マシン管理
クラスターマシンの追加および保守
概要
第1章 マシン管理の概要
マシン管理を使用して、Amazon Web Services (AWS)、Azure、Google Cloud Platform (GCP)、OpenStack、Red Hat Virtualization (RHV)、および vSphere などの基礎となるインフラストラクチャーを柔軟に使用して OpenShift Container Platform クラスターを管理できます。クラスターを制御し、特定のワークロードポリシーに基づいてクラスターをスケールアップやスケールダウンするなどの自動スケーリングを実行できます。
OpenShift Container Platform クラスターは、負荷の増減時に水平にスケールアップおよびスケールダウンできます。ワークロードの変更に適応するクラスターがあることが重要になります。
マシン管理は カスタムリソース定義 (CRD) として実装されます。CRD オブジェクトは、クラスター内に新規の固有オブジェクト Kind を定義し、Kubernetes API サーバーはオブジェクトのライフサイクル全体を処理できます。
Machine API Operator は以下のリソースをプロビジョニングします。
- MachineSet
- マシン
- Cluster Autoscaler
- Machine Autoscaler
- Machine Health Checks
1.1. マシン API の概要
マシン API は、アップストリームのクラスター API プロジェクトおよびカスタム OpenShift Container Platform リソースに基づく重要なリソースの組み合わせです。
OpenShift Container Platform 4.11 クラスターの場合、マシン API はクラスターインストールの終了後にすべてのノードホストのプロビジョニングの管理アクションを実行します。このシステムにより、OpenShift Container Platform 4.11 はパブリックまたはプライベートのクラウドインフラストラクチャーに加えて弾力性があり、動的なプロビジョニング方法を提供します。
以下の 2 つのリソースは重要なリソースになります。
- Machines
-
ノードのホストを記述する基本的なユニットです。マシンには、複数の異なるクラウドプラットフォーム用に提供されるコンピュートノードのタイプを記述する
providerSpec仕様があります。たとえば、コンピュートノードのマシンタイプは、特定のマシンタイプと必要なメタデータを定義する場合があります。 - マシンセット
MachineSetリソースはマシンのグループです。マシンセットとマシンの関係は、レプリカセットと Pod の関係と同様です。マシンを追加する必要がある場合や、マシンの数を縮小したりする必要がある場合、コンピューティングのニーズに応じてマシンセットの replicas フィールドを変更します。警告コントロールプレーンマシンは、マシンセットで管理することはできません。
以下のカスタムリソースは、クラスターに機能を追加します。
- Machine Autoscaler
MachineAutoscalerリソースは、クラウド内のコンピューティングマシンを自動的にスケーリングします。指定したコンピューティングマシンセット内のノードの最小および最大スケーリング境界を設定でき Machine Autoscaler はそのノード範囲を維持します。MachineAutoscalerオブジェクトはClusterAutoscalerオブジェクトの設定後に有効になります。ClusterAutoscalerおよびMachineAutoscalerリソースは、どちらもClusterAutoscalerOperatorオブジェクトによって利用可能にされます。- Cluster Autoscaler
- このリソースはアップストリームの Cluster Autoscaler プロジェクトに基づいています。OpenShift Container Platform の実装では、これはマシンセット API を拡張することによってクラスター API に統合されます。コア、ノード、メモリー、および GPU などのリソースのクラスター全体でのスケーリング制限を設定できます。優先順位を設定することにより、重要度の低い Pod のために新規ノードがオンラインにならないようにクラスターで Pod の優先順位付けを実行できます。また、スケーリングポリシーを設定してノードをスケールダウンせずにスケールアップできるようにすることもできます。
- マシンのヘルスチェック
-
MachineHealthCheckリソースはマシンの正常でない状態を検知し、マシンを削除し、サポートされているプラットフォームでは新規マシンを作成します。
OpenShift Container Platform バージョン 3.11 では、クラスターでマシンのプロビジョニングが管理されないためにマルチゾーンアーキテクチャーを容易にデプロイメントすることができませんでした。しかし、OpenShift Container Platform バージョン 4.1 以降、このプロセスはより簡単になりました。それぞれのマシンセットのスコープが単一ゾーンに設定されるため、インストールプログラムはユーザーに代わって、アベイラビリティーゾーン全体にマシンセットを送信します。さらに、コンピューティングは動的に展開されるため、ゾーンに障害が発生した場合の、マシンのリバランスが必要な場合に使用するゾーンを常に確保できます。複数のアベイラビリティーゾーンを持たないグローバル Azure リージョンでは、アベイラビリティーセットを使用して高可用性を確保できます。Autoscaler はクラスターの有効期間中にベストエフォートでバランシングを提供します。
1.2. コンピューティングマシンの管理
クラスター管理者として、以下を実行できます。
以下でマシンセットを作成する。
- ベアメタルのデプロイメント用マシンセットの作成: ベアメタルでのコンピュートマシンセットの作成
- マシンセットからマシンを追加または削除して、マシンセットを手動でスケーリングする。
-
MachineSetYAML 設定ファイルを使用して マシンセットを変更 します。 - マシンを 削除する。
- インフラストラクチャーマシンセットを作成する。
- マシンヘルスチェック を設定してデプロイし、マシンプール内の破損したマシンを自動的に修正する。
1.3. OpenShift Container Platform クラスターへの自動スケーリングの適用
ワークロードの変化に対する柔軟性を確保するために、OpenShift Container Platform クラスターを自動的にスケーリングできます。クラスターを 自動スケーリング するには、Cluster Autoscaler をデプロイしてから、各コンピュートマシンセットに Machine Autoscaler をデプロイする必要があります。
- Cluster Autoscaler は、デプロイメントのニーズに応じてクラスターのサイズを拡大し、縮小します。
- Machine Autoscaler は、OpenShift Container Platform クラスターにデプロイするマシンセットのコンピュートマシン数を調整します。
1.4. ユーザーがプロビジョニングしたインフラストラクチャーへのコンピューティングマシンの追加
ユーザーによってプロビジョニングされるインフラストラクチャーとは、OpenShift Container Platform をホストするコンピュート、ネットワーク、ストレージリソースなどのインフラストラクチャーをデプロイできる環境です。インストールプロセス中またはインストールプロセス後に、ユーザーがプロビジョニングしたインフラストラクチャー上のクラスターに コンピューティングマシンを追加 できます。
1.5. RHEL コンピュートマシンのクラスターへの追加
クラスター管理者は、次のアクションを実行できます。
- ユーザーによってプロビジョニングされるインフラストラクチャークラスターまたはインストールでプロビジョニングされるクラスターに、Red Hat Enterprise Linux (RHEL) コンピュートマシン (ワーカーマシンとしても知られる) を追加する。
