클러스터 관리
AWS 클러스터에서 Red Hat OpenShift Service 구성
초록
1장. 클러스터 알림
클러스터 알림(서비스 로그라고도 함)은 클러스터의 상태, 상태 또는 성능에 대한 메시지입니다.
클러스터 알림은 Red Hat site Reliability Engineering(SRE)이 관리형 클러스터의 상태에 대해 귀하와 통신하는 기본 방법입니다. Red Hat SRE는 클러스터 알림을 사용하여 클러스터 문제를 해결하거나 방지하기 위해 작업을 수행하도록 요청할 수도 있습니다.
클러스터 소유자 및 관리자는 클러스터가 정상 상태로 유지되고 지원되는지 확인하기 위해 클러스터 알림을 정기적으로 검토하고 조치를 취해야 합니다.
클러스터의 클러스터 기록 탭에서 Red Hat Hybrid Cloud Console에서 클러스터 알림을 볼 수 있습니다. 기본적으로 클러스터 소유자만 이메일로 클러스터 알림을 수신합니다. 다른 사용자가 클러스터 알림 이메일을 수신해야 하는 경우 각 사용자를 클러스터에 대한 알림 연락처로 추가합니다.
1.2. 클러스터 알림에서 예상되는 사항
클러스터 관리자는 클러스터의 상태 및 관리 요구를 효과적으로 이해하기 위해 클러스터 알림과 유형 및 심각도 수준을 전송하는 시기와 이유를 알고 있어야 합니다.
1.2.1. 클러스터 알림 정책
클러스터 알림은 클러스터의 상태와 영향을 미치는 높은 영향을 미치는 이벤트에 대한 정보를 유지하도록 설계되었습니다.
대부분의 클러스터 알림은 자동으로 생성되고 전송되어 즉시 문제에 대한 정보 또는 클러스터 상태에 대한 중요한 변경 사항을 확인할 수 있습니다.
특정 상황에서 Red Hat 사이트 안정성 엔지니어링(SRE)은 클러스터 알림을 생성하고 전송하여 복잡한 문제에 대한 추가 컨텍스트 및 지침을 제공합니다.
영향을 받지 않는 이벤트, 위험이 낮은 보안 업데이트, 일상적인 운영 및 유지 관리 또는 Red Hat SRE가 신속하게 해결하는 일시적인 문제에 대해서는 클러스터 알림이 전송되지 않습니다.
Red Hat 서비스는 다음과 같은 경우 자동으로 알림을 보냅니다.
- 원격 상태 모니터링 또는 환경 확인 검사에서는 작업자 노드에 디스크 공간이 부족한 경우와 같이 클러스터에서 문제를 감지합니다.
- 예를 들어 예정된 유지 관리 또는 업그레이드가 시작되는 경우 심각한 클러스터 라이프 사이클 이벤트가 발생하거나 클러스터 작업이 이벤트의 영향을 받지만 고객의 개입은 필요하지 않습니다.
- 예를 들어 클러스터 소유권 또는 관리 제어가 한 사용자에서 다른 사용자로 전송되는 경우와 같이 중요한 클러스터 관리 변경이 발생합니다.
- 예를 들어 Red Hat이 클러스터에서 서브스크립션 조건 또는 기능을 업데이트할 때 클러스터 서브스크립션이 변경 또는 업데이트됩니다.
SRE는 다음과 같은 경우 알림을 생성하고 보냅니다.
- 사고로 인해 클러스터의 가용성 또는 성능에 영향을 미치는 성능 저하 또는 중단이 발생합니다(예: 클라우드 공급자의 경우 지역 중단). SRE는 사고 해결 진행 상황을 알려주기 위해 후속 알림을 보냅니다.
- 클러스터에서 보안 취약점, 보안 위반 또는 비정상적인 활동이 감지됩니다.
- Red Hat은 변경 사항이 생성 중이거나 클러스터 불안정성을 초래할 수 있음을 감지합니다.
- Red Hat은 워크로드가 클러스터에서 성능 저하 또는 불안정성을 초래하고 있음을 감지합니다.
1.2.2. 클러스터 알림 심각도 수준
각 클러스터 알림에는 비즈니스에 가장 큰 영향을 미치는 알림을 식별하는 데 도움이 되는 관련 심각도 수준이 있습니다. 클러스터의 클러스터 기록 탭에서 Red Hat Hybrid Cloud Console의 심각도 수준에 따라 클러스터 알림을 필터링할 수 있습니다.
Red Hat은 가장 심각한 클러스터 알림에 다음과 같은 심각도 수준을 사용합니다.
- 심각
- 즉각적인 조치가 필요합니다. 서비스 또는 클러스터의 하나 이상의 주요 기능이 작동하지 않거나 곧 작동하지 않습니다. 중요한 경고는 직원에게 호출하고 일반 워크플로우를 중단할 수 있을 만큼 중요합니다.
- major
- 즉각적인 조치가 강력히 권장됩니다. 클러스터의 하나 이상의 주요 기능이 곧 작동하지 않습니다. 주요 문제는 적시에 해결되지 않는 경우 중요한 문제로 이어질 수 있습니다.
- 경고
- 가능한 한 빨리 조치가 필요합니다. 클러스터의 하나 이상의 주요 기능이 최적으로 작동하지 않고 추가로 성능이 저하될 수 있지만 클러스터 작동에 즉각적인 위험이 발생하지 않습니다.
- 정보
- 작업이 필요하지 않습니다. 이 심각도는 처리해야 하는 문제를 설명하지 않으며 의미 있거나 중요한 라이프 사이클, 서비스 또는 클러스터 이벤트에 대한 중요한 정보만 설명합니다.
- Debug
- 작업이 필요하지 않습니다. 디버그 알림은 예기치 않은 동작을 디버깅하는 데 도움이 되도록 덜 중요한 라이프사이클, 서비스 또는 클러스터 이벤트에 대한 낮은 수준의 정보를 제공합니다.
1.2.3. 클러스터 알림 유형
각 클러스터 알림에는 역할 및 역할과 관련된 알림을 식별하는 데 도움이 되는 관련 알림 유형이 있습니다. 클러스터의 클러스터 기록 탭에서 Red Hat Hybrid Cloud Console에서 이러한 유형에 따라 클러스터 알림을 필터링할 수 있습니다.
Red Hat은 다음 알림 유형을 사용하여 알림을 표시합니다.
- 용량 관리
- 노드 풀, 시스템 풀, 컴퓨팅 복제본 또는 할당량(로드 밸런서, 스토리지 등) 업데이트, 생성 또는 삭제와 관련된 이벤트 알림.
- 클러스터 액세스
- STS 인증 정보가 만료되었거나 AWS 역할에 구성 문제가 있는 경우 또는 ID 공급자를 추가하거나 제거할 때와 같은 그룹, 역할 또는 ID 공급자 추가 또는 ID 공급자와 관련된 이벤트에 대한 알림입니다.
- 클러스터 애드온
- 애드온의 애드온 관리 또는 업그레이드 유지 관리와 관련된 이벤트의 알림(예: 애드온을 설치, 업그레이드 또는 제거)하거나 미해결 요구 사항으로 인해 설치할 수 없습니다.
- 클러스터 구성
- 클러스터 튜닝 이벤트, 워크로드 모니터링 및 진행 중인 검사에 대한 알림입니다.
- 클러스터 라이프사이클
- 클러스터 또는 클러스터 리소스 생성, 삭제 및 등록에 대한 알림 또는 클러스터 또는 리소스 상태 변경(예: 준비 또는 누락).
- 클러스터 네트워킹
- HTTP/S 프록시, 라우터 및 수신 상태를 포함한 클러스터 네트워킹과 관련된 알림.
- 클러스터 소유권
- 클러스터 소유권과 관련된 알림은 한 사용자의 다른 사용자로 이동합니다.
- 클러스터 스케일링
- 노드 풀, 머신 풀, 컴퓨팅 복제본 또는 할당량 업데이트, 생성 또는 삭제와 관련된 알림입니다.
- 클러스터 보안
- 예를 들어 클러스터 보안과 관련된 이벤트(예: 실패한 액세스 시도 횟수, 신뢰 번들에 대한 업데이트 또는 보안에 영향을 미치는 소프트웨어 업데이트 등)
- 클러스터 서브스크립션
- 클러스터 만료, 평가판 클러스터 알림 또는 무료에서 유료로 전환.
- 클러스터 업데이트
- 업그레이드 유지 관리 또는 활성화와 같은 업그레이드 관련 항목입니다.
- 고객 지원
- 지원 케이스 상태에 대한 업데이트
- 일반 알림
- 기본 알림 유형입니다. 이는 더 구체적인 카테고리가 없는 알림에만 사용됩니다.
1.3. Red Hat Hybrid Cloud Console을 사용하여 클러스터 알림 보기
클러스터 알림은 클러스터 상태에 대한 중요한 정보를 제공합니다. Red Hat Hybrid Cloud Console의 클러스터 기록 탭에서 클러스터로 전송된 알림을 볼 수 있습니다.
사전 요구 사항
- 하이브리드 클라우드 콘솔에 로그인되어 있습니다.
프로세스
- 하이브리드 클라우드 콘솔의 클러스터 페이지로 이동합니다.
- 클러스터 이름을 클릭하여 클러스터 세부 정보 페이지로 이동합니다.
클러스터 기록 탭을 클릭합니다.
클러스터 알림은 클러스터 기록 제목 아래에 표시됩니다.
선택 사항: 관련 클러스터 알림에 대해 필터링
필터 컨트롤을 사용하여 사용자의 전문 영역에 집중하거나 중요한 문제를 해결할 수 있도록 사용자와 관련이 없는 클러스터 알림을 숨깁니다. 알림 설명의 텍스트, 심각도 수준, 알림 유형, 알림이 수신될 때 및 알림을 트리거한 시스템 또는 사람을 기반으로 알림을 필터링할 수 있습니다.
1.4. 클러스터 알림 이메일
기본적으로 클러스터 알림이 클러스터로 전송되면 클러스터 소유자의 이메일도 전송됩니다. 적절한 모든 사용자가 클러스터 상태에 대한 정보를 유지할 수 있도록 알림 이메일에 대한 추가 수신자를 구성할 수 있습니다.
1.4.1. 클러스터에 알림 연락처 추가
알림 연락처는 클러스터 알림이 클러스터로 전송될 때 이메일을 수신합니다. 기본적으로 클러스터 소유자만 클러스터 알림 이메일을 수신합니다. 클러스터 지원 설정에서 다른 클러스터 사용자를 추가 알림 연락처로 구성할 수 있습니다.
사전 요구 사항
- 클러스터가 Red Hat Hybrid Cloud Console에 배포 및 등록되었습니다.
- 클러스터 소유자 또는 클러스터 편집기 역할의 사용자로 하이브리드 클라우드 콘솔에 로그인되어 있습니다.
- 의도된 알림 수신자에는 클러스터 소유자와 동일한 조직과 연결된 Red Hat 고객 포털 계정이 있습니다.
프로세스
- 하이브리드 클라우드 콘솔의 클러스터 페이지로 이동합니다.
- 클러스터 이름을 클릭하여 클러스터 세부 정보 페이지로 이동합니다.
- 지원 탭을 클릭합니다.
- 지원 탭에서 알림 연락처 섹션을 찾습니다.
- 알림 연락처 추가를 클릭합니다.
- Red Hat 사용자 이름 또는 이메일 필드에 이메일 주소 또는 새 수신자의 사용자 이름을 입력합니다.
- 연락처 추가를 클릭합니다.
검증 단계
- "알림 연락처가 성공적으로 추가됨" 메시지가 표시됩니다.
문제 해결
- 알림 연락처 추가 버튼이 비활성화됨
- 알림 연락처를 추가할 수 있는 권한이 없는 사용자에게는 이 버튼이 비활성화됩니다. 클러스터 소유자, 클러스터 편집기 또는 클러스터 관리자 역할을 사용하여 계정에 로그인하고 다시 시도하십시오.
- 오류: <
username> 또는 <email-address>로 식별된 계정을 찾을 수 없습니다 - 이 오류는 의도된 알림 수신자가 클러스터 소유자와 동일한 Red Hat 계정 조직에 속하지 않을 때 발생합니다. 조직 관리자에게 문의하여 의도된 수신자를 관련 조직에 추가하고 다시 시도하십시오.
1.4.2. 클러스터에서 알림 연락처 제거
알림 연락처는 클러스터 알림이 클러스터로 전송될 때 이메일을 수신합니다.
클러스터 지원 설정에서 알림 연락처를 제거하여 알림 이메일을 수신하지 못하도록 할 수 있습니다.
사전 요구 사항
- 클러스터가 Red Hat Hybrid Cloud Console에 배포 및 등록되었습니다.
- 클러스터 소유자 또는 클러스터 편집기 역할의 사용자로 하이브리드 클라우드 콘솔에 로그인되어 있습니다.
프로세스
- 하이브리드 클라우드 콘솔의 클러스터 페이지로 이동합니다.
- 클러스터 이름을 클릭하여 클러스터 세부 정보 페이지로 이동합니다.
- 지원 탭을 클릭합니다.
- 지원 탭에서 알림 연락처 섹션을 찾습니다.
- 제거하려는 수신자 옆에 있는 옵션 메뉴(t)를 클릭합니다.
- 삭제를 클릭합니다.
검증 단계
- "알림 연락처가 성공적으로 삭제됨" 메시지가 표시됩니다.
1.5. 문제 해결
클러스터 알림 이메일을 수신하지 못하는 경우
-
@redhat.com주소에서 전송된 이메일이 이메일 수신함에서 필터링되지 않았는지 확인합니다. - 올바른 이메일 주소가 클러스터의 알림 연락처로 나열되어 있는지 확인합니다.
- 클러스터 소유자 또는 관리자에게 알림 연락처로 추가하도록 요청합니다. 클러스터 알림 이메일.
클러스터가 알림을 수신하지 않는 경우
-
클러스터가
api.openshift.com에서 리소스에 액세스할 수 있는지 확인합니다.
2장. 개인 연결 구성
2.1. 개인 연결 구성
AWS 환경에서 Red Hat OpenShift Service의 요구에 맞게 프라이빗 클러스터 액세스를 구현할 수 있습니다.
프로세스
AWS 계정에서 Red Hat OpenShift Service에 액세스하고 다음 방법 중 하나 이상을 사용하여 클러스터에 대한 개인 연결을 설정합니다.
- AWS VPC 피어링 구성 : VPC 피어링 을 활성화하여 두 개인 IP 주소 간에 네트워크 트래픽을 라우팅합니다.
- AWS VPN 구성: 프라이빗 네트워크를 Amazon Virtual Private Cloud에 안전하게 연결하기 위해 가상 사설 네트워크를 구축합니다.
- AWS Direct Connect 구성: AWS Direct Connect를 구성하여 프라이빗 네트워크와 AWS Direct Connect 위치 간의 전용 네트워크 연결을 설정합니다.
2.2. AWS VPC 피어링 구성
이 샘플 프로세스는 다른 AWS VPC 네트워크와 피어링할 AWS 클러스터의 Red Hat OpenShift Service가 포함된 AWS(Amazon Web Services) VPC를 구성합니다. AWS VPC 피어링 연결 생성 또는 기타 사용 가능한 구성에 대한 자세한 내용은 AWS VPC 피어링 가이드를 참조하십시오.
2.2.1. VPC 피어링 용어
두 개의 개별 AWS 계정에서 두 VPC 간 VPC 피어링 연결을 설정할 때 다음 용어가 사용됩니다.
| Red Hat OpenShift Service on AWS 계정 | AWS 클러스터의 Red Hat OpenShift Service가 포함된 AWS 계정입니다. |
| Red Hat OpenShift Service on AWS Cluster VPC | AWS 클러스터의 Red Hat OpenShift Service가 포함된 VPC입니다. |
| 고객 AWS 계정 | AWS 계정의 Red Hat OpenShift Service가 아닌 경우 피어링할 수 있습니다. |
| 고객 VPC | AWS 계정과 피어링할 VPC입니다. |
| 고객 VPC 리전 | 고객의 VPC가 있는 리전입니다. |
2018년 7월 현재 AWS는 중국을 제외한 모든 상용 리전 간에 리전 간 VPC 피어링을 지원합니다.
2.2.2. VPC 피어 요청 시작
AWS 계정의 Red Hat OpenShift Service에서 고객 AWS 계정으로 VPC 피어링 연결 요청을 보낼 수 있습니다.
사전 요구 사항
피어링 요청을 시작하는 데 필요한 고객 VPC에 대한 다음 정보를 수집합니다.
- 고객 AWS 계정 번호
- 고객 VPC ID
- 고객 VPC 리전
- 고객 VPC CIDR
- AWS Cluster VPC의 Red Hat OpenShift Service에서 사용하는 CIDR 블록을 확인합니다. 고객 VPC의 CIDR 블록이 겹치거나 일치하는 경우 이 두 VPC 간의 피어링을 수행할 수 없습니다. 자세한 내용은 Amazon VPC Unsupported VPC Peering Configurations 설명서를 참조하십시오. CIDR 블록이 겹치지 않으면 절차를 계속할 수 있습니다.
프로세스
- AWS 계정의 Red Hat OpenShift Service에 대한 웹 콘솔에 로그인하고 클러스터가 호스팅되는 리전의 VPC 대시보드 로 이동합니다.
- 피어링 연결 페이지로 이동하여 피어링 연결 만들기 버튼을 클릭합니다.
로그인한 계정의 세부 정보와 연결 중인 계정 및 VPC의 세부 정보를 확인합니다.
- 피어링 연결 이름 태그: VPC 피어링 연결에 대한 설명이 포함된 이름을 설정합니다.
- VPC(Requester): 목록에서 AWS Cluster VPC ID의 Red Hat OpenShift Service를 선택합니다.
- 계정: 다른 계정을 선택하고 고객 AWS 계정 번호 *(대시 제외)를 제공합니다.
