시스템 설계 가이드
RHEL 8 시스템 설계
초록
Red Hat 문서에 관한 피드백 제공
문서 개선을 위한 의견에 감사드립니다. 어떻게 개선할 수 있는지 알려주십시오.
Jira를 통해 피드백 제출 (계정 필요)
- Jira 웹 사이트에 로그인합니다.
- 상단 탐색 모음에서 생성 을 클릭합니다.
- 요약 필드에 설명 제목을 입력합니다.
- 설명 필드에 개선을 위한 제안을 입력합니다. 문서의 관련 부분에 대한 링크를 포함합니다.
- 대화 상자 하단에서 생성 을 클릭합니다.
I 부. 설치 설계
1장. 시스템 요구 사항 및 지원되는 아키텍처
Red Hat Enterprise Linux 8은 적은 노력으로 보다 빠르게 워크로드를 제공하는 데 필요한 툴을 사용하여 하이브리드 클라우드 배포 전반에 걸쳐 안정적이고 안전하며 일관된 기반을 제공합니다. 지원되는 하이퍼바이저 및 클라우드 공급자 환경에 RHEL을 게스트로 배포할 수 있으므로 애플리케이션이 선도적인 하드웨어 아키텍처 플랫폼의 혁신을 활용할 수 있습니다.
설치하기 전에 시스템, 하드웨어, 보안, 메모리, RAID에 제공된 지침을 검토하십시오.
시스템을 가상화 호스트로 사용하려면 가상화에 필요한 하드웨어 요구 사항을 살펴보십시오.
Red Hat Enterprise Linux는 다음과 같은 아키텍처를 지원합니다.
- AMD 및 Intel 64비트 아키텍처
- 64비트 ARM 아키텍처
- IBM Power Systems, Little Endian
- 64비트 IBM Z 아키텍처
1.1. 지원되는 설치 대상
설치 대상은 Red Hat Enterprise Linux를 저장하고 시스템을 부팅하는 스토리지 장치입니다. Red Hat Enterprise Linux는 IBMZ , IBM Power, AMD64, Intel 64 및 64비트 ARM 시스템에 대해 다음과 같은 설치 대상을 지원합니다.
- DASD, SCSI, SATA 또는 SAS와 같은 표준 내부 인터페이스로 연결된 스토리지
- Intel64, AMD64 및 arm64 아키텍처의 BIOS/firmware RAID 장치
-
Intel64 및 AMD64 아키텍처의 섹터 모드의 NVDIMM 장치는
nd_pmem드라이버에서 지원합니다. - DASD(IBM Z 아키텍처만 해당) 및 다중 경로 장치를 포함한 SCSI LUN과 같은 파이버 채널 호스트 버스 어댑터를 통해 연결된 스토리지입니다. 일부에는 벤더 제공 드라이버가 필요할 수 있습니다.
- Cryostat 가상 머신의 Intel 프로세서의 Cryostat 블록 장치입니다.
- KVM 가상 머신의 Intel 프로세서의 virtio 블록 장치.
Red Hat은 USB 드라이브 또는 SD 메모리 카드에 대한 설치를 지원하지 않습니다. 타사 가상화 기술 지원에 대한 자세한 내용은 Red Hat 하드웨어 호환성 목록을 참조하십시오.
1.2. 시스템 사양
Red Hat Enterprise Linux 설치 프로그램은 시스템의 하드웨어를 자동으로 감지하고 설치하므로 특정 시스템 정보를 제공할 필요가 없습니다. 그러나 특정 Red Hat Enterprise Linux 설치 시나리오에서는 나중에 참조할 수 있도록 시스템 사양을 기록하는 것이 좋습니다. 이러한 시나리오에는 다음이 포함됩니다.
사용자 지정 파티션 레이아웃을 사용하여 RHEL 설치
레코드: 시스템에 연결된 디스크의 모델 번호, 크기, 유형 및 인터페이스입니다. 예를 들어 SATA0의 Cryostat ST3320613AS 320GB는 SATA1의 Western Digital WD7500AAKS 750GB입니다.
기존 시스템에서 RHEL을 추가 운영 체제로 설치
레코드: 시스템에서 사용되는 파티션입니다. 이 정보에는 파일 시스템 유형, 장치 노드 이름, 파일 시스템 레이블 및 크기가 포함될 수 있으며 파티션 프로세스 중에 특정 파티션을 식별할 수 있습니다. 운영 체제 중 하나가 Unix 운영 체제인 경우 Red Hat Enterprise Linux는 장치 이름을 다르게 보고할 수 있습니다. 추가 정보는 mount 명령과 blkid 명령과 /etc/fstab 파일에 해당하는 명령을 실행하여 확인할 수 있습니다.
여러 운영 체제가 설치된 경우 Red Hat Enterprise Linux 설치 프로그램은 자동으로 탐지하고 부팅하도록 부트 로더를 구성하려고 합니다. 추가 운영 체제가 자동으로 감지되지 않는 경우 수동으로 구성할 수 있습니다.
로컬 디스크의 이미지에서 RHEL 설치
레코드: 이미지를 보유한 디스크 및 디렉터리입니다.
네트워크 위치에서 RHEL 설치
네트워크를 수동으로 구성해야 하는 경우 DHCP는 사용되지 않습니다.
레코드:
- IP 주소
- 넷마스크
- 게이트웨이 IP 주소
- 필요한 경우 서버 IP 주소
네트워킹 요구 사항에 대한 지원이 필요한 경우 네트워크 관리자에게 문의하십시오.
iSCSI 대상에 RHEL 설치
레코드: iSCSI 대상의 위치입니다. 네트워크에 따라 CHAP 사용자 이름 및 암호와 역방향 CHAP 사용자 이름과 암호가 필요할 수 있습니다.
시스템이 도메인의 일부인 경우 RHEL 설치
도메인 이름이 DHCP 서버에서 제공되었는지 확인합니다. 그렇지 않은 경우 설치 중에 도메인 이름을 입력합니다.
1.3. 디스크 및 메모리 요구 사항
여러 운영 체제가 설치된 경우 할당된 디스크 공간이 Red Hat Enterprise Linux에 필요한 디스크 공간과 분리되어 있는지 확인하는 것이 중요합니다. 경우에 따라 특정 파티션을 Red Hat Enterprise Linux에 전용으로 사용하는 것이 중요합니다(예: AMD64, Intel 64 및 64비트 ARM의 경우 최소 두 개의 파티션(/ 및 스왑)은 RHEL 및 IBM Power Systems 서버의 경우 최소 3개의 파티션(/, swap, PReP 부팅 파티션)을 RHEL로 전용해야 합니다.
또한 최소 10GiB의 사용 가능한 디스크 공간이 있어야 합니다. Red Hat Enterprise Linux를 설치하려면 파티션되지 않은 디스크 공간 또는 삭제할 수 있는 파티션에 최소 10GiB의 공간이 있어야 합니다. 자세한 내용은 파티셔닝 참조를 참조하십시오.
| 설치 유형 | 최소 RAM |
|---|---|
| 로컬 미디어 설치 (USB, DVD) |
|
| NFS 네트워크 설치 |
|
| HTTP, HTTPS 또는 FTP 네트워크 설치 |
|
최소 요구 사항보다 적은 메모리로 설치를 완료할 수 있습니다. 정확한 요구 사항은 환경 및 설치 경로에 따라 다릅니다. 다양한 구성을 테스트하여 환경에 필요한 최소 RAM을 확인합니다. Kickstart 파일을 사용하여 Red Hat Enterprise Linux를 설치하면 표준 설치와 최소 RAM 요구 사항이 있습니다. 그러나 Kickstart 파일에 추가 메모리가 필요한 명령을 포함하거나 RAM 디스크에 데이터를 쓰는 경우 추가 RAM이 필요할 수 있습니다. 자세한 내용은 RHEL 자동 설치를 참조하십시오.
1.4. 그래픽 디스플레이 확인 요구 사항
시스템에 Red Hat Enterprise Linux의 원활하고 오류가 없는 설치를 보장하기 위해 다음과 같은 최소 해결 방법이 있어야 합니다.
| 제품 버전 | 해결 |
|---|---|
| Red Hat Enterprise Linux 8 | 최소: 800 x 600 권장 사항: 1026 x 768 |
1.5. UEFI Secure Boot 및 베타 릴리스 요구 사항
UEFI Secure Boot가 활성화된 시스템에 Red Hat Enterprise Linux 베타 릴리스를 설치하려면 먼저 UEFI Secure Boot 옵션을 비활성화한 다음 설치를 시작합니다.
UEFI Secure Boot를 사용하려면 시스템의 펌웨어가 해당 공개 키를 사용하여 확인하는 인식된 개인 키로 운영 체제 커널에 서명해야 합니다. Red Hat Enterprise Linux 베타 릴리스의 경우 커널은 Red Hat 베타별 공개 키로 서명되어 시스템이 기본적으로 인식되지 않습니다. 결과적으로 시스템은 설치 미디어를 부팅하지 못합니다.
2장. 설치 미디어 사용자 정의
자세한 내용은 사용자 지정 RHEL 시스템 이미지 구성을 참조하십시오.
3장. RHEL의 부팅 가능 설치 미디어 생성
고객 포털에서 ISO 파일을 다운로드하여 USB 또는 DVD와 같은 부팅 가능한 물리적 설치 미디어를 준비할 수 있습니다. RHEL 8부터 Red Hat은 더 이상 서버 및 워크스테이션에 대해 별도의 변형을 제공하지 않습니다. Red Hat Enterprise Linux for x86_64 에는 Server 및 Workstation 기능이 모두 포함되어 있습니다. Server 와 Workstation 간의 차이점은 설치 또는 구성 프로세스 중에 시스템 용도 역할을 통해 관리됩니다.
고객 포털에서 ISO 파일을 다운로드한 후 USB 또는 DVD와 같은 부팅 가능한 물리적 설치 미디어를 생성하여 설치 프로세스를 계속합니다.
USB 드라이브가 금지되는 보안 환경 케이스의 경우 이미지 빌더를 사용하여 참조 이미지를 생성하고 배포하는 것이 좋습니다. 이 방법을 사용하면 시스템 무결성을 유지하면서 보안 정책을 준수할 수 있습니다. 자세한 내용은 이미지 빌더 설명서를 참조하십시오.
기본적으로 inst.stage2= 부팅 옵션은 설치 미디어에서 사용되며 특정 레이블(예: inst.stage2=hd:LABEL=RHEL8\x86_64 )으로 설정됩니다. 런타임 이미지가 포함된 파일 시스템의 기본 레이블을 수정하거나 사용자 지정 절차를 사용하여 설치 시스템을 부팅하는 경우 라벨이 올바른 값으로 설정되어 있는지 확인합니다.
3.1. 설치 부팅 미디어 옵션
Red Hat Enterprise Linux 설치 프로그램을 시작하는 데 사용할 수 있는 몇 가지 옵션이 있습니다.
- 전체 설치 DVD 또는 USB 드라이브
- DVD ISO 이미지를 사용하여 전체 설치 DVD 또는 USB 플래시 드라이브를 만듭니다. DVD 또는 USB 플래시 드라이브를 부팅 장치로 사용하고 소프트웨어 패키지를 설치하기 위한 설치 소스로 사용할 수 있습니다.
- 최소 설치 DVD, CD 또는 USB 플래시 드라이브
- 시스템을 부팅하고 설치 프로그램을 시작하는 데 필요한 최소 파일만 포함하는 Boot ISO 이미지를 사용하여 최소 설치 CD, DVD 또는 USB 플래시 드라이브를 만듭니다. CDN(Content Delivery Network)을 사용하여 필요한 소프트웨어 패키지를 다운로드하지 않는 경우 Boot ISO 이미지에 필요한 소프트웨어 패키지가 포함된 설치 소스가 필요합니다.
- PXE 서버
- PXE(P reboot Execution Environment ) 서버를 사용하면 설치 프로그램이 네트워크를 통해 부팅할 수 있습니다. 시스템을 부팅한 후에는 로컬 디스크 또는 네트워크 위치와 같은 다른 설치 소스의 설치를 완료해야 합니다.
- 이미지 빌더
- 이미지 빌더를 사용하면 사용자 지정 시스템 및 클라우드 이미지를 생성하여 가상 및 클라우드 환경에 Red Hat Enterprise Linux를 설치할 수 있습니다.
3.2. 부팅 가능한 DVD 만들기
굽기 소프트웨어 및 DVD 버너를 사용하여 부팅 가능한 설치 DVD를 만들 수 있습니다. ISO 이미지 파일에서 DVD를 생성하는 정확한 단계는 운영 체제 및 디스크 굽기 소프트웨어에 따라 크게 달라집니다. ISO 이미지 파일에서 DVD를 구울 수있는 정확한 단계는 시스템의 소프트웨어 문서를 참조하십시오.
DVD ISO 이미지(전체 설치) 또는 부팅 ISO 이미지(최소 설치)를 사용하여 부팅 가능한 DVD를 생성할 수 있습니다. 그러나 DVD ISO 이미지는 4.7GB보다 크므로 단일 또는 듀얼 계층 DVD에 적합하지 않을 수 있습니다. 계속하기 전에 DVD ISO 이미지 파일의 크기를 확인하십시오. DVD ISO 이미지를 사용할 때 USB 플래시 드라이브를 사용하여 부팅 가능한 설치 미디어를 생성합니다. USB 드라이브가 금지되는 환경 케이스는 이미지 빌더 설명서를 참조하십시오.
3.3. Linux에서 부팅 가능한 USB 장치 생성
부팅 가능한 USB 장치를 생성한 다음 다른 시스템에 Red Hat Enterprise Linux를 설치할 수 있습니다. 이 절차에서는 경고 없이 USB 드라이브의 기존 데이터를 덮어씁니다. 모든 데이터를 백업하거나 빈 플래시 드라이브를 사용합니다. 데이터 저장에는 부팅 가능한 USB 드라이브를 사용할 수 없습니다.
사전 요구 사항
- 제품 다운로드 페이지에서 전체 설치 DVD ISO 또는 최소 설치 부팅 ISO 이미지를 다운로드 했습니다.
- ISO 이미지에 충분한 용량이 있는 USB 플래시 드라이브가 있습니다. 필요한 크기는 다르지만 권장 USB 크기는 8GB입니다.
프로세스
- USB플러그 드라이브를 시스템에 연결합니다.
터미널 창을 열고 최근 이벤트 로그를 표시합니다.
dmesg|tail
$ dmesg|tailCopy to Clipboard Copied! Toggle word wrap Toggle overflow 연결된 USB 플래시 드라이브로 인한 메시지가 로그 하단에 표시됩니다. 연결된 장치의 이름을 기록합니다.
root 사용자로 로그인합니다.
su -
$ su -Copy to Clipboard Copied! Toggle word wrap Toggle overflow 메시지가 표시되면 root 암호를 입력합니다.
드라이브에 할당된 장치 노드를 찾습니다. 이 예에서 드라이브 이름은
sdd입니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
삽입된 USB 장치가 자동으로 마운트되는 경우 다음 단계를 계속하기 전에 마운트 해제합니다. 마운트 해제하려면
umount명령을 사용합니다. 자세한 내용은 umount 를 사용하여 파일 시스템 마운트 해제를 참조하십시오. ISO 이미지를 USB 장치에 직접 씁니다.
dd if=/image_directory/image.iso of=/dev/device
# dd if=/image_directory/image.iso of=/dev/deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - /image_directory/image.iso 를 다운로드한 ISO 이미지 파일의 전체 경로로 바꿉니다.
장치를 검색한 장치 이름으로
dmesg명령으로 교체합니다.이 예에서 ISO 이미지의 전체 경로는
/home/hiera/Downloads/rhel-8-x86_64-boot.iso이고 장치 이름은sdd입니다.dd if=/home/testuser/Downloads/rhel-8-x86_64-boot.iso of=/dev/sdd
# dd if=/home/testuser/Downloads/rhel-8-x86_64-boot.iso of=/dev/sddCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파티션 이름은 일반적으로 숫자 접미사가 있는 장치 이름입니다. 예를 들어
sdd는 장치 이름이고sdd1은 장치sdd의 파티션 이름입니다.
-
dd명령이 장치에 이미지 쓰기를 마칠 때까지 기다립니다.sync명령을 실행하여 장치에 캐시된 쓰기를 동기화합니다. # 프롬프트가 표시되면 데이터 전송이 완료됩니다. 프롬프트가 표시되면 root 계정에서 로그아웃하고 USB 드라이브를 분리합니다. 이제 USB 드라이브를 부팅 장치로 사용할 준비가 되었습니다.
3.4. Windows에서 부팅 가능한 USB 장치 생성
다양한 도구를 사용하여 Windows 시스템에서 부팅 가능한 USB 장치를 생성할 수 있습니다. https://github.com/FedoraQt/MediaWriter/releases 에서 다운로드할 수 있는 Fedora Media Writer를 사용할 수 있습니다. Fedora Media Writer는 커뮤니티 제품이며 Red Hat에서 지원하지 않습니다. 이 툴의 모든 문제는 https://github.com/FedoraQt/MediaWriter/issues에서 보고할 수 있습니다.
부팅 가능한 드라이브를 생성하면 경고 없이 USB 드라이브의 기존 데이터를 덮어씁니다. 모든 데이터를 백업하거나 빈 플래시 드라이브를 사용합니다. 데이터 저장에는 부팅 가능한 USB 드라이브를 사용할 수 없습니다.
사전 요구 사항
- 제품 다운로드 페이지에서 전체 설치 DVD ISO 또는 최소 설치 부팅 ISO 이미지를 다운로드 했습니다.
- ISO 이미지에 충분한 용량이 있는 USB 플래시 드라이브가 있습니다. 필요한 크기는 다양합니다.
프로세스
- https://github.com/FedoraQt/MediaWriter/releases에서 Fedora Media Writer를 다운로드하여 설치합니다.
- USB플러그 드라이브를 시스템에 연결합니다.
- Fedora Media Writer를 엽니다.
- 메인 창에서 를 클릭하고 이전에 다운로드한 Red Hat Enterprise Linux ISO 이미지를 선택합니다.
- 사용자 지정 이미지 작성 창에서 사용할 드라이브를 선택합니다.
- 를 클릭합니다. 부팅 미디어 생성 프로세스가 시작됩니다. 작업이 완료될 때까지 드라이브를 분리하지 마십시오. 이 작업은 ISO 이미지의 크기와 USB 드라이브의 쓰기 속도에 따라 몇 분이 걸릴 수 있습니다.
- 작업이 완료되면 USB 드라이브를 마운트 해제합니다. USB 드라이브를 부팅 장치로 사용할 준비가 되었습니다.
3.5. macOS에서 부팅 가능한 USB 장치 생성
부팅 가능한 USB 장치를 생성한 다음 다른 시스템에 Red Hat Enterprise Linux를 설치할 수 있습니다. 부팅 가능한 USB 드라이브를 생성하면 경고없이 USB 드라이브에 이전에 저장된 모든 데이터를 덮어씁니다. 모든 데이터를 백업하거나 빈 플래시 드라이브를 사용합니다. 데이터 저장에는 부팅 가능한 USB 드라이브를 사용할 수 없습니다.
사전 요구 사항
- 제품 다운로드 페이지에서 전체 설치 DVD ISO 또는 최소 설치 부팅 ISO 이미지를 다운로드 했습니다.
- ISO 이미지에 충분한 용량이 있는 USB 플래시 드라이브가 있습니다. 필요한 크기는 다양합니다.
프로세스
- USB플러그 드라이브를 시스템에 연결합니다.
diskutil list명령을 사용하여 장치 경로를 식별합니다. 장치 경로의 형식은/dev/disknumber입니다. 여기서number는 디스크 수입니다. 디스크 수가 0(0)에서 시작합니다. 일반적으로disk0은 OS X 복구 디스크이며disk1은 기본 OS X 설치입니다. 다음 예에서 USB 장치는disk2입니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - NAME, TYPE 및 SIZE 열을 플래쉬 드라이브와 비교하여 USB 플래시 드라이브를 식별합니다. 예를 들어 NAME은 Finder 도구의 플래시 드라이브 아이콘 제목이어야 합니다. 이러한 값을 플래쉬 드라이브의 정보 패널에 있는 값과 비교할 수도 있습니다.
플래시 드라이브의 파일 시스템 볼륨을 마운트 해제합니다.
diskutil unmountDisk /dev/disknumber Unmount of all volumes on disknumber was successful
$ diskutil unmountDisk /dev/disknumber Unmount of all volumes on disknumber was successfulCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령이 완료되면 홈 드라이브의 아이콘이 데스크탑에서 사라집니다. 아이콘이 사라지지 않으면 잘못된 디스크를 선택했을 수 있습니다. 시스템 디스크를 실수로 마운트 해제하려고 하면 마운트 해제하지 못했습니다.
플래시 드라이브에 ISO 이미지를 작성합니다. macOS는 각 스토리지 장치에 대해 블록 (
/dev/disk*) 및 문자 장치 (/dev/rdisk*) 파일을 모두 제공합니다./dev/rdisknumber문자 장치에 이미지를 쓰는 것이/dev/disknumber블록 장치에 쓰는 것보다 빠릅니다. 예를 들어/Users/user_name/Downloads/rhel-8-x86_64-boot.iso파일을/dev/rdisk2장치에 작성하려면 다음 명령을 입력합니다.sudo dd if=/Users/user_name/Downloads/rhel-8-x86_64-boot.iso of=/dev/rdisk2 bs=512K status=progress
# sudo dd if=/Users/user_name/Downloads/rhel-8-x86_64-boot.iso of=/dev/rdisk2 bs=512K status=progressCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
if=- 설치 이미지의 경로입니다. -
of=- 대상 디스크를 나타내는 원시 디스크 장치 (/dev/rdisknumber) 입니다. -
BS=512K- 더 빠른 데이터 전송을 위해 블록 크기를 512KB로 설정합니다. -
status=progress- 작업 중 진행률 표시기를 표시합니다.
-
-
dd명령이 장치에 이미지 쓰기를 마칠 때까지 기다립니다. # 프롬프트가 표시되면 데이터 전송이 완료됩니다. 프롬프트가 표시되면 루트 계정에서 로그아웃하고 USB 드라이브를 분리합니다. USB 드라이브를 부팅 장치로 사용할 준비가 되었습니다.
4장. 설치 미디어 부팅
USB 또는 DVD를 사용하여 Red Hat Enterprise Linux 설치를 부팅할 수 있습니다.
Red Hat CDN(Content Delivery Network)을 사용하여 RHEL을 등록할 수 있습니다. CDN은 지리적으로 분산된 웹 서버 시리즈입니다. 이러한 서버는 유효한 서브스크립션을 사용하여 RHEL 호스트에 대한 패키지 및 업데이트를 제공합니다.
설치 중에 CDN에서 RHEL을 등록하고 설치하면 다음과 같은 이점이 있습니다.
- 설치 후 즉시 최신 시스템에 최신 패키지 사용
- Red Hat Insights에 연결하고 시스템 용도를 활성화하기 위한 통합 지원.
RHEL 9.6부터 DISA(DISA) 보안 기술 구현 가이드(STIG) 및 기타 보안 프로필은 최초 부팅 시 연방 정보 처리 표준(FIPS) 모드를 자동으로 활성화하지 않습니다. FIPS 호환 상태를 유지하려면 fips=1 커널 부팅 옵션을 추가하거나 FIPS를 명시적으로 활성화하는 Kickstart 구성을 사용하여 설치가 시작되기 전에 FIPS 모드를 수동으로 활성화해야 합니다. 설치 전에 FIPS를 활성화하지 않으면 이러한 보안 프로필을 사용하여 구축된 시스템이 호환되지 않을 수 있으며 사용자는 호환되지 않는 시스템을 인식하지 못할 수 있습니다. 규정 준수 문제를 방지하려면 그래픽 또는 텍스트 기반 설치 프로그램을 시작하기 전에 부팅 단계에서 FIPS가 활성화되어 있는지 확인합니다.
사전 요구 사항
- 부팅 가능한 설치 미디어( USB 또는 DVD)를 생성했습니다.
프로세스
- Red Hat Enterprise Linux를 설치하는 시스템의 전원을 끕니다.
- 시스템에서 드라이브를 분리합니다.
- 시스템의 전원을 켭니다.
- 부팅 가능한 설치 미디어(USB, DVD 또는 CD)를 삽입합니다.
- 시스템의 전원을 끄지만 부팅 미디어를 제거하지 마십시오.
- 시스템의 전원을 켭니다.
- 미디어에서 부팅하거나 미디어에서 부팅하도록 시스템의BIOS(기본 입력/출력 시스템)를 구성하려면 특정 키 또는 키 조합을 눌러야 할 수 있습니다. 자세한 내용은 시스템과 함께 제공된 설명서를 참조하십시오.
- Red Hat Enterprise Linux 부팅 창이 열리고 다양한 사용 가능한 부팅 옵션에 대한 정보가 표시됩니다.
키보드의 화살표 키를 사용하여 필요한 부팅 옵션을 선택하고 Enter 키를 눌러 부팅 옵션을 선택합니다. welcome to Red Hat Enterprise Linux 창이 열리고 그래픽 사용자 인터페이스를 사용하여 Red Hat Enterprise Linux를 설치할 수 있습니다.
60초 이내에 부팅 창에서 작업이 수행되지 않으면 설치 프로그램이 자동으로 시작됩니다.
선택 사항: 사용 가능한 부팅 옵션을 편집합니다.
- UEFI 기반 시스템: E 를 눌러 편집 모드로 전환합니다. 사전 정의된 명령줄을 변경하여 부팅 옵션을 추가하거나 제거합니다. Enter 를 눌러 선택을 확인합니다.
- BIOS 기반 시스템: 키보드에서 Tab 키를 눌러 편집 모드로 전환합니다. 사전 정의된 명령줄을 변경하여 부팅 옵션을 추가하거나 제거합니다. Enter 를 눌러 선택을 확인합니다.
5장. 선택 사항: 부팅 옵션 사용자 정의
x86_64 또는 ARM64 아키텍처에 RHEL을 설치하는 경우 부팅 옵션을 편집하여 특정 환경에 따라 설치 프로세스를 사용자 지정할 수 있습니다.
5.1. 부팅 옵션
부팅 명령줄에 공백으로 구분된 여러 옵션을 추가할 수 있습니다. 설치 프로그램과 관련된 부팅 옵션은 항상 inst 로 시작합니다. 다음은 사용 가능한 부팅 옵션입니다.
- "=" 기호"가 있는 옵션
-
=기호를 사용하는 부팅 옵션의 값을 지정해야 합니다. 예를 들어inst.vncpassword=옵션에는 값(이 예에서는 암호)이 포함되어야 합니다. 이 예제의 올바른 구문은inst.vncpassword=password입니다. - "=" 기호"가 없는 옵션
-
이 부팅 옵션은 값 또는 매개변수를 허용하지 않습니다. 예를 들어,
rd.live.check옵션은 설치를 시작하기 전에 설치 미디어를 강제로 설치 프로그램에 강제 적용합니다. 이 부팅 옵션이 있는 경우 설치 프로그램이 확인을 수행하고 부팅 옵션이 없으면 확인을 건너뜁니다.
다음과 같은 방법으로 특정 메뉴 항목에 대한 부팅 옵션을 사용자 지정할 수 있습니다.
-
BIOS 기반 시스템에서 다음을 수행합니다.
Tab키를 누른 후 명령줄에 사용자 지정 부팅 옵션을 추가합니다.Esc키를 눌러boot:프롬프트에 액세스할 수도 있지만 필수 부팅 옵션은 사전 설정되어 있지 않습니다. 이 시나리오에서는 다른 부팅 옵션을 사용하기 전에 항상 Linux 옵션을 지정해야 합니다. 자세한 내용은 BIOS에서 boot: 프롬프트 편집을참조하십시오. -
UEFI 기반 시스템에서 다음을 수행합니다.
e키를 누른 후 명령줄에 사용자 지정 부팅 옵션을 추가합니다. 준비가 되면Ctrl+X를 눌러 수정된 옵션을 부팅합니다.
자세한 내용은 UEFI 기반 시스템의 부팅 옵션편집을 참조하십시오.
5.2. BIOS에서 boot: 프롬프트 편집
boot: 프롬프트를 사용하는 경우 첫 번째 옵션은 로드할 설치 프로그램 이미지 파일을 항상 지정해야 합니다. 대부분의 경우 키워드를 사용하여 이미지를 지정할 수 있습니다. 요구 사항에 따라 추가 옵션을 지정할 수 있습니다.
사전 요구 사항
- 부팅 가능한 설치 미디어( USB, CD 또는 DVD)를 생성했습니다.
- 미디어에서 설치를 부팅했으며 설치 부팅 메뉴가 열립니다.
프로세스
- 부팅 메뉴를 열고 키보드의 Esc 키를 누릅니다.
-
이제
boot:프롬프트에 액세스할 수 있습니다. - 키보드에서 Tab 키를 눌러 도움말 명령을 표시합니다.
-
키보드에서 Enter 키를 눌러 옵션으로 설치를 시작합니다.
boot:프롬프트에서 부팅 메뉴로 돌아가려면 시스템을 재시작하고 설치 미디어에서 다시 부팅합니다.
5.3. > 프롬프트를 사용하여 사전 정의된 부팅 옵션 편집
BIOS 기반 AMD64 및 Intel 64 시스템에서는 > 프롬프트를 사용하여 사전 정의된 부팅 옵션을 편집할 수 있습니다.
사전 요구 사항
- 부팅 가능한 설치 미디어( USB, CD 또는 DVD)를 생성했습니다.
- 미디어에서 설치를 부팅했으며 설치 부팅 메뉴가 열립니다.
프로세스
-
부팅 메뉴에서 옵션을 선택하고 키보드의 Tab 키를 누릅니다. &
gt; 프롬프트에 액세스하고 사용 가능한 옵션이 표시됩니다. -
선택 사항: 전체 옵션 세트를 보려면
이 미디어 테스트 를 선택하고 RHEL 8을 설치합니다. 필요한 옵션을
>프롬프트에 추가합니다.예를 들어 연방 정보 처리 표준(FIPS) 140에서 요구하는 암호화 모듈 자체 점검을 활성화하려면
fips=1을 추가합니다.>vmlinuz initrd=initrd.img inst.stage2=hd:LABEL=RHEL-9-5-0-BaseOS-x86_64 rd.live.check quiet fips=1
>vmlinuz initrd=initrd.img inst.stage2=hd:LABEL=RHEL-9-5-0-BaseOS-x86_64 rd.live.check quiet fips=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - Enter를 눌러 설치를 시작합니다.
- Esc 를 눌러 편집을 취소하고 부팅 메뉴로 돌아갑니다.
5.5. 설치 중 드라이버 업데이트
Red Hat Enterprise Linux 설치 프로세스 중에 드라이버를 업데이트할 수 있습니다. 드라이버를 업데이트하는 것은 완전히 선택 사항입니다. 필요한 경우가 아니면 드라이버 업데이트를 수행하지 마십시오. Red Hat, 하드웨어 벤더 또는 신뢰할 수 있는 타사 벤더가 Red Hat Enterprise Linux 설치 중에 드라이버 업데이트가 필요하다는 알림을 받았습니다.
5.5.1. 개요
Red Hat Enterprise Linux는 많은 하드웨어 장치에 대한 드라이버를 지원하지만 일부 새로 릴리스된 드라이버는 지원되지 않을 수 있습니다. 드라이버 업데이트는 지원되지 않는 드라이버가 설치가 완료되지 않는 경우에만 수행해야 합니다. 일반적으로 설치 중에 드라이버를 업데이트하는 것은 특정 구성을 지원하는 데만 필요합니다. 예를 들어 시스템의 스토리지 장치에 대한 액세스를 제공하는 스토리지 어댑터 카드용 드라이버를 설치합니다.
드라이버 업데이트 디스크에서 충돌하는 커널 드라이버를 비활성화할 수 있습니다. 드문 경우지만 커널 모듈을 언로드하면 설치 오류가 발생할 수 있습니다.
5.5.2. 드라이버 업데이트 유형
Red Hat, 하드웨어 벤더 또는 신뢰할 수 있는 타사는 드라이버 업데이트를 ISO 이미지 파일로 제공합니다. ISO 이미지 파일이 표시되면 드라이버 업데이트 유형을 선택합니다.
드라이버 업데이트 유형
- 자동
-
이 드라이버 업데이트 방법에서
OEMDRV레이블이 지정된 스토리지 장치(CD, DVD 또는 USB 플래시 드라이브 포함)가 시스템에 물리적으로 연결되어 있습니다. 설치가 시작될 때OEMDRV스토리지 장치가 있는 경우 드라이버 업데이트 디스크로 처리되고 설치 프로그램이 해당 드라이버를 자동으로 로드합니다. - 지원됨
-
설치 프로그램에서 드라이버 업데이트를 찾도록 요청합니다.
OEMDRV이외의 레이블과 함께 로컬 스토리지 장치를 사용할 수 있습니다. 설치를 시작할 때inst.dd부팅 옵션이 지정됩니다. 매개 변수 없이 이 옵션을 사용하는 경우 설치 프로그램은 시스템에 연결된 모든 스토리지 장치를 표시하고 드라이버 업데이트가 포함된 장치를 선택하라는 메시지를 표시합니다. - 수동
-
드라이버 업데이트 이미지 또는 RPM 패키지의 경로를 수동으로 지정합니다.
OEMDRV이외의 레이블과 함께 로컬 스토리지 장치 또는 설치 시스템에서 액세스할 수 있는 네트워크 위치를 사용할 수 있습니다.inst.dd=location부팅 옵션은 설치를 시작할 때 지정됩니다. 여기서 location 은 드라이버 업데이트 디스크 또는 ISO 이미지의 경로입니다. 이 옵션을 지정하면 설치 프로그램에서 지정된 위치에 있는 드라이버 업데이트를 로드하려고 합니다. 수동 드라이버 업데이트를 사용하면 로컬 스토리지 장치 또는 네트워크 위치(HTTP, HTTPS 또는 FTP 서버)를 지정할 수 있습니다.inst.dd=location및inst.dd둘 다 동시에 사용할 수 있습니다. 여기서 location은 드라이버 업데이트 디스크 또는 ISO 이미지의 경로입니다. 이 시나리오에서 설치 프로그램은 위치에서 사용 가능한 드라이버 업데이트를 로드하고 드라이버 업데이트가 포함된 장치를 선택하라는 메시지를 표시합니다.
네트워크 위치에서 드라이버 업데이트를 로드할 때 ip= option을 사용하여 네트워크를 초기화합니다.
제한 사항
Secure Boot 기술이 활성화된 UEFI 시스템에서 모든 드라이버에 유효한 인증서로 서명해야 합니다. Red Hat 드라이버는 Red Hat의 개인 키 중 하나에서 서명하고 커널의 해당 공개 키로 인증합니다. 추가 드라이버를 로드하는 경우 해당 드라이버가 서명되었는지 확인합니다.
5.5.3. 드라이버 업데이트 준비
이 절차에서는 CD 및 DVD에서 드라이버 업데이트를 준비하는 방법을 설명합니다.
사전 요구 사항
- Red Hat, 하드웨어 벤더 또는 신뢰할 수 있는 타사 벤더의 드라이버 업데이트 ISO 이미지를 받았습니다.
- 드라이버 업데이트 ISO 이미지를 CD 또는 DVD로 구웠습니다.
.iso로 끝나는 단일 ISO 이미지 파일만 CD 또는 DVD에서 사용할 수 있는 경우, 굽기 프로세스가 성공하지 못했습니다. ISO 이미지를 CD 또는 DVD에 구울 수있는 방법에 대한 지침은 시스템의 소프트웨어 문서를 참조하십시오.
프로세스
- 드라이버 업데이트 CD 또는 DVD를 시스템의 CD/DVD 드라이브에 삽입하고 시스템의 파일 관리자 툴을 사용하여 찾습니다.
-
단일 파일
rhdd3을 사용할 수 있는지 확인합니다.rhdd3은 드라이버 설명과 다양한 아키텍처의 실제 드라이버가 포함된rpms라는 디렉터리가 포함된 서명 파일입니다.
5.5.4. 자동 드라이버 업데이트 수행
다음 절차에서는 설치 중에 자동 드라이버 업데이트를 수행하는 방법을 설명합니다.
사전 요구 사항
-
OEMDRV라벨을 사용하여 표준 디스크 파티션에 드라이버 업데이트 이미지를 배치하거나OEMDRV드라이버를 CD 또는 DVD로 업데이트했습니다. 드라이버 업데이트 프로세스 중에 RAID 또는 LVM 볼륨과 같은 고급 스토리지에 액세스할 수 없습니다. -
OEMDRV볼륨 레이블과 블록 장치를 시스템에 연결하거나 설치 프로세스를 시작하기 전에 준비된 CD 또는 DVD를 시스템의 CD/DVD 드라이브에 삽입했습니다.
프로세스
- 사전 요구 사항 단계를 완료하면 설치 프로그램이 시작될 때 드라이버가 자동으로 로드되고 시스템 설치 프로세스 중에 설치됩니다.
5.5.5. 지원되는 드라이버 업데이트 수행
다음 절차에서는 설치 중에 지원 드라이버 업데이트를 수행하는 방법을 설명합니다.
사전 요구 사항
-
OEMDRV볼륨 레이블이 없는 블록 장치를 시스템에 연결하고 드라이버 디스크 이미지를 이 장치에 복사하거나 드라이버 업데이트 CD 또는 DVD를 준비하여 설치 프로세스를 시작하기 전에 시스템의 CD 또는 DVD 드라이브에 삽입했습니다.
ISO 이미지 파일을 CD 또는 DVD에 구울 수 있지만 OEMDRV 볼륨 레이블이 없는 경우 인수 없이 inst.dd 옵션을 사용할 수 있습니다. 설치 프로그램은 CD 또는 DVD에서 드라이버를 스캔하고 선택할 수 있는 옵션을 제공합니다. 이 시나리오에서는 설치 프로그램에서 드라이버 업데이트 ISO 이미지를 선택하라는 메시지가 표시되지 않습니다. 또 다른 시나리오는 inst.dd=location 부팅 옵션과 함께 CD 또는 DVD를 사용하는 것입니다. 이렇게 하면 설치 프로그램에서 CD 또는 DVD에서 드라이버 업데이트를 자동으로 스캔할 수 있습니다. 자세한 내용은 수동 드라이버 업데이트 수행을 참조하십시오.
프로세스
- 부팅 메뉴 창의 키보드에서 Tab 키를 눌러 부팅 명령줄을 표시합니다.
-
inst.dd부팅 옵션을 명령줄에 추가하고 Enter 키를 눌러 부팅 프로세스를 실행합니다. - 메뉴에서 로컬 디스크 파티션 또는 CD 또는 DVD 장치를 선택합니다. 설치 프로그램은 ISO 파일 또는 드라이버 업데이트 RPM 패키지를 스캔합니다.
선택 사항: 드라이버 업데이트 ISO 파일을 선택합니다.
이 단계는 선택한 장치 또는 파티션에 ISO 이미지 파일이 아닌 드라이버 업데이트 RPM 패키지가 포함된 경우(예: 드라이버 업데이트 CD 또는 DVD가 포함된 광 드라이브)가 필요하지 않습니다.
필요한 드라이버를 선택합니다.
- 키보드의 숫자 키를 사용하여 드라이버 선택을 전환합니다.
- c를 눌러 선택한 드라이버를 설치합니다. 선택한 드라이버가 로드되고 설치 프로세스가 시작됩니다.
5.5.6. 수동 드라이버 업데이트 수행
다음 절차에서는 설치 중에 수동 드라이버 업데이트를 수행하는 방법을 설명합니다.
사전 요구 사항
- 드라이버 업데이트 ISO 이미지 파일을 USB 플래시 드라이브 또는 웹 서버에 배치하고 컴퓨터에 연결했습니다.
프로세스
- 부팅 메뉴 창의 키보드에서 Tab 키를 눌러 부팅 명령줄을 표시합니다.
-
inst.dd=location부트 옵션을 명령줄에 추가합니다. 여기서 location은 드라이버 업데이트의 경로입니다. 일반적으로 이미지 파일은 웹 서버(예: http://server.example.com/dd.iso) 또는 USB 플래시 드라이브(예:/dev/sdb1)에 있습니다. 드라이버 업데이트가 포함된 RPM 패키지를 지정할 수도 있습니다(예: http://server.example.com/dd.rpm). - Enter를 눌러 부팅 프로세스를 실행합니다. 지정된 위치에서 사용할 수 있는 드라이버가 자동으로 로드되고 설치 프로세스가 시작됩니다.
5.5.7. 드라이버 비활성화
다음 절차에서는 오작동 드라이버를 비활성화하는 방법을 설명합니다.
사전 요구 사항
- 설치 프로그램 부팅 메뉴를 부팅했습니다.
프로세스
- 부팅 메뉴에서 키보드의 Tab 키를 눌러 부팅 명령줄을 표시합니다.
modprobe.blacklist=driver_name부팅 옵션을 명령줄에 추가합니다.driver_name을 비활성화하려는 드라이버 또는 드라이버 이름으로 교체합니다. 예를 들면 다음과 같습니다.
modprobe.blacklist=ahci
modprobe.blacklist=ahciCopy to Clipboard Copied! Toggle word wrap Toggle overflow modprobe.blacklist=boot 옵션을 사용하여 비활성화된 드라이버는 설치된 시스템에서 비활성화된 상태로 남아 있으며/etc/modprobe.d/anaconda-blacklist.conf파일에 나타납니다.- Enter를 눌러 부팅 프로세스를 실행합니다.
6장. 설치 프로그램에서 시스템 사용자 정의
설치의 사용자 지정 단계에서 Red Hat Enterprise Linux를 설치할 수 있도록 특정 구성 작업을 수행해야 합니다. 다음과 같은 가상화 작업이 지원됩니다.
- 스토리지를 구성하고 마운트 지점을 할당합니다.
- 소프트웨어를 설치할 기본 환경 선택.
- root 사용자의 암호 설정 또는 로컬 사용자 생성.
선택적으로 시스템 설정을 구성하고 호스트를 네트워크에 연결하여 시스템을 추가로 사용자 지정할 수 있습니다.
6.1. 설치 프로그램 언어 설정
설치를 시작하기 전에 설치 프로그램에서 사용할 언어를 선택할 수 있습니다.
사전 요구 사항
- 설치 미디어가 생성되어 있습니다.
- 부팅 ISO 이미지 파일을 사용하는 경우 설치 소스를 지정했습니다.
- 설치를 부팅했습니다.
프로세스
- 부팅 메뉴에서 Install Red hat Enterprise Linux 옵션을 선택하면 welcome to Red Hat Enterprise Screen 이 표시됩니다.
welcome to Red Hat Enterprise Linux 창 왼쪽 창에서 언어를 선택합니다. 또는 텍스트 상자를 사용하여 선호하는 언어를 검색합니다.
참고언어는 기본적으로 사전 선택됩니다. 네트워크 액세스가 구성된 경우 즉, 로컬 미디어 대신 네트워크 서버에서 부팅한 경우 사전 선택된 언어는 GeoIP 모듈의 자동 위치 탐지 기능에 따라 결정됩니다. 부팅 명령줄 또는 PXE 서버 구성에서
inst.lang=옵션을 사용하는 경우 부팅 옵션으로 정의한 언어가 선택됩니다.- welcome to Red Hat Enterprise Linux 창 오른쪽 창에서 해당 리전과 관련된 위치를 선택합니다.
- 를 클릭하여 그래픽 설치 창을 진행합니다.
Red Hat Enterprise Linux의 시험판 버전을 설치하는 경우 설치 미디어의 시험판 상태에 대한 경고 메시지가 표시됩니다.
- 설치를 계속하려면 계속 , 또는
- 설치를 종료하고 시스템을 재부팅하려면 the installation을 클릭합니다.
6.2. 스토리지 장치 구성
다양한 스토리지 장치에 Red Hat Enterprise Linux를 설치할 수 있습니다. 설치 대상 창에서 로컬로 액세스할 수 있는 기본 스토리지 장치를 구성할 수 있습니다. 디스크 및 솔리드 스테이트 드라이브와 같은 로컬 시스템에 직접 연결된 기본 스토리지 장치는 창의 로컬 표준 디스크 섹션에 표시됩니다. 64비트 IBM Z에서 이 섹션에는 활성화된 DASD(직접 액세스 스토리지 장치)가 포함되어 있습니다.
알려진 문제로 인해 설치가 완료된 후 HyperPAV 별칭으로 구성된 DASD가 자동으로 시스템에 연결되지 않습니다. 이러한 스토리지 장치는 설치 중에 사용할 수 있지만 설치를 완료하고 재부팅한 후에는 즉시 액세스할 수 없습니다. HyperPAV 별칭 장치를 연결하려면 시스템의 /etc/dasd.conf 구성 파일에 수동으로 추가합니다.
6.2.1. 설치 대상 구성
Installation Destination 창을 사용하여 스토리지 옵션(예: Red Hat Enterprise Linux 설치의 설치 대상으로 사용할 디스크)을 구성할 수 있습니다. 디스크를 하나 이상 선택해야 합니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
- 이미 데이터가 포함된 디스크를 사용하려는 경우 데이터를 백업해야 합니다. 예를 들어 기존 Microsoft Windows 파티션을 축소하고 Red Hat Enterprise Linux를 두 번째 시스템으로 설치하거나 이전 Red Hat Enterprise Linux 릴리스를 업그레이드하는 경우. 파티션을 조작하는 것은 항상 위험이 있습니다. 예를 들어 디스크의 어떤 이유로든 프로세스가 중단되거나 실패하는 경우 해당 프로세스가 손실될 수 있습니다.
프로세스
Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창에서 다음 작업을 수행합니다.
로컬 표준 디스크 섹션에서 필요한 스토리지 장치를 선택합니다. 흰색 확인 표시는 선택을 나타냅니다. 설치 프로세스 중에 흰색 확인 표시가 없는 디스크는 사용되지 않습니다. 자동 파티션을 선택하면 무시되며 수동 파티션에서 사용할 수 없습니다.
로컬 표준 디스크 는 SATA, IDE 및 SCSI 디스크, USB 플래시 및 외부 디스크와 같이 로컬에서 사용 가능한 모든 스토리지 장치를 표시합니다. 설치 프로그램이 시작된 후 연결된 스토리지 장치가 감지되지 않습니다. 이동식 드라이브를 사용하여 Red Hat Enterprise Linux를 설치하는 경우 장치를 제거하면 시스템을 사용할 수 없습니다.
선택 사항: 새 디스크를 연결하도록 추가 로컬 스토리지 장치를 구성하려면 창의 오른쪽 아래에 있는 새로 고침 링크를 클릭합니다. Rescan Disks 대화 상자가 열립니다.
를 클릭하고 스캔 프로세스가 완료될 때까지 기다립니다.
설치 중에 수행한 모든 스토리지 변경 사항은 Rescan Disks 를 클릭하면 손실됩니다.
- 클릭하여 설치 대상 창으로 돌아갑니다. 새 디스크를 포함하여 감지된 모든 디스크가 로컬 표준 디스크 섹션에 표시됩니다.
선택 사항: 클릭하여 특수 스토리지 장치를 추가합니다.
스토리지 장치 선택 창이 열리고 설치 프로그램에서 액세스할 수 있는 모든 스토리지 장치가 나열됩니다.
선택 사항: 스토리지 구성에서 자동 파티셔닝을 위한 자동 라디오 버튼을 선택합니다.
사용자 지정 파티셔닝을 구성할 수도 있습니다. 자세한 내용은 수동 파티션 구성을 참조하십시오.
- 선택 사항: 기존 파티션 레이아웃에서 공간을 회수하기 위해 추가 공간을 확보하려면 I would like to make additional space available to reclaim space from an existing partitioning layout을 선택합니다. 예를 들어 사용하려는 디스크에 이미 다른 운영 체제가 있고 이 시스템의 파티션을 줄여 Red Hat Enterprise Linux에 더 많은 공간을 허용하려는 경우입니다.
선택 사항: LUKS( Linux Unified Key Setup )를 사용하여 시스템을 부팅하는 데 필요한 파티션(예:
/boot)을 제외한 모든 파티션을 암호화하려면 데이터 암호화를 선택합니다. 디스크를 암호화하여 추가 보안 계층을 추가합니다.을 클릭합니다. 디스크 암호화 암호 대화 상자가 열립니다.
- 암호를 암호 및 확인 필드에 입력합니다.
를 클릭하여 디스크 암호화를 완료합니다.
주의LUKS 암호를 분실하는 경우 암호화된 파티션과 해당 데이터에 완전히 액세스할 수 없습니다. 분실된 암호를 복구할 방법은 없습니다. 그러나 Kickstart 설치를 수행하는 경우 암호화 암호를 저장하고 설치 중에 백업 암호화 암호를 생성할 수 있습니다. 자세한 내용은 RHEL 자동 설치 문서를 참조하십시오.
선택 사항: 창의 왼쪽 아래에 있는 전체 디스크 요약 및 부트로더 링크를 클릭하여 부트 로더가 포함된 스토리지 장치를 선택합니다. 자세한 내용은 부트 로더 구성을 참조하십시오.
대부분의 경우 부트 로더를 기본 위치에 두면 충분합니다. 예를 들어 다른 부트 로더에서 체인 로드가 필요한 일부 구성에서는 부팅 드라이브를 수동으로 지정해야 합니다.
- 을 클릭합니다.
선택 사항: 자동 파티셔닝 을 선택하고 추가 공간을 제공하려는 경우 또는 Red Hat Enterprise Linux를 설치하기 위해 선택한 디스크에 여유 공간이 충분하지 않은 경우 Reclaim Disk Space (디스크 공간 회수) 대화 상자가 표시됩니다. 구성된 모든 디스크 장치 및 해당 장치의 모든 파티션을 나열합니다. 대화 상자에는 현재 선택한 패키지 세트와 회수된 공간이 있는 설치에 필요한 최소 디스크 공간에 대한 정보가 표시됩니다. 회수 프로세스를 시작하려면 다음을 수행합니다.
- 사용 가능한 스토리지 장치의 표시된 목록을 검토합니다. Reclaimable Space 열에는 각 항목에서 회수할 수 있는 공간이 표시됩니다.
- 공간을 회수할 디스크 또는 파티션을 선택합니다.
- 버튼을 사용하여 기존 데이터를 유지하면서 파티션에서 사용 가능한 공간을 사용합니다.
- 버튼을 사용하여 기존 데이터를 포함하여 선택한 디스크의 파티션 또는 모든 파티션을 삭제합니다.
- 버튼을 사용하여 기존 데이터를 포함한 모든 디스크의 기존 파티션을 모두 삭제하고 Red Hat Enterprise Linux를 설치하는 데 이 공간을 사용할 수 있도록 합니다.
를 클릭하여 변경 사항을 적용하고 그래픽 설치로 돌아갑니다.
설치 요약 창에서 시작을 클릭할 때까지 디스크 변경이 수행되지 않습니다. 공간 회수 대화 상자는 크기 조정 또는 삭제를 위한 파티션만 표시합니다. 작업이 수행되지 않습니다.
6.2.2. 설치 대상 구성 중 특수 사례
다음은 설치 대상을 구성할 때 고려해야 할 몇 가지 특수한 사례입니다.
-
일부 BIOS 유형은 RAID 카드 부팅을 지원하지 않습니다. 이러한 경우
/boot파티션을 별도의 디스크와 같이 RAID 배열 외부의 파티션에 만들어야 합니다. RAID 카드가 문제가 있는 파티션 생성을 위해 내부 디스크를 사용해야 합니다. 소프트웨어 RAID 설정에도/boot파티션이 필요합니다. 시스템을 자동으로 파티션하도록 선택하는 경우/boot파티션을 수동으로 편집해야 합니다. - 다른 부트 로더의 부하를 체인 하도록 Red Hat Enterprise Linux 부트 로더를 구성하려면 Installation Destination 창에서 전체 디스크 요약 및 부트로더 링크를 클릭하여 수동으로 부팅 드라이브를 지정해야 합니다.
- 다중 경로 및 비 다중 경로 스토리지 장치가 모두 있는 시스템에 Red Hat Enterprise Linux를 설치하면 설치 프로그램의 자동 파티션 레이아웃은 다중 경로 및 비 멀티패스 장치가 포함된 볼륨 그룹을 생성합니다. 이로 인해 다중 경로 스토리지의 목적을 지웁니다. Installation Destination 창에서 multipath 또는 non-multipath 장치를 선택합니다. 또는 수동 파티셔닝을 진행합니다.
6.2.3. 부트 로더 구성
Red Hat Enterprise Linux는 AMD64 및 Intel 64, IBM Power Systems 및 ARM의 부트 로더로 GRand Unified Bootloader 버전 2(GRUB2)를 사용합니다. 64비트 IBM Z의 경우 zipl 부트 로더가 사용됩니다.
부트 로더는 시스템이 시작될 때 실행되고 컨트롤을 운영 체제로 로드 및 전송하는 역할을 하는 첫 번째 프로그램입니다. GRUB2 는 호환 가능한 운영 체제(Microsoft Windows 포함)를 부팅할 수 있으며 체인 로드를 사용하여 지원되지 않는 운영 체제의 다른 부트 로더로 제어를 전송할 수도 있습니다.
GRUB2 를 설치하면 기존 부트 로더를 덮어쓸 수 있습니다.
운영 체제가 이미 설치된 경우 Red Hat Enterprise Linux 설치 프로그램은 다른 운영 체제를 시작하도록 부트 로더를 자동으로 감지하고 구성하려고 합니다. 부트 로더가 탐지되지 않으면 설치를 완료한 후 추가 운영 체제를 수동으로 구성할 수 있습니다.
두 개 이상의 디스크가 있는 Red Hat Enterprise Linux 시스템을 설치하는 경우 부트 로더를 설치하려는 디스크를 수동으로 지정할 수 있습니다.
절차
Installation Destination 창에서 전체 디스크 요약 및 부트로더 링크를 클릭합니다. 선택한 디스크 대화 상자가 열립니다.
부트 로더는 선택한 장치 또는 UEFI 시스템에 설치됩니다. EFI 시스템 파티션이 안내된 파티션 중에 대상 장치에 생성됩니다.
- 부팅 장치를 변경하려면 목록에서 장치를 선택하고 를 클릭합니다. 하나의 장치만 부팅 장치로 설정할 수 있습니다.
- 새 부트 로더 설치를 비활성화하려면 현재 부팅용으로 표시된 장치를 선택하고 를 클릭합니다. 이렇게 하면 GRUB2 가 어떤 장치에도 설치되지 않습니다.
부트 로더를 설치하지 않도록 선택하는 경우 시스템을 직접 부팅할 수 없으며 독립 실행형 상용 부트 로더 애플리케이션과 같은 다른 부팅 방법을 사용해야 합니다. 시스템을 부팅하는 다른 방법이 있는 경우에만 이 옵션을 사용합니다.
또한 부트 로더는 시스템이 BIOS 또는 UEFI 펌웨어를 사용하는지 또는 부팅 드라이브에 GUID 파티션 테이블 (GPT) 또는 마스터 부팅 레코드 (MBR) 레이블이 있는지에 따라 특수 파티션을 생성해야 할 수도 있습니다. 자동 파티션을 사용하는 경우 설치 프로그램이 파티션을 생성합니다.
6.2.4. 스토리지 장치 선택
스토리지 장치 선택 창에는 설치 프로그램이 액세스할 수 있는 모든 스토리지 장치가 나열됩니다. 시스템 및 사용 가능한 하드웨어에 따라 일부 탭이 표시되지 않을 수 있습니다. 장치는 다음 탭 아래에 그룹화됩니다.
- 다중 경로 장치
- 동일한 시스템의 여러 SCSI 컨트롤러 또는 파이버 채널 포트를 통해 두 개 이상의 경로를 통해 액세스할 수 있는 스토리지 장치입니다. 설치 프로그램은 일련 번호가 16 또는 32자인 다중 경로 스토리지 장치만 감지합니다.
- 기타 SAN 장치
- SAN(Storage Area Network)에서 사용 가능한 장치.
- 펌웨어 RAID
- 펌웨어 RAID 컨트롤러에 연결된 스토리지 장치입니다.
- NVDIMM 장치
- 특정 상황에서 Red Hat Enterprise Linux 8은 Intel 64 및 AMD64 아키텍처의 섹터 모드에서 (NVDIMM) 장치에서 부팅 및 실행할 수 있습니다.
- IBM Z 장치
- 스토리지 장치 또는 논리 단위(LUN)는 zSeries Linux FCP(Fiber Channel Protocol) 드라이버를 통해 연결된 DASD입니다.
6.2.5. 스토리지 장치 필터링
스토리지 장치 선택 창에서 WWID(World Wide Identifier) 또는 포트, 대상 또는 LUN(Logical Unit Number)을 통해 스토리지 장치를 필터링할 수 있습니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
절차
- Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창이 열리고 사용 가능한 모든 드라이브가 나열됩니다.
- Specialized & Network Disks 섹션에서 클릭합니다. 스토리지 장치 선택 창이 열립니다.
포트, 대상, LUN 또는 WWID로 검색하려면 검색 기준 탭을 클릭합니다.
WWID 또는 LUN으로 검색하려면 해당 입력 텍스트 필드에 추가 값이 필요합니다.
- 검색 드롭다운 메뉴에서 필요한 옵션을 선택합니다.
- 클릭하여 검색을 시작합니다. 각 장치는 해당 확인란이 있는 별도의 행에 표시됩니다.
설치 프로세스 중에 필요한 장치를 활성화하려면 확인란을 선택합니다.
나중에 설치 과정에서 선택한 장치에 Red Hat Enterprise Linux를 설치하도록 선택할 수 있으며, 설치된 시스템의 일부로 선택한 다른 장치를 자동으로 마운트하도록 선택할 수 있습니다. 선택한 장치는 설치 프로세스에서 자동으로 삭제되지 않으며 장치를 선택하면 장치에 저장된 데이터가 위험하지 않습니다.
참고/etc/fstab파일을 수정하여 설치 후 시스템에 장치를 추가할 수 있습니다.- 을 클릭하여 Installation Destination 창으로 돌아갑니다.
선택하지 않은 스토리지 장치는 설치 프로그램에서 완전히 숨겨집니다. 체인이 다른 부트 로더에서 부트 로더를 로드하려면 존재하는 모든 장치를 선택합니다.
6.2.6. 고급 스토리지 옵션 사용
고급 스토리지 장치를 사용하려면 iSCSI(TCP/IP를 통한 iSCSI) 대상 또는 FCoE(Fibre Channel over Ethernet) SAN(Storage Area Network)을 구성할 수 있습니다.
설치에 iSCSI 스토리지 장치를 사용하려면 설치 프로그램에서 iSCSI 대상으로 검색하고 iSCSI 세션을 생성하여 액세스할 수 있어야 합니다. 이러한 각 단계에는 CHP(Chalge Handshake Authentication Protocol) 인증을 위한 사용자 이름과 암호가 필요할 수 있습니다. 또한 검색 및 세션에 대해 대상이 연결된 시스템에서 iSCSI 이니시에이터를 인증하도록 iSCSI 대상을 구성할 수 있습니다. 함께 사용되는 CHAP 및 역방향 CHAP는 상호 CHAP 또는 양방향 CHAP라고 합니다. 상호 CHAP는 특히 사용자 이름과 암호가 CHAP 인증 및 역방향 CHAP 인증에 대해 다른 경우 iSCSI 연결에 가장 큰 수준의 보안을 제공합니다.
iSCSI 검색 및 iSCSI 로그인 단계를 반복하여 필요한 모든 iSCSI 스토리지를 추가합니다. 처음으로 검색을 시도한 후에는 iSCSI 이니시에이터의 이름을 변경할 수 없습니다. iSCSI 이니시에이터 이름을 변경하려면 설치를 다시 시작해야 합니다.
6.2.6.1. iSCSI 세션 검색 및 시작
Red Hat Enterprise Linux 설치 프로그램은 다음 두 가지 방법으로 iSCSI 디스크를 검색하고 로그인할 수 있습니다.
- iSCSI 부팅 펌웨어 테이블(iBFT)
-
설치 프로그램이 시작되면 시스템의 BIOS 또는 애드온 부팅 1)이 iBFT를 지원하는지 확인합니다. iSCSI에서 부팅할 수 있는 시스템용 BIOS 확장입니다. BIOS가 iBFT를 지원하는 경우 설치 프로그램은 BIOS에서 구성된 부팅 디스크에 대한 iSCSI 대상 정보를 읽고 이 대상에 로그인하여 설치 대상으로 사용할 수 있도록 합니다. iSCSI 대상에 자동으로 연결하려면 대상에 액세스하기 위해 네트워크 장치를 활성화합니다. 이렇게 하려면
ip=ibft부팅 옵션을 사용합니다. 자세한 내용은 네트워크 부팅 옵션을 참조하십시오. - iSCSI 대상 검색 및 수동 추가
- iSCSI 세션을 검색하고 시작하여 설치 프로그램의 그래픽 사용자 인터페이스에서 사용 가능한 iSCSI 대상(네트워크 스토리지 장치)을 확인할 수 있습니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
절차
- Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창이 열리고 사용 가능한 모든 드라이브가 나열됩니다.
- Specialized & Network Disks 섹션에서 클릭합니다. 스토리지 장치 선택 창이 열립니다.
클릭합니다. iSCSI 스토리지 대상 추가 창이 열립니다.
중요이 방법을 사용하여 수동으로 추가한 iSCSI 대상에
/boot파티션을 배치할 수 없습니다. iBFT와 함께 사용하도록/boot파티션이 포함된 iSCSI 대상을 구성해야 합니다. 그러나 설치된 시스템이 펌웨어 iBFT 이외의 방법으로 제공되는 iBFT 구성으로 iSCSI에서 부팅해야 하는 경우 예를 들어 iPXE를 사용하는 경우inst.nonibftiscsiboot설치 프로그램 부팅 옵션을 사용하여/boot파티션 제한을 제거할 수 있습니다.- 대상 IP 주소 필드에 iSCSI 대상의 IP 주소를 입력합니다.
iSCSI 정규화된 이름 (IQN) 형식의 iSCSI 이니시에이터의 iSCSI 초기자 이름 필드에 이름을 입력합니다. 유효한 IQN 항목에는 다음 정보가 포함됩니다.
-
문자열
iqn(시간 참조). -
조직의 인터넷 도메인 또는 하위 도메인 이름이 등록된 연도 및 월을 지정하는 날짜 코드는 연도, 대시, 한 달의 4 자리 숫자와 마침표로 표시됩니다. 예를 들어 2010년 9월은
2010-09로 표시됩니다. -
조직의 인터넷 도메인 또는 하위 도메인 이름이 먼저 최상위 도메인과 역순으로 표시됩니다. 예를 들어, 하위 도메인
storage.example.com을com.example.storage로 나타냅니다. 콜론 뒤에는 도메인 또는 하위 도메인 내에서 이 특정 iSCSI 이니시에이터를 고유하게 식별하는 문자열이 옵니다. 예:
:diskarrays-sn-a8675309.완전한 IQN은
iqn.2010-09.storage.example.com:diskarrays-sn-a8675309. 설치 프로그램은iSCSI Initiator Name필드를 이 형식의 이름으로 미리 채워 구조를 지원합니다. IQN에 대한 자세한 내용은 tools.ietf .org 및 1에서 제공되는 RFC 3720 - iSCSI(Internet Small Computer Systems Interface) 의 3.2.6. iSCSI 이름을 참조하십시오. tools.ietf.org에서 사용할 수 있는 RFC 3721 - iSCSI(Internet Small Computer Systems Interface) 이름 지정 및 검색에서 사용할 수 있습니다.
-
문자열
Discovery Authentication Type드롭다운 메뉴를 선택하여 iSCSI 검색에 사용할 인증 유형을 지정합니다. 다음 옵션을 사용할 수 있습니다.- 인증 정보 없음
- CHAP 쌍
- CHAP 쌍 및 역방향 쌍
다음 중 하나를 수행합니다.
-
CHAP 쌍을인증 유형으로 선택한 경우 CHAP 사용자 이름 및CHAP 암호필드에 iSCSI 대상의 사용자 이름 -
CHAP 쌍과 역방향 쌍을인증 유형으로 선택한 경우 CHAP 사용자 이름 및 CHAP 암호 필드에 iSCSI 대상의 사용자 이름과 암호를 입력하고 ReverseCHAPUsernameReverseAP이름과 암호를 입력합니다.Password필드에 iSCSI 이니시에이터의 사용자
-
-
선택 사항:
Bind targets to network interfaces확인란을 선택합니다. 클릭합니다.
설치 프로그램은 제공된 정보를 기반으로 iSCSI 대상을 검색하려고 합니다. 검색에 성공하면
iSCSI 스토리지 대상 추가 창에 대상에서 검색된 모든 iSCSI 노드 목록이 표시됩니다.설치에 사용할 노드의 확인란을 선택합니다.
Node login authentication type메뉴에는Discovery Authentication Type메뉴와 동일한 옵션이 포함되어 있습니다. 그러나 검색 인증에 대한 인증 정보가 필요한 경우 동일한 인증 정보를 사용하여 검색된 노드에 로그인합니다.-
검색 드롭다운 메뉴에서 추가
Use the credentials from discovery를 클릭합니다. 적절한 인증 정보를 제공하면 버튼을 사용할 수 있게 됩니다. - 을 클릭하여 iSCSI 세션을 시작합니다.
설치 프로그램은 iscsiadm 을 사용하여 iSCSI 대상을 찾아 로그인하는 반면 iscsiadm 은 iscsiadm iSCSI 데이터베이스에 이러한 대상에 대한 모든 정보를 자동으로 저장합니다. 그런 다음 설치 프로그램이 이 데이터베이스를 설치된 시스템에 복사하고 루트 파티션에 사용되지 않는 iSCSI 대상을 표시하여 시스템이 시작될 때 자동으로 로그인하도록 합니다. 루트 파티션이 iSCSI 대상에 배치된 경우 initrd 는 이 대상에 로그하고 설치 프로그램은 동일한 대상에 여러 번 로그인하려고 시도하지 않도록 시작 스크립트에 이 대상을 포함하지 않습니다.
6.2.6.2. FCoE 매개변수 구성
FCoE 매개변수를 구성하여 설치 대상 창에서 FCoE(Fibre Channel over Ethernet) 장치를 검색할 수 있습니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
절차
- Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창이 열리고 사용 가능한 모든 드라이브가 나열됩니다.
- Specialized & Network Disks 섹션에서 클릭합니다. 스토리지 장치 선택 창이 열립니다.
- 클릭합니다. FCoE 스토리지 장치를 검색하기 위해 네트워크 인터페이스를 구성할 수 있는 대화 상자가 열립니다.
-
NIC드롭다운 메뉴에서 FCoE 스위치에 연결된 네트워크 인터페이스를 선택합니다. - 를 클릭하여 SAN 장치의 네트워크를 스캔합니다.
필요한 확인란을 선택합니다.
- DCB 사용:DCB(Data Center Bridging )는 스토리지 네트워크 및 클러스터에서 이더넷 연결의 효율성을 높이기 위해 설계된 이더넷 프로토콜의 개선 사항 세트입니다. DCB에 대한 설치 프로그램의 인식을 활성화하거나 비활성화하려면 확인란을 선택합니다. 호스트 기반 DCBX 클라이언트가 필요한 네트워크 인터페이스에만 이 옵션을 활성화합니다. 하드웨어 DCBX 클라이언트를 사용하는 인터페이스의 구성의 경우 확인란을 비활성화합니다.
- 자동 vlan:자동 VLAN 은 기본적으로 활성화되어 있으며 VLAN 검색을 수행해야 하는지 여부를 나타냅니다. 이 확인란이 활성화되면 FIP(FCoE Initiation Protocol) VLAN 검색 프로토콜이 링크 구성을 검증할 때 이더넷 인터페이스에서 실행됩니다. 아직 구성되지 않은 경우 검색된 FCoE VLAN에 대한 네트워크 인터페이스가 자동으로 생성되고 VLAN 인터페이스에 FCoE 인스턴스가 생성됩니다.
-
검색된 FCoE 장치는 설치 대상 창의
기타 SAN 장치탭에 표시됩니다.
6.2.6.3. DASD 스토리지 장치 구성
설치 대상 창에서 DASD 스토리지 장치를 검색하고 구성할 수 있습니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
절차
- Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창이 열리고 사용 가능한 모든 드라이브가 나열됩니다.
- Specialized & Network Disks 섹션에서 클릭합니다. 스토리지 장치 선택 창이 열립니다.
- 클릭합니다. DASD 스토리지 대상 추가 대화 상자가 열리고 0.0.0204 와 같은 장치 번호를 지정하고 설치를 시작할 때 감지되지 않은 추가 DASD를 연결하라는 메시지를 표시합니다.
- 장치 번호 필드에 연결할 DASD의 장치 번호를 입력합니다.
클릭합니다.
지정된 장치 번호가 있는 DASD가 발견되고 아직 연결되지 않은 경우 대화 상자가 닫히고 새로 발견된 드라이브가 드라이브 목록에 표시됩니다. 그런 다음 필요한 장치에 대한 확인란을 선택하고 를 클릭합니다. 새로운 DASD를 선택할 수 있으며, 설치 대상 창의 로컬 표준 디스크 섹션에서
DASD 장치 0.0.xxxx로 표시됩니다.
잘못된 장치 번호를 입력하거나 지정된 장치 번호가 있는 DASD가 이미 시스템에 연결된 경우 오류 상자에 오류 메시지가 표시되고 다른 장치 번호로 다시 시도하라는 메시지가 표시됩니다.
6.2.6.4. FCP 장치 구성
FCP 장치를 사용하면 64비트 IBM Z에서 직접 액세스 스토리지 장치(DASD) 장치 대신 또는 SCSI 장치를 사용할 수 있습니다. FCP 장치는 64비트 IBM Z 시스템이 기존 DASD 장치 외에도 디스크 장치로 SCSI LUN을 사용할 수 있는 전환 패브릭 토폴로지를 제공합니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
-
FCP 전용 설치의 경우 CMS 구성 파일 또는
rd.dasd=옵션에서DASD=옵션을 제거하여 DASD가 없음을 나타냅니다.
절차
- Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창이 열리고 사용 가능한 모든 드라이브가 나열됩니다.
- Specialized & Network Disks 섹션에서 클릭합니다. 스토리지 장치 선택 창이 열립니다.
클릭합니다. FCP(Fibre Channel Protocol) 스토리지 장치를 추가할 수 있도록 zFCP 스토리지 대상 추가 대화 상자가 열립니다.
64비트 IBM Z를 사용하려면 설치 프로그램이 FCP LUN을 활성화할 수 있도록 FCP 장치를 수동으로 입력해야 합니다. 그래픽 설치에서 FCP 장치를 입력하거나 매개 변수 또는 CMS 구성 파일에서 고유한 매개 변수 항목으로 입력할 수 있습니다. 입력한 값은 구성하는 각 사이트에 고유해야 합니다.
- 장치 번호 필드에 4 자리 16진수 장치 번호를 입력합니다.
RHEL-8.6 또는 이전 릴리스를 설치하거나
zFCP장치가 NPIV 모드에서 구성되지 않은 경우 또는zfcp.allow_lun_scan=0커널 모듈 매개변수에 의해자동 LUN스캔을 비활성화하면 다음 값을 제공합니다.- WWPN 필드에 16 자리 16진수 WWPN(World Wide Port Number)을 입력합니다.
- LUN 필드에 16 자리 16진수 FCP LUN 식별자를 입력합니다.
- 클릭하여 FCP 장치에 연결합니다.
새로 추가된 장치는 설치 대상 창의 IBM Z 탭에 표시됩니다.
16진수 값에서 소문자만 사용합니다. 잘못된 값을 입력하고 클릭하면 설치 프로그램에 경고가 표시됩니다. 구성 정보를 편집하고 검색 시도를 다시 시도할 수 있습니다. 이러한 값에 대한 자세한 내용은 하드웨어 설명서를 참조하고 시스템 관리자에게 확인하십시오.
6.2.7. NVDIMM 장치에 설치
non-Volatile Dual In-line Memory Module (NVDIMM) 장치는 전원이 공급되지 않을 때 RAM의 성능을 디스크와 같은 데이터 지속성과 결합합니다. 특정 상황에서 Red Hat Enterprise Linux 8은 NVDIMM 장치에서 부팅 및 실행할 수 있습니다.
6.2.7.1. NVDIMM 장치를 설치 대상으로 사용하기 위한 기준
Intel 64 및 AMD64 아키텍처의 섹터 모드에서 nd_pmem 드라이버에서 지원하는 NVDIMM(Non-Volatile Dual In-line Memory Module) 장치에 Red Hat Enterprise Linux 8을 설치할 수 있습니다.
NVDIMM 장치를 스토리지로 사용하기 위한 조건
NVDIMM 장치를 스토리지로 사용하려면 다음 조건을 충족해야 합니다.
- 시스템의 아키텍처는 Intel 64 또는 AMD64입니다.
- NVDIMM 장치는 섹터 모드로 구성됩니다. 설치 프로그램은 NVDIMM 장치를 이 모드로 재구성할 수 있습니다.
- NVDIMM 장치는 nd_pmem 드라이버에서 지원해야 합니다.
NVDIMM 장치에서 부팅하는 조건
다음과 같은 조건에서 NVDIMM 장치에서 부팅할 수 있습니다.
- 스토리지로 NVDIMM 장치를 사용하기 위한 모든 조건이 충족됩니다.
- 시스템은 UEFI를 사용합니다.
- NVDIMM 장치는 시스템에서 사용 가능한 펌웨어 또는 UEFI 드라이버에서 지원해야 합니다. UEFI 드라이버는 장치 자체의 옵션rom에서 로드될 수 있습니다.
- NVDIMM 장치는 네임스페이스에서 사용할 수 있어야 합니다.
부팅 중에 NVDIMM 장치의 고성능을 활용하고 장치에 /boot 및 /boot/efi 디렉토리를 배치합니다. NVDIMM 장치의 Execute-in-place (XIP) 기능은 부팅 중에 지원되지 않으며 커널은 기존 메모리에 로드됩니다.
6.2.7.2. 그래픽 설치 모드를 사용하여 NVDIMM 장치 구성
Red Hat Enterprise Linux 8에서 그래픽 설치를 사용하도록 NVMe(Non-Volatile Dual In-line Memory Module) 장치를 올바르게 구성해야 합니다.
NVDIMM 장치 프로세스를 재구성하면 장치에 저장된 모든 데이터가 제거됩니다.
사전 요구 사항
- NVDIMM 장치가 시스템에 존재하며 다른 모든 사용 조건을 설치 대상으로 충족합니다.
- 설치가 부팅되고 설치 요약 창이 열립니다.
절차
- Installation Summary 창에서 Installation Destination 을 클릭합니다. 설치 대상 창이 열리고 사용 가능한 모든 드라이브가 나열됩니다.
- Specialized & Network Disks 섹션에서 클릭합니다. 스토리지 장치 선택 창이 열립니다.
- NVDIMM 장치 탭을 클릭합니다.
장치를 재구성하려면 목록에서 해당 장치를 선택합니다.
장치가 나열되지 않은 경우 섹터 모드에 있지 않습니다.
- 클릭합니다. 재구성 대화 상자가 열립니다.
필요한 섹터 크기를 입력하고 클릭합니다.
지원되는 섹터 크기는 512 및 4096바이트입니다.
- 재구성이 완료되면 를 클릭합니다.
- 장치 확인란을 선택합니다.
을 클릭하여 Installation Destination 창으로 돌아갑니다.
재구성한 NVDIMM 장치는 Specialized & Network Disks 섹션에 표시됩니다.
- 을 클릭하여 Installation Summary 창으로 돌아갑니다.
이제 설치 대상으로 선택할 수 있는 NVDIMM 장치를 사용할 수 있습니다. 또한 장치가 부팅 요구 사항을 충족하는 경우 장치를 부팅 장치로 설정할 수 있습니다.
6.3. root 사용자 구성 및 로컬 계정 생성
6.3.1. root 암호 구성
설치 프로세스를 완료하고 시스템 관리 작업에 사용되는 관리자(슈퍼유저 또는 root ) 계정에 로그인하도록 루트 암호를 구성해야 합니다. 이러한 작업에는 소프트웨어 패키지 설치 및 업데이트, 네트워크 및 방화벽 설정, 스토리지 옵션, 사용자, 그룹 및 파일 권한 추가 또는 수정과 같은 시스템 전체 구성 변경이 포함됩니다.
설치된 시스템에 대한 root 권한을 얻으려면 root 계정을 사용하거나 관리 권한이 있는 사용자 계정을 만듭니다( wheel 그룹의 구성원). root 계정은 설치 중에 항상 생성됩니다. 관리자 액세스 권한이 필요한 작업을 수행해야 하는 경우에만 관리자 계정으로 전환합니다.
root 계정은 시스템을 완전히 제어할 수 있습니다. 권한이 없는 사용자가 계정에 액세스할 수 있는 경우 사용자의 개인 파일에 액세스하거나 삭제할 수 있습니다.
절차
- 설치 요약 창에서 사용자 설정 > 루트 암호를 선택합니다. Root Password 창이 열립니다.
Root Password 필드에 암호를 입력합니다.
강력한 root 암호를 생성하기 위한 요구 사항은 다음과 같습니다.
- 길이가 8자 이상이어야 합니다.
- 숫자, 문자 (upper and lower case) 및 기호를 포함할 수 있습니다.
- 대소문자를 구분합니다.
- Confirm 필드에 동일한 암호를 입력합니다.
을 클릭하여 root 암호를 확인하고 Installation Summary 창으로 돌아갑니다.
약한 암호를 사용하는 경우 를 두 번 클릭해야 합니다.
6.3.2. 사용자 계정 생성
설치를 완료하기 위해 사용자 계정을 생성합니다. 사용자 계정을 생성하지 않으면 root 로 시스템에 직접 로그인해야 합니다. 이 방법은 권장되지 않습니다.
절차
- 설치 요약 창에서 사용자 설정 > 사용자 생성 을 선택합니다. Create User 창이 열립니다.
- 전체 이름 필드에 사용자 계정 이름을 입력합니다. 예를 들면 다음과 같습니다. Joys입니다.
사용자 이름 필드에 사용자 이름을 입력합니다(예: jsmith).
사용자 이름은 명령줄에서 로그인하는 데 사용됩니다. 그래픽 환경을 설치하는 경우 그래픽 로그인 관리자는 전체 이름을 사용합니다.
사용자가 관리 권한이 필요한 경우 Make this user administrator 확인란을 선택합니다(설치 프로그램에서 사용자를
wheel그룹에 추가합니다).관리자는
sudo명령을 사용하여root암호 대신 사용자 암호를 사용하여root에서만 사용할 수 있는 작업을 수행할 수 있습니다. 더 편리할 수도 있지만 보안 위험이 발생할 수도 있습니다.이 계정을 사용하려면 암호 필요 확인란을 선택합니다.
사용자에게 관리자 권한을 부여하는 경우 계정이 암호로 보호되었는지 확인합니다. 계정에 암호를 할당하지 않고 사용자에게 관리자 권한을 부여하지 마십시오.
- 암호 필드에 암호를 입력합니다.
- Confirm password 필드에 동일한 암호를 입력합니다.
- 을 클릭하여 변경 사항을 적용하고 Installation Summary 창으로 돌아갑니다.
6.3.3. 고급 사용자 설정 편집
다음 절차에서는 고급 사용자 구성 대화 상자에서 사용자 계정의 기본 설정을 편집하는 방법을 설명합니다.
절차
- Create User 창에서 를 클릭합니다.
-
필요한 경우 홈 디렉터리 필드에서 세부 정보를 편집합니다. 필드는 기본적으로
/home/사용자 이름으로채워집니다. 사용자 및 그룹 ID 섹션에서 다음을 수행할 수 있습니다.
수동으로 사용자 ID 지정 확인란을 선택하고 또는 를 사용하여 필요한 값을 입력합니다.
기본값은 1000입니다. UID(사용자 ID) 0-999는 시스템에서 예약하므로 사용자에게 할당할 수 없습니다.
수동으로 그룹 ID 지정 확인란을 선택하고 또는 를 사용하여 필요한 값을 입력합니다.
기본 그룹 이름은 사용자 이름과 동일하며 기본 그룹 ID(GID)는 1000입니다. GID 0-999는 시스템에서 예약하므로 사용자 그룹에 할당할 수 없습니다.
그룹 멤버십 필드에서 추가 그룹을 쉼표로 구분된 목록으로 지정합니다. 아직 존재하지 않는 그룹이 생성됩니다. 추가 그룹에 대한 사용자 지정 GID를 지정할 수 있습니다. 새 그룹에 대한 사용자 지정 GID를 지정하지 않으면 새 그룹이 GID를 자동으로 수신합니다.
생성된 사용자 계정에는 항상 하나의 기본 그룹 멤버십(사용자 ID 지정에 ID가 설정된 사용자 기본 그룹)이 있습니다.
- (변경 사항 저장)를 클릭하여 업데이트를 적용하고 Create User 창으로 돌아갑니다.
6.4. 수동 파티션 설정
수동 파티션을 사용하여 디스크 파티션 및 마운트 지점을 구성하고 Red Hat Enterprise Linux가 설치된 파일 시스템을 정의할 수 있습니다. 설치하기 전에 파티션 또는 파티션되지 않은 디스크 장치를 사용할지 여부를 고려해야 합니다. 직접 또는 LVM을 사용하여 LUN에서 파티셔닝을 사용할 때의 이점과 단점에 대한 자세한 내용은 LUN에서 파티셔닝을 사용하는 Red Hat 지식베이스 솔루션의 이점과 단점을 참조하십시오.
표준 파티션 , LVM 및 및 스토리지 옵션을 사용할 수 있습니다. 이러한 옵션은 시스템 스토리지를 효과적으로 관리하기 위한 다양한 이점과 구성을 제공합니다.
LVM 씬 프로비저닝
- 표준 파티션
-
표준 파티션에는 파일 시스템 또는 스왑 공간이 포함됩니다. 표준 파티션은
/boot및BIOS 부팅및EFI 시스템 파티션에가장 일반적으로 사용됩니다. 대부분의 다른 용도에서 LVM 논리 볼륨을 사용할 수 있습니다. - LVM
-
장치 유형으로
LVM(또는 논리 볼륨 관리)을 선택하면 LVM 논리 볼륨이 생성됩니다. LVM은 물리적 디스크를 사용할 때 성능을 향상시키고, 하나의 마운트 지점에 여러 물리적 디스크를 사용하고 성능, 안정성 또는 둘 다를 위해 소프트웨어 RAID를 설정하는 것과 같은 고급 설정을 허용합니다. - LVM 씬 프로비저닝
- 씬 프로비저닝을 사용하면 애플리케이션에서 필요할 때 임의의 수의 장치에 할당할 수 있는 씬 풀이라는 여유 공간의 스토리지 풀을 관리할 수 있습니다. 필요한 경우 스토리지 공간을 비용 효율적으로 할당하는 데 필요한 경우 풀을 동적으로 확장할 수 있습니다.
Red Hat Enterprise Linux를 설치하려면 최소 하나의 파티션이 필요하지만 / , /home, , / bootswap. 필요에 따라 추가 파티션 및 볼륨을 생성할 수도 있습니다.
데이터 손실을 방지하려면 계속하기 전에 데이터를 백업하는 것이 좋습니다. 듀얼 부팅 시스템을 업그레이드하거나 생성하는 경우 스토리지 장치에서 유지하려는 데이터를 백업해야 합니다.
6.4.1. 권장되는 파티션 스키마
다음 마운트 지점에 별도의 파일 시스템을 생성합니다. 그러나 필요한 경우 /usr,/var, /tmp 마운트 지점에 파일 시스템을 생성할 수도 있습니다.
-
/boot -
/(root) -
/home -
swap -
/boot/efi -
PReP
이 파티션 스키마는 베어 메탈 배포에는 권장되며 가상 및 클라우드 배포에는 적용되지 않습니다.
/boot파티션 - 최소 1GiB의 권장 크기-
/boot에 마운트된 파티션에는 운영 체제 커널이 포함되어 있으므로 시스템은 부트스트랩 프로세스 중에 사용되는 파일과 함께 Red Hat Enterprise Linux 8을 부팅할 수 있습니다. 대부분의 펌웨어의 제한 사항으로 인해 이러한 상태를 유지할 작은 파티션을 만듭니다. 대부분의 시나리오에서는 1GiB 부팅 파티션이 적합합니다. 다른 마운트 지점과 달리/boot에 LVM 볼륨을 사용할 수 없습니다./boot는 별도의 디스크 파티션에 있어야 합니다.
RAID 카드가 있는 경우 일부 BIOS 유형에서 RAID 카드 부팅을 지원하지 않습니다. 이러한 경우 /boot 파티션을 별도의 디스크와 같이 RAID 배열 외부의 파티션에 만들어야 합니다.
-
일반적으로
/boot파티션은 설치 프로그램에 의해 자동으로 생성됩니다. 그러나/(root) 파티션이 2TiB보다 크고 (U)EFI가 부팅에 사용되는 경우 시스템을 성공적으로 부팅하기 위해 2TiB보다 작은 별도의/boot파티션을 만들어야 합니다. -
수동 파티셔닝 중에
/boot파티션이 디스크의 처음 2TB 내에 있는지 확인합니다./boot파티션을 2TB 경계 이상으로 배치하면 설치가 성공할 수 있지만 BIOS에서 이 제한을 초과하여/boot파티션을 읽을 수 없기 때문에 시스템이 부팅되지 않습니다.
root- 권장 크기 10GiB여기서 "/" 또는 루트 디렉터리가 있습니다.
루트 디렉터리는 디렉터리 구조의 최상위 수준입니다. 기본적으로 다른 파일 시스템이 기록되는 경로에 마운트되지 않는 한,/boot또는/home과 같이 모든 파일이 이 파일 시스템에 작성됩니다.5GiB 루트 파일 시스템을 사용하면 최소 설치를 설치할 수 있지만 원하는 만큼 패키지 그룹을 설치할 수 있도록 최소 10GiB를 할당하는 것이 좋습니다.
/ 디렉토리를 /root 디렉토리와 혼동하지 마십시오. /root 디렉터리는 root 사용자의 홈 디렉터리입니다. /root 디렉토리를 루트 디렉토리와 구별하기 위해 슬래시 루트 라고도 합니다.
/home- 최소 1GiB의 권장 크기-
시스템 데이터와 별도로 사용자 데이터를 저장하려면
/home디렉터리에 대한 전용 파일 시스템을 만듭니다. 로컬에 저장된 데이터 양, 사용자 수 등에서 파일 시스템 크기를 기반으로 합니다. 사용자 데이터 파일을 삭제하지 않고 Red Hat Enterprise Linux 8을 업그레이드하거나 다시 설치할 수 있습니다. 자동 파티셔닝을 선택하는 경우/home파일 시스템이 생성되었는지 확인하려면 설치에 최소 55GiB의 디스크 공간을 사용하는 것이 좋습니다. 스왑파티션 - 권장 크기 1GiB스왑 파일 시스템은 가상 메모리를 지원합니다. 시스템은 처리 중인 데이터를 저장하기에 충분한 RAM이 없을 때 데이터가 스왑 파일 시스템에 작성됩니다. 스왑 크기는 총 시스템 메모리가 아닌 시스템 메모리의 기능이므로 총 시스템 메모리 크기와 동일하지 않습니다. 시스템이 실행 중인 애플리케이션을 분석하는 것이 중요하며 이러한 애플리케이션이 시스템 메모리 워크로드를 결정하기 위해 작동합니다. 애플리케이션 공급자 및 개발자는 지침을 제공할 수 있습니다.
시스템이 스왑 공간이 부족하면 시스템 RAM 메모리가 소모되면 커널이 프로세스를 종료합니다. 스왑 공간을 너무 많이 구성하면 스토리지 장치가 할당되지만 유휴 상태가 되고 리소스가 제대로 사용되지 않습니다. 스왑 공간이 너무 많으면 메모리 누수를 숨길 수도 있습니다. 스왑 파티션 및 기타 추가 정보의 최대 크기는
mkswap(8)매뉴얼 페이지에서 확인할 수 있습니다.다음 표에서는 시스템의 RAM 양과 시스템의 최대 절전 메모리가 필요한 경우 스왑 파티션의 권장 크기를 제공합니다. 설치 프로그램이 시스템을 자동으로 파티션하도록 하면 다음 지침을 사용하여 스왑 파티션 크기가 설정됩니다. 자동 파티션 설정은 하이버네이션을 사용하지 않는 것으로 가정합니다. 스왑 파티션의 최대 크기는 전체 디스크 크기의 10%로 제한되며 설치 프로그램은 1TiB를 초과하는 스왑 파티션을 생성할 수 없습니다. 완화를 허용할 수 있는 스왑 공간을 충분히 설정하거나 스왑 파티션 크기를 시스템의 스토리지 공간의 10% 이상으로 설정하려면 파티션 레이아웃을 수동으로 편집해야 합니다.
| 시스템의 RAM 크기 | 권장 스왑 공간 | 최대 절전 모드를 허용하는 경우 권장 스왑 공간 |
|---|---|---|
| 2GiB 미만 | RAM의 2 배 | RAM의 3 배 |
| 2GiB - 8GiB | RAM의 양과 같음 | RAM의 2 배 |
| 8GiB - 64GiB | 4GiB에서 0.5배 정도의 RAM 크기 | RAM의 1.5 배 |
| 64GiB 이상 | 워크로드에 따라 (최소 4GiB) | 최대 절전 모드는 권장되지 않음 |
/boot/efi파티션 - 권장 크기 200MiB- UEFI 기반 AMD64, Intel 64 및 64비트 ARM에는 200MiB EFI 시스템 파티션이 필요합니다. 권장 최소 크기는 200MiB이고 기본 크기는 600MiB이며 최대 크기는 600MiB입니다. BIOS 시스템에는 EFI 시스템 파티션이 필요하지 않습니다.
예를 들어 2GiB, 8GiB 또는 64GiB 시스템 RAM이 있는 시스템 간의 경계에서 선택한 스왑 공간 및 하이버네이션 지원과 관련하여 재량에 따라 재량에 따라 조치를 취할 수 있습니다. 시스템 리소스에서 허용하는 경우 스왑 공간을 늘리면 성능이 향상될 수 있습니다.
특히 빠른 드라이브, 컨트롤러 및 인터페이스가 있는 시스템에서 스왑 공간을 분산하면 스왑 공간 성능도 향상됩니다.
많은 시스템에 필요한 최소보다 많은 파티션과 볼륨이 있습니다. 특정 시스템 요구 사항에 따라 파티션을 선택합니다. 파티션 구성에 대해 잘 모르는 경우 설치 프로그램에서 제공하는 자동 기본 파티션 레이아웃을 수락합니다.
즉시 필요한 파티션에 스토리지 용량만 할당합니다. 언제든지 사용 가능한 공간을 할당하고 요구 사항을 충족할 수 있습니다.
Prep부팅 파티션 - 권장 크기 4 ~ 8MiB-
IBM Power System 서버에 Red Hat Enterprise Linux를 설치할 때 디스크의 첫 번째 파티션에
PReP부팅 파티션이 포함되어야 합니다. 여기에는 다른 IBM Power Systems 서버가 Red Hat Enterprise Linux를 부팅할 수 있는 GRUB 부트 로더가 포함되어 있습니다.
6.4.2. 지원되는 하드웨어 스토리지
스토리지 기술이 어떻게 구성되어 있고 Red Hat Enterprise Linux의 주요 버전 간에 지원이 어떻게 변경되었는지 이해하는 것이 중요합니다.
하드웨어 RAID
컴퓨터의 메인보드 또는 연결된 컨트롤러 카드에서 제공하는 모든 RAID 기능은 설치 프로세스를 시작하기 전에 구성해야 합니다. 각 활성 RAID 어레이는 Red Hat Enterprise Linux 내에서 하나의 드라이브로 표시됩니다.
소프트웨어 RAID
두 개 이상의 디스크가 있는 시스템에서는 Red Hat Enterprise Linux 설치 프로그램을 사용하여 여러 드라이브를 Linux 소프트웨어 RAID 배열로 작동할 수 있습니다. 소프트웨어 RAID 어레이를 사용하면 RAID 기능이 전용 하드웨어가 아닌 운영 체제에 의해 제어됩니다.
기존 RAID 배열의 멤버 장치가 모두 파티션되지 않은 디스크/드라이브인 경우 설치 프로그램은 배열을 디스크로 처리하고 배열을 제거할 방법이 없습니다.
USB 디스크
설치 후 외부 USB 스토리지를 연결하고 구성할 수 있습니다. 대부분의 장치는 커널에서 인식되지만 일부 장치는 인식되지 않을 수 있습니다. 설치 중에 이러한 디스크를 구성할 필요가 없는 경우 연결 해제하여 잠재적인 문제를 방지합니다.
NVDIMM 장치
NVMe(Non-Volatile Dual In-line Memory Module) 장치를 스토리지로 사용하려면 다음 조건을 충족해야 합니다.
- Red Hat Enterprise Linux 버전은 7.6 이상입니다.
- 시스템의 아키텍처는 Intel 64 또는 AMD64입니다.
- 장치는 섹터 모드로 구성됩니다. Anaconda는 NVDIMM 장치를 이 모드로 재구성할 수 있습니다.
- 장치는 nd_pmem 드라이버에서 지원해야 합니다.
다음과 같은 추가 조건에서 NVDIMM 장치에서 부팅할 수 있습니다.
- 시스템은 UEFI를 사용합니다.
- 장치는 시스템에서 사용 가능한 펌웨어 또는 UEFI 드라이버에서 지원해야 합니다. UEFI 드라이버는 장치 자체의 옵션rom에서 로드될 수 있습니다.
- 장치는 네임스페이스에서 사용할 수 있어야 합니다.
부팅 중에 NVDIMM 장치의 고성능을 활용하려면 장치에 /boot 및 /boot/efi 디렉토리를 배치합니다.
NVDIMM 장치의 Execute-in-place (XIP) 기능은 부팅 중에 지원되지 않으며 커널은 기존 메모리에 로드됩니다.
Intel BIOS RAID 세트 고려 사항
Red Hat Enterprise Linux는 Intel BIOS RAID 세트에 설치할 때 mdraid 를 사용합니다. 이러한 세트는 부팅 프로세스 중에 자동으로 감지되며 해당 장치 노드 경로는 여러 부팅 프로세스에서 변경될 수 있습니다. 장치 노드 경로(예: /dev/sda)를 파일 시스템 레이블 또는 장치 UUID로 교체합니다. blkid 명령을 사용하여 파일 시스템 레이블 및 장치 UUID를 찾을 수 있습니다.
6.4.3. 수동 파티션 시작
수동 파티션을 사용하여 요구 사항에 따라 디스크를 분할할 수 있습니다.
사전 요구 사항
- 설치 요약 화면이 열립니다.
- 모든 디스크를 설치 프로그램에서 사용할 수 있습니다.
절차
설치할 디스크를 선택합니다.
- Installation Destination 을 클릭하여 Installation Destination 창을 엽니다.
- 해당 아이콘을 클릭하여 설치에 필요한 디스크를 선택합니다. 선택한 디스크에는 확인 표시가 표시됩니다.
- 스토리지 구성에서 Custom radio-button을 선택합니다.
- 선택 사항: LUKS로 스토리지 암호화를 활성화하려면 데이터 암호화 확인란을 선택합니다.
- 을 클릭합니다.
스토리지를 암호화하도록 선택하면 디스크 암호화 암호를 입력하기 위한 대화 상자가 열립니다. LUKS 암호를 입력합니다.
두 텍스트 필드에 암호를 입력합니다. 키보드 레이아웃을 전환하려면 키보드 아이콘을 사용합니다.
주의암호를 입력하는 대화 상자에서 키보드 레이아웃을 변경할 수 없습니다. 영어 키보드 레이아웃을 선택하여 설치 프로그램에 암호를 입력합니다.
- 를 클릭합니다. 수동 파티셔닝 창이 열립니다.
감지된 마운트 지점이 왼쪽 창에 나열됩니다. 마운트 지점은 감지된 운영 체제 설치를 통해 구성됩니다. 결과적으로 파티션을 여러 설치 간에 공유하는 경우 일부 파일 시스템이 여러 번 표시될 수 있습니다.
- 왼쪽 창에서 마운트 지점을 선택합니다. 사용자 지정할 수 있는 옵션은 오른쪽 창에 표시됩니다.
- 선택 사항: 시스템에 기존 파일 시스템이 포함된 경우 설치에 충분한 공간을 사용할 수 있는지 확인합니다. 파티션을 제거하려면 목록에서 해당 파티션을 선택하고 버튼을 클릭합니다. 대화 상자에는 삭제된 파티션이 속한 시스템에서 사용하는 다른 모든 파티션을 제거하는 데 사용할 수 있는 확인란이 있습니다.
선택 사항: 기존 파티션이 없고 일련의 파티션을 시작점으로 만들려면 왼쪽 창에서 원하는 파티션 구성표를 선택하고(Red Hat Enterprise Linux의 기본값)을 클릭하고 Click here to create them automatically link를 클릭합니다.
참고사용 가능한 스토리지 크기에 비례하는
/boot스왑볼륨이 생성됩니다. 일반적인 설치를 위한 파일 시스템이지만 추가 파일 시스템과 마운트 지점을 추가할 수 있습니다.- 을 클릭하여 변경 사항을 확인하고 Installation Summary 창으로 돌아갑니다.
6.4.4. 지원되는 파일 시스템
수동 파티셔닝을 구성할 때 Red Hat Enterprise Linux에서 사용할 수 있는 다양한 파일 시스템 및 파티션 유형을 활용하여 성능을 최적화하고 호환성을 보장하며 디스크 공간을 효과적으로 관리할 수 있습니다.
- xfs
-
XFS 파일 시스템은 Red Hat Enterprise Linux의 기본 파일 시스템입니다. 확장 가능한 고성능 파일 시스템으로 최대 16 엑사바이트(약 16만 테라바이트), 최대 8 엑타바이트(약 8만 테라바이트) 파일, 수억 개의 항목이 포함된 디렉터리 구조입니다.
XFS는 메타데이터 저널링도 지원하므로 충돌 복구 속도가 빨라집니다. 단일 XFS 파일 시스템의 최대 지원 크기는 1P입니다. XFS는 여유 공간을 확보하기 위해 축소할 수 없습니다. - ext4
-
ext4파일 시스템은ext3파일 시스템을 기반으로 하며 여러 개선 사항을 제공합니다. 여기에는 대규모 파일 시스템 지원 및 대용량 파일 지원, 보다 빠르고 효율적으로 디스크 공간 할당, 디렉터리 내의 하위 디렉터리 수 제한 없음, 빠른 파일 시스템 검사, 보다 강력한 저널링이 포함됩니다. 단일ext4파일 시스템의 최대 지원 크기는 50TB입니다. - ext3
-
ext3파일 시스템은ext2파일 시스템을 기반으로 하며 저널링이라는 주요 이점이 있습니다. 저널링 파일 시스템을 사용하면 fsck 유틸리티를 실행하여 파일 시스템의 메타데이터 일관성을 확인할 필요가 없으므로 파일 시스템을 예기치 않게 종료한 후 파일 시스템을 복구하는 데 드는 시간을 줄일 수 있습니다. - ext2
-
ext2파일 시스템은 일반 파일, 디렉토리 또는 심볼릭 링크를 포함한 표준 Unix 파일 유형을 지원합니다. 최대 255자까지 긴 파일 이름을 할당할 수 있는 기능을 제공합니다. - swap
- 스왑 파티션은 가상 메모리를 지원하는 데 사용됩니다. 즉, 시스템이 처리하는 데이터를 저장하기에 RAM이 충분하지 않을 때 데이터가 스왑 파티션에 작성됩니다.
- vfat
VFAT파일 시스템은 FAT 파일 시스템에서 Microsoft Windows 긴 파일 이름과 호환되는 Linux 파일 시스템입니다.참고Linux 시스템 파티션에는
VFAT파일 시스템 지원을 사용할 수 없습니다. 예를 들면/,/var,/usr등이 있습니다.- BIOS 부팅
- BIOS 시스템 및 BIOS 호환성 모드에서 GUID 파티션 테이블 (GPT)이 있는 장치에서 부팅하는 데 필요한 매우 작은 파티션입니다.
- EFI 시스템 파티션
- UEFI 시스템에서 GUID 파티션 테이블(GPT)이 있는 장치를 부팅하는 데 필요한 작은 파티션입니다.
- PReP
-
이 작은 부팅 파티션은 디스크의 첫 번째 파티션에 있습니다.
PReP부팅 파티션에는 다른 IBM Power Systems 서버가 Red Hat Enterprise Linux를 부팅할 수 있는 GRUB2 부트 로더가 포함되어 있습니다.
6.4.5. 마운트 지점 파일 시스템 추가
여러 마운트 지점 파일 시스템을 추가할 수 있습니다. XFS, ext4, ext3,ext2, swap, VFAT, BIOS Boot, EFI System Partition 및 PReP와 같은 특정 파티션과 사용 가능한 파일 시스템 및 파티션 유형을 사용하여 시스템 스토리지를 효과적으로 구성할 수 있습니다.
사전 요구 사항
- 파티션을 계획했습니다.
-
/var/mail,/usr/tmp,/lib,/sbin,/lib64,/bin과 같은 심볼릭 링크가 있는 경로에 마운트 지점을 지정하지 않았는지 확인하십시오. RPM 패키지를 포함한 페이로드는 특정 디렉터리에 대한 심볼릭 링크 생성에 따라 다릅니다.
절차
- 를 클릭하여 새 마운트 지점 파일 시스템을 만듭니다. Add a New Mount Point 대화 상자가 열립니다.
-
마운트 지점 드롭다운 메뉴에서 사전 설정된 경로 중 하나를 선택하거나 사용자를 입력합니다. 예를 들어 부팅 파티션의 루트 파티션 또는
/boot에 대해 / 파일 시스템의 크기를 Desired Capacity 필드에 입력합니다(예:
2GiB).Desired Capacity 에서 값을 지정하지 않거나 사용 가능한 공간보다 큰 크기를 지정하는 경우 남은 모든 여유 공간이 사용됩니다.
- 를 클릭하여 파티션을 만들고 수동 파티션 창으로 돌아갑니다.
6.4.6. 마운트 지점 파일 시스템의 스토리지 구성
수동으로 생성된 각 마운트 지점의 파티션 스키마를 설정할 수 있습니다. 사용 가능한 옵션은 표준 파티션,LVM, LVM 씬 프로비저닝 입니다. Red Hat Enterprise Linux 8에서는 Btfrs 지원이 제거되었습니다.
선택한 값에 관계없이 /boot 파티션은 항상 표준 파티션에 있습니다.
절차
- LVM이 아닌 단일 마운트 지점이 있어야 하는 장치를 변경하려면 왼쪽 창에서 필요한 마운트 지점을 선택합니다.
- Device(s) 제목 아래에서 을 클릭합니다. 구성 마운트 지점 대화 상자가 열립니다.
- 하나 이상의 장치를 선택을 클릭하여 선택을 확인하고 수동 파티셔닝 창으로 돌아갑니다.
- 클릭하여 변경 사항을 적용합니다.
- 수동 파티션 창 왼쪽 하단에서 선택한 스토리지 장치를 클릭하여 선택한 디스크 대화 상자를 열고 디스크 정보를 검토합니다.
- 선택 사항: 버튼(회선 화살표 버튼)을 클릭하여 모든 로컬 디스크 및 파티션을 새로 고칩니다. 이는 설치 프로그램 외부에서 고급 파티션 구성을 수행한 후에만 필요합니다. 버튼을 클릭하면 설치 프로그램에서 수행된 모든 구성 변경 사항이 재설정됩니다.
6.4.7. 마운트 지점 파일 시스템 사용자 정의
특정 설정을 설정하려면 파티션 또는 볼륨을 사용자 지정할 수 있습니다. /usr 또는 /var 이 루트 볼륨의 나머지 부분과 별도로 분할되는 경우 이러한 디렉터리에 중요한 구성 요소가 포함되어 있으므로 부팅 프로세스가 훨씬 더 복잡해집니다. 이러한 디렉터리가 iSCSI 드라이브 또는 FCoE 위치에 배치되는 경우와 같은 일부 상황에서는 시스템을 부팅할 수 없거나 장치 의 전원을 끄거나 재부팅할 때 오류가 발생할 수 있습니다.
이 제한은 /usr 또는 /var 에만 적용되며 아래 디렉터리에는 적용되지 않습니다. 예를 들어 /var/www 의 별도의 파티션이 성공적으로 작동합니다.
절차
왼쪽 창에서 마운트 지점을 선택합니다.
그림 6.1. 파티션 사용자 정의

오른쪽 창에서 다음 옵션을 사용자 지정할 수 있습니다.
-
마운트 지점 필드에 파일 시스템 마운트 지점을 입력합니다. 예를 들어 파일 시스템이 루트 파일 시스템인 경우 / ;
/boot/boot를 입력한 후. 스왑 파일 시스템의 경우 파일 시스템 유형을swap으로 설정하는 것만으로는 마운트 지점을 설정하지 마십시오. - Desired Capacity 필드에 파일 시스템의 크기를 입력합니다. KiB 또는 GiB와 같은 일반적인 크기 단위를 사용할 수 있습니다. 다른 단위를 설정하지 않은 경우 기본값은 MiB입니다.
드롭다운 장치 유형 메뉴에서 필요한 장치 유형을 선택합니다.
표준 파티션,LVM또는LVM 프로비저닝.참고RAID는 분할을 위해 두 개 이상의 디스크가 선택된 경우에만 사용할 수 있습니다.RAID를 선택하는 경우 RAID 수준을 설정할 수도있습니다. 마찬가지로LVM을 선택하는 경우 볼륨 그룹을 지정할수 있습니다.- Encrypt 확인란을 선택하여 파티션 또는 볼륨을 암호화합니다. 나중에 설치 프로그램에서 암호를 설정해야 합니다. LUKS 버전 드롭다운 메뉴가 표시됩니다.
- 드롭다운 메뉴에서 필요한 LUKS 버전을 선택합니다.
파일 시스템 드롭다운 메뉴에서 이 파티션 또는 볼륨에 적절한 파일 시스템 유형을 선택합니다.
참고Linux 시스템 파티션에는
VFAT파일 시스템 지원을 사용할 수 없습니다. 예를 들어/,/var,/usr등.- Reformat 확인란을 선택하여 기존 파티션을 포맷하거나 데이터를 유지하려면 Reformat 확인란을 지웁니다. 새로 생성된 파티션과 볼륨을 다시 포맷해야 하며 확인란을 선택 해제할 수 없습니다.
- 레이블 필드에 파티션의 레이블을 입력합니다. 레이블을 사용하여 개별 파티션을 쉽게 인식하고 처리할 수 있습니다.
-
이름 필드에 이름을 입력합니다. 표준 파티션은 생성 시 자동으로 이름이 지정되며 표준 파티션의 이름을 편집할 수 없습니다. 예를 들어
/boot이름sda1을 편집할 수 없습니다.
-
마운트 지점 필드에 파일 시스템 마운트 지점을 입력합니다. 예를 들어 파일 시스템이 루트 파일 시스템인 경우 / ;
- 클릭하여 변경 사항을 적용하고 필요한 경우 다른 파티션을 선택하여 사용자 지정합니다. 설치 요약 창에서 시작을 클릭할 때까지 변경 사항이 적용되지 않습니다.
- 선택 사항: 을 클릭하여 파티션 변경 사항을 삭제합니다.
모든 파일 시스템 및 마운트 지점을 생성하고 사용자 지정한 경우 을 클릭합니다. 파일 시스템을 암호화하도록 선택하면 암호를 생성하라는 메시지가 표시됩니다.
설치 프로그램에 대한 모든 스토리지 작업의 요약이 표시되는 변경 사항 요약 대화 상자가 열립니다.
- 를 클릭하여 변경 사항을 적용하고 Installation Summary 창으로 돌아갑니다.
6.4.8. /home 디렉토리 유지
Red Hat Enterprise Linux 8 그래픽 설치에서는 RHEL 7 시스템에서 사용된 /home 디렉토리를 유지할 수 있습니다. /home 은 /home 디렉터리가 RHEL 7 시스템의 별도의 /home 파티션에 있는 경우에만 가능합니다.
다양한 구성 설정이 포함된 /home 디렉토리를 유지하면 새로운 Red Hat Enterprise Linux 8 시스템의 GNOME 쉘 환경이 RHEL 7 시스템에 있는 것과 동일한 방식으로 설정될 수 있습니다. 이는 이전 RHEL 7 시스템과 동일한 사용자 이름 및 ID가 있는 Red Hat Enterprise Linux 8의 사용자에게만 적용됩니다.
사전 요구 사항
- 컴퓨터에 RHEL 7이 설치되어 있어야 합니다.
-
/home디렉토리는 RHEL 7 시스템의 별도의/home파티션에 있습니다. -
Red Hat Enterprise Linux 8
설치 요약창이 열립니다.
절차
- Installation Destination 을 클릭하여 Installation Destination 창을 엽니다.
- 스토리지 구성에서 사용자 지정 라디오 버튼을 선택합니다. Done 을 클릭합니다.
- 을 클릭하면 Manual Partitioning 창이 열립니다.
/home파티션을 선택하고Mount Point:아래에/home을 입력한 다음 Reformat 확인란을 지웁니다.그림 6.2. /home이 포맷되지 않았는지 확인

