Este conteúdo não está disponível no idioma selecionado.
Chapter 1. Overview of AMQ Streams
AMQ Streams simplifies the process of running Apache Kafka in an OpenShift cluster.
This guide provides instructions for configuring Kafka components and using AMQ Streams Operators. Procedures relate to how you might want to modify your deployment and introduce additional features, such as Cruise Control or distributed tracing.
You can configure your deployment using AMQ Streams custom resources. The Custom resource API reference describes the properties you can use in your configuration.
Looking to get started with AMQ Streams? For step-by-step deployment instructions, see the Deploying and Upgrading AMQ Streams on OpenShift guide.
1.1. Kafka capabilities
The underlying data stream-processing capabilities and component architecture of Kafka can deliver:
- Microservices and other applications to share data with extremely high throughput and low latency
- Message ordering guarantees
- Message rewind/replay from data storage to reconstruct an application state
- Message compaction to remove old records when using a key-value log
- Horizontal scalability in a cluster configuration
- Replication of data to control fault tolerance
- Retention of high volumes of data for immediate access
1.2. Kafka use cases
Kafka’s capabilities make it suitable for:
- Event-driven architectures
- Event sourcing to capture changes to the state of an application as a log of events
- Message brokering
- Website activity tracking
- Operational monitoring through metrics
- Log collection and aggregation
- Commit logs for distributed systems
- Stream processing so that applications can respond to data in real time
1.3. How AMQ Streams supports Kafka
AMQ Streams provides container images and Operators for running Kafka on OpenShift. AMQ Streams Operators are fundamental to the running of AMQ Streams. The Operators provided with AMQ Streams are purpose-built with specialist operational knowledge to effectively manage Kafka.
Operators simplify the process of:
- Deploying and running Kafka clusters
- Deploying and running Kafka components
- Configuring access to Kafka
- Securing access to Kafka
- Upgrading Kafka
- Managing brokers
- Creating and managing topics
- Creating and managing users
1.4. AMQ Streams Operators
AMQ Streams supports Kafka using Operators to deploy and manage the components and dependencies of Kafka to OpenShift.
Operators are a method of packaging, deploying, and managing an OpenShift application. AMQ Streams Operators extend OpenShift functionality, automating common and complex tasks related to a Kafka deployment. By implementing knowledge of Kafka operations in code, Kafka administration tasks are simplified and require less manual intervention.
Operators
AMQ Streams provides Operators for managing a Kafka cluster running within an OpenShift cluster.
- Cluster Operator
- Deploys and manages Apache Kafka clusters, Kafka Connect, Kafka MirrorMaker, Kafka Bridge, Kafka Exporter, and the Entity Operator
- Entity Operator
- Comprises the Topic Operator and User Operator
- Topic Operator
- Manages Kafka topics
- User Operator
- Manages Kafka users
The Cluster Operator can deploy the Topic Operator and User Operator as part of an Entity Operator configuration at the same time as a Kafka cluster.
