クラスター管理
Red Hat OpenShift Service on AWS クラスターの設定
概要
第1章 クラスターの通知
クラスター通知 (サービスログと呼ばれることもあります) は、クラスターのステータス、健全性、またはパフォーマンスに関するメッセージです。
クラスター通知は、Red Hat Site Reliability Engineering (SRE) が管理対象クラスターの健全性をユーザーに通知する際に使用する主な方法です。Red Hat SRE は、クラスター通知を使用して、クラスターの問題を解決または防止するためのアクションを実行するように促すこともあります。
クラスターの所有者と管理者は、クラスターの健全性とサポート対象の状態を維持するために、クラスター通知を定期的に確認して対処する必要があります。
クラスターの通知は、Red Hat Hybrid Cloud Console のクラスターの Cluster history タブで表示できます。デフォルトでは、クラスターの所有者のみがクラスター通知をメールで受信します。他のユーザーがクラスター通知メールを受信する必要がある場合は、各ユーザーをクラスターの通知連絡先として追加します。
1.2. クラスター通知に期待できること
クラスター管理者は、クラスターの健全性と管理上のニーズを効果的に把握するために、クラスター通知が送信されるタイミングと理由、および通知の種類と重大度レベルを認識しておく必要があります。
1.2.1. クラスター通知ポリシー
クラスター通知は、クラスターの健全性とクラスターに大きな影響を与えるイベントに関する情報を常に提供できるように設計されています。
ほとんどのクラスター通知は、クラスターの問題や状態の重要な変更をすぐに通知するために、自動的に生成されて送信されます。
状況によっては、Red Hat Site Reliability Engineering (SRE) がクラスター通知を作成して送信し、複雑な問題に関する追加のコンテキストとガイダンスを提供します。
影響の少ないイベント、リスクの低いセキュリティー更新、日常的な運用とメンテナンス、または Red Hat SRE によってすぐに解決される軽微で一時的な問題は、クラスター通知が送信されません。
次の場合、Red Hat サービスが自動的に通知を送信します。
- リモートヘルスモニタリングまたは環境検証チェックにより、ワーカーノードのディスク領域不足など、クラスター内の問題が検出された場合。
- 重要なクラスターライフサイクルイベントが発生した場合。たとえば、スケジュールされたメンテナンスまたはアップグレードの開始時や、クラスター操作がイベントの影響を受けたが、お客様による介入は必要ない場合などです。
- クラスター管理に大きな変更が発生した場合。たとえば、クラスターの所有権または管理制御が 1 人のユーザーから別のユーザーに移行された場合などです。
- クラスターのサブスクリプションが変更または更新された場合。たとえば、Red Hat がサブスクリプションの条件やクラスターで利用可能な機能を更新した場合などです。
SRE は次の場合に通知を作成して送信します。
- インシデントにより、クラスターの可用性やパフォーマンスに影響を与えるデグレードや停止が発生した場合。たとえば、クラウドプロバイダーで地域的な停止が発生した場合などです。SRE は、インシデント解決の進行状況とインシデントが解決した時期を知らせる後続の通知を送信します。
- クラスターで、セキュリティー脆弱性、セキュリティー侵害、または異常なアクティビティーが検出された場合。
- お客様が行った変更によってクラスターが不安定になっているか、不安定になる可能性があることを Red Hat が検出した場合。
- ワークロードがクラスターのパフォーマンス低下や不安定化を引き起こしていることを Red Hat が検出した場合。
1.2.2. クラスター通知の重大度レベル
各クラスター通知には重大度レベルが関連付けられています。これはビジネスに最も大きな影響を与える通知を識別するのに役立ちます。Red Hat Hybrid Cloud Console のクラスターの Cluster history タブで、この重大度レベルに基づいてクラスター通知をフィルタリングできます。
Red Hat は、クラスター通知に次の重大度レベルを使用します (重大度が最も高いものから最も低いものの順)。
- Critical
- 直ちに対処する必要があります。サービスまたはクラスターの 1 つ以上の主要機能が動作していないか、まもなく動作しなくなります。Critical アラートは、待機中のスタッフに呼び出しをかけ、通常のワークフローを中断すべきほど重要なアラートです。
- Major
- 直ちに対処することを強く推奨します。クラスターの 1 つ以上の主要機能がまもなく動作しなくなります。重大な問題は、速やかに対処しないと、重大な問題につながる可能性があります。
- Warning
- できるだけ早く対処する必要があります。クラスターの 1 つ以上の主要機能が最適に動作しておらず、さらにデグレードが発生する可能性があります。ただし、これはクラスターの機能に直ちに危険をもたらすものではありません。
- Info
- 対処する必要はありません。この重大度は、対処する必要がある問題を示すものではありません。意味のある、または重要なライフサイクル、サービス、またはクラスターイベントに関する重要な情報のみを示します。
- Debug
- 対処する必要はありません。Debug 通知は、予期しない動作のデバッグに役立つ、重要度の低いライフサイクル、サービス、またはクラスターイベントに関する低レベルの情報を提供します。
1.2.3. クラスター通知タイプ
各クラスター通知には通知タイプが関連付けられています。これは自分の役割や責任に関連する通知を識別できるように。Red Hat Hybrid Cloud Console のクラスターの Cluster history タブで、このタイプに基づいてクラスター通知をフィルタリングできます。
Red Hat は、通知の関連性を示すために次の通知タイプを使用します。
- 容量の管理
- ノードプール、マシンプール、コンピュートレプリカ、またはクォータ (ロードバランサー、ストレージなど) の更新、作成、削除に関連するイベントの通知。
- Cluster access
- グループ、ロール、またはアイデンティティープロバイダーの追加または削除に関連するイベントの通知。たとえば、STS 認証情報の有効期限が切れているために SRE がクラスターにアクセスできない場合、AWS ロールの設定に問題がある場合、またはアイデンティティープロバイダーを追加または削除した場合などです。
- Cluster add-ons
- アドオンの管理またはアドオンのアップグレードメンテナンスに関連するイベントの通知。たとえば、アドオンがインストール、アップグレード、削除されたときや、要件が満たされていないためにアドオンをインストールできない場合などです。
- Cluster configuration
- クラスターチューニングイベント、ワークロード監視、およびインフライトチェックに関する通知。
- Cluster lifecycle
- クラスターまたはクラスターリソースの作成、削除、登録、またはクラスターまたはリソースのステータスの変更 (準備完了、休止状態など) に関する通知。
- Cluster networking
- HTTP/S プロキシー、ルーター、Ingress の状態など、クラスターネットワークに関連する通知。
- Cluster ownership
- クラスターの所有権がユーザー間で移動されることに関連する通知。
- Cluster scaling
- ノードプール、マシンプール、コンピュートレプリカ、またはクォータの更新、作成、または削除に関連する通知。
- Cluster security
- クラスターのセキュリティーに関連するイベント。たとえば、失敗したアクセス試行の増加、トラストバンドルの更新、セキュリティーに影響を与えるソフトウェアの更新などです。
- Cluster subscription
- クラスターの有効期限、試用版クラスターの通知、または無料から有料への切り替え。
- Cluster updates
- アップグレードのメンテナンスや有効化など、アップグレードに関連するすべてのもの。
- Customer support
- サポートケースのステータスの更新。
- General notification
- デフォルトの通知タイプ。これは、より具体的なカテゴリーがない通知にのみ使用されます。
1.3. Red Hat Hybrid Cloud Console を使用したクラスター通知の表示
クラスター通知は、クラスターの健全性に関する重要な情報を提供します。クラスターに送信された通知は、Red Hat Hybrid Cloud Console の Cluster history タブで表示できます。
前提条件
- Hybrid Cloud Console にログインしている。
手順
- Hybrid Cloud Console の Clusters ページに移動します。
- クラスターの名前をクリックし、クラスターの詳細ページに移動します。
Cluster history タブをクリックします。
クラスター通知が Cluster history の見出しの下に表示されます。
オプション: 関連するクラスター通知をフィルタリングします。
専門分野や重要な問題の解決に集中できるように、フィルターコントロールを使用して、自分に関係のないクラスター通知を非表示にします。通知の説明のテキスト、重大度レベル、通知タイプ、通知の受信日時、通知をトリガーしたシステムまたはユーザーに基づいて通知をフィルタリングできます。
1.4. クラスター通知メール
デフォルトでは、クラスター通知がクラスターに送信されると、クラスター所有者にもメールとして送信されます。通知メールの受信者を追加設定することで、適切なユーザー全員にクラスターの状態に関する通知を届けることができます。
1.4.1. クラスターへの通知連絡先の追加
クラスター通知がクラスターに送信されると、通知連絡先にメールが送信されます。デフォルトでは、クラスターの所有者のみがクラスター通知をメールで受信します。クラスターサポート設定で、他のクラスターユーザーを追加の通知連絡先として設定できます。
前提条件
- クラスターがデプロイされ、Red Hat Hybrid Cloud Console に登録されている。
- クラスターの所有者または cluster editor ロールを持つユーザーとして、Hybrid Cloud Console にログインする。
- 通知の対象となる受信者が、クラスター所有者と同じ組織に関連付けられた Red Hat カスタマーポータルアカウントを持っている。
手順
- Hybrid Cloud Console の Clusters ページに移動します。
- クラスターの名前をクリックし、クラスターの詳細ページに移動します。
- Support タブをクリックします。
- Support タブで、Notification contacts セクションを見つけます。
- Add notification contact をクリックします。
- Red Hat username or email フィールドに、新しい受信者のメールアドレスまたはユーザー名を入力します。
- Add contact をクリックします。
検証手順
- "Notification contact added successfully" というメッセージが表示されます。
トラブルシューティング
- Add notification contact ボタンが無効になっています
- 通知連絡先を追加する権限を持たないユーザーの場合、このボタンは無効になります。cluster owner、cluster editor、または cluster administrator のロールを持つアカウントにログインして、再試行してください。
- エラー:
Could not find any account identified by <username>または<email-address> - このエラーは、通知の受信者がクラスター所有者と同じ Red Hat アカウント組織に属していない場合に発生します。組織管理者に連絡して、対象の受信者を関連する組織に追加し、もう一度お試しください。
1.4.2. クラスターからの通知連絡先の削除
クラスター通知がクラスターに送信されると、通知連絡先にメールが送信されます。
クラスターサポート設定で通知連絡先を削除して、通知メールが届かないようにすることができます。
前提条件
- クラスターがデプロイされ、Red Hat Hybrid Cloud Console に登録されている。
- クラスターの所有者または cluster editor ロールを持つユーザーとして、Hybrid Cloud Console にログインする。
手順
- Hybrid Cloud Console の Clusters ページに移動します。
- クラスターの名前をクリックし、クラスターの詳細ページに移動します。
- Support タブをクリックします。
- Support タブで、Notification contacts セクションを見つけます。
- 削除する受信者の横にあるオプションメニュー (⚙) をクリックします。
- Delete をクリックします。
検証手順
- "Notification contact deleted successfully" というメッセージが表示されます。
1.5. トラブルシューティング
クラスター通知メールが届かない場合
-
@redhat.comアドレスから送信されたメールがメールの受信トレイからフィルターで除外されていないことを確認します。 - クラスターの通知連絡先として正しいメールアドレスがリストされていることを確認します。
- クラスターの所有者または管理者に、お使いのメールアドレスを通知連絡先として追加するよう依頼します (Cluster notification emails を参照)。
クラスターに通知が届かない場合
-
クラスターが
api.openshift.comのリソースにアクセスできることを確認します。
第2章 プライベート接続の設定
2.1. プライベート接続の設定
Red Hat OpenShift Service on AWS 環境のニーズに合わせて、クラスターへのプライベートアクセスを実装できます。
手順
Red Hat OpenShift Service on AWS の AWS アカウントにアクセスし、以下の 1 つ以上の方法を使用してクラスターへのプライベート接続を確立します。
- AWS VPC ピアリングの設定: VPC ピアリングを有効にして、2 つのプライベート IP アドレス間のネットワークトラフィックをルーティングします。
- AWS VPN の設定: プライベートネットワークを Amazon Virtual Private Cloud にセキュアに接続するために、仮想プライベートネットワークを確立します。
- AWS Direct Connect の設定: プライベートネットワークと AWS Direct Connect の場所との間に専用のネットワーク接続を確立するように AWS Direct Connect を設定します。
2.2. AWS VPC ピアリングの設定
このサンプルプロセスでは、Red Hat OpenShift Service on AWS クラスターが含まれる Amazon Web Services (AWS) VPC を、別の AWS VPC ネットワークとピア接続するように設定します。AWS VPC ピアリング接続の作成または他の設定に関する詳細は、AWS VPC Peering ガイドを参照してください。
2.2.1. VPC ピアリングの用語
2 つの別々の AWS アカウントで 2 つの VPC 間で VPC ピアリング接続を設定する場合は、以下の用語が使用されます。
| Red Hat OpenShift Service on AWS の AWS アカウント | Red Hat OpenShift Service on AWS クラスターが含まれる AWS アカウント。 |
| Red Hat OpenShift Service on AWS クラスター VPC | Red Hat OpenShift Service on AWS クラスターが含まれる VPC。 |
| Customer AWS アカウント | ピア接続する Red Hat OpenShift Service on AWS 以外の AWS アカウント。 |
| カスタマー VPC | ピア接続する AWS アカウントの VPC。 |
| カスタマー VPC リージョン | お客様の VPC が置かれるリージョン。 |
2018 年 7 月時点で、AWS は、中国を除く すべての商業地域でのリージョン間の VPC ピアリングをサポートします。
2.2.2. VPC ピア要求の開始
VPC ピアリング接続要求を Red Hat OpenShift Service on AWS アカウントから Customer AWS アカウントに送信できます。
前提条件
ピア要求を開始するために必要な Customer VPC に関する以下の情報を収集します。
- Customer AWS アカウント番号
- カスタマー VPC ID
- カスタマー VPC リージョン
- カスタマー VPC CIDR
- Red Hat OpenShift Service on AWS クラスター VPC によって使用される CIDR ブロックを確認する。カスタマー VPC の CIDR ブロックとの重複や一致があると、この 2 つの VPC 間のピアリングを実行できません。詳細は、Amazon VPC の Unsupported VPC Peering Configurations を参照してください。CIDR ブロックが重複していない場合は、手順を続行できます。
手順
- AWS の AWS アカウントで Red Hat OpenShift Service の Web コンソールにログインし、クラスターがホストされるリージョンの VPC Dashboard に移動します。
- Peering Connections ページに移動し、Create Peering Connection ボタンをクリックします。
ログインしているアカウントの詳細と、接続しているアカウントおよび VPC の詳細を確認します。
- Peering connection name tag: VPC ピアリング接続を説明する名前を設定します。
- VPC (Requester): リストから Red Hat OpenShift Service on AWS クラスター VPC の ID を選択します。
- Account: Another account を選択し、Customer AWS アカウント番号 *(ダッシュなし) を指定します。
- Region: カスタマー VPC リージョンが現在のリージョンと異なる場合は、Another Region を選択し、リストからカスタマー VPC リージョンを選択します。
- VPC (Accepter): カスタマー VPC ID を設定します。
- Create Peering Connection をクリックします。
- 要求の状態が Pending になっていることを確認します。Failed 状態になった場合は、詳細を確認し、このプロセスを繰り返します。
2.2.3. VPC ピア要求の許可
VPC ピアリング接続を作成したら、Customer AWS アカウントで要求を受け入れる必要があります。
前提条件
- VPC ピア要求を開始します。
手順
- AWS Web Console にログインします。
- VPC Service に移動します。
- Peering Connections に移動します。
- Pending peering connection をクリックします。
- 要求の発信元の AWS アカウントおよび VPC ID を確認します。これは、Red Hat OpenShift Service on AWS の AWS アカウントおよび Red Hat OpenShift Service on AWS クラスター VPC から取得する必要があります。
- Accept Request をクリックします。
2.2.4. ルーティングテーブルの設定
VPC のピアリング要求を受け入れた後に、両方の VPC がピアリング接続間で通信するようにルートを設定する必要があります。
前提条件
- VPC ピア要求を開始して、受け入れている。
