionNumber よりも小さい番号のリビジョンも含まれます。これは、このクエリーが「prop1 が変更され、prop2 が変更されない revisionNumber で変更された MyEntities をすべて返す」とは読み取られないことを意味します。
次のクエリーは forEntitiesModifiedAtRevision クエリーを使用してこの結果をどのように返すことができるかを示します。
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());特定のリビジョンで修正されたクエリーエンティティー
次の例は、特定のリビジョンで変更されたエンティティーに対する基本的なクエリーになります。読み出される特定のリビジョンで、エンティティー名と対応する Java クラスを変更できます。
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber);org.hibernate.envers.CrossTypeRevisionChangesReader からもアクセスできる他のクエリーは以下のとおりです。
List<Object> findEntities(Number)-
特定のリビジョンで変更 (追加、更新、削除)されたすべての監査済みエンティティーのスナップショットを返します。
n+1個の SQL クエリを実行します (nは指定のリビジョン内で変更された異なるエンティティークラスの数になります)。 List<Object> findEntities(Number, RevisionType)-
変更タイプによってフィルターされた特定のリビジョンで変更 (追加、更新、削除) されたすべての監査済みエンティティーのスナップショットを返します。
n+1個の SQL クエリーを実行します (nは指定のリビジョン内で変更された異なるエンティティークラスの数です)。Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType(Number)-
修正操作 (追加、更新、削除など) によってグループ化されたエンティティースナップショットの一覧が含まれるマップを返します。
3n+1個の SQL クエリーを実行します (nは指定のリビジョン内で変更された異なるエンティティークラスの数になります)。
12.11. パフォーマンスチューニング
12.11.1. 代替のバッチローディングアルゴリズム
Hibernate では、4 つのフェッチングストラテジー (join、select、subselect、および batch) のいずれかを使用してアソシエーションのデータをロードできます。batch ローディングは select フェッチングの最適化ストラテジーであるため、パフォーマンスを最大化できます。このストラテジーでは、主キーまたは外部キーのリストを指定することで、Hibernate が単一の SELECT ステートメントでエンティティーインスタンスまたはコレクションのバッチを読み出します。batch フェッチングは、レイジー select フェッチングストラテジーの最適化です。
batch フェッチングを設定する方法には、クラスごとのレベルと、コレクションごとのレベルの 2 つの方法があります。
クラスごとのレベル
Hibernate がクラスごとのレベルでデータをロードする場合、クエリー時に事前ロードするアソシエーションのバッチサイズが必要になります。たとえば、起動時に
carオブジェクトの 30 個のインスタンスがセッションでロードされるとします。各carオブジェクトはownerオブジェクトに属します。lazyローディングで、すべてのcarオブジェクトを繰り返し、これらの owner (所有者) を要求する場合、Hibernate は owner ごとに 1 つ、合計 30 個の select ステートメントを発行します。これは、パフォーマンス上のボトルネックになります。この代わりに、クエリーによって要求される前に次の owner のバッチに対してデータを事前ロードするよう Hibernate を指示できます。
ownerオブジェクトがクエリーされると、Hibernate は同じ SELECT ステートメントでこれらのオブジェクトをさらに多くクエリーします。事前にクエリーされる
ownerオブジェクトの数は、設定時に指定されたbatch-sizeパラメーターによって異なります。<class name="owner" batch-size="10"></class>
これは、今後必要になると見込まれる最低 10 個の
ownerオブジェクトをクエリーするよう Hibernate に指示します。ユーザーがcar Aのownerをクエリーする場合、car Bのownerはすでにバッチローディングの一部としてロードされていることがあります。ユーザーが実際にcar Bのownerを必要とする場合、データーベースにアクセスして SELECT ステートメントを発行する代わりに、現在のセッションから値を読み出すことができます。Hibernate 4.2.0 には、
batch-sizeパラメーターの他に、バッチローディングのパフォーマンスを向上する新しい設定項目が追加されました。この設定項目はBatch Fetch Style設定と呼ばれ、hibernate.batch_fetch_styleパラメーターによって指定されます。LEGACY、PADDED、および DYNAMIC の 3 つのバッチフェッチスタイルがサポートされます。使用するスタイルを指定するには、
org.hibernate.cfg.AvailableSettings#BATCH_FETCH_STYLEを使用します。LEGACY: LEGACY スタイルのローディングでは、
ArrayHelper.getBatchSizes(int)に基づいた一連の事前ビルド済みバッチサイズが使用されます。バッチは、既存のバッチ可能な識別子の数から、次に小さい事前ビルド済みバッチサイズを使用してロードされます。前述の例を用いた場合、
