Kapitel 1. Überblick über das Load Balancer Add-On
Anmerkung
Ab Red Hat Enterprise Linux 6.6 bietet Red Hat Unterstützung für HAProxy und keepalived zusätzlich zur Piranha-Lastverteilungssoftware. Informationen über die Konfiguration eines Red Hat Enterprise Linux Systems mit HAProxy und keepalived finden Sie in der Dokumentation zur Lastverteilungsadministration für Red Hat Enterprise Linux 7.
Das Load Balancer Add-On ist eine Gruppe integrierter Softwarekomponenten, die Linux Virtual Servers (LVS) zur Verteilung von IP-Lasten auf eine Reihe von realen Servern bereitstellen. Das Load Balancer Add-On läuft auf einem aktiven LVS-Router sowie auf einem Backup-LVS-Router. Der aktive LVS-Router hat zwei Aufgaben:
- Gleichmäßige Verteilung der Auslastung unter den realen Servern.
- Überprüfung der Integrität der Dienste auf jedem realen Server.
Der Backup-LVS-Router überwacht den aktiven LVS-Router und übernimmt dessen Aufgaben im Falle eines Ausfalls.
Dieses Kapitel liefert einen Überblick über die Komponenten und Funktionen des Load Balancer Add-Ons und besteht aus den folgenden Abschnitten:
1.1. Eine grundlegende Load Balancer Add-On Konfiguration
Link kopierenLink in die Zwischenablage kopiert!
Abbildung 1.1, »Eine grundlegende Load Balancer Add-On Konfiguration« zeigt eine einfache Load Balancer Add-On Konfiguration bestehend aus zwei Schichten. Auf der ersten Schicht befindet sich ein aktiver und ein Backup-LVS-Router. Jeder LVS-Router hat zwei Netzwerkschnittstellen, eine zum Internet und eine zum privaten Netzwerk, sodass sie den Datenverkehr zwischen den zwei Netzwerken steuern können. In diesem Beispiel verwendet der aktive Router Network Address Translation oder kurz NAT, um Datenverkehr vom Internet an eine variable Anzahl von realen Servern auf der zweiten Schicht zu leiten, die die notwendigen Dienste bereitstellen. Somit sind die realen Server in diesem Beispiel alle mit einem dedizierten privaten Netzwerksegment verbunden und leiten sämtlichen öffentlichen Datenverkehr durch den aktiven LVS-Router. Nach außen hin erscheinen die Server als eine einzige Einheit.
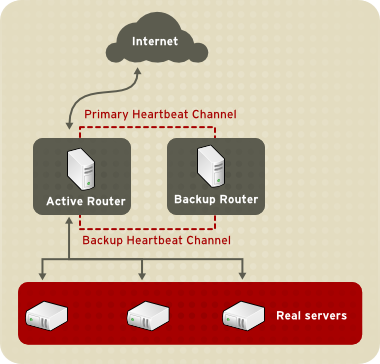
Abbildung 1.1. Eine grundlegende Load Balancer Add-On Konfiguration
Dienstanfragen, die den LVS-Router erreichen, sind an eine virtuelle IP-Adresse oder kurz VIP adressiert. Dies ist eine öffentlich routbare Adresse, die der Administrator des Netzwerks mit einem vollqualifizierten Domainnamen wie z. B. www.example.com verknüpft und die mit einem oder mehreren virtuellen Servern verknüpft ist. Ein virtueller Server ist ein Dienst, der zum Lauschen auf einer bestimmten virtuellen IP konfiguriert ist. In Abschnitt 4.6, »VIRTUAL SERVERS« finden Sie weitere Informationen über die Konfiguration eines virtuellen Servers mithilfe des Piranha-Konfigurationstools. Eine VIP-Adresse migriert im Falle eines Ausfalls von einem LVS-Router auf den anderen und gewährleistet somit die Verfügbarkeit an der IP-Adresse (auch Floating-IP-Adresse genannt).
VIP-Adressen können eine Alias-Bezeichnung für dasselbe Gerät erhalten, das den LVS-Router mit dem Internet verbindet. Wenn zum Beispiel eth0 mit dem Internet verbunden ist, dann können mehrere virtuelle Server eine Alias-Bezeichnung
eth0:1 erhalten. Alternativ kann jeder virtuelle Server mit einem separaten Gerät pro Dienst verknüpft werden. Beispielsweise kann HTTP-Datenverkehr auf eth0:1 und FTP-Datenverkehr auf eth0:2 verwaltet werden.