Operators within the AMQ Streams architecture
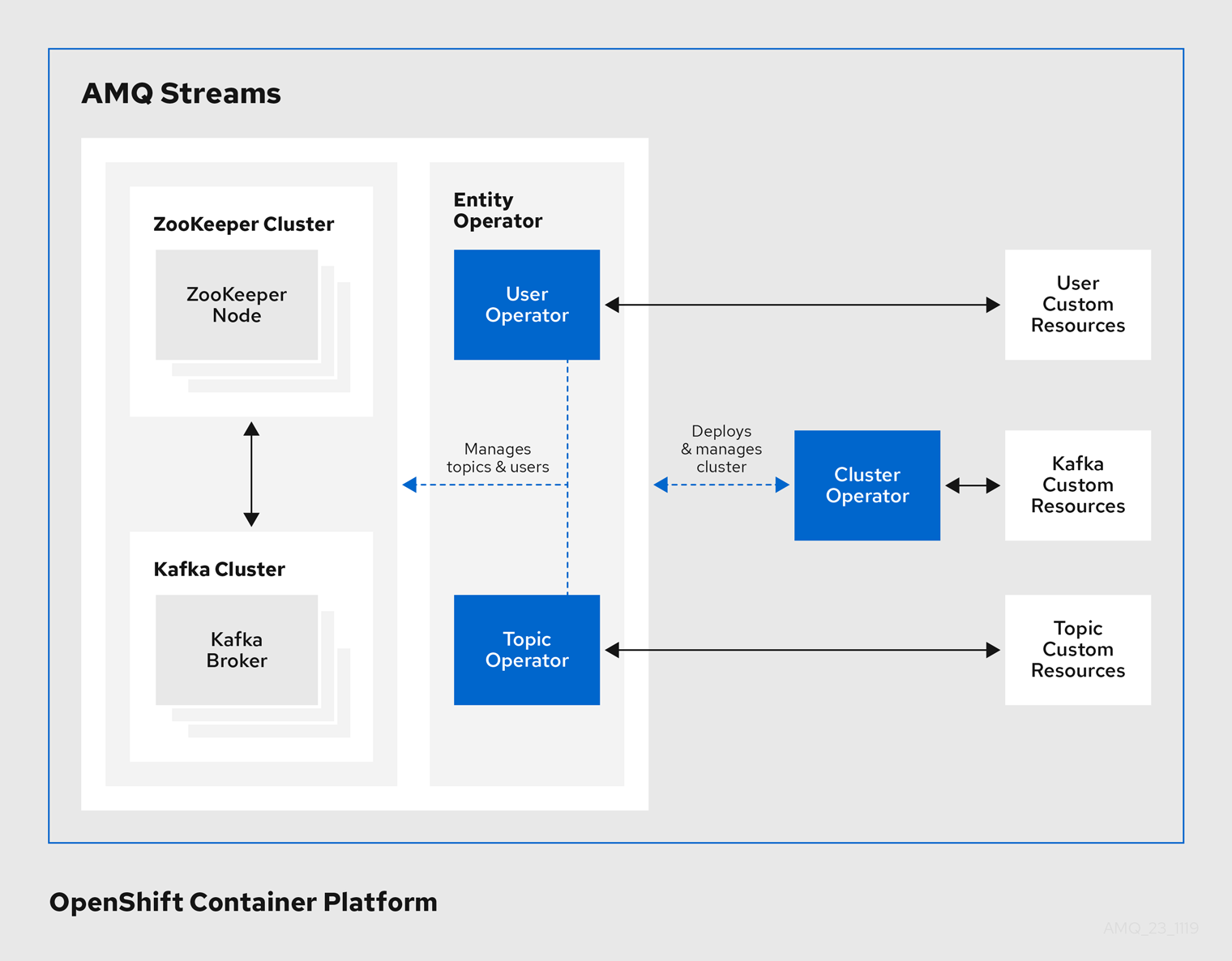
1.4.1. Cluster Operator
AMQ Streams uses the Cluster Operator to deploy and manage clusters for:
- Kafka (including ZooKeeper, Entity Operator, Kafka Exporter, and Cruise Control)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
Custom resources are used to deploy the clusters.
For example, to deploy a Kafka cluster:
-
A
Kafkaresource with the cluster configuration is created within the OpenShift cluster. -
The Cluster Operator deploys a corresponding Kafka cluster, based on what is declared in the
Kafkaresource.
The Cluster Operator can also deploy (through configuration of the Kafka resource):
-
A Topic Operator to provide operator-style topic management through
KafkaTopiccustom resources -
A User Operator to provide operator-style user management through
KafkaUsercustom resources
The Topic Operator and User Operator function within the Entity Operator on deployment.