- 既存のクラスターに Red Hat Enterprise Linux (RHEL) コンピュートマシンをさらに追加する。
第2章 Machine API を使用したコンピュートマシンの管理
2.1. Alibaba Cloud でマシンセットを作成する
Alibaba Cloud 上の Open Shift Container Platform クラスターで特定の目的を果たすために別のマシンセットを作成できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.1.1. Alibaba Cloud 上のマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は、リージョン内の指定された Alibaba Cloud ゾーンで実行され、node-role.kubernetes.io/<role>: "" というラベルの付いたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
credentialsSecret:
name: alibabacloud-credentials
imageId: <image_id>
instanceType: <instance_type>
kind: AlibabaCloudMachineProviderConfig
ramRoleName: <infrastructure_id>-role-worker
regionId: <region>
resourceGroup:
id: <resource_group_id>
type: ID
securityGroups:
- tags:
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tags
systemDisk:
category: cloud_essd
size: <disk_size>
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
userDataSecret:
name: <user_data_secret>
vSwitch:
tags:
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags
vpcId: ""
zoneId: <zone> - 1 5 7
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9
- 追加するノードラベルを指定します。
- 4 6 10
- インフラストラクチャー ID、ノードラベル、およびゾーンを指定します。
- 11
- 使用するイメージを指定します。クラスターに設定されている既存のデフォルトマシンのイメージを使用します。
- 12
- マシンセットに使用するインスタンスタイプを指定します。
- 13
- マシンセットに使用する RAM ロールの名前を指定します。インストーラーがデフォルトのマシンセットに入力する値を使用します。
- 14
- マシンを配置するリージョンを指定します。
- 15
- クラスターのリソースグループとタイプを指定します。インストーラーがデフォルトのマシンセットに入力する値を使用するか、別の値を指定できます。
- 16 18 20
- マシンセットに使用するタグを指定します。少なくとも、この例に示されているタグを、クラスターに適切な値とともに含める必要があります。必要に応じて、インストーラーが作成するデフォルトのマシンセットに設定するタグなど、追加のタグを含めることができます。
- 17
- ルートディスクのタイプとサイズを指定します。インストーラーが作成するデフォルトのマシンセットに入力する
category値を使用します。必要に応じて、sizeにギガバイト単位の別の値を指定します。 - 19
openshift-machine-api名前空間にあるユーザーデータ YAML ファイルでシークレットの名前を指定します。インストーラーがデフォルトのマシンセットに入力する値を使用します。- 21
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
2.1.1.1. Alibaba Cloud 使用統計のマシンセットパラメーター
インストーラーが Alibaba Cloud クラスター用に作成するデフォルトのマシンセットには、Alibaba Cloud が使用統計を追跡するために内部的に使用する不要なタグ値が含まれています。これらのタグは、spec.template.spec.provider Spec.valueリストの securityGroups、tag、およびvSwitch パラメーターに入力されます。
追加のマシンをデプロイするマシンセットを作成するときは、必要な Kubernetes タグを含める必要があります。使用統計タグは、作成するマシンセットで指定されていない場合でも、デフォルトで適用されます。必要に応じて、追加のタグを含めることもできます。
次の YAML スニペットは、デフォルトのマシンセットのどのタグがオプションでどれが必須かを示しています。
spec.template.spec.providerSpec.value.securityGroups のタグ
spec:
template:
spec:
providerSpec:
value:
securityGroups:
- tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tagsspec.template.spec.providerSpec.value.tag のタグ
spec:
template:
spec:
providerSpec:
value:
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocpspec.template.spec.providerSpec.value.vSwitch のタグ
spec:
template:
spec:
providerSpec:
value:
vSwitch:
tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags2.1.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.2. AWS でのマシンセットの作成
Amazon Web Services (AWS) で OpenShift Container Platform クラスターの特定の目的を果たすように異なるマシンセットを作成することができます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.2.1. AWS 上のマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は us-east-1a Amazon Web Services (AWS) ゾーンで実行され、node-role.kubernetes.io/<role>:"" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-<role>-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
ami:
id: ami-046fe691f52a953f9
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: <infrastructure_id>-worker-profile
instanceType: m6i.large
kind: AWSMachineProviderConfig
placement:
availabilityZone: <zone>
region: <region>
securityGroups:
- filters:
- name: tag:Name
values:
- <infrastructure_id>-worker-sg
subnet:
filters:
- name: tag:Name
values:
