第 9 章 配置事务
驻留在分布式系统上的数据容易受到临时网络中断、系统故障或只是简单人为错误造成的错误。这些外部因素不可控制,但可能会给数据质量造成严重后果。数据损坏的影响范围从降低客户的满意度到导致服务不可用的昂贵系统协调。
Data Grid 可以执行 ACID (原子性、一致性、隔离、持久性)事务,以确保缓存状态一致。
9.1. Transactions
Data Grid 可以配置为使用和参与 JTA 兼容事务。
或者,如果禁用了事务支持,它等同于在 JDBC 调用中使用 autocommit,其中修改可能会在每次更改后复制(如果启用了复制)。
在每个缓存操作 Data Grid 中执行以下操作:
- 检索与线程关联的当前 事务
- 如果尚未完成,请将 XAResource 与事务管理器注册,以便在事务提交或回滚时获得通知。
要执行此操作,必须将缓存提供给对环境的 TransactionManager 的引用。这通常是通过使用类名称配置 TransactionManagerLookup 接口的实施来实现的。当缓存启动时,它将创建此类的实例并调用其 getTransactionManager () 方法,它将返回对 TransactionManager 的引用。
Data Grid 附带几个事务管理器查找类:
事务管理器查找实现
- EmbeddedTransactionManagerLookup :这提供了一个基本的事务管理器,该管理器应在没有其他实施可用时用于嵌入式模式。这个实现对并发事务和恢复有一些严重的限制。
-
JBossStandaloneJTAManagerLookup :如果您在独立环境中运行 Data Grid,或者在 JBoss AS 7 及更早版本中运行,且 WildFly 8 9 和 10,则这应该是您的事务管理器的默认选择。它是基于 JBoss 交易的全面交易经理,它克服了
嵌入式TransactionManager的所有责任。 - WildflyTransactionManagerLookup :如果您在 WildFly 11 或更高版本中运行 Data Grid,则应该是您事务管理器的默认选择。
-
GenericTransactionManagerLookup :这是在最流行的 Java EE 应用服务器中查找事务管理器的查找类。如果没有找到事务管理器,则默认为
EmbeddedTransactionManager。
初始化后,TransactionManager 也可以从 缓存 本身获取:
//the cache must have a transactionManagerLookupClass defined Cache cache = cacheManager.getCache(); //equivalent with calling TransactionManagerLookup.getTransactionManager(); TransactionManager tm = cache.getAdvancedCache().getTransactionManager();
9.1.1. 配置事务
事务在缓存级别上配置。以下是影响每个配置属性的事务和少量描述的配置。
<locking isolation="READ_COMMITTED"/> <transaction locking="OPTIMISTIC" auto-commit="true" complete-timeout="60000" mode="NONE" notifications="true" reaper-interval="30000" recovery-cache="__recoveryInfoCacheName__" stop-timeout="30000" transaction-manager-lookup="org.infinispan.transaction.lookup.GenericTransactionManagerLookup"/>
或以编程方式:
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.locking()
.isolationLevel(IsolationLevel.READ_COMMITTED);
builder.transaction()
.lockingMode(LockingMode.OPTIMISTIC)
.autoCommit(true)
.completedTxTimeout(60000)
.transactionMode(TransactionMode.NON_TRANSACTIONAL)
.useSynchronization(false)
.notifications(true)
.reaperWakeUpInterval(30000)
.cacheStopTimeout(30000)
.transactionManagerLookup(new GenericTransactionManagerLookup())
.recovery()
.enabled(false)
.recoveryInfoCacheName("__recoveryInfoCacheName__");-
isolation- 配置隔离级别。如需更多详细信息,请参阅 隔离级别。默认为REPEATABLE_READ。 -
locking- 配置缓存是否使用 optimistic 或 pessimistic locking。检查部分 事务锁定 以了解更多详细信息。默认为OPTIMISTIC。 -
auto-commit- if enable,用户不需要为单个操作手动启动事务。事务会自动启动并运行。默认为true。 -