Example architecture for the Cluster Operator
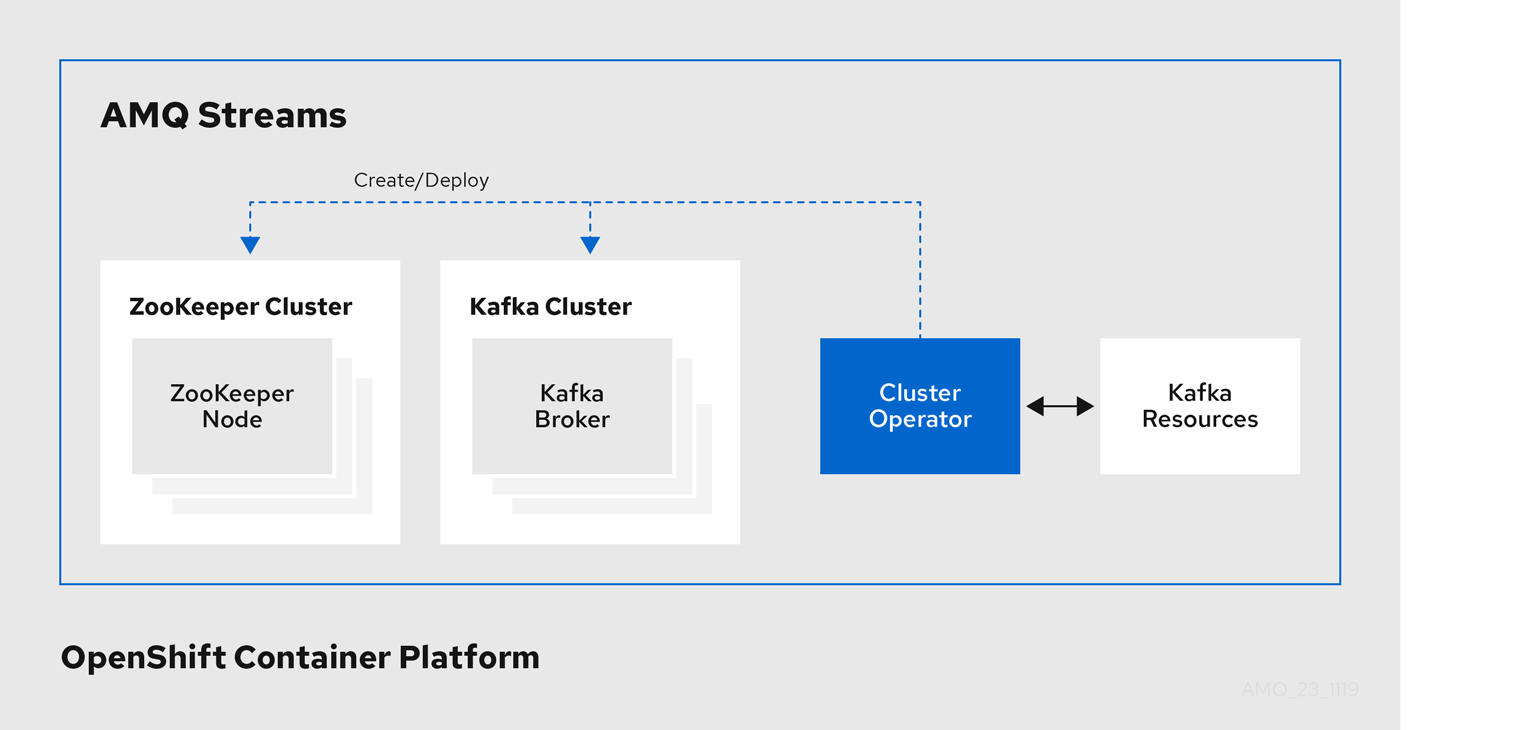
1.4.2. Topic Operator
The Topic Operator provides a way of managing topics in a Kafka cluster through OpenShift resources.
Example architecture for the Topic Operator

The role of the Topic Operator is to keep a set of KafkaTopic OpenShift resources describing Kafka topics in-sync with corresponding Kafka topics.
Specifically, if a KafkaTopic is:
- Created, the Topic Operator creates the topic
- Deleted, the Topic Operator deletes the topic
- Changed, the Topic Operator updates the topic
Working in the other direction, if a topic is:
-
Created within the Kafka cluster, the Operator creates a
KafkaTopic -
Deleted from the Kafka cluster, the Operator deletes the
KafkaTopic -
Changed in the Kafka cluster, the Operator updates the
KafkaTopic
This allows you to declare a KafkaTopic as part of your application’s deployment and the Topic Operator will take care of creating the topic for you. Your application just needs to deal with producing or consuming from the necessary topics.
