托管 control plane
在 OpenShift Container Platform 中使用托管 control plane
摘要
第 1 章 托管 control plane 发行注记
发行注记包含有关新的和已弃用的功能、更改以及已知问题的信息。
在这个版本中,OpenShift Container Platform 4.17 托管 control plane 可用。OpenShift Container Platform 4.17 托管 control plane 支持 Kubernetes Operator 版本 2.7 的多集群引擎。
1.1.1. 新功能及功能增强
此版本对以下方面进行了改进:
1.1.1.1. 自定义污点和容限(技术预览)
现在,您可以使用 hcp CLI -tolerations 参数或使用 hc.Spec.Tolerations API 文件将容限应用到托管的 control plane pod。此功能作为技术预览功能提供。如需更多信息,请参阅自定义污点和容限。
对于 OpenShift Virtualization 上的托管 control plane,您可以将一个或多个 NVIDIA 图形处理单元(GPU) 设备附加到节点池。此功能作为技术预览功能提供。如需更多信息,请参阅使用 hcp CLI 附加 NVIDIA GPU 设备,以及使用 NodePool 资源附加 NVIDIA GPU 设备。
1.1.1.3. 支持 AWS 上的租期
当您在 AWS 上创建托管集群时,您可以指定 EC2 实例是否应该在共享或单租户硬件上运行。如需更多信息,请参阅在 AWS 上创建托管集群。
1.1.1.4. 支持托管的集群中的 OpenShift Container Platform 版本
您可以在托管集群中部署一系列支持的 OpenShift Container Platform 版本。如需更多信息,请参阅托管集群中的支持的 OpenShift Container Platform 版本。
在本发行版本中,在断开连接的环境中的 OpenShift Virtualization 上托管 control plane 为正式发布。如需更多信息,请参阅 在断开连接的环境中在 OpenShift Virtualization 上部署托管 control plane。
在本发行版本中,AWS 上的 ARM64 OpenShift Container Platform 集群的托管 control plane 正式发布。如需更多信息,请参阅在 ARM64 架构上运行托管集群。
1.1.1.7. IBM Z 上的托管 control plane 正式发布
在本发行版本中,IBM Z 上的托管 control plane 正式发布。如需更多信息,请参阅在 IBM Z 上部署托管 control plane。
1.1.1.8. IBM Power 上的托管 control plane 正式发布
在本发行版本中,IBM Power 上的托管 control plane 正式发布。如需更多信息,请参阅在 IBM Power 上部署托管 control plane。
1.1.2. 程序错误修复
-
在以前的版本中,当配置托管集群代理并使用具有 HTTP 或 HTTPS 端点的身份提供程序 (IDP) 时,IDP 的主机名在通过代理发送它前没有被解决。因此,只能由 data plane 解析的主机名无法为 IDP 解析。在这个版本中,在通过
konnectivity隧道发送 IPD 流量前会执行 DNS 查找。因此,Control Plane Operator 可以验证只能由 data plane 解析的主机名的 IDP。(OCPBUGS-41371) -
在以前的版本中,当托管集群
controllerAvailabilityPolicy设置为SingleReplica时,网络组件的podAntiAffinity会阻止组件的可用性。在这个版本中,这个问题已解决。(OCPBUGS-39313) -
在以前的版本中,在托管集群镜像配置中指定的
AdditionalTrustedCA不会被协调到openshift-config命名空间中,image-registry-operator的预期,且组件不可用。在这个版本中,这个问题已解决。(OCPBUGS-39225) - 在以前的版本中,因为对核心操作系统的更改,Red Hat HyperShift 定期合规作业会失败。这些失败的作业会导致 OpenShift API 部署失败。在这个版本中,更新会递归复制单独的可信证书颁发机构(CA)证书,而不是复制单个文件,因此定期一致性作业会成功,OpenShift API 会按预期运行。(OCPBUGS-38941)
-
在以前的版本中,托管集群中的 Konnectity 代理代理总是通过 HTTP/S 代理发送所有 TCP 流量。它还会忽略
NO_PROXY配置中的主机名,因为它仅在其流量中接收解析的 IP 地址。因此,无论配置是什么,不应被代理的流量(如 LDAP 流量)都会被代理。在这个版本中,代理会在源 (control plane) 中完成,在 Konnectity 代理中的代理配置被删除。因此,不应被代理的流量(如 LDAP 流量)不再被代理。满足包含主机名的NO_PROXY配置。(OCPBUGS-38637) -
在以前的版本中,在使用
registryOverride时,azure-disk-csi-driver-controller镜像不会获得适当的覆盖值。这是有意设计的,以避免将值传播到azure-disk-csi-driverdata plane 镜像。在这个版本中,通过添加单独的镜像覆盖值来解决这个问题。因此,azure-disk-csi-driver-controller可以与registryOverride一起使用,不再影响azure-disk-csi-driverdata plane 镜像。(OCPBUGS-38183) - 在以前的版本中,在代理管理集群上运行的托管 control plane 中的 AWS 云控制器管理器不会将代理用于云 API 通信。在这个版本中,这个问题已被解决。(OCPBUGS-37832)
在以前的版本中,在托管集群的 control plane 中运行的 Operator 代理是通过在 data plane 中运行的 Konnectity 代理 pod 上的代理设置执行的。无法区分需要基于应用程序协议的代理。
对于 OpenShift Container Platform 的奇偶校验,通过 HTTPS 或 HTTP 的 IDP 通信应该会被代理,但 LDAP 通信不应被代理。这种类型的代理还忽略依赖于主机名的
NO_PROXY条目,因为通过时间流量到达 Konnectity 代理,只有目标 IP 地址可用。在这个版本中,在托管的集群中,通过
konnectivity-https-proxy和konnectivity-socks5-proxy在 control plane 中调用代理,代理流量会从 Konnectivity 代理停止。因此,针对 LDAP 服务器的流量不再会被代理。其他 HTTPS 或 HTTPS 流量被正确代理。指定主机名时,会遵守NO_PROXY设置。(OCPBUGS-37052)在以前的版本中,Konnectity 代理中发生 IDP 通信的代理。通过时间流量达到 Konnectivity,其协议和主机名不再可用。因此,OAUTH 服务器 pod 无法正确进行代理。它无法区分需要代理的协议 (
http/s) 和不需要代理的协议 (ldap://)。另外,它不遵循HostedCluster.spec.configuration.proxyspec 中配置的no_proxy变量。在这个版本中,您可以在 OAUTH 服务器的 Konnectity sidecar 上配置代理,以便正确路由流量,并遵循您的
no_proxy设置。因此,当为托管集群配置代理时,OAUTH 服务器可以与身份提供程序正确通信。(OCPBUGS-36932)-
在以前的版本中,在从
HostedCluster对象中删除ImageContentSources字段后,托管 Cluster Config Operator (HCCO) 不会删除ImageDigestMirrorSetCR (IDMS)。因此,当 IDMS 不应该被保留在HostedCluster对象中,IDMS 会保留。在这个版本中,HCCO 管理从HostedCluster对象中删除 IDMS 资源。(OCPBUGS-34820) -
在以前的版本中,在断开连接的环境中部署
hostedCluster需要设置hypershift.openshift.io/control-plane-operator-image注解。在这个版本中,不再需要注解。另外,元数据检查器在托管 Operator 协调过程中可以正常工作,OverrideImages会如预期填充。(OCPBUGS-34734) - 在以前的版本中,AWS 上的托管集群利用其 VPC 的主 CIDR 范围在 data plane 上生成安全组规则。因此,如果您将托管集群安装到具有多个 CIDR 范围的 AWS VPC 中,则生成的安全组规则可能不足。在这个版本中,安全组规则根据提供的机器 CIDR 范围生成,解决了这个问题。(OCPBUGS-34274)
- 在以前的版本中,OpenShift Cluster Manager 容器没有正确的 TLS 证书。因此,您无法在断开连接的部署中使用镜像流。在这个版本中,TLS 证书作为投射卷添加,解决了这个问题。(OCPBUGS-31446)
- 在以前的版本中,OpenShift Virtualization 的 Kubernetes Operator 控制台的多集群引擎中的 bulk destroy 选项不会销毁托管集群。在这个版本中,这个问题已解决。(ACM-10165)
-
在以前的版本中,更新托管 control plane 集群配置中的
additionalTrustBundle参数不会应用到计算节点。在这个版本中,确保对additionalTrustBundle参数的更新会自动应用到托管 control plane 集群中存在的计算节点。如果您更新到包含此修复的版本,则会选择现有节点的自动推出部署。(OCPBUGS-36680)
1.1.3. 已知问题
-
如果注解和
ManagedCluster资源名称不匹配,Kubernetes Operator 控制台的多集群引擎会显示集群为Pending import。多集群引擎 Operator 无法使用集群。当没有注解且ManagedCluster名称与HostedCluster资源的Infra-ID值不匹配时,会出现同样的问题。 - 当使用 multicluster engine for Kubernetes Operator 控制台将新节点池添加到现有托管集群时,相同的 OpenShift Container Platform 版本可能会在选项列表中出现多次。您可以在列表中为您想要的版本选择任何实例。
当节点池缩减为 0 个 worker 时,控制台中的主机列表仍然会显示处于
Ready状态的节点。您可以通过两种方式验证节点数:- 在控制台中,进入节点池并验证它是否有 0 个节点。
在命令行界面中运行以下命令:
运行以下命令,验证有 0 个节点在节点池中:
$ oc get nodepool -A运行以下命令验证集群中有 0 个节点:
$ oc get nodes --kubeconfig运行以下命令验证报告了 0 个代理被绑定到集群:
$ oc get agents -A
当您在使用双栈网络的环境中创建托管集群时,您可能会遇到以下与 DNS 相关的问题:
-
service-ca-operatorpod 中的CrashLoopBackOff状态:当 pod 试图通过托管的 control plane 访问 Kubernetes API 服务器时,pod 无法访问服务器,因为kube-system命名空间中的 data plane 代理无法解析请求。出现这个问题的原因是,前端使用 IP 地址,后端使用 pod 无法解析的 DNS 名称。 -
Pod 处于
ContainerCreating状态 :出现这个问题,因为openshift-service-ca-operator无法生成 DNS pod 需要 DNS 解析的metrics-tlssecret。因此,pod 无法解析 Kubernetes API 服务器。要解决这些问题,请配置双栈网络的 DNS 服务器设置。
-
-
在 Agent 平台上,托管 control plane 功能定期轮转 Agent 用来拉取 ignition 的令牌。因此,如果您有一个创建一段时间的 Agent 资源,它可能无法拉取 ignition。作为临时解决方案,在 Agent 规格中,删除
IgnitionEndpointTokenReference属性的 secret,然后在 Agent 资源上添加或修改任何标签。系统使用新令牌重新创建 secret。 如果您在与其受管集群相同的命名空间中创建了托管集群,分离受管集群会删除受管集群命名空间中的所有集群(包括托管集群)。以下情况会在与受管集群相同的命名空间中创建托管集群:
- 已使用默认托管集群集群命名空间,通过 multicluster engine for Kubernetes Operator 控制台在 Agent 平台上创建托管集群。
- 您可以通过命令行界面或 API 创建托管集群,方法是将指定托管的集群命名空间指定为与托管集群名称相同。
如果您为新的托管集群配置了集群范围代理,则该集群的部署可能会失败,因为当配置了集群范围代理时 worker 节点无法访问 Kubernetes API 服务器。要解决这个问题,在托管集群的配置文件中,将任何以下信息添加到
noProxy字段中,以便数据平面的流量会跳过代理:- 外部 API 地址。
-
内部 API 地址。默认值为
172.20.0.1。 -
短语
kubernetes。 - 服务网络 CIDR。
- 集群网络 CIDR。
1.1.4. 正式发布(GA)和技术预览(TP)功能
正式发布(GA)的功能被完全支持,并适用于生产环境。技术预览功能为实验性功能,不适用于生产环境。有关 TP 功能的更多信息,请参阅红帽客户门户网站中的支持范围。
对于 IBM Power 和 IBM Z,您必须在基于 64 位 x86 架构的机器类型以及 IBM Power 或 IBM Z 上的节点池上运行 control plane。
参阅下表以了解托管 control plane GA 和 TP 功能:
| 功能 | 4.15 | 4.16 | 4.17 |
|---|---|---|---|
| 在 Amazon Web Services (AWS) 上托管 OpenShift Container Platform 的 control plane。 | 技术预览 | 正式发布 | 正式发布 |
| 在裸机上托管 OpenShift Container Platform 的 control plane | 公开发行 | 公开发行 | 公开发行 |
| 在 OpenShift Virtualization 上为 OpenShift Container Platform 托管 control plane | 正式发布 | 正式发布 | 正式发布 |
| 使用非裸机代理机器托管 OpenShift Container Platform 的 control plane | 技术预览 | 技术预览 | 技术预览 |
| 在 Amazon Web Services 上为 ARM64 OpenShift Container Platform 集群托管 control plane | 技术预览 | 技术预览 | 正式发布 |
| 在 IBM Power 上托管 OpenShift Container Platform 的 control plane | 技术预览 | 技术预览 | 正式发布 |
| 在 IBM Z 上托管 OpenShift Container Platform 的 control plane | 技术预览 | 技术预览 | 正式发布 |
| 在 RHOSP 上托管 OpenShift Container Platform 的 control plane | 不可用 | 不可用 | 开发者预览 |
第 2 章 托管 control plane 概述
您可以使用两个不同的 control plane 配置部署 OpenShift Container Platform 集群:独立或托管的 control plane。独立配置使用专用虚拟机或物理机器来托管 control plane。通过为 OpenShift Container Platform 托管 control plane,您可以在托管集群中创建 pod 作为 control plane,而无需为每个 control plane 使用专用虚拟机或物理机器。
2.1. 托管 control plane 简介
使用以下平台上的 Kubernetes Operator 支持的多集群引擎版本来托管 control plane:
- 使用 Agent 供应商进行裸机
- 非裸机代理机器作为技术预览功能
- OpenShift Virtualization
- Amazon Web Services (AWS)
- IBM Z
- IBM Power
托管的 control plane 功能默认启用。
multicluster engine Operator 是 Red Hat Advanced Cluster Management (RHACM)的一个完整部分,它默认使用 RHACM 启用。但是,您不需要 RHACM 来使用托管的 control plane。
2.1.1. 托管 control plane 的架构
OpenShift Container Platform 通常以组合或独立部署,集群由 control plane 和数据平面组成。control plane 包括 API 端点、存储端点、工作负载调度程序和确保状态的指示器。data plane 包括运行工作负载的计算、存储和网络。
独立的 control plane 由一组专用的节点(可以是物理或虚拟)托管,最小数字来确保仲裁数。网络堆栈被共享。对集群的管理员访问权限提供了对集群的 control plane、机器管理 API 和有助于对集群状态贡献的其他组件的可见性。
虽然独立模式运行良好,但在某些情况下需要与 control plane 和数据平面分离的架构。在这些情况下,data plane 位于带有专用物理托管环境的独立网络域中。control plane 使用 Kubernetes 原生的高级别原语(如部署和有状态集)托管。control plane 被视为其他工作负载。
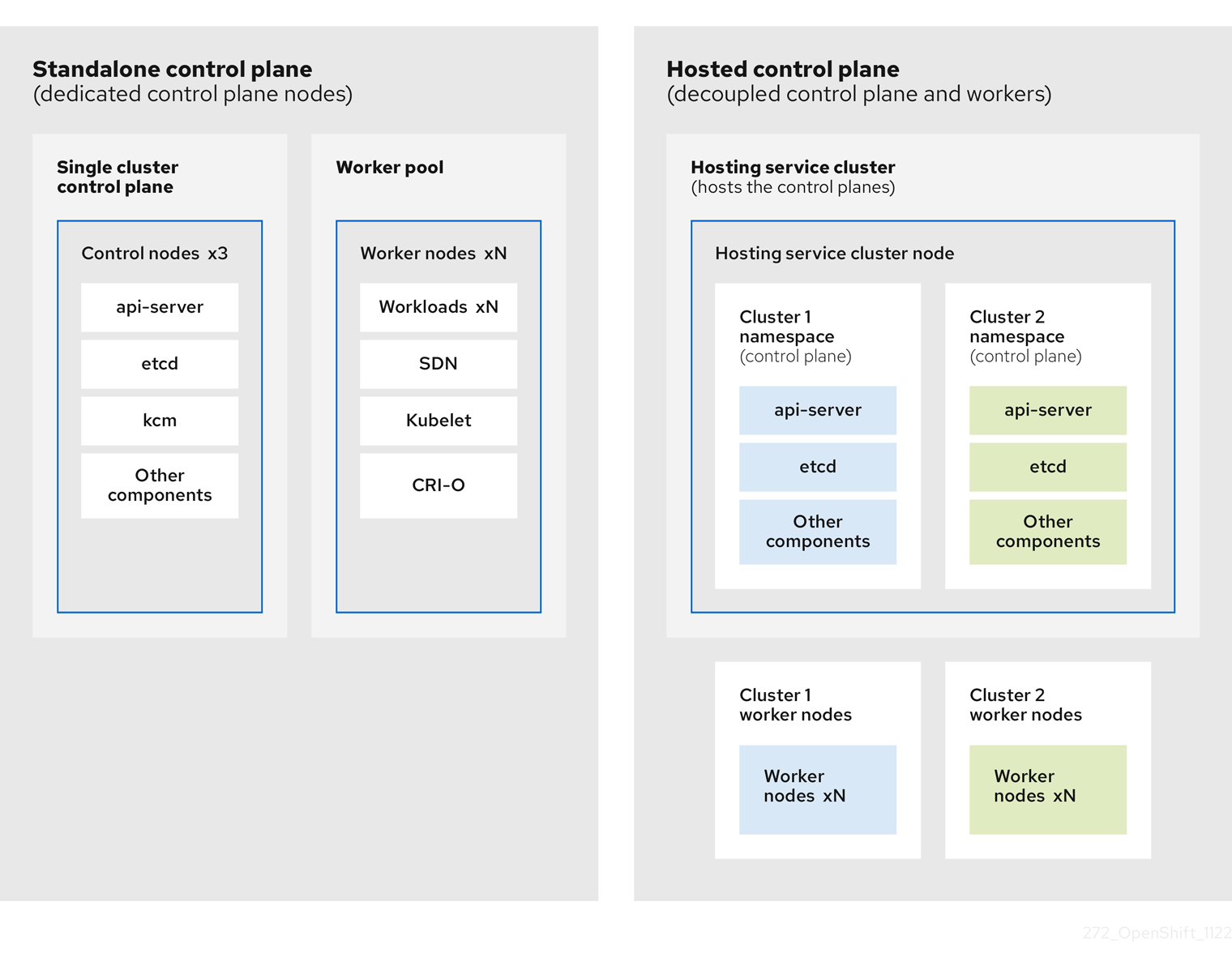
2.1.2. 托管 control plane 的优点
使用托管的 control plane,您可以为真正的混合云方法打下基础,并享受一些其他优势。
- 管理和工作负载之间的安全界限很强大,因为 control plane 分离并在专用的托管服务集群中托管。因此,您无法将集群的凭证泄漏到其他用户。因为基础架构 secret 帐户管理也已被分离,所以集群基础架构管理员无法意外删除 control plane 基础架构。
- 使用托管 control plane,您可以在较少的节点上运行多个 control plane。因此,集群更为经济。
- 因为 control plane 由 OpenShift Container Platform 上启动的 pod 组成,所以 control planes 快速启动。同样的原则适用于 control plane 和工作负载,如监控、日志记录和自动扩展。
- 从基础架构的角度来看,您可以将 registry、HAProxy、集群监控、存储节点和其他基础架构组件推送到租户的云供应商帐户,将使用情况隔离到租户。
- 从操作的角度来看,多集群管理更为集中,从而减少了影响集群状态和一致性的外部因素。站点可靠性工程师具有调试问题并进入集群的数据平面的中心位置,这可能会导致更短的时间解析 (TTR) 并提高生产效率。
托管 control plane 是 OpenShift Container Platform 的一个形式。托管集群和独立 OpenShift Container Platform 集群的配置和管理方式会有所不同。请参阅以下表以了解 OpenShift Container Platform 和托管的 control plane 之间的区别:
2.2.1. 集群创建和生命周期
| OpenShift Container Platform | 托管 control plane |
|---|---|
|
您可以使用 |
您可以在现有 OpenShift Container Platform 集群中使用 |
2.2.2. 集群配置
| OpenShift Container Platform | 托管 control plane |
|---|---|
|
您可以使用 |
您可以配置影响 |
2.2.3. etcd 加密
| OpenShift Container Platform | 托管 control plane |
|---|---|
|
您可以使用带有 AES-GCM 或 AES-CBC 的 |
您可以使用带有 AES-CBC 或 KMS 的 |
2.2.4. Operator 和 control plane
| OpenShift Container Platform | 托管 control plane |
|---|---|
| 独立的 OpenShift Container Platform 集群为每个 control plane 组件都包括了独立的 Operator。 | 托管的集群包含一个名为 Control Plane Operator 的单个 Operator,它在管理集群的托管 control plane 命名空间中运行。 |
| etcd 使用挂载到 control plane 节点上的存储。etcd 集群 Operator 管理 etcd。 | etcd 使用持久性卷声明进行存储,并由 Control Plane Operator 管理。 |
| Ingress Operator、网络相关的 Operator 和 Operator Lifecycle Manager (OLM) 在集群中运行。 | Ingress Operator、网络相关的 Operator 和 Operator Lifecycle Manager (OLM) 在管理集群的托管 control plane 命名空间中运行。 |
| OAuth 服务器在集群中运行,并通过集群中的路由公开。 | OAuth 服务器在 control plane 中运行,并通过管理集群上的路由、节点端口或负载均衡器公开。 |
2.2.5. 更新
| OpenShift Container Platform | 托管 control plane |
|---|---|
|
Cluster Version Operator (CVO) 编配更新过程并监控 |
托管的 control plane 更新会对 |
| 更新 OpenShift Container Platform 集群后,control plane 和计算机器都会更新。 | 更新托管集群后,只会更新 control plane。您可以单独执行节点池更新。 |
2.2.6. 机器配置和管理
| OpenShift Container Platform | 托管 control plane |
|---|---|
|
|
|
| 存在一组 control plane 机器。 | 不存在一组 control plane 机器。 |
|
您可以使用 |
您可以通过 |
|
您可以使用 |
您可以通过 |
| 在集群中公开机器和机器集。 | 来自上游 Cluster CAPI Operator 的机器、机器集和机器部署用于管理机器,但不会暴露给用户。 |
| 在更新集群时,所有机器集会自动升级。 | 您可以独立于托管集群更新节点池。 |
| 集群只支持原位升级。 | 托管集群中支持替换和原位升级。 |
| Machine Config Operator 管理机器的配置。 | 托管 control plane 中不存在 Machine Config Operator。 |
|
您可以使用从 |
您可以通过 |
| Machine Config Daemon (MCD) 管理每个节点上的配置更改和更新。 | 对于原位升级,节点池控制器会创建一个运行一次的 pod,它根据您的配置更新机器。 |
| 您可以修改机器配置资源,如 SR-IOV Operator。 | 您无法修改机器配置资源。 |
2.2.7. 网络
| OpenShift Container Platform | 托管 control plane |
|---|---|
| Kube API 服务器直接与节点通信,因为 Kube API 服务器和节点位于同一虚拟私有云(VPC)中。 | Kube API 服务器通过 Konnectivity 与节点通信。Kube API 服务器和节点存在于不同的 Virtual Private Cloud (VPC) 中。 |
| 节点通过内部负载均衡器与 Kube API 服务器通信。 | 节点通过外部负载均衡器或节点端口与 Kube API 服务器通信。 |
2.2.8. Web 控制台
| OpenShift Container Platform | 托管 control plane |
|---|---|
| Web 控制台显示 control plane 的状态。 | Web 控制台不显示 control plane 的状态。 |
| 您可以使用 Web 控制台更新集群。 | 您不能使用 Web 控制台更新托管集群。 |
| Web 控制台显示基础架构资源,如机器。 | Web 控制台不显示基础架构资源。 |
|
您可以使用 web 控制台通过 | 您不能使用 web 控制台配置机器。 |
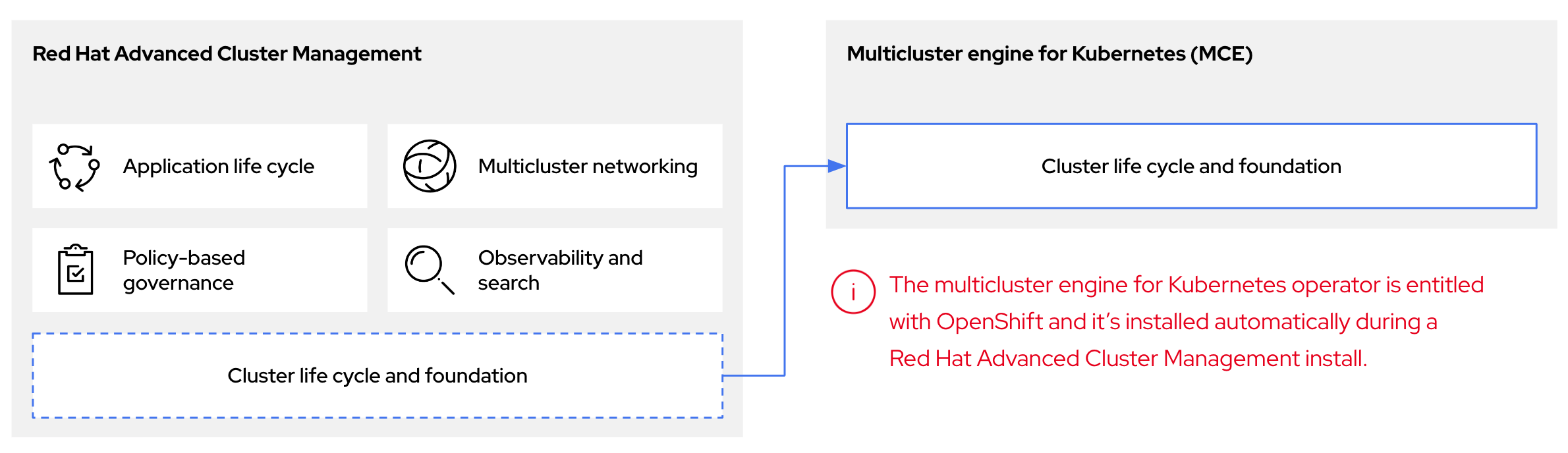
2.3. 托管 control plane、多集群引擎 Operator 和 RHACM 之间的关系
您可以使用 Kubernetes Operator 的多集群引擎配置托管的 control plane。multicluster engine Operator 集群生命周期定义了在不同基础架构云供应商、私有云和内部数据中心的创建、导入、管理和销毁 Kubernetes 集群的过程。
multicluster engine Operator 是 Red Hat Advanced Cluster Management (RHACM)的一个完整部分,它默认使用 RHACM 启用。但是,您不需要 RHACM 来使用托管的 control plane。
multicluster engine operator 是集群生命周期 Operator,它为 OpenShift Container Platform 和 RHACM hub 集群提供集群管理功能。multicluster engine Operator 增强了集群管理功能,并支持跨云和数据中心的 OpenShift Container Platform 集群生命周期管理。
图 2.1. 集群生命周期和基础
您可以将 multicluster engine Operator 与 OpenShift Container Platform 用作一个独立的集群管理器,或作为 RHACM hub 集群的一部分。
管理集群也称为托管集群。
您可以使用两个不同的 control plane 配置部署 OpenShift Container Platform 集群:独立或托管的 control plane。独立配置使用专用虚拟机或物理机器来托管 control plane。通过为 OpenShift Container Platform 托管 control plane,您可以在托管集群中创建 pod 作为 control plane,而无需为每个 control plane 使用专用虚拟机或物理机器。
图 2.2. RHACM 和多集群引擎 Operator 简介图
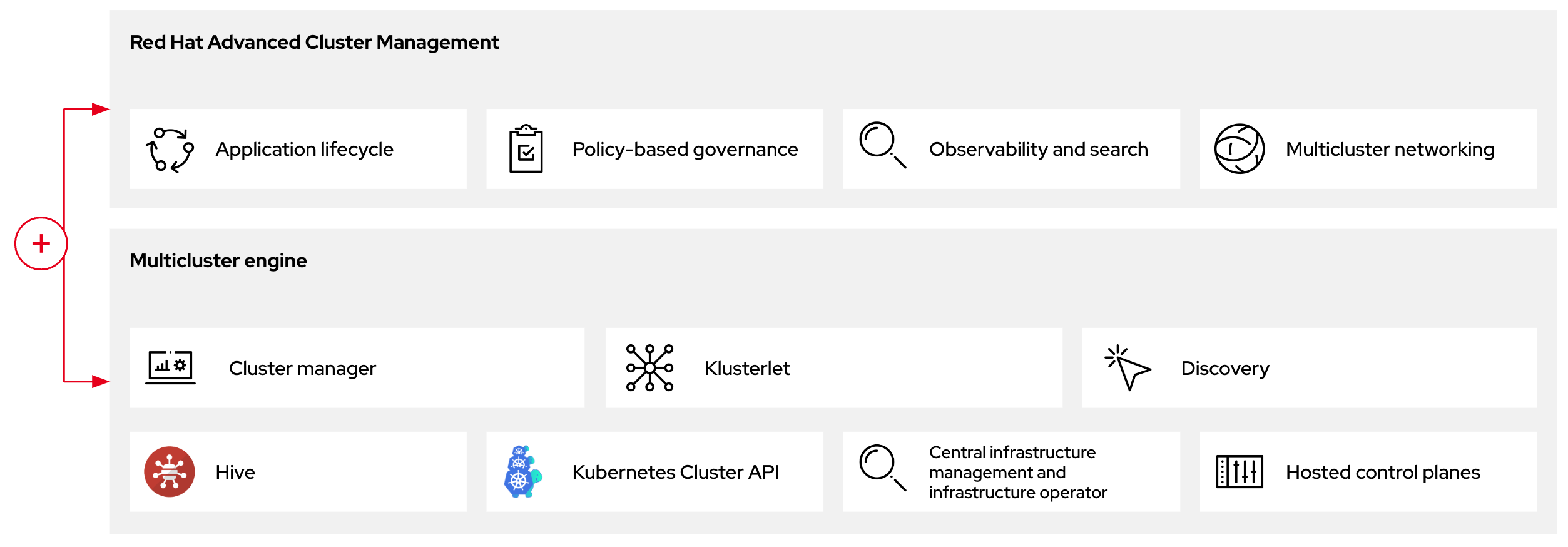
2.3.1. 在 RHACM 中发现多集群引擎 Operator 托管的集群
如果要将托管集群带到 Red Hat Advanced Cluster Management (RHACM) hub 集群,以便使用 RHACM 管理组件管理它们,请参阅 Red Hat Advanced Cluster Management 官方文档中的说明。
2.4. 托管 control plane 的版本控制
托管 control plane 功能包括以下组件,它们可能需要独立的版本控制和支持级别:
- 管理集群
- HyperShift Operator
-
托管 control plane (
hcp) 命令行界面 (CLI) -
hypershift.openshift.ioAPI - Control Plane Operator
2.4.1. 管理集群
在用于生产环境的受管集群中,您需要 Kubernetes Operator 的多集群引擎,该 Operator 可通过 OperatorHub 提供。multicluster engine Operator 捆绑包是受支持的 HyperShift Operator 构建。要使管理集群保持支持,您必须使用运行多集群引擎 Operator 的 OpenShift Container Platform 版本。通常,多集群引擎 Operator 的新发行版本在以下 OpenShift Container Platform 版本上运行:
- OpenShift Container Platform 的最新正式发行版本
- OpenShift Container Platform 最新正式发行版本前的两个版本
您可以通过管理集群上的 HyperShift Operator 安装的完整 OpenShift Container Platform 版本列表取决于 HyperShift Operator 的版本。但是,该列表至少包含与管理集群相同的 OpenShift Container Platform 版本,以及相对于管理集群的两个次版本。例如,如果管理集群运行 4.17 和受支持的 multicluster engine Operator 版本,则 HyperShift Operator 可以安装 4.17、4.16、4.15 和 4.14 托管集群。
对于 OpenShift Container Platform 的每个主要、次版本或补丁版本,会发布两个托管的 control plane 组件:
- HyperShift Operator
-
hcp命令行界面 (CLI)
2.4.2. HyperShift Operator
HyperShift Operator 管理由 HostedCluster API 资源表示的托管集群的生命周期。HyperShift Operator 会随每个 OpenShift Container Platform 发行版本一起发布。HyperShift Operator 在 hypershift 命名空间中创建 supported-versions 配置映射。配置映射包含受支持的托管集群版本。
您可以在同一管理集群中托管不同版本的 control plane。
supported-versions 配置映射对象示例
apiVersion: v1
data:
supported-versions: '{"versions":["4.17"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift2.4.3. 托管 control plane CLI
您可以使用 hcp CLI 创建托管集群。您可以从多集群引擎 Operator 下载 CLI。运行 hcp version 命令时,输出显示 CLI 针对您的 kubeconfig 文件支持的最新 OpenShift Container Platform。
2.4.4. HyperShift.openshift.io API
您可以使用 hypershift.openshift.io API 资源,如 HostedCluster 和 NodePool,以大规模创建和管理 OpenShift Container Platform 集群。HostedCluster 资源包含 control plane 和通用数据平面配置。当您创建 HostedCluster 资源时,您有一个完全正常工作的 control plane,没有附加的节点。NodePool 资源是一组可扩展的 worker 节点,附加到 HostedCluster 资源。
API 版本策略通常与 Kubernetes API 版本 的策略一致。
托管 control plane 的更新涉及更新托管集群和节点池。如需更多信息,请参阅"更新托管 control plane"。
2.4.5. Control Plane Operator
Control Plane Operator 作为以下架构的每个 OpenShift Container Platform 有效负载发行镜像的一部分发布:
- amd64
- arm64
- 多架构
2.5. 托管控制平面(control plane)的常见概念和用户角色表
当使用托管的 control plane 用于 OpenShift Container Platform 时,了解其关键概念和涉及的用户角色非常重要。
2.5.1. 概念
- data plane
- 集群的一部分,其中包含运行工作负载的计算、存储和网络。
- 托管的集群
- 一个 OpenShift Container Platform 集群,其控制平面和 API 端点托管在管理集群中。托管的集群包括控制平面和它的对应的数据平面。
- 托管的集群基础架构
- 存在于租户或最终用户云账户中的网络、计算和存储资源。
- 托管控制平面
- 在管理集群上运行的 OpenShift Container Platform 控制平面,它由托管集群的 API 端点公开。控制平面的组件包括 etcd、Kubernetes API 服务器、Kubernetes 控制器管理器和 VPN。
- 托管集群
- 请参阅管理集群。
- 受管集群
- hub 集群管理的集群。此术语特定于在 Red Hat Advanced Cluster Management 中管理 Kubernetes Operator 的多集群引擎的集群生命周期。受管集群(managed cluster)与管理集群(management cluster)不同。如需更多信息,请参阅管理的集群。
- 管理集群
- 部署 HyperShift Operator,以及用于托管集群的控制平面所在的 OpenShift Container Platform 集群。管理集群与托管集群(hosting cluster)是同义的。
- 管理集群基础架构
- 管理集群的网络、计算和存储资源。
- 节点池
- 管理与托管集群关联的一组计算节点的资源。计算节点在托管的集群中运行应用程序和工作负载。
2.5.2. Personas
- 集群实例管理员
-
假设此角色的用户等同于独立 OpenShift Container Platform 中的管理员。此用户在置备的集群中具有
cluster-admin角色,但可能无法在更新或配置集群时关闭。此用户可能具有只读访问权限,来查看投射到集群中的一些配置。 - 集群实例用户
- 假设此角色的用户等同于独立 OpenShift Container Platform 中的开发人员。此用户没有 OperatorHub 或机器的视图。
- 集群服务消费者
- 假设此角色的用户可以请求控制平面和 worker 节点,驱动更新或修改外部化配置。通常,此用户无法管理或访问云凭证或基础架构加密密钥。集群服务消费者人员可以请求托管集群并与节点池交互。假设此角色的用户具有在逻辑边界中创建、读取、更新或删除托管集群和节点池的用户。
- 集群服务提供商
假设此角色的用户通常具有管理集群上的
cluster-admin角色,并具有 RBAC 来监控并拥有 HyperShift Operator 的可用性,以及租户托管的集群的 control plane。集群服务提供商用户角色负责多个活动,包括以下示例:- 拥有服务级别的对象,用于实现控制平面可用性、正常运行时间和稳定性。
- 为管理集群配置云帐户以托管控制平面
- 配置用户置备的基础架构,其中包括主机对可用计算资源的了解
第 3 章 准备部署托管的 control plane
3.1. 托管 control plane 的要求
在托管 control plane 的上下文中,管理集群 是一个 OpenShift Container Platform 集群,部署 HyperShift Operator,以及托管集群的 control plane 的位置。
control plane 与托管集群关联,并作为 pod 在单个命名空间中运行。当集群服务消费者创建托管集群时,它会创建一个独立于 control plane 的 worker 节点。
以下要求适用于托管的 control plane:
- 为了运行 HyperShift Operator,您的管理集群至少需要三个 worker 节点。
- 您可以在内部运行管理集群和 worker 节点,比如在裸机平台或 OpenShift Virtualization 中。另外,您可以在云基础架构上运行管理集群和 worker 节点,如 Amazon Web Services (AWS)。
-
如果您使用混合基础架构(如在 AWS 和 worker 节点上运行内部的 worker 节点),或在 AWS 和您的管理集群内部运行 worker 节点,则必须使用
PublicAndPrivate发布策略,并遵循支持列表中的延迟要求。 - 在 Bare Metal Host (BMH) 部署中,BMH 在其中启动机器,托管的 control plane 必须能够访问基板管理控制器(BMC)。如果您的安全配置集不允许 Cluster Baremetal Operator 访问 BMH 具有其 BMC 的网络,以便启用 Redfish 自动化,您可以使用 BYO ISO 支持。但是,在 BYO 模式中,OpenShift Container Platform 无法自动打开 BMH 的电源。
3.1.1. 托管 control plane 的支持列表
因为 Kubernetes Operator 的多集群引擎包含 HyperShift Operator,托管 control plane 的发行版本与 multicluster engine Operator 发行版本保持一致。如需更多信息,请参阅 OpenShift Operator 生命周期。
3.1.1.1. 管理集群支持
任何支持的独立 OpenShift Container Platform 集群都可以是一个管理集群。
不支持单节点 OpenShift Container Platform 集群作为管理集群。如果您有资源限制,可以在独立的 OpenShift Container Platform control plane 和托管的 control plane 间共享基础架构。如需更多信息,请参阅"托管和独立 control plane 之间的共享基础架构"。
下表将多集群引擎 Operator 版本映射到支持它们的管理集群版本:
| 管理集群版本 | 支持的多集群引擎 Operator 版本 |
|---|---|
| 4.14 - 4.15 | 2.4 |
| 4.14 - 4.16 | 2.5 |
| 4.14 - 4.17 | 2.6 |
| 4.15 - 4.17 | 2.7 |
3.1.1.2. 托管的集群支持
对于托管集群,管理集群版本和托管的集群版本之间没有直接关系。托管的集群版本取决于 multicluster engine Operator 版本中包含的 HyperShift Operator。
确保管理集群和托管的集群间的最大延迟 200 ms。这个要求对于混合基础架构部署来说尤其重要,如您的管理集群位于 AWS 上,且您的 worker 节点处于内部状态时。
下表将多集群引擎 Operator 版本映射到使用与该多集群引擎 Operator 版本关联的 HyperShift Operator 创建的托管集群版本:
| 托管的集群版本 | multicluster engine Operator 2.4 | multicluster engine Operator 2.5 | multicluster engine Operator 2.6 | multicluster engine Operator 2.7 |
|---|---|---|---|---|
| 4.14 | 是 | 是 | 是 | 是 |
| 4.15 | 否 | 是 | 是 | 是 |
| 4.16 | 否 | 否 | 是 | 是 |
| 4.17 | 否 | 否 | 否 | 是 |
3.1.1.3. 托管的集群平台支持
下表指明了托管 control plane 的每个平台都支持哪些 OpenShift Container Platform 版本。
对于 IBM Power 和 IBM Z,您必须在基于 64 位 x86 架构的机器类型以及 IBM Power 或 IBM Z 上的节点池上运行 control plane。
在下表中,管理集群版本指的是启用了 multicluster engine Operator 的 OpenShift Container Platform 版本:
| 托管的集群平台 | 管理集群版本 | 托管的集群版本 |
|---|---|---|
| Amazon Web Services | 4.16 - 4.17 | 4.16 - 4.17 |
| IBM Power | 4.17 | 4.17 |
| IBM Z | 4.17 | 4.17 |
| OpenShift Virtualization | 4.14 - 4.17 | 4.14 - 4.17 |
| 裸机 | 4.14 - 4.17 | 4.14 - 4.17 |
| 非裸机代理机器(技术预览) | 4.16 - 4.17 | 4.16 - 4.17 |
3.1.1.4. 多集群引擎 Operator 的更新
当您升级到 multicluster engine Operator 的另一个版本时,如果 multicluster engine Operator 版本中包含的 HyperShift Operator 支持托管的集群版本,则托管集群可以继续运行。下表显示了在哪些更新的多集群引擎 Operator 版本中支持哪些托管集群版本:
| 更新了多集群引擎 Operator 版本 | 支持的托管集群版本 |
|---|---|
| 从 2.4 更新至 2.5 | OpenShift Container Platform 4.14 |
| 从 2.5 更新至 2.6 | OpenShift Container Platform 4.14 - 4.15 |
| 从 2.6 更新至 2.7 | OpenShift Container Platform 4.14 - 4.16 |
例如,如果您在管理集群中有一个 OpenShift Container Platform 4.14 托管集群,且从 multicluster engine Operator 2.4 更新至 2.5,则托管集群可以继续运行。
3.1.1.5. 技术预览功能
以下列表显示了本发行版本的技术预览功能:
- 在断开连接的环境中在 IBM Z 上托管 control plane
- 托管 control plane 的自定义污点和容限
- 托管 control plane for OpenShift Virtualization 上的 NVIDIA GPU 设备
3.1.2. 托管 control plane 的 CIDR 范围
要在 OpenShift Container Platform 上部署托管的 control plane,请使用以下所需的无类别域间路由(CIDR)子网范围:
-
v4InternalSubnet: 100.65.0.0/16 (OVN-Kubernetes) -
clusterNetwork: 10.132.0.0/14 (pod network) -
serviceNetwork: 172.31.0.0/16
如需有关 OpenShift Container Platform CIDR 范围定义的更多信息,请参阅"CIDR 范围定义"。
3.2. 托管 control plane 的大小指导
许多因素(包括托管集群工作负载和 worker 节点数)会影响到特定数量的 worker 节点可以容纳多少个托管的 control plane。使用此大小指南来帮助托管集群容量规划。这个指南假设一个高可用的托管 control plane 拓扑。基于负载的大小示例是在裸机集群中测量的。基于云的实例可能具有不同的限制因素,如内存大小。
您可以覆盖以下资源使用率大小测量,并禁用指标服务监控。
请参阅以下高度可用的托管 control plane 要求,该要求已使用 OpenShift Container Platform 版本 4.12.9 及更新版本进行测试:
- 78 个 pod
- etcd:三个 8 GiB PV
- 最小 vCPU:大约 5.5 个内核
- 最小内存:大约 19 GiB
3.2.1. Pod 限值
每个节点的 maxPods 设置会影响 control-plane 节点可以包括多少个托管集群。记录所有 control-plane 节点上的 maxPods 值非常重要。为每个高可用性托管的 control plane 计划大约 75 个 pod。
对于裸机节点,默认的 maxPods 设置为 250,这可能会成为一个限制因素,因为根据 pod 的要求,每个节点大约可以包括三个托管 control plane,即使机器中存在大量可用资源。通过配置 KubeletConfig 值将 maxPods 设置为 500,允许更大的托管的 control plane 密度,这有助于利用额外的计算资源。
3.2.2. 基于请求的资源限值
集群可以托管的 control plane 的最大数量是根据来自 pod 的托管 control plane CPU 和内存请求进行计算的。
高可用性托管 control plane 由请求 5 个 vCPU 和 18 GiB 内存的 78 个 pod 组成。这些基线数据与集群 worker 节点资源容量进行比较,以估算托管 control plane 的最大数量。
3.2.3. 基于负载的限制
当某些工作负载放在托管的 control plane Kubernetes API 服务器上时,集群可以托管的 control plane pod CPU 和内存使用率计算的最大托管 control plane 数量。
在工作负载增加时,以下方法用于测量托管的 control plane 资源利用率:
- 在使用 KubeVirt 平台时,具有 9 个 worker 的、使用 8 个 vCPU 和 32 GiB 的托管集群
根据以下定义,配置为专注于 API control-plane 压力的工作负载测试配置集:
- 为每个命名空间创建对象,最多扩展 100 个命名空间
- 持续的对象删除和创建会造成额外的 API 压力
- 工作负载查询每秒(QPS)和 Burst 设置设置为高,以删除任何客户端节流
当负载增加 1000 QPS 时,托管的 control plane 资源使用率会增加 9 个 vCPU 和 2.5 GB 内存。
对于常规的大小设置,请考虑 1000 QPS API 的比率,它是一个 中型 托管集群负载;以及 2000 QPS API,它是一个 大型 托管的集群负载。
此测试提供了一个估算因素,用于根据预期的 API 负载增加计算资源利用率。确切的利用率可能会因集群工作负载的类型和节奏而有所不同。
以下示例显示了工作负载和 API 比率定义的托管 control plane 资源扩展:
| QPS (API rate) | vCPU 使用量 | 内存用量 (GiB) |
|---|---|---|
| 低负载 (小于 50 QPS) | 2.9 | 11.1 |
| 中型负载 (1000 QPS) | 11.9 | 13.6 |
| 高负载 (2000 QPS) | 20.9 | 16.1 |
托管 control plane 的大小针对于会导致大量 API 活动、etcd 活动或这两者的 control-plane 负载和工作负载。专注于 data-plane 负载的托管 pod 工作负载(如运行数据库)可能无法产生高 API 速率。
3.2.4. 大小计算示例
这个示例为以下场景提供大小指导:
-
三个裸机 worker,标记为
hypershift.openshift.io/control-plane节点 -
maxPods值设为 500 - 预期的 API 速率是中型或大约 1000,具体取决于基于负载的限制
| 限制描述 | Server 1 | Server 2 |
|---|---|---|
| worker 节点上的 vCPU 数量 | 64 | 128 |
| worker 节点上的内存 (GiB) | 128 | 256 |
| 每个 worker 的最大 pod 数量 | 500 | 500 |
| 用于托管 control plane 的 worker 数量 | 3 | 3 |
| 最大 QPS 目标比率(每秒的 API 请求) | 1000 | 1000 |
| 根据 worker 节点大小和 API 速率计算的值 | Server 1 | Server 2 | 计算备注 |
| 基于 vCPU 请求的每个 worker 的最大托管 control plane | 12.8 | 25.6 | worker vCPUs 数量 ÷ 5 总 vCPU 请求每个托管的 control plane |
| 基于 vCPU 使用的每个 worker 的最大托管 control plane | 5.4 | 10.7 | vCPUS 数量 ÷ (2.9 测量的空闲 vCPU 使用量 + (QPS 目标率 ÷ 1000) × 9.0 测量的 vCPU 使用量每 1000 QPS 增长) |
| 基于内存请求的每个 worker 的最大托管 control plane | 7.1 | 14.2 | Worker 内存 GiB ÷ 18 GiB 总内存请求每个托管 control plane |
| 根据内存用量,每个 worker 的最大托管 control plane | 9.4 | 18.8 | Worker 内存 GiB ÷ (11.1 测量的空闲内存使用量 + (QPS 目标率 ÷ 1000) × 2.5 测量的内存使用量每 1000 QPS 增加) |
| 每个 worker 的最大托管 control plane 基于每个节点 pod 限制 | 6.7 | 6.7 |
500 |
| 前面提到的最大值 | 5.4 | 6.7 | |
| vCPU 限制因素 |
| ||
| 一个管理集群中的托管 control plane 的最大数量 | 16 | 20 | 前面提到的最大的最小值 × 3 control-plane workers |
| Name | 描述 |
|
| 根据高可用性托管的 control plane 资源请求,集群可以托管的最大托管 control plane 数量。 |
|
| 如果所有托管的 control plane 都针对集群 Kube API 服务器有大约 50 个 QPS,则集群可以托管的最大托管 control plane 数量。 |
|
| 如果所有托管的 control plane 都针对集群 Kube API 服务器大约为 1000 QPS,则估计集群可以托管的最大 control plane 数量。 |
|
| 如果所有托管的 control plane 都针对集群 Kube API 服务器有大约 2000 个 QPS,则集群可以托管的最大托管 control plane 数量。 |
|
| 根据现有托管 control plane 的平均 QPS,估计集群可以托管的最大托管 control plane 数量。如果您没有活跃的托管 control plane,您可以预期低的 QPS。 |
3.3. 覆盖资源利用率测量
资源利用率的基线测量集合在每个托管的集群中可能会有所不同。
3.3.1. 覆盖托管集群的资源利用率测量
您可以根据集群工作负载的类型和节奏覆盖资源利用率测量。
流程
运行以下命令来创建
ConfigMap资源:$ oc create -f <your-config-map-file.yaml>将
<your-config-map-file.yaml>替换为包含hcp-sizing-baseline配置映射的 YAML 文件的名称。在
local-cluster命名空间中创建hcp-sizing-baseline配置映射,以指定您要覆盖的测量。您的配置映射可能类似以下 YAML 文件:kind: ConfigMap apiVersion: v1 metadata: name: hcp-sizing-baseline namespace: local-cluster data: incrementalCPUUsagePer1KQPS: "9.0" memoryRequestPerHCP: "18" minimumQPSPerHCP: "50.0"运行以下命令,删除
hypershift-addon-agent部署以重启hypershift-addon-agentpod:$ oc delete deployment hypershift-addon-agent \ -n open-cluster-management-agent-addon
验证
观察
hypershift-addon-agentpod 日志。运行以下命令,验证配置映射中是否更新了覆盖的测量:$ oc logs hypershift-addon-agent -n open-cluster-management-agent-addon您的日志可能类似以下输出:
输出示例
2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:793 setting cpuRequestPerHCP to 5 2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:802 setting memoryRequestPerHCP to 18 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:141 The worker nodes have 12.000000 vCPUs 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:142 The worker nodes have 49.173369 GB memory如果在
hcp-sizing-baseline配置映射中没有正确更新覆盖的测量,您可能会在hypershift-addon-agentpod 日志中看到以下错误信息:错误示例
2024-01-05T19:53:54.052Z ERROR agent.agent-reconciler agent/agent.go:788 failed to get configmap from the hub. Setting the HCP sizing baseline with default values. {"error": "configmaps \"hcp-sizing-baseline\" not found"}
3.3.2. 禁用指标服务监控
启用 hypershift-addon 受管集群附加组件后,会默认配置指标服务监控,以便 OpenShift Container Platform 监控可以从 hypershift-addon 收集指标。
流程
您可以通过完成以下步骤禁用指标服务监控:
运行以下命令登录到您的 hub 集群:
$ oc login运行以下命令来编辑
hypershift-addon-deploy-config附加组件部署配置规格:$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine在规格中添加
disableMetrics=true自定义变量,如下例所示:apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: disableMetrics1 value: "true"- 1
disableMetrics=true自定义变量为新的和现有的hypershift-addon受管集群附加组件禁用指标服务监控。
运行以下命令,将更改应用到配置规格:
$ oc apply -f <filename>.yaml
3.4. 安装托管的 control plane 命令行界面
托管 control plane 命令行界面 hcp 是一款可用于托管 control plane 的工具。对于第 2 天操作,如管理和配置,请使用 GitOps 或您自己的自动化工具。
3.4.1. 从终端安装托管的 control plane 命令行界面
您可以从终端安装托管的 control plane 命令行界面(CLI) hcp。
先决条件
- 在 OpenShift Container Platform 集群中,已为 Kubernetes Operator 2.5 或更高版本安装了多集群引擎。安装 Red Hat Advanced Cluster Management 时会自动安装 multicluster engine Operator。您还可以在没有 Red Hat Advanced Management 的情况下安装 multicluster engine Operator,作为 OpenShift Container Platform OperatorHub 中的 Operator。
流程
运行以下命令,获取用于下载
hcp二进制文件的 URL:$ oc get ConsoleCLIDownload hcp-cli-download -o json | jq -r ".spec"运行以下命令来下载
hcp二进制文件:$ wget <hcp_cli_download_url>1 - 1
- 将
hcp_cli_download_url替换为您在上一步中获取的 URL。
运行以下命令来解包下载的存档:
$ tar xvzf hcp.tar.gz运行以下命令使
hcp二进制文件可执行:$ chmod +x hcp运行以下命令,将
hcp二进制文件移到路径中的目录中:$ sudo mv hcp /usr/local/bin/.