-
선택 사항: 마운트 지점 파일 시스템 사용자 지정에 설명된 대로 Red Hat Enterprise Linux 8 시스템에 필요한
/home파티션의 다양한 측면을 사용자 지정할 수도 있습니다. 그러나 RHEL 7 시스템에서/home을 유지하려면 Reformat 확인란을 지워야 합니다. - 요구 사항에 따라 모든 파티션을 사용자 지정한 후 를 클릭합니다. 변경 사항 요약 대화 상자가 열립니다.
-
변경 사항 요약 대화 상자에
/home에 대한 변경 사항이 표시되지 않는지 확인합니다. 즉,/home파티션이 유지됩니다. - 을 클릭하여 변경 사항을 적용하고 설치 요약 창으로 돌아갑니다.
6.4.9. 설치 중 소프트웨어 RAID 생성
RAID(Independent Disks) 장치의 중복 배열은 성능 향상을 위해 정렬된 여러 스토리지 장치에서 구성되며 일부 구성에서는 내결함성이 향상됩니다. RAID 장치는 한 단계에서 생성되며 디스크는 필요에 따라 추가 또는 제거됩니다. 시스템의 각 물리적 디스크에 대해 하나의 RAID 파티션을 구성하여 설치 프로그램에서 사용할 수 있는 디스크 수가 사용 가능한 RAID 장치의 수준을 결정하도록 할 수 있습니다. 예를 들어 시스템에 두 개의 디스크가 있는 경우 RAID 10 장치를 생성할 수 없습니다. 최소 3개의 별도의 디스크가 필요하기 때문입니다. 시스템의 스토리지 성능과 신뢰성을 최적화하기 위해 RHEL은 설치된 시스템에 스토리지를 설정하기 위해 LVM 및 LVM Thin Provisioning을 사용하여 소프트웨어 RAID 0,RAID 1,RAID 4,RAID 5,RAID 6 및 RAID 10 유형을 지원합니다.
64비트 IBM Z에서 스토리지 하위 시스템은 RAID를 투명하게 사용합니다. 소프트웨어 RAID를 수동으로 구성할 필요는 없습니다.
사전 요구 사항
- RAID 구성 옵션이 표시되기 전에 설치를 위해 두 개 이상의 디스크를 선택했습니다. 생성할 RAID 유형에 따라 두 개 이상의 디스크가 필요합니다.
- 마운트 지점을 생성했습니다. 마운트 지점을 구성하면 RAID 장치를 구성할 수 있습니다.
- 설치 대상 창에서 라디오 버튼을 선택했습니다.
절차
- 수동 파티션 창의 왼쪽 창에서 필요한 파티션을 선택합니다.
- 장치 섹션에서 을 클릭합니다. 마운트 지점 구성 대화 상자가 열립니다.
- RAID 장치에 포함할 디스크를 선택하고 를 클릭합니다.
- 장치 유형 드롭다운 메뉴를 클릭하고 RAID 를 선택합니다.
- 파일 시스템 드롭다운 메뉴를 클릭하고 선호하는 파일 시스템 유형을 선택합니다.
- RAID 수준 드롭다운 메뉴를 클릭하고 원하는 RAID 수준을 선택합니다.
- 클릭하여 변경 사항을 저장합니다.
- 을 클릭하여 설정을 적용하여 Installation Summary 창으로 돌아갑니다.
6.4.10. LVM 논리 볼륨 생성
LVM(Logical Volume Manager)은 디스크 또는 LUN과 같은 기본 물리 스토리지 공간에 대한 간단한 논리 뷰를 제공합니다. 물리 스토리지의 파티션은 볼륨 그룹으로 함께 그룹화할 수 있는 물리 볼륨으로 표시됩니다. 각 볼륨 그룹을 표준 디스크 파티션과 유사한 여러 논리 볼륨으로 나눌 수 있습니다. 따라서 LVM 논리 볼륨은 여러 물리 디스크에 걸쳐 있을 수 있는 파티션으로 작동합니다.
- LVM 구성은 그래픽 설치 프로그램에서만 사용할 수 있습니다. 텍스트 모드 설치 중에 LVM 구성을 사용할 수 없습니다.
-
LVM 구성을 생성하려면 Ctrl+Alt+F2 눌러 다른 가상 콘솔에서 쉘 프롬프트를 사용합니다. 이 쉘에서
Cryostatcreate및lvm명령을 실행할 수 있습니다. 텍스트 모드 설치로 돌아가려면 Ctrl+Alt+F1 을 누릅니다.
절차
수동 파티셔닝 창에서 다음 옵션을 사용하여 새 마운트 지점을 만듭니다.
- Click here to create them automatically 옵션을 선택하거나 + 버튼을 클릭합니다.
- 드롭다운 목록에서 마운트 지점을 선택하거나 수동으로 입력합니다.
파일 시스템의 크기를 Desired Capacity 필드에 입력합니다. 예를 들면 / , / ,
/boot참고: 기존 마운트 지점을 사용하려면 이 단계를 건너뜁니다.
- 마운트 지점을 선택합니다.
드롭다운 메뉴에서
LVM을 선택합니다. Volume Group 드롭다운 메뉴가 새로 생성된 볼륨 그룹 이름과 함께 표시됩니다.참고구성 대화 상자에서 볼륨 그룹의 물리 확장 영역의 크기를 지정할 수 없습니다. 크기는 항상 기본값인 4MiB로 설정됩니다. 다른 물리 확장 영역이 있는 볼륨 그룹을 만들려면 대화형 쉘로 전환하여 수동으로
생성하거나,volgroup --pesize=size명령으로 Kickstart 파일을 사용해야 합니다. Kickstart에 대한 자세한 내용은 RHEL 자동 설치를 참조하십시오.- 을 클릭하여 Installation Summary 창으로 돌아갑니다.
6.4.11. LVM 논리 볼륨 구성
요구 사항에 따라 새로 생성된 LVM 논리 볼륨을 구성할 수 있습니다.
LVM 볼륨에 /boot 파티션을 배치하는 것은 지원되지 않습니다.
절차
수동 파티셔닝 창에서 다음 옵션을 사용하여 마운트 지점을 만듭니다.
- Click here to create them automatically 옵션을 선택하거나 + 버튼을 클릭합니다.
- 드롭다운 목록에서 마운트 지점을 선택하거나 수동으로 입력합니다.
파일 시스템의 크기를 Desired Capacity 필드에 입력합니다. 예를 들면 / , / ,
/boot참고: 기존 마운트 지점을 사용하려면 이 단계를 건너뜁니다.
- 마운트 지점을 선택합니다.
-
장치 유형 드롭다운 메뉴를 클릭하고
LVM을 선택합니다. Volume Group 드롭다운 메뉴가 새로 생성된 볼륨 그룹 이름과 함께 표시됩니다. 를 클릭하여 새로 생성된 볼륨 그룹을 구성합니다. 볼륨 그룹 구성 대화 상자가 열립니다.
참고구성 대화 상자에서 볼륨 그룹의 물리 확장 영역의 크기를 지정할 수 없습니다. 크기는 항상 기본값인 4MiB로 설정됩니다. 다른 물리 확장 영역이 있는 볼륨 그룹을 만들려면 대화형 쉘로 전환하여 수동으로
생성하거나,volgroup --pesize=size명령으로 Kickstart 파일을 사용해야 합니다. 자세한 내용은 RHEL 자동 설치 문서를 참조하십시오.선택 사항: RAID 수준 드롭다운 메뉴에서 필요한 RAID 수준을 선택합니다.
사용 가능한 RAID 수준은 실제 RAID 장치와 동일합니다.
- Encrypt 확인란을 선택하여 암호화의 볼륨 그룹을 표시합니다.
크기 정책 드롭다운 메뉴에서 볼륨 그룹에 대해 다음 크기 정책을 선택합니다.
사용 가능한 정책 옵션은 다음과 같습니다.
- 자동
- 볼륨 그룹의 크기는 구성된 논리 볼륨을 포함할 수 있을 만큼 충분히 커지도록 자동으로 설정됩니다. 볼륨 그룹 내에서 사용 가능한 공간이 필요하지 않은 경우 최적입니다.
- 가능한 한 크게
- 볼륨 그룹은 포함된 구성된 논리 볼륨의 크기에 관계없이 최대 크기로 생성됩니다. LVM에 대부분의 데이터를 보관하고 나중에 기존 논리 볼륨의 크기를 늘리거나 이 그룹 내에 추가 논리 볼륨을 생성해야 하는 경우 최적입니다.
- 수정됨
- 볼륨 그룹의 정확한 크기를 설정할 수 있습니다. 구성된 모든 논리 볼륨은 이 고정 크기 내에 적합해야 합니다. 볼륨 그룹이 얼마나 큰지 정확히 알고 있는 경우 유용합니다.
- 클릭하여 설정을 적용하고 수동 파티셔닝 창으로 돌아갑니다.
- 클릭하여 변경 사항을 저장합니다.
- 을 클릭하여 Installation Summary 창으로 돌아갑니다.
6.4.12. 파티션에 대한 도움말
모든 시스템을 파티션하는 가장 좋은 방법은 없습니다. 최적의 설정은 설치 중인 시스템을 사용하는 방법에 따라 다릅니다. 그러나 다음 팁은 필요에 맞게 최적의 레이아웃을 찾는 데 도움이 될 수 있습니다.
- 예를 들어 특정 파티션이 특정 디스크에 있어야 하는 경우 먼저 특정 요구 사항이 있는 파티션을 만듭니다.
-
중요한 데이터를 포함할 수 있는 파티션과 볼륨을 암호화하는 것이 좋습니다. 암호화는 권한이 없는 사용자가 물리적 저장 장치에 액세스할 수 있는 경우에도 파티션의 데이터에 액세스하지 못하도록 합니다. 대부분의 경우 사용자 데이터를 포함하는
/home파티션을 최소한 암호화해야 합니다. -
경우에 따라 / ,
/boot및/homeMySQL데이터베이스를 실행하는 서버에서/var/lib/mysql에 대한 별도의 마운트 지점을 사용하면 이후에 백업에서 복원하지 않고도 데이터베이스를 다시 설치할 수 있습니다. 그러나 불필요한 마운트 지점이 있으면 스토리지 관리가 더 어려워집니다. -
일부 특수 제한 사항은 파티션 레이아웃을 배치할 수 있는 특정 디렉터리에 적용됩니다. 특히
/boot디렉토리는 항상 물리 파티션(LVM 볼륨이 아님)에 있어야 합니다. - Linux를 처음 사용하는 경우 다양한 시스템 디렉토리 및 해당 콘텐츠에 대한 정보는 Linux 파일 시스템 계층 구조 표준을 검토하는 것이 좋습니다.
- 각 커널은 대략적으로 필요합니다. 60MiB(초 34MiB, 11MiB vmlinuz, 5MiB System.map)
- 복구 모드의 경우: 100MiB(초 76MiB, 11MiB vmlinuz, 5MiB 시스템 맵)
시스템에서
kdump를 활성화하면 약 40MiB(33MiB의 다른 initrd)가 필요합니다./boot에 대한 1GiB의 기본 파티션 크기만으로도 대부분의 일반적인 사용 사례에 충분합니다. 그러나 여러 커널 릴리스 또는 에라타 커널을 유지하려는 경우 이 파티션의 크기를 늘립니다.-
/var디렉터리에는 Apache 웹 서버를 포함한 여러 애플리케이션에 대한 콘텐츠가 있으며 YUM 패키지 관리자가 다운로드한 패키지 업데이트를 임시로 저장하는 데 사용됩니다./var을 포함하는 파티션 또는 볼륨이 5GiB 이상인지 확인합니다. -
/usr디렉터리에는 일반적인 Red Hat Enterprise Linux 설치에 대부분의 소프트웨어가 있습니다. 따라서 이 디렉터리를 포함하는 파티션 또는 볼륨은 최소 설치의 경우 5GiB 이상이어야 하며 그래픽 환경이 있는 설치의 경우 최소 10GiB여야 합니다. /usr또는/var이 나머지 루트 볼륨과 별도로 분할되는 경우 이러한 디렉터리에 부팅 중요한 구성 요소가 포함되어 있기 때문에 부팅 프로세스가 훨씬 더 복잡해집니다. 이러한 디렉터리가 iSCSI 드라이브 또는 FCoE 위치에 배치되는 경우와 같은 일부 상황에서는 시스템을 부팅할 수 없거나 전원을 끄거나 재부팅할 때장치가 바빠질 수 있습니다.이 제한은
/usr또는/var에만 적용되며 그 아래의 디렉터리에는 적용되지 않습니다. 예를 들어/var/www의 별도의 파티션은 문제 없이 작동합니다.중요일부 보안 정책에서는 관리가 더 복잡해도
/usr및/var을 분리해야 합니다.-
LVM 볼륨 그룹에 할당되지 않은 공간의 일부를 두는 것이 좋습니다. 이 할당되지 않은 공간은 공간 요구 사항이 변경되었지만 다른 볼륨에서 데이터를 제거하지 않으려는 경우 유연성을 제공합니다. 파티션의
LVM Thin Provisioning장치 유형을 선택하여 사용되지 않은 공간을 볼륨에서 자동으로 처리할 수도 있습니다. - XFS 파일 시스템의 크기를 줄일 수 없습니다. 이 파일 시스템을 작은 파티션이나 볼륨을 만들어야 하는 경우 데이터를 백업하고 파일 시스템을 제거하고 그 위치에 새 파일 시스템을 생성해야 합니다. 따라서 나중에 파티션 레이아웃을 변경하려면 대신 ext4 파일 시스템을 사용해야 합니다.
-
설치 후 디스크를 추가하거나 가상 머신 디스크를 확장하여 스토리지를 확장하려는 경우 LVM(Logical Volume Manager)을 사용합니다. LVM을 사용하면 새 드라이브에 물리 볼륨을 만든 다음 적합한 볼륨 그룹 및 논리 볼륨에 할당할 수 있습니다. 예를 들어 시스템의
/home(또는 논리 볼륨에 있는 기타 디렉터리)을 쉽게 확장할 수 있습니다. - 시스템의 펌웨어, 부팅 드라이브 크기 및 부팅 드라이브 디스크 레이블에 따라 BIOS 부팅 파티션 또는 EFI 시스템 파티션을 생성해야 할 수 있습니다. 시스템에 필요하지 않은 경우 그래픽 설치에서 BIOS 부팅 또는 EFI 시스템 파티션을 생성할 수 없습니다. 이 경우 메뉴에서 숨겨집니다.
-
설치 후 스토리지 구성을 변경해야 하는 경우 Red Hat Enterprise Linux 리포지토리에서 이러한 작업을 수행하는 데 도움이 되는 여러 가지 툴을 제공합니다. 명령줄 툴을 원하는 경우
system-storage-manager를 사용해 보십시오.
6.5. 기본 환경 및 추가 소프트웨어 선택
소프트웨어 선택 창을 사용하여 필요한 소프트웨어 패키지를 선택합니다. 패키지는 기본 환경 및 추가 소프트웨어로 구성됩니다.
- 기본 환경에는 사전 정의된 패키지가 포함되어 있습니다. 하나의 기본 환경(예: GUI(기본값), 서버, 최소 설치, 워크스테이션, 사용자 지정 운영 체제, 가상화 호스트)만 선택할 수 있습니다. 가용성은 설치 소스로 사용되는 설치 ISO 이미지에 따라 다릅니다.
- 선택한 환경에 대한 추가 소프트웨어 패키지에 는 기본 환경을 위한 추가 소프트웨어 패키지가 포함되어 있습니다. 여러 소프트웨어 패키지를 선택할 수 있습니다.
사전 정의된 환경 및 추가 소프트웨어를 사용하여 시스템을 사용자 지정합니다. 그러나 표준 설치에서는 설치할 개별 패키지를 선택할 수 없습니다. 특정 환경에 포함된 패키지를 보려면 설치 소스 미디어(DVD, CD, USB)의 리포지토리/repodata/*-comps-repository.architecture.xml 파일을 참조하십시오. XML 파일에는 기본 환경의 일부로 설치된 패키지의 세부 정보가 포함되어 있습니다. 사용 가능한 환경은 < ;environment& gt; 태그로 표시되고 추가 소프트웨어 패키지는 태그로 표시됩니다 .
설치할 패키지를 잘 모를 경우 최소 설치 기본 환경을 선택합니다. 최소 설치는 최소한의 추가 소프트웨어로 Red Hat Enterprise Linux의 기본 버전을 설치합니다. 시스템이 설치를 완료하고 처음으로 로그인하면 YUM 패키지 관리자를 사용하여 추가 소프트웨어를 설치할 수 있습니다. YUM 패키지 관리자에 대한 자세한 내용은 기본 시스템 설정 구성 문서를 참조하십시오.
-
모든 RHEL 8 시스템에서
yum group list명령을 사용하여 소프트웨어 선택의 일부로 시스템에 설치되는 패키지 목록을 확인합니다. 자세한 내용은 기본 시스템 설정 구성을 참조하십시오. -
설치된 패키지를 제어해야 하는 경우 Kickstart 파일을 사용하고
%packages섹션에 패키지를 정의할 수 있습니다.
사전 요구 사항
- 설치 소스를 구성했습니다.
- 설치 프로그램에서 패키지 메타데이터를 다운로드했습니다.
- Installation Summary 창이 열립니다.
절차
- Installation Summary 창에서 Software Selection을 클릭합니다. Software Selection 창이 열립니다.
Base Environment 창에서 기본 환경을 선택합니다. 하나의 기본 환경(예: GUI(기본값), 서버, 최소 설치, 워크스테이션, 사용자 지정 운영 체제, 가상화 호스트)만 선택할 수 있습니다. 기본적으로 GUI 기본 환경이 있는 서버 가 선택됩니다.
그림 6.3. Red Hat Enterprise Linux 소프트웨어 선택
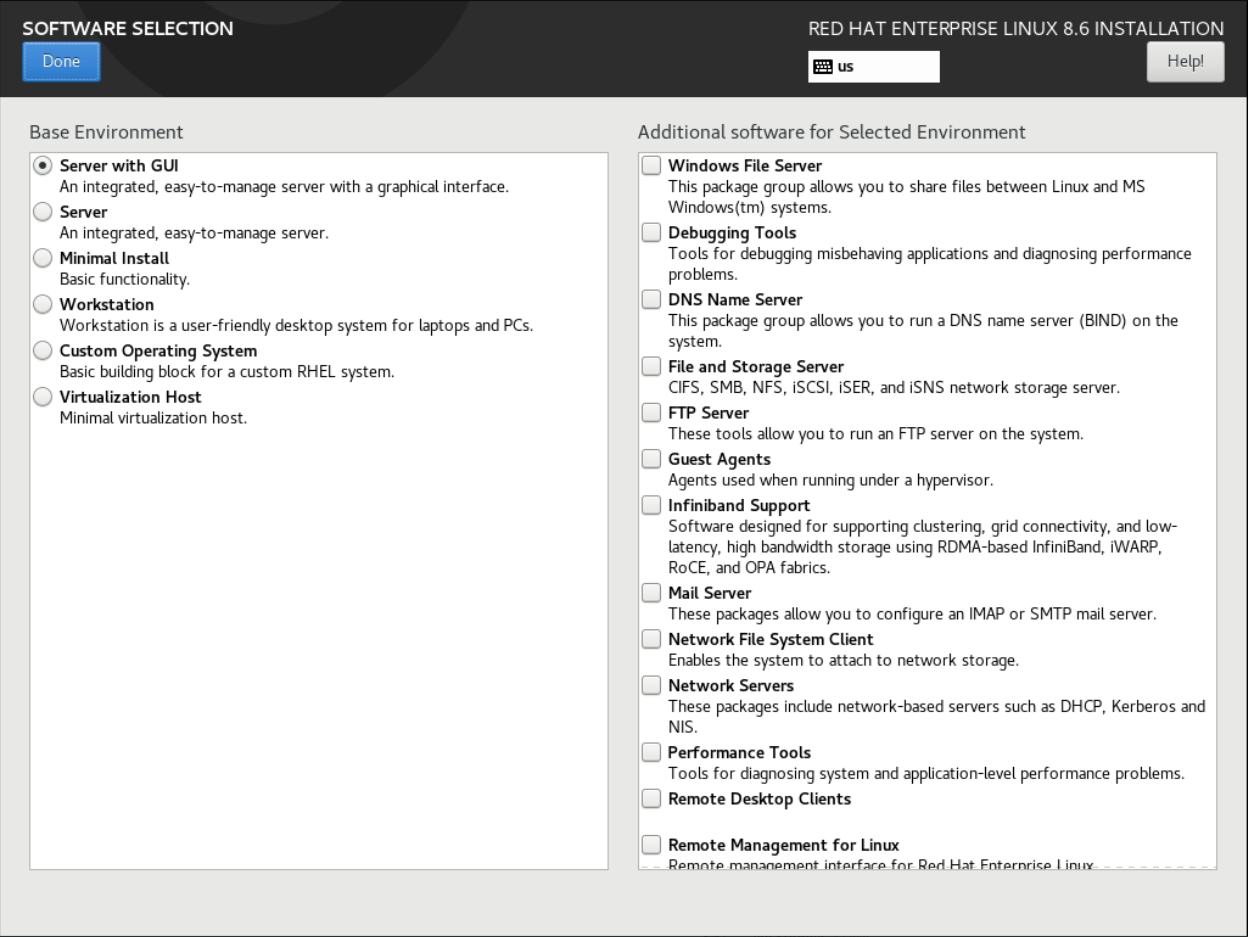
- 선택한 환경에 대한 추가 소프트웨어 창에서 하나 이상의 옵션을 선택합니다.
- 을 클릭하여 설정을 적용하고 그래픽 설치로 돌아갑니다.
6.6. 선택 사항: 네트워크 및 호스트 이름 구성
네트워크 및 호스트 이름 창을 사용하여 네트워크 인터페이스를 구성합니다. 여기에서 선택하는 옵션은 원격 위치 및 설치된 시스템에서 패키지를 다운로드하는 것과 같은 작업을 위해 설치 중에 사용할 수 있습니다.
이 절차의 단계에 따라 네트워크 및 호스트 이름을 구성합니다.
절차
- 설치 요약 창에서 .
- 왼쪽 창의 목록에서 인터페이스를 선택합니다. 자세한 내용은 오른쪽 창에 표시됩니다.
선택한 인터페이스를 활성화하거나 비활성화하려면 스위치를 전환합니다.
인터페이스를 수동으로 추가하거나 제거할 수 없습니다.
- 를 클릭하여 가상 네트워크 인터페이스를 추가합니다. 팀, 본딩, 브리지 또는 VLAN.
- 를 클릭하여 가상 인터페이스를 제거합니다.
- (구성)를 클릭하여 IP 주소, DNS 서버 또는 기존 인터페이스(가상 및 물리적)의 라우팅 구성과 같은 설정을 변경합니다.
호스트 이름 필드에 시스템의 호스트 이름을 입력합니다.
호스트 이름은
hostname.domainname형식의 FQDN(정규화된 도메인 이름)이거나 도메인이 없는 짧은 호스트 이름일 수 있습니다. 많은 네트워크에는 연결된 시스템에 도메인 이름을 자동으로 제공하는 DHCP(Dynamic Host Configuration Protocol) 서비스가 있습니다. DHCP 서비스에서 이 시스템에 도메인 이름을 할당할 수 있도록 하려면 짧은 호스트 이름만 지정합니다.호스트 이름에는 영숫자 및
-또는 . .만 포함할 수 있습니다.호스트 이름은 64자 이상이어야 합니다. 호스트 이름은-및 로 시작하거나 종료할 수 없습니다.DNS를 준수하기 위해 FQDN의 각 부분은 63자 이상이어야 하며 점을 포함한 전체 FQDN 길이는 255자를 초과해서는 안 됩니다.localhost값은 대상 시스템의 특정 정적 호스트 이름이 구성되지 않으며, 설치된 시스템의 실제 호스트 이름은 네트워크 구성 처리 중에 구성됩니다(예: DHCP 또는 DNS를 사용하는 NetworkManager에 의해).고정 IP 및 호스트 이름 구성을 사용하는 경우 계획된 시스템 사용 사례에 따라 짧은 이름 또는 FQDN을 사용할지 여부에 따라 달라집니다. Red Hat Identity Management는 프로비저닝 중에 FQDN을 구성하지만 일부 타사 소프트웨어 제품에는 짧은 이름이 필요할 수 있습니다. 두 경우 모두 모든 상황에서 두 양식의 가용성을 보장하기 위해
IP FQDN short-alias형식으로/etc/hosts의 호스트에 대한 항목을 추가합니다.- 를 클릭하여 설치 프로그램 환경에 호스트 이름을 적용합니다.
- 또는 네트워크 및 호스트 이름 창에서 wireless 옵션을 선택할 수 있습니다. 오른쪽 창에서 클릭하여 Cryostat 연결을 선택하고 필요한 경우 암호를 입력한 다음 를 클릭합니다.
6.6.1. 가상 네트워크 인터페이스 추가
가상 네트워크 인터페이스를 추가할 수 있습니다.
절차
- 네트워크 및 호스트 이름 창에서 버튼을 클릭하여 가상 네트워크 인터페이스를 추가합니다. 장치 추가 대화 상자가 열립니다.
사용 가능한 가상 인터페이스의 네 가지 유형 중 하나를 선택합니다.
- 본딩: NIC(Network Interface Controller) 본딩은 여러 물리적 네트워크 인터페이스를 단일 결합된 채널에 결합하는 방법입니다.
- 브리지: 여러 별도의 네트워크를 하나의 집계 네트워크에 연결하는 방법인 NIC 브리징을 나타냅니다.
- 팀: NIC 티밍은 작은 커널 드라이버를 제공하여 패킷 흐름의 빠른 처리를 구현하고 다양한 애플리케이션에서 사용자 공간의 다른 모든 작업을 수행하도록 설계된 새로운 구현입니다.
- VLAN (가상 LAN): 상호 격리되는 여러 개의 개별 브로드캐스트 도메인을 생성하는 방법입니다.
인터페이스 유형을 선택하고 를 클릭합니다. 선택한 인터페이스 유형에 대해 사용 가능한 설정을 편집할 수 있는 편집 인터페이스 대화 상자가 열립니다.
자세한 내용은 네트워크 인터페이스 편집을 참조하십시오.
- 클릭하여 가상 인터페이스 설정을 확인하고 Network & Host name 창으로 돌아갑니다.
- 선택 사항: 가상 인터페이스의 설정을 변경하려면 인터페이스를 선택하고 를 클릭합니다.
6.6.2. 네트워크 인터페이스 구성 편집
설치 중에 사용되는 일반적인 유선 연결의 구성을 편집할 수 있습니다. 다른 유형의 네트워크 구성은 특정 구성 매개변수가 다를 수 있지만 광범위하게 유사합니다.
64비트 IBM Z에서는 네트워크 하위 채널을 그룹화하고 사전에 온라인 상태로 설정해야 하므로 새 연결을 추가할 수 없으며 현재 부팅 단계에서만 수행됩니다.
절차
네트워크 연결을 수동으로 구성하려면 네트워크 및 호스트 이름 창에서 인터페이스를 선택하고 를 클릭합니다.
선택한 인터페이스와 관련된 편집 대화 상자가 열립니다. 존재하는 옵션은 연결 유형에 따라 달라집니다. 사용 가능한 옵션은 연결 유형이 물리적 인터페이스(선선 또는 무선 네트워크 인터페이스 컨트롤러)인지 아니면 이전에 가상 인터페이스 추가 에서 구성한 가상 인터페이스(Bond, Bridge, Team 또는 Vlan)인지 여부에 따라 약간 다릅니다.
6.6.3. 인터페이스 연결 활성화 또는 비활성화
특정 인터페이스 연결을 활성화하거나 비활성화할 수 있습니다.
절차
- 일반 탭을 클릭합니다.
-
우선 순위로 자동으로 연결 확인란을 선택하여 연결을 기본적으로 활성화합니다. 기본 우선순위 설정을
0에서 유지합니다. 선택 사항: All users may connect to this network option을 사용하여 시스템의 모든 사용자가 이 네트워크에 연결하지 않도록 설정 또는 비활성화합니다. 이 옵션을 비활성화하면
root만 이 네트워크에 연결할 수 있습니다.중요유선 연결에서 활성화된 경우 시스템을 시작하거나 재부팅하는 동안 시스템이 자동으로 연결됩니다. 무선 연결에서 인터페이스는 범위의 알려진 무선 네트워크에 연결을 시도합니다.
nm-connection-editor툴을 포함한 NetworkManager에 대한 자세한 내용은 네트워킹 구성 및 관리를 참조하십시오.클릭하여 변경 사항을 적용하고 네트워크 및 호스트 이름 창으로 돌아갑니다.
설치 중 이 시점에서 다른 사용자가 생성되지 않으므로
root이외의 사용자만 이 인터페이스를 사용할 수 없습니다. 다른 사용자에 대한 연결이 필요한 경우 설치 후 구성해야 합니다.
6.6.4. 정적 IPv4 또는 IPv6 설정 설정
기본적으로 IPv4 및 IPv6는 현재 네트워크 설정에 따라 자동 구성으로 설정됩니다. 즉, 인터페이스가 네트워크에 연결될 때 로컬 IP 주소, DNS 주소 및 기타 설정과 같은 주소가 자동으로 감지됩니다. 대부분의 경우 이 문제로는 충분하지만 IPv4 설정 및 IPv6 설정 탭에 정적 구성을 제공할 수도 있습니다. IPv4 또는 IPv6 설정을 구성하려면 다음 단계를 완료합니다.
절차
- 정적 네트워크 구성을 설정하려면 IPv Settings 탭 중 하나로 이동하고 Method 드롭다운 메뉴에서 Automatic 이외의 방법을 선택합니다(예: Manual ). Address pane이 활성화되어 있습니다.
- 선택 사항: IPv6 설정 탭에서 이 인터페이스에서 IPv6를 비활성화하도록 메서드를 Ignore 로 설정할 수도 있습니다.
- 클릭하고 주소 설정을 입력합니다.
-
추가 DNS servers 필드에 IP 주소를 입력합니다. DNS 서버의 IP 주소를 하나 이상 허용합니다(예:
10.0.0.1,10.0.0.8). 이 연결을 위해 Require IPvX addressing for this connection to complete 확인란을 선택합니다.
IPv4 설정 또는 IPv 6 설정 탭에서 이 옵션을 선택하면 IPv 4 또는 IPv6에 성공한 경우에만 이 연결을 허용합니다. IPv4 및 IPv6 모두에 대해 이 옵션이 비활성화된 상태로 남아 있으면 구성이 IP 프로토콜에서 성공하면 인터페이스가 연결할 수 있습니다.
- 클릭하여 변경 사항을 적용하고 네트워크 및 호스트 이름 창으로 돌아갑니다.
6.6.5. 경로 구성
경로를 구성하여 특정 연결 액세스를 제어할 수 있습니다.
절차
- IPv4 설정 및 IPv6 설정 탭에서 클릭하여 인터페이스에서 특정 IP 프로토콜에 대한 라우팅 설정을 구성합니다. 인터페이스와 관련된 편집 경로 대화 상자가 열립니다.
- 를 클릭하여 경로를 추가합니다.
- Ignore automatically obtained routes 확인란을 선택하여 하나 이상의 정적 경로를 구성하고 특별히 구성되지 않은 모든 경로를 비활성화합니다.
네트워크 상의 리소스에만 이 연결 사용 확인란을 선택하여 연결이 기본 경로가 되지 않도록 합니다.
이 옵션은 정적 경로를 구성하지 않은 경우에도 선택할 수 있습니다. 이 경로는 로컬 또는 VPN 연결이 필요한 인트라넷 페이지와 같은 특정 리소스에 액세스하는 데만 사용됩니다. 다른 (기본) 경로는 공개적으로 사용 가능한 리소스에 사용됩니다. 구성된 추가 경로와 달리 이 설정은 설치된 시스템으로 전송됩니다. 이 옵션은 둘 이상의 인터페이스를 구성할 때만 유용합니다.
- 클릭하여 설정을 저장하고 인터페이스와 관련된 편집 경로 대화 상자로 돌아갑니다.
- 클릭하여 설정을 적용하고 네트워크 및 호스트 이름 창으로 돌아갑니다.
6.7. 선택 사항: 키보드 레이아웃 구성
설치 요약 화면에서 키보드 레이아웃을 구성할 수 있습니다.
러시아어 와 같이 라틴 문자를 허용할 수 없는 레이아웃을 사용하는 경우 영어(United States) 레이아웃을 추가하고 두 레이아웃 간에 전환하도록 키보드 조합을 구성합니다. 라틴 문자가 없는 레이아웃을 선택하는 경우 나중에 설치 프로세스에서 유효한 root 암호 및 사용자 인증 정보를 입력하지 못할 수 있습니다. 이로 인해 설치를 완료하지 못할 수 있습니다.
절차
- 설치 요약 창에서 Cryo stat 를 클릭합니다.
- 를 클릭하여 Add a Cryostat Layout 창을 열어 다른 레이아웃으로 변경합니다.
- 목록을 검색하여 레이아웃을 선택하거나 검색 필드를 사용합니다.
- 필요한 레이아웃을 선택하고 를 클릭합니다. 새 레이아웃이 기본 레이아웃 아래에 표시됩니다.
- 클릭하여 사용 가능한 레이아웃을 순환하는 데 사용할 수 있는 키보드 스위치를 선택적으로 구성합니다. 레이아웃 전환 옵션 창이 열립니다.
- 전환에 사용할 키 조합을 구성하려면 하나 이상의 키 조합을 선택하고 를 클릭하여 선택을 확인합니다.
- 선택 사항: 레이아웃을 선택할 때 Cryostat 버튼을 클릭하여 선택한 레이아웃의 시각적 표현이 표시되는 새 대화 상자를 엽니다.
- 을 클릭하여 설정을 적용하고 그래픽 설치로 돌아갑니다.
6.8. 선택 사항: 언어 지원 구성
설치 요약 화면에서 언어 설정을 변경할 수 있습니다.
절차
- 설치 요약 창에서 언어 지원을 클릭합니다. 언어 지원 창이 열립니다. 왼쪽 창에는 사용 가능한 언어 그룹이 나열됩니다. 그룹에서 하나 이상의 언어가 구성된 경우 확인 표시가 표시되고 지원되는 언어가 강조 표시됩니다.
- 왼쪽 창에서 그룹을 클릭하여 추가 언어를 선택하고 오른쪽 창에서 지역 옵션을 선택합니다. 구성하려는 모든 언어에 대해 이 프로세스를 반복합니다.
- 선택 사항: 필요한 경우 텍스트 상자에 입력하여 언어 그룹을 검색합니다.
- 을 클릭하여 설정을 적용하고 그래픽 설치로 돌아갑니다.
6.10. 선택 사항: Red Hat Insights 서브스크립션 및 활성화
Red Hat Insights는 등록된 Red Hat 기반 시스템에 대한 지속적인 심층적인 분석을 제공하여 물리적, 가상 및 클라우드 환경 및 컨테이너 배포 전반에 걸쳐 보안, 성능 및 안정성에 대한 위협을 사전에 식별하는 SaaS(Software-as-a-Service) 서비스입니다. Red Hat Insights에 RHEL 시스템을 등록하면 예측 분석, 보안 경고 및 성능 최적화 툴에 액세스할 수 있으므로 안전하고 효율적이며 안정적인 IT 환경을 유지할 수 있습니다.
Red Hat 계정 또는 활성화 키 세부 정보를 사용하여 Red Hat에 등록할 수 있습니다. Red Hat에 연결 옵션을 사용하여 시스템을 Red Hat Insights에 연결할 수 있습니다.
절차
- 설치 요약 화면에서 소프트웨어에서 Red Hat에 연결을 클릭합니다.
계정 또는 활성화 키를 선택합니다.
- 계정을 선택하는 경우 Red Hat 고객 포털 사용자 이름과 암호 세부 정보를 입력합니다.
활성화 키를 선택하는 경우 조직 ID 및 활성화 키를 입력합니다.
활성화 키가 서브스크립션에 등록된 경우 두 개 이상의 활성화 키를 쉼표로 구분할 수 있습니다.
Set System Purpose 확인란을 선택합니다.
- 계정에 Simple Content Access 모드가 활성화된 경우에도 시스템 용도 값을 설정하는 것이 서브스크립션 서비스의 소비를 정확하게 보고하는 데 여전히 중요합니다.
- 귀하의 계정이 인타이틀먼트 모드에 있는 경우, 시스템 용도를 통해 인타이틀먼트 서버가 Red Hat Enterprise Linux 8 시스템의 의도된 사용을 충족하기 위해 가장 적합한 서브스크립션을 결정하고 자동으로 연결할 수 있습니다.
- 해당 드롭다운 목록에서 필요한 Role,SLA 및 Usage 를 선택합니다.
- Red Hat Insights에 연결 확인란은 기본적으로 활성화되어 있습니다. Red Hat Insights에 연결하지 않으려면 확인란의 선택을 해제합니다.
선택 사항: 옵션을 확장합니다.
- 네트워크 환경에서 외부 인터넷 액세스만 허용하거나 HTTP 프록시를 통해 콘텐츠 서버에 액세스할 수 있는 경우 HTTP 프록시 사용 확인란을 선택합니다. HTTP 프록시를 사용하지 않는 경우 HTTP 프록시 사용 확인란의 선택을 해제합니다.
Satellite Server를 실행 중이거나 내부 테스트를 수행하는 경우 Custom Server URL 및 Custom base URL 확인란을 선택하고 필요한 세부 정보를 입력합니다.
중요-
Custom Server URL 필드에는 HTTP 프로토콜(예:
nameofhost.com)이 필요하지 않습니다. 그러나 사용자 정의 기본 URL 필드에는 HTTP 프로토콜이 필요합니다. - 등록 후 사용자 정의 기본 URL 을 변경하려면 등록 취소, 새 세부 정보를 제공한 다음 다시 등록해야 합니다.
-
Custom Server URL 필드에는 HTTP 프로토콜(예:
을 클릭하여 시스템을 등록합니다. 시스템이 성공적으로 등록되고 서브스크립션이 연결되면 Red Hat에 연결 창에 연결된 서브스크립션 세부 정보가 표시됩니다.
서브스크립션 수에 따라 등록 및 첨부 프로세스를 완료하는 데 최대 1분이 걸릴 수 있습니다.
을 클릭하여 Installation Summary 창으로 돌아갑니다.
Red Hat Connect to Red Hat 에 등록된 메시지가 표시됩니다.
6.11. 선택 사항: 설치에 네트워크 기반 리포지토리 사용
자동 감지 설치 미디어, Red Hat CDN 또는 네트워크에서 설치 소스를 구성할 수 있습니다. 설치 요약 창이 처음 열 때 설치 프로그램은 시스템을 부팅하는 데 사용된 미디어 유형에 따라 설치 소스를 구성하려고 합니다. 전체 Red Hat Enterprise Linux Server DVD는 소스를 로컬 미디어로 구성합니다.
사전 요구 사항
- 제품 다운로드 페이지에서 전체 설치 DVD ISO 또는 최소 설치 부팅 ISO 이미지를 다운로드 했습니다.
- 부팅 가능한 설치 미디어가 생성되어 있습니다.
- Installation Summary 창이 열립니다.
절차
Installation Summary 창에서 Installation Source 를 클릭합니다. 설치 소스 창이 열립니다.
- 자동 감지 설치 미디어 섹션을 검토하여 세부 정보를 확인합니다. 설치 소스가 포함된 미디어에서 설치 프로그램을 시작한 경우(예: DVD) 이 옵션이 기본적으로 선택됩니다.
- 을 클릭하여 미디어 무결성을 확인합니다.
추가 리포지토리 섹션을 검토하고 AppStream 확인란이 기본적으로 선택되어 있는지 확인합니다.
BaseOS 및 AppStream 리포지토리는 전체 설치 이미지의 일부로 설치됩니다. 전체 Red Hat Enterprise Linux 8을 설치하려면 AppStream 리포지토리 확인란을 비활성화하지 마십시오.
- 선택 사항: Red Hat CDN 옵션을 선택하여 시스템을 등록하고 RHEL 서브스크립션을 연결한 후 Red Hat CDN(Content Delivery Network)에서 RHEL을 설치합니다.
선택 사항: On the network 옵션을 선택하여 로컬 미디어 대신 네트워크 위치에서 패키지를 다운로드하고 설치합니다. 이 옵션은 네트워크 연결이 활성화된 경우에만 사용할 수 있습니다. GUI에서 네트워크 연결을 구성하는 방법에 대한 정보는 네트워크 및 호스트 이름 옵션 구성 을 참조하십시오.
참고네트워크 위치에서 추가 리포지토리를 다운로드하여 설치하지 않으려면 소프트웨어 선택 구성 로 이동합니다.
- On the network 드롭다운 메뉴를 선택하여 패키지 다운로드 프로토콜을 지정합니다. 이 설정은 사용하려는 서버에 따라 다릅니다.
-
주소 필드에 서버 주소(프로토콜 제외)를 입력합니다. NFS를 선택하면 사용자 지정 NFS 마운트 옵션을 지정할 수 있는 두 번째 입력 필드가 열립니다. 이 필드는 시스템의
nfs(5)도움말 페이지에 나열된 옵션을 허용합니다. NFS 설치 소스를 선택할 때 호스트 이름을 경로와 분리하는 콜론(
:) 문자가 있는 주소를 지정합니다. 예를 들어server.example.com:/path/to/directory.다음 단계는 선택 사항이며 네트워크 액세스에 프록시를 사용하는 경우에만 필요합니다.
- HTTP 또는 HTTPS 소스에 대한 프록시를 구성하려면 프록시 클릭합니다.
- Enable HTTP proxy 확인란을 선택하고 Proxy Host 필드에 URL을 입력합니다.
- 프록시 서버에 인증이 필요한 경우 Use Authentication 확인란을 선택합니다.
- 사용자 이름과 암호를 입력합니다.
를 클릭하여 구성을 완료하고 Proxy 설정…을 종료합니다. 대화 상자.
참고HTTP 또는 HTTPS URL이 저장소 미러를 참조하는 경우 URL 유형 드롭다운 목록에서 필요한 옵션을 선택합니다. 소스 구성을 완료하면 모든 환경 및 추가 소프트웨어 패키지를 선택할 수 있습니다.
- 를 클릭하여 리포지토리를 추가합니다.
- 리포지토리를 삭제하려면 를 클릭합니다.
- 설치 소스 창을 열 때 아이콘을 클릭하여 현재 항목을 설정으로 되돌립니다.
리포지토리를 활성화하거나 비활성화하려면 목록의 각 항목에 대해 Enabled 열에서 확인란을 클릭합니다.
네트워크의 기본 리포지토리와 동일한 방식으로 추가 리포지토리의 이름을 지정하고 구성할 수 있습니다.
- 을 클릭하여 설정을 적용하고 Installation Summary 창으로 돌아갑니다.
6.12. 선택 사항: Kdump 커널 크래시 덤프 메커니즘 구성
kdump 는 커널 크래시 덤프 메커니즘입니다. 시스템 충돌이 발생하는 경우 Kdump 는 오류 발생 시 시스템 메모리의 콘텐츠를 캡처합니다. 이 캡처된 메모리는 충돌의 원인을 확인하기 위해 분석될 수 있습니다. Kdump 가 활성화된 경우 시스템 메모리(RAM)의 일부가 자체적으로 예약되어 있어야 합니다. 이 예약된 메모리는 기본 커널에서 액세스할 수 없습니다.
절차
- Installation Summary 창에서 Kdump 를 클릭합니다. Kdump 창이 열립니다.
- kdump 활성화 확인란을 선택합니다.
- 자동 또는 수동 메모리 예약 설정을 선택합니다.
- Manual 을 선택하는 경우 + 및 - 버튼을 사용하여 예약할 메모리에 예약할 메모리 양(MB)을 입력합니다. 예약 입력 필드 아래에 있는 시스템 메모리 읽기 필드는 선택한 RAM 용량을 예약한 후 기본 시스템에 액세스할 수 있는 메모리 양을 보여줍니다.
- 을 클릭하여 설정을 적용하고 그래픽 설치로 돌아갑니다.
예약한 메모리 양은 시스템 아키텍처(AMD64 및 Intel 64의 경우 IBM Power와 다른 요구 사항)와 총 시스템 메모리 양에 따라 결정됩니다. 대부분의 경우 자동 예약은 만족스럽습니다.
커널 크래시 덤프를 저장할 위치와 같은 추가 설정은 system-config-kdump 그래픽 인터페이스를 사용하거나 /etc/kdump.conf 구성 파일에서 수동으로 설치한 후에만 구성할 수 있습니다.
6.13. 선택 사항: 보안 프로필 선택
Red Hat Enterprise Linux 8 설치 중에 보안 정책을 적용하고 처음 부팅하기 전에 시스템에서 사용하도록 구성할 수 있습니다.
6.13.1. 보안 정책 정보
Red Hat Enterprise Linux에는 특정 보안 정책과 일치하여 시스템의 자동 구성을 활성화하는 OpenSCAP 제품군이 포함되어 있습니다. 이 정책은 SCAP(Security Content Automation Protocol) 표준을 사용하여 구현됩니다. 패키지는 AppStream 리포지토리에서 사용할 수 있습니다. 그러나 기본적으로 설치 및 설치 후 프로세스는 정책을 적용하지 않으므로 구체적으로 구성하지 않는 한 검사가 수행되지 않습니다.
보안 정책을 적용하는 것은 설치 프로그램의 필수 기능이 아닙니다. 시스템에 보안 정책을 적용하면 선택한 프로필에 정의된 제한을 사용하여 설치됩니다. openscap-scanner 및 scap-security-guide 패키지가 패키지 선택에 추가되어 규정 준수 및 취약점 검사를 위한 사전 설치된 도구가 제공됩니다.
보안 정책을 선택할 때 Anaconda GUI 설치 프로그램은 정책의 요구 사항을 준수하기 위해 구성이 필요합니다. 패키지 선택과 개별 파티션이 충돌할 수 있습니다. 모든 요구 사항이 충족된 후에만 설치를 시작할 수 있습니다.
설치 프로세스가 끝나면 선택한 OpenSCAP 보안 정책이 시스템을 자동으로 강화하여 규정 준수를 확인하여 검사 결과를 설치된 시스템의 /root/openscap_data 디렉터리에 저장합니다.
기본적으로 설치 프로그램은 설치 이미지에 번들된 scap-security-guide 패키지의 콘텐츠를 사용합니다. HTTP, HTTPS 또는 FTP 서버에서 외부 콘텐츠를 로드할 수도 있습니다.
6.13.2. 보안 프로필 구성
설치 요약 창에서 보안 정책을 구성할 수 있습니다.
사전 요구 사항
- Installation Summary 창이 열립니다.
절차
- 설치 요약 창에서 보안 프로필 을 클릭합니다. Security Profile 창이 열립니다.
- 시스템에서 보안 정책을 활성화하려면 Apply security policy을 ON으로 전환합니다.
- 상단 창에 나열된 프로필 중 하나를 선택합니다.
클릭합니다.
설치 아래에 표시되기 전에 적용해야 하는 프로필 변경 사항입니다.
사용자 지정 프로필을 사용하려면 클릭합니다.
유효한 보안 콘텐츠에 대한 URL을 입력할 수 있는 별도의 창이 열립니다.
를 클릭하여 URL을 검색합니다.
HTTP,HTTPS 또는 FTP 서버에서 사용자 지정 프로필을 로드할 수 있습니다. 프로토콜을 포함하여 콘텐츠의 전체 주소를 사용합니다(예: http:// ). 사용자 지정 프로필을 로드하려면 네트워크 연결을 활성화해야 합니다. 설치 프로그램은 콘텐츠 유형을 자동으로 감지합니다.
- 를 클릭하여 Security Profile 창으로 돌아갑니다.
- 을 클릭하여 설정을 적용하고 Installation Summary 창으로 돌아갑니다.
6.13.3. GUI에서 서버와 호환되지 않는 프로파일
SCAP 보안 가이드의 일부로 제공되는 특정 보안 프로필은 GUI 기본 환경에서 서버에 포함된 확장 패키지 세트와 호환되지 않습니다. 따라서 다음 프로필 중 하나와 호환되는 시스템을 설치할 때 GUI를 사용하여 서버를 선택하지 마십시오.
| 프로파일 이름 | 프로파일 ID | 이유 | 참고 |
|---|---|---|---|
| CIS Red Hat Enterprise Linux 8 Benchmark for Level 2 - 서버 |
|
패키지 | |
| CIS Red Hat Enterprise Linux 8 Benchmark for Level 1 - 서버 |
|
패키지 | |
| 비연방 정보 시스템 및 조직의 분류되지 않은 정보(NIST 800-171) |
|
| |
| 일반적인 용도 운영 체제를 위한 보안 프로필 |
|
| |
| DISA STIG for Red Hat Enterprise Linux 8 |
|
패키지 | RHEL 버전 8.4 이상에서 GUI 가 DISA STIG에 맞는 서버로 RHEL 시스템을 설치하려면 GUI 프로필과 함께 DISA STIG 를 사용할 수 있습니다. |
6.13.4. Kickstart를 사용하여 기준 준수 RHEL 시스템 배포
특정 기준과 일치하는 RHEL 시스템을 배포할 수 있습니다. 이 예에서는 OSDPP(General Purpose Operating System)에 보안 프로필을 사용합니다.
사전 요구 사항
-
scap-security-guide패키지는 RHEL 8 시스템에 설치됩니다.
절차
-
선택한 편집기에서
/usr/share/scap-security-guide/kickstart/ssg-rhel8-ospp-ks.cfgKickstart 파일을 엽니다. -
구성 요구 사항에 맞게 파티션 구성표를 업데이트합니다. OSPP 규정 준수의 경우
/boot,/home,/var,/tmp,/var/log,/var/tmp,/var/log/audit에 대한 별도의 파티션을 유지해야 하며 파티션 크기를 변경할 수 있습니다. - Kickstart를 사용하여 자동 설치를 수행하는 방법에 설명된 대로 Kickstart 설치를 시작합니다.
Kickstart 파일의 암호는 OSPP 요구 사항에 대해 확인되지 않습니다.
검증
설치가 완료된 후 시스템의 현재 상태를 확인하려면 시스템을 재부팅하고 새 검사를 시작합니다.
oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
7장. 서브스크립션 서비스 변경
서브스크립션을 관리하려면 Red Hat Subscription Management Server 또는 Red Hat Satellite Server로 RHEL 시스템을 등록할 수 있습니다. 필요한 경우 나중에 서브스크립션 서비스를 변경할 수 있습니다. 등록된 서브스크립션 서비스를 변경하려면 현재 서비스에서 시스템을 등록 해제한 다음 새 서비스에 등록합니다.
시스템 업데이트를 받으려면 시스템을 관리 서버 중 하나에 등록합니다.
이 섹션에서는 Red Hat Subscription Management Server 및 Red Hat Satellite Server에서 RHEL 시스템을 등록 해제하는 방법에 대해 설명합니다.
사전 요구 사항
다음 중 하나에 시스템을 등록했습니다.
- Red Hat Subscription Management Server
- Red Hat Satellite Server 버전 6.11
시스템 업데이트를 받으려면 시스템을 관리 서버 중 하나에 등록합니다.
7.1. 서브스크립션 관리 서버에서 등록 취소
이 섹션에서는 명령줄 및 서브스크립션 관리자 사용자 인터페이스를 사용하여 Red Hat Subscription Management Server에서 RHEL 시스템을 등록 해제하는 방법에 대해 설명합니다.
7.1.1. 명령줄을 사용하여 등록 취소
unregister 명령을 사용하여 Red Hat Subscription Management Server에서 RHEL 시스템을 등록 취소합니다.
절차
추가 매개 변수 없이 등록 취소 명령을 root 사용자로 실행합니다.
subscription-manager unregister
# subscription-manager unregisterCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 메시지가 표시되면 root 암호를 입력합니다.
시스템은 서브스크립션 관리 서버에서 등록 취소되며 '시스템이 현재 등록되지 않은 상태' 상태는 버튼이 활성화된 상태로 표시됩니다.
중단되지 않는 서비스를 계속하려면 시스템을 관리 서비스 중 하나로 다시 등록합니다. 시스템을 관리 서비스에 등록하지 않으면 시스템 업데이트를 받지 못할 수 있습니다. 시스템 등록에 대한 자세한 내용은 명령줄을 사용하여 시스템 등록을 참조하십시오.
7.1.2. 서브스크립션 관리자 사용자 인터페이스를 사용하여 등록 해제
Subscription Manager 사용자 인터페이스를 사용하여 Red Hat Subscription Management Server에서 RHEL 시스템을 등록 해제할 수 있습니다.
절차
- 시스템에 로그인합니다.
- 창 왼쪽 상단에서 활동 을 클릭합니다.
- 메뉴 옵션에서 애플리케이션 표시 아이콘을 클릭합니다.
- Red Hat Subscription Manager 아이콘을 클릭하거나 검색에 Red Hat Subscription Manager 를 입력합니다.
Authentication Required 대화 상자에 관리자 암호를 입력합니다. 서브스크립션 창이 표시되고 서브스크립션, 시스템 용도 및 설치된 제품의 현재 상태가 표시됩니다. 등록되지 않은 제품에는 빨간색 X가 표시됩니다.
시스템에서 권한 있는 작업을 수행하려면 인증이 필요합니다.
- 취소 버튼을 클릭합니다.
시스템은 서브스크립션 관리 서버에서 등록 취소되며 '시스템이 현재 등록되지 않은 상태' 상태는 버튼이 활성화된 상태로 표시됩니다.
중단되지 않는 서비스를 계속하려면 시스템을 관리 서비스 중 하나로 다시 등록합니다. 시스템을 관리 서비스에 등록하지 않으면 시스템 업데이트를 받지 못할 수 있습니다. 시스템 등록에 대한 자세한 내용은 서브스크립션 관리자 사용자 인터페이스를 사용하여 시스템 등록을 참조하십시오.
7.2. Satellite 서버에서 등록 해제
Satellite Server에서 Red Hat Enterprise Linux 시스템의 등록을 취소하려면 Satellite 서버에서 시스템을 제거합니다.
자세한 내용은 Red Hat Satellite에서 호스트 제거를 참조하십시오.
8장. RHEL 베타 릴리스를 설치하고 부팅하기 위해 UEFI Secure Boot가 활성화된 시스템 준비
운영 체제의 보안을 강화하려면 UEFI Secure Boot가 활성화된 시스템에서 Red Hat Enterprise Linux 베타 릴리스를 부팅할 때 UEFI Secure Boot 기능을 사용하여 서명 확인을 수행합니다.
8.1. UEFI Secure Boot 및 RHEL Beta 릴리스
UEFI Secure Boot를 사용하려면 운영 체제 커널이 인식된 개인 키로 서명해야 합니다. UEFI Secure Boot는 해당 공개 키를 사용하여 서명을 확인합니다.
Red Hat Enterprise Linux 베타 릴리스의 경우 커널은 Red Hat 베타 고유의 개인 키로 서명됩니다. UEFI Secure Boot는 해당 공개 키를 사용하여 서명을 확인하려고 하지만 하드웨어가 베타 개인 키를 인식하지 않기 때문에 Red Hat Enterprise Linux Beta 릴리스 시스템이 부팅되지 않습니다. 따라서 베타 릴리스와 함께 UEFI Secure Boot를 사용하려면 MOK(Machine Owner Key) 기능을 사용하여 시스템에 Red Hat 베타 공개 키를 추가합니다.
8.2. UEFI Secure Boot의 베타 공개 키 추가
이 섹션에서는 UEFI Secure Boot를 위한 Red Hat Enterprise Linux 베타 공개 키를 추가하는 방법에 대해 설명합니다.
사전 요구 사항
- 시스템에서 UEFI Secure Boot가 비활성화되어 있습니다.
- Red Hat Enterprise Linux 베타 릴리스가 설치되고 시스템 재부팅 후에도 Secure Boot가 비활성화됩니다.
- 시스템에 로그인한 후 Initial Setup 창의 작업이 완료됩니다.
절차
시스템의 MOK(Machine Owner Key) 목록에 Red Hat 베타 공개 키 등록을 시작합니다.
mokutil --import /usr/share/doc/kernel-keys/$(uname -r)/kernel-signing-ca.cer
# mokutil --import /usr/share/doc/kernel-keys/$(uname -r)/kernel-signing-ca.cerCopy to Clipboard Copied! Toggle word wrap Toggle overflow $(uname -r)은 커널 버전 (예: 4.18.0-80.el8.x86_64 )으로 교체됩니다.- 메시지가 표시되면 암호를 입력합니다.
- 시스템을 재부팅하고 임의의 키를 눌러 시작합니다. Shim UEFI 키 관리 유틸리티는 시스템을 시작하는 동안 시작됩니다.
- Enroll MOK를 선택합니다.
- Continue를 선택합니다.
- Yes를 선택하고 암호를 입력합니다. 키를 시스템의 펌웨어로 가져옵니다.
- Reboot를 선택합니다.
- 시스템에서 Secure Boot를 활성화합니다.
8.3. 베타 공개 키 제거
Red Hat Enterprise Linux 베타 릴리스를 제거하고 Red Hat Enterprise Linux General Availability (GA) 릴리스 또는 다른 운영 체제를 설치하려는 경우 베타 공개 키를 제거하십시오.
이 절차에서는 베타 공개 키를 제거하는 방법을 설명합니다.
절차
시스템의 MOK(Machine Owner Key) 목록에서 Red Hat 베타 공개 키를 제거하십시오.
mokutil --reset
# mokutil --resetCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 메시지가 표시되면 암호를 입력합니다.
- 시스템을 재부팅하고 임의의 키를 눌러 시작합니다. Shim UEFI 키 관리 유틸리티는 시스템을 시작하는 동안 시작됩니다.
- Reset MOK을 선택합니다.
- Continue를 선택합니다.
- Yes를 선택하고 2단계에서 지정한 암호를 입력합니다. 키는 시스템 펌웨어에서 제거됩니다.
- Reboot를 선택합니다.
부록 A. 부팅 옵션 참조
부팅 옵션을 사용하여 설치 프로그램의 기본 동작을 수정할 수 있습니다.
A.1. 설치 소스 부팅 옵션
이 섹션에서는 다양한 설치 소스 부팅 옵션에 대해 설명합니다.
- inst.repo=
inst.repo=부팅 옵션은 설치 소스(즉, 패키지 리포지토리를 제공하는 위치)와 이를 설명하는 유효한.treeinfo파일을 지정합니다. 예:inst.repo=cdrom.inst.repo=옵션의 대상은 다음 설치 미디어 중 하나여야 합니다.-
설치 프로그램 이미지, 패키지 및 리포지토리 데이터와 유효한
.treeinfo파일이 포함된 디렉터리 구조인 설치 가능한 트리 - DVD(시스템 DVD 드라이브에 있는 물리적 디스크)
전체 Red Hat Enterprise Linux 설치 DVD의 ISO 이미지는 디스크 또는 시스템에서 액세스할 수 있는 네트워크 위치에 배치됩니다.
inst.repo=부트 옵션을 사용하여 다른 형식을 사용하여 다양한 설치 방법을 구성합니다. 다음 표에는inst.repo=부트 옵션 구문에 대한 세부 정보가 포함되어 있습니다.Expand 표 A.1. inst.repo= 부팅 옵션 및 설치 소스의 유형 및 형식 소스 유형 부팅 옵션 형식 소스 형식 CD/DVD 드라이브
inst.repo=cdrom:<device>DVD를 물리적 디스크로 설치 [a]
마운트 가능한 장치 (HDD 및 USB 고착)
inst.repo=hd:<device>:/<path>설치 DVD의 이미지 파일입니다.
NFS 서버
inst.repo=nfs:[options:]<server>:/<path>설치 DVD의 이미지 파일 또는 설치 DVD에 있는 디렉터리 및 파일의 전체 사본인 설치 트리입니다. [b]
HTTP 서버
inst.repo=http://<host>/<path>설치 DVD에 있는 디렉터리 및 파일의 전체 사본인 설치 트리입니다.
HTTPS 서버
inst.repo=https://<host>/<path>FTP 서버
inst.repo=ftp://<username>:<password>@<host>/<path>HMC
inst.repo=hmc[a] 장치가 없는 경우 설치 프로그램은 설치 DVD가 포함된 드라이브를 자동으로 검색합니다.[b] NFS Server 옵션은 기본적으로 NFS 프로토콜 버전 3을 사용합니다. 다른 버전을 사용하려면nfsvers=X를 options에 추가하고 X를 사용하려는 버전 번호로 대체합니다.
-
설치 프로그램 이미지, 패키지 및 리포지토리 데이터와 유효한
다음과 같은 형식으로 디스크 장치 이름을 설정합니다.
-
커널 장치 이름 (예:
/dev/sda1또는sdb2) -
파일 시스템 레이블 (예:
LABEL= skopeo또는LABEL=RHEL8) -
파일 시스템 UUID (예:
UUID=8176c7bf-04ff-403a-a832-9557f94e61db)
영숫자가 아닌 문자는 \xNN으로 표시되어야 합니다. 여기서 NN은 문자의 16진수 표현입니다. 예를 들어 \x20은 공백 (" ") 입니다.
- inst.addrepo=
inst.addrepo=부팅 옵션을 사용하여 기본 리포지토리(inst.repo=)와 함께 다른 설치 소스로 사용할 수 있는 추가 리포지토리를 추가합니다. 부팅 중에inst.addrepo=부트 옵션을 여러 번 사용할 수 있습니다. 다음 표에는inst.addrepo=부팅 옵션 구문에 대한 세부 정보가 포함되어 있습니다.참고REPO_NAME은 리포지토리의 이름이며 설치 프로세스에 필요합니다. 이러한 리포지토리는 설치 프로세스 중에만 사용되며 설치된 시스템에 설치되지 않습니다.
통합 ISO에 대한 자세한 내용은 통합 ISO를 참조하십시오.
| 설치 소스 | 부팅 옵션 형식 | 추가 정보 |
|---|---|---|
| URL에 설치 가능한 트리 |
| 지정된 URL에서 설치 가능한 트리를 찾습니다. |
| NFS 경로에 설치 가능한 트리 |
|
지정된 NFS 경로에서 설치 가능한 트리를 찾습니다. 호스트 다음에 콜론이 필요합니다. 설치 프로그램은 RFC 2224에 따른 URL 구문 분석 대신 |
| 설치 환경에 설치 가능한 트리 |
|
설치 환경의 지정된 위치에서 설치할 수 있는 트리를 찾습니다. 이 옵션을 사용하려면 설치 프로그램에서 사용 가능한 소프트웨어 그룹을 로드하기 전에 리포지토리를 마운트해야 합니다. 이 옵션을 사용하면 하나의 부팅 가능 ISO에 여러 리포지토리를 사용할 수 있으며, ISO에서 기본 리포지토리와 추가 리포지토리를 모두 설치할 수 있습니다. 추가 리포지토리의 경로는 |
| 디스크 |
| 지정된 <device> 파티션을 마운트하고 <path>에 지정된 ISO에서 설치합니다. <path>를 지정하지 않으면 설치 프로그램은 <device>에서 유효한 설치 ISO를 찾습니다. 이 설치 방법을 사용하려면 설치 가능한 유효한 트리가 있는 ISO가 필요합니다. |
- inst.stage2=
inst.stage2=부트 옵션은 설치 프로그램의 런타임 이미지의 위치를 지정합니다. 이 옵션은 유효한.treeinfo파일이 포함된 디렉터리의 경로를 예상하고.treeinfo파일에서 런타임 이미지 위치를 읽습니다..treeinfo파일을 사용할 수 없는 경우 설치 프로그램은images/install.img에서 이미지를 로드하려고 합니다.inst.stage2옵션을 지정하지 않으면 설치 프로그램에서inst.repo옵션으로 지정된 위치를 사용하려고 합니다.나중에 설치 프로그램에서 설치 소스를 수동으로 지정하려면 이 옵션을 사용합니다. 예를 들어, CDN(Content Delivery Network)을 설치 소스로 선택하려는 경우입니다. 설치 DVD 및 부팅 ISO에는 이미 해당 ISO에서 설치 프로그램을 부팅하기 위한 적절한
inst.stage2옵션이 포함되어 있습니다.설치 소스를 지정하려면 대신
inst.repo=옵션을 사용합니다.참고기본적으로
inst.stage2=부트 옵션은 설치 미디어에서 사용되며 특정 레이블로 설정됩니다(예:inst.stage2=hd:LABEL=RHEL-x-0-BaseOS-x86_64). 런타임 이미지가 포함된 파일 시스템의 기본 레이블을 수정하거나 사용자 지정 프로시저를 사용하여 설치 시스템을 부팅하는 경우inst.stage2=부팅 옵션이 올바른 값으로 설정되어 있는지 확인합니다.- inst.noverifyssl
inst.noverifyssl부팅 옵션을 사용하여 설치 프로그램이 추가 Kickstart 리포지토리를 제외하고 모든 HTTPS 연결에 대한 SSL 인증서를 확인하지 않도록 합니다. 여기서--noverifyssl을 리포지토리별로 설정할 수 있습니다.예를 들어 원격 설치 소스가 자체 서명된 SSL 인증서를 사용하는 경우
inst.noverifyssl부팅 옵션을 사용하면 설치 프로그램이 SSL 인증서를 확인하지 않고 설치를 완료할 수 있습니다.inst.stage2=를 사용하여 소스를 지정할 때의 예inst.stage2=https://hostname/path_to_install_image/ inst.noverifyssl
inst.stage2=https://hostname/path_to_install_image/ inst.noverifysslCopy to Clipboard Copied! Toggle word wrap Toggle overflow inst.repo=를 사용하여 소스를 지정할 때의 예inst.repo=https://hostname/path_to_install_repository/ inst.noverifyssl
inst.repo=https://hostname/path_to_install_repository/ inst.noverifysslCopy to Clipboard Copied! Toggle word wrap Toggle overflow - inst.stage2.all
inst.stage2.all부팅 옵션을 사용하여 여러 HTTP, HTTPS 또는 FTP 소스를 지정합니다.inst.stage2=부팅 옵션을inst.stage2.all옵션과 함께 여러 번 사용하여 성공할 때까지 소스에서 이미지를 순차적으로 가져올 수 있습니다. 예를 들면 다음과 같습니다.inst.stage2.all inst.stage2=http://hostname1/path_to_install_tree/ inst.stage2=http://hostname2/path_to_install_tree/ inst.stage2=http://hostname3/path_to_install_tree/
inst.stage2.all inst.stage2=http://hostname1/path_to_install_tree/ inst.stage2=http://hostname2/path_to_install_tree/ inst.stage2=http://hostname3/path_to_install_tree/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - inst.dd=
-
inst.dd=부팅 옵션은 설치 중에 드라이버 업데이트를 수행하는 데 사용됩니다. 설치 중에 드라이버를 업데이트하는 방법에 대한 자세한 내용은 설치 중에 드라이버 업데이트를 참조하십시오. - inst.repo=hmc
이 옵션은 외부 네트워크 설정 요구 사항을 제거하고 설치 옵션을 확장합니다. 바이너리 DVD에서 부팅할 때 설치 프로그램에서 추가 커널 매개 변수를 입력하라는 메시지를 표시합니다. DVD를 설치 소스로 설정하려면
inst.repo=hmc옵션을 커널 매개 변수에 추가합니다. 그러면 설치 프로그램에서 지원 요소(SE) 및 하드웨어 관리 콘솔(HMC) 파일 액세스를 활성화하고, DVD에서 stage2 이미지를 가져온 다음 소프트웨어 선택을 위해 DVD의 패키지에 액세스할 수 있습니다.중요inst.repo부팅 옵션을 사용하려면 사용자가 최소 Privilege Class B 로 구성되어 있는지 확인합니다. 사용자 구성에 대한 자세한 내용은 IBM 설명서를 참조하십시오.- proxy=
이 부팅 옵션은 HTTP, HTTPS 및 FTP 프로토콜에서 설치를 수행할 때 사용됩니다. 예를 들면 다음과 같습니다.
[PROTOCOL://][USERNAME[:PASSWORD]@]HOST[:PORT]
[PROTOCOL://][USERNAME[:PASSWORD]@]HOST[:PORT]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - inst.nosave=
inst.nosave=부팅 옵션을 사용하여 설치된 시스템에 저장되지 않은 설치 로그 및 관련 파일(예:input_ks,output_ks,all_ks쉼표로 구분된 여러 값을 결합할 수 있습니다. 예를 들면 다음과 같습니다.inst.nosave=Input_ks,logs
inst.nosave=Input_ks,logsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고inst.nosave부팅 옵션은 로그 및 입력/출력 Kickstart 결과와 같은 Kickstart %post 스크립트에서 제거할 수 없는 설치된 시스템의 파일을 제외하는 데 사용됩니다.input_ks- 입력 Kickstart 결과를 저장하는 기능을 비활성화합니다.
output_ks- 설치 프로그램에서 생성된 출력 Kickstart 결과를 저장하는 기능을 비활성화합니다.
all_ks- 입력 및 출력 Kickstart 결과를 저장하는 기능을 비활성화합니다.
logs- 모든 설치 로그를 저장하는 기능을 비활성화합니다.
all- 모든 Kickstart 결과 및 모든 로그를 저장하는 기능을 비활성화합니다.
- inst.multilib
-
inst.multilib부팅 옵션을 사용하여 DNF의multilib_policy를 best가 아닌 all로 설정합니다. - inst.memcheck
-
inst.memcheck부팅 옵션은 설치를 완료하는 데 충분한 RAM이 있는지 확인하는 검사를 수행합니다. RAM이 충분하지 않으면 설치 프로세스가 중지됩니다. 설치 중에 시스템 점검은 대략적이고 메모리 사용은 패키지 선택, 사용자 인터페이스(예: 그래픽 또는 텍스트) 및 기타 매개 변수에 따라 달라집니다. - inst.nomemcheck
-
inst.nomemcheck부팅 옵션은 설치를 완료하기에 충분한 RAM이 있는지 확인하기 위해 검사를 수행하지 않습니다. 최소 메모리 양보다 적은 설치를 시도하면 지원되지 않으며 설치 프로세스가 실패할 수 있습니다.
A.2. 네트워크 부팅 옵션
시나리오에 로컬 이미지에서 부팅하는 대신 네트워크를 통해 이미지를 부팅해야 하는 경우 다음 옵션을 사용하여 네트워크 부팅을 사용자 지정할 수 있습니다.
dracut 툴을 사용하여 네트워크를 초기화합니다. 전체 dracut 옵션 목록은 시스템의 dracut.cmdline(7) 매뉴얼 페이지를 참조하십시오.
- ip=
ip= boot옵션을 사용하여 하나 이상의 네트워크 인터페이스를 구성합니다. 여러 인터페이스를 구성하려면 다음 방법 중 하나를 사용합니다.-
각 인터페이스에
ip옵션을 여러 번 사용합니다. 이렇게 하려면rd.neednet=1옵션을 사용하고bootdev옵션을 사용하여 기본 부팅 인터페이스를 지정합니다. -
ip옵션을 한 번 사용한 다음 Kickstart를 사용하여 추가 인터페이스를 설정합니다. 이 옵션에는 여러 다른 형식을 사용할 수 있습니다. 다음 테이블에는 가장 일반적인 옵션에 대한 정보가 포함되어 있습니다.
-
각 인터페이스에
다음 표에서는 다음을 수행합니다.
-
ip매개 변수는 클라이언트 IP 주소를 지정하고IPv6에는 대괄호(예: 192.0.2.1 또는 [2001:db8::99])가 필요합니다. -
gateway매개 변수는 기본 게이트웨이입니다.IPv6에는 대괄호가 필요합니다. -
netmask매개 변수는 사용할 넷마스크입니다. 전체 넷마스크(예: 255.255.255.0) 또는 접두사(예: 64)일 수 있습니다. hostname매개 변수는 클라이언트 시스템의 호스트 이름입니다. 이 매개변수는 선택 사항입니다.Expand 표 A.3. 네트워크 인터페이스를 구성하는 부팅 옵션 형식 부팅 옵션 형식 구성 방법 ip=method인터페이스 자동 설정
ip=interface:method특정 인터페이스의 자동 설정
ip=ip::gateway:netmask:hostname:interface:none정적 구성(예: IPv4:
ip=192.0.2.1::192.0.2.254:255.255.255.0:server.example.com:enp1s0:none)IPv6:
ip=[2001:db8::1]::[2001:db8::fffe]:64:server.example.com:enp1s0:noneip=ip::gateway:netmask:hostname:interface:method:mtu덮어쓰기를 사용하는 특정 인터페이스의 자동 구성
자동 인터페이스 구성 방법
재정의가 있는 특정 인터페이스의 자동 구성은dhcp와 같이 지정된 자동 구성 방법을 사용하여 인터페이스를 열지만 자동으로 가져온 IP 주소, 게이트웨이, 넷마스크, 호스트 이름 또는 기타 지정된 매개 변수를 재정의합니다. 모든 매개변수는 선택 사항이므로 재정의할 매개변수만 지정합니다.method매개변수는 다음 중 하나일 수 있습니다.- DHCP
-
dhcp - IPv6 DHCP
-
dhcp6 - IPv6 자동 구성
-
auto6 - iSCSI 부팅 펌웨어 테이블(iBFT)
-
ibft
참고-
ip 옵션을 지정하지 않고
inst.ks=http://host/path와 같은 네트워크 액세스가 필요한 부팅 옵션을 사용하는 경우ip옵션의 기본값은ip=dhcp -
iSCSI 대상에 자동으로 연결하려면
ip=ibft부팅 옵션을 사용하여 대상에 액세스하기 위한 네트워크 장치를 활성화합니다.
- nameserver=
nameserver=옵션은 이름 서버의 주소를 지정합니다. 이 옵션을 여러 번 사용할 수 있습니다.참고ip=매개 변수에는 대괄호가 필요합니다. 그러나 IPv6 주소는 대괄호로 묶지 않습니다. IPv6 주소에 사용할 올바른 구문의 예는nameserver=2001:db8::1입니다.- bootdev=
-
bootdev=옵션은 부팅 인터페이스를 지정합니다.ip옵션을 두 개 이상 사용하는 경우 이 옵션이 필요합니다. - ifname=
ifname=옵션은 지정된 MAC 주소가 있는 네트워크 장치에 인터페이스 이름을 할당합니다. 이 옵션을 여러 번 사용할 수 있습니다. 구문은ifname=interface:MAC입니다. 예를 들면 다음과 같습니다.ifname=eth0:01:23:45:67:89:ab
ifname=eth0:01:23:45:67:89:abCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고ifname=옵션은 설치 중에 사용자 지정 네트워크 인터페이스 이름을 설정하는 유일한 방법입니다.- inst.dhcpclass=
-
inst.dhcpclass=옵션은 DHCP 공급업체 클래스 식별자를 지정합니다.dhcpd서비스는 이 값을vendor-class-identifier로 인식합니다. 기본값은anaconda-$(uname -srm)입니다.inst.dhcpclass=옵션이 올바르게 적용되도록 하려면ip옵션도 추가하여 설치 초기 단계에서 네트워크 활성화를 요청합니다. - inst.waitfornet=
-
inst.waitfornet=SECONDS부팅 옵션을 사용하면 설치 시스템이 설치 전에 네트워크 연결을 기다릴 수 있습니다.SECONDS인수에서 제공되는 값은 시간 초과 전에 네트워크 연결을 대기하고 네트워크 연결이 존재하지 않는 경우에도 설치 프로세스를 계속할 때까지 대기하는 최대 시간을 지정합니다. - vlan=
vlan=옵션을 사용하여 지정된 이름의 지정된 인터페이스에서 VLAN(Virtual LAN) 장치를 구성합니다. 구문은vlan=name:interface입니다. 예를 들면 다음과 같습니다.vlan=vlan5:enp0s1
vlan=vlan5:enp0s1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이렇게 하면
enp0s1인터페이스에서vlan5라는 VLAN 장치가 구성됩니다. 이름은 다음 형식을 사용할 수 있습니다.
-
VLAN_PLUS_VID:
vlan0005 -
VLAN_PLUS_VID_NO_PAD:
vlan5 -
DEV_PLUS_VID:
enp0s1.0005 DEV_PLUS_VID_NO_PAD:
enp0s1.5- bond=
bond=옵션을 사용하여bond=name[:interfaces][:options]구문을 사용하여 본딩 장치를 구성합니다. name을 본딩 장치 이름으로, 인터페이스를 쉼표로 구분된 물리(Ethernet) 인터페이스로, 옵션을 쉼표로 구분된 본딩 옵션 목록으로 교체합니다. 예를 들면 다음과 같습니다.bond=bond0:enp0s1,enp0s2:mode=active-backup,tx_queues=32,downdelay=5000
bond=bond0:enp0s1,enp0s2:mode=active-backup,tx_queues=32,downdelay=5000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 사용 가능한 옵션 목록을 보려면
modinfo본딩 명령을 실행합니다.- team=
team=옵션을 사용하여team=name:interfaces구문으로 팀 장치를 구성합니다. name 을 팀 장치의 원하는 이름으로 바꾸고 interfaces 를 팀 장치에서 기본 인터페이스로 사용할 물리적 장치(Ethernet) 장치 목록으로 바꿉니다. 예를 들면 다음과 같습니다.team=team0:enp0s1,enp0s2
team=team0:enp0s1,enp0s2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - bridge=
bridge=옵션을 사용하여bridge=name:interfaces구문을 사용하여 브리지 장치를 구성합니다. name을 브리지 장치 및 interfaces의 원하는 이름으로 교체하고, 브릿지 장치에서 기본 인터페이스로 사용할 물리적(Ethernet) 장치 목록을 쉼표로 구분한 목록으로 바꿉니다. 예를 들면 다음과 같습니다.bridge=bridge0:enp0s1,enp0s2
bridge=bridge0:enp0s1,enp0s2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
A.3. 콘솔 부팅 옵션
이 섹션에서는 콘솔의 부팅 옵션을 구성하고 디스플레이 및 키보드를 모니터링하는 방법을 설명합니다.
- console=
-
console=옵션을 사용하여 기본 콘솔로 사용할 장치를 지정합니다. 예를 들어 첫 번째 직렬 포트에서 콘솔을 사용하려면console=ttyS0을 사용합니다.console=인수를 사용하면 설치가 텍스트 UI로 시작됩니다.console=옵션을 여러 번 사용해야 하는 경우 지정된 모든 콘솔에 부팅 메시지가 표시됩니다. 그러나 설치 프로그램은 마지막으로 지정된 콘솔만 사용합니다. 예를 들어console=ttyS0 console=ttyS1을 지정하면 설치 프로그램에서ttyS1을 사용합니다. - inst.lang=
-
설치 중에 사용할 언어를 설정하려면
inst.lang=옵션을 사용합니다. 로케일 목록을 보려면locale -a | grep _또는localectl list-locales | grep _명령을 입력합니다. - inst.singlelang
-
inst.singlelang옵션을 사용하여 단일 언어 모드로 설치하면 설치 언어 및 언어 지원 구성에 사용할 수 있는 대화형 옵션이 없습니다.inst.lang부팅 옵션 또는langKickstart 명령을 사용하여 언어를 지정하는 경우 사용됩니다. 언어를 지정하지 않으면 설치 프로그램은 기본적으로en_US.UTF-8입니다. - inst.geoloc=
설치 프로그램에서
inst.geoloc=옵션을 사용하여 위치 사용을 구성합니다. Geolocation은 언어 및 시간대를 사전 설정하는 데 사용되며inst.geoloc=value구문을 사용합니다.value는 다음 매개변수 중 하나일 수 있습니다.-
geolocation:
inst.geoloc=0 -
Fedora GeoIP API 사용:
inst.geoloc=provider_fedora_geoip. Hostip.info GeoIP API:
inst.geoloc=provider_hostip를 사용합니다.inst.geoloc=옵션을 지정하지 않으면 기본 옵션은provider_fedora_geoip입니다.
-
geolocation:
- inst.keymap=
-
inst.keymap=옵션을 사용하여 설치에 사용할 키보드 레이아웃을 지정합니다. - inst.cmdline
-
inst.cmdline옵션을 사용하여 설치 프로그램이 명령줄 모드에서 실행되도록 합니다. 이 모드는 상호 작용을 허용하지 않으며 Kickstart 파일 또는 명령줄의 모든 옵션을 지정해야 합니다. - inst.graphical
-
inst.graphical옵션을 사용하여 설치 프로그램이 그래픽 모드에서 실행되도록 합니다. 그래픽 모드는 기본값입니다. - inst.text
-
inst.text옵션을 사용하여 설치 프로그램이 그래픽 모드 대신 텍스트 모드에서 실행되도록 합니다. - inst.noninteractive
-
비대화형 모드에서 설치 프로그램을 실행하려면
inst.noninteractive부팅 옵션을 사용합니다. 비대화형 모드에서는 사용자 상호 작용이 허용되지 않으며inst.non옵션을 그래픽 또는 텍스트 설치와 함께 사용할 수 있습니다. 텍스트 모드에서interactiveinst.noninteractive옵션을 사용하면inst.cmdline옵션과 동일하게 작동합니다. - inst.resolution=
-
inst.resolution=옵션을 사용하여 그래픽 모드에서 화면 해상도를 지정합니다. 형식은NxM입니다. 여기서 N은 화면 너비이고 M은 화면 높이(px)입니다. 권장 해상도는 1024x768입니다. - inst.vnc
-
VNC(Virtual Network Computing)를 사용하여 그래픽 설치를 실행하려면
inst.vnc옵션을 사용합니다. 설치 프로그램과 상호 작용하려면 VNC 클라이언트 애플리케이션을 사용해야 합니다. VNC 공유가 활성화되면 여러 클라이언트가 연결할 수 있습니다. VNC를 사용하여 설치된 시스템은 텍스트 모드에서 시작됩니다. - inst.vncpassword=
-
설치 프로그램에서 사용하는 VNC 서버에서 암호를 설정하려면
inst.vncpassword=옵션을 사용합니다. - inst.vncconnect=
-
inst.vncconnect=옵션을 사용하여 지정된 호스트 위치에서 수신 대기 VNC 클라이언트에 연결합니다(예:inst.vncconnect=<host>[:<port>]기본 포트는 5900입니다.vncviewer -listen명령을 입력하여 이 옵션을 사용할 수 있습니다. - inst.xdriver=
-
inst.xdriver=옵션을 사용하여 설치 및 설치된 시스템에서 둘 다 사용할 X 드라이버의 이름을 지정합니다. - inst.usefbx
-
inst.usefbx옵션을 사용하여 하드웨어별 드라이버 대신 프레임 버퍼 X 드라이버를 사용하도록 설치 프로그램에 메시지를 표시합니다. 이 옵션은inst.xdriver=fbdev옵션과 동일합니다. - modprobe.blacklist=
modprobe.blacklist=옵션을 사용하여 하나 이상의 드라이버를 차단 목록에 표시하거나 완전히 비활성화합니다. 이 옵션을 사용하여 비활성화한 드라이버(mods)는 설치가 시작될 때 로드할 수 없습니다. 설치가 완료되면 설치된 시스템은 이러한 설정을 유지합니다. blocklisted 드라이버 목록은/etc/modprobe.d/디렉토리에서 찾을 수 있습니다. 쉼표로 구분된 목록을 사용하여 여러 드라이버를 비활성화합니다. 예를 들면 다음과 같습니다.modprobe.blacklist=ahci,firewire_ohci
modprobe.blacklist=ahci,firewire_ohciCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고modprobe.blacklist를 다른 명령행 옵션과 함께 사용할 수 있습니다. 예를 들어inst.dd옵션과 함께 사용하여 기존 드라이버의 업데이트된 버전이 드라이버 업데이트 디스크에서 로드되었는지 확인합니다.modprobe.blacklist=virtio_blk
modprobe.blacklist=virtio_blkCopy to Clipboard Copied! Toggle word wrap Toggle overflow - inst.xtimeout=
-
inst.xtimeout=옵션을 사용하여 X 서버를 시작하는 데 시간 초과를 초 단위로 지정합니다. - inst.sshd
SSH를 사용하여 시스템에 연결하고 설치 진행 상황을 모니터링할 수 있도록
inst.sshd옵션을 사용하여 설치 중에sshd서비스를 시작합니다. SSH에 대한 자세한 내용은 시스템의ssh(1)도움말 페이지를 참조하십시오. 기본적으로sshd옵션은 64비트 IBM Z 아키텍처에서만 자동으로 시작됩니다. 다른 아키텍처에서inst.sshd옵션을 사용하지 않는 경우sshd가 시작되지 않습니다.참고설치하는 동안 root 계정에는 기본적으로 암호가 없습니다.
sshpwKickstart 명령을 사용하여 설치 중에 root 암호를 설정할 수 있습니다.- inst.kdump_addon=
-
inst.kdump_addon=옵션을 사용하여 설치 프로그램에서 Kdump 구성 화면(add-on)을 활성화하거나 비활성화합니다. 이 화면은 기본적으로 활성화되어 있습니다.inst.kdump_addon=off를 사용하여 비활성화합니다. 애드온을 비활성화하면 그래픽 및 텍스트 기반 인터페이스의 Kdump 화면과%addon com_redhat_kdumpKickstart 명령이 비활성화됩니다.
A.4. 디버그 부팅 옵션
이 섹션에서는 문제를 디버깅할 때 사용할 수 있는 옵션에 대해 설명합니다.
- inst.rescue
-
inst.rescue옵션을 사용하여 시스템 진단 및 수정을 위해 복구 환경을 실행합니다. 자세한 내용은 복구 모드에서 파일 시스템 복구 Red Hat 지식베이스 솔루션을 참조하십시오. - inst.updates=
inst.updates=옵션을 사용하여 설치 중에 적용할updates.img파일의 위치를 지정합니다.updates.img파일은 여러 소스 중 하나에서 파생될 수 있습니다.Expand 표 A.4. updates.img 파일 소스 소스 설명 예 네트워크에서 업데이트
updates.img의 네트워크 위치를 지정합니다. 설치 트리를 수정할 필요가 없습니다. 이 방법을 사용하려면inst.updates를 포함하도록 커널 명령행을 편집합니다.inst.updates=http://website.com/path/to/updates.img.디스크 이미지에서 업데이트
updates.img를 플로피 드라이브 또는 USB 키에 저장합니다. 이는ext2파일 시스템 유형의updates.img에서만 수행할 수 있습니다. 이미지 내용을 플로피 드라이브에 저장하려면 플로피 디스크를 삽입하고 명령을 실행합니다.DD if=updates.img of=/dev/fd0 bs=72k count=20. USB 키 또는 플래시 미디어를 사용하려면/dev/fd0을 USB 플래시 드라이브의 장치 이름으로 바꿉니다.설치 트리에서 업데이트
CD, 디스크, HTTP 또는 FTP 설치를 사용하는 경우 모든 설치에서
.img파일을 감지할 수 있도록 설치 트리에updates.img를 저장합니다. 파일 이름은updates.img여야 합니다.NFS 설치의 경우
images/디렉터리 또는RHupdates/디렉터리에 파일을 저장합니다.- inst.loglevel=
inst.loglevel=옵션을 사용하여 터미널에 로깅된 최소 메시지 수준을 지정합니다. 이 옵션은 터미널 로깅에만 적용됩니다. 로그 파일에는 항상 모든 수준의 메시지가 포함됩니다. 이 옵션에 대해 가장 낮은 수준의 가능한 값은 다음과 같습니다.-
debug -
info -
경고 -
error -
심각
-
기본값은 info 입니다. 즉, 기본적으로 로깅 터미널은 info 에서 critical 까지의 메시지를 표시합니다.
- inst.syslog=
-
설치가 시작될 때 지정된 호스트의
syslog프로세스에 로그 메시지를 보냅니다. 원격syslog프로세스가 수신 연결을 수락하도록 구성된 경우에만inst.syslog=를 사용할 수 있습니다. - inst.virtiolog=
-
inst.virtiolog=옵션을 사용하여 로그를 전달하는 데 사용할 virtio 포트(/dev/virtio-ports/name)를 지정합니다. 기본값은org.fedoraproject.anaconda.log.0입니다. - inst.zram=
설치 중에 zRAM 스왑의 사용을 제어합니다. 옵션은 시스템 RAM 내에 압축된 블록 장치를 생성하고 디스크를 사용하는 대신 스왑 공간에 사용합니다. 이 설정을 사용하면 설치 프로그램을 더 적은 메모리로 실행하고 설치 속도를 향상시킬 수 있습니다. 다음 값을 사용하여
inst.zram=옵션을 구성할 수 있습니다.- inst.zram=1: 시스템 메모리 크기에 관계없이 zRAM 스왑을 활성화합니다. 기본적으로 zRAM의 스왑은 2GiB 이상의 RAM이 있는 시스템에서 활성화됩니다.
- 시스템 메모리 크기에 관계없이 zRAM 스왑을 비활성화하려면 inst.zram=0입니다. 기본적으로 zRAM의 스왑은 2GiB 이상의 메모리가 있는 시스템에서 비활성화됩니다.
- rd.live.ram
-
images/install.img의단계 2이미지를 RAM에 복사합니다. 이렇게 하면 이미지 크기에 필요한 메모리가 일반적으로 400MB에서 800MB 사이로 증가합니다. - inst.nokill
- 치명적인 오류가 발생하거나 설치 프로세스가 종료될 때 설치 프로그램이 재부팅되지 않도록 합니다. 이를 사용하여 재부팅 시 손실되는 설치 로그를 캡처합니다.
- inst.noshell
- 설치하는 동안 터미널 세션 2(tty2)의 쉘을 방지합니다.
- inst.notmux
- 설치 중에 tmux를 사용하지 마십시오. 출력은 터미널 제어 문자 없이 생성되며 대화형이 아닌 용도로 사용됩니다.
- inst.remotelog=
-
TCP 연결을 사용하여 모든 로그를 원격
host:port로 보냅니다. 리스너가 없고 설치가 정상적으로 진행되면 연결이 중단됩니다.
A.5. 스토리지 부팅 옵션
이 섹션에서는 스토리지 장치에서 부팅을 사용자 지정하도록 지정할 수 있는 옵션에 대해 설명합니다.
- inst.nodmraid
-
dmraid지원을 비활성화합니다.
이 옵션을 주의해서 사용하십시오. 펌웨어 RAID 어레이의 일부로 잘못 식별되는 디스크가 있는 경우 dmraid 또는 wipefs 와 같은 적절한 도구를 사용하여 제거해야 하는 일부 오래된 RAID 메타데이터가 있을 수 있습니다.
- inst.nompath
- 다중 경로 장치 지원을 비활성화합니다. 시스템에 일반 블록 장치를 다중 경로 장치로 잘못 식별하는 false-positive가 있는 경우에만 이 옵션을 사용합니다.
이 옵션을 주의해서 사용하십시오. 다중 경로 하드웨어와 함께 이 옵션을 사용하지 마십시오. 이 옵션을 사용하여 다중 경로 장치의 단일 경로에 설치하는 것은 지원되지 않습니다.
- inst.gpt
-
마스터 부트 레코드(MBR) 대신 GUID 파티션 테이블(GPT)에 파티션 정보를 설치하도록 설치 프로그램에서 강제 적용합니다. 이 옵션은 BIOS 호환성 모드에 있지 않는 한 UEFI 기반 시스템에서 유효하지 않습니다. 일반적으로 BIOS 기반 시스템 및 BIOS 호환성 모드의 UEFI 기반 시스템은 디스크 크기가 2^32 섹터이거나 큰 경우 파티션 정보를 저장하기 위해 DASD 스키마를 사용하려고 합니다. 디스크 섹터는 일반적으로 크기가 512바이트이므로 일반적으로 2TiB와 동일합니다.
inst.gpt부팅 옵션을 사용하면 GPT를 작은 디스크에 쓸 수 있습니다. - inst.wait_for_disks=
-
inst.wait_for_disks=옵션을 사용하여 설치 시작 시 디스크 장치가 표시될 때까지 대기할 설치 프로그램 초를 지정합니다.OEMDRV 레이블이 지정된장치를 사용하여 Kickstart 파일 또는 커널 드라이버를 자동으로 로드하지만 부팅 프로세스 중에 장치가 표시되는 데 시간이 오래 걸리는 경우 이 옵션을 사용합니다. 기본적으로 설치 프로그램은5초 동안 기다립니다. 지연을 최소화하기 위해0초를 사용합니다.
A.6. 더 이상 사용되지 않는 부팅 옵션
이 섹션에는 더 이상 사용되지 않는 부팅 옵션에 대한 정보가 포함되어 있습니다. 이러한 옵션은 설치 프로그램에서 계속 허용되지만 더 이상 사용되지 않으며 향후 Red Hat Enterprise Linux 릴리스에서 제거될 예정입니다.
- method
-
method옵션은inst.repo의 별칭입니다. - dns
-
dns대신nameserver를 사용합니다. 이름 서버는 쉼표로 구분된 목록을 허용하지 않습니다. 대신 여러 네임서버 옵션을 사용합니다. - 넷마스크, 게이트웨이, 호스트 이름
-
넷마스크,게이트웨이및호스트 이름옵션은ip옵션의 일부로 제공됩니다. - ip=bootif
-
PXE 제공
BOOTIF옵션이 자동으로 사용되므로ip=bootif를 사용할 필요가 없습니다. - ksdevice
Expand 표 A.5. ksdevice 부팅 옵션의 값 값 정보 존재하지 않음
해당 없음
ksdevice=link이 옵션으로 무시되는 것은 기본 동작과 동일합니다.
ksdevice=bootifBOOTIF=가 있는 경우 이 옵션이 기본값이므로 무시됨ksdevice=ibftip=ibft로 교체되었습니다. 자세한 내용은ip를 참조하십시오.ksdevice=<MAC>BOOTIF=${MAC/:/-}로 교체됨ksdevice=<DEV>bootdev로 교체됨
A.7. 제거된 부팅 옵션
이 섹션에는 Red Hat Enterprise Linux에서 제거된 부팅 옵션이 포함되어 있습니다.
dracut 은 고급 부팅 옵션을 제공합니다. dracut 에 대한 자세한 내용은 시스템의 dracut.cmdline(7) 매뉴얼 페이지를 참조하십시오.
- askmethod, asknetwork
-
initramfs는 완전히 비대화성이므로askmethod및asknetwork옵션이 제거되었습니다.inst.repo를 사용하거나 적절한 네트워크 옵션을 지정합니다. - 블랙리스트, nofirewire
-
modprobe옵션은 이제 커널 모듈 차단을 처리합니다.modprobe.blacklist=<mod1>,<mod2>를사용합니다.modprobe.blacklist=firewire_ohci를 사용하여 firewire 모듈을 차단할 수 있습니다. - inst.headless=
-
headless=옵션은 설치 중인 시스템에 디스플레이 하드웨어가 없고 설치 프로그램이 디스플레이 하드웨어를 찾을 필요가 없음을 지정했습니다. - inst.decorated
-
inst.decorated옵션은 데코레이션 창에서 그래픽 설치를 지정하는 데 사용되었습니다. 기본적으로 창은 데코레이팅되지 않으므로 제목 표시줄, 크기 조정 컨트롤 등이 없습니다.By default, the window is not decorated, so it does not have a title bar, resize controls, and so on. 이 옵션은 더 이상 필요하지 않습니다. - repo=nfsiso
-
inst.repo=nfs:옵션을 사용합니다. - 직렬
-
console=ttyS0옵션을 사용합니다. - 업데이트
-
inst.updates옵션을 사용합니다. - ESSID, wepkey, wpakey
- dracut은 무선 네트워킹을 지원하지 않습니다.
- ethtool
- 이 옵션은 더 이상 필요하지 않습니다.
- gdb
-
dracut-based
initramfs디버깅에 많은 옵션을 사용할 수 있으므로 이 옵션이 제거되었습니다. - inst.mediacheck
-
dracut 옵션 rd.live.check옵션을 사용합니다. - ks=floppy
-
inst.ks=hd:<device> 옵션을사용합니다. - 표시
-
UI의 원격 디스플레이는
inst.vnc옵션을 사용합니다. - utf8
- 기본 TERM 설정이 예상대로 작동하기 때문에 이 옵션이 더 이상 필요하지 않았습니다.
- noipv6
-
ipv6는 커널에 빌드되며 설치 프로그램에서 제거할 수 없습니다.
ipv6.disable=1을 사용하여 ipv6를 비활성화할 수 있습니다. 이 설정은 설치된 시스템에서 사용합니다. - upgradeany
- 설치 프로그램에서 더 이상 업그레이드를 처리하지 않으므로 이 옵션이 더 이상 필요하지 않았습니다.
9장. 사용자 지정 RHEL 시스템 이미지 구성
9.1. RHEL 이미지 빌더 설명
시스템을 배포하려면 시스템 이미지를 생성합니다. RHEL 시스템 이미지를 생성하려면 RHEL 이미지 빌더 툴을 사용합니다. RHEL 이미지 빌더를 사용하여 클라우드 플랫폼에 배포할 수 있는 시스템 이미지를 포함하여 RHEL의 사용자 지정 시스템 이미지를 생성할 수 있습니다. RHEL 이미지 빌더는 각 출력 유형에 대한 설정 세부 정보를 자동으로 처리하므로 이미지 생성 방법보다 사용하기 쉽고 빠르게 작업할 수 있습니다. composer-cli 툴의 명령줄 또는 RHEL 웹 콘솔에서 그래픽 사용자 인터페이스를 사용하여 RHEL 이미지 빌더 기능에 액세스할 수 있습니다.
RHEL 8.3 이후 osbuild-composer 백엔드는 lorax-composer 를 대체합니다. 새 서비스는 이미지 빌드를 위한 REST API를 제공합니다.
9.1.1. RHEL 이미지 빌더 용어
RHEL 이미지 빌더에서는 다음 개념을 사용합니다.
- 블루프린트
사용자 지정 시스템 이미지에 대한 설명입니다. 시스템의 일부가 될 패키지 및 사용자 정의가 나열됩니다. 사용자 지정으로 done을 편집하고 특정 버전으로 저장할 수 있습니다. 블루프린트에서 시스템 이미지를 생성하면 이미지가 RHEL 이미지 빌더 인터페이스의 블루프린트와 연결됩니다.
TOML 형식으로 블루프린트를 생성합니다.
- 작성
- 작문은 특정 버전의 특정 버전에 따라 시스템 이미지의 개별 빌드입니다. 용어로 작성하면 시스템 이미지, 생성, 입력, 메타데이터 및 프로세스 자체의 로그가 참조됩니다.
- 사용자 정의
- 사용자 지정은 패키지가 아닌 이미지의 사양입니다. 여기에는 사용자, 그룹 및 SSH 키가 포함됩니다.
9.1.2. RHEL 이미지 빌더 출력 형식
RHEL 이미지 빌더는 다음 표에 표시된 여러 출력 형식으로 이미지를 생성할 수 있습니다.
| 설명 | CLI 이름 | 파일 확장자 |
|---|---|---|
| QEMU 이미지 |
|
|
| 디스크 아카이브 |
|
|
| Amazon Web Services |
|
|
| Microsoft Azure |
|
|
| Google Cloud Platform |
|
|
| VMware vSphere |
|
|
| VMware vSphere |
|
|
| OpenStack |
|
|
| 에지 커밋 RHEL |
|
|
| 에지 컨테이너용 RHEL |
|
|
| 에지 설치 프로그램 RHEL |
|
|
| RHEL for Edge Raw Image |
|
|
| Edge Simplified Installer용 RHEL |
|
|
| RHEL for Edge AMI |
|
|
| RHEL for Edge VMDK |
|
|
| RHEL 설치 프로그램 |
|
|
| Oracle Cloud Infrastructure |
|
|
지원되는 유형을 확인하려면 명령을 실행합니다.
composer-cli compose types
# composer-cli compose types9.1.3. 이미지 빌드에 지원되는 아키텍처
RHEL 이미지 빌더에서는 다음 아키텍처의 이미지 빌드를 지원합니다.
-
AMD 및 Intel 64비트(
x86_64) -
ARM64 (
aarch64) -
IBM Z (
s390x) - IBM POWER 시스템
그러나 RHEL 이미지 빌더에서는 다중 아키텍처 빌드를 지원하지 않습니다. 이는 실행 중인 것과 동일한 시스템 아키텍처의 이미지만 빌드합니다. 예를 들어 RHEL 이미지 빌더가 x86_64 시스템에서 실행되는 경우 x86_64 아키텍처의 이미지만 빌드할 수 있습니다.
9.2. RHEL 이미지 빌더 설치
RHEL 이미지 빌더는 사용자 정의 시스템 이미지를 생성하는 툴입니다. RHEL 이미지 빌더를 사용하기 전에 설치해야 합니다.
9.2.1. RHEL 이미지 빌더 시스템 요구 사항
RHEL 이미지 빌더를 실행하는 호스트는 다음 요구 사항을 충족해야 합니다.
| 매개변수 | 필요한 최소한의 값 |
|---|---|
| 시스템 유형 | 전용 호스트 또는 가상 머신. Red Hat UBI(Universal Base Images)를 포함한 컨테이너에서 RHEL 이미지 빌더는 지원되지 않습니다. |
| 프로세서 | 2개 코어 |
| 메모리 | 4GiB |
| 디스크 공간 | ' /var/cache/' 파일 시스템에서 20GiB의 여유 공간 |
| 액세스 권한 | root |
| 네트워크 | Red Hat CDN(Content Delivery Network)에 대한 인터넷 연결. |
인터넷 연결이 없는 경우 격리된 네트워크에서 RHEL 이미지 빌더를 사용합니다. 이를 위해 Red Hat CDN(Content Delivery Network)에 연결되지 않도록 로컬 리포지토리를 가리키도록 기본 리포지토리를 재정의해야 합니다. 내부 컨텐츠를 미러링하거나 Red Hat Satellite를 사용해야 합니다.
9.2.2. RHEL 이미지 빌더 설치
모든 osbuild-composer 패키지 기능에 액세스할 수 있도록 RHEL 이미지 빌더를 설치합니다.
사전 요구 사항
- RHEL 이미지 빌더를 설치하려는 RHEL 호스트에 로그인되어 있습니다.
- 호스트는 RHSM(Red Hat Subscription Manager) 또는 Red Hat Satellite에 가입되어 있습니다.
-
BaseOS및AppStream리포지토리를 활성화하여 RHEL 이미지 빌더 패키지를 설치할 수 있습니다.
절차
RHEL 이미지 빌더 및 기타 필요한 패키지를 설치합니다.
yum install osbuild-composer composer-cli cockpit-composer
# yum install osbuild-composer composer-cli cockpit-composerCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
osbuild-composer- 사용자 지정된 RHEL 운영 체제 이미지를 빌드하는 서비스입니다. -
composer-cli- 이 패키지를 사용하면 CLI 인터페이스에 액세스할 수 있습니다. -
Cockpit-composer- 이 패키지를 사용하면 웹 UI 인터페이스에 액세스할 수 있습니다. 웹 콘솔은cockpit-composer패키지의 종속성으로 설치됩니다.
-
RHEL 이미지 빌더 소켓을 활성화하고 시작합니다.
systemctl enable --now osbuild-composer.socket
# systemctl enable --now osbuild-composer.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow 웹 콘솔에서 RHEL 이미지 빌더를 사용하려면 활성화한 후 시작합니다.
systemctl enable --now cockpit.socket
# systemctl enable --now cockpit.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow osbuild-composer및cockpit서비스는 첫 번째 액세스 시 자동으로 시작됩니다.로그아웃하지 않고
composer-cli명령의 자동 완성 기능이 즉시 작동하도록 쉘 구성 스크립트를 로드합니다.source /etc/bash_completion.d/composer-cli
$ source /etc/bash_completion.d/composer-cliCopy to Clipboard Copied! Toggle word wrap Toggle overflow
osbuild-composer 패키지는 새 백엔드 엔진으로, Red Hat Enterprise Linux 8.3 이상부터 시작하는 모든 새 기능의 기본 기본 기능 및 초점을 맞춥니다. 이전 백엔드 lorax-composer 패키지는 더 이상 사용되지 않는 것으로 간주되며, Red Hat Enterprise Linux 8 라이프 사이클의 나머지 부분에 대해서만 일부 수정 사항을 받을 수 있으며 향후 주요 릴리스에서는 생략됩니다. osbuild -composer를 대신하여 lorax-composer 를 제거하는 것이 좋습니다.
검증
composer-cli:을 실행하여 설치가 작동하는지 확인합니다.composer-cli status show
# composer-cli status showCopy to Clipboard Copied! Toggle word wrap Toggle overflow
문제 해결
시스템 저널을 사용하여 RHEL 이미지 빌더 활동을 추적할 수 있습니다. 또한 파일에서 로그 메시지를 찾을 수 있습니다.
역추적에 대한 저널 출력을 찾으려면 다음 명령을 실행합니다.
journalctl | grep osbuild
$ journalctl | grep osbuildCopy to Clipboard Copied! Toggle word wrap Toggle overflow 여러 서비스 인스턴스를 시작할 수 있는 템플릿 서비스인
osbuild-worker@.service와 같은 로컬 작업자를 표시하려면 다음을 실행합니다.journalctl -u osbuild-worker*
$ journalctl -u osbuild-worker*Copy to Clipboard Copied! Toggle word wrap Toggle overflow 실행 중인 서비스를 표시하려면 다음을 수행합니다.
journalctl -u osbuild-composer.service
$ journalctl -u osbuild-composer.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.2.3. lorax-composer RHEL 이미지 빌더 백엔드로 되돌리기
osbuild-composer 백엔드는 훨씬 더 확장 가능하지만 현재 이전 lorax-composer 백엔드와 기능 패리티를 달성하지 않습니다.
이전 백엔드로 되돌리려면 단계를 따르십시오.
사전 요구 사항
-
osbuild-composer패키지를 설치했습니다.
절차
osbuild-composer 백엔드를 제거합니다.
yum remove osbuild-composer yum remove weldr-client
# yum remove osbuild-composer # yum remove weldr-clientCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/yum.conf 파일에osbuild-composer패키지에 대한 exclude 항목을 추가합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow lorax-composer패키지를 설치합니다.yum install lorax-composer composer-cli
# yum install lorax-composer composer-cliCopy to Clipboard Copied! Toggle word wrap Toggle overflow 재부팅할 때마다
lorax-composer서비스를 활성화 및 시작하여 시작합니다.systemctl enable --now lorax-composer.socket systemctl start lorax-composer
# systemctl enable --now lorax-composer.socket # systemctl start lorax-composerCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3. RHEL 이미지 빌더 CLI를 사용하여 시스템 이미지 생성
RHEL 이미지 빌더는 사용자 정의 시스템 이미지를 생성하는 툴입니다. RHEL 이미지 빌더를 제어하고 사용자 정의 시스템 이미지를 생성하려면 CLI(명령줄) 또는 웹 콘솔 인터페이스를 사용할 수 있습니다.
9.3.1. RHEL 이미지 빌더 명령줄 인터페이스 소개
RHEL 이미지 빌더 CLI(명령줄 인터페이스)를 사용하여 적절한 옵션 및 하위 명령으로 composer-cli 명령을 실행하여 블루프린트를 생성할 수 있습니다.
명령줄의 워크플로는 다음과 같이 요약할 수 있습니다.
- 기존 블루프린트 정의를 일반 텍스트 파일에 블루프린트 또는 내보내기(저장) 생성
- 텍스트 편집기에서 이 파일 편집
- 블루프린트 텍스트 파일을 다시 이미지 빌더로 가져오기
- 작성을 실행하여 블루프린트에서 이미지를 빌드합니다.
- 이미지 파일을 내보내서 다운로드합니다.
블루프린트를 생성하기 위한 기본 하위 명령 외에도 composer-cli 명령은 구성된 블루프린트의 상태를 검사하고 구성합니다.
9.3.2. RHEL 이미지 빌더를 루트가 아닌 사용자로 사용
composer-cli 명령을 root가 아닌 것으로 실행하려면 사용자가 weldr 그룹에 있어야 합니다.
사전 요구 사항
- 사용자를 생성했습니다.
절차
weldr또는root그룹에 사용자를 추가하려면 다음 명령을 실행하십시오.sudo usermod -a -G weldr user newgrp weldr
$ sudo usermod -a -G weldr user $ newgrp weldrCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.3. 명령줄을 사용하여 블루프린트 생성
RHEL 이미지 빌더 CLI(명령줄 인터페이스)를 사용하여 새 블루프린트를 생성할 수 있습니다. 청사진은 최종 이미지와 패키지 및 커널 사용자 지정과 같은 사용자 정의를 설명합니다.
사전 요구 사항
-
root 사용자 또는
weldr그룹의 멤버인 사용자로 로그인했습니다.
절차
다음 내용을 사용하여 일반 텍스트 파일을 생성합니다.
name = "BLUEPRINT-NAME" description = "LONG FORM DESCRIPTION TEXT" version = "0.0.1" modules = [] groups = []
name = "BLUEPRINT-NAME" description = "LONG FORM DESCRIPTION TEXT" version = "0.0.1" modules = [] groups = []Copy to Clipboard Copied! Toggle word wrap Toggle overflow BLUEPRINT-NAME 및 LONG FORM DESCRIPTION TEXT 를 블루프린트의 이름 및 설명으로 바꿉니다.
0.0.1 을 Semantic Versioning 스키마에 따른 버전 번호로 바꿉니다.
블루프린트에 포함하려는 모든 패키지에 대해 파일에 다음 행을 추가합니다.
[[packages]] name = "package-name" version = "package-version"
[[packages]] name = "package-name" version = "package-version"Copy to Clipboard Copied! Toggle word wrap Toggle overflow package-name 을
httpd,gdb-doc또는coreutils와 같은 패키지 이름으로 교체합니다.선택적으로 package-version 을 사용할 버전으로 교체합니다. 이 필드는
dnf버전 사양을 지원합니다.- 특정 버전의 경우 8.7.0 과 같은 정확한 버전 번호를 사용하십시오.
- 사용 가능한 최신 버전의 경우 별표 * 를 사용합니다.
- 최신 마이너 버전의 경우 8.*와 같은 형식을 사용하십시오.
필요에 맞게 청사진을 사용자 지정합니다. 예를 들어 SMT(Simultaneous Multi Threading)를 비활성화하여 CloudEvent 파일에 다음 행을 추가합니다.
[customizations.kernel] append = "nosmt=force"
[customizations.kernel] append = "nosmt=force"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 사용 가능한 추가 사용자 정의는 지원되는 이미지 사용자 지정을 참조하십시오.
[]및[[]]는 TOML로 표현되는 다양한 데이터 구조입니다.-
[customizations.kernel]헤더는 키 및 해당 값 쌍으로 정의된 단일 테이블을 나타냅니다(예:append = "nosmt=force"). -
[[packages]]헤더는 테이블 배열을 나타냅니다. 첫 번째 인스턴스는 배열과 첫 번째 테이블 요소(예:name = "package-name"및version = "package-version")를 정의하고 각 후속 인스턴스는 사용자가 정의한 순서대로 해당 배열에 새 테이블 요소를 생성하고 정의합니다.
-
- 예를 들어 파일을 BLUEPRINT-NAME.toml로 저장하고 텍스트 편집기를 종료합니다.
선택 사항: 블루프린트 TOML 파일의 모든 설정이 올바르게 구문 분석되었는지 확인합니다. 블루프린트를 저장하고 저장된 출력을 입력 파일과 비교합니다.
composer-cli blueprints save BLUEPRINT-NAME.toml
# composer-cli blueprints save BLUEPRINT-NAME.tomlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
저장된
BLUEPRINT-NAME.toml를 입력 파일과 비교합니다.
-
저장된
블루프린트를 푸시합니다.
composer-cli blueprints push BLUEPRINT-NAME.toml
# composer-cli blueprints push BLUEPRINT-NAME.tomlCopy to Clipboard Copied! Toggle word wrap Toggle overflow BLUEPRINT-NAME 을 이전 단계에서 사용한 값으로 바꿉니다.
참고composer-cli를 사용하여 root가 아닌 이미지를 만들려면 사용자를weldr또는root그룹에 추가합니다.usermod -a -G weldr user newgrp weldr
# usermod -a -G weldr user $ newgrp weldrCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
기존 기능 목록을 나열하여 해당 기능이 푸시되고 있는지 확인합니다.
composer-cli blueprints list
# composer-cli blueprints listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 방금 추가한 청사진 구성을 표시합니다.
composer-cli blueprints show BLUEPRINT-NAME
# composer-cli blueprints show BLUEPRINT-NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트 및 해당 종속 항목에 나열된 구성 요소 및 버전이 유효한지 확인합니다.
composer-cli blueprints depsolve BLUEPRINT-NAME
# composer-cli blueprints depsolve BLUEPRINT-NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 이미지 빌더에서 사용자 정의 리포지토리에서 패키지의 종속 항목을 해결할 수 없는 경우
osbuild-composer캐시를 제거합니다.sudo rm -rf /var/cache/osbuild-composer/* sudo systemctl restart osbuild-composer
$ sudo rm -rf /var/cache/osbuild-composer/* $ sudo systemctl restart osbuild-composerCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.4. 명령줄을 사용하여 블루프린트 편집
예를 들어 새 패키지를 추가하거나 새 그룹을 정의하고 사용자 지정 이미지를 생성하기 위해 CLI(명령줄)에서 기존 블루프린트를 편집할 수 있습니다.
사전 요구 사항
- 블루프린트를 생성했습니다.
절차
기존 블루프린트를 나열합니다.
composer-cli blueprints list
# composer-cli blueprints listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트를 로컬 텍스트 파일에 저장합니다.
composer-cli blueprints save BLUEPRINT-NAME
# composer-cli blueprints save BLUEPRINT-NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow - 텍스트 편집기로 BLUEPRINT-NAME.toml 파일을 편집하고 변경합니다.
편집을 완료하기 전에 파일이 유효한 청사진인지 확인합니다.
블루프린트에서 다음 행을 제거합니다.
packages = []
packages = []Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 버전 번호를 0.0.1에서 0.1.0으로 늘립니다. RHEL 이미지 빌더 블루프린트 버전에서는 Semantic Versioning 스키마를 사용해야 합니다. 또한 버전을 변경하지 않으면 패치 버전 구성 요소가 자동으로 증가합니다.
- 파일을 저장하고 텍스트 편집기를 종료합니다.
블루프린트를 RHEL 이미지 빌더로 다시 푸시합니다.
composer-cli blueprints push BLUEPRINT-NAME.toml
# composer-cli blueprints push BLUEPRINT-NAME.tomlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고블루프린트를 RHEL 이미지 빌더로 다시 가져오려면
.toml확장을 포함한 파일 이름을 제공하고 다른 명령에서는 블루프린트 이름만 사용합니다.
검증
RHEL 이미지 빌더에 업로드된 콘텐츠가 편집 내용과 일치하는지 확인하려면 블루프린트 내용을 나열합니다.
composer-cli blueprints show BLUEPRINT-NAME
# composer-cli blueprints show BLUEPRINT-NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트 및 해당 종속 항목에 나열된 구성 요소 및 버전이 유효한지 확인합니다.
composer-cli blueprints depsolve BLUEPRINT-NAME
# composer-cli blueprints depsolve BLUEPRINT-NAMECopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.5. 명령줄에서 RHEL 이미지 빌더를 사용하여 시스템 이미지 생성
RHEL 이미지 빌더 명령줄 인터페이스를 사용하여 사용자 지정 RHEL 이미지를 빌드할 수 있습니다. 이를 위해 블루프린트와 이미지 유형을 지정해야 합니다. 선택적으로 배포를 지정할 수도 있습니다. 배포를 지정하지 않으면 호스트 시스템과 동일한 배포 및 버전을 사용합니다. 아키텍처는 호스트의 아키텍처와 동일합니다.
사전 요구 사항
- 이미지에 대해 준비된 청사진이 있습니다. 명령줄을 사용하여 RHEL 이미지 빌더 블루프린트 생성을 참조하십시오.
절차
선택 사항: 생성할 수 있는 이미지 형식을 나열합니다.
composer-cli compose types
# composer-cli compose typesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 작성을 시작합니다.
composer-cli compose start BLUEPRINT-NAME IMAGE-TYPE
# composer-cli compose start BLUEPRINT-NAME IMAGE-TYPECopy to Clipboard Copied! Toggle word wrap Toggle overflow BLUEPRINT-NAME 을 블루프린트 이름으로 바꾸고, IMAGE-TYPE 을 이미지 유형으로 바꿉니다. 사용 가능한 값은
composer-cli compose types명령의 출력을 참조하십시오.compose 프로세스는 백그라운드에서 시작되고 composer Universally Unique Identifier (UUID)를 표시합니다.
이미지 생성을 완료하는 데 최대 10분이 걸릴 수 있습니다.
작성 상태를 확인하려면 다음을 수행합니다.
composer-cli compose status
# composer-cli compose statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 완료된 작성에는 FINISHED 상태 값이 표시됩니다. 목록에서 Composer를 식별하려면 해당 UUID를 사용합니다.
작성 프로세스가 완료되면 결과 이미지 파일을 다운로드합니다.
composer-cli compose image UUID
# composer-cli compose image UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow UUID 를 이전 단계에 표시된 UUID 값으로 바꿉니다.
검증
이미지를 생성한 후 다음 명령을 사용하여 이미지 생성 진행 상황을 확인할 수 있습니다.
이미지의 메타데이터를 다운로드하여 구성 요소에 대한 메타데이터의
.tar파일을 가져옵니다.sudo composer-cli compose metadata UUID
$ sudo composer-cli compose metadata UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미지 로그를 다운로드합니다.
sudo composer-cli compose logs UUID
$ sudo composer-cli compose logs UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 이미지 생성을 위한 로그가 포함된
.tar파일을 생성합니다. 로그가 비어 있으면 저널을 확인할 수 있습니다.저널 확인:
journalctl | grep osbuild
$ journalctl | grep osbuildCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미지 매니페스트를 확인합니다.
sudo cat /var/lib/osbuild-composer/jobs/job_UUID.json
$ sudo cat /var/lib/osbuild-composer/jobs/job_UUID.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow journal에서 job_UUID.json을 찾을 수 있습니다.
9.3.6. 기본 RHEL 이미지 빌더 명령줄 명령
RHEL 이미지 빌더 명령줄 인터페이스는 다음 하위 명령을 제공합니다.
블루프린트 조작
- 사용 가능한 모든 블루프린트 나열
composer-cli blueprints list
# composer-cli blueprints listCopy to Clipboard Copied! Toggle word wrap Toggle overflow - TOML 형식의 블루프린트 콘텐츠 표시
composer-cli blueprints show <BLUEPRINT-NAME>
# composer-cli blueprints show <BLUEPRINT-NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - TOML 형식으로 블루프린트 내용을 파일 BLUEPRINT-NAME.todir에 저장합니다.
composer-cli blueprints save <BLUEPRINT-NAME>
# composer-cli blueprints save <BLUEPRINT-NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 블루프린트 제거
composer-cli blueprints delete <BLUEPRINT-NAME>
# composer-cli blueprints delete <BLUEPRINT-NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - TOML 형식의 블루프린트 파일을 RHEL 이미지 빌더로 푸시(가져오기)
composer-cli blueprints push <BLUEPRINT-NAME>
# composer-cli blueprints push <BLUEPRINT-NAME>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
블루프린트에서 이미지 구성
- 사용 가능한 이미지 유형 나열
composer-cli compose types
# composer-cli compose typesCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 작성 시작
composer-cli compose start <BLUEPRINT> <COMPOSE-TYPE>
# composer-cli compose start <BLUEPRINT> <COMPOSE-TYPE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 모든 작성 사항 나열
composer-cli compose list
# composer-cli compose listCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 모든 작성 및 해당 상태 나열
composer-cli compose status
# composer-cli compose statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 실행 중인 작성 취소
composer-cli compose cancel <COMPOSE-UUID>
# composer-cli compose cancel <COMPOSE-UUID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 완료된 작성 삭제
composer-cli compose delete <COMPOSE-UUID>
# composer-cli compose delete <COMPOSE-UUID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 작성에 대한 자세한 정보 표시
composer-cli compose info <COMPOSE-UUID>
# composer-cli compose info <COMPOSE-UUID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 작성 이미지 파일 다운로드
composer-cli compose image <COMPOSE-UUID>
# composer-cli compose image <COMPOSE-UUID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 더 많은 하위 명령 및 옵션 보기
composer-cli help
# composer-cli helpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.7. RHEL 이미지 빌더 블루프린트 형식
RHEL 이미지 빌더 블루프린트는 TOML 형식의 일반 텍스트로 사용자에게 제공됩니다.
일반적인 청사진 파일의 요소는 다음과 같습니다.
- 블루프린트 메타데이터
name = "<BLUEPRINT-NAME>" description = "<LONG FORM DESCRIPTION TEXT>" version = "<VERSION>"
name = "<BLUEPRINT-NAME>" description = "<LONG FORM DESCRIPTION TEXT>" version = "<VERSION>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow BLUEPRINT-NAME 및 LOECDHE FORM DESCRIPTION TEXT 필드는 귀하의 청사진의 이름과 설명입니다.
VERSION 은 Semantic Versioning 스키마에 따른 버전 번호이며 전체 블루프린트 파일에 대해 한 번만 제공됩니다.
- 이미지에 포함할 그룹
[[groups]] name = "group-name"
[[groups]] name = "group-name"Copy to Clipboard Copied! Toggle word wrap Toggle overflow group 항목은 이미지에 설치할 패키지 그룹을 설명합니다. 그룹은 다음과 같은 패키지 범주를 사용합니다.
- 필수 항목
- Default
선택 사항
group-name 은 그룹의 이름입니다(예: anaconda-tools, 위젯, Clair 또는 사용자 ). templates는 필수 및 기본 패키지를 설치합니다. 옵션 패키지를 선택하는 메커니즘은 없습니다.
- 이미지에 포함할 패키지
[[packages]] name = "<package-name>" version = "<package-version>"
[[packages]] name = "<package-name>" version = "<package-version>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow package-name 은 httpd, gdb-doc 또는 coreutils 와 같은 패키지 이름입니다.
package-version 은 사용할 버전입니다. 이 필드는
dnf버전 사양을 지원합니다.- 특정 버전의 경우 8.7.0 과 같은 정확한 버전 번호를 사용하십시오.
- 사용 가능한 최신 버전의 경우 별표 * 를 사용합니다.
최신 마이너 버전의 경우 8과 같은 형식을 사용합니다.*
포함할 모든 패키지에 대해 이 블록을 반복합니다.
RHEL 이미지 빌더 툴의 패키지와 모듈 간에 차이가 없습니다. 둘 다 RPM 패키지 종속성으로 처리됩니다.
9.3.8. 지원되는 이미지 사용자 정의
다음과 같은 블루프린트에 사용자 지정을 추가하여 이미지를 사용자 지정할 수 있습니다.
- 추가 RPM 패키지 추가
- 서비스 활성화
- 커널 명령줄 매개 변수 사용자 정의.
다른 사람 사이입니다. sshd 내에서 여러 이미지 사용자 지정을 사용할 수 있습니다. 사용자 지정을 사용하면 기본 패키지에서 사용할 수 없는 이미지에 패키지 및 그룹을 추가할 수 있습니다. 이러한 옵션을 사용하려면 블루프린트에서 사용자 지정을 구성하고 RHEL 이미지 빌더로 가져오기(push)합니다.
9.3.8.1. 배포 선택
distro 필드를 사용하여 이미지를 구성하거나 블루프린트의 종속성을 해결할 때 사용할 배포를 지정할 수 있습니다. distro 필드를 비워 두면 블루프린트에서 호스트의 운영 체제 배포를 자동으로 사용합니다. 배포를 지정하지 않으면 블루프린트에서 호스트 배포를 사용합니다. 호스트 운영 체제를 업그레이드할 때 업그레이드된 운영 체제 버전을 사용하여 지정된 배포 빌드 이미지가 없는 블루프린트입니다.
최신 시스템에서 이전 주요 버전의 이미지를 빌드할 수 있습니다. 예를 들어 RHEL 10 호스트를 사용하여 RHEL 9 및 RHEL 8 이미지를 생성할 수 있습니다. 그러나 이전 시스템에서 최신 주요 버전의 이미지를 빌드할 수 없습니다.
RHEL 이미지 빌더 호스트와 다른 운영 체제 이미지를 빌드할 수 없습니다. 예를 들어 RHEL 시스템을 사용하여 Fedora 또는 CentOS 이미지를 빌드할 수 없습니다.
항상 지정된 RHEL 이미지를 빌드하도록 RHEL 배포를 사용하여 블루프린트를 사용자 지정합니다.
name = "blueprint_name" description = "blueprint_version" version = "0.1" distro = "different_minor_version"
name = "blueprint_name" description = "blueprint_version" version = "0.1" distro = "different_minor_version"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
name = "tmux" description = "tmux image with openssh" version = "1.2.16" distro = "rhel-9.5"
name = "tmux" description = "tmux image with openssh" version = "1.2.16" distro = "rhel-9.5"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
"different_minor_version"을 교체하여 다른 마이너 버전을 빌드합니다. 예를 들어 RHEL 8.10 이미지를 빌드하려면 distro = "rhel-810"을 사용합니다. RHEL 8.10 이미지에서 RHEL 8.9 및 이전 릴리스와 같은 마이너 버전을 빌드할 수 있습니다.
9.3.8.2. 패키지 그룹 선택
패키지 그룹으로 블루프린트를 사용자 지정합니다. 그룹 목록은 이미지에 설치할 패키지 그룹을 설명합니다. 패키지 그룹은 리포지토리 메타데이터에 정의되어 있습니다. 각 그룹에는 주로 사용자 인터페이스에 표시하는 데 사용되는 설명적인 이름과 Kickstart 파일에서 일반적으로 사용되는 ID가 있습니다. 이 경우 ID를 사용하여 그룹을 나열해야 합니다. 그룹에는 필수, 기본값, 선택 사항 등 패키지를 분류하는 세 가지 방법이 있습니다. 필수 및 기본 패키지만 블루프린트에 설치됩니다. 선택적 패키지를 선택할 수 없습니다.
name 속성은 필수 문자열이며 리포지토리의 패키지 그룹 ID와 정확히 일치해야 합니다.
현재 osbuild-composer 의 패키지와 모듈 간에는 차이가 없습니다. 둘 다 RPM 패키지 종속성으로 취급됩니다.
패키지로 블루프린트를 사용자 지정합니다.
[[groups]] name = "group_name"
[[groups]] name = "group_name"Copy to Clipboard Copied! Toggle word wrap Toggle overflow group_name을 그룹 이름으로 교체합니다. 예:anaconda-tools:[[groups]] name = "anaconda-tools"
[[groups]] name = "anaconda-tools"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.3. 컨테이너 포함
블루프린트를 사용자 지정하여 최신 RHEL 컨테이너를 포함할 수 있습니다. 컨테이너 목록에는 소스가 있는 오브젝트와 필요한 경우 tls-verify 속성이 포함되어 있습니다.
컨테이너 목록 항목은 이미지에 포함할 컨테이너 이미지를 설명합니다.
-
Source- 필수 필드입니다. 레지스트리의 컨테이너 이미지에 대한 참조입니다. 이 예에서는registry.access.redhat.com레지스트리를 사용합니다. 태그 버전을 지정할 수 있습니다. 기본 태그 버전은 latest입니다. -
name- 로컬 레지스트리에 있는 컨테이너의 이름입니다. -
tls-verify- 부울 필드. tls-verify 부울 필드는 전송 계층 보안을 제어합니다. 기본값은 true입니다.
포함된 컨테이너는 자동으로 시작되지 않습니다. 시작하려면 파일 사용자 지정이 포함된 systemd 장치 파일 또는 사각형을 만듭니다.
registry.access.redhat.com/ubi9/ubi:latest의 컨테이너와 호스트의 컨테이너를 포함하려면 블루프린트에 다음 사용자 지정을 추가합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
containers-auth.json 파일을 사용하여 보호된 컨테이너 리소스에 액세스할 수 있습니다. 컨테이너 레지스트리 인증 정보를 참조하십시오.
9.3.8.4. 이미지 호스트 이름 설정
customization .hostname 은 최종 이미지 호스트 이름을 구성하는 데 사용할 수 있는 선택적 문자열입니다. 이 사용자 지정은 선택 사항이며 설정하지 않으면 블루프린트에서 기본 호스트 이름을 사용합니다.
블루프린트를 사용자 지정하여 호스트 이름을 구성합니다.
[customizations] hostname = "baseimage"
[customizations] hostname = "baseimage"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.5. 추가 사용자 지정
이미지에 사용자를 추가하고 선택적으로 SSH 키를 설정합니다. 이 섹션의 모든 필드는 이름을 제외하고 선택 사항입니다.
절차
이미지에 사용자를 추가하도록 블루프린트를 사용자 지정합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow GID는 선택 사항이며 이미지에 이미 있어야 합니다. 선택적으로 패키지에서 이를 생성하거나,
[customizations.group]항목을 사용하여 GID를 생성합니다.PASSWORD-HASH 를 실제
암호 해시로 바꿉니다.암호 해시를 생성하려면 다음과 같은 명령을 사용합니다.python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다른 자리 표시자를 적절한 값으로 바꿉니다.
name값을 입력하고 필요하지 않은 행을 생략합니다.모든 사용자가 포함할 이 블록을 반복합니다.
9.3.8.6. 추가 그룹 지정
결과 시스템 이미지에 대한 그룹을 지정합니다. name 및 gid 속성은 모두 필수입니다.
그룹으로 블루프린트를 사용자 지정합니다.
[[customizations.group]] name = "GROUP-NAME" gid = NUMBER
[[customizations.group]] name = "GROUP-NAME" gid = NUMBERCopy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 그룹이 포함할 이 블록을 반복합니다. 예를 들면 다음과 같습니다.
[[customizations.group]] name = "widget" gid = 1130
[[customizations.group]] name = "widget" gid = 1130Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.7. 기존 사용자를 위한 SSH 키 설정
custom .sshkey 를 사용하여 최종 이미지에 있는 기존 사용자의 SSH 키를 설정할 수 있습니다. 사용자 및 키 속성은 모두 필수입니다.
기존 사용자의 SSH 키를 설정하여 블루프린트를 사용자 지정합니다.
[[customizations.sshkey]] user = "root" key = "PUBLIC-SSH-KEY"
[[customizations.sshkey]] user = "root" key = "PUBLIC-SSH-KEY"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
[[customizations.sshkey]] user = "root" key = "SSH key for root"
[[customizations.sshkey]] user = "root" key = "SSH key for root"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고기존 사용자에 대한 customization
.sshkey 사용자지정만 구성할 수 있습니다. 사용자를 생성하고 SSH 키를 설정하려면 추가 사용자 사용자 지정을 참조하십시오.
9.3.8.8. 커널 인수 추가
부트 로더 커널 명령줄에 인수를 추가할 수 있습니다. 기본적으로 RHEL 이미지 빌더는 기본 커널을 이미지에 빌드합니다. 그러나 블루프린트에서 커널을 구성하여 커널을 사용자 지정할 수 있습니다.
커널 부팅 매개변수 옵션을 기본값에 추가합니다.
[customizations.kernel] append = "KERNEL-OPTION"
[customizations.kernel] append = "KERNEL-OPTION"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
[customizations.kernel] name = "kernel-debug" append = "nosmt=force"
[customizations.kernel] name = "kernel-debug" append = "nosmt=force"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.9. 실시간 커널을 사용하여 RHEL 이미지 빌드
실시간 커널(kernel-rt)을 사용하여 RHEL 이미지를 빌드하려면 리포지토리를 재정의해야 kernel-rt 가 기본 커널로 올바르게 선택되는 이미지를 빌드할 수 있습니다. /usr/share/osbuild-composer/repositories/ 디렉터리의 .json 을 사용합니다. 그런 다음 시스템에 빌드한 이미지를 배포하고 실시간 커널 기능을 사용할 수 있습니다.
실시간 커널은 Red Hat Enterprise Linux 실행을 위해 인증된 AMD64 및 Intel 64 서버 플랫폼에서 실행됩니다.
사전 요구 사항
- 시스템이 등록되고 RHEL이 RHEL for Real Time 서브스크립션에 연결되어 있습니다. dnf를 사용하여 실시간 RHEL 설치를 참조하십시오.
절차
다음 디렉터리를 생성합니다.
mkdir /etc/osbuild-composer/repositories/
# mkdir /etc/osbuild-composer/repositories/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /usr/share/osbuild-composer/repositories/rhel-8.버전.json파일의 내용을 새 디렉터리로 복사합니다.cp /usr/share/osbuild-composer/repositories/rhel-8.version.json /etc/osbuild-composer/repositories
# cp /usr/share/osbuild-composer/repositories/rhel-8.version.json /etc/osbuild-composer/repositoriesCopy to Clipboard Copied! Toggle word wrap Toggle overflow RT 커널 리포지터리를 포함하도록
/etc/osbuild-composer/repositories/rhel-8.버전.json파일을 편집합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 서비스를 다시 시작하십시오.
systemctl restart osbuild-composer
# systemctl restart osbuild-composerCopy to Clipboard Copied! Toggle word wrap Toggle overflow kernel-rt가.json파일에 포함되어 있는지 확인합니다.composer-cli sources list composer-cli sources info kernel-rt
# composer-cli sources list # composer-cli sources info kernel-rtCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전에 구성한 URL이 표시됩니다.
블루프린트를 생성합니다. 블루프린트에서 "[customizations.kernel]" 사용자 지정을 추가합니다. 다음은 블루프린트에 "[customizations.kernel]"을 포함하는 예입니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트를 서버로 푸시합니다.
composer-cli blueprints push rt-kernel-image.toml
# composer-cli blueprints push rt-kernel-image.tomlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 생성한 블루프린트에서 이미지를 빌드합니다. 다음 예제에서는 (
.qcow2) 이미지를 빌드합니다.composer-cli compose start rt-kernel-image qcow2
# composer-cli compose start rt-kernel-image qcow2Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 실시간 커널 기능을 사용하려는 시스템에 빌드한 이미지를 배포합니다.
검증
이미지에서 VM을 부팅한 후 이미지가 기본
커널로올바르게 선택되었는지 확인합니다.cat /proc/cmdline BOOT_IMAGE=(hd0,got3)/vmlinuz-5.14.0-362.24.1..el8_version_.x86_64+rt...
$ cat /proc/cmdline BOOT_IMAGE=(hd0,got3)/vmlinuz-5.14.0-362.24.1..el8_version_.x86_64+rt...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.10. 시간대 및 NTP 설정
블루프린트를 사용자 지정하여 시간대 및 NTP( Network Time Protocol )를 구성할 수 있습니다. timezone 및 ntpservers 속성은 모두 선택적 문자열입니다. 시간대를 사용자 지정하지 않으면 시스템은 UTC( Universal Time, Coordinated )를 사용합니다. NTP 서버를 설정하지 않으면 시스템은 기본 배포를 사용합니다.
시간대및 원하는ntpservers로 블루프린트를 사용자 지정합니다.[customizations.timezone] timezone = "TIMEZONE" ntpservers = "NTP_SERVER"
[customizations.timezone] timezone = "TIMEZONE" ntpservers = "NTP_SERVER"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
[customizations.timezone] timezone = "US/Eastern" ntpservers = ["0.north-america.pool.ntp.org", "1.north-america.pool.ntp.org"]
[customizations.timezone] timezone = "US/Eastern" ntpservers = ["0.north-america.pool.ntp.org", "1.north-america.pool.ntp.org"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Google Cloud와 같은 일부 이미지 유형에는 이미 NTP 서버가 설정되어 있습니다. 이미지에 선택한 환경에서 NTP 서버를 부팅해야 하므로 재정의할 수 없습니다. 그러나 블루프린트에서 시간대를 사용자 지정할 수 있습니다.
9.3.8.11. 로케일 설정 사용자 정의
결과 시스템 이미지에 대한 로케일 설정을 사용자 지정할 수 있습니다. 언어 및 키보드 속성은 모두 필수입니다. 다른 많은 언어를 추가할 수 있습니다. 첫 번째 언어는 기본 언어이며 다른 언어는 보조 언어입니다.
절차
로케일 설정을 설정합니다.
[customizations.locale] languages = ["LANGUAGE"] keyboard = "KEYBOARD"
[customizations.locale] languages = ["LANGUAGE"] keyboard = "KEYBOARD"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
[customizations.locale] languages = ["en_US.UTF-8"] keyboard = "us"
[customizations.locale] languages = ["en_US.UTF-8"] keyboard = "us"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 언어에서 지원하는 값을 나열하려면 다음 명령을 실행합니다.
localectl list-locales
$ localectl list-localesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 키보드에서 지원하는 값을 나열하려면 다음 명령을 실행합니다.
localectl list-keymaps
$ localectl list-keymapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.12. 방화벽 사용자 정의
결과 시스템 이미지에 대한 방화벽을 설정합니다. 기본적으로 방화벽은 sshd 와 같이 포트를 명시적으로 활성화하는 서비스를 제외하고 들어오는 연결을 차단합니다.
[customizations.firewall] 또는 [customizations.firewall.services] 를 사용하지 않으려는 경우 속성을 제거하거나 빈 목록 []으로 설정합니다. 기본 방화벽 설정만 사용하려는 경우 블루프린트에서 사용자 지정을 생략할 수 있습니다.
Google 및 OpenStack 템플릿은 해당 환경의 방화벽을 명시적으로 비활성화합니다. 블루프린트를 설정하여 이 동작을 재정의할 수 없습니다.
절차
다음 설정으로 블루프린트를 사용자 지정하여 다른 포트 및 서비스를 엽니다.
[customizations.firewall] ports = ["PORTS"]
[customizations.firewall] ports = ["PORTS"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서 port는 열 포트 또는 포트 및 프로토콜 범위를 포함하는 선택적 문자열 목록입니다.
port:protocol형식을 사용하여 포트를 구성할 수 있습니다.portA-portB:protocol형식을 사용하여 포트 범위를 구성할 수 있습니다. 예를 들면 다음과 같습니다.[customizations.firewall] ports = ["22:tcp", "80:tcp", "imap:tcp", "53:tcp", "53:udp", "30000-32767:tcp", "30000-32767:udp"]
[customizations.firewall] ports = ["22:tcp", "80:tcp", "imap:tcp", "53:tcp", "53:udp", "30000-32767:tcp", "30000-32767:udp"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 숫자 포트 또는
/etc/services의 해당 이름을 사용하여 포트 목록을 활성화하거나 비활성화할 수 있습니다.customization
.firewall.service 섹션에서 활성화 또는 비활성화할 방화벽 서비스를 지정합니다.[customizations.firewall.services] enabled = ["SERVICES"] disabled = ["SERVICES"]
[customizations.firewall.services] enabled = ["SERVICES"] disabled = ["SERVICES"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 사용 가능한 방화벽 서비스를 확인할 수 있습니다.
firewall-cmd --get-services
$ firewall-cmd --get-servicesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
[customizations.firewall.services] enabled = ["ftp", "ntp", "dhcp"] disabled = ["telnet"]
[customizations.firewall.services] enabled = ["ftp", "ntp", "dhcp"] disabled = ["telnet"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고firewall.services에 나열된 서비스는/etc/services파일에서 사용할 수 있는 서비스이름과다릅니다.
9.3.8.13. 서비스 활성화 또는 비활성화
부팅 시 활성화할 서비스를 제어할 수 있습니다. 일부 이미지 유형에는 이미지가 올바르게 작동하고 이 설정을 재정의할 수 없도록 서비스가 이미 활성화되어 있거나 비활성화되어 있습니다. 블루프린트의 [customizations.services] 설정은 이러한 서비스를 대체하지 않고 이미지 템플릿에 이미 있는 서비스 목록에 서비스를 추가합니다.
부팅 시 활성화할 서비스를 사용자 지정합니다.
[customizations.services] enabled = ["SERVICES"] disabled = ["SERVICES"]
[customizations.services] enabled = ["SERVICES"] disabled = ["SERVICES"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
[customizations.services] enabled = ["sshd", "cockpit.socket", "httpd"] disabled = ["postfix", "telnetd"]
[customizations.services] enabled = ["sshd", "cockpit.socket", "httpd"] disabled = ["postfix", "telnetd"]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.14. ISO 이미지에 Kickstart 파일 삽입
[customization.installer] 블루프린트 사용자 지정을 사용하여 이미지 설치 프로그램 또는 빌드에 고유한 Kickstart 파일을 추가하고 베어 메탈 배포를 위한 ISO 이미지를 빌드할 때 유연성을 높일 수 있습니다.
에지 설치 프로그램과 같은 ISO 설치 프로그램
Kickstart는 시스템의 첫 번째 디스크를 자동으로 다시 포맷하도록 구성되므로 기존 운영 체제 또는 데이터를 사용하여 시스템에서 ISO를 부팅하는 것은 안전하지 않을 수 있습니다.
다음 옵션을 선택하여 고유한 Kickstart 파일을 추가할 수 있습니다.
- 설치 프로세스 중에 모든 값을 설정합니다.
-
Kickstart에서
unattended = true필드를 활성화하고 기본값으로 완전히 무인 설치를 가져옵니다. - Kickstart 필드를 사용하여 자체 Kickstart 삽입. 이렇게 하면 모든 필수 필드를 지정하거나 설치 관리자가 누락될 수 있는 일부 필드를 묻는 경우 완전히 무인 설치가 발생할 수 있습니다.
Anaconda 설치 프로그램 ISO 이미지 유형은 다음 블루프린트 사용자 지정을 지원합니다.
[customizations.installer] unattended = true sudo-nopasswd = ["user", "%wheel"]
[customizations.installer]
unattended = true
sudo-nopasswd = ["user", "%wheel"]
무인: 설치를 완전히 자동으로 만드는 Kickstart 파일을 만듭니다. 여기에는 기본적으로 다음 옵션 설정이 포함됩니다.
- 텍스트 표시 모드
- en_US.UTF-8 언어/로컬
- us keyboard layout
- UTC 시간대
- zerombr, clearpart, autopart를 입력하여 첫 번째 디스크를 자동으로 지우고 파티션합니다.
- dhcp 및 auto-activation을 활성화하는 네트워크 옵션
다음은 예제입니다.
sudo-nopasswd: 설치 후 /etc/sudoers.d 에 드롭인 파일을 생성하여 지정된 사용자 및 그룹이 암호 없이 sudo를 실행할 수 있도록 Kickstart 파일에 스니펫을 추가합니다. 그룹 앞에 % 를 붙여야 합니다. 예를 들어 값을 ["user"로 설정하면 "%wheel"] 에서 다음 Kickstart %post 섹션이 생성됩니다.
설치 프로그램 Kickstart
또는 다음 사용자 지정을 사용하여 사용자 지정 Kickstart를 포함할 수 있습니다.
osbuild-composer 는 image-installer 또는 edge-installer 이미지 유형과 관련된 경우 system: liveimg 또는 ostreesetup 을 설치하는 명령을 자동으로 추가합니다. 다른 설치 프로그램 사용자 정의와 함께 [customizations.installer.kickstart] 사용자 지정을 사용할 수 없습니다.
9.3.8.15. 파티션 모드 지정
partitioning_mode 변수를 사용하여 빌드 중인 디스크 이미지를 파티션하는 방법을 선택합니다. 다음과 같은 지원되는 모드로 이미지를 사용자 지정할 수 있습니다.
-
auto-lvm: 하나 이상의 파일 시스템 사용자 지정이 없는 경우 원시 파티션 모드를 사용합니다. 이 경우 LVM 파티션 모드를 사용합니다. -
lvm: 추가 마운트 지점이 없는 경우에도 LVM 파티션 모드를 사용합니다. -
Raw: 마운트 지점이 하나 이상 있는 경우에도 원시 파티션을 사용합니다. 다음 사용자 지정을 사용하여
partitioning_mode변수로 블루프린트를 사용자 지정할 수 있습니다.[customizations] partitioning_mode = "lvm"
[customizations] partitioning_mode = "lvm"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.3.8.16. 사용자 정의 파일 시스템 구성 지정
블루프린트에서 사용자 지정 파일 시스템 구성을 지정하고 기본 레이아웃 구성 대신 특정 디스크 레이아웃으로 이미지를 생성할 수 있습니다. 블루프린트에서 기본이 아닌 레이아웃 구성을 사용하면 다음과 같은 이점을 얻을 수 있습니다.
- 보안 벤치마크 준수
- 디스크 부족 오류로부터 보호
- 성능 개선
- 기존 설정과의 일관성
OSTree 이미지에는 읽기 전용과 같은 자체 마운트 규칙이 있으므로 OSTree 시스템은 파일 시스템 사용자 정의를 지원하지 않습니다. 다음 이미지 유형은 지원되지 않습니다.
-
image-installer -
edge-installer -
edge-simplified-installer
또한 이러한 이미지 유형은 분할된 운영 체제 이미지를 생성하지 않으므로 다음 이미지 유형에서는 파일 시스템 사용자 정의를 지원하지 않습니다.
-
edge-commit -
edge-container -
tar -
container
그러나 다음 이미지 유형에서는 파일 시스템 사용자 지정을 지원합니다.
-
simplified-installer -
edge-raw-image -
edge-ami -
edge-vsphere
OSTree 시스템에 대한 몇 가지 추가 예외를 제외하고 파일 시스템의 /root 수준에서 임의의 디렉터리 이름을 선택할 수 있습니다(예: '/local',' /mypartition', /$ CryostatITION ). 논리 볼륨에서 이러한 변경 사항은 LVM 파티션 시스템에서 수행됩니다. 다음 디렉터리는 별도의 논리 볼륨에서 /var,' /var/log' 및 /var/lib/containers 가 지원됩니다. root 수준에서 예외는 다음과 같습니다.
- "/home": {Deny: true},
- "/mnt": {Deny: true},
- "/opt": {Deny: true},
- "/ostree": {Deny: true},
- "/root": {Deny: true},
- "/srv": {Deny: true},
- "/var/home": {Deny: true},
- "/var/mnt": {Deny: true},
- "/var/opt": {Deny: true},
- "/var/roothome": {Deny: true},
- "/var/srv": {Deny: true},
- "/var/usrlocal": {Deny: true},
RHEL 8.10 및 9.5 이전의 릴리스 배포의 경우 블루프린트는 다음 마운트 지점 및 해당 하위 디렉터리를 지원합니다.
-
/- 루트 마운트 지점 -
/var -
/home -
/opt -
/srv -
/usr -
/app -
/data -
/tmp
RHEL 9.5 및 8.10 릴리스 이후 릴리스 배포에서는 운영 체제용으로 예약된 특정 경로를 제외하고 임의의 사용자 지정 마운트 지점을 지정할 수 있습니다.
다음 마운트 지점 및 해당 하위 디렉터리에 임의의 사용자 지정 마운트 지점을 지정할 수 없습니다.
-
/bin -
/boot/efi -
/dev -
/etc -
/lib -
/lib64 -
/lost+found -
/proc -
/run -
/sbin -
/sys -
/sysroot -
/var/lock -
/var/run
/usr 사용자 지정 마운트 지점의 블루프린트에서 파일 시스템을 사용자 지정할 수 있지만 하위 디렉터리는 허용되지 않습니다.
마운트 지점 사용자 지정은 CLI를 사용하여 RHEL 8.5 이후에만 지원됩니다. 이전 배포에서는 루트 파티션을 마운트 지점으로만 지정하고 size 인수를 이미지 크기의 별칭으로 지정할 수 있습니다. RHEL 8.6부터 osbuild-composer-46.1-1.el8 RPM 및 이후 버전의 경우 물리적 파티션을 더 이상 사용할 수 없으며 파일 시스템 사용자 지정으로 논리 볼륨을 생성합니다.
사용자 지정된 이미지에 두 개 이상의 파티션이 있는 경우 LVM에 사용자 지정된 파일 시스템 파티션을 사용하여 이미지를 만들고 런타임 시 해당 파티션의 크기를 조정할 수 있습니다. 이렇게 하려면 블루프린트에서 사용자 지정 파일 시스템 구성을 지정하고 필요한 디스크 레이아웃을 사용하여 이미지를 생성할 수 있습니다. 기본 파일 시스템 레이아웃은 변경되지 않은 상태로 유지됩니다. 파일 시스템 사용자 지정 없이 일반 이미지를 사용하고 cloud-init 는 루트 파티션의 크기를 조정합니다.
블루프린트는 파일 시스템 사용자 지정을 LVM 파티션으로 자동 변환합니다.
사용자 지정 파일 블루프린트 사용자 지정을 사용하여 새 파일을 생성하거나 기존 파일을 교체할 수 있습니다. 지정한 파일의 상위 디렉터리가 있어야 합니다. 그렇지 않으면 이미지 빌드가 실패합니다. [customizations.directories] 사용자 지정에 상위 디렉터리가 있는지 확인합니다.
파일 사용자 정의를 다른 블루프린트 사용자 정의와 결합하면 다른 사용자 정의 기능에 영향을 주거나 현재 파일 사용자 정의를 재정의할 수 있습니다.
9.3.8.16.1. 블루프린트에 사용자 지정 파일 지정
[customizations.files] 블루프린트 사용자 지정을 사용하면 다음을 수행할 수 있습니다.
- 새 텍스트 파일을 생성합니다.
- 기존 파일 수정. 경고: 기존 콘텐츠를 덮어쓸 수 있습니다.
- 생성 중인 파일에 대한 사용자 및 그룹 소유권을 설정합니다.
- 8진수 형식으로 모드 권한을 설정합니다.
다음 파일을 생성하거나 교체할 수 없습니다.
-
/etc/fstab -
/etc/shadow -
/etc/passwd -
/etc/group
[customizations.files] 및 및 디렉터리를 생성할 수 있습니다. 이러한 사용자 지정은 [[customizations.directories]] 블루프린트 사용자 지정을 사용하여 이미지에 사용자 지정 파일/etc 디렉토리에서만 사용할 수 있습니다.
이러한 블루프린트 사용자 정의는 edge-raw-image,edge-installer, edge-simplified-installer 와 같은 OSTree 커밋을 배포하는 이미지 유형을 제외하고 모든 이미지 유형에서 지원됩니다.
이미 설정된 모드,사용자 또는 그룹이 설정된 이미지에 이미 존재하는 디렉터리 경로에 custom .directories 를 사용하는 경우 이미지 빌드에서 기존 디렉터리의 소유권 또는 권한을 변경하지 못합니다.
9.3.8.16.2. 블루프린트에 사용자 지정 디렉터리 지정
[customizations.directories] 블루프린트 사용자 지정을 사용하면 다음을 수행할 수 있습니다.
- 새 디렉토리를 만듭니다.
- 생성 중인 디렉터리에 대한 사용자 및 그룹 소유권을 설정합니다.
- 8진수 형식으로 디렉터리 모드 권한을 설정합니다.
- 필요에 따라 상위 디렉터리가 생성되었는지 확인합니다.
[customizations.files] 블루프린트 사용자 지정을 사용하면 다음을 수행할 수 있습니다.
- 새 텍스트 파일을 생성합니다.
- 기존 파일 수정. 경고: 기존 콘텐츠를 덮어쓸 수 있습니다.
- 생성 중인 파일에 대한 사용자 및 그룹 소유권을 설정합니다.
- 8진수 형식으로 모드 권한을 설정합니다.
다음 파일을 생성하거나 교체할 수 없습니다.
-
/etc/fstab -
/etc/shadow -
/etc/passwd -
/etc/group
다음 사용자 지정을 사용할 수 있습니다.
블루프린트에서 파일 시스템 구성을 사용자 지정합니다.
[[customizations.filesystem]] mountpoint = "MOUNTPOINT" minsize = MINIMUM-PARTITION-SIZE
[[customizations.filesystem]] mountpoint = "MOUNTPOINT" minsize = MINIMUM-PARTITION-SIZECopy to Clipboard Copied! Toggle word wrap Toggle overflow Mi
NIMUM-PARTITION-SIZE값은 기본 크기 형식이 없습니다. 사용자 지정은 kB에서 TB까지, KiB~TiB의 값 및 단위를 지원합니다. 예를 들어 마운트 지점 크기를 바이트 단위로 정의할 수 있습니다.[[customizations.filesystem]] mountpoint = "/var" minsize = 1073741824
[[customizations.filesystem]] mountpoint = "/var" minsize = 1073741824Copy to Clipboard Copied! Toggle word wrap Toggle overflow 단위를 사용하여 마운트 지점 크기를 정의합니다. 예를 들면 다음과 같습니다.
[[customizations.filesystem]] mountpoint = "/opt" minsize = "20 GiB"
[[customizations.filesystem]] mountpoint = "/opt" minsize = "20 GiB"Copy to Clipboard Copied! Toggle word wrap Toggle overflow [[customizations.filesystem]] mountpoint = "/boot" minsize = "1 GiB"
[[customizations.filesystem]] mountpoint = "/boot" minsize = "1 GiB"Copy to Clipboard Copied! Toggle word wrap Toggle overflow minsize를 설정하여 최소 파티션을 정의합니다. 예를 들면 다음과 같습니다.[[customizations.filesystem]] mountpoint = "/var" minsize = 2147483648
[[customizations.filesystem]] mountpoint = "/var" minsize = 2147483648Copy to Clipboard Copied! Toggle word wrap Toggle overflow [customizations.directories] :을 사용하여 이미지의/etc디렉터리에 사용자 지정 디렉토리를 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트 항목은 다음과 같이 설명되어 있습니다.
-
경로- 필수 - 생성하려는 디렉터리의 경로를 입력합니다./etc디렉토리 아래의 절대 경로여야 합니다. -
mode- 선택 사항 - 디렉터리에 대한 액세스 권한을 8진수 형식으로 설정합니다. 권한을 지정하지 않으면 기본값은 0755입니다. 앞에 0은 선택 사항입니다. -
user- 선택 사항 - 사용자를 디렉터리의 소유자로 설정합니다. 사용자를 지정하지 않으면 기본값은root입니다. 사용자를 문자열 또는 정수로 지정할 수 있습니다. -
group- 선택 사항 - 그룹을 디렉터리의 소유자로 설정합니다. 그룹을 지정하지 않으면 기본값은root입니다. 그룹을 문자열 또는 정수로 지정할 수 있습니다. -
ensure_parents- 선택 사항 - 필요에 따라 상위 디렉터리를 생성할지 여부를 지정합니다. 값을 지정하지 않으면 기본값은false입니다.
-
[customizations.directories] :을 사용하여 이미지의/etc디렉터리에 사용자 지정 파일을 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트 항목은 다음과 같이 설명되어 있습니다.
-
path- Mandatory - 생성하려는 파일의 경로를 입력합니다./etc디렉토리 아래의 절대 경로여야 합니다. -
modeOptional - 8진수 형식으로 파일에 대한 액세스 권한을 설정합니다. 권한을 지정하지 않으면 기본값은 0644입니다. 앞에 0은 선택 사항입니다. -
user- Optional - 사용자를 파일의 소유자로 설정합니다. 사용자를 지정하지 않으면 기본값은root입니다. 사용자를 문자열 또는 정수로 지정할 수 있습니다. -
group- 선택 사항 - 그룹을 파일의 소유자로 설정합니다. 그룹을 지정하지 않으면 기본값은root입니다. 그룹을 문자열 또는 정수로 지정할 수 있습니다. -
data- 선택 사항 - 일반 텍스트 파일의 내용을 지정합니다. 콘텐츠를 지정하지 않으면 빈 파일이 생성됩니다.
-
9.3.8.17. 블루프린트에서 볼륨 그룹 및 논리 볼륨 이름 지정
다음 작업에 RHEL 이미지 빌더를 사용할 수 있습니다.
-
고급 파티션 레이아웃을 사용하여 RHEL 디스크 이미지를 생성합니다. 사용자 지정 마운트 지점, LVM 기반 파티션 및 LVM 기반 SWAP를 사용하여 디스크 이미지를 생성할 수 있습니다. 예를 들어
config.toml파일을 사용하여/및/boot디렉터리의 크기를 변경합니다. -
사용할 파일 시스템을 선택합니다.
ext4와xfs중에서 선택할 수 있습니다. - 스왑 파티션 및 LV를 추가합니다. 디스크 이미지에는 LV 기반 SWAP가 포함될 수 있습니다.
- LVM 엔터티의 이름을 변경합니다. 이미지 내의 논리 볼륨(LV) 및 볼륨 그룹(VG)에는 사용자 지정 이름이 있을 수 있습니다.
다음 옵션은 지원되지 않습니다.
- 하나의 이미지에 여러 PV 또는 VG가 있습니다.
- SWAP 파일
-
/dev/shm,/tmp와 같은 비 물리적 파티션의 마운트 옵션.
예제: 파일 시스템이 있는 VG 및 LG 사용자 지정 이름을 추가합니다.
9.3.9. RHEL 이미지 빌더에서 설치한 패키지
RHEL 이미지 빌더를 사용하여 시스템 이미지를 생성할 때 시스템은 기본 패키지 그룹 세트를 설치합니다.
청사진에 추가 구성 요소를 추가할 때 추가한 구성 요소의 패키지가 다른 패키지 구성 요소와 충돌하지 않는지 확인합니다. 그렇지 않으면 시스템이 종속성을 해결하지 못하고 사용자 지정된 이미지를 생성하지 못합니다. 다음 명령을 실행하여 패키지 간에 충돌이 없는지 확인할 수 있습니다.
composer-cli blueprints depsolve BLUEPRINT-NAME
# composer-cli blueprints depsolve BLUEPRINT-NAME
기본적으로 RHEL 이미지 빌더에서는 Core 그룹을 기본 패키지 목록으로 사용합니다.
| 이미지 유형 | 기본 패키지 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9.3.10. 사용자 정의 이미지에서 서비스 활성화
이미지 빌더를 사용하여 사용자 정의 이미지를 구성할 때 이미지에 사용되는 기본 서비스는 다음 사항에 따라 결정됩니다.
-
osbuild-composer유틸리티를 사용하는 RHEL 릴리스 - 이미지 유형
예를 들어 ami 이미지 유형을 사용하면 기본적으로 sshd,chronyd, cloud-init 서비스를 활성화합니다. 이러한 서비스가 활성화되지 않으면 사용자 정의 이미지가 부팅되지 않습니다.
| 이미지 유형 | 기본 활성화된 서비스 |
|---|---|
|
| sshd, cloud-init, cloud-init-local, cloud-config, cloud-final |
|
| sshd, cloud-init, cloud-init-local, cloud-config, cloud-final |
|
| cloud-init |
|
| 추가 서비스는 기본적으로 활성화되어 있지 않습니다. |
|
| 추가 서비스는 기본적으로 활성화되어 있지 않습니다. |
|
| sshd, chronyd, waagent, cloud-init, cloud-init-local, cloud-config, cloud-final |
|
| sshd, chronyd, vmtoolsd, cloud-init |
참고: 시스템을 부팅하는 동안 활성화할 서비스를 사용자 지정할 수 있습니다. 그러나 사용자 지정은 언급된 이미지 유형에 대해 기본적으로 활성화된 서비스를 재정의하지 않습니다.
9.4. RHEL 이미지 빌더 웹 콘솔 인터페이스를 사용하여 시스템 이미지 생성
RHEL 이미지 빌더는 사용자 정의 시스템 이미지를 생성하는 툴입니다. RHEL 이미지 빌더를 제어하고 사용자 정의 시스템 이미지를 생성하려면 웹 콘솔 인터페이스를 사용할 수 있습니다.
9.4.1. RHEL 웹 콘솔에서 RHEL 이미지 빌더 대시보드에 액세스
RHEL 웹 콘솔용 cockpit-composer 플러그인을 사용하면 그래픽 인터페이스를 사용하여 이미지 빌더 청사진을 관리하고 구성할 수 있습니다.
사전 요구 사항
- 시스템에 대한 루트 액세스 권한이 있어야 합니다.
- RHEL 이미지 빌더가 설치되어 있어야 합니다.
-
cockpit-composer패키지를 설치했습니다.
절차
-
호스트에서 웹 브라우저에서
https://<_localhost_>:9090/을 엽니다. - 웹 콘솔에 root 사용자로 로그인합니다.
RHEL 이미지 빌더 컨트롤을 표시하려면 창의 왼쪽 상단에 있는 빌더 버튼을 클릭합니다.
RHEL 이미지 빌더 대시보드가 열리고 기존 블루프린트가 나열됩니다(있는 경우).
9.4.2. 웹 콘솔 인터페이스에서 블루프린트 생성
블루프린트 생성은 사용자 지정된 RHEL 시스템 이미지를 빌드하기 전에 필요한 단계입니다. 사용 가능한 모든 사용자 지정은 선택 사항입니다. 다음 옵션을 사용하여 사용자 지정 블루프린트를 생성할 수 있습니다.
- CLI 사용. 지원되는 이미지 사용자 정의를 참조하십시오.
- 웹 콘솔 사용. 다음 단계를 따르십시오.
Red Hat Enterprise Linux 9.2 이상 버전 및 Red Hat Enterprise Linux 8.8 이상 버전에서 이러한 블루프린트 사용자 지정을 사용할 수 있습니다.
사전 요구 사항
- 브라우저에서 웹 콘솔에서 RHEL 이미지 빌더 앱을 열었습니다. RHEL 웹 콘솔에서 RHEL 이미지 빌더 GUI 액세스를 참조하십시오.
절차
오른쪽 상단에 있는 를 클릭합니다.
이름 및 설명에 대한 필드가 있는 대화 상자가 열립니다.
세부 정보페이지에서 다음을 수행합니다.- 이름을 입력하고 선택적으로 해당 설명을 입력합니다.
- 을 클릭합니다.
선택 사항:
패키지페이지에서 다음을 수행합니다.-
사용
가능한 패키지 검색에서 패키지이름을 입력합니다. - 다음 패키지 필드로 이동하려면 > 버튼을 클릭합니다.
- 이전 단계를 반복하여 원하는 만큼 패키지를 검색하고 포함합니다.
을 클릭합니다.
참고이러한 사용자 지정은 별도로 지정하지 않는 한 모두 선택 사항입니다.
-
사용
-
커널페이지에서 커널 이름과 명령줄 인수를 입력합니다. 파일 시스템페이지에서자동 파티션 사용을선택하거나 이미지 파일 시스템에 대한파티션을 수동으로 구성할수 있습니다. 파티션을 수동으로 구성하려면 다음 단계를 완료합니다.수동으로 버튼을 클릭합니다.
Configure partitions섹션이 열리고 Red Hat 표준 및 보안 가이드를 기반으로 구성이 표시됩니다.드롭다운 메뉴에서 세부 정보를 제공하여 파티션을 구성합니다.
마운트 지점필드의 경우 다음 마운트 지점 유형 옵션 중 하나를 선택합니다.-
/- 루트 마운트 지점 -
/app -
/boot -
/data -
/home -
/opt -
/srv -
/usr -
/usr/local /var마운트 지점에/tmp와 같은 추가 경로를 추가할 수도 있습니다. 예: 접두사인/var, 추가 경로인/tmp는/var/tmp가 됩니다.참고선택한 마운트 지점 유형에 따라 파일 시스템 유형이
xfs로 변경됩니다.
-
파일 시스템의
최소 크기 파티션필드의 경우 필요한 최소 파티션 크기를 입력합니다. Minimum size(최소 크기) 드롭다운 메뉴에서GiB,MiB또는KiB와 같은 일반 크기 단위를 사용할 수 있습니다. 기본 단위는GiB입니다.참고최소 크기는RHEL 이미지 빌더가 여전히 파티션 크기를 늘릴 수 있음을 의미합니다. 작업 이미지를 생성할 수 없을 경우 파티션 크기를 늘릴 수 있습니다.
파티션을 추가하려면 버튼을 클릭합니다. 다음 오류 메시지가 표시되는 경우:
중복 파티션: 각 마운트 지점의 파티션은 하나만 생성할 수 있습니다., 다음을 수행할 수 있습니다.- 버튼을 클릭하여 중복 파티션을 제거합니다.
- 만들 파티션의 새 마운트 지점을 선택합니다.
- 파티션 구성을 완료한 후 클릭합니다.
서비스페이지에서 서비스를 활성화하거나 비활성화할 수 있습니다.- 활성화 또는 비활성화하려는 서비스 이름을 입력하여 쉼표로 구분하거나 키를 눌러 입력합니다. 을 클릭합니다.
-
활성화된 서비스를입력합니다. -
Disabled 서비스를입력합니다.
방화벽페이지에서 방화벽 설정을 설정합니다.-
포트및 활성화 또는 비활성화하려는 방화벽 서비스를 입력합니다. - 버튼을 클릭하여 각 영역의 방화벽 규칙을 독립적으로 관리합니다. 을 클릭합니다.
-
사용자페이지에서 다음 단계에 따라 사용자를 추가합니다.- 클릭합니다.
-
Username,Password,SSH 키를입력합니다.서버 관리자확인란을 클릭하여 사용자를 권한 있는 사용자로 표시할 수도 있습니다. 을 클릭합니다.
그룹페이지에서 다음 단계를 완료하여 그룹을 추가합니다.버튼을 클릭합니다.
-
그룹 이름과를 입력합니다. 더 많은 그룹을 추가할 수 있습니다. 을 클릭합니다.그룹ID
-
SSH 키 페이지에서 키를추가합니다.버튼을 클릭합니다.
- SSH 키를 입력합니다.
-
사용자를
입력합니다. 을 클릭합니다.
시간대 페이지에서 시간대설정을 설정합니다.시간대필드에 시스템 이미지에 추가할 시간대를 입력합니다. 예를 들어 다음 표준 시간대 형식을 추가합니다. "US/Eastern".시간대를 설정하지 않으면 시스템은 Universal Time, Coordinated (UTC)를 기본값으로 사용합니다.
-
NTP 서버를 입력합니다. 을 클릭합니다.
Locale페이지에서 다음 단계를 완료합니다.-
시스템 이미지에 추가할 패키지 이름을 입력합니다.
예: ["en_US.UTF-8"]. -
Languages검색 필드에 시스템 이미지에 추가할 패키지 이름을 입력합니다. 예: "us". 을 클릭합니다.
-
시스템 이미지에 추가할 패키지 이름을 입력합니다.
기타페이지에서 다음 단계를 완료합니다.-
Hostname필드에 시스템 이미지에 추가할 호스트 이름을 입력합니다. 호스트 이름을 추가하지 않으면 운영 체제가 호스트 이름을 결정합니다. -
Simplifier 설치 프로그램 이미지에만 필요합니다.
설치 장치필드에서 시스템 이미지에 유효한 노드를 입력합니다. 예:dev/sda1을 클릭합니다.
-
FDO용 이미지를 빌드하는 경우에만 필수:
FIDO 장치 온보딩페이지에서 다음 단계를 완료합니다.제조 서버 URL필드에 다음 정보를 입력합니다.-
vmware
UN 공개 키 비보안필드에 비보안 공개 키를 입력합니다. -
Please
UN 공개 키 해시필드에 공개 키 해시를 입력합니다. -
Please
UN 공개 키 루트 인증서필드에 공개 키 루트 인증서를 입력합니다. 을 클릭합니다.
-
vmware
OpenSCAP페이지에서 다음 단계를 완료합니다.-
Datastream필드에 시스템 이미지에 추가할datastream수정 지침을 입력합니다. -
프로필 ID필드에 시스템 이미지에 추가할profile_id보안 프로필을 입력합니다. 을 클릭합니다.
-
Ignition을 사용하는 이미지를 빌드하는 경우에만 필수입니다.
Ignition페이지에서 다음 단계를 완료합니다.-
Firstboot URL필드에 시스템 이미지에 추가할 패키지 이름을 입력합니다. -
Cryo
stat 데이터필드에서 파일을 드래그하거나 업로드합니다. 을 클릭합니다.
-
-
.
검토페이지에서 블루프린트에 대한 세부 정보를 검토합니다. 을 클릭합니다.
RHEL 이미지 빌더 보기가 열리고 기존 블루프린트가 나열됩니다.
9.4.3. RHEL 이미지 빌더 웹 콘솔 인터페이스에서 블루프린트 가져오기
기존 블루프린트를 가져와서 사용할 수 있습니다. 시스템은 모든 종속 항목을 자동으로 해결합니다.
사전 요구 사항
- 브라우저에서 웹 콘솔에서 RHEL 이미지 빌더 앱을 열었습니다.
- RHEL 이미지 빌더 웹 콘솔 인터페이스에서 사용하기 위해 가져오려는 블루프린트가 있습니다.
절차
-
RHEL 이미지 빌더 대시보드에서 를 클릭합니다.
블루프린트 가져오기마법사가 열립니다. -
Upload필드에서 기존 블루프린트를 드래그하거나 업로드합니다. 이 블루프린트는TOML또는JSON형식일 수 있습니다. - 를 클릭합니다. 대시보드에는 가져온 블루프린트가 나열됩니다.
검증
가져온 블루프린트를 클릭하면 가져온 블루프린트에 대한 모든 사용자 지정이 있는 대시보드에 액세스할 수 있습니다.
가져온 블루프린트로 선택한 패키지를 확인하려면
패키지탭으로 이동합니다.- 모든 패키지 종속 항목을 나열하려면 를 클릭합니다. 목록은 검색 가능하며 주문될 수 있습니다.
다음 단계
선택 사항: 사용자 지정을 수정하려면 다음을 수행합니다.
-
사용자 지정대시보드에서 변경할 사용자 지정을 클릭합니다. 필요한 경우 클릭하여 사용 가능한 모든 사용자 지정 옵션으로 이동할 수 있습니다.
-
9.4.4. RHEL 이미지 빌더 웹 콘솔 인터페이스에서 블루프린트 내보내기
다른 시스템에서 사용자 지정을 사용하도록 블루프린트를 내보낼 수 있습니다. TOML 또는 JSON 형식으로 블루프린트를 내보낼 수 있습니다. 두 형식 모두 CLI 및 API 인터페이스에서도 작동합니다.
사전 요구 사항
- 브라우저에서 웹 콘솔에서 RHEL 이미지 빌더 앱을 열었습니다.
- 내보낼 블루프린트가 있습니다.
프로세스
- 이미지 빌더 대시보드에서 내보낼 블루프린트를 선택합니다.
-
블루프린트 내보내기를 클릭합니다.블루프린트 내보내기마법사가 열립니다. 버튼을 클릭하여 블루프린트를 파일로 다운로드하거나 버튼을 클릭하여 블루프린트를 클립보드에 복사합니다.
- 선택 사항: 버튼을 클릭하여 블루프린트를 복사합니다.
검증
- 텍스트 편집기에서 내보낸 블루프린트를 열어 검사하고 검토합니다.
9.4.5. 웹 콘솔 인터페이스에서 RHEL 이미지 빌더를 사용하여 시스템 이미지 생성
다음 단계를 완료하여 블루프린트에서 사용자 지정 RHEL 시스템 이미지를 생성할 수 있습니다.
사전 요구 사항
- 브라우저에서 웹 콘솔에서 RHEL 이미지 빌더 앱을 열었습니다.
- 사용자가 만든 것입니다.
절차
- RHEL 이미지 빌더 대시보드에서 블루프린트 탭을 클릭합니다.
- FlexVolume 테이블에서 이미지를 빌드하려는 경우 해당 이미지를 찾습니다.
- 선택한 이미지의 오른쪽에서 를 클릭합니다. 이미지 생성 대화 상자 마법사가 열립니다.
이미지 출력 페이지에서 다음 단계를 완료합니다.
- Select a 블루프린트 목록에서 원하는 이미지 유형을 선택합니다.
이미지 출력 유형 목록에서 원하는 이미지 출력 유형을 선택합니다.
선택한 이미지 유형에 따라 세부 정보를 추가해야 합니다.
- 을 클릭합니다.
검토 페이지에서 이미지 생성에 대한 세부 정보를 검토하고 이미지 생성을 클릭합니다.
이미지 빌드가 시작되고 완료하는 데 최대 20분이 걸립니다.
검증
이미지가 완료되면 다음을 수행할 수 있습니다.
이미지를 다운로드합니다.
- RHEL 이미지 빌더 대시보드에서 노드 옵션(밀리초) 메뉴 를 클릭하고 이미지 다운로드를 선택합니다.
이미지 로그를 다운로드하여 요소를 검사하고 문제가 있는지 확인합니다.
- RHEL 이미지 빌더 대시보드에서 노드 옵션(밀리초) 메뉴 를 클릭하고 로그 다운로드를 선택합니다.
9.5. RHEL 이미지 빌더를 사용하여 클라우드 이미지 준비 및 업로드
RHEL 이미지 빌더는 다양한 클라우드 플랫폼에서 사용할 준비가 된 사용자 정의 시스템 이미지를 생성할 수 있습니다. 클라우드에서 사용자 지정 RHEL 시스템 이미지를 사용하려면 선택한 출력 유형을 사용하여 RHEL 이미지 빌더로 시스템 이미지를 생성하고, 이미지를 업로드하도록 시스템을 구성하고, 이미지를 클라우드 계정에 업로드합니다. RHEL 웹 콘솔의 이미지 빌더 애플리케이션을 통해 사용자 지정 이미지 클라우드를 푸시할 수 있으며, AWS 및 Microsoft Azure 클라우드와 같이 당사가 지원하는 서비스 공급자 서브 세트에 사용할 수 있습니다. AWS Cloud AMI에 직접 이미지 생성 및 자동 업로드 및 Microsoft Azure 클라우드에 직접 VHD 이미지 생성 및 자동 업로드를 참조하십시오.
9.5.1. AWS에 AMI 이미지 준비 및 업로드
사용자 지정 이미지를 생성하여 RHEL 이미지 빌더를 사용하여 수동으로 또는 자동으로 AWS 클라우드로 업데이트할 수 있습니다.
9.5.1.1. AWS AMI 이미지 수동 업로드 준비
AWS AMI 이미지를 업로드하기 전에 이미지를 업로드하는 시스템을 구성해야 합니다.
사전 요구 사항
- AWS IAM 계정 관리자에 Access Key ID가 구성되어 있어야 합니다.
- 쓰기 가능한 S3 버킷이 준비되어 있어야 합니다. S3 버킷 생성 을 참조하십시오.
프로세스
Python 3 및
pip툴을 설치합니다.yum install python3 python3-pip
# yum install python3 python3-pipCopy to Clipboard Copied! Toggle word wrap Toggle overflow pip:을 사용하여 AWS 명령줄 툴 을 설치합니다.pip3 install awscli
# pip3 install awscliCopy to Clipboard Copied! Toggle word wrap Toggle overflow 프로필을 설정합니다. 터미널에 인증 정보, 지역 및 출력 형식을 제공하라는 메시지가 표시됩니다.
aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]:
$ aws configure AWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 버킷 이름을 정의하고 버킷을 생성합니다.
BUCKET=bucketname aws s3 mb s3://$BUCKET
$ BUCKET=bucketname $ aws s3 mb s3://$BUCKETCopy to Clipboard Copied! Toggle word wrap Toggle overflow 버킷 이름을실제 버킷 이름으로 교체합니다. 전역적으로 고유한 이름이어야 합니다. 결과적으로 버킷이 생성됩니다.S3 버킷에 액세스할 수 있는 권한을 부여하려면 이전에는 AWS Identity and Access Management(IAM)에서
vmimportS3 역할을 생성합니다.신뢰 정책 구성을 사용하여 JSON 형식으로
trust-policy.json파일을 생성합니다. 예를 들면 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 역할 정책 구성을 사용하여 JSON 형식으로
role-policy.json파일을 생성합니다. 예를 들면 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow trust-policy.json파일을 사용하여 Amazon Web Services 계정에 대한 역할을 생성합니다.aws iam create-role --role-name vmimport --assume-role-policy-document file://trust-policy.json
$ aws iam create-role --role-name vmimport --assume-role-policy-document file://trust-policy.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow role-policy.json파일을 사용하여 인라인 정책 문서를 삽입합니다.aws iam put-role-policy --role-name vmimport --policy-name vmimport --policy-document file://role-policy.json
$ aws iam put-role-policy --role-name vmimport --policy-name vmimport --policy-document file://role-policy.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.1.2. CLI를 사용하여 AWS에 AMI 이미지를 수동으로 업로드
RHEL 이미지 빌더를 사용하여 CLI를 사용하여 ami 이미지를 빌드하고 수동으로 Amazon AWS Cloud 서비스 공급자에 직접 업로드할 수 있습니다.
사전 요구 사항
프로세스
텍스트 편집기를 사용하여 다음 내용으로 구성 파일을 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 필드의 값을
accessKeyID,secretAccessKey,버킷에 대한 인증 정보로바꿉니다.IMAGE_KEY값은 EC2에 업로드할 VM 이미지의 이름입니다.- 파일을 CONFIGURATION-FILE.toml로 저장하고 텍스트 편집기를 종료합니다.
작성을 시작하여 AWS에 업로드합니다.
composer-cli compose start blueprint-name image-type image-key configuration-file.toml
# composer-cli compose start blueprint-name image-type image-key configuration-file.tomlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
- 생성한 블루프린트의 이름이 있는 블루프린트- 이름
-
ami이미지 유형이 있는 이미지 유형. - EC2에 업로드할 VM 이미지의 이름이 있는 이미지 키 입니다.
클라우드 공급자의 구성 파일 이름이 있는 configuration-file.toml.
참고사용자 지정 이미지를 보낼 버킷에 대한 올바른 AWS IAM(Identity and Access Management) 설정이 있어야 합니다. 이미지를 업로드하려면 먼저 버킷에 정책을 설정해야 합니다.
이미지 빌드 상태를 확인합니다.
composer-cli compose status
# composer-cli compose statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미지 업로드 프로세스가 완료되면 "FINISHED" 상태가 표시됩니다.
검증
이미지 업로드에 성공했는지 확인하려면 다음을 수행하십시오.
-
메뉴에서 EC2 에 액세스하고 AWS 콘솔에서 올바른 리전을 선택합니다. 이미지가 성공적으로 업로드되었음을 나타내기 위해
사용 가능한상태가 있어야 합니다. - 대시보드에서 이미지를 선택하고 클릭합니다.
9.5.1.3. AWS Cloud AMI에 이미지 생성 및 자동 업로드
RHEL 이미지 빌더를 사용하여 (.raw) 이미지를 생성하고 AWS에 업로드 확인란을 선택하여 Amazon AWS Cloud AMI 서비스 공급자에 직접 생성하는 출력 이미지를 자동으로 푸시할 수 있습니다.
사전 요구 사항
-
시스템에 대한
root또는wheel그룹 사용자 액세스 권한이 있어야 합니다. - 브라우저에서 RHEL 웹 콘솔의 RHEL 이미지 빌더 인터페이스를 열었습니다.
- 블루프린트를 생성했습니다. 웹 콘솔 인터페이스에서 블루프린트 생성을 참조하십시오.
- AWS IAM 계정 관리자에 Access Key ID가 구성되어 있어야 합니다.
- 쓰기 가능한 S3 버킷 이 준비되어 있어야 합니다.
프로세스
- RHEL 이미지 빌더 대시보드에서 이전에 생성한 블루프린트 이름을 클릭합니다.
- 탭을 선택합니다.
를 클릭하여 사용자 지정 이미지를 생성합니다.
이미지 생성 창이 열립니다.
-
유형 드롭다운 메뉴 목록에서
Amazon Machine Image Disk (.raw)를 선택합니다. - Upload to AWS (AWS에 업로드) 확인란을 선택하여 이미지를 AWS Cloud에 업로드하고 를 클릭합니다.
AWS에 대한 액세스를 인증하려면 해당 필드에
AWS 액세스 키 ID및AWS 시크릿 액세스 키를입력합니다. 을 클릭합니다.참고새 액세스 키 ID를 생성하는 경우에만 AWS 시크릿 액세스 키를 볼 수 있습니다. 시크릿 키를 모르는 경우 새 액세스 키 ID를 생성합니다.
-
이미지 이름 필드에
이미지 이름을입력하고 AmazonS3 버킷 이름 필드에 Amazon 버킷 이름을입력하고 사용자 지정 이미지를 추가할 버킷의AWS 리전필드를 입력합니다. 을 클릭합니다. 정보를 검토하고 을 클릭합니다.
필요한 경우 를 클릭하여 잘못된 세부 정보를 수정합니다.
참고사용자 지정 이미지를 보낼 버킷에 대한 올바른 IAM 설정이 있어야 합니다. 이 절차에서는 IAM 가져오기 및 내보내기를 사용하므로 이미지를 업로드하기 전에 버킷에 정책을 설정해야 합니다. 자세한 내용은 IAM 사용자의 필수 권한을 참조하십시오.
-
유형 드롭다운 메뉴 목록에서
오른쪽 상단에 있는 팝업에 저장 진행 상황을 알려줍니다. 또한 이미지 생성이 시작되어 이 이미지 생성 진행 상황 및 AWS Cloud에 업로드되었음을 알립니다.
프로세스가 완료되면 이미지 빌드 전체 상태를 확인할 수 있습니다.
브라우저에서 Service CryostatEC2 에 액세스합니다.
-
AWS 콘솔 대시보드 메뉴에서 올바른 리전 을 선택합니다. 이미지가 업로드되었음을 나타내기 위해
Available상태가 있어야 합니다. - AWS 대시보드에서 이미지를 선택하고 클릭합니다.
-
AWS 콘솔 대시보드 메뉴에서 올바른 리전 을 선택합니다. 이미지가 업로드되었음을 나타내기 위해
- 새 창이 열립니다. 이미지를 시작하는 데 필요한 리소스에 따라 인스턴스 유형을 선택합니다. 클릭합니다.
- 인스턴스 시작 세부 정보를 검토합니다. 변경해야 하는 경우 각 섹션을 편집할 수 있습니다. 시작을 클릭합니다
인스턴스를 시작하기 전에 공개 키를 선택하여 액세스합니다.
이미 있는 키 쌍을 사용하거나 새 키 쌍을 만들 수 있습니다.
다음 단계에 따라 EC2에 새 키 쌍을 생성하여 새 인스턴스에 연결합니다.
- 드롭다운 메뉴 목록에서 새 키 쌍 만들기 를 선택합니다.
- 새 키 쌍의 이름을 입력합니다. 새 키 쌍을 생성합니다.
- 로컬 시스템에 새 키 쌍을 저장하려면 Download Key Pair 를 클릭합니다.
그런 다음 인스턴스를 시작할 수 있습니다.
Initializing 으로 표시되는 인스턴스의 상태를 확인할 수 있습니다.
- 인스턴스 상태가 실행 중 이면 버튼을 사용할 수 있게 됩니다.
을 클릭합니다. SSH를 사용하여 연결하는 방법에 대한 지침과 함께 창이 표시됩니다.
- 에 대한 기본 연결 방법으로 독립 실행형 SSH 클라이언트를 선택하고 터미널을 엽니다.
개인 키를 저장하는 위치에서 SSH가 작동하도록 키를 공개적으로 볼 수 있는지 확인합니다. 이렇게 하려면 다음 명령을 실행합니다.
chmod 400 <_your-instance-name.pem_>
$ chmod 400 <_your-instance-name.pem_>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 공용 DNS를 사용하여 인스턴스에 연결합니다.
ssh -i <_your-instance-name.pem_> ec2-user@<_your-instance-IP-address_>
$ ssh -i <_your-instance-name.pem_> ec2-user@<_your-instance-IP-address_>Copy to Clipboard Copied! Toggle word wrap Toggle overflow yes를 입력하여 계속 연결할지 확인합니다.결과적으로 SSH를 통해 인스턴스에 연결됩니다.
검증
- SSH를 사용하여 인스턴스에 연결하는 동안 작업을 수행할 수 있는지 확인합니다.
9.5.2. Microsoft Azure에 VHD 이미지 준비 및 업로드
사용자 지정 이미지를 생성하고 RHEL 이미지 빌더를 사용하여 수동으로 또는 자동으로 Microsoft Azure 클라우드로 업데이트할 수 있습니다.
9.5.2.1. Microsoft Azure VHD 이미지를 수동으로 업로드하기 위한 준비
Microsoft Azure 클라우드에 수동으로 업로드할 수 있는 VHD 이미지를 생성하려면 RHEL 이미지 빌더를 사용할 수 있습니다.
사전 요구 사항
- Microsoft Azure 리소스 그룹 및 스토리지 계정이 있어야 합니다.
-
Python이 설치되어 있어야 합니다.
AZ CLI툴은 python에 따라 다릅니다.
프로세스
Microsoft 리포지토리 키를 가져옵니다.
rpm --import https://packages.microsoft.com/keys/microsoft.asc
# rpm --import https://packages.microsoft.com/keys/microsoft.ascCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 정보를 사용하여 로컬
azure-cli.repo리포지토리를 생성합니다.azure-cli.repo리포지토리를/etc/yum.repos.d/아래에 저장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Microsoft Azure CLI를 설치합니다.
yumdownloader azure-cli rpm -ivh --nodeps azure-cli-2.0.64-1.el7.x86_64.rpm
# yumdownloader azure-cli # rpm -ivh --nodeps azure-cli-2.0.64-1.el7.x86_64.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Microsoft Azure CLI 패키지의 다운로드된 버전은 현재 사용 가능한 버전에 따라 다를 수 있습니다.
Microsoft Azure CLI를 실행합니다.
az login
$ az loginCopy to Clipboard Copied! Toggle word wrap Toggle overflow 터미널에는 다음 메시지가 표시됩니다
참고, 로그인할 수 있도록 브라우저를 시작했습니다. 장치 코드에 대한 이전 환경의 경우 "az login --use-device-code를 사용하십시오. 그런 다음 터미널에서 로그인할 수 있는 https://microsoft.com/devicelogin 에 대한 링크가 포함된 브라우저를 엽니다.참고원격(SSH) 세션을 실행하는 경우 브라우저에서 로그인 페이지 링크가 열려 있지 않습니다. 이 경우 브라우저에 대한 링크를 복사하고 로그인하여 원격 세션을 인증할 수 있습니다. 로그인하려면 웹 브라우저를 사용하여 https://microsoft.com/devicelogin 페이지를 열고 인증할 장치 코드를 입력합니다.
Microsoft Azure에서 스토리지 계정의 키를 나열합니다.
az storage account keys list --resource-group <resource_group_name> --account-name <storage_account_name>
$ az storage account keys list --resource-group <resource_group_name> --account-name <storage_account_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow resource-group-name 을 Microsoft Azure 리소스 그룹의 이름으로, storage-account-name 을 Microsoft Azure 스토리지 계정 이름으로 교체합니다.
참고다음 명령을 사용하여 사용 가능한 리소스를 나열할 수 있습니다.
az resource list
$ az resource listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 명령의 출력에서 값
key1을 기록해 둡니다.스토리지 컨테이너를 생성합니다.
az storage container create --account-name <storage_account_name>\ --account-key <key1_value> --name <storage_account_name>
$ az storage container create --account-name <storage_account_name>\ --account-key <key1_value> --name <storage_account_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow storage-account-name 을 스토리지 계정 이름으로 교체합니다.
9.5.2.2. Microsoft Azure 클라우드에 VHD 이미지를 수동으로 업로드
사용자 지정 VHD 이미지를 생성한 후 Microsoft Azure 클라우드에 수동으로 업로드할 수 있습니다.
사전 요구 사항
- Microsoft Azure VHD 이미지를 업로드하려면 시스템을 설정해야 합니다. Microsoft Azure VHD 이미지를 업로드할 준비를 참조하십시오.
RHEL 이미지 빌더에서 생성한 Microsoft Azure VHD 이미지가 있어야 합니다.
-
GUI에서
Azure Disk Image (.vhd)이미지 유형을 사용합니다. -
CLI에서
vhd출력 유형을 사용합니다.
-
GUI에서
프로세스
이미지를 Microsoft Azure에 푸시하고 해당 이미지에서 인스턴스를 생성합니다.
az storage blob upload --account-name <_account_name_> --container-name <_container_name_> --file <_image_-disk.vhd> --name <_image_-disk.vhd> --type page ...
$ az storage blob upload --account-name <_account_name_> --container-name <_container_name_> --file <_image_-disk.vhd> --name <_image_-disk.vhd> --type page ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow Microsoft Azure Blob 스토리지에 업로드한 후 Microsoft Azure 이미지를 생성합니다.
az image create --resource-group <_resource_group_name_> --name <_image_>-disk.vhd --os-type linux --location <_location_> --source https://$<_account_name_>.blob.core.windows.net/<_container_name_>/<_image_>-disk.vhd - Running ...
$ az image create --resource-group <_resource_group_name_> --name <_image_>-disk.vhd --os-type linux --location <_location_> --source https://$<_account_name_>.blob.core.windows.net/<_container_name_>/<_image_>-disk.vhd - Running ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고RHEL 이미지 빌더를 사용하여 생성한 이미지는 V1 = BIOS 및 V2 = UEFI 인스턴스 유형 모두에 지원하는 하이브리드 이미지를 생성하므로
--hyper-v-generation인수를 지정할 수 있습니다. 기본 인스턴스 유형은 V1입니다.
검증
Microsoft Azure 포털을 사용하여 인스턴스 또는 다음과 유사한 명령을 생성합니다.
az vm create --resource-group <_resource_group_name_> --location <_location_> --name <_vm_name_> --image <_image_>-disk.vhd --admin-username azure-user --generate-ssh-keys - Running ...
$ az vm create --resource-group <_resource_group_name_> --location <_location_> --name <_vm_name_> --image <_image_>-disk.vhd --admin-username azure-user --generate-ssh-keys - Running ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
SSH를 통해 개인 키를 사용하여 결과 인스턴스에 액세스합니다.
azure-user로 로그인합니다. 이 사용자 이름은 이전 단계에서 설정되었습니다.
9.5.2.3. Microsoft Azure 클라우드에 VHD 이미지 생성 및 자동 업로드
Microsoft Azure Cloud 서비스 공급자의 Blob 스토리지에 자동으로 업로드되는 RHEL 이미지 빌더를 사용하여 .vhd 이미지를 생성할 수 있습니다.
사전 요구 사항
- 시스템에 대한 root 액세스 권한이 있습니다.
- RHEL 웹 콘솔의 RHEL 이미지 빌더 인터페이스에 액세스할 수 있습니다.
- 블루프린트를 생성하셨습니다. 웹 콘솔 인터페이스에서 RHEL 이미지 빌더 블루프린트 생성을 참조하십시오.
- Microsoft 스토리지 계정이 생성되어 있습니다.
- 쓰기 가능한 Blob 스토리지 가 준비되어 있습니다.
프로세스
- RHEL 이미지 빌더 대시보드에서 사용하려는 블루프린트를 선택합니다.
- 탭을 클릭합니다.
를 클릭하여 사용자 지정
.vhd이미지를 만듭니다.이미지 생성 마법사가 열립니다.
-
유형 드롭다운 메뉴 목록에서
Microsoft Azure (.vhd)를 선택합니다. - 이미지를 Microsoft Azure Cloud에 업로드하려면 Azure에 업로드 확인란을 선택합니다.
- 이미지 크기를 입력하고 클릭합니다.
-
유형 드롭다운 메뉴 목록에서
Azure에 업로드 페이지에서 다음 정보를 입력합니다.
인증 페이지에서 다음을 입력합니다.
- 스토리지 계정 이름입니다. 스토리지 계정 페이지에서 Microsoft Azure 포털 에서 찾을 수 있습니다.
- 스토리지 액세스 키: 액세스 키 스토리지 페이지에서 찾을 수 있습니다.
- 을 클릭합니다.
인증 페이지에서 다음을 입력합니다.
- 이미지 이름입니다.
- 스토리지 컨테이너 입니다. 이미지를 업로드할 Blob 컨테이너입니다. Microsoft Azure 포털에서 Blob 서비스 섹션에서 찾습니다.
- 을 클릭합니다.
검토 페이지에서 을 클릭합니다. RHEL 이미지 빌더 및 업로드 프로세스가 시작됩니다.
Microsoft Azure Cloud 에 내보낸 이미지에 액세스합니다.
- Microsoft Azure 포털에 액세스합니다.
- 검색 모음에서 "스토리지 계정"을 입력하고 목록에서 스토리지 계정을 클릭합니다.
- 검색 모음에서 "Images"를 입력하고 Services 아래에서 첫 번째 항목을 선택합니다. 이미지 대시보드 로 리디렉션됩니다.
- 탐색 패널에서 컨테이너를 클릭합니다.
-
생성한 컨테이너를 찾습니다. 컨테이너 내부에서는 RHEL 이미지 빌더를 사용하여 생성하고 푸시한
.vhd파일입니다.
검증
VM 이미지를 생성하고 시작할 수 있는지 확인합니다.
- 검색 모음에서 이미지 계정을 입력하고 목록에서 이미지를 클릭합니다.
- 를 클릭합니다.
- 드롭다운 목록에서 이전에 사용한 리소스 그룹을 선택합니다.
- 이미지의 이름을 입력합니다.
- OS 유형에 대해 Linux 를 선택합니다.
- VM 생성에 대해 Gen 2 를 선택합니다.
- 스토리지 Blob 에서 VHD 파일에 도달할 때까지 를 클릭하고 스토리지 계정 및 컨테이너를 클릭합니다.
- 페이지 끝에 있는 Select 를 클릭합니다.
- 계정 유형을 선택합니다(예: Standard SSD ).
- 클릭한 다음 클릭합니다. 이미지 생성을 위해 잠시 기다립니다.
VM을 시작하려면 단계를 따르십시오.
- 클릭합니다.
- 헤더의 메뉴 표시줄에서 을 클릭합니다.
- 가상 머신의 이름을 입력합니다.
- 크기 및 관리자 계정 섹션을 완료합니다.
클릭한 다음 클릭합니다. 배포 진행 상황을 확인할 수 있습니다.
배포가 완료되면 가상 시스템 이름을 클릭하여 SSH를 사용하여 연결할 인스턴스의 공용 IP 주소를 검색합니다.
- 터미널을 열어 VM에 연결할 SSH 연결을 생성합니다.
9.5.2.4. vSphere에서 VMDK 이미지 업로드 및 RHEL 가상 머신 생성
RHEL 이미지 빌더를 사용하면 Open Virtualization 형식(.ova) 또는 가상 디스크(.vmdk) 형식으로 사용자 지정 VMware vSphere 시스템 이미지를 생성할 수 있습니다. 이러한 이미지를 VMware vSphere 클라이언트에 업로드할 수 있습니다. govc import 이미지를 VMware vSphere에 업로드할 수 있습니다. 생성한 .vmdk CLI 툴을 사용하여 .vmdk 또는 . ovavmdk 에는 cloud-init 패키지가 설치되어 있으며 사용자 데이터를 사용하여 사용자를 프로비저닝하는 데 사용할 수 있습니다(예: 사용자 데이터).
VMware vSphere GUI를 사용하여 vmdk 이미지를 업로드하는 것은 지원되지 않습니다.
사전 요구 사항
- 사용자 이름 및 암호 사용자 지정이 포함된 블루프린트를 생성했습니다.
-
RHEL 이미지 빌더를 사용하여
.ova또는.vmdk형식으로 VMware vSphere 이미지를 생성하고 호스트 시스템에 다운로드합니다. -
import.vmdk명령을 사용할 수 있도록govcCLI 툴을 설치 및 구성하셨습니다.
프로세스
GOVC 환경 변수를 사용하여 사용자 환경에서 다음 값을 구성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - VMware vSphere 이미지를 다운로드한 디렉터리로 이동합니다.
단계에 따라 vSphere에서 VMware vSphere 이미지를 시작합니다.
VMware vSphere 이미지를 vSphere로 가져옵니다.
govc import.vmdk ./composer-api.vmdk foldername
$ govc import.vmdk ./composer-api.vmdk foldernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow .ova형식의 경우:govc import.ova ./composer-api.ova foldername
$ govc import.ova ./composer-api.ova foldernameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 전원을 켜지 않고 vSphere에서 VM을 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow .ova형식의 경우-firmware=efi -disk="foldername/composer-api.vmdk" \를 '-firmware=efi -disk="foldername/composer-api.ova" \로 바꿉니다.VM의 전원을 켭니다.
govc vm.power -on vmname
govc vm.power -on vmnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VM IP 주소를 검색합니다.
govc vm.ip vmname
govc vm.ip vmnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 블루프린트에 지정한 사용자 이름과 암호를 사용하여 VM에 SSH를 사용하여 로그인합니다.
ssh admin@<_ip_address_of_the_vm_>
$ ssh admin@<_ip_address_of_the_vm_>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고govc datastore.upload명령을 사용하여 로컬 호스트에서 대상으로.vmdk이미지를 복사한 경우 결과 이미지를 사용할 수 없습니다. vSphere GUI에서import.vmdk명령을 사용할 수 있는 옵션이 없으므로 vSphere GUI에서 직접 업로드를 지원하지 않습니다. 결과적으로 vSphere GUI에서.vmdk이미지를 사용할 수 없습니다.
9.5.2.5. 이미지 빌더 GUI를 사용하여 VMDK 이미지를 vSphere에 생성하고 자동으로 업로드
RHEL 이미지 빌더 GUI 툴을 사용하여 VMware 이미지를 빌드하고 이미지를 vSphere 인스턴스로 직접 푸시할 수 있습니다. 이렇게 하면 이미지 파일을 다운로드하여 수동으로 푸시할 필요가 없습니다. 생성한 vmdk 에는 cloud-init 패키지가 설치되어 있으며 사용자 데이터를 사용하여 사용자를 프로비저닝하는 데 사용할 수 있습니다(예: 사용자 데이터). RHEL 이미지 빌더를 사용하여 .vmdk 이미지를 빌드하고 vSphere 인스턴스 서비스 공급자로 직접 푸시하려면 다음 단계를 따르십시오.
사전 요구 사항
-
루트또는weldr그룹의 멤버입니다. - 브라우저에서 link:https://localhost:9090/RHEL 이미지 빌더를 열었습니다.
- 블루프린트를 생성했습니다. 웹 콘솔 인터페이스에서 RHEL 이미지 빌더 블루프린트 생성을 참조하십시오.
- vSphere 계정이 있습니다.
프로세스
- 생성한 블루프린트의 경우 탭을 클릭합니다.
를 클릭하여 사용자 지정 이미지를 생성합니다.
이미지 유형 창이 열립니다.
이미지 유형 창에서 다음을 수행합니다.
- 드롭다운 메뉴에서 유형을 선택합니다. VMware vSphere(.vmdk).
- 이미지를 vSphere 에 업로드하려면 VMware 에 업로드 확인란을 선택합니다.
- 선택 사항: 인스턴스화할 이미지의 크기를 설정합니다. 최소 기본 크기는 2GB입니다.
- 을 클릭합니다.
VMware에 업로드 창에서 인증 에서 다음 세부 정보를 입력합니다.
- username: vSphere 계정의 사용자 이름입니다.
- password : vSphere 계정의 암호입니다.
VMware에 업로드 창에서 대상 아래에 이미지 업로드 대상에 대한 다음 세부 정보를 입력합니다.
- image name : 이미지 의 이름입니다.
- 호스트: VMware vSphere의 URL입니다.
- 클러스터: 클러스터의 이름입니다.
- 데이터 센터: 데이터 센터의 이름입니다.
- 데이터 저장소: 데이터 저장소의 이름입니다.
- 다음을 클릭합니다.
검토 창에서 이미지 생성 세부 정보를 검토하고 을 클릭합니다.
를 클릭하여 잘못된 세부 정보를 수정할 수 있습니다.
RHEL 이미지 빌더는 RHEL vSphere 이미지 구성을 큐에 추가하고 지정한 vSphere 인스턴스의 클러스터에 이미지를 생성하고 업로드합니다.
참고이미지 빌드 및 업로드 프로세스를 완료하는 데 몇 분이 걸립니다.
프로세스가 완료되면 이미지 빌드 전체 상태를 확인할 수 있습니다.
검증
이미지 상태 업로드가 성공적으로 완료되면 업로드한 이미지에서 VM(가상 머신)을 생성하고 로그인할 수 있습니다. 이렇게 하려면 다음을 수행합니다.
- VMware vSphere Client에 액세스합니다.
- 지정한 vSphere 인스턴스의 클러스터에서 이미지를 검색합니다.
- 업로드한 이미지를 선택합니다.
- 선택한 이미지를 마우스 오른쪽 버튼으로 클릭합니다.
New Virtual Machine을 클릭합니다.새 가상 머신 창이 열립니다.
New Virtual Machine 창에서 다음 세부 정보를 제공합니다.
-
새 가상 머신을 선택합니다. - VM의 이름과 폴더를 선택합니다.
- 컴퓨터 리소스 선택: 이 작업에 대한 대상 컴퓨터 리소스를 선택합니다.
- 스토리지 선택: 예를 들어 NFS-Node1을 선택합니다.
- 호환성 선택: 이미지는 BIOS 여야 합니다.
- 게스트 운영 체제를 선택합니다. 예를 들어 Linux 및 Red Hat Fedora(64비트) 를 선택합니다.
- 사용자 정의 하드웨어: VM을 생성할 때 오른쪽 상단에 있는 장치 구성 버튼에서 기본 New Hard Disk를 삭제하고 드롭다운을 사용하여 기존 하드 디스크 이미지를 선택합니다.
- 완료 준비: 세부 정보를 검토하고 완료 를 클릭하여 이미지를 만듭니다.
-
VMs 탭으로 이동합니다.
- 목록에서 생성한 VM을 선택합니다.
- 패널에서 시작 버튼을 클릭합니다. VM 이미지 로드를 보여주는 새 창이 표시됩니다.
- 블루프린트에 대해 생성한 인증 정보로 로그인합니다.
블루프린트에 추가한 패키지가 설치되어 있는지 확인할 수 있습니다. 예를 들면 다음과 같습니다.
rpm -qa | grep firefox
$ rpm -qa | grep firefoxCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.3. 사용자 정의 GCE 이미지 준비 및 GCP에 업로드
사용자 지정 이미지를 생성한 다음 RHEL 이미지 빌더를 사용하여 Oracle Cloud Infrastructure(OCI) 인스턴스로 자동으로 업데이트할 수 있습니다.
9.5.3.1. RHEL 이미지 빌더를 사용하여 GCP에 이미지 업로드
RHEL 이미지 빌더를 사용하면 gce 이미지를 빌드하고 사용자 또는 GCP 서비스 계정에 대한 인증 정보를 제공한 다음 gce 이미지를 GCP 환경에 직접 업로드할 수 있습니다.
9.5.3.1.1. CLI를 사용하여 GCP에 gce 이미지 구성 및 업로드
RHEL 이미지 빌더 CLI를 사용하여 gce 이미지를 GCP에 업로드하도록 인증 정보가 포함된 구성 파일을 설정합니다.
이미지가 부팅되지 않으므로 gce 이미지를 GCP에 수동으로 가져올 수 없습니다. gcloud 또는 RHEL 이미지 빌더를 사용하여 업로드해야 합니다.
사전 요구 사항
이미지를 GCP에 업로드할 수 있는 유효한 Google 계정 및 인증 정보가 있습니다. 자격 증명은 사용자 계정 또는 서비스 계정에서 있을 수 있습니다. 인증 정보와 연결된 계정에는 최소한 다음 IAM 역할이 할당되어 있어야 합니다.
-
roles/storage.admin- 스토리지 오브젝트 생성 및 삭제 -
roles/compute.storageAdmin- VM 이미지를 Compute Engine으로 가져옵니다.
-
- 기존 GCP 버킷이 있습니다.
프로세스
텍스트 편집기를 사용하여 다음 내용으로
gcp-config.toml구성 파일을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
GCP_BUCKET은 기존 버킷을 가리킵니다. 업로드 중인 이미지의 중간 스토리지 오브젝트를 저장하는 데 사용됩니다. -
GCP_STORAGE_REGION은 일반 Google 스토리지 영역과 이중 또는 멀티 영역입니다. -
OBJECT_KEY는 중간 스토리지 오브젝트의 이름입니다. 업로드 전에는 존재하지 않아야 하며 업로드 프로세스가 완료되면 삭제됩니다. 오브젝트 이름이.tar.gz로 끝나지 않으면 확장이 오브젝트 이름에 자동으로 추가됩니다. GCP_CREDENTIALS는 GCP에서 다운로드한 인증 정보 JSON 파일의Base64인코딩 체계입니다. 인증 정보에 따라 GCP에서 이미지를 업로드할 프로젝트가 결정됩니다.참고GCP로 인증하는 다른 메커니즘을 사용하는 경우
gcp-config.toml파일에GCP_CREDENTIALS를 지정하는 것은 선택 사항입니다. 기타 인증 방법은 GCP로 인증 을 참조하십시오.
-
GCP에서 다운로드한 JSON 파일에서
GCP_CREDENTIALS를 검색합니다.sudo base64 -w 0 cee-gcp-nasa-476a1fa485b7.json
$ sudo base64 -w 0 cee-gcp-nasa-476a1fa485b7.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 추가 이미지 이름 및 클라우드 공급자 프로필을 사용하여 작성을 생성합니다.
sudo composer-cli compose start BLUEPRINT-NAME gce IMAGE_KEY gcp-config.toml
$ sudo composer-cli compose start BLUEPRINT-NAME gce IMAGE_KEY gcp-config.tomlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미지 빌드, 업로드 및 클라우드 등록 프로세스를 완료하는 데 최대 10분이 걸릴 수 있습니다.
검증
이미지 상태가 FINISHED인지 확인합니다.
sudo composer-cli compose status
$ sudo composer-cli compose statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.3.1.2. RHEL 이미지 빌더가 다른 GCP 인증 정보의 인증 순서를 정렬하는 방법
RHEL 이미지 빌더에서 여러 다른 유형의 인증 정보를 사용하여 GCP로 인증할 수 있습니다. RHEL 이미지 빌더 구성이 여러 인증 정보 세트를 사용하여 GCP에서 인증하도록 설정된 경우 다음과 같은 기본 설정 순서대로 인증 정보를 사용합니다.
-
구성 파일에서
composer-cli명령으로 지정된 인증 정보입니다. -
osbuild-composer작업자 구성에 구성된 인증 정보입니다. 다음 옵션을 사용하여 자동으로 인증할 수 있는
Google GCP SDK라이브러리의Application Default Credentials(애플리케이션 기본 인증 정보)입니다.- GOOGLE_APPLICATION_CREDENTIALS 환경 변수가 설정된 경우 애플리케이션 기본 자격 증명은 변수가 가리키는 파일에서 인증 정보를 로드하고 사용합니다.
애플리케이션 기본 인증 정보는 코드를 실행하는 리소스에 연결된 서비스 계정을 사용하여 인증을 시도합니다. 예를 들면 Google Compute Engine VM입니다.
참고GCP 인증 정보를 사용하여 이미지를 업로드할 GCP 프로젝트를 결정해야 합니다. 따라서 모든 이미지를 동일한 GCP 프로젝트에 업로드하지 않으려면
composer-cli명령을 사용하여gcp-config.toml구성 파일에 인증 정보를 지정해야 합니다.
9.5.3.1.2.1. composer-cli 명령을 사용하여 GCP 인증 정보 지정
업로드 대상 구성 gcp-config.toml 파일에 GCP 인증 자격 증명을 지정할 수 있습니다. Base64-encoded scheme of the Google account credentials JSON 파일을 사용하여 시간을 절약합니다.
프로세스
다음 명령을 실행하여
GOOGLE_APPLICATION_CREDENTIALS환경 변수에 저장된 경로를 사용하여 Google 계정 자격 증명 파일의 인코딩된 콘텐츠를 가져옵니다.base64 -w 0 "${GOOGLE_APPLICATION_CREDENTIALS}"$ base64 -w 0 "${GOOGLE_APPLICATION_CREDENTIALS}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 업로드 대상 구성
gcp-config.toml파일에서 인증 정보를 설정합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.3.1.2.2. osbuild-composer 작업자 구성에서 인증 정보 지정
모든 이미지 빌드에 전역적으로 GCP에 사용하도록 GCP 인증 인증 정보를 구성할 수 있습니다. 이렇게 하면 이미지를 동일한 GCP 프로젝트로 가져오려면 GCP에 모든 이미지 업로드에 동일한 인증 정보를 사용할 수 있습니다.
프로세스
/etc/osbuild-worker/osbuild-worker.toml작업자 구성에서 다음 인증 정보 값을 설정합니다.[gcp] credentials = "PATH_TO_GCP_ACCOUNT_CREDENTIALS"
[gcp] credentials = "PATH_TO_GCP_ACCOUNT_CREDENTIALS"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
9.5.4. OCI에 사용자 정의 이미지 직접 준비 및 업로드
사용자 지정 이미지를 생성한 다음 RHEL 이미지 빌더를 사용하여 Oracle Cloud Infrastructure(OCI) 인스턴스로 자동으로 업데이트할 수 있습니다.
9.5.4.1. OCI에 사용자 정의 이미지 생성 및 자동 업로드
RHEL 이미지 빌더를 사용하여 사용자 지정 이미지를 빌드하고 Oracle Cloud Infrastructure(OCI) 인스턴스에 직접 푸시합니다. 그런 다음 OCI 대시보드에서 이미지 인스턴스를 시작할 수 있습니다.
사전 요구 사항
-
root또는weldr그룹 사용자가 시스템에 액세스할 수 있습니다. - Oracle Cloud 계정이 있습니다.
- 관리자가 OCI 정책에서 보안 액세스 권한을 부여해야 합니다.
-
선택한
OCI_REGION에 OCI Bucket을 생성했습니다.
프로세스
- 브라우저에서 웹 콘솔의 RHEL 이미지 빌더 인터페이스를 엽니다.
- 클릭합니다. 블루프린트 생성 마법사가 열립니다.
- 세부 정보 페이지에서 블루프린트의 이름을 입력하고 설명을 선택적으로 입력합니다. 을 클릭합니다.
- 패키지 페이지에서 이미지에 포함할 구성 요소 및 패키지를 선택합니다. 을 클릭합니다.
- 사용자 지정 페이지에서 블루프린트에 필요한 사용자 지정을 구성합니다. 을 클릭합니다.
- 검토 페이지에서 을 클릭합니다.
- 이미지를 생성하려면 클릭합니다. 이미지 생성 마법사가 열립니다.
이미지 출력 페이지에서 다음 단계를 완료합니다.
- " Select a blueprint" 드롭다운 메뉴에서 원하는 블루프린트를 선택합니다.
-
"Image output type" 드롭다운 메뉴에서
Oracle Cloud Infrastructure (.qcow2)를 선택합니다. - "Upload OCI ( OCI 업로드) 확인란을 선택하여 이미지를 OCI에 업로드합니다.
- "이미지 크기" 를 입력합니다. 을 클릭합니다.
OCI - 인증 업로드 페이지에서 다음 필수 세부 정보를 입력합니다.
- 사용자 OCID: 사용자 세부 정보를 표시하는 페이지의 콘솔에서 찾을 수 있습니다.
- 개인 키
OCI - 대상 업로드 페이지에서 다음 필수 세부 정보를 입력하고 클릭합니다.
- 이미지 이름: 업로드할 이미지의 이름입니다.
- OCI 버킷
- 버킷 네임스페이스
- 버킷 리전
- 버킷 compartment
- 버킷 테넌시
- 마법사의 세부 정보를 검토하고 을 클릭합니다.
RHEL 이미지 빌더에서는 RHEL .qcow2 이미지 작성을 큐에 추가합니다.
검증
- OCI 대시보드 → 사용자 지정 이미지에 액세스합니다.
- 이미지에 지정한 Compartment 를 선택하고 이미지 가져오기 테이블에서 이미지를 찾습니다.
- 이미지 이름을 클릭하고 이미지 정보를 확인합니다.
9.5.5. 사용자 지정 QCOW2 이미지를 OpenStack에 직접 준비 및 업로드
RHEL 이미지 빌더를 사용하여 사용자 지정 .qcow2 이미지를 생성하고 OpenStack 클라우드 배포에 수동으로 업로드할 수 있습니다.
9.5.5.1. OpenStack에 QCOW2 이미지 업로드
RHEL 이미지 빌더 툴을 사용하면 OpenStack 클라우드 배포에 업로드하는 데 적합한 사용자 지정 .qcow2 이미지를 생성하고 인스턴스를 시작할 수 있습니다. RHEL 이미지 빌더는 QCOW2 형식으로 이미지를 생성하지만 OpenStack에 특정한 변경 사항을 적용합니다.
QCOW2 형식에서도 RHEL 이미지 빌더를 사용하여 생성한 일반 QCOW2 이미지 유형 출력 형식을 잘못 사용하지 말고 OpenStack과 관련된 추가 변경 사항이 포함되어 있습니다.
사전 요구 사항
- 사용자 계정을 생성했습니다.
절차
QCOW2이미지 작성을 시작합니다.composer-cli compose start blueprint_name openstack
# composer-cli compose start blueprint_name openstackCopy to Clipboard Copied! Toggle word wrap Toggle overflow 빌딩의 상태를 확인합니다.
composer-cli compose status
# composer-cli compose statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미지 빌드가 완료되면 이미지를 다운로드할 수 있습니다.
QCOW2이미지를 다운로드합니다.composer-cli compose image UUID
# composer-cli compose image UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow - OpenStack 대시보드에 액세스하여 를 클릭합니다.
-
왼쪽 메뉴에서
Admin탭을 선택합니다. System Panel에서 이미지를클릭합니다.이미지 생성마법사가 열립니다.이미지 생성마법사에서 다음을 수행합니다.- 이미지 이름을 입력합니다.
-
찾아보기를클릭하여QCOW2이미지를 업로드합니다. -
형식드롭다운 목록에서QCOW2 - QEMU Emulator를 선택합니다. 클릭합니다.
왼쪽 메뉴에서
프로젝트탭을 선택합니다.-
Compute메뉴에서Instances를 선택합니다. (인스턴스 시작) 버튼을 클릭합니다.
인스턴스 시작마법사가 열립니다.-
세부 정보페이지에서 인스턴스의 이름을 입력합니다. 을 클릭합니다. -
소스페이지에서 업로드한 이미지의 이름을 선택합니다. 을 클릭합니다. 플레이버페이지에서 요구 사항에 가장 적합한 시스템 리소스를 선택합니다. 시작을 .
-
-
이미지의 모든 메커니즘(CLI 또는 OpenStack 웹 UI)을 사용하여 이미지 인스턴스를 실행할 수 있습니다. SSH를 통해 개인 키를 사용하여 결과로 생성된 인스턴스에 액세스합니다.
cloud-user로 로그인합니다.
9.5.6. Alibaba Cloud에 사용자 지정 RHEL 이미지 준비 및 업로드
RHEL 이미지 빌더를 사용하여 생성한 사용자 지정 .ami 이미지를 Alibaba Cloud에 업로드할 수 있습니다.
9.5.6.1. Alibaba Cloud에 사용자 지정 RHEL 이미지 업로드 준비
사용자 지정 RHEL 이미지를 Alibaba Cloud에 배포하려면 먼저 사용자 지정 이미지를 확인해야 합니다. 사용자가 사용하기 전에 특정 요구 사항을 충족하도록 사용자 지정 이미지를 요청하므로 이미지는 성공적으로 부팅하기 위한 특정 구성이 필요합니다.
RHEL 이미지 빌더는 Alibaba의 요구 사항을 준수하는 이미지를 생성합니다. 그러나 Red Hat은 CloudEvent image_check 툴 을 사용하여 이미지의 형식 준수를 확인하는 것이 좋습니다.
사전 요구 사항
- RHEL 이미지 빌더를 사용하여 Alibaba 이미지를 생성해야 합니다.
절차
- Alibaba image_check 툴을 사용하여 확인할 이미지가 포함된 시스템에 연결합니다.
image_check 툴을 다운로드합니다.
curl -O https://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/73848/cn_zh/1557459863884/image_check
$ curl -O https://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/73848/cn_zh/1557459863884/image_checkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미지 규정 준수 도구의 파일 권한을 변경합니다.
chmod +x image_check
# chmod +x image_checkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령을 실행하여 이미지 규정 준수 도구 점검을 시작합니다.
./image_check
# ./image_checkCopy to Clipboard Copied! Toggle word wrap Toggle overflow 툴은 시스템 구성을 확인하고 화면에 표시되는 보고서를 생성합니다. image_check 툴은 이 보고서를 이미지 규정 준수 도구가 실행 중인 동일한 폴더에 저장합니다.
문제 해결
감지 항목 중 하나라도 실패하면 터미널의 지침에 따라 수정합니다.
9.5.6.2. hieradata에 사용자 지정 RHEL 이미지 업로드
RHEL 이미지 빌더를 사용하여 생성한 사용자 지정 AMI 이미지를 Object Storage Service(OSS)에 업로드할 수 있습니다.
사전 요구 사항
- 시스템의 이미지 업로드를 위해 설정됩니다. CloudEvent에 이미지 업로드 준비를 참조하십시오.
-
RHEL 이미지 빌더를 사용하여
ami이미지를 생성했습니다. - 버킷이 있습니다. 버킷 생성을 참조하십시오.
- 활성 계정을 가지고 있습니다.
- OSS 를 활성화했습니다.
절차
- OSS 콘솔에 로그인합니다.
- 왼쪽의 Bucket 메뉴에서 이미지를 업로드할 버킷을 선택합니다.
- 오른쪽 상단 메뉴에서 파일 탭을 클릭합니다.
를 클릭합니다. 오른쪽에 대화 상자가 열립니다. 다음을 구성합니다.
- 업로드 대상: 파일을 현재 디렉토리 또는 지정된 디렉토리에 업로드하도록 선택합니다.
- 파일 ACL: 업로드한 파일의 권한 유형을 선택합니다.
- 를 클릭합니다.
- OSS 콘솔에 업로드할 이미지를 선택합니다.
- 클릭합니다.
9.5.6.3. Alibaba Cloud로 이미지 가져오기
RHEL 이미지 빌더를 사용하여 ECS(Elastic Compute Service)로 생성한 사용자 지정 Alibaba RHEL 이미지를 가져오려면 다음 단계를 따르십시오.
사전 요구 사항
- 시스템의 이미지 업로드를 위해 설정됩니다. CloudEvent에 이미지 업로드 준비를 참조하십시오.
-
RHEL 이미지 빌더를 사용하여
ami이미지를 생성했습니다. - 버킷이 있습니다. 버킷 생성을 참조하십시오.
- 활성 계정을 가지고 있습니다.
- OSS 를 활성화했습니다.
- 이미지를 OSD(오브젝트 스토리지 서비스)에 업로드했습니다. iPXE 에 이미지 업로드를 참조하십시오.
절차
- 왼쪽 메뉴에서 클릭합니다.
- 오른쪽 상단에서 를 클릭합니다. 대화 상자 창이 열립니다.
이미지가 있는 올바른 지역을 설정했는지 확인합니다. 다음 정보를 입력합니다.
-
OSS 오브젝트 주소: OSS 개체 주소를 얻는 방법을 확인하십시오. -
이미지 이름 -
운영 체제 -
시스템 디스크 크기 -
시스템 아키텍처 -
플랫폼: Red Hat
-
선택 사항: 다음 세부 정보를 제공합니다.
-
이미지 형식: 업로드된 이미지 형식에 따라qcow2또는ami입니다. -
이미지 설명 데이터 디스크 이미지 추가주소는 OSS 관리 콘솔에서 확인할 수 있습니다. 왼쪽 메뉴에서 필요한 버킷을 선택한 후:
-
-
파일섹션을 선택합니다. 적절한 이미지에 대한 오른쪽에 있는 세부 정보 링크를 클릭합니다.
화면 오른쪽에 창이 표시되고 이미지 세부 정보가 표시됩니다.
OSS개체 주소는URL상자에 있습니다.클릭합니다.
참고가져오기 프로세스 시간은 이미지 크기에 따라 다를 수 있습니다.
사용자 지정 이미지를 ECS 콘솔로 가져옵니다.
9.5.6.4. Alibaba Cloud를 사용하여 사용자 지정 RHEL 이미지의 인스턴스 생성
Alibaba ECS 콘솔을 사용하여 사용자 지정 RHEL 이미지의 인스턴스를 생성할 수 있습니다.
사전 요구 사항
- OSS 를 활성화하고 사용자 지정 이미지를 업로드했습니다.
- 이미지를 ECS 콘솔로 가져왔습니다. iPXE 로 이미지 가져오기를 참조하십시오.
절차
- ECS 콘솔에 로그인합니다.
- 왼쪽 메뉴에서 Instances 를 선택합니다.
- 오른쪽 상단에서 인스턴스 만들기 를 클릭합니다. 새 창으로 리디렉션됩니다.
- 필요한 모든 정보를 입력합니다. 자세한 내용은 마법사를 사용하여 인스턴스 생성을 참조하십시오.
Create Instance (인스턴스 만들기)를 클릭하고 주문을 확인합니다.
참고서브스크립션에 따라 인스턴스 생성 대신 Create Order (인스턴스 만들기) 옵션을 확인할 수 있습니다.
결과적으로 CloudEvent ECS 콘솔에서 배포할 준비가 된 활성 인스턴스가 있습니다.
10장. Kickstart를 사용하여 자동 설치 수행
10.1. 자동 설치 워크플로
Kickstart 설치는 로컬 DVD, 로컬 디스크 또는 NFS, FTP, HTTP 또는 HTTPS 서버를 사용하여 수행할 수 있습니다. 이 섹션에서는 Kickstart 사용에 대한 간략한 개요를 제공합니다.
- Kickstart 파일을 만듭니다. 직접 작성하고 수동 설치 후 저장된 Kickstart 파일을 복사하거나 온라인 생성 도구를 사용하여 파일을 생성하고 나중에 편집할 수 있습니다.
- HTTP(S), FTP 또는 NFS 서버를 사용하여 이동식 미디어, 디스크 또는 네트워크 위치의 설치 프로그램에서 Kickstart 파일을 사용하도록 설정합니다.
- 설치를 시작하는 데 사용할 부팅 미디어를 만듭니다.
- 설치 프로그램에서 설치 소스를 사용할 수 있도록 합니다.
- 부팅 미디어와 Kickstart 파일을 사용하여 설치를 시작합니다. Kickstart 파일에 필수 명령 및 섹션이 포함된 경우 설치가 자동으로 완료됩니다. 이러한 필수 부품 중 하나 이상이 누락되었거나 오류가 발생한 경우 설치를 완료하려면 수동 개입이 필요합니다.
10.2. Kickstart 파일 생성
다음 방법을 사용하여 Kickstart 파일을 생성할 수 있습니다.
- 온라인 Kickstart 구성 툴을 사용합니다.
- 수동 설치에서 생성된 Kickstart 파일을 복사합니다.
- 전체 Kickstart 파일을 수동으로 작성합니다.
Red Hat Enterprise Linux 8 설치를 위한 Red Hat Enterprise Linux 7 Kickstart 파일을 변환합니다.
변환 툴에 대한 자세한 내용은 Kickstart 생성기 랩 을 참조하십시오.
- 가상 및 클라우드 환경의 경우 Image Builder를 사용하여 사용자 지정 시스템 이미지를 만듭니다.
Kickstart 파일을 수동으로 편집하는 경우에만 특정 설치 옵션을 구성할 수 있습니다.
10.2.1. Kickstart 구성 툴로 Kickstart 파일 생성
Red Hat 고객 포털 계정이 있는 사용자는 고객 포털 랩의 Kickstart 생성 툴을 사용하여 온라인에서 Kickstart 파일을 생성할 수 있습니다. 이 툴은 기본 구성을 안내하고 결과 Kickstart 파일을 다운로드할 수 있도록 합니다.
사전 요구 사항
- 고객님에게 Red Hat 고객 포털 계정과 유효한 Red Hat 서브스크립션이 있습니다.
절차
- https://access.redhat.com/labsinfo/kickstartconfig 에서 Kickstart 생성기 랩 정보 페이지를 엽니다.
- 제목 왼쪽에 있는 Go to Application 버튼을 클릭하고 다음 페이지가 로드될 때까지 기다립니다.
- 드롭다운 메뉴에서 Red Hat Enterprise Linux 8 을 선택하고 페이지가 업데이트될 때까지 기다립니다.
양식의 필드를 사용하여 설치할 시스템을 설명합니다.
양식 왼쪽의 링크를 사용하여 양식의 섹션 사이를 빠르게 탐색할 수 있습니다.
생성된 Kickstart 파일을 다운로드하려면 페이지 상단에 있는 빨간색 다운로드 버튼을 클릭합니다.
웹 브라우저에서 파일을 저장합니다.
pykickstart 패키지를 설치합니다.
yum install pykickstart
# yum install pykickstartCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kickstart 파일에서
ksvalidator를 실행합니다.ksvalidator -v RHEL8 /path/to/kickstart.ks
$ ksvalidator -v RHEL8 /path/to/kickstart.ksCopy to Clipboard Copied! Toggle word wrap Toggle overflow /path/to/kickstart.ks를 확인할 Kickstart 파일의 경로로 바꿉니다.
검증 툴에서 설치에 성공했는지 보장할 수 없습니다. 이 경우 구문만 올바르며 파일에 더 이상 사용되지 않는 옵션이 포함되지 않습니다. Kickstart 파일의
%pre,%post및%packages섹션의 유효성을 검증하지 않습니다.
10.2.2. 수동 설치를 수행하여 Kickstart 파일 생성
Kickstart 파일을 생성하는 데 권장되는 접근 방식은 Red Hat Enterprise Linux 수동 설치로 생성된 파일을 사용하는 것입니다. 설치가 완료되면 설치 중에 수행한 모든 선택 사항이 설치된 시스템의 /root/ 디렉터리에 있는 anaconda-ks.cfg 라는 Kickstart 파일에 저장됩니다. 이 파일을 사용하여 이전과 동일한 방식으로 설치를 재현할 수 있습니다. 또는 이 파일을 복사하여 필요한 사항을 변경하고 추가 설치를 위해 결과 구성 파일을 사용합니다.
절차
RHEL을 설치합니다. 자세한 내용은 설치 미디어에서 대화형으로 RHEL 설치를 참조하십시오.
설치 중에 관리자 권한이 있는 사용자를 만듭니다.
- 설치를 완료하고 설치된 시스템으로 재부팅합니다.
- 관리자 계정으로 시스템에 로그인합니다.
/root/anaconda-ks.cfg파일을 선택한 위치로 복사합니다. 파일에는 사용자와 암호에 대한 정보가 포함되어 있습니다.터미널에서 파일 내용을 표시하려면 다음을 수행합니다.
cat /root/anaconda-ks.cfg
# cat /root/anaconda-ks.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력을 복사하여 선택한 다른 파일에 저장할 수 있습니다.
- 파일을 다른 위치로 복사하려면 파일 관리자를 사용합니다. 루트가 아닌 사용자가 파일을 읽을 수 있도록 복사에서 권한을 변경해야 합니다.
pykickstart 패키지를 설치합니다.
yum install pykickstart
# yum install pykickstartCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kickstart 파일에서
ksvalidator를 실행합니다.ksvalidator -v RHEL8 /path/to/kickstart.ks
$ ksvalidator -v RHEL8 /path/to/kickstart.ksCopy to Clipboard Copied! Toggle word wrap Toggle overflow /path/to/kickstart.ks를 확인할 Kickstart 파일의 경로로 바꿉니다.
검증 툴에서 설치에 성공했는지 보장할 수 없습니다. 이 경우 구문만 올바르며 파일에 더 이상 사용되지 않는 옵션이 포함되지 않습니다. Kickstart 파일의 %pre,%post 및 %packages 섹션의 유효성을 검증하지 않습니다.
10.2.3. 이전 RHEL 설치에서 Kickstart 파일 변환
Kickstart Cryostat 툴을 사용하여 RHEL 8 또는 9 설치에 사용할 RHEL 7 Kickstart 파일을 변환하거나 RHEL 9에서 사용할 RHEL 8 Kickstart 파일을 변환할 수 있습니다. 툴과 이를 사용하여 RHEL Kickstart 파일을 변환하는 방법에 대한 자세한 내용은 https://access.redhat.com/labs/kickstartconvert/ 을 참조하십시오.
절차
Kickstart 파일을 준비한 후 pykickstart 패키지를 설치합니다.
yum install pykickstart
# yum install pykickstartCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kickstart 파일에서
ksvalidator를 실행합니다.ksvalidator -v RHEL8 /path/to/kickstart.ks
$ ksvalidator -v RHEL8 /path/to/kickstart.ksCopy to Clipboard Copied! Toggle word wrap Toggle overflow /path/to/kickstart.ks를 확인할 Kickstart 파일의 경로로 바꿉니다.
검증 툴에서 설치에 성공했는지 보장할 수 없습니다. 이 경우 구문만 올바르며 파일에 더 이상 사용되지 않는 옵션이 포함되지 않습니다. Kickstart 파일의 %pre,%post 및 %packages 섹션의 유효성을 검증하지 않습니다.
10.2.4. 이미지 빌더를 사용하여 사용자 정의 이미지 생성
Red Hat Image Builder를 사용하여 가상 및 클라우드 배포를 위한 사용자 지정 시스템 이미지를 만들 수 있습니다.
이미지 빌더를 사용하여 사용자 지정 이미지 생성에 대한 자세한 내용은 사용자 지정 RHEL 시스템 이미지 구성 문서를 참조하십시오.
10.3. UEFI HTTP 또는 PXE 설치 소스에 Kickstart 파일 추가
Kickstart 파일이 준비되면 대상 시스템에 설치할 수 있습니다.
10.3.1. 네트워크 기반 설치를 위한 포트
다음 표에는 각 네트워크 기반 설치 유형에 대한 파일을 제공하기 위해 서버에서 열어야 하는 포트가 나열되어 있습니다.
| 사용된 프로토콜 | 오픈할 포트 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 21 |
| NFS | 2049, 111, 20048 |
| TFTP | 69 |
10.3.2. NFS 서버에서 설치 파일 공유
Kickstart 스크립트 파일을 NFS 서버에 저장할 수 있습니다. NFS 서버에 저장하면 Kickstart 파일에 물리적 미디어를 사용하지 않고도 단일 소스에서 여러 시스템을 설치할 수 있습니다.
사전 요구 사항
- 로컬 네트워크에 Red Hat Enterprise Linux 8이 있는 서버에 대한 관리자 수준의 액세스 권한이 있습니다.
- 설치할 시스템이 서버에 연결할 수 있습니다.
- 서버의 방화벽은 설치하려는 시스템에서 연결할 수 있습니다.
inst.ks 및 inst.repo 에서 다른 경로를 사용하는지 확인하십시오. NFS를 사용하여 Kickstart를 호스팅할 때 동일한 nfs 공유를 사용하여 설치 소스를 호스팅할 수 없습니다.
절차
root로 다음 명령을 실행하여
nfs-utils패키지를 설치합니다.yum install nfs-utils
# yum install nfs-utilsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - Kickstart 파일을 NFS 서버의 디렉터리에 복사합니다.
텍스트 편집기를 사용하여
/etc/exports파일을 열고 다음 구문으로 행을 추가합니다./exported_directory/ clients
/exported_directory/ clientsCopy to Clipboard Copied! Toggle word wrap Toggle overflow /exported_directory/를 Kickstart 파일이 포함된 디렉토리의 전체 경로로 바꿉니다. 클라이언트 대신 이 NFS 서버에서 설치할 컴퓨터의 호스트 이름 또는 IP 주소를 사용합니다. 모든 컴퓨터가 ISO 이미지를 사용하도록 하려면 모든 컴퓨터가 ISO 이미지에 액세스할 수 있는 서브네트워크 또는 별표 기호(
*)를 사용합니다. 이 필드의 형식에 대한 자세한 내용은 exports(5) 도움말 페이지를 참조하십시오./rhel8-install/디렉토리를 모든 클라이언트에 읽기 전용으로 사용할 수 있도록 하는 기본 구성은 다음과 같습니다./rhel8-install *
/rhel8-install *Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
/etc/exports파일을 저장하고 텍스트 편집기를 종료합니다. nfs 서비스를 시작합니다.
systemctl start nfs-server.service
# systemctl start nfs-server.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/exports파일을 변경하기 전에 서비스가 실행 중인 경우 실행 중인 NFS 서버가 구성을 다시 로드하기 위해 다음 명령을 입력합니다.systemctl reload nfs-server.service
# systemctl reload nfs-server.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 NFS를 통해 Kickstart 파일에 액세스할 수 있으며 설치에 사용할 준비가 되었습니다.
Kickstart 소스를 지정할 때 nfs: 를 프로토콜로, 서버의 호스트 이름 또는 IP 주소, 콜론 기호(:), 파일을 보유한 디렉터리 내부의 경로를 사용합니다. 예를 들어 서버의 호스트 이름이 myserver.example.com이고 /rhel8-install/my-ks.cfg에 파일을 저장한 경우 inst.ks=nfs:myserver.example.com:/rhel8-install/my-ks.cfg를 설치 소스 부팅 옵션으로 지정합니다.
10.3.3. HTTP 또는 HTTPS 서버에서 설치 파일 공유
Kickstart 스크립트 파일을 HTTP 또는 HTTPS 서버에 저장할 수 있습니다. HTTP 또는 HTTPS 서버에 Kickstart 파일을 저장하면 Kickstart 파일에 물리적 미디어를 사용하지 않고도 단일 소스에서 여러 시스템을 설치할 수 있습니다.
사전 요구 사항
- 로컬 네트워크에 Red Hat Enterprise Linux 8이 있는 서버에 대한 관리자 수준의 액세스 권한이 있습니다.
- 설치할 시스템이 서버에 연결할 수 있습니다.
- 서버의 방화벽은 설치하려는 시스템에서 연결할 수 있습니다.
절차
Kickstart 파일을 HTTP에 저장하려면
httpd패키지를 설치합니다.yum install httpd
# yum install httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kickstart 파일을 HTTPS에 저장하려면
httpd및mod_ssl패키지를 설치합니다.yum install httpd mod_ssl
# yum install httpd mod_sslCopy to Clipboard Copied! Toggle word wrap Toggle overflow 주의Apache 웹 서버 구성이 SSL 보안을 활성화하는 경우 TLSv1 프로토콜만 활성화하고 SSLv2 및 SSLv3을 비활성화하는지 확인합니다. 이는 POODLE SSL 취약점(CVE-2014-3566) 때문입니다. 자세한 내용은 POODLE SSLv3.0 취약점에 대한 Red Hat 지식베이스 솔루션 해결을 참조하십시오.
중요자체 서명된 인증서가 있는 HTTPS 서버를 사용하는 경우
inst.noverifyssl옵션을 사용하여 설치 프로그램을 부팅해야 합니다.-
Kickstart 파일을 HTTP(S) 서버에
/var/www/html/디렉터리의 하위 디렉터리로 복사합니다. httpd 서비스를 시작합니다.
systemctl start httpd.service
# systemctl start httpd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 Kickstart 파일에 액세스할 수 있으며 설치에 사용할 준비가 되었습니다.
Kickstart 파일의 위치를 지정하는 경우
http://또는https://를 프로토콜로 서버의 호스트 이름 또는 IP 주소 및 HTTP 서버 루트에 상대적인 Kickstart 파일의 경로를 사용합니다. 예를 들어 HTTP를 사용하는 경우 서버의 호스트 이름은myserver.example.com이고 Kickstart 파일을/var/www/html/rhel8-install/my-ks.cfg로 복사한 경우http://myserver.example.com/rhel8-install/my-ks.cfg을 파일 위치로 지정합니다.
10.3.4. FTP 서버에서 설치 파일 공유
Kickstart 스크립트 파일을 FTP 서버에 저장할 수 있습니다. FTP 서버에 스크립트를 저장하면 Kickstart 파일에 물리적 미디어를 사용하지 않고도 단일 소스에서 여러 시스템을 설치할 수 있습니다.
사전 요구 사항
- 로컬 네트워크에 Red Hat Enterprise Linux 8이 있는 서버에 대한 관리자 수준의 액세스 권한이 있습니다.
- 설치할 시스템이 서버에 연결할 수 있습니다.
- 서버의 방화벽은 설치하려는 시스템에서 연결할 수 있습니다.
절차
root로 다음 명령을 실행하여
vsftpd패키지를 설치합니다.yum install vsftpd
# yum install vsftpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 텍스트 편집기에서
/etc/vsftpd/vsftpd.conf구성 파일을 열고 편집합니다.-
anonymous_enable=NO행을anonymous_enable=YES로 변경합니다. -
write_enable=YES행을write_enable=NO로 변경합니다. pasv_min_port=min_port및pasv_max_port=max_port행을 추가합니다.min_port및max_port를 패시브 모드의 FTP 서버에서 사용하는 포트 번호 범위(예:10021및10031)로 바꿉니다.이 단계는 다양한 방화벽/NAT 설정을 갖춘 네트워크 환경에서 필요할 수 있습니다.
선택 사항: 구성에 사용자 정의 변경 사항을 추가합니다. 사용 가능한 옵션은 vsftpd.conf(5) 도움말 페이지를 참조하십시오. 이 절차에서는 기본 옵션이 사용된다고 가정합니다.
주의vsftpd.conf파일에 SSL/TLS 보안을 구성한 경우 TLSv1 프로토콜만 활성화하고 SSLv2 및 SSLv3을 비활성화해야 합니다. 이는 POODLE SSL 취약점(CVE-2014-3566) 때문입니다. 자세한 내용은 POODLE SSLv3.0 취약점에 대한 Red Hat 지식베이스 솔루션 해결을 참조하십시오.
-
서버 방화벽을 구성합니다.
방화벽을 활성화합니다.
systemctl enable firewalld systemctl start firewalld
# systemctl enable firewalld # systemctl start firewalldCopy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽에서 이전 단계의 FTP 포트 및 포트 범위를 활성화합니다.
firewall-cmd --add-port min_port-max_port/tcp --permanent firewall-cmd --add-service ftp --permanent firewall-cmd --reload
# firewall-cmd --add-port min_port-max_port/tcp --permanent # firewall-cmd --add-service ftp --permanent # firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow min_port-max_port를
/etc/vsftpd/vsftpd.conf구성 파일에 입력한 포트 번호로 바꿉니다.
-
Kickstart 파일을 FTP 서버에
/var/ftp/디렉토리 또는 해당 하위 디렉터리에 복사합니다. 파일에 올바른 SELinux 컨텍스트 및 액세스 모드가 설정되어 있는지 확인합니다.
restorecon -r /var/ftp/your-kickstart-file.ks chmod 444 /var/ftp/your-kickstart-file.ks
# restorecon -r /var/ftp/your-kickstart-file.ks # chmod 444 /var/ftp/your-kickstart-file.ksCopy to Clipboard Copied! Toggle word wrap Toggle overflow vsftpd서비스를 시작합니다.systemctl start vsftpd.service
# systemctl start vsftpd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/vsftpd/vsftpd.conf파일을 변경하기 전에 서비스가 실행 중인 경우 서비스를 다시 시작하여 편집된 파일을 로드합니다.systemctl restart vsftpd.service
# systemctl restart vsftpd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 부팅 프로세스 중에 시작되도록
vsftpd서비스를 활성화합니다.systemctl enable vsftpd
# systemctl enable vsftpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 Kickstart 파일에 액세스할 수 있으며 동일한 네트워크의 시스템에서 설치할 준비가 되었습니다.
참고설치 소스를 구성할 때 프로토콜, 서버의 호스트 이름 또는 IP 주소, FTP 서버 루트를 기준으로 Kickstart 파일의 경로를 사용하여
ftp://를 사용합니다. 예를 들어 서버의 호스트 이름이myserver.example.com이고 파일을/var/ftp/my-ks.cfg에 복사한 경우 설치 소스로ftp://myserver.example.com/my-ks.cfg를 지정합니다.
10.4. 반자동 설치: RHEL 설치 프로그램에서 Kickstart 파일을 사용할 수 있도록 설정
Kickstart 파일이 준비되면 대상 시스템에 설치할 수 있습니다.
10.4.1. 로컬 볼륨에서 설치 파일 공유
다음 절차에서는 설치할 시스템의 볼륨에 Kickstart 스크립트 파일을 저장하는 방법을 설명합니다. 이 방법을 사용하면 다른 시스템의 필요성을 무시할 수 있습니다.
사전 요구 사항
- 설치할 시스템으로 이동할 수 있는 드라이브(예: USB 스틱)가 있습니다.
-
드라이브에는 설치 프로그램에서 읽을 수 있는 파티션이 포함되어 있습니다. 지원되는 유형은
ext2,ext3,ext4,xfs및fat입니다. - 드라이브가 시스템에 연결되고 해당 볼륨이 마운트됩니다.
절차
볼륨 정보를 나열하고 Kickstart 파일을 복사할 볼륨의 UUID를 확인합니다.
lsblk -l -p -o name,rm,ro,hotplug,size,type,mountpoint,uuid
# lsblk -l -p -o name,rm,ro,hotplug,size,type,mountpoint,uuidCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 볼륨의 파일 시스템으로 이동합니다.
- Kickstart 파일을 이 파일 시스템에 복사합니다.
-
나중에
inst.ks=옵션과 함께 사용하도록 문자열을 기록합니다. 이 문자열은 다음과 같은 형식으로 되어 있습니다:UUID=volume-UUID:path/to/kickstart-file.cfg. 경로는 파일 시스템 계층 구조의/루트가 아닌 파일 시스템 루트와 관련이 있습니다. volume-UUID 를 앞에서 언급한 UUID로 바꿉니다. 모든 드라이브 볼륨을 마운트 해제합니다.
umount /dev/xyz ...
# umount /dev/xyz ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 볼륨을 명령에 공백으로 구분하여 추가합니다.
10.4.2. 자동 로드를 위해 로컬 볼륨에서 설치 파일 공유
특별히 이름이 지정된 Kickstart 파일인 는 설치할 시스템에서 특별히 이름이 지정된 볼륨의 루트에 있을 수 있습니다. 이를 통해 다른 시스템의 요구 사항을 무시하고 설치 프로그램에서 파일을 자동으로 로드할 수 있습니다.
사전 요구 사항
- 설치할 시스템으로 이동할 수 있는 드라이브(예: USB 스틱)가 있습니다.
-
드라이브에는 설치 프로그램에서 읽을 수 있는 파티션이 포함되어 있습니다. 지원되는 유형은
ext2,ext3,ext4,xfs및fat입니다. - 드라이브가 시스템에 연결되고 해당 볼륨이 마운트됩니다.
절차
Kickstart 파일을 복사할 볼륨 정보를 나열합니다.
lsblk -l -p
# lsblk -l -pCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 볼륨의 파일 시스템으로 이동합니다.
- Kickstart 파일을 이 파일 시스템의 루트로 복사합니다.
-
Kickstart 파일의 이름을
ks.cfg로 바꿉니다. 볼륨의 이름을
OEMDRV로 변경합니다.ext2,ext3및ext4파일 시스템의 경우 다음을 수행합니다.e2label /dev/xyz OEMDRV
# e2label /dev/xyz OEMDRVCopy to Clipboard Copied! Toggle word wrap Toggle overflow XFS 파일 시스템의 경우:
xfs_admin -L OEMDRV /dev/xyz
# xfs_admin -L OEMDRV /dev/xyzCopy to Clipboard Copied! Toggle word wrap Toggle overflow
/dev/xyz를 볼륨 블록 장치의 경로로 바꿉니다.
모든 드라이브 볼륨을 마운트 해제합니다.
umount /dev/xyz ...
# umount /dev/xyz ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 볼륨을 명령에 공백으로 구분하여 추가합니다.
10.5. Kickstart 설치 시작
여러 가지 방법으로 Kickstart 설치를 시작할 수 있습니다.
- PXE 부팅에서 부팅 옵션을 편집하여 자동으로 수행합니다.
- 특정 이름으로 볼륨에 파일을 제공하여 자동으로 수행합니다.
Red Hat CDN(Content Delivery Network)을 사용하여 RHEL을 등록할 수 있습니다. CDN은 지리적으로 분산된 웹 서버 시리즈입니다. 이러한 서버는 유효한 서브스크립션을 사용하여 RHEL 호스트에 대한 패키지 및 업데이트를 제공합니다.
설치 중에 CDN에서 RHEL을 등록하고 설치하면 다음과 같은 이점이 있습니다.
- 설치 후 즉시 최신 시스템에 최신 패키지 사용
- Red Hat Insights에 연결하고 시스템 용도를 활성화하기 위한 통합 지원.
10.5.1. PXE를 사용하여 자동으로 Kickstart 설치 시작
AMD64, Intel 64 및 64비트 ARM 시스템 및 IBM Power Systems 서버는 PXE 서버를 사용하여 부팅할 수 있습니다. PXE 서버를 구성할 때 부트 로더 구성 파일에 부트 옵션을 추가하면 자동으로 설치를 시작할 수 있습니다. 이 방법을 사용하면 부팅 프로세스를 포함하여 설치를 완전히 자동화할 수 있습니다.
이 절차는 일반적인 참조로 제공됩니다. 시스템의 아키텍처에 따라 자세한 단계가 다르며 모든 아키텍처에서 모든 옵션을 사용할 수있는 것은 아닙니다(예: 64비트 IBM Z에서 PXE 부팅을 사용할 수 없음).
사전 요구 사항
- 설치할 시스템에서 액세스할 수 있는 위치에 Kickstart 파일이 준비되어 있습니다.
- 시스템을 부팅하고 설치를 시작하는 데 사용할 수 있는 PXE 서버가 있습니다.
절차
PXE 서버에서 부트 로더 구성 파일을 열고
inst.ks=부트 옵션을 적절한 행에 추가합니다. 파일 및 해당 구문의 이름은 시스템의 아키텍처 및 하드웨어에 따라 다릅니다.BIOS가 있는 AMD64 및 Intel 64 시스템에서 파일 이름은 기본 또는 시스템의 IP 주소를 기반으로 할 수 있습니다. 이 경우 설치 항목의 append 행에
inst.ks=옵션을 추가합니다. 구성 파일의 샘플 추가 행은 다음과 유사합니다.append initrd=initrd.img inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfg
append initrd=initrd.img inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow UEFI 펌웨어 및 IBM Power Systems 서버가 있는 GRUB 부트 로더(AMD64, Intel 64 및 64비트 ARM 시스템)를 사용하는 시스템에서 파일 이름은
grub.cfg입니다. 이 파일에서 설치 항목의 kernel 행에inst.ks=옵션을 추가합니다. 설정 파일의 샘플 커널 행은 다음과 유사합니다.kernel vmlinuz inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfg
kernel vmlinuz inst.ks=http://10.32.5.1/mnt/archive/RHEL-8/8.x/x86_64/kickstarts/ks.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
네트워크 서버에서 설치를 부팅합니다.
이제 Kickstart 파일에 지정된 설치 옵션을 사용하여 설치가 시작됩니다. Kickstart 파일이 유효하고 모든 필수 명령이 포함된 경우 설치가 완전히 자동화됩니다.
UEFI Secure Boot가 활성화된 시스템에서 Red Hat Enterprise Linux Beta 릴리스를 설치한 경우 Beta 공개 키를 시스템의 MOK(Machine Owner Key) 목록에 추가합니다.
10.5.2. 로컬 볼륨을 사용하여 자동으로 Kickstart 설치 시작
특정 이름이 지정된 스토리지 볼륨에 특정 이름으로 Kickstart 파일을 배치하여 Kickstart 설치를 시작할 수 있습니다.
사전 요구 사항
-
OEMDRV레이블이 있고 root에ks.cfg로 Kickstart 파일이 있는 볼륨이 있습니다. - 이 볼륨을 포함하는 드라이브는 설치 프로그램이 부팅될 때 시스템에서 사용할 수 있습니다.
절차
- 로컬 미디어(CD, DVD 또는 USB 플래시 드라이브)를 사용하여 시스템을 부팅합니다.
부팅 프롬프트에서 필요한 부팅 옵션을 지정합니다.
-
필수 리포지토리가 네트워크 위치에 있는 경우
ip=옵션을 사용하여 네트워크를 구성해야 할 수 있습니다. 설치 프로그램에서 이 옵션 없이 기본적으로 DHCP 프로토콜을 사용하여 모든 네트워크 장치를 구성하려고 합니다. 필요한 패키지를 설치할 소프트웨어 소스에 액세스하려면
inst.repo=옵션을 추가해야 할 수도 있습니다. 이 옵션을 지정하지 않으면 Kickstart 파일에 설치 소스를 지정해야 합니다.설치 소스에 대한 자세한 내용은 설치 프로그램 구성 및 흐름 제어를 위한 Kickstart 명령을 참조하십시오.
-
필수 리포지토리가 네트워크 위치에 있는 경우
추가된 부팅 옵션을 확인하여 설치를 시작합니다.
이제 설치가 시작되고 Kickstart 파일이 자동으로 탐지되어 자동화된 Kickstart 설치를 시작하는 데 사용됩니다.
UEFI Secure Boot가 활성화된 시스템에서 Red Hat Enterprise Linux Beta 릴리스를 설치한 경우 Beta 공개 키를 시스템의 MOK(Machine Owner Key) 목록에 추가합니다. UEFI Secure Boot 및 Red Hat Enterprise Linux 베타 릴리스에 대한 자세한 내용은 UEFI Secure Boot 및 Beta 릴리스 요구 사항을 참조하십시오.
10.5.3. LPAR에 RHEL을 설치하기 위해 IBM Z에 설치 부팅
10.5.3.1. IBM Z LPAR에 설치할 SFTP, FTPS 또는 FTP 서버에서 RHEL 설치 부팅
SFTP, FTPS 또는 FTP 서버를 사용하여 LPAR에 RHEL을 설치할 수 있습니다.
절차
- IBM Z Hardware Management Console(HMC) 또는 지원 요소(SE)에 새 운영 체제를 LPAR에 설치하기에 충분한 권한이 있는 사용자로 로그인합니다.
- 시스템 탭에서 작업하려는 가상 네트워크를 선택한 다음 파티션 탭에서 설치할 LPAR을 선택합니다.
- 화면 하단에서 운영 체제 메시지를 찾습니다. 운영 체제 메시지를 두 번 클릭하여 Linux 부팅 메시지가 표시되는 텍스트 콘솔을 표시합니다.
- Removable Media 또는 Server에서 로드 를 두 번 클릭합니다.
다음 대화 상자에서 SFTP/FTPS/FTP Server 를 선택하고 다음 정보를 입력합니다.
- 호스트 컴퓨터 - 설치하려는 FTP 서버의 호스트 이름 또는 IP 주소(예: ftp.redhat.com)
- 사용자 ID - FTP 서버의 사용자 이름입니다. 또는 anonymous를 지정합니다.
- 암호 - 암호. 익명으로 로그인하는 경우 이메일 주소를 사용합니다.
- 파일 위치(선택 사항) - IBM Z용 Red Hat Enterprise Linux를 보유하는 FTP 서버의 디렉터리입니다(예: /rhel/s390x/ ).
- Continue 를 클릭합니다.
- 다음 대화 상자에서 기본 generic.ins 를 계속 선택하고 Continue 를 클릭합니다.
10.5.3.2. IBM Z LPAR에 설치할 준비 DASD에서 RHEL 설치 부팅
이미 준비된 DASD를 사용하여 Red Hat Enterprise Linux를 LPAR에 설치할 때 다음 절차를 사용하십시오.
절차
- IBM Z Hardware Management Console(HMC) 또는 지원 요소(SE)에 새 운영 체제를 LPAR에 설치하기에 충분한 권한이 있는 사용자로 로그인합니다.
- 시스템 탭에서 작업하려는 가상 네트워크를 선택한 다음 파티션 탭에서 설치할 LPAR을 선택합니다.
- 화면 하단에서 운영 체제 메시지를 찾습니다. 운영 체제 메시지를 두 번 클릭하여 Linux 부팅 메시지가 표시되는 텍스트 콘솔을 표시합니다.
- 로드 를 두 번 클릭합니다.
- 다음과 같은 대화 상자에서 Load type 으로 Normal 을 선택합니다.
- Load address 로 DASD의 장치 번호를 입력합니다.
- OK 버튼을 클릭합니다.
10.5.3.3. IBM Z LPAR에 설치하기 위해 FCP 연결 SCSI 디스크에서 RHEL 설치 부팅
이미 준비된 FCP가 SCSI 디스크를 연결하여 LPAR에 Red Hat Enterprise Linux를 설치할 때 다음 절차를 사용하십시오.
절차
- IBM Z Hardware Management Console(HMC) 또는 지원 요소(SE)에 새 운영 체제를 LPAR에 설치하기에 충분한 권한이 있는 사용자로 로그인합니다.
- 시스템 탭에서 작업하려는 가상 네트워크를 선택한 다음 파티션 탭에서 설치할 LPAR을 선택합니다.
- 화면 하단에서 운영 체제 메시지를 찾습니다. 운영 체제 메시지를 두 번 클릭하여 Linux 부팅 메시지가 표시되는 텍스트 콘솔을 표시합니다.
- 로드 를 두 번 클릭합니다.
- 다음 대화 상자에서 로드 유형으로 SCSI 를 선택합니다.
- 로드 주소 로서 SCSI 디스크와 연결된 FCP 채널의 장치 번호를 입력합니다.
- World wide port name 로서 16자리 16진수로 디스크를 포함하는 스토리지 시스템의 WWPN을 입력합니다.
- 논리 단위 번호 로서 16자리 16진수로 디스크의 LUN을 입력합니다.
- Boot record 논리 블록 주소를 0 으로 두고 운영 체제별 로드 매개변수를 비워 둡니다.
- OK 버튼을 클릭합니다.
10.5.3.4. IBM Z LPAR에 설치하기 위해 FCP 연결 SCSI DVD 드라이브에서 RHEL 설치 부팅
이를 위해서는 FCP-to-SCSI 브릿지에 연결된 SCSI DVD 드라이브가 필요하므로 IBM Z 머신의 FCP 어댑터에 연결됩니다. FCP 어댑터는 LPAR에서 구성하고 사용할 수 있어야 합니다.
절차
- IBM Z Hardware Management Console(HMC) 또는 지원 요소(SE)에 새 운영 체제를 LPAR에 설치하기에 충분한 권한이 있는 사용자로 로그인합니다.
- 시스템 탭에서 작업하려는 가상 네트워크를 선택한 다음 파티션 탭에서 설치할 LPAR을 선택합니다.
- 화면 하단에 있는 daily에서 운영 체제 메시지를 찾습니다. 운영 체제 메시지를 두 번 클릭하여 Linux 부팅 메시지가 표시되는 텍스트 콘솔을 표시합니다.
- 64비트 IBM Z DVD용 Red Hat Enterprise Linux를 DVD 드라이브에 삽입합니다.
- 로드 를 두 번 클릭합니다.
- 다음 대화 상자에서 로드 유형으로 SCSI 를 선택합니다.
- 로드 주소 로서 FCP-to-SCSI 브리지와 연결된 FCP 채널의 장치 번호를 입력합니다.
- World wide port name 로서 FCP-to-SCSI 브리지의 WWPN을 16자리 16진수로 입력합니다.
- 논리 단위 번호 로서 DVD 드라이브의 LUN을 16자리 16진수로 채우십시오.
- 부팅 프로그램 선택기 로 숫자 1 을 작성하여 64비트 IBM Z DVD용 Red Hat Enterprise Linux에서 부팅 항목을 선택합니다.
- Boot record 논리 블록 주소를 0 으로 두고 운영 체제별 로드 매개변수를 비워 둡니다.
- OK 버튼을 클릭합니다.
10.5.4. IBM Z에 설치 부팅하여 z/VM에 RHEL 설치
z/VM 아래에 설치할 때 다음에서 부팅할 수 있습니다.
- z/VM 가상 리더
- zipl 부트 로더로 준비된 DASD 또는 FCP 연결 SCSI 디스크
- FCP 연결 SCSI DVD 드라이브
10.5.4.1. z/VM 리더를 사용하여 RHEL 설치 부팅
z/VM 리더에서 부팅할 수 있습니다.
절차
필요한 경우 z/VM TCP/IP 도구가 포함된 장치를 CMS 디스크 목록에 추가합니다. 예를 들면 다음과 같습니다.
cp link tcpmaint 592 592 acc 592 fm
cp link tcpmaint 592 592 acc 592 fmCopy to Clipboard Copied! Toggle word wrap Toggle overflow fm 을
FILEMODE문자로 바꿉니다.FTPS 서버에 연결하려면 다음을 입력합니다.
ftp <host> (secure
ftp <host> (secureCopy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서
host는 부팅 이미지를 호스팅하는 FTP 서버의 호스트 이름 또는 IP 주소입니다(kernel.img및initrd.img).로그인하고 다음 명령을 실행합니다. 기존
kernel.img,initrd.img,generic.prm또는redhat.exec파일을 덮어쓰는 경우(repl옵션을 사용합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 수신된 파일과 형식을 표시하기 위해 CMS 명령
filelist를 사용하여 파일이 올바르게 전송되었는지 확인합니다.kernel.img및initrd.img는 Format 열에서 F로 표시된 고정된 레코드 길이 형식과 Lrecl 열에서 레코드 길이 80을 갖는 것이 중요합니다. 예를 들면 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow PF3 을 눌러 filelist를 종료하고 CMS 프롬프트로 돌아갑니다.
필요한 경우
generic.prm에서 부팅 매개변수를 사용자 지정합니다. 자세한 내용은 부팅 매개변수 사용자 지정을 참조하십시오.스토리지 및 네트워크 장치를 구성하는 또 다른 방법은 CMS 구성 파일을 사용하는 것입니다. 이러한 경우
CMSDASD=및CMSCONFFILE=매개 변수를generic.prm에 추가합니다.마지막으로 REXX 스크립트 redhat.exec를 실행하여 설치 프로그램을 부팅합니다.
redhat
redhatCopy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5.4.2. 준비된 DASD를 사용하여 RHEL 설치 부팅
준비 DASD를 사용하려면 다음 단계를 수행합니다.
절차
준비된 DASD에서 부팅하고 Red Hat Enterprise Linux 설치 프로그램을 참조하는 zipl 부팅 메뉴 항목을 선택합니다. 다음 형식의 명령을 사용합니다.
cp ipl DASD_device_number loadparm boot_entry_number
cp ipl DASD_device_number loadparm boot_entry_numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow DASD_device_number 를 부팅 장치의 장치 번호로 바꾸고 boot_entry_number 를 이 장치의 zipl 구성 메뉴로 바꿉니다. 예를 들면 다음과 같습니다.
cp ipl eb1c loadparm 0
cp ipl eb1c loadparm 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5.4.3. FCP 연결 SCSI 디스크를 사용하여 RHEL 설치 부팅
다음 단계를 수행하여 준비된 FCP 연결 SCSI 디스크에서 부팅합니다.
절차
FCP 스토리지 영역 네트워크의 준비된 SCSI 디스크에 액세스하도록 z/VM의 SCSI 부트 로더를 구성합니다. Red Hat Enterprise Linux 설치 프로그램을 참조하는 준비된 zipl 부팅 메뉴 항목을 선택합니다. 다음 형식의 명령을 사용합니다.
cp set loaddev portname WWPN lun LUN bootprog boot_entry_number
cp set loaddev portname WWPN lun LUN bootprog boot_entry_numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow WWPN 을 스토리지 시스템의 World Wide Port Name으로, LUN 을 디스크의 논리 단위 번호로 바꿉니다. 16자리 16진수는 각각 8자리의 두 쌍으로 분할되어야 합니다. 예를 들면 다음과 같습니다.
cp set loaddev portname 50050763 050b073d lun 40204011 00000000 bootprog 0
cp set loaddev portname 50050763 050b073d lun 40204011 00000000 bootprog 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 명령을 사용하여 설정을 확인합니다.
query loaddev
query loaddevCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 사용하여 디스크를 포함하는 스토리지 시스템과 연결된 FCP 장치를 부팅합니다.
cp ipl FCP_device
cp ipl FCP_deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
cp ipl fc00
cp ipl fc00Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5.4.4. FCP 연결 SCSI DVD 드라이브를 사용하여 RHEL 설치 부팅
준비 FCP 연결 SCSI DVD 드라이브를 사용하려면 다음 단계를 수행합니다.
사전 요구 사항
- 이를 위해서는 FCP-to-SCSI 브릿지에 연결된 SCSI DVD 드라이브가 필요하며, 이는 64비트 IBM Z의 FCP 어댑터에 연결되어 있습니다. FCP 어댑터는 z/VM에서 구성하고 사용할 수 있어야 합니다.
절차
- 64비트 IBM Z DVD용 Red Hat Enterprise Linux를 DVD 드라이브에 삽입합니다.
FCP 스토리지 영역 네트워크의 DVD 드라이브에 액세스하도록 z/VM의 SCSI 부트 로더를 구성하고 64비트 IBM Z DVD용 Red Hat Enterprise Linux의 부팅 항목에 대해
1을 지정합니다. 다음 형식의 명령을 사용합니다.cp set loaddev portname WWPN lun FCP_LUN bootprog 1
cp set loaddev portname WWPN lun FCP_LUN bootprog 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow WWPN 을 FCP-to-SCSI 브리지의 WWPN과 FCP_LUN 을 DVD 드라이브의 LUN으로 바꿉니다. 16자리의 16진수 16진수는 각각 8자의 두 쌍으로 분할되어야 합니다. 예를 들면 다음과 같습니다.
cp set loaddev portname 20010060 eb1c0103 lun 00010000 00000000 bootprog 1
cp set loaddev portname 20010060 eb1c0103 lun 00010000 00000000 bootprog 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 명령을 사용하여 설정을 확인합니다.
cp query loaddev
cp query loaddevCopy to Clipboard Copied! Toggle word wrap Toggle overflow FCP-to-SCSI 브리지와 연결된 FCP 장치의 IPL
cp ipl FCP_device
cp ipl FCP_deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
cp ipl fc00
cp ipl fc00Copy to Clipboard Copied! Toggle word wrap Toggle overflow
10.5.5. 설치 중에 콘솔 및 로깅
Red Hat Enterprise Linux 설치 프로그램은 tmux 터미널 멀티플렉서를 사용하여 기본 인터페이스 외에도 여러 창을 표시하고 제어합니다. 이러한 창은 각각 다른 용도로 사용됩니다. 여러 다른 로그를 표시하며 이는 설치 프로세스 중 문제를 해결하는 데 사용할 수 있습니다. 이 프롬프트가 부팅 옵션 또는 Kickstart 명령을 사용하여 구체적으로 비활성화되지 않은 한 창 중 하나는 root 권한이 있는 대화형 쉘 프롬프트를 제공합니다.
터미널 멀티플렉서는 가상 콘솔 1에서 실행됩니다. 실제 설치 환경에서 tmux로 전환하려면 Ctrl+Alt+F1을 누릅니다. 가상 콘솔 6에서 실행되는 기본 설치 인터페이스로 돌아가려면 Ctrl+Alt+F6를 누릅니다. 텍스트 모드 설치 중에 가상 콘솔 1(tmux)에서 시작하고 콘솔 6으로 전환하면 그래픽 인터페이스 대신 쉘 프롬프트가 열립니다.
tmux를 실행하는 콘솔에는 5개의 사용 가능한 창이 있습니다. 해당 내용은 키보드 바로 가기와 함께 다음 표에 설명되어 있습니다. 바로 가기 키는 두 부분으로 구성됩니다. 먼저 Ctrl+b 누른 다음 두 키를 모두 해제하고 사용하려는 창의 숫자 키를 누릅니다.
Ctrl+b n,Alt+ Tab, Ctrl+b p 를 사용하여 각각 다음 또는 이전 tmux 창으로 전환할 수도 있습니다.
| 바로 가기 | 내용 |
|---|---|
| Ctrl+b 1 | 기본 설치 프로그램 창입니다. 텍스트 기반 프롬프트(텍스트 모드 설치 확인 또는 VNC 직접 모드를 사용하는 경우) 및 일부 디버깅 정보를 포함합니다. |
| Ctrl+b 2 |
|
| Ctrl+b 3 |
설치 로그; |
| Ctrl+b 4 |
스토리지 로그; |
| Ctrl+b 5 |
프로그램 로그; 설치 프로세스 중에 실행되는 유틸리티의 메시지를 표시하고 |
11장. 고급 구성 옵션
11.1. 시스템 용도 구성
시스템 용도를 사용하여 Red Hat Enterprise Linux 8 시스템의 용도를 기록합니다. 시스템 용도를 설정하면 인타이틀먼트 서버가 가장 적합한 서브스크립션을 자동으로 첨부할 수 있습니다. 이 섹션에서는 Kickstart를 사용하여 시스템 용도를 구성하는 방법에 대해 설명합니다.
이점은 다음과 같습니다.
- 시스템 관리자 및 비즈니스 운영에 대한 심층적인 시스템 수준 정보입니다.
- 시스템이 유도된 이유와 의도한 목적을 결정할 때 오버헤드 감소.
- 서브스크립션 관리자 자동 연결뿐만 아니라 시스템 사용량 자동 검색 및 조정의 고객 환경 개선
11.1.1. 개요
다음 방법 중 하나로 시스템 용도 데이터를 입력할 수 있습니다.
- 이미지 생성 중
- Red Hat 에 연결 화면을 사용하여 시스템을 등록하고 Red Hat 서브스크립션을 연결할 때 GUI를 설치하는 동안
-
syspurpose Kickstart명령을 사용할 때 Kickstart 설치 중 -
syspurposeCLI(명령줄) 툴을 사용하여 설치 후
시스템의 의도된 용도를 기록하기 위해 다음과 같은 시스템 용도 구성 요소를 구성할 수 있습니다. 선택한 값은 시스템에 가장 적합한 서브스크립션을 연결하기 위해 등록 시 인타이틀먼트 서버에서 사용합니다.
- Role
- Red Hat Enterprise Linux Server
- Red Hat Enterprise Linux Workstation
- Red Hat Enterprise Linux Compute Node
- 서비스 수준 계약
- Premium
- Standard
- Self-Support
- 사용법
- 프로덕션
- 개발/테스트
- 재해 복구
11.1.2. Kickstart 파일에서 시스템 용도 구성
설치 중에 시스템 용도를 구성하려면 다음 절차의 단계를 따르십시오. 이를 위해 Kickstart 구성 파일에서 syspurpose Kickstart 명령을 사용합니다.
시스템 용도는 Red Hat Enterprise Linux 설치 프로그램의 선택적 기능이지만 가장 적합한 서브스크립션을 자동으로 첨부하도록 시스템 용도를 구성하는 것이 좋습니다.
설치가 완료된 후 시스템 용도를 활성화할 수도 있습니다. 이렇게 하려면 syspurpose 명령줄 툴을 사용합니다. syspurpose 툴 명령은 syspurpose Kickstart 명령과 다릅니다.
syspurpose Kickstart 명령에 다음 작업을 사용할 수 있습니다.
- role
시스템의 의도한 역할을 설정합니다. 이 작업은 다음 형식을 사용합니다.
syspurpose --role=
syspurpose --role=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 할당된 역할은 다음과 같습니다.
-
Red Hat Enterprise Linux Server -
Red Hat Enterprise Linux Workstation -
Red Hat Enterprise Linux Compute Node
-
- SLA
시스템의 SLA를 설정합니다. 이 작업은 다음 형식을 사용합니다.
syspurpose --sla=
syspurpose --sla=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 할당된 Sla는 다음을 수행할 수 있습니다.
-
Premium -
Standard -
Self-Support
-
- 사용법
시스템의 의도된 사용량을 설정합니다. 이 작업은 다음 형식을 사용합니다.
syspurpose --usage=
syspurpose --usage=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 할당된 사용은 다음과 같습니다.
-
Production -
Development/Test -
Disaster Recovery
-
- 애드온
추가 계층화된 제품 또는 기능입니다. 여러 항목을 추가하려면 계층화된 제품/기능별로
--addon을 여러 번 지정합니다. 이 작업은 다음 형식을 사용합니다.syspurpose --addon=
syspurpose --addon=Copy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2. UEFI HTTP 설치 소스 준비
로컬 네트워크의 서버 관리자는 네트워크의 다른 시스템에 대해 HTTP 부팅 및 네트워크 설치를 활성화하도록 HTTP 서버를 구성할 수 있습니다.
11.2.1. 네트워크 설치 개요
네트워크 설치를 통해 설치 서버에 액세스할 수 있는 시스템에 Red Hat Enterprise Linux를 설치할 수 있습니다. 최소한 네트워크 설치에는 두 개의 시스템이 필요합니다.
- 서버
- DHCP 서버, HTTP, HTTPS, FTP 또는 NFS 서버를 실행하는 시스템 및 PXE 부팅 사례에서 TFTP 서버입니다. 각 서버는 다른 물리적 시스템에서 실행할 수 있지만 이 섹션의 절차에서는 단일 시스템이 모든 서버를 실행하고 있다고 가정합니다.
- 클라이언트
- Red Hat Enterprise Linux를 설치하는 시스템. 설치가 시작되면 클라이언트는 DHCP 서버에 쿼리하고 HTTP 또는 TFTP 서버에서 부팅 파일을 수신하고 HTTP, HTTPS, FTP 또는 NFS 서버에서 설치 이미지를 다운로드합니다. 다른 설치 방법과 달리 클라이언트에는 설치를 시작하는 데 물리적 부팅 미디어가 필요하지 않습니다.
네트워크에서 클라이언트를 부팅하려면 펌웨어 또는 클라이언트의 빠른 부팅 메뉴에서 네트워크 부팅을 활성화합니다. 일부 하드웨어에서는 네트워크에서 부팅하는 옵션이 비활성화되거나 사용할 수 없는 경우가 있습니다.
HTTP 또는 PXE를 사용하여 네트워크에서 Red Hat Enterprise Linux 설치를 준비하는 워크플로우 단계는 다음과 같습니다.
절차
- 설치 ISO 이미지 또는 설치 트리를 NFS, HTTPS, HTTP 또는 FTP 서버로 내보냅니다.
- HTTP 또는 TFTP 서버와 DHCP 서버를 구성하고 서버에서 HTTP 또는 TFTP 서비스를 시작합니다.
- 클라이언트를 부팅하고 설치를 시작합니다.
다음 네트워크 부팅 프로토콜 중에서 선택할 수 있습니다.
- HTTP
- 클라이언트 UEFI에서 지원하는 경우 HTTP 부팅을 사용하는 것이 좋습니다. HTTP 부팅은 일반적으로 더 안정적입니다.
- PXE (TFTP)
- PXE 부팅은 클라이언트 시스템에서 더 널리 지원되지만 이 프로토콜을 통해 부팅 파일을 전송하는 속도가 느려 시간 초과 오류가 발생할 수 있습니다.
11.2.2. 네트워크 부팅을 위한 DHCPv4 서버 구성
서버에서 DHCP 버전 4(DHCPv4) 서비스를 활성화하여 네트워크 부팅 기능을 제공합니다.
사전 요구 사항
IPv4 프로토콜을 통해 네트워크 설치를 준비하고 있습니다.
IPv6 의 경우 대신 네트워크 부팅을 위한 DHCPv6 서버 구성 을 참조하십시오.
서버의 네트워크 주소를 찾습니다.
다음 예제에서 서버에는 이 설정이 포함된 네트워크 카드가 있습니다.
- IPv4 주소
- 192.168.124.2/24
- IPv4 게이트웨이
- 192.168.124.1
절차
DHCP 서버를 설치합니다.
yum install dhcp-server
yum install dhcp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv4 서버를 설정합니다.
/etc/dhcp/dhcpd.conf파일에 다음 구성을 입력합니다. 네트워크 카드와 일치하도록 주소를 바꿉니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv4 서비스를 시작합니다.
systemctl enable --now dhcpd
# systemctl enable --now dhcpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.3. 네트워크 부팅을 위한 DHCPv6 서버 구성
서버에서 DHCP 버전 6(DHCPv4) 서비스를 활성화하여 네트워크 부팅 기능을 제공합니다.
사전 요구 사항
IPv6 프로토콜을 통해 네트워크 설치를 준비하고 있습니다.
IPv4 의 경우 대신 네트워크 부팅을 위한 DHCPv4 서버 구성 을 참조하십시오.
서버의 네트워크 주소를 찾습니다.
다음 예제에서 서버에는 이 설정이 포함된 네트워크 카드가 있습니다.
- IPv6 주소
- fd33:eb1b:9b36::2/64
- IPv6 게이트웨이
- fd33:eb1b:9b36::1
절차
DHCP 서버를 설치합니다.
yum install dhcp-server
yum install dhcp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv6 서버를 설정합니다.
/etc/dhcp/dhcpd6.conf파일에 다음 구성을 입력합니다. 네트워크 카드와 일치하도록 주소를 바꿉니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv6 서비스를 시작합니다.
systemctl enable --now dhcpd6
# systemctl enable --now dhcpd6Copy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv6 패킷이 방화벽의 RP 필터에 의해 삭제되는 경우 해당 로그를 확인합니다. 로그에
rpfilter_DROP항목이 포함된 경우/etc/firewalld/firewalld.conf파일에서 다음 구성을 사용하여 필터를 비활성화합니다.IPv6_rpfilter=no
IPv6_rpfilter=noCopy to Clipboard Copied! Toggle word wrap Toggle overflow
11.2.4. HTTP 부팅을 위한 HTTP 서버 구성
서버에서 네트워크에서 HTTP 부팅 리소스를 제공할 수 있도록 httpd 서비스를 설치하고 활성화해야 합니다.
사전 요구 사항
서버의 네트워크 주소를 찾습니다.
다음 예제에서 서버에는
192.168.124.2IPv4 주소가 있는 네트워크 카드가 있습니다.
절차
HTTP 서버를 설치합니다.
yum install httpd
# yum install httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow /var/www/html/redhat/디렉터리를 생성합니다.mkdir -p /var/www/html/redhat/
# mkdir -p /var/www/html/redhat/Copy to Clipboard Copied! Toggle word wrap Toggle overflow - RHEL DVD ISO 파일을 다운로드합니다. 모든 Red Hat Enterprise Linux 다운로드를 참조하십시오.
ISO 파일의 마운트 지점을 생성합니다.
mkdir -p /var/www/html/redhat/iso/
# mkdir -p /var/www/html/redhat/iso/Copy to Clipboard Copied! Toggle word wrap Toggle overflow ISO 파일을 마운트합니다.
mount -o loop,ro -t iso9660 path-to-RHEL-DVD.iso /var/www/html/redhat/iso
# mount -o loop,ro -t iso9660 path-to-RHEL-DVD.iso /var/www/html/redhat/isoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 마운트된 ISO 파일의 부트 로더, kernel 및
initramfs를 HTML 디렉터리로 복사합니다.cp -r /var/www/html/redhat/iso/images /var/www/html/redhat/ cp -r /var/www/html/redhat/iso/EFI /var/www/html/redhat/
# cp -r /var/www/html/redhat/iso/images /var/www/html/redhat/ # cp -r /var/www/html/redhat/iso/EFI /var/www/html/redhat/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 부트 로더 구성을 편집할 수 있도록 합니다.
chmod 644 /var/www/html/redhat/EFI/BOOT/grub.cfg
# chmod 644 /var/www/html/redhat/EFI/BOOT/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow /var/www/html/redhat/EFI/BOOT/grub.cfg파일을 편집하고 해당 콘텐츠를 다음으로 바꿉니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 파일에서 다음 문자열을 교체합니다.
- RHEL-9-3-0-BaseOS-x86_64 및 Red Hat Enterprise Linux 9.3
- 다운로드한 RHEL 버전과 일치하도록 버전 번호를 편집합니다.
- 192.168.124.2
- 를 서버의 IP 주소로 바꿉니다.
EFI 부팅 파일을 실행 가능하게 만듭니다.
chmod 755 /var/www/html/redhat/EFI/BOOT/BOOTX64.EFI
# chmod 755 /var/www/html/redhat/EFI/BOOT/BOOTX64.EFICopy to Clipboard Copied! Toggle word wrap Toggle overflow HTTP(80), DHCP(67, 68) 및 DHCPv6(546, 547) 트래픽을 허용하도록 방화벽에서 포트를 엽니다.
firewall-cmd --zone public \ --add-port={80/tcp,67/udp,68/udp,546/udp,547/udp}# firewall-cmd --zone public \ --add-port={80/tcp,67/udp,68/udp,546/udp,547/udp}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 다음 서버가 재부팅될 때까지 임시 액세스를 활성화합니다.
-
선택 사항: 영구 액세스를 활성화하려면 명령에
--permanent옵션을 추가합니다. 방화벽 규칙을 다시 로드합니다.
firewall-cmd --reload
# firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow HTTP 서버를 시작합니다.
systemctl enable --now httpd
# systemctl enable --now httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow html디렉토리와 해당 콘텐츠를 읽을 수 있고 실행 가능하게 만듭니다.chmod -cR u=rwX,g=rX,o=rX /var/www/html
# chmod -cR u=rwX,g=rX,o=rX /var/www/htmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow html디렉터리의 SELinux 컨텍스트를 복원합니다.restorecon -FvvR /var/www/html
# restorecon -FvvR /var/www/htmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12장. PXE 설치 소스 준비
PXE 부팅 및 네트워크 설치를 활성화하려면 PXE 서버에서 TFTP 및 DHCP를 구성해야 합니다.
12.1. 네트워크 설치 개요
네트워크 설치를 통해 설치 서버에 액세스할 수 있는 시스템에 Red Hat Enterprise Linux를 설치할 수 있습니다. 최소한 네트워크 설치에는 두 개의 시스템이 필요합니다.
- 서버
- DHCP 서버, HTTP, HTTPS, FTP 또는 NFS 서버를 실행하는 시스템 및 PXE 부팅 사례에서 TFTP 서버입니다. 각 서버는 다른 물리적 시스템에서 실행할 수 있지만 이 섹션의 절차에서는 단일 시스템이 모든 서버를 실행하고 있다고 가정합니다.
- 클라이언트
- Red Hat Enterprise Linux를 설치하는 시스템. 설치가 시작되면 클라이언트는 DHCP 서버에 쿼리하고 HTTP 또는 TFTP 서버에서 부팅 파일을 수신하고 HTTP, HTTPS, FTP 또는 NFS 서버에서 설치 이미지를 다운로드합니다. 다른 설치 방법과 달리 클라이언트에는 설치를 시작하는 데 물리적 부팅 미디어가 필요하지 않습니다.
네트워크에서 클라이언트를 부팅하려면 펌웨어 또는 클라이언트의 빠른 부팅 메뉴에서 네트워크 부팅을 활성화합니다. 일부 하드웨어에서는 네트워크에서 부팅하는 옵션이 비활성화되거나 사용할 수 없는 경우가 있습니다.
HTTP 또는 PXE를 사용하여 네트워크에서 Red Hat Enterprise Linux 설치를 준비하는 워크플로우 단계는 다음과 같습니다.
절차
- 설치 ISO 이미지 또는 설치 트리를 NFS, HTTPS, HTTP 또는 FTP 서버로 내보냅니다.
- HTTP 또는 TFTP 서버와 DHCP 서버를 구성하고 서버에서 HTTP 또는 TFTP 서비스를 시작합니다.
- 클라이언트를 부팅하고 설치를 시작합니다.
다음 네트워크 부팅 프로토콜 중에서 선택할 수 있습니다.
- HTTP
- 클라이언트 UEFI에서 지원하는 경우 HTTP 부팅을 사용하는 것이 좋습니다. HTTP 부팅은 일반적으로 더 안정적입니다.
- PXE (TFTP)
- PXE 부팅은 클라이언트 시스템에서 더 널리 지원되지만 이 프로토콜을 통해 부팅 파일을 전송하는 속도가 느려 시간 초과 오류가 발생할 수 있습니다.
12.2. 네트워크 부팅을 위한 DHCPv4 서버 구성
서버에서 DHCP 버전 4(DHCPv4) 서비스를 활성화하여 네트워크 부팅 기능을 제공합니다.
사전 요구 사항
IPv4 프로토콜을 통해 네트워크 설치를 준비하고 있습니다.
IPv6 의 경우 대신 네트워크 부팅을 위한 DHCPv6 서버 구성 을 참조하십시오.
서버의 네트워크 주소를 찾습니다.
다음 예제에서 서버에는 이 설정이 포함된 네트워크 카드가 있습니다.
- IPv4 주소
- 192.168.124.2/24
- IPv4 게이트웨이
- 192.168.124.1
절차
DHCP 서버를 설치합니다.
yum install dhcp-server
yum install dhcp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv4 서버를 설정합니다.
/etc/dhcp/dhcpd.conf파일에 다음 구성을 입력합니다. 네트워크 카드와 일치하도록 주소를 바꿉니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv4 서비스를 시작합니다.
systemctl enable --now dhcpd
# systemctl enable --now dhcpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12.3. 네트워크 부팅을 위한 DHCPv6 서버 구성
서버에서 DHCP 버전 6(DHCPv4) 서비스를 활성화하여 네트워크 부팅 기능을 제공합니다.
사전 요구 사항
IPv6 프로토콜을 통해 네트워크 설치를 준비하고 있습니다.
IPv4 의 경우 대신 네트워크 부팅을 위한 DHCPv4 서버 구성 을 참조하십시오.
서버의 네트워크 주소를 찾습니다.
다음 예제에서 서버에는 이 설정이 포함된 네트워크 카드가 있습니다.
- IPv6 주소
- fd33:eb1b:9b36::2/64
- IPv6 게이트웨이
- fd33:eb1b:9b36::1
절차
DHCP 서버를 설치합니다.
yum install dhcp-server
yum install dhcp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv6 서버를 설정합니다.
/etc/dhcp/dhcpd6.conf파일에 다음 구성을 입력합니다. 네트워크 카드와 일치하도록 주소를 바꿉니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv6 서비스를 시작합니다.
systemctl enable --now dhcpd6
# systemctl enable --now dhcpd6Copy to Clipboard Copied! Toggle word wrap Toggle overflow DHCPv6 패킷이 방화벽의 RP 필터에 의해 삭제되는 경우 해당 로그를 확인합니다. 로그에
rpfilter_DROP항목이 포함된 경우/etc/firewalld/firewalld.conf파일에서 다음 구성을 사용하여 필터를 비활성화합니다.IPv6_rpfilter=no
IPv6_rpfilter=noCopy to Clipboard Copied! Toggle word wrap Toggle overflow
12.4. BIOS 기반 클라이언트용 TFTP 서버 구성
TFTP 서버와 DHCP 서버를 구성하고 BIOS 기반 AMD 및 Intel 64비트 시스템의 PXE 서버에서 TFTP 서비스를 시작해야 합니다.
절차
root 로서 다음 패키지를 설치합니다.
yum install tftp-server
# yum install tftp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽에서
tftp service에 대한 수신 연결을 허용합니다.firewall-cmd --add-service=tftp
# firewall-cmd --add-service=tftpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 다음 서버가 재부팅될 때까지 임시 액세스를 활성화합니다.
선택 사항: 영구 액세스를 활성화하려면 명령에
--permanent옵션을 추가합니다.설치 ISO 파일의 위치에 따라 HTTP 또는 기타 서비스에 대해 들어오는 연결을 허용해야 할 수 있습니다.
DVD ISO 이미지 파일의
SYSLINUX패키지에서pxelinux.0파일에 액세스합니다. 여기서 my_local_directory는 생성한 디렉터리의 이름입니다.mount -t iso9660 /path_to_image/name_of_image.iso /mount_point -o loop,ro
# mount -t iso9660 /path_to_image/name_of_image.iso /mount_point -o loop,roCopy to Clipboard Copied! Toggle word wrap Toggle overflow cp -pr /mount_point/BaseOS/Packages/syslinux-tftpboot-version-architecture.rpm /my_local_directory
# cp -pr /mount_point/BaseOS/Packages/syslinux-tftpboot-version-architecture.rpm /my_local_directoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow umount /mount_point
# umount /mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 패키지를 추출합니다.
rpm2cpio syslinux-tftpboot-version-architecture.rpm | cpio -dimv
# rpm2cpio syslinux-tftpboot-version-architecture.rpm | cpio -dimvCopy to Clipboard Copied! Toggle word wrap Toggle overflow tftpboot/에pxelinux/디렉터리를 만들고 디렉터리의 모든 파일을pxelinux/디렉터리에 복사합니다.mkdir /var/lib/tftpboot/pxelinux
# mkdir /var/lib/tftpboot/pxelinuxCopy to Clipboard Copied! Toggle word wrap Toggle overflow cp /my_local_directory/tftpboot/* /var/lib/tftpboot/pxelinux
# cp /my_local_directory/tftpboot/* /var/lib/tftpboot/pxelinuxCopy to Clipboard Copied! Toggle word wrap Toggle overflow pxelinux/디렉터리에pxelinux.cfg/디렉터리를 만듭니다.mkdir /var/lib/tftpboot/pxelinux/pxelinux.cfg
# mkdir /var/lib/tftpboot/pxelinux/pxelinux.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow default라는 구성 파일을 생성하고 다음 예와 같이pxelinux.cfg/디렉터리에 추가합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
설치 프로그램은 런타임 이미지 없이는 부팅할 수 없습니다.
inst.stage2부팅 옵션을 사용하여 이미지 위치를 지정합니다. 또는inst.repo=옵션을 사용하여 이미지와 설치 소스를 지정할 수 있습니다. -
inst.repo와 함께 사용되는 설치 소스 위치에는 유효한.treeinfo파일이 포함되어야 합니다. -
RHEL8 설치 DVD를 설치 소스로 선택하면
.treeinfo파일은 BaseOS 및 AppStream 리포지토리를 가리킵니다. 단일inst.repo옵션을 사용하여 두 리포지토리를 로드할 수 있습니다.
-
설치 프로그램은 런타임 이미지 없이는 부팅할 수 없습니다.
/var/lib/tftpboot/디렉터리에 부팅 이미지 파일을 저장하고 부팅 이미지 파일을 디렉터리에 복사합니다. 이 예에서 디렉터리는/var/lib/tftpboot/pxelinux/images/RHEL-8/:입니다.mkdir -p /var/lib/tftpboot/pxelinux/images/RHEL-8/ cp /path_to_x86_64_images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/pxelinux/images/RHEL-8/# mkdir -p /var/lib/tftpboot/pxelinux/images/RHEL-8/ # cp /path_to_x86_64_images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/pxelinux/images/RHEL-8/Copy to Clipboard Copied! Toggle word wrap Toggle overflow tftp.socket서비스를 시작하고 활성화합니다.systemctl enable --now tftp.socket
# systemctl enable --now tftp.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 PXE 부팅 서버가 PXE 클라이언트를 제공할 준비가 되었습니다. Red Hat Enterprise Linux를 설치하는 시스템인 클라이언트를 시작하고, 부팅 소스를 지정하라는 메시지가 표시되면 PXE 부팅 을 선택한 다음 네트워크 설치를 시작할 수 있습니다.
12.5. UEFI 기반 클라이언트용 TFTP 서버 구성
TFTP 서버와 DHCP 서버를 구성하고 UEFI 기반 AMD64, Intel 64 및 64비트 ARM 시스템의 PXE 서버에서 TFTP 서비스를 시작해야 합니다.
Red Hat Enterprise Linux 8 UEFI PXE 부팅은 MAC 기반 GRUB 메뉴 파일의 소문자 파일 형식을 지원합니다. 예를 들어 GRUB의 MAC 주소 파일 형식은 grub.cfg-01-aa-bb-cc-dd-ee-ff입니다.
절차
root 로서 다음 패키지를 설치합니다.
yum install tftp-server
# yum install tftp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽에서
tftp service에 대한 수신 연결을 허용합니다.firewall-cmd --add-service=tftp
# firewall-cmd --add-service=tftpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 다음 서버가 재부팅될 때까지 임시 액세스를 활성화합니다.
선택 사항: 영구 액세스를 활성화하려면 명령에
--permanent옵션을 추가합니다.설치 ISO 파일의 위치에 따라 HTTP 또는 기타 서비스에 대해 들어오는 연결을 허용해야 할 수 있습니다.
DVD ISO 이미지에서 EFI 부팅 이미지 파일에 액세스합니다.
mount -t iso9660 /path_to_image/name_of_image.iso /mount_point -o loop,ro
# mount -t iso9660 /path_to_image/name_of_image.iso /mount_point -o loop,roCopy to Clipboard Copied! Toggle word wrap Toggle overflow DVD ISO 이미지에서 EFI 부팅 이미지를 복사합니다.
mkdir /var/lib/tftpboot/redhat cp -r /mount_point/EFI /var/lib/tftpboot/redhat/ umount /mount_point
# mkdir /var/lib/tftpboot/redhat # cp -r /mount_point/EFI /var/lib/tftpboot/redhat/ # umount /mount_pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 복사된 파일의 권한을 수정합니다.
chmod -R 755 /var/lib/tftpboot/redhat/
# chmod -R 755 /var/lib/tftpboot/redhat/Copy to Clipboard Copied! Toggle word wrap Toggle overflow /var/lib/tftpboot/redhat/efi/boot/grub.cfg내용을 다음 예로 바꿉니다.set timeout=60 menuentry 'RHEL 8' { linux images/RHEL-8/vmlinuz ip=dhcp inst.repo=http://192.168.124.2/RHEL-8/x86_64/iso-contents-root/ initrd images/RHEL-8/initrd.img }set timeout=60 menuentry 'RHEL 8' { linux images/RHEL-8/vmlinuz ip=dhcp inst.repo=http://192.168.124.2/RHEL-8/x86_64/iso-contents-root/ initrd images/RHEL-8/initrd.img }Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
설치 프로그램은 런타임 이미지 없이는 부팅할 수 없습니다.
inst.stage2부팅 옵션을 사용하여 이미지 위치를 지정합니다. 또는inst.repo=옵션을 사용하여 이미지와 설치 소스를 지정할 수 있습니다. -
inst.repo와 함께 사용되는 설치 소스 위치에는 유효한.treeinfo파일이 포함되어야 합니다. -
RHEL8 설치 DVD를 설치 소스로 선택하면
.treeinfo파일은 BaseOS 및 AppStream 리포지토리를 가리킵니다. 단일inst.repo옵션을 사용하여 두 리포지토리를 로드할 수 있습니다.
-
설치 프로그램은 런타임 이미지 없이는 부팅할 수 없습니다.
/var/lib/tftpboot/디렉터리에 부팅 이미지 파일을 저장하고 부팅 이미지 파일을 디렉터리에 복사합니다. 이 예에서 디렉터리는/var/lib/tftpboot/images/RHEL-8/:입니다.mkdir -p /var/lib/tftpboot/images/RHEL-8/ cp /mount_point/images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/images/RHEL-8/# mkdir -p /var/lib/tftpboot/images/RHEL-8/ # cp /mount_point/images/pxeboot/{vmlinuz,initrd.img} /var/lib/tftpboot/images/RHEL-8/Copy to Clipboard Copied! Toggle word wrap Toggle overflow tftp.socket서비스를 시작하고 활성화합니다.systemctl enable --now tftp.socket
# systemctl enable --now tftp.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 PXE 부팅 서버가 PXE 클라이언트를 제공할 준비가 되었습니다. Red Hat Enterprise Linux를 설치하는 시스템인 클라이언트를 시작하고, 부팅 소스를 지정하라는 메시지가 표시되면 PXE 부팅 을 선택한 다음 네트워크 설치를 시작할 수 있습니다.
12.6. IBM Power 시스템용 네트워크 서버 구성
GRUB을 사용하여 IBM Power 시스템에 대한 네트워크 부팅 서버를 구성할 수 있습니다.
절차
root 로서 다음 패키지를 설치합니다.
yum install tftp-server dhcp-server
# yum install tftp-server dhcp-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽에서
tftp서비스에 대한 수신 연결을 허용합니다.firewall-cmd --add-service=tftp
# firewall-cmd --add-service=tftpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 다음 서버가 재부팅될 때까지 임시 액세스를 활성화합니다.
선택 사항: 영구 액세스를 활성화하려면 명령에
--permanent옵션을 추가합니다.설치 ISO 파일의 위치에 따라 HTTP 또는 기타 서비스에 대해 들어오는 연결을 허용해야 할 수 있습니다.
TFTP 루트 내에 GRUB 네트워크 부팅 디렉토리를 만듭니다.
grub2-mknetdir --net-directory=/var/lib/tftpboot Netboot directory for powerpc-ieee1275 created. Configure your DHCP server to point to /boot/grub2/powerpc-ieee1275/core.elf
# grub2-mknetdir --net-directory=/var/lib/tftpboot Netboot directory for powerpc-ieee1275 created. Configure your DHCP server to point to /boot/grub2/powerpc-ieee1275/core.elfCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령 출력은 이 절차에 설명된 DHCP 구성에서 구성해야 하는 파일 이름을 알려줍니다.
PXE 서버가 x86 시스템에서 실행되는 경우 tftp 루트 내에
GRUB2네트워크 부팅 디렉토리를 생성하기 전에grub2-ppc64le-modules를 설치해야 합니다.yum install grub2-ppc64le-modules
# yum install grub2-ppc64le-modulesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 예와 같이 GRUB 설정 파일
/var/lib/tftpboot/boot/grub2/grub.cfg를 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
설치 프로그램은 런타임 이미지 없이는 부팅할 수 없습니다.
inst.stage2부팅 옵션을 사용하여 이미지 위치를 지정합니다. 또는inst.repo=옵션을 사용하여 이미지와 설치 소스를 지정할 수 있습니다. -
inst.repo와 함께 사용되는 설치 소스 위치에는 유효한.treeinfo파일이 포함되어야 합니다. -
RHEL8 설치 DVD를 설치 소스로 선택하면
.treeinfo파일은 BaseOS 및 AppStream 리포지토리를 가리킵니다. 단일inst.repo옵션을 사용하여 두 리포지토리를 로드할 수 있습니다.
-
설치 프로그램은 런타임 이미지 없이는 부팅할 수 없습니다.
명령을 사용하여 DVD ISO 이미지를 마운트합니다.
mount -t iso9660 /path_to_image/name_of_iso/ /mount_point -o loop,ro
# mount -t iso9660 /path_to_image/name_of_iso/ /mount_point -o loop,roCopy to Clipboard Copied! Toggle word wrap Toggle overflow 디렉토리를 만들고
initrd.img및vmlinuz파일을 DVD ISO 이미지로 복사합니다. 예를 들면 다음과 같습니다.cp /mount_point/ppc/ppc64/{initrd.img,vmlinuz} /var/lib/tftpboot/grub2-ppc64/# cp /mount_point/ppc/ppc64/{initrd.img,vmlinuz} /var/lib/tftpboot/grub2-ppc64/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예와 같이
GRUB2와 함께 패키지된 부팅 이미지를 사용하도록 DHCP 서버를 구성합니다. DHCP 서버가 이미 구성된 경우 DHCP 서버에서 이 단계를 수행합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
네트워크 구성에 맞게 샘플 매개 변수
서브넷,넷마스크,라우터,고정 주소및하드웨어 이더넷을 조정합니다.file name매개변수입니다. 이 절차의 앞부분에 있는grub2-mknetdir명령으로 출력된 파일 이름입니다. DHCP 서버에서
dhcpd서비스를 시작하고 활성화합니다. localhost에 DHCP 서버를 구성한 경우 localhost에서dhcpd서비스를 시작하고 활성화합니다.systemctl enable --now dhcpd
# systemctl enable --now dhcpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow tftp.socket서비스를 시작하고 활성화합니다.systemctl enable --now tftp.socket
# systemctl enable --now tftp.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 PXE 부팅 서버가 PXE 클라이언트를 제공할 준비가 되었습니다. Red Hat Enterprise Linux를 설치하는 시스템인 클라이언트를 시작하고, 부팅 소스를 지정하라는 메시지가 표시되면 PXE 부팅 을 선택한 다음 네트워크 설치를 시작할 수 있습니다.
13장. 킥스타트 참조
부록 B. Kickstart 스크립트 파일 형식 참조
이 참조는 Kickstart 파일 형식을 자세히 설명합니다.
B.1. Kickstart 파일 형식
Kickstart 스크립트는 설치 프로그램에서 인식하는 키워드가 포함된 일반 텍스트 파일입니다. 이 파일은 설치에 대한 지침으로 사용됩니다. Linux 시스템에서 Gedit이나 vim 또는 Windows 시스템의 Notepad와 같은 ASCII 텍스트로 파일을 저장할 수 있는 텍스트 편집기를 사용하여 Kickstart 파일을 만들고 편집할 수 있습니다. Kickstart 구성의 파일 이름은 중요하지 않지만 나중에 다른 구성 파일 또는 대화 상자에서 이 이름을 지정해야 하므로 간단한 이름을 사용하는 것이 좋습니다.
- 명령
- 명령은 설치에 대한 지침으로 사용되는 키워드입니다. 각 명령은 한 줄에 있어야 합니다. 명령은 옵션을 사용할 수 있습니다. 명령 및 옵션 지정은 쉘에서 Linux 명령을 사용하는 것과 유사합니다.
- 섹션
-
퍼센트
%로 시작하는 특정 특수 명령은 섹션을 시작합니다. 섹션의 명령 해석은 섹션 외부에 배치된 명령과 다릅니다. 모든 섹션은%end명령으로 완료되어야 합니다. - 섹션 유형
사용 가능한 섹션은 다음과 같습니다.
-
애드온 섹션. 이러한 섹션에서는
%addon addon_name명령을 사용합니다. -
패키지 선택 섹션.
%packages로 시작합니다. 이 파일을 사용하여 패키지 그룹 또는 모듈과 같은 간접 수단을 포함하여 설치용 패키지를 나열합니다. -
스크립트 섹션. 이러한 작업은
%pre,%pre-install,%post,%onerror로 시작합니다. 이러한 섹션은 필수가 아닙니다.
-
애드온 섹션. 이러한 섹션에서는
- 명령 섹션
-
명령 섹션은 스크립트 섹션 또는
%packages섹션에 포함되지 않은 Kickstart 파일의 명령에 사용되는 용어입니다. - 스크립트 섹션 수 및 순서
-
명령 섹션을 제외한 모든 섹션은 선택 사항이며 여러 번 존재할 수 있습니다. 특정 유형의 스크립트 섹션을 평가할 때 Kickstart에 존재하는 유형의 모든 섹션이 표시되는 순서대로 두
%post섹션이 차례로 평가됩니다. 그러나 다양한 유형의 스크립트 섹션을 순서대로 지정할 필요는 없습니다.%pre섹션 앞에%post섹션이 있는지는 중요하지 않습니다.
- 주석
-
Kickstart 주석은 해시
#문자로 시작하는 행입니다. 이러한 행은 설치 프로그램에서 무시됩니다.
필요하지 않은 항목은 생략할 수 있습니다. 필요한 항목을 생략하면 설치 프로그램이 대화식 모드로 변경되어 사용자가 일반 대화식 설치와 마찬가지로 사용자가 관련 항목에 대한 답변을 제공할 수 있습니다. 또한 cmdline 명령을 사용하여 kickstart 스크립트를 비대화형으로 선언할 수도 있습니다. 비대화형 모드에서는 답변이 누락되면 설치 프로세스가 중단됩니다.
텍스트 또는 그래픽 모드로 Kickstart를 설치하는 동안 사용자 상호 작용이 필요한 경우 설치를 완료하기 위해 업데이트가 필요한 창만 입력합니다. spokes를 입력하면 Kickstart 구성이 재설정될 수 있습니다. 설정 재설정은 특히 설치 대상 창을 입력한 후 스토리지와 관련된 Kickstart 명령에 적용됩니다.
B.2. Kickstart의 패키지 선택
Kickstart는 설치할 패키지를 선택하기 위해 %packages 명령으로 시작된 섹션을 사용합니다. 이러한 방식으로 패키지, 그룹, 환경, 모듈 스트림 및 모듈 프로필을 설치할 수 있습니다.
B.2.1. 패키지 선택 섹션
설치할 소프트웨어 패키지를 설명하는 Kickstart 섹션을 시작하려면 %packages 명령을 사용합니다. %packages 섹션은 %end 명령으로 끝나야 합니다.
환경, 그룹, 모듈 스트림, 모듈 프로필 또는 해당 패키지 이름으로 패키지를 지정할 수 있습니다. 관련 패키지가 포함된 여러 환경 및 그룹이 정의됩니다. 환경 및 그룹 목록은 Red Hat Enterprise Linux 8 설치 DVD의 리포지토리/repodata/*-comps- 리포지토리.architecture.xml 파일을 참조하십시오.
*-comps-리포지토리.architecture.xml 파일에는 사용 가능한 환경(< environment > 태그로 표시됨) 및 그룹(태그)을 설명하는 구조가 포함되어 있습니다. 각 항목에는 ID, 사용자 가시성 값, 이름, 설명 및 패키지 목록이 있습니다. 설치에 대해 그룹을 선택하는 경우 패키지 목록에서 필수 로 표시된 패키지가 항상 설치되고, 특별히 다른 곳에서 제외되지 않은 경우 default 패키지가 설치되고, 그룹을 선택할 때에도 선택 옵션으로 표시된 패키지를 구체적으로 포함해야 합니다.
해당 ID(< id > 태그) 또는 이름(<name> 태그)을 사용하여 패키지 그룹 또는 환경을 지정할 수 있습니다.
설치해야 하는 패키지가 확실하지 않은 경우 최소 설치 환경을 선택하는 것이 좋습니다. minimal Install 은 Red Hat Enterprise Linux 8을 실행하는 데 필요한 패키지만 제공합니다. 이로 인해 시스템이 취약점의 영향을 받을 가능성이 크게 줄어듭니다. 필요한 경우 설치 후 나중에 추가 패키지를 추가할 수 있습니다. 최소 설치 방법에 대한 자세한 내용은 Security Hardening 문서의 최소 패키지 설치 섹션을 참조하십시오. 데스크탑 환경과 X Window 시스템이 설치에 포함되어 있고 그래픽 로그인이 활성화된 경우가 아니면 Kickstart 파일에서 시스템을 설치한 후에는 Initial Setup 을 실행할 수 없습니다.
64비트 시스템에 32비트 패키지를 설치하려면 다음을 수행합니다.
-
%packages섹션에--multilib옵션을 지정합니다. -
패키지가 빌드된 32비트 아키텍처(예:
glibc.i686)를 사용하여 패키지 이름을 추가합니다.
B.2.2. 패키지 선택 명령
이러한 명령은 Kickstart 파일의 %packages 섹션에서 사용할 수 있습니다.
- 환경 지정
@^기호로 시작하는 줄로 설치할 전체 환경을 지정합니다.%packages @^Infrastructure Server %end
%packages @^Infrastructure Server %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow 그러면
Infrastructure Server환경의 일부인 모든 패키지가 설치됩니다. 사용 가능한 모든 환경은 Red Hat Enterprise Linux 8 설치 DVD의리포지토리/repodata/*-comps- 리포지토리.architecture.xml파일에 설명되어 있습니다.Kickstart 파일에 단일 환경만 지정해야 합니다. 더 많은 환경이 지정되면 마지막으로 지정된 환경만 사용됩니다.
- 그룹 지정
@기호부터 시작하여 한 줄에 하나의 항목을 지정한 다음*-comps-repository.architecture.xml파일에 지정된 대로 전체 그룹 이름 또는 그룹 ID를 지정합니다. 예를 들면 다음과 같습니다.%packages @X Window System @Desktop @Sound and Video %end
%packages @X Window System @Desktop @Sound and Video %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow Core그룹은 항상 선택됩니다.%packages섹션에 지정할 필요는 없습니다.- 개별 패키지 지정
개별 패키지를 이름으로 한 줄에 하나의 항목을 지정합니다. 별표 문자(
*)를 패키지 이름에서 와일드카드로 사용할 수 있습니다. 예를 들면 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow docbook*항목에는 와일드카드와 표시되는 패턴과 일치하는 패키지docbook-dtds및docbook-style이 포함되어 있습니다.- 모듈 스트림의 프로필 지정
프로필 구문을 사용하여 한 줄에 한 항목씩 모듈 스트림에 대한 프로필을 지정합니다.
%packages @module:stream/profile %end
%packages @module:stream/profile %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이렇게 하면 모듈 스트림의 지정된 프로필에 나열된 모든 패키지가 설치됩니다.
- 모듈에 기본 스트림을 지정하면 해당 스트림을 해제할 수 있습니다. 기본 스트림을 지정하지 않으면 이를 지정해야 합니다.
- 모듈 스트림에 기본 프로필이 지정되면 그대로 둘 수 있습니다. 기본 프로필을 지정하지 않으면 이 프로필을 지정해야 합니다.
- 다른 스트림을 사용하여 모듈을 여러 번 설치할 수 없습니다.
- 동일한 모듈과 스트림의 여러 프로필을 설치할 수 있습니다.
모듈과 그룹은
@기호로 시작하는 것과 동일한 구문을 사용합니다. 동일한 이름의 모듈 및 패키지 그룹이 있는 경우 모듈이 우선합니다.Red Hat Enterprise Linux 8에서 모듈은 AppStream 리포지토리에만 있습니다. 사용 가능한 모듈을 나열하려면 설치된 Red Hat Enterprise Linux 8 시스템에서
yum module list명령을 사용합니다.또한
moduleKickstart 명령을 사용하여 모듈 스트림을 활성화한 다음 직접 이름을 지정하여 모듈 스트림에 포함된 패키지를 설치할 수도 있습니다.- 환경, 그룹 또는 패키지 제외
선행 대시(
-)를 사용하여 설치에서 제외할 패키지 또는 그룹을 지정합니다. 예를 들면 다음과 같습니다.%packages -@Graphical Administration Tools -autofs -ipa*compat %end
%packages -@Graphical Administration Tools -autofs -ipa*compat %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow
Kickstart 파일에서 * 만 사용하여 사용 가능한 모든 패키지를 설치하는 것은 지원되지 않습니다.
여러 옵션을 사용하여 %packages 섹션의 기본 동작을 변경할 수 있습니다. 일부 옵션은 전체 패키지 선택에서 작동하며 다른 옵션은 특정 그룹에만 사용됩니다.
B.2.3. 일반적인 패키지 선택 옵션
%packages 섹션에 다음 옵션을 사용할 수 있습니다. 옵션을 사용하려면 패키지 선택 섹션의 시작 부분에 추가합니다. 예를 들면 다음과 같습니다.
%packages --multilib --ignoremissing
%packages --multilib --ignoremissing--default- 기본 패키지 세트를 설치합니다. 이는 대화형 설치 중에 Package Selection 화면에서 다른 선택 항목이 없는 경우 설치되는 패키지 세트에 해당합니다.
--excludedocs-
패키지에 포함된 문서는 설치하지 마십시오. 대부분의 경우 이는
/usr/share/doc디렉터리에 정상적으로 설치된 모든 파일을 제외하지만 제외할 특정 파일은 개별 패키지에 따라 다릅니다. --ignoremissing- 설치를 중단하거나 계속해야 하는지 묻는 대신 설치 소스에서 누락된 패키지, 그룹, 모듈 스트림, 모듈 프로필 및 환경을 무시합니다.
--instLangs=- 설치할 언어 목록을 지정합니다. 이는 패키지 그룹 수준 선택과 다릅니다. 이 옵션은 설치해야 하는 패키지 그룹을 설명하지 않습니다. 대신 개별 패키지에서 어떤 변환 파일을 설치해야 하는지 제어하는 RPM 매크로를 설정합니다.
--multilibmultilib 패키지에 설치된 시스템을 구성하고, 64비트 시스템에 32비트 패키지를 설치할 수 있도록 구성하고, 이와 같이 이 섹션에 지정된 패키지를 설치합니다.
일반적으로 AMD64 및 Intel 64 시스템에서는 x86_64 및 noarch 패키지만 설치할 수 있습니다. 그러나 multilib 옵션을 사용하면 32비트 AMD 및 i686 Intel 시스템 패키지가 있는 경우 자동으로 설치할 수 있습니다.
이는
%packages섹션에 명시적으로 지정된 패키지에만 적용됩니다. Kickstart 파일에 지정되지 않고 종속 항목으로만 설치되는 패키지는 더 많은 아키텍처에서 사용할 수 있더라도 필요한 아키텍처 버전에만 설치됩니다.사용자는 시스템을 설치하는 동안
multilib모드에서 패키지를 설치하도록 Anaconda를 구성할 수 있습니다. 다음 옵션 중 하나를 사용하여multilib모드를 활성화합니다.다음 행을 사용하여 Kickstart 파일을 설정합니다.
%packages --multilib --default %end
%packages --multilib --default %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 설치 이미지를 부팅하는 동안 inst.multilib 부팅 옵션을 추가합니다.
--nocore그렇지 않으면 기본적으로 설치된
@Core패키지 그룹의 설치를 비활성화합니다.--nocore로@Core패키지 그룹을 비활성화하면 경량 컨테이너를 생성하는 데만 사용해야 합니다.--nocore를 사용하여 데스크탑 또는 서버 시스템을 설치하면 시스템을 사용할 수 없게 됩니다.참고--excludeWeakdeps- 약한 종속성에서 패키지 설치를 비활성화합니다. 이러한 패키지는 Recommends 및 Supplements 플래그에서 설정한 선택한 패키지에 연결됩니다. 기본적으로 약한 종속성이 설치됩니다.
--retries=- YUM이 패키지 다운로드(retries)를 시도하는 횟수를 설정합니다. 기본값은 10입니다. 이 옵션은 설치 중에만 적용되며 설치된 시스템의 YUM 구성에 영향을 미치지 않습니다.
--timeout=- YUM 시간 초과를 초 단위로 설정합니다. 기본값은 30입니다. 이 옵션은 설치 중에만 적용되며 설치된 시스템의 YUM 구성에 영향을 미치지 않습니다.
B.2.4. 특정 패키지 그룹 옵션
이 목록의 옵션은 단일 패키지 그룹에만 적용됩니다. Kickstart 파일의 %packages 명령에 사용하는 대신 그룹 이름에 추가합니다. 예를 들면 다음과 같습니다.
%packages @Graphical Administration Tools --optional %end
%packages
@Graphical Administration Tools --optional
%end--nodefaults- 기본 선택 항목이 아닌 그룹의 필수 패키지만 설치합니다.
--optional기본 선택 항목을 설치하는 것 외에도
*-comps-repository.architecture.xml파일의 그룹 정의에서 선택 사항으로 표시된 패키지를 설치합니다.Scientific Support와 같은 일부 패키지 그룹에는 필수 또는 기본 패키지가 지정되지 않음 - 선택적 패키지만 있습니다. 이 경우--optional옵션을 항상 사용해야 합니다. 그렇지 않으면 이 그룹의 패키지가 설치되지 않습니다.
--nodefaults 및 --optional 옵션은 함께 사용할 수 없습니다. --nodefaults를 사용하여 설치 중에 필수 패키지만 설치하고 설치된 시스템 사후 설치에 선택적 패키지를 설치할 수 있습니다.
B.3. Kickstart 파일의 스크립트
Kickstart 파일은 다음 스크립트를 포함할 수 있습니다.
-
%pre -
%pre-install -
%post
이 섹션에서는 스크립트에 대한 다음 세부 정보를 제공합니다.
- 실행 시간
- 스크립트에 포함될 수 있는 명령 유형입니다.
- 스크립트의 목적
- 스크립트 옵션
B.3.1. %pre 스크립트
%pre 스크립트는 Kickstart 파일이 로드된 직후 시스템에서 실행되지만 완전히 구문 분석되고 설치가 시작되기 전에 실행됩니다. 이러한 각 섹션은 %pre로 시작하고 %end로 끝나야 합니다.
%pre 스크립트는 네트워킹 및 스토리지 장치의 활성화 및 구성에 사용할 수 있습니다. 설치 환경에서 사용 가능한 인터프리터를 사용하여 스크립트를 실행할 수도 있습니다. 설치를 진행하기 전에 특수 구성이 필요한 네트워킹 및 스토리지가 있거나 추가 로깅 매개변수 또는 환경 변수를 설정하는 스크립트가 있는 경우 %pre 스크립트를 추가할 수 있습니다.
%pre 스크립트의 문제를 디버깅하기 어려울 수 있으므로 필요한 경우에만 %pre 스크립트를 사용하는 것이 좋습니다.
Kickstart의 %pre 섹션은 설치 단계(inst.stage2)를 가져온 후 실행됩니다. 즉, root가 설치 프로그램 환경(설치 프로그램 이미지)으로 전환된 후 Anaconda 설치 프로그램 자체를 시작한 후 를 의미합니다. 그런 다음 %pre 의 구성이 적용되고 Kickstart의 URL로 구성된 설치 리포지토리에서 패키지를 가져오는 데 사용할 수 있습니다. 그러나 네트워크에서 이미지(inst.stage2)를 가져오도록 네트워크를 구성하는 데 사용할 수 없습니다.
네트워킹, 스토리지 및 파일 시스템과 관련된 명령은 설치 환경 /sbin 및 /bin 디렉터리에 있는 대부분의 유틸리티 외에 %pre 스크립트에서 사용할 수 있습니다.
%pre 섹션에서 네트워크에 액세스할 수 있습니다. 그러나 이 시점에서 이름 서비스가 구성되지 않았으므로 URL이 아닌 IP 주소만 작동합니다.
pre 스크립트는 chroot 환경에서 실행되지 않습니다.
B.3.1.1. %pre 스크립트 섹션 옵션
다음 옵션을 사용하여 사전 설치 스크립트의 동작을 변경할 수 있습니다. 옵션을 사용하려면 스크립트 시작 시 %pre 줄에 추가합니다. 예를 들면 다음과 같습니다.
%pre --interpreter=/usr/libexec/platform-python -- Python script omitted -- %end
%pre --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end--interpreter=Python과 같은 다른 스크립팅 언어를 지정할 수 있습니다. 시스템에서 사용 가능한 모든 스크립팅 언어를 사용할 수 있습니다. 대부분의 경우
/usr/bin/sh,/usr/bin/bash및/usr/libexec/platform-python입니다.platform-python인터프리터는 Python 버전 3.6을 사용합니다. 새 경로와 버전의 Python 스크립트를 이전 RHEL 버전에서 변경해야 합니다. 또한platform-python은 시스템 툴을 위한 것입니다. 설치 환경 외부의python36패키지를 사용합니다. Red Hat Enterprise Linux의 Python에 대한 자세한 내용은 기본 시스템 설정 구성 의 Python 소개를 참조하십시오.--erroronfail-
스크립트가 실패하면 오류를 표시하고 설치를 중지합니다. 오류 메시지는 실패의 원인이 기록되는 위치로 안내합니다. 설치된 시스템은 불안정하고 부팅 불가능한 상태가 될 수 있습니다.
inst.nokill옵션을 사용하여 스크립트를 디버깅할 수 있습니다. --log=스크립트의 출력을 지정된 로그 파일에 기록합니다. 예를 들면 다음과 같습니다.
%pre --log=/tmp/ks-pre.log
%pre --log=/tmp/ks-pre.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow
B.3.2. %pre-install 스크립트
pre-install 스크립트의 명령은 다음 작업이 완료된 후 실행됩니다.
- 시스템이 분할됨
- 파일 시스템은 /mnt/sysroot에 생성 및 마운트됨
- 네트워크가 부팅 옵션 및 Kickstart 명령에 따라 구성되었습니다.
%pre-install 각 섹션은 %pre-install로 시작하고 %end로 끝나야 합니다.
%pre-install 스크립트를 사용하여 설치를 수정하고 패키지 설치 전에 보장된 ID가 있는 사용자 및 그룹을 추가할 수 있습니다.
설치에 필요한 수정 사항에 대해 %post 스크립트를 사용하는 것이 좋습니다. %post 스크립트가 필요한 수정 사항에 대한 짧은 경우에만 %pre-install 스크립트를 사용합니다.
pre-install 스크립트는 chroot 환경에서 실행되지 않습니다.
B.3.2.1. %pre-install 스크립트 섹션 옵션
다음 옵션을 사용하여 pre-install 스크립트의 동작을 변경할 수 있습니다. 옵션을 사용하려면 스크립트 시작 시 %pre-install 행에 추가합니다. 예를 들면 다음과 같습니다.
%pre-install --interpreter=/usr/libexec/platform-python -- Python script omitted -- %end
%pre-install --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end
동일한 인터프리터 또는 다른 인터프리터와 함께 %pre-install 섹션이 여러 개 있을 수 있습니다. Kickstart 파일에 나타나는 순서에 따라 평가됩니다.
--interpreter=Python과 같은 다른 스크립팅 언어를 지정할 수 있습니다. 시스템에서 사용 가능한 모든 스크립팅 언어를 사용할 수 있습니다. 대부분의 경우
/usr/bin/sh,/usr/bin/bash및/usr/libexec/platform-python입니다.platform-python인터프리터는 Python 버전 3.6을 사용합니다. 새 경로와 버전의 Python 스크립트를 이전 RHEL 버전에서 변경해야 합니다. 또한platform-python은 시스템 툴을 위한 것입니다. 설치 환경 외부의python36패키지를 사용합니다. Red Hat Enterprise Linux의 Python에 대한 자세한 내용은 기본 시스템 설정 구성 의 Python 소개를 참조하십시오.--erroronfail-
스크립트가 실패하면 오류를 표시하고 설치를 중지합니다. 오류 메시지는 실패의 원인이 기록되는 위치로 안내합니다. 설치된 시스템은 불안정하고 부팅 불가능한 상태가 될 수 있습니다.
inst.nokill옵션을 사용하여 스크립트를 디버깅할 수 있습니다. --log=스크립트의 출력을 지정된 로그 파일에 기록합니다. 예를 들면 다음과 같습니다.
%pre-install --log=/mnt/sysroot/root/ks-pre.log
%pre-install --log=/mnt/sysroot/root/ks-pre.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow
B.3.3. %post 스크립트
%post 스크립트는 설치가 완료된 후에 실행되는 설치 후 스크립트이지만 시스템을 처음 재부팅하기 전에 실행됩니다. 이 섹션을 사용하여 시스템 서브스크립션과 같은 작업을 실행할 수 있습니다.
설치가 완료되면 시스템에서 실행할 명령을 추가하는 옵션이 있지만 시스템을 처음 재부팅하기 전에 실행할 수 있습니다. 이 섹션은 %post 로 시작하고 %end 로 끝나야 합니다.
%post 섹션은 추가 소프트웨어 설치 또는 추가 이름 서버 구성과 같은 기능에 유용합니다. 설치 후 스크립트는 chroot 환경에서 실행되므로 설치 미디어에서 스크립트 또는 RPM 패키지를 복사하는 것은 기본적으로 작동하지 않습니다. 아래 설명된 대로 --nochroot 옵션을 사용하여 이 동작을 변경할 수 있습니다. 그런 다음 %post 스크립트가 설치된 대상 시스템의 chroot 가 아닌 설치 환경에서 실행됩니다.
설치 후 스크립트는 chroot 환경에서 실행되므로 대부분의 systemctl 명령은 모든 작업 수행을 거부합니다.
%post 섹션을 실행하는 동안 설치 미디어가 계속 삽입되어야 합니다.
B.3.3.1. %post 스크립트 섹션 옵션
다음 옵션을 사용하여 설치 후 스크립트의 동작을 변경할 수 있습니다. 옵션을 사용하려면 스크립트 시작 부분에 있는 %post 줄에 추가합니다. 예를 들면 다음과 같습니다.
%post --interpreter=/usr/libexec/platform-python -- Python script omitted -- %end
%post --interpreter=/usr/libexec/platform-python
-- Python script omitted --
%end--interpreter=Python과 같은 다른 스크립팅 언어를 지정할 수 있습니다. 예를 들면 다음과 같습니다.
%post --interpreter=/usr/libexec/platform-python
%post --interpreter=/usr/libexec/platform-pythonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템에서 사용 가능한 모든 스크립팅 언어를 사용할 수 있습니다. 대부분의 경우
/usr/bin/sh,/usr/bin/bash및/usr/libexec/platform-python입니다.platform-python인터프리터는 Python 버전 3.6을 사용합니다. 새 경로와 버전의 Python 스크립트를 이전 RHEL 버전에서 변경해야 합니다. 또한platform-python은 시스템 툴을 위한 것입니다. 설치 환경 외부의python36패키지를 사용합니다. Red Hat Enterprise Linux의 Python에 대한 자세한 내용은 기본 시스템 설정 구성 의 Python 소개를 참조하십시오.--nochrootchroot 환경 외부에서 실행하려는 명령을 지정할 수 있습니다.
다음 예제에서는 /etc/resolv.conf 파일을 방금 설치한 파일 시스템에 복사합니다.
%post --nochroot cp /etc/resolv.conf /mnt/sysroot/etc/resolv.conf %end
%post --nochroot cp /etc/resolv.conf /mnt/sysroot/etc/resolv.conf %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow --erroronfail-
스크립트가 실패하면 오류를 표시하고 설치를 중지합니다. 오류 메시지는 실패의 원인이 기록되는 위치로 안내합니다. 설치된 시스템은 불안정하고 부팅 불가능한 상태가 될 수 있습니다.
inst.nokill옵션을 사용하여 스크립트를 디버깅할 수 있습니다. --log=스크립트의 출력을 지정된 로그 파일에 기록합니다. 로그 파일의 경로는
--nochroot옵션을 사용할지 여부를 고려해야 합니다. 예를 들어--nochroot가 없는 경우:%post --log=/root/ks-post.log
%post --log=/root/ks-post.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow --nochroot와 함께 다음을 수행합니다.%post --nochroot --log=/mnt/sysroot/root/ks-post.log
%post --nochroot --log=/mnt/sysroot/root/ks-post.logCopy to Clipboard Copied! Toggle word wrap Toggle overflow
B.3.3.2. 예제: 설치 후 스크립트에서 NFS 마운트
%post 섹션의 예에서는 NFS 공유를 마운트하고 공유의 /usr/new-machines/ 에 있는 runme 라는 스크립트를 실행합니다. Kickstart 모드에서는 NFS 파일 잠금이 지원되지 않으므로 -o nolock 옵션이 필요합니다.
B.3.3.3. 예제: subscription-manager를 설치 후 스크립트로 실행
Kickstart 설치에서 가장 일반적인 설치 후 스크립트 사용 중 하나는 Red Hat Subscription Manager를 사용하여 설치된 시스템을 자동으로 등록하는 것입니다. 다음은 %post 스크립트의 자동 서브스크립션의 예입니다.
%post --log=/root/ks-post.log subscription-manager register --username=admin@example.com --password=secret --auto-attach %end
%post --log=/root/ks-post.log
subscription-manager register --username=admin@example.com --password=secret --auto-attach
%end
subscription-manager 명령줄 스크립트는 시스템을 Red Hat 서브스크립션 관리 서버(고객 포털 서브스크립션 관리, Satellite 6 또는 CloudForms 시스템 엔진)에 등록합니다. 이 스크립트는 해당 시스템과 가장 일치하는 시스템에 서브스크립션을 자동으로 할당하거나 연결하는 데 사용할 수도 있습니다. 고객 포털에 등록할 때 Red Hat Network 로그인 자격 증명을 사용하십시오. Satellite 6 또는 CloudForms 시스템 엔진에 등록할 때 --serverurl,--org,--environment 와 같은 subscription-manager 옵션 및 로컬 관리자가 제공하는 인증 정보를 지정해야 할 수도 있습니다. --org --activationkey 조합 형식의 인증 정보는 공유 kickstart 파일에 --username --password 값을 노출하지 않는 좋은 방법입니다.
추가 옵션은 등록 명령과 함께 사용하여 시스템의 기본 서비스 수준을 설정하고 이전 스트림에서 수정되어야 하는 확장 업데이트 지원 서브스크립션이 있는 고객을 위해 업데이트 및 에라타를 RHEL의 특정 마이너 릴리스 버전으로 제한하기 위해 사용할 수 있습니다.
subscription-manager 명령 사용에 대한 자세한 내용은 Kickstart 파일에서 subscription-manager를 사용하는 방법 Red Hat Knowledgebase 솔루션을 참조하십시오.
B.4. Anaconda 구성 섹션
추가 설치 옵션은 Kickstart 파일의 %anaconda 섹션에서 구성할 수 있습니다. 이 섹션에서는 설치 시스템의 사용자 인터페이스 동작을 제어합니다.
이 섹션은 Kickstart 파일 끝에 있는 Kickstart 명령 다음에 배치되어야 하며 %anaconda 로 시작하고 %end 로 끝나야 합니다.
현재 %anaconda 섹션에서 사용할 수 있는 유일한 명령은 pwpolicy 입니다.
예 B.1. 샘플 %anaconda 스크립트
다음은 %anaconda 섹션의 예입니다.
%anaconda pwpolicy root --minlen=10 --strict %end
%anaconda
pwpolicy root --minlen=10 --strict
%end
이 예제 %anaconda 섹션은 루트 암호가 10자 이상이어야 하고 이 요구 사항과 일치하지 않는 암호를 엄격하게 금지하는 암호 정책을 설정합니다.
B.5. Kickstart 오류 처리 섹션
Red Hat Enterprise Linux 7부터 Kickstart 설치는 설치 프로그램에서 치명적인 오류가 발생하면 사용자 지정 스크립트를 실행합니다. 예제 시나리오에는 설치에 요청된 패키지의 오류, 구성에 지정된 경우 VNC가 시작되지 않거나 스토리지 장치를 검사하는 동안 오류가 발생합니다. 이러한 이벤트의 경우 설치가 중단됩니다. 이러한 이벤트를 분석하기 위해 설치 프로그램은 Kickstart 파일에 제공된 대로 모든 %onerror 스크립트를 chronologically 실행합니다. traceback의 경우 %onerror 스크립트를 실행할 수 있습니다.
%end로 종료하려면 각 %onerror 스크립트가 필요합니다.
inst.cmdline 을 사용하여 모든 오류를 치명적 오류로 설정하여 오류 처리기를 적용할 수 있습니다.
오류 처리 섹션에는 다음 옵션을 사용할 수 있습니다.
--erroronfail-
스크립트가 실패하면 오류를 표시하고 설치를 중지합니다. 오류 메시지는 실패의 원인이 기록되는 위치로 안내합니다. 설치된 시스템은 불안정하고 부팅 불가능한 상태가 될 수 있습니다.
inst.nokill옵션을 사용하여 스크립트를 디버깅할 수 있습니다. --interpreter=Python과 같은 다른 스크립팅 언어를 지정할 수 있습니다. 예를 들면 다음과 같습니다.
%onerror --interpreter=/usr/libexec/platform-python
%onerror --interpreter=/usr/libexec/platform-pythonCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템에서 사용 가능한 모든 스크립팅 언어를 사용할 수 있습니다. 대부분의 경우
/usr/bin/sh,/usr/bin/bash및/usr/libexec/platform-python입니다.platform-python인터프리터는 Python 버전 3.6을 사용합니다. 새 경로와 버전의 Python 스크립트를 이전 RHEL 버전에서 변경해야 합니다. 또한platform-python은 시스템 툴을 위한 것입니다. 설치 환경 외부의python36패키지를 사용합니다. Red Hat Enterprise Linux의 Python에 대한 자세한 내용은 기본 시스템 설정 구성 의 Python 소개를 참조하십시오.--log=- 스크립트의 출력을 지정된 로그 파일에 기록합니다.
B.6. Kickstart 애드온 섹션
Red Hat Enterprise Linux 7부터 Kickstart 설치는 애드온을 지원합니다. 이러한 추가 기능은 다양한 방식으로 기본 Kickstart(및 Anaconda) 기능을 확장할 수 있습니다.
Kickstart 파일에서 애드온을 사용하려면 %addon addon_name options 명령을 사용하고 사전 설치 및 설치 후 스크립트 섹션과 유사하게 %end 문과 함께 명령을 완료합니다. 예를 들어 기본적으로 Anaconda와 함께 배포되는 Kdump 애드온을 사용하려면 다음 명령을 사용합니다.
%addon com_redhat_kdump --enable --reserve-mb=auto %end
%addon com_redhat_kdump --enable --reserve-mb=auto
%end
%addon 명령에는 자체적으로 옵션이 포함되어 있지 않습니다. 모든 옵션은 실제 애드온에 따라 다릅니다.
부록 C. Kickstart 명령 및 옵션 참조
이 참조는 Red Hat Enterprise Linux 설치 프로그램에서 지원하는 모든 Kickstart 명령의 전체 목록입니다. 명령은 몇 가지 광범위한 카테고리로 알파벳순으로 정렬됩니다. 명령이 여러 카테고리에 속할 수 있는 경우 모든 카테고리에 나열됩니다.
C.1. Kickstart 변경
다음 섹션에서는 Red Hat Enterprise Linux 8의 Kickstart 명령 및 옵션 변경 사항에 대해 설명합니다.
RHEL 8에서 auth 또는 authconfig가 더 이상 사용되지 않음
authconfig 툴과 패키지가 제거되었기 때문에 auth 또는 authconfig Kickstart 명령은 Red Hat Enterprise Linux 8에서 더 이상 사용되지 않습니다.
명령행에서 실행된 authconfig 명령과 마찬가지로 Kickstart 스크립트의 authconfig 명령은 이제 authselect-compat 툴을 사용하여 새 authselect 툴을 실행합니다. 이 호환성 계층 및 알려진 문제에 대한 설명은 수동 페이지 authselect-migration(7)을 참조하십시오. 설치 프로그램은 더 이상 사용되지 않는 명령의 사용을 자동으로 감지하고 호환성 계층을 제공하기 위해 authselect-compat 패키지를 시스템에 설치합니다.
Kickstart는 더 이상 Btrfs를 지원하지 않음
Red Hat Enterprise Linux 8에서는 RuntimeClass 파일 시스템이 지원되지 않습니다. 그 결과 Graphical User Interface(GPU)와 Kickstart 명령이 더 이상 vGPU를 지원하지 않습니다.
이전 RHEL 릴리스의 Kickstart 파일 사용
이전 RHEL 릴리스의 Kickstart 파일을 사용하는 경우 Red Hat Enterprise Linux 8 BaseOS 및 AppStream 리포지토리에 대한 자세한 내용은 RHEL 8 도입 고려 사항 의 리포지토리 섹션을 참조하십시오.
C.1.1. 더 이상 사용되지 않는 Kickstart 명령 및 옵션
Red Hat Enterprise Linux 8에서는 다음 Kickstart 명령 및 옵션이 더 이상 사용되지 않습니다.
특정 옵션만 나열된 경우에도 기본 명령 및 기타 옵션은 계속 사용할 수 있으며 더 이상 사용되지 않습니다.
-
auth또는authconfig- 대신authselect사용 -
device -
deviceprobe -
dmraid -
install- 하위 명령 또는 방법을 명령으로 직접 사용 -
multipath -
bootloader --upgrade -
ignoredisk --interactive -
partition --active -
reboot --kexec -
syspurpose- 대신subscription-manager syspurpose사용
auth 또는 authconfig 명령을 제외하고 Kickstart 파일에서 명령을 사용하면 로그에 경고가 출력됩니다.
auth 또는 authconfig 명령을 제외하고 inst.ksstrict 부팅 옵션을 사용하여 더 이상 사용되지 않는 명령 경고를 오류로 전환할 수 있습니다.
C.1.2. 제거된 Kickstart 명령 및 옵션
Red Hat Enterprise Linux 8에서는 다음 Kickstart 명령과 옵션이 완전히 제거되었습니다. Kickstart 파일에서 사용하면 오류가 발생합니다.
-
device -
deviceprobe -
dmraid -
install- 하위 명령 또는 방법을 명령으로 직접 사용 -
multipath -
bootloader --upgrade -
ignoredisk --interactive -
partition --active -
harddrive --biospart -
업그레이드(이 명령은 이전에 더 이상 사용되지 않음) -
btrfs -
part/partition btrfs -
part --fstype btrfs또는partition --fstype btrfs -
logvol --fstype btrfs -
raid --fstype btrfs -
unsupported_hardware
특정 옵션과 값만 나열된 경우 기본 명령 및 기타 옵션을 계속 사용할 수 있으며 제거되지 않습니다.
C.2. 설치 프로그램 구성 및 흐름 제어를 위한 Kickstart 명령
이 목록의 Kickstart 명령은 설치 모드와 설치 과정을 제어하며 결국 수행되는 작업을 제어합니다.
C.2.1. cdrom
cdrom Kickstart 명령은 선택 사항입니다. 시스템의 첫 번째 광 드라이브의 설치를 수행합니다. 이 명령은 한 번만 사용하십시오.
구문
cdrom
cdrom참고
-
이전에는
install명령과 함께cdrom명령을 사용해야 했습니다.install명령은 더 이상 사용되지 않으며cdrom은install을 의미합니다. - 이 명령에는 옵션이 없습니다.
-
설치를 실제로 실행하려면
inst.repo옵션이 커널 명령줄에 지정되지 않는 한cdrom,harddrive,hmc,nfs,liveimg,ostreesetup,rhsm또는url중 하나를 지정해야 합니다.
C.2.2. cmdline
cmdline Kickstart 명령은 선택 사항입니다. 완전히 비대화형 명령줄 모드에서 설치를 수행합니다. 상호 작용에 대한 프롬프트가 표시되면 설치가 중지됩니다. 이 명령은 한 번만 사용하십시오.
구문
cmdline
cmdline참고
-
완전히 자동 설치의 경우 사용 가능한 모드(
graphical,text또는cmdline) 중 하나를 Kickstart 파일에서 지정해야 합니다. 그렇지 않으면console=부팅 옵션을 사용해야 합니다. 모드가 지정되지 않은 경우 시스템은 그래픽 모드를 사용하거나 VNC 및 텍스트 모드에서 선택하라는 메시지를 표시합니다. - 이 명령에는 옵션이 없습니다.
- 이 모드는 x3270 터미널이 있는 64비트 IBM Z 시스템에서 유용합니다.
C.2.3. driverdisk
driverdisk Kickstart 명령은 선택 사항입니다. 이를 사용하여 설치 프로그램에 추가 드라이버를 제공합니다.
기본적으로 포함되어 있지 않은 추가 드라이버를 제공하기 위해 Kickstart 설치 중에 드라이버 디스크를 사용할 수 있습니다. 드라이버 디스크 콘텐츠를 시스템 디스크에 있는 파티션의 루트 디렉터리에 복사해야 합니다. 그런 다음 driverdisk 명령을 사용하여 설치 프로그램이 드라이버 디스크와 해당 위치를 찾도록 지정해야 합니다. 이 명령은 한 번만 사용하십시오.
구문
driverdisk [partition|--source=url|--biospart=biospart]
driverdisk [partition|--source=url|--biospart=biospart]옵션
다음 방법 중 하나로 드라이버 디스크의 위치를 지정해야 합니다.
-
partition - 드라이버 디스크를 포함하는 파티션입니다. 파티션 이름(예: sdb1 )뿐만 아니라 파티션을 전체 경로(예:
/dev/)로 지정해야 합니다.sdb1 --source=- 드라이버 디스크의 URL입니다. 예를 들면 다음과 같습니다.driverdisk --source=ftp://path/to/dd.img driverdisk --source=http://path/to/dd.img driverdisk --source=nfs:host:/path/to/dd.img
driverdisk --source=ftp://path/to/dd.img driverdisk --source=http://path/to/dd.img driverdisk --source=nfs:host:/path/to/dd.imgCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--biospart=- 드라이버 디스크가 포함된 BIOS 파티션(예:82p2)
참고
드라이버 디스크는 네트워크를 통해 로드되거나 initrd 에서 로드되는 대신 로컬 디스크 또는 유사한 장치에서 로드할 수도 있습니다. 다음 절차를 따르십시오.
- 디스크 드라이브, USB 또는 유사한 장치에 드라이버 디스크를 로드합니다.
- 레이블(예: DD )을 이 장치로 설정합니다.
Kickstart 파일에 다음 행을 추가합니다.
driverdisk LABEL=DD:/e1000.rpm
driverdisk LABEL=DD:/e1000.rpmCopy to Clipboard Copied! Toggle word wrap Toggle overflow
DD를 특정 레이블로 바꾸고 e1000.rpm을 특정 이름으로 교체합니다. LABEL 대신 inst.repo 명령에서 지원하는 모든 항목을 사용하여 디스크 드라이브를 지정합니다.
C.2.4. eula
eula Kickstart 명령은 선택 사항입니다. 이 옵션을 사용하여 사용자 개입 없이 EULA(최종 사용자 라이센스 계약)를 수락합니다. 이 옵션을 지정하면 설치를 완료한 후 Initial Setup에서 라이센스 계약을 수락하라는 메시지를 표시하고 시스템을 처음 재부팅합니다. 이 명령은 한 번만 사용하십시오.
구문
eula [--agreed]
eula [--agreed]옵션
-
--agreed(필수) - EULA를 수락합니다. 이 옵션을 항상 사용해야 합니다. 그러지 않으면eula명령은 의미가 없습니다.
C.2.5. firstboot
firstboot Kickstart 명령은 선택 사항입니다. 시스템을 처음 부팅할 때 Initial Setup 애플리케이션이 시작되는지 여부를 결정합니다. 활성화된 경우 initial-setup 패키지가 설치되어 있어야 합니다. 지정하지 않으면 이 옵션은 기본적으로 비활성화되어 있습니다. 이 명령은 한 번만 사용하십시오.
구문
firstboot OPTIONS
firstboot OPTIONS옵션
-
--enable또는--enabled- 시스템을 처음 부팅할 때 Initial Setup이 시작됩니다. -
--disable또는--disabled- 시스템을 처음 부팅할 때 Initial Setup이 시작되지 않습니다. -
--reconfig- 재구성 모드에서 부팅 시 Initial Setup을 시작할 수 있습니다. 이 모드는 기본 암호 외에도 루트 암호, 시간 및 날짜 및 네트워킹 및 호스트 이름 구성 옵션을 활성화합니다.
C.2.6. graphical
graphical Kickstart 명령은 선택 사항입니다. 그래픽 모드에서 설치를 수행합니다. 이는 기본값입니다. 이 명령은 한 번만 사용하십시오.
구문
graphical [--non-interactive]
graphical [--non-interactive]옵션
-
--non-interactive- 완전히 비대화형 모드로 설치를 수행합니다. 이 모드는 사용자 상호 작용이 필요한 경우 설치를 종료합니다.
참고
-
완전히 자동 설치의 경우 사용 가능한 모드(
graphical,text또는cmdline) 중 하나를 Kickstart 파일에서 지정해야 합니다. 그렇지 않으면console=부팅 옵션을 사용해야 합니다. 모드가 지정되지 않은 경우 시스템은 그래픽 모드를 사용하거나 VNC 및 텍스트 모드에서 선택하라는 메시지를 표시합니다.
C.2.7. halt
halt Kickstart 명령은 선택 사항입니다.
설치가 성공적으로 완료된 후 시스템을 중지합니다. 이는 수동 설치와 유사합니다. Anaconda에서 메시지를 표시하고 사용자가 재부팅하기 전에 키를 누를 때까지 기다립니다. Kickstart 설치 중에 완료 방법이 지정되지 않은 경우 이 옵션이 기본값으로 사용됩니다. 이 명령은 한 번만 사용하십시오.
구문
halt
halt참고
-
halt명령은shutdown -H명령과 동일합니다. 자세한 내용은 시스템의 shutdown(8) 도움말 페이지를 참조하십시오. -
다른 완료 방법은
poweroff,reboot,shutdown명령을 참조하십시오. - 이 명령에는 옵션이 없습니다.
C.2.8. harddrive
harddrive Kickstart 명령은 선택 사항입니다. 로컬 드라이브의 Red Hat 설치 트리 또는 전체 설치 ISO 이미지에서 설치를 수행합니다. 드라이브는 설치 프로그램이 마운트할 수 있는 파일 시스템인 ext2, ext3, ext4, vfat, xfs로 포맷해야 합니다. 이 명령은 한 번만 사용하십시오.
구문
harddrive OPTIONS
harddrive OPTIONS옵션
-
--partition=- 설치할 파티션 (예:sdb2). -
--dir=- 설치 트리의변형디렉터리 또는 전체 설치 DVD의 ISO 이미지를 포함하는 디렉터리입니다.
예
harddrive --partition=hdb2 --dir=/tmp/install-tree
harddrive --partition=hdb2 --dir=/tmp/install-tree참고
-
이전에는
harddrive명령을install명령과 함께 사용해야 했습니다.install명령은 더 이상 사용되지 않으며harddrive는install을 의미합니다. -
설치를 실제로 실행하려면
inst.repo옵션이 커널 명령줄에 지정되지 않는 한cdrom,harddrive,hmc,nfs,liveimg,ostreesetup,rhsm또는url중 하나를 지정해야 합니다.
C.2.9. 설치(더 이상 사용되지 않음)
install Kickstart 명령은 Red Hat Enterprise Linux 8에서 더 이상 사용되지 않습니다. 해당 방법을 별도의 명령으로 사용합니다.
install Kickstart 명령은 선택 사항입니다. 기본 설치 모드를 지정합니다.
구문
install installation_method
install
installation_method참고
-
install명령 다음에 설치 방법 명령 다음에 와야 합니다. 설치 방법 명령은 별도의 줄에 있어야 합니다. 방법은 다음과 같습니다.
-
cdrom -
harddrive -
HMC -
nfs -
liveimg -
url
메서드에 대한 자세한 내용은 별도의 참조 페이지를 참조하십시오.
-
C.2.10. liveimg
liveimg Kickstart 명령은 선택 사항입니다. 패키지 대신 디스크 이미지에서 설치를 수행합니다. 이 명령은 한 번만 사용하십시오.
구문
liveimg --url=SOURCE [OPTIONS]
liveimg --url=SOURCE [OPTIONS]필수 옵션
-
--URL=- 설치할 위치입니다. 지원되는 프로토콜은HTTP,HTTPS,FTP,file입니다.
선택적 옵션
-
--URL=- 설치할 위치입니다. 지원되는 프로토콜은HTTP,HTTPS,FTP,file입니다. -
--proxy=- 설치를 수행하는 동안 사용할HTTP,HTTPS또는FTP프록시를 지정합니다. -
--checksum=- 확인에 사용되는 이미지 파일의SHA256체크섬이 있는 선택적 인수입니다. -
--noverifyssl-HTTPS서버에 연결할 때 SSL 확인을 비활성화합니다.
예
liveimg --url=file:///images/install/squashfs.img --checksum=03825f567f17705100de3308a20354b4d81ac9d8bed4bb4692b2381045e56197 --noverifyssl
liveimg --url=file:///images/install/squashfs.img --checksum=03825f567f17705100de3308a20354b4d81ac9d8bed4bb4692b2381045e56197 --noverifyssl참고
-
이미지는 라이브 ISO 이미지의
squashfs.img파일, 압축 tar 파일 (.tar,.tbz,.tgz,.txz,.tar.bz2,.) 또는 설치 미디어가 마운트할 수 있는 모든 파일 시스템일 수 있습니다. 지원되는 파일 시스템은tar.gz.ext2,ext3,ext4,vfat,xfs입니다. -
드라이버 디스크와 함께
liveimg설치 모드를 사용하면 디스크의 드라이버가 설치된 시스템에 자동으로 포함되지 않습니다. 필요한 경우 이러한 드라이버를 수동으로 설치하거나 kickstart 스크립트의%post섹션에 설치해야 합니다. -
설치를 실제로 실행하려면
inst.repo옵션이 커널 명령줄에 지정되지 않는 한cdrom,harddrive,hmc,nfs,liveimg,ostreesetup,rhsm또는url중 하나를 지정해야 합니다. -
이전에는
liveimg명령을install명령과 함께 사용해야 했습니다.install명령은 더 이상 사용되지 않으며liveimg는install을 의미합니다.
C.2.11. logging
logging Kickstart 명령은 선택 사항입니다. 설치 중에 Anaconda의 로깅 오류를 제어합니다. 이는 설치된 시스템에 영향을 미치지 않습니다. 이 명령은 한 번만 사용하십시오.
로깅은 TCP에서만 지원됩니다. 원격 로깅의 경우 --port= 옵션에 지정하는 포트 번호가 원격 서버에서 열려 있는지 확인합니다. 기본 포트는 514입니다.
구문
logging OPTIONS
logging OPTIONS선택적 옵션
-
--host=- 원격 로깅을 수락하도록 구성된 syslogd 프로세스를 실행해야 하는 지정된 원격 호스트에 로깅 정보를 보냅니다. -
--port=- 원격 syslogd 프로세스에서 기본값 이외의 포트를 사용하는 경우 이 옵션을 사용하여 설정합니다. -
--level=- tty3에 표시되는 최소 메시지 수준을 지정합니다. 그러나 이 수준에 관계없이 모든 메시지는 여전히 로그 파일로 전송됩니다. 가능한 값은debug,info,warning,error또는critical입니다.
C.2.12. mediacheck
mediacheck Kickstart 명령은 선택 사항입니다. 이 명령은 설치를 시작하기 전에 설치 프로그램이 미디어 검사를 수행하도록 강제합니다. 이 명령을 실행하려면 설치에 참여해야 하므로 기본적으로 비활성화되어 있습니다. 이 명령은 한 번만 사용하십시오.
구문
mediacheck
mediacheck참고
-
이 Kickstart 명령은
rd.live.check부팅 옵션과 동일합니다. - 이 명령에는 옵션이 없습니다.
C.2.13. nfs
nfs Kickstart 명령은 선택 사항입니다. 지정된 NFS 서버에서 설치를 수행합니다. 이 명령은 한 번만 사용하십시오.
구문
nfs OPTIONS
nfs OPTIONS옵션
-
--server=- 설치할 서버(호스트 이름 또는 IP)입니다. -
--dir=- 설치 트리의변형디렉터리가 포함된 디렉터리입니다. -
--opts=- NFS 내보내기를 마운트하는 데 사용할 마운트 옵션입니다. (선택 사항)
예
nfs --server=nfsserver.example.com --dir=/tmp/install-tree
nfs --server=nfsserver.example.com --dir=/tmp/install-tree참고
-
이전에는
nfs명령을install명령과 함께 사용해야 했습니다.install명령은 더 이상 사용되지 않으며nfs는install을 의미합니다. -
설치를 실제로 실행하려면
inst.repo옵션이 커널 명령줄에 지정되지 않는 한cdrom,harddrive,hmc,nfs,liveimg,ostreesetup,rhsm또는url중 하나를 지정해야 합니다.
C.2.14. ostreesetup
ostreesetup Kickstart 명령은 선택 사항입니다. 이는 OStree 기반 설치를 설정하는 데 사용됩니다. 이 명령은 한 번만 사용하십시오.
구문
ostreesetup --osname=OSNAME [--remote=REMOTE] --url=URL --ref=REF [--nogpg]
ostreesetup --osname=OSNAME [--remote=REMOTE] --url=URL --ref=REF [--nogpg]필수 옵션:
-
--osname=OSNAME- OS 설치를 위한 관리 루트입니다. -
--URL=URL- 설치할 리포지토리의 URL입니다. -
--ref=REF- 설치에 사용할 저장소의 분기 이름입니다.
선택적 옵션:
-
--remote=REMOTE- 원격 리포지토리 위치입니다. -
--nogpg- GPG 키 확인을 비활성화합니다.
참고
- OStree 툴에 대한 자세한 내용은 업스트림 문서를 참조하십시오. https://ostreedev.github.io/ostree/
C.2.15. poweroff
poweroff Kickstart 명령은 선택 사항입니다. 설치가 완료되면 시스템을 종료하고 전원을 끕니다. 일반적으로 수동 설치 중에 Anaconda는 메시지를 표시하고 사용자가 재부팅하기 전에 키를 누를 때까지 기다립니다. 이 명령은 한 번만 사용하십시오.
구문
poweroff
poweroff참고
-
poweroff옵션은shutdown -P명령과 동일합니다. 자세한 내용은 시스템의 shutdown(8) 도움말 페이지를 참조하십시오. -
기타 완료 방법은
halt,reboot,shutdownKickstart 명령을 참조하십시오. Kickstart 파일에 다른 방법이 명시적으로 지정되지 않은 경우halt옵션은 기본 완료 방법입니다. -
poweroff명령은 사용 중인 시스템 하드웨어에 따라 크게 달라집니다. 특히 BIOS, APM(고급 전원 관리) 및 ACPI(고급 구성 및 전원 인터페이스)와 같은 특정 하드웨어 구성 요소는 시스템 커널과 상호 작용할 수 있어야 합니다. 시스템의 APM/ACPI 기능에 대한 자세한 내용은 하드웨어 설명서를 참조하십시오. - 이 명령에는 옵션이 없습니다.
C.2.16. reboot
reboot Kickstart 명령은 선택 사항입니다. 설치가 성공적으로 완료된 후 설치 프로그램을 재부팅하도록 지시합니다(패키지 없음). 일반적으로 Kickstart는 메시지를 표시하고 사용자가 재부팅하기 전에 키를 누를 때까지 기다립니다. 이 명령은 한 번만 사용하십시오.
구문
reboot OPTIONS
reboot OPTIONS옵션
-
--eject- 재부팅하기 전에 부팅 가능한 미디어(DVD, USB 또는 기타 미디어)를 제거하려고 합니다. --kexec- 전체 재부팅을 수행하는 대신kexec시스템 호출을 사용하여 설치된 시스템을 메모리로 즉시 로드하여 BIOS 또는 펌웨어에서 일반적으로 수행하는 하드웨어 초기화를 바이패스합니다.중요이 옵션은 더 이상 사용되지 않으며 기술 프리뷰로만 제공됩니다. 기술 프리뷰 기능에 대한 Red Hat 지원 범위 정보는 기술 프리뷰 기능 지원 범위 문서를 참조하십시오.
kexec를 사용하면 장치 레지스터(일반적으로 전체 시스템 재부팅 중에 지워짐)가 데이터로 채워지고 일부 장치 드라이버에 대한 문제가 발생할 수 있습니다.
참고
-
재부팅옵션을 사용하면 설치 미디어 및 방법에 따라 끝없는 설치 루프가 발생할 수 있습니다. -
reboot옵션은shutdown -r명령과 동일합니다. 자세한 내용은 시스템의 shutdown(8) 도움말 페이지를 참조하십시오. -
64비트 IBM Z에 명령줄 모드로 설치할 때 설치를 완전히 자동화하려면
reboot를 지정합니다. -
기타 완료 방법은
halt,poweroff,shutdownKickstart 옵션을 참조하십시오. Kickstart 파일에 다른 방법이 명시적으로 지정되지 않은 경우halt옵션은 기본 완료 방법입니다.
C.2.17. rhsm
rhsm Kickstart 명령은 선택 사항입니다. CDN에서 RHEL을 등록하고 설치하도록 설치 프로그램에 지시합니다. 이 명령은 한 번만 사용하십시오.
rhsm Kickstart 명령은 시스템을 등록할 때 사용자 지정 %post 스크립트를 사용하는 요구 사항을 제거합니다.
옵션
-
--organization=- CDN에서 RHEL을 등록하고 설치하려면 조직 ID를 사용합니다. -
--activation-key=- 활성화 키를 사용하여 CDN에서 RHEL을 등록하고 설치합니다. 이 활성화 키가 서브스크립션에 등록된 경우 활성화 키당 한 번 옵션을 여러 번 사용할 수 있습니다. -
--connect-to-insights- 대상 시스템을 Red Hat Insights에 연결합니다. -
--proxy=- HTTP 프록시를 설정합니다.
rhsmKickstart 명령을 사용하여 설치 소스 리포지토리를 CDN으로 전환하려면 다음 조건을 충족해야 합니다.-
커널 명령줄에서
inst.stage2= <URL>을 사용하여 설치 이미지를 가져오지만inst.repo=를 사용하여 설치 소스를 지정하지 않았습니다. -
Kickstart 파일에서
url,cdrom,harddrive,liveimg,nfs및ostreesetup 명령을 사용하여 설치 소스를 지정하지 않았습니다.
-
커널 명령줄에서
-
부팅 옵션을 사용하여 지정하거나 Kickstart 파일에 포함된 설치 소스 URL은 유효한 인증 정보가 있는
rhsm명령이 포함되어 있어도 CDN보다 우선합니다. 시스템이 등록되었지만 URL 설치 소스에서 설치됩니다. 이렇게 하면 이전 설치 프로세스가 정상적으로 작동합니다.
C.2.18. shutdown
shutdown Kickstart 명령은 선택 사항입니다. 설치가 성공적으로 완료된 후 시스템이 종료됩니다. 이 명령은 한 번만 사용하십시오.
구문
shutdown
shutdown참고
-
shutdownKickstart 옵션은shutdown명령과 동일합니다. 자세한 내용은 시스템의 shutdown(8) 도움말 페이지를 참조하십시오. -
다른 완료 방법의 경우
halt,poweroff,rebootKickstart 옵션을 참조하십시오. Kickstart 파일에 다른 방법이 명시적으로 지정되지 않은 경우halt옵션은 기본 완료 방법입니다. - 이 명령에는 옵션이 없습니다.
C.2.19. sshpw
sshpw Kickstart 명령은 선택 사항입니다.
설치하는 동안 설치 프로그램과 상호 작용하고 SSH 연결을 통해 진행 상황을 모니터링할 수 있습니다. sshpw 명령을 사용하여 로그인할 임시 계정을 만듭니다. 명령의 각 인스턴스는 설치 환경에만 존재하는 별도의 계정을 생성합니다. 이러한 계정은 설치된 시스템으로 전송되지 않습니다.
구문
sshpw --username=name [OPTIONS] password
sshpw --username=name [OPTIONS] password필수 옵션
-
--username=name - 사용자 이름을 제공합니다. 이 옵션은 필수입니다. - password - 사용자에게 사용할 암호입니다. 이 옵션은 필수입니다.
선택적 옵션
--iscrypted- 이 옵션이 있는 경우 암호 인수가 이미 암호화된 것으로 간주됩니다. 이 옵션은--plaintext와 함께 사용할 수 없습니다. 암호화된 암호를 만들려면 Python을 사용할 수 있습니다.python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'$ python3 -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 그러면 임의의 Salt를 사용하여 암호의 sha512 crypt 호환 해시가 생성됩니다.
-
--plaintext- 이 옵션이 있는 경우 password 인수는 일반 텍스트로 간주됩니다. 이 옵션은--iscrypted와 함께 사용할 수 없습니다. -
--lock- 이 옵션이 있는 경우 이 계정은 기본적으로 잠깁니다. 즉, 사용자가 콘솔에서 로그인할 수 없습니다. -
--sshkey- 옵션이 있는 경우 <password> 문자열이 ssh 키 값으로 해석됩니다.
참고
-
기본적으로 설치 중에
ssh서버가 시작되지 않습니다. 설치 중에ssh를 사용할 수 있도록 하려면 커널 부팅 옵션inst.sshd를 사용하여 시스템을 부팅합니다. root
ssh액세스를 비활성화하려면 다른 사용자ssh액세스를 허용하는 동안 다음을 사용하십시오.sshpw --username=example_username example_password --plaintext sshpw --username=root example_password --lock
sshpw --username=example_username example_password --plaintext sshpw --username=root example_password --lockCopy to Clipboard Copied! Toggle word wrap Toggle overflow root
ssh액세스를 비활성화하려면 다음을 사용하십시오.sshpw --username=root example_password --lock
sshpw --username=root example_password --lockCopy to Clipboard Copied! Toggle word wrap Toggle overflow
C.2.20. text
text Kickstart 명령은 선택 사항입니다. Kickstart 설치를 텍스트 모드로 수행합니다. Kickstart 설치는 기본적으로 그래픽 모드에서 수행됩니다. 이 명령은 한 번만 사용하십시오.
구문
text [--non-interactive]
text [--non-interactive]옵션
-
--non-interactive- 완전히 비대화형 모드로 설치를 수행합니다. 이 모드는 사용자 상호 작용이 필요한 경우 설치를 종료합니다.
참고
-
완전 자동 설치의 경우 사용 가능한 모드(
graphical,text또는cmdline)를 Kickstart 파일에서 지정해야 합니다. 그렇지 않으면console=부팅 옵션을 사용해야 합니다. 모드가 지정되지 않은 경우 시스템은 그래픽 모드를 사용하거나 VNC 및 텍스트 모드에서 선택하라는 메시지를 표시합니다.
C.2.21. url
url Kickstart 명령은 선택 사항입니다. FTP, HTTP 또는 HTTPS 프로토콜을 사용하여 원격 서버의 설치 트리 이미지에서 설치하는 데 사용됩니다. 하나의 URL만 지정할 수 있습니다. 이 명령은 한 번만 사용하십시오.
--url,--metalink 또는 --mirrorlist 옵션 중 하나를 지정해야 합니다.
구문
url --url=FROM [OPTIONS]
url --url=FROM [OPTIONS]옵션
-
--URL=FROM- 설치할HTTP,HTTPS,FTP또는file위치를 지정합니다. -
--mirrorlist=- 설치할 미러 URL을 지정합니다. -
--proxy=- 설치 중에 사용할HTTP,HTTPS또는FTP프록시를 지정합니다. -
--noverifyssl-HTTPS서버에 연결할 때 SSL 확인을 비활성화합니다. -
--Metalink=URL- 설치할 metalink URL을 지정합니다. URL의$releasever및$basearch에 대해 변수 대체가 수행됩니다.
예
HTTP 서버에서 설치하려면 다음을 수행합니다.
url --url=http://server/path
url --url=http://server/pathCopy to Clipboard Copied! Toggle word wrap Toggle overflow FTP 서버에서 설치하려면 다음을 수행합니다.
url --url=ftp://username:password@server/path
url --url=ftp://username:password@server/pathCopy to Clipboard Copied! Toggle word wrap Toggle overflow
참고
-
이전에는
install명령과 함께url명령을 사용해야 했습니다.install명령은 더 이상 사용되지 않으며url은install을 의미하기 때문에 자체적으로 사용할 수 있습니다. -
설치를 실제로 실행하려면
inst.repo옵션이 커널 명령줄에 지정되지 않는 한cdrom,harddrive,hmc,nfs,liveimg,ostreesetup,rhsm또는url중 하나를 지정해야 합니다.
C.2.22. vnc
vnc Kickstart 명령은 선택 사항입니다. VNC를 통해 그래픽 설치를 원격으로 볼 수 있습니다.
일반적으로 이 방법은 텍스트 설치에 일부 크기 및 언어 제한이 있으므로 텍스트 모드에서 기본 설정됩니다. 추가 옵션이 없으면 이 명령은 암호 없이 설치 시스템에서 VNC 서버를 시작하고 연결하는 데 필요한 세부 정보를 표시합니다. 이 명령은 한 번만 사용하십시오.
구문
vnc [--host=host_name] [--port=port] [--password=password]
vnc [--host=host_name] [--port=port] [--password=password]옵션
--host=- 지정된 호스트 이름에서 수신 대기하는 VNC 뷰어 프로세스에 연결합니다.
--port=- 원격 VNC 뷰어 프로세스가 수신 대기 중인 포트를 제공합니다. 제공되지 않는 경우 Anaconda는 VNC 기본 포트 5900을 사용합니다.
--password=- VNC 세션에 연결하기 위해 제공해야 하는 암호를 설정합니다. 이는 선택 사항이지만 권장됩니다.
C.2.23. HMC
hmc kickstart 명령은 선택 사항입니다. IBM Z에서 SE/HMC를 사용하여 설치 매체에서 설치하는 데 이 명령을 사용합니다. 이 명령에는 옵션이 없습니다.
구문
hmc
hmcC.2.24. %include
%include Kickstart 명령은 선택 사항입니다.
내용이 Kickstart 파일에 있는 %include 명령의 위치에 있는 것처럼 Kickstart 파일에 다른 파일의 내용을 포함하려면 %include 명령을 사용합니다.
이러한 포함은 %pre 스크립트 섹션 이후에만 평가되므로 %pre 섹션의 스크립트에서 생성된 파일을 포함하는 데 사용할 수 있습니다. %pre 섹션을 평가하기 전에 파일을 포함하려면 %ksappend 명령을 사용합니다.
구문
%include path/to/file
%include path/to/fileC.2.25. %ksappend
%ksappend Kickstart 명령은 선택 사항입니다.
내용이 Kickstart 파일에서 %ksappend 명령의 위치에 있는 것처럼 Kickstart 파일에 다른 파일의 내용을 포함하도록 %ksappend 명령을 사용합니다.
이러한 포함은 %include 명령과 달리 %pre 스크립트 섹션보다 먼저 평가됩니다.
구문
%ksappend path/to/file
%ksappend path/to/fileC.3. 시스템 구성을 위한 Kickstart 명령
이 목록의 Kickstart 명령은 사용자, 리포지토리 또는 서비스와 같은 결과 시스템에 대한 자세한 내용을 구성합니다.
C.3.1. auth 또는 authconfig(더 이상 사용되지 않음)
더 이상 사용되지 않는 auth 또는 authconfig Kickstart 명령 대신 새 authselect 명령을 사용합니다. auth 및 authconfig 는 이전 버전과의 제한된 호환성을 위해서만 사용할 수 있습니다.
auth 또는 authconfig Kickstart 명령은 선택 사항입니다. authconfig 도구를 사용하여 시스템의 인증 옵션을 설정합니다. 이 옵션은 설치가 완료된 후에도 명령줄에서 실행할 수 있습니다. 이 명령은 한 번만 사용하십시오.
구문
authconfig [OPTIONS]
authconfig [OPTIONS]참고
-
이전에는
authconfig툴이라는auth또는authconfigKickstart 명령도 있었습니다. 이 툴은 Red Hat Enterprise Linux 8에서 더 이상 사용되지 않습니다. 이러한 Kickstart 명령에서는authselect-compat툴을 사용하여 새authselect툴을 호출합니다. 호환성 계층 및 알려진 문제에 대한 설명은 수동 페이지 authselect-migration(7) 을 참조하십시오. 설치 프로그램은 더 이상 사용되지 않는 명령의 사용을 자동으로 감지하고 호환성 계층을 제공하기 위해authselect-compat패키지를 시스템에 설치합니다. - 암호는 기본적으로 섀도우됩니다.
-
보안을 위해 OpenLDAP를
SSL프로토콜과 함께 사용하는 경우 서버 구성에서SSLv2및SSLv3프로토콜을 비활성화해야 합니다. 이는 POODLE SSL 취약점(CVE-2014-3566) 때문입니다. 자세한 내용은 POODLE SSLv3.0 취약점에 대한 Red Hat 지식베이스 솔루션 해결을 참조하십시오.
C.3.2. Authselect
authselect Kickstart 명령은 선택 사항입니다. authselect 명령을 사용하여 시스템의 인증 옵션을 설정합니다. 이 명령은 설치가 완료된 후 명령줄에서 실행할 수도 있습니다. 이 명령은 한 번만 사용하십시오.
구문
authselect [OPTIONS]
authselect [OPTIONS]참고
-
이 명령은 모든 옵션을
authselect명령에 전달합니다. 자세한 내용은 authselect(8) 매뉴얼 페이지 및authselect --help명령을 참조하십시오. -
이 명령은 Red Hat Enterprise Linux 8에서 더 이상 사용되지 않는
auth또는authconfig명령을authconfig툴과 함께 대체합니다. - 암호는 기본적으로 섀도우됩니다.
-
보안을 위해 OpenLDAP를
SSL프로토콜과 함께 사용하는 경우 서버 구성에서SSLv2및SSLv3프로토콜을 비활성화해야 합니다. 이는 POODLE SSL 취약점(CVE-2014-3566) 때문입니다. 자세한 내용은 POODLE SSLv3.0 취약점에 대한 Red Hat 지식베이스 솔루션 해결을 참조하십시오.
C.3.3. 방화벽
firewall Kickstart 명령은 선택 사항입니다. 설치된 시스템의 방화벽 구성을 지정합니다.
구문
firewall --enabled|--disabled [incoming] [OPTIONS]
firewall --enabled|--disabled [incoming] [OPTIONS]필수 옵션
-
--enabled또는--enable- DNS 응답 또는 DHCP 요청과 같은 아웃바운드 요청에 응답하지 않는 들어오는 연결을 제거합니다. 이 시스템에서 실행 중인 서비스에 대한 액세스가 필요한 경우 방화벽을 통해 특정 서비스를 허용하도록 선택할 수 있습니다. -
--disabled또는--disable- iptables 규칙을 구성하지 않습니다.
선택적 옵션
-
--trust- 여기에em1과 같은 장치를 나열하면 해당 장치에서 들어오는 모든 트래픽이 방화벽을 통과할 수 있습니다. 둘 이상의 장치를 나열하려면 옵션을--trust em1 --trust em2와 같은 여러 번 사용합니다.--trust em1, em2와 같은 쉼표로 구분된 형식을 사용하지 마십시오. -
--remove-service- 방화벽을 통한 서비스를 허용하지 않습니다. 수신 - 방화벽을 통해 지정된 서비스를 허용하려면 다음 중 하나 이상으로 바꿉니다.
-
--ssh -
--smtp -
--http -
--ftp
-
-
--port=- port:protocol 형식을 사용하여 방화벽을 통해 포트를 허용하도록 지정할 수 있습니다. 예를 들어 방화벽을 통해 Cryostat 액세스를 허용하려면imap:tcp를 지정합니다. 숫자 포트도 명시적으로 지정할 수 있습니다. 예를 들어 를 통해 포트 1234에서 UDP 패킷을 허용하려면1234:udp를 지정합니다. 여러 포트를 지정하려면 쉼표로 구분합니다. --service=- 이 옵션은 방화벽을 통해 서비스를 허용하는 고급 방법을 제공합니다. 일부 서비스(예:cups,avahi등)에는 서비스가 작동하려면 여러 포트가 열려 있거나 기타 특수 구성이 필요합니다.--port옵션을 사용하여 각 개별 포트를 지정하거나--service=를 지정하고 한 번에 모두 열 수 있습니다.유효한 옵션은 firewalld 패키지의
firewall-offline-cmd프로그램에서 인식하는 모든 항목입니다.firewalld서비스가 실행 중인 경우firewall-cmd --get-services는 알려진 서비스 이름 목록을 제공합니다.-
--use-system-defaults- 방화벽을 전혀 구성하지 마십시오. 이 옵션은 anaconda에 아무것도 수행하지 않고 시스템이 패키지 또는 ostree와 함께 제공된 기본값을 사용할 수 있도록 지시합니다. 이 옵션을 다른 옵션과 함께 사용하면 다른 모든 옵션이 무시됩니다.
C.3.4. group
group Kickstart 명령은 선택 사항입니다. 시스템에 새 사용자 그룹을 생성합니다.
group --name=name [--gid=gid]
group --name=name [--gid=gid]필수 옵션
-
--name=- 그룹 이름을 제공합니다.
선택적 옵션
-
--GID=- 그룹의 GID입니다. 제공되지 않는 경우 기본값은 다음 사용 가능한 시스템 GID입니다.
참고
- 지정된 이름 또는 GID 그룹이 이미 존재하는 경우 이 명령이 실패합니다.
-
user명령은 새로 생성된 사용자에 대한 새 그룹을 생성하는 데 사용할 수 있습니다.
C.3.5. 키보드(필수)
keyboard Kickstart 명령이 필요합니다. 시스템에 사용 가능한 키보드 레이아웃을 하나 이상 설정합니다. 이 명령은 한 번만 사용하십시오.
구문
keyboard --vckeymap|--xlayouts OPTIONS
keyboard --vckeymap|--xlayouts OPTIONS옵션
-
--vckeymap=- 사용해야 하는Cryostatonsole 키 맵을 지정합니다. 유효한 이름은.map.gz확장자 없이/usr/lib/kbd/keymaps/xkb/디렉터리의 파일 목록에 해당합니다. --xlayouts=- 공백 없이 쉼표로 구분된 목록으로 사용해야 하는 X 레이아웃 목록을 지정합니다.setxkbmap(1)과 동일한 형식의 값을레이아웃형식(예:cz) 또는레이아웃 (예:형식으로 사용할 수 있습니다.cz(qwerty))사용 가능한 모든 레이아웃은
Layouts아래의xkeyboard-config(7)도움말 페이지에서 볼 수 있습니다.--switch=- layout-switching 옵션 목록을 지정합니다(여러 키보드 레이아웃 사이 전환을 위한 단축). 여러 옵션은 공백 없이 쉼표로 구분해야 합니다.setxkbmap(1)과 동일한 형식의 값을 허용합니다.사용 가능한 전환 옵션은 옵션 의
xkeyboard-config(7)도움말 페이지에서 볼 수 있습니다.
참고
-
--vckeymap=또는--xlayouts=옵션을 사용해야 합니다.
예
다음 예제에서는 --xlayouts= 옵션을 사용하여 두 개의 키보드 레이아웃(영어(US) 및 Czech(qwerty)을 설정하고 Alt+Shift 를 사용하여 전환할 수 있습니다.
keyboard --xlayouts=us,'cz (qwerty)' --switch=grp:alt_shift_toggle
keyboard --xlayouts=us,'cz (qwerty)' --switch=grp:alt_shift_toggleC.3.6. Lang (필수)
lang Kickstart 명령이 필요합니다. 설치 중에 사용할 언어와 설치된 시스템에서 사용할 기본 언어를 설정합니다. 이 명령은 한 번만 사용하십시오.
구문
lang language [--addsupport=language,...]
lang language [--addsupport=language,...]필수 옵션
-
Language- 이 언어에 대한 지원을 설치하고 시스템 기본값으로 설정합니다.
선택적 옵션
--addsupport=- 추가 언어에 대한 지원 추가 공백 없이 쉼표로 구분된 목록의 형식을 사용합니다. 예를 들면 다음과 같습니다.lang en_US --addsupport=cs_CZ,de_DE,en_UK
lang en_US --addsupport=cs_CZ,de_DE,en_UKCopy to Clipboard Copied! Toggle word wrap Toggle overflow
참고
-
locale -a | grep _또는localectl list-locales | grep _명령은 지원되는 로케일 목록을 반환합니다. -
특정 언어(예: 중국어, 일본어, 한국어 및 Indic 언어)는 텍스트 모드 설치 중에 지원되지 않습니다.
lang명령을 사용하여 이러한 언어 중 하나를 지정하면 설치 프로세스가 영어로 계속되지만 설치된 시스템은 선택을 기본 언어로 사용합니다.
예
언어를 English로 설정하려면 Kickstart 파일에 다음 행이 포함되어야 합니다.
lang en_US
lang en_USC.3.7. module
모듈 Kickstart 명령은 선택 사항입니다. 이 명령을 사용하여 kickstart 스크립트 내에서 패키지 모듈 스트림을 활성화합니다.
구문
module --name=NAME [--stream=STREAM]
module --name=NAME [--stream=STREAM]필수 옵션
--name=- 활성화할 모듈의 이름을 지정합니다. NAME 을 실제 이름으로 바꿉니다.
선택적 옵션
--stream=활성화할 모듈 스트림의 이름을 지정합니다. STREAM 을 실제 이름으로 교체합니다.
기본 스트림이 정의된 모듈에 이 옵션을 지정할 필요가 없습니다. 기본 스트림이 없는 모듈의 경우 이 옵션은 필수이며 그대로 둡니다. 다른 스트림으로 모듈을 여러 번 활성화하는 것은 불가능합니다.
참고
-
이 명령과
%packages섹션을 함께 사용하면 모듈과 스트림을 명시적으로 지정하지 않고 활성화된 모듈 및 스트림 조합에서 제공하는 패키지를 설치할 수 있습니다. 모듈은 패키지 설치 전에 활성화해야 합니다.module명령을 사용하여 모듈을 활성화한 후%packages섹션에 나열하여 이 모듈에서 활성화한 패키지를 설치할 수 있습니다. -
단일
모듈명령은 단일 모듈 및 스트림 조합만 활성화할 수 있습니다. 여러 모듈을 활성화하려면 여러모듈명령을 사용합니다. 다른 스트림으로 모듈을 여러 번 활성화하는 것은 불가능합니다. -
Red Hat Enterprise Linux 8에서 모듈은 AppStream 리포지토리에만 있습니다. 사용 가능한 모듈을 나열하려면 유효한 서브스크립션과 함께 설치된 Red Hat Enterprise Linux 8 시스템에서
yum module list명령을 사용하십시오.
C.3.8. 리포지토리
repo Kickstart 명령은 선택 사항입니다. 패키지 설치의 소스로 사용할 수 있는 추가 yum 리포지토리를 구성합니다. 리포지토리 라인을 여러 개 추가할 수 있습니다.
구문
repo --name=repoid [--baseurl=url|--mirrorlist=url|--metalink=url] [OPTIONS]
repo --name=repoid [--baseurl=url|--mirrorlist=url|--metalink=url] [OPTIONS]필수 옵션
-
--name=- 리포지토리 ID입니다. 이 옵션은 필수입니다. 리포지토리에 이전에 추가한 다른 리포지토리와 충돌하는 이름이 있는 경우 무시됩니다. 설치 프로그램에서 사전 설정된 리포지토리 목록을 사용하므로 사전 설정된 리포지토리와 동일한 이름의 리포지토리를 추가할 수 없습니다.
URL 옵션
이러한 옵션은 함께 사용할 수 없으며 선택 사항입니다. yum 리포지토리 구성 파일에서 사용할 수 있는 변수는 여기에서 지원되지 않습니다. $releasever 및 $basearch 문자열을 사용할 수 있으며 URL의 해당 값으로 교체됩니다.
-
--baseurl=- 리포지토리의 URL입니다. -
--mirrorlist=- 저장소의 미러 목록을 가리키는 URL입니다. -
--metalink=- 리포지토리의 metalink가 있는 URL입니다.
선택적 옵션
-
--install-/etc/yum.repos.d/디렉터리에 설치된 시스템에 제공된 리포지토리 구성을 저장합니다. 이 옵션을 사용하지 않으면 Kickstart 파일에 구성된 리포지토리는 설치된 시스템이 아닌 설치 프로세스 중에만 사용할 수 있습니다. -
--cost=- 이 리포지토리에 비용을 할당하는 정수 값입니다. 여러 리포지토리에서 동일한 패키지를 제공하는 경우 이 번호는 다른 리포지토리보다 먼저 사용할 리포지토리의 우선 순위를 지정하는 데 사용됩니다. 비용이 낮은 리포지토리는 비용이 더 높은 리포지토리보다 우선합니다. -
--excludepkgs=- 이 리포지토리에서 가져오지 않아야 하는 쉼표로 구분된 패키지 이름 목록입니다. 여러 리포지토리가 동일한 패키지를 제공하고 특정 리포지토리에서 제공하는지 확인하려는 경우 유용합니다. 전체 패키지 이름(예:publican) 및 globs(예:gnome-*)가 허용됩니다. -
--includepkgs=- 이 리포지토리에서 가져올 수 있는 쉼표로 구분된 패키지 이름 및 glob 목록입니다. 리포지토리에서 제공하는 다른 패키지는 무시됩니다. 이는 리포지토리에서 제공하는 다른 모든 패키지를 제외하는 동안 리포지토리에서 단일 패키지 또는 패키지 세트를 설치하려는 경우에 유용합니다. -
--proxy=[protocol://][username[:password]@]host[:port]- 이 리포지토리에만 사용할 HTTP/HTTPS/FTP 프록시를 지정합니다. 이 설정은 다른 리포지토리나 HTTP 설치 시install.img를 가져오는 방법에는 영향을 미치지 않습니다. -
--noverifyssl-HTTPS서버에 연결할 때 SSL 확인을 비활성화합니다.
참고
- 설치에 사용되는 리포지토리는 안정적이어야 합니다. 설치가 완료되기 전에 리포지토리가 수정되면 설치에 실패할 수 있습니다.
C.3.9. rootPW(필수)
rootpw Kickstart 명령이 필요합니다. 시스템의 root 암호를 password 인수로 설정합니다. 이 명령은 한 번만 사용하십시오.
구문
rootpw [--iscrypted|--plaintext] [--lock] password
rootpw [--iscrypted|--plaintext] [--lock] password필수 옵션
-
암호 - 암호 사양. 일반 텍스트 또는 암호화된 문자열입니다. 아래
--iscrypted및--plaintext를 참조하십시오.
옵션
--iscrypted- 이 옵션이 있는 경우 암호 인수가 이미 암호화된 것으로 간주됩니다. 이 옵션은--plaintext와 함께 사용할 수 없습니다. 암호화된 암호를 생성하려면 python을 사용할 수 있습니다.python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'$ python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 그러면 임의의 Salt를 사용하여 암호의 sha512 crypt 호환 해시가 생성됩니다.
-
--plaintext- 이 옵션이 있는 경우 password 인수는 일반 텍스트로 간주됩니다. 이 옵션은--iscrypted와 함께 사용할 수 없습니다. -
--lock- 이 옵션이 있는 경우 기본적으로 root 계정이 잠깁니다. 즉, root 사용자는 콘솔에서 로그인할 수 없습니다. 이 옵션은 그래픽 및 텍스트 기반 수동 설치 모두에서 루트 암호 화면을 비활성화합니다.
C.3.10. selinux
selinux Kickstart 명령은 선택 사항입니다. 설치된 시스템에 SELinux의 상태를 설정합니다. 기본 SELinux 정책은 enforcing 입니다. 이 명령은 한 번만 사용하십시오.
구문
selinux [--disabled|--enforcing|--permissive]
selinux [--disabled|--enforcing|--permissive]옵션
--enforcing-
기본 대상 정책을 적용하여 SELinux를
활성화합니다. --permissive- SELinux 정책을 기반으로 경고를 출력하지만 실제로 정책을 적용하지는 않습니다.
--disabled- 시스템에서 SELinux를 완전히 비활성화합니다.
C.3.11. services
services Kickstart 명령은 선택 사항입니다. 기본 systemd 대상에서 실행할 기본 서비스 세트를 수정합니다. 비활성화된 서비스 목록은 활성화된 서비스 목록보다 먼저 처리됩니다. 따라서 두 목록에 서비스가 모두 표시되면 활성화됩니다.
구문
services [--disabled=list] [--enabled=list]
services [--disabled=list] [--enabled=list]옵션
-
--disabled=- 쉼표로 구분된 목록에 지정된 서비스를 비활성화합니다. -
--enabled=- 쉼표로 구분된 목록에 지정된 서비스를 활성화합니다.
참고
-
services요소를 사용하여systemd서비스를 활성화하는 경우%packages섹션에 지정된 서비스 파일이 포함된 패키지를 포함해야 합니다. 여러 서비스를 공백 없이 쉼표로 구분하여 포함해야 합니다. 예를 들어 4개의 서비스를 비활성화하려면 다음을 입력합니다.
services --disabled=auditd,cups,smartd,nfslock
services --disabled=auditd,cups,smartd,nfslockCopy to Clipboard Copied! Toggle word wrap Toggle overflow 공백을 포함하는 경우 Kickstart는 첫 번째 공간까지 서비스만 활성화하거나 비활성화합니다. 예를 들면 다음과 같습니다.
services --disabled=auditd, cups, smartd, nfslock
services --disabled=auditd, cups, smartd, nfslockCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이렇게 하면
auditd서비스만 비활성화됩니다. 4개의 서비스를 모두 비활성화하려면 이 항목에 공백을 포함하지 않아야 합니다.
C.3.12. skipx
skipx Kickstart 명령은 선택 사항입니다. 존재하는 경우 X는 설치된 시스템에 구성되지 않습니다.
패키지 선택 옵션에 디스플레이 관리자를 설치하는 경우 이 패키지는 X 구성을 생성하고 설치된 시스템은 기본적으로 graphical.target 입니다. 이렇게 하면 skipx 옵션의 효과가 재정의됩니다. 이 명령은 한 번만 사용하십시오.
구문
skipx
skipx참고
- 이 명령에는 옵션이 없습니다.
C.3.13. sshKey
sshkey Kickstart 명령은 선택 사항입니다. 설치된 시스템에 지정된 사용자의 authorized_keys 파일에 SSH 키를 추가합니다.
구문
sshkey --username=user "ssh_key"
sshkey --username=user "ssh_key"필수 옵션
-
--username=- 키가 설치될 사용자입니다. - ssh_key - 전체 SSH 키 지문입니다. 따옴표로 묶어야 합니다.
C.3.14. syspurpose
syspurpose Kickstart 명령은 선택 사항입니다. 이를 사용하여 설치 후 시스템의 사용 방법을 설명하는 시스템 용도를 설정합니다. 이 정보는 시스템에 올바른 서브스크립션 인타이틀먼트를 적용하는 데 도움이 됩니다. 이 명령은 한 번만 사용하십시오.
Red Hat Enterprise Linux 8.6 이상에서는 하나의 subscription,-manager syspurpose 모듈에서 사용할 수 있는 역할, 서비스 수준사용법, 애드온 하위 명령을 설정하여 단일 모듈로 시스템 용도 속성을 관리하고 표시할 수 있습니다. 이전에는 시스템 관리자가 4개의 독립 실행형 syspurpose 명령 중 하나를 사용하여 각 특성을 관리했습니다. 이 독립 실행형 syspurpose 명령은 RHEL 8.6부터 더 이상 사용되지 않으며 RHEL 9에서 제거될 예정입니다. Red Hat은 현재 릴리스 라이프사이클 동안 이 기능에 대한 버그 수정 및 지원을 제공하지만 이 기능은 더 이상 개선 사항을 받지 않습니다. RHEL 9부터 단일 subscription-manager syspurpose 명령 및 관련 하위 명령은 시스템 용도를 사용하는 유일한 방법입니다.
구문
syspurpose [OPTIONS]
syspurpose [OPTIONS]옵션
--role=- 의도한 시스템 역할을 설정합니다. 사용 가능한 값은 다음과 같습니다.- Red Hat Enterprise Linux Server
- Red Hat Enterprise Linux Workstation
- Red Hat Enterprise Linux Compute Node
--SLA=- 서비스 수준 계약을 설정합니다. 사용 가능한 값은 다음과 같습니다.- Premium
- Standard
- Self-Support
--usage=- 시스템의 의도된 용도입니다. 사용 가능한 값은 다음과 같습니다.- Production
- Disaster Recovery
- Development/Test
-
--Addon=- 추가 계층화된 제품 또는 기능을 지정합니다. 이 옵션을 여러 번 사용할 수 있습니다.
참고
공백이 있는 값을 입력하고 큰따옴표로 묶습니다.
syspurpose --role="Red Hat Enterprise Linux Server"
syspurpose --role="Red Hat Enterprise Linux Server"Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
시스템 용도를 구성하는 것이 좋지만 Red Hat Enterprise Linux 설치 프로그램의 선택적 기능입니다. 설치가 완료된 후 시스템 용도를 활성화하려면
syspurpose명령줄 툴을 사용하여 수행할 수 있습니다.
Red Hat Enterprise Linux 8.6 이상에서는 하나의 subscription,-manager syspurpose 모듈에서 사용할 수 있는 역할, 서비스 수준사용법, 애드온 하위 명령을 설정하여 단일 모듈로 시스템 용도 속성을 관리하고 표시할 수 있습니다. 이전에는 시스템 관리자가 4개의 독립 실행형 syspurpose 명령 중 하나를 사용하여 각 특성을 관리했습니다. 이 독립 실행형 syspurpose 명령은 RHEL 8.6부터 더 이상 사용되지 않으며 RHEL 9에서 제거될 예정입니다. Red Hat은 현재 릴리스 라이프사이클 동안 이 기능에 대한 버그 수정 및 지원을 제공하지만 이 기능은 더 이상 개선 사항을 받지 않습니다. RHEL 9부터 단일 subscription-manager syspurpose 명령 및 관련 하위 명령은 시스템 용도를 사용하는 유일한 방법입니다.
C.3.15. 시간대 (필수)
시간대 Kickstart 명령이 필요합니다. 시스템 시간대를 설정합니다. 이 명령은 한 번만 사용하십시오.
구문
timezone timezone [OPTIONS]
timezone timezone [OPTIONS]필수 옵션
- timezone - 시스템에 설정할 시간대입니다.
선택적 옵션
-
--UTC- 시스템에서 하드웨어 클록이 UTC(Greenwich Mean) 시간으로 설정되어 있다고 가정합니다. -
--nontp- NTP 서비스 자동 시작을 비활성화합니다. -
--ntpservers=- 공백 없이 쉼표로 구분된 목록으로 사용할 NTP 서버 목록을 지정합니다.
참고
Red Hat Enterprise Linux 8에서 시간대 이름은 pytz 패키지에서 제공하는 pytz.all_timezones 목록을 사용하여 검증됩니다. 이전 릴리스에서는 현재 사용된 목록의 하위 집합인 pytz.common_timezones 에 대해 이름이 검증되었습니다. 그래픽 및 텍스트 모드 인터페이스는 여전히 더 제한된 pytz.common_timezones 목록을 사용합니다. Kickstart 파일을 사용하여 추가 시간대 정의를 사용해야 합니다.
C.3.16. user
user Kickstart 명령은 선택 사항입니다. 시스템에 새 사용자를 생성합니다.
구문
user --name=username [OPTIONS]
user --name=username [OPTIONS]필수 옵션
-
--name=- 사용자 이름을 제공합니다. 이 옵션은 필수입니다.
선택적 옵션
-
--GECOS=- 사용자에게 GECOS 정보를 제공합니다. 쉼표로 구분된 다양한 시스템별 필드의 문자열입니다. 사용자의 전체 이름, 사무실 번호 등을 지정하는 데 자주 사용됩니다. 자세한 내용은passwd(5)도움말 페이지를 참조하십시오. -
--groups=- 기본 그룹 외에도 사용자가 속해야 하는 그룹 이름의 쉼표로 구분된 목록입니다. 그룹은 사용자 계정을 생성하기 전에 존재해야 합니다.group명령을 참조하십시오. -
--homedir=- 사용자의 홈 디렉터리입니다. 제공되지 않는 경우 기본값은/home/username입니다. -
--lock- 이 옵션이 있는 경우 이 계정은 기본적으로 잠깁니다. 즉, 사용자가 콘솔에서 로그인할 수 없습니다. 이 옵션은 그래픽 및 텍스트 기반 수동 설치 모두에서 사용자 만들기 화면을 비활성화합니다. -
--password=- 새 사용자의 암호입니다. 제공되지 않으면 기본적으로 계정이 잠깁니다. --iscrypted- 이 옵션이 있는 경우 암호 인수가 이미 암호화된 것으로 간주됩니다. 이 옵션은--plaintext와 함께 사용할 수 없습니다. 암호화된 암호를 생성하려면 python을 사용할 수 있습니다.python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'$ python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw) if (pw==getpass.getpass("Confirm: ")) else exit())'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 그러면 임의의 Salt를 사용하여 암호의 sha512 crypt 호환 해시가 생성됩니다.
-
--plaintext- 이 옵션이 있는 경우 password 인수는 일반 텍스트로 간주됩니다. 이 옵션은--iscrypted와 함께 사용할 수 없습니다. -
--shell=- 사용자의 로그인 쉘입니다. 제공되지 않으면 시스템 기본값이 사용됩니다. -
--UID=- 사용자의 UID(사용자 ID)입니다. 제공되지 않는 경우 기본값은 다음 사용 가능한 시스템 이외의 UID입니다. -
--GID=- 사용자 그룹에 사용할 GID(그룹 ID)입니다. 제공되지 않는 경우 기본값은 다음 사용 가능한 시스템 이외의 그룹 ID입니다.
참고
--uid및--gid옵션을 사용하여1000개 대신5000에서 시작하는 범위에서 일반 사용자 ID와 기본 그룹을 설정하는 것이 좋습니다. 이는 시스템 사용자 및 그룹용으로 예약된 범위0-999가 향후 증가하여 일반 사용자의 ID와 중복될 수 있기 때문입니다.설치 후 최소 UID 및 GID 제한을 변경하려면 선택한 UID 및 GID 범위가 사용자 생성에 자동으로 적용되도록 하는 경우 기본 시스템 설정 문서의 Cryostat 섹션을 사용하여 새 파일에 대한 기본 권한 설정을 참조하십시오.
파일 및 디렉터리는 다양한 권한으로 생성되며, 파일 또는 디렉터리를 생성하는 데 사용되는 애플리케이션에서 지정합니다. 예를 들어, Cryo
stat명령은 모든 권한이 활성화된 디렉터리를 생성합니다. 그러나 애플리케이션은사용자 file-creation mask 설정에 지정된 대로 새로 생성된 파일에특정 권한을 부여할 수 없습니다.사용자 파일 생성 마스크는 Cryostat명령을 사용하여 제어할 수 있습니다.새 사용자를 위한사용자 파일 생성 마스크의 기본 설정은 설치된 시스템의/etc/login.defs구성 파일의UMASK변수에 의해 정의됩니다. 설정되지 않은 경우 기본값은022입니다. 즉, 애플리케이션에서 파일을 생성할 때 기본적으로 파일 소유자 이외의 사용자에게 쓰기 권한을 부여할 수 없습니다. 그러나 다른 설정이나 스크립트로 재정의할 수 있습니다.자세한 내용은 기본 시스템 설정 구성 문서의 Cryostat 섹션을 사용하여 새 파일에 대한 기본 권한 설정에서 확인할 수 있습니다.
C.3.17. xconfig
xconfig Kickstart 명령은 선택 사항입니다. X Window System을 구성합니다. 이 명령은 한 번만 사용하십시오.
구문
xconfig [--startxonboot]
xconfig [--startxonboot]옵션
-
--startxonboot- 설치된 시스템에서 그래픽 로그인을 사용합니다.
참고
-
Red Hat Enterprise Linux 8에는 Cryostat 데스크탑 환경이 포함되어 있지 않으므로 업스트림에 설명된
--defaultdesktop=을 사용하지 마십시오.
C.4. 네트워크 구성을 위한 Kickstart 명령
이 목록의 Kickstart 명령을 사용하면 시스템에서 네트워킹을 구성할 수 있습니다.
C.4.1. 네트워크(선택 사항)
선택적 network Kickstart 명령을 사용하여 대상 시스템의 네트워크 정보를 구성하고 설치 환경에서 네트워크 장치를 활성화합니다. 첫 번째 network 명령에 지정된 장치는 자동으로 활성화됩니다. --activate 옵션을 사용하여 명시적으로 장치를 활성화해야 할 수도 있습니다.
실행 중인 설치 프로그램에서 사용 중인 이미 활성 네트워크 장치를 재구성하면 설치에 실패하거나 정지할 수 있습니다. 이러한 경우 NFS를 통해 설치 프로그램 런타임 이미지(stage2)에 액세스하는 데 사용되는 네트워크 장치를 재구성하지 마십시오.
구문
network OPTIONS
network OPTIONS옵션
--activate- 설치 환경에서 이 장치를 활성화합니다.이미 활성화된 장치에서
--activate옵션을 사용하는 경우(예: 시스템이 Kickstart 파일을 검색할 수 있도록 부팅 옵션으로 구성한 인터페이스) 장치가 다시 활성화되어 Kickstart 파일에 지정된 세부 정보를 사용합니다.장치가 기본 경로를 사용하지 못하도록
--nodefroute옵션을 사용합니다.--no-activate- 설치 환경에서 이 장치를 활성화하지 마십시오.기본적으로 Anaconda는
--activate옵션과 관계없이 Kickstart 파일에서 첫 번째 네트워크 장치를 활성화합니다.--no-activate옵션을 사용하여 기본 설정을 비활성화할 수 있습니다.--BOOTPROTO=-dhcp,bootp,ibft또는static중 하나입니다. 기본 옵션은dhcp입니다.dhcp및bootp옵션은 동일하게 처리됩니다. 장치의ipv4구성을 비활성화하려면--noipv4옵션을 사용합니다.참고이 옵션은 장치의 ipv4 구성을 구성합니다. ipv6 구성의 경우
--ipv6및--ipv6gateway옵션을 사용합니다.DHCP 방법은 DHCP 서버 시스템을 사용하여 네트워킹 구성을 가져옵니다. BOOTP 방법은 유사합니다. BOOTP 서버는 네트워킹 구성을 제공해야 합니다. DHCP를 사용하도록 시스템을 지시하려면 다음을 수행합니다.
network --bootproto=dhcp
network --bootproto=dhcpCopy to Clipboard Copied! Toggle word wrap Toggle overflow BOOTP를 사용하도록 시스템에 네트워킹 구성을 가져오도록 지정하려면 Kickstart 파일에서 다음 행을 사용합니다.
network --bootproto=bootp
network --bootproto=bootpCopy to Clipboard Copied! Toggle word wrap Toggle overflow iBFT에 지정된 구성을 사용하도록 머신을 지시하려면 다음을 사용합니다.
network --bootproto=ibft
network --bootproto=ibftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 정적방법을 사용하려면 최소한 Kickstart 파일에서 IP 주소와 넷마스크를 지정해야 합니다. 이 정보는 정적이며 설치 중 및 설치 후 사용됩니다.모든 정적 네트워킹 구성 정보는 한 줄에 지정해야 합니다. 명령줄에서 가능한 한 백슬래시(
\)를 사용하여 행을 래핑할 수 없습니다.network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=10.0.2.1
network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=10.0.2.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 동시에 여러 네임서버를 구성할 수도 있습니다. 이렇게 하려면
--nameserver=옵션을 한 번 사용하고 각 IP 주소를 쉼표로 구분하여 지정합니다.network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=192.168.2.1,192.168.3.1
network --bootproto=static --ip=10.0.2.15 --netmask=255.255.255.0 --gateway=10.0.2.254 --nameserver=192.168.2.1,192.168.3.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow --device=-network명령을 사용하여 구성할 장치(및 Anaconda에서 결국 활성화)를 지정합니다.network명령을 처음 사용할 때--device=옵션이 없는 경우inst.ks.device=Anaconda 부팅 옵션 값이 사용됩니다(사용 가능한 경우). 이는 더 이상 사용되지 않는 동작으로 간주됩니다. 대부분의 경우 모든네트워크명령에 대해 항상--device=를 지정해야 합니다.--device=옵션이 누락된 경우 동일한 Kickstart 파일에서 후속network명령의 동작이 지정되지 않습니다. 첫 번째 이후의 모든네트워크명령에 이 옵션을 지정하는지 확인합니다.다음 방법 중 하나로 활성화할 장치를 지정할 수 있습니다.
-
인터페이스의 장치 이름(예:
em1) -
인터페이스의 MAC 주소(예:
01:23:45:67:89:ab) -
키워드
링크:up상태의 해당 링크를 사용하여 첫 번째 인터페이스를 지정합니다. -
BOOTIF변수에 설정된 pxelinux를 사용하는 MAC 주소를 사용하는 키워드bootif.pxelinux.cfg파일에서IPAPPEND 2를BOOTIF변수를 설정하도록 설정합니다.
예를 들면 다음과 같습니다.
network --bootproto=dhcp --device=em1
network --bootproto=dhcp --device=em1Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
인터페이스의 장치 이름(예:
--ipv4-dns-search/--ipv6-dns-search- DNS 검색 도메인을 수동으로 설정합니다. 이러한 옵션을--device옵션과 함께 사용하고 각각의 NetworkManager 속성을 미러링해야 합니다. 예를 들면 다음과 같습니다.network --device ens3 --ipv4-dns-search domain1.example.com,domain2.example.com
network --device ens3 --ipv4-dns-search domain1.example.com,domain2.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--ipv4-ignore-auto-dns/--ipv6-ignore-auto-dns- DHCP의 DNS 설정을 무시하도록 설정 이러한 옵션을--device옵션과 함께 사용해야 하며 이러한 옵션에는 인수가 필요하지 않습니다. -
--ip=- 장치의 IP 주소입니다. -
--ipv6=- 주소 [/접두사 길이] 형식의 IPv6 주소(예:3ffe:ffff:0:1::1/128)입니다. 접두사 가 생략되면64가 사용됩니다. 자동 구성에auto또는 DHCPv6 전용 구성(라우터 알림 없음)에dhcp를 사용할 수도 있습니다. -
--gateway=- 단일 IPv4 주소로 기본 게이트웨이입니다. -
--ipv6gateway=- 단일 IPv6 주소로 기본 게이트웨이입니다. -
--nodefroute- 기본 경로로 설정되는 인터페이스를 차단합니다. iSCSI 대상의 별도의 서브넷의 NIC와 같이--activate=옵션을 사용하여 추가 장치를 활성화할 때 이 옵션을 사용합니다. -
--nameserver=- IP 주소로 DNS 이름 서버입니다. 두 개 이상의 이름 서버를 지정하려면 이 옵션을 한 번 사용하고 각 IP 주소를 쉼표로 구분합니다. -
--netmask=- 설치된 시스템의 네트워크 마스크입니다. --hostname=- 대상 시스템의 호스트 이름을 구성하는 데 사용됩니다. 호스트 이름은hostname.domainname형식의 FQDN(정규화된 도메인 이름)이거나 도메인이 없는 짧은 호스트 이름일 수 있습니다. 많은 네트워크에는 연결된 시스템에 도메인 이름을 자동으로 제공하는 DHCP(Dynamic Host Configuration Protocol) 서비스가 있습니다. DHCP 서비스에서 이 시스템에 도메인 이름을 할당할 수 있도록 하려면 짧은 호스트 이름만 지정합니다.고정 IP 및 호스트 이름 구성을 사용하는 경우 계획된 시스템 사용 사례에 따라 짧은 이름 또는 FQDN을 사용할지 여부에 따라 달라집니다. Red Hat Identity Management는 프로비저닝 중에 FQDN을 구성하지만 일부 타사 소프트웨어 제품에는 짧은 이름이 필요할 수 있습니다. 두 경우 모두 모든 상황에서 두 양식의 가용성을 보장하기 위해
IP FQDN short-alias형식으로/etc/hosts의 호스트에 대한 항목을 추가합니다.localhost값은 대상 시스템의 특정 정적 호스트 이름이 구성되지 않으며, 설치된 시스템의 실제 호스트 이름은 네트워크 구성 처리 중에 구성됩니다(예: DHCP 또는 DNS를 사용하는 NetworkManager에 의해).호스트 이름에는 영숫자 및
-또는 . .만 포함할 수 있습니다.호스트 이름은 64자 이상이어야 합니다. 호스트 이름은-및 로 시작하거나 종료할 수 없습니다.DNS를 준수하기 위해 FQDN의 각 부분은 63자 이상이어야 하며 점을 포함한 전체 FQDN 길이는 255자를 초과해서는 안 됩니다.대상 시스템의 호스트 이름만 구성하려면
network명령에서--hostname옵션을 사용하고 다른 옵션은 포함하지 마십시오.호스트 이름을 구성할 때 추가 옵션을 제공하는 경우
network명령은 지정된 옵션을 사용하여 장치를 구성합니다.--device옵션을 사용하여 구성할 장치를 지정하지 않으면 기본--device link값이 사용됩니다. 또한--bootproto옵션을 사용하여 프로토콜을 지정하지 않으면 장치는 기본적으로 DHCP를 사용하도록 구성됩니다.-
--ethtool=- ethtool 프로그램에 전달될 네트워크 장치의 추가 하위 수준 설정을 지정합니다. -
--ONBOOT= - 부팅시 장치를 활성화할지 여부입니다. -
--dhcpclass=- DHCP 클래스입니다. -
--mTU=- 장치의 MTU입니다. -
--noipv4- 이 장치에서 IPv4를 비활성화합니다. -
--noipv6- 이 장치에서 IPv6를 비활성화합니다. --bondslaves=--device=옵션에 지정된 본딩 장치가 생성됩니다. 예를 들면 다음과 같습니다.network --device=bond0 --bondslaves=em1,em2
network --device=bond0 --bondslaves=em1,em2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 명령은
em1및em2인터페이스를 보조 장치로 사용하여bond0이라는 본딩 장치를 생성합니다.--bondopts=---bondslaves=및--device=옵션을 사용하여 지정하는 본딩된 인터페이스의 선택적 매개변수 목록입니다. 이 목록의 옵션은 쉼표(",") 또는 하이픈(";")으로 구분해야 합니다. 옵션 자체에 쉼표가 포함된 경우 option을 사용하여 옵션을 구분합니다. 예를 들면 다음과 같습니다.network --bondopts=mode=active-backup,balance-rr;primary=eth1
network --bondopts=mode=active-backup,balance-rr;primary=eth1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요--bondopts=mode=매개변수는0또는3과 같은 숫자 표현이 아닌balance-rr또는broadcast와 같은 전체 모드 이름만 지원합니다. 사용 가능한 지원 모드 목록은 네트워킹 구성 및 관리 가이드를 참조하십시오.-
--vlanid=---device=에 지정된 장치를 사용하여 상위 장치로 생성된 장치에 대해 가상 LAN(VLAN) ID 번호(802.1q 태그)를 지정합니다. 예를 들어network --device=em1 --vlanid=171은 가상 LAN 장치em1.171을 생성합니다. --interfaceName=- 가상 LAN 장치의 사용자 지정 인터페이스 이름을 지정합니다. 이 옵션은--vlanid=옵션으로 생성된 기본 이름이 바람직하지 않은 경우 사용해야 합니다. 이 옵션은--vlanid=와 함께 사용해야 합니다. 예를 들면 다음과 같습니다.network --device=em1 --vlanid=171 --interfacename=vlan171
network --device=em1 --vlanid=171 --interfacename=vlan171Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 명령은 ID가
171인em1장치에vlan171이라는 가상 LAN 인터페이스를 생성합니다.인터페이스 이름은 임의의 값일 수 있지만(예:
my-vlan) 특정 경우에는 다음 규칙을 따라야 합니다.-
이름에 점(
..)이 포함된 경우NAME.ID의 형식을 사용해야 합니다. NAME 은 임의의 값이지만 ID 는 VLAN ID여야 합니다. 예:em1.171또는my-vlan.171. -
vlan으로 시작하는 이름은vlanID형식을 사용해야 합니다(예:vlan171).
-
이름에 점(
--teamslaves=---device=옵션으로 지정된 팀 장치는 이 옵션에 지정된 보조 장치를 사용하여 생성됩니다. 보조 장치는 쉼표로 구분됩니다. 보조 장치 뒤에는\문자로 이스케이프된 큰따옴표가 있는 작은따옴표 JSON 문자열인 해당 구성 뒤에 있을 수 있습니다. 예를 들면 다음과 같습니다.network --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'"network --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'"Copy to Clipboard Copied! Toggle word wrap Toggle overflow --teamconfig=옵션도 참조하십시오.--teamconfig=- double quotes이\문자로 이스케이프된 JSON 문자열인 double-quoted 팀 장치 구성입니다. 장치 이름은--device=옵션과 보조 장치 및--teamslaves=옵션별 해당 구성으로 지정됩니다. 예를 들면 다음과 같습니다.network --device team0 --activate --bootproto static --ip=10.34.102.222 --netmask=255.255.255.0 --gateway=10.34.102.254 --nameserver=10.34.39.2 --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'" --teamconfig="{\"runner\": {\"name\": \"activebackup\"}}"network --device team0 --activate --bootproto static --ip=10.34.102.222 --netmask=255.255.255.0 --gateway=10.34.102.254 --nameserver=10.34.39.2 --teamslaves="p3p1'{\"prio\": -10, \"sticky\": true}',p3p2'{\"prio\": 100}'" --teamconfig="{\"runner\": {\"name\": \"activebackup\"}}"Copy to Clipboard Copied! Toggle word wrap Toggle overflow --bridgeslaves=- 이 옵션을 사용하면--device=옵션을 사용하여 지정된 장치 이름이 있는 네트워크 브리지가 생성되고--bridgeslaves=옵션에 정의된 장치가 브리지에 추가됩니다. 예를 들면 다음과 같습니다.network --device=bridge0 --bridgeslaves=em1
network --device=bridge0 --bridgeslaves=em1Copy to Clipboard Copied! Toggle word wrap Toggle overflow --bridgeopts=- 브리지된 인터페이스에 대해 쉼표로 구분된 선택적 매개변수 목록입니다. 사용 가능한 값은stp,priority,forward-delay,hello-time,max-age,ageing-time입니다. 이러한 매개변수에 대한 자세한 내용은nm-settings(5)도움말 페이지 또는 Network Configuration Setting Specification 의 bridge 설정 테이블을 참조하십시오.네트워크 브리징에 대한 일반적인 정보는 네트워킹 구성 및 관리 문서를 참조하십시오.
-
--bindto=mac- 기본 바인딩 대신 설치된 시스템의 장치 구성 파일을 인터페이스 이름(DEVICE)에 바인딩하지 않고 장치 MAC 주소(HWADDR)에 바인딩합니다. 이 옵션은--device=옵션과 독립적입니다 ---bindto=mac는 동일한네트워크명령도 장치 이름,링크또는bootif를 지정하는 경우에도 적용됩니다.
참고
-
이름 지정 체계의 변경으로 인해
eth0과 같은ethN장치 이름은 Red Hat Enterprise Linux에서 더 이상 사용할 수 없습니다. 장치 이름 지정 체계에 대한 자세한 내용은 업스트림 문서 Predictable Network Interface Names 를 참조하십시오. - Kickstart 옵션 또는 부팅 옵션을 사용하여 네트워크에 설치 리포지토리를 지정했지만 설치를 시작할 때 사용할 수 있는 네트워크가 없는 경우 설치 프로그램에 설치 요약 창이 표시되기 전에 네트워크 연결을 설정할 수 있는 네트워크 구성 창이 표시됩니다. 자세한 내용은 네트워크 및 호스트 이름 옵션 구성을 참조하십시오.
C.4.2. realm
realm Kickstart 명령은 선택 사항입니다. Active Directory 또는 IPA 도메인에 가입하는 데 사용합니다. 이 명령에 대한 자세한 내용은 시스템의 realm(8) 도움말 페이지의 조인 섹션을 참조하십시오.
구문
realm join [OPTIONS] domain
realm join [OPTIONS] domain필수 옵션
-
domain- 결합할 도메인입니다.
옵션
-
--computer-ou=OU=- 컴퓨터 계정을 생성하기 위해 조직 단위의 고유 이름을 제공합니다. 고유 이름의 정확한 형식은 클라이언트 소프트웨어 및 멤버십 소프트웨어에 따라 다릅니다. 고유 이름의 루트 DSE 부분은 일반적으로 생략할 수 있습니다. -
--no-password- 암호 없이 자동으로 가입합니다. -
--one-time-password=- 일회성 암호를 사용하여 결합합니다. 이는 모든 유형의 영역에서는 불가능합니다. -
--client-software=- 이 클라이언트 소프트웨어를 실행할 수 있는 영역만 결합합니다. 유효한 값에는sssd및winbind가 포함됩니다. 모든 영역이 모든 값을 지원하는 것은 아닙니다. 기본적으로 클라이언트 소프트웨어는 자동으로 선택됩니다. -
--server-software=- 이 서버 소프트웨어를 실행할 수 있는 영역에만 결합합니다. 가능한 값에는active-directory또는freeipa가 포함됩니다. -
--membership-software=- 영역에 참여할 때 이 소프트웨어를 사용합니다. 유효한 값에는samba및adcli가 포함됩니다. 모든 영역이 모든 값을 지원하는 것은 아닙니다. 기본적으로 멤버십 소프트웨어는 자동으로 선택됩니다.
C.5. 스토리지를 처리하기 위한 Kickstart 명령
이 섹션의 Kickstart 명령은 장치, 디스크, 파티션, LVM 및 파일 시스템과 같은 스토리지의 측면을 구성합니다.
sdX (또는 /dev/sdX) 형식은 재부팅 시 일관성 있는 장치 이름을 보장하지 않으므로 일부 Kickstart 명령 사용이 어려워질 수 있습니다. 명령에 장치 노드 이름이 필요한 경우 /dev/disk 의 모든 항목을 대안으로 사용할 수 있습니다. 예를 들어 다음 장치 이름을 사용하는 대신 다음을 수행합니다.
part / --fstype=xfs --onpart=sda1
다음 중 하나와 유사한 항목을 사용할 수 있습니다.
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1
part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1
이 방법을 사용하면 명령은 항상 동일한 스토리지 장치를 대상으로 합니다. 이는 특히 대규모 스토리지 환경에서 유용합니다. 시스템에서 사용 가능한 장치 이름을 살펴보려면 대화형 설치 중에 ls -lR /dev/disk 명령을 사용할 수 있습니다. 스토리지 장치를 일관되게 참조하는 다양한 방법에 대한 자세한 내용은 영구 이름 지정 속성 개요 를 참조하십시오.
C.5.1. 장치(더 이상 사용되지 않음)
device Kickstart 명령은 선택 사항입니다. 이를 사용하여 추가 커널 모듈을 로드합니다.
대부분의 PCI 시스템에서 설치 프로그램은 이더넷 및 SCSI 카드를 자동으로 감지합니다. 그러나 이전 시스템 및 일부 PCI 시스템에서 Kickstart에는 적절한 장치를 찾으려면 힌트가 필요합니다. 설치 프로그램에 추가 모듈을 설치하도록 지시하는 device 명령은 다음 형식을 사용합니다.
구문
device moduleName --opts=options
device moduleName --opts=options옵션
- MODULE NAME - 설치해야 하는 커널 모듈의 이름으로 바꿉니다.
--opts=- 커널 모듈에 전달하는 옵션. 예를 들면 다음과 같습니다.device --opts="aic152x=0x340 io=11"
device --opts="aic152x=0x340 io=11"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
C.5.2. ignoredisk
ignoredisk Kickstart 명령은 선택 사항입니다. 이로 인해 설치 프로그램에서 지정된 디스크를 무시합니다.
이 기능은 자동 파티션을 사용하고 일부 디스크를 무시하려는 경우에 유용합니다. 예를 들어 ignoredisk 없이 SAN-cluster에 배포하려고 하면 설치 프로그램에서 파티션 테이블을 반환하지 않는 SAN에 대한 수동 경로를 감지하므로 Kickstart가 실패합니다. 이 명령은 한 번만 사용하십시오.
구문
ignoredisk --drives=drive1,drive2,... | --only-use=drive
ignoredisk --drives=drive1,drive2,... | --only-use=drive옵션
-
--drives=driveN,…- driveN 을sda,sdb,… 중 하나로 교체,hda,… 등. --only-use=driveN,…- 설치 프로그램이 사용할 디스크 목록을 지정합니다. 다른 모든 디스크는 무시됩니다. 예를 들어 설치 중에 디스크sda를 사용하고 다른 모든 디스크를 무시하려면 다음을 수행합니다.ignoredisk --only-use=sda
ignoredisk --only-use=sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow LVM을 사용하지 않는 다중 경로 장치를 포함하려면 다음을 수행합니다.
ignoredisk --only-use=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017
ignoredisk --only-use=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017Copy to Clipboard Copied! Toggle word wrap Toggle overflow LVM을 사용하는 다중 경로 장치를 포함하려면 다음을 수행합니다.
ignoredisk --only-use==/dev/disk/by-id/dm-uuid-mpath-
ignoredisk --only-use==/dev/disk/by-id/dm-uuid-mpath-Copy to Clipboard Copied! Toggle word wrap Toggle overflow bootloader --location=mbr
bootloader --location=mbrCopy to Clipboard Copied! Toggle word wrap Toggle overflow
--drives 또는 --only-use 중 하나만 지정해야 합니다.
참고
-
Red Hat Enterprise Linux 8에서는
--interactive옵션이 더 이상 사용되지 않습니다. 이 옵션을 사용하면 사용자가 고급 스토리지 화면을 수동으로 탐색할 수 있습니다. LVM(Logical Volume Manager)을 사용하지 않는 다중 경로 장치를 무시하려면
disk/by-id/dm-uuid-mpath-WWID형식을 사용합니다. 여기서 WWID 는 장치의 전역 식별자입니다. 예를 들어 WWID2416CD96995134CA5D787F00A5AA11017인 디스크를 무시하려면 다음을 사용합니다.ignoredisk --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017
ignoredisk --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
mpatha와 같은 장치 이름으로 다중 경로 장치를 지정하지 마십시오. 이와 같은 장치 이름은 특정 디스크에 한정되지 않습니다. 설치하는 동안 이름이/dev/mpatha인 디스크가 예상했던 것과 다를 수 있습니다. 따라서clearpart명령은 잘못된 디스크를 대상으로 할 수 있습니다. sdX(또는/dev/sdX) 형식은 재부팅 시 일관성 있는 장치 이름을 보장하지 않으므로 일부 Kickstart 명령 사용이 어려워질 수 있습니다. 명령에 장치 노드 이름이 필요한 경우/dev/disk의 모든 항목을 대안으로 사용할 수 있습니다. 예를 들어 다음 장치 이름을 사용하는 대신 다음을 수행합니다.part / --fstype=xfs --onpart=sda1
part / --fstype=xfs --onpart=sda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 중 하나와 유사한 항목을 사용할 수 있습니다.
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 방법을 사용하면 명령은 항상 동일한 스토리지 장치를 대상으로 합니다. 이는 특히 대규모 스토리지 환경에서 유용합니다. 시스템에서 사용 가능한 장치 이름을 살펴보려면 대화형 설치 중에
ls -lR /dev/disk명령을 사용할 수 있습니다. 스토리지 장치를 일관되게 참조하는 다양한 방법에 대한 자세한 내용은 영구 이름 지정 속성 개요 를 참조하십시오.
C.5.3. clearpart
clearpart Kickstart 명령은 선택 사항입니다. 새 파티션을 만들기 전에 시스템에서 파티션을 제거합니다. 기본적으로 파티션은 제거되지 않습니다. 이 명령은 한 번만 사용하십시오.
구문
clearpart OPTIONS
clearpart OPTIONS옵션
--all- 시스템에서 모든 파티션을 지웁니다.이 옵션은 연결된 네트워크 스토리지를 포함하여 설치 프로그램에서 연결할 수 있는 모든 디스크를 지웁니다. 이 옵션을 주의해서 사용하십시오.
나중에 네트워크 스토리지를 연결하거나(예: Kickstart 파일의
%post섹션에서) 네트워크 스토리지를 연결하거나 네트워크 스토리지에 액세스하는 데 사용되는 커널 모듈을 차단하여--drives=옵션을 사용하여 보존하려는 스토리지가 지워지지 않도록 할 수 있습니다.--drives=- 파티션을 지울 드라이브를 지정합니다. 예를 들어 다음은 기본 IDE 컨트롤러의 처음 두 드라이브의 모든 파티션을 지웁니다.clearpart --drives=hda,hdb --all
clearpart --drives=hda,hdb --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다중 경로 장치를 지우려면
disk/by-id/scsi-WWID형식을 사용합니다. 여기서 WWID 는 장치의 전역 식별자입니다. 예를 들어 WWID58095BEC5510947BE8C0360F604351918로 디스크를 지우려면 다음을 사용합니다.clearpart --drives=disk/by-id/scsi-58095BEC5510947BE8C0360F604351918
clearpart --drives=disk/by-id/scsi-58095BEC5510947BE8C0360F604351918Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 형식은 모든 다중 경로 장치에 선호되지만 오류가 발생하면 LVM(Logical Volume Manager)을 사용하지 않는 다중 경로 장치도
disk/by-id/dm-uuid-mpath-WWID형식을 사용하여 지울 수 있습니다. 여기서 WWID 는 장치의 전역 식별자입니다. 예를 들어 WWID2416CD96995134CA5D787F00A5AA11017로 디스크를 지우려면 다음을 사용합니다.clearpart --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017
clearpart --drives=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017Copy to Clipboard Copied! Toggle word wrap Toggle overflow mpatha와 같은 장치 이름으로 다중 경로 장치를 지정하지 마십시오. 이와 같은 장치 이름은 특정 디스크에 한정되지 않습니다. 설치하는 동안 이름이/dev/mpatha인 디스크가 예상했던 것과 다를 수 있습니다. 따라서clearpart명령은 잘못된 디스크를 대상으로 할 수 있습니다.--initlabel- 포맷을 위해 지정된 각 아키텍처의 모든 디스크에 대한 기본 디스크 레이블을 만들어 디스크(또는 디스크)를 만듭니다(예: x86의 msdos).--initlabel은 모든 디스크를 볼 수 있기 때문에 포맷할 드라이브만 연결되어 있는지 확인하는 것이 중요합니다.clearpart로 지워진 디스크는--initlabel을 사용하지 않는 경우에도 레이블이 생성됩니다.clearpart --initlabel --drives=names_of_disks
clearpart --initlabel --drives=names_of_disksCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
clearpart --initlabel --drives=dasda,dasdb,dasdc
clearpart --initlabel --drives=dasda,dasdb,dasdcCopy to Clipboard Copied! Toggle word wrap Toggle overflow --list=- 지울 파티션을 지정합니다. 이 옵션은 사용된 경우--all및--linux옵션을 재정의합니다. 여러 드라이브에서 사용할 수 있습니다. 예를 들면 다음과 같습니다.clearpart --list=sda2,sda3,sdb1
clearpart --list=sda2,sda3,sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
--disklabel=LABEL- 기본 disklabel을 사용하도록 설정합니다. 플랫폼에 지원되는 디스크 레이블만 허용됩니다. 예를 들어 64비트 Intel 및 AMD 아키텍처에서는msdos및gpt디스크 라벨이 허용되지만dasd는 허용되지 않습니다. -
--Linux- 모든 Linux 파티션을 지웁니다. -
--none(기본값) - 파티션을 제거하지 않습니다. -
--CDL - 모든 LDL DASD를 CDL 형식으로 다시 포맷합니다.
참고
sdX(또는/dev/sdX) 형식은 재부팅 시 일관성 있는 장치 이름을 보장하지 않으므로 일부 Kickstart 명령 사용이 어려워질 수 있습니다. 명령에 장치 노드 이름이 필요한 경우/dev/disk의 모든 항목을 대안으로 사용할 수 있습니다. 예를 들어 다음 장치 이름을 사용하는 대신 다음을 수행합니다.part / --fstype=xfs --onpart=sda1
part / --fstype=xfs --onpart=sda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 중 하나와 유사한 항목을 사용할 수 있습니다.
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 방법을 사용하면 명령은 항상 동일한 스토리지 장치를 대상으로 합니다. 이는 특히 대규모 스토리지 환경에서 유용합니다. 시스템에서 사용 가능한 장치 이름을 살펴보려면 대화형 설치 중에
ls -lR /dev/disk명령을 사용할 수 있습니다. 스토리지 장치를 일관되게 참조하는 다양한 방법에 대한 자세한 내용은 영구 이름 지정 속성 개요 를 참조하십시오.-
clearpart명령을 사용하는 경우 논리 파티션에서part --onpart명령을 사용할 수 없습니다.
C.5.4. zerombr
zerombr Kickstart 명령은 선택 사항입니다. zerombr 은 디스크에 있는 잘못된 파티션 테이블을 초기화하고 잘못된 파티션 테이블이 있는 디스크의 모든 내용을 제거합니다. 이 명령은 포맷되지 않은 DASD(Direct Access Storage Device) 디스크가 있는 64비트 IBM Z 시스템에서 설치를 수행할 때 필요합니다. 그렇지 않으면 포맷되지 않은 디스크는 설치 중에 포맷되지 않고 사용됩니다. 이 명령은 한 번만 사용하십시오.
구문
zerombr
zerombr참고
-
64비트 IBM Z에서
zerombr이 지정되면 아직 낮은 수준의 형식이 아닌 설치 프로그램에 표시되는 모든 Direct Access Storage Device(DASD)가 자동으로 dasdfmt로 포맷됩니다. 또한 명령은 대화형 설치 중에 사용자 선택을 방지합니다. -
zerombr를 지정하지 않고 설치 프로그램에 표시되지 않는 포맷되지 않은 DASD가 하나 이상 있는 경우 비대화형 Kickstart 설치가 실패합니다. -
zerombr이 지정되지 않고 설치 프로그램에 표시되는 포맷되지 않은 DASD가 하나 이상 있는 경우 사용자가 모든 보기 및 포맷되지 않은 DASD 포맷에 동의하지 않으면 대화형 설치가 종료됩니다. 이를 우회하려면 설치 중에 사용할 DASD만 활성화합니다. 설치가 완료된 후 항상 DASD를 추가할 수 있습니다. - 이 명령에는 옵션이 없습니다.
C.5.5. bootloader
부트로더 Kickstart 명령이 필요합니다. 부트 로더를 설치하는 방법을 지정합니다. 이 명령은 한 번만 사용하십시오.
구문
bootloader [OPTIONS]
bootloader [OPTIONS]옵션
--append=- 추가 커널 매개변수를 지정합니다. 여러 매개변수를 지정하려면 공백으로 구분합니다. 예를 들면 다음과 같습니다.bootloader --location=mbr --append="hdd=ide-scsi ide=nodma"
bootloader --location=mbr --append="hdd=ide-scsi ide=nodma"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서 지정하지 않거나
--append=명령을 전혀 사용하지 않더라도plymouth패키지가 설치될 때rhgb및quiet매개변수가 자동으로 추가됩니다. 이 동작을 비활성화하려면plymouth의 설치를 명시적으로 허용하지 않습니다.%packages -plymouth %end
%packages -plymouth %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 옵션은 최신 프로세서(CVE-2017-5754, CVE-2017-5753 및 CVE-2017-5715)에서 발견된 Meltdown 및 Spectre speculative 실행 취약점을 완화하기 위해 구현된 메커니즘을 비활성화하는 데 유용합니다. 경우에 따라 이러한 메커니즘이 필요하지 않을 수 있으며 이를 사용하도록 설정하면 보안이 향상되지 않고 성능이 저하될 수 있습니다. 이러한 메커니즘을 비활성화하려면 AMD64/Intel 64 시스템에서
부트로더 --append="nopti noibpb"와 같이 Kickstart 파일에 수행할 옵션을 추가합니다.주의취약점 완화 메커니즘을 비활성화하기 전에 시스템이 공격 위험이 없는지 확인합니다. Meltdown 및 Spectre 취약점에 대한 정보는 Red Hat 취약점 대응 문서를 참조하십시오.
--boot-drive=- 작성할 드라이브로 부트 로더를 지정하고, 따라서 컴퓨터가 부팅될 드라이브를 지정합니다. 다중 경로 장치를 부팅 드라이브로 사용하는 경우 disk/by-id/dm-uuid-mpath-WWID 이름을 사용하여 장치를 지정합니다.중요현재
zipl부트 로더를 사용하여 64비트 IBM Z 시스템의 Red Hat Enterprise Linux 설치에서는--boot-drive=옵션이 무시되고 있습니다.zipl이 설치되면 자체적으로 부팅 드라이브를 결정합니다.-
--leavebootorder- 설치 프로그램은 Red Hat Enterprise Linux 8을 부트 로더에 설치된 시스템 목록 상단에 추가하고 모든 기존 항목을 그대로 유지합니다.
이 옵션은 전원 시스템에만 적용되며 UEFI 시스템은 이 옵션을 사용해서는 안 됩니다.
--driveorder=- BIOS 부팅 순서에서 먼저 어떤 드라이브가 있는지 지정합니다. 예를 들면 다음과 같습니다.bootloader --driveorder=sda,hda
bootloader --driveorder=sda,hdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow --location=- 부팅 레코드가 기록된 위치를 지정합니다. 유효한 값은 다음과 같습니다.MBR- 기본 옵션입니다. 드라이브가 MBR(Master Boot Record) 또는 GUID 파티션 테이블(GPT) 체계를 사용하는지 여부에 따라 달라집니다.GPT 형식의 디스크에서 이 옵션은 부트 로더의 단계 1.5를 BIOS 부팅 파티션에 설치합니다.
MBR 형식의 디스크에서 1.5단계는 MBR과 첫 번째 파티션 사이의 빈 공간에 설치됩니다.
-
partition- 커널이 포함된 파티션의 첫 번째 섹터에 부트 로더를 설치합니다. -
none- 부트 로더를 설치하지 마십시오.
대부분의 경우 이 옵션을 지정할 필요가 없습니다.
-
--nombr- MBR에 부트 로더를 설치하지 마십시오. --password=- GRUB을 사용하는 경우 이 옵션으로 지정된 부트 로더 암호를 설정합니다. 임의의 커널 옵션을 전달할 수 있는 GRUB 쉘에 대한 액세스를 제한하는 데 사용해야 합니다.암호를 지정하면 GRUB에서 사용자 이름도 요청합니다. 사용자 이름은 항상
root입니다.--iscrypted- 일반적으로--password=옵션을 사용하여 부트 로더 암호를 지정하면 Kickstart 파일에 일반 텍스트로 저장됩니다. 암호를 암호화하려면 이 옵션과 암호화된 암호를 사용하십시오.암호화된 암호를 생성하려면
grub2-mkpasswd-pbkdf2명령을 사용하여 사용하려는 암호를 입력하고 명령의 출력(grub.pbkdf2로 시작하는 해시)을 Kickstart 파일에 복사합니다. 암호화된 암호가 있는부트로더Kickstart 항목의 예는 다음과 유사합니다.bootloader --iscrypted --password=grub.pbkdf2.sha512.10000.5520C6C9832F3AC3D149AC0B24BE69E2D4FB0DBEEDBD29CA1D30A044DE2645C4C7A291E585D4DC43F8A4D82479F8B95CA4BA4381F8550510B75E8E0BB2938990.C688B6F0EF935701FF9BD1A8EC7FE5BD2333799C98F28420C5CC8F1A2A233DE22C83705BB614EA17F3FDFDF4AC2161CEA3384E56EB38A2E39102F5334C47405E
bootloader --iscrypted --password=grub.pbkdf2.sha512.10000.5520C6C9832F3AC3D149AC0B24BE69E2D4FB0DBEEDBD29CA1D30A044DE2645C4C7A291E585D4DC43F8A4D82479F8B95CA4BA4381F8550510B75E8E0BB2938990.C688B6F0EF935701FF9BD1A8EC7FE5BD2333799C98F28420C5CC8F1A2A233DE22C83705BB614EA17F3FDFDF4AC2161CEA3384E56EB38A2E39102F5334C47405ECopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--timeout=- 기본 옵션(초)을 부팅하기 전에 부트 로더가 대기하는 시간을 지정합니다. -
--default=- 부트 로더 구성에서 기본 부팅 이미지를 설정합니다. -
--extlinux- GRUB 대신 extlinux 부트 로더를 사용합니다. 이 옵션은 extlinux에서 지원하는 시스템에서만 작동합니다. -
--disabled- 이 옵션은 더 강력한--location=none버전입니다.--location=none은 부트 로더 설치를 단순히 비활성화하지만--disabled는 부트 로더 설치를 비활성화하고 부트 로더가 포함된 패키지 설치를 비활성화하여 공간을 절약합니다.
참고
- Red Hat은 모든 시스템에서 부트 로더 암호를 설정하는 것이 좋습니다. 보호되지 않은 부트 로더를 사용하면 잠재적인 공격자가 시스템의 부팅 옵션을 수정하고 시스템에 대한 무단 액세스를 얻을 수 있습니다.
- AMD64, Intel 64 및 64비트 ARM 시스템에 부트 로더를 설치하려면 특수 파티션이 필요합니다. 이 파티션의 유형과 크기는 마스터 부트 레코드(MBR) 또는 GUID 파티션 테이블(GPT) 스키마를 사용하기 위해 부트 로더를 설치하는 디스크의 유형에 따라 달라집니다. 자세한 내용은 부트 로더 구성 섹션을 참조하십시오.
sdX(또는/dev/sdX) 형식은 재부팅 시 일관성 있는 장치 이름을 보장하지 않으므로 일부 Kickstart 명령 사용이 어려워질 수 있습니다. 명령에 장치 노드 이름이 필요한 경우/dev/disk의 모든 항목을 대안으로 사용할 수 있습니다. 예를 들어 다음 장치 이름을 사용하는 대신 다음을 수행합니다.part / --fstype=xfs --onpart=sda1
part / --fstype=xfs --onpart=sda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 중 하나와 유사한 항목을 사용할 수 있습니다.
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 방법을 사용하면 명령은 항상 동일한 스토리지 장치를 대상으로 합니다. 이는 특히 대규모 스토리지 환경에서 유용합니다. 시스템에서 사용 가능한 장치 이름을 살펴보려면 대화형 설치 중에
ls -lR /dev/disk명령을 사용할 수 있습니다. 스토리지 장치를 일관되게 참조하는 다양한 방법에 대한 자세한 내용은 영구 이름 지정 속성 개요 를 참조하십시오.-
Red Hat Enterprise Linux 8에서는
--upgrade옵션이 더 이상 사용되지 않습니다.
C.5.6. autopart
autopart Kickstart 명령은 선택 사항입니다. 파티션을 자동으로 생성합니다.
자동으로 생성된 파티션은 루트(/) 파티션(1GiB 이상), 스왑 파티션 및 아키텍처에 적합한 /boot 파티션입니다. 충분히 큰 드라이브(50GiB 이상)에서 /home 파티션도 생성됩니다. 이 명령은 한 번만 사용하십시오.
구문
autopart OPTIONS
autopart OPTIONS옵션
--type=- 사용하려는 사전 정의된 자동 분할 체계 중 하나를 선택합니다. 다음 값을 허용합니다.-
lvm: LVM 파티션 스키마입니다. -
plain: LVM이 없는 일반 파티션. -
thinp: LVM 씬 프로비저닝 파티셔닝 스키마입니다.
-
-
--fstype=- 사용 가능한 파일 시스템 유형 중 하나를 선택합니다. 사용 가능한 값은ext2,ext3,ext4,xfs,vfat입니다. 기본 파일 시스템은xfs입니다. -
--nohome-/home파티션의 자동 생성을 비활성화합니다. -
--nolvm- 자동 파티셔닝에 LVM을 사용하지 마십시오. 이 옵션은--type=plain과 동일합니다. -
--noboot-/boot파티션을 만들지 마십시오. -
--noswap- 스왑 파티션을 만들지 마십시오. --encrypted- Linux Unified Key Setup(LUKS)을 사용하여 모든 파티션을 암호화합니다. 이는 수동 그래픽 설치 중에 초기 파티션 화면의 Encrypt 파티션 확인란을 확인하는 것과 동일합니다.참고하나 이상의 파티션을 암호화할 때 Anaconda는 256비트의 엔트로피를 수집하여 파티션을 안전하게 암호화하려고 합니다. 엔트로피 수집에는 약간의 시간이 걸릴 수 있습니다. 충분한 엔트로피가 수집되었는지에 관계없이 프로세스가 최대 10분 후에 중지됩니다.
이 프로세스는 설치 시스템과 상호 작용(키보드에서 연결 또는 마우스 이동)을 통해 증가할 수 있습니다. 가상 머신에 설치하는 경우
virtio-rng장치(가상 임의 번호 생성기)를 게스트에 연결할 수도 있습니다.-
--LUKS-version=LUKS_VERSION- 파일 시스템을 암호화하는 데 사용해야 하는 LUKS 형식을 지정합니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--passphrase=- 모든 암호화된 장치에 대한 기본 시스템 전체 암호를 제공합니다. -
--escrowcert= URL_of_X.509_certificate- URL_of_X.509_certificate로 지정된 URL의 X.509 인증서를 사용하여 암호화된 모든 암호화된 볼륨의 데이터 암호화 키를/root의 파일로 저장합니다. 키는 암호화된 각 볼륨에 대해 별도의 파일로 저장됩니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--backuppassphrase- 임의로 생성된 각 볼륨에 암호를 추가합니다. 이러한 암호는--escrowcert로 지정된 X.509 인증서를 사용하여 암호화된/root에 있는 별도의 파일에 저장합니다. 이 옵션은--escrowcert가 지정된 경우에만 의미가 있습니다. -
--cipher=- Anaconda 기본aes-xts-plain64가 적절하지 않은 경우 사용할 암호화 유형을 지정합니다. 이 옵션을--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. 사용 가능한 암호화 유형은 보안 강화 문서에 나열되어 있지만 Red Hat은aes-xts-plain64또는aes-cbc-essiv:sha256을 사용하는 것이 좋습니다. -
--PBKDF=PBKDF- LUKS 키 슬롯에 대해 PBKDF(암호 기반 키 비활성화 기능) 알고리즘을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--PBKDF-memory=PBKDF_MEMORY- PBKDF의 메모리 비용을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--PBKDF-time=PBKDF_TIME- PBKDF 암호 처리와 함께 사용할 밀리초 수를 설정합니다. 도움말 페이지 cryptsetup(8) 에서--iter-time을 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-iterations와 함께 사용할 수 없습니다. -
--PBKDF-iterations=PBKDF_ITERATIONS- 반복 횟수를 직접 설정하고 PBKDF 벤치마크를 방지합니다. 도움말 페이지 cryptsetup(8) 의--pbkdf-force-iterations를 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-time과 함께 사용할 수 없습니다.
참고
-
autopart옵션은 동일한 Kickstart 파일에서part/partition,raid,logvol또는volgroup옵션과 함께 사용할 수 없습니다. -
autopart명령은 필수 사항은 아니지만 Kickstart 스크립트에part또는mount명령이 없는 경우 포함해야 합니다. -
CMS 유형의 단일 FBA DASD에 설치할 때
autopart --nohomeKickstart 옵션을 사용하는 것이 좋습니다. 이렇게 하면 설치 프로그램이 별도의/home파티션을 생성하지 않습니다. 그런 다음 설치가 성공적으로 진행됩니다. -
LUKS 암호를 분실하는 경우 암호화된 파티션과 해당 데이터에 완전히 액세스할 수 없습니다. 분실된 암호를 복구할 방법은 없습니다. 그러나
--escrowcert를 사용하여 암호화 암호를 저장하고--backuppassphrase옵션을 사용하여 백업 암호화 암호를 생성할 수 있습니다. -
autopart,autopart --type=lvm또는autopart=thinp를 사용할 때 디스크 섹터 크기가 일관되게 유지되는지 확인합니다.
C.5.7. REqpart
reqpart Kickstart 명령은 선택 사항입니다. 하드웨어 플랫폼에 필요한 파티션을 자동으로 생성합니다. 여기에는 UEFI 펌웨어가 있는 시스템의 /boot/efi 파티션, BIOS 펌웨어 및 GPT가 있는 시스템의 BIOS 부팅 파티션, IBM Power Systems용 PRePBoot 파티션이 포함됩니다. 이 명령은 한 번만 사용하십시오.
구문
reqpart [--add-boot]
reqpart [--add-boot]옵션
-
--add-boot- 기본 명령으로 생성된 플랫폼별 파티션 외에도 별도의/boot파티션을 만듭니다.
참고
-
autopart와 함께 이 명령은 사용할 수 없습니다.autopart는reqpart명령이 수행하는 모든 작업을 수행하고, 또한/및스왑과 같은 다른 파티션 또는 논리 볼륨을 생성하므로 이 명령은 autopart와 함께 사용할 수 없습니다.autopart와 달리 이 명령은 플랫폼별 파티션만 생성하고 나머지 드라이브를 비워 두므로 사용자 지정 레이아웃을 생성할 수 있습니다.
C.5.8. 부분 또는 파티션
part 또는 partition Kickstart 명령이 필요합니다. 시스템에 파티션을 생성합니다.
구문
part|partition mntpoint [OPTIONS]
part|partition mntpoint [OPTIONS]옵션
mntpoint - 파티션이 마운트된 위치입니다. 값은 다음 양식 중 하나여야 합니다.
/path예:
/,/usr,/homeswap파티션은 스왑 공간으로 사용됩니다.
스왑 파티션의 크기를 자동으로 확인하려면
--recommended옵션을 사용합니다.swap --recommended
swap --recommendedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 할당된 크기는 효과적이지만 시스템에 맞게 정확하게 조정되지는 않습니다.
스왑 파티션의 크기를 자동으로 결정하되 시스템이 최대 절전할 수 있는 추가 공간을 허용하려면
--hibernation옵션을 사용합니다.swap --hibernation
swap --hibernationCopy to Clipboard Copied! Toggle word wrap Toggle overflow 할당된 크기는
--recommended로 할당된 스왑 공간과 시스템의 RAM 양과 동일합니다. 이러한 명령으로 할당된 스왑 크기는 AMD64, Intel 64 및 64비트 ARM 시스템의 권장 파티션 구성 스키마를 참조하십시오.RAID.id파티션은 소프트웨어 RAID에 사용됩니다(
raid참조).pv.id파티션은 LVM에 사용됩니다(Log
vol참조).biosboot파티션은 BIOS 부팅 파티션에 사용됩니다. GUID 파티션 테이블(GPT)을 사용하는 BIOS 기반 AMD64 및 Intel 64 시스템에는 1MiB BIOS 부팅 파티션이 필요합니다. 부트 로더가 여기에 설치됩니다. UEFI 시스템에서는 필요하지 않습니다.
bootloader명령도 참조하십시오./boot/efiEFI 시스템 파티션. UEFI 기반 AMD64, Intel 64 및 64비트 ARM에는 50MiB EFI 파티션이 필요합니다. 권장 크기는 200MiB입니다. BIOS 시스템에서는 필요하지 않습니다.
bootloader명령도 참조하십시오.
-
--size=- 최소 파티션 크기(MiB)입니다. 여기에500과 같은 정수 값을 지정합니다(단위를 포함하지 마십시오). 지정된 크기가 너무 작으면 설치에 실패합니다.--size값을 필요한 최소 공간으로 설정합니다. 크기 권장 사항은 권장 파티션 구성 계획을 참조하십시오. -
--grow- 사용 가능한 공간을 채우거나(있는 경우) 최대 크기 설정(지정된 경우)을 채우도록 파티션을 지정합니다. 스왑 파티션에서--maxsize=를 설정하지 않고--grow=을 사용하는 경우 Anaconda는 스왑 파티션의 최대 크기를 제한합니다. 물리적 메모리가 2GiB 미만인 시스템의 경우 부과된 제한은 물리적 메모리의 두 배입니다. 2GiB가 넘는 시스템의 경우, 부과된 제한은 물리적 메모리와 2GiB의 크기입니다. -
--maxSize=- 파티션이 증가로 설정된 경우 최대 파티션 크기(MiB)입니다. 여기에500과 같은 정수 값을 지정합니다(단위를 포함하지 마십시오). -
--noformat---onpart명령과 함께 사용하려면 파티션을 포맷하지 않도록 지정합니다. --onpart=또는--usepart=- 파티션을 배치할 장치를 지정합니다. 기존의 빈 장치를 사용하여 새로운 지정된 유형으로 포맷합니다. 예를 들면 다음과 같습니다.partition /home --onpart=hda1
partition /home --onpart=hda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow /home을/dev/hda1에 배치합니다.이러한 옵션은 논리 볼륨에 파티션을 추가할 수도 있습니다. 예를 들면 다음과 같습니다.
partition pv.1 --onpart=hda2
partition pv.1 --onpart=hda2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 장치가 이미 시스템에 있어야 합니다
. --onpart옵션은 생성되지 않습니다.파티션이 아닌 전체 드라이브를 지정할 수도 있습니다. 이 경우 Anaconda는 파티션 테이블을 만들지 않고 드라이브를 포맷하고 사용할 수 있습니다. 그러나 이러한 방식으로 포맷된 장치에서 GRUB 설치는 지원되지 않으며 파티션 테이블이 있는 드라이브에 배치해야 합니다.
partition pv.1 --onpart=hdb
partition pv.1 --onpart=hdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow --ondisk=또는--ondrive=- 기존 디스크에 파티션(부분명령으로 지정)을 만듭니다. 이 명령은 항상 파티션을 생성합니다. 특정 디스크에 파티션을 강제로 만듭니다. 예를 들어,--ondisk=sdb는 시스템의 두 번째 SCSI 디스크에 파티션을 둡니다.LVM(Logical Volume Manager)을 사용하지 않는 다중 경로 장치를 지정하려면
disk/by-id/dm-uuid-mpath-WWID형식을 사용합니다. 여기서 WWID 는 장치의 전역 식별자입니다. 예를 들어 WWID2416CD96995134CA5D787F00A5AA11017디스크를 지정하려면 다음을 사용합니다.part / --fstype=xfs --grow --asprimary --size=8192 --ondisk=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017
part / --fstype=xfs --grow --asprimary --size=8192 --ondisk=disk/by-id/dm-uuid-mpath-2416CD96995134CA5D787F00A5AA11017Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의mpatha와 같은 장치 이름으로 다중 경로 장치를 지정하지 마십시오. 이와 같은 장치 이름은 특정 디스크에 한정되지 않습니다. 설치하는 동안 이름이/dev/mpatha인 디스크가 예상했던 것과 다를 수 있습니다. 따라서part명령은 잘못된 디스크를 대상으로 할 수 있습니다.-
--asprimary- 파티션을 기본 파티션으로 할당합니다. 파티션을 기본 파티션으로 할당할 수 없는 경우(일반적으로 이미 할당된 기본 파티션이 너무 많기 때문에) 파티션 프로세스가 실패합니다. 이 옵션은 디스크가 마스터 부트 레코드(MBR)를 사용하는 경우에만 적합합니다. GUID 파티션 테이블(GPT) 레이블 디스크의 경우 이 옵션은 의미가 없습니다. -
--fsprofile=- 이 파티션에서 파일 시스템을 만드는 프로그램에 전달할 사용 유형을 지정합니다. 사용 유형은 파일 시스템을 만들 때 사용할 다양한 튜닝 매개 변수를 정의합니다. 이 옵션을 사용하려면 파일 시스템에서 사용 유형의 개념을 지원해야 하며 유효한 유형을 나열하는 구성 파일이 있어야 합니다.ext2,ext3,ext4의 경우 이 구성 파일은/etc/mke2fs.conf입니다. --mkfsoptions=- 이 파티션에서 파일 시스템을 만드는 프로그램에 전달할 추가 매개변수를 지정합니다. 이는--fsprofile과 유사하지만 프로필 개념을 지원하는 파일 시스템뿐만 아니라 모든 파일 시스템에서 작동합니다. 인수 목록에서 처리가 수행되지 않으므로 mkfs 프로그램에 직접 전달할 수 있는 형식으로 제공해야 합니다. 즉, 파일 시스템에 따라 쉼표로 구분되거나 큰따옴표로 묶어야 합니다. 예를 들면 다음과 같습니다.part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"
part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
자세한 내용은 생성 중인 파일 시스템의 도움말 페이지를 참조하십시오. 예를 들어 mkfs.ext4 또는 mkfs.xfs.
-
--fstype=- 파티션의 파일 시스템 유형을 설정합니다. 유효한 값은xfs,ext2,ext3,ext4,swap,vfat,efi및biosboot입니다. --fsoptions- 파일 시스템을 마운트할 때 사용할 자유 형식의 옵션 문자열을 지정합니다. 이 문자열은 설치된 시스템의/etc/fstab파일에 복사되며 따옴표로 묶어야 합니다.참고EFI 시스템 파티션(
/boot/efi)에서 anaconda 하드 코딩은 값을 코딩하고 지정된--fsoptions값을 무시합니다.-
--label=- 개별 파티션에 레이블을 할당합니다. -
--recommended- 파티션의 크기를 자동으로 결정합니다. 권장 체계에 대한 자세한 내용은 AMD64, Intel 64 및 64비트 ARM에 대한 권장 파티션 구성 스키마를 참조하십시오. 이 옵션은/boot파티션 및스왑공간과 같은 파일 시스템을 생성하는 파티션에만 사용할 수 있습니다. LVM 물리 볼륨 또는 RAID 멤버를 생성하는 데 사용할 수 없습니다. -
--onbiosdisk- BIOS에서 검색한 대로 특정 디스크에 파티션을 만듭니다. --encrypted---passphrase옵션에 제공된 암호를 사용하여 이 파티션을 LUKS(Linux Unified Key Setup)로 암호화하도록 지정합니다. 암호를 지정하지 않으면 Anaconda는autopart --passphrase명령으로 설정된 기본 시스템 전체 암호를 사용하거나 설치를 중지하고 기본값이 설정되지 않은 경우 암호를 제공하도록 요청합니다.참고하나 이상의 파티션을 암호화할 때 Anaconda는 256비트의 엔트로피를 수집하여 파티션을 안전하게 암호화하려고 합니다. 엔트로피 수집에는 약간의 시간이 걸릴 수 있습니다. 충분한 엔트로피가 수집되었는지에 관계없이 프로세스가 최대 10분 후에 중지됩니다.
이 프로세스는 설치 시스템과 상호 작용(키보드에서 연결 또는 마우스 이동)을 통해 증가할 수 있습니다. 가상 머신에 설치하는 경우
virtio-rng장치(가상 임의 번호 생성기)를 게스트에 연결할 수도 있습니다.-
--LUKS-version=LUKS_VERSION- 파일 시스템을 암호화하는 데 사용해야 하는 LUKS 형식을 지정합니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--passphrase=- 이 파티션을 암호화할 때 사용할 암호를 지정합니다. 이 옵션을--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. -
--cipher=- Anaconda 기본aes-xts-plain64가 적절하지 않은 경우 사용할 암호화 유형을 지정합니다. 이 옵션을--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. 사용 가능한 암호화 유형은 보안 강화 문서에 나열되어 있지만 Red Hat은aes-xts-plain64또는aes-cbc-essiv:sha256을 사용하는 것이 좋습니다. -
--escrowcert= URL_of_X.509_certificate- URL_of_X.509_certificate로 지정된 URL의 X.509 인증서를 사용하여 암호화된 모든 암호화된 파티션의 데이터 암호화 키를/root의 파일로 저장합니다. 키는 암호화된 각 파티션에 대해 별도의 파일로 저장됩니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--backuppassphrase- 임의로 생성된 각 파티션에 암호를 추가합니다. 이러한 암호는--escrowcert로 지정된 X.509 인증서를 사용하여 암호화된/root에 있는 별도의 파일에 저장합니다. 이 옵션은--escrowcert가 지정된 경우에만 의미가 있습니다. -
--PBKDF=PBKDF- LUKS 키 슬롯에 대해 PBKDF(암호 기반 키 비활성화 기능) 알고리즘을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--PBKDF-memory=PBKDF_MEMORY- PBKDF의 메모리 비용을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--PBKDF-time=PBKDF_TIME- PBKDF 암호 처리와 함께 사용할 밀리초 수를 설정합니다. 도움말 페이지 cryptsetup(8) 에서--iter-time을 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-iterations와 함께 사용할 수 없습니다. -
--PBKDF-iterations=PBKDF_ITERATIONS- 반복 횟수를 직접 설정하고 PBKDF 벤치마크를 방지합니다. 도움말 페이지 cryptsetup(8) 의--pbkdf-force-iterations를 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-time과 함께 사용할 수 없습니다. -
--resize=- 기존 파티션의 크기를 조정합니다. 이 옵션을 사용하는 경우--size=옵션을 사용하여 대상 크기(MiB)를 지정하고--onpart=옵션을 사용하여 대상 파티션을 지정합니다.
참고
-
part명령은 필수 사항은 아니지만 Kickstart 스크립트에part,autopart또는mount를 포함해야 합니다. -
Red Hat Enterprise Linux 8에서는
--active옵션이 더 이상 사용되지 않습니다. - 어떤 이유로든 분할이 실패하면 가상 콘솔 3에 진단 메시지가 표시됩니다.
-
--noformat및--onpart를 사용하지 않는 한 생성된 모든 파티션은 설치 프로세스의 일부로 포맷됩니다. sdX(또는/dev/sdX) 형식은 재부팅 시 일관성 있는 장치 이름을 보장하지 않으므로 일부 Kickstart 명령 사용이 어려워질 수 있습니다. 명령에 장치 노드 이름이 필요한 경우/dev/disk의 모든 항목을 대안으로 사용할 수 있습니다. 예를 들어 다음 장치 이름을 사용하는 대신 다음을 수행합니다.part / --fstype=xfs --onpart=sda1
part / --fstype=xfs --onpart=sda1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 중 하나와 유사한 항목을 사용할 수 있습니다.
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1
part / --fstype=xfs --onpart=/dev/disk/by-path/pci-0000:00:05.0-scsi-0:0:0:0-part1 part / --fstype=xfs --onpart=/dev/disk/by-id/ata-ST3160815AS_6RA0C882-part1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 방법을 사용하면 명령은 항상 동일한 스토리지 장치를 대상으로 합니다. 이는 특히 대규모 스토리지 환경에서 유용합니다. 시스템에서 사용 가능한 장치 이름을 살펴보려면 대화형 설치 중에
ls -lR /dev/disk명령을 사용할 수 있습니다. 스토리지 장치를 일관되게 참조하는 다양한 방법에 대한 자세한 내용은 영구 이름 지정 속성 개요 를 참조하십시오.-
LUKS 암호를 분실하는 경우 암호화된 파티션과 해당 데이터에 완전히 액세스할 수 없습니다. 분실된 암호를 복구할 방법은 없습니다. 그러나
--escrowcert를 사용하여 암호화 암호를 저장하고--backuppassphrase옵션을 사용하여 백업 암호화 암호를 생성할 수 있습니다.
C.5.9. RAID
raid Kickstart 명령은 선택 사항입니다. 소프트웨어 RAID 장치를 어셈블합니다.
구문
raid mntpoint --level=level --device=device-name partitions*
raid mntpoint --level=level --device=device-name partitions*옵션
mntpoint - RAID 파일 시스템이 마운트된 위치입니다. 부팅 파티션(
/boot/boot파티션은 수준 1이어야 하며 루트(/) 파티션은 사용 가능한 유형 중 하나일 수 있습니다. 파티션* (여러 파티션을 나열할 수 있음을 나타내는) RAID 배열에 추가할 RAID 식별자가 나열됩니다.중요-
IBM Power Systems에서 RAID 장치가 준비되고 설치 중에 다시 포맷되지 않은 경우
/boot및 PReP 파티션을 RAID 장치에 배치하려는 경우 RAID 메타데이터 버전이0.90또는1.0인지 확인하십시오./boot및 PReP 파티션에는mdadm메타데이터 버전1.1및1.2가 지원되지 않습니다. -
PowerNV 시스템에는
PReP부트 파티션이 필요하지 않습니다.
-
IBM Power Systems에서 RAID 장치가 준비되고 설치 중에 다시 포맷되지 않은 경우
-
--level=- 사용할 RAID 수준 (0, 1, 4, 5, 6, 10). --device=- 사용할 RAID 장치의 이름입니다(예:--device=root).중요md0형식으로mdraid이름을 사용하지 마십시오. 이러한 이름은 영구적이지 않습니다. 대신루트또는스왑과 같은 의미 있는 이름을 사용합니다. 의미 있는 이름을 사용하면/dev/md/이름에서배열에 할당된/dev/mdX노드가 있는 심볼릭 링크가 생성됩니다.이름을 할당할 수 없는 오래된 (v0.90 메타데이터) 배열이 있는 경우 파일 시스템 레이블 또는 UUID로 배열을 지정할 수 있습니다. 예를 들어
--device=LABEL=root또는--device=UUID=93348e56-4631-d0f0-6f5b-45c47f570b88.RAID 장치의 파일 시스템 UUID 또는 RAID 장치 자체의 UUID를 사용할 수 있습니다. RAID 장치의 UUID는
8-4-4-4-12형식이어야 합니다. mdadm에서 보고한 UUID는 변경해야 하는8:8:8:8형식입니다. 예를 들어93348e56:4631d0:6f5b45c4:7f570b88은93348e56-4631-d0f0-6f5b-45c47f570b88로 변경해야 합니다.-
--CHUNKSIZE=- RAID 스토리지의 청크 크기를 KiB로 설정합니다. 경우에 따라 기본값(512 Kib)과 다른 청크 크기를 사용하면 RAID의 성능을 향상시킬 수 있습니다. -
--spares=- RAID 배열에 할당된 예비 드라이브 수를 지정합니다. 예비 드라이브는 드라이브 오류가 발생할 경우 배열을 다시 빌드하는 데 사용됩니다. -
--fsprofile=- 이 파티션에서 파일 시스템을 만드는 프로그램에 전달할 사용 유형을 지정합니다. 사용 유형은 파일 시스템을 만들 때 사용할 다양한 튜닝 매개 변수를 정의합니다. 이 옵션을 사용하려면 파일 시스템에서 사용 유형의 개념을 지원해야 하며 유효한 유형을 나열하는 구성 파일이 있어야 합니다. ext2,ext3 및 ext4의 경우 이 구성 파일은/etc/mke2fs.conf입니다. -
--fstype=- RAID 배열의 파일 시스템 유형을 설정합니다. 유효한 값은xfs,ext2,ext3,ext4,swap,vfat입니다. -
--fsoptions=- 파일 시스템을 마운트할 때 사용할 자유 형식의 옵션 문자열을 지정합니다. 이 문자열은 설치된 시스템의/etc/fstab파일에 복사되며 따옴표로 묶어야 합니다. EFI 시스템 파티션(/boot/efi)에서 anaconda 하드 코딩은 값을 코딩하고 지정된--fsoptions값을 무시합니다. --mkfsoptions=- 이 파티션에서 파일 시스템을 만드는 프로그램에 전달할 추가 매개변수를 지정합니다. 인수 목록에서 처리가 수행되지 않으므로 mkfs 프로그램에 직접 전달할 수 있는 형식으로 제공해야 합니다. 즉, 파일 시스템에 따라 쉼표로 구분되거나 큰따옴표로 묶어야 합니다. 예를 들면 다음과 같습니다.part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"
part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
자세한 내용은 생성 중인 파일 시스템의 도움말 페이지를 참조하십시오. 예를 들어 mkfs.ext4 또는 mkfs.xfs.
-
--label=- 만들 파일 시스템에 제공할 레이블을 지정합니다. 지정된 레이블이 다른 파일 시스템에서 이미 사용 중인 경우 새 레이블이 생성됩니다. -
--noformat- 기존 RAID 장치를 사용하고 RAID 배열을 포맷하지 마십시오. -
--useexisting- 기존 RAID 장치를 사용하여 형식을 다시 지정합니다. --encrypted---passphrase옵션에 제공된 암호를 사용하여 이 RAID 장치를 LUKS(Linux Unified Key Setup)로 암호화하도록 지정합니다. 암호를 지정하지 않으면 Anaconda는autopart --passphrase명령으로 설정된 기본 시스템 전체 암호를 사용하거나 설치를 중지하고 기본값이 설정되지 않은 경우 암호를 제공하도록 요청합니다.참고하나 이상의 파티션을 암호화할 때 Anaconda는 256비트의 엔트로피를 수집하여 파티션을 안전하게 암호화하려고 합니다. 엔트로피 수집에는 약간의 시간이 걸릴 수 있습니다. 충분한 엔트로피가 수집되었는지에 관계없이 프로세스가 최대 10분 후에 중지됩니다.
이 프로세스는 설치 시스템과 상호 작용(키보드에서 연결 또는 마우스 이동)을 통해 증가할 수 있습니다. 가상 머신에 설치하는 경우
virtio-rng장치(가상 임의 번호 생성기)를 게스트에 연결할 수도 있습니다.-
--LUKS-version=LUKS_VERSION- 파일 시스템을 암호화하는 데 사용해야 하는 LUKS 형식을 지정합니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--cipher=- Anaconda 기본aes-xts-plain64가 적절하지 않은 경우 사용할 암호화 유형을 지정합니다. 이 옵션을--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. 사용 가능한 암호화 유형은 보안 강화 문서에 나열되어 있지만 Red Hat은aes-xts-plain64또는aes-cbc-essiv:sha256을 사용하는 것이 좋습니다. -
--passphrase=- 이 RAID 장치를 암호화할 때 사용할 암호를 지정합니다. 이 옵션을--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. -
--escrowcert= URL_of_X.509_certificate- URL_of_X.509_certificate로 지정된 URL의 X.509 인증서를 사용하여 암호화한/root에 이 장치의 데이터 암호화 키를 저장합니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--backuppassphrase- 임의로 생성된 암호를 이 장치에 추가합니다./root의 파일에 암호를 저장하고--escrowcert로 지정된 X.509 인증서를 사용하여 암호화합니다. 이 옵션은--escrowcert가 지정된 경우에만 의미가 있습니다. -
--PBKDF=PBKDF- LUKS 키 슬롯에 대해 PBKDF(암호 기반 키 비활성화 기능) 알고리즘을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--PBKDF-memory=PBKDF_MEMORY- PBKDF의 메모리 비용을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. -
--PBKDF-time=PBKDF_TIME- PBKDF 암호 처리와 함께 사용할 밀리초 수를 설정합니다. 도움말 페이지 cryptsetup(8) 에서--iter-time을 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-iterations와 함께 사용할 수 없습니다. -
--PBKDF-iterations=PBKDF_ITERATIONS- 반복 횟수를 직접 설정하고 PBKDF 벤치마크를 방지합니다. 도움말 페이지 cryptsetup(8) 의--pbkdf-force-iterations를 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-time과 함께 사용할 수 없습니다.
예
다음 예제에서는 / 에 대해 RAID 수준 1 파티션을 생성하는 방법과 에 대해 RAID 수준 5를 생성하는 방법을 보여줍니다. 시스템에 SCSI 디스크가 3개 있다고 가정합니다. 또한 각 드라이브에 하나씩 세 개의 스왑 파티션을 생성합니다.
/ home
참고
-
LUKS 암호를 분실하는 경우 암호화된 파티션과 해당 데이터에 완전히 액세스할 수 없습니다. 분실된 암호를 복구할 방법은 없습니다. 그러나
--escrowcert를 사용하여 암호화 암호를 저장하고--backuppassphrase옵션을 사용하여 백업 암호화 암호를 생성할 수 있습니다.
C.5.10. volgroup
volgroup Kickstart 명령은 선택 사항입니다. LVM(Logical Volume Manager) 그룹을 생성합니다.
구문
volgroup name [OPTIONS] [partition*]
volgroup name [OPTIONS] [partition*]필수 옵션
- name - 새 볼륨 그룹의 이름입니다.
옵션
- partition - 볼륨 그룹의 백업 스토리지로 사용할 물리적 볼륨 파티션입니다.
-
--noformat- 기존 볼륨 그룹을 사용하고 포맷하지 마십시오. --useexisting- 기존 볼륨 그룹을 사용하여 형식을 다시 지정합니다. 이 옵션을 사용하는 경우 파티션을 지정하지 마십시오. 예를 들면 다음과 같습니다.volgroup rhel00 --useexisting --noformat
volgroup rhel00 --useexisting --noformatCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--pesize=- 볼륨 그룹의 물리 확장 영역 크기를 KiB로 설정합니다. 기본값은 4096(4MiB), 최소값은 1024(1MiB)입니다. -
--reserved-space=- 볼륨 그룹에 사용되지 않는 공간을 MiB로 지정합니다. 새로 생성된 볼륨 그룹에만 적용됩니다. -
--reserved-percent=- 사용되지 않을 총 볼륨 그룹 공간의 백분율을 지정합니다. 새로 생성된 볼륨 그룹에만 적용됩니다.
참고
먼저 파티션을 만든 다음 논리 볼륨 그룹을 만든 다음 논리 볼륨을 만듭니다. 예를 들면 다음과 같습니다.
part pv.01 --size 10000 volgroup my_volgrp pv.01 logvol / --vgname=my_volgrp --size=2000 --name=root
part pv.01 --size 10000 volgroup my_volgrp pv.01 logvol / --vgname=my_volgrp --size=2000 --name=rootCopy to Clipboard Copied! Toggle word wrap Toggle overflow Kickstart를 사용하여 Red Hat Enterprise Linux를 설치할 때 논리 볼륨 및 볼륨 그룹 이름에 대시(
-) 문자를 사용하지 마십시오. 이 문자를 사용하는 경우 설치가 정상적으로 완료되지만/dev/mapper/디렉터리에 대시가 두 배가 되는 이러한 볼륨 및 볼륨 그룹이 나열됩니다. 예를 들어logvol-01이라는 논리 볼륨이 포함된volgrp-01이라는 볼륨 그룹이/dev/mapper/volgrp--01-logvol--01로 나열됩니다.이 제한은 새로 생성된 논리 볼륨 및 볼륨 그룹 이름에만 적용됩니다.
--noformat옵션을 사용하여 기존 항목을 재사용하는 경우 해당 이름은 변경되지 않습니다.
C.5.11. logvol
logvol Kickstart 명령은 선택 사항입니다. LVM(Logical Volume Manager)에 대한 논리 볼륨을 생성합니다.
구문
logvol mntpoint --vgname=name --name=name [OPTIONS]
logvol mntpoint --vgname=name --name=name [OPTIONS]필수 옵션
mntpoint파티션이 마운트된 마운트 지점입니다. 다음 양식 중 하나여야 합니다.
/path예를 들면
/또는/home입니다.swap파티션은 스왑 공간으로 사용됩니다.
스왑 파티션의 크기를 자동으로 확인하려면
--recommended옵션을 사용합니다.swap --recommended
swap --recommendedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스왑 파티션의 크기를 자동으로 결정하고 시스템이 최대 절전할 수 있는 추가 공간을 허용하려면
--hibernation옵션을 사용합니다.swap --hibernation
swap --hibernationCopy to Clipboard Copied! Toggle word wrap Toggle overflow 할당된 크기는
--recommended로 할당된 스왑 공간과 시스템의 RAM 양과 동일합니다. 이러한 명령으로 할당된 스왑 크기는 AMD64, Intel 64 및 64비트 ARM 시스템의 권장 파티션 구성 스키마를 참조하십시오.
--vgname=name- 볼륨 그룹의 이름입니다.
--name=name- 논리 볼륨의 이름입니다.
선택적 옵션
--noformat- 기존 논리 볼륨을 사용하고 포맷하지 마십시오.
--useexisting- 기존 논리 볼륨을 사용하여 형식을 다시 지정합니다.
--fstype=-
논리 볼륨의 파일 시스템 유형을 설정합니다. 유효한 값은
xfs,ext2,ext3,ext4,swap,vfat입니다. --fsoptions=파일 시스템을 마운트할 때 사용할 옵션의 자유 양식 문자열을 지정합니다. 이 문자열은 설치된 시스템의
/etc/fstab파일에 복사되며 따옴표로 묶어야 합니다.참고EFI 시스템 파티션(
/boot/efi)에서 anaconda 하드 코딩은 값을 코딩하고 지정된--fsoptions값을 무시합니다.--mkfsoptions=이 파티션에서 파일 시스템을 만드는 프로그램에 전달할 추가 매개 변수를 지정합니다. 인수 목록에서 처리가 수행되지 않으므로 mkfs 프로그램에 직접 전달할 수 있는 형식으로 제공해야 합니다. 즉, 파일 시스템에 따라 쉼표로 구분되거나 큰따옴표로 묶어야 합니다. 예를 들면 다음과 같습니다.
part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"
part /opt/foo1 --size=512 --fstype=ext4 --mkfsoptions="-O ^has_journal,^flex_bg,^metadata_csum" part /opt/foo2 --size=512 --fstype=xfs --mkfsoptions="-m bigtime=0,finobt=0"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
자세한 내용은 생성 중인 파일 시스템의 도움말 페이지를 참조하십시오. 예를 들어 mkfs.ext4 또는 mkfs.xfs.
--fsprofile=-
이 파티션에서 파일 시스템을 만드는 프로그램에 전달할 사용 유형을 지정합니다. 사용 유형은 파일 시스템을 만들 때 사용할 다양한 튜닝 매개 변수를 정의합니다. 이 옵션을 사용하려면 파일 시스템에서 사용 유형의 개념을 지원해야 하며 유효한 유형을 나열하는 구성 파일이 있어야 합니다.
ext2,ext3및ext4의 경우 이 구성 파일은/etc/mke2fs.conf입니다. --label=- 논리 볼륨의 레이블을 설정합니다.
--grow- 논리 볼륨을 확장하여 사용 가능한 공간을 차지하거나(있는 경우) 지정된 최대 크기까지 차지합니다. 옵션은 디스크 이미지에 최소 스토리지 공간을 미리 할당하고 볼륨을 늘리고 사용 가능한 공간을 차지하도록 하는 경우에만 사용해야 합니다. 물리적 환경에서 이는 일회성 작업입니다. 그러나 가상 환경에서는 가상 머신이 가상 디스크에 데이터를 쓸 때 볼륨 크기가 다음과 같이 증가합니다.
--size=-
논리 볼륨의 크기(MiB)입니다. 이 옵션은
--percent=옵션과 함께 사용할 수 없습니다. --percent=정적으로 크기가 지정된 논리 볼륨을 고려한 후 볼륨 그룹에서 사용 가능한 공간의 백분율로 논리 볼륨의 크기입니다. 이 옵션은
--size=옵션과 함께 사용할 수 없습니다.중요새 논리 볼륨을 생성할 때
--size=옵션을 사용하여 정적으로 크기를 지정하거나--percent=옵션을 사용하여 나머지 여유 공간의 백분율로 지정해야 합니다. 동일한 논리 볼륨에서 이러한 옵션을 모두 사용할 수 없습니다.--maxsize=-
논리 볼륨이 확장되도록 설정된 경우 최대 크기(MiB)입니다. 여기에
500과 같은 정수 값을 지정합니다(단위를 포함하지 마십시오). --recommended- 시스템의 하드웨어에 따라 이 볼륨의 크기를 자동으로 결정하도록 논리 볼륨을 생성할 때 이 옵션을 사용합니다. 권장 방법에 대한 자세한 내용은 AMD64, Intel 64 및 64비트 ARM 시스템에 대한 권장 파티션 구성 스키마를 참조하십시오.
--resize-
논리 볼륨의 크기 조정. 이 옵션을 사용하는 경우
--useexisting및--size도 지정해야 합니다. --encrypted--passphrase=옵션에 제공된 암호를 사용하여 이 논리 볼륨을 Linux 통합 키 설정(LUKS)으로 암호화하도록 지정합니다. 암호를 지정하지 않으면 설치 프로그램은autopart --passphrase명령으로 설정된 기본 시스템 전체 암호를 사용하거나 설치를 중지하고 기본값이 설정되지 않은 경우 암호를 제공하라는 메시지를 표시합니다.참고하나 이상의 파티션을 암호화할 때 Anaconda는 256비트의 엔트로피를 수집하여 파티션을 안전하게 암호화하려고 합니다. 엔트로피 수집에는 약간의 시간이 걸릴 수 있습니다. 충분한 엔트로피가 수집되었는지에 관계없이 프로세스가 최대 10분 후에 중지됩니다.
이 프로세스는 설치 시스템과 상호 작용(키보드에서 연결 또는 마우스 이동)을 통해 증가할 수 있습니다. 가상 머신에 설치하는 경우
virtio-rng장치(가상 임의 번호 생성기)를 게스트에 연결할 수도 있습니다.--passphrase=-
이 논리 볼륨을 암호화할 때 사용할 암호를 지정합니다. 이 옵션을
--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. --cipher=-
Anaconda 기본
aes-xts-plain64가 적절하지 않은 경우 사용할 암호화 유형을 지정합니다. 이 옵션을--encrypted옵션과 함께 사용해야 합니다. 이 옵션 자체는 적용되지 않습니다. 사용 가능한 암호화 유형은 보안 강화 문서에 나열되어 있지만 Red Hat은aes-xts-plain64또는aes-cbc-essiv:sha256을 사용하는 것이 좋습니다. --escrowcert=URL_of_X.509_certificate-
/root의 파일로 암호화된 모든 암호화된 볼륨의 데이터 암호화 키를 URL_of_X.509_certificate 로 지정된 URL에서 X.509 인증서를 사용하여 암호화합니다. 키는 암호화된 각 볼륨에 대해 별도의 파일로 저장됩니다. 이 옵션은--encrypted가 지정된 경우에만 의미가 있습니다. --luks-version=LUKS_VERSION-
파일 시스템을 암호화하는 데 사용해야 하는 LUKS 형식의 버전을 지정합니다. 이 옵션은
--encrypted가 지정된 경우에만 의미가 있습니다. --backuppassphrase-
임의로 생성된 각 볼륨에 암호를 추가합니다. 이러한 암호는
--escrowcert로 지정된 X.509 인증서를 사용하여 암호화된/root에 있는 별도의 파일에 저장합니다. 이 옵션은--escrowcert가 지정된 경우에만 의미가 있습니다. --pbkdf=PBKDF-
LUKS 키 슬롯에 대해 암호 기반 키 비활성화 기능(PBKDF) 알고리즘을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은
--encrypted가 지정된 경우에만 의미가 있습니다. --pbkdf-memory=PBKDF_MEMORY-
PBKDF의 메모리 비용을 설정합니다. 도움말 페이지 cryptsetup(8) 도 참조하십시오. 이 옵션은
--encrypted가 지정된 경우에만 의미가 있습니다. --pbkdf-time=PBKDF_TIME-
PBKDF 암호 처리에 사용할 시간(밀리초)을 설정합니다. 도움말 페이지 cryptsetup(8) 에서
--iter-time을 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-iterations와 함께 사용할 수 없습니다. --pbkdf-iterations=PBKDF_ITERATIONS-
반복 횟수를 직접 설정하고 PBKDF 벤치마크를 방지합니다. 도움말 페이지 cryptsetup(8) 의
--pbkdf-force-iterations를 참조하십시오. 이 옵션은--encrypted가 지정된 경우에만 의미가 있으며--pbkdf-time과 함께 사용할 수 없습니다. --thinpool-
thin pool 논리 볼륨을 생성합니다. (중요한 마운트 지점을
사용) --metadatasize=size- 새 씬 풀 장치의 메타데이터 영역 크기(MiB)를 지정합니다.
--chunksize=size- 새 씬 풀 장치의 청크 크기(KiB)를 지정합니다.
--thin-
thin 논리 볼륨을 만듭니다. (
--poolname사용 필요) --poolname=name-
thin 논리 볼륨을 생성할 thin 풀의 이름을 지정합니다.
--thin옵션이 필요합니다. --profile=name-
thin 논리 볼륨에 사용할 구성 프로필 이름을 지정합니다. 사용되는 경우 지정된 논리 볼륨의 메타데이터에도 이름이 포함됩니다. 기본적으로 사용 가능한 프로필은
default및thin-performance이며/etc/lvm/profile/디렉터리에 정의됩니다. 자세한 내용은lvm(8)도움말 페이지를 참조하십시오. --cachepvs=- 이 볼륨의 캐시로 사용해야 하는 쉼표로 구분된 물리 볼륨 목록입니다.
--cachemode=이 논리 볼륨을 캐시하는 데 사용할 모드를 지정합니다(
writeback또는writethrough).참고캐시된 논리 볼륨 및 모드에 대한 자세한 내용은 시스템의
lvmcache(7)도움말 페이지를 참조하십시오.--cachesize=-
논리 볼륨에 연결된 캐시 크기(MiB로 지정됨). 이 옵션에는
--cachepvs=옵션이 필요합니다.
참고
Kickstart를 사용하여 Red Hat Enterprise Linux를 설치할 때 논리 볼륨 및 볼륨 그룹 이름에 대시(
-) 문자를 사용하지 마십시오. 이 문자를 사용하는 경우 설치가 정상적으로 완료되지만/dev/mapper/디렉터리에 대시가 두 배가 되는 이러한 볼륨 및 볼륨 그룹이 나열됩니다. 예를 들어logvol-01이라는 논리 볼륨이 포함된volgrp-01이라는 볼륨 그룹이/dev/mapper/volgrp-로 나열됩니다.01-logvol—01.이 제한은 새로 생성된 논리 볼륨 및 볼륨 그룹 이름에만 적용됩니다.
--noformat옵션을 사용하여 기존 항목을 재사용하는 경우 해당 이름은 변경되지 않습니다.-
LUKS 암호를 분실하는 경우 암호화된 파티션과 해당 데이터에 완전히 액세스할 수 없습니다. 분실된 암호를 복구할 방법은 없습니다. 그러나
--escrowcert를 사용하여 암호화 암호를 저장하고--backuppassphrase옵션을 사용하여 백업 암호화 암호를 생성할 수 있습니다.
예
먼저 파티션을 만들고 논리 볼륨 그룹을 만든 다음 논리 볼륨을 만듭니다.
part pv.01 --size 3000 volgroup myvg pv.01 logvol / --vgname=myvg --size=2000 --name=rootvol
part pv.01 --size 3000 volgroup myvg pv.01 logvol / --vgname=myvg --size=2000 --name=rootvolCopy to Clipboard Copied! Toggle word wrap Toggle overflow 먼저 파티션을 만들고 논리 볼륨 그룹을 만든 다음 볼륨 그룹의 나머지 공간 중 90%를 차지할 논리 볼륨을 만듭니다.
part pv.01 --size 1 --grow volgroup myvg pv.01 logvol / --vgname=myvg --name=rootvol --percent=90
part pv.01 --size 1 --grow volgroup myvg pv.01 logvol / --vgname=myvg --name=rootvol --percent=90Copy to Clipboard Copied! Toggle word wrap Toggle overflow
C.5.12. 스냅샷
snapshot Kickstart 명령은 선택 사항입니다. 이를 사용하여 설치 프로세스 중에 LVM 씬 볼륨 스냅샷을 생성합니다. 이를 통해 설치 전이나 후에 논리 볼륨을 백업할 수 있습니다.
여러 스냅샷을 생성하려면 snaphost Kickstart 명령을 여러 번 추가합니다.
구문
snapshot vg_name/lv_name --name=snapshot_name --when=pre-install|post-install
snapshot vg_name/lv_name --name=snapshot_name --when=pre-install|post-install옵션
-
VG_NAME /lv_name- 스냅샷을 만들 볼륨 그룹 및 논리 볼륨의 이름을 설정합니다. -
--name=snapshot_name- 스냅샷 이름을 설정합니다. 이 이름은 볼륨 그룹 내에서 고유해야 합니다. -
--when=pre-install|post-install- 설치가 시작되기 전에 또는 설치가 완료된 후 스냅샷이 생성되는 경우 설정됩니다.
C.5.13. Mount
mount Kickstart 명령은 선택 사항입니다. 기존 블록 장치에 마운트 지점을 할당하고 선택적으로 지정된 형식으로 다시 포맷합니다.
구문
mount [OPTIONS] device mountpoint
mount [OPTIONS] device mountpoint필수 옵션:
-
Device- 마운트할 블록 장치입니다. -
mountpoint-장치를 마운트할 위치입니다. 유효한 마운트 지점(예:/또는/usr)이거나 장치를 마운트 해제할 수 있는 경우(예:스왑)이없어야합니다.
선택적 옵션:
-
--reformat=- 장치를 다시 포맷해야 하는 새로운 형식(예:ext4)을 지정합니다. -
--mkfsoptions=---reformat=에 지정된 새 파일 시스템을 생성하는 명령에 전달할 추가 옵션을 지정합니다. 여기에서 제공되는 옵션 목록은 처리되지 않으므로mkfs프로그램에 직접 전달할 수 있는 형식으로 지정해야 합니다. 옵션 목록은 파일 시스템에 따라 쉼표로 구분되거나 큰따옴표로 묶어야 합니다. 자세한 내용은 만들려는 파일 시스템의mkfs도움말 페이지(예:mkfs.ext4(8)또는mkfs.xfs(8))를 참조하십시오. -
--mountOptions=- 파일 시스템을 마운트할 때 사용할 옵션이 포함된 자유 양식 문자열을 지정합니다. 문자열은 설치된 시스템의/etc/fstab파일에 복사되며 큰따옴표로 묶어야 합니다. 기본 사항은mount(8)도움말 페이지에서 전체 마운트 옵션 및fstab(5)를 참조하십시오.
참고
-
Kickstart의 다른 스토리지 구성 명령과 달리
mount는 Kickstart 파일의 전체 스토리지 구성을 설명할 필요가 없습니다. 설명된 블록 장치가 시스템에 있는지 확인하기만 하면 됩니다. 그러나 마운트된 모든 장치를 사용하여 스토리지 스택을 생성하려면part와 같은 다른 명령을 사용하여 이를 수행해야 합니다. -
동일한 Kickstart 파일에
mount, part ,logvol또는auto와 같은 다른 스토리지 관련 명령과 함께 마운트를 사용할 수 없습니다.part
C.5.14. zipl
zipl Kickstart 명령은 선택 사항입니다. 64비트 IBM Z의 ZIPL 구성을 지정합니다. 이 명령은 한 번만 사용합니다.
옵션
-
--secure-boot- 설치 시스템에서 지원하는 경우 보안 부팅을 활성화합니다.
IBM z14 이후의 시스템에 설치하는 경우 설치된 시스템은 IBM z14 또는 이전 모델에서 부팅할 수 없습니다.
-
--force-secure-boot- 무조건 보안 부팅을 활성화합니다.
IBM z14 및 이전 모델에서는 설치가 지원되지 않습니다.
-
--no-secure-boot- 보안 부팅을 비활성화합니다.
Secure Boot는 IBM z14 및 이전 모델에서는 지원되지 않습니다. IBM z14 및 이전 모델에서 설치된 시스템을 부팅하려는 경우 --no-secure-boot 를 사용합니다.
C.5.15. fcoe
fcoe Kickstart 명령은 선택 사항입니다. ED(Enhanced Disk Drive Services)에서 발견한 장치 외에도 자동으로 활성화해야 하는 FCoE 장치를 지정합니다.
구문
fcoe --nic=name [OPTIONS]
fcoe --nic=name [OPTIONS]옵션
-
--NIC=(필수) - 활성화할 장치의 이름입니다. -
--dcB=- DCB(Data Center Bridging) 설정을 구축합니다. -
--autovlan- VLAN을 자동으로 검색합니다. 이 옵션은 기본적으로 활성화되어 있습니다.
C.5.16. iscsi
iscsi Kickstart 명령은 선택 사항입니다. 설치하는 동안 연결할 추가 iSCSI 스토리지를 지정합니다.
구문
iscsi --ipaddr=address [OPTIONS]
iscsi --ipaddr=address [OPTIONS]필수 옵션
-
--ipaddr=(필수) - 연결할 대상의 IP 주소입니다.
선택적 옵션
-
--port=(필수) - 포트 번호입니다. 없는 경우--port=3260이 기본적으로 자동으로 사용됩니다. -
--target=- 대상 IQN(iSCSI 정규화된 이름)입니다. -
--iface=- 기본적으로 네트워크 계층에 의해 결정된 인터페이스를 사용하는 대신 특정 네트워크 인터페이스에 연결을 바인딩합니다. 일단 사용되면 전체 Kickstart 파일에 있는iscsi명령의 모든 인스턴스에서 지정해야 합니다. -
--user=- 대상 인증에 필요한 사용자 이름입니다. -
--password=- 대상에 지정된 사용자 이름에 해당하는 암호입니다. -
--reverse-user=- 역방향 CHAP 인증을 사용하는 대상에서 이니시에이터로 인증하는 데 필요한 사용자 이름입니다. -
--reverse-password=- 개시자에 지정된 사용자 이름에 해당하는 암호입니다.
참고
-
iscsi명령을 사용하는 경우iscsiname명령을 사용하여 iSCSI 노드에 이름도 할당해야 합니다.iscsiname명령은 Kickstart 파일의iscsi명령 앞에 표시되어야 합니다. -
가능한 경우
iscsi명령을 사용하는 대신 시스템 BIOS 또는 펌웨어(Intel 시스템의 경우 iBFT)에서 iSCSI 스토리지를 구성합니다. Anaconda는 BIOS 또는 펌웨어에 구성된 디스크를 자동으로 감지하고 사용하며 Kickstart 파일에 특별한 구성이 필요하지 않습니다. -
iscsi명령을 사용해야 하는 경우 설치 시작 시 네트워킹이 활성화되었는지 확인하고clearpart또는ignoredisk와 같은 명령을 사용하여 iSCSI 디스크를 참조 하기 전에iscsi명령이 Kickstart 파일에 표시되는지 확인합니다.
C.5.17. iscsiname
iscsiname Kickstart 명령은 선택 사항입니다. iscsi 명령으로 지정한 iSCSI 노드에 이름을 할당합니다. 이 명령은 한 번만 사용하십시오.
구문
iscsiname iqname
iscsiname iqname옵션
-
iqname- iSCSI 노드에 할당할 이름입니다.
참고
-
Kickstart 파일에서
iscsi명령을 사용하는 경우 Kickstart 파일에서 이전에iscsiname을 지정해야 합니다.
C.5.18. nvdimm
nvdimm Kickstart 명령은 선택 사항입니다. NVMe(Non-Volatile Dual In-line Memory Module) 장치에서 작업을 수행합니다. 기본적으로 NVDIMM 장치는 설치 프로그램에서 무시됩니다. 이러한 장치에 설치를 활성화하려면 nvdimm 명령을 사용해야 합니다.
구문
nvdimm action [OPTIONS]
nvdimm action [OPTIONS]작업
재구성- 특정 NVDIMM 장치를 지정된 모드로 재구성합니다. 또한 지정된 장치는 사용하도록 암시적으로 표시되어 있으므로 동일한 장치에 대한 후속nvdimm use명령은 중복입니다. 이 작업은 다음 형식을 사용합니다.nvdimm reconfigure [--namespace=NAMESPACE] [--mode=MODE] [--sectorsize=SECTORSIZE]
nvdimm reconfigure [--namespace=NAMESPACE] [--mode=MODE] [--sectorsize=SECTORSIZE]Copy to Clipboard Copied! Toggle word wrap Toggle overflow --namespace=- 네임스페이스별 장치 사양입니다. 예를 들면 다음과 같습니다.nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512
nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
--mode=- 모드 사양입니다. 현재는 값섹터만 사용할 수 있습니다. --sectorsize=- 섹터 모드의 섹터 크기입니다. 예를 들면 다음과 같습니다.nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512
nvdimm reconfigure --namespace=namespace0.0 --mode=sector --sectorsize=512Copy to Clipboard Copied! Toggle word wrap Toggle overflow 지원되는 섹터 크기는 512 및 4096바이트입니다.
use- NVDIMM 장치를 설치 대상으로 지정합니다.nvdimm reconfigure명령으로 장치를 섹터 모드로 이미 구성해야 합니다. 이 작업은 다음 형식을 사용합니다.nvdimm use [--namespace=NAMESPACE|--blockdevs=DEVICES]
nvdimm use [--namespace=NAMESPACE|--blockdevs=DEVICES]Copy to Clipboard Copied! Toggle word wrap Toggle overflow --namespace=- 네임스페이스별 장치를 지정합니다. 예를 들면 다음과 같습니다.nvdimm use --namespace=namespace0.0
nvdimm use --namespace=namespace0.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow --blockdevs=- 사용할 NVDIMM 장치에 해당하는 쉼표로 구분된 블록 장치 목록을 지정합니다. 별표*와일드카드가 지원됩니다. 예를 들면 다음과 같습니다.nvdimm use --blockdevs=pmem0s,pmem1s nvdimm use --blockdevs=pmem*
nvdimm use --blockdevs=pmem0s,pmem1s nvdimm use --blockdevs=pmem*Copy to Clipboard Copied! Toggle word wrap Toggle overflow
C.5.19. zfcp
zfcp Kickstart 명령은 선택 사항입니다. 파이버 채널 장치를 정의합니다.
이 옵션은 64비트 IBM Z에만 적용됩니다. 아래에 설명된 모든 옵션을 지정해야 합니다.
구문
zfcp --devnum=devnum [--wwpn=wwpn --fcplun=lun]
zfcp --devnum=devnum [--wwpn=wwpn --fcplun=lun]옵션
-
--devnum=- 장치 번호(zFCP 어댑터 장치 버스 ID)입니다. -
--wWPN=- 장치의 WWPN(World Wide Port Name)입니다. 16자리 숫자 앞에0x가 붙습니다. -
--fcplun=- 장치의 논리 단위 번호(LUN)입니다. 16자리 숫자 앞에0x가 붙습니다.
자동 LUN 검사를 사용할 수 있고 8개 이상의 릴리스를 설치할 때 FCP 장치 버스 ID를 지정하는 것으로 충분합니다. 그렇지 않으면 세 가지 매개변수가 모두 필요합니다. 자동 LUN 스캔은 zfcp.allow_lun_scan 모듈 매개변수를 통해 비활성화되지 않는 경우 NPIV 모드에서 작동하는 FCP 장치에 사용할 수 있습니다(기본적으로 사용 가능). 지정된 버스 ID로 FCP 장치에 연결된 스토리지 영역 네트워크에 있는 모든 SCSI 장치에 대한 액세스를 제공합니다.
예
zfcp --devnum=0.0.4000 --wwpn=0x5005076300C213e9 --fcplun=0x5022000000000000 zfcp --devnum=0.0.4000
zfcp --devnum=0.0.4000 --wwpn=0x5005076300C213e9 --fcplun=0x5022000000000000
zfcp --devnum=0.0.4000C.6. RHEL 설치 프로그램과 함께 제공되는 애드온을 위한 Kickstart 명령
이 섹션의 Kickstart 명령은 기본적으로 Red Hat Enterprise Linux 설치 프로그램과 함께 제공되는 애드온과 관련이 있습니다. kdump 및 OpenSCAP.
C.6.1. %Addon com_redhat_kdump
%addon com_redhat_kdump Kickstart 명령은 선택 사항입니다. 이 명령은 kdump 커널 크래시 덤프 메커니즘을 구성합니다.
구문
%addon com_redhat_kdump [OPTIONS] %end
%addon com_redhat_kdump [OPTIONS]
%end이 명령의 구문은 기본 제공 Kickstart 명령이 아닌 추가 기능이므로 비정상적인 경우가 많습니다.
참고
kdump는 나중에 분석을 위해 시스템 메모리의 내용을 저장할 수 있는 커널 크래시 덤프 메커니즘입니다. 시스템을 재부팅하지 않고 다른 커널의 컨텍스트에서 Linux 커널을 부팅하고 손실되는 첫 번째 커널 메모리의 콘텐츠를 유지하는 데 사용할 수 있는 kexec 를 사용합니다.
시스템이 충돌하는 경우 kexec 가 두 번째 커널( 캡처 커널)으로 부팅됩니다. 이 캡처 커널은 시스템 메모리의 예약된 부분에 있습니다. kdump는 충돌된 커널 메모리(드래드 덤프)의 내용을 캡처하여 지정된 위치에 저장합니다. 위치는 이 Kickstart 명령을 사용하여 구성할 수 없습니다. /etc/kdump.conf 구성 파일을 편집하여 설치 후 구성해야 합니다.
Kdump에 대한 자세한 내용은 kdump 설치를 참조하십시오.
옵션
-
--enable- 설치된 시스템에서 kdump를 활성화합니다. -
--disable- 설치된 시스템에서 kdump를 비활성화합니다. --Reserve-mb=- kdump에 예약할 메모리 양(MiB)입니다. 예를 들면 다음과 같습니다.%addon com_redhat_kdump --enable --reserve-mb=128 %end
%addon com_redhat_kdump --enable --reserve-mb=128 %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow 숫자 값 대신
auto를 지정할 수도 있습니다. 이 경우 설치 프로그램은 커널 문서 관리, 모니터링 및 업데이트 의 kdump 섹션에 설명된 기준에 따라 자동으로 메모리 양을 결정합니다.kdump를 활성화하고
--reserve-mb=옵션을 지정하지 않으면auto값이 사용됩니다.-
--enablefadump- 이를 허용하는 시스템에서 펌웨어 지원 덤프를 활성화합니다(특히 IBM Power Systems 서버).
C.6.2. %addon org_fedora_oscap
%addon org_fedora_oscap Kickstart 명령은 선택 사항입니다.
OpenSCAP 설치 프로그램 애드온은 설치된 시스템에 SCAP(Security Content Automation Protocol) 콘텐츠 - 보안 정책을 적용하는 데 사용됩니다. 이 애드온은 Red Hat Enterprise Linux 7.2부터 기본적으로 활성화되어 있습니다. 이 기능을 제공하는 데 필요한 패키지가 자동으로 설치됩니다. 그러나 기본적으로 정책은 적용되지 않습니다. 즉, 구체적으로 구성하지 않는 한 설치 중 또는 설치 후 검사가 수행되지 않습니다.
모든 시스템에서 보안 정책을 적용할 필요는 없습니다. 이 명령은 조직 규칙 또는 정부 규정에서 특정 정책을 요구하는 경우에만 사용해야 합니다.
대부분의 다른 명령과 달리 이 애드온은 일반 옵션을 허용하지 않지만 %addon 정의 본문에 키-값 쌍을 대신 사용합니다. 이러한 쌍은 공백과 무관합니다. 값은 선택적으로 작은따옴표(') 또는 큰따옴표(")로 묶을 수 있습니다.
구문
%addon org_fedora_oscap key = value %end
%addon org_fedora_oscap
key = value
%end키
다음 키는 애드온에서 인식됩니다.
content-type보안 콘텐츠 유형입니다. 가능한 값은
datastream,archive,rpm,scap-security-guide입니다.content-type이scap-security-guide인 경우 애드온은 부팅 미디어에 있는 scap-security-guide 패키지에서 제공하는 콘텐츠를 사용합니다. 즉,프로필을제외한 다른 모든 키는 적용되지 않습니다.content-url- 보안 콘텐츠의 위치입니다. HTTP, HTTPS 또는 FTP를 사용하여 콘텐츠에 액세스할 수 있어야 합니다. 로컬 스토리지는 현재 지원되지 않습니다. 원격 위치의 콘텐츠 정의에 연결하려면 네트워크 연결을 사용할 수 있어야 합니다.
datastream-id-
content-url값에서 참조되는 데이터 스트림의 ID입니다.content-type이datastream인 경우에만 사용됩니다. xccdf-id- 사용하려는 벤치마크의 ID입니다.
content-path- 아카이브의 상대 경로로 제공되는 datastream 또는 XCCDF 파일의 경로입니다.
profile-
적용할 프로필의 ID입니다.
default를 사용하여 기본 프로필을 적용합니다. fingerprint-
content-url에서 참조하는 콘텐츠의 MD5, SHA1 또는 SHA2 체크섬입니다. tailoring-path- 아카이브의 상대 경로로 제공되어야 하는 맞춤형 파일의 경로입니다.
예
다음은 설치 미디어의 scap-security-guide 의 콘텐츠를 사용하는
%addon org_fedora_oscap섹션의 예입니다.예 C.1. SCAP 보안 가이드를 사용한 샘플 OpenSCAP 애드온 정의
%addon org_fedora_oscap content-type = scap-security-guide profile = xccdf_org.ssgproject.content_profile_pci-dss %end
%addon org_fedora_oscap content-type = scap-security-guide profile = xccdf_org.ssgproject.content_profile_pci-dss %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음은 웹 서버에서 사용자 지정 프로필을 로드하는 더 복잡한 예제입니다.
예 C.2. Datastream을 사용한 샘플 OpenSCAP 애드온 정의
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
C.7. Anaconda에서 사용되는 명령
pwpolicy 명령은 Kickstart 파일의 %anaconda 섹션에서만 사용할 수 있는 Anaconda UI 특정 명령입니다.
C.7.1. pwpolicy
pwpolicy Kickstart 명령은 선택 사항입니다. 이 명령을 사용하여 설치 중에 사용자 지정 암호 정책을 적용합니다. 정책을 사용하려면 root, users 또는 luks 사용자 계정에 대한 암호를 생성해야 합니다. 암호 길이 및 strength와 같은 요인은 암호의 유효성을 결정합니다.
구문
pwpolicy name [--minlen=length] [--minquality=quality] [--strict|--notstrict] [--emptyok|--notempty] [--changesok|--nochanges]
pwpolicy name [--minlen=length] [--minquality=quality] [--strict|--notstrict] [--emptyok|--notempty] [--changesok|--nochanges]필수 옵션
-
name - 각각
루트암호,사용자암호 또는 LUKS 암호에 대한 정책을 적용하려면root, user 또는luks로 바꿉니다.
선택적 옵션
-
--minlen=- 허용되는 최소 암호 길이를 문자로 설정합니다. 기본값은6입니다. -
--minquality=-libpwquality라이브러리에서 정의한 대로 허용되는 최소 암호 품질을 설정합니다. 기본값은1입니다. -
--strict- 엄격한 암호 적용 활성화.--minquality=및--minlen=에 지정된 요구 사항을 충족하지 않는 암호는 허용되지 않습니다. 이 옵션은 기본적으로 비활성화되어 있습니다. -
--notstrict- GUI에서 두 번 완료 후--minquality=및-minlen=옵션에 지정된 최소 품질 요구 사항을 충족하지 않는 암호는 허용됩니다. 텍스트 모드 인터페이스의 경우 유사한 메커니즘이 사용됩니다. -
--emptyok- 빈 암호를 사용할 수 있습니다. 사용자 암호에 대해 기본적으로 활성화되어 있습니다. -
--notempty- 빈 암호를 사용하지 않습니다. 기본적으로 root 암호 및 LUKS 암호에 대해 활성화됩니다. -
--changesok- Kickstart 파일에서 이미 암호를 지정하는 경우에도 사용자 인터페이스에서 암호를 변경할 수 있습니다. 기본적으로 비활성되어 있습니다. -
--nochanges- Kickstart 파일에 이미 설정된 암호 변경을 취소합니다. 기본적으로 활성화되어 있습니다.
참고
-
pwpolicy명령은 Kickstart 파일의%anaconda섹션에서만 사용할 수 있는 Anaconda-UI 특정 명령입니다. -
libpwquality라이브러리는 최소 암호 요구 사항(장 및 품질)을 확인하는 데 사용됩니다. libpwquality 패키지에서 제공하는pwscore및pwmake명령을 사용하여 암호의 품질 점수를 확인하거나 지정된 점수로 임의의 암호를 생성할 수 있습니다. 이러한 명령에 대한 자세한 내용은pwscore(1)및pwmake(1)매뉴얼 페이지를 참조하십시오.
C.8. 시스템 복구를 위한 Kickstart 명령
이 섹션의 Kickstart 명령은 설치된 시스템을 복구합니다.
C.8.1. rescue
rescue Kickstart 명령은 선택 사항입니다. 쉘 환경에 root 권한 및 시스템 관리 툴 세트를 제공하여 설치를 복구하고 다음과 같은 문제를 해결합니다.
- 파일 시스템을 읽기 전용으로 마운트
- 드라이버 디스크에 제공된 드라이버 목록 또는 추가
- 시스템 패키지 설치 또는 업그레이드
- 파티션 관리
Kickstart 복구 모드는 시스템 및 서비스 관리자의 일부로 제공되는 복구 모드 및 긴급 모드와 다릅니다.
rescue 명령은 자체적으로 시스템을 수정하지 않습니다. 읽기-쓰기 모드에서 /mnt/sysimage 아래에 시스템을 마운트하여 복구 환경만 설정합니다. 시스템을 마운트하지 않도록 선택하거나 읽기 전용 모드로 마운트할 수 있습니다. 이 명령은 한 번만 사용하십시오.
구문
rescue [--nomount|--romount]
rescue [--nomount|--romount]옵션
-
--nomount또는--romount- 복구 환경에서 설치된 시스템을 마운트하는 방법을 제어합니다. 기본적으로 설치 프로그램은 시스템을 찾아 읽기-쓰기 모드로 마운트하여 이 마운트를 수행한 위치를 알려줍니다. 선택적으로 아무것도 마운트하지 않도록 선택하거나 (-nomount옵션) 또는 읽기 전용 모드(--romount옵션)로 마운트하도록 선택할 수 있습니다. 이 두 옵션 중 하나만 사용할 수 있습니다.
참고
복구 모드를 실행하려면 Kickstart 파일의 사본을 만들고 rescue 명령을 포함합니다.
rescue 명령을 사용하면 설치 프로그램이 다음 단계를 수행합니다.
-
%pre스크립트를 실행합니다. 복구 모드를 위한 환경을 설정합니다.
다음 Kickstart 명령이 적용됩니다.
- 업데이트
- sshpw
- logging
- lang
- network
고급 스토리지 환경을 설정합니다.
다음 Kickstart 명령이 적용됩니다.
- fcoe
- iscsi
- iscsiname
- nvdimm
- zfcp
시스템 마운트
rescue [--nomount|--romount]
rescue [--nomount|--romount]Copy to Clipboard Copied! Toggle word wrap Toggle overflow %post 스크립트 실행
이 단계는 설치된 시스템이 읽기-쓰기 모드로 마운트된 경우에만 실행됩니다.
- 쉘 시작
- 시스템 재부팅
II 부. 보안 설계
14장. 설치 중 및 오른쪽 설치 후 RHEL 보안
Red Hat Enterprise Linux 설치를 시작하기 전에도 보안이 시작됩니다. 처음부터 안전하게 시스템을 구성하면 나중에 추가 보안 설정을 더 쉽게 구현할 수 있습니다.
14.1. 디스크 파티션 설정
디스크 파티셔닝에 대한 권장 사례는 베어 메탈 시스템에 설치하고 이미 설치된 운영 체제를 포함하는 가상 디스크 하드웨어 및 파일 시스템 조정을 지원하는 가상화 또는 클라우드 환경의 경우 다릅니다.
베어 메탈 설치에서 데이터를 분리하고 보호하려면 /boot, / , /home,/ tmp , /var 디렉토리에 대한 별도의 파티션을 만듭니다.
/tmp /
/boot-
이 파티션은 부팅 중에 시스템에서 읽은 첫 번째 파티션입니다. 시스템을 RHEL 8로 부팅하는 데 사용되는 부트 로더 및 커널 이미지는 이 파티션에 저장됩니다. 이 파티션은 암호화해서는 안 됩니다. 이 파티션이
/에 포함되어 있고 해당 파티션을 암호화하거나 사용할 수 없게 되면 시스템을 부팅할 수 없습니다. /home-
사용자 데이터(
/home)가 별도의 파티션 대신/에 저장되면 파티션이 채워지면 운영 체제가 불안정해집니다. 또한 시스템을 RHEL 8의 다음 버전으로 업그레이드할 때 데이터를/home파티션에 덮어쓰지 않으므로 업그레이드가 더 쉽습니다. 루트 파티션(/)이 손상되면 데이터가 영구적으로 손실될 수 있습니다. 별도의 파티션을 사용하면 데이터 손실에 대해 약간 더 많이 보호됩니다. 빈번한 백업을 위해 이 파티션을 대상으로 지정할 수도 있습니다. /tmp및/var/tmp/-
/tmp및/var/tmp/디렉터리는 모두 장기간 저장하지 않아도 되는 데이터를 저장하는 데 사용됩니다. 그러나 이러한 디렉토리 중 하나에 많은 데이터가 플러시되는 경우 모든 스토리지 공간을 소비할 수 있습니다. 이 경우 이러한 디렉토리가/내에 저장되면 시스템이 불안정해 충돌할 수 있습니다. 따라서 이러한 디렉터리를 해당 파티션으로 이동하는 것이 좋습니다.
가상 머신 또는 클라우드 인스턴스 의 경우 별도의 /boot,/home,/tmp 및 /var/tmp 파티션은 가상 디스크 크기 및 / 파티션을 늘릴 수 있기 때문에 선택 사항입니다. 적절하게 가상 디스크 크기를 늘리기 전에는 가상 디스크 크기를 늘리기 전에는 / 파티션 사용을 정기적으로 점검하도록 모니터링을 설정합니다.
설치 프로세스 중에 파티션을 암호화할 수 있는 옵션이 있습니다. 암호를 제공해야 합니다. 이 암호는 파티션의 데이터를 보호하는 데 사용되는 대량 암호화 키의 잠금을 해제하는 키 역할을 합니다.
14.2. 설치 프로세스 중에 네트워크 연결 제한
RHEL 8을 설치할 때 설치 미디어는 특정 시간에 시스템의 스냅샷을 나타냅니다. 이로 인해 최신 보안 수정 사항이 최신 상태가 아닐 수 있으며 설치 미디어에서 제공한 시스템이 릴리스된 후에만 수정된 특정 문제에 취약해질 수 있습니다.
잠재적으로 취약한 운영 체제를 설치하는 경우 항상 가장 필요한 네트워크 영역으로만 노출을 제한합니다. 가장 안전한 선택은 "네트워크 없음" 영역으로, 설치 프로세스 중에 시스템의 연결이 끊어진 상태로 두는 것을 의미합니다. 인터넷 연결이 가장 위험한 경우에는 LAN 또는 인트라넷 연결만으로도 충분합니다. 최상의 보안 사례를 따르려면 네트워크에서 RHEL 8을 설치하는 동안 리포지토리에서 가장 가까운 영역을 선택합니다.
14.3. 필요한 최소 패키지 설치
컴퓨터에 있는 각 소프트웨어에 취약점이 있을 수 있으므로 사용할 패키지만 설치하는 것이 좋습니다. DVD 미디어에서 설치하는 경우 설치 중에 설치할 패키지를 정확하게 선택할 수 있습니다. 다른 패키지가 필요한 경우 나중에 시스템에 항상 추가할 수 있습니다.
14.4. 설치 후 절차
다음 단계는 RHEL 8을 설치한 직후 수행해야 하는 보안 관련 절차입니다.
시스템을 업데이트합니다. root로 다음 명령을 입력합니다.
yum update
# yum updateCopy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽 서비스
firewalld는 Red Hat Enterprise Linux 설치를 통해 자동으로 활성화되지만 Kickstart 구성에서는 명시적으로 비활성화할 수 있습니다. 이러한 경우 방화벽을 다시 활성화합니다.firewalld를 시작하려면 root로 다음 명령을 입력합니다.systemctl start firewalld systemctl enable firewalld
# systemctl start firewalld # systemctl enable firewalldCopy to Clipboard Copied! Toggle word wrap Toggle overflow 보안을 강화하려면 필요하지 않은 서비스를 비활성화합니다. 예를 들어 컴퓨터에 프린터가 설치되어 있지 않은 경우 다음 명령을 사용하여
cups서비스를 비활성화합니다.systemctl disable cups
# systemctl disable cupsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 활성 서비스를 검토하려면 다음 명령을 입력합니다.
systemctl list-units | grep service
$ systemctl list-units | grep serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
14.5. 웹 콘솔을 사용하여 CPU 보안 문제를 방지하기 위해 SMT 비활성화
CPU SMT를 오용하는 공격의 경우 SMT(Simultaneous Multi Threading)를 비활성화합니다. SMT를 비활성화하면 L1TF 또는 MDS와 같은 보안 취약점을 완화할 수 있습니다.
SMT를 비활성화하면 시스템 성능이 저하될 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 개요 탭에서 시스템 정보 필드를 찾아 하드웨어 세부 정보 보기를 클릭합니다.
CPU 보안 행에서 Mitigations 를 클릭합니다.
이 링크가 없으면 시스템이 SMT를 지원하지 않으므로 취약하지 않습니다.
- CPU Security Toggles 표에서 Disable concurrent multithreading (nosmt) 옵션을 켭니다.
- 버튼을 클릭합니다.
시스템을 다시 시작한 후 CPU에서 더 이상 SMT를 사용하지 않습니다.
15장. 시스템 전체 암호화 정책 사용
시스템 전체의 암호화 정책은 TLS, IPsec, SSH, DNSSec 및 Kerberos 프로토콜을 다루는 코어 암호화 하위 시스템을 구성하는 시스템 구성 요소입니다. 관리자가 선택할 수 있는 몇 가지 정책 세트를 제공합니다.
15.1. 시스템 전체 암호화 정책
시스템 전체 정책이 설정되면 RHEL의 애플리케이션은 이를 따르며 애플리케이션을 명시적으로 요청하지 않는 한, 정책을 준수하지 않는 알고리즘과 프로토콜을 사용하지 않습니다. 즉, 이 정책은 시스템 제공 구성으로 실행할 때 애플리케이션의 기본 동작에 적용되지만 필요한 경우 이를 재정의할 수 있습니다.
RHEL 8에는 다음과 같은 사전 정의된 정책이 포함되어 있습니다.
기본값- 기본 시스템 전체 암호화 정책 수준은 현재 위협 모델에 대한 보안 설정을 제공합니다. 이 보안 설정은 TLS 1.2 및 1.3 프로토콜과 IKEv2 및 SSH2 프로토콜을 허용합니다. RSA 키와 Diffie-Hellman 매개변수는 2048비트 이상인 경우 허용됩니다.
레거시-
Red Hat Enterprise Linux 5 및 이전 버전과의 호환성을 극대화하며 공격 면적이 증가하여 보안이 떨어집니다.
DEFAULT수준 알고리즘 및 프로토콜 외에도 TLS 1.0 및 1.1 프로토콜 지원이 포함됩니다. 알고리즘 DSA, 3DES, RC4는 사용할 수 있지만 RSA 키와 Diffie-Hellman 매개변수는 최소 1023비트인 경우 허용됩니다. FUTURE가능한 향후 정책을 테스트하기 위한 보다 엄격한 미래 지향 보안 수준입니다. 이 정책은 서명 알고리즘에서 SHA-1을 사용할 수 없습니다. 이 보안 설정은 TLS 1.2 및 1.3 프로토콜과 IKEv2 및 SSH2 프로토콜을 허용합니다. RSA 키와 Diffie-Hellman 매개변수는 최소 3072비트인 경우 허용됩니다. 시스템이 공용 인터넷에서 통신할 경우 상호 운용성 문제에 직면할 수 있습니다.
중요고객 포털 API의 인증서에서 사용하는 암호화 키가
FUTURE시스템 전체 암호화 정책의 요구 사항을 충족하지 않으므로redhat-support-tool유틸리티는 현재 이 정책 수준에서 작동하지 않습니다.이 문제를 해결하려면 고객 포털 API에 연결하는 동안
DEFAULT암호화 정책을 사용합니다.FIPSFIPS 140 요구 사항을 준수합니다. RHEL 시스템을 FIPS 모드로 전환하는
fips-mode-setup툴은 내부적으로 이 정책을 사용합니다.FIPS정책으로 전환해도 FIPS 140 표준을 준수하지 않습니다. 또한 시스템을 FIPS 모드로 설정한 후 모든 암호화 키를 다시 생성해야 합니다. 많은 경우에서는 이 작업을 수행할 수 없습니다.RHEL은 CC(Common Criteria) 인증에 필요한 암호화 알고리즘에 대한 추가 제한이 포함된
FIPS:OSPP시스템 전체 하위 정책을 제공합니다. 이 하위 정책을 설정한 후 시스템이 상호 운용성이 떨어집니다. 예를 들어 3072비트, 추가 SSH 알고리즘 및 여러 TLS 그룹보다 짧은 RSA 및 DH 키를 사용할 수 없습니다.FIPS:OSPP를 설정하면 Red Hat CDN(Content Delivery Network) 구조에 연결할 수 없습니다. 또한FIPS:OSPP를 사용하는 IdM 배포에는 AD(Active Directory)를 통합할 수 없으며FIPS:OSPP및 AD 도메인을 사용하는 RHEL 호스트 간 통신이 작동하지 않거나 일부 AD 계정이 인증할 수 없을 수 있습니다.참고FIPS:OSPP암호화 하위 정책을 설정한 후에는 시스템이 CC와 호환되지 않습니다. RHEL 시스템을 CC 표준을 준수하는 유일한 방법은cc-config패키지에 제공된 지침을 따르는 것입니다. 인증된 RHEL 버전, 검증 보고서 및 CC 가이드 링크 목록은 제품 규정 준수 Red Hat 고객 포털 페이지의 Common Criteria 섹션을 참조하십시오.
Red Hat은 LEGACY 정책을 사용하는 경우를 제외하고 모든 라이브러리가 보안 기본값을 제공하도록 모든 정책 수준을 지속적으로 조정합니다. LEGACY 프로필은 보안 기본값을 제공하지 않지만 쉽게 사용할 수 있는 알고리즘은 포함되지 않습니다. 따라서 Red Hat Enterprise Linux의 수명 동안 활성화된 알고리즘이나 제공된 정책의 주요 크기 집합이 변경될 수 있습니다.
이러한 변경 사항은 새로운 보안 표준과 새로운 보안 연구를 반영합니다. Red Hat Enterprise Linux의 전체 수명 동안 특정 시스템과의 상호 운용성을 보장해야 하는 경우 시스템과 상호 작용하는 구성 요소에 대한 시스템 전체 암호화 정책을 비활성화하거나 사용자 지정 암호화 정책을 사용하여 특정 알고리즘을 다시 활성화해야 합니다.
정책 수준에서 허용되는 대로 설명된 특정 알고리즘 및 암호는 애플리케이션에서 지원하는 경우에만 사용할 수 있습니다.
레거시 | 기본값 | FIPS | FUTURE | |
|---|---|---|---|---|
| IKEv1 | 아니요 | 아니요 | 아니요 | 아니요 |
| 3DES | 제공됨 | 아니요 | 아니요 | 아니요 |
| RC4 | 제공됨 | 아니요 | 아니요 | 아니요 |
| DH | 최소 1024비트 | 최소 2048비트 | 최소 2048비트[a] | 최소 3072비트 |
| RSA | 최소 1024비트 | 최소 2048비트 | 최소 2048비트 | 최소 3072비트 |
| DSA | 제공됨 | 아니요 | 아니요 | 아니요 |
| TLS v1.0 | 제공됨 | 아니요 | 아니요 | 아니요 |
| TLS v1.1 | 제공됨 | 아니요 | 아니요 | 아니요 |
| 디지털 서명의 SHA-1 | 제공됨 | 제공됨 | 아니요 | 아니요 |
| CBC 모드 암호 | 제공됨 | 제공됨 | 제공됨 | 아니요[b] |
| 키가 있는 대칭 암호 < 256비트 | 제공됨 | 제공됨 | 제공됨 | 아니요 |
| 인증서의 SHA-1 및 SHA-224 서명 | 제공됨 | 제공됨 | 제공됨 | 아니요 |
[a]
RFC 7919 및 RFC 3526에 정의된 Diffie-Hellman 그룹만 사용할 수 있습니다.
[b]
CBC 암호가 TLS에 대해 비활성화되어 있습니다. 비 TLS 시나리오에서는 AES-128-CBC 가 비활성화되지만 AES-256-CBC 가 활성화됩니다. AES-256-CBC 도 비활성화하려면 사용자 지정 하위 정책을 적용합니다.
| ||||
15.2. 시스템 전체 암호화 정책 변경
update-crypto-policies 도구를 사용하여 시스템에서 시스템 전체 암호화 정책을 변경하고 시스템을 다시 시작할 수 있습니다.
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
절차
선택 사항: 현재 암호화 정책을 표시합니다.
update-crypto-policies --show DEFAULT
$ update-crypto-policies --show DEFAULTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 암호화 정책을 설정합니다.
update-crypto-policies --set <POLICY> <POLICY>
# update-crypto-policies --set <POLICY> <POLICY>Copy to Clipboard Copied! Toggle word wrap Toggle overflow <
POLICY>를 설정할 정책 또는 하위 정책(예:FUTURE,LEGACY또는FIPS:OSPP)으로 바꿉니다.시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
현재 암호화 정책을 표시합니다.
update-crypto-policies --show <POLICY>
$ update-crypto-policies --show <POLICY>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.3. 시스템 전체 암호화 정책을 이전 릴리스와 호환되는 모드로 전환
Red Hat Enterprise Linux 8의 기본 시스템 전체 암호화 정책은 이전의 안전하지 않은 프로토콜을 사용한 통신을 허용하지 않습니다. Red Hat Enterprise Linux 6 및 이전 릴리스와 호환되어야 하는 환경의 경우 LEGACY 정책 수준을 사용할 수 있습니다.
LEGACY 정책 수준으로 전환하면 덜 안전한 시스템 및 애플리케이션이 됩니다.
절차
시스템 전체 암호화 정책을
LEGACY수준으로 전환하려면root로 다음 명령을 입력합니다.update-crypto-policies --set LEGACY Setting system policy to LEGACY
# update-crypto-policies --set LEGACY Setting system policy to LEGACYCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.4. 웹 콘솔에서 시스템 전체 암호화 정책 설정
RHEL 웹 콘솔 인터페이스에서 직접 시스템 전체 암호화 정책 및 하위 정책 중 하나를 설정할 수 있습니다. 사전 정의된 시스템 전체 암호화 정책 외에도 그래픽 인터페이스를 통해 다음과 같은 정책 및 하위 정책 조합을 적용할 수도 있습니다.
DEFAULT:SHA1-
SHA-1알고리즘이 활성화된DEFAULT정책입니다. LEGACY:AD-SUPPORT-
Active Directory 서비스의 상호 운용성을 개선하는 보안 설정이 적은
LEGACY정책입니다. FIPS:OSPP-
정보 기술 보안 평가 표준에 대해 Common Criteria에 필요한 추가 제한이 있는
FIPS정책입니다.
FIPS:OSPP 시스템 전체 하위 정책에는 CC(Common Criteria) 인증에 필요한 암호화 알고리즘에 대한 추가 제한이 포함되어 있으므로 설정한 후 시스템이 상호 운용이 불가능합니다. 예를 들어 3072비트, 추가 SSH 알고리즘 및 여러 TLS 그룹보다 짧은 RSA 및 DH 키를 사용할 수 없습니다. FIPS:OSPP 를 설정하면 Red Hat CDN(Content Delivery Network) 구조에 연결할 수 없습니다. 또한 FIPS:OSPP 를 사용하는 IdM 배포에는 AD(Active Directory)를 통합할 수 없으며 FIPS:OSPP 및 AD 도메인을 사용하는 RHEL 호스트 간 통신이 작동하지 않거나 일부 AD 계정이 인증할 수 없을 수 있습니다.
FIPS:OSPP 암호화 하위 정책을 설정한 후에는 시스템이 CC와 호환되지 않습니다. RHEL 시스템을 CC 표준을 준수하는 유일한 방법은 cc-config 패키지에 제공된 지침을 따르는 것입니다. 인증된 RHEL 버전, 검증 보고서 및 NIAP(National Information Assurance Partnership) 웹 사이트에서 호스팅되는 CC 가이드 링크를 보려면 제품 규정 준수 Red Hat 고객 포털 페이지의 Common Criteria 섹션을 참조하십시오.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
sudo를 사용하여 관리 명령을 입력할 수 있는루트권한 또는 권한이 있습니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
개요 페이지의 구성 카드에서 policy 옆에 있는 현재 정책 값을 클릭합니다.