手順
- Red Hat OpenShift Service on AWS の AWS アカウントで AWS Web Console にログインします。
- VPC Service に移動してから Route tables に移動します。
Red Hat OpenShift Service on AWS クラスター VPC の Route Table を選択します。
注記クラスターによっては、特定の VPC に複数のルートテーブルが存在する場合があります。明示的に関連付けられた多数のサブネットを持つプライベートのルートテーブルを選択します。
- Routes タブを選択してから Edit を選択します。
- Destination テキストボックスにカスタマー VPC CIDR ブロックを入力します。
- Target テキストボックスにピアリング接続 ID を入力します。
- Save をクリックします。
他の VPC の CIDR ブロックで同じプロセスを完了する必要があります。
- Customer AWS Web Console → VPC Service → Route Tables にログインします。
- VPC の Route Table を選択します。
- Routes タブを選択してから Edit を選択します。
- Destination テキストボックスに Red Hat OpenShift Service on AWS クラスター VPC CIDR ブロックを入力します。
- Target テキストボックスにピアリング接続 ID を入力します。
- Save changes をクリックします。
VPC ピアリング接続が完了しました。検証手順に従い、ピアリング接続間の接続が機能していることを確認します。
2.2.5. VPC ピアリング設定の確認およびトラブルシューティング
VPC ピアリング接続を設定したら、これが設定されており、正常に機能していることを確認することが推奨されます。
前提条件
- VPC ピア要求を開始して、受け入れている。
- ルーティングテーブルを設定している。
手順
AWS コンソールで、ピア接続されるクラスター VPC のルートテーブルを確認します。ルーティングテーブルの設定手順に従い、ピアリング接続のターゲットに VPC CIDR 範囲の宛先を指定するルートテーブルエントリーがあることを確認します。
Red Hat OpenShift Service on AWS クラスター VPC のルートテーブルとカスタマー VPC のルートテーブルの両方でルートが正しいと思われる場合は、以下の
netcatメソッドを使用して接続をテストしてください。テストの呼び出しが成功すれば、VPC ピアリングは正常に動作しています。エンドポイントデバイスへのネットワーク接続をテストする場合のトラブルシューティングツールとしては、
nc(またはnetcat) が役に立ちます。これはデフォルトのイメージに含まれ、接続を確立できる場合に迅速かつ明確に出力を提供します。busyboxイメージを使用して一時的な Pod を作成します。これは後で自身をクリーンアップします。$ oc run netcat-test \ --image=busybox -i -t \ --restart=Never --rm \ -- /bin/shncを使用して接続を確認します。正常な接続の結果の例:
/ nc -zvv 192.168.1.1 8080 10.181.3.180 (10.181.3.180:8080) open sent 0, rcvd 0失敗した接続の結果の例:
/ nc -zvv 192.168.1.2 8080 nc: 10.181.3.180 (10.181.3.180:8081): Connection refused sent 0, rcvd 0
コンテナーを終了します。これにより、Pod が自動的に削除されます。
/ exit
2.3. AWS VPN の設定
このサンプルプロセスでは、Amazon Web Services (AWS) Red Hat OpenShift Service on AWS を、お客様のオンサイトのハードウェア VPN デバイスを使用するように設定します。
現時点で AWS VPN は、NAT を VPN トラフィックに適用するための管理オプションを提供しません。詳細は、AWS Knowledge Center を参照してください。
プライベート接続を使用したすべてのトラフィックのルーティング (0.0.0.0/0 など) はサポートされていません。この場合は、SRE 管理トラフィックを無効にするインターネットゲートウェイを削除する必要があります。
ハードウェア VPN デバイスを使用して AWS VPC をリモートネットワークに接続する方法は、Amazon VPC の VPN Connections ドキュメントを参照してください。
2.3.1. VPN 接続の作成
以下の手順に従って、Amazon Web Services (AWS) Red Hat OpenShift Service on AWS クラスターを、お客様のオンサイトのハードウェア VPN デバイスを使用できるように設定できます。
前提条件
- ハードウェア VPN ゲートウェイデバイスモデルおよびソフトウェアバージョン (例: Cisco ASA バージョン 8.3 を実行)。Amazon VPC の ネットワーク管理者ガイド を参照して、お使いのゲートウェイデバイスが AWS でサポートされているかどうかを確認します。
- VPN ゲートウェイデバイスのパブリック静的 IP アドレス。
- BGP または静的ルーティング: BGP の場合は、ASN が必要です。静的ルーティングの場合は、1 つ以上の静的ルートを設定する必要があります。
- オプション: VPN 接続をテストするための到達可能なサービスの IP とポート/プロトコル。
2.3.1.1. VPN 接続の設定
手順
- AWS の AWS Account Dashboard で Red Hat OpenShift Service にログインし、VPC Dashboard に移動します。
- Virtual Private Cloud で Your VPCs をクリックし、Red Hat OpenShift Service on AWS クラスターを含む VPC の名前と VPC ID を特定します。
- Virtual private network (VPN) で、Customer gateways をクリックします。
- Create customer gateway をクリックし、わかりやすい名前を付けます。
- BGP ASN フィールドに、カスタマーゲートウェイデバイスの ASN を入力します。
- IP address フィールドに、カスタマーゲートウェイデバイスの外部インターフェイス IP アドレスを入力します。
- Create customer gateway をクリックします。
仮想プライベートゲートウェイが目的の VPC に割り当てられていない場合:
- VPC Dashboard から、Virtual Private Gateway をクリックします。
- Create virtual private gateway をクリックし、わかりやすい名前を付けます。
- Create virtual private gateway をクリックします。Amazon default ASN はそのままにします。
- 新しく作成したゲートウェイを選択します。
- リストから Actions を選択し、Attach to VPC をクリックします。
- Available VPC で、新しく作成したゲートウェイを選択し、Attach to VPC をクリックして、以前に特定したクラスター VPC にゲートウェイを割り当てます。
2.3.1.2. VPN 接続の確立
手順
- VPC Dashboard の Virtual private network (VPN) で、Site-to-Site VPN connections をクリックします。
Create VPN connection をクリックします。
- わかりやすい名前タグを付けます。
- 以前に作成した仮想プライベートゲートウェイを選択します。
- カスタマーゲートウェイに Existing を選択します。
- カスタマーゲートウェイ ID を名前で選択します。
- VPN で BGP を使用する場合は Dynamic を選択します。使用しない場合は Static を選択して静的 IP の CIDR を入力します。複数の CIDR がある場合は、各 CIDR を Another Rule として追加します。
- Create VPN connection をクリックします。
- State で VPN ステータスが Pending から Available に変わるまで、約 5 - 10 分待ちます。
先ほど作成した VPN を選択し、Download configuration をクリックします。
- リストからカスタマーゲートウェイデバイスのベンダー、プラットフォーム、バージョンを選択し、Download をクリックします。
- Generic ベンダー設定は、プレーンテキスト形式で情報を取得する場合にも利用できます。
VPN 接続が確立されたら、Route Propagation をセットアップしてください。セットアップしない場合、VPN が予想通りに機能しない可能性があります。
VPC サブネット情報をメモします。これは、リモートネットワークとして設定に追加する必要があります。
2.3.1.3. VPN ルート伝播の有効化
VPN 接続を設定したら、必要なルートが VPC のルートテーブルに追加されるように、ルートの伝播が有効にされていることを確認する必要があります。
手順
- VPC Dashboard の Virtual private cloud で、Route tables をクリックします。
Red Hat OpenShift Service on AWS クラスターが含まれる VPC に関連付けられたプライベートルートテーブルを選択します。
注記クラスターによっては、特定の VPC に複数のルートテーブルが存在する場合があります。明示的に関連付けられた多数のサブネットを持つプライベートのルートテーブルを選択します。
- Route Propagation タブをクリックします。
表示される表に、以前に作成した仮想プライベートゲートウェイが表示されるはずです。Propagate 列の値を確認します。
- Propagation が No に設定されている場合は、Edit route propagation をクリックし、伝播の Enable チェックボックスをオンにして、Save をクリックします。
VPN トンネルを設定し、AWS がこれを Up として検出すると、静的ルートまたは BGP ルートは自動的にルートテーブルに追加されます。
2.3.2. VPN 接続の検証
ご使用の側から VPN トンネルを設定した後に、そのトンネルが AWS コンソールで稼働していること、およびトンネル全体で接続が機能していることを確認します。
前提条件
- VPN 接続を作成します。
手順
AWS でトンネルが稼働していることを検証します。
- VPC Dashboard の Virtual private network (VPN) で、Site-to-Site VPN connections をクリックします。
- 以前に作成した VPN 接続を選択し、Tunnel details タブをクリックします。
- 少なくとも 1 つの VPN トンネルが Up 状態になっていることがわかります。
接続を検証します。
エンドポイントデバイスへのネットワーク接続をテストする場合のトラブルシューティングツールとしては、
nc(またはnetcat) が役に立ちます。これはデフォルトのイメージに含まれ、接続を確立できる場合に迅速かつ明確に出力を提供します。busyboxイメージを使用して一時的な Pod を作成します。これは後で自身をクリーンアップします。$ oc run netcat-test \ --image=busybox -i -t \ --restart=Never --rm \ -- /bin/shncを使用して接続を確認します。正常な接続の結果の例:
/ nc -zvv 192.168.1.1 8080 10.181.3.180 (10.181.3.180:8080) open sent 0, rcvd 0失敗した接続の結果の例:
/ nc -zvv 192.168.1.2 8080 nc: 10.181.3.180 (10.181.3.180:8081): Connection refused sent 0, rcvd 0
コンテナーを終了します。これにより、Pod が自動的に削除されます。
/ exit
2.3.3. VPN 接続のトラブルシューティング
トンネルが接続されていない
トンネル接続がまだ ダウン している場合は、以下を確認できます。
- AWS トンネルは VPN 接続を開始しません。接続の試行はカスタマーゲートウェイから開始する必要があります。
- ソーストラフィックが、設定されたカスタマーゲートウェイと同じ IP から送信されることを確認します。AWS は、ソース IP アドレスが一致しないゲートウェイへのすべてのトラフィックを通知なしでドロップします。
- 設定が AWS でサポートされる 値と一致することを確認します。これには、IKE バージョン、DH グループ、IKE ライフタイムなどが含まれます。
- VPC のルートテーブルを再確認します。伝播が有効で、先にターゲットとして作成した仮想プライベートゲートウェイを持つルートテーブルにエントリーがあることを確認します。
- 中断が発生する可能性があるファイアウォールルールが存在しないことを確認します。
- ポリシーベースの VPN を使用しているかどうかを確認します。これを使用している場合は、その設定によっては複雑な状態が生じる可能性があります。
- トラブルシューティングの手順の詳細は、AWS ナレッジセンター を参照してください。
トンネルが接続状態にならない
トンネル接続を一貫して Up の状態にすることができない場合は、すべての AWS トンネル接続がゲートウェイから開始される必要があることに注意してください。AWS トンネルは トンネリングを開始しません。
Red Hat は、ご使用の側から SLA モニター (Cisco ASA) または一部のデバイスをセットアップすることを推奨しています。これにより、VPC CIDR 範囲内で設定されるすべての IP アドレスで、ping、nc、telnet などの対象 ("interesting") トラフィックが絶えず送信されます。接続が成功したかどうかにかかわらず、トラフィックがトンネルにダイレクトされます。
Down 状態のセカンダリートンネル
VPN トンネルが作成されると、AWS は追加のフェイルオーバートンネルを作成します。ゲートウェイデバイスによっては、セカンダリートンネルが Down 状態として表示される場合があります。
AWS 通知は以下のようになります。
You have new non-redundant VPN connections
One or more of your vpn connections are not using both tunnels. This mode of
operation is not highly available and we strongly recommend you configure your
second tunnel. View your non-redundant VPN connections.2.4. AWS Direct Connect の設定
このプロセスでは、Red Hat OpenShift Service on AWS で AWS Direct Connect 仮想インターフェイスを受け入れる方法を説明します。AWS Direct Connect のタイプおよび設定の詳細は、AWS Direct Connect コンポーネント を参照してください。
2.4.1. AWS Direct Connect の方法
Direct Connect 接続には、Direct Connect Gateway (DXGateway) に接続されるホスト型の仮想インターフェイス (VIF) が必要です。これは、同じまたは別のアカウントでリモート VPC にアクセスするために、Virtual Gateway (VGW) または Transit Gateway に関連付けられます。
既存の DXGateway がない場合、通常のプロセスではホストされた VIF を作成し、Red Hat OpenShift Service on AWS の AWS アカウントに DXGateway および VGW が作成されます。
既存の DXGateway が 1 つ以上の既存の VGW に接続されている場合、このプロセスでは、Red Hat OpenShift Service on AWS の AWS アカウントが Association Proposal (関連付けの提案) を DXGateway の所有者に送信します。DXGateway の所有者は、提案される CIDR が関連付けのあるその他の VGW と競合しないことを確認する必要があります。
詳細は、以下の AWS ドキュメントを参照してください。
既存の DXGateway への接続は、有料 となります。
選択可能な設定オプションは、以下の 2 つです。
| 方法 1 | ホストされた VIF を作成してから、DXGateway および VGW を作成します。 |
| 方法 2 | 所有する既存の Direct Connect ゲートウェイ経由で接続を要求します。 |
2.4.2. ホストされた仮想インターフェイスの作成
前提条件
- AWS の AWS Account ID で Red Hat OpenShift Service を収集する。
2.4.2.1. Direct Connect 接続のタイプの決定
Direct Connect 仮想インターフェイスの詳細を表示して、接続の種類を判別します。
手順
- AWS の AWS Account Dashboard の Red Hat OpenShift Service にログインし、正しいリージョンを選択します。
- Services メニューから Direct Connect を選択します。
- 受け入れを待機している 1 つ以上の仮想インターフェイスがあります。いずれかの仮想インターフェイスを選択して Summary を表示します。
- 仮想インターフェイスタイプ (private または public) を表示します。
- Amazon side ASN の値を記録します。
Direct Connect 仮想インターフェイスの種類が Private の場合は、仮想プライベートゲートウェイが作成されます。Direct Connect Virtual Interface が Public の場合は、Direct Connect Gateway が作成されます。
2.4.2.2. Private Direct Connect の作成
Direct Connect Virtual Interface タイプが Private の場合は、Private Direct Connect が作成されます。
手順
- AWS の AWS Account Dashboard の Red Hat OpenShift Service にログインし、正しいリージョンを選択します。
- AWS リージョンで、Services メニューから VPC を選択します。
- Virtual private network (VPN) から、Virtual private gateways を選択します。
- Create virtual private gateway をクリックします。
- 仮想プライベートゲートウェイに適切な名前を指定します。
- Enter custom ASN フィールドで Custom ASN を選択し、以前に収集した Amazon side ASN 値を入力します。
- Create virtual private gateway をクリックします。
- 新規に作成された仮想プライベートゲートウェイをクリックし、Actions タブで Attach to VPC を選択します。
- リストから Red Hat OpenShift Service on AWS Cluster VPC を選択し、Attach VPC をクリックします。
注記: kubelet 設定を編集すると、マシンプールのノードが再作成されます。This ma???