如果您在 Mac 计算机上下载 CLI,您可能会看到有关 hcp 二进制文件的警告。您需要调整安全设置,以允许运行二进制文件。
验证
运行以下命令,验证您是否可以看到可用参数列表:
$ hcp create cluster <platform> --help1 - 1
- 您可以使用
hcp create cluster命令来创建和管理托管集群。支持的平台包括aws、agent和kubevirt。
3.4.2. 使用 Web 控制台安装托管的 control plane 命令行界面
您可以使用 OpenShift Container Platform Web 控制台安装托管的 control plane 命令行界面 (CLI) hcp。
先决条件
- 在 OpenShift Container Platform 集群中,已为 Kubernetes Operator 2.5 或更高版本安装了多集群引擎。安装 Red Hat Advanced Cluster Management 时会自动安装 multicluster engine Operator。您还可以在没有 Red Hat Advanced Management 的情况下安装 multicluster engine Operator,作为 OpenShift Container Platform OperatorHub 中的 Operator。
流程
- 在 OpenShift Container Platform web 控制台中点 Help 图标 → Command Line Tools。
- 为您的平台点 Download hcp CLI。
运行以下命令来解包下载的存档:
$ tar xvzf hcp.tar.gz运行以下命令使二进制文件可执行:
$ chmod +x hcp运行以下命令,将二进制文件移到路径中的目录中:
$ sudo mv hcp /usr/local/bin/.
如果您在 Mac 计算机上下载 CLI,您可能会看到有关 hcp 二进制文件的警告。您需要调整安全设置,以允许运行二进制文件。
验证
运行以下命令,验证您是否可以看到可用参数列表:
$ hcp create cluster <platform> --help1 - 1
- 您可以使用
hcp create cluster命令来创建和管理托管集群。支持的平台包括aws、agent和kubevirt。
3.4.3. 使用内容网关安装托管的 control plane 命令行界面
您可以使用内容网关安装托管的 control plane 命令行界面 (CLI) hcp。
先决条件
- 在 OpenShift Container Platform 集群中,已为 Kubernetes Operator 2.5 或更高版本安装了多集群引擎。安装 Red Hat Advanced Cluster Management 时会自动安装 multicluster engine Operator。您还可以在没有 Red Hat Advanced Management 的情况下安装 multicluster engine Operator,作为 OpenShift Container Platform OperatorHub 中的 Operator。
流程
-
访问内容网关并下载
hcp二进制文件。 运行以下命令来解包下载的存档:
$ tar xvzf hcp.tar.gz运行以下命令使
hcp二进制文件可执行:$ chmod +x hcp运行以下命令,将
hcp二进制文件移到路径中的目录中:$ sudo mv hcp /usr/local/bin/.
如果您在 Mac 计算机上下载 CLI,您可能会看到有关 hcp 二进制文件的警告。您需要调整安全设置,以允许运行二进制文件。
验证
运行以下命令,验证您是否可以看到可用参数列表:
$ hcp create cluster <platform> --help1 - 1
- 您可以使用
hcp create cluster命令来创建和管理托管集群。支持的平台包括aws、agent和kubevirt。
3.5. 分发托管集群工作负载
在开始使用 OpenShift Container Platform 托管 control plane 之前,您必须正确标记节点,以便托管集群的 pod 可以调度到基础架构节点。节点标签也因以下原因非常重要:
-
确保高可用性和正确的工作负载部署。例如,您可以设置
node-role.kubernetes.io/infra标签,以避免将 control-plane 工作负载计数设置为 OpenShift Container Platform 订阅。 - 确保 control plane 工作负载与管理集群中的其他工作负载分开。
不要将管理集群用于工作负载。工作负载不能在运行 control plane 的节点上运行。
3.5.1. 标记管理集群节点
正确的节点标签是部署托管 control plane 的先决条件。
作为管理集群管理员,您可以在管理集群节点中使用以下标签和污点来调度 control plane 工作负载:
-
HyperShift.openshift.io/control-plane: true:使用此标签和污点将节点专用于运行托管的 control plane 工作负载。通过设置true值,您可以避免与其他组件共享 control plane 节点,例如管理集群的基础架构组件或任何其他错误部署的工作负载。 -
HyperShift.openshift.io/cluster: ${HostedControlPlane Namespace}: 当您要将节点专用于单个托管集群时,请使用此标签和污点。
在托管 control-plane pod 的节点上应用以下标签:
-
node-role.kubernetes.io/infra: 使用该标签避免将 control-plane 工作负载计数设置为您的订阅。 topology.kubernetes.io/zone:在管理集群节点上使用此标签在故障域中部署高可用性集群。区域可能是设置区的节点的位置、机架名称或主机名。例如,管理集群具有以下节点:worker-1a、worker-1b、worker-2a、worker-2a和worker-2b。worker-1a和worker-1b节点位于rack1中,worker-2a和 worker-2b 节点位于rack2中。要将每个机架用作可用区,请输入以下命令:$ oc label node/worker-1a node/worker-1b topology.kubernetes.io/zone=rack1$ oc label node/worker-2a node/worker-2b topology.kubernetes.io/zone=rack2
托管集群的 Pod 具有容限,调度程序使用关联性规则来调度它们。Pod 容限污点用于 control-plane 和 cluster 用于 pod。调度程序将 pod 调度到标记为 hypershift.openshift.io/control-plane 和 hypershift.openshift.io/cluster: ${HostedControlPlane Namespace} 的节点。
对于 ControllerAvailabilityPolicy 选项,请使用 HighlyAvailable,这是托管 control plane 命令行界面 hcp 部署的默认值。使用该选项时,您可以通过将 topology.kubernetes.io/zone 设置为拓扑键,将托管集群中每个部署的 pod 调度到不同的故障域中。在跨不同故障域的托管集群中为部署调度 pod,仅适用于高可用性 control plane。
流程
要让托管集群要求其 pod 调度到基础架构节点,请设置 HostedCluster.spec.nodeSelector,如下例所示:
spec:
nodeSelector:
node-role.kubernetes.io/infra: ""这样,每个托管的集群的托管 control plane 都是符合基础架构节点工作负载,您不需要授权底层 OpenShift Container Platform 节点。
3.5.2. 优先级类
四个内置优先级类会影响托管集群 pod 的优先级与抢占。您可以根据从高到低的顺序在管理集群中创建 pod:
-
hypershift-operator: HyperShift Operator pod. -
hypershift-etcd: etcd 的 Pod -
HyperShift-api-critical: API 调用和资源准入所需的 Pod 才能成功。这些 pod 包括kube-apiserver、聚合的 API 服务器和 web hook 等 pod。 -
HyperShift-control-plane: control plane 中不是 API-critical 但仍然需要升级的优先级的 Pod,如集群版本 Operator。
3.5.3. 自定义污点和容限
默认情况下,托管集群的 pod 可以容忍 control-plane 和 cluster 污点。但是,您还可以在节点上使用自定义污点,以便托管集群可以通过设置 HostedCluster.spec.tolerations 来容许每个托管的集群的污点。
为托管集群传递容限只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
配置示例
spec:
tolerations:
- effect: NoSchedule
key: kubernetes.io/custom
operator: Exists
您还可以使用 --tolerations hcp CLI 参数,在创建集群时在托管集群上设置容限。
CLI 参数示例
--toleration="key=kubernetes.io/custom,operator=Exists,effect=NoSchedule"
要基于每个集群对托管集群 pod 放置进行精细控制,请使用 nodeSelectors 的自定义容限。您可以并置托管集群的组,并将它们与其他托管集群隔离。您还可以将托管集群放在 infra 和 control plane 节点上。
托管的集群中的容限只适用于 control plane 的 pod。要配置在管理集群和基础架构相关的 pod (如运行虚拟机的 pod)上运行的其他 pod,您需要使用不同的进程。
3.6. 启用或禁用托管的 control plane 功能
托管的 control plane 功能以及 hypershift-addon 受管集群附加组件会被默认启用。如果要禁用这个功能,或者禁用了这个功能并希望手动启用它,请参阅以下步骤。
3.6.1. 手动启用托管的 control plane 功能
如果您需要手动启用托管的 control plane,请完成以下步骤。
流程
运行以下命令来启用该功能:
$ oc patch mce multiclusterengine --type=merge -p \ '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'1 - 1
- 默认
MultiClusterEngine资源实例名称是multiclusterengine,但您可以通过运行以下命令来从集群中获取MultiClusterEngine:$ oc get mce。
运行以下命令,以验证
MultiClusterEngine自定义资源中是否启用了hypershift和hypershift-local-hosting功能:$ oc get mce multiclusterengine -o yaml1 - 1
- 默认
MultiClusterEngine资源实例名称是multiclusterengine,但您可以通过运行以下命令来从集群中获取MultiClusterEngine:$ oc get mce。
输出示例
apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: true - name: hypershift-local-hosting enabled: true
3.6.1.1. 为 local-cluster 手动启用 hypershift-addon 受管集群附加组件
启用托管的 control plane 功能会自动启用 hypershift-addon 受管集群附加组件。如果您需要手动启用 hypershift-addon 受管集群附加组件,请完成以下步骤,使用 hypershift-addon 在 local-cluster 上安装 HyperShift Operator。
流程
通过创建一个类似以下示例的文件,创建名为
hypershift-addon的ManagedClusterAddon附加组件:apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: hypershift-addon namespace: local-cluster spec: installNamespace: open-cluster-management-agent-addon运行以下命令来应用该文件:
$ oc apply -f <filename>使用您创建的文件的名称替换
filename。运行以下命令确认安装了
hypershift-addon受管集群附加组件:$ oc get managedclusteraddons -n local-cluster hypershift-addon如果安装了附加组件,输出类似以下示例:
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True
已安装 hypershift-addon 受管集群附加组件,托管集群可用于创建和管理托管集群。
3.6.2. 禁用托管的 control plane 功能
您可以卸载 HyperShift Operator,并禁用托管的 control plane 功能。当禁用托管的 control plane 功能时,您必须在多集群引擎 Operator 上销毁托管集群和受管集群资源,如管理托管集群主题中所述。
3.6.2.1. 卸载 HyperShift Operator
要卸载 HyperShift Operator 并从 local-cluster 禁用 hypershift-addon,请完成以下步骤:
流程
运行以下命令,以确保没有托管集群:
$ oc get hostedcluster -A重要如果托管集群正在运行,HyperShift Operator 不会卸载,即使
hypershift-addon被禁用。运行以下命令禁用
hypershift-addon:$ oc patch mce multiclusterengine --type=merge -p \1 '{"spec":{"overrides":{"components":[{"name":"hypershift-local-hosting","enabled": false}]}}}'- 1
- 默认
MultiClusterEngine资源实例名称是multiclusterengine,但您可以通过运行以下命令来从集群中获取MultiClusterEngine:$ oc get mce。
注意在禁用
hypershift-addon后,您还可以从 multicluster engine Operator 控制台禁用local-cluster的hypershift-addon。
3.6.2.2. 禁用托管的 control plane 功能
要禁用托管的 control plane 功能,请完成以下步骤。
先决条件
- 您已卸载了 HyperShift Operator。如需更多信息,请参阅"卸载 HyperShift Operator"。
流程
运行以下命令以禁用托管的 control plane 功能:
$ oc patch mce multiclusterengine --type=merge -p \1 '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": false}]}}}'- 1
- 默认
MultiClusterEngine资源实例名称是multiclusterengine,但您可以通过运行以下命令来从集群中获取MultiClusterEngine:$ oc get mce。
您可以运行以下命令来验证
hypershift和hypershift-local-hosting功能是否在MultiClusterEngine自定义资源中禁用:$ oc get mce multiclusterengine -o yaml1 - 1
- 默认
MultiClusterEngine资源实例名称是multiclusterengine,但您可以通过运行以下命令来从集群中获取MultiClusterEngine:$ oc get mce。
请参阅以下示例,其中
hypershift和hypershift-local-hosting的enabled:标记被设置为false:apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: false - name: hypershift-local-hosting enabled: false
第 4 章 部署托管的 control plane
4.1. 在 AWS 上部署托管的 control plane
托管的集群 是一个 OpenShift Container Platform 集群,其 API 端点和 control plane 托管在管理集群中。托管的集群包括控制平面和它的对应的数据平面。要在内部配置托管的 control plane,您必须在管理集群中安装 Kubernetes Operator 的多集群引擎。通过使用 hypershift-addon 受管集群附加组件在现有受管集群上部署 HyperShift Operator,您可以启用该集群作为管理集群,并开始创建托管集群。默认情况下,local-cluster 受管集群默认启用 hypershift-addon 受管集群。
您可以使用 multicluster engine Operator 控制台或托管的 control plane 命令行界面 (CLI) hcp 创建托管集群。托管的集群自动导入为受管集群。但是,您可以将此自动导入功能禁用到多集群引擎 Operator 中。
4.1.1. 准备在 AWS 上部署托管的 control plane
当您准备在 Amazon Web Services (AWS) 上部署托管 control plane 时,请考虑以下信息:
- 每个托管集群都必须具有集群范围的唯一名称。托管的集群名称不能与任何现有的受管集群相同,以便多集群引擎 Operator 可以管理它。
-
不要使用
clusters作为托管的集群名称。 - 在托管 control plane 的同一平台上运行管理集群和 worker。
- 无法在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
4.1.1.1. 配置管理集群的先决条件
您必须满足以下先决条件才能配置管理集群:
- 您已在 OpenShift Container Platform 集群中安装了 Kubernetes Operator 2.5 及之后的版本的多集群引擎。安装 Red Hat Advanced Cluster Management (RHACM) 时会自动安装 multicluster engine Operator。multicluster engine Operator 也可以在没有 RHACM 作为 OpenShift Container Platform OperatorHub 中的 Operator 的情况下安装。
至少有一个受管 OpenShift Container Platform 集群用于多集群引擎 Operator。
local-cluster在 multicluster engine Operator 版本 2.5 及更新的版本中自动导入。您可以运行以下命令来检查 hub 集群的状态:$ oc get managedclusters local-cluster-
已安装
aws命令行界面(CLI)。 -
已安装托管的 control plane CLI
hcp。
4.1.2. 使用 hcp CLI 访问 AWS 上的托管集群
您可以使用 hcp 命令行界面(CLI)访问托管集群来生成 kubeconfig 文件。
流程
输入以下命令生成
kubeconfig文件:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig保存
kubeconfig文件后,您可以输入以下命令访问托管集群:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
4.1.3. 创建 Amazon Web Services S3 存储桶和 S3 OIDC secret
在 Amazon Web Services (AWS) 上创建和管理托管集群之前,您必须创建 S3 存储桶和 S3 OIDC secret。
流程
运行以下命令,创建一个可对集群托管 OIDC 发现文档的公共访问权限的 S3 存储桶:
$ aws s3api create-bucket --bucket <bucket_name> \1 --create-bucket-configuration LocationConstraint=<region> \2 --region <region>3 $ aws s3api delete-public-access-block --bucket <bucket_name>1 - 1
- 将
<bucket_name>替换为您要创建的 S3 存储桶的名称。
$ echo '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<bucket_name>/*"1 } ] }' | envsubst > policy.json- 1
- 将
<bucket_name>替换为您要创建的 S3 存储桶的名称。
$ aws s3api put-bucket-policy --bucket <bucket_name> \1 --policy file://policy.json- 1
- 将
<bucket_name>替换为您要创建的 S3 存储桶的名称。
注意如果使用 Mac 计算机,则必须导出存储桶名称才能使策略正常工作。
-
为 HyperShift Operator 创建一个名为
hypershift-operator-oidc-provider-s3-credentials的 OIDC S3 secret。 -
将 secret 保存到
local-cluster命名空间中。 请查看下表以验证 secret 是否包含以下字段:
Expand 表 4.1. AWS secret 的必填字段 字段名称 描述 bucket包含具有公共访问权限的 S3 存储桶,用于保存托管集群的 OIDC 发现文档。
credentials对包含可以访问存储桶的
default配置集凭证的文件的引用。默认情况下,HyperShift 仅使用default配置集来运行bucket。region指定 S3 存储桶的区域。
要创建 AWS secret,请运行以下命令:
$ oc create secret generic <secret_name> \ --from-file=credentials=<path>/.aws/credentials \ --from-literal=bucket=<s3_bucket> \ --from-literal=region=<region> \ -n local-cluster注意secret 的灾难恢复备份不会被自动启用。要添加启用
hypershift-operator-oidc-provider-s3-credentialssecret 的标签来备份灾难恢复,请运行以下命令:$ oc label secret hypershift-operator-oidc-provider-s3-credentials \ -n local-cluster cluster.open-cluster-management.io/backup=true
4.1.4. 为托管集群创建可路由的公共区
要访问托管的集群中的应用程序,您必须配置可路由的公共区。如果 public 区域存在,请跳过这一步。否则,public 区域会影响现有功能。
流程
要为 DNS 记录创建可路由的公共区,请输入以下命令:
$ aws route53 create-hosted-zone \ --name <basedomain> \1 --caller-reference $(whoami)-$(date --rfc-3339=date)- 1
- 将
<basedomain>替换为您的基域,例如www.example.com。
4.1.5. 创建 AWS IAM 角色和 STS 凭证
在 Amazon Web Services (AWS) 上创建托管集群前,您必须创建一个 AWS IAM 角色和 STS 凭证。
流程
运行以下命令,获取用户的 Amazon 资源名称(ARN):
$ aws sts get-caller-identity --query "Arn" --output text输出示例
arn:aws:iam::1234567890:user/<aws_username>使用此输出作为下一步中
<arn>的值。创建一个包含角色信任关系配置的 JSON 文件。请参见以下示例:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<arn>"1 }, "Action": "sts:AssumeRole" } ] }- 1
- 将
<arn>替换为您在上一步中记下的用户的 ARN。
运行以下命令来创建 Identity and Access Management (IAM) 角色:
$ aws iam create-role \ --role-name <name> \1 --assume-role-policy-document file://<file_name>.json \2 --query "Role.Arn"输出示例
arn:aws:iam::820196288204:role/myrole创建名为
policy.json的 JSON 文件,其中包含您的角色的以下权限策略:{ "Version": "2012-10-17", "Statement": [ { "Sid": "EC2", "Effect": "Allow", "Action": [ "ec2:CreateDhcpOptions", "ec2:DeleteSubnet", "ec2:ReplaceRouteTableAssociation", "ec2:DescribeAddresses", "ec2:DescribeInstances", "ec2:DeleteVpcEndpoints", "ec2:CreateNatGateway", "ec2:CreateVpc", "ec2:DescribeDhcpOptions", "ec2:AttachInternetGateway", "ec2:DeleteVpcEndpointServiceConfigurations", "ec2:DeleteRouteTable", "ec2:AssociateRouteTable", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:CreateRoute", "ec2:CreateInternetGateway", "ec2:RevokeSecurityGroupEgress", "ec2:ModifyVpcAttribute", "ec2:DeleteInternetGateway", "ec2:DescribeVpcEndpointConnections", "ec2:RejectVpcEndpointConnections", "ec2:DescribeRouteTables", "ec2:ReleaseAddress", "ec2:AssociateDhcpOptions", "ec2:TerminateInstances", "ec2:CreateTags", "ec2:DeleteRoute", "ec2:CreateRouteTable", "ec2:DetachInternetGateway", "ec2:DescribeVpcEndpointServiceConfigurations", "ec2:DescribeNatGateways", "ec2:DisassociateRouteTable", "ec2:AllocateAddress", "ec2:DescribeSecurityGroups", "ec2:RevokeSecurityGroupIngress", "ec2:CreateVpcEndpoint", "ec2:DescribeVpcs", "ec2:DeleteSecurityGroup", "ec2:DeleteDhcpOptions", "ec2:DeleteNatGateway", "ec2:DescribeVpcEndpoints", "ec2:DeleteVpc", "ec2:CreateSubnet", "ec2:DescribeSubnets" ], "Resource": "*" }, { "Sid": "ELB", "Effect": "Allow", "Action": [ "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DeleteTargetGroup" ], "Resource": "*" }, { "Sid": "IAMPassRole", "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:*:iam::*:role/*-worker-role", "Condition": { "ForAnyValue:StringEqualsIfExists": { "iam:PassedToService": "ec2.amazonaws.com" } } }, { "Sid": "IAM", "Effect": "Allow", "Action": [ "iam:CreateInstanceProfile", "iam:DeleteInstanceProfile", "iam:GetRole", "iam:UpdateAssumeRolePolicy", "iam:GetInstanceProfile", "iam:TagRole", "iam:RemoveRoleFromInstanceProfile", "iam:CreateRole", "iam:DeleteRole", "iam:PutRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateOpenIDConnectProvider", "iam:ListOpenIDConnectProviders", "iam:DeleteRolePolicy", "iam:UpdateRole", "iam:DeleteOpenIDConnectProvider", "iam:GetRolePolicy" ], "Resource": "*" }, { "Sid": "Route53", "Effect": "Allow", "Action": [ "route53:ListHostedZonesByVPC", "route53:CreateHostedZone", "route53:ListHostedZones", "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets", "route53:DeleteHostedZone", "route53:AssociateVPCWithHostedZone", "route53:ListHostedZonesByName" ], "Resource": "*" }, { "Sid": "S3", "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets", "s3:ListBucket", "s3:DeleteObject", "s3:DeleteBucket" ], "Resource": "*" } ] }运行以下命令,将
policy.json文件附加到角色中:$ aws iam put-role-policy \ --role-name <role_name> \1 --policy-name <policy_name> \2 --policy-document file://policy.json3 运行以下命令,在名为
sts-creds.json的 JSON 文件中检索 STS 凭证:$ aws sts get-session-token --output json > sts-creds.jsonsts-creds.json文件示例{ "Credentials": { "AccessKeyId": "<access_key_id", "SecretAccessKey": "<secret_access_key>”, "SessionToken": "<session_token>", "Expiration": "<time_stamp>" } }
4.1.6. 为托管 control plane 启用 AWS PrivateLink
要使用 PrivateLink 在 Amazon Web Services (AWS) 上置备托管的 control plane,请为托管 control plane 启用 AWS PrivateLink。
流程
-
为 HyperShift Operator 创建 AWS 凭证 secret,并将其命名为
hypershift-operator-private-link-credentials。secret 必须位于用作管理集群的受管集群的命名空间中。如果使用local-cluster,请在local-cluster命名空间中创建 secret。 - 下表确认 secret 包含必填字段:
| 字段名称 | 描述 | 可选或必需的 |
|---|---|---|
|
| 与私有链接一起使用的区域 | 必填 |
|
| 凭证访问密钥 ID。 | 必填 |
|
| 凭证访问密钥 secret。 | 必填 |
要创建 AWS secret,请运行以下命令:
$ oc create secret generic <secret_name> \
--from-literal=aws-access-key-id=<aws_access_key_id> \
--from-literal=aws-secret-access-key=<aws_secret_access_key> \
--from-literal=region=<region> -n local-cluster
secret 的灾难恢复备份不会被自动启用。运行以下命令添加可备份 hypershift-operator-private-link-credentials secret 的标签:
$ oc label secret hypershift-operator-private-link-credentials \
-n local-cluster \
cluster.open-cluster-management.io/backup=""4.1.7. 为 AWS 上托管的 control plane 启用外部 DNS
control plane 和数据平面在托管的 control plane 中是相互独立的。您可以在两个独立区域中配置 DNS:
-
托管集群中的工作负载的 Ingress,如以下域:
*.apps.service-consumer-domain.com。 -
管理集群中的服务端点的 Ingress,如通过服务提供商域提供 API 或 OAuth 端点:
service-provider-domain.com。
hostedCluster.spec.dns 的输入管理托管集群中工作负载的入口。hostedCluster.spec.services.servicePublishingStrategy.route.hostname 的输入管理管理集群中服务端点的 ingress。
外部 DNS 为托管的集群服务创建名称记录,用于指定 LoadBalancer 或 Route 的发布类型,并为该发布类型提供主机名。对于带有 Private 或 PublicAndPrivate 端点访问类型的托管集群,只有 APIServer 和 OAuth 服务支持主机名。对于 私有 托管集群,DNS 记录解析为 VPC 中 Virtual Private Cloud (VPC) 端点的专用 IP 地址。
托管 control plane 会公开以下服务:
-
APIServer -
OIDC
您可以使用 HostedCluster 规格中的 servicePublishingStrategy 字段来公开这些服务。默认情况下,对于 LoadBalancer 和 Route 类型的 servicePublishingStrategy,您可以通过以下方法之一发布该服务:
-
通过使用处于
LoadBalancer类型的Service状态的负载均衡器的主机名。 -
通过使用
Route资源的status.host字段。
但是,当您在受管服务上下文中部署托管 control plane 时,这些方法可以公开底层管理集群的 ingress 子域,并限制管理集群生命周期和灾难恢复的选项。
当 DNS 间接在 LoadBalancer 和 Route 发布类型上分层时,受管服务操作员可以使用服务级别域发布所有公共托管集群服务。这个架构允许将 DNS 名称重新映射到新的 LoadBalancer 或 Route,且不会公开管理集群的 ingress 域。托管 control plane 使用外部 DNS 来实现间接层。
您可以在管理集群的 hypershift 命名空间中部署 external-dns 和 HyperShift Operator。用于监视具有 external-dns.alpha.kubernetes.io/hostname 注解的 Services 或 Routes 的外部 DNS该注解用于创建指向 Service 的 DNS 记录,如 A 记录或 Route,如 CNAME 记录。
您只能在云环境中使用外部 DNS。对于其他环境,您需要手动配置 DNS 和服务。
有关外部 DNS 的更多信息,请参阅外部 DNS。
4.1.7.1. 先决条件
在 Amazon Web Services (AWS) 上为托管 control plane 设置外部 DNS 之前,您必须满足以下先决条件:
- 您创建了外部公共域。
- 您可以访问 AWS Route53 管理控制台。
- 为托管 control plane 启用了 AWS PrivateLink。
4.1.7.2. 为托管的 control plane 设置外部 DNS
您可以使用外部 DNS 或服务级别 DNS 置备托管的 control plane。
-
为 HyperShift Operator 创建 Amazon Web Services (AWS) 凭证 secret,并将其命名为
local-cluster命名空间中的hypershift-operator-external-dns-credentials。 查看下表以验证 secret 是否具有必填字段:
Expand 表 4.3. AWS secret 的必填字段 字段名称 描述 可选或必需的 provider管理服务级别 DNS 区的 DNS 供应商。
必需
domain-filter服务级别域。
必需
credentials支持所有外部 DNS 类型的凭据文件。
在使用 AWS 密钥时是可选的
aws-access-key-id凭证访问密钥 ID。
在使用 AWS DNS 服务时是可选的
aws-secret-access-key凭证访问密钥 secret。
在使用 AWS DNS 服务时是可选的
要创建 AWS secret,请运行以下命令:
$ oc create secret generic <secret_name> \ --from-literal=provider=aws \ --from-literal=domain-filter=<domain_name> \ --from-file=credentials=<path_to_aws_credentials_file> -n local-cluster注意secret 的灾难恢复备份不会被自动启用。要为灾难恢复备份 secret,请输入以下命令添加
hypershift-operator-external-dns-credentials:$ oc label secret hypershift-operator-external-dns-credentials \ -n local-cluster \ cluster.open-cluster-management.io/backup=""
4.1.7.3. 创建公共 DNS 托管区
External DNS Operator 使用公共 DNS 托管区来创建公共托管集群。
您可以创建公共 DNS 托管区来用作外部 DNS domain-filter。在 AWS Route 53 管理控制台中完成以下步骤。
流程
- 在 Route 53 管理控制台中,点 Create hosted zone。
- 在 Hosted zone 配置 页面中,键入域名,验证 Public hosted zone 已选为类型,然后单击 Create hosted zone。
- 创建区域后,在 Records 选项卡中,请注意 Value/Route traffic to 栏中的值。
- 在主域中,创建一个 NS 记录,将 DNS 请求重定向到委派的区域。在 Value 字段中,输入您在上一步中记录的值。
- 点 Create records。
通过在新子区中创建测试条目并使用
dig命令进行测试,以验证 DNS 托管区是否正常工作,如下例所示:$ dig +short test.user-dest-public.aws.kerberos.com输出示例
192.168.1.1要创建为
LoadBalancer和Route服务设置主机名的托管集群,请输入以下命令:$ hcp create cluster aws --name=<hosted_cluster_name> \ --endpoint-access=PublicAndPrivate \ --external-dns-domain=<public_hosted_zone> ...1 - 1
- 将
<public_hosted_zone>替换为您创建的公共托管区。
托管集群的
services块示例platform: aws: endpointAccess: PublicAndPrivate ... services: - service: APIServer servicePublishingStrategy: route: hostname: api-example.service-provider-domain.com type: Route - service: OAuthServer servicePublishingStrategy: route: hostname: oauth-example.service-provider-domain.com type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: Ignition servicePublishingStrategy: type: Route
Control Plane Operator 创建 Services 和 Routes 资源,并使用 external-dns.alpha.kubernetes.io/hostname 注解为它们添加注解。对于 Services 和 Routes,Control Plane Operator 将 servicePublishingStrategy 字段中的 hostname 参数的值用于服务端点。要创建 DNS 记录,您可以使用某种机制,如 external-dns 部署。
您只能为公共服务配置服务级别 DNS 间接。您不能为私有服务设置主机名,因为它们使用 hypershift.local 私有区。
下表显示了何时能够为服务和端点组合设置主机名:
| service | 公开 | PublicAndPrivate | 私有 |
|---|---|---|---|
|
| Y | Y | N |
|
| Y | Y | N |
|
| Y | N | N |
|
| Y | N | N |
4.1.7.4. 使用 AWS 上的外部 DNS 创建托管集群
要使用 Amazon Web Services (AWS) 上的 PublicAndPrivate 或 Public 策略来创建托管集群,您必须在管理集群中配置以下工件:
- 公共 DNS 托管区
- External DNS Operator
- HyperShift Operator
您可以使用 hcp 命令行界面 (CLI)部署托管集群。
流程
要访问您的管理集群,请输入以下命令:
$ export KUBECONFIG=<path_to_management_cluster_kubeconfig>输入以下命令验证 External DNS Operator 是否正在运行:
$ oc get pod -n hypershift -lapp=external-dns输出示例
NAME READY STATUS RESTARTS AGE external-dns-7c89788c69-rn8gp 1/1 Running 0 40s要使用外部 DNS 创建托管集群,请输入以下命令:
$ hcp create cluster aws \ --role-arn <arn_role> \1 --instance-type <instance_type> \2 --region <region> \3 --auto-repair \ --generate-ssh \ --name <hosted_cluster_name> \4 --namespace clusters \ --base-domain <service_consumer_domain> \5 --node-pool-replicas <node_replica_count> \6 --pull-secret <path_to_your_pull_secret> \7 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --external-dns-domain=<service_provider_domain> \9 --endpoint-access=PublicAndPrivate10 --sts-creds <path_to_sts_credential_file>11 - 1
- 指定 Amazon Resource Name (ARN),例如
arn:aws:iam::820196288204:role/myrole。 - 2
- 指定实例类型,如
m6i.xlarge。 - 3
- 指定 AWS 区域,如
us-east-1。 - 4
- 指定托管集群名称,如
my-external-aws。 - 5
- 指定服务消费者拥有的公共托管区,如
service-consumer-domain.com。 - 6
- 指定节点副本数,例如
2。 - 7
- 指定 pull secret 文件的路径。
- 8
- 指定您要使用的 OpenShift Container Platform 版本,如
4.17.0-multi。 - 9
- 指定服务提供商拥有的公共托管区,如
service-provider-domain.com。 - 10
- 设置为
PublicAndPrivate。您只能使用Public或PublicAndPrivate配置来使用外部 DNS。 - 11
- 指定 AWS STS 凭证文件的路径,例如
/home/user/sts-creds/sts-creds.json。
4.1.8. 在 AWS 上创建托管集群
您可以使用 hcp 命令行界面 (CLI) 在 Amazon Web Services (AWS) 上创建托管集群。
默认情况下,对于 Amazon Web Services (AWS)上的托管 control plane,您可以使用 AMD64 托管的集群。但是,您可以启用托管的 control plane 在 ARM64 托管的集群中运行。如需更多信息,请参阅"在 ARM64 架构上运行托管集群"。
有关节点池和托管集群兼容组合,请参阅下表:
| 托管的集群 | 节点池 |
|---|---|
| AMD64 | AMD64 或 ARM64 |
| ARM64 | ARM64 或 AMD64 |
先决条件
-
您已设置了托管的 control plane CLI
hcp。 -
您已启用了
local-cluster受管集群作为管理集群。 - 您创建了 AWS Identity and Access Management (IAM) 角色和 AWS 安全令牌服务(STS) 凭证。
流程
要在 AWS 上创建托管集群,请运行以下命令:
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --base-domain <basedomain> \3 --sts-creds <path_to_sts_credential_file> \4 --pull-secret <path_to_pull_secret> \5 --region <region> \6 --generate-ssh \ --node-pool-replicas <node_pool_replica_count> \7 --namespace <hosted_cluster_namespace> \8 --role-arn <role_name> \9 --render-into <file_name>.yaml10 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定您的基础架构名称。您必须为
<hosted_cluster_name>和<infra_id>提供相同的值。否则,集群可能无法在 Kubernetes Operator 控制台的多集群引擎中正确显示。 - 3
- 指定您的基域,例如
example.com。 - 4
- 指定 AWS STS 凭证文件的路径,例如
/home/user/sts-creds/sts-creds.json。 - 5
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 6
- 指定 AWS 区域名称,如
us-east-1。 - 7
- 指定节点池副本数,例如
3。 - 8
- 默认情况下,所有
HostedCluster和NodePool自定义资源都会在clusters命名空间中创建。您可以使用--namespace <namespace>参数,在特定命名空间中创建HostedCluster和NodePool自定义资源。 - 9
- 指定 Amazon Resource Name (ARN),例如
arn:aws:iam::820196288204:role/myrole。 - 10
- 如果要指明 EC2 实例是否在共享或单个租户硬件上运行,请包含此字段。
--render-into标志会将 Kubernetes 资源呈现到您在此字段中指定的 YAML 文件中。然后,继续执行下一步来编辑 YAML 文件。
如果在上一命令中包含了
--render-into标志,请编辑指定的 YAML 文件。编辑 YAML 文件中的NodePool规格,以指示 EC2 实例是否应该在共享或单租户硬件上运行,如下例所示:YAML 文件示例
apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <nodepool_name>1 spec: platform: aws: placement: tenancy: "default"2
验证
验证托管集群的状态,以检查
AVAILABLE的值是否为True。运行以下命令:$ oc get hostedclusters -n <hosted_cluster_namespace>运行以下命令,获取节点池列表:
$ oc get nodepools --namespace <hosted_cluster_namespace>
4.1.8.1. 访问 AWS 上的托管集群
您可以通过直接从资源获取 kubeconfig 文件和 kubeadmin 凭证来访问托管集群。
您必须熟悉托管集群的访问 secret。托管的集群命名空间包含托管的集群资源,托管的 control plane 命名空间是托管的 control plane 运行的位置。secret 名称格式如下:
-
kubeconfigsecret: <hosted-cluster-namespace>-<name>-admin-kubeconfig.例如clusters-hypershift-demo-admin-kubeconfig。 -
kubeadminpassword secret: <hosted-cluster-namespace>-<name>-kubeadmin-password.例如,clusters-hypershift-demo-kubeadmin-password。
流程
kubeconfigsecret 包含一个 Base64 编码的kubeconfig字段,您可以解码并保存到要使用以下命令使用的文件中:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodeskubeadmin密码 secret 也为 Base64 编码的。您可以对它进行解码,并使用密码登录到托管集群的 API 服务器或控制台。
4.1.8.2. 使用 kubeadmin 凭证在 AWS 上访问托管集群
在 Amazon Web Services (AWS) 上创建托管集群后,您可以通过获取 kubeconfig 文件、访问 secret 和 kubeadmin 凭证来访问托管集群。
托管的集群命名空间包含托管的集群资源和访问 secret。托管 control plane 在托管的 control plane 命名空间中运行。
secret 名称格式如下:
-
kubeconfigsecret:<hosted_cluster_namespace>-<name>-admin-kubeconfig.例如clusters-hypershift-demo-admin-kubeconfig。 -
kubeadmin密码 secret:<hosted_cluster_namespace>-<name>-kubeadmin-password。例如,clusters-hypershift-demo-kubeadmin-password。
kubeadmin 密码 secret 是 Base64 编码的,kubeconfig secret 包含以 Base64 编码的 kubeconfig 配置。您必须对 Base64 编码的 kubeconfig 配置进行解码,并将其保存到 <hosted_cluster_name>.kubeconfig 文件中。
流程
使用包含解码的
kubeconfig配置的<hosted_cluster_name>.kubeconfig文件来访问托管集群。输入以下命令:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes您必须对
kubeadmin密码 secret 进行解码,才能登录到 API 服务器或托管集群的控制台。
4.1.8.3. 使用 hcp CLI 访问 AWS 上的托管集群
您可以使用 hcp 命令行界面 (CLI)访问托管集群。
流程
输入以下命令生成
kubeconfig文件:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig保存
kubeconfig文件后,输入以下命令访问托管集群:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
4.1.9. 在托管集群中配置自定义 API 服务器证书
要为 API 服务器配置自定义证书,请在 HostedCluster 配置的 spec.configuration.apiServer 部分中指定证书详情。
您可以在第 1 天或第 2 天操作期间配置自定义证书。但是,由于在托管集群创建过程中设置服务发布策略后,服务发布策略不可变,所以您必须知道您要配置的 Kubernetes API 服务器的主机名。
先决条件
您创建了包含管理集群中的自定义证书的 Kubernetes secret。secret 包含以下键:
-
tls.crt: 证书 -
tls.key:私钥
-
-
如果您的
HostedCluster配置包含使用负载均衡器的服务发布策略,请确保证书的 Subject Alternative Names (SAN)与内部 API 端点(api-int)不冲突。内部 API 端点由您的平台自动创建和管理。如果您在自定义证书和内部 API 端点中使用相同的主机名,则可能会出现路由冲突。此规则的唯一例外是,当您将 AWS 用作供应商时,使用Private或PublicAndPrivate配置。在这些情况下,SAN 冲突由平台管理。 - 证书必须对外部 API 端点有效。
- 证书的有效性周期与集群的预期生命周期一致。
流程
输入以下命令使用自定义证书创建 secret:
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>使用自定义证书详情更新
HostedCluster配置,如下例所示:spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert输入以下命令将更改应用到
HostedCluster配置:$ oc apply -f <hosted_cluster_config>.yaml
验证
- 检查 API 服务器 pod,以确保挂载了新证书。
- 使用自定义域名测试与 API 服务器的连接。
-
在浏览器中或使用
openssl等工具验证证书详情。
4.1.10. 在 AWS 上的多个区中创建托管集群
您可以使用 hcp 命令行界面 (CLI)在 Amazon Web Services (AWS) 上的多个区域中创建托管集群。
先决条件
- 您创建了 AWS Identity and Access Management (IAM) 角色和 AWS 安全令牌服务(STS) 凭证。
流程
运行以下命令,在 AWS 上的多个区中创建托管集群:
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas=<node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --role-arn <arn_role> \5 --region <region> \6 --zones <zones> \7 --sts-creds <path_to_sts_credential_file>8 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定节点池副本数,例如
2。 - 3
- 指定您的基域,例如
example.com。 - 4
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 5
- 指定 Amazon Resource Name (ARN),例如
arn:aws:iam::820196288204:role/myrole。 - 6
- 指定 AWS 区域名称,如
us-east-1。 - 7
- 指定 AWS 区域中的可用区,如
us-east-1a和us-east-1b。 - 8
- 指定 AWS STS 凭证文件的路径,例如
/home/user/sts-creds/sts-creds.json。
对于每个指定区,会创建以下基础架构:
- 公共子网
- 专用子网
- NAT 网关
- 私有路由表
公共路由表在公共子网之间共享。
为每个区创建一个 NodePool 资源。节点池名称带有区名称后缀。区的专用子网在 spec.platform.aws.subnet.id 中设置。
4.1.10.1. 通过提供 AWS STS 凭证来创建托管集群
当使用 hcp create cluster aws 命令创建托管集群时,您必须提供 Amazon Web Services (AWS) 帐户凭证来为托管集群创建基础架构资源。
基础架构资源包括以下示例:
- 虚拟私有云(VPC)
- 子网
- 网络地址转换 (NAT) 网关
您可以使用以下任一方法提供 AWS 凭证:
- AWS 安全令牌服务 (STS) 凭证
- 来自多集群引擎 Operator 的 AWS 云供应商 secret
流程
要通过提供 AWS STS 凭证在 AWS 上创建托管集群,请输入以下命令:
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --role-arn <arn_role>7
4.1.11. 在 ARM64 架构上运行托管集群
默认情况下,对于 Amazon Web Services (AWS)上的托管 control plane,您可以使用 AMD64 托管的集群。但是,您可以启用托管的 control plane 在 ARM64 托管的集群中运行。
有关节点池和托管集群兼容组合,请参阅下表:
| 托管的集群 | 节点池 |
|---|---|
| AMD64 | AMD64 或 ARM64 |
| ARM64 | ARM64 或 AMD64 |
4.1.11.1. 在 ARM64 OpenShift Container Platform 集群中创建托管集群
您可以使用多架构发行镜像覆盖默认的发行镜像,在 ARM64 OpenShift Container Platform 集群中为 Amazon Web Services (AWS) 运行托管集群。
如果没有使用多架构发行镜像,则节点池中的计算节点不会被创建,协调过程会停止,直到您在托管集群中使用了一个多架构发行镜像,或根据发行镜像更新了 NodePool 自定义资源。
先决条件
- 您必须有一个在 AWS 上安装 64 位 ARM 基础架构的 OpenShift Container Platform 集群。如需更多信息,请参阅创建 OpenShift Container Platform Cluster: AWS (ARM)。
- 您必须创建一个 AWS Identity and Access Management (IAM) 角色和 AWS 安全令牌服务(STS) 凭证。如需更多信息,请参阅"创建 AWS IAM 角色和 STS 凭证"。
流程
输入以下命令在 ARM64 OpenShift Container Platform 集群上创建托管集群:
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \7 --role-arn <role_name>8 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定节点池副本数,例如
3。 - 3
- 指定您的基域,例如
example.com。 - 4
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 5
- 指定 AWS STS 凭证文件的路径,例如
/home/user/sts-creds/sts-creds.json。 - 6
- 指定 AWS 区域名称,如
us-east-1。 - 7
- 指定您要使用的 OpenShift Container Platform 版本,如
4.17.0-multi。如果您使用断开连接的环境,将<ocp_release_image>替换为摘要镜像。要提取 OpenShift Container Platform 发行镜像摘要,请参阅"提取 OpenShift Container Platform 发行镜像摘要"。 - 8
- 指定 Amazon Resource Name (ARN),例如
arn:aws:iam::820196288204:role/myrole。
4.1.11.2. 在 AWS 托管集群中创建 ARM 或 AMD NodePool 对象
您可以调度应用程序负载,它是来自同一托管的 control plane 的 64 位 ARM 和 AMD 上的 NodePool 对象。您可以在 NodePool 规格中定义 arch 字段,为 NodePool 对象设置所需的处理器架构。arch 字段的有效值如下:
-
arm64 -
amd64
先决条件
-
您必须具有多架构镜像才能使用
HostedCluster自定义资源。您可以访问 multi-architecture nightly 镜像。
流程
运行以下命令,将 ARM 或 AMD
NodePool对象添加到 AWS 上的托管集群:$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <node_pool_name> \2 --node-count <node_pool_replica_count> \3 --arch <architecture>4
4.1.12. 在 AWS 上创建私有托管集群
在启用了 local-cluster 作为托管集群后,您可以在 Amazon Web Services (AWS) 上部署托管集群或私有托管集群。
默认情况下,托管集群可以通过公共 DNS 和管理集群的默认路由器公开访问。
对于 AWS 上的私有集群,所有与托管集群的通信都会通过 AWS PrivateLink 进行。
先决条件
- 您已启用了 AWS PrivateLink。如需更多信息,请参阅"启用 AWS PrivateLink"。
- 您创建了 AWS Identity and Access Management (IAM) 角色和 AWS 安全令牌服务(STS) 凭证。如需更多信息,请参阅"创建 AWS IAM 角色和 STS 凭证"和"Identity and Access Management (IAM)权限"。
- 您在 AWS 上配置了堡垒实例。
流程
输入以下命令在 AWS 上创建私有托管集群:
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas=<node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --endpoint-access Private \7 --role-arn <role_name>8 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定节点池副本数,例如
3。 - 3
- 指定您的基域,例如
example.com。 - 4
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 5
- 指定 AWS STS 凭证文件的路径,例如
/home/user/sts-creds/sts-creds.json。 - 6
- 指定 AWS 区域名称,如
us-east-1。 - 7
- 定义集群是公共还是私有。
- 8
- 指定 Amazon Resource Name (ARN),例如
arn:aws:iam::820196288204:role/myrole。有关 ARN 角色的更多信息,请参阅"Identity and Access Management (IAM) 权限"。
托管集群的以下 API 端点可通过私有 DNS 区域访问:
-
api.<hosted_cluster_name>.hypershift.local -
*.apps.<hosted_cluster_name>.hypershift.local
4.2. 在裸机上部署托管的 control plane
您可以通过将集群配置为充当管理集群来部署托管的 control plane。管理集群是托管 control plane 的 OpenShift Container Platform 集群。在某些上下文中,管理集群也称为托管集群。
受管集群与受管集群不同。受管集群是 hub 集群管理的集群。
托管的 control plane 功能默认启用。
multicluster engine Operator 只支持默认的 local-cluster,它是管理的 hub 集群,而 hub 集群作为管理集群。如果安装了 Red Hat Advanced Cluster Management,您可以使用受管 hub 集群(也称为 local-cluster )作为管理集群。
托管的集群 是一个 OpenShift Container Platform 集群,其 API 端点和 control plane 托管在管理集群中。托管的集群包括控制平面和它的对应的数据平面。您可以使用多集群引擎 Operator 控制台或托管的 control plane 命令行界面(hcp)来创建托管集群。
托管的集群自动导入为受管集群。如果要禁用此自动导入功能,请参阅"禁用托管集群自动导入到多集群引擎 Operator"。
4.2.1. 准备在裸机上部署托管的 control plane
当您准备在裸机上部署托管 control plane 时,请考虑以下信息:
- 在托管 control plane 的同一平台上运行管理集群和 worker。
-
所有裸机主机都需要手动从中央基础架构管理提供的发现镜像 ISO 开始。您可以使用
Cluster-Baremetal-Operator手动启动主机或通过自动化来启动主机。每个主机启动后,它会运行一个代理进程来发现主机详情并完成安装。Agent自定义资源代表每个主机。 - 当您为托管 control plane 配置存储时,请考虑推荐的 etcd 实践。要确保您满足延迟要求,请将快速存储设备专用于每个 control-plane 节点上运行的所有托管 control plane etcd 实例。您可以使用 LVM 存储为托管的 etcd pod 配置本地存储类。如需更多信息,请参阅"推荐 etcd 实践"和"使用逻辑卷管理器存储的持久性存储"。
4.2.1.1. 配置管理集群的先决条件
- 您需要为 Kubernetes Operator 2.2 及之后的版本安装在 OpenShift Container Platform 集群上的多集群引擎。您可以从 OpenShift Container Platform OperatorHub 将 multicluster engine Operator 安装为 Operator。
multicluster engine Operator 必须至少有一个受管 OpenShift Container Platform 集群。
local-cluster在多集群引擎 Operator 2.2 及更高版本中自动导入。有关local-cluster的更多信息,请参阅 Red Hat Advanced Cluster Management 中的高级配置部分。您可以运行以下命令来检查 hub 集群的状态:$ oc get managedclusters local-cluster-
您必须将
topology.kubernetes.io/zone标签添加到管理集群中的裸机主机中。确保每个主机具有topology.kubernetes.io/zone的唯一值。否则,所有托管的 control plane pod 都调度到单一节点上,从而导致单点故障。 - 要在裸机上置备托管的 control plane,您可以使用 Agent 平台。Agent 平台使用中央基础架构管理服务将 worker 节点添加到托管的集群中。如需更多信息,请参阅启用中央基础架构管理服务。
- 您需要安装托管的 control plane 命令行界面。
4.2.1.2. 裸机防火墙、端口和服务要求
您必须满足防火墙、端口和服务要求,以便端口可以在管理集群、control plane 和托管集群之间进行通信。
服务在其默认端口上运行。但是,如果您使用 NodePort 发布策略,服务在由 NodePort 服务分配的端口上运行。
使用防火墙规则、安全组或其他访问控制来仅限制对所需源的访问。除非需要,否则请避免公开公开端口。对于生产环境部署,请使用负载均衡器来简化通过单个 IP 地址的访问。
如果您的 hub 集群有代理配置,请通过将所有托管集群 API 端点添加到 Proxy 对象的 noProxy 字段来确保它可以访问托管集群 API 端点。如需更多信息,请参阅"配置集群范围代理"。
托管 control plane 在裸机上公开以下服务:
APIServer-
APIServer服务默认在端口 6443 上运行,需要入口访问 control plane 组件之间的通信。 - 如果使用 MetalLB 负载均衡,允许入口访问用于负载均衡器 IP 地址的 IP 范围。
-
OAuthServer-
当使用路由和入口来公开服务时,
OAuthServer服务默认在端口 443 上运行。 -
如果使用
NodePort发布策略,请为OAuthServer服务使用防火墙规则。
-
当使用路由和入口来公开服务时,
Konnectivity-
当使用路由和入口来公开服务时,
Konnectivity服务默认在端口 443 上运行。 -
Konnectity代理建立一个反向隧道,允许 control plane 访问托管集群的网络。代理使用出口连接到Konnectivity服务器。服务器通过使用端口 443 上的路由或手动分配的NodePort来公开。 - 如果集群 API 服务器地址是一个内部 IP 地址,允许从工作负载子网访问端口 6443 上的 IP 地址。
- 如果地址是一个外部 IP 地址,允许从节点通过端口 6443 出口到该外部 IP 地址。
-
当使用路由和入口来公开服务时,
Ignition-
当使用路由和入口来公开服务时,
Ignition服务默认在端口 443 上运行。 -
如果使用
NodePort发布策略,请为Ignition服务使用防火墙规则。
-
当使用路由和入口来公开服务时,
在裸机上不需要以下服务:
-
OVNSbDb -
OIDC
4.2.1.3. 裸机基础架构要求
Agent 平台不会创建任何基础架构,但它对基础架构有以下要求:
- 代理 : 代理 代表使用发现镜像引导的主机,并准备好置备为 OpenShift Container Platform 节点。
- DNS :API 和入口端点必须可以被路由。
4.2.2. 裸机上的 DNS 配置
托管集群的 API 服务器作为 NodePort 服务公开。必须存在 api.<hosted_cluster_name>.<base_domain> 的 DNS 条目,它指向可以访问 API 服务器的目标。
DNS 条目可以作为记录,指向运行托管 control plane 管理集群中的一个节点。该条目也可以指向部署的负载均衡器,将传入的流量重定向到入口 pod。
DNS 配置示例
api.example.krnl.es. IN A 192.168.122.20
api.example.krnl.es. IN A 192.168.122.21
api.example.krnl.es. IN A 192.168.122.22
api-int.example.krnl.es. IN A 192.168.122.20
api-int.example.krnl.es. IN A 192.168.122.21
api-int.example.krnl.es. IN A 192.168.122.22
`*`.apps.example.krnl.es. IN A 192.168.122.23
在上例中,*.apps.example.krnl.es。IN A 192.168.122.23 是托管的集群中的节点,如果已经配置了负载均衡器,则是一个负载均衡器。
如果您要为 IPv6 网络上的断开连接的环境配置 DNS,则配置类似以下示例。
IPv6 网络的 DNS 配置示例
api.example.krnl.es. IN A 2620:52:0:1306::5
api.example.krnl.es. IN A 2620:52:0:1306::6
api.example.krnl.es. IN A 2620:52:0:1306::7
api-int.example.krnl.es. IN A 2620:52:0:1306::5
api-int.example.krnl.es. IN A 2620:52:0:1306::6
api-int.example.krnl.es. IN A 2620:52:0:1306::7
`*`.apps.example.krnl.es. IN A 2620:52:0:1306::10如果您要为双栈网络上的断开连接的环境配置 DNS,请务必包括 IPv4 和 IPv6 的条目。
双栈网络的 DNS 配置示例
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10
host-record=api.hub-dual.dns.base.domain.name,192.168.126.10
address=/apps.hub-dual.dns.base.domain.name/192.168.126.11
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2
host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2
address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6]
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7]
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8]
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]4.2.3. 创建 InfraEnv 资源
在裸机上创建托管集群前,您需要一个 InfraEnv 资源。
4.2.3.1. 创建 InfraEnv 资源并添加节点
在托管的 control plane 上,control-plane 组件作为 pod 在管理集群中作为 pod 运行,而 data plane 在专用节点上运行。您可以使用 Assisted Service 使用发现 ISO 引导硬件,该 ISO 将您的硬件添加到硬件清单中。之后,当您创建托管集群时,使用清单中的硬件来置备 data-plane 节点。用于获取发现 ISO 的对象是一个 InfraEnv 资源。您需要创建一个 BareMetalHost 对象,将集群配置为从发现 ISO 引导裸机节点。
流程
输入以下命令创建一个命名空间来存储硬件清单:
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig create \ namespace <namespace_example>其中:
- <directory_example>
-
是保存管理集群的
kubeconfig文件的目录名称。 - <namespace_example>
是您要创建的命名空间的名称,如
hardware-inventory。输出示例
namespace/hardware-inventory created
输入以下命令复制管理集群的 pull secret:
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n openshift-config get secret pull-secret -o yaml \ | grep -vE "uid|resourceVersion|creationTimestamp|namespace" \ | sed "s/openshift-config/<namespace_example>/g" \ | oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n <namespace> apply -f -其中:
- <directory_example>
-
是保存管理集群的
kubeconfig文件的目录名称。 - <namespace_example>
是您要创建的命名空间的名称,如
hardware-inventory。输出示例
secret/pull-secret created
通过在 YAML 文件中添加以下内容来创建
InfraEnv资源:apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: hosted namespace: <namespace_example> spec: additionalNTPSources: - <ip_address> pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key> # ...输入以下命令将更改应用到 YAML 文件:
$ oc apply -f <infraenv_config>.yaml将
<infraenv_config> 替换为您的文件的名称。输入以下命令验证
InfraEnv资源是否已创建:$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n <namespace_example> get infraenv hosted通过以下两种方法之一添加裸机主机:
如果不使用 Metal3 Operator,请从
InfraEnv资源获取发现 ISO,并完成以下步骤手动引导主机:输入以下命令下载 live ISO:
$ oc get infraenv -A$ oc get infraenv <namespace_example> -o jsonpath='{.status.isoDownloadURL}' -n <namespace_example> <iso_url>-
引导 ISO。节点与 Assisted Service 通信,并作为代理注册到与
InfraEnv资源相同的命名空间中。 对于每个代理,设置安装磁盘 ID 和主机名,并批准它以指示代理可以使用。输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agents输出示例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign$ oc -n <hosted_control_plane_namespace> \ patch agent 86f7ac75-4fc4-4b36-8130-40fa12602218 \ -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-0.example.krnl.es"}}' \ --type merge$ oc -n <hosted_control_plane_namespace> \ patch agent 23d0c614-2caa-43f5-b7d3-0b3564688baa -p \ '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-1.example.krnl.es"}}' \ --type merge$ oc -n <hosted_control_plane_namespace> get agents输出示例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
如果使用 Metal3 Operator,您可以通过创建以下对象来自动进行裸机主机注册:
创建 YAML 文件并添加以下内容:
apiVersion: v1 kind: Secret metadata: name: hosted-worker0-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: hosted-worker1-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: hosted-worker2-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker0 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker0 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker0-bmc-secret bootMACAddress: aa:aa:aa:aa:02:01 online: true --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker1 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker1 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker1-bmc-secret bootMACAddress: aa:aa:aa:aa:02:02 online: true --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker2 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker2 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker2-bmc-secret bootMACAddress: aa:aa:aa:aa:02:03 online: true --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: capi-provider-role namespace: <namespace_example> rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'其中:
- <namespace_example>
- 是您的命名空间。
- <password>
- 是 secret 的密码。
- <username>
- 是 secret 的用户名。
- <bmc_address>
是
BareMetalHost对象的 BMC 地址。注意应用此 YAML 文件时,会创建以下对象:
- 带有基板管理控制器(BMC)凭证的 secret
-
BareMetalHost对象 - HyperShift Operator 的角色,用于管理代理
注意如何使用
infraenvs.agent-install.openshift.io: hostedcustom 标签在BareMetalHost对象中引用InfraEnv资源。这样可确保节点使用生成的 ISO 引导。
输入以下命令将更改应用到 YAML 文件:
$ oc apply -f <bare_metal_host_config>.yaml将
<bare_metal_host_config> 替换为您的文件的名称。
输入以下命令,然后等待几分钟后
BareMetalHost对象移至Provisioning状态:$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig -n <namespace_example> get bmh输出示例
NAME STATE CONSUMER ONLINE ERROR AGE hosted-worker0 provisioning true 106s hosted-worker1 provisioning true 106s hosted-worker2 provisioning true 106s输入以下命令验证节点是否已引导,并以代理的形式显示。这个过程可能需要几分钟时间,您可能需要多次输入命令。
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig -n <namespace_example> get agent输出示例
NAME CLUSTER APPROVED ROLE STAGE aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0201 true auto-assign aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0202 true auto-assign aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0203 true auto-assign
4.2.3.2. 使用控制台创建 InfraEnv 资源
要使用控制台创建 InfraEnv 资源,请完成以下步骤。
流程
- 打开 OpenShift Container Platform Web 控制台,并输入您的管理员凭证登录。有关打开控制台的说明,请参阅"访问 Web 控制台"。
- 在控制台标头中,确保选择了 All Clusters。
- 点 Infrastructure → Host inventory → Create infrastructure environment。
-
创建
InfraEnv资源后,单击 Add hosts 并从可用选项中选择,从 InfraEnv 视图中添加裸机主机。
4.2.4. 在裸机上创建托管集群
您可以使用命令行界面(CLI)、控制台或使用镜像 registry 在裸机上创建托管集群。
4.2.4.1. 使用 CLI 创建托管集群
在裸机基础架构上,您可以创建或导入托管集群。在为多集群引擎 Operator 启用 Assisted Installer 作为附加组件后,您可以使用 Agent 平台创建一个托管集群,HyperShift Operator 会在托管的 control plane 命名空间中安装 Agent Cluster API 供应商。Agent Cluster API 供应商连接托管 control plane 和一个仅由计算节点组成的托管集群的管理集群。
先决条件
- 每个托管集群都必须具有集群范围的唯一名称。托管的集群名称都不能与任何现有受管集群相同。否则,多集群引擎 Operator 无法管理托管集群。
-
不要使用单词
cluster作为托管的集群名称。 - 您不能在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
- 为获得最佳安全性和管理实践,请创建一个与其他托管集群分开的托管集群。
- 验证您是否为集群配置了默认存储类。否则,您可能会看到待处理的持久性卷声明(PVC)。
-
默认情况下,当使用
hcp create cluster agent命令时,命令会创建一个带有配置的节点端口的托管集群。裸机上托管集群的首选发布策略通过负载均衡器公开服务。如果使用 Web 控制台或使用 Red Hat Advanced Cluster Management 创建托管集群,要为 Kubernetes API 服务器以外的服务设置发布策略,您必须在HostedCluster自定义资源中手动指定servicePublishingStrategy信息。 确保您满足裸机上托管 control plane 的 "Requirements for hosted control plane" 中描述的要求,其中包括与基础架构、防火墙、端口和服务相关的要求。例如,这些要求描述了如何在管理集群中的裸机主机中添加适当的区标签,如下例所示:
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- 确保您已将裸机节点添加到硬件清单中。
流程
运行以下命令来创建命名空间:
$ oc create ns <hosted_cluster_namespace>将
<hosted_cluster_namespace> 替换为托管集群命名空间的标识符。HyperShift Operator 创建命名空间。在裸机基础架构上托管集群创建过程中,生成的 Cluster API 供应商角色需要命名空间已存在。输入以下命令为托管集群创建配置文件:
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- 指定托管集群的名称,
如。 - 2
- 指定 pull secret 的路径,如
/user/name/pullsecret。 - 3
- 指定托管的 control plane 命名空间,如
cluster-example。使用oc get agent -n <hosted_control_plane_namespace>命令,确保此命名空间中有代理可用。 - 4
- 指定您的基域,如
krnl.es。 - 5
--api-server-address标志定义用于托管集群中的 Kubernetes API 通信的 IP 地址。如果没有设置--api-server-address标志,您必须登录以连接到管理集群。- 6
- 指定 etcd 存储类名称,如
lvm-storageclass。 - 7
- 指定 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 8
- 指定托管集群命名空间。
- 9
- 指定托管 control plane 组件的可用性策略。支持的选项包括
SingleReplica和HighlyAvailable。默认值为HighlyAvailable。 - 10
- 指定您要使用的 OpenShift Container Platform 版本,如
4.19.0-multi。如果您使用断开连接的环境,将<ocp_release_image>替换为摘要镜像。要提取 OpenShift Container Platform 发行镜像摘要,请参阅 提取 OpenShift Container Platform 发行镜像摘要。 - 11
- 指定节点池副本数,如
3。您必须将副本数指定为0或更高,才能创建相同数量的副本。否则,您不会创建节点池。 - 12
- 在
--ssh-key标志后,指定 SSH 密钥的路径,如user/.ssh/id_rsa。
配置服务发布策略。默认情况下,托管集群使用
NodePort服务发布策略,因为节点端口始终在没有额外基础架构的情况下可用。但是,您可以将服务发布策略配置为使用负载均衡器。-
如果您使用默认的
NodePort策略,请将 DNS 配置为指向托管的集群计算节点,而不是管理集群节点。如需更多信息,请参阅"裸机上的 DNS 配置"。 对于生产环境,请使用
LoadBalancer策略,因为此策略提供证书处理和自动 DNS 解析。以下示例演示了在托管集群配置文件中更改服务发布LoadBalancer策略:# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- 指定
LoadBalancer作为 API 服务器类型。对于所有其他服务,将Route指定为类型。
-
如果您使用默认的
输入以下命令将更改应用到托管集群配置文件:
$ oc apply -f hosted_cluster_config.yaml输入以下命令检查托管集群、节点池和 pod 的创建:
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
确认托管集群已就绪。
Available: True的状态表示集群的就绪状态,节点池状态显示AllMachinesReady: True。这些状态表示所有集群 Operator 的运行状况。 在托管集群中安装 MetalLB:
从托管集群中提取
kubeconfig文件,并输入以下命令为托管集群访问设置环境变量:$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"通过创建
install-metallb-operator.yaml文件来安装 MetalLB Operator:apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...输入以下命令应用该文件:
$ oc apply -f install-metallb-operator.yaml通过创建
deploy-metallb-ipaddresspool.yaml文件来配置 MetalLB IP 地址池:apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...输入以下命令应用配置:
$ oc apply -f deploy-metallb-ipaddresspool.yaml输入以下命令检查 Operator 状态、IP 地址池和
L2Advertisement资源来验证 MetalLB 的安装:$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
为入口配置负载均衡器:
创建
ingress-loadbalancer.yaml文件:apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...输入以下命令应用配置:
$ oc apply -f ingress-loadbalancer.yaml输入以下命令验证负载均衡器服务是否按预期工作:
$ oc get svc metallb-ingress -n openshift-ingress输出示例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
配置 DNS 以使用负载均衡器:
-
通过将 5.2.