- <infrastructure_id>-private-<zone>
tags:
- name: kubernetes.io/cluster/<infrastructure_id>
value: owned
userDataSecret:
name: worker-user-data- 1 3 5 11 14 16
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- インフラストラクチャー ID、ノードラベル、およびゾーンを指定します。
- 6 7 9
- 追加するノードラベルを指定します。
- 10
- OpenShift Container Platform ノードの AWS ゾーンに有効な Red Hat Enterprise Linux CoreOS (RHCOS) AMI を指定します。AWS Marketplace イメージを使用する場合は、AWS Marketplace から OpenShift Container Platform サブスクリプションを完了して、リージョンの AMI ID を取得する必要があります。
- 12
- ゾーン (例:
us-east-1a) を指定します。 - 13
- リージョン (例:
us-east-1) を指定します。 - 15
- インフラストラクチャー ID とゾーンを指定します。
2.2.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml- 他のアベイラビリティーゾーンでコンピュートマシンセットが必要な場合、このプロセスを繰り返して追加のコンピュートマシンセットを作成します。
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.2.3. Amazon EC2 インスタンスメタデータサービスのマシンセットオプション
マシンセットを使用して、Amazon EC2 インスタンスメタデータサービス (IMDS) の特定のバージョンを使用するコンピュートマシンを作成できます。マシンセットは、IMDSv1 と IMDSv2 の両方の使用を許可するコンピュートマシン、または IMDSv2 の使用を必要とするコンピュートマシンを作成できます。
IMDSv2 の使用は、OpenShift Container Platform バージョン 4.7 以降で作成された AWS クラスターでのみサポートされます。
既存のコンピュートマシンの IMDS 設定を変更するには、それらのマシンを管理するマシンセット YAML ファイルを編集します。好みの IMDS 設定で新しいコンピュートマシンをデプロイメントするには、適切な値を使用してマシンセット YAML ファイルを作成します。
コントロールプレーンマシンの IMDS 設定は、クラスターのインストール時に設定されます。コントロールプレーンマシンの IMDS 設定を変更するには、AWS CLI を使用する必要があります。詳細は、既存のインスタンスのインスタンスメタデータオプション を変更する方法に関する AWS のドキュメントを参照してください。
IMDSv2 を必要とするコンピュートマシンを作成するようにマシンセットを設定する前に、AWS メタデータサービスと相互作用するすべてのワークロードが IMDSv2 をサポートしていることを確認してください。
2.2.3.1. マシンセットを使用した IMDS の設定
コンピュートマシンのマシンセット YAML ファイルで metadataServiceOptions.authentication の値を追加または編集することで、IMDSv2 の使用を要求するかどうかを指定できます。
前提条件
- IMDSv2 を使用するには、AWS クラスターが OpenShift Container Platform バージョン 4.7 以降で作成されている必要があります。
手順
providerSpecフィールドの下に次の行を追加または編集します。providerSpec: value: metadataServiceOptions: authentication: Required1 - 1
- IMDSv2 を要求するには、パラメーター値を
Requiredに設定します。IMDSv1 と IMDSv2 の両方の使用を許可するには、パラメーター値をOptionalに設定します。値が指定されていない場合、IMDSv1 と IMDSv2 の両方が許可されます。
2.2.4. マシンを専有インスタンス (Dedicated Instance) としてデプロイするマシンセット
マシンを専有インスタンス (Dedicated Instance) としてデプロイする AWS で実行されるマシンセットを作成できます。専有インスタンス (Dedicated Instance) は、単一のお客様専用のハードウェア上の仮想プライベートクラウド (VPC) で実行されます。これらの Amazon EC2 インスタンスは、ホストのハードウェアレベルで物理的に分離されます。インスタンスが単一つの有料アカウントにリンクされている別の AWS アカウントに属する場合でも、専有インスタンス (Dedicated Instance) の分離が生じます。ただし、専用ではない他のインスタンスは、それらが同じ AWS アカウントに属する場合は、ハードウェアを専有インスタンス (Dedicated Instance) と共有できます。
パブリックまたは専用テナンシーのいずれかを持つインスタンスは、マシン API によってサポートされます。パブリックテナンシーを持つインスタンスは、共有ハードウェア上で実行されます。パブリックテナンシーはデフォルトのテナンシーです。専用のテナンシーを持つインスタンスは、単一テナントのハードウェアで実行されます。
2.2.4.1. マシンセットの使用による専有インスタンス (Dedicated Instance) の作成
マシン API 統合を使用して、専有インスタンス (Dedicated Instance) によってサポートされるマシンを実行できます。マシンセット YAML ファイルの tenancy フィールドを設定し、AWS で専有インスタンス (Dedicated Instance) を起動します。
手順
providerSpecフィールドに専用テナンシーを指定します。providerSpec: placement: tenancy: dedicated
2.2.5. マシンを Spot インスタンスとしてデプロイするマシンセット
マシンを保証されていない Spot インスタンスとしてデプロイする AWS で実行されるマシンセットを作成して、コストを節約できます。Spot インスタンスは未使用の AWS EC2 容量を使用し、On-Demand インスタンスよりもコストが低くなります。Spot インスタンスは、バッチやステートレス、水平的に拡張可能なワークロードなどの割り込みを許容できるワークロードに使用することができます。
AWS EC2 は Spot インスタンスをいつでも終了できます。AWS は、中断の発生時にユーザーに警告を 2 分間表示します。OpenShift Container Platform は、AWS が終了についての警告を発行する際に影響を受けるインスタンスからワークロードを削除し始めます。
以下の理由により、Spot インスタンスを使用すると中断が生じる可能性があります。
- インスタンス価格は最大価格を超えます。
- Spot インスタンスの需要は増大します。
- Spot インスタンスの供給は減少します。
AWS がインスタンスを終了すると、Spot インスタンスノードで実行される終了ハンドラーによりマシンリソースが削除されます。マシンセットの replicas の量を満たすために、マシンセットは Spot インスタンスを要求するマシンを作成します。
2.2.5.1. マシンセットの使用による Spot インスタンスの作成
spotMarketOptions をマシンセットの YAML ファイルに追加して、AWS で Spot インスタンスを起動できます。
手順
providerSpecフィールドの下に以下の行を追加します。providerSpec: value: spotMarketOptions: {}オプションで、Spot インスタンスのコストを制限するために、