- region: Customer VPC Region이 현재 리전과 다른 경우 Another Region 을 선택하고 목록에서 고객 VPC 리전을 선택합니다.
- VPC(Accepter): 고객 VPC ID를 설정합니다.
- 피어링 연결 생성을 클릭합니다.
- 요청이 Pending 상태가 되었는지 확인합니다. Failed 상태가 되면 세부 정보를 확인하고 프로세스를 반복합니다.
2.2.3. VPC 피어 요청 수락
VPC 피어링 연결을 생성한 후 Customer AWS 계정의 요청을 수락해야 합니다.
사전 요구 사항
- VPC 피어 요청을 시작합니다.
프로세스
- AWS 웹 콘솔에 로그인합니다.
- VPC 서비스로 이동합니다.
- 피어링 연결로 이동합니다.
- 보류 중 피어 연결을 클릭합니다.
- 요청이 시작된 AWS 계정 및 VPC ID를 확인합니다. 이는 AWS 계정의 Red Hat OpenShift Service 및 AWS Cluster VPC의 Red Hat OpenShift Service 여야 합니다.
- Accept Request 를 클릭합니다.
2.2.4. 라우팅 테이블 구성
VPC 피어링 요청을 수락한 후 두 VPC 모두 피어링 연결에서 통신하도록 경로를 구성해야 합니다.
사전 요구 사항
- VPC 피어 요청을 시작하고 수락합니다.
프로세스
- AWS 계정의 Red Hat OpenShift 서비스에 대해 AWS 웹 콘솔에 로그인합니다.
- VPC 서비스로 이동한 다음 Route tables.
AWS Cluster VPC에서 Red Hat OpenShift Service의 경로 테이블을 선택합니다.
참고일부 클러스터에서는 특정 VPC에 대해 두 개 이상의 경로 테이블이 있을 수 있습니다. 명시적으로 연결된 여러 서브넷이 있는 개인을 선택합니다.
- 경로 탭을 선택한 다음 편집 을 선택합니다.
- 대상 텍스트 상자에 Customer VPC CIDR 블록을 입력합니다.
- 대상 텍스트 상자에 피어링 연결 ID를 입력합니다.
- 저장을 클릭합니다.
다른 VPC의 CIDR 블록으로 동일한 프로세스를 완료해야 합니다.
- 고객 AWS 웹 콘솔 → VPC 서비스 → 경로 테이블에 로그인합니다.
- VPC의 경로 테이블을 선택합니다.
- 경로 탭을 선택한 다음 편집 을 선택합니다.
- 대상 텍스트 상자에 AWS Cluster VPC CIDR 블록의 Red Hat OpenShift Service를 입력합니다.
- 대상 텍스트 상자에 피어링 연결 ID를 입력합니다.
- 변경 사항 저장을 클릭합니다.
이제 VPC 피어링 연결이 완료되었습니다. 확인 절차에 따라 피어링 연결을 통한 연결이 작동하는지 확인합니다.
2.2.5. VPC 피어링 확인 및 문제 해결
VPC 피어링 연결을 설정한 후에는 해당 연결이 구성되어 올바르게 작동하는지 확인하는 것이 가장 좋습니다.
사전 요구 사항
- VPC 피어 요청을 시작하고 수락합니다.
- 라우팅 테이블을 구성합니다.
프로세스
AWS 콘솔에서 피어링된 클러스터 VPC의 경로 테이블을 확인합니다. 라우팅 테이블을 구성하는 단계가 수행되었으며 VPC CIDR 범위 대상을 피어링 연결 대상으로 가리키는 경로 테이블 항목이 있는지 확인합니다.
AWS Cluster VPC 경로 테이블 및 Customer VPC 경로 테이블의 Red Hat OpenShift Service에서 경로가 올바르게 표시되면 아래
netcat방법을 사용하여 연결을 테스트해야 합니다. 테스트 호출이 성공하면 VPC 피어링이 올바르게 작동합니다.엔드포인트 장치에 대한 네트워크 연결을 테스트하기 위해
nc(또는netcat)는 문제 해결 툴입니다. 연결을 설정할 수 있는 경우 기본 이미지에 포함되어 있으며 빠르고 명확한 출력을 제공합니다.busybox이미지를 사용하여 임시 Pod를 생성하여 자체적으로 정리합니다.$ oc run netcat-test \ --image=busybox -i -t \ --restart=Never --rm \ -- /bin/shnc를 사용하여 연결을 확인합니다.성공적인 연결 결과 예:
/ nc -zvv 192.168.1.1 8080 10.181.3.180 (10.181.3.180:8080) open sent 0, rcvd 0실패한 연결 결과 예:
/ nc -zvv 192.168.1.2 8080 nc: 10.181.3.180 (10.181.3.180:8081): Connection refused sent 0, rcvd 0
컨테이너를 종료하여 Pod를 자동으로 삭제합니다.
/ exit
2.3. AWS VPN 구성
이 샘플 프로세스는 고객의 현장 하드웨어 VPN 장치를 사용하도록 AWS 클러스터에서 AWS(Amazon Web Services) Red Hat OpenShift Service를 구성합니다.
AWS VPN은 현재 VPN 트래픽에 NAT를 적용하는 관리 옵션을 제공하지 않습니다. 자세한 내용은 AWS Knowledge Center 를 참조하십시오.
개인 연결을 통해 0.0.0.0/0 과 같은 모든 트래픽을 라우팅하는 것은 지원되지 않습니다. 이를 위해서는 SRE 관리 트래픽을 비활성화하는 인터넷 게이트웨이를 삭제해야 합니다.
하드웨어 VPN 장치를 사용하여 AWS VPC를 원격 네트워크에 연결하는 방법에 대한 자세한 내용은 Amazon VPC VPN 연결 설명서를 참조하십시오.
2.3.1. VPN 연결 생성
다음 절차에 따라 고객의 현장 하드웨어 VPN 장치를 사용하도록 AWS 클러스터에서 AWS(Amazon Web Services) Red Hat OpenShift Service를 구성할 수 있습니다.
사전 요구 사항
- 하드웨어 VPN 게이트웨이 장치 모델 및 소프트웨어 버전(예: 버전 8.3을 실행하는 Cisco ASA). AWS에서 게이트웨이 장치를 지원하는지 확인하려면 Amazon VPC 네트워크 관리자 가이드를 참조하십시오.
- VPN 게이트웨이 장치의 공용 고정 IP 주소입니다.
- BGP 또는 정적 라우팅: BGP인 경우 ASN이 필요합니다. 정적 라우팅인 경우 하나 이상의 정적 경로를 구성해야 합니다.
- 선택 사항: VPN 연결을 테스트하기 위해 연결할 수 있는 서비스의 IP 및 포트/프로토콜.
2.3.1.1. VPN 연결 구성
프로세스
- AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 VPC 대시보드로 이동합니다.
- 가상 프라이빗 클라우드에서 VPC를 클릭하고 AWS 클러스터의 Red Hat OpenShift Service가 포함된 VPC의 이름과 VPC ID를 식별합니다.
- VPN(Virtual Private Network) 에서 고객 게이트웨이 를 클릭합니다.
- Create customer gateway 를 클릭하고 의미 있는 이름을 지정합니다.
- BGP ASN 필드에 고객 게이트웨이 장치의 ASN을 입력합니다.
- IP 주소 필드에 고객 게이트웨이 장치의 외부 인터페이스의 IP 주소를 입력합니다.
- 고객 게이트웨이 만들기를 클릭합니다.
의도한 VPC에 가상 프라이빗 게이트웨이가 연결되어 있지 않은 경우:
- VPC 대시보드에서 Virtual Private Gateways 를 클릭합니다.
- 가상 개인 게이트웨이 만들기를 클릭하고 의미 있는 이름을 지정합니다.
- 가상 개인 게이트웨이 만들기를 클릭하고 Amazon 기본 ASN을 유지합니다.
- 새로 생성된 게이트웨이를 선택합니다.
- 목록에서 작업을 선택하고 VPC에 연결을 클릭합니다.
- Available VPC에서 새로 생성된 게이트웨이를 선택하고 Attach to VPC 를 클릭하여 이전에 확인한 클러스터 VPC에 연결합니다.
2.3.1.2. VPN 연결 설정
프로세스
- VPC 대시보드의 VPN(Virtual Private Network)에서 사이트 간 VPN 연결을 클릭합니다.
VPN 연결 만들기를 클릭합니다.
- 의미 있는 이름 태그를 지정합니다.
- 이전에 만든 가상 개인 게이트웨이를 선택합니다.
- 고객 게이트웨이의 경우 기존 을 선택합니다.
- 이름별로 고객 게이트웨이 ID를 선택합니다.
- VPN에서 BGP를 사용하는 경우 Dynamic 을 선택합니다. 그렇지 않으면 Static 을 선택하고 정적 IP CIDR을 입력합니다. CIDR이 여러 개인 경우 각 CIDR을 다른 규칙으로 추가합니다.
- VPN 연결 만들기를 클릭합니다.
- State 에서 VPN 상태가 Pending (보류 중)에서 Available (사용 가능)에서 약 5분에서 10분으로 변경될 때까지 기다립니다.
방금 만든 VPN을 선택하고 구성 다운로드를 클릭합니다.
- 목록에서 고객 게이트웨이 장치의 공급 업체, 플랫폼 및 버전을 선택한 다음 다운로드를 클릭합니다.
- 일반 텍스트 형식으로 정보를 검색하는 데 일반 공급업체 구성도 사용할 수 있습니다.
VPN 연결이 설정된 후 경로 전파를 설정하거나 VPN이 예상대로 작동하지 않을 수 있습니다.
구성에 원격 네트워크로 추가해야 하는 VPC 서브넷 정보를 기록해 둡니다.
2.3.1.3. VPN 경로 전파 활성화
VPN 연결을 설정한 후 필요한 경로가 VPC의 경로 테이블에 추가되도록 경로 전파가 활성화되어 있는지 확인해야 합니다.
프로세스
- VPC 대시보드의 가상 프라이빗 클라우드에서 경로 테이블을 클릭합니다.
AWS 클러스터에서 Red Hat OpenShift Service가 포함된 VPC와 연결된 프라이빗 경로 테이블을 선택합니다.
참고일부 클러스터에서는 특정 VPC에 대해 두 개 이상의 경로 테이블이 있을 수 있습니다. 명시적으로 연결된 여러 서브넷이 있는 개인을 선택합니다.
- 경로 전파 탭을 클릭합니다.
표시되는 테이블에는 이전에 만든 가상 프라이빗 게이트웨이가 표시됩니다. Propagate 열의 값을 확인합니다.
- Propagation 이 No 로 설정된 경우 경로 전파 편집을 클릭하고 Propagation에서 Enable 확인란을 선택하고 저장을 클릭합니다.
VPN 터널을 구성하고 AWS가 Up 으로 감지하면 정적 또는 BGP 경로가 경로 테이블에 자동으로 추가됩니다.
2.3.2. VPN 연결 확인
VPN 터널을 설정한 후 터널이 AWS 콘솔에 있고 터널 간 연결이 작동하는지 확인할 수 있습니다.
사전 요구 사항
- VPN 연결을 생성했습니다.
프로세스
AWS에서 터널이 있는지 확인합니다.
- VPC 대시보드의 VPN(Virtual Private Network) 에서 사이트 간 VPN 연결을 클릭합니다.
- 이전에 만든 VPN 연결을 선택하고 터널 세부 정보 탭을 클릭합니다.
- VPN 터널 중 하나 이상이 Up 상태인지 확인해야 합니다.
연결을 확인합니다.
엔드포인트 장치에 대한 네트워크 연결을 테스트하기 위해
nc(또는netcat)는 문제 해결 툴입니다. 연결을 설정할 수 있는 경우 기본 이미지에 포함되어 있으며 빠르고 명확한 출력을 제공합니다.busybox이미지를 사용하여 임시 Pod를 생성하여 자체적으로 정리합니다.$ oc run netcat-test \ --image=busybox -i -t \ --restart=Never --rm \ -- /bin/shnc를 사용하여 연결을 확인합니다.성공적인 연결 결과 예:
/ nc -zvv 192.168.1.1 8080 10.181.3.180 (10.181.3.180:8080) open sent 0, rcvd 0실패한 연결 결과 예:
/ nc -zvv 192.168.1.2 8080 nc: 10.181.3.180 (10.181.3.180:8081): Connection refused sent 0, rcvd 0
컨테이너를 종료하여 Pod를 자동으로 삭제합니다.
/ exit
2.3.3. VPN 연결 문제 해결
터널이 연결되지 않음
터널 연결이 아직 Down 이면 다음과 같은 몇 가지 사항을 확인할 수 있습니다.
- AWS 터널은 VPN 연결을 시작하지 않습니다. 고객 게이트웨이에서 연결 시도를 시작해야 합니다.
- 구성된 고객 게이트웨이와 동일한 IP에서 소스 트래픽이 수신되는지 확인합니다. AWS는 소스 IP 주소가 일치하지 않는 게이트웨이로의 모든 트래픽을 자동으로 삭제합니다.
- 구성이 AWS에서 지원하는 값과 일치하는지 확인합니다. 여기에는 IKE 버전, DH 그룹, IKE 수명 등이 포함됩니다.
- VPC의 라우팅 테이블을 다시 확인합니다. 전파가 활성화되어 있고 경로 테이블에 대상으로 만든 가상 개인 게이트웨이가 있는 항목이 있는지 확인합니다.
- 중단될 수 있는 방화벽 규칙이 없는지 확인합니다.
- 정책 기반 VPN을 사용하는 경우 구성 방법에 따라 복잡한 문제가 발생할 수 있으므로 이를 확인합니다.
- 추가 문제 해결 단계는 AWS Knowledge Center 에서 확인할 수 있습니다.
터널은 계속 연결되어 있지 않습니다.
터널 연결이 지속적으로 Up 을 유지하는 데 문제가 있는 경우 게이트웨이에서 모든 AWS 터널 연결을 시작해야 함을 알고 있습니다. AWS 터널 은 터널링을 시작하지 않습니다.
Red Hat은 VPC CIDR 범위 내에 구성된 모든 IP 주소로 SLA 모니터(Cisco ASA) 또는 터널 옆에 있는 일부 장치(예: ping,nc, telnet )를 설정할 것을 권장합니다. 연결이 성공했는지는 중요하지 않으며 트래픽이 터널에서 전달되고 있습니다.
Down 상태의 보조 터널
VPN 터널이 생성되면 AWS는 추가 페일오버 터널을 생성합니다. 게이트웨이 장치에 따라 보조 터널이 Down 상태에서 로 표시되는 경우가 있습니다.
AWS 알림은 다음과 같습니다.
You have new non-redundant VPN connections
One or more of your vpn connections are not using both tunnels. This mode of
operation is not highly available and we strongly recommend you configure your
second tunnel. View your non-redundant VPN connections.2.4. AWS Direct Connect 구성
이 프로세스는 AWS에서 Red Hat OpenShift Service를 사용하여 AWS Direct Connect 가상 인터페이스를 수락하는 방법을 설명합니다. AWS Direct Connect 유형 및 구성에 대한 자세한 내용은 AWS Direct Connect 구성 요소 설명서를 참조하십시오.
2.4.1. AWS Direct Connect 방법
직접 연결 연결에는 직접 연결 게이트웨이(DXGateway)에 연결된 호스트형 가상 인터페이스(VXGateway)가 필요하며, 이는 동일한 계정 또는 다른 계정의 원격 VPC에 액세스하기 위해 VGW(Virtual Gateway) 또는 Transit Gateway에 연결됩니다.
기존 CryostatGateway가 없는 경우 일반적인 프로세스에는 호스팅 VIF를 생성해야 하며, AWS 계정의 Red Hat OpenShift Service에서 CryostatGateway 및 VGW가 생성됩니다.
기존의 CryostatGateway가 하나 이상의 기존 VGW에 연결되어 있는 경우 이 프로세스에는 AWS 계정의 Red Hat OpenShift Service가 AWS 계정의 Red Hat OpenShift Service를 involves sending an Association Proposal to the CryostatGateway 소유자입니다. CryostatGateway 소유자는 제안된 CIDR이 연결된 다른 VGW와 충돌하지 않도록 해야 합니다.
자세한 내용은 다음 AWS 설명서를 참조하십시오.
기존 CryostatGateway에 연결할 때 귀하는 비용을 부담 합니다.
다음 두 가지 구성 옵션을 사용할 수 있습니다.
| 방법 1 | 호스팅된 VIF를 만든 다음 CryostatGateway 및 VGW를 만듭니다. |
| 방법 2 | 사용자가 소유한 기존 Direct Connect 게이트웨이를 통해 연결을 요청합니다. |
2.4.2. 호스트 가상 인터페이스 생성
사전 요구 사항
- AWS 계정 ID에서 Red Hat OpenShift Service를 수집합니다.
2.4.2.1. 직접 연결 연결 유형 확인
직접 연결 가상 인터페이스 세부 정보를 보고 연결 유형을 확인합니다.
프로세스
- AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 올바른 리전을 선택합니다.
- 서비스 메뉴에서 Direct Connect 를 선택합니다.
- 승인 대기 중인 가상 인터페이스가 한 개 이상 있으며, 해당 인터페이스 중 하나를 선택하여 요약 을 확인합니다.
- 가상 인터페이스 유형: private 또는 public을 확인합니다.
- Amazon 사이드 ASN 값을 기록합니다.
Direct Connect 가상 인터페이스 유형이 프라이빗인 경우 가상 프라이빗 게이트웨이가 생성됩니다. 직접 연결 가상 인터페이스가 공용인 경우 직접 연결 게이트웨이가 생성됩니다.
2.4.2.2. 개인 직접 연결 만들기
Direct Connect 가상 인터페이스 유형이 프라이빗인 경우 Private Direct Connect가 생성됩니다.
프로세스
- AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 올바른 리전을 선택합니다.
- AWS 리전의 Services 메뉴에서 VPC 를 선택합니다.