apps.<hosted_cluster_namespace>.<base_domain> 通配符 DNS 记录指向负载均衡器 IP 地址,为 apps域配置 DNS。 输入以下命令验证 DNS 解析:
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>输出示例
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
通过将 5.2.
验证
输入以下命令检查集群 Operator:
$ oc get clusteroperators确保所有 Operator 显示
AVAILABLE: True,PROGRESSING: False, 和DEGRADED: False。输入以下命令检查节点:
$ oc get nodes确保每个节点都有
READY状态。通过在 Web 浏览器中输入以下 URL 来测试对控制台的访问:
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.2.4.2. 使用控制台在裸机上创建托管集群
要使用控制台创建托管集群,请完成以下步骤。
流程
- 打开 OpenShift Container Platform Web 控制台,并输入您的管理员凭证登录。有关打开控制台的说明,请参阅"访问 Web 控制台"。
- 在控制台标头中,确保选择了 All Clusters。
- 点 Infrastructure → Clusters。
点 Create cluster → Host inventory → Hosted control plane。
此时会显示 Create cluster 页。
在 Create cluster 页中,按照提示输入集群、节点池、网络和自动化的详细信息。
注意在输入集群详情时,您可能会发现以下提示很有用:
- 如果要使用预定义的值来自动填充控制台中的字段,您可以创建主机清单凭证。如需更多信息,请参阅"为内部环境创建凭证"。
- 在 Cluster details 页中,pull secret 是用于访问 OpenShift Container Platform 资源的 OpenShift Container Platform pull secret。如果您选择了主机清单凭证,则会自动填充 pull secret。
- 在 Node pool 页中,命名空间包含节点池的主机。如果使用控制台创建主机清单,控制台会创建一个专用命名空间。
-
在 Networking 页上,您可以选择 API 服务器发布策略。托管集群的 API 服务器可以通过使用现有负载均衡器或
NodePort类型的服务公开。必须存在api.<hosted_cluster_name>.<base_domain>的 DNS 条目,指向可以访问 API 服务器的目标。此条目可以是指向管理集群中某一节点的记录,也可以是指向将传入流量重定向到 Ingress pod 的负载均衡器的记录。
检查您的条目并点 Create。
此时会显示 Hosted 集群视图。
- 在托管集群视图中监控托管集群的部署。
- 如果您没有看到托管集群的信息,请确保选择了 All Clusters,然后点集群名称。
- 等待 control plane 组件就绪。这个过程可能需要几分钟时间。
- 要查看节点池状态,请滚动到 NodePool 部分。安装节点的过程需要大约 10 分钟。您还可以点 Nodes 来确认节点是否加入托管集群。
后续步骤
- 要访问 Web 控制台,请参阅访问 Web 控制台。
4.2.4.3. 使用镜像 registry 在裸机上创建托管集群
您可以通过在 hcp create cluster 命令中指定 --image-content-sources 标志,来使用镜像 registry 在裸机上创建托管集群。
流程
创建 YAML 文件来定义镜像内容源策略 (ICSP)。请参见以下示例:
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
将文件保存为
icsp.yaml。此文件包含您的镜像 registry。 要使用您的镜像 registry 创建托管集群,请运行以下命令:
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --image-content-sources icsp.yaml \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>9 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 3
- 指定托管的 control plane 命名空间,如
cluster-example。使用oc get agent -n <hosted-control-plane-namespace>命令,确保此在命名空间中有可用的代理。 - 4
- 指定您的基域,如
krnl.es。 - 5
--api-server-address标志定义用于托管集群中的 Kubernetes API 通信的 IP 地址。如果没有设置--api-server-address标志,您必须登录以连接到管理集群。- 6
- 指定定义 ICSP 和您的镜像 registry 的
icsp.yaml文件。 - 7
- 指定 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 8
- 指定托管集群命名空间。
- 9
- 指定您要使用的 OpenShift Container Platform 版本,如
4.17.0-multi。如果您使用断开连接的环境,将<ocp_release_image>替换为摘要镜像。要提取 OpenShift Container Platform 发行镜像摘要,请参阅"提取 OpenShift Container Platform 发行镜像摘要"。
后续步骤
- 要创建在使用控制台创建托管集群时重复使用的凭证,请参阅为内部环境创建凭证。
- 要访问托管集群,请参阅访问托管集群。
- 要使用发现镜像将主机添加到主机清单中,请参阅使用发现镜像将主机添加到主机清单中。
- 要提取 OpenShift Container Platform 发行镜像摘要,请参阅提取 OpenShift Container Platform 发行镜像摘要。
4.2.5. 验证托管集群创建
部署过程完成后,您可以验证托管集群是否已成功创建。在创建托管集群后,按照以下步骤操作。
流程
输入 extract 命令,获取新的托管集群的 kubeconfig :
$ oc extract -n <hosted-control-plane-namespace> secret/admin-kubeconfig \ --to=- > kubeconfig-<hosted-cluster-name>使用 kubeconfig 查看托管集群的集群 Operator。输入以下命令:
$ oc get co --kubeconfig=kubeconfig-<hosted-cluster-name>输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s dns 4.10.26 True False False 2m52s image-registry 4.10.26 True False False 2m8s ingress 4.10.26 True False False 22m您还可以输入以下命令来查看在托管集群中运行的 pod:
$ oc get pods -A --kubeconfig=kubeconfig-<hosted-cluster-name>输出示例
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-node-tuning-operator tuned-dhw5p 1/1 Running 0 109s openshift-cluster-storage-operator cluster-storage-operator-5f784969f5-vwzgz 1/1 Running 1 (113s ago) 20m openshift-cluster-storage-operator csi-snapshot-controller-6b7687b7d9-7nrfw 1/1 Running 0 3m8s openshift-console console-5cbf6c7969-6gk6z 1/1 Running 0 119s openshift-console downloads-7bcd756565-6wj5j 1/1 Running 0 4m3s openshift-dns-operator dns-operator-77d755cd8c-xjfbn 2/2 Running 0 21m openshift-dns dns-default-kfqnh 2/2 Running 0 113s
4.2.6. 在托管集群中配置自定义 API 服务器证书
要为 API 服务器配置自定义证书,请在 HostedCluster 配置的 spec.configuration.apiServer 部分中指定证书详情。
您可以在第 1 天或第 2 天操作期间配置自定义证书。但是,由于在托管集群创建过程中设置服务发布策略后,服务发布策略不可变,所以您必须知道您要配置的 Kubernetes API 服务器的主机名。
先决条件
您创建了包含管理集群中的自定义证书的 Kubernetes secret。secret 包含以下键:
-
tls.crt: 证书 -
tls.key:私钥
-
-
如果您的
HostedCluster配置包含使用负载均衡器的服务发布策略,请确保证书的 Subject Alternative Names (SAN)与内部 API 端点(api-int)不冲突。内部 API 端点由您的平台自动创建和管理。如果您在自定义证书和内部 API 端点中使用相同的主机名,则可能会出现路由冲突。此规则的唯一例外是,当您将 AWS 用作供应商时,使用Private或PublicAndPrivate配置。在这些情况下,SAN 冲突由平台管理。 - 证书必须对外部 API 端点有效。
- 证书的有效性周期与集群的预期生命周期一致。
流程
输入以下命令使用自定义证书创建 secret:
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>使用自定义证书详情更新
HostedCluster配置,如下例所示:spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert输入以下命令将更改应用到
HostedCluster配置:$ oc apply -f <hosted_cluster_config>.yaml
验证
- 检查 API 服务器 pod,以确保挂载了新证书。
- 使用自定义域名测试与 API 服务器的连接。
-
在浏览器中或使用
openssl等工具验证证书详情。
4.3. 在 OpenShift Virtualization 上部署托管的 control plane
使用托管的 control plane 和 OpenShift Virtualization,您可以使用 KubeVirt 虚拟机托管的 worker 节点创建 OpenShift Container Platform 集群。OpenShift Virtualization 上的托管 control plane 提供了几个优点:
- 通过在相同的底层裸机基础架构中打包托管的 control plane 和托管集群来提高资源使用量
- 分离托管的 control plane 和托管集群,以提供强大的隔离
- 通过删除裸机节点 bootstrap 过程来减少集群置备时间
- 管理同一基本 OpenShift Container Platform 集群中的多个发行版本
托管的 control plane 功能默认启用。
您可以使用托管的 control plane 命令行界面 hcp 创建 OpenShift Container Platform 托管的集群。托管的集群自动导入为受管集群。如果要禁用此自动导入功能,请参阅"禁用托管集群自动导入到多集群引擎 Operator"。
当您准备在 OpenShift Virtualization 上部署托管 control plane 时,请考虑以下信息:
- 在裸机上运行管理集群。
- 每个托管集群都必须具有集群范围的唯一名称。
-
不要使用
clusters作为托管的集群名称。 - 无法在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
- 当您为托管 control plane 配置存储时,请考虑推荐的 etcd 实践。要确保您满足延迟要求,请将快速存储设备专用于每个 control-plane 节点上运行的所有托管 control plane etcd 实例。您可以使用 LVM 存储为托管的 etcd pod 配置本地存储类。如需更多信息,请参阅"推荐 etcd 实践"和"使用逻辑卷管理器存储的持久性存储"。
4.3.1.1. 先决条件
您必须满足以下先决条件,才能在 OpenShift Virtualization 上创建 OpenShift Container Platform 集群:
-
您需要管理员访问由
KUBECONFIG环境变量指定的 OpenShift Container Platform 集群版本 4.14 或更高版本。 OpenShift Container Platform 管理集群必须启用通配符 DNS 路由,如下所示:
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'- OpenShift Container Platform 管理集群安装了 OpenShift Virtualization 版本 4.14 或更高版本。如需更多信息,请参阅"使用 Web 控制台安装 OpenShift Virtualization"。
- OpenShift Container Platform 管理集群是内部裸机。
-
OpenShift Container Platform 管理集群必须配置为
OVNKubernetes作为默认 pod 网络 Container Network Interface (CNI)。只有在 CNI 是 OVN-Kubernetes 时,节点才支持实时迁移。 OpenShift Container Platform 管理集群有一个默认存储类。如需更多信息,请参阅"安装后存储配置"。以下示例演示了如何设置默认存储类:
$ oc patch storageclass ocs-storagecluster-ceph-rbd \ -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'-
您有
quay.io/openshift-release-dev仓库的有效 pull secret 文件。如需更多信息,请参阅"在任何带有用户置备的基础架构的 x86_64 平台上安装 OpenShift"。 - 已安装托管的 control plane 命令行界面。
- 您已配置了负载均衡器。如需更多信息,请参阅"配置 MetalLB"。
为获得最佳网络性能,请在托管 KubeVirt 虚拟机的 OpenShift Container Platform 集群上使用网络最大传输单元(MTU)为 9000 或更高。如果您使用较低的 MTU 设置,则托管 pod 的网络延迟和吞吐量会受到影响。只有在 MTU 为 9000 或更高时,在节点池中启用 multiqueue。
重要您不能作为安装后任务更改集群的 MTU 值。
multicluster engine Operator 至少有一个受管 OpenShift Container Platform 集群。
local-cluster会自动导入。有关local-cluster的更多信息,请参阅 multicluster engine Operator 文档中的"高级配置"。您可以运行以下命令来检查 hub 集群的状态:$ oc get managedclusters local-cluster-
在托管 OpenShift Virtualization 虚拟机的 OpenShift Container Platform 集群中,您使用
ReadWriteMany(RWX)存储类,以便启用实时迁移。
4.3.1.2. 防火墙和端口要求
确保满足防火墙和端口要求,以便端口可以在管理集群、control plane 和托管的集群间进行通信:
kube-apiserver服务默认在端口 6443 上运行,需要入口访问 control plane 组件之间的通信。-
如果使用
NodePort发布策略,请确保公开分配给kube-apiserver服务的节点端口。 - 如果使用 MetalLB 负载均衡,允许入口访问用于负载均衡器 IP 地址的 IP 范围。
-
如果使用
-
如果使用
NodePort发布策略,请为ignition-server和Oauth-server设置使用防火墙规则。 konnectivity代理建立一个反向隧道,允许在托管集群上进行双向通信,需要在端口 6443 上访问集群 API 服务器地址。通过该出口访问权限,代理可以访问kube-apiserver服务。- 如果集群 API 服务器地址是一个内部 IP 地址,允许从工作负载子网访问端口 6443 上的 IP 地址。
- 如果地址是一个外部 IP 地址,允许从节点通过端口 6443 出口到该外部 IP 地址。
- 如果您更改了 6443 的默认端口,请调整规则以反映该更改。
- 确保打开集群中运行的工作负载所需的端口。
- 使用防火墙规则、安全组或其他访问控制来仅限制对所需源的访问。除非需要,否则请避免公开公开端口。
- 对于生产环境部署,请使用负载均衡器来简化通过单个 IP 地址的访问。
4.3.2. 计算节点实时迁移
虽然托管集群(VM)的管理集群正在进行更新或维护,但托管集群虚拟机可以自动实时迁移,以防止破坏托管集群工作负载。因此,可以在不影响 KubeVirt 平台托管集群的可用性和操作的情况下更新管理集群。
KubeVirt 虚拟机的实时迁移默认是启用的,虚拟机对根卷和映射到 kubevirt-csi CSI 供应商的存储类使用 ReadWriteMany (RWX) 存储。
您可以通过检查 NodePool 对象的 status 部分中的 KubeVirtNodesLiveMigratable 条件来验证节点池中的虚拟机是否能够实时迁移。
在以下示例中,无法实时迁移虚拟机,因为没有使用 RWX 存储。
虚拟机无法实时迁移的配置示例
- lastTransitionTime: "2024-10-08T15:38:19Z"
message: |
3 of 3 machines are not live migratable
Machine user-np-ngst4-gw2hz: DisksNotLiveMigratable: user-np-ngst4-gw2hz is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-gw2hz-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
Machine user-np-ngst4-npq7x: DisksNotLiveMigratable: user-np-ngst4-npq7x is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-npq7x-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
Machine user-np-ngst4-q5nkb: DisksNotLiveMigratable: user-np-ngst4-q5nkb is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-q5nkb-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
observedGeneration: 1
reason: DisksNotLiveMigratable
status: "False"
type: KubeVirtNodesLiveMigratable在下一个示例中,虚拟机满足实时迁移的要求。
虚拟机可实时迁移的配置示例
- lastTransitionTime: "2024-10-08T15:38:19Z"
message: "All is well"
observedGeneration: 1
reason: AsExpected
status: "True"
type: KubeVirtNodesLiveMigratable虽然实时迁移可以防止虚拟机正常中断,但基础架构节点故障等事件可能会导致在故障节点上托管的任何虚拟机都硬重启。要使实时迁移成功,在其上托管虚拟机的源节点必须可以正常工作。
当节点池中的虚拟机无法实时迁移时,在管理集群中的维护过程中可能会发生对托管集群的工作负载中断的问题。默认情况下,托管 control plane 控制器会尝试排空在虚拟机停止前无法实时迁移的 KubeVirt 虚拟机上托管的工作负载。在停止虚拟机前排空托管集群节点可让 pod 中断预算保护托管集群中的工作负载可用性。
4.3.3. 使用 KubeVirt 平台创建托管集群
在 OpenShift Container Platform 4.14 及更新的版本中,您可以使用 KubeVirt 创建集群,使其包含使用外部基础架构创建。
4.3.3.1. 使用 CLI 创建带有 KubeVirt 平台的托管集群
要创建托管集群,您可以使用托管的 control plane 命令行界面(CLI) hcp。
流程
输入以下命令创建带有 KubeVirt 平台的托管集群:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --etcd-storage-class=<etcd_storage_class>6 注意您可以使用
--release-image标志使用特定的 OpenShift Container Platform 发行版本设置托管集群。根据
--node-pool-replicas标志,为集群创建具有两个虚拟机 worker 副本的集群的默认节点池。片刻后,输入以下命令验证托管的 control plane pod 是否正在运行:
$ oc -n clusters-<hosted-cluster-name> get pods输出示例
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66s具有 KubeVirt 虚拟机支持的 worker 节点托管的集群通常需要 10-15 分钟才能被完全置备。
验证
要检查托管集群的状态,请输入以下命令查看对应的
HostedCluster资源:$ oc get --namespace clusters hostedclusters请参见以下示例输出,它演示了一个完全置备的
HostedCluster对象:NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters my-hosted-cluster <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
4.3.3.2. 使用外部基础架构创建带有 KubeVirt 平台的托管集群
默认情况下,HyperShift Operator 同时托管托管集群的 control plane pod 和同一集群中的 KubeVirt worker 虚拟机。使用外部基础架构功能,您可以将 worker 节点虚拟机放在与 control plane pod 的独立集群中。
- 管理集群是运行 HyperShift Operator 的 OpenShift Container Platform 集群,用于托管托管集群的 control plane pod。
- 基础架构集群是为托管集群运行 KubeVirt worker 虚拟机的 OpenShift Container Platform 集群。
- 默认情况下,管理集群也充当托管虚拟机的基础架构集群。但是,对于外部基础架构,管理和基础架构集群会有所不同。
先决条件
- 您必须在外部基础架构集群中有一个命名空间,才能托管 KubeVirt 节点。
-
您必须具有外部基础架构集群的
kubeconfig文件。
流程
您可以使用 hcp 命令行界面创建托管集群。
要将 KubeVirt worker 虚拟机放在基础架构集群中,请使用
--infra-kubeconfig-file和--infra-namespace参数,如下例所示:$ hcp create cluster kubevirt \ --name <hosted-cluster-name> \1 --node-pool-replicas <worker-count> \2 --pull-secret <path-to-pull-secret> \3 --memory <value-for-memory> \4 --cores <value-for-cpu> \5 --infra-namespace=<hosted-cluster-namespace>-<hosted-cluster-name> \6 --infra-kubeconfig-file=<path-to-external-infra-kubeconfig>7 输入该命令后,control plane pod 托管在运行 HyperShift Operator 的管理集群上,并且 KubeVirt 虚拟机托管在单独的基础架构集群中。
4.3.3.3. 使用控制台创建托管集群
要使用控制台创建带有 KubeVirt 平台的托管集群,请完成以下步骤。
流程
- 打开 OpenShift Container Platform Web 控制台,并输入您的管理员凭证登录。
- 在控制台标头中,确保选择了 All Clusters。
- 点 Infrastructure > Clusters。
- 点 Create cluster > Red Hat OpenShift Virtualization > Hosted。
在 Create cluster 页中,按照提示输入集群和节点池详情。
注意- 如果要使用预定义的值来自动填充控制台中的字段,您可以创建 OpenShift Virtualization 凭证。如需更多信息,请参阅为内部环境创建凭证。
- 在 Cluster details 页中,pull secret 是用于访问 OpenShift Container Platform 资源的 OpenShift Container Platform pull secret。如果选择了 OpenShift Virtualization 凭证,则会自动填充 pull secret。
检查您的条目并点 Create。
此时会显示 Hosted 集群视图。
验证
- 在托管集群视图中监控托管集群的部署。如果您没有看到托管集群的信息,请确保选择了 All Clusters,然后点集群名称。
- 等待 control plane 组件就绪。这个过程可能需要几分钟时间。
- 要查看节点池状态,请滚动到 NodePool 部分。安装节点的过程需要大约 10 分钟。您还可以点 Nodes 来确认节点是否加入托管集群。
每个 OpenShift Container Platform 集群都包含一个默认应用程序 Ingress Controller,它必须具有与其关联的通配符 DNS 记录。默认情况下,使用 HyperShift KubeVirt 供应商创建的托管集群会自动成为 KubeVirt 虚拟机在其上运行的 OpenShift Container Platform 集群的子域。
例如,OpenShift Container Platform 集群可能具有以下默认入口 DNS 条目:
*.apps.mgmt-cluster.example.com
因此,名为 guest 的 KubeVirt 托管集群,在该底层 OpenShift Container Platform 集群上运行的集群有以下默认入口:
*.apps.guest.apps.mgmt-cluster.example.com流程
要使默认入口 DNS 正常工作,托管 KubeVirt 虚拟机的集群必须允许通配符 DNS 路由。
您可以输入以下命令来配置此行为:
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'
当您使用默认托管集群入口时,连接仅限于通过端口 443 的 HTTPS 流量。通过端口 80 的普通 HTTP 流量被拒绝。这个限制只适用于默认的入口行为。
4.3.5. 自定义入口和 DNS 行为
如果您不想使用默认的 ingress 和 DNS 行为,您可以在创建时配置带有唯一基域的 KubeVirt 托管集群。此选项需要在创建过程中手动配置步骤,并涉及三个主要步骤:集群创建、负载均衡器创建和通配符 DNS 配置。
4.3.5.1. 部署指定基域的托管集群
要创建指定基域的托管集群,请完成以下步骤。
流程
输入以下命令:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --base-domain <basedomain>6 因此,托管集群有一个入口通配符,它被配置为集群名称和基域,如
.apps.example.hypershift.lab。托管的集群处于Partial状态,因为在创建具有唯一基域的托管集群后,您必须配置所需的 DNS 记录和负载均衡器。
验证
输入以下命令来查看托管集群的状态:
$ oc get --namespace clusters hostedclusters输出示例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available输入以下命令访问集群:
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console <4.x.0> False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress <4.x.0> True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
后续步骤
要修复输出中的错误,请完成"设置负载均衡器"和"设置通配符 DNS"中的步骤。
如果您的托管集群位于裸机上,您可能需要 MetalLB 设置负载均衡器服务。如需更多信息,请参阅"配置 MetalLB"。
4.3.5.2. 设置负载均衡器
设置负载均衡器服务,将入口流量路由到 KubeVirt 虚拟机,并为负载均衡器 IP 地址分配通配符 DNS 条目。
流程
公开托管集群入口的
NodePort服务已存在。您可以导出节点端口并创建以这些端口为目标的负载均衡器服务。输入以下命令来获取 HTTP 节点端口:
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'请注意在下一步中要使用的 HTTP 节点端口值。
输入以下命令来获取 HTTPS 节点端口:
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'请注意下一步要使用的 HTTPS 节点端口值。
在 YAML 文件中输入以下信息:
apiVersion: v1 kind: Service metadata: labels: app: <hosted_cluster_name> name: <hosted_cluster_name>-apps namespace: clusters-<hosted_cluster_name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https_node_port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http_node_port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer运行以下命令来创建负载均衡器服务:
$ oc create -f <file_name>.yaml
4.3.5.3. 设置通配符 DNS
设置通配符 DNS 记录或 CNAME,该记录引用负载均衡器服务的外部 IP。
流程
输入以下命令来获取外部 IP 地址:
$ oc -n clusters-<hosted_cluster_name> get service <hosted-cluster-name>-apps \ -o jsonpath='{.status.loadBalancer.ingress[0].ip}'输出示例
192.168.20.30配置引用外部 IP 地址的通配符 DNS 条目。查看以下示例 DNS 条目:
*.apps.<hosted_cluster_name\>.<base_domain\>.DNS 条目必须能够在集群内部和外部路由。
DNS 解析示例
dig +short test.apps.example.hypershift.lab 192.168.20.30
验证
输入以下命令检查托管集群状态是否已从
Partial变为Completed:$ oc get --namespace clusters hostedclusters输出示例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
4.3.6. 配置 MetalLB
在配置 MetalLB 前,您必须安装 MetalLB Operator。
流程
完成以下步骤,在托管集群中配置 MetalLB:
通过在
configure-metallb.yaml文件中保存以下示例 YAML 内容来创建MetalLB资源:apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system输入以下命令应用 YAML 内容:
$ oc apply -f configure-metallb.yaml输出示例
metallb.metallb.io/metallb created通过在
create-ip-address-pool.yaml文件中保存以下示例 YAML 内容来创建IPAddressPool资源:apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: addresses: - 192.168.216.32-192.168.216.1221 - 1
- 在节点网络中创建带有可用 IP 地址范围的地址池。将 IP 地址范围替换为网络中未使用的可用 IP 地址池。
输入以下命令应用 YAML 内容:
$ oc apply -f create-ip-address-pool.yaml输出示例
ipaddresspool.metallb.io/metallb created通过在
l2advertisement.yaml文件中保存以下示例 YAML 内容来创建L2Advertisement资源:apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb输入以下命令应用 YAML 内容:
$ oc apply -f l2advertisement.yaml输出示例
l2advertisement.metallb.io/metallb created
4.3.7. 为节点池配置额外网络、保证 CPU 和虚拟机调度
如果您需要为节点池配置额外网络,请为虚拟机(VM)请求保证的 CPU 访问权限,或者管理 KubeVirt 虚拟机的调度,请参阅以下步骤。
4.3.7.1. 将多个网络添加到节点池中
默认情况下,节点池生成的节点附加到 pod 网络。您可以使用 Multus 和 NetworkAttachmentDefinition 将额外网络附加到节点。
流程
要将多个网络添加到节点,请运行以下命令来使用
--additional-network参数:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --additional-network name:<namespace/name> \6 –-additional-network name:<namespace/name>
4.3.7.1.1. 使用额外网络作为默认
您可以通过禁用默认 pod 网络,将额外网络添加为节点的默认网络。
流程
要将额外网络作为默认添加到节点,请运行以下命令:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --attach-default-network false \6 --additional-network name:<namespace>/<network_name>7
4.3.7.2. 请求保证的 CPU 资源
默认情况下,KubeVirt 虚拟机可能会与节点上的其他工作负载共享其 CPU。这可能会影响虚拟机的性能。为了避免性能影响,您可以为虚拟机请求保证的 CPU 访问。
流程
要请求保证的 CPU 资源,请运行以下命令将
--qos-class参数设置为Guaranteed:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --qos-class Guaranteed6
4.3.7.3. 在一组节点上调度 KubeVirt 虚拟机
默认情况下,由节点池创建的 KubeVirt 虚拟机会调度到任何可用的节点。您可以将 KubeVirt 虚拟机调度到有足够能力来运行虚拟机的特定节点上。
流程
要在特定节点组中的节点池中调度 KubeVirt 虚拟机,请运行以下命令来使用
--vm-node-selector参数:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --vm-node-selector <label_key>=<label_value>,<label_key>=<label_value>6
4.3.8. 扩展节点池
您可以使用 oc scale 命令手动扩展节点池。
流程
运行以下命令:
NODEPOOL_NAME=${CLUSTER_NAME}-work NODEPOOL_REPLICAS=5 $ oc scale nodepool/$NODEPOOL_NAME --namespace clusters \ --replicas=$NODEPOOL_REPLICAS片刻后,输入以下命令查看节点池的状态:
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes输出示例
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca
4.3.8.1. 添加节点池
您可以通过指定名称、副本数和任何其他信息(如内存和 CPU 要求)为托管集群创建节点池。
流程
要创建节点池,请输入以下信息:在本例中,节点池会将更多 CPU 分配给虚拟机:
export NODEPOOL_NAME=${CLUSTER_NAME}-extra-cpu export WORKER_COUNT="2" export MEM="6Gi" export CPU="4" export DISK="16" $ hcp create nodepool kubevirt \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $WORKER_COUNT \ --memory $MEM \ --cores $CPU \ --root-volume-size $DISK通过列出
cluster命名空间中的nodepool资源来检查节点池的状态:$ oc get nodepools --namespace clusters输出示例
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False <4.x.0> example-extra-cpu example 2 False False True True Minimum availability requires 2 replicas, current 0 available将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
验证
一段时间后,您可以输入以下命令来检查节点池的状态:
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes输出示例
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca example-extra-cpu-zh9l5 Ready worker 2m6s v1.27.4+18eadca example-extra-cpu-zr8mj Ready worker 102s v1.27.4+18eadca输入以下命令验证节点池是否处于您期望的状态:
$ oc get nodepools --namespace clusters输出示例
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False <4.x.0> example-extra-cpu example 2 2 False False <4.x.0>将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
4.3.9. 在 OpenShift Virtualization 上验证托管集群创建
要验证托管集群是否已成功创建,请完成以下步骤。
流程
输入以下命令验证
HostedCluster资源是否已过渡到completed状态:$ oc get --namespace clusters hostedclusters <hosted_cluster_name>输出示例
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters example 4.12.2 example-admin-kubeconfig Completed True False The hosted control plane is available输入以下命令验证托管集群中的所有集群 Operator 是否在线:
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc get co --kubeconfig=<hosted_cluster_name>-kubeconfig输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.12.2 True False False 2m38s csi-snapshot-controller 4.12.2 True False False 4m3s dns 4.12.2 True False False 2m52s image-registry 4.12.2 True False False 2m8s ingress 4.12.2 True False False 22m kube-apiserver 4.12.2 True False False 23m kube-controller-manager 4.12.2 True False False 23m kube-scheduler 4.12.2 True False False 23m kube-storage-version-migrator 4.12.2 True False False 4m52s monitoring 4.12.2 True False False 69s network 4.12.2 True False False 4m3s node-tuning 4.12.2 True False False 2m22s openshift-apiserver 4.12.2 True False False 23m openshift-controller-manager 4.12.2 True False False 23m openshift-samples 4.12.2 True False False 2m15s operator-lifecycle-manager 4.12.2 True False False 22m operator-lifecycle-manager-catalog 4.12.2 True False False 23m operator-lifecycle-manager-packageserver 4.12.2 True False False 23m service-ca 4.12.2 True False False 4m41s storage 4.12.2 True False False 4m43s
4.3.10. 在托管集群中配置自定义 API 服务器证书
要为 API 服务器配置自定义证书,请在 HostedCluster 配置的 spec.configuration.apiServer 部分中指定证书详情。
您可以在第 1 天或第 2 天操作期间配置自定义证书。但是,由于在托管集群创建过程中设置服务发布策略后,服务发布策略不可变,所以您必须知道您要配置的 Kubernetes API 服务器的主机名。
先决条件
您创建了包含管理集群中的自定义证书的 Kubernetes secret。secret 包含以下键:
-
tls.crt: 证书 -
tls.key:私钥
-
-
如果您的
HostedCluster配置包含使用负载均衡器的服务发布策略,请确保证书的 Subject Alternative Names (SAN)与内部 API 端点(api-int)不冲突。内部 API 端点由您的平台自动创建和管理。如果您在自定义证书和内部 API 端点中使用相同的主机名,则可能会出现路由冲突。此规则的唯一例外是,当您将 AWS 用作供应商时,使用Private或PublicAndPrivate配置。在这些情况下,SAN 冲突由平台管理。 - 证书必须对外部 API 端点有效。
- 证书的有效性周期与集群的预期生命周期一致。
流程
输入以下命令使用自定义证书创建 secret:
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>使用自定义证书详情更新
HostedCluster配置,如下例所示:spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert输入以下命令将更改应用到
HostedCluster配置:$ oc apply -f <hosted_cluster_config>.yaml
验证
- 检查 API 服务器 pod,以确保挂载了新证书。
- 使用自定义域名测试与 API 服务器的连接。
-
在浏览器中或使用
openssl等工具验证证书详情。
4.4. 在非裸机代理机器上部署托管的 control plane
您可以通过将集群配置为充当托管集群来部署托管 control plane。托管的集群是一个托管 control plane 的 OpenShift Container Platform 集群。托管集群也称为管理集群。
在非裸机代理机器上托管 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
受管集群与受管集群不同。受管集群是 hub 集群管理的集群。
托管的 control plane 功能默认启用。
multicluster engine Operator 只支持默认的 local-cluster 受管集群。在 Red Hat Advanced Cluster Management (RHACM) 2.10 上,您可以使用 local-cluster 管理的 hub 集群作为托管集群。
托管的集群 是一个 OpenShift Container Platform 集群,其 API 端点和 control plane 托管在托管集群中。托管的集群包括控制平面和它的对应的数据平面。您可以使用 multicluster engine Operator 控制台或 hcp 命令行界面(CLI)创建托管集群。
托管的集群自动导入为受管集群。如果要禁用此自动导入功能,请参阅"禁用托管集群自动导入到多集群引擎 Operator"。
4.4.1. 准备在非裸机代理机器上部署托管的 control plane
当您准备在裸机上部署托管 control plane 时,请考虑以下信息:
- 您可以使用 Agent 平台将代理机器作为 worker 节点添加到托管集群。代理机器表示使用 Discovery 镜像引导的主机,并准备好置备为 OpenShift Container Platform 节点。Agent 平台是中央基础架构管理服务的一部分。如需更多信息,请参阅启用中央基础架构管理服务。
- 不是裸机的所有主机都需要通过中央基础架构管理提供的发现镜像 ISO 进行手动引导。
- 当您扩展节点池时,会为每个副本创建一个机器。对于每个机器,Cluster API 供应商会找到并安装已批准的代理,通过验证(验证)当前没有被使用,并满足节点池规格中指定的要求。您可以通过检查其状态和条件来监控代理的安装。
- 当您缩减节点池时,代理会从对应的集群绑定。在重复使用代理前,您必须使用 Discovery 镜像重启它们。
- 当您为托管 control plane 配置存储时,请考虑推荐的 etcd 实践。要确保您满足延迟要求,请将快速存储设备专用于每个 control-plane 节点上运行的所有托管 control plane etcd 实例。您可以使用 LVM 存储为托管的 etcd pod 配置本地存储类。如需更多信息,请参阅 OpenShift Container Platform 文档中的"推荐 etcd 实践"和"使用逻辑卷管理器存储的持久性存储"。
4.4.1.1. 在非裸机代理机器上部署托管 control plane 的先决条件
在非裸机代理机器上部署托管的 control plane 前,请确定您满足以下先决条件:
- 您必须在 OpenShift Container Platform 集群上安装 Kubernetes Operator 2.5 或更高版本的多集群引擎。您可以从 OpenShift Container Platform OperatorHub 将 multicluster engine Operator 安装为 Operator。
您必须至少有一个受管 OpenShift Container Platform 集群用于 multicluster engine Operator。
local-cluster管理集群会被自动导入。有关local-cluster的更多信息,请参阅 Red Hat Advanced Cluster Management 文档中的高级配置。您可以运行以下命令来检查管理集群的状态:$ oc get managedclusters local-cluster- 您已启用了中央基础架构管理。如需更多信息,请参阅 Red Hat Advanced Cluster Management 文档中的启用中央基础架构管理服务。
-
已安装
hcp命令行界面。 - 托管集群具有集群范围的唯一名称。
- 您在同一基础架构上运行管理集群和 worker。
4.4.1.2. 非裸机代理机器的防火墙、端口和服务要求
确保满足防火墙和端口要求,以便端口可以在管理集群、control plane 和托管的集群间进行通信:
服务在其默认端口上运行。但是,如果您使用 NodePort 发布策略,服务在由 NodePort 服务分配的端口上运行。
使用防火墙规则、安全组或其他访问控制来仅限制对所需源的访问。除非需要,否则请避免公开公开端口。对于生产环境部署,请使用负载均衡器来简化通过单个 IP 地址的访问。
托管 control plane 在非裸机代理机器上公开以下服务:
APIServer-
APIServer服务默认在端口 6443 上运行,需要入口访问 control plane 组件之间的通信。 - 如果使用 MetalLB 负载均衡,允许入口访问用于负载均衡器 IP 地址的 IP 范围。
-
OAuthServer-
当使用路由和入口来公开服务时,
OAuthServer服务默认在端口 443 上运行。 -
如果使用
NodePort发布策略,请为OAuthServer服务使用防火墙规则。
-
当使用路由和入口来公开服务时,
Konnectivity-
当使用路由和入口来公开服务时,
Konnectivity服务默认在端口 443 上运行。 -
Konnectity代理建立一个反向隧道,允许 control plane 访问托管集群的网络。代理使用出口连接到Konnectivity服务器。服务器通过使用端口 443 上的路由或手动分配的NodePort来公开。 - 如果集群 API 服务器地址是一个内部 IP 地址,允许从工作负载子网访问端口 6443 上的 IP 地址。
- 如果地址是一个外部 IP 地址,允许从节点通过端口 6443 出口到该外部 IP 地址。
-
当使用路由和入口来公开服务时,
Ignition-
当使用路由和入口来公开服务时,
Ignition服务默认在端口 443 上运行。 -
如果使用
NodePort发布策略,请为Ignition服务使用防火墙规则。
-
当使用路由和入口来公开服务时,
在非裸机代理机器上不需要以下服务:
-
OVNSbDb -
OIDC
4.4.1.3. 非裸机代理机器的基础架构要求
Agent 平台不会创建任何基础架构,但它有以下基础架构要求:
- 代理 : 代理 代表使用发现镜像引导的主机,并准备好置备为 OpenShift Container Platform 节点。
- DNS :API 和入口端点必须可以被路由。
4.4.2. 在非裸机代理机器上配置 DNS
托管集群的 API 服务器作为 NodePort 服务公开。必须存在 api.<hosted_cluster_name>.<basedomain> 的 DNS 条目,它指向可以访问 API 服务器的目标。
DNS 条目可以是一个简单的记录,指向运行托管 control plane 的受管集群中的一个节点。该条目也可以指向部署的负载均衡器,将传入的流量重定向到入口 pod。
如果您要为 IPv4 网络上的连接的环境配置 DNS,请查看以下 DNS 配置示例:
api.example.krnl.es. IN A 192.168.122.20 api.example.krnl.es. IN A 192.168.122.21 api.example.krnl.es. IN A 192.168.122.22 api-int.example.krnl.es. IN A 192.168.122.20 api-int.example.krnl.es. IN A 192.168.122.21 api-int.example.krnl.es. IN A 192.168.122.22 `*`.apps.example.krnl.es. IN A 192.168.122.23如果您要为 IPv6 网络上的断开连接的环境配置 DNS,请查看以下 DNS 配置示例:
api.example.krnl.es. IN A 2620:52:0:1306::5 api.example.krnl.es. IN A 2620:52:0:1306::6 api.example.krnl.es. IN A 2620:52:0:1306::7 api-int.example.krnl.es. IN A 2620:52:0:1306::5 api-int.example.krnl.es. IN A 2620:52:0:1306::6 api-int.example.krnl.es. IN A 2620:52:0:1306::7 `*`.apps.example.krnl.es. IN A 2620:52:0:1306::10如果您要为双栈网络上的断开连接的环境配置 DNS,请务必包括 IPv4 和 IPv6 的条目。请参见以下 DNS 配置示例:
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10 host-record=api.hub-dual.dns.base.domain.name,192.168.126.10 address=/apps.hub-dual.dns.base.domain.name/192.168.126.11 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20 dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21 dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22 dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25 dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26 host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2 host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2 address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5] dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6] dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7] dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8] dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]
4.4.3. 使用 CLI 在非裸机代理机器上创建托管集群
当使用 Agent 平台创建托管集群时,HyperShift Operator 会在托管的 control plane 命名空间中安装 Agent Cluster API 供应商。您可以在裸机上创建托管集群或导入一个集群。
在创建托管集群时,请查看以下准则:
- 每个托管集群都必须具有集群范围的唯一名称。托管的集群名称不能与任何现有的受管集群相同,以便多集群引擎 Operator 可以管理它。
-
不要使用
clusters作为托管的集群名称。 - 无法在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
流程
输入以下命令来创建托管的 control plane 命名空间:
$ oc create ns <hosted_cluster_namespace>-<hosted_cluster_name>1 - 1
- 将
<hosted_cluster_namespace>替换为托管集群命名空间名称,如clusters。将<hosted_cluster_name>替换为托管集群的名称。
输入以下命令创建托管集群:
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --control-plane-availability-policy HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release> \10 --node-pool-replicas <node_pool_replica_count>11 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 3
- 指定托管的 control plane 命名空间,如
cluster-example。使用oc get agent -n <hosted-control-plane-namespace>命令,确保此在命名空间中有可用的代理。 - 4
- 指定您的基域,如
krnl.es。 - 5
--api-server-address标志定义用于托管集群中的 Kubernetes API 通信的 IP 地址。如果没有设置--api-server-address标志,您必须登录以连接到管理集群。- 6
- 验证您是否为集群配置了默认存储类。否则,您可能会使用待处理的 PVC 结束。指定 etcd 存储类名称,如
lvm-storageclass。 - 7
- 指定 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 8
- 指定托管集群命名空间。
- 9
- 指定托管 control plane 组件的可用性策略。支持的选项包括
SingleReplica和HighlyAvailable。默认值为HighlyAvailable。 - 10
- 指定您要使用的 OpenShift Container Platform 版本,如
4.17.0-multi。 - 11
- 指定节点池副本数,例如
3。您必须将副本数指定为0或更高,才能创建相同数量的副本。否则,不会创建节点池。
验证
片刻后,输入以下命令验证托管 control plane pod 是否正在运行:
$ oc -n <hosted_cluster_namespace>-<hosted_cluster_name> get pods输出示例
NAME READY STATUS RESTARTS AGE catalog-operator-6cd867cc7-phb2q 2/2 Running 0 2m50s control-plane-operator-f6b4c8465-4k5dh 1/1 Running 0 4m32s
4.4.3.1. 使用 Web 控制台在非裸机代理机器上创建托管集群
您可以使用 OpenShift Container Platform Web 控制台在非裸机代理机器上创建托管集群。
先决条件
-
您可以使用
cluster-admin权限访问集群。 - 访问 OpenShift Container Platform web 控制台。
流程
- 打开 OpenShift Container Platform Web 控制台,并输入您的管理员凭证登录。
- 在控制台标头中,选择 All Clusters。
- 点 Infrastructure → Clusters。
点 Create cluster Host inventory → Hosted control plane。
此时会显示 Create cluster 页。
- 在 Create cluster 页中,按照提示输入集群、节点池、网络和自动化的详细信息。
在输入集群详情时,您可能会发现以下提示很有用:
- 如果要使用预定义的值来自动填充控制台中的字段,您可以创建主机清单凭证。如需更多信息,请参阅为内部环境创建凭证。
- 在 Cluster details 页中,pull secret 是用于访问 OpenShift Container Platform 资源的 OpenShift Container Platform pull secret。如果您选择了主机清单凭证,则会自动填充 pull secret。
- 在 Node pool 页中,命名空间包含节点池的主机。如果使用控制台创建主机清单,控制台会创建一个专用命名空间。
在 Networking 页上,您可以选择 API 服务器发布策略。托管集群的 API 服务器可以通过使用现有负载均衡器或
NodePort类型的服务公开。必须存在api.<hosted_cluster_name>.<basedomain>的 DNS 条目,指向可以访问 API 服务器的目标。此条目可以是指向管理集群中某一节点的记录,也可以是指向将传入流量重定向到 Ingress pod 的负载均衡器的记录。- 检查您的条目并点 Create。
此时会显示 Hosted 集群视图。
- 在托管集群视图中监控托管集群的部署。如果您没有看到托管集群的信息,请确保选择了 All Clusters,然后点集群名称。等待 control plane 组件就绪。这个过程可能需要几分钟时间。
- 要查看节点池状态,请滚动到 NodePool 部分。安装节点的过程需要大约 10 分钟。您还可以点 Nodes 来确认节点是否加入托管集群。
后续步骤
- 要访问 Web 控制台,请参阅访问 Web 控制台。
4.4.3.2. 使用镜像 registry 在非裸机代理机器上创建托管集群
您可以通过在 hcp create cluster 命令中指定-- image-content-sources 标志,使用镜像 registry 在非裸机代理机器上创建托管集群。
流程
创建 YAML 文件来定义镜像内容源策略 (ICSP)。请参见以下示例:
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
将文件保存为
icsp.yaml。此文件包含您的镜像 registry。 要使用您的镜像 registry 创建托管集群,请运行以下命令:
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --image-content-sources icsp.yaml \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>9 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 3
- 指定托管的 control plane 命名空间,如
cluster-example。使用oc get agent -n <hosted-control-plane-namespace>命令,确保此在命名空间中有可用的代理。 - 4
- 指定您的基域,如
krnl.es。 - 5
--api-server-address标志定义用于托管集群中的 Kubernetes API 通信的 IP 地址。如果没有设置--api-server-address标志,您必须登录以连接到管理集群。- 6
- 指定定义 ICSP 和您的镜像 registry 的
icsp.yaml文件。 - 7
- 指定 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 8
- 指定托管集群命名空间。
- 9
- 指定您要使用的 OpenShift Container Platform 版本,如
4.17.0-multi。如果您使用断开连接的环境,将<ocp_release_image>替换为摘要镜像。要提取 OpenShift Container Platform 发行镜像摘要,请参阅 提取 OpenShift Container Platform 发行镜像摘要。
后续步骤
- 要创建在使用控制台创建托管集群时重复使用的凭证,请参阅为内部环境创建凭证。
- 要访问托管集群,请参阅访问托管集群。
- 要使用发现镜像将主机添加到主机清单中,请参阅使用发现镜像将主机添加到主机清单中。
- 要提取 OpenShift Container Platform 发行镜像摘要,请参阅提取 OpenShift Container Platform 发行镜像摘要。
4.4.4. 在非裸机代理机器上验证托管集群创建
部署过程完成后,您可以验证托管集群是否已成功创建。在创建托管集群后,按照以下步骤操作。
流程
输入以下命令获取新托管集群的
kubeconfig文件:$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>使用
kubeconfig文件查看托管集群的集群 Operator。输入以下命令:$ oc get co --kubeconfig=kubeconfig-<hosted_cluster_name>输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s csi-snapshot-controller 4.10.26 True False False 4m3s dns 4.10.26 True False False 2m52s输入以下命令来查看在托管集群中运行的 pod:
$ oc get pods -A --kubeconfig=kubeconfig-<hosted_cluster_name>输出示例
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-samples-operator cluster-samples-operator-6b5bcb9dff-kpnbc 2/2 Running 0 20m openshift-monitoring alertmanager-main-0 6/6 Running 0 100s openshift-monitoring openshift-state-metrics-677b9fb74f-qqp6g 3/3 Running 0 104s
4.4.5. 在托管集群中配置自定义 API 服务器证书
要为 API 服务器配置自定义证书,请在 HostedCluster 配置的 spec.configuration.apiServer 部分中指定证书详情。
您可以在第 1 天或第 2 天操作期间配置自定义证书。但是,由于在托管集群创建过程中设置服务发布策略后,服务发布策略不可变,所以您必须知道您要配置的 Kubernetes API 服务器的主机名。
先决条件
您创建了包含管理集群中的自定义证书的 Kubernetes secret。secret 包含以下键:
-
tls.crt: 证书 -
tls.key:私钥
-
-
如果您的
HostedCluster配置包含使用负载均衡器的服务发布策略,请确保证书的 Subject Alternative Names (SAN)与内部 API 端点(api-int)不冲突。内部 API 端点由您的平台自动创建和管理。如果您在自定义证书和内部 API 端点中使用相同的主机名,则可能会出现路由冲突。此规则的唯一例外是,当您将 AWS 用作供应商时,使用Private或PublicAndPrivate配置。在这些情况下,SAN 冲突由平台管理。 - 证书必须对外部 API 端点有效。
- 证书的有效性周期与集群的预期生命周期一致。
流程
输入以下命令使用自定义证书创建 secret:
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>使用自定义证书详情更新
HostedCluster配置,如下例所示:spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert输入以下命令将更改应用到
HostedCluster配置:$ oc apply -f <hosted_cluster_config>.yaml
验证
- 检查 API 服务器 pod,以确保挂载了新证书。
- 使用自定义域名测试与 API 服务器的连接。
-
在浏览器中或使用
openssl等工具验证证书详情。
4.5. 在 IBM Z 上部署托管的 control plane
对于 IBM Z 上的托管 control plane,您必须根据 64 位 x86 架构在机器类型上运行 control plane,以及 IBM Power 或 IBM Z 上的节点池。有关其他架构上的 IBM Z 上托管的 control plane 的信息,请参阅 托管 control plane 的支持列表。
您可以通过将集群配置为充当管理集群来部署托管的 control plane。管理集群是托管 control plane 的 OpenShift Container Platform 集群。管理集群也称为托管集群。
管理集群不是受管集群。受管集群是 hub 集群管理的集群。
您可以使用 hypershift 附加组件将受管集群转换为管理集群。然后,您可以开始创建托管集群。
multicluster engine Operator 只支持默认的 local-cluster,它是管理的 hub 集群,而 hub 集群作为管理集群。
要在裸机上置备托管的 control plane,您可以使用 Agent 平台。Agent 平台使用中央基础架构管理服务将 worker 节点添加到托管的集群中。如需更多信息,请参阅"启用中央基础架构管理服务"。
每个 IBM Z 系统主机都必须通过中央基础架构管理提供的 PXE 镜像启动。每个主机启动后,它会运行一个代理进程来发现主机的详细信息并完成安装。Agent 自定义资源代表每个主机。
当使用 Agent 平台创建托管集群时,HyperShift Operator 会在托管的 control plane 命名空间中安装 Agent Cluster API 供应商。
4.5.1. 在 IBM Z 上配置托管的 control plane 的先决条件
- Kubernetes Operator 版本 2.5 或更高版本的多集群引擎必须安装在 OpenShift Container Platform 集群中。您可以从 OpenShift Container Platform OperatorHub 将 multicluster engine Operator 安装为 Operator。
multicluster engine Operator 必须至少有一个受管 OpenShift Container Platform 集群。
local-cluster在多集群引擎 Operator 2.5 及更新的版本中自动导入。有关local-cluster的更多信息,请参阅 Red Hat Advanced Cluster Management 中的高级配置部分。您可以运行以下命令来检查 hub 集群的状态:$ oc get managedclusters local-cluster- 您需要一个至少有三个 worker 节点的托管集群来运行 HyperShift Operator。
- 您需要启用中央基础架构管理服务。如需更多信息,请参阅启用中央基础架构管理服务。
- 您需要安装托管的 control plane 命令行界面。如需更多信息,请参阅安装托管的 control plane 命令行界面。
4.5.2. IBM Z 基础架构要求
Agent 平台不会创建任何基础架构,但需要以下基础架构资源:
- 代理 : 代理 代表使用发现镜像或 PXE 镜像引导的主机,并准备好置备为 OpenShift Container Platform 节点。
- DNS :API 和入口端点必须可以被路由。
托管的 control plane 功能默认启用。如果您禁用了该功能并希望手动启用它,或者需要禁用该功能,请参阅启用或禁用托管的 control plane 功能。
4.5.3. IBM Z 上托管的 control plane 的 DNS 配置
托管集群的 API 服务器作为 NodePort 服务公开。必须存在 api.<hosted_cluster_name>.<base_domain> 的 DNS 条目,指向可以访问 API 服务器的目标。
DNS 条目可以是一个简单的记录,指向运行托管 control plane 的受管集群中的一个节点。
该条目也可以指向部署的负载均衡器,将传入的流量重定向到 Ingress pod。
请参阅以下 DNS 配置示例:
$ cat /var/named/<example.krnl.es.zone>输出示例
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- 记录指的是 API 负载均衡器的 IP 地址,用于处理托管 control plane 的入口和出口流量。
对于 IBM z/VM,添加与代理 IP 地址对应的 IP 地址。
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy4.5.4. 使用 CLI 创建托管集群
在裸机基础架构上,您可以创建或导入托管集群。在为多集群引擎 Operator 启用 Assisted Installer 作为附加组件后,您可以使用 Agent 平台创建一个托管集群,HyperShift Operator 会在托管的 control plane 命名空间中安装 Agent Cluster API 供应商。Agent Cluster API 供应商连接托管 control plane 和一个仅由计算节点组成的托管集群的管理集群。
先决条件
- 每个托管集群都必须具有集群范围的唯一名称。托管的集群名称都不能与任何现有受管集群相同。否则,多集群引擎 Operator 无法管理托管集群。
-
不要使用单词
cluster作为托管的集群名称。 - 您不能在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
- 为获得最佳安全性和管理实践,请创建一个与其他托管集群分开的托管集群。
- 验证您是否为集群配置了默认存储类。否则,您可能会看到待处理的持久性卷声明(PVC)。
-
默认情况下,当使用
hcp create cluster agent命令时,命令会创建一个带有配置的节点端口的托管集群。裸机上托管集群的首选发布策略通过负载均衡器公开服务。如果使用 Web 控制台或使用 Red Hat Advanced Cluster Management 创建托管集群,要为 Kubernetes API 服务器以外的服务设置发布策略,您必须在HostedCluster自定义资源中手动指定servicePublishingStrategy信息。 确保您满足裸机上托管 control plane 的 "Requirements for hosted control plane" 中描述的要求,其中包括与基础架构、防火墙、端口和服务相关的要求。例如,这些要求描述了如何在管理集群中的裸机主机中添加适当的区标签,如下例所示:
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- 确保您已将裸机节点添加到硬件清单中。
流程
运行以下命令来创建命名空间:
$ oc create ns <hosted_cluster_namespace>将
<hosted_cluster_namespace> 替换为托管集群命名空间的标识符。HyperShift Operator 创建命名空间。在裸机基础架构上托管集群创建过程中,生成的 Cluster API 供应商角色需要命名空间已存在。输入以下命令为托管集群创建配置文件:
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- 指定托管集群的名称,
如。 - 2
- 指定 pull secret 的路径,如
/user/name/pullsecret。 - 3
- 指定托管的 control plane 命名空间,如
cluster-example。使用oc get agent -n <hosted_control_plane_namespace>命令,确保此命名空间中有代理可用。 - 4
- 指定您的基域,如
krnl.es。 - 5
--api-server-address标志定义用于托管集群中的 Kubernetes API 通信的 IP 地址。如果没有设置--api-server-address标志,您必须登录以连接到管理集群。- 6
- 指定 etcd 存储类名称,如
lvm-storageclass。 - 7
- 指定 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 8
- 指定托管集群命名空间。
- 9
- 指定托管 control plane 组件的可用性策略。支持的选项包括
SingleReplica和HighlyAvailable。默认值为HighlyAvailable。 - 10
- 指定您要使用的 OpenShift Container Platform 版本,如
4.19.0-multi。如果您使用断开连接的环境,将<ocp_release_image>替换为摘要镜像。要提取 OpenShift Container Platform 发行镜像摘要,请参阅 提取 OpenShift Container Platform 发行镜像摘要。 - 11
- 指定节点池副本数,如
3。您必须将副本数指定为0或更高,才能创建相同数量的副本。否则,您不会创建节点池。 - 12
- 在
--ssh-key标志后,指定 SSH 密钥的路径,如user/.ssh/id_rsa。
配置服务发布策略。默认情况下,托管集群使用
NodePort服务发布策略,因为节点端口始终在没有额外基础架构的情况下可用。但是,您可以将服务发布策略配置为使用负载均衡器。-
如果您使用默认的
NodePort策略,请将 DNS 配置为指向托管的集群计算节点,而不是管理集群节点。如需更多信息,请参阅"裸机上的 DNS 配置"。 对于生产环境,请使用
LoadBalancer策略,因为此策略提供证书处理和自动 DNS 解析。以下示例演示了在托管集群配置文件中更改服务发布LoadBalancer策略:# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- 指定
LoadBalancer作为 API 服务器类型。对于所有其他服务,将Route指定为类型。
-
如果您使用默认的
输入以下命令将更改应用到托管集群配置文件:
$ oc apply -f hosted_cluster_config.yaml输入以下命令检查托管集群、节点池和 pod 的创建:
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
确认托管集群已就绪。
Available: True的状态表示集群的就绪状态,节点池状态显示AllMachinesReady: True。这些状态表示所有集群 Operator 的运行状况。 在托管集群中安装 MetalLB:
从托管集群中提取
kubeconfig文件,并输入以下命令为托管集群访问设置环境变量:$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"通过创建
install-metallb-operator.yaml文件来安装 MetalLB Operator:apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...输入以下命令应用该文件:
$ oc apply -f install-metallb-operator.yaml通过创建
deploy-metallb-ipaddresspool.yaml文件来配置 MetalLB IP 地址池:apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...输入以下命令应用配置:
$ oc apply -f deploy-metallb-ipaddresspool.yaml输入以下命令检查 Operator 状态、IP 地址池和
L2Advertisement资源来验证 MetalLB 的安装:$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
为入口配置负载均衡器:
创建
ingress-loadbalancer.yaml文件:apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...输入以下命令应用配置:
$ oc apply -f ingress-loadbalancer.yaml输入以下命令验证负载均衡器服务是否按预期工作:
$ oc get svc metallb-ingress -n openshift-ingress输出示例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
配置 DNS 以使用负载均衡器:
-
通过将 5.2.