spotMarketOptions.maxPriceフィールドを設定できます。たとえば、maxPrice: '2.50'を設定できます。maxPriceが設定されている場合、この値は毎時の最大 Spot 価格として使用されます。これを設定しないと、デフォルトで最大価格として On-Demand インスタンス価格までチャージされます。注記デフォルトの On-Demand 価格を
maxPrice値として使用し、Spot インスタンスの最大価格を設定しないことが強く推奨されます。
2.3. Azure でのマシンセットの作成
Microsoft Azure 上の OpenShift Container Platform クラスターで特定の目的を果たすように異なるマシンセットを作成することができます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.3.1. Azure 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、リージョンの 1 Microsoft Azure ゾーンで実行され、node-role.kubernetes.io/<role>: "" というラベルの付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
spec:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-machineset: <machineset_name>
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: azureproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
tags:
- name: <custom_tag_name>
value: <custom_tag_value>
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_D4s_v3
vnet: <infrastructure_id>-vnet
zone: "1" - 1 5 7 15 16 19 22
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster以下のコマンドを実行してサブネットを取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1以下のコマンドを実行して vnet を取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 20 21
- 追加するノードラベルを指定します。
- 4 6 10
- インフラストラクチャー ID、ノードラベル、およびリージョンを指定します。
- 12
- マシンセットのイメージの詳細を指定します。Azure Marketplace イメージを使用する場合は、Azure Marketplace イメージの選択を参照してください。
- 13
- インスタンスタイプと互換性のあるイメージを指定します。インストールプログラムによって作成された Hyper-V 世代の V2 イメージには接尾辞
-gen2が付いていますが、V1 イメージには接尾辞のない同じ名前が付いています。 - 14
- マシンを配置するリージョンを指定します。
- 23
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
- 17 18
- オプション: マシンセットでカスタムタグを指定します。
<custom_tag_name>フィールドにタグ名を指定し、対応するタグ値を<custom_tag_value>フィールドに指定します。
2.3.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.3.3. Azure Marketplace イメージの選択
Azure Marketplace サービスを使用するマシンをデプロイする、Azure で実行するマシンセットを作成できます。このサービスを使用するには、まず Azure Marketplace イメージを取得する必要があります。イメージを取得するときは、次の点を考慮してください。
-
イメージは同じですが、Azure Marketplace のパブリシャーは地域によって異なります。北米にお住まいの場合は、
redhatをパブリッシャーとして指定してください。EMEA にお住まいの場合は、redhat-limitedをパブリッシャーとして指定してください。 -
このオファーには、
rh-ocp-workerSKU とrh-ocp-worker-gen1SKU が含まれています。rh-ocp-workerSKU は、Hyper-V 世代のバージョン 2 VM イメージを表します。OpenShift Container Platform で使用されるデフォルトのインスタンスタイプは、バージョン 2 と互換性があります。バージョン 1 のみと互換性のあるインスタンスタイプを使用する場合は、rh-ocp-worker-gen1SKU に関連付けられたイメージを使用します。rh-ocp-worker-gen1SKU は、Hyper-V バージョン 1 VM イメージを表します。
前提条件
-
Azure CLI クライアント
(az)をインストールしている。 - お客様の Azure アカウントにはオファーのエンタイトルメントがあり、Azure CLI クライアントを使用してこのアカウントにログインしている。
手順
以下のいずれかのコマンドを実行して、利用可能なすべての OpenShift Container Platform イメージを表示します。
北米:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat -o table出力例
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker RedHat rh-ocp-worker RedHat:rh-ocp-worker:rh-ocpworker:4.8.2021122100 4.8.2021122100 rh-ocp-worker RedHat rh-ocp-worker-gen1 RedHat:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100EMEA:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat-limited -o table出力例
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker redhat-limited rh-ocp-worker redhat-limited:rh-ocp-worker:rh-ocp-worker:4.8.2021122100 4.8.2021122100 rh-ocp-worker redhat-limited rh-ocp-worker-gen1 redhat-limited:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100
注記インストールする OpenShift Container Platform のバージョンに関係なく、使用する Azure Marketplace イメージの正しいバージョンは 4.8.x です。必要に応じて、インストールプロセスの一環として、VM が自動的にアップグレードされます。
次のいずれかのコマンドを実行して、オファーのイメージを調べます。
北米:
$ az vm image show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>EMEA:
$ az vm image show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
次のコマンドのいずれかを実行して、オファーの条件を確認します。
北米:
$ az vm image terms show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>EMEA:
$ az vm image terms show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
次のコマンドのいずれかを実行して、オファリングの条件に同意します。
北米:
$ az vm image terms accept --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>EMEA:
$ az vm image terms accept --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
-
オファーのイメージの詳細 (具体的には
publisher、offer、sku、およびversionの値) を記録します。 オファーのイメージの詳細を使用して、マシンセット YAML ファイルの
providerSpecセクションに次のパラメーターを追加します。Azure Marketplace コンピュートマシンのサンプルの
providerSpecイメージ値providerSpec: value: image: offer: rh-ocp-worker publisher: redhat resourceID: "" sku: rh-ocp-worker type: MarketplaceWithPlan version: 4.8.2021122100
2.3.4. マシンを Spot 仮想マシンとしてデプロイするマシンセット
マシンを保証されていない Spot 仮想マシンとしてデプロイする Azure で実行されるマシンセットを作成して、コストを節約できます。Spot 仮想マシンは未使用の Azure 容量を使用し、標準の仮想マシンよりもコストが低くなります。Spot 仮想マシンは、バッチやステートレス、水平的に拡張可能なワークロードなどの割り込みを許容できるワークロードに使用することができます。
Azure は Spot 仮想マシンをいつでも終了できます。Azure は、中断の発生時にユーザーに警告を 30 秒間表示します。OpenShift Container Platform は、Azure が終了についての警告を発行する際に影響を受けるインスタンスからワークロードを削除し始めます。
以下の理由により、Spot 仮想マシンを使用すると中断が生じる可能性があります。
- インスタンス価格は最大価格を超えます。
- Spot 仮想マシンの供給は減少します。
- Azure は容量を戻す必要があります。
Azure がインスタンスを終了すると、Spot 仮想マシンノードで実行される終了ハンドラーによりマシンリソースが削除されます。マシンセットの replicas の量を満たすために、マシンセットは Spot 仮想マシンを要求するマシンを作成します。
2.3.4.1. マシンセットの使用による Spot 仮想マシンの作成
spotVMOptions をマシンセットの YAML ファイルに追加して、Azure で Spot 仮想マシンを起動できます。
手順
providerSpecフィールドの下に以下の行を追加します。providerSpec: value: spotVMOptions: {}オプションで、Spot 仮想マシンのコストを制限するために、
spotVMOptions.maxPriceフィールドを設定できます。たとえば、maxPrice: '0.98765'を設定できます。maxPriceが設定されている場合、この値は毎時の最大 Spot 価格として使用されます。設定されていない場合、最大価格はデフォルトの-1に設定され、標準の仮想マシン価格までチャージされます。Azure は標準価格で Spot 仮想マシン価格を制限します。インスタンスがデフォルトの
maxPriceで設定されている場合、Azure は価格設定によりインスタンスをエビクトしません。ただし、インスタンスは容量の制限によって依然としてエビクトできます。
デフォルトの仮想マシンの標準価格を maxPrice 値として使用し、Spot 仮想マシンの最大価格を設定しないことが強く推奨されます。
2.3.5. マシンを一時 OS ディスクにデプロイするマシンセット
マシンを Ephemeral OS ディスクにデプロイする Azure で実行されるマシンセットを作成できます。Azure Ephemeral OS ディスクは、リモートの Azure Storage ではなく、ローカルの VM 容量を使用します。したがって、この設定により、追加コストがなく、読み取り、書き込み、および再イメージ化のレイテンシーが短くなります。
2.3.5.1. マシンセットの使用による一時 OS ディスクでのマシンの作成
マシンセット YAML ファイルを編集して、Azure で Ephemeral OS ディスクでマシンを起動できます。
前提条件
- 既存の Microsoft Azure クラスターがある。
手順
以下のコマンドを実行してカスタムリソース (CR) を編集します。
$ oc edit machineset <machine-set-name>ここで、
<machine-set-name>は、エフェメラル OS ディスクにマシンをプロビジョニングするマシンセットです。以下を
providerSpecフィールドに追加します。providerSpec: value: ... osDisk: ... diskSettings:1 ephemeralStorageLocation: Local2 cachingType: ReadOnly3 managedDisk: storageAccountType: Standard_LRS4 ...重要OpenShift Container Platform での Ephemeral OS ディスクのサポートの実装は、
CacheDisk配置タイプのみをサポートします。placement設定は変更しないでください。更新された設定を使用してマシンセットを作成します。
$ oc create -f <machine-set-config>.yaml
検証
-
Microsoft Azure ポータルで、マシンセットによってデプロイされたマシンの Overview ページを確認し、
Ephemeral OS ディスクフィールドがOSキャッシュ配置に設定されていることを確認します。
2.3.6. Machine sets that deploy machines with ultra disks as data disks
Ultra ディスクと共にマシンをデプロイする Azure で実行されるマシンセットを作成できます。Ultra ディスクは、最も要求の厳しいデータワークロードでの使用を目的とした高性能ストレージです。
Azure ウルトラディスクに支えられたストレージクラスに動的にバインドし、それらを Pod にマウントする永続ボリューム要求 (PVC) を作成することもできます。
データディスクは、ディスクスループットまたはディスク IOPS を指定する機能をサポートしていません。これらのプロパティーは、PVC を使用して設定できます。
2.3.6.1. マシンセットを使用した Ultra ディスクを持つマシンの作成
マシンセットの YAML ファイルを編集することで、Azure 上に Ultra ディスクと共にマシンをデプロイできます。
前提条件
- 既存の Microsoft Azure クラスターがある。
手順
次のコマンドを実行して、ワーカーデータシークレットを使用して
openshift-machine-apinamespace にカスタムシークレットを作成します。$ oc -n openshift-machine-api \ get secret worker-user-data \ --template='{{index .data.userData | base64decode}}' | jq > userData.txtここで、
userData.txtは新しいカスタムシークレットの名前です。テキストエディターで、
userData.txtファイルを開き、ファイル内の最後の}文字を見つけます。-