Nur jeweils ein LVS-Router ist aktiv. Die Aufgabe des aktiven Routers ist es, Dienstanfragen von virtuellen IP-Adressen an die realen Server umzuleiten. Die Umleitung basiert auf einem von acht Algorithmen für die Lastverteilung, die in Abschnitt 1.3, »Übersicht über das Load Balancer Add-On Scheduling« näher beschrieben werden.
Der aktive Router überwacht zudem dynamisch die Gesamtverfassung der speziellen Dienste auf den realen Servern durch einfache send/expect-Skripte. Als Hilfe bei der Analyse der Verfassung eines Dienstes, der dynamische Daten wie HTTPS oder SSL benötigt, kann der Administrator auch externe ausführbare Dateien aufrufen. Falls ein Dienst auf einem realen Server nicht ordnungsgemäß funktioniert, hört der aktive Router auf, Jobs an diesen Server zu senden, bis dieser wieder ordnungsgemäß läuft.
Der Backup-Router übernimmt die Rolle eines Systems in Bereitschaft. Der LVS-Router tauscht regelmäßig Heartbeat-Meldungen über die primäre externe öffentliche Schnittstelle und im Falle eines Failovers über die private Schnittstelle aus. Erhält der Backup-Router keine Heartbeat-Meldung innerhalb eines erwarteten Intervalls, leitet er die Ausfallsicherung ein und übernimmt die Rolle des aktiven Routers. Während der Ausfallsicherung übernimmt der Backup-Router die VIP-Adressen, die vom ausgefallenen Router bereitgestellt wurden, unter Verwendung einer Technik, die als ARP-Spoofing bekannt ist – hierbei zeigt der Backup-LVS-Router an, dass er das Ziel für IP-Adressen darstellt, die an den ausgefallenen Knoten gerichtet sind. Falls der ausgefallene Knoten wieder aktiv wird, nimmt der Backup-Knoten seine Backup-Rolle wieder auf.
Die einfache Konfiguration mit zwei Schichten in Abbildung 1.1, »Eine grundlegende Load Balancer Add-On Konfiguration« ist am besten geeignet für die Bereitstellung von Daten, die sich nicht sehr häufig ändern – wie z. B. eine statische Website – da die einzelnen realen Server nicht automatisch die Daten zwischen den Knoten synchronisieren.
1.1.1. Daten replizieren und gemeinsam verwenden auf realen Servern
Link kopierenLink in die Zwischenablage kopiert!
Da es keine integrierte Komponente im Load Balancer Add-On gibt, die dieselben Daten auf den realen Servern verteilt, hat der Administrator zwei Möglichkeiten:
- Synchronisation der Daten auf den realen Servern
- Hinzufügen einer dritten Schicht zur Topologie für den Zugriff auf gemeinsam genutzte Daten
Die erste Option wird vorzugsweise für Server verwendet, die einer großen Anzahl von Benutzern das Hochladen oder Verändern von Daten auf den realen Servern untersagt. Falls die Konfiguration es einer großen Anzahl von Benutzern gestattet, Daten zu verändern, wie beispielsweise einer E-Commerce-Website, ist das Hinzufügen einer dritten Schicht besser.
1.1.1.1. Konfigurieren von realen Servern zur Synchronisierung von Daten
Link kopierenLink in die Zwischenablage kopiert!
Es gibt viele Möglichkeiten, wie ein Administrator Daten im Pool der realen Server synchronisieren kann. Beispielsweise können Shell-Skripte verwendet werden, die, sobald eine Website aktualisiert wird, diese Seite an alle Server gleichzeitig verteilen. Der Systemadministrator kann auch Programme wie
rsync dazu verwenden, um veränderte Daten in bestimmten Abständen auf alle Knoten zu replizieren.
Allerdings funktioniert diese Art der Datensynchronisation nicht optimal, falls die Konfiguration überladen ist mit Benutzern, die permanent Dateien hochladen oder Datenbanktransaktionen vornehmen. Für eine Konfiguration mit hoher Auslastung ist eine dreischichtige Topologie die beste Lösung.