암호화 정책 변경 대화 상자에서 시스템에서 사용을 시작할 정책을 클릭합니다.
- 버튼을 클릭합니다.
검증
다시 시작한 후 웹 콘솔에 다시 로그인하고 Crypto 정책 값이 선택한 값에 해당하는지 확인합니다.
또는
update-crypto-policies --show명령을 입력하여 현재 시스템 전체 암호화 정책을 터미널에 표시할 수 있습니다.
15.5. 다음 시스템 전체 암호화 정책에서 애플리케이션 제외
애플리케이션에서 직접 지원되는 암호화 제품군 및 프로토콜을 구성하여 애플리케이션에서 사용하는 암호화 설정을 사용자 지정할 수 있습니다.
애플리케이션과 관련된 심볼릭 링크를 /etc/crypto-policies/back-ends 디렉터리에서 제거하고 사용자 지정 암호화 설정으로 바꿀 수도 있습니다. 이 구성을 사용하면 제외된 백엔드를 사용하는 애플리케이션의 시스템 전체 암호화 정책을 사용할 수 없습니다. 또한 이러한 수정은 Red Hat에서 지원하지 않습니다.
15.5.1. 시스템 전체 암호화 정책 옵트아웃의 예
wget
wget 네트워크 다운로드자가 사용하는 암호화 설정을 사용자 지정하려면 --secure-protocol 및 --ciphers 옵션을 사용합니다. 예를 들면 다음과 같습니다.
wget --secure-protocol=TLSv1_1 --ciphers="SECURE128" https://example.com
$ wget --secure-protocol=TLSv1_1 --ciphers="SECURE128" https://example.com
자세한 내용은 wget(1) 도움말 페이지의 HTTPS(SSL/TLS) 옵션 섹션을 참조하십시오.
curl
curl 툴에서 사용하는 암호를 지정하려면 --ciphers 옵션을 사용하고 콜론으로 구분된 암호 목록을 값으로 제공합니다. 예를 들면 다음과 같습니다.
curl https://example.com --ciphers '@SECLEVEL=0:DES-CBC3-SHA:RSA-DES-CBC3-SHA'
$ curl https://example.com --ciphers '@SECLEVEL=0:DES-CBC3-SHA:RSA-DES-CBC3-SHA'
자세한 내용은 curl(1) 도움말 페이지를 참조하십시오.
Firefox
Firefox 웹 브라우저에서 시스템 전체 암호화 정책을 비활성화할 수는 없지만 Firefox 의 구성 편집기에서 지원되는 암호 및 TLS 버전을 추가로 제한할 수 있습니다. 주소 표시줄에 about:config 를 입력하고 필요에 따라 security.tls.version.min 옵션의 값을 변경합니다. security.tls.version.min 을 1 로 설정하면 필요한 최소 TLS 1.0이 허용되며, security.tls.version.min 2 는 TLS 1.1을 활성화합니다.
OpenSSH
OpenSSH 서버에 대한 시스템 전체 암호화 정책을 비활성화하려면 /etc/sysconfig/sshd 파일에서 CRYPTO_POLICY= 변수로 행의 주석을 제거합니다. 이 변경 후 /etc/ssh/sshd_config 파일의 Ciphers, MACs, KexAlgoritms, GSSAPIKexAlgorithms 섹션에 지정하는 값은 재정의되지 않습니다.
자세한 내용은 sshd_config(5) 도움말 페이지를 참조하십시오.
OpenSSH 클라이언트에 대한 시스템 전체 암호화 정책을 비활성화하려면 다음 작업 중 하나를 수행합니다.
-
지정된 사용자의 경우
~/.ssh/를 재정의합니다.config 파일의 사용자별 구성으로 글로벌 ssh_config -
전체 시스템의 경우
/etc/ssh/ssh_config.d/디렉터리에 있는 드롭인 구성 파일에 암호화 정책을 지정하고, 두 자리 숫자 접두사가 5보다 작도록 하여05-redhat.conf파일 앞에 .conf 접미사와.conf접미사(예:04-crypto-policy-override.conf)를 사용합니다.
자세한 내용은 ssh_config(5) 도움말 페이지를 참조하십시오.
Libreswan
자세한 내용은 보안 네트워크 문서에서 시스템 전체 암호화 정책을 거부하는 IPsec 연결 구성을 참조하십시오.
15.6. 하위 정책을 사용하여 시스템 전체 암호화 정책 사용자 정의
활성화된 암호화 알고리즘 또는 프로토콜 집합을 조정하려면 다음 절차를 사용하십시오.
기존 시스템 전체 암호화 정책 위에 사용자 지정 하위 항목을 적용하거나 이러한 정책을 처음부터 정의할 수 있습니다.
범위가 지정된 정책을 사용하면 다양한 백엔드에 대해 다양한 알고리즘 세트를 활성화할 수 있습니다. 각 구성 지시문을 특정 프로토콜, 라이브러리 또는 서비스로 제한할 수 있습니다.
또한 지시문은 와일드카드를 사용하여 여러 값을 지정하는 데 별표를 사용할 수 있습니다.
/etc/crypto-policies/state/CURRENT.pol 파일에는 와일드카드 확장 후 현재 적용되는 시스템 전체 암호화 정책의 모든 설정이 나열됩니다. 암호화 정책을 보다 엄격하게 설정하려면 /usr/share/crypto-policies/policies/FUTURE.pol 파일에 나열된 값을 사용하는 것이 좋습니다.
/usr/share/crypto-policies/policies/modules/ 디렉터리에서 하위 정책 예제를 찾을 수 있습니다. 이 디렉터리의 하위 정책 파일에는 주석 처리된 행에도 설명이 포함되어 있습니다.
RHEL 8.2에서는 시스템 전체 암호화 정책의 사용자 지정을 사용할 수 있습니다. 범위가 지정된 정책 개념과 RHEL 8.5 이상에서 와일드카드를 사용하는 옵션을 사용할 수 있습니다.
절차
/etc/crypto-policies/policies/modules/디렉토리로 체크아웃합니다.cd /etc/crypto-policies/policies/modules/
# cd /etc/crypto-policies/policies/modules/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 조정을 위한 하위 정책을 생성합니다. 예를 들면 다음과 같습니다.
touch MYCRYPTO-1.pmod touch SCOPES-AND-WILDCARDS.pmod
# touch MYCRYPTO-1.pmod # touch SCOPES-AND-WILDCARDS.pmodCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중요정책 모듈의 파일 이름에 대문자를 사용합니다.
선택한 텍스트 편집기에서 정책 모듈을 열고 시스템 전체 암호화 정책을 수정하는 옵션을 삽입합니다. 예를 들면 다음과 같습니다.
vi MYCRYPTO-1.pmod
# vi MYCRYPTO-1.pmodCopy to Clipboard Copied! Toggle word wrap Toggle overflow min_rsa_size = 3072 hash = SHA2-384 SHA2-512 SHA3-384 SHA3-512
min_rsa_size = 3072 hash = SHA2-384 SHA2-512 SHA3-384 SHA3-512Copy to Clipboard Copied! Toggle word wrap Toggle overflow vi SCOPES-AND-WILDCARDS.pmod
# vi SCOPES-AND-WILDCARDS.pmodCopy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 모듈 파일의 변경 사항을 저장합니다.
DEFAULT시스템 전체 암호화 정책 수준에 정책 조정을 적용합니다.update-crypto-policies --set DEFAULT:MYCRYPTO-1:SCOPES-AND-WILDCARDS
# update-crypto-policies --set DEFAULT:MYCRYPTO-1:SCOPES-AND-WILDCARDSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미 실행 중인 서비스 및 애플리케이션에 암호화 설정을 적용하려면 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
/etc/crypto-policies/state/CURRENT.pol파일에 변경 사항이 포함되어 있는지 확인합니다. 예를 들면 다음과 같습니다.cat /etc/crypto-policies/state/CURRENT.pol | grep rsa_size min_rsa_size = 3072
$ cat /etc/crypto-policies/state/CURRENT.pol | grep rsa_size min_rsa_size = 3072Copy to Clipboard Copied! Toggle word wrap Toggle overflow
15.7. 시스템 전체 암호화 정책을 사용자 지정하여 SHA-1 비활성화
SHA-1 해시 함수에는 본질적으로 약한 디자인이 있으며 발전된 암호화 기능이 공격에 취약하기 때문에 RHEL 8은 기본적으로 SHA-1을 사용하지 않습니다. 하지만 일부 타사 애플리케이션(예: 공개 서명)은 여전히 SHA-1을 사용합니다. 시스템의 서명 알고리즘에서 SHA-1 사용을 비활성화하려면 NO-SHA1 정책 모듈을 사용할 수 있습니다.
NO-SHA1 정책 모듈은 다른 위치에서는 서명에서만 SHA-1 해시 기능을 비활성화합니다. 특히 NO-SHA1 모듈은 여전히 SHA-1과 해시 기반 메시지 인증 코드(HMAC)를 사용할 수 있습니다. 이는 HMAC 보안 속성이 해당 해시 기능의 충돌 내성에 의존하지 않으므로 SHA-1에 대한 최근 공격으로 SHA-1의 SHA-1 사용에 미치는 영향이 크게 낮기 때문입니다.
시나리오에 특정 키 교환(KEX) 알고리즘 조합(예: diffie-hellman-group-exchange-sha1 )을 비활성화해야 하지만 여전히 관련 KEX 및 알고리즘을 모두 사용하려는 경우 Red Hat 지식베이스 솔루션 단계를 참조하여 시스템 전체 시스템 정책 옵트아웃에 대한 지침을 SSH에서 diffie-hellman-group1-sha1 알고리즘을 비활성화 하십시오.
SHA-1을 비활성화하는 모듈은 RHEL 8.3에서 사용할 수 있습니다. RHEL 8.2에서는 시스템 전체 암호화 정책의 사용자 지정을 사용할 수 있습니다.
절차
DEFAULT시스템 전체 암호화 정책 수준에 정책 조정을 적용합니다.update-crypto-policies --set DEFAULT:NO-SHA1
# update-crypto-policies --set DEFAULT:NO-SHA1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이미 실행 중인 서비스 및 애플리케이션에 암호화 설정을 적용하려면 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.8. 사용자 정의 시스템 전체 암호화 정책 생성 및 설정
특정 시나리오의 경우 전체 정책 파일을 생성하고 사용하여 시스템 전체 암호화 정책을 사용자 지정할 수 있습니다.
RHEL 8.2에서는 시스템 전체 암호화 정책의 사용자 지정을 사용할 수 있습니다.
절차
사용자 지정 정책 파일을 생성합니다.
cd /etc/crypto-policies/policies/ touch MYPOLICY.pol
# cd /etc/crypto-policies/policies/ # touch MYPOLICY.polCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 사전 정의된 4가지 정책 수준 중 하나를 복사하여 시작합니다.
cp /usr/share/crypto-policies/policies/DEFAULT.pol /etc/crypto-policies/policies/MYPOLICY.pol
# cp /usr/share/crypto-policies/policies/DEFAULT.pol /etc/crypto-policies/policies/MYPOLICY.polCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음과 같은 요구 사항에 맞게 선택한 텍스트 편집기에서 사용자 지정 암호화 정책으로 파일을 편집합니다.
vi /etc/crypto-policies/policies/MYPOLICY.pol
# vi /etc/crypto-policies/policies/MYPOLICY.polCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템 전체 암호화 정책을 사용자 지정 수준으로 전환합니다.
update-crypto-policies --set MYPOLICY
# update-crypto-policies --set MYPOLICYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이미 실행 중인 서비스 및 애플리케이션에 암호화 설정을 적용하려면 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
15.9. crypto_policies RHEL 시스템 역할을 사용하여 FUTURE 암호화 정책으로 보안 강화
crypto_policies RHEL 시스템 역할을 사용하여 관리 노드에서 FUTURE 정책을 구성할 수 있습니다. 이 정책은 다음을 수행하는 데 도움이 됩니다.
- 새로운 위협에 대한 미래 지향적: 컴퓨팅 성능이 향상될 것으로 예상합니다.
- 강화된 보안: 강력한 암호화 표준에는 더 긴 키 길이와 더 안전한 알고리즘이 필요합니다.
- 고도의 보안 표준 준수(예: 의료, 통신, 금융 등)는 데이터 민감도가 높고 강력한 암호화의 가용성도 중요합니다.
일반적으로 FUTURE 는 매우 민감한 데이터를 처리하는 환경, 향후 규정을 준비하거나 장기 보안 전략을 채택하는 데 적합합니다.
레거시 시스템이나 소프트웨어는 FUTURE 정책에서 시행하는 보다 현대적이고 엄격한 알고리즘 및 프로토콜을 지원할 필요가 없습니다. 예를 들어 이전 시스템은 TLS 1.3 또는 더 큰 키 크기를 지원하지 않을 수 있습니다. 이로 인해 호환성 문제가 발생할 수 있습니다.
또한 강력한 알고리즘을 사용하면 일반적으로 컴퓨팅 워크로드가 증가하여 시스템 성능에 부정적인 영향을 미칠 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
crypto_policies_policy: 미래-
관리 노드에서 필요한 암호화 정책(
FUTURE)을 구성합니다. 기본 정책 또는 일부 하위 정책이 있는 기본 정책일 수 있습니다. 지정된 기본 정책 및 하위 정책을 관리 노드에서 사용할 수 있어야 합니다. 기본값은null입니다. 즉, 구성이 변경되지 않고crypto_policiesRHEL 시스템 역할은 Ansible 팩트만 수집합니다. crypto_policies_reboot_ok: true-
암호화 정책이 변경된 후 시스템이 재부팅되어 모든 서비스와 애플리케이션이 새 구성 파일을 읽습니다. 기본값은
false입니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.crypto_policies/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
FIPS:OSPP 시스템 전체 하위 정책에는 CC(Common Criteria) 인증에 필요한 암호화 알고리즘에 대한 추가 제한이 포함되어 있으므로 설정한 후 시스템이 상호 운용이 불가능합니다. 예를 들어 3072비트, 추가 SSH 알고리즘 및 여러 TLS 그룹보다 짧은 RSA 및 DH 키를 사용할 수 없습니다. FIPS:OSPP 를 설정하면 Red Hat CDN(Content Delivery Network) 구조에 연결할 수 없습니다. 또한 FIPS:OSPP 를 사용하는 IdM 배포에는 AD(Active Directory)를 통합할 수 없으며 FIPS:OSPP 및 AD 도메인을 사용하는 RHEL 호스트 간 통신이 작동하지 않거나 일부 AD 계정이 인증할 수 없을 수 있습니다.
FIPS:OSPP 암호화 하위 정책을 설정한 후에는 시스템이 CC와 호환되지 않습니다. RHEL 시스템을 CC 표준을 준수하는 유일한 방법은 cc-config 패키지에 제공된 지침을 따르는 것입니다. 인증된 RHEL 버전, 검증 보고서 및 NIAP(National Information Assurance Partnership) 웹 사이트에서 호스팅되는 CC 가이드 링크를 보려면 제품 규정 준수 Red Hat 고객 포털 페이지의 Common Criteria 섹션을 참조하십시오.
검증
제어 노드에서
verify_playbook.yml:이라는 다른 플레이북을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
crypto_policies_active-
crypto_policies_policy변수에서 수락한 형식으로 현재 활성 정책 이름이 포함된 내보낸 Ansible 팩트입니다.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/verify_playbook.yml
$ ansible-playbook --syntax-check ~/verify_playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북을 실행합니다.
ansible-playbook ~/verify_playbook.yml TASK [debug] ************************** ok: [host] => { "crypto_policies_active": "FUTURE" }$ ansible-playbook ~/verify_playbook.yml TASK [debug] ************************** ok: [host] => { "crypto_policies_active": "FUTURE" }Copy to Clipboard Copied! Toggle word wrap Toggle overflow crypto_policies_active변수는 관리 노드의 활성 정책을 표시합니다.
16장. PKCS #11을 통해 암호화 하드웨어를 사용하도록 애플리케이션 구성
서버 애플리케이션을 위한 스마트 카드 및 암호화 토큰과 같은 전용 암호화 장치에 대한 시크릿 정보의 부분을 분리하면 서버 애플리케이션을 위한 HSM(하드웨어 보안 모듈)이 추가로 제공됩니다. RHEL에서 PKCS #11 API를 통한 암호화 하드웨어 지원은 서로 다른 애플리케이션에서 일관성이 유지되며 암호화 하드웨어에서 시크릿을 격리하는 작업이 복잡하지 않습니다.
16.1. PKCS #11을 통한 하드웨어 지원
PKI(Public-Key Cryptography Standard) #11은 암호화 정보를 유지하고 암호화 기능을 수행하는 장치를 암호화하기 위한 API(애플리케이션 프로그래밍 인터페이스)를 정의합니다.
PKCS #11에는 각 하드웨어 또는 소프트웨어 장치를 통합된 방식으로 애플리케이션에 제공하는 오브젝트인 암호화 토큰이 도입되었습니다. 따라서 애플리케이션은 일반적으로 개인에 의해 사용되는 스마트 카드와 같은 장치를 봅니다. 일반적으로 PKCS #11 암호화 토큰으로 컴퓨터에서 사용하는 하드웨어 보안 모듈입니다.
PKCS #11 토큰은 인증서, 데이터 오브젝트 및 공용, 개인 키 또는 비밀 키를 비롯한 다양한 오브젝트 유형을 저장할 수 있습니다. 이러한 오브젝트는 PKCS #11 URI(Uniform Resource Identifier) 체계를 통해 고유하게 식별할 수 있습니다.
PKCS #11 URI는 개체 특성에 따라 PKCS #11 모듈에서 특정 오브젝트를 식별하는 표준 방법입니다. 이를 통해 URI 형식으로 동일한 구성 문자열로 모든 라이브러리 및 애플리케이션을 구성할 수 있습니다.
RHEL은 기본적으로 스마트 카드용 OpenSC PKCS #11 드라이버를 제공합니다. 그러나 하드웨어 토큰과 HSM에는 시스템에 해당되지 않는 자체 PKCS #11 모듈이 있을 수 있습니다. 시스템에서 등록된 스마트 카드 드라이버를 통해 래퍼 역할을 하는 p11-kit 도구로 이러한 PKCS #11 모듈을 등록할 수 있습니다.
고유한 PKCS #11 모듈이 시스템에서 작동하도록 하려면 새 텍스트 파일을 /etc/pkcs11/modules/ 디렉토리에 추가합니다.
/etc/pkcs11/modules/ 디렉터리에 새 텍스트 파일을 생성하여 자체 PKCS #11 모듈을 시스템에 추가할 수 있습니다. 예를 들어 p11-kit 의 OpenSC 구성 파일은 다음과 같습니다.
cat /usr/share/p11-kit/modules/opensc.module module: opensc-pkcs11.so
$ cat /usr/share/p11-kit/modules/opensc.module
module: opensc-pkcs11.so16.2. 스마트 카드에 저장된 SSH 키로 인증
스마트 카드에 ECDSA 및 RSA 키를 생성 및 저장하고 OpenSSH 클라이언트의 스마트 카드로 인증할 수 있습니다. 스마트 카드 인증은 기본 암호 인증을 대체합니다.
사전 요구 사항
-
클라이언트 측에서
opensc패키지가 설치되고pcscd서비스가 실행 중입니다.
절차
PKCS #11 URI를 포함하여 OpenSC PKCS #11 모듈에서 제공하는 모든 키를 나열하고 출력을
keys.pub파일에 저장합니다.ssh-keygen -D pkcs11: > keys.pub
$ ssh-keygen -D pkcs11: > keys.pubCopy to Clipboard Copied! Toggle word wrap Toggle overflow 공개 키를 원격 서버로 전송합니다. 이전 단계에서 만든
keys.pub파일과 함께ssh-copy-id명령을 사용합니다.ssh-copy-id -f -i keys.pub <username@ssh-server-example.com>
$ ssh-copy-id -f -i keys.pub <username@ssh-server-example.com>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ECDSA 키를 사용하여 < ssh-server-example.com >에 연결합니다. 키를 고유하게 참조하는 URI의 하위 집합만 사용할 수 있습니다. 예를 들면 다음과 같습니다.
ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenSSH는
p11-kit-proxy래퍼를 사용하고 OpenSC PKCS #11 모듈이p11-kit툴에 등록되므로 이전 명령을 단순화할 수 있습니다.ssh -i "pkcs11:id=%01" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ ssh -i "pkcs11:id=%01" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow PKCS #11 URI의
id=부분을 건너뛰면 OpenSSH는 proxy 모듈에서 사용할 수 있는 모든 키를 로드합니다. 이렇게 하면 필요한 입력 횟수가 줄어듭니다.ssh -i pkcs11: <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ ssh -i pkcs11: <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항:
~/.ssh/config파일에서 동일한 URI 문자열을 사용하여 구성을 영구적으로 만들 수 있습니다.cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이제
ssh클라이언트 유틸리티에서 이 URI와 스마트 카드의 키를 자동으로 사용합니다.
16.3. 스마트 카드에서 인증서를 사용하여 인증을 위한 애플리케이션 구성
애플리케이션에서 스마트 카드를 사용하여 인증하면 보안이 향상되고 자동화가 간소화될 수 있습니다. 다음 방법을 사용하여 PKI(Public Key Cryptography Standard) #11 URI를 애플리케이션에 통합할 수 있습니다.
-
Firefox웹 브라우저에서p11-kit-proxyPKCS #11 모듈을 자동으로 로드합니다. 즉, 시스템에서 지원되는 모든 스마트 카드가 자동으로 감지됩니다. TLS 클라이언트 인증을 사용하려면 추가 설정이 필요하지 않으며 서버가 요청할 때 스마트 카드의 키와 인증서가 자동으로 사용됩니다. -
애플리케이션에서
GnuTLS또는NSS라이브러리를 사용하는 경우 PKCS #11 URI를 이미 지원합니다. 또한OpenSSL라이브러리에 의존하는 애플리케이션은openssl-pkcs11패키지에서 제공하는pkcs11엔진을 통해 스마트 카드를 포함한 암호화 하드웨어 모듈에 액세스할 수 있습니다. -
스마트 카드에서 개인 키로 작업해야 하며
NSS,GnuTLS또는OpenSSL을 사용하지 않는 애플리케이션에서는 특정 PKCS #11 모듈의 PKCS #11 API를 사용하는 대신, 스마트 카드를 포함한 암호화 하드웨어 모듈과 함께 작업하는 데 직접p11-kitAPI를 사용할 수 있습니다. wget네트워크 다운 로더를 사용하면 로컬에 저장된 개인 키 및 인증서에 대한 경로 대신 PKCS #11 URI를 지정할 수 있습니다. 이렇게 하면 안전하게 저장된 개인 키와 인증서가 필요한 작업의 스크립트 생성이 간소화될 수 있습니다. 예를 들면 다음과 같습니다.wget --private-key 'pkcs11:token=softhsm;id=%01;type=private?pin-value=111111' --certificate 'pkcs11:token=softhsm;id=%01;type=cert' https://example.com/
$ wget --private-key 'pkcs11:token=softhsm;id=%01;type=private?pin-value=111111' --certificate 'pkcs11:token=softhsm;id=%01;type=cert' https://example.com/Copy to Clipboard Copied! Toggle word wrap Toggle overflow curl툴을 사용할 때 PKCS #11 URI를 지정할 수도 있습니다.curl --key 'pkcs11:token=softhsm;id=%01;type=private?pin-value=111111' --cert 'pkcs11:token=softhsm;id=%01;type=cert' https://example.com/
$ curl --key 'pkcs11:token=softhsm;id=%01;type=private?pin-value=111111' --cert 'pkcs11:token=softhsm;id=%01;type=cert' https://example.com/Copy to Clipboard Copied! Toggle word wrap Toggle overflow
16.4. Apache의 개인 키 보호 HSM 사용
Apache HTTP 서버는 HSM(하드웨어 보안 모듈)에 저장된 개인 키로 작동할 수 있으므로 키 공개 및 중간자 공격을 방지하는 데 도움이 됩니다. 이 경우 일반적으로 사용 중인 서버에는 고성능 HSM이 필요합니다.
HTTPS 프로토콜 형식의 보안 통신을 위해 Apache HTTP 서버(httpd)는OpenSSL 라이브러리를 사용합니다. OpenSSL은 기본적으로 PKCS #11을 지원하지 않습니다. HSM을 사용하려면 엔진 인터페이스를 통해 PKCS #11 모듈에 대한 액세스를 제공하는 openssl-pkcs11 패키지를 설치해야 합니다. 일반 파일 이름 대신 PKCS #11 URI를 사용하여 /etc/httpd/conf.d/ssl.conf 구성 파일에 서버 키와 인증서를 지정할 수 있습니다. 예를 들면 다음과 같습니다.
SSLCertificateFile "pkcs11:id=%01;token=softhsm;type=cert" SSLCertificateKeyFile "pkcs11:id=%01;token=softhsm;type=private?pin-value=111111"
SSLCertificateFile "pkcs11:id=%01;token=softhsm;type=cert"
SSLCertificateKeyFile "pkcs11:id=%01;token=softhsm;type=private?pin-value=111111"
httpd-manual 패키지를 설치하여 TLS 구성을 포함하여 Apache HTTP Server에 대한 전체 문서를 가져옵니다. /etc/httpd/conf.d/ssl.conf 구성 파일에서 사용 가능한 지시문은 /usr/share/httpd/manual/mod/mod_ssl.html 파일에 자세히 설명되어 있습니다.
16.5. Nginx의 개인 키 보호 HSM 사용
Nginx HTTP 서버는 HSM(하드웨어 보안 모듈)에 저장된 개인 키로 작동할 수 있으므로 키 공개 및 중간자 공격을 방지하는 데 도움이 됩니다. 이 경우 일반적으로 사용 중인 서버에는 고성능 HSM이 필요합니다.
Nginx 는 암호화 작업에도 OpenSSL을 사용하므로 PKCS #11에 대한 지원은 openssl-pkcs11 엔진을 통과해야 합니다. Nginx 는 현재 HSM에서 개인 키 로드만 지원하며 인증서는 일반 파일로 별도로 제공해야 합니다. /etc/nginx/nginx.conf 구성 파일의
server 섹션에서 옵션을 수정합니다.ssl_certificate 및 ssl_certificate_key
ssl_certificate /path/to/cert.pem ssl_certificate_key "engine:pkcs11:pkcs11:token=softhsm;id=%01;type=private?pin-value=111111";
ssl_certificate /path/to/cert.pem
ssl_certificate_key "engine:pkcs11:pkcs11:token=softhsm;id=%01;type=private?pin-value=111111";
Nginx 구성 파일의 PKCS #11 URI에는 engine:pkcs11: 접두사가 필요합니다. 이는 다른 pkcs11 접두사가 엔진 이름을 참조하기 때문입니다.
18장. 보안 준수 및 취약점을 위해 시스템 스캔
18.1. RHEL의 구성 준수 도구
다음 구성 규정 준수 툴을 사용하여 Red Hat Enterprise Linux에서 완전히 자동화된 규정 준수 감사를 수행할 수 있습니다. 이러한 툴은 SCAP(Security Content Automation Protocol) 표준을 기반으로 하며 규정 준수 정책의 자동화된 조정을 위해 설계되었습니다.
- SCAP Workbench
-
scap-workbench그래픽 유틸리티는 단일 로컬 또는 원격 시스템에서 구성 및 취약점 검사를 수행하도록 설계되었습니다. 또한 이러한 스캔 및 평가를 기반으로 보안 보고서를 생성하는 데 사용할 수도 있습니다. - OpenSCAP
oscap명령줄 유틸리티가 포함된OpenSCAP라이브러리는 로컬 시스템에서 구성 및 취약점 검사를 수행하고 구성 규정 준수 콘텐츠를 검증하고 이러한 검사 및 평가를 기반으로 보고서 및 가이드를 생성하도록 설계되었습니다.중요OpenSCAP 을 사용하는 동안 메모리 사용량 문제가 발생할 수 있으므로 프로그램을 조기 중단하고 결과 파일이 생성되지 않을 수 있습니다. 자세한 내용은 OpenSCAP 메모리 사용 문제 지식 베이스 문서를 참조하십시오.
- SCAP Security Guide (SSG)
-
scap-security-guide패키지는 Linux 시스템에 대한 보안 정책 컬렉션을 제공합니다. 지침은 실제 강화 조언 카탈로그로 구성되며, 적용되는 정부 요구 사항과 연결됩니다. 이 프로젝트는 일반화된 정책 요구 사항과 특정 구현 지침 간의 격차를 해소합니다. - 스크립트 검사 엔진(SCE)
-
SCAP 프로토콜에 대한 확장인 SCE를 사용하면 관리자가 Bash, Python, Ruby와 같은 스크립팅 언어를 사용하여 보안 콘텐츠를 작성할 수 있습니다. SCE 확장은
openscap-engine-sce패키지에 제공됩니다. SCE 자체는 SCAP 표준의 일부가 아닙니다.
여러 시스템에서 원격으로 자동화된 규정 준수 감사를 수행하려면 Red Hat Satellite에 OpenSCAP 솔루션을 사용할 수 있습니다.
18.2. Red Hat 보안 공지 OVAL 피드
Red Hat Enterprise Linux 보안 감사 기능은 SCAP(Security Content Automation Protocol) 표준을 기반으로 합니다. SCAP는 자동화된 구성, 취약점 및 패치 검사, 기술 제어 준수 활동 및 보안 측정을 지원하는 다용도 사양 프레임워크입니다.
SCAP 사양은 스캐너 또는 정책 편집기를 구현하지 않아도 보안 콘텐츠 형식이 잘 알려져 표준화되어 있는 에코시스템을 생성합니다. 이를 통해 조직은 채택한 보안 벤더 수에 관계없이 SCC(보안 정책)를 한 번 구축할 수 있습니다.
OVAL(Open Vulnerability Assessment Language)은 SCAP에서 필수적이고 오래된 구성 요소입니다. 다른 툴 및 사용자 지정 스크립트와 달리 OVAL은 선언적 방식으로 필요한 리소스 상태를 설명합니다. OVAL 코드는 직접 실행되지 않지만 scanner라는 OVAL 인터프리터 툴을 사용합니다. OVAL의 선언적 특성은 평가된 시스템의 상태가 실수로 수정되지 않도록 합니다.
다른 모든 SCAP 구성 요소와 마찬가지로, OVAL은 XML을 기반으로 합니다. SCAP 표준은 여러 문서 형식을 정의합니다. 각각 다른 유형의 정보를 포함하며 다른 목적을 제공합니다.
Red Hat Product Security 는 Red Hat 고객에게 영향을 미치는 모든 보안 문제를 추적하고 조사하여 고객이 위험을 평가하고 관리할 수 있도록 지원합니다. Red Hat 고객 포털에서 적시에 간결한 패치와 보안 공지를 제공합니다. Red Hat은 OVAL 패치 정의를 생성 및 지원하여 시스템에서 읽을 수 있는 보안 권고 버전을 제공합니다.
플랫폼, 버전 및 기타 요인 간의 차이로 인해 취약점의 Red Hat 제품 보안 질적 심각도 등급은 타사에서 제공하는 CVSS(Common Vulnerability Scoring System) 기준 평가와 직접적으로 일치하지 않습니다. 따라서 타사가 제공하는 정의 대신 RHSA OVAL 정의를 사용하는 것이 좋습니다.
RHSA OVAL 정의는 개별적으로 및 전체 패키지로 사용할 수 있으며 Red Hat 고객 포털에서 사용할 수 있는 새 보안 권고를 1시간 이내에 업데이트합니다.
각 OVAL 패치 정의는 일대일로 Red Hat 보안 권고(RHSA)에 매핑됩니다. RHSA에는 여러 취약점에 대한 수정 사항이 포함될 수 있으므로 각 취약점은 CVE(Common Vulnerabilities and Exposures) 이름으로 별도로 나열되며 공개 버그 데이터베이스에 해당 항목에 대한 링크가 있습니다.
RHSA OVAL 정의는 시스템에 설치된 취약한 버전의 RPM 패키지를 확인하도록 설계되었습니다. 예를 들어 이러한 정의를 확장하여 추가 검사를 포함하여 패키지가 취약한 구성에서 사용 중인지 확인할 수 있습니다. 이러한 정의는 Red Hat이 제공하는 소프트웨어 및 업데이트를 포괄하도록 설계되었습니다. 타사 소프트웨어의 패치 상태를 감지하려면 추가 정의가 필요합니다.
Red Hat Enterprise Linux 규정 준수 서비스를 위한 Red Hat Insights는 IT 보안 및 규정 준수 관리자가 Red Hat Enterprise Linux 시스템의 보안 정책 준수를 평가, 모니터링 및 보고할 수 있도록 지원합니다. 규정 준수 서비스 UI 내에서 SCAP 보안 정책을 완전히 생성하고 관리할 수도 있습니다.
18.3. 취약점 검사
18.3.1. Red Hat 보안 공지 OVAL 피드
Red Hat Enterprise Linux 보안 감사 기능은 SCAP(Security Content Automation Protocol) 표준을 기반으로 합니다. SCAP는 자동화된 구성, 취약점 및 패치 검사, 기술 제어 준수 활동 및 보안 측정을 지원하는 다용도 사양 프레임워크입니다.
SCAP 사양은 스캐너 또는 정책 편집기를 구현하지 않아도 보안 콘텐츠 형식이 잘 알려져 표준화되어 있는 에코시스템을 생성합니다. 이를 통해 조직은 채택한 보안 벤더 수에 관계없이 SCC(보안 정책)를 한 번 구축할 수 있습니다.
OVAL(Open Vulnerability Assessment Language)은 SCAP에서 필수적이고 오래된 구성 요소입니다. 다른 툴 및 사용자 지정 스크립트와 달리 OVAL은 선언적 방식으로 필요한 리소스 상태를 설명합니다. OVAL 코드는 직접 실행되지 않지만 scanner라는 OVAL 인터프리터 툴을 사용합니다. OVAL의 선언적 특성은 평가된 시스템의 상태가 실수로 수정되지 않도록 합니다.
다른 모든 SCAP 구성 요소와 마찬가지로, OVAL은 XML을 기반으로 합니다. SCAP 표준은 여러 문서 형식을 정의합니다. 각각 다른 유형의 정보를 포함하며 다른 목적을 제공합니다.
Red Hat Product Security 는 Red Hat 고객에게 영향을 미치는 모든 보안 문제를 추적하고 조사하여 고객이 위험을 평가하고 관리할 수 있도록 지원합니다. Red Hat 고객 포털에서 적시에 간결한 패치와 보안 공지를 제공합니다. Red Hat은 OVAL 패치 정의를 생성 및 지원하여 시스템에서 읽을 수 있는 보안 권고 버전을 제공합니다.
플랫폼, 버전 및 기타 요인 간의 차이로 인해 취약점의 Red Hat 제품 보안 질적 심각도 등급은 타사에서 제공하는 CVSS(Common Vulnerability Scoring System) 기준 평가와 직접적으로 일치하지 않습니다. 따라서 타사가 제공하는 정의 대신 RHSA OVAL 정의를 사용하는 것이 좋습니다.
RHSA OVAL 정의는 개별적으로 및 전체 패키지로 사용할 수 있으며 Red Hat 고객 포털에서 사용할 수 있는 새 보안 권고를 1시간 이내에 업데이트합니다.
각 OVAL 패치 정의는 일대일로 Red Hat 보안 권고(RHSA)에 매핑됩니다. RHSA에는 여러 취약점에 대한 수정 사항이 포함될 수 있으므로 각 취약점은 CVE(Common Vulnerabilities and Exposures) 이름으로 별도로 나열되며 공개 버그 데이터베이스에 해당 항목에 대한 링크가 있습니다.
RHSA OVAL 정의는 시스템에 설치된 취약한 버전의 RPM 패키지를 확인하도록 설계되었습니다. 예를 들어 이러한 정의를 확장하여 추가 검사를 포함하여 패키지가 취약한 구성에서 사용 중인지 확인할 수 있습니다. 이러한 정의는 Red Hat이 제공하는 소프트웨어 및 업데이트를 포괄하도록 설계되었습니다. 타사 소프트웨어의 패치 상태를 감지하려면 추가 정의가 필요합니다.
Red Hat Enterprise Linux 규정 준수 서비스를 위한 Red Hat Insights는 IT 보안 및 규정 준수 관리자가 Red Hat Enterprise Linux 시스템의 보안 정책 준수를 평가, 모니터링 및 보고할 수 있도록 지원합니다. 규정 준수 서비스 UI 내에서 SCAP 보안 정책을 완전히 생성하고 관리할 수도 있습니다.
18.3.2. 시스템에서 취약점 스캔
oscap 명령줄 유틸리티를 사용하면 로컬 시스템을 스캔하고, 구성 준수 콘텐츠를 검증하고, 이러한 스캔 및 평가를 기반으로 보고서 및 가이드를 생성할 수 있습니다. 이 유틸리티는 OpenSCAP 라이브러리의 프런트엔드 역할을 하며 처리하는 SCAP 콘텐츠 유형에 따라 해당 기능을 모듈(하위 명령)에 그룹화합니다.
사전 요구 사항
-
openscap-scanner및0.0/162패키지를 설치합니다.
절차
시스템에 대한 최신 RHSA OVAL 정의를 다운로드합니다.
wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xml
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템에서 취약점을 스캔하고 결과를 vulnerability.html 파일에 저장합니다.
oscap oval eval --report vulnerability.html rhel-8.oval.xml
# oscap oval eval --report vulnerability.html rhel-8.oval.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
선택한 브라우저의 결과를 확인합니다. 예를 들면 다음과 같습니다.
firefox vulnerability.html &
$ firefox vulnerability.html &Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.3.3. 원격 시스템에서 취약점 스캔
SSH 프로토콜을 통해 oscap-ssh 툴을 사용하여 OpenSCAP 스캐너가 있는 취약점이 원격 시스템에 있는지 확인할 수 있습니다.
사전 요구 사항
-
스캔에 사용하는 시스템에
openscap-utils및bzip2패키지가 설치되어 있습니다. -
openscap-scanner패키지는 원격 시스템에 설치됩니다. - SSH 서버는 원격 시스템에서 실행되고 있습니다.
절차
시스템에 대한 최신 RHSA OVAL 정의를 다운로드합니다.
wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xml
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원격 시스템에서 취약점을 스캔하고 결과를 파일에 저장합니다.
oscap-ssh <username>@<hostname> <port> oval eval --report <scan-report.html> rhel-8.oval.xml
# oscap-ssh <username>@<hostname> <port> oval eval --report <scan-report.html> rhel-8.oval.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
<username> @ <hostname> 및 원격 시스템의 사용자 이름 및 호스트 이름입니다. -
원격 시스템에 액세스할 수 있는 포트 번호가 있는 <port>(예:
22) -
oscap이 검사 결과를 저장하는 파일 이름이<scan-report.html>입니다.
-
18.4. 구성 규정 준수 스캔
18.4.1. RHEL의 구성 규정 준수
구성 규정 준수 스캔을 사용하여 특정 조직에서 정의한 기준을 준수할 수 있습니다. 예를 들어, 미국 정부와 협력하는 경우 시스템을 OSPP(운영 체제 보호 프로필)에 맞춰야 할 수 있으며 결제 프로세서인 경우 시스템을 PCI-DSS(Payment Card Industry Data Security Standard)에 맞춰 조정해야 할 수 있습니다. 구성 준수 스캔을 수행하여 시스템 보안을 강화할 수도 있습니다.
영향을 받는 구성 요소에 대한 Red Hat 모범 사례에 부합하므로 SCAP Security Guide 패키지에 제공된 SCAP(Security Content Automation Protocol) 콘텐츠를 따르는 것이 좋습니다.
SCAP 보안 가이드 패키지는 SCAP 1.2 및 SCAP 1.3 표준을 준수하는 콘텐츠를 제공합니다. openscap 스캐너 유틸리티는 SCAP 보안 가이드 패키지에 제공된 SCAP 1.2 및 SCAP 1.3 콘텐츠와 호환됩니다.
구성 규정 준수 스캔을 수행해도 시스템이 규정을 준수하는 것은 아닙니다.
SCAP 보안 가이드 제품군은 여러 플랫폼의 프로필을 데이터 스트림 문서 형태로 제공합니다. 데이터 스트림은 정의, 벤치마크, 프로필 및 개별 규칙이 포함된 파일입니다. 각 규칙은 규정 준수에 대한 적용 가능성 및 요구 사항을 지정합니다. RHEL에서는 보안 정책을 준수하기 위해 여러 프로필을 제공합니다. 업계 표준 외에도 Red Hat 데이터 스트림에는 실패한 규칙의 수정에 대한 정보도 포함되어 있습니다.
컴플라이언스 검사 리소스 구조
프로필은 OSPP, PCI-DSS 및 HIPAA(Health Insurance Portability and Accountability Act)와 같은 보안 정책을 기반으로 하는 규칙 집합입니다. 이를 통해 보안 표준을 준수하는 자동화된 방식으로 시스템을 감사할 수 있습니다.
프로필을 수정하여 특정 규칙(예: 암호 길이)을 사용자 지정할 수 있습니다. 프로필 맞춤에 대한 자세한 내용은 SCAP Workbench를 사용하여 보안 프로필 사용자 지정을 참조하십시오.
18.4.2. OpenSCAP 스캔의 가능한 결과
OpenSCAP 스캔에 적용되는 데이터 스트림 및 프로필과 시스템의 다양한 속성에 따라 각 규칙이 특정 결과를 생성할 수 있습니다. 이러한 결과는 그 의미에 대한 간략한 설명과 함께 가능한 결과입니다.
- pass
- 검사에서 이 규칙과의 충돌을 찾지 못했습니다.
- 실패
- 검사에서 이 규칙과 충돌하는 것을 발견했습니다.
- 확인되지 않음
- OpenSCAP에서는 이 규칙을 자동으로 평가하지 않습니다. 시스템이 이 규칙을 수동으로 준수하는지 확인합니다.
- 해당 없음
- 이 규칙은 현재 구성에 적용되지 않습니다.
- 선택되지 않음
- 이 규칙은 프로필에 포함되지 않습니다. OpenSCAP은 이 규칙을 평가하지 않으며 결과에 이러한 규칙을 표시하지 않습니다.
- 오류
-
검사에 오류가 발생했습니다. 자세한 내용은
--verbose DEVEL옵션을 사용하여oscap명령을 입력할 수 있습니다. Red Hat 고객 포털에서 지원 케이스를 제출하거나 Red Hat Jira의 RHEL 프로젝트에서 티켓을 엽니 다. - 알 수 없음
-
검사에 예기치 않은 상황이 발생했습니다. 자세한 내용은
'--verbose DEVEL옵션을 사용하여oscap명령을 입력합니다. Red Hat 고객 포털에서 지원 케이스를 제출하거나 Red Hat Jira의 RHEL 프로젝트에서 티켓을 엽니 다.
18.4.3. 구성 규정 준수 프로필 보기
검사 또는 수정을 위해 프로필을 사용하기 전에 나열한 후 oscap info 하위 명령을 사용하여 자세한 설명을 확인할 수 있습니다.
사전 요구 사항
-
openscap-scanner및scap-security-guide패키지가 설치됩니다.
절차
SCAP 보안 가이드 프로젝트에서 제공하는 보안 준수 프로필이 있는 사용 가능한 모든 파일을 나열합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow oscap info하위 명령을 사용하여 선택한 데이터 스트림에 대한 세부 정보를 표시합니다. 데이터 스트림을 포함하는 XML 파일은 이름에-ds문자열로 표시됩니다.Profiles(프로필) 섹션에서 사용 가능한 프로필 및 해당 ID 목록을 찾을 수 있습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터 스트림 파일에서 프로필을 선택하고 선택한 프로필에 대한 추가 세부 정보를 표시합니다. 이렇게 하려면
--profile옵션 다음에 이전 명령의 출력에 표시된 ID의 마지막 섹션과 함께oscap info를 사용합니다. 예를 들어 HIPPA 프로파일의 ID는xccdf_org.ssgproject.content_profile_hipaa이며--profile옵션의 값은hipaa입니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.4.4. 특정 기준의 구성 준수 평가
시스템 또는 원격 시스템이 특정 기준을 준수하는지 여부를 확인하고 oscap 명령줄 도구를 사용하여 결과를 보고서에 저장할 수 있습니다.
사전 요구 사항
-
openscap-scanner및scap-security-guide패키지가 설치됩니다. - 시스템이 준수해야 하는 기준 내에서 프로필의 ID를 알고 있습니다. ID를 찾으려면 구성 규정 준수에 대한 프로필 보기 섹션을 참조하십시오.
절차
로컬 시스템에서 선택한 프로필을 준수하는지 스캔하여 검사 결과를 파일에 저장합니다.
oscap xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
$ oscap xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
oscap이 검사 결과를 저장하는 파일 이름이<scan-report.html>입니다. -
시스템이 준수해야 하는
프로파일 ID가 있는 <profileID>(예:hipaa).
-
선택 사항: 원격 시스템에서 선택한 프로필을 준수하는지 스캔하여 검사 결과를 파일에 저장합니다.
oscap-ssh <username>@<hostname> <port> xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
$ oscap-ssh <username>@<hostname> <port> xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
<username> @ <hostname> 및 원격 시스템의 사용자 이름 및 호스트 이름입니다. -
원격 시스템에 액세스할 수 있는 포트 번호가 있는 <port>입니다.
-
oscap이 검사 결과를 저장하는 파일 이름이<scan-report.html>입니다. -
시스템이 준수해야 하는
프로파일 ID가 있는 <profileID>(예:hipaa).
-
18.5. 특정 기준선에 맞게 시스템 수정
특정 기준선에 맞게 RHEL 시스템을 수정할 수 있습니다. SCAP 보안 가이드에서 제공하는 모든 프로필에 맞게 시스템을 교정할 수 있습니다. 사용 가능한 프로필 나열에 대한 자세한 내용은 구성 규정 준수에 대한 프로필 보기 섹션을 참조하십시오.
신중하게 사용하지 않는 경우 Remediate 옵션을 활성화하여 시스템 평가를 실행하면 시스템에 작동하지 않을 수 있습니다. Red Hat은 보안 강화 수정으로 인한 변경 사항을 되돌릴 수 있는 자동화된 방법을 제공하지 않습니다. 수정은 기본 구성의 RHEL 시스템에서 지원됩니다. 설치 후 시스템이 변경된 경우 수정을 실행하여 필요한 보안 프로필을 준수하지 못할 수 있습니다.
사전 요구 사항
-
scap-security-guide패키지가 설치됩니다.
절차
--remediate옵션과 함께oscap명령을 사용하여 시스템을 교정합니다.oscap xccdf eval --profile <profileID> --remediate /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap xccdf eval --profile <profileID> --remediate /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;profileID>를 시스템이 준수해야 하는 프로필 ID로 바꿉니다(예:hipaa).- 시스템을 다시 시작합니다.
검증
프로필로 시스템 규정 준수를 평가하고 검사 결과를 파일에 저장합니다.
oscap xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
$ oscap xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
oscap이 검사 결과를 저장하는 파일 이름이<scan-report.html>입니다. -
시스템이 준수해야 하는
프로파일 ID가 있는 <profileID>(예:hipaa).
-
18.6. SSG Ansible Playbook을 사용하여 특정 기준과 일치하도록 시스템 수정
SCAP 보안 가이드 프로젝트의 Ansible 플레이북 파일을 사용하여 특정 기준과 일치하도록 시스템을 교정할 수 있습니다. SCAP 보안 가이드에서 제공하는 모든 프로필에 맞게 문제를 해결할 수 있습니다.
신중하게 사용하지 않는 경우 Remediate 옵션을 활성화하여 시스템 평가를 실행하면 시스템에 작동하지 않을 수 있습니다. Red Hat은 보안 강화 수정으로 인한 변경 사항을 되돌릴 수 있는 자동화된 방법을 제공하지 않습니다. 수정은 기본 구성의 RHEL 시스템에서 지원됩니다. 설치 후 시스템이 변경된 경우 수정을 실행하여 필요한 보안 프로필을 준수하지 못할 수 있습니다.
사전 요구 사항
-
scap-security-guide패키지가 설치됩니다. -
ansible-core패키지가 설치되어 있습니다. 자세한 내용은 Ansible 설치 가이드를 참조하십시오. -
rhc-worker-playbook패키지가 설치되어 있습니다. - 시스템을 수정하려는 프로필에 따라 프로필 ID를 알고 있습니다. 자세한 내용은 구성 규정 준수의 프로필 보기를 참조하십시오.
RHEL 8.6 이상이 설치되어 있어야 합니다. RHEL 설치에 대한 자세한 내용은 설치 미디어에서 RHEL 상호 작용 설치를 참조하십시오.
참고RHEL 8.5 및 이전 버전에서 Ansible 패키지는 Ansible Core가 아닌 다른 수준의 지원을 통해 Ansible Engine을 통해 제공되었습니다. 패키지가 RHEL 8.6 이상에서 Ansible 자동화 콘텐츠와 호환되지 않을 수 있으므로 Ansible Engine을 사용하지 마십시오. 자세한 내용은 RHEL 9 및 RHEL 8.6 이상 AppStream 리포지토리에 포함된 Ansible Core 패키지에 대한 지원 범위를 참조하십시오.
절차
Ansible을 사용하여 선택한 프로필에 맞게 시스템을 교정합니다.
ANSIBLE_COLLECTIONS_PATH=/usr/share/rhc-worker-playbook/ansible/collections/ansible_collections/ ansible-playbook -i "localhost," -c local /usr/share/scap-security-guide/ansible/rhel8-playbook-<profileID>.yml
# ANSIBLE_COLLECTIONS_PATH=/usr/share/rhc-worker-playbook/ansible/collections/ansible_collections/ ansible-playbook -i "localhost," -c local /usr/share/scap-security-guide/ansible/rhel8-playbook-<profileID>.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령이 플레이북을 실행하려면
ANSIBLE_COLLECTIONS_PATH환경 변수가 필요합니다.&
lt;profileID>를 선택한 프로필의 프로필 ID로 바꿉니다.- 시스템을 다시 시작합니다.
검증
선택한 프로필을 사용하여 시스템의 규정 준수를 평가하고 검사 결과를 파일에 저장합니다.
oscap xccdf eval --profile <profileID> --report <scan-report.html> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap xccdf eval --profile <profileID> --report <scan-report.html> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;scan-report.html>을oscap이 검사 결과를 저장하는 파일 이름으로 바꿉니다.
18.7. 시스템을 특정 기준과 정렬하는 수정 Ansible 플레이북 생성
시스템을 특정 기준과 조정하는 데 필요한 수정 사항만 포함하는 Ansible 플레이북을 생성할 수 있습니다. 이 플레이북은 이미 충족된 요구 사항을 다루지 않기 때문에 더 적습니다. 플레이북을 생성하면 시스템을 어떤 식으로든 수정하지 않으며 이후 애플리케이션을 위한 파일만 준비합니다.
RHEL 8.6에서는 Ansible Engine이 기본 제공 모듈만 포함된 ansible-core 패키지로 교체됩니다. 많은 Ansible 수정에서는 기본 제공 모듈에 포함되지 않은 커뮤니티 및 이식 가능한 운영 체제 인터페이스(POSIX) 컬렉션의 모듈을 사용합니다. 이 경우 Bash 수정을 Ansible 수정을 대신 사용할 수 있습니다. RHEL 8.6의 Red Hat Connector에는 수정 플레이북이 Ansible Core와 함께 작동하는 데 필요한 Ansible 모듈이 포함되어 있습니다.
사전 요구 사항
-
scap-security-guide패키지가 설치됩니다. -
ansible-core패키지가 설치되어 있습니다. 자세한 내용은 Ansible 설치 가이드를 참조하십시오. -
rhc-worker-playbook패키지가 설치되어 있습니다. - 시스템을 수정하려는 프로필에 따라 프로필 ID를 알고 있습니다. 자세한 내용은 구성 규정 준수의 프로필 보기를 참조하십시오.
절차
시스템을 스캔하고 결과를 저장합니다.
oscap xccdf eval --profile <profileID> --results <profile-results.xml> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap xccdf eval --profile <profileID> --results <profile-results.xml> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 결과를 사용하여 파일에서 결과 ID 값을 찾습니다.
oscap info <profile-results.xml>
# oscap info <profile-results.xml>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 1단계에서 생성된 파일을 기반으로 Ansible 플레이북을 생성합니다.
oscap xccdf generate fix --fix-type ansible --result-id xccdf_org.open-scap_testresult_xccdf_org.ssgproject.content_profile_<profileID> --output <profile-remediations.yml> <profile-results.xml>
# oscap xccdf generate fix --fix-type ansible --result-id xccdf_org.open-scap_testresult_xccdf_org.ssgproject.content_profile_<profileID> --output <profile-remediations.yml> <profile-results.xml>Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
생성된 <
profile-remediations.yml> 파일에 1단계에서 수행한 검사에 실패한 규칙에 대한 Ansible 수정이 포함되어 있는지 검토합니다. Ansible을 사용하여 선택한 프로필에 맞게 시스템을 교정합니다.
ANSIBLE_COLLECTIONS_PATH=/usr/share/rhc-worker-playbook/ansible/collections/ansible_collections/ ansible-playbook -i "localhost," -c local <profile-remediations.yml>`
# ANSIBLE_COLLECTIONS_PATH=/usr/share/rhc-worker-playbook/ansible/collections/ansible_collections/ ansible-playbook -i "localhost," -c local <profile-remediations.yml>`Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령이 플레이북을 실행하려면
ANSIBLE_COLLECTIONS_PATH환경 변수가 필요합니다.주의신중하게 사용하지 않는 경우
Remediate옵션을 활성화하여 시스템 평가를 실행하면 시스템에 작동하지 않을 수 있습니다. Red Hat은 보안 강화 수정으로 인한 변경 사항을 되돌릴 수 있는 자동화된 방법을 제공하지 않습니다. 수정은 기본 구성의 RHEL 시스템에서 지원됩니다. 설치 후 시스템이 변경된 경우 수정을 실행하여 필요한 보안 프로필을 준수하지 못할 수 있습니다.
검증
선택한 프로필을 사용하여 시스템의 규정 준수를 평가하고 검사 결과를 파일에 저장합니다.
oscap xccdf eval --profile <profileID> --report <scan-report.html> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap xccdf eval --profile <profileID> --report <scan-report.html> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;scan-report.html>을oscap이 검사 결과를 저장하는 파일 이름으로 바꿉니다.
18.8. 이후 애플리케이션에 대한 해결 Bash 스크립트 생성
이 절차를 사용하여 시스템을 HIPAA와 같은 보안 프로필에 정렬하는 수정이 포함된 Bash 스크립트를 생성합니다. 다음 단계를 사용하여 시스템을 수정하지 않고 이후 애플리케이션을 위한 파일만 준비합니다.
사전 요구 사항
-
scap-security-guide패키지가 RHEL 시스템에 설치되어 있습니다.
절차
oscap명령을 사용하여 시스템을 스캔하고 결과를 XML 파일에 저장합니다. 다음 예에서oscap은hipaa프로필에 대해 시스템을 평가합니다.oscap xccdf eval --profile hipaa --results <hipaa-results.xml> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap xccdf eval --profile hipaa --results <hipaa-results.xml> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 결과를 사용하여 파일에서 결과 ID 값을 찾습니다.
oscap info <hipaa-results.xml>
# oscap info <hipaa-results.xml>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 1단계에서 생성된 결과 파일을 기반으로 Bash 스크립트를 생성합니다.
oscap xccdf generate fix --fix-type bash --result-id <xccdf_org.open-scap_testresult_xccdf_org.ssgproject.content_profile_hipaa> --output <hipaa-remediations.sh> <hipaa-results.xml>
# oscap xccdf generate fix --fix-type bash --result-id <xccdf_org.open-scap_testresult_xccdf_org.ssgproject.content_profile_hipaa> --output <hipaa-remediations.sh> <hipaa-results.xml>Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
&
lt;hipaa-remediations.sh> 파일에는 1단계에서 수행한 검사 중에 실패한 규칙에 대한 수정이 포함되어 있습니다. 생성된 이 파일을 검토한 후 이 파일과 동일한 디렉터리에 있는 경우./ <hipaa-remediations.sh> 명령으로 적용할 수 있습니다.
검증
-
선택한 텍스트 편집기에서 <
hipaa-remediations.sh> 파일에 1단계에서 수행한 검사에 실패한 규칙이 포함되어 있는지 검토합니다.
18.9. SCAP Workbench를 사용하여 사용자 지정 프로필로 시스템 스캔
scap-workbench 패키지에 포함된 SCAP Workbench 는 사용자가 단일 로컬 또는 원격 시스템에서 구성 및 취약점 검사를 수행하고 시스템 수정을 수행하고 스캔 평가를 기반으로 보고서를 생성하는 그래픽 유틸리티입니다. SCAP Workbench 에는 oscap 명령줄 유틸리티에 비해 기능이 제한되어 있습니다. SCAP Workbench 는 데이터 스트림 파일 형식으로 보안 콘텐츠를 처리합니다.
18.9.1. SCAP Workbench를 사용하여 시스템 검사 및 교정
선택한 보안 정책에 대해 시스템을 평가하려면 다음 절차를 사용합니다.
사전 요구 사항
-
scap-workbench패키지가 시스템에 설치되어 있습니다.
절차
GNOME Classic데스크탑 환경에서SCAP Workbench를 실행하려면 Super 키를 눌러Activities Overview(활동 개요)를 입력하고scap-workbench를 입력한 다음 Enter 키를 누릅니다. 또는 다음을 사용합니다.scap-workbench &
$ scap-workbench &Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 옵션 중 하나를 사용하여 보안 정책을 선택합니다.
-
시작 창에서
컨텐츠 로드버튼 -
SCAP 보안 가이드에서 콘텐츠 열기 File(파일) 메뉴에서기타 콘텐츠를 열고해당 XCCDF, SCAP RPM 또는 데이터 스트림 파일을 검색합니다.
-
시작 창에서
(고급) 확인란을 선택하여 시스템 구성을 자동으로 수정할 수 있습니다. 이 옵션을 활성화하면
SCAP Workbench는 정책에서 적용하는 보안 규칙에 따라 시스템 구성을 변경하려고 합니다. 이 프로세스는 시스템 검사 중에 실패하는 관련 검사를 수정해야 합니다.주의신중하게 사용하지 않는 경우
Remediate옵션을 활성화하여 시스템 평가를 실행하면 시스템에 작동하지 않을 수 있습니다. Red Hat은 보안 강화 수정으로 인한 변경 사항을 되돌릴 수 있는 자동화된 방법을 제공하지 않습니다. 수정은 기본 구성의 RHEL 시스템에서 지원됩니다. 설치 후 시스템이 변경된 경우 수정을 실행하여 필요한 보안 프로필을 준수하지 못할 수 있습니다.Scan(검사) 버튼을 클릭하여 선택한 프로필로 시스템을 .
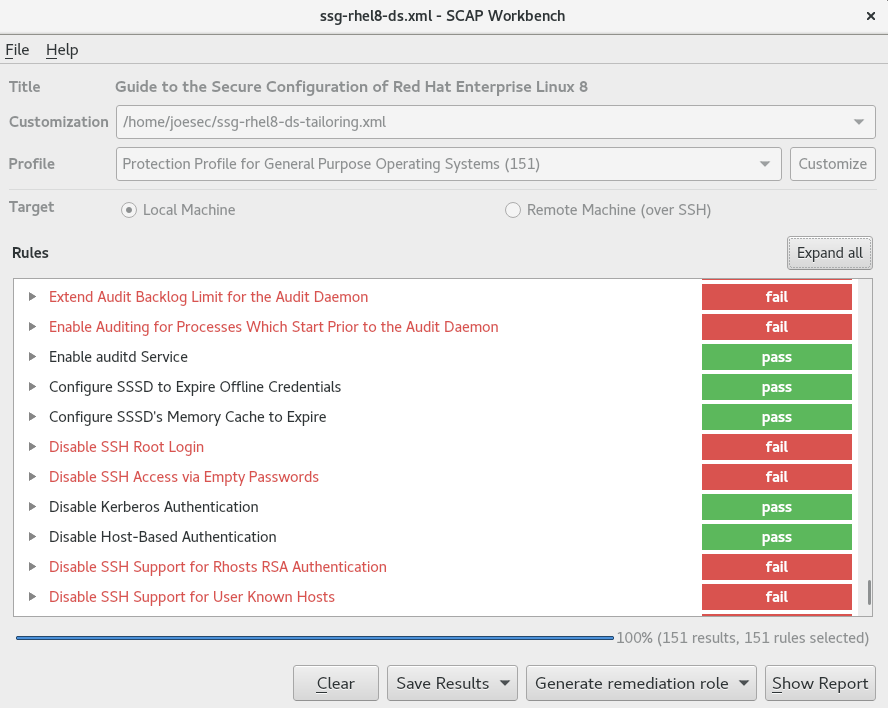
-
검사 결과를 XCCDF, ARF 또는 HTML 파일의 형식으로 저장하려면 콤보 상자를 클릭합니다.
HTML Report옵션을 선택하여 사용자가 읽을 수 있는 형식으로 스캔 보고서를 생성합니다. XCCDF 및 ARF(데이터 스트림) 형식은 추가 자동 처리에 적합합니다. 세 가지 옵션을 모두 반복적으로 선택할 수 있습니다. - 결과 기반 수정을 파일로 내보내려면 팝업 메뉴를 사용합니다.
18.9.2. SCAP Workbench를 사용하여 보안 프로필 사용자 정의
특정 규칙(예: 최소 암호 길이)에서 매개 변수를 변경하고, 다른 방식으로 적용되는 규칙을 제거하고 추가 규칙을 선택하여 내부 정책을 구현하여 보안 프로필을 사용자 지정할 수 있습니다. 프로필을 사용자 지정하여 새 규칙을 정의할 수 없습니다.
다음 절차에서는 프로필을 사용자 지정하는 데 SCAP Workbench 를 사용하는 방법을 보여줍니다. oscap 명령줄 유틸리티와 함께 사용할 맞춤형 프로필을 저장할 수도 있습니다.
사전 요구 사항
-
scap-workbench패키지가 시스템에 설치되어 있습니다.
절차
-
SCAP Workbench를 실행하고Open content from SCAP Security Guide(SCAP 보안 가이드에서 콘텐츠 열기) 또는파일메뉴에서 OpenOther Content(기타 콘텐츠 열기)를 사용하여 사용자 지정할 프로필을 선택합니다. 요구 사항에 따라 선택한 보안 프로필을 조정하려면 (사용자 지정) 버튼을 클릭합니다.
그러면 원래 데이터 스트림 파일을 변경하지 않고 현재 선택한 프로필을 수정할 수 있는 새 Customization(사용자 지정) 창이 열립니다. 새 프로필 ID를 선택합니다.

- 논리 그룹 또는 (검색) 필드로 구성된 규칙과 함께 트리 구조를 사용하여 수정하는 규칙을 찾습니다.
트리 구조의 확인란을 사용하여 규칙을 포함하거나 제외하거나 해당하는 규칙의 값을 수정합니다.
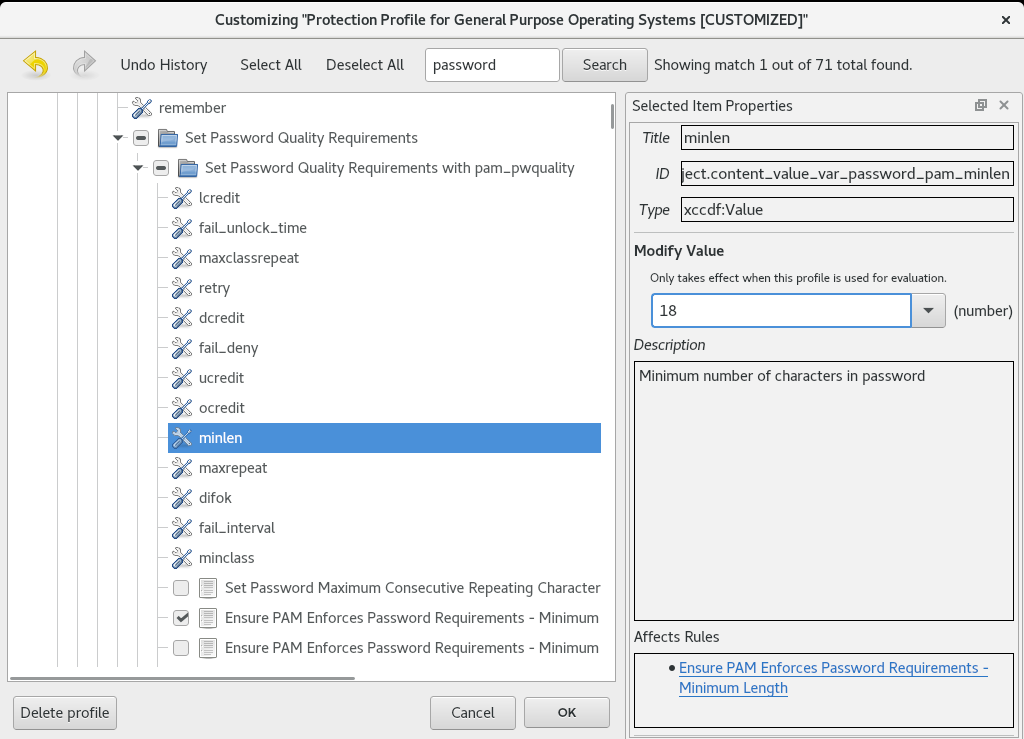
- (확인) 버튼을 클릭하여 변경 사항을 확인합니다.
변경 사항을 영구적으로 저장하려면 다음 옵션 중 하나를 사용합니다.
-
File(파일) 메뉴에서Save Customization only(사용자 지정만저장)을 사용하여 사용자 지정 파일을 별도로 저장합니다. File(파일) 메뉴에서Save All(모두 저장)을 사용하여 한 번에 모든 보안 콘텐츠를 저장합니다.Into a directory옵션을 선택하면SCAP Workbench는 데이터 스트림 파일과 사용자 지정 파일을 지정된 위치에 모두 저장합니다. 이를 백업 솔루션으로 사용할 수 있습니다.As RPM(RPM) 옵션을 선택하면SCAP Workbench에 데이터 스트림 파일과 사용자 지정 파일이 포함된 RPM 패키지를 생성하도록 지시할 수 있습니다. 이 기능은 원격으로 스캔할 수 없는 시스템에 보안 콘텐츠를 배포하고 추가 처리를 위해 콘텐츠를 전달하는 데 유용합니다.
-
SCAP Workbench 는 맞춤형 프로필의 결과 기반 수정을 지원하지 않으므로 oscap 명령줄 유틸리티와 함께 내보낸 수정을 사용합니다.
18.10. 컨테이너 및 컨테이너 이미지에서 취약점 스캔
컨테이너 또는 컨테이너 이미지에서 보안 취약점을 찾으려면 다음 절차를 사용하십시오.
oscap-podman 명령은 RHEL 8.2에서 사용할 수 있습니다. RHEL 8.1 및 8.0의 경우 RHEL 8 Knowledgebase 문서의 컨테이너 스캔을 위해 OpenSCAP 사용 방법에 설명된 해결 방법을 사용하십시오.
사전 요구 사항
-
openscap-utils및bzip2패키지가 설치됩니다.
절차
시스템에 대한 최신 RHSA OVAL 정의를 다운로드합니다.
wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xml
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 컨테이너 또는 컨테이너 이미지의 ID를 가져옵니다. 예를 들면 다음과 같습니다.
podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MB
# podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MBCopy to Clipboard Copied! Toggle word wrap Toggle overflow 컨테이너 또는 컨테이너 이미지에서 취약점을 검사하고 결과를 vulnerability.html 파일에 저장합니다.
oscap-podman 096cae65a207 oval eval --report vulnerability.html rhel-8.oval.xml
# oscap-podman 096cae65a207 oval eval --report vulnerability.html rhel-8.oval.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow oscap-podman명령에는 루트 권한이 필요하며 컨테이너 ID는 첫 번째 인수입니다.
검증
선택한 브라우저의 결과를 확인합니다. 예를 들면 다음과 같습니다.
firefox vulnerability.html &
$ firefox vulnerability.html &Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.11. 특정 기준에서 컨테이너 또는 컨테이너 이미지의 보안 준수 평가
OSP(운영 체제 보호 프로필), PCI-DSS(Payment Card Industry Data Security Standard) 및 HIPAA(Health Insurance Portability and Accountability Act)와 같은 특정 보안 기준이 있는 컨테이너 또는 컨테이너 이미지의 규정 준수를 평가할 수 있습니다.
oscap-podman 명령은 RHEL 8.2에서 사용할 수 있습니다. RHEL 8.1 및 8.0의 경우 RHEL 8 Knowledgebase 문서의 컨테이너 스캔을 위해 OpenSCAP 사용 방법에 설명된 해결 방법을 사용하십시오.
사전 요구 사항
-
openscap-utils및scap-security-guide패키지가 설치됩니다. - 시스템에 대한 루트 액세스 권한이 있습니다.
절차
컨테이너 또는 컨테이너 이미지의 ID를 찾습니다.
-
컨테이너 ID를 찾으려면
podman ps -a명령을 입력합니다. -
컨테이너 이미지의 ID를 찾으려면
podman images명령을 입력합니다.
-
컨테이너 ID를 찾으려면
프로필이 있는 컨테이너 또는 컨테이너 이미지의 규정 준수를 평가하고 검사 결과를 파일에 저장합니다.
oscap-podman <ID> xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
# oscap-podman <ID> xccdf eval --report <scan-report.html> --profile <profileID> /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
컨테이너 또는 컨테이너 이미지의 ID가 있는 <ID>
-
oscap이 검사 결과를 저장하는 파일 이름이 <scan-report.html> -
<profileID> 시스템이 준수해야 하는 프로필 ID(예:hipaa,ospp또는pci-dss) 사용
-
컨테이너 또는 컨테이너 이미지의 ID가 있는 <ID>
검증
선택한 브라우저의 결과를 확인합니다. 예를 들면 다음과 같습니다.
firefox <scan-report.html> &
$ firefox <scan-report.html> &Copy to Clipboard Copied! Toggle word wrap Toggle overflow
notapplicable 로 표시된 규칙은 컨테이너 또는 컨테이너 이미지에는 적용되지 않고 베어 메탈 및 가상화된 시스템에만 적용됩니다.
18.12. AIDE로 무결성 확인
AIDE(Advanced Intrusion Detection Environment)는 시스템에서 파일 데이터베이스를 만든 다음 해당 데이터베이스를 사용하여 파일 무결성을 보장하고 시스템 침입을 감지하는 유틸리티입니다.
18.12.1. AIDE 설치
AIDE를 사용하여 file-integrity 검사를 시작하려면 해당 패키지를 설치하고 AIDE 데이터베이스를 시작해야 합니다.
사전 요구 사항
-
AppStream리포지토리가 활성화되어 있습니다.
절차
aide패키지를 설치합니다.yum install aide
# yum install aideCopy to Clipboard Copied! Toggle word wrap Toggle overflow 초기 데이터베이스를 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
선택 사항: 기본 구성에서
aide --init명령은/etc/aide.conf파일에 정의된 디렉토리와 파일 집합만 확인합니다. AIDE 데이터베이스에 추가 디렉터리 또는 파일을 포함시키고 감시된 매개 변수를 변경하려면 그에 따라/etc/aide.conf를 편집합니다. 데이터베이스 사용을 시작하려면 초기 데이터베이스 파일 이름에서
.new하위 문자열을 제거합니다.mv /var/lib/aide/aide.db.new.gz /var/lib/aide/aide.db.gz
# mv /var/lib/aide/aide.db.new.gz /var/lib/aide/aide.db.gzCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
선택 사항: AIDE 데이터베이스의 위치를 변경하려면
/etc/aide.conf파일을 편집하고DBDIR값을 수정합니다. 보안을 강화하기 위해 데이터베이스, 구성 및/usr/sbin/aide바이너리 파일을 읽기 전용 미디어와 같은 보안 위치에 저장하십시오.
18.12.2. AIDE를 사용하여 무결성 검사 수행
crond 서비스를 사용하여 AIDE에서 일반 file-integrity 검사를 예약할 수 있습니다.
사전 요구 사항
- AIDE가 올바르게 설치되고 데이터베이스가 초기화됩니다. AIDE 설치 참조
절차
수동 검사를 시작하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 최소한 AIDE가 매주 AIDE를 실행하도록 시스템을 구성합니다. 최적으로 AIDE를 매일 실행합니다. 예를 들어
cron명령을 사용하여 매일 AIDE 실행을 04:05 a.m로 예약하려면/etc/crontab파일에 다음 행을 추가합니다.05 4 * * * root /usr/sbin/aide --check
05 4 * * * root /usr/sbin/aide --checkCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.12.3. AIDE 데이터베이스 업데이트
패키지 업데이트 또는 구성 파일 조정과 같은 시스템 변경 사항을 확인한 후 기본 AIDE 데이터베이스도 업데이트합니다.
사전 요구 사항
- AIDE가 올바르게 설치되고 데이터베이스가 초기화됩니다. AIDE 설치 참조
절차
기준 AIDE 데이터베이스를 업데이트합니다.
aide --update
# aide --updateCopy to Clipboard Copied! Toggle word wrap Toggle overflow aide --update명령은/var/lib/aide/aide.db.new.gz데이터베이스 파일을 만듭니다.-
업데이트된 데이터베이스를 사용하여 무결성 검사를 시작하려면 파일 이름에서
.new하위 문자열을 제거합니다.
18.12.4. 파일 통합 도구: AIDE 및 IMA
Red Hat Enterprise Linux는 시스템에서 파일 및 디렉토리의 무결성을 확인하고 유지하기 위한 몇 가지 도구를 제공합니다. 다음 표는 시나리오에 가장 적합한 도구를 결정하는 데 도움이 됩니다.
| 질문 | AIDE(Advanced Intrusion Detection Environment) | 무결성 측정 아키텍처(IMA) |
|---|---|---|
| 내용 | AIDE는 시스템에 파일 및 디렉터리의 데이터베이스를 생성하는 유틸리티입니다. 이 데이터베이스는 파일 무결성을 확인하고 침입을 감지하는 데 사용됩니다. | IMA는 이전에 저장된 확장 속성과 비교하여 파일 측정(해시 값)을 확인하여 파일이 변경되는지 여부를 감지합니다. |
| 방법 | AIDE에서는 규칙을 사용하여 파일과 디렉터리의 무결성 상태를 비교합니다. | IMA는 파일 해시 값을 사용하여 침입을 감지합니다. |
| 왜 | 탐지 - AIDE에서 규칙을 확인하여 파일을 수정했는지 감지합니다. | 감지 및 조작 - IMA는 파일의 확장된 속성을 대체하여 공격을 탐지하고 방지합니다. |
| 사용법 | AIDE에서는 파일 또는 디렉터리가 수정될 때 위협을 탐지합니다. | IMA는 다른 사람이 전체 파일을 변경하려고 할 때 위협을 감지합니다. |
| 확장 | AIDE에서는 로컬 시스템에서 파일 및 디렉터리의 무결성을 검사합니다. | IMA는 로컬 및 원격 시스템에서 보안을 보장합니다. |
18.13. LUKS를 사용하여 블록 장치 암호화
디스크 암호화를 사용하면 블록 장치의 데이터를 암호화하여 보호할 수 있습니다. 장치의 암호 해독된 콘텐츠에 액세스하려면 암호 또는 키를 인증으로 입력합니다. 이는 시스템에서 물리적으로 제거된 경우에도 장치의 콘텐츠를 보호하는 데 도움이 되므로 모바일 컴퓨터와 이동식 미디어에 중요합니다. LUKS 형식은 Red Hat Enterprise Linux에서 블록 장치 암호화의 기본 구현입니다.
18.13.1. LUKS 디스크 암호화
Linux Unified Key Setup-on-disk-format(LUKS)은 암호화된 장치 관리를 간소화하는 툴 세트를 제공합니다. LUKS를 사용하면 블록 장치를 암호화하고 여러 사용자 키를 활성화하여 마스터 키를 해독할 수 있습니다. 파티션의 대량 암호화의 경우 이 마스터 키를 사용합니다.
Red Hat Enterprise Linux는 LUKS를 사용하여 블록 장치 암호화를 수행합니다. 기본적으로 블록 장치를 암호화하는 옵션은 설치 중에 선택되지 않습니다. 디스크를 암호화할 옵션을 선택하면 시스템을 부팅할 때마다 시스템에서 암호를 입력하라는 메시지가 표시됩니다. 이 암호는 파티션을 해독하는 대량 암호화 키의 잠금을 해제합니다. 기본 파티션 테이블을 수정하려면 암호화할 파티션을 선택할 수 있습니다. 이는 파티션 테이블 설정에서 설정됩니다.
암호화
LUKS에 사용되는 기본 암호는 aes-xts-plain64 입니다. LUKS의 기본 키 크기는 512비트입니다. Anaconda XTS 모드가 있는 LUKS의 기본 키 크기는 512비트입니다. 다음은 사용 가능한 암호입니다.
- AES(Advanced Encryption Standard)
- Twofish
- serpent
LUKS에서 수행하는 작업
- LUKS는 전체 블록 장치를 암호화하므로 이동식 스토리지 미디어 또는 랩톱 디스크 드라이브와 같은 모바일 장치의 콘텐츠를 보호하는 데 적합합니다.
- 암호화된 블록 장치의 기본 내용은 임의이므로 스왑 장치를 암호화하는 데 유용합니다. 이는 데이터 저장을 위해 특별히 포맷된 블록 장치를 사용하는 특정 데이터베이스에서도 유용할 수 있습니다.
- LUKS는 기존 장치 매퍼 커널 하위 시스템을 사용합니다.
- LUKS는 사전 공격으로부터 보호하는 암호 강화를 제공합니다.
- LUKS 장치에는 여러 개의 키 슬롯이 포함되어 있으므로 백업 키 또는 암호를 추가할 수 있습니다.
다음 시나리오에는 LUKS를 사용하지 않는 것이 좋습니다.
- LUKS와 같은 디스크 암호화 솔루션은 시스템이 꺼져 있는 경우에만 데이터를 보호합니다. 시스템이 있고 LUKS가 디스크의 암호를 해독하면 해당 디스크의 파일을 액세스할 수 있는 모든 사용자가 사용할 수 있습니다.
- 여러 사용자가 동일한 장치에 대한 고유한 액세스 키를 보유해야 하는 시나리오. LUKS1 형식은 8개의 키 슬롯을 제공하며 LUKS2는 최대 32개의 키 슬롯을 제공합니다.
- 파일 수준 암호화가 필요한 애플리케이션입니다.
18.13.2. RHEL의 LUKS 버전
Red Hat Enterprise Linux에서 LUKS 암호화의 기본 형식은 LUKS2입니다. 이전 LUKS1 형식은 완전히 지원되며 이전 Red Hat Enterprise Linux 릴리스와 호환되는 형식으로 제공됩니다. LUKS2 재암호화는 LUKS1 재암호화에 비해 더 강력하고 안전한 것으로 간주됩니다.
LUKS2 형식을 사용하면 바이너리 구조를 수정할 필요 없이 다양한 부분을 나중에 업데이트할 수 있습니다. 내부적으로는 메타데이터에 JSON 텍스트 형식을 사용하고, 메타데이터의 중복성을 제공하고, 메타데이터 손상을 감지하고, 메타데이터 복사본에서 자동으로 복구합니다.
LUKS2 및 LUKS1은 디스크를 암호화하기 위해 다른 명령을 사용하므로 LUKS1만 지원하는 시스템에서 LUKS2를 사용하지 마십시오. LUKS 버전에 잘못된 명령을 사용하면 데이터가 손실될 수 있습니다.
| LUKS 버전 | 암호화 명령 |
|---|---|
| LUKS2 |
|
| LUKS1 |
|
온라인 재암호화
LUKS2 형식은 장치가 사용 중인 동안 암호화된 장치 재암호화를 지원합니다. 예를 들어 다음 작업을 수행하기 위해 장치에서 파일 시스템을 마운트 해제할 필요가 없습니다.
- 볼륨 키 변경
암호화 알고리즘 변경
암호화되지 않은 장치를 암호화할 때 파일 시스템을 마운트 해제해야 합니다. 암호화를 간단히 초기화한 후 파일 시스템을 다시 마운트할 수 있습니다.
LUKS1 형식은 온라인 재암호화 기능을 지원하지 않습니다.
변환
특정 상황에서 LUKS1을 LUKS2로 변환할 수 있습니다. 다음 시나리오에서는 변환이 특히 불가능합니다.
-
LUKS1 장치는 PBD(Policy-Based Decryption) Clevis 솔루션에서 사용하는 것으로 표시됩니다.
cryptsetup툴은 일부luksmeta메타데이터가 감지되면 장치를 변환하지 않습니다. - 장치가 활성 상태입니다. 변환이 가능하려면 장치가 비활성 상태여야 합니다.
18.13.3. LUKS2 재암호화 중에 데이터 보호 옵션
LUKS2는 재암호화 프로세스 중에 성능 또는 데이터 보호 우선 순위를 지정하는 여러 옵션을 제공합니다. 복원력 옵션에 대해 다음 모드를 제공하며, cryptsetup reencrypt -- 선택할 수 있습니다. 여기서 < resilience resilience-mode /dev/ <device_ID> 명령을 사용하여 이러한 모드를device_ID >를 장치의 ID로 교체할 수 있습니다.
checksum기본 모드입니다. 데이터 보호 및 성능 균형 유지.
이 모드는 재암호화 영역에 섹터의 개별 체크섬을 저장하므로 복구 프로세스에서 LUKS2에서 다시 암호화한 섹터를 감지할 수 있습니다. 이 모드에서는 블록 장치 섹터 쓰기가 atomic이어야 합니다.
journal- 가장 안전한 모드이지만 가장 느린 모드이기도 합니다. 이 모드는 바이너리 영역에 재암호화 영역을 저널링하므로 LUKS2는 데이터를 두 번 씁니다.
none-
none모드는 성능에 우선 순위를 지정하며 데이터 보호를 제공하지 않습니다. 이는SIGTERM신호 또는 Ctrl+C 키를 누른 사용자와 같은 안전한 프로세스 종료로부터만 데이터를 보호합니다. 예기치 않은 시스템 오류 또는 애플리케이션 오류로 인해 데이터가 손상될 수 있습니다.
LUKS2 재암호화 프로세스가 강제 종료되면 LUKS2는 다음 방법 중 하나로 복구를 수행할 수 있습니다.
- 자동
다음 작업 중 하나를 수행하면 다음 LUKS2 장치의 열려 있는 작업 중에 자동 복구 작업이 트리거됩니다.
-
cryptsetup open명령을 실행합니다. -
systemd-cryptsetup명령을 사용하여 장치를 연결합니다.
-
- 수동
-
LUKS2 장치에서
cryptsetup repair /dev/ <device_ID> 명령을 사용하여 다음을 수행합니다.
18.13.4. LUKS2를 사용하여 블록 장치의 기존 데이터 암호화
LUKS2 형식을 사용하여 아직 암호화되지 않은 장치에서 기존 데이터를 암호화할 수 있습니다. 새 LUKS 헤더가 장치의 헤드에 저장됩니다.
사전 요구 사항
- 블록 장치에는 파일 시스템이 있습니다.
데이터를 백업했습니다.
주의하드웨어, 커널 또는 인적 오류로 인해 암호화 프로세스 중에 데이터가 손실될 수 있습니다. 데이터 암호화를 시작하기 전에 신뢰할 수 있는 백업이 있는지 확인합니다.
절차
암호화하려는 장치에서 모든 파일 시스템을 마운트 해제합니다. 예를 들면 다음과 같습니다.
umount /dev/mapper/vg00-lv00
# umount /dev/mapper/vg00-lv00Copy to Clipboard Copied! Toggle word wrap Toggle overflow LUKS 헤더 저장에 사용 가능한 공간을 만듭니다. 시나리오에 맞는 다음 옵션 중 하나를 사용합니다.
논리 볼륨을 암호화하는 경우 파일 시스템의 크기를 조정하지 않고 논리 볼륨을 확장할 수 있습니다. 예를 들면 다음과 같습니다.
lvextend -L+32M /dev/mapper/vg00-lv00
# lvextend -L+32M /dev/mapper/vg00-lv00Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
parted와 같은 파티션 관리 도구를 사용하여 파티션을 확장합니다. -
장치의 파일 시스템을 축소합니다. ext
2, ext3 또는 ext4 파일 시스템에 resize2fs유틸리티를 사용할 수 있습니다. XFS 파일 시스템을 축소할 수 없습니다.
암호화를 초기화합니다.
cryptsetup reencrypt --encrypt --init-only --reduce-device-size 32M /dev/mapper/vg00-lv00 lv00_encrypted /dev/mapper/lv00_encrypted is now active and ready for online encryption.
# cryptsetup reencrypt --encrypt --init-only --reduce-device-size 32M /dev/mapper/vg00-lv00 lv00_encrypted /dev/mapper/lv00_encrypted is now active and ready for online encryption.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 장치를 마운트합니다.
mount /dev/mapper/lv00_encrypted /mnt/lv00_encrypted
# mount /dev/mapper/lv00_encrypted /mnt/lv00_encryptedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영구 매핑 항목을
/etc/crypttab파일에 추가합니다.luksUUID찾기:cryptsetup luksUUID /dev/mapper/vg00-lv00 a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325
# cryptsetup luksUUID /dev/mapper/vg00-lv00 a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택한 텍스트 편집기에서
/etc/crypttab을 열고 이 파일에 장치를 추가합니다.vi /etc/crypttab lv00_encrypted UUID=a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 none
$ vi /etc/crypttab lv00_encrypted UUID=a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 noneCopy to Clipboard Copied! Toggle word wrap Toggle overflow a52e2cc9-a5be-47b8-a95d-6bdf4f2d9325 를 장치의
luksUUID로 교체합니다.dracut을 사용하여 initramfs 새로 고침 :dracut -f --regenerate-all
$ dracut -f --regenerate-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
/etc/fstab파일에 영구 마운트 항목을 추가합니다.활성 LUKS 블록 장치의 파일 시스템의 UUID를 찾습니다.
blkid -p /dev/mapper/lv00_encrypted /dev/mapper/lv00-encrypted: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"
$ blkid -p /dev/mapper/lv00_encrypted /dev/mapper/lv00-encrypted: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택한 텍스트 편집기에서
/etc/fstab를 열고 이 파일에 장치를 추가합니다. 예를 들면 다음과 같습니다.vi /etc/fstab UUID=37bc2492-d8fa-4969-9d9b-bb64d3685aa9 /home auto rw,user,auto 0
$ vi /etc/fstab UUID=37bc2492-d8fa-4969-9d9b-bb64d3685aa9 /home auto rw,user,auto 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 37bc2492-d8fa-4969-9d9b-bb64d3685aa9 를 파일 시스템의 UUID로 교체합니다.
온라인 암호화를 다시 시작합니다.
cryptsetup reencrypt --resume-only /dev/mapper/vg00-lv00 Enter passphrase for /dev/mapper/vg00-lv00: Auto-detected active dm device 'lv00_encrypted' for data device /dev/mapper/vg00-lv00. Finished, time 00:31.130, 10272 MiB written, speed 330.0 MiB/s
# cryptsetup reencrypt --resume-only /dev/mapper/vg00-lv00 Enter passphrase for /dev/mapper/vg00-lv00: Auto-detected active dm device 'lv00_encrypted' for data device /dev/mapper/vg00-lv00. Finished, time 00:31.130, 10272 MiB written, speed 330.0 MiB/sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
기존 데이터가 암호화되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 암호화된 빈 블록 장치의 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.13.5. 분리된 헤더로 LUKS2를 사용하여 블록 장치에서 기존 데이터 암호화
LUKS 헤더를 저장하기 위한 여유 공간을 생성하지 않고 블록 장치에서 기존 데이터를 암호화할 수 있습니다. 헤더는 분리된 위치에 저장되며 추가 보안 계층 역할을 합니다. 절차에서는 LUKS2 암호화 형식을 사용합니다.
사전 요구 사항
- 블록 장치에는 파일 시스템이 있습니다.
데이터가 백업됩니다.
주의하드웨어, 커널 또는 인적 오류로 인해 암호화 프로세스 중에 데이터가 손실될 수 있습니다. 데이터 암호화를 시작하기 전에 신뢰할 수 있는 백업이 있는지 확인합니다.
프로세스
장치의 모든 파일 시스템을 마운트 해제합니다. 예를 들면 다음과 같습니다.
umount /dev/<nvme0n1p1>
# umount /dev/<nvme0n1p1>Copy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;nvme0n1p1>을 마운트 해제하려는 파티션에 해당하는 장치 식별자로 바꿉니다.암호화를 초기화합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 교체:
-
LUKS
헤더가 분리된 파일 경로가 있는 </home/header>입니다. LUKS 분리 헤더는 나중에 암호화된 장치의 잠금을 해제하려면 액세스할 수 있어야 합니다. -
암호화 후 생성된 장치 매퍼의 이름이 <
nvme_encrypted>입니다.
-
LUKS
장치를 마운트합니다.
mount /dev/mapper/<nvme_encrypted> /mnt/<nvme_encrypted>
# mount /dev/mapper/<nvme_encrypted> /mnt/<nvme_encrypted>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 영구 매핑 항목을
/etc/crypttab파일에 추가합니다.<nvme_encrypted> /dev/disk/by-id/<nvme-partition-id> none header=</home/header>
# <nvme_encrypted> /dev/disk/by-id/<nvme-partition-id> none header=</home/header>Copy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;nvme-partition-id>를 NVMe 파티션의 식별자로 바꿉니다.dracut을 사용하여 initramfs를 다시 생성 :dracut -f --regenerate-all -v
# dracut -f --regenerate-all -vCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstab파일에 영구 마운트 항목을 추가합니다.활성 LUKS 블록 장치의 파일 시스템의 UUID를 찾습니다.
blkid -p /dev/mapper/<nvme_encrypted> /dev/mapper/<nvme_encrypted>: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"
$ blkid -p /dev/mapper/<nvme_encrypted> /dev/mapper/<nvme_encrypted>: UUID="37bc2492-d8fa-4969-9d9b-bb64d3685aa9" BLOCK_SIZE="4096" TYPE="xfs" USAGE="filesystem"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 텍스트 편집기에서
/etc/fstab를 열고 이 파일에 장치를 추가합니다. 예를 들면 다음과 같습니다.UUID=<file_system_UUID> /home auto rw,user,auto 0
UUID=<file_system_UUID> /home auto rw,user,auto 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;file_system_UUID>를 이전 단계에서 찾은 파일 시스템의 UUID로 바꿉니다.
온라인 암호화를 다시 시작합니다.
cryptsetup reencrypt --resume-only --header </home/header> /dev/<nvme0n1p1> Enter passphrase for /dev/<nvme0n1p1>: Auto-detected active dm device '<nvme_encrypted>' for data device /dev/<nvme0n1p1>. Finished, time 00m51s, 10 GiB written, speed 198.2 MiB/s
# cryptsetup reencrypt --resume-only --header </home/header> /dev/<nvme0n1p1> Enter passphrase for /dev/<nvme0n1p1>: Auto-detected active dm device '<nvme_encrypted>' for data device /dev/<nvme0n1p1>. Finished, time 00m51s, 10 GiB written, speed 198.2 MiB/sCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
분리된 헤더와 함께 LUKS2를 사용하여 블록 장치의 기존 데이터가 암호화되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 암호화된 빈 블록 장치의 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.13.6. LUKS2를 사용하여 빈 블록 장치 암호화
LUKS2 형식을 사용하여 암호화된 스토리지에 사용할 수 있는 빈 블록 장치를 암호화할 수 있습니다.
사전 요구 사항
-
빈 블록 장치입니다.
lsblk와 같은 명령을 사용하여 해당 장치에 실제 데이터(예: 파일 시스템)가 없는지 확인할 수 있습니다.
프로세스
파티션을 암호화된 LUKS 파티션으로 설정합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 암호화된 LUKS 파티션을 엽니다.
cryptsetup open /dev/nvme0n1p1 nvme0n1p1_encrypted Enter passphrase for /dev/nvme0n1p1:
# cryptsetup open /dev/nvme0n1p1 nvme0n1p1_encrypted Enter passphrase for /dev/nvme0n1p1:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이렇게 하면 파티션 잠금을 해제하고 장치 매퍼를 사용하여 새 장치에 매핑됩니다. 암호화된 데이터를 덮어쓰지 않으려면 이 명령은
/dev/mapper/device_mapped_name경로를 사용하여 장치가 암호화된 장치이고 LUKS를 통해 처리됨을 커널에 알립니다.암호화된 데이터를 파티션에 쓸 파일 시스템을 생성합니다. 이 파티션은 장치 매핑된 이름을 통해 액세스해야 합니다.
mkfs -t ext4 /dev/mapper/nvme0n1p1_encrypted
# mkfs -t ext4 /dev/mapper/nvme0n1p1_encryptedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 장치를 마운트합니다.
mount /dev/mapper/nvme0n1p1_encrypted mount-point
# mount /dev/mapper/nvme0n1p1_encrypted mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
빈 블록 장치가 암호화되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 암호화된 빈 블록 장치의 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.13.7. 웹 콘솔에서 LUKS 암호 구성
시스템의 기존 논리 볼륨에 암호화를 추가하려면 볼륨 포맷을 통해서만 이 작업을 수행할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치됩니다. - 암호화 없이 기존 논리 볼륨을 사용할 수 있습니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 패널에서 스토리지를 클릭합니다.
- 스토리지 테이블에서 암호화할 스토리지 대한 메뉴 버튼을 클릭하고 을 클릭합니다.
- 암호화 필드에서 암호화 사양, LUKS1 또는 LUKS2 를 선택합니다.
- 새 암호를 설정하고 확인합니다.
- 선택 사항: 추가 암호화 옵션을 수정합니다.
- 형식 설정 완료.
- 형식 을 클릭합니다.
18.13.8. 웹 콘솔에서 LUKS 암호 변경
웹 콘솔의 암호화된 디스크 또는 파티션에서 LUKS 암호를 변경합니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치됩니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 패널에서 스토리지를 클릭합니다.
- 스토리지 테이블에서 암호화된 데이터가 있는 디스크를 선택합니다.
- 디스크 페이지에서 Keys 섹션으로 스크롤하여 편집 버튼을 클릭합니다.
암호 변경 대화 상자 창에서 다음을 수행합니다.
- 현재 암호를 입력합니다.
- 새 암호를 입력합니다.
- 새 암호를 확인합니다.
- 저장을 클릭합니다.
18.13.9. 명령줄을 사용하여 LUKS 암호 변경
명령줄을 사용하여 암호화된 디스크 또는 파티션에서 LUKS 암호를 변경합니다. cryptsetup 유틸리티를 사용하면 다양한 구성 옵션 및 기능으로 암호화 프로세스를 제어하고 기존 자동화 워크플로에 통합할 수 있습니다.
사전 요구 사항
-
sudo를 사용하여 관리 명령을 입력할 수 있는루트권한 또는 권한이 있습니다.
프로세스
LUKS 암호화된 장치에서 기존 암호를 변경합니다.
cryptsetup luksChangeKey /dev/<device_ID>
# cryptsetup luksChangeKey /dev/<device_ID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;device_ID>를 장치 지정자로 바꿉니다(예:sda).여러 개의 키 슬롯이 구성된 경우 작업할 슬롯을 지정할 수 있습니다.
cryptsetup luksChangeKey /dev/<device_ID> --key-slot <slot_number>
# cryptsetup luksChangeKey /dev/<device_ID> --key-slot <slot_number>Copy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;slot_number>를 수정할 키 슬롯 수로 바꿉니다.현재 암호와 새 암호를 삽입합니다.
Enter passphrase to be changed: Enter new passphrase: Verify passphrase:
Enter passphrase to be changed: Enter new passphrase: Verify passphrase:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 새 암호를 확인합니다.
cryptsetup --verbose open --test-passphrase /dev/<device_ID>
# cryptsetup --verbose open --test-passphrase /dev/<device_ID>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
새 암호가 장치의 잠금을 해제할 수 있는지 확인합니다.
Enter passphrase for /dev/<device_ID>: Key slot <slot_number> unlocked. Command successful.
Enter passphrase for /dev/<device_ID>: Key slot <slot_number> unlocked. Command successful.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.13.10. 스토리지 RHEL 시스템 역할을 사용하여 LUKS2 암호화된 볼륨 생성
storage 역할을 사용하여 Ansible 플레이북을 실행하여 LUKS로 암호화된 볼륨을 생성하고 구성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
중요한 변수를 암호화된 파일에 저장합니다.
자격 증명 모음을 생성합니다.
ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ansible-vault create명령이 편집기를 열고 <key > : < value> 형식으로 중요한 데이터를 입력합니다.luks_password: <password>
luks_password: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 변경 사항을 저장하고 편집기를 종료합니다. Ansible은 자격 증명 모음의 데이터를 암호화합니다.
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --ask-vault-pass --syntax-check ~/playbook.yml
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook --ask-vault-pass ~/playbook.yml
$ ansible-playbook --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
LUKS 암호화된 볼륨의
luksUUID값을 찾습니다.ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5c
# ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5cCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨의 암호화 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 생성된 LUKS 암호화된 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14. 정책 기반 암호 해독을 사용하여 암호화된 볼륨의 자동 잠금 해제 구성
정책 기반 암호 해독(Policy-Based Decryption)은 물리적 및 가상 머신에서 암호화된 루트 및 보조 드라이브의 하드 드라이브의 잠금을 해제할 수 있는 기술 컬렉션입니다. PBD는 사용자 암호, 신뢰할 수 있는 플랫폼 모듈(TPM) 장치, 시스템에 연결된 PKCS #11 장치(예: 스마트 카드 또는 특수 네트워크 서버)와 같은 다양한 잠금 해제 방법을 사용합니다.
PBD를 사용하면 다른 잠금 해제 방법을 정책에 결합하여 동일한 볼륨을 다른 방식으로 잠금 해제할 수 있습니다. RHEL에서 PBD의 현재 구현은 Clevis 프레임워크와 pins라는 플러그인으로 구성되어 있습니다. 각 핀은 별도의 잠금 해제 기능을 제공합니다. 현재 다음 핀을 사용할 수 있습니다.
Tang- 네트워크 서버를 사용하여 볼륨 잠금을 허용합니다.
tpm2- TPM2 정책을 사용하여 볼륨 잠금을 허용합니다.
sss- Shamir의 Secret Sharing (SSS) 암호화 체계를 사용하여 고가용성 시스템을 배포할 수 있습니다.
18.14.1. 네트워크 바인딩 디스크 암호화
NBDE(Network Bound Disc Encryption)는 암호화된 볼륨을 특수 네트워크 서버에 바인딩할 수 있는 정책 기반 암호 해독(Policy-Based Decryption)의 하위 범주입니다. Clevis의 현재 구현에는 Tang 서버 및 Tang 서버 자체에 대한 Clevis 핀이 포함되어 있습니다.
RHEL에서 NBDE는 다음 구성 요소 및 기술을 통해 구현됩니다.
그림 18.1. LUKS1 암호화 볼륨을 사용할 때의 NBDE 스키마입니다 luksmeta 패키지는 LUKS2 볼륨에 사용되지 않습니다.

Tang은 데이터를 네트워크 상에 바인딩하는 서버입니다. 시스템이 특정 보안 네트워크에 바인딩될 때 데이터를 포함하는 시스템을 사용할 수 있습니다. Tang은 상태 비저장이며 TLS 또는 인증이 필요하지 않습니다. 서버가 모든 암호화 키를 저장하고 사용된 모든 키에 대한 지식이 있는 에스크로 기반 솔루션과 달리 Tang은 클라이언트 키와 상호 작용하지 않으므로 클라이언트로부터 식별 정보를 얻을 수 없습니다.
Clevis는 자동 암호 해독을 위한 플러그형 프레임워크입니다. KnativeServing에서 Clevis는 LUKS 볼륨의 자동 잠금을 해제하는 기능을 제공합니다. clevis 패키지는 기능의 클라이언트 측면을 제공합니다.
Clevis PIN은 Clevis 프레임워크의 플러그인입니다. 이러한 핀 중 하나는 NBDE 서버 - Tang과의 상호 작용을 구현하는 플러그인입니다.
Clevis 및 Tang은 네트워크 바인딩 암호화를 제공하는 일반 클라이언트 및 서버 구성 요소입니다. RHEL에서는 LUKS와 함께 네트워크-Bound 디스크 암호화를 수행하기 위해 루트 및 루트가 아닌 스토리지 볼륨을 암호화하고 암호 해독하는 데 사용됩니다.
클라이언트 및 서버 측 구성 요소 모두 José 라이브러리를 사용하여 암호화 및 암호 해독 작업을 수행합니다.
Clevis 프로비저닝을 시작할 때 Tang 서버의 Clevis 핀은 Tang 서버의 공개된 symmetric 키 목록을 가져옵니다. 또는 키가 symmetric이므로 Tang의 공개 키 목록을 대역에서 배포할 수 있으므로 클라이언트가 Tang 서버에 액세스하지 않고도 작동할 수 있습니다. 이 모드를 오프라인 프로비저닝 이라고 합니다.
Tang의 Clevis 핀은 공개 키 중 하나를 사용하여 고유하고 암호화 방식으로 암호화 키를 생성합니다. 이 키를 사용하여 데이터를 암호화하면 키가 삭제됩니다. Clevis 클라이언트는 이 프로비저닝 작업에서 생성한 상태를 편리한 위치에 저장해야 합니다. 데이터를 암호화하는 이 프로세스는 프로비저닝 단계입니다.
LUKS 버전 2(LUKS2)는 RHEL의 기본 disk-encryption 형식입니다. 따라서 Clevis의 프로비저닝 상태는 LUKS2 헤더에 토큰으로 저장됩니다. luksmeta 패키지에 의해 NBDE의 프로비저닝 상태를 활용하는 것은 LUKS1로 암호화된 볼륨에만 사용됩니다.
Tang의 Clevis 핀은 사양 없이 LUKS1 및 LUKS2를 모두 지원합니다. Clevis는 일반 텍스트 파일을 암호화할 수 있지만 block 장치를 암호화하기 위해 cryptsetup 툴을 사용해야 합니다. 자세한 내용은 LUKS를 사용하여 블록 장치 암호화를 참조하십시오.
클라이언트가 데이터에 액세스할 준비가 되면 프로비저닝 단계에서 생성된 메타데이터를 로드하고 암호화 키를 복구할 수 있습니다. 이 과정은 회복 단계입니다.
Clevis는 자동으로 잠금 해제될 수 있도록 핀을 사용하여 LUKS 볼륨을 바인딩합니다. 바인딩 프로세스가 성공적으로 완료되면 제공된 Dracut unlocker를 사용하여 디스크의 잠금을 해제할 수 있습니다.
kdump 커널 크래시 덤프 메커니즘이 시스템 메모리의 콘텐츠를 LUKS 암호화 장치에 저장하도록 설정된 경우 두 번째 커널 부팅 중에 암호를 입력하라는 메시지가 표시됩니다.
18.14.2. 강제 모드에서 SELinux를 사용하여 Tang 서버 배포
Tang 서버를 사용하여 Clevis 지원 클라이언트에서 LUKS 암호화 볼륨을 자동으로 잠금 해제할 수 있습니다. 최소 시나리오에서는 tang 패키지를 설치하고 systemctl enable tangd.socket --now 명령을 입력하여 포트 80에 Tang 서버를 배포합니다. 다음 예제 절차에서는 사용자 지정 포트에서 실행되는 Tang 서버를 SELinux 강제 모드에서 제한된 서비스로 배포하는 방법을 보여줍니다.
사전 요구 사항
-
policycoreutils-python-utils패키지 및 해당 종속 항목이 설치됩니다. -
firewalld서비스가 실행 중입니다.
프로세스
tang패키지 및 해당 종속 항목을 설치하려면root로 다음 명령을 입력합니다.yum install tang
# yum install tangCopy to Clipboard Copied! Toggle word wrap Toggle overflow (예: 7500/tcp ) .occupied 포트를 선택하고
tangd서비스가 해당 포트에 바인딩되도록 허용합니다.semanage port -a -t tangd_port_t -p tcp 7500
# semanage port -a -t tangd_port_t -p tcp 7500Copy to Clipboard Copied! Toggle word wrap Toggle overflow 포트는 한 번에 하나의 서비스에서만 사용할 수 있으므로 이미 사용되고 있는 포트를 사용하려는 경우
ValueError를 의미합니다. 포트가 이미 정의된오류 메시지입니다.방화벽에서 포트를 엽니다.
firewall-cmd --add-port=7500/tcp firewall-cmd --runtime-to-permanent
# firewall-cmd --add-port=7500/tcp # firewall-cmd --runtime-to-permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow tangd서비스를 활성화합니다.systemctl enable tangd.socket
# systemctl enable tangd.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow 덮어쓰기 파일을 생성합니다.
systemctl edit tangd.socket
# systemctl edit tangd.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 편집기 화면에서
/etc/systemd/system/tangd.socket.d/디렉터리에 있는 빈override.conf파일을 열고 다음 행을 추가하여 Tang 서버의 기본 포트를 80에서 이전에 선택한 숫자로 변경합니다.[Socket] ListenStream= ListenStream=7500
[Socket] ListenStream= ListenStream=7500Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요이 아래에있는 줄과# 줄 사이에 이전코드 조각을 삽입합니다. 그렇지 않으면 시스템은 변경 사항을 삭제합니다.-
변경 사항을 저장하고 편집기를 종료합니다. 기본
vi편집기에서 Esc 를 눌러 명령 모드로 전환하고:wq를 입력한 후 Enter 키를 눌러 수행할 수 있습니다. 변경된 구성을 다시 로드합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 구성이 작동하는지 확인합니다.
systemctl show tangd.socket -p Listen Listen=[::]:7500 (Stream)
# systemctl show tangd.socket -p Listen Listen=[::]:7500 (Stream)Copy to Clipboard Copied! Toggle word wrap Toggle overflow tangd서비스를 시작합니다.systemctl restart tangd.socket
# systemctl restart tangd.socketCopy to Clipboard Copied! Toggle word wrap Toggle overflow tangd는systemd소켓 활성화 메커니즘을 사용하므로 첫 번째 연결이 들어오는 즉시 서버가 시작됩니다. 새로 생성된 암호화 키 세트는 처음 시작할 때 자동으로 생성됩니다. 수동 키 생성과 같은 암호화 작업을 수행하려면jose유틸리티를 사용합니다.
검증
NBDE 클라이언트에서 다음 명령을 사용하여 Tang 서버가 올바르게 작동하는지 확인합니다. 명령은 암호화 및 암호 해독을 위해 전달하는 동일한 메시지를 반환해야 합니다.
echo test | clevis encrypt tang '{"url":"<tang.server.example.com:7500>"}' -y | clevis decrypt test# echo test | clevis encrypt tang '{"url":"<tang.server.example.com:7500>"}' -y | clevis decrypt testCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.3. 클라이언트에서 Tang 서버 키 교체 및 바인딩 업데이트
보안상의 이유로 Tang 서버 키를 교체하고 클라이언트에서 기존 바인딩을 정기적으로 업데이트합니다. 교체해야하는 정확한 간격은 애플리케이션, 키 크기 및 기관 정책에 따라 다릅니다.
또는 nbde_server RHEL 시스템 역할을 사용하여 Tang 키를 교체할 수 있습니다. 자세한 내용은 nbde_server 시스템 역할을 사용하여 여러 Tang 서버 설정을 참조하십시오.
사전 요구 사항
- Tang 서버가 실행 중입니다.
-
clevis및clevis-luks패키지가 클라이언트에 설치됩니다. -
clevis luks list,clevis luks report,clevis luks regen은 RHEL 8.2에서 도입되었습니다.
프로세스
/var/db/tang키 데이터베이스 디렉터리의 모든 키 이름을 앞에.로 바꿔서 광고에서 숨길 수 있습니다. 다음 예제의 파일 이름은 Tang 서버의 키 데이터베이스 디렉터리에 있는 고유한 파일 이름과 다릅니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이름이 변경되었고, 따라서 Tang 서버 광고에서 모든 키를 숨겼는지 확인합니다.
ls -l total 0
# ls -l total 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow Tang 서버의
/var/db/tang에서/usr/libexec/tangd-keygen명령을 사용하여 새 키를 생성합니다./usr/libexec/tangd-keygen /var/db/tang ls /var/db/tang 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk zyLuX6hijUy_PSeUEFDi7hi38.jwk
# /usr/libexec/tangd-keygen /var/db/tang # ls /var/db/tang 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk zyLuX6hijUy_PSeUEFDi7hi38.jwkCopy to Clipboard Copied! Toggle word wrap Toggle overflow Tang 서버가 새 키 쌍에서 서명 키를 알리는지 확인합니다. 예를 들면 다음과 같습니다.
tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54
# tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54Copy to Clipboard Copied! Toggle word wrap Toggle overflow EgressIP 클라이언트에서
clevis luks report명령을 사용하여 Tang 서버에서 광고하는 키가 동일하게 남아 있는지 확인합니다. 다음과 같이clevis luks list명령을 사용하여 관련 바인딩으로 슬롯을 식별할 수 있습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 새 키에 대해 LUKS 메타데이터를 다시 생성하려면 이전 명령의 프롬프트에
y를 누르거나clevis luks regen명령을 사용합니다.clevis luks regen -d /dev/sda2 -s 1
# clevis luks regen -d /dev/sda2 -s 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 이전 클라이언트가 새 키를 사용하도록 확신하면 Tang 서버에서 이전 키를 제거할 수 있습니다. 예를 들면 다음과 같습니다.
cd /var/db/tang rm .*.jwk
# cd /var/db/tang # rm .*.jwkCopy to Clipboard Copied! Toggle word wrap Toggle overflow
클라이언트가 계속 사용하는 동안 이전 키를 제거하면 데이터 손실이 발생할 수 있습니다. 실수로 이러한 키를 제거하는 경우 클라이언트에서 clevis luks regen 명령을 사용하고 수동으로 LUKS 암호를 제공하십시오.
18.14.4. 웹 콘솔에서 Tang 키를 사용하여 자동 잠금 해제 구성
Tang 서버에서 제공하는 키를 사용하여 LUKS 암호화 스토리지 장치의 자동 잠금 해제를 구성할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged및clevis-luks패키지가 시스템에 설치됩니다. -
cockpit.socket서비스는 포트 9090에서 실행됩니다. - Tang 서버를 사용할 수 있습니다. 자세한 내용은 강제 모드에서 SELinux를 사용하여 Tang 서버 배포를 참조하십시오.
-
sudo를 사용하여 관리 명령을 입력할 수 있는루트권한 또는 권한이 있습니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 관리 액세스로 전환하고 자격 증명을 제공하고 스토리지를 . 스토리지 테이블에서 잠금 해제를 위해 추가할 암호화된 볼륨이 포함된 디스크를 클릭합니다.
선택한 디스크에 대한 세부 정보가 있는 다음 페이지에서 Keys 섹션에서 를 클릭하여 Tang 키를 추가합니다.
Tang 키 서버를키 소스로선택하고 Tang 서버의 주소 및 LUKS 암호화 장치를 잠금 해제하는 암호를 제공합니다. 를 클릭하여 확인합니다.
다음 대화 상자 창에서 키 해시가 일치하는지 확인하는 명령을 제공합니다.
Tang 서버의 터미널에서
tang-show-keys명령을 사용하여 비교할 키 해시를 표시합니다. 이 예에서 Tang 서버는 포트 7500에서 실행되고 있습니다.tang-show-keys 7500 x100_1k6GPiDOaMlL3WbpCjHOy9ul1bSfdhI3M08wO0
# tang-show-keys 7500 x100_1k6GPiDOaMlL3WbpCjHOy9ul1bSfdhI3M08wO0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 웹 콘솔의 키 해시와 이전에 나열된 명령의 출력에서와 이전에 나열된 명령의 출력에서 신뢰 키를 클릭하면 를 클릭합니다.
-
RHEL 8.8 이상에서는 암호화된 루트 파일 시스템 및 Tang 서버를 선택한 후 커널 명령줄에
rd.neednet=1매개변수 추가를 건너뛰고clevis-dracut패키지를 설치하고 초기 RAM 디스크(Initrd )를 다시 생성할 수 있습니다.루트가 아닌 파일 시스템의 경우 웹 콘솔에서remote-cryptsetup.target및clevis-luks-akspass.pathsystemd장치를 활성화하고clevis-systemd패키지를 설치하고_netdev매개 변수를fstab및crypttab구성 파일에 추가합니다.
검증
새로 추가된 Tang 키가
Keyserver유형의 Keys 섹션에 나열되어 있는지 확인합니다.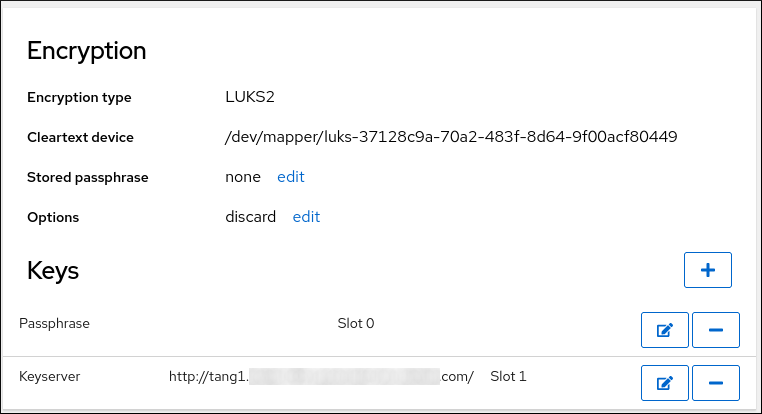
초기 부팅에 바인딩을 사용할 수 있는지 확인합니다. 예를 들면 다음과 같습니다.
lsinitrd | grep clevis-luks lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …
# lsinitrd | grep clevis-luks lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.5. 기본 Clevis 및 TPM2 암호화-클라이언트 작업
Clevis 프레임워크는 일반 텍스트 파일을 암호화하고 JSON 웹 암호화(JWE) 형식과 LUKS 암호화 블록 장치의 암호화 텍스트를 모두 해독할 수 있습니다. Clevis 클라이언트는 암호화 작업을 위해 Tang 네트워크 서버 또는 신뢰할 수 있는 Platform Module 2.0(TPM 2.0) 칩을 사용할 수 있습니다.
다음 명령은 일반 텍스트 파일을 포함하는 예제의 Clevis에서 제공하는 기본 기능을 보여줍니다. Clevis 또는 Clevis+TPM 배포 문제를 해결하는 데도 사용할 수 있습니다.
Tang 서버에 바인딩된 암호화 클라이언트
Clevis 암호화 클라이언트가 Tang 서버에 바인딩되는지 확인하려면
clevis encrypt tang하위 명령을 사용합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위 예제의
http://tang.srv:portURL을tang이 설치된 서버의 URL과 일치하도록 변경합니다.secret.jwe출력 파일에는 JWE 형식의 암호화된 암호 텍스트가 포함되어 있습니다. 이 암호화 방식 텍스트는input-plain.txt입력 파일에서 읽습니다.또는 구성에 SSH 액세스 권한이 없는 Tang 서버와의 비대화형 통신이 필요한 경우 광고를 다운로드하여 파일에 저장할 수 있습니다.
curl -sfg http://tang.srv:port/adv -o adv.jws
$ curl -sfg http://tang.srv:port/adv -o adv.jwsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 또는 메시지의 암호화와 같은 다음 작업에 대해
adv.jws파일의 광고를 사용합니다.echo 'hello' | clevis encrypt tang '{"url":"http://tang.srv:port","adv":"adv.jws"}'$ echo 'hello' | clevis encrypt tang '{"url":"http://tang.srv:port","adv":"adv.jws"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터의 암호를 해독하려면
clevis decrypt명령을 사용하여 JWE(암호화 텍스트)를 제공합니다.clevis decrypt < secret.jwe > output-plain.txt
$ clevis decrypt < secret.jwe > output-plain.txtCopy to Clipboard Copied! Toggle word wrap Toggle overflow
TPM 2.0을 사용하는 암호화 클라이언트
TPM 2.0 칩을 사용하여 암호화하려면 JSON 구성 개체 형식의 유일한 인수와 함께
clevis encrypt tpm2하위 명령을 사용하십시오.clevis encrypt tpm2 '{}' < input-plain.txt > secret.jwe$ clevis encrypt tpm2 '{}' < input-plain.txt > secret.jweCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다른 계층 구조, 해시 및 키 알고리즘을 선택하려면 구성 속성을 지정합니다.
clevis encrypt tpm2 '{"hash":"sha256","key":"rsa"}' < input-plain.txt > secret.jwe$ clevis encrypt tpm2 '{"hash":"sha256","key":"rsa"}' < input-plain.txt > secret.jweCopy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터의 암호를 해독하려면 JSON 웹 암호화(JWE) 형식으로 암호화 텍스트를 제공합니다.
clevis decrypt < secret.jwe > output-plain.txt
$ clevis decrypt < secret.jwe > output-plain.txtCopy to Clipboard Copied! Toggle word wrap Toggle overflow
또한 핀은 PCR(Platform Configuration Registers) 상태에 대한 데이터 잠금을 지원합니다. 이렇게 하면 PCR 해시 값이 봉인할 때 사용된 정책과 일치하는 경우에만 데이터를 봉인 해제할 수 있습니다.
예를 들어 SHA-256 뱅크의 인덱스 0과 7로 PCR에 데이터를 봉인하려면 다음과 같이 하십시오.
clevis encrypt tpm2 '{"pcr_bank":"sha256","pcr_ids":"0,7"}' < input-plain.txt > secret.jwe
$ clevis encrypt tpm2 '{"pcr_bank":"sha256","pcr_ids":"0,7"}' < input-plain.txt > secret.jwePCR의 해시는 다시 작성할 수 있으며 더 이상 암호화된 볼륨을 잠금 해제할 수 없습니다. 따라서 PCR의 값이 변경된 경우에도 암호화된 볼륨을 수동으로 잠금 해제할 수 있는 강력한 암호를 추가합니다.
shim-x64 패키지를 업그레이드한 후 시스템이 암호화된 볼륨을 자동으로 잠금 해제할 수 없는 경우 Red Hat Knowledgebase 솔루션 Clevis TPM2가 다시 시작한 후 LUKS 장치의 암호를 해독하지 않음을 참조하십시오.
18.14.6. LUKS 암호화 볼륨의 자동 잠금 해제를 위해 NBDE 클라이언트 구성
Clevis 프레임워크를 사용하면 선택한 Tang 서버를 사용할 수 있을 때 LUKS 암호화 볼륨의 자동 잠금 해제를 위해 클라이언트를 구성할 수 있습니다. 그러면 NBDE(Network-Bound Disk Encryption) 배포가 생성됩니다.
사전 요구 사항
- Tang 서버가 실행 중이고 사용 가능합니다.
프로세스
기존 LUKS 암호화된 볼륨의 잠금을 자동으로 해제하려면
clevis-luks하위 패키지를 설치합니다.yum install clevis-luks
# yum install clevis-luksCopy to Clipboard Copied! Toggle word wrap Toggle overflow PBD의 LUKS 암호화 볼륨을 식별합니다. 다음 예에서 블록 장치는 /dev/sda2 라고 합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow clevis luks bind명령을 사용하여 볼륨을 Tang 서버에 바인딩합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 다음 네 가지 단계를 수행합니다.
- LUKS 마스터 키와 동일한 엔트로피를 사용하여 새 키를 만듭니다.
- Clevis를 사용하여 새 키를 암호화합니다.
- LUKS2 헤더에 Clevis JWE 오브젝트를 저장하거나 기본이 아닌 LUKS1 헤더가 사용되는 경우 LUKSMeta를 사용합니다.
- LUKS에 사용할 새 키를 활성화합니다.
참고바인딩 절차에서는 사용 가능한 LUKS 암호 슬롯이 하나 이상 있다고 가정합니다.
clevis luks bind명령은 슬롯 중 하나를 사용합니다.이제 Clevis 정책과 함께 기존 암호를 사용하여 볼륨을 잠금 해제할 수 있습니다.
초기 부팅 시스템이 디스크 바인딩을 처리할 수 있도록 하려면 이미 설치된 시스템에서
dracut툴을 사용합니다. RHEL에서 Clevis는 호스트별 구성 옵션 없이 일반initrd(초기 RAM 디스크)를 생성하고 커널 명령줄에rd.neednet=1과 같은 매개변수를 자동으로 추가하지 않습니다. 구성이 초기 부팅 중에 네트워크가 필요한 Tang 핀을 사용하는 경우--hostonly-cmdline인수를 사용하고dracut은 Tang 바인딩을 감지할 때rd.neednet=1을 추가합니다.clevis-dracut패키지를 설치합니다.yum install clevis-dracut
# yum install clevis-dracutCopy to Clipboard Copied! Toggle word wrap Toggle overflow 초기 RAM 디스크를 다시 생성합니다.
dracut -fv --regenerate-all --hostonly-cmdline
# dracut -fv --regenerate-all --hostonly-cmdlineCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는
/etc/dracut.conf.d/디렉터리에 .conf 파일을 생성하고hostonly_cmdline=yes옵션을 파일에 추가합니다. 그런 다음--hostonly-cmdline없이dracut을 사용할 수 있습니다. 예를 들면 다음과 같습니다.echo "hostonly_cmdline=yes" > /etc/dracut.conf.d/clevis.conf dracut -fv --regenerate-all
# echo "hostonly_cmdline=yes" > /etc/dracut.conf.d/clevis.conf # dracut -fv --regenerate-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow Clevis가 설치된 시스템에서
grubby툴을 사용하여 초기 부팅 시 Tang 핀의 네트워킹을 사용할 수 있는지 확인할 수도 있습니다.grubby --update-kernel=ALL --args="rd.neednet=1"
# grubby --update-kernel=ALL --args="rd.neednet=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Clevis JWE 오브젝트가 LUKS 헤더에 성공적으로 배치되었는지 확인하고
clevis luks list명령을 사용합니다.clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv:port"}'# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv:port"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 초기 부팅에 바인딩을 사용할 수 있는지 확인합니다. 예를 들면 다음과 같습니다.
lsinitrd | grep clevis-luks lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …
# lsinitrd | grep clevis-luks lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.7. 고정 IP 구성을 사용하여 NBDE 클라이언트 구성
고정 IP 구성(DHCP 제외)이 있는 클라이언트에 대해 NBDE를 사용하려면 네트워크 구성을 dracut 툴에 수동으로 전달해야 합니다.
사전 요구 사항
- Tang 서버가 실행 중이고 사용 가능합니다.
NBDE 클라이언트는 Tang 서버에서 암호화된 볼륨의 자동 잠금 해제를 수행하도록 구성됩니다.
자세한 내용은 LUKS 암호화 볼륨의 자동 잠금 해제를 위해 NBDE 클라이언트 구성 을 참조하십시오.
프로세스
정적 네트워크 구성을
dracut명령에서kernel-cmdline옵션 값으로 제공할 수 있습니다. 예를 들면 다음과 같습니다.dracut -fv --regenerate-all --kernel-cmdline "ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none nameserver=192.0.2.100"
# dracut -fv --regenerate-all --kernel-cmdline "ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none nameserver=192.0.2.100"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 정적 네트워크 정보를 사용하여
/etc/dracut.conf.d/디렉터리에 .conf 파일을 생성한 다음 초기 RAM 디스크 이미지를 다시 생성합니다.cat /etc/dracut.conf.d/static_ip.conf kernel_cmdline="ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none nameserver=192.0.2.100" dracut -fv --regenerate-all
# cat /etc/dracut.conf.d/static_ip.conf kernel_cmdline="ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none nameserver=192.0.2.100" # dracut -fv --regenerate-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.8. TPM 2.0 정책을 사용하여 LUKS 암호화 볼륨 수동 등록 구성
신뢰할 수 있는 플랫폼 모듈 2.0(TPM 2.0) 정책을 사용하여 LUKS 암호화 볼륨의 잠금을 구성할 수 있습니다.
사전 요구 사항
- 액세스 가능한 TPM 2.0 호환 장치.
- 64비트 Intel 또는 64비트 AMD 아키텍처가 있는 시스템.
프로세스
기존 LUKS 암호화된 볼륨의 잠금을 자동으로 해제하려면
clevis-luks하위 패키지를 설치합니다.yum install clevis-luks
# yum install clevis-luksCopy to Clipboard Copied! Toggle word wrap Toggle overflow PBD의 LUKS 암호화 볼륨을 식별합니다. 다음 예에서 블록 장치는 /dev/sda2 라고 합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow clevis luks bind명령을 사용하여 TPM 2.0 장치에 볼륨을 바인딩합니다. 예를 들면 다음과 같습니다.clevis luks bind -d /dev/sda2 tpm2 '{"hash":"sha256","key":"rsa"}' ... Do you wish to initialize /dev/sda2? [yn] y Enter existing LUKS password:# clevis luks bind -d /dev/sda2 tpm2 '{"hash":"sha256","key":"rsa"}' ... Do you wish to initialize /dev/sda2? [yn] y Enter existing LUKS password:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 다음 네 가지 단계를 수행합니다.
- LUKS 마스터 키와 동일한 엔트로피를 사용하여 새 키를 만듭니다.
- Clevis를 사용하여 새 키를 암호화합니다.
- LUKS2 헤더에 Clevis JWE 오브젝트를 저장하거나 기본이 아닌 LUKS1 헤더가 사용되는 경우 LUKSMeta를 사용합니다.
LUKS에 사용할 새 키를 활성화합니다.
참고바인딩 절차에서는 사용 가능한 LUKS 암호 슬롯이 하나 이상 있다고 가정합니다.
clevis luks bind명령은 슬롯 중 하나를 사용합니다.또는 데이터를 특정 플랫폼 구성 등록 (PCR) 상태로 전환하려는 경우
pcr_bank및pcr_ids값을clevis luks bind명령에 추가합니다.clevis luks bind -d /dev/sda2 tpm2 '{"hash":"sha256","key":"rsa","pcr_bank":"sha256","pcr_ids":"0,1"}'# clevis luks bind -d /dev/sda2 tpm2 '{"hash":"sha256","key":"rsa","pcr_bank":"sha256","pcr_ids":"0,1"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요PCR 해시 값이 밀봉 및 해시를 다시 작성할 때 사용되는 정책과 일치하는 경우에만 데이터가 음소거될 수 있으므로 PCR의 값이 변경될 때 암호화된 볼륨을 수동으로 잠금 해제할 수 있는 강력한 암호를 추가합니다.
shim-x64패키지를 업그레이드한 후 시스템이 암호화된 볼륨을 자동으로 잠금 해제할 수 없는 경우 Red Hat Knowledgebase 솔루션 Clevis TPM2가 다시 시작한 후 LUKS 장치의 암호를 해독하지 않음을 참조하십시오.
- 이제 Clevis 정책과 함께 기존 암호를 사용하여 볼륨을 잠금 해제할 수 있습니다.
초기 부팅 시스템이 디스크 바인딩을 처리할 수 있도록 하려면 이미 설치된 시스템에서
dracut툴을 사용합니다.yum install clevis-dracut dracut -fv --regenerate-all
# yum install clevis-dracut # dracut -fv --regenerate-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Clevis JWE 오브젝트가 LUKS 헤더에 성공적으로 배치되었는지 확인하려면
clevis luks list명령을 사용합니다.clevis luks list -d /dev/sda2 1: tpm2 '{"hash":"sha256","key":"rsa"}'# clevis luks list -d /dev/sda2 1: tpm2 '{"hash":"sha256","key":"rsa"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.9. LUKS 암호화된 볼륨에서 Clevis 핀 제거 수동으로 제거
clevis luks bind 명령으로 생성된 메타데이터를 수동으로 제거하고 Clevis에서 추가한 암호가 포함된 키 슬롯을 삭제하려면 다음 절차를 사용하십시오.
LUKS 암호화 볼륨에서 Clevis 핀을 제거하는 권장 방법은 clevis luks unbind 명령을 사용하는 것입니다. clevis luks unbind를 사용하는 제거 절차는 하나의 단계로 구성되며 LUKS1 및 LUKS2 볼륨 모두에 대해 작동합니다. 다음 예제 명령은 바인딩 단계에서 생성한 메타데이터를 제거하고 /dev/sda2 장치의 키 슬롯 1 을 지웁니다.
clevis luks unbind -d /dev/sda2 -s 1
# clevis luks unbind -d /dev/sda2 -s 1사전 요구 사항
- Clevis 바인딩이 있는 LUKS 암호화 볼륨.
프로세스
볼륨(예:
/dev/sda2)이 암호화된 LUKS 버전을 확인하고 Clevis에 바인딩된 슬롯과 토큰을 식별합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 예에서 Clevis 토큰은
0으로 식별되고 연결된 키 슬롯은1입니다.LUKS2 암호화의 경우 토큰을 제거합니다.
cryptsetup token remove --token-id 0 /dev/sda2
# cryptsetup token remove --token-id 0 /dev/sda2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 장치가 LUKS1에 의해 암호화된 경우
Version으로 표시됩니다. 1string in the output of thecryptsetup luksDump명령 출력의 문자열luksmeta wipe명령을 사용하여 다음 추가 단계를 수행합니다.luksmeta wipe -d /dev/sda2 -s 1
# luksmeta wipe -d /dev/sda2 -s 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow Clevis 암호가 포함된 키 슬롯을 지웁니다.
cryptsetup luksKillSlot /dev/sda2 1
# cryptsetup luksKillSlot /dev/sda2 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.10. Kickstart를 사용하여 LUKS 암호화 볼륨 자동 등록 구성
이 절차의 단계에 따라 LUKS 암호화 볼륨 등록에 Clevis를 사용하는 자동화된 설치 프로세스를 구성합니다.
프로세스
Kickstart에 임시 암호로
/boot이외의 모든 마운트 지점에 대해 LUKS 암호화가 활성화되도록 디스크를 파티션하도록 지시합니다. 암호는 이 등록 프로세스 단계에서 임시적입니다.part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --grow --encrypted --passphrase=temppass
part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --grow --encrypted --passphrase=temppassCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들어 OSPP 호환 시스템에는 더 복잡한 구성이 필요합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow %packages섹션에 나열하여 관련 Clevis 패키지를 설치합니다.%packages clevis-dracut clevis-luks clevis-systemd %end
%packages clevis-dracut clevis-luks clevis-systemd %endCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 선택 사항: 필요한 경우 암호화된 볼륨을 수동으로 잠금 해제할 수 있도록 임시 암호를 제거하기 전에 강력한 암호를 추가합니다. 자세한 내용은 Red Hat Knowledgebase 솔루션에서 기존 LUKS 장치에 암호, 키 또는 키 파일을 추가하는 방법을 참조하십시오.
%post섹션에서 바인딩을 수행하기 위해clevis luks bind를 호출합니다. 임시 암호를 삭제합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 구성이 초기 부팅 중에 네트워크가 필요한 Tang 핀을 사용하거나 고정 IP 구성으로 NBDE 클라이언트를 사용하는 경우 LUKS 암호화 볼륨 수동 등록 구성에 설명된 대로
dracut명령을 수정해야 합니다.RHEL 8.3에서
clevis luks bind명령의-y옵션을 사용할 수 있습니다. RHEL 8.2 이상에서는-y를clevis luks bind명령에서-f로 바꾸고 Tang 서버에서 광고를 다운로드합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의cryptsetup luksRemoveKey명령은 적용한 LUKS2 장치의 추가 관리를 방지합니다. LUKS1 장치에 대해서만dmsetup명령을 사용하여 제거된 마스터 키를 복구할 수 있습니다.
Tang 서버 대신 TPM 2.0 정책을 사용할 때 유사한 절차를 사용할 수 있습니다.
18.14.11. LUKS 암호화 이동식 스토리지 장치의 자동 잠금 해제 구성
LUKS 암호화 USB 스토리지 장치의 자동 잠금 해제 프로세스를 설정할 수 있습니다.
프로세스
USB 드라이브와 같은 LUKS로 암호화된 이동식 스토리지 장치의 잠금을 자동으로 해제하려면
clevis-udisks2패키지를 설치합니다.yum install clevis-udisks2
# yum install clevis-udisks2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템을 재부팅한 다음 LUKS 암호화 볼륨 수동 등록 구성에 설명된 대로
clevis luks bind명령을 사용하여 바인딩 단계를 수행합니다. 예를 들면 다음과 같습니다.clevis luks bind -d /dev/sdb1 tang '{"url":"http://tang.srv"}'# clevis luks bind -d /dev/sdb1 tang '{"url":"http://tang.srv"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 GNOME 데스크탑 세션에서 LUKS로 암호화된 이동식 장치의 잠금을 자동으로 해제할 수 있습니다. Clevis 정책에 바인딩된 장치는
clevis luks unlock명령으로 잠금 해제할 수도 있습니다.clevis luks unlock -d /dev/sdb1
# clevis luks unlock -d /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
Tang 서버 대신 TPM 2.0 정책을 사용할 때 유사한 절차를 사용할 수 있습니다.
18.14.12. 고가용성 NBDE 시스템 배포
Tang은 고가용성 배포를 구축하기 위한 두 가지 방법을 제공합니다.
- 클라이언트 중복(권장)
-
클라이언트를 여러 Tang 서버에 바인딩할 수 있는 기능으로 구성해야 합니다. 이 설정에서 각 Tang 서버에는 자체 키가 있으며 클라이언트는 이러한 서버의 하위 집합에 연결하여 암호를 해독할 수 있습니다. Clevis는 이미
sss플러그인을 통해 이 워크플로를 지원합니다. Red Hat은 고가용성 배포를 위해 이 방법을 권장합니다. - 키 공유
-
중복을 위해 두 개 이상의 Tang 인스턴스를 배포할 수 있습니다. 두 번째 또는 후속 인스턴스를 설정하려면
tang패키지를 설치하고SSH를 통해rsync를 사용하여 키 디렉터리를 새 호스트에 복사합니다. 키를 공유하면 주요 손상의 위험이 증가하고 추가 자동화 인프라가 필요하므로 Red Hat은 이 방법을 권장하지 않습니다.
Shamir의 Secret Sharing을 사용한 고가용성 NBDE
Shamir's SSS(Secret Sharing)는 비밀을 몇 가지 고유한 부분으로 나누는 암호화 체계입니다. 비밀을 재구축하려면 다음과 같은 여러 부분이 필요합니다. 숫자는 임계값이라고 하며 SSS는 임계값 체계라고도 합니다.
Clevis는 SSS 구현을 제공합니다. 키를 만들어 여러 개의 조각으로 나눕니다. 각 조각은 SSS도 반복적으로 포함하여 다른 고정을 사용하여 암호화됩니다. 또한 t 임계값을 정의합니다. NBDE 배포에서 최소한 t 조각을 암호 해독하면 암호화 키를 복구하고 암호 해독 프로세스가 성공합니다. Clevis가 임계값에 지정된 것보다 적은 수의 부분을 감지하면 오류 메시지를 출력합니다.
예 1: 두 개의 Tang 서버로 구성된 중복
다음 명령은 두 개의 Tang 서버 중 하나 이상을 사용할 수 있는 경우 LUKS 암호화 장치를 암호 해독합니다.
clevis luks bind -d /dev/sda1 sss '{"t":1,"pins":{"tang":[{"url":"http://tang1.srv"},{"url":"http://tang2.srv"}]}}'
# clevis luks bind -d /dev/sda1 sss '{"t":1,"pins":{"tang":[{"url":"http://tang1.srv"},{"url":"http://tang2.srv"}]}}'이전 명령은 다음 구성 체계를 사용했습니다.
이 구성에서 SSS 임계값 t 가 1 로 설정되고 clevis luks bind 명령이 나열된 두 개의 tang 서버에서 하나 이상 사용할 수 있는 경우 시크릿을 성공적으로 재구축합니다.
예 2: Tang 서버 및 TPM 장치의 공유 비밀
다음 명령은 tang 서버와 tpm2 장치를 모두 사용할 수 있는 경우 LUKS 암호화 장치를 성공적으로 암호 해독합니다.
clevis luks bind -d /dev/sda1 sss '{"t":2,"pins":{"tang":[{"url":"http://tang1.srv"}], "tpm2": {"pcr_ids":"0,7"}}}'
# clevis luks bind -d /dev/sda1 sss '{"t":2,"pins":{"tang":[{"url":"http://tang1.srv"}], "tpm2": {"pcr_ids":"0,7"}}}'SSS 임계값 't'가 '2'로 설정된 구성 스키마가 이제 다음과 같습니다.
18.14.13. NBDE 네트워크에서 가상 머신 배포
clevis luks bind 명령은 LUKS 마스터 키를 변경하지 않습니다. 즉, 가상 머신 또는 클라우드 환경에서 사용하기 위해 LUKS로 암호화된 이미지를 생성하면 이 이미지를 실행하는 모든 인스턴스가 마스터 키를 공유합니다. 이는 매우 안전하지 않으며 항상 피해야 합니다.
이는 Clevis의 제한 사항이 아니라 LUKS의 설계 원칙입니다. 시나리오에서 클라우드에서 암호화된 루트 볼륨을 필요로 하는 경우 클라우드에서 Red Hat Enterprise Linux의 각 인스턴스에 대해 설치 프로세스(일반적으로 Kickstart 사용)를 수행합니다. LUKS 마스터 키를 공유하지 않고는 이미지를 공유할 수 없습니다.
가상화 환경에서의 자동 잠금 해제를 배포하려면 lorax 또는 virt-install 과 같은 시스템을 Kickstart 파일과 함께 사용하십시오( Kickstart를 사용하여 LUKS 암호화 볼륨 자동 등록 구성 참조) 또는 다른 자동화된 프로비저닝 툴을 사용하여각 암호화된 VM에 고유한 마스터 키가 있는지 확인합니다.
18.14.14. NBDE를 사용하여 클라우드 환경에 대해 자동으로 등록할 수 있는 VM 이미지 빌드
클라우드 환경에 자동으로 등록 가능한 암호화된 이미지를 배포하면 고유한 도전 과제를 제공할 수 있습니다. 다른 가상화 환경과 마찬가지로 LUKS 마스터 키 공유를 피하려면 단일 이미지에서 시작된 인스턴스 수를 줄이는 것이 좋습니다.
따라서 공용 리포지토리에서 공유되지 않고 제한된 인스턴스 배포를 위한 기반을 제공하는 사용자 지정 이미지를 생성하는 것이 좋습니다. 생성할 인스턴스 수는 배포의 보안 정책에 따라 정의하고 LUKS 마스터 키 공격 벡터와 관련된 위험 허용 오차를 기반으로 정의해야 합니다.
LUKS 지원 자동 배포를 빌드하려면 이미지 빌드 프로세스 중에 마스터 키 고유성을 보장하기 위해 Kickstart 파일과 함께 Lorax 또는 virt-install과 같은 시스템을 사용해야 합니다.
클라우드 환경에서는 여기에서 고려할 두 개의 Tang 서버 배포 옵션을 사용할 수 있습니다. 먼저, Tang 서버는 클라우드 환경 자체 내에 배포할 수 있습니다. 둘째, Tang 서버는 두 인프라 간에 VPN 링크를 사용하여 독립적인 인프라에 클라우드 외부에 배포할 수 있습니다.
기본적으로 클라우드에 Tang을 배포하면 쉽게 배포할 수 있습니다. 그러나 인프라를 다른 시스템의 암호화 텍스트의 데이터 지속성 계층과 공유하는 경우 Tang 서버의 개인 키와 Clevis 메타데이터가 동일한 물리적 디스크에 저장할 수 있습니다. 이 물리적 디스크에 액세스하면 암호 텍스트 데이터가 완전히 손상될 수 있습니다.
항상 데이터가 저장된 위치와 Tang이 실행 중인 시스템을 물리적으로 분리합니다. 클라우드와 Tang 서버 간의 이 분리는 Tang 서버의 개인 키를 실수로 Clevis 메타데이터와 결합할 수 없도록 합니다. 클라우드 인프라가 위험할 경우 Tang 서버의 로컬 제어도 제공합니다.
18.14.15. Tang을 컨테이너로 배포
tang 컨테이너 이미지는 OpenShift Container Platform (OCP) 클러스터 또는 별도의 가상 시스템에서 실행되는 Clevis 클라이언트에 대해 Tang-server 암호 해독 기능을 제공합니다.
사전 요구 사항
-
podman패키지 및 해당 종속성은 시스템에 설치됩니다. -
podman login컨테이너 카탈로그에 로그인했습니다. 자세한 내용은 Red Hat Container Registry Authentication 을 참조하십시오.registry.redhat.io명령을 사용하여 registry.redhat.io - Clevis 클라이언트는 Tang 서버를 사용하여 자동으로 잠금 해제하려는 LUKS 암호화된 볼륨이 포함된 시스템에 설치됩니다.
절차
registry.redhat.io레지스트리에서tang컨테이너 이미지를 가져옵니다.podman pull registry.redhat.io/rhel8/tang
# podman pull registry.redhat.io/rhel8/tangCopy to Clipboard Copied! Toggle word wrap Toggle overflow 컨테이너를 실행하고 포트를 지정하고 Tang 키의 경로를 지정합니다. 이전 예제에서는
tang컨테이너를 실행하고 포트 7500 을 지정하고/var/db/tang디렉터리의 Tang 키의 경로를 나타냅니다.podman run -d -p 7500:7500 -v tang-keys:/var/db/tang --name tang registry.redhat.io/rhel8/tang
# podman run -d -p 7500:7500 -v tang-keys:/var/db/tang --name tang registry.redhat.io/rhel8/tangCopy to Clipboard Copied! Toggle word wrap Toggle overflow Tang은 기본적으로 포트 80을 사용하지만 Apache HTTP 서버와 같은 다른 서비스와 충돌할 수 있습니다.
선택 사항: 보안 강화를 위해 Tang 키를 주기적으로 순환합니다. 다음과 같이
tangd-rotate-keys스크립트를 사용할 수 있습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Tang 서버에 의해 자동으로 잠금 해제하기 위해 LUKS 암호화 볼륨이 포함된 시스템에서 Clevis 클라이언트가 Tang을 사용하여 일반 텍스트 메시지를 암호화하고 암호를 해독할 수 있는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 예제 명령은 Tang 서버를 localhost URL에서 사용할 수 있고 포트 7500 을 통해 통신할 때 출력 끝에
테스트문자열을 표시합니다.
18.14.16. RHEL 시스템 역할을 사용하여 NBDE 구성
Clevis 및 Tang을 사용하여 PBD(Policy-Based Decryption) 솔루션의 자동 배포를 위해 nbde_client 및 nbde_server RHEL 시스템 역할을 사용할 수 있습니다. rhel-system-roles 패키지에는 이러한 시스템 역할, 관련 예제 및 참조 문서가 포함되어 있습니다.
18.14.16.1. nbde_server RHEL 시스템 역할을 사용하여 여러 Tang 서버를 설정
nbde_server 시스템 역할을 사용하면 Tang 서버를 자동화된 디스크 암호화 솔루션의 일부로 배포하고 관리할 수 있습니다. 이 역할은 다음 기능을 지원합니다.
- Tang 키 순환
- Tang 키 배포 및 백업
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제 플레이북은 Tang 서버와 키 교체의 배포를 확인합니다.
예제 플레이북에 지정된 설정은 다음과 같습니다.
nbde_server_manage_firewall: true-
방화벽시스템 역할을 사용하여nbde_server역할에서 사용하는 포트를 관리합니다. nbde_server_manage_selinux: trueselinux시스템 역할을 사용하여nbde_server역할에서 사용하는 포트를 관리합니다.플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.nbde_server/README.md파일을 참조하십시오.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
NBDE 클라이언트에서 다음 명령을 사용하여 Tang 서버가 올바르게 작동하는지 확인합니다. 명령은 암호화 및 암호 해독을 위해 전달하는 동일한 메시지를 반환해야 합니다.
ansible managed-node-01.example.com -m command -a 'echo test | clevis encrypt tang '{"url":"<tang.server.example.com>"}' -y | clevis decrypt' test# ansible managed-node-01.example.com -m command -a 'echo test | clevis encrypt tang '{"url":"<tang.server.example.com>"}' -y | clevis decrypt' testCopy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.16.2. nbde_client RHEL 시스템 역할을 사용하여 DHCP로 Clevis 클라이언트 설정
nbde_client 시스템 역할을 사용하면 자동화된 방식으로 여러 Clevis 클라이언트를 배포할 수 있습니다.
이 역할은 LUKS 암호화 볼륨을 하나 이상의 NBDE(Network-Bound) 서버 - Tang 서버에 바인딩할 수 있도록 지원합니다. 기존 볼륨 암호화를 암호로 보존하거나 제거할 수 있습니다. 암호를 제거한 후 NBDE만 사용하여 볼륨을 잠금 해제할 수 있습니다. 이 기능은 시스템을 프로비저닝한 후 제거해야 하는 임시 키 또는 암호를 사용하여 볼륨을 처음 암호화할 때 유용합니다.
암호와 키 파일을 둘 다 제공하면 이 역할은 먼저 제공한 정보를 사용합니다. 유효한 이러한 항목을 찾지 못하면 기존 바인딩에서 암호를 검색하려고 합니다.
정책 기반 암호 해독(Policy-Based Decryption)은 장치를 슬롯에 매핑하는 것으로 바인딩을 정의합니다. 즉, 동일한 장치에 대해 여러 바인딩을 가질 수 있습니다. 기본 슬롯은 슬롯 1입니다.
nbde_client 시스템 역할은 Tang 바인딩만 지원합니다. 따라서 TPM2 바인딩에는 사용할 수 없습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. - LUKS를 사용하여 이미 암호화된 볼륨입니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제 플레이북은 두 개 이상의 Tang 서버 중 하나를 사용할 수 있을 때 두 개의 LUKS 암호화 볼륨의 잠금 해제를 자동화하도록 Clevis 클라이언트를 구성합니다.
예제 플레이북에 지정된 설정은 다음과 같습니다.
state: present-
state값은 플레이북을 실행한 후 구성을 나타냅니다. 새 바인딩을 생성하거나 기존 바인딩을 업데이트하려면present값을 사용합니다.clevis luks bind명령과 반대로state: present를 사용하여 장치 슬롯의 기존 바인딩을 덮어쓸 수도 있습니다.absent값은 지정된 바인딩을 제거합니다. nbde_client_early_boot: truenbde_client역할은 기본적으로 초기 부팅 중에 Tang 핀의 네트워킹을 사용할 수 있도록 합니다. 이 기능을 비활성화해야 하는 경우nbde_client_early_boot: false변수를 플레이북에 추가합니다.플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.nbde_client/README.md파일을 참조하십시오.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
NBDE 클라이언트에서 Tang 서버에서 자동으로 잠금 해제해야 하는 암호화된 볼륨에 LUKS 핀에 해당 정보가 포함되어 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'clevis luks list -d /dev/rhel/root' 1: tang '{"url":"<http://server1.example.com/>"}' 2: tang '{"url":"<http://server2.example.com/>"}'# ansible managed-node-01.example.com -m command -a 'clevis luks list -d /dev/rhel/root' 1: tang '{"url":"<http://server1.example.com/>"}' 2: tang '{"url":"<http://server2.example.com/>"}'Copy to Clipboard Copied! Toggle word wrap Toggle overflow nbde_client_early_boot: false변수를 사용하지 않는 경우 초기 부팅에 바인딩을 사용할 수 있는지 확인합니다. 예를 들면 다음과 같습니다.ansible managed-node-01.example.com -m command -a 'lsinitrd | grep clevis-luks' lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …
# ansible managed-node-01.example.com -m command -a 'lsinitrd | grep clevis-luks' lrwxrwxrwx 1 root root 48 Jan 4 02:56 etc/systemd/system/cryptsetup.target.wants/clevis-luks-askpass.path -> /usr/lib/systemd/system/clevis-luks-askpass.path …Copy to Clipboard Copied! Toggle word wrap Toggle overflow
18.14.16.3. nbde_client RHEL 시스템 역할을 사용하여 static-IP Clevis 클라이언트 설정
nbde_client RHEL 시스템 역할은 DHCP(Dynamic Host Configuration Protocol)가 있는 시나리오만 지원합니다. 고정 IP 구성이 있는 NBDE 클라이언트에서 네트워크 구성을 커널 부팅 매개변수로 전달해야 합니다.
일반적으로 관리자는 플레이북을 재사용하고 초기 부팅 중에 Ansible이 고정 IP 주소를 할당하는 각 호스트에 대해 개별 플레이북을 유지 관리하지 않습니다. 이 경우 플레이북에서 변수를 사용하고 외부 파일에 설정을 제공할 수 있습니다. 따라서 설정이 있는 하나의 플레이북과 하나의 파일만 필요합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. - LUKS를 사용하여 이미 암호화된 볼륨입니다.
절차
호스트의 네트워크 설정으로 파일을 생성하고(예:
static-ip-settings-clients.yml) 호스트에 동적으로 할당할 값을 추가합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 플레이북은
~/static-ip-settings-clients.yml파일에 나열된 각 호스트에 대해 동적으로 특정 값을 읽습니다.플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.network/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19장. SELinux 사용
19.1. SELinux 시작하기
SELinux(Security Enhanced Linux)는 추가 시스템 보안 계층을 제공합니다. SELinux는 기본적으로 질문에 대답합니다. <subject>는 <action>에서 <object>?로 실행할 수 있습니다. 예를 들면 다음과 같습니다. 웹 서버가 사용자의 홈 디렉토리에 있는 파일에 액세스할 수 있습니까?
19.1.1. SELinux 소개
DAC(Degretionary Access Control)라고 하는 사용자, 그룹 및 기타 권한을 기반으로 하는 표준 액세스 정책에서는 시스템 관리자가 로그 파일을 볼 수 있도록 특정 애플리케이션을 제한하는 것과 같은 포괄적이고 세분화된 보안 정책을 생성할 수 없습니다. 또한 다른 애플리케이션에서는 로그 파일에 새 데이터를 추가할 수 없습니다.
SELinux(Security Enhanced Linux)는 MAC(강제적 액세스 제어)를 구현합니다. 모든 프로세스 및 시스템 리소스에는 SELinux 컨텍스트 라는 특수 보안 레이블이 있습니다. SELinux 레이블이라고도 하는 SELinux 컨텍스트는 시스템 수준 세부 정보를 추상화하고 엔터티의 보안 속성에 중점을 두는 식별자입니다. 이렇게 하면 SELinux 정책에서 오브젝트를 참조하는 일관된 방법을 제공할 뿐만 아니라 다른 식별 방법에서 볼 수 있는 모호성이 제거됩니다. 예를 들어, 파일은 바인드 마운트를 사용하는 시스템에서 여러 개의 유효한 경로 이름을 가질 수 있습니다.
SELinux 정책은 프로세스가 서로 상호 작용하는 방법과 다양한 시스템 리소스와 상호 작용하는 방법을 정의하는 일련의 규칙에서 이러한 컨텍스트를 사용합니다. 기본적으로 정책은 규칙에서 명시적으로 액세스 권한을 부여하지 않는 한 상호 작용을 허용하지 않습니다.
DAC 규칙 다음에 SELinux 정책 규칙을 확인합니다. DAC 규칙이 먼저 액세스를 거부하면 SELinux 정책 규칙이 사용되지 않습니다. 즉, 기존 DAC 규칙이 액세스를 차단하는 경우 SELinux 거부가 기록되지 않습니다.
SELinux 컨텍스트에는 사용자, 역할, 유형, 보안 수준 등 여러 필드가 있습니다. SELinux 유형 정보는 전체 SELinux 컨텍스트가 아니라 프로세스와 시스템 리소스 간에 허용되는 상호 작용을 정의하는 가장 일반적인 정책 규칙이므로 SELinux 정책과 관련하여 가장 중요한 정보일 수 있습니다. SELinux 유형은 _t 로 끝납니다. 예를 들어 웹 서버의 유형 이름은 httpd_t 입니다. /var/www/html/ 에서 일반적으로 발견되는 파일 및 디렉토리의 유형 컨텍스트는 httpd_sys_content_t 입니다. /tmp 및 . 웹 서버 포트의 유형 컨텍스트는 /var/tmp/ 에서 일반적으로 발견되는 파일 및 디렉토리에 대한 유형 컨텍스트는 tmp_t 입니다http_port_t 입니다.
Apache(httpd _t로 실행하는 웹 서버 프로세스)가 /var/www/html/ 및 기타 웹 서버 디렉터리(httpd_sys_content_t)에서 일반적으로 발견되는 컨텍스트의 파일 및 디렉터리에 액세스할 수 있도록 허용하는 정책 규칙이 있습니다. /tmp 및 액세스가 허용되지 않습니다. SELinux를 사용하면 Apache가 손상되어 악의적인 스크립트에서 액세스를 제공하더라도 /var/tmp/ 에서 일반적으로 발견되는 파일에 대한 정책에 허용 규칙이 없으므로/tmp 디렉토리에 액세스할 수 없습니다.
그림 19.1. SELinux가 안전한 방식으로 Apache 및 MariaDB를 실행하는 데 어떤 도움을 줄 수 있는지의 예는 다음과 같습니다.