2.4.2.3. Public Direct Connect の作成
Direct Connect Virtual Interface タイプが Public の場合は、Public Direct Connect が作成されます。
手順
- AWS の AWS Account Dashboard の Red Hat OpenShift Service にログインし、正しいリージョンを選択します。
- AWS の AWS アカウントリージョンの Red Hat OpenShift Service の Services メニューから Direct Connect を選択します。
- Direct Connect gateways および Create Direct Connect gateway を選択します。
- Direct Connect ゲートウェイに適切な名前を付けます。
- Amazon side ASN で、以前に収集した Amazon side ASN 値を入力します。
- Create the Direct Connect gateway をクリックします。
2.4.2.4. 仮想インターフェイスの確認
Direct Connect 仮想インターフェイスが許可されたら、少しの間待機してから、インターフェイスの状態を確認します。
手順
- AWS の AWS Account Dashboard の Red Hat OpenShift Service にログインし、正しいリージョンを選択します。
- AWS の AWS アカウントリージョンの Red Hat OpenShift Service の Services メニューから Direct Connect を選択します。
- リストから Direct Connect 仮想インターフェイスのいずれかを選択します。
- インターフェイスの状態が Available になったことを確認します。
- インターフェイス BGP のステータスが Up になったことを確認します。
- 残りの Direct Connect インターフェイスに対してこの検証を繰り返します。
Direct Connect Virtual Interface が利用可能になった後に、AWS の AWS Account Dashboard で Red Hat OpenShift Service にログインし、ユーザーの側の設定用に Direct Connect 設定ファイルをダウンロードできます。
2.4.3. 既存の Direct Connect ゲートウェイへの接続
前提条件
- AWS VPC の Red Hat OpenShift Service の CIDR 範囲が、関連付けた他の VGW と競合しないことを確認します。
以下の情報を収集します。
- Direct Connect Gateway ID。
- 仮想インターフェイスに関連付けられた AWS アカウント ID。
- DXGateway に割り当てられた BGP ASN。必要に応じて、Amazon のデフォルト ASN も使用できます。
手順
- AWS の AWS Account Dashboard の Red Hat OpenShift Service にログインし、正しいリージョンを選択します。
- AWS の AWS アカウントリージョンの Red Hat OpenShift Service の Services メニューから VPC を選択します。
- Virtual private network (VPN) から、Virtual private gateways を選択します。
- Create virtual private gateway を選択します。
- Details フィールドで仮想プライベートゲートウェイに適切な名前を付けます。
- Custom ASN をクリックし、以前に使用された Amazon side ASN 値を入力するか、Amazon で提供される ASN を使用します。
- Create virtual private gateway をクリックします。
- AWS の AWS アカウントリージョンの Red Hat OpenShift Service の Services メニューから Direct Connect を選択します。
- virtual private gateways をクリックし、仮想プライベートゲートウェイを選択します。
- View details をクリックします。
- Direct Connect gateway associations タブをクリックします。
- Associate Direct Connect gateway をクリックします。
- Association account type の Account owner で、Another account をクリックします。
- Direct Connect ゲートウェイ ID の Association settings に、Direct Connect ゲートウェイの ID を入力します。
- Direct Connect gateway owner に、Direct Connect ゲートウェイを所有する AWS アカウントの ID を入力します。
- オプション: Allowed prefixes に接頭辞を追加します。接頭辞はコンマで区切るか、別の行に配置します。
- Associate Direct Connect gateway をクリックします。
- Association Proposal (関連付けの提案) が送信されたら、承認されるのを待っています。実行する必要のある最終手順は、AWS ドキュメンテーション を参照してください。
2.4.4. Direct Connect のトラブルシューティング
トラブルシューティングの詳細は、AWS Direct Connect のトラブルシューティング を参照してください。
第3章 Red Hat OpenShift Service on AWS のクラスター自動スケーリング
Red Hat OpenShift Service on AWS クラスターに自動スケーリングを適用するには、自動スケーリングを使用して 1 つ以上のマシンプールを設定する必要があります。クラスターオートスケーラーを使用すると、自動スケーリングが実行されるすべてのマシンプールに適用可能な、クラスター全体の自動スケーリングをさらに設定できます。
3.1. クラスターオートスケーラーについて
クラスターオートスケーラーは、現在のデプロイメントのニーズに合わせて、Red Hat OpenShift Service on AWS クラスターのサイズを調整します。これは、Kubernetes 形式の宣言引数を使用して、特定のクラウドプロバイダーのオブジェクトに依存しないインフラストラクチャー管理を提供します。クラスターオートスケーラーはクラスタースコープであり、特定の namespace には関連付けられていません。Red Hat OpenShift Service on AWS では、クラスターオートスケーラーはフルマネージドです。つまり、コントロールプレーンとともにホストされています。
クラスターオートスケーラーは、リソース不足のために現在のワーカーノードのいずれにもスケジュールできない Pod がある場合や、デプロイメントのニーズを満たすために別のノードが必要な場合に、クラスターのサイズを拡大します。クラスターオートスケーラーは、指定の制限を超えてクラスターリソースを拡大することはありません。
クラスターオートスケーラーは、自動スケーリングが設定されているマシンプールに属するノードだけを対象として、合計メモリー、CPU、GPU を計算します。自動スケーリングされていないすべてのマシンプールノードは、この集計から除外されます。たとえば、3 つのマシンプールがあり、そのうち 1 つのマシンプールが自動スケーリングされていない Red Hat OpenShift Service on AWS クラスターで maxNodesTotal を 50 に設定した場合、クラスターオートスケーラーは、自動スケーリングされている 2 つのマシンプールのみで合計ノード数を 50 に制限します。単一の手動スケーリングマシンプールに追加のノードを含めることができ、クラスター全体のノードの合計は 50 を超える可能性があります。
3.1.1. 自動ノード削除
クラスターオートスケーラーは 10 秒ごとにクラスター内の不要なノードをチェックし、そのノードを削除します。クラスターオートスケーラーは、次の条件が当てはまる場合に、ノードを削除対象とみなします。
-
ノード使用率が、クラスターの ノード使用率 レベルのしきい値を下回っている。ノード使用率レベルとは、要求されたリソースの合計をノードに割り当てられたリソースで除算したものです。
ClusterAutoscalerカスタムリソースで値が指定されいない場合、クラスターオートスケーラーはデフォルト値の0.5を使用します。これは 50% の使用率に相当します。 - クラスターオートスケーラーが、ノード上で実行されているすべての Pod を他のノードに移動できる。Kubernetes スケジューラーは、ノード上の Pod のスケジュールを担当します。
- クラスターオートスケーラーに、スケールダウンを無効にするアノテーションがない。
ノードに次のタイプの Pod が存在する場合、クラスターオートスケーラーはノードを削除しません。
- 制限のある Pod Disruption Budget を持つ Pod。
- デフォルトでノードで実行されない kube-system Pod。
- PDB を持たないか、制限が厳しい PDB を持つ kube-system Pod。
- デプロイメント、レプリカセット、またはステートフルセットなどのコントローラーオブジェクトによってサポートされない Pod。
- ローカルストレージを持つ Pod。
- リソース不足、互換性のないノードセレクターまたはアフィニティー、アンチアフィニティーの一致などの理由で、他の場所に移動できない Pod。
-
それらに
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"アノテーションがない場合、"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"アノテーションを持つ Pod。
たとえば、CPU の上限を 64 コアに設定し、それぞれ 8 コアのマシンのみを作成するようにクラスターオートスケーラーを設定したとします。クラスターが 30 コアで起動した場合、クラスターオートスケーラーはさらに最大 4 ノードを追加して 32 コアを増やし、合計 62 コアにすることができます。
3.1.2. 制限事項
クラスターオートスケーラーを設定する場合は、使用に関する追加の制限が適用されます。
- 自動スケーリングされたノードグループにあるノードを直接変更しないようにしてください。同じノードグループ内のすべてのノードには同じ容量およびラベルがあり、同じシステム Pod を実行します。
- Pod の要求を指定します。
- Pod がすぐに削除されるのを防ぐ必要がある場合、適切な PDB を設定します。
- クラウドプロバイダーのクォータが、設定する最大のノードプールに対応できる十分な大きさであることを確認します。
- クラウドプロバイダーで提供されるものなどの、追加のノードグループの Autoscaler を実行しないようにしてください。
クラスターオートスケーラーが自動スケーリング対象のノードグループにノードを追加するのは、その追加によって Pod がスケジュール可能になる場合に限られます。利用可能なノードタイプが Pod 要求の要件を満たすことができない場合、またはその要件を満たすことができるノードグループが最大サイズに達している場合、クラスターオートスケーラーはスケールアップできません。
3.1.3. 他のスケジュール機能との連携
Horizontal Pod Autoscaler (HPA) とクラスターオートスケーラーは、異なる方法でクラスターリソースを変更します。HPA は、現在の CPU 負荷に基づいてデプロイメント、またはレプリカセットのレプリカ数を変更します。負荷が増大すると、HPA はクラスターで利用できるリソース量に関係なく、新規レプリカを作成します。リソースが不足している場合、クラスターオートスケーラーは、HPA によって作成された Pod が実行できるようにリソースを追加します。負荷が減少する場合、HPA は一部のレプリカを停止します。この動作によってノードの使用率が低下するか、ノードが完全に空になった場合、クラスターオートスケーラーは不要なノードを削除します。
クラスターオートスケーラーは Pod の優先度を考慮します。Pod の優先度とプリエンプション機能を使用すると、クラスターに十分なリソースがない場合に優先度に基づいて Pod をスケジュールできますが、クラスターオートスケーラーにより、クラスターにすべての Pod を実行するためのリソースが確保されます。両方の機能の意図を反映するために、クラスターオートスケーラーには、優先度のカットオフ機能が搭載されています。このカットオフ機能を使用すると、"ベストエフォート" の Pod をスケジュールできます。この Pod は、クラスターオートスケーラーによるリソースの増加を引き起こすことなく、予備のリソースが利用可能な場合にのみ実行されます。
カットオフ値よりも低い優先度を持つ Pod は、クラスターのスケールアップを引き起さず、クラスターのスケールダウンを妨げることもありません。これらの Pod を実行するために新規ノードは追加されず、これらの Pod を実行しているノードはリソースを解放するために削除される可能性があります。
3.2. ROSA CLI の対話モードを使用して、クラスターの作成中に自動スケーリングを有効にする
ターミナルの対話モード (使用可能な場合) で ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、クラスターの作成中にクラスター全体の自動スケーリング動作を設定できます。
対話型モードでは、使用可能な設定可能なパラメーターに関する詳細情報が提供されます。対話型モードでは、基本的なチェックとプリフライト検証も実行されます。つまり、指定された値が無効な場合、端末は有効な入力を求めるプロンプトを出力します。
手順
クラスターの作成中に、
--enable-autoscalingパラメーターと--interactiveパラメーターを使用してクラスターの自動スケーリングを有効にします。例
$ rosa create cluster --cluster-name <cluster_name> --enable-autoscaling --interactive
クラスター名が 15 文字を超える場合、*.openshiftapps.com にプロビジョニングされたクラスターのサブドメインとして自動生成されたドメイン接頭辞が含まれます。
サブドメインをカスタマイズするには、--domain-prefix フラグを使用します。ドメイン接頭辞は 15 文字を超えてはならず、一意である必要があり、クラスターの作成後に変更できません。
次のプロンプトが表示されたら、y を入力して、使用可能なすべての自動スケーリングオプションを実行します。
対話型プロンプトの例
? Configure cluster-autoscaler (optional): [? for help] (y/N) y <enter>3.3. ROSA CLI を使用してクラスター作成中に自動スケーリングを有効にする
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、クラスターの作成中にクラスター全体の自動スケーリング動作を設定できます。オートスケーラーはマシン全体で有効にすることも、クラスターのみで有効にすることもできます。
手順
-
クラスターの作成中に、クラスター名の後に
--enable autoscalingと入力して、マシンの自動スケーリングを有効にします。
クラスター名が 15 文字を超える場合、*.openshiftapps.com にプロビジョニングされたクラスターのサブドメインとして自動生成されたドメイン接頭辞が含まれます。
サブドメインをカスタマイズするには、--domain-prefix フラグを使用します。ドメイン接頭辞は 15 文字を超えてはならず、一意である必要があり、クラスターの作成後に変更できません。
例
$ rosa create cluster --cluster-name <cluster_name> --enable-autoscaling次のコマンドを実行して、クラスターの自動スケーリングを有効にするために少なくとも 1 つのパラメーターを設定します。
例
$ rosa create cluster --cluster-name <cluster_name> --enable-autoscaling <parameter>3.4. ROSA CLI を使用したクラスター自動スケーリングパラメーター
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用する場合、クラスター作成コマンドに次のパラメーターを追加して、オートスケーラーのパラメーターを設定できます。
| 設定 | 説明 | 型または範囲 | 例/命令 |
|---|---|---|---|
|
| スケールダウンする前の Pod の正常な終了時間を秒単位で指定します。コマンドの int を、使用する秒数に置き換えます。 |
|
|
|
| クラスターオートスケーラーに追加のノードをデプロイさせるために、Pod が超えている必要のある優先度。コマンド内の int を、使用する数値に置き換えます。負の値も使用できます。 |
|
|
|
| クラスターオートスケーラーがノードのプロビジョニングを待機する最大時間。コマンド内の 文字列 を整数と時間単位 (ns、us、µs、ms、s、m、h) に置き換えます。 |
|
|
|
| クラスター内のノードの最大数 (自動スケールされたノードを含む)。コマンドの int を使用する数値に置き換えます。 |
|
|
3.5. ROSA CLI を使用してクラスター作成後に自動スケーリングを編集する
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用すると、オートスケーラーを作成した後で、クラスターオートスケーラーの特定のパラメーターを編集できます。
手順
クラスターオートスケーラーを編集するには、次のコマンドを実行します。
例
$ rosa edit autoscaler --cluster=<mycluster>特定のパラメーターを編集するには、次のコマンドを実行します。
例
$ rosa edit autoscaler --cluster=<mycluster> <parameter>
3.6. ROSA CLI を使用してオートスケーラーの設定を表示する
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用するときに、rosa describe autoscaler コマンドを使用してクラスターオートスケーラーの設定を表示できます。
手順
クラスターオートスケーラーの設定を表示するには、次のコマンドを実行します。
例
$ rosa describe autoscaler -h --cluster=<mycluster>
第4章 マシンプールを使用したコンピュートノードの管理
4.1. マシンプールについて
Red Hat OpenShift Service on AWS は、クラウドインフラストラクチャーで柔軟性があり動的なプロビジョニング方法としてマシンプールを使用します。
主要なリソースは、マシン、コンピューティングマシンセット、およびマシンプールです。
4.1.1. マシン
マシンは、ワーカーノードのホストを記述する基本的な単位です。
4.1.2. マシンセット
MachineSet リソースはコンピュートマシンのグループです。より多くのマシンが必要な場合、またはマシンをスケールダウンする必要がある場合は、コンピュートマシンセットが属するマシンプール内のレプリカの数を変更します。
マシンセットは、Red Hat OpenShift Service on AWS では直接変更できません。
4.1.3. マシンプール
マシンプールは、マシンセットを計算するための上位レベルの構造です。
コンピュートマシンプールは、アベイラビリティーゾーン全体で同じ設定のクローンがすべて含まれるマシンセットを作成します。マシンプールは、ワーカーノードですべてのホストノードのプロビジョニング管理アクションを実行します。より多くのマシンが必要な場合、またはマシンをスケールダウンする必要がある場合は、コンピュートのニーズに合わせてマシンプール内のレプリカの数を変更してください。スケーリングは手動または自動の設定ができます。
Red Hat OpenShift Service on AWS クラスターでは、インストール先のクラウドリージョン内にある複数のアベイラビリティーゾーン (AZ) にまたがって Hosted Control Plane が配置されます。Red Hat OpenShift Service on AWS クラスター内の各マシンプールは、単一の AZ 内の単一のサブネットにデプロイされます。