apps.<hosted_cluster_namespace>.<base_domain> 通配符 DNS 记录指向负载均衡器 IP 地址,为 apps域配置 DNS。 输入以下命令验证 DNS 解析:
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>输出示例
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
通过将 5.2.
验证
输入以下命令检查集群 Operator:
$ oc get clusteroperators确保所有 Operator 显示
AVAILABLE: True,PROGRESSING: False, 和DEGRADED: False。输入以下命令检查节点:
$ oc get nodes确保每个节点都有
READY状态。通过在 Web 浏览器中输入以下 URL 来测试对控制台的访问:
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.5.5. 为 IBM Z 上托管的 control plane 创建 InfraEnv 资源
InfraEnv 是一个使用 PXE 镜像引导的主机可作为代理加入的环境。在这种情况下,代理会在与您托管的 control plane 相同的命名空间中创建。
流程
创建 YAML 文件以包含配置。请参见以下示例:
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_control_plane_namespace> spec: cpuArchitecture: s390x pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key>-
将文件保存为
infraenv-config.yaml。 输入以下命令应用配置:
$ oc apply -f infraenv-config.yaml要获取下载 PXE 镜像的 URL,如
initrd.img、kernel.img或rootfs.img,它允许 IBM Z 机器作为代理加入,请输入以下命令:$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name> -o json
4.5.6. 在 InfraEnv 资源中添加 IBM Z 代理
要将计算节点附加到托管的 control plane,请创建有助于您扩展节点池的代理。在 IBM Z 环境中添加代理需要额外的步骤,这在本节中详细介绍。
除非另有说明,否则这些步骤适用于 IBM Z 和 IBM LinuxONE 上的 z/VM 和 RHEL KVM 安装。
4.5.6.1. 将 IBM Z KVM 作为代理添加
对于带有 KVM 的 IBM Z,运行以下命令,使用从 InfraEnv 资源下载的 PXE 镜像启动 IBM Z 环境。创建代理后,主机与 Assisted Service 通信,并注册与管理集群上的 InfraEnv 资源相同的命名空间中。
流程
运行以下命令:
virt-install \ --name "<vm_name>" \1 --autostart \ --ram=16384 \ --cpu host \ --vcpus=4 \ --location "<path_to_kernel_initrd_image>,kernel=kernel.img,initrd=initrd.img" \2 --disk <qcow_image_path> \3 --network network:macvtap-net,mac=<mac_address> \4 --graphics none \ --noautoconsole \ --wait=-1 --extra-args "rd.neednet=1 nameserver=<nameserver> coreos.live.rootfs_url=http://<http_server>/rootfs.img random.trust_cpu=on rd.luks.options=discard ignition.firstboot ignition.platform.id=metal console=tty1 console=ttyS1,115200n8 coreos.inst.persistent-kargs=console=tty1 console=ttyS1,115200n8"5 对于 ISO 引导,从
InfraEnv资源下载 ISO,并运行以下命令来引导节点:virt-install \ --name "<vm_name>" \1 --autostart \ --memory=16384 \ --cpu host \ --vcpus=4 \ --network network:macvtap-net,mac=<mac_address> \2 --cdrom "<path_to_image.iso>" \3 --disk <qcow_image_path> \ --graphics none \ --noautoconsole \ --os-variant <os_version> \4 --wait=-1
4.5.6.2. 添加 IBM Z LPAR 作为代理
您可以在 IBM Z 或 IBM LinuxONE 上将逻辑分区(LPAR)作为计算节点添加到托管的 control plane。
流程
为代理创建引导参数文件:
参数文件示例
rd.neednet=1 cio_ignore=all,!condev \ console=ttysclp0 \ ignition.firstboot ignition.platform.id=metal coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \1 coreos.inst.persistent-kargs=console=ttysclp0 ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \2 rd.znet=qeth,<network_adaptor_range>,layer2=1 rd.<disk_type>=<adapter> \3 zfcp.allow_lun_scan=0 ai.ip_cfg_override=1 \4 random.trust_cpu=on rd.luks.options=discard- 1
- 对于
coreos.live.rootfs_url工件,请为您要启动的kernel和initramfs指定匹配的rootfs工件。仅支持 HTTP 和 HTTPS 协议。 - 2
- 对于
ip参数,请手动分配 IP 地址,如 在 IBM Z 和 IBM LinuxONE 中使用 z/VM 安装集群中所述。 - 3
- 对于在 DASD 类型磁盘中安装,请使用
rd.dasd指定要安装 Red Hat Enterprise Linux CoreOS (RHCOS) 的 DASD。对于在 FCP 类型磁盘中安装,请使用rd.zfcp=<adapter>,<wwpn>,<lun>指定要安装 RHCOS 的 FCP 磁盘。 - 4
- 使用 Open Systems Adapter (OSA) 或 HiperSockets 时指定此参数。
从
InfraEnv资源下载.ins和initrd.img.addrsize文件。默认情况下,
InfraEnv资源中没有.ins和initrd.img.addrsize文件的 URL。您必须编辑 URL 来获取这些工件。运行以下命令,将内核 URL 端点更新为包含
ins-file:$ curl -k -L -o generic.ins "< url for ins-file >"URL 示例
https://…/boot-artifacts/ins-file?arch=s390x&version=4.17.0更新
initrdURL 端点,使其包含s390x-initrd-addrsize:URL 示例
https://…./s390x-initrd-addrsize?api_key=<api-key>&arch=s390x&version=4.17.0
-
将
initrd、kernel、common.ins和initrd.img.addrsize参数文件传输到文件服务器。有关如何使用 FTP 和引导传输文件的更多信息,请参阅"在 LPAR 中安装"。 - 启动机器。
- 对集群中的所有其他机器重复这个过程。
4.5.6.3. 添加 IBM z/VM 作为代理
如果要将静态 IP 用于 z/VM 客户机,您必须为 z/VM 代理配置 NMStateConfig 属性,以便 IP 参数保留在第二个启动中。
完成以下步骤,使用从 InfraEnv 资源下载的 PXE 镜像启动 IBM Z 环境。创建代理后,主机与 Assisted Service 通信,并注册与管理集群上的 InfraEnv 资源相同的命名空间中。
流程
更新参数文件,以添加
rootfs_url、network_adaptor和disk_type值。参数文件示例
rd.neednet=1 cio_ignore=all,!condev \ console=ttysclp0 \ ignition.firstboot ignition.platform.id=metal \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \1 coreos.inst.persistent-kargs=console=ttysclp0 ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \2 rd.znet=qeth,<network_adaptor_range>,layer2=1 rd.<disk_type>=<adapter> \3 zfcp.allow_lun_scan=0 ai.ip_cfg_override=1 \4 - 1
- 对于
coreos.live.rootfs_url工件,请为您要启动的kernel和initramfs指定匹配的rootfs工件。仅支持 HTTP 和 HTTPS 协议。 - 2
- 对于
ip参数,请手动分配 IP 地址,如 在 IBM Z 和 IBM LinuxONE 中使用 z/VM 安装集群中所述。 - 3
- 对于在 DASD 类型磁盘中安装,请使用
rd.dasd指定要安装 Red Hat Enterprise Linux CoreOS (RHCOS) 的 DASD。对于在 FCP 类型磁盘中安装,请使用rd.zfcp=<adapter>,<wwpn>,<lun>指定要安装 RHCOS 的 FCP 磁盘。 - 4
- 使用 Open Systems Adapter (OSA) 或 HiperSockets 时指定此参数。
运行以下命令,将
initrd、内核镜像和参数文件移到客户虚拟机中:vmur pun -r -u -N kernel.img $INSTALLERKERNELLOCATION/<image name>vmur pun -r -u -N generic.parm $PARMFILELOCATION/paramfilenamevmur pun -r -u -N initrd.img $INSTALLERINITRAMFSLOCATION/<image name>从客户机虚拟机控制台运行以下命令:
cp ipl c要列出代理及其属性,请输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agents输出示例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a auto-assign运行以下命令来批准代理。
$ oc -n <hosted_control_plane_namespace> patch agent \ 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d -p \ '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-zvm-0.hostedn.example.com"}}' \1 --type merge- 1
- 另外,您还可以在规格中设置代理 ID
<installation_disk_id>和<hostname>。
运行以下命令验证代理是否已批准:
$ oc -n <hosted_control_plane_namespace> get agents输出示例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign
4.5.7. 为 IBM Z 上托管集群扩展 NodePool 对象
NodePool 对象在创建托管集群时创建。通过扩展 NodePool 对象,您可以在托管的 control plane 中添加更多计算节点。
当您扩展节点池时,会创建一个机器。Cluster API 供应商会找到已批准的、通过验证的、当前没有被使用但满足节点池规格中指定的要求的代理。您可以通过检查其状态和条件来监控代理的安装。
当您缩减节点池时,代理会从对应的集群绑定。在重复使用集群前,您必须使用 PXE 镜像引导集群以更新节点数。
流程
运行以下命令,将
NodePool对象扩展到两个节点:$ oc -n <clusters_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 代理供应商会随机选择两个分配给托管集群的代理。这些代理会经历不同的状态,最终将托管集群作为 OpenShift Container Platform 节点加入。代理按以下顺序通过转换阶段:
-
binding -
discovering -
insufficient -
installing -
install-in-progress -
added-to-existing-cluster
-
运行以下命令,以查看特定扩展代理的状态:
$ oc -n <hosted_control_plane_namespace> get agent -o \ jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} \ Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'输出示例
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient运行以下命令来查看转换阶段:
$ oc -n <hosted_control_plane_namespace> get agent输出示例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign运行以下命令以生成
kubeconfig文件来访问托管集群:$ hcp create kubeconfig \ --namespace <clusters_namespace> \ --name <hosted_cluster_namespace> > <hosted_cluster_name>.kubeconfig代理访问
added-to-existing-cluster状态后,输入以下命令验证您可以看到 OpenShift Container Platform 节点:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes输出示例
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8f集群 Operator 开始通过向节点添加工作负载来协调。
输入以下命令验证在扩展
NodePool对象时是否创建了两台机器:$ oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io输出示例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0运行以下命令来检查集群版本:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0-ec.2 True False 40h Cluster version is 4.15.0-ec.2运行以下命令来检查集群 Operator 状态:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators
对于集群的每个组件,输出显示以下集群操作器状态: NAME,VERSION,AVAILABLE,PROGRESSING,DEGRADED,SINCE, 和 MESSAGE。
如需输出示例,请参阅 Initial Operator 配置。
4.6. 在 IBM Power 上部署托管的 control plane
您可以通过将集群配置为充当托管集群来部署托管 control plane。此配置为管理许多集群提供了高效且可扩展的解决方案。托管的集群是托管 control plane 的 OpenShift Container Platform 集群。托管集群也称为管理集群。
管理集群不是受管集群。受管集群是 hub 集群管理的集群。
multicluster engine Operator 只支持默认的 local-cluster,它是一个受管 hub 集群,hub 集群作为托管集群。
要在裸机基础架构上置备托管的 control plane,您可以使用 Agent 平台。Agent 平台使用中央基础架构管理服务将计算节点添加到托管集群。如需更多信息,请参阅"启用中央基础架构管理服务"。
您必须使用中央基础架构管理提供的发现镜像启动每个 IBM Power 主机。每个主机启动后,它会运行一个代理进程来发现主机的详细信息并完成安装。Agent 自定义资源代表每个主机。
当使用 Agent 平台创建托管集群时,Hyper HyperShift 会在托管的 control plane 命名空间中安装 Agent Cluster API 供应商。
4.6.1. 在 IBM Power 上配置托管的 control plane 的先决条件
- 在 OpenShift Container Platform 集群上安装 Kubernetes Operator 版本 2.7 及更新的版本。安装 Red Hat Advanced Cluster Management (RHACM) 时会自动安装 multicluster engine Operator。您还可以在没有 RHACM 的情况下从 OpenShift Container Platform OperatorHub 安装 multicluster engine Operator。
multicluster engine Operator 必须至少有一个受管 OpenShift Container Platform 集群。
local-cluster受管 hub 集群会在 multicluster engine Operator 版本 2.7 及更高版本中自动导入。有关local-cluster的更多信息,请参阅 RHACM 文档中的高级配置。您可以运行以下命令来检查 hub 集群的状态:$ oc get managedclusters local-cluster- 您需要具有至少 3 个计算节点的托管集群来运行 HyperShift Operator。
- 您需要启用中央基础架构管理服务。如需更多信息,请参阅"启用中央基础架构管理服务"。
- 您需要安装托管的 control plane 命令行界面。如需更多信息,请参阅"安装托管的 control plane 命令行界面"。
托管的 control plane 功能默认启用。如果您禁用了这个功能并希望手动启用该功能,请参阅"手动启用托管的 control plane 功能"。如果您需要禁用该功能,请参阅"禁用托管的 control planes 功能"。
4.6.2. IBM Power 基础架构要求
Agent 平台不会创建任何基础架构,但需要以下基础架构资源:
- 代理 : 代理 代表使用 Discovery 镜像引导的主机,您可以置备为 OpenShift Container Platform 节点。
- DNS :API 和入口端点必须可以被路由。
4.6.3. IBM Power 上托管的 control plane 的 DNS 配置
集群外的客户端可以访问托管集群的 API 服务器。必须存在 api.<hosted_cluster_name>.<basedomain> 的 DNS 条目,指向可以访问 API 服务器的目标。
DNS 条目可以像一个记录一样简单,该记录指向运行托管 control plane 的受管集群中的一个节点。
该条目也可以指向部署的负载均衡器,将传入的流量重定向到入口 pod。
请参阅以下 DNS 配置示例:
$ cat /var/named/<example.krnl.es.zone>输出示例
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps.<hosted_cluster_name>.<basedomain> IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- 记录指的是 API 负载均衡器的 IP 地址,用于处理托管 control plane 的入口和出口流量。
对于 IBM Power,添加与代理 IP 地址对应的 IP 地址。
配置示例
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy4.6.4. 使用 CLI 创建托管集群
在裸机基础架构上,您可以创建或导入托管集群。在为多集群引擎 Operator 启用 Assisted Installer 作为附加组件后,您可以使用 Agent 平台创建一个托管集群,HyperShift Operator 会在托管的 control plane 命名空间中安装 Agent Cluster API 供应商。Agent Cluster API 供应商连接托管 control plane 和一个仅由计算节点组成的托管集群的管理集群。
先决条件
- 每个托管集群都必须具有集群范围的唯一名称。托管的集群名称都不能与任何现有受管集群相同。否则,多集群引擎 Operator 无法管理托管集群。
-
不要使用单词
cluster作为托管的集群名称。 - 您不能在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
- 为获得最佳安全性和管理实践,请创建一个与其他托管集群分开的托管集群。
- 验证您是否为集群配置了默认存储类。否则,您可能会看到待处理的持久性卷声明(PVC)。
-
默认情况下,当使用
hcp create cluster agent命令时,命令会创建一个带有配置的节点端口的托管集群。裸机上托管集群的首选发布策略通过负载均衡器公开服务。如果使用 Web 控制台或使用 Red Hat Advanced Cluster Management 创建托管集群,要为 Kubernetes API 服务器以外的服务设置发布策略,您必须在HostedCluster自定义资源中手动指定servicePublishingStrategy信息。 确保您满足裸机上托管 control plane 的 "Requirements for hosted control plane" 中描述的要求,其中包括与基础架构、防火墙、端口和服务相关的要求。例如,这些要求描述了如何在管理集群中的裸机主机中添加适当的区标签,如下例所示:
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- 确保您已将裸机节点添加到硬件清单中。
流程
运行以下命令来创建命名空间:
$ oc create ns <hosted_cluster_namespace>将
<hosted_cluster_namespace> 替换为托管集群命名空间的标识符。HyperShift Operator 创建命名空间。在裸机基础架构上托管集群创建过程中,生成的 Cluster API 供应商角色需要命名空间已存在。输入以下命令为托管集群创建配置文件:
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- 指定托管集群的名称,
如。 - 2
- 指定 pull secret 的路径,如
/user/name/pullsecret。 - 3
- 指定托管的 control plane 命名空间,如
cluster-example。使用oc get agent -n <hosted_control_plane_namespace>命令,确保此命名空间中有代理可用。 - 4
- 指定您的基域,如
krnl.es。 - 5
--api-server-address标志定义用于托管集群中的 Kubernetes API 通信的 IP 地址。如果没有设置--api-server-address标志,您必须登录以连接到管理集群。- 6
- 指定 etcd 存储类名称,如
lvm-storageclass。 - 7
- 指定 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 8
- 指定托管集群命名空间。
- 9
- 指定托管 control plane 组件的可用性策略。支持的选项包括
SingleReplica和HighlyAvailable。默认值为HighlyAvailable。 - 10
- 指定您要使用的 OpenShift Container Platform 版本,如
4.19.0-multi。如果您使用断开连接的环境,将<ocp_release_image>替换为摘要镜像。要提取 OpenShift Container Platform 发行镜像摘要,请参阅 提取 OpenShift Container Platform 发行镜像摘要。 - 11
- 指定节点池副本数,如
3。您必须将副本数指定为0或更高,才能创建相同数量的副本。否则,您不会创建节点池。 - 12
- 在
--ssh-key标志后,指定 SSH 密钥的路径,如user/.ssh/id_rsa。
配置服务发布策略。默认情况下,托管集群使用
NodePort服务发布策略,因为节点端口始终在没有额外基础架构的情况下可用。但是,您可以将服务发布策略配置为使用负载均衡器。-
如果您使用默认的
NodePort策略,请将 DNS 配置为指向托管的集群计算节点,而不是管理集群节点。如需更多信息,请参阅"裸机上的 DNS 配置"。 对于生产环境,请使用
LoadBalancer策略,因为此策略提供证书处理和自动 DNS 解析。以下示例演示了在托管集群配置文件中更改服务发布LoadBalancer策略:# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- 指定
LoadBalancer作为 API 服务器类型。对于所有其他服务,将Route指定为类型。
-
如果您使用默认的
输入以下命令将更改应用到托管集群配置文件:
$ oc apply -f hosted_cluster_config.yaml输入以下命令检查托管集群、节点池和 pod 的创建:
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
确认托管集群已就绪。
Available: True的状态表示集群的就绪状态,节点池状态显示AllMachinesReady: True。这些状态表示所有集群 Operator 的运行状况。 在托管集群中安装 MetalLB:
从托管集群中提取
kubeconfig文件,并输入以下命令为托管集群访问设置环境变量:$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"通过创建
install-metallb-operator.yaml文件来安装 MetalLB Operator:apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...输入以下命令应用该文件:
$ oc apply -f install-metallb-operator.yaml通过创建
deploy-metallb-ipaddresspool.yaml文件来配置 MetalLB IP 地址池:apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...输入以下命令应用配置:
$ oc apply -f deploy-metallb-ipaddresspool.yaml输入以下命令检查 Operator 状态、IP 地址池和
L2Advertisement资源来验证 MetalLB 的安装:$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
为入口配置负载均衡器:
创建
ingress-loadbalancer.yaml文件:apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...输入以下命令应用配置:
$ oc apply -f ingress-loadbalancer.yaml输入以下命令验证负载均衡器服务是否按预期工作:
$ oc get svc metallb-ingress -n openshift-ingress输出示例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
配置 DNS 以使用负载均衡器:
-
通过将 5.2.
apps.<hosted_cluster_namespace>.<base_domain> 通配符 DNS 记录指向负载均衡器 IP 地址,为 apps域配置 DNS。 输入以下命令验证 DNS 解析:
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>输出示例
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
通过将 5.2.
验证
输入以下命令检查集群 Operator:
$ oc get clusteroperators确保所有 Operator 显示
AVAILABLE: True,PROGRESSING: False, 和DEGRADED: False。输入以下命令检查节点:
$ oc get nodes确保每个节点都有
READY状态。通过在 Web 浏览器中输入以下 URL 来测试对控制台的访问:
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
第 5 章 管理托管的 control plane
5.1. 在 AWS 上管理托管的 control plane
当您为 Amazon Web Services (AWS) 上的 OpenShift Container Platform 使用托管的 control plane 时,基础架构要求会因设置而异。
5.1.1. 管理 AWS 基础架构和 IAM 权限的先决条件
要在 Amazon Web Services (AWS) 上为 OpenShift Container Platform 配置托管的 control plane,您必须满足以下要求:
- 在创建托管集群前,配置了托管的 control plane。
- 您创建了 AWS Identity and Access Management (IAM) 角色和 AWS 安全令牌服务(STS) 凭证。
5.1.1.1. AWS 的基础架构要求
当您在 Amazon Web Services (AWS) 上使用托管的 control plane 时,基础架构要求适合以下类别:
- 任意 AWS 帐户中的 HyperShift Operator 的 Prerequired 和 unmanaged 基础架构
- 托管集群 AWS 帐户中的 Prerequired 和 unmanaged 基础架构
- 在管理 AWS 帐户中托管 control planes 管理的基础架构
- 在托管集群 AWS 帐户中托管 control plane 管理的基础架构
- 托管集群 AWS 帐户中的 Kubernetes 管理基础架构
Prerequired 表示托管 control plane 需要 AWS 基础架构才能正常工作。Unmanaged 意味着没有 Operator 或控制器为您创建基础架构。
5.1.1.2. AWS 帐户中的 HyperShift Operator 的非受管基础架构
任意 Amazon Web Services (AWS) 帐户取决于托管的 control plane 服务的供应商。
在自我管理的托管 control plane 中,集群服务提供商控制 AWS 帐户。集群服务提供商是托管集群 control plane 并负责运行时间的管理员。在托管的 control plane 中,AWS 帐户属于红帽。
在 HyperShift Operator 的预必需和非受管基础架构中,为管理集群 AWS 帐户应用以下基础架构要求:
一个 S3 存储桶
- OpenID Connect(OIDC)
路由 53 托管区域
- 托管集群的私有和公共条目的域
5.1.1.3. 管理 AWS 帐户的非受管基础架构要求
当您的基础架构在托管集群 Amazon Web Services (AWS) 帐户中预必需且非受管时,所有访问模式的基础架构要求如下:
- 一个 VPC
- 一个 DHCP 选项
两个子网
- 作为内部数据平面子网的专用子网
- 允许从数据平面访问互联网的公共子网
- 一个互联网网关
- 一个弹性 IP
- 一个 NAT 网关
- 一个安全组 (worker 节点)
- 两个路由表(一个私有和一个公共)
- 两个 Route 53 托管区
以下项目有足够的配额:
- 公共托管集群的一个 Ingress 服务负载均衡器
- 私有托管集群的一个私有链接端点
要使私有链接网络正常工作,托管集群 AWS 帐户中的端点区必须与管理集群 AWS 帐户中的服务端点解析的实例区匹配。在 AWS 中,区域名称是别名,如 us-east-2b,它不一定映射到不同帐户中的同一区域。因此,要使私有链接正常工作,管理集群在其区域的所有区域中都有子网或 worker。
5.1.1.4. 管理 AWS 帐户的基础架构要求
当您的基础架构由管理 AWS 帐户中的托管 control plane 管理时,基础架构要求会因集群是公共、私有还是组合而异。
对于具有公共集群的帐户,基础架构要求如下:
网络负载均衡器:负载均衡器 Kube API 服务器
- Kubernetes 创建一个安全组
卷
- 对于 etcd (根据是否为高可用性,一个或三个)
- 对于 OVN-Kube
对于带有私有集群的帐户,基础架构要求如下:
- 网络负载均衡器:负载均衡器私有路由器
- 端点服务(专用链接)
对于具有公共和私有集群的帐户,基础架构要求如下:
- 网络负载均衡器:负载均衡器公共路由器
- 网络负载均衡器:负载均衡器私有路由器
- 端点服务(专用链接)
卷
- 对于 etcd (根据是否为高可用性,一个或三个)
- 对于 OVN-Kube
5.1.1.5. 托管集群中的 AWS 帐户的基础架构要求
当您的基础架构由托管集群 Amazon Web Services (AWS) 帐户中托管的 control plane 管理时,基础架构要求会根据集群是公共、私有还是组合而有所不同。
对于具有公共集群的帐户,基础架构要求如下:
-
节点池必须具有定义
Role和RolePolicy的 EC2 实例。
对于带有私有集群的帐户,基础架构要求如下:
- 每个可用区有一个私有链接端点
- 节点池的 EC2 实例
对于具有公共和私有集群的帐户,基础架构要求如下:
- 每个可用区有一个私有链接端点
- 节点池的 EC2 实例
5.1.1.6. 托管集群 AWS 帐户中的 Kubernetes 管理基础架构
当 Kubernetes 在托管集群 Amazon Web Services (AWS) 帐户中管理您的基础架构时,基础架构要求如下:
- 默认入口的网络负载均衡器
- registry 的 S3 存储桶
5.1.2. Identity and Access Management (IAM) 权限
在托管 control plane 的上下文中,使用者负责创建 Amazon 资源名称 (ARN) 角色。consumer 是生成权限文件的自动化过程。消费者可以是 CLI 或 OpenShift Cluster Manager。托管 control plane 可以达到最低特权组件的原则,这意味着每个组件都使用自己的角色来运行或创建 Amazon Web Services (AWS) 对象,角色仅限于产品正常工作所需的内容。
托管的集群接收 ARN 角色作为输入,消费者为每个组件创建一个 AWS 权限配置。因此,组件可以通过 STS 和预配置的 OIDC IDP 进行身份验证。
以下角色由 control plane 上运行的托管 control plane 中的一些组件使用,并在数据平面上运行:
-
controlPlaneOperatorARN -
imageRegistryARN -
ingressARN -
kubeCloudControllerARN -
nodePoolManagementARN -
storageARN -
networkARN
以下示例显示了对托管集群的 IAM 角色的引用:
...