直前の行に、
,を追加します。 ,の後に新しい行を作成し、以下の設定内容を追加します。"storage": { "disks": [1 { "device": "/dev/disk/azure/scsi1/lun0",2 "partitions": [3 { "label": "lun0p1",4 "sizeMiB": 1024,5 "startMiB": 0 } ] } ], "filesystems": [6 { "device": "/dev/disk/by-partlabel/lun0p1", "format": "xfs", "path": "/var/lib/lun0p1" } ] }, "systemd": { "units": [7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var/lib/lun0p1\nWhat=/dev/disk/by-partlabel/lun0p1\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n",8 "enabled": true, "name": "var-lib-lun0p1.mount" } ] }- 1
- ウルトラディスクとしてノードに接続するディスクの設定の詳細。
- 2
- 使用しているマシンセットの
dataDisksスタンザで定義されているlun値を指定します。たとえば、マシンセットにlun:0が含まれている場合は、lun0を指定します。この設定ファイルで複数の"disks"エントリーを指定することにより、複数のデータディスクを初期化できます。複数の"disks"エントリーを指定する場合は、それぞれのlun値がマシンセットの値と一致することを確認してください。 - 3
- ディスク上の新しいパーティションの設定の詳細。
- 4
- パーティションのラベルを指定します。
lun0の最初のパーティションにlun0p1などの階層名を使用すると便利な場合があります。 - 5
- パーティションの合計サイズを MiB で指定します。
- 6
- パーティションをフォーマットするときに使用するファイルシステムを指定します。パーティションラベルを使用して、パーティションを指定します。
- 7
- 起動時にパーティションをマウントする
systemdユニットを指定します。パーティションラベルを使用して、パーティションを指定します。この設定ファイルで複数の"partitions"エントリーを指定することにより、複数のパーティションを作成できます。複数の"partitions"エントリーを指定する場合は、それぞれにsystemdユニットを指定する必要があります。 - 8
Whereには、storage.filesystems.pathの値を指定します。Whatには、storage.filesystems.deviceの値を指定します。
-
直前の行に、
次のコマンドを実行して、無効化テンプレート値を
disableTemplating.txtというファイルに抽出します。$ oc -n openshift-machine-api get secret worker-user-data \ --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txt次のコマンドを実行して、
userData.txtファイルとdisableTemplating.txtファイルを組み合わせてデータシークレットファイルを作成します。$ oc -n openshift-machine-api create secret generic worker-user-data-x5 \ --from-file=userData=userData.txt \ --from-file=disableTemplating=disableTemplating.txtここで、
worker-user-data-x5はシークレットの名前です。既存の Azure
MachineSetカスタムリソース (CR) をコピーし、次のコマンドを実行して編集します。$ oc edit machineset <machine-set-name>ここで、
<machine-set-name>は、Ultra ディスクと共にマシンをプロビジョニングするマシンセットです。示された位置に次の行を追加します。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... spec: ... template: ... spec: metadata: ... labels: ... disk: ultrassd1 ... providerSpec: value: ... ultraSSDCapability: Enabled2 dataDisks:3 - nameSuffix: ultrassd lun: 0 diskSizeGB: 4 deletionPolicy: Delete cachingType: None managedDisk: storageAccountType: UltraSSD_LRS userDataSecret: name: worker-user-data-x54 ...次のコマンドを実行して、更新された設定を使用してマシンセットを作成します。
$ oc create -f <machine-set-name>.yaml
検証
次のコマンドを実行して、マシンが作成されていることを確認します。
$ oc get machinesマシンは
Running状態になっているはずです。実行中でノードが接続されているマシンの場合、次のコマンドを実行してパーティションを検証します。
$ oc debug node/<node-name> -- chroot /host lsblkこのコマンドでは、
oc debug node/<node-name>がノード<node-name>でデバッグシェルを開始し、--を付けてコマンドを渡します。渡されたコマンドchroot /hostは、基盤となるホスト OS バイナリーへのアクセスを提供し、lsblkは、ホスト OS マシンに接続されているブロックデバイスを表示します。
次のステップ
Pod 内から Ultra ディスクを使用するには、マウントポイントを使用するワークロードを作成します。次の例のような YAML ファイルを作成します。
apiVersion: v1 kind: Pod metadata: name: ssd-benchmark1 spec: containers: - name: ssd-benchmark1 image: nginx ports: - containerPort: 80 name: "http-server" volumeMounts: - name: lun0p1 mountPath: "/tmp" volumes: - name: lun0p1 hostPath: path: /var/lib/lun0p1 type: DirectoryOrCreate nodeSelector: disktype: ultrassd
2.3.6.2. Ultra ディスクを有効にするマシンセットのリソースに関するトラブルシューティング
このセクションの情報を使用して、発生する可能性のある問題を理解し、回復してください。
2.3.6.2.1. ウルトラディスク設定が正しくありません
マシンセットで ultraSSDCapability パラメーターの誤った設定が指定されている場合、マシンのプロビジョニングは失敗します。
たとえば、ultraSSDCapability パラメーターが Disabled に設定されているが、dataDisks パラメーターでウルトラディスクが指定されている場合、次のエラーメッセージが表示されます。
StorageAccountType UltraSSD_LRS can be used only when additionalCapabilities.ultraSSDEnabled is set.- この問題を解決するには、マシンセットの設定が正しいことを確認してください。
2.3.6.2.2. サポートされていないディスクパラメーター