ワーカーノードは永続性が保証されておらず、OpenShift の通常の運用および管理の一環として、いつでも置き換えられる可能性があります。ノードのライフサイクルの詳細は、関連情報 を参照してください。
単一のクラスターに複数のマシンプールを配置することができます。各マシンプールには、一意のノードタイプとノードサイズ (AWS EC2 インスタンスのタイプとサイズ) 設定を含めることができます。
4.1.3.1. クラスターインストール中のマシンプール
デフォルトでは、クラスターに 1 つのマシンプールがあります。クラスターのインストール中に、インスタンスのタイプまたはサイズを定義し、このマシンプールにラベルを追加したり、ルートディスクのサイズを定義したりできます。
4.1.3.2. クラスターのインストール後のマシンプール設定
クラスターのインストール後:
- 任意のマシンプールに対してラベルを削除または追加できます。
- 既存のクラスターに追加のマシンプールを追加できます。
- taint のないマシンプールが 1 つある場合、マシンプールに taint を追加できます。
taint のないマシンプールが 1 つあり、レプリカが 2 つ以上ある場合、マシンプールを作成または削除できます。
注記マシンプールノードのタイプやサイズは変更できません。マシンプールノードのタイプまたはサイズは、作成時にのみ指定されます。別のノードタイプまたはサイズが必要な場合は、マシンプールを再作成し、必要なノードタイプまたはサイズの値を指定する必要があります。
- 追加された各マシンプールにラベルを追加できます。
ワーカーノードは永続性が保証されておらず、OpenShift の通常の運用および管理の一環として、いつでも置き換えられる可能性があります。ノードのライフサイクルの詳細は、関連情報 を参照してください。
手順
オプション: デフォルトのマシンプールラベルを使用して次のコマンドを実行し、設定後にデフォルトのマシンプールにラベルを追加します。
$ rosa edit machinepool -c <cluster_name> <machinepool_name> -i入力の例
$ rosa edit machinepool -c mycluster worker -i ? Enable autoscaling: No ? Replicas: 3 ? Labels: mylabel=true I: Updated machine pool 'worker' on cluster 'mycluster'
4.1.3.3. マシンプールのアップグレード要件
Red Hat OpenShift Service on AWS クラスター内の各マシンプールは、個別にアップグレードされます。マシンプールは個別にアップグレードされるため、Hosted Control Plane の 2 つのマイナー (y-stream) バージョン内にとどまる必要があります。たとえば、Hosted Control Plane が 4.16.z の場合、マシンプールは少なくとも 4.14.z である必要があります。
次の図は、Red Hat OpenShift Service on AWS クラスター内でマシンプールがどのように機能するかを示しています。
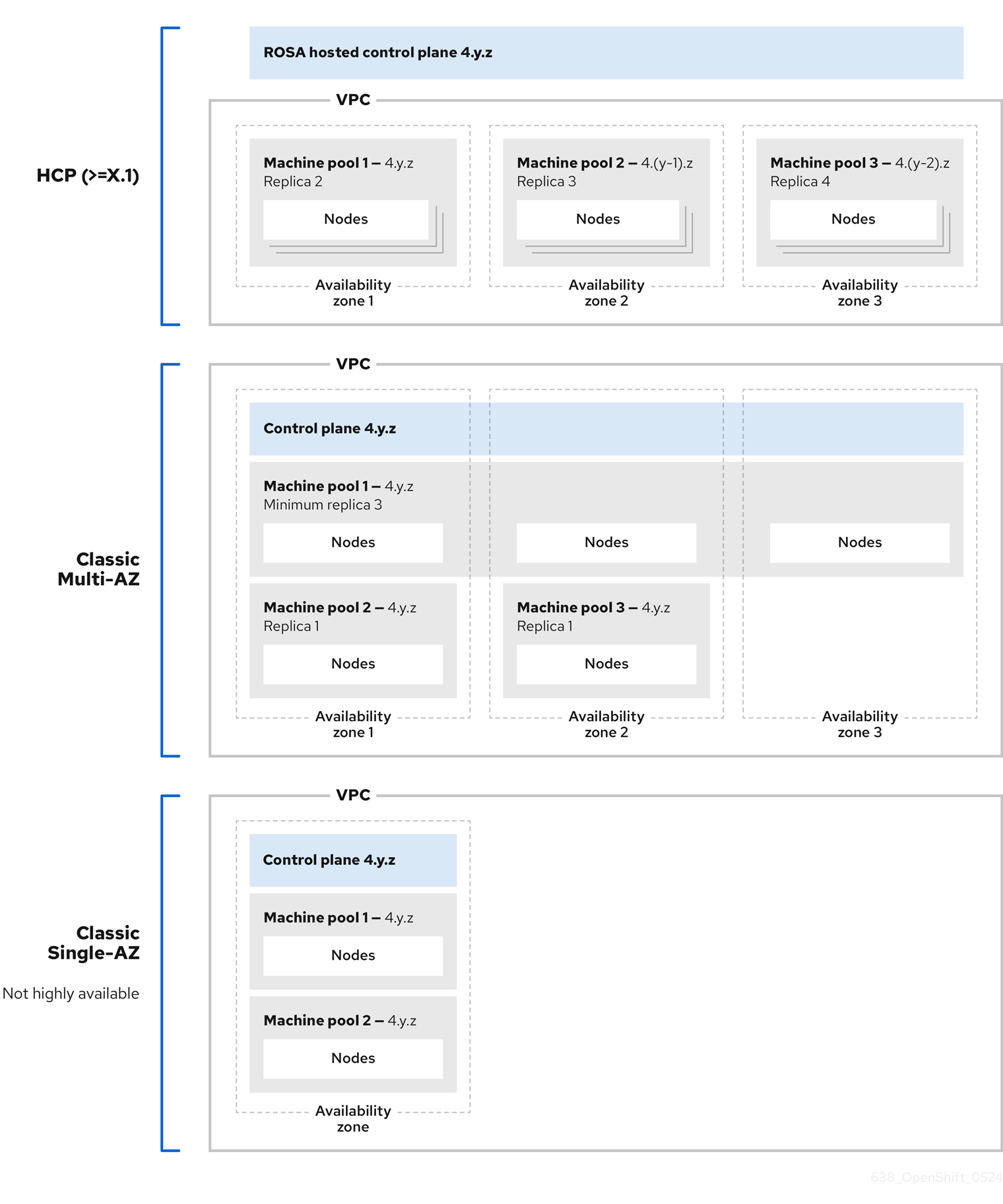
Red Hat OpenShift Service on AWS クラスターのマシンプールは、それぞれ個別にアップグレードされます。マシンプールのバージョンは、コントロールプレーンのマイナー (Y-stream) バージョンから 2 バージョン以内に維持する必要があります。
4.1.4. 関連情報
4.2. コンピュートノードの管理
このドキュメントでは、Red Hat OpenShift Service on AWS でコンピュート (ワーカーとも呼ばれる) ノードを管理する方法を説明します。
コンピュートノードの変更の大半は、マシンプールで設定されます。マシンプールは、管理を容易にするために、同じ設定を持つクラスター内のコンピュートノードのグループです。
スケーリング、ノードラベルの追加、テイントの追加などのマシンプール設定オプションを編集できます。
Capacity Reservation を使用して新しいマシンプールを作成することもできます。
AWS Capacity Reservation の概要
特定のインスタンスの種類とアベイラビリティーゾーン (AZ) に対して AWS Capacity Reservations を使用してコンピュートの容量を予約した場合は、Red Hat OpenShift Service on AWS ワークロードにその容量を使用できます。機械学習 (ML) ワークロード向けの On-Demand Capacity Reservation と Capacity Block の両方がサポートされています。
AWS で直接 Capacity Reservation を購入し、管理します。容量を予約した後、Red Hat OpenShift Service on AWS クラスターで新しいマシンプールを作成するときに、Capacity Reservation ID をそのマシンプールに追加します。AWS 組織内の別の AWS アカウントから共有された Capacity Reservation を使用することもできます。
Red Hat OpenShift Service on AWS で Capacity Reservation を設定すると、AWS アカウントを使用して、アカウント内のすべてのワークロードの予約容量の使用状況を監視できるようになります。
Red Hat OpenShift Service on AWS クラスターのマシンプールで Capacity Reservation を使用するには、次の前提条件と制限があります。
- ROSA CLI バージョン 1.2.57 以上がインストールされている。
- Red Hat OpenShift Service on AWS クラスターのバージョンが 4.19 以降である。
- クラスターに Capacity Reservation または taint を使用していないマシンプールがすでに存在する。マシンプールに少なくとも 2 つのワーカーノードがある。
- 作成しているマシンプールの AZ で必要なインスタンスタイプに対して、Capacity Reservation を購入した。
- Capacity Reservation ID は新しいマシンプールにのみ追加できます。
- Capacity Reservation が設定されたマシンプールでは自動スケーリングを使用できません。
- Capacity Reservation が設定されているマシンプールをアップグレードできません。
Capacity Reservation でマシンプールを作成するには、ROSA CLI を使用して Capacity Reservation が設定されたマシンプールを作成する を参照してください。
4.2.1. マシンセットの作成
Red Hat OpenShift Service on AWS クラスターをインストールすると、マシンプールが作成されます。インストール後に、OpenShift Cluster Manager または ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、クラスターに追加のマシンプールを作成できます。
rosa バージョン 1.2.25 以前を使用している場合、クラスターとともに作成されたマシンプールは Default として識別されます。rosa バージョン 1.2.26 以降を使用している場合、クラスターとともに作成されたマシンプールは worker として識別されます。
4.2.1.1. OpenShift Cluster Manager を使用したマシンプールの作成
OpenShift Cluster Manager を使用して、Red Hat OpenShift Service on AWS クラスターに追加のマシンプールを作成できます。
前提条件
- Red Hat OpenShift Service on AWS クラスターを作成した。
手順
- OpenShift Cluster Manager に移動し、クラスターを選択します。
- Machine pools タブで、Add machine pool をクリックします。
- Machine pool name を追加します。
リストから Compute node instance type を選択します。インスタンスタイプは、マシンプール内の各コンピュートノードの仮想 CPU およびメモリー割り当てを定義します。
注記プールを作成した後に、マシンプールのインスタンスタイプを変更することはできません。
オプション: マシンプールの自動スケーリングを設定します。
- Enable autoscaling を選択し、デプロイメントのニーズを満たすためにマシンプール内のマシン数を自動的にスケーリングします。
自動スケーリングの最小および最大のノード数制限を設定します。クラスターオートスケーラーが、指定の制限を超えてマシンプールのノード数を増減することはありません。
注記または、マシンプールの作成後にマシンプールの自動スケーリングを設定できます。
- 自動スケーリングを有効にしていない場合は、ドロップダウンメニューから Compute node count を選択します。これは、アベイラビリティーゾーンのマシンプールにプロビジョニングするコンピュートノードの数を定義します。
- オプション: Root disk size を設定します。
オプション: マシンプールのノードラベルおよびテイントを追加します。
- Edit node labels and taints メニューを展開します。
- Node labels で、ノードラベルの Key および Value のエントリーを追加します。
Taints で、テイントの Key および Value エントリーを追加します。
注記テイントを含むマシンプールの作成は、クラスターにテイントのないマシンプールが少なくとも 1 つすでに存在する場合にのみ可能です。
テイントごとに、ドロップダウンメニューから Effect を選択します。使用できるオプションには、
NoSchedule、PreferNoSchedule、およびNoExecuteが含まれます。注記または、マシンプールの作成後にノードラベルおよびテイントを追加できます。
オプション: このマシンプール内のノードに使用する追加のカスタムセキュリティーグループを選択します。すでにセキュリティーグループを作成し、このクラスター用に選択した VPC にそのグループを関連付けている必要があります。マシンプールの作成後は、セキュリティーグループを追加または編集することはできません。
重要Red Hat OpenShift Service on AWS クラスターのマシンプールには、最大 10 個の追加セキュリティーグループを使用できます。
- Add machine pool をクリックしてマシンプールを作成します。
検証
- マシンプールが Machine pools ページに表示され、設定が想定どおりに表示されていることを確認します。
4.2.1.2. ROSA CLI を使用したマシンプールの作成
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、Red Hat OpenShift Service on AWS クラスターに追加のマシンプールを作成できます。
事前に購入した Capacity Reservation をマシンプールに追加するには、Capacity Reservation が設定されたマシンプールの作成 を参照してください。
前提条件
- ワークステーションに最新の ROSA CLI をインストールして設定した。
- ROSA CLI を使用して Red Hat アカウントにログインした。
- Red Hat OpenShift Service on AWS クラスターを作成した。
手順
自動スケーリングを使用しないマシンプールを追加するには、マシンプールを作成し、インスタンスタイプ、コンピュート (ワーカーとも呼ばれる) ノード数、およびノードラベルを定義します。
$ rosa create machinepool --cluster=<cluster-name> \ --name=<machine_pool_id> \ --replicas=<replica_count> \ --instance-type=<instance_type> \ --labels=<key>=<value>,<key>=<value> \ --taints=<key>=<value>:<effect>,<key>=<value>:<effect> \ --disk-size=<disk_size> \ --availability-zone=<availability_zone_name> \ --additional-security-group-ids <sec_group_id> \ --subnet <subnet_id>ここでは、以下のようになります。
--name=<machine_pool_id>- マシンプールの名前を指定します。
--replicas=<replica_count>-
プロビジョニングするコンピュートノードの数を指定します。単一のアベイラビリティーゾーンを使用して Red Hat OpenShift Service on AWS をデプロイした場合、この引数は、そのゾーンのマシンプールにプロビジョニングするコンピュートノードの数を定義します。複数のアベイラビリティーゾーンを使用してクラスターをデプロイした場合、この引数は、すべてのゾーンにわたってプロビジョニングするコンピュートノードの合計数を定義します。また、その数は 3 の倍数である必要があります。
--replicas引数は、自動スケーリングが設定されていない場合に必要です。 --instance-type=<instance_type>-
オプション: マシンプールのコンピュートノードのインスタンスタイプを設定します。インスタンスタイプは、プール内の各コンピュートノードの仮想 CPU およびメモリー割り当てを定義します。
<instance_type>をインスタンスタイプに置き換えます。デフォルトはm5.xlargeです。プールを作成した後に、マシンプールのインスタンスタイプを変更することはできません。 --labels=<key>=<value>,<key>=<value>-
オプション: マシンプールのラベルを定義します。
<key>=<value>,<key>=<value>は、キーと値のペアのコンマ区切りリストに置き換えます (例:--labels=key1=value1,key2=value2)。 --taints=<key>=<value>:<effect>,<key>=<value>:<effect>-
オプション: マシンプールのテイントを定義します。
<key>=<value>:<effect>,<key>=<value>:<effect>は、各テイントのキー、値、および影響に置き換えます (例:--taints=key1=value1:NoSchedule,key2=value2:NoExecute)。利用可能な影響には、NoSchedule、PreferNoSchedule、およびNoExecuteが含まれます。 --disk-size=<disk_size>-
オプション: ワーカーノードのディスクサイズを指定します。値は GB、GiB、TB、または TiB 単位で指定できます。
<disk_size>は、数値と単位に置き換えます (例:--disk-size=200GiB)。 --availability-zone=<availability_zone_name>-
オプション: 任意のアベイラビリティーゾーンにマシンプールを作成できます。
<availability_zone_name>は、アベイラビリティーゾーン名に置き換えます。 --additional-security-group-ids <sec_group_id>オプション: Red Hat 管理の VPC がないクラスター内のマシンプールの場合、マシンプールで使用する追加のカスタムセキュリティーグループを選択できます。すでにセキュリティーグループを作成し、このクラスター用に選択した VPC にそのグループを関連付けている必要があります。マシンプールの作成後は、セキュリティーグループを追加または編集することはできません。
重要Red Hat OpenShift Service on AWS クラスターのマシンプールには、最大 10 個の追加セキュリティーグループを使用できます。
--subnet <subnet_id>オプション: BYO VPC クラスターの場合、サブネットを選択してシングル AZ マシンプールを作成できます。サブネットがクラスター作成サブネットの外にある場合は、キーが
kubernetes.io/cluster/<infra-id>で値がsharedのタグが必要です。お客様は、次のコマンドを使用して Infra ID を取得できます。$ rosa describe cluster -c <cluster name>|grep "Infra ID:"出力例
Infra ID: mycluster-xqvj7注記--subnetと--availability-zoneの両方を同時に設定できません。Single-AZ マシンプールの作成には 1 つだけが許可されます。
以下の例では、
m5.xlargeインスタンスタイプを使用し、コンピュートノードレプリカが 2 つ含まれるmymachinepoolという名前のマシンプールを作成します。この例では、ワークロード固有のラベルも 2 つ追加します。$ rosa create machinepool --cluster=mycluster --name=mymachinepool --replicas=2 --instance-type=m5.xlarge --labels=app=db,tier=backend出力例
I: Machine pool 'mymachinepool' created successfully on cluster 'mycluster' I: To view all machine pools, run 'rosa list machinepools -c mycluster'自動スケーリングを使用するマシンプールを追加するには、マシンプールを作成して、自動スケーリング設定、インスタンスタイプ、およびノードラベルを定義します。
$ rosa create machinepool --cluster=<cluster-name> \ --name=<machine_pool_id> \ --enable-autoscaling \ --min-replicas=<minimum_replica_count> \ --max-replicas=<maximum_replica_count> \ --instance-type=<instance_type> \ --labels=<key>=<value>,<key>=<value> \ --taints=<key>=<value>:<effect>,<key>=<value>:<effect> \ --availability-zone=<availability_zone_name>ここでは、以下のようになります。
--name=<machine_pool_id>-
マシンプールの名前を指定します。
<machine_pool_id>をマシンプールの名前に置き換えます。 --enable-autoscaling- マシンプールの自動スケーリングを有効にし、デプロイメントのニーズに対応します。
--min-replicas=<minimum_replica_count>および--max-replicas=<maximum_replica_count>コンピュートノードの最小および最大の制限を定義します。クラスターオートスケーラーが、指定の制限を超えてマシンプールのノード数を増減することはありません。
--min-replicasおよび--max-replicas引数は、アベイラビリティーゾーンのマシンプールにおける自動スケーリングの制限を定義します。--instance-type=<instance_type>-
オプション: マシンプールのコンピュートノードのインスタンスタイプを設定します。インスタンスタイプは、プール内の各コンピュートノードの仮想 CPU およびメモリー割り当てを定義します。
<instance_type>をインスタンスタイプに置き換えます。デフォルトはm5.xlargeです。プールを作成した後に、マシンプールのインスタンスタイプを変更することはできません。 --labels=<key>=<value>,<key>=<value>-
オプション: マシンプールのラベルを定義します。
<key>=<value>,<key>=<value>は、キーと値のペアのコンマ区切りリストに置き換えます (例:--labels=key1=value1,key2=value2)。 --taints=<key>=<value>:<effect>,<key>=<value>:<effect>-
オプション: マシンプールのテイントを定義します。
