Kapitel 1. Überblick über Linux Virtual Server
Linux Virtual Server (LVS) ist ein Set integrierter Software-Komponenten für das gleichmäßige Verteilen von IP-Load innerhalb einer Gruppe realer Server. LVS läuft auf einem Paar gleich konfigurierter Computer: Ein Computer, der einen aktiven LVS-Router darstellt und ein Computer, der als ein Backup-LVS-Router agiert. Der aktive LVS-Router erfüllt zwei Rollen:
- Gleichmäßige Verteilung der Auslastung unter den realen Servern.
- Überprüfung der Integrität der Dienste auf jedem realen Server.
Der Backup-LVS-Router überwacht den aktiven LVS-Router und übernimmt dessen Aufgaben im Falle eines Ausfalls.
Dieses Kapitel liefert einen Überblick über die LVS-Komponenten und -funktionen und besteht aus den folgenden Abschnitten:
1.1. A Basic LVS Configuration
Link kopierenLink in die Zwischenablage kopiert!
Abbildung 1.1, »A Basic LVS Configuration« shows a simple LVS configuration consisting of two layers. On the first layer are two LVS routers — one active and one backup. Each of the LVS routers has two network interfaces, one interface on the Internet and one on the private network, enabling them to regulate traffic between the two networks. For this example the active router is using Network Address Translation or NAT to direct traffic from the Internet to a variable number of real servers on the second layer, which in turn provide the necessary services. Therefore, the real servers in this example are connected to a dedicated private network segment and pass all public traffic back and forth through the active LVS router. To the outside world, the servers appears as one entity.
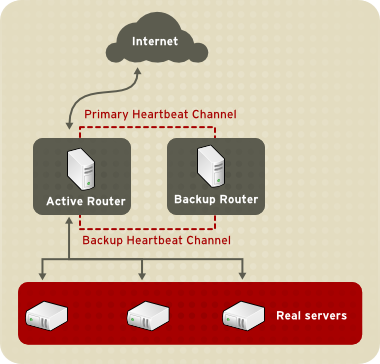
Abbildung 1.1. A Basic LVS Configuration
Service requests arriving at the LVS routers are addressed to a virtual IP address, or VIP. This is a publicly-routable address the administrator of the site associates with a fully-qualified domain name, such as www.example.com, and is assigned to one or more virtual servers. A virtual server is a service configured to listen on a specific virtual IP. Refer to Abschnitt 4.6, »VIRTUAL SERVERS« for more information on configuring a virtual server using the Piranha Configuration Tool. A VIP address migrates from one LVS router to the other during a failover, thus maintaining a presence at that IP address (also known as floating IP addresses).
VIP-Adressen können eine Alias-Bezeichnung mit demselben Gerät erhalten, welches den LVS-Router mit dem öffentlichen Netzwerk verbindet. Wenn zum Beispiel eth0 mit dem Internet verbunden ist, dann können mehrere virtuelle Server eine Alias-Bezeichnung
eth0:1 erhalten. Alternativ kann jeder virtuelle Server mit einem separaten Gerät pro Dienst verknüpft werden. Beispielsweise kann HTTP-Datenverkehr auf eth0:1 und FTP-Datenverkehr auf eth0:2 verwaltet werden.
Only one LVS router is active at a time. The role of the active router is to redirect service requests from virtual IP addresses to the real servers. The redirection is based on one of eight supported load-balancing algorithms described further in Abschnitt 1.3, »LVS Scheduling-Überblick«.
Auch überwacht der aktive Router dynamisch die Gesamtverfassung der speziellen Dienste auf den realen Servern durch einfache send/expect-Skripte. Als Hilfe bei der Analyse des Zustands eines Dienstes, der dynamische Daten wie HTTPS oder SSL benötigt, können Sie auch externe ausführbare Dateien aufrufen. Falls ein Dienst auf einem realen Server nicht ordnungsgemäß funktioniert, hört der aktive Router auf, Jobs an diesen Server zu senden, bis dieser wieder auf normalem Betriebslevel ist.
Der Backup-Router übernimmt die Rolle eines Systems in Bereitschaft. Die LVS-Router tauschen periodisch Heartbeat-Meldungen durch die primäre externe öffentliche Schnittstelle, und im Falle einer Ausfallsicherung, durch die private Schnittstelle aus. Erhält der Backup-Knoten keine Heartbeat-Meldung innerhalb eines erwarteten Intervalls, leitet er eine Ausfallsicherung ein und übernimmt die Rolle des aktiven Routers. Während der Ausfallsicherung übernimmt der Backup-Router die VIP-Adressen, die vom ausgefallenen Router bereitgestellt wurden, unter Verwendung einer Technik, die als ARP-Spoofing bekannt ist — hier zeigt der Backup-LVS-Router an, dass er das Ziel für IP-Pakete, die an den ausgefallenen Knoten gerichtet sind, darstellt. Falls der ausgefallene Knoten wieder aktiv wird, nimmt der Backup-Knoten seine Backup-Rolle wieder auf.
The simple, two-layered configuration used in Abbildung 1.1, »A Basic LVS Configuration« is best for serving data which does not change very frequently — such as static webpages — because the individual real servers do not automatically sync data between each node.
1.1.1. Datenreplikation und Datenaustausch zwischen realen Servern
Link kopierenLink in die Zwischenablage kopiert!
Da es keine integrierte Komponente in LVS gibt, um dieselben Daten unter realen Servern gemeinsam zu nutzen, stehen dem Administrator zwei Grundoptionen zur Verfügung:
- Synchronisation der Daten innerhalb des Pools der realen Server.
- Hinzufügen einer dritten Ebene zur Topologie für den Zugriff auf gemeinsam genutzte Daten.
Die erste Option wird vorzugsweise für Server verwendet, bei denen einer großen Anzahl von Benutzern das Hochladen oder Verändern von Daten auf realen Servern verweigert wird. Falls die Konfiguration einer großen Anzahl von Benutzern gestattet, Daten zu verändern, wie beispielsweise einer E-Commerce-Website, ist das Hinzufügen einer dritten Schicht besser.
1.1.1.1. Konfiguration von realen Servern zur Synchronisation von Daten
Link kopierenLink in die Zwischenablage kopiert!
Administratoren steht eine Reihe von Möglichkeiten zur Auswahl, um Daten innerhalb des Pools von realen Servern zu synchronisieren. So können beispielsweise Shell-Skripte eingesetzt werden, so dass bei einer Aktualisierung einer Seite durch einen Web-Engineer, diese gleichzeitig an alle Server versendet wird. Auch kann der Systemadministrator Programme wie
rsync verwenden, um Daten, die sich geändert haben, auf allen Knoten zu einem festgelegten Zeitintervall zu replizieren.
Diese Art der Datensynchronisation funktioniert allerdings nicht optimal, wenn die Konfiguration mit Benutzern überlastet ist, die anhaltend Dateien hochladen oder Datenbanktransaktionen ausführen. Für eine Konfiguration mit hoher Auslastung ist eine Three-Tiered-Topologie die ideale Lösung.