endpointAccess: Public
region: us-east-2
resourceTags:
- key: kubernetes.io/cluster/example-cluster-bz4j5
value: owned
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-controller
networkARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-node-pool
storageARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-aws-ebs-csi-driver-controller
type: AWS
...以下示例中显示了托管 control plane 使用的角色:
ingressARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "elasticloadbalancing:DescribeLoadBalancers", "tag:GetResources", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets" ], "Resource": [ "arn:aws:route53:::PUBLIC_ZONE_ID", "arn:aws:route53:::PRIVATE_ZONE_ID" ] } ] }imageRegistryARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketTagging", "s3:GetBucketTagging", "s3:PutBucketPublicAccessBlock", "s3:GetBucketPublicAccessBlock", "s3:PutEncryptionConfiguration", "s3:GetEncryptionConfiguration", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:GetBucketLocation", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucketMultipartUploads", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": "\*" } ] }storageARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:AttachVolume", "ec2:CreateSnapshot", "ec2:CreateTags", "ec2:CreateVolume", "ec2:DeleteSnapshot", "ec2:DeleteTags", "ec2:DeleteVolume", "ec2:DescribeInstances", "ec2:DescribeSnapshots", "ec2:DescribeTags", "ec2:DescribeVolumes", "ec2:DescribeVolumesModifications", "ec2:DetachVolume", "ec2:ModifyVolume" ], "Resource": "\*" } ] }networkARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "ec2:DescribeInstanceTypes", "ec2:UnassignPrivateIpAddresses", "ec2:AssignPrivateIpAddresses", "ec2:UnassignIpv6Addresses", "ec2:AssignIpv6Addresses", "ec2:DescribeSubnets", "ec2:DescribeNetworkInterfaces" ], "Resource": "\*" } ] }kubeCloudControllerARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:DescribeInstances", "ec2:DescribeImages", "ec2:DescribeRegions", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVolumes", "ec2:CreateSecurityGroup", "ec2:CreateTags", "ec2:CreateVolume", "ec2:ModifyInstanceAttribute", "ec2:ModifyVolume", "ec2:AttachVolume", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateRoute", "ec2:DeleteRoute", "ec2:DeleteSecurityGroup", "ec2:DeleteVolume", "ec2:DetachVolume", "ec2:RevokeSecurityGroupIngress", "ec2:DescribeVpcs", "elasticloadbalancing:AddTags", "elasticloadbalancing:AttachLoadBalancerToSubnets", "elasticloadbalancing:ApplySecurityGroupsToLoadBalancer", "elasticloadbalancing:CreateLoadBalancer", "elasticloadbalancing:CreateLoadBalancerPolicy", "elasticloadbalancing:CreateLoadBalancerListeners", "elasticloadbalancing:ConfigureHealthCheck", "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DeleteLoadBalancerListeners", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeLoadBalancerAttributes", "elasticloadbalancing:DetachLoadBalancerFromSubnets", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:ModifyLoadBalancerAttributes", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:SetLoadBalancerPoliciesForBackendServer", "elasticloadbalancing:AddTags", "elasticloadbalancing:CreateListener", "elasticloadbalancing:CreateTargetGroup", "elasticloadbalancing:DeleteListener", "elasticloadbalancing:DeleteTargetGroup", "elasticloadbalancing:DescribeListeners", "elasticloadbalancing:DescribeLoadBalancerPolicies", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DescribeTargetHealth", "elasticloadbalancing:ModifyListener", "elasticloadbalancing:ModifyTargetGroup", "elasticloadbalancing:RegisterTargets", "elasticloadbalancing:SetLoadBalancerPoliciesOfListener", "iam:CreateServiceLinkedRole", "kms:DescribeKey" ], "Resource": [ "\*" ], "Effect": "Allow" } ] }nodePoolManagementARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:AllocateAddress", "ec2:AssociateRouteTable", "ec2:AttachInternetGateway", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateInternetGateway", "ec2:CreateNatGateway", "ec2:CreateRoute", "ec2:CreateRouteTable", "ec2:CreateSecurityGroup", "ec2:CreateSubnet", "ec2:CreateTags", "ec2:DeleteInternetGateway", "ec2:DeleteNatGateway", "ec2:DeleteRouteTable", "ec2:DeleteSecurityGroup", "ec2:DeleteSubnet", "ec2:DeleteTags", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeAvailabilityZones", "ec2:DescribeImages", "ec2:DescribeInstances", "ec2:DescribeInternetGateways", "ec2:DescribeNatGateways", "ec2:DescribeNetworkInterfaces", "ec2:DescribeNetworkInterfaceAttribute", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs", "ec2:DescribeVpcAttribute", "ec2:DescribeVolumes", "ec2:DetachInternetGateway", "ec2:DisassociateRouteTable", "ec2:DisassociateAddress", "ec2:ModifyInstanceAttribute", "ec2:ModifyNetworkInterfaceAttribute", "ec2:ModifySubnetAttribute", "ec2:ReleaseAddress", "ec2:RevokeSecurityGroupIngress", "ec2:RunInstances", "ec2:TerminateInstances", "tag:GetResources", "ec2:CreateLaunchTemplate", "ec2:CreateLaunchTemplateVersion", "ec2:DescribeLaunchTemplates", "ec2:DescribeLaunchTemplateVersions", "ec2:DeleteLaunchTemplate", "ec2:DeleteLaunchTemplateVersions" ], "Resource": [ "\*" ], "Effect": "Allow" }, { "Condition": { "StringLike": { "iam:AWSServiceName": "elasticloadbalancing.amazonaws.com" } }, "Action": [ "iam:CreateServiceLinkedRole" ], "Resource": [ "arn:*:iam::*:role/aws-service-role/elasticloadbalancing.amazonaws.com/AWSServiceRoleForElasticLoadBalancing" ], "Effect": "Allow" }, { "Action": [ "iam:PassRole" ], "Resource": [ "arn:*:iam::*:role/*-worker-role" ], "Effect": "Allow" } ] }controlPlaneOperatorARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:CreateVpcEndpoint", "ec2:DescribeVpcEndpoints", "ec2:ModifyVpcEndpoint", "ec2:DeleteVpcEndpoints", "ec2:CreateTags", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets" ], "Resource": "arn:aws:route53:::%s" } ] }
5.1.3. 创建 AWS 基础架构和 IAM 资源分离
默认情况下,hcp create cluster aws 命令使用托管集群创建云基础架构并应用它。您可以单独创建云基础架构部分,以便您可以使用 hcp create cluster aws 命令只创建集群,或者在应用前呈现它进行修改。
要单独创建云基础架构部分,您需要创建 Amazon Web Services (AWS) 基础架构,创建 AWS Identity and Access (IAM) 资源并创建集群。
5.1.3.1. 单独创建 AWS 基础架构
要创建 Amazon Web Services (AWS) 基础架构,您需要为集群创建 Virtual Private Cloud (VPC) 和其他资源。您可以使用 AWS 控制台或基础架构自动化和置备工具。有关使用 AWS 控制台的说明,请参阅 AWS 文档中的创建 VPC 和其他 VPC 资源。
VPC 必须包含用于外部访问的私有和公共子网和资源,如网络地址转换(NAT)网关和互联网网关。除了 VPC 外,还需要集群入口的一个私有托管区。如果您要创建使用 PrivateLink (Private 或 PublicAndPrivate 访问模式)的集群,则需要一个额外的托管区用于 PrivateLink。
使用以下示例配置为托管集群创建 AWS 基础架构:
---
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: clusters
spec: {}
status: {}
---
apiVersion: v1
data:
.dockerconfigjson: xxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <pull_secret_name>
namespace: clusters
---
apiVersion: v1
data:
key: xxxxxxxxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <etcd_encryption_key_name>
namespace: clusters
type: Opaque
---
apiVersion: v1
data:
id_rsa: xxxxxxxxx
id_rsa.pub: xxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <ssh-key-name>
namespace: clusters
---
apiVersion: hypershift.openshift.io/v1beta1
kind: HostedCluster
metadata:
creationTimestamp: null
name: <hosted_cluster_name>
namespace: clusters
spec:
autoscaling: {}
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: <dns_domain>
privateZoneID: xxxxxxxx
publicZoneID: xxxxxxxx
etcd:
managed:
storage:
persistentVolume:
size: 8Gi
storageClassName: gp3-csi
type: PersistentVolume
managementType: Managed
fips: false
infraID: <infra_id>
issuerURL: <issuer_url>
networking:
clusterNetwork:
- cidr: 10.132.0.0/14
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- cidr: 172.31.0.0/16
olmCatalogPlacement: management
platform:
aws:
cloudProviderConfig:
subnet:
id: <subnet_xxx>
vpc: <vpc_xxx>
zone: us-west-1b
endpointAccess: Public
multiArch: false
region: us-west-1
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/<infra_id>-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/<infra_id>-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/<infra_id>-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/<infra_id>-cloud-controller
networkARN: arn:aws:iam::820196288204:role/<infra_id>-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/<infra_id>-node-pool
storageARN: arn:aws:iam::820196288204:role/<infra_id>-aws-ebs-csi-driver-controller
type: AWS
pullSecret:
name: <pull_secret_name>
release:
image: quay.io/openshift-release-dev/ocp-release:4.16-x86_64
secretEncryption:
aescbc:
activeKey:
name: <etcd_encryption_key_name>
type: aescbc
services:
- service: APIServer
servicePublishingStrategy:
type: LoadBalancer
- service: OAuthServer
servicePublishingStrategy:
type: Route
- service: Konnectivity
servicePublishingStrategy:
type: Route
- service: Ignition
servicePublishingStrategy:
type: Route
- service: OVNSbDb
servicePublishingStrategy:
type: Route
sshKey:
name: <ssh_key_name>
status:
controlPlaneEndpoint:
host: ""
port: 0
---
apiVersion: hypershift.openshift.io/v1beta1
kind: NodePool
metadata:
creationTimestamp: null
name: <node_pool_name>
namespace: clusters
spec:
arch: amd64
clusterName: <hosted_cluster_name>
management:
autoRepair: true
upgradeType: Replace
nodeDrainTimeout: 0s
platform:
aws:
instanceProfile: <instance_profile_name>
instanceType: m6i.xlarge
rootVolume:
size: 120
type: gp3
subnet:
id: <subnet_xxx>
type: AWS
release:
image: quay.io/openshift-release-dev/ocp-release:4.16-x86_64
replicas: 2
status:
replicas: 0- 1
- 将
<pull_secret_name>替换为 pull secret 的名称。 - 2
- 将
<etcd_encryption_key_name>替换为 etcd 加密密钥的名称。 - 3
- 将
<ssh_key_name>替换为 SSH 密钥的名称。 - 4
- 将
<hosted_cluster_name>替换为托管集群的名称。 - 5
- 将
<dns_domain>替换为您的基本 DNS 域,如example.com。 - 6
- 将
<infra_id>替换为用于标识与托管集群关联的 IAM 资源的值。 - 7
- 将
<issuer_url>替换为您的签发者 URL,其结尾是infra_id值。例如,https://example-hosted-us-west-1.s3.us-west-1.amazonaws.com/example-hosted-infra-id。 - 8
- 将
<subnet_xxx>替换为您的子网 ID。私有和公共子网都需要标记。对于公共子网,使用kubernetes.io/role/elb=1。对于私有子网,使用kubernetes.io/role/internal-elb=1。 - 9
- 将
<vpc_xxx>替换为您的 VPC ID。 - 10
- 将
<node_pool_name>替换为NodePool资源的名称。 - 11
- 将
<instance_profile_name>替换为 AWS 实例的名称。
5.1.3.2. 创建 AWS IAM 资源
在 Amazon Web Services (AWS) 中,您必须创建以下 IAM 资源:
- IAM 中的 OpenID Connect (OIDC)身份提供程序,这是启用 STS 身份验证所必需的。
- 七个角色,它们分别用于与提供程序交互的每个组件,如 Kubernetes 控制器管理器、集群 API 供应商和 registry
- 实例配置集,这是分配给集群所有 worker 实例的配置集
5.1.3.3. 单独创建托管集群
您可以在 Amazon Web Services (AWS) 上单独创建托管集群。
要单独创建托管集群,请输入以下命令:
$ hcp create cluster aws \
--infra-id <infra_id> \
--name <hosted_cluster_name> \
--sts-creds <path_to_sts_credential_file> \
--pull-secret <path_to_pull_secret> \
--generate-ssh \
--node-pool-replicas 3
--role-arn <role_name> - 1
- 将
<infra_id>替换为您在create infra aws命令中指定的相同 ID。这个值标识与托管集群关联的 IAM 资源。 - 2
- 将
<hosted_cluster_name>替换为托管集群的名称。 - 3
- 将
<path_to_sts_credential_file>替换为您在create infra aws命令中指定的相同名称。 - 4
- 将
<path_to_pull_secret>替换为包含有效 OpenShift Container Platform pull secret 的文件名称。 - 5
--generate-ssh标志是可选的,但最好包括,它在 SSH 到您的 worker 时需要。为您生成 SSH 密钥,并作为 secret 存储在与托管集群相同的命名空间中。- 6
- 将
<role_name>替换为 Amazon Resource Name (ARN),例如arn:aws:iam::820196288204:role/myrole。指定 Amazon Resource Name (ARN),例如arn:aws:iam::820196288204:role/myrole。有关 ARN 角色的更多信息,请参阅"Identity and Access Management (IAM) 权限"。
您还可以在命令中添加 --render 标志,并将输出重定向到文件,您可以在其中编辑资源,然后再将它们应用到集群。
运行命令后,以下资源将应用到集群:
- 一个命名空间
- 带有 pull secret 的 secret
-
A
HostedCluster -
A
NodePool - control plane 组件的三个 AWS STS secret
-
如果指定了
--generate-ssh标志,则一个 SSH 密钥 secret。
5.1.4. 将托管集群从单架构转换到多架构
您可以将单架构 64 位 AMD 托管的集群转换到 Amazon Web Services (AWS)上的多架构托管集群,以降低在集群中运行工作负载的成本。例如,您可以在迁移到 64 位 ARM 时在 64 位 AMD 上运行现有工作负载,您可以从中央 Kubernetes 集群管理这些工作负载。
单一架构托管的集群只能管理一个特定 CPU 架构的节点池。但是,一个多架构托管集群可以管理具有不同 CPU 架构的节点池。在 AWS 上,托管集群的多架构可以管理 64 位 AMD 和 64 位 ARM 节点池。
先决条件
- 您已在带有 multicluster engine for Kubernetes Operator 的 Red Hat Advanced Cluster Management (RHACM) 上安装了 OpenShift Container Platform 管理集群。
- 您有一个现有的单架构托管集群,它使用 OpenShift Container Platform 发行有效负载的 64 位 AMD 变体。
- 一个现有节点池,它使用 OpenShift Container Platform 版本有效负载相同的 64 位 AMD 变体,并由现有的托管集群管理。
确保安装了以下命令行工具:
-
oc -
kubectl -
hcp -
skopeo
-
流程
运行以下命令,查看单架构托管的集群的现有 OpenShift Container Platform 发行镜像:
$ oc get hostedcluster/<hosted_cluster_name> \1 -o jsonpath='{.spec.release.image}'- 1
- 将
<hosted_cluster_name>替换为托管集群的名称。
输出示例
quay.io/openshift-release-dev/ocp-release:<4.y.z>-x86_641 - 1
- 将
<4.y.z>替换为您使用的受支持 OpenShift Container Platform 版本。
在 OpenShift Container Platform 发行镜像中,如果使用摘要而不是标签,找到发行镜像的多架构标签版本:
运行以下命令,为 OpenShift Container Platform 版本设置
OCP_VERSION环境变量:$ OCP_VERSION=$(oc image info quay.io/openshift-release-dev/ocp-release@sha256:ac78ebf77f95ab8ff52847ecd22592b545415e1ff6c7ff7f66bf81f158ae4f5e \ -o jsonpath='{.config.config.Labels["io.openshift.release"]}')运行以下命令,为您的发行镜像的多架构标签版本设置
MULTI_ARCH_TAG环境变量:$ MULTI_ARCH_TAG=$(skopeo inspect docker://quay.io/openshift-release-dev/ocp-release@sha256:ac78ebf77f95ab8ff52847ecd22592b545415e1ff6c7ff7f66bf81f158ae4f5e \ | jq -r '.RepoTags' | sed 's/"//g' | sed 's/,//g' \ | grep -w "$OCP_VERSION-multi$" | xargs)运行以下命令,为多架构发行镜像名称设置
IMAGE环境变量:$ IMAGE=quay.io/openshift-release-dev/ocp-release:$MULTI_ARCH_TAG要查看多架构镜像摘要列表,请运行以下命令:
$ oc image info $IMAGE输出示例
OS DIGEST linux/amd64 sha256:b4c7a91802c09a5a748fe19ddd99a8ffab52d8a31db3a081a956a87f22a22ff8 linux/ppc64le sha256:66fda2ff6bd7704f1ba72be8bfe3e399c323de92262f594f8e482d110ec37388 linux/s390x sha256:b1c1072dc639aaa2b50ec99b530012e3ceac19ddc28adcbcdc9643f2dfd14f34 linux/arm64 sha256:7b046404572ac96202d82b6cb029b421dddd40e88c73bbf35f602ffc13017f21
将托管集群从单架构转换为多架构:
在托管集群中将
multiArch标志设置为true,以便托管集群可以同时创建 64 位 AMD 和 64 位 ARM 节点池。运行以下命令:$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p '{"spec":{"platform":{"aws":{"multiArch":true}}}}' --type=merge运行以下命令,确认托管集群中的
multiArch标志被设置为true:$ oc get hostedcluster/<hosted_cluster_name> -o jsonpath='{.spec.platform.aws.multiArch}'通过确保使用与托管集群相同的 OpenShift Container Platform 版本,为托管集群设置多架构 OpenShift Container Platform 发行镜像。运行以下命令:
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p \ '{"spec":{"release":{"image":"quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi"}}}' \1 --type=merge- 1
- 将
<4.y.z>替换为您使用的受支持 OpenShift Container Platform 版本。
运行以下命令确认托管集群中设置了多架构镜像:
$ oc get hostedcluster/<hosted_cluster_name> \ -o jsonpath='{.spec.release.image}'
运行以下命令,检查
HostedControlPlane资源的状态是否为Progressing:$ oc get hostedcontrolplane -n <hosted_control_plane_namespace> -oyaml输出示例
#... - lastTransitionTime: "2024-07-28T13:07:18Z" message: HostedCluster is deploying, upgrading, or reconfiguring observedGeneration: 5 reason: Progressing status: "True" type: Progressing #...运行以下命令,检查
HostedCluster资源的状态是否为Progressing:$ oc get hostedcluster <hosted_cluster_name> \ -n <hosted_cluster_namespace> -oyaml
验证
运行以下命令,验证节点池是否使用
HostedControlPlane资源中的多架构发行镜像:$ oc get hostedcontrolplane -n clusters-example -oyaml输出示例
#... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi1 url: https://access.redhat.com/errata/RHBA-2024:4855 version: 4.16.5 history: - completionTime: "2024-07-28T13:10:58Z" image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi startedTime: "2024-07-28T13:10:27Z" state: Completed verified: false version: <4.x.y>- 1
- 将
<4.y.z>替换为您使用的受支持 OpenShift Container Platform 版本。
注意多架构 OpenShift Container Platform 发行镜像在
HostedCluster、HostedControlPlane资源和托管的 control plane pod 中更新。但是,您的现有节点池不会自动与多架构镜像转换,因为发行镜像转换在托管集群和节点池间分离。您必须在新的多架构托管集群中创建新节点池。
后续步骤
- 在托管集群的多架构集群中创建节点池
5.1.5. 在托管集群的多架构集群中创建节点池
将托管集群从单架构转换为多架构后,根据 64 位 AMD 和 64 位 ARM 架构在计算机器上创建节点池。
流程
输入以下命令,根据 64 位 ARM 架构创建节点池:
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count=<node_count> \3 --arch arm64输入以下命令基于 64 位 AMD 架构创建节点池:
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count=<node_count> \3 --arch amd64
验证
输入以下命令验证节点池是否使用多架构发行镜像:
$ oc get nodepool/<nodepool_name> -oyaml64 位 AMD 节点池的输出示例
#... spec: arch: amd64 #... release: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi1 - 1
- 将
<4.y.z>替换为您使用的受支持 OpenShift Container Platform 版本。
64 位 ARM 节点池的输出示例
#... spec: arch: arm64 #... release: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi
5.2. 在裸机上管理托管的 control plane
在裸机上部署托管的 control plane 后,您可以通过完成以下任务来管理托管集群。
5.2.1. 访问托管集群
您可以通过直接从资源获取 kubeconfig 文件和 kubeadmin 凭证来访问托管集群,或使用 hcp 命令行界面生成 kubeconfig 文件。
先决条件
要通过直接从资源获取 kubeconfig 文件和凭证来访问托管集群,您必须熟悉托管集群的访问 secret。托管的集群(hosting) 命名空间包含托管的集群资源和访问 secret。托管 control plane 命名空间是托管 control plane 运行的位置。
secret 名称格式如下:
-
kubeconfigsecret:<hosted_cluster_namespace>-<name>-admin-kubeconfig。例如clusters-hypershift-demo-admin-kubeconfig。 -
kubeadmin密码 secret:<hosted_cluster_namespace>-<name>-kubeadmin-password。例如,clusters-hypershift-demo-kubeadmin-password。
kubeconfig secret 包含一个 Base64 编码的 kubeconfig 字段,您可以解码并保存到要使用以下命令使用的文件中:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin 密码 secret 也为 Base64 编码的。您可以对它进行解码,并使用密码登录到托管集群的 API 服务器或控制台。
流程
要使用
hcpCLI 访问托管集群来生成kubeconfig文件,请执行以下步骤:输入以下命令生成
kubeconfig文件:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig保存
kubeconfig文件后,您可以输入以下示例命令来访问托管集群:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.2.2. 为托管集群扩展 NodePool 对象
您可以通过在托管集群中添加节点来扩展 NodePool 对象。当您扩展节点池时,请考虑以下信息:
- 当您由节点池扩展副本时,会创建一个机器。对于每台机器,Cluster API 供应商会找到并安装一个满足节点池规格中指定的要求的 Agent。您可以通过检查其状态和条件来监控代理的安装。
- 当您缩减节点池时,代理会从对应的集群绑定。在重复使用代理前,您必须使用 Discovery 镜像重启它们。
流程
将
NodePool对象扩展到两个节点:$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 代理供应商会随机选择两个分配给托管集群的代理。这些代理会经历不同的状态,最终将托管集群作为 OpenShift Container Platform 节点加入。代理按以下顺序传递状态:
-
binding -
discovering -
insufficient -
installing -
install-in-progress -
added-to-existing-cluster
-
输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agent输出示例
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'输出示例
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficient输入 extract 命令,获取新的托管集群的 kubeconfig :
$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>代理访问
added-to-existing-cluster状态后,输入以下命令验证是否可以看到托管的集群中的 OpenShift Container Platform 节点:$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get nodes输出示例
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8f集群 Operator 开始通过向节点添加工作负载来协调。
输入以下命令验证在扩展
NodePool对象时是否创建了两台机器:$ oc -n <hosted_control_plane_namespace> get machines输出示例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.x.z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.x.zclusterversion协调过程最终达到缺少 Ingress 和 Console 集群 Operator 的时间点。输入以下命令:
$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get clusterversion,co输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.x.z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
5.2.2.1. 添加节点池
您可以通过指定名称、副本数和任何其他信息,如代理标签选择器,为托管集群创建节点池。
每个托管集群只支持一个代理命名空间。因此,当您将节点池添加到托管集群时,节点池必须来自单个 InfraEnv 资源,或者来自同一代理命名空间中的 InfraEnv 资源。
流程
要创建节点池,请输入以下信息:
$ hcp create nodepool agent \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <worker_node_count> \3 --agentLabelSelector size=medium4 通过列出
cluster命名空间中的nodepool资源来检查节点池的状态:$ oc get nodepools --namespace clusters输入以下命令提取
admin-kubeconfigsecret:$ oc extract -n <hosted_control_plane_namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm输出示例
hostedcluster-secrets/kubeconfig一段时间后,您可以输入以下命令来检查节点池的状态:
$ oc --kubeconfig ./hostedcluster-secrets get nodes
验证
输入以下命令验证可用节点池的数量是否与预期的节点池数量匹配:
$ oc get nodepools --namespace clusters
5.2.2.2. 为托管集群启用节点自动扩展
当托管集群和备用代理有更多容量时,您可以启用自动扩展来安装新的 worker 节点。
流程
要启用自动扩展,请输入以下命令:
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'注意在示例中,最少的节点数量为 2,最大值为 5。添加的最大节点数可能会被您的平台绑定。例如,如果您使用 Agent 平台,则最大节点数量由可用代理数量绑定。
创建需要新节点的工作负载。
使用以下示例创建一个包含工作负载配置的 YAML 文件:
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
将文件保存为
workload-config.yaml。 输入以下命令应用 YAML:
$ oc apply -f workload-config.yaml
输入以下命令提取
admin-kubeconfigsecret:$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm输出示例
hostedcluster-secrets/kubeconfig您可以输入以下命令来检查新节点是否处于
Ready状态:$ oc --kubeconfig ./hostedcluster-secrets get nodes要删除节点,请输入以下命令删除工作负载:
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>等待几分钟,无需额外容量。在 Agent 平台上,代理已停用,可以被重复使用。您可以输入以下命令确认节点已被删除:
$ oc --kubeconfig ./hostedcluster-secrets get nodes
对于 IBM Z 代理,计算节点只适用于带有 KVM 代理的 IBM Z。对于 z/VM 和 LPAR,您必须手动删除计算节点。
代理只能对带有 KVM 的 IBM Z 重新使用。对于 z/VM 和 LPAR,需要重新创建代理以将其用作计算节点。
5.2.2.3. 为托管集群禁用节点自动扩展
要禁用节点自动扩展,请完成以下步骤。
流程
输入以下命令为托管集群禁用节点自动扩展:
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify_value_to_scale_replicas>]'命令从 YAML 文件中删除
"spec.autoScaling",并添加"spec.replicas",并将"spec.replicas"设置为您指定的整数值。
5.2.3. 在裸机上的托管集群中处理 ingress
每个 OpenShift Container Platform 集群都有一个默认应用程序 Ingress Controller,它通常关联有一个外部 DNS 记录。例如,如果您创建一个名为 example 的托管集群,其基域为 krnl.es,您可以预期通配符域 *.apps.example.krnl.es 可以被路由。
流程
要为 *.apps 域设置负载均衡器和通配符 DNS 记录,请在客户机集群上执行以下操作:
通过创建包含 MetalLB Operator 配置的 YAML 文件来部署 MetalLB:
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
将文件保存为
metallb-operator-config.yaml。 输入以下命令应用配置:
$ oc apply -f metallb-operator-config.yamlOperator 运行后,创建 MetalLB 实例:
创建包含 MetalLB 实例的配置的 YAML 文件:
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
将文件保存为
metallb-instance-config.yaml。 输入以下命令创建 MetalLB 实例:
$ oc apply -f metallb-instance-config.yaml
使用单个 IP 地址创建
IPAddressPool资源。此 IP 地址必须与集群节点使用的网络位于同一个子网中。创建一个文件,如
ipaddresspool.yaml,其内容类似以下示例:apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb name: <ip_address_pool_name>1 spec: addresses: - <ingress_ip>-<ingress_ip>2 autoAssign: false输入以下命令为 IP 地址池应用配置:
$ oc apply -f ipaddresspool.yaml
创建 L2 广告。
创建一个文件,如
l2advertisement.yaml,内容类似以下示例:apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: <l2_advertisement_name>1 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>2 输入以下命令应用配置:
$ oc apply -f l2advertisement.yaml
创建
LoadBalancer类型的服务后,MetalLB 为该服务添加外部 IP 地址。配置一个新的负载均衡器服务,通过创建名为
metallb-loadbalancer-service.yaml的 YAML 文件将入口流量路由到 ingress 部署:kind: Service apiVersion: v1 metadata: annotations: metallb.io/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
保存
metallb-loadbalancer-service.yaml文件。 输入以下命令应用 YAML 配置:
$ oc apply -f metallb-loadbalancer-service.yaml输入以下命令访问 OpenShift Container Platform 控制台:
$ curl -kI https://console-openshift-console.apps.example.krnl.es输出示例
HTTP/1.1 200 OK检查
clusterversion和clusteroperator值,以验证所有内容是否正在运行。输入以下命令:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m将
<4.x.y>替换为您要使用的受支持 OpenShift Container Platform 版本,如4.17.0-multi。
5.2.4. 在裸机上启用机器健康检查
您可以在裸机上启用机器健康检查,以修复并自动替换不健康的受管集群节点。您必须具有可在受管集群上安装的附加代理机器。
在启用机器健康检查前请考虑以下限制:
-
您无法修改
MachineHealthCheck对象。 -
只有在至少有两个节点处于
False或Unknown状态超过 8 分钟时,机器健康检查才会替换节点。
为受管集群节点启用机器健康检查后,MachineHealthCheck 对象会在托管集群中创建。
流程
要在托管集群中启用机器健康检查,请修改 NodePool 资源。完成以下步骤:
验证
NodePool资源中的spec.nodeDrainTimeout值是否大于0s。将<hosted_cluster_namespace>替换为托管集群命名空间的名称,将<nodepool_name>替换为节点池名称。运行以下命令:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep nodeDrainTimeout输出示例
nodeDrainTimeout: 30s如果
spec.nodeDrainTimeout值不大于0s,请运行以下命令修改值:$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec":{"nodeDrainTimeout": "30m"}}' --type=merge通过将
NodePool资源中的spec.management.autoRepair字段设置为true来启用机器健康检查。运行以下命令:$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":true}}}' --type=merge运行以下命令,使用
autoRepair: true值验证NodePool资源是否已更新:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.2.5. 在裸机上禁用机器健康检查
要禁用受管集群节点的机器健康检查,请修改 NodePool 资源。
流程
通过将
NodePool资源中的spec.management.autoRepair字段设置为false来禁用机器健康检查。运行以下命令:$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":false}}}' --type=merge运行以下命令,验证
NodePool资源是否使用autoRepair: false值更新:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.3. 在 OpenShift Virtualization 中管理托管的 control plane
在 OpenShift Virtualization 上部署托管集群后,您可以完成以下步骤来管理集群。
5.3.1. 访问托管集群
您可以通过直接从资源获取 kubeconfig 文件和 kubeadmin 凭证来访问托管集群,或使用 hcp 命令行界面生成 kubeconfig 文件。
先决条件
要通过直接从资源获取 kubeconfig 文件和凭证来访问托管集群,您必须熟悉托管集群的访问 secret。托管的集群(hosting) 命名空间包含托管的集群资源和访问 secret。托管 control plane 命名空间是托管 control plane 运行的位置。
secret 名称格式如下:
-
kubeconfigsecret:<hosted_cluster_namespace>-<name>-admin-kubeconfig(clusters-hypershift-demo-admin-kubeconfig) -
kubeadmin密码 secret:<hosted_cluster_namespace>-<name>-kubeadmin-password(clusters-hypershift-demo-kubeadmin-password)
kubeconfig secret 包含一个 Base64 编码的 kubeconfig 字段,您可以解码并保存到要使用以下命令使用的文件中:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin 密码 secret 也为 Base64 编码的。您可以对它进行解码,并使用密码登录到托管集群的 API 服务器或控制台。
流程
要使用
hcpCLI 访问托管集群来生成kubeconfig文件,请执行以下步骤:输入以下命令生成
kubeconfig文件:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig保存
kubeconfig文件后,您可以输入以下示例命令来访问托管集群:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.3.2. 为托管集群启用节点自动扩展
当托管集群和备用代理有更多容量时,您可以启用自动扩展来安装新的 worker 节点。
流程
要启用自动扩展,请输入以下命令:
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'注意在示例中,最少的节点数量为 2,最大值为 5。添加的最大节点数可能会被您的平台绑定。例如,如果您使用 Agent 平台,则最大节点数量由可用代理数量绑定。
创建需要新节点的工作负载。
使用以下示例创建一个包含工作负载配置的 YAML 文件:
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
将文件保存为
workload-config.yaml。 输入以下命令应用 YAML:
$ oc apply -f workload-config.yaml
输入以下命令提取
admin-kubeconfigsecret:$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm输出示例
hostedcluster-secrets/kubeconfig您可以输入以下命令来检查新节点是否处于
Ready状态:$ oc --kubeconfig ./hostedcluster-secrets get nodes要删除节点,请输入以下命令删除工作负载:
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>等待几分钟,无需额外容量。在 Agent 平台上,代理已停用,可以被重复使用。您可以输入以下命令确认节点已被删除:
$ oc --kubeconfig ./hostedcluster-secrets get nodes
对于 IBM Z 代理,计算节点只适用于带有 KVM 代理的 IBM Z。对于 z/VM 和 LPAR,您必须手动删除计算节点。
代理只能对带有 KVM 的 IBM Z 重新使用。对于 z/VM 和 LPAR,需要重新创建代理以将其用作计算节点。
如果没有提供任何高级存储配置,则默认存储类用于 KubeVirt 虚拟机(VM)镜像、KubeVirt Container Storage Interface (CSI)映射和 etcd 卷。
下表列出了基础架构必须提供以支持托管集群中的持久性存储的功能:
| 基础架构 CSI 供应商 | 托管的集群 CSI 供应商 | 托管的集群功能 | 注 |
|---|---|---|---|
|
任何 RWX |
|
Basic: RWO | 推荐的 |
|
任何 RWX | Red Hat OpenShift Data Foundation 外部模式 | Red Hat OpenShift Data Foundation 功能集 | |
|
任何 RWX | Red Hat OpenShift Data Foundation 内部模式 | Red Hat OpenShift Data Foundation 功能集 | 不要使用 |
5.3.3.1. 映射 KubeVirt CSI 存储类
kubevirt CSI 支持映射一个可以 ReadWriteMany (RWX) 访问的基础架构存储类。您可以在集群创建过程中将基础架构存储类映射到托管的存储类。
流程
要将基础架构存储类映射到托管的存储类,请运行以下命令来使用
--infra-storage-class-mapping参数:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class> \6
创建托管集群后,基础架构存储类会在托管集群中看到。当您在使用其中一个存储类的托管集群中创建持久性卷声明 (PVC) 时,KubeVirt CSI 使用您在集群创建过程中配置的基础架构存储类映射来置备该卷。
kubevirt CSI 仅支持映射一个能够 RWX 访问的基础架构存储类。
下表显示了卷和访问模式如何映射到 KubeVirt CSI 存储类:
| 基础架构 CSI 功能 | 托管的集群 CSI 功能 | VM 实时迁移支持 | 注 |
|---|---|---|---|
|
RWX: |
仅限 | 支持 |
使用 |
|
RWO |
RWO | 不支持 | 缺少实时迁移支持会影响更新托管 KubeVirt 虚拟机的底层基础架构集群的能力。 |
|
RWO |
RWO | 不支持 |
缺少实时迁移支持会影响更新托管 KubeVirt 虚拟机的底层基础架构集群的能力。使用基础架构 |
5.3.3.2. 映射单个 KubeVirt CSI 卷快照类
您可以使用 KubeVirt CSI 将基础架构卷快照类公开给托管集群。
流程
要将卷快照类映射到托管集群,请在创建托管集群时使用
--infra-volumesnapshot-class-mapping参数。运行以下命令:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class> \6 --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>7 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定 worker 数,如
2。 - 3
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 4
- 为内存指定一个值,如
8Gi。 - 5
- 为 CPU 指定一个值,例如
2。 - 6
- 将
<infrastructure_storage_class>替换为基础架构集群中的存储类。将<hosted_storage_class>替换为托管集群中存在的存储类。 - 7
- 将
<infrastructure_volume_snapshot_class>替换为基础架构集群中的卷快照类。将<hosted_volume_snapshot_class>替换为托管的集群中的卷快照类。
注意如果不使用
--infra-storage-class-mapping和--infra-volumesnapshot-class-mapping参数,则使用默认存储类和卷快照类创建一个托管集群。因此,您必须在基础架构集群中设置默认存储类和卷快照类。
5.3.3.3. 映射多个 KubeVirt CSI 卷快照类
您可以通过将多个卷快照类分配给特定的组来将多个卷快照类映射到托管集群。基础架构存储类和卷快照类仅在属于同一组时相互兼容。
流程
要将多个卷快照类映射到托管集群,请在创建托管集群时使用
group选项。运行以下命令:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \6 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \ --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \ --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>,group=<group_name> \7 --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>,group=<group_name>- 1
- 指定托管集群的名称,如
example。 - 2
- 指定 worker 数,如
2。 - 3
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 4
- 为内存指定一个值,如
8Gi。 - 5
- 为 CPU 指定一个值,例如
2。 - 6
- 将
<infrastructure_storage_class>替换为基础架构集群中的存储类。将<hosted_storage_class>替换为托管集群中存在的存储类。使用组名称替换<group_name>。例如:infra-storage-class-mygroup/hosted-storage-class-mygroup,group=mygroup和infra-storage-class-mymap/hosted-storage-class-mymap,group=mymap。 - 7
- 将
<infrastructure_volume_snapshot_class>替换为基础架构集群中的卷快照类。将<hosted_volume_snapshot_class>替换为托管的集群中的卷快照类。例如:infra-vol-snap-mygroup/hosted-vol-snap-mygroup,group=mygroup和infra-vol-snap-mymap/hosted-vol-snap-mymap,group=mymap.
5.3.3.4. 配置 KubeVirt VM 根卷
在集群创建时,您可以使用 --root-volume-storage-class 参数配置用于托管 KubeVirt 虚拟机根卷的存储类。
流程
要为 KubeVirt 虚拟机设置自定义存储类和卷大小,请运行以下命令:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --root-volume-storage-class <root_volume_storage_class> \6 --root-volume-size <volume_size>7 因此,您会收到使用在 PVC 上托管的虚拟机创建的托管集群。
5.3.3.5. 启用 KubeVirt VM 镜像缓存
您可以使用 KubeVirt VM 镜像缓存来优化集群启动时间和存储使用情况。kubevirt VM 镜像缓存支持使用能够智能克隆和 ReadWriteMany 访问模式的存储类。有关智能克隆的更多信息,请参阅使用智能克隆清理数据卷。
镜像缓存按如下方式工作:
- 虚拟机镜像导入到与托管集群关联的 PVC 中。
- 该 PVC 的唯一克隆是为将作为 worker 节点添加到集群中的每个 KubeVirt 虚拟机创建的唯一克隆。
镜像缓存通过只需要单个镜像导入来减少虚拟机启动时间。当存储类支持写时复制克隆时,它可以进一步减少集群存储使用。
流程
要启用镜像缓存,在集群创建过程中,运行以下命令使用
--root-volume-cache-strategy=PVC参数:$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --root-volume-cache-strategy=PVC6
5.3.3.6. kubevirt CSI 存储安全性和隔离
kubevirt Container Storage Interface (CSI) 将底层基础架构集群的存储功能扩展到托管集群。CSI 驱动程序使用以下安全限制来确保对基础架构存储类和托管集群的安全和隔离访问:
- 托管集群的存储与其他托管集群隔离。
- 托管集群中的 worker 节点无法直接访问基础架构集群。托管的集群只能通过受控的 KubeVirt CSI 接口在基础架构集群中置备存储。
- 托管的集群无法访问 KubeVirt CSI 集群控制器。因此,托管集群无法访问没有与托管集群关联的基础架构集群中的任意存储卷。KubeVirt CSI 集群控制器在托管的 control plane 命名空间中的 pod 中运行。
- KubeVirt CSI 集群控制器的基于角色的访问控制(RBAC) 将持久性卷声明 (PVC) 限制为托管的 control plane 命名空间。因此,KubeVirt CSI 组件无法从其他命名空间中访问存储。
5.3.3.7. 配置 etcd 存储
在集群创建时,您可以使用 --etcd-storage-class 参数配置用于托管 etcd 数据的存储类。
流程
要为 etcd 配置存储类,请运行以下命令:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --etcd-storage-class=<etcd_storage_class_name>6
5.3.4. 使用 hcp CLI 附加 NVIDIA GPU 设备
您可以使用 OpenShift Virtualization 上托管的集群中的 hcp 命令行界面(CLI)将一个或多个 NVIDIA 图形处理单元(GPU)设备附加到节点池。
将 NVIDIA GPU 设备附加到节点池只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
先决条件
- 您已在 GPU 设备所在的节点上公开 NVIDIA GPU 设备作为资源。如需更多信息,请参阅使用 OpenShift Virtualization 的 NVIDIA GPU Operator。
- 您已将 NVIDIA GPU 设备公开为节点上的 扩展资源,将其分配给节点池。
流程
您可以运行以下命令来在集群创建过程中将 GPU 设备附加到节点池中:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --host-device-name="<gpu_device_name>,count:<value>"6 - 1
- 指定托管集群的名称,如
example。 - 2
- 指定 worker 数量,如
3。 - 3
- 指定 pull secret 的路径,例如
/user/name/pullsecret。 - 4
- 为内存指定一个值,如
16Gi。 - 5
- 为 CPU 指定一个值,例如
2。 - 6
- 指定 GPU 设备名称和数量,如
--host-device-name="nvidia-a100,count:2"。--host-device-name参数使用来自基础架构节点的 GPU 设备的名称和数量,它代表您要附加到每个节点池中的每个虚拟机(VM)的 GPU 设备数量。默认计数为1。例如,如果您将 2 个 GPU 设备附加到 3 个节点池副本,节点池中的所有 3 个虚拟机都会附加到 2 个 GPU 设备。
提示您可以多次使用
--host-device-name参数来附加不同类型的多个设备。
5.3.5. 使用 NodePool 资源附加 NVIDIA GPU 设备
您可以通过在 NodePool 资源中配置 nodepool.spec.platform.kubevirt.hostDevices 字段,将一个或多个 NVIDIA 图形处理单元(GPU)设备附加到节点池。
将 NVIDIA GPU 设备附加到节点池只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
流程
将一个或多个 GPU 设备附加到节点池:
要附加单个 GPU 设备,请使用以下示例配置
NodePool资源:apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: kubevirt: attachDefaultNetwork: true compute: cores: <cpu>3 memory: <memory>4 hostDevices:5 - count: <count>6 deviceName: <gpu_device_name>7 networkInterfaceMultiqueue: Enable rootVolume: persistent: size: 32Gi type: Persistent type: KubeVirt replicas: <worker_node_count>8 要附加多个 GPU 设备,请使用以下示例配置
NodePool资源:apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: kubevirt: attachDefaultNetwork: true compute: cores: <cpu> memory: <memory> hostDevices: - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> networkInterfaceMultiqueue: Enable rootVolume: persistent: size: 32Gi type: Persistent type: KubeVirt replicas: <worker_node_count>
5.3.6. 驱除 KubeVirt 虚拟机
如果 KubeVirt 虚拟机(VM)无法实时迁移,比如当您使用 GPU 透传时,虚拟机必须与托管集群的 NodePool 资源同时被驱除。否则,可以在不从工作负载排空的情况下关闭计算节点。当您升级 OpenShift Virtualization Operator 时,也会发生这种情况。要实现同步的重启,您可以在 超融合 资源上设置 evictionStrategy 参数,以确保只有从工作负载排空的虚拟机才会重启。
流程
要了解更多有关
hyperconverged资源以及evictionStrategy参数允许的值的信息,请输入以下命令:$ oc explain hyperconverged.spec.evictionStrategy输入以下命令来修补
超融合资源:$ oc -n openshift-cnv patch hyperconverged kubevirt-hyperconverged \ --type=merge \ -p '{"spec": {"evictionStrategy": "External"}}'输入以下命令来修补工作负载更新策略和工作负载更新方法:
$ oc -n openshift-cnv patch hyperconverged kubevirt-hyperconverged \ --type=merge \ -p '{"spec": {"workloadUpdateStrategy": {"workloadUpdateMethods": ["LiveMigrate","Evict"]}}}'通过应用此补丁,您可以指定应尽可能实时迁移的虚拟机,且只有无法实时迁移的虚拟机应该被驱除。
验证
输入以下命令检查 patch 命令是否已正确应用:
$ oc -n openshift-cnv get hyperconverged kubevirt-hyperconverged -ojsonpath='{.spec.evictionStrategy}'输出示例
External
5.4. 在非裸机代理机器上管理托管的 control plane
在非裸机代理机器上部署托管的 control plane 后,您可以通过完成以下任务来管理托管集群。
5.4.1. 访问托管集群
您可以通过直接从资源获取 kubeconfig 文件和 kubeadmin 凭证来访问托管集群,或使用 hcp 命令行界面生成 kubeconfig 文件。
先决条件
要通过直接从资源获取 kubeconfig 文件和凭证来访问托管集群,您必须熟悉托管集群的访问 secret。托管的集群(hosting) 命名空间包含托管的集群资源和访问 secret。托管 control plane 命名空间是托管 control plane 运行的位置。
secret 名称格式如下:
-
kubeconfigsecret:<hosted_cluster_namespace>-<name>-admin-kubeconfig。例如clusters-hypershift-demo-admin-kubeconfig。 -
kubeadmin密码 secret:<hosted_cluster_namespace>-<name>-kubeadmin-password。例如,clusters-hypershift-demo-kubeadmin-password。
kubeconfig secret 包含一个 Base64 编码的 kubeconfig 字段,您可以解码并保存到要使用以下命令使用的文件中:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin 密码 secret 也为 Base64 编码的。您可以对它进行解码,并使用密码登录到托管集群的 API 服务器或控制台。
流程
要使用
hcpCLI 访问托管集群来生成kubeconfig文件,请执行以下步骤:输入以下命令生成
kubeconfig文件:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig保存
kubeconfig文件后,您可以输入以下示例命令来访问托管集群:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.4.2. 为托管集群扩展 NodePool 对象
您可以通过在托管集群中添加节点来扩展 NodePool 对象。当您扩展节点池时,请考虑以下信息:
- 当您由节点池扩展副本时,会创建一个机器。对于每台机器,Cluster API 供应商会找到并安装一个满足节点池规格中指定的要求的 Agent。您可以通过检查其状态和条件来监控代理的安装。
- 当您缩减节点池时,代理会从对应的集群绑定。在重复使用代理前,您必须使用 Discovery 镜像重启它们。
流程
将
NodePool对象扩展到两个节点:$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 代理供应商会随机选择两个分配给托管集群的代理。这些代理会经历不同的状态,最终将托管集群作为 OpenShift Container Platform 节点加入。代理按以下顺序传递状态:
-
binding -
discovering -
insufficient -
installing -
install-in-progress -
added-to-existing-cluster
-
输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agent输出示例
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'输出示例
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficient输入 extract 命令,获取新的托管集群的 kubeconfig :
$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>代理访问
added-to-existing-cluster状态后,输入以下命令验证是否可以看到托管的集群中的 OpenShift Container Platform 节点:$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get nodes输出示例
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8f集群 Operator 开始通过向节点添加工作负载来协调。
输入以下命令验证在扩展
NodePool对象时是否创建了两台机器:$ oc -n <hosted_control_plane_namespace> get machines输出示例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.x.z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.x.zclusterversion协调过程最终达到缺少 Ingress 和 Console 集群 Operator 的时间点。输入以下命令:
$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get clusterversion,co输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.x.z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
5.4.2.1. 添加节点池
您可以通过指定名称、副本数和任何其他信息,如代理标签选择器,为托管集群创建节点池。
每个托管集群只支持一个代理命名空间。因此,当您将节点池添加到托管集群时,节点池必须来自单个 InfraEnv 资源,或者来自同一代理命名空间中的 InfraEnv 资源。
流程
要创建节点池,请输入以下信息:
$ hcp create nodepool agent \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <worker_node_count> \3 --agentLabelSelector size=medium4 通过列出
cluster命名空间中的nodepool资源来检查节点池的状态:$ oc get nodepools --namespace clusters输入以下命令提取
admin-kubeconfigsecret:$ oc extract -n <hosted_control_plane_namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm输出示例
hostedcluster-secrets/kubeconfig一段时间后,您可以输入以下命令来检查节点池的状态:
$ oc --kubeconfig ./hostedcluster-secrets get nodes
验证
输入以下命令验证可用节点池的数量是否与预期的节点池数量匹配:
$ oc get nodepools --namespace clusters
5.4.2.2. 为托管集群启用节点自动扩展
当托管集群和备用代理有更多容量时,您可以启用自动扩展来安装新的 worker 节点。
流程
要启用自动扩展,请输入以下命令:
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'注意在示例中,最少的节点数量为 2,最大值为 5。添加的最大节点数可能会被您的平台绑定。例如,如果您使用 Agent 平台,则最大节点数量由可用代理数量绑定。
创建需要新节点的工作负载。
使用以下示例创建一个包含工作负载配置的 YAML 文件:
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
将文件保存为
workload-config.yaml。 输入以下命令应用 YAML:
$ oc apply -f workload-config.yaml
输入以下命令提取
admin-kubeconfigsecret:$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm输出示例
hostedcluster-secrets/kubeconfig您可以输入以下命令来检查新节点是否处于
Ready状态:$ oc --kubeconfig ./hostedcluster-secrets get nodes要删除节点,请输入以下命令删除工作负载:
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>等待几分钟,无需额外容量。在 Agent 平台上,代理已停用,可以被重复使用。您可以输入以下命令确认节点已被删除:
$ oc --kubeconfig ./hostedcluster-secrets get nodes
对于 IBM Z 代理,计算节点只适用于带有 KVM 代理的 IBM Z。对于 z/VM 和 LPAR,您必须手动删除计算节点。
代理只能对带有 KVM 的 IBM Z 重新使用。对于 z/VM 和 LPAR,需要重新创建代理以将其用作计算节点。
5.4.2.3. 为托管集群禁用节点自动扩展
要禁用节点自动扩展,请完成以下步骤。
流程
输入以下命令为托管集群禁用节点自动扩展:
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify_value_to_scale_replicas>]'命令从 YAML 文件中删除
"spec.autoScaling",并添加"spec.replicas",并将"spec.replicas"设置为您指定的整数值。
5.4.3. 在非裸机代理机器上处理托管集群中的入口
每个 OpenShift Container Platform 集群都有一个默认应用程序 Ingress Controller,它通常关联有一个外部 DNS 记录。例如,如果您创建一个名为 example 的托管集群,其基域为 krnl.es,您可以预期通配符域 *.apps.example.krnl.es 可以被路由。
流程
要为 *.apps 域设置负载均衡器和通配符 DNS 记录,请在客户机集群上执行以下操作:
通过创建包含 MetalLB Operator 配置的 YAML 文件来部署 MetalLB:
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
将文件保存为
metallb-operator-config.yaml。 输入以下命令应用配置:
$ oc apply -f metallb-operator-config.yamlOperator 运行后,创建 MetalLB 实例:
创建包含 MetalLB 实例的配置的 YAML 文件:
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
将文件保存为
metallb-instance-config.yaml。 输入以下命令创建 MetalLB 实例:
$ oc apply -f metallb-instance-config.yaml
使用单个 IP 地址创建
IPAddressPool资源。此 IP 地址必须与集群节点使用的网络位于同一个子网中。创建一个文件,如
ipaddresspool.yaml,其内容类似以下示例:apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb name: <ip_address_pool_name>1 spec: addresses: - <ingress_ip>-<ingress_ip>2 autoAssign: false输入以下命令为 IP 地址池应用配置:
$ oc apply -f ipaddresspool.yaml
创建 L2 广告。
创建一个文件,如
l2advertisement.yaml,内容类似以下示例:apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: <l2_advertisement_name>1 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>2 输入以下命令应用配置:
$ oc apply -f l2advertisement.yaml
创建
LoadBalancer类型的服务后,MetalLB 为该服务添加外部 IP 地址。配置一个新的负载均衡器服务,通过创建名为
metallb-loadbalancer-service.yaml的 YAML 文件将入口流量路由到 ingress 部署:kind: Service apiVersion: v1 metadata: annotations: metallb.io/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
保存
metallb-loadbalancer-service.yaml文件。 输入以下命令应用 YAML 配置:
$ oc apply -f metallb-loadbalancer-service.yaml输入以下命令访问 OpenShift Container Platform 控制台:
$ curl -kI https://console-openshift-console.apps.example.krnl.es输出示例
HTTP/1.1 200 OK检查
clusterversion和clusteroperator值,以验证所有内容是否正在运行。输入以下命令:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m将
<4.x.y>替换为您要使用的受支持 OpenShift Container Platform 版本,如4.17.0-multi。
5.4.4. 在非裸机代理机器上启用机器健康检查
您可以在裸机上启用机器健康检查,以修复并自动替换不健康的受管集群节点。您必须具有可在受管集群上安装的附加代理机器。
在启用机器健康检查前请考虑以下限制:
-
您无法修改
MachineHealthCheck对象。 -
只有在至少有两个节点处于
False或Unknown状态超过 8 分钟时,机器健康检查才会替换节点。
为受管集群节点启用机器健康检查后,MachineHealthCheck 对象会在托管集群中创建。
流程
要在托管集群中启用机器健康检查,请修改 NodePool 资源。完成以下步骤:
验证
NodePool资源中的spec.nodeDrainTimeout值是否大于0s。将<hosted_cluster_namespace>替换为托管集群命名空间的名称,将<nodepool_name>替换为节点池名称。运行以下命令:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep nodeDrainTimeout输出示例
nodeDrainTimeout: 30s如果
spec.nodeDrainTimeout值不大于0s,请运行以下命令修改值:$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec":{"nodeDrainTimeout": "30m"}}' --type=merge通过将
NodePool资源中的spec.management.autoRepair字段设置为true来启用机器健康检查。运行以下命令:$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":true}}}' --type=merge运行以下命令,使用
autoRepair: true值验证NodePool资源是否已更新:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.4.5. 在非裸机代理机器上禁用机器健康检查
要禁用受管集群节点的机器健康检查,请修改 NodePool 资源。
流程
通过将
NodePool资源中的spec.management.autoRepair字段设置为false来禁用机器健康检查。运行以下命令:$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":false}}}' --type=merge运行以下命令,验证
NodePool资源是否使用autoRepair: false值更新:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.5. 在 IBM Power 上管理托管的 control plane
在 IBM Power 上部署托管 control plane 后,您可以通过完成以下任务来管理托管集群。
5.5.1. 为 IBM Power 上的托管 control plane 创建 InfraEnv 资源
InfraEnv 是启动 live ISO 的主机可以作为代理加入的环境。在这种情况下,代理会在与您托管的 control plane 相同的命名空间中创建。
您可以在 64 位 x86 裸机上为 IBM Power 计算节点创建托管 control plane 的 InfraEnv 资源。
流程
创建 YAML 文件来配置
InfraEnv资源。请参见以下示例:apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> \1 namespace: <hosted_control_plane_namespace> \2 spec: cpuArchitecture: ppc64le pullSecretRef: name: pull-secret sshAuthorizedKey: <path_to_ssh_public_key>3 -
将文件保存为
infraenv-config.yaml。 输入以下命令应用配置:
$ oc apply -f infraenv-config.yaml要获取用于下载 live ISO 的 URL,它允许 IBM Power 机器作为代理加入,请输入以下命令:
$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name> \ -o json
5.5.2. 在 InfraEnv 资源中添加 IBM Power 代理
您可以通过手动配置机器以使用 live ISO 来添加代理。
流程
-
下载 live ISO,并使用它来启动裸机或虚拟机(VM)主机。您可以在
InfraEnv资源的status.isoDownloadURL字段中找到 live ISO 的 URL。在启动时,主机与 Assisted Service 通信,并作为与InfraEnv资源相同的命名空间中的代理注册。 要列出代理及其属性,请输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agents输出示例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign创建每个代理后,您可以选择为代理设置
installation_disk_id和hostname:要为代理设置
installation_disk_id字段,请输入以下命令:$ oc -n <hosted_control_plane_namespace> patch agent <agent_name> -p '{"spec":{"installation_disk_id":"<installation_disk_id>","approved":true}}' --type merge要为代理设置
hostname字段,请输入以下命令:$ oc -n <hosted_control_plane_namespace> patch agent <agent_name> -p '{"spec":{"hostname":"<hostname>","approved":true}}' --type merge
验证
要验证代理是否已批准使用,请输入以下命令:
$ oc -n <hosted_control_plane_namespace> get agents输出示例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
5.5.3. 为 IBM Power 上的托管集群扩展 NodePool 对象
NodePool 对象在创建托管集群时创建。通过扩展 NodePool 对象,您可以将更多计算节点添加到托管的 control plane。
流程
运行以下命令,将
NodePool对象扩展到两个节点:$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API 代理供应商会随机选择两个分配给托管集群的代理。这些代理会经历不同的状态,最终将托管集群作为 OpenShift Container Platform 节点加入。代理按以下顺序通过转换阶段:
-
binding -
discovering -
insufficient -
installing -
install-in-progress -
added-to-existing-cluster
-
运行以下命令,以查看特定扩展代理的状态:
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'输出示例
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient运行以下命令来查看转换阶段:
$ oc -n <hosted_control_plane_namespace> get agent输出示例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign运行以下命令以生成
kubeconfig文件来访问托管集群:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig代理访问
added-to-existing-cluster状态后,输入以下命令验证您可以看到 OpenShift Container Platform 节点:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes输出示例
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8f输入以下命令验证在扩展
NodePool对象时是否创建了两台机器:$ oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io输出示例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0运行以下命令来检查集群版本:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion输出示例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0 True False 40h Cluster version is 4.15.0运行以下命令来检查 Cluster Operator 状态:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators对于集群的每个组件,输出显示以下 Cluster Operator 状态:
-
NAME -
VERSION -
AVAILABLE -
PROGRESSING -
DEGRADED -
SINCE -
MESSAGE
-
第 6 章 在断开连接的环境中部署托管的 control plane
6.1. 在断开连接的环境中托管 control plane 简介
在托管 control plane 的上下文中,断开连接的环境是一个没有连接到互联网的 OpenShift Container Platform 部署,它使用托管的 control plane 作为基础。您可以在裸机或 OpenShift Virtualization 在断开连接的环境中部署托管的 control plane。
在断开连接的环境中托管的 control plane 与独立的 OpenShift Container Platform 不同:
- control plane 位于管理集群中。control plane 是托管 control plane 的 pod 由 Control Plane Operator 运行和管理的位置。
- data plane 位于托管集群的 worker 中。data plane 是工作负载和其他 pod 的运行位置,它们都由 HostedClusterConfig Operator 管理。
根据 pod 的运行位置,它们会受到管理集群中创建的 ImageDigestMirrorSet (IDMS) 或 ImageContentSourcePolicy (ICSP) 或 ImageContentSourcePolicy (ICSP) 的影响,或由托管集群的 spec 字段中设置的 ImageContentSource 的影响。spec 字段转换为托管集群中的 IDMS 对象。
您可以在 IPv4、IPv6 和双栈网络断开连接的环境中部署托管的 control plane。IPv4 是在断开连接的环境中部署托管 control plane 的最简单的网络配置之一。IPv4 范围所需的外部组件数量少于 IPv6 或双栈设置。对于在断开连接的环境中的 OpenShift Virtualization 上托管的 control plane,请使用 IPv4 或双栈网络。
在双栈网络的断开连接的环境中托管 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
当您在断开连接的环境中部署托管 control plane 时,其中一些步骤因您使用的平台而异。以下步骤特定于在 OpenShift Virtualization 中部署。
6.2.1. 先决条件
- 您有一个断开连接的 OpenShift Container Platform 环境,作为您的管理集群。
- 您有一个内部 registry 来 mirror 镜像。如需更多信息,请参阅关于断开连接的安装镜像。
6.2.2. 在断开连接的环境中为托管 control plane 配置镜像镜像
镜像镜像(mirror)是从外部 registry (如 registry.redhat.com 或 quay.io )获取镜像的过程,并将其存储在私有 registry 中。
在以下步骤中,使用 oc-mirror 工具,它是一个使用 ImageSetConfiguration 对象的二进制文件。在文件中,您可以指定以下信息:
-
要镜像的 OpenShift Container Platform 版本。版本位于
quay.io中。 - 要镜像的额外 Operator。单独选择软件包。
- 要添加到存储库中的额外镜像。
先决条件
- 在启动镜像过程前,请确保 registry 服务器正在运行。
流程
要配置镜像镜像,请完成以下步骤:
-
确保
${HOME}/.docker/config.json文件已使用您要从镜像(mirror)的 registry 更新,并使用您要将镜像推送到的私有 registry。 通过使用以下示例,创建一个
ImageSetConfiguration对象以用于镜像。根据需要替换值,使其与您的环境匹配:apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: channels: - name: candidate-{product-version} minVersion: <4.x.y-build>1 maxVersion: <4.x.y-build>2 type: ocp kubeVirtContainer: true3 graph: true operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.17 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged4 输入以下命令启动镜像过程:
$ oc-mirror --v2 --config imagesetconfig.yaml \ --workspace file://mirror-file docker://<registry>镜像过程完成后,您有一个名为
mirror-file的新文件夹,其中包含ImageDigestMirrorSet(IDMS)、ImageTagMirrorSet(ITMS)和要应用到托管的集群的目录源。通过配置
imagesetconfig.yaml文件,对 OpenShift Container Platform 的每日或 CI 版本进行镜像,如下所示:apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: graph: true release: registry.ci.openshift.org/ocp/release:<4.x.y-build>1 kubeVirtContainer: true2 # ...如果您有部分断开连接的环境,请输入以下命令将镜像从镜像集配置镜像到 registry:
$ oc mirror -c imagesetconfig.yaml \ --workspace file://<file_path> docker://<mirror_registry_url> --v2如需更多信息,请参阅"在部分断开连接的环境中镜像镜像集"。
如果您有一个完全断开连接的环境,请执行以下步骤:
输入以下命令将指定镜像设置配置中的镜像镜像到磁盘:
$ oc mirror -c imagesetconfig.yaml file://<file_path> --v2如需更多信息,请参阅"完全断开连接的环境中镜像设置"。
输入以下命令处理磁盘上的镜像集文件,并将内容镜像到目标镜像 registry:
$ oc mirror -c imagesetconfig.yaml \ --from file://<file_path> docker://<mirror_registry_url> --v2
- 按照在断开连接的网络中安装中的步骤来镜像最新的多集群引擎 Operator 镜像。
6.2.3. 在管理集群中应用对象
镜像过程完成后,您需要在管理集群中应用两个对象:
-
ImageContentSourcePolicy(ICSP) 或ImageDigestMirrorSet(IDMS) - 目录源
使用 oc-mirror 工具时,输出工件位于名为 oc-mirror-workspace/results-XXXXXX/ 的文件夹。
ICSP 或 IDMS 启动 MachineConfig 更改,它不会重启您的节点,而是在每个节点上重启 kubelet。节点标记为 READY 后,您需要应用新生成的目录源。
目录源在 openshift-marketplace Operator 中启动操作,如下载目录镜像并处理它来检索该镜像中包含的所有 PackageManifests。
流程
要检查新源,请使用新的
CatalogSource作为源运行以下命令:$ oc get packagemanifest要应用工件,请完成以下步骤:
输入以下命令创建 ICSP 或 IDMS 工件:
$ oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml等待节点就绪,然后输入以下命令:
$ oc apply -f catalogSource-XXXXXXXX-index.yaml
镜像 OLM 目录并配置托管集群以指向镜像。
当您使用
management(默认)OLMCatalogPlacement 模式时,用于 OLM 目录的镜像流不会自动满足管理集群中 ICSP 中的覆盖信息。-
如果使用原始名称和标签将 OLM 目录正确镜像到内部 registry,请将
hypershift.openshift.io/olm-catalogs-is-registry-overrides注解添加到HostedCluster资源。格式为"sr1=dr1,sr2=dr2",其中源 registry 字符串是一个键,目标 registry 是一个值。 要绕过 OLM 目录镜像流机制,请使用
HostedCluster资源上的以下四个注解直接指定用于 OLM Operator 目录的四个镜像的地址:-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
-
-
如果使用原始名称和标签将 OLM 目录正确镜像到内部 registry,请将
在这种情况下,镜像流不会被创建,您必须在 Operator 更新中刷新内部镜像以拉取(pull)时更新注解值。
后续步骤
通过完成 为托管 control plane 断开连接的安装部署多集群引擎 Operator 中的步骤来部署多集群引擎 Operator。
Kubernetes Operator 的多集群引擎在跨供应商部署集群时会扮演重要角色。如果您没有安装 multicluster engine Operator,请参阅以下文档来了解安装它的先决条件和步骤:
6.2.5. 为托管 control plane 的断开连接的安装配置 TLS 证书
为确保断开连接的部署中正常工作,您需要在管理集群中配置 registry CA 证书,并为托管集群配置 worker 节点。
6.2.5.1. 将 registry CA 添加到管理集群中
要将 registry CA 添加到管理集群中,请完成以下步骤。
流程
创建类似以下示例的配置映射:
apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <config_map_namespace>2 data:3 <registry_name>..<port>: |4 -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----对集群范围的对象
image.config.openshift.io进行补丁,使其包含以下规格:spec: additionalTrustedCA: - name: registry-config因此,control plane 节点可以从私有 registry 检索镜像,HyperShift Operator 可以为托管集群部署提取 OpenShift Container Platform 有效负载。
修补对象的过程可能需要几分钟才能完成。
6.2.5.2. 将 registry CA 添加到托管集群的 worker 节点
要让托管的集群中的 data plane worker 可以从私有 registry 检索镜像,您需要将 registry CA 添加到 worker 节点。
流程
在
hc.spec.additionalTrustBundle文件中,添加以下规格:spec: additionalTrustBundle: - name: user-ca-bundle1 - 1
user-ca-bundle条目是您在下一步中创建的配置映射。
在创建
HostedCluster对象的同一命名空间中,创建user-ca-bundle配置映射。配置映射类似以下示例:apiVersion: v1 data: ca-bundle.crt: | // Registry1 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry2 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry3 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 - 1
- 指定创建
HostedCluster对象的命名空间。
6.2.6. 在 OpenShift Virtualization 上创建托管集群
托管的集群是一个 OpenShift Container Platform 集群,其 control plane 和 API 端点托管在管理集群中。托管的集群包括控制平面和它的对应的数据平面。
当您准备在 OpenShift Virtualization 上部署托管 control plane 时,请考虑以下信息:
- 在裸机上运行管理集群。
- 每个托管集群都必须具有集群范围的唯一名称。
-
不要使用
clusters作为托管的集群名称。 - 无法在多集群引擎 Operator 受管集群的命名空间中创建托管集群。
- 当您为托管 control plane 配置存储时,请考虑推荐的 etcd 实践。要确保您满足延迟要求,请将快速存储设备专用于每个 control-plane 节点上运行的所有托管 control plane etcd 实例。您可以使用 LVM 存储为托管的 etcd pod 配置本地存储类。如需更多信息,请参阅"推荐 etcd 实践"和"使用逻辑卷管理器存储的持久性存储"。
6.2.6.2. 使用 CLI 创建带有 KubeVirt 平台的托管集群
要创建托管集群,您可以使用托管的 control plane 命令行界面(CLI) hcp。
流程
输入以下命令创建带有 KubeVirt 平台的托管集群:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --etcd-storage-class=<etcd_storage_class>6 注意您可以使用
--release-image标志使用特定的 OpenShift Container Platform 发行版本设置托管集群。根据
--node-pool-replicas标志,为集群创建具有两个虚拟机 worker 副本的集群的默认节点池。片刻后,输入以下命令验证托管的 control plane pod 是否正在运行:
$ oc -n clusters-<hosted-cluster-name> get pods输出示例
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66s具有 KubeVirt 虚拟机支持的 worker 节点托管的集群通常需要 10-15 分钟才能被完全置备。
验证
要检查托管集群的状态,请输入以下命令查看对应的
HostedCluster资源:$ oc get --namespace clusters hostedclusters请参见以下示例输出,它演示了一个完全置备的
HostedCluster对象:NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters my-hosted-cluster <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
每个 OpenShift Container Platform 集群都包含一个默认应用程序 Ingress Controller,它必须具有与其关联的通配符 DNS 记录。默认情况下,使用 HyperShift KubeVirt 供应商创建的托管集群会自动成为 KubeVirt 虚拟机在其上运行的 OpenShift Container Platform 集群的子域。
例如,OpenShift Container Platform 集群可能具有以下默认入口 DNS 条目:
*.apps.mgmt-cluster.example.com
因此,名为 guest 的 KubeVirt 托管集群,在该底层 OpenShift Container Platform 集群上运行的集群有以下默认入口:
*.apps.guest.apps.mgmt-cluster.example.com流程
要使默认入口 DNS 正常工作,托管 KubeVirt 虚拟机的集群必须允许通配符 DNS 路由。
您可以输入以下命令来配置此行为:
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'
当您使用默认托管集群入口时,连接仅限于通过端口 443 的 HTTPS 流量。通过端口 80 的普通 HTTP 流量被拒绝。这个限制只适用于默认的入口行为。
6.2.6.4. 自定义入口和 DNS 行为
如果您不想使用默认的 ingress 和 DNS 行为,您可以在创建时配置带有唯一基域的 KubeVirt 托管集群。此选项需要在创建过程中手动配置步骤,并涉及三个主要步骤:集群创建、负载均衡器创建和通配符 DNS 配置。
6.2.6.4.1. 部署指定基域的托管集群
要创建指定基域的托管集群,请完成以下步骤。
流程
输入以下命令:
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --base-domain <basedomain>6 因此,托管集群有一个入口通配符,它被配置为集群名称和基域,如
.apps.example.hypershift.lab。托管的集群处于Partial状态,因为在创建具有唯一基域的托管集群后,您必须配置所需的 DNS 记录和负载均衡器。
验证
输入以下命令来查看托管集群的状态:
$ oc get --namespace clusters hostedclusters输出示例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available输入以下命令访问集群:
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get co输出示例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console <4.x.0> False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress <4.x.0> True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
后续步骤
要修复输出中的错误,请完成"设置负载均衡器"和"设置通配符 DNS"中的步骤。
如果您的托管集群位于裸机上,您可能需要 MetalLB 设置负载均衡器服务。如需更多信息,请参阅"配置 MetalLB"。
6.2.6.4.2. 设置负载均衡器
设置负载均衡器服务,将入口流量路由到 KubeVirt 虚拟机,并为负载均衡器 IP 地址分配通配符 DNS 条目。
流程
公开托管集群入口的
NodePort服务已存在。您可以导出节点端口并创建以这些端口为目标的负载均衡器服务。输入以下命令来获取 HTTP 节点端口:
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'请注意在下一步中要使用的 HTTP 节点端口值。
输入以下命令来获取 HTTPS 节点端口:
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'请注意下一步要使用的 HTTPS 节点端口值。
在 YAML 文件中输入以下信息:
apiVersion: v1 kind: Service metadata: labels: app: <hosted_cluster_name> name: <hosted_cluster_name>-apps namespace: clusters-<hosted_cluster_name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https_node_port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http_node_port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer运行以下命令来创建负载均衡器服务:
$ oc create -f <file_name>.yaml
6.2.6.4.3. 设置通配符 DNS
设置通配符 DNS 记录或 CNAME,该记录引用负载均衡器服务的外部 IP。
流程
输入以下命令来获取外部 IP 地址:
$ oc -n clusters-<hosted_cluster_name> get service <hosted-cluster-name>-apps \ -o jsonpath='{.status.loadBalancer.ingress[0].ip}'输出示例
192.168.20.30配置引用外部 IP 地址的通配符 DNS 条目。查看以下示例 DNS 条目:
*.apps.<hosted_cluster_name\>.<base_domain\>.DNS 条目必须能够在集群内部和外部路由。
DNS 解析示例
dig +short test.apps.example.hypershift.lab 192.168.20.30
验证
输入以下命令检查托管集群状态是否已从
Partial变为Completed:$ oc get --namespace clusters hostedclusters输出示例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available将
<4.x.0>替换为您要使用支持的 OpenShift Container Platform 版本。
6.2.7. 完成部署
您可以从两个视角监控托管集群的部署:control plane 和数据平面。
6.2.7.1. 监控 control plane
在部署进行时,您可以通过收集有关以下工件的信息来监控 control plane:
- HyperShift Operator
-
HostedControlPlanepod - 裸机主机
- 代理
-
InfraEnv资源 -
HostedCluster和NodePool资源
流程
输入以下命令来监控 control plane:
$ export KUBECONFIG=/root/.kcli/clusters/hub-ipv4/auth/kubeconfig$ watch "oc get pod -n hypershift;echo;echo;\ oc get pod -n clusters-hosted-ipv4;echo;echo;\ oc get bmh -A;echo;echo;\ oc get agent -A;echo;echo;\ oc get infraenv -A;echo;echo;\ oc get hostedcluster -A;echo;echo;\ oc get nodepool -A;echo;echo;"
6.2.7.2. 监控数据平面
在部署进行时,您可以通过收集有关以下工件的信息来监控数据平面:
- 集群版本
- 特别是关于节点是否加入集群
- 集群 Operator
流程
输入以下命令:
$ oc get secret -n clusters-hosted-ipv4 admin-kubeconfig \ -o jsonpath='{.data.kubeconfig}' | base64 -d > /root/hc_admin_kubeconfig.yaml$ export KUBECONFIG=/root/hc_admin_kubeconfig.yaml$ watch "oc get clusterversion,nodes,co"
6.3. 在断开连接的环境中在裸机上部署托管的 control plane
当您在裸机上置备托管的 control plane 时,您可以使用 Agent 平台。Kubernetes Operator 的 Agent 平台和多集群引擎协同工作,以启用断开连接的部署。Agent 平台使用中央基础架构管理服务将 worker 节点添加到托管的集群中。有关中央基础架构管理服务简介,请参阅启用中央基础架构管理服务。
6.3.1. 裸机的断开连接的环境架构
下图演示了断开连接的环境的示例架构:

- 配置基础架构服务,包括带有 TLS 支持、Web 服务器和 DNS 的 registry 证书部署,以确保断开连接的部署正常工作。
在
openshift-config命名空间中创建配置映射。在本例中,配置映射名为registry-config。配置映射的内容是 Registry CA 证书。配置映射的 data 字段必须包含以下键/值:-
键:
<registry_dns_domain_name>..<port>,例如registry.hypershiftdomain.lab..5000:。在指定端口时,请确保在 registry DNS 域名后放置..。 值: 证书内容
有关创建配置映射的更多信息,请参阅为托管 control plane 的断开连接的安装配置 TLS 证书。
-
键:
-
修改
images.config.openshift.io自定义资源(CR)规格,并添加名为additionalTrustedCA的新字段,值为name: registry-config。 创建一个包含两个数据字段的配置映射。一个字段包含
RAW格式的registries.conf文件,另一个字段包含 Registry CA,并命名为ca-bundle.crt。配置映射属于multicluster-engine命名空间,配置映射名称在其他对象中引用。如需配置映射的示例,请参阅以下示例配置:apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- # ... -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.ocp-edge-cluster-0.qe.lab.redhat.com:5000/openshift4" [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true # ... # ...-
在 multicluster engine Operator 命名空间中,您要创建
multiclusterengineCR,该 CR 启用 Agent 和hypershift-addon附加组件。multicluster engine Operator 命名空间必须包含配置映射才能修改断开连接的部署中的行为。命名空间还包含multicluster-engine、assisted-service和hypershift-addon-managerpod。 创建部署托管集群所需的以下对象:
- secret :Secret 包含 pull secret、SSH 密钥和 etcd 加密密钥。
- 配置映射:配置映射包含私有 registry 的 CA 证书。
-
HostedCluster:HostedCluster资源定义用户创建的集群的配置。 -
NodePool:NodePool资源标识引用用于数据平面的机器的节点池。
-
创建托管集群对象后,HyperShift Operator 会建立
HostedControlPlane命名空间来容纳 control plane pod。命名空间还托管组件,如 Agents、裸机主机 (BMH)和InfraEnv资源。之后,您可以创建InfraEnv资源,并在 ISO 创建后创建 BMH 及其包含基板管理控制器(BMC)凭证的 secret。 -
openshift-machine-api命名空间中的 Metal3 Operator 会检查新的 BMH。然后,Metal3 Operator 会尝试连接到 BMC 来使用 multicluster engine Operator 命名空间中的AgentServiceConfigCR 指定的LiveISO和RootFS值来启动它们。 -
启动
HostedCluster资源的 worker 节点后,会启动一个 Agent 容器。此代理与 Assisted Service 建立联系人,它会编配操作以完成部署。最初,您需要将NodePool资源扩展到HostedCluster资源的 worker 节点数量。Assisted Service 管理剩余的任务。 - 此时,您需要等待部署过程完成。
6.3.2. 在断开连接的环境中在裸机上部署托管 control plane 的要求
要在断开连接的环境中配置托管的 control plane,您必须满足以下先决条件:
- CPU:提供的 CPU 数量决定了并发运行多少个托管集群。通常,每个节点使用 16 个 CPU 用于 3 个节点。对于最小开发,您可以对 3 个节点使用 12 个 CPU。
- Memory :RAM 量会影响可以托管的托管集群的数量。每个节点使用 48 GB RAM。对于最小开发,18 GB RAM 可能已足够。
Storage:为多集群引擎 Operator 使用 SSD 存储。
- 管理集群: 250 GB.