ウルトラディスクと互換性のないリージョン、アベイラビリティーゾーン、またはインスタンスサイズがマシンセットで指定されている場合、マシンのプロビジョニングは失敗します。ログで次のエラーメッセージを確認してください。
failed to create vm <machine_name>: failure sending request for machine <machine_name>: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="Storage Account type 'UltraSSD_LRS' is not supported <more_information_about_why>."- この問題を解決するには、サポートされている環境でこの機能を使用していること、およびマシンセットの設定が正しいことを確認してください。
2.3.6.2.3. ディスクを削除できません
データディスクとしてのウルトラディスクの削除が期待どおりに機能しない場合、マシンが削除され、データディスクが孤立します。必要に応じて、孤立したディスクを手動で削除する必要があります。
2.3.7. マシンセットの顧客管理の暗号鍵の有効化
Azure に暗号化キーを指定して、停止中に管理ディスクのデータを暗号化できます。マシン API を使用して、顧客管理の鍵でサーバー側の暗号化を有効にすることができます。
お客様が管理する鍵を使用するために、Azure Key Vault、ディスク暗号化セット、および暗号化キーが必要です。ディスク暗号化セットは、Cloud Credential Operator (CCO) にパーミッションが付与されたリソースグループに事前に存在する必要があります。これがない場合は、ディスク暗号化セットで追加のリーダーロールを指定する必要があります。
前提条件
手順
マシンセット YAML ファイルの
providerSpecフィールドでディスクの暗号化キーを設定します。以下に例を示します。... providerSpec: value: ... osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS ...
2.3.8. Microsoft Azure 仮想マシンのネットワークアクセラレート
アクセラレートネットワークは、Single Root I/O Virtualization (SR-IOV) を使用して、スイッチへのより直接的なパスを持つ Microsoft Azure 仮想マシンを提供します。これにより、ネットワークパフォーマンスが向上します。この機能は、インストール時またはインストール後に有効にできます。
2.3.8.1. 制限事項
Accelerated Networking を使用するかどうかを決定する際には、以下の制限を考慮してください。
- ネットワークのアクセラレートは、マシン API が機能しているクラスターでのみサポートされます。
-
Azure ワーカーノードの最小要件は 2 つの vCPU ですが、Accelerated Networking には 4 つ以上の vCPU を含む Azure 仮想マシンのサイズが必要です。この要件を満たすには、マシンセットの
vmSizeの値を変更します。Azure VM サイズの詳細は、Microsoft Azure のドキュメント を参照してください。 - この機能が既存の Azure クラスターで有効にされている場合、新たにプロビジョニングされたノードのみが影響を受けます。現在実行中のノードは調整されていません。全ノードで機能を有効にするには、それぞれの既存マシンを置き換える必要があります。これは、各マシンに対して個別に行うか、レプリカをゼロにスケールダウンしてから、必要なレプリカ数にスケールアップして実行できます。
2.3.8.2. 既存の Microsoft Azure クラスターでの Accelerated Networking の有効化
Azure で Accelerated Networking を有効にするには、Networking を マシンセットの YAML ファイルに追加します。
前提条件
- マシン API が機能している既存の Microsoft Azure クラスターがあること。
手順
以下のコマンドを実行して、クラスター内のマシンセットをリスト表示します。
$ oc get machinesets -n openshift-machine-apiマシンセットは
<cluster-id>-worker-<region>の形式で一覧表示されます。出力例
NAME DESIRED CURRENT READY AVAILABLE AGE jmywbfb-8zqpx-worker-centralus1 1 1 1 1 15m jmywbfb-8zqpx-worker-centralus2 1 1 1 1 15m jmywbfb-8zqpx-worker-centralus3 1 1 1 1 15mそれぞれのマシンセットについて以下を実行します。
以下のコマンドを実行してカスタムリソース (CR) を編集します。
$ oc edit machineset <machine-set-name>以下を
providerSpecフィールドに追加します。providerSpec: value: ... acceleratedNetworking: true1 ... vmSize: <azure-vm-size>2 ...- 1
- この行は Accelerated Networking を有効にします。
- 2
- 4 つ以上の vCPU を含む Azure 仮想マシンのサイズを指定します。仮想マシンのサイズに関する情報は、Microsoft Azure のドキュメント を参照してください。
- 現在実行中のノードで機能を有効にするには、それぞれの既存マシンを置き換える必要があります。これは、各マシンに対して個別に行うか、レプリカをゼロにスケールダウンしてから、必要なレプリカ数にスケールアップして実行できます。
検証
-
Microsoft Azure ポータルで、マシンセットによってプロビジョニングされるマシンの Networking 設定ページを確認し、
Accelerated networkingフィールドがEnabledに設定されていることを確認します。
2.4. Azure Stack Hub でのマシンセットの作成
Microsoft Azure Stack Hub の OpenShift Container Platform クラスターで特定の目的を果たすように異なるマシンセットを作成することができます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.4.1. Azure Stack Hub 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、リージョンの 1 Microsoft Azure ゾーンで実行され、node-role.kubernetes.io/<role>: "" というラベルの付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
availabilitySet: <availability_set>
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_DS4_v2
vnet: <infrastructure_id>-vnet
zone: "1" - 1 5 7 13 15 16 17 20
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster以下のコマンドを実行してサブネットを取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1以下のコマンドを実行して vnet を取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 18 19
- 追加するノードラベルを指定します。
- 4 6 10
- インフラストラクチャー ID、ノードラベル、およびリージョンを指定します。
- 14
- マシンを配置するリージョンを指定します。
- 21
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