<key>=<value>:<effect>,<key>=<value>:<effect>は、各テイントのキー、値、および影響に置き換えます (例:--taints=key1=value1:NoSchedule,key2=value2:NoExecute)。利用可能な影響には、NoSchedule、PreferNoSchedule、およびNoExecuteが含まれます。 --availability-zone=<availability_zone_name>-
オプション: 任意のアベイラビリティーゾーンにマシンプールを作成できます。
<availability_zone_name>は、アベイラビリティーゾーン名に置き換えます。
以下の例では、
m5.xlargeインスタンスタイプを使用し、自動スケーリングが有効になっているmymachinepoolという名前のマシンプールを作成します。コンピュートノードの最小制限は 3 で、最大制限は全体で 6 です。この例では、ワークロード固有のラベルも 2 つ追加します。$ rosa create machinepool --cluster=mycluster --name=mymachinepool --enable-autoscaling --min-replicas=3 --max-replicas=6 --instance-type=m5.xlarge --labels=app=db,tier=backend出力例
I: Machine pool 'mymachinepool' created successfully on hosted cluster 'mycluster' I: To view all machine pools, run 'rosa list machinepools -c mycluster'
Windows License Included が有効なマシンプールを Red Hat OpenShift Service on AWS クラスターに追加するには、AWS Windows License Included for Red Hat OpenShift Service on AWS を参照してください。
Windows License Included が有効なマシンプールは、次の条件が満たされた場合にのみ作成できます。
- ホストクラスターが Red Hat OpenShift Service on AWS クラスターである。
インスタンスタイプがベアメタル EC2 である。
重要AWS Windows License Included for Red Hat OpenShift Service on AWS は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat では、実稼働環境での使用を推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
検証
クラスターのすべてのマシンプールをリストするか、個々のマシンプールの詳細情報を表示します。
クラスターで使用可能なマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR Default No 1/1 m5. xlarge us-east-2c subnet-00552ad67728a6ba3 4.14.34 Yes mymachinepool Yes 3/3-6 m5.xlarge app=db, tier=backend us-east-2a subnet-0cb56f5f41880c413 4.14.34 Yesクラスター内の特定のマシンプールの詳細情報を表示します。
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=mymachinepool出力例
ID: mymachinepool Cluster ID: 2d6010rjvg17anri30v84vspf7c7kr6v Autoscaling: Yes Desired replicas: 3-6 Current replicas: 3 Instance type: m5.xlarge Labels: app=db, tier=backend Taints: Availability zone: us-east-2a Subnet: subnet-0cb56f5f41880c413 Version: 4.14.34 Autorepair: Yes Tuning configs: Additional security group IDs: Node drain grace period: Message:- マシンプールが出力に含まれ、設定が想定どおりであることを確認します。
4.2.1.3. ROSA CLI を使用して Capacity Reservation が設定されたマシンプールを作成する
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、Capacity Reservation を備えた新しいマシンプールを作成できます。ML 向けに On-Demand Capacity Reservation および Capacity Block の両方がサポートされています。
現在、Capacity Reservation が設定されたマシンプールでは、マシンプールのアップグレードと自動スケーリングの有効化はサポートされていません。
前提条件
- ROSA CLI バージョン 1.2.57 以上がインストールおよび設定されている。
- ROSA CLI を使用して Red Hat アカウントにログインした。
- Red Hat OpenShift Service on AWS クラスターバージョン 4.19 以上を作成した。
- クラスターに Capacity Reservation または taint を使用していないマシンプールがすでに存在する。マシンプールに少なくとも 2 つのワーカーノードがある。
- Capacity Reservation ID があり、作成するマシンプールのアベイラビリティーゾーン (AZ) で必要なインスタンスタイプに対して容量が予約されている。
手順
次のコマンドを実行して、マシンプールを作成し、インスタンスタイプ、ワーカーノード数、Capacity Reservation ID を定義します。
$ rosa create machinepool --cluster=<cluster-name> \ --name=<machine_pool_id> \ --replicas=<replica_count> \ --capacity-reservation-id cr-<capacity_reservation_id> \ --instance-type=<instance_type> \ --subnet <subnet_id>ここでは、以下のようになります。
- <machine_pool_id>
- マシンプールの名前を指定します。
- <replica_count>
-
プロビジョニングされたコンピュートノードの数を指定します。単一の AZ を使用して Red Hat OpenShift Service on AWS をデプロイする場合、これは AZ のマシンプールにプロビジョニングされるコンピュートノードの数を定義します。複数の AZ を使用してクラスターをデプロイする場合、これによりすべての AZ にわたってプロビジョニングされるコンピュートノードの合計数が定義されます。マルチゾーンクラスターの場合、コンピュートノード数は 3 の倍数である必要があります。
--replicas引数は、自動スケーリングが設定されていない場合に必要です。 - cr-<capacity_reservation_id>
-
予約 ID を指定します。AWS から Capacity Reservation を購入すると、
cr-<capacity_reservation_id>形式の ID が取得されます。ID は ML 向けの On-Demand Capacity Reservations or Capacity Block の両方に使用できます。予約タイプを指定する必要はありません。 - <instance_type>
-
オプション: マシンプール内のコンピュートノードのインスタンスの種類を指定します。インスタンスタイプは、プール内の各コンピュートノードの仮想 CPU およびメモリー割り当てを定義します。
<instance_type>をインスタンスタイプに置き換えます。デフォルトはm5.xlargeです。プールを作成した後に、マシンプールのインスタンスタイプを変更することはできません。 - <subnet_id>
オプション: サブネット ID を指定します。Bring Your Own Virtual Private Cloud (BYO VPC) クラスターの場合、サブネットを選択して単一の AZ マシンプールを作成できます。クラスターの初期作成時に指定されなかったサブネットを選択した場合は、そのサブネットに
kubernetes.io/cluster/<infra-id>キーとshared値をタグ付けする必要があります。次のコマンドを実行して Infra ID を取得できます。$ rosa describe cluster --cluster <cluster_name>|grep "Infra ID:"出力例
Infra ID: mycluster-xqvj7
例
以下の例では、c5.xlarge インスタンスタイプを使用し、コンピュートノードレプリカが 1 つ含まれる mymachinepool という名前のマシンプールを作成します。この例では、Capacity Reservation ID も追加されます。例: 出入力
$ rosa create machinepool --cluster=mycluster --name=mymachinepool --replicas 1 --capacity-reservation-id <capacity_reservation_id> --subnet <subnet_id> --instance-type c5.xlargeI: Checking available instance types for machine pool 'mymachinepool'
I: Machine pool 'mymachinepool' created successfully on hosted cluster 'mycluster'検証
クラスターのすべてのマシンプールをリストするか、個々のマシンプールの詳細情報を表示します。
次のコマンドを実行して、クラスター内で使用可能なマシンプールをリスト表示します。
$ rosa list machinepools --cluster <cluster_name>次のコマンドを実行して、クラスター内の特定のマシンプールの情報を表示します。
$ rosa describe machinepool --cluster <cluster_name> --machinepool <machine_pool_name>出力例
ID: <machine_pool_name> Cluster ID: <cluster-id> Autoscaling: No Desired replicas: 1 Current replicas: 1 Instance type: c5.xlarge Labels: Tags: red-hat-managed=true, api.openshift.com/environment=production, api.openshift.com/id=<cluster_name>, api.openshift.com/legal-entity-id=<legal_entity_id>, api.openshift.com/name=<cluster_name>, api.openshift.com/nodepool-hypershift=<cluster_name>-<machine_pool_name>, api.openshift.com/nodepool-ocm=<machine_pool_name>, red-hat-clustertype=rosa Taints: Availability zone: us-east-1a Subnet: <subnet-id> Disk Size: 300 GiB Version: 4.19.10 EC2 Metadata Http Tokens: optional Autorepair: Yes Tuning configs: Kubelet configs: Additional security group IDs: Node drain grace period: Capacity Reservation: - ID: <capacity-reservation-id> - Type: OnDemand Management upgrade: - Type: Replace - Max surge: 1 - Max unavailable: 0 Message: Minimum availability requires 1 replicas, current 1 available出力には、Capacity Reservation ID とタイプが含まれます。
4.2.2. マシンプールディスクボリュームの設定
マシンプールのディスクボリュームサイズは、柔軟性を高めるために設定できます。デフォルトのディスクサイズは 300 GiB です。
Red Hat OpenShift Service on AWS クラスターの場合、ディスクサイズは最小 75 GiB から最大 16,384 GiB まで設定できます。
クラスターのマシンプールのディスクサイズは、OpenShift Cluster Manager または ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して設定できます。
既存のクラスターおよびマシンプールノードのボリュームのサイズは変更できません。
クラスター作成の前提条件
- クラスターのインストール中に、デフォルトのマシンプールのノードディスクサイズを選択するオプションがあります。
クラスター作成の手順
- Red Hat OpenShift Service on AWS クラスターウィザードから、Cluster settings に移動します。
- Machine pool の手順に移動します。
- 目的の Root disk size を選択します。
- Next を選択してクラスターの作成を続行します。
マシンプール作成の前提条件
- クラスターのインストール後に、新しいマシンプールのノードディスクサイズを選択するオプションがあります。
マシンプール作成の手順
- OpenShift Cluster Manager に移動し、クラスターを選択します。
- Machine pool タブ に移動します。
- Add machine pool をクリックします。
- 目的の Root disk size を選択します。
- Add machine pool を選択してマシンプールを作成します。
4.2.2.1. ROSA CLI を使用したマシンプールディスクボリュームの設定
クラスター作成の前提条件
- クラスターのインストール中に、デフォルトのマシンプールのルートディスクのサイズを選択するオプションがあります。
クラスター作成の手順
必要なルートディスクサイズの OpenShift クラスターを作成するときに、次のコマンドを実行します。
$ rosa create cluster --worker-disk-size=<disk_size>値は GB、GiB、TB、または TiB 単位で指定できます。
<disk_size>は、数値と単位に置き換えます (例:--worker-disk-size=200GiB)。数字と単位は、分離できません。空白は、使用できます。
マシンプール作成の前提条件
- クラスターのインストール後に、新しいマシンプールのルートディスクのサイジングを選択するオプションがあります。
マシンプール作成の手順
以下のコマンドを実行してクラスターをスケールアップします。
$ rosa create machinepool --cluster=<cluster_id> \1 --disk-size=<disk_size>2 - AWS コンソールにログインして新規のマシンプールのディスクサイズを確認し、EC2 仮想マシンのルートボリュームサイズを見つけます。
4.2.3. マシンプールの削除
ワークロード要件が変更され、現在のマシンプールがニーズを満たさなくなった場合は、マシンプールを削除できます。
マシンプールは、Red Hat OpenShift Cluster Manager または ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して削除できます。
4.2.3.1. OpenShift Cluster Manager を使用したマシンプールの削除
Red Hat OpenShift Cluster Manager を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプールを削除できます。
前提条件
- Red Hat OpenShift Service on AWS クラスターを作成した。
- クラスターが準備状態にある。
- テイントのない既存のマシンプールがあり、シングル AZ クラスターの場合は少なくとも 2 つのインスタンス、マルチ AZ クラスターの場合は少なくとも 3 つのインスタンスがある。
手順
- OpenShift Cluster Manager から、Cluster List ページに移動し、削除するマシンプールを含むクラスターを選択します。
- 選択したクラスターで、Machine pools タブを選択します。
-
Machine pools タブで、削除するマシンプールの Options メニュー
 をクリックします。
をクリックします。
Delete をクリックします。
選択したマシンプールが削除されます。
4.2.3.2. ROSA CLI を使用したマシンプールの削除
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプールを削除できます。
rosa バージョン 1.2.25 以前を使用している場合、クラスターとともに作成されたマシンプール (ID = 'Default') を削除することはできません。rosa バージョン 1.2.26 以降を使用している場合、クラスター内に taint を含まないマシンプールが 1 つあり、レプリカが 2 つ以上 (シングル AZ クラスターの場合) または 3 つ以上 (マルチ AZ クラスターの場合) あれば、クラスターとともに作成されたマシンプール (ID='worker') を削除できます。
前提条件
- Red Hat OpenShift Service on AWS クラスターを作成した。
- クラスターが準備状態にある。
- テイントのない既存のマシンプールがあり、シングル AZ クラスターの場合は少なくとも 2 つのインスタンス、マルチ AZ クラスターの場合は少なくとも 3 つのインスタンスがある。
手順
ROSA CLI から次のコマンドを実行します。
$ rosa delete machinepool -c=<cluster_name> <machine_pool_ID>出力例
? Are you sure you want to delete machine pool <machine_pool_ID> on cluster <cluster_name>? (y/N)yを入力してマシンプールを削除します。選択したマシンプールが削除されます。
4.2.4. コンピュートノードの手動によるスケーリング
マシンプールの自動スケーリングを有効にしていない場合は、デプロイメントのニーズに合わせてプール内のコンピュート (ワーカーとも呼ばれる) ノードの数を手動でスケーリングできます。
各マシンプールを個別にスケーリングする必要があります。
前提条件
-
ワークステーションに最新の ROSA コマンドラインインターフェイス (CLI) (
rosa) をインストールして設定した。 - ROSA CLI を使用して Red Hat アカウントにログインした。
- Red Hat OpenShift Service on AWS クラスターを作成した。
- 既存のマシンプールがある。
手順
クラスターのマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONES DISK SIZE SG IDs default No 2 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2 mp1 No 2 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2マシンプール内のコンピュートノードのレプリカ数を増減します。
$ rosa edit machinepool --cluster=<cluster_name> \ --replicas=<replica_count> \1 <machine_pool_id>2
検証