- Registry:所需的存储取决于托管的发行版本、操作器和镜像的数量。一个可接受的数字可能是 500 GB,最好与托管托管集群的磁盘分开。
- Web 服务器:所需的存储取决于托管的 ISO 和镜像的数量。可接受的数字可能为 500 GB。
生产环境: 对于生产环境,将管理集群、registry 和 Web 服务器分开在不同的磁盘上。本例演示了生产环境的可能配置:
- Registry: 2 TB
- 管理集群:500 GB
- Web 服务器:2 TB
6.3.3. 提取发行镜像摘要
您可以使用标记的镜像提取 OpenShift Container Platform 发行镜像摘要。
流程
运行以下命令来获取镜像摘要:
$ oc adm release info <tagged_openshift_release_image> | grep "Pull From"将
<tagged_openshift_release_image>替换为支持的 OpenShift Container Platform 版本标记的镜像,如quay.io/openshift-release-dev/ocp-release:4.14.0-x8_64。输出示例
Pull From: quay.io/openshift-release-dev/ocp-release@sha256:69d1292f64a2b67227c5592c1a7d499c7d00376e498634ff8e1946bc9ccdddfe
6.3.4. 裸机上的 DNS 配置
托管集群的 API 服务器作为 NodePort 服务公开。必须存在 api.<hosted_cluster_name>.<base_domain> 的 DNS 条目,它指向可以访问 API 服务器的目标。
DNS 条目可以作为记录,指向运行托管 control plane 管理集群中的一个节点。该条目也可以指向部署的负载均衡器,将传入的流量重定向到入口 pod。
DNS 配置示例
api.example.krnl.es. IN A 192.168.122.20
api.example.krnl.es. IN A 192.168.122.21
api.example.krnl.es. IN A 192.168.122.22
api-int.example.krnl.es. IN A 192.168.122.20
api-int.example.krnl.es. IN A 192.168.122.21
api-int.example.krnl.es. IN A 192.168.122.22
`*`.apps.example.krnl.es. IN A 192.168.122.23
在上例中,*.apps.example.krnl.es。IN A 192.168.122.23 是托管的集群中的节点,如果已经配置了负载均衡器,则是一个负载均衡器。
如果您要为 IPv6 网络上的断开连接的环境配置 DNS,则配置类似以下示例。
IPv6 网络的 DNS 配置示例
api.example.krnl.es. IN A 2620:52:0:1306::5
api.example.krnl.es. IN A 2620:52:0:1306::6
api.example.krnl.es. IN A 2620:52:0:1306::7
api-int.example.krnl.es. IN A 2620:52:0:1306::5
api-int.example.krnl.es. IN A 2620:52:0:1306::6
api-int.example.krnl.es. IN A 2620:52:0:1306::7
`*`.apps.example.krnl.es. IN A 2620:52:0:1306::10如果您要为双栈网络上的断开连接的环境配置 DNS,请务必包括 IPv4 和 IPv6 的条目。
双栈网络的 DNS 配置示例
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10
host-record=api.hub-dual.dns.base.domain.name,192.168.126.10
address=/apps.hub-dual.dns.base.domain.name/192.168.126.11
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2
host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2
address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6]
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7]
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8]
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]6.3.5. 在断开连接的环境中为托管的 control plane 部署 registry
对于开发环境,使用 Podman 容器部署小型自托管的 registry。对于生产环境,部署企业托管的 registry,如 Red Hat Quay、Nexus 或 Artifactory。
流程
要使用 Podman 部署小 registry,请完成以下步骤:
以特权用户身份,访问
${HOME}目录并创建以下脚本:#!/usr/bin/env bash set -euo pipefail PRIMARY_NIC=$(ls -1 /sys/class/net | grep -v podman | head -1) export PATH=/root/bin:$PATH export PULL_SECRET="/root/baremetal/hub/openshift_pull.json"1 if [[ ! -f $PULL_SECRET ]];then echo "Pull Secret not found, exiting..." exit 1 fi dnf -y install podman httpd httpd-tools jq skopeo libseccomp-devel export IP=$(ip -o addr show $PRIMARY_NIC | head -1 | awk '{print $4}' | cut -d'/' -f1) REGISTRY_NAME=registry.$(hostname --long) REGISTRY_USER=dummy REGISTRY_PASSWORD=dummy KEY=$(echo -n $REGISTRY_USER:$REGISTRY_PASSWORD | base64) echo "{\"auths\": {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\", \"email\": \"sample-email@domain.ltd\"}}}" > /root/disconnected_pull.json mv ${PULL_SECRET} /root/openshift_pull.json.old jq ".auths += {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\",\"email\": \"sample-email@domain.ltd\"}}" < /root/openshift_pull.json.old > $PULL_SECRET mkdir -p /opt/registry/{auth,certs,data,conf} cat <<EOF > /opt/registry/conf/config.yml version: 0.1 log: fields: service: registry storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry delete: enabled: true http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 compatibility: schema1: enabled: true EOF openssl req -newkey rsa:4096 -nodes -sha256 -keyout /opt/registry/certs/domain.key -x509 -days 3650 -out /opt/registry/certs/domain.crt -subj "/C=US/ST=Madrid/L=San Bernardo/O=Karmalabs/OU=Guitar/CN=$REGISTRY_NAME" -addext "subjectAltName=DNS:$REGISTRY_NAME" cp /opt/registry/certs/domain.crt /etc/pki/ca-trust/source/anchors/ update-ca-trust extract htpasswd -bBc /opt/registry/auth/htpasswd $REGISTRY_USER $REGISTRY_PASSWORD podman create --name registry --net host --security-opt label=disable --replace -v /opt/registry/data:/var/lib/registry:z -v /opt/registry/auth:/auth:z -v /opt/registry/conf/config.yml:/etc/docker/registry/config.yml -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry" -e "REGISTRY_HTTP_SECRET=ALongRandomSecretForRegistry" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry/certs:/certs:z -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key docker.io/library/registry:latest [ "$?" == "0" ] || !! systemctl enable --now registry- 1
- 将
PULL_SECRET的位置替换为您设置的适当位置。
将脚本文件命名为
registry.sh并保存。运行脚本时,它会拉取以下信息:- registry 名称,基于 hypervisor 主机名
- 所需的凭证和用户访问详情
通过添加执行标记来调整权限,如下所示:
$ chmod u+x ${HOME}/registry.sh要在没有任何参数的情况下运行脚本,请输入以下命令:
$ ${HOME}/registry.sh脚本将启动服务器。该脚本使用
systemd服务来管理目的。如果需要管理该脚本,您可以使用以下命令:
$ systemctl status$ systemctl start$ systemctl stop
registry 的根目录位于 /opt/registry 目录中,包含以下子目录:
-
certs包含 TLS 证书。 -
auth包含凭据。 -
data包含 registry 镜像。 -
conf包含 registry 配置。
6.3.6. 在断开连接的环境中为托管 control plane 设置管理集群
要设置 OpenShift Container Platform 管理集群,您需要确保安装了 Kubernetes Operator 的多集群引擎。multicluster engine Operator 在跨供应商部署集群时会扮演重要角色。
先决条件
- 管理集群和目标裸机主机(BMH)的 Baseboard Management Controller (BMH)之间必须有双向连接。另外,您还可通过代理提供商遵循 Boot it Yourself 方法。
托管的集群必须能够解析和访问管理集群主机名和 3.0.
apps主机名的 API 主机名。以下是管理集群和 3.0.apps主机名的 API 主机名示例:-
api.management-cluster.internal.domain.com -
console-openshift-console.apps.management-cluster.internal.domain.com
-
管理集群必须能够解析和访问托管集群的 API 和
3.0.apps主机名。以下是托管集群和*.apps主机名的 API 主机名示例:-
api.sno-hosted-cluster-1.internal.domain.com -
console-openshift-console.apps.sno-hosted-cluster-1.internal.domain.com
-
流程
- 在 OpenShift Container Platform 集群上安装 multicluster engine Operator 2.4 或更高版本。您可以从 OpenShift Container Platform OperatorHub 将 multicluster engine Operator 安装为 Operator。HyperShift Operator 包含在多集群引擎 Operator 中。有关安装多集群引擎 Operator 的更多信息,请参阅 Red Hat Advanced Cluster Management 文档中的"安装和升级多集群引擎 operator"。
- 确保安装了 HyperShift Operator。HyperShift Operator 会自动包含在多集群引擎 Operator 中,但如果您需要手动安装它,请按照"手动为 local-cluster 启用 hypershift-addon 受管集群附加组件 中的步骤操作"。
后续步骤
接下来,配置 Web 服务器。
6.3.7. 在断开连接的环境中为托管 control plane 配置 web 服务器
您需要配置额外的 web 服务器来托管与您要部署为托管集群的 OpenShift Container Platform 版本关联的 Red Hat Enterprise Linux CoreOS (RHCOS) 镜像。
流程
要配置 Web 服务器,请完成以下步骤:
输入以下命令从您要使用的 OpenShift Container Platform 发行版本中提取
openshift-install二进制文件:$ oc adm -a ${LOCAL_SECRET_JSON} release extract --command=openshift-install \ "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"运行以下脚本:该脚本在
/opt/srv目录中创建文件夹。文件夹包含用于置备 worker 节点的 RHCOS 镜像。#!/bin/bash WEBSRV_FOLDER=/opt/srv ROOTFS_IMG_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.pxe.rootfs.location')"1 LIVE_ISO_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location')"2 mkdir -p ${WEBSRV_FOLDER}/images curl -Lk ${ROOTFS_IMG_URL} -o ${WEBSRV_FOLDER}/images/${ROOTFS_IMG_URL##*/} curl -Lk ${LIVE_ISO_URL} -o ${WEBSRV_FOLDER}/images/${LIVE_ISO_URL##*/} chmod -R 755 ${WEBSRV_FOLDER}/* ## Run Webserver podman ps --noheading | grep -q websrv-ai if [[ $? == 0 ]];then echo "Launching Registry pod..." /usr/bin/podman run --name websrv-ai --net host -v /opt/srv:/usr/local/apache2/htdocs:z quay.io/alosadag/httpd:p8080 fi
下载完成后,容器将运行以托管 Web 服务器上的镜像。容器使用官方 HTTPd 镜像的一种变体,它也能够与 IPv6 网络一起使用。
6.3.8. 在断开连接的环境中为托管 control plane 配置镜像镜像
镜像镜像(mirror)是从外部 registry (如 registry.redhat.com 或 quay.io )获取镜像的过程,并将其存储在私有 registry 中。
在以下步骤中,使用 oc-mirror 工具,它是一个使用 ImageSetConfiguration 对象的二进制文件。在文件中,您可以指定以下信息:
-
要镜像的 OpenShift Container Platform 版本。版本位于
quay.io中。 - 要镜像的额外 Operator。单独选择软件包。
- 要添加到存储库中的额外镜像。
先决条件
- 在启动镜像过程前,请确保 registry 服务器正在运行。
流程
要配置镜像镜像,请完成以下步骤:
-
确保
${HOME}/.docker/config.json文件已使用您要从镜像(mirror)的 registry 更新,并使用您要将镜像推送到的私有 registry。 通过使用以下示例,创建一个
ImageSetConfiguration对象以用于镜像。根据需要替换值,使其与您的环境匹配:apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: channels: - name: candidate-{product-version} minVersion: <4.x.y-build>1 maxVersion: <4.x.y-build>2 type: ocp kubeVirtContainer: true3 graph: true operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.17 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged4 输入以下命令启动镜像过程:
$ oc-mirror --v2 --config imagesetconfig.yaml \ --workspace file://mirror-file docker://<registry>镜像过程完成后,您有一个名为
mirror-file的新文件夹,其中包含ImageDigestMirrorSet(IDMS)、ImageTagMirrorSet(ITMS)和要应用到托管的集群的目录源。通过配置
imagesetconfig.yaml文件,对 OpenShift Container Platform 的每日或 CI 版本进行镜像,如下所示:apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: graph: true release: registry.ci.openshift.org/ocp/release:<4.x.y-build>1 kubeVirtContainer: true2 # ...如果您有部分断开连接的环境,请输入以下命令将镜像从镜像集配置镜像到 registry:
$ oc mirror -c imagesetconfig.yaml \ --workspace file://<file_path> docker://<mirror_registry_url> --v2如需更多信息,请参阅"在部分断开连接的环境中镜像镜像集"。
如果您有一个完全断开连接的环境,请执行以下步骤:
输入以下命令将指定镜像设置配置中的镜像镜像到磁盘:
$ oc mirror -c imagesetconfig.yaml file://<file_path> --v2如需更多信息,请参阅"完全断开连接的环境中镜像设置"。
输入以下命令处理磁盘上的镜像集文件,并将内容镜像到目标镜像 registry:
$ oc mirror -c imagesetconfig.yaml \ --from file://<file_path> docker://<mirror_registry_url> --v2
- 按照在断开连接的网络中安装中的步骤来镜像最新的多集群引擎 Operator 镜像。
6.3.9. 在管理集群中应用对象
镜像过程完成后,您需要在管理集群中应用两个对象:
-
ImageContentSourcePolicy(ICSP) 或ImageDigestMirrorSet(IDMS) - 目录源
使用 oc-mirror 工具时,输出工件位于名为 oc-mirror-workspace/results-XXXXXX/ 的文件夹。
ICSP 或 IDMS 启动 MachineConfig 更改,它不会重启您的节点,而是在每个节点上重启 kubelet。节点标记为 READY 后,您需要应用新生成的目录源。
目录源在 openshift-marketplace Operator 中启动操作,如下载目录镜像并处理它来检索该镜像中包含的所有 PackageManifests。
流程
要检查新源,请使用新的
CatalogSource作为源运行以下命令:$ oc get packagemanifest要应用工件,请完成以下步骤:
输入以下命令创建 ICSP 或 IDMS 工件:
$ oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yaml等待节点就绪,然后输入以下命令:
$ oc apply -f catalogSource-XXXXXXXX-index.yaml
镜像 OLM 目录并配置托管集群以指向镜像。
当您使用
management(默认)OLMCatalogPlacement 模式时,用于 OLM 目录的镜像流不会自动满足管理集群中 ICSP 中的覆盖信息。-
如果使用原始名称和标签将 OLM 目录正确镜像到内部 registry,请将
hypershift.openshift.io/olm-catalogs-is-registry-overrides注解添加到HostedCluster资源。格式为"sr1=dr1,sr2=dr2",其中源 registry 字符串是一个键,目标 registry 是一个值。 要绕过 OLM 目录镜像流机制,请使用
HostedCluster资源上的以下四个注解直接指定用于 OLM Operator 目录的四个镜像的地址:-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
-
-
如果使用原始名称和标签将 OLM 目录正确镜像到内部 registry,请将
在这种情况下,镜像流不会被创建,您必须在 Operator 更新中刷新内部镜像以拉取(pull)时更新注解值。
后续步骤
通过完成 为托管 control plane 断开连接的安装部署多集群引擎 Operator 中的步骤来部署多集群引擎 Operator。
6.3.10. 部署 AgentServiceConfig 资源
AgentServiceConfig 自定义资源是 Assisted Service add-on 的基本组件,它是 multicluster engine Operator 的一部分。它负责裸机集群部署。启用附加组件后,您将部署 AgentServiceConfig 资源来配置附加组件。
除了配置 AgentServiceConfig 资源外,还需要包含额外的配置映射,以确保多集群引擎 Operator 在断开连接的环境中正常工作。
流程
通过添加以下配置映射来配置自定义 registry,其中包含自定义部署断开连接的详情:
apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.dns.base.domain.name:5000/openshift4"1 [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true # ... # ...- 1
- 将
dns.base.domain.name替换为 DNS 基本域名。
对象包含两个字段:
- Custom CAs:此字段包含加载到部署不同进程的证书颁发机构(CA)。
-
Registry:
Registries.conf字段包含有关需要从镜像 registry 而不是原始源 registry 使用的镜像和命名空间的信息。
通过添加
AssistedServiceConfig对象来配置 Assisted Service,如下例所示:apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: annotations: unsupported.agent-install.openshift.io/assisted-service-configmap: assisted-service-config1 name: agent namespace: multicluster-engine spec: mirrorRegistryRef: name: custom-registries2 databaseStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi filesystemStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 20Gi osImages:3 - cpuArchitecture: x86_644 openshiftVersion: "4.14" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live-rootfs.x86_64.img5 url: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live.x86_64.iso version: 414.92.202308281054-0 - cpuArchitecture: x86_64 openshiftVersion: "4.15" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-415.92.202403270524-0-live-rootfs.x86_64.img url: http://registry.dns.base.domain.name:8080/images/rhcos-415.92.202403270524-0-live.x86_64.iso version: 415.92.202403270524-0- 1
metadata.annotations["unsupported.agent-install.openshift.io/assisted-service-configmap"]注解引用 Operator 使用的配置映射名称来自定义行为。- 2
spec.mirrorRegistryRef.name注解指向包含 Assisted Service Operator 使用断开连接的 registry 信息的配置映射。此配置映射在部署过程中添加这些资源。- 3
spec.osImages字段包含可供此 Operator 部署的不同版本。这个字段是必须的。本例假设您已下载了RootFS和LiveISO文件。- 4
- 为您要部署的每个 OpenShift Container Platform 版本添加
cpuArchitecture子部分。在本例中,cpuArchitecture子部分包含在 4.14 和 4.15 中。 - 5
- 在
rootFSUrl和url字段中,将dns.base.domain.name替换为 DNS 基域名称。
通过将所有对象串联到一个文件中,并将它们应用到管理集群,以部署它们。要做到这一点,请输入以下命令:
$ oc apply -f agentServiceConfig.yaml命令会触发两个容器集。
输出示例
assisted-image-service-0 1/1 Running 2 11d1 assisted-service-668b49548-9m7xw 2/2 Running 5 11d2
后续步骤
配置 TLS 证书。
6.3.11. 为托管 control plane 的断开连接的安装配置 TLS 证书
为确保断开连接的部署中正常工作,您需要在管理集群中配置 registry CA 证书,并为托管集群配置 worker 节点。
6.3.11.1. 将 registry CA 添加到管理集群中
要将 registry CA 添加到管理集群中,请完成以下步骤。
流程
创建类似以下示例的配置映射:
apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <config_map_namespace>2 data:3 <registry_name>..<port>: |4 -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----对集群范围的对象
image.config.openshift.io进行补丁,使其包含以下规格:spec: additionalTrustedCA: - name: registry-config因此,control plane 节点可以从私有 registry 检索镜像,HyperShift Operator 可以为托管集群部署提取 OpenShift Container Platform 有效负载。
修补对象的过程可能需要几分钟才能完成。
6.3.11.2. 将 registry CA 添加到托管集群的 worker 节点
要让托管的集群中的 data plane worker 可以从私有 registry 检索镜像,您需要将 registry CA 添加到 worker 节点。
流程
在
hc.spec.additionalTrustBundle文件中,添加以下规格:spec: additionalTrustBundle: - name: user-ca-bundle1 - 1
user-ca-bundle条目是您在下一步中创建的配置映射。
在创建
HostedCluster对象的同一命名空间中,创建user-ca-bundle配置映射。配置映射类似以下示例:apiVersion: v1 data: ca-bundle.crt: | // Registry1 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry2 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry3 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 - 1
- 指定创建
HostedCluster对象的命名空间。
6.3.12. 在裸机上创建托管集群
托管的集群是一个 OpenShift Container Platform 集群,其 control plane 和 API 端点托管在管理集群中。托管的集群包括控制平面和它的对应的数据平面。
6.3.12.1. 部署托管集群对象
通常,HyperShift Operator 会创建 HostedControlPlane 命名空间。但是,在这种情况下,您要在 HyperShift Operator 开始协调 HostedCluster 对象前包括所有对象。然后,当 Operator 启动协调过程时,它会找到所有对象。
流程
使用有关命名空间的以下信息创建 YAML 文件:
--- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: <hosted_cluster_namespace>-<hosted_cluster_name>1 spec: {} status: {} --- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: <hosted_cluster_namespace>2 spec: {} status: {}创建一个 YAML 文件,其中包含以下有关配置映射和 secret 的信息,以包含在
HostedCluster部署中:--- apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 --- apiVersion: v1 data: .dockerconfigjson: xxxxxxxxx kind: Secret metadata: creationTimestamp: null name: <hosted_cluster_name>-pull-secret2 namespace: <hosted_cluster_namespace>3 --- apiVersion: v1 kind: Secret metadata: name: sshkey-cluster-<hosted_cluster_name>4 namespace: <hosted_cluster_namespace>5 stringData: id_rsa.pub: ssh-rsa xxxxxxxxx --- apiVersion: v1 data: key: nTPtVBEt03owkrKhIdmSW8jrWRxU57KO/fnZa8oaG0Y= kind: Secret metadata: creationTimestamp: null name: <hosted_cluster_name>-etcd-encryption-key6 namespace: <hosted_cluster_namespace>7 type: Opaque创建包含 RBAC 角色的 YAML 文件,以便 Assisted Service 代理可以与托管的 control plane 位于同一个
HostedControlPlane命名空间中,并仍然由集群 API 管理:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: capi-provider-role namespace: <hosted_cluster_namespace>-<hosted_cluster_name>1 2 rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'创建一个 YAML 文件,其中包含有关
HostedCluster对象的信息,根据需要替换值:apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: additionalTrustBundle: name: "user-ca-bundle" olmCatalogPlacement: guest imageContentSources:3 - source: quay.io/openshift-release-dev/ocp-v4.0-art-dev mirrors: - registry.<dns.base.domain.name>:5000/openshift/release4 - source: quay.io/openshift-release-dev/ocp-release mirrors: - registry.<dns.base.domain.name>:5000/openshift/release-images5 - mirrors: ... ... autoscaling: {} controllerAvailabilityPolicy: SingleReplica dns: baseDomain: <dns.base.domain.name>6 etcd: managed: storage: persistentVolume: size: 8Gi restoreSnapshotURL: null type: PersistentVolume managementType: Managed fips: false networking: clusterNetwork: - cidr: 10.132.0.0/14 - cidr: fd01::/48 networkType: OVNKubernetes serviceNetwork: - cidr: 172.31.0.0/16 - cidr: fd02::/112 platform: agent: agentNamespace: <hosted_cluster_namespace>-<hosted_cluster_name>7 8 type: Agent pullSecret: name: <hosted_cluster_name>-pull-secret9 release: image: registry.<dns.base.domain.name>:5000/openshift/release-images:<4.x.y>-x86_6410 11 secretEncryption: aescbc: activeKey: name: <hosted_cluster_name>-etcd-encryption-key12 type: aescbc services: - service: APIServer servicePublishingStrategy: type: LoadBalancer - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: Ignition servicePublishingStrategy: type: Route sshKey: name: sshkey-cluster-<hosted_cluster_name>13 status: controlPlaneEndpoint: host: "" port: 0通过将 YAML 文件串联到一个文件中,并将它们应用到管理集群来创建它们。要做到这一点,请输入以下命令:
$ oc apply -f 01-4.14-hosted_cluster-nodeport.yaml输出示例
NAME READY STATUS RESTARTS AGE capi-provider-5b57dbd6d5-pxlqc 1/1 Running 0 3m57s catalog-operator-9694884dd-m7zzv 2/2 Running 0 93s cluster-api-f98b9467c-9hfrq 1/1 Running 0 3m57s cluster-autoscaler-d7f95dd5-d8m5d 1/1 Running 0 93s cluster-image-registry-operator-5ff5944b4b-648ht 1/2 Running 0 93s cluster-network-operator-77b896ddc-wpkq8 1/1 Running 0 94s cluster-node-tuning-operator-84956cd484-4hfgf 1/1 Running 0 94s cluster-policy-controller-5fd8595d97-rhbwf 1/1 Running 0 95s cluster-storage-operator-54dcf584b5-xrnts 1/1 Running 0 93s cluster-version-operator-9c554b999-l22s7 1/1 Running 0 95s control-plane-operator-6fdc9c569-t7hr4 1/1 Running 0 3m57s csi-snapshot-controller-785c6dc77c-8ljmr 1/1 Running 0 77s csi-snapshot-controller-operator-7c6674bc5b-d9dtp 1/1 Running 0 93s csi-snapshot-webhook-5b8584875f-2492j 1/1 Running 0 77s dns-operator-6874b577f-9tc6b 1/1 Running 0 94s etcd-0 3/3 Running 0 3m39s hosted-cluster-config-operator-f5cf5c464-4nmbh 1/1 Running 0 93s ignition-server-6b689748fc-zdqzk 1/1 Running 0 95s ignition-server-proxy-54d4bb9b9b-6zkg7 1/1 Running 0 95s ingress-operator-6548dc758b-f9gtg 1/2 Running 0 94s konnectivity-agent-7767cdc6f5-tw782 1/1 Running 0 95s kube-apiserver-7b5799b6c8-9f5bp 4/4 Running 0 3m7s kube-controller-manager-5465bc4dd6-zpdlk 1/1 Running 0 44s kube-scheduler-5dd5f78b94-bbbck 1/1 Running 0 2m36s machine-approver-846c69f56-jxvfr 1/1 Running 0 92s oauth-openshift-79c7bf44bf-j975g 2/2 Running 0 62s olm-operator-767f9584c-4lcl2 2/2 Running 0 93s openshift-apiserver-5d469778c6-pl8tj 3/3 Running 0 2m36s openshift-controller-manager-6475fdff58-hl4f7 1/1 Running 0 95s openshift-oauth-apiserver-dbbc5cc5f-98574 2/2 Running 0 95s openshift-route-controller-manager-5f6997b48f-s9vdc 1/1 Running 0 95s packageserver-67c87d4d4f-kl7qh 2/2 Running 0 93s当托管集群可用时,输出类似以下示例。
输出示例
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters hosted-dual hosted-admin-kubeconfig Partial True False The hosted control plane is available
6.3.12.2. 为托管集群创建 NodePool 对象
NodePool 是与托管集群关联的一组可扩展的 worker 节点。NodePool 机器架构在特定池中保持一致,独立于 control plane 的机器架构。
流程
使用有关
NodePool对象的以下信息创建 YAML 文件,根据需要替换值:apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: <hosted_cluster_name> \1 namespace: <hosted_cluster_namespace> \2 spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false \3 upgradeType: InPlace \4 nodeDrainTimeout: 0s platform: type: Agent release: image: registry.<dns.base.domain.name>:5000/openshift/release-images:4.x.y-x86_64 \5 replicas: 26 status: replicas: 2- 1
- 将
<hosted_cluster_name>替换为您的托管集群。 - 2
- 将
<hosted_cluster_namespace>替换为托管集群命名空间的名称。 - 3
autoRepair字段设置为false,因为如果删除了该节点,则不会重新创建该节点。- 4
upgradeType设置为InPlace,这表示在升级过程中重复使用相同的裸机节点。- 5
- 此
NodePool中包含的所有节点都基于以下 OpenShift Container Platform 版本:4.x.y-x86_64。将<dns.base.domain.name>值替换为您的 DNS 基本域名,并将4.x.y值替换为您要使用的支持的 OpenShift Container Platform 版本。 - 6
- 您可以将
replicas值设置为2,以在托管集群中创建两个节点池副本。
运行以下命令来创建
NodePool对象:$ oc apply -f 02-nodepool.yaml输出示例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted-dual hosted 0 False False 4.x.y-x86_64
6.3.12.3. 为托管集群创建 InfraEnv 资源
InfraEnv 资源是一个 Assisted Service 对象,其中包含重要详情,如 pullSecretRef 和 sshAuthorizedKey。这些详情用于创建为托管集群自定义的 Red Hat Enterprise Linux CoreOS (RHCOS) 引导镜像。
您可以托管多个 InfraEnv 资源,各自采用特定类型的主机。例如,您可能想要在具有更大 RAM 容量的主机间划分服务器场。
流程
使用以下有关
InfraEnv资源的信息创建一个 YAML 文件,根据需要替换值:apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: pullSecretRef: name: pull-secret sshAuthorizedKey: ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDk7ICaUE+/k4zTpxLk4+xFdHi4ZuDi5qjeF52afsNkw0w/glILHhwpL5gnp5WkRuL8GwJuZ1VqLC9EKrdmegn4MrmUlq7WTsP0VFOZFBfq2XRUxo1wrRdor2z0Bbh93ytR+ZsDbbLlGngXaMa0Vbt+z74FqlcajbHTZ6zBmTpBVq5RHtDPgKITdpE1fongp7+ZXQNBlkaavaqv8bnyrP4BWahLP4iO9/xJF9lQYboYwEEDzmnKLMW1VtCE6nJzEgWCufACTbxpNS7GvKtoHT/OVzw8ArEXhZXQUS1UY8zKsX2iXwmyhw5Sj6YboA8WICs4z+TrFP89LmxXY0j6536TQFyRz1iB4WWvCbH5n6W+ABV2e8ssJB1AmEy8QYNwpJQJNpSxzoKBjI73XxvPYYC/IjPFMySwZqrSZCkJYqQ023ySkaQxWZT7in4KeMu7eS2tC+Kn4deJ7KwwUycx8n6RHMeD8Qg9flTHCv3gmab8JKZJqN3hW1D378JuvmIX4V0=其中:
- <hosted_cluster_namespace>
- 指定托管集群命名空间的名称。
- pullSecretRef
-
指定与使用 pull secret 的
InfraEnv相同的命名空间中的配置映射引用。 - sshAuthorizedKey
-
指定引导镜像中的 SSH 公钥。SSH 密钥允许以
core用户身份访问 worker 节点。
运行以下命令来创建
InfraEnv资源:$ oc apply -f 03-infraenv.yaml输出示例
NAMESPACE NAME ISO CREATED AT clusters-hosted-dual hosted 2023-09-11T15:14:10Z
6.3.12.4. 为托管集群创建裸机主机
裸机主机 是一个 openshift-machine-api 对象,其中包含物理和逻辑详情,以便它可以被 Metal3 Operator 识别。这些详细信息与其他 Assisted Service 对象关联,称为代理(agent)。
先决条件
- 在创建裸机主机和目标节点前,您必须让目标机器就绪。
- 您已在裸机基础架构上安装了 Red Hat Enterprise Linux CoreOS (RHCOS)计算机器,以便在集群中使用。
流程
要创建裸机主机,请完成以下步骤:
使用以下信息创建 YAML 文件:有关为裸机主机输入的详情的更多信息,请参阅使用 BMO"在用户置备的集群中配置新主机"。
因为至少有一个 secret 包含裸机主机凭证,所以您需要为每个 worker 节点至少创建两个对象。
apiVersion: v1 kind: Secret metadata: name: <hosted_cluster_name>-worker0-bmc-secret namespace: <hosted_cluster_namespace> data: password: YWRtaW4= username: YWRtaW4= type: Opaque # ... apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <hosted_cluster_name>-worker0 namespace: <hosted_cluster_namespace> labels: infraenvs.agent-install.openshift.io: <hosted_cluster_name> annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: <hosted_cluster_name>-worker0 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: true address: redfish-virtualmedia://[192.168.126.1]:9000/redfish/v1/Systems/local/<hosted_cluster_name>-worker0 credentialsName: <hosted_cluster_name>-worker0-bmc-secret bootMACAddress: aa:aa:aa:aa:02:11 online: true其中:
- <hosted_cluster_name>
- 指定托管集群的名称。
- <hosted_cluster_namespace>
- 指定托管集群命名空间的名称。
- password
- 以 Base64 格式指定基板管理控制器(BMC)的密码。
- username
- 以 Base64 格式指定 BMC 的用户名。
- infraenvs.agent-install.openshift.io
-
作为 Assisted Installer 和
BareMetalHost对象之间的链接。 - bmac.agent-install.openshift.io/hostname
- 代表部署期间采用的节点名称。
- automatedCleaningMode
- 防止 Metal3 Operator 清除节点。
- disableCertificateVerification
-
设置为
true,以从客户端绕过证书验证。 - address
- 表示 worker 节点的 BMC 地址。
- credentialsName
- 指向存储用户和密码凭证的 secret。
- bootMACAddress
- 表示节点从中启动的接口 MAC 地址。
- online
-
在
BareMetalHost对象创建后定义节点的状态。
输入以下命令部署
BareMetalHost对象:$ oc apply -f 04-bmh.yaml在此过程中,您可以查看以下输出:
此输出显示进程正在尝试访问节点:
输出示例
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 registering true 2s clusters-hosted hosted-worker1 registering true 2s clusters-hosted hosted-worker2 registering true 2s此输出显示节点正在启动:
输出示例
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioning true 16s clusters-hosted hosted-worker1 provisioning true 16s clusters-hosted hosted-worker2 provisioning true 16s此输出显示节点成功启动:
输出示例
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioned true 67s clusters-hosted hosted-worker1 provisioned true 67s clusters-hosted hosted-worker2 provisioned true 67s
节点启动后,注意命名空间中的代理,如下例所示:
输出示例
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 true auto-assign代理代表可用于安装的节点。要将节点分配给托管集群,请扩展节点池。
6.3.12.5. 扩展节点池
创建裸机主机后,其状态会从 Registering 变为 Provisioning 再变为 Provisioned。节点以代理的 LiveISO 开头,以及名为 agent 的默认 pod。该代理负责从 Assisted Service Operator 接收说明来安装 OpenShift Container Platform 有效负载。
流程
要扩展节点池,请输入以下命令:
$ oc -n <hosted_cluster_namespace> scale nodepool <hosted_cluster_name> \ --replicas 3其中:
-
<hosted_cluster_namespace>是托管集群命名空间的名称。 -
<hosted_cluster_name>是托管集群的名称。
-
在扩展过程完成后,请注意代理被分配给托管集群:
输出示例
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 hosted true auto-assign另请注意,节点池副本已设置:
输出示例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted hosted 3 False False <4.x.y>-x86_64 Minimum availability requires 3 replicas, current 0 available将
<4.x.y>替换为您要使用支持的 OpenShift Container Platform 版本。- 等待节点加入集群。在此过程中,代理会为其阶段和状态提供更新。
6.4. 在断开连接的环境中在 IBM Z 上部署托管的 control plane
在断开连接的环境中的 IBM Z 上托管 control plane 只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅以下链接:
在断开连接的环境中托管的 control plane 部署与独立的 OpenShift Container Platform 不同。
托管 control plane 涉及两个不同的环境:
- control plane:在管理集群中,托管 control plane pod 由 Control Plane Operator 运行和管理。
- data plane:查找托管集群的 worker,工作负载和其他几个 pod 运行,由 Hosted Cluster Config Operator 管理。
data plane 的 ImageContentSourcePolicy (ICSP) 自定义资源通过托管集群清单中的 ImageContentSources API 管理。
对于 control plane,ICSP 对象在管理集群中管理。这些对象由 HyperShift Operator 解析,并作为与 Control Plane Operator 的 registry-overrides 条目共享。这些条目作为环境变量注入托管 control plane 命名空间中的任何可用部署之一。
要在托管 control plane 中使用断开连接的 registry,您必须首先在管理集群中创建适当的 ICSP。然后,要在数据平面中部署断开连接的工作负载,您需要将您要的条目添加到托管集群清单中的 ImageContentSources 字段中。
6.4.1. 在断开连接的环境中在 IBM Z 上部署托管 control plane 的先决条件
- 镜像 registry。如需更多信息,请参阅"使用 mirror registry for Red Hat OpenShift 创建镜像 registry"。
- 用于断开连接的安装的镜像。如需更多信息,请参阅"使用 oc-mirror 插件为断开连接的安装镜像镜像"。
6.4.2. 将凭证和 registry 证书颁发机构添加到管理集群
要从管理集群中拉取 mirro registry 镜像,您必须首先将 registry 的 mirro registry 的证书颁发机构添加到管理集群。使用以下步骤:
流程
运行以下命令,使用 mirro registry 的证书创建
ConfigMap:$ oc apply -f registry-config.yamlregistry-config.yaml 文件示例
apiVersion: v1 kind: ConfigMap metadata: name: registry-config namespace: openshift-config data: <mirror_registry>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----对
image.config.openshift.io集群范围的对象进行补丁,使其包含以下条目:spec: additionalTrustedCA: - name: registry-config更新管理集群 pull secret,以添加 mirro registry 的凭证。
运行以下命令,以 JSON 格式从集群获取 pull secret:
$ oc get secret/pull-secret -n openshift-config -o json \ | jq -r '.data.".dockerconfigjson"' \ | base64 -d > authfile编辑获取的 secret JSON 文件,使其包含带有证书颁发机构凭证的部分:
"auths": { "<mirror_registry>": {1 "auth": "<credentials>",2 "email": "you@example.com" } },运行以下命令更新集群中的 pull secret:
$ oc set data secret/pull-secret -n openshift-config \ --from-file=.dockerconfigjson=authfile
当您将 mirro registry 用于镜像时,代理需要信任 registry 的证书来安全地拉取镜像。您可以通过创建 ConfigMap 将镜像 registry 的证书颁发机构添加到 AgentServiceConfig 自定义资源中。
先决条件
- 您必须为 Kubernetes Operator 安装多集群引擎。
流程
在安装多集群引擎 Operator 的同一命名空间中,使用 mirro registry 详情创建一个
ConfigMap资源。此ConfigMap资源可确保为托管集群 worker 授予从 mirro registry 检索镜像的功能。ConfigMap 文件示例
apiVersion: v1 kind: ConfigMap metadata: name: mirror-config namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | [[registry]] location = "registry.stage.redhat.io" insecure = false blocked = false mirror-by-digest-only = true prefix = "" [[registry.mirror]] location = "<mirror_registry>" insecure = false [[registry]] location = "registry.redhat.io/multicluster-engine" insecure = false blocked = false mirror-by-digest-only = true prefix = "" [[registry.mirror]] location = "<mirror_registry>/multicluster-engine"1 insecure = false- 1
- 其中:
<mirror_registry>是 mirro registry 的名称。
对
AgentServiceConfig资源进行补丁,使其包含您创建的ConfigMap资源。如果AgentServiceConfig资源不存在,请使用嵌入到其中的以下内容创建AgentServiceConfig资源:spec: mirrorRegistryRef: name: mirror-config
6.4.4. 将 registry 证书颁发机构添加到托管集群
当您在断开连接的环境中在 IBM Z 上部署托管 control plane 时,请包含 additional-trust-bundle 和 image-content-sources 资源。这些资源允许托管集群将证书颁发机构注入 data plane worker,以便从 registry 中拉取镜像。
使用
image-content-sources信息创建icsp.yaml文件。image-content-sources信息可在ImageContentSourcePolicyYAML 文件中使用oc-mirror来镜像后生成的。ImageContentSourcePolicy 文件示例
# cat icsp.yaml - mirrors: - <mirror_registry>/openshift/release source: quay.io/openshift-release-dev/ocp-v4.0-art-dev - mirrors: - <mirror_registry>/openshift/release-images source: quay.io/openshift-release-dev/ocp-release创建托管集群并提供
additional-trust-bundle证书以使用证书更新计算节点,如下例所示:$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \ --etcd-storage-class=<etcd_storage_class> \5 --ssh-key <path_to_ssh_public_key> \6 --namespace <hosted_cluster_namespace> \7 --control-plane-availability-policy SingleReplica \ --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --additional-trust-bundle <path for cert> \9 --image-content-sources icsp.yaml- 1
- 将
<hosted_cluster_name>替换为托管集群的名称。 - 2
- 替换 pull secret 的路径,例如
/user/name/pullsecret。 - 3
- 将
<hosted_control_plane_namespace>替换为托管的 control plane 命名空间的名称,如cluster-hosted。 - 4
- 将 name 替换为您的基域,例如
example.com。 - 5
- 替换 etcd 存储类名称,如
lvm-storageclass。 - 6
- 替换 SSH 公钥的路径。默认文件路径为
~/.ssh/id_rsa.pub。 - 7 8
- 使用您要使用的支持的 OpenShift Container Platform 版本替换,如
4.17.0-multi。 - 9
- 替换证书颁发机构 registry 的路径。
6.5. 在断开连接的环境中监控用户工作负载
hypershift-addon 受管集群附加组件在 HyperShift Operator 中启用 --enable-uwm-telemetry-remote-write 选项。通过启用该选项,您可以确保启用了用户工作负载监控,并且可以从 control plane 远程写入遥测指标。
6.5.1. 解决用户工作负载监控问题
如果您在没有连接到互联网的 OpenShift Container Platform 集群上安装 multicluster engine Operator,当您尝试通过输入以下命令来运行 HyperShift Operator 的用户工作负载监控功能时,该功能会失败并显示以下错误:
$ oc get events -n hypershift错误示例
LAST SEEN TYPE REASON OBJECT MESSAGE
4m46s Warning ReconcileError deployment/operator Failed to ensure UWM telemetry remote write: cannot get telemeter client secret: Secret "telemeter-client" not found
要解决错误,您必须通过在 local-cluster 命名空间中创建配置映射来禁用用户工作负载监控选项。您可以在启用附加组件前或之后创建配置映射。附加组件代理重新配置 HyperShift Operator。
流程
创建以下配置映射:
kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "" installFlagsToRemove: "--enable-uwm-telemetry-remote-write"运行以下命令来应用配置映射:
$ oc apply -f <filename>.yaml
6.5.2. 验证托管 control plane 功能的状态
托管的 control plane 功能默认启用。
流程
如果这个功能被禁用且您要启用它,请输入以下命令。将
<multiclusterengine>替换为多集群引擎 Operator 实例的名称:$ oc patch mce <multiclusterengine> --type=merge -p \ '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'当您启用该功能时,
hypershift-addon受管集群附加组件会在local-cluster受管集群中安装,附加组件代理会在多集群引擎 Operator hub 集群上安装 HyperShift Operator。输入以下命令确认已安装
hypershift-addon受管集群附加组件:$ oc get managedclusteraddons -n local-cluster hypershift-addon输出示例
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True False要避免在此过程中超时,请输入以下命令:
$ oc wait --for=condition=Degraded=True managedclusteraddons/hypershift-addon \ -n local-cluster --timeout=5m$ oc wait --for=condition=Available=True managedclusteraddons/hypershift-addon \ -n local-cluster --timeout=5m当过程完成后,
hypershift-addon受管集群附加组件和 HyperShift Operator 会被安装,local-cluster受管集群可用于托管和管理托管集群。
6.5.3. 配置 hypershift-addon 受管集群附加组件以便在基础架构节点上运行
默认情况下,没有为 hypershift-addon 受管集群附加组件指定节点放置首选项。考虑在基础架构节点上运行附加组件,因为这样做可防止对订阅计数造成计费成本,以及单独的维护和管理任务。
流程
- 登录到 hub 集群。
输入以下命令打开
hypershift-addon-deploy-config附加组件部署配置规格进行编辑:$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine在规格中添加
nodePlacement字段,如下例所示:apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: nodePlacement: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra operator: Exists-
保存更改。
hypershift-addon受管集群附加组件部署在用于新的和现有受管集群的基础架构节点上。
第 7 章 为托管的 control plane 配置证书
使用托管的 control plane,配置证书的步骤与独立的 OpenShift Container Platform 不同。
7.1. 在托管集群中配置自定义 API 服务器证书
要为 API 服务器配置自定义证书,请在 HostedCluster 配置的 spec.configuration.apiServer 部分中指定证书详情。
您可以在第 1 天或第 2 天操作期间配置自定义证书。但是,由于在托管集群创建过程中设置服务发布策略后,服务发布策略不可变,所以您必须知道您要配置的 Kubernetes API 服务器的主机名。
先决条件
您创建了包含管理集群中的自定义证书的 Kubernetes secret。secret 包含以下键:
-
tls.crt: 证书 -
tls.key:私钥
-
-
如果您的
HostedCluster配置包含使用负载均衡器的服务发布策略,请确保证书的 Subject Alternative Names (SAN)与内部 API 端点(api-int)不冲突。内部 API 端点由您的平台自动创建和管理。如果您在自定义证书和内部 API 端点中使用相同的主机名,则可能会出现路由冲突。此规则的唯一例外是,当您将 AWS 用作供应商时,使用Private或PublicAndPrivate配置。在这些情况下,SAN 冲突由平台管理。 - 证书必须对外部 API 端点有效。
- 证书的有效性周期与集群的预期生命周期一致。
流程
输入以下命令使用自定义证书创建 secret:
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>使用自定义证书详情更新
HostedCluster配置,如下例所示:spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert输入以下命令将更改应用到
HostedCluster配置:$ oc apply -f <hosted_cluster_config>.yaml
验证
- 检查 API 服务器 pod,以确保挂载了新证书。
- 使用自定义域名测试与 API 服务器的连接。
-
在浏览器中或使用
openssl等工具验证证书详情。
7.2. 为托管集群配置 Kubernetes API 服务器
如果要为托管集群自定义 Kubernetes API 服务器,请完成以下步骤。
先决条件
- 您有一个正在运行的托管集群。
-
您可以访问修改
HostedCluster资源。 您有一个用于 Kubernetes API 服务器的自定义 DNS 域。
- 自定义 DNS 域必须正确配置并可解析。
- DNS 域必须配置有效的 TLS 证书。
- 环境中必须正确配置对域的网络访问。
- 自定义 DNS 域必须在托管集群中唯一。
- 您已配置了自定义证书。如需更多信息,请参阅"在托管集群中配置自定义 API 服务器证书"。
流程
在供应商平台中,配置 DNS 记录,以便
kubeAPIServerDNSNameURL 指向 Kubernetes API 服务器所公开的 IP 地址。DNS 记录必须正确配置并可从集群解析。配置 DNS 记录的命令示例
$ dig + short kubeAPIServerDNSName在
HostedCluster规格中,修改kubeAPIServerDNSName字段,如下例所示:apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert kubeAPIServerDNSName: api-custom-cert-sample-hosted.sample-hosted.example.com3 # ...输入以下命令应用配置:
$ oc -f <hosted_cluster_spec>.yaml应用配置后,HyperShift Operator 会生成一个新的
kubeconfigsecret,指向您的自定义 DNS 域。使用 CLI 或控制台检索
kubeconfigsecret。要使用 CLI 检索 secret,请输入以下命令:
$ kubectl get secret <hosted_cluster_name>-custom-admin-kubeconfig \ -n <cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' | base64 -d要使用控制台检索 secret,进入托管集群并点 Download Kubeconfig。
注意您不能在控制台中使用 show login 命令 选项来使用新的
kubeconfigsecret。
7.3. 使用自定义 DNS 访问托管集群进行故障排除
如果您在使用自定义 DNS 访问托管集群时遇到问题,请完成以下步骤。
流程
- 验证 DNS 记录是否已正确配置并解决。
输入以下命令检查自定义域的 TLS 证书是否有效,验证您的 SAN 是否正确:
$ oc get secret \ -n clusters <serving_certificate_name> \ -o jsonpath='{.data.tls\.crt}' | base64 \ -d |openssl x509 -text -noout -- 确保到自定义域的网络连接正常工作。
在
HostedCluster资源中,验证状态是否显示正确的自定义kubeconfig信息,如下例所示:HostedCluster状态示例status: customKubeconfig: name: sample-hosted-custom-admin-kubeconfig输入以下命令检查
HostedControlPlane命名空间中的kube-apiserver日志:$ oc logs -n <hosted_control_plane_namespace> \ -l app=kube-apiserver -f -c kube-apiserver
第 8 章 更新托管的 control plane
托管 control plane 的更新涉及更新托管集群和节点池。要使集群在更新过程中完全正常工作,您必须在完成 control plane 和节点更新时满足 Kubernetes 版本偏移策略的要求。
8.1. 升级托管的 control plane 的要求
Kubernetes operator 的多集群引擎可以管理一个或多个 OpenShift Container Platform 集群。在 OpenShift Container Platform 上创建托管集群后,您必须在 multicluster engine operator 中导入托管集群作为受管集群。然后,您可以使用 OpenShift Container Platform 集群作为管理集群。
在开始更新托管的 control plane 前,请考虑以下要求:
- 当使用 OpenShift Virtualization 作为供应商时,您必须为 OpenShift Container Platform 集群使用裸机平台。
-
您必须使用裸机或 OpenShift Virtualization 作为托管集群的云平台。您可以在
HostedCluster自定义资源 (CR) 的spec.Platform.type规格中找到托管集群的平台类型。
您必须按照以下顺序更新托管的 control plane:
- 将 OpenShift Container Platform 集群升级到最新版本。如需更多信息,请参阅"使用 Web 控制台更新集群"或"使用 CLI 更新集群"。
- 将多集群引擎 Operator 升级到最新版本。如需更多信息,请参阅"更新已安装的 Operator"。
- 将托管的集群和节点池从以前的 OpenShift Container Platform 版本升级到最新版本。如需更多信息,请参阅"在托管集群中更新 control plane"和"更新托管集群中的节点池"。
8.2. 在托管集群中设置频道
您可以在 HostedCluster 自定义资源 (CR) 的 HostedCluster.Status 字段中看到可用的更新。
可用的更新不会从托管集群的 Cluster Version Operator (CVO) 获取。可用的更新列表可能与 HostedCluster 自定义资源 (CR) 的以下字段提供的更新不同:
-
status.version.availableUpdates -
status.version.conditionalUpdates
初始 HostedCluster CR 在 status.version.availableUpdates 和 status.version.conditionalUpdates 字段中没有任何信息。将 spec.channel 字段设置为 stable OpenShift Container Platform 发行版本后,HyperShift Operator 会协调 HostedCluster CR,并使用可用的和条件更新 status.version 字段。
请参阅以下包含频道配置的 HostedCluster CR 示例:
spec:
autoscaling: {}
channel: stable-4.y
clusterID: d6d42268-7dff-4d37-92cf-691bd2d42f41
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: dev11.red-chesterfield.com
privateZoneID: Z0180092I0DQRKL55LN0
publicZoneID: Z00206462VG6ZP0H2QLWK- 1
- 将
<4.y>替换为您在spec.release中指定的 OpenShift Container Platform 发行版本。例如,如果您将spec.release设置为ocp-release:4.16.4-multi,您必须将spec.channel设置为stable-4.16。
在 HostedCluster CR 中配置频道后,要查看 status.version.availableUpdates 和 status.version.conditionalUpdates 字段的输出,请运行以下命令:
$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> -o yaml输出示例
version:
availableUpdates:
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:b7517d13514c6308ae16c5fd8108133754eb922cd37403ed27c846c129e67a9a
url: https://access.redhat.com/errata/RHBA-2024:6401
version: 4.16.11
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:d08e7c8374142c239a07d7b27d1170eae2b0d9f00ccf074c3f13228a1761c162
url: https://access.redhat.com/errata/RHSA-2024:6004
version: 4.16.10
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:6a80ac72a60635a313ae511f0959cc267a21a89c7654f1c15ee16657aafa41a0
url: https://access.redhat.com/errata/RHBA-2024:5757
version: 4.16.9
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:ea624ae7d91d3f15094e9e15037244679678bdc89e5a29834b2ddb7e1d9b57e6
url: https://access.redhat.com/errata/RHSA-2024:5422
version: 4.16.8
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:e4102eb226130117a0775a83769fe8edb029f0a17b6cbca98a682e3f1225d6b7
url: https://access.redhat.com/errata/RHSA-2024:4965
version: 4.16.6
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:f828eda3eaac179e9463ec7b1ed6baeba2cd5bd3f1dd56655796c86260db819b
url: https://access.redhat.com/errata/RHBA-2024:4855
version: 4.16.5
conditionalUpdates:
- conditions:
- lastTransitionTime: "2024-09-23T22:33:38Z"
message: |-
Could not evaluate exposure to update risk SRIOVFailedToConfigureVF (creating PromQL round-tripper: unable to load specified CA cert /etc/tls/service-ca/service-ca.crt: open /etc/tls/service-ca/service-ca.crt: no such file or directory)
SRIOVFailedToConfigureVF description: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions include kernel datastructure changes which are not compatible with older versions of the SR-IOV operator. Please update SR-IOV operator to versions dated 20240826 or newer before updating OCP.