이전 체계에서 볼 수 있듯이 SELinux를 사용하면 httpd_t 로 실행되는 Apache 프로세스가 /var/www/html/ 디렉터리에 액세스할 수 있으며 httpd_t 및 유형 컨텍스트에 대한 허용 규칙이 없기 때문에 mysqld_db_t /data/mysql/ 디렉터리에 액세스하는 프로세스가 거부됩니다. 반면 mysqld_t 로 실행되는 MariaDB 프로세스는 /data/mysql/ 디렉터리에 액세스할 수 있으며 SELinux도 mysqld_t 유형의 프로세스를 올바르게 거부하여 로 레이블이 지정된 httpd_sys_content_t /var/www/html/ 디렉터리에 액세스합니다.
19.1.2. SELinux 실행의 이점
SELinux는 다음과 같은 이점을 제공합니다.
- 모든 프로세스와 파일에 레이블이 지정됩니다. SELinux 정책 규칙은 프로세스가 파일과 상호 작용하는 방법과 프로세스가 서로 상호 작용하는 방식을 정의합니다. 액세스는 특별히 허용하는 SELinux 정책 규칙이 있는 경우에만 허용됩니다.
- SELinux는 세분화된 액세스 제어를 제공합니다. 사용자 재량에 Linux 사용자 및 그룹 ID에 따라 제어되는 기존 UNIX 권한을 벗어나 SELinux 액세스 결정은 SELinux 사용자, 역할, 유형 및 선택적으로 보안 수준과 같은 사용 가능한 모든 정보를 기반으로 합니다.
- SELinux 정책은 관리 방식으로 정의되고 시스템 전체에 적용됩니다.
- SELinux는 권한 에스컬레이션 공격을 완화할 수 있습니다. 프로세스는 도메인에서 실행되므로 서로 분리됩니다. SELinux 정책 규칙은 프로세스가 파일 및 기타 프로세스에 액세스하는 방법을 정의합니다. 프로세스가 손상되면 공격자는 해당 프로세스의 일반 기능에만 액세스할 수 있으며 프로세스가 액세스하도록 구성된 파일에만 액세스할 수 있습니다. 예를 들어 Apache HTTP 서버가 손상되면 공격자는 특정 SELinux 정책 규칙을 추가하거나 이러한 액세스를 허용하도록 구성하지 않은 한 해당 프로세스를 사용하여 사용자 홈 디렉토리의 파일을 읽을 수 없습니다.
- SELinux는 데이터 기밀성과 무결성을 강제 적용할 수 있으며 신뢰할 수 없는 입력에서 프로세스를 보호할 수 있습니다.
SELinux는 안티바이러스 소프트웨어, 보안 암호, 방화벽 또는 기타 보안 시스템을 대체하지 않고 기존 보안 솔루션을 개선하도록 설계되었습니다. SELinux를 실행하는 경우에도 분석하기 어려운 암호 및 방화벽을 사용하여 소프트웨어를 최신 상태로 유지하는 등 모범적인 보안 사례를 계속 따르는 것이 중요합니다.
19.1.3. SELinux 예
다음 예제에서는 SELinux가 보안을 강화하는 방법을 보여줍니다.
- 기본 작업은 deny입니다. 파일을 여는 프로세스와 같이 액세스를 허용하기 위한 SELinux 정책 규칙이 없으면 액세스가 거부됩니다.
-
SELinux는 Linux 사용자를 제한할 수 있습니다. SELinux 정책에는 많은 제한된 SELinux 사용자가 있습니다. 제한된 SELinux 사용자에게 Linux 사용자를 매핑하여 보안 규칙 및 메커니즘을 활용할 수 있습니다. 예를 들어 Linux 사용자를 SELinux
user_u사용자에게 매핑하면 sudo 및 su와 같은sudo및su와 같은 사용자 ID(setuid) 애플리케이션을 설정하지 않으면 Linux 사용자가 실행되지 않습니다. - 프로세스 및 데이터 분리 증가. SELinux 도메인 개념을 사용하면 특정 파일 및 디렉터리에 액세스할 수 있는 프로세스를 정의할 수 있습니다. 예를 들어, SELinux를 실행할 때 공격자는 Samba 서버를 손상시킬 수 없으며 MariaDB 데이터베이스와 같은 다른 프로세스에서 사용하는 파일을 읽고 쓸 수 있는 공격 벡터로 해당 Samba 서버를 사용할 수 없습니다.
-
SELinux를 사용하면 구성 실수로 인한 손상을 완화할 수 있습니다. DNS(Domain Name System) 서버는 영역 전송에서 서로 간에 정보를 복제하는 경우가 많습니다. 공격자는 영역 전송을 사용하여 false 정보로 DNS 서버를 업데이트할 수 있습니다. RHEL에서 DNS 서버로 Berkeley Internet Name Domain(BIND)을 실행하는 경우, 관리자가 영역 전송을 수행할 수 있는 서버를 제한하지 않더라도 기본 SELinux 정책은 영역 파일의 업데이트를 방지합니다. [1] 데몬
이라는BIND에서 영역 전송을 사용하고 다른 프로세스에 의해 영역 전송을 사용합니다. -
SELinux가 없으면 공격자는 Apache 웹 서버에서 보안 취약점을 해결하고 다음과 같은 특수 요소를 사용하여 파일 시스템에 저장된 파일 및 디렉터리에 액세스할 수 있습니다.
httpd프로세스가 액세스할 수 없는 파일에 대한 액세스를 거부합니다. SELinux는 이러한 유형의 공격을 완전히 차단할 수는 없지만 효과적으로 완화합니다. -
강제 모드의 SELinux는 비SMAP 플랫폼에서 커널 NULL 포인터 역참조 연산자(CVE-2019-9213)를 악용하지 않습니다. 공격자는
mmap함수의 취약점을 악용하여 null 페이지의 매핑을 확인하지 않고 이 페이지에 임의의 코드를 배치합니다. -
deny_ptraceSELinux 부울 및 SELinux 강제 모드의 SELinux는 PTRACE_TRACEME 취약점(CVE-2019-13272)으로부터 시스템을 보호합니다. 이러한 구성으로 인해 공격자가root권한을 얻을 수 있는 시나리오가 방지됩니다. -
nfs_export_all_rw및nfs_export_all_roSELinux 부울을 사용하면 실수로/home디렉터리와 같은 NFS(Network File System)의 잘못된 설정을 방지하기 위해 사용하기 쉬운 툴이 제공됩니다.
19.1.4. SELinux 아키텍처 및 패키지
SELinux는 Linux 커널에 빌드된 Linux 보안 모듈(LSM)입니다. 커널의 SELinux 하위 시스템은 관리자가 제어하고 부팅 시 로드하는 보안 정책에 의해 구동됩니다. 시스템의 모든 보안 관련 커널 수준 액세스 작업은 SELinux에서 가로채고 로드된 보안 정책 컨텍스트에서 검사합니다. 로드된 정책에서 작업을 허용하면 작업을 계속합니다. 그렇지 않으면 작업이 차단되고 프로세스가 오류를 수신합니다.
액세스 허용 또는 허용하지 않기와 같은 SELinux 결정은 캐시됩니다. 이 캐시를 AVC(액세스 벡터 캐시)라고 합니다. 이러한 캐시된 의사 결정을 사용할 때는 SELinux 정책 규칙을 보다 적게 확인하여 성능이 향상되어야 합니다. DAC 규칙이 먼저 액세스를 거부하면 SELinux 정책 규칙이 적용되지 않습니다. 원시 감사 메시지는 /var/log/audit/audit.log 에 기록되며 type=AVC 문자열로 시작합니다.
RHEL 8에서는 시스템 서비스가 systemd 데몬에 의해 제어됩니다. systemd 는 모든 서비스를 시작하고 중지하며, 사용자와 프로세스는 systemctl 유틸리티를 사용하여 systemd 와 통신합니다. systemd 데몬은 SELinux 정책을 참조하여 호출 프로세스의 레이블과 호출자가 관리하려는 유닛 파일의 레이블을 확인한 다음, 호출자가 액세스할 수 있는지 여부를 SELinux에 요청할 수 있습니다. 이 접근 방식을 통해 시스템 서비스의 시작 및 중지를 비롯한 중요한 시스템 기능에 대한 액세스 제어를 강화합니다.
systemd 데몬은 SELinux 액세스 관리자로도 작동합니다. systemctl 을 실행하는 프로세스 또는 D-Bus 메시지를 systemd 로 보낸 프로세스의 레이블을 검색합니다. 그런 다음 데몬은 프로세스가 구성하려는 유닛 파일의 레이블을 조회합니다. 마지막으로 SELinux 정책에서 프로세스 레이블과 유닛 파일 레이블 간의 특정 액세스를 허용하는 경우 systemd 는 커널에서 정보를 검색할 수 있습니다. 즉, 특정 서비스의 systemd 와 상호 작용해야 하는 손상된 애플리케이션은 이제 SELinux에서 제한할 수 있습니다. 정책 작성자는 이러한 세분화된 제어를 사용하여 관리자를 제한할 수도 있습니다.
프로세스에서 D-Bus 메시지를 다른 프로세스에 전송하고 SELinux 정책에서 이러한 두 프로세스의 D-Bus 통신을 허용하지 않으면 시스템은 USER_AVC 거부 메시지와 D-Bus 통신 시간이 초과됩니다. 두 프로세스 간의 D-Bus 통신은 양방향으로 작동합니다.
잘못된 SELinux 레이블 지정 및 후속 문제를 방지하려면 systemctl start 명령을 사용하여 서비스를 시작해야 합니다.
RHEL 8에서는 SELinux를 사용하기 위한 다음 패키지를 제공합니다.
-
policy:
selinux-policy-targeted,selinux-policy-mls -
툴:
policycoreutils,policycoreutils-gui,libselinux-utils,policycoreutils-python-utils,setools-console,checkpolicy
19.1.5. SELinux 상태 및 모드
SELinux는 세 가지 모드(강제, 허용 또는 비활성화) 중 하나로 실행될 수 있습니다.
- 강제 모드는 기본 및 권장되는 작업 모드입니다. 강제 모드에서 SELinux는 정상적으로 작동하여 전체 시스템에서 로드된 보안 정책을 적용합니다.
- 허용 모드에서는 SELinux가 개체에 레이블을 지정하고 로그에 액세스 거부 항목을 내보내는 등 로드된 보안 정책을 적용하는 것처럼 동작하지만 실제로는 어떤 작업도 거부하지 않습니다. 프로덕션 시스템에는 권장되지 않지만 허용 모드는 SELinux 정책 개발 및 디버깅에 유용할 수 있습니다.
- 비활성화 모드는 강력하지 않습니다. 시스템이 SELinux 정책을 적용하지 않을 뿐만 아니라 파일과 같은 영구 오브젝트의 레이블을 방지하여 나중에 SELinux를 활성화하기가 어렵습니다.
setenforce 유틸리티를 사용하여 강제 모드와 허용 모드 간에 변경합니다. setenforce 를 사용한 변경 사항은 재부팅 시 유지되지 않습니다. 강제 모드로 변경하려면 Linux root 사용자로 setenforce 1 명령을 입력합니다. 허용 모드로 변경하려면 setenforce 0 명령을 입력합니다. getenforce 유틸리티를 사용하여 현재 SELinux 모드를 확인합니다.
getenforce Enforcing
# getenforce
Enforcingsetenforce 0 getenforce Permissive
# setenforce 0
# getenforce
Permissivesetenforce 1 getenforce Enforcing
# setenforce 1
# getenforce
EnforcingRed Hat Enterprise Linux에서는 개별 도메인을 허용 모드로 설정할 수 있으며 강제 모드에서 시스템을 실행할 수 있습니다. 예를 들어 httpd_t 도메인을 허용하려면 다음을 수행합니다.
semanage permissive -a httpd_t
# semanage permissive -a httpd_t허용 도메인은 시스템의 보안을 손상시킬 수 있는 강력한 도구입니다. 예를 들어 특정 시나리오를 디버깅하는 경우 허용 도메인을 주의해서 사용하는 것이 좋습니다.
19.2. SELinux 상태 및 모드 변경
활성화되면 SELinux를 강제 또는 허용 모드의 두 가지 모드 중 하나로 실행할 수 있습니다. 다음 섹션에서는 이러한 모드로 영구적으로 변경하는 방법을 보여줍니다.
19.2.1. SELinux 상태 및 모드의 영구 변경
SELinux 상태 및 모드에서 설명한 대로 SELinux를 활성화하거나 비활성화할 수 있습니다. 활성화되는 경우 SELinux에는 강제 및 허용 모드의 두 가지 모드가 있습니다.
getenforce 또는 sestatus 명령을 사용하여 SELinux가 실행 중인 모드를 확인합니다. getenforce 명령은 Enforcing,Permissive 또는 Disabled 를 반환합니다.
sestatus 명령은 SELinux 상태 및 사용 중인 SELinux 정책을 반환합니다.
시스템이 허용 모드에서 SELinux를 실행하는 경우 사용자와 프로세스는 다양한 파일 시스템 오브젝트에 잘못 레이블을 지정할 수 있습니다. SELinux가 비활성화되는 동안 생성된 파일 시스템 오브젝트는 레이블로 지정되지 않습니다. 이 동작은 SELinux가 파일 시스템 오브젝트의 올바른 레이블을 사용하므로 강제 모드로 변경할 때 문제가 발생합니다.
레이블이 지정되지 않은 파일에 잘못 레이블이 지정되지 않은 파일을 방지하기 위해 SELinux는 비활성화 상태에서 허용 또는 강제 모드로 변경될 때 파일 시스템의 레이블을 자동으로 다시 지정합니다. 다음 재부팅 시 파일의 레이블을 다시 지정하려면 root로 fixfiles -F onboot 명령을 사용하여 -F 옵션이 포함된 /.autorelabel 파일을 만듭니다.
레이블을 다시 지정하기 위해 시스템을 재부팅하기 전에, 예를 들어 enforcing=0 커널 옵션을 사용하여 허용 모드로 부팅되는지 확인합니다. 이렇게 하면 selinux-autorelabel 서비스를 시작하기 전에 시스템에 systemd 에 필요한 레이블이 지정되지 않은 파일이 포함된 경우 시스템이 부팅되지 않습니다. 자세한 내용은 RHBZ#2021835 를 참조하십시오.
19.2.2. SELinux를 허용 모드로 변경
SELinux가 허용 모드로 실행 중이면 SELinux 정책이 적용되지 않습니다. 시스템이 작동 상태로 남아 있으며 SELinux는 작업을 거부하지 않고 AVC 메시지만 기록합니다. 그러면 문제 해결, 디버깅 및 SELinux 정책 개선에 사용할 수 있습니다. 각 AVC는 이 경우 한 번만 로깅됩니다.
사전 요구 사항
-
selinux-policy-targeted,libselinux-utils및policycoreutils패키지가 시스템에 설치됩니다. -
selinux=0또는enforcing=0커널 매개 변수는 사용되지 않습니다.
절차
선택한 텍스트 편집기에서
/etc/selinux/config파일을 엽니다. 예를 들면 다음과 같습니다.vi /etc/selinux/config
# vi /etc/selinux/configCopy to Clipboard Copied! Toggle word wrap Toggle overflow SELINUX=permissive옵션을 구성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
시스템이 다시 시작되면
getenforce명령이Permissive를 반환하는지 확인합니다.getenforce Permissive
$ getenforce PermissiveCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19.2.3. SELinux를 강제 모드로 변경
SELinux가 강제 모드에서 실행 중인 경우 SELinux 정책을 적용하고 SELinux 정책 규칙에 따라 액세스를 거부합니다. RHEL에서는 SELinux를 사용하여 처음 시스템을 설치할 때 강제 모드가 기본적으로 활성화됩니다.
사전 요구 사항
-
selinux-policy-targeted,libselinux-utils및policycoreutils패키지가 시스템에 설치됩니다. -
selinux=0또는enforcing=0커널 매개 변수는 사용되지 않습니다.
절차
선택한 텍스트 편집기에서
/etc/selinux/config파일을 엽니다. 예를 들면 다음과 같습니다.vi /etc/selinux/config
# vi /etc/selinux/configCopy to Clipboard Copied! Toggle word wrap Toggle overflow SELINUX=enforcing옵션을 구성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 변경 사항을 저장하고 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 부팅 시 SELinux는 시스템 내의 모든 파일과 디렉터리의 레이블을 다시 지정하고 SELinux가 비활성화될 때 생성된 파일과 디렉토리에 대해 SELinux 컨텍스트를 추가합니다.
검증
시스템이 다시 시작되면
getenforce명령이Enforcing:getenforce Enforcing
$ getenforce EnforcingCopy to Clipboard Copied! Toggle word wrap Toggle overflow
문제 해결
강제 모드로 변경한 후 SELinux는 올바르지 않거나 누락된 SELinux 정책 규칙으로 인해 일부 작업을 거부할 수 있습니다.
SELinux 거부 작업을 보려면 root로 다음 명령을 입력합니다.
ausearch -m AVC,USER_AVC,SELINUX_ERR,USER_SELINUX_ERR -ts today
# ausearch -m AVC,USER_AVC,SELINUX_ERR,USER_SELINUX_ERR -ts todayCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는
se rsh-server패키지가 설치되어 있으면 다음을 입력합니다.grep "SELinux is preventing" /var/log/messages
# grep "SELinux is preventing" /var/log/messagesCopy to Clipboard Copied! Toggle word wrap Toggle overflow SELinux가 활성화되어 있고 감사 데몬(
auditd)이 시스템에서 실행되지 않는 경우dmesg명령의 출력에서 특정 SELinux 메시지를 검색합니다.dmesg | grep -i -e type=1300 -e type=1400
# dmesg | grep -i -e type=1300 -e type=1400Copy to Clipboard Copied! Toggle word wrap Toggle overflow
자세한 내용은 SELinux와 관련된 문제 해결을 참조하십시오.
19.2.4. 이전에 비활성화한 시스템에서 SELinux 활성화
이전에 비활성화한 시스템에서 SELinux를 활성화하거나 처리할 수 없는 시스템과 같은 문제를 방지하려면 허용 모드에서 AVC(Access Vector Cache) 메시지를 먼저 해결합니다.
시스템이 허용 모드에서 SELinux를 실행하는 경우 사용자와 프로세스는 다양한 파일 시스템 오브젝트에 잘못 레이블을 지정할 수 있습니다. SELinux가 비활성화되는 동안 생성된 파일 시스템 오브젝트는 레이블로 지정되지 않습니다. 이 동작은 SELinux가 파일 시스템 오브젝트의 올바른 레이블을 사용하므로 강제 모드로 변경할 때 문제가 발생합니다.
레이블이 지정되지 않은 파일에 잘못 레이블이 지정되지 않은 파일을 방지하기 위해 SELinux는 비활성화 상태에서 허용 또는 강제 모드로 변경될 때 파일 시스템의 레이블을 자동으로 다시 지정합니다.
레이블을 다시 지정하기 위해 시스템을 재부팅하기 전에, 예를 들어 enforcing=0 커널 옵션을 사용하여 허용 모드로 부팅되는지 확인합니다. 이렇게 하면 selinux-autorelabel 서비스를 시작하기 전에 시스템에 systemd 에 필요한 레이블이 지정되지 않은 파일이 포함된 경우 시스템이 부팅되지 않습니다. 자세한 내용은 RHBZ#2021835 를 참조하십시오.
절차
- 허용 모드에서 SELinux를 활성화합니다. 자세한 내용은 허용 모드로 변경에서 참조하십시오.
시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow - SELinux 거부 메시지를 확인합니다. 자세한 내용은 SELinux 거부 식별 을 참조하십시오.
다음 재부팅 시 파일의 레이블을 다시 지정했는지 확인합니다.
fixfiles -F onboot
# fixfiles -F onbootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이렇게 하면
-F옵션이 포함된/.autorelabel파일이 생성됩니다.주의fixfiles -F onboot명령을 시작하기 전에 항상 허용 모드로 전환합니다.기본적으로
autorelabel은 시스템에 사용 가능한 CPU 코어만큼 많은 스레드를 병렬로 사용합니다. 자동 레이블을 다시 지정하는 동안 단일 스레드만 사용하려면fixfiles -T 1 onboot명령을 사용합니다.- 거부가 없는 경우 강제 모드로 전환합니다. 자세한 내용은 부팅 시 SELinux 모드 변경을 참조하십시오.
검증
시스템이 다시 시작되면
getenforce명령이Enforcing:getenforce Enforcing
$ getenforce EnforcingCopy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 단계
SELinux를 강제 모드로 사용자 지정 애플리케이션을 실행하려면 다음 시나리오 중 하나를 선택하십시오.
-
unconfined_service_t도메인에서 애플리케이션을 실행합니다. - 애플리케이션에 대한 새 정책을 작성합니다. 자세한 내용은 사용자 지정 SELinux 정책 작성 섹션을 참조하십시오.
19.2.5. SELinux 비활성화
SELinux를 비활성화하면 시스템이 SELinux 정책을 로드하지 않습니다. 결과적으로 시스템은 SELinux 정책을 적용하지 않고 AVC(Access Vector Cache) 메시지를 기록하지 않습니다. 따라서 SELinux 실행의 모든 이점이 사라집니다.
성능이 취약한 보안으로 인해 상당한 위험이 발생하지 않는 시스템과 같이 특정 시나리오를 제외하고 SELinux를 비활성화하지 마십시오.
프로덕션 환경에서 디버깅을 수행해야 하는 경우 SELinux를 영구적으로 비활성화하는 대신 허용 모드를 일시적으로 사용합니다. 허용 모드에 대한 자세한 내용은 허용 모드로 변경을 참조하십시오.
사전 요구 사항
grubby패키지가 설치되어 있습니다.rpm -q grubby grubby-<version>
$ rpm -q grubby grubby-<version>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
절차
selinux=0을 커널 명령줄에 추가하도록 부트 로더를 구성합니다.sudo grubby --update-kernel ALL --args selinux=0
$ sudo grubby --update-kernel ALL --args selinux=0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템을 다시 시작하십시오.
reboot
$ rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
재부팅 후
getenforce명령이Disabled:을 반환하는지 확인합니다.getenforce Disabled
$ getenforce DisabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow
대체 방법
RHEL 8에서는 /etc/selinux/config 파일에서 SELINUX=disabled 옵션을 사용하여 더 이상 사용되지 않는 SELinux를 비활성화하는 방법을 계속 사용할 수 있습니다. 그러면 SELinux가 활성화된 상태로 커널이 부팅되고 부팅 프로세스 후반부에서 비활성화 모드로 전환됩니다. 결과적으로 커널 패닉을 유발하는 메모리 누수 및 경쟁 조건이 발생할 수 있었습니다. 이 방법을 사용하려면 다음을 수행합니다.
선택한 텍스트 편집기에서
/etc/selinux/config파일을 엽니다. 예를 들면 다음과 같습니다.vi /etc/selinux/config
# vi /etc/selinux/configCopy to Clipboard Copied! Toggle word wrap Toggle overflow SELINUX=disabled옵션을 구성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 변경 사항을 저장하고 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
19.2.6. 부팅 시 SELinux 모드 변경
부팅 시 다음 커널 매개변수를 설정하여 SELinux가 실행되는 방식을 변경할 수 있습니다.
enforcing=0이 매개 변수를 설정하면 시스템이 허용 모드로 시작되므로 문제를 해결할 때 유용합니다. 파일 시스템이 너무 손상된 경우 허용 모드를 사용하는 것이 문제를 감지하는 유일한 옵션일 수 있습니다. 또한 허용 모드에서 시스템은 라벨을 올바르게 만듭니다. 이 모드에서 생성되는 AVC 메시지는 강제 모드에서와 다를 수 있습니다.
허용 모드에서는 일련의 동일한 거부 중 첫 번째 거부만 보고됩니다. 그러나 강제 모드에서는 디렉터리 읽기와 관련된 거부가 발생할 수 있으며 애플리케이션이 중지될 수 있습니다. 허용 모드에서는 동일한 AVC 메시지가 표시되지만 애플리케이션은 디렉토리에 있는 파일을 계속 읽고 각 거부에 대해 AVC도 받습니다.
selinux=0이 매개 변수를 사용하면 커널이 SELinux 인프라의 일부를 로드하지 않습니다. init 스크립트는 시스템이
selinux=0매개 변수로 부팅되었으며/.autorelabel파일을 터치합니다. 이로 인해 SELinux를 활성화한 다음 부팅할 때 시스템이 자동으로 레이블을 다시 지정합니다.중요프로덕션 환경에서는
selinux=0매개변수를 사용하지 마십시오. 시스템을 디버깅하려면 SELinux를 비활성화하는 대신 일시적으로 허용 모드를 사용합니다.autorelabel=1이 매개변수는 시스템에서 다음 명령과 유사하게 레이블을 다시 지정하도록 강제 적용합니다.
touch /.autorelabel reboot
# touch /.autorelabel # rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템에 레이블이 잘못 지정된 오브젝트가 많은 경우 허용 모드로 시스템을 시작하여 자동 레이블 프로세스가 성공적으로 수행됩니다.
III 부. 네트워크 설계
20장. ifcfg 파일로 ip 네트워킹 구성
인터페이스 구성(ifcfg) 파일은 개별 네트워크 장치에 대한 소프트웨어 인터페이스를 제어합니다. 시스템이 부팅되면 이러한 파일을 사용하여 가져올 인터페이스와 구성 방법을 결정합니다. 이러한 파일의 이름은 ifcfg- name_pass 입니다. 여기서 접미사 이름은 구성 파일이 제어하는 장치의 이름을 나타냅니다. 규칙에 따라 ifcfg 파일의 접미사는 구성 파일 자체의 DEVICE 지시문에서 지정한 문자열과 동일합니다.
NetworkManager는 키 파일 형식으로 저장된 프로필을 지원합니다. 그러나 NetworkManager는 NetworkManager API를 사용하여 프로필을 만들거나 업데이트할 때 기본적으로 ifcfg 형식을 사용합니다.
향후 주요 RHEL 릴리스에서는 키 파일 형식이 기본값이 됩니다. 구성 파일을 수동으로 생성하고 관리하려면 키 파일 형식을 사용하는 것이 좋습니다. 자세한 내용은 키 파일 형식의 NetworkManager 연결 프로필을 참조하십시오.
20.1. ifcfg 파일을 사용하여 정적 네트워크 설정으로 인터페이스 구성
NetworkManager 유틸리티 및 애플리케이션을 사용하지 않는 경우 ifcfg 파일을 생성하여 네트워크 인터페이스를 수동으로 구성할 수 있습니다.
절차
이름이
enp1s0인 인터페이스의 경우ifcfg파일을 사용하여 정적 네트워크 설정으로 인터페이스를 구성하려면/etc/sysconfig/network-scripts/디렉터리에 이름이ifcfg-enp1s0인 파일을 만듭니다.IPv4구성의 경우:Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv6구성의 경우:DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes IPV6INIT=yes IPV6ADDR=2001:db8:1::2/64
DEVICE=enp1s0 BOOTPROTO=none ONBOOT=yes IPV6INIT=yes IPV6ADDR=2001:db8:1::2/64Copy to Clipboard Copied! Toggle word wrap Toggle overflow
20.2. ifcfg 파일을 사용하여 동적 네트워크 설정으로 인터페이스 구성
NetworkManager 유틸리티 및 애플리케이션을 사용하지 않는 경우 ifcfg 파일을 생성하여 네트워크 인터페이스를 수동으로 구성할 수 있습니다.
절차
ifcfg파일을 사용하여 동적 네트워크 설정으로 em1 이라는 인터페이스를 구성하려면 다음을 포함하는/etc/sysconfig/network-scripts/디렉터리에 이름이ifcfg-em1인 파일을 만듭니다.DEVICE=em1 BOOTPROTO=dhcp ONBOOT=yes
DEVICE=em1 BOOTPROTO=dhcp ONBOOT=yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 전송할 인터페이스를 구성하려면 다음을 수행합니다.
DHCP서버에 다른 호스트 이름을 추가하고 다음 행을ifcfg파일에 추가합니다.DHCP_HOSTNAME=hostname
DHCP_HOSTNAME=hostnameCopy to Clipboard Copied! Toggle word wrap Toggle overflow DHCP서버에 다른 정규화된 도메인 이름(FQDN)을 사용하여 다음 행을ifcfg파일에 추가합니다.DHCP_FQDN=fully.qualified.domain.name
DHCP_FQDN=fully.qualified.domain.nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
참고이러한 설정 중 하나만 사용할 수 있습니다.
DHCP_HOSTNAME및DHCP_FQDN을 모두 지정하는 경우DHCP_FQDN만 사용됩니다.특정
DNS서버를 사용하도록 인터페이스를 구성하려면ifcfg파일에 다음 행을 추가합니다.PEERDNS=no DNS1=ip-address DNS2=ip-address
PEERDNS=no DNS1=ip-address DNS2=ip-addressCopy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서 ip-address 는
DNS서버의 주소입니다. 이로 인해 네트워크 서비스에서 지정된DNS서버로/etc/resolv.conf를 업데이트합니다. 하나의DNS서버 주소만 필요하며 다른 주소는 선택 사항입니다.
20.3. ifcfg 파일을 사용하여 시스템 전체 및 개인 연결 프로필 관리
기본적으로 호스트의 모든 사용자는 ifcfg 파일에 정의된 연결을 사용할 수 있습니다. ifcfg 파일에 USERS 매개변수를 추가하여 이 동작을 특정 사용자로 제한할 수 있습니다.
사전 요구 사항
-
ifcfg파일이 이미 있습니다.
절차
특정 사용자로 제한하려는
/etc/sysconfig/network-scripts/디렉터리에서ifcfg파일을 편집하고 다음을 추가합니다.USERS="username1 username2 ..."
USERS="username1 username2 ..."Copy to Clipboard Copied! Toggle word wrap Toggle overflow 연결을 reactive합니다.
nmcli connection up connection_name
# nmcli connection up connection_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
21장. IPVLAN 시작하기
IPVLAN은 컨테이너 환경에서 호스트 네트워크에 액세스하는 데 사용할 수 있는 가상 네트워크 장치의 드라이버입니다. IPVLAN은 호스트 네트워크 내에서 생성된 IPVLAN 장치 수에 관계없이 단일 MAC 주소를 외부 네트워크에 노출합니다. 즉, 사용자가 여러 컨테이너에 여러 IPVLAN 장치를 가질 수 있으며 해당 스위치는 단일 MAC 주소를 읽습니다. IPVLAN 드라이버는 로컬 스위치에서 관리할 수 있는 총 MAC 주소 수에 제약 조건을 적용할 때 유용합니다.
21.1. IPVLAN 모드
다음 모드를 IPVLAN에 사용할 수 있습니다.
L2 모드
IPVLAN L2 모드에서 가상 장치는ARP(Address Resolution Protocol) 요청을 수신하고 응답합니다.
netfilter프레임워크는 가상 장치를 소유한 컨테이너 내에서만 실행됩니다. 컨테이너화된 트래픽의 기본 네임스페이스에서netfilter체인이 실행되지 않습니다. L2 모드를 사용하면 좋은 성능이지만 네트워크 트래픽을 제어할 수 없습니다.L3 모드
L3 모드에서 가상 장치는 L3 트래픽만 처리합니다. 가상 장치는 ARP 요청에 응답하지 않으며 사용자는 관련 피어에서 IPVLAN IP 주소에 대한 항목을 수동으로 구성해야 합니다. 관련 컨테이너의 송신 트래픽은 기본 네임스페이스의
netfilterPOSTROUTING 및 OUTPUT 체인에 배치되며 수신 트래픽이 L2 모드와 동일한 방식으로 스레드됩니다. L3 모드를 사용하면 양호한 제어 기능이 제공되지만 네트워크 트래픽 성능이 저하됩니다.L3S 모드
L3S 모드에서 가상 장치는 L3 모드에서 와 동일한 방식으로 처리합니다. 단, 관련 컨테이너의 송신 및 수신 트래픽은 기본 네임스페이스의
netfilter체인에 배치됩니다. L3S 모드는 L3 모드와 유사한 방식으로 작동하지만 네트워크를 더 잘 제어합니다.
IPVLAN 가상 장치는 L3 및 L3 S 모드의 경우 브로드캐스트 및 멀티 캐스트 트래픽을 수신하지 않습니다.
21.2. IPVLAN 및 MACVLAN 비교
다음 표에서는 MACVLAN과 IPVLAN의 주요 차이점을 보여줍니다.
| MACVLAN | IPVLAN |
|---|---|
| 각 MACVLAN 장치에 MAC 주소를 사용합니다. 스위치가 MAC 테이블에 저장할 수 있는 최대 MAC 주소 수에 도달하면 연결이 끊어질 수 있습니다. | IPVLAN 장치의 수를 제한하지 않는 단일 MAC 주소를 사용합니다. |
| 글로벌 네임스페이스의 Netfilter 규칙은 하위 네임스페이스의 MACVLAN 장치 또는 MACVLAN 장치에 대한 트래픽에 영향을 미칠 수 없습니다. | L3 모드 및 L3S 모드에서 IPVLAN 장치에 대한 트래픽 또는 트래픽을 제어할 수 있습니다. |
IPVLAN 및 MACVLAN 모두 수준의 캡슐화가 필요하지 않습니다.
21.3. iproute2를 사용하여 IPVLAN 장치 생성 및 구성
다음 절차에서는 iproute2 를 사용하여 IPVLAN 장치를 설정하는 방법을 보여줍니다.
프로세스
IPVLAN 장치를 생성하려면 다음 명령을 입력합니다.
ip link add link real_NIC_device name IPVLAN_device type ipvlan mode l2
# ip link add link real_NIC_device name IPVLAN_device type ipvlan mode l2Copy to Clipboard Copied! Toggle word wrap Toggle overflow NIC(네트워크 인터페이스 컨트롤러)는 컴퓨터를 네트워크에 연결하는 하드웨어 구성 요소입니다.
예 21.1. IPVLAN 장치 생성
ip link add link enp0s31f6 name my_ipvlan type ipvlan mode l2 ip link 47: my_ipvlan@enp0s31f6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether e8:6a:6e:8a:a2:44 brd ff:ff:ff:ff:ff:ff
# ip link add link enp0s31f6 name my_ipvlan type ipvlan mode l2 # ip link 47: my_ipvlan@enp0s31f6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether e8:6a:6e:8a:a2:44 brd ff:ff:ff:ff:ff:ffCopy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4또는IPv6주소를 인터페이스에 할당하려면 다음 명령을 입력합니다.ip addr add dev IPVLAN_device IP_address/subnet_mask_prefix
# ip addr add dev IPVLAN_device IP_address/subnet_mask_prefixCopy to Clipboard Copied! Toggle word wrap Toggle overflow L3 모드 또는 L3S 모드에서 IPVLAN 장치를 구성하는 경우 다음과 같이 설정합니다.
원격 호스트에서 원격 피어에 대한 인접 설정을 구성합니다.
ip neigh add dev peer_device IPVLAN_device_IP_address lladdr MAC_address
# ip neigh add dev peer_device IPVLAN_device_IP_address lladdr MAC_addressCopy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서 MAC_address 는 IPVLAN 장치를 기반으로 하는 실제 NIC의 MAC 주소입니다.
다음 명령을 사용하여 L3 모드 의 IPVLAN 장치를 구성합니다.
ip route add dev <real_NIC_device> <peer_IP_address/32>
# ip route add dev <real_NIC_device> <peer_IP_address/32>Copy to Clipboard Copied! Toggle word wrap Toggle overflow L3S 모드 의 경우:
ip route add dev real_NIC_device peer_IP_address/32
# ip route add dev real_NIC_device peer_IP_address/32Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서 IP-address는 원격 피어의 주소를 나타냅니다.
IPVLAN 장치를 활성으로 설정하려면 다음 명령을 입력합니다.
ip link set dev IPVLAN_device up
# ip link set dev IPVLAN_device upCopy to Clipboard Copied! Toggle word wrap Toggle overflow IPVLAN 장치가 활성화되어 있는지 확인하려면 원격 호스트에서 다음 명령을 실행합니다.
ping IP_address
# ping IP_addressCopy to Clipboard Copied! Toggle word wrap Toggle overflow 여기서 IP_address 는 IPVLAN 장치의 IP 주소를 사용합니다.
22장. 다른 인터페이스에서 동일한 IP 주소 재사용
가상 라우팅 및 전달(VRF)을 사용하면 관리자가 동일한 호스트에서 여러 라우팅 테이블을 동시에 사용할 수 있습니다. 이를 위해 VRF는 계층 3에서 네트워크를 분할합니다. 이를 통해 관리자는 VRF 도메인당 별도의 독립 경로 테이블을 사용하여 트래픽을 분리할 수 있습니다. 이 기술은 계층 2에서 네트워크를 분할하는 VLAN(가상 LAN)과 유사합니다. 운영 체제가 다른 VLAN 태그를 사용하여 동일한 물리적 미디어를 공유하는 트래픽을 분리합니다.
계층 2에서 VRF 파티셔닝을 통해 VRF의 한 가지 장점은 관련 동료 수를 고려하면 라우팅이 더 잘 확장된다는 것입니다.
Red Hat Enterprise Linux는 각 VRF 도메인에 대해 가상 vrt 장치를 사용하고 기존 네트워크 장치를 VRF 장치에 추가하여 VRF 도메인에 경로를 추가합니다. 원래 장치에 이전에 연결된 주소와 경로는 VRF 도메인 내에서 이동합니다.
각 VRF 도메인은 서로 격리됩니다.
22.1. 다른 인터페이스에서 동일한 IP 주소를 영구적으로 재사용
VRF(가상 라우팅 및 전달) 기능을 사용하여 하나의 서버에서 다른 인터페이스에서 동일한 IP 주소를 영구적으로 사용할 수 있습니다.
원격 피어가 동일한 IP 주소를 재사용하는 동안 두 VRF 인터페이스에 연결할 수 있도록 하려면 네트워크 인터페이스가 다른 브로드캐스트 도메인에 속해야 합니다. 네트워크의 브로드캐스트 도메인은 노드 세트로, 해당 노드에서 전송된 브로드캐스트 트래픽을 수신합니다. 대부분의 구성에서 동일한 스위치에 연결된 모든 노드는 동일한 브로드캐스트 도메인에 속합니다.
사전 요구 사항
-
root사용자로 로그인합니다. - 네트워크 인터페이스가 구성되지 않았습니다.
프로세스
첫 번째 VRF 장치를 생성하고 구성합니다.
VRF 장치에 대한 연결을 생성하고 라우팅 테이블에 할당합니다. 예를 들어
1001라우팅 테이블에 할당된vrf0이라는 VRF 장치를 생성하려면 다음을 수행합니다.nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabled
# nmcli connection add type vrf ifname vrf0 con-name vrf0 table 1001 ipv4.method disabled ipv6.method disabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow vrf0장치를 활성화합니다.nmcli connection up vrf0
# nmcli connection up vrf0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 방금 생성된 VRF에 네트워크 장치를 할당합니다. 예를 들어
enp1s0이더넷 장치를vrf0VRF 장치에 추가하고 IP 주소와 서브넷 마스크를enp1s0에 할당하려면 다음을 입력합니다.nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24
# nmcli connection add type ethernet con-name vrf.enp1s0 ifname enp1s0 master vrf0 ipv4.method manual ipv4.address 192.0.2.1/24Copy to Clipboard Copied! Toggle word wrap Toggle overflow vrf.enp1s0연결을 활성화합니다.nmcli connection up vrf.enp1s0
# nmcli connection up vrf.enp1s0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 VRF 장치를 생성하고 구성합니다.
VRF 장치를 생성하고 라우팅 테이블에 할당합니다. 예를 들어
1002라우팅 테이블에 할당된vrf1이라는 VRF 장치를 생성하려면 다음을 입력합니다.nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabled
# nmcli connection add type vrf ifname vrf1 con-name vrf1 table 1002 ipv4.method disabled ipv6.method disabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow vrf1장치를 활성화합니다.nmcli connection up vrf1
# nmcli connection up vrf1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 방금 생성된 VRF에 네트워크 장치를 할당합니다. 예를 들어,
enp7s0이더넷 장치를vrf1VRF 장치에 추가하고 IP 주소와 서브넷 마스크를enp7s0에 할당하려면 다음을 입력합니다.nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24
# nmcli connection add type ethernet con-name vrf.enp7s0 ifname enp7s0 master vrf1 ipv4.method manual ipv4.address 192.0.2.1/24Copy to Clipboard Copied! Toggle word wrap Toggle overflow vrf.enp7s0장치를 활성화합니다.nmcli connection up vrf.enp7s0
# nmcli connection up vrf.enp7s0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
22.2. 다른 인터페이스에서 동일한 IP 주소를 일시적으로 재사용
VRF(가상 라우팅 및 전달) 기능을 사용하여 하나의 서버에서 다른 인터페이스에서 동일한 IP 주소를 일시적으로 사용할 수 있습니다. 시스템을 재부팅한 후 구성이 임시적이고 손실되므로 테스트 목적으로만 이 절차를 사용하십시오.
원격 피어가 동일한 IP 주소를 재사용하는 동안 두 VRF 인터페이스에 연결할 수 있도록 하려면 네트워크 인터페이스가 다른 브로드캐스트 도메인에 속해야 합니다. 네트워크의 브로드캐스트 도메인은 해당 도메인에서 보낸 브로드캐스트 트래픽을 수신하는 노드 집합입니다. 대부분의 구성에서 동일한 스위치에 연결된 모든 노드는 동일한 브로드캐스트 도메인에 속합니다.
사전 요구 사항
-
root사용자로 로그인합니다. - 네트워크 인터페이스가 구성되지 않았습니다.
프로세스
첫 번째 VRF 장치를 생성하고 구성합니다.
VRF 장치를 생성하고 라우팅 테이블에 할당합니다. 예를 들어
1001라우팅 테이블에 할당된blue라는 VRF 장치를 생성하려면 다음을 수행합니다.ip link add dev blue type vrf table 1001
# ip link add dev blue type vrf table 1001Copy to Clipboard Copied! Toggle word wrap Toggle overflow 파란색장치를 활성화합니다.ip link set dev blue up
# ip link set dev blue upCopy to Clipboard Copied! Toggle word wrap Toggle overflow 네트워크 장치를 VRF 장치에 할당합니다. 예를 들어,
enp1s0이더넷 장치를blueVRF 장치에 추가하려면 다음을 수행합니다.ip link set dev enp1s0 master blue
# ip link set dev enp1s0 master blueCopy to Clipboard Copied! Toggle word wrap Toggle overflow enp1s0장치를 활성화합니다.ip link set dev enp1s0 up
# ip link set dev enp1s0 upCopy to Clipboard Copied! Toggle word wrap Toggle overflow enp1s0장치에 IP 주소 및 서브넷 마스크를 할당합니다. 예를 들어192.0.2.1/24로 설정하려면 다음을 수행합니다.ip addr add dev enp1s0 192.0.2.1/24
# ip addr add dev enp1s0 192.0.2.1/24Copy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 VRF 장치를 생성하고 구성합니다.
VRF 장치를 생성하고 라우팅 테이블에 할당합니다. 예를 들어
1002라우팅 테이블에 할당된빨간색이라는 VRF 장치를 생성하려면 다음을 수행합니다.ip link add dev red type vrf table 1002
# ip link add dev red type vrf table 1002Copy to Clipboard Copied! Toggle word wrap Toggle overflow 빨간색장치를 활성화합니다.ip link set dev red up
# ip link set dev red upCopy to Clipboard Copied! Toggle word wrap Toggle overflow 네트워크 장치를 VRF 장치에 할당합니다. 예를 들어
enp7s0이더넷 장치를빨간색VRF 장치에 추가하려면 다음을 수행합니다.ip link set dev enp7s0 master red
# ip link set dev enp7s0 master redCopy to Clipboard Copied! Toggle word wrap Toggle overflow enp7s0장치를 활성화합니다.ip link set dev enp7s0 up
# ip link set dev enp7s0 upCopy to Clipboard Copied! Toggle word wrap Toggle overflow blueVRF 도메인에서enp1s0에 사용한 것과 동일한 IP 주소 및 서브넷 마스크를enp7s0장치에 할당합니다.ip addr add dev enp7s0 192.0.2.1/24
# ip addr add dev enp7s0 192.0.2.1/24Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 선택 사항: 위에서 설명한 대로 추가 VRF 장치를 생성합니다.
23장. 네트워크 보안
23.1. OpenSSH로 두 시스템 간의 보안 통신 사용
SSH(Secure Shell)는 클라이언트-서버 아키텍처를 사용하여 두 시스템 간에 보안 통신을 제공하고 사용자가 서버 호스트 시스템에 원격으로 로그인할 수 있는 프로토콜입니다. FTP 또는 Telnet과 같은 다른 원격 통신 프로토콜과 달리 SSH는 로그인 세션을 암호화하여 침입자가 연결에서 암호화되지 않은 암호를 수집하지 못하도록 합니다.
23.1.1. SSH 키 쌍 생성
로컬 시스템에서 SSH 키 쌍을 생성하고 생성된 공개 키를 OpenSSH 서버에 복사하여 암호를 입력하지 않고 OpenSSH 서버에 로그인할 수 있습니다. 키를 생성하려는 각 사용자는 이 절차를 실행해야 합니다.
시스템을 다시 설치한 후 이전에 생성된 키 쌍을 유지하려면 새 키를 만들기 전에 ~/.ssh/ 디렉터리를 백업하십시오. 다시 설치한 후 홈 디렉터리로 복사합니다. root를 포함하여 시스템의 모든 사용자에 대해 이 작업을 수행할 수 있습니다.
사전 요구 사항
- 키를 사용하여 OpenSSH 서버에 연결하려는 사용자로 로그인했습니다.
- OpenSSH 서버는 키 기반 인증을 허용하도록 구성됩니다.
프로세스
ECDSA 키 쌍을 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow ssh-keygen-t ed25519 명령을 입력하여 매개 변수 또는 Ed25519 키 쌍 없이 ssh-keygen명령을 사용하여 RSA 키 쌍을 생성할 수도 있습니다. Ed25519 알고리즘은 FIPS-140과 호환되지 않으며 OpenSSH는 FIPS 모드에서 Ed25519 키와 함께 작동하지 않습니다.공개 키를 원격 머신에 복사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow <
;username> @ <ssh-server-example.com>을 사용자 인증 정보로 바꿉니다.세션에서
ssh-agent프로그램을 사용하지 않는 경우 이전 명령은 가장 최근에 수정된~/.ssh/id*.pub공개 키를 아직 설치하지 않은 경우 복사합니다. 다른 공개 키 파일을 지정하거나ssh-agent로 메모리에 캐시된 키보다 파일의 키 우선 순위를 지정하려면ssh-copy-id명령을-i옵션과 함께 사용합니다.
검증
키 파일을 사용하여 OpenSSH 서버에 로그인합니다.
ssh -o PreferredAuthentications=publickey <username>@<ssh-server-example.com>
$ ssh -o PreferredAuthentications=publickey <username>@<ssh-server-example.com>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.1.2. OpenSSH 서버에서 유일한 방법으로 키 기반 인증 설정
시스템 보안을 강화하려면 OpenSSH 서버에서 암호 인증을 비활성화하여 키 기반 인증을 시행합니다.
사전 요구 사항
-
openssh-server패키지가 설치되어 있어야 합니다. -
sshd데몬이 서버에서 실행되고 있어야 합니다. 키를 사용하여 OpenSSH 서버에 이미 연결할 수 있습니다.
자세한 내용은 SSH 키 쌍 생성 섹션을 참조하십시오.
프로세스
텍스트 편집기에서
/etc/ssh/sshd_config구성을 엽니다. 예를 들면 다음과 같습니다.vi /etc/ssh/sshd_config
# vi /etc/ssh/sshd_configCopy to Clipboard Copied! Toggle word wrap Toggle overflow PasswordAuthentication옵션을no로 변경합니다.PasswordAuthentication no
PasswordAuthentication noCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
새 기본 설치 이외의 시스템에서
PubkeyAuthentication매개변수가 설정되지 않았거나yes로 설정되어 있는지 확인합니다. ChallengeResponseAuthentication지시문을no로 설정합니다.해당 항목은 구성 파일에서 주석 처리되며 기본값은
yes입니다.NFS로 마운트된 홈 디렉토리에서 키 기반 인증을 사용하려면
use_nfs_home_dirsSELinux 부울을 활성화합니다.setsebool -P use_nfs_home_dirs 1
# setsebool -P use_nfs_home_dirs 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 콘솔 또는 대역 외 액세스를 사용하지 않고 원격으로 연결하는 경우 암호 인증을 비활성화하기 전에 키 기반 로그인 프로세스를 테스트합니다.
sshd데몬을 다시 로드하여 변경 사항을 적용합니다.systemctl reload sshd
# systemctl reload sshdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.1.3. ssh-agent를 사용하여 SSH 인증 정보 캐싱
SSH 연결을 시작할 때마다 암호를 입력하지 않으려면 ssh-agent 유틸리티를 사용하여 로그인 세션의 개인 SSH 키를 캐시할 수 있습니다. 에이전트가 실행 중이고 키가 잠금 해제되면 키의 암호를 다시 입력하지 않고도 이러한 키를 사용하여 SSH 서버에 로그인할 수 있습니다. 개인 키와 암호는 안전하게 유지됩니다.
사전 요구 사항
- SSH 데몬이 실행되고 네트워크를 통해 연결할 수 있는 원격 호스트가 있습니다.
- IP 주소 또는 호스트 이름 및 인증 정보를 통해 원격 호스트에 로그인합니다.
암호를 사용하여 SSH 키 쌍을 생성하고 공개 키를 원격 시스템으로 전송했습니다.
자세한 내용은 SSH 키 쌍 생성 섹션을 참조하십시오.
프로세스
세션에서
ssh-agent를 자동으로 시작하는 명령을~/.bashrc파일에 추가합니다.선택한 텍스트 편집기에서
~/.bashrc를 엽니다. 예를 들면 다음과 같습니다.vi ~/.bashrc
$ vi ~/.bashrcCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 줄을 파일에 추가하세요.
eval $(ssh-agent)
eval $(ssh-agent)Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 변경 사항을 저장하고 편집기를 종료합니다.
~/.ssh/config파일에 다음 행을 추가합니다.AddKeysToAgent yes
AddKeysToAgent yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 옵션과
ssh-agent가 세션에서 시작되면 에이전트는 호스트에 처음 연결할 때만 암호를 입력하라는 메시지를 표시합니다.
검증
에이전트에서 캐시된 개인 키의 해당 공개 키를 사용하는 호스트에 로그인합니다. 예를 들면 다음과 같습니다.
ssh <example.user>@<ssh-server@example.com>
$ ssh <example.user>@<ssh-server@example.com>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 암호를 입력할 필요가 없습니다.
23.1.4. 스마트 카드에 저장된 SSH 키로 인증
스마트 카드에 ECDSA 및 RSA 키를 생성 및 저장하고 OpenSSH 클라이언트의 스마트 카드로 인증할 수 있습니다. 스마트 카드 인증은 기본 암호 인증을 대체합니다.
사전 요구 사항
-
클라이언트 측에서
opensc패키지가 설치되고pcscd서비스가 실행 중입니다.
프로세스
PKCS #11 URI를 포함하여 OpenSC PKCS #11 모듈에서 제공하는 모든 키를 나열하고 출력을
keys.pub파일에 저장합니다.ssh-keygen -D pkcs11: > keys.pub
$ ssh-keygen -D pkcs11: > keys.pubCopy to Clipboard Copied! Toggle word wrap Toggle overflow 공개 키를 원격 서버로 전송합니다. 이전 단계에서 만든
keys.pub파일과 함께ssh-copy-id명령을 사용합니다.ssh-copy-id -f -i keys.pub <username@ssh-server-example.com>
$ ssh-copy-id -f -i keys.pub <username@ssh-server-example.com>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ECDSA 키를 사용하여 < ssh-server-example.com >에 연결합니다. 키를 고유하게 참조하는 URI의 하위 집합만 사용할 수 있습니다. 예를 들면 다음과 같습니다.
ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow OpenSSH는
p11-kit-proxy래퍼를 사용하고 OpenSC PKCS #11 모듈이p11-kit툴에 등록되므로 이전 명령을 단순화할 수 있습니다.ssh -i "pkcs11:id=%01" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ ssh -i "pkcs11:id=%01" <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow PKCS #11 URI의
id=부분을 건너뛰면 OpenSSH는 proxy 모듈에서 사용할 수 있는 모든 키를 로드합니다. 이렇게 하면 필요한 입력 횟수가 줄어듭니다.ssh -i pkcs11: <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ ssh -i pkcs11: <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항:
~/.ssh/config파일에서 동일한 URI 문자열을 사용하여 구성을 영구적으로 만들 수 있습니다.cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $
$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh <ssh-server-example.com> Enter PIN for 'SSH key': [ssh-server-example.com] $Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이제
ssh클라이언트 유틸리티에서 이 URI와 스마트 카드의 키를 자동으로 사용합니다.
23.2. TLS 계획 및 구현
TLS(Transport Layer Security)는 네트워크 통신을 보호하는 데 사용되는 암호화 프로토콜입니다. 기본 키 교환 프로토콜, 인증 방법 및 암호화 알고리즘을 구성하여 시스템 보안 설정을 강화할 때 지원되는 클라이언트 범위를 넓혀 보안을 강화해야 합니다. 반대로 엄격한 보안 설정은 클라이언트와의 호환성이 제한되어 일부 사용자가 시스템에서 잠길 수 있습니다. 가장 엄격한 사용 가능한 구성을 대상으로 하고 호환성을 위해 필요한 경우에만 완화해야 합니다.
23.2.1. SSL 및 TLS 프로토콜
SSL(Secure Sockets Layer) 프로토콜은 원래 Netscape Corporation에서 인터넷을 통한 보안 통신을 위한 메커니즘을 제공하기 위해 개발되었습니다. 그 후 이 프로토콜은 IETF(Internet Engineering Task Force)에서 채택했으며 TLS(Transport Layer Security)로 이름이 변경되었습니다.
TLS 프로토콜은 애플리케이션 프로토콜 계층과 TCP/IP와 같은 신뢰할 수 있는 전송 계층 사이에 있습니다. 애플리케이션 프로토콜과 독립적이므로 다음과 같이 다양한 프로토콜 아래에 계층화할 수 있습니다. HTTP, FTP, SMTP 등.
| 프로토콜 버전 | 사용 권장 사항 |
|---|---|
| SSL v2 | 사용하지 마십시오. 심각한 보안 취약점이 있습니다. RHEL 7 이후 코어 암호화 라이브러리에서 제거되었습니다. |
| SSL v3 | 사용하지 마십시오. 심각한 보안 취약점이 있습니다. RHEL 8 이후 코어 암호화 라이브러리에서 제거되었습니다. |
| TLS 1.0 |
사용하지 않는 것이 좋습니다. 상호 운용성을 보장하고 최신 암호화 제품군을 지원하지 않는 방식으로 완화할 수 없는 문제가 있습니다. RHEL 8에서는 |
| TLS 1.1 |
필요한 경우 상호 운용성을 목적으로 사용합니다. 최신 암호화 제품군을 지원하지 않습니다. RHEL 8에서는 |
| TLS 1.2 | 최신 AEAD 암호화 제품군을 지원합니다. 이 버전은 모든 시스템 전체 암호화 정책에서 활성화되지만, 이 프로토콜의 선택적 부분에는 취약점이 포함되어 있으며 TLS 1.2에서는 오래된 알고리즘도 허용합니다. |
| TLS 1.3 | 권장 버전입니다. TLS 1.3은 문제가 있는 알려진 옵션을 제거하고, 협상 핸드셰이크를 더 많이 암호화하여 추가적인 프라이버시를 제공하며 보다 효율적인 최신 암호화 알고리즘을 사용하여 더 빠르게 사용될 수 있습니다. TLS 1.3은 모든 시스템 전체 암호화 정책에서도 활성화됩니다. |
23.2.2. RHEL 8에서 TLS의 보안 고려 사항
RHEL 8에서는 시스템 전체 암호화 정책으로 인해 암호화 관련 고려 사항이 크게 단순화됩니다. DEFAULT 암호화 정책은 TLS 1.2 및 1.3만 허용합니다. 시스템이 이전 버전의 TLS를 사용하여 연결을 협상할 수 있도록 하려면 애플리케이션의 다음 암호화 정책을 비활성화하거나 update-crypto-policies 명령을 사용하여 LEGACY 정책으로 전환해야 합니다. 자세한 내용은 시스템 전체 암호화 정책 사용을 참조하십시오.
RHEL 8에 포함된 라이브러리에서 제공하는 기본 설정은 대부분의 배포에 충분히 안전합니다. TLS 구현에서는 가능한 경우 또는 기존 클라이언트 또는 서버의 연결을 방지할 수 없는 보안 알고리즘을 사용합니다. 보안 알고리즘 또는 프로토콜을 지원하지 않는 레거시 클라이언트나 서버가 연결되지 않거나 연결할 수 없는 엄격한 보안 요구 사항을 충족하는 환경에서 강화된 설정을 적용합니다.
TLS 구성을 강화하는 가장 간단한 방법은 update-crypto-policies --set FUTURE 명령을 사용하여 시스템 전체 암호화 정책 수준을 FUTURE로 전환하는 것입니다.
LEGACY 암호화 정책에 대해 비활성화된 알고리즘은 Red Hat의 RHEL 8 보안 비전을 준수하지 않으며 보안 속성을 신뢰할 수 없습니다. 다시 활성화하는 대신 이러한 알고리즘 사용에서 벗어나는 것이 좋습니다. 예를 들어 이전 하드웨어와의 상호 운용성을 위해 다시 활성화하기로 결정한 경우, 이를 안전하지 않은 것으로 처리하고 네트워크 상호 작용을 별도의 네트워크 세그먼트에 격리하는 등의 추가 보호 조치를 적용합니다. 공용 네트워크에서 사용하지 마십시오.
RHEL 시스템 전체 암호화 정책을 따르거나 설정에 맞는 사용자 지정 암호화 정책을 생성하기로 결정한 경우 사용자 정의 구성에서 선호하는 프로토콜, 암호화 제품군 및 키 길이에 다음 권장 사항을 사용하십시오.
23.2.2.1. 프로토콜
최신 버전의 TLS는 최상의 보안 메커니즘을 제공합니다. 이전 버전의 TLS에 대한 지원을 포함할 수 있는 강력한 이유가 없는 경우 시스템에서 최소 TLS 버전 1.2를 사용하여 연결을 협상할 수 있습니다.
RHEL 8에서는 TLS 버전 1.3을 지원하지만 이 프로토콜의 일부 기능은 RHEL 8 구성 요소에서 완전히 지원되지는 않습니다. 예를 들어 연결 대기 시간을 줄이는 0-RTT(round Trip Time) 기능은 Apache 웹 서버에서 아직 완전히 지원하지 않습니다.
23.2.2.2. 암호화 제품군
최신 보안 암호화 제품군은 안전하지 않은 이전 암호화 제품군을 선호해야 합니다. 항상 암호화 또는 인증을 전혀 제공하지 않는 eNULL 및 aNULL 암호화 제품군 사용을 비활성화합니다. 가능한 경우 심각한 단점이 있는 RC4 또는 HMAC-MD5를 기반으로 하는 암호 제품군도 비활성화해야 합니다. 즉, 의도적으로 약해졌던 수출 암호 모음에도 동일하게 적용됩니다. 따라서 쉽게 중단할 수 있습니다.
즉시 안전하지 않지만 128비트 미만의 보안을 제공하는 암호화 제품군은 짧은 유효 기간 동안 고려해서는 안 됩니다. 128비트의 보안을 사용하는 알고리즘은 적어도 몇 년 동안 중단되지 않을 수 있으므로 강력하게 권장합니다. 3DES 암호화는 168비트 사용을 알리지만 실제로 112비트의 보안을 제공합니다.
항상 서버 키가 손상된 경우에도 암호화된 데이터의 기밀성을 보장하는 PFS(forward secrecy)를 지원하는 암호화 제품군을 선호합니다. 이 규칙은 빠른 RSA 키 교환을 제한하지만 ECDHE 및 DHE를 사용할 수 있습니다. 이 둘 중 ECDHE는 더 빠르고 선호되는 선택입니다.
또한 Oracle 공격에 취약하지 않으므로 CBC-GCM 이상의 AEAD 암호를 선호해야 합니다. 또한 대부분의 경우 AES-GCM은 특히 하드웨어에 AES용 암호화 가속기가 있는 경우 CBC 모드에서 AES보다 빠릅니다.
또한 ECDSA 인증서와 함께 ECDSA 키 교환을 사용할 때는 트랜잭션이 순수 RSA 키 교환보다 훨씬 빠릅니다. 레거시 클라이언트를 지원하기 위해 서버에 두 쌍의 인증서와 키(새 클라이언트용)와 RSA 키가 있는 키(기존 클라이언트의 경우)를 설치할 수 있습니다.
23.2.2.3. 공개 키 길이
RSA 키를 사용하는 경우 항상 최소 SHA-256에서 서명한 3072비트 이상의 키 길이를 선호하며, 이는 실제 128비트의 보안을 위해 충분히 큽니다.
시스템의 보안은 체인에서 가장 약한 링크만큼 강력합니다. 예를 들어 강력한 암호만으로는 좋은 보안이 보장되지 않습니다. 키와 인증서는 키에 서명하는 데 CA(인증 기관)에서 사용하는 해시 기능 및 키뿐만 아니라 중요합니다.
23.2.3. 애플리케이션에서 TLS 구성 강화
RHEL에서 시스템 전체 암호화 정책은 암호화 라이브러리를 사용하는 애플리케이션에서 알려진 비보안 프로토콜, 암호 또는 알고리즘을 허용하지 않도록 하는 편리한 방법을 제공합니다.
사용자 지정 암호화 설정으로 TLS 관련 구성을 강화하려면 이 섹션에 설명된 암호화 구성 옵션을 사용하고 필요한 최소 용량의 시스템 전체 암호화 정책을 재정의할 수 있습니다.
사용하도록 선택한 구성과 관계없이 항상 서버 애플리케이션에서 서버 측 암호 순서를 적용하여 사용할 암호화 모음을 구성하는 순서에 따라 결정되도록 합니다.
23.2.3.1. TLS를 사용하도록 Apache HTTP 서버 구성
Apache HTTP Server는 TLS 요구 사항에 따라 OpenSSL 및 NSS 라이브러리를 모두 사용할 수 있습니다. RHEL 8에서는 잘못된 패키지를 통해 mod_ssl 기능을 제공합니다.
yum install mod_ssl
# yum install mod_ssl
mod_ssl 패키지는 Apache HTTP Server의 TLS 관련 설정을 수정하는 데 사용할 수 있는 /etc/httpd/conf.d/ssl.conf 구성 파일을 설치합니다.
httpd-manual 패키지를 설치하여 TLS 구성을 포함하여 Apache HTTP Server 에 대한 전체 문서를 가져옵니다. /etc/httpd/conf.d/ssl.conf 구성 파일에서 사용 가능한 지시문은 /usr/share/httpd/manual/mod/mod_ssl.html 파일에 자세히 설명되어 있습니다. 다양한 설정의 예는 /usr/share/httpd/manual/ssl/ssl_howto.html 파일에 설명되어 있습니다.
/etc/httpd/conf.d/ssl.conf 구성 파일의 설정을 수정할 때 최소한 다음 세 가지 지시문을 고려해야 합니다.
SSLProtocol- 이 지시문을 사용하여 허용하려는 TLS 또는 SSL 버전을 지정합니다.
SSLCipherSuite- 이 지시문을 사용하여 선호하는 암호화 제품군을 지정하거나 허용하지 않을 암호화 제품군을 비활성화합니다.
SSLHonorCipherOrder-
연결 클라이언트가 지정한 암호 순서를 준수하는지 확인하기 위해 이 지시문의 주석을
on으로 설정합니다.
예를 들어 TLS 1.2 및 1.3 프로토콜만 사용하려면 다음을 수행합니다.
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.1
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.1자세한 내용은 다양한 유형의 서버 배포 문서의 Apache HTTP Server에서 TLS 암호화 구성 장을 참조하십시오.
23.2.3.2. TLS를 사용하도록 Nginx HTTP 및 프록시 서버 구성
Nginx 에서 TLS 1.3 지원을 활성화하려면 /etc/nginx/nginx.conf 구성 파일의 server 섹션에 있는 ssl_protocols 옵션에 TLSv1.3 값을 추가합니다.
자세한 내용은 다양한 유형의 서버 배포 문서의 Nginx 웹 서버에 TLS 암호화 추가 장을 참조하십시오.
23.2.3.3. TLS를 사용하도록 Dovecot 메일 서버 구성
TLS를 사용하도록 Dovecot 메일 서버의 설치를 구성하려면 /etc/dovecot/conf.d/10-ssl.conf 구성 파일을 수정합니다. 해당 파일에서 사용할 수 있는 기본 구성 지시문 중 일부에 대한 설명은 Dovecot 의 표준 설치와 함께 설치된 /usr/share/doc/dovecot/whaproxy/SSL.DovecotConfiguration.txt 파일에서 찾을 수 있습니다.
/etc/dovecot/conf.d/10-ssl.conf 구성 파일의 설정을 수정할 때 다음 세 지시문을 최소한으로 고려해야 합니다.
ssl_protocols- 이 지시문을 사용하여 허용 또는 비활성화하려는 TLS 또는 SSL 버전을 지정합니다.
ssl_cipher_list- 이 지시문을 사용하여 선호하는 암호화 제품군을 지정하거나 허용하지 않을 암호화 제품군을 비활성화합니다.
ssl_prefer_server_ciphers-
연결 클라이언트가 지정한 암호 순서를 준수하는지 확인하기 위해 이 지시문의 주석을 제거하고
yes로 설정합니다.
예를 들어 /etc/dovecot/conf.d/10-ssl.conf 의 다음 행에서는 TLS 1.1 이상만 허용합니다.
ssl_protocols = !SSLv2 !SSLv3 !TLSv1
ssl_protocols = !SSLv2 !SSLv3 !TLSv123.3. IPsec VPN 설정
VPN(가상 사설 네트워크)은 인터넷을 통해 로컬 네트워크에 연결하는 방법입니다. Libreswan 에서 제공하는 IPsec 은 VPN을 생성하는 기본 방법입니다. Libreswan 은 VPN을 위한 사용자 공간 IPsec 구현입니다. VPN은 인터넷과 같은 중간 네트워크에서 터널을 설정하여 LAN과 다른 LAN 간의 통신을 활성화합니다. 보안상의 이유로 VPN 터널은 항상 인증 및 암호화를 사용합니다. 암호화 작업의 경우 Libreswan 은 NSS 라이브러리를 사용합니다.
23.3.1. IPsec VPN 구현으로 Libreswan
RHEL에서는 Libreswan 애플리케이션에서 지원하는 IPsec 프로토콜을 사용하여 VPN(Virtual Private Network)을 구성할 수 있습니다. Libreswan은 Openswan 애플리케이션이 계속되고 있으며 Openswan 설명서의 많은 예제는 Libreswan과 상호 교환 할 수 있습니다.
VPN의 IPsec 프로토콜은IKE(Internet Key Exchange) 프로토콜을 사용하여 구성됩니다. IPsec과 IKE라는 용어는 서로 바꿔 사용할 수 있습니다. IPsec VPN은 IKE VPN, IKEv2 VPN, XAUTH VPN, Cisco VPN 또는 IKE/IPsec VPN이라고도 합니다. Layer 2 tunneling Protocol(L2TP)을 사용하는 IPsec VPN의 변형은 일반적으로 선택적 리포지토리에서 제공하는 xl2tpd 패키지가 필요한 L2TP/IPsec VPN이라고 합니다.
Libreswan은 오픈 소스 사용자 공간 IKE 구현입니다. IKE v1 및 v2는 사용자 수준 데몬으로 구현됩니다. IKE 프로토콜도 암호화됩니다. IPsec 프로토콜은 Linux 커널에 의해 구현되며 Libreswan은 VPN 터널 구성을 추가하고 제거하도록 커널을 구성합니다.
IKE 프로토콜은 UDP 포트 500 및 4500을 사용합니다. IPsec 프로토콜은 다음 두 프로토콜로 구성됩니다.
- 프로토콜 번호가 50인 캡슐화된 ESP(Security Payload)입니다.
- 프로토콜 번호 51이 있는 AH(인증된 헤더)입니다.
AH 프로토콜은 사용하지 않는 것이 좋습니다. AH 사용자는 null 암호화로 ESP로 마이그레이션하는 것이 좋습니다.
IPsec 프로토콜은 두 가지 작동 모드를 제공합니다.
- 터널 모드(기본값)
- 전송 모드
IKE 없이 IPsec을 사용하여 커널을 구성할 수 있습니다. 이를 수동 키링 이라고 합니다. ip xfrm 명령을 사용하여 수동 인증도 구성할 수 있지만 보안상의 이유로 이 방법은 권장되지 않습니다. Libreswan은 Netlink 인터페이스를 사용하여 Linux 커널과 통신합니다. 커널은 패킷 암호화 및 암호 해독을 수행합니다.
Libreswan은 NSS(Network Security Services) 암호화 라이브러리를 사용합니다. NSS는FIPS( Federal Information Processing Standard ) 발행 140-2와 함께 사용하도록 인증되었습니다.
Libreswan 및 Linux 커널에서 구현하는 IKE/IPsec VPN은 RHEL에서 사용하는 데 권장되는 유일한 VPN 기술입니다. 이렇게하는 위험을 이해하지 않고 다른 VPN 기술을 사용하지 마십시오.
RHEL에서 Libreswan은 기본적으로 시스템 전체 암호화 정책을 따릅니다. 이렇게 하면 Libreswan이 IKEv2를 기본 프로토콜로 포함한 현재 위협 모델에 대한 보안 설정을 사용할 수 있습니다. 자세한 내용은 시스템 전체 암호화 정책 사용을 참조하십시오.
Libreswan은 IKE/IPsec이 피어 간 프로토콜이므로 "소스" 및 "대상" 또는 "서버" 및 "클라이언트"라는 용어를 사용하지 않습니다. 대신 "left" 및 "right"라는 용어를 사용하여 엔드 포인트(호스트)를 나타냅니다. 또한 대부분의 경우 두 끝점 모두에서 동일한 구성을 사용할 수 있습니다. 그러나 관리자는 일반적으로 로컬 호스트에 대해 항상 "left"를 사용하고 원격 호스트에 대해 "오른쪽"을 사용하도록 선택합니다.
leftid 및 rightid 옵션은 인증 프로세스에서 해당 호스트를 식별하는 역할을 합니다. 자세한 내용은 ipsec.conf(5) 도움말 페이지를 참조하십시오.
23.3.2. Libreswan의 인증 방법
Libreswan은 각각 다른 시나리오에 맞는 여러 인증 방법을 지원합니다.
Pre-Shared 키(PSK)
PSK( Pre-Shared Key )는 가장 간단한 인증 방법입니다. 보안상의 이유로, 64개의 임의 문자보다 짧은 PSK를 사용하지 마십시오. FIPS 모드에서 PSK는 사용된 무결성 알고리즘에 따라 최소 요구 사항을 준수해야 합니다. authby=secret 연결을 사용하여 PSK를 설정할 수 있습니다.
원시 RSA 키
원시 RSA 키는 일반적으로 정적 host-host 또는 subnet-to-subnet IPsec 구성에 사용됩니다. 각 호스트는 다른 모든 호스트의 공개 RSA 키를 사용하여 수동으로 구성하고 Libreswan은 각 호스트 쌍 간에 IPsec 터널을 설정합니다. 이 방법은 많은 호스트에 대해 잘 확장되지 않습니다.
ipsec newhostkey 명령을 사용하여 호스트에서 원시 RSA 키를 생성할 수 있습니다. ipsec showhostkey 명령을 사용하여 생성된 키를 나열할 수 있습니다. CKA ID 키를 사용하는 연결 구성에는 leftrsasigkey= 행이 필요합니다. 원시 RSA 키에 authby=rsasig 연결 옵션을 사용합니다.
X.509 인증서
X.509 인증서 는 일반적으로 공통 IPsec 게이트웨이에 연결된 호스트로 대규모 배포에 사용됩니다. 중앙 인증 기관 (CA)은 호스트 또는 사용자의 RSA 인증서에 서명합니다. 이 중앙 CA는 개별 호스트 또는 사용자의 취소를 포함하여 신뢰 중계를 담당합니다.
예를 들어 openssl 명령 및 NSS certutil 명령을 사용하여 X.509 인증서를 생성할 수 있습니다. Libreswan은 왼쪽cert= 구성 옵션의 인증서의 닉네임을 사용하여 NSS 데이터베이스에서 사용자 인증서를 읽기 때문에 인증서를 만들 때 닉네임을 제공합니다.
사용자 정의 CA 인증서를 사용하는 경우 NSS(Network Security Services) 데이터베이스로 가져와야 합니다. ipsec import 명령을 사용하여 PKCS #12 형식의 인증서를 Libreswan NSS 데이터베이스로 가져올 수 있습니다.
Libreswan은 RFC 4945의 섹션 3.1 에 설명 된 모든 피어 인증서에 대한 주제 대체 이름 (SAN)으로 인터넷 키 교환 (IKE) 피어 ID가 필요합니다. require-id-on-certificate=no 연결 옵션을 설정하여 이 검사를 비활성화하면 시스템이 중간자 공격에 취약해질 수 있습니다.
RSA with SHA-1 및 SHA-2를 사용하는 X.509 인증서를 기반으로 하는 인증에 authby=rsasig 연결 옵션을 사용합니다. authby=을 ecdsa 및 RSA Probabilistic Signature scheme (RSASSA-PSS) 디지털 서명과 를 통해 SHA-2로 설정하여 SHA-2를 사용하여 ECDSA 디지털 서명에 대한 제한을 추가로 제한할 수 있습니다. 기본값은 authby= rsa-sha2authby=rsasig,ecdsa 입니다.
인증서 및 authby= 서명 방법과 일치해야 합니다. 이로 인해 상호 운용성이 증가하고 하나의 디지털 서명 시스템에서 인증을 유지합니다.
NULL 인증
NULL 인증은 인증 없이 메시 암호화를 얻는 데 사용됩니다. 수동적인 공격을 방지하지만 적극적인 공격으로 인한 것은 아닙니다. 그러나 IKEv2에서는 symmetric 인증 방법을 허용하므로 인터넷 규모의 opportunistic IPsec에도 NULL 인증을 사용할 수 있습니다. 이 모델에서 클라이언트는 서버를 인증하지만 서버는 클라이언트를 인증하지 않습니다. 이 모델은 TLS를 사용하는 보안 웹 사이트와 유사합니다. NULL 인증을 위해 authby=null 을 사용합니다.
섀도우 컴퓨터 보호
앞서 언급한 인증 방법 외에도 Post-quantum Pre-shared Key (PPK) 방법을 사용하여 computer의 가능한 공격으로부터 보호할 수 있습니다. 개별 클라이언트 또는 클라이언트 그룹이 구성된 사전 공유 키에 해당하는 PPK ID를 지정하여 자체 PPK를 사용할 수 있습니다.
IKEv1을 사전 공유 키와 함께 사용하면 정크 공격자로부터 보호됩니다. IKEv2의 재 설계는 이러한 보호 기능을 기본적으로 제공하지 않습니다. Libreswan은 압 공격으로부터 IKEv2 연결을 보호하기 위해 Post-quantum Pre-shared Key (PPK)를 사용하여 IKEv2 연결을 보호합니다.
선택적 PPK 지원을 활성화하려면 연결 정의에 ppk=yes 를 추가합니다. PPK를 요구하려면 ppk=insist 를 추가합니다. 그런 다음, 각 클라이언트에 범위를 벗어난 비밀 값이 있는 PPK ID를 제공할 수 있습니다(및 더 바람직하게 압축하는 경우). PPK는 사전 단어를 기반으로 하지 않고 무작위로 매우 강력해야 합니다. PPK ID 및 PPK 데이터는 ipsec.secrets 파일에 저장됩니다. 예를 들면 다음과 같습니다.
@west @east : PPKS "user1" "thestringismeanttobearandomstr"
@west @east : PPKS "user1" "thestringismeanttobearandomstr"
PPKS 옵션은 정적 PPK를 나타냅니다. 이 실험적 기능은 일회성 기반 동적 PPK를 사용합니다. 각 연결시 한 번 패드의 새로운 부분이 PPK로 사용됩니다. 사용할 때 파일 내부의 동적 PPK의 해당 부분은 다시 사용하지 않도록 0으로 덮어씁니다. 더 이상 일회성-패드 자료가 남아 있지 않으면 연결이 실패합니다. 자세한 내용은 ipsec.secrets(5) 도움말 페이지를 참조하십시오.
동적 PPK의 구현은 지원되지 않는 기술 프리뷰로 제공됩니다. 주의해서 사용하십시오.
23.3.3. Libreswan 설치
Libreswan IPsec/IKE 구현을 통해 VPN을 설정하려면 해당 패키지를 설치하고 ipsec 서비스를 시작하고 방화벽에서 서비스를 허용해야 합니다.
사전 요구 사항
-
AppStream리포지토리가 활성화되어 있습니다.
절차
libreswan패키지를 설치합니다.yum install libreswan
# yum install libreswanCopy to Clipboard Copied! Toggle word wrap Toggle overflow Libreswan을 다시 설치하는 경우 이전 데이터베이스 파일을 제거하고 새 데이터베이스를 만듭니다.
systemctl stop ipsec rm /etc/ipsec.d/*db ipsec initnss
# systemctl stop ipsec # rm /etc/ipsec.d/*db # ipsec initnssCopy to Clipboard Copied! Toggle word wrap Toggle overflow ipsec서비스를 시작하고 부팅 시 서비스를 자동으로 시작합니다.systemctl enable ipsec --now
# systemctl enable ipsec --nowCopy to Clipboard Copied! Toggle word wrap Toggle overflow ipsec서비스를 추가하여 IKE, ESP 및 AH 프로토콜에 500 및 4500/UDP 포트를 허용하도록 방화벽을 구성합니다.firewall-cmd --add-service="ipsec" firewall-cmd --runtime-to-permanent
# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.3.4. 호스트 대 호스트 VPN 생성
원시 RSA 키의 인증을 사용하여 왼쪽 및 오른쪽 이라는 두 호스트 간에 host-to-host IPsec VPN을 생성하도록 Libreswan을 구성할 수 있습니다.
사전 요구 사항
-
Libreswan이 설치되고 각 노드에서
ipsec서비스가 시작됩니다.
절차
각 호스트에 원시 RSA 키 쌍을 생성합니다.
ipsec newhostkey
# ipsec newhostkeyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 단계에서 생성된 키의
c¢d가 반환되었습니다. 예를 들면 왼쪽에서 다음 명령과함께cutord 를 사용합니다.ipsec showhostkey --left --ckaid 2d3ea57b61c9419dfd6cf43a1eb6cb306c0e857d
# ipsec showhostkey --left --ckaid 2d3ea57b61c9419dfd6cf43a1eb6cb306c0e857dCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 명령의 출력에서 구성에 필요한
leftrsasigkey=행을 생성했습니다. 두 번째 호스트에서 동일한 작업을 수행합니다(오른쪽):ipsec showhostkey --right --ckaid a9e1f6ce9ecd3608c24e8f701318383f41798f03
# ipsec showhostkey --right --ckaid a9e1f6ce9ecd3608c24e8f701318383f41798f03Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/ipsec.d/디렉터리에 새my_host-to-host.conf파일을 만듭니다. 이전 단계에서ipsec showhostkey명령의 출력에서 RSA 호스트 키를 새 파일로 작성합니다. 예를 들면 다음과 같습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 키를 가져온 후
ipsec서비스를 다시 시작하십시오.systemctl restart ipsec
# systemctl restart ipsecCopy to Clipboard Copied! Toggle word wrap Toggle overflow 연결을 로드합니다.
ipsec auto --add mytunnel
# ipsec auto --add mytunnelCopy to Clipboard Copied! Toggle word wrap Toggle overflow 터널을 설정합니다.
ipsec auto --up mytunnel
# ipsec auto --up mytunnelCopy to Clipboard Copied! Toggle word wrap Toggle overflow ipsec서비스가 시작될 때 터널을 자동으로 시작하려면 연결 정의에 다음 행을 추가합니다.auto=start
auto=startCopy to Clipboard Copied! Toggle word wrap Toggle overflow - DHCP 또는 SLAAC(상태 비저장 주소 자동 구성)가 있는 네트워크에서 이 호스트를 사용하는 경우 연결이 리디렉션될 수 있습니다. 자세한 내용 및 완화 단계는 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당을 참조하십시오.
23.3.5. 사이트 간 VPN 구성
두 개의 네트워크에 가입하여 사이트 간 IPsec VPN을 생성하려면 두 호스트 간의 IPsec 터널이 생성됩니다. 따라서 호스트는 하나 이상의 서브넷의 트래픽이 통과할 수 있도록 구성된 엔드포인트 역할을 합니다. 따라서 호스트를 네트워크의 원격 부분에 대한 게이트웨이로 간주할 수 있습니다.
사이트-사이트 VPN의 구성은 하나 이상의 네트워크 또는 서브넷이 구성 파일에 지정해야 한다는 점에서 호스트 대 호스트 VPN과만 다릅니다.
사전 요구 사항
- 호스트 대 호스트 VPN이 이미 구성되어 있습니다.
절차
host-to-host VPN의 구성으로 파일을 새 파일로 복사합니다. 예를 들면 다음과 같습니다.
cp /etc/ipsec.d/my_host-to-host.conf /etc/ipsec.d/my_site-to-site.conf
# cp /etc/ipsec.d/my_host-to-host.conf /etc/ipsec.d/my_site-to-site.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 단계에서 만든 파일에 서브넷 구성을 추가합니다. 예를 들면 다음과 같습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - DHCP 또는 SLAAC(상태 비저장 주소 자동 구성)가 있는 네트워크에서 이 호스트를 사용하는 경우 연결이 리디렉션될 수 있습니다. 자세한 내용 및 완화 단계는 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당을 참조하십시오.
23.3.6. 원격 액세스 VPN 구성
오로지 전사들은 모바일 클라이언트와 동적으로 할당된 IP 주소를 가진 사용자를 이동시키고 있습니다. 모바일 클라이언트는 X.509 인증서를 사용하여 인증합니다.
다음 예제에서는 IKEv2 에 대한 구성을 보여주며 IKEv1 XAUTH 프로토콜 사용을 방지합니다.
서버에서 다음을 수행합니다.
모바일 클라이언트에서 로드 해커의 장치는 이전 구성의 약간의 변형을 사용합니다.
DHCP 또는 SLAAC(상태 비저장 주소 자동 구성)가 있는 네트워크에서 이 호스트를 사용하는 경우 연결이 리디렉션될 수 있습니다. 자세한 내용 및 완화 단계는 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당을 참조하십시오.
23.3.7. 메시 VPN 구성
임의 의 VPN이라고도 하는 메시 VPN 네트워크는 모든 노드가 IPsec을 사용하여 통신하는 네트워크입니다. 구성을 사용하면 IPsec을 사용할 수 없는 노드에 예외가 발생할 수 있습니다. 메시 VPN 네트워크는 두 가지 방법으로 구성할 수 있습니다.
- IPsec이 필요합니다.
- IPsec을 선호하지만 대체 텍스트를 사용하여 일반 텍스트 통신을 허용합니다.
노드 간 인증은 X.509 인증서 또는 DNSSEC(DNS Security Extensions)를 기반으로 할 수 있습니다.
이러한 연결은 right=%opportunisticgroup 항목에 정의된 opportunistic IPsec 을 제외하고 일반 Libreswan 구성이므로 opportunistic IPsec에 일반 IKEv2 인증 방법을 사용할 수 있습니다. 일반적인 인증 방법은 일반적으로 공유 CA(인증 기관)를 사용하여 X.509 인증서를 기반으로 호스트가 서로 인증하는 것입니다. 클라우드 배포에서는 일반적으로 표준 절차의 일부로 클라우드에 있는 각 노드의 인증서를 발급합니다.
손상된 호스트 하나로 인해 그룹 PSK도 손상될 수 있으므로 PreSharedKey(PSK) 인증을 사용하지 마십시오.
NULL 인증을 사용하여 수동 공격자로부터만 보호하는 인증 없이 노드 간에 암호화를 배포할 수 있습니다.
다음 절차에서는 X.509 인증서를 사용합니다. Dogtag Certificate System과 같은 모든 종류의 CA 관리 시스템을 사용하여 이러한 인증서를 생성할 수 있습니다. Dogtag는 각 노드의 인증서를 개인 키, 노드 인증서 및 다른 노드의 X.509 인증서의 유효성을 검사하는 데 사용되는 루트 CA 인증서가 포함된 PKCS #12 형식(.p12 파일)에서 사용할 수 있다고 가정합니다.
각 노드에는 X.509 인증서를 제외하고 동일한 구성이 있습니다. 이를 통해 네트워크의 기존 노드를 재구성하지 않고 새 노드를 추가할 수 있습니다. PKCS #12 파일에는 "간단한 이름"이 필요합니다. 이 경우 친숙한 이름을 참조하는 구성 파일이 모든 노드에서 동일하게 유지되도록 이름 "노드"를 사용합니다.
사전 요구 사항
-
Libreswan이 설치되어 각 노드에서
ipsec서비스가 시작됩니다. 새 NSS 데이터베이스가 초기화됩니다.
이전 NSS 데이터베이스가 이미 있는 경우 이전 데이터베이스 파일을 제거하십시오.
systemctl stop ipsec rm /etc/ipsec.d/*db
# systemctl stop ipsec # rm /etc/ipsec.d/*dbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 사용하여 새 데이터베이스를 초기화할 수 있습니다.
ipsec initnss
# ipsec initnssCopy to Clipboard Copied! Toggle word wrap Toggle overflow
절차
각 노드에서 PKCS #12 파일을 가져옵니다. 이 단계에서는 PKCS #12 파일을 생성하는 데 사용되는 암호가 필요합니다.
ipsec import nodeXXX.p12
# ipsec import nodeXXX.p12Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPsec 필수(사설), IPsec(공유옵션) 및(공유) 프로필에 대해 다음 세 가지 연결 정의를 만듭니다.No IPsecCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1
auto변수에는 몇 가지 옵션이 있습니다.opportunistic IPsec과 함께
온 디맨드연결 옵션을 사용하여 IPsec 연결을 시작하거나 항상 활성화할 필요가 없는 명시적으로 구성된 연결에 사용할 수 있습니다. 이 옵션은 커널에 트랩 XFRM 정책을 설정하여 해당 정책과 일치하는 첫 번째 패킷을 수신할 때 IPsec 연결을 시작할 수 있습니다.다음 옵션을 사용하여 Opportunistic IPsec 또는 명시적으로 구성된 연결을 사용하는지 여부에 관계없이 IPsec 연결을 효과적으로 구성하고 관리할 수 있습니다.
추가옵션-
연결 구성을 로드하고 원격 시작에 응답하기 위해 준비합니다. 그러나 연결은 로컬 측에서 자동으로 시작되지 않습니다.
ipsec auto --up명령을 사용하여 IPsec 연결을 수동으로 시작할 수 있습니다. 시작옵션- 연결 구성을 로드하고 원격 시작에 응답하기 위해 준비합니다. 또한 원격 피어에 대한 연결을 즉시 시작합니다. 영구 및 항상 활성 연결에 이 옵션을 사용할 수 있습니다.
- 2
leftid및rightid변수는 IPsec 터널 연결의 오른쪽과 왼쪽 채널을 식별합니다. 이러한 변수를 사용하여 구성된 경우 로컬 IP 주소의 값 또는 로컬 인증서의 제목 DN을 가져올 수 있습니다.- 3
leftcert변수는 사용하려는 NSS 데이터베이스의 닉네임을 정의합니다.
네트워크의 IP 주소를 해당 카테고리에 추가합니다. 예를 들어 모든 노드가
10.15.0.0/16네트워크에 있고 모든 노드가 IPsec 암호화를 사용해야 하는 경우 다음을 수행합니다.echo "10.15.0.0/16" >> /etc/ipsec.d/policies/private
# echo "10.15.0.0/16" >> /etc/ipsec.d/policies/privateCopy to Clipboard Copied! Toggle word wrap Toggle overflow 특정 노드(예:
10.15.34.0/24)가 IPsec과 함께 작동하도록 허용하려면 해당 노드를 private-or-clear 그룹에 추가합니다.echo "10.15.34.0/24" >> /etc/ipsec.d/policies/private-or-clear
# echo "10.15.34.0/24" >> /etc/ipsec.d/policies/private-or-clearCopy to Clipboard Copied! Toggle word wrap Toggle overflow IPsec을 clear 그룹으로 할 수 없는 호스트(예:
10.15.1.2)를 정의하려면 다음을 사용합니다.echo "10.15.1.2/32" >> /etc/ipsec.d/policies/clear
# echo "10.15.1.2/32" >> /etc/ipsec.d/policies/clearCopy to Clipboard Copied! Toggle word wrap Toggle overflow 각 새 노드의 템플릿에서
/etc/ipsec.d/policies디렉터리에 파일을 생성하거나 Puppet 또는 Ansible을 사용하여 파일을 프로비저닝할 수 있습니다.모든 노드에는 예외 또는 트래픽 흐름 예상과 동일한 목록이 있습니다. 따라서 두 노드는 IPsec이 필요하며 다른 노드는 IPsec을 사용할 수 없기 때문에 통신할 수 없습니다.
노드를 재시작하여 구성된 메시에 추가합니다.
systemctl restart ipsec
# systemctl restart ipsecCopy to Clipboard Copied! Toggle word wrap Toggle overflow - DHCP 또는 SLAAC(상태 비저장 주소 자동 구성)가 있는 네트워크에서 이 호스트를 사용하는 경우 연결이 리디렉션될 수 있습니다. 자세한 내용 및 완화 단계는 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당을 참조하십시오.
검증
ping명령을 사용하여 IPsec 터널을 엽니다.ping <nodeYYY>
# ping <nodeYYY>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 가져온 인증서를 사용하여 NSS 데이터베이스를 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 노드에서 열려 있는 터널을 확인합니다.
ipsec trafficstatus 006 #2: "private#10.15.0.0/16"[1] ...<nodeYYY>, type=ESP, add_time=1691399301, inBytes=512, outBytes=512, maxBytes=2^63B, id='C=US, ST=NC, O=Example Organization, CN=east'
# ipsec trafficstatus 006 #2: "private#10.15.0.0/16"[1] ...<nodeYYY>, type=ESP, add_time=1691399301, inBytes=512, outBytes=512, maxBytes=2^63B, id='C=US, ST=NC, O=Example Organization, CN=east'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.3.8. FIPS 호환 IPsec VPN 배포
Libreswan을 사용하여 FIPS 호환 IPsec VPN 솔루션을 배포할 수 있습니다. 이를 위해 사용 가능한 암호화 알고리즘과 FIPS 모드에서 Libreswan에 대해 비활성화된 암호화 알고리즘을 식별할 수 있습니다.
사전 요구 사항
-
AppStream리포지토리가 활성화되어 있습니다.
절차
libreswan패키지를 설치합니다.yum install libreswan
# yum install libreswanCopy to Clipboard Copied! Toggle word wrap Toggle overflow Libreswan을 다시 설치하는 경우 이전 NSS 데이터베이스를 제거하십시오.
systemctl stop ipsec rm /etc/ipsec.d/*db
# systemctl stop ipsec # rm /etc/ipsec.d/*dbCopy to Clipboard Copied! Toggle word wrap Toggle overflow ipsec서비스를 시작하고 부팅 시 서비스를 자동으로 시작합니다.systemctl enable ipsec --now
# systemctl enable ipsec --nowCopy to Clipboard Copied! Toggle word wrap Toggle overflow ipsec서비스를 추가하여 IKE, ESP 및 AH 프로토콜에500및4500UDP 포트를 허용하도록 방화벽을 구성합니다.firewall-cmd --add-service="ipsec" firewall-cmd --runtime-to-permanent
# firewall-cmd --add-service="ipsec" # firewall-cmd --runtime-to-permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템을 FIPS 모드로 전환합니다.
fips-mode-setup --enable
# fips-mode-setup --enableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널이 FIPS 모드로 전환되도록 시스템을 다시 시작하십시오.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Libreswan이 FIPS 모드에서 실행 중인지 확인합니다.
ipsec whack --fipsstatus 000 FIPS mode enabled
# ipsec whack --fipsstatus 000 FIPS mode enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는
systemd저널의ipsec유닛 항목을 확인합니다.journalctl -u ipsec ... Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Product: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Kernel: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Mode: YES
$ journalctl -u ipsec ... Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Product: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Kernel: YES Jan 22 11:26:50 localhost.localdomain pluto[3076]: FIPS Mode: YESCopy to Clipboard Copied! Toggle word wrap Toggle overflow FIPS 모드에서 사용 가능한 알고리즘을 보려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow FIPS 모드에서 비활성화된 알고리즘을 쿼리하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow FIPS 모드에서 허용되는 모든 알고리즘 및 암호를 나열하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.3.9. 암호로 IPsec NSS 데이터베이스 보호
기본적으로 IPsec 서비스는 처음 시작하는 동안 비어 있는 암호를 사용하여 NSS(Network Security Services) 데이터베이스를 생성합니다. 보안을 강화하기 위해 암호 보호를 추가할 수 있습니다.
이전 버전의 RHEL 6.6 버전에서는 NSS 암호화 라이브러리가 FIPS야 수준 2 표준에 대해 인증되었기 때문에 FIPSRuntimeConfig 요구 사항을 충족하기 위해 IPsec NSS 데이터베이스를 보호해야 했습니다. RHEL 8에서 NIST는 이 표준의 레벨 1로 NSS를 인증했으며, 이 상태에는 데이터베이스에 대한 암호 보호가 필요하지 않습니다.
사전 요구 사항
-
/etc/ipsec.d/디렉터리에는 NSS 데이터베이스 파일이 포함되어 있습니다.
절차
Libreswan의
NSS데이터베이스에 대한 암호 보호를 활성화합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 단계에서 설정한 암호가 포함된
/etc/ipsec.d/nsspassword파일을 만듭니다. 예를 들면 다음과 같습니다.cat /etc/ipsec.d/nsspassword NSS Certificate DB:_<password>_
# cat /etc/ipsec.d/nsspassword NSS Certificate DB:_<password>_Copy to Clipboard Copied! Toggle word wrap Toggle overflow nsspassword파일은 다음 구문을 사용합니다.<token_1>:<password1> <token_2>:<password2>
<token_1>:<password1> <token_2>:<password2>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기본 NSS 소프트웨어 토큰은
NSS 인증서 DB입니다. 시스템이 FIPS 모드에서 실행 중인 경우 토큰 이름은NSS FIPS 140-2 인증서 DB입니다.시나리오에 따라
nsspassword파일을 완료한 후ipsec서비스를 시작하거나 다시 시작합니다.systemctl restart ipsec
# systemctl restart ipsecCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
NSS 데이터베이스에 비어 있지 않은 암호를 추가한 후
ipsec서비스가 실행 중인지 확인합니다.systemctl status ipsec ● ipsec.service - Internet Key Exchange (IKE) Protocol Daemon for IPsec Loaded: loaded (/usr/lib/systemd/system/ipsec.service; enabled; vendor preset: disable> Active: active (running)...
# systemctl status ipsec ● ipsec.service - Internet Key Exchange (IKE) Protocol Daemon for IPsec Loaded: loaded (/usr/lib/systemd/system/ipsec.service; enabled; vendor preset: disable> Active: active (running)...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 저널로그에 초기화에 성공했는지 확인하는 항목이 포함되어 있는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.3.10. TCP를 사용하도록 IPsec VPN 구성
Libreswan은 RFC 8229에 설명된 대로 IKE 및 IPsec 패킷을 TCP 캡슐화를 지원합니다. 이 기능을 사용하면 UDP를 통해 전송되는 트래픽을 방지하고 ESB(Security Payload)를 캡슐화하는 네트워크에서 IPsec VPN을 설정할 수 있습니다. TCP를 대체 또는 기본 VPN 전송 프로토콜로 사용하도록 VPN 서버와 클라이언트를 구성할 수 있습니다. TCP 캡슐화는 성능 비용이 늘어날 수 있으므로 시나리오에서 UDP가 영구적으로 차단된 경우에만 TCP를 기본 VPN 프로토콜로 사용하십시오.
사전 요구 사항
- 원격 액세스 VPN 이 이미 구성되어 있습니다.
절차
config setup섹션의/etc/ipsec.conf파일에 다음 옵션을 추가합니다.listen-tcp=yes
listen-tcp=yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow UDP를 처음 시도하지 못하면 TCP 캡슐화를 대체 옵션으로 사용하려면 클라이언트의 연결 정의에 다음 두 옵션을 추가합니다.
enable-tcp=fallback tcp-remoteport=4500
enable-tcp=fallback tcp-remoteport=4500Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 UDP가 영구적으로 차단되었음을 알고 있는 경우 클라이언트 연결 구성에서 다음 옵션을 사용합니다.
enable-tcp=yes tcp-remoteport=4500
enable-tcp=yes tcp-remoteport=4500Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.3.11. IPsec 연결 속도를 높이기 위해 ESP 하드웨어 오프로드 자동 감지 및 사용 구성
ESP(Security Payload)를 하드웨어로 오프로드하면 이더넷을 통해 IPsec 연결이 가속화됩니다. 기본적으로 Libreswan은 하드웨어가 이 기능을 지원하는지 감지하여 ESP 하드웨어 오프로드를 활성화합니다. 기능을 비활성화하거나 명시적으로 활성화한 경우 자동 탐지로 다시 전환할 수 있습니다.
사전 요구 사항
- 네트워크 카드는 ESP 하드웨어 오프로드를 지원합니다.
- 네트워크 드라이버는 ESP 하드웨어 오프로드를 지원합니다.
- IPsec 연결이 구성되고 작동합니다.
절차
-
ESP 하드웨어 오프로드 지원의 자동 검색을 사용해야 하는 연결의
/etc/ipsec.d/디렉터리에서 Libreswan 구성 파일을 편집합니다. -
nic-offload매개변수가 연결 설정에 설정되지 않았는지 확인합니다. nic-offload를 제거한 경우ipsec서비스를 다시 시작합니다.systemctl restart ipsec
# systemctl restart ipsecCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
IPsec 연결에 사용하는 이더넷 장치의
tx_ipsec및rx_ipsec카운터를 표시합니다.ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPsec 터널을 통해 트래픽을 전송합니다. 예를 들어 원격 IP 주소를 ping합니다.
ping -c 5 remote_ip_address
# ping -c 5 remote_ip_addressCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이더넷 장치의
tx_ipsec및rx_ipsec카운터를 다시 표시합니다.ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15Copy to Clipboard Copied! Toggle word wrap Toggle overflow 카운터 값이 증가하면 ESP 하드웨어 오프로드가 작동합니다.
23.3.12. IPsec 연결을 가속화하도록 본딩에 ESP 하드웨어 오프로드 구성
하드웨어로 ESB(Security Payload)를 오프로드하면 IPsec 연결 속도가 빨라집니다. 네트워크 본딩을 장애 조치의 이유로 사용하는 경우 ESP 하드웨어 오프로드를 구성하는 절차와 일반 이더넷 장치를 사용하는 절차가 다릅니다. 예를 들어 이 시나리오에서는 본딩에 대한 오프로드 지원을 활성화하고 커널은 설정을 본딩 포트에 적용합니다.
사전 요구 사항
-
본딩의 모든 네트워크 카드는 ESP 하드웨어 오프로드를 지원합니다.
ethtool -k < interface_name > | grep "esp-hw-offload"명령을 사용하여 각 본딩 포트가 이 기능을 지원하는지 확인합니다. - 본딩이 구성되고 작동합니다.
-
본딩에서는
active-backup모드를 사용합니다. 본딩 드라이버는 이 기능에 대해 다른 모드를 지원하지 않습니다. - IPsec 연결이 구성되고 작동합니다.
절차
네트워크 본딩에서 ESP 하드웨어 오프로드 지원을 활성화합니다.
nmcli connection modify bond0 ethtool.feature-esp-hw-offload on
# nmcli connection modify bond0 ethtool.feature-esp-hw-offload onCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령을 사용하면
bond0연결에서 ESP 하드웨어 오프로드를 지원할 수 있습니다.bond0연결을 다시 활성화합니다.nmcli connection up bond0
# nmcli connection up bond0Copy to Clipboard Copied! Toggle word wrap Toggle overflow ESP 하드웨어 오프로드를 사용해야 하는 연결의
/etc/ipsec.d/디렉터리에서 Libreswan 구성 파일을 편집하고nic-offload=yes문을 연결 항목에 추가합니다.conn example ... nic-offload=yesconn example ... nic-offload=yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow ipsec서비스를 다시 시작하십시오.systemctl restart ipsec
# systemctl restart ipsecCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
확인 방법은 커널 버전 및 드라이버와 같은 다양한 측면에 따라 다릅니다. 예를 들어 특정 드라이버는 카운터를 제공하지만 이름은 다를 수 있습니다. 자세한 내용은 네트워크 드라이버 설명서를 참조하십시오.
다음 확인 단계는 Red Hat Enterprise Linux 8의 ixgbe 드라이버에서 작동합니다.
본딩의 활성 포트를 표시합니다.
grep "Currently Active Slave" /proc/net/bonding/bond0 Currently Active Slave: enp1s0
# grep "Currently Active Slave" /proc/net/bonding/bond0 Currently Active Slave: enp1s0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 활성 포트의
tx_ipsec및rx_ipsec카운터를 표시합니다.ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 10 rx_ipsec: 10Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPsec 터널을 통해 트래픽을 전송합니다. 예를 들어 원격 IP 주소를 ping합니다.
ping -c 5 remote_ip_address
# ping -c 5 remote_ip_addressCopy to Clipboard Copied! Toggle word wrap Toggle overflow 활성 포트의
tx_ipsec및rx_ipsec카운터를 다시 표시합니다.ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15# ethtool -S enp1s0 | grep -E "_ipsec" tx_ipsec: 15 rx_ipsec: 15Copy to Clipboard Copied! Toggle word wrap Toggle overflow 카운터 값이 증가하면 ESP 하드웨어 오프로드가 작동합니다.
23.3.13. RHEL 시스템 역할을 사용하여 VPN 연결 구성
VPN은 신뢰할 수 없는 네트워크를 통해 트래픽을 안전하게 전송하기 위한 암호화된 연결입니다. vpn RHEL 시스템 역할을 사용하면 VPN 구성 생성 프로세스를 자동화할 수 있습니다.
vpn RHEL 시스템 역할은 IPsec 구현인 Libreswan만 VPN 공급자로 지원합니다.
23.3.13.1. vpn RHEL 시스템 역할을 사용하여 PSK 인증을 사용하여 호스트 간 IPsec VPN 생성
IPsec을 사용하여 VPN을 통해 서로 직접 호스트를 연결할 수 있습니다. 호스트는 PSK(사전 공유 키)를 사용하여 서로 인증할 수 있습니다. vpn RHEL 시스템 역할을 사용하면 PSK 인증을 사용하여 IPsec 호스트 간 연결 생성 프로세스를 자동화할 수 있습니다.
기본적으로 이 역할은 터널 기반 VPN을 생성합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
호스트: < ;list>VPN을 구성하려는 호스트를 사용하여 YAML 사전을 정의합니다. 항목이 Ansible 관리형 노드가 아닌 경우
hostname매개변수에서 FQDN(정규화된 도메인 이름) 또는 IP 주소를 지정해야 합니다. 예를 들면 다음과 같습니다.... - hosts: ... external-host.example.com: hostname: 192.0.2.1... - hosts: ... external-host.example.com: hostname: 192.0.2.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 역할은 각 관리 노드에서 VPN 연결을 구성합니다. 연결 이름은 <
host_A> -to- <host_B>입니다(예:managed-node-01.example.com-to-managed-node-02.example.com). 역할은 외부(관리되지 않음) 노드에 Libreswan을 구성할 수 없습니다. 이러한 호스트에 구성을 수동으로 생성해야 합니다.auth_method: psk-
호스트 간 PSK 인증을 활성화합니다. 역할은 제어 노드에서
openssl을 사용하여 PSK를 생성합니다. auto: <start-up_method>-
연결의 시작 메서드를 지정합니다. 유효한 값은
add,ondemand,start및ignore입니다. 자세한 내용은 Libreswan이 설치된 시스템의ipsec.conf(5)도움말 페이지를 참조하십시오. 이 변수의 기본값은 null이며 자동 시작 작업이 없음을 의미합니다. vpn_manage_firewall: true-
역할이 관리 노드의
firewalld서비스에서 필요한 포트를 열도록 정의합니다. vpn_manage_selinux: true- 역할이 IPsec 포트에 필요한 SELinux 포트 유형을 설정하도록 정의합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.vpn/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
연결이 성공적으로 시작되었는지 확인합니다. 예를 들면 다음과 같습니다.
ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "managed-node-01.example.com-to-managed-node-02.example.com"' ... 006 #3: "managed-node-01.example.com-to-managed-node-02.example.com", type=ESP, add_time=1741857153, inBytes=38622, outBytes=324626, maxBytes=2^63B, id='@managed-node-02.example.com'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 VPN 연결이 활성화된 경우에만 성공합니다. 플레이북의
auto변수를start이외의 값으로 설정하는 경우 먼저 관리 노드에서 연결을 수동으로 활성화해야 할 수 있습니다.
23.3.13.2. vpn RHEL 시스템 역할을 사용하여 PSK 인증을 사용하여 호스트 간 IPsec VPN 생성 및 데이터 및 컨트롤 플레인 분리
IPsec을 사용하여 VPN을 통해 서로 직접 호스트를 연결할 수 있습니다. 예를 들어, 인터셉트 또는 중단되는 제어 메시지의 위험을 최소화하여 보안을 강화하기 위해 데이터 트래픽과 제어 트래픽에 대해 별도의 연결을 구성할 수 있습니다. vpn RHEL 시스템 역할을 사용하면 별도의 데이터 및 컨트롤 플레인 및 PSK 인증을 사용하여 IPsec 호스트 간 연결 생성 프로세스를 자동화할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
호스트: < ;list>VPN을 구성하려는 호스트를 사용하여 YAML 사전을 정의합니다. 연결 이름은 <
name> - <IP_address_A> -to- <IP_address_B>입니다(예:control_plane_vpn-203.0.113.1-to-198.51.100.2).역할은 각 관리 노드에서 VPN 연결을 구성합니다. 역할은 외부(관리되지 않음) 노드에 Libreswan을 구성할 수 없습니다. 이러한 호스트에 구성을 수동으로 생성해야 합니다.
auth_method: psk-
호스트 간 PSK 인증을 활성화합니다. 역할은 제어 노드에서
openssl을 사용하여 사전 공유 키를 생성합니다. auto: <start-up_method>-
연결의 시작 메서드를 지정합니다. 유효한 값은
add,ondemand,start및ignore입니다. 자세한 내용은 Libreswan이 설치된 시스템의ipsec.conf(5)도움말 페이지를 참조하십시오. 이 변수의 기본값은 null이며 자동 시작 작업이 없음을 의미합니다. vpn_manage_firewall: true-
역할이 관리 노드의
firewalld서비스에서 필요한 포트를 열도록 정의합니다. vpn_manage_selinux: true- 역할이 IPsec 포트에 필요한 SELinux 포트 유형을 설정하도록 정의합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.vpn/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
연결이 성공적으로 시작되었는지 확인합니다. 예를 들면 다음과 같습니다.
ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "control_plane_vpn-203.0.113.1-to-198.51.100.2"' ... 006 #3: "control_plane_vpn-203.0.113.1-to-198.51.100.2", type=ESP, add_time=1741860073, inBytes=0, outBytes=0, maxBytes=2^63B, id='198.51.100.2'
# ansible managed-node-01.example.com -m shell -a 'ipsec trafficstatus | grep "control_plane_vpn-203.0.113.1-to-198.51.100.2"' ... 006 #3: "control_plane_vpn-203.0.113.1-to-198.51.100.2", type=ESP, add_time=1741860073, inBytes=0, outBytes=0, maxBytes=2^63B, id='198.51.100.2'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 VPN 연결이 활성화된 경우에만 성공합니다. 플레이북의
auto변수를start이외의 값으로 설정하는 경우 먼저 관리 노드에서 연결을 수동으로 활성화해야 할 수 있습니다.
23.3.13.3. vpn RHEL 시스템 역할을 사용하여 인증서 기반 인증을 사용하여 여러 호스트에서 IPsec 메시 VPN 생성
Libreswan은 opportunistic 메시를 생성하여 각 호스트에서 단일 구성으로 많은 호스트 간에 IPsec 연결을 설정할 수 있도록 지원합니다. 메시에 호스트를 추가하는 경우 기존 호스트의 구성을 업데이트할 필요가 없습니다. 보안을 강화하려면 Libreswan에서 인증서 기반 인증을 사용하십시오.
vpn RHEL 시스템 역할을 사용하면 관리형 노드 간의 인증서 기반 인증을 사용하여 VPN 메시 구성을 자동화할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. 각 관리 노드에 대해 PKCS #12 파일을 준비합니다.
각 파일에는 다음이 포함됩니다.
- CA(인증 기관) 인증서
- 노드의 개인 키
- 노드의 클라이언트 인증서
-
파일의 이름은 <
managed_node_name_as_in_the_inventory > .p12입니다. - 파일은 플레이북과 동일한 디렉터리에 저장됩니다.
절차
~/inventory파일을 편집하고cert_name변수를 추가합니다.managed-node-01.example.com cert_name=managed-node-01.example.com managed-node-02.example.com cert_name=managed-node-02.example.com managed-node-03.example.com cert_name=managed-node-03.example.com
managed-node-01.example.com cert_name=managed-node-01.example.com managed-node-02.example.com cert_name=managed-node-02.example.com managed-node-03.example.com cert_name=managed-node-03.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow cert_name변수를 각 호스트의 인증서에 사용된 CN(일반 이름) 필드 값으로 설정합니다. 일반적으로 CN 필드는 FQDN(정규화된 도메인 이름)으로 설정됩니다.중요한 변수를 암호화된 파일에 저장합니다.
자격 증명 모음을 생성합니다.
ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ansible-vault create명령이 편집기를 열고 <key > : < value> 형식으로 중요한 데이터를 입력합니다.pkcs12_pwd: <password>
pkcs12_pwd: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 변경 사항을 저장하고 편집기를 종료합니다. Ansible은 자격 증명 모음의 데이터를 암호화합니다.
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
opportunistic: true-
여러 호스트 간에 opportunistic 메시를 활성화합니다.
policies변수는 암호화해야 하거나 암호화할 수 있는 서브넷 및 호스트 트래픽에 대해 정의하며, 이 중 어느 서브넷이 일반 텍스트 연결을 계속 사용해야 하는지 정의합니다. auth_method: cert- 인증서 기반 인증을 활성화합니다. 이를 위해서는 인벤토리에서 각 관리 노드 인증서의 닉네임을 지정해야 합니다.
policies: <list_of_policies>YAML 목록 형식으로 Libreswan 정책을 정의합니다.
기본 정책은
private-or-clear입니다.개인으로 변경하기 위해 위의 플레이북에는 기본cidr항목에 대한 따라 정책이 포함되어 있습니다.Ansible 제어 노드가 관리형 노드와 동일한 IP 서브넷에 있는 경우 플레이북 실행 중에 SSH 연결이 손실되는 것을 방지하려면 제어 노드의 IP 주소에 대한
명확한정책을 추가합니다. 예를 들어, Mesh를192.0.2.0/24서브넷에 대해 구성하고 제어 노드에서 IP 주소192.0.2.1을 사용하는 경우 플레이북에 표시된 대로192.0.2.1/32에 대한명확한정책이 필요합니다.정책에 대한 자세한 내용은 Libreswan이 설치된 시스템의
ipsec.conf(5)도움말 페이지를 참조하십시오.vpn_manage_firewall: true-
역할이 관리 노드의
firewalld서비스에서 필요한 포트를 열도록 정의합니다. vpn_manage_selinux: true- 역할이 IPsec 포트에 필요한 SELinux 포트 유형을 설정하도록 정의합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.vpn/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --ask-vault-pass --syntax-check ~/playbook.yml
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook --ask-vault-pass ~/playbook.yml
$ ansible-playbook --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
메시의 노드에서 다른 노드를 ping하여 연결을 활성화합니다.
ping managed-node-02.example.com
[root@managed-node-01]# ping managed-node-02.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 연결이 활성 상태인지 확인합니다.
ipsec trafficstatus 006 #2: "private#192.0.2.0/24"[1] ...192.0.2.2, type=ESP, add_time=1741938929, inBytes=372408, outBytes=545728, maxBytes=2^63B, id='CN=managed-node-02.example.com'
[root@managed-node-01]# ipsec trafficstatus 006 #2: "private#192.0.2.0/24"[1] ...192.0.2.2, type=ESP, add_time=1741938929, inBytes=372408, outBytes=545728, maxBytes=2^63B, id='CN=managed-node-02.example.com'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.3.14. 시스템 전체 암호화 정책에서 비활성화된 IPsec 연결 구성
연결에 대한 시스템 전체 암호화 정책 덮어쓰기
RHEL 시스템 전체 암호화 정책은 %default 라는 특수 연결을 생성합니다. 이 연결에는 the ikev2,esp 및 ike 옵션의 기본값이 포함되어 있습니다. 그러나 연결 구성 파일에 언급된 옵션을 지정하여 기본값을 재정의할 수 있습니다.
예를 들어 다음 구성에서는 AES 및 SHA-1 또는 SHA-2와 함께 IKEv1을 사용하고 IPsec(ESP)을 AES-GCM 또는 AES-CBC와 함께 사용하는 연결을 허용합니다.
AES-GCM은 IPsec (ESP) 및 IKEv2에서는 사용할 수 있지만 IKEv1에는 사용할 수 없습니다.
모든 연결에 대한 시스템 전체 암호화 정책 비활성화
모든 IPsec 연결에 대한 시스템 전체 암호화 정책을 비활성화하려면 /etc/ipsec.conf 파일에서 다음 행을 주석 처리하십시오.
include /etc/crypto-policies/back-ends/libreswan.config
include /etc/crypto-policies/back-ends/libreswan.config
그런 다음 연결 구성 파일에 the ikev2=never 옵션을 추가합니다.
23.3.15. IPsec VPN 구성 문제 해결
IPsec VPN 구성과 관련된 문제는 여러 가지 주요 이유로 발생합니다. 이러한 문제가 발생하면 문제의 원인이 다음 시나리오에 해당하는지 확인하고 해당 솔루션을 적용할 수 있습니다.
기본 연결 문제 해결
VPN 연결에 대한 대부분의 문제는 관리자가 구성 옵션과 일치하지 않는 엔드포인트를 구성한 새로운 배포에서 발생합니다. 또한 작동 중인 구성은 새로 호환되지 않는 값 때문에 갑자기 작동을 중지할 수 있습니다. 이는 관리자가 구성을 변경한 결과일 수 있습니다. 또는 관리자가 암호화 알고리즘과 같은 특정 옵션에 대해 다양한 기본값을 사용하여 펌웨어 업데이트 또는 패키지 업데이트를 설치할 수 있습니다.
IPsec VPN 연결이 설정되었는지 확인하려면 다음을 수행하십시오.
ipsec trafficstatus 006 #8: "vpn.example.com"[1] 192.0.2.1, type=ESP, add_time=1595296930, inBytes=5999, outBytes=3231, id='@vpn.example.com', lease=100.64.13.5/32
# ipsec trafficstatus
006 #8: "vpn.example.com"[1] 192.0.2.1, type=ESP, add_time=1595296930, inBytes=5999, outBytes=3231, id='@vpn.example.com', lease=100.64.13.5/32출력이 비어 있거나 연결 이름이 인 항목이 표시되지 않으면 터널이 손상됩니다.
문제가 연결에 있는지 확인하려면 다음을 수행하십시오.
vpn.example.com 연결을 다시 로드합니다.
ipsec auto --add vpn.example.com 002 added connection description "vpn.example.com"
# ipsec auto --add vpn.example.com 002 added connection description "vpn.example.com"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음으로 VPN 연결을 시작합니다.
ipsec auto --up vpn.example.com
# ipsec auto --up vpn.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
방화벽 관련 문제
가장 일반적인 문제는 IPsec 엔드포인트 중 하나 또는 엔드포인트 사이의 라우터에 있는 방화벽이 모든 IKE(Internet Key Exchange) 패킷을 삭제하는 것입니다.
IKEv2의 경우 다음 예제와 유사한 출력은 방화벽에 문제가 있음을 나타냅니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow IKEv1의 경우 시작 명령의 출력은 다음과 같습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
IPsec을 설정하는 데 사용되는 IKE 프로토콜은 암호화되므로 tcpdump 도구를 사용하여 제한된 문제 하위 집합만 해결할 수 있습니다. 방화벽이 IKE 또는 IPsec 패킷을 삭제하는 경우 tcpdump 유틸리티를 사용하여 원인을 찾을 수 있습니다. 그러나 tcpdump 는 IPsec VPN 연결의 다른 문제를 진단할 수 없습니다.
eth0인터페이스에서 VPN과 암호화된 모든 데이터의 협상을 캡처하려면 다음을 수행합니다.tcpdump -i eth0 -n -n esp or udp port 500 or udp port 4500 or tcp port 4500
# tcpdump -i eth0 -n -n esp or udp port 500 or udp port 4500 or tcp port 4500Copy to Clipboard Copied! Toggle word wrap Toggle overflow
일치하지 않는 알고리즘, 프로토콜 및 정책
VPN 연결에서는 엔드포인트에 IKE 알고리즘, IPsec 알고리즘 및 IP 주소 범위가 일치해야 합니다. 불일치가 발생하면 연결에 실패합니다. 다음 방법 중 하나를 사용하여 일치하지 않는 경우 알고리즘, 프로토콜 또는 정책을 조정하여 수정합니다.
원격 엔드포인트가 IKE/IPsec을 실행 중이 아닌 경우 이를 나타내는 ICMP 패킷이 표시됩니다. 예를 들면 다음과 같습니다.
ipsec auto --up vpn.example.com ... 000 "vpn.example.com"[1] 192.0.2.2 #16: ERROR: asynchronous network error report on wlp2s0 (192.0.2.2:500), complainant 198.51.100.1: Connection refused [errno 111, origin ICMP type 3 code 3 (not authenticated)] ...
# ipsec auto --up vpn.example.com ... 000 "vpn.example.com"[1] 192.0.2.2 #16: ERROR: asynchronous network error report on wlp2s0 (192.0.2.2:500), complainant 198.51.100.1: Connection refused [errno 111, origin ICMP type 3 code 3 (not authenticated)] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 일치하지 않는 알고리즘의 예:
ipsec auto --up vpn.example.com ... 003 "vpn.example.com"[1] 193.110.157.148 #3: dropping unexpected IKE_SA_INIT message containing NO_PROPOSAL_CHOSEN notification; message payloads: N; missing payloads: SA,KE,Ni
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com"[1] 193.110.157.148 #3: dropping unexpected IKE_SA_INIT message containing NO_PROPOSAL_CHOSEN notification; message payloads: N; missing payloads: SA,KE,NiCopy to Clipboard Copied! Toggle word wrap Toggle overflow 일치하지 않는 IPsec 알고리즘의 예:
ipsec auto --up vpn.example.com ... 182 "vpn.example.com"[1] 193.110.157.148 #5: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_256 group=MODP2048} 002 "vpn.example.com"[1] 193.110.157.148 #6: IKE_AUTH response contained the error notification NO_PROPOSAL_CHOSEN# ipsec auto --up vpn.example.com ... 182 "vpn.example.com"[1] 193.110.157.148 #5: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_256 group=MODP2048} 002 "vpn.example.com"[1] 193.110.157.148 #6: IKE_AUTH response contained the error notification NO_PROPOSAL_CHOSENCopy to Clipboard Copied! Toggle word wrap Toggle overflow 일치하는 버전과 일치하지 않으면 응답 없이 원격 엔드포인트가 요청을 삭제할 수도 있었습니다. 이는 모든 IKE 패킷을 삭제하는 방화벽과 동일합니다.
IKEv2 (Traffic Selectors - TS)의 일치하지 않는 IP 주소 범위의 예:
ipsec auto --up vpn.example.com ... 1v2 "vpn.example.com" #1: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_512 group=MODP2048} 002 "vpn.example.com" #2: IKE_AUTH response contained the error notification TS_UNACCEPTABLE# ipsec auto --up vpn.example.com ... 1v2 "vpn.example.com" #1: STATE_PARENT_I2: sent v2I2, expected v2R2 {auth=IKEv2 cipher=AES_GCM_16_256 integ=n/a prf=HMAC_SHA2_512 group=MODP2048} 002 "vpn.example.com" #2: IKE_AUTH response contained the error notification TS_UNACCEPTABLECopy to Clipboard Copied! Toggle word wrap Toggle overflow IKEv1의 일치하지 않는 IP 주소 범위의 예:
ipsec auto --up vpn.example.com ... 031 "vpn.example.com" #2: STATE_QUICK_I1: 60 second timeout exceeded after 0 retransmits. No acceptable response to our first Quick Mode message: perhaps peer likes no proposal
# ipsec auto --up vpn.example.com ... 031 "vpn.example.com" #2: STATE_QUICK_I1: 60 second timeout exceeded after 0 retransmits. No acceptable response to our first Quick Mode message: perhaps peer likes no proposalCopy to Clipboard Copied! Toggle word wrap Toggle overflow IKEv1에서 PreSharedKeys ()를 사용할 때 양쪽이 동일한 에 배치되지 않으면 전체 IKE 메시지가 읽을 수 없게 됩니다.
ipsec auto --up vpn.example.com ... 003 "vpn.example.com" #1: received Hash Payload does not match computed value 223 "vpn.example.com" #1: sending notification INVALID_HASH_INFORMATION to 192.0.2.23:500
# ipsec auto --up vpn.example.com ... 003 "vpn.example.com" #1: received Hash Payload does not match computed value 223 "vpn.example.com" #1: sending notification INVALID_HASH_INFORMATION to 192.0.2.23:500Copy to Clipboard Copied! Toggle word wrap Toggle overflow IKEv2에서 불일치- 오류로 인해 AUTHENTICATION_FAILED 메시지가 표시됩니다.
ipsec auto --up vpn.example.com ... 002 "vpn.example.com" #1: IKE SA authentication request rejected by peer: AUTHENTICATION_FAILED
# ipsec auto --up vpn.example.com ... 002 "vpn.example.com" #1: IKE SA authentication request rejected by peer: AUTHENTICATION_FAILEDCopy to Clipboard Copied! Toggle word wrap Toggle overflow
최대 전송 단위
IKE 또는 IPsec 패킷을 차단하는 방화벽 이외의 네트워킹 문제의 가장 일반적인 원인은 암호화된 패킷의 증가된 패킷 크기와 관련이 있습니다. 최대 전송 단위(MTU)보다 큰 네트워크 하드웨어 조각 패킷(예: 1500바이트). 종종 조각이 손실되고 패킷이 다시 집계되지 않습니다. 이로 인해 작은 규모의 패킷을 사용하는 ping 테스트가 작동하지만 다른 트래픽이 실패하면 간헐적인 오류가 발생합니다. 이 경우 SSH 세션을 설정할 수 있지만 원격 호스트에 'ls -al /usr' 명령을 입력하여 바로 터미널이 중지됩니다.
이 문제를 해결하려면 터널 구성 파일에 the mtu=1400 옵션을 추가하여 MTU 크기를 줄입니다.
또는 TCP 연결의 경우 MSS 값을 변경하는 iptables 규칙을 활성화합니다.
iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
이전 명령에서 시나리오의 문제를 해결하지 않으면 set-mss 매개변수에 더 작은 크기를 직접 지정합니다.
iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1380
# iptables -I FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1380NAT(네트워크 주소 변환)
IPsec 호스트가 NAT 라우터 역할을 할 때 실수로 패킷을 다시 매핑할 수 있습니다. 다음 예제 구성은 문제를 보여줍니다.
주소가 172.16.0.1인 시스템에는 NAT 규칙이 있습니다.
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADE
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADE주소 10.0.2.33의 시스템이 패킷을 192.168.0.1로 보내는 경우 라우터는 IPsec 암호화를 적용하기 전에 소스 10.0.2.33을 172.16.0.1로 변환합니다.
그런 다음 소스 주소가 10.0.2.33인 패킷이 더 이상 conn myvpn 설정과 일치하지 않으며 IPsec은 이 패킷을 암호화하지 않습니다.
이 문제를 해결하려면 라우터의 대상 IPsec 서브넷 범위에 대해 NAT를 제외하는 규칙을 삽입합니다. 예를 들면 다음과 같습니다.
iptables -t nat -I POSTROUTING -s 10.0.2.0/24 -d 192.168.0.0/16 -j RETURN
iptables -t nat -I POSTROUTING -s 10.0.2.0/24 -d 192.168.0.0/16 -j RETURN커널 IPsec 하위 시스템 버그
예를 들어 버그로 인해 IKE 사용자 공간과 IPsec 커널이 동기화 해제되는 경우 커널 IPsec 하위 시스템이 실패할 수 있습니다. 이러한 문제를 확인하려면 다음을 수행합니다.
cat /proc/net/xfrm_stat XfrmInError 0 XfrmInBufferError 0 ...
$ cat /proc/net/xfrm_stat
XfrmInError 0
XfrmInBufferError 0
...이전 명령의 출력에 0이 아닌 값은 문제가 있음을 나타냅니다. 이 문제가 발생하면 새 지원 케이스 를 열고 해당 IKE 로그와 함께 이전 명령의 출력을 연결합니다.
Libreswan 로그
Libreswan은 기본적으로 syslog 프로토콜을 사용합니다. journalctl 명령을 사용하여 IPsec과 관련된 로그 항목을 찾을 수 있습니다. 로그에 대한 해당 항목은 pluto IKE 데몬에 의해 전송되므로 "pluto" 키워드를 검색합니다. 예를 들면 다음과 같습니다.
journalctl -b | grep pluto
$ journalctl -b | grep pluto
ipsec 서비스에 대한 실시간 로그를 표시하려면 다음을 수행합니다.
journalctl -f -u ipsec
$ journalctl -f -u ipsec
기본 로깅 수준에 설정 문제가 표시되지 않으면 /etc/ipsec.conf 파일의 config setup 섹션에 plutodebug=all 옵션을 추가하여 디버그 로그를 활성화합니다.
디버그 로깅은 많은 항목을 생성하며, journald 또는 syslogd 서비스 속도에 따라 syslog 메시지가 제한될 수 있습니다. 전체 로그가 있는지 확인하려면 로깅을 파일로 리디렉션합니다. /etc/ipsec.conf 를 편집하고 구성 설정 섹션에 logfile=/var/log/pluto.log 를 추가합니다.
23.3.16. control-center를 사용하여 VPN 연결 구성
그래픽 인터페이스와 함께 Red Hat Enterprise Linux를 사용하는 경우 GNOME 제어 센터에서 VPN 연결을 구성할 수 있습니다.
사전 요구 사항
-
NetworkManager-libreswan-gnome패키지가 설치되어 있습니다.
절차
-
Super 키를 누른 상태에서
Settings를 입력하고 Enter 를 눌러control-center애플리케이션을 엽니다. -
왼쪽에서
Network항목을 선택합니다. - + 아이콘을 클릭합니다.
-
VPN을 선택합니다. ID메뉴 항목을 선택하여 기본 구성 옵션을 확인합니다.일반
gateway - 원격 VPN 게이트웨이의 이름 또는
IP주소입니다.인증
유형-
IKEv2 (Certificate)- 클라이언트는 인증서로 인증됩니다. 더 안전합니다(기본값). IKEv1(XAUTH)- 클라이언트는 사용자 이름 및 암호 또는 PSK(사전 공유 키)로 인증됩니다.다음 구성 설정은
고급섹션에서 사용할 수 있습니다.그림 23.1. VPN 연결의 고급 옵션
 주의
주의gnome-control-center애플리케이션을 사용하여 IPsec 기반 VPN 연결을 구성할 때고급대화 상자에 구성이 표시되지만 변경 사항은 허용하지 않습니다. 결과적으로 사용자는 고급 IPsec 옵션을 변경할 수 없습니다. 대신nm-connection-editor또는nmcli툴을 사용하여 고급 속성 구성을 수행합니다.식별
Domain- 필요한 경우 도메인 이름을 입력합니다.보안
-
Phase1 알고리즘- Libreswan 매개변수와 같이 - 암호화된 채널을 인증하고 설정하는 데 사용할 알고리즘을 입력합니다. Phase2 알고리즘-espLibreswan 매개변수에 해당합니다 -IPsec협상에 사용할 알고리즘을 입력합니다.PFS를 지원하지 않는 이전 서버와의 호환성을 확인하려면 PFS(Perfect Forward Secrecy)를 해제하려면 PFS 필드를 선택합니다.-
Phase1 Lifetime-ikelifetimeLibreswan 매개변수 - 트래픽을 암호화하는 데 사용되는 키의 유효 기간에 해당합니다. Phase2 Lifetime-salifetimeLibreswan 매개변수 - 만료되기 전에 특정 연결 인스턴스가 얼마나 오래되어야 하는지에 해당합니다.보안상의 이유로 암호화 키를 수시로 변경해야 합니다.
원격 네트워크-rightsubnetLibreswan 매개변수 - VPN을 통해 도달해야 하는 대상 프라이빗 원격 네트워크에 해당합니다.범위를 좁
힐수 있도록 좁은 필드를 확인합니다. IKEv2 협상에서만 효과가 있습니다.-
조각화 활성화- IKE 조각화를 허용할지 여부에 관계없이fragmentationLibreswan 매개변수에 해당합니다. 유효한 값은yes(기본값) 또는no입니다. -
Mobike 활성화-mobikeLibreswan 매개변수에 해당합니다. - Cryostat 및 Multihoming Protocol (MOBIKE, RFC 4555)을 허용할지 여부에 따라 연결을 처음부터 다시 시작할 필요없이 끝점을 마이그레이션할 수 있습니다. 이는 유선, 무선 또는 모바일 데이터 연결 간에 전환하는 모바일 장치에서 사용됩니다. 값은no(기본값) 또는yes입니다.
-
메뉴 항목을 선택합니다.
IPv4 방법
-
Automatic (DHCP)- 연결하는 네트워크가DHCP서버를 사용하여 동적IP주소를 할당하는 경우 이 옵션을 선택합니다. -
Link-Local Only- 연결된 네트워크에DHCP서버가 없고IP주소를 수동으로 할당하지 않는 경우 이 옵션을 선택합니다. 임의의 주소는 접두사169.254/16인 RFC 3927 에 따라 할당됩니다. -
수동-IP주소를 수동으로 할당하려는 경우 이 옵션을 선택합니다. disable-IPv4는 이 연결에 대해 비활성화되어 있습니다.DNS
DNS섹션에서Automatic이ON인 경우OFF로 전환하여 IP를 쉼표로 분리하는 데 사용할 DNS 서버의 IP 주소를 입력합니다.라우트
경로섹션에서Automatic이ON인 경우 DHCP의 경로가 사용되지만 정적 경로도 추가할 수 있습니다.OFF인 경우 정적 경로만 사용됩니다.-
address- 원격 네트워크 또는 호스트의IP주소를 입력합니다. -
넷마스크 -위에서 입력한IP주소의 넷마스크 또는 접두사 길이입니다. -
gateway - 위에서 입력한 원격 네트워크 또는 호스트로 이어지는 게이트웨이의
IP주소입니다. metric- 네트워크 비용, 이 경로에 제공할 기본 값입니다. 더 낮은 값이 더 높은 값보다 우선합니다.이 연결은 네트워크의 리소스에만 사용
연결이 기본 경로가 되지 않도록 하려면 이 확인란을 선택합니다. 이 옵션을 선택하면 연결을 통해 자동으로 학습되거나 여기에 입력된 경로로 특별히 예정된 트래픽만 연결을 통해 라우팅됩니다.
-
VPN연결에서IPv6설정을 구성하려면 메뉴 항목을 선택합니다.IPv6 방법
-
자동-IPv6SLAAC(상태 비저장 주소 자동 구성)를 사용하여 하드웨어 주소 및RA(라우터 알림)를 기반으로 자동, 상태 비저장 구성을 만들려면 이 옵션을 선택합니다. -
자동, DHCP만- 이 옵션을 선택하여 RA를 사용하지 않고DHCPv6에서 정보를 직접 요청하여 상태 저장 구성을 생성합니다. -
Link-Local Only- 연결된 네트워크에DHCP서버가 없고IP주소를 수동으로 할당하지 않는 경우 이 옵션을 선택합니다. 임의의 주소는FE80::0접두사를 사용하여 RFC 4862 에 따라 할당됩니다. -
수동-IP주소를 수동으로 할당하려는 경우 이 옵션을 선택합니다. disable- 이 연결에 대해IPv6가 비활성화되어 있습니다.DNS,경로,이 연결을 네트워크의 리소스에만 사용하는것은IPv4설정에 공통입니다.
-
-
VPN연결 편집을 완료하면 버튼을 클릭하여 구성을 사용자 지정하거나 버튼을 클릭하여 기존 연결을 위해 저장합니다. -
프로필을
ON으로 전환하여VPN연결을 활성화합니다. - DHCP 또는 SLAAC(상태 비저장 주소 자동 구성)가 있는 네트워크에서 이 호스트를 사용하는 경우 연결이 리디렉션될 수 있습니다. 자세한 내용 및 완화 단계는 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당을 참조하십시오.
23.3.17. nm-connection-editor를 사용하여 VPN 연결 구성
Red Hat Enterprise Linux를 그래픽 인터페이스와 함께 사용하는 경우 nm-connection-editor 애플리케이션에서 VPN 연결을 구성할 수 있습니다.
사전 요구 사항
-
NetworkManager-libreswan-gnome패키지가 설치되어 있습니다. IKEv2(Internet Key Exchange 버전 2) 연결을 구성하는 경우:
- 인증서는 IPsec 네트워크 보안 서비스(NSS) 데이터베이스로 가져옵니다.
- NSS 데이터베이스에서 인증서의 닉네임을 알고 있습니다.
절차
터미널을 열고 다음을 입력합니다.
nm-connection-editor
$ nm-connection-editorCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 버튼을 클릭하여 새 연결을 추가합니다.
-
IPsec 기반 VPN연결 유형을 선택하고 을 클릭합니다. VPN탭에서 다음을 수행합니다.VPN 게이트웨이의 호스트 이름 또는 IP 주소를
게이트웨이필드에 입력하고 인증 유형을 선택합니다. 인증 유형에 따라 다른 추가 정보를 입력해야 합니다.-
IKEv2(Certifiate)는 더 안전한 인증서를 사용하여 클라이언트를 인증합니다. 이 설정에는 IPsec NSS 데이터베이스에 있는 인증서의 닉네임이 필요합니다. IKEv1(XAUTH)은 사용자 이름 및 암호(사전 공유 키)를 사용하여 사용자를 인증합니다. 이 설정을 사용하려면 다음 값을 입력해야 합니다.- 사용자 이름
- 암호
- 그룹 이름
- Secret
-
원격 서버가 IKE 교환의 로컬 식별자를 지정하는 경우
Remote ID필드에 정확한 문자열을 입력합니다. 원격 서버에서 Libreswan을 실행하면 이 값은 서버의leftid매개변수에 설정됩니다.
선택 사항: 버튼을 클릭하여 추가 설정을 구성합니다. 다음 설정을 구성할 수 있습니다.
식별
-
domain- 필요한 경우 도메인 이름을 입력합니다.
-
보안
-
Phase1 알고리즘은 like Libreswan 매개변수에 해당합니다. 암호화 채널을 인증하고 설정하는 데 사용할 알고리즘을 입력합니다. Phase2 알고리즘은espLibreswan 매개변수에 해당합니다.IPsec협상에 사용할 알고리즘을 입력합니다.PFS를 지원하지 않는 이전 서버와의 호환성을 확인하려면 PFS(Perfect Forward Secrecy)를 해제하려면 PFS 필드를 선택합니다.-
Phase1 Lifetime은ikelifetimeLibreswan 매개변수에 해당합니다. 이 매개변수는 트래픽을 암호화하는 데 사용된 키가 유효한 시간을 정의합니다. -
Phase2 Lifetime은salifetimeLibreswan 매개변수에 해당합니다. 이 매개 변수는 보안 연관이 유효한 기간을 정의합니다.
-
연결
원격 네트워크는rightsubnetLibreswan 매개변수에 해당하며 VPN을 통해 도달해야 하는 대상 프라이빗 원격 네트워크를 정의합니다.범위를 좁
힐수 있도록 좁은 필드를 확인합니다. IKEv2 협상에서만 효과가 있습니다.-
조각화는 Libreswan 매개변수에 해당하고 IKE 조각화를 허용할지 여부를 정의합니다.유효한 값은yes(기본값) 또는no입니다. -
Enable Mobike는mobikeLibreswan 매개변수에 해당합니다. 매개 변수는 MTU 및 Multihoming Protocol(RFC 4555)(RFC 4555)을 허용하여 연결을 처음부터 다시 시작할 필요 없이 끝점을 마이그레이션할지 여부를 정의합니다. 이는 유선, 무선 또는 모바일 데이터 연결 간에 전환하는 모바일 장치에서 사용됩니다. 값은no(기본값) 또는yes입니다.
IPv4 Settings탭에서 IP 할당 방법을 선택하고 선택적으로 추가 정적 주소, DNS 서버, 검색 도메인 및 경로를 설정합니다.
- 연결을 저장합니다.
-
nm-connection-editor를 종료합니다. - DHCP 또는 SLAAC(상태 비저장 주소 자동 구성)가 있는 네트워크에서 이 호스트를 사용하는 경우 연결이 리디렉션될 수 있습니다. 자세한 내용 및 완화 단계는 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당을 참조하십시오.
버튼을 클릭하여 새 연결을 추가하면 NetworkManager 가 해당 연결에 대한 새 구성 파일을 만든 다음 기존 연결을 편집하는 데 사용되는 동일한 대화 상자를 엽니다. 이러한 대화 상자의 차이점은 기존 연결 프로필에 세부 정보 메뉴 항목이 있다는 것입니다.
23.3.18. 연결이 터널을 우회하지 못하도록 전용 라우팅 테이블에 VPN 연결 할당
DHCP 서버와 SLAAC(상태 비저장 주소 자동 구성) 모두 클라이언트의 라우팅 테이블에 경로를 추가할 수 있습니다. 예를 들어 악의적인 DHCP 서버는 이 기능을 사용하여 VPN 터널 대신 물리적 인터페이스를 통해 트래픽을 리디렉션하도록 VPN 연결이 있는 호스트를 강제 수행할 수 있습니다. 이 취약점은 tunnelVision이라고도 하며 CVE-2024-3661 취약점 문서에 설명되어 있습니다.
이 취약점을 완화하기 위해 전용 라우팅 테이블에 VPN 연결을 할당할 수 있습니다. 이렇게 하면 DHCP 구성 또는 SLAAC가 VPN 터널을 위해 의도된 네트워크 패킷의 라우팅 결정을 조작할 수 없습니다.
사용자 환경에 하나 이상의 조건이 적용되는 경우 단계를 따르십시오.
- 하나 이상의 네트워크 인터페이스에서 DHCP 또는 SLAAC를 사용합니다.
- 네트워크에서는 잘못된 DHCP 서버를 방지하는 DHCP 스누핑과 같은 메커니즘을 사용하지 않습니다.
VPN을 통해 전체 트래픽을 라우팅하면 호스트가 로컬 네트워크 리소스에 액세스할 수 없습니다.
사전 요구 사항
- NetworkManager 1.40.16-18 이상을 사용합니다.
프로세스
- 사용할 라우팅 테이블을 결정합니다. 다음 단계는 표 75을 사용합니다. 기본적으로 RHEL은 테이블 1-254를 사용하지 않으며 이 테이블 중 하나를 사용할 수 있습니다.
VPN 경로를 전용 라우팅 테이블에 배치하도록 VPN 연결 프로필을 구성합니다.
nmcli connection modify <vpn_connection_profile> ipv4.route-table 75 ipv6.route-table 75
# nmcli connection modify <vpn_connection_profile> ipv4.route-table 75 ipv6.route-table 75Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 명령에서 사용한 테이블에 대해 우선순위가 낮은 값을 설정합니다.
nmcli connection modify <vpn_connection_profile> ipv4.routing-rules "priority 32345 from all table 75" ipv6.routing-rules "priority 32345 from all table 75"
# nmcli connection modify <vpn_connection_profile> ipv4.routing-rules "priority 32345 from all table 75" ipv6.routing-rules "priority 32345 from all table 75"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 우선순위 값은 1에서 32766 사이의 모든 값일 수 있습니다. 값이 작을수록 우선순위가 높습니다.
VPN 연결을 다시 연결합니다.
nmcli connection down <vpn_connection_profile> nmcli connection up <vpn_connection_profile>
# nmcli connection down <vpn_connection_profile> # nmcli connection up <vpn_connection_profile>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
표 75에 IPv4 경로를 표시합니다.
ip route show table 75 ... 192.0.2.0/24 via 192.0.2.254 dev vpn_device proto static metric 50 default dev vpn_device proto static scope link metric 50
# ip route show table 75 ... 192.0.2.0/24 via 192.0.2.254 dev vpn_device proto static metric 50 default dev vpn_device proto static scope link metric 50Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력은 원격 네트워크에 대한 경로와 기본 게이트웨이가 라우팅 테이블 75에 할당되므로 모든 트래픽이 터널을 통해 라우팅되는지 확인합니다. VPN 연결 프로필에
ipv4.never-default true를 설정하면 기본 경로가 생성되지 않으므로 이 출력에 표시되지 않습니다.표 75에 IPv6 경로를 표시합니다.
ip -6 route show table 75 ... 2001:db8:1::/64 dev vpn_device proto kernel metric 50 pref medium default dev vpn_device proto static metric 50 pref medium
# ip -6 route show table 75 ... 2001:db8:1::/64 dev vpn_device proto kernel metric 50 pref medium default dev vpn_device proto static metric 50 pref mediumCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력은 원격 네트워크에 대한 경로와 기본 게이트웨이가 라우팅 테이블 75에 할당되므로 모든 트래픽이 터널을 통해 라우팅되는지 확인합니다. VPN 연결 프로필에
ipv4.never-default true를 설정하면 기본 경로가 생성되지 않으므로 이 출력에 표시되지 않습니다.
23.4. MACsec을 사용하여 동일한 물리적 네트워크에서 계층 2 트래픽 암호화
MACsec을 사용하여 두 장치 간 통신을 보호할 수 있습니다(포인트 간 통신). 예를 들어, 브랜치 사무실은 중앙 사무실과 Metro-Ethernet 연결을 통해 연결되어 있으며, 사무실을 연결하는 두 호스트에서 MACsec을 구성하여 보안을 강화할 수 있습니다.
23.4.1. MACsec을 통한 보안 향상 방법
MACsec(Media Access Control Security)은 다음과 같이 이더넷 링크를 통해 다양한 트래픽 유형을 보호하는 계층 2 프로토콜입니다.
- DHCP(Dynamic Host Configuration Protocol)
- 주소 확인 프로토콜 (ARP)
- IPv4 및 IPv6 트래픽
- TCP 또는 UDP와 같은 IP를 통한 모든 트래픽
MACsec은 기본적으로 GCM-AES-128 알고리즘을 사용하여 LAN의 모든 트래픽을 암호화하고 인증하며, 사전 공유 키를 사용하여 참가자 호스트 간 연결을 설정합니다. 사전 공유 키를 변경하려면 MACsec을 사용하는 모든 네트워크 호스트에서 NM 구성을 업데이트해야 합니다.
MACsec 연결은 이더넷 네트워크 카드, VLAN 또는 터널 장치와 같은 이더넷 장치를 상위로 사용합니다. 암호화된 연결을 사용하여 다른 호스트와만 통신하도록 MACsec 장치에서만 IP 구성을 설정하거나 상위 장치에 IP 구성을 설정할 수도 있습니다. 후자의 경우, 암호화되지 않은 연결을 사용하고 MACsec 장치를 사용하여 암호화된 연결에 MACsec 장치를 사용하여 다른 호스트와 통신하는 데 상위 장치를 사용할 수 있습니다.
MACsec에는 특별한 하드웨어가 필요하지 않습니다. 예를 들어 호스트와 스위치 간의 트래픽만 암호화하려는 경우를 제외하고 모든 스위치를 사용할 수 있습니다. 이 시나리오에서는 스위치에서 MACsec도 지원해야 합니다.
즉, 두 가지 일반적인 시나리오에 대해 MACsec을 구성할 수 있습니다.
- host-to-host
- host-to-switch 및 switch-to-other-hosts
MACsec은 동일한 물리적 LAN 또는 가상 LAN에 있는 호스트 간에만 사용할 수 있습니다.
OSI(Open Systems Interconnection) 모델의 계층 2라고도 하는 링크 계층에서 통신 보안을 위해 MACsec 보안 표준을 사용하면 다음과 같은 주요 이점이 있습니다.
- 계층 2에서 암호화하면 계층 7에서 개별 서비스를 암호화할 필요가 없습니다. 이렇게 하면 각 호스트의 각 끝점에 대해 많은 수의 인증서를 관리하는 것과 관련된 오버헤드가 줄어듭니다.
- 라우터 및 스위치와 같이 직접 연결된 네트워크 장치 간의 지점 간 보안입니다.
- 애플리케이션 및 상위 계층 프로토콜에 필요한 변경 사항이 없습니다.
23.4.2. nmcli를 사용하여 MACsec 연결 구성
nmcli 유틸리티를 사용하여 MACsec을 사용하도록 이더넷 인터페이스를 구성할 수 있습니다. 예를 들어 이더넷을 통해 연결된 두 호스트 간에 MACsec 연결을 생성할 수 있습니다.
절차
MACsec을 구성하는 첫 번째 호스트에서 다음을 수행합니다.
사전 공유 키에 대한 연결 키(CAK) 및 연결 연결 키 이름(CKN)을 만듭니다.
16바이트 16바이트 16진수 CAK를 생성합니다.
dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' 50b71a8ef0bd5751ea76de6d6c98c03a
# dd if=/dev/urandom count=16 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' 50b71a8ef0bd5751ea76de6d6c98c03aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 32바이트 16진수 CKN을 생성합니다.
dd if=/dev/urandom count=32 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550
# dd if=/dev/urandom count=32 bs=1 2> /dev/null | hexdump -e '1/2 "%04x"' f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- MACsec 연결을 통해 연결하려는 두 호스트 모두에서 다음을 수행합니다.
MACsec 연결을 생성합니다.
nmcli connection add type macsec con-name macsec0 ifname macsec0 connection.autoconnect yes macsec.parent enp1s0 macsec.mode psk macsec.mka-cak 50b71a8ef0bd5751ea76de6d6c98c03a macsec.mka-ckn f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550
# nmcli connection add type macsec con-name macsec0 ifname macsec0 connection.autoconnect yes macsec.parent enp1s0 macsec.mode psk macsec.mka-cak 50b71a8ef0bd5751ea76de6d6c98c03a macsec.mka-ckn f2b4297d39da7330910a74abc0449feb45b5c0b9fc23df1430e1898fcf1c4550Copy to Clipboard Copied! Toggle word wrap Toggle overflow macsec.mka-cak및macsec.mka-ckn매개변수의 이전 단계에서 생성된 CAK 및 CKN을 사용합니다. MACsec 보호 네트워크의 모든 호스트에서 값이 동일해야 합니다.MACsec 연결에서 IP 설정을 구성합니다.
IPv4설정을 구성합니다. 예를 들어 정적IPv4주소, 네트워크 마스크, 기본 게이트웨이 및 DNS 서버를macsec0연결로 설정하려면 다음을 입력합니다.nmcli connection modify macsec0 ipv4.method manual ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253'
# nmcli connection modify macsec0 ipv4.method manual ipv4.addresses '192.0.2.1/24' ipv4.gateway '192.0.2.254' ipv4.dns '192.0.2.253'Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv6설정을 구성합니다. 예를 들어 정적IPv6주소, 네트워크 마스크, 기본 게이트웨이 및 DNS 서버를macsec0연결로 설정하려면 다음을 입력합니다.nmcli connection modify macsec0 ipv6.method manual ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd'
# nmcli connection modify macsec0 ipv6.method manual ipv6.addresses '2001:db8:1::1/32' ipv6.gateway '2001:db8:1::fffe' ipv6.dns '2001:db8:1::fffd'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
연결을 활성화합니다.
nmcli connection up macsec0
# nmcli connection up macsec0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
트래픽이 암호화되었는지 확인합니다.
tcpdump -nn -i enp1s0
# tcpdump -nn -i enp1s0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 암호화되지 않은 트래픽을 표시합니다.
tcpdump -nn -i macsec0
# tcpdump -nn -i macsec0Copy to Clipboard Copied! Toggle word wrap Toggle overflow MACsec 통계를 표시합니다.
ip macsec show
# ip macsec showCopy to Clipboard Copied! Toggle word wrap Toggle overflow 각 보호 유형에 대한 개별 카운터 표시: 무결성 전용(암호화 전용) 및 암호화(암호화)
ip -s macsec show
# ip -s macsec showCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5. firewalld 사용 및 구성
방화벽은 외부에서 원하지 않는 트래픽으로부터 시스템을 보호하는 방법입니다. 사용자는 방화벽 규칙 집합을 정의하여 호스트 시스템에서 들어오는 네트워크 트래픽을 제어할 수 있습니다. 이러한 규칙은 들어오는 트래픽을 정렬하고 차단하거나 통과하는 데 사용됩니다.
firewalld 는 D-Bus 인터페이스를 사용하여 사용자 지정 가능한 동적 방화벽을 제공하는 방화벽 서비스 데몬입니다. 동적이므로 규칙이 변경될 때마다 방화벽 데몬을 다시 시작할 필요 없이 규칙을 생성, 변경 및 삭제할 수 있습니다.
firewalld 를 사용하여 대부분의 일반적인 경우에 필요한 패킷 필터링을 구성할 수 있습니다. firewalld 가 시나리오를 다루지 않거나 규칙을 완전히 제어하려면 nftables 프레임워크를 사용합니다.
firewalld 는 영역, 정책 및 서비스의 개념을 사용하여 트래픽 관리를 단순화합니다. 영역은 네트워크를 논리적으로 분리합니다. 네트워크 인터페이스 및 소스를 영역에 할당할 수 있습니다. 정책은 영역 간 트래픽 흐름을 거부하거나 허용하는 데 사용됩니다. 방화벽 서비스는 들어오는 트래픽을 특정 서비스에 대해 허용하는 데 필요한 모든 설정을 처리하는 사전 정의된 규칙이며 영역 내에 적용됩니다.
서비스는 네트워크 통신에 하나 이상의 포트 또는 주소를 사용합니다. 방화벽은 포트를 기반으로 통신을 필터링합니다. 서비스에 대한 네트워크 트래픽을 허용하려면 포트를 열어야 합니다. firewalld 는 명시적으로 open으로 설정되지 않은 포트의 모든 트래픽을 차단합니다. trusted와 같은 일부 영역에서 기본적으로 모든 트래픽을 허용합니다.
firewalld 는 별도의 런타임 및 영구 구성을 유지 관리합니다. 이를 통해 런타임 전용 변경 사항이 허용됩니다. firewalld 를 다시 로드하거나 다시 시작한 후에는 런타임 구성이 유지되지 않습니다. 시작 시 영구 구성에서 채워집니다.
nftables 백엔드가 있는 firewalld 는 --direct 옵션을 사용하여 사용자 정의 nftables 규칙을 firewalld 에 전달하는 것을 지원하지 않습니다.
23.5.1. firewalld, nftables 또는 iptables를 사용하는 경우
RHEL 8에서는 시나리오에 따라 다음 패킷 필터링 유틸리티를 사용할 수 있습니다.
-
firewalld:firewalld유틸리티는 일반적인 사용 사례에 대한 방화벽 구성을 간소화합니다. -
nftables:nftables유틸리티를 사용하여 전체 네트워크에 대해 과 같이 복잡하고 성능이 중요한 방화벽을 설정합니다. -
iptables: Red Hat Enterprise Linux의iptables유틸리티는기존 백엔드 대신를 사용합니다.nf_tables커널 APInf_tablesAPI는iptables명령을 사용하는 스크립트가 Red Hat Enterprise Linux에서 계속 작동하도록 이전 버전과의 호환성을 제공합니다. 새 방화벽 스크립트의 경우nftables를 사용합니다.
다른 방화벽 관련 서비스(firewalld,nftables 또는 iptables)가 서로 영향을 미치지 않도록 하려면 RHEL 호스트에서 해당 서비스 중 하나만 실행하고 다른 서비스를 비활성화합니다.
23.5.2. 방화벽 영역
firewalld 유틸리티를 사용하여 해당 네트워크 내의 인터페이스 및 트래픽과 함께 있는 신뢰 수준에 따라 네트워크를 다른 영역으로 분리할 수 있습니다. 연결은 하나의 영역의 일부일 수 있지만 많은 네트워크 연결에 해당 영역을 사용할 수 있습니다.
firewalld 는 영역과 관련하여 엄격한 원칙을 따릅니다.
- 트래픽 수신은 하나의 영역만 포함됩니다.
- 트래픽은 하나의 영역만 송신합니다.
- 영역은 신뢰 수준을 정의합니다.
- 기본적으로 Intrazone 트래픽(동일한 영역 내)이 허용됩니다.
- 영역 간 트래픽은 기본적으로 거부됩니다.
규칙 4와 5는 원칙 3의 결과입니다.
원칙 4는 영역 옵션 --remove-forward 를 통해 구성할 수 있습니다. 원칙 5는 새로운 정책을 추가하여 구성할 수 있습니다.
NetworkManager 는 인터페이스 영역의 firewalld 에 알립니다. 다음 유틸리티를 사용하여 인터페이스에 영역을 할당할 수 있습니다.
-
NetworkManager -
firewall-configutility -
firewall-cmdutility - RHEL 웹 콘솔
RHEL 웹 콘솔, firewall-config 및 firewall-cmd 는 적절한 NetworkManager 구성 파일만 편집할 수 있습니다. 웹 콘솔, firewall-cmd 또는 firewall-config 를 사용하여 인터페이스 영역을 변경하면 요청이 NetworkManager 로 전달되고firewalld 에서 처리되지 않습니다.
/usr/lib/firewalld/zones/ 디렉터리는 사전 정의된 영역을 저장하고 사용 가능한 네트워크 인터페이스에 즉시 적용할 수 있습니다. 이러한 파일은 수정된 후에만 /etc/firewalld/zones/ 디렉토리에 복사됩니다. 사전 정의된 영역의 기본 설정은 다음과 같습니다.
블록-
적합한 대상: 들어오는 네트워크 연결은
IPv4및 IPv6-adm-prohibited에 대한 icmp-host-prohibited 메시지와 함께 거부됩니다. - 허용: 시스템 내에서 시작된 네트워크 연결만 수행합니다.
-
적합한 대상: 들어오는 네트워크 연결은
dmz- 적합한 대상: DMZ의 컴퓨터는 내부 네트워크에 대한 액세스 제한으로 공개적으로 액세스할 수 있습니다.
- 허용: 선택한 연결만 제공됩니다.
drop적합한 대상: 들어오는 네트워크 패킷은 알림 없이 삭제됩니다.
- 허용: 나가는 네트워크 연결만 가능합니다.
external- 적합한 대상: 특히 라우터에 대해 마스커레이딩이 활성화된 외부 네트워크입니다. 네트워크에서 다른 컴퓨터를 신뢰하지 않는 경우입니다.
- 허용: 선택한 연결만 제공됩니다.
홈- 적합한 대상: 네트워크상의 다른 컴퓨터를 주로 신뢰하는 홈 환경.
- 허용: 선택한 연결만 제공됩니다.
internal- 적합한 대상: 네트워크에 있는 다른 컴퓨터를 주로 신뢰하는 내부 네트워크입니다.
- 허용: 선택한 연결만 제공됩니다.
public- 적합한 대상: 네트워크에서 다른 컴퓨터를 신뢰하지 않는 공용 영역입니다.
- 허용: 선택한 연결만 제공됩니다.
신뢰할 수 있는- 허용: 모든 네트워크 연결
작업적합한 대상: 네트워크에 있는 다른 컴퓨터를 주로 신뢰하는 작업 환경.
- 허용: 선택한 연결만 제공됩니다.
이러한 영역 중 하나는 기본 영역으로 설정됩니다. NetworkManager 에 인터페이스 연결이 추가되면 기본 영역에 할당됩니다. 설치 시 firewalld 의 기본 영역은 퍼블릭 영역입니다. 기본 영역을 변경할 수 있습니다.
네트워크 영역 이름을 자체 설명하여 사용자가 신속하게 이해할 수 있도록 합니다.
보안 문제를 방지하려면 기본 영역 구성을 검토하고 요구 사항 및 위험 평가에 따라 불필요한 서비스를 비활성화합니다.
23.5.3. 방화벽 정책
방화벽 정책은 원하는 네트워크 보안 상태를 지정합니다. 다양한 유형의 트래픽에 대해 수행할 규칙과 작업을 간략하게 설명합니다. 일반적으로 정책에는 다음 유형의 트래픽에 대한 규칙이 포함됩니다.
- 들어오는 트래픽
- 나가는 트래픽
- 전송 트래픽
- 특정 서비스 및 애플리케이션
- NAT(네트워크 주소 변환)
방화벽 정책은 방화벽 영역의 개념을 사용합니다. 각 영역은 허용되는 트래픽을 결정하는 특정 방화벽 규칙 세트와 연결됩니다. 정책은 상태 저장되지 않은 방식으로 방화벽 규칙을 적용합니다. 즉, 트래픽의 한 방향만 고려합니다. firewalld 의 상태 저장 필터링으로 인해 트래픽 반환 경로는 암시적으로 허용됩니다.
정책은 Ingress 영역 및 송신 영역과 연결됩니다. Ingress 영역은 트래픽이 시작된 위치(received)입니다. 송신 영역은 트래픽이 떠나는 위치입니다(sent).
정책에 정의된 방화벽 규칙은 방화벽 영역을 참조하여 여러 네트워크 인터페이스에 일관된 구성을 적용할 수 있습니다.
23.5.4. 방화벽 규칙
방화벽 규칙을 사용하여 네트워크 트래픽을 허용하거나 차단하는 특정 구성을 구현할 수 있습니다. 따라서 네트워크 트래픽 흐름을 제어하여 시스템을 보안 위협으로부터 보호할 수 있습니다.
방화벽 규칙은 일반적으로 다양한 속성을 기반으로 특정 기준을 정의합니다. 속성은 다음과 같습니다.
- 소스 IP 주소
- 대상 IP 주소
- 전송 프로토콜 (TCP, UDP, …)
- 포트
- 네트워크 인터페이스
firewalld 유틸리티는 방화벽 규칙을 영역(예: 공용,내부 및 기타) 및 정책으로 구성합니다. 각 영역에는 특정 영역과 연결된 네트워크 인터페이스에 대한 트래픽 자유 수준을 결정하는 자체 규칙 세트가 있습니다.
23.5.5. 방화벽 직접 규칙
firewalld 서비스는 다음을 포함하여 규칙을 구성하는 여러 방법을 제공합니다.
- 일반 규칙
- 직접 규칙
이러한 차이점 중 하나는 각 방법이 기본 백엔드(iptables 또는 nftables)와 상호 작용하는 방법입니다.
직접 규칙은 iptables 와 직접 상호 작용을 허용하는 고급 하위 수준 규칙입니다. firewalld 의 구조화된 영역 기반 관리를 바이패스하여 더 많은 제어 권한을 부여합니다. raw iptables 구문을 사용하여 firewall-cmd 명령을 사용하여 직접 규칙을 수동으로 정의합니다. 예를 들어 firewall-cmd --direct --add-rule ipv4는 INPUT 0 -s 198.51.100.1 -j DROP. 이 명령은 198.51.100.1 소스 IP 주소에서 트래픽을 삭제하는 iptables 규칙을 추가합니다.
그러나 직접 규칙을 사용하면 단점도 있습니다. 특히 nftables 가 기본 방화벽 백엔드인 경우입니다. 예를 들면 다음과 같습니다.
-
직접 규칙은 유지 관리하기가 더 어렵고
nftables기반firewalld구성과 충돌할 수 있습니다. -
직접 규칙은 원시 표현식 및 stateful 오브젝트와 같은
nftables에서 찾을 수 있는 고급 기능을 지원하지 않습니다. -
직접적인 규칙은 미래 지향적인 것이 아닙니다.
iptables구성 요소는 더 이상 사용되지 않으며 결국 RHEL에서 제거됩니다.
이전 이유로 firewalld 직접 규칙을 nftables 로 교체할 수 있습니다. 자세한 내용을 보려면 Knowledgebase 솔루션에서 firewalld 직접 규칙을 nftables로 교체하는 방법을 검토하십시오.
23.5.6. 사전 정의된 firewalld 서비스
사전 정의된 firewalld 서비스는 하위 수준 방화벽 규칙에 대해 기본 추상화 계층을 제공합니다. SSH 또는 HTTP와 같은 일반적으로 사용되는 네트워크 서비스를 해당 포트 및 프로토콜에 매핑하여 수행할 수 있습니다. 매번 수동으로 지정하는 대신 이름이 사전 정의된 서비스를 참조할 수 있습니다. 이를 통해 방화벽 관리가 간소화되고 오류가 발생하기 쉽고 직관적입니다.
사용 가능한 사전 정의된 서비스를 보려면 다음을 수행합니다.
firewall-cmd --get-services RH-Satellite-6 RH-Satellite-6-capsule afp amanda-client amanda-k5-client amqp amqps apcupsd audit ausweisapp2 bacula bacula-client bareos-director bareos-filedaemon bareos-storage bb bgp bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc bittorrent-lsd ceph ceph-exporter ceph-mon cfengine checkmk-agent cockpit collectd condor-collector cratedb ctdb dds...
# firewall-cmd --get-services RH-Satellite-6 RH-Satellite-6-capsule afp amanda-client amanda-k5-client amqp amqps apcupsd audit ausweisapp2 bacula bacula-client bareos-director bareos-filedaemon bareos-storage bb bgp bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc bittorrent-lsd ceph ceph-exporter ceph-mon cfengine checkmk-agent cockpit collectd condor-collector cratedb ctdb dds...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 사전 정의된 특정 서비스를 추가로 검사하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 출력은
RH-Satellite-6사전 정의된 서비스가 포트 5000/tcp 5646-5647/tcp 5671/tcp 8000/tcp 8080/tcp 9090/tcp에서 수신 대기함을 보여줍니다. 또한RH-Satellite-6는 사전 정의된 다른 서비스의 규칙을 상속합니다. 이 경우에는foreman입니다.
사전 정의된 각 서비스는 /usr/lib/firewalld/services/ 디렉터리에 이름이 동일한 XML 파일로 저장됩니다.
23.5.7. firewalld 영역 작업
영역은 들어오는 트래픽을 보다 투명하게 관리하는 개념을 나타냅니다. 영역은 네트워킹 인터페이스에 연결되거나 다양한 소스 주소가 할당됩니다. 각 영역에 대해 개별적으로 방화벽 규칙을 관리하므로 복잡한 방화벽 설정을 정의하고 트래픽에 적용할 수 있습니다.
23.5.7.1. 보안을 강화하기 위해 특정 영역에 대한 방화벽 설정 사용자 정의
방화벽 설정을 수정하고 특정 네트워크 인터페이스 또는 특정 방화벽 영역과 연결하여 네트워크 보안을 강화할 수 있습니다. 영역에 대한 세분화된 규칙 및 제한을 정의하면 원하는 보안 수준에 따라 인바운드 및 아웃바운드 트래픽을 제어할 수 있습니다.
예를 들어 다음과 같은 이점을 얻을 수 있습니다.
- 민감한 데이터 보호
- 무단 액세스 방지
- 잠재적인 네트워크 위협 완화
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
프로세스
사용 가능한 방화벽 영역을 나열합니다.
firewall-cmd --get-zones
# firewall-cmd --get-zonesCopy to Clipboard Copied! Toggle word wrap Toggle overflow firewall-cmd --get-zones명령은 시스템에서 사용 가능한 모든 영역을 표시하지만 특정 영역에 대한 세부 정보는 표시되지 않습니다. 모든 영역에 대한 자세한 정보를 보려면firewall-cmd --list-all-zones명령을 사용합니다.- 이 구성에 사용할 영역을 선택합니다.
선택한 영역에 대한 방화벽 설정을 수정합니다. 예를 들어
SSH서비스를 허용하고ftp서비스를 제거하려면 다음을 수행합니다.firewall-cmd --add-service=ssh --zone=<your_chosen_zone> firewall-cmd --remove-service=ftp --zone=<same_chosen_zone>
# firewall-cmd --add-service=ssh --zone=<your_chosen_zone> # firewall-cmd --remove-service=ftp --zone=<same_chosen_zone>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽 영역에 네트워크 인터페이스를 할당합니다.
사용 가능한 네트워크 인터페이스를 나열합니다.
firewall-cmd --get-active-zones
# firewall-cmd --get-active-zonesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영역의 작업은 해당 구성과 일치하는 네트워크 인터페이스 또는 소스 주소 범위가 있는지에 따라 결정됩니다. 기본 영역은 분류되지 않은 트래픽에 대해 활성 상태이지만 트래픽이 규칙과 일치하지 않는 경우 항상 활성 상태인 것은 아닙니다.
선택한 영역에 네트워크 인터페이스를 할당합니다.
firewall-cmd --zone=<your_chosen_zone> --change-interface=<interface_name> --permanent
# firewall-cmd --zone=<your_chosen_zone> --change-interface=<interface_name> --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영역에 네트워크 인터페이스를 할당하는 것은 특정 인터페이스(물리적 또는 가상)의 모든 트래픽에 일관된 방화벽 설정을 적용하는 데 더 적합합니다.
firewall-cmd명령을--permanent옵션과 함께 사용하는 경우 종종 NetworkManager 연결 프로필을 업데이트하여 방화벽 구성을 영구적으로 변경해야 합니다.firewalld와 NetworkManager 간의 통합은 일관된 네트워크 및 방화벽 설정을 보장합니다.
검증
선택한 영역에 대한 업데이트된 설정을 표시합니다.
firewall-cmd --zone=<your_chosen_zone> --list-all
# firewall-cmd --zone=<your_chosen_zone> --list-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령 출력은 할당된 서비스, 네트워크 인터페이스 및 네트워크 연결(소스)을 포함한 모든 영역 설정을 표시합니다.
23.5.7.2. 기본 영역 변경
시스템 관리자는 구성 파일의 네트워킹 인터페이스에 영역을 할당합니다. 인터페이스가 특정 영역에 할당되지 않은 경우 기본 영역에 할당됩니다. firewalld 서비스를 다시 시작할 때마다 firewalld 는 기본 영역의 설정을 로드하고 활성화합니다. 다른 모든 영역에 대한 설정은 유지되며 사용할 준비가 되어 있습니다.
일반적으로 영역은 NetworkManager 연결 프로필의 connection.zone 설정에 따라 NetworkManager에 의해 인터페이스에 할당됩니다. 또한 재부팅 후 NetworkManager는 해당 영역의 "활성화" 할당을 관리합니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
프로세스
기본 영역을 설정하려면 다음을 수행합니다.
현재 기본 영역을 표시합니다.
firewall-cmd --get-default-zone
# firewall-cmd --get-default-zoneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 기본 영역을 설정합니다.
firewall-cmd --set-default-zone <zone_name>
# firewall-cmd --set-default-zone <zone_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고이 절차 후 설정은
--permanent옵션 없이 영구적인 설정입니다.
23.5.7.3. 영역에 네트워크 인터페이스 할당
다양한 영역에 대한 다양한 규칙 세트를 정의한 다음, 사용 중인 인터페이스의 영역을 변경하여 설정을 빠르게 변경할 수 있습니다. 여러 인터페이스를 사용하면 각 인터페이스에 대해 특정 영역을 설정하여 통과하는 트래픽을 구분할 수 있습니다.
프로세스
특정 인터페이스에 영역을 할당하려면 다음을 수행합니다.
활성 영역과 연결된 인터페이스를 나열합니다.
firewall-cmd --get-active-zones
# firewall-cmd --get-active-zonesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 인터페이스를 다른 영역에 할당합니다.
firewall-cmd --zone=zone_name --change-interface=interface_name --permanent
# firewall-cmd --zone=zone_name --change-interface=interface_name --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.4. 소스 추가
들어오는 트래픽을 특정 영역으로 라우팅하려면 해당 영역에 소스를 추가합니다. 소스는 CIDR(Classless inter-domain routing) 표기법의 IP 주소 또는 IP 마스크일 수 있습니다.
네트워크 범위가 겹치는 여러 영역을 추가하는 경우 영역 이름으로 영숫자로 정렬되며 첫 번째 영역만 고려됩니다.
현재 영역에서 소스를 설정하려면 다음을 수행합니다.
firewall-cmd --add-source=<source>
# firewall-cmd --add-source=<source>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 특정 영역의 소스 IP 주소를 설정하려면 다음을 수행합니다.
firewall-cmd --zone=zone-name --add-source=<source>
# firewall-cmd --zone=zone-name --add-source=<source>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 절차에서는 신뢰할 수 있는 영역의 192.168.2.15 에서 들어오는 모든 트래픽을 허용합니다.
프로세스
사용 가능한 모든 영역을 나열합니다.
firewall-cmd --get-zones
# firewall-cmd --get-zonesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영구 모드에서 신뢰할 수 있는 영역에 소스 IP를 추가합니다.
firewall-cmd --zone=trusted --add-source=192.168.2.15
# firewall-cmd --zone=trusted --add-source=192.168.2.15Copy to Clipboard Copied! Toggle word wrap Toggle overflow 새 설정을 영구적으로 설정합니다.
firewall-cmd --runtime-to-permanent
# firewall-cmd --runtime-to-permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.5. 소스 제거
영역에서 소스를 제거하면 소스에서 시작된 트래픽은 더 이상 해당 소스에 지정된 규칙을 통해 전달되지 않습니다. 대신 트래픽이 시작된 인터페이스와 연결된 영역의 규칙 및 설정으로 대체되거나 기본 영역으로 이동합니다.
프로세스
필수 영역에 허용되는 소스를 나열합니다.
firewall-cmd --zone=zone-name --list-sources
# firewall-cmd --zone=zone-name --list-sourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영역에서 소스를 영구적으로 제거합니다.
firewall-cmd --zone=zone-name --remove-source=<source>
# firewall-cmd --zone=zone-name --remove-source=<source>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 새 설정을 영구적으로 설정합니다.
firewall-cmd --runtime-to-permanent
# firewall-cmd --runtime-to-permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.6. nmcli를 사용하여 연결에 영역 할당
nmcli 유틸리티를 사용하여 NetworkManager 연결에 firewalld 영역을 추가할 수 있습니다.
프로세스
NetworkManager연결 프로필에 영역을 할당합니다.nmcli connection modify profile connection.zone zone_name
# nmcli connection modify profile connection.zone zone_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 연결을 활성화합니다.
nmcli connection up profile
# nmcli connection up profileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.7. ifcfg 파일에서 네트워크 연결에 수동으로 영역을 할당
NetworkManager 에서 연결을 관리하는 경우 해당 연결을 사용하는 영역을 알고 있어야 합니다. 모든 네트워크 연결 프로필의 경우 이동식 장치가 있는 컴퓨터의 위치에 따라 다양한 방화벽 설정의 유연성을 제공하는 영역을 지정할 수 있습니다. 따라서 회사 또는 집과 같은 다른 위치에 대해 영역 및 설정을 지정할 수 있습니다.
프로세스
연결 영역을 설정하려면
/etc/sysconfig/network-scripts/ifcfg-connection_name파일을 편집하고 이 연결에 영역을 할당하는 행을 추가합니다.ZONE=zone_name
ZONE=zone_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.8. 새 영역 생성
사용자 지정 영역을 사용하려면 새 영역을 생성하고 사전 정의된 영역과 마찬가지로 사용합니다. 새 영역에는 --permanent 옵션이 필요합니다. 그러지 않으면 명령이 작동하지 않습니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
프로세스
새 영역을 생성합니다.
firewall-cmd --permanent --new-zone=zone-name
# firewall-cmd --permanent --new-zone=zone-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 영역을 사용할 수 있도록 설정합니다.
firewall-cmd --reload
# firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 이미 실행 중인 네트워크 서비스를 중단하지 않고 최근 방화벽 구성에 변경 사항을 적용합니다.
검증
새 영역이 영구 설정에 추가되었는지 확인합니다.
firewall-cmd --get-zones --permanent
# firewall-cmd --get-zones --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.9. 웹 콘솔을 사용하여 영역 활성화
RHEL 웹 콘솔을 통해 특정 인터페이스 또는 IP 주소 범위에 사전 정의된 기존 방화벽 영역을 적용할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 네트워킹 을 클릭합니다.
버튼을 클릭합니다.
버튼이 표시되지 않으면 관리자 권한으로 웹 콘솔에 로그인합니다.
- 방화벽 섹션에서 새 영역 추가 를 클릭합니다.
영역 추가 대화 상자의 신뢰 수준 옵션에서 영역을 선택합니다.
웹 콘솔은
firewalld서비스에 사전 정의된 모든 영역을 표시합니다.- 인터페이스 부분에서 선택한 영역이 적용되는 인터페이스 또는 인터페이스를 선택합니다.
허용된 주소 부분에서 영역이 적용되는지 여부를 선택할 수 있습니다.
- 전체 서브넷
또는 다음 형식의 IP 주소 범위:
- 192.168.1.0
- 192.168.1.0/24
- 192.168.1.0/24, 192.168.1.0
버튼을 클릭합니다.
검증
방화벽 섹션에서 구성을 확인합니다.

23.5.7.10. 웹 콘솔을 사용하여 영역 비활성화
웹 콘솔을 사용하여 방화벽 구성에서 방화벽 영역을 비활성화할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 네트워킹 을 클릭합니다.
버튼을 클릭합니다.
버튼이 표시되지 않으면 관리자 권한으로 웹 콘솔에 로그인합니다.
제거하려는 영역에서 옵션 아이콘을 클릭합니다.

- 삭제를 클릭합니다.
이제 영역이 비활성화되어 인터페이스에 영역에 구성된 열린 서비스 및 포트가 포함되지 않습니다.
23.5.7.11. 영역 대상을 사용하여 들어오는 트래픽에 대한 기본 동작 설정
모든 영역에 대해 추가로 지정되지 않은 들어오는 트래픽을 처리하는 기본 동작을 설정할 수 있습니다. 이러한 동작은 영역의 대상을 설정하여 정의됩니다. 4가지 옵션이 있습니다.
-
허용: 특정 규칙에 의해 허용되지 않는 경우를 제외하고 들어오는 모든 패킷을 수락합니다. -
REJECT: 특정 규칙에서 허용되는 패킷을 제외한 모든 들어오는 패킷을 거부합니다.firewalld가 패킷을 거부하면 소스 시스템에 거부에 대한 정보가 표시됩니다. -
DROP: 특정 규칙에서 허용되는 경우를 제외한 들어오는 모든 패킷을 삭제합니다.firewalld가 패킷을 삭제하면 소스 시스템에 패킷 드롭에 대한 정보가 표시되지 않습니다. -
기본값:REJECT와 유사하지만 특정 시나리오에서 특별한 의미가 있습니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
프로세스
영역의 대상을 설정하려면 다음을 수행합니다.
특정 영역에 대한 정보를 나열하여 기본 대상을 확인합니다.
firewall-cmd --zone=zone-name --list-all
# firewall-cmd --zone=zone-name --list-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영역에 새 대상을 설정합니다.
firewall-cmd --permanent --zone=zone-name --set-target=<default|ACCEPT|REJECT|DROP>
# firewall-cmd --permanent --zone=zone-name --set-target=<default|ACCEPT|REJECT|DROP>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.7.12. IP 세트를 사용하여 허용 목록에 대한 동적 업데이트 구성
예측할 수 없는 조건에서도 IP 세트의 특정 IP 주소 또는 범위를 유연하게 허용하도록 거의 실시간 업데이트를 수행할 수 있습니다. 이러한 업데이트는 보안 위협 탐지 또는 네트워크 동작 변경과 같은 다양한 이벤트에 의해 트리거될 수 있습니다. 일반적으로 이러한 솔루션은 자동화를 활용하여 수동 작업을 줄이고 상황에 신속하게 대응하여 보안을 개선합니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
절차
의미 있는 이름으로 IP 세트를 생성합니다.
firewall-cmd --permanent --new-ipset=allowlist --type=hash:ip
# firewall-cmd --permanent --new-ipset=allowlist --type=hash:ipCopy to Clipboard Copied! Toggle word wrap Toggle overflow allowlist라는 새 IP 세트에는 방화벽에서 허용할 IP 주소가 포함되어 있습니다.IP 세트에 동적 업데이트를 추가합니다.
firewall-cmd --permanent --ipset=allowlist --add-entry=198.51.100.10
# firewall-cmd --permanent --ipset=allowlist --add-entry=198.51.100.10Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 구성은 방화벽에서 네트워크 트래픽을 전달할 수 있는 새로 추가된 IP 주소로
허용 목록IP 세트를 업데이트합니다.이전에 생성한 IP 세트를 참조하는 방화벽 규칙을 생성합니다.
firewall-cmd --permanent --zone=public --add-source=ipset:allowlist
# firewall-cmd --permanent --zone=public --add-source=ipset:allowlistCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 규칙이 없으면 IP 세트가 네트워크 트래픽에 영향을 미치지 않습니다. 기본 방화벽 정책이 우선합니다.
방화벽 구성을 다시 로드하여 변경 사항을 적용합니다.
firewall-cmd --reload
# firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
모든 IP 세트를 나열합니다.
firewall-cmd --get-ipsets allowlist
# firewall-cmd --get-ipsets allowlistCopy to Clipboard Copied! Toggle word wrap Toggle overflow 활성 규칙을 나열합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령줄 출력의
소스섹션에서는 특정 방화벽 영역에 대한 액세스 허용 또는 거부되는 트래픽(호스트, 인터페이스, IP 세트, 서브넷 등)에 대한 인사이트를 제공합니다. 이 경우허용 목록IP 세트에 포함된 IP 주소는공용영역의 방화벽을 통해 트래픽을 전달할 수 있습니다.IP 세트의 내용을 살펴봅니다.
cat /etc/firewalld/ipsets/allowlist.xml <?xml version="1.0" encoding="utf-8"?> <ipset type="hash:ip"> <entry>198.51.100.10</entry> </ipset>
# cat /etc/firewalld/ipsets/allowlist.xml <?xml version="1.0" encoding="utf-8"?> <ipset type="hash:ip"> <entry>198.51.100.10</entry> </ipset>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 단계
-
스크립트 또는 보안 유틸리티를 사용하여 위협 정보 피드를 가져오고 이에 따라
허용 목록을자동화된 방식으로 업데이트합니다.
23.5.8. firewalld를 사용하여 네트워크 트래픽 제어
firewalld 패키지는 사전 정의된 많은 서비스 파일을 설치하고 더 추가하거나 사용자 지정할 수 있습니다. 그런 다음 이러한 서비스 정의를 사용하여 사용하는 프로토콜과 포트 번호를 모르는 상태에서 서비스의 포트를 열거나 닫을 수 있습니다.
23.5.8.1. CLI를 사용하여 사전 정의된 서비스로 트래픽 제어
트래픽을 제어하는 가장 간단한 방법은 firewalld 에 사전 정의된 서비스를 추가하는 것입니다. 그러면 필요한 모든 포트가 열리고 서비스 정의 파일 에 따라 다른 설정을 수정합니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
프로세스
firewalld의 서비스가 아직 허용되지 않았는지 확인합니다.firewall-cmd --list-services ssh dhcpv6-client
# firewall-cmd --list-services ssh dhcpv6-clientCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 기본 영역에서 활성화된 서비스를 나열합니다.
firewalld에서 사전 정의된 모든 서비스를 나열합니다.firewall-cmd --get-services RH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ...
# firewall-cmd --get-services RH-Satellite-6 amanda-client amanda-k5-client bacula bacula-client bitcoin bitcoin-rpc bitcoin-testnet bitcoin-testnet-rpc ceph ceph-mon cfengine condor-collector ctdb dhcp dhcpv6 dhcpv6-client dns docker-registry ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 기본 영역에 사용 가능한 서비스 목록을 표시합니다.
firewalld에서 허용하는 서비스 목록에 서비스를 추가합니다.firewall-cmd --add-service=<service_name>
# firewall-cmd --add-service=<service_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 지정된 서비스를 기본 영역에 추가합니다.
새 설정을 영구적으로 설정합니다.
firewall-cmd --runtime-to-permanent
# firewall-cmd --runtime-to-permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 이러한 런타임 변경 사항을 방화벽의 영구 구성에 적용합니다. 기본적으로 이러한 변경 사항은 기본 영역의 구성에 적용됩니다.
검증
모든 영구 방화벽 규칙을 나열합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 기본 방화벽 영역(
공용)의 영구 방화벽 규칙을 사용하여 전체 구성을 표시합니다.firewalld서비스의 영구 구성의 유효성을 확인합니다.firewall-cmd --check-config success
# firewall-cmd --check-config successCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영구 구성이 유효하지 않으면 명령에서 추가 세부 정보와 함께 오류를 반환합니다.
firewall-cmd --check-config Error: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}# firewall-cmd --check-config Error: INVALID_PROTOCOL: 'public.xml': 'tcpx' not from {'tcp'|'udp'|'sctp'|'dccp'}Copy to Clipboard Copied! Toggle word wrap Toggle overflow 영구 구성 파일을 수동으로 검사하여 설정을 확인할 수도 있습니다. 기본 설정 파일은
/etc/firewalld/firewalld.conf입니다. 영역별 구성 파일은/etc/firewalld/zones/디렉터리에 있으며 정책은/etc/firewalld/policies/디렉터리에 있습니다.
23.5.8.2. 웹 콘솔을 사용하여 방화벽에서 서비스 활성화
기본적으로 서비스는 기본 방화벽 영역에 추가됩니다. 더 많은 네트워크 인터페이스에서 방화벽 영역을 사용하는 경우 먼저 영역을 선택한 다음 포트로 서비스를 추가해야 합니다.
RHEL 8 웹 콘솔에는 사전 정의된 firewalld 서비스가 표시되고 활성 방화벽 영역에 추가할 수 있습니다.
RHEL 8 웹 콘솔은 firewalld 서비스를 구성합니다.
웹 콘솔은 웹 콘솔에 나열되지 않은 일반 firewalld 규칙을 허용하지 않습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 네트워킹 을 클릭합니다.
버튼을 클릭합니다.
버튼이 표시되지 않으면 관리자 권한으로 웹 콘솔에 로그인합니다.
방화벽 섹션에서 서비스를 추가할 영역을 선택하고 서비스 추가 를 클릭합니다.

- 서비스 추가 대화 상자에서 방화벽에서 활성화할 서비스를 찾습니다.
시나리오에 따라 서비스를 활성화합니다.
- 서비스 추가를 클릭합니다.
이 시점에서 RHEL 8 웹 콘솔에 서비스가 영역의 서비스 목록에 표시됩니다.
23.5.8.3. 웹 콘솔을 사용하여 사용자 정의 포트 구성
RHEL 웹 콘솔을 통해 서비스에 대한 사용자 지정 포트를 구성할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
firewalld서비스가 실행 중입니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 네트워킹 을 클릭합니다.
버튼을 클릭합니다.
버튼이 표시되지 않으면 관리 권한으로 웹 콘솔에 로그인합니다.
방화벽 섹션에서 사용자 지정 포트를 구성할 영역을 선택하고 서비스 추가 를 클릭합니다.
- 서비스 추가 대화 상자에서 라디오 버튼을 클릭합니다.
TCP 및 UDP 필드에서 예제에 따라 포트를 추가합니다. 다음 형식으로 포트를 추가할 수 있습니다.
- 22와 같은 포트 번호
- 5900-5910과 같은 포트 번호 범위
- nfs, rsync와 같은 별칭
참고각 필드에 여러 값을 추가할 수 있습니다. 값은 쉼표 없이 쉼표로 구분해야 합니다. 예를 들면 다음과 같습니다. 8080,8081,http
TCP filed에 포트 번호를 추가한 후, UDP 가 제출되었거나 둘 다되면 Name 필드에서 서비스 이름을 확인합니다.
Name 필드에는 이 포트가 예약된 서비스 이름이 표시됩니다. 이 포트를 자유롭게 사용할 수 있고 이 포트에서 서버가 통신할 필요가 없는 경우 이름을 다시 작성할 수 있습니다.
- 이름 필드에 정의된 포트를 포함한 서비스의 이름을 추가합니다.
.