batch-sizeの設定が 30 であると、事前ビルドされたバッチサイズは [30, 15, 10, 9, 8, 7, .., 1] になります。29 個の識別子をバッチロードしようとすると、バッチは 15、10、および 4 になります。対応する 3 つの SQL クエリーが生成され、各クエリーはデータベースより 15、10、および 4 人の owner をロードします。PADDED - PADDED は LEGACY スタイルのバッチローディングと似ています。PADDED も事前ビルドされたバッチサイズを使用しますが、次に大きなバッチサイズを使用し、余分な識別子プレースホルダーを埋め込みます。
上記の例で、30 個の owner オブジェクトが初期化される場合は、データベースに対して 1 つのクエリーのみが実行されます。
29 個の owner オブジェクトが初期化される場合、Hibernate は同様にバッチサイズが 30 の SQL select ステートメントを 1 つ実行しますが、余分なスペースが繰り替えされる識別子で埋め込みされます。
DYNAMIC - DYNAMIC スタイルのバッチローディングはバッチサイズの制限に準拠しますが、実際にロードされるオブジェクトの数を使用して SQL SELECT ステートメントを動的にビルドします。
たとえば、30 個の owner オブジェクトで最大バッチサイズが 30 の場合、 30 個の owner オブジェクトの読み出しは 1 つの SQL SELECT ステートメントによって実行されます。35 個の owner オブジェクトを読み出す場合は、SQL ステートメントが 2 つになり、それぞれのバッチサイズが 30 と 5 になります。Hibernate は、制限どおりにバッチサイズを 30 以下とし、2 つ目の SQL ステートメントを動的に変更して、必要数である 5 にします。PADDED とは異なり、2 つ目の SQL は埋め込みされません。また、2 つ目の SQL ステートメントは動的に作成され、固定サイズでないことが LEGACY とは異なります。
30 個未満のクエリーでは、このスタイルは要求された識別子の数のみを動的にロードします。
コレクションごとのレベル
Hibernate は、前項の「クラスごとのレベル」で説明したバッチフェッチサイズとスタイルを維持してコレクションをバッチロードすることもできます。
前項の例を逆にして、各
ownerオブジェクトによって所有されるすべてのcarオブジェクトをロードする必要があるとします。10 個のownerオブジェクトがすべての owner を繰り返し、現セッションにロードされた場合、getCars()メソッドの呼び出しごとに 1 つの SELECT ステートメントが生成されるため、合計で 10 個の SELECT ステートメントが生成されます。owner のマッピングでの car コレクションのバッチフェッチングを有効にすると、Hibernate は下記のようにこれらのコレクションを事前フェッチできます。<class name="Owner"><set name="cars" batch-size="5"></set></class>
よって、バッチサイズが 5 でレガシーバッチスタイルを使用して 10 個のコレクションをロードする場合、Hibernate は 2 つの SELECT ステートメントを実行し、各ステートメントは 5 つのコレクションを読み出します。
12.11.2. 不変データのオブジェクト参照の 2 次キャッシング
Hibernate はパフォーマンスを向上するため、自動的にデータをメモリー内にキャッシュします。これは、データベースのルックアップが必要となる回数を削減する (特にほとんど変更されないデータに対し) インメモリーキャッシュによって実現されます。
Hibernate は 2 つのタイプのキャッシュを保持します。1 次キャッシュ (プライマリーキャッシュ) は必須のキャッシュです。このキャッシュは現在のセッションと関連し、すべてのリクエストが通過する必要があります。2 次キャッシュ (セカンダリーキャッシュ) は任意のキャッシュで、1 次キャッシュがアクセスされた後でのみアクセスされます。
データは、最初にステートアレイに逆アセンブルされ、2 次キャッシュに保存されます。このアレイはディープコピーされ、ディープコピーがキャッシュに格納されます。キャッシュからデータを読み取る場合は、この逆のプロセスが発生します。この仕組みは、変化するデータ (可変データ) ではうまく機能しますが、不変データでは不十分です。
データのディープコピーは、メモリーの使用と処理速度に負荷のかかる操作です。大きなデータセットでは、メモリーおよび処理速度がパフォーマンスを制限する要素になります。Hibernate では、不変データがコピーされずに参照されるよう指定できます。Hibernate はデータセット全体をコピーする代わりに、データへの参照をキャッシュに保存できます。
これは、設定 hibernate.cache.use_reference_entries の値を true に変更することによって行えます。デフォルトでは、hibernate.cache.use_reference_entries は false に設定されます。
hibernate.cache.use_reference_entries が true に設定されると、アソシエーションを持たない不変データオブジェクトは 2 次キャッシュにコピーされず、不変データオブジェクトへの参照のみが保存されます。
hibernate.cache.use_reference_entries が true に設定されても、アソシエーションを持つ不変データオブジェクトは 2 次キャッシュにディープコピーされます。