- VPN(Virtual Private Network) 에서 Virtual Private Gateway를 선택합니다.
- 가상 개인 게이트웨이 만들기를 클릭합니다.
- 가상 사설 게이트웨이에 적절한 이름을 지정합니다.
- Enter custom ASN 필드에서 Custom ASN 을 선택합니다.
- 가상 개인 게이트웨이 만들기를 클릭합니다.
- 새로 생성된 Virtual Private Gateway를 클릭하고 Actions 탭에서 VPC에 연결을 선택합니다.
- 목록에서 Red Hat OpenShift Service on AWS Cluster VPC 를 선택하고 Attach VPC 를 클릭합니다.
참고: kubelet 구성을 편집하면 머신 풀의 노드가 다시 생성됩니다. 이 마??
2.4.2.3. 공개 직접 연결 만들기
Direct Connect 가상 인터페이스 유형이 공용인 경우 공용 Direct Connect가 생성됩니다.
프로세스
- AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 올바른 리전을 선택합니다.
- AWS 계정의 Red Hat OpenShift Service의 서비스 메뉴에서 Direct Connect 를 선택합니다.
- Direct Connect 게이트웨이 를 선택하고 Direct Connect 게이트웨이 만들기를 선택합니다.
- Direct Connect 게이트웨이에 적절한 이름을 지정합니다.
- Amazon 사이드 ASN 에서 이전에 수집한 Amazon 사이드 ASN 값을 입력합니다.
- Direct Connect 게이트웨이 만들기를 클릭합니다.
2.4.2.4. 가상 인터페이스 확인
Direct Connect 가상 인터페이스가 승인되면 짧은 기간을 기다렸다가 인터페이스 상태를 확인합니다.
프로세스
- AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 올바른 리전을 선택합니다.
- AWS 계정의 Red Hat OpenShift Service의 서비스 메뉴에서 Direct Connect 를 선택합니다.
- 목록에서 직접 연결 가상 인터페이스 중 하나를 선택합니다.
- 인터페이스 상태가 사용 가능으로 표시되었는지 확인합니다.
- Interface BGP Status가 up이 되었는지 확인합니다.
- 나머지 Direct Connect 인터페이스에 대해 이 확인을 반복합니다.
직접 연결 가상 인터페이스를 사용할 수 있는 후 AWS AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 구성을 위해 직접 연결 구성 파일을 다운로드할 수 있습니다.
2.4.3. 기존 Direct Connect Gateway에 연결
사전 요구 사항
- AWS VPC에서 Red Hat OpenShift Service의 CIDR 범위가 연결된 다른 VGW와 충돌하지 않는지 확인합니다.
다음 정보를 수집합니다.
- Direct Connect 게이트웨이 ID입니다.
- 가상 인터페이스와 연결된 AWS 계정 ID입니다.
- CryostatGateway에 할당된 BGP ASN입니다. 선택 사항: Amazon 기본 ASN도 사용할 수 있습니다.
프로세스
- AWS 계정 대시보드에서 Red Hat OpenShift Service에 로그인하고 올바른 리전을 선택합니다.
- AWS 계정의 Red Hat OpenShift Service에서 Services 메뉴에서 VPC 를 선택합니다.
- VPN(Virtual Private Network) 에서 Virtual Private Gateway를 선택합니다.
- 가상 개인 게이트웨이 만들기를 선택합니다.
- 세부 정보 필드에 가상 개인 게이트웨이에 적절한 이름을 지정합니다.
- Custom ASN 을 클릭하고 이전에 수집된 Amazon 사이드 ASN 값을 입력하거나 Amazon Provided ASN을 사용합니다.
- 가상 개인 게이트웨이 만들기를 클릭합니다.
- AWS 계정의 Red Hat OpenShift Service의 서비스 메뉴에서 Direct Connect 를 선택합니다.
- 가상 개인 게이트웨이 를 클릭하고 가상 개인 게이트웨이를 선택합니다.
- 세부 정보 보기를 클릭합니다.
- Direct Connect 게이트웨이 연결 탭을 클릭합니다.
- 직접 연결 게이트웨이 연결을클릭합니다.
- 연결 계정 유형에서 계정 소유자의 경우 다른 계정을 클릭합니다.
- 연결 설정에서 Direct Connect 게이트웨이 ID의 경우 Direct Connect 게이트웨이의 ID를 입력합니다.
- Direct Connect 게이트웨이 소유자의 경우 Direct Connect 게이트웨이 를 소유한 AWS 계정의 ID를 입력합니다.
- 선택 사항: 허용된 접두사에 접두사 를 추가하고 쉼표를 사용하여 분리하거나 별도의 줄에 넣습니다.
- Associate Direct Connect Gateway를 클릭합니다.
- 연계 제안이 발송되면 귀하의 동의를 기다리고 있을 것입니다. 수행해야 하는 최종 단계는 AWS 문서에서 사용할 수 있습니다.
2.4.4. Direct Connect 문제 해결
자세한 문제 해결은 AWS Direct Connect 문제 해결 설명서에서 확인할 수 있습니다.
3장. AWS에서 Red Hat OpenShift Service에 대한 클러스터 자동 스케일링
AWS 클러스터에서 Red Hat OpenShift Service에 자동 스케일링을 적용하려면 자동 스케일링을 사용하여 하나 이상의 머신 풀을 구성해야 합니다. 클러스터 자동 스케일러를 사용하여 자동 스케일링인 모든 머신 풀에 적용할 수 있는 클러스터 전체 자동 스케일링을 추가로 구성할 수 있습니다.
3.1. 클러스터 자동 스케일러 정보
클러스터 자동 스케일러는 현재 배포 요구 사항에 맞게 AWS 클러스터의 Red Hat OpenShift Service 크기를 조정합니다. 이는 Kubernetes 형식의 선언적 인수를 사용하여 특정 클라우드 공급자의 개체에 의존하지 않는 인프라 관리를 제공합니다. 클러스터 자동 스케일러에는 클러스터 범위가 있으며 특정 네임 스페이스와 연결되어 있지 않습니다. AWS의 Red Hat OpenShift Service에서 클러스터 자동 스케일러가 완전히 관리되므로 컨트롤 플레인과 함께 호스팅됩니다.
리소스가 부족하여 현재 작업자 노드에서 Pod를 예약할 수 없거나 배포 요구를 충족하기 위해 다른 노드가 필요한 경우 클러스터 자동 스케일러는 클러스터 크기를 늘립니다. 클러스터 자동 스케일러는 사용자가 지정한 제한을 초과하여 클러스터 리소스를 늘리지 않습니다.
클러스터 자동 스케일러는 머신 풀 자동 스케일링에 속하는 노드에서만 총 메모리, CPU 및 GPU를 계산합니다. 자동 스케일링이 아닌 모든 머신 풀 노드는 이 집계에서 제외됩니다. 예를 들어 단일 머신 풀이 자동 스케일링되지 않는 3개의 머신 풀을 AWS 클러스터의 Red Hat OpenShift Service에서 maxNodesTotal 을 50 으로 설정하면 클러스터 자동 스케일러는 자동 스케일링되는 두 개의 머신 풀에서만 총 노드를 50 으로 제한합니다. 머신 풀을 수동으로 스케일링하는 단일 노드에는 추가 노드가 있을 수 있으므로 전체 클러스터 노드가 총 50 개를 초과할 수 있습니다.
3.1.1. 자동 노드 제거
10초마다 클러스터 자동 스케일러는 클러스터에서 불필요한 노드를 확인하고 제거합니다. 다음 조건이 적용되는 경우 클러스터 자동 스케일러는 노드가 제거되도록 간주합니다.
-
노드 사용률은 클러스터의 노드 사용률 수준 임계값보다 적습니다. 노드 사용률 수준은 요청된 리소스의 합계를 노드에 할당된 리소스로 나눈 값입니다.
ClusterAutoscaler사용자 지정 리소스에서 값을 지정하지 않으면 클러스터 자동 스케일러는 기본값0.5를 사용하며 이는 사용률 50%에 해당합니다. - 클러스터 자동 스케일러는 노드에서 실행 중인 모든 Pod를 다른 노드로 이동할 수 있습니다. Kubernetes 스케줄러는 노드에 Pod를 예약해야 합니다.
- 클러스터 자동 스케일러에는 축소 비활성화 주석이 없습니다.
노드에 다음 유형의 pod가 있는 경우 클러스터 자동 스케일러는 해당 노드를 제거하지 않습니다.
- 제한적인 PDB (Pod Disruption Budgets)가 있는 pod
- 기본적으로 노드에서 실행되지 않는 Kube 시스템 pod
- PDB가 없거나 제한적인 PDB가있는 Kube 시스템 pod
- deployment, replica set 또는 stateful set와 같은 컨트롤러 객체가 지원하지 않는 pod
- 로컬 스토리지가 있는 pod
- 리소스 부족, 호환되지 않는 노드 선택기 또는 어피니티(affinity), 안티-어피니티(anti-affinity) 일치 등으로 인해 다른 위치로 이동할 수 없는 pod
-
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"주석이없는 경우"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"주석이 있는 pod
예를 들어 최대 CPU 제한을 64코어로 설정하고 각각 코어가 8개인 머신만 생성하도록 클러스터 자동 스케일러를 구성합니다. 클러스터가 30개의 코어로 시작하는 경우 클러스터 자동 스케일러는 총 62개에 대해 32개의 코어가 있는 노드를 최대 4개까지 추가할 수 있습니다.
3.1.2. 제한
클러스터 자동 스케일러를 구성하면 추가 사용 제한이 적용됩니다.
- 자동 스케일링된 노드 그룹에 있는 노드를 직접 변경하지 마십시오. 동일한 노드 그룹 내의 모든 노드는 동일한 용량 및 레이블을 가지며 동일한 시스템 pod를 실행합니다.
- pod 요청을 지정합니다.
- pod가 너무 빨리 삭제되지 않도록 해야 하는 경우 적절한 PDB를 구성합니다.
- 클라우드 제공자 할당량이 구성하는 최대 노드 풀을 지원할 수 있는 충분한 크기인지를 확인합니다.
- 추가 노드 그룹 Autoscaler, 특히 클라우드 제공자가 제공하는 Autoscaler를 실행하지 마십시오.
클러스터 자동 스케일러는 예약 가능한 Pod가 생성되는 경우에만 자동 스케일링된 노드 그룹에 노드를 추가합니다. 사용 가능한 노드 유형이 Pod 요청에 대한 요구 사항을 충족할 수 없거나 이러한 요구 사항을 충족할 수 있는 노드 그룹이 최대 크기에 있는 경우 클러스터 자동 스케일러를 확장할 수 없습니다.
3.1.3. 다른 스케줄링 기능과의 상호 작용
HPA (Horizond Pod Autoscaler) 및 클러스터 자동 스케일러는 다른 방식으로 클러스터 리소스를 변경합니다. HPA는 현재 CPU 로드를 기준으로 배포 또는 복제 세트의 복제 수를 변경합니다. 로드가 증가하면 HPA는 클러스터에 사용 가능한 리소스 양에 관계없이 새 복제본을 만듭니다. 리소스가 충분하지 않은 경우 클러스터 자동 스케일러는 리소스를 추가하고 HPA가 생성한 pod를 실행할 수 있도록 합니다. 로드가 감소하면 HPA는 일부 복제를 중지합니다. 이 동작으로 일부 노드가 충분히 활용되지 않거나 완전히 비어 있을 경우 클러스터 자동 스케일러가 불필요한 노드를 삭제합니다.
클러스터 자동 스케일러는 pod 우선 순위를 고려합니다. Pod 우선 순위 및 선점 기능을 사용하면 클러스터에 충분한 리소스가 없는 경우 우선 순위에 따라 pod를 예약할 수 있지만 클러스터 자동 스케일러는 클러스터에 모든 pod를 실행하는 데 필요한 리소스가 있는지 확인합니다. 두 기능을 충족하기 위해 클러스터 자동 스케일러에는 우선 순위 컷오프 기능이 포함되어 있습니다. 이 컷오프 기능을 사용하여 "best-effort" pod를 예약하면 클러스터 자동 스케일러가 리소스를 늘리지 않고 사용 가능한 예비 리소스가 있을 때만 실행됩니다.
컷오프 값보다 우선 순위가 낮은 pod는 클러스터가 확장되지 않거나 클러스터가 축소되지 않도록합니다. pod를 실행하기 위해 추가된 새 노드가 없으며 이러한 pod를 실행하는 노드는 리소스를 확보하기 위해 삭제될 수 있습니다.
3.2. ROSA CLI와 함께 대화형 모드를 사용하여 클러스터 생성 중 자동 스케일링 활성화
사용 가능한 경우 터미널의 대화형 모드에서 ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 클러스터 생성 중에 클러스터 전체 자동 스케일링 동작을 설정할 수 있습니다.
대화형 모드는 사용 가능한 구성 가능한 매개변수에 대한 자세한 정보를 제공합니다. 대화형 모드는 기본 검사 및 preflight 검증을 수행합니다. 즉, 제공된 값이 유효하지 않으면 터미널에서 유효한 입력을 요청하는 프롬프트가 출력됩니다.
프로세스
클러스터 생성 중에
--enable-autoscaling및--interactive매개변수를 사용하여 클러스터 자동 스케일링을 활성화합니다.예
$ rosa create cluster --cluster-name <cluster_name> --enable-autoscaling --interactive
클러스터 이름이 15자보다 긴 경우 *.openshiftapps.com 에서 프로비저닝된 클러스터의 하위 도메인으로 자동 생성된 도메인 접두사가 포함됩니다.
하위 도메인을 사용자 지정하려면 --domain-prefix 플래그를 사용합니다. 도메인 접두사는 15자를 초과할 수 없으며 고유해야 하며 클러스터 생성 후에는 변경할 수 없습니다.
다음 프롬프트가 표시되면 y 를 입력하여 사용 가능한 모든 자동 스케일링 옵션을 통과합니다.
대화형 프롬프트 예
? Configure cluster-autoscaler (optional): [? for help] (y/N) y <enter>3.3. ROSA CLI를 사용하여 클러스터 생성 중 자동 스케일링 활성화
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 클러스터 생성 중에 클러스터 전체 자동 스케일링 동작을 설정할 수 있습니다. 전체 머신 또는 클러스터에서만 자동 스케일러를 활성화할 수 있습니다.
프로세스
-
클러스터 생성 중에 클러스터 이름 뒤에
--enable 자동 스케일링을입력하여 머신 자동 스케일링을 활성화합니다.
클러스터 이름이 15자보다 긴 경우 *.openshiftapps.com 에서 프로비저닝된 클러스터의 하위 도메인으로 자동 생성된 도메인 접두사가 포함됩니다.
하위 도메인을 사용자 지정하려면 --domain-prefix 플래그를 사용합니다. 도메인 접두사는 15자를 초과할 수 없으며 고유해야 하며 클러스터 생성 후에는 변경할 수 없습니다.
예
$ rosa create cluster --cluster-name <cluster_name> --enable-autoscaling다음 명령을 실행하여 클러스터 자동 스케일링을 활성화하려면 하나 이상의 매개변수를 설정합니다.
예
$ rosa create cluster --cluster-name <cluster_name> --enable-autoscaling <parameter>3.4. ROSA CLI를 사용한 클러스터 자동 스케일링 매개변수
ROSA CLI(명령줄 인터페이스)(rosa)를 사용할 때 자동 스케일러 매개변수를 구성하려면 클러스터 생성 명령에 다음 매개변수를 추가할 수 있습니다.
| 설정 | 설명 | 유형 또는 범위 | 예/디렉션 |
|---|---|---|---|
|
| 축소 전 Pod의 정상 종료 시간을 초 단위로 측정합니다. 명령에서 int 를 사용하려는 초 수로 바꿉니다. |
|
|
|
| 클러스터 자동 스케일러가 추가 노드를 배포하도록 하려면 Pod가 초과해야하는 우선 순위입니다. 명령에서 int 를 사용할 번호로 바꿉니다. 음수가 될 수 있습니다. |
|
|
|
| 클러스터 자동 스케일러가 노드를 프로비저닝할 때까지 대기하는 최대 시간입니다. 명령의 문자열 을 정수 및 시간 단위(ns,us, Cryostats,ms,s,m,h)로 바꿉니다. |
|
|
|
| 자동 스케일링된 노드를 포함하여 클러스터의 최대 노드 양입니다. 명령에서 int 를 사용할 번호로 바꿉니다. |
|
|
3.5. ROSA CLI를 사용하여 클러스터 생성 후 자동 스케일링 편집
ROSA CLI(명령줄 인터페이스)(rosa)를 사용할 때 자동 스케일러를 생성한 후 클러스터 자동 스케일러의 특정 매개변수를 편집할 수 있습니다.
프로세스
클러스터 자동 스케일러를 편집하려면 다음 명령을 실행합니다.
예
$ rosa edit autoscaler --cluster=<mycluster>특정 매개변수를 편집하려면 다음 명령을 실행합니다.
예
$ rosa edit autoscaler --cluster=<mycluster> <parameter>
3.6. ROSA CLI를 사용하여 자동 스케일러 구성 보기
ROSA CLI(명령줄 인터페이스)( rosa describe)를 사용할 때 구성을 볼 수 있습니다.
rosadescribe Autoscaler 명령을 사용하여 클러스터 자동 스케일러
프로세스
클러스터 자동 스케일러 구성을 보려면 다음 명령을 실행합니다.
예
$ rosa describe autoscaler -h --cluster=<mycluster>
4장. 머신 풀을 사용하여 컴퓨팅 노드 관리
4.1. 머신 풀 정보
AWS의 Red Hat OpenShift Service는 클라우드 인프라에 더하여 탄력적이고 동적인 프로비저닝 방법으로 머신 풀을 사용합니다.
기본 리소스는 시스템, 컴퓨팅 머신 세트, 머신 풀입니다.
4.1.1. Machine
시스템은 작업자 노드의 호스트를 설명하는 기본 단위입니다.