설정을 확인하려면 방화벽 페이지로 이동하여 영역의 서비스 목록에서 서비스를 찾습니다.
23.5.9. 영역 간에 전달된 트래픽 필터링
firewalld 를 사용하면 서로 다른 firewalld 영역 간의 네트워크 데이터 흐름을 제어할 수 있습니다. 규칙과 정책을 정의하면 이러한 영역 간에 이동할 때 트래픽이 허용되거나 차단되는 방법을 관리할 수 있습니다.
정책 오브젝트 기능은 firewalld 에서 전달 및 출력 필터링 기능을 제공합니다. firewalld 를 사용하여 다른 영역 간 트래픽을 필터링하여 로컬 호스트 VM에 대한 액세스를 통해 호스트를 연결할 수 있습니다.
23.5.9.1. 정책 오브젝트와 영역 간의 관계
정책 오브젝트를 사용하면 사용자가 서비스, 포트 및 리치 규칙과 같은 firewalld 기본 기능을 정책에 연결할 수 있습니다. 상태 저장 및 단방향 방식으로 영역 간에 통과하는 트래픽에 정책 오브젝트를 적용할 수 있습니다.
firewall-cmd --permanent --new-policy myOutputPolicy firewall-cmd --permanent --policy myOutputPolicy --add-ingress-zone HOST firewall-cmd --permanent --policy myOutputPolicy --add-egress-zone ANY
# firewall-cmd --permanent --new-policy myOutputPolicy
# firewall-cmd --permanent --policy myOutputPolicy --add-ingress-zone HOST
# firewall-cmd --permanent --policy myOutputPolicy --add-egress-zone ANY
HOST 및 ANY 는 수신 및 송신 영역 목록에 사용되는 심볼릭 영역입니다.
-
HOST심볼릭 영역을 사용하면 에서 시작되는 트래픽에 대한 정책이 허용되거나 firewalld를 실행하는 호스트의 대상이 있습니다. -
ANY심볼릭 영역은 현재 및 향후 모든 영역에 정책을 적용합니다.ANY심볼릭 영역은 모든 영역의 와일드카드 역할을 합니다.
23.5.9.2. 우선순위를 사용하여 정책 정렬
여러 정책을 동일한 트래픽 집합에 적용할 수 있으므로 적용할 수 있는 정책에 대한 우선 순위 순서를 생성하는 데 우선순위를 사용해야 합니다.
정책을 정렬할 우선 순위를 설정하려면 다음을 수행합니다.
firewall-cmd --permanent --policy mypolicy --set-priority -500
# firewall-cmd --permanent --policy mypolicy --set-priority -500위의 예에서 -500 은 우선 순위가 낮지만 우선 순위가 높습니다. 따라서 -500은 -100 이전에 실행됩니다.
낮은 숫자 우선순위 값은 우선순위가 높고 먼저 적용됩니다.
23.5.9.3. 정책 오브젝트를 사용하여 로컬 호스트 컨테이너와 호스트에 물리적으로 연결된 네트워크 간의 트래픽을 필터링
정책 오브젝트 기능을 사용하면 사용자가 Podman과 firewalld 영역 간의 트래픽을 필터링할 수 있습니다.
Red Hat은 기본적으로 모든 트래픽을 차단하고 Podman 유틸리티에 필요한 선택적 서비스를 여는 것이 좋습니다.
절차
새 방화벽 정책을 생성합니다.
firewall-cmd --permanent --new-policy podmanToAny
# firewall-cmd --permanent --new-policy podmanToAnyCopy to Clipboard Copied! Toggle word wrap Toggle overflow Podman에서 다른 영역으로의 모든 트래픽을 차단하고 Podman에서 필요한 서비스만 허용합니다.
firewall-cmd --permanent --policy podmanToAny --set-target REJECT firewall-cmd --permanent --policy podmanToAny --add-service dhcp firewall-cmd --permanent --policy podmanToAny --add-service dns firewall-cmd --permanent --policy podmanToAny --add-service https
# firewall-cmd --permanent --policy podmanToAny --set-target REJECT # firewall-cmd --permanent --policy podmanToAny --add-service dhcp # firewall-cmd --permanent --policy podmanToAny --add-service dns # firewall-cmd --permanent --policy podmanToAny --add-service httpsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 Podman 영역을 생성합니다.
firewall-cmd --permanent --new-zone=podman
# firewall-cmd --permanent --new-zone=podmanCopy to Clipboard Copied! Toggle word wrap Toggle overflow 정책의 수신 영역을 정의합니다.
firewall-cmd --permanent --policy podmanToHost --add-ingress-zone podman
# firewall-cmd --permanent --policy podmanToHost --add-ingress-zone podmanCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다른 모든 영역에 대한 송신 영역을 정의합니다.
firewall-cmd --permanent --policy podmanToHost --add-egress-zone ANY
# firewall-cmd --permanent --policy podmanToHost --add-egress-zone ANYCopy to Clipboard Copied! Toggle word wrap Toggle overflow 송신 영역을 ANY로 설정하면 Podman에서 다른 영역으로 필터링합니다. 호스트에 필터링하려면 송신 영역을 HOST로 설정합니다.
firewalld 서비스를 다시 시작합니다.
systemctl restart firewalld
# systemctl restart firewalldCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Podman 방화벽 정책을 다른 영역에 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.9.4. 정책 오브젝트의 기본 대상 설정
정책에 --set-target 옵션을 지정할 수 있습니다. 다음 대상을 사용할 수 있습니다.
-
ACCEPT- 패킷을 수락 -
DROP- 원하지 않는 패킷을 삭제합니다. -
REJECT- ICMP 응답을 사용하여 원하지 않는 패킷을 거부 CONTINUE(기본값) - 패킷에는 다음 정책 및 영역의 규칙이 적용됩니다.firewall-cmd --permanent --policy mypolicy --set-target CONTINUE
# firewall-cmd --permanent --policy mypolicy --set-target CONTINUECopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
정책에 대한 정보 확인
firewall-cmd --info-policy mypolicy
# firewall-cmd --info-policy mypolicyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.10. firewalld를 사용하여 NAT 구성
firewalld 를 사용하면 다음 NAT(네트워크 주소 변환) 유형을 구성할 수 있습니다.
- 마스커레이딩
- 대상 NAT(DNAT)
- 리디렉션
23.5.10.1. 네트워크 주소 변환 유형
다음은 다양한 NAT(네트워크 주소 변환) 유형입니다.
- 마스커레이딩
이러한 NAT 유형 중 하나를 사용하여 패킷의 소스 IP 주소를 변경합니다. 예를 들어, 인터넷 서비스 공급자(ISP)는
10.0.0.0/8과 같은 개인 IP 범위를 라우팅하지 않습니다. 네트워크에서 개인 IP 범위를 사용하고 사용자가 인터넷의 서버에 연결할 수 있어야 하는 경우 이러한 범위의 패킷의 소스 IP 주소를 공용 IP 주소에 매핑합니다.마스커레이딩은 나가는 인터페이스의 IP 주소를 자동으로 사용합니다. 따라서 나가는 인터페이스에서 동적 IP 주소를 사용하는 경우 마스커레이딩을 사용합니다.
- 대상 NAT(DNAT)
- 이 NAT 유형을 사용하여 들어오는 패킷의 대상 주소와 포트를 다시 작성합니다. 예를 들어 웹 서버가 개인 IP 범위의 IP 주소를 사용하므로 인터넷에서 직접 액세스할 수 없는 경우 라우터에 DNAT 규칙을 설정하여 수신 트래픽을 이 서버로 리디렉션할 수 있습니다.
- 리디렉션
- 이 유형은 패킷을 로컬 시스템의 다른 포트로 리디렉션하는 특수한 DNAT의 경우입니다. 예를 들어 서비스가 표준 포트와 다른 포트에서 실행되는 경우 표준 포트에서 들어오는 트래픽을 이 특정 포트로 리디렉션할 수 있습니다.
23.5.10.2. IP 주소 마스커레이딩 구성
시스템에서 IP 마스커레이딩을 활성화할 수 있습니다. IP 마스커레이딩은 인터넷에 액세스할 때 게이트웨이 뒤에 있는 개별 머신을 숨깁니다.
절차
IP 마스커레이드가 활성화되어 있는지 확인하려면 (예:
외부영역의 경우) 다음 명령을root로 입력합니다.firewall-cmd --zone=external --query-masquerade
# firewall-cmd --zone=external --query-masqueradeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 활성화된 경우 종료 상태
0으로yes를 출력합니다. 그렇지 않으면 종료 상태1로no를 출력합니다.영역을생략하면 기본 영역이 사용됩니다.IP 마스커레이딩을 사용하려면
root로 다음 명령을 입력합니다.firewall-cmd --zone=external --add-masquerade
# firewall-cmd --zone=external --add-masqueradeCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
이 설정을 영구적으로 설정하려면 명령에
--permanent옵션을 전달합니다. IP 마스커레이딩을 비활성화하려면
root로 다음 명령을 입력합니다.firewall-cmd --zone=external --remove-masquerade
# firewall-cmd --zone=external --remove-masqueradeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 설정을 영구적으로 설정하려면 명령에
--permanent옵션을 전달합니다.
23.5.10.3. DNAT를 사용하여 들어오는 HTTP 트래픽 전달
대상 네트워크 주소 변환(DNAT)을 사용하여 들어오는 트래픽을 하나의 대상 주소 및 포트에서 다른 대상 주소로 보낼 수 있습니다. 일반적으로 외부 네트워크 인터페이스에서 특정 내부 서버 또는 서비스로 들어오는 요청을 리디렉션하는 데 유용합니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
절차
들어오는 HTTP 트래픽을 전달합니다.
firewall-cmd --zone=public --add-forward-port=port=80:proto=tcp:toaddr=198.51.100.10:toport=8080 --permanent
# firewall-cmd --zone=public --add-forward-port=port=80:proto=tcp:toaddr=198.51.100.10:toport=8080 --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 명령은 다음 설정으로 DNAT 규칙을 정의합니다.
-
--zone=public- DNAT 규칙을 구성하는 방화벽 영역입니다. 필요한 모든 영역에 맞게 조정할 수 있습니다. -
--add-forward-port- 포트 전달 규칙을 추가 중임을 나타내는 옵션입니다. -
port=80- 외부 대상 포트입니다. -
proto=tcp- TCP 트래픽을 전달함을 나타내는 프로토콜입니다. -
toaddr=198.51.100.10- 대상 IP 주소입니다. -
toport=8080- 내부 서버의 대상 포트입니다. -
--permanent- 재부팅 시 DNAT 규칙을 유지할 수 있는 옵션입니다.
-
방화벽 구성을 다시 로드하여 변경 사항을 적용합니다.
firewall-cmd --reload
# firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
사용한 방화벽 영역에 대한 DNAT 규칙을 확인합니다.
firewall-cmd --list-forward-ports --zone=public port=80:proto=tcp:toport=8080:toaddr=198.51.100.10
# firewall-cmd --list-forward-ports --zone=public port=80:proto=tcp:toport=8080:toaddr=198.51.100.10Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 해당 XML 구성 파일을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.10.4. 비표준 포트에서 트래픽을 리디렉션하여 표준 포트에서 웹 서비스에 액세스하도록 설정
리디렉션 메커니즘을 사용하여 사용자가 URL에 포트를 지정할 필요 없이 내부적으로 비표준 포트에서 실행되는 웹 서비스를 만들 수 있습니다. 결과적으로 URL은 더 간단하며 더 나은 검색 환경을 제공하는 반면 비표준 포트는 여전히 내부적으로 또는 특정 요구 사항에 사용됩니다.
사전 요구 사항
-
firewalld서비스가 실행 중입니다.
절차
NAT 리디렉션 규칙을 생성합니다.
firewall-cmd --zone=public --add-forward-port=port=<standard_port>:proto=tcp:toport=<non_standard_port> --permanent
# firewall-cmd --zone=public --add-forward-port=port=<standard_port>:proto=tcp:toport=<non_standard_port> --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 명령은 다음 설정으로 NAT 리디렉션 규칙을 정의합니다.
-
--zone=public- 규칙을 구성하는 방화벽 영역입니다. 필요한 모든 영역에 맞게 조정할 수 있습니다. -
--add-forward-port=port= <non_standard_port> - 들어오는 트래픽을 처음 수신하는 소스 포트를 사용하여 포트 전달(리렉션) 규칙을 추가 중임을 나타내는 옵션입니다. -
proto=tcp- TCP 트래픽을 리디렉션함을 나타내는 프로토콜입니다. -
toport=<standard_port> - 소스 포트에서 수신한 후 들어오는 트래픽을 리디렉션해야 하는 대상 포트입니다. -
--permanent- 다시 부팅 시 규칙을 유지할 수 있는 옵션입니다.
-
방화벽 구성을 다시 로드하여 변경 사항을 적용합니다.
firewall-cmd --reload
# firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
다음을 사용한 방화벽 영역의 리디렉션 규칙을 확인합니다.
firewall-cmd --list-forward-ports port=8080:proto=tcp:toport=80:toaddr=
# firewall-cmd --list-forward-ports port=8080:proto=tcp:toport=80:toaddr=Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 해당 XML 구성 파일을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.11. 리치 규칙 우선순위 지정
리치 규칙은 방화벽 규칙을 정의하는 보다 고급적이고 유연한 방법을 제공합니다. 리치 규칙은 서비스, 포트 등이 복잡한 방화벽 규칙을 표현하기에 충분하지 않은 경우 특히 유용합니다.
리치 규칙의 개념:
- 세분성 및 유연성
- 보다 구체적인 기준에 따라 네트워크 트래픽에 대한 자세한 조건을 정의할 수 있습니다.
- 규칙 구조
리치 규칙은 제품군(IPv4 또는 IPv6)과 조건 및 작업으로 구성됩니다.
rule family="ipv4|ipv6" [conditions] [actions]
rule family="ipv4|ipv6" [conditions] [actions]Copy to Clipboard Copied! Toggle word wrap Toggle overflow - conditions
- 이러한 규칙을 사용하면 특정 기준이 충족되는 경우에만 리치 규칙을 적용할 수 있습니다.
- 작업
- 조건과 일치하는 네트워크 트래픽에 발생하는 작업을 정의할 수 있습니다.
- 여러 조건 결합
- 보다 구체적이고 복잡한 필터링을 생성할 수 있습니다.
- 계층적 제어 및 재사용 가능
- 리치 규칙을 영역 또는 서비스와 같은 다른 방화벽 메커니즘과 결합할 수 있습니다.
기본적으로 리치 규칙은 규칙 동작을 기반으로 구성됩니다. 예를 들어 거부 규칙은 허용 규칙보다 우선합니다. 리치 규칙의 priority 매개 변수는 관리자가 리치 규칙과 실행 순서를 세부적으로 제어할 수 있습니다. priority 매개변수를 사용하는 경우 규칙은 우선 순위 값으로 오름차순으로 정렬됩니다. 더 많은 규칙에 동일한 우선 순위가 있는 경우 규칙 작업에 따라 순서가 결정되며, 작업이 동일한 경우 순서가 정의되지 않을 수 있습니다.
23.5.11.1. 우선순위 매개변수가 규칙을 다른 체인으로 구성하는 방법
리치 규칙의 priority 매개변수를 -32768 과 32767 사이의 임의의 숫자로 설정할 수 있으며 더 낮은 숫자 값은 우선 순위가 높습니다.
firewalld 서비스는 우선순위 값에 따라 규칙을 다른 체인으로 구성합니다.
-
0보다 낮은 우선 순위: 규칙이
_pre접미사가 있는 체인으로 리디렉션됩니다. -
0보다 높은 우선 순위: 규칙이
_post접미사가 있는 체인으로 리디렉션됩니다. -
priority equals 0: action에 따라 규칙이
_log,_deny, 또는_allowthe action이 있는 체인으로 리디렉션됩니다.
이러한 하위 체인 내에서 firewalld 는 우선 순위 값에 따라 규칙을 정렬합니다.
23.5.11.2. 리치 규칙의 우선 순위 설정
다음은 priority 매개변수를 사용하여 다른 규칙에서 허용하거나 거부하지 않는 모든 트래픽을 기록하는 리치 규칙을 생성하는 방법의 예입니다. 이 규칙을 사용하여 예기치 않은 트래픽에 플래그를 지정할 수 있습니다.
절차
우선 순위가 매우 낮은 리치 규칙을 추가하여 다른 규칙과 일치하지 않는 모든 트래픽을 기록합니다.
firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'
# firewall-cmd --add-rich-rule='rule priority=32767 log prefix="UNEXPECTED: " limit value="5/m"'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 또한 로그 항목 수를 분당
5개로 제한합니다.
검증
이전 단계에서 생성된 명령을 사용하여
nftables규칙을 표시합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.12. firewalld 영역에서 다양한 인터페이스 또는 소스 간 트래픽 전달 활성화
영역 내 전달은 firewalld 영역 내의 인터페이스 또는 소스 간 트래픽 전달을 활성화하는 firewalld 기능입니다.
23.5.12.1. 기본 타겟이 ACCEPT로 설정된 영역 내 전달과 영역의 차이점
영역 내 전달이 활성화된 경우 단일 firewalld 영역 내의 트래픽이 하나의 인터페이스 또는 소스에서 다른 인터페이스 또는 소스로 전달될 수 있습니다. zone은 인터페이스 및 소스의 신뢰 수준을 지정합니다. 신뢰 수준이 동일한 경우 트래픽은 동일한 영역 내에 유지됩니다.
firewalld 의 기본 영역에서 영역 내 전달을 활성화하면 현재 기본 영역에 추가된 인터페이스와 소스에만 적용됩니다.
firewalld 는 다른 영역을 사용하여 들어오고 나가는 트래픽을 관리합니다. 각 영역에는 고유한 규칙과 동작 세트가 있습니다. 예를 들어 신뢰할 수 있는 영역은 기본적으로 전달된 모든 트래픽을 허용합니다.
다른 영역에는 기본 동작이 다를 수 있습니다. 표준 영역에서 영역의 대상이 기본값으로 설정된 경우 전달된 트래픽은 일반적으로 기본적으로 삭제됩니다.
영역 내의 다양한 인터페이스 또는 소스 간에 트래픽이 전달되는 방법을 제어하려면 해당 영역의 대상을 적절하게 이해하고 구성해야 합니다.
23.5.12.2. 이더넷과 Wi-Fi 네트워크 간에 트래픽 전달을 위해 영역 내 전달
intra-zone 전달을 사용하여 동일한 firewalld 영역 내의 인터페이스와 소스 간에 트래픽을 전달할 수 있습니다. 이 기능은 다음과 같은 이점을 제공합니다.
-
유선 및 무선 장치 간의 원활한 연결(W
lp에 연결된 이더넷 네트워크와 Wi-Fi 네트워크 간에 트래픽을 전달할 수 있음)0s20 - 유연한 작업 환경 지원
- 프린터, 데이터베이스, 네트워크 연결 스토리지 등 여러 장치 또는 네트워크에서 액세스하고 사용하는 공유 리소스
- 효율적인 내부 네트워킹(예: 원활한 통신, 대기 시간 감소, 리소스 접근성 등)
개별 firewalld 영역에 대해 이 기능을 활성화할 수 있습니다.
절차
커널에서 패킷 전달을 활성화합니다.
echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 영역 내 전달을 활성화할 인터페이스가
내부영역에만 할당되도록 합니다.firewall-cmd --get-active-zones
# firewall-cmd --get-active-zonesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 인터페이스가 현재
내부이외의 영역에 할당되면 이를 다시 할당합니다.firewall-cmd --zone=internal --change-interface=interface_name --permanent
# firewall-cmd --zone=internal --change-interface=interface_name --permanentCopy to Clipboard Copied! Toggle word wrap Toggle overflow enp1s0및wlp0s20인터페이스를내부영역에 추가합니다.firewall-cmd --zone=internal --add-interface=enp1s0 --add-interface=wlp0s20
# firewall-cmd --zone=internal --add-interface=enp1s0 --add-interface=wlp0s20Copy to Clipboard Copied! Toggle word wrap Toggle overflow 영역 내 전달을 활성화합니다.
firewall-cmd --zone=internal --add-forward
# firewall-cmd --zone=internal --add-forwardCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
다음 확인에서는 nmap-ncat 패키지가 두 호스트 모두에 설치되어 있어야 합니다.
-
영역 전달을 활성화한 호스트의
enp1s0인터페이스와 동일한 네트워크에 있는 호스트에 로그인합니다. ncat을 사용하여 echo 서비스를 시작하여 연결을 테스트합니다.ncat -e /usr/bin/cat -l 12345
# ncat -e /usr/bin/cat -l 12345Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
wlp0s20인터페이스와 동일한 네트워크에 있는 호스트에 로그인합니다. enp1s0과 동일한 네트워크에 있는 호스트에서 실행 중인 에코 서버에 연결합니다.ncat <other_host> 12345
# ncat <other_host> 12345Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 어떤 것을 입력하고 키를 누릅니다. 텍스트가 다시 전송되었는지 확인합니다.
23.5.13. RHEL 시스템 역할을 사용하여 firewalld 구성
RHEL 시스템 역할은 Ansible 자동화 유틸리티의 콘텐츠 집합입니다. 이 콘텐츠는 Ansible 자동화 유틸리티와 함께 여러 시스템을 한 번에 원격으로 관리할 수 있는 일관된 구성 인터페이스를 제공합니다.
rhel-system-roles 패키지에는 rhel-system-roles.firewall RHEL 시스템 역할이 포함되어 있습니다. 이 역할은 firewalld 서비스의 자동 구성을 위해 도입되었습니다.
방화벽 RHEL 시스템 역할을 사용하면 다양한 firewalld 매개변수를 구성할 수 있습니다. 예를 들면 다음과 같습니다.
- 영역
- 패킷을 허용해야 하는 서비스
- 포트에 대한 트래픽 액세스 권한 부여, 거부 또는 삭제
- 영역의 포트 또는 포트 범위 전달
23.5.13.1. 방화벽 RHEL 시스템 역할을 사용하여 firewalld 설정 재설정
시간이 지남에 따라 방화벽 구성을 업데이트하면 의도하지 않은 보안 위험이 발생할 수 있습니다. 방화벽 RHEL 시스템 역할을 사용하면 firewalld 설정을 자동으로 기본 상태로 재설정할 수 있습니다. 이렇게 하면 의도하지 않거나 안전하지 않은 방화벽 규칙을 효율적으로 제거하고 관리를 단순화할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
이전: 교체기존 사용자 정의 설정을 모두 제거하고
firewalld설정을 기본값으로 재설정합니다.이전:replaced매개변수를 다른 설정과 결합하면firewall역할은 새 설정을 적용하기 전에 기존 설정을 모두 제거합니다.플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.firewall/README.md파일을 참조하십시오.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
제어 노드에서 이 명령을 실행하여 관리 노드의 모든 방화벽 구성이 기본값으로 재설정되었는지 원격으로 확인합니다.
ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-all-zones'
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-all-zones'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.13.2. 방화벽 RHEL 시스템 역할을 사용하여 하나의 로컬 포트에서 다른 로컬 포트로 firewalld 에서 들어오는 트래픽 전달
방화벽 RHEL 시스템 역할을 사용하여 하나의 로컬 포트에서 다른 로컬 포트로 들어오는 트래픽 전달을 원격으로 구성할 수 있습니다.
예를 들어 여러 서비스가 동일한 시스템에 공존하고 동일한 기본 포트가 필요한 환경이 있는 경우 포트 충돌이 발생할 수 있습니다. 이러한 충돌로 인해 서비스가 중단되고 다운타임이 발생할 수 있습니다. 방화벽 RHEL 시스템 역할을 사용하면 트래픽을 대체 포트로 효율적으로 전달하여 구성을 수정하지 않고도 서비스를 동시에 실행할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
forward_port: 8080/tcp;443- TCP 프로토콜을 사용하여 로컬 포트 8080으로 들어오는 트래픽은 포트 443으로 전달됩니다.
runtime: true런타임 구성에서 변경 사항을 활성화합니다. 기본값은
true로 설정됩니다.플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.firewall/README.md파일을 참조하십시오.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
제어 노드에서 다음 명령을 실행하여 관리 노드에서 forwarded-ports를 원격으로 확인합니다.
ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-forward-ports' managed-node-01.example.com | CHANGED | rc=0 >> port=8080:proto=tcp:toport=443:toaddr=
# ansible managed-node-01.example.com -m ansible.builtin.command -a 'firewall-cmd --list-forward-ports' managed-node-01.example.com | CHANGED | rc=0 >> port=8080:proto=tcp:toport=443:toaddr=Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.5.13.3. 방화벽 RHEL 시스템 역할을 사용하여 firewalld DMZ 영역 구성
시스템 관리자는 방화벽 RHEL 시스템 역할을 사용하여 enp1s0 인터페이스에서 dmz 영역을 구성하여 HTTPS 트래픽을 영역에 허용할 수 있습니다. 이렇게 하면 외부 사용자가 웹 서버에 액세스할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.firewall/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
제어 노드에서 다음 명령을 실행하여 관리 노드의
dmz영역에 대한 정보를 원격으로 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6. nftables 시작하기
시나리오가 firewalld 에서 다루는 일반적인 패킷 필터링 사례에 속하지 않거나 규칙을 완전히 제어하려는 경우 nftables 프레임워크를 사용할 수 있습니다.
nftables 프레임워크는 패킷을 분류하고 iptables,ip6tables,arptables,ebtables 및 ipset 유틸리티의 후속 조치입니다. 이전의 패킷 필터링 툴에 비해 편의성, 기능 및 성능이 크게 향상되었으며 주요 개선 사항은 다음과 같습니다.
- 선형 처리 대신 기본 제공 조회 테이블
-
IPv4및IPv6프로토콜 모두를 위한 단일 프레임워크 - 전체 규칙 세트를 가져오고, 업데이트하고, 저장하는 대신 트랜잭션을 통해 배치된 커널 규칙 세트 업데이트
-
규칙 세트(
nftrace) 및 모니터링 추적 이벤트(nft툴에서) 디버깅 및 추적 지원 - 프로토콜별 확장 없이 보다 일관되고 컴팩트한 구문
- 타사 애플리케이션을 위한 Netlink API
nftables 프레임워크는 테이블을 사용하여 체인을 저장합니다. 체인에는 작업을 수행하기 위한 개별 규칙이 포함되어 있습니다. nft 유틸리티는 이전 패킷 필터링 프레임워크의 모든 도구를 대체합니다. libnftables 라이브러리를 사용하여 libnftnl 라이브러리를 통해 nftables Netlink API와 낮은 수준의 상호 작용을 수행할 수 있습니다.
규칙 세트 변경의 효과를 표시하려면 nft list ruleset 명령을 사용합니다. 커널 규칙 세트를 지우려면 nft flush ruleset 명령을 사용합니다. 이는 동일한 커널 인프라를 사용하므로 iptables-nft 명령으로 설치한 규칙 세트에도 영향을 미칠 수 있습니다.
23.6.1. nftables 테이블, 체인 및 규칙 생성 및 관리
nftables 규칙 세트를 표시하고 관리할 수 있습니다.
23.6.1.1. nftables 테이블 기본
nftables 의 테이블은 체인, 규칙, 세트 및 기타 오브젝트 컬렉션을 포함하는 네임스페이스입니다.
각 테이블에는 주소 제품군이 할당되어 있어야 합니다. 주소 family는 이 테이블이 처리하는 패킷 유형을 정의합니다. 테이블을 만들 때 다음 주소 제품군 중 하나를 설정할 수 있습니다.
-
ip: 일치하는 IPv4 패킷 만 일치합니다. 주소 제품군을 지정하지 않으면 기본값입니다. -
ip6: IPv6 패킷 만 일치합니다. -
inet: IPv4 및 IPv6 패킷과 일치합니다. -
ARP: IPv4 ARP(Address Resolution Protocol) 패킷과 일치합니다. -
브릿지: 브리지 장치를 통과하는 패킷과 일치합니다. -
netdev: 수신에서 패킷 일치.
테이블을 추가하려면 사용할 형식은 방화벽 스크립트에 따라 다릅니다.
기본 구문 스크립트의 경우 다음을 사용합니다.
table <table_address_family> <table_name> { }table <table_address_family> <table_name> { }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 쉘 스크립트에서는 다음을 사용합니다.
nft add table <table_address_family> <table_name>
nft add table <table_address_family> <table_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.1.2. nftables 체인의 기본 사항
테이블은 체인으로 구성되며, 이 체인은 규칙용 컨테이너입니다. 다음 두 가지 규칙 유형이 있습니다.
- 기본 체인: 기본 체인을 네트워킹 스택의 패킷 진입점으로 사용할 수 있습니다.
-
일반 체인: 규칙을 더 잘 구성하기 위해 일반 체인을
이동대상으로 사용할 수 있습니다.
테이블에 기본 체인을 추가하려면 사용할 형식은 방화벽 스크립트에 따라 다릅니다.
기본 구문 스크립트의 경우 다음을 사용합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 쉘 스크립트에서는 다음을 사용합니다.
nft add chain <table_address_family> <table_name> <chain_name> { type <type> hook <hook> priority <priority> \; policy <policy> \; }nft add chain <table_address_family> <table_name> <chain_name> { type <type> hook <hook> priority <priority> \; policy <policy> \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 쉘이 명령 끝으로 해석되지 않도록 하려면 \ 이스케이프 문자 앞에
\이스케이프 문자를 배치합니다.
두 예에서는 기본 체인을 생성합니다. 일반 체인 을 생성하려면 중괄호에서 매개 변수를 설정하지 마십시오.
체인 유형
다음은 체인 유형 및 제품군과 후크를 사용할 수 있는 개요입니다.
| 유형 | 주소 제품군 | 후크 | 설명 |
|---|---|---|---|
|
| 모두 | 모두 | 표준 체인 유형 |
|
|
IP , |
| 이 유형의 체인은 연결 추적 항목을 기반으로 기본 주소 변환을 수행합니다. 첫 번째 패킷만 이 체인 유형을 통과합니다. |
|
|
|
| 이 체인 유형을 트래버스하는 수락된 패킷은 IP 헤더의 관련 부분이 변경된 경우 새로운 경로 조회를 유발합니다. |
체인 우선순위
priority 매개변수는 패킷이 동일한 후크 값을 사용하는 체인을 트래버스하는 순서를 지정합니다. 이 매개변수를 정수 값으로 설정하거나 표준 우선순위 이름을 사용할 수 있습니다.
다음 매트릭스는 표준 우선 순위 이름과 해당 숫자 값에 대한 개요와 함께 사용할 수 있는 제품군과 후크를 처리합니다.
| 텍스트 값 | 숫자 값 | 주소 제품군 | 후크 |
|---|---|---|---|
|
|
|
IP , | 모두 |
|
|
|
IP , | 모두 |
|
|
|
IP , |
|
|
|
|
| |
|
|
|
IP , | 모두 |
|
|
| 모두 | |
|
|
|
IP , | 모두 |
|
|
|
IP , |
|
|
|
|
| |
|
|
|
|
|
체인 정책
체인 정책은 이 체인의 규칙이 작업을 지정하지 않는 경우 nftables 가 패킷을 수락하거나 삭제해야 하는지 여부를 정의합니다. 체인에서 다음 정책 중 하나를 설정할 수 있습니다.
-
수락(기본값) -
drop
23.6.1.3. nftables 규칙의 기본 사항
규칙은 이 규칙을 포함하는 체인을 전달하는 패킷에서 수행할 작업을 정의합니다. 규칙에 일치하는 표현식도 포함된 경우 nftables 는 모든 이전 표현식이 적용되는 경우에만 작업을 수행합니다.
체인에 규칙을 추가하려면 사용할 형식은 방화벽 스크립트에 따라 다릅니다.
기본 구문 스크립트의 경우 다음을 사용합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 쉘 스크립트에서는 다음을 사용합니다.
nft add rule <table_address_family> <table_name> <chain_name> <rule>
nft add rule <table_address_family> <table_name> <chain_name> <rule>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 쉘 명령은 체인 끝에 새 규칙을 추가합니다. 체인 시작 부분에 규칙을 추가하려면
nft add대신nft insert명령을 사용하십시오.
23.6.1.4. nft 명령을 사용하여 테이블, 체인 및 규칙 관리
명령줄 또는 쉘 스크립트에서 nftables 방화벽을 관리하려면 nft 유틸리티를 사용합니다.
이 절차의 명령은 일반적인 워크플로우를 나타내지 않으며 최적화되지 않습니다. 이 절차에서는 일반적으로 nft 명령을 사용하여 테이블, 체인 및 규칙을 관리하는 방법을 보여줍니다.
절차
테이블이 IPv4 및 IPv6 패킷을 모두 처리할 수 있도록
inet주소 Family를 사용하여nftables_svc라는 테이블을 만듭니다.nft add table inet nftables_svc
# nft add table inet nftables_svcCopy to Clipboard Copied! Toggle word wrap Toggle overflow 들어오는 네트워크 트래픽을 처리하는
INPUT라는 기본 체인을inet nftables_svc테이블에 추가합니다.nft add chain inet nftables_svc INPUT { type filter hook input priority filter \; policy accept \; }# nft add chain inet nftables_svc INPUT { type filter hook input priority filter \; policy accept \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 쉘이 명령 마지막으로 해석되지 않도록 하려면
\문자를 사용하여 together을 이스케이프합니다.INPUT체인에 규칙을 추가합니다. 예를 들어 포트 22 및 443에서 수신되는 TCP 트래픽을 허용하고INPUT체인의 마지막 규칙으로 IMP(Internet Control Message Protocol) 포트에 연결할 수 없는 다른 트래픽을 거부합니다.nft add rule inet nftables_svc INPUT tcp dport 22 accept nft add rule inet nftables_svc INPUT tcp dport 443 accept nft add rule inet nftables_svc INPUT reject with icmpx type port-unreachable
# nft add rule inet nftables_svc INPUT tcp dport 22 accept # nft add rule inet nftables_svc INPUT tcp dport 443 accept # nft add rule inet nftables_svc INPUT reject with icmpx type port-unreachableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 표시된 대로
nft add 규칙명령을 입력하면nft는 명령을 실행할 때와 동일한 순서로 규칙을 추가합니다.처리를 포함한 현재 규칙 세트를 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow handle 3을 사용하여 기존 규칙 앞에 규칙을 삽입합니다. 예를 들어 포트 636에서 TCP 트래픽을 허용하는 규칙을 삽입하려면 다음을 입력합니다.
nft insert rule inet nftables_svc INPUT position 3 tcp dport 636 accept
# nft insert rule inet nftables_svc INPUT position 3 tcp dport 636 acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow handle 3을 사용하여 기존 규칙 뒤에 규칙을 추가합니다. 예를 들어 포트 80에서 TCP 트래픽을 허용하는 규칙을 삽입하려면 다음을 입력합니다.
nft add rule inet nftables_svc INPUT position 3 tcp dport 80 accept
# nft add rule inet nftables_svc INPUT position 3 tcp dport 80 acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow handles를 사용하여 규칙 세트를 다시 표시합니다. 나중에 추가된 규칙이 지정된 위치에 추가되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow handle 6을 사용하여 규칙을 제거합니다.
nft delete rule inet nftables_svc INPUT handle 6
# nft delete rule inet nftables_svc INPUT handle 6Copy to Clipboard Copied! Toggle word wrap Toggle overflow 규칙을 제거하려면 처리를 지정해야 합니다.
규칙 세트를 표시하고 제거된 규칙이 더 이상 존재하지 않는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow INPUT체인에서 나머지 모든 규칙을 제거하십시오.nft flush chain inet nftables_svc INPUT
# nft flush chain inet nftables_svc INPUTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 규칙 세트를 표시하고
INPUT체인이 비어 있는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow INPUT체인을 삭제합니다.nft delete chain inet nftables_svc INPUT
# nft delete chain inet nftables_svc INPUTCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또한 이 명령을 사용하여 규칙이 포함된 체인을 삭제할 수도 있습니다.
규칙 세트를 표시하고
INPUT체인이 삭제되었는지 확인합니다.nft list table inet nftables_svc table inet nftables_svc { }# nft list table inet nftables_svc table inet nftables_svc { }Copy to Clipboard Copied! Toggle word wrap Toggle overflow nftables_svc테이블을 삭제합니다.nft delete table inet nftables_svc
# nft delete table inet nftables_svcCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령을 사용하여 체인이 계속 포함된 테이블을 삭제할 수도 있습니다.
참고전체 규칙 세트를 삭제하려면 별도의 명령에서 모든 규칙, 체인 및 테이블을 수동으로 삭제하는 대신
nft flush ruleset명령을 사용합니다.
23.6.2. iptables에서 nftables로 마이그레이션
방화벽 구성이 여전히 iptables 규칙을 사용하는 경우 iptables 규칙을 nftables 로 마이그레이션할 수 있습니다.
23.6.2.1. firewalld, nftables 또는 iptables 사용 시기
RHEL 8에서는 시나리오에 따라 다음 패킷 필터링 유틸리티를 사용할 수 있습니다.
-
firewalld:firewalld유틸리티는 일반적인 사용 사례에 대한 방화벽 구성을 간소화합니다. -
nftables:nftables유틸리티를 사용하여 전체 네트워크에 대해 복잡하고 성능에 중요한 방화벽을 설정합니다. -
iptables: Red Hat Enterprise Linux의iptables유틸리티는레거시백엔드 대신nf_tables커널 API를 사용합니다.nf_tablesAPI는 이전 버전과의 호환성을 제공하므로iptables명령을 사용하는 스크립트는 Red Hat Enterprise Linux에서 계속 작동합니다. 새 방화벽 스크립트의 경우nftables를 사용합니다.
다른 방화벽 관련 서비스(firewalld,nftables 또는 iptables)가 서로 영향을 미치지 않도록 하려면 RHEL 호스트에서 해당 서비스 중 하나만 실행하고 다른 서비스를 비활성화합니다.
23.6.2.2. nftables 프레임워크의 개념
iptables 프레임워크와 비교하여 nftables 는 보다 현대적이고 효율적이며 유연한 대안을 제공합니다. nftables 프레임워크는 iptables 를 통해 고급 기능과 개선 사항을 제공하여 규칙 관리를 단순화하고 성능을 향상시킵니다. 이로 인해 nftables 가 복잡하고 고성능 네트워킹 환경을 위한 최신 대안으로 사용할 수 있습니다.
- 테이블 및 네임스페이스
-
nftables에서 테이블은 관련 방화벽 체인, 세트, 흐름 테이블 및 기타 오브젝트를 함께 그룹화하는 조직 단위 또는 네임스페이스를 나타냅니다.nftables에서는 테이블이 방화벽 규칙 및 관련 구성 요소를 구성하는 보다 유연한 방법을 제공합니다.iptables에서는 테이블이 특정 목적에 따라 보다 효율적으로 정의되었습니다. - 테이블 제품군
-
nftables의 각 테이블은 특정 제품군(ip,ip6,inet,arp,bridge또는netdev)과 연결되어 있습니다. 이 연결은 테이블이 처리할 수 있는 패킷을 결정합니다. 예를 들어ip제품군의 테이블은 IPv4 패킷만 처리합니다. 반면inet은 테이블 가정의 특별한 경우입니다. IPv4 및 IPv6 패킷을 모두 처리할 수 있으므로 프로토콜 간에 통합된 접근 방식을 제공합니다. 특수 테이블 제품군의 또 다른 경우는netdev입니다. 네트워크 장치에 직접 적용되는 규칙에 사용되어 장치 수준에서 필터링이 가능하기 때문입니다. - 기본 체인
nftables의 기본 체인은 패킷 처리 파이프라인에서 구성 가능한 진입점으로, 사용자가 다음을 지정할 수 있습니다.- 체인의 유형 (예: "filter"
- 패킷 처리 경로의 후크 지점(예: "input", "output", "forward")
- 체인의 우선순위
이러한 유연성을 통해 규칙이 네트워크 스택을 통과할 때 패킷에 적용되는 시기와 방법을 정확하게 제어할 수 있습니다. 체인의 특수 사례는 패킷 헤더를 기반으로 커널에 의해 이루어진 라우팅 결정에 영향을 미치는 데 사용되는
경로체인입니다.- 규칙 처리를 위한 가상 머신
nftables프레임워크는 내부 가상 시스템을 사용하여 규칙을 처리합니다. 이 가상 머신은 어셈블리 언어 작업과 유사한 명령을 실행합니다(기록으로 데이터를 로드하고 비교 수행 등). 이러한 메커니즘은 매우 유연하고 효율적인 규칙 처리를 허용합니다.nftables의 개선 사항은 해당 가상 머신에 대한 새로운 지침으로 도입될 수 있습니다. 일반적으로 새 커널 모듈과libnftnl라이브러리 및nft명령줄 유틸리티를 업데이트해야 합니다.또는 커널 수정 없이도 기존 지침을 혁신적으로 결합하여 새로운 기능을 도입할 수 있습니다.
nftables규칙의 구문은 기본 가상 시스템의 유연성을 반영합니다. 예를 들어meta 마크가 tcp dport 맵을 설정하는 규칙 { 22: 1, 80: 2 }는 TCP 대상 포트가 22인 경우 패킷의 방화벽 표시를 1로 설정하고 포트가 80인 경우 2로 설정합니다. 이것은 복잡한 논리를 간결하게 표현 할 수있는 방법을 보여줍니다.- 복잡한 필터링 및 확인 맵
nftables프레임워크는 IP 주소, 포트, 기타 데이터 유형 및 가장 중요한 조합에서iptables에서 사용되는ipset유틸리티의 기능을 통합하고 확장합니다. 이러한 통합을 통해nftables내에서 직접 대규모의 동적 데이터 세트를 쉽게 관리할 수 있습니다. 다음으로nftables는 모든 데이터 유형에 대한 여러 값 또는 범위를 기반으로 일치하는 패킷을 기본적으로 지원하므로 복잡한 필터링 요구 사항을 처리하는 기능이 향상됩니다.nftables를 사용하면 패킷 내의 모든 필드를 조작할 수 있습니다.nftables에서 세트는 이름이 지정되거나 익명일 수 있습니다. 명명된 세트는 여러 규칙에서 참조하고 동적으로 수정할 수 있습니다. 익명 세트는 규칙 내에서 인라인으로 정의되며 변경할 수 없습니다. 세트에는 다양한 유형의 조합(예: IP 주소 및 포트 번호 쌍)이 포함된 요소가 포함될 수 있습니다. 이 기능을 사용하면 복잡한 기준과 일치하는 유연성이 향상됩니다. 세트를 관리하기 위해 커널은 특정 요구 사항(성능, 메모리 효율성 등)에 따라 가장 적절한 백엔드를 선택할 수 있습니다. 세트는 키-값 쌍이 있는 맵으로 기능할 수도 있습니다. value 부분은 데이터 포인트(패치 헤더에 쓸 값) 또는 이동할 정성 또는 체인으로 사용할 수 있습니다. 이를 통해 "verdict maps"라는 복잡하고 동적인 규칙 동작을 사용할 수 있습니다.- 유연한 규칙 형식
nftables규칙의 구조는 간단합니다. 조건 및 작업은 왼쪽에서 오른쪽으로 순차적으로 적용됩니다. 이 직관적인 형식을 사용하면 규칙을 만들고 문제를 해결할 수 있습니다.규칙의 조건은 논리적으로( AND 연산자를 사용하여) 함께 연결되므로 규칙이 일치하도록 모든 조건을 "true"로 평가해야 합니다. 조건이 하나라도 실패하면 평가가 다음 규칙으로 이동합니다.
nftables의 작업은삭제또는수락과 같은 최종 작업이 될 수 있으므로 패킷에 대한 추가 규칙 처리를 중지합니다.카운터 로그 메타 마크 세트 0x3과 같은 터미널이 아닌 작업은 특정 작업(패킷, 로깅, 마크 설정 등)을 수행하지만 후속 규칙을 평가할 수 있습니다.
23.6.2.3. 더 이상 사용되지 않는 iptables 프레임워크의 개념
적극적으로 유지 관리되는 nftables 프레임워크와 유사하게 더 이상 사용되지 않는 iptables 프레임워크를 사용하면 다양한 패킷 필터링 작업, 로깅 및 감사, NAT 관련 구성 작업 등을 수행할 수 있습니다.
iptables 프레임워크는 각 테이블이 특정 목적을 위해 설계된 여러 테이블로 구성되어 있습니다.
filter- 기본 테이블은 일반 패킷 필터링을 보장합니다.
nat- NAT(Network Address Translation)의 경우 패킷의 소스 및 대상 주소 변경을 포함합니다.
mangle- 특정 패킷 변경을 위해 고급 라우팅 결정에 대해 패킷 헤더를 수정할 수 있습니다.
raw- 연결 추적 전에 수행해야 하는 구성의 경우
이러한 테이블은 별도의 커널 모듈로 구현되며, 각 테이블은 INPUT,OUTPUT, FORWARD 와 같은 고정된 내장 체인 세트를 제공합니다. 체인은 패킷이 평가되는 일련의 규칙입니다. 이러한 체인은 커널의 패킷 처리 흐름의 특정 지점에 연결됩니다. 체인은 여러 테이블 간에 이름이 동일하지만 실행 순서는 해당 후크 우선 순위에 따라 결정됩니다. 우선순위는 커널에서 내부적으로 관리되므로 규칙이 올바른 순서로 적용되는지 확인합니다.
원래 iptables 는 IPv4 트래픽을 처리하도록 설계되었습니다. 그러나 IPv6 프로토콜을 도입하면 비슷한 기능( iptables)을 제공하고 사용자가 IPv6 패킷에 대한 방화벽 규칙을 생성하고 관리할 수 있도록 ip6tables 유틸리티를 도입해야 합니다. 동일한 논리를 통해 arptables 유틸리티는 ARP(Address Resolution Protocol)를 처리하기 위해 생성되었으며 ebtables 유틸리티는 이더넷 브리징 프레임을 처리하기 위해 개발되었습니다. 이러한 툴은 iptables 의 패킷 필터링 기능을 다양한 네트워크 프로토콜에 적용하고 포괄적인 네트워크 범위를 제공할 수 있도록 합니다.
iptables 의 기능을 개선하기 위해 확장 기능을 개발하기 시작했습니다. 기능 확장은 일반적으로 사용자 공간 동적 공유 오브젝트(DSO)와 페어링되는 커널 모듈로 구현됩니다. 확장 기능으로 방화벽 규칙에 더 정교한 작업을 수행할 수 있는 "matches" 및 "대상"이 도입되었습니다. 확장 기능을 사용하면 복잡한 일치 및 대상을 활성화할 수 있습니다. 예를 들어 특정 계층 4 프로토콜 헤더 값을 일치시키거나 조작하고, rate-limiting을 수행하고 할당량을 적용할 수 있습니다. 일부 확장 기능은 기본 iptables 구문의 제한 사항을 해결하도록 설계되었습니다(예: "multiport" 일치 확장). 이 확장을 사용하면 단일 규칙이 일치되지 않은 여러 포트를 일치시켜 규칙 정의를 단순화하고 필요한 개별 규칙 수를 줄일 수 있습니다.
ipset 은 iptables 에 대한 특별한 종류의 기능 확장입니다. iptables 와 함께 사용하여 IP 주소, 포트 번호 및 패킷과 일치시킬 수 있는 기타 네트워크 관련 요소 컬렉션을 생성하는 커널 수준 데이터 구조입니다. 이러한 세트는 방화벽 규칙을 작성하고, 작성하고, 관리하는 프로세스를 크게 간소화, 최적화 및 가속화합니다.
23.6.2.4. iptables 및 ip6tables 규칙 세트를 nftables로 변환
iptables-restore-translate 및 ip6tables-restore-translate 유틸리티를 사용하여 iptables 및 ip6tables 규칙 세트를 nftables 로 변환합니다.
사전 요구 사항
-
nftables및iptables패키지가 설치됩니다. -
시스템에는
iptables및ip6tables규칙이 구성되어 있습니다.
프로세스
iptables및ip6tables규칙을 파일에 씁니다.iptables-save >/root/iptables.dump ip6tables-save >/root/ip6tables.dump
# iptables-save >/root/iptables.dump # ip6tables-save >/root/ip6tables.dumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 덤프 파일을
nftables명령으로 변환합니다.iptables-restore-translate -f /root/iptables.dump > /etc/nftables/ruleset-migrated-from-iptables.nft ip6tables-restore-translate -f /root/ip6tables.dump > /etc/nftables/ruleset-migrated-from-ip6tables.nft
# iptables-restore-translate -f /root/iptables.dump > /etc/nftables/ruleset-migrated-from-iptables.nft # ip6tables-restore-translate -f /root/ip6tables.dump > /etc/nftables/ruleset-migrated-from-ip6tables.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
필요한 경우 생성된
nftables규칙을 수동으로 업데이트합니다. nftables서비스가 생성된 파일을 로드하도록 활성화하려면/etc/sysconfig/nftables.conf파일에 다음을 추가합니다.include "/etc/nftables/ruleset-migrated-from-iptables.nft" include "/etc/nftables/ruleset-migrated-from-ip6tables.nft"
include "/etc/nftables/ruleset-migrated-from-iptables.nft" include "/etc/nftables/ruleset-migrated-from-ip6tables.nft"Copy to Clipboard Copied! Toggle word wrap Toggle overflow iptables서비스를 중지하고 비활성화합니다.systemctl disable --now iptables
# systemctl disable --now iptablesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 사용자 지정 스크립트를 사용하여
iptables규칙을 로드한 경우 스크립트가 더 이상 자동으로 시작되지 않고 재부팅되어 모든 테이블을 플러시합니다.nftables서비스를 활성화하고 시작합니다.systemctl enable --now nftables
# systemctl enable --now nftablesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
nftables규칙 세트를 표시합니다.nft list ruleset
# nft list rulesetCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.2.5. 단일 iptables 및 ip6tables 규칙을 nftables로 변환
Red Hat Enterprise Linux는 iptables 또는 ip6tables 규칙을 nftables 에 해당하는 규칙으로 변환하는 iptables-translate 및 ip6tables-translate 유틸리티를 제공합니다.
사전 요구 사항
-
nftables패키지가 설치되어 있습니다.
프로세스
iptables또는ip6tables대신iptables-translate또는ip6tables-translate유틸리티를 사용하여 해당nftables규칙을 표시합니다.iptables-translate -A INPUT -s 192.0.2.0/24 -j ACCEPT nft add rule ip filter INPUT ip saddr 192.0.2.0/24 counter accept
# iptables-translate -A INPUT -s 192.0.2.0/24 -j ACCEPT nft add rule ip filter INPUT ip saddr 192.0.2.0/24 counter acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow 일부 확장 기능에는 해당 지원이 누락되어 있는 경우도 있습니다. 이 경우 유틸리티는
#기호로 접두사가 지정된 번역되지 않은 규칙을 출력합니다. 예를 들면 다음과 같습니다.iptables-translate -A INPUT -j CHECKSUM --checksum-fill nft # -A INPUT -j CHECKSUM --checksum-fill
# iptables-translate -A INPUT -j CHECKSUM --checksum-fill nft # -A INPUT -j CHECKSUM --checksum-fillCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.2.6. 일반적인 iptables 및 nftables 명령 비교
다음은 일반적인 iptables 및 nftables 명령을 비교합니다.
모든 규칙을 나열합니다.
Expand iptables nftables iptables-savenft 목록 규칙 세트특정 테이블 및 체인을 나열:
Expand iptables nftables iptables -Lnft 목록 테이블 IP 필터iptables -L INPUTnft 목록 체인 IP 필터 INPUTiptables -t nat -L PREROUTINGnft 목록 체인 IP nat PREROUTINGnft명령은 테이블 및 체인을 사전 생성하지 않습니다. 사용자가 수동으로 생성한 경우에만 존재합니다.firewalld에서 생성한 규칙 나열:
nft list table inet firewalld nft list table ip firewalld nft list table ip6 firewalld
# nft list table inet firewalld # nft list table ip firewalld # nft list table ip6 firewalldCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.3. nftables를 사용하여 NAT 구성
nftables 에서는 다음 NAT(네트워크 주소 변환) 유형을 구성할 수 있습니다.
- masquerading
- 소스 NAT(SNAT)
- 대상 NAT(DNAT)
- 리디렉션
iifname 및 oifname 매개변수에만 실제 인터페이스 이름을 사용할 수 있으며 대체 이름(altname)은 지원되지 않습니다.
23.6.3.1. NAT 유형
이는 다른 NAT(네트워크 주소 변환) 유형입니다.
- masquerading 및 source NAT(SNAT)
이러한 NAT 유형 중 하나를 사용하여 패킷의 소스 IP 주소를 변경합니다. 예를 들어, 인터넷 서비스 공급자(ISP)는
10.0.0.0/8과 같은 개인 IP 범위를 라우팅하지 않습니다. 네트워크에서 개인 IP 범위를 사용하고 사용자가 인터넷의 서버에 연결할 수 있어야 하는 경우 이러한 범위의 패킷의 소스 IP 주소를 공용 IP 주소에 매핑합니다.마스커레이딩과 SNAT는 서로 매우 유사합니다. 차이점은 다음과 같습니다.
- 마스커레이딩은 발신 인터페이스의 IP 주소를 자동으로 사용합니다. 따라서 발신 인터페이스에서 동적 IP 주소를 사용하는 경우 masquerading을 사용합니다.
- SNAT는 패킷의 소스 IP 주소를 지정된 IP로 설정하고 발신 인터페이스의 IP를 동적으로 검색하지 않습니다. 따라서 SNAT는 masquerading보다 빠릅니다. 발신 인터페이스에서 고정 IP 주소를 사용하는 경우 SNAT를 사용합니다.
- 대상 NAT(DNAT)
- 이 NAT 유형을 사용하여 들어오는 패킷의 대상 주소와 포트를 다시 작성합니다. 예를 들어 웹 서버가 개인 IP 범위의 IP 주소를 사용하므로 인터넷에서 직접 액세스할 수 없는 경우 라우터에 DNAT 규칙을 설정하여 수신 트래픽을 이 서버로 리디렉션할 수 있습니다.
- 리디렉션
- 이 유형은 체인 후크에 따라 패킷을 로컬 시스템으로 리디렉션하는 특수한 DNAT의 경우입니다. 예를 들어 서비스가 표준 포트와 다른 포트에서 실행되는 경우 표준 포트에서 들어오는 트래픽을 이 특정 포트로 리디렉션할 수 있습니다.
23.6.3.2. nftables를 사용하여 마스커레이딩 구성
마스커레이딩을 사용하면 라우터에서 인터페이스를 통해 인터페이스의 IP 주소로 전송된 패킷의 소스 IP를 동적으로 변경할 수 있습니다. 즉, 인터페이스가 새 IP가 할당되면 nftables 는 소스 IP를 교체할 때 새 IP를 자동으로 사용합니다.
ens3 인터페이스를 통해 호스트를 나가는 패킷의 소스 IP를 ens3 에 설정된 IP로 바꿉니다.
프로세스
테이블을 생성합니다.
nft add table nat
# nft add table natCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 표에
다음 체인을추가합니다.nft add chain nat postrouting { type nat hook postrouting priority 100 \; }# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요prerouting체인에 규칙을 추가하지 않더라도nftables프레임워크에는 수신되는 패킷 응답과 일치하도록 이 체인이 필요합니다.쉘이 음수 우선순위 값을
nft명령의 옵션으로 해석하지 못하도록--옵션을nft명령에 전달해야 합니다.ens3인터페이스에서 발신 패킷과 일치하는postrouting체인에 규칙을 추가합니다.nft add rule nat postrouting oifname "ens3" masquerade
# nft add rule nat postrouting oifname "ens3" masqueradeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.3.3. nftables를 사용하여 소스 NAT 구성
라우터에서 소스 NAT(SNAT)를 사용하면 인터페이스를 통해 전송된 패킷의 IP를 특정 IP 주소로 변경할 수 있습니다. 그런 다음 라우터는 발신 패킷의 소스 IP를 대체합니다.
프로세스
테이블을 생성합니다.
nft add table nat
# nft add table natCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 표에
다음 체인을추가합니다.nft add chain nat postrouting { type nat hook postrouting priority 100 \; }# nft add chain nat postrouting { type nat hook postrouting priority 100 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요postrouting체인에 규칙을 추가하지 않더라도nftables프레임워크에는 이 체인이 발신 패킷 응답과 일치해야 합니다.쉘이 음수 우선순위 값을
nft명령의 옵션으로 해석하지 못하도록--옵션을nft명령에 전달해야 합니다.ens3을 통해 발신 패킷의 소스 IP를192.0.2.1로 대체하는postrouting체인에 규칙을 추가합니다.nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1
# nft add rule nat postrouting oifname "ens3" snat to 192.0.2.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.3.4. nftables를 사용하여 대상 NAT 구성
대상 NAT(DNAT)를 사용하면 라우터의 트래픽을 인터넷에서 직접 액세스할 수 없는 호스트로 리디렉션할 수 있습니다.
예를 들어, DNAT를 사용하면 라우터에서 포트 80 및 443 으로 전송되는 들어오는 트래픽을 IP 주소 192.0.2.1 이 있는 웹 서버로 리디렉션합니다.
프로세스
테이블을 생성합니다.
nft add table nat
# nft add table natCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 표에
다음 체인을추가합니다.nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } nft add chain nat postrouting { type nat hook postrouting priority 100 \; }# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; } # nft add chain nat postrouting { type nat hook postrouting priority 100 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요postrouting체인에 규칙을 추가하지 않더라도nftables프레임워크에는 이 체인이 발신 패킷 응답과 일치해야 합니다.쉘이 음수 우선순위 값을
nft명령의 옵션으로 해석하지 못하도록--옵션을nft명령에 전달해야 합니다.라우터의
ens3인터페이스에서 IP 주소192.0.2.1을 사용하여 웹 서버로 들어오는 트래픽을 포트80및443으로 리디렉션하는이전체인에 규칙을 추가합니다.nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1# nft add rule nat prerouting iifname ens3 tcp dport { 80, 443 } dnat to 192.0.2.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 환경에 따라 SNAT 또는 마스커레이딩 규칙을 추가하여 웹 서버에서 발신자로 반환되는 패킷의 소스 주소를 변경합니다.
ens3인터페이스에서 동적 IP 주소를 사용하는 경우 마스커레이딩 규칙을 추가합니다.nft add rule nat postrouting oifname "ens3" masquerade
# nft add rule nat postrouting oifname "ens3" masqueradeCopy to Clipboard Copied! Toggle word wrap Toggle overflow ens3인터페이스에서 고정 IP 주소를 사용하는 경우 SNAT 규칙을 추가합니다. 예를 들어ens3에서198.51.100.1IP 주소를 사용하는 경우 다음을 실행합니다.nft add rule nat postrouting oifname "ens3" snat to 198.51.100.1
# nft add rule nat postrouting oifname "ens3" snat to 198.51.100.1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
패킷 전달을 활성화합니다.
echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.3.5. nftables를 사용하여 리디렉션 구성
리디렉션 기능은 체인 후크에 따라 패킷을 로컬 시스템으로 리디렉션하는 대상 DNAT(네트워크 주소 변환)의 특수한 사례입니다.
예를 들어 로컬 호스트의 포트 22 로 전송된 수신 및 전달된 트래픽을 포트 2222 로 리디렉션할 수 있습니다.
프로세스
테이블을 생성합니다.
nft add table nat
# nft add table natCopy to Clipboard Copied! Toggle word wrap Toggle overflow 테이블에
사전체인을 추가합니다.nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }# nft -- add chain nat prerouting { type nat hook prerouting priority -100 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 쉘이 음수 우선순위 값을
nft명령의 옵션으로 해석하지 못하도록--옵션을nft명령에 전달해야 합니다.포트 22에서 들어오는 트래픽을 포트
22로 리디렉션하는사전아웃 체인에 규칙을 추가합니다.nft add rule nat prerouting tcp dport 22 redirect to 2222
# nft add rule nat prerouting tcp dport 22 redirect to 2222Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.4. nftables 스크립트 작성 및 실행
nftables 프레임워크를 사용할 때의 주요 이점은 스크립트 실행이 atomic이라는 것입니다. 즉, 시스템이 전체 스크립트를 적용하거나 오류가 발생하면 실행을 방지합니다. 이렇게 하면 방화벽이 항상 일관된 상태로 유지됩니다.
또한 nftables 스크립트 환경을 사용하면 다음을 수행할 수 있습니다.
- 댓글 추가
- 변수 정의
- 기타 규칙 세트 파일 포함
nftables 패키지를 설치하면 Red Hat Enterprise Linux가 /etc/nftables/ 디렉터리에 *.nft 스크립트가 자동으로 생성됩니다. 이러한 스크립트에는 서로 다른 용도로 테이블 및 빈 체인을 만드는 명령이 포함되어 있습니다.
23.6.4.1. 지원되는 nftables 스크립트 형식
nftables 스크립팅 환경에서 다음 형식으로 스크립트를 작성할 수 있습니다.
nft list ruleset명령과 동일한 형식은 규칙 세트를 표시합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow nft명령과 동일한 구문:Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.4.2. nftables 스크립트 실행
nft 유틸리티에 전달하거나 스크립트를 직접 실행하여 nftables 스크립트를 실행할 수 있습니다.
프로세스
nft유틸리티에 전달하여nftables스크립트를 실행하려면 다음을 입력합니다.nft -f /etc/nftables/<example_firewall_script>.nft
# nft -f /etc/nftables/<example_firewall_script>.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow nftables스크립트를 직접 실행하려면 다음을 수행합니다.이 작업을 수행하는 동안 다음을 수행합니다.
스크립트가 다음 shebang 시퀀스로 시작하는지 확인합니다.
#!/usr/sbin/nft -f
#!/usr/sbin/nft -fCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중요-f매개변수를 생략하면nft유틸리티에서 스크립트를 읽지 않고 다음을 표시합니다.오류: 구문 오류, 예기치 않은 줄 바꿈, 문자열이필요합니다.선택 사항: 스크립트 소유자를
root로 설정합니다.chown root /etc/nftables/<example_firewall_script>.nft
# chown root /etc/nftables/<example_firewall_script>.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 소유자가 스크립트를 실행할 수 있도록 설정합니다.
chmod u+x /etc/nftables/<example_firewall_script>.nft
# chmod u+x /etc/nftables/<example_firewall_script>.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow
스크립트를 실행합니다.
/etc/nftables/<example_firewall_script>.nft
# /etc/nftables/<example_firewall_script>.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력이 표시되지 않으면 시스템이 스크립트를 성공적으로 실행했습니다.
nft 가 스크립트를 성공적으로 실행하고 규칙, 누락된 매개 변수 또는 스크립트의 기타 문제를 잘못 배치하면 방화벽이 예상대로 작동하지 않을 수 있습니다.
23.6.4.3. nftables 스크립트에서 주석 사용
nftables 스크립팅 환경은 줄 끝 부분에 # 문자 오른쪽에 있는 모든 항목을 주석으로 해석합니다.
주석은 줄 시작 시 또는 명령 옆에 있을 수 있습니다.
23.6.4.4. nftables 스크립트에서 변수 사용
nftables 스크립트에서 변수를 정의하려면 define 키워드를 사용합니다. 단일 값과 익명 세트를 변수에 저장할 수 있습니다. 더 복잡한 시나리오의 경우 세트 또는 확인 맵을 사용합니다.
- 단일 값이 있는 변수
다음 예제에서는
enp1s0값이 있는INET_DEV변수를 정의합니다.define INET_DEV = enp1s0
define INET_DEV = enp1s0Copy to Clipboard Copied! Toggle word wrap Toggle overflow $기호 뒤에 변수 이름을 입력하여 스크립트에서 변수를 사용할 수 있습니다.... add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept ...
... add rule inet example_table example_chain iifname $INET_DEV tcp dport ssh accept ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 익명 세트가 포함된 변수
다음 예제에서는 익명 세트가 포함된 변수를 정의합니다.
define DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }define DNS_SERVERS = { 192.0.2.1, 192.0.2.2 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow $기호 뒤에 변수 이름을 작성하여 스크립트의 변수를 사용할 수 있습니다.add rule inet example_table example_chain ip daddr $DNS_SERVERS accept
add rule inet example_table example_chain ip daddr $DNS_SERVERS acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고중괄호에는 변수가 집합을 표시함을 나타내기 때문에 규칙에서 사용할 때 특수한 의미가 있습니다.
23.6.4.5. nftables 스크립트에 파일 포함
nftables 스크립팅 환경에서는 include 문을 사용하여 다른 스크립트를 포함할 수 있습니다.
절대 경로 또는 상대 경로 없이 파일 이름만 지정하면 nftables 에는 기본 검색 경로의 파일(Red Hat Enterprise Linux에서 /etc 로 설정됨)이 포함됩니다.
예 23.1. 기본 검색 디렉터리에서 파일 포함
기본 검색 디렉터리의 파일을 포함하려면 다음을 수행합니다.
include "example.nft"
include "example.nft"예 23.2. 디렉터리에서 모든 *.nft 파일 포함
/etc/nftables/rulesets/ 디렉터리에 저장된 *.nft 로 끝나는 모든 파일을 포함하려면 다음을 수행합니다.
include "/etc/nftables/rulesets/*.nft"
include "/etc/nftables/rulesets/*.nft"
include 문이 점으로 시작하는 파일과 일치하지 않습니다.
23.6.4.6. 시스템이 부팅될 때 nftables 규칙 자동 로드
nftables systemd 서비스는 /etc/sysconfig/nftables.conf 파일에 포함된 방화벽 스크립트를 로드합니다.
사전 요구 사항
-
nftables스크립트는/etc/nftables/디렉터리에 저장됩니다.
프로세스
/etc/sysconfig/nftables.conf파일을 편집합니다.-
nftables패키지 설치와 함께/etc/nftables/에 생성된*.nft스크립트를 수정한 경우 이러한 스크립트의include문의 주석을 제거합니다. 새 스크립트를 작성한 경우
include문을 추가하여 이러한 스크립트를 포함합니다. 예를 들어nftables서비스가 시작될 때/etc/nftables/예.nft스크립트를 로드하려면 다음을 추가합니다.include "/etc/nftables/_example_.nft"
include "/etc/nftables/_example_.nft"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
선택 사항: 시스템을 재부팅하지 않고
nftables서비스를 시작하여 방화벽 규칙을 로드합니다.systemctl start nftables
# systemctl start nftablesCopy to Clipboard Copied! Toggle word wrap Toggle overflow nftables서비스를 활성화합니다.systemctl enable nftables
# systemctl enable nftablesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.5. nftables 명령에서 세트 사용
nftables 프레임워크는 기본적으로 세트를 지원합니다. 예를 들어 규칙이 여러 IP 주소, 포트 번호, 인터페이스 또는 기타 일치 기준과 일치해야 하는 경우 세트를 사용할 수 있습니다.
23.6.5.1. nftables에서 익명 세트 사용
익명 집합에는 규칙에서 직접 사용하는 { 22, 80, 443 } 과 같이 중괄호로 묶은 쉼표로 구분된 값이 포함되어 있습니다. IP 주소 및 기타 일치 조건에도 익명 세트를 사용할 수 있습니다.
익명 세트의 단점은 집합을 변경하려면 규칙을 교체해야 한다는 것입니다. 동적 솔루션의 경우 nftables에서 명명된 세트 사용에 설명된 대로 이름이 지정된 세트를 사용합니다.
사전 요구 사항
-
inet제품군의example_chain체인과example_table테이블이 있습니다.
프로세스
예를 들어 포트
22,80및443으로 들어오는 트래픽을 허용하는example_table에서example_chain에 규칙을 추가하려면 다음을 수행합니다.nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } accept# nft add rule inet example_table example_chain tcp dport { 22, 80, 443 } acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항:
example_table에 모든 체인과 해당 규칙을 표시합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.5.2. nftables에서 named set 사용
nftables 프레임워크는 변경 가능한 이름이 설정된 세트를 지원합니다. 명명된 세트는 테이블 내의 여러 규칙에서 사용할 수 있는 요소 목록 또는 범위입니다. 익명 세트를 통한 또 다른 이점은 세트를 사용하는 규칙을 교체하지 않고도 이름이 지정된 세트를 업데이트할 수 있다는 것입니다.
명명된 세트를 만들 때 집합에 포함된 요소 유형을 지정해야 합니다. 다음 유형을 설정할 수 있습니다.
-
192.0.2.1또는192.0.2.0/24와 같은 IPv4 주소 또는 범위가 포함된 세트의ipv4_addr. -
2001:db8:1::1 또는
2001:db8:1::1/64ipv6_addr -
52:54:00:6b:66:42와 같은 미디어 액세스 제어(MAC) 주소 목록이 포함된 세트의ether_addr -
inet_proto는tcp와 같은 인터넷 프로토콜 유형 목록이 포함된 세트의 경우입니다. -
ssh와 같은 인터넷 서비스 목록이 포함된 세트의inet_service. -
패킷 표시 목록을 포함하는 세트의
마크입니다. 패킷 표시는 모든 양의 32비트 정수 값(0~2147483647)일 수 있습니다.
사전 요구 사항
-
example_chain체인과example_table테이블이 있습니다.
프로세스
빈 세트를 만듭니다. 다음 예제에서는 IPv4 주소에 대한 세트를 생성합니다.
여러 개별 IPv4 주소를 저장할 수 있는 세트를 생성하려면 다음을 수행합니다.
nft add set inet example_table example_set { type ipv4_addr \; }# nft add set inet example_table example_set { type ipv4_addr \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 주소 범위를 저장할 수 있는 세트를 생성하려면 다음을 수행합니다.
nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
중요쉘이 명령의 마지막으로 message를 해석하지 못하도록 하려면 백슬래시를 사용하여 together을 이스케이프해야 합니다.
선택 사항: 세트를 사용하는 규칙을 생성합니다. 예를 들어 다음 명령은
example_table의example_chain에 규칙을 추가하여example_set의 IPv4 주소에서 모든 패킷을 삭제합니다.nft add rule inet example_table example_chain ip saddr @example_set drop
# nft add rule inet example_table example_chain ip saddr @example_set dropCopy to Clipboard Copied! Toggle word wrap Toggle overflow example_set는 여전히 비어 있으므로 규칙은 현재 적용되지 않습니다.example_set에 IPv4 주소를 추가합니다.개별 IPv4 주소를 저장하는 세트를 생성하는 경우 다음을 입력합니다.
nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }# nft add element inet example_table example_set { 192.0.2.1, 192.0.2.2 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 범위를 저장하는 세트를 생성하는 경우 다음을 입력합니다.
nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }# nft add element inet example_table example_set { 192.0.2.0-192.0.2.255 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow IP 주소 범위를 지정하면 위 예제에서
192.0.2.0/24와 같은 CIDR(Classless Inter-Domain Routing) 표기법을 사용할 수 있습니다.
23.6.5.3. 동적 세트를 사용하여 패킷 경로의 항목 추가
nftables 프레임워크의 동적 세트를 사용하면 패킷 데이터에서 요소를 자동으로 추가할 수 있습니다. 예를 들어 IP 주소, 대상 포트, MAC 주소 등이 있습니다. 이 기능을 사용하면 이러한 요소를 실시간으로 수집하고 거부 목록을 만들고, 목록을 금지하고, 보안 위협에 즉시 대응할 수 있도록 다른 요소를 사용할 수 있습니다.
사전 요구 사항
-
inet제품군의example_chain체인과example_table테이블이 있습니다.
프로세스
빈 세트를 만듭니다. 다음 예제에서는 IPv4 주소에 대한 세트를 생성합니다.
여러 개별 IPv4 주소를 저장할 수 있는 세트를 생성하려면 다음을 수행합니다.
nft add set inet example_table example_set { type ipv4_addr \; }# nft add set inet example_table example_set { type ipv4_addr \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 주소 범위를 저장할 수 있는 세트를 생성하려면 다음을 수행합니다.
nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }# nft add set inet example_table example_set { type ipv4_addr \; flags interval \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요쉘이 명령의 마지막으로 message를 해석하지 못하도록 하려면 백슬래시를 사용하여 together을 이스케이프해야 합니다.
들어오는 패킷의 소스 IPv4 주소를
example_set세트에 동적으로 추가하는 규칙을 만듭니다.nft add rule inet example_table example_chain set add ip saddr @example_set
# nft add rule inet example_table example_chain set add ip saddr @example_setCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은
example_chain규칙 체인에 새 규칙을 생성하고example_table은 패킷의 소스 IPv4 주소를example_set에 동적으로 추가합니다.
검증
규칙이 추가되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 현재
nftables에 로드된 전체 규칙 세트를 표시합니다. IP가 적극적으로 규칙을 트리거하고 있으며example_set이 관련 주소로 업데이트되고 있음을 보여줍니다.
다음 단계
동적 IP 세트가 있으면 다양한 보안, 필터링 및 트래픽 제어 목적으로 사용할 수 있습니다. 예를 들면 다음과 같습니다.
- 블록, 제한 또는 네트워크 트래픽 로그
- 신뢰할 수 있는 사용자를 금지하기 위해 허용 목록과 결합
- 자동 시간 초과를 사용하여 초과 차단 방지
23.6.6. nftables 명령에서 검증 맵 사용
사전이라고도 하는 정점 맵을 사용하면 nft 가 일치 기준을 작업에 매핑하여 패킷 정보를 기반으로 작업을 수행할 수 있습니다.
23.6.6.1. nftables에서 익명 맵 사용
익명 맵은 규칙에서 직접 사용하는 { match_ crite lack : action } 문입니다. 문에는 쉼표로 구분된 여러 매핑이 포함될 수 있습니다.
익명 맵의 단점은 맵을 변경하려면 규칙을 교체해야 합니다. 동적 솔루션의 경우 nftables에서 이름이 지정된 맵 사용에 설명된 대로 이름이 지정된 맵 을 사용합니다.
예를 들어 익명 맵을 사용하여 IPv4 및 IPv6 프로토콜의 TCP 및 UDP 패킷을 서로 다른 체인으로 라우팅하여 들어오는 TCP 및 UDP 패킷을 별도로 계산할 수 있습니다.
절차
새 테이블을 만듭니다.
nft add table inet example_table
# nft add table inet example_tableCopy to Clipboard Copied! Toggle word wrap Toggle overflow example_table에서tcp_packets체인을 만듭니다.nft add chain inet example_table tcp_packets
# nft add chain inet example_table tcp_packetsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 체인의 트래픽을 계산하는
tcp_packets에 규칙을 추가합니다.nft add rule inet example_table tcp_packets counter
# nft add rule inet example_table tcp_packets counterCopy to Clipboard Copied! Toggle word wrap Toggle overflow example_table에udp_packets체인 생성nft add chain inet example_table udp_packets
# nft add chain inet example_table udp_packetsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 체인의 트래픽을 계산하는
udp_packets에 규칙을 추가합니다.nft add rule inet example_table udp_packets counter
# nft add rule inet example_table udp_packets counterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 들어오는 트래픽에 사용할 체인을 만듭니다. 예를 들어 들어오는 트래픽을 필터링하는
example_table에서incoming_traffic라는 체인을 생성하려면 다음을 수행합니다.nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }# nft add chain inet example_table incoming_traffic { type filter hook input priority 0 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow anonymous map이 있는 규칙을
incoming_traffic에 추가합니다.nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }# nft add rule inet example_table incoming_traffic ip protocol vmap { tcp : jump tcp_packets, udp : jump udp_packets }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 익명 맵은 패킷을 구분하여 프로토콜을 기반으로 다른 카운터 체인으로 보냅니다.
트래픽 카운터를 나열하려면
example_table을 표시합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow tcp_packets및udp_packets체인의 카운터는 수신된 패킷 수와 바이트 수를 모두 표시합니다.
23.6.6.2. nftables에서 이름이 지정된 맵 사용
nftables 프레임워크는 이름이 지정된 map을 지원합니다. 이러한 맵은 테이블 내의 여러 규칙에 사용할 수 있습니다. 익명 맵의 또 다른 장점은 이름을 사용하는 규칙을 대체하지 않고 이름이 지정된 맵을 업데이트할 수 있다는 것입니다.
이름이 지정된 맵을 생성할 때 요소 유형을 지정해야 합니다.
-
일치하는 부분이 있는 맵의
ipv4_addr에는192.0.2.1과 같은 IPv4 주소가 포함되어 있습니다. -
2001:db8:1::1과 같은 IPv6 주소를 포함하는 맵의ipv6_addr. -
52:54:00:6b:66:42와 같은 MAC(Media Access Control) 주소가 일치하는 맵의ether_addr. -
inet_proto일치하는 부분이 있는 맵의 경우tcp와 같은 인터넷 프로토콜 유형이 포함되어 있습니다. -
inet_service일치하는 맵의 경우ssh또는22와 같은 인터넷 서비스 이름 포트 번호가 포함되어 있습니다. -
일치하는 부분에 패킷
표시가포함된 맵의 경우 표시됩니다. 패킷 마크는 모든 양의 32 비트 정수 값 (0에서2147483647)일 수 있습니다. -
카운터값이 일치 하는 맵에 대 한 카운터입니다.A counter for a map whose match part contains a counter value. 카운터 값은 모든 양의 64비트 정수 값일 수 있습니다. -
일치 부분에
할당량값이 포함된 맵의 할당량입니다. 할당량 값은 모든 양의 64비트 정수 값일 수 있습니다.
예를 들어 소스 IP 주소를 기반으로 들어오는 패킷을 허용하거나 삭제할 수 있습니다. 이름 지정된 맵을 사용하면 IP 주소 및 작업이 맵에 동적으로 저장되는 동안 이 시나리오를 구성하는 단일 규칙만 필요합니다.
절차
테이블을 만듭니다. 예를 들어 IPv4 패킷을 처리하는
example_table라는 테이블을 만들려면 다음을 실행합니다.nft add table ip example_table
# nft add table ip example_tableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 체인을 만듭니다. 예를 들어
example_table에서example_chain이라는 체인을 생성하려면 다음을 수행합니다.nft add chain ip example_table example_chain { type filter hook input priority 0 \; }# nft add chain ip example_table example_chain { type filter hook input priority 0 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요쉘이 명령 끝부분을 해석하지 못하도록 하려면 백슬래시를 사용하여 host를 이스케이프해야 합니다.
빈 맵을 생성합니다. 예를 들어 IPv4 주소에 대한 맵을 생성하려면 다음을 수행합니다.
nft add map ip example_table example_map { type ipv4_addr : verdict \; }# nft add map ip example_table example_map { type ipv4_addr : verdict \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 맵을 사용하는 규칙을 만듭니다. 예를 들어 다음 명령은
example_map에 정의된 IPv4 주소에 작업을 적용하는example_table의example_chain에 규칙을 추가합니다.nft add rule example_table example_chain ip saddr vmap @example_map
# nft add rule example_table example_chain ip saddr vmap @example_mapCopy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 주소 및 해당 작업을
example_map에 추가합니다.nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }# nft add element ip example_table example_map { 192.0.2.1 : accept, 192.0.2.2 : drop }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서는 작업에 대한 IPv4 주소 매핑을 정의합니다. 위에서 생성된 규칙과 함께 방화벽은
192.0.2.1의 패킷을 수락하고192.0.2.2에서 패킷을 삭제합니다.선택 사항: 다른 IP 주소 및 action 문을 추가하여 맵을 개선합니다.
nft add element ip example_table example_map { 192.0.2.3 : accept }# nft add element ip example_table example_map { 192.0.2.3 : accept }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 맵에서 항목을 제거합니다.
nft delete element ip example_table example_map { 192.0.2.1 }# nft delete element ip example_table example_map { 192.0.2.1 }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 규칙 세트를 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.7. 예제: nftables 스크립트를 사용하여 LAN 및 DMZ 보호
RHEL 라우터의 nftables 프레임워크를 사용하여 내부 LAN의 네트워크 클라이언트와 DMZ의 웹 서버를 인터넷 및 기타 네트워크에서 무단 액세스로부터 보호하는 방화벽 스크립트를 작성하고 설치합니다.
이 예는 예시 목적으로만 사용되며 특정 요구 사항이 있는 시나리오를 설명합니다.
방화벽 스크립트는 네트워크 인프라 및 보안 요구 사항에 따라 크게 달라집니다. 사용자 환경에 대한 스크립트를 작성할 때 nftables 방화벽의 개념을 알아보려면 이 예제를 사용합니다.
23.6.7.1. 네트워크 조건
이 예제의 네트워크에는 다음 조건이 있습니다.
라우터는 다음 네트워크에 연결되어 있습니다.
-
인터페이스
enp1s0을 통한 인터넷 -
내부 LAN through 인터페이스
enp7s0 -
enp8s0을 통한 DMZ
-
인터페이스
-
라우터의 인터넷 인터페이스에는 정적 IPv4 주소(
203.0.113.1)와 IPv6 주소(2001:db8:a::1)가 할당되어 있습니다. -
내부 LAN의 클라이언트는
10.0.0.0/24범위의 개인 IPv4 주소만 사용합니다. 결과적으로 LAN에서 인터넷으로 전송되는 경우 소스 네트워크 주소 변환(SNAT)이 필요합니다. -
내부 LAN의 관리자는 IP 주소
10.0.0.100및10.0.0.200을 사용합니다. -
DMZ는
198.51.100.0/24및2001:db8:b::/56범위의 공용 IP 주소를 사용합니다. -
DMZ의 웹 서버는
198.51.100.5및2001:db8:b::5IP 주소를 사용합니다. - 라우터는 LAN 및 DMZ에 있는 호스트에 대한 캐싱 DNS 서버 역할을 합니다.
23.6.7.2. 방화벽 스크립트에 대한 보안 요구 사항
다음은 예제 네트워크의 nftables 방화벽에 대한 요구 사항입니다.
라우터는 다음을 수행할 수 있어야 합니다.
- DNS 쿼리를 반복적으로 확인합니다.
- 루프백 인터페이스에서 모든 연결을 수행합니다.
내부 LAN의 클라이언트는 다음을 수행할 수 있어야 합니다.
- 라우터에서 실행 중인 캐싱 DNS 서버를 쿼리합니다.
- DMZ의 HTTPS 서버에 액세스합니다.
- 인터넷의 모든 HTTPS 서버에 액세스합니다.
- 관리자는 SSH를 사용하여 라우터 및 DMZ의 모든 서버에 액세스할 수 있어야 합니다.
DMZ의 웹 서버는 다음을 수행할 수 있어야 합니다.
- 라우터에서 실행 중인 캐싱 DNS 서버를 쿼리합니다.
- 인터넷의 HTTPS 서버에 액세스하여 업데이트를 다운로드합니다.
인터넷의 호스트는 다음을 수행할 수 있어야 합니다.
- DMZ의 HTTPS 서버에 액세스합니다.
또한 다음과 같은 보안 요구 사항이 있습니다.
- 명시적으로 허용되지 않은 연결 시도는 삭제해야 합니다.
- 삭제된 패킷이 기록되어야 합니다.
23.6.7.3. 삭제된 패킷의 로깅 구성
기본적으로 systemd 는 삭제된 패킷과 같은 커널 메시지를 저널에 기록합니다. 또한 이러한 항목을 별도의 파일에 기록하도록 rsyslog 서비스를 구성할 수 있습니다. 로그 파일이 무한대로 확장되지 않도록 하려면 순환 정책을 구성합니다.
사전 요구 사항
-
rsyslog패키지가 설치되어 있어야 합니다. -
rsyslog서비스가 실행 중입니다.
절차
다음 콘텐츠를 사용하여
/etc/ECDHE.d/nftables.conf파일을 만듭니다.:msg, startswith, "nft drop" -/var/log/nftables.log & stop
:msg, startswith, "nft drop" -/var/log/nftables.log & stopCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 구성을 사용하여
rsyslog서비스는 /var/log/ECDHE 대신/var/log/nftables.log파일에 패킷을로그했습니다.rsyslog서비스를 다시 시작하십시오.systemctl restart rsyslog
# systemctl restart rsyslogCopy to Clipboard Copied! Toggle word wrap Toggle overflow 크기가 10MB를 초과하는 경우
/etc/logrotate.d/nftables.log를 교체하여/var/log/nftables.log를 순환하도록 /etc/logrotate.d/nftables 파일을 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow maxage 30설정은 다음 순환 작업 중에 30일이 지난 순환 로그를 제거하도록 정의합니다.
23.6.7.4. nftables 스크립트 작성 및 활성화
이 예는 RHEL 라우터에서 실행되고 DMZ의 내부 LAN과 웹 서버의 클라이언트를 보호하는 nftables 방화벽 스크립트입니다. 예제에 사용된 방화벽의 네트워크 및 요구 사항에 대한 자세한 내용은 방화벽 스크립트에 대한 네트워크 조건 및 보안 요구 사항을 참조하십시오.
이 nftables 방화벽 스크립트는 설명용으로만 사용됩니다. 환경 및 보안 요구 사항에 맞게 조정하지 않고 사용하지 마십시오.
사전 요구 사항
- 네트워크는 네트워크 조건에 설명된 대로 구성됩니다.
절차
다음 콘텐츠를 사용하여
/etc/nftables/firewall.nft스크립트를 만듭니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/nftables/firewall.nft스크립트를/etc/sysconfig/nftables.conf파일에 포함합니다.include "/etc/nftables/firewall.nft"
include "/etc/nftables/firewall.nft"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 전달을 활성화합니다.
echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf sysctl -p /etc/sysctl.d/95-IPv4-forwarding.conf
# echo "net.ipv4.ip_forward=1" > /etc/sysctl.d/95-IPv4-forwarding.conf # sysctl -p /etc/sysctl.d/95-IPv4-forwarding.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow nftables서비스를 활성화하고 시작합니다.systemctl enable --now nftables
# systemctl enable --now nftablesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
선택 사항:
nftables규칙 세트를 확인합니다.nft list ruleset ...
# nft list ruleset ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 방화벽에서 방지하는 액세스를 시도합니다. 예를 들어 DMZ에서 SSH를 사용하여 라우터에 액세스하십시오.
ssh router.example.com ssh: connect to host router.example.com port 22: Network is unreachable
# ssh router.example.com ssh: connect to host router.example.com port 22: Network is unreachableCopy to Clipboard Copied! Toggle word wrap Toggle overflow 로깅 설정에 따라 검색합니다.
차단된 패킷의
systemd저널:journalctl -k -g "nft drop" Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...
# journalctl -k -g "nft drop" Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 차단된 패킷의
/var/log/nftables.log파일:Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...
Oct 14 17:27:18 router kernel: nft drop IN : IN=enp8s0 OUT= MAC=... SRC=198.51.100.5 DST=198.51.100.1 ... PROTO=TCP SPT=40464 DPT=22 ... SYN ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.8. nftables를 사용하여 연결 수 제한
nftables 를 사용하여 연결 수를 제한하거나 지정된 양의 연결을 설정하려는 IP 주소를 차단하여 너무 많은 시스템 리소스를 사용하지 않도록 할 수 있습니다.
23.6.8.1. nftables를 사용하여 연결 수 제한
nft 유틸리티의 ct count 매개변수를 사용하면 IP 주소당 동시 연결 수를 제한할 수 있습니다. 예를 들어 이 기능을 사용하여 각 소스 IP 주소가 호스트에 대한 두 개의 병렬 SSH 연결만 설정할 수 있도록 구성할 수 있습니다.
절차
inet주소 제품군을 사용하여filter테이블을 생성합니다.nft add table inet filter
# nft add table inet filterCopy to Clipboard Copied! Toggle word wrap Toggle overflow inet 필터테이블에입력체인을 추가합니다.nft add chain inet filter input { type filter hook input priority 0 \; }# nft add chain inet filter input { type filter hook input priority 0 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 주소에 대한 동적 세트를 생성합니다.
nft add set inet filter limit-ssh { type ipv4_addr\; flags dynamic \;}# nft add set inet filter limit-ssh { type ipv4_addr\; flags dynamic \;}Copy to Clipboard Copied! Toggle word wrap Toggle overflow IPv4 주소에서 SSH 포트(22)에 동시에 들어오는 연결만 허용하는
입력체인에 규칙을 추가하고 동일한 IP에서 추가 연결을 모두 거부합니다.nft add rule inet filter input tcp dport ssh ct state new add @limit-ssh { ip saddr ct count over 2 } counter reject# nft add rule inet filter input tcp dport ssh ct state new add @limit-ssh { ip saddr ct count over 2 } counter rejectCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
- 동일한 IP 주소에서 호스트로의 두 개 이상의 새 동시 SSH 연결을 설정합니다. 두 연결이 이미 설정된 경우 nftables는 SSH 포트에 대한 연결을 거부합니다.
limit-ssh동적 세트를 표시합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow elements항목은 현재 규칙과 일치하는 주소를 표시합니다. 이 예제에서요소는SSH 포트에 활성 연결이 있는 IP 주소를 나열합니다. 출력은 활성 연결 수 또는 연결이 거부된 경우 표시되지 않습니다.
23.6.8.2. 1분 이내에 10개 이상의 새로 들어오는 TCP 연결을 시도하는 IP 주소 차단
1분 이내에 IPv4 TCP 연결을 10개 이상 설정하는 호스트를 일시적으로 차단할 수 있습니다.
절차
ipaddress family를 사용하여필터테이블을 생성합니다.nft add table ip filter
# nft add table ip filterCopy to Clipboard Copied! Toggle word wrap Toggle overflow 필터테이블에입력체인을 추가합니다.nft add chain ip filter input { type filter hook input priority 0 \; }# nft add chain ip filter input { type filter hook input priority 0 \; }Copy to Clipboard Copied! Toggle word wrap Toggle overflow 1분 내에 10개 이상의 TCP 연결을 설정하려고 시도하는 소스 주소에서 모든 패킷을 삭제하는 규칙을 추가합니다.
nft add rule ip filter input ip protocol tcp ct state new, untracked meter ratemeter { ip saddr timeout 5m limit rate over 10/minute } drop# nft add rule ip filter input ip protocol tcp ct state new, untracked meter ratemeter { ip saddr timeout 5m limit rate over 10/minute } dropCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시간 초과 5m매개변수는 계측이 오래된 항목으로 채워지지 않도록nftables가 5분 후에 자동으로 항목을 제거하도록 정의합니다.
검증
미터의 콘텐츠를 표시하려면 다음을 입력합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.9. nftables 규칙 디버깅
nftables 프레임워크는 관리자가 규칙을 디버그하고 패킷이 일치하는 경우 다양한 옵션을 제공합니다.
23.6.9.1. 카운터를 사용하여 규칙 생성
규칙이 일치되는지 확인하려면 카운터를 사용할 수 있습니다.
-
기존 규칙에 카운터를 추가하는 프로시저에 대한 자세한 내용은
네트워킹 구성 및 관리의기존 규칙에 카운터 추가를 참조하십시오.
사전 요구 사항
- 규칙을 추가하려는 체인이 있습니다.
프로세스
counter매개 변수를 사용하여 새 규칙을 체인에 추가합니다. 다음 예제에서는 포트 22에서 TCP 트래픽을 허용하는 카운터가 포함된 규칙을 추가하고 이 규칙과 일치하는 패킷 및 트래픽을 계산합니다.nft add rule inet example_table example_chain tcp dport 22 counter accept
# nft add rule inet example_table example_chain tcp dport 22 counter acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow 카운터 값을 표시하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.9.2. 기존 규칙에 카운터 추가
규칙이 일치하는지 확인하려면 카운터를 사용할 수 있습니다.
-
카운터를 사용하여 새 규칙을 추가하는 절차에 대한 자세한 내용은
네트워킹 구성 및 관리에서카운터를 사용하여 규칙 생성 을 참조하십시오.
사전 요구 사항
- 카운터를 추가하려는 규칙이 있습니다.
프로세스
프로세스를 포함하여 체인의 규칙을 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 규칙을 교체하지만 카운터 매개 변수를 사용하여
카운터를 추가합니다. 다음 예제에서는 이전 단계에서 표시되는 규칙을 교체하고 카운터를 추가합니다.nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter accept
# nft replace rule inet example_table example_chain handle 4 tcp dport 22 counter acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow 카운터 값을 표시하려면 다음을 수행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.9.3. 기존 규칙과 일치하는 패킷 모니터링
nft monitor 명령과 함께 nftables 의 추적 기능을 사용하면 관리자가 규칙과 일치하는 패킷을 표시할 수 있습니다. 이 규칙과 일치하는 패킷을 모니터링하는 데 사용하는 규칙에 대한 추적을 활성화할 수 있습니다.
사전 요구 사항
- 카운터를 추가하려는 규칙이 있습니다.
프로세스
프로세스를 포함하여 체인의 규칙을 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 규칙을 교체하지만
meta nftrace set 1매개변수를 사용하여 추적 기능을 추가합니다. 다음 예제에서는 이전 단계에서 표시된 규칙을 교체하고 추적을 활성화합니다.nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 accept
# nft replace rule inet example_table example_chain handle 4 tcp dport 22 meta nftrace set 1 acceptCopy to Clipboard Copied! Toggle word wrap Toggle overflow nft monitor명령을 사용하여 추적을 표시합니다. 다음 예제에서는 명령의 출력을 필터링하여inet example_table example_chain을 포함하는 항목만 표시합니다.nft monitor | grep "inet example_table example_chain" trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240 trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept) ...
# nft monitor | grep "inet example_table example_chain" trace id 3c5eb15e inet example_table example_chain packet: iif "enp1s0" ether saddr 52:54:00:17:ff:e4 ether daddr 52:54:00:72:2f:6e ip saddr 192.0.2.1 ip daddr 192.0.2.2 ip dscp cs0 ip ecn not-ect ip ttl 64 ip id 49710 ip protocol tcp ip length 60 tcp sport 56728 tcp dport ssh tcp flags == syn tcp window 64240 trace id 3c5eb15e inet example_table example_chain rule tcp dport ssh nftrace set 1 accept (verdict accept) ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의추적이 활성화된 규칙 수 및 일치하는 트래픽 양에 따라
nft monitor명령은 많은 출력을 표시할 수 있습니다.grep또는 기타 유틸리티를 사용하여 출력을 필터링합니다.
23.6.10. nftables 규칙 세트 백업 및 복원
nftables 규칙을 파일에 백업하고 나중에 복원할 수 있습니다. 또한 관리자는 규칙과 함께 파일을 사용하여 규칙을 다른 서버로 전송할 수도 있습니다.
23.6.10.1. 파일에 nftables 규칙 세트 백업
nft 유틸리티를 사용하여 파일에 설정된 nftables 규칙을 백업할 수 있습니다.
프로세스
nftables규칙을 백업하려면 다음을 수행합니다.nft 목록 규칙 세트 형식으로 생성된 형식:nft list ruleset > file.nft
# nft list ruleset > file.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow JSON 형식의 경우:
nft -j list ruleset > file.json
# nft -j list ruleset > file.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
23.6.10.2. 파일에서 nftables 규칙 세트 복원
파일에서 nftables 규칙 세트를 복원할 수 있습니다.
프로세스
nftables규칙을 복원하려면 다음을 수행합니다.복원할 파일이
nft 목록 규칙 세트로 생성되거나명령이 직접 포함된 형식인 경우:nftnft -f file.nft
# nft -f file.nftCopy to Clipboard Copied! Toggle word wrap Toggle overflow 복원할 파일이 JSON 형식인 경우:
nft -j -f file.json
# nft -j -f file.jsonCopy to Clipboard Copied! Toggle word wrap Toggle overflow
IV 부. 하드 디스크의 설계
24장. 사용 가능한 파일 시스템 개요
애플리케이션에 적합한 파일 시스템을 선택하는 것은 사용 가능한 많은 옵션과 관련된 절충으로 인해 중요한 결정입니다.
다음 섹션에서는 Red Hat Enterprise Linux 8에 기본적으로 포함된 파일 시스템과 애플리케이션에 가장 적합한 파일 시스템에 대한 권장 사항에 대해 설명합니다.
24.1. 파일 시스템 유형
Red Hat Enterprise Linux 8은 다양한 파일 시스템(FS)을 지원합니다. 다양한 유형의 파일 시스템은 다양한 종류의 문제를 해결하며 애플리케이션별로 사용됩니다. 가장 일반적인 수준에서 사용 가능한 파일 시스템을 다음과 같은 주요 유형으로 그룹화할 수 있습니다.
| 유형 | 파일 시스템 | 속성 및 사용 사례 |
|---|---|---|
| 디스크 또는 로컬 FS | XFS | XFS는 RHEL의 기본 파일 시스템입니다. Red Hat은 성능에 대한 호환성 또는 코너 사례와 같은 구체적인 이유가 없는 한 XFS를 로컬 파일 시스템으로 배포하는 것이 좋습니다. |
| ext4 | ext4는 이전 ext2 및 ext3 파일 시스템에서 진화한 Linux의 이점을 제공합니다. 대부분의 경우 성능에서 XFS를 경쟁합니다. ext4 파일 시스템 및 파일 크기에 대한 지원 제한은 XFS의 지원 한도보다 낮습니다. | |
| 네트워크 또는 클라이언트 및 서버 FS | NFS | NFS를 사용하여 동일한 네트워크의 여러 시스템 간에 파일을 공유합니다. |
| SMB | Microsoft Windows 시스템에서 파일 공유에 SMB를 사용합니다. | |
| 공유 스토리지 또는 공유 디스크 FS | GFS2 | Cryostat2는 컴퓨팅 클러스터 구성원에게 공유 쓰기 액세스 권한을 제공합니다. 이는 가능한 한 로컬 파일 시스템의 기능적 경험을 바탕으로 안정성과 안정성에 중점을 두고 있습니다. SAS Grid, Tibco MQ, IBM Websphere MQ 및 Red Hat Active MQ가 Cryostat2에 성공적으로 배포되었습니다. |
| volume-managing FS | Stratis(기술 프리뷰) | Stratis는 XFS 및 LVM의 조합에 구축된 볼륨 관리자입니다. Stratis의 목적은 Btrfs 및 ZFS와 같은 볼륨 관리 파일 시스템에서 제공하는 기능을 에뮬레이션하는 것입니다. 이 스택을 수동으로 빌드할 수는 있지만 Stratis는 구성 복잡성을 줄이고 모범 사례를 구현하며 오류 정보를 통합합니다. |
24.2. 로컬 파일 시스템
로컬 파일 시스템은 로컬 서버에서 실행되고 스토리지에 직접 연결된 파일 시스템입니다.
예를 들어 로컬 파일 시스템은 내부 SATA 또는 SAS 디스크에 대한 유일한 선택이며 서버에 로컬 드라이브가 있는 내부 하드웨어 RAID 컨트롤러가 있는 경우 사용됩니다. 로컬 파일 시스템은 SAN에서 내보낸 장치를 공유하지 않을 때 SAN에 연결된 스토리지에 사용되는 가장 일반적인 파일 시스템이기도 합니다.
모든 로컬 파일 시스템은 POSIX와 호환되며 지원되는 모든 Red Hat Enterprise Linux 릴리스와 완벽하게 호환됩니다. POSIX 호환 파일 시스템은 read(), write() 및 seek() 와 같은 잘 정의된 시스템 호출 세트를 지원합니다.
파일 시스템 선택을 고려할 때 파일 시스템이 얼마나 커야 하는지, 어떤 고유 기능이 있어야 하는지, 워크로드에서 수행하는 방법에 따라 파일 시스템을 선택합니다.
- 사용 가능한 로컬 파일 시스템
- XFS
- ext4
24.3. XFS 파일 시스템
XFS는 단일 호스트에서 매우 큰 파일 및 파일 시스템을 지원하는 확장성이 뛰어나고 강력한 고성능 저널링 파일 시스템입니다. 이는 Red Hat Enterprise Linux 8의 기본 파일 시스템입니다. XFS는 원래 SGI 초반에서 개발되었으며 매우 큰 서버 및 스토리지 어레이에서 오랫동안 실행되고 있습니다.
XFS의 기능은 다음과 같습니다.
- 신뢰성
- 메타데이터 저널링: 시스템을 다시 시작하고 파일 시스템을 다시 마운트할 때 재생할 수 있는 파일 시스템 작업 기록을 유지하여 시스템 충돌 후 파일 시스템 무결성을 보장합니다.
- 광범위한 런타임 메타데이터 일관성 검사
- 확장 가능한 빠른 복구 유틸리티
- 할당량 저널링. 이로 인해 충돌 후 긴 할당량 일관성 점검이 필요하지 않습니다.
- 확장 및 성능
- 지원되는 파일 시스템 크기 최대 1024TiB
- 다수의 동시 작업을 지원하는 기능
- 사용 가능한 공간 관리의 확장성을 위한 B-트리 인덱싱
- 정교한 메타데이터 읽기 알고리즘
- 스트리밍 비디오 워크로드에 대한 최적화
- 할당 체계
- 범위 기반 할당
- 스트라이프 인식 할당 정책
- 지연된 할당
- 공간 사전 할당
- 동적으로 할당된 inode
- 기타 기능
- reflink 기반 파일 복사
- 긴밀하게 통합된 백업 및 복원 유틸리티
- 온라인 조각 모음
- 온라인 파일 시스템 확장
- 포괄적인 진단 기능
-
확장 속성(
xattr). 이를 통해 시스템은 파일당 여러 개의 추가 이름/값 쌍을 연결할 수 있습니다. - 프로젝트 또는 디렉터리 할당량. 이렇게 하면 디렉터리 트리에 대한 할당량 제한이 허용됩니다.
- 하위 타임 스탬프
성능 특성
XFS는 엔터프라이즈 워크로드가 있는 대규모 시스템에서 높은 성능을 제공합니다. 대규모 시스템은 비교적 많은 CPU 수, 여러 HBA 및 외부 디스크 어레이에 대한 연결이 있는 시스템입니다. XFS는 다중 스레드 병렬 I/O 워크로드가 있는 소규모 시스템에서도 잘 작동합니다.
XFS는 단일 스레드 메타데이터 집약적인 워크로드(예: 단일 스레드에서 많은 수의 작은 파일을 만들거나 삭제하는 워크로드)에 대해 상대적으로 낮은 성능을 제공합니다.
24.4. ext4 파일 시스템
ext4 파일 시스템은 ext 파일 시스템 제품군의 4세대입니다. 이는 Red Hat Enterprise Linux 6의 기본 파일 시스템입니다.
ext4 드라이버는 ext2 및 ext3 파일 시스템을 읽고 쓸 수 있지만 ext4 파일 시스템 형식은 ext2 및 ext3 드라이버와 호환되지 않습니다.
ext4는 다음과 같은 몇 가지 새롭고 향상된 기능을 추가합니다.
- 지원되는 파일 시스템 크기 최대 50TiB
- 범위 기반 메타데이터
- 지연된 할당
- 저널 체크섬
- 대규모 스토리지 지원
범위 기반 메타데이터 및 지연된 할당 기능은 파일 시스템에서 사용된 공간을 추적하는 보다 작고 효율적인 방법을 제공합니다. 이러한 기능을 통해 파일 시스템 성능이 향상되고 메타데이터에서 사용하는 공간을 줄일 수 있습니다. 지연된 할당을 사용하면 데이터가 디스크에 플러시될 때까지 파일 시스템이 새로 작성된 사용자 데이터에 대한 영구 위치를 연기할 수 있습니다. 이렇게 하면 더 크고 연속적인 할당을 허용할 수 있으므로 성능이 향상되어 파일 시스템이 훨씬 더 나은 정보로 결정을 내릴 수 있습니다.
ext4에서 fsck 유틸리티를 사용하는 파일 시스템 복구 시간은 ext2 및 ext3보다 훨씬 빠릅니다. 일부 파일 시스템 복구에는 최대 6배의 성능 향상이 입증되었습니다.
24.5. XFS 및 ext4 비교
XFS는 RHEL의 기본 파일 시스템입니다. 이 섹션에서는 XFS 및 ext4의 사용과 기능을 비교합니다.
- 메타데이터 오류 동작
-
ext4에서는 파일 시스템에 메타데이터 오류가 발생할 때 동작을 구성할 수 있습니다. 기본 동작은 작업을 계속하는 것입니다. XFS는 복구할 수 없는 메타데이터 오류가 발생하면 파일 시스템을 종료하고
EFSCORRUPTED오류를 반환합니다. - 할당량
ext4에서는 파일 시스템을 생성할 때 기존 파일 시스템에서 할당량을 활성화할 수 있습니다. 그런 다음 마운트 옵션을 사용하여 할당량 시행을 구성할 수 있습니다.
XFS 할당량은 다시 마운트할 수 있는 옵션이 아닙니다. 초기 마운트에서 할당량을 활성화해야 합니다.
XFS 파일 시스템에서
quotacheck명령을 실행하면 적용되지 않습니다. 할당량 회계를 처음 활성화하면 XFS는 할당량을 자동으로 확인합니다.- 파일 시스템 크기 조정
- XFS에는 파일 시스템의 크기를 줄이는 유틸리티가 없습니다. XFS 파일 시스템의 크기만 늘릴 수 있습니다. 이에 비해 ext4는 파일 시스템의 확장 및 축소를 모두 지원합니다.
- inode 번호
ext4 파일 시스템은 2개 이상의 inode를 지원하지 않습니다.
XFS는 동적 inode 할당을 지원합니다. XFS 파일 시스템에서 사용할 수 있는 공간의 양은 전체 파일 시스템 공간의 백분율로 계산됩니다. 시스템이 inode가 실행되지 않도록 하려면 파일 시스템에 여유 공간이 남아 있는 경우 관리자는 파일 시스템을 생성한 후 이 백분율을 조정할 수 있습니다.
특정 애플리케이션은 XFS 파일 시스템에서 232 보다 큰 inode 번호를 올바르게 처리할 수 없습니다. 이러한 애플리케이션에서는
EOVERFLOW반환 값을 사용하여 32비트 stat 호출이 실패할 수 있습니다. inode 수는 다음 조건에서 232 를 초과합니다.- 파일 시스템은 256바이트 inode가 있는 1TiB보다 큽니다.
- 파일 시스템은 512바이트 inode가 있는 2TiB보다 큽니다.
애플리케이션이 대규모 inode 번호로 실패하는 경우
-o inode32옵션으로 XFS 파일 시스템을 마운트하여 232 미만의 inode 번호를 적용합니다.inode32를 사용하면 64비트 숫자로 이미 할당된 inode에는 영향을 미치지 않습니다.중요특정 환경에 필요한 경우가 아니면
inode32옵션을 사용하지 마십시오.inode32옵션은 할당 동작을 변경합니다. 그 결과 더 낮은 디스크 블록에 inode를 할당할 수 있는 공간이 없는 경우ENOSPC오류가 발생할 수 있습니다.
24.6. 로컬 파일 시스템 선택
애플리케이션 요구 사항을 충족하는 파일 시스템을 선택하려면 파일 시스템을 배포할 대상 시스템을 이해해야 합니다. 일반적으로 ext4에 대한 특정 사용 사례가 없는 경우 XFS를 사용합니다.
- XFS
- 대규모 배포의 경우 특히 대규모 파일(MB 단위) 및 높은 I/O 동시성을 처리할 때 XFS를 사용합니다. XFS는 대역폭이 200MB/s보다 크고 IOPS가 1000개 이상인 환경에서 최적의 성능을 발휘합니다. 그러나 ext4에 비해 메타데이터 작업에 더 많은 CPU 리소스를 사용하고 파일 시스템 축소를 지원하지 않습니다.
- ext4
- I/O 대역폭이 제한된 소규모 시스템 또는 환경의 경우 ext4가 더 적합할 수 있습니다. 처리량이 낮은 I/O 워크로드 및 환경에서 더 나은 성능을 제공합니다. ext4는 오프라인 축소 기능도 지원하므로 파일 시스템의 크기를 조정해야 합니다.
대상 서버 및 스토리지 시스템에 애플리케이션의 성능을 벤치마킹하여 선택한 파일 시스템이 성능 및 확장성 요구 사항을 충족하는지 확인합니다.
| 시나리오 | 권장되는 파일 시스템 |
|---|---|
| 특수 사용 사례 없음 | XFS |
| 대규모 서버 | XFS |
| 대규모 스토리지 장치 | XFS |
| 대용량 파일 | XFS |
| 다중 스레드 I/O | XFS |
| 단일 스레드 I/O | ext4 |
| 제한된 I/O 기능 (1000 IOPS 미만) | ext4 |
| 제한된 대역폭 (200MB/s 미만) | ext4 |
| CPU 바인딩된 워크로드 | ext4 |
| 오프라인 축소 지원 | ext4 |
24.7. 네트워크 파일 시스템
클라이언트/서버 파일 시스템이라고도 하는 네트워크 파일 시스템을 사용하면 클라이언트 시스템이 공유 서버에 저장된 파일에 액세스할 수 있습니다. 이를 통해 여러 시스템의 여러 사용자가 파일 및 스토리지 리소스를 공유할 수 있습니다.
이러한 파일 시스템은 파일 시스템 집합을 하나 이상의 클라이언트로 내보내는 하나 이상의 서버에서 빌드됩니다. 클라이언트 노드는 기본 블록 스토리지에 액세스할 수 없지만 더 나은 액세스 제어를 허용하는 프로토콜을 사용하여 스토리지와 상호 작용합니다.
- 사용 가능한 네트워크 파일 시스템
- RHEL 고객을 위한 가장 일반적인 클라이언트/서버 파일 시스템은 NFS 파일 시스템입니다. RHEL은 네트워크를 통해 로컬 파일 시스템을 내보낼 NFS 서버 구성 요소와 이러한 파일 시스템을 가져오는 NFS 클라이언트를 모두 제공합니다.
- RHEL에는 Windows 상호 운용성을 위해 널리 사용되는 Microsoft SMB 파일 서버를 지원하는 CIFS 클라이언트도 포함되어 있습니다. 사용자 공간 Samba 서버는 Windows 클라이언트에 RHEL 서버의 Microsoft SMB 서비스를 제공합니다.
24.10. 볼륨 관리 파일 시스템
볼륨 관리 파일 시스템은 단순성 및 스택 내 최적화를 위해 전체 스토리지 스택을 통합합니다.
- 사용 가능한 볼륨 관리 파일 시스템
- Red Hat Enterprise Linux 8은 Stratis 볼륨 관리자를 기술 프리뷰로 제공합니다. Stratis는 파일 시스템 계층에 XFS를 사용하여 LVM, 장치 매퍼 및 기타 구성 요소와 통합합니다.
Stratis는 Red Hat Enterprise Linux 8.0에서 처음 릴리스되었습니다. Red Hat은 더 이상 사용되지 않는 Btrfs를 사용할 때 생성되는 격차를 채우는 것이 중요합니다. Stratis 1.0은 사용자의 복잡성을 숨기는 동시에 중요한 스토리지 관리 작업을 수행할 수 있는 직관적인 명령줄 기반 볼륨 관리자입니다.
- 볼륨 관리
- 풀 생성
- 씬 스토리지 풀
- 스냅샷
- 자동화된 읽기 캐시
Stratis는 강력한 기능을 제공하지만 현재 Btrfs 또는 ZFS와 비교할 수 있는 특정 기능이 없습니다. 특히 CRC는 자기 회복을 위해 지원하지 않습니다.
26장. 영구 이름 지정 특성 개요
시스템 관리자는 여러 시스템 부팅보다 안정적인 스토리지 설정을 구축하기 위해 영구 이름 지정 속성을 사용하여 스토리지 볼륨을 참조해야 합니다.
26.1. 비영구 이름 지정 속성의 단점
Red Hat Enterprise Linux는 스토리지 장치를 식별하는 다양한 방법을 제공합니다. 특히 드라이브를 설치하거나 다시 포맷할 때 실수로 잘못된 장치에 액세스하지 못하도록 각 장치를 식별하는 데 올바른 옵션을 사용하는 것이 중요합니다.
전통적으로 /dev/sd(major number)형식의 비영구적인 이름(고유 번호) 은 Linux에서 스토리지 장치를 참조하는 데 사용됩니다. 주요 및 마이너 번호 범위 및 관련 sd 이름은 감지 시 각 장치에 할당됩니다. 즉, 장치 감지 순서가 변경될 경우 메이저 및 마이너 번호 범위 및 관련 sd 이름 간의 연결이 변경될 수 있습니다.
순서 변경은 다음과 같은 상황에서 발생할 수 있습니다.
- 시스템 부팅 프로세스의 병렬화는 시스템 부팅마다 다른 순서로 스토리지 장치를 감지합니다.
-
디스크의 전원을 켜거나 SCSI 컨트롤러에 응답하지 않습니다. 이로 인해 일반 장치 프로브에 의해 감지되지 않습니다. 디스크는 시스템에서 액세스할 수 없으며 다음 장치에는 연결된
sd이름이 변경된 것을 포함하여 주요 번호 범위가 있습니다. 예를 들어 일반적으로sdb라고 하는 디스크가 감지되지 않으면 일반적으로sdc라고 하는 디스크는 대신sdb로 표시됩니다. -
SCSI 컨트롤러(호스트 버스 어댑터 또는 HBA)가 초기화되지 않아 해당 HBA에 연결된 모든 디스크가 감지되지 않습니다. 이후 프로브된 HBA에 연결된 모든 디스크에는 다른 주요 및 마이너 번호 범위 및 서로 다른 연결된
sd이름이 할당됩니다. - 시스템에 HBA의 다른 유형이 있는 경우 드라이버 초기화 순서가 변경됩니다. 이로 인해 해당 HBA에 연결된 디스크가 다른 순서로 탐지됩니다. 이로 인해 HBA가 시스템의 다른 PCI 슬롯으로 이동되는 경우에도 발생할 수 있습니다.
-
예를 들어 스토리지 어레이 또는 전원이 꺼진 스위치로 인해 스토리지 장치가 검색되는 시점에 파이버 채널, iSCSI 또는 FCoE 어댑터가 시스템에 연결된 디스크에 액세스할 수 없습니다. 이는 정전 후 시스템을 재부팅할 때 시스템 부팅에 걸리는 스토리지 어레이보다 온라인 상태가 더 오래 걸리는 경우 발생할 수 있습니다. 일부 파이버 채널 드라이버는 WWPN 매핑에 영구 SCSI 대상 ID를 지정하는 메커니즘을 지원하지만, 이로 인해 주요 번호 범위 및 관련
sd이름이 예약되지 않으며 일관된 SCSI 대상 ID 번호만 제공합니다.
이러한 이유로 /etc/fstab 파일과 같이 장치를 참조할 때 메이저 및 마이너 번호 범위 또는 관련 sd 이름을 사용하지 않도록 합니다. 잘못된 장치가 마운트되고 데이터 손상이 발생할 가능성이 있습니다.
그러나 장치에서 오류를 보고하는 경우와 같이 다른 메커니즘이 사용되는 경우에도 sd 이름을 참조해야 하는 경우가 있습니다. 이는 Linux 커널이 장치와 관련된 커널 메시지에서 sd 이름(및 SCSI host/channel/target/LUN tuples)을 사용하기 때문입니다.
26.2. 파일 시스템 및 장치 식별자
파일 시스템 식별자는 파일 시스템 자체에 연결되지만 장치 식별자는 물리적 블록 장치에 연결됩니다. 적절한 스토리지 관리를 위해서는 차이점을 이해하는 것이 중요합니다.
파일 시스템 식별자
파일 시스템 식별자는 블록 장치에서 생성된 특정 파일 시스템에 연결됩니다. 식별자는 파일 시스템의 일부로 저장됩니다. 파일 시스템을 다른 장치에 복사하는 경우에도 동일한 파일 시스템 식별자를 전달합니다. 그러나 mkfs 유틸리티로 포맷하여 장치를 다시 작성하는 경우 장치는 특성을 손실됩니다.
파일 시스템 식별자는 다음과 같습니다.
- 고유 식별자(UUID)
- 레이블
장치 식별자
장치 식별자는 블록 장치에 연결됩니다(예: 디스크 또는 파티션). mkfs 유틸리티로 포맷팅하는 등의 장치를 다시 작성하는 경우 장치는 파일 시스템에 저장되지 않기 때문에 특성을 유지합니다.
장치 식별자는 다음과 같습니다.
- World Wide Identifier(WWWID)
- 파티션 UUID
- 일련 번호
권장 사항
- 논리 볼륨과 같은 일부 파일 시스템은 여러 장치에 걸쳐 있습니다. Red Hat은 장치 식별자 대신 파일 시스템 식별자를 사용하여 이러한 파일 시스템에 액세스하는 것이 좋습니다.
26.3. /dev/disk/에서 udev 메커니즘이 관리하는 장치 이름
udev 메커니즘은 Linux의 모든 유형의 장치에 사용되며 스토리지 장치에만 국한되지 않습니다. /dev/disk/ 디렉터리에 다양한 종류의 영구 이름 지정 속성을 제공합니다. 스토리지 장치의 경우 Red Hat Enterprise Linux에는 /dev/disk/ 디렉터리에 심볼릭 링크를 생성하는 udev 규칙이 포함되어 있습니다. 이를 통해 스토리지 장치를 참조할 수 있습니다.
- 해당 콘텐츠
- 고유 식별자
- 일련 번호입니다.
udev 이름 지정 속성은 영구적이지만 시스템 재부팅 시 자체적으로 변경되지 않으며 일부는 구성할 수도 있습니다.
26.3.1. 파일 시스템 식별자
/dev/disk/by-uuid/의 UUID 속성
이 디렉터리의 항목은 장치에 저장된 콘텐츠의 UUID(즉, 데이터)로 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다. 예를 들면 다음과 같습니다.
/dev/disk/by-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
/dev/disk/by-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
다음 구문을 사용하여 UUID를 사용하여 /etc/fstab 파일의 장치를 참조할 수 있습니다.
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6파일 시스템을 생성할 때 UUID 특성을 구성할 수 있으며 나중에도 변경할 수 있습니다.
/dev/disk/by-label/의 Label 속성
이 디렉터리의 항목은 장치에 저장된 콘텐츠(즉, 데이터)의 레이블 로 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다.
예를 들면 다음과 같습니다.
/dev/disk/by-label/Boot
/dev/disk/by-label/Boot
레이블을 사용하여 다음 구문을 사용하여 /etc/fstab 파일의 장치를 참조할 수 있습니다.
LABEL=Boot
LABEL=Boot파일 시스템을 생성할 때 Label 속성을 구성할 수 있으며 나중에 변경할 수도 있습니다.
26.3.2. 장치 식별자
/dev/disk/by-id/의 WWID 속성
World Wide Identifier(WWID)는 모든 SCSI 장치에서 SCSI 표준에 필요한 영구적인 시스템 독립적 식별자입니다. WWID 식별자는 모든 저장 장치에 대해 고유하며 장치에 액세스하는 데 사용되는 경로와는 독립적입니다. 식별자는 장치의 속성이지만 장치의 콘텐츠(즉, 데이터)에 저장되지 않습니다.
이 식별자는 장치 식별 Vital 제품 데이터 (page 0x83) 또는 단위 일련 번호 (페이지 0x80)를 검색하기 위한 SCSI 기술서를 발행하여 얻을 수 있습니다.
Red Hat Enterprise Linux는 WWID 기반 장치 이름과 해당 시스템의 현재 /dev/sd 이름으로 적절한 매핑을 자동으로 유지합니다. 애플리케이션은 /dev/disk/by-id/ 이름을 사용하여 장치 경로가 변경되거나 다른 시스템의 장치에 액세스하는 경우에도 디스크의 데이터를 참조할 수 있습니다.
예 26.1. WWID 매핑
| WWID 심볼릭 링크 | 비영구 장치 | 참고 |
|---|---|---|
|
|
|
페이지 |
|
|
|
페이지 |
|
|
| 디스크 파티션 |
시스템에서 제공하는 이러한 영구 이름 외에도 udev 규칙을 사용하여 스토리지의 WWID에 매핑된 고유한 영구 이름을 구현할 수도 있습니다.
/dev/disk/by-partuuid의 파티션 UUID 특성
파티션 UUID(PARTUUID) 특성은 GPT 파티션 테이블에 정의된 파티션을 식별합니다.
예 26.2. 파티션 UUID 매핑
| PARTUUID 심볼릭 링크 | 비영구 장치 |
|---|---|
|
|
|
|
|
|
|
|
|
/dev/disk/by-path/의 Path 속성
이 속성은 장치에 액세스하는 데 사용되는 하드웨어 경로에서 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다.
하드웨어 경로의 모든 부분(예: PCI ID, 대상 포트 또는 LUN 번호)이 변경되면 Path 속성이 실패합니다. 따라서 Path 속성은 신뢰할 수 없습니다. 그러나 Path 속성은 다음 시나리오 중 하나에서 유용할 수 있습니다.However, the Path attribute may be useful in one of the following scenarios:
- 나중에 교체하려는 디스크를 식별해야 합니다.
- 특정 위치의 디스크에 스토리지 서비스를 설치할 계획입니다.
26.4. DM Multipath를 통한 World Wide Identifier
WWID(Wide Wide Identifier)와 비영구 장치 이름 간에 매핑하도록 DM(Device Mapper) 다중 경로를 구성할 수 있습니다.
시스템에서 장치로의 경로가 여러 개인 경우 DM Multipath는 WWID를 사용하여 이를 감지합니다. 그러면 DM Multipath가 /dev/mapper/wwid 디렉터리에 단일 "pseudo-device"를 제공합니다(예: /dev/mapper/3600508b400105df70000e00000ac0000 ).
multipath -l 명령은 비영구 식별자에 대한 매핑을 표시합니다.
-
Host:Channel:Target:LUN -
/dev/sd이름 -
major:마이너번호
예 26.3. 다중 경로 구성의 WWID 매핑
multipath -l 명령의 출력 예:
DM Multipath는 시스템의 해당 /dev/sd 이름에 각 WWID 기반 장치 이름의 적절한 매핑을 자동으로 유지합니다. 이러한 이름은 경로 변경 시 지속되며 다른 시스템의 장치에 액세스할 때 일관되게 유지됩니다.
DM Multipath의 user_friendly_names 기능을 사용하면 WWID가 /dev/mapper/mpathN 형식의 이름에 매핑됩니다. 기본적으로 이 매핑은 /etc/multipath/bindings 파일에서 유지됩니다. 이러한 mpathN 이름은 해당 파일이 유지되는 한 영구적입니다.
user_friendly_names 를 사용하는 경우 클러스터에서 일관된 이름을 얻으려면 추가 단계가 필요합니다.
26.5. udev 장치 이름 지정 규칙의 제한 사항
다음은 udev 이름 지정 규칙의 몇 가지 제한 사항입니다.
-
udev메커니즘이udev이벤트를 위해udev를 처리할 때 스토리지 장치를 쿼리하는 기능에 의존할 수 있기 때문에 쿼리가 수행될 때 장치에 액세스할 수 없을 수도 있습니다. 이는 장치가 서버 섀시에 없는 경우 파이버 채널, iSCSI 또는 FCoE 스토리지 장치에서 발생할 가능성이 큽니다. -
커널은 언제든지
udev이벤트를 보낼 수 있으므로 규칙을 처리하여 장치에 액세스할 수 없는 경우/dev/disk/by-*/링크가 제거됩니다. -
udev이벤트가 생성되는 경우와 많은 수의 장치가 감지되는 경우와 사용자 공간udev서비스가 감지되는 경우와 각 이벤트에 대한 규칙을 처리하는 데 약간의 시간이 걸리는 시간 사이에 지연이 발생할 수 있습니다. 이로 인해 커널이 장치를 탐지할 때와/dev/disk/by-*/이름을 사용할 수 있는 시간 사이에 지연될 수 있습니다. -
규칙에 의해 호출되는
blkid와 같은 외부 프로그램은 짧은 기간 동안 장치를 열 수 있으므로 다른 용도로 장치에 액세스할 수 없게 됩니다. -
/dev/disk/에서
udev메커니즘이 관리하는 장치 이름은 주요 릴리스마다 변경될 수 있으므로 링크를 업데이트해야 합니다.
26.6. 영구 이름 지정 속성 나열
비영구 스토리지 장치의 영구 이름 지정 속성을 확인할 수 있습니다.
절차
UUID 및 라벨 속성을 나열하려면
lsblk유틸리티를 사용합니다.lsblk --fs storage-device
$ lsblk --fs storage-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
예 26.4. 파일 시스템의 UUID 및 레이블 보기
lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /boot
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow PARTUUID 속성을 나열하려면
lsblk유틸리티를--output +PARTUUID옵션과 함께 사용하십시오.lsblk --output +PARTUUID
$ lsblk --output +PARTUUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
예 26.5. 파티션의 PARTUUID 속성 보기
lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01
$ lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01Copy to Clipboard Copied! Toggle word wrap Toggle overflow WWID 속성을 나열하려면
/dev/disk/by-id/디렉토리에서 심볼릭 링크의 대상을 검사합니다. 예를 들면 다음과 같습니다.예 26.6. 시스템에 있는 모든 스토리지 장치의 WWID 보기
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
26.7. 영구 이름 지정 특성 수정
파일 시스템의 UUID 또는 레이블 영구 이름 지정 속성을 변경할 수 있습니다.
udev 속성 변경은 백그라운드에서 수행되며 시간이 오래 걸릴 수 있습니다. udevadm settle 명령은 변경 사항이 완전히 등록될 때까지 대기하여 다음 명령이 새 속성을 올바르게 사용할 수 있도록 합니다.
다음 명령에서는 다음을 수행합니다.
-
new-uuid 를 설정할 UUID로 바꿉니다(예:
1cdfbc07-1c90-4984-b5ec-f61943f5ea50).uuidgen명령을 사용하여 UUID를 생성할 수 있습니다. -
new-label 을 레이블로 바꿉니다(예:
backup_data).
사전 요구 사항
- XFS 파일 시스템의 속성을 수정하는 경우 먼저 마운트 해제합니다.
절차
XFS 파일 시스템의 UUID 또는 라벨 속성을 변경하려면
xfs_admin유틸리티를 사용합니다.xfs_admin -U new-uuid -L new-label storage-device udevadm settle
# xfs_admin -U new-uuid -L new-label storage-device # udevadm settleCopy to Clipboard Copied! Toggle word wrap Toggle overflow ext4,ext3 또는 ext2 파일 시스템의 UUID 또는 레이블 속성을 변경하려면
tune2fs유틸리티를 사용합니다.tune2fs -U new-uuid -L new-label storage-device udevadm settle
# tune2fs -U new-uuid -L new-label storage-device # udevadm settleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스왑 볼륨의 UUID 또는 라벨 속성을 변경하려면
swaplabel유틸리티를 사용합니다.swaplabel --uuid new-uuid --label new-label swap-device udevadm settle
# swaplabel --uuid new-uuid --label new-label swap-device # udevadm settleCopy to Clipboard Copied! Toggle word wrap Toggle overflow
27장. 파티션 시작하기
디스크 파티션을 사용하여 디스크를 하나 이상의 논리 영역으로 분할하여 각 파티션에 대해 개별적으로 작업할 수 있습니다. 하드 디스크는 파티션 테이블에 있는 각 디스크 파티션의 위치와 크기에 대한 정보를 저장합니다. 테이블을 사용하면 각 파티션이 운영 체제에 대한 논리 디스크로 표시됩니다. 그런 다음 개별 디스크를 읽고 쓸 수 있습니다.
블록 장치에서 파티션을 사용할 때의 이점과 단점에 대한 개요 는 Red Hat 지식베이스 솔루션에서 직접 또는 LVM 사이에 LVM을 사용하여 LUN에서 파티션을 사용할 때의 이점과 단점 을 참조하십시오. .
27.1. parted가 있는 디스크에 파티션 테이블 만들기
파티션 테이블을 사용하여 블록 장치를 더 쉽게 포맷하려면 parted 유틸리티를 사용합니다.
블록 장치를 파티션 테이블로 포맷하면 장치에 저장된 모든 데이터가 삭제됩니다.
절차
대화형
parted쉘을 시작합니다.parted block-device
# parted block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 장치에 이미 파티션 테이블이 있는지 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow 장치에 파티션이 이미 포함된 경우 다음 단계에서 삭제됩니다.
새 파티션 테이블 만들기:
(parted) mklabel table-type
(parted) mklabel table-typeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 테이블 유형을 원하는 파티션 테이블 유형으로 바꿉니다.
-
MSDOSfor MBR -
GPT용 GPT
-
예 27.1. GPG(Guid 파티션 테이블) 테이블 생성
디스크에 GPT 테이블을 만들려면 다음을 사용합니다.
(parted) mklabel gpt
(parted) mklabel gptCopy to Clipboard Copied! Toggle word wrap Toggle overflow 변경 사항은 이 명령을 입력한 후 적용됩니다.
파티션 테이블을 보고 해당 테이블이 생성되었는지 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow parted쉘을 종료합니다.(parted) quit
(parted) quitCopy to Clipboard Copied! Toggle word wrap Toggle overflow
27.2. parted가 있는 파티션 테이블 보기
블록 장치의 파티션 테이블을 표시하여 파티션 레이아웃과 개별 파티션에 대한 세부 정보를 확인합니다. parted 유틸리티를 사용하여 블록 장치의 파티션 테이블을 볼 수 있습니다.
절차
parted유틸리티를 시작합니다. 예를 들어 다음 출력에는/dev/sda장치가 나열되어 있습니다.parted /dev/sda
# parted /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파티션 테이블 보기:
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 다음을 검토할 장치로 전환합니다.
(parted) select block-device
(parted) select block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
출력 명령 출력에 대한 자세한 내용은 다음을 참조하십시오.
모델 번호: ATA waySUNG MZNLN256 (scsi)- 디스크 유형, 제조업체, 모델 번호 및 인터페이스.
디스크 /dev/sda: 256GB- 블록 장치 및 스토리지 용량의 파일 경로입니다.
파티션 테이블: msdos- 디스크 레이블 유형입니다.
숫자-
파티션 번호입니다. 예를 들어, 마이너 번호 1이 있는 파티션은
/dev/sda1에 해당합니다. 시작및종료- 파티션이 시작되고 끝나는 장치의 위치입니다.
유형- 유효한 유형은 metadata, free, primary, extended 또는 logical입니다.
파일 시스템-
파일 시스템 유형입니다. 장치의
파일 시스템필드에 값이 표시되지 않으면 파일 시스템 유형을 알 수 없음을 의미합니다.parted유틸리티는 암호화된 장치에서 파일 시스템을 인식할 수 없습니다. 플래그-
파티션에 설정된 플래그를 나열합니다. 사용 가능한 플래그는
boot,root,swap,hidden,raid,lvm, Mia입니다.
27.3. parted로 파티션 생성
시스템 관리자는 parted 유틸리티를 사용하여 디스크에서 새 파티션을 만들 수 있습니다.
필요한 파티션은 스왑,/boot/, / (root) 입니다.
사전 요구 사항
- 디스크의 파티션 테이블.
- 만들 파티션이 2TiB보다 크면 GUID 파티션 테이블(GPT) 으로 디스크를 포맷합니다.
프로세스
parted유틸리티를 시작합니다.parted block-device
# parted block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 현재 파티션 테이블을 보고 사용 가능한 공간이 충분한지 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 여유 공간이 충분하지 않은 경우 파티션 크기를 조정합니다.
파티션 테이블에서 다음을 확인합니다.
- 새 파티션의 시작 및 끝점입니다.
- MBR에서 파티션 유형은 무엇입니까.
새 파티션을 만듭니다.
(parted) mkpart part-type name fs-type start end
(parted) mkpart part-type name fs-type start endCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
part-type 을
기본,논리또는 확장으로바꿉니다. 이는 MBR 파티션 테이블에만 적용됩니다. - name 을 임의의 파티션 이름으로 바꿉니다. 이는 GPT 파티션 테이블에 필요합니다.
-
fs-type 을
xfs,ext2,ext3,ext4,fat16,fat32,hfs+linux-swap,ntfs또는reiserfs로 바꿉니다. fs-type 매개변수는 선택 사항입니다.parted유틸리티는 파티션에 파일 시스템을 생성하지 않습니다. -
start 및 end 를 파티션의 시작 및 종료 지점을 결정하는 크기로 교체하여 디스크 시작부터 계산됩니다.
512MiB,20GiB또는1.5TiB와 같은 size 접미사를 사용할 수 있습니다. 기본 크기는 메가바이트 단위입니다.
예 27.2. 작은 기본 파티션 만들기
MBR 테이블에 1024MiB에서 2048MiB까지 기본 파티션을 만들려면 다음을 사용합니다.
(parted) mkpart primary 1024MiB 2048MiB
(parted) mkpart primary 1024MiB 2048MiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령을 입력한 후 변경 사항이 적용됩니다.
-
part-type 을
파티션 테이블을 보고 생성된 파티션이 올바른 파티션 유형, 파일 시스템 유형 및 크기가 있는 파티션 테이블에 있는지 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow parted쉘을 종료합니다.(parted) quit
(parted) quitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 장치 노드를 등록합니다.
udevadm settle
# udevadm settleCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널이 새 파티션을 인식하는지 확인합니다.
cat /proc/partitions
# cat /proc/partitionsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
27.4. Cryostat를 사용하여 파티션 유형 설정
Cryostat 유틸리티를 사용하여 파티션 유형 또는 플래그를 설정할 수 있습니다.
사전 요구 사항
- 디스크의 파티션입니다.
프로세스
대화형 Cryostat 쉘
을시작합니다.fdisk block-device
# fdisk block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 현재 파티션 테이블을 보고 마이너 파티션 번호를 확인합니다.
Command (m for help): print
Command (m for help): printCopy to Clipboard Copied! Toggle word wrap Toggle overflow 현재 파티션 유형은
Type열에 있고 해당 유형 ID는Id열에서 확인할 수 있습니다.partition type 명령을 입력하고 마이너 번호를 사용하여 파티션을 선택합니다.
Command (m for help): type Partition number (1,2,3 default 3): 2
Command (m for help): type Partition number (1,2,3 default 3): 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 16진수 코드의 목록을 확인합니다.
Hex code (type L to list all codes): L
Hex code (type L to list all codes): LCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파티션 유형을 설정합니다.
Hex code (type L to list all codes): 8e
Hex code (type L to list all codes): 8eCopy to Clipboard Copied! Toggle word wrap Toggle overflow 변경 사항을 작성하고 Cryostat 쉘
을종료합니다.Command (m for help): write The partition table has been altered. Syncing disks.
Command (m for help): write The partition table has been altered. Syncing disks.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 변경 사항을 확인합니다.
fdisk --list block-device
# fdisk --list block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
27.5. parted로 파티션 크기 조정
parted 유틸리티를 사용하여 사용하지 않는 디스크 공간을 사용하도록 파티션을 확장하거나 다른 용도로 용량을 사용하도록 파티션을 줄입니다.
사전 요구 사항
- 파티션을 축소하기 전에 데이터를 백업합니다.
- 만들 파티션이 2TiB보다 크면 GUID 파티션 테이블(GPT) 으로 디스크를 포맷합니다.
- 파티션을 축소하려면 먼저 파일 시스템을 축소하여 크기가 조정된 파티션보다 크지 않도록 합니다.
XFS는 축소를 지원하지 않습니다.
프로세스
parted유틸리티를 시작합니다.parted block-device
# parted block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 현재 파티션 테이블을 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파티션 테이블에서 다음을 확인합니다.
- 파티션의 작은 수입니다.
- 크기 조정 후 기존 파티션의 위치와 새 종료 지점입니다.
파티션 크기를 조정합니다.
(parted) resizepart 1 2GiB
(parted) resizepart 1 2GiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 1 을 크기 조정하려는 파티션의 마이너 번호로 바꿉니다.
-
2 를 디스크 시작부터 계산한 크기가 조정된 파티션의 새 끝 지점을 결정하는 크기로 바꿉니다.
512MiB,20GiB또는1.5TiB와 같은 size 접미사를 사용할 수 있습니다. 기본 크기는 메가바이트 단위입니다.
파티션 테이블을 보고 크기가 올바른 파티션 테이블에 있는지 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow parted쉘을 종료합니다.(parted) quit
(parted) quitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널이 새 파티션을 등록하는지 확인합니다.
cat /proc/partitions
# cat /proc/partitionsCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 선택 사항: 파티션을 확장한 경우 파일 시스템도 확장합니다.
27.6. parted로 파티션 제거
parted 유틸리티를 사용하여 디스크 파티션을 제거하여 디스크 공간을 확보할 수 있습니다.
프로세스
대화형 파트링 쉘
을시작합니다.parted block-device
# parted block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
block-device 를 파티션을 제거하려는 장치 경로로 교체합니다(예:
/dev/sda).
-
block-device 를 파티션을 제거하려는 장치 경로로 교체합니다(예:
현재 파티션 테이블을 보고 제거할 파티션의 마이너 번호를 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파티션을 제거합니다.
(parted) rm minor-number
(parted) rm minor-numberCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 마이너 번호를 제거하려는 파티션의 마이너 번호로 바꿉니다.
이 명령을 입력하는 즉시 변경 사항이 적용됩니다.
파티션 테이블에서 파티션을 제거했는지 확인합니다.
(parted) print
(parted) printCopy to Clipboard Copied! Toggle word wrap Toggle overflow parted쉘을 종료합니다.(parted) quit
(parted) quitCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널이 파티션이 제거되었는지 확인합니다.
cat /proc/partitions
# cat /proc/partitionsCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
/etc/fstab파일이 있는 경우 해당 파티션을 제거합니다. 제거된 파티션을 선언하는 행을 찾아 파일에서 제거합니다. 시스템이 새
/etc/fstab구성을 등록하도록 마운트 단위를 다시 생성합니다.systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스왑 파티션을 삭제하거나 LVM을 제거한 경우 커널 명령줄에서 파티션에 대한 모든 참조를 제거합니다.
활성 커널 옵션을 나열하고 옵션이 제거된 파티션을 참조하는지 확인합니다.
grubby --info=ALL
# grubby --info=ALLCopy to Clipboard Copied! Toggle word wrap Toggle overflow 제거된 파티션을 참조하는 커널 옵션을 제거합니다.
grubby --update-kernel=ALL --remove-args="option"
# grubby --update-kernel=ALL --remove-args="option"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
초기 부팅 시스템에서 변경 사항을 등록하려면
initramfs파일 시스템을 다시 빌드합니다.dracut --force --verbose
# dracut --force --verboseCopy to Clipboard Copied! Toggle word wrap Toggle overflow
28장. XFS 시작하기
XFS 파일 시스템을 생성하고 유지 관리하는 방법에 대한 개요입니다.
28.1. XFS 파일 시스템
XFS는 단일 호스트에서 매우 큰 파일 및 파일 시스템을 지원하는 확장성이 뛰어나고 강력한 고성능 저널링 파일 시스템입니다. 이는 Red Hat Enterprise Linux 8의 기본 파일 시스템입니다. XFS는 원래 SGI 초반에서 개발되었으며 매우 큰 서버 및 스토리지 어레이에서 오랫동안 실행되고 있습니다.
XFS의 기능은 다음과 같습니다.
- 신뢰성
- 메타데이터 저널링: 시스템을 다시 시작하고 파일 시스템을 다시 마운트할 때 재생할 수 있는 파일 시스템 작업 기록을 유지하여 시스템 충돌 후 파일 시스템 무결성을 보장합니다.
- 광범위한 런타임 메타데이터 일관성 검사
- 확장 가능한 빠른 복구 유틸리티
- 할당량 저널링. 이로 인해 충돌 후 긴 할당량 일관성 점검이 필요하지 않습니다.
- 확장 및 성능
- 지원되는 파일 시스템 크기 최대 1024TiB
- 다수의 동시 작업을 지원하는 기능
- 사용 가능한 공간 관리의 확장성을 위한 B-트리 인덱싱
- 정교한 메타데이터 읽기 알고리즘
- 스트리밍 비디오 워크로드에 대한 최적화
- 할당 체계
- 범위 기반 할당
- 스트라이프 인식 할당 정책
- 지연된 할당
- 공간 사전 할당
- 동적으로 할당된 inode
- 기타 기능
- reflink 기반 파일 복사
- 긴밀하게 통합된 백업 및 복원 유틸리티
- 온라인 조각 모음
- 온라인 파일 시스템 확장
- 포괄적인 진단 기능
-
확장 속성(
xattr). 이를 통해 시스템은 파일당 여러 개의 추가 이름/값 쌍을 연결할 수 있습니다. - 프로젝트 또는 디렉터리 할당량. 이렇게 하면 디렉터리 트리에 대한 할당량 제한이 허용됩니다.
- 하위 타임 스탬프
성능 특성
XFS는 엔터프라이즈 워크로드가 있는 대규모 시스템에서 높은 성능을 제공합니다. 대규모 시스템은 비교적 많은 CPU 수, 여러 HBA 및 외부 디스크 어레이에 대한 연결이 있는 시스템입니다. XFS는 다중 스레드 병렬 I/O 워크로드가 있는 소규모 시스템에서도 잘 작동합니다.
XFS는 단일 스레드 메타데이터 집약적인 워크로드(예: 단일 스레드에서 많은 수의 작은 파일을 만들거나 삭제하는 워크로드)에 대해 상대적으로 낮은 성능을 제공합니다.
28.2. ext4 및 XFS와 함께 사용되는 툴 비교
이 섹션에서는 ext4 및 XFS 파일 시스템에서 일반적인 작업을 수행하는 데 사용할 툴을 비교합니다.
| Task | ext4 | XFS |
|---|---|---|
| 파일 시스템 생성 |
|
|
| 파일 시스템 검사 |
|
|
| 파일 시스템 크기 조정 |
|
|
| 파일 시스템의 이미지 저장 |
|
|
| 파일 시스템 레이블 또는 튜닝 |
|
|
| 파일 시스템 백업 |
|
|
| 할당량 관리 |
|
|
| 파일 매핑 |
|
|
29장. 파일 시스템 마운트
시스템 관리자는 시스템에 파일 시스템을 마운트하여 데이터에 액세스할 수 있습니다.
29.1. Linux 마운트 메커니즘
Linux에서 파일 시스템을 마운트하는 기본 개념은 다음과 같습니다.
Linux, UNIX 및 유사한 운영 체제에서는 서로 다른 파티션 및 이동식 장치(예: CD, DVD 또는 USB 플래시 드라이브)의 파일 시스템을 디렉토리 트리의 특정 지점(마운트 지점)에 연결한 다음 다시 분리할 수 있습니다. 파일 시스템은 디렉터리에 마운트되지만 디렉터리의 원래 콘텐츠에 액세스할 수 없습니다.
Linux에서는 파일 시스템이 이미 연결된 디렉터리에 파일 시스템을 마운트하지 않습니다.
마운트 시 다음을 통해 장치를 식별할 수 있습니다.
-
범용 고유 식별자(UUID): 예를 들어
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cb -
볼륨 레이블: 예:
LABEL=home -
비영구 블록 장치의 전체 경로(예:
/dev/sda3)
필요한 모든 정보 없이 mount 명령을 사용하여 파일 시스템을 마운트할 때 장치 이름, 대상 디렉터리 또는 파일 시스템 유형이 없는 경우 mount 유틸리티는 지정된 파일 시스템이 나열되어 있는지 확인하기 위해 /etc/fstab 파일의 내용을 읽습니다. /etc/fstab 파일에는 장치 이름 및 선택한 파일 시스템이 마운트되도록 설정된 디렉터리와 파일 시스템 유형 및 마운트 옵션이 포함되어 있습니다. 따라서 /etc/fstab 에 지정된 파일 시스템을 마운트할 때 다음 명령 구문으로 충분합니다.
마운트 지점별 마운트:
mount directory
# mount directoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow 블록 장치에 의해 마운트:
mount device
# mount deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.2. 현재 마운트된 파일 시스템 나열
findmnt 유틸리티를 사용하여 명령줄에서 현재 마운트된 모든 파일 시스템을 나열합니다.
절차
마운트된 모든 파일 시스템을 나열하려면
findmnt유틸리티를 사용합니다.findmnt
$ findmntCopy to Clipboard Copied! Toggle word wrap Toggle overflow 나열된 파일 시스템을 특정 파일 시스템 유형으로만 제한하려면
--types옵션을 추가합니다.findmnt --types fs-type
$ findmnt --types fs-typeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
예 29.1. XFS 파일 시스템만 나열
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
29.3. 마운트를 사용하여 파일 시스템 마운트
mount 유틸리티를 사용하여 파일 시스템을 마운트합니다.
사전 요구 사항
선택한 마운트 지점에 파일 시스템이 이미 마운트되어 있지 않은지 확인합니다.
findmnt mount-point
$ findmnt mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
절차
특정 파일 시스템을 연결하려면
mount유틸리티를 사용합니다.mount device mount-point
# mount device mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 29.2. XFS 파일 시스템 마운트
예를 들어 UUID로 식별되는 로컬 XFS 파일 시스템을 마운트하려면 다음을 수행합니다.
mount UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /mnt/data
# mount UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /mnt/dataCopy to Clipboard Copied! Toggle word wrap Toggle overflow mount가 파일 시스템 유형을 자동으로 인식할 수 없는 경우--types옵션을 사용하여 지정합니다.mount --types type device mount-point
# mount --types type device mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 29.3. NFS 파일 시스템 마운트
예를 들어 원격 NFS 파일 시스템을 마운트하려면 다음을 수행합니다.
mount --types nfs4 host:/remote-export /mnt/nfs
# mount --types nfs4 host:/remote-export /mnt/nfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.4. 마운트 지점 이동
마운트 유틸리티를 사용하여 마운트된 파일 시스템의 마운트 지점을 다른 디렉토리로 변경합니다.
절차
파일 시스템이 마운트된 디렉터리를 변경하려면 다음을 수행합니다.
mount --move old-directory new-directory
# mount --move old-directory new-directoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 29.4. 홈 파일 시스템 이동
예를 들어
/mnt/userdirs/디렉터리에 마운트된 파일 시스템을/home/마운트 지점으로 이동하려면 다음을 실행합니다.mount --move /mnt/userdirs /home
# mount --move /mnt/userdirs /homeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템이 예상대로 이동되었는지 확인합니다.
findmnt ls old-directory ls new-directory
$ findmnt $ ls old-directory $ ls new-directoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow
29.5. unmount를 사용하여 파일 시스템 마운트 해제
umount 유틸리티를 사용하여 파일 시스템을 마운트 해제합니다.
절차
다음 명령 중 하나를 사용하여 파일 시스템을 마운트 해제합니다.
마운트 지점의 경우:
umount mount-point
# umount mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 장치별:
umount device
# umount deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
명령이 다음과 유사한 오류로 인해 실패하는 경우 프로세스에서 리소스를 사용하고 있기 때문에 파일 시스템이 사용 중임을 나타냅니다.
umount: /run/media/user/FlashDrive: target is busy.
umount: /run/media/user/FlashDrive: target is busy.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템이 사용 중인 경우
fuser유틸리티를 사용하여 액세스 중인 프로세스를 확인합니다. 예를 들면 다음과 같습니다.fuser --mount /run/media/user/FlashDrive /run/media/user/FlashDrive: 18351
$ fuser --mount /run/media/user/FlashDrive /run/media/user/FlashDrive: 18351Copy to Clipboard Copied! Toggle word wrap Toggle overflow 나중에 파일 시스템을 사용하여 프로세스를 중지하고 다시 마운트 해제하십시오.
29.6. 웹 콘솔에서 파일 시스템 마운트 및 마운트 해제
RHEL 시스템에서 파티션을 사용할 수 있으려면 파티션에 파일 시스템을 장치로 마운트해야 합니다.
파일 시스템도 마운트 해제할 수 있으며 RHEL 시스템은 이를 사용하지 않습니다. 파일 시스템을 마운트 해제하면 장치를 삭제, 제거 또는 다시 포맷할 수 있습니다.
사전 요구 사항
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다.
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
- 파일 시스템을 마운트 해제하려면 시스템에 파티션에 저장된 파일, 서비스 또는 애플리케이션을 사용하지 않는지 확인합니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지 탭을 클릭합니다.
- 스토리지 테이블의 파티션을 삭제할 볼륨을 선택합니다.
- GPT 파티션 섹션에서 마운트 또는 마운트 해제하려는 파일 시스템이 있는 파티션 옆에 있는 메뉴 버튼을 클릭합니다.
- 또는 클릭합니다.
29.7. 일반 마운트 옵션
다음 표에는 mount 유틸리티의 가장 일반적인 옵션이 나열되어 있습니다. 다음 구문을 사용하여 이러한 마운트 옵션을 적용할 수 있습니다.
mount --options option1,option2,option3 device mount-point
# mount --options option1,option2,option3 device mount-point| 옵션 | 설명 |
|---|---|
|
| 파일 시스템에서 비동기 입력 및 출력 작업을 활성화합니다. |
|
|
|
|
|
|
|
| 특정 파일 시스템에서 바이너리 파일을 실행할 수 있습니다. |
|
| 이미지를 루프 장치로 마운트합니다. |
|
|
기본 동작은 |
|
| 특정 파일 시스템에서 바이너리 파일의 실행을 허용하지 않습니다. |
|
| 파일 시스템을 마운트 및 마운트 해제하기 위해 일반 사용자(즉, root가 아닌)를 허용하지 않습니다. |
|
| 이미 마운트된 경우 파일 시스템을 다시 마운트합니다. |
|
| 읽기 전용으로 파일 시스템을 마운트합니다. |
|
| 읽고 쓰기 위해 파일 시스템을 마운트합니다. |
|
| 일반 사용자(즉, root가 아닌)를 사용하여 파일 시스템을 마운트 및 마운트 해제할 수 있습니다. |
30장. 여러 마운트 지점에 마운트 공유
시스템 관리자는 마운트 지점을 복제하여 여러 디렉토리에서 파일 시스템에 액세스할 수 있도록 할 수 있습니다.
30.2. 개인 마운트 지점 중복 생성
마운트 지점을 개인 마운트로 복제합니다. 나중에 중복 또는 원래 마운트 지점 아래에 마운트한 파일 시스템은 다른 시스템에 반영되지 않습니다.
절차
원래 마운트 지점에서 가상 파일 시스템(VFS) 노드를 생성합니다.
mount --bind original-dir original-dir
# mount --bind original-dir original-dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원본 마운트 지점을 개인용으로 표시합니다.
mount --make-private original-dir
# mount --make-private original-dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 선택한 마운트 지점의 마운트 유형과 그 아래에 있는 모든 마운트 지점을 변경하려면
--make-private대신--make-rprivate옵션을 사용합니다.중복을 생성합니다.
mount --bind original-dir duplicate-dir
# mount --bind original-dir duplicate-dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow
예 30.1. 개인 마운트 지점으로 /media를 /media into /mnt로 복제
/media디렉터리에서 VFS 노드를 생성합니다.mount --bind /media /media
# mount --bind /media /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow /media디렉토리를 비공개로 표시합니다.mount --make-private /media
# mount --make-private /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow /mnt에 중복 생성:mount --bind /media /mnt
# mount --bind /media /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제
/media및/mnt공유 콘텐츠를 확인할 수 있지만/media내에 있는 마운트는/mnt에 표시되지 않습니다. 예를 들어 CD-ROM 드라이브에 비어 있지 않은 미디어가 포함되어 있고/media/cdrom/디렉터리가 있는 경우 다음을 사용합니다.mount /dev/cdrom /media/cdrom ls /media/cdrom EFI GPL isolinux LiveOS ls /mnt/cdrom #
# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom #Copy to Clipboard Copied! Toggle word wrap Toggle overflow /mnt디렉터리에 마운트된 파일 시스템이/media에 반영되지 않았는지도 확인할 수 있습니다. 예를 들어/dev/sdc1장치를 사용하는 비어 있지 않은 USB 플래시 드라이브가 연결되고/mnt/flashdisk/디렉터리가 있는 경우 다음을 사용합니다.mount /dev/sdc1 /mnt/flashdisk ls /media/flashdisk ls /mnt/flashdisk en-US publican.cfg
# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
30.4. 슬레이브 마운트 지점 중복 생성
마운트 지점을 슬레이브 마운트 유형으로 복제합니다. 나중에 원래 마운트 지점 아래에 마운트한 파일 시스템은 중복에 반영되지만 다른 방법은 반영되지 않습니다.
절차
원래 마운트 지점에서 가상 파일 시스템(VFS) 노드를 생성합니다.
mount --bind original-dir original-dir
# mount --bind original-dir original-dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원래 마운트 지점을 공유로 표시합니다.
mount --make-shared original-dir
# mount --make-shared original-dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 선택한 마운트 지점의 마운트 유형과 그 아래의 모든 마운트 지점을 변경하려면
--make-shared대신--make-rshared옵션을 사용합니다.중복을 생성하고
슬레이브유형으로 표시합니다.mount --bind original-dir duplicate-dir mount --make-slave duplicate-dir
# mount --bind original-dir duplicate-dir # mount --make-slave duplicate-dirCopy to Clipboard Copied! Toggle word wrap Toggle overflow
예 30.3. 슬레이브 마운트 지점으로 /media를 /media를 /mnt로 복제
이 예에서는 /media 디렉터리의 콘텐츠를 /mnt 에 표시하는 방법을 보여줍니다. 그러나 /media 에 반영할 /mnt 디렉터리에 마운트가 없습니다.
/media디렉터리에서 VFS 노드를 생성합니다.mount --bind /media /media
# mount --bind /media /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow /media디렉토리를 공유로 표시합니다.mount --make-shared /media
# mount --make-shared /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow /mnt에 중복을 생성하고슬레이브로 표시합니다.mount --bind /media /mnt mount --make-slave /mnt
# mount --bind /media /mnt # mount --make-slave /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow /media내의 마운트도/mnt에 표시되는지 확인합니다. 예를 들어 CD-ROM 드라이브에 비어 있지 않은 미디어가 포함되어 있고/media/cdrom/디렉터리가 있는 경우 다음을 사용합니다.mount /dev/cdrom /media/cdrom ls /media/cdrom EFI GPL isolinux LiveOS ls /mnt/cdrom EFI GPL isolinux LiveOS
# mount /dev/cdrom /media/cdrom # ls /media/cdrom EFI GPL isolinux LiveOS # ls /mnt/cdrom EFI GPL isolinux LiveOSCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또한
/mnt디렉터리에 마운트된 파일 시스템이/media에 반영되지 않았는지도 확인합니다. 예를 들어/dev/sdc1장치를 사용하는 비어 있지 않은 USB 플래시 드라이브가 연결되고/mnt/flashdisk/디렉터리가 있는 경우 다음을 사용합니다.mount /dev/sdc1 /mnt/flashdisk ls /media/flashdisk ls /mnt/flashdisk en-US publican.cfg
# mount /dev/sdc1 /mnt/flashdisk # ls /media/flashdisk # ls /mnt/flashdisk en-US publican.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
30.5. 마운트 지점의 중복 방지
마운트 지점을 바인딩할 수 없음으로 표시하여 다른 마운트 지점에서 복제할 수 없습니다.
절차
마운트 지점 유형을 바인딩할 수 없는 마운트로 변경하려면 다음을 사용합니다.
mount --bind mount-point mount-point mount --make-unbindable mount-point
# mount --bind mount-point mount-point # mount --make-unbindable mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 선택한 마운트 지점 및 그 아래에 있는 모든 마운트 지점의 마운트 유형을 변경하려면
--make-unbindable대신--make-runbindable옵션을 사용합니다.다음 오류와 함께 이 마운트를 중복하려고 하면 실패합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
예 30.4. /media가 중복되는 것을 방지
/media디렉토리가 공유되지 않도록 하려면 다음을 사용합니다.mount --bind /media /media mount --make-unbindable /media
# mount --bind /media /media # mount --make-unbindable /mediaCopy to Clipboard Copied! Toggle word wrap Toggle overflow
31장. 파일 시스템 영구적으로 마운트
시스템 관리자는 지속적으로 파일 시스템을 마운트하여 비모식 스토리지를 구성할 수 있습니다.
31.1. /etc/fstab 파일
/etc/fstab 구성 파일을 사용하여 파일 시스템의 영구 마운트 지점을 제어합니다. /etc/fstab 파일의 각 행은 파일 시스템의 마운트 지점을 정의합니다.
6개의 필드가 공백으로 구분되어 있습니다.
-
영구 속성 또는
/dev디렉터리의 경로로 식별되는 블록 장치입니다. - 장치가 마운트될 디렉터리입니다.
- 장치의 파일 시스템입니다.
-
부팅 시 파티션을 기본 옵션으로 마운트하는
defaults옵션이 포함된 파일 시스템의 마운트 옵션입니다. 마운트 옵션 필드는x-도 인식합니다.systemd. 옵션 형식의 systemd 마운트 장치 옵션옵션 -
dump유틸리티의 백업 옵션. -
fsck유틸리티의 순서를 확인합니다.
systemd-fstab-generator 는 /etc/fstab 파일에서 systemd-mount 단위로 항목을 동적으로 변환합니다. systemd 마운트 장치를 마스킹하지 않는 한 수동 활성화 중에 systemd 자동 마운트가 .
/etc/fstab 의 LVM 볼륨을 마운트합니다
예 31.1. /etc/fstab의 /boot 파일 시스템
| 블록 장치 | 마운트 지점 | 파일 시스템 | 옵션 | Backup | 확인 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
systemd 서비스는 /etc/fstab 의 항목에서 마운트 장치를 자동으로 생성합니다.
31.2. /etc/fstab에 파일 시스템 추가
/etc/fstab 구성 파일에서 파일 시스템의 영구 마운트 지점을 구성합니다.
절차
파일 시스템의 UUID 속성을 확인합니다.
lsblk --fs storage-device
$ lsblk --fs storage-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예를 들면 다음과 같습니다.
예 31.2. 파티션의 UUID 보기
lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot ea74bbec-536d-490c-b8d9-5b40bbd7545b /bootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 마운트 지점 디렉터리가 없는 경우 다음을 생성합니다.
mkdir --parents mount-point
# mkdir --parents mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 루트 사용자로
/etc/fstab파일을 편집하고 UUID로 식별되는 파일 시스템의 행을 추가합니다.예를 들면 다음과 같습니다.
예 31.3. /etc/fstab의 /boot 마운트 지점
UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot xfs defaults 0 0
UUID=ea74bbec-536d-490c-b8d9-5b40bbd7545b /boot xfs defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템에서 새 구성을 등록하도록 마운트 장치를 다시 생성합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템을 마운트하여 구성이 작동하는지 확인합니다.
mount mount-point
# mount mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
32장. 필요에 따라 파일 시스템 마운트
시스템 관리자는 필요할 때 자동으로 마운트하도록 NFS와 같은 파일 시스템을 구성할 수 있습니다.
32.1. autofs 서비스
autofs 서비스는 파일 시스템을 자동으로 마운트 및 마운트 해제하므로 시스템 리소스를 절약할 수 있습니다. NFS, AFS, SMBFS, CIFS, 로컬 파일 시스템과 같은 파일 시스템을 마운트하는 데 사용할 수 있습니다.
/etc/fstab 구성을 사용하여 영구 마운트의 한 가지 단점은 사용자가 마운트된 파일 시스템에 액세스하는 방법에 관계없이 마운트된 파일 시스템을 유지하기 위해 리소스를 전용으로 지정해야 한다는 것입니다. 예를 들어 시스템이 한 번에 여러 시스템에 NFS 마운트를 유지 관리하는 경우 시스템 성능에 영향을 줄 수 있습니다.
/etc/fstab 의 대안은 kernel-based autofs 서비스를 사용하는 것입니다. 다음 구성 요소로 구성됩니다.
- 파일 시스템을 구현하는 커널 모듈, 및
- 다른 모든 기능을 수행하는 사용자 공간 서비스입니다.
32.2. autofs 설정 파일
이 섹션에서는 autofs 서비스에서 사용하는 설정 파일의 사용과 구문을 설명합니다.
마스터 맵 파일
autofs 서비스는 /etc/auto.master (마스터 맵)를 기본 기본 설정 파일로 사용합니다. 이는 이름 서비스 스위치(NSS) 메커니즘과 함께 /etc/autofs.conf 구성 파일의 autofs 설정을 사용하여 지원되는 다른 네트워크 소스와 이름을 사용하도록 변경할 수 있습니다.
모든 온 디맨드 마운트 지점은 마스터 맵에서 구성해야 합니다. 마운트 지점, 호스트 이름, 내보낸 디렉터리 및 옵션은 각 호스트에 대해 수동으로 구성하는 대신 파일 집합(또는 기타 지원되는 네트워크 소스)에서 모두 지정할 수 있습니다.
마스터 맵 파일은 autofs 로 제어되는 마운트 지점과 자동 마운트 맵이라는 해당 설정 파일 또는 네트워크 소스를 나열합니다. 마스터 맵 형식은 다음과 같습니다.
mount-point map-name options
mount-point map-name options이 형식에 사용되는 변수는 다음과 같습니다.
- mount-point
-
autofs마운트 지점(예:/mnt/data). - map-file
- 마운트 지점 목록 및 해당 마운트 지점을 마운트해야 하는 파일 시스템 위치가 포함된 맵 소스 파일입니다.
- options
- 제공된 경우 지정된 맵의 모든 항목에 해당 옵션이 지정되지 않은 경우 적용됩니다.
예 32.1. /etc/auto.master 파일
다음은 /etc/auto.master 파일의 샘플 행입니다.
/mnt/data /etc/auto.data
/mnt/data /etc/auto.data파일 매핑
매핑 파일은 개별 온 디맨드 마운트 지점의 속성을 구성합니다.
자동 마운터는 디렉터리가 없는 경우 디렉토리를 생성합니다. 자동 마운터가 시작되기 전에 디렉토리가 존재하는 경우, 자동 마운터는 종료 시 해당 디렉토리를 제거하지 않습니다. 시간 초과를 지정하면 시간 제한 기간 동안 디렉터리에 액세스하지 않으면 디렉터리가 자동으로 마운트 해제됩니다.
맵의 일반적인 형식은 마스터 맵과 유사합니다. 그러나 options 필드는 마스터 맵과 같이 항목 끝에 대신 마운트 지점과 위치 사이에 표시됩니다.
mount-point options location
mount-point options location이 형식에 사용되는 변수는 다음과 같습니다.
- mount-point
-
이는
autofs마운트 지점을 나타냅니다. 간접 마운트를 위한 단일 디렉터리 이름 또는 직접 마운트를 위한 마운트 지점의 전체 경로일 수 있습니다. 각 직접 및 간접 맵 항목 키(마운트 지점) 뒤에는 오프셋 디렉토리(각각/로 시작하는 하위 디렉토리 이름)의 공백으로 구분된 목록이 올 수 있으며, 이를 다중 마운트 항목이라고 합니다. - options
-
제공되는 경우 이러한 옵션은 구성 항목
append_options가no로 설정된 경우 마스터 맵 옵션 대신 또는 사용되는 경우 마스터 맵 항목 옵션(있는 경우)에 추가됩니다. - 위치
-
이는 로컬 파일 시스템 경로( Sun map format escape 문자
:로 시작하는 맵 이름), NFS 파일 시스템 또는 기타 유효한 파일 시스템 위치와 같은 파일 시스템 위치를 나타냅니다.
예 32.2. 맵 파일
다음은 맵 파일의 샘플입니다(예: /etc/auto.misc ):
payroll -fstype=nfs4 personnel:/exports/payroll sales -fstype=xfs :/dev/hda4
payroll -fstype=nfs4 personnel:/exports/payroll
sales -fstype=xfs :/dev/hda4
맵 파일의 첫 번째 열은 customers 마운트 지점: sales 및 staff 이라는 서버의 Pay 및 payroll 을 나타냅니다. 두 번째 열은 autofs 마운트 옵션을 나타냅니다. 세 번째 열은 마운트 소스를 나타냅니다.
지정된 설정에 따라 autofs 마운트 지점은 /home/payroll 및 / home/ale 입니다. -fstype= 옵션은 종종 생략되며 시스템 기본값은 NFS 마운트용 NFSv4인 경우 파일 시스템이 NFS인 경우 NFSv4에 대한 마운트를 포함하여 필요하지 않습니다.
지정된 구성을 사용하여 프로세스에서 /home/payroll/2006/July.sxc 와 같은 autofs 마운트 해제된 디렉토리에 액세스해야 하는 경우 autofs 서비스는 자동으로 디렉터리를 마운트합니다.
amd 맵 형식
autofs 서비스는 amd 형식의 맵 설정도 인식합니다. 이는 Red Hat Enterprise Linux에서 제거된 am-utils 서비스에 작성된 기존 자동 마이터 설정을 재사용하려는 경우 유용합니다.
그러나 Red Hat은 이전 섹션에 설명된 간단한 autofs 형식을 사용할 것을 권장합니다.
32.3. autofs 마운트 지점 구성
Cryostat 서비스를 사용하여 온디맨드 마운트 지점을 구성합니다.
사전 요구 사항
autofs패키지를 설치합니다.yum install autofs
# yum install autofsCopy to Clipboard Copied! Toggle word wrap Toggle overflow autofs서비스를 시작하고 활성화합니다.systemctl enable --now autofs
# systemctl enable --now autofsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
절차
-
/etc/auto.identifier에 있는 온디맨드 마운트 지점의 맵 파일을 만듭니다. 식별자 를 마운트 지점을 식별하는 이름으로 바꿉니다. - 맵 파일에서 The Cryostat 구성 파일 섹션에 설명된 대로 마운트 지점, 옵션 및 위치 필드를 입력합니다.
- The Cryostat 구성 파일 섹션에 설명된 대로 마스터 맵 파일에 맵 파일을 등록합니다.
서비스가 설정을 다시 읽도록 허용하여 새로 구성된
autofs마운트를 관리할 수 있습니다.systemctl reload autofs.service
# systemctl reload autofs.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 온디맨드 디렉터리의 콘텐츠에 액세스해 보십시오.
ls automounted-directory
# ls automounted-directoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow
32.4. autofs 서비스를 사용하여 NFS 서버 사용자 홈 디렉토리 자동 마운트
사용자 홈 디렉터리를 자동으로 마운트하도록 Cryostat 서비스를 구성합니다.
사전 요구 사항
- autofs 패키지가 설치되어 있어야 합니다.
- autofs 서비스가 활성화되어 실행됩니다.
절차
사용자 홈 디렉터리를 마운트해야 하는 서버의
/etc/auto.master파일을 편집하여 맵 파일의 마운트 지점 및 위치를 지정합니다. 이렇게 하려면/etc/auto.master파일에 다음 행을 추가합니다./home /etc/auto.home
/home /etc/auto.homeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 사용자 홈 디렉터리를 마운트해야 하는 서버에
/etc/auto.home이름으로 맵 파일을 생성하고 다음 매개 변수를 사용하여 파일을 편집합니다.* -fstype=nfs,rw,sync host.example.com:/home/&
* -fstype=nfs,rw,sync host.example.com:/home/&Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기본적으로
nfs이므로fstype매개 변수를 건너뛸 수 있습니다. 자세한 내용은 시스템의 Cryostat(5)도움말 페이지를 참조하십시오.autofs서비스를 다시 로드합니다.systemctl reload autofs
# systemctl reload autofsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
32.5. autofs 사이트 설정 파일 덮어쓰기 또는 보강
경우에 따라 클라이언트 시스템의 특정 마운트 지점에 대한 사이트 기본값을 덮어쓰는 것이 유용합니다.
예 32.3. 초기 조건
예를 들어 다음 조건을 고려하십시오.
자동 마운터 맵은 NIS에 저장되고
/etc/nsswitch.conf파일에는 다음 지시문이 있습니다.automount: files nis
automount: files nisCopy to Clipboard Copied! Toggle word wrap Toggle overflow auto.master파일에는 다음이 포함됩니다.+auto.master
+auto.masterCopy to Clipboard Copied! Toggle word wrap Toggle overflow NIS
auto.master맵 파일에는 다음이 포함됩니다./home auto.home
/home auto.homeCopy to Clipboard Copied! Toggle word wrap Toggle overflow NIS
auto.home맵에는 다음이 포함됩니다.beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&Copy to Clipboard Copied! Toggle word wrap Toggle overflow autofs설정 옵션BROWSE_MODE가yes로 설정됩니다.BROWSE_MODE="yes"
BROWSE_MODE="yes"Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
파일 맵
/etc/auto.home이 없습니다.
절차
이 섹션에서는 다른 서버의 홈 디렉토리 마운트 및 선택된 항목만 사용하여 auto.home 을 보강하는 예를 설명합니다.
예 32.4. 다른 서버의 홈 디렉터리 마운트
앞의 조건에 따라 클라이언트 시스템이 NIS 맵 auto.home 을 재정의하고 다른 서버의 홈 디렉터리를 마운트해야 한다고 가정하겠습니다.
이 경우 클라이언트는 다음
/etc/auto.master맵을 사용해야 합니다./home /etc/auto.home +auto.master
/home /etc/auto.home +auto.masterCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/auto.home맵에는 항목이 포함되어 있습니다.* host.example.com:/export/home/&
* host.example.com:/export/home/&Copy to Clipboard Copied! Toggle word wrap Toggle overflow
자동 마운터는 마운트 지점의 첫 번째 발생만 처리하므로 /home 디렉토리에는 NIS auto.home 맵 대신 /etc/ 콘텐츠가 포함되어 있습니다.
auto.home
예 32.5. auto.home과 선택한 항목만 늘리기
또는 사이트 전체 auto.home 맵을 몇 개의 항목으로 보강하기 위해 다음을 수행하십시오.
/etc/auto.home파일 맵을 만들고 새 항목이 배치됩니다. 끝에 NISauto.home맵을 포함합니다. 그런 다음/etc/auto.home파일 맵은 다음과 유사합니다.mydir someserver:/export/mydir +auto.home
mydir someserver:/export/mydir +auto.homeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이러한 NIS
auto.home맵 조건을 사용하여/home디렉토리 출력의 내용을 나열합니다.ls /home beth joe mydir
$ ls /home beth joe mydirCopy to Clipboard Copied! Toggle word wrap Toggle overflow
이 마지막 예는 {} 에서 읽은 이름과 동일한 이름의 파일 맵 콘텐츠를 포함하지 않기 때문에 예상대로 작동합니다. 따라서 autofs 는 nsswitch 구성의 다음 맵 소스로 이동합니다.
32.6. LDAP를 사용하여 자동 마운터 맵 저장
Cryo stat 맵 파일이 아닌 LDAP 구성에 있는 map 맵을 저장하도록 Cryo stat 를 구성합니다.
사전 요구 사항
-
LDAP에서 자동 마운터 맵을 검색하도록 구성된 모든 시스템에 LDAP 클라이언트 라이브러리가 설치되어 있어야 합니다. Red Hat Enterprise Linux에서
openldap패키지는autofs패키지의 종속성으로 자동 설치되어야 합니다.
절차
-
LDAP 액세스를 구성하려면
/etc/openldap/ldap.conf파일을 수정합니다.BASE,URI,스키마옵션이 사이트에 맞게 적절하게 설정되어 있는지 확인합니다. LDAP에 자동 마운트 맵을 저장하기 위해 최근 설정된 스키마는
rfc2307bis초안에 설명되어 있습니다. 이 스키마를 사용하려면 스키마 정의에서 주석 문자를 제거하여/etc/autofs.conf구성 파일에 설정합니다. 예를 들면 다음과 같습니다.예 32.6. autofs 구성 설정
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다른 모든 스키마 항목이 구성에서 주석 처리되었는지 확인합니다.
rfc2307bis스키마의 autoscalingKey속성은rfc2307스키마의cn속성을 대체합니다. 다음은 LDAP Data Interchange Format(LDIF) 구성의 예입니다.예 32.7. LDIF 설정
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
32.7. systemd.automount를 사용하여 필요에 따라 /etc/fstab에 파일 시스템 마운트
마운트 지점이 /etc/fstab 에 정의된 경우 systemd 장치를 사용하여 필요에 따라 파일 시스템을 마운트합니다. 각 마운트에 대해 자동 마운트 장치를 추가하고 활성화해야 합니다.
절차
파일 시스템 영구 마운트에 설명된 대로 원하는 fstab 항목을 추가합니다. 예를 들면 다음과 같습니다.
/dev/disk/by-id/da875760-edb9-4b82-99dc-5f4b1ff2e5f4 /mount/point xfs defaults 0 0
/dev/disk/by-id/da875760-edb9-4b82-99dc-5f4b1ff2e5f4 /mount/point xfs defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
이전 단계에서 만든 항목의 options 필드에
x-systemd.automount를 추가합니다. 시스템이 새 구성을 등록하도록 새로 생성된 장치를 로드합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 자동 마운트 장치를 시작합니다.
systemctl start mount-point.automount
# systemctl start mount-point.automountCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
mount-point.automount가 실행 중인지 확인합니다.systemctl status mount-point.automount
# systemctl status mount-point.automountCopy to Clipboard Copied! Toggle word wrap Toggle overflow 자동 마운트된 디렉토리에 필요한 콘텐츠가 있는지 확인합니다.
ls /mount/point
# ls /mount/pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
32.8. systemd.automount를 사용하여 마운트 단위와 함께 온디맨드로 파일 시스템 마운트
마운트 지점을 마운트 단위로 정의할 때 systemd 장치를 사용하여 필요에 따라 파일 시스템을 마운트합니다. 각 마운트에 대해 자동 마운트 장치를 추가하고 활성화해야 합니다.
절차
마운트 장치를 생성합니다. 예를 들면 다음과 같습니다.
mount-point.mount [Mount] What=/dev/disk/by-uuid/f5755511-a714-44c1-a123-cfde0e4ac688 Where=/mount/point Type=xfs
mount-point.mount [Mount] What=/dev/disk/by-uuid/f5755511-a714-44c1-a123-cfde0e4ac688 Where=/mount/point Type=xfsCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
마운트 단위와 이름이 동일하지만 확장자는
.automount인 유닛 파일을 만듭니다. 파일을 열고
[자동 마운트]섹션을 만듭니다.Where=옵션을 마운트 경로로 설정합니다.[Automount] Where=/mount/point [Install] WantedBy=multi-user.target
[Automount] Where=/mount/point [Install] WantedBy=multi-user.targetCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템이 새 구성을 등록하도록 새로 생성된 장치를 로드합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 대신 자동 마운트 장치를 활성화하고 시작합니다.
systemctl enable --now mount-point.automount
# systemctl enable --now mount-point.automountCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
mount-point.automount가 실행 중인지 확인합니다.systemctl status mount-point.automount
# systemctl status mount-point.automountCopy to Clipboard Copied! Toggle word wrap Toggle overflow 자동 마운트된 디렉토리에 필요한 콘텐츠가 있는지 확인합니다.
ls /mount/point
# ls /mount/pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
33장. IdM에서 SSSD 구성 요소 사용
SSSD(System Security Services Daemon)는 원격 서비스 디렉터리 및 인증 메커니즘에 액세스하는 시스템 서비스입니다. 데이터 캐싱은 네트워크 연결 속도가 느린 경우 유용합니다. autofs 맵을 캐시하도록 SSSD 서비스를 구성하려면 이 섹션의 다음 절차를 따르십시오.
33.1. IdM 서버를 LDAP 서버로 사용하도록 autofs 수동 설정
IdM 서버 를 LDAP 서버로 사용하도록 Cryostat를 구성합니다.
절차
/etc/autofs.conf파일을 편집하여autofs가 검색하는 스키마 속성을 지정합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고사용자는
/etc/autofs.conf파일에서 하위 및 상위 케이스에 속성을 작성할 수 있습니다.선택 사항: LDAP 구성을 지정합니다. 이 작업을 수행하는 방법은 두 가지가 있습니다. 가장 간단한 방법은 자동 마운트 서비스가 LDAP 서버 및 위치를 자동으로 검색하도록 하는 것입니다.
ldap_uri = "ldap:///dc=example,dc=com"
ldap_uri = "ldap:///dc=example,dc=com"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 옵션을 사용하려면 DNS에서 검색 가능한 서버에 대한 SRV 레코드를 포함해야 합니다.
또는 사용할 LDAP 서버 및 LDAP 검색의 기본 DN을 명시적으로 설정합니다.
ldap_uri = "ldap://ipa.example.com" search_base = "cn=location,cn=automount,dc=example,dc=com"
ldap_uri = "ldap://ipa.example.com" search_base = "cn=location,cn=automount,dc=example,dc=com"Copy to Clipboard Copied! Toggle word wrap Toggle overflow autofs가 IdM LDAP 서버와의 클라이언트 인증을 허용하도록
/etc/autofs_ldap_auth.conf파일을 편집합니다.-
authrequired를 yes로 변경합니다. IdM LDAP 서버의 Kerberos 호스트 주체인 host/FQDN@REALM. 보안 주체 이름은 GSS 클라이언트 인증의 일부로 IdM 디렉터리에 연결하는 데 사용됩니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 호스트 주체에 대한 자세한 내용은 IdM에서 표준 DNS 호스트 이름 사용을 참조하십시오.
필요한 경우
klist -k를 실행하여 정확한 호스트 주체 정보를 가져옵니다.
-
33.2. autofs 맵을 캐시하도록 SSSD 구성
SSSD 서비스를 사용하면 IdM 서버를 전혀 사용하도록 autofs 를 구성하지 않고도 IdM 서버에 저장된 autofs 맵을 캐시할 수 있습니다.
사전 요구 사항
-
sssd패키지가 설치되어 있습니다.
절차
SSSD 구성 파일을 엽니다.
vim /etc/sssd/sssd.conf
# vim /etc/sssd/sssd.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow SSSD에서 처리하는 서비스 목록에
autofs서비스를 추가합니다.[sssd] domains = ldap services = nss,pam,autofs
[sssd] domains = ldap services = nss,pam,autofsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새
[autofs]섹션을 만듭니다.autofs서비스의 기본 설정이 대부분의 인프라에서 작동하므로 이 설정을 비워 둘 수 있습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 자세한 내용은 시스템의
sssd.conf도움말 페이지를 참조하십시오.선택 사항: Cryostat 항목에 대한 검색 기반을 설정합니다.
기본적으로 LDAP 검색 기반이지만ldap_autofs_search_base매개변수에 하위 트리를 지정할 수 있습니다.[domain/EXAMPLE] ldap_search_base = "dc=example,dc=com" ldap_autofs_search_base = "ou=automount,dc=example,dc=com"
[domain/EXAMPLE] ldap_search_base = "dc=example,dc=com" ldap_autofs_search_base = "ou=automount,dc=example,dc=com"Copy to Clipboard Copied! Toggle word wrap Toggle overflow SSSD 서비스를 다시 시작하십시오.
systemctl restart sssd.service
# systemctl restart sssd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow SSSD가 audit 설정 소스로 나열되도록
/etc/nsswitch.conf파일을 확인합니다.automount: sss files
automount: sss filesCopy to Clipboard Copied! Toggle word wrap Toggle overflow Cryostat
서비스를다시 시작하십시오.systemctl restart autofs.service
# systemctl restart autofs.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow /home에 대한 마스터 맵 항목이 있다고 가정하면 사용자의/home디렉토리를 나열하여 구성을 테스트합니다.ls /home/userName
# ls /home/userNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원격 파일 시스템을 마운트하지 않으면
/var/log/messages파일에 오류가 있는지 확인합니다. 필요한 경우logging매개 변수를 debug로 설정하여/etc/sysconfig/autofs파일에서디버그수준을 늘립니다.
34장. root 파일 시스템에 대한 읽기 전용 권한 설정
경우에 따라 읽기 전용 권한으로 루트 파일 시스템(/)을 마운트해야 합니다. 사용 사례에는 예기치 않은 시스템 전원 끄기 후 보안 강화 또는 데이터 무결성 보장이 포함됩니다.
34.1. 쓰기 권한을 항상 유지하는 파일 및 디렉토리
시스템이 제대로 작동하려면 일부 파일과 디렉터리가 쓰기 권한을 유지해야 합니다. 루트 파일 시스템이 읽기 전용 모드로 마운트되면 이러한 파일은 tmpfs 임시 파일 시스템을 사용하여 RAM에 마운트됩니다.
이러한 파일과 디렉터리의 기본 세트는 /etc/rwtab 파일에서 읽습니다. 이 파일이 시스템에 있는 경우 readonly-root 패키지가 필요합니다.
/etc/rwtab 파일의 항목은 다음 형식을 따릅니다.
copy-method path
copy-method path이 구문에서는 다음을 수행합니다.
- copy-method 를 파일 또는 디렉터리가 tmpfs에 복사되는 방법을 지정하는 키워드 중 하나로 바꿉니다.
- path 를 파일 또는 디렉터리의 경로로 바꿉니다.
/etc/rwtab 파일은 파일 또는 디렉토리를 tmpfs 에 복사할 수 있는 다음과 같은 방법을 인식합니다.
빈빈 경로가
tmpfs에 복사됩니다. 예를 들면 다음과 같습니다.empty /tmp
empty /tmpCopy to Clipboard Copied! Toggle word wrap Toggle overflow dirs디렉터리 트리가
tmpfs, empty로 복사됩니다. 예를 들면 다음과 같습니다.dirs /var/run
dirs /var/runCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일파일 또는 디렉터리 트리가 그대로
tmpfs에 복사됩니다. 예를 들면 다음과 같습니다.files /etc/resolv.conf
files /etc/resolv.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow
/etc/rwtab.d/ 에 사용자 지정 경로를 추가할 때 동일한 형식이 적용됩니다.
34.2. 부팅 시 읽기 전용 권한으로 마운트하도록 루트 파일 시스템 구성
이 절차를 통해 루트 파일 시스템은 다음 모든 부팅에 읽기 전용으로 마운트됩니다.
프로세스
/etc/sysconfig/readonly-root파일에서READONLY옵션을yes로 설정하여 파일 시스템을 읽기 전용으로 마운트합니다.READONLY=yes
READONLY=yesCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstab파일의 루트 항목(/)에ro옵션을 추가합니다./dev/mapper/luks-c376919e... / xfs x-systemd.device-timeout=0,ro 1 1
/dev/mapper/luks-c376919e... / xfs x-systemd.device-timeout=0,ro 1 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow ro커널 옵션을 활성화합니다.grubby --update-kernel=ALL --args="ro"
# grubby --update-kernel=ALL --args="ro"Copy to Clipboard Copied! Toggle word wrap Toggle overflow rw커널 옵션이 비활성화되어 있는지 확인합니다.grubby --update-kernel=ALL --remove-args="rw"
# grubby --update-kernel=ALL --remove-args="rw"Copy to Clipboard Copied! Toggle word wrap Toggle overflow tmpfs파일 시스템에서 쓰기 권한으로 마운트할 파일과 디렉토리를 추가해야 하는 경우/etc/rwtab.d/디렉터리에 텍스트 파일을 생성하고 여기에 구성을 배치합니다.예를 들어 쓰기 권한으로
/etc/example/file파일을 마운트하려면 다음 행을/etc/rwtab.d/example파일에 추가합니다.files /etc/example/file
files /etc/example/fileCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중요tmpfs의 파일 및 디렉터리에 대한 변경 사항은 부팅 시 유지되지 않습니다.- 시스템을 재부팅하여 변경 사항을 적용합니다.
문제 해결
읽기 전용 권한으로 root 파일 시스템을 실수로 마운트하는 경우 다음 명령을 사용하여 읽기 및 쓰기 권한으로 다시 마운트할 수 있습니다.
mount -o remount,rw /
# mount -o remount,rw /Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35장. 스토리지 장치 관리
35.1. Stratis 파일 시스템 설정
Stratis는 Red Hat Enterprise Linux를 위한 로컬 스토리지 관리 솔루션입니다. 단순성과 사용 편의성에 중점을 두고 있으며 고급 스토리지 기능에 액세스할 수 있습니다.
Stratis는 물리적 스토리지 장치 풀을 관리하는 서비스로 실행되며, 복잡한 스토리지 구성을 설정하고 관리하는 동시에 쉽게 로컬 스토리지 관리를 단순화합니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. Red Hat은 프로덕션 환경에서 사용하는 것을 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 을 참조하십시오.
Stratis는 다음을 지원합니다.
- 초기 스토리지 구성
- 나중에 변경 사항 적용
- 고급 스토리지 기능 사용
Stratis의 중앙 개념은 스토리지 풀입니다. 이 풀은 하나 이상의 로컬 디스크 또는 파티션에서 생성되며 파일 시스템은 풀에서 생성됩니다. 이 풀은 다음과 같은 기능을 활성화합니다.
- 파일 시스템 스냅샷
- 씬 프로비저닝
- 캐싱
- Encryption
35.1.1. Stratis 파일 시스템의 구성 요소
외부에서 Stratis는 명령줄과 API를 통해 다음 파일 시스템 구성 요소를 제공합니다.
blockdev- 디스크 또는 디스크 파티션과 같은 블록 장치입니다.
pool하나 이상의 블록 장치로 구성됩니다.
풀은 블록 장치의 크기와 동일한 총 크기가 고정되어 있습니다.
풀에는
dm-cache대상을 사용하는 비휘발성 데이터 캐시와 같은 대부분의 Stratis 계층이 포함되어 있습니다.Stratis는 각 풀에 대해
/dev/stratis/my-pool/디렉터리를 생성합니다. 이 디렉터리에는 풀의 Stratis 파일 시스템을 나타내는 장치에 대한 링크가 포함되어 있습니다.
filesystem각 풀은 0개 이상의 파일 시스템을 포함할 수 있습니다. 파일 시스템을 포함하는 풀은 원하는 수의 파일을 저장할 수 있습니다.
파일 시스템은 씬 프로비저닝되며 전체 크기가 고정되어 있지 않습니다. 파일 시스템의 실제 크기는 저장된 데이터와 함께 증가합니다. 데이터 크기가 파일 시스템의 가상 크기에 도달하면 Stratis에서 씬 볼륨과 파일 시스템을 자동으로 확장합니다.
파일 시스템은 XFS 파일 시스템으로 포맷됩니다.
중요Stratis는 XFS가 인식하지 못하는 파일 시스템에 대한 정보를 추적하고 XFS를 사용하여 변경한 내용은 Stratis에서 자동으로 업데이트를 생성하지 않습니다. Stratis에서 관리하는 XFS 파일 시스템을 다시 포맷하거나 재구성해서는 안 됩니다.
Stratis는
/dev/stratis/my-pool/my-fs경로에 파일 시스템에 대한 링크를 생성합니다.
Stratis는 dmsetup list 및 /proc/partitions 파일에 표시되는 많은 장치 매퍼 장치를 사용합니다. 마찬가지로 lsblk 명령 출력은 Stratis의 내부 작업 및 계층을 반영합니다.
35.1.2. Stratis와 호환되는 블록 장치
Stratis와 함께 사용할 수 있는 스토리지 장치.
지원되는 장치
Stratis 풀은 이러한 유형의 블록 장치에서 작동하도록 테스트되었습니다.
- LUKS
- LVM 논리 볼륨
- MD RAID
- DM Multipath
- iSCSI
- HDD 및 SSD
- NVMe 장치
지원되지 않는 장치
Stratis에는 씬 프로비저닝 계층이 포함되어 있으므로 이미 씬 프로비저닝된 블록 장치에 Stratis 풀을 배치하지 않는 것이 좋습니다.
35.1.3. Stratis 설치
Stratis에 필요한 패키지를 설치합니다.
절차
Stratis 서비스 및 명령줄 유틸리티를 제공하는 패키지를 설치합니다.
dnf install stratisd stratis-cli
# dnf install stratisd stratis-cliCopy to Clipboard Copied! Toggle word wrap Toggle overflow stratisd서비스를 시작하고 부팅 시 시작되도록 활성화하려면 다음을 수행합니다.systemctl enable --now stratisd
# systemctl enable --now stratisdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
stratisd서비스가 활성화되어 있고 실행 중인지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.4. 암호화되지 않은 Stratis 풀 생성
하나 이상의 블록 장치에서 암호화되지 않은 Stratis 풀을 생성할 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 풀을 생성 중인 블록 장치는 사용 중이 아니며, 마운트 해제되고, 공간이 1GB 이상입니다.
IBM Z 아키텍처에서
/dev/dasd*블록 장치를 파티셔닝해야 합니다. Stratis 풀을 생성하려면 파티션 장치를 사용합니다.DASD 장치 파티셔닝에 대한 자세한 내용은 IBM Z에서 Linux 인스턴스 구성을 참조하십시오.
생성 중에 Stratis 풀만 암호화할 수 있으며 나중에는 암호화할 수 없습니다.
절차
Stratis 풀에서 사용하려는 각 블록 장치에 존재하는 파일 시스템, 파티션 테이블 또는 RAID 서명을 삭제합니다.
wipefs --all block-device
# wipefs --all block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow block-device값은 블록 장치의 경로입니다(예:/dev/sdb).선택한 블록 장치에서 암호화되지 않은 새로운 Stratis 풀을 생성합니다.
stratis pool create my-pool block-device
# stratis pool create my-pool block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow block-device값은 비어 있거나 지워진 블록 장치의 경로입니다.다음 명령을 사용하여 한 줄에 여러 블록 장치를 지정할 수도 있습니다.
stratis pool create my-pool block-device-1 block-device-2
# stratis pool create my-pool block-device-1 block-device-2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
새 Stratis 풀이 생성되었는지 확인합니다.
stratis pool list
# stratis pool listCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.5. 웹 콘솔을 사용하여 암호화되지 않은 Stratis 풀 생성
웹 콘솔을 사용하여 하나 이상의 블록 장치에서 암호화되지 않은 Stratis 풀을 생성할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 풀을 생성 중인 블록 장치는 사용 중이 아니며, 마운트 해제되고, 공간이 1GB 이상입니다.
암호화되지 않은 Stratis 풀을 생성한 후에는 암호화할 수 없습니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 표에서 메뉴 버튼을 클릭하고 Create Stratis pool 을 선택합니다.
- 이름 필드에 Stratis 풀의 이름을 입력합니다.
- Stratis 풀을 생성할 블록 장치를 선택합니다.
- 선택 사항: 풀에서 생성된 각 파일 시스템의 최대 크기를 지정하려면 파일 시스템 크기 관리를 선택합니다.
- 을 클릭합니다.
검증
- 스토리지 섹션으로 이동하여 장치 테이블에서 새 Stratis 풀을 볼 수 있는지 확인합니다.
35.1.6. 커널 키링에서 키를 사용하여 암호화된 Stratis 풀 생성
데이터를 보호하려면 커널 인증 키를 사용하여 하나 이상의 블록 장치에서 암호화된 Stratis 풀을 생성할 수 있습니다.
이러한 방식으로 암호화된 Stratis 풀을 생성하면 커널 인증 키가 기본 암호화 메커니즘으로 사용됩니다. 후속 시스템을 재부팅한 후 이 커널 인증 키는 암호화된 Stratis 풀을 잠금 해제하는 데 사용됩니다.
하나 이상의 블록 장치에서 암호화된 Stratis 풀을 생성할 때 다음 사항에 유의하십시오.
-
각 블록 장치는
cryptsetup라이브러리를 사용하여 암호화되며LUKS2형식을 구현합니다. - 각 Stratis 풀에는 고유한 키를 포함하거나 다른 풀과 동일한 키를 공유할 수 있습니다. 이러한 키는 커널 인증 키에 저장됩니다.
- Stratis 풀을 구성하는 블록 장치는 암호화되거나 모든 암호화되지 않은 상태여야 합니다. 동일한 Stratis 풀에 암호화 및 암호화되지 않은 블록 장치를 둘 다 사용할 수 없습니다.
- 암호화된 Stratis 풀의 데이터 캐시에 추가된 블록 장치는 자동으로 암호화됩니다.
사전 요구 사항
-
Stratis v2.1.0 이상이 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 풀을 생성 중인 블록 장치는 사용 중이 아니며, 마운트 해제되고, 공간이 1GB 이상입니다.
IBM Z 아키텍처에서
/dev/dasd*블록 장치를 파티셔닝해야 합니다. Stratis 풀에서 파티션을 사용합니다.DASD 장치 파티셔닝에 대한 자세한 내용은 IBM Z에서 Linux 인스턴스 구성을 참조하십시오.
절차
Stratis 풀에서 사용하려는 각 블록 장치에 존재하는 파일 시스템, 파티션 테이블 또는 RAID 서명을 삭제합니다.
wipefs --all block-device
# wipefs --all block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow block-device값은 블록 장치의 경로입니다(예:/dev/sdb).키를 이미 설정하지 않은 경우 다음 명령을 실행하고 프롬프트에 따라 암호화에 사용할 키 세트를 생성합니다.
stratis key set --capture-key key-description
# stratis key set --capture-key key-descriptionCopy to Clipboard Copied! Toggle word wrap Toggle overflow key-description은 커널 인증 키에 생성되는 키에 대한 참조입니다. 명령줄에 키 값을 입력하라는 메시지가 표시됩니다. 키 값을 파일에 저장하고--capture-key옵션 대신--keyfile-path옵션을 사용할 수도 있습니다.암호화된 Stratis 풀을 생성하고 암호화에 사용할 키 설명을 지정합니다.
stratis pool create --key-desc key-description my-pool block-device
# stratis pool create --key-desc key-description my-pool block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow key-description- 이전 단계에서 생성한 커널 인증 키에 존재하는 키를 참조합니다.
my-pool- 새 Stratis 풀의 이름을 지정합니다.
block-device비어 있거나 초기화된 블록 장치의 경로를 지정합니다.
다음 명령을 사용하여 한 줄에 여러 블록 장치를 지정할 수도 있습니다.
stratis pool create --key-desc key-description my-pool block-device-1 block-device-2
# stratis pool create --key-desc key-description my-pool block-device-1 block-device-2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
새 Stratis 풀이 생성되었는지 확인합니다.
stratis pool list
# stratis pool listCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.7. 웹 콘솔을 사용하여 암호화된 Stratis 풀 생성
데이터를 보호하려면 웹 콘솔을 사용하여 하나 이상의 블록 장치에서 암호화된 Stratis 풀을 생성할 수 있습니다.
하나 이상의 블록 장치에서 암호화된 Stratis 풀을 생성할 때 다음 사항에 유의하십시오.
- 각 블록 장치는 cryptsetup 라이브러리를 사용하여 암호화되며 LUKS2 형식을 구현합니다.
- 각 Stratis 풀에는 고유한 키를 포함하거나 다른 풀과 동일한 키를 공유할 수 있습니다. 이러한 키는 커널 인증 키에 저장됩니다.
- Stratis 풀을 구성하는 블록 장치는 암호화되거나 모든 암호화되지 않은 상태여야 합니다. 동일한 Stratis 풀에 암호화 및 암호화되지 않은 블록 장치를 둘 다 사용할 수 없습니다.
- 암호화된 Stratis 풀의 데이터 계층에 추가된 블록 장치는 자동으로 암호화됩니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
Stratis v2.1.0 이상이 설치되고
stratisd서비스가 실행 중입니다. - Stratis 풀을 생성 중인 블록 장치는 사용 중이 아니며, 마운트 해제되고, 공간이 1GB 이상입니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 표에서 메뉴 버튼을 클릭하고 Create Stratis pool 을 선택합니다.
- 이름 필드에 Stratis 풀의 이름을 입력합니다.
- Stratis 풀을 생성할 블록 장치를 선택합니다.
암호화 유형을 선택합니다. 암호, Tang 키 서버 또는 둘 다 사용할 수 있습니다.
암호:
- 암호를 입력합니다.
- 암호를 확인합니다.
Tang 키 서버:
- 키 서버 주소를 입력합니다. 자세한 내용은 강제 모드에서 SELinux를 사용하여 Tang 서버 배포를 참조하십시오.
- 선택 사항: 풀에서 생성된 각 파일 시스템의 최대 크기를 지정하려면 파일 시스템 크기 관리를 선택합니다.
- 을 클릭합니다.
검증
- 스토리지 섹션으로 이동하여 장치 테이블에서 새 Stratis 풀을 볼 수 있는지 확인합니다.
35.1.8. 웹 콘솔을 사용하여 Stratis 풀 이름 변경
웹 콘솔을 사용하여 기존 Stratis 풀의 이름을 변경할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
Stratis가 설치되고
stratisd서비스가 실행 중입니다.웹 콘솔은 기본적으로 Stratis를 감지하고 설치합니다. 그러나 Stratis를 수동으로 설치하려면 Stratis 설치를 참조하십시오.
- Stratis 풀이 생성됩니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 테이블에서 이름을 변경할 Stratis 풀을 클릭합니다.
- Stratis 풀 페이지에서 이름 필드 옆에 있는 클릭합니다.
- Rename Stratis 풀 대화 상자에 새 이름을 입력합니다.
- 을 클릭합니다.
35.1.9. Stratis 파일 시스템에서 프로비저닝 모드 설정
기본적으로 모든 Stratis 풀이 프로비저닝되므로 논리 파일 시스템 크기가 물리적으로 할당된 공간을 초과할 수 있습니다. Stratis는 파일 시스템 사용량을 모니터링하고 필요한 경우 사용 가능한 공간을 사용하여 자동으로 할당을 늘립니다. 그러나 사용 가능한 모든 공간이 이미 할당되어 있고 풀이 가득 차면 파일 시스템에 추가 공간을 할당할 수 없습니다.
파일 시스템이 공간이 부족하면 사용자가 데이터가 손실될 수 있습니다. 데이터가 손실될 위험이 초과된 애플리케이션의 경우 이 기능을 비활성화할 수 있습니다.
Stratis는 풀 사용량을 지속적으로 모니터링하고 D-Bus API를 사용하여 값을 보고합니다. 스토리지 관리자는 이러한 값을 모니터링하고 필요에 따라 풀에 장치를 추가하여 용량에 도달하지 못하도록 해야 합니다.
사전 요구 사항
- Stratis가 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
절차
풀을 올바르게 설정하려면 다음 두 가지 가능성이 있습니다.
하나 이상의 블록 장치에서 풀을 생성합니다.
stratis pool create pool-name /dev/sdb
# stratis pool create pool-name /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 풀에서 overprovisioning 모드를 설정합니다.
stratis pool overprovision pool-name <yes|no>
# stratis pool overprovision pool-name <yes|no>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - "yes"로 설정하면 풀로 Overprovisioning을 활성화합니다. 즉, 풀에서 지원하는 Stratis 파일 시스템의 논리 크기 합계는 사용 가능한 데이터 공간 크기를 초과할 수 있습니다. 풀이 초과 프로비저닝되고 모든 파일 시스템의 논리 크기 합계가 풀에서 사용 가능한 공간을 초과하면 시스템은 프로비저닝을 끄고 오류를 반환할 수 없습니다.
검증
Stratis 풀의 전체 목록을 확인합니다.
stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540
# stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
stratis pool list출력의 pool overprovisioning 모드 플래그가 있는지 확인합니다. " ~"은 "NOT"의 수치 기호이므로~Op는 프로비저닝이 없음을 의미합니다. 선택 사항: 특정 풀에서 프로비저닝을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.10. NBDE에 Stratis 풀 바인딩
암호화된 Stratis 풀을 NBDE(Network Bound Disk Encryption)에 바인딩하려면 Tang 서버가 필요합니다. Stratis 풀이 포함된 시스템이 재부팅되면 Tang 서버와 연결하여 커널 인증 키 설명을 제공하지 않고도 암호화된 풀의 잠금을 자동으로 해제합니다.
Stratis 풀을 보조 Clevis 암호화 메커니즘에 바인딩해도 기본 커널 인증 키 암호화는 제거되지 않습니다.
사전 요구 사항
-
Stratis v2.3.0 이상이 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - 암호화된 Stratis 풀이 생성되고 암호화에 사용된 키에 대한 주요 설명이 있습니다. 자세한 내용은 커널 키링의 키를 사용하여 암호화된 Stratis 풀 생성을 참조하십시오.
- Tang 서버에 연결할 수 있습니다. 자세한 내용은 강제 모드에서 SELinux를 사용하여 Tang 서버 배포를 참조하십시오.
프로세스
암호화된 Stratis 풀을 NBDE에 바인딩합니다.
stratis pool bind nbde --trust-url my-pool tang-server
# stratis pool bind nbde --trust-url my-pool tang-serverCopy to Clipboard Copied! Toggle word wrap Toggle overflow my-pool- 암호화된 Stratis 풀의 이름을 지정합니다.
tang-server- Tang 서버의 IP 주소 또는 URL을 지정합니다.
35.1.11. Stratis 풀을 TPM에 바인딩
암호화된 Stratis 풀을 신뢰할 수 있는 플랫폼 모듈(TPM) 2.0에 바인딩하면 풀이 재부팅되고 커널 키링 설명을 제공하지 않고도 풀이 자동으로 잠금 해제됩니다.
사전 요구 사항
-
Stratis v2.3.0 이상이 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - 암호화된 Stratis 풀이 생성되고 암호화에 사용된 키에 대한 주요 설명이 있습니다. 자세한 내용은 커널 키링의 키를 사용하여 암호화된 Stratis 풀 생성을 참조하십시오.
- 시스템이 TPM 2.0을 지원합니다.
프로세스
암호화된 Stratis 풀을 TPM에 바인딩합니다.
stratis pool bind tpm my-pool
# stratis pool bind tpm my-poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow my-pool- 암호화된 Stratis 풀의 이름을 지정합니다.
key-description- 암호화된 Stratis 풀을 생성할 때 생성된 커널 인증 키에 존재하는 키를 참조합니다.
35.1.12. 커널 인증 키를 사용하여 암호화된 Stratis 풀 잠금 해제
시스템을 재부팅한 후 암호화된 Stratis 풀 또는 이를 구성하는 블록 장치가 표시되지 않을 수 있습니다. 풀을 암호화하는 데 사용된 커널 인증 키를 사용하여 풀 잠금을 해제할 수 있습니다.
사전 요구 사항
-
Stratis v2.1.0이 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - 암호화된 Stratis 풀이 생성됩니다. 자세한 내용은 커널 키링의 키를 사용하여 암호화된 Stratis 풀 생성을 참조하십시오.
프로세스
이전에 사용된 것과 동일한 키 설명을 사용하여 키 세트를 다시 생성합니다.
stratis key set --capture-key key-description
# stratis key set --capture-key key-descriptionCopy to Clipboard Copied! Toggle word wrap Toggle overflow key-description은 암호화된 Stratis 풀을 생성할 때 생성된 커널 인증 키에 존재하는 키를 참조합니다.Stratis 풀이 표시되는지 확인합니다.
stratis pool list
# stratis pool listCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.13. 보조 암호화에서 Stratis 풀 바인딩 해제
지원되는 보조 암호화 메커니즘에서 암호화된 Stratis 풀을 바인딩 해제하면 기본 커널 키링 암호화가 그대로 유지됩니다. 처음부터 Clevis 암호화로 생성된 풀에는 사실이 아닙니다.
사전 요구 사항
- Stratis v2.3.0 이상이 시스템에 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
- 암호화된 Stratis 풀이 생성됩니다. 자세한 내용은 커널 키링의 키를 사용하여 암호화된 Stratis 풀 생성을 참조하십시오.
- 암호화된 Stratis 풀은 지원되는 보조 암호화 메커니즘에 바인딩됩니다.
프로세스
보조 암호화 메커니즘에서 암호화된 Stratis 풀을 바인딩 해제합니다.
stratis pool unbind clevis my-pool
# stratis pool unbind clevis my-poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow my-pool은 바인딩 해제하려는 Stratis 풀의 이름을 지정합니다.
35.1.14. Stratis 풀 시작 및 중지
Stratis 풀을 시작하고 중지할 수 있습니다. 이 옵션을 사용하면 파일 시스템, 캐시 장치, 씬 풀, 암호화된 장치와 같이 풀을 구성하는 데 사용된 모든 오브젝트를 제거하거나 중단할 수 있습니다. 풀이 장치 또는 파일 시스템을 적극적으로 사용하는 경우 경고가 표시될 수 있으며 중지할 수 없습니다.
중지된 상태는 풀의 메타데이터에 기록됩니다. 이러한 풀은 풀이 start 명령을 수신할 때까지 다음 부팅에서 시작되지 않습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - 암호화되지 않은 Stratis 또는 암호화된 Stratis 풀이 생성됩니다. 자세한 내용은 암호화되지 않은 Stratis 풀 생성 또는 커널 인증 키의 키를 사용하여 암호화된 Stratis 풀 생성을 참조하십시오.
프로세스
다음 명령을 사용하여 Stratis 풀을 중지합니다. 이렇게 하면 스토리지 스택이 제거되지만 모든 메타데이터는 그대로 유지됩니다.
stratis pool stop --name pool-name
# stratis pool stop --name pool-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 사용하여 Stratis 풀을 시작합니다.
--unlock-method옵션은 암호화된 경우 풀 잠금을 해제하는 방법을 지정합니다.stratis pool start --unlock-method <keyring|clevis> --name pool-name
# stratis pool start --unlock-method <keyring|clevis> --name pool-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고풀 이름 또는 풀 UUID를 사용하여 풀을 시작할 수 있습니다.
검증
다음 명령을 사용하여 시스템의 모든 활성 풀을 나열합니다.
stratis pool list
# stratis pool listCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 사용하여 중지된 모든 풀을 나열합니다.
stratis pool list --stopped
# stratis pool list --stoppedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중지된 풀에 대한 자세한 정보를 보려면 다음 명령을 사용합니다. UUID가 지정되면 명령은 UUID에 해당하는 풀에 대한 자세한 정보를 출력합니다.
stratis pool list --stopped --uuid UUID
# stratis pool list --stopped --uuid UUIDCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.15. Stratis 파일 시스템 생성
기존 Stratis 풀에서 Stratis 파일 시스템을 생성합니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 풀이 생성됩니다. 자세한 내용은 암호화되지 않은 Stratis 풀 생성 또는 커널 인증 키의 키 사용을 참조하십시오.
프로세스
풀에 Stratis 파일 시스템을 생성합니다.
stratis filesystem create --size number-and-unit my-pool my-fs
# stratis filesystem create --size number-and-unit my-pool my-fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow number-and-unit- 파일 시스템의 크기를 지정합니다. 사양 형식은 입력에 대한 표준 크기 사양 형식(B, KiB, MiB, GiB, TiB 또는 PiB)을 따라야 합니다.
my-pool- Stratis 풀의 이름을 지정합니다.
my-fs파일 시스템의 임의의 이름을 지정합니다.
예를 들면 다음과 같습니다.
예 35.1. Stratis 파일 시스템 생성
stratis filesystem create --size 10GiB pool1 filesystem1
# stratis filesystem create --size 10GiB pool1 filesystem1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
풀 내에 파일 시스템을 나열하여 Stratis 파일 시스템이 생성되었는지 확인합니다.
stratis fs list my-pool
# stratis fs list my-poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.1.16. 웹 콘솔을 사용하여 Stratis 풀에서 파일 시스템 생성
웹 콘솔을 사용하여 기존 Stratis 풀에서 파일 시스템을 생성할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 풀이 생성됩니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 파일 시스템을 생성할 Stratis 풀을 클릭합니다.
- Stratis 풀 페이지에서 Stratis 파일 시스템 섹션으로 스크롤하고 .
- 파일 시스템의 이름을 입력합니다.
- 파일 시스템의 마운트 지점을 입력합니다.
- 마운트 옵션을 선택합니다.
- 부팅 시 드롭다운 메뉴에서 파일 시스템을 마운트할 시기를 선택합니다.
파일 시스템을 생성합니다.
- 파일 시스템을 생성하고 마운트하려면 를 클릭합니다.
- 파일 시스템만 만들려면 을 클릭합니다.
검증
- 새 파일 시스템은 Stratis 파일 시스템 탭 아래의 Stratis 풀 페이지에 표시됩니다.
35.1.17. Stratis 파일 시스템 마운트
기존 Stratis 파일 시스템을 마운트하여 콘텐츠에 액세스합니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 파일 시스템이 생성됩니다. 자세한 내용은 Stratis 파일 시스템 생성을 참조하십시오.
프로세스
파일 시스템을 마운트하려면 Stratis가
/dev/stratis/디렉터리에서 유지 관리하는 항목을 사용합니다.mount /dev/stratis/my-pool/my-fs mount-point
# mount /dev/stratis/my-pool/my-fs mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
이제 파일 시스템이 마운트 지점 디렉터리에 마운트 되어 사용할 준비가 되었습니다.
중지하기 전에 풀에 속하는 모든 파일 시스템을 마운트 해제합니다. 파일 시스템이 여전히 마운트된 경우 풀이 중지되지 않습니다.
35.1.18. systemd 서비스를 사용하여 /etc/fstab에서 루트가 아닌 Stratis 파일 시스템 설정
systemd 서비스를 사용하여 /etc/fstab 에서 루트가 아닌 파일 시스템 설정을 관리할 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 파일 시스템이 생성됩니다. 자세한 내용은 Stratis 파일 시스템 생성을 참조하십시오.
프로세스
root 로서
/etc/fstab파일을 편집하고 root가 아닌 파일 시스템을 설정하는 행을 추가합니다./dev/stratis/my-pool/my-fs mount-point xfs defaults,x-systemd.requires=stratis-fstab-setup@pool-uuid.service,x-systemd.after=stratis-fstab-setup@pool-uuid.service dump-value fsck_value
/dev/stratis/my-pool/my-fs mount-point xfs defaults,x-systemd.requires=stratis-fstab-setup@pool-uuid.service,x-systemd.after=stratis-fstab-setup@pool-uuid.service dump-value fsck_valueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
암호화된 Stratis 풀에서 Stratis 파일 시스템을 영구적으로 마운트하면 암호가 제공될 때까지 부팅 프로세스가 중지될 수 있습니다. 자동 메커니즘을 사용하여 풀을 암호화하는 경우(예: NBDE 또는 TPM2) Stratis 풀은 자동으로 잠금 해제됩니다. 그렇지 않은 경우 사용자가 콘솔에 암호를 입력해야 합니다.
35.2. 추가 블록 장치를 사용하여 Stratis 풀 확장
Stratis 풀에 추가 블록 장치를 연결하여 Stratis 파일 시스템에 더 많은 스토리지 용량을 제공할 수 있습니다. 수동으로 또는 웹 콘솔을 사용하여 수행할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. Red Hat은 프로덕션 환경에서 사용하는 것을 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 을 참조하십시오.
35.2.1. Stratis 풀에 블록 장치 추가
Stratis 풀에 하나 이상의 블록 장치를 추가할 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 풀을 생성 중인 블록 장치는 사용 중이 아니며, 마운트 해제되고, 공간이 1GB 이상입니다.
프로세스
하나 이상의 블록 장치를 풀에 추가하려면 다음을 사용합니다.
stratis pool add-data my-pool device-1 device-2 device-n
# stratis pool add-data my-pool device-1 device-2 device-nCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.2.2. 웹 콘솔을 사용하여 Stratis 풀에 블록 장치 추가
웹 콘솔을 사용하여 기존 Stratis 풀에 블록 장치를 추가할 수 있습니다. 캐시를 블록 장치로 추가할 수도 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 풀이 생성됩니다.
- Stratis 풀을 생성 중인 블록 장치는 사용 중이 아니며, 마운트 해제되고, 공간이 1GB 이상입니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 테이블에서 블록 장치를 추가할 Stratis 풀을 클릭합니다.
- Stratis 풀 페이지에서 데이터 또는 캐시로 추가할 계층 위치를 선택합니다.
- 암호로 암호화된 Stratis 풀에 블록 장치를 추가하는 경우 암호를 입력합니다.
- 블록 장치에서 풀에 추가할 장치를 선택합니다.
- 를 클릭합니다.
35.3. Stratis 파일 시스템 모니터링
Stratis 사용자는 시스템의 Stratis 파일 시스템에 대한 정보를 확인하여 상태 및 여유 공간을 모니터링할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. Red Hat은 프로덕션 환경에서 사용하는 것을 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 을 참조하십시오.
35.3.1. Stratis 파일 시스템에 대한 정보 표시
stratis 유틸리티를 사용하여 풀에 속한 총 크기 또는 파일 시스템 및 블록 장치와 같은 Stratis 파일 시스템에 대한 통계를 나열할 수 있습니다.
XFS 파일 시스템의 크기는 관리할 수 있는 총 사용자 데이터 양입니다. 씬 프로비저닝된 Stratis 풀에서 Stratis 파일 시스템에는 할당된 공간보다 큰 크기가 있는 것처럼 보일 수 있습니다. XFS 파일 시스템은 이 명확한 크기와 일치하도록 크기가 조정되므로 일반적으로 할당된 공간보다 큽니다. df와 같은 표준 Linux 유틸리티는 XFS 파일 시스템의 크기를 보고합니다. 이 값은 일반적으로 XFS 파일 시스템에 필요한 공간을 초과하므로 Stratis에서 할당된 공간을 덮어씁니다.
과도하게 프로비저닝된 Stratis 풀의 사용을 정기적으로 모니터링합니다. 파일 시스템 사용량이 할당된 공간에 접근하면 Stratis는 풀에서 사용 가능한 공간을 사용하여 자동으로 할당을 늘립니다. 그러나 사용 가능한 모든 공간이 이미 할당되어 있고 풀이 가득 차면 추가 공간을 할당할 수 없으므로 파일 시스템이 공간이 부족해집니다. 이로 인해 Stratis 파일 시스템을 사용하여 애플리케이션에서 데이터가 손실될 위험이 발생할 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오.
프로세스
시스템의 Stratis에 사용되는 모든 블록 장치에 대한 정보를 표시하려면 다음을 수행합니다.
stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use Data
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use DataCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템의 모든 Stratis 풀에 대한 정보를 표시하려면 다음을 수행합니다.
stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiB
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템의 모든 Stratis 파일 시스템에 대한 정보를 표시하려면 다음을 수행합니다.
stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /dev/stratis/my-pool/my-fs
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /dev/stratis/my-pool/my-fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.3.2. 웹 콘솔을 사용하여 Stratis 풀 보기
웹 콘솔을 사용하여 기존 Stratis 풀 및 포함된 파일 시스템을 볼 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 기존 Stratis 풀이 있습니다.
프로세스
- RHEL 8 웹 콘솔에 로그인합니다.
- 스토리지를 .
스토리지 테이블에서 볼 Stratis 풀을 클릭합니다.
Stratis 풀 페이지에는 풀에 대한 모든 정보와 풀에서 생성한 파일 시스템이 표시됩니다.
35.4. Stratis 파일 시스템에서 스냅샷 사용
Stratis 파일 시스템의 스냅샷을 사용하여 임의의 시간에 파일 시스템 상태를 캡처하고 나중에 복원할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. Red Hat은 프로덕션 환경에서 사용하는 것을 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 을 참조하십시오.
35.4.1. Stratis 스냅샷의 특성
Stratis에서 스냅샷은 다른 Stratis 파일 시스템의 사본으로 생성된 일반 Stratis 파일 시스템입니다.
Stratis의 현재 스냅샷 구현은 다음과 같습니다.
- 파일 시스템의 스냅샷은 다른 파일 시스템입니다.
- 스냅샷과 원본은 수명 동안 연결되지 않습니다. 스냅샷된 파일 시스템은 생성된 파일 시스템보다 오래 지속될 수 있습니다.
- 스냅샷 생성을 위해 파일 시스템을 마운트할 필요가 없습니다.
- 각 스냅샷은 XFS 로그에 필요한 실제 백업 스토리지의 약 절반을 사용합니다.
35.4.2. Stratis 스냅샷 생성
Stratis 파일 시스템을 기존 Stratis 파일 시스템의 스냅샷으로 생성할 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 파일 시스템을 생성했습니다. 자세한 내용은 Stratis 파일 시스템 생성을 참조하십시오.
프로세스
Stratis 스냅샷을 생성합니다.
stratis fs snapshot my-pool my-fs my-fs-snapshot
# stratis fs snapshot my-pool my-fs my-fs-snapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow
스냅샷은 첫 번째 클래스 Stratis 파일 시스템입니다. 여러 Stratis 스냅샷을 생성할 수 있습니다. 여기에는 단일 원본 파일 시스템 또는 다른 스냅샷 파일 시스템의 스냅샷이 포함됩니다. 파일 시스템이 스냅샷인 경우 origin 필드는 자세한 파일 시스템 목록에 원본 파일 시스템의 UUID를 표시합니다.
35.4.3. Stratis 스냅샷의 콘텐츠에 액세스
Stratis 파일 시스템의 스냅샷을 마운트하여 읽기 및 쓰기 작업에서 액세스할 수 있도록 할 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 스냅샷을 생성했습니다. 자세한 내용은 Stratis 스냅샷 생성을 참조하십시오.
프로세스
스냅샷에 액세스하려면
/dev/stratis/my-pool/디렉토리에서 일반 파일 시스템으로 마운트하십시오.mount /dev/stratis/my-pool/my-fs-snapshot mount-point
# mount /dev/stratis/my-pool/my-fs-snapshot mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.4.4. Stratis 파일 시스템을 이전 스냅샷으로 되돌리기
Stratis 파일 시스템의 콘텐츠를 Stratis 스냅샷에 캡처된 상태로 되돌릴 수 있습니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 스냅샷을 생성했습니다. 자세한 내용은 Stratis 스냅샷 생성을 참조하십시오.
프로세스
선택 사항: 나중에 액세스할 수 있도록 파일 시스템의 현재 상태를 백업합니다.
stratis filesystem snapshot my-pool my-fs my-fs-backup
# stratis filesystem snapshot my-pool my-fs my-fs-backupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원래 파일 시스템을 마운트 해제하고 제거합니다.
umount /dev/stratis/my-pool/my-fs stratis filesystem destroy my-pool my-fs
# umount /dev/stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원본 파일 시스템의 이름으로 스냅샷의 사본을 생성합니다.
stratis filesystem snapshot my-pool my-fs-snapshot my-fs
# stratis filesystem snapshot my-pool my-fs-snapshot my-fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이제 원래 파일 시스템과 동일한 이름으로 액세스할 수 있는 스냅샷을 마운트합니다.
mount /dev/stratis/my-pool/my-fs mount-point
# mount /dev/stratis/my-pool/my-fs mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow
my-fs 라는 파일 시스템의 내용은 이제 스냅샷 my-fs-snapshot 과 동일합니다.
35.4.5. Stratis 스냅샷 제거
풀에서 Stratis 스냅샷을 제거할 수 있습니다. 스냅샷의 데이터가 손실됩니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 스냅샷을 생성했습니다. 자세한 내용은 Stratis 스냅샷 생성을 참조하십시오.
프로세스
스냅샷을 마운트 해제합니다.
umount /dev/stratis/my-pool/my-fs-snapshot
# umount /dev/stratis/my-pool/my-fs-snapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스냅샷을 삭제합니다.
stratis filesystem destroy my-pool my-fs-snapshot
# stratis filesystem destroy my-pool my-fs-snapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.5. Stratis 파일 시스템 제거
기존 Stratis 파일 시스템 또는 풀을 제거할 수 있습니다. Stratis 파일 시스템 또는 풀이 제거되면 복구할 수 없습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. Red Hat은 프로덕션 환경에서 사용하는 것을 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 을 참조하십시오.
35.5.1. Stratis 파일 시스템 제거
기존 Stratis 파일 시스템을 제거할 수 있습니다. 저장된 데이터는 손실됩니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. - Stratis 파일 시스템을 생성했습니다. 자세한 내용은 Stratis 파일 시스템 생성을 참조하십시오.
절차
파일 시스템을 마운트 해제합니다.
umount /dev/stratis/my-pool/my-fs
# umount /dev/stratis/my-pool/my-fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템을 삭제합니다.
stratis filesystem destroy my-pool my-fs
# stratis filesystem destroy my-pool my-fsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
파일 시스템이 더 이상 존재하지 않는지 확인합니다.
stratis filesystem list my-pool
# stratis filesystem list my-poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.5.2. 웹 콘솔을 사용하여 Stratis 풀에서 파일 시스템 삭제
웹 콘솔을 사용하여 기존 Stratis 풀에서 파일 시스템을 삭제할 수 있습니다.
Stratis 풀 파일 시스템을 삭제하면 포함된 모든 데이터가 지워집니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
Stratis가 설치되고
stratisd서비스가 실행 중입니다.웹 콘솔은 기본적으로 Stratis를 감지하고 설치합니다. 그러나 Stratis를 수동으로 설치하려면 Stratis 설치를 참조하십시오.
- 기존 Stratis 풀이 있고 Stratis 풀에 파일 시스템이 생성됩니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 표에서 파일 시스템을 삭제할 Stratis 풀을 클릭합니다.
- Stratis 풀 페이지에서 Stratis 파일 시스템 섹션으로 스크롤하고 삭제하려는 파일 시스템의 메뉴 버튼을 클릭합니다.
- 드롭다운 메뉴에서 를 선택합니다.
- 삭제 확인 대화 상자에서 삭제 를 클릭합니다.
35.5.3. Stratis 풀 제거
기존 Stratis 풀을 제거할 수 있습니다. 저장된 데이터는 손실됩니다.
사전 요구 사항
-
Stratis가 설치되고
stratisd서비스가 실행 중입니다. 자세한 내용은 Stratis 설치를 참조하십시오. Stratis 풀을 생성했습니다.
- 암호화되지 않은 풀을 만들려면 암호화되지 않은 Stratis 풀 생성을 참조하십시오.
- 암호화된 풀을 생성하려면 커널 인증 키의 키를 사용하여 암호화된 Stratis 풀 생성을 참조하십시오.
프로세스
풀의 파일 시스템을 나열합니다.
stratis filesystem list my-pool
# stratis filesystem list my-poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow 풀의 모든 파일 시스템을 마운트 해제합니다.
umount /dev/stratis/my-pool/my-fs-1 \ /dev/stratis/my-pool/my-fs-2 \ /dev/stratis/my-pool/my-fs-n# umount /dev/stratis/my-pool/my-fs-1 \ /dev/stratis/my-pool/my-fs-2 \ /dev/stratis/my-pool/my-fs-nCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템을 삭제합니다.
stratis filesystem destroy my-pool my-fs-1 my-fs-2
# stratis filesystem destroy my-pool my-fs-1 my-fs-2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 풀을 삭제합니다.
stratis pool destroy my-pool
# stratis pool destroy my-poolCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
풀이 더 이상 존재하지 않는지 확인합니다.
stratis pool list
# stratis pool listCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.5.4. 웹 콘솔을 사용하여 Stratis 풀 삭제
웹 콘솔을 사용하여 기존 Stratis 풀을 삭제할 수 있습니다.
Stratis 풀을 삭제하면 포함된 모든 데이터가 지워집니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 기존 Stratis 풀이 있습니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 테이블에서 삭제하려는 Stratis 대한 메뉴 버튼을 클릭합니다.
- 드롭다운 메뉴에서 를 선택합니다.
- Permanently delete pool 대화 상자에서 를 클릭합니다.
35.6. 스왑 시작하기
스왑 공간을 사용하여 비활성 프로세스 및 데이터에 임시 스토리지를 제공하고 물리적 메모리가 가득 차면 메모리 부족 오류를 방지합니다. 스왑 공간은 실제 메모리의 확장 기능 역할을 하며 물리적 메모리가 소진된 경우에도 시스템이 원활하게 계속 실행되도록 합니다. 스왑 공간을 사용하면 시스템 성능이 저하될 수 있으므로 스왑 공간을 사용하기 전에 물리적 메모리 사용을 최적화할 수 있습니다.
35.6.1. 스왑 공간 개요
Linux의 스왑 공간은 실제 메모리(RAM)가 가득 차면 사용됩니다. 시스템에 더 많은 메모리 리소스가 필요하고 RAM이 가득 차 있으면 메모리의 비활성 페이지가 스왑 공간으로 이동합니다. 스왑 공간은 RAM이 적은 시스템에 도움이 될 수 있지만 더 많은 RAM을 대체하는 것은 아닙니다.
스왑 공간은 실제 메모리보다 더 느린 액세스 시간이 있는 하드 드라이브에 있습니다. 스왑 공간은 전용 스왑 파티션(권장), 스왑 파일 또는 스왑 파티션과 스왑 파일의 조합일 수 있습니다.
지난 몇 년 간 권장 스왑 공간은 시스템의 RAM 양과 함께 선형적으로 증가했습니다. 그러나 최신 시스템에는 수백 기가바이트의 RAM이 포함된 경우가 많습니다. 따라서 권장되는 스왑 공간은 시스템 메모리가 아닌 시스템 메모리 워크로드의 기능으로 간주됩니다.
35.6.2. 권장되는 시스템 스왑 공간
스왑 파티션의 권장 크기는 시스템의 RAM 크기와 시스템이 hibernate에 충분한 메모리를 원하는지에 따라 달라집니다. 권장되는 스왑 파티션 크기는 설치 중에 자동으로 설정됩니다. 하지만 최대 절전 모드를 허용하려면 사용자 지정 파티션 단계에서 스왑 공간을 편집해야 합니다.
메모리 부족(예: 1GB 이하)에서 다음 권장 사항은 특히 중요합니다. 이러한 시스템에 충분한 스왑 공간을 할당하지 않으면 불안정과 같은 문제가 발생할 수 있거나 설치된 시스템을 부팅할 수 없게 될 수도 있습니다.
| 시스템의 RAM 크기 | 권장 스왑 공간 | 최대 절전 모드를 허용하는 경우 권장 스왑 공간 |
|---|---|---|
| 2GB | RAM의 2 배 | RAM의 3 배 |
| > 2 GB - 8 GB | RAM의 양과 같음 | RAM의 2 배 |
| > 8 GB - 64 GB | 최소 4GB | RAM의 1.5 배 |
| > 64GB | 최소 4GB | 최대 절전 모드는 권장되지 않음 |
2GB, 8GB 또는 64GB의 시스템 RAM과 같은 경계 값의 경우 요구 사항 또는 기본 설정에 따라 스왑 크기를 선택합니다. 시스템 리소스에서 허용하는 경우 스왑 공간을 늘리면 성능이 향상될 수 있습니다.
여러 스토리지 장치에 스왑 공간을 분산하면 특히 빠른 드라이브, 컨트롤러 및 인터페이스가 있는 시스템에서 스왑 공간 성능이 향상됩니다.
스왑 공간으로 할당된 파일 시스템 및 LVM2 볼륨은 수정 시 사용해서는 안 됩니다. 스왑을 수정하려는 시도는 시스템 프로세스 또는 커널이 스왑 공간을 사용하는 경우 실패합니다. free 및 cat /proc/swaps 명령을 사용하여 스왑이 사용 중인 양과 위치를 확인합니다.
스왑 공간 크기를 조정하려면 시스템에서 일시적으로 제거해야 합니다. 이는 실행 중인 애플리케이션이 추가 스왑 공간을 사용하고 메모리 부족 상황에서 실행될 수 있는 경우 문제가 될 수 있습니다. 복구 모드에서 스왑 크기 조정을 수행하는 것이 좋습니다. 디버그 부팅 옵션을 참조하십시오. 파일 시스템을 마운트하라는 메시지가 표시되면 을 선택합니다.
35.6.3. 스왑을 위한 LVM2 논리 볼륨 생성
스왑에 사용할 LVM2 논리 볼륨을 만들 수 있습니다. /dev/VolGroup00/LogVol02 를 추가하려는 스왑 볼륨이라고 가정합니다.
사전 요구 사항
- 디스크 공간이 충분합니다.
프로세스
2GB 크기의 LVM2 논리 볼륨을 만듭니다.
lvcreate VolGroup00 -n LogVol02 -L 2G
# lvcreate VolGroup00 -n LogVol02 -L 2GCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 스왑 공간을 포맷합니다.
mkswap /dev/VolGroup00/LogVol02
# mkswap /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstab파일에 다음 항목을 추가합니다./dev/VolGroup00/LogVol02 none swap defaults 0 0
/dev/VolGroup00/LogVol02 none swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템이 새 구성을 등록하도록 마운트 단위를 다시 생성합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨에서 스왑을 활성화합니다.
swapon -v /dev/VolGroup00/LogVol02
# swapon -v /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
스왑 논리 볼륨이 성공적으로 생성되고 활성화되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
cat /proc/swaps total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 22Gi 0B 22Gi# cat /proc/swaps total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 22Gi 0B 22GiCopy to Clipboard Copied! Toggle word wrap Toggle overflow free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 995Mi 28Gi Swap: 17Gi 0B 17Gi# free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 995Mi 28Gi Swap: 17Gi 0B 17GiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.6.4. 스왑 파일 만들기
스왑 파일을 만들어 시스템이 메모리에서 부족해지는 경우 솔리드 스테이트 드라이브 또는 하드 디스크에 임시 스토리지 공간을 만들 수 있습니다.
사전 요구 사항
- 디스크 공간이 충분합니다.
프로세스
- 새 스왑 파일의 크기를 메가바이트 단위로 결정하고 1024를 곱하여 블록 수를 결정합니다. 예를 들어 64MB 스왑 파일의 블록 크기는 65536입니다.
빈 파일을 생성합니다.
dd if=/dev/zero of=/swapfile bs=1024 count=65536
# dd if=/dev/zero of=/swapfile bs=1024 count=65536Copy to Clipboard Copied! Toggle word wrap Toggle overflow 65536 을 필요한 블록 크기와 동일한 값으로 바꿉니다.
명령을 사용하여 스왑 파일을 설정합니다.
mkswap /swapfile
# mkswap /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스왑 파일의 보안을 세계로 읽을 수 없도록 변경합니다.
chmod 0600 /swapfile
# chmod 0600 /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow 부팅 시 스왑 파일을 활성화하려면 다음 항목으로
/etc/fstab파일을 편집합니다./swapfile none swap defaults 0 0
/swapfile none swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음에 시스템이 부팅되면 새 스왑 파일이 활성화됩니다.
시스템이 새
/etc/fstab구성을 등록하도록 마운트 단위를 다시 생성합니다.systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 즉시 스왑 파일을 활성화합니다.
swapon /swapfile
# swapon /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
새 스왑 파일이 성공적으로 생성되고 활성화되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
cat /proc/swaps
$ cat /proc/swapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow free -h
$ free -hCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.6.5. 스토리지 RHEL 시스템 역할을 사용하여 스왑 볼륨 생성
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 기본 매개 변수를 사용하여 블록 장치에서 스왑 볼륨을 생성하거나 스왑 볼륨이 없는 경우 스왑 볼륨을 수정하는 데 스토리지 역할을 적용합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 이름(예의
swap_fs)은 현재 임의의 상태입니다.스토리지역할은disks:속성에 나열된 디스크 장치로 볼륨을 식별합니다.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.6.6. LVM2 논리 볼륨에서 스왑 확장
기존 LVM2 논리 볼륨에서 스왑 공간을 확장할 수 있습니다. /dev/VolGroup00/LogVol01 이 2GB 까지 확장할 볼륨이라고 가정합니다.
사전 요구 사항
- 디스크 공간이 충분합니다.
프로세스
연결된 논리 볼륨의 스왑을 비활성화합니다.
swapoff -v /dev/VolGroup00/LogVol01
# swapoff -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow LVM2 논리 볼륨의 크기를 2GB 로 조정합니다.
lvresize /dev/VolGroup00/LogVol01 -L +2G
# lvresize /dev/VolGroup00/LogVol01 -L +2GCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 스왑 공간을 포맷합니다.
mkswap /dev/VolGroup00/LogVol01
# mkswap /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 확장 논리 볼륨을 활성화합니다.
swapon -v /dev/VolGroup00/LogVol01
# swapon -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
스왑 논리 볼륨이 성공적으로 확장 및 활성화되었는지 테스트하려면 활성 스왑 공간을 검사합니다.
cat /proc/swaps Filename Type Size Used Priority /dev/dm-1 partition 16322556 0 -2 /dev/dm-4 partition 7340028 0 -3
# cat /proc/swaps Filename Type Size Used Priority /dev/dm-1 partition 16322556 0 -2 /dev/dm-4 partition 7340028 0 -3Copy to Clipboard Copied! Toggle word wrap Toggle overflow free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 22Gi 0B 22Gi# free -h total used free shared buff/cache available Mem: 30Gi 1.2Gi 28Gi 12Mi 994Mi 28Gi Swap: 22Gi 0B 22GiCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.6.7. LVM2 논리 볼륨에서 스왑 감소
LVM2 논리 볼륨에서 스왑을 줄일 수 있습니다. /dev/VolGroup00/LogVol01 이 줄려는 볼륨이라고 가정합니다.
프로세스
연결된 논리 볼륨의 스왑을 비활성화합니다.
swapoff -v /dev/VolGroup00/LogVol01
# swapoff -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 스왑 서명을 정리합니다.
wipefs -a /dev/VolGroup00/LogVol01
# wipefs -a /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow LVM2 논리 볼륨을 512MB로 줄입니다.
lvreduce /dev/VolGroup00/LogVol01 -L -512M
# lvreduce /dev/VolGroup00/LogVol01 -L -512MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새 스왑 공간을 포맷합니다.
mkswap /dev/VolGroup00/LogVol01
# mkswap /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨에서 스왑을 활성화합니다.
swapon -v /dev/VolGroup00/LogVol01
# swapon -v /dev/VolGroup00/LogVol01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
스왑 논리 볼륨이 성공적으로 감소되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
cat /proc/swaps
$ cat /proc/swapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow free -h
$ free -hCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.6.8. 스왑을 위한 LVM2 논리 볼륨 제거
스왑의 LVM2 논리 볼륨을 제거할 수 있습니다. /dev/VolGroup00/LogVol02 를 제거하려는 스왑 볼륨이라고 가정합니다.
프로세스
연결된 논리 볼륨의 스왑을 비활성화합니다.
swapoff -v /dev/VolGroup00/LogVol02
# swapoff -v /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow LVM2 논리 볼륨을 제거합니다.
lvremove /dev/VolGroup00/LogVol02
# lvremove /dev/VolGroup00/LogVol02Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/fstab파일에서 다음 관련 항목을 제거합니다./dev/VolGroup00/LogVol02 none swap defaults 0 0
/dev/VolGroup00/LogVol02 none swap defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 마운트 단위를 다시 생성하여 새 구성을 등록합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
논리 볼륨이 성공적으로 제거되었는지 테스트합니다. 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
cat /proc/swaps
$ cat /proc/swapsCopy to Clipboard Copied! Toggle word wrap Toggle overflow free -h
$ free -hCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.6.9. 스왑 파일 제거
스왑 파일을 제거할 수 있습니다.
프로세스
/swapfile스왑 파일을 비활성화합니다.swapoff -v /swapfile
# swapoff -v /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
그에 따라
/etc/fstab파일에서 해당 항목을 제거합니다. 시스템이 새 구성을 등록하도록 마운트 단위를 다시 생성합니다.
systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 실제 파일을 제거합니다.
rm /swapfile
# rm /swapfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7. RHEL 시스템 역할을 사용하여 로컬 스토리지 관리
Ansible을 사용하여 LVM 및 로컬 파일 시스템(FS)을 관리하려면 RHEL 8에서 사용할 수 있는 RHEL 시스템 역할 중 하나인 스토리지 역할을 사용할 수 있습니다.
스토리지 역할을 사용하면 RHEL 7.7부터 여러 시스템 및 모든 RHEL 버전에서 디스크 및 논리 볼륨에서 파일 시스템 관리를 자동화할 수 있습니다.
RHEL 시스템 역할 및 적용 방법에 대한 자세한 내용은 RHEL 시스템 역할 소개를 참조하십시오.
35.7.1. 스토리지 RHEL 시스템 역할을 사용하여 블록 장치에서 XFS 파일 시스템 생성
예제 Ansible 플레이북은 storage 역할을 사용하여 기본 매개 변수를 사용하여 블록 장치에 XFS 파일 시스템을 생성합니다. /dev/sdb 장치 또는 마운트 지점 디렉터리의 파일 시스템이 없으면 플레이북에서 해당 시스템을 생성합니다.
스토리지 역할은 파티션되지 않은 전체 디스크 또는 LV(논리 볼륨)에서만 파일 시스템을 생성할 수 있습니다. 파티션에 파일 시스템을 만들 수 없습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
이름: barefs-
볼륨 이름(예의
barefs)은 현재 임의의 상태입니다.스토리지역할은disks특성에 나열된 디스크 장치로 볼륨을 식별합니다. fs_type: <file_system>-
기본 파일 시스템 XFS를 사용하려면
fs_type매개변수를 생략할 수 있습니다. disks: <list_of_disks_and_volumes>디스크 및 LV 이름의 YAML 목록입니다. LV에 파일 시스템을 생성하려면 볼륨 그룹을 포함하여
disks속성 아래에 LVM 설정을 제공합니다. 자세한 내용은 스토리지 RHEL 시스템 역할을 사용하여 논리 볼륨 생성 또는 크기 조정을 참조하십시오.LV 장치의 경로를 제공하지 마십시오.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.2. 스토리지 RHEL 시스템 역할을 사용하여 파일 시스템을 영구적으로 마운트
예제 Ansible 플레이북은 storage 역할을 사용하여 기존 파일 시스템을 영구적으로 마운트합니다. 이를 통해 /etc/fstab 파일에 적절한 항목을 추가하여 파일 시스템을 즉시 사용할 수 있고 영구적으로 마운트할 수 있습니다. 이렇게 하면 재부팅 시 파일 시스템을 마운트 상태로 유지할 수 있습니다. /dev/sdb 장치 또는 마운트 지점 디렉터리의 파일 시스템이 없으면 플레이북에서 해당 시스템을 생성합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.3. 스토리지 RHEL 시스템 역할을 사용하여 논리 볼륨 생성 또는 크기 조정
스토리지 역할을 사용하여 다음 작업을 수행합니다.
- 여러 디스크로 구성된 볼륨 그룹에 LVM 논리 볼륨을 만들려면 다음을 수행합니다.
- LVM에서 기존 파일 시스템의 크기를 조정하려면 다음을 수행합니다.
- 풀의 총 크기의 백분율로 LVM 볼륨 크기를 표현하려면
볼륨 그룹이 없으면 역할이 생성됩니다. 논리 볼륨이 볼륨 그룹에 있는 경우 크기가 플레이북에 지정된 것과 일치하지 않으면 크기가 조정됩니다.
논리 볼륨을 줄이는 경우 데이터 손실을 방지하기 위해 논리 볼륨의 파일 시스템이 축소되는 논리 볼륨의 공간을 사용하지 않도록 해야 합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
크기: < ;size>- 단위(예: GiB) 또는 백분율(예: 60 %)을 사용하여 크기를 지정해야 합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
지정된 볼륨이 요청된 크기로 생성되거나 크기가 조정되었는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lvs myvg'
# ansible managed-node-01.example.com -m command -a 'lvs myvg'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.4. 스토리지 RHEL 시스템 역할을 사용하여 온라인 블록 삭제 활성화
온라인 블록 삭제 옵션으로 XFS 파일 시스템을 마운트하여 사용되지 않는 블록을 자동으로 삭제할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
온라인 블록 삭제 옵션이 활성화되어 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.5. 스토리지 RHEL 시스템 역할을 사용하여 파일 시스템 생성 및 마운트
예제 Ansible 플레이북은 storage 역할을 사용하여 파일 시스템을 생성하고 마운트합니다. 이를 통해 /etc/fstab 파일에 적절한 항목을 추가하여 파일 시스템을 즉시 사용할 수 있고 영구적으로 마운트할 수 있습니다. 이렇게 하면 재부팅 시 파일 시스템을 마운트 상태로 유지할 수 있습니다. /dev/sdb 장치 또는 마운트 지점 디렉터리의 파일 시스템이 없으면 플레이북에서 해당 시스템을 생성합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
disks: <list_of_devices>- 역할이 볼륨을 생성할 때 사용하는 장치 이름의 YAML 목록입니다.
fs_type: <file_system>-
역할이 볼륨에 설정해야 하는 파일 시스템을 지정합니다.
xfs,ext3,ext4,swap또는포맷되지않음을 선택할 수 있습니다. label-name: <file_system_label>- 선택 사항: 파일 시스템의 레이블을 설정합니다.
mount_point: < directory>-
선택 사항: 볼륨을 자동으로 마운트해야 하는 경우
mount_point변수를 볼륨을 마운트해야 하는 디렉터리로 설정합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.6. 스토리지 RHEL 시스템 역할을 사용하여 RAID 볼륨 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform 및 Ansible-Core를 사용하여 RHEL에서 RAID 볼륨을 구성할 수 있습니다. 요구 사항에 맞게 RAID 볼륨을 구성하는 매개 변수를 사용하여 Ansible 플레이북을 생성합니다.
장치 이름은 예를 들어 시스템에 새 디스크를 추가할 때 특정 상황에서 변경될 수 있습니다. 따라서 데이터 손실을 방지하려면 플레이북에서 영구 이름 지정 속성을 사용합니다. 영구 이름 지정 속성에 대한 자세한 내용은 영구 이름 지정 특성 개요 를 참조하십시오.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
배열이 올바르게 생성되었는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'mdadm --detail /dev/md/data'
# ansible managed-node-01.example.com -m command -a 'mdadm --detail /dev/md/data'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.7. 스토리지 RHEL 시스템 역할을 사용하여 RAID로 LVM 풀 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform을 사용하여 RHEL에서 RAID로 LVM 풀을 구성할 수 있습니다. 사용 가능한 매개 변수로 Ansible 플레이북을 설정하여 RAID로 LVM 풀을 구성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
풀이 RAID에 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lsblk'
# ansible managed-node-01.example.com -m command -a 'lsblk'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.8. 스토리지 RHEL 시스템 역할을 사용하여 RAID LVM 볼륨의 스트라이프 크기 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform을 사용하여 RHEL에서 RAID LVM 볼륨의 스트라이프 크기를 구성할 수 있습니다. 사용 가능한 매개 변수로 Ansible 플레이북을 설정하여 RAID로 LVM 풀을 구성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
스트라이프 크기가 필요한 크기로 설정되어 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'
# ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.9. 스토리지 RHEL 시스템 역할을 사용하여 LVM-VDO 볼륨 구성
스토리지 RHEL 시스템 역할을 사용하여 활성화된 압축 및 중복 제거로 LVM(LVM-VDO)에서 VDO 볼륨을 생성할 수 있습니다.
스토리지 시스템 역할은 LVM-VDO를 사용하므로 풀당 하나의 볼륨만 생성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
vdo_pool_size: <size>- 볼륨이 장치에서 사용하는 실제 크기입니다. 사용자가 읽을 수 있는 형식으로 크기를 지정할 수 있습니다(예: 10GiB). 단위를 지정하지 않으면 기본값은 바이트입니다.
크기: < ;size>- VDO 볼륨의 가상 크기입니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
압축 및 중복 제거의 현재 상태를 확인합니다.
ansible managed-node-01.example.com -m command -a 'lvs -o+vdo_compression,vdo_compression_state,vdo_deduplication,vdo_index_state' LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState VDODeduplication VDOIndexState mylv1 myvg vwi-a-v--- 3.00t vpool0 enabled online enabled online
$ ansible managed-node-01.example.com -m command -a 'lvs -o+vdo_compression,vdo_compression_state,vdo_deduplication,vdo_index_state' LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert VDOCompression VDOCompressionState VDODeduplication VDOIndexState mylv1 myvg vwi-a-v--- 3.00t vpool0 enabled online enabled onlineCopy to Clipboard Copied! Toggle word wrap Toggle overflow
35.7.10. 스토리지 RHEL 시스템 역할을 사용하여 LUKS2 암호화된 볼륨 생성
storage 역할을 사용하여 Ansible 플레이북을 실행하여 LUKS로 암호화된 볼륨을 생성하고 구성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
중요한 변수를 암호화된 파일에 저장합니다.
자격 증명 모음을 생성합니다.
ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>
$ ansible-vault create ~/vault.yml New Vault password: <vault_password> Confirm New Vault password: <vault_password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow ansible-vault create명령이 편집기를 열고 <key > : < value> 형식으로 중요한 데이터를 입력합니다.luks_password: <password>
luks_password: <password>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 변경 사항을 저장하고 편집기를 종료합니다. Ansible은 자격 증명 모음의 데이터를 암호화합니다.
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --ask-vault-pass --syntax-check ~/playbook.yml
$ ansible-playbook --ask-vault-pass --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook --ask-vault-pass ~/playbook.yml
$ ansible-playbook --ask-vault-pass ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
LUKS 암호화된 볼륨의
luksUUID값을 찾습니다.ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5c
# ansible managed-node-01.example.com -m command -a 'cryptsetup luksUUID /dev/sdb' 4e4e7970-1822-470e-b55a-e91efe5d0f5cCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨의 암호화 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 생성된 LUKS 암호화된 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36장. 스토리지 중복 및 압축
36.1. VDO 배포
시스템 관리자는 VDO를 사용하여 중복 및 압축 스토리지 풀을 생성할 수 있습니다.
36.1.1. VDO 소개
VDO(Virtual Data Optimizer)는 중복 제거, 압축 및 씬 프로비저닝의 형태로 Linux에 대한 인라인 데이터 감소를 제공합니다. VDO 볼륨을 설정할 때 VDO 볼륨을 구성할 블록 장치와 제공할 논리 스토리지 양을 지정합니다.
- 활성 VM 또는 컨테이너를 호스팅하는 경우 Red Hat은 10:1 논리적 대 물리적 비율로 스토리지를 프로비저닝하는 것이 좋습니다. 즉, 1TB의 물리적 스토리지를 사용하는 경우 논리 스토리지의 10TB로 제공할 수 있습니다.
- Ceph에서 제공하는 유형과 같은 오브젝트 스토리지의 경우 Red Hat은 3:1 논리적 비율로 사용할 것을 권장합니다. 즉, 1TB의 물리적 스토리지가 3TB 논리 스토리지로 표시됩니다.
두 경우 모두 VDO에서 제공하는 논리 장치 상단에 파일 시스템을 배치한 다음 직접 또는 분산 클라우드 스토리지 아키텍처의 일부로 사용할 수 있습니다.
VDO는 씬 프로비저닝되므로 파일 시스템과 애플리케이션은 사용 중인 논리 공간만 보고 사용 가능한 실제 공간을 인식하지 못합니다. 스크립팅을 사용하여 실제 사용 가능한 공간을 모니터링하고, 사용 가능한 경우(예: VDO 볼륨이 80%인 경우) 임계값을 초과하는 경우 경고를 생성합니다.
36.1.2. VDO 배포 시나리오
다음과 같은 다양한 방법으로 VDO를 배포하여 중복 스토리지를 제공할 수 있습니다.
- 블록 및 파일 액세스
- 로컬 및 원격 스토리지 모두
VDO는 중복된 스토리지를 표준 Linux 블록 장치로 노출하므로 표준 파일 시스템, iSCSI 및 FC 대상 드라이버 또는 통합 스토리지로 사용할 수 있습니다.
현재 Ceph RADOS Block Device(RBD) 상단에 VDO 볼륨 배포가 지원됩니다. 그러나 VDO 볼륨 상단에 Red Hat Ceph Storage 클러스터 구성 요소를 배포하는 것은 현재 지원되지 않습니다.
KVM
Direct Attached Storage로 구성된 KVM 서버에 VDO를 배포할 수 있습니다.

파일 시스템
VDO 상단에 파일 시스템을 생성하고 NFS 서버 또는 Samba를 사용하여 NFS 또는 CIFS 사용자에게 노출할 수 있습니다.

iSCSI에 VDO 배치
VDO 스토리지 대상 전체를 iSCSI 대상으로 원격 iSCSI 이니시에이터에 내보낼 수 있습니다.

iSCSI에서 VDO 볼륨을 생성할 때 iSCSI 계층 위의 VDO 볼륨을 배치할 수 있습니다. 고려해야 할 많은 고려 사항이 있지만 환경에 가장 적합한 방법을 선택하는 데 도움이 되는 몇 가지 지침이 여기에 제공됩니다.
iSCSI 계층 아래의 iSCSI 서버(대상)에 VDO 볼륨을 배치하는 경우:
- VDO 볼륨은 다른 iSCSI LUN과 유사하게 이니시에이터와 투명합니다. 클라이언트의 씬 프로비저닝 및 공간을 숨기면 LUN의 모양을 모니터링하고 유지 관리하기가 쉬워집니다.
- VDO 메타데이터 읽기 또는 쓰기가 없기 때문에 네트워크 트래픽이 줄어들고 dedupe 조언에 대한 읽기 확인이 네트워크에서 발생하지 않습니다.
- iSCSI 대상에서 사용 중인 메모리 및 CPU 리소스는 성능이 향상될 수 있습니다. 예를 들어 iSCSI 대상에서 볼륨 감소가 발생하기 때문에 하이퍼바이저 수를 늘리는 기능이 있습니다.
- 클라이언트가 이니시에이터에서 암호화를 구현하고 대상 아래에 VDO 볼륨이 있는 경우 공간 절약을 실현하지 못합니다.
iSCSI 계층 위의 iSCSI 클라이언트(initiator)에 VDO 볼륨을 배치할 때:
- 높은 수준의 공간 절약을 달성하면 ASYNC 모드에서 네트워크에서 네트워크 트래픽이 줄어들 수 있습니다.
- 공간 절약을 직접 보고 제어하고 사용량을 모니터링할 수 있습니다.
-
예를 들어
dm-crypt를 사용하여 데이터를 암호화하려면 crypt 위에서 VDO를 구현하고 공간 효율성을 활용할 수 있습니다.
LVM
기능이 더 많은 시스템에서 LVM을 사용하여 동일한 중복 스토리지 풀에서 모두 지원하는 여러 LUN(Logical Unit Number)을 제공할 수 있습니다.
다음 다이어그램에서 VDO 대상은 LVM에서 관리할 수 있도록 물리 볼륨으로 등록됩니다. 여러 논리 볼륨(RPC1 에서 LV4까지)이 deduplicated 스토리지 풀에서 생성됩니다. 이러한 방식으로 VDO는 기본 중복 스토리지 풀에 대한 다중 프로토콜 통합 블록 또는 파일 액세스를 지원할 수 있습니다.
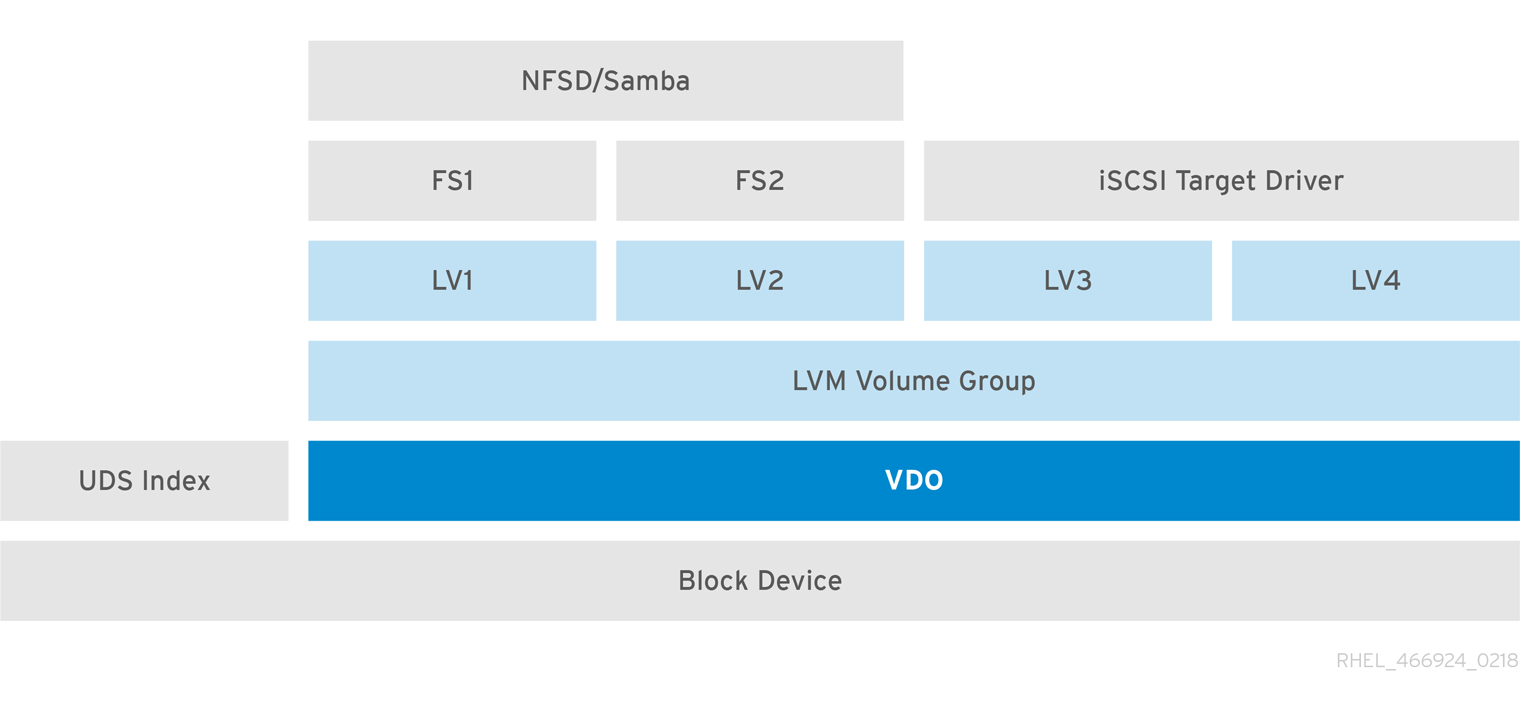
중복된 통합 스토리지 설계를 통해 여러 파일 시스템이 LVM 툴을 통해 동일한 중복 제거 도메인을 공동으로 사용할 수 있습니다. 또한 파일 시스템은 VDO 상단에 LVM 스냅샷, COW(Copy-On-Write) 및 축소 또는 증가 기능을 활용할 수 있습니다.
Encryption
DM Crypt와 같은 DM(Device Mapper) 메커니즘은 VDO와 호환됩니다. VDO 볼륨을 암호화하면 데이터 보안 및 VDO 위의 모든 파일 시스템이 여전히 중복됩니다.
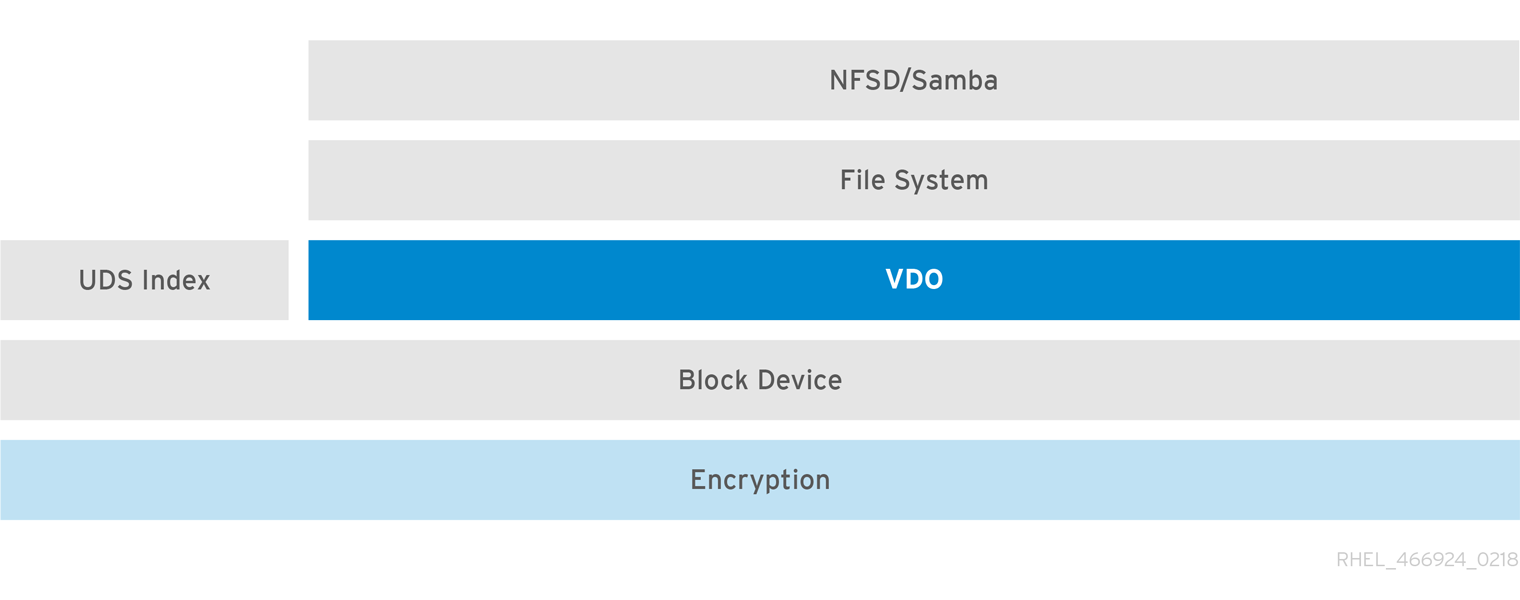
VDO 위의 암호화 계층을 적용하면 데이터 중복 제거가 거의 발생하지 않습니다. 암호화는 VDO를 복제하기 전에 중복 블록을 다르게 만듭니다.
항상 VDO 아래에 암호화 계층을 배치합니다.
36.1.3. VDO 볼륨의 구성 요소
VDO는 블록 장치를 백업 저장소로 사용합니다. 여기에는 하나 이상의 디스크, 파티션 또는 플랫 파일로 구성된 물리적 스토리지 집계가 포함될 수 있습니다. 스토리지 관리 도구가 VDO 볼륨을 생성할 때 VDO는 UDS 인덱스 및 VDO 볼륨을 위한 볼륨 공간을 예약합니다. UDS 인덱스 및 VDO 볼륨은 서로 상호 작용하여 중복된 블록 스토리지를 제공합니다.
그림 36.1. VDO 디스크 조직