SRIOVFailedToConfigureVF URL: https://issues.redhat.com/browse/NHE-1171
reason: EvaluationFailed
status: Unknown
type: Recommended
release:
channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:fb321a3f50596b43704dbbed2e51fdefd7a7fd488ee99655d03784d0cd02283f
url: https://access.redhat.com/errata/RHSA-2024:5107
version: 4.16.7
risks:
- matchingRules:
- promql:
promql: |
group(csv_succeeded{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41", name=~"sriov-network-operator[.].*"})
or
0 * group(csv_count{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41"})
type: PromQL
message: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions
include kernel datastructure changes which are not compatible with older
versions of the SR-IOV operator. Please update SR-IOV operator to versions
dated 20240826 or newer before updating OCP.
name: SRIOVFailedToConfigureVF
url: https://issues.redhat.com/browse/NHE-11718.3. 更新托管的集群中的 OpenShift Container Platform 版本
托管 control plane 启用在 control plane 和数据平面之间分离更新。
作为集群服务提供商或集群管理员,您可以单独管理 control plane 和数据。
您可以通过修改 NodePool CR 来修改 HostedCluster 自定义资源(CR) 和节点来更新 control plane。HostedCluster 和 NodePool CR 在 .release 字段中指定 OpenShift Container Platform 发行镜像。
要在更新过程中保持托管集群完全正常工作,control plane 和节点更新必须遵循 Kubernetes 版本偏移策略。
8.3.1. multicluster engine Operator hub 管理集群
Kubernetes Operator 的多集群引擎需要特定的 OpenShift Container Platform 版本来管理集群才能保持支持的状态。您可以在 OpenShift Container Platform Web 控制台中从 OperatorHub 安装 multicluster engine Operator。
请参阅以下对多集群引擎 Operator 版本的支持:
multicluster engine Operator 支持以下 OpenShift Container Platform 版本:
- 最新的未发布版本
- 最新发布的版本
- 最新发布版本前的两个版本
您还可以获取 multicluster engine Operator 版本作为 Red Hat Advanced Cluster Management (RHACM) 的一部分。
8.3.2. 托管集群中的 OpenShift Container Platform 版本
在部署托管集群时,管理集群的 OpenShift Container Platform 版本不会影响托管集群的 OpenShift Container Platform 版本。
HyperShift Operator 在 hypershift 命名空间中创建 supported-versions ConfigMap。supported-versions ConfigMap 描述了您可以部署的受支持 OpenShift Container Platform 版本的范围。
请参阅以下 supported-versions ConfigMap 示例:
apiVersion: v1
data:
server-version: 2f6cfe21a0861dea3130f3bed0d3ae5553b8c28b
supported-versions: '{"versions":["4.17","4.16","4.15","4.14"]}'
kind: ConfigMap
metadata:
creationTimestamp: "2024-06-20T07:12:31Z"
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
resourceVersion: "927029"
uid: f6336f91-33d3-472d-b747-94abae725f70
要创建托管集群,您必须使用支持版本范围内的 OpenShift Container Platform 版本。但是,多集群引擎 Operator 只能在 n+1 和 n-2 OpenShift Container Platform 版本之间管理,其中 n 定义当前的次版本。您可以检查 multicluster engine Operator 支持列表,以确保由 multicluster engine Operator 管理的托管集群位于支持的 OpenShift Container Platform 范围内。
要在 OpenShift Container Platform 上部署托管集群的更高版本,您必须将 multicluster engine Operator 更新至新的次版本,以部署 Hypershift Operator 的新版本。将 multicluster engine Operator 升级到新的补丁(或 z-stream)发行版本不会将 HyperShift Operator 更新至下一版本。
请参阅以下 hcp version 命令的输出示例,它显示了管理集群中的 OpenShift Container Platform 4.16 支持的 OpenShift Container Platform 版本:
Client Version: openshift/hypershift: fe67b47fb60e483fe60e4755a02b3be393256343. Latest supported OCP: 4.17.0
Server Version: 05864f61f24a8517731664f8091cedcfc5f9b60d
Server Supports OCP Versions: 4.17, 4.16, 4.15, 4.148.4. 托管集群的更新
spec.release.image 值决定了 control plane 的版本。HostedCluster 对象将预期的 spec.release.image 值传送到 HostedControlPlane.spec.releaseImage 值,并运行适当的 Control Plane Operator 版本。
托管的 control plane 会管理 control plane 组件的新版本的推出,以及任何 OpenShift Container Platform 组件通过 Cluster Version Operator (CVO) 的新版本。
在托管的 control plane 中,NodeHealthCheck 资源无法检测 CVO 的状态。在执行关键操作(如更新集群)前,集群管理员必须手动暂停 NodeHealthCheck 触发的补救,以防止新的补救操作与集群更新进行交互。
要暂停补救,请输入字符串数组,如 pause-test-cluster,作为 NodeHealthCheck 资源中的 pauseRequests 字段的值。如需更多信息,请参阅关于 Node Health Check Operator。
集群更新后,您可以编辑或删除补救。进入到 Compute → NodeHealthCheck 页,点节点健康检查,然后点 Actions,它会显示一个下拉列表。
8.5. 节点池的更新
使用节点池,您可以通过公开 spec.release 和 spec.config 值来配置在节点上运行的软件。您可以使用以下方法启动滚动节点池更新:
-
更改
spec.release或spec.config值。 - 更改任何特定于平台的字段,如 AWS 实例类型。结果是一组带有新类型的新实例。
- 如果要将更改传播到节点,修改集群配置。
节点池支持替换更新和原位升级。nodepool.spec.release 值指定任何特定节点池的版本。NodePool 对象根据 .spec.management.upgradeType 值完成替换或原位滚动更新。
创建节点池后,您无法更改更新类型。如果要更改更新类型,您必须创建一个节点池并删除另一个节点池。
8.5.1. 替换节点池的更新
一个替换(replace)更新会在新版本中创建实例,并从以前的版本中删除旧的实例。对于这个级别的不可变性具有成本效率的云环境中,这个更新类型会非常有效。
替换更新不会保留任何手动更改,因为节点会被完全重新置备。
8.5.2. 节点池的原位更新
原位(in-place)会直接更新实例的操作系统。这个类型适用于对于基础架构的限制比较高的环境(如裸机)。
原位升级可保留手动更改,但在对集群直接关键的任何文件系统获操作系统配置(如 kubelet 证书)进行手工修改时会报告错误。
8.6. 更新托管集群中的节点池
您可以通过更新托管集群中的节点池来更新 OpenShift Container Platform 版本。节点池版本不能超过托管的 control plane 版本。
NodePool 自定义资源 (CR) 中的 .spec.release 字段显示节点池的版本。
流程
输入以下命令更改节点池中的
spec.release.image值:$ oc patch nodepool <node_pool_name> -n <hosted_cluster_namespace> \1 --type=merge \ -p '{"spec":{"nodeDrainTimeout":"60s","release":{"image":"<openshift_release_image>"}}}'2
验证
要验证新版本是否已推出,请运行以下命令检查节点池中的
.status.conditions值:$ oc get -n <hosted_cluster_namespace> nodepool <node_pool_name> -o yaml输出示例
status: conditions: - lastTransitionTime: "2024-05-20T15:00:40Z" message: 'Using release image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64'1 reason: AsExpected status: "True" type: ValidReleaseImage- 1
- 将
<4.y.z>替换为支持的 OpenShift Container Platform 版本。
8.7. 更新托管的集群中的 control plane
在托管的 control plane 上,您可以通过更新托管集群来升级 OpenShift Container Platform 的版本。HostedCluster 自定义资源 (CR) 中的 .spec.release 显示 control plane 的版本。HostedCluster 将 .spec.release 字段更新为 HostedControlPlane.spec.release,并运行适当的 Control Plane Operator 版本。
HostedControlPlane 资源通过 Cluster Version Operator (CVO) 的新版本编配 control plane 组件的推出以及数据平面中的 OpenShift Container Platform 组件。HostedControlPlane 包括以下工件:
- CVO
- Cluster Network Operator (CNO)
- Cluster Ingress Operator
- Kube API 服务器、调度程序和管理器的清单
- 机器批准
- Autoscaler(自动缩放器)
- 基础架构资源为 control plane 端点启用入口,如 Kube API 服务器、ignition 和 konnectivity
您可以使用 status.version.availableUpdates 和 status.version.conditionalUpdates 字段中的信息,将 HostedCluster CR 中的 .spec.release 字段设置为更新 control plane。
流程
输入以下命令将
hypershift.openshift.io/force-upgrade-to=<openshift_release_image>注解添加到托管集群:$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> <hosted_cluster_name> \1 "hypershift.openshift.io/force-upgrade-to=<openshift_release_image>" \2 --overwrite输入以下命令更改托管的集群中的
spec.release.image值:$ oc patch hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ --type=merge \ -p '{"spec":{"release":{"image":"<openshift_release_image>"}}}'
验证
要验证新版本是否已推出,请运行以下命令检查托管的集群中的
.status.conditions和.status.version值:$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> \ -o yaml输出示例
status: conditions: - lastTransitionTime: "2024-05-20T15:01:01Z" message: Payload loaded version="4.y.z" image="quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64"1 status: "True" type: ClusterVersionReleaseAccepted #... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_642 version: 4.y.z
8.8. 使用多集群引擎 Operator 控制台更新托管集群
您可以使用 multicluster engine Operator 控制台更新托管集群。
在更新托管集群前,您必须引用托管集群的可用和条件更新。选择错误的发行版本可能会破坏托管集群。
流程
- 选择 All clusters。
- 进入到 Infrastructure → Clusters 以查看受管集群。
- 点 Upgrade available 链接来更新 control plane 和节点池。
第 9 章 托管 control plane 的高可用性
9.1. 关于托管 control plane 的高可用性
您可以通过实施以下操作来维护托管 control plane 的高可用性 (HA):
- 为托管集群恢复 etcd 成员。
- 为托管集群备份和恢复 etcd。
- 为托管集群执行灾难恢复过程。
9.1.1. 故障管理集群组件的影响
如果管理集群组件失败,您的工作负载将保持不变。在 OpenShift Container Platform 管理集群中,控制平面(control plane)与数据平面(data plane)分离,以提供弹性。
下表涵盖了 control plane 和数据平面上失败的管理集群组件的影响。但是,该表不会涵盖管理集群组件失败的所有场景。
| 失败组件的名称 | 托管 control plane API 状态 | 托管的集群数据平面状态 |
|---|---|---|
| Worker节点 | 可用 | 可用 |
| 可用区 | 可用 | 可用 |
| 管理集群 control plane | 可用 | 可用 |
| 管理集群 control plane 和 worker 节点 | 不可用 | 可用 |
9.2. 恢复不健康的 etcd 集群
在高可用性 control plane 中,三个 etcd pod 作为 etcd 集群中有状态集的一部分运行。要恢复 etcd 集群,请通过检查 etcd 集群健康状况来识别不健康的 etcd pod。
9.2.1. 检查 etcd 集群的状态
您可以通过登录到任何 etcd pod 来检查 etcd 集群健康状态。
流程
输入以下命令登录到 etcd pod:
$ oc rsh -n openshift-etcd -c etcd <etcd_pod_name>输入以下命令输出 etcd 集群的健康状况:
sh-4.4# etcdctl endpoint status -w table输出示例
+------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://192.168.1xxx.20:2379 | 8fxxxxxxxxxx | 3.5.12 | 123 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.21:2379 | a5xxxxxxxxxx | 3.5.12 | 122 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.22:2379 | 7cxxxxxxxxxx | 3.5.12 | 124 MB | true | false | 10 | 180156 | 180156 | | +-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
9.2.2. 恢复失败的 etcd pod
3 节点集群的每个 etcd pod 都有自己的持久性卷声明 (PVC) 来存储其数据。由于数据损坏或缺少数据,etcd pod 可能会失败。您可以恢复 etcd pod 及其 PVC 失败。
流程
要确认 etcd pod 失败,请输入以下命令:
$ oc get pods -l app=etcd -n openshift-etcd输出示例
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 64m etcd-1 2/2 Running 0 45m etcd-2 1/2 CrashLoopBackOff 1 (5s ago) 64m失败的 etcd pod 可能具有
CrashLoopBackOff或Error状态。输入以下命令删除失败的 pod 及其 PVC:
$ oc delete pods etcd-2 -n openshift-etcd
验证
输入以下命令验证新 etcd pod 是否正在运行:
$ oc get pods -l app=etcd -n openshift-etcd输出示例
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 67m etcd-1 2/2 Running 0 48m etcd-2 2/2 Running 0 2m2s
9.3. 在内部环境中备份和恢复 etcd
您可以在内部环境中的托管集群中备份和恢复 etcd,以修复失败。
9.3.1. 在内部环境中的托管集群中备份和恢复 etcd
通过在托管集群中备份和恢复 etcd,您可以修复故障,如在三个节点集群的 etcd 成员中损坏或缺少数据。如果 etcd 集群的多个成员遇到数据丢失或具有 CrashLoopBackOff 状态,则这种方法有助于防止 etcd 仲裁丢失。
先决条件
-
已安装
oc和jq二进制文件。
流程
首先,设置环境变量:
输入以下命令为您的托管集群设置环境变量,根据需要替换值:
$ CLUSTER_NAME=my-cluster$ HOSTED_CLUSTER_NAMESPACE=clusters$ CONTROL_PLANE_NAMESPACE="${HOSTED_CLUSTER_NAMESPACE}-${CLUSTER_NAME}"输入以下命令暂停托管集群的协调,根据需要替换值:
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"true"}}' --type=merge
接下来,使用以下方法之一生成 etcd 快照:
- 使用之前备份的 etcd 快照。
如果您有可用的 etcd pod,通过完成以下步骤从活跃 etcd pod 创建快照:
输入以下命令列出 etcd pod:
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd输入以下命令为 pod 数据库生成快照并将其保存在您的机器中:
$ ETCD_POD=etcd-0$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- \ env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=https://localhost:2379 \ snapshot save /var/lib/snapshot.db输入以下命令验证快照是否成功:
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- \ env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status \ /var/lib/snapshot.db
输入以下命令制作快照的本地副本:
$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/snapshot.db \ /tmp/etcd.snapshot.db从 etcd 持久性存储生成快照数据库副本:
输入以下命令列出 etcd pod:
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd输入以下命令查找正在运行的 pod,并将其名称设置为
ETCD_POD: ETCD_POD=etcd-0,然后复制其快照数据库:$ oc cp -c etcd \ ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/data/member/snap/db \ /tmp/etcd.snapshot.db
接下来,输入以下命令缩减 etcd statefulset:
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=0输入以下命令删除第二个和第三个成员的卷:
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pvc/data-etcd-2创建 pod 以访问第一个 etcd 成员的数据:
输入以下命令来获取 etcd 镜像:
$ ETCD_IMAGE=$(oc get -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd \ -o jsonpath='{ .spec.template.spec.containers[0].image }')创建允许访问 etcd 数据的 pod:
$ cat << EOF | oc apply -n ${CONTROL_PLANE_NAMESPACE} -f - apiVersion: apps/v1 kind: Deployment metadata: name: etcd-data spec: replicas: 1 selector: matchLabels: app: etcd-data template: metadata: labels: app: etcd-data spec: containers: - name: access image: $ETCD_IMAGE volumeMounts: - name: data mountPath: /var/lib command: - /usr/bin/bash args: - -c - |- while true; do sleep 1000 done volumes: - name: data persistentVolumeClaim: claimName: data-etcd-0 EOF输入以下命令检查
etcd-datapod 的状态并等待它正在运行:$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd-data输入以下命令来获取
etcd-datapod 的名称:$ DATA_POD=$(oc get -n ${CONTROL_PLANE_NAMESPACE} pods --no-headers \ -l app=etcd-data -o name | cut -d/ -f2)
输入以下命令将 etcd 快照复制到 pod 中:
$ oc cp /tmp/etcd.snapshot.db \ ${CONTROL_PLANE_NAMESPACE}/${DATA_POD}:/var/lib/restored.snap.db输入以下命令从
etcd-datapod 中删除旧数据:$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm -rf /var/lib/data$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- mkdir -p /var/lib/data输入以下命令恢复 etcd 快照:
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- \ etcdutl snapshot restore /var/lib/restored.snap.db \ --data-dir=/var/lib/data --skip-hash-check \ --name etcd-0 \ --initial-cluster-token=etcd-cluster \ --initial-cluster etcd-0=https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-1=https://etcd-1.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-2=https://etcd-2.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380 \ --initial-advertise-peer-urls https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380输入以下命令从 pod 中删除临时 etcd 快照:
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- \ rm /var/lib/restored.snap.db输入以下命令删除数据访问部署:
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} deployment/etcd-data输入以下命令扩展 etcd 集群:
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=3输入以下命令等待 etcd 成员 pod 返回并报告 available:
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd -w
输入以下命令恢复托管集群的协调:
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"null"}}' --type=merge输入以下命令手动推出托管集群:
$ oc annotate hostedcluster -n \ <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)Multus 准入控制器和网络节点身份 pod 尚未启动。
输入以下命令删除第二个和第三个 etcd 成员及其 PVC 的 pod:
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pod/etcd-1 --wait=false$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-2 pod/etcd-2 --wait=false输入以下命令手动推出托管集群:
$ oc annotate hostedcluster -n \ <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds) \ --overwrite几分钟后,control plane pod 开始运行。
9.4. 在 AWS 上备份和恢复 etcd
您可以在 Amazon Web Services (AWS) 上的托管集群中备份和恢复 etcd,以修复失败。
9.4.1. 为托管集群生成 etcd 快照
要为托管集群备份 etcd,您必须执行 etcd 快照。之后,您可以使用快照恢复 etcd。
此流程需要 API 停机时间。
流程
输入以下命令暂停托管集群的协调:
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"true"}}' --type=merge输入以下命令停止所有 etcd-writer 部署:
$ oc scale deployment -n <hosted_cluster_namespace> --replicas=0 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver要进行 etcd 快照,请输入以下命令在每个 etcd 容器中使用
exec命令:$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- \ env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=localhost:2379 \ snapshot save /var/lib/data/snapshot.db要检查快照状态,请运行以下命令在每个 etcd 容器中使用
exec命令:$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- \ env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status \ /var/lib/data/snapshot.db将快照数据复制到稍后检索它的位置,如 S3 存储桶。请参见以下示例。
注意以下示例使用签名版本 2。如果您位于支持签名版本 4 的区域,如
us-east-2区域,请使用签名版本 4。否则,当将快照复制到 S3 存储桶时,上传会失败。Example
BUCKET_NAME=somebucket CLUSTER_NAME=cluster_name FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` HOSTED_CLUSTER_NAMESPACE=hosted_cluster_namespace oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db要稍后在新集群中恢复快照,请保存托管集群引用的加密 secret。
输入以下命令来获取 secret 加密密钥:
$ oc get hostedcluster <hosted_cluster_name> \ -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"<hosted_cluster_name>-etcd-encryption-key"}}输入以下命令保存 secret 加密密钥:
$ oc get secret <hosted_cluster_name>-etcd-encryption-key \ -o=jsonpath='{.data.key}'您可以在新集群中恢复快照时解密此密钥。
输入以下命令重启所有 etcd-writer 部署:
$ oc scale deployment -n <control_plane_namespace> --replicas=3 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver输入以下命令恢复托管集群的协调:
$ oc patch -n <hosted_cluster_namespace> \ -p '[\{"op": "remove", "path": "/spec/pausedUntil"}]' --type=json
后续步骤
恢复 etcd 快照。
9.4.2. 在托管集群中恢复 etcd 快照
如果从托管集群中有 etcd 快照,可以恢复它。目前,您只能在集群创建过程中恢复 etcd 快照。
要恢复 etcd 快照,您需要修改 create cluster --render 命令的输出,并在 HostedCluster 规格的 etcd 部分中定义 restoreSnapshotURL 值。
hcp create 命令中的 --render 标志不会呈现 secret。要呈现 secret,您必须在 hcp create 命令中使用 --render 和 --render-sensitive 标志。
先决条件
在托管集群中执行 etcd 快照。
流程
在
aws命令行界面 (CLI) 中,创建一个预签名的 URL,以便您可以从 S3 下载 etcd 快照,而无需将凭证传递给 etcd 部署:ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})修改
HostedCluster规格以引用 URL:spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
确保从
spec.secretEncryption.aescbc值引用的 secret 包含您在前面的步骤中保存的相同 AES 密钥。
9.5. 在 OpenShift Virtualization 上备份和恢复托管集群
您可以在 OpenShift Virtualization 上备份和恢复托管集群,以修复失败。
9.5.1. 在 OpenShift Virtualization 上备份托管集群
当您备份 OpenShift Virtualization 上的托管集群时,托管集群可以保持运行。备份包含托管的 control plane 组件和托管集群的 etcd。
当托管集群没有在外部基础架构上运行计算节点时,存储在由 KubeVirt CSI 置备的持久性卷声明(PVC)中的托管集群工作负载数据也会被备份。备份不包含用作计算节点的任何 KubeVirt 虚拟机(VM)。这些虚拟机会在恢复过程完成后自动创建。
流程
通过创建一个类似以下示例的 YAML 文件来创建 Velero 备份资源:
apiVersion: velero.io/v1 kind: Backup metadata: name: hc-clusters-hosted-backup namespace: openshift-adp labels: velero.io/storage-location: default spec: includedNamespaces:1 - clusters - clusters-hosted includedResources: - sa - role - rolebinding - deployment - statefulset - pv - pvc - bmh - configmap - infraenv - priorityclasses - pdb - hostedcluster - nodepool - secrets - hostedcontrolplane - cluster - datavolume - service - route excludedResources: [ ] labelSelector:2 matchExpressions: - key: 'hypershift.openshift.io/is-kubevirt-rhcos' operator: 'DoesNotExist' storageLocation: default preserveNodePorts: true ttl: 4h0m0s snapshotMoveData: true3 datamover: "velero"4 defaultVolumesToFsBackup: false5 - 1
- 此字段从对象中选择要备份的命名空间。包括来自托管集群和托管的 control plane 的命名空间。在本例中,
clusters是一个来自托管集群的命名空间,clusters-hosted是一个来自托管的 control plane 的命名空间。默认情况下,HostedControlPlane命名空间是clusters-<hosted_cluster_name>。 - 2
- 用作托管集群节点的虚拟机的引导镜像存储在大型 PVC 中。要减少备份时间和存储大小,您可以通过添加此标签选择器来过滤这些 PVC。
- 3
- 此字段和
datamover字段启用自动上传 CSIVolumeSnapshot到远程云存储。 - 4
- 此字段和
snapshotMoveData字段启用自动将 CSIVolumeSnapshot上传到远程云存储。 - 5
- 此字段指示 pod 卷文件系统备份默认用于所有卷。将此值设置为
false以备份您想要的 PVC。
输入以下命令将更改应用到 YAML 文件:
$ oc apply -f <backup_file_name>.yaml将
<backup_file_name>替换为您的文件的名称。监控备份对象状态和 Velero 日志中的备份过程。
要监控备份对象状态,请输入以下命令:
$ watch "oc get backups.velero.io -n openshift-adp <backup_file_name> -o jsonpath='{.status}' | jq"要监控 Velero 日志,请输入以下命令:
$ oc logs -n openshift-adp -ldeploy=velero -f
验证
-
当
status.phase字段为Completed时,备份过程被视为 complete。
9.5.2. 在 OpenShift Virtualization 上恢复托管集群
在 OpenShift Virtualization 上备份托管集群后,您可以恢复备份。
恢复过程只能在创建备份的同一管理集群中完成。
流程
-
确保
HostedControlPlane命名空间中没有运行 pod 或持久性卷声明 (PVC)。 从管理集群中删除以下对象:
-
HostedCluster -
NodePool - PVCs
-
创建类似以下示例的恢复清单 YAML 文件:
apiVersion: velero.io/v1 kind: Restore metadata: name: hc-clusters-hosted-restore namespace: openshift-adp spec: backupName: hc-clusters-hosted-backup restorePVs: true1 existingResourcePolicy: update2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io输入以下命令将更改应用到 YAML 文件:
$ oc apply -f <restore_resource_file_name>.yaml将
<restore_resource_file_name>替换为您的文件的名称。通过检查 restore status 字段和 Velero 日志来监控恢复过程。
要检查恢复状态字段,请输入以下命令:
$ watch "oc get restores.velero.io -n openshift-adp <backup_file_name> -o jsonpath='{.status}' | jq"要检查 Velero 日志,请输入以下命令:
$ oc logs -n openshift-adp -ldeploy=velero -f
验证
-
当
status.phase字段为Completed时,恢复过程被视为完成。
后续步骤
- 一段时间后,会创建 KubeVirt 虚拟机,并将托管集群作为计算节点加入。确保托管集群工作负载如预期再次运行。
9.6. AWS 中托管集群的灾难恢复
您可以将托管集群恢复到 Amazon Web Services (AWS) 中的同一区域。例如,当升级管理集群时,需要灾难恢复,且托管集群处于只读状态。
灾难恢复过程涉及以下步骤:
- 在源集群中备份托管集群
- 在目标管理集群中恢复托管集群
- 从源管理集群中删除托管的集群
您的工作负载在此过程中保持运行。集群 API 可能会在一段时间内不可用,但不会影响 worker 节点上运行的服务。
源管理集群和目标管理集群必须具有 --external-dns 标志才能维护 API 服务器 URL。这样,服务器 URL 以 https://api-sample-hosted.sample-hosted.aws.openshift.com 结尾。请参见以下示例:
示例:外部 DNS 标记
--external-dns-provider=aws \
--external-dns-credentials=<path_to_aws_credentials_file> \
--external-dns-domain-filter=<basedomain>
如果您没有包含 --external-dns 标志来维护 API 服务器 URL,则无法迁移托管集群。
9.6.1. 备份和恢复过程概述
备份和恢复过程按如下方式工作:
在管理集群 1 中,您可以将其视为源管理集群,control plane 和 worker 使用 ExternalDNS API 进行交互。可以访问外部 DNS API,并且一个负载均衡器位于管理集群之间。

您为托管集群执行快照,其中包括 etcd、control plane 和 worker 节点。在此过程中,worker 节点仍然会尝试访问外部 DNS API,即使无法访问它,工作负载正在运行,control plane 存储在本地清单文件中,etcd 会备份到 S3 存储桶。data plane 处于活跃状态,control plane 已暂停。

在管理集群 2 中,您可以将其视为目标管理集群,您可以从 S3 存储桶中恢复 etcd,并从本地清单文件恢复 control plane。在此过程中,外部 DNS API 会停止,托管集群 API 变得不可访问,任何使用 API 的 worker 都无法更新其清单文件,但工作负载仍在运行。

外部 DNS API 可以再次访问,worker 节点使用它来移至管理集群 2。外部 DNS API 可以访问指向 control plane 的负载均衡器。

在管理集群 2 中,control plane 和 worker 节点使用外部 DNS API 进行交互。资源从管理集群 1 中删除,但 etcd 的 S3 备份除外。如果您尝试在 mangagement 集群 1 上再次设置托管集群,它将无法正常工作。

9.6.2. 在 AWS 上备份托管集群
要在目标管理集群中恢复托管集群,首先需要备份所有相关数据。
流程
输入以下命令创建配置映射文件来声明源管理集群:
$ oc create configmap mgmt-parent-cluster -n default \ --from-literal=from=${MGMT_CLUSTER_NAME}输入以下命令在托管集群和节点池中关闭协调:
$ PAUSED_UNTIL="true"$ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge$ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} \ -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator运行以下 bash 脚本备份 etcd 并将数据上传到 S3 存储桶:
提示将此脚本嵌套在函数中,并从主功能调用它。
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db done有关备份 etcd 的更多信息,请参阅 "Backing and restore etcd on a hosted cluster"。
输入以下命令备份 Kubernetes 和 OpenShift Container Platform 对象。您需要备份以下对象:
-
来自 HostedCluster 命名空间的
HostedCluster和NodePool对象 -
来自 HostedCluster 命名空间中的
HostedClustersecret -
来自 Hosted Control Plane 命名空间中的
HostedControlPlane -
来自 Hosted Control Plane 命名空间的
Cluster -
来自 Hosted Control Plane 命名空间的
AWSCluster,AWSMachineTemplate, 和AWSMachine -
来自 Hosted Control Plane 命名空间的
MachineDeployments,MachineSets, 和Machines。 来自 Hosted Control Plane 命名空间的
ControlPlane输入以下命令:
$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ chmod 700 ${BACKUP_DIR}/namespaces/使用以下命令从
HostedCluster命名空间中备份HostedCluster对象:$ echo "Backing Up HostedCluster Objects:"$ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml$ echo "--> HostedCluster"$ sed -i '' -e '/^status:$/,$d' \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml输入以下命令从
HostedCluster命名空间中备份NodePool对象:$ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml$ echo "--> NodePool"$ sed -i '' -e '/^status:$/,$ d' \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml运行以下 shell 脚本备份
HostedCluster命名空间中的 secret:$ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done运行以下 shell 脚本,备份
HostedClustercontrol plane 命名空间中的 secret:$ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done输入以下命令备份托管的 control plane:
$ echo "--> HostedControlPlane:"$ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml输入以下命令备份集群:
$ echo "--> Cluster:"$ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} \ -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME})$ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml输入以下命令备份 AWS 集群:
$ echo "--> AWS Cluster:"$ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml输入以下命令备份 AWS
MachineTemplate对象:$ echo "--> AWS Machine Template:"$ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml运行以下 shell 脚本备份 AWS
Machines对象:$ echo "--> AWS Machine:"$ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done运行以下 shell 脚本备份
MachineDeployments对象:$ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done运行以下 shell 脚本备份
MachineSet对象:$ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done运行以下 shell 脚本,备份来自 Hosted Control Plane 命名空间中的
Machines对象:$ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
来自 HostedCluster 命名空间的
输入以下命令清理
ControlPlane路由:$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all输入该命令,您可以启用 ExternalDNS Operator 来删除 Route53 条目。
运行以下脚本验证 Route53 条目是否清理:
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
验证
检查所有 OpenShift Container Platform 对象和 S3 存储桶,以验证所有内容是否如预期。
后续步骤
恢复托管集群。
9.6.3. 恢复托管集群
收集您备份和恢复目标管理集群中的所有对象。
先决条件
您已从源集群备份数据。
确保目标管理集群的 kubeconfig 文件放置在 KUBECONFIG 变量中,或者在 MGMT2_KUBECONFIG 变量中设置。使用 export KUBECONFIG=<Kubeconfig FilePath>,或者使用 export KUBECONFIG=${MGMT2_KUBECONFIG}。
流程
输入以下命令验证新管理集群是否不包含您要恢复的集群中的任何命名空间:
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup目标管理集群中的命名空间删除
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true输入以下命令重新创建已删除的命名空间:
命名空间创建命令
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}输入以下命令恢复 HC 命名空间中的 secret:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*输入以下命令恢复
HostedClustercontrol plane 命名空间中的对象:恢复 secret 命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*集群恢复命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*如果您要恢复节点和节点池来重复利用 AWS 实例,请输入以下命令恢复 HC control plane 命名空间中的对象:
AWS 命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*机器的命令
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*运行此 bash 脚本恢复 etcd 数据和托管集群:
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fi如果您要恢复节点和节点池来重复利用 AWS 实例,请输入以下命令恢复节点池:
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
验证
要验证节点是否已完全恢复,请使用此功能:
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
后续步骤
关闭并删除集群。
9.6.4. 从源集群中删除托管集群
备份托管集群并将其恢复到目标管理集群后,您将关闭并删除源管理集群中的托管集群。
先决条件
您备份了数据并将其恢复到源管理集群。
确保目标管理集群的 kubeconfig 文件放置在 KUBECONFIG 变量中,或者在 MGMT_KUBECONFIG 变量中设置。使用 export KUBECONFIG=<Kubeconfig FilePath> 或使用脚本,请使用 export KUBECONFIG=${MGMT_KUBECONFIG}。
流程
输入以下命令来扩展
deployment和statefulset对象:重要如果其
spec.persistentVolumeClaimRetentionPolicy.whenScaled字段被设置为Delete,则不要扩展有状态的集合,因为这可能会导致数据丢失。作为临时解决方案,将
spec.persistentVolumeClaimRetentionPolicy.whenScaled字段的值更新为Retain。确保不存在协调有状态集的控制器,并将值返回为Delete,这可能会导致丢失数据。$ export KUBECONFIG=${MGMT_KUBECONFIG}缩减部署命令
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15输入以下命令来删除
NodePool对象:NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi输入以下命令删除
machine和machineset对象:# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true输入以下命令删除集群对象:
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all输入这些命令来删除 AWS 机器 (Kubernetes 对象)。不用担心删除实际的 AWS 机器。云实例不会受到影响。
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done输入以下命令删除
HostedControlPlane和ControlPlaneHC 命名空间对象:删除 HCP 和 ControlPlane HC NS 命令
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true输入以下命令删除
HostedCluster和 HC 命名空间对象:删除 HC 和 HC 命名空间命令
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
验证
要验证所有内容是否正常工作,请输入以下命令:
验证命令
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 内的命令
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
后续步骤
删除托管的集群中的 OVN pod,以便您可以连接到新管理集群中运行的新 OVN control plane:
-
使用托管的集群的 kubeconfig 路径加载
KUBECONFIG环境变量。 输入这个命令:
$ oc delete pod -n openshift-ovn-kubernetes --all
9.7. 使用 OADP 的托管集群的灾难恢复
您可以使用 OpenShift API for Data Protection (OADP) Operator 在 Amazon Web Services (AWS) 和裸机上执行灾难恢复。
OpenShift API for Data Protection (OADP)的灾难恢复过程涉及以下步骤:
- 准备您的平台,如 Amazon Web Services 或裸机,以使用 OADP
- 备份数据平面工作负载
- 备份 control plane 工作负载
- 使用 OADP 恢复托管集群
9.7.1. 先决条件
您必须在管理集群中满足以下先决条件:
- 已安装 OADP Operator。
- 您创建了存储类。
-
您可以使用
cluster-admin权限访问集群。 - 您可以通过目录源访问 OADP 订阅。
- 您可以访问与 OADP 兼容的云存储供应商,如 S3、Microsoft Azure、Google Cloud 或 MinIO。
- 在断开连接的环境中,您可以访问与 OADP 兼容的自托管存储供应商,如 Red Hat OpenShift Data Foundation 或 MinIO。
- 您的托管的 control plane pod 已启动并运行。
9.7.2. 准备 AWS 以使用 OADP
要为托管集群执行灾难恢复,您可以在 Amazon Web Services (AWS) S3 兼容存储上使用 OpenShift API 进行数据保护 (OADP)。创建 DataProtectionApplication 对象后,会在 openshift-adp 命名空间中创建新的 velero 部署和 node-agent pod。
要准备 AWS 以使用 OADP,请参阅"配置 OpenShift API for Data Protection with Multicloud Object Gateway"。
后续步骤
- 备份数据平面工作负载
- 备份 control plane 工作负载
9.7.3. 准备裸机以使用 OADP
要为托管集群执行灾难恢复,您可以在裸机上使用 OpenShift API 进行数据保护 (OADP)。创建 DataProtectionApplication 对象后,会在 openshift-adp 命名空间中创建新的 velero 部署和 node-agent pod。
要准备裸机以使用 OADP,请参阅"配置 OpenShift API for Data Protection with AWS S3 兼容存储"。
后续步骤
- 备份数据平面工作负载
- 备份 control plane 工作负载
9.7.4. 备份数据平面工作负载
如果 data plane 工作负载不重要,您可以跳过这个过程。要使用 OADP Operator 备份数据平面工作负载,请参阅"恢复应用程序"。
后续步骤
- 使用 OADP 恢复托管集群
9.7.5. 备份 control plane 工作负载
您可以通过创建 Backup 自定义资源 (CR) 来备份 control plane 工作负载。
要监控并观察备份过程,请参阅"保留备份和恢复进程"。
流程
运行以下命令暂停
HostedCluster资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'运行以下命令,获取托管集群的基础架构 ID:
$ oc get hostedcluster -n local-cluster <hosted_cluster_name> -o=jsonpath="{.spec.infraID}"记录下在下一步要使用的基础架构 ID。
运行以下命令暂停
cluster.cluster.x-k8s.io资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch cluster.cluster.x-k8s.io \ -n local-cluster-<hosted_cluster_name> <hosted_cluster_infra_id> \ --type json -p '[{"op": "add", "path": "/spec/paused", "value": true}]'运行以下命令暂停
NodePool资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'运行以下命令暂停
AgentCluster资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'运行以下命令暂停
AgentMachine资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'运行以下命令,注解
HostedCluster资源以防止删除托管的 control plane 命名空间:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace=true创建定义
BackupCR 的 YAML 文件:例 9.1.
backup-control-plane.yaml文件示例apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_resource_name>1 namespace: openshift-adp labels: velero.io/storage-location: default spec: hooks: {} includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 includedResources: - sa - role - rolebinding - pod - pvc - pv - bmh - configmap - infraenv5 - priorityclasses - pdb - agents - hostedcluster - nodepool - secrets - hostedcontrolplane - cluster - agentcluster - agentmachinetemplate - agentmachine - machinedeployment - machineset - machine excludedResources: [] storageLocation: default ttl: 2h0m0s snapshotMoveData: true6 datamover: "velero"7 defaultVolumesToFsBackup: true8 - 1
- 将
backup_resource_name替换为Backup资源的名称。 - 2
- 选择特定命名空间来备份对象。您必须包含托管集群命名空间和托管的 control plane 命名空间。
- 3
- 将
<hosted_cluster_namespace>替换为托管集群命名空间的名称,如clusters。 - 4
- 将
<hosted_control_plane_namespace>替换为托管的 control plane 命名空间的名称,如cluster-hosted。 - 5
- 您必须在单独的命名空间中创建
infraenv资源。不要在备份过程中删除infraenv资源。 - 6 7
- 启用 CSI 卷快照,并自动将 control plane 工作负载上传到云存储中。
- 8
- 将持久性卷 (PV) 的
fs-backup备份方法设置为默认。当您使用 Container Storage Interface (CSI) 卷快照和fs-backup方法的组合时,此设置很有用。
注意如果要使用 CSI 卷快照,您必须在 PV 中添加
backup.velero.io/backup-volumes-excludes=<pv_name>注解。运行以下命令来应用
BackupCR:$ oc apply -f backup-control-plane.yaml
验证
运行以下命令,验证
status.phase的值是否为Completed:$ oc get backups.velero.io <backup_resource_name> -n openshift-adp \ -o jsonpath='{.status.phase}'
后续步骤
- 使用 OADP 恢复托管集群
9.7.6. 使用 OADP 恢复托管集群
您可以通过创建 Restore 自定义资源(CR)来恢复托管集群。
- 如果您使用 原位(in-place)升级,则 InfraEnv 不需要备用节点。您需要从新的管理集群重新置备 worker 节点。
- 如果使用 替换(replace) 更新,则需要一些备用节点才能部署 worker 节点。
备份托管集群后,您必须销毁它来启动恢复过程。要启动节点置备,您必须在删除托管集群前备份数据平面中的工作负载。
先决条件
- 已完成了使用控制台删除集群中的步骤删除您的托管集群。
- 完成了删除集群后删除剩余的资源中的步骤。
要监控并观察备份过程,请参阅"保留备份和恢复进程"。
流程
运行以下命令,验证托管的 control plane 命名空间中没有 pod 和持久性卷声明 (PVC):
$ oc get pod pvc -n <hosted_control_plane_namespace>预期输出
No resources found创建定义
RestoreCR 的 YAML 文件:restore-hosted-cluster.yaml文件示例apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_resource_name>1 namespace: openshift-adp spec: backupName: <backup_resource_name>2 restorePVs: true3 existingResourcePolicy: update4 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io重要您必须在单独的命名空间中创建
infraenv资源。不要在恢复过程中删除infraenv资源。要重新置备新节点,infraenv资源是必须的。运行以下命令来应用
RestoreCR:$ oc apply -f restore-hosted-cluster.yaml运行以下命令,验证
status.phase的值是否为Completed:$ oc get hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ -o jsonpath='{.status.phase}'恢复过程完成后,启动您在备份 control plane 工作负载过程中暂停的
HostedCluster和NodePool资源的协调:运行以下命令启动
HostedCluster资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json \ -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'运行以下命令,启动
NodePool资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json \ -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'
启动您在备份 control plane 工作负载过程中暂停的 Agent 供应商资源的协调:
运行以下命令启动
AgentCluster资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all运行以下命令,启动
AgentMachine资源的协调:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all
运行以下命令,删除
HostedCluster资源中的hypershift.openshift.io/skip-delete-hosted-controlplane-namespace-注解,以避免手动删除托管的 control plane 命名空间:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace- \ --overwrite=true --all运行以下命令,将
NodePool资源扩展到所需的副本数:$ oc --kubeconfig <management_cluster_kubeconfig_file> \ scale nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --replicas <replica_count>1 - 1
- 将
<replica_count>替换为整数值,如3。
9.7.7. 观察备份和恢复过程
当使用 OpenShift API for Data Protection (OADP) 来备份和恢复托管集群时,您可以监控并观察进程。
流程
运行以下命令观察备份过程:
$ watch "oc get backups.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"运行以下命令观察恢复过程:
$ watch "oc get restores.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"运行以下命令观察 Velero 日志:
$ oc logs -n openshift-adp -ldeploy=velero -f运行以下命令,观察所有 OADP 对象的进度:
$ watch "echo BackupRepositories:;echo;oc get backuprepositories.velero.io -A;echo; echo BackupStorageLocations: ;echo; oc get backupstoragelocations.velero.io -A;echo;echo DataUploads: ;echo;oc get datauploads.velero.io -A;echo;echo DataDownloads: ;echo;oc get datadownloads.velero.io -n openshift-adp; echo;echo VolumeSnapshotLocations: ;echo;oc get volumesnapshotlocations.velero.io -A;echo;echo Backups:;echo;oc get backup -A; echo;echo Restores:;echo;oc get restore -A"
9.7.8. 使用 velero CLI 描述备份和恢复资源
当使用 OpenShift API 进行数据保护时,您可以使用 velero 命令行界面 (CLI) 获取 Backup 和 Restore 资源的更多详情。
流程
运行以下命令,创建一个别名,以便从容器中使用
veleroCLI:$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'运行以下命令,获取
Restore自定义资源 (CR) 的详情:$ velero restore describe <restore_resource_name> --details1 - 1
- 将
<restore_resource_name>替换为Restore资源的名称。
运行以下命令,获取
BackupCR 的详情:$ velero restore describe <backup_resource_name> --details1 - 1
- 将
<backup_resource_name>替换为Backup资源的名称。
第 10 章 托管 control plane 的身份验证和授权
OpenShift Container Platform control plane 包含内置的 OAuth 服务器。您可以获取 OAuth 访问令牌来向 OpenShift Container Platform API 进行身份验证。创建托管集群后,您可以通过指定身份提供程序来配置 OAuth。
10.1. 使用 CLI 为托管集群配置 OAuth 服务器
您可以使用 CLI 为托管集群配置内部 OAuth 服务器。
您可以为以下支持的身份提供程序配置 OAuth:
-
oidc -
htpasswd -
keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
在 OAuth 配置中添加任何身份提供程序会删除默认的 kubeadmin 用户提供程序。
在配置身份提供程序时,您必须事先在托管集群中配置至少一个 NodePool 副本。DNS 解析的流量通过 worker 节点发送。您不需要提前为 htpasswd 和 request-header 身份提供程序配置 NodePool 副本。
先决条件
- 已创建托管集群。
流程
运行以下命令,在托管集群上编辑
HostedCluster自定义资源(CR):$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>使用以下示例在
HostedClusterCR 中添加 OAuth 配置:apiVersion: hypershift.openshift.io/v1alpha1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: oauth: identityProviders: - openID:3 claims: email:4 - <email_address> name:5 - <display_name> preferredUsername:6 - <preferred_username> clientID: <client_id>7 clientSecret: name: <client_id_secret_name>8 issuer: https://example.com/identity9 mappingMethod: lookup10 name: IAM type: OpenID- 1
- 指定托管的集群名称。
- 2
- 指定托管集群的命名空间。
- 3
- 此提供程序名称作为前缀放在身份声明值前,以此组成身份名称。提供程序名称也用于构建重定向 URL。
- 4
- 定义用作电子邮件地址的属性列表。
- 5
- 定义用作显示名称的属性列表。
- 6
- 定义用作首选用户名的属性列表。
- 7
- 定义在 OpenID 提供程序中注册的客户端的 ID。您必须允许客户端重定向到
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>URL。 - 8
- 定义在 OpenID 供应商中注册的客户端的机密。
- 9
- OpenID 规范中描述的颁发者标识符。您必须使用没有查询或片段组件的
https。 - 10
- 定义一个映射方法,用于控制如何在此供应商和
User对象的身份之间建立映射。
- 保存文件以使改变生效。
10.2. 使用 web 控制台为托管集群配置 OAuth 服务器
您可以使用 OpenShift Container Platform Web 控制台为托管集群配置内部 OAuth 服务器。
您可以为以下支持的身份提供程序配置 OAuth:
-
oidc -
htpasswd -
keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
在 OAuth 配置中添加任何身份提供程序会删除默认的 kubeadmin 用户提供程序。
在配置身份提供程序时,您必须事先在托管集群中配置至少一个 NodePool 副本。DNS 解析的流量通过 worker 节点发送。您不需要提前为 htpasswd 和 request-header 身份提供程序配置 NodePool 副本。
先决条件
-
以具有
cluster-admin权限的用户身份登录。 - 已创建托管集群。
流程
- 进入到 Home → API Explorer。
-
使用 Filter by kind 复选框搜索您的
HostedCluster资源。 -
点您要编辑的
HostedCluster资源。 - 点 实例 选项卡。
-
点托管集群名称条目旁边的 Options 菜单
 ,然后点 Edit HostedCluster。
,然后点 Edit HostedCluster。
在 YAML 文件中添加 OAuth 配置:
spec: configuration: oauth: identityProviders: - openID:1 claims: email:2 - <email_address> name:3 - <display_name> preferredUsername:4 - <preferred_username> clientID: <client_id>5 clientSecret: name: <client_id_secret_name>6 issuer: https://example.com/identity7 mappingMethod: lookup8 name: IAM type: OpenID- 1
- 此提供程序名称作为前缀放在身份声明值前,以此组成身份名称。提供程序名称也用于构建重定向 URL。
- 2
- 定义用作电子邮件地址的属性列表。
- 3
- 定义用作显示名称的属性列表。
- 4
- 定义用作首选用户名的属性列表。
- 5
- 定义在 OpenID 提供程序中注册的客户端的 ID。您必须允许客户端重定向到
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>URL。 - 6
- 定义在 OpenID 供应商中注册的客户端的机密。
- 7
- OpenID 规范中描述的颁发者标识符。您必须使用没有查询或片段组件的
https。 - 8
- 定义一个映射方法,用于控制如何在此供应商和
User对象的身份之间建立映射。
- 点击 Save。
10.3. 使用 AWS 上托管的集群中的 CCO 分配组件 IAM 角色
您可以使用 Amazon Web Services (AWS) 上的托管的集群中的 Cloud Credential Operator (CCO) 分配提供简短、有限权限安全凭证的组件 IAM 角色。默认情况下,CCO 在托管的 control plane 中运行。
CCO 仅支持 AWS 上的托管集群的手动模式。默认情况下,托管集群以手动模式配置。管理集群可能使用 manual 以外的模式。
10.4. 在 AWS 上的托管集群中验证 CCO 安装
您可以验证 Cloud Credential Operator (CCO) 是否在托管 control plane 中正确运行。
先决条件
- 您已在 Amazon Web Services (AWS) 上配置了托管集群。
流程
运行以下命令,验证 CCO 是否在托管集群的手动模式中配置:
$ oc get cloudcredentials <hosted_cluster_name> \ -n <hosted_cluster_namespace> \ -o=jsonpath={.spec.credentialsMode}预期输出
Manual运行以下命令,验证
serviceAccountIssuer资源的值是否不为空:$ oc get authentication cluster --kubeconfig <hosted_cluster_name>.kubeconfig \ -o jsonpath --template '{.spec.serviceAccountIssuer }'输出示例
https://aos-hypershift-ci-oidc-29999.s3.us-east-2.amazonaws.com/hypershift-ci-29999
10.5. 启用 Operator 以支持使用 AWS STS 的基于 CCO 的工作流
作为 Operator 作者设计在 Operator Lifecycle Manager (OLM)上运行的项目,您可以通过自定义项目来支持 Cloud Credential Operator (CCO),使 Operator 能够对启用了 STS 的 OpenShift Container Platform 集群上的 AWS 进行身份验证。
使用此方法,Operator 负责创建 CredentialsRequest 对象并读取生成的 Secret 对象,并需要 RBAC 权限。
默认情况下,与 Operator 部署相关的 pod 会挂载 serviceAccountToken 卷,以便在生成的 Secret 对象中引用服务帐户令牌。
先决条件
- OpenShift Container Platform 4.14 或更高版本
- 处于 STS 模式的集群
- 基于 OLM 的 Operator 项目
流程
更新 Operator 项目的
ClusterServiceVersion(CSV)对象:确保 Operator 有 RBAC 权限来创建
CredentialsRequests对象:例 10.1.
clusterPermissions列表示例# ... install: spec: clusterPermissions: - rules: - apiGroups: - "cloudcredential.openshift.io" resources: - credentialsrequests verbs: - create - delete - get - list - patch - update - watch添加以下注解来声明对使用 AWS STS 的基于 CCO 工作流的方法的支持:
# ... metadata: annotations: features.operators.openshift.io/token-auth-aws: "true"
更新 Operator 项目代码:
从 pod 上由
Subscription对象设置的环境变量获取角色 ARN。例如:// Get ENV var roleARN := os.Getenv("ROLEARN") setupLog.Info("getting role ARN", "role ARN = ", roleARN) webIdentityTokenPath := "/var/run/secrets/openshift/serviceaccount/token"确保具有
CredentialsRequest对象已准备好修补并应用。例如:例 10.2.