complete-timeout- 持续时间(以毫秒为单位),以保持有关已完成的事务的信息。默认值为60000。 mode- 配置缓存是事务性。默认为NONE。可用的选项有:-
NONE非事务缓存 -
FULL_XA- XA 事务缓存,并启用了恢复。有关恢复的详情,请查看 Transaction recovery 部分。 -
NON_DURABLE_XA- XA 事务缓存,并禁用了恢复。 -
NON_XA- 通过 同步 而不是 XA 集成事务缓存。检查部分 Enlisting Synchronizations 以了解详细信息。 -
BATCH- 事务缓存,使用批处理对操作进行分组。检查部分批处理 以了解详细信息。
-
-
notifications- 启用/禁用在缓存监听程序中触发事务事件。默认为true。 -
Reaper-interval- 以 millisecond 为单位的时间间隔,其中线程会清除事务完成信息。默认值为30000。 -
recovery-cache- 配置缓存名称来存储恢复信息。有关恢复的详情,请查看 Transaction recovery 部分。默认为recoveryInfoCacheName。 -
stop-timeout- 缓存停止时 millisecond 等待的时间,以等待持续事务。默认值为30000。 -
transaction-manager-lookup- 配置类的完全限定域名,该类查找对jakarta.transaction.TransactionManager的引用。默认为org.infinispan.transaction.lookup.GenericTransactionManagerLookup。
有关如何在 Data Grid 中实施 Two-Phase-Commit (2PC)的更多详细信息,以及如何获取锁定,请参见以下部分。有关配置设置的更多详细信息,请参阅配置 参考。
9.1.2. 隔离级别
Data Grid 提供两种隔离级别 - READ_COMMITTED 和 REPEATABLE_READ。
这些隔离级别决定读者何时看到并发写入,并使用 MVCCEntry 的不同子类在内部实施,它们在不同状态如何提交回数据容器。
下面是一个更详细的示例,它可以帮助了解 Data Grid 上下文 READ_COMMITTED 和 REPEATABLE_READ 之间的差别。使用 READ_COMMITTED 时,如果同一键上的两个连续读取调用之间,密钥已被另一个事务更新,第二个读取可能会返回新的更新值:
Thread1: tx1.begin() Thread1: cache.get(k) // returns v Thread2: tx2.begin() Thread2: cache.get(k) // returns v Thread2: cache.put(k, v2) Thread2: tx2.commit() Thread1: cache.get(k) // returns v2! Thread1: tx1.commit()
使用 REPEATABLE_READ,最终 get 仍会返回 v。因此,如果您要在事务中多次检索同一密钥,您应该使用 REPEATABLE_READ。
但是,因为 read-locks 甚至没有为 REPEATABLE_READ 获取,因此这种现象可能会发生:
cache.get("A") // returns 1
cache.get("B") // returns 1
Thread1: tx1.begin()
Thread1: cache.put("A", 2)
Thread1: cache.put("B", 2)
Thread2: tx2.begin()
Thread2: cache.get("A") // returns 1
Thread1: tx1.commit()
Thread2: cache.get("B") // returns 2
Thread2: tx2.commit()9.1.3. 事务锁定
9.1.3.1. Pessimistic 事务缓存
从锁定的角度来看,模糊的事务会在写入密钥时获得密钥锁定。
- 锁定请求发送到主所有者(可以是显式锁定请求或操作)
主所有者尝试获取锁定:
- 如果成功,它会发送回正回复;
- 否则,会发送负回复,事务会被回滚。
例如:
transactionManager.begin(); cache.put(k1,v1); //k1 is locked. cache.remove(k2); //k2 is locked when this returns transactionManager.commit();
当 cache.put (k1,v1) 返回时,k1 被锁定,并且集群中任何其它事务都可以写入它。仍可读取 k1。当事务完成时(提交或回滚)时,k1 上的锁定会被释放。
对于条件操作,验证在原始卷中执行。
9.1.3.2. 最佳事务缓存
使用最佳事务锁定会在交易准备时获取,且仅保留事务提交(或回滚)的点。这与 5.0 默认锁定模型不同,其中本地锁定在进行写入时获得,在准备过程中会获取集群锁定。
- 准备将发送到所有所有者。
主要所有者尝试获取所需的锁定:
- 如果锁定成功,它将执行写入偏移检查。
- 如果写入偏移检查成功(或被禁用),请发送正回复。
- 否则,发送负回复并回滚事务。
例如:
transactionManager.begin(); cache.put(k1,v1); cache.remove(k2); transactionManager.commit(); //at prepare time, K1 and K2 is locked until committed/rolled back.
对于条件命令,验证仍然在原始卷中发生。
9.1.3.3. 我需要什么 - 保守或最佳事务?