VDO 솔루션은 다음 구성 요소로 구성됩니다.
kvdoLinux 장치 매퍼 계층에 로드되는 커널 모듈은 중복되고 압축되며 씬 프로비저닝된 블록 스토리지 볼륨을 제공합니다.
kvdo모듈은 블록 장치를 노출합니다. 블록 스토리지를 위해 이 블록 장치에 직접 액세스하거나 XFS 또는 ext4와 같은 Linux 파일 시스템을 통해 제공할 수 있습니다.kvdo가 VDO 볼륨에서 데이터의 논리 블록을 읽기 위한 요청을 수신하면 요청된 논리 블록을 기본 물리적 블록에 매핑한 다음 요청된 데이터를 읽고 반환합니다.kvdo가 VDO 볼륨에 데이터 블록을 쓰기 위한 요청을 수신하면 먼저 요청이 DISCARD 또는 TRIM 요청인지 또는 데이터가 균일하게 0인지 여부를 확인합니다. 이러한 조건 중 하나가 true이면kvdo는 블록 맵을 업데이트하고 요청을 승인합니다. 그렇지 않으면 VDO는 데이터를 처리하고 최적화합니다.UDS볼륨의 Universal Deduplication Service(UDS) 인덱스와 통신하는 커널 모듈이며 중복을 위해 데이터를 분석합니다. 새로운 데이터의 각 부분에 대해 UDS는 이전에 저장된 데이터 조각과 동일한지 빠르게 결정합니다. 인덱스가 일치하는 항목을 찾으면 스토리지 시스템은 동일한 정보를 두 번 이상 저장하지 않도록 기존 항목을 내부적으로 참조할 수 있습니다.
UDS 인덱스는
uds커널 모듈로 커널 내부에서 실행됩니다.- 명령줄 툴
- 최적화된 스토리지를 구성하고 관리하는 데 사용됩니다.
36.1.4. VDO 볼륨의 물리 및 논리적 크기
VDO는 다음과 같은 방법으로 물리적, 사용 가능한 물리적 크기 및 논리 크기를 활용합니다.
- 물리적 크기
이는 기본 블록 장치와 크기가 동일합니다. VDO는 다음 용도로 이 스토리지를 사용합니다.
- 사용자 데이터가 분할되고 압축될 수 있습니다.
- VDO 메타데이터(예: UDS 인덱스)
- 사용 가능한 물리적 크기
이는 VDO가 사용자 데이터에 사용할 수 있는 물리적 크기의 부분입니다.
물리 크기와 같습니다. 메타데이터의 크기를 뺀 후 나머지 볼륨을 지정된 slab 크기로 slabs로 분할한 후 나머지를 뺀 값입니다.
- 논리 크기
이는 VDO 볼륨이 애플리케이션에 제공하는 프로비저닝된 크기입니다. 일반적으로 사용 가능한 물리적 크기보다 큽니다.
--vdoLogicalSize옵션이 지정되지 않은 경우 논리 볼륨의 프로비저닝이 이제1:1비율로 프로비저닝됩니다. 예를 들어 VDO 볼륨이 20GB 블록 장치 위에 배치된 경우 UDS 인덱스(기본 인덱스 크기가 사용되는 경우) 2.5GB가 예약되어 있습니다. 나머지 17.5GB는 VDO 메타데이터 및 사용자 데이터에 제공됩니다. 결과적으로 사용할 수 있는 스토리지는 17.5GB를 초과하지 않으며 실제 VDO 볼륨을 구성하는 메타데이터로 인해 줄어들 수 있습니다.VDO는 현재 최대 논리 크기가 4PB인 물리 볼륨의 크기를 254배까지 지원합니다.
그림 36.2. VDO 디스크 조직
이 그림에서 VDO 중복된 스토리지 대상은 블록 장치의 상단에 완전히 배치되므로 VDO 볼륨의 물리적 크기는 기본 블록 장치와 같습니다.
36.1.5. VDO의 Slab 크기
VDO 볼륨의 물리 스토리지는 여러 slabs로 나뉩니다. 각 스lab은 물리적 공간의 연속된 영역입니다. 지정된 볼륨에 대한 모든 slabs의 크기는 같으며, 이는 128MB에서 최대 32GB의 2개의 전원을 사용할 수 있습니다.
기본 slab 크기는 작은 테스트 시스템에서 VDO를 쉽게 평가할 수 있도록 2GB입니다. 하나의 VDO 볼륨은 최대 8192 개의 slabs를 가질 수 있습니다. 따라서 2GB slabs를 사용하는 기본 구성에서 허용되는 최대 물리 스토리지는 16TB입니다. 32GB slabs를 사용하는 경우 허용되는 최대 물리 스토리지는 256TB입니다. VDO는 항상 메타데이터를 위해 하나 이상의 전체 slab을 예약하므로 예약된 slab은 사용자 데이터를 저장하는 데 사용할 수 없습니다.
Slab 크기는 VDO 볼륨의 성능에 영향을 미치지 않습니다.
| 물리 볼륨 크기 | 권장되는 Slab 크기 |
|---|---|
| 10-99GB | 1GB |
| 100GB - 1TB | 2GB |
| 2-256 TB | 32GB |
기본 설정 2GB slab 크기와 0.25 밀도 인덱스를 사용하는 VDO 볼륨의 최소 디스크 사용량에는 approx 4.7GB가 필요합니다. 이는 0% 중복 제거 또는 압축에서 쓸 수 있는 2GB의 물리적 데이터보다 약간 적습니다.
여기에서 최소 디스크 사용은 기본 slab 크기 및 dense 인덱스의 합계입니다.
lvcreate 명령에 --vdo_slab_size_mb=size-in-megabytes' 옵션을 제공하여 slab 크기를 제어할 수 있습니다.
36.1.6. VDO 요구 사항
VDO에는 배치 및 시스템 리소스에 대한 특정 요구 사항이 있습니다.
36.1.6.1. VDO 메모리 요구 사항
각 VDO 볼륨에는 두 가지 고유한 메모리 요구 사항이 있습니다.
- VDO 모듈
VDO에는 고정된 38MB의 RAM 및 여러 가지 변수 양이 필요합니다.
- 구성된 블록 맵 캐시 크기의 1MB마다 1.15MB의 RAM입니다. 블록 맵 캐시에는 최소 150MB의 RAM이 필요합니다.
- 1TB의 논리 공간당 1.6MB의 RAM.
- 볼륨에서 관리하는 물리 스토리지 1TB마다 268MB의 RAM입니다.
- UDS 인덱스
Universal Deduplication Service(UDS)에는 최소 250MB의 RAM이 필요하며 이는 중복 제거에서 사용하는 기본 용량이기도 합니다. VDO 볼륨을 포맷할 때 값을 구성할 수 있습니다. 이 값은 인덱스에 필요한 스토리지 양에도 영향을 미치기 때문입니다.
UDS 인덱스에 필요한 메모리는 인덱스 유형 및 중복 제거 창의 필요한 크기에 따라 결정됩니다. 중복 제거 창은 VDO가 일치하는 블록을 확인할 수 있는 이전에 작성된 데이터의 양입니다.
Expand 인덱스 유형 중복 제거 창 밀도
1GB RAM당 1GB
스파스
1GB RAM당 10GB
참고기본 설정 2GB slab 크기와 0.25 밀도 인덱스를 사용하는 VDO 볼륨의 최소 디스크 사용량에는 approx 4.7GB가 필요합니다. 이는 0% 중복 제거 또는 압축에서 쓸 수 있는 2GB의 물리적 데이터보다 약간 적습니다.
여기에서 최소 디스크 사용은 기본 slab 크기 및 dense 인덱스의 합계입니다.
36.1.6.2. VDO 스토리지 공간 요구사항
VDO 볼륨은 최대 256TB의 물리적 스토리지를 사용하도록 구성할 수 있습니다. 물리적 스토리지의 특정 부분만 데이터를 저장하는 데 사용할 수 있습니다.
VDO에는 두 가지 유형의 VDO 메타데이터와 UDS 인덱스에 대한 스토리지가 필요합니다. 다음 계산을 사용하여 VDO 관리 볼륨의 사용 가능한 크기를 확인합니다.
- VDO 메타데이터의 첫 번째 유형은 4GB의 물리적 스토리지에 대해 약 1MB를 사용하고 slab당 추가 1MB를 사용합니다.
- VDO 메타데이터의 두 번째 유형은 1GB의 논리 스토리지에 대해 약 1.25MB를 사용하며 가장 가까운 slab으로 반올림됩니다.
- UDS 인덱스에 필요한 스토리지 크기는 인덱스 유형과 인덱스에 할당된 RAM 크기에 따라 달라집니다. 1GB의 RAM에 대해 밀도가 높은 UDS 인덱스는 17GB의 스토리지를 사용하며 스파스 UDS 인덱스는17GB의 스토리지를 사용합니다.
36.1.6.3. 스토리지 스택에 VDO 배치
배치 요구 사항에 맞게 스토리지 계층을 위 또는 VDO(Virtual Data Optimizer)에 배치합니다.
VDO 볼륨은 씬 프로비저닝된 블록 장치입니다. 나중에 확장할 수 있는 스토리지 계층 위에 볼륨을 배치하여 물리적 공간이 부족해지는 것을 방지할 수 있습니다. 이러한 확장 가능한 스토리지의 예로는 LVM(Logical Volume Manager) 볼륨 또는 다중 장치 Redundant Array Inexpensive(Expersive Disks) 배열이 있습니다.
VDO 위에 번거롭게 프로비저닝된 레이어를 배치 할 수 있습니다. 맹렬한 프로비저닝 계층에는 다음 두 가지 측면을 고려해야 합니다.
- 사용되지 않는 논리 공간에 새 데이터를 기록하면 두려운 장치에서 새 데이터를 작성합니다. VDO 또는 기타 씬 프로비저닝된 스토리지를 사용하는 경우 장치는 이러한 쓰기 작업 중에 공간이 부족함을 보고할 수 있습니다.
- 새로운 데이터가 있는 두려운 장치에서 논리 공간을 덮어 씁니다. VDO를 사용할 때 데이터를 덮어 쓰기하면 장치 공간이 부족해질 수 있습니다.
이러한 제한은 VDO 계층 위의 모든 계층에 영향을 미칩니다. VDO 장치를 모니터링하지 않으면 VDO 위의 맹렬한 프로비저닝 볼륨에서 예기치 않게 물리적 공간을 실행할 수 있습니다.
지원되는 VDO 볼륨 구성의 다음 예제를 참조하십시오.
그림 36.3. 지원되는 VDO 볼륨 구성
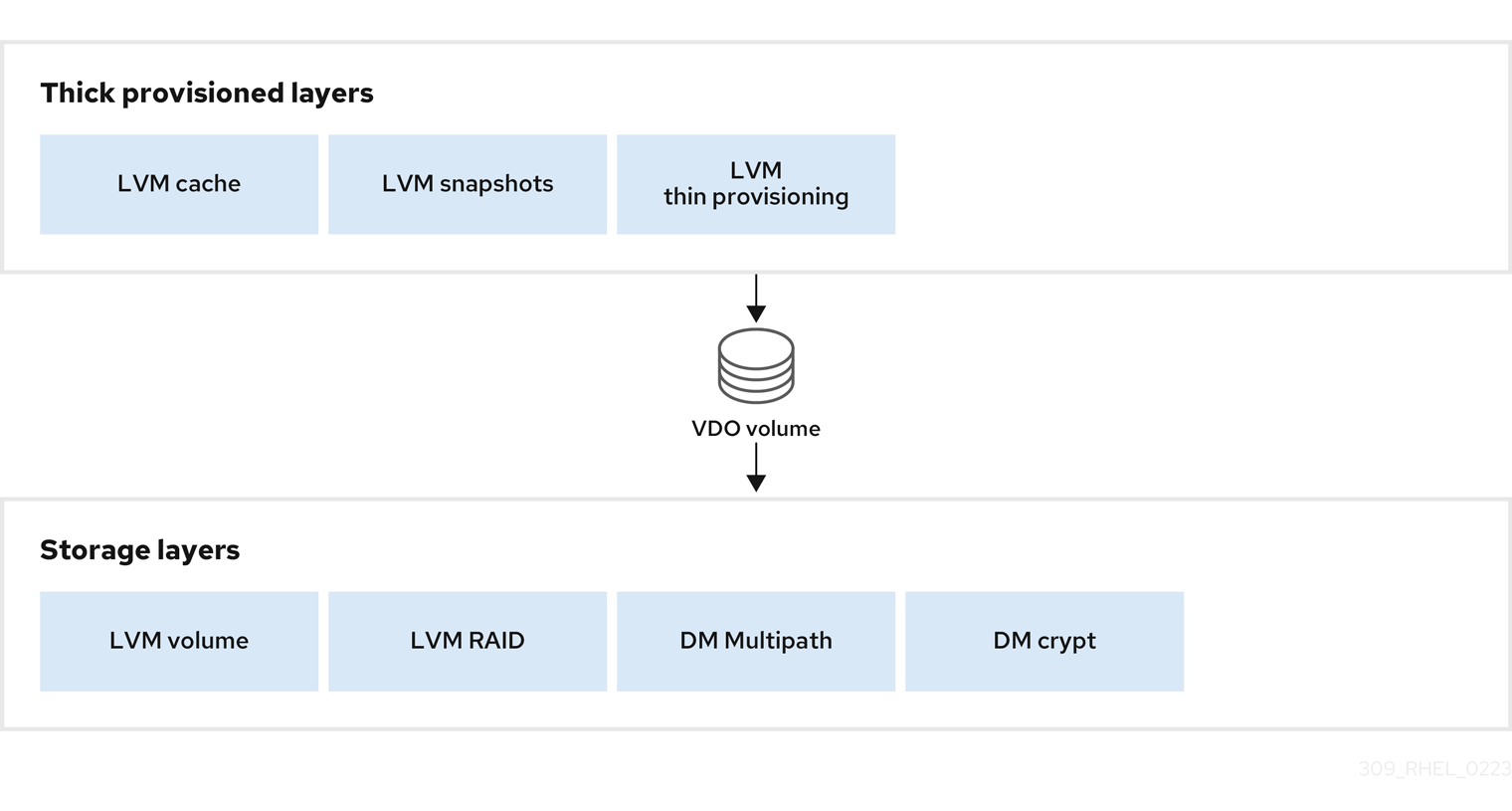
그림 36.4. 지원되지 않는 VDO 볼륨 구성
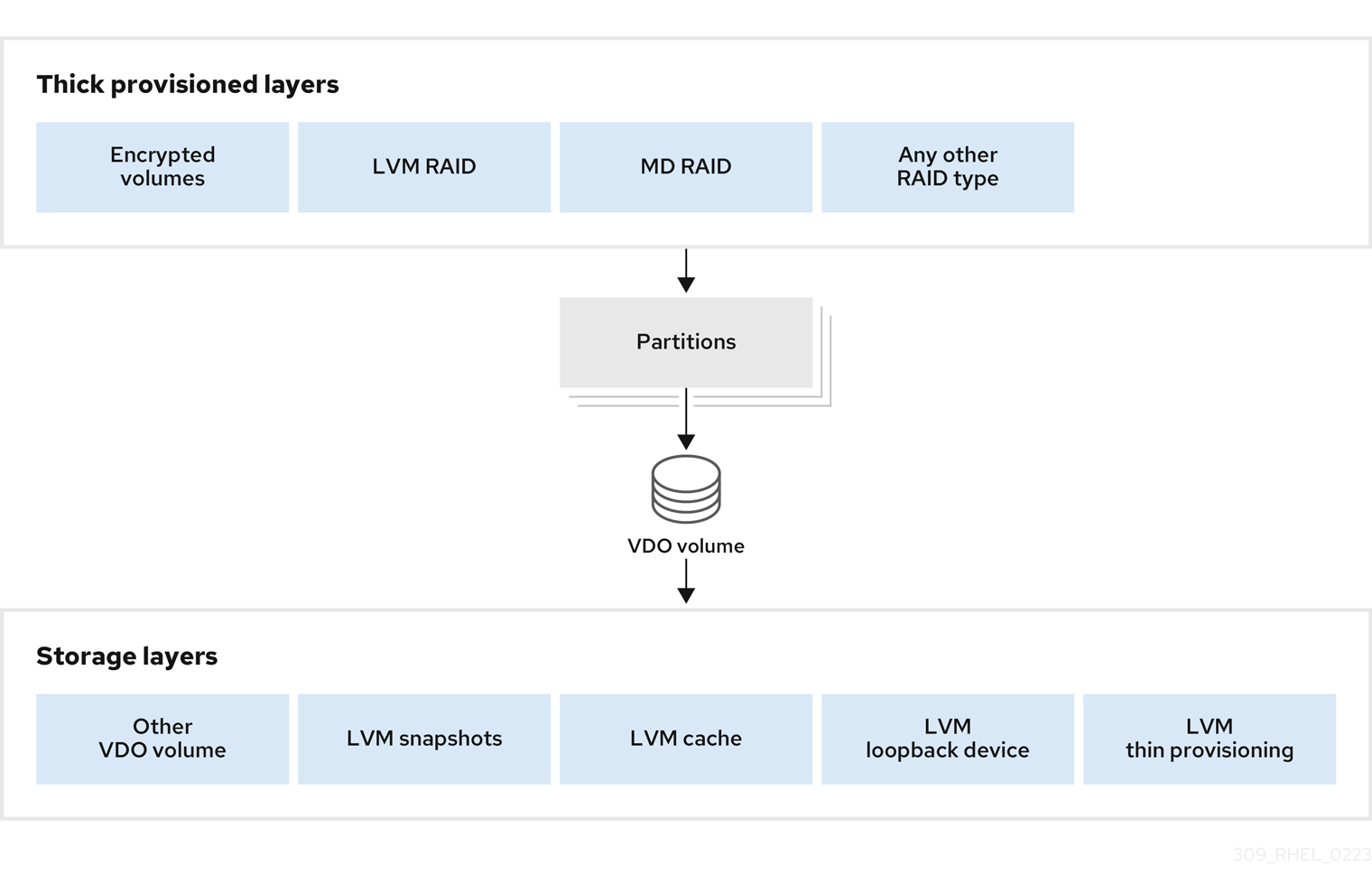
36.1.6.4. 물리적 크기별 VDO 요구 사항의 예
다음 표에서는 기본 볼륨의 물리적 크기에 따라 VDO의 대략적인 시스템 요구 사항을 제공합니다. 각 표에는 기본 스토리지 또는 백업 스토리지와 같은 원하는 배포에 적합한 요구 사항이 나열됩니다.
정확한 숫자는 VDO 볼륨의 구성에 따라 다릅니다.
- 기본 스토리지 배포
기본 스토리지 경우 UDS 인덱스는 물리 크기의 크기가 0.01%에서 25% 사이입니다.
Expand 표 36.2. 기본 스토리지에 대한 스토리지 및 메모리 구성의 예 물리적 크기 RAM 사용: UDS RAM 사용: VDO 디스크 사용량 인덱스 유형 1TB
250MB
472MB
2.5GB
밀도
10TB
1GB
3GB
10GB
밀도
250MB
22GB
스파스
50TB
1GB
14GB
85GB
스파스
100TB
3GB
27GB
255GB
스파스
256TB
5GB
69GB
425 GB
스파스
- 백업 스토리지 배포
백업 스토리지의 경우 중복 제거 창이 백업 세트보다 커야 합니다. 백업 세트 또는 물리적 크기가 나중에 증가할 것으로 예상하는 경우 이를 인덱스 크기로 가져옵니다.
Expand 표 36.3. 백업 스토리지를 위한 스토리지 및 메모리 구성의 예 중복 제거 창 RAM 사용: UDS 디스크 사용량 인덱스 유형 1TB
250MB
2.5GB
밀도
10TB
2GB
21GB
밀도
50TB
2GB
CRYOSTATGB
스파스
100TB
4GB
340GB
스파스
256TB
8GB
700GB
스파스
36.1.7. VDO 설치
VDO 볼륨을 생성, 마운트 및 관리하는 데 필요한 VDO 소프트웨어를 설치할 수 있습니다.
절차
VDO 소프트웨어를 설치합니다.
yum install lvm2 kmod-kvdo vdo
# yum install lvm2 kmod-kvdo vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.1.8. VDO 볼륨 생성
이 절차에서는 블록 장치에 VDO 볼륨을 생성합니다.
사전 요구 사항
- VDO 소프트웨어를 설치합니다. 36.1.7절. “VDO 설치”을 참조하십시오.
- 확장 가능한 스토리지를 백업 블록 장치로 사용합니다. 자세한 내용은 36.1.6.3절. “스토리지 스택에 VDO 배치”의 내용을 참조하십시오.
절차
다음 모든 단계에서 EgressIP -name 을 VDO 볼륨에 사용하려는 식별자로 바꿉니다(예:${1) . 시스템에서 VDO의 각 인스턴스에 다른 이름과 장치를 사용해야합니다.
VDO 볼륨을 생성할 블록 장치의 영구 이름을 찾습니다. 영구 이름에 대한 자세한 내용은 26장. 영구 이름 지정 특성 개요 을 참조하십시오.
비영구 장치 이름을 사용하는 경우 장치 이름이 변경되면 VDO가 나중에 제대로 시작되지 않을 수 있습니다.
VDO 볼륨을 생성합니다.
vdo create \ --name=vdo-name \ --device=block-device \ --vdoLogicalSize=logical-size# vdo create \ --name=vdo-name \ --device=block-device \ --vdoLogicalSize=logical-sizeCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
block-device 를 VDO 볼륨을 생성할 블록 장치의 영구 이름으로 교체합니다. 예를 들어
/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f입니다. logical-size 를 VDO 볼륨이 제공해야 하는 논리 스토리지 양으로 교체합니다.
-
활성 VM 또는 컨테이너 스토리지의 경우 블록 장치의 물리적 크기가 10 배인 논리 크기를 사용합니다. 예를 들어, 블록 장치의 크기가 1TB인 경우 여기에서
10T를 사용하십시오. -
오브젝트 스토리지의 경우 블록 장치의 물리적 크기를 세 배인 논리 크기를 사용합니다. 예를 들어, 블록 장치의 크기가 1TB인 경우 여기에서
3T를 사용하십시오.
-
활성 VM 또는 컨테이너 스토리지의 경우 블록 장치의 물리적 크기가 10 배인 논리 크기를 사용합니다. 예를 들어, 블록 장치의 크기가 1TB인 경우 여기에서
물리 블록 장치가 16TiB보다 큰 경우
--vdoSlabSize=32G옵션을 추가하여 볼륨의 slab 크기를 32GiB로 늘립니다.16TiB 이상의 블록 장치에서 기본 slab 크기2GiB를 사용하면 EgressIP
create명령이 다음과 같은 오류로 인해 실패합니다.vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supported
vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supportedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
예 36.1. 컨테이너 스토리지용 VDO 생성
예를 들어 1TB 블록 장치에서 컨테이너 스토리지에 대한 VDO 볼륨을 생성하려면 다음을 사용할 수 있습니다.
vdo create \ --name=vdo1 \ --device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f \ --vdoLogicalSize=10T# vdo create \ --name=vdo1 \ --device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f \ --vdoLogicalSize=10TCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중요VDO 볼륨을 만들 때 오류가 발생하면 정리할 볼륨을 제거합니다. 자세한 내용은 실패한 VDO 볼륨 제거를 참조하십시오.
-
block-device 를 VDO 볼륨을 생성할 블록 장치의 영구 이름으로 교체합니다. 예를 들어
VDO 볼륨 상단에 파일 시스템을 생성합니다.
XFS 파일 시스템의 경우:
mkfs.xfs -K /dev/mapper/vdo-name
# mkfs.xfs -K /dev/mapper/vdo-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow ext4 파일 시스템의 경우:
mkfs.ext4 -E nodiscard /dev/mapper/vdo-name
# mkfs.ext4 -E nodiscard /dev/mapper/vdo-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고새로 생성된 VDO 볼륨에서
-K및-E nodiscard옵션의 용도는 할당되지 않은 블록에 영향을 미치지 않으므로 요청을 보내는 데 시간을 소비하지 않는 것입니다. 새로운 VDO 볼륨은 할당되지 않은 100%를 시작합니다.
다음 명령을 사용하여 시스템이 새 장치 노드를 등록할 때까지 기다립니다.
udevadm settle
# udevadm settleCopy to Clipboard Copied! Toggle word wrap Toggle overflow
다음 단계
- 파일 시스템을 마운트합니다. 자세한 내용은 36.1.9절. “VDO 볼륨 마운트” 를 참조하십시오.
-
VDO 장치에서 파일 시스템의
삭제기능을 활성화합니다. 자세한 내용은 36.1.10절. “주기적인 블록 삭제 활성화” 를 참조하십시오.
36.1.9. VDO 볼륨 마운트
이 절차에서는 수동으로 또는 영구적으로 VDO 볼륨에 파일 시스템을 마운트합니다.
사전 요구 사항
- 시스템에 VDO 볼륨이 생성되었습니다. 자세한 내용은 36.1.8절. “VDO 볼륨 생성”에서 참조하십시오.
절차
VDO 볼륨에 파일 시스템을 수동으로 마운트하려면 다음을 사용합니다.
mount /dev/mapper/vdo-name mount-point
# mount /dev/mapper/vdo-name mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 부팅 시 자동으로 마운트되도록 파일 시스템을 구성하려면
/etc/fstab파일에 행을 추가합니다.XFS 파일 시스템의 경우:
/dev/mapper/vdo-name mount-point xfs defaults 0 0
/dev/mapper/vdo-name mount-point xfs defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow ext4 파일 시스템의 경우:
/dev/mapper/vdo-name mount-point ext4 defaults 0 0
/dev/mapper/vdo-name mount-point ext4 defaults 0 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
VDO 볼륨이 iSCSI와 같은 네트워크가 필요한 블록 장치에 있는 경우
_netdev마운트 옵션을 추가합니다.
36.1.10. 주기적인 블록 삭제 활성화
systemd 타이머를 활성화하여 지원되는 모든 파일 시스템에서 사용되지 않는 블록을 정기적으로 삭제할 수 있습니다.
절차
systemd타이머를 활성화하고 시작합니다.systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.
# systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
타이머 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36.1.11. VDO 모니터링
이 절차에서는 VDO 볼륨에서 사용 및 효율성 정보를 얻는 방법을 설명합니다.
사전 요구 사항
- VDO 소프트웨어를 설치합니다. VDO 설치를 참조하십시오.
절차
EgressIP
stats유틸리티를 사용하여 VDO 볼륨에 대한 정보를 가져옵니다.vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
# vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2. VDO 유지 관리
VDO 볼륨을 배포한 후 특정 작업을 수행하여 유지 관리하거나 최적화할 수 있습니다. 다음 작업 중 일부는 VDO 볼륨이 올바르게 작동하려면 필요합니다.
사전 요구 사항
- VDO가 설치 및 배포됩니다. 36.1절. “VDO 배포”을 참조하십시오.
36.2.1. VDO 볼륨에서 여유 공간 관리
VDO는 씬 프로비저닝된 블록 스토리지 대상입니다. 이로 인해 VDO 볼륨에서 공간 사용량을 적극적으로 모니터링하고 관리해야 합니다.
36.2.1.1. VDO 볼륨의 물리 및 논리적 크기
VDO는 다음과 같은 방법으로 물리적, 사용 가능한 물리적 크기 및 논리 크기를 활용합니다.
- 물리적 크기
이는 기본 블록 장치와 크기가 동일합니다. VDO는 다음 용도로 이 스토리지를 사용합니다.
- 사용자 데이터가 분할되고 압축될 수 있습니다.
- VDO 메타데이터(예: UDS 인덱스)
- 사용 가능한 물리적 크기
이는 VDO가 사용자 데이터에 사용할 수 있는 물리적 크기의 부분입니다.
물리 크기와 같습니다. 메타데이터의 크기를 뺀 후 나머지 볼륨을 지정된 slab 크기로 slabs로 분할한 후 나머지를 뺀 값입니다.
- 논리 크기
이는 VDO 볼륨이 애플리케이션에 제공하는 프로비저닝된 크기입니다. 일반적으로 사용 가능한 물리적 크기보다 큽니다.
--vdoLogicalSize옵션이 지정되지 않은 경우 논리 볼륨의 프로비저닝이 이제1:1비율로 프로비저닝됩니다. 예를 들어 VDO 볼륨이 20GB 블록 장치 위에 배치된 경우 UDS 인덱스(기본 인덱스 크기가 사용되는 경우) 2.5GB가 예약되어 있습니다. 나머지 17.5GB는 VDO 메타데이터 및 사용자 데이터에 제공됩니다. 결과적으로 사용할 수 있는 스토리지는 17.5GB를 초과하지 않으며 실제 VDO 볼륨을 구성하는 메타데이터로 인해 줄어들 수 있습니다.VDO는 현재 최대 논리 크기가 4PB인 물리 볼륨의 크기를 254배까지 지원합니다.
그림 36.5. VDO 디스크 조직
이 그림에서 VDO 중복된 스토리지 대상은 블록 장치의 상단에 완전히 배치되므로 VDO 볼륨의 물리적 크기는 기본 블록 장치와 같습니다.
36.2.1.2. VDO의 씬 프로비저닝
VDO는 씬 프로비저닝된 블록 스토리지 대상입니다. VDO 볼륨에서 사용하는 물리 공간의 양은 스토리지 사용자에게 제공되는 볼륨의 크기와 다를 수 있습니다. 이러한 차이를 사용하여 스토리지 비용을 절감할 수 있습니다.
공간 부족 조건
기록된 데이터가 예상 최적화 속도를 얻지 못하는 경우 스토리지 공간이 예기치 않게 실행되지 않도록 주의해야 합니다.
논리 블록(가상 스토리지)의 수가 물리적 블록 수를 초과할 때마다 파일 시스템 및 애플리케이션이 예기치 않게 공간이 부족해질 수 있습니다. 이러한 이유로 VDO를 사용하는 스토리지 시스템은 VDO 볼륨에서 사용 가능한 풀의 크기를 모니터링하는 방법을 제공해야 합니다.
EgressIP stats 유틸리티를 사용하여 이 사용 가능한 풀의 크기를 확인할 수 있습니다. 이 유틸리티의 기본 출력에는 Linux df 유틸리티와 유사한 형식으로 실행 중인 모든 VDO 볼륨에 대한 정보가 나열됩니다. 예를 들면 다음과 같습니다.
Device 1K-blocks Used Available Use% /dev/mapper/vdo-name 211812352 105906176 105906176 50%
Device 1K-blocks Used Available Use%
/dev/mapper/vdo-name 211812352 105906176 105906176 50%VDO 볼륨의 물리적 스토리지 용량이 거의 가득 차면 VDO는 다음과 같이 시스템 로그에 경고를 보고합니다.
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name.
Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full.
Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full.
Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full.
Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
이러한 경고 메시지는 lvm2-monitor 서비스가 실행 중인 경우에만 표시됩니다. 기본적으로 활성화되어 있습니다.
공간 부족 조건을 방지하는 방법
무료 풀의 크기가 특정 수준 아래로 떨어지면 다음을 통해 조치를 취할 수 있습니다.
- 데이터 삭제. 이렇게 하면 삭제된 데이터가 중복되지 않을 때마다 공간이 확보됩니다. 데이터를 삭제하면 삭제가 실행된 후에만 공간을 확보합니다.
- 물리적 스토리지 추가
VDO 볼륨에서 물리적 공간을 모니터링하여 공간 부족 상황을 방지합니다. 물리적 블록이 부족하면 VDO 볼륨에서 최근에 기록되지 않은 데이터가 손실될 수 있습니다.
씬 프로비저닝 및 TRIM 및 DISCARD 명령
씬 프로비저닝의 스토리지 절감을 활용하려면 물리적 스토리지 계층에서 데이터가 삭제되는 시기를 알아야 합니다. 씬 프로비저닝된 스토리지에서 작동하는 파일 시스템은 TRIM 또는 DISCARD 명령을 전송하여 논리 블록이 더 이상 필요하지 않은 경우 스토리지 시스템에 알립니다.
TRIM 또는 DISCARD 명령을 보내는 몇 가지 방법을 사용할 수 있습니다.
-
discard마운트 옵션을 사용하면 파일 시스템에서 블록이 삭제될 때마다 이러한 명령을 보낼 수 있습니다. -
fstrim과 같은 유틸리티를 사용하여 제어된 방식으로 명령을 보낼 수 있습니다. 이 유틸리티는 파일 시스템에 사용되지 않는 논리 블록을 감지하고TRIM또는DISCARD명령 형태로 스토리지 시스템으로 정보를 전송하도록 지시합니다.
사용하지 않는 블록에서 TRIM 또는 DISCARD 를 사용할 필요는 VDO에 고유하지 않습니다. 씬 프로비저닝된 스토리지 시스템은 모두 동일한 문제가 있습니다.
36.2.1.3. VDO 모니터링
이 절차에서는 VDO 볼륨에서 사용 및 효율성 정보를 얻는 방법을 설명합니다.
사전 요구 사항
- VDO 소프트웨어를 설치합니다. VDO 설치를 참조하십시오.
절차
EgressIP
stats유틸리티를 사용하여 VDO 볼륨에 대한 정보를 가져옵니다.vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
# vdostats --human-readable Device 1K-blocks Used Available Use% Space saving% /dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73% /dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.1.4. 파일 시스템에서 VDO용 공간 회수
이 절차에서는 파일 시스템을 호스팅하는 VDO 볼륨에서 스토리지 공간을 회수합니다.
VDO는 파일 시스템이 DISCARD,TRIM 또는 UNMAP 명령을 사용하여 블록을 자유롭게 통신하는 경우 공간을 회수할 수 없습니다.
절차
- VDO 볼륨의 파일 시스템에서 삭제 작업을 지원하는 경우 활성화합니다. 사용되지 않는 블록 분리를 참조하십시오.
-
DISCARD,TRIM또는UNMAP를 사용하지 않는 파일 시스템의 경우 여유 공간을 수동으로 회수할 수 있습니다. 바이너리 0으로 구성된 파일을 저장하여 사용 가능한 공간을 채우고 해당 파일을 삭제합니다.
36.2.1.5. 파일 시스템없이 VDO용 공간 회수
이 절차에서는 파일 시스템 없이 블록 스토리지 대상으로 사용되는 VDO 볼륨에서 스토리지 공간을 회수합니다.
절차
blkdiscard유틸리티를 사용합니다.예를 들어 단일 VDO 볼륨은 위에 LVM을 배포하여 여러 하위 볼륨으로 분할할 수 있습니다. 논리 볼륨 프로비저닝을 해제하기 전에
blkdiscard유틸리티를 사용하여 이전에 해당 논리 볼륨에서 사용한 공간을 확보합니다.LVM은
REQ_DISCARD명령을 지원하고 공간을 확보하기 위해 적절한 논리 블록 주소에서 VDO로 요청을 전달합니다. 다른 볼륨 관리자를 사용하는 경우REQ_DISCARD를 지원하거나 SCSI 장치의 경우UNMAP또는 ATA 장치의 경우TRIM을 지원해야 합니다.
36.2.1.6. 파이버 채널 또는 이더넷 네트워크에서 VDO를 위한 공간 회수
이 절차에서는 LIO 또는 SCST와 같은 SCSI 대상 프레임워크를 사용하여 파이버 채널 스토리지 패브릭에서 호스트에 프로비저닝된 VDO 볼륨(또는 볼륨의 일부)의 스토리지 공간을 회수합니다.
절차
SCSI 이니시에이터는
UNMAP명령을 사용하여 씬 프로비저닝된 스토리지 대상의 공간을 확보할 수 있지만, 이 명령에 대한 지원을 알리도록 SCSI 대상 프레임워크를 구성해야 합니다. 일반적으로 이러한 볼륨은 씬 프로비저닝을 활성화하여 수행됩니다.다음 명령을 실행하여 Linux 기반 SCSI 이니시에이터에서
UNMAP에 대한 지원을 확인합니다.sg_vpd --page=0xb0 /dev/device
# sg_vpd --page=0xb0 /dev/deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력에서 Maximum unmap LBA 개수 값이 0보다 큰지 확인합니다.
36.2.2. VDO 볼륨 시작 또는 중지
지정된 VDO 볼륨 또는 모든 VDO 볼륨 및 관련 UDS 인덱스를 시작하거나 중지할 수 있습니다.
36.2.2.1. VDO 볼륨 시작 및 활성화
시스템 부팅 중에 EgressIP 장치는 활성화된 대로 구성된 모든 VDO 장치를 자동으로 시작합니다.
systemd
Egress IP systemd 장치가 설치될 때 기본적으로 설치 및 활성화됩니다. 이 유닛은 시스템 시작 시 EgressIP start --all 명령을 자동으로 실행하여 활성화된 모든 VDO 볼륨을 가져옵니다.
또한 EgressIP create 명령에 --activate=disabled 옵션을 추가하여 자동으로 시작하지 않는 VDO 볼륨을 생성할 수도 있습니다.
시작 순서
일부 시스템은 LVM 볼륨을 VDO 볼륨 위에 두 개 이상 저장할 수 있습니다. 이러한 시스템에서는 적절한 순서로 서비스를 시작해야 합니다.
- LVM의 하위 계층을 먼저 시작해야 합니다. 대부분의 시스템에서 이 계층을 시작하는 것은 LVM 패키지가 설치될 때 자동으로 구성됩니다.
-
그런
다음cabundlesystemd장치를 시작해야 합니다. - 마지막으로 실행 중인 VDO 볼륨 상단에서 LVM 볼륨 또는 기타 서비스를 시작하려면 추가 스크립트를 실행해야 합니다.
볼륨을 중지하는 데 걸리는 시간
VDO 볼륨을 중지하려면 스토리지 장치의 속도와 볼륨에서 써야 하는 데이터 양에 따라 시간이 걸립니다.
- 볼륨은 항상 UDS 인덱스의 1GiB마다 1GiB 정도를 씁니다.
- 볼륨은 블록 맵 캐시 크기와 slab당 최대 8MiB와 동일한 데이터의 양을 기록합니다.
- 볼륨에서 모든 미해결 IO 요청 처리를 완료해야 합니다.
36.2.2.2. VDO 볼륨 시작
이 절차에서는 지정된 VDO 볼륨 또는 시스템의 모든 VDO 볼륨을 시작합니다.
절차
지정된 VDO 볼륨을 시작하려면 다음을 사용합니다.
vdo start --name=my-vdo
# vdo start --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 VDO 볼륨을 시작하려면 다음을 사용하십시오.
vdo start --all
# vdo start --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.2.3. VDO 볼륨 중지
이 절차에서는 시스템의 지정된 VDO 볼륨 또는 모든 VDO 볼륨을 중지합니다.
절차
볼륨을 중지합니다.
지정된 VDO 볼륨을 중지하려면 다음을 사용합니다.
vdo stop --name=my-vdo
# vdo stop --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 VDO 볼륨을 중지하려면 다음을 사용합니다.
vdo stop --all
# vdo stop --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- 볼륨이 디스크에 데이터 쓰기를 완료할 때까지 기다립니다.
36.2.3. 시스템 부팅 시 VDO 볼륨 자동 시작
VDO 볼륨은 시스템 부팅 시 자동으로 시작되도록 구성할 수 있습니다. 자동 시작을 비활성화할 수도 있습니다.
36.2.3.1. VDO 볼륨 시작 및 활성화
시스템 부팅 중에 EgressIP 장치는 활성화된 대로 구성된 모든 VDO 장치를 자동으로 시작합니다.
systemd
Egress IP systemd 장치가 설치될 때 기본적으로 설치 및 활성화됩니다. 이 유닛은 시스템 시작 시 EgressIP start --all 명령을 자동으로 실행하여 활성화된 모든 VDO 볼륨을 가져옵니다.
또한 EgressIP create 명령에 --activate=disabled 옵션을 추가하여 자동으로 시작하지 않는 VDO 볼륨을 생성할 수도 있습니다.
시작 순서
일부 시스템은 LVM 볼륨을 VDO 볼륨 위에 두 개 이상 저장할 수 있습니다. 이러한 시스템에서는 적절한 순서로 서비스를 시작해야 합니다.
- LVM의 하위 계층을 먼저 시작해야 합니다. 대부분의 시스템에서 이 계층을 시작하는 것은 LVM 패키지가 설치될 때 자동으로 구성됩니다.
-
그런
다음cabundlesystemd장치를 시작해야 합니다. - 마지막으로 실행 중인 VDO 볼륨 상단에서 LVM 볼륨 또는 기타 서비스를 시작하려면 추가 스크립트를 실행해야 합니다.
볼륨을 중지하는 데 걸리는 시간
VDO 볼륨을 중지하려면 스토리지 장치의 속도와 볼륨에서 써야 하는 데이터 양에 따라 시간이 걸립니다.
- 볼륨은 항상 UDS 인덱스의 1GiB마다 1GiB 정도를 씁니다.
- 볼륨은 블록 맵 캐시 크기와 slab당 최대 8MiB와 동일한 데이터의 양을 기록합니다.
- 볼륨에서 모든 미해결 IO 요청 처리를 완료해야 합니다.
36.2.3.2. VDO 볼륨 활성화
이 절차에서는 VDO 볼륨을 활성화하여 자동으로 시작할 수 있습니다.
절차
특정 볼륨을 활성화하려면 다음을 수행합니다.
vdo activate --name=my-vdo
# vdo activate --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 볼륨을 활성화하려면 다음을 수행합니다.
vdo activate --all
# vdo activate --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.3.3. VDO 볼륨 비활성화
이 절차에서는 VDO 볼륨이 자동으로 시작되지 않도록 비활성화합니다.
절차
특정 볼륨을 비활성화하려면 다음을 수행합니다.
vdo deactivate --name=my-vdo
# vdo deactivate --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 볼륨을 비활성화하려면 다음을 수행합니다.
vdo deactivate --all
# vdo deactivate --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.4. VDO 쓰기 모드 선택
기본 블록 장치에 필요한 내용에 따라 VDO 볼륨에 대한 쓰기 모드를 구성할 수 있습니다. 기본적으로 VDO는 쓰기 모드를 자동으로 선택합니다.
36.2.4.1. VDO 쓰기 모드
VDO는 다음과 같은 쓰기 모드를 지원합니다.
syncVDO가
동기화모드인 경우 위의 계층에서는 쓰기 명령이 영구 스토리지에 데이터를 쓰는 것으로 가정합니다. 그 결과, 파일 시스템 또는 애플리케이션이 FLUSH를 발행하거나 FUA(단위 액세스) 요청을 강제 실행하여 데이터가 중요한 시점에서 영구화되도록 할 필요가 없습니다.VDO는 쓰기 명령이 완료될 때 기본 스토리지로 데이터가 영구 스토리지에 기록되도록만
동기화모드로 설정해야 합니다. 즉, 스토리지에 휘발성 쓰기 캐시가 없거나 캐시를 통한 쓰기가 있어야 합니다.asyncVDO가
async모드에 있는 경우 VDO는 쓰기 명령을 승인할 때 데이터가 영구 스토리지에 기록된다는 것을 보장하지 않습니다. 파일 시스템 또는 애플리케이션에는 각 트랜잭션의 중요 시점에 데이터 지속성을 보장하기 위해 FLUSH 또는 FUA 요청을 발행해야 합니다.쓰기 명령이 완료될 때 기본 저장소가 영구 스토리지에 기록된다는 것을 보장하지 않는 경우 VDO는
async모드로 설정해야 합니다. 즉, 스토리지에 휘발성 쓰기 백 캐시가 있는 경우입니다.async-unsafe이 모드는
async와 동일한 속성을 가지고 있지만 Atomicity, Consistency, Isolation, Durability (ACID)와 호환되지 않습니다. async와 비교하여async-unsafe주의ACID 컴플라이언스 준수를 가정하는 애플리케이션 또는 파일 시스템이 VDO 볼륨 위에서 작동하는 경우
async-unsafemode로 인해 예기치 않은 데이터가 손실될 수 있습니다.auto-
자동모드는 각 장치의 특성에 따라동기화또는async를 자동으로 선택합니다. 이는 기본 옵션입니다.
36.2.4.2. VDO 쓰기 모드의 내부 처리
VDO의 쓰기 모드는 동기화 및 async 입니다. 다음 정보는 이러한 모드의 작업에 대해 설명합니다.
kvdo 모듈이 동기 (동시 )모드로작동하는 경우:
- 요청에 데이터를 일시적으로 기록한 다음 요청을 승인합니다.
- 승인이 완료되면 VDO 인덱스로 전송되는 블록 데이터의 MurmurHash-3 서명을 컴퓨팅하여 블록을 분리하려고 시도합니다.
-
VDO 인덱스에 동일한 서명이 있는 블록에 대한 항목이 포함된 경우
kvdo는 표시된 블록을 읽고 두 블록의 바이트 단위로 비교하여 동일한지 확인합니다. -
실제로 동일한 경우
kvdo는 블록 맵을 업데이트하여 논리 블록이 해당 물리적 블록을 가리키고 할당된 물리적 블록을 해제하도록 합니다. -
VDO 인덱스에 작성된 블록의 서명에 대한 항목이 포함되어 있지 않거나 표시된 블록에 실제로 동일한 데이터가 포함되지 않은 경우
kvdo는 블록 맵을 업데이트하여 임시 물리적 블록을 영구적으로 만듭니다.
kvdo 가 비동기(async) 모드로 작동하는 경우:
- 데이터를 작성하지 않고 즉시 요청을 승인합니다.
- 그런 다음 위에서 설명한 것과 동일한 방식으로 블록을 복제하려고 시도합니다.
-
블록이 중복되는 경우
kvdo는 블록 맵을 업데이트하고 할당된 블록을 해제합니다. 그렇지 않으면 요청에 데이터를 쓰고 블록 맵을 업데이트하여 물리적 블록을 영구적으로 만듭니다.
36.2.4.3. VDO 볼륨에서 쓰기 모드 확인
이 절차에서는 선택한 VDO 볼륨의 활성 쓰기 모드를 나열합니다.
절차
다음 명령을 사용하여 VDO 볼륨에서 사용하는 쓰기 모드를 확인합니다.
vdo status --name=my-vdo
# vdo status --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 출력 목록은 다음과 같습니다.
-
동기화,async또는auto에서 선택한 옵션인 구성된 쓰기 정책 -
VDO에서 적용한 특정 쓰기 모드인 쓰기 정책 (
sync또는async)
-
36.2.4.4. 휘발성 캐시 확인
이 절차에서는 블록 장치에 휘발성 캐시가 있는지 여부를 결정합니다. 정보를 사용하여 동기화 및 async VDO 쓰기 모드 중에서 선택할 수 있습니다.
절차
다음 방법 중 하나를 사용하여 장치에 나중 쓰기 캐시가 있는지 확인합니다.
/sys/block/ 블록 장치 /device/scsi_disk/식별자/cache_typesysfs파일을 읽습니다. 예를 들면 다음과 같습니다.cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write back
$ cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write backCopy to Clipboard Copied! Toggle word wrap Toggle overflow cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' None
$ cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' NoneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 위에서 언급한 장치에 커널 부팅 로그에 쓰기 캐시가 있는지 여부를 확인할 수 있습니다.
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, does not support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUA
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, does not support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUACopy to Clipboard Copied! Toggle word wrap Toggle overflow
이전 예에서 다음을 수행합니다.
-
장치
sda는 쓰기 캐시가 있음을 나타냅니다. 에 대해async모드를 사용합니다. -
장치
sdb는 나중 쓰기 캐시 가 없음을 나타냅니다.동기화모드를 사용합니다.
cache_type값이None또는write through인 경우동기화쓰기 모드를 사용하도록 VDO를 구성해야 합니다.-
장치
36.2.4.5. VDO 쓰기 모드 설정
이 절차에서는 기존 또는 새 볼륨을 생성할 때 VDO 볼륨의 쓰기 모드를 설정합니다.
잘못된 쓰기 모드를 사용하면 정전, 시스템 충돌 또는 디스크와 예상치 못한 연락처 손실 후 데이터가 손실될 수 있습니다.
사전 요구 사항
- 장치에 적합한 쓰기 모드를 결정합니다. 36.2.4.4절. “휘발성 캐시 확인”을 참조하십시오.
프로세스
기존 VDO 볼륨에서 또는 새 볼륨을 생성할 때 쓰기 모드를 설정할 수 있습니다.
기존 VDO 볼륨을 수정하려면 다음을 사용합니다.
vdo changeWritePolicy --writePolicy=sync|async|async-unsafe|auto \ --name=vdo-name# vdo changeWritePolicy --writePolicy=sync|async|async-unsafe|auto \ --name=vdo-nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
VDO 볼륨을 생성할 때 쓰기 모드를 지정하려면
--writePolicy=sync|async|async-unsafe|auto옵션을vdo create명령에 추가합니다.
36.2.5. 정리되지 않은 종료 후 VDO 볼륨 복구
정리 해제 종료 후 VDO 볼륨을 복구하여 계속 작동할 수 있습니다. 작업은 대부분 자동화됩니다. 또한 프로세스의 실패로 인해 VDO 볼륨이 생성되지 않은 후 정리할 수 있습니다.
36.2.5.1. VDO 쓰기 모드
VDO는 다음 쓰기 모드를 지원합니다.
syncVDO가
동기화모드에 있는 경우 위의 계층은 쓰기 명령이 데이터를 영구 스토리지에 쓰는 것으로 가정합니다. 결과적으로 파일 시스템 또는 애플리케이션(예: file system 또는 application)을 발행하여 중요한 시점에 데이터가 영구적으로 유지되도록 FUA(인전 단위 액세스) 요청을 실행할 필요가 없습니다.VDO는 쓰기 명령이 완료될 때 데이터를 영구 스토리지에 기록해야 하는 경우에만
동기화모드로 설정해야 합니다. 즉, 스토리지에 휘발성 쓰기 캐시가 없거나 캐시를 통해 쓰기가 있어야 합니다.asyncVDO가 동기화
모드에있는 경우 VDO는 쓰기 명령을 승인할 때 데이터가 영구 스토리지에 기록되는 것을 보장하지 않습니다. 파일 시스템 또는 애플리케이션에서 각 트랜잭션의 중요한 지점에서 데이터 지속성을 보장하기 위해 파일 시스템 또는 FUA 요청을 발행해야 합니다.쓰기 명령이 완료되면 기본 스토리지에서 영구 스토리지에 기록되는 것을 보장하지 않는 경우 VDO를
async모드로 설정해야 합니다. 즉, 스토리지에 휘발성 쓰기 백 캐시가 있는 경우입니다.async-unsafe이 모드는
async와 동일하지만 Atomicity, Consistency, Isolation, Durability (ACID)와 호환되지 않습니다. 동기화와 비교하여async-unsafe주의ACID 규정 준수가 VDO 볼륨 위에서 작동하는 애플리케이션 또는 파일 시스템이 경우
async-unsafe모드로 인해 예기치 않은 데이터가 손실될 수 있습니다.auto-
자동모드는 각 장치의 특성에 따라동기화또는async를 자동으로 선택합니다. 이는 기본 옵션입니다.
36.2.5.2. VDO 볼륨 복구
정리 해제를 종료한 후 VDO 볼륨이 다시 시작되면 VDO는 다음 작업을 수행합니다.
- 볼륨의 메타데이터 일관성을 확인합니다.
- 필요한 경우 메타데이터의 일부를 다시 작성하여 복구합니다.
다시 빌드는 자동이며 사용자 개입이 필요하지 않습니다.
VDO는 활성 쓰기 모드에 따라 다양한 쓰기를 다시 빌드할 수 있습니다.
sync-
VDO가 동기 스토리지에서 실행 중이고 쓰기 정책이
sync로 설정된 경우 볼륨에 기록된 모든 데이터가 완전히 복구됩니다. async-
쓰기 정책이 동기화된 경우
쓰기정책이 동기화되지 않은 경우 일부 쓰기가 복구되지 않을 수 있습니다. 이 작업은 VDO a#16USH 명령 또는 FUA (force unit access) 플래그를 사용하여 태그된 쓰기 I/O를 전송하여 수행됩니다.fsync,fdatasync,sync또는umount와 같은 데이터 무결성 작업을 호출하여 사용자 모드에서 이 작업을 수행할 수 있습니다.
두 모드 모두 풀링되지 않았거나 플러시가 뒤따르지 않은 일부 쓰기도 다시 빌드될 수 있습니다.
자동 및 수동 복구
VDO 볼륨이 복구 모드로 전환되면 VDO는 다시 온라인 상태가 된 후 정리되지 않은 VDO 볼륨을 자동으로 다시 빌드합니다. 이를 온라인 복구 라고 합니다.
VDO 볼륨을 성공적으로 복구할 수 없는 경우 볼륨을 볼륨을 다시 시작할 때마다 유지되는 읽기 전용 운영 모드로 배치합니다. 다시 빌드를 강제 적용하여 문제를 수동으로 해결해야 합니다.
36.2.5.3. VDO 운영 모드
이 섹션에서는 VDO 볼륨이 정상적으로 작동하는지 또는 오류를 복구하고 있는지 여부를 나타내는 모드를 설명합니다.
EgressIP stats --verbose device 명령을 사용하여 VDO 볼륨의 현재 작동 모드를 표시할 수 있습니다. 출력의 운영 모드 특성을 참조하십시오.
normal-
기본 작동 모드입니다. 다음 상태 중 하나가 다른 모드를 강제 적용하지 않는 한 VDO 볼륨은 항상
일반모드입니다. 새로 생성된 VDO 볼륨은일반모드로 시작됩니다. 복구VDO 볼륨이 종료되기 전에 모든 메타데이터를 저장하지 않으면 다음에 시작할 때
복구모드로 자동 전환됩니다. 이 모드로 전환하는 일반적인 이유는 정전이 갑작스럽거나 기본 스토리지 장치의 문제입니다.VDO는
복구모드에서는 장치의 각 물리적 데이터 블록에 대한 참조 수를 수정하고 있습니다. 회복은 일반적으로 오래 걸리지 않습니다. 시간은 VDO 볼륨의 크기, 기본 스토리지 장치가 얼마나 빠른지, VDO가 동시에 처리하는 다른 요청 수에 따라 달라집니다. VDO 볼륨 기능은 일반적으로 다음과 같은 예외와 함께 작동합니다.- 처음에는 볼륨에서 쓰기 요청에 사용할 수 있는 공간의 양이 제한될 수 있습니다. 메타데이터가 더 많이 복구됨에 따라 더 많은 여유 공간을 사용할 수 있게 됩니다.
- VDO 볼륨이 복구되는 동안 작성된 데이터는 데이터가 아직 복구되지 않은 볼륨의 일부에 있는 경우 충돌 전에 기록된 데이터에 대해 중복되지 않을 수 있습니다. VDO는 볼륨을 복구하는 동안 데이터를 압축할 수 있습니다. 여전히 압축 블록을 읽거나 덮어 쓸 수 있습니다.
- 온라인 복구 중에 특정 통계를 사용할 수 없습니다. 예를 들어 사용 중인 블록 과 블록은 free 입니다. 다시 빌드가 완료되면 이러한 통계를 사용할 수 있습니다.
- 지속적인 복구 작업으로 인해 읽기 및 쓰기에 대한 응답 시간이 평상보다 느려질 수 있습니다.
복구모드에서 VDO 볼륨을 안전하게 종료할 수 있습니다. 시스템을 종료하기 전에 복구가 완료되지 않으면 다음에 시작될 때 장치가복구모드로 다시 시작됩니다.VDO 볼륨은
복구모드를 자동으로 종료하고 모든 참조 수를 수정한 경우일반모드로 이동합니다. 관리자 작업이 필요하지 않습니다. 자세한 내용은 36.2.5.4절. “온라인 VDO 볼륨 복구”의 내용을 참조하십시오.읽기 전용VDO 볼륨이 치명적인 내부 오류가 발생하면
읽기 전용모드로 전환됩니다.읽기 전용모드로 이어질 수 있는 이벤트에는 메타데이터 손상 또는 백업 스토리지 장치가 읽기 전용인 경우가 있습니다. 이 모드는 오류 상태입니다.읽기 전용모드에서는 데이터가 정상적으로 작동하지만 데이터 쓰기는 항상 실패합니다. VDO 볼륨은 관리자가 문제를 해결할 때까지읽기 전용모드로 유지됩니다.VDO 볼륨을
읽기 전용모드로 안전하게 종료할 수 있습니다. 모드는 일반적으로 VDO 볼륨을 다시 시작한 후 지속됩니다. 드문 경우지만 VDO 볼륨은 백업 스토리지 장치에읽기 전용상태를 기록할 수 없습니다. 이러한 경우 VDO는 대신 복구를 시도합니다.볼륨이 읽기 전용 모드에 있으면 볼륨의 데이터가 손실되거나 손상되지 않았음을 보장할 수 없습니다. 이러한 경우 Red Hat은 읽기 전용 볼륨에서 데이터를 복사하고 백업에서 볼륨을 복원할 것을 권장합니다.
데이터 손상의 위험이 허용되는 경우 VDO 볼륨 메타데이터를 오프라인으로 다시 빌드하여 볼륨을 온라인 상태로 되돌릴 수 있도록 할 수 있습니다. 다시 빌드된 데이터의 무결성은 보장할 수 없습니다. 자세한 내용은 36.2.5.5절. “VDO 볼륨 메타데이터를 오프라인으로 다시 빌드”의 내용을 참조하십시오.
36.2.5.4. 온라인 VDO 볼륨 복구
이 절차에서는 정리되지 않은 종료 후 메타데이터를 복구하기 위해 VDO 볼륨에서 온라인 복구를 수행합니다.
프로세스
VDO 볼륨이 아직 시작되지 않은 경우 다음을 시작합니다.
vdo start --name=my-vdo
# vdo start --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 추가 단계는 필요하지 않습니다. 복구는 백그라운드에서 실행됩니다.
- 사용 중인 블록과 블록과 같은 볼륨 통계를 자유롭게 사용하는 경우 사용할 수 있을 때까지 기다립니다.
36.2.5.5. VDO 볼륨 메타데이터를 오프라인으로 다시 빌드
이 절차에서는 정리되지 않은 종료 후 복구하기 위해 VDO 볼륨 메타데이터의 강제 오프라인 재구축을 수행합니다.
이 절차에서는 볼륨에서 데이터가 손실될 수 있습니다.
사전 요구 사항
- VDO 볼륨이 시작됩니다.
프로세스
볼륨이 읽기 전용 모드인지 확인합니다. 명령 출력에서 작동 모드 속성을 참조하십시오.
vdo status --name=my-vdo
# vdo status --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨이 읽기 전용 모드가 아닌 경우 오프라인에서 강제로 다시 빌드할 필요가 없습니다. 36.2.5.4절. “온라인 VDO 볼륨 복구” 에 설명된 대로 온라인 복구를 수행합니다.
실행 중인 경우 볼륨을 중지합니다.
vdo stop --name=my-vdo
# vdo stop --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow --forceRebuild옵션을 사용하여 볼륨을 다시 시작합니다.vdo start --name=my-vdo --forceRebuild
# vdo start --name=my-vdo --forceRebuildCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.5.6. 성공적으로 생성된 VDO 볼륨 제거
이 절차에서는 VDO 볼륨을 중간 상태로 정리합니다. 볼륨을 생성할 때 오류가 발생하면 볼륨이 중간 상태가 됩니다. 예를 들어 다음과 같은 상황이 발생할 수 있습니다.
- 시스템 충돌
- 전원 실패
-
관리자가 실행 중인
vdo create명령을 중단
프로세스
정리하려면
--force옵션을 사용하여 성공적으로 생성된 볼륨을 제거합니다.vdo remove --force --name=my-vdo
# vdo remove --force --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 관리자가 볼륨이 생성되지 않았기 때문에 시스템 구성을 변경하여 충돌이 발생할 수 있으므로
--force옵션이 필요합니다.--force옵션이 없으면 다음 메시지와 함께vdo remove명령이 실패합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.6. UDS 인덱스 최적화
UDS 인덱스의 특정 설정을 구성하여 시스템에서 최적화할 수 있습니다.
VDO 볼륨을 생성한 후에는 UDS 인덱스의 속성을 변경할 수 없습니다.
36.2.6.1. VDO 볼륨의 구성 요소
VDO는 블록 장치를 백업 저장소로 사용하며, 하나 이상의 디스크, 파티션 또는 플랫 파일로 구성된 물리적 스토리지 집계를 포함할 수 있습니다. 스토리지 관리 도구가 VDO 볼륨을 생성하면 VDO는 UDS 인덱스 및 VDO 볼륨에 대한 볼륨 공간을 예약합니다. UDS 인덱스와 VDO 볼륨은 함께 상호 작용하여 중복된 블록 스토리지를 제공합니다.
그림 36.6. VDO 디스크 조직
VDO 솔루션은 다음 구성 요소로 구성됩니다.
kvdoLinux 장치 매퍼 계층으로 로드되는 커널 모듈은 중복, 압축 및 씬 프로비저닝된 블록 스토리지 볼륨을 제공합니다.
kvdo모듈은 블록 장치를 노출합니다. 블록 저장을 위해 이 블록 장치에 직접 액세스하거나 XFS 또는 ext4와 같은 Linux 파일 시스템을 통해 제공할 수 있습니다.kvdo가 VDO 볼륨에서 데이터의 논리 블록을 읽는 요청을 수신하면 요청된 논리 블록을 기본 물리적 블록에 매핑한 다음 요청된 데이터를 읽고 반환합니다.kvdo가 VDO 볼륨에 데이터 블록을 작성하라는 요청을 수신하면 먼저 요청이 DISCARD 또는 TRIM 요청인지 또는 데이터가 균일하게 0인지 여부를 확인합니다. 이러한 조건 중 하나가 true인 경우kvdo는 블록 맵을 업데이트하고 요청을 승인합니다. 그렇지 않으면 VDO가 데이터를 처리하고 최적화합니다.uds볼륨의 UBI(Universal Deduplication Service) 인덱스와 통신하고 중복을 위해 데이터를 분석하는 커널 모듈입니다. 각 새로운 데이터에 대해 UDS는 해당 조각이 이전에 저장된 데이터와 동일한지 여부를 신속하게 결정합니다. 인덱스가 일치하는 항목을 찾으면 스토리지 시스템이 내부적으로 기존 항목을 참조하여 동일한 정보를 두 번 이상 저장하지 않도록 할 수 있습니다.
UDS 인덱스는
uds커널 모듈로 커널 내에서 실행됩니다.- 명령줄 툴
- 최적화된 스토리지 구성 및 관리를 위한 것입니다.
36.2.6.2. UDS 인덱스
VDO는 UDS라는 고성능 중복 제거 인덱스를 사용하여 저장된 대로 중복 데이터 블록을 감지합니다.
UDS 인덱스는 VDO 제품의 기반을 제공합니다. 데이터의 새로운 각 부분에 대해, 해당 조각이 이전에 저장된 모든 데이터와 동일한지 여부를 신속하게 결정합니다. 인덱스가 일치하면 스토리지 시스템이 내부적으로 기존 항목을 참조하여 동일한 정보를 두 번 이상 저장하지 않도록 할 수 있습니다.
UDS 인덱스는 uds 커널 모듈로 커널 내에서 실행됩니다.
중복 제거 창 은 인덱스에서 기억하는 이전에 작성된 블록 수입니다. 중복 제거 창의 크기는 구성할 수 있습니다. 지정된 창 크기의 경우 인덱스에는 특정 양의 RAM과 특정 양의 디스크 공간이 필요합니다. 일반적으로 창 크기는 --indexMem=size 옵션을 사용하여 인덱스 메모리 크기를 지정하여 결정됩니다. 그런 다음 VDO는 자동으로 사용할 디스크 공간의 양을 결정합니다.
UDS 인덱스는 다음 두 부분으로 구성됩니다.
- 컴팩트한 표현은 고유한 블록당 하나 이상의 항목을 포함하는 메모리에 사용됩니다.
- 인덱스에 표시된 연결된 블록 이름을 순서대로 기록하는 디스크상 구성 요소입니다.
UDS는 캐시를 포함하여 메모리의 항목당 평균 4바이트를 사용합니다.
디스크상의 구성 요소는 UDS로 전달되는 데이터의 바인딩된 기록을 유지 관리합니다. UDS는 가장 최근에 표시된 블록의 이름이 포함된 이 중복 제거 창에 포함된 데이터에 대한 중복 제거 조언을 제공합니다. 중복 제거 창을 사용하면 UDS가 대규모 데이터 저장소를 인덱싱하는 데 필요한 메모리 양을 제한하면서 데이터를 최대한 효율적으로 인덱싱할 수 있습니다. 중복 제거 창의 바인딩된 특성에도 불구하고 높은 수준의 중복 제거가 있는 대부분의 데이터 세트는 높은 수준의 일시적인 현지성을 나타냅니다. 즉, 거의 동시에 기록된 블록 세트 간에 대부분의 중복 제거가 발생합니다. 또한 일반적으로 작성된 데이터는 오래 전에 작성된 데이터보다 최근에 기록된 데이터를 복제할 가능성이 높습니다. 따라서 지정된 시간 간격 동안 지정된 워크로드의 경우 UDS가 가장 최근 데이터 또는 모든 데이터만 인덱싱할지 여부에 관계없이 중복 제거율이 종종 동일합니다.
중복된 데이터는 일시적인 지역성을 표시하는 경향이 있기 때문에 스토리지 시스템의 모든 블록을 인덱싱할 필요가 거의 필요하지 않습니다. 이로 인해 인덱스 메모리 비용이 중복 제거로 인한 스토리지 비용 절감을 줄일 수 있었습니다. 인덱스 크기 요구 사항은 데이터 수집 속도와 더 밀접하게 관련이 있습니다. 예를 들어 100TB의 총 용량이 있지만 주당 1TB의 수집 속도가 있는 스토리지 시스템을 고려해 보십시오. 중복 제거 창이 4TB인 경우 UDS는 지난 한 달 내에 작성된 데이터 중에서 대부분 중복성을 감지할 수 있습니다.
36.2.6.3. 권장되는 UDS 인덱스 구성
이 섹션에서는 의도한 사용 사례에 따라 UDS 인덱스와 함께 사용할 권장 옵션에 대해 설명합니다.
일반적으로 Red Hat은 모든 프로덕션 사용 사례에 스파스 UDS 인덱스를 사용하는 것이 좋습니다. 이는 매우 효율적인 인덱싱 데이터 구조로, 중복 제거 창에서 블록당 RAM 바이트의 약 1/4이 필요합니다. 디스크에서 블록당 약 72바이트의 디스크 공간이 필요합니다. 이 인덱스의 최소 구성에서는 256MB의 RAM과 디스크의 약 25GB 공간을 사용합니다.
이 구성을 사용하려면 vdo create 명령에 --sparseIndex=enabled --indexMem=0.25 옵션을 지정합니다. 이 구성으로 인해 2.5TB의 중복 제거 창이 표시됩니다(즉, 2.5TB의 기록이 기억됨). 대부분의 사용 사례에서 2.5TB의 중복 제거 창은 최대 10TB의 스토리지 풀 중복에 적합합니다.
그러나 인덱스의 기본 구성은 밀도가 높은 인덱스를 사용하는 것입니다. 이 인덱스는 RAM에서 상당히 덜 효율적이지만 제한된 환경의 평가에 더 편리합니다(또한 10배까지 낮은 최소 요구 디스크 공간).
일반적으로 VDO 볼륨의 물리 크기 중 1/4에 해당하는 중복 제거 창이 권장되는 구성입니다. 그러나 이는 실제 요구 사항이 아닙니다. 심지어 작은 중복 제거 창 (물리 스토리지의 양과 비교)도 많은 사용 사례에서 상당한 양의 중복 데이터를 찾을 수 있습니다. 더 큰 창도 사용할 수 있지만 대부분의 경우 추가 이점이 거의 없습니다.
36.2.7. VDO에서 중복 제거 활성화 또는 비활성화
경우에 따라 볼륨에서 읽고 쓰는 기능을 계속 유지하면서 VDO 볼륨에 기록되는 데이터의 중복 제거를 일시적으로 비활성화해야 할 수 있습니다. 중복 제거를 비활성화하면 후속 쓰기가 중복되지 않지만 이미 중복된 데이터는 그대로 유지됩니다.
36.2.7.1. VDO에서 중복 제거
중복 제거는 중복 블록의 여러 복사본을 제거하여 스토리지 리소스 사용을 줄이기 위한 기술입니다.
동일한 데이터를 두 번 이상 작성하는 대신 VDO는 각 중복 블록을 감지하고 원래 블록에 대한 참조로 기록합니다. VDO는 VDO 위의 스토리지 계층에서 VDO의 스토리지 계층에서 사용하는 물리 블록 주소로 사용되는 논리 블록 주소의 매핑을 유지 관리합니다.
중복 제거 후 여러 논리 블록 주소를 동일한 물리적 블록 주소에 매핑할 수 있습니다. 이를 공유 블록이라고 합니다. 블록 공유는 VDO가 존재하지 않는 것처럼 블록을 읽고 쓰는 스토리지 사용자에게 표시되지 않습니다.
공유 블록을 덮어쓸 때 VDO는 새 블록 데이터를 저장하기 위해 새 물리 블록을 할당하여 공유 물리적 블록에 매핑된 다른 논리 블록 주소가 수정되지 않도록 합니다.
36.2.7.2. VDO 볼륨에서 중복 제거 활성화
이 절차에서는 연결된 UDS 인덱스를 다시 시작하고 VDO 볼륨에 중복 제거가 다시 활성 상태임을 알립니다.
중복 제거는 기본적으로 활성화되어 있습니다.
프로세스
VDO 볼륨에서 중복 제거를 다시 시작하려면 다음 명령을 사용합니다.
vdo enableDeduplication --name=my-vdo
# vdo enableDeduplication --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.7.3. VDO 볼륨에서 중복 제거 비활성화
이 절차에서는 연결된 UDS 인덱스를 중지하고 VDO 볼륨에 중복 제거가 더 이상 활성화되지 않음을 알립니다.
프로세스
VDO 볼륨에서 중복 제거를 중지하려면 다음 명령을 사용합니다.
vdo disableDeduplication --name=my-vdo
# vdo disableDeduplication --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
--deduplication=disabled옵션을vdo create명령에 추가하여 새 VDO 볼륨을 생성할 때 중복 제거를 비활성화할 수도 있습니다.
36.2.8. VDO에서 압축 활성화 또는 비활성화
VDO는 데이터 압축을 제공합니다. 이를 비활성화하면 성능을 극대화하고 압축할 가능성이 없는 데이터 처리를 가속화할 수 있습니다. 다시 활성화하면 공간 절약을 늘릴 수 있습니다.
36.2.8.1. VDO의 압축
블록 수준 중복 제거 외에도 VDO는 HIOPS Compression™ 기술을 사용하여 인라인 블록 수준 압축도 제공합니다.
VDO 볼륨 압축은 기본적으로 활성화되어 있습니다.
중복 제거는 가상 머신 환경 및 백업 애플리케이션에 적합한 솔루션이지만 압축은 로그 파일 및 데이터베이스와 같은 블록 수준 중복성을 나타내지 않는 구조화된 비정형 파일 형식과 매우 잘 작동합니다.
압축은 중복으로 식별되지 않은 블록에서 작동합니다. VDO가 처음으로 고유한 데이터를 볼 때 데이터를 압축합니다. 이미 저장된 데이터의 후속 복사본은 추가 압축 단계가 필요하지 않고 중복됩니다.
압축 기능은 여러 압축 작업을 한 번에 처리할 수 있는 병렬화된 패키징 알고리즘을 기반으로 합니다. 블록을 처음 저장하고 요청자에게 응답한 후 최상의 패킹 알고리즘은 압축 시 단일 물리적 블록에 들어갈 수 있는 여러 블록을 찾습니다. 특정 물리적 블록이 추가 압축 블록을 보유할 수 없다고 판단되면 스토리지에 기록되고 압축되지 않은 블록이 해제되고 재사용됩니다.
요청자에게 이미 응답한 후 압축 및 패키징 작업을 수행하면 압축을 사용하면 대기 시간이 최소화됩니다.
36.2.8.2. VDO 볼륨에서 압축 활성화
이 절차를 통해 VDO 볼륨의 압축을 통해 공간 절약을 늘릴 수 있습니다.
압축은 기본적으로 활성화되어 있습니다.
프로세스
다시 시작하려면 다음 명령을 사용합니다.
vdo enableCompression --name=my-vdo
# vdo enableCompression --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.8.3. VDO 볼륨에서 압축 비활성화
이 절차에서는 VDO 볼륨에서 압축을 중지하여 성능을 극대화하거나 압축할 가능성이 없는 데이터 처리 속도를 향상시킵니다.
프로세스
기존 VDO 볼륨에서 압축을 중지하려면 다음 명령을 사용합니다.
vdo disableCompression --name=my-vdo
# vdo disableCompression --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
또는 새 볼륨을 생성할 때
--compression=disabled옵션을vdo create명령에 추가하여 압축을 비활성화할 수 있습니다.
36.2.9. VDO 볼륨의 크기 증가
VDO 볼륨의 물리 크기를 늘리면 기본 스토리지 용량을 더 많이 활용하거나 논리 크기를 확장하여 볼륨에 더 많은 용량을 제공할 수 있습니다.
36.2.9.1. VDO 볼륨의 물리 및 논리 크기
VDO는 다음과 같은 방법으로 물리적, 사용 가능한 물리적 및 논리 크기를 활용합니다.
- 물리적 크기
이는 기본 블록 장치와 동일한 크기입니다. VDO는 다음을 위해 이 스토리지를 사용합니다.
- 사용자 데이터, 중복 제거 및 압축 가능
- UDS 인덱스와 같은 VDO 메타데이터
- 사용 가능한 물리적 크기
VDO가 사용자 데이터에 사용할 수 있는 물리적 크기의 일부입니다.
물리 크기는 지정된 slab 크기로 볼륨을 slabs로 분할한 후 나머지를 메타데이터의 크기를 뺀 것과 동일합니다.
- 논리 크기
VDO 볼륨이 애플리케이션에 제공하는 프로비저닝된 크기입니다. 일반적으로 사용 가능한 물리적 크기보다 큽니다.
--vdoLogicalSize옵션을 지정하지 않으면 이제 논리 볼륨의 프로비저닝이1:1비율로 프로비저닝됩니다. 예를 들어 VDO 볼륨이 20GB 블록 장치 위에 배치되면 UDS 인덱스용으로 2.5GB가 예약되어 있습니다(기본 인덱스 크기가 사용되는 경우). 나머지 17.5GB는 VDO 메타데이터 및 사용자 데이터에 대해 제공됩니다. 결과적으로 사용할 수 있는 스토리지는 17.5GB를 넘지 않으며 실제 VDO 볼륨을 구성하는 메타데이터로 인해 더 적을 수 있습니다.VDO는 현재 최대 논리 크기가 4PB인 물리 볼륨의 크기에서 최대 254배까지 논리 크기를 지원합니다.
그림 36.7. VDO 디스크 조직
이 그림에서 VDO 중복 스토리지 대상은 블록 장치의 상단에 완전히 있습니다. 즉, VDO 볼륨의 물리 크기는 기본 블록 장치와 동일합니다.
36.2.9.2. VDO의 씬 프로비저닝
VDO는 씬 프로비저닝된 블록 스토리지 대상입니다. VDO 볼륨에서 사용하는 물리 공간의 양은 스토리지 사용자에게 제공되는 볼륨의 크기와 다를 수 있습니다. 이러한 차이를 사용하여 스토리지 비용을 절감할 수 있습니다.
공간 외 조건
기록된 데이터가 예상 최적화 속도를 달성하지 못하는 경우 예기치 않은 스토리지 공간을 사용하지 않도록 주의하십시오.
논리 블록(가상 스토리지)의 수가 물리적 블록(실제 스토리지) 수를 초과할 때마다 파일 시스템 및 애플리케이션이 예기치 않게 비어 있지 않게 실행될 수 있습니다. 따라서 VDO를 사용하는 스토리지 시스템은 VDO 볼륨에서 사용 가능한 풀의 크기를 모니터링하는 방법을 제공해야 합니다.
vdostats 유틸리티를 사용하여 사용 가능한 풀의 크기를 확인할 수 있습니다. 이 유틸리티의 기본 출력에는 Linux df 유틸리티와 유사한 형식으로 실행 중인 모든 VDO 볼륨에 대한 정보가 나열됩니다. 예를 들면 다음과 같습니다.
Device 1K-blocks Used Available Use% /dev/mapper/vdo-name 211812352 105906176 105906176 50%
Device 1K-blocks Used Available Use%
/dev/mapper/vdo-name 211812352 105906176 105906176 50%VDO 볼륨의 물리 스토리지 용량이 거의 가득 차면 VDO는 다음과 같이 시스템 로그에 경고를 보고합니다.
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo-name.
Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 80.69% full.
Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo-name is now 85.25% full.
Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo-name is now 90.64% full.
Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo-name is now 96.07% full.
이러한 경고 메시지는 lvm2-monitor 서비스가 실행 중인 경우에만 표시됩니다. 기본적으로 활성화되어 있습니다.
공간 부족 조건을 방지하는 방법
사용 가능한 풀의 크기가 특정 수준 아래로 떨어지면 다음 작업을 수행할 수 있습니다.
- 데이터 삭제. 이렇게 하면 삭제된 데이터가 중복되지 않을 때마다 공간을 회수합니다. 데이터 삭제는 삭제가 실행된 후에만 공간을 확보합니다.
- 물리적 스토리지 추가
공간 부족 상황을 방지하기 위해 VDO 볼륨의 물리적 공간을 모니터링합니다. 물리 블록을 실행하지 않으면 최근에 기록되고 인식되지 않은 VDO 볼륨에서 데이터가 손실될 수 있습니다.
씬 프로비저닝 및 TRIM 및 DISCARD 명령
씬 프로비저닝의 스토리지 절감을 활용하기 위해 물리적 스토리지 계층은 데이터 삭제 시기를 알아야 합니다. 씬 프로비저닝된 스토리지에서 작동하는 파일 시스템은 TRIM 또는 DISCARD 명령을 전송하여 더 이상 논리 블록이 필요하지 않은 경우 스토리지 시스템에 알립니다.
TRIM 또는 DISCARD 명령을 전송하는 몇 가지 방법을 사용할 수 있습니다.
-
삭제마운트 옵션을 사용하면 파일이 삭제될 때마다 파일 시스템에서 이러한 명령을 보낼 수 있습니다. -
fstrim과 같은 유틸리티를 사용하여 제어된 방식으로 명령을 보낼 수 있습니다. 이러한 유틸리티는 파일 시스템에 사용되지 않는 논리 블록을 감지하고TRIM또는DISCARD명령 형태로 스토리지 시스템으로 정보를 보냅니다.
사용되지 않는 블록에서 TRIM 또는 DISCARD 를 사용할 필요가 없습니다. VDO에는 고유하지 않습니다. 씬 프로비저닝된 스토리지 시스템은 동일한 문제를 안고 있습니다.
36.2.9.3. VDO 볼륨의 논리 크기 증가
이 절차에서는 지정된 VDO 볼륨의 논리 크기를 늘립니다. 이는 처음에 공간 부족에서 안전하게 실행할 수 있을 만큼 작은 논리 크기를 가진 VDO 볼륨을 만들 수 있습니다. 일정 기간 후에 데이터 감소의 실제 속도를 평가할 수 있으며 충분한 경우 VDO 볼륨의 논리 크기를 늘릴 수 있으므로 공간 절약을 활용할 수 있습니다.
VDO 볼륨의 논리 크기를 줄일 수 없습니다.
프로세스
논리 크기를 늘리려면 다음을 사용합니다.
vdo growLogical --name=my-vdo \ --vdoLogicalSize=new-logical-size# vdo growLogical --name=my-vdo \ --vdoLogicalSize=new-logical-sizeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 크기가 증가함에 따라 VDO는 새 크기의 볼륨 상단에 있는 장치 또는 파일 시스템에 대해 알립니다.
36.2.9.4. VDO 볼륨의 물리 크기 증가
이 절차에서는 VDO 볼륨에서 사용할 수 있는 물리 스토리지 양을 늘립니다.
이러한 방식으로 VDO 볼륨을 축소할 수 없습니다.
사전 요구 사항
기본 블록 장치에는 VDO 볼륨의 현재 물리적 크기보다 큰 용량이 있습니다.
그렇지 않은 경우 장치의 크기를 늘릴 수 있습니다. 정확한 절차는 장치의 유형에 따라 다릅니다. 예를 들어 MBR 또는 GPT 파티션의 크기를 조정하려면 스토리지 장치 관리 가이드의 파티션 복구 섹션을 참조하십시오.
프로세스
VDO 볼륨에 새 물리 스토리지 공간을 추가합니다.
vdo growPhysical --name=my-vdo
# vdo growPhysical --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.10. VDO 볼륨 제거
시스템에서 기존 VDO 볼륨을 제거할 수 있습니다.
36.2.10.1. 작동 중인 VDO 볼륨 제거
이 절차에서는 VDO 볼륨 및 관련 UDS 인덱스를 제거합니다.
프로세스
- 파일 시스템을 마운트 해제하고 VDO 볼륨에서 스토리지를 사용하는 애플리케이션을 중지합니다.
시스템에서 VDO 볼륨을 제거하려면 다음을 사용합니다.
vdo remove --name=my-vdo
# vdo remove --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow
36.2.10.2. 성공적으로 생성된 VDO 볼륨 제거
이 절차에서는 VDO 볼륨을 중간 상태로 정리합니다. 볼륨을 생성할 때 오류가 발생하면 볼륨이 중간 상태가 됩니다. 예를 들어 다음과 같은 상황이 발생할 수 있습니다.
- 시스템 충돌
- 전원 실패
-
관리자가 실행 중인
vdo create명령을 중단
프로세스
정리하려면
--force옵션을 사용하여 성공적으로 생성된 볼륨을 제거합니다.vdo remove --force --name=my-vdo
# vdo remove --force --name=my-vdoCopy to Clipboard Copied! Toggle word wrap Toggle overflow 관리자가 볼륨이 생성되지 않았기 때문에 시스템 구성을 변경하여 충돌이 발생할 수 있으므로
--force옵션이 필요합니다.--force옵션이 없으면 다음 메시지와 함께vdo remove명령이 실패합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36.3. 사용되지 않는 블록 삭제
이를 지원하는 블록 장치에서 삭제 작업을 수행하거나 예약할 수 있습니다. 블록 삭제 작업은 마운트된 파일 시스템에서 더 이상 사용되지 않는 기본 스토리지와 통신합니다. 블록 삭제 작업을 통해 SSD는 가비지 컬렉션 루틴을 최적화할 수 있으며 씬 프로비저닝된 스토리지에 사용되지 않는 물리적 블록을 다시 사용하도록 알릴 수 있습니다.
요구 사항
파일 시스템의 기본 블록 장치는 물리적 삭제 작업을 지원해야 합니다.
/sys/block/ <device> /queue/discard_max_bytes파일의 값이 0이 아닌 경우 물리적 삭제 작업이 지원됩니다.
36.3.1. 블록 삭제 작업 유형
다른 방법을 사용하여 삭제 작업을 실행할 수 있습니다.
- 배치 삭제
- 사용자에 의해 명시적으로 트리거되고 선택한 파일 시스템에서 사용되지 않는 모든 블록을 삭제합니다.
- 온라인 삭제
-
마운트 시 지정되며 사용자 개입 없이 실시간으로 트리거됩니다. 온라인 삭제 작업은
사용된상태에서free상태로 전환되는 블록만 삭제합니다. - 주기적 삭제
-
systemd서비스에서 정기적으로 실행되는 배치 작업입니다.
모든 유형은 XFS 및 ext4 파일 시스템에서 지원됩니다.
권장 사항
일괄 처리 또는 주기적 삭제 사용을 권장합니다.
온라인 삭제는 다음 경우에만 사용하십시오.
- 시스템의 워크로드는 배치 삭제가 불가능하거나
- 성능을 유지하려면 온라인 삭제 작업이 필요합니다.
36.3.2. 배치 블록 삭제 수행
배치 블록 삭제 작업을 수행하여 마운트된 파일 시스템에서 사용되지 않는 블록을 삭제할 수 있습니다.
사전 요구 사항
- 파일 시스템이 마운트되었습니다.
- 파일 시스템의 기본 블록 장치는 물리적 삭제 작업을 지원합니다.
프로세스
fstrim유틸리티를 사용합니다.선택한 파일 시스템에서만 삭제 작업을 수행하려면 다음을 사용합니다.
fstrim mount-point
# fstrim mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow 마운트된 모든 파일 시스템에서 삭제 작업을 수행하려면 다음을 사용합니다.
fstrim --all
# fstrim --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
다음에서 fstrim 명령을 실행하는 경우:
- 삭제 작업을 지원하지 않는 장치, 또는
- 장치 중 하나가 삭제 작업을 지원하지 않는 여러 장치로 구성된 논리 장치(LVM 또는 MD)
다음 메시지가 표시됩니다.
fstrim /mnt/non_discard fstrim: /mnt/non_discard: the discard operation is not supported
# fstrim /mnt/non_discard
fstrim: /mnt/non_discard: the discard operation is not supported36.3.3. 온라인 블록 삭제 활성화
온라인 블록 삭제 작업을 수행하여 지원되는 모든 파일 시스템에서 사용되지 않는 블록을 자동으로 삭제할 수 있습니다.
프로세스
마운트 시 온라인 삭제 활성화:
파일 시스템을 수동으로 마운트할 때
-o discard마운트 옵션을 추가합니다.mount -o discard device mount-point
# mount -o discard device mount-pointCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
파일 시스템을 영구적으로 마운트하는 경우
/etc/fstab파일의 마운트 항목에삭제옵션을 추가합니다.
36.3.4. 스토리지 RHEL 시스템 역할을 사용하여 온라인 블록 삭제 활성화
온라인 블록 삭제 옵션으로 XFS 파일 시스템을 마운트하여 사용되지 않는 블록을 자동으로 삭제할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
온라인 블록 삭제 옵션이 활성화되어 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'
# ansible managed-node-01.example.com -m command -a 'findmnt /mnt/data'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
36.3.5. 주기적인 블록 삭제 활성화
systemd 타이머를 활성화하여 지원되는 모든 파일 시스템에서 사용되지 않는 블록을 정기적으로 삭제할 수 있습니다.
프로세스
systemd타이머를 활성화하고 시작합니다.systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.
# systemctl enable --now fstrim.timer Created symlink /etc/systemd/system/timers.target.wants/fstrim.timer → /usr/lib/systemd/system/fstrim.timer.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
타이머 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
V 부. 로그 파일 설계
37장. 시스템 감사
감사는 시스템에 추가 보안을 제공하지 않지만 이를 사용하여 시스템에서 보안 정책 위반을 검색할 수 있습니다. 그런 다음 SELinux와 같은 추가 보안 조치를 구성하여 향후 이러한 위반을 방지할 수 있습니다.
37.1. Linux 감사
Linux 감사 시스템은 시스템에 대한 보안 관련 정보를 추적하는 방법을 제공합니다. 사전 구성된 규칙에 따라 감사는 로그 항목을 생성하여 시스템에서 발생하는 이벤트에 대한 정보를 가능한 한 많이 기록합니다. 이 정보는 미션 크리티컬한 환경과 보안 정책의 위반 및 수행 조치를 결정하는 데 중요합니다.
다음 목록에는 감사가 로그 파일에 기록할 수 있는 몇 가지 정보가 요약되어 있습니다.
- 이벤트 날짜 및 시간, 유형 및 결과
- 주체 및 오브젝트의 민감도 레이블
- 이벤트를 트리거한 사용자의 ID와 이벤트 연결
- 감사 구성에 대한 모든 수정 사항 및 감사 로그 파일에 액세스 시도
- SSH, Kerberos 등과 같은 인증 메커니즘의 모든 사용
-
신뢰할 수 있는 데이터베이스(예:
/etc/passwd)에 대한 변경 사항 - 시스템 내 또는 시스템으로 정보를 가져오거나 내보내려는 시도
- 사용자 ID, 주체 및 오브젝트 라벨 및 기타 특성을 기반으로 이벤트를 포함하거나 제외
감사 시스템 사용은 여러 보안 관련 인증을 위한 요구 사항이기도 합니다. 감사는 다음 인증 또는 규정 준수 가이드의 요구 사항을 충족하거나 초과하도록 설계되었습니다.
- CAPP(Controled Access Protection Profile)
- 보안 보호 프로필(LSPP)으로 레이블이 지정
- 규칙 세트 기본 액세스 제어(RSBAC)
- National Industrial Security Program Operating Manual (NISPOM)
- 연방 정보 보안 관리법 (FISMA)
- 결제 카드 산업 - 데이터 보안 표준 (PCI-DSS)
- STIG(Security Technical Implementation Guide)
감사는 또한 National Information Assurance Partnership (NIAP) 및 Best Security Industries (BSI)에 의해 평가되었습니다.
사용 사례
- 파일 액세스 모니터링
- 감사는 파일 또는 디렉터리가 액세스, 수정, 실행 또는 파일의 속성이 변경되었는지 여부를 추적할 수 있습니다. 예를 들어 중요한 파일에 대한 액세스를 감지하고 이러한 파일 중 하나가 손상된 경우 감사 추적을 사용할 수 있는 데 유용합니다.
- 시스템 호출 모니터링
-
특정 시스템 호출을 사용할 때마다 로그 항목을 생성하도록 감사를 구성할 수 있습니다. 예를 들어
settime ,clock_adjtime및 기타 시간 관련 시스템 호출을 모니터링하여 시스템 시간 변경 사항을 추적하는 데 사용할 수 있습니다. - 사용자가 실행하는 명령 기록
-
감사는 파일이 실행되었는지 여부를 추적할 수 있으므로 특정 명령의 모든 실행을 기록하도록 규칙을 정의할 수 있습니다. 예를 들어
/bin디렉터리의 모든 실행 파일에 대해 규칙을 정의할 수 있습니다. 그런 다음 결과 로그 항목을 사용자 ID로 검색하여 사용자당 실행된 명령의 감사 추적을 생성할 수 있습니다. - 시스템 경로 이름 실행 기록
- 규칙 호출 시 inode로 경로를 변환하는 파일 액세스를 감시하는 것 외에도, 이제 규칙 호출 시 존재하지 않거나 규칙이 호출된 후 파일이 교체된 경우에도 감사에서 경로 실행을 확인할 수 있습니다. 이를 통해 프로그램 실행 파일을 업그레이드하거나 설치하기 전에 규칙을 계속 작동할 수 있습니다.
- 보안 이벤트 기록
-
pam_faillock인증 모듈은 실패한 로그인 시도를 기록할 수 있습니다. 실패한 로그인 시도를 기록하도록 감사를 설정하고 로그인을 시도한 사용자에 대한 추가 정보를 제공할 수 있습니다. - 이벤트 검색
-
audit은 로그 항목을 필터링하고 여러 조건에 따라 전체 감사 추적을 제공하는 데 사용할 수 있는
ausearch유틸리티를 제공합니다. - 요약 보고서 실행
-
aureport유틸리티는 기록 된 이벤트에 대한 일일 보고서를 생성하는 데 사용할 수 있습니다. 시스템 관리자는 이러한 보고서를 분석하고 의심 스러운 활동을 추가로 조사할 수 있습니다. - 네트워크 액세스 모니터링
-
시스템 관리자가 네트워크 액세스를 모니터링할 수 있도록
nftables,iptables,ebtables유틸리티를 구성하여 감사 이벤트를 트리거할 수 있습니다.
감사에서 수집하는 정보의 양에 따라 시스템 성능에 영향을 미칠 수 있습니다.
37.2. 감사 시스템 아키텍처
감사 시스템은 사용자 공간 애플리케이션 및 유틸리티와 커널 측 시스템 호출 처리의 두 가지 주요 부분으로 구성됩니다. 커널 구성 요소는 사용자 공간 애플리케이션에서 시스템 호출을 수신하고 사용자,작업,fstype 또는 exit 중 하나를 통해 필터링합니다.
시스템 호출이 exclude 필터를 통과하면 감사 규칙 구성에 따라 앞서 언급한 필터 중 하나를 통해 전송되며, 추가 처리를 위해 감사 데몬으로 전송됩니다.
사용자 공간 감사 데몬은 커널에서 정보를 수집하고 로그 파일에 항목을 생성합니다. 기타 감사 사용자 공간 유틸리티는 감사 데몬, 커널 감사 구성 요소 또는 감사 로그 파일과 상호 작용합니다.
-
auditctl감사 제어 유틸리티는 커널 감사 구성 요소와 상호 작용하여 규칙을 관리하고 이벤트 생성 프로세스의 많은 설정 및 매개 변수를 제어합니다. -
나머지 감사 유틸리티는 감사 로그 파일의 내용을 입력으로 사용하고 사용자 요구 사항에 따라 출력을 생성합니다. 예를 들어
aureport유틸리티는 기록된 모든 이벤트에 대한 보고서를 생성합니다.
RHEL 8에서 감사 디스패치 데몬(audisp) 기능이 감사 데몬(auditd)에 통합되어 있습니다. 감사 이벤트와 실시간 분석 프로그램의 상호 작용을 위한 플러그인의 구성 파일은 기본적으로 /etc/audit/plugins.d/ 디렉토리에 있습니다.
37.3. 보안 환경을 위해 auditd 구성
기본 auditd 구성은 대부분의 환경에 적합해야 합니다. 그러나 환경이 엄격한 보안 정책을 충족해야 하는 경우 /etc/audit/auditd.conf 파일에서 감사 데몬 구성에 대해 다음 설정을 변경할 수 있습니다.
log_file-
감사 로그 파일(일반적으로
/var/log/audit/)이 있는 디렉터리는 별도의 마운트 지점에 있어야 합니다. 이렇게 하면 다른 프로세스가 이 디렉터리에서 공간을 소비하지 않으며 감사 데몬의 나머지 공간을 정확하게 감지할 수 있습니다. max_log_file-
감사 로그 파일이 있는 파티션에서 사용 가능한 공간을 완전히 사용하려면 단일 감사 로그 파일의 최대 크기를 지정해야 합니다.
max_log_file'매개 변수는 최대 파일 크기를 메가바이트 단위로 지정합니다. 지정된 값은 숫자여야 합니다. max_log_file_action-
max_log_file에 설정된 제한에 도달하면 감사 로그 파일을 덮어쓰지 않도록keep_logs로 설정해야 하는 작업을 결정합니다. space_left-
space_left_action매개 변수에 설정된 작업이 트리거되는 디스크에 남은 여유 공간의 양을 지정합니다. 관리자에게 충분한 시간을 제공하고 디스크 공간을 확보할 수 있는 번호로 설정해야 합니다.space_left값은 감사 로그 파일이 생성되는 비율에 따라 달라집니다. space_left 값이 정수로 지정되면 절대 크기(MiB)로 해석됩니다. 값이 1에서 99 사이의 숫자로 지정되고 백분율 기호(예: 5%)가 있으면 감사 데몬은log_file을 포함하는 파일 시스템의 크기에 따라 절대 크기를 메가바이트 단위로 계산합니다. space_left_action-
space_left_action매개 변수를이메일또는 적절한 알림 방법을 사용하여exec로 설정하는 것이 좋습니다. admin_space_left-
admin_space_left_action매개변수에 설정된 작업이 트리거되는 절대 최소 공간 크기를 관리자가 수행하는 작업을 로깅할 충분한 공간을 남겨 두는 값으로 설정해야 합니다. 이 매개변수의 숫자 값은 space_left의 숫자보다 작아야 합니다. 또한 감사 데몬이 디스크 파티션 크기에 따라 숫자를 계산하도록 숫자에 백분율 기호(예: 1%)를 추가할 수도 있습니다. admin_space_left_action-
단일 사용자 모드로 시스템을 배치하려면
single-user로 설정하고 관리자가 일부 디스크 공간을 확보할 수 있도록 해야 합니다. disk_full_action-
감사 로그 파일을 보유한 파티션에서 사용 가능한 공간이 없는 경우 트리거되는 작업을
중지또는단일로 설정해야 합니다. 이렇게 하면 감사가 더 이상 이벤트를 로깅할 수 없는 경우 시스템이 단일 사용자 모드로 종료되거나 작동합니다. disk_error_action-
감사 로그 파일을 보유하는 파티션에서 오류가 감지되는 경우, 하드웨어 오작동의 처리와 관련된 로컬 보안 정책에 따라
syslog,단일또는중단으로 설정해야 하는 경우 트리거되는 작업을 지정합니다. flush-
incremental_async로 설정해야 합니다. 하드 드라이브와 하드 동기화를 강제하기 전에 디스크에 보낼 수 있는 레코드 수를 결정하는freq매개변수와 함께 작동합니다.freq매개변수는100으로 설정해야 합니다. 이러한 매개 변수를 사용하면 활동 버스트에 적합한 성능을 유지하면서 감사 이벤트 데이터가 디스크의 로그 파일과 동기화됩니다.
나머지 구성 옵션은 로컬 보안 정책에 따라 설정해야 합니다.
37.4. auditd 시작 및 제어
auditd 가 구성된 후 서비스를 시작하여 감사 정보를 수집하여 로그 파일에 저장합니다. auditd 를 시작하려면 root 사용자로 다음 명령을 사용합니다.
service auditd start
# service auditd start
부팅 시 시작하도록 auditd 를 구성하려면 다음을 수행합니다.
systemctl enable auditd
# systemctl enable auditd
# auditctl -e 0 명령을 사용하여 auditd 를 일시적으로 비활성화하고 # auditctl -e 1 을 사용하여 다시 활성화할 수 있습니다.
service auditd < action> 명령을 사용하여 에서 다른 작업을 수행할 수 있습니다. 여기서 < action >은 다음 중 하나일 수 있습니다.
auditd
중지-
auditd를 중지합니다. 재시작-
auditd를 다시 시작합니다. 다시 로드또는강제 로드-
/etc/audit/auditd.conf파일에서auditd구성을 다시 로드합니다. rotate-
/var/log/audit/디렉터리에서 로그 파일을 순환합니다. resume- 감사 로그 파일을 보유하는 디스크 파티션에 사용 가능한 공간이 충분하지 않은 경우와 같이 이전에 일시 중지된 후 감사 이벤트의 로깅을 재개합니다.
condrestart또는try-restart-
auditd가 이미 실행 중인 경우에만 다시 시작합니다. status-
auditd의 실행 상태를 표시합니다.
service 명령은 auditd 데몬과 올바르게 상호 작용하는 유일한 방법입니다. auid 값이 올바르게 기록되도록 service 명령을 사용해야 합니다. systemctl 명령은 두 가지 작업인 enable 및 status 에만 사용할 수 있습니다.
37.5. 로그 파일 감사 이해
기본적으로 감사 시스템은 /var/log/audit/audit.log 파일에 로그 항목을 저장합니다. 로그 순환이 활성화된 경우 순환된 audit.log 파일이 동일한 디렉터리에 저장됩니다.
/etc/ssh/sshd_config 파일을 읽거나 수정하기 위해 모든 시도를 기록하려면 다음 감사 규칙을 추가합니다.
auditctl -w /etc/ssh/sshd_config -p warx -k sshd_config
# auditctl -w /etc/ssh/sshd_config -p warx -k sshd_config
예를 들어 다음 명령을 사용하여 auditd 데몬이 실행 중인 경우 감사 로그 파일에 새 이벤트가 생성됩니다.
cat /etc/ssh/sshd_config
$ cat /etc/ssh/sshd_config
audit.log 파일의 이 이벤트는 다음과 같습니다.
type=SYSCALL msg=audit(1364481363.243:24287): arch=c000003e syscall=2 success=no exit=-13 a0=7fffd19c5592 a1=0 a2=7fffd19c4b50 a3=a items=1 ppid=2686 pid=3538 auid=1000 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=1 comm="cat" exe="/bin/cat" subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key="sshd_config" type=CWD msg=audit(1364481363.243:24287): cwd="/home/shadowman" type=PATH msg=audit(1364481363.243:24287): item=0 name="/etc/ssh/sshd_config" inode=409248 dev=fd:00 mode=0100600 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:etc_t:s0 nametype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0 type=PROCTITLE msg=audit(1364481363.243:24287) : proctitle=636174002F6574632F7373682F737368645F636F6E666967
type=SYSCALL msg=audit(1364481363.243:24287): arch=c000003e syscall=2 success=no exit=-13 a0=7fffd19c5592 a1=0 a2=7fffd19c4b50 a3=a items=1 ppid=2686 pid=3538 auid=1000 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=1 comm="cat" exe="/bin/cat" subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key="sshd_config"
type=CWD msg=audit(1364481363.243:24287): cwd="/home/shadowman"
type=PATH msg=audit(1364481363.243:24287): item=0 name="/etc/ssh/sshd_config" inode=409248 dev=fd:00 mode=0100600 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:etc_t:s0 nametype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0
type=PROCTITLE msg=audit(1364481363.243:24287) : proctitle=636174002F6574632F7373682F737368645F636F6E666967
위의 이벤트는 동일한 타임스탬프와 일련 번호를 공유하는 네 개의 레코드로 구성됩니다. 레코드는 항상 type= 키워드로 시작합니다. 각 레코드는 공백이나 쉼표로 구분된 여러 name=값 쌍으로 구성됩니다. 위 이벤트의 자세한 분석은 다음과 같습니다.
첫 번째 레코드
type=SYSCALL-
type필드에는 레코드의 유형이 포함됩니다. 이 예에서SYSCALL값은 이 레코드가 커널에 대한 시스템 호출에 의해 트리거되었음을 지정합니다.
msg=audit(1364481363.243:24287):msg필드는 다음과 같이 기록합니다.-
audit(time_stamp: ID ) 형식의 타임스탬프와 고유한 레코드ID입니다. 동일한 감사 이벤트의 일부로 생성된 경우 여러 레코드가 동일한 타임스탬프 및 ID를 공유할 수 있습니다. 타임 스탬프는 1970년 1월 1일 00:00:00부터 UTC 이후의 Unix 시간 형식을 사용합니다. -
커널 또는 사용자 공간 애플리케이션에서 제공하는 다양한 이벤트별
이름=값쌍입니다.
-
arch=c000003e-
arch필드에는 시스템의 CPU 아키텍처에 대한 정보가 포함되어 있습니다. 값c000003e은 16진수 표기법으로 인코딩됩니다.ausearch명령으로 감사 레코드를 검색할 때-i또는--interpret옵션을 사용하여 16진수 값을 사람이 읽을 수 있는 동등한 값으로 자동 변환합니다.c000003e값은x86_64로 해석됩니다. syscall=2-
syscall필드는 커널에 전송된 시스템 호출 유형을 기록합니다. 값2는/usr/include/asm/unistd_64.h파일에서 사람이 읽을 수 있는 것과 일치시킬 수 있습니다. 이 경우2는공개시스템 호출입니다.ausyscall유틸리티를 사용하면 시스템 호출 번호를 사람이 읽을 수 있는 해당 번호로 변환할 수 있습니다.ausyscall --dump명령을 사용하여 숫자와 함께 모든 시스템 호출 목록을 표시합니다. 자세한 내용은ausyscall(8) 매뉴얼 페이지를 참조하십시오. success=no-
success필드는 특정 이벤트에 기록된 시스템 호출이 성공 또는 실패인지를 기록합니다. 이 경우 전화가 성공하지 못했습니다. exit=-13exit필드에는 시스템 호출에서 반환된 종료 코드를 지정하는 값이 포함되어 있습니다. 이 값은 다른 시스템 호출에 따라 다릅니다. 다음 명령을 사용하여 사람이 읽을 수 있는 해당 값을 해석할 수 있습니다.ausearch --interpret --exit -13
# ausearch --interpret --exit -13Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이전 예에서는 감사 로그에 종료 코드
-13로 실패한 이벤트가 포함되어 있다고 가정합니다.a0=7fffd19c5592,a1=0,a2=7fffd19c5592,a3=a-
a0필드의a0 필드는 이 이벤트에서 시스템 호출의 16진수 표기법으로 인코딩된 처음 네 개의 인수를 기록합니다. 이러한 인수는 사용되는 시스템 호출에 따라 다릅니다.ausearch유틸리티에서 해석할 수 있습니다. items=1-
items필드에는 syscall 레코드를 따르는 PATH 보조 레코드 수가 포함되어 있습니다. ppid=2686-
ppid필드는 PPID(Parent Process ID)를 기록합니다. 이 경우2686은 상위 프로세스의 PPID(예:bash)였습니다. pid=3538-
pid필드는 PID(프로세스 ID)를 기록합니다. 이 경우3538은cat프로세스의 PID입니다. auid=1000-
auid필드는 loginuid인 감사 사용자 ID를 기록합니다. 이 ID는 로그인 시 사용자에게 할당되며, 예를 들어 사용자 계정을su - john명령으로 전환하여 모든 프로세스에서 상속됩니다. uid=1000-
uid필드는 분석 프로세스를 시작한 사용자의 사용자 ID를 기록합니다. 사용자 ID는 다음 명령을 사용하여 사용자 이름으로 해석될 수 있습니다.ausearch -i --uid UID. gid=1000-
gid필드는 분석 프로세스를 시작한 사용자의 그룹 ID를 기록합니다. euid=1000-
euid필드는 분석 프로세스를 시작한 사용자의 유효한 사용자 ID를 기록합니다. suid=1000-
suid필드는 분석 프로세스를 시작한 사용자의 설정된 사용자 ID를 기록합니다. fsuid=1000-
fsuid필드는 분석 프로세스를 시작한 사용자의 파일 시스템 사용자 ID를 기록합니다. egid=1000-
egid필드는 분석 프로세스를 시작한 사용자의 유효한 그룹 ID를 기록합니다. sgid=1000-
sgid필드는 분석 프로세스를 시작한 사용자의 세트 그룹 ID를 기록합니다. fsgid=1000-
fsgid필드는 분석 프로세스를 시작한 사용자의 파일 시스템 그룹 ID를 기록합니다. tty=pts0-
tty필드는 분석 프로세스가 호출된 터미널을 기록합니다. ses=1-
ses필드는 분석 프로세스가 호출된 세션의 세션 ID를 기록합니다. comm="cat"-
comm필드는 분석 프로세스를 호출하는 데 사용된 명령의 명령줄 이름을 기록합니다. 이 경우cat명령을 사용하여 이 감사 이벤트를 트리거했습니다. exe="/bin/cat"-
exe필드는 분석 프로세스를 호출하는 데 사용된 실행 파일의 경로를 기록합니다. subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023-
subj필드는 분석 프로세스가 실행 시 레이블이 지정된 SELinux 컨텍스트를 기록합니다. key="sshd_config"-
key필드는 감사 로그에서 이 이벤트를 생성한 규칙과 연관된 관리자 정의 문자열을 기록합니다.
두 번째 레코드
type=CWD두 번째 레코드에서
type필드 값은CWD- 현재 작업 디렉터리입니다. 이 유형은 첫 번째 레코드에 지정된 시스템 호출을 호출한 프로세스가 실행된 작업 디렉터리를 기록하는 데 사용됩니다.이 레코드의 목적은 상대 경로가 연결된 PATH 레코드에 캡처되는 경우 현재 프로세스의 위치를 기록하는 것입니다. 이렇게 하면 절대 경로를 재구성할 수 있습니다.
msg=audit(1364481363.243:24287)-
msg필드는 첫 번째 레코드의 값과 동일한 타임스탬프 및 ID 값을 보유합니다. 타임 스탬프는 1970년 1월 1일 00:00:00부터 UTC 이후의 Unix 시간 형식을 사용합니다. cwd="/home/user_name"-
cwd필드에는 시스템 호출이 호출된 디렉터리의 경로가 포함됩니다.
세 번째 레코드
type=PATH-
세 번째 레코드에서
type필드 값은PATH입니다. 감사 이벤트에는 시스템 호출에 인수로 전달되는 모든 경로에 대한PATH-type 레코드가 포함됩니다. 이 감사 이벤트에서는 하나의 경로(/etc/ssh/sshd_config)만 인수로 사용되었습니다. msg=audit(1364481363.243:24287):-
msg필드는 첫 번째 및 두 번째 레코드의 값과 동일한 타임스탬프 및 ID 값을 보유합니다. item=0-
item필드는SYSCALL유형 레코드에서 참조되는 총 항목 수, 현재 레코드를 나타냅니다. 이 숫자는 0을 기반으로 하며, 값이0이면 첫 번째 항목임을 의미합니다. name="/etc/ssh/sshd_config"-
name필드는 시스템 호출에 전달된 파일 또는 디렉터리의 경로를 인수로 기록합니다. 이 경우/etc/ssh/sshd_config파일이었습니다. inode=409248inode필드에는 이 이벤트에 기록된 파일 또는 디렉터리와 연결된 inode 번호가 포함됩니다. 다음 명령은409248inode 번호와 연결된 파일 또는 디렉터리를 표시합니다.find / -inum 409248 -print /etc/ssh/sshd_config
# find / -inum 409248 -print /etc/ssh/sshd_configCopy to Clipboard Copied! Toggle word wrap Toggle overflow dev=fd:00-
dev필드는 이 이벤트에 기록된 파일 또는 디렉터리가 포함된 장치의 마이너 및 주요 ID를 지정합니다. 이 경우 값은/dev/fd/0장치를 나타냅니다. mode=0100600-
mode필드는st_mode필드의stat명령에서 반환된 대로 숫자 표기법으로 인코딩된 파일 또는 디렉터리 권한을 기록합니다. 자세한 내용은stat(2)매뉴얼 페이지를 참조하십시오. 이 경우0100600은-rw-------로 해석될 수 있습니다. 즉, root 사용자만/etc/ssh/sshd_config파일에 대한 읽기 및 쓰기 권한을 갖습니다. ouid=0-
O
uid필드는 오브젝트 소유자의 사용자 ID를 기록합니다. ogid=0-
ogid필드는 오브젝트 소유자의 그룹 ID를 기록합니다. rdev=00:00-
rdev필드에는 특수 파일에 대한 기록된 장치 식별자만 포함됩니다. 이 경우 기록된 파일이 일반 파일이므로 사용되지 않습니다. obj=system_u:object_r:etc_t:s0-
obj필드는 실행 시 기록된 파일 또는 디렉터리의 레이블이 지정된 SELinux 컨텍스트를 기록합니다. nametype=NORMAL-
nametype필드는 지정된 syscall의 컨텍스트에서 각 경로 레코드의 작업의 의도를 기록합니다. cap_fp=none-
cap_fp필드는 파일 또는 디렉터리 오브젝트의 허용된 파일 시스템 기반 기능의 설정과 관련된 데이터를 기록합니다. cap_fi=none-
cap_fi필드는 파일 또는 디렉터리 오브젝트의 상속된 파일 시스템 기반 기능의 설정과 관련된 데이터를 기록합니다. cap_fe=0-
cap_fe필드는 파일 또는 디렉터리 오브젝트의 유효 시스템 기반 기능의 설정을 기록합니다. cap_fver=0-
cap_fver필드는 파일 또는 디렉터리 오브젝트의 파일 시스템 기반 기능의 버전을 기록합니다.
네 번째 레코드
type=PROCTITLE-
type필드에는 레코드의 유형이 포함됩니다. 이 예제에서PROCTITLE값은 이 레코드가 커널에 대한 시스템 호출에 의해 트리거되는 이 감사 이벤트를 트리거한 전체 명령줄을 제공하도록 지정합니다. proctitle=636174002F6574632F7373682F737368645F636F6E666967-
proctitle필드는 분석 프로세스를 호출하는 데 사용된 명령의 전체 명령줄을 기록합니다. 이 필드는 사용자가 감사 로그 구문 분석기에 영향을 미치지 않도록 16진수 표기법으로 인코딩됩니다. 텍스트는 이 감사 이벤트를 트리거한 명령에 대해 디코딩합니다.ausearch명령으로 감사 레코드를 검색할 때-i또는--interpret옵션을 사용하여 16진수 값을 사람이 읽을 수 있는 동등한 값으로 자동 변환합니다.636174002F6574632F7373682F736F636F6E666967값은cat /etc/ssh/sshd_config로 해석됩니다.
37.6. 감사 규칙 정의 및 실행에 auditctl 사용
감사 시스템은 로그 파일에 캡처된 항목을 정의하는 일련의 규칙에서 작동합니다. auditctl 유틸리티를 사용하여 명령줄에서 또는 /etc/audit/rules.d/ 디렉터리에서 감사 규칙을 설정할 수 있습니다.
auditctl 명령을 사용하면 감사 시스템의 기본 기능을 제어하고 기록된 감사 이벤트를 결정하는 규칙을 정의할 수 있습니다.
파일 시스템 규칙 예
/etc/passwd 파일의 모든 쓰기 액세스 권한을 로깅하는 규칙을 정의하기 위해
/etc/passwd파일의 모든 속성 변경 사항:auditctl -w /etc/passwd -p wa -k passwd_changes
# auditctl -w /etc/passwd -p wa -k passwd_changesCopy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/selinux/디렉터리에 있는 모든 파일에 대한 모든 쓰기 액세스 권한을 로깅하는 규칙을 정의하기 위해 다음을 수행하십시오.auditctl -w /etc/selinux/ -p wa -k selinux_changes
# auditctl -w /etc/selinux/ -p wa -k selinux_changesCopy to Clipboard Copied! Toggle word wrap Toggle overflow
시스템 호출 규칙 예
adjtimex또는settimeofofday시스템 호출이 프로그램에서 사용될 때마다 로그 항목을 생성하는 규칙을 정의하기 위해 64비트 아키텍처를 사용합니다.auditctl -a always,exit -F arch=b64 -S adjtimex -S settimeofday -k time_change
# auditctl -a always,exit -F arch=b64 -S adjtimex -S settimeofday -k time_changeCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일이 삭제될 때마다 로그 항목을 생성하는 규칙을 정의하거나 ID가 1000 이상인 시스템 사용자로 이름을 변경하려면 다음을 수행합니다.
auditctl -a always,exit -S unlink -S unlinkat -S rename -S renameat -F auid>=1000 -F auid!=4294967295 -k delete
# auditctl -a always,exit -S unlink -S unlinkat -S rename -S renameat -F auid>=1000 -F auid!=4294967295 -k deleteCopy to Clipboard Copied! Toggle word wrap Toggle overflow -F auid!=4294967295옵션은 로그인 UID가 설정되지 않은 사용자를 제외하는 데 사용됩니다.
실행 파일 규칙
/bin/id 프로그램의 모든 실행을 로깅하는 규칙을 정의하려면 다음 명령을 실행합니다.
auditctl -a always,exit -F exe=/bin/id -F arch=b64 -S execve -k execution_bin_id
# auditctl -a always,exit -F exe=/bin/id -F arch=b64 -S execve -k execution_bin_id37.7. 영구 감사 규칙 정의
재부팅 후에도 지속되는 감사 규칙을 정의하려면 /etc/audit/rules.d/audit.rules 파일에 직접 포함하거나 /etc/audit/rules.d/ 디렉터리에 있는 규칙을 읽는 augenrules 프로그램을 사용해야 합니다.
auditd 서비스가 시작될 때마다 /etc/audit/audit.rules 파일이 생성됩니다. /etc/audit/rules.d/ 의 파일은 동일한 auditctl 명령줄 구문을 사용하여 규칙을 지정합니다. 해시 기호(#) 뒤에 오는 빈 줄과 텍스트는 무시됩니다.
또한 auditctl 명령을 사용하여 -R 옵션을 사용하여 지정된 파일에서 규칙을 읽을 수 있습니다. 예를 들면 다음과 같습니다.
auditctl -R /usr/share/audit/sample-rules/30-stig.rules
# auditctl -R /usr/share/audit/sample-rules/30-stig.rules37.8. 표준 준수를 위해 사전 구성된 감사 규칙 파일
OSPP, PCI DSS 또는 STIG와 같은 특정 인증 표준 준수에 대한 감사를 구성하려면 감사 패키지와 함께 설치된 사전 구성된 규칙 파일 집합을 시작점으로 사용할 수 있습니다. 샘플 규칙은 /usr/share/audit/sample-rules 디렉터리에 있습니다.
보안 표준이 동적이고 변경될 수 있으므로 sample-rules 디렉터리의 감사 샘플 규칙은 완전히 또는 최신 상태가 아닙니다. 이러한 규칙은 감사 규칙을 구성하고 작성할 수 있는 방법을 증명하기 위해서만 제공됩니다. 최신 보안 표준을 즉시 준수하지는 않습니다. 특정 보안 지침에 따라 시스템이 최신 보안 표준을 준수하도록 하려면 SCAP 기반 보안 규정 준수 툴 을 사용합니다.
30-nispom.rules- 국가 산업 보안 프로그램 운영 설명서의 정보 시스템 보안 장에 지정된 요구 사항을 충족하는 감사 규칙 구성.
30-ospp-v42*.rules- OSPP(Protection Profile for General Purpose Operating Systems) 프로파일 버전 4.2에 정의된 요구 사항을 충족하는 감사 규칙 구성.
30-pci-dss-v31.rules- PCIDSS(Payment Card Industry Data Security Standard) v3.1로 설정된 요구 사항을 충족하는 감사 규칙 구성.
30-STIG.rules- STIG(Security Technical Implementation Guides)에 의해 설정된 요구 사항을 충족하는 감사 규칙 구성.
이러한 구성 파일을 사용하려면 /etc/audit/rules.d/ 디렉터리에 복사하고 augenrules --load 명령을 사용합니다. 예를 들면 다음과 같습니다.
cd /usr/share/audit/sample-rules/ cp 10-base-config.rules 30-stig.rules 31-privileged.rules 99-finalize.rules /etc/audit/rules.d/ augenrules --load
# cd /usr/share/audit/sample-rules/
# cp 10-base-config.rules 30-stig.rules 31-privileged.rules 99-finalize.rules /etc/audit/rules.d/
# augenrules --load
번호가 매겨진 스키마를 사용하여 감사 규칙을 정렬할 수 있습니다. 자세한 내용은 /usr/share/audit/sample-rules/README-rules 파일을 참조하십시오.
37.9. augenrules를 사용하여 영구 규칙 정의
augenrules 스크립트는 /etc/audit/rules.d/ 디렉터리에 있는 규칙을 읽고 audit.rules 파일로 컴파일합니다. 이 스크립트는 자연적인 정렬 순서에 따라 .rules 로 끝나는 모든 파일을 특정 순서로 처리합니다. 이 디렉터리의 파일은 다음과 같은 의미를 사용하여 그룹으로 구성됩니다.
- 10
- kernel 및 auditctl 구성
- 20
- 일반적인 규칙과 일치할 수 있지만 다른 일치를 원하는 규칙
- 30
- 주요 규칙
- 40
- 선택적 규칙
- 50
- 서버별 규칙
- 70
- 시스템 로컬 규칙
- 90
- 종료 가능(immutable)
이 규칙은 한 번에 모두 사용할 수 없습니다. 이러한 정책은 간주해야 하는 정책의 일부이며, 개별 파일을 /etc/audit/rules.d/ 로 복사합니다. 예를 들어 STIG 구성에서 시스템을 설정하려면 규칙 10-base-config,30-stig,31-privileged, 99-finalize 를 복사합니다.
/etc/audit/rules.d/ 디렉터리에 규칙이 있으면 --load 지시문을 사용하여 augenrules 스크립트를 실행하여 로드합니다.
37.10. augenrules 비활성화
다음 단계를 사용하여 augenrules 유틸리티를 비활성화합니다. 이 스위치는 감사를 수행하여 /etc/audit/audit.rules 파일에 정의된 규칙을 사용합니다.
절차
/usr/lib/systemd/system/auditd.service파일을/etc/systemd/system/디렉터리에 복사합니다.cp -f /usr/lib/systemd/system/auditd.service /etc/systemd/system/
# cp -f /usr/lib/systemd/system/auditd.service /etc/systemd/system/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택한 텍스트 편집기에서
/etc/systemd/system/auditd.service파일을 편집합니다. 예를 들면 다음과 같습니다.vi /etc/systemd/system/auditd.service
# vi /etc/systemd/system/auditd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow augenrules가 포함된 행을 주석 처리하고auditctl -R명령이 포함된 행의 주석을 제거합니다.#ExecStartPost=-/sbin/augenrules --load ExecStartPost=-/sbin/auditctl -R /etc/audit/audit.rules
#ExecStartPost=-/sbin/augenrules --load ExecStartPost=-/sbin/auditctl -R /etc/audit/audit.rulesCopy to Clipboard Copied! Toggle word wrap Toggle overflow systemd데몬을 다시 로드하여auditd.service파일의 변경 사항을 가져옵니다.systemctl daemon-reload
# systemctl daemon-reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow auditd서비스를 다시 시작하십시오.service auditd restart
# service auditd restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
37.11. 소프트웨어 업데이트 모니터링을 위한 감사 설정
RHEL 8.6 이상 버전에서는 사전 구성된 규칙 44-installers.rules 를 사용하여 소프트웨어를 설치하는 다음 유틸리티를 모니터링하도록 감사를 구성할 수 있습니다.
-
dnf[2] -
yum -
pip -
npm -
CPAN -
gem -
luarocks
기본적으로 rpm 은 패키지를 설치하거나 업데이트할 때 감사 SOFTWARE_UPDATE 이벤트를 이미 제공합니다. 명령줄에서 ausearch -m SOFTWARE_UPDATE 를 입력하여 나열할 수 있습니다.
RHEL 8.5 및 이전 버전에서는 수동으로 규칙을 추가하여 /etc/audit/rules.d/ 디렉터리 내의 .rules 파일에 소프트웨어를 설치하는 유틸리티를 모니터링할 수 있습니다.
ppc64le 및 aarch64 아키텍처가 있는 시스템에서는 사전 구성된 규칙 파일을 사용할 수 없습니다.
사전 요구 사항
-
auditd는 보안 환경에 대해 auditd 구성에 제공된 설정에 따라 구성됩니다.
절차
RHEL 8.6 이상에서는
/usr/share/audit/sample-rules/디렉터리에서/etc/audit/rules.d/디렉터리에 사전 구성된 규칙 파일44-installers.rules를 복사합니다.cp /usr/share/audit/sample-rules/44-installers.rules /etc/audit/rules.d/
# cp /usr/share/audit/sample-rules/44-installers.rules /etc/audit/rules.d/Copy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.5 이하에서
44-installers.rules라는/etc/audit/rules.d/디렉터리에 새 파일을 생성하고 다음 규칙을 삽입합니다.-a always,exit -F perm=x -F path=/usr/bin/dnf-3 -F key=software-installer -a always,exit -F perm=x -F path=/usr/bin/yum -F
-a always,exit -F perm=x -F path=/usr/bin/dnf-3 -F key=software-installer -a always,exit -F perm=x -F path=/usr/bin/yum -FCopy to Clipboard Copied! Toggle word wrap Toggle overflow 동일한 구문을 사용하여 소프트웨어를 설치하는 다른 유틸리티에 대한 규칙을 추가할 수 있습니다(예:
pip및npm).감사 규칙을 로드합니다.
augenrules --load
# augenrules --loadCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
로드된 규칙을 나열합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 설치를 수행합니다. 예를 들면 다음과 같습니다.
yum reinstall -y vim-enhanced
# yum reinstall -y vim-enhancedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 최근 설치 이벤트의 감사 로그를 검색합니다. 예를 들면 다음과 같습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
dnf 는 RHEL의 심볼릭 링크이므로 dnf 감사 규칙의 경로에 symlink의 대상이 포함되어야 합니다. 올바른 감사 이벤트를 수신하려면 path=/usr/bin/dnf path를 /usr/bin/dnf-3 으로 변경하여 44-installers.rules 파일을 수정합니다.
37.12. 감사를 사용하여 사용자 로그인 시간 모니터링
특정 시간에 로그인한 사용자를 모니터링하려면 특별한 방법으로 감사를 구성할 필요가 없습니다. 동일한 정보를 제공하는 다양한 방법을 제공하는 ausearch 또는 aureport 도구를 사용할 수 있습니다.
사전 요구 사항
-
auditd는 보안 환경에 대해 auditd 구성에 제공된 설정에 따라 구성됩니다.
절차
사용자 로그인 시간을 표시하려면 다음 명령 중 하나를 사용합니다.
USER_LOGIN메시지 유형의 감사 로그를 검색합니다.ausearch -m USER_LOGIN -ts '12/02/2020' '18:00:00' -sv no time->Mon Nov 22 07:33:22 2021 type=USER_LOGIN msg=audit(1637584402.416:92): pid=1939 uid=0 auid=4294967295 ses=4294967295 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=login acct="(unknown)" exe="/usr/sbin/sshd" hostname=? addr=10.37.128.108 terminal=ssh res=failed'
# ausearch -m USER_LOGIN -ts '12/02/2020' '18:00:00' -sv no time->Mon Nov 22 07:33:22 2021 type=USER_LOGIN msg=audit(1637584402.416:92): pid=1939 uid=0 auid=4294967295 ses=4294967295 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=login acct="(unknown)" exe="/usr/sbin/sshd" hostname=? addr=10.37.128.108 terminal=ssh res=failed'Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
ts옵션을 사용하여 날짜와 시간을 지정할 수 있습니다. 이 옵션을 사용하지 않는 경우ausearch는 오늘부터 결과를 제공하며 시간을 생략하면ausearch는 자정에서 결과를 제공합니다. -
-sv yes옵션을 사용하여 성공적인 로그인 시도를 필터링하고 실패한 로그인 시도에는-sv no를 사용할 수 있습니다.
-
ausearch명령의 원시 출력을aulast유틸리티로 파이프하여마지막명령의 출력과 유사한 형식으로 출력을 표시합니다. 예를 들면 다음과 같습니다.ausearch --raw | aulast --stdin root ssh 10.37.128.108 Mon Nov 22 07:33 - 07:33 (00:00) root ssh 10.37.128.108 Mon Nov 22 07:33 - 07:33 (00:00) root ssh 10.22.16.106 Mon Nov 22 07:40 - 07:40 (00:00) reboot system boot 4.18.0-348.6.el8 Mon Nov 22 07:33
# ausearch --raw | aulast --stdin root ssh 10.37.128.108 Mon Nov 22 07:33 - 07:33 (00:00) root ssh 10.37.128.108 Mon Nov 22 07:33 - 07:33 (00:00) root ssh 10.22.16.106 Mon Nov 22 07:40 - 07:40 (00:00) reboot system boot 4.18.0-348.6.el8 Mon Nov 22 07:33Copy to Clipboard Copied! Toggle word wrap Toggle overflow aureport명령을--login -i옵션과 함께 사용하여 로그인 이벤트 목록을 표시합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
VI 부. 커널 설계
38장. Linux 커널
Red Hat (Red Hat 커널)에서 제공하고 유지 관리하는 Linux 커널 및 Linux 커널 RPM 패키지에 대해 알아보십시오. 운영 체제에 최신 버그 수정, 성능 향상 및 패치가 모두 제공되며 새로운 하드웨어와 호환되도록 Red Hat 커널을 계속 업데이트하십시오.
38.1. 커널의 정의
커널은 시스템 리소스를 관리하고 하드웨어와 소프트웨어 애플리케이션 간의 인터페이스를 제공하는 Linux 운영 체제의 핵심 부분입니다.
Red Hat 커널은 Red Hat 엔지니어가 최신 기술 및 하드웨어와의 안정성과 호환성을 바탕으로 향후 개발 및 강화되는 업스트림 Linux 메인라인 커널을 기반으로 맞춤형으로 구축된 커널입니다.
Red Hat이 새 커널 버전을 출시하기 전에 커널은 엄격한 품질 보증 테스트 세트를 전달해야 합니다.
Red Hat 커널은 YUM 패키지 관리자가 쉽게 업그레이드하고 확인할 수 있도록 RPM 형식으로 패키지됩니다.
Red Hat에서 컴파일하지 않은 커널은 Red Hat에서 지원하지 않습니다.
38.2. RPM 패키지
RPM 패키지는 이러한 파일을 설치 및 삭제하는 데 사용되는 파일 및 메타데이터의 아카이브로 구성됩니다. 특히 RPM 패키지에는 다음 부분이 포함되어 있습니다.
- GPG 서명
- GPG 서명은 패키지의 무결성을 확인하는 데 사용됩니다.
- 헤더(패키지 메타데이터)
- RPM 패키지 관리자는 이 메타데이터를 사용하여 패키지 종속성, 파일 설치 위치 및 기타 정보를 확인합니다.
- 페이로드
-
페이로드는 시스템에 설치할 파일이 포함된
cpio아카이브입니다.
RPM에는 두 가지 유형의 RPM 패키지가 있습니다. 두 유형 모두 파일 형식과 툴링을 공유하지만 내용이 다르므로 서로 다른 용도로 사용됩니다.
소스 RPM(SRPM)
SRPM에는 소스 코드와
사양파일이 포함되어 있으며, 바이너리 RPM에 소스 코드를 빌드하는 방법을 설명합니다. 선택적으로 SRPM은 소스 코드에 대한 패치를 포함할 수 있습니다.바이너리 RPM
바이너리 RPM에는 소스 및 패치에서 빌드된 바이너리가 포함되어 있습니다.
38.3. Linux 커널 RPM 패키지 개요
커널 RPM은 파일이 포함되어 있지 않은 메타 패키지이지만 다음과 같은 필수 하위 패키지가 올바르게 설치되었는지 확인합니다.
kernel-core-
커널의 바이너리 이미지, 시스템을 부트스트랩하기 위한 모든
initramfs- 관련 오브젝트, 핵심 기능을 보장하기 위한 최소 커널 모듈 수를 제공합니다. 이 하위 패키지만 가상화 및 클라우드 환경에서 사용하면 Red Hat Enterprise Linux 8 커널에서 빠른 부팅 시간과 작은 디스크 크기를 제공할 수 있습니다. kernel-modules-
kernel-core에 없는 나머지 커널 모듈을 제공합니다.
위의 작은 커널 하위 패키지 세트는 특히 가상화 및 클라우드 환경에서 시스템 관리자에게 유지 관리 영역을 줄이는 것을 목표로 합니다.
선택적 커널 패키지는 다음과 같습니다.
kernel-modules-extra- 드문 하드웨어에 대한 커널 모듈을 제공합니다. 모듈 로드는 기본적으로 비활성화되어 있습니다.
kernel-debug- 성능 저하를 통해 커널 진단을 위해 사용할 수 있는 많은 디버깅 옵션을 커널에 제공합니다.
kernel-tools- Linux 커널 및 지원 문서를 조작하는 툴을 제공합니다.
kernel-devel-
커널 패키지에 대해 모듈을 빌드하는 데 충분한
커널헤더 및 makefiles를 제공합니다. kernel-abi-stablelists-
외부 Linux 커널 모듈에 필요한 커널 기호 목록과 시행을 지원하는
yum플러그인 등 RHEL 커널 ABI 관련 정보를 제공합니다. kernel-headers- Linux 커널과 사용자 공간 라이브러리 및 프로그램 간의 인터페이스를 지정하는 C 헤더 파일이 포함되어 있습니다. 헤더 파일은 대부분의 표준 프로그램을 빌드하는 데 필요한 구조와 상수를 정의합니다.
38.4. 커널 패키지의 콘텐츠 표시
리포지토리를 쿼리하면 커널 패키지가 모듈과 같은 특정 파일을 제공하는지 확인할 수 있습니다. 파일 목록을 표시하기 위해 패키지를 다운로드하거나 설치할 필요는 없습니다.
dnf 유틸리티를 사용하여 kernel-core,kernel-modules-core 또는 kernel-modules 패키지의 파일 목록을 쿼리합니다. 커널 패키지는 파일이 포함되어 있지 않은 메타 패키지입니다.
절차
사용 가능한 패키지 버전을 나열합니다.
yum repoquery <package_name>
$ yum repoquery <package_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 패키지에 있는 파일 목록을 표시합니다.
yum repoquery -l <package_name>
$ yum repoquery -l <package_name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
38.5. 특정 커널 버전 설치
yum 패키지 관리자를 사용하여 새 커널을 설치합니다.
절차
특정 커널 버전을 설치하려면 다음 명령을 입력합니다.
yum install kernel-5.14.0
# yum install kernel-5.14.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
38.6. 커널 업데이트
yum 패키지 관리자를 사용하여 커널을 업데이트합니다.
절차
커널을 업데이트하려면 다음 명령을 입력합니다.
yum update kernel
# yum update kernelCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 모든 종속 항목과 함께 커널을 사용 가능한 최신 버전으로 업데이트합니다.
- 변경 사항을 적용하려면 시스템을 재부팅합니다.
RHEL 7에서 RHEL 8로 업그레이드할 때 RHEL 7에서 RHEL 8로 업그레이드 섹션의 관련 섹션을 따르십시오.
38.7. 커널을 기본값으로 설정
grubby 명령줄 툴과 GRUB을 사용하여 특정 커널을 기본값으로 설정합니다.
절차
grubby툴을 사용하여 커널을 기본값으로 설정합니다.grubby툴을 사용하여 커널을 기본값으로 설정하려면 다음 명령을 입력합니다.grubby --set-default $kernel_path
# grubby --set-default $kernel_pathCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은
.conf접미사가 없는 머신 ID를 인수로 사용합니다.참고시스템 ID는
/boot/loader/entries/디렉터리에 있습니다.
id인수를 사용하여 커널을 기본값으로 설정합니다.id인수를 사용하여 부팅 항목을 나열한 다음 의도한 커널을 기본값으로 설정합니다.grubby --info ALL | grep id grubby --set-default /boot/vmlinuz-<version>.<architecture>
# grubby --info ALL | grep id # grubby --set-default /boot/vmlinuz-<version>.<architecture>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고title인수를 사용하여 부팅 항목을 나열하려면# grubby --info=ALL | grep title명령을 실행합니다.
다음 부팅에 대해서만 기본 커널을 설정합니다.
다음 명령을 실행하여
grub2-reboot명령을 사용하여 다음 재부팅에만 기본 커널을 설정합니다.grub2-reboot <index|title|id>
# grub2-reboot <index|title|id>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의신중하게 다음 부팅에 대해서만 기본 커널을 설정합니다. 새 커널 RPM을 설치하고 자체 빌드 커널을 설치하고
/boot/loader/entries/디렉터리에 항목을 수동으로 추가하면 인덱스 값이 변경될 수 있습니다.
39장. 커널 명령줄 매개변수 구성
커널 명령줄 매개 변수를 사용하면 부팅 시 Red Hat Enterprise Linux 커널의 특정 측면의 동작을 변경할 수 있습니다. 시스템 관리자는 부팅 시 설정되는 옵션을 제어합니다. 특정 커널 동작은 부팅 시에만 설정할 수 있습니다.
커널 명령줄 매개 변수를 수정하여 시스템 동작을 변경하면 시스템에 부정적인 영향을 미칠 수 있습니다. 프로덕션에 배포하기 전에 항상 변경 사항을 테스트합니다. 자세한 내용은 Red Hat 지원에 문의하십시오.
39.1. 커널 명령줄 매개변수란 무엇입니까?
커널 명령줄 매개 변수를 사용하면 기본값을 덮어쓰고 특정 하드웨어 설정을 설정할 수 있습니다. 부팅 시 다음 기능을 구성할 수 있습니다.
- Red Hat Enterprise Linux 커널
- 초기 RAM 디스크
- 사용자 공간 기능
기본적으로 GRUB 부트 로더를 사용하는 시스템의 커널 명령줄 매개 변수는 각 커널 부팅 항목에 대해 /boot/grub2/grubenv 파일의 kernelopts 변수에 정의됩니다.
IBM Z의 경우 zipl 부트 로더가 환경 변수를 지원하지 않기 때문에 커널 명령줄 매개변수는 부팅 항목 구성 파일에 저장됩니다. 따라서 kernelopts 환경 변수를 사용할 수 없습니다.
grubby 유틸리티를 사용하여 부트 로더 구성 파일을 조작할 수 있습니다. grubby 를 사용하면 다음 작업을 수행할 수 있습니다.
- 기본 부팅 항목을 변경합니다.
- GRUB 메뉴 항목에서 인수를 추가하거나 제거합니다.
39.2. 부팅 항목 이해
부팅 항목은 구성 파일에 저장되고 특정 커널 버전에 연결된 옵션 컬렉션입니다. 실제로 시스템에 커널을 설치한 만큼 많은 부팅 항목이 있습니다. 부팅 항목 구성 파일은 /boot/loader/entries/ 디렉터리에 있습니다.
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
위의 파일 이름은 /etc/machine-id 파일에 저장된 시스템 ID와 커널 버전으로 구성됩니다.
부팅 항목 구성 파일에는 커널 버전, 초기 램디스크 이미지 및 커널 명령줄 매개변수가 포함된 kernelopts 환경 변수에 대한 정보가 포함되어 있습니다. 구성 파일에는 다음 내용이 있을 수 있습니다.
kernelopts 환경 변수는 /boot/grub2/grubenv 파일에 정의됩니다.
39.3. 모든 부팅 항목에 대한 커널 명령줄 매개변수 변경
시스템의 모든 부팅 항목에 대해 커널 명령줄 매개 변수를 변경합니다.
사전 요구 사항
-
grubby유틸리티가 시스템에 설치되어 있습니다. -
zipl유틸리티는 IBM Z 시스템에 설치됩니다.
프로세스
매개변수를 추가하려면 다음을 수행합니다.
grubby --update-kernel=ALL --args="<NEW_PARAMETER>"
# grubby --update-kernel=ALL --args="<NEW_PARAMETER>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow GRUB 부트 로더를 사용하는 시스템의 경우 명령은 해당 파일의
kernelopts변수에 새 커널 매개 변수를 추가하여/boot/grub2/grubenv파일을 업데이트합니다.IBM Z에서 부팅 메뉴를 업데이트합니다.
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
매개변수를 제거하려면 다음을 수행합니다.
grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"
# grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IBM Z에서 부팅 메뉴를 업데이트합니다.
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
새로 설치된 커널은 이전에 구성된 커널의 커널 명령줄 매개 변수를 상속합니다.
39.4. 단일 부팅 항목에 대한 커널 명령줄 매개변수 변경
시스템의 단일 부팅 항목에 대한 커널 명령줄 매개 변수를 변경합니다.
사전 요구 사항
-
grubby및zipl유틸리티가 시스템에 설치됩니다.
프로세스
매개변수를 추가하려면 다음을 수행합니다.
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IBM Z에서 부팅 메뉴를 업데이트합니다.
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
매개변수를 제거하려면 다음을 수행합니다.
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow IBM Z에서 부팅 메뉴를 업데이트합니다.
zipl
# ziplCopy to Clipboard Copied! Toggle word wrap Toggle overflow
grub.cfg 파일을 사용하는 시스템에서는 기본적으로 kernelopts 변수로 설정된 각 커널 부팅 항목에 대한 options 매개 변수가 있습니다. 이 변수는 /boot/grub2/grubenv 구성 파일에 정의됩니다.
GRUB 시스템에서 다음을 수행합니다.
-
모든 부팅 항목에 대해 커널 명령줄 매개 변수가 수정되면
grubby유틸리티는/boot/grub2/grubenv파일에서kernelopts변수를 업데이트합니다. -
커널 명령줄 매개변수가 단일 부팅 항목에 대해 수정되면
kernelopts변수가 확장되고, 커널 매개변수가 수정되고 결과 값은 해당 부팅 항목의 /boot/loader/entries/<RELEVANT_KERNEL_ENTRY.conf> 파일에 저장됩니다.
zIPL 시스템에서:
-
grubby는 /boot/loader/entries/<ENTRY>.conf 파일에 개별 커널 부팅항목의 커널 명령줄 매개 변수를 수정하고 저장합니다.
39.5. 부팅 시 커널 명령줄 매개변수 변경
커널 매개 변수를 단일 부팅 프로세스 중에만 변경하여 커널 메뉴 항목을 임시로 변경합니다.
이 절차는 단일 부팅에만 적용되며 영구적으로 변경되지 않습니다.
프로세스
- GRUB 부팅 메뉴로 부팅합니다.
- 시작할 커널을 선택합니다.
- e 키를 눌러 커널 매개 변수를 편집합니다.
-
커서를 아래로 이동하여 커널 명령줄을 찾습니다. 커널 명령줄은 64 bit IBM Power Series 및 x86-64 BIOS 기반 시스템에서
linux또는 UEFI 시스템의linuxefi로 시작합니다. 커서를 줄의 끝으로 이동합니다.
참고Ctrl+a 눌러 행의 시작 부분으로 이동하고 Ctrl+e 눌러 줄 끝으로 이동합니다. 일부 시스템에서는 홈 및 종료 키도 작동할 수 있습니다.
필요에 따라 커널 매개변수를 편집합니다. 예를 들어 시스템을 긴급 모드에서 실행하려면
linux행 끝에emergency매개변수를 추가합니다.linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergency
linux ($root)/vmlinuz-4.18.0-348.12.2.el8_5.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet emergencyCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템 메시지를 활성화하려면
rhgb및quiet매개변수를 제거합니다.- Ctrl+x 눌러 선택한 커널 및 수정된 명령줄 매개 변수를 사용하여 부팅합니다.
Esc 키를 눌러 명령줄 편집을 종료하면 사용자가 변경한 모든 내용이 삭제됩니다.
39.6. 직렬 콘솔 연결을 활성화하도록 GRUB 설정 구성
직렬 콘솔은 헤드리스 서버 또는 임베디드 시스템에 연결해야 하고 네트워크가 다운된 경우 유용합니다. 또는 보안 규칙을 방지하고 다른 시스템에서 로그인 액세스 권한을 얻을 필요가 있는 경우입니다.
직렬 콘솔 연결을 사용하려면 몇 가지 기본 GRUB 설정을 구성해야 합니다.
사전 요구 사항
- root 권한이 있습니다.
절차
/etc/default/grub파일에 다음 두 행을 추가합니다.GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"
GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 첫 번째 줄은 그래픽 터미널을 비활성화합니다.
GRUB_TERMINAL_INPUTGRUB_TERMINAL_OUTPUT키의 값을 덮어씁니다.두 번째 줄은 기본 속도(
--speed), 패리티 및 기타 값을 조정하여 환경과 하드웨어에 맞게 조정합니다. 훨씬 높은 기본 속도(예: 115200)는 다음 로그 파일과 같은 작업에 더 적합합니다.GRUB 설정 파일을 업데이트합니다.
BIOS 기반 시스템에서 다음을 수행합니다.
grub2-mkconfig -o /boot/grub2/grub.cfg
# grub2-mkconfig -o /boot/grub2/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow UEFI 기반 시스템에서 다음을 수행합니다.
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
- 변경 사항을 적용하려면 시스템을 재부팅합니다.
40장. 런타임에 커널 매개변수 구성
시스템 관리자는 런타임 시 Red Hat Enterprise Linux 커널의 동작의 여러 측면을 수정할 수 있습니다. sysctl 명령을 사용하고 /etc/sysctl.d/ 및 /proc/sys/ 디렉터리의 구성 파일을 수정하여 런타임에 커널 매개 변수를 구성합니다.
프로덕션 시스템에서 커널 매개 변수를 구성하려면 신중하게 계획해야 합니다. 계획되지 않은 변경으로 인해 커널을 불안정하게 만들 수 있으므로 시스템을 재부팅해야 합니다. 커널 값을 변경하기 전에 유효한 옵션을 사용하고 있는지 확인합니다.
IBM DB2에서 커널 튜닝에 대한 자세한 내용은 IBM DB2 용 Red Hat Enterprise Linux 튜닝 을 참조하십시오.
40.1. 커널 매개변수란
커널 매개변수는 시스템이 실행되는 동안 조정할 수 있는 조정 가능한 값입니다. 변경 사항을 적용하려면 시스템을 재부팅하거나 커널을 다시 컴파일할 필요가 없습니다.
다음을 통해 커널 매개변수를 처리할 수 있습니다.
-
sysctl명령 -
/proc/sys/디렉터리에 마운트된 가상 파일 시스템 -
/etc/sysctl.d/디렉터리의 구성 파일
튜닝 가능 항목은 커널 하위 시스템에서 클래스로 나뉩니다. Red Hat Enterprise Linux에는 다음과 같은 튜닝 가능한 클래스가 있습니다.
| 튜닝 가능 클래스 | 하위 시스템 |
|---|---|
|
| 실행 도메인 및 특성 |
|
| 암호화 인터페이스 |
|
| 커널 디버깅 인터페이스 |
|
| 장치별 정보 |
|
| 글로벌 및 특정 파일 시스템 튜닝 가능 항목 |
|
| 글로벌 커널 튜닝 가능 항목 |
|
| 네트워크 튜닝 가능 항목 |
|
| Sun Remote Procedure Call (NFS) |
|
| 사용자 네임스페이스 제한 |
|
| 메모리, 버퍼 및 캐시 튜닝 및 관리 |
40.2. sysctl을 사용하여 커널 매개변수를 일시적으로 구성
sysctl 명령을 사용하여 런타임 시 커널 매개변수를 일시적으로 설정합니다. 명령은 튜닝 가능 항목을 나열하고 필터링하는 데도 유용합니다.
사전 요구 사항
- 루트 권한
절차
모든 매개변수 및 해당 값을 나열합니다.
sysctl -a
# sysctl -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고# sysctl -a명령은 런타임 시 및 부팅 시 조정할 수 있는 커널 매개 변수를 표시합니다.매개변수를 일시적으로 구성하려면 다음을 입력합니다.
sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>
# sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 샘플 명령은 시스템이 실행되는 동안 매개 변수 값을 변경합니다. 변경 사항은 다시 시작할 필요 없이 즉시 적용됩니다.
참고변경 사항은 시스템을 재부팅한 후 기본값으로 돌아갑니다.
40.3. sysctl을 사용하여 커널 매개변수를 영구적으로 구성
sysctl 명령을 사용하여 커널 매개 변수를 영구적으로 설정합니다.
사전 요구 사항
- 루트 권한
절차
모든 매개변수를 나열합니다.
sysctl -a
# sysctl -aCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 런타임 시 구성할 수 있는 모든 커널 매개 변수를 표시합니다.
매개변수를 영구적으로 구성합니다.
sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.conf
# sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.confCopy to Clipboard Copied! Toggle word wrap Toggle overflow 샘플 명령은 튜닝 가능 항목 값을 변경하고
/etc/sysctl.conf파일에 작성하여 커널 매개변수의 기본값을 덮어씁니다. 변경 사항은 다시 시작할 필요 없이 즉시 영구적으로 적용됩니다.
커널 매개 변수를 영구적으로 수정하려면 /etc/sysctl.d/ 디렉터리의 구성 파일을 수동으로 변경할 수도 있습니다.
40.4. /etc/sysctl.d/에서 구성 파일을 사용하여 커널 매개변수 조정
커널 매개변수를 영구적으로 설정하려면 /etc/sysctl.d/ 디렉터리의 구성 파일을 수동으로 수정해야 합니다.
사전 요구 사항
- root 권한이 있습니다.
프로세스
/etc/sysctl.d/:에 새 구성 파일을 생성합니다.vim /etc/sysctl.d/<some_file.conf>
# vim /etc/sysctl.d/<some_file.conf>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 한 줄에 하나씩 커널 매개변수를 포함합니다.
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 구성 파일을 저장합니다.
변경 사항을 적용하려면 시스템을 재부팅합니다.
또는 재부팅하지 않고 변경 사항을 적용합니다.
sysctl -p /etc/sysctl.d/<some_file.conf>
# sysctl -p /etc/sysctl.d/<some_file.conf>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령을 사용하면 이전에 만든 구성 파일에서 값을 읽을 수 있습니다.
40.5. /proc/sys/를 통해 일시적으로 커널 매개변수 구성
/proc/sys/ 가상 파일 시스템 디렉터리의 파일을 통해 커널 매개 변수를 일시적으로 설정합니다.
사전 요구 사항
- 루트 권한
프로세스
구성할 커널 매개변수를 식별합니다.
ls -l /proc/sys/<TUNABLE_CLASS>/
# ls -l /proc/sys/<TUNABLE_CLASS>/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령에서 반환된 쓰기 가능한 파일을 사용하여 커널을 구성할 수 있습니다. 읽기 전용 권한이 있는 파일은 현재 설정에 대한 피드백을 제공합니다.
커널 매개 변수에 대상 값을 할당합니다.
echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
# echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령을 사용하여 적용되는 구성 변경 사항은 영구적으로 적용되지 않으며 시스템을 다시 시작하면 사라집니다.
검증
새로 설정된 kernel 매개변수의 값을 확인합니다.
cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
# cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
41장. kdump 설치 및 구성
41.1. kdump 설치
새로운 버전의 RHEL 8 설치에서 kdump 서비스가 기본적으로 설치 및 활성화됩니다.
41.1.1. kdump란 무엇입니까?
kdump 는 크래시 덤프 메커니즘을 제공하고 크래시 덤프 또는 vmcore 덤프 파일을 생성하는 서비스입니다. vmcore 에는 분석 및 문제 해결을 위해 시스템 메모리의 내용이 포함됩니다. kdump 는 kexec 시스템 호출을 사용하여 두 번째 커널로 부팅하고 재부팅하지 않고 커널을 캡처합니다. 이 커널은 충돌한 커널 메모리의 내용을 캡처하여 파일에 저장합니다. 두 번째 커널은 시스템 메모리의 예약된 부분에서 사용할 수 있습니다.
커널 크래시 덤프는 시스템 오류가 발생한 경우 사용 가능한 유일한 정보일 수 있습니다. 따라서 작업 kdump 는 미션 크리티컬 환경에서 중요합니다. Red Hat은 일반 커널 업데이트 주기에서 kexec-tools 를 정기적으로 업데이트하고 테스트하는 것이 좋습니다. 이는 새 커널 기능을 설치할 때 중요합니다.
머신에 여러 커널이 있는 경우 설치된 모든 커널 또는 지정된 커널에 대해 kdump 를 활성화할 수 있습니다. kdump 를 설치할 때 시스템은 기본 /etc/kdump.conf 파일을 생성합니다. /etc/kdump.conf 에는 kdump 구성을 사용자 지정하도록 편집할 수 있는 기본 최소 kdump 구성이 포함되어 있습니다.
41.1.2. Anaconda를 사용하여 kdump 설치
Anaconda 설치 프로그램은 대화형 설치 중에 kdump 구성에 대한 그래픽 인터페이스 화면을 제공합니다. kdump 를 활성화하고 필요한 메모리 양을 예약할 수 있습니다.
프로세스
Anaconda 설치 프로그램에서 KDUMP 를 클릭하고
kdump를 활성화합니다.
- Kdump 메모리 예약 에서 메모리 예약을 사용자 지정해야 하는 경우 Manual'을 선택합니다.
KDUMP > Memory to be Reserved(MB) 에서
kdump에 필요한 메모리 예약을 설정합니다.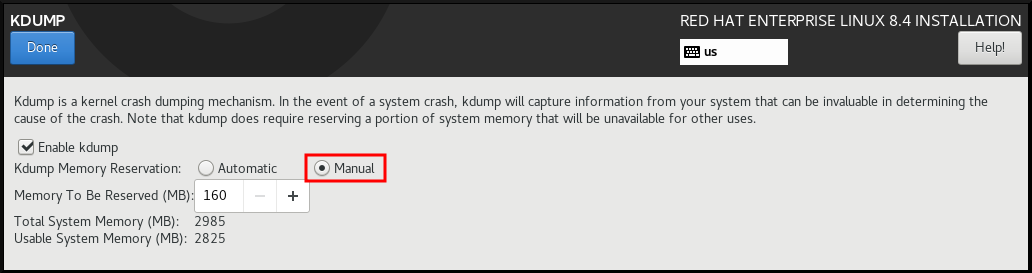
41.1.3. 명령줄에 kdump 설치
사용자 지정 Kickstart 설치와 같은 설치 옵션은 경우에 따라 기본적으로 kdump 를 설치하거나 활성화 하지 않습니다. 다음 절차에서는 이 경우 kdump 를 활성화하는 데 도움이 됩니다.
사전 요구 사항
- 활성 RHEL 서브스크립션입니다.
-
시스템 CPU 아키텍처용
kexec-tools패키지가 포함된 리포지토리입니다. -
kdump구성 및 대상에 대한 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오.
프로세스
kdump가 시스템에 설치되어 있는지 확인합니다.rpm -q kexec-tools
# rpm -q kexec-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 패키지가 설치된 경우 출력됩니다.
kexec-tools-2.0.17-11.el8.x86_64
kexec-tools-2.0.17-11.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 패키지가 설치되지 않은 경우 출력됩니다.
package kexec-tools is not installed
package kexec-tools is not installedCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump및 기타 필수 패키지를 설치합니다.dnf install kexec-tools
# dnf install kexec-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
kernel-3.10.0-693.el7 이후의 Intel IOMMU 드라이버는 kdump 에서 지원됩니다. kernel-3.10.0-514[.XYZ].el7 및 초기 버전의 경우 응답하지 않는 캡처 커널을 방지하려면 Intel IOMMU 가 비활성화되어 있어야 합니다.
41.2. 명령줄에서 kdump 구성
kdump 의 메모리는 시스템 부팅 중에 예약되어 있습니다. 시스템의 GRUB(GRUB) 구성 파일에서 메모리 크기를 구성할 수 있습니다. 메모리 크기는 구성 파일에 지정된 crashkernel= 값과 시스템의 실제 메모리에 따라 다릅니다.
41.2.1. kdump 크기 추정
kdump 환경을 계획하고 구축할 때는 크래시 덤프 파일에 필요한 공간을 알아야 합니다.
makedumpfile --mem-usage 명령은 크래시 덤프 파일에 필요한 공간을 추정합니다. 메모리 사용량 보고서를 생성합니다. 이 보고서를 사용하면 덤프 수준과 제외할 수 있는 페이지를 결정하는 데 도움이 됩니다.
프로세스
다음 명령을 입력하여 메모리 사용량 보고서를 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
makedumpfile --mem-usage 명령은 필요한 메모리를 페이지에 보고합니다. 즉, 커널 페이지 크기에 대해 사용 중인 메모리 크기를 계산해야 합니다.
41.2.2. kdump 메모리 사용량 구성
kdump 의 메모리 예약은 시스템 부팅 중에 수행됩니다. 메모리 크기는 시스템의 GRUB(GRUB) 구성에서 설정됩니다. 메모리 크기는 구성 파일에 지정된 crashkernel= 옵션 값과 시스템 물리적 메모리 크기에 따라 다릅니다.
crashkernel= 옵션을 여러 가지 방법으로 정의할 수 있습니다. crashkernel= 값을 지정하거나 auto 옵션을 구성할 수 있습니다. crashkernel=auto 매개 변수는 시스템의 총 실제 메모리 크기에 따라 메모리를 자동으로 예약합니다. 구성되면 커널은 캡처 커널에 적절한 양의 필요한 메모리를 자동으로 예약합니다. 이렇게 하면 OOM(메모리 부족) 오류를 방지할 수 있습니다.
kdump 의 자동 메모리 할당은 시스템 하드웨어 아키텍처 및 사용 가능한 메모리 크기에 따라 다릅니다.
시스템에 자동 할당을 위한 최소 메모리 임계값보다 적은 경우 예약된 메모리 양을 수동으로 구성할 수 있습니다.
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
-
kdump구성 및 대상에 대한 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오.
프로세스
crashkernel=옵션을 준비합니다.예를 들어 128MB의 메모리를 예약하려면 다음을 사용합니다.
crashkernel=128M
crashkernel=128MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 설치된 총 메모리 크기에 따라 예약된 메모리 양을 변수로 설정할 수 있습니다. 변수에 대한 메모리 예약 구문은
crashkernel= <range1> : <size1 > , <range2 > : <size2> 입니다. 예를 들면 다음과 같습니다.crashkernel=512M-2G:64M,2G-:128M
crashkernel=512M-2G:64M,2G-:128MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 총 시스템 메모리 양이 512MB 및 2GB의 범위에 있는 경우 64MB의 메모리를 예약합니다. 총 메모리 양이 2GB를 초과하면 메모리 예약은 128MB입니다.
예약된 메모리를 오프셋합니다.
크래시커널예약이 조기에 수행되므로 일부 시스템은 특정 고정 오프셋이 있는 메모리를 예약해야 하며 특수 사용을 위해 더 많은 메모리를 예약해야 할 수 있습니다. 오프셋을 정의하면 예약된 메모리가 여기에서 시작됩니다. 예약된 메모리를 오프셋하려면 다음 구문을 사용합니다.crashkernel=128M@16M
crashkernel=128M@16MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서
kdump는 16MB(실제 주소0x01000000)부터 128MB의 메모리를 예약합니다. offset 매개변수를 0으로 설정하거나 완전히 생략하면kdump가 예약된 메모리를 자동으로 오프셋합니다. 변수 메모리 예약을 설정할 때 이 구문을 사용할 수도 있습니다. 이 경우 오프셋은 항상 last으로 지정됩니다. 예를 들면 다음과 같습니다.crashkernel=512M-2G:64M,2G-:128M@16M
crashkernel=512M-2G:64M,2G-:128M@16MCopy to Clipboard Copied! Toggle word wrap Toggle overflow
crashkernel=옵션을 부트 로더 구성에 적용합니다.grubby --update-kernel=ALL --args="crashkernel=<value>"
# grubby --update-kernel=ALL --args="crashkernel=<value>"Copy to Clipboard Copied! Toggle word wrap Toggle overflow &
lt;value>를 이전 단계에서 준비한crashkernel=옵션 값으로 바꿉니다.
41.2.3. kdump 대상 구성
크래시 덤프는 일반적으로 장치에 직접 작성된 로컬 파일 시스템에 파일로 저장됩니다. 선택적으로 NFS 또는 SSH 프로토콜을 사용하여 네트워크를 통해 크래시 덤프를 보낼 수 있습니다. 크래시 덤프 파일을 보존하기 위한 이러한 옵션 중 하나만 한 번에 설정할 수 있습니다. 기본 동작은 로컬 파일 시스템의 /var/crash/ 디렉터리에 저장하는 것입니다.
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
-
kdump구성 및 대상에 대한 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오.
프로세스
크래시 덤프 파일을 로컬 파일 시스템의
/var/crash/디렉터리에 저장하려면/etc/kdump.conf파일을 편집하고 경로를 지정합니다.path /var/crash
path /var/crashCopy to Clipboard Copied! Toggle word wrap Toggle overflow 옵션
경로 /var/crash는kdump에서 크래시 덤프 파일을 저장하는 파일 시스템의 경로를 나타냅니다.참고-
/etc/kdump.conf파일에 덤프 대상을 지정하면 경로는 지정된 덤프 대상과 관련이 있습니다. -
/etc/kdump.conf파일에 덤프 대상을 지정하지 않으면 경로는 루트 디렉터리의 절대 경로를 나타냅니다.
현재 시스템에 마운트된 파일 시스템에 따라 덤프 대상 및 조정된 덤프 경로가 자동으로 구성됩니다.
-
크래시 덤프 파일과
kdump에서 생성된 관련 파일을 보호하려면 사용자 권한 및 SELinux 컨텍스트와 같은 대상 대상 디렉터리에 대한 적절한 속성을 설정해야 합니다. 또한 다음과 같이kdump.conf파일에서kdump_post.sh스크립트를 정의할 수 있습니다.kdump_post <path_to_kdump_post.sh>
kdump_post <path_to_kdump_post.sh>Copy to Clipboard Copied! Toggle word wrap Toggle overflow kdump_post지시문은kdump가 캡처를 완료하고 지정된 대상에 크래시 덤프를 저장한 후 실행되는 쉘 스크립트 또는 명령을 지정합니다. 이 메커니즘을 사용하여kdump의 기능을 확장하여 파일 권한 조정을 포함하여 작업을 수행할 수 있습니다.-
kdump대상 구성
# *grep -v ^# /etc/kdump.conf | grep -v ^$* ext4 /dev/mapper/vg00-varcrashvol path /var/crash core_collector makedumpfile -c --message-level 1 -d 31
# *grep -v ^# /etc/kdump.conf | grep -v ^$*
ext4 /dev/mapper/vg00-varcrashvol
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
덤프 대상은 (ext4 /dev/mapper/vg00-varcrashvol) 지정되므로 /var/crash 에 마운트됩니다. path 옵션도 /var/crash 로 설정됩니다. 따라서 kdump 는 vmcore 파일을 /var/crash/var/crash 디렉터리에 저장합니다.
크래시 덤프 저장을 위해 로컬 디렉터리를 변경하려면
/etc/kdump.conf구성 파일을root사용자로 편집합니다.-
#path /var/crash 값을 의도한 디렉터리 경로로 바꿉니다. 예를 들면 다음과 같습니다.
path /usr/local/cores
path /usr/local/coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow 중요RHEL 8에서
path지시문을 사용하여kdump대상으로 정의된 디렉터리는kdumpsystemd서비스가 실패하는 것을 방지할 때 존재해야 합니다. 이전 버전의 RHEL과 달리 서비스가 시작될 때 디렉터리가 없는 경우 더 이상 자동으로 생성되지 않습니다.
-
파일을 다른 파티션에 작성하려면
/etc/kdump.conf구성 파일을 편집합니다.선택한 항목에 따라
#ext4-
장치 이름(
#ext4 /dev/vg/lv_kdump행) -
파일 시스템 레이블(
#ext4 LABEL=/boot행) -
UUID (
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937행)
-
장치 이름(
파일 시스템 유형과 장치 이름, 레이블 또는 UUID를 필수 값으로 변경합니다. UUID 값을 지정하는 올바른 구문은
UUID="correct-uuid"및UUID=correct-uuid입니다. 예를 들면 다음과 같습니다.ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937
ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요LABEL=또는UUID=를 사용하여 스토리지 장치를 지정하는 것이 좋습니다./dev/sda3과 같은 디스크 장치 이름은 재부팅 시 일관성이 유지되지 않습니다.IBM Z 하드웨어에서 Direct Access Storage Device(DASD)를 사용하는 경우
kdump를 진행하기 전에 덤프 장치가/etc/dasd.conf에 올바르게 지정되었는지 확인합니다.
크래시 덤프를 장치에 직접 작성하려면
/etc/kdump.conf구성 파일을 편집합니다.-
#raw /dev/vg/lv_kdump 값을 원하는 장치 이름으로 바꿉니다. 예를 들면 다음과 같습니다.
raw /dev/sdb1
raw /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
NFS프로토콜을 사용하여 크래시 덤프를 원격 시스템에 저장하려면 다음을 수행합니다.-
#nfs my.server.com:/export/tmp 값을 유효한 호스트 이름 및 디렉터리 경로로 바꿉니다. 예를 들면 다음과 같습니다.
nfs penguin.example.com:/export/cores
nfs penguin.example.com:/export/coresCopy to Clipboard Copied! Toggle word wrap Toggle overflow 변경 사항을 적용하려면
kdump서비스를 다시 시작하십시오.sudo systemctl restart kdump.service
sudo systemctl restart kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고NFS 지시문을 사용하여 NFS 대상을 지정하는 동안
kdump.service는 자동으로 NFS 대상을 마운트하여 디스크 공간을 확인합니다. NFS 대상을 미리 마운트할 필요가 없습니다.kdump.service가 대상을 마운트하지 않도록 하려면kdump.conf에서dracut_args --mount지시문을 사용합니다. 그러면kdump.service가--mount인수와 함께dracut유틸리티를 호출하여 NFS 대상을 지정할 수 있습니다.
-
SSH 프로토콜을 사용하여 크래시 덤프를 원격 시스템에 저장하려면 다음을 수행합니다.
-
#ssh user@my.server.com - 값을 유효한 사용자 이름 및 호스트 이름으로 바꿉니다.
구성에 SSH 키를 포함합니다.
-
#sshkey /root/.ssh/kdump_id_rsa행의 시작 부분에서 해시 기호를 제거합니다. 덤프하려는 서버에서 유효한 키 위치로 값을 변경합니다. 예를 들면 다음과 같습니다.
ssh john@penguin.example.com sshkey /root/.ssh/mykey
ssh john@penguin.example.com sshkey /root/.ssh/mykeyCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
-
41.2.4. kdump 코어 수집기 구성
kdump 서비스는 core_collector 프로그램을 사용하여 크래시 덤프 이미지를 캡처합니다. RHEL에서 makedumpfile 유틸리티는 기본 코어 수집기입니다. 다음과 같이 덤프 파일을 줄이는 데 도움이 됩니다.
- 크래시 덤프 파일의 크기를 압축하고 다양한 덤프 수준을 사용하여 필요한 페이지만 복사합니다.
- 불필요한 크래시 덤프 페이지 제외.
- 크래시 덤프에 포함될 페이지 유형 필터링.
RHEL 7 이상에서는 크래시 덤프 파일 압축이 기본적으로 활성화됩니다.
크래시 덤프 파일 압축을 사용자 지정해야 하는 경우 다음 절차를 따르십시오.
구문
core_collector makedumpfile -l --message-level 1 -d 31
core_collector makedumpfile -l --message-level 1 -d 31옵션
-
-c-l-p:,zlibfor -c 옵션을 사용하여 각 페이지에서 덤프 파일 형식을 압축하거나 -l 옵션에 대해lzo또는-p옵션을 위해snappy를 지정합니다. -
-d(dump_level): 덤프 파일에 복사되지 않도록 페이지를 제외합니다. -
--message-level: 메시지 유형을 지정합니다. 이 옵션으로message_level을 지정하여 출력된 출력을 제한할 수 있습니다. 예를 들어 7을message_level으로 지정하면 일반적인 메시지 및 오류 메시지가 출력됩니다.message_level의 최대값은 31입니다.
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
-
kdump구성 및 대상에 대한 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오.
프로세스
-
루트로서/etc/kdump.conf구성 파일을 편집하고#core_collector makedumpfile -l --message-level 1 -d 31의 시작 부분에서 해시 기호("#")를 제거합니다. - 크래시 덤프 파일 압축을 활성화하려면 다음 명령을 입력합니다.
core_collector makedumpfile -l --message-level 1 -d 31
core_collector makedumpfile -l --message-level 1 -d 31
l 옵션은 덤프 압축 파일 형식을 지정합니다. d 옵션은 덤프 수준을 31로 지정합니다. --message-level 옵션은 메시지 수준을 1로 지정합니다.
또한 -c 및 -p 옵션을 사용하여 다음 예제를 고려하십시오.
-c를 사용하여 크래시 덤프 파일을 압축하려면 다음을 수행합니다.core_collector makedumpfile -c -d 31 --message-level 1
core_collector makedumpfile -c -d 31 --message-level 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 크래시 덤프 파일을 압축하려면
-p:core_collector makedumpfile -p -d 31 --message-level 1
core_collector makedumpfile -p -d 31 --message-level 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
41.2.5. kdump 기본 실패 응답 구성
기본적으로 kdump 가 구성된 대상 위치에서 크래시 덤프 파일을 생성하지 못하면 시스템이 재부팅되고 프로세스에서 덤프가 손실됩니다. 기본 실패 응답을 변경하고 코어 덤프를 기본 대상에 저장하지 못할 때 다른 작업을 수행하도록 kdump 를 구성할 수 있습니다. 추가 작업은 다음과 같습니다.
dump_to_rootfs-
코어 덤프를
루트파일 시스템에 저장합니다. reboot- 시스템을 재부팅하여 프로세스의 코어 덤프가 손실됩니다.
halt- 시스템에서 시스템을 중지하고 프로세스에서 코어 덤프를 손실합니다.
poweroff- 시스템의 전원을 끄고 프로세스의 코어 덤프를 끊습니다.
shell-
initramfs내에서 쉘 세션을 실행하면 코어 덤프를 수동으로 기록할 수 있습니다. final_action-
kdump에 성공한 후 또는 shell 또는dump_to_rootfs실패 작업이 완료될 때reboot,halt,poweroff와 같은 추가 작업을 활성화합니다. 기본값은reboot입니다. failure_action-
커널 충돌에서 덤프가 실패할 때 수행할 작업을 지정합니다. 기본값은
reboot입니다.
사전 요구 사항
- 루트 권한.
-
kdump구성 및 대상에 대한 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오.
프로세스
-
root사용자로/etc/kdump.conf구성 파일의#failure_action 값을 필수 작업으로 바꿉니다.
failure_action poweroff
failure_action poweroffCopy to Clipboard Copied! Toggle word wrap Toggle overflow
41.2.6. kdump 설정 파일
kdump 커널의 설정 파일은 /etc/sysconfig/kdump 입니다. 이 파일은 kdump 커널 명령줄 매개변수를 제어합니다. 대부분의 구성에서 기본 옵션을 사용합니다. 그러나 일부 시나리오에서는 kdump 커널 동작을 제어하도록 특정 매개변수를 수정해야 할 수 있습니다. 예를 들어 KDUMP_COMMANDLINE_APPEND 옵션을 수정하여 kdump 커널 명령줄을 추가하여 자세한 디버깅 출력을 얻거나 kdump 명령줄에서 인수를 제거하도록 KDUMP_COMMANDLINE_REMOVE 옵션을 변경합니다.
KDUMP_COMMANDLINE_REMOVE이 옵션은 현재
kdump명령줄에서 인수를 제거합니다.kdump오류 또는kdump커널 부팅 실패를 유발할 수 있는 매개변수를 제거합니다. 이러한 매개변수는 이전KDUMP_COMMANDLINE프로세스에서 구문 분석되었거나/proc/cmdline파일에서 상속되었을 수 있습니다.이 변수가 구성되지 않은 경우
/proc/cmdline파일의 모든 값을 상속합니다. 이 옵션을 구성하면 문제를 디버깅하는 데 유용한 정보도 제공합니다.특정 인수를 제거하려면 다음과 같이
KDUMP_COMMANDLINE_REMOVE에 추가합니다.
KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"
# KDUMP_COMMANDLINE_REMOVE="hugepages hugepagesz slub_debug quiet log_buf_len swiotlb"KDUMP_COMMANDLINE_APPEND이 옵션은 현재 명령줄에 인수를 추가합니다. 이러한 인수는 이전
KDUMP_COMMANDLINE_REMOVE변수에서 구문 분석되었을 수 있습니다.kdump커널의 경우mce,cgroup,numa,hest_disable과 같은 특정 모듈을 비활성화하면 커널 오류를 방지할 수 있습니다. 이러한 모듈은kdump용으로 예약된 커널 메모리의 중요한 부분을 사용하거나kdump커널 부팅 실패를 유발할 수 있습니다.kdump커널 명령줄에서 메모리cgroup을 비활성화하려면 다음과 같이 명령을 실행합니다.
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"
KDUMP_COMMANDLINE_APPEND="cgroup_disable=memory"41.2.7. kdump 설정 테스트
kdump 를 구성한 후 시스템 충돌을 수동으로 테스트하고 vmcore 파일이 정의된 kdump 대상에 생성되었는지 확인해야 합니다. vmcore 파일은 새로 부팅된 커널의 컨텍스트에서 캡처됩니다. 따라서 vmcore 에는 커널 충돌을 디버깅하는 데 중요한 정보가 있습니다.
활성 프로덕션 시스템에서 kdump 를 테스트하지 마십시오. kdump 를 테스트하는 명령으로 인해 커널이 데이터 손실과 충돌합니다. 시스템 아키텍처에 따라 kdump 테스트에서 부팅 시간이 긴 몇 가지 재부팅이 필요할 수 있으므로 상당한 유지 관리 시간을 예약해야 합니다.
kdump 테스트 중에 vmcore 파일이 생성되지 않으면 kdump 테스트를 위해 테스트를 다시 실행하기 전에 문제를 식별하고 수정합니다.
수동 시스템을 수정하는 경우 시스템 수정이 끝날 때 kdump 구성을 테스트해야 합니다. 예를 들어 다음 변경 사항을 수행하는 경우 다음을 위한 최적의 kdump 성능에 대한 kdump 구성을 테스트해야 합니다.
- 패키지 업그레이드.
- 하드웨어 수준 변경(예: 스토리지 또는 네트워킹 변경)
- 펌웨어 업그레이드.
- 타사 모듈을 포함하는 새로운 설치 및 애플리케이션 업그레이드.
- 핫플러그 메커니즘을 사용하여 이 메커니즘을 지원하는 하드웨어에 메모리를 추가하는 경우.
-
/etc/kdump.conf또는/etc/sysconfig/kdump파일을 변경한 후
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
-
모든 중요한 데이터를 저장했습니다.
kdump를 테스트하는 명령으로 인해 커널이 데이터 손실과 충돌합니다. - 시스템 아키텍처에 따라 상당한 머신 유지 관리 시간을 예약했습니다.
프로세스
kdump서비스를 활성화합니다.kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpctl을 사용하여kdump서비스의 상태를 확인합니다.kdumpctl status kdump:Kdump is operational
# kdumpctl status kdump:Kdump is operationalCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택적으로
systemctl명령을 사용하는 경우 출력은systemd저널에 출력됩니다.커널 충돌을 시작하여
kdump구성을 테스트합니다.sysrq-trigger키 조합을 사용하면 커널이 충돌하고 필요한 경우 시스템을 재부팅할 수 있습니다.echo c > /proc/sysrq-trigger
# echo c > /proc/sysrq-triggerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널 재부팅 시
주소-YYYY-MM-DD-HH:MM:SS/vmcore파일이/etc/kdump.conf파일에 지정된 위치에 생성됩니다. 기본값은/var/crash/입니다.
41.2.8. 시스템 충돌 후 kdump에 의해 생성된 파일
시스템 충돌 후 kdump 서비스는 덤프 파일(vmcore)에 커널 메모리를 캡처하고 문제 해결 및 postmortem 분석을 지원하기 위해 추가 진단 파일을 생성합니다.
kdump 에 의해 생성된 파일:
-
vmcore- 충돌 시 시스템 메모리를 포함하는 주요 커널 메모리 덤프 파일입니다.kdump구성에 지정된core_collector프로그램의 구성에 따라 데이터를 포함합니다. 기본적으로 커널 데이터 구조, 프로세스 정보, 스택 추적 및 기타 진단 정보. -
vmcore-dmesg.txt- 패닉 상태인 기본 커널의 커널 링 버퍼 로그(dmesg)의 내용입니다. -
kexec-dmesg.log-vmcore데이터를 수집하는 보조kexec커널 실행으로부터의 커널 및 시스템 로그 메시지가 있습니다.
41.2.9. kdump 서비스 활성화 및 비활성화
특정 커널 또는 설치된 모든 커널에서 kdump 기능을 활성화하거나 비활성화하도록 구성할 수 있습니다. kdump 기능을 정기적으로 테스트하고 올바르게 작동하는지 확인해야 합니다.
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
-
구성 및 대상에 대한
kdump요구 사항을 완료했습니다. 지원되는 kdump 구성 및 대상 을 참조하십시오. -
kdump설치에 대한 모든 구성은 필요에 따라 설정됩니다.
프로세스
multi-user.target에 대해kdump서비스를 활성화합니다.systemctl enable kdump.service
# systemctl enable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 현재 세션에서 서비스를 시작합니다.
systemctl start kdump.service
# systemctl start kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump서비스를 중지합니다.systemctl stop kdump.service
# systemctl stop kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump서비스를 비활성화합니다.systemctl disable kdump.service
# systemctl disable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
kptr_restrict=1 을 기본값으로 설정하는 것이 좋습니다. kptr_restrict 가 기본값으로 설정된 경우 kdumpctl 서비스는KASLR(커널 주소 공간 레이아웃)이 활성화되었는지 여부에 관계없이 크래시 커널을 로드합니다.
kptr_restrict 가 1 로 설정되지 않고 KASLR이 활성화된 경우 /proc/kore 파일의 콘텐츠가 모든 0으로 생성됩니다. kdumpctl 서비스가 /proc/kcore 파일에 액세스하지 못하고 크래시 커널을 로드합니다. kexec-kdump-howto.txt 파일에는 kptr_restrict=1 을 설정할 것을 권장하는 경고 메시지가 표시됩니다. sysctl.conf 파일에서 다음을 확인하여 kdumpctl 서비스가 크래시 커널을 로드하는지 확인합니다.
-
sysctl.conf파일의 커널kptr_restrict=1.
41.2.10. 커널 드라이버가 kdump에 대한 로드되지 않음
/etc/sysconfig/kdump 구성 파일에 KDUMP_COMMANDLINE_APPEND= 변수를 추가하여 캡처 커널이 특정 커널 드라이버를 로드하지 않도록 제어할 수 있습니다. 이 방법을 사용하면 kdump 초기 RAM 디스크 이미지 initramfs 가 지정된 커널 모듈을 로드하지 못하도록 할 수 있습니다. 이렇게 하면 OOM(메모리 부족) 중단 오류 또는 기타 크래시 커널 실패를 방지할 수 있습니다.
다음 구성 옵션 중 하나를 사용하여 KDUMP_COMMANDLINE_APPEND= 변수를 추가할 수 있습니다.
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
프로세스
현재 실행 중인 커널에 로드된 모듈 목록을 표시합니다. 로드에서 차단할 커널 모듈을 선택합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/sysconfig/kdump파일에서KDUMP_COMMANDLINE_APPEND=변수를 업데이트합니다. 예를 들면 다음과 같습니다.KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"
KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또한
modprobe.blacklist= <modules> 구성 옵션을 사용하여 다음 예제를 고려하십시오.KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"
KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"Copy to Clipboard Copied! Toggle word wrap Toggle overflow kdump서비스를 다시 시작하십시오.systemctl restart kdump
# systemctl restart kdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
41.2.11. 암호화된 디스크가 있는 시스템에서 kdump 실행
LUKS 암호화된 파티션을 실행할 때 시스템에 특정 양의 사용 가능한 메모리가 필요합니다. 시스템에 필요한 양의 메모리보다 적은 경우 cryptsetup 유틸리티에서 파티션을 마운트하지 못합니다. 결과적으로 두 번째 커널(capture 커널)에서 vmcore 파일을 암호화된 대상 위치로 캡처할 수 없습니다.
kdumpctl estimate 명령은 kdump . kdump ctl 추정에 필요한 메모리 양을 추정하는 데 도움이 됩니다.kdumpctl 추정은 kdump 에 필요한 메모리 크기에 가장 적합한 크래시커널 값을 출력합니다.
권장되는 crashkernel 값은 현재 커널 크기, 커널 모듈, initramfs 및 LUKS 암호화된 대상 메모리 요구 사항을 기반으로 계산됩니다.
사용자 정의 crashkernel= 옵션을 사용하는 경우 kdumpctl 추정치 는 필요한 크기 값을 출력합니다. 값은 LUKS 암호화된 대상에 필요한 메모리 크기입니다.
프로세스
추정치
crashkernel=값을 출력합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
crashkernel=값을 늘려 필요한 메모리 양을 구성합니다. - 시스템을 재부팅합니다.
kdump 서비스가 여전히 덤프 파일을 암호화된 대상에 저장하지 못하는 경우 필요에 따라 crashkernel= 값을 늘립니다.
41.3. kdump 활성화
RHEL 8 시스템의 경우 특정 커널 또는 설치된 모든 커널에서 kdump 기능 활성화 또는 비활성화를 구성할 수 있습니다. 그러나 kdump 기능을 정기적으로 테스트하고 작동 상태를 검증해야 합니다.
41.3.1. 설치된 모든 커널에 kdump 활성화
kdump 서비스는 kexec 툴이 설치된 후 kdump.service 를 활성화하여 시작합니다. 머신에 설치된 모든 커널에 대해 kdump 서비스를 활성화하고 시작할 수 있습니다.
사전 요구 사항
- 관리자 권한이 있습니다.
프로세스
설치된 모든 커널에
crashkernel=명령줄 매개변수를 추가합니다.grubby --update-kernel=ALL --args="crashkernel=xxM"
# grubby --update-kernel=ALL --args="crashkernel=xxM"Copy to Clipboard Copied! Toggle word wrap Toggle overflow XXM은 필요한 메모리(MB)입니다.시스템을 재부팅합니다.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump서비스를 활성화합니다.systemctl enable --now kdump.service
# systemctl enable --now kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
kdump서비스가 실행 중인지 확인합니다.systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
41.3.2. 설치된 특정 커널에 대해 kdump 활성화
머신에서 특정 커널에 대해 kdump 서비스를 활성화할 수 있습니다.
사전 요구 사항
- 관리자 권한이 있습니다.
프로세스
시스템에 설치된 커널을 나열합니다.
ls -a /boot/vmlinuz-* /boot/vmlinuz-0-rescue-2930657cd0dc43c2b75db480e5e5b4a9 /boot/vmlinuz-4.18.0-330.el8.x86_64 /boot/vmlinuz-4.18.0-330.rt7.111.el8.x86_64
# ls -a /boot/vmlinuz-* /boot/vmlinuz-0-rescue-2930657cd0dc43c2b75db480e5e5b4a9 /boot/vmlinuz-4.18.0-330.el8.x86_64 /boot/vmlinuz-4.18.0-330.rt7.111.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템의 GRUB(GRUB) 설정에 특정
kdump커널을 추가합니다.예를 들면 다음과 같습니다.
grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"
# grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=xxM"Copy to Clipboard Copied! Toggle word wrap Toggle overflow XXM은 필요한 메모리 예약(MB)입니다.kdump서비스를 활성화합니다.systemctl enable --now kdump.service
# systemctl enable --now kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
kdump서비스가 실행 중인지 확인합니다.systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)# systemctl status kdump.service ○ kdump.service - Crash recovery kernel arming Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled) Active: active (live)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
41.3.3. kdump 서비스 비활성화
kdump.service 를 중지하고 RHEL 8 시스템에서 서비스가 시작되지 않도록 비활성화할 수 있습니다.
사전 요구 사항
-
kdump구성 및 대상에 대한 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오. -
kdump설치에 대한 모든 구성은 필요에 따라 설정됩니다. 자세한 내용은 kdump 설치를 참조하십시오.
프로세스
현재 세션에서
kdump서비스를 중지하려면 다음을 수행합니다.systemctl stop kdump.service
# systemctl stop kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump서비스를 비활성화하려면 다음을 수행합니다.systemctl disable kdump.service
# systemctl disable kdump.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
kptr_restrict=1 을 기본값으로 설정하는 것이 좋습니다. kptr_restrict 가 기본값으로 설정된 경우 kdumpctl 서비스는KASLR(커널 주소 공간 레이아웃)이 활성화되었는지 여부에 관계없이 크래시 커널을 로드합니다.
kptr_restrict 가 1 로 설정되지 않고 KASLR 이 활성화된 경우 /proc/kore 파일의 콘텐츠가 모든 0으로 생성됩니다. kdumpctl 서비스가 /proc/kcore 파일에 액세스하지 못하고 크래시 커널을 로드합니다. kexec-kdump-howto.txt 파일에는 kptr_restrict=1 을 설정할 것을 권장하는 경고 메시지가 표시됩니다. sysctl.conf 파일에서 다음을 확인하여 kdumpctl 서비스가 크래시 커널을 로드하는지 확인합니다.
-
sysctl.conf파일의 커널kptr_restrict=1.
41.4. 웹 콘솔에서 kdump 구성
RHEL 8 웹 콘솔을 사용하여 kdump 구성을 설정하고 테스트할 수 있습니다. 웹 콘솔은 부팅 시 kdump 서비스를 활성화할 수 있습니다. 웹 콘솔을 사용하면 kdump 에 대해 예약된 메모리를 구성하고 압축되지 않았거나 압축되지 않은 형식으로 vmcore 저장 위치를 선택할 수 있습니다.
41.4.1. 웹 콘솔에서 kdump 메모리 사용량 및 대상 위치 구성
kdump 커널에 대한 메모리 예약을 구성하고 RHEL 웹 콘솔 인터페이스를 사용하여 vmcore 덤프 파일을 캡처할 대상 위치도 지정할 수 있습니다.
사전 요구 사항
- 웹 콘솔을 설치하고 액세스할 수 있어야 합니다. 자세한 내용은 웹 콘솔 설치를 참조하십시오.
프로세스
-
웹 콘솔에서 스위치를 on으로 설정하여
kdump서비스를 시작합니다. 터미널에서
kdump메모리 사용량을 구성합니다. 예를 들면 다음과 같습니다.sudo grubby --update-kernel ALL --args crashkernel=512M
$ sudo grubby --update-kernel ALL --args crashkernel=512MCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템을 다시 시작하여 변경 사항을 적용합니다.
- 커널 덤프 탭에서 Crash 덤프 위치 필드의 끝에 있는 편집 을 클릭합니다.
vmcore덤프 파일을 저장할 대상 디렉터리를 지정합니다.- 로컬 파일 시스템의 드롭다운 메뉴에서 로컬 파일 시스템을 선택합니다.
SSH 프로토콜을 사용하여 원격 시스템의 경우 드롭다운 메뉴에서 SSH를 통한 Remote 를 선택하고 다음 필드를 지정합니다.
- 서버 필드에 원격 서버 주소를 입력합니다.
- SSH 키 필드에 SSH 키 위치를 입력합니다.
- 디렉터리 필드에 대상 디렉터리를 입력합니다.
NFS 프로토콜을 사용하여 원격 시스템의 경우 드롭다운 메뉴에서 Remote over NFS 를 선택하고 다음 필드를 지정합니다.
- 서버 필드에 원격 서버 주소를 입력합니다.
- 내보내기 필드에 NFS 서버의 공유 폴더 위치를 입력합니다.
디렉터리 필드에 대상 디렉터리를 입력합니다.
참고Compression 확인란을 선택하여
vmcore파일의 크기를 줄일 수 있습니다.
선택 사항: 자동화 스크립트 보기를 클릭하여 자동화 스크립트를 표시합니다.
생성된 스크립트가 있는 창이 열립니다. 쉘 스크립트 및 Ansible 플레이북 생성 옵션 탭을 찾을 수 있습니다.
선택 사항: Copy to 클립보드를 클릭하여 스크립트를 복사합니다.
이 스크립트를 사용하여 여러 시스템에 동일한 구성을 적용할 수 있습니다.
검증
- 클릭합니다.
kdump 설정 테스트에서 Crash 시스템을 클릭합니다.
주의시스템 충돌을 시작하면 커널 작업이 중지되고 데이터 손실로 인해 시스템이 중단됩니다.
41.5. 지원되는 kdump 구성 및 대상
kdump 메커니즘은 커널 충돌 발생 시 크래시 덤프 파일을 생성하는 Linux 커널의 기능입니다. 커널 덤프 파일에는 커널 충돌의 근본 원인을 분석하고 결정하는 데 도움이 되는 중요한 정보가 있습니다. 충돌은 다양한 요인, 하드웨어 문제 또는 타사 커널 모듈 문제로 인해 몇 가지 이름을 지정할 수 있습니다.
제공된 정보 및 절차를 사용하면 다음 작업을 수행할 수 있습니다.
- RHEL 8 시스템에 대해 지원되는 구성 및 대상을 식별합니다.
- kdump를 구성합니다.
- kdump 작업을 확인합니다.
41.5.1. kdump의 메모리 요구 사항
kdump 에서 커널 크래시 덤프를 캡처하고 추가 분석을 위해 저장하려면 시스템 메모리의 일부를 캡처 커널에 영구적으로 예약해야 합니다. 예약되면 시스템 메모리의 이 부분을 기본 커널에서 사용할 수 없습니다.
메모리 요구 사항은 특정 시스템 매개변수에 따라 다릅니다. 주요 요인 중 하나는 시스템의 하드웨어 아키텍처입니다. x86_64라고도 하는 Intel 64 및 AMD64와 같은 정확한 시스템 아키텍처를 식별하고 표준 출력에 인쇄하려면 다음 명령을 사용합니다.
uname -m
$ uname -m
명시된 최소 메모리 요구 사항 목록을 사용하여 사용 가능한 최신 버전에서 kdump 의 메모리를 자동으로 예약하도록 적절한 메모리 크기를 설정할 수 있습니다. 메모리 크기는 시스템의 아키텍처 및 사용 가능한 실제 메모리에 따라 다릅니다.
| 아키텍처 | 사용 가능한 메모리 | 최소 예약 메모리 |
|---|---|---|
|
AMD64 및 Intel 64 ( | 1GB에서 4GB | 192MB RAM |
| 4GB에서 64GB | 256MB RAM | |
| 64GB 이상 | 512MB RAM | |
|
64비트 ARM 아키텍처( | 2GB 이상 | 480MB의 RAM |
|
IBM Power Systems ( | 2GB에서 4GB | 384MB의 RAM |
| 4GB ~ 16GB | 512MB RAM | |
| 16GB에서 64GB | 1GB RAM | |
| 64GB에서 128GB | 2GB RAM | |
| 128GB 이상 | 4GB RAM | |
|
IBM Z ( | 1GB에서 4GB | 192MB RAM |
| 4GB에서 64GB | 256MB RAM | |
| 64GB 이상 | 512MB RAM |
많은 시스템에서 kdump 는 필요한 메모리 양을 추정하고 자동으로 예약할 수 있습니다. 이 동작은 기본적으로 활성화되어 있지만 시스템 아키텍처에 따라 다른 특정 양의 사용 가능한 메모리가 있는 시스템에서만 작동합니다.
시스템의 총 메모리 양을 기반으로 예약된 메모리의 자동 구성은 최선의 노력 추정입니다. I/O 장치와 같은 다른 요인에 따라 실제 필요한 메모리가 다를 수 있습니다. 메모리가 충분하지 않으면 커널 패닉의 경우 디버그 커널을 캡처 커널로 부팅할 수 없습니다. 이 문제를 방지하려면 크래시 커널 메모리를 충분히 늘립니다.
41.5.2. 자동 메모리 예약의 최소 임계값
기본적으로 kexec-tools 유틸리티는 crashkernel 명령줄 매개변수를 구성하고 kdump 에 대해 일정 양의 메모리를 예약합니다. 그러나 일부 시스템에서는 부트 로더 구성 파일에서 crashkernel=auto 매개 변수를 사용하거나 그래픽 구성 유틸리티에서 이 옵션을 활성화하여 kdump 에 메모리를 할당할 수 있습니다. 이 자동 예약이 작동하려면 시스템에서 특정 양의 총 메모리를 사용할 수 있어야 합니다. 메모리 요구 사항은 시스템의 아키텍처에 따라 다릅니다. 시스템 메모리가 지정된 임계값보다 작으면 메모리를 수동으로 구성해야 합니다.
| 아키텍처 | 필요한 메모리 |
|---|---|
|
AMD64 및 Intel 64 ( | 2GB |
|
IBM Power Systems ( | 2GB |
|
IBM Z ( | 4GB |
부팅 명령줄의 crashkernel=auto 옵션은 RHEL 9 이상 릴리스에서 더 이상 지원되지 않습니다.
41.5.3. 지원되는 kdump 대상
커널 충돌이 발생하면 운영 체제는 구성된 또는 기본 대상 위치에 덤프 파일을 저장합니다. 덤프 파일을 장치에 직접 저장하거나 로컬 파일 시스템에 파일로 저장하거나 네트워크를 통해 덤프 파일을 보낼 수 있습니다. 다음 덤프 대상 목록을 사용하면 kdump 에서 현재 지원되거나 지원되지 않는 대상을 알 수 있습니다.
| 대상 유형 | 지원되는 대상 | 지원되지 않는 대상 |
|---|---|---|
| 물리적 스토리지 |
|
|
| 네트워크 |
|
|
| 하이퍼바이저 |
| |
| 파일 시스템 | ext[234], XFS 및 NFS 파일 시스템. |
|
| 펌웨어 |
|
41.5.4. 지원되는 kdump 필터링 수준
kdump 는 덤프 파일의 크기를 줄이기 위해 makedumpfile 코어 수집기를 사용하여 데이터를 압축하고 원하지 않는 정보를 제외합니다. 예를 들어 -8 수준을 사용하여 hugepages 및 hugetlbfs 페이지를 제거할 수 있습니다. 현재 dumpfile 에서 지원하는 수준은 'kdump'에 대한 수준 필터링을 위해 표에서 확인할 수 있습니다.
| 옵션 | 설명 |
|---|---|
|
| 0 페이지 |
|
| 캐시 페이지 |
|
| 캐시 비공개 캐시 |
|
| 사용자 페이지 |
|
| 무료 페이지 |
41.5.5. 지원되는 기본 실패 응답
기본적으로 kdump 가 코어 덤프를 생성하지 못하는 경우 운영 체제가 재부팅됩니다. 그러나 코어 덤프를 기본 대상에 저장하지 못하는 경우 다른 작업을 수행하도록 kdump 를 구성할 수 있습니다.
| 옵션 | 설명 |
|---|---|
|
| 코어 덤프를 루트 파일 시스템에 저장합니다. 이 옵션은 네트워크 대상과 함께 특히 유용합니다. 네트워크 대상에 연결할 수 없는 경우 이 옵션은 코어 덤프를 로컬로 저장하도록 kdump를 구성합니다. 시스템이 나중에 재부팅됩니다. |
|
| 시스템을 재부팅하여 프로세스에서 코어 덤프를 손실합니다. |
|
| 시스템을 중단하고 프로세스의 코어 덤프를 손실합니다. |
|
| 시스템의 전원을 끄고 프로세스의 코어 덤프를 끊습니다. |
|
| initramfs 내에서 쉘 세션을 실행하여 사용자가 코어 덤프를 수동으로 기록할 수 있습니다. |
|
|
|
41.5.6. final_action 매개변수 사용
kdump 가 성공하거나 kdump 가 구성된 대상에 vmcore 파일을 저장하지 못하는 경우, final_action 매개변수를 사용하여 reboot,halt, poweroff 와 같은 추가 작업을 수행할 수 있습니다. final_action 매개변수를 지정하지 않으면 재부팅이 기본 응답입니다.
프로세스
final_action을 구성하려면/etc/kdump.conf파일을 편집하고 다음 옵션 중 하나를 추가합니다.-
final_action reboot -
final_action halt -
final_action poweroff
-
변경 사항을 적용하려면
kdump서비스를 다시 시작하십시오.kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
41.5.7. failure_action 매개변수 사용
failure_action 매개 변수는 커널 충돌 시 덤프가 실패할 때 수행할 작업을 지정합니다. 시스템을 재부팅 하는 failure_action 의 기본 동작은 재부팅입니다.
매개변수는 수행할 다음 작업을 인식합니다.
reboot- 덤프 실패 후 시스템을 재부팅합니다.
dump_to_rootfs- 루트가 아닌 덤프 대상이 구성된 경우 덤프 파일을 루트 파일 시스템에 저장합니다.
halt- 시스템을 중지합니다.
poweroff- 시스템에서 실행 중인 작업을 중지합니다.
shell-
initramfs내에서 쉘 세션을 시작하여 추가 복구 작업을 수동으로 수행할 수 있습니다.
프로세스
덤프가 실패하는 경우 수행할 작업을 구성하려면
/etc/kdump.conf파일을 편집하고failure_action옵션 중 하나를 지정합니다.-
failure_action reboot -
failure_action halt -
failure_action poweroff -
failure_action 쉘 -
failure_action dump_to_rootfs
-
변경 사항을 적용하려면
kdump서비스를 다시 시작하십시오.kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow
41.6. kdump 설정 테스트
kdump 를 구성한 후 시스템 충돌을 수동으로 테스트하고 vmcore 파일이 정의된 kdump 대상에 생성되었는지 확인해야 합니다. vmcore 파일은 새로 부팅된 커널의 컨텍스트에서 캡처됩니다. 따라서 vmcore 에는 커널 충돌을 디버깅하는 데 중요한 정보가 있습니다.
활성 프로덕션 시스템에서 kdump 를 테스트하지 마십시오. kdump 를 테스트하는 명령으로 인해 커널이 데이터 손실과 충돌합니다. 시스템 아키텍처에 따라 kdump 테스트에서 부팅 시간이 긴 몇 가지 재부팅이 필요할 수 있으므로 상당한 유지 관리 시간을 예약해야 합니다.
kdump 테스트 중에 vmcore 파일이 생성되지 않으면 kdump 테스트를 위해 테스트를 다시 실행하기 전에 문제를 식별하고 수정합니다.
수동 시스템을 수정하는 경우 시스템 수정이 끝날 때 kdump 구성을 테스트해야 합니다. 예를 들어 다음 변경 사항을 수행하는 경우 다음을 위한 최적의 kdump 성능에 대한 kdump 구성을 테스트해야 합니다.
- 패키지 업그레이드.
- 하드웨어 수준 변경(예: 스토리지 또는 네트워킹 변경)
- 펌웨어 업그레이드.
- 타사 모듈을 포함하는 새로운 설치 및 애플리케이션 업그레이드.
- 핫플러그 메커니즘을 사용하여 이 메커니즘을 지원하는 하드웨어에 메모리를 추가하는 경우.
-
/etc/kdump.conf또는/etc/sysconfig/kdump파일을 변경한 후
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
-
모든 중요한 데이터를 저장했습니다.
kdump를 테스트하는 명령으로 인해 커널이 데이터 손실과 충돌합니다. - 시스템 아키텍처에 따라 상당한 머신 유지 관리 시간을 예약했습니다.
프로세스
kdump서비스를 활성화합니다.kdumpctl restart
# kdumpctl restartCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdumpctl을 사용하여kdump서비스의 상태를 확인합니다.kdumpctl status kdump:Kdump is operational
# kdumpctl status kdump:Kdump is operationalCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택적으로
systemctl명령을 사용하는 경우 출력은systemd저널에 출력됩니다.커널 충돌을 시작하여
kdump구성을 테스트합니다.sysrq-trigger키 조합을 사용하면 커널이 충돌하고 필요한 경우 시스템을 재부팅할 수 있습니다.echo c > /proc/sysrq-trigger
# echo c > /proc/sysrq-triggerCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널 재부팅 시
주소-YYYY-MM-DD-HH:MM:SS/vmcore파일이/etc/kdump.conf파일에 지정된 위치에 생성됩니다. 기본값은/var/crash/입니다.
41.7. kexec를 사용하여 다른 커널로 부팅
kexec 시스템 호출을 사용하여 현재 실행 중인 커널에서 다른 커널로 로드 및 부팅할 수 있습니다. kexec 는 커널 내에서 부트 로더의 기능을 수행합니다.
kexec 유틸리티는 다른 커널로 부팅하기 위해 kexec 시스템 호출의 커널 및 initramfs 이미지를 로드합니다.
다음 절차에서는 kexec 유틸리티를 사용하여 다른 커널로 재부팅할 때 시스템 호출을 수동으로 호출하는 방법을 설명합니다.
kexec
프로세스
kexec유틸리티를 실행합니다.kexec -l /boot/vmlinuz-3.10.0-1040.el7.x86_64 --initrd=/boot/initramfs-3.10.0-1040.el7.x86_64.img --reuse-cmdline
# kexec -l /boot/vmlinuz-3.10.0-1040.el7.x86_64 --initrd=/boot/initramfs-3.10.0-1040.el7.x86_64.img --reuse-cmdlineCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은
kexec시스템 호출의 커널 및initramfs이미지를 수동으로 로드합니다.시스템을 재부팅합니다.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 커널을 감지하고 모든 서비스를 종료한 다음
kexec시스템 호출을 호출하여 이전 단계에서 제공한 커널로 재부팅합니다.
kexec -e 명령을 사용하여 시스템을 다른 커널로 재부팅하면 다음 커널을 시작하기 전에 시스템은 표준 종료 시퀀스를 통과하지 않습니다. 이로 인해 데이터 손실 또는 응답하지 않는 시스템이 발생할 수 있습니다.
41.8. 커널 드라이버가 kdump에 대한 로드되지 않음
/etc/sysconfig/kdump 구성 파일에 KDUMP_COMMANDLINE_APPEND= 변수를 추가하여 캡처 커널이 특정 커널 드라이버를 로드하지 않도록 제어할 수 있습니다. 이 방법을 사용하면 kdump 초기 RAM 디스크 이미지 initramfs 가 지정된 커널 모듈을 로드하지 못하도록 할 수 있습니다. 이렇게 하면 OOM(메모리 부족) 중단 오류 또는 기타 크래시 커널 실패를 방지할 수 있습니다.
다음 구성 옵션 중 하나를 사용하여 KDUMP_COMMANDLINE_APPEND= 변수를 추가할 수 있습니다.
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
사전 요구 사항
- 시스템에 대한 root 권한이 있습니다.
프로세스
현재 실행 중인 커널에 로드된 모듈 목록을 표시합니다. 로드에서 차단할 커널 모듈을 선택합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/sysconfig/kdump파일에서KDUMP_COMMANDLINE_APPEND=변수를 업데이트합니다. 예를 들면 다음과 같습니다.KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"
KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또한
modprobe.blacklist= <modules> 구성 옵션을 사용하여 다음 예제를 고려하십시오.KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"
KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"Copy to Clipboard Copied! Toggle word wrap Toggle overflow kdump서비스를 다시 시작하십시오.systemctl restart kdump
# systemctl restart kdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow
41.9. 암호화된 디스크가 있는 시스템에서 kdump 실행
LUKS 암호화된 파티션을 실행할 때 시스템에 특정 양의 사용 가능한 메모리가 필요합니다. 시스템에 필요한 양의 메모리보다 적은 경우 cryptsetup 유틸리티에서 파티션을 마운트하지 못합니다. 결과적으로 두 번째 커널(capture 커널)에서 vmcore 파일을 암호화된 대상 위치로 캡처할 수 없습니다.
kdumpctl estimate 명령은 kdump . kdump ctl 추정에 필요한 메모리 양을 추정하는 데 도움이 됩니다.kdumpctl 추정은 kdump 에 필요한 메모리 크기에 가장 적합한 크래시커널 값을 출력합니다.
권장되는 crashkernel 값은 현재 커널 크기, 커널 모듈, initramfs 및 LUKS 암호화된 대상 메모리 요구 사항을 기반으로 계산됩니다.
사용자 정의 crashkernel= 옵션을 사용하는 경우 kdumpctl 추정치 는 필요한 크기 값을 출력합니다. 값은 LUKS 암호화된 대상에 필요한 메모리 크기입니다.
프로세스
추정치
crashkernel=값을 출력합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
crashkernel=값을 늘려 필요한 메모리 양을 구성합니다. - 시스템을 재부팅합니다.
kdump 서비스가 여전히 덤프 파일을 암호화된 대상에 저장하지 못하는 경우 필요에 따라 crashkernel= 값을 늘립니다.
41.10. 펌웨어 지원 덤프 메커니즘
펌웨어 지원 덤프(fadump)는 IBM POWER 시스템의 kdump 메커니즘에 대한 대안으로 제공되는 덤프 캡처 메커니즘입니다. kexec 및 kdump 메커니즘은 AMD64 및 Intel 64 시스템에서 코어 덤프를 캡처하는 데 유용합니다. 그러나 미니 시스템 및 가상 머신과 같은 일부 하드웨어는 온보드 펌웨어를 사용하여 메모리 영역을 분리하고 충돌 분석에 중요한 데이터의 우발적인 덮어쓰기를 방지합니다. fadump 유틸리티는 IBM POWER 시스템에서 RHEL과의 통합 및 fadump 메커니즘에 최적화되어 있습니다.
41.10.1. IBM PowerPC 하드웨어에서 펌웨어 지원 덤프
fadump 유틸리티는 PCI 및 I/O 장치가 있는 완전히 재설정 시스템에서 vmcore 파일을 캡처합니다. 이 메커니즘은 펌웨어를 사용하여 충돌 중에 메모리 영역을 유지한 다음 kdump 사용자 공간 스크립트를 재사용하여 vmcore 파일을 저장합니다. 메모리 영역은 부팅 메모리, 시스템 레지스터, 하드웨어 페이지 테이블 항목(PTE)을 제외한 모든 시스템 메모리 콘텐츠로 구성됩니다.
fadump 메커니즘은 파티션을 재부팅하고 새 커널을 사용하여 이전 커널 충돌의 데이터를 덤프하여 기존 덤프 유형에 대한 안정성을 향상시킵니다. fadump 에는 IBM POWER6 프로세서 기반 또는 이후 버전 하드웨어 플랫폼이 필요합니다.
하드웨어 재설정을 위한 PowerPC 특정 방법을 포함한 fadump 메커니즘에 대한 자세한 내용은 /usr/share/doc/kexec-tools/fadump-howto.txt 파일을 참조하십시오.
부트 메모리라는 보존되지 않은 메모리 영역은 크래시 이벤트 후 커널을 성공적으로 부팅하는 데 필요한 RAM의 양입니다. 기본적으로 부팅 메모리 크기는 전체 시스템 RAM의 256MB 또는 5%이며 더 큰 경우입니다.
kexec-initiated 이벤트와 달리 fadump 메커니즘은 production 커널을 사용하여 크래시 덤프를 복구합니다. 충돌 후 부팅할 때 PowerPC 하드웨어는 장치 노드 /proc/device-tree/rtas/ibm.kernel-dump 를 proc 파일 시스템(procfs)에서 사용할 수 있도록 합니다. fadump 인식 kdump 스크립트를 사용하여 저장된 vmcore 를 확인한 다음 시스템이 정상적으로 재부팅되도록 완료합니다.
41.10.2. 펌웨어 지원 덤프 메커니즘 활성화
펌웨어 지원 덤프(fadump) 메커니즘을 활성화하여 IBM POWER 시스템의 크래시 덤프 기능을 개선할 수 있습니다.
Secure Boot 환경에서 GRUB 부트 로더는 RMA(Real Mode Area)라고 하는 부팅 메모리 영역을 할당합니다. RMA의 크기는 부팅 구성 요소로 나뉩니다. 구성 요소가 크기 할당을 초과하면OOM(메모리 부족) 오류와 함께 GRUB 이 실패합니다.
RHEL 8.7 및 8.6 버전의 Secure Boot 환경에서 펌웨어 지원 덤프(fadump) 메커니즘을 활성화하지 마십시오. GRUB2 부트 로더가 실패하고 다음 오류가 발생합니다.
error: ../../grub-core/kern/mm.c:376:out of memory. Press any key to continue…
error: ../../grub-core/kern/mm.c:376:out of memory.
Press any key to continue…
fadump 구성으로 인해 기본 initramfs 크기를 늘리는 경우에만 시스템을 복구할 수 있습니다.
시스템을 복구하는 해결 방법에 대한 자세한 내용은 GRUB OOM(Out of Memory) 문서의 시스템 부팅을 참조하십시오.
프로세스
-
kdump를 설치하고 구성합니다. fadump=on커널 옵션을 활성화합니다.grubby --update-kernel=ALL --args="fadump=on"
# grubby --update-kernel=ALL --args="fadump=on"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 기본값을 사용하는 대신 예약된 부팅 메모리를 지정하려면
crashkernel=xxM옵션을 활성화합니다. 여기서xx는 메가바이트로 필요한 메모리 양입니다.grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"
# grubby --update-kernel=ALL --args="crashkernel=xxM fadump=on"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 중요부팅 구성 옵션을 지정할 때 실행하기 전에 모든 부팅 구성 옵션을 테스트합니다.
kdump커널이 부팅되지 않으면crashkernel=인수에 지정된 값을 점진적으로 늘려 적절한 값을 설정합니다.
41.10.3. IBM Z 하드웨어에서 펌웨어 지원 덤프 메커니즘
IBM Z 시스템은 다음과 같은 펌웨어 지원 덤프 메커니즘을 지원합니다.
-
독립 실행형 덤프(sadump) -
VMDUMP
kdump 인프라는 IBM Z 시스템에서 지원 및 활용됩니다. 그러나 IBM Z의 펌웨어 지원 덤프(fadump) 방법 중 하나를 사용하면 다음과 같은 이점이 있습니다.
-
시스템 콘솔은
sadump메커니즘을 시작하고 제어하며IPL부팅 가능한 장치에 저장합니다. -
VMDUMP메커니즘은sadump와 유사합니다. 이 툴은 시스템 콘솔에서도 시작되지만 하드웨어에서 결과 덤프를 검색하여 분석을 위해 시스템에 복사합니다. -
이러한 방법(다른 하드웨어 기반 덤프 메커니즘과 동일)은
kdump서비스가 시작되기 전에 초기 부팅 단계에서 시스템의 상태를 캡처할 수 있습니다. -
VMDUMP에는 덤프 파일을 Red Hat Enterprise Linux 시스템으로 수신하는 메커니즘이 포함되어 있지만VMDUMP의 구성 및 제어는 IBM Z 하드웨어 콘솔에서 관리됩니다.
41.10.4. Fujitsu PRIMEQUEST 시스템에서 sadump 사용
kdump 를 성공적으로 완료할 수 없는 경우 Fujitsu sadump 메커니즘은 폴백 덤프 캡처를 제공합니다. 시스템 관리 보드(MMB) 인터페이스에서 sadump 를 수동으로 호출할 수 있습니다. MMB를 사용하여 Intel 64 또는 AMD64 서버의 경우와 같이 kdump 를 구성한 다음 sadump 를 활성화합니다.
프로세스
/etc/sysctl.conf파일에서 다음 행을 추가하거나 편집하여kdump가sadump에 대해 예상대로 시작되도록 합니다.kernel.panic=0 kernel.unknown_nmi_panic=1
kernel.panic=0 kernel.unknown_nmi_panic=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의특히
kdump후 시스템이 재부팅되지 않았는지 확인하십시오.kdump가vmcore파일을 저장하지 못한 후 시스템이 재부팅되면sadump를 호출할 수 없습니다./etc/kdump.conf에서failure_action매개변수를halt또는shell로 적절하게 설정합니다.failure_action shell
failure_action shellCopy to Clipboard Copied! Toggle word wrap Toggle overflow
41.11. 코어 덤프 분석
시스템 충돌의 원인을 확인하려면 GNU Debugger(GDB)와 유사한 대화형 프롬프트를 제공하는 크래시 유틸리티를 사용할 수 있습니다. 크래시 를 사용하면 kdump,netdump,diskdump 또는 xendump 및 실행 중인 Linux 시스템에서 생성된 코어 덤프를 분석할 수 있습니다. 또는 Kernel Oops Analyzer 또는 Kdump Helper 툴을 사용할 수 있습니다.
41.11.1. 크래시 유틸리티 설치
제공된 정보를 사용하여 필요한 패키지 및 크래시 유틸리티를 설치하는 절차를 이해하십시오. 크래시 유틸리티는 RHEL 8 시스템에 기본적으로 설치되지 않을 수 있습니다. 크래시 기능은 실행 중이거나 커널 크래시가 발생하고 코어 덤프 파일이 생성되는 동안 시스템의 상태를 대화형으로 분석하는 툴입니다. 코어 덤프 파일은 vmcore 파일이라고도 합니다.
프로세스
관련 리포지토리를 활성화합니다.
subscription-manager repos --enable baseos repository
# subscription-manager repos --enable baseos repositoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow subscription-manager repos --enable appstream repository
# subscription-manager repos --enable appstream repositoryCopy to Clipboard Copied! Toggle word wrap Toggle overflow subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpms
# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow crash패키지를 설치합니다.yum install crash
# yum install crashCopy to Clipboard Copied! Toggle word wrap Toggle overflow kernel-debuginfo패키지를 설치합니다.yum install kernel-debuginfo
# yum install kernel-debuginfoCopy to Clipboard Copied! Toggle word wrap Toggle overflow kernel-debuginfo패키지는 실행 중인 커널에 대응하고 덤프 분석에 필요한 데이터를 제공합니다.
41.11.2. 크래시 유틸리티 실행 및 종료
크래시 유틸리티는 kdump 를 분석하기 위한 강력한 도구입니다. 크래시 덤프 파일에서 크래시를 실행하면 충돌 시 시스템의 상태에 대한 통찰력을 얻고, 문제의 근본 원인을 식별하고, 커널 관련 문제를 해결할 수 있습니다.
사전 요구 사항
-
현재 실행 중인 커널을 확인합니다(예:
4.18.0-5.el8.x86_64).
프로세스
크래시유틸리티를 시작하려면 다음 두 가지 필수 매개변수를 전달합니다.-
debug-info(압축된 vmlinuz 이미지)입니다(예: 특정
kernel-debuginfo패키지를 통해 제공되는/usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux). 실제 vmcore 파일(예:
/var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore).생성된
크래시명령은 다음과 같습니다.crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore
# crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump에서 캡처한 것과 동일한 & lt;kernel> 버전을 사용합니다.예 41.1. 크래시 유틸리티 실행
다음 예제에서는 4.18.0-5.el8.x86_64 커널을 사용하여 2018년 10월 6일 14:05 오후에 생성된 코어 덤프를 분석하는 방법을 보여줍니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
-
debug-info(압축된 vmlinuz 이미지)입니다(예: 특정
대화형 프롬프트를 종료하고
크래시를 중지하려면exit또는q를 입력합니다.crash> exit ~]#
crash> exit ~]#Copy to Clipboard Copied! Toggle word wrap Toggle overflow
크래시 명령은 라이브 시스템을 디버깅하기 위한 강력한 도구로도 사용됩니다. 그러나 시스템 수준 문제를 방지하려면 주의해야 합니다.
41.11.3. 크래시 유틸리티에 다양한 표시기 표시
크래시 유틸리티를 사용하여 커널 메시지 버퍼, 백추적, 프로세스 상태, 가상 메모리 정보 및 열려 있는 파일과 같은 다양한 지표를 표시합니다.
메시지 버퍼 표시
커널 메시지 버퍼를 표시하려면 대화형 프롬프트에서
log명령을 입력합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령 사용에 대한 자세한 내용은
도움말 로그를 입력합니다.참고커널 메시지 버퍼에는 시스템 충돌에 대한 가장 중요한 정보가 포함됩니다. 항상
vmcore-dmesg.txt파일에서 먼저 덤프됩니다. 예를 들어 대상 위치에 공간이 부족하여 전체vmcore파일을 가져오지 못하면 커널 메시지 버퍼에서 필요한 정보를 얻을 수 있습니다. 기본적으로vmcore-dmesg.txt는/var/crash/디렉터리에 배치됩니다.
역추적 표시
커널 스택 추적을 표시하려면
bt명령을 사용합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow bt< pidhelp bt를 입력합니다.
프로세스 상태 표시
시스템의 프로세스 상태를 표시하려면
ps명령을 사용합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow ps & lt;pid>를 사용하여 단일 특정 프로세스의 상태를 표시합니다.ps사용에 대한 자세한 내용은 help ps 를 사용하십시오.
가상 메모리 정보 표시
기본 가상 메모리 정보를 표시하려면 대화형 프롬프트에서
vm명령을 입력합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow vm& lt;pidhelp vm를 사용합니다.
열려 있는 파일 표시
열려 있는 파일에 대한 정보를 표시하려면
files명령을 사용합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 & lt;pid>를 사용하여 선택한 프로세스로 열린파일을 표시하거나 파일 사용에 대한 자세한 내용은 도움말파일을사용합니다.
41.11.4. 커널 Oops Analyzer 사용
Kernel Oops Analyzer 툴은 oops 메시지와 기술 자료의 알려진 문제를 비교하여 크래시 덤프를 분석합니다.
사전 요구 사항
-
커널 Oops Analyzer를 제공하기 위해
oops메시지가 보호됩니다.
프로세스
- Kernel Oops Analyzer 툴에 액세스합니다.
커널 충돌 문제를 진단하려면
vmcore에서 생성된 커널 oops 로그를 업로드합니다.-
또는 텍스트 메시지 또는
vmcore-dmesg.txt를 입력으로 제공하여 커널 충돌 문제를 진단할 수 있습니다.
-
또는 텍스트 메시지 또는
-
DETECT를 클릭하여makedumpfile의 정보를 알려진 솔루션과 비교하여oops메시지를 비교합니다.
41.11.5. Kdump Helper 툴
Kdump Helper 툴은 제공된 정보를 사용하여 kdump 를 설정하는 데 도움이 됩니다. kdump Helper는 기본 설정에 따라 설정 스크립트를 생성합니다. 서버에서 스크립트를 시작하고 실행하면 kdump 서비스가 설정됩니다.
41.12. 초기 kdump를 사용하여 부팅 시간 충돌 캡처
early kdump는 시스템 서비스가 시작되기 전에 부팅 프로세스의 초기 단계에서 시스템 또는 커널 충돌이 발생하는 경우 vmcore 파일을 캡처하는 kdump 메커니즘의 기능입니다. early kdump는 크래시 커널과 initramfs 를 메모리에 로드합니다.
커널 충돌은 kdump 서비스가 시작되기 전에 초기 부팅 단계에서 발생할 수 있으며 충돌하는 커널 메모리의 내용을 캡처하고 저장할 수 있습니다. 따라서 문제 해결에 중요한 정보가 손실되는 충돌과 관련된 중요한 정보가 손실됩니다. 이 문제를 해결하려면 kdump 서비스의 일부인 초기 kdump 기능을 사용할 수 있습니다.
41.12.1. 초기 kdump 활성화
early kdump 기능은 크래시 커널과 초기 RAM 디스크 이미지(initramfs)를 설정하여 조기 충돌을 위해 vmcore 정보를 캡처할 수 있을 만큼 조기에 로드되도록 설정합니다. 이를 통해 초기 부팅 커널 충돌에 대한 정보가 손실될 위험이 제거됩니다.
사전 요구 사항
- 활성 RHEL 서브스크립션입니다.
-
시스템 CPU 아키텍처용
kexec-tools패키지가 포함된 리포지토리입니다. -
kdump구성 및 대상 요구 사항을 충족했습니다. 자세한 내용은 지원되는 kdump 구성 및 대상 을 참조하십시오.
프로세스
kdump서비스가 활성화되어 활성화되어 있는지 확인합니다.systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled active
# systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled activeCopy to Clipboard Copied! Toggle word wrap Toggle overflow kdump가 활성화되어 실행되지 않은 경우 필요한 구성을 모두 설정하고kdump서비스가 활성화되어 있는지 확인합니다.초기 kdump기능을 사용하여 부팅 커널의initramfs이미지를 다시 빌드합니다.dracut -f --add earlykdump
# dracut -f --add earlykdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow rd.earlykdump커널 명령줄 매개변수를 추가합니다.grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템을 재부팅하여 변경 사항을 반영합니다.
reboot
# rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
rd.earlykdump가 성공적으로 추가되고early kdump기능이 활성화되어 있는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
42장. 커널 실시간 패치를 사용하여 패치 적용
Red Hat Enterprise Linux 커널 실시간 패치 솔루션을 사용하여 프로세스를 재부팅하거나 다시 시작하지 않고도 실행 중인 커널을 패치할 수 있습니다.
이 솔루션을 사용하면 시스템 관리자가 다음을 수행합니다.
- 중요한 보안 패치를 커널에 즉시 적용할 수 있습니다.
- 장기 실행 작업이 완료되거나 사용자가 로그아웃하거나 예약된 다운 타임이 발생할 때까지 기다릴 필요가 없습니다.
- 시스템의 가동 시간을 더 많이 제어하고 보안 또는 안정성을 희생하지 않습니다.
커널 실시간 패치를 사용하면 보안 패치에 필요한 재부팅 횟수를 줄일 수 있습니다. 그러나 중요하거나 중요한 모든 CVE를 처리할 수 없습니다. 실시간 패치 범위에 대한 자세한 내용은 Red Hat Enterprise Linux에서 지원되는 Red Hat Knowledgebase 솔루션 Is live kernel patch (kpatch) 를 참조하십시오.
커널 실시간 패치와 기타 커널 하위 구성 요소 간에 일부 비호환성이 있습니다. 커널 실시간 패치를 사용하기 전에 kpatch의 제한 사항을 주의 깊게 읽으십시오.
커널 라이브 패치 업데이트의 지원 주기에 대한 자세한 내용은 다음을 참조하십시오.
42.1. kpatch의 제한 사항
-
kpatch기능을 사용하면 즉각적인 시스템 재부팅이 필요하지 않은 간단한 보안 및 버그 수정 업데이트를 적용할 수 있습니다. -
패치를 로드하는 동안 또는 패치를 로드한 후
SystemTap또는kprobe툴을 사용해서는 안 됩니다. 프로브가 제거될 때까지 패치가 적용되지 않을 수 있습니다.
42.2. 타사 실시간 패치 지원
kpatch 유틸리티는 Red Hat 리포지토리에서 제공하는 RPM 모듈을 사용하여 Red Hat에서 지원하는 유일한 커널 실시간 패치 유틸리티입니다. Red Hat은 타사에서 제공하는 실시간 패치를 지원하지 않습니다.
타사 소프트웨어 지원 정책에 대한 자세한 내용은 타사 구성 요소를 사용할 때 Red Hat이 어떻게 지원됩니까?
42.3. 커널 라이브 패치에 액세스
커널 모듈(kmod)은 커널 실시간 패치 기능을 구현하고 RPM 패키지로 제공됩니다.
모든 고객은 일반 채널을 통해 제공되는 커널 라이브 패치에 액세스할 수 있습니다. 그러나 연장된 지원 오퍼링에 가입하지 않은 고객은 다음 마이너 릴리스가 출시되면 현재 마이너 릴리스의 새로운 패치에 대한 액세스 권한이 손실됩니다. 예를 들어 표준 서브스크립션을 사용하는 고객은 RHEL 8.3 커널이 릴리스될 때까지 RHEL 8.2 커널을 실시간으로 패치할 수 있습니다.
커널 실시간 패치의 구성 요소는 다음과 같습니다.
- 커널 패치 모듈
- 커널 라이브 패치를 위한 제공 메커니즘.
- 커널 패치를 위해 특별히 빌드된 커널 모듈입니다.
- patch 모듈에는 커널에 필요한 수정 코드가 포함되어 있습니다.
-
패치 모듈은
livepatch커널 하위 시스템에 등록하고 대체 함수에 대한 포인터와 함께 교체할 원래 함수를 지정합니다. 커널 패치 모듈은 RPM으로 제공됩니다. -
이름 지정 규칙은
kpatch_<kernel version>_<kpatch version>_<kpatch release>입니다. 이름의 "커널 버전" 부분에는 밑줄 로 대체된 점이 있습니다.
kpatch유틸리티- 패치 모듈을 관리하는 명령줄 유틸리티입니다.
kpatch서비스-
multiuser.target에 필요한systemd서비스. 이 대상은 부팅 시 커널 패치 모듈을 로드합니다. kpatch-dnf패키지- RPM 패키지 형태로 제공되는 DNF 플러그인. 이 플러그인은 커널 라이브 패치에 대한 자동 서브스크립션을 관리합니다.
42.4. 실시간 패치 커널 프로세스
kpatch 커널 패치 솔루션은 라이브 패치 커널 하위 시스템을 사용하여 오래된 기능을 업데이트된 함수로 리디렉션합니다. 시스템에 실시간 커널 패치를 적용하면 다음 프로세스가 트리거됩니다.
-
커널 패치 모듈은
/var/lib/kpatch/디렉터리에 복사되고 다음 부팅 시systemd를 통해 커널에 다시 애플리케이션하기 위해 등록됩니다. -
kpatch모듈은 실행 중인 커널에 로드되고 새 기능은 새 코드 메모리의 위치에 대한 포인터와 함께ftrace메커니즘에 등록됩니다.
커널이 패치된 함수에 액세스하면 ftrace 메커니즘이 이를 리디렉션하여 원래 기능을 우회하고 커널을 패치된 함수 버전으로 안내합니다.
그림 42.1. 커널 실시간 패치 작동 방식
42.5. 현재 설치된 커널을 실시간 패치 스트림에 구독
패치되는 커널 버전과 관련된 커널 패치 모듈은 RPM 패키지로 제공됩니다. 각 RPM 패키지는 시간이 지남에 따라 누적 업데이트됩니다.
다음 절차에서는 지정된 커널에 대해 향후 누적 실시간 패치 업데이트를 구독하는 방법을 설명합니다. 실시간 패치는 누적되므로 지정된 커널에 배포되는 개별 패치를 선택할 수 없습니다.
Red Hat은 Red Hat 지원 시스템에 적용되는 타사 라이브 패치를 지원하지 않습니다.
사전 요구 사항
- root 권한이 있습니다.
절차
선택 사항: 커널 버전을 확인합니다.
uname -r 4.18.0-94.el8.x86_64
# uname -r 4.18.0-94.el8.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 커널 버전에 해당하는 라이브 패치 패키지를 검색합니다.
yum search $(uname -r)
# yum search $(uname -r)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 실시간 패치 패키지를 설치합니다.
yum install "kpatch-patch = $(uname -r)"
# yum install "kpatch-patch = $(uname -r)"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 명령은 해당 특정 커널에 대해서만 최신 누적 라이브 패치를 설치하고 적용합니다.
라이브 패치 패키지의 버전이 1-1 이상이면 패키지에 패치 모듈이 포함됩니다. 이 경우 라이브 패치 패키지를 설치하는 동안 커널이 자동으로 패치됩니다.
커널 패치 모듈은 향후 재부팅 중에
systemd시스템 및 서비스 관리자가 로드할/var/lib/kpatch/디렉터리에도 설치됩니다.참고지정된 커널에 사용할 수 있는 실시간 패치가 없으면 빈 실시간 패치 패키지가 설치됩니다. 라이브 패치 패키지에는 kpatch_version-kpatch_release 가 0-0입니다(예:
kpatch-patch-4_18_0-94-0.el8.x86_64.rpm). 빈 RPM을 설치하면 해당 커널의 향후 실시간 패치에 시스템을 서브스크립션합니다.
검증
설치된 모든 커널이 패치되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력에서는 커널 패치 모듈이
kpatch-patch-4_18_0-94-1.el8.x86_64.rpm패키지의 최신 수정 사항과 함께 패치된 커널에 로드되었음을 보여줍니다.참고kpatch list명령을 입력하면 빈 라이브 패치 패키지가 반환되지 않습니다. 대신rpm -qa | grep kpatch명령을 사용합니다.rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarch
# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarchCopy to Clipboard Copied! Toggle word wrap Toggle overflow
42.6. 향후 커널을 실시간 패치 스트림에 자동으로 구독
kpatch-dnf YUM 플러그인을 사용하여 커널 라이브 패치라고도 하는 커널 패치 모듈에서 제공하는 수정 사항에 시스템을 서브스크립션할 수 있습니다. 이 플러그인은 현재 시스템에서 현재 사용하고 있는 모든 커널에 대해 자동 서브스크립션 을 활성화하고 향후 커널에 설치할 수도 있습니다.
사전 요구 사항
- root 권한이 있습니다.
프로세스
선택 사항: 설치된 모든 커널 및 현재 실행 중인 커널을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow kpatch-dnf플러그인을 설치합니다.yum install kpatch-dnf
# yum install kpatch-dnfCopy to Clipboard Copied! Toggle word wrap Toggle overflow 커널 라이브 패치에 대한 자동 서브스크립션을 활성화합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 현재 설치된 모든 커널을 서브스크립션하여 커널 라이브 패치를 수신합니다. 또한 이 명령은 설치된 모든 커널에 대해 최신 누적 라이브 패치(있는 경우)를 설치하고 적용합니다.
커널을 업데이트하면 새 커널 설치 프로세스 중에 라이브 패치가 자동으로 설치됩니다.
커널 패치 모듈은 향후 재부팅 중에
systemd시스템 및 서비스 관리자가 로드할/var/lib/kpatch/디렉터리에도 설치됩니다.참고지정된 커널에 사용할 수 있는 실시간 패치가 없으면 빈 실시간 패치 패키지가 설치됩니다. 라이브 패치 패키지에는 kpatch_version-kpatch_release 가 0-0입니다(예:
kpatch-patch-4_18_0-240-0.el8.x86_64.rpm). 빈 RPM을 설치하면 해당 커널의 향후 실시간 패치에 시스템을 서브스크립션합니다.
검증
설치된 모든 커널이 패치되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 출력은 실행 중인 커널과 다른 설치된 커널 모두 kpatch-patch-4_18_0-240_
1-0-1.rpm 및패키지의 수정 사항과 함께 패치되었습니다.kpatch-patch-4_18_0-240_15_1-0-1.rpm참고kpatch list명령을 입력하면 빈 라이브 패치 패키지가 반환되지 않습니다. 대신rpm -qa | grep kpatch명령을 사용합니다.rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarch
# rpm -qa | grep kpatch kpatch-patch-4_18_0-477_21_1-0-0.el8_8.x86_64 kpatch-dnf-0.9.7_0.4-2.el8.noarch kpatch-0.9.7-2.el8.noarchCopy to Clipboard Copied! Toggle word wrap Toggle overflow
42.7. 실시간 패치 스트림에 대한 자동 서브스크립션 비활성화
커널 패치 모듈에서 제공하는 수정 사항에 맞게 시스템을 서브스크립션하면 서브스크립션이 자동으로 수행됩니다. 이 기능을 비활성화하여 kpatch-patch 패키지의 자동 설치를 비활성화할 수 있습니다.
사전 요구 사항
- root 권한이 있습니다.
프로세스
선택 사항: 설치된 모든 커널 및 현재 실행 중인 커널을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 커널 라이브 패치에 대한 자동 서브스크립션을 비활성화합니다.
yum kpatch manual Updating Subscription Management repositories.
# yum kpatch manual Updating Subscription Management repositories.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
성공적인 결과를 확인할 수 있습니다.
yum kpatch status ... Updating Subscription Management repositories. Last metadata expiration check: 0:30:41 ago on Tue Jun 14 15:59:26 2022. Kpatch update setting: manual
# yum kpatch status ... Updating Subscription Management repositories. Last metadata expiration check: 0:30:41 ago on Tue Jun 14 15:59:26 2022. Kpatch update setting: manualCopy to Clipboard Copied! Toggle word wrap Toggle overflow
42.8. 커널 패치 모듈 업데이트
커널 패치 모듈은 RPM 패키지를 통해 전달 및 적용됩니다. 누적 커널 패치 모듈을 업데이트하는 프로세스는 다른 RPM 패키지를 업데이트하는 것과 유사합니다.
사전 요구 사항
프로세스
현재 커널의 새 누적 버전으로 업데이트합니다.
yum update "kpatch-patch = $(uname -r)"
# yum update "kpatch-patch = $(uname -r)"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 명령은 현재 실행 중인 커널에 사용 가능한 모든 업데이트를 자동으로 설치하고 적용합니다. 향후 릴리스되는 누적 라이브 패치를 포함합니다.
또는 설치된 모든 커널 패치 모듈을 업데이트합니다.
yum update "kpatch-patch"
# yum update "kpatch-patch"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
시스템이 동일한 커널로 재부팅되면 kpatch.service systemd 서비스에 의해 커널이 자동으로 다시 패치됩니다.
42.9. 실시간 패치 패키지 제거
실시간 패치 패키지를 제거하여 Red Hat Enterprise Linux 커널 실시간 패치 솔루션을 비활성화합니다.
사전 요구 사항
- 루트 권한
- 실시간 패치 패키지가 설치되어 있습니다.
프로세스
실시간 패치 패키지를 선택합니다.
yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …
# yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 출력에는 사용자가 설치한 실시간 패치 패키지가 나열됩니다.
실시간 패치 패키지를 제거합니다.
yum remove kpatch-patch-4_18_0-94.x86_64
# yum remove kpatch-patch-4_18_0-94.x86_64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 라이브 패치 패키지가 제거되면 커널은 다음 재부팅될 때까지 패치되지만 커널 패치 모듈이 디스크에서 제거됩니다. 나중에 재부팅 시 해당 커널이 더 이상 패치되지 않습니다.
- 시스템을 재부팅합니다.
실시간 패치 패키지가 제거되었는지 확인합니다.
yum list installed | grep kpatch-patch
# yum list installed | grep kpatch-patchCopy to Clipboard Copied! Toggle word wrap Toggle overflow 패키지가 성공적으로 제거된 경우 명령은 출력을 표시하지 않습니다.
검증
커널 실시간 패치 솔루션이 비활성화되어 있는지 확인합니다.
kpatch list Loaded patch modules:
# kpatch list Loaded patch modules:Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 출력은 커널이 패치되지 않았으며 현재 로드된 패치 모듈이 없기 때문에 실시간 패치 솔루션이 활성화되어 있지 않음을 보여줍니다.
현재 Red Hat은 시스템을 재부팅하지 않고 실시간 패치를 되돌리는 것을 지원하지 않습니다. 문제가 있는 경우 지원 팀에 문의하십시오.
42.10. 커널 패치 모듈 설치 제거
Red Hat Enterprise Linux 커널 실시간 패치 솔루션이 후속 부팅 시 커널 패치 모듈을 적용하지 못하도록 합니다.
사전 요구 사항
- 루트 권한
- 실시간 패치 패키지가 설치되어 있습니다.
- 커널 패치 모듈이 설치되어 로드되었습니다.
프로세스
커널 패치 모듈을 선택합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택한 커널 패치 모듈을 설치 제거합니다.
kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)
# kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 설치 제거된 커널 패치 모듈이 계속 로드됩니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택한 모듈이 제거되면 커널은 다음 재부팅 때까지 패치가 유지되지만 커널 패치 모듈이 디스크에서 제거됩니다.
- 시스템을 재부팅합니다.
검증
커널 패치 모듈이 제거되었는지 확인합니다.
kpatch list Loaded patch modules: …
# kpatch list Loaded patch modules: …Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제 출력에는 로드되거나 설치된 커널 패치 모듈이 표시되지 않으므로 커널이 패치되지 않고 커널 실시간 패치 솔루션이 활성 상태가 아닙니다.
42.11. kpatch.service 비활성화
Red Hat Enterprise Linux 커널 실시간 패치 솔루션이 이후 부팅 시 전역적으로 모든 커널 패치 모듈을 적용하지 못하도록 합니다.
사전 요구 사항
- 루트 권한
- 실시간 패치 패키지가 설치되어 있습니다.
- 커널 패치 모듈이 설치되어 로드되었습니다.
프로세스
kpatch.service가 활성화되었는지 확인합니다.systemctl is-enabled kpatch.service enabled
# systemctl is-enabled kpatch.service enabledCopy to Clipboard Copied! Toggle word wrap Toggle overflow kpatch.service를 비활성화합니다.systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.
# systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 적용된 커널 패치 모듈이 계속 로드됩니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
- 시스템을 재부팅합니다.
선택 사항:
kpatch.service의 상태를 확인합니다.systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)
# systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 출력에서는
kpatch.service가 비활성화되어 있음을 테스트합니다. 따라서 커널 실시간 패치 솔루션이 활성화되지 않습니다.커널 패치 모듈이 언로드되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 위의 예제 출력은 커널 패치 모듈이 여전히 설치되어 있지만 커널이 패치되지 않았음을 보여줍니다.
현재 Red Hat은 시스템을 재부팅하지 않고 실시간 패치를 되돌리는 것을 지원하지 않습니다. 문제가 있는 경우 지원 팀에 문의하십시오.
43장. 제어 그룹을 사용하여 애플리케이션의 시스템 리소스 제한 설정
제어 그룹(cgroup) 커널 기능을 사용하면 애플리케이션의 리소스 사용량을 제어하여 보다 효율적으로 사용할 수 있습니다.
다음 작업에 cgroup 을 사용할 수 있습니다.
- 시스템 리소스 할당에 대한 제한 설정.
- 특정 프로세스에 대한 하드웨어 리소스 할당 우선 순위를 지정합니다.
- 특정 프로세스에서 하드웨어 리소스를 가져오지 못하도록 격리합니다.
43.1. 제어 그룹 소개
제어 그룹 Linux 커널 기능을 사용하여 프로세스를 계층적으로 정렬된 그룹인 cgroup 으로 구성할 수 있습니다. /sys/fs/cgroup/ 디렉터리에 기본적으로 마운트된 cgroups 가상 파일 시스템에 구조를 제공하여 계층 구조(제어 그룹 트리)를 정의합니다.
systemd 서비스 관리자는 cgroup 을 사용하여 관리하는 모든 장치 및 서비스를 구성합니다. 수동으로 /sys/fs/cgroup/ 디렉터리에 하위 디렉터리를 생성하고 제거하여 cgroup 의 계층 구조를 관리할 수 있습니다.
그런 다음 커널의 리소스 컨트롤러는 해당 프로세스의 시스템 리소스를 제한, 우선 지정 또는 할당하여 cgroup 의 프로세스 동작을 수정합니다. 이러한 리소스에는 다음이 포함됩니다.
- CPU 시간
- 메모리
- 네트워크 대역폭
- 이러한 리소스의 조합
cgroup 의 주요 사용 사례는 시스템 프로세스를 집계하고 애플리케이션 및 사용자 간에 하드웨어 리소스를 분할하는 것입니다. 이를 통해 환경의 효율성, 안정성 및 보안을 강화할 수 있습니다.
- 제어 그룹 버전 1
제어 그룹 버전 1 (
cgroups-v1)은 리소스별 컨트롤러 계층 구조를 제공합니다. CPU, 메모리 또는 I/O와 같은 각 리소스에는 자체 제어 그룹 계층 구조가 있습니다. 하나의 컨트롤러에서 각각의 리소스를 관리할 때 다른 컨트롤러와 조정할 수 있는 방식으로 서로 다른 제어 그룹 계층 구조를 결합할 수 있습니다. 그러나 두 컨트롤러가 서로 다른 프로세스 계층에 속하는 경우 조정이 제한됩니다.cgroups-v1컨트롤러는 많은 기간 동안 개발되어 제어 파일의 동작과 이름이 일치하지 않습니다.- 제어 그룹 버전 2
제어 그룹 버전 2 (
cgroups-v2)는 모든 리소스 컨트롤러가 마운트된 단일 제어 그룹 계층 구조를 제공합니다.제어 파일 동작 및 이름 지정은 서로 다른 컨트롤러 간에 일관되게 유지됩니다.
참고cgroups-v2는 RHEL 8.2 이상 버전에서 완전하게 지원됩니다. 자세한 내용은 RHEL 8에서 Control Group v2가 완전히 지원됩니다.
43.2. 커널 리소스 컨트롤러 소개
커널 리소스 컨트롤러를 사용하면 제어 그룹의 기능을 사용할 수 있습니다. RHEL 8에서는 제어 그룹 버전 1 (cgroups-v1) 및 제어 그룹 버전 2()에 대한 다양한 컨트롤러를 지원합니다.
cgroups-v2
제어 그룹 하위 시스템이라고도 하는 리소스 컨트롤러는 CPU 시간, 메모리, 네트워크 대역폭 또는 디스크 I/O와 같은 단일 리소스를 나타내는 커널 하위 시스템입니다. Linux 커널은 systemd 서비스 관리자가 자동으로 마운트하는 다양한 리소스 컨트롤러를 제공합니다. 현재 마운트된 리소스 컨트롤러 목록은 /proc/cgroups 파일에서 찾을 수 있습니다.
cgroups-v1 에서 사용 가능한 컨트롤러:
blkio- 블록 장치에 대한 입력/출력 액세스 제한을 설정합니다.
cpu-
제어 그룹의 작업에 대한 CFS(Completely Fair Scheduler)의 매개변수를 조정합니다.
cpu컨트롤러는 동일한 마운트에cpuacct컨트롤러와 함께 마운트됩니다. cpuacct-
제어 그룹의 작업에서 사용하는 CPU 리소스에 대한 자동 보고서를 생성합니다.
cpuacct컨트롤러는 동일한 마운트에cpu컨트롤러와 함께 마운트됩니다. cpuset- CPU의 지정된 하위 집합에서만 실행되도록 제어 그룹 작업을 제한하고 지정된 메모리 노드에서만 메모리를 사용하도록 작업에 지시합니다.
devices- 제어 그룹의 작업에 대한 장치에 대한 액세스를 제어합니다.
freezer- 제어 그룹에서 작업을 일시 중지하거나 재개합니다.
메모리- 제어 그룹의 작업에서 메모리 사용량에 대한 제한을 설정하고 해당 작업에서 사용하는 메모리 리소스에 대한 자동 보고서를 생성합니다.
net_cls-
Linux 트래픽 컨트롤러(
tc명령)를 활성화하여 특정 제어 그룹 작업에서 시작된 패킷을 식별하는 클래스 식별자(classid)가 있는 네트워크 패킷을 태그합니다.net_cls의 하위 시스템인net_filter(iptables)도 이 태그를 사용하여 이러한 패킷에 대한 작업을 수행할 수 있습니다.net_filter는 Linux 방화벽에서 특정 제어 그룹 작업에서 시작된 패킷을 식별할 수 있는 방화벽 식별자(fwid)로 네트워크 소켓을 태그합니다(iptables명령을 사용하여). net_prio- 네트워크 트래픽의 우선 순위를 설정합니다.
pids- 컨트롤 그룹에서 여러 프로세스 및 해당 하위 항목에 대한 제한을 설정합니다.
perf_event-
perf성능 모니터링 및 보고 유틸리티를 통한 모니터링을 위한 작업을 그룹화합니다. rdma- 제어 그룹의 Remote Direct Memory Access/InfiniBand 특정 리소스에 대한 제한을 설정합니다.
hugetlb- 컨트롤 그룹의 작업별 대규모 가상 메모리 페이지 사용을 제한합니다.
cgroups-v2 에서 사용 가능한 컨트롤러:
io- 블록 장치에 대한 입력/출력 액세스 제한을 설정합니다.
메모리- 제어 그룹의 작업에서 메모리 사용량에 대한 제한을 설정하고 해당 작업에서 사용하는 메모리 리소스에 대한 자동 보고서를 생성합니다.
pids- 컨트롤 그룹에서 여러 프로세스 및 해당 하위 항목에 대한 제한을 설정합니다.
rdma- 제어 그룹의 Remote Direct Memory Access/InfiniBand 특정 리소스에 대한 제한을 설정합니다.
cpu- 제어 그룹의 작업에 대한 CFS(Completely Fair Scheduler) 매개변수를 조정하고 제어 그룹의 작업에서 사용하는 CPU 리소스에 대한 자동 보고서를 생성합니다.
cpuset-
CPU의 지정된 하위 집합에서만 실행되도록 제어 그룹 작업을 제한하고 지정된 메모리 노드에서만 메모리를 사용하도록 작업에 지시합니다. 새 파티션 기능이 있는 코어 기능(
cpus{,.effective},mems{,.effective})만 지원합니다. perf_event-
perf성능 모니터링 및 보고 유틸리티에 의한 모니터링을 위한 그룹 작업입니다.perf_event는 v2 계층에서 자동으로 활성화됩니다.
리소스 컨트롤러는 cgroups-v1 계층 구조 또는 cgroups-v2 계층에서 동시에 사용할 수 있습니다.
43.3. 네임스페이스 소개
네임스페이스는 소프트웨어 오브젝트 구성 및 식별을 위한 별도의 공간을 생성합니다. 이는 서로 영향을 미치는 것을 방지합니다. 결과적으로 각 소프트웨어 오브젝트에는 동일한 시스템을 공유하더라도 마운트 지점, 네트워크 장치 또는 호스트 이름과 같은 자체 리소스 세트가 포함됩니다.
네임스페이스를 사용하는 가장 일반적인 기술 중 하나는 컨테이너입니다.
특정 글로벌 리소스에 대한 변경 사항은 해당 네임스페이스의 프로세스에만 표시되고 나머지 시스템 또는 기타 네임스페이스에는 영향을 미치지 않습니다.
프로세스가 멤버인 네임스페이스를 검사하려면 /proc/<PID>/ns/ 디렉토리에서 심볼릭 링크를 확인할 수 있습니다.
| 네임스페이스 | 격리 |
|---|---|
| Mount | 마운트 지점 |
| UTS | 호스트 이름 및 NIS 도메인 이름 |
| IPC | System V IPC, POSIX 메시지 대기열 |
| PID | 프로세스 ID |
| 네트워크 | 네트워크 장치, 스택, 포트 등 |
| 사용자 | 사용자 및 그룹 ID |
| 제어 그룹 | 제어 그룹 루트 디렉터리 |
43.4. cgroups-v1을 사용하여 애플리케이션에 대한 CPU 제한 설정
제어 그룹 버전 1 (cgroups-v1)을 사용하여 애플리케이션에 대한 CPU 제한을 구성하려면 /sys/fs/ 가상 파일 시스템을 사용합니다.
사전 요구 사항
- root 권한이 있습니다.
- 시스템에 설치된 CPU 사용을 제한하는 애플리케이션이 있습니다.
cgroups-v1컨트롤러가 마운트되었는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
프로세스
CPU 소비에서 제한하려는 애플리케이션의 PID(프로세스 ID)를 식별합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PID 6955가 있는sha1sum예제 애플리케이션은 많은 양의 CPU 리소스를 사용합니다.cpu리소스 컨트롤러 디렉터리에 하위 디렉터리를 생성합니다.mkdir /sys/fs/cgroup/cpu/Example/
# mkdir /sys/fs/cgroup/cpu/Example/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 디렉터리는 특정 프로세스를 배치하고 프로세스에 특정 CPU 제한을 적용할 수 있는 제어 그룹을 나타냅니다. 동시에 여러
cgroups-v1인터페이스 파일과cpu컨트롤러별 파일이 디렉터리에 생성됩니다.선택 사항: 새로 생성된 제어 그룹을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow cpuacct.usage,cpu.cfs._period_us와 같은 파일은예제제어 그룹의 프로세스에 대해 설정할 수 있는 특정 구성 및/또는 제한을 나타냅니다. 파일 이름 앞에는 자신이 속한 제어 그룹 컨트롤러의 이름이 접두어 있습니다.기본적으로 새로 생성된 제어 그룹은 제한 없이 시스템의 전체 CPU 리소스에 대한 액세스를 상속합니다.
제어 그룹에 대한 CPU 제한을 구성합니다.
echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us
# echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us # echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_usCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
cpu.cfs_period_us파일은 CPU 리소스에 대한 제어 그룹의 액세스를 다시 할당해야 하는 빈도를 나타냅니다. 기간은 마이크로초(microsecondss, "us")입니다. 상한은 1 000 000 마이크로초이며 더 낮은 제한은 1000 마이크로초입니다. cpu.cfs_quota_us파일은cpu.cfs_period_us에서 정의한 대로 제어 그룹의 모든 프로세스가 한 기간 동안 집합적으로 실행할 수 있는 마이크로초 단위로 총 시간을 나타냅니다. 제어 그룹의 프로세스에서 단일 기간 동안 할당량에 의해 지정된 모든 시간을 사용하는 경우 나머지 기간 동안 제한되며 다음 기간까지 실행할 수 없습니다. 낮은 제한은 1000 마이크로초입니다.위의 예제 명령은 CPU 시간 제한을 설정하여
Example제어 그룹의 모든 프로세스가 1초(cpu.cfs_quota_us로 정의됨) 1초(cpu.cfs_period_us로 정의됨) 동안 0.2초 동안만 실행할 수 있도록 CPU 시간 제한을 설정합니다.
-
선택 사항: 제한을 확인합니다.
cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000
# cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000Copy to Clipboard Copied! Toggle word wrap Toggle overflow 애플리케이션의 PID를
Example제어 그룹에 추가합니다.echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procs
# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령을 수행하면 특정 애플리케이션이
Example제어 그룹의 멤버가 되고Example제어 그룹에 구성된 CPU 제한을 초과하지 않습니다. PID는 시스템의 기존 프로세스를 표현해야 합니다. 여기에PID 6955는sha1sum /dev/zero & process에 할당되었으며cpu컨트롤러의 사용 사례를 설명합니다.
검증
애플리케이션이 지정된 제어 그룹에서 실행되는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 애플리케이션의 프로세스는 애플리케이션의 프로세스에 CPU 제한을 적용하는
예제제어 그룹에서 실행됩니다.제한된 애플리케이션의 현재 CPU 사용을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow PID 6955의 CPU 사용량이 99 %에서 20%로 감소했습니다.
cpu.cfs_period_us 및 cpu.cfs_quota_us 의 cgroups-v2 카운터는 cpu.max 파일입니다. cpu.max 파일은 cpu 컨트롤러를 통해 사용할 수 있습니다.
44장. BPF Compiler Collection을 사용하여 시스템 성능 분석
BPF Compiler Collection(BCC)은 BPF(Berkeley Packet Filter)의 기능을 결합하여 시스템 성능을 분석합니다. BPF를 사용하면 커널 내에서 사용자 지정 프로그램을 안전하게 실행하여 성능 모니터링, 추적 및 디버깅을 위해 시스템 이벤트 및 데이터에 액세스할 수 있습니다. BCC는 사용자가 시스템에서 중요한 통찰력을 추출 할 수있는 도구 및 라이브러리를 사용하여 BPF 프로그램의 개발 및 배포를 단순화합니다.
44.1. bcc-tools 패키지 설치
BCC(BBF Compiler Collection) 라이브러리도 종속성으로 설치하는 bcc-tools 패키지를 설치합니다.
프로세스
bcc-tools를 설치합니다.yum install bcc-tools
# yum install bcc-toolsCopy to Clipboard Copied! Toggle word wrap Toggle overflow BCC 툴은
/usr/share/bcc/tools/디렉터리에 설치됩니다.
검증
설치된 툴을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 목록의
doc디렉터리에는 각 툴에 대한 문서가 있습니다.
44.2. 성능 분석에 선택한 bcc-tools 사용
BCC(BBF Compiler Collection) 라이브러리에서 미리 생성된 특정 프로그램을 사용하여 이벤트별로 시스템 성능을 효율적이고 안전하게 분석합니다. BCC 라이브러리에서 미리 생성된 프로그램 세트는 추가 프로그램 생성을 위한 예제 역할을 할 수 있습니다.
사전 요구 사항
- 설치된 bcc-tools 패키지
- 루트 권한
프로세스
execsnoop를 사용하여 시스템 프로세스 검사-
하나의 터미널에서
execsnoop프로그램을 실행합니다.
/usr/share/bcc/tools/execsnoop
# /usr/share/bcc/tools/execsnoopCopy to Clipboard Copied! Toggle word wrap Toggle overflow ls명령의 수명이 짧은 프로세스를 생성하려면 다른 터미널에서 다음을 입력합니다.ls /usr/share/bcc/tools/doc/
$ ls /usr/share/bcc/tools/doc/Copy to Clipboard Copied! Toggle word wrap Toggle overflow execsnoop를 실행하는 터미널에는 다음과 유사한 출력이 표시됩니다.PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...
PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow execsnoop프로그램은 시스템 리소스를 사용하는 각 새 프로세스에 대한 출력 행을 출력합니다.ls와 같이 곧 실행되는 프로그램의 프로세스도 감지할 수 있으며 대부분의 모니터링 도구는 등록하지 않습니다.execsnoop출력에는 다음 필드가 표시됩니다.
-
하나의 터미널에서
- PCOMM
-
상위 프로세스 이름입니다. (
ls) - PID
-
프로세스 ID입니다. (
8382) - PPID
-
상위 프로세스 ID입니다. (
8287) - RET
-
프로그램 코드를 새 프로세스로 로드하는
exec()시스템 호출(0)의 반환 값입니다. - ARGS
- 시작된 프로그램의 인수와 관련된 위치입니다.
execsnoop 에 대한 자세한 내용, 예제 및 옵션은 /usr/share/bcc/tools/doc/execsnoop_example.txt 파일을 참조하십시오.
exec() 에 대한 자세한 내용은 exec Cryostat 매뉴얼 페이지를 참조하십시오.
opensnoop을 사용하여 명령이 열리는 파일을 추적-
한 터미널에서
opensnoop프로그램을 실행하여uname명령 프로세스에서만 열린 파일의 출력을 출력합니다.
/usr/share/bcc/tools/opensnoop -n uname
# /usr/share/bcc/tools/opensnoop -n unameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다른 터미널에서 명령을 입력하여 특정 파일을 엽니다.
uname
$ unameCopy to Clipboard Copied! Toggle word wrap Toggle overflow opensnoop을 실행하는 터미널에는 다음과 유사한 출력이 표시됩니다.PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...
PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow opensnoop프로그램은 전체 시스템에서open()시스템 호출을 감시하고uname이 이 방법을 따라 열려고 시도한 각 파일에 대한 출력 행을 출력합니다.opensnoop출력에는 다음 필드가 표시됩니다.- PID
-
프로세스 ID입니다. (
8596) - COMM
-
프로세스 이름입니다. (
uname) - FD
-
파일 설명자 -
open()이 열려 있는 파일을 참조하기 위해 반환하는 값입니다. (3) - ERR
- 모든 오류.
- 경로
-
open()가 열려는 파일의 위치입니다.
명령이 존재하지 않는 파일을 읽으려고 하면
FD열은-1을 반환하고ERR열은 관련 오류에 해당하는 값을 출력합니다. 결과적으로opensnoop는 제대로 작동하지 않는 애플리케이션을 식별하는 데 도움이 될 수 있습니다.
-
한 터미널에서
opensnoop 에 대한 자세한 정보, 예제 및 옵션은 /usr/share/bcc/tools/doc/opensnoop_example.txt 파일을 참조하십시오.
open() 에 대한 자세한 내용은 open(2) 매뉴얼 페이지를 참조하십시오.
biotop를 사용하여 디스크에서 I/O 작업을 수행하는 상위 프로세스 모니터링-
인수
30을 사용하여 하나의 터미널에서biotop프로그램을 실행하여 30초 요약을 생성합니다.
/usr/share/bcc/tools/biotop 30
# /usr/share/bcc/tools/biotop 30Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고인수가 제공되지 않으면 기본적으로 1초마다 출력 화면이 새로 고쳐집니다.
다른 터미널에서 명령을 입력하여 로컬 하드 디스크 장치의 내용을 읽고 출력을
/dev/zero파일에 씁니다.dd if=/dev/vda of=/dev/zero
# dd if=/dev/vda of=/dev/zeroCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 단계는
biotop를 설명하기 위해 특정 I/O 트래픽을 생성합니다.biotop를 실행하는 터미널에는 다음과 유사한 출력이 표시됩니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow biotop출력에는 다음 필드가 표시됩니다.
-
인수
- PID
-
프로세스 ID입니다. (
9568) - COMM
-
프로세스 이름입니다. (
dd) - 디스크
-
읽기 작업을 수행하는 디스크입니다. (
vda) - I/O
- 수행된 읽기 작업 수입니다. (16294)
- kbytes
- 읽기 작업에서 도달한 K바이트 수입니다. (14,440,636)
- AVGms
- 평균 읽기 작업의 I/O 시간입니다. (3.69)
biotop 에 대한 자세한 내용, 예제 및 옵션은 /usr/share/bcc/tools/doc/biotop_example.txt 파일을 참조하십시오.
dd 에 대한 자세한 내용은 dd(1) 매뉴얼 페이지를 참조하십시오.
xfsslower 를 사용하여 예기치 않게 느린 파일 시스템 작업 노출
xfsslower 는 읽기, 쓰기, 열기 또는 동기화(fsync) 작업을 수행하는 XFS 파일 시스템에서 사용하는 시간을 측정합니다. 1 인수를 사용하면 프로그램에서 1ms보다 느린 작업만 표시합니다.
한 터미널에서
xfsslower프로그램을 실행합니다./usr/share/bcc/tools/xfsslower 1
# /usr/share/bcc/tools/xfsslower 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고제공된 인수가 없는 경우
xfsslower는 기본적으로 10ms보다 느린 작업을 표시합니다.다른 터미널에서 명령을 입력하여
vim편집기에 텍스트 파일을 생성하여 XFS 파일 시스템과의 상호 작용을 시작합니다.vim text
$ vim textCopy to Clipboard Copied! Toggle word wrap Toggle overflow xfsslower를 실행하는 터미널은 이전 단계의 파일을 저장할 때 유사한 것을 보여줍니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 각 행은 파일 시스템의 작업을 나타내며 특정 임계값보다 많은 시간이 걸렸습니다.
xfsslower는 가능한 파일 시스템 문제를 감지하여 예기치 않은 느린 작업을 수행할 수 있습니다.xfsslower출력에는 다음 필드가 표시됩니다.- COMM
-
프로세스 이름입니다. (
b'bash') - T
작업 유형입니다. (
R)- Read
- w rite
- s ync
- OFF_KB
- KB의 파일 오프셋입니다. (0)
- 파일 이름
- 읽기, 쓰기 또는 동기화된 파일입니다.
xfsslower 에 대한 자세한 정보, 예제 및 옵션은 /usr/share/bcc/tools/doc/xfsslower_example.txt 파일을 참조하십시오.
fsync 에 대한 자세한 내용은 fsync(2) 매뉴얼 페이지를 참조하십시오.
VII 부. 고가용성 시스템 설계
45장. 고가용성 애드온 개요
고가용성 애드온은 중요한 프로덕션 서비스에 안정성, 확장성 및 가용성을 제공하는 클러스터 시스템입니다.
클러스터는 작업을 수행하기 위해 함께 작동하는 두 개 이상의 컴퓨터( 노드 또는 멤버라고 함)입니다. 클러스터는 고가용성 서비스 또는 리소스를 제공하는 데 사용할 수 있습니다. 여러 유형의 장애를 보호하는 데 여러 시스템의 중복이 사용됩니다.
고가용성 클러스터는 단일 장애 지점을 제거하고 노드가 작동하지 않는 경우 한 클러스터 노드에서 다른 클러스터 노드로 서비스를 통해 실패하여 고가용성 서비스를 제공합니다. 일반적으로 고가용성 클러스터의 서비스 읽기 및 쓰기 데이터(읽기-쓰기 마운트된 파일 시스템 사용). 따라서 하나의 클러스터 노드에서 다른 클러스터 노드에서 서비스 제어를 인수하므로 고가용성 클러스터에서 데이터 무결성을 유지해야 합니다. 고가용성 클러스터의 노드 오류는 클러스터 외부의 클라이언트에서 볼 수 없습니다. (고가용성 클러스터를 장애 조치(failover) 클러스터라고도 합니다.) 고가용성 애드온은 고가용성 서비스 관리 구성 요소인 Pacemaker 를 통해 고가용성 클러스터링을 제공합니다.
Red Hat은 Red Hat 고가용성 클러스터를 계획, 구성 및 유지 관리하기 위한 다양한 문서를 제공합니다. Red Hat 클러스터 문서의 다양한 영역에 가이드 인덱스를 제공하는 문서 목록은 Red Hat High Availability Add-On 설명서 를 참조하십시오.
45.1. 고가용성 애드온 구성 요소
Red Hat High Availability 애드온은 고가용성 서비스를 제공하는 여러 구성 요소로 구성됩니다.
고가용성 애드온의 주요 구성 요소는 다음과 같습니다.
- 클러스터 인프라 - 구성 파일 관리, 멤버십 관리, 잠금 관리 및 펜싱과 같은 노드가 클러스터로 함께 작업할 수 있는 기본 기능을 제공합니다.
- 고가용성 서비스 관리 - 노드가 작동하지 않는 경우 한 클러스터 노드에서 다른 클러스터 노드로 서비스 장애 조치를 제공합니다.
- 클러스터 관리 툴 - 고가용성 애드온 설정, 구성 및 관리를 위한 구성 및 관리 툴입니다. 툴은 클러스터 인프라 구성 요소, 고가용성 및 서비스 관리 구성 요소 및 스토리지와 함께 사용됩니다.
고가용성 애드온은 다음 구성 요소로 보완할 수 있습니다.
- Red Hat Cryostat2(Global File System 2) - 탄력적 스토리지 애드온의 일부로 고가용성 애드온과 함께 사용할 클러스터 파일 시스템을 제공합니다. Cryostat2를 사용하면 스토리지가 각 클러스터 노드에 로컬로 연결된 것처럼 여러 노드가 블록 수준에서 스토리지를 공유할 수 있습니다. Cryostat2 클러스터 파일 시스템에는 클러스터 인프라가 필요합니다.
-
LVM 잠금 데몬(
lvmlockd) - 탄력적 스토리지 애드온의 일부로 클러스터 스토리지의 볼륨 관리 기능을 제공합니다.lvmlockd지원에도 클러스터 인프라가 필요합니다. - HAProxy - TCP(계층 4) 및 계층 7(HTTP, HTTPS) 서비스에서 고가용성 로드 밸런싱 및 페일오버를 제공하는 라우팅 소프트웨어입니다.
45.2. 고가용성 애드온 개념
Red Hat High Availability Add-On 클러스터의 주요 개념 중 일부는 다음과 같습니다.
45.2.1. fencing
클러스터의 단일 노드와 통신하는 데 실패하는 경우 클러스터의 다른 노드는 실패한 클러스터 노드에서 액세스할 수 있는 리소스에 대한 액세스를 제한하거나 해제할 수 있어야 합니다. 클러스터 노드가 응답하지 않을 수 있으므로 클러스터 노드에 연결하여 수행할 수 없습니다. 대신 차단 에이전트를 사용한 펜싱이라는 외부 방법을 제공해야 합니다. 차단 장치는 클러스터가 잘못된 노드에 의해 공유 리소스에 대한 액세스를 제한하거나 클러스터 노드에서 하드 재부팅을 발행하는 데 사용할 수 있는 외부 장치입니다.
차단 장치를 구성하지 않으면 연결이 끊긴 클러스터 노드에서 이전에 사용한 리소스가 해제되었음을 알 수 없으며 이로 인해 서비스가 다른 클러스터 노드에서 실행되지 않을 수 있습니다. 반대로 시스템은 클러스터 노드가 리소스를 해제한 것으로 잘못 가정할 수 있으며 이로 인해 데이터가 손상되고 데이터가 손실될 수 있습니다. 차단 장치가 구성된 데이터 무결성을 보장할 수 없으며 클러스터 구성은 지원되지 않습니다.
펜싱이 진행 중인 경우 다른 클러스터 작업을 실행할 수 없습니다. 클러스터의 정상적인 작업은 펜싱이 완료되거나 클러스터 노드가 재부팅된 후 클러스터에 다시 참여할 때까지 다시 시작할 수 없습니다.
펜싱에 대한 자세한 내용은 Red Hat High Availability Cluster의 Fencing Red Hat Knowledgebase 솔루션을 참조하십시오.
45.2.2. 쿼럼
클러스터 무결성 및 가용성을 유지하기 위해 클러스터 시스템은 쿼럼 이라는 개념을 사용하여 데이터 손상 및 손실을 방지합니다. 클러스터 노드의 절반 이상이 온라인 상태이면 클러스터에 쿼럼이 있습니다. 실패로 인한 데이터 손상 가능성을 완화하기 위해 Pacemaker는 클러스터에 쿼럼이 없는 경우 기본적으로 모든 리소스를 중지합니다.
쿼럼은 투표 시스템을 사용하여 설정됩니다. 클러스터 노드가 제대로 작동하지 않거나 나머지 클러스터와의 통신이 손실되면 대부분의 작업 노드는 분리에 투표하여 필요한 경우 서비스를 위해 노드를 펜싱할 수 있습니다.
예를 들어 6-노드 클러스터에서는 클러스터 노드가 4개 이상 작동할 때 쿼럼이 설정됩니다. 대부분의 노드가 오프라인 상태가 되거나 사용할 수 없게 되면 클러스터에 더 이상 쿼럼이 없으며 Pacemaker에서 클러스터형 서비스를 중지합니다.
Pacemaker의 쿼럼 기능을 사용하면 클러스터가 통신과 분리되지만 각 부분이 계속해서 별도의 클러스터로 작동하여 동일한 데이터에 기록되고 손상 또는 손실이 발생할 수 있습니다. 분할 상태에 있다는 의미와 일반적으로 쿼럼 개념에 대한 자세한 내용은 RHEL High Availability Clusters - Quorum의 Red Hat 지식베이스 문서 탐색 문서를 참조하십시오.
Red Hat Enterprise Linux High Availability Add-On 클러스터는 펜싱과 함께 votequorum 서비스를 사용하여 분할된 뇌 상황을 방지합니다. 클러스터의 각 시스템에 여러 개의 투표가 할당되며, 클러스터 작업은 대부분의 투표가 있는 경우에만 진행할 수 있습니다.
45.2.3. 클러스터 리소스
클러스터 리소스는 클러스터 서비스에서 관리할 프로그램, 데이터 또는 애플리케이션의 인스턴스입니다. 이러한 리소스는 클러스터 환경에서 리소스를 관리하기 위한 표준 인터페이스를 제공하는 에이전트에 의해 추상화됩니다.
리소스가 정상 상태로 유지되도록 리소스 정의에 모니터링 작업을 추가할 수 있습니다. 리소스에 대한 모니터링 작업을 지정하지 않으면 기본적으로 하나씩 추가됩니다.
제약 조건 을 구성하여 클러스터에서 리소스의 동작을 확인할 수 있습니다. 다음과 같은 제약 조건을 구성할 수 있습니다.
- 위치 제한 조건 - 위치 제한 조건은 리소스가 실행할 수 있는 노드를 결정합니다.
- 순서 지정 제약 조건 - 순서 지정 제약 조건에 따라 리소스가 실행되는 순서가 결정됩니다.
- 공동 배치 제약 조건 - 공동 배치 제약 조건에 따라 리소스가 다른 리소스를 기준으로 배치되는 위치가 결정됩니다.Colocation constraints - a colocation constraint determines where resources will be placed relative to other resources.
클러스터의 가장 일반적인 요소 중 하나는 함께 배치하고 순차적으로 시작하고 역순으로 중지해야 하는 리소스 집합입니다. 이 구성을 단순화하기 위해 Pacemaker는 그룹 개념을 지원합니다.
45.3. Pacemaker 개요
Pacemaker는 클러스터 리소스 관리자입니다. 클러스터 인프라의 메시징 및 멤버십 기능을 사용하여 노드와 리소스 수준에서의 장애를 억제하고 복구하여 클러스터 서비스 및 리소스에 대한 가용성을 극대화할 수 있습니다.
45.3.1. Pacemaker 아키텍처 구성 요소
Pacemaker로 구성된 클러스터는 클러스터 멤버십을 모니터링하는 별도의 구성 요소 데몬, 서비스를 관리하는 스크립트, 분산된 리소스를 모니터링하는 리소스 관리 하위 시스템으로 구성됩니다.
다음 구성 요소는 Pacemaker 아키텍처를 형성합니다.
- CIB(Cluster Information Base)
- 내부적으로 XML을 사용하는 Pacemaker 정보 데몬: DC(Designated Coordinator)에서 현재 구성 및 상태 정보를 배포하고 동기화하는 Pacemaker 정보 데몬은 Pacemaker에서 할당한 노드인 CIB를 통해 클러스터 상태 및 작업을 다른 모든 클러스터 노드에 저장하고 배포합니다.
- CRMd(Cluster Resource Management Daemon)
Pacemaker 클러스터 리소스 작업은 이 데몬을 통해 라우팅됩니다. Cryostatd에서 관리하는 리소스는 클라이언트 시스템에서 쿼리하고, 이동하고, 인스턴스화하고, 필요한 경우 변경할 수 있습니다.
각 클러스터 노드에는 Cryostatd와 리소스 간의 인터페이스 역할을 하는 로컬 리소스 관리자 데몬(LRMd)도 포함됩니다. LRMd는 status 정보를 시작 및 중지 및 중계하는 등 Cryostatd의 명령을 에이전트로 전달합니다.
- 헤드에서 다른 노드 종료 (STONITH)
- STONITH는 Pacemaker 펜싱 구현입니다. 차단 요청을 처리하고 노드를 강제로 종료하고 클러스터에서 제거하여 데이터 무결성을 보장하는 Pacemaker의 클러스터 리소스 역할을 합니다. STONITH는 CIB에 구성되어 있으며 일반 클러스터 리소스로 모니터링할 수 있습니다.
- Corosync
Corosync는 고가용성 클러스터에 필요한 코어 멤버십 및 멤버 통신 요구 사항을 제공하는 구성 요소 및 동일한 이름의 데몬입니다. 고가용성 애드온이 작동하려면 필수 항목입니다.이러한 멤버십 및 메시징 기능 외에도
corosync도 마찬가지입니다.- 쿼럼 규칙 및 결정을 관리합니다.
- 클러스터의 여러 멤버에서 조정하거나 작동하는 애플리케이션에 대한 메시징 기능을 제공하므로 인스턴스 간 상태 저장 또는 기타 정보를 통신해야 합니다.
-
kronosnet라이브러리를 네트워크 전송으로 사용하여 여러 중복 링크 및 자동 페일오버를 제공합니다.
45.3.2. Pacemaker 구성 및 관리 툴
고가용성 애드온은 클러스터 배포, 모니터링 및 관리를 위한 두 가지 구성 툴을 제공합니다.
pcspcs명령줄 인터페이스는 Pacemaker 및corosync하트비트 데몬을 제어하고 구성합니다. 명령줄 기반 프로그램인pcs는 다음 클러스터 관리 작업을 수행할 수 있습니다.- Pacemaker/Corosync 클러스터 생성 및 구성
- 실행 중 클러스터 구성 수정
- Pacemaker 및 Corosync와 클러스터의 상태 정보를 시작, 중지 및 표시하는 원격으로 구성
pcsdWeb UI- Pacemaker/Corosync 클러스터를 생성하고 구성하는 그래픽 사용자 인터페이스입니다.
45.3.3. 클러스터 및 Pacemaker 구성 파일
Red Hat High Availability Add-On의 구성 파일은 corosync.conf 및 cib.xml 입니다.
corosync.conf 파일은 Pacemaker가 구축된 클러스터 관리자인 corosync 에서 사용하는 클러스터 매개변수를 제공합니다. 일반적으로 corosync.conf 를 직접 편집해서는 안 되지만 대신 pcs 또는 pcsd 인터페이스를 사용해야 합니다.
cib.xml 파일은 클러스터의 구성과 클러스터에 있는 모든 리소스의 현재 상태를 나타내는 XML 파일입니다. 이 파일은 Pacemaker의 CIB(Cluster Information Base)에서 사용합니다. CIB의 내용은 전체 클러스터에서 자동으로 동기화됩니다. cib.xml 파일을 직접 편집하지 마십시오. 대신 pcs 또는 pcsd 인터페이스를 사용하십시오.
46장. Pacemaker 시작하기
Pacemaker 클러스터를 생성하는 데 사용하는 툴과 프로세스를 숙지하려면 다음 절차를 실행할 수 있습니다. 클러스터 소프트웨어의 모양과 작동 중인 클러스터를 구성할 필요 없이 클러스터 소프트웨어의 모양과 방법을 확인하는 데 관심이 있는 사용자를 위한 것입니다.
이러한 절차에서는 두 개 이상의 노드와 펜싱 장치의 구성이 필요한 지원되는 Red Hat 클러스터를 생성하지 않습니다. RHEL High Availability 클러스터에 대한 Red Hat 지원 정책, 요구 사항 및 제한 사항에 대한 자세한 내용은 RHEL 고가용성 클러스터에 대한 지원 정책을 참조하십시오.
46.1. Pacemaker 사용 방법 알아보기
이 절차를 통해 작업하면 Pacemaker를 사용하여 클러스터를 설정하는 방법, 클러스터 상태를 표시하는 방법 및 클러스터 서비스 구성 방법을 알아봅니다. 이 예제에서는 클러스터 리소스로 Apache HTTP 서버를 생성하고 리소스가 실패할 때 클러스터가 응답하는 방법을 보여줍니다.
이 예제에서는 다음을 수행합니다.
-
노드는
z1.example.com입니다. - 유동 IP 주소는 192.168.122.120입니다.
사전 요구 사항
- RHEL 8을 실행하는 단일 노드
- 노드의 정적으로 할당된 IP 주소 중 하나와 동일한 네트워크에 상주하는 부동 IP 주소
-
실행 중인 노드의 이름이
/etc/hosts파일에 있습니다.
절차
High Availability 채널에서 Red Hat High Availability Add-On 소프트웨어 패키지를 설치하고
pcsd서비스를 시작하고 활성화합니다.yum install pcs pacemaker fence-agents-all ... systemctl start pcsd.service systemctl enable pcsd.service
# yum install pcs pacemaker fence-agents-all ... # systemctl start pcsd.service # systemctl enable pcsd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow firewalld데몬을 실행하는 경우 Red Hat High Availability Add-On에 필요한 포트를 활성화합니다.firewall-cmd --permanent --add-service=high-availability firewall-cmd --reload
# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 각 노드에서 사용자
haclusterpcs명령을 실행할 노드의 클러스터의 각 노드에 대해 사용자 hacluster를 인증합니다. 이 예제에서는 명령을 실행하는 노드인 단일 노드만 사용하지만 지원되는 Red Hat High Availability 멀티 노드 클러스터를 구성하는 데 필요한 단계이므로 이 단계가 여기에 포함됩니다.passwd hacluster ... pcs host auth z1.example.com
# passwd hacluster ... # pcs host auth z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 멤버 중 하나로
my_cluster라는 클러스터를 생성하고 클러스터 상태를 확인합니다. 이 명령은 한 단계로 클러스터를 생성하고 시작합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat High Availability 클러스터를 사용하려면 클러스터에 대한 펜싱을 구성해야 합니다. 이러한 요구 사항의 이유는 Red Hat High Availability Cluster의 Red Hat Knowledgebase 솔루션에 설명되어 있습니다. 그러나 기본 Pacemaker 명령을 사용하는 방법만 표시하는 이 소개에서는
stonith사용 클러스터 옵션을false로 설정하여 펜싱을 비활성화합니다.주의stonith-enabled=false를 사용하는 것은 프로덕션 클러스터에 완전히 부적절합니다. 실패한 노드가 안전하게 펜싱됨을 간단히 가정하도록 클러스터에 지시합니다.pcs property set stonith-enabled=false
# pcs property set stonith-enabled=falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 시스템에서 웹 브라우저를 구성하고 간단한 텍스트 메시지를 표시할 웹 페이지를 만듭니다.
firewalld데몬을 실행하는 경우httpd에 필요한 포트를 활성화합니다.참고systemctl enable를 사용하여 클러스터에서 관리하는 모든 서비스가 시스템 부팅 시 시작되도록 활성화하지 마십시오.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Apache 리소스 에이전트가 Apache의 상태를 가져오려면 기존 구성에 다음을 추가하여 상태 서버 URL을 활성화합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터에서 관리할
IPaddr2및apache리소스를 생성합니다.IPaddr2리소스는 이미 물리적 노드와 연결되어 있지 않은 유동 IP 주소입니다.IPaddr2리소스의 NIC 장치가 지정되지 않은 경우 유동 IP는 노드에서 사용하는 정적으로 할당된 IP 주소와 동일한 네트워크에 있어야 합니다.pcs resource list명령을 사용하여 사용 가능한 모든 리소스 유형 목록을 표시할 수 있습니다.pcs resource describe resourcetype명령을 사용하여 지정된 리소스 유형에 대해 설정할 수 있는 매개변수를 표시할 수 있습니다. 예를 들어 다음 명령은apache유형 리소스에 대해 설정할 수 있는 매개변수를 표시합니다.pcs resource describe apache ...
# pcs resource describe apache ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 IP 주소 리소스 및 apache 리소스는 모두
apachegroup이라는 그룹의 일부로 구성되어 있어 작동 중인 다중 노드 클러스터를 구성할 때 동일한 노드에서 리소스를 계속 실행하도록 합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 리소스를 구성한 후
pcs resource config명령을 사용하여 해당 리소스에 대해 구성된 옵션을 표시할 수 있습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 구성한 유동 IP 주소를 사용하여 설정한 웹 사이트를 가리킵니다. 정의한 텍스트 메시지가 표시되어야 합니다.
apache 웹 서비스를 중지하고 클러스터 상태를 확인합니다.
killall -9를 사용하면 애플리케이션 수준 충돌을 시뮬레이션합니다.killall -9 httpd
# killall -9 httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인합니다. 웹 서비스를 중지하면 작업이 실패했지만 클러스터 소프트웨어가 서비스를 다시 시작하고 여전히 웹 사이트에 액세스할 수 있어야 함을 확인해야 합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 서비스가 가동되어 다시 실행되면 실패한 리소스의 실패 상태를 지울 수 있으며 클러스터 상태를 볼 때 실패한 작업 알림이 더 이상 나타나지 않습니다.
pcs resource cleanup WebSite
# pcs resource cleanup WebSiteCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 및 클러스터 상태를 보고 완료되면 노드에서 클러스터 서비스를 중지합니다. 이 도입을 위해 하나의 노드에서만 서비스를 시작했지만 실제 다중 노드 클러스터의 모든 노드에서 클러스터 서비스를 중지하므로
--all매개변수가 포함됩니다.pcs cluster stop --all
# pcs cluster stop --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
46.2. 페일오버 구성 학습
다음 절차에서는 서비스가 실행 중인 노드를 사용할 수 없게 되는 경우 한 노드에서 다른 노드로 장애 조치되는 Pacemaker 클러스터를 생성하는 방법을 소개합니다. 이 절차를 통해 두 노드 클러스터에서 서비스를 생성하는 방법을 배울 수 있으며, 실행 중인 노드에서 오류가 발생하면 해당 서비스에 어떤 일이 발생하는지 확인할 수 있습니다.
이 예제 절차에서는 Apache HTTP 서버를 실행하는 2-노드 Pacemaker 클러스터를 구성합니다. 그런 다음 한 노드에서 Apache 서비스를 중지하여 서비스를 계속 사용할 수 있는 방법을 확인할 수 있습니다.
이 예제에서는 다음을 수행합니다.
-
노드는
z1.example.com및z2.example.com입니다. - 유동 IP 주소는 192.168.122.120입니다.
사전 요구 사항
- RHEL 8을 실행하는 두 개의 노드가 서로 통신할 수 있습니다.
- 노드의 정적으로 할당된 IP 주소 중 하나와 동일한 네트워크에 상주하는 부동 IP 주소
-
실행 중인 노드의 이름이
/etc/hosts파일에 있습니다.
절차
두 노드 모두에서 High Availability 채널에서 Red Hat High Availability Add-On 소프트웨어 패키지를 설치하고
pcsd서비스를 시작하고 활성화합니다.yum install pcs pacemaker fence-agents-all ... systemctl start pcsd.service systemctl enable pcsd.service
# yum install pcs pacemaker fence-agents-all ... # systemctl start pcsd.service # systemctl enable pcsd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow firewalld데몬을 실행하는 경우 두 노드 모두에서 Red Hat High Availability Add-On에 필요한 포트를 활성화합니다.firewall-cmd --permanent --add-service=high-availability firewall-cmd --reload
# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 두 노드 모두에서
hacluster사용자의 암호를 설정합니다.passwd hacluster
# passwd haclusterCopy to Clipboard Copied! Toggle word wrap Toggle overflow pcs명령을 실행할 노드의 클러스터의 각 노드에 대해 사용자hacluster를 인증합니다.pcs host auth z1.example.com z2.example.com
# pcs host auth z1.example.com z2.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 두 노드 모두 클러스터 구성원으로 있는
my_cluster라는 클러스터를 만듭니다. 이 명령은 한 단계로 클러스터를 생성하고 시작합니다.pcs구성 명령이 전체 클러스터에 적용되므로 클러스터의 한 노드에서만 이 값을 실행해야 합니다.클러스터의 한 노드에서 다음 명령을 실행합니다.
pcs cluster setup my_cluster --start z1.example.com z2.example.com
# pcs cluster setup my_cluster --start z1.example.com z2.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow Red Hat High Availability 클러스터를 사용하려면 클러스터에 대한 펜싱을 구성해야 합니다. 이러한 요구 사항의 이유는 Red Hat High Availability Cluster의 Red Hat Knowledgebase 솔루션에 설명되어 있습니다. 그러나 이 도입에서는 이 구성에서 페일오버가 작동하는 방식만 표시하려면
stonith사용 클러스터 옵션을false로 설정하여 펜싱을 비활성화합니다.주의stonith-enabled=false를 사용하는 것은 프로덕션 클러스터에 완전히 부적절합니다. 실패한 노드가 안전하게 펜싱됨을 간단히 가정하도록 클러스터에 지시합니다.pcs property set stonith-enabled=false
# pcs property set stonith-enabled=falseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터를 생성하고 펜싱을 비활성화한 후 클러스터 상태를 확인합니다.
참고pcs cluster status명령을 실행하면 시스템 구성 요소가 시작될 때 일시적으로 예제와 약간 다른 출력이 표시될 수 있습니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 두 노드 모두에서 웹 브라우저를 구성하고 웹 페이지를 생성하여 간단한 텍스트 메시지를 표시합니다.
firewalld데몬을 실행하는 경우httpd에 필요한 포트를 활성화합니다.참고systemctl enable를 사용하여 클러스터에서 관리하는 모든 서비스가 시스템 부팅 시 시작되도록 활성화하지 마십시오.Copy to Clipboard Copied! Toggle word wrap Toggle overflow Apache 리소스 에이전트가 클러스터의 각 노드에서 Apache의 상태를 가져오려면 기존 구성에 다음을 추가하여 상태 서버 URL을 활성화합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터에서 관리할
IPaddr2및apache리소스를 생성합니다.IPaddr2리소스는 이미 물리적 노드와 연결되어 있지 않은 유동 IP 주소입니다.IPaddr2리소스의 NIC 장치가 지정되지 않은 경우 유동 IP는 노드에서 사용하는 정적으로 할당된 IP 주소와 동일한 네트워크에 있어야 합니다.pcs resource list명령을 사용하여 사용 가능한 모든 리소스 유형 목록을 표시할 수 있습니다.pcs resource describe resourcetype명령을 사용하여 지정된 리소스 유형에 대해 설정할 수 있는 매개변수를 표시할 수 있습니다. 예를 들어 다음 명령은apache유형 리소스에 대해 설정할 수 있는 매개변수를 표시합니다.pcs resource describe apache ...
# pcs resource describe apache ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예제에서 IP 주소 리소스와 apache 리소스는 모두
apachegroup이라는 그룹의 일부로 구성되므로 리소스가 동일한 노드에서 실행되도록 유지됩니다.클러스터의 한 노드에서 다음 명령을 실행합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 인스턴스에서
apachegroup서비스는 z1.example.com 노드에서 실행되고 있습니다.생성한 웹 사이트에 액세스하여 실행 중인 노드에서 서비스를 중지하고 서비스가 두 번째 노드로 장애 조치되는 방식을 확인합니다.
- 구성한 유동 IP 주소를 사용하여 만든 웹 사이트를 가리킵니다. 이에는 사용자가 정의한 텍스트 메시지가 표시되고 웹사이트가 실행 중인 노드의 이름이 표시됩니다.
apache 웹 서비스를 중지합니다.
killall -9를 사용하면 애플리케이션 수준 충돌을 시뮬레이션합니다.killall -9 httpd
# killall -9 httpdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인합니다. 웹 서비스를 중지하면 작업이 실패했지만 클러스터 소프트웨어가 실행 중인 노드에서 서비스를 다시 시작하고 웹 브라우저에 액세스할 수 있어야 함을 확인해야 합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 서비스가 가동되고 다시 실행되면 실패 상태를 지웁니다.
pcs resource cleanup WebSite
# pcs resource cleanup WebSiteCopy to Clipboard Copied! Toggle word wrap Toggle overflow 서비스가 실행 중인 노드를 대기 모드로 설정합니다. 펜싱을 비활성화했기 때문에 이러한 상황에서 클러스터를 복구하려면 펜싱이 필요하므로 노드 수준 장애(예: 전원 케이블 가져오기)를 효과적으로 시뮬레이션할 수 없습니다.
pcs node standby z1.example.com
# pcs node standby z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인하고 서비스가 현재 실행 중인 위치를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 웹 사이트에 액세스합니다. 서비스가 손실되지 않아야 하지만 표시 메시지는 현재 서비스가 실행 중인 노드를 표시해야 합니다.
클러스터 서비스를 첫 번째 노드로 복원하려면 노드를 대기 모드로 전환합니다. 이 경우 서비스를 해당 노드로 다시 이동할 필요가 없습니다.
pcs node unstandby z1.example.com
# pcs node unstandby z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 마지막 정리를 위해 두 노드 모두에서 클러스터 서비스를 중지합니다.
pcs cluster stop --all
# pcs cluster stop --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
47장. pcs 명령줄 인터페이스
pcs 명령줄 인터페이스는 구성 파일에 더 쉬운 인터페이스를 제공하여 corosync,pacemaker,booth 및 sbd 와 같은 클러스터 서비스를 제어하고 구성합니다.
cib.xml 구성 파일을 직접 편집해서는 안 됩니다. 대부분의 경우 Pacemaker는 직접 수정된 cib.xml 파일을 거부합니다.
47.1. pcs help 표시
pcs 의 -h 옵션을 사용하여 pcs 명령의 매개변수와 해당 매개변수에 대한 설명을 표시합니다.
다음 명령은 pcs resource 명령의 매개 변수를 표시합니다.
pcs resource -h
# pcs resource -h47.2. 원시 클러스터 구성 보기
클러스터 구성 파일을 직접 편집해서는 안 되지만 pcs cluster cib 명령을 사용하여 원시 클러스터 구성을 볼 수 있습니다.
pcs cluster cib filename 명령을 사용하여 원시 클러스터 구성을 지정된 파일에 저장할 수 있습니다. 이전에 클러스터를 구성하고 이미 활성 CIB가 있는 경우 다음 명령을 사용하여 raw xml 파일을 저장합니다.
pcs cluster cib filename
pcs cluster cib filename
예를 들어 다음 명령은 CIB의 raw xml를 testfile 이라는 파일에 저장합니다.
pcs cluster cib testfile
# pcs cluster cib testfile47.3. 작업 파일에 구성 변경 저장
클러스터를 구성할 때 활성 CIB에 영향을 주지 않고 지정된 파일에 구성 변경 사항을 저장할 수 있습니다. 이를 통해 개별 업데이트마다 현재 실행 중인 클러스터 구성을 즉시 업데이트하지 않고 구성 업데이트를 지정할 수 있습니다.
CIB를 파일에 저장하는 방법에 대한 자세한 내용은 원시 클러스터 구성 보기를 참조하십시오. 해당 파일을 생성한 후에는 pcs 명령의 -f 옵션을 사용하여 활성 CIB 대신 구성 변경 사항을 저장할 수 있습니다. 변경 사항을 완료하고 활성 CIB 파일을 업데이트할 준비가 되면 pcs cluster cib-push 명령을 사용하여 해당 파일 업데이트를 푸시할 수 있습니다.
절차
다음은 변경 사항을 CIB 파일로 푸시하는 데 권장되는 절차입니다. 이 절차에서는 원본 저장된 CIB 파일의 사본을 생성하고 해당 사본을 변경합니다. 이러한 변경 사항을 활성 CIB로 푸시할 때 이 절차에서는 원래 파일과 업데이트된 파일 간의 변경 사항만 CIB로 푸시되도록 pcs cluster cib-push 명령의 diff-against 옵션을 지정합니다. 이를 통해 사용자는 서로 덮어쓰지 않는 병렬로 변경할 수 있으며, 전체 구성 파일을 구문 분석할 필요가 없는 Pacemaker의 로드가 줄어듭니다.
활성 CIB를 파일에 저장합니다. 이 예제에서는 CIB를
original.xml이라는 파일에 저장합니다.pcs cluster cib original.xml
# pcs cluster cib original.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 저장된 파일을 구성 업데이트에 사용할 작업 파일에 복사합니다.
cp original.xml updated.xml
# cp original.xml updated.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 필요에 따라 구성을 업데이트합니다. 다음 명령은
updated.xml파일에 리소스를 생성하지만 현재 실행 중인 클러스터 구성에 해당 리소스를 추가하지 않습니다.pcs -f updated.xml resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 op monitor interval=30s
# pcs -f updated.xml resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 op monitor interval=30sCopy to Clipboard Copied! Toggle word wrap Toggle overflow 업데이트된 파일을 활성 CIB로 푸시하여 원본 파일의 변경 사항만 푸시하도록 지정합니다.
pcs cluster cib-push updated.xml diff-against=original.xml
# pcs cluster cib-push updated.xml diff-against=original.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
또는 다음 명령을 사용하여 CIB 파일의 전체 현재 콘텐츠를 푸시할 수 있습니다.
pcs cluster cib-push filename
pcs cluster cib-push filename
전체 CIB 파일을 푸시할 때 Pacemaker에서 버전을 확인하고 클러스터에 있는 버전보다 오래된 CIB 파일을 푸시할 수 없습니다. 클러스터에 있는 버전보다 오래된 버전으로 전체 CIB 파일을 업데이트해야 하는 경우 pcs cluster cib-push 명령의 --config 옵션을 사용할 수 있습니다.
pcs cluster cib-push --config filename
pcs cluster cib-push --config filename47.4. 클러스터 상태 표시
클러스터 및 해당 구성 요소의 상태를 표시하는 데 사용할 수 있는 다양한 명령이 있습니다.
다음 명령을 사용하여 클러스터 및 클러스터 리소스의 상태를 표시할 수 있습니다.
pcs status
# pcs status
리소스, 클러스터,노드 또는 pcsd 를 지정하여 pcs status 명령의 commands 매개변수를 사용하여 특정클러스터 구성 요소의 상태를 표시할 수 있습니다.
pcs status commands
pcs status commands예를 들어 다음 명령은 클러스터 리소스의 상태를 표시합니다.
pcs status resources
# pcs status resources다음 명령은 클러스터의 상태를 표시하지만 클러스터 리소스는 표시하지 않습니다.
pcs cluster status
# pcs cluster status47.5. 전체 클러스터 구성 표시
다음 명령을 사용하여 전체 현재 클러스터 구성을 표시합니다.
pcs config
# pcs config47.6. pcs 명령으로 corosync.conf 파일 수정
Red Hat Enterprise Linux 8.4 이상에서는 pcs 명령을 사용하여 corosync.conf 파일의 매개변수를 수정할 수 있습니다.
다음 명령은 corosync.conf 파일의 매개 변수를 수정합니다.
pcs cluster config update [transport pass:quotes[transport options]] [compression pass:quotes[compression options]] [crypto pass:quotes[crypto options]] [totem pass:quotes[totem options]] [--corosync_conf pass:quotes[path]]
pcs cluster config update [transport pass:quotes[transport options]] [compression pass:quotes[compression options]] [crypto pass:quotes[crypto options]] [totem pass:quotes[totem options]] [--corosync_conf pass:quotes[path]]
다음 예제 명령은 knet_pmtud_interval 전송 값과 토큰 을 지정하고 totem 값을 결합합니다.
pcs cluster config update transport knet_pmtud_interval=35 totem token=10000 join=100
# pcs cluster config update transport knet_pmtud_interval=35 totem token=10000 join=10047.7. pcs 명령으로 corosync.conf 파일 표시
다음 명령은 corosync.conf 클러스터 구성 파일의 내용을 표시합니다.
pcs cluster corosync
# pcs cluster corosync
Red Hat Enterprise Linux 8.4 이상에서는 다음 예와 같이 pcs cluster config 명령을 사용하여 사람이 읽을 수 있는 형식으로 corosync.conf 파일의 내용을 출력할 수 있습니다.
클러스터가 RHEL 8.7 이상에서 생성된 경우 또는 UUID가 UUID로 클러스터 식별에 설명된 대로 수동으로 추가된 경우 이 명령의 출력에는 클러스터의 UUID가 포함되어 있습니다.
RHEL 8.4 이상에서는 --output-format=cmd 옵션과 함께 pcs cluster config show 명령을 실행하여 다음 예제와 같이 기존 corosync.conf 파일을 다시 생성하는 데 사용할 수 있는 pcs 구성 명령을 표시할 수 있습니다.
48장. Pacemaker를 사용하여 Red Hat High-Availability 클러스터 생성
다음 절차에 따라 pcs 명령줄 인터페이스를 사용하여 Red Hat High Availability 2-node 클러스터를 생성합니다.
이 예제에서 클러스터를 구성하려면 시스템에 다음 구성 요소가 포함되어야 합니다.
-
2개의 노드, 클러스터를 만드는 데 사용됩니다. 이 예에서 사용되는 노드는
z1.example.com및z2.example.com입니다. - 사설 네트워크의 네트워크 스위치. 클러스터 노드 및 네트워크 전원 스위치 및 파이버 채널 스위치와 같은 기타 클러스터 하드웨어 간의 통신을 위해 프라이빗 네트워크가 필요하지는 않습니다.
-
클러스터의 각 노드에 대한 펜싱 장치입니다. 이 예에서는 호스트 이름이
zapc.example.com인 APC 전원 스위치의 두 포트를 사용합니다.
구성이 Red Hat의 지원 정책을 준수하는지 확인해야 합니다. RHEL High Availability 클러스터에 대한 Red Hat 지원 정책, 요구 사항 및 제한 사항에 대한 자세한 내용은 RHEL 고가용성 클러스터에 대한 지원 정책을 참조하십시오.
48.1. 클러스터 소프트웨어 설치
다음 절차에 따라 클러스터 소프트웨어를 설치하고 클러스터 생성을 위해 시스템을 구성합니다.
절차
클러스터의 각 노드에서 시스템 아키텍처에 해당하는 고가용성을 위해 리포지토리를 활성화합니다. 예를 들어 x86_64 시스템에 고가용성 리포지토리를 활성화하려면 다음
subscription-manager명령을 입력합니다.subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
# subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 각 노드에서 고가용성 채널에서 사용 가능한 모든 차단 에이전트와 함께 Red Hat High Availability Add-On 소프트웨어 패키지를 설치합니다.
yum install pcs pacemaker fence-agents-all
# yum install pcs pacemaker fence-agents-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 다음 명령과 함께 필요한 차단 에이전트만 함께 Red Hat High Availability Add-On 소프트웨어 패키지를 설치할 수 있습니다.
yum install pcs pacemaker fence-agents-model
# yum install pcs pacemaker fence-agents-modelCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령은 사용 가능한 차단 에이전트 목록을 표시합니다.
rpm -q -a | grep fence fence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...
# rpm -q -a | grep fence fence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의Red Hat High Availability Add-On 패키지를 설치한 후 소프트웨어 업데이트 기본 설정이 설정되어 있지 않은지 자동으로 설치해야 합니다. 실행 중인 클러스터에 설치하면 예기치 않은 동작이 발생할 수 있습니다. 자세한 내용은 RHEL High Availability 또는 Resilient Storage Cluster에 소프트웨어 업데이트를 적용하는 권장 사례를 참조하십시오.
firewalld데몬을 실행하는 경우 다음 명령을 실행하여 Red Hat High Availability Add-On에 필요한 포트를 활성화합니다.참고rpm -qfirewalld명령을 사용하여 시스템에 firewalld 데몬이 설치되었는지 확인할 수 있습니다. 설치된 경우firewall-cmd --state명령을 사용하여 실행 중인지 확인할 수 있습니다.firewall-cmd --permanent --add-service=high-availability firewall-cmd --add-service=high-availability
# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고클러스터 구성 요소에 대한 이상적인 방화벽 구성은 로컬 환경에 따라 다릅니다. 여기서 노드에 여러 네트워크 인터페이스가 있는지 또는 오프 호스트 방화벽이 있는지 여부와 같은 고려 사항을 고려해야 할 수 있습니다. 여기서는 Pacemaker 클러스터에 일반적으로 필요한 포트를 여는 예제는 로컬 조건에 맞게 수정해야 합니다. 고가용성 애드온 의 포트를 활성화하면 Red Hat High Availability Add-On 에 사용할 수 있는 포트가 표시되고 각 포트가 사용되는 기능에 대한 설명을 제공합니다.
pcs를 사용하여 클러스터를 구성하고 노드 간에 통신하려면pcs관리 계정인 사용자 IDhacluster의 각 노드에 암호를 설정해야 합니다. 사용자hacluster의 암호는 각 노드에서 동일한 것이 좋습니다.passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.
# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터를 구성하려면 각 노드에서 부팅 시 시작되도록
pcsd데몬을 시작하고 활성화해야 합니다. 이 데몬은pcs명령과 함께 작동하여 클러스터의 노드에서 구성을 관리합니다.클러스터의 각 노드에서 다음 명령을 실행하여
pcsd서비스를 시작하고 시스템을 시작할 때pcsd를 활성화합니다.systemctl start pcsd.service systemctl enable pcsd.service
# systemctl start pcsd.service # systemctl enable pcsd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
48.2. pcp-zeroconf 패키지 설치 (권장)
클러스터를 설정할 때 PCP(Performance Co- Cryostat) 툴용 pcp-zeroconf 패키지를 설치하는 것이 좋습니다. PCP는 RHEL 시스템을 위한 Red Hat의 권장 리소스 모니터링 툴입니다. pcp-zeroconf 패키지를 설치하면 클러스터를 중단하는 펜싱, 리소스 오류 및 기타 이벤트에 대한 조사의 이점을 위해 성능 모니터링 데이터를 실행하고 성능 모니터링 데이터를 수집할 수 있습니다.
PCP가 활성화된 클러스터 배포에는 /var/log/pcp/ 가 포함된 파일 시스템에서 PCP의 캡처된 데이터에 사용할 수 있는 충분한 공간이 필요합니다. PCP의 일반적인 공간 사용은 배포마다 다르지만 일반적으로 pcp-zeroconf 기본 설정을 사용할 때 10Gb로 충분하며 일부 환경에는 덜 필요합니다. 일반적인 활동 14일 동안 이 디렉토리의 사용량을 모니터링하면 보다 정확한 사용 기대치를 제공할 수 있습니다.
절차
pcp-zeroconf 패키지를 설치하려면 다음 명령을 실행합니다.
yum install pcp-zeroconf
# yum install pcp-zeroconf
이 패키지는 pmcd 를 활성화하고 10초 간격으로 데이터 캡처를 설정합니다.
PCP 데이터 검토에 대한 자세한 내용은 Red Hat Knowledgebase 솔루션에서 RHEL 고가용성 클러스터 노드 재부팅을 수행한 이유 및 다시 발생하지 않도록 하는 방법을 참조하십시오. .
48.3. 고가용성 클러스터 생성
다음 절차에 따라 Red Hat High Availability Add-On 클러스터를 생성합니다. 이 예제 절차에서는 z1.example.com 및 z2.example.com 노드로 구성된 클러스터를 생성합니다.
절차
pcs를 실행할 노드의 클러스터의 각 노드에 대해pcsuserhacluster를 인증합니다.다음 명령은
z1.example.com및z2.example.com으로 구성된 2-노드 클러스터의 두 노드에 대해z1.example.com의 사용자hacluster를 인증합니다.pcs host auth z1.example.com z2.example.com Username: hacluster Password: z1.example.com: Authorized z2.example.com: Authorized
[root@z1 ~]# pcs host auth z1.example.com z2.example.com Username: hacluster Password: z1.example.com: Authorized z2.example.com: AuthorizedCopy to Clipboard Copied! Toggle word wrap Toggle overflow z1.example.comz2.example.com노드로 구성된 2-노드 클러스터my_cluster를 생성합니다. 이렇게 하면 클러스터 구성 파일이 클러스터의 두 노드에 모두 전파됩니다. 이 명령에는 클러스터의 두 노드에서 클러스터 서비스를 시작하는--start옵션이 포함되어 있습니다.pcs cluster setup my_cluster --start z1.example.com z2.example.com
[root@z1 ~]# pcs cluster setup my_cluster --start z1.example.com z2.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 노드가 부팅될 때 클러스터의 각 노드에서 클러스터 서비스를 실행하도록 활성화합니다.
참고특정 환경의 경우 이 단계를 건너뛰어 클러스터 서비스를 비활성화 상태로 두도록 선택할 수 있습니다. 이를 통해 노드가 중단되면 노드가 클러스터에 다시 참여하기 전에 클러스터 또는 리소스의 문제가 해결되도록 할 수 있습니다. 클러스터 서비스를 비활성화한 상태로 두면 해당 노드에서
pcs cluster start명령을 실행하여 노드를 재부팅할 때 서비스를 수동으로 시작해야 합니다.pcs cluster enable --all
[root@z1 ~]# pcs cluster enable --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
pcs cluster status 명령을 사용하여 클러스터의 현재 상태를 표시할 수 있습니다. pcs cluster setup 명령의 --start 옵션을 사용하여 클러스터 서비스를 시작하고 실행하기 전에 클러스터가 잠시 지연될 수 있으므로 클러스터와 해당 구성에서 후속 작업을 수행하기 전에 클러스터가 가동 및 실행 중인지 확인해야 합니다.
48.4. 여러 링크를 사용하여 고가용성 클러스터 생성
pcs cluster setup 명령을 사용하여 각 노드의 모든 링크를 지정하여 여러 링크가 있는 Red Hat High Availability 클러스터를 생성할 수 있습니다.
두 개의 링크가 있는 2-노드 클러스터를 생성하는 기본 명령의 형식은 다음과 같습니다.
pcs cluster setup pass:quotes[cluster_name] pass:quotes[node1_name] addr=pass:quotes[node1_link0_address] addr=pass:quotes[node1_link1_address] pass:quotes[node2_name] addr=pass:quotes[node2_link0_address] addr=pass:quotes[node2_link1_address]
pcs cluster setup pass:quotes[cluster_name] pass:quotes[node1_name] addr=pass:quotes[node1_link0_address] addr=pass:quotes[node1_link1_address] pass:quotes[node2_name] addr=pass:quotes[node2_link0_address] addr=pass:quotes[node2_link1_address]
이 명령의 전체 구문은 pcs(8) 도움말 페이지를 참조하십시오.
여러 개의 링크를 사용하여 클러스터를 생성할 때 다음 사항을 고려해야 합니다.
-
addr=address매개 변수의 순서가 중요합니다. 노드 이름 뒤에 지정된 첫 번째 주소는link0이고, 두 번째 주소는link1입니다. -
기본적으로 링크에
link_priority가 지정되지 않은 경우 링크의 우선순위는 링크 번호와 동일합니다. 링크 우선순위는 지정된 순서에 따라 0, 1, 2, 3 등이며, 0은 가장 높은 링크 우선순위입니다. -
기본 링크 모드는
passive이므로 가장 낮은 번호의 링크 우선 순위가 있는 활성 링크가 사용됩니다. -
link_mode및link_priority의 기본값을 사용하면 지정된 첫 번째 링크가 가장 높은 우선 순위 링크로 사용되며 해당 링크가 실패하면 지정된 다음 링크가 사용됩니다. -
기본 전송 프로토콜인
knet전송 프로토콜을 사용하여 최대 8개의 링크를 지정할 수 있습니다. -
모든 노드에는 동일한 수의
addr=매개 변수가 있어야 합니다. -
RHEL 8.1 이상에서는
pcs cluster link add,pcs cluster link remove,pcs cluster link delete및pcs cluster link update명령을 사용하여 기존 클러스터의 링크를 추가, 제거 및 변경할 수 있습니다. - 단일 링크 클러스터에서와 마찬가지로 하나의 링크에서 IPv4 및 IPv6 주소를 혼합하지 마십시오. IPv4 및 실행 중인 IPv6를 실행하는 하나의 링크가 있을 수 있습니다.
- 단일 링크 클러스터에서와 마찬가지로 이름이 IPv4 또는 IPv6 주소로 해석되는 한, 하나의 링크에서 IPv4 및 IPv6 주소가 혼합되지 않는 한 주소를 IP 주소로 지정할 수 있습니다.
다음 예제에서는 두 개의 노드 rh80-node1 및 rh80-node2 를 사용하여 my_twolink_cluster 라는 2-노드 클러스터를 생성합니다. rh80-node1 에는 두 개의 인터페이스가 있습니다. IP 주소 192.168.122.201을 link0 으로, 192.168.123.201을 로,link1 rh80-node2 에는 두 개의 인터페이스인 IP 주소 192.168.122.202가 link0 으로, 192.168.123.202입니다.
pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202
링크 우선 순위를 링크 번호인 기본값과 다른 값으로 설정하려면 pcs cluster setup 명령의 link_priority 옵션을 사용하여 link 우선순위를 설정할 수 있습니다. 다음 두 예제 명령 각각은 첫 번째 링크인 link 0의 두 개의 인터페이스가 있는 2-노드 클러스터를 생성합니다. 여기서 link 0은 1이고 두 번째 링크의 링크 우선 순위는 0입니다. 링크 1이 먼저 사용되며 링크 0은 장애 조치 링크 역할을 합니다. 링크 모드를 지정하지 않으므로 기본값은 passive입니다.
이 두 명령은 동일합니다. link 키워드 다음에 링크 번호를 지정하지 않으면 pcs 인터페이스는 사용되지 않는 가장 낮은 링크 번호부터 시작하여 링크 번호를 자동으로 추가합니다.
pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202 transport knet link link_priority=1 link link_priority=0 pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202 transport knet link linknumber=1 link_priority=0 link link_priority=1
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202 transport knet link link_priority=1 link link_priority=0
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202 transport knet link linknumber=1 link_priority=0 link link_priority=1여러 링크가 있는 기존 클러스터에 노드를 추가하는 방법에 대한 자세한 내용은 여러 링크가 있는 클러스터에 노드 추가를 참조하십시오.
여러 링크를 사용하여 기존 클러스터의 링크를 변경하는 방법에 대한 자세한 내용은 기존 클러스터의 링크 추가 및 수정을 참조하십시오.
48.5. 펜싱 구성
클러스터의 각 노드에 대해 펜싱 장치를 구성해야 합니다. fence 구성 명령 및 옵션에 대한 자세한 내용은 Red Hat High Availability 클러스터에서 펜싱 구성을 참조하십시오.
Red Hat High Availability 클러스터에서 펜싱과 그 중요성에 대한 일반 정보는 Red Hat High Availability Cluster의 Red Hat 지식베이스 솔루션 Fencing 을 참조하십시오.
펜싱 장치를 구성할 때 해당 장치가 클러스터의 노드 또는 장치와 전원을 공유하는지 여부에 주의해야 합니다. 노드와 해당 차단 장치가 전원을 공유하는 경우, 전원과 해당 차단 장치가 손실되어야 하는 경우 클러스터가 해당 노드를 펜싱할 수 없는 위험이 있을 수 있습니다. 이러한 클러스터에는 차단 장치 및 노드에 대한 중복 전원 공급 장치 또는 전원을 공유하지 않는 중복 차단 장치가 있어야 합니다. SBD 또는 스토리지 펜싱과 같은 펜싱의 다른 방법으로는 분리 전력 손실이 발생할 경우 중복성이 발생할 수 있습니다.
절차
이 예에서는 호스트 이름 zapc.example.com 과 함께 APC 전원 스위치를 사용하여 노드를 펜싱하고 fence_apc_snmp 펜싱 에이전트를 사용합니다. 두 노드 모두 동일한 펜싱 에이전트로 펜싱되므로 pcmk_host_map 옵션을 사용하여 두 펜싱 장치를 단일 리소스로 구성할 수 있습니다.
pcs stonith create 명령을 사용하여 장치를 stonith 리소스로 구성하여 펜싱 장치를 생성합니다. 다음 명령은 z1.example.com 및 z2.example.com 노드에 fence_apc_snmp 펜싱 에이전트를 사용하는 myapc 라는 stonith 리소스를 구성합니다. pcmk_host_map 옵션은 z1.example.com 을 포트 1에 매핑하고 z2.example.com 을 포트 2에 매핑합니다. APC 장치의 로그인 값과 암호는 apc 입니다. 기본적으로 이 장치는 각 노드에 대해 60초의 모니터 간격을 사용합니다.
노드의 호스트 이름을 지정할 때 IP 주소를 사용할 수 있습니다.
pcs stonith create myapc fence_apc_snmp ipaddr="zapc.example.com" pcmk_host_map="z1.example.com:1;z2.example.com:2" login="apc" passwd="apc"
[root@z1 ~]# pcs stonith create myapc fence_apc_snmp ipaddr="zapc.example.com" pcmk_host_map="z1.example.com:1;z2.example.com:2" login="apc" passwd="apc"다음 명령은 기존 펜싱 장치의 매개 변수를 표시합니다.
pcs stonith config myapc Resource: myapc (class=stonith type=fence_apc_snmp) Attributes: ipaddr=zapc.example.com pcmk_host_map=z1.example.com:1;z2.example.com:2 login=apc passwd=apc Operations: monitor interval=60s (myapc-monitor-interval-60s)
[root@rh7-1 ~]# pcs stonith config myapc
Resource: myapc (class=stonith type=fence_apc_snmp)
Attributes: ipaddr=zapc.example.com pcmk_host_map=z1.example.com:1;z2.example.com:2 login=apc passwd=apc
Operations: monitor interval=60s (myapc-monitor-interval-60s)펜스 장치를 구성한 후 장치를 테스트해야 합니다. 펜스 장치를 테스트하는 방법에 대한 자세한 내용은 차단 장치 테스트를 참조하십시오.
네트워크 인터페이스를 비활성화하여 펜스 장치를 테스트하지 마십시오. 펜싱을 제대로 테스트하지 않기 때문입니다.
펜싱이 구성되고 클러스터가 시작되면 네트워크 재시작이 노드의 펜싱을 트리거하여 시간 초과를 초과하지 않는 경우에도 네트워크를 다시 시작합니다. 따라서 노드에서 의도하지 않은 펜싱을 트리거하므로 클러스터 서비스가 실행되는 동안 네트워크 서비스를 재시작하지 마십시오.
48.6. 클러스터 구성 백업 및 복원
다음 명령은 tar 아카이브에 클러스터 구성을 백업하고 백업의 모든 노드에서 클러스터 구성 파일을 복원합니다.
절차
다음 명령을 사용하여 tar 아카이브로 클러스터 구성을 백업합니다. 파일 이름을 지정하지 않으면 표준 출력이 사용됩니다.
pcs config backup filename
pcs config backup filename
pcs config backup 명령은 CIB에 구성된 클러스터 구성 자체만 백업합니다. 리소스 데몬 구성은 이 명령의 범위를 벗어납니다. 예를 들어 클러스터에서 Apache 리소스를 구성한 경우, Apache 데몬 설정('/etc/httpd'에 설정된)과 서비스하는 파일이 백업되지 않는 리소스 설정(CIB에 있음)이 백업됩니다. 마찬가지로 클러스터에 데이터베이스 리소스가 구성된 경우 CIB(데이터베이스 리소스 구성)는 데이터베이스 리소스 구성(CIB)이 되는 동안 데이터베이스 자체는 백업되지 않습니다.
다음 명령을 사용하여 백업에서 모든 클러스터 노드의 클러스터 구성 파일을 복원합니다. --local 옵션을 지정하면 이 명령을 실행하는 노드에서만 클러스터 구성 파일이 복원됩니다. 파일 이름을 지정하지 않으면 표준 입력이 사용됩니다.
pcs config restore [--local] [filename]
pcs config restore [--local] [filename]48.7. 고가용성 애드온용 포트 활성화
클러스터 구성 요소에 대한 이상적인 방화벽 구성은 로컬 환경에 따라 다릅니다. 여기서 노드에 여러 네트워크 인터페이스가 있는지 또는 오프 호스트 방화벽이 있는지 여부와 같은 고려 사항을 고려해야 할 수 있습니다.
firewalld 데몬을 실행하는 경우 다음 명령을 실행하여 Red Hat High Availability Add-On에 필요한 포트를 활성화합니다.
firewall-cmd --permanent --add-service=high-availability firewall-cmd --add-service=high-availability
# firewall-cmd --permanent --add-service=high-availability
# firewall-cmd --add-service=high-availability로컬 조건에 맞게 열려 있는 포트를 수정해야 할 수 있습니다.
rpm -q firewalld 명령을 사용하여 시스템에 firewalld 데몬이 설치되었는지 확인할 수 있습니다. firewalld 데몬이 설치된 경우 firewall-cmd --state 명령을 사용하여 실행 중인지 확인할 수 있습니다.
다음 표에서는 Red Hat High Availability Add-On에 사용할 수 있는 포트를 보여주고 포트를 사용하는 방법에 대한 설명을 제공합니다.
| 포트 | 필수인 경우 |
|---|---|
| TCP 2224 |
모든 노드에 기본
2224 포트를 여는 것이 중요합니다. 이러한 방식으로 모든 노드의 |
| TCP 3121 | 클러스터에 Pacemaker 원격 노드가 있는 경우 모든 노드에 필요합니다.
전체 클러스터 노드의 Pacemaker |
| TCP 5403 |
|
| UDP 5404-5412 |
노드 간 통신을 용이하게 하려면 corosync 노드에 필요합니다. 모든 노드에서 |
| TCP 21064 |
클러스터에 DLM이 필요한 리소스(예: Cryostat |
| TCP 9929, UDP 9929 | Booth 티켓 관리자가 다중 사이트 클러스터를 설정하는 데 사용될 때 동일한 노드의 연결에 모든 클러스터 노드와 Booth 중재자 노드에서 열려 있어야 합니다. |
49장. Red Hat High Availability 클러스터에서 활성/수동 Apache HTTP 서버 구성
다음 절차에 따라 2-노드 Red Hat Enterprise Linux High Availability Add-On 클러스터에서 활성/수동 Apache HTTP 서버를 구성합니다. 이 사용 사례에서 클라이언트는 유동 IP 주소를 통해 Apache HTTP 서버에 액세스합니다. 웹 서버는 클러스터의 두 노드 중 하나에서 실행됩니다. 웹 서버가 실행 중인 노드가 작동하지 않게 되면 서비스 중단을 최소화하여 클러스터의 두 번째 노드에서 웹 서버가 다시 시작됩니다.
다음 그림은 클러스터가 네트워크 전원 스위치 및 공유 스토리지로 구성된 2-노드 Red Hat High Availability 클러스터인 클러스터에 대한 개괄적인 개요를 보여줍니다. 클러스터 노드는 가상 IP를 통해 Apache HTTP 서버에 대한 클라이언트 액세스용 공용 네트워크에 연결됩니다. Apache 서버는 노드 1 또는 노드 2에서 실행됩니다. 각 서버는 Apache 데이터가 보관되는 스토리지에 액세스할 수 있습니다. 이 그림에서는 노드 1이 작동하지 않는 경우 노드 2를 사용하여 서버를 실행할 수 있는 동안 웹 서버가 노드 1에서 실행되고 있습니다.
그림 49.1. Red Hat High Availability Two-Node Cluster의 Apache