CredentialsRequest对象创建示例import ( minterv1 "github.com/openshift/cloud-credential-operator/pkg/apis/cloudcredential/v1" corev1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) var in = minterv1.AWSProviderSpec{ StatementEntries: []minterv1.StatementEntry{ { Action: []string{ "s3:*", }, Effect: "Allow", Resource: "arn:aws:s3:*:*:*", }, }, STSIAMRoleARN: "<role_arn>", } var codec = minterv1.Codec var ProviderSpec, _ = codec.EncodeProviderSpec(in.DeepCopyObject()) const ( name = "<credential_request_name>" namespace = "<namespace_name>" ) var CredentialsRequestTemplate = &minterv1.CredentialsRequest{ ObjectMeta: metav1.ObjectMeta{ Name: name, Namespace: "openshift-cloud-credential-operator", }, Spec: minterv1.CredentialsRequestSpec{ ProviderSpec: ProviderSpec, SecretRef: corev1.ObjectReference{ Name: "<secret_name>", Namespace: namespace, }, ServiceAccountNames: []string{ "<service_account_name>", }, CloudTokenPath: "", }, }另外,如果您从 YAML 表单的
CredentialsRequest对象开始(例如,作为 Operator 项目代码的一部分),您可以以不同的方式处理它:例 10.3. 以 YAML 格式创建
CredentialsRequest对象示例// CredentialsRequest is a struct that represents a request for credentials type CredentialsRequest struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` Metadata struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"metadata"` Spec struct { SecretRef struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"secretRef"` ProviderSpec struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` StatementEntries []struct { Effect string `yaml:"effect"` Action []string `yaml:"action"` Resource string `yaml:"resource"` } `yaml:"statementEntries"` STSIAMRoleARN string `yaml:"stsIAMRoleARN"` } `yaml:"providerSpec"` // added new field CloudTokenPath string `yaml:"cloudTokenPath"` } `yaml:"spec"` } // ConsumeCredsRequestAddingTokenInfo is a function that takes a YAML filename and two strings as arguments // It unmarshals the YAML file to a CredentialsRequest object and adds the token information. func ConsumeCredsRequestAddingTokenInfo(fileName, tokenString, tokenPath string) (*CredentialsRequest, error) { // open a file containing YAML form of a CredentialsRequest file, err := os.Open(fileName) if err != nil { return nil, err } defer file.Close() // create a new CredentialsRequest object cr := &CredentialsRequest{} // decode the yaml file to the object decoder := yaml.NewDecoder(file) err = decoder.Decode(cr) if err != nil { return nil, err } // assign the string to the existing field in the object cr.Spec.CloudTokenPath = tokenPath // return the modified object return cr, nil }注意目前不支持在 Operator 捆绑包中添加
CredentialsRequest对象。在凭证请求中添加角色 ARN 和 Web 身份令牌路径,并在 Operator 初始化过程中应用它:
例 10.4. 在 Operator 初始化过程中应用
CredentialsRequest对象示例// apply CredentialsRequest on install credReq := credreq.CredentialsRequestTemplate credReq.Spec.CloudTokenPath = webIdentityTokenPath c := mgr.GetClient() if err := c.Create(context.TODO(), credReq); err != nil { if !errors.IsAlreadyExists(err) { setupLog.Error(err, "unable to create CredRequest") os.Exit(1) } }确保 Operator 可以等待
Secret对象从 CCO 显示,如下例所示,以及您在 Operator 中协调的其他项目:例 10.5. 等待
Secret对象示例// WaitForSecret is a function that takes a Kubernetes client, a namespace, and a v1 "k8s.io/api/core/v1" name as arguments // It waits until the secret object with the given name exists in the given namespace // It returns the secret object or an error if the timeout is exceeded func WaitForSecret(client kubernetes.Interface, namespace, name string) (*v1.Secret, error) { // set a timeout of 10 minutes timeout := time.After(10 * time.Minute)1 // set a polling interval of 10 seconds ticker := time.NewTicker(10 * time.Second) // loop until the timeout or the secret is found for { select { case <-timeout: // timeout is exceeded, return an error return nil, fmt.Errorf("timed out waiting for secret %s in namespace %s", name, namespace) // add to this error with a pointer to instructions for following a manual path to a Secret that will work on STS case <-ticker.C: // polling interval is reached, try to get the secret secret, err := client.CoreV1().Secrets(namespace).Get(context.Background(), name, metav1.GetOptions{}) if err != nil { if errors.IsNotFound(err) { // secret does not exist yet, continue waiting continue } else { // some other error occurred, return it return nil, err } } else { // secret is found, return it return secret, nil } } } }- 1
timeout值基于 CCO 检测添加的CredentialsRequest对象并生成Secret对象的速度。您可能会考虑降低时间或为集群管理员创建自定义反馈,这可能会导致 Operator 尚未访问云资源的原因。
通过从凭证请求中读取 CCO 创建的 secret 并设置 AWS 配置,并创建包含该 secret 数据的 AWS 配置文件:
例 10.6. AWS 配置创建示例
func SharedCredentialsFileFromSecret(secret *corev1.Secret) (string, error) { var data []byte switch { case len(secret.Data["credentials"]) > 0: data = secret.Data["credentials"] default: return "", errors.New("invalid secret for aws credentials") } f, err := ioutil.TempFile("", "aws-shared-credentials") if err != nil { return "", errors.Wrap(err, "failed to create file for shared credentials") } defer f.Close() if _, err := f.Write(data); err != nil { return "", errors.Wrapf(err, "failed to write credentials to %s", f.Name()) } return f.Name(), nil }重要secret 被假定为存在,但在使用此 secret 时,您的 Operator 代码应等待和重试,以提供 CCO 创建 secret 的时间。
另外,等待周期最终应该超时,并警告用户 OpenShift Container Platform 集群版本,因此 CCO 可能会是一个较早的版本,它不支持使用 STS 检测的
CredentialsRequest对象工作流。在这种情况下,指示用户必须使用其他方法添加 secret。配置 AWS SDK 会话,例如:
例 10.7. AWS SDK 会话配置示例
sharedCredentialsFile, err := SharedCredentialsFileFromSecret(secret) if err != nil { // handle error } options := session.Options{ SharedConfigState: session.SharedConfigEnable, SharedConfigFiles: []string{sharedCredentialsFile}, }
第 11 章 为托管 control plane 处理机器配置
在一个独立的 OpenShift Container Platform 集群中,机器配置池管理一组节点。您可以使用 MachineConfigPool 自定义资源 (CR) 处理机器配置。
您可以在 NodePool CR 的 nodepool.spec.config 字段中引用任何 machineconfiguration.openshift.io 资源。
在托管的 control plane 中,MachineConfigPool CR 不存在。节点池包含一组计算节点。您可以使用节点池处理机器配置。
11.1. 为托管的 control plane 配置节点池
在托管的 control plane 上,您可以通过在管理集群中的配置映射中创建 MachineConfig 对象来配置节点池。
流程
要在管理集群中的配置映射中创建
MachineConfig对象,请输入以下信息:apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: ${PATH}1 - 1
- 在存储
MachineConfig对象的节点上设置路径。
将对象添加到配置映射后,您可以将配置映射应用到节点池,如下所示:
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- 将
<configmap_name>替换为配置映射的名称。
11.2. 在节点池中引用 kubelet 配置
要在节点池中引用 kubelet 配置,您可以在配置映射中添加 kubelet 配置,然后在 NodePool 资源中应用配置映射。
流程
输入以下信息,在管理集群中的配置映射中添加 kubelet 配置:
带有 kubelet 配置的
ConfigMap对象示例apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name>1 namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: <kubeletconfig_name>2 spec: kubeletConfig: registerWithTaints: - key: "example.sh/unregistered" value: "true" effect: "NoExecute"输入以下命令将配置映射应用到节点池:
$ oc edit nodepool <nodepool_name> --namespace clusters1 - 1
- 将
<nodepool_name>替换为节点池的名称。
NodePool资源配置示例apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- 将
<configmap_name>替换为配置映射的名称。
11.3. 在托管集群中配置节点性能优化
要在托管集群中的节点上设置节点级别性能优化,您可以使用 Node Tuning Operator。在托管的 control plane 中,您可以通过创建包含 Tuned 对象并在节点池中引用这些配置映射的配置映射来配置节点调整。
流程
创建包含有效 tuned 清单的配置映射,并引用节点池中的清单。在以下示例中,
Tuned清单定义了一个配置文件,在包含tuned-1-node-label节点标签的节点上将vm.dirty_ratio设为 55。将以下ConfigMap清单保存到名为tuned-1.yaml的文件中:apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile注意如果您没有将任何标签添加到 Tuned spec 的
spec.recommend部分中的条目中,则假定基于 node-pool 的匹配,因此spec.recommend部分中的最高优先级配置集应用于池中的节点。虽然您可以通过在 Tuned.spec.recommend.match部分中设置标签值来实现更精细的节点标记匹配,除非您将节点池的.spec.management.upgradeType值设置为InPlace。在管理集群中创建
ConfigMap对象:$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml通过编辑节点池或创建节点池的
spec.tuningConfig字段中引用ConfigMap对象。在本例中,假设您只有一个NodePool,名为nodepool-1,它含有 2 个节点。apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...注意您可以在多个节点池中引用同一配置映射。在托管的 control plane 中,Node Tuning Operator 会将节点池名称和命名空间的哈希值附加到 Tuned CR 的名称中,以区分它们。在这种情况下,请不要为同一托管集群在不同的 Tuned CR 中创建多个名称相同的 TuneD 配置集。
验证
现在,您已创建包含 Tuned 清单的 ConfigMap 对象并在 NodePool 中引用它,Node Tuning Operator 会将 Tuned 对象同步到托管集群中。您可以验证定义了 Tuned 对象,以及将 TuneD 配置集应用到每个节点。
列出托管的集群中的
Tuned对象:$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator输出示例
NAME AGE default 7m36s rendered 7m36s tuned-1 65s列出托管的集群中的
Profile对象:$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator输出示例
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s注意如果没有创建自定义配置集,则默认应用
openshift-node配置集。要确认正确应用了调整,请在节点上启动一个 debug shell,并检查 sysctl 值:
$ oc --kubeconfig="$HC_KUBECONFIG" \ debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio输出示例
vm.dirty_ratio = 55
11.4. 为托管 control plane 部署 SR-IOV Operator
配置和部署托管服务集群后,您可以在托管集群中创建 SR-IOV Operator 订阅。SR-IOV pod 在 worker 机器上运行而不是在 control plane 上运行。
先决条件
您必须在 AWS 上配置和部署托管集群。
流程
创建命名空间和 Operator 组:
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator创建 SR-IOV Operator 的订阅:
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: stable name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: redhat-operators sourceNamespace: openshift-marketplace
验证
要验证 SR-IOV Operator 是否已就绪,请运行以下命令并查看生成的输出:
$ oc get csv -n openshift-sriov-network-operator输出示例
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.17.0-202211021237 SR-IOV Network Operator 4.17.0-202211021237 sriov-network-operator.4.17.0-202210290517 Succeeded要验证 SR-IOV pod 是否已部署,请运行以下命令:
$ oc get pods -n openshift-sriov-network-operator
11.5. 为托管集群配置 NTP 服务器
您可以使用 Butane 为托管集群配置网络时间协议(NTP)服务器。
流程
创建一个 Butane 配置文件
99-worker-chrony.bu,其中包含chrony.conf文件的内容。有关 Butane 的更多信息,请参阅"使用 Butane 创建机器配置"。99-worker-chrony.bu配置示例# ... variant: openshift version: 4.17.0 metadata: name: 99-worker-chrony labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 06441 overwrite: true contents: inline: | pool 0.rhel.pool.ntp.org iburst2 driftfile /var/lib/chrony/drift makestep 1.0 3 rtcsync logdir /var/log/chrony # ...注意对于机器到机器的通信,用户数据报协议(UDP)端口上的 NTP 为
123。如果配置了外部 NTP 时间服务器,您必须打开 UDP 端口123。使用 Butane 生成
MachineConfig对象文件99-worker-chrony.yaml,其中包含 Butane 发送到节点的配置。运行以下命令:$ butane 99-worker-chrony.bu -o 99-worker-chrony.yaml99-worker-chrony.yaml配置示例# Generated by Butane; do not edit apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path在管理集群的配置映射中添加
99-worker-chrony.yaml文件的内容:配置映射示例
apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: <namespace>1 data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path # ...- 1
- 将
<namespace>替换为创建节点池的命名空间的名称,如clusters。
运行以下命令,将配置映射应用到节点池:
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>NodePool配置示例apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
- 将
<configmap_name>替换为配置映射的名称。
在
infra-env.yaml文件中添加 NTP 服务器列表,该文件定义InfraEnv自定义资源(CR):infra-env.yaml文件示例apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv # ... spec: additionalNTPSources: - <ntp_server>1 - <ntp_server1> - <ntp_server2> # ...- 1
- 将
<ntp_server>替换为 NTP 服务器的名称。有关创建主机清单和InfraEnvCR 的详情,请参阅"创建主机清单"。
运行以下命令来应用
InfraEnvCR:$ oc apply -f infra-env.yaml
验证
检查以下字段以了解主机清单的状态:
-
conditions:指示镜像是否已成功创建的标准 Kubernetes 条件。 -
isoDownloadURL:下载发现镜像的 URL。 createdTime:镜像最后一次创建的时间。如果您修改了InfraEnvCR,请确保在下载新镜像前更新了时间戳。运行以下命令验证您的主机清单是否已创建:
$ oc describe infraenv <infraenv_resource_name> -n <infraenv_namespace>注意如果您修改了
InfraEnvCR,请通过查看createdTime字段来确认InfraEnvCR 已创建新的 Discovery Image。如果您已经引导的主机,请使用最新的发现镜像再次引导它们。
-
第 12 章 在托管集群中使用功能门
您可以使用托管集群中的功能门启用不是默认功能集合的功能。您可以使用托管集群中的功能门启用 TechPreviewNoUpgrade 功能集。
12.1. 使用功能门启用功能集
您可以使用 OpenShift CLI 编辑 HostedCluster 自定义资源 (CR),在托管集群中启用 TechPreviewNoUpgrade 功能集。
先决条件
-
已安装 OpenShift CLI(
oc)。
流程
运行以下命令,打开
HostedClusterCR 以在托管集群上进行编辑:$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>通过在
featureSet字段中输入值来定义功能集。例如:apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: featureGate: featureSet: TechPreviewNoUpgrade3 警告在集群中启用
TechPreviewNoUpgrade功能集无法撤消,并会阻止次版本更新。此功能集允许您在测试集群中启用这些技术预览功能,您可以在测试集群中完全测试它们。不要在生产环境集群中启用此功能。- 保存文件以使改变生效。
验证
运行以下命令,验证您的受管集群中是否启用了
TechPreviewNoUpgrade功能门:$ oc get featuregate cluster -o yaml
第 13 章 托管 control plane 的可观察性
您可以通过配置指标集来收集托管 control plane 的指标。HyperShift Operator 可以为它管理的每个托管集群在管理集群中创建或删除监控仪表板。
13.1. 为托管 control plane 配置指标集
为 Red Hat OpenShift Container Platform 托管 control plane 会在每个 control plane 命名空间中创建 ServiceMonitor 资源,允许 Prometheus 堆栈从 control plane 收集指标。ServiceMonitor 资源使用指标重新标记来定义从特定组件(如 etcd 或 Kubernetes API 服务器)包含或排除哪些指标。control plane 生成的指标数量会直接影响收集它们的监控堆栈的资源要求。
您可以配置一个指标集来标识为每个 control plane 生成的一组指标,而不是生成固定的指标数量。支持以下指标集:
-
Telemetry:遥测需要这些指标。这个集合是默认设置,是最小指标集合。 -
SRE:此集合包含生成警报并允许对 control plane 组件的故障排除所需的指标。 -
All:此集合包括由独立 OpenShift Container Platform control plane 组件生成的所有指标。
要配置指标集,请输入以下命令在 HyperShift Operator 部署中设置 METRICS_SET 环境变量:
$ oc set env -n hypershift deployment/operator METRICS_SET=All13.1.1. 配置 SRE 指标集
当您指定 SRE 指标集时,HyperShift Operator 会查找带有一个键 config 的名为 sre-metric-set 的配置映射。config 键的值必须包含一组由 control plane 组件组织的 RelabelConfigs。
您可以指定以下组件:
-
etcd -
kubeAPIServer -
kubeControllerManager -
openshiftAPIServer -
openshiftControllerManager -
openshiftRouteControllerManager -
cvo -
olm -
catalogOperator -
registryOperator -
nodeTuningOperator -
controlPlaneOperator -
hostedClusterConfigOperator
以下示例中演示了 SRE 指标集的配置:
kubeAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "transformation_(transformation_latencies_microseconds|failures_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "network_plugin_operations_latency_microseconds|sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
kubeControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "rest_client_request_latency_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "root_ca_cert_publisher_sync_duration_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
openshiftAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
openshiftControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
openshiftRouteControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
olm:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
catalogOperator:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
cvo:
- action: drop
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]13.2. 在托管集群中启用监控仪表板
您可以通过创建配置映射来在托管集群中启用监控仪表板。
流程
在
local-cluster命名空间中创建hypershift-operator-install-flags配置映射。请参见以下示例配置:kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "--monitoring-dashboards --metrics-set=All"1 installFlagsToRemove: ""- 1
--monitoring-dashboards --metrics-set=All标志添加所有指标的监控仪表板。
等待几分钟,使
hypershift命名空间中的 HyperShift Operator 部署被更新,使其包含以下环境变量:- name: MONITORING_DASHBOARDS value: "1"当启用监控仪表板时,对于 HyperShift Operator 管理的每个托管集群,Operator 会在
openshift-config-managed命名空间中创建一个名为cp-<hosted_cluster_namespace>-<hosted_cluster_name>的配置映射,其中<hosted_cluster_namespace>是托管集群的命名空间,<hosted_cluster_name>是托管集群的名称。因此,在管理集群的管理控制台中会添加新仪表板。- 要查看仪表板,请登录到管理控制台,并通过点 Observe → Dashboards 进入托管集群的仪表板。
-
可选: 要在托管集群中禁用监控仪表板,请从
hypershift-operator-install标志。当您删除托管集群时,其对应的仪表板也会被删除。-flags配置映射中删除--monitoring-dashboards --metrics-set=All
13.2.1. 仪表板自定义
要为每个托管集群生成仪表板,HyperShift Operator 使用存储在 Operator 命名空间中的 monitoring-dashboard-template 配置映射中的模板 (hypershift)。此模板包含一组 Grafana 面板,其中包含仪表板的指标。您可以编辑配置映射的内容来自定义仪表板。
当生成仪表板时,以下字符串将被替换为与特定托管集群对应的值:
| Name | 描述 |
|---|---|
|
| 托管集群的名称 |
|
| 托管集群的命名空间 |
|
| 放置托管集群的 control plane pod 的命名空间 |
|
|
托管集群的 UUID,它与托管集群指标的 |
第 14 章 托管 control plane 故障排除
如果您在托管 control plane 时遇到问题,请参阅以下信息来引导您完成故障排除。
14.1. 收集信息以对托管 control plane 进行故障排除
当需要对托管集群问题进行故障排除时,您可以通过运行 must-gather 命令来收集信息。该命令为管理集群和托管集群生成输出。
管理集群的输出包含以下内容:
- 集群范围的资源:这些资源是管理集群的节点定义。
-
hypershift-dump压缩文件: 如果您需要与其他人员共享内容,该文件非常有用。 - 命名空间资源:这些资源包括来自相关命名空间中的所有对象,如配置映射、服务、事件和日志。
- 网络日志:这些日志包括 OVN 北向和南向数据库和每个数据库的状态。
- 托管的集群:此级别的输出涉及托管集群内的所有资源。
托管集群的输出包含以下内容:
- 集群范围的资源:这些资源包含所有集群范围的对象,如节点和 CRD。
- 命名空间资源:这些资源包括来自相关命名空间中的所有对象,如配置映射、服务、事件和日志。
虽然输出不包含集群中的任何 secret 对象,但它可以包含对 secret 名称的引用。
先决条件
-
您必须具有对管理集群的
cluster-admin访问权限。 -
您需要
HostedCluster资源的name值以及部署 CR 的命名空间。 -
已安装
hcp命令行界面。如需更多信息,请参阅"安装托管的 control plane 命令行界面"。 -
已安装 OpenShift CLI (
oc)。 -
您必须确保
kubeconfig文件已被加载,并指向管理集群。
流程
要收集故障排除的输出,请输入以下命令:
$ oc adm must-gather \ --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:v<mce_version> \ /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE \ hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=NAME ; tar -cvzf NAME.tgz NAME其中:
-
您可以将
<mce_version>替换为您使用的多集群引擎 Operator 版本,例如2.6。 -
hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE参数是可选的。如果没有包括它,命令会像托管集群一样在默认命名空间(clusters)中运行。 -
如果要将命令结果保存到一个压缩文件中,请指定
--dest-dir=NAME参数,并将NAME替换为您要保存结果的目录的名称。
-
您可以将
14.2. 为托管集群收集 OpenShift Container Platform 数据
您可以使用 multicluster engine Operator web 控制台或使用 CLI 为托管集群收集 OpenShift Container Platform 调试信息。
14.2.1. 使用 CLI 为托管集群收集数据
您可以使用 CLI 为托管集群收集 OpenShift Container Platform 调试信息。
先决条件
-
您必须具有对管理集群的
cluster-admin访问权限。 -
您需要
HostedCluster资源的name值以及部署 CR 的命名空间。 -
已安装
hcp命令行界面。如需更多信息,请参阅"安装托管的 control plane 命令行界面"。 -
已安装 OpenShift CLI (
oc)。 -
您必须确保
kubeconfig文件已被加载,并指向管理集群。
流程
输入以下命令生成
kubeconfig文件:$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfig保存
kubeconfig文件后,您可以输入以下示例命令来访问托管集群:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes.输入以下命令收集 must-gather 信息:
$ oc adm must-gather
14.2.2. 使用 Web 控制台为托管集群收集数据
您可以使用 multicluster engine Operator web 控制台为托管集群收集 OpenShift Container Platform 调试信息。
先决条件
-
您必须具有对管理集群的
cluster-admin访问权限。 -
您需要
HostedCluster资源的name值以及部署 CR 的命名空间。 -
已安装
hcp命令行界面。如需更多信息,请参阅"安装托管的 control plane 命令行界面"。 -
已安装 OpenShift CLI (
oc)。 -
您必须确保
kubeconfig文件已被加载,并指向管理集群。
流程
- 在 Web 控制台中,选择 All Clusters 并选择您要故障排除的集群。
- 在右上角,选择 Download kubeconfig。
-
导出下载的
kubeconfig文件。 输入以下命令收集 must-gather 信息:
$ oc adm must-gather
14.3. 在断开连接的环境中输入 must-gather 命令
完成以下步骤,在断开连接的环境中运行 must-gather 命令。
流程
- 在断开连接的环境中,将 Red Hat Operator 目录镜像镜像(mirror)到其 mirror registry 中。如需更多信息,请参阅在断开连接的网络中安装。
运行以下命令以提取日志,从其 mirror registry 中引用镜像:
REGISTRY=registry.example.com:5000 IMAGE=$REGISTRY/multicluster-engine/must-gather-rhel8@sha256:ff9f37eb400dc1f7d07a9b6f2da9064992934b69847d17f59e385783c071b9d8 $ oc adm must-gather \ --image=$IMAGE /usr/bin/gather \ hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE \ hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=./data
14.4. OpenShift Virtualization 上托管集群故障排除
当您对 OpenShift Virtualization 上的托管集群进行故障排除时,从顶层 HostedCluster 和 NodePool 资源开始,然后关闭堆栈,直到找到根本原因。以下步骤可帮助您发现常见问题的根本原因。
14.4.1. HostedCluster 资源处于部分状态
如果因为 HostedCluster 资源处于待处理而没有完全在线托管的 control plane,请通过检查先决条件、资源条件和节点和 Operator 状态来识别问题。
流程
- 确保您满足 OpenShift Virtualization 上托管集群的所有先决条件。
-
查看
HostedCluster和NodePool资源的条件,以了解防止进度的验证错误。 通过使用托管集群的
kubeconfig文件,检查托管集群的状态:-
查看
oc get clusteroperators命令的输出,以查看哪些集群 Operator 处于待处理状态。 -
查看
oc get nodes命令的输出,以确保 worker 节点已就绪。
-
查看
14.4.2. 没有注册 worker 节点
如果托管 control plane 没有注册 worker 节点而无法完全在线,请通过检查托管 control plane 的不同部分的状态来识别问题。
流程
-
查看带有故障的
HostedCluster和NodePool条件,以指示问题可能是什么。 输入以下命令查看
NodePool资源的 KubeVirt worker 节点虚拟机 (VM) 状态:$ oc get vm -n <namespace>如果虚拟机处于 provisioning 状态,请输入以下命令查看 VM 命名空间中的 CDI 导入 pod,以说明导入程序 pod 没有被完成的原因:
$ oc get pods -n <namespace> | grep "import"如果虚拟机处于 start 状态,请输入以下命令查看 virt-launcher pod 的状态:
$ oc get pods -n <namespace> -l kubevirt.io=virt-launcher如果 virt-launcher pod 处于待处理状态,请调查不调度 pod 的原因。例如,可能没有足够的资源来运行 virt-launcher pod。
- 如果虚拟机正在运行,但没有注册为 worker 节点,请使用 Web 控制台获取受影响虚拟机的 VNC 访问权限。VNC 输出指示是否应用了 ignition 配置。如果虚拟机在启动时无法访问托管的 control plane ignition 服务器,则无法正确置备虚拟机。
- 如果应用了 ignition 配置,但虚拟机仍然没有注册为节点,请参阅 识别问题:访问虚拟机控制台日志 以了解如何在启动过程中访问虚拟机控制台日志。
14.4.3. worker 节点处于 NotReady 状态
在集群创建过程中,节点在推出网络堆栈时临时进入 NotReady 状态。该流程的这一部分是正常的。但是,如果进程的这部分时间超过 15 分钟,请通过调查节点对象和 pod 来识别问题。
流程
输入以下命令查看节点对象中的条件,并确定节点未就绪的原因:
$ oc get nodes -o yaml输入以下命令查找集群中的 pod 失败:
$ oc get pods -A --field-selector=status.phase!=Running,status,phase!=Succeeded
14.4.4. Ingress 和控制台集群 operator 没有在线
如果托管的 control plane 没有完全在线,因为 Ingress 和控制台集群 Operator 没有在线,请检查通配符 DNS 路由和负载均衡器。
流程
如果集群使用默认的 Ingress 行为,请输入以下命令来确保在托管虚拟机的 OpenShift Container Platform 集群上启用了通配符 DNS 路由:
$ oc patch ingresscontroller -n openshift-ingress-operator \ default --type=json -p \ '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'如果您将自定义基域用于托管的 control plane,请完成以下步骤:
- 确保负载均衡器正确以虚拟机 pod 为目标。
- 确保通配符 DNS 条目以负载均衡器 IP 地址为目标。
14.4.5. 托管集群的负载均衡器服务不可用
如果托管的 control plane 没有完全在线,因为负载均衡器服务不可用,请检查事件、详情和 Kubernetes 集群配置管理器(KCCM) pod。
流程
- 查找与托管集群中的负载均衡器服务关联的事件和详情。
默认情况下,托管集群的负载均衡器由托管的 control plane 命名空间中的 kubevirt-cloud-controller-manager 处理。确保 KCCM pod 在线,并查看其日志以查找错误或警告。要识别托管的 control plane 命名空间中的 KCCM pod,请输入以下命令:
$ oc get pods -n <hosted_control_plane_namespace> \ -l app=cloud-controller-manager
14.4.6. 托管的集群 PVC 不可用
如果托管的 control plane 没有被完全在线,因为托管集群的持久性卷声明 (PVC) 不可用,请检查 PVC 事件和详情,以及组件日志。
流程
- 查找与 PVC 关联的事件和详情,以了解发生的错误。
如果 PVC 无法附加到 pod,请查看托管集群中 kubevirt-csi-node
daemonset组件的日志,以进一步调查问题。要识别每个节点的 kubevirt-csi-node pod,请输入以下命令:$ oc get pods -n openshift-cluster-csi-drivers -o wide \ -l app=kubevirt-csi-driver如果 PVC 无法绑定到持久性卷 (PV),查看托管 control plane 命名空间中的 kubevirt-csi-controller 组件的日志。要识别托管的 control plane 命名空间中的 kubevirt-csi-controller pod,请输入以下命令:
$ oc get pods -n <hcp namespace> -l app=kubevirt-csi-driver
14.4.7. VM 节点没有正确加入集群
如果托管的 control plane 无法完全在线,因为 VM 节点没有正确加入集群,访问 VM 控制台日志。
流程
14.4.8. RHCOS 镜像镜像失败
对于在断开连接的环境中的 OpenShift Virtualization 上托管的 control plane,oc-mirror 无法自动将 Red Hat Enterprise Linux CoreOS (RHCOS) 镜像镜像到内部 registry。当您创建第一个托管集群时,Kubevirt 虚拟机无法引导,因为引导镜像在内部 registry 中不可用。
要解决这个问题,请手动将 RHCOS 镜像镜像到内部 registry。
流程
运行以下命令来获取内部 registry 名称:
$ oc get imagecontentsourcepolicy -o json \ | jq -r '.items[].spec.repositoryDigestMirrors[0].mirrors[0]'运行以下命令来获取有效负载镜像:
$ oc get clusterversion version -ojsonpath='{.status.desired.image}'提取
0000_50_installer_coreos-bootimages.yaml文件,该文件包含来自托管集群上的有效负载镜像的引导镜像。将<payload_image>替换为有效负载镜像的名称。运行以下命令:$ oc image extract \ --file /release-manifests/0000_50_installer_coreos-bootimages.yaml \ <payload_image> --confirm运行以下命令来获取 RHCOS 镜像:
$ cat 0000_50_installer_coreos-bootimages.yaml | yq -r .data.stream \ | jq -r '.architectures.x86_64.images.kubevirt."digest-ref"'将 RHCOS 镜像镜像(mirror)到内部 registry。将
<rhcos_image>替换为您的 RHCOS 镜像,例如quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:d9643ead36b1c026be664c9c65c11433c6cdf71bfd93ba229141d134a4a6dd94。将<internal_registry>替换为内部 registry 的名称;例如,virthost.ostest.test.metalkube.org:5000/localimages/ocp-v4.0-art-dev。运行以下命令:$ oc image mirror <rhcos_image> <internal_registry>创建名为
rhcos-boot-kubevirt.yaml的 YAML 文件,该文件定义ImageDigestMirrorSet对象。请参见以下示例配置:apiVersion: config.openshift.io/v1 kind: ImageDigestMirrorSet metadata: name: rhcos-boot-kubevirt spec: repositoryDigestMirrors: - mirrors: - virthost.ostest.test.metalkube.org:5000/localimages/ocp-v4.0-art-dev1 source: quay.io/openshift-release-dev/ocp-v4.0-art-dev2 运行以下命令应用
rhcos-boot-kubevirt.yaml文件来创建ImageDigestMirrorSet对象:$ oc apply -f rhcos-boot-kubevirt.yaml
14.4.9. 将非裸机集群返回到后向绑定池
如果您在没有 BareMetalHosts 的情况下使用后绑定受管集群,您必须完成额外的手动步骤来删除后绑定集群,并将节点返回到 Discovery ISO。
对于没有 BareMetalHosts 的绑定受管集群,删除集群信息不会自动将所有节点返回到 Discovery ISO。
流程
要使用后绑定非裸机节点,请完成以下步骤:
- 删除集群信息。如需更多信息,请参阅从管理中删除集群。
- 清理根磁盘。
- 使用 Discovery ISO 手动重新引导。
14.5. 裸机上托管集群故障排除
以下信息适用于对裸机上的托管 control plane 进行故障排除。
14.5.1. 节点无法添加到裸机上的托管 control plane 中
当您使用 Assisted Installer 置备的节点扩展托管的 control plane 集群时,主机无法拉取包含端口 22642 的 URL。对于托管 control plane,该 URL 无效,并表示集群存在问题。
流程
要确定这个问题,请查看 assisted-service 日志:
$ oc logs -n multicluster-engine <assisted_service_pod_name>1 - 1
- 指定 Assisted Service pod 名称。
在日志中查找类似这些示例的错误:
error="failed to get pull secret for update: invalid pull secret data in secret pull-secret"pull secret must contain auth for \"registry.redhat.io\"要解决这个问题,请参阅 Kubernetes Operator 的多集群引擎中的"将 pull secret 添加到命名空间"。
注意要使用托管的 control plane,您必须安装 multicluster engine Operator,可以是独立 Operator,或作为 Red Hat Advanced Cluster Management 的一部分。因为 Operator 与 Red Hat Advanced Cluster Management 紧密关联,所以该 Operator 的文档会在该产品的文档中发布。即使不使用 Red Hat Advanced Cluster Management,覆盖多集群引擎 Operator 的文档部分也会与托管 control plane 相关。
14.6. 重启托管的 control plane 组件
如果您是托管 control plane 的管理员,您可以使用 hypershift.openshift.io/restart-date 注解来重启特定 HostedCluster 资源的所有 control plane 组件。例如,您可能需要重启 control plane 组件以进行证书轮转。
流程
要重启 control plane,请输入以下命令注解
HostedCluster资源:$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> \ <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)1 - 1
- 每当注解值更改时,control plane 都会重启。
date命令充当唯一字符串的来源。该注解被视为字符串,而不是时间戳。
验证
重启 control plane 后,通常会重启以下托管的 control plane 组件:
您可能会看到一些其他组件作为其他组件所实施的更改的副作用。
- catalog-operator
- certified-operators-catalog
- cluster-api
- cluster-autoscaler
- cluster-policy-controller
- cluster-version-operator
- community-operators-catalog
- control-plane-operator
- hosted-cluster-config-operator
- ignition-server
- ingress-operator
- konnectivity-agent
- konnectivity-server
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- machine-approver
- oauth-openshift
- olm-operator
- openshift-apiserver
- openshift-controller-manager
- openshift-oauth-apiserver
- packageserver
- redhat-marketplace-catalog
- redhat-operators-catalog
14.7. 暂停托管集群和托管的 control plane 的协调
如果您是集群管理员,您可以暂停托管集群和托管的控制平面的协调。当您备份和恢复 etcd 数据库或需要调试托管集群或托管的 control plane 的问题时,您可能希望暂停协调。
流程
要暂停托管集群和托管的 control plane 的协调,请填充
HostedCluster资源的pausedUntil字段。要暂停协调直到特定时间,请输入以下命令:
$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"<timestamp>"}}' \ --type=merge1 - 1
- 以 RFC339 格式指定时间戳,例如
2024-03-03T03:28:48Z。协调会暂停,直到经过了指定的时间。
要无限期暂停协调,请输入以下命令:
$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"true"}}' \ --type=merge协调会暂停,直到您从
HostedCluster资源中删除了字段。当为
HostedCluster资源填充暂停协调字段时,该字段会自动添加到关联的HostedControlPlane资源中。
要删除
pausedUntil字段,请输入以下 patch 命令:$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":null}}' \ --type=merge
14.8. 将数据平面缩减为零
如果您没有使用托管的控制平面,为了保存资源和成本,您可以将数据平面缩减为零。
确保您准备将数据平面缩减为零。因为 worker 节点的工作负载在缩减后会消失。
流程
运行以下命令,设置
kubeconfig文件以访问托管集群:$ export KUBECONFIG=<install_directory>/auth/kubeconfig运行以下命令,获取与托管集群关联的
NodePool资源的名称:$ oc get nodepool --namespace <hosted_cluster_namespace>可选: 要防止 pod 排空,请运行以下命令在
NodePool资源中添加nodeDrainTimeout字段:$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>输出示例
apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: arch: amd64 clusterName: clustername1 management: autoRepair: false replace: rollingUpdate: maxSurge: 1 maxUnavailable: 0 strategy: RollingUpdate upgradeType: Replace nodeDrainTimeout: 0s2 # ...注意要允许节点排空过程在特定时间段内继续,您可以相应地设置
nodeDrainTimeout字段的值,例如nodeDrainTimeout: 1m。运行以下命令来缩减与托管集群关联的
NodePool资源:$ oc scale nodepool/<nodepool_name> --namespace <hosted_cluster_namespace> \ --replicas=0注意将数据计划缩减为零后,control plane 中的一些 pod 会一直处于
Pending状态,托管的 control plane 会保持启动并运行。如果需要,您可以扩展NodePool资源。可选:运行以下命令来扩展与托管集群关联的
NodePool资源:$ oc scale nodepool/<nodepool_name> --namespace <hosted_cluster_namespace> --replicas=1在重新扩展
NodePool资源后,请等待几分钟,让NodePool资源变为Ready状态。
验证
运行以下命令,验证
nodeDrainTimeout字段的值是否大于0s:$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -ojsonpath='{.spec.nodeDrainTimeout}'
第 15 章 销毁托管集群
15.1. 销毁 AWS 上的托管集群
您可以使用命令行界面(CLI)在 Amazon Web Services (AWS)上销毁托管集群及其受管集群资源。
15.1.1. 使用 CLI 销毁 AWS 上的托管集群
您可以使用命令行界面(CLI)销毁 Amazon Web Services (AWS)上的托管集群。
流程
运行以下命令,删除多集群引擎 Operator 上的受管集群资源:
$ oc delete managedcluster <hosted_cluster_name>1 - 1
- 将
<hosted_cluster_name>替换为集群的名称。
运行以下命令来删除托管集群及其后端资源:
$ hcp destroy cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --role-arn <arn_role> \3 --sts-creds <path_to_sts_credential_file> \4 --base-domain <basedomain>5 重要如果您的 AWS 安全令牌服务(STS)的会话令牌已过期,请运行以下命令在名为
sts-creds.json的 JSON 文件中检索 STS 凭证:$ aws sts get-session-token --output json > sts-creds.json
15.2. 在裸机上销毁托管集群
您可以使用命令行界面(CLI)或 multicluster engine Operator web 控制台来破坏裸机上的托管集群。
15.2.1. 使用 CLI 在裸机上销毁托管集群
如果使用命令行界面(CLI)创建了托管集群,您可以通过运行命令来销毁该托管集群及其后端资源。
流程
运行以下命令来删除托管集群及其后端资源:
$ oc delete -f <hosted_cluster_config>.yaml1 - 1
- 指定创建托管集群时呈现的配置 YAML 文件的名称。
注意如果您在其配置文件中指定--
render and--render-sensitive标志的情况下创建了托管集群,则必须手动删除其后端资源。
15.2.2. 使用 Web 控制台在裸机上销毁托管集群
您可以使用 multicluster engine Operator web 控制台在裸机上销毁托管集群。
流程
- 在控制台中,点 Infrastructure → Clusters。
- 在 Clusters 页上,选择您要销毁的集群。
- 在 Actions 菜单中,选择 Destroy cluster 以删除集群。
15.3. 销毁 OpenShift Virtualization 上的托管集群
您可以使用命令行界面(CLI)在 OpenShift Virtualization 上销毁托管集群及其受管集群资源。
15.3.1. 使用 CLI 销毁 OpenShift Virtualization 上的托管集群
您可以使用命令行界面(CLI)在 OpenShift Virtualization 上销毁托管集群及其受管集群资源。
流程
运行以下命令,删除多集群引擎 Operator 上的受管集群资源:
$ oc delete managedcluster <hosted_cluster_name>运行以下命令来删除托管集群及其后端资源:
$ hcp destroy cluster kubevirt --name <hosted_cluster_name>
15.4. 销毁 IBM Z 上的托管集群
您可以使用命令行界面(CLI)在带有 IBM Z 计算节点及其受管集群的 x86 裸机上销毁托管集群。
15.4.1. 使用 IBM Z 计算节点在 x86 裸机上销毁托管集群
要使用 IBM Z 计算节点在 x86 裸机上销毁托管集群及其受管集群,您可以使用命令行界面(CLI)。
流程
运行以下命令,将
NodePool对象扩展到0节点:$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> \ --replicas 0在
NodePool对象扩展到0后,计算节点会从托管集群分离。在 OpenShift Container Platform 版本 4.17 中,这个功能只适用于带有 KVM 的 IBM Z。对于 z/VM 和 LPAR,您必须手动删除计算节点。如果要将计算节点重新连接到集群,您可以使用您想要的计算节点数量扩展
NodePool对象。要使 z/VM 和 LPAR 重复使用代理,您必须使用Discovery镜像重新创建它们。重要如果计算节点没有从托管集群或处于
Notready状态分离,请运行以下命令手动删除计算节点:$ oc --kubeconfig <hosted_cluster_name>.kubeconfig delete \ node <compute_node_name>输入以下命令验证计算节点的状态:
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes在计算节点从托管集群分离后,代理的状态将更改为
auto-assign。运行以下命令从集群中删除代理:
$ oc -n <hosted_control_plane_namespace> delete agent <agent_name>注意您可在从集群中删除代理后删除作为代理创建的虚拟机。
运行以下命令来销毁托管集群:
$ hcp destroy cluster agent --name <hosted_cluster_name> \ --namespace <hosted_cluster_namespace>
15.5. 销毁 IBM Power 上的托管集群
您可以使用命令行界面 (CLI) 在 IBM Power 上销毁托管集群。
15.5.1. 使用 CLI 销毁 IBM Power 上的托管集群
要销毁 IBM Power 上的托管集群,您可以使用 hcp 命令行界面 (CLI)。
15.6. 在非裸机代理机器上销毁托管集群
您可以使用命令行界面(CLI)或多集群引擎 Operator web 控制台在非裸机代理机器上销毁托管集群。
15.6.1. 在非裸机代理机器上销毁托管集群
您可以使用 hcp 命令行界面(CLI)在非裸机代理机器上销毁托管集群。
流程
运行以下命令来删除托管集群及其后端资源:
$ hcp destroy cluster agent --name <hosted_cluster_name>1 - 1
- 将
<hosted_cluster_name>替换为托管集群的名称。
15.6.2. 使用 Web 控制台在非裸机代理机器上销毁托管集群
您可以使用 multicluster engine Operator web 控制台在非裸机代理机器上销毁托管集群。
流程
- 在控制台中,点 Infrastructure → Clusters。
- 在 Clusters 页上,选择您要销毁的集群。
- 在 Actions 菜单中,选择 Destroy cluster 以删除集群。
第 16 章 手动导入托管集群
在托管 control plane 可用时,托管集群会自动导入到多集群引擎 Operator 中。
16.1. 管理导入的托管集群的限制
托管的集群会自动导入到 Kubernetes Operator 的本地多集群引擎中,与独立的 OpenShift Container Platform 或第三方集群不同。托管集群在托管模式下运行一些代理,以便代理不使用集群的资源。
如果您选择自动导入托管集群,您可以使用管理集群中的 HostedCluster 资源更新节点池和托管的集群中的 control plane。要更新节点池和控制平面,请参阅"更新托管集群中的节点池"和"更新托管集群中的控制平面"。
您可以使用 Red Hat Advanced Cluster Management (RHACM) 将托管集群导入到本地多集群引擎 Operator 以外的位置。如需更多信息,请参阅"在 Red Hat Advanced Cluster Management 中"为 Kubernetes Operator 托管集群的多集群引擎。
在这个拓扑中,您必须使用命令行界面或托管集群的 Kubernetes Operator 的本地多集群引擎控制台来更新托管集群。您无法通过 RHACM hub 集群更新托管集群。
16.3. 手动导入托管集群
如果要手动导入托管集群,请完成以下步骤。
流程
- 在控制台中,点 Infrastructure → Clusters 并选择您要导入的托管集群。
点 Import hosted cluster。
注意对于发现的托管集群,您还可以从控制台导入,但集群必须处于 upgradable 状态。如果托管集群没有处于 upgradable 状态,则集群中的导入会被禁用,因为托管的 control plane 不可用。点 Import 以开始进程。当集群接收更新时状态为
Importing,然后改为Ready。
16.4. 在 AWS 上手动导入托管集群
您还可以使用命令行界面在 Amazon Web Services (AWS)上导入托管集群。
流程
使用以下 YAML 文件示例创建
ManagedCluster资源:apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: import.open-cluster-management.io/hosting-cluster-name: local-cluster import.open-cluster-management.io/klusterlet-deploy-mode: Hosted open-cluster-management/created-via: hypershift labels: cloud: auto-detect cluster.open-cluster-management.io/clusterset: default name: <hosted_cluster_name>1 vendor: OpenShift name: <hosted_cluster_name> spec: hubAcceptsClient: true leaseDurationSeconds: 60- 1
- 将
<hosted_cluster_name>替换为托管集群的名称。
运行以下命令以应用资源:
$ oc apply -f <file_name>1 - 1
- 将
<file_name>替换为您在上一步中创建的 YAML 文件名。
如果安装了 Red Hat Advanced Cluster Management,请使用以下示例 YAML 文件创建
KlusterletAddonConfig资源。如果您只安装了 multicluster engine Operator,请跳过这一步:apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: clusterName: <hosted_cluster_name> clusterNamespace: <hosted_cluster_namespace> clusterLabels: cloud: auto-detect vendor: auto-detect applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: false运行以下命令以应用资源:
$ oc apply -f <file_name>1 - 1
- 将
<file_name>替换为您在上一步中创建的 YAML 文件名。
导入过程完成后,您的托管集群在控制台中可见。您还可以运行以下命令来检查托管集群的状态:
$ oc get managedcluster <hosted_cluster_name>
16.5. 禁用托管集群自动导入到多集群引擎 Operator
在 control plane 可用时,托管集群会自动导入到多集群引擎 Operator 中。如果需要,您可以禁用托管集群的自动导入。
任何之前导入的托管集群都不会受到影响,即使您禁用自动导入。当您升级到 multicluster engine Operator 2.5 并启用自动导入时,如果 control plane 可用,所有没有导入的托管集群都会被自动导入。
如果安装了 Red Hat Advanced Cluster Management,则会启用所有 Red Hat Advanced Cluster Management 附加组件。
当禁用自动导入时,只有新创建的托管集群不会被自动导入。已导入的托管集群不会受到影响。您仍然可以使用控制台或创建 ManagedCluster 和 KlusterletAddonConfig 自定义资源来手动导入集群。
流程
要禁用托管集群的自动导入,请完成以下步骤:
在 hub 集群中,输入以下命令打开安装 multicluster engine Operator 的命名空间中的
AddonDeploymentConfig资源中的hypershift-addon-deploy-config规格:$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine在
spec.customizedVariables部分中,添加autoImportDisabled变量设为"true",如下例所示:apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: autoImportDisabled value: "true"-
要重新启用自动导入,将
autoImportDisabled变量的值设置为"false",或者从AddonDeploymentConfig资源中删除变量。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.