4.1.2. 머신 세트
MachineSet 리소스는 컴퓨팅 머신 그룹입니다. 더 많은 머신이 필요하거나 축소해야 하는 경우 컴퓨팅 시스템 세트가 속한 시스템 풀의 복제본 수를 변경합니다.
AWS의 Red Hat OpenShift Service에서는 머신 세트를 직접 수정할 수 없습니다.
4.1.3. 머신 풀
머신 풀은 컴퓨팅 머신 세트에 더 높은 수준의 구성입니다.
시스템 풀은 가용성 영역에서 모두 동일한 구성을 복제하는 컴퓨팅 머신 세트를 생성합니다. 머신 풀은 작업자 노드에서 모든 호스트 노드 프로비저닝 관리 작업을 수행합니다. 더 많은 머신이 필요하거나 축소해야 하는 경우 컴퓨팅 요구 사항에 맞게 시스템 풀의 복제본 수를 변경합니다. 수동으로 스케일링을 구성하거나 자동 스케일링을 설정할 수 있습니다.
AWS 클러스터의 Red Hat OpenShift Service에서 호스팅되는 컨트롤 플레인은 설치된 클라우드 리전의 여러 가용성 영역(AZ)을 확장합니다. AWS 클러스터의 Red Hat OpenShift Service의 각 머신 풀은 단일 AZ 내의 단일 서브넷에 배포됩니다.
작업자 노드는 수명이 보장되지 않으며 OpenShift의 정상적인 작동 및 관리의 일부로 언제든지 교체될 수 있습니다. 노드 라이프사이클에 대한 자세한 내용은 추가 리소스 를 참조하십시오.
단일 클러스터에 여러 머신 풀이 존재할 수 있으며 각 머신 풀에 고유한 노드 유형 및 노드 크기(AWS EC2 인스턴스 유형 및 크기) 구성이 포함될 수 있습니다.
4.1.3.1. 클러스터 설치 중 머신 풀
기본적으로 클러스터에는 하나의 시스템 풀이 있습니다. 클러스터 설치 중에 인스턴스 유형 또는 크기를 정의하고 이 시스템 풀에 레이블을 추가하고 루트 디스크 크기를 정의할 수 있습니다.
4.1.3.2. 클러스터 설치 후 머신 풀 구성
클러스터 설치 후 다음을 수행합니다.
- 머신 풀에 레이블을 제거하거나 추가할 수 있습니다.
- 기존 클러스터에 머신 풀을 추가할 수 있습니다.
- 테인트 없이 머신 풀이 한 개 있는 경우 머신 풀에 테인트를 추가할 수 있습니다.
테인트 및 두 개 이상의 복제본이 없는 머신 풀이 있는 경우 머신 풀을 생성하거나 삭제할 수 있습니다.
참고머신 풀 노드 유형 또는 크기는 변경할 수 없습니다. 머신 풀 노드 유형 또는 크기는 생성 중에만 지정됩니다. 다른 노드 유형 또는 크기가 필요한 경우 머신 풀을 다시 생성하고 필요한 노드 유형 또는 크기 값을 지정해야 합니다.
- 추가된 각 머신 풀에 레이블을 추가할 수 있습니다.
작업자 노드는 수명이 보장되지 않으며 OpenShift의 정상적인 작동 및 관리의 일부로 언제든지 교체될 수 있습니다. 노드 라이프사이클에 대한 자세한 내용은 추가 리소스 를 참조하십시오.
프로세스
선택 사항: 기본 머신 풀 레이블을 사용하고 다음 명령을 실행하여 구성 후 기본 머신 풀에 레이블을 추가합니다.
$ rosa edit machinepool -c <cluster_name> <machinepool_name> -i입력 예
$ rosa edit machinepool -c mycluster worker -i ? Enable autoscaling: No ? Replicas: 3 ? Labels: mylabel=true I: Updated machine pool 'worker' on cluster 'mycluster'
4.1.3.3. 머신 풀 업그레이드 요구 사항
AWS 클러스터의 Red Hat OpenShift Service의 각 머신 풀은 독립적으로 업그레이드됩니다. 머신 풀은 독립적으로 업그레이드되므로 호스트된 컨트롤 플레인의 두 가지 마이너(Y-stream) 버전 내에 있어야 합니다. 예를 들어 호스트된 컨트롤 플레인이 4.16.z인 경우 머신 풀은 4.14.z 이상이어야 합니다.
다음 이미지는 AWS 클러스터의 Red Hat OpenShift Service 내에서 머신 풀이 작동하는 방식을 보여줍니다.
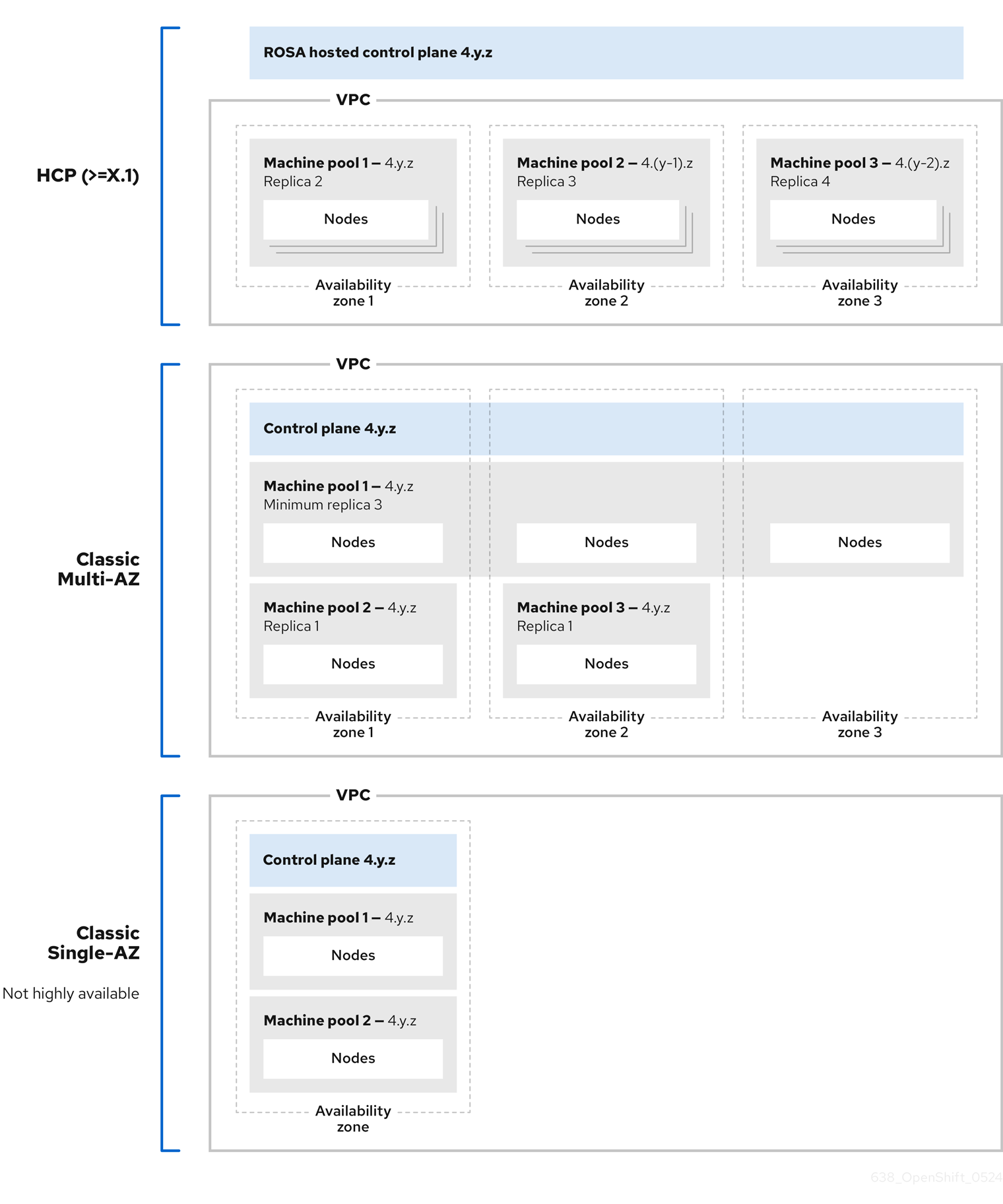
AWS 클러스터의 Red Hat OpenShift Service의 머신 풀은 개별적으로 업그레이드되며 머신 풀 버전은 컨트롤 플레인의 두 가지 마이너 (Y-stream) 버전 내에 있어야 합니다.
4.1.4. 추가 리소스
4.2. 컴퓨팅 노드 관리
이 문서에서는 AWS에서 Red Hat OpenShift Service를 사용하여 컴퓨팅(작업자) 노드를 관리하는 방법을 설명합니다.
컴퓨팅 노드의 대부분의 변경 사항은 시스템 풀에 구성됩니다. 시스템 풀은 동일한 구성이 있는 클러스터의 컴퓨팅 노드 그룹으로, 관리가 용이합니다.
확장, 노드 레이블 추가, 테인트 추가와 같은 머신 풀 구성 옵션을 편집할 수 있습니다.
용량 예약으로 새 머신 풀을 생성할 수도 있습니다.
AWS 용량 예약 개요
특정 인스턴스 유형 및 가용성 영역(AZ)에 대해 AWS 용량 예약을 사용하여 컴퓨팅 용량을 예약한 경우 AWS 작업자 노드의 Red Hat OpenShift 서비스에 사용할 수 있습니다. 머신 러닝(ML) 워크로드에 대한 온 디맨드 용량 예약 및 용량 블록 모두 지원됩니다.
AWS로 직접 용량 예약을 구매하고 관리합니다. 용량을 예약한 후 AWS 클러스터의 Red Hat OpenShift Service에 생성할 때 새 머신 풀에 용량 예약 ID를 추가합니다. AWS 조직 내의 다른 AWS 계정에서 공유되는 용량 예약도 사용할 수 있습니다.
AWS의 Red Hat OpenShift Service에서 용량 예약을 구성한 후 AWS 계정을 사용하여 계정의 모든 워크로드에서 예약된 용량 사용량을 모니터링할 수 있습니다.
AWS 클러스터의 Red Hat OpenShift Service에서 용량 예약을 사용하면 다음과 같은 사전 요구 사항과 제한 사항이 있습니다.
- ROSA CLI 버전 1.2.57 이상을 설치했습니다.
- AWS 클러스터의 Red Hat OpenShift Service는 4.19 이상입니다.
- 클러스터에 이미 용량 예약 또는 테인트를 사용하지 않는 머신 풀이 있습니다. 머신 풀에는 작업자 노드가 2개 이상 있어야 합니다.
- 생성 중인 머신 풀의 AZ에 필요한 인스턴스 유형에 대한 용량 예약을 구입했습니다.
- 새 머신 풀에만 용량 예약 ID를 추가할 수 있습니다.
- 용량 예약이 구성된 머신 풀에서 자동 스케일링을 사용할 수 없습니다.
- 구성된 용량 예약으로 머신 풀을 업그레이드할 수 없습니다.
용량 예약이 있는 머신 풀을 생성하려면 ROSA CLI를 사용하여 용량 예약이 있는 머신 풀 생성을 참조하십시오.
4.2.1. 머신 풀 생성
AWS 클러스터에 Red Hat OpenShift Service를 설치할 때 머신 풀이 생성됩니다. 설치 후 OpenShift Cluster Manager 또는 CLI(명령줄 인터페이스)(rosa)를 사용하여 클러스터에 대한 추가 머신 풀을 생성할 수 있습니다.
rosa 버전 1.2.25 및 이전 버전의 사용자의 경우 클러스터와 함께 생성된 시스템 풀은 Default 로 식별됩니다. rosa 버전 1.2.26 이상 사용자의 경우 클러스터와 함께 생성된 시스템 풀은 worker 로 식별됩니다.
4.2.1.1. OpenShift Cluster Manager를 사용하여 머신 풀 생성
OpenShift Cluster Manager를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service에 대한 추가 머신 풀을 생성할 수 있습니다.
사전 요구 사항
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
프로세스
- OpenShift Cluster Manager 로 이동하여 클러스터를 선택합니다.
- 머신 풀 탭에서 머신 풀 추가 를 클릭합니다.
- 머신 풀 이름을 추가합니다.
목록에서 컴퓨팅 노드 인스턴스 유형을 선택합니다. 인스턴스 유형은 시스템 풀의 각 계산 노드에 대한 vCPU 및 메모리 할당을 정의합니다.
참고풀을 생성한 후에는 머신 풀의 인스턴스 유형을 변경할 수 없습니다.
선택 사항: 머신 풀에 대한 자동 스케일링을 구성합니다.
- 자동 스케일링 사용을 선택하여 배포 요구 사항에 맞게 시스템 풀의 머신 수를 자동으로 확장합니다.
자동 스케일링을 위해 최소 및 최대 노드 수 제한을 설정합니다. 클러스터 자동 스케일러는 사용자가 지정하는 제한을 초과하여 머신 풀 노드 수를 줄이거나 늘리지 않습니다.
참고또는 머신 풀을 생성한 후 머신 풀에 대한 자동 스케일링 기본 설정을 설정할 수 있습니다.
- 자동 스케일링을 활성화하지 않은 경우 드롭다운 메뉴에서 컴퓨팅 노드 수 를 선택합니다. 이는 가용성 영역의 시스템 풀에 프로비저닝할 컴퓨팅 노드 수를 정의합니다.
- 선택 사항: 루트 디스크 크기를 구성합니다.
선택사항: 머신 풀의 노드 레이블 및 테인트를 추가합니다.
- 노드 레이블 및 테인트 메뉴를 확장합니다.
- 노드 레이블 에서 노드 라벨에 대한 키 및 값 항목을 추가합니다.
Taints 에서 테인트에 대한 키 및 값 항목을 추가합니다.
참고테인트를 사용하여 머신 풀을 생성하는 것은 클러스터에 테인트 없이 하나 이상의 머신 풀이 이미 있는 경우에만 가능합니다.
각 테인트의 드롭다운 메뉴에서 Effect 를 선택합니다. 사용 가능한 옵션에는
NoSchedule,PreferNoSchedule,NoExecute가 있습니다.참고또는 머신 풀을 생성한 후 노드 레이블 및 테인트를 추가할 수 있습니다.
선택 사항: 이 머신 풀의 노드에 사용할 추가 사용자 지정 보안 그룹을 선택합니다. 보안 그룹을 이미 생성하여 이 클러스터에 대해 선택한 VPC와 연결되어야 합니다. 머신 풀을 생성한 후에는 보안 그룹을 추가하거나 편집할 수 없습니다.
중요AWS 클러스터의 Red Hat OpenShift Service의 머신 풀에 최대 10개의 추가 보안 그룹을 사용할 수 있습니다.
- 시스템 풀 추가 를 클릭하여 머신 풀을 생성합니다.
검증
- 머신 풀이 머신 풀 페이지에 표시되고 구성이 예상대로 표시되는지 확인합니다.
4.2.1.2. ROSA CLI를 사용하여 머신 풀 생성
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service에 대한 추가 머신 풀을 생성할 수 있습니다.
머신 풀에 사전 구매 용량 예약을 추가하려면 용량 예약이 있는 머신 풀 생성 을 참조하십시오.
사전 요구 사항
- 워크스테이션에 최신 ROSA CLI를 설치하고 구성했습니다.
- ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
프로세스
자동 스케일링을 사용하지 않는 머신 풀을 추가하려면 시스템 풀을 생성하고 인스턴스 유형, compute(작업자) 노드 수 및 노드 레이블을 정의합니다.
$ rosa create machinepool --cluster=<cluster-name> \ --name=<machine_pool_id> \ --replicas=<replica_count> \ --instance-type=<instance_type> \ --labels=<key>=<value>,<key>=<value> \ --taints=<key>=<value>:<effect>,<key>=<value>:<effect> \ --disk-size=<disk_size> \ --availability-zone=<availability_zone_name> \ --additional-security-group-ids <sec_group_id> \ --subnet <subnet_id>다음과 같습니다.
--name=<machine_pool_id>- 머신 풀의 이름을 지정합니다.
--replicas=<replica_count>-
프로비저닝할 컴퓨팅 노드 수를 지정합니다. 단일 가용성 영역을 사용하여 AWS에 Red Hat OpenShift Service를 배포한 경우 영역의 시스템 풀에 프로비저닝할 컴퓨팅 노드 수를 정의합니다. 여러 가용성 영역을 사용하여 클러스터를 배포한 경우 모든 영역에서 총 프로비저닝할 컴퓨팅 노드 수를 정의하고 개수는 3의 배수여야 합니다. 자동 스케일링이 구성되지 않은 경우
--replicas인수가 필요합니다. --instance-type=<instance_type>-
선택 사항: 시스템 풀의 컴퓨팅 노드의 인스턴스 유형을 설정합니다. 인스턴스 유형은 풀의 각 계산 노드에 대한 vCPU 및 메모리 할당을 정의합니다. <
;instance_type>을 인스턴스 유형으로 바꿉니다. 기본값은m5.xlarge입니다. 풀을 생성한 후에는 머신 풀의 인스턴스 유형을 변경할 수 없습니다. --labels=<key>=<value>,<key>=<value>-
선택 사항: 머신 풀의 레이블을 정의합니다. <
key>=<value>,<key>=<value>를 쉼표로 구분된 키-값 쌍 목록(예:--labels=key1=value1,key2=value2)으로 바꿉니다. --taints=<key>=<value>:<effect>,<key>=<value>:<effect>-
선택 사항: 머신 풀의 테인트를 정의합니다. <
key>=<value>:<effect>,<key>=<value>:<effect>를 각 테인트의 키, 값 및 효과(예:--taints=key1=value1:NoExecute)로 바꿉니다. 사용 가능한 효과에는NoSchedule,PreferNoSchedule,NoExecute가 포함됩니다. --disk-size=<disk_size>-
선택 사항: 작업자 노드 디스크 크기를 지정합니다. 값은 GB, GiB, TB 또는 TiB일 수 있습니다. <
;disk_size>를 숫자 값 및 단위(예:--disk-size=200GiB)로 바꿉니다. --availability-zone=<availability_zone_name>-
선택 사항: 선택한 가용성 영역에서 머신 풀을 생성할 수 있습니다. &
lt;availability_zone_name>을 가용성 영역 이름으로 바꿉니다. --additional-security-group-ids <sec_group_id>선택 사항: Red Hat 관리 VPC가 없는 클러스터의 머신 풀의 경우 머신 풀에서 사용할 추가 사용자 지정 보안 그룹을 선택할 수 있습니다. 보안 그룹을 이미 생성하여 이 클러스터에 대해 선택한 VPC와 연결되어야 합니다. 머신 풀을 생성한 후에는 보안 그룹을 추가하거나 편집할 수 없습니다.