从用例的角度来看,当同时运行多个事务之间没有许多竞争时,应使用最佳事务。这是因为,如果在读取数据和提交时间(启用了写偏移检查)之间更改了数据,则最佳事务回滚。
另一方面,当密钥和事务回滚中发生大量竞争时,模糊的事务可能会更加适合。Pessimistic 事务的性质更加昂贵:每个写入操作都可能涉及对锁定的 RPC。
9.1.4. 写 Skews
当两个事务独立,同时读取和写入同一密钥时,写入 skews。写入偏移的结果是,两个事务都成功将更新提交到同一密钥,但具有不同值。
Data Grid 会自动执行写入偏移检查,以确保在最佳事务中 REPEATABLE_READ 隔离级别的数据一致性。这使得 Data Grid 能够检测并回滚其中一个交易。
在 LOCAL 模式中运行时,写 skew 检查依赖于 Java 对象引用来比较区别,它为写 skews 提供可靠的技术。
9.1.4.1. 在 pessimitic 事务中强制写入锁定
为了避免写入带有 pessimistic 事务的 skews,使用 Flag.FORCE_WRITE_LOCK 在读取时锁定密钥。
-
在非事务缓存中,
Flag.FORCE_WRITE_LOCK无法正常工作。get ()调用读取键值,但不会远程获取锁定。 -
您应该使用
Flag.FORCE_WRITE_LOCK,并在稍后在同一事务中更新实体的事务。
将以下代码片段与 Flag.FORCE_WRITE_LOCK 示例进行比较:
// begin the transaction
if (!cache.getAdvancedCache().lock(key)) {
// abort the transaction because the key was not locked
} else {
cache.get(key);
cache.put(key, value);
// commit the transaction
}// begin the transaction
try {
// throws an exception if the key is not locked.
cache.getAdvancedCache().withFlags(Flag.FORCE_WRITE_LOCK).get(key);
cache.put(key, value);
} catch (CacheException e) {
// mark the transaction rollback-only
}
// commit or rollback the transaction9.1.5. 处理异常
如果 CacheException (或其子类)被 JTA 事务范围内的缓存方法抛出,则事务会自动标记为回滚。
9.1.6. Enlisting Synchronizations
默认情况下,通过 XAResource,将自身注册为分布式交易的第一类参与者。在某些情况下,Data Grid 不需要成为交易中的参与者,但只有其生命周期(准备、完成):例如,Data Grid 在 Hibernate 中用作第二级缓存。
网格允许通过同步进行事务 列表。若要启用它,只需使用 NON_XA 事务模式。
同步具有优势,它们允许 TransactionManager 使用 1PC 优化 2PC,其中只有其他资源被该事务列出(最后一个资源提交优化)。例如Hibernate 第二级缓存:如果 Data Grid 将自身注册到 TransactionManager 作为 XAResource 而非提交时,TransactionManager 会看到两个 XAResource (缓存和数据库),且不会进行此优化。在需要在两个资源间协调协调,才能将 tx 日志写入磁盘。另一方面,将 Data Grid 注册为 同步 会导致 TransactionManager 跳过将日志写入磁盘(性能改进)。
9.1.7. 批处理
批处理允许事务的原子性和某些特征,但不能完全混合 JTA 或 XA 功能。批量的交易通常比全体的交易要低得多。
通常而言,每当交易中唯一参与者是一个 Data Grid 集群时,应使用批处理 API。另一方面,每当事务涉及多个系统时,应使用 JTA 事务(涉及 TransactionManager)。例如,考虑交易的"Hello world!"的交易:将资金从一个银行帐户转移到另一个交易。如果这两个帐户都存储在 Data Grid 中,则可使用批处理。如果一个帐户位于数据库中,而另一个帐户是 Data Grid,则需要分布式事务。
您不必 定义事务管理器来使用批处理。
9.1.7.1. API
将缓存配置为使用批处理后,您可以通过在 Cache 上调用 startBatch () 和 endBatch () 来使用它。例如,
Cache cache = cacheManager.getCache();
// not using a batch
cache.put("key", "value"); // will replicate immediately
// using a batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k2", "value");
cache.endBatch(true); // This will now replicate the modifications since the batch was started.