이 사용 사례에서는 시스템에 다음 구성 요소를 포함해야 합니다.
- 각 노드에 전원 펜싱이 구성된 2-노드 Red Hat High Availability 클러스터입니다. 추천하지만 사설 네트워크가 필요하지 않습니다. 이 절차에서는 Pacemaker가 있는 Red Hat High-Availability 클러스터 생성에 제공된 클러스터 예제를 사용합니다.
- Apache에 필요한 공용 가상 IP 주소입니다.
- iSCSI, 파이버 채널 또는 기타 공유 네트워크 블록 장치를 사용하여 클러스터의 노드의 공유 스토리지입니다.
클러스터는 웹 서버에 필요한 클러스터 구성 요소(예: LVM 리소스, 파일 시스템 리소스, IP 주소 리소스, 웹 서버 리소스)를 포함하는 Apache 리소스 그룹으로 구성됩니다. 이 리소스 그룹은 클러스터의 한 노드에서 다른 노드로 장애 조치하여 웹 서버를 실행할 수 있습니다. 이 클러스터에 대한 리소스 그룹을 생성하기 전에 다음 절차를 수행합니다.
-
논리 볼륨
my_lv에 XFS 파일 시스템을 구성합니다. - 웹 서버를 구성합니다.
이러한 단계를 수행한 후 리소스 그룹과 포함된 리소스를 생성합니다.
49.1. Pacemaker 클러스터에서 XFS 파일 시스템으로 LVM 볼륨 구성
다음 절차에 따라 클러스터 노드 간에 공유되는 LVM 논리 볼륨을 스토리지에 생성합니다.
LVM 볼륨과 클러스터 노드에서 사용하는 해당 파티션 및 장치는 클러스터 노드에만 연결되어 있어야 합니다.
다음 절차에서는 LVM 논리 볼륨을 생성한 다음 Pacemaker 클러스터에서 사용할 해당 볼륨에 XFS 파일 시스템을 생성합니다. 이 예에서 공유 파티션 /dev/sdb1 은 LVM 논리 볼륨이 생성될 LVM 물리 볼륨을 저장하는 데 사용됩니다.
절차
클러스터의 두 노드에서 다음 단계를 수행하여 LVM 시스템 ID의 값을 시스템의
uname식별자 값으로 설정합니다. LVM 시스템 ID는 클러스터만 볼륨 그룹을 활성화할 수 있도록 하는 데 사용됩니다./etc/lvm/lvm.conf구성 파일의system_id_source구성 옵션을uname으로 설정합니다.# Configuration option global/system_id_source. system_id_source = "uname"
# Configuration option global/system_id_source. system_id_source = "uname"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 노드의 LVM 시스템 ID가 노드의
uname과 일치하는지 확인합니다.lvm systemid system ID: z1.example.com uname -n z1.example.com
# lvm systemid system ID: z1.example.com # uname -n z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
LVM 볼륨을 생성하고 해당 볼륨에 XFS 파일 시스템을 만듭니다.
/dev/sdb1파티션은 공유된 스토리지이므로 하나의 노드에서만 이 절차를 수행합니다.pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created
[root@z1 ~]# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고LVM 볼륨 그룹에 iSCSI 대상과 같이 원격 블록 스토리지에 있는 하나 이상의 물리 볼륨이 포함된 경우 Pacemaker를 시작하기 전에 서비스가 시작되도록 하는 것이 좋습니다. Pacemaker 클러스터에서 사용하는 원격 물리 볼륨의 시작 순서를 구성하는 방법에 대한 자세한 내용은 Pacemaker에서 관리하지 않는 리소스 종속 항목의 시작 순서 구성 을 참조하십시오.
물리 볼륨
/dev/sdb1로 구성된my_vg볼륨 그룹을 만듭니다.RHEL 8.5 이상에서는 클러스터에서 Pacemaker에서 관리하는 볼륨 그룹이 시작 시 자동으로 활성화되지 않도록
--setautoactivation n플래그를 지정합니다. 생성 중인 LVM 볼륨에 기존 볼륨 그룹을 사용하는 경우 볼륨 그룹에 대해--setautoactivation n명령을 사용하여 이 플래그를 재설정할 수 있습니다.vgcreate --setautoactivation n my_vg /dev/sdb1 Volume group "my_vg" successfully created
[root@z1 ~]# vgcreate --setautoactivation n my_vg /dev/sdb1 Volume group "my_vg" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.4 및 이전 버전의 경우 다음 명령을 사용하여 볼륨 그룹을 만듭니다.
vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully created
[root@z1 ~]# vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.4 및 이전 버전의 시작 시 클러스터의 Pacemaker에서 관리하는 볼륨 그룹이 자동으로 활성화되지 않도록 하는 방법에 대한 자세한 내용은 여러 클러스터 노드에서 볼륨 그룹 활성화를 참조하십시오.
새 볼륨 그룹에 실행 중인 노드의 시스템 ID와 볼륨 그룹을 생성한 노드의 시스템 ID가 있는지 확인합니다.
vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.com
[root@z1 ~]# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹
my_vg를 사용하여 논리 볼륨을 생성합니다.lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" created
[root@z1 ~]# lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow lvs명령을 사용하여 논리 볼륨을 표시할 수 있습니다.lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...
[root@z1 ~]# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨
my_lv에 XFS 파일 시스템을 생성합니다.mkfs.xfs /dev/my_vg/my_lv meta-data=/dev/my_vg/my_lv isize=512 agcount=4, agsize=28928 blks = sectsz=512 attr=2, projid32bit=1 ...[root@z1 ~]# mkfs.xfs /dev/my_vg/my_lv meta-data=/dev/my_vg/my_lv isize=512 agcount=4, agsize=28928 blks = sectsz=512 attr=2, projid32bit=1 ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
(RHEL 8.5 이상)
lvm.conf파일에서use_devicesfile = 1을 설정하여 장치 파일을 사용하도록 설정한 경우 클러스터의 두 번째 노드의 장치 파일에 공유 장치를 추가합니다. 기본적으로 장치 파일 사용은 활성화되어 있지 않습니다.lvmdevices --adddev /dev/sdb1
[root@z2 ~]# lvmdevices --adddev /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
49.2. 볼륨 그룹이 여러 클러스터 노드에서 활성화되지 않았는지 확인(RHEL 8.4 및 이전 버전)
다음 절차에 따라 클러스터의 Pacemaker에서 관리하는 볼륨 그룹이 시작 시 자동으로 활성화되지 않도록 할 수 있습니다. Pacemaker가 아닌 시작 시 볼륨 그룹을 자동으로 활성화하면 볼륨 그룹이 동시에 여러 노드에서 활성화될 위험이 있으므로 볼륨 그룹의 메타데이터가 손상될 수 있습니다.
RHEL 8.5 이상 버전의 경우 Pacemaker 클러스터에서 XFS 파일 시스템을 사용하여 LVM 볼륨 구성에 설명된 대로 볼륨 그룹을 생성할 때 볼륨 그룹에 대한 자동 활성화를 비활성화할 수 있습니다.
이 절차에서는 /etc/lvm/lvm.conf 구성 파일의 auto_activation_volume_list 항목을 수정합니다. auto_activation_volume_list 항목은 자동 활성화를 특정 논리 볼륨으로 제한하는 데 사용됩니다. auto_activation_volume_list 를 빈 목록으로 설정하면 자동 활성화가 완전히 비활성화됩니다.
Pacemaker에서 공유되지 않고 관리하지 않는 로컬 볼륨은 노드의 로컬 루트 및 홈 디렉터리와 관련된 볼륨 그룹을 포함하여 auto_activation_volume_list 항목에 포함되어야 합니다. 클러스터 관리자가 관리하는 모든 볼륨 그룹은 auto_activation_volume_list 항목에서 제외되어야 합니다.
절차
클러스터의 각 노드에서 다음 절차를 수행합니다.
다음 명령을 사용하여 현재 로컬 스토리지에 구성된 볼륨 그룹을 확인합니다. 그러면 현재 구성된 볼륨 그룹 목록이 출력됩니다. root 및 이 노드의 홈 디렉터리에 대해 별도의 볼륨 그룹에 할당된 공간이 있는 경우 이 예와 같이 출력에 해당 볼륨이 표시됩니다.
vgs --noheadings -o vg_name my_vg rhel_home rhel_root
# vgs --noheadings -o vg_name my_vg rhel_home rhel_rootCopy to Clipboard Copied! Toggle word wrap Toggle overflow my_vg이외의 볼륨 그룹(클러스터에 대해 정의한 볼륨 그룹)을/etc/lvm/lvm.conf구성 파일의auto_activation_volume_list에 추가합니다.예를 들어 루트 및 홈 디렉토리에 대해 별도의 볼륨 그룹에 할당된 공간이 있는 경우
lvm.conf파일의auto_activation_volume_list행의 주석을 제거하고 이러한 볼륨 그룹을 다음과 같이auto_activation_volume_list에 항목으로 추가합니다. 클러스터에 대해 정의한 볼륨 그룹(이 예제의my_vg)은 이 목록에 없습니다.auto_activation_volume_list = [ "rhel_root", "rhel_home" ]
auto_activation_volume_list = [ "rhel_root", "rhel_home" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고클러스터 관리자 외부에 활성화할 노드에 로컬 볼륨 그룹이 없는 경우 auto_activation_volume_list 항목을
auto_activation_로 초기화해야 합니다.volume_list= []initramfs부팅 이미지를 다시 빌드하여 부팅 이미지가 클러스터에서 제어하는 볼륨 그룹을 활성화하지 않도록 합니다. 다음 명령으로initramfs장치를 업데이트합니다. 이 명령을 완료하는 데 최대 1분이 걸릴 수 있습니다.dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)
# dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 노드를 재부팅합니다.
참고부팅 이미지를 생성한 노드를 부팅한 후 새 Linux 커널을 설치한 경우 새
initrd이미지는 노드를 재부팅할 때 실행 중인 새 커널이 아니라 실행 중인 커널에 사용됩니다. 재부팅 전후에uname -r명령을 실행하여 실행 중인 커널 릴리스를 확인하여 올바른initrd장치가 사용 중인지 확인할 수 있습니다. 릴리스가 동일하지 않은 경우 새 커널로 재부팅한 후initrd파일을 업데이트한 다음 노드를 재부팅합니다.노드가 재부팅되면 해당 노드에서
pcs cluster status명령을 실행하여 해당 노드에서 클러스터 서비스가 다시 시작되었는지 확인합니다.Error: cluster is not currently running on this node메시지가 표시되면 다음 명령을 입력합니다.pcs cluster start
# pcs cluster startCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 다음 명령을 사용하여 클러스터의 각 노드를 재부팅하고 클러스터의 모든 노드에서 클러스터 서비스를 시작할 때까지 기다릴 수 있습니다.
pcs cluster start --all
# pcs cluster start --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
49.3. Apache HTTP Server 구성
다음 절차에 따라 Apache HTTP Server를 구성합니다.
절차
클러스터의 각 노드에 Apache HTTP Server가 설치되어 있는지 확인합니다. 또한 Apache HTTP Server의 상태를 확인할 수 있도록
wget툴이 클러스터에 설치되어 있어야 합니다.각 노드에서 다음 명령을 실행합니다.
yum install -y httpd wget
# yum install -y httpd wgetCopy to Clipboard Copied! Toggle word wrap Toggle overflow firewalld데몬을 실행하는 경우 클러스터의 각 노드에서 Red Hat High Availability Add-On에 필요한 포트를 활성화하고httpd를 실행하는 데 필요한 포트를 활성화합니다. 이 예제에서는 공용 액세스를 위해httpd포트를 활성화하지만httpd에 대해 활성화할 특정 포트는 프로덕션 용도에 따라 다를 수 있습니다.firewall-cmd --permanent --add-service=http firewall-cmd --permanent --zone=public --add-service=http firewall-cmd --reload
# firewall-cmd --permanent --add-service=http # firewall-cmd --permanent --zone=public --add-service=http # firewall-cmd --reloadCopy to Clipboard Copied! Toggle word wrap Toggle overflow Apache 리소스 에이전트가 클러스터의 각 노드에서 Apache의 상태를 가져오려면 기존 구성에 다음을 추가하여 상태 서버 URL을 활성화합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Apache가 제공할 웹 페이지를 만듭니다.
클러스터의 한 노드에서 XFS 파일 시스템을 사용하여 LVM 볼륨 구성에서 생성한 논리 볼륨이 활성화되었는지 확인하고, 해당 논리 볼륨에서 생성한 파일 시스템을 마운트하고 해당 파일 시스템에 파일
index.html을 생성한 다음 파일 시스템을 마운트 해제합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
49.4. 리소스 및 리소스 그룹 생성
다음 절차에 따라 클러스터의 리소스를 생성합니다. 이러한 리소스가 모두 동일한 노드에서 실행되도록 리소스 그룹 apachegroup 의 일부로 구성됩니다. 생성할 리소스는 다음과 같습니다.
-
XFS 파일 시스템으로
LVM 볼륨 구성에서 생성한 LVM 볼륨 그룹을 사용하는-활성화 리소스.my_lvm이라는 LVM -
XFS 파일 시스템을 사용하여 LVM 볼륨 구성에서 생성한 파일 시스템 장치
/dev/my_vg/my_lv를 사용하는my_fs라는Filesystem리소스. -
apachegroup리소스 그룹의 유동 IP 주소인IPaddr2리소스입니다. IP 주소는 이미 물리적 노드와 연결되어 있지 않아야 합니다.IPaddr2리소스의 NIC 장치를 지정하지 않으면 유동 IP가 노드의 정적으로 할당된 IP 주소 중 하나와 동일한 네트워크에 있어야 합니다. 그렇지 않으면 유동 IP 주소를 할당하는 NIC 장치를 올바르게 감지할 수 없습니다. -
index.html파일과 Apache HTTP 서버 구성에서 정의한 Apache 구성을 사용하는website라는apache리소스입니다.
다음 절차에서는 리소스 그룹 apachegroup 과 그룹에 포함된 리소스를 생성합니다. 리소스는 그룹에 추가하는 순서대로 시작되고 그룹에 추가된 역순으로 중지합니다. 클러스터의 한 노드에서만 이 절차를 실행합니다.
절차
다음 명령은
LVM-activate리소스my_lvm을 생성합니다. 리소스 그룹apachegroup은 아직 존재하지 않으므로 이 명령은 리소스 그룹을 생성합니다.참고활성/수동 HA 구성에서 동일한
LVM 볼륨 그룹을 사용하는 두 개 이상의 LVM 활성화리소스를 구성하지 마십시오. 이로 인해 데이터 손상이 발생할 수 있습니다. 또한LVM-activate리소스를 활성/수동 HA 구성에 복제 리소스로 구성하지 마십시오.pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroup
[root@z1 ~]# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 리소스를 생성하면 리소스가 자동으로 시작됩니다. 다음 명령을 사용하여 리소스가 생성되고 시작되었는지 확인할 수 있습니다.
pcs resource status Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): Started# pcs resource status Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): StartedCopy to Clipboard Copied! Toggle word wrap Toggle overflow pcs resource disable및pcs resource enable명령을 사용하여 개별 리소스를 수동으로 중지하고 시작할 수 있습니다.다음 명령은 구성에 대한 나머지 리소스를 생성하여 기존 리소스 그룹
apachegroup에 추가합니다.pcs resource create my_fs Filesystem device="/dev/my_vg/my_lv" directory="/var/www" fstype="xfs" --group apachegroup pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 cidr_netmask=24 --group apachegroup pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroup
[root@z1 ~]# pcs resource create my_fs Filesystem device="/dev/my_vg/my_lv" directory="/var/www" fstype="xfs" --group apachegroup [root@z1 ~]# pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 cidr_netmask=24 --group apachegroup [root@z1 ~]# pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 리소스 및 리소스가 포함된 리소스 그룹을 생성한 후 클러스터 상태를 확인할 수 있습니다. 4개의 리소스 모두 동일한 노드에서 실행되고 있습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 펜싱 장치를 구성하지 않은 경우 기본적으로 리소스가 시작되지 않습니다.
클러스터가 가동되어 실행되면 브라우저에서
IPaddr2리소스로 정의된 IP 주소를 가리키면 간단한 단어 "Hello"로 구성된 샘플 디스플레이를 볼 수 있습니다.Hello
HelloCopy to Clipboard Copied! Toggle word wrap Toggle overflow 구성한 리소스가 실행되고 있지 않은 경우
pcs resource debug-start resource명령을 실행하여 리소스 구성을 테스트할 수 있습니다.apache리소스 에이전트를 사용하여 Apache를 관리하면systemd를 사용하지 않습니다. 이로 인해systemctl을 사용하여 Apache를 다시 로드하지 않도록 Apache와 함께 제공된logrotate스크립트를 편집해야 합니다.클러스터의 각 노드에서
/etc/logrotate.d/httpd파일에서 다음 행을 제거합니다./bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.6 이상의 경우 제거된 행을 다음 세 줄로 교체하여
/var/run/httpd-website.pid를 PID 파일 경로로 지정합니다. 여기서 website 가 Apache 리소스의 이름입니다. 이 예제에서 Apache 리소스 이름은website입니다./usr/bin/test -f /var/run/httpd-Website.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /var/run/httpd-Website.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /var/run/httpd-Website.pid" -k graceful > /dev/null 2>/dev/null || true
/usr/bin/test -f /var/run/httpd-Website.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /var/run/httpd-Website.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /var/run/httpd-Website.pid" -k graceful > /dev/null 2>/dev/null || trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.5 및 이전 버전의 경우 제거한 행을 다음 세 줄로 바꿉니다.
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
49.5. 리소스 구성 테스트
다음 절차에 따라 클러스터에서 리소스 구성을 테스트합니다.
리소스 및 리소스 그룹 생성에 표시된 클러스터 상태 디스플레이에서 모든 리소스가 z1.example.com 노드에서 실행되고 있습니다. 다음 절차에 따라 리소스 그룹이 노드 z2.example.com 으로 장애 조치되는지 여부를 테스트할 수 있습니다. 그러면 노드가 더 이상 리소스를 호스팅할 수 없게 됩니다.
절차
다음 명령은 노드
z1.example.com을standby모드에 둡니다.pcs node standby z1.example.com
[root@z1 ~]# pcs node standby z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 노드
z1을standby모드에 배치한 후 클러스터 상태를 확인합니다. 이제 리소스가 모두z2에서 실행되어야 합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 정의된 IP 주소에 있는 웹 사이트는 중단 없이 계속 표시되어야 합니다.
대기모드에서z1을 제거하려면 다음 명령을 입력합니다.pcs node unstandby z1.example.com
[root@z1 ~]# pcs node unstandby z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고standby모드에서 노드를 제거해도 리소스가 해당 노드로 되돌아가지 않습니다. 이는 리소스의resource-stickiness값에 따라 달라집니다.resource-stickinessmeta 속성에 대한 자세한 내용은 현재 노드를 선호하도록 리소스 구성을 참조하십시오.
50장. Red Hat High Availability 클러스터에서 활성/수동 NFS 서버 구성
Red Hat High Availability Add-On은 공유 스토리지를 사용하여 Red Hat Enterprise Linux High Availability Add-On 클러스터에서 고가용성/패시브 NFS 서버를 실행할 수 있도록 지원합니다. 다음 예제에서는 클라이언트가 유동 IP 주소를 통해 NFS 파일 시스템에 액세스하는 2-노드 클러스터를 구성하고 있습니다. NFS 서버는 클러스터의 두 노드 중 하나에서 실행됩니다. NFS 서버가 실행 중인 노드가 작동하지 않게 되면 서비스 중단을 최소화하여 클러스터의 두 번째 노드에서 NFS 서버가 다시 시작됩니다.
이 사용 사례에서는 시스템에 다음 구성 요소를 포함해야 합니다.
- 각 노드에 전원 펜싱이 구성된 2-노드 Red Hat High Availability 클러스터입니다. 추천하지만 사설 네트워크가 필요하지 않습니다. 이 절차에서는 Pacemaker가 있는 Red Hat High-Availability 클러스터 생성에 제공된 클러스터 예제를 사용합니다.
- NFS 서버에 필요한 공용 가상 IP 주소입니다.
- iSCSI, 파이버 채널 또는 기타 공유 네트워크 블록 장치를 사용하여 클러스터의 노드의 공유 스토리지입니다.
기존의 2-노드 Red Hat Enterprise Linux High Availability 클러스터에 고가용성 활성/패시브 NFS 서버를 구성하려면 다음 단계를 수행해야 합니다.
- 클러스터의 노드의 공유 스토리지의 LVM 논리 볼륨에서 파일 시스템을 구성합니다.
- LVM 논리 볼륨의 공유 스토리지에 NFS 공유를 구성합니다.
- 클러스터 리소스를 생성합니다.
- 구성한 NFS 서버를 테스트합니다.
50.1. Pacemaker 클러스터에서 XFS 파일 시스템으로 LVM 볼륨 구성
다음 절차에 따라 클러스터 노드 간에 공유되는 LVM 논리 볼륨을 스토리지에 생성합니다.
LVM 볼륨과 클러스터 노드에서 사용하는 해당 파티션 및 장치는 클러스터 노드에만 연결되어 있어야 합니다.
다음 절차에서는 LVM 논리 볼륨을 생성한 다음 Pacemaker 클러스터에서 사용할 해당 볼륨에 XFS 파일 시스템을 생성합니다. 이 예에서 공유 파티션 /dev/sdb1 은 LVM 논리 볼륨이 생성될 LVM 물리 볼륨을 저장하는 데 사용됩니다.
절차
클러스터의 두 노드에서 다음 단계를 수행하여 LVM 시스템 ID의 값을 시스템의
uname식별자 값으로 설정합니다. LVM 시스템 ID는 클러스터만 볼륨 그룹을 활성화할 수 있도록 하는 데 사용됩니다./etc/lvm/lvm.conf구성 파일의system_id_source구성 옵션을uname으로 설정합니다.# Configuration option global/system_id_source. system_id_source = "uname"
# Configuration option global/system_id_source. system_id_source = "uname"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 노드의 LVM 시스템 ID가 노드의
uname과 일치하는지 확인합니다.lvm systemid system ID: z1.example.com uname -n z1.example.com
# lvm systemid system ID: z1.example.com # uname -n z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
LVM 볼륨을 생성하고 해당 볼륨에 XFS 파일 시스템을 만듭니다.
/dev/sdb1파티션은 공유된 스토리지이므로 하나의 노드에서만 이 절차를 수행합니다.pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created
[root@z1 ~]# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고LVM 볼륨 그룹에 iSCSI 대상과 같이 원격 블록 스토리지에 있는 하나 이상의 물리 볼륨이 포함된 경우 Pacemaker를 시작하기 전에 서비스가 시작되도록 하는 것이 좋습니다. Pacemaker 클러스터에서 사용하는 원격 물리 볼륨의 시작 순서를 구성하는 방법에 대한 자세한 내용은 Pacemaker에서 관리하지 않는 리소스 종속 항목의 시작 순서 구성 을 참조하십시오.
물리 볼륨
/dev/sdb1로 구성된my_vg볼륨 그룹을 만듭니다.RHEL 8.5 이상에서는 클러스터에서 Pacemaker에서 관리하는 볼륨 그룹이 시작 시 자동으로 활성화되지 않도록
--setautoactivation n플래그를 지정합니다. 생성 중인 LVM 볼륨에 기존 볼륨 그룹을 사용하는 경우 볼륨 그룹에 대해--setautoactivation n명령을 사용하여 이 플래그를 재설정할 수 있습니다.vgcreate --setautoactivation n my_vg /dev/sdb1 Volume group "my_vg" successfully created
[root@z1 ~]# vgcreate --setautoactivation n my_vg /dev/sdb1 Volume group "my_vg" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.4 및 이전 버전의 경우 다음 명령을 사용하여 볼륨 그룹을 만듭니다.
vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully created
[root@z1 ~]# vgcreate my_vg /dev/sdb1 Volume group "my_vg" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow RHEL 8.4 및 이전 버전의 시작 시 클러스터의 Pacemaker에서 관리하는 볼륨 그룹이 자동으로 활성화되지 않도록 하는 방법에 대한 자세한 내용은 여러 클러스터 노드에서 볼륨 그룹 활성화를 참조하십시오.
새 볼륨 그룹에 실행 중인 노드의 시스템 ID와 볼륨 그룹을 생성한 노드의 시스템 ID가 있는지 확인합니다.
vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.com
[root@z1 ~]# vgs -o+systemid VG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹
my_vg를 사용하여 논리 볼륨을 생성합니다.lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" created
[root@z1 ~]# lvcreate -L450 -n my_lv my_vg Rounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow lvs명령을 사용하여 논리 볼륨을 표시할 수 있습니다.lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...
[root@z1 ~]# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨
my_lv에 XFS 파일 시스템을 생성합니다.mkfs.xfs /dev/my_vg/my_lv meta-data=/dev/my_vg/my_lv isize=512 agcount=4, agsize=28928 blks = sectsz=512 attr=2, projid32bit=1 ...[root@z1 ~]# mkfs.xfs /dev/my_vg/my_lv meta-data=/dev/my_vg/my_lv isize=512 agcount=4, agsize=28928 blks = sectsz=512 attr=2, projid32bit=1 ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow
(RHEL 8.5 이상)
lvm.conf파일에서use_devicesfile = 1을 설정하여 장치 파일을 사용하도록 설정한 경우 클러스터의 두 번째 노드의 장치 파일에 공유 장치를 추가합니다. 기본적으로 장치 파일 사용은 활성화되어 있지 않습니다.lvmdevices --adddev /dev/sdb1
[root@z2 ~]# lvmdevices --adddev /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
50.2. 볼륨 그룹이 여러 클러스터 노드에서 활성화되지 않았는지 확인(RHEL 8.4 및 이전 버전)
다음 절차에 따라 클러스터의 Pacemaker에서 관리하는 볼륨 그룹이 시작 시 자동으로 활성화되지 않도록 할 수 있습니다. Pacemaker가 아닌 시작 시 볼륨 그룹을 자동으로 활성화하면 볼륨 그룹이 동시에 여러 노드에서 활성화될 위험이 있으므로 볼륨 그룹의 메타데이터가 손상될 수 있습니다.
RHEL 8.5 이상 버전의 경우 Pacemaker 클러스터에서 XFS 파일 시스템을 사용하여 LVM 볼륨 구성에 설명된 대로 볼륨 그룹을 생성할 때 볼륨 그룹에 대한 자동 활성화를 비활성화할 수 있습니다.
이 절차에서는 /etc/lvm/lvm.conf 구성 파일의 auto_activation_volume_list 항목을 수정합니다. auto_activation_volume_list 항목은 자동 활성화를 특정 논리 볼륨으로 제한하는 데 사용됩니다. auto_activation_volume_list 를 빈 목록으로 설정하면 자동 활성화가 완전히 비활성화됩니다.
Pacemaker에서 공유되지 않고 관리하지 않는 로컬 볼륨은 노드의 로컬 루트 및 홈 디렉터리와 관련된 볼륨 그룹을 포함하여 auto_activation_volume_list 항목에 포함되어야 합니다. 클러스터 관리자가 관리하는 모든 볼륨 그룹은 auto_activation_volume_list 항목에서 제외되어야 합니다.
절차
클러스터의 각 노드에서 다음 절차를 수행합니다.
다음 명령을 사용하여 현재 로컬 스토리지에 구성된 볼륨 그룹을 확인합니다. 그러면 현재 구성된 볼륨 그룹 목록이 출력됩니다. root 및 이 노드의 홈 디렉터리에 대해 별도의 볼륨 그룹에 할당된 공간이 있는 경우 이 예와 같이 출력에 해당 볼륨이 표시됩니다.
vgs --noheadings -o vg_name my_vg rhel_home rhel_root
# vgs --noheadings -o vg_name my_vg rhel_home rhel_rootCopy to Clipboard Copied! Toggle word wrap Toggle overflow my_vg이외의 볼륨 그룹(클러스터에 대해 정의한 볼륨 그룹)을/etc/lvm/lvm.conf구성 파일의auto_activation_volume_list에 추가합니다.예를 들어 루트 및 홈 디렉토리에 대해 별도의 볼륨 그룹에 할당된 공간이 있는 경우
lvm.conf파일의auto_activation_volume_list행의 주석을 제거하고 이러한 볼륨 그룹을 다음과 같이auto_activation_volume_list에 항목으로 추가합니다. 클러스터에 대해 정의한 볼륨 그룹(이 예제의my_vg)은 이 목록에 없습니다.auto_activation_volume_list = [ "rhel_root", "rhel_home" ]
auto_activation_volume_list = [ "rhel_root", "rhel_home" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고클러스터 관리자 외부에 활성화할 노드에 로컬 볼륨 그룹이 없는 경우 auto_activation_volume_list 항목을
auto_activation_로 초기화해야 합니다.volume_list= []initramfs부팅 이미지를 다시 빌드하여 부팅 이미지가 클러스터에서 제어하는 볼륨 그룹을 활성화하지 않도록 합니다. 다음 명령으로initramfs장치를 업데이트합니다. 이 명령을 완료하는 데 최대 1분이 걸릴 수 있습니다.dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)
# dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 노드를 재부팅합니다.
참고부팅 이미지를 생성한 노드를 부팅한 후 새 Linux 커널을 설치한 경우 새
initrd이미지는 노드를 재부팅할 때 실행 중인 새 커널이 아니라 실행 중인 커널에 사용됩니다. 재부팅 전후에uname -r명령을 실행하여 실행 중인 커널 릴리스를 확인하여 올바른initrd장치가 사용 중인지 확인할 수 있습니다. 릴리스가 동일하지 않은 경우 새 커널로 재부팅한 후initrd파일을 업데이트한 다음 노드를 재부팅합니다.노드가 재부팅되면 해당 노드에서
pcs cluster status명령을 실행하여 해당 노드에서 클러스터 서비스가 다시 시작되었는지 확인합니다.Error: cluster is not currently running on this node메시지가 표시되면 다음 명령을 입력합니다.pcs cluster start
# pcs cluster startCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는 다음 명령을 사용하여 클러스터의 각 노드를 재부팅하고 클러스터의 모든 노드에서 클러스터 서비스를 시작할 때까지 기다릴 수 있습니다.
pcs cluster start --all
# pcs cluster start --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
50.4. 클러스터에서 NFS 서버의 리소스 및 리소스 그룹 구성
다음 절차에 따라 클러스터에서 NFS 서버의 클러스터 리소스를 구성합니다.
클러스터의 펜싱 장치를 구성하지 않은 경우 기본적으로 리소스가 시작되지 않습니다.
구성한 리소스가 실행되고 있지 않은 경우 pcs resource debug-start resource 명령을 실행하여 리소스 구성을 테스트할 수 있습니다. 이렇게 하면 클러스터의 제어 및 지식 외부에서 서비스가 시작됩니다. 구성된 리소스가 다시 실행 중인 시점에 pcs resourcecleanup 리소스 를 실행하여 클러스터에 업데이트를 알립니다.
절차
다음 절차에서는 시스템 리소스를 구성합니다. 이러한 리소스가 모두 동일한 노드에서 실행되도록 리소스 그룹 nfsgroup 의 일부로 구성됩니다. 리소스는 그룹에 추가하는 순서대로 시작되고 그룹에 추가된 역순으로 중지합니다. 클러스터의 한 노드에서만 이 절차를 실행합니다.
my_lvm이라는 LVM-activate 리소스를 만듭니다. 리소스 그룹nfsgroup이 아직 존재하지 않기 때문에 이 명령은 리소스 그룹을 생성합니다.주의이 위험이 데이터 손상될 수 있으므로 활성/수동 HA 구성에서 동일한 LVM 볼륨 그룹을 사용하는 두 개 이상의 LVM
활성화리소스를 구성하지 마십시오. 또한LVM-activate리소스를 활성/수동 HA 구성에 복제 리소스로 구성하지 마십시오.pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group nfsgroup
[root@z1 ~]# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group nfsgroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인하여 리소스가 실행 중인지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의
Filesystem리소스를 구성합니다.다음 명령은
nfsshare라는 XFSFilesystem리소스를nfsgroup리소스 그룹의 일부로 구성합니다. 이 파일 시스템은 XFS 파일 시스템으로 LVM 볼륨 구성에서 생성한 LVM 볼륨 그룹과 XFS 파일 시스템을 사용하며, NFS 공유 구성에서 생성한/nfsshare디렉터리에 마운트됩니다.pcs resource create nfsshare Filesystem device=/dev/my_vg/my_lv directory=/nfsshare fstype=xfs --group nfsgroup
[root@z1 ~]# pcs resource create nfsshare Filesystem device=/dev/my_vg/my_lv directory=/nfsshare fstype=xfs --group nfsgroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow options= options매개변수를 사용하여Filesystem리소스의 리소스 구성의 일부로 마운트 옵션을 지정할 수있습니다. 전체 구성 옵션에 대해pcs resource describe Filesystem명령을 실행합니다.my_lvm및nfsshare리소스가 실행 중인지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 리소스 그룹
nfsgroup의 일부로nfs-daemon이라는nfsserver리소스를 생성합니다.참고nfsserver리소스를 사용하면 NFS 서버가 NFS 관련 상태 저장 정보를 저장하는 데 사용하는 디렉터리인nfs_shared_infodir매개변수를 지정할 수 있습니다.이 속성을 이 내보내기 컬렉션에서 생성한
Filesystem리소스 중 하나의 하위 디렉터리로 설정하는 것이 좋습니다. 이렇게 하면 이 리소스 그룹을 재배치해야 하는 경우 NFS 서버에서 다른 노드에서 사용할 수 있게 되는 장치에 상태 저장 정보를 저장하고 있습니다. 이 예에서는; In this example;-
/nfsshare는Filesystem리소스에서 관리하는 shared-storage 디렉터리입니다. -
/nfsshare/exports/export1및/nfsshare/exports/export2는 내보내기 디렉터리입니다. -
/nfsshare/nfsinfo는nfsserver리소스의 shared-information 디렉터리입니다.
pcs resource create nfs-daemon nfsserver nfs_shared_infodir=/nfsshare/nfsinfo nfs_no_notify=true --group nfsgroup pcs status ...
[root@z1 ~]# pcs resource create nfs-daemon nfsserver nfs_shared_infodir=/nfsshare/nfsinfo nfs_no_notify=true --group nfsgroup [root@z1 ~]# pcs status ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
exportfs리소스를 추가하여/nfsshare/exports디렉터리를 내보냅니다. 이러한 리소스는 리소스 그룹nfsgroup의 일부입니다. 그러면 NFSv4 클라이언트용 가상 디렉터리가 빌드됩니다. NFSv3 클라이언트는 이러한 내보내기에도 액세스할 수 있습니다.참고fsid=0옵션은 NFSv4 클라이언트용 가상 디렉터리를 생성하려는 경우에만 필요합니다. 자세한 내용은 Red Hat Knowledgebase 솔루션에서 NFS 서버의 /etc/exports 파일에서 fsid 옵션을 구성하는 방법을 참조하십시오. .pcs resource create nfs-root exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports fsid=0 --group nfsgroup pcs resource create nfs-export1 exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports/export1 fsid=1 --group nfsgroup pcs resource create nfs-export2 exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports/export2 fsid=2 --group nfsgroup
[root@z1 ~]# pcs resource create nfs-root exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports fsid=0 --group nfsgroup [root@z1 ~]# pcs resource create nfs-export1 exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports/export1 fsid=1 --group nfsgroup [root@z1 ~]# pcs resource create nfs-export2 exportfs clientspec=192.168.122.0/255.255.255.0 options=rw,sync,no_root_squash directory=/nfsshare/exports/export2 fsid=2 --group nfsgroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFS 클라이언트가 NFS 공유에 액세스하는 데 사용할 부동 IP 주소 리소스를 추가합니다. 이 리소스는 리소스 그룹
nfsgroup의 일부입니다. 이 예제 배포에서는 유동 IP 주소로 192.168.122.200을 사용하고 있습니다.pcs resource create nfs_ip IPaddr2 ip=192.168.122.200 cidr_netmask=24 --group nfsgroup
[root@z1 ~]# pcs resource create nfs_ip IPaddr2 ip=192.168.122.200 cidr_netmask=24 --group nfsgroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 전체 NFS 배포가 초기화되면 NFSv3 재부팅 알림을 보내기 위한
nfsnotify리소스를 추가합니다. 이 리소스는 리소스 그룹nfsgroup의 일부입니다.참고NFS 알림을 올바르게 처리하려면 유동 IP 주소에 NFS 서버 및 NFS 클라이언트 모두에서 일관된 호스트 이름이 있어야 합니다.
pcs resource create nfs-notify nfsnotify source_host=192.168.122.200 --group nfsgroup
[root@z1 ~]# pcs resource create nfs-notify nfsnotify source_host=192.168.122.200 --group nfsgroupCopy to Clipboard Copied! Toggle word wrap Toggle overflow 리소스 및 리소스 제약 조건을 생성한 후 클러스터 상태를 확인할 수 있습니다. 모든 리소스가 동일한 노드에서 실행되고 있습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
50.5. NFS 리소스 구성 테스트
다음 절차에 따라 고가용성 클러스터에서 NFS 리소스 구성을 확인할 수 있습니다. NFSv3 또는 NFSv4를 사용하여 내보낸 파일 시스템을 마운트할 수 있습니다.
50.5.1. NFS 내보내기 테스트
-
클러스터 노드에서
firewalld데몬을 실행하는 경우 시스템에 NFS 액세스에 필요한 포트가 모든 노드에서 활성화되어 있는지 확인합니다. 배포와 동일한 네트워크에 있는 클러스터 외부의 노드에서 NFS 공유를 마운트하여 NFS 공유를 볼 수 있는지 확인합니다. 이 예제에서는 192.168.122.0/24 네트워크를 사용하고 있습니다.
showmount -e 192.168.122.200 Export list for 192.168.122.200: /nfsshare/exports/export1 192.168.122.0/255.255.255.0 /nfsshare/exports 192.168.122.0/255.255.255.0 /nfsshare/exports/export2 192.168.122.0/255.255.255.0
# showmount -e 192.168.122.200 Export list for 192.168.122.200: /nfsshare/exports/export1 192.168.122.0/255.255.255.0 /nfsshare/exports 192.168.122.0/255.255.255.0 /nfsshare/exports/export2 192.168.122.0/255.255.255.0Copy to Clipboard Copied! Toggle word wrap Toggle overflow NFSv4를 사용하여 NFS 공유를 마운트할 수 있는지 확인하려면 NFS 공유를 클라이언트 노드의 디렉터리에 마운트합니다. 마운트 후 내보내기 디렉터리의 콘텐츠가 표시되는지 확인합니다. 테스트 후 공유를 마운트 해제합니다.
mkdir nfsshare mount -o "vers=4" 192.168.122.200:export1 nfsshare ls nfsshare clientdatafile1 umount nfsshare
# mkdir nfsshare # mount -o "vers=4" 192.168.122.200:export1 nfsshare # ls nfsshare clientdatafile1 # umount nfsshareCopy to Clipboard Copied! Toggle word wrap Toggle overflow NFSv3를 사용하여 NFS 공유를 마운트할 수 있는지 확인합니다. 마운트 후 테스트 파일
clientdatafile1이 표시되는지 확인합니다. NFSv4와 달리 NFSv3는 가상 파일 시스템을 사용하지 않으므로 특정 내보내기를 마운트해야 합니다. 테스트 후 공유를 마운트 해제합니다.mkdir nfsshare mount -o "vers=3" 192.168.122.200:/nfsshare/exports/export2 nfsshare ls nfsshare clientdatafile2 umount nfsshare
# mkdir nfsshare # mount -o "vers=3" 192.168.122.200:/nfsshare/exports/export2 nfsshare # ls nfsshare clientdatafile2 # umount nfsshareCopy to Clipboard Copied! Toggle word wrap Toggle overflow
50.5.2. 페일오버 테스트
클러스터 외부의 노드에서 NFS 공유를 마운트하고 NFS 공유 구성에서 생성한
clientdatafile1파일에 대한 액세스를 확인합니다. https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_and_managing_high_availability_clusters/assembly_configuring-active-passive-nfs-server-in-a-cluster-configuring-and-managing-high-availability-clusters#proc_configuring-nfs-share-configuring-ha-nfsmkdir nfsshare mount -o "vers=4" 192.168.122.200:export1 nfsshare ls nfsshare clientdatafile1
# mkdir nfsshare # mount -o "vers=4" 192.168.122.200:export1 nfsshare # ls nfsshare clientdatafile1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 내의 노드에서
nfsgroup을 실행 중인 클러스터의 노드를 확인합니다. 이 예에서nfsgroup은z1.example.com에서 실행 중입니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 내의 노드에서
nfsgroup을 대기 모드로 실행 중인 노드를 배치합니다.pcs node standby z1.example.com
[root@z1 ~]# pcs node standby z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다른 클러스터 노드에서
nfsgroup이 성공적으로 시작되었는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow NFS 공유를 마운트한 클러스터 외부의 노드에서 이 외부 노드가 여전히 NFS 마운트 내의 테스트 파일에 계속 액세스할 수 있는지 확인합니다.
ls nfsshare clientdatafile1
# ls nfsshare clientdatafile1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 장애 조치(failover) 중에 클라이언트에 대해 서비스에 대해 잠시 손실되지만 사용자 개입 없이 클라이언트가 복구해야 합니다. 기본적으로 NFSv4를 사용하는 클라이언트는 마운트를 복구하는 데 최대 90초가 걸릴 수 있습니다. 이 90초는 시작 시 서버에서 관찰하는 NFSv4 파일 리스 유예 기간을 나타냅니다. NFSv3 클라이언트는 몇 초 내에 마운트에 대한 액세스를 복구해야 합니다.
클러스터 내의 노드에서 처음에
nfsgroup을 실행한 노드를 standby 모드에서 제거합니다.참고standby모드에서 노드를 제거해도 리소스가 해당 노드로 되돌아가지 않습니다. 이는 리소스의resource-stickiness값에 따라 달라집니다.resource-stickinessmeta 속성에 대한 자세한 내용은 현재 노드를 선호하도록 리소스 구성을 참조하십시오.pcs node unstandby z1.example.com
[root@z1 ~]# pcs node unstandby z1.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
51장. 클러스터의 Cryostat2 파일 시스템
다음 관리 절차를 사용하여 Red Hat 고가용성 클러스터에서 Cryostat2 파일 시스템을 구성합니다.
51.1. 클러스터에서 Cryostat2 파일 시스템 구성
다음 절차에 따라 ReplicaSet2 파일 시스템이 포함된 Pacemaker 클러스터를 설정할 수 있습니다. 이 예에서는 2-노드 클러스터의 3개의 논리 볼륨에 3개의 Cryostat2 파일 시스템을 생성합니다.
사전 요구 사항
- 클러스터 노드 모두에 클러스터 소프트웨어를 설치 및 시작하고 기본 2-노드 클러스터를 생성합니다.
- 클러스터의 펜싱을 구성합니다.
Pacemaker 클러스터 생성 및 클러스터의 펜싱 구성에 대한 자세한 내용은 Pacemaker를 사용하여 Red Hat High-Availability 클러스터 생성 을 참조하십시오.
프로세스
클러스터의 두 노드에서 시스템 아키텍처에 해당하는 탄력적 스토리지의 리포지토리를 활성화합니다. 예를 들어 x86_64 시스템에 탄력적 스토리지 리포지토리를 활성화하려면 다음
subscription-manager명령을 입력합니다.subscription-manager repos --enable=rhel-8-for-x86_64-resilientstorage-rpms
# subscription-manager repos --enable=rhel-8-for-x86_64-resilientstorage-rpmsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 복구 스토리지 리포지토리는 고가용성 리포지토리의 상위 세트입니다. 탄력적 스토리지 리포지토리를 활성화하는 경우 고가용성 리포지토리도 활성화할 필요가 없습니다.
클러스터의 두 노드에서
lvm2-lockd,gfs2-utils및dlm패키지를 설치합니다. 이러한 패키지를 지원하려면 AppStream 채널 및 탄력적 스토리지 채널에 가입해야 합니다.yum install lvm2-lockd gfs2-utils dlm
# yum install lvm2-lockd gfs2-utils dlmCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 두 노드에서
/etc/lvm/lvm.conf파일에서use_lvmlockd구성 옵션을use_lvmlockd=1로 설정합니다.... use_lvmlockd = 1 ...
... use_lvmlockd = 1 ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 글로벌 Pacemaker 매개변수
no-quorum-policy를freeze로 설정합니다.참고기본적으로
no-quorum-policy값은stop으로 설정되어 쿼럼이 손실되면 나머지 파티션의 모든 리소스가 즉시 중지됨을 나타냅니다. 일반적으로 이 기본값은 가장 안전하고 최적의 옵션이지만 대부분의 리소스와 달리 Cryostat2가 작동하려면 쿼럼이 필요합니다. quorum2 마운트를 사용하는 애플리케이션 모두에서 쿼럼이 손실되고 polkit2 마운트 자체를 올바르게 중지할 수 없습니다. 쿼럼 없이 이러한 리소스를 중지하려고 하면 결국 쿼럼이 손실될 때마다 전체 클러스터가 펜싱됩니다.이 상황을 해결하려면 Cryostat2를 사용 중인 경우
no-quorum-policy를freeze로 설정합니다. 즉, 쿼럼이 손실되면 쿼럼이 될 때까지 나머지 파티션은 아무 작업도 수행하지 않습니다.pcs property set no-quorum-policy=freeze
[root@z1 ~]# pcs property set no-quorum-policy=freezeCopy to Clipboard Copied! Toggle word wrap Toggle overflow dlm리소스를 설정합니다. 이는 클러스터에서 Cryostat2 파일 시스템을 구성하는 데 필요한 종속 항목입니다. 이 예제에서는locking이라는 리소스 그룹의 일부로dlm리소스를 생성합니다.pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fence
[root@z1 ~]# pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fenceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 두 노드에서 리소스 그룹을 활성화할 수 있도록
잠금리소스 그룹을 복제합니다.pcs resource clone locking interleave=true
[root@z1 ~]# pcs resource clone locking interleave=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow 잠금리소스 그룹의 일부로lvmlockd리소스를 설정합니다.pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fence
[root@z1 ~]# pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fenceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인하여 클러스터의 두 노드에서
잠금리소스 그룹이 시작되었는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 한 노드에서 두 개의 공유 볼륨 그룹을 생성합니다. 하나의 볼륨 그룹에는 2개의 Cryostat2 파일 시스템이 포함되어 있으며 다른 볼륨 그룹에는 하나의 Cryostat2 파일 시스템이 포함됩니다.
참고LVM 볼륨 그룹에 iSCSI 대상과 같이 원격 블록 스토리지에 있는 하나 이상의 물리 볼륨이 포함된 경우 Pacemaker를 시작하기 전에 서비스가 시작되도록 하는 것이 좋습니다. Pacemaker 클러스터에서 사용하는 원격 물리 볼륨의 시작 순서를 구성하는 방법에 대한 자세한 내용은 Pacemaker에서 관리하지 않는 리소스 종속 항목의 시작 순서 구성 을 참조하십시오.
다음 명령은
/dev/vdb에 공유 볼륨 그룹shared_vg1을 생성합니다.vgcreate --shared shared_vg1 /dev/vdb Physical volume "/dev/vdb" successfully created. Volume group "shared_vg1" successfully created VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready...
[root@z1 ~]# vgcreate --shared shared_vg1 /dev/vdb Physical volume "/dev/vdb" successfully created. Volume group "shared_vg1" successfully created VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령은
/dev/ Cryostat 에 공유 볼륨 그룹.shared_vg2를 생성합니다vgcreate --shared shared_vg2 /dev/vdc Physical volume "/dev/vdc" successfully created. Volume group "shared_vg2" successfully created VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...
[root@z1 ~]# vgcreate --shared shared_vg2 /dev/vdc Physical volume "/dev/vdc" successfully created. Volume group "shared_vg2" successfully created VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 두 번째 노드에서 다음을 수행합니다.
(RHEL 8.5 이상)
lvm.conf파일에서use_devicesfile = 1을 설정하여 장치 파일을 사용하도록 설정한 경우 공유 장치를 장치 파일에 추가합니다. 기본적으로 장치 파일 사용은 활성화되어 있지 않습니다.lvmdevices --adddev /dev/vdb lvmdevices --adddev /dev/vdc
[root@z2 ~]# lvmdevices --adddev /dev/vdb [root@z2 ~]# lvmdevices --adddev /dev/vdcCopy to Clipboard Copied! Toggle word wrap Toggle overflow 각 공유 볼륨 그룹에 대해 잠금 관리자를 시작합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
클러스터의 한 노드에서 공유 논리 볼륨을 생성하고 Cryostat2 파일 시스템으로 볼륨을 포맷합니다. 파일 시스템을 마운트하는 각 노드에는 저널이 필요합니다. 클러스터의 각 노드에 충분한 저널을 생성해야 합니다. 잠금 테이블 이름의 형식은 ClusterName:FSName 입니다. 여기서 ClusterName 은 pacemaker2 파일 시스템이 생성되는 클러스터의 이름이며 FSName 은 클러스터상의 모든
lock_dlm파일 시스템에 고유해야 하는 파일 시스템 이름입니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 각 논리 볼륨에 대해
LVM-활성화리소스를 생성하여 모든 노드에서 해당 논리 볼륨을 자동으로 활성화합니다.shared_vg1볼륨 그룹에 논리 볼륨shared_lv1에 대해sharedlv1이라는LVM-activate리소스를 만듭니다. 이 명령은 리소스를 포함하는 리소스 그룹shared_vg1도 생성합니다. 이 예에서 리소스 그룹의 이름은 논리 볼륨을 포함하는 공유 볼륨 그룹과 동일합니다.pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockd
[root@z1 ~]# pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCopy to Clipboard Copied! Toggle word wrap Toggle overflow shared_vg1볼륨 그룹에 논리 볼륨shared_lv2에 대해sharedlv2라는LVM-활성화리소스를 만듭니다. 이 리소스는 리소스 그룹shared_vg1의 일부이기도 합니다.pcs resource create sharedlv2 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv2 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockd
[root@z1 ~]# pcs resource create sharedlv2 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv2 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCopy to Clipboard Copied! Toggle word wrap Toggle overflow shared_vg2볼륨 그룹에 논리 볼륨shared_lv1에 대해sharedlv3이라는LVM-activate리소스를 만듭니다. 이 명령은 리소스를 포함하는 리소스 그룹shared_vg2도 생성합니다.pcs resource create sharedlv3 --group shared_vg2 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg2 activation_mode=shared vg_access_mode=lvmlockd
[root@z1 ~]# pcs resource create sharedlv3 --group shared_vg2 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg2 activation_mode=shared vg_access_mode=lvmlockdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
두 개의 새 리소스 그룹을 복제합니다.
pcs resource clone shared_vg1 interleave=true pcs resource clone shared_vg2 interleave=true
[root@z1 ~]# pcs resource clone shared_vg1 interleave=true [root@z1 ~]# pcs resource clone shared_vg2 interleave=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow dlm및lvmlockd리소스를 포함하는잠금리소스 그룹이 먼저 시작되도록 순서 제한 조건을 구성합니다.pcs constraint order start locking-clone then shared_vg1-clone Adding locking-clone shared_vg1-clone (kind: Mandatory) (Options: first-action=start then-action=start) pcs constraint order start locking-clone then shared_vg2-clone Adding locking-clone shared_vg2-clone (kind: Mandatory) (Options: first-action=start then-action=start)
[root@z1 ~]# pcs constraint order start locking-clone then shared_vg1-clone Adding locking-clone shared_vg1-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@z1 ~]# pcs constraint order start locking-clone then shared_vg2-clone Adding locking-clone shared_vg2-clone (kind: Mandatory) (Options: first-action=start then-action=start)Copy to Clipboard Copied! Toggle word wrap Toggle overflow colocation 제약 조건을 구성하여 Cryostat
1및 Cryostat2리소스 그룹이잠금리소스 그룹과 동일한 노드에서 시작되도록 합니다.pcs constraint colocation add shared_vg1-clone with locking-clone pcs constraint colocation add shared_vg2-clone with locking-clone
[root@z1 ~]# pcs constraint colocation add shared_vg1-clone with locking-clone [root@z1 ~]# pcs constraint colocation add shared_vg2-clone with locking-cloneCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 두 노드에서 논리 볼륨이 활성 상태인지 확인합니다. 몇 초가 지연될 수 있습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템 리소스를 생성하여 모든 노드에 각 devfile2 파일 시스템을 자동으로 마운트합니다.
Pacemaker 클러스터 리소스로 관리되므로 파일 시스템을
/etc/fstab파일에 추가해서는 안 됩니다. 마운트 옵션은options= 옵션을 사용하여 리소스 구성의 일부로 지정할 수 있습니다.pcs resource describe Filesystem명령을 실행하여 전체 구성 옵션을 표시합니다.다음 명령은 파일 시스템 리소스를 생성합니다. 이러한 명령은 각 리소스를 해당 파일 시스템의 논리 볼륨 리소스를 포함하는 리소스 그룹에 추가합니다.
pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence pcs resource create sharedfs2 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv2" directory="/mnt/gfs2" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence pcs resource create sharedfs3 --group shared_vg2 ocf:heartbeat:Filesystem device="/dev/shared_vg2/shared_lv1" directory="/mnt/gfs3" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence
[root@z1 ~]# pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence [root@z1 ~]# pcs resource create sharedfs2 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv2" directory="/mnt/gfs2" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence [root@z1 ~]# pcs resource create sharedfs3 --group shared_vg2 ocf:heartbeat:Filesystem device="/dev/shared_vg2/shared_lv1" directory="/mnt/gfs3" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fenceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Cryostat2 파일 시스템이 클러스터의 두 노드에 마운트되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
51.2. 클러스터에서 암호화된 Cryostat2 파일 시스템 구성
(RHEL 8.4 이상) 다음 절차에 따라 LUKS 암호화된 Cryostat2 파일 시스템을 포함하는 Pacemaker 클러스터를 생성할 수 있습니다. 이 예에서는 논리 볼륨에 하나의 Cryostat2 파일 시스템을 생성하고 파일 시스템을 암호화합니다. 암호화된 Cryostat2 파일 시스템은 LUKS 암호화를 지원하는 crypt 리소스 에이전트를 사용하여 지원됩니다.
이 절차에는 세 가지 부분이 있습니다.
- Pacemaker 클러스터에서 공유 논리 볼륨 구성
-
논리 볼륨 암호화 및
crypt리소스 생성 - Cryostat2 파일 시스템을 사용하여 암호화된 논리 볼륨 포맷 및 클러스터에 대한 파일 시스템 리소스 생성
51.2.2. 논리 볼륨을 암호화하고 crypt 리소스를 생성
사전 요구 사항
- Pacemaker 클러스터에 공유 논리 볼륨을 구성했습니다.
프로세스
클러스터의 한 노드에서 crypt 키를 포함하는 새 파일을 생성하고 root로만 읽을 수 있도록 파일에 대한 권한을 설정합니다.
touch /etc/crypt_keyfile chmod 600 /etc/crypt_keyfile
[root@z1 ~]# touch /etc/crypt_keyfile [root@z1 ~]# chmod 600 /etc/crypt_keyfileCopy to Clipboard Copied! Toggle word wrap Toggle overflow crypt 키를 만듭니다.
dd if=/dev/urandom bs=4K count=1 of=/etc/crypt_keyfile 1+0 records in 1+0 records out 4096 bytes (4.1 kB, 4.0 KiB) copied, 0.000306202 s, 13.4 MB/s scp /etc/crypt_keyfile root@z2.example.com:/etc/
[root@z1 ~]# dd if=/dev/urandom bs=4K count=1 of=/etc/crypt_keyfile 1+0 records in 1+0 records out 4096 bytes (4.1 kB, 4.0 KiB) copied, 0.000306202 s, 13.4 MB/s [root@z1 ~]# scp /etc/crypt_keyfile root@z2.example.com:/etc/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 설정한 권한을 유지하기 위해
-p매개변수를 사용하여 crypt 키 파일을 클러스터의 다른 노드에 배포합니다.scp -p /etc/crypt_keyfile root@z2.example.com:/etc/
[root@z1 ~]# scp -p /etc/crypt_keyfile root@z2.example.com:/etc/Copy to Clipboard Copied! Toggle word wrap Toggle overflow 암호화된 Cryostat2 파일 시스템을 구성할 LVM 볼륨에 암호화된 장치를 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow shared_vg1볼륨 그룹의 일부로 crypt 리소스를 생성합니다.pcs resource create crypt --group shared_vg1 ocf:heartbeat:crypt crypt_dev="luks_lv1" crypt_type=luks2 key_file=/etc/crypt_keyfile encrypted_dev="/dev/shared_vg1/shared_lv1"
[root@z1 ~]# pcs resource create crypt --group shared_vg1 ocf:heartbeat:crypt crypt_dev="luks_lv1" crypt_type=luks2 key_file=/etc/crypt_keyfile encrypted_dev="/dev/shared_vg1/shared_lv1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
crypt 리소스가 crypt 장치를 생성했는지 확인합니다. 이 예에서는 /dev/mapper/luks_lv1 입니다.
ls -l /dev/mapper/ ... lrwxrwxrwx 1 root root 7 Mar 4 09:52 luks_lv1 -> ../dm-3 ...
[root@z1 ~]# ls -l /dev/mapper/
...
lrwxrwxrwx 1 root root 7 Mar 4 09:52 luks_lv1 -> ../dm-3
...51.2.3. 암호화된 논리 볼륨 포맷을 Cryostat2 파일 시스템으로 포맷하고 클러스터에 대한 파일 시스템 리소스 생성
사전 요구 사항
- 논리 볼륨을 암호화하고 crypt 리소스를 생성했습니다.
프로세스
클러스터의 한 노드에서 polkit2 파일 시스템으로 볼륨을 포맷합니다. 파일 시스템을 마운트하는 각 노드에는 저널이 필요합니다. 클러스터의 각 노드에 충분한 저널을 생성해야 합니다. 잠금 테이블 이름의 형식은 ClusterName:FSName 입니다. 여기서 ClusterName 은 pacemaker2 파일 시스템이 생성되는 클러스터의 이름이며 FSName 은 클러스터상의 모든
lock_dlm파일 시스템에 고유해야 하는 파일 시스템 이름입니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템 리소스를 생성하여 모든 노드에 Cryostat2 파일 시스템을 자동으로 마운트합니다.
Pacemaker 클러스터 리소스로 관리되므로 파일 시스템을
/etc/fstab파일에 추가하지 마십시오. 마운트 옵션은options= 옵션을 사용하여 리소스 구성의 일부로 지정할 수 있습니다. 전체 구성 옵션에 대해pcs resource describe Filesystem명령을 실행합니다.다음 명령은 파일 시스템 리소스를 생성합니다. 이 명령은 해당 파일 시스템의 논리 볼륨 리소스를 포함하는 리소스 그룹에 리소스를 추가합니다.
pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/mapper/luks_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence
[root@z1 ~]# pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/mapper/luks_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fenceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
Cryostat2 파일 시스템이 클러스터의 두 노드에 마운트되었는지 확인합니다.
mount | grep gfs2 /dev/mapper/luks_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) mount | grep gfs2 /dev/mapper/luks_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel)
[root@z1 ~]# mount | grep gfs2 /dev/mapper/luks_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) [root@z2 ~]# mount | grep gfs2 /dev/mapper/luks_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 상태를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
51.3. Cryostat2 파일 시스템을 RHEL7에서 RHEL8로 마이그레이션
Cryostat2 파일 시스템을 포함하는 RHEL 8 클러스터를 구성할 때 기존 Red Hat Enterprise 7 논리 볼륨을 사용할 수 있습니다.
Red Hat Enterprise Linux 8에서 LVM은 활성/활성 클러스터에서 공유 스토리지 장치를 관리하는 데 clvmd 대신 LVM 잠금 데몬 lvmlockd 를 사용합니다. 이를 위해서는 활성/활성 클러스터가 공유 논리 볼륨으로 필요한 논리 볼륨을 구성해야 합니다. 또한 LVM-activate 리소스를 사용하여 LVM 볼륨을 관리하고 lvmlockd 리소스 에이전트를 사용하여 lvmlockd 데몬을 관리해야 합니다. 공유 논리 볼륨 을 사용하여 Cryostat2 파일 시스템을 포함하는 Pacemaker 클러스터를 구성하기 위한 전체 프로시저는 클러스터에서 Cryostat2 파일 시스템 구성 을 참조하십시오.
Cryostat2 파일 시스템이 포함된 RHEL8 클러스터를 구성할 때 기존 Red Hat Enterprise Linux 7 논리 볼륨을 사용하려면 RHEL8 클러스터에서 다음 절차를 수행합니다. 이 예에서 클러스터형 RHEL 7 논리 볼륨은 볼륨 그룹 upgrade_gfs_vg 의 일부입니다.
RHEL8 클러스터는 기존 파일 시스템을 유효하게 하려면 RHEL7 클러스터와 동일한 이름이 있어야 합니다.
프로세스
- Cryostat2 파일 시스템을 포함하는 논리 볼륨이 현재 비활성 상태인지 확인합니다. 이 절차는 볼륨 그룹을 사용하여 모든 노드가 중지된 경우에만 안전합니다.
클러스터의 한 노드에서 볼륨 그룹을 강제로 로컬로 변경합니다.
vgchange --lock-type none --lock-opt force upgrade_gfs_vg Forcibly change VG lock type to none? [y/n]: y Volume group "upgrade_gfs_vg" successfully changed
[root@rhel8-01 ~]# vgchange --lock-type none --lock-opt force upgrade_gfs_vg Forcibly change VG lock type to none? [y/n]: y Volume group "upgrade_gfs_vg" successfully changedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 한 노드에서 로컬 볼륨 그룹을 공유 볼륨 그룹으로 변경합니다.
vgchange --lock-type dlm upgrade_gfs_vg Volume group "upgrade_gfs_vg" successfully changed
[root@rhel8-01 ~]# vgchange --lock-type dlm upgrade_gfs_vg Volume group "upgrade_gfs_vg" successfully changedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터의 각 노드에서 볼륨 그룹에 대한 잠금을 시작합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
이 절차를 수행한 후 각 논리 볼륨에 대해 LVM-활성화 리소스를 생성할 수 있습니다.
52장. Red Hat High Availability 클러스터에서 펜싱 구성
응답하지 않는 노드는 여전히 데이터에 액세스 중일 수 있습니다. 데이터가 안전하다는 것을 확인하는 유일한 방법은 STONITH를 사용하여 노드를 차단하는 것입니다. STONITH는 "Shoot The Other Node In The Head"의 약자이며 데이터가 악성 노드 또는 동시 액세스로 손상되지 않도록 보호합니다. STONITH를 사용하면 다른 노드에서 데이터에 액세스할 수 있도록 허용하기 전에 노드가 실제로 오프라인 상태인지 확인할 수 있습니다.
또한 STONITH에는 클러스터형 서비스를 중지할 수 없는 경우 수행할 수 있는 역할이 있습니다. 이 경우 클러스터는 STONITH를 사용하여 전체 노드를 오프라인으로 강제 적용하여 다른 곳에서 서비스를 안전하게 시작할 수 있습니다.
Red Hat High Availability 클러스터의 펜싱 및 중요성에 대한 자세한 내용은 Red Hat High Availability Cluster의 Red Hat 지식베이스 솔루션 Fencing 을 참조하십시오.
클러스터 노드에 대한 차단 장치를 구성하여 Pacemaker 클러스터에서 STONITH를 구현합니다.
52.1. 사용 가능한 차단 에이전트 및 옵션 표시
다음 명령은 특정 펜싱 에이전트에서 사용 가능한 펜싱 에이전트 및 사용 가능한 옵션을 확인하는 데 사용할 수 있습니다.
시스템의 하드웨어에 따라 클러스터에 사용할 펜싱 장치 유형이 결정됩니다. 지원되는 플랫폼 및 아키텍처 및 다양한 펜싱 장치에 대한 자세한 내용은 RHEL 고가용성 클러스터에 대한 지원 정책의 클러스터 플랫폼 및 아키텍처 섹션을 참조하십시오.
다음 명령을 실행하여 사용 가능한 모든 펜싱 에이전트를 나열합니다. 필터를 지정하면 이 명령은 필터와 일치하는 펜싱 에이전트만 표시합니다.
pcs stonith list [filter]
pcs stonith list [filter]다음 명령을 실행하여 지정된 펜싱 에이전트의 옵션을 표시합니다.
pcs stonith describe [stonith_agent]
pcs stonith describe [stonith_agent]예를 들어 다음 명령은 telnet/SSH를 통한 APC에 대한 차단 에이전트의 옵션을 표시합니다.
메서드 옵션을 제공하는 차단 에이전트의 경우 fence_sbd 에이전트를 제외하고 주기 값이 지원되지 않으며 데이터 손상이 발생할 수 있으므로 지정하지 않아야 합니다. 그러나 fence_sbd 의 경우에도 메서드를 지정하지 않고 기본값을 사용해야 합니다.
52.2. 차단 장치 생성
펜스 장치를 생성하는 명령의 형식은 다음과 같습니다. 사용 가능한 차단 장치 생성 옵션 목록은 pcs stonith -h 디스플레이를 참조하십시오.
pcs stonith create stonith_id stonith_device_type [stonith_device_options] [op operation_action operation_options]
pcs stonith create stonith_id stonith_device_type [stonith_device_options] [op operation_action operation_options]다음 명령은 단일 노드에 대한 단일 펜싱 장치를 생성합니다.
pcs stonith create MyStonith fence_virt pcmk_host_list=f1 op monitor interval=30s
# pcs stonith create MyStonith fence_virt pcmk_host_list=f1 op monitor interval=30s일부 차단 장치는 단일 노드만 펜싱할 수 있지만 다른 장치는 여러 노드를 펜싱할 수 있습니다. 차단 장치를 생성할 때 지정하는 매개변수는 차단 장치가 지원하고 요구하는 사항에 따라 다릅니다.
- 일부 차단 장치는 펜싱할 수 있는 노드를 자동으로 결정할 수 있습니다.
-
차단 장치를 생성할 때
pcmk_host_list매개 변수를 사용하여 해당 펜싱 장치에서 제어하는 모든 시스템을 지정할 수 있습니다. -
일부 차단 장치에는 호스트 이름을 펜스 장치에서 이해하는 사양에 매핑해야 합니다. 펜싱 장치를 생성할 때
pcmk_host_map매개변수를 사용하여 호스트 이름을 매핑할 수 있습니다.
pcmk_host_list 및 pcmk_host_map 매개변수에 대한 자세한 내용은 펜싱 장치의 일반 속성을 참조하십시오.
펜스 장치를 구성한 후에는 장치를 테스트하여 올바르게 작동하는지 확인해야 합니다. 펜스 장치를 테스트하는 방법에 대한 자세한 내용은 차단 장치 테스트를 참조하십시오.
52.3. 펜싱 장치의 일반 속성
펜싱 장치에 대해 설정할 수 있는 일반 속성과 펜싱 동작을 결정하는 다양한 클러스터 속성이 있습니다.
클러스터 노드는 fence 리소스가 시작 또는 중지되었는지 여부에 관계없이 모든 차단 장치로 다른 클러스터 노드를 펜싱할 수 있습니다. 리소스가 시작되었는지 여부는 다음 예외와 함께 사용할 수 있는지 여부에 관계없이 장치에 대한 반복 모니터만 제어합니다.
-
pcs stonith_id명령을 실행하여 펜싱 장치를 비활성화할수 있습니다. 이렇게 하면 모든 노드가 해당 장치를 사용하지 않습니다. -
특정 노드에서 펜싱 장치를 사용하지 않도록
pcs 제약 조건 위치 …를 사용하여 펜싱 리소스에 대한 위치 제약 조건을 구성할 수 있습니다.명령을 방지합니다. -
stonith-enabled=false를 구성하면 펜싱이 완전히 비활성화됩니다. 그러나 Red Hat은 프로덕션 환경에 적합하지 않으므로 펜싱이 비활성화된 경우 클러스터를 지원하지 않습니다.
다음 표에서는 펜싱 장치에 대해 설정할 수 있는 일반 속성을 설명합니다.
| 필드 | 유형 | Default | 설명 |
|---|---|---|---|
|
| string |
호스트 이름을 지원하지 않는 장치의 포트 번호에 호스트 이름 매핑. 예를 들어 | |
|
| string |
이 장치에서 제어하는 머신 목록입니다( | |
|
| string |
*
* 그렇지 않으면 차단 장치가 목록 작업을 지원하는 경우
* 그렇지 않으면 차단 장치가
* 다른 방법 |
장치에서 제어하는 머신을 결정하는 방법 허용되는 값: |
다음 표에는 펜싱 장치에 설정할 수 있는 추가 속성이 요약되어 있습니다. 이러한 속성은 고급 용도로만 사용됩니다.
| 필드 | 유형 | Default | 설명 |
|---|---|---|---|
|
| string | port |
포트 대신 제공할 대체 매개변수입니다. 일부 장치는 표준 포트 매개 변수를 지원하지 않거나 추가 포트를 제공할 수 있습니다. 이를 사용하여 시스템을 펜싱해야 함을 나타내는 대체 장치별 매개 변수를 지정합니다. 값이 |
|
| string | reboot |
|
|
| time | 60s |
|
|
| integer | 2 |
시간 제한 기간 내에 |
|
| string | off |
|
|
| time | 60s |
|
|
| integer | 2 | 시간 제한 기간 내에 off 명령을 재시도하는 최대 횟수입니다. 일부 장치는 여러 연결을 지원하지 않습니다. 장치가 다른 작업에서 사용 중이면 작업이 실패할 수 있으므로 시간이 남아 있는 경우 Pacemaker에서 작업을 자동으로 다시 시도합니다. 이 옵션을 사용하여 Pacemaker에서 중단하기 전에 작업을 재시도하는 횟수를 변경합니다. |
|
| string | list |
|
|
| time | 60s | 목록 작업에 사용할 대체 시간 초과를 지정합니다. 일부 장치는 정상보다 완료하는 데 훨씬 더 많은 시간이 필요합니다. 이를 사용하여 목록 작업에 대한 대체 장치별 시간 초과를 지정합니다. |
|
| integer | 2 |
시간 초과 기간 내에 |
|
| string | 모니터 |
|
|
| time | 60s |
|
|
| integer | 2 |
시간 초과 기간 내에 |
|
| string | status |
|
|
| time | 60s |
|
|
| integer | 2 | 시간 제한 기간 내에 status 명령을 재시도하는 최대 횟수입니다. 일부 장치는 여러 연결을 지원하지 않습니다. 장치가 다른 작업에서 사용 중이면 작업이 실패할 수 있으므로 시간이 남아 있는 경우 Pacemaker에서 작업을 자동으로 다시 시도합니다. 이 옵션을 사용하여 Pacemaker에서 종료하기 전에 상태 작업을 재시도하는 횟수를 변경합니다. |
|
| string | 0s |
펜싱 작업에 대한 기본 지연을 활성화하고 기본 지연 값을 지정합니다. Red Hat Enterprise Linux 8.6 이상에서는 |
|
| time | 0s |
펜싱 작업에 대한 임의의 지연을 활성화하고 결합된 기본 지연 및 임의 지연의 최대 값인 최대 지연을 지정합니다. 예를 들어 기본 지연이 3이고 |
|
| integer | 1 |
이 장치에서 병렬로 수행할 수 있는 최대 작업 수입니다. 클러스터 속성 |
|
| string | On |
고급 사용 전용: 에서 대신 |
|
| time | 60s |
고급 사용 전용: |
|
| integer | 2 |
고급 사용 전용: 시간 초과 기간 내에 |
개별 차단 장치에 대해 설정할 수 있는 속성 외에도 다음 표에 설명된 대로 펜싱 동작을 결정하는 클러스터 속성을 설정할 수도 있습니다.
| 옵션 | Default | 설명 |
|---|---|---|
|
| true |
중지할 수 없는 리소스가 있는 실패한 노드 및 노드를 펜싱해야 함을 나타냅니다. 데이터를 보호하려면 이 값을 설정해야 합니다.
Red Hat은 이 값이 |
|
| reboot |
펜싱 장치에 전달할 작업입니다. 허용되는 값: |
|
| 60s | STONITH 작업이 완료될 때까지 대기하는 시간입니다. |
|
| 10 | 클러스터가 더 이상 즉시 다시 시도하지 않기 전에 대상에 대해 펜싱이 실패할 수 있는 횟수입니다. |
|
| 노드가 하드웨어 워치독에 의해 종료되었다고 간주될 때까지 대기하는 최대 시간입니다. 이 값을 하드웨어 워치독 시간 제한의 두 배 값으로 설정하는 것이 좋습니다. 이 옵션은 워치독 전용 SBD 구성이 펜싱에 사용되는 경우에만 필요합니다. | |
|
| True (RHEL 8.1 이상) | 펜싱 작업을 병렬로 수행할 수 있습니다. |
|
| 중지 |
(Red Hat Enterprise Linux 8.2 이상) 자체 펜싱 알림을 받는 경우 클러스터 노드가 어떻게 반응해야 하는지 결정합니다. 펜싱이 잘못 구성된 경우 클러스터 노드는 자체 펜싱에 대한 알림을 수신할 수 있습니다. 그렇지 않으면 클러스터 통신이 중단되지 않는 패브릭 펜싱을 사용하고 있습니다. 허용되는 값은 Pacemaker를 즉시 중지하고 중지된 상태를 유지하거나 로컬 노드를 즉시 재부팅하려고 시도하여 실패 시 다시 중지되도록 하는 것입니다.
이 속성의 기본값은 |
|
| 0 (비활성화됨) | (RHEL 8.3 이상) 2 노드 클러스터를 구성할 수 있는 펜싱 지연을 설정하여 split- Cryostat 상황에서 가장 적은 리소스가 실행되는 노드가 펜싱되는 노드임을 나타냅니다. 펜싱 지연 매개 변수 및 상호 작용에 대한 일반적인 정보는 지연 을 참조하십시오. |
클러스터 속성 설정에 대한 자세한 내용은 클러스터 속성 설정 및 제거를 참조하십시오.
52.4. 펜싱 지연
2-노드 클러스터에서 클러스터 통신이 손실되면 한 노드에서 먼저 이를 감지하고 다른 노드를 펜싱할 수 있습니다. 그러나 두 노드 모두 동시에 이를 감지하면 각 노드가 다른 노드의 펜싱을 시작하여 두 노드의 전원이 꺼지거나 재설정될 수 있습니다. 펜싱 지연을 설정하면 두 클러스터 노드가 서로 펜싱될 가능성을 줄일 수 있습니다. 두 개 이상의 노드가 있는 클러스터에서 지연을 설정할 수 있지만 쿼럼이 있는 파티션만 펜싱을 시작하기 때문에 일반적으로는 이점이 없습니다.
시스템 요구 사항에 따라 다양한 유형의 펜싱 지연을 설정할 수 있습니다.
정적 펜싱 지연
정적 펜싱 지연은 미리 정의된 고정된 지연입니다. 한 노드에 정적 지연을 설정하면 노드가 펜싱될 가능성이 높아집니다. 이로 인해 다른 노드가 통신 손실된 통신을 탐지한 후 먼저 펜싱을 시작할 가능성이 높아집니다. 활성/수동 클러스터에서 패시브 노드에서 지연을 설정하면 통신이 중단될 때 패시브 노드가 펜싱될 가능성이 높아집니다.
pcs_delay_base클러스터 속성을 사용하여 정적 지연을 구성합니다. 각 노드에 별도의 차단 장치를 사용하거나 모든 노드에 단일 차단 장치를 사용하는 경우 RHEL 8.6에서 이 속성을 설정할 수 있습니다.동적 펜싱 지연
동적 펜싱 지연은 임의적입니다. 이는 다를 수 있으며 펜싱 시에 결정됩니다. 임의의 지연을 구성하고
pcs_delay_max클러스터 속성을 사용하여 결합된 기본 지연 및 임의의 지연을 지정합니다. 각 노드의 펜싱 지연이 임의적인 경우 펜싱되는 노드도 임의적입니다. 이 기능은 클러스터가 활성/활성 설계의 모든 노드에 대해 단일 차단 장치로 구성된 경우 유용할 수 있습니다.우선 순위 펜싱 지연
우선 순위 펜싱 지연은 활성 리소스 우선 순위를 기반으로 합니다. 모든 리소스의 우선 순위가 동일한 경우 가장 적은 리소스가 실행되는 노드는 펜싱되는 노드입니다. 대부분의 경우 하나의 지연 관련 매개변수만 사용하지만 결합할 수 있습니다. 지연 관련 매개 변수를 결합하면 리소스의 우선 순위 값이 함께 추가되어 총 지연이 생성됩니다.
priority-fencing-delay클러스터 속성을 사용하여 우선순위 펜싱 지연을 구성합니다. 이 기능은 노드 간 통신이 손실될 때 가장 적은 리소스를 실행하는 노드가 차단될 수 있으므로 활성/활성 클러스터 설계에서 유용할 수 있습니다.
pcmk_delay_base 클러스터 속성
pcmk_delay_base 클러스터 속성을 설정하면 펜싱의 기본 지연이 활성화되고 기본 지연 값을 지정합니다.
pcmk_delay_max 클러스터 속성을 pcmk_delay_base 속성 외에도 설정할 때 전체 지연은 이 정적 지연에 추가된 임의의 지연 값에서 파생되어 합계가 최대 지연 아래로 유지됩니다. pcmk_delay_base 를 설정했지만 pcmk_delay_max 를 설정하지 않으면 지연에 임의의 구성 요소가 없으며 pcmk_delay_base 의 값이 됩니다.
Red Hat Enterprise Linux 8.6 이상에서는 pcmk_delay_base 매개변수를 사용하여 다른 노드에 대해 다른 값을 지정할 수 있습니다. 이를 통해 두 노드 클러스터에서 단일 펜스 장치를 사용할 수 있으며 각 노드에 대해 다른 지연이 발생합니다. 별도의 지연을 사용하도록 두 개의 개별 장치를 구성할 필요가 없습니다. 다른 노드에 대해 다른 값을 지정하려면 유사한 구문을 사용하여 pcmk_host_map 과 유사한 노드의 지연 값에 호스트 이름을 매핑합니다. 예를 들어 는 node1을 펜싱할 때 지연 없이, node1:0;node2:10snode2 를 펜싱할 때 10초 지연을 사용합니다.
pcmk_delay_max 클러스터 속성
pcmk_delay_max 클러스터 속성을 설정하면 펜싱 작업에 대한 임의의 지연을 활성화하고 결합된 기본 지연 및 임의 지연의 최대 값인 최대 지연 시간을 지정합니다. 예를 들어 기본 지연이 3이고 pcmk_delay_max 가 10이면 임의 지연은 3에서 10 사이입니다.
pcmk_delay_base 클러스터 속성을 pcmk_delay_max 속성 외에도 설정할 때 전체 지연은 이 정적 지연에 추가된 임의의 지연 값에서 파생되어 합계가 최대 지연 아래로 유지됩니다. pcmk_delay_max 를 설정했지만 pcmk_delay_base 를 설정하지 않으면 지연에 대한 정적 구성 요소가 없습니다.
priority-fencing-delay 클러스터 속성
(RHEL 8.3 이상) priority-fencing-delay 클러스터 속성을 설정하면 분할에서 가장 적은 리소스가 실행되는 노드가 펜싱되는 노드가 되도록 2-노드 클러스터를 구성할 수 있습니다.
priority-fencing-delay 속성은 시간 기간으로 설정할 수 있습니다. 이 속성의 기본값은 0입니다(비활성화됨). 이 속성이 0이 아닌 값으로 설정되고 우선 순위 meta-attribute가 하나 이상의 리소스에 대해 구성된 경우 분할에서 실행 중인 모든 리소스의 우선 순위가 가장 높은 노드가 작동 상태를 유지할 가능성이 더 높습니다. 예를 들어 pcs resource defaults update priority=1 및 pcs 속성이 priority-fencing-delay=15s 를 설정하고 다른 우선순위가 설정되지 않은 경우 다른 노드가 펜싱을 시작하기 전에 15초를 기다리므로 대부분의 리소스를 실행하는 노드가 계속 작동할 가능성이 더 높습니다. 특정 리소스가 나머지 리소스보다 중요한 경우 우선 순위를 높일 수 있습니다.
승격 가능한 복제의 master 역할을 실행하는 노드는 해당 복제본에 대한 우선 순위가 구성된 경우 추가 1 포인트를 가져옵니다.
펜싱 지연의 상호 작용
펜싱 지연 유형을 두 개 이상 설정하면 다음과 같은 결과가 발생합니다.
-
priority-fencing-delay속성으로 설정된 지연은pcmk_delay_base및pcmk_delay_max차단 장치 속성의 지연에 추가됩니다. 이 동작은on-fail=fencing이 리소스 모니터 작업에 설정된 경우와 같이 노드 손실 이외의 이유로 두 노드를 모두 펜싱해야 하는 경우 두 노드를 모두 지연할 수 있습니다. 이러한 지연을 조합하여 설정할 때priority-fencing-delay속성을pcmk_delay_base및pcmk_delay_max의 최대 지연보다 훨씬 큰 값으로 설정합니다. 이 속성을 두 번으로 설정하면 이 값은 항상 안전합니다. -
Pacemaker 자체에서 예약한 펜싱만 펜싱 지연을 관찰합니다.
dlm_controld및pcs stonith fence명령으로 구현된 펜싱과 같은 외부 코드에서 예약한 펜싱은 펜싱 장치에 필요한 정보를 제공하지 않습니다. -
일부 개별 차단 에이전트는 에이전트에 의해 결정되며
pcmk_delay_* 속성으로 구성된 지연과 관계없이 지연 매개 변수를 구현합니다. 이러한 두 지연이 모두 구성된 경우 함께 추가되며 일반적으로 함께 사용되지 않습니다.
52.5. 차단 장치 테스트
펜싱은 Red Hat Cluster 인프라의 기본 부분이며 펜싱이 제대로 작동하는지 검증하거나 테스트하는 것이 중요합니다.
Pacemaker 클러스터 노드 또는 Pacemaker 원격 노드를 펜싱하는 경우 운영 체제를 정상적으로 종료하지 않고 하드 종료가 발생해야 합니다. 시스템이 노드를 펜싱할 때 정상 종료가 발생하면 /etc/systemd/logind.conf 파일에서 ACPI 소프트오프를 비활성화하여 시스템이 power-button-pressed 신호를 무시하도록 합니다. logind.conf 파일에서 ACPI 소프트오프를 비활성화하는 방법은 logind.conf 파일에서 ACPI 소프트 오프 비활성화를 참조하십시오.
프로세스
다음 절차를 사용하여 차단 장치를 테스트합니다.
ssh, telnet, HTTP 또는 장치에 연결하여 수동으로 로그인하고 테스트하거나 지정된 출력을 확인하는 데 사용되는 원격 프로토콜을 사용합니다. 예를 들어 IPMI 사용 장치에 대한 펜싱을 구성하는 경우
ipmitool을 사용하여 원격으로 로그인합니다. 펜싱 에이전트를 사용할 때 이러한 옵션이 필요할 수 있으므로 수동으로 로그인할 때 사용되는 옵션을 기록해 두십시오.차단 장치에 로그인할 수 없는 경우 장치가 ping 가능한지 확인합니다. 이 방화벽 구성에서는 차단 장치에 대한 액세스를 방지하고 펜싱 장치에서 원격 액세스가 활성화되고 인증 정보가 올바른지 확인합니다.
차단 에이전트 스크립트를 사용하여 차단 에이전트를 수동으로 실행합니다. 이 작업을 수행하려면 클러스터에서 장치를 구성하기 전에 이 단계를 수행할 수 있도록 클러스터 서비스가 실행되고 있지 않습니다. 이렇게 하면 계속하기 전에 펜스 장치가 올바르게 응답하는지 확인할 수 있습니다.
참고이러한 예에서는 iLO 장치에
fence_ipmilan차단 에이전트 스크립트를 사용합니다. 사용할 실제 차단 에이전트와 해당 에이전트를 호출하는 명령은 서버 하드웨어에 따라 달라집니다. 지정할 옵션을 결정하려면 사용 중인 차단 에이전트의 도움말 페이지를 참조해야 합니다. 일반적으로 차단 장치의 로그인 및 암호 및 차단 장치와 관련된 기타 정보를 알아야 합니다.다음 예제에서는 실제로 펜싱하지 않고 다른 노드에서 차단 장치 인터페이스의 상태를 확인하기 위해
-o status매개변수를 사용하여fence_ipmilan차단 에이전트 스크립트를 실행하는 데 사용하는 형식을 보여줍니다. 이를 통해 노드를 재부팅하기 전에 장치를 테스트하고 작동하게 할 수 있습니다. 이 명령을 실행하는 경우 iLO 장치에 대한 권한을 켜거나 끄는 iLO 사용자의 이름과 암호를 지정합니다.fence_ipmilan -a ipaddress -l username -p password -o status
# fence_ipmilan -a ipaddress -l username -p password -o statusCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예제에서는
-o reboot매개변수를 사용하여fence_ipmilan차단 에이전트 스크립트를 실행하는 데 사용하는 형식을 보여줍니다. 한 노드에서 이 명령을 실행하면 이 iLO 장치에서 관리하는 노드가 재부팅됩니다.fence_ipmilan -a ipaddress -l username -p password -o reboot
# fence_ipmilan -a ipaddress -l username -p password -o rebootCopy to Clipboard Copied! Toggle word wrap Toggle overflow 펜스 에이전트가 상태, 해제, on 또는 reboot 작업을 제대로 수행하지 못한 경우 하드웨어, 차단 장치 구성 및 명령의 구문을 확인해야 합니다. 또한 디버그 출력이 활성화된 상태에서 fence 에이전트 스크립트를 실행할 수 있습니다. 디버그 출력은 일부 펜싱 에이전트에서 차단 장치에 로그인할 때 펜싱 에이전트 스크립트가 실패하는지 확인하는 데 유용합니다.
fence_ipmilan -a ipaddress -l username -p password -o status -D /tmp/$(hostname)-fence_agent.debug
# fence_ipmilan -a ipaddress -l username -p password -o status -D /tmp/$(hostname)-fence_agent.debugCopy to Clipboard Copied! Toggle word wrap Toggle overflow 발생한 오류를 진단할 때 차단 장치에 수동으로 로그인할 때 지정한 옵션이 fence 에이전트 스크립트를 사용하여 차단 에이전트에 전달한 것과 동일한지 확인해야 합니다.
암호화된 연결을 지원하는 차단 에이전트의 경우 인증서 유효성 검사 실패로 인한 오류가 표시될 수 있으며, 호스트를 신뢰하거나 차단 에이전트의
ssl-insecure매개변수를 사용해야 할 수 있습니다. 마찬가지로 대상 장치에서 SSL/TLS가 비활성화된 경우 차단 에이전트의 SSL 매개변수를 설정할 때 이를 고려해야 할 수 있습니다.참고테스트 중인 펜스 에이전트가 계속 실패하는 시스템 관리 장치의
fence_drac,fence_ilo또는 기타 일부 펜싱 에이전트인 경우fence_ipmilan을 다시 시도합니다. 대부분의 시스템 관리 카드는 IPMI 원격 로그인을 지원하며 지원되는 유일한 펜싱 에이전트는fence_ipmilan입니다.다음 예와 같이 클러스터에서 작업하는 것과 동일한 옵션을 사용하여 클러스터에서 차단 장치를 구성한 후 모든 노드에서
pcs stonith fence명령을 사용하여 펜싱을 테스트합니다(또는 다른 노드에서 여러 번).pcs stonith fence명령은 CIB에서 클러스터 구성을 읽고 fence 작업을 실행하도록 구성된 fence 에이전트를 호출합니다. 이렇게 하면 클러스터 구성이 올바른지 확인합니다.pcs stonith fence node_name
# pcs stonith fence node_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow pcs stonith fence명령이 제대로 작동하는 경우 차단 이벤트가 발생할 때 클러스터의 펜싱 구성이 작동해야 합니다. 명령이 실패하면 클러스터 관리가 검색한 구성을 통해 차단 장치를 호출할 수 없음을 의미합니다. 다음 문제를 확인하고 필요에 따라 클러스터 구성을 업데이트합니다.- 펜스 구성을 확인합니다. 예를 들어 호스트 맵을 사용한 경우 시스템에서 제공한 호스트 이름을 사용하여 노드를 찾을 수 있는지 확인해야 합니다.
- 장치의 암호 및 사용자 이름에 bash 쉘에서 잘못 해석할 수 있는 특수 문자가 포함되어 있는지 확인합니다. 따옴표로 묶은 암호와 사용자 이름을 입력했는지 확인하면 이 문제를 해결할 수 있습니다.
-
pcs stonith명령에 지정한 정확한 IP 주소 또는 호스트 이름을 사용하여 장치에 연결할 수 있는지 확인합니다. 예를 들어 stonith 명령에 호스트 이름을 지정하지만 IP 주소를 사용하여 테스트하는 경우 유효한 테스트가 아닙니다. 펜스 장치에서 사용하는 프로토콜에 액세스할 수 있는 경우 해당 프로토콜을 사용하여 장치에 연결을 시도합니다. 예를 들어 많은 에이전트가 ssh 또는 telnet을 사용합니다. 장치를 구성할 때 제공한 인증 정보를 사용하여 장치에 연결을 시도하여 유효한 프롬프트가 표시되는지 확인하고 장치에 로그인할 수 있습니다.
모든 매개변수가 적합하지만 차단 장치에 연결하는 데 문제가 있는 경우 장치가 이를 제공하는 경우 사용자가 연결된 명령과 사용자가 실행한 명령을 표시하는 경우 차단 장치 자체에서 로깅을 확인할 수 있습니다. 또한
/var/log/messages파일을 통해 stonith 및 error 인스턴스를 검색할 수 있으며 이로 인해 전송되는 내용에 대한 아이디어를 제공할 수 있지만 일부 에이전트는 추가 정보를 제공할 수 있습니다.
펜스 장치 테스트가 작동하고 클러스터가 가동되어 실행되면 실제 실패를 테스트합니다. 이렇게 하려면 토큰 손실을 시작해야 하는 클러스터에서 작업을 수행합니다.
네트워크를 끕니다. 네트워크를 사용하는 방법은 특정 구성에 따라 다릅니다. 대부분의 경우 호스트에서 네트워크 또는 전원 케이블을 물리적으로 끌어올 수 있습니다. 네트워크 장애 시뮬레이션에 대한 자세한 내용은 RHEL 클러스터에서 네트워크 오류를 시뮬레이션하는 적절한 방법은 무엇입니까?
참고일반적인 실제 장애를 정확하게 시뮬레이션하지 않기 때문에 네트워크 또는 전원 케이블을 물리적으로 연결 해제하지 않고 로컬 호스트에서 네트워크 인터페이스를 비활성화하는 것은 펜싱 테스트로 권장되지 않습니다.
로컬 방화벽을 사용하는 인바운드 및 아웃바운드 블록 corosync 트래픽입니다.
다음 예제 블록 corosync 기본 corosync 포트가 사용되면
firewalld는 로컬 방화벽으로 사용되며 corosync에서 사용하는 네트워크 인터페이스는 기본 방화벽 영역에 있습니다.firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" drop
# firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP # firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" dropCopy to Clipboard Copied! Toggle word wrap Toggle overflow sysrq-trigger를 사용하여 크래시를 시뮬레이션하고 시스템에 패닉을 발생시킵니다. 그러나 커널 패닉을 트리거하면 데이터가 손실될 수 있습니다. 먼저 클러스터 리소스를 비활성화하는 것이 좋습니다.echo c > /proc/sysrq-trigger
# echo c > /proc/sysrq-triggerCopy to Clipboard Copied! Toggle word wrap Toggle overflow
52.6. 펜싱 수준 구성
Pacemaker에서는 펜싱 토폴로지라는 기능을 통해 여러 장치가 있는 노드 펜싱을 지원합니다. 토폴로지를 구현하려면 일반적으로 개별 장치를 생성한 다음 구성의 펜싱 토폴로지 섹션에 하나 이상의 펜싱 수준을 정의합니다.
Pacemaker는 다음과 같이 펜싱 수준을 처리합니다.
- 각 수준은 1부터 오름차순으로 오름차순으로 시도됩니다.
- 장치가 실패하면 현재 수준에 대한 처리가 종료됩니다. 해당 수준의 추가 장치가 수행되지 않으며 다음 수준이 대신 시도됩니다.
- 모든 장치가 성공적으로 펜싱되면 해당 수준이 성공했으며 다른 수준은 시도하지 않습니다.
- 수준이 통과(성공)되거나 모든 수준을 시도한 경우 작업이 완료됩니다(실패).
다음 명령을 사용하여 노드에 펜싱 수준을 추가합니다. 장치는 해당 수준에서 노드에 대해 시도되는 쉼표로 구분된 stonith ids 목록으로 제공됩니다.
pcs stonith level add level node devices
pcs stonith level add level node devices다음 명령은 현재 구성된 모든 펜싱 수준을 나열합니다.
pcs stonith level
pcs stonith level
다음 예제에는 rh7-2 노드에 대해 두 개의 차단 장치가 있습니다. 노드 rh7-2: my_ilo 라는 ilo fence 장치 및 my_apc 라는 apc 차단 장치가 있습니다. 이러한 명령은 장치 my_ilo 가 실패하고 노드를 펜싱할 수 없는 경우 Pacemaker에서 장치 my_apc 를 사용하도록 차단 수준을 설정합니다. 이 예에서는 수준이 구성된 후 pcs stonith 수준 명령의 출력도 보여줍니다.
다음 명령은 지정된 노드 및 장치의 펜스 수준을 제거합니다. 노드 또는 장치를 지정하지 않으면 지정한 차단 수준이 모든 노드에서 제거됩니다.
pcs stonith level remove level [node_id] [stonith_id] ... [stonith_id]
pcs stonith level remove level [node_id] [stonith_id] ... [stonith_id]다음 명령은 지정된 노드 또는 stonith ID의 펜스 수준을 지웁니다. 노드 또는 stonith ID를 지정하지 않으면 모든 차단 수준이 지워집니다.
pcs stonith level clear [node]|stonith_id(s)]
pcs stonith level clear [node]|stonith_id(s)]다음 예제와 같이 두 개 이상의 stonith ID를 쉼표로 구분하고 공백을 사용하지 않아야 합니다.
pcs stonith level clear dev_a,dev_b
# pcs stonith level clear dev_a,dev_b다음 명령은 fence 수준에 지정된 모든 차단 장치 및 노드가 있는지 확인합니다.
pcs stonith level verify
pcs stonith level verify
노드 이름 및 해당 값에 적용되는 정규식으로 펜싱 토폴로지의 노드를 지정할 수 있습니다. 예를 들어 다음 명령은 노드 node1,node2 및 node3 을 구성하여 차단 장치 apc1 및 apc2, node4 , node4,node5, node6 을 사용하여 차단 장치 apc3 및 apc4 를 사용합니다.
pcs stonith level add 1 "regexp%node[1-3]" apc1,apc2 pcs stonith level add 1 "regexp%node[4-6]" apc3,apc4
# pcs stonith level add 1 "regexp%node[1-3]" apc1,apc2
# pcs stonith level add 1 "regexp%node[4-6]" apc3,apc4다음 명령은 노드 특성 일치를 사용하여 동일한 결과를 제공합니다.
52.7. 중복 전원 공급 장치를 위한 펜싱 구성
중복 전원 공급 장치를 구성할 때 클러스터에서 호스트 재부팅을 시도할 때 두 전원 공급 장치를 모두 꺼야 전원 공급 장치를 다시 켜야 합니다.
노드의 전원이 완전히 손실되지 않으면 노드에서 해당 리소스를 해제하지 못할 수 있습니다. 이렇게 하면 노드가 이러한 리소스에 동시에 액세스하고 손상될 수 있습니다.
다음 예제와 같이 각 장치를 한 번만 정의하고 노드를 펜싱해야 함을 지정해야 합니다.
52.8. 구성된 차단 장치 표시
다음 명령은 현재 구성된 모든 차단 장치를 보여줍니다. stonith_id 가 지정된 경우 명령은 구성된 펜싱 장치에 대한 옵션만 표시합니다. --full 옵션을 지정하면 구성된 모든 펜싱 옵션이 표시됩니다.
pcs stonith config [stonith_id] [--full]
pcs stonith config [stonith_id] [--full]52.9. fence 장치 를 pcs 명령으로 내보내기
Red Hat Enterprise Linux 8.7 이상에서는 명령의 pcs stonith config--output-format=cmd 옵션을 사용하여 다른 시스템에서 구성된 차단 장치를 다시 생성하는 데 사용할 수 있는 pcs 명령을 표시할 수 있습니다.
다음 명령은 fence_apc_snmp 차단 장치를 생성하고 장치를 다시 생성하는 데 사용할 수 있는 pcs 명령을 표시합니다.
52.10. 차단 장치 수정 및 삭제
다음 명령을 사용하여 현재 구성된 펜싱 장치에 옵션을 수정하거나 추가합니다.
pcs stonith update stonith_id [stonith_device_options]
pcs stonith update stonith_id [stonith_device_options]
pcs stonith update 명령을 사용하여 SCSI 펜싱 장치를 업데이트하면 펜싱 리소스가 실행 중인 동일한 노드에서 실행되는 모든 리소스가 다시 시작됩니다. RHEL 8.5 이상에서는 다음 명령 중 하나를 사용하여 다른 클러스터 리소스를 재시작하지 않고 SCSI 장치를 업데이트할 수 있습니다. RHEL 8.7 이상에서는 SCSI 펜싱 장치를 다중 경로 장치로 구성할 수 있습니다.
pcs stonith update-scsi-devices stonith_id set device-path1 device-path2 pcs stonith update-scsi-devices stonith_id add device-path1 remove device-path2
pcs stonith update-scsi-devices stonith_id set device-path1 device-path2
pcs stonith update-scsi-devices stonith_id add device-path1 remove device-path2
현재 구성에서 펜싱 장치를 제거하려면 pcs stonith delete stonith_id 명령을 사용합니다. 다음 명령은 펜싱 장치 stonith1 을 제거합니다.
pcs stonith delete stonith1
# pcs stonith delete stonith152.11. 수동으로 클러스터 노드 펜싱
다음 명령을 사용하여 노드를 수동으로 펜싱할 수 있습니다. --off 를 지정하면 off API 호출을 사용하여 stonith를 사용하여 노드를 재부팅하지 않고 꺼집니다.
pcs stonith fence node [--off]
pcs stonith fence node [--off]펜스 장치가 더 이상 활성 상태가 아니더라도 노드를 펜싱할 수 없는 경우 클러스터는 노드의 리소스를 복구하지 못할 수 있습니다. 이 경우 노드의 전원이 꺼졌는지 수동으로 확인한 후 다음 명령을 입력하여 노드의 전원이 꺼졌는지 확인하고 복구를 위해 해당 리소스를 해제할 수 있습니다.
지정한 노드가 실제로 꺼져 있지 않지만 클러스터에서 일반적으로 제어하는 클러스터 소프트웨어 또는 서비스를 실행하면 데이터 손상/클러스터 오류가 발생합니다.
pcs stonith confirm node
pcs stonith confirm node52.12. 차단 장치 비활성화
펜싱 장치/리소스를 비활성화하려면 pcs stonith disable 명령을 실행합니다.
다음 명령은 차단 장치 myapc 를 비활성화합니다.
pcs stonith disable myapc
# pcs stonith disable myapc52.13. 노드에서 펜싱 장치를 사용하지 못하도록 방지
특정 노드가 펜싱 장치를 사용하지 않도록 하려면 펜싱 리소스의 위치 제약 조건을 구성할 수 있습니다.
다음 예제에서는 fence 장치 node1-ipmi 가 node1 에서 실행되지 않도록 합니다.
pcs constraint location node1-ipmi avoids node1
# pcs constraint location node1-ipmi avoids node152.14. 통합 펜스 장치와 함께 사용할 ACPI 구성
클러스터에서 통합 펜스 장치를 사용하는 경우 즉시 펜싱을 완료하도록 ACPI(고급 구성 및 전원 인터페이스)를 구성해야 합니다.
클러스터 노드가 통합 차단 장치에 의해 펜싱되도록 구성된 경우 해당 노드에 대해 ACPI Soft-Off를 비활성화합니다. ACPI soft-Off를 비활성화하면 통합 차단 장치가 완전히 종료를 시도하지 않고 노드를 즉시 끌 수 있습니다(예: shutdown -h now). 그렇지 않으면 ACPI Soft-Off가 활성화된 경우 통합 차단 장치가 노드를 끄는 데 4초 이상 걸릴 수 있습니다(다음 참고 사항 참조). 또한 ACPI Soft-Off가 활성화되고 종료 중에 노드가 패닉되거나 정지되면 통합 차단 장치가 노드를 끄지 못할 수 있습니다. 이러한 상황에서는 펜싱이 지연되거나 실패합니다. 결과적으로 통합 차단 장치로 노드를 펜싱하고 ACPI Soft-Off가 활성화되면 클러스터는 느리게 복구되거나 복구하기 위해 관리 개입이 필요합니다.
노드를 펜싱하는 데 필요한 시간은 사용된 통합 차단 장치에 따라 다릅니다. 일부 통합 차단 장치는 전원 버튼을 누른 상태에서 유지하는 것과 동등한 작업을 수행하므로 차단 장치가 4~5초 내에 노드를 끕니다. 다른 통합 차단 장치는 일시적으로 전원 버튼을 누르면서 운영 체제에 따라 노드를 끄는 것과 동일한 작업을 수행합니다. 따라서 차단 장치는 4~5초보다 훨씬 더 긴 시간 내에 노드를 끕니다.
- ACPI Soft-Off를 비활성화하는 기본 방법은 BIOS 설정을 "instant-off" 또는 "보통으로 ACPI Soft-Off 비활성화"에 설명된 대로 지연없이 노드를 끄는 동등한 설정으로 변경하는 것입니다.
BIOS로 ACPI Soft-Off를 비활성화하면 일부 시스템에서 가능하지 않을 수 있습니다. BIOS로 ACPI Soft-Off를 비활성화하면 클러스터에 대한 불만이 없는 경우 다음 대체 방법 중 하나를 사용하여 ACPI Soft-Off를 비활성화할 수 있습니다.
-
/etc/systemd/logind.conf파일에서HandlePowerKey=ignore를 설정하고 아래의 logind.conf 파일에서 ACPI Soft-Off 비활성화에 설명된 대로 노드가 펜싱 시 즉시 꺼졌는지 확인합니다. 이는 ACPI Soft-Off를 비활성화하는 첫 번째 대체 방법입니다. 아래 GRUB 파일에서 ACPI 비활성화에 설명된 대로
acpi=off를 커널 부팅 명령줄에 추가합니다. 이는 ACPI soft-Off를 비활성화하는 두 번째 대체 방법입니다. 기본 설정 또는 첫 번째 대체 방법을 사용할 수 없습니다.중요이 방법은 ACPI를 완전히 비활성화합니다. ACPI를 완전히 비활성화하면 일부 컴퓨터가 올바르게 부팅되지 않습니다. 다른 방법이 클러스터에 효과가 없는 경우에만 이 방법을 사용합니다.
52.14.1. BIOS로 ACPI soft-Off 비활성화
다음 절차에 따라 각 클러스터 노드의 BIOS를 구성하여 ACPI Soft-Off를 비활성화할 수 있습니다.
BIOS로 ACPI Soft-Off를 비활성화하는 절차는 서버 시스템마다 다를 수 있습니다. 하드웨어 설명서에서 이 절차를 확인해야 합니다.
프로세스
-
노드를 재부팅하고
BIOS CMOS 설정 유틸리티프로그램을 시작합니다. - Power 메뉴(또는 동등한 전원 관리 메뉴)로 이동합니다.
Power 메뉴에서
PWR-BTTN함수(또는 이에 해당하는 경우)를Instant-Off로 설정합니다(또는 지연 없이 전원 버튼을 사용하여 노드를 끄는 동등한 설정). 아래BIOS CMOS 설정사용률 예제에는PWR-BTTN이로 설정된Instant-OffACPI Function이Enabled로 설정된 Power 메뉴가 표시되어 있습니다.참고ACPI 기능,PWR-BTTN에 의한 soft-Off에해당하는 것으로,Instant-Off는 컴퓨터마다 다를 수 있습니다. 그러나 이 절차의 목적은 컴퓨터를 지연 없이 전원 버튼을 통해 꺼지도록 BIOS를 구성하는 것입니다.-
BIOS CMOS 설정 유틸리티프로그램을 종료하고 BIOS 구성을 저장합니다. - 펜싱 시 노드가 즉시 꺼졌는지 확인합니다. 펜스 장치를 테스트하는 방법에 대한 자세한 내용은 차단 장치 테스트를 참조하십시오.
BIOS CMOS 설정 유틸리티:
`Soft-Off by PWR-BTTN` set to `Instant-Off`
`Soft-Off by PWR-BTTN` set to
`Instant-Off`
이 예에서는 ACPI Function 이 Enabled 로 설정되고 PWR-BTTN이 -Off를 보여줍니다.
Instant-Off 로 설정된 soft
52.14.2. logind.conf 파일에서 ACPI soft-Off 비활성화
/etc/systemd/logind.conf 파일에서 전원 키 전달을 비활성화하려면 다음 절차를 사용하십시오.
프로세스
/etc/systemd/logind.conf파일에 다음 구성을 정의합니다.HandlePowerKey=ignore
HandlePowerKey=ignoreCopy to Clipboard Copied! Toggle word wrap Toggle overflow systemd-logind서비스를 다시 시작하십시오.systemctl restart systemd-logind.service
# systemctl restart systemd-logind.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 펜싱 시 노드가 즉시 꺼졌는지 확인합니다. 펜스 장치를 테스트하는 방법에 대한 자세한 내용은 차단 장치 테스트를 참조하십시오.
52.14.3. GRUB 파일에서 ACPI를 완전히 비활성화
커널의 GRUB 메뉴 항목에 acpi=off 를 추가하여 ACPI Soft-Off를 비활성화할 수 있습니다.
이 방법은 ACPI를 완전히 비활성화합니다. ACPI를 완전히 비활성화하면 일부 컴퓨터가 올바르게 부팅되지 않습니다. 다른 방법이 클러스터에 효과가 없는 경우에만 이 방법을 사용합니다.
프로세스
GRUB 파일에서 ACPI를 비활성화하려면 다음 절차를 사용하십시오.
grubby툴의--update-kernel옵션과 함께--args옵션을 사용하여 다음과 같이 각 클러스터 노드의grub.cfg파일을 변경합니다.grubby --args=acpi=off --update-kernel=ALL
# grubby --args=acpi=off --update-kernel=ALLCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 노드를 재부팅합니다.
- 펜싱 시 노드가 즉시 꺼졌는지 확인합니다. 펜스 장치를 테스트하는 방법에 대한 자세한 내용은 차단 장치 테스트를 참조하십시오.
53장. 클러스터 리소스 구성
다음 명령을 사용하여 클러스터 리소스를 생성하고 삭제합니다.
클러스터 리소스를 생성하는 명령의 형식은 다음과 같습니다.
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options [operation_action operation options]...] [meta meta_options...] [clone [clone_options] | master [master_options] [--wait[=n]]
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options [operation_action operation options]...] [meta meta_options...] [clone [clone_options] | master [master_options] [--wait[=n]]주요 클러스터 리소스 생성 옵션에는 다음이 포함됩니다.
-
--before및--after옵션은 리소스 그룹에 이미 존재하는 리소스를 기준으로 추가된 리소스의 위치를 지정합니다. -
--disabled옵션을 지정하면 리소스가 자동으로 시작되지 않음을 나타냅니다.
클러스터에 생성할 수 있는 리소스 수에는 제한이 없습니다.
해당 리소스에 대한 제약 조건을 구성하여 클러스터에서 리소스의 동작을 확인할 수 있습니다.
리소스 생성 예
다음 명령은 표준 ocf 의 VirtualIP, 공급자 하트비트, IPaddr2 유형으로 리소스를 생성합니다. 이 리소스의 유동 주소는 192.168.0.120이며 시스템은 30초마다 리소스가 실행 중인지 확인합니다.
pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
또는 표준 및 공급자 필드를 생략하고 다음 명령을 사용할 수 있습니다. 이는 기본적으로 ocf 표준 및 하트비트 공급자로 설정됩니다.
pcs resource create VirtualIP IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
# pcs resource create VirtualIP IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s구성된 리소스 삭제
다음 명령을 사용하여 구성된 리소스를 삭제합니다.
pcs resource delete resource_id
pcs resource delete resource_id
예를 들어 다음 명령은 VirtualIP 라는 리소스 ID를 사용하여 기존 리소스를 삭제합니다.
pcs resource delete VirtualIP
# pcs resource delete VirtualIP53.1. 리소스 에이전트 식별자
리소스에 대해 정의한 식별자는 클러스터에 리소스에 사용할 에이전트, 해당 에이전트를 찾을 위치 및 표준을 찾는 위치를 알려줍니다.
다음 표에서는 리소스 에이전트의 이러한 속성에 대해 설명합니다.
| 필드 | 설명 |
|---|---|
| Standard | 에이전트가 준수하는 표준입니다. 허용되는 값과 그 의미:
* OCF - 지정된 유형은 Open Cluster Framework Resource Agent API를 따르는 실행 파일의 이름이며
*
*
* specified type 은 |
| type |
사용하려는 리소스 에이전트의 이름(예: |
| provider |
OCF 사양을 사용하면 여러 공급업체가 동일한 리소스 에이전트를 제공할 수 있습니다. Red Hat에서 제공하는 대부분의 에이전트는 |
다음 표에는 사용 가능한 리소스 속성을 표시하는 명령이 요약되어 있습니다.
| pcs Display 명령 | 출력 결과 |
|---|---|
|
| 사용 가능한 모든 리소스 목록을 표시합니다. |
|
| 사용 가능한 리소스 에이전트 표준 목록을 표시합니다. |
|
| 사용 가능한 리소스 에이전트 공급자 목록을 표시합니다. |
|
| 지정된 문자열로 필터링되는 사용 가능한 리소스 목록을 표시합니다. 이 명령을 사용하여 표준, 공급자 또는 유형의 이름으로 필터링된 리소스를 표시할 수 있습니다. |
53.2. 리소스별 매개변수 표시
개별 리소스에 대해 다음 명령을 사용하여 리소스에 대한 설명, 해당 리소스에 설정할 수 있는 매개변수, 리소스에 설정된 기본값을 표시할 수 있습니다.
pcs resource describe [standard:[provider:]]type
pcs resource describe [standard:[provider:]]type
예를 들어 다음 명령은 apache 유형의 리소스에 대한 정보를 표시합니다.
53.3. 리소스 메타 옵션 구성
리소스별 매개변수 외에도 모든 리소스에 대한 추가 리소스 옵션을 구성할 수 있습니다. 이러한 옵션은 클러스터에서 리소스 작동 방식을 결정하는 데 사용됩니다.
다음 표에서는 리소스 메타 옵션을 설명합니다.
| 필드 | 기본 | 설명 |
|---|---|---|
|
|
| 모든 리소스를 활성화할 수 없는 경우 우선 순위가 높은 리소스를 활성 상태로 유지하기 위해 클러스터가 우선순위가 낮은 리소스를 중지합니다. |
|
|
| 클러스터가 이 리소스를 유지하려고 시도하는 상태를 나타냅니다. 허용되는 값:
*
*
RHEL 8.5 이상에서 |
|
|
|
클러스터가 리소스를 시작하고 중지할 수 있는지 여부를 나타냅니다. 허용되는 값: |
|
| 0 | 리소스가 있는 위치를 유지하는 것을 선호하는 값을 나타냅니다. 이 속성에 대한 자세한 내용은 현재 노드를 선호하도록 리소스 구성을 참조하십시오. |
|
| 계산된 | 리소스를 시작할 수 있는 조건에서 나타냅니다.
아래 표시된 조건을 제외하고 기본값은
*
*
* |
|
|
|
이 노드가 이 리소스를 호스팅할 수 없는 것으로 표시되기 전에 노드에서 이 리소스에 대해 발생할 수 있는 오류 수입니다. 값이 0이면 이 기능이 비활성화되어 있음을 나타냅니다(노드는 자격 없는 것으로 표시되지 않음). 반면 클러스터는 |
|
|
| 이 시간이 새로운 실패 없이 통과된 후 이전에 실패한 리소스 작업을 무시합니다. 이로 인해 이전에 마이그레이션 임계값에 도달한 경우 리소스가 실패한 노드로 다시 이동할 수 있습니다. 값 0은 실패가 만료되지 않음을 나타냅니다. 경고: 이 값이 낮고 보류 중인 클러스터 활동으로 인해 클러스터가 해당 시간 내에 장애에 응답하지 않게 되면 오류가 완전히 무시되고 반복 작업이 계속 실패를 보고하더라도 리소스 복구가 발생하지 않습니다. 이 옵션의 값은 클러스터의 모든 리소스에 대해 가장 긴 작업 시간 초과보다 커야 합니다. 시간 또는 일 단위의 값은 합리적입니다. |
|
|
| 둘 이상의 노드에서 활성 리소스를 찾은 경우 클러스터에서 수행할 작업을 나타냅니다. 허용되는 값:
*
*
*
* |
|
|
|
(RHEL 8.4 이상) 리소스가 리소스 그룹의 일부일 때 생성된 암시적 공동 배치 제약 조건을 포함하여 리소스를 종속 리소스(target_resource)로 포함하는 |
|
|
|
(RHEL 8.7 이상) |
53.3.1. 리소스 옵션의 기본값 변경
Red Hat Enterprise Linux 8.3 이상에서는 pcs resource defaults update 명령을 사용하여 모든 리소스에 대한 리소스 옵션의 기본값을 변경할 수 있습니다. 다음 명령은 resource-stickiness 의 기본값을 100으로 재설정합니다.
pcs resource defaults update resource-stickiness=100
# pcs resource defaults update resource-stickiness=100
이전 릴리스의 모든 리소스에 대한 기본값을 설정하는 원래 pcs resource defaults name=value 명령은 기본값이 두 개 이상 구성된 경우를 제외하고 계속 지원됩니다. 그러나 pcs resource defaults update 는 이제 기본 버전의 명령입니다.
53.3.2. 리소스 세트의 리소스 옵션 기본값 변경
Red Hat Enterprise Linux 8.3 이상에서는 pcs resource defaults set create 명령을 사용하여 여러 리소스 기본값 세트를 생성할 수 있으므로 리소스 표현식이 포함된 규칙을 지정할 수 있습니다. RHEL 8.3에서는 및 를 포함한 리소스 식만 이 명령으로 지정하는 규칙에 허용됩니다. RHEL 8.4 이상에서는 및 를 포함한 리소스 및 날짜 표현식만 이 명령으로 지정하는 규칙에 허용됩니다.
pcs resource defaults set create 명령을 사용하면 특정 유형의 모든 리소스에 대한 기본 리소스 값을 구성할 수 있습니다. 예를 들어 중지하는 데 시간이 오래 걸리는 데이터베이스를 실행 중인 경우 데이터베이스 유형의 모든 리소스에 대한 resource-stickiness 기본값을 늘릴 수 있으므로 해당 리소스가 원하는 것보다 더 자주 다른 노드로 이동하지 못하도록 할 수 있습니다.
다음 명령은 pqsql 유형의 모든 리소스에 대해 resource-stickiness 의 기본값을 100으로 설정합니다.
-
리소스 기본값 집합의 이름을 지정하는
id옵션은 필수가 아닙니다. 이 옵션을 설정하지 않으면pcs가 ID를 자동으로 생성합니다. 이 값을 설정하면 더 설명이 포함된 이름을 제공할 수 있습니다. 이 예에서
::pgsql은 모든 클래스의 리소스, 모든 공급자, typepgsql을 의미합니다.-
ocf:heartbeat:pgsql을 지정하면 클래스ocf, providerheartbeat, typepgsql을 나타냅니다. -
ocf:pacemaker:는 클래스ocf, providerpacemaker의 모든 리소스를 모든 유형을 나타냅니다.
-
pcs resource defaults set create id=pgsql-stickiness meta resource-stickiness=100 rule resource ::pgsql
# pcs resource defaults set create id=pgsql-stickiness meta resource-stickiness=100 rule resource ::pgsql
기존 세트의 기본값을 변경하려면 pcs resource defaults set update 명령을 사용합니다.
53.3.3. 현재 구성된 리소스 기본값 표시
pcs resource defaults 명령은 사용자가 지정한 규칙을 포함하여 리소스 옵션에 대해 현재 구성된 기본값 목록을 표시합니다.
다음 예제에서는 resource-stickiness 의 기본값을 100으로 설정한 후 이 명령의 출력을 보여줍니다.
pcs resource defaults Meta Attrs: rsc_defaults-meta_attributes resource-stickiness=100
# pcs resource defaults
Meta Attrs: rsc_defaults-meta_attributes
resource-stickiness=100
다음 예제에서는 pqsql 유형의 모든 리소스에 대해 resource-stickiness 의 기본값을 100으로 재설정하고 id 옵션을 id=pgsql-stickiness 로 설정한 후 이 명령의 출력을 보여줍니다.
pcs resource defaults
Meta Attrs: pgsql-stickiness
resource-stickiness=100
Rule: boolean-op=and score=INFINITY
Expression: resource ::pgsql
# pcs resource defaults
Meta Attrs: pgsql-stickiness
resource-stickiness=100
Rule: boolean-op=and score=INFINITY
Expression: resource ::pgsql53.3.4. 리소스 생성에 대한 메타 옵션 설정
리소스 메타 옵션의 기본값을 재설정했는지 여부에 관계없이 리소스를 생성할 때 특정 리소스의 리소스 옵션을 기본값 이외의 값으로 설정할 수 있습니다. 다음은 리소스 메타 옵션의 값을 지정할 때 사용하는 pcs resource create 명령의 형식을 보여줍니다.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta meta_options...]
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta meta_options...]
예를 들어 다음 명령은 resource-stickiness 값이 50인 리소스를 생성합니다.
pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 meta resource-stickiness=50
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 meta resource-stickiness=50다음 명령을 사용하여 기존 리소스, 그룹 또는 복제 리소스의 리소스 메타 옵션 값을 설정할 수도 있습니다.
pcs resource meta resource_id | group_id | clone_id meta_options
pcs resource meta resource_id | group_id | clone_id meta_options
다음 예제에는 dummy_resource 라는 기존 리소스가 있습니다. 이 명령을 수행하면 리소스가 20초 내에 동일한 노드에서 다시 시작할 수 있도록 failure-timeout 메타 옵션을 20초로 설정합니다.
pcs resource meta dummy_resource failure-timeout=20s
# pcs resource meta dummy_resource failure-timeout=20s
이 명령을 실행한 후 리소스의 값을 표시하여 failure-timeout=20s 가 설정되었는지 확인할 수 있습니다.
pcs resource config dummy_resource Resource: dummy_resource (class=ocf provider=heartbeat type=Dummy) Meta Attrs: failure-timeout=20s ...
# pcs resource config dummy_resource
Resource: dummy_resource (class=ocf provider=heartbeat type=Dummy)
Meta Attrs: failure-timeout=20s
...53.4. 리소스 그룹 구성
클러스터의 가장 일반적인 요소 중 하나는 함께 배치하고 순차적으로 시작하고 역순으로 중지해야 하는 리소스 집합입니다. 이 구성을 단순화하기 위해 Pacemaker는 리소스 그룹 개념을 지원합니다.
53.4.1. 리소스 그룹 생성
다음 명령을 사용하여 리소스 그룹을 생성하고 그룹에 포함할 리소스를 지정합니다. 그룹이 없는 경우 이 명령은 그룹을 생성합니다. 그룹이 존재하는 경우 이 명령은 그룹에 리소스를 추가합니다. 리소스는 이 명령으로 지정하는 순서대로 시작되고 시작 순서의 역순으로 중지됩니다.
pcs resource group add group_name resource_id [resource_id] ... [resource_id] [--before resource_id | --after resource_id]
pcs resource group add group_name resource_id [resource_id] ... [resource_id] [--before resource_id | --after resource_id]
이 명령의 --before 및 --after 옵션을 사용하여 그룹에 이미 존재하는 리소스를 기준으로 추가된 리소스의 위치를 지정할 수 있습니다.
다음 명령을 사용하여 리소스를 생성할 때 기존 그룹에 새 리소스를 추가할 수도 있습니다. 생성한 리소스가 group_name 이라는 그룹에 추가됩니다. group_name 이 없으면 생성됩니다.
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options] --group group_name
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options] --group group_name그룹에 포함할 수 있는 리소스 수에는 제한이 없습니다. 그룹의 기본 속성은 다음과 같습니다.
- 리소스는 그룹 내에 배치됩니다.
- 리소스는 지정하는 순서대로 시작됩니다. 그룹의 리소스를 실행할 수 없는 경우 해당 리소스를 실행할 수 있는 후 지정된 리소스가 없습니다.
- 리소스가 지정하는 역순으로 중지됩니다.
다음 예제에서는 기존 리소스 IPaddr 및 Email 을 포함하는 shortcut 라는 리소스 그룹을 생성합니다.
pcs resource group add shortcut IPaddr Email
# pcs resource group add shortcut IPaddr Email이 예제에서는 다음을 수행합니다.
-
IPaddr이 먼저 시작되고Email. -
Email리소스가 먼저 중지되고IPAddr. -
IPaddr은 아무데도 실행할 수 없는 경우이메일도 실행할 수 없습니다. -
그러나
이메일이아무데도 실행할 수 없는 경우IPaddr에는 영향을 미치지 않습니다.
53.4.2. 리소스 그룹 제거
다음 명령을 사용하여 그룹에서 리소스를 제거합니다. 그룹에 남아 있는 리소스가 없으면 이 명령은 그룹 자체를 제거합니다.
pcs resource group remove group_name resource_id...
pcs resource group remove group_name resource_id...53.4.3. 리소스 그룹 표시
다음 명령은 현재 구성된 모든 리소스 그룹을 나열합니다.
pcs resource group list
pcs resource group list53.4.4. 그룹 옵션
리소스 그룹에 대해 다음 옵션을 설정할 수 있으며 단일 리소스에 대해 설정된 경우와 동일한 의미를 유지할 수 있습니다( priority,target-role,is-managed ). 리소스 메타 옵션에 대한 자세한 내용은 리소스 메타 옵션 구성을 참조하십시오.
53.4.5. 그룹 고정
고정성, 리소스가 있는 곳에 유지하려는 정도를 측정하는 것은 그룹에서 추가됩니다. 그룹의 모든 활성 리소스는 그룹 합계에 고정 값을 제공합니다. 따라서 기본 resource-stickiness 가 100이고 그룹에 7개의 멤버가 있고 그 중 5개가 활성 상태인 경우 그룹 전체의 점수가 500인 현재 위치를 선호합니다.
53.5. 리소스 동작 확인
해당 리소스에 대한 제약 조건을 구성하여 클러스터에서 리소스의 동작을 확인할 수 있습니다. 다음과 같은 제약 조건을 구성할 수 있습니다.
-
위치제한 조건 - 위치 제한 조건은 리소스가 실행할 수 있는 노드를 결정합니다. 위치 제약 조건을 구성하는 방법에 대한 자세한 내용은 리소스가 실행할 수 있는 노드 결정을 참조하십시오. -
순서제한 조건 - 순서 제한 조건은 리소스가 실행되는 순서를 결정합니다. 순서 제한 조건 구성에 대한 자세한 내용은 클러스터 리소스가 실행되는 순서 결정을 참조하십시오. -
공동 배치 제약 조건 - 공동 배치 제약 조건에 따라 리소스가 다른 리소스를 기준으로 배치되는 위치가 결정됩니다.Colocation constraints - a
colocationconstraint determines where resources will be placed relative to other resources. 공동 배치 제약 조건에 대한 자세한 내용은 클러스터 리소스 배치를 참조하십시오.
리소스 세트를 함께 찾고 리소스가 순차적으로 시작하고 역순으로 중지되도록 하는 제약 조건 집합을 간단하게 구성하는 것입니다. Pacemaker에서는 리소스 그룹 개념을 지원합니다. 리소스 그룹을 생성한 후에는 개별 리소스에 대한 제약 조건을 구성하는 것처럼 그룹 자체에 대한 제약 조건을 구성할 수 있습니다.
54장. 리소스를 실행할 수 있는 노드 확인
위치 제한 조건은 리소스를 실행할 수 있는 노드를 결정합니다. 리소스가 지정된 노드를 선호하거나 방지할지 여부를 결정하도록 위치 제약 조건을 구성할 수 있습니다.
위치 제약 조건 외에도 리소스가 실행되는 노드는 해당 리소스의 resource-stickiness 값의 영향을 받으며, 이 값은 리소스가 현재 실행 중인 노드에 남아 있는 정도를 결정합니다. resource-stickiness 값을 설정하는 방법에 대한 자세한 내용은 현재 노드를 선호하도록 리소스 구성을 참조하십시오.
54.1. 위치 제약 조건 구성
기본 위치 제약 조건을 구성하여 제약 조건에 대한 상대적 우선 순위 수준을 나타내는 선택적 점수 값과 함께 리소스가 선호하는지 또는 방지하는지 여부를 지정할 수 있습니다.
다음 명령은 지정된 노드 또는 노드를 선호하는 리소스에 대한 위치 제약 조건을 생성합니다. 단일 명령을 사용하여 두 개 이상의 노드에 대한 특정 리소스에 대한 제약 조건을 생성할 수 있습니다.
pcs constraint location rsc prefers node[=score] [node[=score]] ...
pcs constraint location rsc prefers node[=score] [node[=score]] ...다음 명령은 지정된 노드 또는 노드를 방지하기 위해 리소스에 대한 위치 제약 조건을 생성합니다.
pcs constraint location rsc avoids node[=score] [node[=score]] ...
pcs constraint location rsc avoids node[=score] [node[=score]] ...다음 표에는 위치 제약 조건을 구성하기 위한 기본 옵션의 의미가 요약되어 있습니다.
| 필드 | 설명 |
|---|---|
|
| 리소스 이름 |
|
| 노드 이름 |
|
|
지정된 리소스가 지정된 노드를 선호하거나 피해야 하는지에 대한 기본 설정 정도를 나타내는 양의 정수 값입니다.
숫자 점수(즉, |
다음 명령은 위치 제약 조건을 생성하여 Webserver 리소스가 노드 node1 을 선호하도록 지정합니다.
pcs constraint location Webserver prefers node1
# pcs constraint location Webserver prefers node1
pcs 는 명령줄의 위치 제약 조건에서 정규식을 지원합니다. 이러한 제약 조건은 리소스 이름과 일치하는 정규식을 기반으로 여러 리소스에 적용됩니다. 이를 통해 단일 명령줄을 사용하여 여러 위치 제약 조건을 구성할 수 있습니다.
다음 명령은 위치 제약 조건을 생성하여 dummy0 에서 dummy9 prefer node1 로 지정합니다.
pcs constraint location 'regexp%dummy[0-9]' prefers node1
# pcs constraint location 'regexp%dummy[0-9]' prefers node1Pacemaker는 http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04 에 설명된 대로 POSIX 확장 정규식을 사용하므로 다음 명령을 사용하여 동일한 제약 조건을 지정할 수 있습니다.
pcs constraint location 'regexp%dummy[[:digit:]]' prefers node1
# pcs constraint location 'regexp%dummy[[:digit:]]' prefers node154.2. 리소스 검색을 노드 서브 세트로 제한
Pacemaker에서 리소스를 시작하기 전에 먼저 모든 노드에서 일회성 모니터 작업(종종 "프로브")을 실행하여 리소스가 이미 실행되고 있는지 확인합니다. 이 리소스 검색 프로세스에서는 모니터를 실행할 수 없는 노드에 오류가 발생할 수 있습니다.
노드에서 위치 제한 조건을 구성할 때 pcs constraint location 명령의 resource-discovery 옵션을 사용하여 지정된 리소스에 대해 Pacemaker에서 리소스 검색을 수행해야 하는지에 대한 기본 설정을 표시할 수 있습니다. 리소스 검색을 실제로 실행할 수 있는 노드 서브 세트로 제한하면 많은 노드 세트가 있는 경우 성능이 크게 향상될 수 있습니다. pacemaker_remote 를 사용하여 노드 수를 수백 개의 노드 범위로 확장하면 이 옵션을 고려해야 합니다.
다음 명령은 pcs constraint location 명령의 resource-discovery 옵션을 지정하는 형식을 보여줍니다. 이 명령에서 점수에 대한 양의 값은 노드를 선호하도록 리소스를 구성하는 기본 위치 제약 조건에 해당하며, 음수 값은 노드를 피하기 위해 리소스를 구성하는 기본 위치의constraint에 해당합니다. 기본 위치 제약 조건과 마찬가지로 이러한 제약 조건이 있는 리소스에 대해 정규식을 사용할 수 있습니다.
pcs constraint location add id rsc node score [resource-discovery=option]
pcs constraint location add id rsc node score [resource-discovery=option]다음 표에는 리소스 검색에 대한 제약 조건을 구성하기 위한 기본 매개변수의 의미가 요약되어 있습니다.
| 필드 | 설명 |
|
| 제약 조건 자체에 대한 사용자 선택 이름입니다. |
|
| 리소스 이름 |
|
| 노드 이름 |
|
| 지정된 리소스가 지정된 노드를 선호하거나 피해야 하는지에 대한 기본 설정 정도를 나타내는 정수 값입니다. 점수에 대한 양의 값은 노드를 선호하도록 리소스를 구성하는 기본 위치 제약 조건에 해당하며 점수에 대한 음수 값은 노드를 피하기 위해 리소스를 구성하는 기본 위치 제약 조건에 해당합니다.
숫자 점수(즉, |
|
|
* |
resource-discovery 를 never 또는 exclusive 로 설정하면 Pacemaker에서 실행 중인 서비스의 원하지 않는 인스턴스를 탐지하고 중지하는 기능이 제거됩니다. 시스템 관리자는 리소스 검색 없이(예: 관련 소프트웨어를 제거한 상태로 두는 등) 노드에서 서비스를 활성화할 수 없는지 확인합니다.
54.3. 위치 제약 조건 전략 구성
위치 제약 조건을 사용하는 경우 리소스가 실행할 수 있는 노드를 지정하는 일반적인 전략을 구성할 수 있습니다.
- 옵트인 클러스터 - 기본적으로 어느 곳에서나 리소스를 실행할 수 없는 클러스터를 구성한 다음 특정 리소스에 대해 허용된 노드를 선택적으로 활성화할 수 있습니다.
- 옵트아웃 클러스터 - 기본적으로 모든 리소스를 실행할 수 있는 클러스터를 구성한 다음 특정 노드에서 실행할 수 없는 리소스에 대한 위치 제약 조건을 생성할 수 있습니다.
클러스터를 옵트인 또는 옵트아웃 클러스터로 구성하도록 선택해야 하는지 여부는 개인 기본 설정과 클러스터 작성에 따라 다릅니다. 대부분의 리소스가 대부분의 노드에서 실행될 수 있는 경우 옵트아웃 배열은 더 간단한 구성을 초래할 수 있습니다. 반면 대부분의 리소스가 노드의 작은 하위 집합에서만 실행할 수 있는 경우 옵트인 구성이 더 간단할 수 있습니다.
54.3.1. "Opt-In" 클러스터 구성
옵트인 클러스터를 생성하려면 기본적으로 리소스가 어디에서나 실행되지 않도록 symmetric-cluster 클러스터 속성을 false 로 설정합니다.
pcs property set symmetric-cluster=false
# pcs property set symmetric-cluster=false
개별 리소스에 대해 노드를 활성화합니다. 다음 명령은 리소스 Webserver 가 노드 example-1 을 선호하도록 위치 제약 조건을 구성합니다. 리소스 데이터베이스 는 노드 example-2 를 선호하며, 두 리소스 모두 기본 노드가 실패하면 노드 example-3 으로 장애 조치될 수 있습니다. 옵트인 클러스터에 대한 위치 제약 조건을 구성할 때 0으로 점수를 설정하면 노드를 선호하거나 방지할 수 있는 기본 설정을 표시하지 않고 노드에서 리소스를 실행할 수 있습니다.
pcs constraint location Webserver prefers example-1=200 pcs constraint location Webserver prefers example-3=0 pcs constraint location Database prefers example-2=200 pcs constraint location Database prefers example-3=0
# pcs constraint location Webserver prefers example-1=200
# pcs constraint location Webserver prefers example-3=0
# pcs constraint location Database prefers example-2=200
# pcs constraint location Database prefers example-3=054.3.2. "Opt-Out" 클러스터 구성
옵트아웃 클러스터를 생성하려면 기본적으로 모든 위치에서 리소스를 실행할 수 있도록 symmetric-cluster 클러스터 속성을 true 로 설정합니다. symmetric-cluster 가 명시적으로 설정되지 않은 경우 이는 기본 구성입니다.
pcs property set symmetric-cluster=true
# pcs property set symmetric-cluster=true
그러면 다음 명령은 "Opt-In" 클러스터 구성의 예와 동일한 구성을 생성합니다. 모든 노드에 암시적 점수가 0이므로 두 리소스 모두 노드 example-3 으로 장애 조치될 수 있습니다.
pcs constraint location Webserver prefers example-1=200 pcs constraint location Webserver avoids example-2=INFINITY pcs constraint location Database avoids example-1=INFINITY pcs constraint location Database prefers example-2=200
# pcs constraint location Webserver prefers example-1=200
# pcs constraint location Webserver avoids example-2=INFINITY
# pcs constraint location Database avoids example-1=INFINITY
# pcs constraint location Database prefers example-2=200점수에 대한 기본값이므로 이러한 명령에서 INFINITY 점수를 지정할 필요가 없습니다.
54.4. 현재 노드를 선호하도록 리소스 구성
리소스에는 리소스 메타 옵션 구성에 설명된 대로 리소스를 생성할 때 메타 속성으로 설정할 수 있는 resource-stickiness 값이 있습니다. resource-stickiness 값은 리소스가 현재 실행 중인 노드에서 유지하려는 양을 결정합니다. Pacemaker에서는 다른 설정(예: 위치 제약 조건의 점수 값)과 함께 resource-stickiness 값을 고려하여 리소스를 다른 노드로 이동할지 아니면 제 위치에 둘지 결정합니다.
resource-stickiness 값이 0인 경우 클러스터에서 필요에 따라 리소스를 이동하여 노드 간에 리소스의 균형을 조정할 수 있습니다. 이로 인해 관련이 없는 리소스가 시작되거나 중지될 때 리소스가 이동할 수 있습니다. 긍정적인 고정성을 통해 리소스는 자신이 있는 위치를 유지하는 기본 설정을 가지며, 다른 상황이 고착성을 벗어나는 경우에만 이동합니다. 이로 인해 관리자가 개입하지 않고 새로 추가된 노드에 리소스가 할당되지 않을 수 있습니다.
기본적으로 리소스는 resource-stickiness 값이 0인 상태로 생성됩니다. resource-stickiness 가 0으로 설정되어 있고 클러스터 노드 간에 균등하게 분산되도록 리소스를 이동하는 위치 제약 조건이 없는 경우 Pacemaker의 기본 동작입니다. 이로 인해 정상 리소스가 원하는 것보다 더 자주 이동할 수 있습니다. 이 동작을 방지하려면 기본 resource-stickiness 값을 1로 설정할 수 있습니다. 이 기본값은 클러스터의 모든 리소스에 적용됩니다. 이 작은 값은 생성한 다른 제약 조건으로 쉽게 덮어쓸 수 있지만 Pacemaker가 클러스터 주위에 불필요하게 이동하는 정상 리소스가 발생하지 않도록하기에 충분합니다.
다음 명령은 기본 resource-stickiness 값을 1로 설정합니다.
pcs resource defaults update resource-stickiness=1
# pcs resource defaults update resource-stickiness=1
양의 resource-stickiness 값을 사용하면 리소스가 새로 추가된 노드로 이동되지 않습니다. 이 시점에서 리소스 밸런싱이 필요한 경우 resource-stickiness 값을 0으로 일시적으로 설정할 수 있습니다.
위치 제한 조건 점수가 resource-stickiness 값보다 크면 클러스터에서 여전히 정상적인 리소스를 위치 제약 조건이 가리키는 노드로 이동할 수 있습니다.
Pacemaker에서 리소스를 배치할 위치를 결정하는 방법에 대한 자세한 내용은 노드 배치 전략 구성을 참조하십시오.
55장. 클러스터 리소스 실행 순서 확인
리소스 실행 순서를 결정하려면 순서 제약 조건을 구성합니다.
다음은 순서 제약 조건을 구성하는 명령의 형식을 보여줍니다.
pcs constraint order [action] resource_id then [action] resource_id [options]
pcs constraint order [action] resource_id then [action] resource_id [options]다음 표에는 순서 제약 조건을 구성하기 위한 속성 및 옵션이 요약되어 있습니다.
| 필드 | 설명 |
|---|---|
| resource_id | 작업이 수행되는 리소스의 이름입니다. |
| 작업 | 리소스에서 정렬할 작업입니다. action 속성의 가능한 값은 다음과 같습니다.
*
*
*
*
작업이 지정되지 않은 경우 기본 작업이 |
|
|
제약 조건을 적용하는 방법.
*
직렬화 |
|
|
true인 경우 제약 조건의 반대는 반대 동작에 적용됩니다(예: A가 시작된 후 B가 시작되면 A가 중지되기 전에 B가 중지됩니다). type이 |
다음 명령을 사용하여 순서 지정 제약 조건에서 리소스를 제거합니다.
pcs constraint order remove resource1 [resourceN]...
pcs constraint order remove resource1 [resourceN]...55.1. 필수 순서 구성
필수 순서 제한 조건은 첫 번째 리소스에 대한 첫 번째 작업이 완료될 때까지 두 번째 작업을 두 번째 리소스에 대해 시작하지 않아야 함을 나타냅니다. 주문될 수 있는 작업은 중지,시작 및 프로모션 가능한 복제, 데모 및 . 예를 들어 "A then B"( "시작 A 후 B 시작")는 A가 성공적으로 시작될 때까지 B가 시작되지 않음을 의미합니다. 제약 조건에 대한 승격에 대한 것입니다kind 옵션이 Mandatory 로 설정되어 있거나 기본값으로 남아 있는 경우 순서 제약 조건이 필요합니다.
symmetrical 옵션이 true 로 설정되거나 기본값으로 남아 있으면 반대 작업이 반대로 정렬됩니다. 시작 및 중지 작업은 반대이며, 데모와 프로모션 은 반대입니다. 예를 들어 대칭인 "promote A" 순서는 "B 중지"를 의미합니다. 즉, B가 성공적으로 중지되지 않는 한 A를 시연할 수 없습니다. 대칭 순서는 A의 상태의 변경이 B에 대해 작업을 예약할 수 있음을 의미합니다. 예를 들어 "A then B"가 실패로 인해 재시작되면 B가 먼저 중지되고 A가 시작되고, B가 시작됩니다.
클러스터는 각 상태 변경에 반응합니다. 첫 번째 리소스가 재시작되고 두 번째 리소스가 중지 작업을 시작하기 전에 다시 시작된 경우 두 번째 리소스를 다시 시작할 필요가 없습니다.
55.2. 권고 순서 구성
순서 제약 조건에 kind=Optional 옵션이 지정되면 제약 조건은 선택 사항으로 간주되며 두 리소스가 모두 지정된 작업을 실행하는 경우에만 적용됩니다. 사용자가 지정하는 첫 번째 리소스에 의한 상태가 변경되면 지정하는 두 번째 리소스에는 영향을 미치지 않습니다.
다음 명령은 VirtualIP 및 dummy_resource 라는 리소스에 대한 권고 순서 제한 조건을 구성합니다.
pcs constraint order VirtualIP then dummy_resource kind=Optional
# pcs constraint order VirtualIP then dummy_resource kind=Optional55.3. 정렬된 리소스 세트 구성
일반적으로 관리자는 정렬된 리소스 체인을 생성하는 것입니다. 예를 들어 리소스 C 전에 시작하는 리소스 A 앞에 리소스 A가 시작됩니다. 구성에 배치되어 시작된 리소스 세트를 순서대로 생성해야 하는 경우 해당 리소스가 포함된 리소스 그룹을 구성할 수 있습니다.
그러나 리소스 그룹이 적절하지 않으므로 지정된 순서로 시작해야 하는 리소스를 구성하는 경우가 있습니다.
- 리소스를 순서대로 구성해야 할 수 있으며, 리소스가 반드시 배치되지는 않습니다.
- 리소스 A 또는 B가 시작된 후 시작해야 하는 리소스 C가 있을 수 있지만 A와 B 사이에는 관계가 없습니다.
- A와 B 리소스 모두 시작된 후 시작해야 하는 리소스 C와 D가 있을 수 있지만 A와 B 사이에는 관계가 없습니다.
이러한 상황에서는 pcs constraint order set 명령을 사용하여 리소스 세트 또는 리소스 세트에 대해 순서 제한 조건을 생성할 수 있습니다.
pcs constraint order set 명령을 사용하여 리소스 세트에 대해 다음 옵션을 설정할 수 있습니다.
리소스 집합을 서로 기준으로 정렬해야 하는지 여부를 나타내기 위해
true또는false로 설정할 수 있습니다.기본값은true입니다.순서가
false로 설정하면 멤버가 서로 정렬되지 않고 순서가 지정된 제약 조건에서 다른 집합을 기준으로 집합을 정렬할 수 있습니다.Settingsequentialto false allows a set to be ordered relative to other sets in the ordering constraint, without its members being ordered relative to each other. 따라서 이 옵션은 제약 조건에 여러 세트가 나열된 경우에만 적합합니다. 그렇지 않으면 제약 조건이 적용되지 않습니다.-
모두true또는false로 설정하여 계속하기 전에 세트의 모든 리소스를 활성화해야 하는지 여부를 나타낼 수 있습니다.require-all을false로 설정하면 다음 세트를 계속하기 전에 세트의 하나의 리소스만 시작해야 합니다.require-all을false로 설정하면순차적이false로 설정된 순서가 지정되지 않은 세트와 함께 사용되지 않는 한 효과가 없습니다. 기본값은true입니다. -
작업: 클러스터 리소스가 실행되는 순서를 결정하는 "주문 제약 조건의 속성" 테이블에 설명된 대로시작,승격,데모또는중지하도록 설정할 수 있습니다. -
역할:중지됨,시작됨,마스터또는 슬라브로 설정할 수있습니다. RHEL 8.5 이상에서pcs명령줄 인터페이스는Promoted및Unpromoted를역할값으로 허용합니다.Promoted및Unpromoted역할은Master및Slave역할과 동등한 기능입니다.
pcs constraint order set 명령의 setoptions 매개변수에 따라 리소스 세트에 대해 다음 제약 조건 옵션을 설정할 수 있습니다.
-
정의 중인 제약 조건의 이름을 제공하기 위해 ID입니다.
-
kind: 클러스터 리소스가 실행되는 순서를 결정하는 데 있는 "주문 제약 조건의 속성" 테이블에 설명된 대로 제약 조건을 적용하는 방법을 나타냅니다. -
대칭에서는 클러스터 리소스가 실행되는 순서를 결정하는 "주문 제약 조건의 속성" 테이블에 설명된 대로 제약 조건의 반대 동작에 적용되는지 여부를 설정합니다.
pcs constraint order set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]
pcs constraint order set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]] [setoptions [constraint_options]]
D1,D2 및 D3 이라는 리소스가 세 개 있는 경우 다음 명령은 이를 정렬된 리소스 세트로 구성합니다.
pcs constraint order set D1 D2 D3
# pcs constraint order set D1 D2 D3
A,B,C,D,E, F 라는 6 개의 리소스가 있는 경우 이 예제에서는 다음과 같이 시작할 리소스 세트에 대한 순서 제한 조건을 구성합니다.
-
A및B는 서로 독립적으로 시작 -
C는A또는B가 시작된 후 시작됩니다. -
C가 시작된 후D시작 -
E및F는D가 시작될 때 서로 독립적으로 시작
symmetrical=false 가 설정되어 있으므로 리소스를 중지하는 것은 이 제약 조건의 영향을 받지 않습니다.
pcs constraint order set A B sequential=false require-all=false set C D set E F sequential=false setoptions symmetrical=false
# pcs constraint order set A B sequential=false require-all=false set C D set E F sequential=false setoptions symmetrical=false55.4. Pacemaker에서 관리하지 않는 리소스 종속 항목에 대한 시작 순서 구성
클러스터에서 클러스터에서 자체적으로 관리하지 않는 종속 항목이 있는 리소스를 포함할 수 있습니다. 이 경우 Pacemaker를 중지한 후 Pacemaker를 시작하기 전에 해당 종속 항목이 시작되고 중지되었는지 확인해야 합니다.
systemd resource-agents-deps 대상을 통해 이 상황을 설명하도록 시작 순서를 구성할 수 있습니다. 이 대상의 systemd 드롭인 장치를 생성할 수 있으며 Pacemaker에서 이 대상을 기준으로 적절하게 순서를 지정할 수 있습니다.
예를 들어 클러스터에 클러스터에서 관리하지 않는 외부 서비스 foo 에 의존하는 리소스가 포함된 경우 다음 절차를 수행합니다.
다음 항목이 포함된
/etc/systemd/system/resource-agents-deps.target.d/foo.conf드롭다운 장치를 생성합니다.[Unit] Requires=foo.service After=foo.service
[Unit] Requires=foo.service After=foo.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
systemctl daemon-reload명령을 실행합니다.
이러한 방식으로 지정된 클러스터 종속성은 서비스 이외의 것일 수 있습니다. 예를 들어 /srv 에서 파일 시스템을 마운트하는 데 종속성이 있을 수 있습니다. 이 경우 다음 절차를 수행합니다.
-
/srv가/etc/fstab파일에 나열되어 있는지 확인합니다. 시스템 관리자의 구성이 다시 로드되면 부팅 시systemd파일srv.mount로 자동 변환됩니다. 자세한 내용은systemd.mount(5) 및systemd-fstab-generator(8) 매뉴얼 페이지를 참조하십시오. 디스크가 마운트된 후 Pacemaker가 시작되도록 하려면 다음을 포함하는 드롭인 단위
/etc/systemd/system/resource-agents-deps.target.d/srv.conf를 만듭니다.[Unit] Requires=srv.mount After=srv.mount
[Unit] Requires=srv.mount After=srv.mountCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
systemctl daemon-reload명령을 실행합니다.
Pacemaker 클러스터에서 사용하는 LVM 볼륨 그룹에 iSCSI 대상과 같이 원격 블록 스토리지에 있는 하나 이상의 물리 볼륨이 포함된 경우 Pacemaker를 시작하기 전에 서비스가 시작되도록 대상의 대상 및 systemd 드롭인 장치를 구성할 수 있습니다.
systemd resource-agents-deps
다음 절차에서는 blk-availability.service 를 종속성으로 구성합니다. blk-availability.service 서비스는 iscsi.service 를 포함하는 래퍼입니다. 배포에 필요한 경우 iscsi.service (iSCSI 전용) 또는 remote-fs.target 을 blk-availability 대신 종속성으로 구성할 수 있습니다.
다음을 포함하는 드롭인 장치
/etc/systemd/system/resource-agents-deps.target.d/blk-availability.conf를 생성합니다.[Unit] Requires=blk-availability.service After=blk-availability.service
[Unit] Requires=blk-availability.service After=blk-availability.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
systemctl daemon-reload명령을 실행합니다.
56장. 클러스터 리소스 공동 작업
한 리소스의 위치가 다른 리소스의 위치에 따라 달라지도록 지정하려면 공동 배치 제약 조건을 구성합니다.
두 리소스 간에 공동 배치 제약 조건을 생성할 때 중요한 측면이 있습니다. 이는 리소스가 노드에 할당된 순서에 영향을 미칩니다. 이는 리소스 B가 어디에 있는지 모르는 한 리소스 B에 상대적인 리소스를 배치할 수 없기 때문입니다. 따라서 공동 배치 제약 조건을 생성할 때 리소스 B 또는 리소스 B를 리소스 A와 함께 배치해야 하는지 여부를 고려해야 합니다.
공동 배치 제약 조건을 생성할 때 고려해야 할 또 다른 사항은 리소스 A가 리소스 B와 배치된다고 가정할 때 클러스터에서 리소스 B에 대해 선택할 노드를 결정할 때 리소스 A의 기본 설정도 고려해야 한다는 것입니다.
다음 명령은 공동 배치 제약 조건을 생성합니다.
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]다음 표에는 공동 배치 제약 조건을 구성하기 위한 속성 및 옵션이 요약되어 있습니다.
| 매개변수 | 설명 |
|---|---|
| source_resource | colocation 소스입니다. 제약 조건을 충족할 수 없는 경우 클러스터에서 리소스를 전혀 실행하도록 허용하지 않을 수 있습니다. |
| target_resource | colocation 대상입니다. 클러스터는 이 리소스를 먼저 배치할 위치를 결정한 다음 소스 리소스를 배치할 위치를 결정합니다. |
| 점수 |
양수 값은 리소스가 동일한 노드에서 실행되어야 함을 나타냅니다. 음수 값은 동일한 노드에서 리소스를 실행하지 않아야 함을 나타냅니다. 기본값인 + |
|
| (RHEL 8.4 이상) 종속 리소스가 실패의 마이그레이션 임계값에 도달하면 클러스터가 기본 리소스(source_resource) 및 종속 리소스(target_resource) 를 모두 다른 노드로 이동할지 또는 클러스터가 서비스 전환을 유발하지 않고 종속 리소스를 오프라인 상태로 둘지 여부를 결정합니다.
이 옵션의 값이
이 옵션의 값이 |
56.1. 리소스의 필수 배치 지정
제약 조건의 점수가 +INFINITY 또는 -INFINITY 일 때마다 필수 배치가 수행됩니다. 이러한 경우 제약 조건을 충족할 수 없는 경우 source_resource 를 실행할 수 없습니다. score=INFINITY 의 경우 target_resource 가 활성 상태가 아닌 경우가 포함됩니다.
myresource1 이 항상 myresource2 와 동일한 머신에서 실행해야 하는 경우 다음 제약 조건을 추가합니다.
pcs constraint colocation add myresource1 with myresource2 score=INFINITY
# pcs constraint colocation add myresource1 with myresource2 score=INFINITY
INFINITY 가 사용되었기 때문에 myresource2 를 클러스터 노드(어떤 이유로든)에서 실행할 수 없는 경우 myresource1 은 실행할 수 없습니다.
또는 반대를 구성해야 할 수 있습니다. myresource1 은 myresource2 와 동일한 시스템에서 실행할 수 없습니다. 이 경우 score=-INFINITY사용
pcs constraint colocation add myresource1 with myresource2 score=-INFINITY
# pcs constraint colocation add myresource1 with myresource2 score=-INFINITY
다시 말해 -INFINITY 를 지정하면 제약 조건이 바인딩됩니다. 따라서 실행할 유일한 위치가 myresource2 가 이미 있는 경우 myresource1 은 아무데도 실행되지 않을 수 있습니다.
56.2. 리소스에 대한 권고 배치 지정
리소스의 권고 배치는 리소스의 배치가 기본 설정이지만 필수는 아님을 나타냅니다. -INFINITY 보다 크고 INFINITY 보다 낮은 제약 조건의 경우 클러스터는 원하는 사항을 수용하려고 시도하지만 대안은 일부 클러스터 리소스를 중지하는 경우 무시할 수 있습니다.
56.3. 리소스 세트 배치
구성에 배치 및 시작된 리소스 세트를 순서대로 생성해야 하는 경우 해당 리소스가 포함된 리소스 그룹을 구성할 수 있습니다. 그러나 리소스 그룹으로 배치해야 하는 리소스를 구성하는 것은 적절하지 않은 경우도 있습니다.
- 리소스 세트를 배치해야 할 수도 있지만 리소스가 순서대로 시작될 필요는 없습니다.
- 리소스 A 또는 B와 함께 배치해야 하는 리소스 C가 있을 수 있지만 A와 B 사이에는 관계가 없습니다.
- 리소스 B와 B와 함께 배치해야 하는 리소스 C와 D가 있을 수 있지만 A와 B 사이에는 관계가 없습니다.
이러한 상황에서는 pcs constraint colocation set 명령을 사용하여 리소스 세트 또는 리소스 세트에 공동 배치 제약 조건을 생성할 수 있습니다.
pcs constraint colocation set 명령을 사용하여 리소스 세트에 대해 다음 옵션을 설정할 수 있습니다.
집합의 멤버가 서로 배치되어야 하는지 여부를 나타내기 위해
true또는false로 설정할 수 있습니다.false로순차적으로설정하면 이 세트의 멤버가 활성 상태의 멤버와 관계없이 제약 조건의 뒷부분에 나열된 다른 세트와 함께 이 집합의 멤버를 배치할 수 있습니다. 따라서 이 옵션은 제약 조건의 이 뒤에 다른 세트가 나열된 경우에만 적합합니다. 그렇지 않으면 제약 조건이 적용되지 않습니다.-
역할:중지됨,시작됨,마스터또는 슬라브로 설정할 수있습니다.
pcs constraint colocation set 명령의 setoptions 매개변수에 따라 리소스 세트에 대해 다음 제약 조건 옵션을 설정할 수 있습니다.
-
정의 중인 제약 조건의 이름을 제공하기 위해 ID입니다.
-
이
제약조건에 대한 기본 설정 수준을 나타냅니다.Represents the degree of preference for this constraint. 이 옵션에 대한 자세한 내용은 위치 제약 조건 구성의 "Location Constraint Options" 표를 참조하십시오.
집합의 멤버를 나열하면 각 멤버가 앞에 있는 멤버와 함께 배치됩니다. 예를 들어 "B 설정"은 "B가 A"와 배치됨을 의미합니다. 그러나 여러 세트를 나열하면 각 세트가 뒤에 있는 세트와 함께 배치됩니다. 예를 들어, "set C D sequential=false set A B"는 "set C D (C and D have no relationship between each other) is colocated with set A (여기서 B is colocated with A)"를 의미합니다.
다음 명령은 리소스 세트 또는 집합에 공동 배치 제약 조건을 생성합니다.
pcs constraint colocation set resource1 resource2] [resourceN]... [options] [set resourceX resourceY] ... [options]] [setoptions [constraint_options]]
pcs constraint colocation set resource1 resource2] [resourceN]... [options] [set resourceX resourceY] ... [options]] [setoptions [constraint_options]]다음 명령을 사용하여 source_resource 의 공동 배치 제약 조건을 제거합니다.
pcs constraint colocation remove source_resource target_resource
pcs constraint colocation remove source_resource target_resource57장. 리소스 제약 조건 및 리소스 종속 항목 표시
구성된 제약 조건을 표시하는 데 사용할 수 있는 몇 가지 명령이 있습니다. 구성된 모든 리소스 제약 조건을 표시하거나 리소스 제약 조건을 특정 유형의 리소스 제약 조건으로 제한할 수 있습니다. 또한 구성된 리소스 종속 항목을 표시할 수 있습니다.
구성된 모든 제약 조건 표시
다음 명령은 모든 현재 위치, 순서 및 공동 배치 제약 조건을 나열합니다. --full 옵션이 지정된 경우 내부 제약 조건 ID를 표시합니다.
pcs constraint [list|show] [--full]
pcs constraint [list|show] [--full]RHEL 8.2 이상에서는 기본적으로 리소스 제약 조건을 나열해도 만료된 제약 조건이 더 이상 표시되지 않습니다.
목록에 만료된 constaints를 포함하려면 pcs constraint 명령의 --all 옵션을 사용합니다. 화면에 제한 조건 및 관련 규칙이 (종료됨)되어 만료된 제약 조건이 나열됩니다.
위치 제약 조건 표시
다음 명령은 현재 위치 제약 조건을 모두 나열합니다.
-
리소스가 지정되면 리소스별로 위치 제한 조건이 표시됩니다. 이는 기본 동작입니다. -
노드를 지정하면 노드당 위치 제약 조건이 표시됩니다. - 특정 리소스 또는 노드를 지정하면 해당 리소스 또는 노드에 대한 정보만 표시됩니다.
pcs constraint location [show [resources [resource...]] | [nodes [node...]]] [--full]
pcs constraint location [show [resources [resource...]] | [nodes [node...]]] [--full]순서 제한 조건 표시
다음 명령은 현재 순서 지정 제약 조건을 모두 나열합니다.
pcs constraint order [show]
pcs constraint order [show]공동 배치 제약 조건 표시
다음 명령은 모든 현재 공동 배치 제약 조건을 나열합니다.
pcs constraint colocation [show]
pcs constraint colocation [show]리소스별 제약 조건 표시
다음 명령은 특정 리소스를 참조하는 제약 조건을 나열합니다.
pcs constraint ref resource ...
pcs constraint ref resource ...리소스 종속 항목 표시(Red Hat Enterprise Linux 8.2 이상)
다음 명령은 트리 구조에서 클러스터 리소스 간의 관계를 표시합니다.
pcs resource relations resource [--full]
pcs resource relations resource [--full]
--full 옵션을 사용하는 경우 명령은 제약 조건 ID 및 리소스 유형을 포함하여 추가 정보를 표시합니다.
다음 예제에는 3개의 구성된 리소스가 있습니다. C, D 및 E.
다음 예제에는 두 개의 구성된 리소스가 있습니다. A 및 B는 리소스 그룹 G의 일부입니다.
58장. 규칙을 사용하여 리소스 위치 확인
더 복잡한 위치 제약 조건의 경우 Pacemaker 규칙을 사용하여 리소스의 위치를 확인할 수 있습니다.
58.1. Pacemaker 규칙
Pacemaker 규칙을 사용하여 구성을 보다 동적으로 만들 수 있습니다. 규칙을 사용하는 한 가지 방법은 시간에 따라 다른 처리 그룹에 머신을 할당하고 위치 제약 조건을 생성할 때 해당 속성을 사용하는 것입니다.
각 규칙에는 여러 표현식, date-expressions 및 기타 규칙이 포함될 수 있습니다. 표현식의 결과는 규칙의 boolean-op 필드를 기반으로 결합하여 규칙이 궁극적으로 true 또는 false 로 평가되는지 확인합니다. 다음에 수행되는 작업은 규칙이 사용되는 컨텍스트에 따라 달라집니다.
| 필드 | 설명 |
|---|---|
|
|
리소스가 해당 역할에 있는 경우에만 적용할 규칙을 제한합니다. 허용되는 값: |
|
|
규칙이 |
|
|
규칙이 |
|
|
여러 표현식 오브젝트의 결과를 결합하는 방법 허용되는 값: |
58.1.1. 노드 특성 표현식
노드 특성 표현식은 노드 또는 노드에서 정의한 특성을 기반으로 리소스를 제어하는 데 사용됩니다.
| 필드 | 설명 |
|---|---|
|
| 테스트할 노드 속성 |
|
|
값을 테스트하는 방법을 결정합니다. 허용되는 값: |
|
| 수행할 비교입니다. 허용되는 값:
*
*
*
*
*
* |
|
|
비교를 위해 사용자가 제공한 값( |
관리자가 추가한 속성 외에도 클러스터는 다음 표에 설명된 대로 사용할 수 있는 각 노드에 대한 특수한 기본 제공 노드 속성을 정의합니다.
| 이름 | 설명 |
|---|---|
|
| 노드 이름 |
|
| 노드 ID |
|
|
노드 유형. 가능한 값은 |
|
|
|
|
|
설정된 경우 |
|
|
|
|
| 이 노드에 관련 승격 가능한 복제 역할이 있습니다. 승격 가능한 복제에 대한 위치 제약 조건에 대한 규칙 내에서만 유효합니다. |
58.1.2. 시간/날짜 기반 표현식
날짜 표현식은 현재 날짜/시간을 기반으로 리소스 또는 클러스터 옵션을 제어하는 데 사용됩니다. 선택적 날짜 사양을 포함할 수 있습니다.
| 필드 | 설명 |
|---|---|
|
| ISO8601 사양을 준수하는 날짜/시간. |
|
| ISO8601 사양을 준수하는 날짜/시간. |
|
| 컨텍스트에 따라 현재 날짜/시간을 시작 또는 종료 날짜 또는 시작 및 종료 날짜와 비교합니다. 허용되는 값:
*
*
*
* |
58.1.3. 날짜 사양
날짜 사양은 시간과 관련된 cron과 같은 표현식을 생성하는 데 사용됩니다. 각 필드에는 단일 번호 또는 단일 범위가 포함될 수 있습니다. 기본값을 0으로 설정하는 대신 제공하지 않은 필드는 무시됩니다.
예를 들어 monthdays="1" 은 월의 첫날과 hour ="09-17" 은 오전 9시부터 오후 5시 사이의 시간(포함)과 일치합니다. 그러나 여러 범위가 포함되어 있으므로 weekdays="1,2" 또는 weekdays="1-2,5-6" 를 지정할 수 없습니다.
| 필드 | 설명 |
|---|---|
|
| 날짜의 고유한 이름 |
|
| 허용되는 값: 0-23 |
|
| 허용되는 값: 0-31 (연도에 따라 다름) |
|
| 허용되는 값: 1-7 (1=Monday, 7=Sunday) |
|
| 허용되는 값: 1~366 (연도에 따라 다름) |
|
| 허용되는 값: 1-12 |
|
|
허용되는 값: 1-53 ( |
|
| 1년차에 따라 |
|
|
예를 들어 |
|
| 허용되는 값: 0-7 (0은 새로운, 4는 풀 달입니다.) |
58.2. 규칙을 사용하여 Pacemaker 위치 제약 조건 구성
다음 명령을 사용하여 규칙을 사용하는 Pacemaker 제약 조건을 구성합니다. 점수 가 생략되면 기본값은 INFINITY입니다. resource-discovery 를 생략하면 기본값은 always 입니다.
resource-discovery 옵션에 대한 자세한 내용은 노드의 하위 집합으로 리소스 검색 제한을 참조하십시오.
기본 위치 제약 조건과 마찬가지로 이러한 제약 조건이 있는 리소스에 대해 정규식을 사용할 수 있습니다.
규칙을 사용하여 위치 제약 조건을 구성할 때 점수 값은 양수 또는 음수일 수 있으며 "prefers" 및 "avoids"를 나타내는 음수 값을 나타냅니다.
pcs constraint location rsc rule [resource-discovery=option] [role=master|slave] [score=score | score-attribute=attribute] expression
pcs constraint location rsc rule [resource-discovery=option] [role=master|slave] [score=score | score-attribute=attribute] expression표현식 옵션은 date 사양의 "날짜 사양의 속성"에 설명된 대로 duration_options 및 date_spec_options: hour, monthdays, yeardays, months, weeks, years, weekyears, 달 중 하나일 수 있습니다. https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_and_managing_high_availability_clusters/assembly_determining-resource-location-with-rules-configuring-and-managing-high-availability-clusters#date_specifications
-
정의된|not_defined 특성 -
속성 lt|gt|lte|gte|eq|ne [string|integer|number(RHEL 8.4 이상)|version] 값 -
날짜 gt|lt date -
날짜 in_range 날짜 -
date in_range date to duration duration_options … -
date-spec date_spec_options -
표현식 및|또는 표현식 -
(표현식)
기간은 계산을 통해 in_range 작업에 대한 끝을 지정하는 대체 방법입니다. 예를 들어 19 개월의 기간을 지정할 수 있습니다.
다음 위치 제약 조건에서는 2018년도에 언제든지 존재하는 경우 true인 표현식을 구성합니다.
pcs constraint location Webserver rule score=INFINITY date-spec years=2018
# pcs constraint location Webserver rule score=INFINITY date-spec years=2018다음 명령은 월요일부터 금요일까지 오전 9시부터 오후 5시까지 true인 표현식을 구성합니다. 시간 값 16은 숫자 값(시간)이 계속 일치하므로 최대 16:59:59와 일치합니다.
pcs constraint location Webserver rule score=INFINITY date-spec hours="9-16" weekdays="1-5"
# pcs constraint location Webserver rule score=INFINITY date-spec hours="9-16" weekdays="1-5"다음 명령은 13일 금요일에 전체 달이 있을 때 true인 표현식을 구성합니다.
pcs constraint location Webserver rule date-spec weekdays=5 monthdays=13 moon=4
# pcs constraint location Webserver rule date-spec weekdays=5 monthdays=13 moon=4규칙을 제거하려면 다음 명령을 사용합니다. 제거 중인 규칙이 제약 조건의 마지막 규칙인 경우 제약 조건이 제거됩니다.
pcs constraint rule remove rule_id
pcs constraint rule remove rule_id59장. 클러스터 리소스 관리
클러스터 리소스를 표시, 수정 및 관리하는 데 사용할 수 있는 다양한 명령이 있습니다.
59.1. 구성된 리소스 표시
구성된 모든 리소스 목록을 표시하려면 다음 명령을 사용합니다.
pcs resource status
pcs resource status
예를 들어 시스템이 VirtualIP 라는 리소스와 WebSite 라는 리소스로 구성된 경우 pcs resource status 명령은 다음 출력을 생성합니다.
pcs resource status VirtualIP (ocf::heartbeat:IPaddr2): Started WebSite (ocf::heartbeat:apache): Started
# pcs resource status
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Started리소스에 대해 구성된 매개 변수를 표시하려면 다음 명령을 사용합니다.
pcs resource config resource_id
pcs resource config resource_id
예를 들어 다음 명령은 VirtualIP 리소스에 대해 현재 구성된 매개변수를 표시합니다.
pcs resource config VirtualIP Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat) Attributes: ip=192.168.0.120 cidr_netmask=24 Operations: monitor interval=30s
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30sRHEL 8.5 이상에서 개별 리소스의 상태를 표시하려면 다음 명령을 사용합니다.
pcs resource status resource_id
pcs resource status resource_id
예를 들어 시스템이 VirtualIP 라는 리소스로 구성된 경우 pcs 리소스 상태 VirtualIP 명령은 다음 출력을 생성합니다.
pcs resource status VirtualIP VirtualIP (ocf::heartbeat:IPaddr2): Started
# pcs resource status VirtualIP
VirtualIP (ocf::heartbeat:IPaddr2): StartedRHEL 8.5 이상에서 특정 노드에서 실행 중인 리소스의 상태를 표시하려면 다음 명령을 사용합니다. 이 명령을 사용하여 클러스터 및 원격 노드 모두에 리소스 상태를 표시할 수 있습니다.
pcs resource status node=node_id
pcs resource status node=node_id
예를 들어 node-01 이 VirtualIP 이고 WebSite 라는 리소스를 실행하는 경우 pcs 리소스 status node=node-01 명령을 실행하면 다음과 같은 출력이 발생할 수 있습니다.
pcs resource status node=node-01 VirtualIP (ocf::heartbeat:IPaddr2): Started WebSite (ocf::heartbeat:apache): Started
# pcs resource status node=node-01
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Started59.2. pcs 명령으로 클러스터 리소스 내보내기
Red Hat Enterprise Linux 8.7 이상에서는 명령의 pcs resource config--output-format=cmd 옵션을 사용하여 다른 시스템에서 구성된 클러스터 리소스를 다시 생성하는 데 사용할 수 있는 pcs 명령을 표시할 수 있습니다.
다음 명령은 Red Hat 고가용성 클러스터에서 활성/수동 Apache HTTP 서버에 대해 생성된 4개의 리소스를 생성합니다. 즉 LVM-activate 리소스, Filesystem 리소스, IPaddr2 리소스 및 Apache 리소스가 생성됩니다.
pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroup pcs resource create my_fs Filesystem device="/dev/my_vg/my_lv" directory="/var/www" fstype="xfs" --group apachegroup pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 cidr_netmask=24 --group apachegroup pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroup
# pcs resource create my_lvm ocf:heartbeat:LVM-activate vgname=my_vg vg_access_mode=system_id --group apachegroup
# pcs resource create my_fs Filesystem device="/dev/my_vg/my_lv" directory="/var/www" fstype="xfs" --group apachegroup
# pcs resource create VirtualIP IPaddr2 ip=198.51.100.3 cidr_netmask=24 --group apachegroup
# pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroup
리소스를 생성한 후 다음 명령은 다른 시스템에서 해당 리소스를 다시 생성하는 데 사용할 수 있는 pcs 명령을 표시합니다.
pcs 명령 또는 명령을 표시하려면 구성된 리소스 하나만 다시 생성하는 데 사용할 수 있는 해당 리소스의 리소스 ID를 지정합니다.
59.3. 리소스 매개변수 수정
구성된 리소스의 매개 변수를 수정하려면 다음 명령을 사용합니다.
pcs resource update resource_id [resource_options]
pcs resource update resource_id [resource_options]
다음 명령 시퀀스는 리소스 VirtualIP 에 대해 구성된 매개변수의 초기 값, ip 매개변수의 값을 변경하는 명령, update 명령 뒤에 있는 값을 보여줍니다.
pcs resource update 명령을 사용하여 리소스 작업을 업데이트하면 구체적으로 호출하지 않는 모든 옵션이 기본값으로 재설정됩니다.
59.4. 클러스터 리소스의 실패 상태 지우기
리소스가 실패하면 pcs status 명령을 사용하여 클러스터 상태를 표시할 때 실패 메시지가 표시됩니다. 실패의 원인을 해결한 후 pcs status 명령을 다시 실행하여 리소스의 업데이트된 상태를 확인할 수 있으며 pcs resource failcount show --full 명령을 사용하여 클러스터 리소스의 실패 수를 확인할 수 있습니다.
pcs resource cleanup 명령을 사용하여 리소스의 실패 상태를 지울 수 있습니다. pcs resource cleanup 명령은 리소스의 리소스 상태 및 failcount 값을 재설정합니다. 이 명령은 또한 리소스의 작업 기록을 제거하고 현재 상태를 다시 감지합니다.
다음 명령은 resource_id 에서 지정한 리소스의 리소스 상태 및 failcount 값을 재설정합니다.
pcs resource cleanup resource_id
pcs resource cleanup resource_id
resource_id 를 지정하지 않으면 pcs resource cleanup 명령에서 실패 횟수가 있는 모든 리소스의 리소스 상태 및 failcount 값을 재설정합니다.
pcs resource cleanup resource_id 명령 외에도 리소스 상태를 재설정하고 pcs resource refresh resource refresh resource_id 명령을 사용하여 리소스의 작업 기록을 지울 수도 있습니다. pcs resource cleanup 명령과 마찬가지로 지정된 옵션 없이 pcs resource refresh 명령을 실행하여 모든 리소스의 리소스 상태 및 failcount 값을 재설정할 수 있습니다.
pcs resource cleanup 및 pcs resource refresh 명령은 모두 리소스의 작업 기록을 지우고 리소스의 현재 상태를 다시 감지합니다. pcs resource cleanup 명령은 클러스터 상태에 표시된 것처럼 실패한 작업으로만 작동하는 반면 pcs resource refresh 명령은 현재 상태와 관계없이 리소스에서 작동합니다.
59.5. 클러스터에서 리소스 이동
Pacemaker는 한 노드에서 다른 노드로 이동하고 필요한 경우 리소스를 수동으로 이동하도록 리소스를 구성하는 다양한 메커니즘을 제공합니다.
수동 이동 클러스터 리소스에 설명된 대로 pcs resource move 및 pcs resource relocate 명령을 사용하여 클러스터에서 리소스를 수동으로 이동할 수 있습니다. 이러한 명령 외에도 클러스터 리소스 비활성화, 활성화 및 금지에 설명된 대로 리소스를 활성화, 비활성화 및 비활성화하여 클러스터 리소스 의 동작을 제어할 수도 있습니다.
정의된 수의 실패 후 새 노드로 이동하도록 리소스를 구성하고 외부 연결이 끊어지면 리소스를 이동하도록 클러스터를 구성할 수 있습니다.
59.5.1. 실패로 인한 리소스 이동
리소스를 생성할 때 해당 리소스에 대한 migration-threshold 옵션을 설정하여 정의된 수의 실패 후 새 노드로 이동하도록 리소스를 구성할 수 있습니다. 임계값에 도달하면 이 노드는 다음을 까지 더 이상 실패한 리소스를 실행할 수 없습니다.
-
리소스의
failure-timeout값에 도달합니다. -
관리자는
pcs resource cleanup명령을 사용하여 리소스 실패 횟수를 수동으로 재설정합니다.
migration-threshold 값은 기본적으로 INFINITY 로 설정됩니다. INFINITY 는 내부적으로 매우 크지만 유한한 숫자로 정의됩니다. 값이 0이면 migration-threshold 기능을 비활성화합니다.
리소스에 대한 migration-threshold 는 마이그레이션용 리소스를 구성하는 것과 동일하지 않으며, 이 경우 리소스가 상태 손실 없이 다른 위치로 이동합니다.
다음 예제에서는 dummy_resource 라는 리소스에 10의 마이그레이션 임계값을 추가하여 10개의 실패 후 리소스가 새 노드로 이동됨을 나타냅니다.
pcs resource meta dummy_resource migration-threshold=10
# pcs resource meta dummy_resource migration-threshold=10다음 명령을 사용하여 전체 클러스터의 기본값에 마이그레이션 임계값을 추가할 수 있습니다.
pcs resource defaults update migration-threshold=10
# pcs resource defaults update migration-threshold=10
리소스의 현재 실패 상태 및 제한을 확인하려면 pcs resource failcount show 명령을 사용합니다.
마이그레이션 임계값 개념에는 두 가지 예외가 있습니다. 리소스를 시작하지 못하거나 중지하지 못할 때 발생합니다. 클러스터 속성 start-failure-is-fatal 이 true (기본값)로 설정된 경우 시작 실패로 인해 failcount 가 INFINITY 로 설정되고 항상 리소스가 즉시 이동합니다.
중지 실패는 약간 다르며 중요합니다. 리소스가 중지되지 않고 STONITH가 활성화된 경우 클러스터는 노드를 펜싱하여 다른 위치에서 리소스를 시작할 수 있습니다. STONITH가 활성화되지 않은 경우 클러스터는 계속 진행할 방법이 없으며 다른 위치에서 리소스를 시작하려고 시도하지 않지만 실패가 시간 초과된 후 다시 중지하려고 합니다.
59.5.2. 연결 변경으로 인한 리소스 이동
외부 연결이 끊어지면 리소스를 이동하도록 클러스터를 설정하는 것은 두 가지 단계입니다.
-
클러스터에
ping리소스를 추가합니다.ping리소스는 동일한 이름의 시스템 유틸리티를 사용하여 (DNS 호스트 이름 또는 IPv4/IPv6 주소로 지정) 목록(DNS 호스트 이름 또는 IPv4/IPv6 주소로 지정)에 연결할 수 있는지 테스트하고 결과를 사용하여pingd라는 노드 특성을 유지 관리합니다. - 연결이 끊어지면 리소스를 다른 노드로 이동하는 리소스에 대한 위치 제한 조건을 구성합니다.
다음 표에서는 ping 리소스에 대해 설정할 수 있는 속성에 대해 설명합니다.
| 필드 | 설명 |
|---|---|
|
| 추가 변경이 발생할 때까지 대기(조정) 시간입니다. 이렇게 하면 클러스터 노드가 약간 다른 시간에 연결 손실을 알 때 리소스가 클러스터를 표시하지 않습니다. |
|
| 연결된 ping 노드의 수에 이 값을 곱하여 점수를 얻습니다. 여러 개의 ping 노드가 구성된 경우 유용합니다. |
|
| 현재 연결 상태를 확인하기 위해 연결할 머신입니다. 허용되는 값에는 확인 가능한 DNS 호스트 이름, IPv4 및 IPv6 주소가 포함됩니다. 호스트 목록의 항목은 공백으로 구분되어 있습니다. |
다음 예제 명령은 gateway.example.com 에 대한 연결을 확인하는 ping 리소스를 생성합니다. 실제로 네트워크 게이트웨이/라우터에 대한 연결을 확인합니다. 리소스가 모든 클러스터 노드에서 실행되도록 ping 리소스를 복제로 구성합니다.
pcs resource create ping ocf:pacemaker:ping dampen=5s multiplier=1000 host_list=gateway.example.com clone
# pcs resource create ping ocf:pacemaker:ping dampen=5s multiplier=1000 host_list=gateway.example.com clone
다음 예제에서는 Webserver 라는 기존 리소스에 대한 위치 제약 조건 규칙을 구성합니다. 그러면 현재 실행 중인 호스트가 gateway.example.com 을 ping할 수 없는 경우 Webserver 리소스가 gateway.example.com 을 ping할 수 있는 호스트로 이동합니다.
pcs constraint location Webserver rule score=-INFINITY pingd lt 1 or not_defined pingd
# pcs constraint location Webserver rule score=-INFINITY pingd lt 1 or not_defined pingd59.6. 모니터 작업 비활성화
반복 모니터를 중지하는 가장 쉬운 방법은 삭제하는 것입니다. 그러나 일시적으로만 비활성화하려는 경우가 있을 수 있습니다. 이러한 경우 작업 정의에 enabled="false" 를 추가합니다. 모니터링 작업을 다시 실행하려는 경우 enabled="true" 를 작업 정의로 설정합니다.
pcs resource update 명령을 사용하여 리소스 작업을 업데이트하면 구체적으로 호출하지 않는 모든 옵션이 기본값으로 재설정됩니다. 예를 들어 사용자 정의 시간 제한 값 600으로 모니터링 작업을 구성한 경우 다음 명령을 실행하면 시간 초과 값을 기본값인 20으로 재설정합니다(또는 기본값을 pcs resource op defaults 명령을 사용하여 로 설정한 경우).
pcs resource update resourceXZY op monitor enabled=false pcs resource update resourceXZY op monitor enabled=true
# pcs resource update resourceXZY op monitor enabled=false
# pcs resource update resourceXZY op monitor enabled=true이 옵션에 대해 원래 값을 600으로 유지하려면 모니터링 작업을 다시 실행할 때 다음 예제와 같이 해당 값을 지정해야 합니다.
pcs resource update resourceXZY op monitor timeout=600 enabled=true
# pcs resource update resourceXZY op monitor timeout=600 enabled=true59.7. 클러스터 리소스 태그 구성 및 관리
Red Hat Enterprise Linux 8.3 이상에서는 pcs 명령을 사용하여 클러스터 리소스에 태그를 지정할 수 있습니다. 이를 통해 단일 명령으로 지정된 리소스 세트를 활성화, 비활성화, 관리 또는 관리할 수 있습니다.
59.7.1. 카테고리별로 관리를 위한 클러스터 리소스 태그
다음 절차에서는 리소스 태그에 두 개의 리소스에 태그를 지정하고 태그된 리소스를 비활성화합니다. 이 예에서 태그를 지정할 기존 리소스의 이름은 d-01 및 d-02 입니다.
절차
d-01및d-02리소스에 대한special-resources라는 태그를 생성합니다.pcs tag create special-resources d-01 d-02
[root@node-01]# pcs tag create special-resources d-01 d-02Copy to Clipboard Copied! Toggle word wrap Toggle overflow 리소스 태그 구성을 표시합니다.
pcs tag config special-resources d-01 d-02
[root@node-01]# pcs tag config special-resources d-01 d-02Copy to Clipboard Copied! Toggle word wrap Toggle overflow special-resources태그가 지정된 모든 리소스를 비활성화합니다.pcs resource disable special-resources
[root@node-01]# pcs resource disable special-resourcesCopy to Clipboard Copied! Toggle word wrap Toggle overflow 리소스 상태를 표시하여
d-01및d-02리소스가 비활성화되어 있는지 확인합니다.pcs resource * d-01 (ocf::pacemaker:Dummy): Stopped (disabled) * d-02 (ocf::pacemaker:Dummy): Stopped (disabled)
[root@node-01]# pcs resource * d-01 (ocf::pacemaker:Dummy): Stopped (disabled) * d-02 (ocf::pacemaker:Dummy): Stopped (disabled)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
pcs resource disable 명령 외에도 pcs resource enable,pcs resource manage 및 pcs resource unmanage 명령은 태그된 리소스 관리를 지원합니다.
리소스 태그를 생성한 후 다음을 수행합니다.
-
pcs tag delete명령을 사용하여 리소스 태그를 삭제할 수 있습니다. -
pcs tag update명령을 사용하여 기존 리소스 태그의 리소스 태그 구성을 수정할 수 있습니다.
59.7.2. 태그된 클러스터 리소스 삭제
pcs 명령을 사용하여 태그된 클러스터 리소스를 삭제할 수 없습니다. 태그된 리소스를 삭제하려면 다음 절차를 사용하십시오.
절차
resource 태그를 제거합니다.
다음 명령은 해당 태그가 있는 모든 리소스에서 리소스 태그
special-resources를 제거합니다.pcs tag remove special-resources pcs tag No tags defined
[root@node-01]# pcs tag remove special-resources [root@node-01]# pcs tag No tags definedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령은 리소스
d-01에서만 리소스 태그special-resources를 제거합니다.pcs tag update special-resources remove d-01
[root@node-01]# pcs tag update special-resources remove d-01Copy to Clipboard Copied! Toggle word wrap Toggle overflow
리소스를 삭제합니다.
pcs resource delete d-01 Attempting to stop: d-01... Stopped
[root@node-01]# pcs resource delete d-01 Attempting to stop: d-01... StoppedCopy to Clipboard Copied! Toggle word wrap Toggle overflow
60장. 여러 노드에서 활성 상태인 클러스터 리소스 생성(복제 리소스)
여러 노드에서 리소스를 활성화할 수 있도록 클러스터 리소스를 복제할 수 있습니다. 예를 들어 복제된 리소스를 사용하여 노드 밸런싱을 위해 클러스터 전체에 배포하도록 IP 리소스의 여러 인스턴스를 구성할 수 있습니다. 리소스 에이전트가 지원하는 모든 리소스를 복제할 수 있습니다. 복제본은 하나의 리소스 또는 하나의 리소스 그룹으로 구성됩니다.
동시에 여러 노드에서 활성화할 수 있는 리소스만 복제에 적합합니다. 예를 들어 공유 메모리 장치에서 ext4 와 같은 클러스터되지 않은 파일 시스템을 마운트하는 Filesystem 리소스는 복제해서는 안 됩니다. ext4 파티션은 클러스터를 인식하지 않으므로 이 파일 시스템은 여러 노드에서 동시에 발생하는 읽기/쓰기 작업에 적합하지 않습니다.
60.1. 복제된 리소스 생성 및 제거
리소스 및 해당 리소스의 복제본을 동시에 생성할 수 있습니다.
다음 단일 명령을 사용하여 리소스를 생성하고 리소스를 복제합니다.
RHEL 8.4 이상:
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone_id] [clone options]
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone_id] [clone options]RHEL 8.3 이상:
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone options]
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone options]
기본적으로 복제 이름은 resource_id-clone 입니다.
RHEL 8.4 이상에서는 clone_id 옵션의 값을 지정하여 복제본의 사용자 지정 이름을 설정할 수 있습니다.
단일 명령으로 리소스 그룹과 해당 리소스 그룹의 복제본을 생성할 수 없습니다.
또는 다음 명령을 사용하여 이전에 생성한 리소스 또는 리소스 그룹의 복제본을 생성할 수 있습니다.
RHEL 8.4 이상:
pcs resource clone resource_id | group_id [clone_id][clone options]...
pcs resource clone resource_id | group_id [clone_id][clone options]...RHEL 8.3 이상:
pcs resource clone resource_id | group_id [clone options]...
pcs resource clone resource_id | group_id [clone options]...
기본적으로 복제 이름은 resource_id-clone 또는 group_name-clone 입니다. RHEL 8.4 이상에서는 clone_id 옵션의 값을 지정하여 복제본의 사용자 지정 이름을 설정할 수 있습니다.
하나의 노드에서만 리소스 구성 변경 사항을 구성해야 합니다.
제약 조건을 구성할 때 항상 그룹 또는 복제 이름을 사용합니다.
리소스 복제본을 생성할 때 기본적으로 복제는 -clone 이 이름에 추가된 리소스의 이름을 사용합니다. 다음 명령은 webfarm이라는 apache 유형 및 이라는 해당 리소스의 복제본을 생성합니다.
webfarm -clone
pcs resource create webfarm apache clone
# pcs resource create webfarm apache clone
다른 복제 후에 정렬할 리소스 또는 리소스 그룹 복제를 생성하는 경우 거의 항상 interleave=true 옵션을 설정해야 합니다. 이렇게 하면 종속 복제의 사본이 동일한 노드에서 종속된 복제본이 중지되거나 시작된 경우 이를 중지하거나 시작할 수 있습니다. 이 옵션을 설정하지 않으면 복제된 리소스 B가 복제된 리소스 A에 종속되고 노드가 클러스터를 떠나면 노드가 해당 노드로 돌아가면 모든 노드에서 리소스 B의 모든 사본이 다시 시작됩니다. 종속 복제 리소스에 interleave 옵션이 설정되어 있지 않은 경우 해당 리소스의 모든 인스턴스가 종속된 리소스의 실행 중인 모든 인스턴스에 따라 다르기 때문입니다.
다음 명령을 사용하여 리소스 또는 리소스 그룹의 복제본을 제거합니다. 리소스 또는 리소스 그룹 자체를 제거하지 않습니다.
pcs resource unclone resource_id | clone_id | group_name
pcs resource unclone resource_id | clone_id | group_name다음 표에서는 복제된 리소스에 지정할 수 있는 옵션을 설명합니다.
| 필드 | 설명 |
|---|---|
|
| |
|
| 시작할 리소스의 사본 수입니다. 기본값은 클러스터의 노드 수입니다. |
|
|
단일 노드에서 시작할 수 있는 리소스의 사본 수입니다. 기본값은 |
|
|
복제본 사본을 중지하거나 시작할 때 다른 모든 사본에 대해 미리 그리고 작업이 성공했는지 알려줍니다. 허용되는 값: |
|
|
복제의 각 사본이 다른 기능을 수행합니까? 허용되는 값:
이 옵션의 값이
이 옵션의 값이 |
|
|
복사본을 연속으로 시작해야 합니다(동시에 있는 대신). 허용되는 값: |
|
|
두 번째 복제본의 동일한 노드에 있는 복사본이 시작되거나 중지되는 즉시 첫 번째 복제본의 복사본이 시작되거나 중지되도록 (두 번째 복제본의 모든 인스턴스가 시작 또는 중지될 때까지 대기하지 않도록 (복제 복제 간) 순서 지정 동작을 변경합니다. 허용되는 값: |
|
|
값을 지정하면 |
안정적인 할당 패턴을 얻기 위해 복제본은 기본적으로 약간 고정되며, 이는 실행 중인 노드를 유지하는 데 약간의 선호가 있음을 나타냅니다. resource-stickiness 에 대한 값이 제공되지 않으면 복제에서 값 1을 사용합니다. 작은 값이기 때문에 다른 리소스의 점수 계산이 최소화되지만 Pacemaker에서 클러스터 주변의 복사본을 불필요하게 이동하지 못하도록 하는 데 충분합니다. resource-stickiness 리소스 meta-option 설정에 대한 자세한 내용은 리소스 메타 옵션 구성을 참조하십시오.
60.2. 복제 리소스 제약 조건 구성
대부분의 경우 복제본은 각 활성 클러스터 노드에 단일 사본이 있습니다. 그러나 리소스 복제의 clone-max 를 클러스터의 총 노드 수보다 작은 값으로 설정할 수 있습니다. 이 경우 클러스터에서 리소스 위치 제약 조건을 사용하여 복사본을 우선순위로 할당해야 하는 노드를 나타낼 수 있습니다. 이러한 제약 조건은 복제의 ID를 사용해야 한다는 점을 제외하고 일반 리소스의 경우와는 다르게 작성됩니다.
다음 명령은 클러스터의 위치 제약 조건을 생성하여 webfarm-clone 을 node1 에 우선순위로 할당합니다.
pcs constraint location webfarm-clone prefers node1
# pcs constraint location webfarm-clone prefers node1
순서 지정 제한 조건은 복제본에 대해 약간 다르게 작동합니다. 아래 예제에서 interleave clone 옵션은 기본값으로 그대로 유지되므로 webfarm-stats 의 인스턴스가 시작되어야 하는 webfarm-clone 의 모든 인스턴스가 완료될 때까지 시작되지 않습니다. webfarm-clone 을 시작할 수 없는 경우에만 webfarm-stats 가 활성화되지 않습니다. 또한 webfarm-clone 은 자체적으로 중지하기 전에 webfarm-stats 가 중지될 때까지 기다립니다.
pcs constraint order start webfarm-clone then webfarm-stats
# pcs constraint order start webfarm-clone then webfarm-stats복제본과 일반(또는 그룹) 리소스를 공동 배치하면 복제의 활성 사본이 있는 모든 시스템에서 리소스를 실행할 수 있습니다. 클러스터는 복제가 실행 중인 위치와 리소스의 고유한 위치 기본 설정에 따라 복사본을 선택합니다.
복제 간 배치도 가능합니다. 이러한 경우 복제에 허용되는 위치 세트는 복제가 활성 상태이거나 활성 상태인 노드로 제한됩니다. 그런 다음 할당이 정상적으로 수행됩니다.
다음 명령은 colocation 제약 조건을 생성하여 webfarm-clone 리소스의 활성 사본과 동일한 노드에서 webfarm-stats 가 실행되는지 확인합니다.
pcs constraint colocation add webfarm-stats with webfarm-clone
# pcs constraint colocation add webfarm-stats with webfarm-clone60.3. 승격 가능한 복제 리소스
승격 가능한 복제 리소스는 승격 가능한 메타 속성이 true 로 설정된 복제 리소스입니다. 인스턴스를 두 가지 운영 모드 중 하나에 속할 수 있습니다. 이러한 모드를 master 및 slave 라고 합니다. 모드의 이름에는 인스턴스가 시작될 때 Slave 상태로 표시되어야 한다는 제한을 제외하고 특정 의미가 없습니다.
60.3.1. 승격 가능한 복제 리소스 생성
다음 단일 명령을 사용하여 승격 가능한 복제로 리소스를 생성할 수 있습니다.
RHEL 8.4 이상:
pcs resource create resource_id [standard:[provider:]]type [resource options] promotable [clone_id] [clone options]
pcs resource create resource_id [standard:[provider:]]type [resource options] promotable [clone_id] [clone options]RHEL 8.3 이상:
pcs resource create resource_id [standard:[provider:]]type [resource options] promotable [clone options]
pcs resource create resource_id [standard:[provider:]]type [resource options] promotable [clone options]
기본적으로 승격 가능한 복제의 이름은 resource_id-clone 입니다.
RHEL 8.4 이상에서는 clone_id 옵션의 값을 지정하여 복제본의 사용자 지정 이름을 설정할 수 있습니다.
또는 다음 명령을 사용하여 이전에 생성한 리소스 또는 리소스 그룹에서 승격 가능한 리소스를 생성할 수 있습니다.
RHEL 8.4 이상:
pcs resource promotable resource_id [clone_id] [clone options]
pcs resource promotable resource_id [clone_id] [clone options]RHEL 8.3 이상:
pcs resource promotable resource_id [clone options]
pcs resource promotable resource_id [clone options]
기본적으로 승격 가능한 복제의 이름은 resource_id-clone 또는 group_name-clone 입니다.
RHEL 8.4 이상에서는 clone_id 옵션의 값을 지정하여 복제본의 사용자 지정 이름을 설정할 수 있습니다.
다음 표에서는 승격 가능한 리소스에 지정할 수 있는 추가 복제 옵션을 설명합니다.
| 필드 | 설명 |
|---|---|
|
| 승격할 수 있는 리소스의 사본 수입니다. 기본값은 1입니다. |
|
| 리소스 사본 수를 단일 노드에서 승격할 수 있습니다. 기본값은 1입니다. |
60.3.2. 승격 가능한 리소스 제약 조건 구성
대부분의 경우 승격 가능한 리소스에는 각 활성 클러스터 노드에 단일 사본이 있습니다. 그렇지 않은 경우 클러스터에서 리소스 위치 제약 조건을 사용하여 복사본을 우선순위로 할당해야 하는 노드를 나타낼 수 있습니다. 이러한 제약 조건은 일반 리소스에 대한 것과 다르게 작성됩니다.
마스터 또는 슬레이브 역할에서 리소스가 작동하는지 여부를 지정하는 공동 배치 제약 조건을 만들 수 있습니다. 다음 명령은 리소스 공동 배치 제약 조건을 생성합니다.
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]
pcs constraint colocation add [master|slave] source_resource with [master|slave] target_resource [score] [options]공동 배치 제약 조건에 대한 자세한 내용은 클러스터 리소스 배치를 참조하십시오.
승격 가능한 리소스가 포함된 순서 제한 조건을 구성할 때 리소스에 지정할 수 있는 작업 중 하나가 승격되어 리소스가 슬레이브 역할에서 master 역할로 승격됨을 나타냅니다. 또한 리소스를 마스터 역할에서 슬레이브 역할로 시연하는 작업을 지정할 수 있습니다.
순서 제약 조건을 구성하는 명령은 다음과 같습니다.
pcs constraint order [action] resource_id then [action] resource_id [options]
pcs constraint order [action] resource_id then [action] resource_id [options]리소스 순서 제약 조건에 대한 자세한 내용은 클러스터 리소스가 실행되는 순서 결정을 참조하십시오.
60.4. 실패 시 승격된 리소스 데모
RHEL 8.3 이상에서는 해당 리소스에 대한 승격 또는 모니터링 작업이 실패하거나 리소스가 실행 중인 파티션이 쿼럼을 손실하지만 완전히 중지되지 않도록 승격 가능한 리소스를 구성할 수 있습니다. 이렇게 하면 리소스를 완전히 중지해야 하는 상황에서 수동 개입이 필요하지 않을 수 있습니다.
승격 작업이
실패할 때 데모할작업 메타 옵션을승격가능한 리소스를 구성하려면 다음 예와 같이 실패demote로 설정합니다.pcs resource op add my-rsc promote on-fail="demote"
# pcs resource op add my-rsc promote on-fail="demote"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모니터작업이실패할 때 데모할 승격 가능한 리소스를 구성하려면작업 메타 옵션을interval을 0이 아닌 값으로 설정하고, 실패 시demote로 설정하고, 다음 예와 같이역할을Master로 설정합니다.pcs resource op add my-rsc monitor interval="10s" on-fail="demote" role="Master"
# pcs resource op add my-rsc monitor interval="10s" on-fail="demote" role="Master"Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
클러스터 파티션이 쿼럼이 손실될 때 승격된 리소스가 거부되지만 실행 중인 상태로 남아 있고 다른 모든 리소스가 중지되도록 클러스터를 구성하려면
no-quorum-policy클러스터 속성을demote로 설정합니다.
작업에 대해 on-fail meta-attribute를 demote 로 설정해도 리소스 승격을 결정하는 방법에는 영향을 미치지 않습니다. 영향을 받는 노드에 여전히 가장 높은 승격 점수가 있는 경우 다시 승격하도록 선택됩니다.
61장. 클러스터 노드 관리
클러스터 서비스를 시작 및 중지하고 클러스터 노드를 추가 및 제거하는 명령을 포함하여 클러스터 노드를 관리하는 데 사용할 수 있는 다양한 pcs 명령이 있습니다.
61.1. 클러스터 서비스 중지
다음 명령은 지정된 노드 또는 노드에서 클러스터 서비스를 중지합니다. pcs cluster start 와 마찬가지로 --all 옵션은 모든 노드에서 클러스터 서비스를 중지하고 노드를 지정하지 않으면 로컬 노드에서만 클러스터 서비스가 중지됩니다.
pcs cluster stop [--all | node] [...]
pcs cluster stop [--all | node] [...]
다음 명령을 사용하여 로컬 노드에서 클러스터 서비스를 강제로 중지하여 kill -9 명령을 수행할 수 있습니다.
pcs cluster kill
pcs cluster kill61.2. 클러스터 서비스 활성화 및 비활성화
다음 명령을 사용하여 클러스터 서비스를 활성화합니다. 이렇게 하면 지정된 노드 또는 노드에서 시작 시 실행되도록 클러스터 서비스가 구성됩니다.
활성화하면 노드가 펜싱된 후 클러스터에 자동으로 다시 참여할 수 있으므로 클러스터가 완전한 강도보다 적은 시간을 최소화할 수 있습니다. 클러스터 서비스가 활성화되지 않은 경우 관리자는 클러스터 서비스를 수동으로 시작하기 전에 문제가 발생한 사항을 수동으로 조사할 수 있으므로, 하드웨어 문제가 있는 노드는 다시 실패할 가능성이 있을 때 다시 클러스터로 돌아갈 수 없습니다.
-
--all옵션을 지정하면 명령은 모든 노드에서 클러스터 서비스를 활성화합니다. - 노드를 지정하지 않으면 로컬 노드에서만 클러스터 서비스가 활성화됩니다.
pcs cluster enable [--all | node] [...]
pcs cluster enable [--all | node] [...]다음 명령을 사용하여 지정된 노드 또는 노드에서 시작 시 실행되지 않도록 클러스터 서비스를 구성합니다.
-
--all옵션을 지정하면 명령은 모든 노드에서 클러스터 서비스를 비활성화합니다. - 노드를 지정하지 않으면 로컬 노드에서만 클러스터 서비스가 비활성화됩니다.
pcs cluster disable [--all | node] [...]
pcs cluster disable [--all | node] [...]61.3. 클러스터 노드 추가
다음 절차에 따라 기존 클러스터에 새 노드를 추가합니다.
이 절차에서는 corosync 를 실행하는 표준 클러스터 노드를 추가합니다. 비corosync 노드를 클러스터에 통합하는 방법에 대한 자세한 내용은 non-corosync 노드를 클러스터로 통합( pacemaker_remote 서비스 )을 참조하십시오.
프로덕션 유지 관리 기간 중에만 기존 클러스터에 노드를 추가하는 것이 좋습니다. 이를 통해 새 노드 및 해당 펜싱 구성에 대해 적절한 리소스 및 배포 테스트를 수행할 수 있습니다.
이 예에서 기존 클러스터 노드는 clusternode-01.example.com,clusternode-02.example.com, clusternode-03.example.com 입니다. 새 노드는 newnode.example.com 입니다.
프로세스
클러스터에 추가할 새 노드에서 다음 작업을 수행합니다.
클러스터 패키지를 설치합니다. 클러스터에서 SBD, Booth 티켓 관리자 또는 쿼럼 장치를 사용하는 경우 새 노드에 해당 패키지(
sbd,booth-site,corosync-qdevice)를 수동으로 설치해야 합니다.yum install -y pcs fence-agents-all
[root@newnode ~]# yum install -y pcs fence-agents-allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 클러스터 패키지 외에도 기존 클러스터 노드에 설치된 클러스터에서 실행 중인 모든 서비스를 설치하고 구성해야 합니다. 예를 들어 Red Hat 고가용성 클러스터에서 Apache HTTP 서버를 실행하는 경우 추가하는 노드에 서버와 서버 상태를 확인하는
wget툴을 설치해야 합니다.firewalld데몬을 실행하는 경우 다음 명령을 실행하여 Red Hat High Availability Add-On에 필요한 포트를 활성화합니다.firewall-cmd --permanent --add-service=high-availability firewall-cmd --add-service=high-availability
# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availabilityCopy to Clipboard Copied! Toggle word wrap Toggle overflow 사용자 ID
hacluster의 암호를 설정합니다. 클러스터의 각 노드에 동일한 암호를 사용하는 것이 좋습니다.passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.
[root@newnode ~]# passwd hacluster Changing password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 실행하여
pcsd서비스를 시작하고 시스템을 시작할 때pcsd를 활성화합니다.systemctl start pcsd.service systemctl enable pcsd.service
# systemctl start pcsd.service # systemctl enable pcsd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow
기존 클러스터의 노드에서 다음 작업을 수행합니다.
새 클러스터 노드에서 사용자
hacluster를 인증합니다.pcs host auth newnode.example.com Username: hacluster Password: newnode.example.com: Authorized
[root@clusternode-01 ~]# pcs host auth newnode.example.com Username: hacluster Password: newnode.example.com: AuthorizedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 클러스터에 새 노드를 추가합니다. 이 명령은 또한 클러스터 구성 파일
corosync.conf를 추가하는 새 노드를 포함하여 클러스터의 모든 노드에 동기화합니다.pcs cluster node add newnode.example.com
[root@clusternode-01 ~]# pcs cluster node add newnode.example.comCopy to Clipboard Copied! Toggle word wrap Toggle overflow
클러스터에 추가할 새 노드에서 다음 작업을 수행합니다.
새 노드에서 클러스터 서비스를 시작하고 활성화합니다.
pcs cluster start Starting Cluster... pcs cluster enable
[root@newnode ~]# pcs cluster start Starting Cluster... [root@newnode ~]# pcs cluster enableCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 새 클러스터 노드의 펜싱 장치를 구성하고 테스트했는지 확인합니다.
61.4. 클러스터 노드 제거
다음 명령은 지정된 노드를 종료하고 클러스터의 다른 모든 노드의 클러스터 구성 파일 corosync.conf 에서 제거합니다.
pcs cluster node remove node
pcs cluster node remove node61.5. 여러 링크를 사용하여 클러스터에 노드 추가
여러 링크가 있는 클러스터에 노드를 추가할 때 모든 링크의 주소를 지정해야 합니다.
다음 예제에서는 노드 rh80-node3 을 클러스터에 추가하여 첫 번째 링크에 IP 주소 192.168.122.203을 지정하고 두 번째 링크로 192.168.123.203을 지정합니다.
pcs cluster node add rh80-node3 addr=192.168.122.203 addr=192.168.123.203
# pcs cluster node add rh80-node3 addr=192.168.122.203 addr=192.168.123.20361.6. 기존 클러스터에서 링크 추가 및 수정
RHEL 8.1 이상에서는 대부분의 경우 클러스터를 다시 시작하지 않고 기존 클러스터의 링크를 추가하거나 수정할 수 있습니다.
61.6.1. 기존 클러스터에서 링크 추가 및 제거
실행 중인 클러스터에 새 링크를 추가하려면 pcs cluster link add 명령을 사용합니다.
- 링크를 추가할 때 각 노드의 주소를 지정해야 합니다.
-
링크를 추가하고 제거하는 것은
knet전송 프로토콜을 사용하는 경우에만 가능합니다. - 클러스터에서 하나 이상의 링크를 언제든지 정의해야 합니다.
- 클러스터의 최대 링크 수는 8개이며 번호 0-7입니다. 어떤 링크가 정의되어 있는지는 중요하지 않으므로 3, 6 및 7 링크만 정의할 수 있습니다.
-
링크 번호를 지정하지 않고 링크를 추가하면
pcs에서 사용 가능한 가장 낮은 링크를 사용합니다. -
현재 구성된 링크의 링크 번호는
corosync.conf파일에 포함됩니다.corosync.conf파일을 표시하려면pcs cluster corosync명령 또는 (RHEL 8.4 이상)pcs cluster config show명령을 실행합니다.
다음 명령은 링크 번호 5를 3개의 노드 클러스터에 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=5
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=5
기존 링크를 제거하려면 pcs cluster link delete 또는 pcs cluster link remove 명령을 사용합니다. 다음 명령 중 하나가 클러스터에서 링크 번호 5를 제거합니다.
[root@node1 ~] # pcs cluster link delete 5 [root@node1 ~] # pcs cluster link remove 5
[root@node1 ~] # pcs cluster link delete 5
[root@node1 ~] # pcs cluster link remove 561.6.2. 여러 링크를 사용하여 클러스터의 링크 수정
클러스터에 여러 링크가 있고 해당 링크 중 하나를 변경하려면 다음 절차를 수행합니다.
프로세스
변경하려는 링크를 제거합니다.
[root@node1 ~] # pcs cluster link remove 2
[root@node1 ~] # pcs cluster link remove 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 업데이트된 주소와 옵션을 사용하여 링크를 다시 클러스터에 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
61.6.3. 단일 링크를 사용하여 클러스터의 링크 주소 수정
클러스터가 하나의 링크만 사용하고 다른 주소를 사용하도록 해당 링크를 수정하려면 다음 절차를 수행합니다. 이 예제에서 원본 링크는 링크 1입니다.
새 주소 및 옵션을 사용하여 새 링크를 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 원본 링크를 제거합니다.
[root@node1 ~] # pcs cluster link remove 1
[root@node1 ~] # pcs cluster link remove 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
클러스터에 대한 링크를 추가할 때 현재 사용 중인 주소를 지정할 수 없습니다. 예를 들어 하나의 링크가 있는 2-노드 클러스터가 있고 한 노드의 주소를 변경하려면 위의 절차를 사용하여 하나의 새 주소와 기존 주소를 지정하는 새 링크를 추가할 수 없습니다. 대신 다음 예제와 같이 기존 링크를 제거하고 업데이트된 주소로 다시 추가하기 전에 임시 링크를 추가할 수 있습니다.
이 예제에서는 다음을 수행합니다.
- 기존 클러스터의 링크는 노드 1에 10.0.5.11 주소를 사용하고 노드 2에 10.0.5.12 주소를 사용하는 link 1입니다.
- 노드 2의 주소를 10.0.5.31으로 변경하려고 합니다.
프로세스
단일 링크로 2-노드 클러스터의 주소 중 하나만 업데이트하려면 다음 절차를 사용하십시오.
현재 사용되지 않는 주소를 사용하여 기존 클러스터에 새 임시 링크를 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 원본 링크를 제거합니다.
[root@node1 ~] # pcs cluster link remove 1
[root@node1 ~] # pcs cluster link remove 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 수정된 새 링크를 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.31 options linknumber=1
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.31 options linknumber=1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 생성한 임시 링크 삭제
[root@node1 ~] # pcs cluster link remove 2
[root@node1 ~] # pcs cluster link remove 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
61.6.4. 단일 링크를 사용하여 클러스터의 링크 옵션 수정
클러스터가 하나의 링크만 사용하고 해당 링크의 옵션을 수정하려고 하지만 사용할 주소를 변경하지 않으려면 수정할 링크를 제거하고 업데이트하기 전에 임시 링크를 추가할 수 있습니다.
이 예제에서는 다음을 수행합니다.
- 기존 클러스터의 링크는 노드 1에 10.0.5.11 주소를 사용하고 노드 2에 10.0.5.12 주소를 사용하는 link 1입니다.
-
link_priority를 11로 변경하고 싶습니다.
프로세스
다음 절차에 따라 단일 링크를 사용하여 클러스터의 link 옵션을 수정합니다.
현재 사용되지 않는 주소를 사용하여 기존 클러스터에 새 임시 링크를 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2
[root@node1 ~] # pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Copy to Clipboard Copied! Toggle word wrap Toggle overflow 원본 링크를 제거합니다.
[root@node1 ~] # pcs cluster link remove 1
[root@node1 ~] # pcs cluster link remove 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 업데이트된 옵션을 사용하여 원본 링크를 다시 추가합니다.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 options linknumber=1 link_priority=11
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 options linknumber=1 link_priority=11Copy to Clipboard Copied! Toggle word wrap Toggle overflow 임시 링크를 삭제합니다.
[root@node1 ~] # pcs cluster link remove 2
[root@node1 ~] # pcs cluster link remove 2Copy to Clipboard Copied! Toggle word wrap Toggle overflow
61.6.5. 새 링크를 추가할 때 링크를 수정할 수 없습니다.
어떤 이유로 구성에서 새 링크를 추가할 수 없고 유일한 옵션은 하나의 기존 링크를 수정하는 것입니다. 이 절차를 사용하려면 클러스터를 종료해야 합니다.
프로세스
다음 예제 절차에서는 클러스터의 링크 번호 1을 업데이트하고 링크에 대한 link_priority 옵션을 11로 설정합니다.
클러스터의 클러스터 서비스를 중지합니다.
[root@node1 ~] # pcs cluster stop --all
[root@node1 ~] # pcs cluster stop --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow 링크 주소 및 옵션을 업데이트합니다.
pcs cluster link update명령은 모든 노드 주소와 옵션을 지정할 필요가 없습니다. 대신 변경할 주소만 지정할 수 있습니다. 이 예에서는node1및node3의 주소와link_priority옵션만 수정합니다.[root@node1 ~] # pcs cluster link update 1 node1=10.0.5.11 node3=10.0.5.31 options link_priority=11
[root@node1 ~] # pcs cluster link update 1 node1=10.0.5.11 node3=10.0.5.31 options link_priority=11Copy to Clipboard Copied! Toggle word wrap Toggle overflow 옵션을 제거하려면option
=format을 사용하여 옵션을 null 값으로 설정할 수 있습니다.클러스터 재시작
[root@node1 ~] # pcs cluster start --all
[root@node1 ~] # pcs cluster start --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow
61.7. 노드 상태 전략 구성
노드는 클러스터 멤버십을 유지하기에 충분히 잘 작동할 수 있지만 리소스에 대한 바람직하지 않은 위치로 만드는 일부 측면에서는 비정상이 될 수 있습니다. 예를 들어 디스크 드라이브가 SMART 오류를 보고하거나 CPU가 로드될 수 있습니다. RHEL 8.7 이상에서는 Pacemaker에서 노드 상태 전략을 사용하여 리소스를 비정상 노드에서 자동으로 이동할 수 있습니다.
CPU 및 디스크 상태에 따라 노드 속성을 설정하는 다음 상태 노드 리소스 에이전트를 사용하여 노드 상태를 모니터링할 수 있습니다.
-
OCF:pacemaker:HealthCPU는 CPU 유휴 상태를 모니터링합니다. -
OCF:pacemaker:HealthIOWait... CPU I/O 대기 시간을 모니터링합니다. -
OCF:pacemaker:HealthSMART: 디스크 드라이브의 SMART 상태를 모니터링합니다. -
oCF:pacemaker:SysInfo: 로컬 시스템 정보를 사용하여 다양한 노드 속성을 설정하고 또한 상태 에이전트 모니터링 디스크 공간 사용으로 기능함
또한 모든 리소스 에이전트에서 상태 노드 전략을 정의하는 데 사용할 수 있는 노드 속성을 제공할 수 있습니다.
프로세스
다음 절차에서는 CPU I/O 대기 시간이 15%를 초과하는 노드에서 리소스를 이동하는 클러스터의 상태 노드 전략을 구성합니다.
health-node-strategy클러스터 속성을 설정하여 Pacemaker가 노드 상태 변경에 응답하는 방법을 정의합니다.pcs property set node-health-strategy=migrate-on-red
# pcs property set node-health-strategy=migrate-on-redCopy to Clipboard Copied! Toggle word wrap Toggle overflow 상태 노드 리소스 에이전트를 사용하는 복제된 클러스터 리소스를 생성하고
allow-unhealthy-nodes리소스 메타 옵션을 설정하여 노드의 상태가 복구되는지 여부를 감지하고 리소스를 노드로 다시 이동합니다. 모든 노드의 상태를 지속적으로 점검하도록 반복 모니터 작업을 사용하여 이 리소스를 구성합니다.이 예에서는 CPU I/O 대기를 모니터링하는
HealthIOWait리소스 에이전트를 생성하여 노드에서 리소스를 15 %로 이동하기 위한 빨간색 제한을 설정합니다. 이 명령은allow-unhealthy-nodes리소스 메타 옵션을true로 설정하고 반복적인 모니터 간격을 10초로 구성합니다.pcs resource create io-monitor ocf:pacemaker:HealthIOWait red_limit=15 op monitor interval=10s meta allow-unhealthy-nodes=true clone
# pcs resource create io-monitor ocf:pacemaker:HealthIOWait red_limit=15 op monitor interval=10s meta allow-unhealthy-nodes=true cloneCopy to Clipboard Copied! Toggle word wrap Toggle overflow
61.8. 리소스가 많은 대규모 클러스터 구성
배포하는 클러스터가 많은 수의 노드와 많은 리소스로 구성된 경우 클러스터에 대해 다음 매개변수의 기본값을 수정해야 할 수 있습니다.
cluster-ipc-limit클러스터 속성cluster-ipc-limitcluster 속성은 하나의 클러스터 데몬의 연결을 해제하기 전에 최대 IPC 메시지 백로그입니다. 대규모 클러스터에서 많은 리소스를 정리하거나 동시에 수정하면 CIB 업데이트가 한 번에 제공됩니다. 이로 인해 Pacemaker 서비스에서 CIB 이벤트 큐 임계값에 도달하기 전에 모든 구성 업데이트를 처리할 시간이 없는 경우 느린 클라이언트가 제거될 수 있습니다.대규모 클러스터에서 사용할 수 있도록
cluster-ipc-limit의 권장 값은 클러스터의 리소스 수에 노드 수를 곱한 값입니다. 로그에 클러스터 데몬 PID에 대한 "클라이언트 제거" 메시지가 표시되면 이 값이 발생할 수 있습니다.pcs property set명령을 사용하여cluster-ipc-limit의 값을 기본값 500에서 늘릴 수 있습니다. 예를 들어, 200개의 리소스가 있는 ten-node 클러스터의 경우 다음 명령을 사용하여cluster-ipc-limit값을 2000으로 설정할 수 있습니다.pcs property set cluster-ipc-limit=2000
# pcs property set cluster-ipc-limit=2000Copy to Clipboard Copied! Toggle word wrap Toggle overflow PCMK_ipc_bufferPacemaker 매개변수대규모 배포에서 내부 Pacemaker 메시지는 메시지 버퍼의 크기를 초과할 수 있습니다. 이 경우 다음 형식의 시스템 로그에 메시지가 표시됩니다.
Compressed message exceeds X% of configured IPC limit (X bytes); consider setting PCMK_ipc_buffer to X or higher
Compressed message exceeds X% of configured IPC limit (X bytes); consider setting PCMK_ipc_buffer to X or higherCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 메시지가 표시되면 각 노드의
/etc/sysconfig/pacemaker구성 파일에서PCMK_ipc_buffer값을 늘릴 수 있습니다. 예를 들어PCMK_ipc_buffer의 값을 기본값에서 13396332 바이트로 늘리려면 클러스터의 각 노드의 주석 해제된PCMK_ipc_buffer필드를/etc/sysconfig/pacemaker파일에서 변경합니다.PCMK_ipc_buffer=13396332
PCMK_ipc_buffer=13396332Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 변경 사항을 적용하려면 다음 명령을 실행합니다.
systemctl restart pacemaker
# systemctl restart pacemakerCopy to Clipboard Copied! Toggle word wrap Toggle overflow
62장. Pacemaker 클러스터 속성
클러스터 속성은 클러스터 작업 중에 발생할 수 있는 상황에서 클러스터가 작동하는 방식을 제어합니다.
62.1. 클러스터 속성 및 옵션 요약
다음 표에서는 Pacemaker 클러스터 속성을 요약하여 속성의 기본값과 해당 속성에 대해 설정할 수 있는 값을 표시합니다.
펜싱 동작을 결정하는 추가 클러스터 속성이 있습니다. 이러한 속성에 대한 자세한 내용은 펜싱 장치의 일반 속성에서 펜싱 동작을 결정하는 클러스터 속성 표를 참조하십시오.
이 표에 설명된 속성 외에도 클러스터 소프트웨어에 의해 노출되는 추가 클러스터 속성이 있습니다. 이러한 속성의 경우 기본값에서 값을 변경하지 않는 것이 좋습니다.
| 옵션 | Default | 설명 |
|---|---|---|
|
| 0 | 클러스터를 병렬로 실행할 수 있는 리소스 작업 수입니다. "올바른" 값은 네트워크 및 클러스터 노드의 속도와 로드에 따라 달라집니다. 기본값인 0은 노드에 높은 CPU 로드가 있을 때 클러스터가 동적으로 제한을 적용한다는 것을 의미합니다. |
|
| -1(제한되지 않음) | 클러스터에서 병렬로 실행할 수 있는 마이그레이션 작업 수입니다. |
|
| 중지 | 클러스터에 쿼럼이 없는 경우 수행할 작업. 허용되는 값: * 무시 - 모든 리소스 관리를 계속합니다. * 고정 - 리소스 관리를 계속하지만 영향을 받는 파티션에 없는 노드에서 리소스를 복구하지 마십시오. * stop - 영향을 받는 클러스터 파티션의 모든 리소스 중지 * 고충 - 영향을 받는 클러스터 파티션의 모든 노드를 펜싱 * demote - 클러스터 파티션이 쿼럼이 끊어지면 승격된 리소스를 해제하고 다른 모든 리소스를 중지합니다. |
|
| true | 기본적으로 모든 노드에서 리소스를 실행할 수 있는지 여부를 나타냅니다. |
|
| 60s | 네트워크에 대한 왕복 지연(작업 실행 제외)입니다. "올바른" 값은 네트워크 및 클러스터 노드의 속도와 로드에 따라 달라집니다. |
|
| 20s | 시작하는 동안 다른 노드의 응답을 대기하는 시간입니다. "올바른" 값은 네트워크의 속도와 로드와 사용된 스위치 유형에 따라 달라집니다. |
|
| true | 삭제된 리소스를 중지해야 하는지 여부를 나타냅니다. |
|
| true | 삭제된 작업을 취소해야 하는지 여부를 나타냅니다. |
|
| true |
특정 노드에서 리소스를 시작하지 못하는 경우 해당 노드에서 추가 시작 시도가 발생하지 않는지를 나타냅니다.
|
|
| -1 (모두) | 스케줄러 입력 수로 인해 ERROR가 저장됩니다. 문제를 보고할 때 사용됩니다. |
|
| -1 (모두) | 스케줄러 입력 수로 인해 저장이 발생합니다. 문제를 보고할 때 사용됩니다. |
|
| -1 (모두) | 저장할 "일반" 스케줄러 입력 수입니다. 문제를 보고할 때 사용됩니다. |
|
| Pacemaker가 현재 실행 중인 메시징 스택입니다. 사용자 설정 및 진단이 아닌 정보 및 진단 목적으로 사용됩니다. | |
|
| 클러스터의 Designated Controller (DC)의 Pacemaker 버전입니다. 진단 목적으로 사용되며 user-configurable은 아닙니다. | |
|
| 15분 |
Pacemaker는 주로 이벤트 중심이며 클러스터의 장애 시간 초과와 대부분의 시간 기반 규칙을 다시 점검해야 할 시기를 미리 알고 있습니다. 또한 Pacemaker는 이 속성에서 지정한 비활성 기간 후에 클러스터를 다시 확인합니다. 이 클러스터 재확인에는 두 가지 용도가 있습니다. |
|
| false | 유지 관리 모드는 클러스터가 "hands off" 모드로 이동하고, 달리 지시될 때까지 서비스를 시작하거나 중지하도록 지시합니다. 유지 관리 모드가 완료되면 클러스터는 서비스의 현재 상태에 대한 온전성 검사를 수행한 다음 필요한 모든 서비스를 중지하거나 시작합니다. |
|
| 20min | 그런 다음 정상적으로 종료하려는 시도를 포기하고 종료합니다. 고급 용도로만 사용됩니다. |
|
| false | 클러스터가 모든 리소스를 중지해야 합니다. |
|
| false |
|
|
| default | 클러스터 노드에 리소스 배치를 결정할 때 클러스터가 사용률 속성을 고려하고 있는지 여부를 나타냅니다. |
|
| none | 상태 리소스 에이전트와 함께 사용하면 Pacemaker에서 노드 상태 변경에 응답하는 방법을 제어합니다. 허용되는 값:
*
*
*
* |
62.2. 클러스터 속성 설정 및 제거
클러스터 속성 값을 설정하려면 다음 pcs 명령을 사용합니다.
pcs property set property=value
pcs property set property=value
예를 들어 symmetric-cluster 의 값을 false 로 설정하려면 다음 명령을 사용합니다.
pcs property set symmetric-cluster=false
# pcs property set symmetric-cluster=false다음 명령을 사용하여 구성에서 클러스터 속성을 제거할 수 있습니다.
pcs property unset property
pcs property unset property
또는 pcs property set 명령의 value 필드를 비워 두어 구성에서 클러스터 속성을 제거할 수 있습니다. 이렇게 하면 해당 속성이 기본값으로 복원됩니다. 예를 들어, 이전에 symmetric-cluster 속성을 false 로 설정한 경우 다음 명령은 구성에서 설정한 값을 제거하고 symmetric-cluster 값을 기본값인 true 로 복원합니다.
pcs property set symmetic-cluster=
# pcs property set symmetic-cluster=62.3. 클러스터 속성 설정 쿼리
대부분의 경우 pcs 명령을 사용하여 다양한 클러스터 구성 요소의 값을 표시하는 경우 pcs list 또는 pcs show interchangeably를 사용할 수 있습니다. 다음 예제에서 pcs list 는 둘 이상의 속성에 대한 모든 설정의 전체 목록을 표시하는 데 사용되는 형식이며 pcs show 는 특정 속성의 값을 표시하는 데 사용되는 형식입니다.
클러스터에 설정된 속성 설정 값을 표시하려면 다음 pcs 명령을 사용합니다.
pcs property list
pcs property list명시적으로 설정되지 않은 속성 설정의 기본값을 포함하여 클러스터의 속성 설정 값을 모두 표시하려면 다음 명령을 사용합니다.
pcs property list --all
pcs property list --all특정 클러스터 속성의 현재 값을 표시하려면 다음 명령을 사용합니다.
pcs property show property
pcs property show property
예를 들어 cluster-infrastructure 속성의 현재 값을 표시하려면 다음 명령을 실행합니다.
pcs property show cluster-infrastructure Cluster Properties: cluster-infrastructure: cman
# pcs property show cluster-infrastructure
Cluster Properties:
cluster-infrastructure: cman정보를 제공하기 위해 다음 명령을 사용하여 기본값 이외의 값으로 설정되어 있는지 여부에 관계없이 속성의 모든 기본값 목록을 표시할 수 있습니다.
pcs property [list|show] --defaults
pcs property [list|show] --defaults62.4. 클러스터 속성을 pcs 명령으로 내보내기
Red Hat Enterprise Linux 8.9 이상에서는 명령의 pcs property config--output-format=cmd 옵션을 사용하여 다른 시스템에서 구성된 클러스터 속성을 다시 생성하는 데 사용할 수 있는 pcs 명령을 표시할 수 있습니다.
다음 명령은 migration-limit cluster 속성을 10으로 설정합니다.
pcs property set migration-limit=10
# pcs property set migration-limit=10
클러스터 속성을 설정한 후 다음 명령은 다른 시스템에서 클러스터 속성을 설정하는 데 사용할 수 있는 pcs 명령을 표시합니다.
pcs property config --output-format=cmd pcs property set --force -- \ migration-limit=10 \ placement-strategy=minimal
# pcs property config --output-format=cmd
pcs property set --force -- \
migration-limit=10 \
placement-strategy=minimal63장. 가상 도메인을 리소스로 구성
libvirt 가상화 프레임워크에서 관리하는 가상 도메인을 pcs resource create 명령을 사용하여 클러스터 리소스로 구성하고 VirtualDomain 을 리소스 유형으로 지정할 수 있습니다.
가상 도메인을 리소스로 구성할 때 다음 고려 사항을 고려하십시오.
- 가상 도메인을 클러스터 리소스로 구성하기 전에 중지해야 합니다.
- 가상 도메인이 클러스터 리소스이면 클러스터 툴을 제외하고 시작, 중지 또는 마이그레이션해서는 안 됩니다.
- 호스트가 부팅될 때 시작할 클러스터 리소스로 구성한 가상 도메인을 구성하지 마십시오.
- 가상 도메인을 실행할 수 있는 모든 노드는 해당 가상 도메인에 필요한 구성 파일 및 스토리지 장치에 액세스할 수 있어야 합니다.
클러스터가 가상 도메인 자체 내에서 서비스를 관리하도록 하려면 가상 도메인을 게스트 노드로 구성할 수 있습니다.
63.1. 가상 도메인 리소스 옵션
다음 표에서는 VirtualDomain 리소스에 대해 구성할 수 있는 리소스 옵션에 대해 설명합니다.
| 필드 | 기본 | 설명 |
|---|---|---|
|
|
(필수) 이 가상 도메인의 | |
|
| 시스템 종속 |
연결할 하이퍼바이저 URI입니다. |
|
|
|
항상 도메인을 중지 시 강제로 종료합니다("destroy"). 기본 동작은 정상 종료 시도가 실패한 경우에만 강제로 종료하는 것입니다. 가상 도메인(또는 가상화 백엔드)이 정상 종료를 지원하지 않는 경우에만 이 값을 |
|
| 시스템 종속 |
마이그레이션하는 동안 원격 하이퍼바이저에 연결하는 데 사용되는 전송입니다. 이 매개 변수를 생략하면 리소스는 |
|
| 전용 마이그레이션 네트워크를 사용합니다. 마이그레이션 URI는 이 매개변수의 값을 노드 이름 끝에 추가하여 구성됩니다. 노드 이름이 FQDN(정규화된 도메인 이름)인 경우 FQDN의 첫 번째 기간(.) 앞에 접미사를 삽입합니다. 이 구성된 호스트 이름을 로컬에서 확인할 수 있고, 선호하는 네트워크를 통해 연결된 IP 주소에 연결할 수 있는지 확인합니다. | |
|
|
가상 도메인 내에서 서비스를 추가로 모니터링하려면 모니터링할 스크립트 목록으로 이 매개변수를 추가합니다. 참고: 모니터 스크립트가 사용되면 모든 모니터 스크립트가 성공적으로 완료된 경우에만 | |
|
|
|
|
|
|
|
true로 설정하면 에이전트는 |
|
| 임의의 높은 포트 |
이 포트는 |
|
|
가상 머신 이미지가 저장될 스냅샷 디렉터리의 경로입니다. 이 매개 변수가 설정되면 중지된 경우 가상 시스템의 RAM 상태가 스냅샷 디렉터리의 파일에 저장됩니다. 도메인에 대해 상태 파일을 시작할 때 도메인은 마지막으로 중지되기 직전에 있는 것과 동일한 상태로 복원됩니다. 이 옵션은 |
VirtualDomain 리소스 옵션 외에도 allow-migrate 메타데이터 옵션을 구성하여 리소스를 다른 노드로 실시간 마이그레이션할 수 있습니다. 이 옵션을 true 로 설정하면 상태 손실 없이 리소스를 마이그레이션할 수 있습니다. 이 옵션을 false 로 설정하면 기본 상태인 가상 도메인이 첫 번째 노드에서 종료되고 한 노드에서 다른 노드로 이동하면 두 번째 노드에서 다시 시작됩니다.
63.2. 가상 도메인 리소스 생성
다음 절차에서는 이전에 생성한 가상 머신에 대해 클러스터에 VirtualDomain 리소스를 생성합니다.
절차
가상 머신 관리를 위한
VirtualDomain리소스 에이전트를 생성하려면 Pacemaker에서 가상 머신의xml구성 파일을 디스크의 파일에 덤프해야 합니다. 예를 들어guest1이라는 가상 머신을 생성한 경우 게스트를 실행할 클러스터 노드 중 하나에xml파일을 파일로 덤프합니다. 선택한 파일 이름을 사용할 수 있습니다. 이 예에서는/etc/pacemaker/guest1.xml을 사용합니다.virsh dumpxml guest1 > /etc/pacemaker/guest1.xml
# virsh dumpxml guest1 > /etc/pacemaker/guest1.xmlCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
가상 머신의
xml구성 파일을 각 노드의 동일한 위치에서 게스트를 실행할 수 있는 다른 모든 클러스터 노드에 복사합니다. - 가상 도메인을 실행할 수 있는 모든 노드가 해당 가상 도메인에 필요한 스토리지 장치에 액세스할 수 있는지 확인합니다.
- 가상 도메인이 가상 도메인을 실행할 각 노드에서 시작하고 중지할 수 있는지 별도로 테스트합니다.
- 실행 중인 경우 게스트 노드를 종료합니다. Pacemaker는 클러스터에 구성된 경우 노드를 시작합니다. 호스트가 부팅될 때 가상 시스템을 자동으로 시작하도록 구성해서는 안 됩니다.
pcs resource create명령을 사용하여VirtualDomain리소스를 구성합니다. 예를 들어 다음 명령은VM이라는VirtualDomain리소스를 구성합니다.allow-migrate옵션은true로 설정되므로pcs resource move VM nodeX명령이 실시간 마이그레이션으로 수행됩니다.이 예에서는
migration_transport가ssh로 설정됩니다. SSH 마이그레이션이 제대로 작동하려면 키 없는 로깅이 노드 간에 작동해야 합니다.pcs resource create VM VirtualDomain config=/etc/pacemaker/guest1.xml migration_transport=ssh meta allow-migrate=true
# pcs resource create VM VirtualDomain config=/etc/pacemaker/guest1.xml migration_transport=ssh meta allow-migrate=trueCopy to Clipboard Copied! Toggle word wrap Toggle overflow
64장. 클러스터 쿼럼 구성
Red Hat Enterprise Linux High Availability Add-On 클러스터는 펜싱과 함께 votequorum 서비스를 사용하여 분할된 뇌 상황을 방지합니다. 클러스터의 각 시스템에 여러 개의 투표가 할당되며, 클러스터 작업은 대부분의 투표가 있는 경우에만 진행할 수 있습니다. 서비스를 모든 노드 또는 none 노드에 로드해야 합니다. 클러스터 노드의 하위 집합에 로드되면 결과를 예측할 수 없습니다. votequorum 서비스 구성 및 운영에 대한 자세한 내용은 votequorum(5) 매뉴얼 페이지를 참조하십시오.
64.1. 쿼럼 옵션 구성
pcs cluster setup 명령을 사용하여 클러스터를 생성할 때 설정할 수 있는 쿼럼 구성의 몇 가지 특별한 기능이 있습니다. 다음 표에는 이러한 옵션이 요약되어 있습니다.
| 옵션 | 설명 |
|---|---|
|
|
클러스터를 활성화하면 결정적인 방식으로 노드의 최대 50%까지 오류가 발생할 수 있습니다. 클러스터 파티션 또는
|
|
| 활성화하면 모든 노드가 최소한 한 번 이상 표시되는 경우에만 클러스터가 처음으로 정족수에 달합니다.
클러스터에 두 개의 노드가 있고 쿼럼 장치를 사용하지 않고 |
|
|
활성화하면 클러스터는 특정 상황에서 |
|
|
클러스터가 노드가 손실된 후 |
이러한 옵션 구성 및 사용에 대한 자세한 내용은 votequorum(5) 도움말 페이지를 참조하십시오.
64.2. 쿼럼 옵션 수정
pcs quorum update 명령을 사용하여 클러스터의 일반 쿼럼 옵션을 수정할 수 있습니다. 이 명령을 실행하려면 클러스터를 중지해야 합니다. 쿼럼 옵션에 대한 자세한 내용은 votequorum(5) 도움말 페이지를 참조하십시오.
pcs quorum update 명령의 형식은 다음과 같습니다.
pcs quorum update [auto_tie_breaker=[0|1]] [last_man_standing=[0|1]] [last_man_standing_window=[time-in-ms] [wait_for_all=[0|1]]
pcs quorum update [auto_tie_breaker=[0|1]] [last_man_standing=[0|1]] [last_man_standing_window=[time-in-ms] [wait_for_all=[0|1]]
다음 일련의 명령은 wait_for_all 쿼럼 옵션을 수정하고 옵션의 업데이트된 상태를 표시합니다. 이 시스템은 클러스터가 실행되는 동안 이 명령을 실행할 수 없습니다.
64.3. 쿼럼 구성 및 상태 표시
클러스터가 실행되면 다음 클러스터 쿼럼 명령을 입력하여 쿼럼 구성 및 상태를 표시할 수 있습니다.
다음 명령은 쿼럼 구성을 보여줍니다.
pcs quorum [config]
pcs quorum [config]다음 명령은 쿼럼 런타임 상태를 보여줍니다.
pcs quorum status
pcs quorum status64.4. 클러스터 정족
노드를 오랜 기간 동안 클러스터에서 중단하고 해당 노드가 손실되어 쿼럼이 손실되는 경우 pcs quorum- votes 명령을 사용하여 라이브 클러스터에 대한 expected_votes 매개변수 값을 변경할 수 있습니다. 이렇게 하면 쿼럼이 없을 때 클러스터가 계속 작동할 수 있습니다.
클러스터의 예상 투표를 변경하는 것은 매우 주의해야 합니다. 예상 투표를 수동으로 변경했기 때문에 클러스터의 50% 미만이 실행 중인 경우 클러스터의 다른 노드를 별도로 시작하고 클러스터 서비스를 실행하여 데이터 손상 및 기타 예기치 않은 결과를 초래할 수 있습니다. 이 값을 변경하는 경우 wait_for_all 매개변수가 활성화되어 있는지 확인해야 합니다.
다음 명령은 라이브 클러스터의 예상 투표를 지정된 값으로 설정합니다. 이는 라이브 클러스터에만 영향을 미치며 구성 파일을 변경하지 않습니다. expected_votes 값은 다시 로드될 때 설정 파일의 값으로 재설정됩니다.
pcs quorum expected-votes votes
pcs quorum expected-votes votes
클러스터가 정족수와 일치하지만 클러스터를 리소스 관리를 진행하려는 경우 pcs quorum unblock 명령을 사용하여 쿼럼을 설정할 때 클러스터가 모든 노드를 대기하지 못하도록 할 수 있습니다.
이 명령은 극단적인 주의와 함께 사용해야 합니다. 이 명령을 실행하기 전에 현재 클러스터에 없는 노드가 꺼지고 공유 리소스에 대한 액세스 권한이 없는지 확인해야 합니다.
pcs quorum unblock
# pcs quorum unblock65장. 비corosync 노드를 클러스터에 통합: pacemaker_remote 서비스
pacemaker_remote 서비스를 사용하면 노드가 corosync 를 실행하지 않고 클러스터에 실제 클러스터 노드와 마찬가지로 리소스를 관리할 수 있습니다.
pacemaker_remote 서비스에서 제공하는 기능은 다음과 같습니다.
-
pacemaker_remote서비스를 사용하면 Red Hat 지원 제한을 RHEL 8.1에 대해 32개의 노드 제한 이상으로 확장할 수 있습니다. -
pacemaker_remote서비스를 사용하면 가상 환경을 클러스터 리소스로 관리하고 가상 환경 내의 개별 서비스를 클러스터 리소스로 관리할 수 있습니다.
다음 용어는 pacemaker_remote 서비스를 설명하는 데 사용됩니다.
-
클러스터 노드 - 고가용성 서비스(
pacemaker및corosync)를 실행하는 노드입니다. -
원격 노드 -
corosync클러스터 멤버십 없이도 클러스터에 원격으로 통합하기 위해pacemaker_remote를 실행하는 노드입니다. 원격 노드는ocf:pacemaker:remote리소스 에이전트를 사용하는 클러스터 리소스로 구성됩니다. -
게스트 노드 -
pacemaker_remote서비스를 실행하는 가상 게스트 노드입니다. 가상 게스트 리소스는 클러스터에서 관리합니다. 둘 다 클러스터에 의해 시작되고 원격 노드로 클러스터에 통합됩니다. -
pacemaker_remote - Pacemaker 클러스터 환경의 원격 노드 및 KVM 게스트 노드 내에서 원격 애플리케이션 관리를 수행할 수 있는 서비스 데몬입니다. 이 서비스는 corosync를 실행하지 않는 노드에서 원격으로 리소스를 관리할 수 있는 Pacemaker의 로컬 executor 데몬(
pacemaker-execd)의 향상된 버전입니다.
pacemaker_remote 서비스를 실행하는 Pacemaker 클러스터에는 다음과 같은 특징이 있습니다.
-
원격 노드 및 게스트 노드는
pacemaker_remote서비스를 실행합니다(가상 머신 측에 필요한 구성은 거의 없음). -
클러스터 노드에서 실행 중인 클러스터 스택(
pacemaker및corosync)은 원격 노드의pacemaker_remote서비스에 연결하여 클러스터에 통합할 수 있습니다. -
클러스터 스택(
pacemaker및corosync)은 클러스터 노드에서 게스트 노드를 시작하고 게스트 노드의pacemaker_remote서비스에 즉시 연결하여 클러스터에 통합할 수 있습니다.
클러스터 노드와 클러스터 노드가 관리하는 원격 및 게스트 노드의 주요 차이점은 원격 노드와 게스트 노드가 클러스터 스택을 실행하지 않는다는 것입니다. 즉, 원격 및 게스트 노드에 다음과 같은 제한 사항이 있습니다.
- 쿼럼에서는 발생하지 않습니다.
- 펜싱 장치 작업을 실행하지 않음
- 클러스터의 Designated Controller (DC)가 될 수 없습니다.
-
자체적으로
pcs명령의 전체 범위를 실행하지 않습니다.
반면 원격 노드 및 게스트 노드는 클러스터 스택과 관련된 확장성 제한에 바인딩되지 않습니다.
이러한 제한 사항 이외의 원격 및 게스트 노드는 리소스 관리와 관련하여 클러스터 노드처럼 작동하며 원격 및 게스트 노드는 자체적으로 펜싱될 수 있습니다. 클러스터는 각 원격 및 게스트 노드에서 리소스를 완전히 관리하고 모니터링할 수 있습니다. 이러한 제약 조건을 빌드하거나 대기 상태로 두거나 pcs 명령을 사용하여 클러스터 노드에서 수행하는 기타 작업을 수행할 수 있습니다. 원격 및 게스트 노드는 클러스터 노드와 마찬가지로 클러스터 상태 출력에 표시됩니다.
65.1. pacemaker_remote 노드의 호스트 및 게스트 인증
클러스터 노드와 pacemaker_remote 간의 연결은 PSK(사전 공유 키) 암호화 및 TCP를 통한 인증(기본적으로 포트 3121 사용)이 있는 TLS(Transport Layer Security)를 사용하여 보호됩니다. 즉, 클러스터 노드와 pacemaker_remote 를 실행하는 노드 모두 동일한 개인 키를 공유해야 합니다. 기본적으로 이 키는 클러스터 노드와 원격 노드 모두의 /etc/pacemaker/authkey 에 배치해야 합니다.
pcs cluster node add-guest 명령 또는 pcs cluster node add-remote 명령을 처음 실행하면 authkey 를 생성하여 클러스터의 모든 기존 노드에 설치합니다. 나중에 유형의 새 노드를 생성하면 기존 authkey 가 새 노드에 복사됩니다.
65.2. KVM 게스트 노드 구성
Pacemaker 게스트 노드는 pacemaker_remote 서비스를 실행하는 가상 게스트 노드입니다. 가상 게스트 노드는 클러스터에서 관리합니다.
65.2.1. 게스트 노드 리소스 옵션
게스트 노드로 작동하도록 가상 머신을 구성할 때 가상 머신을 관리하는 VirtualDomain 리소스를 생성합니다. VirtualDomain 리소스에 대해 설정할 수 있는 옵션에 대한 설명은 가상 도메인 리소스 옵션의 "가상 도메인 리소스에 대한 리소스 옵션 " 표를 참조하십시오.
VirtualDomain 리소스 옵션 외에도 메타데이터 옵션은 리소스를 게스트 노드로 정의하고 연결 매개 변수를 정의합니다. pcs cluster node add-guest 명령을 사용하여 이러한 리소스 옵션을 설정합니다. 다음 표에서는 이러한 메타데이터 옵션을 설명합니다.
| 필드 | Default | 설명 |
|---|---|---|
|
| <none> | 이 리소스에서 정의하는 게스트 노드의 이름입니다. 이 두 가지 모두 게스트 노드로 리소스를 활성화하고 게스트 노드를 식별하는 데 사용되는 고유한 이름을 정의합니다. 경고: 이 값은 리소스 또는 노드 ID와 중복될 수 없습니다. |
|
| 3121 |
|
|
|
| 연결할 IP 주소 또는 호스트 이름입니다. |
|
| 60s | 보류 중인 게스트 연결이 시간 초과되기 전의 시간 |
65.2.2. 가상 머신을 게스트 노드로 통합
다음 절차에서는 Pacemaker에서 가상 머신을 시작하고 libvirt 및 KVM 가상 게스트를 사용하여 해당 시스템을 게스트 노드로 통합하기 위해 수행할 단계에 대한 간략한 개요입니다.
절차
-
VirtualDomain리소스를 구성합니다. 모든 가상 시스템에서
pacemaker_remote패키지를 설치하고pcsd서비스를 시작하여 시작 시 실행되도록 활성화하고 방화벽을 통해 TCP 포트 3121을 허용합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 각 가상 시스템에 모든 노드에 알려야 하는 정적 네트워크 주소와 고유한 호스트 이름을 지정합니다.
아직 수행하지 않은 경우 노드로 통합할 노드에
pcs를 인증합니다.pcs host auth nodename
# pcs host auth nodenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 사용하여 기존
VirtualDomain리소스를 게스트 노드로 변환합니다. 이 명령은 추가 중인 게스트 노드가 아닌 클러스터 노드에서 실행해야 합니다. 이 명령은 리소스를 변환하는 것 외에도/etc/pacemaker/authkey를 게스트 노드에 복사하고 게스트 노드에서pacemaker_remote데몬을 시작하고 활성화합니다. 임의로 정의할 수 있는 게스트 노드의 노드 이름은 노드의 호스트 이름과 다를 수 있습니다.pcs cluster node add-guest nodename resource_id [options]
# pcs cluster node add-guest nodename resource_id [options]Copy to Clipboard Copied! Toggle word wrap Toggle overflow VirtualDomain리소스를 생성한 후 클러스터의 다른 노드를 처리하는 것처럼 게스트 노드를 처리할 수 있습니다. 예를 들어 리소스를 생성하고 다음 명령과 같이 게스트 노드에서 실행할 리소스에 리소스 제약 조건을 배치할 수 있습니다. 이 제약 조건은 클러스터 노드에서 실행됩니다. 게스트 노드를 그룹에 포함할 수 있으므로 스토리지 장치, 파일 시스템 및 VM을 그룹화할 수 있습니다.pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s pcs constraint location webserver prefers nodename
# pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers nodenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
65.3. Pacemaker 원격 노드 구성
원격 노드는 ocf:pacemaker:remote 를 리소스 에이전트로 사용하여 클러스터 리소스로 정의됩니다. pcs cluster node add-remote 명령을 사용하여 이 리소스를 생성합니다.
65.3.1. 원격 노드 리소스 옵션
다음 표에서는 원격 리소스에 대해 구성할 수 있는 리소스 옵션에 대해 설명합니다.
| 필드 | Default | 설명 |
|---|---|---|
|
| 0 | 원격 노드에 대한 활성 연결이 심각한 후 원격 노드에 다시 연결하기 전에 대기하는 시간(초)입니다. 이 대기는 반복되어 있습니다. 대기 기간 후에 다시 연결할 경우 대기 시간을 관찰한 후 새 재연결 시도가 수행됩니다. 이 옵션을 사용 중이면 Pacemaker에서 계속 연결을 시도하여 대기 간격마다 무기한 원격 노드에 연결을 시도합니다. |
|
|
| 연결할 서버입니다. IP 주소 또는 호스트 이름일 수 있습니다. |
|
| 연결할 TCP 포트입니다. |
65.3.2. 원격 노드 구성 개요
다음 절차에서는 Pacemaker 원격 노드를 구성하고 기존 Pacemaker 클러스터 환경에 통합하기 위해 수행하는 단계에 대한 간략한 개요를 제공합니다.
절차
원격 노드로 구성할 노드에서 로컬 방화벽을 통해 클러스터 관련 서비스를 허용합니다.
firewall-cmd --permanent --add-service=high-availability success firewall-cmd --reload success
# firewall-cmd --permanent --add-service=high-availability success # firewall-cmd --reload successCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고iptables를 직접 사용하거나firewalld이외의 다른 방화벽 솔루션을 사용하는 경우 다음 포트를 열기만 하면 됩니다. TCP 포트 2224 및 3121.원격 노드에
pacemaker_remote데몬을 설치합니다.yum install -y pacemaker-remote resource-agents pcs
# yum install -y pacemaker-remote resource-agents pcsCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원격 노드에서
pcsd를 시작하고 활성화합니다.systemctl start pcsd.service systemctl enable pcsd.service
# systemctl start pcsd.service # systemctl enable pcsd.serviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 아직 수행하지 않은 경우 원격 노드로 추가할 노드에
pcs를 인증합니다.pcs host auth remote1
# pcs host auth remote1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 사용하여 원격 노드 리소스를 클러스터에 추가합니다. 이 명령은 또한 관련 구성 파일을 모든 관련 구성 파일을 새 노드에 동기화하고, 노드를 시작한 다음 부팅 시
pacemaker_remote를 시작하도록 구성합니다. 이 명령은 추가 중인 원격 노드가 아닌 클러스터 노드에서 실행해야 합니다.pcs cluster node add-remote remote1
# pcs cluster node add-remote remote1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 원격리소스를 클러스터에 추가한 후 클러스터의 다른 노드를 처리하는 것처럼 원격 노드를 처리할 수 있습니다. 예를 들어 리소스를 생성하고 리소스 제약 조건을 추가하여 클러스터 노드에서 실행되는 다음 명령과 같이 원격 노드에서 실행할 수 있습니다.pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s pcs constraint location webserver prefers remote1
# pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s # pcs constraint location webserver prefers remote1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 주의리소스 그룹, 공동 배치 제약 조건 또는 순서 제약 조건에 원격 노드 연결 리소스를 포함하지 마십시오.
- 원격 노드의 펜싱 리소스를 구성합니다. 원격 노드는 클러스터 노드와 동일한 방식으로 펜싱됩니다. 클러스터 노드와 동일한 원격 노드에서 사용할 펜싱 리소스를 구성합니다. 그러나 원격 노드는 펜싱 작업을 시작할 수 없습니다. 클러스터 노드만 실제로 다른 노드에 대해 펜싱 작업을 실행할 수 있습니다.
65.4. 기본 포트 위치 변경
Pacemaker 또는 pacemaker_remote 의 기본 포트 위치를 변경해야 하는 경우 두 데몬 모두에 영향을 주는 PCMK_remote_port 환경 변수를 설정할 수 있습니다. 이 환경 변수는 다음과 같이 /etc/sysconfig/pacemaker 파일에 배치하여 활성화할 수 있습니다.
\#==#==# Pacemaker Remote ... # # Specify a custom port for Pacemaker Remote connections PCMK_remote_port=3121
\#==#==# Pacemaker Remote
...
#
# Specify a custom port for Pacemaker Remote connections
PCMK_remote_port=3121
특정 게스트 노드 또는 원격 노드에서 사용하는 기본 포트를 변경할 때는 해당 노드의 /etc/sysconfig/pacemaker 파일에 PCMK_remote_port 변수를 설정해야 하며 게스트 노드 또는 원격 노드 연결을 생성하는 클러스터 리소스도 동일한 포트 번호(게스트 노드에 원격 포트 메타데이터 옵션 사용) 또는 원격 노드의 포트 옵션을 사용해야 합니다.
65.5. pacemaker_remote 노드를 사용하여 시스템 업그레이드
pacemaker_remote 서비스가 활성 Pacemaker 원격 노드에서 중지되면 클러스터를 통해 노드를 중지하기 전에 노드에서 리소스를 정상적으로 마이그레이션합니다. 이를 통해 클러스터에서 노드를 제거하지 않고 소프트웨어 업그레이드 및 기타 일상적인 유지 관리 절차를 수행할 수 있습니다. 그러나 pacemaker_remote 가 종료되면 클러스터는 즉시 다시 연결을 시도합니다. pacemaker_remote 가 리소스의 모니터 시간 초과 내에서 재시작되지 않으면 클러스터에서 모니터 작업이 실패한 것으로 간주합니다.
pacemaker_remote 서비스가 활성 Pacemaker 원격 노드에서 중지될 때 모니터 실패를 방지하려면 pacemaker_remote 를 중지할 수 있는 시스템 관리를 수행하기 전에 다음 절차를 사용하여 클러스터에서 노드를 제거할 수 있습니다.
프로세스
pcs resource disable resourcename명령을 사용하여 노드의 연결 리소스를 중지하여 모든 서비스를 노드에서 이동합니다. 연결 리소스는 원격 노드의ocf:pacemaker:remote리소스 또는 일반적으로 게스트 노드의ocf:heartbeat:VirtualDomain리소스입니다. 게스트 노드의 경우 이 명령도 VM을 중지하므로 VM을 클러스터 외부에서 시작해야 합니다(예:virsh를 사용하여 유지 관리를 수행합니다.pcs resource disable resourcename
pcs resource disable resourcenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 필요한 유지 관리를 수행합니다.
노드를 클러스터로 반환할 준비가 되면
pcs resource enable명령을 사용하여 리소스를 다시 활성화합니다.pcs resource enable resourcename
pcs resource enable resourcenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
66장. 클러스터 유지 관리 수행
클러스터 노드에서 유지보수를 수행하려면 해당 클러스터에서 실행 중인 리소스 및 서비스를 중지하거나 이동해야 할 수 있습니다. 또는 서비스를 그대로 두는 동안 클러스터 소프트웨어를 중지해야 할 수도 있습니다. Pacemaker는 시스템 유지 관리를 수행하는 다양한 방법을 제공합니다.
- 다른 노드의 해당 클러스터에서 실행 중인 서비스를 계속 제공하는 동안 클러스터에서 노드를 중지해야 하는 경우 클러스터 노드를 대기 모드로 설정할 수 있습니다. standby 모드에 있는 노드는 더 이상 리소스를 호스팅할 수 없습니다. 현재 노드에서 활성 상태인 모든 리소스가 다른 노드로 이동되거나 해당 리소스를 실행할 수 있는 다른 노드가 없는 경우 중지됩니다. 대기 모드에 대한 자세한 내용은 노드 Putting a node into standby mode 를 참조하십시오.
개별 리소스를 중지하지 않고 현재 실행 중인 노드에서 개별 리소스를 이동해야 하는 경우
pcs resource move명령을 사용하여 리소스를 다른 노드로 이동할 수 있습니다.pcs resource move명령을 실행할 때 리소스에 제약 조건을 추가하여 현재 실행 중인 노드에서 실행되지 않도록 합니다. 리소스를 다시 이동할 준비가 되면pcs resource clear또는pcs constraint delete명령을 실행하여 제약 조건을 제거할 수 있습니다. 그러나 해당 시점에서 리소스를 실행할 수 있는 위치는 처음에 리소스를 구성하는 방법에 따라 달라질 수 있기 때문에 리소스를 원래 노드로 다시 이동할 필요는 없습니다.pcs resource relocate run명령을 사용하여 리소스를 기본 노드로 재배치할 수 있습니다.-
실행 중인 리소스를 완전히 중지하고 클러스터가 다시 시작되지 않도록 하려면
pcs resource disable명령을 사용할 수 있습니다.pcs resource disable명령에 대한 자세한 내용은 클러스터 리소스 비활성화, 활성화 및 금지 를 참조하십시오. -
Pacemaker에서 리소스에 대한 작업을 수행하지 못하도록 하려면(예: 리소스에서 유지 관리를 수행하는 동안 복구 작업을 비활성화하거나
/etc/sysconfig/pacemaker설정을 다시 로드해야 하는 경우) 리소스 설정에 설명된 대로pcs resource unmanage명령을 사용합니다. Pacemaker 원격 연결 리소스는 관리되지 않아야 합니다. -
서비스를 시작하거나 중지하지 않는 상태로 클러스터를 배치해야 하는 경우
유지 관리 모드클러스터 속성을 설정할 수 있습니다. 클러스터를 유지 관리 모드로 전환하면 모든 리소스가 자동으로 관리되지 않습니다. 클러스터를 유지 관리 모드로 배치하는 방법에 대한 자세한 내용은 클러스터 Putting a cluster in maintenance mode 를 참조하십시오. - RHEL High Availability 및 Resilient Storage 애드온을 구성하는 패키지를 업데이트해야 하는 경우 RHEL 고가용성 클러스터 업데이트에서 요약된 대로 한 번에 또는 전체 클러스터에서 패키지를 업데이트할 수 있습니다.
- Pacemaker 원격 노드에서 유지보수를 수행해야 하는 경우 원격 노드 및 게스트 노드에 설명된 대로 원격 노드 리소스를 비활성화하여 클러스터에서 해당 노드를 제거할 수 있습니다.
- RHEL 클러스터에서 VM을 마이그레이션해야 하는 경우 먼저 VM에서 클러스터 서비스를 중지하여 클러스터에서 노드를 제거한 다음 RHEL 클러스터에서 VM 마이그레이션에 설명된 대로 마이그레이션을 수행한 후 클러스터를 다시 시작해야 합니다.
66.1. 노드를 대기 모드로 전환
클러스터 노드가 standby 모드이면 노드가 더 이상 리소스를 호스팅할 수 없습니다. 현재 노드에 활성 상태인 모든 리소스가 다른 노드로 이동합니다.
다음 명령은 지정된 노드를 대기 모드로 설정합니다. --all 을 지정하면 이 명령은 모든 노드를 대기 모드로 설정합니다.
리소스의 패키지를 업데이트할 때 이 명령을 사용할 수 있습니다. 구성을 테스트할 때 이 명령을 사용하여 노드를 실제로 종료하지 않고 복구를 시뮬레이션할 수도 있습니다.
pcs node standby node | --all
pcs node standby node | --all
다음 명령은 지정된 노드를 대기 모드에서 제거합니다. 이 명령을 실행하면 지정된 노드가 리소스를 호스팅할 수 있습니다. --all 을 지정하면 이 명령은 대기 모드에서 모든 노드를 제거합니다.
pcs node unstandby node | --all
pcs node unstandby node | --all
pcs node standby 명령을 실행하면 표시된 노드에서 리소스가 실행되지 않습니다. pcs node unstandby 명령을 실행하면 표시된 노드에서 리소스를 실행할 수 있습니다. 이는 리소스를 표시된 노드로 다시 이동하는 것은 아닙니다. 해당 시점에서 리소스를 실행할 수 있는 위치는 처음에 리소스를 구성하는 방법에 따라 다릅니다.
66.2. 수동으로 클러스터 리소스 이동
클러스터를 재정의하고 현재 위치에서 리소스를 강제로 이동할 수 있습니다. 이 작업을 수행하려는 경우 두 가지 경우가 있습니다.
- 노드가 유지보수 상태인 경우 해당 노드에서 실행 중인 모든 리소스를 다른 노드로 이동해야 합니다.
- 개별적으로 지정된 리소스를 이동해야 하는 경우
노드에서 실행 중인 모든 리소스를 다른 노드로 이동하려면 노드를 standby 모드에 배치합니다.
다음 방법 중 하나로 개별적으로 지정된 리소스를 이동할 수 있습니다.
-
pcs resource move명령을 사용하여 현재 실행 중인 노드에서 리소스를 이동할 수 있습니다. -
pcs resource relocate run명령을 사용하여 현재 클러스터 상태, 제약 조건, 리소스 및 기타 설정에 따라 결정된 대로 리소스를 기본 노드로 이동할 수 있습니다.
66.2.1. 현재 노드에서 리소스 이동
리소스를 현재 실행 중인 노드에서 이동하려면 다음 명령을 사용하여 정의된 리소스 resource_id 를 지정합니다. 이동 중인 리소스를 실행할 노드를 지정하려면 destination_node 를 지정합니다.
pcs resource move resource_id [destination_node] [--master] [lifetime=lifetime]
pcs resource move resource_id [destination_node] [--master] [lifetime=lifetime]
pcs resource move 명령을 실행할 때 리소스에 제약 조건을 추가하여 현재 실행 중인 노드에서 실행되지 않도록 합니다. RHEL 8.6 이상에서는 이 명령에 --autodelete 옵션을 지정할 수 있으므로 리소스가 이동되면 이 명령에서 생성하는 위치 제약 조건이 자동으로 제거됩니다. 이전 릴리스의 경우 pcs resource clear 또는 pcs constraint delete 명령을 실행하여 제약 조건을 수동으로 제거할 수 있습니다. 제약 조건을 제거해도 리소스를 원래 노드로 다시 이동하는 것은 아닙니다. 해당 시점에서 리소스를 실행할 수 있는 위치는 처음에 리소스를 구성하는 방법에 따라 다릅니다.
pcs resource move 명령의 --master 매개변수를 지정하면 제약 조건이 리소스의 승격된 인스턴스에만 적용됩니다.
선택적으로 pcs resource move 명령에 대해 lifetime 매개변수를 구성하여 제약 조건이 유지되어야 하는 기간을 나타낼 수 있습니다. ISO 8601에 정의된 형식에 따라 수명 매개변수 단위를 지정합니다. 이를 위해서는 Y(년의 경우), M(주당), W(일당), D(일당), M(시간), M(시간), M(시간), M(분) 및 S(초)와 같은 대문자로 단위를 지정해야 합니다.
분 단위와 월 단위(M)를 구분하려면 PT를 분 단위로 표시하기 전에 지정해야 합니다. 예를 들어 수명 매개 변수는 5 개월의 간격을 나타내며 PT5M의 수명 매개 변수는 5 분의 간격을 나타냅니다.
다음 명령은 리소스 resource1 을 노드 example-node2 로 이동하고 원래 1시간 30분 동안 실행되었던 노드로 다시 이동하지 못하도록 합니다.
pcs resource move resource1 example-node2 lifetime=PT1H30M
pcs resource move resource1 example-node2 lifetime=PT1H30M
다음 명령은 리소스 resource1 을 노드 example-node2 로 이동하여 원래 실행 중인 노드로 30분 동안 다시 이동하지 못하도록 합니다.
pcs resource move resource1 example-node2 lifetime=PT30M
pcs resource move resource1 example-node2 lifetime=PT30M66.2.2. 리소스를 기본 노드로 이동
장애 조치(failover) 또는 관리자가 노드를 수동으로 이동하기 때문에 장애 조치(failover)가 수정된 경우에도 리소스가 원래 노드로 다시 이동되는 것은 아닙니다. 리소스를 기본 노드로 재배치하려면 다음 명령을 사용합니다. 기본 노드는 현재 클러스터 상태, 제약 조건, 리소스 위치 및 기타 설정에 따라 결정되며 시간이 지남에 따라 변경될 수 있습니다.
pcs resource relocate run [resource1] [resource2] ...
pcs resource relocate run [resource1] [resource2] ...리소스를 지정하지 않으면 모든 리소스가 기본 노드로 재배치됩니다.
이 명령은 리소스 고정을 무시하고 각 리소스의 기본 노드를 계산합니다. 기본 노드를 계산하면 위치 제약 조건이 생성되어 리소스가 기본 노드로 이동합니다. 리소스가 이동되면 제약 조건이 자동으로 삭제됩니다. pcs resource relocate run 명령으로 생성된 모든 제약 조건을 제거하려면 pcs resource relocate clear 명령을 입력합니다. 리소스의 현재 상태와 해당 최적의 노드가 리소스 고정을 무시하려면 pcs resource relocate show 명령을 입력합니다.
66.3. 클러스터 리소스 비활성화, 활성화 및 금지
pcs resource move 및 pcs resource relocate 명령 외에도 클러스터 리소스의 동작을 제어하는 데 사용할 수 있는 다양한 명령이 있습니다.
클러스터 리소스 비활성화
실행 중인 리소스를 수동으로 중지하고 다음 명령을 사용하여 클러스터가 다시 시작되지 않도록 할 수 있습니다. 나머지 구성(constraint, options, failures 등)에 따라 리소스가 계속 시작될 수 있습니다. --wait 옵션을 지정하면 pcs 는 리소스가 중지될 때까지 'n'초까지 기다린 다음 리소스가 중지되거나 리소스가 중지되지 않은 경우 0초를 반환합니다. 'n'을 지정하지 않으면 기본값은 60분입니다.
pcs resource disable resource_id [--wait[=n]]
pcs resource disable resource_id [--wait[=n]]RHEL 8.2 이상에서는 리소스를 비활성화해도 다른 리소스에 영향을 미치지 않는 경우에만 리소스를 비활성화하도록 지정할 수 있습니다. 복잡한 리소스 관계가 설정될 때 이를 수동으로 수행할 수 없는지 확인합니다.
-
pcs resource disable --simulate명령은 클러스터 구성을 변경하지 않고 리소스를 비활성화하는 효과를 표시합니다. -
pcs resource disable --safe명령은 하나의 노드에서 다른 노드로 마이그레이션되는 등 다른 리소스가 영향을 받지 않는 경우에만 리소스를 비활성화합니다.pcs resource safe-disable명령은pcs resource disable --safe명령의 별칭입니다. -
pcs resource disable --safe --no-strict명령은 다른 리소스를 중지하거나 비활성화하지 않는 경우에만 리소스를 비활성화합니다.
RHEL 8.5 이상에서는 pcs resource disable 에 --brief 옵션을 지정하여 오류만 출력할 수 있습니다. RHEL 8.5부터 pcs resource disable --safe command가 보안 비활성화 작업에 영향을 받는 리소스 ID가 포함된 경우 생성되는 오류 보고입니다. 리소스를 비활성화하여 영향을 받는 리소스의 리소스 ID만 알아야 하는 경우 전체 시뮬레이션 결과를 제공하지 않는 --brief 옵션을 사용합니다.
클러스터 리소스 활성화
다음 명령을 사용하여 클러스터가 리소스를 시작하도록 허용합니다. 나머지 구성에 따라 리소스가 중지된 상태로 유지될 수 있습니다. --wait 옵션을 지정하면 pcs 에서 리소스가 시작될 때까지 최대 'n'초를 기다린 다음 리소스가 시작되거나 리소스가 시작되지 않은 경우 0을 반환합니다. 'n'을 지정하지 않으면 기본값은 60분입니다.
pcs resource enable resource_id [--wait[=n]]
pcs resource enable resource_id [--wait[=n]]특정 노드에서 리소스가 실행되지 않음
다음 명령을 사용하여 리소스가 지정된 노드에서 실행되지 않거나 노드가 지정되지 않은 경우 현재 노드에서 실행되지 않습니다.
pcs resource ban resource_id [node] [--master] [lifetime=lifetime] [--wait[=n]]
pcs resource ban resource_id [node] [--master] [lifetime=lifetime] [--wait[=n]]
pcs resource prohibit 명령을 실행하면 표시된 노드에서 실행되지 않도록 -INFINITY 위치 제약 조건이 리소스에 추가됩니다. pcs resource clear 또는 pcs constraint delete 명령을 실행하여 제약 조건을 제거할 수 있습니다. 이는 리소스를 표시된 노드로 다시 이동하는 것은 아닙니다. 해당 시점에서 리소스를 실행할 수 있는 위치는 처음에 리소스를 구성하는 방법에 따라 다릅니다.
pcs resource prohibit 명령의 --master 매개변수를 지정하는 경우 제약 조건의 범위는 마스터 역할로 제한되며 resource_id 대신 master_id 를 지정해야 합니다.
제약 조건이 유지되어야 하는 기간을 나타내기 위해 pcs resource prohibit 명령에 대해 lifetime 매개변수를 선택적으로 구성할 수 있습니다.
필요한 경우 pcs resource prohibit 명령에 --wait[=n] 매개변수를 구성하여 리소스가 시작되거나 리소스가 아직 시작되지 않은 경우 0을 반환하기 전에 리소스가 대상 노드에서 시작될 때까지 대기하는 시간(초)을 나타낼 수 있습니다. n을 지정하지 않으면 기본 리소스 시간 초과가 사용됩니다.
현재 노드에서 리소스를 시작하도록 강제 적용
pcs resource 명령의 debug-start 매개 변수를 사용하여 클러스터 권장 사항을 무시하고 리소스를 시작할 때 출력을 출력하여 지정된 리소스가 현재 노드에서 시작되도록 합니다. 이는 주로 리소스를 디버깅하는 데 사용됩니다. 클러스터에서 리소스를 시작하는 것은 항상 Pacemaker에서 수행하고 pcs 명령으로 직접 수행하지 않습니다. 리소스가 시작되지 않는 경우 일반적으로 리소스(시스템 로그에서 디버그됨), 리소스가 시작되지 않도록 하는 제약 조건 또는 비활성화 중인 리소스의 구성 오류로 인해 발생합니다. 이 명령을 사용하여 리소스 구성을 테스트할 수 있지만 일반적으로 클러스터에서 리소스를 시작하는 데 사용해서는 안 됩니다.
debug-start 명령의 형식은 다음과 같습니다.
pcs resource debug-start resource_id
pcs resource debug-start resource_id66.4. 관리되지 않는 모드로 리소스 설정
리소스가 관리되지 않는 모드인 경우 리소스는 여전히 구성에 있지만 Pacemaker에서는 리소스를 관리하지 않습니다.
다음 명령은 표시된 리소스를 관리되지 않는 모드로 설정합니다.
pcs resource unmanage resource1 [resource2] ...
pcs resource unmanage resource1 [resource2] ...
다음 명령은 리소스를 기본 상태인 관리 모드로 설정합니다.
pcs resource manage resource1 [resource2] ...
pcs resource manage resource1 [resource2] ...
pcs resource manage 또는 pcs resource unmanage 명령을 사용하여 리소스 그룹의 이름을 지정할 수 있습니다. 명령은 그룹의 모든 리소스에 대해 작동하므로 그룹의 모든 리소스를 단일 명령으로 관리 또는 관리되지 않는 모드로 설정한 다음 포함된 리소스를 개별적으로 관리할 수 있습니다.
66.5. 클러스터를 유지보수 모드로 전환
클러스터가 유지보수 모드에 있는 경우, 그렇지 않으면 클러스터가 서비스를 시작하거나 중지하지 않습니다. 유지 관리 모드가 완료되면 클러스터는 서비스의 현재 상태에 대한 온전성 검사를 수행한 다음 필요한 모든 서비스를 중지하거나 시작합니다.
클러스터를 유지 관리 모드로 설정하려면 다음 명령을 사용하여 유지 관리 모드 클러스터 속성을 true 로 설정합니다.
pcs property set maintenance-mode=true
# pcs property set maintenance-mode=true
유지 관리 모드에서 클러스터를 제거하려면 다음 명령을 사용하여 maintenance-mode 클러스터 속성을 false 로 설정합니다.
pcs property set maintenance-mode=false
# pcs property set maintenance-mode=false다음 명령을 사용하여 구성에서 클러스터 속성을 제거할 수 있습니다.
pcs property unset property
pcs property unset property
또는 pcs property set 명령의 value 필드를 비워 두어 구성에서 클러스터 속성을 제거할 수 있습니다. 이렇게 하면 해당 속성이 기본값으로 복원됩니다. 예를 들어, 이전에 symmetric-cluster 속성을 false 로 설정한 경우 다음 명령은 구성에서 설정한 값을 제거하고 symmetric-cluster 값을 기본값인 true 로 복원합니다.
pcs property set symmetric-cluster=
# pcs property set symmetric-cluster=66.6. RHEL 고가용성 클러스터 업데이트
RHEL High Availability 및 Resilient Storage 애드온을 개별적으로 또는 전체적으로 구성하는 패키지 업데이트는 다음 두 가지 일반적인 방법 중 하나로 수행할 수 있습니다.
- 롤링 업데이트: 서비스에서 한 번에 하나의 노드를 제거하고 소프트웨어를 업데이트한 다음 클러스터에 다시 통합합니다. 이를 통해 각 노드가 업데이트되는 동안 클러스터에서 서비스 및 리소스를 계속 제공할 수 있습니다.
- 전체 클러스터 업데이트: 전체 클러스터를 중지하고 모든 노드에 업데이트를 적용한 다음 클러스터를 다시 시작합니다.
Red Hat Enterprise Linux High Availability 및 Resilient Storage 클러스터에 대한 소프트웨어 업데이트 절차를 수행할 때는 업데이트가 시작되기 전에 클러스터의 활성 멤버가 아닌 노드가 클러스터의 활성 멤버가 아닌지 확인하는 것이 중요합니다.
이러한 각 방법 및 업데이트에 대한 자세한 내용은 RHEL High Availability 또는 Resilient Storage 클러스터에 소프트웨어 업데이트를 적용하는 권장 사례를 참조하십시오.
66.7. 원격 노드 및 게스트 노드 업그레이드
pacemaker_remote 서비스가 활성 원격 노드 또는 게스트 노드에서 중지되면 클러스터를 통해 노드를 중지하기 전에 노드에서 리소스를 정상적으로 마이그레이션합니다. 이를 통해 클러스터에서 노드를 제거하지 않고 소프트웨어 업그레이드 및 기타 일상적인 유지 관리 절차를 수행할 수 있습니다. 그러나 pacemaker_remote 가 종료되면 클러스터는 즉시 다시 연결을 시도합니다. pacemaker_remote 가 리소스의 모니터 시간 초과 내에서 재시작되지 않으면 클러스터에서 모니터 작업이 실패한 것으로 간주합니다.
pacemaker_remote 서비스가 활성 Pacemaker 원격 노드에서 중지될 때 모니터 실패를 방지하려면 pacemaker_remote 를 중지할 수 있는 시스템 관리를 수행하기 전에 다음 절차를 사용하여 클러스터에서 노드를 제거할 수 있습니다.
프로세스
pcs resource disable resourcename명령을 사용하여 노드의 연결 리소스를 중지하여 모든 서비스를 노드에서 이동합니다. 연결 리소스는 원격 노드의ocf:pacemaker:remote리소스 또는 일반적으로 게스트 노드의ocf:heartbeat:VirtualDomain리소스입니다. 게스트 노드의 경우 이 명령도 VM을 중지하므로 VM을 클러스터 외부에서 시작해야 합니다(예:virsh를 사용하여 유지 관리를 수행합니다.pcs resource disable resourcename
pcs resource disable resourcenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow - 필요한 유지 관리를 수행합니다.
노드를 클러스터로 반환할 준비가 되면
pcs resource enable명령을 사용하여 리소스를 다시 활성화합니다.pcs resource enable resourcename
pcs resource enable resourcenameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
66.8. RHEL 클러스터에서 VM 마이그레이션
Red Hat은 RHEL 고가용성 클러스터에 대한 지원 정책 - 가상화 클러스터 멤버를 사용하는 일반 조건의 하이퍼바이저 또는 호스트 간에 활성 클러스터 노드의 실시간 마이그레이션을 지원하지 않습니다. 실시간 마이그레이션을 수행해야 하는 경우 먼저 클러스터에서 노드를 제거하기 위해 VM에서 클러스터 서비스를 중지한 다음 마이그레이션을 수행한 후 클러스터를 다시 시작해야 합니다. 다음 단계에서는 클러스터에서 VM을 제거하고 VM을 마이그레이션하며 VM을 클러스터로 복원하는 절차를 간략하게 설명합니다.
다음 단계에서는 클러스터에서 VM을 제거하고 VM을 마이그레이션하며 VM을 클러스터로 복원하는 절차를 간략하게 설명합니다.
이 절차는 특수 예방 조치없이 실시간 마이그레이션할 수 있는 클러스터 리소스(게스트 노드로 사용되는 VM 포함)로 관리되는 VM에는 전체 클러스터 노드로 사용되는 VM에 적용됩니다. RHEL High Availability 및 Resilient Storage 애드온을 개별적으로 또는 전체적으로 구성하는 패키지를 업데이트하는 데 필요한 전체 프로시저에 대한 일반 정보는 RHEL High Availability 또는 Resilient Storage Cluster에 소프트웨어 업데이트 적용을 위한 권장 사례를 참조하십시오.
이 절차를 수행하기 전에 클러스터 쿼럼의 클러스터 노드 제거에 미치는 영향을 고려하십시오. 예를 들어 3-노드 클러스터가 있고 하나의 노드를 제거하는 경우 클러스터의 노드 장애를 견딜 수 없습니다. 이는 3-노드 클러스터의 한 노드가 이미 다운된 경우 두 번째 노드를 제거하면 쿼럼이 손실되기 때문입니다.
프로세스
- 마이그레이션을 위해 VM에서 실행 중인 리소스 또는 소프트웨어를 중지하거나 이동하기 전에 준비해야 하는 경우 해당 단계를 수행합니다.
VM에서 다음 명령을 실행하여 VM에서 클러스터 소프트웨어를 중지합니다.
pcs cluster stop
# pcs cluster stopCopy to Clipboard Copied! Toggle word wrap Toggle overflow - VM의 실시간 마이그레이션을 수행합니다.
VM에서 클러스터 서비스를 시작합니다.
pcs cluster start
# pcs cluster startCopy to Clipboard Copied! Toggle word wrap Toggle overflow
66.9. UUID로 클러스터 식별
Red Hat Enterprise Linux 8.7 이상에서는 클러스터를 생성할 때 연결된 UUID가 있습니다. 클러스터 이름은 고유한 클러스터 ID가 아니므로 동일한 이름의 여러 클러스터를 관리하는 구성 관리 데이터베이스와 같은 타사 툴은 UUID를 통해 클러스터를 고유하게 식별할 수 있습니다. 출력에 클러스터 UUID를 포함하는 pcs cluster config [show] 명령을 사용하여 현재 클러스터 UUID를 표시할 수 있습니다.
기존 클러스터에 UUID를 추가하려면 다음 명령을 실행합니다.
pcs cluster config uuid generate
# pcs cluster config uuid generate기존 UUID를 사용하여 클러스터의 UUID를 다시 생성하려면 다음 명령을 실행합니다.
pcs cluster config uuid generate --force
# pcs cluster config uuid generate --force67장. 논리 볼륨 구성 및 관리
67.1. 논리 볼륨 관리 개요
LVM(Logical Volume Manager)은 물리 스토리지에 대한 추상화 계층을 생성하므로 논리 스토리지 볼륨을 생성할 수 있습니다. 이를 통해 직접 물리적 스토리지 사용량에 비해 유연성이 향상됩니다.
또한 하드웨어 스토리지 구성이 소프트웨어에 숨겨져 있으므로 애플리케이션을 중지하거나 파일 시스템을 마운트 해제하지 않고도 크기를 조정하고 이동할 수 있습니다. 이로 인해 운영 비용을 줄일 수 있습니다.
67.1.1. LVM 아키텍처
LVM의 구성 요소는 다음과 같습니다.
- 물리 볼륨
- PV(물리 볼륨)는 LVM 사용을 위해 지정된 파티션 또는 전체 디스크입니다. 자세한 내용은 LVM 물리 볼륨 관리를 참조하십시오.
- 볼륨 그룹
- 볼륨 그룹(VG)은 논리 볼륨을 할당할 수 있는 디스크 공간 풀을 생성하는 PV(물리 볼륨) 컬렉션입니다. 자세한 내용은 LVM 볼륨 그룹 관리를 참조하십시오.
- 논리 볼륨
- 논리 볼륨은 사용 가능한 스토리지 장치를 나타냅니다. 자세한 내용은 기본 논리 볼륨 관리 및 고급 논리 볼륨 관리를 참조하십시오.
다음 다이어그램은 LVM의 구성 요소를 보여줍니다.
그림 67.1. LVM 논리 볼륨 구성 요소

67.1.2. LVM의 이점
논리 볼륨은 물리적 스토리지를 직접 사용하는 것보다 다음과 같은 이점을 제공합니다.
- 유연한 용량
- 논리 볼륨을 사용하는 경우 장치 및 파티션을 단일 논리 볼륨으로 집계할 수 있습니다. 이 기능을 사용하면 파일 시스템이 단일 대규모인 것처럼 여러 장치에 걸쳐 확장할 수 있습니다.
- 편리한 장치 이름 지정
- 논리 스토리지 볼륨은 사용자 정의 및 사용자 지정 이름으로 관리할 수 있습니다.
- 크기 조정 가능한 스토리지 볼륨
- 기본 장치를 다시 포맷하고 다시 파티션하지 않고도 논리 볼륨을 확장하거나 간단한 소프트웨어 명령을 사용하여 논리 볼륨을 크기로 줄일 수 있습니다. 자세한 내용은 논리 볼륨 재조정 을 참조하십시오.
- 온라인 데이터 재배치
최신 스토리지 하위 시스템을 배포하려면
pvmove명령을 사용하여 시스템을 활성화하는 동안 데이터를 이동할 수 있습니다. 디스크를 사용하는 동안 디스크에서 데이터를 다시 정렬할 수 있습니다. 예를 들어 제거하기 전에 핫 스왑 가능한 디스크를 비울 수 있습니다.데이터를 마이그레이션하는 방법에 대한 자세한 내용은
pvmove도움말 페이지 및 볼륨 그룹에서 물리 볼륨 제거를 참조하십시오.- 제거된 볼륨
- 두 개 이상의 장치에서 데이터를 스트라이핑하는 논리 볼륨을 만들 수 있습니다. 이로 인해 처리량이 크게 증가할 수 있습니다. 자세한 내용은 스트라이핑된 논리 볼륨 생성 을 참조하십시오.
- RAID 볼륨
- 논리 볼륨은 데이터에 대한 RAID를 구성하는 편리한 방법을 제공합니다. 이를 통해 장치 오류로부터 보호되고 성능이 향상됩니다. 자세한 내용은 RAID 논리 볼륨 구성 을 참조하십시오.
- 볼륨 스냅샷
- 일관된 백업을 위해 논리 볼륨의 지정 시간 복사본인 스냅샷을 사용하거나 실제 데이터에 영향을 주지 않고 변경 사항의 효과를 테스트할 수 있습니다. 자세한 내용은 논리 볼륨 스냅샷 관리를 참조하십시오.
- thin volume
- 논리 볼륨은 씬 프로비저닝할 수 있습니다. 이를 통해 사용 가능한 물리 공간보다 큰 논리 볼륨을 생성할 수 있습니다. 자세한 내용은 thin 논리 볼륨 생성 을 참조하십시오.
- 캐싱
- 캐싱은 SSD와 같은 빠른 장치를 사용하여 논리 볼륨의 데이터를 캐시하여 성능을 향상시킵니다. 자세한 내용은 논리 볼륨 캐싱 을 참조하십시오.
67.2. LVM 물리 볼륨 관리
PV(물리 볼륨)는 LVM에서 사용하는 스토리지 장치의 물리 스토리지 장치 또는 파티션입니다.
초기화 프로세스 중에 LVM 디스크 레이블 및 메타데이터가 장치에 기록되므로 LVM에서 논리 볼륨 관리 스키마의 일부로 이를 추적하고 관리할 수 있습니다.
초기화 후에는 메타데이터 크기를 늘릴 수 없습니다. 더 큰 메타데이터가 필요한 경우 초기화 프로세스 중에 적절한 크기를 설정해야 합니다.
초기화 프로세스가 완료되면 PV를 볼륨 그룹(VG)에 할당할 수 있습니다. 이 VG를 운영 체제와 애플리케이션에 사용할 수 있는 가상 블록 장치인 LV(논리 볼륨)로 나눌 수 있습니다.
최적의 성능을 보장하기 위해 LVM을 사용할 수 있도록 전체 디스크를 단일 PV로 분할합니다.
67.2.1. LVM 물리 볼륨 생성
pvcreate 명령을 사용하여 물리 볼륨 LVM 사용을 초기화할 수 있습니다.
사전 요구 사항
- 관리 액세스.
-
lvm2패키지가 설치되어 있습니다.
프로세스
물리 볼륨으로 사용할 스토리지 장치를 식별합니다. 사용 가능한 모든 스토리지 장치를 나열하려면 다음을 사용합니다.
lsblk
$ lsblkCopy to Clipboard Copied! Toggle word wrap Toggle overflow LVM 물리 볼륨을 생성합니다.
pvcreate /dev/sdb
# pvcreate /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdb 를 물리 볼륨으로 초기화하려는 장치 이름으로 바꿉니다.
검증 단계
생성된 물리 볼륨을 표시합니다.
pvs PV VG Fmt Attr PSize PFree /dev/sdb lvm2 a-- 28.87g 13.87g
# pvs PV VG Fmt Attr PSize PFree /dev/sdb lvm2 a-- 28.87g 13.87gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.2.2. LVM 물리 볼륨 제거
pvremove 명령을 사용하여 LVM 사용의 물리 볼륨을 제거할 수 있습니다.
사전 요구 사항
- 관리 액세스.
프로세스
물리 볼륨을 나열하여 제거할 장치를 식별합니다.
pvs PV VG Fmt Attr PSize PFree /dev/sdb1 lvm2 --- 28.87g 28.87g
# pvs PV VG Fmt Attr PSize PFree /dev/sdb1 lvm2 --- 28.87g 28.87gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 물리 볼륨을 제거합니다.
pvremove /dev/sdb1
# pvremove /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdb1 을 물리 볼륨과 연결된 장치의 이름으로 바꿉니다.
물리 볼륨이 볼륨 그룹의 일부인 경우 먼저 볼륨 그룹에서 제거해야 합니다.
볼륨 그룹에 하나 이상의 물리 볼륨이 포함된 경우 Cryostatreduce
명령을사용합니다.vgreduce VolumeGroupName /dev/sdb1
# vgreduce VolumeGroupName /dev/sdb1Copy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다. /dev/sdb1 을 장치 이름으로 바꿉니다.
볼륨 그룹에 하나의 물리 볼륨이 포함된 경우 Cryostat
remove명령을 사용합니다.vgremove VolumeGroupName
# vgremove VolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다.
검증
물리 볼륨이 제거되었는지 확인합니다.
pvs
# pvsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.2.3. 웹 콘솔에서 논리 볼륨 생성
논리 볼륨은 물리 드라이브 역할을 합니다. RHEL 8 웹 콘솔을 사용하여 볼륨 그룹에 LVM 논리 볼륨을 생성할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치됩니다. - 볼륨 그룹이 생성됩니다.
프로세스
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 클릭합니다.
- 스토리지 테이블에서 논리 볼륨을 생성할 볼륨 그룹을 클릭합니다.
- 논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 만들기 를 클릭합니다.
- 이름 필드에 새 논리 볼륨의 이름을 입력합니다. 이름에 공백을 포함하지 마십시오.
(용도) 드롭다운 메뉴에서 파일 시스템에 대한 블록 장치를 선택합니다.
이 구성을 사용하면 볼륨 그룹에 포함된 모든 드라이브의 용량 합계와 동일한 최대 볼륨 크기를 사용하여 논리 볼륨을 생성할 수 있습니다.
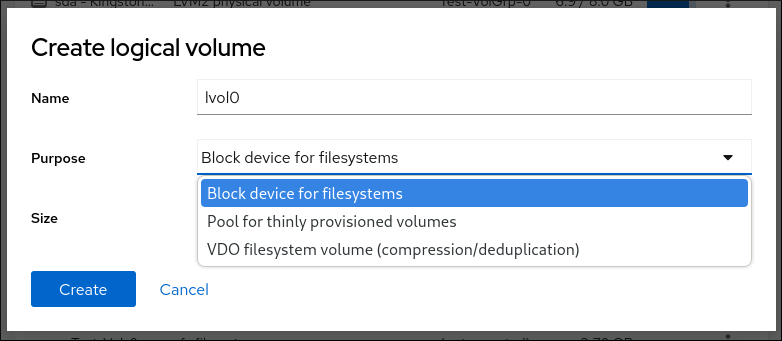
논리 볼륨의 크기를 정의합니다. 다음을 고려하십시오.
- 이 논리 볼륨을 사용하는 시스템에 얼마나 많은 공간이 필요합니까.
- 생성할 논리 볼륨 수입니다.
전체 공간을 사용할 필요는 없습니다. 필요한 경우 나중에 논리 볼륨을 확장할 수 있습니다.