중요AWS 클러스터의 Red Hat OpenShift Service의 머신 풀에 최대 10개의 추가 보안 그룹을 사용할 수 있습니다.
--subnet <subnet_id>선택 사항: BYO VPC 클러스터의 경우 서브넷을 선택하여 Single-AZ 머신 풀을 생성할 수 있습니다. 서브넷이 클러스터 생성 서브넷에서 벗어나는 경우 키
kubernetes.io/cluster/<infra-id> 및 값이shared인 태그가 있어야 합니다. 고객은 다음 명령을 사용하여 Infra ID를 얻을 수 있습니다.$ rosa describe cluster -c <cluster name>|grep "Infra ID:"출력 예
Infra ID: mycluster-xqvj7참고--subnet및--availability-zone을 동시에 설정할 수 없으며 Single-AZ 머신 풀 생성에는 1개만 허용됩니다.
다음 예제에서는
m5.xlarge인스턴스 유형을 사용하고 2개의 컴퓨팅 노드 복제본을 사용하는mymachinepool이라는 시스템 풀을 생성합니다. 이 예제에서는 두 개의 워크로드별 레이블을 추가합니다.$ rosa create machinepool --cluster=mycluster --name=mymachinepool --replicas=2 --instance-type=m5.xlarge --labels=app=db,tier=backend출력 예
I: Machine pool 'mymachinepool' created successfully on cluster 'mycluster' I: To view all machine pools, run 'rosa list machinepools -c mycluster'자동 스케일링을 사용하는 머신 풀을 추가하려면 머신 풀을 생성하고 자동 스케일링 구성, 인스턴스 유형 및 노드 레이블을 정의합니다.
$ rosa create machinepool --cluster=<cluster-name> \ --name=<machine_pool_id> \ --enable-autoscaling \ --min-replicas=<minimum_replica_count> \ --max-replicas=<maximum_replica_count> \ --instance-type=<instance_type> \ --labels=<key>=<value>,<key>=<value> \ --taints=<key>=<value>:<effect>,<key>=<value>:<effect> \ --availability-zone=<availability_zone_name>다음과 같습니다.
--name=<machine_pool_id>-
머신 풀의 이름을 지정합니다. &
lt;machine_pool_id>를 머신 풀 이름으로 바꿉니다. --enable-autoscaling- 시스템 풀에서 자동 스케일링을 통해 배포 요구 사항을 충족할 수 있습니다.
--min-replicas=<minimum_replica_count>and--max-replicas=<maximum_replica_count>최소 및 최대 컴퓨팅 노드 제한을 정의합니다. 클러스터 자동 스케일러는 사용자가 지정하는 제한을 초과하여 머신 풀 노드 수를 줄이거나 늘리지 않습니다.
--min-replicas및--max-replicas인수는 가용성 영역의 시스템 풀에서 자동 스케일링 제한을 정의합니다.--instance-type=<instance_type>-
선택 사항: 시스템 풀의 컴퓨팅 노드의 인스턴스 유형을 설정합니다. 인스턴스 유형은 풀의 각 계산 노드에 대한 vCPU 및 메모리 할당을 정의합니다. <
;instance_type>을 인스턴스 유형으로 바꿉니다. 기본값은m5.xlarge입니다. 풀을 생성한 후에는 머신 풀의 인스턴스 유형을 변경할 수 없습니다. --labels=<key>=<value>,<key>=<value>-
선택 사항: 머신 풀의 레이블을 정의합니다. <
key>=<value>,<key>=<value>를 쉼표로 구분된 키-값 쌍 목록(예:--labels=key1=value1,key2=value2)으로 바꿉니다. --taints=<key>=<value>:<effect>,<key>=<value>:<effect>-
선택 사항: 머신 풀의 테인트를 정의합니다. <
key>=<value>:<effect>,<key>=<value>:<effect>를 각 테인트의 키, 값 및 효과(예:--taints=key1=value1:NoExecute)로 바꿉니다. 사용 가능한 효과에는NoSchedule,PreferNoSchedule,NoExecute가 포함됩니다. --availability-zone=<availability_zone_name>-
선택 사항: 선택한 가용성 영역에서 머신 풀을 생성할 수 있습니다. &
lt;availability_zone_name>을 가용성 영역 이름으로 바꿉니다.
다음 예제에서는
m5.xlarge인스턴스 유형을 사용하고 자동 스케일링이 활성화된mymachinepool이라는 시스템 풀을 생성합니다. 최소 컴퓨팅 노드 제한은 3이고 최대값은 전체적으로 6입니다. 이 예제에서는 두 개의 워크로드별 레이블을 추가합니다.$ rosa create machinepool --cluster=mycluster --name=mymachinepool --enable-autoscaling --min-replicas=3 --max-replicas=6 --instance-type=m5.xlarge --labels=app=db,tier=backend출력 예
I: Machine pool 'mymachinepool' created successfully on hosted cluster 'mycluster' I: To view all machine pools, run 'rosa list machinepools -c mycluster'
AWS 클러스터의 Red Hat OpenShift Service에 Windows 라이센스 포함 머신 풀을 추가하려면 AWS의 Red Hat OpenShift Service에 대한 AWS Windows 라이센스 포함 을 참조하십시오.
Windows 라이센스 포함 머신 풀은 다음 기준이 충족될 때만 생성할 수 있습니다.
- 호스트 클러스터는 AWS 클러스터의 Red Hat OpenShift Service입니다.
인스턴스 유형은 베어 메탈 EC2입니다.
중요AWS Windows 라이센스: AWS의 Red Hat OpenShift Service는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. Red Hat은 프로덕션 환경에서 사용하는 것을 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
검증
클러스터의 모든 머신 풀을 나열하거나 개별 머신 풀을 설명할 수 있습니다.
클러스터에서 사용 가능한 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR Default No 1/1 m5. xlarge us-east-2c subnet-00552ad67728a6ba3 4.14.34 Yes mymachinepool Yes 3/3-6 m5.xlarge app=db, tier=backend us-east-2a subnet-0cb56f5f41880c413 4.14.34 Yes클러스터의 특정 머신 풀 정보를 설명합니다.
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=mymachinepool출력 예
ID: mymachinepool Cluster ID: 2d6010rjvg17anri30v84vspf7c7kr6v Autoscaling: Yes Desired replicas: 3-6 Current replicas: 3 Instance type: m5.xlarge Labels: app=db, tier=backend Taints: Availability zone: us-east-2a Subnet: subnet-0cb56f5f41880c413 Version: 4.14.34 Autorepair: Yes Tuning configs: Additional security group IDs: Node drain grace period: Message:- 시스템 풀이 출력에 포함되어 있고 구성이 예상대로 표시되는지 확인합니다.
4.2.1.3. ROSA CLI를 사용하여 용량 예약이 있는 머신 풀 생성
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 용량 예약이 포함된 새 머신 풀을 생성할 수 있습니다. 온디맨드 용량 예약 및 ML 용 용량 블록 모두 지원됩니다.
현재 머신 풀을 업그레이드하고 용량 예약이 있는 머신 풀에 자동 스케일링이 제공되지 않습니다.
사전 요구 사항
- ROSA CLI 버전 1.2.57 이상을 설치하고 구성했습니다.
- ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
- AWS 클러스터 버전 4.19 이상에서 Red Hat OpenShift Service를 생성하셨습니다.
- 클러스터에 이미 용량 예약 또는 테인트를 사용하지 않는 머신 풀이 있습니다. 머신 풀에는 작업자 노드가 2개 이상 있어야 합니다.
- 용량 예약 ID가 있고 용량은 생성 중인 머신 풀의 가용성 영역(AZ)에 필요한 인스턴스 유형에 대해 예약되어 있습니다.
프로세스
시스템 풀을 생성하고 다음 명령을 실행하여 인스턴스 유형, 작업자 노드 수 및 용량 예약 ID를 정의합니다.
$ rosa create machinepool --cluster=<cluster-name> \ --name=<machine_pool_id> \ --replicas=<replica_count> \ --capacity-reservation-id cr-<capacity_reservation_id> \ --instance-type=<instance_type> \ --subnet <subnet_id>다음과 같습니다.
- <machine_pool_id>
- 머신 풀의 이름을 지정합니다.
- <replica_count>
-
프로비저닝된 컴퓨팅 노드 수를 지정합니다. 단일 AZ를 사용하여 AWS에 Red Hat OpenShift Service를 배포하는 경우 AZ의 시스템 풀에 프로비저닝된 컴퓨팅 노드 수를 정의합니다. 여러 AZ를 사용하여 클러스터를 배포하는 경우 모든 AZ에 프로비저닝된 총 컴퓨팅 노드 수를 정의합니다. 다중 영역 클러스터의 경우 컴퓨팅 노드 수가 3의 배수여야 합니다. 자동 스케일링이 구성되지 않은 경우
--replicas인수가 필요합니다. - cr-<capacity_reservation_id>
-
예약 ID를 지정합니다. AWS에서 용량 예약을 구매할 때
cr-<capacity_reservation_id> 형식으로 ID를 가져옵니다. ID는 온 디맨드 용량 예약 또는 ML의 용량 블록 모두에 사용할 수 있으므로 예약 유형을 지정할 필요가 없습니다. - <instance_type>
-
선택 사항: 머신 풀의 컴퓨팅 노드의 인스턴스 유형을 지정합니다. 인스턴스 유형은 풀의 각 계산 노드에 대한 vCPU 및 메모리 할당을 정의합니다. <
;instance_type>을 인스턴스 유형으로 바꿉니다. 기본값은m5.xlarge입니다. 풀을 생성한 후에는 머신 풀의 인스턴스 유형을 변경할 수 없습니다. - <subnet_id>
선택 사항: 서브넷 ID를 지정합니다. BYO VPC(Bring Your Own Private Cloud) 클러스터의 경우 서브넷을 선택하여 단일 AZ 머신 풀을 생성할 수 있습니다. 초기 클러스터 생성 중에 지정되지 않은 서브넷을 선택하는 경우
kubernetes.io/cluster/<infra-id> 키와공유값으로 서브넷에 태그를 지정해야 합니다. 고객은 다음 명령을 실행하여 Infra ID를 가져올 수 있습니다.$ rosa describe cluster --cluster <cluster_name>|grep "Infra ID:"출력 예
Infra ID: mycluster-xqvj7
예
다음 예제에서는 c5.xlarge 인스턴스 유형을 사용하고 1개의 compute 노드 복제본을 사용하는 mymachinepool 이라는 시스템 풀을 생성합니다. 이 예제에서는 용량 예약 ID도 추가합니다. 입력 및 출력 예:
$ rosa create machinepool --cluster=mycluster --name=mymachinepool --replicas 1 --capacity-reservation-id <capacity_reservation_id> --subnet <subnet_id> --instance-type c5.xlargeI: Checking available instance types for machine pool 'mymachinepool'
I: Machine pool 'mymachinepool' created successfully on hosted cluster 'mycluster'검증
클러스터의 모든 머신 풀을 나열하거나 개별 머신 풀을 설명할 수 있습니다.
다음 명령을 실행하여 클러스터에서 사용 가능한 머신 풀을 나열합니다.
$ rosa list machinepools --cluster <cluster_name>다음 명령을 실행하여 클러스터의 특정 시스템 풀 정보를 설명합니다.
$ rosa describe machinepool --cluster <cluster_name> --machinepool <machine_pool_name>출력 예
ID: <machine_pool_name> Cluster ID: <cluster-id> Autoscaling: No Desired replicas: 1 Current replicas: 1 Instance type: c5.xlarge Labels: Tags: red-hat-managed=true, api.openshift.com/environment=production, api.openshift.com/id=<cluster_name>, api.openshift.com/legal-entity-id=<legal_entity_id>, api.openshift.com/name=<cluster_name>, api.openshift.com/nodepool-hypershift=<cluster_name>-<machine_pool_name>, api.openshift.com/nodepool-ocm=<machine_pool_name>, red-hat-clustertype=rosa Taints: Availability zone: us-east-1a Subnet: <subnet-id> Disk Size: 300 GiB Version: 4.19.10 EC2 Metadata Http Tokens: optional Autorepair: Yes Tuning configs: Kubelet configs: Additional security group IDs: Node drain grace period: Capacity Reservation: - ID: <capacity-reservation-id> - Type: OnDemand Management upgrade: - Type: Replace - Max surge: 1 - Max unavailable: 0 Message: Minimum availability requires 1 replicas, current 1 available출력에는 용량 예약 ID 및 유형이 포함되어야 합니다.
4.2.2. 머신 풀 디스크 볼륨 구성
유연성을 높이기 위해 머신 풀 디스크 볼륨 크기를 구성할 수 있습니다. 기본 디스크 크기는 300GiB입니다.
AWS 클러스터의 Red Hat OpenShift Service의 경우 디스크 크기는 최소 75GiB에서 최대 16,384GiB까지 구성할 수 있습니다.
OpenShift Cluster Manager 또는 CLI(명령줄 인터페이스)(rosa)를 사용하여 클러스터의 머신 풀 디스크 크기를 구성할 수 있습니다.
기존 클러스터 및 머신 풀 노드 볼륨의 크기를 조정할 수 없습니다.
클러스터 생성을 위한 사전 요구 사항
- 클러스터 설치 중에 기본 머신 풀의 노드 디스크 크기 조정을 선택하는 옵션이 있습니다.
클러스터 생성 절차
- AWS 클러스터의 Red Hat OpenShift Service 마법사에서 클러스터 설정으로 이동합니다.
- 머신 풀 단계로 이동합니다.
- 원하는 루트 디스크 크기를 선택합니다.
- 다음을 선택하여 클러스터를 계속 생성합니다.
머신 풀 생성을 위한 사전 요구 사항
- 클러스터를 설치한 후 새 시스템 풀의 노드 디스크 크기 조정을 선택하는 옵션이 있습니다.
머신 풀 생성 절차
- OpenShift Cluster Manager 로 이동하여 클러스터를 선택합니다.
- 머신 풀 탭으로 이동합니다.
- 머신 풀 추가를 클릭합니다.
- 원하는 루트 디스크 크기를 선택합니다.
- 머신 풀 추가 를 선택하여 머신 풀을 생성합니다.
4.2.2.1. ROSA CLI를 사용하여 머신 풀 디스크 볼륨 구성
클러스터 생성을 위한 사전 요구 사항
- 클러스터 설치 중에 기본 머신 풀의 루트 디스크 크기 조정을 선택하는 옵션이 있습니다.
클러스터 생성 절차
원하는 루트 디스크 크기에 맞게 OpenShift 클러스터를 생성할 때 다음 명령을 실행합니다.
$ rosa create cluster --worker-disk-size=<disk_size>값은 GB, GiB, TB 또는 TiB일 수 있습니다. <
disk_size>를 숫자 값 및 단위(예:--worker-disk-size=200GiB)로 바꿉니다. 숫자와 단위를 분리할 수 없습니다. 공백은 허용되지 않습니다.
머신 풀 생성을 위한 사전 요구 사항
- 클러스터를 설치한 후 새 시스템 풀의 루트 디스크 크기 조정을 선택하는 옵션이 있습니다.
머신 풀 생성 절차
다음 명령을 실행하여 클러스터를 확장합니다.
$ rosa create machinepool --cluster=<cluster_id> \1 --disk-size=<disk_size>2 - AWS 콘솔에 로그인하여 새 머신 풀 디스크 볼륨 크기를 확인하고 EC2 가상 머신 루트 볼륨 크기를 찾습니다.
4.2.3. 머신 풀 삭제
워크로드 요구 사항이 변경되고 현재 머신 풀이 더 이상 요구 사항을 충족하지 않는 경우 머신 풀을 삭제할 수 있습니다.
Red Hat OpenShift Cluster Manager 또는 CLI(명령줄 인터페이스)(rosa)를 사용하여 머신 풀을 삭제할 수 있습니다.
4.2.3.1. OpenShift Cluster Manager를 사용하여 머신 풀 삭제
Red Hat OpenShift Cluster Manager를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service의 머신 풀을 삭제할 수 있습니다.
사전 요구 사항
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 클러스터가 ready 상태입니다.
- 테인트 없이 기존 머신 풀이 있고 단일 AZ 클러스터용 인스턴스가 두 개 이상 있거나 다중 AZ 클러스터의 경우 세 개의 인스턴스가 있습니다.
프로세스
- OpenShift Cluster Manager 에서 Cluster List 페이지로 이동하여 삭제할 시스템 풀이 포함된 클러스터를 선택합니다.
- 선택한 클러스터에서 머신 풀 탭을 선택합니다.
-
머신 풀 탭에서 삭제하려는 머신 풀의 옵션 메뉴
 를 클릭합니다.
를 클릭합니다.
삭제를 클릭합니다.
선택한 머신 풀이 삭제됩니다.