// a new batch
cache.startBatch();
cache.put("k1", "value");
cache.put("k2", "value");
cache.put("k3", "value");
cache.endBatch(false); // This will "discard" changes made in the batch9.1.7.2. 批处理和 JTA
在后台,批处理功能会启动 JTA 事务,该范围中的所有调用与其相关联。为此,它使用非常简单(如无恢复)内部 TransactionManager 实现。通过批处理,您将获得:
- 在调用期间进行锁定,直到批处理完成为止
- 在批处理中,更改都会作为批处理的一部分在批处理中复制。减少批处理中每个更新的复制 chatter。
- 如果使用同步复制或失效,则复制/验证失败将导致批处理回滚。
- 所有事务相关的配置也适用于批处理。
9.1.8. 事务恢复
恢复是 XA 事务的一个功能,它处理资源最终甚至可能出现事务管理器失败,并从此类情况中相应地恢复。
9.1.8.1. 何时使用恢复
考虑将成本从存储在外部数据库中的帐户的分布式交易转移到 Data Grid 中存储的帐户。调用 TransactionManager.commit () 时,这两个资源都成功准备(1st 阶段)。在提交(2nd)阶段,数据库在收到事务管理器的提交请求前,成功应用 whilst Data Grid 的更改会失败。此时,系统处于不一致的状态:从外部数据库中的帐户获取成本,但在 Data Grid 中还不可见(因为锁仅在双阶段提交协议的第 2 阶段发布)。恢复涉及这种情况,以确保数据库和数据网格都以一致的状态结束。
9.1.8.2. 它如何工作
恢复由事务管理器协调。事务管理器与 Data Grid 合作,以确定需要手动干预并通知系统管理员(通过电子邮件、日志警报等)的无效事务列表。这个过程是特定于事务管理器的,但通常需要事务管理器上的一些配置。
现在,系统管理员能够连接到 Data Grid 集群,并重新执行事务提交或强制回滚。Data Grid 为此提供了 JMX 工具,这在 Transaction recovery and reconciliation 部分中进行了广泛解释。
9.1.8.3. 配置恢复
Data Grid 中不默认启用恢复。如果禁用,TransactionManager 将无法与 Data Grid 合作来确定 in-doubt 事务。Transaction 配置部分 演示了如何启用它。
注意: restore-cache 属性不是强制的,它是按缓存配置的。
要恢复工作,必须将 mode 设置为 FULL_XA,因为需要全体 XA 事务。
9.1.8.3.1. 启用 JMX 支持
为了能够使用 JMX 管理恢复 JMX 支持,必须明确启用。
9.1.8.4. 恢复缓存
为了跟踪不疑的事务并能够回复它们,Data Grid 会缓存所有事务状态,以备将来使用。这个状态只适用于 in-doubt 事务,在提交/滚动阶段完成后为成功完成事务删除。