クラスターで利用可能なマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONES DISK SIZE SG IDs default No 2 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2 mp1 No 3 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2-
上記のコマンドの出力で、コンピュートノードのレプリカ数がマシンプールで想定通りに設定されていることを確認します。この出力例では、
mp1マシンプールのコンピュートノードレプリカ数は 3 にスケーリングされています。
4.2.5. ノードラベル
ラベルは、Node オブジェクトに適用されるキーと値のペアです。ラベルを使用して一連のオブジェクトを整理し、Pod のスケジューリングを制御できます。
クラスターの作成中または後にラベルを追加できます。ラベルはいつでも変更または更新できます。
4.2.5.1. ノードラベルのマシンプールへの追加
いつでもコンピュート (ワーカーとも呼ばれる) ノードのラベルを追加または編集して、適切な方法でノードを管理します。たとえば、ワークロードのタイプを特定のノードに割り当てることができます。
ラベルは key-value ペアとして割り当てられます。各キーは、割り当てられたオブジェクトに固有のものである必要があります。
前提条件
-
ワークステーションに最新の ROSA コマンドラインインターフェイス (CLI) (
rosa) をインストールして設定した。 - ROSA CLI を使用して Red Hat アカウントにログインした。
- Red Hat OpenShift Service on AWS クラスターを作成した。
- 既存のマシンプールがある。
手順
クラスターのマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yesマシンプールのノードラベルを追加または更新します。
自動スケーリングを使用しないマシンプールのノードラベルを追加または更新するには、以下のコマンドを実行します。
$ rosa edit machinepool --cluster=<cluster_name> \ --labels=<key>=<value>,<key>=<value> \1 <machine_pool_id>- 1
<key>=<value>,<key>=<value>は、キーと値のペアのコンマ区切りリストに置き換えます (例:--labels=key1=value1,key2=value2)。このリストは、継続的にノードラベルに加えられるすべての変更をオーバーライドします。
以下の例では、ラベルを
db-nodes-mpマシンプールに追加します。$ rosa edit machinepool --cluster=mycluster --replicas=2 --labels=app=db,tier=backend db-nodes-mp出力例
I: Updated machine pool 'db-nodes-mp' on cluster 'mycluster'
検証
新しいラベルを持つマシンプールの詳細情報を表示します。
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machine-pool-name>出力例
ID: db-nodes-mp Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: app=db, tier=backend Tags: Taints: Availability zone: us-east-2a Subnet: subnet-0df2ec3377847164f Disk size: 300 GiB Version: 4.16.6 EC2 Metadata Http Tokens: optional Autorepair: Yes Tuning configs: Kubelet configs: Additional security group IDs: Node drain grace period: Management upgrade: - Type: Replace - Max surge: 1 - Max unavailable: 0 Message:- 出力内のマシンプールにラベルが含まれていることを確認します。
4.2.6. マシンプールへのタグの追加
マシンプール内のコンピュートノード (ワーカーノードとも呼ばれます) にタグを追加して、マシンプールのプロビジョニング時に生成される AWS リソースに、カスタムユーザータグを導入できます。マシンプールを作成した後はタグを編集できないことに注意してください。
4.2.6.1. ROSA CLI を使用してマシンプールにタグを追加する
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプールにタグを追加できます。マシンプールを作成した後はタグを編集できません。
タグキーが aws、red-hat-managed、red-hat-clustertype、または Name ではないことを確認する必要があります。また、kubernetes.io/cluster/ で始まるタグキーを設定してはなりません。タグのキーは 128 文字以下とし、タグの値は 256 文字以下とします。Red Hat は、将来的に予約タグをさらに追加する権利を有します。
前提条件
-
ワークステーションに最新の AWS (
aws)、ROSA (rosa)、OpenShift (oc) の CLI をインストールして設定している。 - ROSA CLI を使用して Red Hat アカウントにログイン済みである。
- Red Hat OpenShift Service on AWS クラスターを作成した。
手順
次のコマンドを実行して、カスタムタグを持つマシンプールを作成します。
$ rosa create machinepools --cluster=<name> --replicas=<replica_count> \ --name <mp_name> --tags='<key> <value>,<key> <value>'1 - 1
<key> <value>,<key> <value>を各タグのキーと値に置き換えます。
出力例
$ rosa create machinepools --cluster=mycluster --replicas 2 --tags='tagkey1 tagvalue1,tagkey2 tagvaluev2' I: Checking available instance types for machine pool 'mp-1' I: Machine pool 'mp-1' created successfully on cluster 'mycluster' I: To view the machine pool details, run 'rosa describe machinepool --cluster mycluster --machinepool mp-1' I: To view all machine pools, run 'rosa list machinepools --cluster mycluster'
検証
describeコマンドを使用してタグ付きのマシンプールの詳細を表示し、出力にマシンプールのタグが含まれていることを確認します。$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machinepool_name>出力例
ID: db-nodes-mp Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: red-hat-clustertype=rosa, red-hat-managed=true, tagkey1=tagvalue1, tagkey2=tagvaluev2 Taints: Availability zone: us-east-2a ...
4.2.7. マシンプールへの taint の追加
マシンプール内のコンピュート (ワーカーとも呼ばれる) ノードに taint を追加して、そのノードにスケジュールされる Pod を制御できます。マシンプールに taint を適用すると、Pod 仕様に taint の toleration が含まれている場合を除き、スケジューラーがプール内のノードに Pod を配置できなくなります。taint は、Red Hat OpenShift Cluster Manager または ROSA コマンドラインインターフェイス (CLI) (rosa) を使用してマシンプールに追加できます。
クラスターには、taint が含まれていないマシンプールが少なくとも 1 つ必要です。
4.2.7.1. OpenShift Cluster Manager を使用してマシンプールに taint を追加する
Red Hat OpenShift Cluster Manager を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプールに taint を追加できます。
前提条件
- Red Hat OpenShift Service on AWS クラスターを作成した。
- taint を含まず、少なくとも 2 つのインスタンスを含む既存のマシンプールがある。
手順
- OpenShift Cluster Manager に移動し、クラスターを選択します。
-
Machine pools タブで、taint を追加するマシンプールの Options メニュー
をクリックします。
- Edit taints を選択します。
- taint の Key と Value のエントリーを追加します。
-
リストから taint の Effect を選択します。使用できるオプションには、
NoSchedule、PreferNoSchedule、およびNoExecuteが含まれます。 - オプション: マシンプールにさらに taint を追加する場合は、Add taint を選択します。
- Save をクリックして、taint をマシンプールに適用します。
検証
- Machine pools タブで、マシンプールの横にある > を選択して、ビューを展開します。
- 展開されたビューの Taints の下に taint がリストされていることを確認します。
4.2.7.2. ROSA CLI を使用したマシンプールへのテイントの追加
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプールに taint を追加できます。
rosa バージョン 1.2.25 以前を使用している場合、クラスターとともに作成されたマシンプール (ID = Default) 内の taint の数を変更することはできません。rosa バージョン 1.2.26 以降を使用している場合、クラスターとともに作成されたマシンプール (ID = worker) 内の taint の数を変更できます。taint がなく、2 つ以上のレプリカを持つマシンプールが少なくとも 1 つ必要です。
前提条件
-
ワークステーションに最新の AWS (
aws)、ROSA (rosa)、OpenShift (oc) の CLI をインストールして設定している。 -
rosaCLI を使用して Red Hat アカウントにログイン済みである。 - Red Hat OpenShift Service on AWS クラスターを作成した。
- taint を含まず、少なくとも 2 つのインスタンスを含む既存のマシンプールがある。
手順
次のコマンドを実行して、クラスター内のマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yesマシンプールのテイントを追加または更新します。
自動スケーリングを使用しないマシンプールのテイントを追加または更新するには、以下のコマンドを実行します。
$ rosa edit machinepool --cluster=<cluster_name> \ --taints=<key>=<value>:<effect>,<key>=<value>:<effect> \1 <machine_pool_id>- 1
<key>=<value>:<effect>,<key>=<value>:<effect>は、各テイントのキー、値、および影響に置き換えます (例:--taints=key1=value1:NoSchedule,key2=value2:NoExecute)。影響としてNoSchedule、PreferNoSchedule、およびNoExecuteが使用できます。このリストは、ノードテイントに加えられた変更を継続的にオーバーライドします。
以下の例では、テイントを
db-nodes-mpマシンプールに追加します。$ rosa edit machinepool --cluster=mycluster --replicas 2 --taints=key1=value1:NoSchedule,key2=value2:NoExecute db-nodes-mp出力例
I: Updated machine pool 'db-nodes-mp' on cluster 'mycluster'
検証
新しいテイントを含むマシンプールの詳細情報を表示します。
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machinepool_name>出力例
ID: db-nodes-mp Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: Taints: key1=value1:NoSchedule, key2=value2:NoExecute Availability zone: us-east-2a ...- 出力にマシンプールのテイントが含まれていることを確認します。
4.2.8. マシンプールの AutoRepair の設定
Red Hat OpenShift Service on AWS は、AutoRepair と呼ばれるマシンプールの自動修復プロセスをサポートしています。AutoRepair は、Red Hat OpenShift Service on AWS サービスで特定の異常なノードを検出し、異常なノードに drain (Pod の退避) を実行してノードを再作成する場合に役立ちます。ノードを保持する必要がある場合など、異常なノードを置き換えない場合は、AutoRepair を無効にできます。AutoRepair はマシンプールでデフォルトで有効になっています。
AutoRepair プロセスでは、ノードの状態が NotReady であるか、事前定義された時間 (通常は 8 分)、不明な状態である場合に、ノードが正常でないと判断されます。2 つ以上のノードが同時に異常な状態になった場合に、AutoRepair プロセスはノードの修復を停止します。同様に、事前定義された時間 (通常は 20 分) が経過しても新しいノードが異常な状態で作成された場合、サービスは自動的に修復されます。
マシンプールの AutoRepair は、Red Hat OpenShift Service on AWS クラスターでのみ使用できます。
4.2.8.1. OpenShift Cluster Manager を使用してマシンプールで AutoRepair を設定する
Red Hat OpenShift Cluster Manager を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプール AutoRepair を設定できます。
前提条件
- ROSA with HCP クラスターを作成した。
- 既存のマシンプールがある。
手順
- OpenShift Cluster Manager に移動し、クラスターを選択します。
-
Machine pools タブで、自動修復を設定するマシンプールのオプションメニュー
をクリックします。
- メニューから Edit を選択します。
- 表示される Edit Machine Pool ダイアログボックスから、AutoRepair オプションを見つけます。
- AutoRepair の横にあるボックスを選択または選択解除して、有効または無効にします。
- Save をクリックして、変更をマシンプールに適用します。
検証
- Machine pools タブで、マシンプールの横にある > を選択して、ビューを展開します。
- 展開ビューで、マシンプールの AutoRepair 設定が正しいことを確認します。
4.2.8.2. ROSA CLI を使用してマシンプールの AutoRepair を設定する
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、Red Hat OpenShift Service on AWS クラスターのマシンプールの AutoRepair を設定できます。
前提条件
-
ワークステーションに最新の AWS (
aws) および ROSA (rosa) CLI をインストールして設定している。 -
rosaCLI を使用して Red Hat アカウントにログイン済みである。 - Red Hat OpenShift Service on AWS クラスターを作成した。
- 既存のマシンプールがある。
手順
次のコマンドを実行して、クラスター内のマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yesマシンプールで AutoRepair を有効または無効にします。
マシンプールの AutoRepair を無効にするには、次のコマンドを実行します。
$ rosa edit machinepool --cluster=mycluster --machinepool=<machinepool_name> --autorepair=falseマシンプールの AutoRepair を有効にするには、次のコマンドを実行します。
$ rosa edit machinepool --cluster=mycluster --machinepool=<machinepool_name> --autorepair=true出力例
I: Updated machine pool 'machinepool_name' on cluster 'mycluster'
検証
マシンプールの詳細情報を表示します。
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machinepool_name>出力例
ID: machinepool_name Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: Taints: Availability zone: us-east-2a ... Autorepair: Yes Tuning configs: Kubelet configs: Additional security group IDs: Node drain grace period: Management upgrade: - Type: Replace - Max surge: 1 - Max unavailable: 0- 出力で、マシンプールの AutoRepair 設定が正しいことを確認します。
4.2.9. マシンプールへのノードチューニングの追加
マシンプール内のコンピュート (ワーカーとも呼ばれる) ノードのチューニングを追加して、Red Hat OpenShift Service on AWS クラスターでのコンピュートノードの設定を制御できます。
前提条件
-
ワークステーションに最新の ROSA コマンドラインインターフェイス (CLI) (
rosa) をインストールして設定した。 - 'rosa' を使用して Red Hat アカウントにログインした。
- Red Hat OpenShift Service on AWS クラスターを作成した。
- 既存のマシンプールがある。
- 既存のチューニング設定がある。
手順
クラスター内のすべてのマシンプールをリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR db-nodes-mp No 0/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes workers No 2/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes既存または新規のマシンプールにチューニング設定を追加できます。
マシンプールの作成時にチューニングを追加します。
$ rosa create machinepool -c <cluster-name> --name <machinepoolname> --tuning-configs <tuning_config_name>出力例
? Tuning configs: sample-tuning I: Machine pool 'db-nodes-mp' created successfully on hosted cluster 'sample-cluster' I: To view all machine pools, run 'rosa list machinepools -c sample-cluster'マシンプールのチューニングを追加または更新します。