4.2.3.2. ROSA CLI를 사용하여 머신 풀 삭제
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service의 머신 풀을 삭제할 수 있습니다.
rosa 버전 1.2.25 및 이전 버전의 사용자의 경우 클러스터와 함께 생성된 시스템 풀(ID='Default')은 삭제할 수 없습니다. rosa 버전 1.2.26 이상 사용자의 경우 클러스터와 함께 생성되는 시스템 풀(ID='worker')은 테인트가 없는 클러스터 내에 하나의 시스템 풀이 있고 단일 AZ 클러스터의 경우 두 개 이상의 복제본 또는 Multi-AZ 클러스터에 대한 세 개의 복제본을 삭제할 수 있습니다.
사전 요구 사항
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 클러스터가 ready 상태입니다.
- 테인트 없이 기존 머신 풀이 있고 Single-AZ 클러스터용 인스턴스가 두 개 이상 있거나 Multi-AZ 클러스터의 경우 세 개의 인스턴스가 있습니다.
프로세스
ROSA CLI에서 다음 명령을 실행합니다.
$ rosa delete machinepool -c=<cluster_name> <machine_pool_ID>출력 예
? Are you sure you want to delete machine pool <machine_pool_ID> on cluster <cluster_name>? (y/N)y를 입력하여 시스템 풀을 삭제합니다.선택한 머신 풀이 삭제됩니다.
4.2.4. 수동으로 컴퓨팅 노드 확장
시스템 풀에 자동 스케일링을 활성화하지 않은 경우 배포 요구 사항에 맞게 풀의 컴퓨팅 (작업자라고도 함) 노드 수를 수동으로 확장할 수 있습니다.
각 머신 풀을 별도로 스케일링해야 합니다.
사전 요구 사항
-
워크스테이션에 최신 ROSA CLI(명령줄 인터페이스)(
rosa)를 설치하고 구성했습니다. - ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀이 있습니다.
프로세스
클러스터의 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONES DISK SIZE SG IDs default No 2 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2 mp1 No 2 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2머신 풀의 컴퓨팅 노드 복제본 수를 늘리거나 줄입니다.
$ rosa edit machinepool --cluster=<cluster_name> \ --replicas=<replica_count> \1 <machine_pool_id>2
검증
클러스터에서 사용 가능한 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONES DISK SIZE SG IDs default No 2 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2 mp1 No 3 m5.xlarge us-east-1a 300GiB sg-0e375ff0ec4a6cfa2-
이전 명령의 출력에서 시스템 풀에 대해 compute 노드 복제본 수가 예상대로 있는지 확인합니다. 예제 출력에서
mp1시스템 풀의 계산 노드 복제본 수는 3으로 조정됩니다.
4.2.5. 노드 라벨
레이블은 Node 오브젝트에 적용되는 키-값 쌍입니다. 라벨을 사용하여 오브젝트 세트를 구성하고 Pod 예약을 제어할 수 있습니다.
클러스터 생성 중 또는 이후에 라벨을 추가할 수 있습니다. 레이블은 언제든지 수정하거나 업데이트할 수 있습니다.
4.2.5.1. 머신 풀에 노드 레이블 추가
언제든지 컴퓨팅(작업자) 노드의 레이블을 추가하거나 편집하여 귀하와 관련된 방식으로 노드를 관리합니다. 예를 들어 특정 노드에 워크로드 유형을 할당할 수 있습니다.
레이블은 키-값 쌍으로 할당됩니다. 각 키는 할당된 오브젝트에 고유해야 합니다.
사전 요구 사항
-
워크스테이션에 최신 ROSA CLI(명령줄 인터페이스)(
rosa)를 설치하고 구성했습니다. - ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀이 있습니다.
프로세스
클러스터의 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes머신 풀의 노드 레이블을 추가하거나 업데이트합니다.
자동 스케일링을 사용하지 않는 머신 풀의 노드 레이블을 추가하거나 업데이트하려면 다음 명령을 실행합니다.
$ rosa edit machinepool --cluster=<cluster_name> \ --labels=<key>=<value>,<key>=<value> \1 <machine_pool_id>- 1
- <
key>=<value>,<key>=<value>를 쉼표로 구분된 키-값 쌍 목록(예:--labels=key1=value1,key2=value2)으로 바꿉니다. 이 목록은 노드 라벨에 대한 모든 수정 사항을 지속적으로 덮어씁니다.
다음 예제에서는
db-nodes-mp머신 풀에 레이블을 추가합니다.$ rosa edit machinepool --cluster=mycluster --replicas=2 --labels=app=db,tier=backend db-nodes-mp출력 예
I: Updated machine pool 'db-nodes-mp' on cluster 'mycluster'
검증
새 라벨을 사용하여 머신 풀의 세부 정보를 설명합니다.
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machine-pool-name>출력 예
ID: db-nodes-mp Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: app=db, tier=backend Tags: Taints: Availability zone: us-east-2a Subnet: subnet-0df2ec3377847164f Disk size: 300 GiB Version: 4.16.6 EC2 Metadata Http Tokens: optional Autorepair: Yes Tuning configs: Kubelet configs: Additional security group IDs: Node drain grace period: Management upgrade: - Type: Replace - Max surge: 1 - Max unavailable: 0 Message:- 레이블이 출력에 시스템 풀에 포함되어 있는지 확인합니다.
4.2.6. 머신 풀에 태그 추가
머신 풀에 컴퓨팅 노드(작업자 노드라고도 함)에 대한 태그를 추가하여 시스템 풀을 프로비저닝할 때 생성되는 AWS 리소스에 대한 사용자 지정 사용자 태그를 도입할 수 있습니다. 이 태그는 머신 풀을 생성한 후 편집할 수 없다는 것입니다.
4.2.6.1. ROSA CLI를 사용하여 머신 풀에 태그 추가
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service의 머신 풀에 태그를 추가할 수 있습니다. 머신 풀을 생성한 후에는 태그를 편집할 수 없습니다.
태그 키가 aws,red-hat-managed,red-hat-clustertype 또는 Name 이 아닌지 확인해야 합니다. 또한 kubernetes.io/cluster/ 로 시작하는 태그 키를 설정하지 않아야 합니다. 태그의 키는 128자를 초과할 수 없으며 태그의 값은 256자를 초과할 수 없습니다. Red Hat은 향후 예약된 태그를 추가할 수 있는 권한을 갖습니다.
사전 요구 사항
-
워크스테이션에 최신 AWS(
aws), ROSA(rosa) 및 OpenShift(oc) CLI를 설치하고 구성했습니다. - ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
프로세스
다음 명령을 실행하여 사용자 지정 태그로 머신 풀을 생성합니다.
$ rosa create machinepools --cluster=<name> --replicas=<replica_count> \ --name <mp_name> --tags='<key> <value>,<key> <value>'1 - 1
- <
key> <value>,<key> <value>를 각 태그의 키와 값으로 바꿉니다.
출력 예
$ rosa create machinepools --cluster=mycluster --replicas 2 --tags='tagkey1 tagvalue1,tagkey2 tagvaluev2' I: Checking available instance types for machine pool 'mp-1' I: Machine pool 'mp-1' created successfully on cluster 'mycluster' I: To view the machine pool details, run 'rosa describe machinepool --cluster mycluster --machinepool mp-1' I: To view all machine pools, run 'rosa list machinepools --cluster mycluster'
검증
describe명령을 사용하여 태그가 있는 머신 풀의 세부 정보를 확인하고 출력에 시스템 풀에 태그가 포함되어 있는지 확인합니다.$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machinepool_name>출력 예
ID: db-nodes-mp Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: red-hat-clustertype=rosa, red-hat-managed=true, tagkey1=tagvalue1, tagkey2=tagvaluev2 Taints: Availability zone: us-east-2a ...
4.2.7. 머신 풀에 테인트 추가
머신 풀에서 컴퓨팅(작업자라고도 함) 노드에 대한 테인트를 추가하여 예약된 Pod를 제어할 수 있습니다. 머신 풀에 테인트를 적용하면 Pod 사양에 테인트에 대한 허용 오차가 포함되지 않는 한 스케줄러는 풀의 노드에 Pod를 배치할 수 없습니다. 테인트는 Red Hat OpenShift Cluster Manager 또는 ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 머신 풀에 추가할 수 있습니다.
클러스터에 테인트가 포함되지 않은 하나 이상의 머신 풀이 있어야 합니다.
4.2.7.1. OpenShift Cluster Manager를 사용하여 머신 풀에 테인트 추가
Red Hat OpenShift Cluster Manager를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service의 머신 풀에 테인트를 추가할 수 있습니다.
사전 요구 사항
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀에는 테인트가 포함되지 않고 두 개 이상의 인스턴스가 포함됩니다.
프로세스
- OpenShift Cluster Manager 로 이동하여 클러스터를 선택합니다.
-
머신 풀 탭에서 테인트를 추가할 머신 풀의 옵션 메뉴
를 클릭합니다.
- 테인트 편집을 선택합니다.
- 테인트에 대한 키 및 값 항목을 추가합니다.
-
목록에서 테인트의 영향을 선택합니다. 사용 가능한 옵션에는
NoSchedule,PreferNoSchedule,NoExecute가 있습니다. - 선택 사항: 머신 풀에 테인트 를 추가하려면 테인트 추가를 선택합니다.
- 저장을 클릭하여 머신 풀에 테인트를 적용합니다.
검증
- 머신 풀 탭에서 머신 풀 옆에 있는 >을 선택하여 뷰를 확장합니다.
- 확장된 보기의 Taints 아래에 테인트가 나열되어 있는지 확인합니다.
4.2.7.2. ROSA CLI를 사용하여 머신 풀에 테인트 추가
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service의 머신 풀에 테인트를 추가할 수 있습니다.
rosa 버전 1.2.25 및 이전 버전의 사용자의 경우 클러스터와 함께 생성된 머신 풀(ID=Default) 내에서 테인트 수를 변경할 수 없습니다. rosa 버전 1.2.26 이상 사용자의 경우 클러스터와 함께 생성된 시스템 풀(ID=작업자) 내에서 테인트 수를 변경할 수 있습니다. 테인트 및 두 개 이상의 복제본이 없는 머신 풀이 하나 이상 있어야 합니다.
사전 요구 사항
-
워크스테이션에 최신 AWS(
aws), ROSA(rosa) 및 OpenShift(oc) CLI를 설치하고 구성했습니다. -
rosaCLI를 사용하여 Red Hat 계정에 로그인했습니다. - AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀에는 테인트가 포함되지 않고 두 개 이상의 인스턴스가 포함됩니다.
프로세스
다음 명령을 실행하여 클러스터의 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes머신 풀의 테인트를 추가하거나 업데이트합니다.
자동 스케일링을 사용하지 않는 머신 풀의 테인트를 추가하거나 업데이트하려면 다음 명령을 실행합니다.
$ rosa edit machinepool --cluster=<cluster_name> \ --taints=<key>=<value>:<effect>,<key>=<value>:<effect> \1 <machine_pool_id>- 1
- <
key>=<value>:<effect>,<key>=<value>:<effect>를 각 테인트의 키, 값 및 효과(예:--taints=key1=value1:NoExecute)로 바꿉니다. 사용 가능한 효과에는NoSchedule,PreferNoSchedule및NoExecute가 포함됩니다. 이 목록은 노드 테인트에 대한 모든 수정 사항을 지속적으로 덮어씁니다.
다음 예제에서는
db-nodes-mp머신 풀에 taint를 추가합니다.$ rosa edit machinepool --cluster=mycluster --replicas 2 --taints=key1=value1:NoSchedule,key2=value2:NoExecute db-nodes-mp출력 예
I: Updated machine pool 'db-nodes-mp' on cluster 'mycluster'
검증
새 테인트를 사용하여 머신 풀의 세부 정보를 설명합니다.
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machinepool_name>출력 예
ID: db-nodes-mp Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: Taints: key1=value1:NoSchedule, key2=value2:NoExecute Availability zone: us-east-2a ...- 출력의 머신 풀에 테인트가 포함되어 있는지 확인합니다.
4.2.8. 시스템 풀 자동 복구 구성
Red Hat OpenShift Service on AWS는 AutoRepair라는 머신 풀에 대한 자동 복구 프로세스를 지원합니다. AutoRepair는 AWS 서비스의 Red Hat OpenShift Service가 특정 비정상 노드를 감지하고 비정상 노드를 비우고 노드를 다시 생성하려는 경우에 유용합니다. 노드를 유지해야 하는 경우와 같이 비정상 노드를 교체하지 않아야 하는 경우 AutoRepair를 비활성화할 수 있습니다. 시스템 풀에서 AutoRepair는 기본적으로 활성화되어 있습니다.
AutoRepair 프로세스에서 노드 상태가 NotReady 이거나 사전 정의된 시간(일반적으로 8분) 동안 알 수 없는 상태가 되면 노드의 비정상적인 상태가 됩니다. 두 개 이상의 노드가 동시에 비정상 상태가 될 때마다 AutoRepair 프로세스에서 노드 복구를 중지합니다. 마찬가지로 사전 정의된 시간(일반적으로 20분) 후에도 새 노드가 비정상 상태가 되면 서비스가 자동으로 페어링됩니다.
머신 풀 AutoRepair는 AWS 클러스터의 Red Hat OpenShift Service에서만 사용할 수 있습니다.
4.2.8.1. OpenShift Cluster Manager를 사용하여 시스템 풀에서 AutoRepair 구성
Red Hat OpenShift Cluster Manager를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service에 대한 머신 풀 AutoRepair를 구성할 수 있습니다.
사전 요구 사항
- HCP 클러스터를 사용하여 ROSA를 생성하셨습니다.
- 기존 머신 풀이 있습니다.
프로세스
- OpenShift Cluster Manager 로 이동하여 클러스터를 선택합니다.
-
머신 풀 탭에서 자동 복구를 구성할 머신 풀의 옵션 메뉴
를 클릭합니다.
- 메뉴에서 편집을 선택합니다.
- 표시되는 Edit Machine Pool (시스템 풀 편집) 대화 상자에서 AutoRepair 옵션을 찾습니다.
- AutoRepair 옆에 있는 상자를 선택하거나 지웁니다.
- 저장을 클릭하여 시스템 풀에 변경 사항을 적용합니다.
검증
- 머신 풀 탭에서 머신 풀 옆에 있는 >을 선택하여 뷰를 확장합니다.
- 확장된 보기에서 시스템 풀에 올바른 AutoRepair 설정이 있는지 확인합니다.
4.2.8.2. ROSA CLI를 사용하여 머신 풀 자동 복구 구성
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 AWS 클러스터에서 Red Hat OpenShift Service에 대한 머신 풀 AutoRepair를 구성할 수 있습니다.
사전 요구 사항
-
워크스테이션에 최신 AWS(
aws) 및 ROSA(rosa) CLI를 설치하고 구성하셨습니다. -
rosaCLI를 사용하여 Red Hat 계정에 로그인했습니다. - AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀이 있습니다.
프로세스
다음 명령을 실행하여 클러스터의 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-0df2ec3377847164f 4.16.6 Yes머신 풀에서 AutoRepair를 활성화하거나 비활성화합니다.
시스템 풀의 AutoRepair를 비활성화하려면 다음 명령을 실행합니다.
$ rosa edit machinepool --cluster=mycluster --machinepool=<machinepool_name> --autorepair=false시스템 풀에 AutoRepair를 활성화하려면 다음 명령을 실행합니다.
$ rosa edit machinepool --cluster=mycluster --machinepool=<machinepool_name> --autorepair=true출력 예
I: Updated machine pool 'machinepool_name' on cluster 'mycluster'
검증
머신 풀의 세부 정보를 설명합니다.
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machinepool_name>출력 예
ID: machinepool_name Cluster ID: <ID_of_cluster> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: Taints: Availability zone: us-east-2a ... Autorepair: Yes Tuning configs: Kubelet configs: Additional security group IDs: Node drain grace period: Management upgrade: - Type: Replace - Max surge: 1 - Max unavailable: 0- 출력의 시스템 풀에 AutoRepair 설정이 올바른지 확인합니다.
4.2.9. 머신 풀에 노드 튜닝 추가
머신 풀의 worker라고도 하는 컴퓨팅에 대한 튜닝을 추가하여 AWS 클러스터의 Red Hat OpenShift Service에서 구성을 제어할 수 있습니다.
사전 요구 사항
-
워크스테이션에 최신 ROSA CLI(명령줄 인터페이스)(
rosa)를 설치하고 구성했습니다. - 'rosa'를 사용하여 Red Hat 계정에 로그인했습니다.
- AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀이 있습니다.
- 기존 튜닝 구성이 있습니다.
프로세스
클러스터의 모든 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR db-nodes-mp No 0/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes workers No 2/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes기존 또는 새 머신 풀에 튜닝 구성을 추가할 수 있습니다.
머신 풀을 생성할 때 튜닝을 추가합니다.
$ rosa create machinepool -c <cluster-name> --name <machinepoolname> --tuning-configs <tuning_config_name>출력 예
? Tuning configs: sample-tuning I: Machine pool 'db-nodes-mp' created successfully on hosted cluster 'sample-cluster' I: To view all machine pools, run 'rosa list machinepools -c sample-cluster'머신 풀의 튜닝을 추가하거나 업데이트합니다.
$ rosa edit machinepool -c <cluster-name> --machinepool <machinepoolname> --tuning-configs <tuning_config_name>출력 예
I: Updated machine pool 'db-nodes-mp' on cluster 'mycluster'
검증
튜닝 구성을 추가한 머신 풀을 설명합니다.
$ rosa describe machinepool --cluster=<cluster_name> --machinepool=<machine_pool_name>출력 예
ID: db-nodes-mp Cluster ID: <cluster_ID> Autoscaling: No Desired replicas: 2 Current replicas: 2 Instance type: m5.xlarge Labels: Tags: Taints: Availability zone: us-east-2a Subnet: subnet-08d4d81def67847b6 Version: 4.14.34 EC2 Metadata Http Tokens: optional Autorepair: Yes Tuning configs: sample-tuning ...- 출력에 머신 풀에 튜닝 구성이 포함되어 있는지 확인합니다.