这种不疑事务数据保存在本地缓存中:这允许一块通过缓存加载程序将此信息交换到磁盘,以防其变得太大。此缓存可以通过 recovery-cache 配置属性来指定。如果没有指定 Data Grid,则会为您配置本地缓存。
可以(尽管不强制)在启用了恢复的所有 Data Grid 缓存之间共享相同的恢复缓存。如果覆盖默认恢复缓存,则指定的恢复缓存必须使用 TransactionManagerLookup,它返回不同于缓存本身使用的事务管理器。
9.1.8.5. 与事务管理器集成
虽然这是特定于事务管理器,但通常事务管理器需要引用 XAResource 实现,以便对其调用 XAResource.recover ()。要获得对 Data Grid XAResource 以下 API 的引用:
XAResource xar = cache.getAdvancedCache().getXAResource();
常见的做法是在与运行事务不同的过程中运行恢复。
9.1.8.6. 协调
事务管理器以专有方式向系统管理员告知系统管理员。在这个阶段,假定系统管理员知道事务的 XID (一个字节阵列)。
正常恢复流是:
- 第 1 步 :系统管理员通过 JMX 连接到一个 Data Grid 服务器,并列出问题中的事务。下图展示了 JConsole 连接到一个具有双疑事务的 Data Grid 节点。
图 9.1. 显示 in-doubt 事务
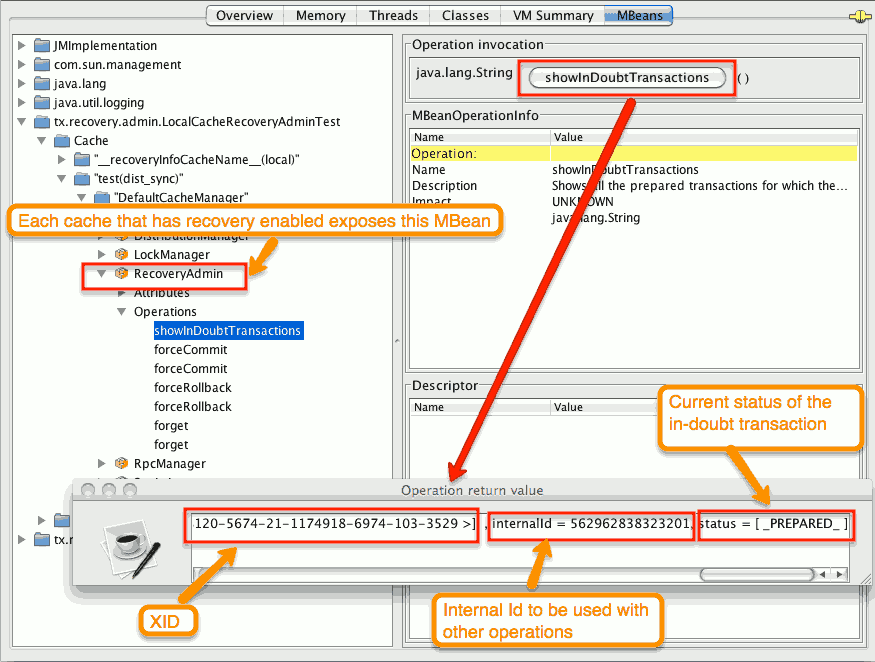
此时会显示每个 in-doubt 事务的状态(在本例中为 " PREPARED ")。status 字段中可能有多个元素,例如:如果事务在特定节点上提交但未在所有这些节点上提交,"REPARED"和"COMMITTED"。
- STEP 2: 系统管理员以视觉方式将从事务管理器收到的 XID 映射到 Data Grid 内部 ID,以数字表示。此步骤是必需的,因为 XID 是一个字节阵列,无法方便地传递给 JMX 工具(如 JConsole),然后在 Data Grid 的一侧重新编译。
- STEP 3 :系统管理员根据内部 ID 通过对应的 jmx 操作强制通过对应的 jmx 操作强制提交/滚动。以下镜像通过根据其内部 ID 强制提交事务来获得。
图 9.2. 强制提交
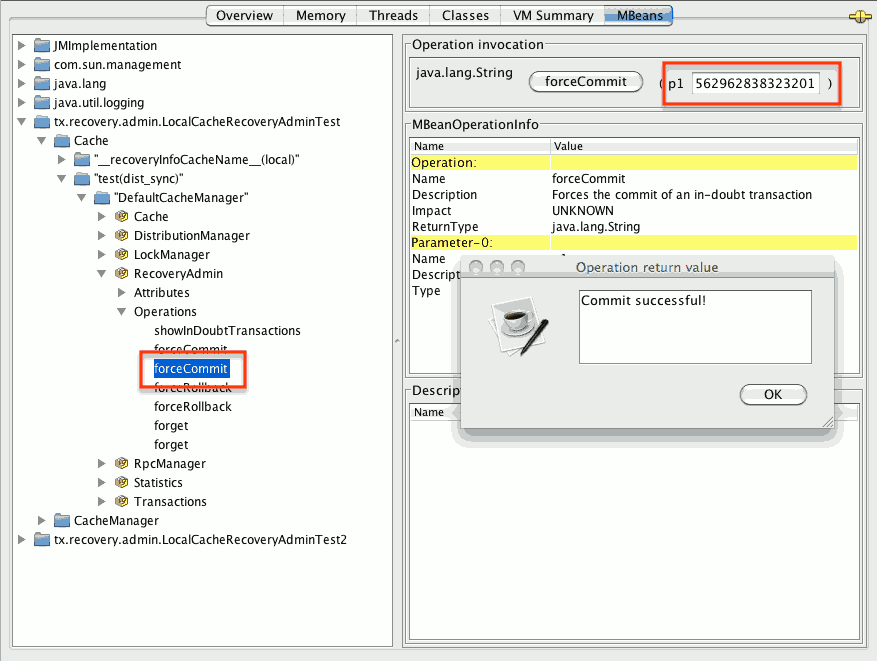
上述所有 JMX 操作都可以在任何节点上执行,无论事务源自的位置。
9.1.8.6.1. 根据 XID 强制提交/滚动
还提供了基于 XID 的 JMX 操作来强制进行交易的提交/滚动回应:这些方法接收描述 XID 的 byte[] 阵列,而不是与事务关联的数字(如第 2 步所述)。这很有用,例如,如果某人希望为某些 In-doubt 事务设置自动完成作业。这个过程被插入到事务管理器的恢复中,并可访问事务管理器的 XID 对象。