The Topic Operator maintains information about each topic in a topic store, which is continually synchronized with updates from Kafka topics or OpenShift KafkaTopic custom resources. Updates from operations applied to a local in-memory topic store are persisted to a backup topic store on disk. If a topic is reconfigured or reassigned to other brokers, the KafkaTopic will always be up to date.
1.4.3. User Operator
The User Operator manages Kafka users for a Kafka cluster by watching for KafkaUser resources that describe Kafka users, and ensuring that they are configured properly in the Kafka cluster.
For example, if a KafkaUser is:
- Created, the User Operator creates the user it describes
- Deleted, the User Operator deletes the user it describes
- Changed, the User Operator updates the user it describes
Unlike the Topic Operator, the User Operator does not sync any changes from the Kafka cluster with the OpenShift resources. Kafka topics can be created by applications directly in Kafka, but it is not expected that the users will be managed directly in the Kafka cluster in parallel with the User Operator.
The User Operator allows you to declare a KafkaUser resource as part of your application’s deployment. You can specify the authentication and authorization mechanism for the user. You can also configure user quotas that control usage of Kafka resources to ensure, for example, that a user does not monopolize access to a broker.
When the user is created, the user credentials are created in a Secret. Your application needs to use the user and its credentials for authentication and to produce or consume messages.
In addition to managing credentials for authentication, the User Operator also manages authorization rules by including a description of the user’s access rights in the KafkaUser declaration.
1.4.4. Feature gates in AMQ Streams Operators
You can enable and disable some features of operators using feature gates.
Feature gates are set in the operator configuration and have three stages of maturity: alpha, beta, or General Availability (GA).
For more information, see Feature gates.
1.5. AMQ Streams custom resources
A deployment of Kafka components to an OpenShift cluster using AMQ Streams is highly configurable through the application of custom resources. Custom resources are created as instances of APIs added by Custom resource definitions (CRDs) to extend OpenShift resources.
CRDs act as configuration instructions to describe the custom resources in an OpenShift cluster, and are provided with AMQ Streams for each Kafka component used in a deployment, as well as users and topics. CRDs and custom resources are defined as YAML files. Example YAML files are provided with the AMQ Streams distribution.
CRDs also allow AMQ Streams resources to benefit from native OpenShift features like CLI accessibility and configuration validation.
Additional resources
1.5.1. AMQ Streams custom resource example
CRDs require a one-time installation in a cluster to define the schemas used to instantiate and manage AMQ Streams-specific resources.
After a new custom resource type is added to your cluster by installing a CRD, you can create instances of the resource based on its specification.
Depending on the cluster setup, installation typically requires cluster admin privileges.
Access to manage custom resources is limited to AMQ Streams administrators. For more information, see Designating AMQ Streams administrators in the Deploying and Upgrading AMQ Streams on OpenShift guide.
A CRD defines a new kind of resource, such as kind:Kafka, within an OpenShift cluster.
The Kubernetes API server allows custom resources to be created based on the kind and understands from the CRD how to validate and store the custom resource when it is added to the OpenShift cluster.
When CRDs are deleted, custom resources of that type are also deleted. Additionally, the resources created by the custom resource, such as pods and statefulsets are also deleted.
Each AMQ Streams-specific custom resource conforms to the schema defined by the CRD for the resource’s kind. The custom resources for AMQ Streams components have common configuration properties, which are defined under spec.
To understand the relationship between a CRD and a custom resource, let’s look at a sample of the CRD for a Kafka topic.
Kafka topic CRD
apiVersion: kafka.strimzi.io/v1beta2 kind: CustomResourceDefinition metadata: 1 name: kafkatopics.kafka.strimzi.io labels: app: strimzi spec: 2 group: kafka.strimzi.io versions: v1beta2 scope: Namespaced names: # ... singular: kafkatopic plural: kafkatopics shortNames: - kt 3 additionalPrinterColumns: 4 # ... subresources: status: {} 5 validation: 6 openAPIV3Schema: properties: spec: type: object properties: partitions: type: integer minimum: 1 replicas: type: integer minimum: 1 maximum: 32767 # ...