4.2.10. 노드 드레이닝 유예 기간 구성
클러스터의 머신 풀에 대한 노드 드레이닝 유예 기간을 구성할 수 있습니다. 머신 풀의 노드 드레이닝 유예 기간은 클러스터가 머신 풀을 업그레이드하거나 교체할 때 Pod 중단 예산 보호 워크로드를 준수하는 시간입니다. 이 유예 기간이 지나면 나머지 모든 워크로드가 강제로 제거됩니다. 노드 드레인 유예 기간의 값 범위는 0 에서 1 주 사이입니다. 기본값인 0 또는 빈 값을 사용하면 머신 풀은 완료될 때까지 시간 제한 없이 드레이닝됩니다.
사전 요구 사항
-
워크스테이션에 최신 ROSA CLI(명령줄 인터페이스)(
rosa)를 설치하고 구성했습니다. - AWS 클러스터에서 Red Hat OpenShift Service를 생성하셨습니다.
- 기존 머신 풀이 있습니다.
프로세스
다음 명령을 실행하여 클러스터의 모든 머신 풀을 나열합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR db-nodes-mp No 2/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes workers No 2/2 m5.xlarge us-east-2a subnet-08d4d81def67847b6 4.14.34 Yes다음 명령을 실행하여 머신 풀의 노드 드레인 유예 기간을 확인합니다.
$ rosa describe machinepool --cluster <cluster_name> --machinepool=<machinepool_name>출력 예
ID: workers Cluster ID: 2a90jdl0i4p9r9k9956v5ocv40se1kqs ... Node drain grace period:1 ...- 1
- 이 값이 비어 있으면 머신 풀은 완료될 때까지 시간 제한 없이 드레이닝합니다.
선택 사항: 다음 명령을 실행하여 머신 풀의 노드 드레인 유예 기간을 업데이트합니다.
$ rosa edit machinepool --node-drain-grace-period="<node_drain_grace_period_value>" --cluster=<cluster_name> <machinepool_name>참고머신 풀 업그레이드 중에 노드 드레이닝 기간을 변경하면 진행 중인 업그레이드가 아닌 향후 업그레이드에 적용됩니다.
검증
다음 명령을 실행하여 머신 풀의 노드 드레인 유예 기간을 확인합니다.
$ rosa describe machinepool --cluster <cluster_name> <machinepool_name>출력 예
ID: workers Cluster ID: 2a90jdl0i4p9r9k9956v5ocv40se1kqs ... Node drain grace period: 30 minutes ...-
출력에서 머신 풀의 올바른
노드 드레이닝 유예 기간을확인합니다.
4.2.11. 추가 리소스
4.3. 클러스터에서 노드 자동 스케일링 정보
자동 스케일러 옵션은 머신 풀의 머신 수를 자동으로 확장하도록 구성할 수 있습니다.
리소스가 부족하여 현재 노드에서 Pod를 예약할 수 없거나 배포 요구를 충족하기 위해 다른 노드가 필요한 경우 클러스터 자동 스케일러는 머신 풀의 크기를 늘립니다. 클러스터 자동 스케일러는 사용자가 지정한 제한을 초과하여 클러스터 리소스를 늘리지 않습니다.
또한 클러스터 자동 스케일러는 리소스 사용이 적고 중요한 Pod가 모두 다른 노드에 적합한 경우와 같이 상당한 기간 동안 일부 노드가 지속적으로 필요하지 않은 경우 머신 풀의 크기를 줄입니다.
자동 스케일링을 활성화하는 경우 최소 및 최대 작업자 노드 수를 설정해야 합니다.
클러스터 소유자 및 조직 관리자만 클러스터를 확장하거나 삭제할 수 있습니다.
4.3.1. 클러스터에서 노드 자동 스케일링 활성화
기존 클러스터의 머신 풀 정의를 편집하여 작업자 노드에서 자동 스케일링을 활성화하여 사용 가능한 노드 수를 늘리거나 줄일 수 있습니다.
4.3.1.1. Red Hat OpenShift Cluster Manager를 사용하여 기존 클러스터에서 노드 자동 스케일링 활성화
OpenShift Cluster Manager 콘솔에서 시스템 풀 정의에서 작업자 노드에 대한 자동 스케일링을 활성화합니다.
프로세스
- OpenShift Cluster Manager 에서 클러스터 목록 페이지로 이동하여 자동 스케일링을 활성화할 클러스터를 선택합니다.
- 선택한 클러스터에서 머신 풀 탭을 선택합니다.
-
자동 스케일링을 활성화하려는 머신 풀 끝에 있는 옵션 메뉴
를 클릭하고 편집을 선택합니다.
- Edit machine pool 대화 상자에서 자동 스케일링 활성화 확인란을 선택합니다.
- 저장을 선택하여 이러한 변경 사항을 저장하고 머신 풀에 대한 자동 스케일링을 활성화합니다.
4.3.1.2. ROSA CLI를 사용하여 기존 클러스터에서 노드 자동 스케일링 활성화
로드에 따라 작업자 노드 수를 동적으로 확장 또는 축소하도록 자동 스케일링을 구성합니다.
자동 스케일링은 AWS 계정에서 올바른 AWS 리소스 할당량을 보유하는 데 따라 달라집니다. 리소스 할당량 및 요청 할당량이 AWS 콘솔에서 증가했는지 확인합니다.
프로세스
클러스터에서 머신 풀 ID를 식별하려면 다음 명령을 입력합니다.
$ rosa list machinepools --cluster=<cluster_name>출력 예
ID AUTOSCALING REPLICAS INSTANCE TYPE LABELS TAINTS AVAILABILITY ZONE SUBNET VERSION AUTOREPAIR workers No 2/2 m5.xlarge us-east-2a subnet-03c2998b482bf3b20 4.16.6 Yes mp1 No 2/2 m5.xlarge us-east-2a subnet-03c2998b482bf3b20 4.16.6 Yes- 구성할 머신 풀의 ID를 가져옵니다.
머신 풀에서 자동 스케일링을 활성화하려면 다음 명령을 입력합니다.
$ rosa edit machinepool --cluster=<cluster_name> <machinepool_ID> --enable-autoscaling --min-replicas=<number> --max-replicas=<number>예
2~5개의 작업자 노드 간에 스케일링하도록 복제본 수를 설정하여
mycluster라는 클러스터에서 ID를 사용하여 머신 풀에서 자동 스케일링을 활성화합니다.$ rosa edit machinepool --cluster=mycluster mp1 --enable-autoscaling --min-replicas=2 --max-replicas=5
4.3.2. 클러스터에서 자동 스케일링 노드 비활성화
기존 클러스터의 머신 풀 정의를 편집하여 작업자 노드에서 자동 스케일링을 비활성화하여 사용 가능한 노드 수를 늘리거나 줄일 수 있습니다.
Red Hat OpenShift Cluster Manager 또는 ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 클러스터에서 자동 스케일링을 비활성화할 수 있습니다.
4.3.2.1. Red Hat OpenShift Cluster Manager를 사용하여 기존 클러스터에서 자동 스케일링 노드 비활성화
OpenShift Cluster Manager의 시스템 풀 정의에서 작업자 노드의 자동 스케일링을 비활성화합니다.
프로세스
- OpenShift Cluster Manager 에서 Cluster List 페이지로 이동하여 비활성화해야 하는 자동 스케일링이 있는 클러스터를 선택합니다.
- 선택한 클러스터에서 머신 풀 탭을 선택합니다.
-
자동 스케일링을 사용하여 머신 풀 끝에 있는 옵션 메뉴
를 클릭하고 편집을 선택합니다.
- Edit machine pool (시스템 풀 편집) 대화 상자에서 자동 스케일링 활성화 확인란을 선택 취소합니다.
- 저장을 선택하여 이러한 변경 사항을 저장하고 시스템 풀에서 자동 스케일링을 비활성화합니다.
4.3.2.2. ROSA CLI를 사용하여 기존 클러스터에서 자동 스케일링 노드 비활성화
ROSA CLI(명령줄 인터페이스)(rosa)를 사용하여 머신 풀 정의에서 작업자 노드의 자동 스케일링을 비활성화합니다.
프로세스
다음 명령을 실행합니다.
$ rosa edit machinepool --cluster=<cluster_name> <machinepool_ID> --enable-autoscaling=false --replicas=<number>예
mycluster라는 클러스터의기본머신 풀에서 자동 스케일링을 비활성화합니다.$ rosa edit machinepool --cluster=mycluster default --enable-autoscaling=false --replicas=3
4.4. 컨테이너 메모리 및 위험 요구 사항을 충족하도록 클러스터 메모리 구성
클러스터 관리자는 다음과 같은 방법으로 애플리케이션 메모리를 관리하여 클러스터를 효율적으로 작동할 수 있습니다.
- 컨테이너화된 애플리케이션 구성 요소의 메모리 및 위험 요구 사항을 확인하고 해당 요구 사항에 맞게 컨테이너 메모리 매개변수를 구성합니다.
- 구성된 컨테이너 메모리 매개변수를 최적으로 준수하도록 컨테이너화된 애플리케이션 런타임(예: OpenJDK)을 구성합니다.
- 컨테이너에서 실행과 연결된 메모리 관련 오류 조건을 진단 및 해결합니다.
4.4.1. 애플리케이션 메모리 관리 이해
계속하기 전에 AWS의 Red Hat OpenShift Service가 컴퓨팅 리소스를 관리하는 방법에 대한 개요를 완전히 확인하는 것이 좋습니다.
각 종류의 리소스(메모리, CPU, 스토리지)에 대해 AWS의 Red Hat OpenShift Service를 사용하면 선택적 요청 및 제한 값을 Pod의 각 컨테이너에 배치할 수 있습니다.
메모리 요청 및 메모리 제한에 대해 다음 사항에 유의하십시오.
메모리 요청
- 메모리 요청 값을 지정하면 AWS 스케줄러에서 Red Hat OpenShift Service에 영향을 미칩니다. 스케줄러는 노드에 컨테이너를 예약할 때 메모리 요청을 고려한 다음 컨테이너 사용을 위해 선택한 노드에서 요청된 메모리를 차단합니다.
- 노드의 메모리가 소진되면 AWS의 Red Hat OpenShift Service는 메모리 사용량이 메모리 요청을 가장 많이 초과하는 컨테이너를 제거하는 우선 순위를 지정합니다. 메모리 소모가 심각한 경우 노드 OOM 종료자는 유사한 메트릭을 기반으로 컨테이너에서 프로세스를 선택하고 종료할 수 있습니다.
- 클러스터 관리자는 메모리 요청 값에 할당량을 할당하거나 기본값을 할당할 수 있습니다.
- 클러스터 관리자는 클러스터 과다 할당을 관리하기 위해 개발자가 지정하는 메모리 요청 값을 덮어쓸 수 있습니다.
메모리 제한
- 메모리 제한 값을 지정하면 컨테이너의 모든 프로세스에 할당될 수 있는 메모리에 대한 하드 제한을 제공합니다.
- 컨테이너의 모든 프로세스에서 할당한 메모리가 메모리 제한을 초과하면 노드의 OOM(Out of Memory) 종료자에서 즉시 컨테이너의 프로세스를 선택하여 종료합니다.
- 메모리 요청 및 제한을 둘 다 지정하면 메모리 제한 값이 메모리 요청보다 크거나 같아야 합니다.
- 클러스터 관리자는 메모리 제한 값에 할당량을 할당하거나 기본값을 할당할 수 있습니다.
-
최소 메모리 제한은 12MB입니다.
메모리를 할당할 수 없음Pod 이벤트로 인해 컨테이너가 시작되지 않으면 메모리 제한이 너무 낮은 것입니다. 메모리 제한을 늘리거나 제거합니다. 제한을 제거하면 Pod에서 바인딩되지 않은 노드 리소스를 사용할 수 있습니다.
4.4.1.1. 애플리케이션 메모리 전략 관리
AWS의 Red Hat OpenShift Service에서 애플리케이션 메모리 크기를 조정하는 단계는 다음과 같습니다.
예상되는 컨테이너 메모리 사용량 확인
필요한 경우 경험적으로 예상되는 평균 및 최대 컨테이너 메모리 사용량을 결정합니다(예: 별도의 부하 테스트를 통해). 컨테이너에서 잠재적으로 병렬로 실행될 수 있는 모든 프로세스를 고려해야 합니다(예: 기본 애플리케이션에서 보조 스크립트를 생성하는지의 여부).
위험 유형 확인
제거와 관련된 위험 유형을 확인합니다. 위험 성향이 낮으면 컨테이너는 예상되는 최대 사용량과 백분율로 된 안전 범위에 따라 메모리를 요청해야 합니다. 위험 성향이 높으면 예상되는 사용량에 따라 메모리를 요청하는 것이 더 적합할 수 있습니다.
컨테이너 메모리 요청 설정
위 내용에 따라 컨테이너 메모리 요청을 설정합니다. 요청이 애플리케이션 메모리 사용량을 더 정확하게 나타낼수록 좋습니다. 요청이 너무 높으면 클러스터 및 할당량 사용이 비효율적입니다. 요청이 너무 낮으면 애플리케이션 제거 가능성이 커집니다.
필요한 경우 컨테이너 메모리 제한 설정
필요한 경우 컨테이너 메모리 제한을 설정합니다. 제한을 설정하면 컨테이너에 있는 모든 프로세스의 메모리 사용량 합계가 제한을 초과하는 경우 컨테이너 프로세스가 즉시 종료되는 효과가 있어 이로 인한 장단점이 발생합니다. 다른 한편으로는 예상치 못한 과도한 메모리 사용을 조기에 확인할 수 있습니다(“빠른 실패”). 그러나 이로 인해 프로세스가 갑자기 종료됩니다.
AWS 클러스터의 일부 Red Hat OpenShift Service는 제한 값을 설정해야 할 수 있습니다. 일부는 제한을 기반으로 요청을 덮어쓸 수 있습니다. 일부 애플리케이션 이미지는 요청 값보다 탐지하기 쉽게 설정되는 제한 값을 사용합니다.
메모리 제한을 설정하는 경우 예상되는 최대 컨테이너 메모리 사용량과 백분율로 된 안전 범위 이상으로 설정해야 합니다.
애플리케이션이 튜닝되었는지 확인
적절한 경우 구성된 요청 및 제한 값과 관련하여 애플리케이션이 튜닝되었는지 확인합니다. 이 단계는 특히 JVM과 같이 메모리를 풀링하는 애플리케이션과 관련이 있습니다. 이 페이지의 나머지 부분에서는 이 작업에 대해 설명합니다.
4.4.2. AWS에서 Red Hat OpenShift Service에 대한 OpenJDK 설정 이해
기본 OpenJDK 설정은 컨테이너화된 환경에서 제대로 작동하지 않습니다. 따라서 컨테이너에서 OpenJDK를 실행할 때마다 몇 가지 추가 Java 메모리 설정을 항상 제공해야 합니다.
JVM 메모리 레이아웃은 복잡하고 버전에 따라 다르며 자세한 설명은 이 문서의 범위를 벗어납니다. 그러나 최소한 다음 세 가지 메모리 관련 작업은 컨테이너에서 OpenJDK를 실행하기 위한 시작점으로서 중요합니다.
- JVM 최대 힙 크기를 덮어씁니다.
- 적절한 경우 JVM에서 사용하지 않는 메모리를 운영 체제에 제공하도록 유도합니다.
- 컨테이너 내의 모든 JVM 프로세스가 적절하게 구성되었는지 확인합니다.
컨테이너에서 실행하기 위해 JVM 워크로드를 최적으로 튜닝하는 것은 이 문서의 범위를 벗어나며 다양한 JVM 옵션을 추가로 설정하는 작업이 포함될 수 있습니다.
4.4.2.1. JVM 최대 힙 크기를 덮어쓰는 방법 이해
OpenJDK는 기본적으로 "heap" 메모리에 대해 최대 25%의 사용 가능한 메모리(컨테이너 메모리 제한을 인식)를 사용합니다. 이 기본값은 보수적이며, 올바르게 구성된 컨테이너 환경에서 이 값은 컨테이너에 할당된 메모리의 75%가 주로 사용되지 않습니다. JVM이 힙 메모리에 사용할 수 있는 백분율(예: 80%)이 컨테이너 수준에서 메모리 제한이 적용되는 컨테이너 컨텍스트에 더 적합합니다.
대부분의 Red Hat 컨테이너에는 JVM이 시작될 때 업데이트된 값을 설정하여 OpenJDK 기본값을 대체하는 시작 스크립트가 포함되어 있습니다.
예를 들어 OpenJDK 컨테이너의 Red Hat 빌드의 기본값은 80%입니다. 이 값은 JAVA_MAX_RAM_RATIO 환경 변수를 정의하여 다른 백분율로 설정할 수 있습니다.
다른 OpenJDK 배포의 경우 다음 명령을 사용하여 기본값 25%를 변경할 수 있습니다.
예
$ java -XX:MaxRAMPercentage=80.04.4.2.2. JVM에서 사용하지 않는 메모리를 운영 체제에 제공하도록 유도하는 방법 이해
기본적으로 OpenJDK는 사용하지 않는 메모리를 운영 체제에 적극적으로 반환하지 않습니다. 이는 대다수의 컨테이너화된 Java 워크로드에 적합할 수 있습니다. 그러나 추가 프로세스가 네이티브인지 추가 JVM인지 또는 이 둘의 조합인지와 관계없이 컨테이너 내에서 추가 활성 프로세스가 JVM과 공존하는 워크로드는 주목할 만한 예외입니다.
Java 기반 에이전트는 다음 JVM 인수를 사용하여 JVM에서 사용하지 않는 메모리를 운영 체제에 제공하도록 유도할 수 있습니다.