을 클릭합니다.
논리 볼륨이 생성됩니다. 논리 볼륨을 사용하려면 볼륨을 포맷하고 마운트해야 합니다.
검증
논리 볼륨 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 새 논리 볼륨이 나열되는지 확인합니다.

67.2.4. 웹 콘솔에서 논리 볼륨 포맷
논리 볼륨은 물리 드라이브 역할을 합니다. 이를 사용하려면 파일 시스템으로 포맷해야 합니다.
논리 볼륨을 포맷하면 볼륨의 모든 데이터가 지워집니다.
선택한 파일 시스템에 논리 볼륨에 사용할 수 있는 구성 매개변수가 결정됩니다. 예를 들어 XFS 파일 시스템은 볼륨 축소를 지원하지 않습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 생성된 논리 볼륨입니다.
- 시스템에 대한 root 액세스 권한이 있습니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 표에서 논리 볼륨의 볼륨 그룹이 생성됩니다.
- 논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤합니다.
- 포맷할 볼륨 그룹 옆에 있는 메뉴 버튼 Cryostat를 클릭합니다.
드롭다운 메뉴에서 선택합니다.
- 이름 필드에 파일 시스템의 이름을 입력합니다.
마운트 지점 필드에서 마운트 경로를 추가합니다.
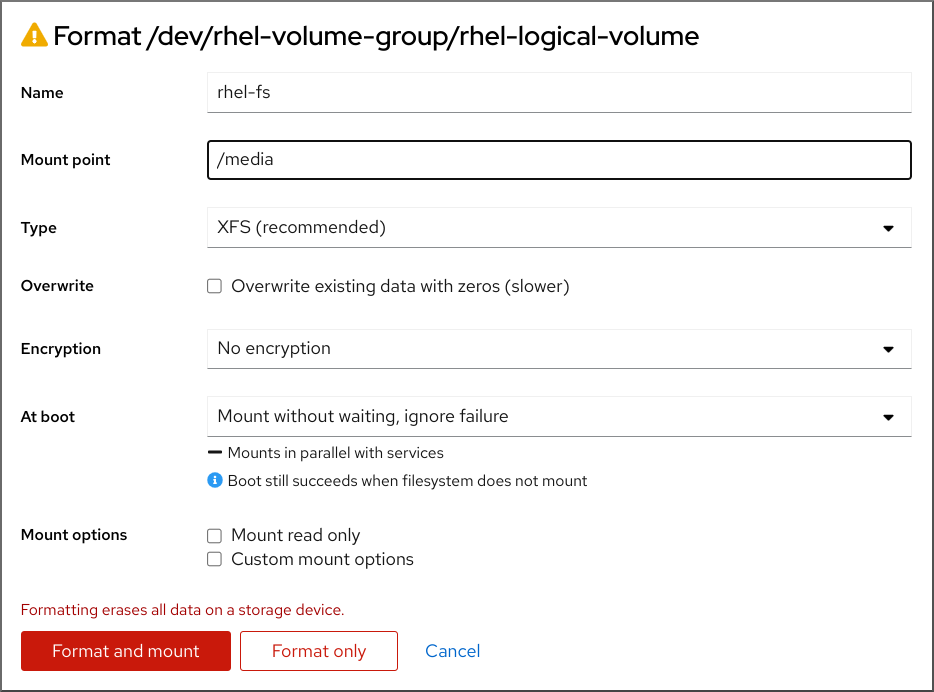
드롭다운 메뉴에서 파일 시스템을 선택합니다.
XFS 파일 시스템은 대규모 논리 볼륨을 지원하며 중단 없이 물리적 드라이브를 온라인 상태로 전환하며 기존 파일 시스템을 확장합니다. 다른 강력한 기본 설정이 없는 경우 이 파일 시스템을 선택한 상태로 두십시오.
XFS는 XFS 파일 시스템으로 포맷된 볼륨의 크기 감소를 지원하지 않습니다.
ext4 파일 시스템은 다음을 지원합니다.
- 논리 볼륨
- 중단 없이 온라인으로 물리적 드라이브 전환
- 파일 시스템 확장
- 파일 시스템 축소
RHEL 웹 콘솔에서 0으로 전체 디스크를 다시 작성하려면 0이 포함된 기존 데이터 덮어쓰기 확인란을 선택합니다. 이 옵션은 프로그램이 전체 디스크를 통과해야 하지만 더 안전합니다. 디스크에 데이터가 포함되어 있고 덮어써야 하는 경우 이 옵션을 사용합니다.
제로가 0인 기존 데이터를 덮어쓰 지 않은 경우 RHEL 웹 콘솔은 디스크 헤더만 다시 작성합니다. 이렇게 하면 포맷 속도가 증가합니다.
드롭다운 메뉴에서 논리 볼륨에서 암호화 유형을 활성화하려면 선택합니다.
LUKS1(Linux Unified Key Setup) 또는 LUKS2 암호화가 있는 버전을 선택하여 암호를 사용하여 볼륨을 암호화할 수 있습니다.
- 드롭다운 메뉴에서 시스템이 부팅된 후 논리 볼륨을 마운트할 시기를 선택합니다.
- 필요한 마운트 옵션을 선택합니다.
논리 볼륨을 포맷합니다.
- 볼륨을 포맷하고 즉시 마운트하려면 합니다.
마운트하지 않고 볼륨을 포맷하려면 클릭합니다.
볼륨 크기 및 선택한 포맷 옵션에 따라 포맷 지정에 몇 분이 걸릴 수 있습니다.
검증
논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 논리 볼륨을 클릭하여 세부 정보 및 추가 옵션을 확인합니다.
- 옵션을 선택한 경우 논리 볼륨 행 끝에 있는 메뉴 버튼을 클릭하고 를 선택하여 논리 볼륨을 사용합니다.
67.2.5. 웹 콘솔에서 논리 볼륨 크기 조정
RHEL 8 웹 콘솔에서 논리 볼륨을 확장하거나 줄일 수 있습니다. 예제 절차에서는 볼륨을 오프라인 상태로 전환하지 않고 논리 볼륨의 크기를 늘리고 줄이는 방법을 보여줍니다.
polkit2 또는 XFS 파일 시스템이 포함된 볼륨을 줄일 수 없습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 논리 볼륨 크기 조정을 지원하는 파일 시스템이 포함된 기존 논리 볼륨.
절차
- RHEL 웹 콘솔에 로그인합니다.
- 스토리지를 .
- 스토리지 표에서 논리 볼륨의 볼륨 그룹이 생성됩니다.
논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 크기를 조정할 볼륨 그룹 옆에 있는 Cryostat 메뉴 버튼을 클릭합니다.
메뉴에서 Grow 또는 Shrink 를 선택하여 볼륨의 크기를 조정합니다.
볼륨 확장:
- 를 선택하여 볼륨의 크기를 늘립니다.
Grow 논리 볼륨 대화 상자에서 논리 볼륨의 크기를 조정합니다.

확장 을 .
LVM은 시스템을 중단하지 않고 논리 볼륨을 늘립니다.
볼륨 축소:
- 를 선택하여 볼륨의 크기를 줄입니다.
Shrink 논리 볼륨 대화 상자에서 논리 볼륨의 크기를 조정합니다.

를 클릭합니다.
LVM은 시스템을 중단하지 않고 논리 볼륨을 축소합니다.
67.3. LVM 볼륨 그룹 관리
볼륨 그룹(VG)을 생성하고 사용하여 단일 스토리지 엔티티로 결합된 여러 PV(물리 볼륨)를 관리하고 크기를 조정할 수 있습니다.
Extent는 LVM에서 할당할 수 있는 가장 작은 공간 단위입니다. 물리 확장 영역(PE) 및 논리 확장 영역(LE)의 기본 크기는 구성할 수 있는 4MiB입니다. 모든 Extent의 크기가 동일합니다.
VG 내에 논리 볼륨(LV)을 생성하면 LVM에서 PV에 물리 확장 영역을 할당합니다. LV 내의 논리 확장 영역은 VG의 물리 확장 영역과 함께 1대1에 해당합니다. LV를 만들기 위해 PE를 지정할 필요가 없습니다. LVM은 사용 가능한 PE를 찾아서 함께 구성하여 요청된 크기의 LV를 만듭니다.
VG 내에서 각각 기존 파티션처럼 작동하지만 물리 볼륨에 걸쳐 확장되고 동적으로 크기를 조정할 수 있는 LV를 여러 개 만들 수 있습니다. VG는 디스크 공간 할당을 자동으로 관리할 수 있습니다.
67.3.1. LVM 볼륨 그룹 생성
Cryostat create 명령을 사용하여 볼륨 그룹(VG)을 생성할 수 있습니다. 매우 크거나 매우 작은 볼륨의 범위 크기를 조정하여 성능 및 스토리지 효율성을 최적화할 수 있습니다. VG를 만들 때 범위 크기를 지정할 수 있습니다. 확장 범위를 변경하려면 볼륨 그룹을 다시 생성해야 합니다.
사전 요구 사항
- 관리 액세스.
-
lvm2패키지가 설치되어 있습니다. - 하나 이상의 물리 볼륨이 생성됩니다. 물리 볼륨 생성에 대한 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
절차
VG에 포함할 PV를 나열하고 식별합니다.
pvs
# pvsCopy to Clipboard Copied! Toggle word wrap Toggle overflow VG를 만듭니다.
vgcreate VolumeGroupName PhysicalVolumeName1 PhysicalVolumeName2
# vgcreate VolumeGroupName PhysicalVolumeName1 PhysicalVolumeName2Copy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 생성하려는 볼륨 그룹의 이름으로 교체합니다. physicalVolumeName 을 PV 이름으로 교체합니다.
VG를 만들 때 확장 범위 크기를 지정하려면
-s ExtentSize옵션을 사용합니다. ExtentSize 를 extent의 크기로 바꿉니다. 크기 접미사를 제공하지 않으면 기본값은 MB입니다.
검증
VG가 생성되었는지 확인합니다.
vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName 1 0 0 wz--n- 28.87g 28.87g
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName 1 0 0 wz--n- 28.87g 28.87gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.3.2. 웹 콘솔에서 볼륨 그룹 생성
하나 이상의 물리 드라이브 또는 기타 스토리지 장치에서 볼륨 그룹을 생성합니다.
논리 볼륨은 볼륨 그룹에서 생성됩니다. 각 볼륨 그룹에는 여러 논리 볼륨이 포함될 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 볼륨 그룹을 생성할 물리 드라이브 또는 기타 유형의 스토리지 장치입니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지를 .
- 스토리지 테이블에서 메뉴 버튼을 클릭합니다.
드롭다운 메뉴에서 LVM2 볼륨 그룹 만들기 를 선택합니다.
- 이름 필드에 볼륨 그룹의 이름을 입력합니다. 이름에는 공백을 포함할 수 없습니다.
결합할 드라이브를 선택하여 볼륨 그룹을 만듭니다.
RHEL 웹 콘솔은 사용되지 않는 블록 장치만 표시합니다. 장치가 목록에 표시되지 않는 경우 시스템에서 사용하지 않는지 확인하거나 비어 있고 사용되지 않도록 포맷합니다. 사용되는 장치는 예를 들면 다음과 같습니다.
- 파일 시스템으로 포맷된 장치
- 다른 볼륨 그룹의 물리 볼륨
- 물리 볼륨은 다른 소프트웨어 RAID 장치의 멤버입니다.
을 클릭합니다.
볼륨 그룹이 생성됩니다.
검증
- 스토리지 페이지에서 스토리지 테이블에 새 볼륨 그룹이 나열되어 있는지 확인합니다.
67.3.3. LVM 볼륨 그룹 이름 변경
Cryostat rename 명령을 사용하여 볼륨 그룹(VG)의 이름을 변경할 수 있습니다.
사전 요구 사항
- 관리 액세스.
-
lvm2패키지가 설치되어 있습니다. - 하나 이상의 물리 볼륨이 생성됩니다. 물리 볼륨 생성에 대한 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 볼륨 그룹이 생성됩니다. 볼륨 그룹 생성에 대한 자세한 내용은 67.3.1절. “LVM 볼륨 그룹 생성” 을 참조하십시오.
절차
이름을 바꿀 VG를 나열하고 식별합니다.
vgs
# vgsCopy to Clipboard Copied! Toggle word wrap Toggle overflow VG의 이름을 변경합니다.
vgrename OldVolumeGroupName NewVolumeGroupName
# vgrename OldVolumeGroupName NewVolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow OldVolumeGroupName 을 VG의 이름으로 교체합니다. NewVolumeGroupName 을 VG의 새 이름으로 바꿉니다.
검증
VG에 새 이름이 있는지 확인합니다.
vgs VG #PV #LV #SN Attr VSize VFree NewVolumeGroupName 1 0 0 wz--n- 28.87g 28.87g
# vgs VG #PV #LV #SN Attr VSize VFree NewVolumeGroupName 1 0 0 wz--n- 28.87g 28.87gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.3.4. LVM 볼륨 그룹 확장
Cryostatextend 명령을 사용하여 PV(물리 볼륨)를 볼륨 그룹(VG)에 추가할 수 있습니다.
사전 요구 사항
- 관리 액세스.
-
lvm2패키지가 설치되어 있습니다. - 하나 이상의 물리 볼륨이 생성됩니다. 물리 볼륨 생성에 대한 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 볼륨 그룹이 생성됩니다. 볼륨 그룹 생성에 대한 자세한 내용은 67.3.1절. “LVM 볼륨 그룹 생성” 을 참조하십시오.
프로세스
확장하려는 VG를 나열하고 식별합니다.
vgs
# vgsCopy to Clipboard Copied! Toggle word wrap Toggle overflow VG에 추가할 PV를 나열하고 식별합니다.
pvs
# pvsCopy to Clipboard Copied! Toggle word wrap Toggle overflow VG를 확장합니다.
vgextend VolumeGroupName PhysicalVolumeName
# vgextend VolumeGroupName PhysicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 VG의 이름으로 바꿉니다. physicalVolumeName 을 PV 이름으로 교체합니다.
검증
VG에 새 PV가 포함되어 있는지 확인합니다.
pvs PV VG Fmt Attr PSize PFree /dev/sda VolumeGroupName lvm2 a-- 28.87g 28.87g /dev/sdd VolumeGroupName lvm2 a-- 1.88g 1.88g
# pvs PV VG Fmt Attr PSize PFree /dev/sda VolumeGroupName lvm2 a-- 28.87g 28.87g /dev/sdd VolumeGroupName lvm2 a-- 1.88g 1.88gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.3.5. LVM 볼륨 그룹 결합
두 개의 기존 볼륨 그룹(VG)을 Cryostat merge 명령과 결합할 수 있습니다. 소스 볼륨이 대상 볼륨에 병합됩니다.
사전 요구 사항
- 관리 액세스.
-
lvm2패키지가 설치되어 있습니다. - 하나 이상의 물리 볼륨이 생성됩니다. 물리 볼륨 생성에 대한 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 두 개 이상의 볼륨 그룹이 생성됩니다. 볼륨 그룹 생성에 대한 자세한 내용은 67.3.1절. “LVM 볼륨 그룹 생성” 을 참조하십시오.
프로세스
병합할 VG를 나열하고 식별합니다.
vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 1 0 0 wz--n- 28.87g 28.87g VolumeGroupName2 1 0 0 wz--n- 1.88g 1.88g
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 1 0 0 wz--n- 28.87g 28.87g VolumeGroupName2 1 0 0 wz--n- 1.88g 1.88gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 소스 VG를 대상 VG에 병합합니다.
vgmerge VolumeGroupName2 VolumeGroupName1
# vgmerge VolumeGroupName2 VolumeGroupName1Copy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName2 를 소스 VG의 이름으로 교체합니다. VolumeGroupName1 을 대상 VG의 이름으로 바꿉니다.
검증
VG에 새 PV가 포함되어 있는지 확인합니다.
vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 0 0 wz--n- 30.75g 30.75g
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 0 0 wz--n- 30.75g 30.75gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.3.6. 볼륨 그룹에서 물리 볼륨 제거
볼륨 그룹(VG)에서 사용되지 않는 PV(물리 볼륨)를 제거하려면 Cryostatreduce 명령을 사용합니다. Cryo stat reduce 명령은 하나 이상의 빈 물리 볼륨을 제거하여 볼륨 그룹의 용량을 줄입니다. 이렇게 하면 이러한 물리 볼륨을 다른 볼륨 그룹에서 사용하거나 시스템에서 제거할 수 있습니다.
프로세스
물리 볼륨이 여전히 사용 중인 경우 동일한 볼륨 그룹에서 다른 물리 볼륨으로 데이터를 마이그레이션합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 볼륨 그룹의 다른 물리 볼륨에 사용 가능한 확장 영역이 충분하지 않은 경우:
/dev/vdb4 에서 새 물리 볼륨을 생성합니다.
pvcreate /dev/vdb4 Physical volume "/dev/vdb4" successfully created
# pvcreate /dev/vdb4 Physical volume "/dev/vdb4" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 새로 생성된 물리 볼륨을 볼륨 그룹에 추가합니다.
vgextend VolumeGroupName /dev/vdb4 Volume group "VolumeGroupName" successfully extended
# vgextend VolumeGroupName /dev/vdb4 Volume group "VolumeGroupName" successfully extendedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터를 /dev/vdb3 에서 /dev/vdb4:로 이동합니다.
pvmove /dev/vdb3 /dev/vdb4 /dev/vdb3: Moved: 33.33% /dev/vdb3: Moved: 100.00%
# pvmove /dev/vdb3 /dev/vdb4 /dev/vdb3: Moved: 33.33% /dev/vdb3: Moved: 100.00%Copy to Clipboard Copied! Toggle word wrap Toggle overflow
볼륨 그룹에서 물리 볼륨 /dev/vdb3 을 제거합니다.
vgreduce VolumeGroupName /dev/vdb3 Removed "/dev/vdb3" from volume group "VolumeGroupName"
# vgreduce VolumeGroupName /dev/vdb3 Removed "/dev/vdb3" from volume group "VolumeGroupName"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
/dev/vdb3 물리 볼륨이 VolumeGroupName 볼륨 그룹에서 제거되었는지 확인합니다.
pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 lvm2 a-- 1020.00m 1008.00m 12.00m
# pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 lvm2 a-- 1020.00m 1008.00m 12.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.3.7. LVM 볼륨 그룹 분할
물리 볼륨에 사용되지 않는 공간이 충분한 경우 새 디스크를 추가하지 않고 새 볼륨 그룹을 생성할 수 있습니다.
초기 설정에서 볼륨 그룹 VolumeGroupName1 은 /dev/vdb1,/dev/vdb2, /dev/vdb3 로 구성됩니다. 이 절차를 완료하면 볼륨 그룹 VolumeGroupName1 은 /dev/vdb1 및 /dev/vdb2 로 구성되며 두 번째 볼륨 그룹인 VolumeGroupName2 에서는 /dev/vdb3 로 구성됩니다.
사전 요구 사항
-
볼륨 그룹에 충분한 공간이 있습니다. Cryo
statscan명령을 사용하여 볼륨 그룹에서 현재 사용 가능한 공간의 양을 결정합니다. -
기존 물리 볼륨에서 사용 가능한 용량에 따라
pvmove명령을 사용하여 사용된 모든 물리 확장 영역을 다른 물리 볼륨으로 이동합니다. 자세한 내용은 볼륨 그룹에서 물리 볼륨 제거를 참조하십시오.
프로세스
기존 볼륨 그룹 VolumeGroupName1 을 새 볼륨 그룹 VolumeGroupName2 로 나눕니다.
vgsplit VolumeGroupName1 VolumeGroupName2 /dev/vdb3 Volume group "VolumeGroupName2" successfully split from "VolumeGroupName1"
# vgsplit VolumeGroupName1 VolumeGroupName2 /dev/vdb3 Volume group "VolumeGroupName2" successfully split from "VolumeGroupName1"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고기존 볼륨 그룹을 사용하여 논리 볼륨을 생성한 경우 다음 명령을 사용하여 논리 볼륨을 비활성화합니다.
lvchange -a n /dev/VolumeGroupName1/LogicalVolumeName
# lvchange -a n /dev/VolumeGroupName1/LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 두 볼륨 그룹의 속성을 확인합니다.
vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 1 0 wz--n- 34.30G 10.80G VolumeGroupName2 1 0 0 wz--n- 17.15G 17.15G
# vgs VG #PV #LV #SN Attr VSize VFree VolumeGroupName1 2 1 0 wz--n- 34.30G 10.80G VolumeGroupName2 1 0 0 wz--n- 17.15G 17.15GCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
새로 생성된 볼륨 그룹 VolumeGroupName2 가 /dev/vdb3 물리 볼륨으로 구성되어 있는지 확인합니다.
pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 VolumeGroupName2 lvm2 a-- 1020.00m 1008.00m 12.00m
# pvs PV VG Fmt Attr PSize PFree Used /dev/vdb1 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 VolumeGroupName1 lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 VolumeGroupName2 lvm2 a-- 1020.00m 1008.00m 12.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.3.8. 볼륨 그룹을 다른 시스템으로 이동
다음 명령을 사용하여 전체 LVM 볼륨 그룹(VG)을 다른 시스템으로 이동할 수 있습니다.
vgexport- 기존 시스템에서 이 명령을 사용하여 비활성 VG가 시스템에서 액세스할 수 없도록 합니다. VG에 액세스할 수 없게 되면 PV(물리 볼륨)를 분리할 수 있습니다.
vgimport- 다른 시스템에서 이 명령을 사용하여 이전 시스템에서 비활성화된 VG를 새 시스템에서 액세스할 수 있도록 합니다.
사전 요구 사항
- 이동 중인 볼륨 그룹의 활성 볼륨의 파일에 액세스 중인 사용자가 없습니다.
프로세스
LogicalVolumeName 논리 볼륨을 마운트 해제합니다.
umount /dev/mnt/LogicalVolumeName
# umount /dev/mnt/LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹의 모든 논리 볼륨을 비활성화하여 볼륨 그룹의 추가 활동을 방지합니다.
vgchange -an VolumeGroupName vgchange -- volume group "VolumeGroupName" successfully deactivated
# vgchange -an VolumeGroupName vgchange -- volume group "VolumeGroupName" successfully deactivatedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹을 내보내 제거 중인 시스템에서 액세스할 수 없도록 합니다.
vgexport VolumeGroupName vgexport -- volume group "VolumeGroupName" successfully exported
# vgexport VolumeGroupName vgexport -- volume group "VolumeGroupName" successfully exportedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 내보낸 볼륨 그룹을 확인합니다.
pvscan PV /dev/sda1 is in exported VG VolumeGroupName [17.15 GB / 7.15 GB free] PV /dev/sdc1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] PV /dev/sdd1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] ...
# pvscan PV /dev/sda1 is in exported VG VolumeGroupName [17.15 GB / 7.15 GB free] PV /dev/sdc1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] PV /dev/sdd1 is in exported VG VolumeGroupName [17.15 GB / 15.15 GB free] ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow - 시스템을 종료하고 볼륨 그룹을 구성하는 디스크를 분리하여 새 시스템에 연결합니다.
디스크를 새 시스템에 연결하고 볼륨 그룹을 가져와 새 시스템에서 액세스할 수 있도록 합니다.
vgimport VolumeGroupName
# vgimport VolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고Cryostat
import명령의--force인수를 사용하여 물리 볼륨이 누락된 볼륨 그룹을 가져와서 나중에--removemissing명령을 실행할 수 있습니다.볼륨 그룹을 활성화합니다.
vgchange -ay VolumeGroupName
# vgchange -ay VolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템을 마운트하여 사용할 수 있도록 합니다.
mkdir -p /mnt/VolumeGroupName/users mount /dev/VolumeGroupName/users /mnt/VolumeGroupName/users
# mkdir -p /mnt/VolumeGroupName/users # mount /dev/VolumeGroupName/users /mnt/VolumeGroupName/usersCopy to Clipboard Copied! Toggle word wrap Toggle overflow
추가 리소스
-
시스템의 Cryostatimport(8), Cryostatexport(8), and Cryostatchange(8)매뉴얼 페이지
67.3.9. LVM 볼륨 그룹 제거
Cryostatremove 명령을 사용하여 기존 볼륨 그룹을 제거할 수 있습니다. 논리 볼륨이 포함되지 않은 볼륨 그룹만 제거할 수 있습니다.
사전 요구 사항
- 관리 액세스.
프로세스
볼륨 그룹에 논리 볼륨이 포함되어 있지 않은지 확인합니다.
vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0
# vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다.
볼륨 그룹을 제거합니다.
vgremove VolumeGroupName
# vgremove VolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다.
67.3.10. 클러스터 환경에서 LVM 볼륨 그룹 제거
클러스터 환경에서 LVM은 lockspace <qualifier>를 사용하여 여러 시스템에서 공유되는 볼륨 그룹에 대한 액세스를 조정합니다. 제거 프로세스 중에 다른 노드에 액세스하거나 수정하지 않으려면 볼륨 그룹을 제거하기 전에 잠금 공간을 중지해야 합니다.
사전 요구 사항
- 관리 액세스.
- 볼륨 그룹에는 논리 볼륨이 포함되어 있지 않습니다.
프로세스
볼륨 그룹에 논리 볼륨이 포함되어 있지 않은지 확인합니다.
vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0
# vgs -o vg_name,lv_count VolumeGroupName VG #LV VolumeGroupName 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다.
볼륨 그룹을 제거하는 노드를 제외한 모든 노드에서
잠금 공간을중지합니다.vgchange --lockstop VolumeGroupName
# vgchange --lockstop VolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 바꾸고 잠금이 중지될 때까지 기다립니다.
볼륨 그룹을 제거합니다.
vgremove VolumeGroupName
# vgremove VolumeGroupNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다.
67.4. LVM 논리 볼륨 관리
논리 볼륨은 파일 시스템, 데이터베이스 또는 애플리케이션에서 사용할 수 있는 가상, 블록 스토리지 장치입니다. LVM 논리 볼륨을 생성하기 위해 PV(물리 볼륨)가 볼륨 그룹(VG)으로 결합됩니다. 그러면 LVM 논리 볼륨(LV)을 할당할 수 있는 디스크 공간 풀이 생성됩니다.
67.4.1. 논리 볼륨 기능 개요
LVM(Logical Volume Manager)을 사용하면 기존 파티션 체계에서 제공할 수 없는 유연하고 효율적인 방식으로 디스크 스토리지를 관리할 수 있습니다. 다음은 스토리지 관리 및 최적화에 사용되는 주요 LVM 기능에 대한 요약입니다.
- 연결
- 연결에는 하나 이상의 물리 볼륨의 공간을 단일 논리 볼륨으로 결합하여 물리적 스토리지를 효과적으로 병합해야 합니다.
- 스트라이핑
- 스트라이핑은 여러 물리 볼륨에 데이터를 분산하여 데이터 I/O 효율성을 최적화합니다. 이 방법은 병렬 I/O 작업을 허용하여 순차적 읽기 및 쓰기에 대한 성능을 향상시킵니다.
- RAID
- LVM은 RAID 수준 0, 1, 4, 5, 6, 10을 지원합니다. RAID 논리 볼륨을 생성할 때 LVM은 배열의 모든 데이터 또는 패리티 하위 볼륨에 대해 크기가 한 범위인 메타데이터 하위 볼륨을 생성합니다.
- 씬 프로비저닝
- 씬 프로비저닝을 사용하면 사용 가능한 물리 스토리지보다 큰 논리 볼륨을 생성할 수 있습니다. 씬 프로비저닝을 사용하면 시스템에서 사전 결정된 양을 미리 할당하는 대신 실제 사용량에 따라 스토리지를 동적으로 할당합니다.
- 스냅샷
- LVM 스냅샷을 사용하면 논리 볼륨의 지정 시간 사본을 생성할 수 있습니다. 스냅샷은 비어 있습니다. 원래 논리 볼륨에서 변경 사항이 발생하면 스냅샷은 COW(Copy-On-Write)를 통해 사전 변경 상태를 캡처하여 원래 논리 볼륨의 상태를 유지하기 위한 변경 사항만 늘립니다.
- 캐싱
- LVM에서는 더 느린 블록 장치를 위해 SSD 드라이브(예: write-back 또는 write-through 캐시)와 같은 빠른 블록 장치를 사용할 수 있습니다. 사용자는 캐시 논리 볼륨을 생성하여 기존 논리 볼륨의 성능을 개선하거나 크고 느린 장치와 결합된 작고 빠른 장치로 구성된 새 캐시 논리 볼륨을 생성할 수 있습니다.
67.4.2. 논리 볼륨 스냅샷 관리
스냅샷은 특정 시점에서 다른 LV의 콘텐츠를 미러링하는 논리 볼륨(LV)입니다.
67.4.2.1. 논리 볼륨 스냅샷 이해
스냅샷을 생성할 때 다른 LV의 지정 시간 사본 역할을 하는 새 LV를 생성합니다. 처음에는 스냅샷 LV에 실제 데이터가 포함되어 있지 않습니다. 대신 스냅샷 생성 시 원래 LV의 데이터 블록을 참조합니다.
스냅샷의 스토리지 사용량을 정기적으로 모니터링하는 것이 중요합니다. 스냅샷이 할당된 공간의 100%에 도달하면 유효하지 않습니다.
스냅샷을 완전히 채워지기 전에 스냅샷을 확장해야 합니다. 이 작업은 lvextend 명령을 사용하거나 /etc/lvm/lvm.conf 파일을 통해 자동으로 수행할 수 있습니다.
- 두꺼운 LV 스냅샷
- 원래 LV의 데이터가 변경되면 COW(Copy-On-Write) 시스템은 변경되지 않은 원본 데이터를 변경하기 전에 스냅샷에 복사합니다. 이렇게 하면 변경 사항이 발생할 때만 스냅샷이 크기가 증가하여 스냅샷 생성 시 원본 볼륨의 상태를 저장합니다. 두꺼운 스냅샷은 어느 정도의 스토리지 공간을 미리 할당해야 하는 LV의 유형입니다. 이 양은 나중에 확장 또는 축소할 수 있지만 원래 LV에 어떤 유형의 변경 사항을 고려해야 합니다. 이렇게 하면 공간을 너무 많이 할당하거나 너무 적게 할당하면 스냅샷 크기를 자주 늘려야 합니다.
- thin LV 스냅샷
씬 스냅샷은 씬 프로비저닝된 기존 LV에서 생성된 LV의 유형입니다. 씬 스냅샷은 추가 공간을 미리 할당할 필요가 없습니다. 처음에 원래 LV와 해당 스냅샷은 모두 동일한 데이터 블록을 공유합니다. 원래 LV를 변경하면 새 데이터를 다른 블록에 쓰는 반면 스냅샷은 원본 블록을 계속 참조하여 스냅샷 생성 시 LV의 데이터에 대한 지정 시간 보기를 유지합니다.
씬 프로비저닝은 필요에 따라 디스크 공간을 할당하여 스토리지를 효율적으로 최적화하고 관리하는 방법입니다. 즉, 각 LV에 대량의 스토리지를 미리 할당할 필요 없이 여러 LV를 생성할 수 있습니다. 스토리지는 씬 풀의 모든 LV에서 공유되므로 리소스를 보다 효율적으로 사용할 수 있습니다. 씬 풀은 필요에 따라 해당 LV에 공간을 할당합니다.
- 씩과 씬 LV 스냅샷 중에서 선택
- 씩 또는 씬 LV 스냅샷 중 하나를 선택하는 것은 스냅샷을 생성하는 LV 유형에 따라 직접 결정됩니다. 원래 LV가 두꺼운 LV인 경우 스냅샷이 두꺼운 것입니다. 원래 LV가 씬된 경우 스냅샷이 씬됩니다.
67.4.2.2. 씩의 논리 볼륨 스냅샷 관리
두꺼운 LV 스냅샷을 생성하는 경우 스냅샷의 스토리지 요구 사항과 수명을 고려해야 합니다. 원래 볼륨에 대한 예상 변경 사항에 따라 충분한 스토리지를 할당해야 합니다. 스냅샷에는 의도한 수명 동안 변경 사항을 캡처하기에 충분한 크기가 있어야 하지만 원래 LV의 크기를 초과할 수 없습니다. 낮은 변경 속도를 예상하는 경우 스냅샷 크기가 10%-15%로 충분할 수 있습니다. 변경 속도가 높은 LV의 경우 30% 이상을 할당해야 할 수 있습니다.
스냅샷을 완전히 채워지기 전에 스냅샷을 확장해야 합니다. 스냅샷이 할당된 공간의 100%에 도달하면 유효하지 않습니다. lvs -o lv_name,data_percent,origin 명령을 사용하여 스냅샷 용량을 모니터링할 수 있습니다.
67.4.2.2.1. 씩의 논리 볼륨 스냅샷 생성
lvcreate 명령을 사용하여 두꺼운 LV 스냅샷을 생성할 수 있습니다.
사전 요구 사항
- 관리 액세스.
- 물리 볼륨이 생성되어 있습니다. 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 볼륨 그룹을 생성했습니다. 자세한 내용은 LVM 볼륨 그룹 생성 을 참조하십시오.
- 논리 볼륨을 생성했습니다. 자세한 내용은 논리 볼륨 생성 을 참조하십시오.
프로세스
스냅샷을 생성할 LV를 확인합니다.
lvs -o vg_name,lv_name,lv_size VG LV LSize VolumeGroupName LogicalVolumeName 10.00g
# lvs -o vg_name,lv_name,lv_size VG LV LSize VolumeGroupName LogicalVolumeName 10.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스냅샷 크기는 LV의 크기를 초과할 수 없습니다.
두꺼운 LV 스냅샷을 생성합니다.
lvcreate --snapshot --size SnapshotSize --name SnapshotName VolumeGroupName/LogicalVolumeName
# lvcreate --snapshot --size SnapshotSize --name SnapshotName VolumeGroupName/LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow SnapshotSize 를 스냅샷에 할당할 크기(예: 10G)로 바꿉니다. SnapshotName 을 스냅샷 논리 볼륨에 부여하려는 이름으로 교체합니다. VolumeGroupName 을 원래 논리 볼륨이 포함된 볼륨 그룹의 이름으로 교체합니다. LogicalVolumeName 을 스냅샷을 생성할 논리 볼륨의 이름으로 교체합니다.
검증
스냅샷이 생성되었는지 확인합니다.
lvs -o lv_name,origin LV Origin LogicalVolumeName SnapshotName LogicalVolumeName
# lvs -o lv_name,origin LV Origin LogicalVolumeName SnapshotName LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.2.2.2. 논리 볼륨 스냅샷 수동 확장
스냅샷이 할당된 공간의 100%에 도달하면 유효하지 않습니다. 스냅샷을 완전히 채워지기 전에 스냅샷을 확장해야 합니다. 이 작업은 lvextend 명령을 사용하여 수동으로 수행할 수 있습니다.
사전 요구 사항
- 관리 액세스.
프로세스
볼륨 그룹, 논리 볼륨, 스냅샷의 소스 볼륨, 사용 백분율 및 크기를 나열합니다.
lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 82.00 5.00g
# lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 82.00 5.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 씩 프로비저닝된 스냅샷을 확장합니다.
lvextend --size +AdditionalSize VolumeGroupName/SnapshotName
# lvextend --size +AdditionalSize VolumeGroupName/SnapshotNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow additional Size 를 스냅샷에 추가할 공간(예: +1G)으로 바꿉니다. VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다. SnapshotName 을 스냅샷 이름으로 교체합니다.
검증
LV가 확장되었는지 확인합니다.
lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 68.33 6.00g
# lvs -o vg_name,lv_name,origin,data_percent,lv_size VG LV Origin Data% LSize VolumeGroupName LogicalVolumeName 10.00g VolumeGroupName SnapshotName LogicalVolumeName 68.33 6.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.2.2.3. 씩의 논리 볼륨 스냅샷 자동 확장
스냅샷이 할당된 공간의 100%에 도달하면 유효하지 않습니다. 스냅샷을 완전히 채워지기 전에 스냅샷을 확장해야 합니다. 이 작업은 자동으로 수행할 수 있습니다.
사전 요구 사항
- 관리 액세스.
프로세스
-
root사용자로 선택한 편집기에서/etc/lvm/lvm.conf파일을 엽니다. snapshot_autoextend_threshold및snapshot_autoextend_percent행의 주석을 제거하고 각 매개변수를 필수 값으로 설정합니다.snapshot_autoextend_threshold = 70 snapshot_autoextend_percent = 20
snapshot_autoextend_threshold = 70 snapshot_autoextend_percent = 20Copy to Clipboard Copied! Toggle word wrap Toggle overflow snapshot_autoextend_threshold는 LVM이 스냅샷을 자동 연장하기 시작하는 백분율을 결정합니다. 예를 들어 매개 변수를 70으로 설정하면 LVM에서 스냅샷이 70% 용량에 도달할 때 스냅샷을 확장하려고 합니다.snapshot_autoextend_percent는 임계값에 도달하면 스냅샷을 확장해야 하는 백분율로 지정합니다. 예를 들어 매개 변수를 20으로 설정하면 스냅샷이 현재 크기의 20%가 증가합니다.- 변경 사항을 저장하고 편집기를 종료합니다.
lvm2-monitor를 다시 시작하십시오.systemctl restart lvm2-monitor
# systemctl restart lvm2-monitorCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.2.2.4. 씩의 논리 볼륨 스냅샷 병합
두꺼운 LV 스냅샷을 스냅샷이 생성된 원래 논리 볼륨에 병합할 수 있습니다. 병합 프로세스는 원래 LV가 스냅샷이 생성될 때의 상태로 되돌리는 것을 의미합니다. 병합이 완료되면 스냅샷이 제거됩니다.
원본과 스냅샷 LV 간의 병합이 활성 상태이면 지연됩니다. LV가 다시 활성화되고 사용되지 않는 경우에만 실행됩니다.
사전 요구 사항
- 관리 액세스.
프로세스
LV, 해당 볼륨 그룹 및 해당 경로를 나열합니다.
lvs -o lv_name,vg_name,lv_path LV VG Path LogicalVolumeName VolumeGroupName /dev/VolumeGroupName/LogicalVolumeName SnapshotName VolumeGroupName /dev/VolumeGroupName/SnapshotName
# lvs -o lv_name,vg_name,lv_path LV VG Path LogicalVolumeName VolumeGroupName /dev/VolumeGroupName/LogicalVolumeName SnapshotName VolumeGroupName /dev/VolumeGroupName/SnapshotNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow LV가 마운트된 위치를 확인합니다.
findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName findmnt -o SOURCE,TARGET /dev/VolumeGroupName/SnapshotName
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName # findmnt -o SOURCE,TARGET /dev/VolumeGroupName/SnapshotNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/VolumeGroupName/LogicalVolumeName 을 논리 볼륨의 경로로 바꿉니다. /dev/VolumeGroupName/SnapshotName 을 스냅샷 경로로 바꿉니다.
LV를 마운트 해제합니다.
umount /LogicalVolume/MountPoint umount /Snapshot/MountPoint
# umount /LogicalVolume/MountPoint # umount /Snapshot/MountPointCopy to Clipboard Copied! Toggle word wrap Toggle overflow /LogicalVolume/MountPoint 를 논리 볼륨의 마운트 지점으로 바꿉니다. /Snapshot/MountPoint 를 스냅샷의 마운트 지점으로 바꿉니다.
LV를 비활성화합니다.
lvchange --activate n VolumeGroupName/LogicalVolumeName lvchange --activate n VolumeGroupName/SnapshotName
# lvchange --activate n VolumeGroupName/LogicalVolumeName # lvchange --activate n VolumeGroupName/SnapshotNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다. LogicalVolumeName 을 논리 볼륨의 이름으로 바꿉니다. SnapshotName 을 스냅샷 이름으로 교체합니다.
두꺼운 LV 스냅샷을 원본으로 병합합니다.
lvconvert --merge SnapshotName
# lvconvert --merge SnapshotNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow SnapshotName 을 스냅샷 이름으로 교체합니다.
LV를 활성화합니다.
lvchange --activate y VolumeGroupName/LogicalVolumeName
# lvchange --activate y VolumeGroupName/LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다. LogicalVolumeName 을 논리 볼륨의 이름으로 바꿉니다.
LV를 마운트합니다.
umount /LogicalVolume/MountPoint
# umount /LogicalVolume/MountPointCopy to Clipboard Copied! Toggle word wrap Toggle overflow /LogicalVolume/MountPoint 를 논리 볼륨의 마운트 지점으로 바꿉니다.
검증
스냅샷이 제거되었는지 확인합니다.
lvs -o lv_name
# lvs -o lv_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.2.3. thin 논리 볼륨 스냅샷 관리
씬 프로비저닝은 스토리지 효율성이 우선 순위인 경우에 적합합니다. 스토리지 공간 동적 할당은 초기 스토리지 비용을 줄이고 사용 가능한 스토리지 리소스 사용을 극대화합니다. 동적 워크로드가 있거나 스토리지가 시간이 지남에 따라 증가하는 환경에서 씬 프로비저닝을 통해 유연성을 높일 수 있습니다. 스토리지 공간을 크게 사전 할당할 필요 없이 스토리지 시스템을 변화하는 요구에 맞게 조정할 수 있습니다. 동적 할당을 사용하면 모든 LV의 총 크기가 씬 풀의 물리적 크기를 초과할 수 있으므로 모든 공간이 동시에 활용되는 것은 아닙니다.
67.4.2.3.1. 씬 논리 볼륨 스냅샷 생성
lvcreate 명령을 사용하여 thin LV 스냅샷을 생성할 수 있습니다. thin LV 스냅샷을 생성할 때 스냅샷 크기를 지정하지 마십시오. size 매개변수를 포함하면 대신 두꺼운 스냅샷이 생성됩니다.
사전 요구 사항
- 관리 액세스.
- 물리 볼륨이 생성되어 있습니다. 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 볼륨 그룹을 생성했습니다. 자세한 내용은 LVM 볼륨 그룹 생성 을 참조하십시오.
- 논리 볼륨을 생성했습니다. 자세한 내용은 논리 볼륨 생성 을 참조하십시오.
프로세스
스냅샷을 생성할 LV를 확인합니다.
lvs -o lv_name,vg_name,pool_lv,lv_size LV VG Pool LSize PoolName VolumeGroupName 152.00m ThinVolumeName VolumeGroupName PoolName 100.00m
# lvs -o lv_name,vg_name,pool_lv,lv_size LV VG Pool LSize PoolName VolumeGroupName 152.00m ThinVolumeName VolumeGroupName PoolName 100.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow thin LV 스냅샷을 생성합니다.
lvcreate --snapshot --name SnapshotName VolumeGroupName/ThinVolumeName
# lvcreate --snapshot --name SnapshotName VolumeGroupName/ThinVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow SnapshotName 을 스냅샷 논리 볼륨에 부여하려는 이름으로 교체합니다. VolumeGroupName 을 원래 논리 볼륨이 포함된 볼륨 그룹의 이름으로 교체합니다. ThinVolumeName 을 스냅샷을 생성할 thin 논리 볼륨의 이름으로 바꿉니다.
검증
스냅샷이 생성되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.2.3.2. 씬 논리 볼륨 스냅샷 병합
thin LV 스냅샷을 생성된 원래 논리 볼륨에 병합할 수 있습니다. 병합 프로세스는 원래 LV가 스냅샷이 생성될 때의 상태로 되돌리는 것을 의미합니다. 병합이 완료되면 스냅샷이 제거됩니다.
사전 요구 사항
- 관리 액세스.
프로세스
LV, 해당 볼륨 그룹 및 해당 경로를 나열합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 원래 LV가 마운트된 위치를 확인합니다.
findmnt -o SOURCE,TARGET /dev/VolumeGroupName/ThinVolumeName
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/ThinVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName/ThinVolumeName 을 논리 볼륨의 경로로 바꿉니다.
LV를 마운트 해제합니다.
umount /ThinLogicalVolume/MountPoint
# umount /ThinLogicalVolume/MountPointCopy to Clipboard Copied! Toggle word wrap Toggle overflow /ThinLogicalVolume/MountPoint 를 논리 볼륨의 마운트 지점으로 바꿉니다. /ThinSnapshot/MountPoint 를 스냅샷의 마운트 지점으로 바꿉니다.
LV를 비활성화합니다.
lvchange --activate n VolumeGroupName/ThinLogicalVolumeName
# lvchange --activate n VolumeGroupName/ThinLogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다. ThinLogicalVolumeName 을 논리 볼륨의 이름으로 바꿉니다.
thin LV 스냅샷을 원본과 병합합니다.
lvconvert --mergethin VolumeGroupName/ThinSnapshotName
# lvconvert --mergethin VolumeGroupName/ThinSnapshotNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName 을 볼륨 그룹의 이름으로 교체합니다. ThinSnapshotName 을 스냅샷 이름으로 교체합니다.
LV를 마운트합니다.
umount /ThinLogicalVolume/MountPoint
# umount /ThinLogicalVolume/MountPointCopy to Clipboard Copied! Toggle word wrap Toggle overflow /ThinLogicalVolume/MountPoint 를 논리 볼륨의 마운트 지점으로 바꿉니다.
검증
원래 LV가 병합되었는지 확인합니다.
lvs -o lv_name
# lvs -o lv_nameCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.3. RAID0 스트라이핑 논리 볼륨 생성
RAID0 논리 볼륨은 스트라이프 크기 단위로 여러 데이터 하위 볼륨에 논리 볼륨 데이터를 분배합니다. 다음 절차에서는 디스크 전체에서 데이터를 스트라이핑하는 mylv 라는 LVM RAID0 논리 볼륨을 생성합니다.
사전 요구 사항
- 세 개 이상의 물리 볼륨을 생성했습니다. 물리 볼륨 생성에 대한 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 볼륨 그룹을 생성했습니다. 자세한 내용은 LVM 볼륨 그룹 생성 을 참조하십시오.
프로세스
기존 볼륨 그룹에서 RAID0 논리 볼륨을 생성합니다. 다음 명령은 볼륨 그룹 myvg 에서 3개의 스트라이프와 4kB 의 스트라이프 크기를 사용하여 크기가 2G 인 mylv 볼륨 mylv를 생성합니다.
lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.
# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID0 논리 볼륨에 파일 시스템을 생성합니다. 다음 명령은 논리 볼륨에 ext4 파일 시스템을 생성합니다.
mkfs.ext4 /dev/my_vg/mylv
# mkfs.ext4 /dev/my_vg/mylvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨을 마운트하고 파일 시스템 디스크 공간 사용량을 보고합니다.
mount /dev/my_vg/mylv /mnt df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mnt
# mount /dev/my_vg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
생성된 RAID0 제거된 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.4. 논리 볼륨에서 디스크 제거
다음 절차에서는 디스크를 교체하거나 디스크를 다른 볼륨의 일부로 사용하려면 기존 논리 볼륨에서 디스크를 제거하는 방법을 설명합니다.
디스크를 제거하려면 먼저 LVM 물리 볼륨의 확장 영역을 다른 디스크 또는 디스크 세트로 이동해야 합니다.
절차
LV를 사용할 때 물리 볼륨의 사용 가능한 공간을 확인합니다.
pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/vdb1 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 myvg lvm2 a-- 1020.00m 1008.00m 12.00m
# pvs -o+pv_used PV VG Fmt Attr PSize PFree Used /dev/vdb1 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 0 1020.00m /dev/vdb3 myvg lvm2 a-- 1020.00m 1008.00m 12.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 데이터를 다른 물리 볼륨으로 이동합니다.
기존 볼륨 그룹의 다른 물리 볼륨에 사용 가능한 확장 영역이 충분한 경우 다음 명령을 사용하여 데이터를 이동합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 볼륨 그룹의 다른 물리 볼륨에 사용 가능한 확장 영역이 충분하지 않은 경우 다음 명령을 사용하여 새 물리 볼륨을 추가하고 새로 생성된 물리 볼륨을 사용하여 볼륨 그룹을 확장한 다음 이 물리 볼륨으로 데이터를 이동합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
물리 볼륨을 제거합니다.
vgreduce myvg /dev/vdb3 Removed "/dev/vdb3" from volume group "myvg"
# vgreduce myvg /dev/vdb3 Removed "/dev/vdb3" from volume group "myvg"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨에 실패하는 물리 볼륨이 포함된 경우 해당 논리 볼륨을 사용할 수 없습니다. 볼륨 그룹에서 누락된 물리 볼륨을 제거하려면 누락된 물리 볼륨에 할당된 논리 볼륨이 없는 경우 volume group에서
--removemissing매개변수를 사용할 수 있습니다.vgreduce --removemissing myvg
# vgreduce --removemissing myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.5. 웹 콘솔을 사용하여 볼륨 그룹에서 물리적 드라이브 변경
RHEL 8 웹 콘솔을 사용하여 볼륨 그룹의 드라이브를 변경할 수 있습니다.
사전 요구 사항
- 오래된 것을 대체하기 위한 새로운 물리적 드라이브 또는 부서진 드라이브
- 이 구성에서는 물리 드라이브가 볼륨 그룹에 구성되어 있어야 합니다.
67.4.5.1. 웹 콘솔의 볼륨 그룹에 물리 드라이브 추가
RHEL 8 웹 콘솔을 사용하여 새 물리 드라이브 또는 기타 유형의 볼륨을 기존 논리 볼륨에 추가할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 볼륨 그룹을 생성해야 합니다.
- 시스템에 연결된 새 드라이브입니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지 를 클릭합니다.
- 스토리지 테이블에서 물리 드라이브를 추가할 볼륨 그룹을 클릭합니다.
- LVM2 볼륨 그룹 페이지에서 를 클릭합니다.
- 디스크 추가 대화 상자에서 기본 드라이브를 선택하고 를 클릭합니다.
검증
- LVM2 볼륨 그룹 페이지에서 물리 볼륨 섹션을 확인하여 볼륨 그룹에서 새 물리 드라이브를 사용할 수 있는지 확인합니다.
67.4.5.2. 웹 콘솔의 볼륨 그룹에서 물리적 드라이브 제거
논리 볼륨에 여러 물리적 드라이브가 포함된 경우 온라인으로 물리적 드라이브 중 하나를 제거할 수 있습니다.
시스템은 제거 과정에서 다른 드라이브로 제거될 드라이브의 모든 데이터를 자동으로 이동합니다. 시간이 걸릴 수 있습니다.
또한 웹 콘솔은 물리 드라이브를 제거할 수 있는 충분한 공간이 있는지 확인합니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 두 개 이상의 물리 드라이브가 연결된 볼륨 그룹입니다.
절차
- RHEL 8 웹 콘솔에 로그인합니다.
- 스토리지 를 클릭합니다.
- 스토리지 테이블에서 물리 드라이브를 추가할 볼륨 그룹을 클릭합니다.
- LVM2 볼륨 그룹 페이지에서 물리 볼륨 섹션으로 스크롤합니다.
- 제거하려는 물리 볼륨 옆에 있는 메뉴 버튼 Cryostat를 클릭합니다.
드롭다운 메뉴에서 선택합니다.
RHEL 8 웹 콘솔은 논리 볼륨에 디스크를 제거할 수 있는 충분한 여유 공간이 있는지 확인합니다. 데이터를 전송할 여유 공간이 없는 경우 디스크를 제거할 수 없으며 볼륨 그룹의 용량을 늘리려면 먼저 다른 디스크를 추가해야 합니다. 자세한 내용은 웹 콘솔의 논리 볼륨에 물리 드라이브 추가를 참조하십시오.
67.4.6. 논리 볼륨 제거
lvremove 명령을 사용하여 스냅샷을 포함한 기존 논리 볼륨을 제거할 수 있습니다.
사전 요구 사항
- 관리 액세스.
절차
논리 볼륨 및 해당 경로를 나열합니다.
lvs -o lv_name,lv_path LV Path LogicalVolumeName /dev/VolumeGroupName/LogicalVolumeName
# lvs -o lv_name,lv_path LV Path LogicalVolumeName /dev/VolumeGroupName/LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨이 마운트된 위치를 확인합니다.
findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName SOURCE TARGET /dev/mapper/VolumeGroupName-LogicalVolumeName /MountPoint
# findmnt -o SOURCE,TARGET /dev/VolumeGroupName/LogicalVolumeName SOURCE TARGET /dev/mapper/VolumeGroupName-LogicalVolumeName /MountPointCopy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/VolumeGroupName/LogicalVolumeName 을 논리 볼륨의 경로로 바꿉니다.
논리 볼륨을 마운트 해제합니다.
umount /MountPoint
# umount /MountPointCopy to Clipboard Copied! Toggle word wrap Toggle overflow /MountPoint 를 논리 볼륨의 마운트 지점으로 바꿉니다.
논리 볼륨을 제거합니다.
lvremove VolumeGroupName/LogicalVolumeName
# lvremove VolumeGroupName/LogicalVolumeNameCopy to Clipboard Copied! Toggle word wrap Toggle overflow VolumeGroupName/LogicalVolumeName 을 논리 볼륨의 경로로 바꿉니다.
67.4.7. RHEL 시스템 역할을 사용하여 LVM 논리 볼륨 관리
스토리지 역할을 사용하여 다음 작업을 수행합니다.
- 여러 디스크로 구성된 볼륨 그룹에 LVM 논리 볼륨을 만듭니다.
- 논리 볼륨에 지정된 레이블이 있는 ext4 파일 시스템을 생성합니다.
- ext4 파일 시스템을 영구적으로 마운트합니다.
사전 요구 사항
-
스토리지역할을 포함한 Ansible Playbook
67.4.7.1. 스토리지 RHEL 시스템 역할을 사용하여 논리 볼륨 생성 또는 크기 조정
스토리지 역할을 사용하여 다음 작업을 수행합니다.
- 여러 디스크로 구성된 볼륨 그룹에 LVM 논리 볼륨을 만들려면 다음을 수행합니다.
- LVM에서 기존 파일 시스템의 크기를 조정하려면 다음을 수행합니다.
- 풀의 총 크기의 백분율로 LVM 볼륨 크기를 표현하려면
볼륨 그룹이 없으면 역할이 생성됩니다. 논리 볼륨이 볼륨 그룹에 있는 경우 크기가 플레이북에 지정된 것과 일치하지 않으면 크기가 조정됩니다.
논리 볼륨을 줄이는 경우 데이터 손실을 방지하기 위해 논리 볼륨의 파일 시스템이 축소되는 논리 볼륨의 공간을 사용하지 않도록 해야 합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예제 플레이북에 지정된 설정은 다음과 같습니다.
크기: < ;size>- 단위(예: GiB) 또는 백분율(예: 60 %)을 사용하여 크기를 지정해야 합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
지정된 볼륨이 요청된 크기로 생성되거나 크기가 조정되었는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lvs myvg'
# ansible managed-node-01.example.com -m command -a 'lvs myvg'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.4.8. 스토리지 RHEL 시스템 역할을 사용하여 LVM에서 기존 파일 시스템 크기 조정
storage RHEL 시스템 역할을 사용하여 파일 시스템으로 LVM 논리 볼륨의 크기를 조정할 수 있습니다.
축소하는 논리 볼륨에 파일 시스템이 있는 경우 데이터 손실을 방지하기 위해 파일 시스템이 축소되는 논리 볼륨의 공간을 사용하지 않도록 해야 합니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
절차
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 플레이북은 다음과 같은 기존 파일 시스템의 크기를 조정합니다.
-
/opt/mount1에 마운트된mylv1볼륨의 Ext4 파일 시스템은 10GiB로 크기를 조정합니다. -
/opt/mount2에 마운트된mylv2볼륨의 Ext4 파일 시스템은 50GiB의 크기를 조정합니다.
플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.-
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
논리 볼륨의 크기가 요청된 크기로 조정되었는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lvs myvg'
# ansible managed-node-01.example.com -m command -a 'lvs myvg'Copy to Clipboard Copied! Toggle word wrap Toggle overflow 파일 시스템 툴을 사용하여 파일 시스템 크기를 확인합니다. 예를 들어 ext4의 경우 dumpe2fs 툴로 보고된 블록 수와 블록 크기를 곱하여 파일 시스템 크기를 계산합니다.
ansible managed-node-01.example.com -m command -a 'dumpe2fs -h /dev/myvg/mylv | grep -E "Block count|Block size"'
# ansible managed-node-01.example.com -m command -a 'dumpe2fs -h /dev/myvg/mylv | grep -E "Block count|Block size"'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.5. 논리 볼륨의 크기 수정
논리 볼륨을 생성한 후 볼륨의 크기를 수정할 수 있습니다.
67.5.1. 제거된 논리 볼륨 확장
필요한 크기와 함께 lvextend 명령을 사용하여 제거된 LV(Logical Volume)를 확장할 수 있습니다.
사전 요구 사항
- 스트라이프를 지원하기 위해 볼륨 그룹(VG)을 구성하는 기본 물리 볼륨(PV)에 충분한 여유 공간이 있습니다.
절차
선택 사항: 볼륨 그룹을 표시합니다.
vgs VG #PV #LV #SN Attr VSize VFree myvg 2 1 0 wz--n- 271.31G 271.31G
# vgs VG #PV #LV #SN Attr VSize VFree myvg 2 1 0 wz--n- 271.31G 271.31GCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 볼륨 그룹의 전체 공간을 사용하여 스트라이프를 만듭니다.
lvcreate -n stripe1 -L 271.31G -i 2 myvg Using default stripesize 64.00 KB Rounding up size to full physical extent 271.31 GiB
# lvcreate -n stripe1 -L 271.31G -i 2 myvg Using default stripesize 64.00 KB Rounding up size to full physical extent 271.31 GiBCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 새 물리 볼륨을 추가하여 myvg 볼륨 그룹을 확장합니다.
vgextend myvg /dev/sdc1 Volume group "myvg" successfully extended
# vgextend myvg /dev/sdc1 Volume group "myvg" successfully extendedCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스트라이프 유형 및 사용된 공간에 따라 충분한 물리 볼륨을 추가하려면 이 단계를 반복합니다. 예를 들어 전체 볼륨 그룹을 사용하는 양방향 스트라이프의 경우 두 개 이상의 물리 볼륨을 추가해야 합니다.
myvg VG의 일부인 제거된 논리 볼륨 스트라이프1 을 확장합니다.
lvextend myvg/stripe1 -L 542G Using stripesize of last segment 64.00 KB Extending logical volume stripe1 to 542.00 GB Logical volume stripe1 successfully resized
# lvextend myvg/stripe1 -L 542G Using stripesize of last segment 64.00 KB Extending logical volume stripe1 to 542.00 GB Logical volume stripe1 successfully resizedCopy to Clipboard Copied! Toggle word wrap Toggle overflow stripe1 논리 볼륨을 확장하여 myvg 볼륨 그룹의 할당되지 않은 모든 공간을 채울 수도 있습니다.
lvextend -l+100%FREE myvg/stripe1 Size of logical volume myvg/stripe1 changed from 1020.00 MiB (255 extents) to <2.00 GiB (511 extents). Logical volume myvg/stripe1 successfully resized.
# lvextend -l+100%FREE myvg/stripe1 Size of logical volume myvg/stripe1 changed from 1020.00 MiB (255 extents) to <2.00 GiB (511 extents). Logical volume myvg/stripe1 successfully resized.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
확장 스트라이핑된 LV의 새 크기를 확인합니다.
lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert stripe1 myvg wi-ao---- 542.00 GB
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert stripe1 myvg wi-ao---- 542.00 GBCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.6. LVM 보고서 사용자 정의
LVM은 사용자 지정 보고서를 생성하기 위한 다양한 구성 및 명령줄 옵션을 제공합니다. 출력을 정렬하고 단위를 지정하고 선택 기준을 사용하고 lvm.conf 파일을 업데이트하여 LVM 보고서를 사용자 지정할 수 있습니다.
67.6.1. LVM 디스플레이 형식 제어
추가 옵션 없이 pvs,lv 또는 Cryostats 명령을 사용하는 경우 기본 정렬 순서에 표시된 기본 필드 세트가 표시됩니다. s pvs 명령의 기본 필드에는 물리 볼륨 이름으로 정렬된 다음 정보가 포함됩니다.
pvs PV VG Fmt Attr PSize PFree /dev/vdb1 VolumeGroupName lvm2 a-- 17.14G 17.14G /dev/vdb2 VolumeGroupName lvm2 a-- 17.14G 17.09G /dev/vdb3 VolumeGroupName lvm2 a-- 17.14G 17.14G
# pvs
PV VG Fmt Attr PSize PFree
/dev/vdb1 VolumeGroupName lvm2 a-- 17.14G 17.14G
/dev/vdb2 VolumeGroupName lvm2 a-- 17.14G 17.09G
/dev/vdb3 VolumeGroupName lvm2 a-- 17.14G 17.14GPV- 물리 볼륨 이름입니다.
VG- 볼륨 그룹 이름.
FMT-
물리 볼륨의 메타데이터 형식:
lvm2또는lvm1. Attr- 물리 볼륨의 상태: (a) - 할당 가능 또는 (x) 내보내기.
PSize- 물리 볼륨의 크기입니다.
PFree- 물리 볼륨에 남아 있는 여유 공간입니다.
사용자 정의 필드 표시
기본값과 다른 필드 세트를 표시하려면 -o 옵션을 사용합니다. 다음 예제는 물리 볼륨의 이름, 크기 및 사용 공간만 표시합니다.
pvs -o pv_name,pv_size,pv_free PV PSize PFree /dev/vdb1 17.14G 17.14G /dev/vdb2 17.14G 17.09G /dev/vdb3 17.14G 17.14G
# pvs -o pv_name,pv_size,pv_free
PV PSize PFree
/dev/vdb1 17.14G 17.14G
/dev/vdb2 17.14G 17.09G
/dev/vdb3 17.14G 17.14GLVM 디스플레이 정렬
특정 기준에 따라 결과를 정렬하려면 -O 옵션을 사용합니다. 다음 예제에서는 물리 볼륨의 사용 가능한 공간을 오름차순으로 정렬합니다.
pvs -o pv_name,pv_size,pv_free -O pv_free PV PSize PFree /dev/vdb2 17.14G 17.09G /dev/vdb1 17.14G 17.14G /dev/vdb3 17.14G 17.14G
# pvs -o pv_name,pv_size,pv_free -O pv_free
PV PSize PFree
/dev/vdb2 17.14G 17.09G
/dev/vdb1 17.14G 17.14G
/dev/vdb3 17.14G 17.14G
결과를 내림차순으로 정렬하려면 - 문자와 함께 -O 옵션을 사용합니다.
pvs -o pv_name,pv_size,pv_free -O -pv_free PV PSize PFree /dev/vdb1 17.14G 17.14G /dev/vdb3 17.14G 17.14G /dev/vdb2 17.14G 17.09G
# pvs -o pv_name,pv_size,pv_free -O -pv_free
PV PSize PFree
/dev/vdb1 17.14G 17.14G
/dev/vdb3 17.14G 17.14G
/dev/vdb2 17.14G 17.09G67.6.2. LVM 디스플레이의 단위 지정
LVM 디스플레이 명령의 --units 인수를 지정하여 기본 2 또는 기본 10 단위로 LVM 장치의 크기를 볼 수 있습니다. 모든 인수에 대해서는 다음 표를 참조하십시오.
| 단위 유형 | 설명 | 사용 가능한 옵션 | 기본 |
|---|---|---|---|
| 기본 2 단위 | 단위는 2의 전원으로 표시됩니다(24의 다중 수). |
|
|
| 기본 10 단위 | 단위는 1000의 배수로 표시됩니다. |
| 해당 없음 |
| 사용자 정의 단위 |
기본 2 또는 기본 10 단위와 수량의 조합. 예를 들어 결과를 4MB로 표시하려면 | 해당 없음 | 해당 없음 |
단위의 값을 지정하지 않으면 기본적으로 사람이 읽을 수 있는 형식(
r)이 사용됩니다. 다음 Cryostat 명령은사람이 읽을 수 있는 형식으로 VG의 크기를 표시합니다. 가장 적합한 단위가 사용되고 반올림 표시기<는 실제 크기가 근사치이며 931 기가바이트 미만인 것을 보여줍니다.vgs myvg VG #PV #LV #SN Attr VSize VFree myvg 1 1 0 wz-n <931.00g <930.00g
# vgs myvg VG #PV #LV #SN Attr VSize VFree myvg 1 1 0 wz-n <931.00g <930.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음
pvs명령은/dev/vdb물리 볼륨의 기본 2 기비바이트 단위로 출력을 표시합니다.pvs --units g /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 931.00g 930.00g
# pvs --units g /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 931.00g 930.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음
pvs명령은/dev/vdb물리 볼륨의 기본 10 기가바이트 단위로 출력을 표시합니다.pvs --units G /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 999.65G 998.58G
# pvs --units G /dev/vdb PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 999.65G 998.58GCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음
pvs명령은 출력을 512바이트 섹터로 표시합니다.pvs --units s PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 1952440320S 1950343168S
# pvs --units s PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 1952440320S 1950343168SCopy to Clipboard Copied! Toggle word wrap Toggle overflow LVM 디스플레이 명령에 사용자 지정 단위를 지정할 수 있습니다. 다음 예제는
pvs명령의 출력을 4 메비바이트 단위로 표시합니다.pvs --units 4m PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 238335.00U 238079.00U
# pvs --units 4m PV VG Fmt Attr PSize PFree /dev/vdb myvg lvm2 a-- 238335.00U 238079.00UCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.6.3. LVM 구성 파일 사용자 정의
lvm.conf 파일을 편집하여 특정 스토리지 및 시스템 요구 사항에 따라 LVM 구성을 사용자 지정할 수 있습니다. 예를 들어 lvm.conf 파일을 편집하여 필터 설정을 수정하거나, 볼륨 그룹 자동 활성화를 구성하거나, 씬 풀을 관리하거나, 스냅샷을 자동으로 확장할 수 있습니다.
절차
-
선택한 편집기에서
lvm.conf파일을 엽니다. 기본 표시 값을 수정하려는 설정을 주석 제거하고 수정하여
lvm.conf파일을 사용자 지정합니다.lvs출력에 표시되는 필드를 사용자 지정하려면lvs_cols매개변수의 주석을 제거하고 수정합니다.lvs_cols="lv_name,vg_name,lv_attr"
lvs_cols="lv_name,vg_name,lv_attr"Copy to Clipboard Copied! Toggle word wrap Toggle overflow pvs, Cryostats 및lvs명령의빈 필드를 숨기려면compact_output=1설정의 주석을 제거합니다.compact_output = 1
compact_output = 1Copy to Clipboard Copied! Toggle word wrap Toggle overflow pvs, Cryostats ,lvs명령의기본 단위로 기가를 설정하려면units = "r"설정을units = "G"로 바꿉니다.units = "G"
units = "G"Copy to Clipboard Copied! Toggle word wrap Toggle overflow
lvm.conf파일의 해당 섹션의 주석을 제거합니다. 예를 들어lvs_cols매개변수를 수정하려면report섹션의 주석을 제거해야 합니다.report { ... }report { ... }Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
lvm.conf파일을 수정한 후 변경된 값을 확인합니다.lvmconfig --typeconfig diff
# lvmconfig --typeconfig diffCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.6.4. LVM 선택 기준 정의
선택 기준은 < field> <operator> <value > 형식으로 된 문 세트이며 비교 연산자를 사용하여 특정 필드의 값을 정의합니다. 그런 다음 선택 기준과 일치하는 오브젝트가 처리되거나 표시됩니다. 오브젝트는 PV(물리 볼륨), 볼륨 그룹(VG) 또는 논리 볼륨(LV)일 수 있습니다. 설명은 논리 및 그룹화 연산자로 결합됩니다.
선택 기준을 정의하려면 -S 또는 --select 옵션 다음에 하나 이상의 문을 사용합니다.
S 옵션은 각 오브젝트의 이름을 지정하는 대신 처리할 오브젝트를 설명하는 방식으로 작동합니다. 이는 많은 오브젝트를 처리할 때 도움이 되며 각 개체를 별도로 찾아서 이름을 지정하거나 복잡한 특성을 가진 오브젝트를 검색할 때 유용합니다. S 옵션은 여러 이름을 입력하지 않도록 바로 가기로 사용할 수도 있습니다.
전체 필드 및 가능한 연산자 세트를 보려면 lvs -S help 명령을 사용합니다. lvs 를 보고 또는 처리 명령으로 교체하여 해당 명령의 세부 정보를 확인합니다.
-
보고 명령에는
pvs, Cryostats ,lvs,pvdisplay, Cryostatdisplay ,lvdisplay,dmsetup info -c가 포함됩니다. -
처리 명령에는
pvchange, Cryostatchange,lvchange, Cryostatimport, Cryostatexport, Cryostatremove,lvremove가 포함됩니다.
pvs 명령을 사용한 선택 기준의 예
다음
pvs명령의 예제에서는nvme문자열이 포함된 이름이 있는 물리 볼륨만 표시합니다.pvs -S name=~nvme PV Fmt Attr PSize PFree /dev/nvme2n1 lvm2 --- 1.00g 1.00g
# pvs -S name=~nvme PV Fmt Attr PSize PFree /dev/nvme2n1 lvm2 --- 1.00g 1.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음
pvs명령의 예는myvg볼륨 그룹에 있는 물리 장치만 표시합니다.pvs -S vg_name=myvg PV VG Fmt Attr PSize PFree /dev/vdb1 myvg lvm2 a-- 1020.00m 396.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 896.00m
# pvs -S vg_name=myvg PV VG Fmt Attr PSize PFree /dev/vdb1 myvg lvm2 a-- 1020.00m 396.00m /dev/vdb2 myvg lvm2 a-- 1020.00m 896.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow
lvs 명령을 사용한 선택 기준의 예
다음
lvs명령은 크기가 100m 미만이지만 200m 미만인 논리 볼륨만 표시합니다.lvs -S 'size > 100m && size < 200m' LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00
# lvs -S 'size > 100m && size < 200m' LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음
lvs명령은lvol과 0에서 2 사이의 임의의 숫자가 포함된 이름이 있는 논리 볼륨만 표시합니다.lvs -S name=~lvol[02] LV VG Attr LSize lvol0 myvg -wi-a----- 100.00m lvol2 myvg -wi------- 100.00m
# lvs -S name=~lvol[02] LV VG Attr LSize lvol0 myvg -wi-a----- 100.00m lvol2 myvg -wi------- 100.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음
lvs명령은raid1세그먼트 유형이 있는 논리 볼륨만 표시합니다.lvs -S segtype=raid1 LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00
# lvs -S segtype=raid1 LV VG Attr LSize Cpy%Sync rr myvg rwi-a-r--- 120.00m 100.00Copy to Clipboard Copied! Toggle word wrap Toggle overflow
고급 예
선택 기준을 다른 옵션과 결합할 수 있습니다.
lvchange명령의 다음 예제에서는 활성 논리 볼륨에만 특정 태그mytag를 추가합니다.lvchange --addtag mytag -S active=1 Logical volume myvg/mylv changed. Logical volume myvg/lvol0 changed. Logical volume myvg/lvol1 changed. Logical volume myvg/rr changed.
# lvchange --addtag mytag -S active=1 Logical volume myvg/mylv changed. Logical volume myvg/lvol0 changed. Logical volume myvg/lvol1 changed. Logical volume myvg/rr changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvs명령의 다음 예제에서는 이름이_pmspare와 일치하지 않는 모든 논리 볼륨을 표시하고 기본 헤더를 사용자 지정 헤더로 변경합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvchange명령의 다음 예제에서는 일반 활성화 명령 중에role=thinsnapshot및origin=thin1이 있는 논리 볼륨에 플래그를 지정합니다.lvchange --setactivationskip n -S 'role=thinsnapshot && origin=thin1' Logical volume myvg/thin1s changed.
# lvchange --setactivationskip n -S 'role=thinsnapshot && origin=thin1' Logical volume myvg/thin1s changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvs명령의 다음 예제에서는 세 조건 모두 일치하는 논리 볼륨만 표시합니다.-
name에는
_tmeta가 포함되어 있습니다. -
역할은
메타데이터입니다. - 크기가 4m보다 작거나 같습니다.
lvs -a -S 'name=~_tmeta && role=metadata && size <= 4m' LV VG Attr LSize [tp_tmeta] myvg ewi-ao---- 4.00m
# lvs -a -S 'name=~_tmeta && role=metadata && size <= 4m' LV VG Attr LSize [tp_tmeta] myvg ewi-ao---- 4.00mCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
name에는
추가 리소스
-
시스템의
lvmreport(7)도움말 페이지
67.7. RAID 논리 볼륨 구성
LVM(Logical Volume Manager)을 사용하여 RAID(Redundant Array of Independent Disks) 볼륨을 생성하고 관리할 수 있습니다. LVM은 RAID 수준 0, 1, 4, 5, 6, 10을 지원합니다. LVM RAID 볼륨에는 다음과 같은 특징이 있습니다.
- LVM은 여러 장치(MD) 커널 드라이버를 활용하는 RAID 논리 볼륨을 생성하고 관리합니다.
- 배열에서 RAID1 이미지를 일시적으로 분할하고 나중에 배열에 다시 병합할 수 있습니다.
- LVM RAID 볼륨은 스냅샷을 지원합니다.
- RAID 논리 볼륨은 클러스터를 인식하지 못합니다. 하나의 시스템에서만 RAID 논리 볼륨을 생성하고 활성화할 수 있지만 둘 이상의 시스템에서 동시에 활성화할 수 없습니다.
-
RAID 논리 볼륨(LV)을 생성할 때 LVM은 배열의 모든 데이터 또는 패리티 하위 볼륨에 대해 크기가 한 범위인 메타데이터 하위 볼륨을 생성합니다. 예를 들어 2방향 RAID1 배열을 생성하면 두 개의 메타데이터 하위 볼륨(
lv_rmeta_0및lv_rmeta_1)과 두 개의 데이터 하위 볼륨(lv_rimage_0및lv_rimage_1)이 생성됩니다. - RAID LV에 무결성을 추가하면 소프트 손상이 줄어들거나 방지됩니다.
67.7.1. RAID 수준 및 선형 지원
다음은 수준 0, 1, 4, 5, 6, 10 및 선형을 포함하여 RAID에서 지원하는 구성입니다.
- 수준 0
RAID 수준 0은 종종 스트라이핑된 성능 지향 데이터 매핑 기술입니다. 즉, 배열에 기록되는 데이터가 스트라이프로 분할되고 배열의 멤버 디스크에 기록되므로 낮은 I/O 성능이 있지만 중복성은 제공되지 않습니다.
RAID 수준 0 구현은 멤버 장치에서 데이터를 배열에서 가장 작은 장치의 크기로만 스트라이프합니다. 즉, 크기가 약간 다른 여러 장치가 있는 경우 각 장치는 가장 작은 드라이브와 동일한 크기인 것처럼 처리됩니다. 따라서 수준 0 배열의 일반적인 스토리지 용량은 모든 디스크의 총 용량입니다. 멤버 디스크의 크기가 다른 경우 RAID0은 사용 가능한 영역을 사용하여 해당 디스크의 모든 공간을 사용합니다.
- 수준 1
RAID 수준 1 또는 미러링은 배열의 각 멤버 디스크에 동일한 데이터를 작성하여 중복을 제공하여 각 디스크에 미러링된 복사본을 남겨 둡니다. 미러링은 단순성과 높은 수준의 데이터 가용성으로 인해 널리 사용됩니다. 수준 1은 두 개 이상의 디스크로 작동하며 우수한 데이터 안정성을 제공하고 읽기 집약적인 애플리케이션의 성능을 개선하지만 비교적 비용이 많이 듭니다.
RAID 레벨 1은 데이터 신뢰성을 제공하지만 레벨 5와 같은 패리티 기반 RAID 수준보다 훨씬 적은 공간 효율적인 방식으로 배열의 모든 디스크에 동일한 정보를 쓰기 때문에 비용이 많이 듭니다. 그러나 이 공간 비효율은 성능 이점을 제공합니다. 이는 패리티를 생성하기 위해 훨씬 더 많은 CPU 성능을 소비하는 패리티 기반 RAID 수준입니다. RAID 수준 1은 단순히 CPU 오버헤드가 적은 여러 RAID 멤버에 동일한 데이터를 두 번 이상 씁니다. 따라서 RAID 레벨 1은 소프트웨어 RAID가 사용되는 시스템에서 패리티 기반 RAID 수준을 초과하여 시스템의 CPU 리소스가 RAID 활동 이외의 작업에 일관되게 과세됩니다.
레벨 1 어레이의 스토리지 용량은 하드웨어 RAID에서 가장 작은 미러링된 하드 디스크 용량 또는 소프트웨어 RAID에서 가장 작은 미러링된 파티션과 동일합니다. 수준 1 중복은 모든 RAID 유형 중에서 가장 높은 수준이며, 배열은 단일 디스크에서만 작동할 수 있습니다.
- 수준 4
레벨 4는 데이터를 보호하기 위해 단일 디스크 드라이브에 중점을 둔 패리티를 사용합니다. 패리티 정보는 배열의 나머지 멤버 디스크의 내용을 기반으로 계산됩니다. 그런 다음 이 정보를 사용하여 배열의 디스크 1개가 실패할 때 데이터를 재구성할 수 있습니다. 복원된 데이터는 교체되기 전에 실패한 디스크에 I/O 요청을 충족하고 실패한 디스크를 교체한 후 다시 생성하는 데 사용할 수 있습니다.
전용 패리티 디스크는 RAID 배열에 대한 모든 쓰기 트랜잭션에 대한 고유한 병목 현상을 나타내며, 레벨 4는 나중 쓰기 캐싱과 같은 관련 기술 없이는 거의 사용되지 않습니다. 또는 시스템 관리자가 의도적으로 이러한 병목 현상을 가진 소프트웨어 RAID 장치를 설계하는 경우 배열이 데이터로 채워지면 쓰기 트랜잭션이 거의 없는 배열과 같이 시스템 관리자가 의도적으로 사용됩니다. RAID 수준 4는 Anaconda에서 옵션으로 사용할 수 없도록 거의 사용되지 않습니다. 그러나 필요한 경우 사용자가 수동으로 생성할 수 있습니다.
하드웨어 RAID 수준 4의 스토리지 용량은 가장 작은 멤버 파티션의 용량에 파티션 수를 - 1을 곱한 것과 같습니다. RAID 수준 4 배열의 성능은 항상 비대칭이며, 이는 outperform 쓰기를 의미합니다. 이는 쓰기 작업이 패리티를 생성할 때 추가 CPU 리소스 및 기본 메모리 대역폭을 소비하고 실제 데이터를 디스크에 쓸 때 추가 버스 대역폭을 소비하기 때문입니다. 데이터 작성뿐만 아니라 패리티도 사용하기 때문입니다. 읽기 작업은 배열이 성능 저하된 상태에 있지 않는 한 패리티가 아닌 데이터 읽기만 있으면 됩니다. 결과적으로 읽기 작업은 일반 작동 조건에서 동일한 양의 데이터 전송에 대해 드라이브의 트래픽과 컴퓨터 전체에서 더 적은 트래픽을 생성합니다.
- 수준 5
RAID의 가장 일반적인 유형입니다. RAID 레벨 5는 모든 멤버 디스크 드라이브에 패리티를 분배함으로써 레벨 4에 내재된 쓰기 병목 현상을 제거합니다. 유일한 성능 장애는 패리티 계산 프로세스 자체입니다. 최신 CPU는 패리티를 매우 빠르게 계산할 수 있습니다. 그러나 RAID 5 배열에 많은 수의 디스크가 있어 모든 장치에서 결합된 집계 데이터 전송 속도가 충분히 높으면 패리티 계산이 병목 현상이 발생할 수 있습니다.
레벨 5에는 비대칭 성능이 있으며 상당한 성능 쓰기를 읽습니다. RAID 수준 5의 스토리지 용량은 수준 4와 동일한 방식으로 계산됩니다.
- 수준 6
이는 데이터 중복성 및 보존이 아닌 데이터가 성능상 중요한 문제이지만 수준 1의 공간 비효율성을 허용하지 않는 경우 RAID의 일반적인 수준입니다. 레벨 6은 복잡한 패리티 체계를 사용하여 배열의 두 드라이브의 손실에서 복구할 수 있습니다. 이러한 복잡한 패리티 체계는 소프트웨어 RAID 장치에 대한 CPU 부담을 크게 높이며 쓰기 트랜잭션 중에 부담을 증가시킵니다. 따라서 레벨 6은 레벨 4와 5보다 성능이 훨씬 더 비대칭적입니다.
RAID 수준 6 배열의 총 용량은 RAID 수준 5 및 4와 유사하게 계산됩니다. 단, 추가 패리티 스토리지 공간을 위해 장치 수에서 두 개의 장치를 뺀 것입니다.
- 수준 10
이 RAID 수준은 수준 0의 성능 이점과 수준 1의 중복성을 결합합니다. 또한 두 개 이상의 장치를 사용하는 레벨 1 배열에서 공간 중 일부를 줄입니다. 레벨 10의 경우, 예를 들어, 각 데이터의 각 조각의 두 복사본만 저장하도록 구성된 3-drive 배열을 생성할 수 있으며, 이를 통해 전체 배열 크기는 3-장치, 레벨 1 어레이와 유사하게 가장 작은 장치뿐만 아니라 최소 장치의 크기를 1.5배로 지정할 수 있습니다. 이렇게 하면 RAID 수준 6과 유사한 패리티를 계산하기 위해 CPU 프로세스 사용을 피할 수 있지만 공간 효율적이 줄어듭니다.
설치 중에 RAID 수준 10 생성은 지원되지 않습니다. 설치 후 수동으로 생성할 수 있습니다.
- 선형 RAID
선형 RAID는 더 큰 가상 드라이브를 만드는 드라이브 그룹입니다.
선형 RAID에서는 청크가 하나의 멤버 드라이브에서 순차적으로 할당되고 첫 번째 드라이브가 완전히 채워지는 경우에만 다음 드라이브로 이동합니다. 이 그룹화는 모든 I/O 작업이 멤버 드라이브 간에 분할되지 않으므로 성능상의 이점을 제공하지 않습니다. 또한 선형 RAID는 중복성을 제공하지 않으며 신뢰성을 낮춥니다. 하나의 멤버 드라이브가 실패하면 전체 배열을 사용할 수 없으며 데이터가 손실될 수 있습니다. 용량은 모든 멤버 디스크의 합계입니다.
67.7.2. LVM RAID 세그먼트 유형
RAID 논리 볼륨을 생성하려면 lvcreate 명령의 --type 인수를 사용하여 RAID 유형을 지정할 수 있습니다. 대부분의 사용자에게 raid1,raid4,raid5,raid6 및 raid10 인 5 가지 기본 유형 중 하나를 지정하면 충분합니다.
다음 표에서는 가능한 RAID 세그먼트 유형을 설명합니다.
| 세그먼트 유형 | 설명 |
|---|---|
|
|
RAID1 미러링. 스트라이핑을 지정하지 않고 |
|
| RAID4 전용 패리티 디스크. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 스트라이핑. RAID0은 스트라이프 크기 단위로 여러 데이터 하위 볼륨에 논리 볼륨 데이터를 분배합니다. 이는 성능을 높이는 데 사용됩니다. 데이터 하위 볼륨이 실패하는 경우 논리 볼륨 데이터가 손실됩니다. |
67.7.3. RAID0 생성을 위한 매개변수
lvcreate --type raid0[meta] --stripes --stripesize Stripesize StripeSize VolumeGroup [PhysicalVolumePath] 명령을 사용하여 RAID0이 제거된 논리 볼륨을 생성할 수 있습니다.
다음 표에는 RAID0 스트라이핑된 논리 볼륨을 만드는 동안 사용할 수 있는 다양한 매개변수가 설명되어 있습니다.
| 매개변수 | 설명 |
|---|---|
|
|
|
|
| 논리 볼륨을 분산할 장치 수를 지정합니다. |
|
| 각 스트라이프의 크기를 킬로바이트 단위로 지정합니다. 이는 다음 장치로 이동하기 전에 한 장치에 기록된 데이터의 양입니다. |
|
| 사용할 볼륨 그룹을 지정합니다. |
|
| 사용할 장치를 지정합니다. 지정하지 않으면 LVM에서 Stripes 옵션에 지정된 장치 수를 선택합니다. 각 스트라이프에 대해 하나씩 선택합니다. |
67.7.4. RAID 논리 볼륨 생성
-m 인수에 지정하는 값에 따라 여러 수의 복사본을 사용하여 RAID1 배열을 생성할 수 있습니다. 마찬가지로 -i 인수를 사용하여 RAID 0, 4, 5, 6, 10 논리 볼륨의 스트라이프 수를 지정할 수 있습니다. -I 인수를 사용하여 스트라이프 크기를 지정할 수도 있습니다. 다음 절차에서는 다양한 유형의 RAID 논리 볼륨을 생성하는 다양한 방법을 설명합니다.
프로세스
2방향 RAID를 생성합니다. 다음 명령은 볼륨 그룹 my_vg 에서 크기가 1G 인 my_lv 라는 2방향 RAID1 배열을 생성합니다.
lvcreate --type raid1 -m 1 -L 1G -n my_lv my_vg Logical volume "my_lv" created.
# lvcreate --type raid1 -m 1 -L 1G -n my_lv my_vg Logical volume "my_lv" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 스트라이프를 사용하여 RAID5 배열을 생성합니다. 다음 명령은 세 개의 스트라이프가 있는 RAID5 배열과 크기 my_lv에서 my_lv 라는 하나의 암시적 패리티 드라이브를 생성합니다. 즉 크기가 1G 입니다. LVM 스트라이핑 볼륨과 유사한 스트라이프 수를 지정할 수 있습니다. 올바른 패리티 드라이브 수가 자동으로 추가됩니다.
lvcreate --type raid5 -i 3 -L 1G -n my_lv my_vg
# lvcreate --type raid5 -i 3 -L 1G -n my_lv my_vgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 스트라이프를 사용하여 RAID6 배열을 생성합니다. 다음 명령은 3개의 스트라이프 3개의 스트라이프와 두 개의 암시적 패리티 드라이브를 사용하여 RAID6 배열을 생성합니다. my_lv 는 볼륨 그룹 my_vg 에서 1G 1 기가바이트 크기입니다.
lvcreate --type raid6 -i 3 -L 1G -n my_lv my_vg
# lvcreate --type raid6 -i 3 -L 1G -n my_lv my_vgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
2방향 RAID1 배열인 LVM 장치 my_vg/my_lv 를 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.5. 스토리지 RHEL 시스템 역할을 사용하여 RAID로 LVM 풀 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform을 사용하여 RHEL에서 RAID로 LVM 풀을 구성할 수 있습니다. 사용 가능한 매개 변수로 Ansible 플레이북을 설정하여 RAID로 LVM 풀을 구성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
풀이 RAID에 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lsblk'
# ansible managed-node-01.example.com -m command -a 'lsblk'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.6. RAID0 스트라이핑 논리 볼륨 생성
RAID0 논리 볼륨은 스트라이프 크기 단위로 여러 데이터 하위 볼륨에 논리 볼륨 데이터를 분배합니다. 다음 절차에서는 디스크 전체에서 데이터를 스트라이핑하는 mylv 라는 LVM RAID0 논리 볼륨을 생성합니다.
사전 요구 사항
- 세 개 이상의 물리 볼륨을 생성했습니다. 물리 볼륨 생성에 대한 자세한 내용은 LVM 물리 볼륨 생성 을 참조하십시오.
- 볼륨 그룹을 생성했습니다. 자세한 내용은 LVM 볼륨 그룹 생성 을 참조하십시오.
프로세스
기존 볼륨 그룹에서 RAID0 논리 볼륨을 생성합니다. 다음 명령은 볼륨 그룹 myvg 에서 3개의 스트라이프와 4kB 의 스트라이프 크기를 사용하여 크기가 2G 인 mylv 볼륨 mylv를 생성합니다.
lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.
# lvcreate --type raid0 -L 2G --stripes 3 --stripesize 4 -n mylv my_vg Rounding size 2.00 GiB (512 extents) up to stripe boundary size 2.00 GiB(513 extents). Logical volume "mylv" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID0 논리 볼륨에 파일 시스템을 생성합니다. 다음 명령은 논리 볼륨에 ext4 파일 시스템을 생성합니다.
mkfs.ext4 /dev/my_vg/mylv
# mkfs.ext4 /dev/my_vg/mylvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨을 마운트하고 파일 시스템 디스크 공간 사용량을 보고합니다.
mount /dev/my_vg/mylv /mnt df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mnt
# mount /dev/my_vg/mylv /mnt # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/my_vg-mylv 2002684 6168 1875072 1% /mntCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
생성된 RAID0 제거된 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.7. 스토리지 RHEL 시스템 역할을 사용하여 RAID LVM 볼륨의 스트라이프 크기 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform을 사용하여 RHEL에서 RAID LVM 볼륨의 스트라이프 크기를 구성할 수 있습니다. 사용 가능한 매개 변수로 Ansible 플레이북을 설정하여 RAID로 LVM 풀을 구성할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 플레이북에 사용되는 모든 변수에 대한 자세한 내용은 제어 노드의
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일을 참조하십시오.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
스트라이프 크기가 필요한 크기로 설정되어 있는지 확인합니다.
ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'
# ansible managed-node-01.example.com -m command -a 'lvs -o+stripesize /dev/my_pool/my_volume'Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.8. 소프트 데이터 손상
데이터 스토리지의 소프트 손상은 스토리지 장치에서 검색된 데이터가 해당 장치에 기록된 데이터와 다르다는 것을 의미합니다. 손상된 데이터는 스토리지 장치에 무기한 존재할 수 있습니다. 이 데이터를 검색하고 사용하려고 할 때까지 이러한 손상된 데이터를 검색하지 못할 수 있습니다.
구성 유형에 따라 RAID(Redundant Array of Independent Disk) 논리 볼륨(LV)은 장치가 실패할 때 데이터 손실을 방지합니다. RAID 배열로 구성된 장치가 실패하면 해당 RAID LV의 일부인 다른 장치에서 데이터를 복구할 수 있습니다. 그러나 RAID 구성은 데이터 자체의 무결성을 보장하지 않습니다. 소프트 손상, 자동 손상, 소프트 오류 및 음소거 오류는 시스템 설계 및 소프트웨어가 예상대로 작동하더라도 손상 된 데이터를 설명하는 용어입니다.
DM 무결성이 있는 새 RAID LV를 생성하거나 기존 RAID LV에 무결성을 추가하는 경우 다음 사항을 고려하십시오.
- 무결성 메타데이터에는 추가 스토리지 공간이 필요합니다. 각 RAID 이미지에 대해 데이터에 추가되는 체크섬으로 인해 500MB의 모든 데이터에 4MB의 추가 스토리지 공간이 필요합니다.
- 일부 RAID 구성은 다른 구성보다 많은 영향을 받지만 DM 무결성을 추가하면 데이터에 액세스할 때 대기 시간 때문에 성능에 영향을 미칩니다. RAID1 구성은 일반적으로 RAID5 또는 변형보다 더 나은 성능을 제공합니다.
- RAID 무결성 블록 크기는 성능에도 영향을 미칩니다. 더 큰 RAID 무결성 블록 크기를 구성하면 성능이 향상됩니다. 그러나 RAID 무결성 블록 크기가 작으면 이전 버전과의 호환성이 향상됩니다.
-
비트맵또는저널의 두 가지 무결성 모드를 사용할 수 있습니다.비트맵무결성 모드는 일반적으로저널모드보다 더 나은 성능을 제공합니다.
성능 문제가 발생하는 경우 RAID1을 무결성으로 사용하거나 특정 RAID 구성의 성능을 테스트하여 요구 사항을 충족하는지 확인합니다.
67.7.9. DM 무결성을 사용하여 RAID 논리 볼륨 생성
DM(Device mapper) 무결성을 사용하여 RAID LV를 생성하거나 기존 RAID 논리 볼륨(LV)에 무결성을 추가하면 소프트 손상으로 인해 데이터가 손실될 위험이 완화됩니다. LV를 사용하기 전에 무결성 동기화 및 RAID 메타데이터가 완료될 때까지 기다립니다. 그렇지 않으면 백그라운드 초기화가 LV의 성능에 영향을 미칠 수 있습니다.
DM(Device mapper) 무결성은 소프트 손상으로 인한 데이터 손실을 완화하거나 방지하기 위해 RAID 수준 1, 4, 5, 6, 10과 함께 사용됩니다. RAID 계층을 사용하면 손상되지 않은 데이터 사본이 소프트 손상 오류를 수정할 수 있습니다.
절차
DM 무결성을 사용하여 RAID LV를 생성합니다. 다음 예제에서는 256M 및 RAID 수준 1 의 사용 가능한 크기로 my_vg 볼륨 그룹에 test-lv 라는 무결성이 있는 새 RAID LV를 생성합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고기존 RAID LV에 DM 무결성을 추가하려면 다음 명령을 사용합니다.
lvconvert --raidintegrity y my_vg/test-lv
# lvconvert --raidintegrity y my_vg/test-lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow RAID LV에 무결성을 추가하면 해당 RAID LV에서 수행할 수 있는 작업 수가 제한됩니다.
선택 사항: 특정 작업을 수행하기 전에 무결성을 제거합니다.
lvconvert --raidintegrity n my_vg/test-lv Logical volume my_vg/test-lv has removed integrity.
# lvconvert --raidintegrity n my_vg/test-lv Logical volume my_vg/test-lv has removed integrity.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
추가된 DM 무결성에 대한 정보를 확인합니다.
my_vg 볼륨 그룹에 생성된 test-lv RAID LV에 대한 정보를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음은 이 출력과 다양한 옵션을 설명합니다.
- G 속성
-
Attr 열 아래의 특성 목록은 RAID 이미지가 무결성을 사용하고 있음을 나타냅니다. 무결성은 체크섬을
_imetaRAID LV에 저장합니다. CPY%Sync열- 이는 최상위 RAID LV와 각 RAID 이미지의 동기화 진행 상황을 나타냅니다.
- RAID 이미지
-
raid_image_N로 LV 열에 표시됩니다. LV열- 동기화 진행 상황을 통해 최상위 RAID LV 및 각 RAID 이미지에 대해 100%로 표시됩니다.
- G 속성
각 RAID LV의 유형을 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 각 RAID 이미지에서 감지된 불일치 수를 계산하는 증분 카운터가 있습니다. my_vg/test-lv 아래의
rimage_0의 무결성으로 감지되는 데이터 불일치를 확인합니다.lvs -o+integritymismatches my_vg/test-lv_rimage_0 LV VG Attr LSize Origin Cpy%Sync IntegMismatches [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 0
# lvs -o+integritymismatches my_vg/test-lv_rimage_0 LV VG Attr LSize Origin Cpy%Sync IntegMismatches [test-lv_rimage_0] my_vg gwi-aor--- 256.00m [test-lv_rimage_0_iorig] 100.00 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 예에서 무결성은 데이터 불일치를 감지하지 못하므로
IntegMismatches카운터는 0(0)을 표시합니다.다음 예와 같이
/var/log/messages로그 파일의 데이터 무결성 정보를 확인합니다.예 67.1. 커널 메시지 로그에서 dm-integrity 불일치의 예
device-mapper: integrity: dm-12: 0x24e7 섹터에서 체크섬이 실패했습니다.
예 67.2. 커널 메시지 로그에서 dm-integrity 데이터 수정의 예
MD/raid1:mdX: Read error corrected (9448 on dm-16)
67.7.10. RAID 논리 볼륨을 다른 RAID 수준으로 변환
LVM은 RAID 논리 볼륨을 하나의 RAID 수준에서 다른 RAID 수준으로 변환하는 것을 의미합니다(예: RAID 5에서 RAID 6로 변환). RAID 수준을 변경하여 장치 오류에 대한 복원력을 늘리거나 줄일 수 있습니다.
절차
RAID 논리 볼륨을 생성합니다.
lvcreate --type raid5 -i 3 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.
# lvcreate --type raid5 -i 3 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리 볼륨을 확인합니다.
lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0) raid5 [my_lv_rimage_0] my_vg iwi-aor--- 168.00m /dev/sda(1) linear
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0) raid5 [my_lv_rimage_0] my_vg iwi-aor--- 168.00m /dev/sda(1) linearCopy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리 볼륨을 다른 RAID 수준으로 변환합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 이 명령이 변환을 반복하도록 요청하는 메시지를 표시하는 경우 다음을 실행합니다.
lvconvert --type raid6 my_vg/my_lv
# lvconvert --type raid6 my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
변환된 RAID 수준으로 RAID 논리 볼륨을 확인합니다.
lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0),my_lv_rimage_4(0) raid6 [my_lv_rimage_0] my_vg iwi-aor--- 172.00m /dev/sda(1) linear
# lvs -a -o +devices,segtype LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices Type my_lv my_vg rwi-a-r--- 504.00m 100.00 my_lv_rimage_0(0),my_lv_rimage_1(0),my_lv_rimage_2(0),my_lv_rimage_3(0),my_lv_rimage_4(0) raid6 [my_lv_rimage_0] my_vg iwi-aor--- 172.00m /dev/sda(1) linearCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.11. 선형 장치를 RAID 논리 볼륨으로 변환
기존 선형 논리 볼륨을 RAID 논리 볼륨으로 변환할 수 있습니다. 이 작업을 수행하려면 lvconvert 명령의 --type 인수를 사용합니다.
RAID 논리 볼륨은 메타데이터 및 데이터 하위 볼륨 쌍으로 구성됩니다. 선형 장치를 RAID1 배열로 변환하면 새 메타데이터 하위 볼륨을 생성하고 선형 볼륨이 있는 동일한 물리 볼륨 중 하나에서 원래 논리 볼륨에 연결합니다. 추가 이미지는 metadata/data 하위 볼륨 쌍에 추가됩니다. 원래 논리 볼륨과 쌍을 동일한 물리 볼륨에 배치할 수 없는 메타데이터 이미지를 동일한 물리 볼륨에 배치할 수 없는 경우 lvconvert 가 실패합니다.
절차
변환해야 하는 논리 볼륨 장치를 확인합니다.
lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(0)
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(0)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선형 논리 볼륨을 RAID 장치로 변환합니다. 다음 명령은 볼륨 그룹 __my_vg의 선형 논리 볼륨 my_lv 를 2방향 RAID1 배열로 변환합니다.
lvconvert --type raid1 -m 1 my_vg/my_lv Are you sure you want to convert linear LV my_vg/my_lv to raid1 with 2 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.
# lvconvert --type raid1 -m 1 my_vg/my_lv Are you sure you want to convert linear LV my_vg/my_lv to raid1 with 2 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
논리 볼륨이 RAID 장치로 변환되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.12. LVM RAID1 논리 볼륨을 LVM 선형 논리 볼륨으로 변환
기존 RAID1 LVM 논리 볼륨을 LVM 선형 논리 볼륨으로 변환할 수 있습니다. 이 작업을 수행하려면 lvconvert 명령을 사용하고 -m0 인수를 지정합니다. 이렇게 하면 RAID 배열을 구성하는 모든 RAID 데이터 하위 볼륨과 RAID 배열을 구성하는 모든 RAID 메타데이터 하위 볼륨이 제거되어 최상위 RAID1 이미지가 선형 논리 볼륨으로 유지됩니다.
절차
기존 LVM RAID1 논리 볼륨을 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 RAID1 LVM 논리 볼륨을 LVM 선형 논리 볼륨으로 변환합니다. 다음 명령은 LVM RAID1 논리 볼륨 my_vg/my_lv 를 LVM 선형 장치로 변환합니다.
lvconvert -m0 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to type linear losing all resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.
# lvconvert -m0 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to type linear losing all resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.Copy to Clipboard Copied! Toggle word wrap Toggle overflow LVM RAID1 논리 볼륨을 LVM 선형 볼륨으로 변환할 때 제거할 물리 볼륨도 지정할 수 있습니다. 다음 예에서
lvconvert명령은 /dev/sde1 을 제거하고 선형 장치를 구성하는 물리 볼륨으로 /dev/sdf1 을 남겨 둡니다.lvconvert -m0 my_vg/my_lv /dev/sde1
# lvconvert -m0 my_vg/my_lv /dev/sde1Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
RAID1 논리 볼륨이 LVM 선형 장치로 변환되었는지 확인합니다.
lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sdf1(1)
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sdf1(1)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.13. 미러링된 LVM 장치를 RAID1 논리 볼륨으로 변환
세그먼트 유형 미러를 사용하여 기존 미러링된 LVM 장치를 RAID1 LVM 장치로 변환할 수 있습니다. 이 작업을 수행하려면 --type raid1 인수와 함께 lvconvert 명령을 사용합니다. mimage 라는 미러 하위 볼륨의 이름을 rimage 라는 RAID 하위 볼륨으로 변경합니다.
또한 미러 로그를 제거하고 해당 데이터 하위 볼륨과 동일한 물리 볼륨의 data 하위 볼륨에 대해 rmeta 라는 메타데이터 하위 볼륨을 생성합니다.
절차
미러링된 논리 볼륨 my_vg/my_lv 의 레이아웃을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 미러링된 논리 볼륨 my_vg/my_lv 를 RAID1 논리 볼륨으로 변환합니다.
lvconvert --type raid1 my_vg/my_lv Are you sure you want to convert mirror LV my_vg/my_lv to raid1 type? [y/n]: y Logical volume my_vg/my_lv successfully converted.
# lvconvert --type raid1 my_vg/my_lv Are you sure you want to convert mirror LV my_vg/my_lv to raid1 type? [y/n]: y Logical volume my_vg/my_lv successfully converted.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
미러링된 논리 볼륨이 RAID1 논리 볼륨으로 변환되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.14. 기존 RAID1 장치의 이미지 수 변경
LVM 미러링 구현의 이미지 수를 변경할 수 있는 방식과 유사하게 기존 RAID1 배열의 이미지 수를 변경할 수 있습니다.
lvconvert 명령을 사용하여 RAID1 논리 볼륨에 이미지를 추가하면 다음 작업을 수행할 수 있습니다.
- 결과 장치의 총 이미지 수를 지정합니다.
- 장치에 추가할 이미지 수 및
- 새 메타데이터/데이터 이미지 쌍이 상주하는 물리 볼륨을 선택적으로 지정할 수 있습니다.
절차
2방향 RAID1 배열인 LVM 장치 my_vg/my_lv 를 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow rmeta라는 메타데이터 하위 볼륨은 항상 data 하위 볼륨rimage와 동일한 물리적 장치에 존재합니다. 메타데이터/데이터 하위 볼륨 쌍은 어디서든--alloc을 지정하지 않는 한 RAID 배열의 다른 metadata/data 하위 볼륨 쌍과 동일한 물리 볼륨에 생성되지 않습니다.2방향 RAID1 논리 볼륨 my_vg/my_lv 를 3방향 RAID1 논리 볼륨으로 변환합니다.
lvconvert -m 2 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 3 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.
# lvconvert -m 2 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 3 images enhancing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음은 기존 RAID1 장치의 이미지 수를 변경하는 몇 가지 예입니다.
RAID에 이미지를 추가하는 동안 사용할 물리 볼륨을 지정할 수도 있습니다. 다음 명령은 배열에 사용할 물리 볼륨 /dev/sdd1 을 지정하여 2-way RAID1 논리 볼륨 my_vg/my_lv 를 3-way RAID1 논리 볼륨으로 변환합니다.
lvconvert -m 2 my_vg/my_lv /dev/sdd1
# lvconvert -m 2 my_vg/my_lv /dev/sdd1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 3방향 RAID1 논리 볼륨을 2방향 RAID1 논리 볼륨으로 변환합니다.
lvconvert -m1 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 2 images reducing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.
# lvconvert -m1 my_vg/my_lv Are you sure you want to convert raid1 LV my_vg/my_lv to 2 images reducing resilience? [y/n]: y Logical volume my_vg/my_lv successfully converted.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 제거할 이미지가 포함된 물리 볼륨 /dev/sde1 을 지정하여 3-way RAID1 논리 볼륨을 2방향 RAID1 논리 볼륨으로 변환합니다.
lvconvert -m1 my_vg/my_lv /dev/sde1
# lvconvert -m1 my_vg/my_lv /dev/sde1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 또한 이미지 및 관련 메타데이터 하위 볼륨을 제거하면 번호가 높은 이미지가 아래로 전환되어 슬롯을 채웁니다.
lv_rimage_0,lv_rimage_1및lv_rimage_2로 구성된 3-way RAID1 배열에서lv_rimage_1을 제거하면lv_rimage_0및lv_rimage_1로 구성된 RAID1 배열이 생성됩니다. 하위 볼륨lv_rimage_2는 이름이 변경되고 빈 슬롯을 대체하여lv_rimage_1이 됩니다.
검증
기존 RAID1 장치의 이미지 수를 변경한 후 RAID1 장치를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.15. RAID 이미지를 별도의 논리 볼륨으로 분할
RAID 논리 볼륨의 이미지를 분할하여 새 논리 볼륨을 형성할 수 있습니다. 기존 RAID1 논리 볼륨에서 RAID 이미지를 제거하거나 장치 중앙에서 RAID 데이터 하위 볼륨 및 관련 메타데이터 하위 볼륨을 제거하면 더 많은 수의 이미지가 슬롯을 채우도록 아래로 이동합니다. 따라서 RAID 배열을 구성하는 논리 볼륨의 인덱스 번호는 정수의 눈에 띄지 않는 시퀀스가 됩니다.
RAID1 배열이 아직 동기화되지 않은 경우 RAID 이미지를 분할할 수 없습니다.
절차
2방향 RAID1 배열인 LVM 장치 my_vg/my_lv 를 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 이미지를 별도의 논리 볼륨으로 분할합니다.
다음 예제에서는 2방향 RAID1 논리 볼륨인 my_lv 를 두 개의 선형 논리 볼륨인 my_lv 및 new 로 분할합니다.
lvconvert --splitmirror 1 -n new my_vg/my_lv Are you sure you want to split raid1 LV my_vg/my_lv losing all resilience? [y/n]: y
# lvconvert --splitmirror 1 -n new my_vg/my_lv Are you sure you want to split raid1 LV my_vg/my_lv losing all resilience? [y/n]: yCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 예제에서는 3방향 RAID1 논리 볼륨인 my_lv 를 2방향 RAID1 논리 볼륨, my_lv 및 선형 논리 볼륨 new 로 분할합니다.
lvconvert --splitmirror 1 -n new my_vg/my_lv
# lvconvert --splitmirror 1 -n new my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
RAID 논리 볼륨의 이미지를 분할한 후 논리 볼륨을 확인합니다.
lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(1) new /dev/sdf1(1)
# lvs -a -o name,copy_percent,devices my_vg LV Copy% Devices my_lv /dev/sde1(1) new /dev/sdf1(1)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.16. RAID 이미지 분할 및 병합
lvconvert 명령의 --splitmirrors 인수와 함께 --trackchanges 인수를 사용하여 변경 사항을 추적하는 동안 읽기 전용 사용을 위해 RAID1 배열의 이미지를 일시적으로 분할할 수 있습니다. 이 기능을 사용하면 나중에 이미지를 배열에 병합하고 이미지가 분할된 이후 변경된 배열의 일부만 다시 동기화할 수 있습니다.
--trackchanges 인수를 사용하여 RAID 이미지를 분할하면 분할할 이미지를 지정할 수 있지만 분할되는 볼륨의 이름을 변경할 수는 없습니다. 또한 결과 볼륨에는 다음과 같은 제약 조건이 있습니다.
- 생성한 새 볼륨은 읽기 전용입니다.
- 새 볼륨의 크기를 조정할 수 없습니다.
- 나머지 배열의 이름을 변경할 수 없습니다.
- 나머지 배열의 크기를 조정할 수 없습니다.
- 새 볼륨과 나머지 배열을 독립적으로 활성화할 수 있습니다.
분할된 이미지를 병합할 수 있습니다. 이미지를 병합할 때 이미지 분할 이후 변경된 배열의 일부만 다시 동기화됩니다.
절차
RAID 논리 볼륨을 생성합니다.
lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" created
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 생성된 RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 생성된 RAID 논리 볼륨에서 이미지를 분할하고 나머지 배열의 변경 사항을 추적합니다.
lvconvert --splitmirrors 1 --trackchanges my_vg/my_lv my_lv_rimage_2 split from my_lv for read-only purposes. Use 'lvconvert --merge my_vg/my_lv_rimage_2' to merge back into my_lv
# lvconvert --splitmirrors 1 --trackchanges my_vg/my_lv my_lv_rimage_2 split from my_lv for read-only purposes. Use 'lvconvert --merge my_vg/my_lv_rimage_2' to merge back into my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 이미지를 분할한 후 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨을 배열에 다시 병합합니다.
lvconvert --merge my_vg/my_lv_rimage_1 my_vg/my_lv_rimage_1 successfully merged back into my_vg/my_lv
# lvconvert --merge my_vg/my_lv_rimage_1 my_vg/my_lv_rimage_1 successfully merged back into my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
병합된 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.17. 할당할 RAID 오류 정책 설정
raid_fault_policy 필드를 /etc/lvm/lvm.conf 파일의 allocate 매개변수로 설정할 수 있습니다. 이 기본 설정을 사용하면 시스템에서 실패한 장치를 볼륨 그룹의 예비 장치로 교체하려고 합니다. 예비 장치가 없으면 시스템 로그에 이 정보가 포함됩니다.
절차
RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdb 장치가 실패하면 RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdb 장치가 실패하는 경우 오류 메시지에 대한 시스템 로그를 볼 수도 있습니다.
lvm.conf파일에할당할raid_fault_policy필드를 설정합니다.vi /etc/lvm/lvm.conf raid_fault_policy = "allocate"
# vi /etc/lvm/lvm.conf raid_fault_policy = "allocate"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고raid_fault_policy를 할당하도록 설정했지만 예비 장치가 없는 경우 할당이 실패하고 논리 볼륨을 그대로 둡니다. 할당에 실패하면lvconvert --repair명령을 사용하여 실패한 장치를 수정하고 교체할 수 있습니다. 자세한 내용은 논리 볼륨에서 실패한 RAID 장치 교체를 참조하십시오.
검증
실패한 장치가 볼륨 그룹의 새 장치로 교체되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고이제 실패한 장치가 교체되었지만 장치가 볼륨 그룹에서 아직 제거되지 않았기 때문에 LVM에서 실패한 장치를 찾을 수 없다는 표시가 계속 표시됩니다.
my_vg명령을 실행하여 볼륨 그룹에서 실패한 장치를 제거할수 있습니다.
67.7.18. 경고로 RAID 오류 정책 설정
raid_fault_policy 필드를 lvm.conf 파일의 warn 매개변수로 설정할 수 있습니다. 이 기본 설정을 사용하면 시스템에서 실패한 장치를 나타내는 경고를 시스템 로그에 추가합니다. 경고에 따라 추가 단계를 확인할 수 있습니다.
기본적으로 raid_fault_policy 필드의 값은 lvm.conf 에서 warn 입니다.
프로세스
RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvm.conf 파일에서 warn로 raid_fault_policy 필드를 설정합니다.
vi /etc/lvm/lvm.conf # This configuration option has an automatic default value. raid_fault_policy = "warn"
# vi /etc/lvm/lvm.conf # This configuration option has an automatic default value. raid_fault_policy = "warn"Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdb 장치가 실패하는 경우 오류 메시지를 표시하도록 시스템 로그를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdb 장치가 실패하면 시스템 로그에 오류 메시지가 표시됩니다. 그러나 이 경우 LVM은 이미지 중 하나를 교체하여 RAID 장치를 자동으로 복구하지 않습니다. 대신 장치가 실패한 경우 장치를
lvconvert명령의--repair인수로 교체할 수 있습니다. 자세한 내용은 논리 볼륨에서 실패한 RAID 장치 교체를 참조하십시오.
67.7.19. 작동 중인 RAID 장치 교체
lvconvert 명령의 --replace 인수를 사용하여 논리 볼륨에서 작동 중인 RAID 장치를 교체할 수 있습니다.
RAID 장치 오류가 발생하는 경우 다음 명령이 작동하지 않습니다.
사전 요구 사항
- RAID 장치가 실패하지 않았습니다.
프로세스
RAID1 배열을 생성합니다.
lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" created
# lvcreate --type raid1 -m 2 -L 1G -n my_lv my_vg Logical volume "my_lv" createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow 생성된 RAID1 배열을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 요구 사항에 따라 RAID 장치를 다음 방법으로 교체합니다.
교체할 물리 볼륨을 지정하여 RAID1 장치를 교체합니다.
lvconvert --replace /dev/sdb2 my_vg/my_lv
# lvconvert --replace /dev/sdb2 my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체에 사용할 물리 볼륨을 지정하여 RAID1 장치를 교체합니다.
lvconvert --replace /dev/sdb1 my_vg/my_lv /dev/sdd1
# lvconvert --replace /dev/sdb1 my_vg/my_lv /dev/sdd1Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여러 교체 인수를 지정하여 한 번에 여러 RAID 장치를 교체합니다.
lvconvert --replace /dev/sdb1 --replace /dev/sdc1 my_vg/my_lv
# lvconvert --replace /dev/sdb1 --replace /dev/sdc1 my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
교체할 물리 볼륨을 지정한 후 RAID1 배열을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 교체에 사용할 물리 볼륨을 지정한 후 RAID1 배열을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 한 번에 여러 RAID 장치를 교체한 후 RAID1 배열을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.20. 논리 볼륨에서 실패한 RAID 장치 교체
RAID는 기존 LVM 미러링과 동일하지 않습니다. LVM 미러링의 경우 실패한 장치를 제거합니다. 그렇지 않으면 RAID 배열이 실패한 장치에서 계속 실행되는 동안 미러링된 논리 볼륨이 중단됩니다. RAID1 이외의 RAID 수준의 경우 장치를 제거하면 RAID6에서 RAID5로 또는 RAID4 또는 RAID0으로의 낮은 RAID 수준으로의 변환을 의미합니다.
실패한 장치를 제거하고 교체를 LVM으로 할당하는 대신 lvconvert 명령의 --repair 인수를 사용하여 RAID 논리 볼륨에서 물리 볼륨으로 사용되는 실패한 장치를 교체할 수 있습니다.
사전 요구 사항
볼륨 그룹에는 실패한 장치를 교체할 수 있는 충분한 여유 용량을 제공하는 물리 볼륨이 포함됩니다.
볼륨 그룹에서 사용 가능한 확장 영역이 충분한 물리 볼륨이 없는 경우 Cryostatextend 유틸리티를 사용하여 충분히 큰
새물리 볼륨을 추가합니다.
프로세스
RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdc 장치가 실패한 후 RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 실패한 장치를 교체합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 실패한 장치를 대체하는 물리 볼륨을 수동으로 지정합니다.
lvconvert --repair my_vg/my_lv replacement_pv
# lvconvert --repair my_vg/my_lv replacement_pvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체를 사용하여 논리 볼륨을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹에서 실패한 장치를 제거할 때까지 LVM 유틸리티에 실패한 장치를 찾을 수 없다는 내용이 계속 표시됩니다.
볼륨 그룹에서 실패한 장치를 제거합니다.
vgreduce --removemissing my_vg
# vgreduce --removemissing my_vgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
실패한 장치를 제거한 후 사용 가능한 물리 볼륨을 확인합니다.
pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]
# pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 실패한 장치를 교체한 후 논리 볼륨을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.21. RAID 논리 볼륨에서 데이터 일관성 확인
LVM은 RAID 논리 볼륨에 대한 스크럽을 제공합니다. RAID 스크러빙은 배열의 모든 데이터 및 패리티 블록을 읽고 일관성이 있는지 확인하는 프로세스입니다. lvchange --syncaction repair 명령은 배열에서 백그라운드 동기화 작업을 시작합니다.
프로세스
선택 사항: 다음 옵션 중 하나를 설정하여 RAID 논리 볼륨이 초기화되는 속도를 제어합니다.
-
--maxrecoveryrate Rate[bBsSkKmMgG]는 RAID 논리 볼륨의 최대 복구 속도를 설정하여 nominal I/O 작업을 확장하지 않도록 합니다. --minrecoveryrate Rate[bBsSkKmMgG]는 RAID 논리 볼륨의 최소 복구 속도를 설정하여 동기화 작업의 I/O가 무분별 I/O가 있는 경우에도 최소 처리량을 달성하도록 합니다.lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.
# lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 4K 를 복구 속도 값으로 바꿉니다. 이 값은 배열의 각 장치에 대한 초당 양입니다. 접미사를 제공하지 않으면 옵션은 장치당 초당 kiB를 가정합니다.
lvchange --syncaction repair my_vg/my_lv
# lvchange --syncaction repair my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 스크러블링 작업을 수행할 때
동기화작업에 필요한 백그라운드 I/O는 볼륨 그룹 메타데이터 업데이트 등 LVM 장치에 대한 다른 I/O의 충돌을 줄일 수 있습니다. 이로 인해 다른 LVM 작업이 느려질 수 있습니다.참고RAID 장치를 생성하는 동안 이러한 최대 및 최소 I/O 속도를 사용할 수도 있습니다. 예를 들어
lvcreate --type raid10 -i 2 -m 1 -l 1 -L 10G --maxrecoveryrate 128 -n my_vg는 128 kiB/sec/device의 최대 복구 속도를 가진 볼륨 그룹 my_vg에 있는 볼륨 그룹 my_vg에서 최대 복구 속도를 가진 크기가 10G인 my_vg를 생성합니다.
-
배열의 불일치 수를 복구하지 않고 표시합니다.
lvchange --syncaction check my_vg/my_lv
# lvchange --syncaction check my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 배열에서 백그라운드 동기화 작업을 시작합니다.
-
선택 사항: 커널 메시지의
var/log/syslog파일을 확인합니다. 배열의 불일치를 수정합니다.
lvchange --syncaction repair my_vg/my_lv
# lvchange --syncaction repair my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 RAID 논리 볼륨에서 실패한 장치를 복구하거나 교체합니다. 이 명령을 실행한 후 커널 메시지의
var/log/syslog파일을 볼 수 있습니다.
검증
스크럽 작업에 대한 정보를 표시합니다.
lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0
# lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.22. RAID1 논리 볼륨에서 I/O 작업
lvchange 명령의 --writemost 및 매개변수를 사용하여 RAID1 논리 볼륨에서 장치의 I/O 작업을 제어할 수 있습니다. 다음은 이러한 매개변수를 사용하는 형식입니다.
--write behind
--[raid]writemostly PhysicalVolume[:{t|y|n}]RAID1 논리 볼륨의 장치를
대부분 쓰기로 표시하고 필요한 경우가 아니면 이러한 드라이브에 대한 모든 읽기 작업을 방지합니다. 이 매개변수를 설정하면 I/O 작업 수가 드라이브에 최소로 유지됩니다.lvchange --writemostly /dev/sdb my_vg/my_lv명령을 사용하여 이 매개변수를 설정합니다.다음과 같은 방법으로
writemostly속성을 설정할 수 있습니다.:y-
기본적으로
writemostly속성 값은 논리 볼륨에서 지정된 물리 볼륨에 대해 yes입니다. :n-
writemostly플래그를 제거하려면:n을 물리 볼륨에 추가합니다. :twritemostly 속성의 값을 토글하려면
--인수를 지정합니다.writemostly단일 명령에서 이 인수를 두 번 이상 사용할 수 있습니다(예:
lvchange --writemostly /dev/sdd1:n --writemostly /dev/sdb1:t --writemostly /dev/sdc1:y my_vg/my_lv). 이를 통해 논리 볼륨의 모든 물리 볼륨에 대한쓰기속성을 한 번에 전환할 수 있습니다.
--[raid]writebehind IOCountwritemostly로 표시된 보류 중인 쓰기의 최대 수를 지정합니다. RAID1 논리 볼륨의 장치에 적용할 수 있는 쓰기 작업 수입니다. 이 매개 변수의 값을 초과한 후 RAID 배열에서 모든 쓰기 작업이 완료되도록 하기 전에 구성 장치에 대한 모든 쓰기 작업이 동기적으로 완료됩니다.lvchange --writebehind 100 my_vg/my_lv명령을 사용하여 이 매개변수를 설정할 수 있습니다.writemostly특성의 값을 0으로 설정하면 기본 설정이 지워집니다. 이 설정을 사용하면 시스템은 임의로 값을 선택합니다.
67.7.23. RAID 볼륨 교체
RAID 교체는 RAID 수준을 변경하지 않고 RAID 논리 볼륨의 속성을 변경하는 것을 의미합니다. 변경할 수 있는 일부 속성에는 RAID 레이아웃, 스트라이프 크기 및 스트라이프 수가 포함됩니다.
프로세스
RAID 논리 볼륨을 생성합니다.
lvcreate --type raid5 -i 2 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.
# lvcreate --type raid5 -i 2 -L 500M -n my_lv my_vg Using default stripesize 64.00 KiB. Rounding size 500.00 MiB (125 extents) up to stripe boundary size 504.00 MiB (126 extents). Logical volume "my_lv" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: RAID 논리 볼륨의
스트라이프이미지 및 스트라이프lvs -o stripes my_vg/my_lv #Str 3# lvs -o stripes my_vg/my_lv #Str 3Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvs -o stripesize my_vg/my_lv Stripe 64.00k
# lvs -o stripesize my_vg/my_lv Stripe 64.00kCopy to Clipboard Copied! Toggle word wrap Toggle overflow 요구 사항에 따라 다음 방법을 사용하여 RAID 논리 볼륨의 속성을 수정합니다.
RAID 논리 볼륨의
스트라이프이미지를 수정합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리
볼륨의 스트라이프크기를 수정합니다.lvconvert --stripesize 128k my_vg/my_lv Converting stripesize 64.00 KiB of raid5 LV my_vg/my_lv to 128.00 KiB. Are you sure you want to convert raid5 LV my_vg/my_lv? [y/n]: y Logical volume my_vg/my_lv successfully converted.
# lvconvert --stripesize 128k my_vg/my_lv Converting stripesize 64.00 KiB of raid5 LV my_vg/my_lv to 128.00 KiB. Are you sure you want to convert raid5 LV my_vg/my_lv? [y/n]: y Logical volume my_vg/my_lv successfully converted.Copy to Clipboard Copied! Toggle word wrap Toggle overflow maxrecoveryrate및minrecoveryrate속성을 수정합니다.lvchange --maxrecoveryrate 4M my_vg/my_lv Logical volume my_vg/my_lv changed.
# lvchange --maxrecoveryrate 4M my_vg/my_lv Logical volume my_vg/my_lv changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvchange --minrecoveryrate 1M my_vg/my_lv Logical volume my_vg/my_lv changed.
# lvchange --minrecoveryrate 1M my_vg/my_lv Logical volume my_vg/my_lv changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow syncaction속성을 수정합니다.lvchange --syncaction check my_vg/my_lv
# lvchange --syncaction check my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow writemostly및writebehind속성을 수정합니다.lvchange --writemostly /dev/sdb my_vg/my_lv Logical volume my_vg/my_lv changed.
# lvchange --writemostly /dev/sdb my_vg/my_lv Logical volume my_vg/my_lv changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvchange --writebehind 100 my_vg/my_lv Logical volume my_vg/my_lv changed.
# lvchange --writebehind 100 my_vg/my_lv Logical volume my_vg/my_lv changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
RAID 논리 볼륨의
스트라이프이미지 및 스트라이프lvs -o stripes my_vg/my_lv #Str 4# lvs -o stripes my_vg/my_lv #Str 4Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvs -o stripesize my_vg/my_lv Stripe 128.00k
# lvs -o stripesize my_vg/my_lv Stripe 128.00kCopy to Clipboard Copied! Toggle word wrap Toggle overflow maxrecoveryrate특성을 수정한 후 RAID 논리 볼륨을 확인합니다.lvs -a -o +raid_max_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MaxSync my_lv my_vg rwi-a-r--- 10.00g 100.00 4096 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]
# lvs -a -o +raid_max_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MaxSync my_lv my_vg rwi-a-r--- 10.00g 100.00 4096 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]Copy to Clipboard Copied! Toggle word wrap Toggle overflow minrecoveryrate특성을 수정한 후 RAID 논리 볼륨을 확인합니다.lvs -a -o +raid_min_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MinSync my_lv my_vg rwi-a-r--- 10.00g 100.00 1024 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]
# lvs -a -o +raid_min_recovery_rate LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert MinSync my_lv my_vg rwi-a-r--- 10.00g 100.00 1024 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]Copy to Clipboard Copied! Toggle word wrap Toggle overflow syncaction속성을 수정한 후 RAID 논리 볼륨을 확인합니다.lvs -a LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert my_lv my_vg rwi-a-r--- 10.00g 2.66 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]
# lvs -a LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert my_lv my_vg rwi-a-r--- 10.00g 2.66 [my_lv_rimage_0] my_vg iwi-aor--- 10.00g [...]Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.7.24. RAID 논리 볼륨에서 영역 크기 변경
RAID 논리 볼륨을 생성할 때 /etc/lvm/lvm.conf 파일의 raid_region_size 매개변수는 RAID 논리 볼륨의 리전 크기를 나타냅니다. RAID 논리 볼륨을 생성한 후 볼륨의 영역 크기를 변경할 수 있습니다. 이 매개 변수는 더티 상태 또는 정리 상태를 추적하는 세분성을 정의합니다. 비트맵의 더티 비트는 RAID 볼륨의 더티 종료 후 동기화할 작업 세트를 정의합니다(예: 시스템 오류).
raid_region_size 를 더 높은 값으로 설정하면 비트맵 크기와 혼잡이 줄어듭니다. 그러나 RAID에 대한 쓰기 는 영역을 동기화할 때까지 지연되기 때문에 영역을 재동기화하는 동안 쓰기 작업에 영향을 미칩니다.
프로세스
RAID 논리 볼륨을 생성합니다.
lvcreate --type raid1 -m 1 -L 10G test Logical volume "lvol0" created.
# lvcreate --type raid1 -m 1 -L 10G test Logical volume "lvol0" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Region 열은 raid_region_size 매개변수의 값을 나타냅니다.
선택 사항:
raid_region_size매개변수의 값을 확인합니다.cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 2048
# cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 2048Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리 볼륨의 영역 크기를 변경합니다.
lvconvert -R 4096K my_vg/my_lv Do you really want to change the region_size 512.00 KiB of LV my_vg/my_lv to 4.00 MiB? [y/n]: y Changed region size on RAID LV my_vg/my_lv to 4.00 MiB.
# lvconvert -R 4096K my_vg/my_lv Do you really want to change the region_size 512.00 KiB of LV my_vg/my_lv to 4.00 MiB? [y/n]: y Changed region size on RAID LV my_vg/my_lv to 4.00 MiB.Copy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 논리 볼륨을 다시 동기화합니다.
lvchange --resync my_vg/my_lv Do you really want to deactivate logical volume my_vg/my_lv to resync it? [y/n]: y
# lvchange --resync my_vg/my_lv Do you really want to deactivate logical volume my_vg/my_lv to resync it? [y/n]: yCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Region 열은
raid_region_size매개변수의 변경된 값을 나타냅니다.lvm.conf파일에서raid_region_size매개변수의 값을 확인합니다.cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 4096
# cat /etc/lvm/lvm.conf | grep raid_region_size # Configuration option activation/raid_region_size. # raid_region_size = 4096Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8. 논리 볼륨의 스냅샷
LVM 스냅샷 기능을 사용하면 서비스 중단 없이 특정 시간에 /dev/sda 와 같은 볼륨의 가상 이미지를 생성할 수 있습니다.
67.8.1. 스냅샷 볼륨 개요
스냅샷을 만든 후 원래 볼륨(원본)을 수정할 때 스냅샷 기능은 볼륨 상태를 재구성할 수 있도록 변경 이전에 수정된 데이터 영역을 복사합니다. 스냅샷을 만들 때 원본 항목에 대한 전체 읽기 및 쓰기 액세스 권한이 유지됩니다.
스냅샷이 생성된 후 변경되는 데이터 영역만 복사하므로 스냅샷 기능에는 최소 스토리지 용량이 필요합니다. 예를 들어 거의 업데이트되지 않은 출처를 사용하면 원본 용량의 3-5 %로 스냅샷을 유지 관리하는 데 충분합니다. 백업 절차를 대체하지 않습니다. 스냅샷 복사본은 가상 복사본이며 실제 미디어 백업이 아닙니다.
스냅샷 크기는 원본 볼륨에 대한 변경 사항을 저장하기 위한 공간을 별도로 제어합니다. 예를 들어 스냅샷을 생성한 다음 원본을 완전히 덮어쓰는 경우 스냅샷은 변경 사항을 보유할 원본 볼륨만큼 커야 합니다. 스냅샷 크기를 정기적으로 모니터링해야 합니다. 예를 들어 /usr 과 같은 읽기 볼륨 스냅샷의 수명이 짧은 스냅샷에는 /home 과 같은 많은 쓰기가 포함되어 있기 때문에 볼륨의 장기 스냅샷보다 적은 공간이 필요합니다.
스냅샷이 가득 차면 원본 볼륨의 변경 사항을 더 이상 추적할 수 없기 때문에 스냅샷이 유효하지 않습니다. 그러나 스냅샷이 유효하지 않게 되도록 LVM을 구성하여 스냅샷이 유효하지 않은 것을 방지하기 위해 snapshot_autoextend_threshold 값을 초과할 때마다 스냅샷을 자동으로 확장할 수 있습니다. 스냅샷은 완전히 재조정 가능하며 다음 작업을 수행할 수 있습니다.
- 스토리지 용량이 있는 경우 스냅샷 볼륨의 크기를 늘릴 수 있으므로 해당 용량이 삭제되지 않습니다.
- 스냅샷 볼륨이 필요한 것보다 크면 볼륨 크기를 줄여 다른 논리 볼륨에 필요한 공간을 확보할 수 있습니다.
스냅샷 볼륨은 다음과 같은 이점을 제공합니다.
- 대부분의 경우 데이터를 지속적으로 업데이트하는 라이브 시스템을 중단하지 않고 논리 볼륨에서 백업을 수행해야 하는 경우 스냅샷을 생성합니다.
-
스냅샷 파일 시스템에서
fsck명령을 실행하여 파일 시스템의 무결성을 확인하고 원래 파일 시스템에 파일 시스템 복구가 필요한지 확인할 수 있습니다. - 스냅샷은 읽기/쓰기이므로 실제 데이터를 건드리지 않고 스냅샷을 작성하고 스냅샷에 대해 테스트를 실행하여 프로덕션 데이터에 대해 애플리케이션을 테스트할 수 있습니다.
- Red Hat Virtualization에서 사용할 LVM 볼륨을 생성할 수 있습니다. LVM 스냅샷을 사용하여 가상 게스트 이미지의 스냅샷을 생성할 수 있습니다. 이러한 스냅샷을 사용하면 최소한의 추가 스토리지를 사용하여 기존 게스트를 수정하거나 새 게스트를 생성할 수 있는 편리한 방법을 제공할 수 있습니다.
67.8.2. Copy-On-Write 스냅샷 생성
생성 시 COW(Copy-On-Write) 스냅샷에 데이터가 포함되지 않습니다. 대신 스냅샷 생성 시 원본 볼륨의 데이터 블록을 참조합니다. 원래 볼륨의 데이터가 변경되면 COW 시스템은 변경되지 않은 원본 데이터를 변경하기 전에 스냅샷에 복사합니다. 이렇게 하면 변경 사항이 발생할 때만 스냅샷이 크기가 증가하여 스냅샷 생성 시 원본 볼륨의 상태를 저장합니다. COW 스냅샷은 최소한의 데이터 변경 사항이 있는 단기 백업 및 상황에 효율적이며 특정 시점을 캡처하고 되돌릴 수 있는 공간을 제공합니다. COW 스냅샷을 생성할 때 원래 볼륨에 대한 예상 변경 사항에 따라 충분한 스토리지를 할당합니다.
스냅샷을 생성하기 전에 스냅샷의 스토리지 요구 사항과 라이프사이클을 고려해야 합니다. 스냅샷의 크기는 의도된 수명 동안 변경 사항을 캡처하기에 충분하지만 원래 LV의 크기를 초과할 수 없습니다. 낮은 변경 속도를 예상하는 경우 스냅샷 크기가 10%-15%로 충분할 수 있습니다. 변경 속도가 높은 LV의 경우 30% 이상을 할당해야 할 수 있습니다.
스냅샷의 스토리지 사용량을 정기적으로 모니터링하는 것이 중요합니다. 스냅샷이 할당된 공간의 100%에 도달하면 유효하지 않습니다. lvs 명령을 사용하여 스냅샷에 대한 정보를 표시할 수 있습니다.
스냅샷을 완전히 채워지기 전에 스냅샷을 확장해야 합니다. 이 작업은 lvextend 명령을 사용하여 수동으로 수행할 수 있습니다. 또는 /etc/lvm/lvm.conf 파일에서 snapshot_autoextend_threshold 및 snapshot_autoextend_percent 매개변수를 설정하여 자동 확장을 설정할 수 있습니다. 이 구성을 사용하면 사용량이 정의된 임계값에 도달하면 dmeventd 에서 스냅샷을 자동으로 확장할 수 있습니다.
COW 스냅샷을 사용하면 스냅샷을 만들 때와 같이 파일 시스템의 읽기 전용 버전에 액세스할 수 있습니다. 이를 통해 원래 파일 시스템에서 지속적인 작업을 중단하지 않고 백업 또는 데이터 분석이 가능합니다. 스냅샷이 마운트 및 사용되는 동안 원래 논리 볼륨과 파일 시스템을 계속 업데이트하고 정상적으로 사용할 수 있습니다.
다음 절차에서는 볼륨 그룹 Cryostat 001 에서 origin 이라는 논리 볼륨을 생성한 다음 snap 이라는 스냅샷을 생성하는 방법을 간략하게 설명합니다.
사전 요구 사항
- 관리 액세스.
- 볼륨 그룹을 생성했습니다. 자세한 내용은 LVM 볼륨 그룹 생성 을 참조하십시오.
프로세스
볼륨 그룹 Cryostat 001 에서 origin 이라는 논리 볼륨을 생성합니다.
lvcreate -L 1G -n origin vg001
# lvcreate -L 1G -n origin vg001Copy to Clipboard Copied! Toggle word wrap Toggle overflow 크기가 100MB 인 snap of /dev/vg001/origin LV라는 스냅샷을 생성합니다.
lvcreate --size 100M --name snap --snapshot /dev/vg001/origin
# lvcreate --size 100M --name snap --snapshot /dev/vg001/originCopy to Clipboard Copied! Toggle word wrap Toggle overflow 원래 볼륨과 사용 중인 스냅샷 볼륨의 현재 백분율을 표시합니다.
lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0) snap vg001 swi-a-s--- 100.00m origin 0.00 /dev/sde1(256)
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0) snap vg001 swi-a-s--- 100.00m origin 0.00 /dev/sde1(256)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8.3. 스냅샷을 원래 볼륨에 병합
lvconvert 명령을 --merge 옵션과 함께 사용하여 스냅샷을 원래(원본) 볼륨에 병합합니다. 데이터 또는 파일이 손실되었거나 시스템을 이전 상태로 복원해야 하는 경우 시스템 롤백을 수행할 수 있습니다. 스냅샷 볼륨을 병합하면 결과 논리 볼륨의 이름, 마이너 번호, UUID가 있습니다. 병합은 진행 중이지만 origin에 대한 읽기 또는 쓰기는 병합되는 스냅샷으로 전달되면 나타납니다. 병합이 완료되면 병합된 스냅샷이 제거됩니다.
origin 및 snapshot 볼륨이 모두 열려 있지 않고 활성 상태가 되면 병합이 즉시 시작됩니다. 그렇지 않으면 원본 또는 스냅샷이 활성화된 후 병합이 시작되고 둘 다 닫힙니다. 원본 볼륨이 활성화된 후 루트 파일 시스템(예: 루트 파일 시스템)을 닫을 수 없는 원본으로 스냅샷을 병합할 수 있습니다.
프로세스
스냅샷 볼륨을 병합합니다. 다음 명령은 스냅샷 볼륨 을 원본과 병합합니다.
lvconvert --merge vg001/snap Merging of volume vg001/snap started. vg001/origin: Merged: 100.00%
# lvconvert --merge vg001/snap Merging of volume vg001/snap started. vg001/origin: Merged: 100.00%Copy to Clipboard Copied! Toggle word wrap Toggle overflow 원본 볼륨 보기:
lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0)
# lvs -a -o +devices LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices origin vg001 owi-a-s--- 1.00g /dev/sde1(0)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8.4. 스냅샷 RHEL 시스템 역할을 사용하여 LVM 스냅샷 생성
새 스냅샷 RHEL 시스템 역할을 사용하여 LVM 스냅샷을 생성할 수 있습니다. 이 시스템 역할은 snapshot_lvm_action 매개변수를 확인하도록 설정하여 생성된 스냅샷에 충분한 공간이 있는지 확인하고 해당 이름과 충돌하지 않는지 확인합니다. 생성된 스냅샷을 마운트하려면 snapshot_lvm_action 을 mount 로 설정합니다.
다음 예제에서는 nouuid 옵션이 설정되며 XFS 파일 시스템으로 작업할 때만 필요합니다. XFS는 동일한 UUID로 여러 파일 시스템을 동시에 마운트하는 것을 지원하지 않습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_set매개변수는 동일한 볼륨 그룹(VG)의 특정 논리 볼륨(LV)을 설명합니다. 이 매개 변수를 설정하는 동안 다른 VG에서 LV를 지정할 수도 있습니다.플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
관리 노드에서 생성된 스냅샷을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 관리 노드에서 /data1_snapshot 및 /data2_snapshot:의 존재를 확인하여 마운트 작업이 성공했는지 확인합니다.
ls -al /data1_snapshot ls -al /data2_snapshot
# ls -al /data1_snapshot # ls -al /data2_snapshotCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8.5. 스냅샷 RHEL 시스템 역할을 사용하여 LVM 스냅샷 마운트 해제
snapshot_lvm_action 매개변수를 umount 로 설정하여 특정 스냅샷 또는 모든 스냅샷을 마운트 해제할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. - 스냅샷 세트에 이름 <_snapset1_>을 사용하여 스냅샷을 생성했습니다.
-
snapshot_lvm_action을 설정하여 스냅샷을마운트하거나 수동으로 마운트했습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.특정 LVM 스냅샷을 마운트 해제합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_lv매개변수는 특정 논리 볼륨(LV)을 설명하고snapshot_lvm_vg매개변수는 특정 볼륨 그룹(VG)을 설명합니다.LVM 스냅샷 세트를 마운트 해제합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_set매개 변수는 동일한 VG의 특정 LV를 설명합니다. 이 매개 변수를 설정하는 동안 다른 VG에서 LV를 지정할 수도 있습니다.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8.6. 스냅샷 RHEL 시스템 역할을 사용하여 LVM 스냅샷 확장
새 스냅샷 RHEL 시스템 역할을 사용하면 snapshot _lvm_action 매개변수를 확장하도록 설정하여 LVM 스냅샷을 확장할 수 있습니다. snapshot_lvm_percent_space_required 매개변수를 확장 후 스냅샷에 할당해야 하는 필수 공간으로 설정할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. - 지정된 볼륨 그룹 및 논리 볼륨에 대해 스냅샷이 생성되어 있습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.percent_space_required매개변수 값을 지정하여 모든 LVM 스냅샷을 확장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_set매개 변수는 동일한 VG의 특정 LV를 설명합니다. 이 매개 변수를 설정하는 동안 다른 VG에서 LV를 지정할 수도 있습니다.집합의 각 VG 및 LV 쌍에 대해
percent_space_required를 다른 값으로 설정하여 설정된 LVM 스냅샷을 확장합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
관리 노드에서 확장된 스냅샷을 30% 정도 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8.7. 스냅샷 RHEL 시스템 역할을 사용하여 LVM 스냅샷 복원
새 스냅샷 RHEL 시스템 역할을 사용하면 snapshot _lvm_action 매개변수를 되돌리도록 설정하여 LVM 스냅샷 을 원래 볼륨으로 되돌릴 수 있습니다.
논리 볼륨과 스냅샷 볼륨이 모두 열려 있지 않고 활성 상태가 아니면 되돌리기 작업이 즉시 시작됩니다. 그렇지 않으면 원본 또는 스냅샷이 활성화된 후 시작하고 둘 다 닫힙니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. - <_snapset1_>을 snapset 이름으로 사용하여 지정된 볼륨 그룹 및 논리 볼륨에 대한 스냅샷을 생성했습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.특정 LVM 스냅샷을 원래 볼륨으로 되돌립니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_lv매개변수는 특정 논리 볼륨(LV)을 설명하고snapshot_lvm_vg매개변수는 특정 볼륨 그룹(VG)을 설명합니다.LVM 스냅샷 세트를 원래 볼륨으로 되돌립니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_set매개 변수는 동일한 VG의 특정 LV를 설명합니다. 이 매개 변수를 설정하는 동안 다른 VG에서 LV를 지정할 수도 있습니다.참고되돌리기작업을 완료하는 데 시간이 다소 걸릴 수 있습니다.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
Playbook을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 호스트를 재부팅하거나 다음 단계를 사용하여 논리 볼륨을 비활성화 및 다시 활성화합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
관리형 노드에서 복원된 스냅샷을 확인합니다.
lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg -wi-a----- 1.00g data2 data_vg -wi-a----- 1.00g
# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert data1 data_vg -wi-a----- 1.00g data2 data_vg -wi-a----- 1.00gCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.8.8. 스냅샷 RHEL 시스템 역할을 사용하여 LVM 스냅샷 제거
새 스냅샷 RHEL 시스템 역할을 사용하면 스냅샷의 접두사 또는 패턴을 지정하고 snapshot_lvm_action 매개변수를 제거하여 모든 LVM 스냅샷을 제거할 수 있습니다.
사전 요구 사항
- 컨트롤 노드 및 관리형 노드를 준비했습니다.
- 관리 노드에서 플레이북을 실행할 수 있는 사용자로 제어 노드에 로그인되어 있습니다.
-
관리 노드에 연결하는 데 사용하는 계정에는
sudo권한이 있습니다. - <_snapset1_>을 snapset 이름으로 사용하여 지정된 스냅샷을 생성했습니다.
프로세스
다음 콘텐츠를 사용하여 플레이북 파일(예:
~/playbook.yml)을 생성합니다.특정 LVM 스냅샷을 제거합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_vg매개변수는 볼륨 그룹(VG)의 특정 논리 볼륨(LV)을 설명합니다.LVM 스냅샷 세트를 제거합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기에서
snapshot_lvm_set매개 변수는 동일한 VG의 특정 LV를 설명합니다. 이 매개 변수를 설정하는 동안 다른 VG에서 LV를 지정할 수도 있습니다.
플레이북 구문을 확인합니다.
ansible-playbook --syntax-check ~/playbook.yml
$ ansible-playbook --syntax-check ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 구문만 검증하고 잘못되었지만 유효한 구성으로부터 보호하지 않습니다.
플레이북을 실행합니다.
ansible-playbook ~/playbook.yml
$ ansible-playbook ~/playbook.ymlCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.9. 씬 프로비저닝된 볼륨 생성 및 관리(볼륨)
Red Hat Enterprise Linux는 씬 프로비저닝된 스냅샷 볼륨 및 논리 볼륨을 지원합니다.
- 씬 프로비저닝된 논리 볼륨을 사용하면 사용 가능한 물리 스토리지보다 큰 논리 볼륨을 생성할 수 있습니다.
- 씬 프로비저닝된 스냅샷 볼륨을 사용하면 동일한 데이터 볼륨에 더 많은 가상 장치를 저장할 수 있습니다.
67.9.1. 씬 프로비저닝 개요
이제 많은 최신 스토리지 스택에서 두꺼운 프로비저닝과 씬 프로비저닝 중에서 선택할 수 있는 기능을 제공합니다.
- 두꺼운 프로비저닝은 실제 사용에 관계없이 블록이 할당되는 블록 스토리지의 기존 동작을 제공합니다.
- 씬 프로비저닝에서는 데이터를 저장하는 물리적 장치보다 크기가 클 수 있는 더 큰 블록 스토리지 풀을 프로비저닝하여 초과 프로비저닝을 수행할 수 있습니다. 개별 블록이 실제로 사용될 때까지 개별 블록이 할당되지 않기 때문에 오버 프로비저닝이 가능합니다. 동일한 풀을 공유하는 씬 프로비저닝된 장치가 여러 개 있는 경우 이러한 장치를 과도하게 프로비저닝할 수 있습니다.
씬 프로비저닝을 사용하면 물리적 스토리지를 오버 커밋할 수 있으며, 대신 씬 풀이라는 여유 공간 풀을 관리할 수 있습니다. 애플리케이션에 필요한 경우 이 씬 풀을 임의의 수의 장치에 할당할 수 있습니다. 필요한 경우 스토리지 공간을 비용 효율적으로 할당하는 데 필요한 경우 씬 풀을 동적으로 확장할 수 있습니다.
예를 들어 10명의 사용자가 각각 애플리케이션에 대해 100GB 파일 시스템을 요청하는 경우 각 사용자에 대해 100GB 파일 시스템으로 표시되는 파일을 생성할 수 있지만 필요한 경우에만 사용되는 실제 스토리지에서 지원합니다.
씬 프로비저닝을 사용할 때는 스토리지 풀을 모니터링하고 사용 가능한 물리적 공간이 부족할 때 용량을 추가하는 것이 중요합니다.
다음은 씬 프로비저닝된 장치를 사용할 때의 몇 가지 이점입니다.
- 사용 가능한 물리 스토리지보다 큰 논리 볼륨을 생성할 수 있습니다.
- 동일한 데이터 볼륨에 더 많은 가상 장치를 저장할 수 있습니다.
- 논리적으로 자동으로 증가할 수 있는 파일 시스템을 만들어 데이터 요구 사항을 지원할 수 있으며 사용하지 않는 블록은 풀의 모든 파일 시스템에서 사용하기 위해 풀로 반환됩니다.
다음은 씬 프로비저닝된 장치 사용의 잠재적인 단점입니다.
- 씬 프로비저닝된 볼륨은 사용 가능한 물리 스토리지가 부족할 위험이 있습니다. 기본 스토리지를 과도하게 프로비저닝한 경우 사용 가능한 물리적 스토리지가 부족하여 중단될 수 있습니다. 예를 들어 백업을 위해 1T 물리적 스토리지만 사용하여 씬 프로비저닝된 스토리지 10T를 생성하면 1T가 소진된 후 볼륨을 사용할 수 없거나 쓸 수 없게 됩니다.
-
씬 프로비저닝된 장치 후 볼륨에 삭제 사항을 전송하지 않으면 사용량 계산이 정확하지 않습니다. 예를 들어
-o 삭제 마운트옵션 없이 파일 시스템을 배치하고 씬 프로비저닝된 장치에서 주기적으로fstrim을 실행하지 않으면 이전에 사용한 스토리지를 할당 해제하지 않습니다. 이러한 경우 실제로 사용하지 않는 경우에도 시간이 지남에 따라 전체 프로비저닝된 양을 사용합니다. - 사용 가능한 물리적 공간이 부족하려면 논리 및 물리적 사용량을 모니터링해야 합니다.
- 스냅샷이 있는 파일 시스템에서 쓰기(CoW) 작업 시 복사 속도가 느려질 수 있습니다.
- 데이터 블록은 여러 파일 시스템 간에 혼합되어 최종 사용자에게 표시되지 않는 경우에도 기본 스토리지의 임의 액세스 제한으로 이어질 수 있습니다.
67.9.2. 씬 프로비저닝된 논리 볼륨 생성
씬 프로비저닝된 논리 볼륨을 사용하면 사용 가능한 물리 스토리지보다 큰 논리 볼륨을 생성할 수 있습니다. 씬 프로비저닝된 볼륨 세트를 생성하면 시스템에서 요청된 전체 스토리지 양을 할당하는 대신 사용하는 항목을 할당할 수 있습니다.
lvcreate 명령의 -T 또는 --thin 옵션을 사용하면 thin 풀 또는 thin 볼륨을 생성할 수 있습니다. 단일 명령을 사용하여 lvcreate 명령의 -T 옵션을 사용하여 씬 풀과 thin 볼륨을 동시에 생성할 수도 있습니다. 다음 절차에서는 씬 프로비저닝된 논리 볼륨을 생성하고 늘리는 방법을 설명합니다.
사전 요구 사항
- 볼륨 그룹을 생성했습니다. 자세한 내용은 LVM 볼륨 그룹 생성 을 참조하십시오.
절차
thin 풀을 생성합니다.
lvcreate -L 100M -T vg001/mythinpool Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.
# lvcreate -L 100M -T vg001/mythinpool Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 물리적 공간 풀을 생성하므로 풀 크기를 지정해야 합니다.
lvcreate명령의-T옵션은 인수를 사용하지 않습니다. 명령으로 추가된 다른 옵션에서 생성할 장치 유형을 결정합니다. 다음 예와 같이 추가 매개변수를 사용하여 thin 풀을 생성할 수도 있습니다.lvcreate명령의--thinpool매개변수를 사용하여 thin 풀을 생성할 수도 있습니다.T옵션과 달리--thinpool매개변수를 사용하려면 생성 중인 thin pool 논리 볼륨의 이름을 지정해야 합니다. 다음 예제에서는--thinpool매개변수를 사용하여 크기가 100M 인 볼륨 그룹 mythinpool 에 mythinpool이라는 thin 풀을 생성합니다.lvcreate -L 100M --thinpool mythinpool vg001 Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.
# lvcreate -L 100M --thinpool mythinpool vg001 Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "mythinpool" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 풀 생성에 대해 스트라이핑이 지원되므로
-i및-I옵션을 사용하여 스트라이프를 만들 수 있습니다. 다음 명령은 두 개의 64 kB 스트라이프와 256 kB 의 청크 크기를 사용하여 볼륨 그룹 Cryostat 001 에서 thinpool 이라는 100M 씬 풀을 생성합니다. 또한 Cryostat 001/thinvolume이라는 1T thin 볼륨을 생성합니다.참고볼륨 그룹에 사용 가능한 공간이 충분한 두 개의 물리 볼륨이 있거나 thin 풀을 만들 수 없는지 확인합니다.
lvcreate -i 2 -I 64 -c 256 -L 100M -T vg001/thinpool -V 1T --name thinvolume
# lvcreate -i 2 -I 64 -c 256 -L 100M -T vg001/thinpool -V 1T --name thinvolumeCopy to Clipboard Copied! Toggle word wrap Toggle overflow
thin 볼륨을 생성합니다.
lvcreate -V 1G -T vg001/mythinpool -n thinvolume WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume "thinvolume" created.
# lvcreate -V 1G -T vg001/mythinpool -n thinvolume WARNING: Sum of all thin volume sizes (1.00 GiB) exceeds the size of thin pool vg001/mythinpool (100.00 MiB). WARNING: You have not turned on protection against thin pools running out of space. WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full. Logical volume "thinvolume" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이 경우 해당 볼륨을 포함하는 풀보다 큰 볼륨의 가상 크기를 지정합니다. 다음 예와 같이 추가 매개변수를 사용하여 thin 볼륨을 생성할 수도 있습니다.
씬 볼륨과 씬 풀을 모두 생성하려면
lvcreate명령의-T옵션을 사용하고 size 및 virtual size 인수를 둘 다 지정합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 나머지 여유 공간을 사용하여 thin volume 및 thin pool을 생성하려면
100%FREE옵션을 사용합니다.lvcreate -V 1G -l 100%FREE -T vg001/mythinpool -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most <15.88 TiB of data. Logical volume "thinvolume" created.
# lvcreate -V 1G -l 100%FREE -T vg001/mythinpool -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most <15.88 TiB of data. Logical volume "thinvolume" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 기존 논리 볼륨을 thin pool 볼륨으로 변환하려면
lvconvert명령의--thinpool매개 변수를 사용합니다. 또한--thinpool매개변수와 함께--poolmetadata매개변수를 사용하여 기존 논리 볼륨을 씬 풀 볼륨의 메타데이터 볼륨으로 변환해야 합니다.다음 예제에서는 볼륨 그룹 lv1 의 기존 논리 볼륨 lv1을 thin 풀 볼륨으로 변환하고 볼륨 그룹 Cryostat 001 의 기존 논리 볼륨 lv2 를 해당 thin 풀 볼륨의 metadata 볼륨으로 변환합니다.
lvconvert --thinpool vg001/lv1 --poolmetadata vg001/lv2 Converted vg001/lv1 to thin pool.
# lvconvert --thinpool vg001/lv1 --poolmetadata vg001/lv2 Converted vg001/lv1 to thin pool.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고논리 볼륨을 씬 풀 볼륨 또는 씬 풀 메타데이터 볼륨으로 변환하는 경우
lvconvert는 장치의 콘텐츠를 보존하지 않고 대신 콘텐츠를 덮어씁니다.기본적으로
lvcreate명령은 다음 공식을 사용하여 씬 풀 메타데이터 논리 볼륨의 크기를 대략적으로 설정합니다.Pool_LV_size / Pool_LV_chunk_size * 64
Pool_LV_size / Pool_LV_chunk_size * 64Copy to Clipboard Copied! Toggle word wrap Toggle overflow 스냅샷 수가 많거나 씬 풀에 대한 청크 크기가 적고 나중에 씬 풀의 크기가 크게 증가할 것으로 예상되는 경우
lvcreate명령의--poolmetadatasize매개변수를 사용하여 thin pool의 메타데이터 볼륨의 기본값을 늘려야 할 수 있습니다. thin pool의 메타데이터 논리 볼륨에 지원되는 값은 2MiB에서 16GiB 사이의 범위에 있습니다.다음 예제에서는 thin 풀의 메타데이터 볼륨의 기본값을 늘리는 방법을 보여줍니다.
lvcreate -V 1G -l 100%FREE -T vg001/mythinpool --poolmetadatasize 16M -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "thinvolume" created.
# lvcreate -V 1G -l 100%FREE -T vg001/mythinpool --poolmetadatasize 16M -n thinvolume Thin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data. Logical volume "thinvolume" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
생성된 thin 풀 및 thin 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항:
lvextend명령을 사용하여 씬 풀의 크기를 확장합니다. 그러나 씬 풀의 크기를 줄일 수 없습니다.참고thin pool 및 thin 볼륨을 생성하는 동안
-l 100%FREE인수를 사용하면 이 명령이 실패합니다.다음 명령은 다른 100M 을 확장하여 크기가 100M 인 기존 씬 풀의 크기를 조정합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: thin pool 및 thin 볼륨의 이름을 바꾸려면 다음 명령을 사용합니다.
lvrename vg001/mythinpool vg001/mythinpool1 Renamed "mythinpool" to "mythinpool1" in volume group "vg001" lvrename vg001/thinvolume vg001/thinvolume1 Renamed "thinvolume" to "thinvolume1" in volume group "vg001"
# lvrename vg001/mythinpool vg001/mythinpool1 Renamed "mythinpool" to "mythinpool1" in volume group "vg001" # lvrename vg001/thinvolume vg001/thinvolume1 Renamed "thinvolume" to "thinvolume1" in volume group "vg001"Copy to Clipboard Copied! Toggle word wrap Toggle overflow 이름을 변경한 후 thin 풀 및 thin volume을 확인합니다.
lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mythinpool1 vg001 twi-a-tz 100.00m 0.00 thinvolume1 vg001 Vwi-a-tz 1.00g mythinpool1 0.00
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mythinpool1 vg001 twi-a-tz 100.00m 0.00 thinvolume1 vg001 Vwi-a-tz 1.00g mythinpool1 0.00Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: thin 풀을 제거하려면 다음 명령을 사용합니다.
lvremove -f vg001/mythinpool1 Logical volume "thinvolume1" successfully removed. Logical volume "mythinpool1" successfully removed.
# lvremove -f vg001/mythinpool1 Logical volume "thinvolume1" successfully removed. Logical volume "mythinpool1" successfully removed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.9.3. 웹 콘솔에서 씬 프로비저닝된 볼륨용 풀 생성
씬 프로비저닝된 볼륨의 풀을 생성합니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 볼륨 그룹이 생성됩니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지 를 클릭합니다.
- 스토리지 테이블에서 씬 볼륨을 생성할 볼륨 그룹을 클릭합니다.
- 논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 만들기 를 클릭합니다.
- 이름 필드에 새 논리 볼륨의 이름을 입력합니다. 이름에 공백을 포함하지 마십시오.
(용도) 드롭다운 메뉴에서 thinly provisioned 볼륨에 대해 Pool 을 선택합니다.
이 구성을 사용하면 볼륨 그룹에 포함된 모든 드라이브의 용량 합계와 동일한 최대 볼륨 크기를 사용하여 논리 볼륨을 생성할 수 있습니다.
논리 볼륨의 크기를 정의합니다. 다음을 고려하십시오.
- 이 논리 볼륨을 사용하는 시스템에 필요한 공간의 양입니다.
- 생성할 논리 볼륨 수입니다.
전체 공간을 사용할 필요는 없습니다. 필요한 경우 나중에 논리 볼륨을 확장할 수 있습니다.
을 클릭합니다.
thin 볼륨의 풀이 생성되고 이제 풀에 thin 볼륨을 추가할 수 있습니다.
67.9.4. 웹 콘솔에서 씬 프로비저닝된 논리 볼륨 생성
웹 콘솔을 사용하여 풀에 씬 프로비저닝된 논리 볼륨을 생성할 수 있습니다. 풀에는 여러 개의 thin 볼륨이 포함될 수 있으며 각 thin 볼륨은 thin 볼륨 자체의 풀만큼 클 수 있습니다.
thin 볼륨을 사용하려면 논리 볼륨의 실제 사용 가능한 물리적 공간을 정기적으로 점검해야 합니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 생성된 thin 볼륨 풀입니다.
절차
RHEL 8 웹 콘솔에 로그인합니다.
자세한 내용은 웹 콘솔에 로그인 을 참조하십시오.
- 스토리지 를 클릭합니다.
- 스토리지 테이블에서 씬 볼륨을 생성할 메뉴 버튼 볼륨 그룹을 클릭합니다.
- 논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 thin 논리 볼륨을 생성할 풀을 클릭합니다.
- 씬 프로비저닝된 LVM2 논리 볼륨 풀 페이지에서 Thinly provisioned LVM2 논리 볼륨 섹션으로 스크롤하고 새로 프로비저닝된 새 논리 볼륨 만들기 를 클릭합니다.
- thin volume 만들기 대화 상자에서 thin 볼륨의 이름을 입력합니다. 이름에 공백을 사용하지 마십시오.
- thin 볼륨의 크기를 정의합니다.
생성을 클릭합니다.
thin 논리 볼륨이 생성됩니다. 볼륨을 사용하려면 볼륨을 포맷해야 합니다.
67.9.5. 청크 크기 개요
청크는 스냅샷 스토리지 전용 물리적 디스크의 가장 큰 단위입니다.
청크 크기를 사용하려면 다음 기준을 사용합니다.
- 청크 크기가 작으면 더 많은 메타데이터가 필요하며 성능을 저하시키지만 스냅샷에서 공간 사용률을 개선할 수 있습니다.
- 더 큰 청크 크기에는 메타데이터 조작이 줄어들지만 스냅샷의 효율성을 줄일 수 있습니다.
기본적으로 lvm2 는 64KiB 청크 크기로 시작하고 이러한 청크 크기에 적합한 메타데이터 크기를 추정합니다. lvm2 의 최소 메타데이터 크기는 2MiB를 생성하고 사용할 수 있습니다. 메타데이터 크기가 128MiB보다 커야 하는 경우 청크 크기를 늘리기 시작하므로 메타데이터 크기가 컴팩트합니다. 그러나 이로 인해 일부 큰 청크 크기 값이 발생할 수 있으므로 스냅샷 사용에 공간이 줄어들 수 있습니다. 이러한 경우 더 작은 청크 크기와 더 큰 메타데이터 크기가 더 나은 옵션입니다.
요구 사항에 따라 청크 크기를 지정하려면 -c 또는 --chunksize 매개변수를 overrule lvm2 estimated chunk size로 사용합니다. thinpool이 생성되면 청크 크기를 변경할 수 없습니다.
볼륨 데이터 크기가 TiB 범위에 있는 경우 지원되는 최대 크기인 ~15.8GiB를 메타데이터 크기로 사용하고 요구 사항에 따라 청크 크기를 설정합니다. 그러나 볼륨의 데이터 크기를 확장하고 청크 크기가 작은 경우 메타데이터 크기를 늘릴 수 없습니다.
청크 크기와 메타데이터 크기의 부적절한 조합을 사용하면 잠재적으로 문제가 발생할 수 있으며, 사용자가 메타데이터 에서 공간을 부족하거나 주소 지정 가능한 씬 풀 데이터 크기로 인해 씬 풀 크기를 추가로 늘리지 못할 수 있습니다.
67.9.6. 씬 프로비저닝된 스냅샷 볼륨
Red Hat Enterprise Linux는 씬 프로비저닝된 스냅샷 볼륨을 지원합니다. 씬 논리 볼륨의 스냅샷은 thin 논리 볼륨(LV)도 생성합니다. thin 스냅샷 볼륨은 다른 씬 볼륨과 동일한 특성을 갖습니다. 볼륨을 독립적으로 활성화, 볼륨 확장, 볼륨 이름 변경, 볼륨 제거, 볼륨 스냅샷도 수행할 수 있습니다.
모든 LVM 스냅샷 볼륨 및 모든 thin 볼륨과 마찬가지로 클러스터의 노드에서 thin 스냅샷 볼륨이 지원되지 않습니다. 스냅샷 볼륨은 하나의 클러스터 노드에서만 활성화해야 합니다.
기존 스냅샷은 생성된 각 스냅샷에 새 공간을 할당해야 하며, 원본이 변경될 때 데이터가 보존됩니다. 그러나 씬 프로비저닝 스냅샷은 원본과 동일한 공간을 공유합니다. 씬 LV의 스냅샷은 씬 LV에 공통되는 데이터 블록과 모든 스냅샷이 공유되기 때문에 효율적입니다. thin LV 또는 기타 씬 스냅샷에서 스냅샷을 생성할 수 있습니다. 반복 스냅샷에 공통된 블록도 thin 풀에서 공유됩니다.
thin snapshot 볼륨은 다음과 같은 이점을 제공합니다.
- 원본의 스냅샷 수를 늘리면 성능에 부정적인 영향을 미칩니다.
- 씬 스냅샷 볼륨은 새 데이터가 기록되고 각 스냅샷에 복사되지 않기 때문에 디스크 사용량을 줄일 수 있습니다.
- 기존 스냅샷의 요구 사항인 원본으로 씬 스냅샷 볼륨을 동시에 활성화할 필요가 없습니다.
- 스냅샷에서 원본을 복원할 때는 씬 스냅샷을 병합할 필요가 없습니다. 원본을 제거하고 대신 스냅샷을 사용할 수 있습니다. 기존 스냅샷에는 다시 복사해야 하는 변경 사항을 저장하는 별도의 볼륨이 있습니다. 즉, 재설정하려면 원본과 병합됩니다.
- 기존 스냅샷에 비해 허용된 스냅샷 수에 훨씬 더 높은 제한이 있습니다.
씬 스냅샷 볼륨을 사용할 때 많은 이점이 있지만 기존 LVM 스냅샷 볼륨 기능이 필요에 더 적합할 수 있는 몇 가지 사용 사례가 있습니다. 기존 스냅샷을 모든 유형의 볼륨에서 사용할 수 있습니다. 그러나 thin-snapshots를 사용하려면 thin-provisioning을 사용해야 합니다.
thin 스냅샷 볼륨의 크기를 제한할 수 없습니다. 스냅샷은 필요한 경우 thin 풀의 모든 공간을 사용합니다. 일반적으로 사용할 스냅샷 형식을 결정할 때 사이트의 특정 요구 사항을 고려해야 합니다.
기본적으로 일반 활성화 명령 중에 thin snapshot 볼륨은 건너뜁니다.
67.9.7. 씬 프로비저닝된 스냅샷 볼륨 생성
씬 프로비저닝된 스냅샷 볼륨을 사용하면 동일한 데이터 볼륨에 더 많은 가상 장치를 저장할 수 있습니다.
thin 스냅샷 볼륨을 생성할 때 볼륨의 크기를 지정하지 마십시오. size 매개변수를 지정하면 생성될 스냅샷은 씬 스냅샷 볼륨이 아니며 데이터를 저장하는 데 thin 풀을 사용하지 않습니다. 예를 들어 lvcreate -s Cryostat/thinvolume -L10M 명령은 원본 볼륨이 thin 볼륨인 경우에도 씬 스냅샷을 생성하지 않습니다.
씬 프로비저닝된 원본 볼륨 또는 씬 프로비저닝되지 않은 원본 볼륨에 대해 씬 스냅샷을 생성할 수 있습니다. 다음 절차에서는 씬 프로비저닝된 스냅샷 볼륨을 생성하는 다양한 방법을 설명합니다.
사전 요구 사항
- 씬 프로비저닝된 논리 볼륨을 생성했습니다. 자세한 내용은 thin provisioning 개요를 참조하십시오.
절차
씬 프로비저닝된 스냅샷 볼륨을 생성합니다. 다음 명령은 씬 프로비저닝된 논리 볼륨 192.0.2. 001/thinvolume의 mysnapshot1 로 씬 프로비저닝된 스냅샷 볼륨을 생성합니다.
lvcreate -s --name mysnapshot1 vg001/thinvolume Logical volume "mysnapshot1" created
# lvcreate -s --name mysnapshot1 vg001/thinvolume Logical volume "mysnapshot1" createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mysnapshot1 vg001 Vwi-a-tz 1.00g mythinpool thinvolume 0.00 mythinpool vg001 twi-a-tz 100.00m 0.00 thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00
# lvs LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert mysnapshot1 vg001 Vwi-a-tz 1.00g mythinpool thinvolume 0.00 mythinpool vg001 twi-a-tz 100.00m 0.00 thinvolume vg001 Vwi-a-tz 1.00g mythinpool 0.00Copy to Clipboard Copied! Toggle word wrap Toggle overflow 참고씬 프로비저닝을 사용할 때는 스토리지 관리자가 스토리지 풀을 모니터링하고 전체화되기 시작하면 용량을 추가하는 것이 중요합니다. thin 볼륨의 크기를 확장하는 방법에 대한 자세한 내용은 씬 프로비저닝된 논리 볼륨 생성 을 참조하십시오.
기본적으로 프로비저닝된 논리 볼륨의 씬 프로비저닝된 스냅샷을 생성할 수도 있습니다. 기본적으로 프로비저닝된 논리 볼륨은 씬 풀에 포함되어 있지 않으므로 외부 원본이라고 합니다. 외부 원본 볼륨은 다른 씬 풀에서도 많은 씬 프로비저닝된 스냅샷 볼륨에서 사용하고 공유할 수 있습니다. 씬 프로비저닝된 스냅샷이 생성되는 시점에 외부 원본은 비활성 상태이고 읽기 전용이어야 합니다.
다음 예제에서는 origin_volume 이라는 읽기 전용 비활성 논리 볼륨의 thin 스냅샷 볼륨을 생성합니다. thin snapshot 볼륨의 이름은 mythinsnap 입니다. 그런 다음 논리 볼륨 origin_volume 은 기존 thin pool Cryostat 001 /pool 을 사용하는 볼륨 그룹 mythinsnap 에서 thin snapshot 볼륨 mythinsnap의 씬 외부 원본이 됩니다. 원본 볼륨은 스냅샷 볼륨과 동일한 볼륨 그룹에 있어야 합니다. origin 논리 볼륨을 지정할 때 볼륨 그룹을 지정하지 마십시오.
lvcreate -s --thinpool vg001/pool origin_volume --name mythinsnap
# lvcreate -s --thinpool vg001/pool origin_volume --name mythinsnapCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령을 실행하여 첫 번째 스냅샷 볼륨의 두 번째 씬 프로비저닝 스냅샷 볼륨을 생성할 수 있습니다.
lvcreate -s vg001/mysnapshot1 --name mysnapshot2 Logical volume "mysnapshot2" created.
# lvcreate -s vg001/mysnapshot1 --name mysnapshot2 Logical volume "mysnapshot2" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 씬 프로비저닝된 세 번째 스냅샷 볼륨을 생성하려면 다음 명령을 사용합니다.
lvcreate -s vg001/mysnapshot2 --name mysnapshot3 Logical volume "mysnapshot3" created.
# lvcreate -s vg001/mysnapshot2 --name mysnapshot3 Logical volume "mysnapshot3" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
thin snapshot 논리 볼륨의 모든 상위 및 하위 항목 목록을 표시합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 여기,
- thinvolume 은 볼륨 그룹의 원본 볼륨 입니다.
- mysnapshot1 은 thinvolume의 스냅샷입니다.
- mysnapshot2 는 mysnapshot1의 스냅샷입니다.
mysnapshot3 은 mysnapshot2의 스냅샷입니다.
참고lv_ancestors및lv_descendants필드에는 기존 종속성이 표시됩니다. 그러나 체인의 중간에서 항목이 제거된 경우 종속성 체인을 중단할 수 있는 제거된 항목을 추적하지 않습니다.
67.9.8. 웹 콘솔을 사용하여 씬 프로비저닝된 스냅샷 볼륨 생성
RHEL 웹 콘솔에서 thin 논리 볼륨의 스냅샷을 생성하여 마지막 스냅샷의 디스크에 기록된 변경 사항을 백업할 수 있습니다.
사전 요구 사항
- RHEL 8 웹 콘솔을 설치했습니다.
- cockpit 서비스를 활성화했습니다.
사용자 계정이 웹 콘솔에 로그인할 수 있습니다.
자세한 내용은 웹 콘솔 설치 및 활성화를 참조하십시오.
-
cockpit-storaged패키지가 시스템에 설치되어 있습니다. - 씬 프로비저닝된 볼륨이 생성됩니다.
절차
- RHEL 8 웹 콘솔에 로그인합니다.
- 스토리지 를 클릭합니다.
- 스토리지 테이블에서 씬 볼륨을 생성할 볼륨 그룹을 클릭합니다.
- 논리 볼륨 그룹 페이지에서 LVM2 논리 볼륨 섹션으로 스크롤하고 thin 논리 볼륨을 생성할 풀을 클릭합니다.
- 씬 프로비저닝된 LVM2 논리 볼륨 풀 페이지에서 Thinly provisioned LVM2 논리 볼륨 섹션으로 스크롤하고 논리 볼륨 옆에 있는 메뉴 버튼 Cryostat를 클릭합니다.
드롭다운 메뉴에서 스냅샷 생성 을 선택합니다.

이름 필드에 스냅샷 이름을 입력합니다.

- 을 클릭합니다.
- 씬 프로비저닝된 LVM2 논리 볼륨 풀 페이지에서 Thinly provisioned LVM2 논리 볼륨 섹션으로 스크롤하고 새로 생성된 스냅샷 옆에 있는 메뉴 버튼 Cryostat를 클릭합니다.
드롭다운 메뉴에서 활성화를 선택하여 볼륨을 활성화합니다.
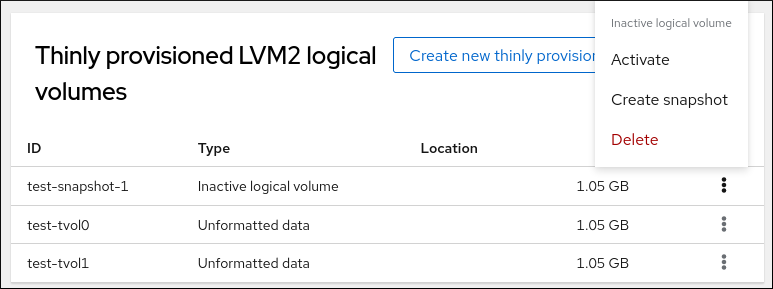
67.10. 캐시를 활성화하여 논리 볼륨 성능을 개선
LVM 논리 볼륨에 캐싱을 추가하여 성능을 향상시킬 수 있습니다. 그런 다음 LVM은 SSD와 같은 빠른 장치를 사용하여 I/O 작업을 논리 볼륨에 캐시합니다.
다음 절차에서는 빠른 장치에서 특수 LV를 생성하고 이 특수 LV를 원래 LV에 연결하여 성능을 향상시킵니다.
67.10.1. LVM의 캐싱 방법
LVM은 다음과 같은 종류의 캐싱을 제공합니다. 각각 논리 볼륨의 다양한 종류의 I/O 패턴에 적합합니다.
dm-cache이 방법은 더 빠른 볼륨에 캐싱하여 자주 사용하는 데이터에 대한 액세스를 가속화합니다. 메서드는 읽기 및 쓰기 작업을 모두 캐시합니다.
dm-메서드는 유형 캐시의 논리 볼륨을 생성합니다.cachedm-writecache이 방법은 쓰기 작업만 캐시합니다. 더 빠른 볼륨은 쓰기 작업을 저장한 다음 백그라운드에서 느린 디스크로 마이그레이션합니다. 더 빠른 볼륨은 일반적으로 SSD 또는 PMEM(영구 메모리) 디스크입니다.
dm-writecache메서드는writecache유형의 논리 볼륨을 생성합니다.
67.10.2. LVM 캐싱 구성 요소
LVM은 LVM 논리 볼륨에 캐시를 추가할 수 있도록 지원합니다. LVM 캐싱은 다음 LVM 논리 볼륨 유형을 사용합니다.
- Main LV
- 큰, 느린, 원래 볼륨입니다.
- 캐시 풀 LV
-
기본 LV에서 데이터를 캐싱하는 데 사용할 수 있는 복합 LV입니다. 두 개의 하위 LV가 있습니다. 캐시 데이터를 관리하기 위한 데이터와 캐시 데이터를 관리하기 위한 데이터입니다. 데이터 및 메타데이터에 대해 특정 디스크를 구성할 수 있습니다. 캐시 풀은
dm-cache에서만 사용할 수 있습니다. - Cachevol LV
-
기본 LV에서 데이터를 캐싱하는 데 사용할 수 있는 선형 LV입니다. 데이터 및 메타데이터에 대해 별도의 디스크를 구성할 수 없습니다.
cachevol은dm-cache또는dm-writecache에서만 사용할 수 있습니다.
연결된 모든 LV는 동일한 볼륨 그룹에 있어야 합니다.
일반적으로 캐시된 데이터를 보유하는 더 빠르고 작은 LV와 기본 논리 볼륨(LV)을 결합할 수 있습니다. 빠른 LV는 SSD 드라이브와 같은 빠른 블록 장치에서 생성됩니다. 논리 볼륨에 대한 캐싱을 활성화하면 LVM에서 원래 볼륨의 이름을 바꾸고 숨기고 원래 논리 볼륨으로 구성된 새 논리 볼륨을 제공합니다. 새 논리 볼륨의 구성은 캐싱 방법 및 cachevol 또는 cachepool 옵션을 사용하는지에 따라 다릅니다.
cachevol 및 cachepool 옵션은 캐싱 구성 요소의 배치에 대해 다양한 수준의 제어 권한을 노출합니다.
-
cachevol옵션을 사용하면 더 빠른 장치는 캐시된 데이터 블록 복사본과 캐시 관리를 위한 메타데이터를 모두 저장합니다. cachepool옵션을 사용하면 별도의 장치가 데이터 블록의 캐시된 복사본과 캐시를 관리하기 위한 메타데이터를 저장할 수 있습니다.dm-writecache방법은cachepool과 호환되지 않습니다.
모든 구성에서 LVM은 모든 캐싱 구성 요소를 그룹화하는 단일 결과 장치를 노출합니다. 결과 장치의 이름은 원본 느린 논리 볼륨과 동일합니다.
67.10.3. 논리 볼륨의 dm-cache 캐싱 활성화
이 절차에서는 dm-cache 방법을 사용하여 논리 볼륨에서 일반적으로 사용되는 데이터의 캐싱을 활성화합니다.
사전 요구 사항
-
dm-cache를 사용하여 속도를 높이려는 느린 논리 볼륨이 시스템에 존재합니다. - 느린 논리 볼륨이 포함된 볼륨 그룹에는 빠른 블록 장치에 사용되지 않은 물리 볼륨도 포함되어 있습니다.
절차
빠른 장치에
cachevol볼륨을 생성합니다.lvcreate --size cachevol-size --name <fastvol> <vg> </dev/fast-pv>
# lvcreate --size cachevol-size --name <fastvol> <vg> </dev/fast-pv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
cachevol-size-
cachevol볼륨의 크기(예:5G) fastvol-
cachevol볼륨의 이름 vg- 볼륨 그룹 이름
/dev/fast-pv빠른 블록 장치의 경로(예:
/dev/sdf)예 67.3.
cachevol볼륨 생성lvcreate --size 5G --name fastvol vg /dev/sdf Logical volume "fastvol" created.
# lvcreate --size 5G --name fastvol vg /dev/sdf Logical volume "fastvol" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cachevol볼륨을 기본 논리 볼륨에 연결하여 캐싱을 시작합니다.lvconvert --type cache --cachevol <fastvol> <vg/main-lv>
# lvconvert --type cache --cachevol <fastvol> <vg/main-lv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
fastvol-
cachevol볼륨의 이름 vg- 볼륨 그룹 이름
main-lv느린 논리 볼륨의 이름
예 67.4. 기본 LV에
cachevol볼륨 연결lvconvert --type cache --cachevol fastvol vg/main-lv Erase all existing data on vg/fastvol? [y/n]: y Logical volume vg/main-lv is now cached.
# lvconvert --type cache --cachevol fastvol vg/main-lv Erase all existing data on vg/fastvol? [y/n]: y Logical volume vg/main-lv is now cached.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
새로 생성된 논리 볼륨에
dm-cache가 활성화되어 있는지 확인합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.10.4. 논리 볼륨의 cachepool을 사용하여 dm-cache 캐싱 활성화
이 절차를 통해 캐시 데이터와 캐시 메타데이터 논리 볼륨을 개별적으로 생성한 다음 볼륨을 캐시 풀로 결합할 수 있습니다.
사전 요구 사항
-
dm-cache를 사용하여 속도를 높이려는 느린 논리 볼륨이 시스템에 존재합니다. - 느린 논리 볼륨이 포함된 볼륨 그룹에는 빠른 블록 장치에 사용되지 않은 물리 볼륨도 포함되어 있습니다.
절차
빠른 장치에
cachepool볼륨을 생성합니다.lvcreate --type cache-pool --size <cachepool-size> --name <fastpool> <vg /dev/fast>
# lvcreate --type cache-pool --size <cachepool-size> --name <fastpool> <vg /dev/fast>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
cachepool-size-
캐시 풀의 크기(예:5G) fastpool-
cachepool볼륨의 이름 vg- 볼륨 그룹 이름
/dev/fast빠른 블록 장치의 경로(예:
/dev/sdf1)참고cache-pool을 생성할 때
--poolmetadata옵션을 사용하여 풀 메타데이터의 위치를 지정할 수 있습니다.예 67.5.
cachepool볼륨 생성lvcreate --type cache-pool --size 5G --name fastpool vg /dev/sde Logical volume "fastpool" created.
# lvcreate --type cache-pool --size 5G --name fastpool vg /dev/sde Logical volume "fastpool" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
캐시 풀을 기본 논리 볼륨에 연결하여 캐싱을 시작합니다.lvconvert --type cache --cachepool <fastpool> <vg/main>
# lvconvert --type cache --cachepool <fastpool> <vg/main>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
fastpool-
cachepool볼륨의 이름 vg- 볼륨 그룹 이름
main느린 논리 볼륨의 이름
예 67.6. 기본 LV에
cachepool연결lvconvert --type cache --cachepool fastpool vg/main Do you want wipe existing metadata of cache pool vg/fastpool? [y/n]: y Logical volume vg/main is now cached.
# lvconvert --type cache --cachepool fastpool vg/main Do you want wipe existing metadata of cache pool vg/fastpool? [y/n]: y Logical volume vg/main is now cached.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
cache-pool유형을 사용하여 새로 생성된 devicevolume을 검사합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.10.5. 논리 볼륨의 dm-writecache 캐싱 활성화
이 절차에서는 dm-writecache 방법을 사용하여 논리 볼륨에 쓰기 I/O 작업을 캐시할 수 있습니다.
사전 요구 사항
-
dm-writecache를 사용하여 속도를 높이려는 느린 논리 볼륨이 시스템에 존재합니다. - 느린 논리 볼륨이 포함된 볼륨 그룹에는 빠른 블록 장치에 사용되지 않은 물리 볼륨도 포함되어 있습니다.
- 느린 논리 볼륨이 활성 상태인 경우 비활성화합니다.
프로세스
느린 논리 볼륨이 활성 상태인 경우 비활성화합니다.
lvchange --activate n <vg>/<main-lv>
# lvchange --activate n <vg>/<main-lv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
vg- 볼륨 그룹 이름
main-lv- 느린 논리 볼륨의 이름
빠른 장치에 비활성화된
cachevol볼륨을 생성합니다.lvcreate --activate n --size <cachevol-size> --name <fastvol> <vg> </dev/fast-pv>
# lvcreate --activate n --size <cachevol-size> --name <fastvol> <vg> </dev/fast-pv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
cachevol-size-
cachevol볼륨의 크기(예:5G) fastvol-
cachevol볼륨의 이름 vg- 볼륨 그룹 이름
/dev/fast-pv빠른 블록 장치의 경로(예:
/dev/sdf)예 67.7. 비활성화된
cachevol볼륨 생성lvcreate --activate n --size 5G --name fastvol vg /dev/sdf WARNING: Logical volume vg/fastvol not zeroed. Logical volume "fastvol" created.
# lvcreate --activate n --size 5G --name fastvol vg /dev/sdf WARNING: Logical volume vg/fastvol not zeroed. Logical volume "fastvol" created.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
cachevol볼륨을 기본 논리 볼륨에 연결하여 캐싱을 시작합니다.lvconvert --type writecache --cachevol <fastvol> <vg/main-lv>
# lvconvert --type writecache --cachevol <fastvol> <vg/main-lv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
fastvol-
cachevol볼륨의 이름 vg- 볼륨 그룹 이름
main-lv느린 논리 볼륨의 이름
예 67.8. 기본 LV에
cachevol볼륨 연결Copy to Clipboard Copied! Toggle word wrap Toggle overflow
결과 논리 볼륨을 활성화합니다.
lvchange --activate y <vg/main-lv>
# lvchange --activate y <vg/main-lv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
vg- 볼륨 그룹 이름
main-lv- 느린 논리 볼륨의 이름
검증
새로 생성된 장치를 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.10.6. 논리 볼륨의 캐싱 비활성화
이 절차에서는 현재 논리 볼륨에서 활성화된 dm-cache 또는 dm-writecache 캐싱을 비활성화합니다.
사전 요구 사항
- 논리 볼륨에서 캐싱이 활성화됩니다.
프로세스
논리 볼륨을 비활성화합니다.
lvchange --activate n <vg>/<main-lv>
# lvchange --activate n <vg>/<main-lv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow Cryo stat 를 볼륨 그룹 이름으로 바꾸고 main-lv 를 캐싱이 활성화된 논리 볼륨의 이름으로 바꿉니다.
cachevol또는cachepool볼륨을 분리합니다.lvconvert --splitcache <vg>/<main-lv>
# lvconvert --splitcache <vg>/<main-lv>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 값을 바꿉니다.
Cryo stat 를 볼륨 그룹 이름으로 바꾸고 main-lv 를 캐싱이 활성화된 논리 볼륨의 이름으로 바꿉니다.
예 67.9.
cachevol또는cachepool볼륨 분리lvconvert --splitcache vg/main-lv Detaching writecache already clean. Logical volume vg/main-lv writecache has been detached.
# lvconvert --splitcache vg/main-lv Detaching writecache already clean. Logical volume vg/main-lv writecache has been detached.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
논리 볼륨이 더 이상 연결되어 있지 않은지 확인합니다.
lvs --all --options +devices <vg> LV Attr Type Devices fastvol -wi------- linear /dev/fast-pv main-lv -wi------- linear /dev/slow-pv
# lvs --all --options +devices <vg> LV Attr Type Devices fastvol -wi------- linear /dev/fast-pv main-lv -wi------- linear /dev/slow-pvCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.11. 논리 볼륨 활성화
기본적으로 논리 볼륨을 생성할 때 활성 상태입니다. 활성 상태인 논리 볼륨은 블록 장치를 통해 사용할 수 있습니다. 활성화된 논리 볼륨에 액세스할 수 있으며 변경될 수 있습니다.
개별 논리 볼륨을 비활성화하여 커널에 알 수 없는 경우 다양한 상황이 있습니다. lvchange 명령의 -a 옵션을 사용하여 개별 논리 볼륨을 활성화하거나 비활성화할 수 있습니다.
다음은 개별 논리 볼륨을 비활성화하는 형식입니다.
lvchange -an vg/lv
# lvchange -an vg/lv다음은 개별 논리 볼륨을 활성화하는 형식입니다.
lvchange -ay vg/lv
# lvchange -ay vg/lv
Cryostat change 명령의 -a 옵션을 사용하여 볼륨 그룹의 모든 논리 볼륨을 활성화하거나 비활성화할 수 있습니다. 이는 볼륨 그룹의 각 개별 논리 볼륨에서 lvchange -a 명령을 실행하는 것과 동일합니다.
다음은 볼륨 그룹의 모든 논리 볼륨을 비활성화하는 형식입니다.
vgchange -an vg
# vgchange -an vg다음은 볼륨 그룹의 모든 논리 볼륨을 활성화하는 형식입니다.
vgchange -ay vg
# vgchange -ay vg
수동 활성화 중에 장치를 마스킹하지 않는 한 systemd는 systemd -mount/etc/fstab 파일에서 해당 마운트 지점을 사용하여 LVM 볼륨을 자동으로 마운트합니다.
67.11.1. 논리 볼륨 및 볼륨 그룹의 자동 활성화 제어
논리 볼륨의 AutoActivation은 시스템을 시작하는 동안 논리 볼륨의 이벤트 기반 자동 활성화를 나타냅니다. 장치가 시스템(장치 온라인 이벤트)에서 사용 가능하게 되면 systemd/udev 는 각 장치에 대해 lvm2-pvscan 서비스를 실행합니다. 이 서비스는 named 장치를 읽는 pvscan --cache -aay device 명령을 실행합니다. 장치가 볼륨 그룹에 속하는 경우 pvscan 명령은 해당 볼륨 그룹의 모든 물리 볼륨이 시스템에 있는지 확인합니다. 이 경우 명령은 해당 볼륨 그룹에서 논리 볼륨을 활성화합니다.
VG 또는 LV에서 autoactivation 속성을 설정할 수 있습니다. autoactivation 속성이 비활성화되면 -aay 옵션을 사용하여 자동 활성화를 수행하는 명령으로 VG 또는 LV가 활성화되지 않습니다(예: -aay 옵션). VG에서 자동 활성화를 비활성화하면 해당 VG에서 LV가 자동으로 활성화되지 않으며 autoactivation 속성이 적용되지 않습니다. VG에서 자동 활성화가 활성화된 경우 개별 LV에 대해 자동 활성화를 비활성화할 수 있습니다.
프로세스
다음 방법 중 하나로 자동 활성화 설정을 업데이트할 수 있습니다.
명령줄을 사용하여 VG의 자동 활성화를 제어합니다.
vgchange --setautoactivation <y|n>
# vgchange --setautoactivation <y|n>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령줄을 사용하여 LV 자동 활성화를 제어합니다.
lvchange --setautoactivation <y|n>
# lvchange --setautoactivation <y|n>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 구성 옵션 중 하나를 사용하여
/etc/lvm/lvm.conf구성 파일에서 LV 자동 활성화를 제어합니다.global/event_activationevent_activation이 비활성화되면systemd/udev는 시스템을 시작하는 동안 물리적 볼륨이 모두 있는 논리 볼륨만 자동으로 활성화합니다. 모든 물리 볼륨이 아직 나타나지 않은 경우 일부 논리 볼륨이 자동으로 활성화되지 않을 수 있습니다.activation/auto_activation_volume_listauto_activation_volume_list를 빈 목록으로 설정하면 자동 활성화가 완전히 비활성화됩니다.auto_activation_volume_list를 특정 논리 볼륨 및 볼륨 그룹으로 설정하면 해당 논리 볼륨으로 자동 활성화가 제한됩니다.
67.11.2. 논리 볼륨 활성화 제어
다음과 같은 방법으로 논리 볼륨의 활성화를 제어할 수 있습니다.
-
/etc/lvm/conf파일의activation/volume_list설정을 통해 다음을 수행합니다. 이를 통해 활성화할 논리 볼륨을 지정할 수 있습니다. 이 옵션 사용에 대한 자세한 내용은/etc/lvm/lvm.conf구성 파일을 참조하십시오. - 논리 볼륨의 활성화 건너뛰기 플래그를 의미합니다. 이 플래그가 논리 볼륨에 대해 설정되면 일반 활성화 명령 중에 볼륨을 건너뜁니다.
또는 lvcreate 또는 lvchange 명령에 --setactivationskip y|n 옵션을 사용하여 활성화 건너뛰기 플래그를 활성화하거나 비활성화할 수 있습니다.
프로세스
다음과 같은 방법으로 논리 볼륨에 활성화 건너뛰기 플래그를 설정할 수 있습니다.
논리 볼륨에 활성화 건너뛰기 플래그가 설정되어 있는지 확인하려면 다음 예와 같이
k속성을 표시하는lvs명령을 실행합니다.lvs vg/thin1s1 LV VG Attr LSize Pool Origin thin1s1 vg Vwi---tz-k 1.00t pool0 thin1
# lvs vg/thin1s1 LV VG Attr LSize Pool Origin thin1s1 vg Vwi---tz-k 1.00t pool0 thin1Copy to Clipboard Copied! Toggle word wrap Toggle overflow standard
-ay또는--activate y옵션 외에도-K또는--ignoreactivationskip옵션을 사용하여k속성이 설정된 논리 볼륨을 활성화할 수 있습니다.기본적으로 씬 스냅샷 볼륨은 활성화 건너뛸 때 플래그가 지정됩니다.
/etc/lvm/lvm.conf파일의auto_set_activation_skip설정을 사용하여 새 thin 스냅샷 볼륨에서 기본 활성화 건너뛰기 설정을 제어할 수 있습니다.다음 명령은 activation skip 플래그가 설정된 thin snapshot 논리 볼륨을 활성화합니다.
lvchange -ay -K VG/SnapLV
# lvchange -ay -K VG/SnapLVCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령은 활성화 skip 플래그 없이 thin 스냅샷을 생성합니다.
lvcreate -n SnapLV -kn -s vg/ThinLV --thinpool vg/ThinPoolLV
# lvcreate -n SnapLV -kn -s vg/ThinLV --thinpool vg/ThinPoolLVCopy to Clipboard Copied! Toggle word wrap Toggle overflow 다음 명령은 스냅샷 논리 볼륨에서 활성화 skip 플래그를 제거합니다.
lvchange -kn VG/SnapLV
# lvchange -kn VG/SnapLVCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
활성화 건너뛰기 플래그가 없는 thin 스냅샷이 생성되었는지 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.11.3. 공유 논리 볼륨 활성화
다음과 같이 lvchange 및 Cryostat change 명령의 -a 옵션을 사용하여 공유 논리 볼륨의 논리 볼륨 활성화를 제어할 수 있습니다.
| 명령 | 활성화 |
|---|---|
|
| 공유 논리 볼륨을 배타적 모드로 활성화하여 단일 호스트만 논리 볼륨을 활성화할 수 있습니다. 활성화에 실패하면 논리 볼륨이 다른 호스트에서 활성 상태이면 오류가 보고됩니다. |
|
| 공유 모드에서 공유 논리 볼륨을 활성화하여 여러 호스트가 논리 볼륨을 동시에 활성화할 수 있습니다. 논리 볼륨이 다른 호스트에서 독점적으로 활성화되어 있는 경우와 같이 활성화에 실패하면 오류가 보고됩니다. 논리 유형이 스냅샷과 같은 공유 액세스를 금지하는 경우 명령에서 오류를 보고하고 실패합니다. 여러 호스트에서 동시에 사용할 수 없는 논리 볼륨 유형에는 thin, cache, raid 및 snapshot이 포함됩니다. |
|
| 논리 볼륨을 비활성화합니다. |
67.11.4. 누락된 장치를 사용하여 논리 볼륨 활성화
lvchange 명령을 --activationmode partial|degraded|complete 옵션과 함께 사용하여 장치 누락된 LV를 활성화할 수 있는지 여부를 제어할 수 있습니다. 값은 다음과 같습니다.
| 활성화 모드 | 의미 |
|---|---|
| 완료 | 누락된 물리 볼륨이 없는 논리 볼륨만 활성화할 수 있습니다. 이것이 가장 제한적인 모드입니다. |
| Degraded | 물리 볼륨이 누락된 RAID 논리 볼륨을 활성화할 수 있습니다. |
| 부분적 | 누락된 물리 볼륨이 있는 모든 논리 볼륨을 활성화할 수 있습니다. 이 옵션은 복구 또는 복구에만 사용해야 합니다. |
활성화 모드 의 기본값은 /etc/lvm/lvm.conf 파일의 activationmode 설정에 따라 결정됩니다. 명령줄 옵션이 제공되지 않는 경우 사용됩니다.
67.12. LVM 장치 가시성 및 사용 제한
LVM에서 스캔할 수 있는 장치를 제어하여 LVM에서 볼 수 있고 LVM(Logical Volume Manager)에 사용 가능한 장치를 제한할 수 있습니다.
LVM 장치 검사 구성을 조정하려면 /etc/lvm/lvm.conf 파일의 LVM 장치 필터 설정을 편집합니다. lvm.conf 파일의 필터는 일련의 간단한 정규식으로 구성됩니다. 시스템은 /dev 디렉토리의 각 장치 이름에 이러한 표현식을 적용하여 감지된 각 블록 장치를 수락하거나 거부할지 결정합니다.
67.12.1. LVM 필터링을 위한 영구 식별자
/dev/sda 와 같은 기존 Linux 장치 이름은 시스템을 수정하고 재부팅하는 동안 변경될 수 있습니다. WWID(WWID), UUID(Universally Unique Identifier) 및 경로 이름과 같은 PNA(영구 이름 지정 속성)는 스토리지 장치의 고유한 특성을 기반으로 하며 하드웨어 구성 변경에 탄력적입니다. 이로 인해 시스템 재부팅 시 보다 안정적이고 예측 가능합니다.
LVM 필터링에 영구 장치 식별자를 구현하면 LVM 구성의 안정성과 안정성이 향상됩니다. 또한 장치 이름의 동적 특성과 관련된 시스템 부팅 실패의 위험을 줄입니다.
67.12.2. LVM 장치 필터
LVM(Logical Volume Manager) 장치 필터는 장치 이름 패턴 목록입니다. 이를 사용하여 시스템에서 장치를 평가하고 LVM에 사용하기 위해 유효한 것으로 간주할 수 있는 필수 기준 집합을 지정할 수 있습니다. LVM 장치 필터를 사용하면 LVM에서 사용하는 장치를 제어할 수 있습니다. 이는 실수로 데이터 손실 또는 저장 장치에 대한 무단 액세스를 방지하는 데 도움이 될 수 있습니다.
67.12.2.1. LVM 장치 필터 패턴 특성
LVM 장치 필터 패턴은 정규식 형태로 제공됩니다. 정규 표현식은 문자와 함께 제한되고 허용을 위해 a 또는 r 거부로 시작합니다. 장치와 일치하는 목록의 첫 번째 정규식은 LVM이 특정 장치를 수락하거나 거부(무시)할지 결정합니다. 그런 다음 LVM은 장치의 경로와 일치하는 목록에서 초기 정규 표현식을 찾습니다. LVM에서는 이 정규식을 사용하여 결과를 사용하여 장치를 승인해야 하는지 또는 r 결과에서 거부해야 하는지 여부를 결정합니다.
단일 장치에 여러 경로 이름이 있는 경우 LVM은 목록 순서에 따라 이러한 경로 이름에 액세스합니다. r 패턴 전에 하나 이상의 경로 이름이 패턴과 일치하는 경우 LVM에서 장치를 승인합니다. 그러나 패턴을 발견하기 전에 모든 경로 이름이 r 패턴과 일치하는 경우 장치가 거부됩니다.
패턴과 일치하지 않는 경로 이름은 장치의 승인 상태에 영향을 미치지 않습니다. 경로 이름이 장치의 패턴에 일치하지 않는 경우 LVM은 계속 장치를 승인합니다.
시스템의 각 장치에 대해 udev 규칙은 여러 심볼릭 링크를 생성합니다. 디렉터리에는 /dev/disk/by-id/, /dev/disk/by-uuid/, /dev/disk/by-path/ 와 같은 심볼릭 링크가 있어 시스템의 각 장치에 여러 경로 이름을 통해 액세스할 수 있습니다.
필터에서 장치를 거부하려면 특정 장치와 연결된 모든 경로 이름이 해당 reject r 표현식과 일치해야 합니다. 그러나 거부에 대해 가능한 모든 경로 이름을 식별하는 것은 어려울 수 있습니다. 따라서 특정 경로를 특별히 수락하고 모든 경로를 거부하는 일련의 특정 표현식과 단일 r|.*| 표현식을 사용하여 다른 경로를 거부하는 필터를 생성하는 것이 좋습니다.
필터에 특정 장치를 정의하는 동안 커널 이름 대신 해당 장치에 심볼릭 링크 이름을 사용합니다. 장치의 커널 이름은 /dev/sda 와 같이 변경될 수 있지만 특정 심볼릭 링크 이름은 /dev/disk/by-id/wwn-* 와 같이 변경되지 않습니다.
기본 장치 필터는 시스템에 연결된 모든 장치를 허용합니다. 이상적인 사용자 구성 장치 필터는 하나 이상의 패턴을 수락하고 다른 모든 패턴을 거부합니다. 예를 들어 r|.*| 로 끝나는 패턴 목록은 다음과 같습니다.
lvm.conf 파일의 devices/filter 및 devices/global_filter 구성 필드에서 LVM 장치 필터 구성을 찾을 수 있습니다. devices/filter 및 devices/global_filter 구성 필드는 동일합니다.
67.12.2.2. LVM 장치 필터 구성의 예
다음 예제에서는 LVM에서 나중에 스캔하고 사용하는 장치를 제어하는 필터 구성을 표시합니다. lvm.conf 파일에서 장치 필터를 구성하려면 다음을 참조하십시오.
복사 또는 복제된 PV를 처리할 때 중복된 PV(물리 볼륨) 경고가 표시될 수 있습니다. 이 문제를 해결하기 위해 필터를 설정할 수 있습니다. 중복 PV 경고를 방지하는 Example LVM 장치 필터의 예제 필터 구성을 참조하십시오.
모든 장치를 스캔하려면 다음을 입력합니다.
filter = [ "a|.*|" ]
filter = [ "a|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 드라이브에 미디어가 없는 경우 지연을 방지하기 위해
cdrom장치를 제거하려면 다음을 입력합니다.filter = [ "r|^/dev/cdrom$|" ]
filter = [ "r|^/dev/cdrom$|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 루프 장치를 추가하고 다른 모든 장치를 제거하려면 다음을 입력합니다.
filter = [ "a|loop|", "r|.*|" ]
filter = [ "a|loop|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 루프 및 SCSI 장치를 추가하고 다른 모든 블록 장치를 제거하려면 다음을 입력합니다.
filter = [ "a|loop|", "a|/dev/sd.*|", "r|.*|" ]
filter = [ "a|loop|", "a|/dev/sd.*|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 첫 번째 SCSI 드라이브에 파티션 8만 추가하고 다른 모든 블록 장치를 제거하려면 다음을 입력합니다.
filter = [ "a|^/dev/sda8$|", "r|.*|" ]
filter = [ "a|^/dev/sda8$|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 다중 경로 장치와 함께 WWID로 식별되는 특정 장치의 모든 파티션을 추가하려면 다음을 입력합니다.
filter = [ "a|/dev/disk/by-id/<disk-id>.|", "a|/dev/mapper/mpath.|", "r|.*|" ]
filter = [ "a|/dev/disk/by-id/<disk-id>.|", "a|/dev/mapper/mpath.|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 명령은 다른 블록 장치도 제거합니다.
67.12.2.3. LVM 장치 필터 구성 적용
lvm.conf 구성 파일에서 필터를 설정하여 LVM 스캔 장치를 제어할 수 있습니다.
사전 요구 사항
- 사용하려는 장치 필터 패턴을 준비했습니다.
절차
/etc/lvm/lvm.conf파일을 실제로 수정하지 않고 다음 명령을 사용하여 장치 필터 패턴을 테스트합니다. 다음은 필터 구성 예제를 포함합니다.lvs --config 'devices{ filter = [ "a|/dev/emcpower.|", "r|.|" ] }'# lvs --config 'devices{ filter = [ "a|/dev/emcpower.|", "r|.|" ] }'Copy to Clipboard Copied! Toggle word wrap Toggle overflow /etc/lvm/lvm.conf파일의 구성 섹션장치에 장치필터 패턴을 추가합니다.filter = [ "a|/dev/emcpower.*|", "r|*.|" ]
filter = [ "a|/dev/emcpower.*|", "r|*.|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 재부팅 시 필요한 장치만 스캔합니다.
dracut --force --verbose
# dracut --force --verboseCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 시스템을 재부팅할 때 LVM이 필요한 장치만 검사하도록
initramfs파일 시스템을 다시 빌드합니다.
67.13. LVM 할당 제어
기본적으로 볼륨 그룹은 일반 할당 정책을 사용합니다. 이렇게 하면 동일한 물리 볼륨에 병렬 스트라이프를 배치하지 않는 등의 공통 밀도 규칙에 따라 물리 확장 영역을 할당합니다. Cryostat create 명령의 수 있습니다. 일반적으로 일반 이외의 할당 정책은 비정상적 또는 비표준 범위 할당을 지정해야 하는 특수한 경우에만 필요합니다. --alloc 인수를 사용하여 다른 할당 정책(,연속적인 ,어디에서나 )을 지정할
67.13.1. 지정된 장치의 확장 영역 할당
명령줄 끝에 있는 장치 인수를 lvcreate 및 lvconvert 명령과 함께 사용하여 특정 장치에서 할당을 제한할 수 있습니다. 더 많은 제어를 위해 각 장치의 실제 범위 범위를 지정할 수 있습니다. 명령은 지정된 물리 볼륨(PV)을 인수로 사용하여 새 논리 볼륨(LV)에 대한 Extent만 할당합니다. 각 PV에서 사용 가능한 확장 영역을 실행한 다음 나열된 다음 PV의 확장 영역을 사용합니다. 요청된 LV 크기에 나열된 모든 PV에 공간이 충분하지 않으면 명령이 실패합니다. 이 명령은 이름이 지정된 PV에서만 할당합니다. RAID LV는 별도의 raid 이미지 또는 별도의 스트라이프에 순차적 PV를 사용합니다. 전체 RAID 이미지에 PV가 충분히 크지 않으면 결과 장치 사용을 완전히 예측할 수 없습니다.
프로세스
볼륨 그룹(VG)을 생성합니다.
vgcreate <vg_name> <PV> ...
# vgcreate <vg_name> <PV> ...Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음과 같습니다.
-
<VG_NAME>은 VG의 이름입니다. -
&
lt;PV>는 PV입니다.
-
PV를 할당하여 선형 또는 raid와 같은 다양한 볼륨 유형을 생성할 수 있습니다.
확장 영역을 할당하여 선형 볼륨을 만듭니다.
lvcreate -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]
# lvcreate -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음과 같습니다.
-
<lv_name>is the name of the LV. -
<lv_size>는 LV의 크기입니다. 기본 단위는 메가바이트입니다. -
<VG_NAME>은 VG의 이름입니다. [ <PV …> ]는 PV입니다.PV 중 하나, 모두 또는 명령줄에서 none을 지정할 수 있습니다.
하나의 PV를 지정하면 해당 LV의 확장 영역이 할당됩니다.
참고PV에 전체 LV에 사용 가능한 확장 영역이 충분하지 않으면
lvcreate이 실패합니다.- 두 PV를 지정하면 해당 LV의 확장 영역이 해당 LV 중 하나에서 할당되거나 둘 다 조합됩니다.
PV를 지정하지 않으면 VG의 PV 중 하나 또는 VG에 있는 모든 PV의 조합에서 Extent가 할당됩니다.
참고이 경우 LVM에서 이름이 지정된 PV 또는 사용 가능한 PV를 모두 사용하지 못할 수 있습니다. 첫 번째 PV에 전체 LV에 사용 가능한 확장 영역이 충분한 경우 다른 PV가 사용되지 않을 수 있습니다. 그러나 첫 번째 PV의 할당 크기가 설정된 여유 Extent가 없는 경우 LV는 첫 번째 PV에서 부분적으로 할당되고 두 번째 PV에서 부분적으로 할당될 수 있습니다.
예 67.10. 하나의 PV에서 확장 영역 할당
이 예에서는
lv1Extent가sda에서 할당됩니다.lvcreate -n lv1 -L1G vg /dev/sda
# lvcreate -n lv1 -L1G vg /dev/sdaCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.11. 두 PV의 확장 영역 할당
이 예에서
lv2Extent는sda또는sdb또는 둘 다 조합에서 할당됩니다.lvcreate -n lv2 L1G vg /dev/sda /dev/sdb
# lvcreate -n lv2 L1G vg /dev/sda /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.12. PV를 지정하지 않고 확장 영역 할당
이 예에서
lv3Extent는 VG의 PV 중 하나 또는 VG에 있는 모든 PV의 조합에서 할당됩니다.lvcreate -n lv3 -L1G vg
# lvcreate -n lv3 -L1G vgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 또는
-
확장 영역을 할당하여 raid 볼륨을 생성합니다.
lvcreate --type <segment_type> -m <mirror_images> -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]
# lvcreate --type <segment_type> -m <mirror_images> -n <lv_name> -L <lv_size> <vg_name> [ <PV> ... ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음과 같습니다.
-
<segment_type>은 지정된 세그먼트 유형입니다(예:raid5,mirror,snapshot). -
<mirror_images>는 지정된 수의 이미지를 사용하여raid1또는 미러링된 LV를 생성합니다. 예를 들어-m 1을 사용하면 두 개의 이미지가 있는raid1LV가 생성됩니다. -
<lv_name>is the name of the LV. -
<lv_size>는 LV의 크기입니다. 기본 단위는 메가바이트입니다. -
<VG_NAME>은 VG의 이름입니다. <[PV …]>는 PV입니다.첫 번째 RAID 이미지는 첫 번째 PV, 두 번째 PV의 두 번째 raid 이미지 등에서 할당됩니다.
예 67.13. 두 PV에서 raid 이미지 할당
이 예에서
lv4첫 번째 raid 이미지는sda에서 할당되고 두 번째 이미지는sdb에서 할당됩니다.lvcreate --type raid1 -m 1 -n lv4 -L1G vg /dev/sda /dev/sdb
# lvcreate --type raid1 -m 1 -n lv4 -L1G vg /dev/sda /dev/sdbCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.14. 세 PV에서 raid 이미지 할당
이 예에서
lv5첫 번째 raid 이미지는sda에서 할당되고 두 번째 이미지는sdb에서 할당되고, 세 번째 이미지는sdc에서 할당됩니다.lvcreate --type raid1 -m 2 -n lv5 -L1G vg /dev/sda /dev/sdb /dev/sdc
# lvcreate --type raid1 -m 2 -n lv5 -L1G vg /dev/sda /dev/sdb /dev/sdcCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
67.13.2. LVM 할당 정책
LVM 작업에서 하나 이상의 논리 볼륨(LV)에 물리 확장 영역을 할당해야 하는 경우 할당은 다음과 같이 진행됩니다.
- 볼륨 그룹에서 할당되지 않은 물리 확장 영역의 전체 세트가 검토를 위해 생성됩니다. 명령줄 끝에 물리 확장 영역 범위를 제공하는 경우 지정된 PV(물리 볼륨)에서 해당 범위 내에서 할당되지 않은 물리 확장 영역만 고려합니다.
-
각 할당 정책은 가장 엄격한 정책(지속적인 )부터 시작하여
--alloc옵션을 사용하여 지정된 할당 정책으로 끝나거나 특정 LV 또는 볼륨 그룹(VG)의 기본값으로 설정됩니다.각 정책에 대해 할당 정책에 따른 제한 사항에 따라 가능한 한 많은 공간을 채워야 하는 빈 LV 공간의 가장 낮은 숫자 논리 범위에서 작업하는 것이 좋습니다. 더 많은 공간이 필요한 경우 LVM은 다음 정책으로 이동합니다.
할당 정책 제한은 다음과 같습니다.
연속정책을 사용하려면 LV의 첫 번째 논리 범위를 제외하고 논리 영역의 물리적 위치가 바로 앞의 논리 확장 영역의 물리적 위치에 있어야 합니다.LV를 제거하거나 미러링하면
연속할당 제한이 공간이 필요한 각 스트라이프 또는 raid 이미지에 독립적으로 적용됩니다.-
클링할당 정책을 사용하려면 논리 범위에 사용된 PV를 해당 LV에서 하나 이상의 논리 범위에서 이미 사용 중인 기존 LV에 추가해야 합니다. -
일반할당 정책은 해당 병렬 LV 내의 동일한 오프셋에서 병렬 LV(즉, 다른 스트라이프 또는 raid 이미지)에 이미 할당된 논리 범위와 동일한 PV를 공유하는 물리적 범위를 선택하지 않습니다. -
할당 요청을 충족할 수 있는 사용 가능한 확장 영역이 충분하지만
일반할당 정책에서 사용하지 않는 경우 동일한 PV에 두 개의 스트라이프를 배치하여 성능이 저하되더라도 아무나의 할당 정책이 사용됩니다.
Cryostatchange 명령을 사용하여 할당 정책을 변경할 수 있습니다.
향후 업데이트에서는 정의된 할당 정책에 따라 레이아웃 동작에 코드 변경을 가져올 수 있습니다. 예를 들어, 명령줄에서 할당에 사용 가능한 여유 물리 확장 영역이 동일한 두 개의 빈 물리 볼륨을 제공하는 경우 LVM은 현재 나열된 순서대로 각 물리 영역을 사용하는 것을 고려합니다. 향후 릴리스에서는 해당 속성을 유지 관리한다는 보장이 없습니다. 특정 LV에 대한 특정 레이아웃이 필요한 경우 일련의 lvcreate 및 lvconvert 단계를 통해 이를 빌드하여 각 단계에 적용된 할당 정책이 레이아웃에 대한 재량에 관계없이 LVM을 남기지 않도록 합니다.
67.13.3. 물리 볼륨에서 할당 방지
pvchange 명령을 사용하여 하나 이상의 물리 볼륨의 사용 가능한 공간에 물리 확장 영역을 할당하지 못할 수 있습니다. 디스크 오류가 있거나 물리 볼륨을 제거하는 경우 이 작업이 필요할 수 있습니다.
프로세스
다음 명령을 사용하여
device_name에서 물리 확장 영역 할당을 허용하지 않습니다.pvchange -x n /dev/sdk1
# pvchange -x n /dev/sdk1Copy to Clipboard Copied! Toggle word wrap Toggle overflow pvchange명령의-xy인수를 사용하여 이전에 허용하지 않은 위치에서 할당을 허용할 수도 있습니다.
67.14. LVM 문제 해결
LVM(Logical Volume Manager) 툴을 사용하여 LVM 볼륨 및 그룹의 다양한 문제를 해결할 수 있습니다.
67.14.1. LVM에서 진단 데이터 수집
LVM 명령이 예상대로 작동하지 않는 경우 다음과 같은 방법으로 진단을 수집할 수 있습니다.
프로세스
다음 방법을 사용하여 다양한 유형의 진단 데이터를 수집합니다.
-
모든 LVM 명령에
-v인수를 추가하여 명령 출력의 상세 정보 표시 수준을 늘립니다.v를 추가하여 상세 정보를 추가로 늘릴 수 있습니다. 최대 4개의 이러한v가허용됩니다(예:-vvvv). -
/etc/lvm/lvm.conf구성 파일의log섹션에서level옵션의 값을 늘립니다. 이로 인해 LVM에서 시스템 로그에 자세한 정보를 제공합니다. 문제가 논리 볼륨 활성화와 관련된 경우 활성화 중에 LVM을 활성화하여 메시지를 기록합니다.
-
/etc/lvm/lvm.conf구성 파일의log섹션에서activation = 1옵션을 설정합니다. -
-vvv옵션과 함께 LVM 명령을 실행합니다. - 명령 출력을 검사합니다.
활성화옵션을0으로 재설정합니다.옵션을
0으로 재설정하지 않으면 메모리 부족 상황에서 시스템이 응답하지 않을 수 있습니다.
-
진단 목적으로 정보 덤프를 표시합니다.
lvmdump
# lvmdumpCopy to Clipboard Copied! Toggle word wrap Toggle overflow 추가 시스템 정보를 표시합니다.
lvs -v
# lvs -vCopy to Clipboard Copied! Toggle word wrap Toggle overflow pvs --all
# pvs --allCopy to Clipboard Copied! Toggle word wrap Toggle overflow dmsetup info --columns
# dmsetup info --columnsCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
/etc/lvm/backup/디렉토리에서 LVM 메타데이터의 마지막 백업과/etc/lvm/archive/디렉터리에 보관된 버전을 검사합니다. 현재 구성 정보를 확인합니다.
lvmconfig
# lvmconfigCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
/run/lvm/hints캐시 파일이 어떤 장치에 물리 볼륨이 있는지 확인합니다.
-
모든 LVM 명령에
67.14.2. 실패한 LVM 장치에 대한 정보 표시
실패한 LVM(Logical Volume Manager) 볼륨에 대한 문제 해결 정보는 실패 이유를 결정하는 데 도움이 될 수 있습니다. 가장 일반적인 LVM 볼륨 오류의 다음 예제를 확인할 수 있습니다.
예 67.15. 볼륨 그룹 실패
이 예에서는 볼륨 그룹 myvg 를 구성하는 장치 중 하나가 실패했습니다. 그러면 볼륨 그룹 사용성이 실패 유형에 따라 달라집니다. 예를 들어 RAID 볼륨도 관련된 경우에도 볼륨 그룹을 계속 사용할 수 있습니다. 실패한 장치에 대한 정보도 볼 수 있습니다.
예 67.16. 논리 볼륨 실패
이 예에서는 장치 중 하나가 실패했습니다. 이는 볼륨 그룹의 논리 볼륨이 실패하는 이유가 될 수 있습니다. 명령 출력에는 실패한 논리 볼륨이 표시됩니다.
예 67.17. RAID 논리 볼륨의 이미지에 실패함
다음 예제에서는 RAID 논리 볼륨의 이미지가 실패한 경우 pvs 및 lvs 유틸리티의 명령 출력을 보여줍니다. 논리 볼륨은 계속 사용할 수 있습니다.
67.14.3. 볼륨 그룹에서 손실된 LVM 물리 볼륨 제거
물리 볼륨이 실패하면 볼륨 그룹의 나머지 물리 볼륨을 활성화하고 볼륨 그룹에서 해당 물리 볼륨을 사용한 모든 논리 볼륨을 제거할 수 있습니다.
프로세스
볼륨 그룹에서 나머지 물리 볼륨을 활성화합니다.
vgchange --activate y --partial myvg
# vgchange --activate y --partial myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 제거할 논리 볼륨을 확인합니다.
vgreduce --removemissing --test myvg
# vgreduce --removemissing --test myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹에서 손실된 물리 볼륨을 사용한 모든 논리 볼륨을 제거합니다.
vgreduce --removemissing --force myvg
# vgreduce --removemissing --force myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 유지하려는 논리 볼륨을 실수로 제거한 경우 Cryostatreduce 작업을 되돌릴 수 있습니다.
vgcfgrestore myvg
# vgcfgrestore myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 주의씬 풀을 제거하는 경우 LVM에서 작업을 되돌릴 수 없습니다.
67.14.4. 누락된 LVM 물리 볼륨의 메타데이터 검색
볼륨 그룹의 물리 볼륨의 메타데이터 영역이 실수로 덮어쓰거나 다른 방법으로 삭제되면 메타데이터 영역이 잘못되었거나 특정 UUID가 있는 물리 볼륨을 찾을 수 없음을 나타내는 오류 메시지가 표시됩니다.
이 절차에서는 누락되거나 손상된 물리 볼륨의 최신 아카이브 메타데이터를 찾습니다.
프로세스
물리 볼륨이 포함된 볼륨 그룹의 아카이브된 메타데이터 파일을 찾습니다. 보관된 메타데이터 파일은
/etc/lvm/archive/volume-group-name_backup-number.vg경로에 있습니다.cat /etc/lvm/archive/myvg_00000-1248998876.vg
# cat /etc/lvm/archive/myvg_00000-1248998876.vgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 00000-1248998876 을 backup-number로 바꿉니다. 볼륨 그룹에 가장 많은 수가 있는 마지막으로 알려진 유효한 메타데이터 파일을 선택합니다.
물리 볼륨의 UUID를 찾습니다. 다음 방법 중 하나를 사용합니다.
논리 볼륨을 나열합니다.
lvs --all --options +devices Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.
# lvs --all --options +devices Couldn't find device with uuid 'FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk'.Copy to Clipboard Copied! Toggle word wrap Toggle overflow -
보관된 메타데이터 파일을 검사합니다. 볼륨 그룹 구성의
physical_volumes섹션에서id =레이블이 지정된 값으로 UUID를 찾습니다. --partial옵션을 사용하여 볼륨 그룹을 비활성화합니다.Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.5. LVM 물리 볼륨에서 메타데이터 복원
이 절차에서는 손상된 물리 볼륨에서 메타데이터를 복원하거나 새 장치로 교체합니다. 물리 볼륨의 메타데이터 영역을 다시 작성하여 물리 볼륨에서 데이터를 복구할 수 있습니다.
작동 중인 LVM 논리 볼륨에서 이 절차를 시도하지 마십시오. 잘못된 UUID를 지정하면 데이터가 손실됩니다.
사전 요구 사항
- 누락된 물리 볼륨의 메타데이터를 확인했습니다. 자세한 내용은 누락된 LVM 물리 볼륨의 메타데이터 찾기를 참조하십시오.
프로세스
물리 볼륨에서 메타데이터를 복원합니다.
pvcreate --uuid physical-volume-uuid \ --restorefile /etc/lvm/archive/volume-group-name_backup-number.vg \ block-device
# pvcreate --uuid physical-volume-uuid \ --restorefile /etc/lvm/archive/volume-group-name_backup-number.vg \ block-deviceCopy to Clipboard Copied! Toggle word wrap Toggle overflow 참고명령은 LVM 메타데이터 영역만 덮어쓰고 기존 데이터 영역에는 영향을 미치지 않습니다.
예 67.18. /dev/vdb1에서 물리 볼륨 복원
다음 예제에서는 다음 속성을 사용하여
/dev/vdb1장치를 물리 볼륨으로 레이블을 지정합니다.-
FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk의 UUID 볼륨 그룹에 대해 가장 최근의 아카이브 메타데이터인
VG_00050.vg에 포함된 메타데이터 정보pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" \ --restorefile /etc/lvm/archive/VG_00050.vg \ /dev/vdb1 ... Physical volume "/dev/vdb1" successfully created
# pvcreate --uuid "FmGRh3-zhok-iVI8-7qTD-S5BI-MAEN-NYM5Sk" \ --restorefile /etc/lvm/archive/VG_00050.vg \ /dev/vdb1 ... Physical volume "/dev/vdb1" successfully createdCopy to Clipboard Copied! Toggle word wrap Toggle overflow
-
볼륨 그룹의 메타데이터를 복원합니다.
vgcfgrestore myvg Restored volume group myvg
# vgcfgrestore myvg Restored volume group myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹의 논리 볼륨을 표시합니다.
lvs --all --options +devices myvg
# lvs --all --options +devices myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨은 현재 비활성 상태입니다. 예를 들면 다음과 같습니다.
LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)
LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)Copy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨의 세그먼트 유형이 RAID인 경우 논리 볼륨을 다시 동기화합니다.
lvchange --resync myvg/mylv
# lvchange --resync myvg/mylvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨을 활성화합니다.
lvchange --activate y myvg/mylv
# lvchange --activate y myvg/mylvCopy to Clipboard Copied! Toggle word wrap Toggle overflow -
on-disk LVM 메타데이터가 오버로이드된 공간만큼 많은 공간을 사용하는 경우 이 절차에서는 물리 볼륨을 복구할 수 있습니다. 메타데이터 영역을 통과한 메타데이터를 덮어쓰는 경우 볼륨의 데이터가 영향을 받을 수 있습니다.
fsck명령을 사용하여 해당 데이터를 복구할 수 있습니다.
검증
활성 논리 볼륨을 표시합니다.
lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)
# lvs --all --options +devices LV VG Attr LSize Origin Snap% Move Log Copy% Devices mylv myvg -wi--- 300.00G /dev/vdb1 (0),/dev/vdb1(0) mylv myvg -wi--- 300.00G /dev/vdb1 (34728),/dev/vdb1(0)Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.6. LVM 출력에서 오류 반올림
볼륨 그룹의 공간 사용량을 보고하는 LVM 명령은 사람이 읽을 수 있는 출력을 제공하기 위해 보고된 수를 2 진수로 반올림합니다. 여기에는 Cryostatdisplay 및 Cryo stats 유틸리티가 포함됩니다.
라운드링으로 인해 보고된 여유 공간 값이 볼륨 그룹의 물리 확장 영역보다 클 수 있습니다. 보고된 여유 공간의 크기를 논리 볼륨을 생성하려고 하면 다음과 같은 오류가 발생할 수 있습니다.
Insufficient free extents
Insufficient free extents오류를 해결하려면 사용 가능한 공간의 정확한 값인 볼륨 그룹의 사용 가능한 물리 확장 영역 수를 검사해야 합니다. 그런 다음 확장 영역 수를 사용하여 논리 볼륨을 성공적으로 만들 수 있습니다.
67.14.7. LVM 볼륨을 생성할 때 반올림 오류 방지
LVM 논리 볼륨을 만들 때 논리 볼륨의 논리 확장 영역 수를 지정하여 반올림 오류를 방지할 수 있습니다.
프로세스
볼륨 그룹에서 사용 가능한 물리 확장 영역 수를 찾습니다.
vgdisplay myvg
# vgdisplay myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.19. 볼륨 그룹에서 확장 영역 사용 가능
예를 들어 다음 볼륨 그룹에는 8780 사용 가능한 물리 확장 영역이 있습니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 논리 볼륨을 만듭니다. 바이트가 아닌 Extent에 볼륨 크기를 입력합니다.
예 67.20. 확장 영역 수를 지정하여 논리 볼륨 생성
lvcreate --extents 8780 --name mylv myvg
# lvcreate --extents 8780 --name mylv myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.21. 나머지 공간을 모두 차지하기 위해 논리 볼륨 만들기
또는 볼륨 그룹에서 남은 사용 가능한 공간의 백분율을 사용하도록 논리 볼륨을 확장할 수 있습니다. 예를 들면 다음과 같습니다.
lvcreate --extents 100%FREE --name mylv myvg
# lvcreate --extents 100%FREE --name mylv myvgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
볼륨 그룹에서 현재 사용 중인 확장 영역 수를 확인합니다.
vgs --options +vg_free_count,vg_extent_count VG #PV #LV #SN Attr VSize VFree Free #Ext myvg 2 1 0 wz--n- 34.30G 0 0 8780
# vgs --options +vg_free_count,vg_extent_count VG #PV #LV #SN Attr VSize VFree Free #Ext myvg 2 1 0 wz--n- 34.30G 0 0 8780Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.8. LVM 메타데이터 및 디스크의 위치
LVM 헤더 및 메타데이터 영역은 다른 오프셋 및 크기에서 사용할 수 있습니다.
기본 LVM 디스크 헤더:
-
label_header및pv_header구조에 있습니다. - 디스크의 두 번째 512바이트 섹터에 있습니다. PV(물리 볼륨)를 생성할 때 기본이 아닌 위치가 지정된 경우 헤더가 첫 번째 또는 세 번째 섹터에 있을 수도 있습니다.
표준 LVM 메타데이터 영역:
- 디스크 시작부터 4096바이트를 시작합니다.
- 디스크 시작부터 1MiB를 종료합니다.
-
mda_header구조를 포함하는 512바이트 섹터로 시작합니다.
메타데이터 텍스트 영역은 mda_header 섹터 후에 시작하여 메타데이터 영역의 끝으로 이동합니다. LVM VG 메타데이터 텍스트는 순환 방식으로 메타데이터 텍스트 영역에 작성됩니다. mda_header 는 텍스트 영역 내의 최신 VG 메타데이터의 위치를 가리킵니다.
# pvck --dump headers /dev/sda 명령을 사용하여 디스크에서 LVM 헤더를 출력할 수 있습니다. 이 명령은 label_header,pv_header,mda_header 및 존재하는 경우 메타데이터 텍스트 위치를 출력합니다. 잘못된 필드는 CHECK 접두사를 사용하여 출력됩니다.
LVM 메타데이터 영역 오프셋은 PV를 생성한 시스템의 페이지 크기와 일치하므로 메타데이터 영역은 디스크 시작 시 8K, 16K 또는 64K를 시작할 수 있습니다.
PV를 생성할 때 더 크거나 작은 메타데이터 영역을 지정할 수 있습니다. 이 경우 메타데이터 영역은 1MiB가 아닌 위치에서 종료될 수 있습니다. pv_header 는 메타데이터 영역의 크기를 지정합니다.
PV를 생성할 때 디스크 끝에 두 번째 메타데이터 영역을 선택적으로 활성화할 수 있습니다. pv_header 에는 메타데이터 영역의 위치가 포함되어 있습니다.
67.14.9. 디스크에서 VG 메타데이터 추출
상황에 따라 디스크에서 VG 메타데이터를 추출하려면 다음 절차 중 하나를 선택합니다. 추출된 메타데이터를 저장하는 방법에 대한 자세한 내용은 추출된 메타데이터를 파일에 저장을 참조하십시오.
복구의 경우 디스크에서 메타데이터를 추출하지 않고 /etc/lvm/backup/ 에서 백업 파일을 사용할 수 있습니다.
프로세스
유효한
mda_header에서 참조된 현재 메타데이터 텍스트를 인쇄 :pvck --dump metadata <disk>
# pvck --dump metadata <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.22. 유효한
mda_header의 메타데이터 텍스트pvck --dump metadata /dev/sdb metadata text at 172032 crc Oxc627522f # vgname test segno 59 --- <raw metadata from disk> ---
# pvck --dump metadata /dev/sdb metadata text at 172032 crc Oxc627522f # vgname test segno 59 --- <raw metadata from disk> ---Copy to Clipboard Copied! Toggle word wrap Toggle overflow 유효한
mda_header를 찾는 방법에 따라 메타데이터 영역에 있는 모든 메타데이터 복사본의 위치를 인쇄합니다.pvck --dump metadata_all <disk>
# pvck --dump metadata_all <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.23. 메타데이터 영역에 있는 메타데이터 복사본의 위치
pvck --dump metadata_all /dev/sdb metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv
# pvck --dump metadata_all /dev/sdb metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53FxvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 헤더가 없거나 손상된 경우
mda_header를 사용하지 않고 메타데이터 영역에 있는 모든 메타데이터 복사본을 검색합니다.pvck --dump metadata_search <disk>
# pvck --dump metadata_search <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.24.
mda_header를 사용하지 않고 메타데이터 영역의 메타데이터 복사본pvck --dump metadata_search /dev/sdb Searching for metadata at offset 4096 size 1044480 metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv
# pvck --dump metadata_search /dev/sdb Searching for metadata at offset 4096 size 1044480 metadata at 4608 length 815 crc 29fcd7ab vg test seqno 1 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 5632 length 1144 crc 50ea61c3 vg test seqno 2 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53Fxv metadata at 7168 length 1450 crc 5652ea55 vg test seqno 3 id FaCsSz-1ZZn-mTO4-Xl4i-zb6G-BYat-u53FxvCopy to Clipboard Copied! Toggle word wrap Toggle overflow dump명령에-v옵션을 포함하여 메타데이터 복사본의 각 설명을 표시합니다.pvck --dump metadata -v <disk>
# pvck --dump metadata -v <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 예 67.25. 각 메타데이터 사본에서 설명 표시
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
이 파일은 복구에 사용할 수 있습니다. 첫 번째 메타데이터 영역은 기본적으로 덤프 메타데이터에 사용됩니다. 디스크 끝에 두 번째 메타데이터 영역이 있는 경우 --settings "mda_num=2" 옵션을 사용하여 덤프 메타데이터에 두 번째 메타데이터 영역을 대신 사용할 수 있습니다.
67.14.10. 추출된 메타데이터를 파일에 저장
복구에 덤프된 메타데이터를 사용해야 하는 경우 추출된 메타데이터를 -f 옵션과 --setings 옵션을 사용하여 파일에 저장해야 합니다.
프로세스
-
-f <filename>이--dump 메타데이터에추가되면 원시 메타데이터가 이름이 지정된 파일에 작성됩니다. 이 파일을 사용하여 복구할 수 있습니다. -
-f <filename>이--dump metadata_all또는--dump metadata_search에 추가된 경우 모든 위치의 원시 메타데이터가 이름이 지정된 파일에 작성됩니다. --dump metadata_all|metadata_search의 메타데이터 텍스트 인스턴스 하나를 저장하려면--settings "metadata_offset=<offset>"을 추가합니다. 여기서 <offset>은 목록 출력의 "metadata at <offset>"입니다.예 67.26. 명령 출력
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.11. pvcreate 및 Cryostatcfgrestore 명령을 사용하여 손상된 LVM 헤더 및 메타데이터로 디스크 복구
손상된 물리 볼륨에서 메타데이터 및 헤더를 복원하거나 새 장치로 교체할 수 있습니다. 물리 볼륨의 메타데이터 영역을 다시 작성하여 물리 볼륨에서 데이터를 복구할 수 있습니다.
이러한 명령은 매우 주의하여 사용해야 하며, 각 명령의 영향, 볼륨의 현재 레이아웃, 달성해야 하는 레이아웃 및 백업 메타데이터 파일의 콘텐츠에 대해 잘 알고 있는 경우에만 사용해야 합니다. 이러한 명령에는 데이터가 손상될 가능성이 있으므로 문제 해결에 도움이 필요한 경우 Red Hat 글로벌 지원 서비스에 문의하는 것이 좋습니다.
사전 요구 사항
- 누락된 물리 볼륨의 메타데이터를 확인했습니다. 자세한 내용은 누락된 LVM 물리 볼륨의 메타데이터 찾기를 참조하십시오.
프로세스
pvcreate및 Cryostatcfgrestore명령에 필요한 다음 정보를 수집합니다.# pvs -o+uuid명령을 실행하여 디스크 및 UUID에 대한 정보를 수집할 수 있습니다.-
metadata-file 은 VG의 최신 메타데이터 백업 파일의 경로입니다(예:
/etc/lvm/backup/ <vg-name>). - VG-name 은 PV가 손상되거나 누락된 VG의 이름입니다.
-
이 장치에서 손상된 PV의 UUID 는
# pvs -i+uuid명령의 출력에서 가져온 값입니다. -
disk 는 PV가 있어야 하는 디스크 이름입니다(예:
/dev/sdb). 이 디스크가 올바른 디스크인지 확인하거나 도움을 구하십시오. 그렇지 않으면 이러한 단계를 수행하면 데이터가 손실될 수 있습니다.
-
metadata-file 은 VG의 최신 메타데이터 백업 파일의 경로입니다(예:
디스크에서 LVM 헤더를 다시 생성합니다.
pvcreate --restorefile <metadata-file> --uuid <UUID> <disk>
# pvcreate --restorefile <metadata-file> --uuid <UUID> <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 필요한 경우 헤더가 유효한지 확인합니다.
pvck --dump headers <disk>
# pvck --dump headers <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 디스크에서 VG 메타데이터를 복원합니다.
vgcfgrestore --file <metadata-file> <vg-name>
# vgcfgrestore --file <metadata-file> <vg-name>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 필요한 경우 메타데이터가 복원되었는지 확인합니다.
pvck --dump metadata <disk>
# pvck --dump metadata <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
VG에 대한 메타데이터 백업 파일이 없는 경우 추출된 메타데이터를 파일에 저장하는 절차를 사용하여 하나를 가져올 수 있습니다.
검증
새 물리 볼륨이 손상되지 않고 볼륨 그룹이 올바르게 작동하는지 확인하려면 다음 명령의 출력을 확인합니다.
vgs
# vgsCopy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.12. pvck 명령을 사용하여 손상된 LVM 헤더 및 메타데이터로 디스크 복구
이는 pvcreate 및 pvcfgrestore 명령을 사용하여 손상된 LVM 헤더 및 메타데이터가 있는 디스크를 복구하는 대신 사용할 수 있습니다. pvcreate 및 Cryostat cfgrestore 명령이 작동하지 않는 경우가 있을 수 있습니다. 이 방법은 손상된 디스크를 더 대상으로 합니다.
이 방법은 pvck --dump 에서 추출한 메타데이터 입력 파일 또는 /etc/lvm/backup 의 백업 파일을 사용합니다. 가능한 경우 동일한 VG의 다른 PV 또는 PV의 두 번째 메타데이터 영역에서 pvck --dump 에 저장된 메타데이터를 사용합니다. 자세한 내용은 추출된 메타데이터를 파일에 저장을 참조하십시오.
프로세스
디스크에서 헤더 및 메타데이터를 복구합니다.
pvck --repair -f <metadata-file> <disk>
# pvck --repair -f <metadata-file> <disk>Copy to Clipboard Copied! Toggle word wrap Toggle overflow 다음과 같습니다.
-
<metadata-file >은 VG에 대한 최신 메타데이터를 포함하는 파일입니다.
/etc/lvm/backup/ Cryostat-name이거나pvck --dump metadata_search명령 출력에서 원시 메타데이터 텍스트가 포함된 파일일 수 있습니다. -
<disk >는 PV가 있어야 하는 디스크 이름입니다(예:
/dev/sdb). 데이터 손실을 방지하려면 가 올바른 디스크인지 확인합니다. 디스크가 올바른지 확실하지 않은 경우 Red Hat 지원팀에 문의하십시오.
-
<metadata-file >은 VG에 대한 최신 메타데이터를 포함하는 파일입니다.
메타데이터 파일이 백업 파일인 경우 VG에서 메타데이터를 보유하는 각 PV에서 pvck --repair 를 실행해야 합니다. 메타데이터 파일이 다른 PV에서 추출된 원시 메타데이터인 경우 pvck --repair 는 손상된 PV에서만 실행해야 합니다.
검증
새 물리 볼륨이 손상되지 않고 볼륨 그룹이 올바르게 작동하는지 확인하려면 다음 명령의 출력을 확인합니다.
vgs <vgname>
# vgs <vgname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow pvs <pvname>
# pvs <pvname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow lvs <lvname>
# lvs <lvname>Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.13. LVM RAID 문제 해결
LVM RAID 장치의 다양한 문제를 해결하여 데이터 오류를 수정하거나 장치를 복구하거나 실패한 장치를 교체할 수 있습니다.
67.14.13.1. RAID 논리 볼륨에서 데이터 일관성 확인
LVM은 RAID 논리 볼륨에 대한 스크럽을 제공합니다. RAID 스크러빙은 배열의 모든 데이터 및 패리티 블록을 읽고 일관성이 있는지 확인하는 프로세스입니다. lvchange --syncaction repair 명령은 배열에서 백그라운드 동기화 작업을 시작합니다.
프로세스
선택 사항: 다음 옵션 중 하나를 설정하여 RAID 논리 볼륨이 초기화되는 속도를 제어합니다.
-
--maxrecoveryrate Rate[bBsSkKmMgG]는 RAID 논리 볼륨의 최대 복구 속도를 설정하여 nominal I/O 작업을 확장하지 않도록 합니다. --minrecoveryrate Rate[bBsSkKmMgG]는 RAID 논리 볼륨의 최소 복구 속도를 설정하여 동기화 작업의 I/O가 무분별 I/O가 있는 경우에도 최소 처리량을 달성하도록 합니다.lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.
# lvchange --maxrecoveryrate 4K my_vg/my_lv Logical volume _my_vg/my_lv_changed.Copy to Clipboard Copied! Toggle word wrap Toggle overflow 4K 를 복구 속도 값으로 바꿉니다. 이 값은 배열의 각 장치에 대한 초당 양입니다. 접미사를 제공하지 않으면 옵션은 장치당 초당 kiB를 가정합니다.
lvchange --syncaction repair my_vg/my_lv
# lvchange --syncaction repair my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow RAID 스크러블링 작업을 수행할 때
동기화작업에 필요한 백그라운드 I/O는 볼륨 그룹 메타데이터 업데이트 등 LVM 장치에 대한 다른 I/O의 충돌을 줄일 수 있습니다. 이로 인해 다른 LVM 작업이 느려질 수 있습니다.참고RAID 장치를 생성하는 동안 이러한 최대 및 최소 I/O 속도를 사용할 수도 있습니다. 예를 들어
lvcreate --type raid10 -i 2 -m 1 -l 1 -L 10G --maxrecoveryrate 128 -n my_vg는 128 kiB/sec/device의 최대 복구 속도를 가진 볼륨 그룹 my_vg에 있는 볼륨 그룹 my_vg에서 최대 복구 속도를 가진 크기가 10G인 my_vg를 생성합니다.
-
배열의 불일치 수를 복구하지 않고 표시합니다.
lvchange --syncaction check my_vg/my_lv
# lvchange --syncaction check my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 배열에서 백그라운드 동기화 작업을 시작합니다.
-
선택 사항: 커널 메시지의
var/log/syslog파일을 확인합니다. 배열의 불일치를 수정합니다.
lvchange --syncaction repair my_vg/my_lv
# lvchange --syncaction repair my_vg/my_lvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 명령은 RAID 논리 볼륨에서 실패한 장치를 복구하거나 교체합니다. 이 명령을 실행한 후 커널 메시지의
var/log/syslog파일을 볼 수 있습니다.
검증
스크럽 작업에 대한 정보를 표시합니다.
lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0
# lvs -o +raid_sync_action,raid_mismatch_count my_vg/my_lv LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert SyncAction Mismatches my_lv my_vg rwi-a-r--- 500.00m 100.00 idle 0Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.13.2. 논리 볼륨에서 실패한 RAID 장치 교체
RAID는 기존 LVM 미러링과 동일하지 않습니다. LVM 미러링의 경우 실패한 장치를 제거합니다. 그렇지 않으면 RAID 배열이 실패한 장치에서 계속 실행되는 동안 미러링된 논리 볼륨이 중단됩니다. RAID1 이외의 RAID 수준의 경우 장치를 제거하면 RAID6에서 RAID5로 또는 RAID4 또는 RAID0으로의 낮은 RAID 수준으로의 변환을 의미합니다.
실패한 장치를 제거하고 교체를 LVM으로 할당하는 대신 lvconvert 명령의 --repair 인수를 사용하여 RAID 논리 볼륨에서 물리 볼륨으로 사용되는 실패한 장치를 교체할 수 있습니다.
사전 요구 사항
볼륨 그룹에는 실패한 장치를 교체할 수 있는 충분한 여유 용량을 제공하는 물리 볼륨이 포함됩니다.
볼륨 그룹에서 사용 가능한 확장 영역이 충분한 물리 볼륨이 없는 경우 Cryostatextend 유틸리티를 사용하여 충분히 큰
새물리 볼륨을 추가합니다.
프로세스
RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow /dev/sdc 장치가 실패한 후 RAID 논리 볼륨을 확인합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 실패한 장치를 교체합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 선택 사항: 실패한 장치를 대체하는 물리 볼륨을 수동으로 지정합니다.
lvconvert --repair my_vg/my_lv replacement_pv
# lvconvert --repair my_vg/my_lv replacement_pvCopy to Clipboard Copied! Toggle word wrap Toggle overflow 교체를 사용하여 논리 볼륨을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow 볼륨 그룹에서 실패한 장치를 제거할 때까지 LVM 유틸리티에 실패한 장치를 찾을 수 없다는 내용이 계속 표시됩니다.
볼륨 그룹에서 실패한 장치를 제거합니다.
vgreduce --removemissing my_vg
# vgreduce --removemissing my_vgCopy to Clipboard Copied! Toggle word wrap Toggle overflow
검증
실패한 장치를 제거한 후 사용 가능한 물리 볼륨을 확인합니다.
pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]
# pvscan PV /dev/sde1 VG rhel_virt-506 lvm2 [<7.00 GiB / 0 free] PV /dev/sdb1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free] PV /dev/sdd1 VG my_vg lvm2 [<60.00 GiB / 59.50 GiB free]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 실패한 장치를 교체한 후 논리 볼륨을 검사합니다.
Copy to Clipboard Copied! Toggle word wrap Toggle overflow
67.14.14. 다중 경로 LVM 장치에 대해 중복된 물리 볼륨 경고 문제 해결
다중 경로 스토리지가 있는 LVM을 사용하는 경우 볼륨 그룹 또는 논리 볼륨을 나열하는 LVM 명령은 다음과 같은 메시지를 표시할 수 있습니다.
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/dm-5 not /dev/sdd Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowerb not /dev/sde Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sddlmab not /dev/sdf
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/dm-5 not /dev/sdd
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowerb not /dev/sde
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sddlmab not /dev/sdf이러한 경고 문제를 해결하여 LVM이 표시되는 이유를 이해하거나 경고를 숨길 수 있습니다.
67.14.14.1. 중복 PV 경고의 근본 원인
DM Multipath(Device Mapper Multipath), EMC PowerPath 또는 Cryostat Dynamic Link Manager(HDLM)와 같은 다중 경로 소프트웨어가 시스템의 스토리지 장치를 관리하는 경우 특정 논리 단위(LUN)로의 각 경로가 다른 SCSI 장치로 등록됩니다.
그런 다음 다중 경로 소프트웨어는 해당 개별 경로에 매핑되는 새 장치를 생성합니다. 각 LUN에는 동일한 기본 데이터를 가리키는 여러 장치 노드가 /dev 디렉터리에 있으므로 모든 장치 노드에 동일한 LVM 메타데이터가 포함됩니다.
| 다중 경로 소프트웨어 | LUN에 대한 SCSI 경로 | 경로에 대한 다중 경로 장치 매핑 |
|---|---|---|
| DM Multipath |
|
|
| EMC PowerPath |
| |
| HDLM |
|
여러 장치 노드의 결과로 LVM 툴은 동일한 메타데이터를 여러 번 찾아 중복으로 보고합니다.
67.14.14.2. 중복 PV 경고의 사례
LVM은 다음 경우 중 하나로 중복된 PV 경고를 표시합니다.
- 동일한 장치에 대한 단일 경로
출력에 표시되는 두 장치는 동일한 장치에 대한 단일 경로입니다.
다음 예제에서는 중복된 장치가 동일한 장치에 대한 단일 경로인 중복 PV 경고를 보여줍니다.
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sdd not /dev/sdf
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/sdd not /dev/sdfCopy to Clipboard Copied! Toggle word wrap Toggle overflow multipath -ll명령을 사용하여 현재 DM Multipath 토폴로지를 나열하는 경우 동일한 다중 경로 맵에서/dev/sdd및/dev/sdf를 모두 찾을 수 있습니다.이러한 중복 메시지는 경고일 뿐이며 LVM 작업이 실패했음을 의미하지는 않습니다. 대신 LVM에서 장치 중 하나만 물리 볼륨으로 사용하고 다른 장치를 무시함을 경고합니다.
LVM이 잘못된 장치를 선택했거나 사용자에게 경고가 중단된 경우 필터를 적용할 수 있습니다. 필터는 물리 볼륨에 필요한 장치만 검색하고 다중 경로 장치에 대한 기본 경로를 종료하도록 LVM을 구성합니다. 결과적으로 경고가 더 이상 나타나지 않습니다.
- 다중 경로 맵
출력에 표시되는 두 장치는 모두 다중 경로 맵입니다.
다음 예제에서는 둘 다 다중 경로 맵인 두 장치에 대해 중복 PV 경고를 보여줍니다. 중복된 물리 볼륨은 동일한 장치에 대한 두 개의 다른 경로가 아닌 두 개의 다른 장치에 있습니다.
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/mapper/mpatha not /dev/mapper/mpathc Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowera not /dev/emcpowerh
Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/mapper/mpatha not /dev/mapper/mpathc Found duplicate PV GDjTZf7Y03GJHjteqOwrye2dcSCjdaUi: using /dev/emcpowera not /dev/emcpowerhCopy to Clipboard Copied! Toggle word wrap Toggle overflow 이 상황은 동일한 장치에 대한 단일 경로의 두 장치에 대해 중복 경고보다 더 심각합니다. 이러한 경고는 종종 시스템이 액세스해서는 안 되는 장치에 액세스 중임을 의미합니다(예: LUN 복제 또는 미러).
시스템에서 제거해야 하는 장치를 명확하게 모르는 경우 이 상황을 복구할 수 없을 수 있습니다. 이 문제를 해결하려면 Red Hat 기술 지원팀에 문의하는 것이 좋습니다.
67.14.14.3. 중복된 PV 경고를 방지하는 LVM 장치 필터의 예
다음 예제에서는 단일 논리 단위(LUN)에 대한 여러 스토리지 경로로 인한 중복된 물리 볼륨 경고를 방지하는 LVM 장치 필터를 보여줍니다.
모든 장치의 메타데이터를 확인하도록 LVM(Logical Volume Manager)의 필터를 구성할 수 있습니다. 메타데이터에는 루트 볼륨 그룹이 있는 로컬 하드 디스크 드라이브와 다중 경로 장치가 포함됩니다. LVM이 다중 경로 장치 자체에서 각 고유한 메타데이터 영역을 찾기 때문에 다중 경로 장치(예: /dev/sdb,/dev/sdd)의 기본 경로를 거부하면 이러한 중복 PV 경고를 방지할 수 있습니다.
첫 번째 하드 디스크 드라이브 및 장치 매퍼 (DM) Multipath 장치에서 두 번째 파티션을 수락하고 다른 모든 것을 거부하려면 다음을 입력합니다.
filter = [ "a|/dev/sda2$|", "a|/dev/mapper/mpath.*|", "r|.*|" ]
filter = [ "a|/dev/sda2$|", "a|/dev/mapper/mpath.*|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 모든 HP SmartArray 컨트롤러 및 EMC PowerPath 장치를 수락하려면 다음을 입력합니다.
filter = [ "a|/dev/cciss/.*|", "a|/dev/emcpower.*|", "r|.*|" ]
filter = [ "a|/dev/cciss/.*|", "a|/dev/emcpower.*|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow 첫 번째 IDE 드라이브 및 다중 경로 장치의 파티션을 수락하려면 다음을 입력합니다.
filter = [ "a|/dev/hda.*|", "a|/dev/mapper/mpath.*|", "r|.*|" ]
filter = [ "a|/dev/hda.*|", "a|/dev/mapper/mpath.*|", "r|.*|" ]Copy to Clipboard Copied! Toggle word wrap Toggle overflow