- 1
- The metadata for the topic CRD, its name and a label to identify the CRD.
- 2
- The specification for this CRD, including the group (domain) name, the plural name and the supported schema version, which are used in the URL to access the API of the topic. The other names are used to identify instance resources in the CLI. For example,
oc get kafkatopic my-topicoroc get kafkatopics. - 3
- The shortname can be used in CLI commands. For example,
oc get ktcan be used as an abbreviation instead ofoc get kafkatopic. - 4
- The information presented when using a
getcommand on the custom resource. - 5
- The current status of the CRD as described in the schema reference for the resource.
- 6
- openAPIV3Schema validation provides validation for the creation of topic custom resources. For example, a topic requires at least one partition and one replica.
You can identify the CRD YAML files supplied with the AMQ Streams installation files, because the file names contain an index number followed by ‘Crd’.
Here is a corresponding example of a KafkaTopic custom resource.
Kafka topic custom resource
apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic 1 metadata: name: my-topic labels: strimzi.io/cluster: my-cluster 2 spec: 3 partitions: 1 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824 status: conditions: 4 lastTransitionTime: "2019-08-20T11:37:00.706Z" status: "True" type: Ready observedGeneration: 1 / ...
- 1
- The
kindandapiVersionidentify the CRD of which the custom resource is an instance. - 2
- A label, applicable only to
KafkaTopicandKafkaUserresources, that defines the name of the Kafka cluster (which is same as the name of theKafkaresource) to which a topic or user belongs. - 3
- The spec shows the number of partitions and replicas for the topic as well as the configuration parameters for the topic itself. In this example, the retention period for a message to remain in the topic and the segment file size for the log are specified.
- 4
- Status conditions for the
KafkaTopicresource. Thetypecondition changed toReadyat thelastTransitionTime.
Custom resources can be applied to a cluster through the platform CLI. When the custom resource is created, it uses the same validation as the built-in resources of the Kubernetes API.
After a KafkaTopic custom resource is created, the Topic Operator is notified and corresponding Kafka topics are created in AMQ Streams.
1.6. Listener configuration
Listeners are used to connect to Kafka brokers.
AMQ Streams provides a generic GenericKafkaListener schema with properties to configure listeners through the Kafka resource.
The GenericKafkaListener provides a flexible approach to listener configuration. You can specify properties to configure internal listeners for connecting within the OpenShift cluster, or external listeners for connecting outside the OpenShift cluster.
Each listener is defined as an array in the Kafka resource. You can configure as many listeners as required, as long as their names and ports are unique.
You might want to configure multiple external listeners, for example, to handle access from networks that require different authentication mechanisms. Or you might need to join your OpenShift network to an outside network. In which case, you can configure internal listeners (using the useServiceDnsDomain property) so that the OpenShift service DNS domain (typically .cluster.local) is not used.
For more information on the configuration options available for listeners, see the GenericKafkaListener schema reference.
Configuring listeners to secure access to Kafka brokers
You can configure listeners for secure connection using authentication. For more information on securing access to Kafka brokers, see Managing access to Kafka.
Configuring external listeners for client access outside OpenShift
You can configure external listeners for client access outside an OpenShift environment using a specified connection mechanism, such as a loadbalancer. For more information on the configuration options for connecting an external client, see Configuring external listeners.
Listener certificates
You can provide your own server certificates, called Kafka listener certificates, for TLS listeners or external listeners which have TLS encryption enabled. For more information, see Kafka listener certificates.
1.7. Document Conventions
Replaceables
In this document, replaceable text is styled in monospace, with italics, uppercase, and hyphens.
For example, in the following code, you will want to replace MY-NAMESPACE with the name of your namespace:
sed -i 's/namespace: .*/namespace: MY-NAMESPACE/' install/cluster-operator/*RoleBinding*.yaml