-XX:+UseParallelGC
-XX:MinHeapFreeRatio=5 -XX:MaxHeapFreeRatio=10 -XX:GCTimeRatio=4
-XX:AdaptiveSizePolicyWeight=90
이러한 인수는 할당된 메모리가 사용 중인 메모리의 110%(-XX:MaxHeapFreeRatio)를 초과할 때마다 힙 메모리를 운영 체제에 반환하기 위한 것으로, 가비지 수집기에서 최대 20%(-XX:GCTimeRatio)의 CPU 시간을 사용합니다. 애플리케이션 힙 할당은 항상 초기 힙 할당(-XX:InitialHeapSize / -Xms로 덮어씀)보다 적지 않습니다. 자세한 내용은 OpenShift에서 Java 풋프린트 튜닝(1부), OpenShift에서 Java 풋프린트 튜닝(2부), OpenJDK 및 컨테이너에서 확인할 수 있습니다.
4.4.2.3. 컨테이너 내의 모든 JVM 프로세스를 적절하게 구성하는 방법 이해
동일한 컨테이너에서 여러 개의 JVM이 실행되는 경우 모든 JVM이 올바르게 구성되어 있는지 확인해야 합니다. 워크로드가 많은 경우 각 JVM에 백분율로 된 메모리 예산을 부여하여 추가 안전 범위를 충분히 유지해야 합니다.
많은 Java 툴은 다양한 환경 변수(JAVA_OPTS,GRADLE_OPTS 등)를 사용하여 JVM을 구성하며 올바른 설정이 올바른 JVM으로 전달되도록 하는 것이 어려울 수 있습니다.
OpenJDK는 항상 JAVA_TOOL_OPTIONS 환경 변수를 준수하고 JAVA_TOOL_OPTIONS에 지정된 값은 JVM 명령줄에 지정된 다른 옵션에서 덮어씁니다. 기본적으로 이러한 옵션이 Java 기반 에이전트 이미지에서 실행되는 모든 JVM 워크로드에 기본적으로 사용되도록 AWS Jenkins Maven 에이전트 이미지의 Red Hat OpenShift Service는 다음 변수를 설정합니다.
JAVA_TOOL_OPTIONS="-Dsun.zip.disableMemoryMapping=true"이러한 설정을 통해 추가 옵션이 필요하지 않다고 보장할 수는 없지만 유용한 시작점이 될 수 있습니다.
4.4.3. Pod 내에서 메모리 요청 및 제한 찾기
Pod 내에서 메모리 요청 및 제한을 동적으로 검색하려는 애플리케이션에서는 Downward API를 사용해야 합니다.
프로세스
MEMORY_REQUEST및MEMORY_LIMIT스탠자를 추가하도록 Pod를 구성합니다.다음과 유사한 YAML 파일을 생성합니다.
apiVersion: v1 kind: Pod metadata: name: test spec: securityContext: runAsNonRoot: false seccompProfile: type: RuntimeDefault containers: - name: test image: fedora:latest command: - sleep - "3600" env: - name: MEMORY_REQUEST1 valueFrom: resourceFieldRef: containerName: test resource: requests.memory - name: MEMORY_LIMIT2 valueFrom: resourceFieldRef: containerName: test resource: limits.memory resources: requests: memory: 384Mi limits: memory: 512Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL]다음 명령을 실행하여 Pod를 생성합니다.
$ oc create -f <file_name>.yaml
검증
원격 쉘을 사용하여 Pod에 액세스합니다.
$ oc rsh test요청된 값이 적용되었는지 확인합니다.
$ env | grep MEMORY | sort출력 예
MEMORY_LIMIT=536870912 MEMORY_REQUEST=402653184
메모리 제한 값은 /sys/fs/cgroup/memory/memory.limit_in_bytes 파일을 통해 컨테이너 내부에서도 확인할 수 있습니다.
4.4.4. OOM 종료 정책 이해
Red Hat OpenShift Service on AWS는 컨테이너에 있는 모든 프로세스의 총 메모리 사용량이 메모리 제한을 초과하거나 노드 메모리 소모가 심각한 경우 컨테이너의 프로세스를 종료할 수 있습니다.
프로세스가 OOM(Out of Memory) 종료되면 컨테이너가 즉시 종료될 수 있습니다. 컨테이너 PID 1 프로세스에서 SIGKILL을 수신하면 컨테이너가 즉시 종료됩니다. 그 외에는 컨테이너 동작이 기타 프로세스의 동작에 따라 달라집니다.
예를 들어 컨테이너 프로세스가 코드 137로 종료되면 SIGKILL 신호가 수신되었음을 나타냅니다.
컨테이너가 즉시 종료되지 않으면 다음과 같이 OOM 종료를 탐지할 수 있습니다.
원격 쉘을 사용하여 Pod에 액세스합니다.
# oc rsh <pod name>다음 명령을 실행하여
/sys/fs/cgroup/memory/memory.oom_control에서 현재 OOM 종료 수를 확인합니다.$ grep '^oom_kill ' /sys/fs/cgroup/memory/memory.oom_control출력 예
oom_kill 0다음 명령을 실행하여 OOM 종료를 유도합니다.
$ sed -e '' </dev/zero출력 예
Killed다음 명령을 실행하여
/sys/fs/cgroup/memory/memory.oom_control에서 OOM 종료 카운터가 증가했는지 확인합니다.$ grep '^oom_kill ' /sys/fs/cgroup/memory/memory.oom_control출력 예
oom_kill 1Pod에서 하나 이상의 프로세스가 OOM 종료된 경우 나중에 Pod가 종료되면(즉시 여부와 관계없이) 단계는 실패, 이유는 OOM 종료가 됩니다.
restartPolicy값에 따라 OOM 종료된 Pod가 다시 시작될 수 있습니다. 재시작되지 않는 경우 복제 컨트롤러와 같은 컨트롤러는 Pod의 실패 상태를 확인하고 새 Pod를 생성하여 이전 Pod를 교체합니다.다음 명령을 사용하여 Pod 상태를 가져옵니다.
$ oc get pod test출력 예
NAME READY STATUS RESTARTS AGE test 0/1 OOMKilled 0 1mPod가 재시작되지 않은 경우 다음 명령을 실행하여 Pod를 확인합니다.
$ oc get pod test -o yaml출력 예
... status: containerStatuses: - name: test ready: false restartCount: 0 state: terminated: exitCode: 137 reason: OOMKilled phase: Failed재시작된 경우 다음 명령을 실행하여 Pod를 확인합니다.
$ oc get pod test -o yaml출력 예
... status: containerStatuses: - name: test ready: true restartCount: 1 lastState: terminated: exitCode: 137 reason: OOMKilled state: running: phase: Running
4.4.5. Pod 제거 이해
Red Hat OpenShift Service on AWS는 노드의 메모리가 소모되면 노드에서 Pod를 제거할 수 있습니다. 메모리 소모 범위에 따라 제거가 정상적으로 수행되지 않을 수 있습니다. 정상적인 제거에서는 프로세스가 아직 종료되지 않은 경우 각 컨테이너의 기본 프로세스(PID 1)에서 SIGTERM 신호를 수신한 다음 잠시 후 SIGKILL 신호를 수신합니다. 비정상적인 제거에서는 각 컨테이너의 기본 프로세스에서 SIGKILL 신호를 즉시 수신합니다.
제거된 Pod의 단계는 실패, 이유는 제거됨입니다. restartPolicy 값과 관계없이 재시작되지 않습니다. 그러나 복제 컨트롤러와 같은 컨트롤러는 Pod의 실패 상태를 확인하고 새 Pod를 생성하여 이전 Pod를 교체합니다.
$ oc get pod test출력 예
NAME READY STATUS RESTARTS AGE
test 0/1 Evicted 0 1m$ oc get pod test -o yaml출력 예
...
status:
message: 'Pod The node was low on resource: [MemoryPressure].'
phase: Failed
reason: Evicted5장. PID 제한 구성
PID(프로세스 ID)는 시스템에서 현재 실행 중인 각 프로세스 또는 스레드에 Linux 커널에서 할당한 고유 식별자입니다. 시스템에서 동시에 실행할 수 있는 프로세스 수는 Linux 커널의 4,194,304로 제한됩니다. 이 숫자는 메모리, CPU 및 디스크 공간과 같은 다른 시스템 리소스에 대한 제한된 액세스의 영향을 받을 수도 있습니다.
AWS 4.11 이상의 Red Hat OpenShift Service에서 Pod는 기본적으로 최대 4,096 PID를 가질 수 있습니다. 워크로드에 그 이상으로 필요한 경우 KubeletConfig 오브젝트를 구성하여 허용되는 최대 PID 수를 늘릴 수 있습니다.
4.11 이전 버전을 실행하는 AWS 클러스터의 Red Hat OpenShift Service는 기본 PID 제한이 1024 를 사용합니다.
5.1. 프로세스 ID 제한 이해
AWS의 Red Hat OpenShift Service에서 클러스터에서 작업을 예약하기 전에 PID(프로세스 ID) 사용에 대해 지원되는 다음 두 가지 제한 사항을 고려하십시오.
Pod당 최대 PID 수입니다.
기본값은 AWS 4.11 이상에서 Red Hat OpenShift Service의 4,096입니다. 이 값은 노드에 설정된
podPidsLimit매개변수에 의해 제어됩니다.노드당 최대 PID 수입니다.
기본값은 노드 리소스에 따라 다릅니다. AWS의 Red Hat OpenShift Service에서 이 값은
--system-reserved매개변수에 의해 제어되며, 노드의 총 리소스에 따라 각 노드에 PID를 예약합니다.
Pod가 Pod당 허용되는 최대 PID 수를 초과하면 Pod가 올바르게 작동을 중지하고 노드에서 제거될 수 있습니다. 자세한 내용은 제거 신호 및 임계값에 대한 Kubernetes 문서를 참조하십시오.
노드가 노드당 허용되는 최대 PID 수를 초과하면 새 프로세스에 PID를 할당할 수 없으므로 노드가 불안정해질 수 있습니다. 추가 프로세스를 생성하지 않고 기존 프로세스를 완료할 수 없는 경우 전체 노드를 사용할 수 없게 되고 재부팅이 필요할 수 있습니다. 이 경우 실행 중인 프로세스 및 애플리케이션에 따라 데이터가 손실될 수 있습니다. 고객 관리자 및 Red Hat 사이트 안정성 엔지니어링은 이 임계값에 도달하면 알림을 받으며 작업자 노드에 PIDPressure 경고가 표시됩니다.
5.2. AWS Pod에서 Red Hat OpenShift Service에 대해 더 높은 프로세스 ID 제한을 설정하는 위험
Pod의 podPidsLimit 매개변수는 해당 Pod에서 동시에 실행할 수 있는 최대 프로세스 및 스레드 수를 제어합니다.
podPidsLimit 의 값을 기본값인 4,096에서 최대 16,384로 늘릴 수 있습니다. podPidsLimit 을 변경하려면 영향을 받는 노드를 재부팅해야 하므로 이 값을 변경하면 애플리케이션의 다운타임이 발생할 수 있습니다.
노드당 다수의 Pod를 실행 중이고 노드에 podPidsLimit 값이 높은 경우 노드의 PID 최대값이 초과될 위험이 있습니다.
노드의 PID 최대값을 초과하지 않고 단일 노드에서 동시에 실행할 수 있는 최대 Pod 수를 찾으려면 podPidsLimit 값으로 3,650,000을 나눕니다. 예를 들어 podPidsLimit 값이 16,384이고 Pod가 프로세스 ID 수에 가깝게 사용할 것으로 예상되는 경우 단일 노드에서 222 Pod를 안전하게 실행할 수 있습니다.
memory, CPU 및 사용 가능한 스토리지는 podPidsLimit 값이 적절하게 설정된 경우에도 동시에 실행할 수 있는 최대 Pod 수를 제한할 수 있습니다. 자세한 내용은 "환경 계획" 및 "제한 및 확장성"을 참조하십시오.
5.3. AWS 클러스터의 Red Hat OpenShift Service의 머신 풀에 더 높은 프로세스 ID 제한 설정
--pod-pids-limit 매개변수를 변경하는 KubeletConfig 오브젝트를 생성하거나 편집하여 AWS 클러스터의 기존 Red Hat OpenShift Service에서 머신 풀에 대해 더 높은 podPidsLimit 을 설정할 수 있습니다.
기존 머신 풀에서 podPidsLimit 을 변경하면 머신 풀의 노드가 한 번에 하나씩 재부팅됩니다. 머신 풀의 워크로드에 대해 최대 사용량 시간을 초과하여 모든 노드가 재부팅될 때까지 클러스터를 업그레이드하거나 중단하지 않도록 합니다.
사전 요구 사항
- AWS 클러스터에 Red Hat OpenShift Service가 있습니다.
-
ROSA CLI(명령줄 인터페이스)(
rosa)를 설치했습니다. - ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
프로세스
새로운
--pod-pids-limit를 지정하는 클러스터의 새KubeletConfig오브젝트를 생성합니다.$ rosa create kubeletconfig -c <cluster_name> --name=<kubeletconfig_name> --pod-pids-limit=<value>예를 들어 다음 명령은 Pod당 최대 16,384개의 PID를 설정하는
my-cluster클러스터에 대한set-high-pidsKubeletConfig오브젝트를 생성합니다.$ rosa create kubeletconfig -c my-cluster --name=set-high-pids --pod-pids-limit=16384새
KubeletConfig오브젝트를 새 머신 풀 또는 기존 머신 풀과 연결합니다.새 머신 풀의 경우:
$ rosa create machinepool -c <cluster_name> --name <machinepool_name> --kubelet-configs=<kubeletconfig_name>기존 머신 풀의 경우:
$ rosa edit machinepool -c <cluster_name> --kubelet-configs=<kubeletconfig_name> <machinepool_name>출력 예
Editing the kubelet config will cause the Nodes for your Machine Pool to be recreated. This may cause outages to your applications. Do you wish to continue? (y/N)
예를 들어 다음 명령은
my-cluster클러스터의high-pid-pool시스템 풀에set-high-pidsKubeletConfig오브젝트를 연결합니다.$ rosa edit machinepool -c my-cluster --kubelet-configs=set-high-pids high-pid-pool기존 머신 풀에 새
KubeletConfig오브젝트가 연결되면 작업자 노드의 롤링 재부팅이 트리거됩니다. 머신 풀 설명에서 롤아웃 진행 상황을 확인할 수 있습니다.$ rosa describe machinepool --cluster <cluster_name> --machinepool <machinepool_name>
검증
시스템 풀의 노드에 새 설정이 있는지 확인합니다.
$ rosa describe kubeletconfig --cluster=<cluster_name> --name <kubeletconfig_name>다음 예와 같이 새 PIDs 제한이 출력에 표시됩니다.
출력 예
Pod Pids Limit: 16384
5.4. 머신 풀에서 사용자 지정 구성 제거
구성 세부 정보가 포함된 KubeletConfig 오브젝트를 제거하여 머신 풀에서 사용자 지정 구성을 제거할 수 있습니다.
사전 요구 사항
- AWS 클러스터에 기존 Red Hat OpenShift Service가 있습니다.
- ROSA CLI(rosa)를 설치했습니다.
- ROSA CLI를 사용하여 Red Hat 계정에 로그인했습니다.
프로세스
머신 풀을 편집하고 제거할
KubeletConfig오브젝트가 생략되도록--kubeletconfigs매개변수를 설정합니다.머신 풀에서
KubeletConfig오브젝트를 모두 제거하려면--kubeletconfigs매개변수의 빈 값을 설정합니다. 예를 들면 다음과 같습니다.$ rosa edit machinepool -c <cluster_name> --kubelet-configs="" <machinepool_name>
검증 단계
제거한
KubeletConfig오브젝트가 머신 풀 설명에 표시되지 않는지 확인합니다.$ rosa describe machinepool --cluster <cluster_name> --machinepool=<machinepool_name>
6장. 다중 아키텍처 컴퓨팅 머신으로 클러스터 관리
여러 아키텍처가 있는 노드가 있는 클러스터를 관리하려면 클러스터를 모니터링하고 워크로드를 관리할 때 노드 아키텍처를 고려해야 합니다. 이를 위해서는 다중 아키텍처 클러스터에서 워크로드를 예약할 때 고려해야 할 추가 고려 사항을 고려해야 합니다.
6.1. 다중 아키텍처 컴퓨팅 머신을 사용하여 클러스터에서 워크로드 예약
다른 아키텍처를 사용하는 컴퓨팅 노드를 사용하여 클러스터에 워크로드를 배포하는 경우 Pod 아키텍처를 기본 노드의 아키텍처와 조정해야 합니다. 또한 기본 노드 아키텍처에 따라 특정 리소스에 대한 추가 구성이 필요할 수도 있습니다.
Multiarch Tuning Operator를 사용하여 다중 아키텍처 컴퓨팅 머신이 있는 클러스터에서 워크로드의 아키텍처 인식 스케줄링을 활성화할 수 있습니다. Multiarch Tuning Operator는 생성 시 Pod에서 지원할 수 있는 아키텍처를 기반으로 Pod 사양에서 추가 스케줄러 서술자를 구현합니다.
Multiarch Tuning Operator에 대한 자세한 내용은 Multiarch Tuning Operator를 사용하여 다중 아키텍처 클러스터에서 워크로드 관리를 참조하십시오.
6.1.1. 다중 아키텍처 노드 워크로드 배포 샘플
아키텍처를 기반으로 하는 적절한 노드에 워크로드를 예약하는 것은 다른 노드 특성을 기반으로 하는 스케줄링과 동일한 방식으로 작동합니다.
nodeAffinity를 사용하여 특정 아키텍처로 노드 예약이미지에서 지원하는 노드 세트에서만 워크로드를 예약할 수 있습니다. Pod의 템플릿 사양에
spec.affinity.nodeAffinity필드를 설정할 수 있습니다.apiVersion: apps/v1 kind: Deployment metadata: # ... spec: # ... template: # ... spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/arch operator: In values:1 - amd64 - arm64- 1
- 지원되는 아키텍처를 지정합니다. 유효한 값에는
amd64,arm64또는 두 값이 모두 포함됩니다.
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.