$ rosa edit machinepool -c <cluster-name> --machinepool <machinepoolname> --tuning-configs <tuning_config_name>出力例
I: Updated machine pool 'db-nodes-mp' on cluster 'mycluster'
検証
チューニング設定を追加したマシンプールの情報を取得します。
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machine_pool_name>出力例
ID: db-nodes-mp Cluster ID: <cluster_ID> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: Taints: Availability zone: us-east-2a Subnet: subnet-08d4d81def67847b6 Version: 4.14.34 EC2 Metadata Http Tokens: optional Autorepair: Yes Tuning configs: sample-tuning ...- マシンプールのチューニング設定が出力に含まれていることを確認します。
4.2.10. ノード drain 猶予期間の設定
クラスター内のマシンプールのノード drain (Pod の退避) 猶予期間を設定できます。マシンプールのノード drain 猶予期間とは、マシンプールをアップグレードまたは置き換えるときに、クラスターが Pod Disruption Budget で保護されたワークロードを考慮する期間のことです。この猶予期間が過ぎると、残りのワークロードがすべて強制的に退避させられます。ノード drain 猶予期間の値の範囲は、0 から 1 week です。デフォルト値 0 または空の値の場合、マシンプールは完了するまで時間制限なしで drain されます。
前提条件
-
ワークステーションに最新の ROSA コマンドラインインターフェイス (CLI) (
rosa) をインストールして設定した。 - Red Hat OpenShift Service on AWS クラスターを作成した。
- 既存のマシンプールがある。
手順
次のコマンドを実行して、クラスター内のマシンプールをすべてリスト表示します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes workers No 2/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes次のコマンドを実行して、マシンプールのノード drain 猶予期間を確認します。
$ rosa describe machinepool --cluster <cluster_name> --machinepool=<machinepool_name>出力例
ID: workers Cluster ID: 2a90jdl0i4p9r9k9956v5ocv40se1kqs ... Node drain grace period:1 ...- 1
- この値が空の場合、マシンプールは完了するまで時間制限なしでドレインされます。
オプション: 次のコマンドを実行して、マシンプールのノード drain 猶予期間を更新します。
$ rosa edit machinepool --node-drain-grace-period="<node_drain_grace_period_value>" --cluster=<cluster_name> <machinepool_name>注記マシンプールのアップグレード中にノード drain 猶予期間を変更すると、進行中のアップグレードではなく、将来のアップグレードに適用されます。
検証
次のコマンドを実行して、マシンプールのノード drain 猶予期間を確認します。
$ rosa describe machinepool --cluster <cluster_name> <machinepool_name>出力例
ID: workers Cluster ID: 2a90jdl0i4p9r9k9956v5ocv40se1kqs ... Node drain grace period: 30 minutes ...-
出力で、マシンプールの
Node drain grace periodが正しいことを確認します。
4.2.11. 関連情報
4.3. クラスターでのノードの自動スケーリングについて
オートスケーラーのオプションを設定すると、マシンプール内のマシンの数を自動的にスケーリングできます。
クラスターオートスケーラーは、リソース不足のために現在のノードのいずれにも Pod をスケジュールできない場合、またはデプロイメントのニーズを満たすために別のノードが必要な場合に、マシンプールのサイズを拡大します。Cluster Autoscaler は、指定の制限を超えてクラスターリソースを拡大することはありません。
さらに、リソース使用量が少なく、重要な Pod がすべて他のノードに収まる場合など、一部のノードが一定期間にわたって継続的に必要ない場合、クラスターオートスケーラーはマシンプールのサイズを縮小します。
自動スケーリングを有効にする場合は、ワーカーノードの最小数および最大数も設定する必要があります。
クラスターの所有者と組織管理者のみがクラスターのスケーリングまたは削除が可能です。
4.3.1. クラスターでのノードの自動スケーリングの有効化
ワーカーノードで自動スケーリングを有効にし、既存クラスターのマシンプール定義を編集して利用可能なノード数を増減できます。
4.3.1.1. Red Hat OpenShift Cluster Manager を使用して既存のクラスターでノードの自動スケーリングを有効にする
OpenShift Cluster Manager コンソールからマシンプール定義でワーカーノードの自動スケーリングを有効にします。
手順
- OpenShift Cluster Manager で、Cluster List ページに移動し、自動スケーリングを有効にするクラスターを選択します。
- 選択したクラスターで、Machine pools タブを選択します。
-
自動スケーリングを有効にするマシンプールの最後にある Options メニュー
をクリックし、Edit を選択します。
- Edit machine pool ダイアログで、Enable autoscaling チェックボックスをオンにします。
- Save を選択してこれらの変更を保存し、マシンプールの自動スケーリングを有効にします。
4.3.1.2. ROSA CLI を使用して既存のクラスターでノードの自動スケーリングを有効にする
負荷に基づいてワーカーノード数を動的にスケールアップまたはスケールダウンできるように自動スケーリングを設定します。
自動スケーリングが正常に実行されるかどうかは、AWS アカウントに正しい AWS リソースクォータがあることかどうかに依存します。AWS コンソール でリソースクォータおよび要求クォータの増加を確認します。
手順
クラスター内のマシンプール ID を識別するには、以下のコマンドを実行します。
$ rosa list machinepools --cluster=<cluster_name>出力例
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-03c2998b482bf3b20 4.16.6 Yes mp1 No 2/2 m5.xlarge us-east-2a subnet-03c2998b482bf3b20 4.16.6 Yes- 設定する必要のあるマシンプールの ID を取得します。
マシンプールで自動スケーリングを有効にするには、以下のコマンドを実行します。
$ rosa edit machinepool --cluster=<cluster_name> <machinepool_ID> --enable-autoscaling --min-replicas=<number> --max-replicas=<number>例
mp1という ID をmyclusterという名前のクラスターに設定し、レプリカの数が 2 から 5 ワーカーノード間でスケーリングするように設定された状態でマシンプールで自動スケーリングを有効にします。$ rosa edit machinepool --cluster=mycluster mp1 --enable-autoscaling --min-replicas=2 --max-replicas=5
4.3.2. クラスターでのノードの自動スケーリングの無効化
既存のクラスターのマシンプール定義を編集することで、ワーカーノードの自動スケーリングを無効にして、使用可能なノードの数を増減できます。
クラスターの自動スケーリングは、Red Hat OpenShift Cluster Manager または ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して無効にできます。
4.3.2.1. Red Hat OpenShift Cluster Manager を使用して既存のクラスターでノードの自動スケーリングを無効にする
OpenShift Cluster Manager からマシンプール定義でワーカーノードの自動スケーリングを無効にします。
手順
- OpenShift Cluster Manager で、Cluster List ページに移動し、無効にする必要のある自動スケーリングでクラスターを選択します。
- 選択したクラスターで、Machine pools タブを選択します。
-
自動スケーリングのあるマシンプールの最後にある Options メニュー
をクリックし、Edit を選択します。
- Edit machine pool ダイアログで、Enable autoscaling チェックボックスをオフにします。
- Save を選択してこれらの変更を保存し、マシンプールの自動スケーリングを無効にします。
4.3.2.2. ROSA CLI を使用して既存のクラスターでノードの自動スケーリングを無効にする
ROSA コマンドラインインターフェイス (CLI) (rosa) を使用して、マシンプール定義内のワーカーノードの自動スケーリングを無効にします。
手順
以下のコマンドを実行します。
$ rosa edit machinepool --cluster=<cluster_name> <machinepool_ID> --enable-autoscaling=false --replicas=<number>例
myclusterという名前のクラスターで、defaultマシンプールの自動スケーリングを無効にします。$ rosa edit machinepool --cluster=mycluster default --enable-autoscaling=false --replicas=3
4.4. コンテナーメモリーとリスク要件を満たすためのクラスターメモリーの設定
クラスター管理者は、以下を実行し、クラスターがアプリケーションメモリーの管理を通じて効率的に動作するようにすることができます。
- コンテナー化されたアプリケーションコンポーネントのメモリーおよびリスク要件を判別し、それらの要件を満たすようコンテナーメモリーパラメーターを設定する
- コンテナー化されたアプリケーションランタイム (OpenJDK など) を、設定されたコンテナーメモリーパラメーターに基づいて最適に実行されるよう設定する
- コンテナーでの実行に関連するメモリー関連のエラー状態を診断し、これを解決する
4.4.1. アプリケーションメモリーの管理について
まず Red Hat OpenShift Service on AWS によるコンピュートリソースの管理方法の概要をよく読んでから次の手順に進むことを推奨します。
各種のリソース (メモリー、cpu、ストレージ) に応じて、Red Hat OpenShift Service on AWS ではオプションの 要求 および 制限 の値を Pod の各コンテナーに設定できます。
メモリー要求とメモリー制限について、以下の点に注意してください。
メモリーリクエスト
- メモリー要求値が指定されている場合、Red Hat OpenShift Service on AWS スケジューラーに影響します。スケジューラーは、コンテナーのノードへのスケジュール時にメモリー要求を考慮し、コンテナーの使用のために選択されたノードで要求されたメモリーをフェンスオフします。
- ノードのメモリーが不足した場合、Red Hat OpenShift Service on AWS は、メモリー使用量がメモリー要求を最も超過しているコンテナーを優先的に退避させます。メモリー枯渇が深刻な場合、ノード OOM キラーが同様のメトリクスに基づいてコンテナー内のプロセスを選択して強制終了することがあります。
- クラスター管理者は、メモリー要求値に対してクォータを割り当てるか、デフォルト値を割り当てることができます。
- クラスター管理者は、クラスターのオーバーコミットを管理するために開発者が指定するメモリー要求の値をオーバーライドできます。
メモリー制限
- メモリー制限値が指定されている場合、コンテナーのすべてのプロセスに割り当て可能なメモリーにハード制限を指定します。
- コンテナーのすべてのプロセスで割り当てられるメモリーがメモリー制限を超過する場合、ノードの OOM (Out of Memory) killer はコンテナーのプロセスをすぐに選択し、これを強制終了します。
- メモリー要求とメモリー制限の両方が指定される場合、メモリー制限の値はメモリー要求の値よりも大きいか、これと等しくなければなりません。
- クラスター管理者は、メモリーの制限値に対してクォータを割り当てるか、デフォルト値を割り当てることができます。
-
最小メモリー制限は 12 MB です。
Cannot allocate memoryPod イベントのためにコンテナーの起動に失敗すると、メモリー制限は低くなります。メモリー制限を引き上げるか、これを削除します。制限を削除すると、Pod は制限のないノードのリソースを消費できるようになります。
4.4.1.1. アプリケーションメモリーストラテジーの管理
Red Hat OpenShift Service on AWS でアプリケーションメモリーをサイジングする手順は以下の通りです。
予想されるコンテナーのメモリー使用の判別
必要時に予想される平均およびピーク時のコンテナーのメモリー使用を判別します (例: 別の負荷テストを実行)。コンテナーで並行して実行されている可能性のあるすべてのプロセスを必ず考慮に入れるようにしてください。たとえば、メインのアプリケーションは付属スクリプトを生成しているかどうかを確認します。
リスク選好 (risk appetite) の判別
退避のリスク選好を判別します。リスク選好のレベルが低い場合、コンテナーは予想されるピーク時の使用量と安全マージンのパーセンテージに応じてメモリーを要求します。リスク選好が高くなる場合、予想される平均の使用量に応じてメモリーを要求することがより適切な場合があります。
コンテナーのメモリー要求の設定
上記に基づいてコンテナーのメモリー要求を設定します。要求がアプリケーションのメモリー使用をより正確に表示することが望ましいと言えます。要求が高すぎる場合には、クラスターおよびクォータの使用が非効率となります。要求が低すぎる場合、アプリケーションの退避の可能性が高まります。
コンテナーのメモリー制限の設定 (必要な場合)
必要時にコンテナーのメモリー制限を設定します。制限を設定すると、コンテナーのすべてのプロセスのメモリー使用量の合計が制限を超える場合にコンテナーのプロセスがすぐに強制終了されるため、いくつかの利点をもたらします。まずは予期しないメモリー使用の超過を早期に明確にする ("fail fast" (早く失敗する)) ことができ、次にプロセスをすぐに中止できます。
一部の Red Hat OpenShift Service on AWS クラスターでは制限値を設定する必要があります。制限に基づいて要求をオーバーライドする場合があります。また、一部のアプリケーションイメージは、要求値よりも検出が簡単なことから設定される制限値に依存します。
メモリー制限が設定される場合、これは予想されるピーク時のコンテナーのメモリー使用量と安全マージンのパーセンテージよりも低い値に設定することはできません。
アプリケーションが調整されていることの確認
適切な場合は、設定される要求および制限値に関連してアプリケーションが調整されていることを確認します。この手順は、JVM などのメモリーをプールするアプリケーションにおいてとくに当てはまります。残りの部分では、これを説明します。
4.4.2. Red Hat OpenShift Service on AWS の OpenJDK 設定について
デフォルトの OpenJDK 設定はコンテナー化された環境では機能しません。そのため、コンテナーで OpenJDK を実行する場合は常に追加の Java メモリー設定を指定する必要があります。
JVM のメモリーレイアウトは複雑で、バージョンに依存しており、この詳細はこのドキュメントでは説明しません。ただし、コンテナーで OpenJDK を実行する際のスタートにあたって少なくとも以下の 3 つのメモリー関連のタスクが主なタスクになります。
- JVM 最大ヒープサイズをオーバーライドする。
- JVM が未使用メモリーをオペレーティングシステムに解放するよう促す (適切な場合)。
- コンテナー内のすべての JVM プロセスが適切に設定されていることを確認する。
コンテナーでの実行に向けて JVM ワークロードを最適に調整する方法はこのドキュメントでは扱いませんが、これには複数の JVM オプションを追加で設定することが必要になる場合があります。
4.4.2.1. JVM の最大ヒープサイズをオーバーライドする方法について
OpenJDK は、デフォルトで、使用可能なメモリーの最大 25% を "ヒープ" メモリーに使用します。その際、コンテナーに設定されたメモリー制限も考慮されます。このデフォルト値は控えめな値であり、適切に設定されたコンテナー環境でこの値を使用すると、コンテナーに割り当てられたメモリーの 75% がほとんど使用されないことになります。コンテナーレベルでメモリー制限が課されるコンテナーコンテキストでは、JVM がヒープメモリーに使用する割合を 80% などかなり高く設定する方が適しています。
ほとんどの Red Hat コンテナーには、JVM の起動時に値を更新して OpenJDK のデフォルト設定を置き換える起動スクリプトが含まれています。
たとえば、Red Hat build of OpenJDK コンテナーのデフォルト値は 80% です。この値は、JAVA_MAX_RAM_RATIO 環境変数を定義することで異なるパーセンテージに設定できます。
その他の OpenJDK デプロイメントの場合、次のコマンドを使用してデフォルト値の 25% を変更できます。
例
$ java -XX:MaxRAMPercentage=80.04.4.2.2. JVM で未使用メモリーをオペレーティングシステムに解放するよう促す方法について
デフォルトで、OpenJDK は未使用メモリーをオペレーティングシステムに積極的に返しません。これは多くのコンテナー化された Java ワークロードには適していますが、例外として、コンテナー内に JVM と共存する追加のアクティブなプロセスがあるワークロードの場合を考慮する必要があります。それらの追加のプロセスはネイティブのプロセスである場合や追加の JVM の場合、またはこれら 2 つの組み合わせである場合もあります。
Java ベースのエージェントは、次の JVM 引数を使用して、JVM が未使用のメモリーをオペレーティングシステムに解放するように促すことができます。
-XX:+UseParallelGC
-XX:MinHeapFreeRatio=5 -XX:MaxHeapFreeRatio=10 -XX:GCTimeRatio=4
-XX:AdaptiveSizePolicyWeight=90
これらの引数は、割り当てられたメモリーが使用中のメモリー (-XX:MaxHeapFreeRatio) の 110% を超え、ガベージコレクター (-XX:GCTimeRatio) での CPU 時間の 20% を使用する場合は常にヒープメモリーをオペレーティングシステムに返すことが意図されています。アプリケーションのヒープ割り当てが初期のヒープ割り当て (-XX:InitialHeapSize / -Xms でオーバーライドされる) を下回ることはありません。詳細は、Tuning Java’s footprint in OpenShift (Part 1)、Tuning Java’s footprint in OpenShift (Part 2)、および OpenJDK and Containers を参照してください。
4.4.2.3. コンテナー内のすべての JVM プロセスが適切に設定されていることを確認する方法について
複数の JVM が同じコンテナーで実行される場合、それらすべてが適切に設定されていることを確認する必要があります。多くのワークロードでは、それぞれの JVM に memory budget のパーセンテージを付与する必要があります。これにより大きな安全マージンが残される場合があります。
多くの Java ツールは JVM を設定するために各種の異なる環境変数 (JAVA_OPTS、GRADLE_OPTS など) を使用します。適切な設定が適切な JVM に渡されていることを確認するのが容易でない場合もあります。
JAVA_TOOL_OPTIONS 環境変数は OpenJDK によって常に考慮されます。JAVA_TOOL_OPTIONS で指定した値は、JVM コマンドラインで指定した他のオプションによってオーバーライドされます。デフォルトでは、Java ベースのエージェントイメージで実行されるすべての JVM ワークロードに対してこれらのオプションがデフォルトで使用されるように、Red Hat OpenShift Service on AWS の Jenkins Maven エージェントイメージによって次の変数が設定されます。
JAVA_TOOL_OPTIONS="-Dsun.zip.disableMemoryMapping=true"この設定は、追加オプションが要求されないことを保証する訳ではなく、有用な開始点になることを意図しています。
4.4.3. Pod 内でのメモリー要求および制限の検索
Pod 内からメモリー要求および制限を動的に検出するアプリケーションでは Downward API を使用する必要があります。
手順
MEMORY_REQUESTとMEMORY_LIMITスタンザを追加するように Pod を設定します。以下のような YAML ファイルを作成します。
apiVersion: v1 kind: Pod metadata: name: test spec: securityContext: runAsNonRoot: false seccompProfile: type: RuntimeDefault containers: - name: test image: fedora:latest command: - sleep - "3600" env: - name: MEMORY_REQUEST1 valueFrom: resourceFieldRef: containerName: test resource: requests.memory - name: MEMORY_LIMIT2 valueFrom: resourceFieldRef: containerName: test resource: limits.memory resources: requests: memory: 384Mi limits: memory: 512Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]以下のコマンドを実行して Pod を作成します。
$ oc create -f <file_name>.yaml
検証
リモートシェルを使用して Pod にアクセスします。
$ oc rsh test要求された値が適用されていることを確認します。
$ env | grep MEMORY | sort出力例
MEMORY_LIMIT=536870912 MEMORY_REQUEST=402653184
メモリー制限値は、/sys/fs/cgroup/memory/memory.limit_in_bytes ファイルによってコンテナー内から読み取ることもできます。
4.4.4. OOM の強制終了ポリシーについて
Red Hat OpenShift Service on AWS は、コンテナーのすべてのプロセスのメモリー使用量の合計がメモリー制限を超えるか、またはノードのメモリーを使い切られるなどの深刻な状態が生じる場合にコンテナーのプロセスを強制終了する場合があります。
プロセスが OOM (Out of Memory) によって強制終了される場合、コンテナーがすぐに終了する場合があります。コンテナーの PID 1 プロセスが SIGKILL を受信する場合、コンテナーはすぐに終了します。それ以外の場合、コンテナーの動作は他のプロセスの動作に依存します。
たとえば、コンテナーのプロセスは、SIGKILL シグナルを受信したことを示すコード 137 で終了します。
コンテナーがすぐに終了しない場合、OOM による強制終了は以下のように検出できます。
リモートシェルを使用して Pod にアクセスします。
# oc rsh <pod name>以下のコマンドを実行して、
/sys/fs/cgroup/memory/memory.oom_controlで現在の OOM kill カウントを表示します。$ grep '^oom_kill ' /sys/fs/cgroup/memory/memory.oom_control出力例
oom_kill 0以下のコマンドを実行して、Out Of Memory (OOM) による強制終了を促します。
$ sed -e '' </dev/zero出力例
Killed以下のコマンドを実行して、
/sys/fs/cgroup/memory/memory.oom_controlの OOM kill カウンターの増分を表示します。$ grep '^oom_kill ' /sys/fs/cgroup/memory/memory.oom_control出力例
oom_kill 1Pod の 1 つ以上のプロセスが OOM で強制終了され、Pod がこれに続いて終了する場合 (即時であるかどうかは問わない)、フェーズは Failed、理由は OOMKilled になります。OOM で強制終了された Pod は
restartPolicyの値によって再起動する場合があります。再起動されない場合は、レプリケーションコントローラーなどのコントローラーが Pod の失敗したステータスを認識し、古い Pod に置き換わる新規 Pod を作成します。Pod のステータスを取得するには、次のコマンドを使用します。
$ oc get pod test出力例
NAME READY STATUS RESTARTS AGE test 0/1 OOMKilled 0 1mPod が再起動されていない場合は、以下のコマンドを実行して Pod を表示します。
$ oc get pod test -o yaml出力例
... status: containerStatuses: - name: test ready: false restartCount: 0 state: terminated: exitCode: 137 reason: OOMKilled phase: Failed再起動した場合は、以下のコマンドを実行して Pod を表示します。
$ oc get pod test -o yaml出力例
... status: containerStatuses: - name: test ready: true restartCount: 1 lastState: terminated: exitCode: 137 reason: OOMKilled state: running: phase: Running
4.4.5. Pod の退避について
Red Hat OpenShift Service on AWS は、ノードのメモリーが使い果たされると、Pod をノードから退避させることがあります。メモリー枯渇の程度に応じて、退避はグレースフルに行われる場合もあれば、そうでない場合もあります。グレースフルな退避とは、各コンテナーのメインプロセス (PID 1) が SIGTERM シグナルを受信し、それでもプロセスがまだ終了していない場合に、しばらくしてから SIGKILL シグナルを受信することを意味します。グレースフルではない退避とは、各コンテナーのメインプロセスが直ちに SIGKILL シグナルを受信することを意味します。
退避した Pod のフェーズは Failed になり、理由は Evicted になります。この場合、restartPolicy の値に関係なく再起動されません。ただし、レプリケーションコントローラーなどのコントローラーは Pod の失敗したステータスを認識し、古い Pod に置き換わる新規 Pod を作成します。
$ oc get pod test出力例
NAME READY STATUS RESTARTS AGE
test 0/1 Evicted 0 1m$ oc get pod test -o yaml出力例
...
status:
message: 'Pod The node was low on resource: [MemoryPressure].'
phase: Failed
reason: Evicted第5章 PID 制限の設定
プロセス識別子 (PID) は、システム上で現在実行されている各プロセスまたはスレッドに Linux カーネルによって割り当てられる一意の識別子です。システム上で同時に実行できるプロセスの数は、Linux カーネルによって 4,194,304 に制限されています。この数値は、メモリー、CPU、ディスク容量などの他のシステムリソースへのアクセス制限によっても影響を受ける可能性があります。
Red Hat OpenShift Service on AWS 4.11 の Pod は、デフォルトで最大 4,096 個の PID を持つことができます。ワークロードでそれ以上の数が必要な場合は、KubeletConfig オブジェクトを設定して、許可される PID の最大数を増やせます。
4.11 より前のバージョンで実行している Red Hat OpenShift Service on AWS クラスターでは、デフォルトの PID 制限である 1024 が使用されます。
5.1. プロセス ID の制限について
Red Hat OpenShift Service on AWS では、クラスターでの作業をスケジュールする前に、プロセス ID (PID) の使用に関してサポートされている次の 2 つの制限を考慮してください。
Pod あたりの PID の最大数。
Red Hat OpenShift Service on AWS 4.11 以降のデフォルト値は 4,096 です。この値はノードに設定された
podPidsLimitパラメーターによって制御されます。ノードあたりの PID の最大数。
デフォルト値は ノードリソース によって異なります。Red Hat OpenShift Service on AWS では、この値は
--system-reservedパラメーターによって制御されます。このパラメーターにより、ノードの合計リソースに基づいて各ノードの PID が予約されます。
Pod が Pod あたりの PID の最大許容数を超えると、Pod が正しく機能しなくなり、ノードから退避させられる可能性があります。詳細は、退避シグナルと閾値に関する Kubernetes ドキュメント を参照してください。
ノードあたりの PID の最大許容数を超えると、ノードが不安定になる可能性があります。これは新しいプロセスに PID を割り当てることができなくなるためです。追加のプロセスを作成せずに既存のプロセスを完了できない場合、ノード全体が使用できなくなり、リブートが必要になる可能性があります。このような状況では、実行中のプロセスやアプリケーションによっては、データ損失が発生する可能性があります。このしきい値に達すると、お客様の管理者と Red Hat Site Reliability Engineering に通知が送信されます。また、Worker node is experiencing PIDPressure という警告がクラスターログに表示されます。
5.2. Red Hat OpenShift Service on AWS の Pod のプロセス ID 制限を引き上げることのリスク
Pod の podPidsLimit パラメーターは、その Pod 内で同時に実行できるプロセスとスレッドの最大数を制御するものです。
podPidsLimit の値は、デフォルトの 4,096 から最大 16,384 まで増やすことができます。podPidsLimit を変更するには、影響を受けるノードをリブートする必要があります。そのため、この値を変更すると、アプリケーションのダウンタイムが発生する可能性があります。
各ノードで多数の Pod を実行しており、ノードの podPidsLimit 値が高い場合は、ノードの PID 最大値を超えるおそれがあります。
1 つのノードでノードの PID 最大値を超えずに同時に実行できる Pod の最大数を確認するには、3,650,000 を podPidsLimit 値で割ります。たとえば、podPidsLimit 値が 16,384 で、Pod がそれに近い数のプロセス ID を使用すると予想される場合、1 つのノードで 222 個の Pod を安全に実行できます。
podPidsLimit 値が適切に設定されている場合でも、メモリー、CPU、および利用可能なストレージによって、同時に実行できる Pod の最大数が制限される場合があります。詳細は、「環境のプランニング」と「制限およびスケーラビリティー」を参照してください。
5.3. Red Hat OpenShift Service on AWS クラスターのマシンプールでプロセス ID 制限を高く設定する
--pod-pids-limit パラメーターを変更する KubeletConfig オブジェクトを作成または編集することで、既存の Red Hat OpenShift Service on AWS クラスター内のマシンプールに対して、より高い podPidsLimit を設定できます。
既存のマシンプールの podPidsLimit を変更すると、マシンプール内のノードが 1 つずつ再起動されます。この変更はマシンプールのワークロードのピーク使用時間外に行い、すべてのノードが再起動されるまでクラスターのアップグレードや休止状態を避けてください。
前提条件
- Red Hat OpenShift Service on AWS クラスターがある。
-
ROSA コマンドラインインターフェイス (CLI) (
rosa) をインストールした。 - ROSA CLI を使用して Red Hat アカウントにログインしている。
手順
新しい
--pod-pids-limitを指定するクラスターの新しいKubeletConfigオブジェクトを作成します。$ rosa create kubeletconfig -c <cluster_name> --name=<kubeletconfig_name> --pod-pids-limit=<value>たとえば次のコマンドは、Pod あたり最大 16,384 個の PID を設定する、
my-clusterクラスターのset-high-pidsKubeletConfigオブジェクトを作成します。$ rosa create kubeletconfig -c my-cluster --name=set-high-pids --pod-pids-limit=16384新しい
KubeletConfigオブジェクトを、新規または既存のマシンプールに関連付けます。新規マシンプールの場合:
$ rosa create machinepool -c <cluster_name> --name <machinepool_name> --kubelet-configs=<kubeletconfig_name>既存マシンプールの場合:
$ rosa edit machinepool -c <cluster_name> --kubelet-configs=<kubeletconfig_name> <machinepool_name>出力例
Editing the kubelet config will cause the Nodes for your Machine Pool to be recreated. This may cause outages to your applications. Do you wish to continue? (y/N)
たとえば次のコマンドは、
set-high-pidsKubeletConfigオブジェクトをmy-clusterクラスターのhigh-pid-poolマシンプールに関連付けます。$ rosa edit machinepool -c my-cluster --kubelet-configs=set-high-pids high-pid-pool新しい
KubeletConfigオブジェクトが既存のマシンプールにアタッチされると、ワーカーノードのローリングリブートがトリガーされます。ロールアウトの進行状況は、マシンプールの説明で確認できます。$ rosa describe machinepool --cluster <cluster_name> --machinepool <machinepool_name>
検証
マシンプール内のノードに、新しい設定が適用されていることを確認します。
$ rosa describe kubeletconfig --cluster=<cluster_name> --name <kubeletconfig_name>次の例に示すように、新しい PID 制限が出力に表示されます。
出力例
Pod Pids Limit: 16384
5.4. マシンプールからカスタム設定を削除する
設定の詳細を含む KubeletConfig オブジェクトを削除することで、マシンプールのカスタム設定を削除できます。
前提条件
- 既存の Red Hat OpenShift Service on AWS クラスターがある。
- ROSA CLI (rosa) がインストール済みである。
- ROSA CLI を使用して Red Hat アカウントにログインしている。
手順
マシンプールを編集し、削除する
KubeletConfigオブジェクトが省略されるように--kubeletconfigsパラメーターを設定します。マシンプールからすべての
KubeletConfigオブジェクトを削除するには、--kubeletconfigsパラメーターに空の値を設定します。以下はその例です。$ rosa edit machinepool -c <cluster_name> --kubelet-configs="" <machinepool_name>
検証手順
削除した
KubeletConfigオブジェクトが、マシンプールの説明に表示されないことを確認します。$ rosa describe machinepool --cluster <cluster_name> --machinepool=<machinepool_name>
第6章 マルチアーキテクチャーコンピュートマシンを含むクラスターの管理
複数のアーキテクチャーを使用するノードを含むクラスターを管理するには、クラスターを監視してワークロードを管理するときに、ノードアーキテクチャーを考慮する必要があります。このため、マルチアーキテクチャークラスターでワークロードをスケジュールするときには、追加事項を考慮する必要があります。
6.1. マルチアーキテクチャーのコンピュートマシンを含むクラスターでワークロードをスケジュールする
異なるアーキテクチャーを使用するコンピュートノードを含むクラスターにワークロードをデプロイする場合は、基盤となるノードのアーキテクチャーに Pod アーキテクチャーを合わせる必要があります。ワークロードによっては、基盤となるノードのアーキテクチャーに応じて、特定のリソースに対する追加の設定が必要になる場合もあります。
Multiarch Tuning Operator を使用すると、マルチアーキテクチャーコンピュートマシンを含むクラスターで、アーキテクチャーを考慮したワークロードのスケジューリングを有効にできます。Multiarch Tuning Operator は、Pod が作成時にサポートできるアーキテクチャーに基づいて、Pod 仕様に追加のスケジューラー述語を実装します。
Multiarch Tuning Operator の詳細は、Multiarch Tuning Operator を使用してマルチアーキテクチャークラスター上のワークロードを管理する を参照してください。
6.1.1. マルチアーキテクチャーノードのワークロードデプロイメントのサンプル
アーキテクチャーに基づいて適切なノードにワークロードをスケジュールする方法は、他のノード特性に基づいてスケジュールする方法と同じです。
nodeAffinityを使用して特定のアーキテクチャーのノードをスケジュールするイメージによってサポートされるアーキテクチャーを持つ一連のノード上でのみワークロードをスケジュールできるようにすることができ、Pod のテンプレート仕様で
spec.affinity.nodeAffinityフィールドを設定できます。apiVersion: apps/v1 kind: Deployment metadata: # ... spec: # ... template: # ... spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/arch operator: In values:1 - amd64 - arm64- 1
- サポートされるアーキテクチャーを指定します。有効な値には、
amd64、arm64、または両方の値が含まれます。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.