- 12
- クラスターの可用性セットを指定します。
2.4.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。 - Azure Stack Hub マシンをデプロイする可用性セットを作成します。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<availability Set>、<cluster ID>、および<role>パラメーター値を必ず設定してください。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.4.3. マシンセットの顧客管理の暗号鍵の有効化
Azure に暗号化キーを指定して、停止中に管理ディスクのデータを暗号化できます。マシン API を使用して、顧客管理の鍵でサーバー側の暗号化を有効にすることができます。
お客様が管理する鍵を使用するために、Azure Key Vault、ディスク暗号化セット、および暗号化キーが必要です。ディスク暗号化セットは、Cloud Credential Operator (CCO) にパーミッションが付与されたリソースグループに事前に存在する必要があります。これがない場合は、ディスク暗号化セットで追加のリーダーロールを指定する必要があります。
前提条件
手順
マシンセット YAML ファイルの
providerSpecフィールドでディスクの暗号化キーを設定します。以下に例を示します。... providerSpec: value: ... osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS ...
2.5. GCP でのマシンセットの作成
異なるマシンセットを作成して、Google Cloud Platform (GCP) 上の OpenShift Container Platform クラスターで特定の目的で使用できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.5.1. GCP 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、Google Cloud Platform (GCP) で実行され、node-role.kubernetes.io/<role>: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-w-a
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: gcpprovider.openshift.io/v1beta1
canIPForward: false
credentialsSecret:
name: gcp-cloud-credentials
deletionProtection: false
disks:
- autoDelete: true
boot: true
image: <path_to_image>
labels: null
sizeGb: 128
type: pd-ssd
gcpMetadata:
- key: <custom_metadata_key>
value: <custom_metadata_value>
kind: GCPMachineProviderSpec
machineType: n1-standard-4
metadata:
creationTimestamp: null
networkInterfaces:
- network: <infrastructure_id>-network
subnetwork: <infrastructure_id>-worker-subnet
projectID: <project_name>
region: us-central1
serviceAccounts:
- email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
tags:
- <infrastructure_id>-worker
userDataSecret:
name: worker-user-data
zone: us-central1-a- 1
<infrastructure_id>は、クラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster- 2
<node>には、追加するノードラベルを指定します。- 3
- 現在のマシンセットで使用されるイメージへのパスを指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してイメージへのパスを取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.disks[0].image}{"\n"}' \ get machineset/<infrastructure_id>-worker-aGCP Marketplace イメージを使用するには、使用するオファーを指定します。
-
OpenShift Container Platform:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-ocp-48-x86-64-202210040145 -
OpenShift Platform Plus:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-opp-48-x86-64-202206140145 -
OpenShift Kubernetes Engine:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-oke-48-x86-64-202206140145
-
OpenShift Container Platform:
- 4
- オプション:
key:valueのペアの形式でカスタムメタデータを指定します。ユースケースの例については、カスタムメタデータの設定 について GCP のドキュメントを参照してください。 - 5
<project_name>には、クラスターに使用する GCP プロジェクトの名前を指定します。
2.5.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.5.3. マシンセットを使用した永続ディスクタイプの設定
マシンセットの YAML ファイルを編集することで、マシンセットがマシンをデプロイする永続ディスクのタイプを設定できます。
永続ディスクの種類、互換性、地域の可用性、制限の詳細については、永続ディスク に関する GCPComputeEngine のドキュメントを参照してください。
手順
- テキストエディターで、既存のマシンセットの YAML ファイルを開くか、新しいマシンセットを作成します。
providerSpecフィールドの下で以下の行を編集します。providerSpec: value: disks: type: <pd-disk-type>1 - 1
- ディスク永続タイプを指定します。有効な値は、
pd-ssd、pd-standard、およびpd-balancedです。デフォルト値はpd-standardです。
検証
-
Google Cloud コンソールで、マシンセットによってデプロイされたマシンの詳細を確認し、
Typeフィールドが設定済みのディスクタイプと一致することを確認します。
2.5.4. マシンをプリエンプション可能な仮想マシンインスタンスとしてデプロイするマシンセット
マシンを保証されていないプリエンプション可能な仮想マシン インスタンスとしてデプロイする GCP で実行されるマシンセットを作成して、コストを節約できます。プリエンプション可能な仮想マシンインスタンスは、追加の Compute Engine 容量を使用し、通常のインスタンスよりもコストが低くなります。プリエンプション可能な仮想マシンインスタンスは、バッチやステートレス、水平的に拡張可能なワークロードなどの割り込みを許容できるワークロードに使用することができます。
GCP Compute Engine は、プリエンプション可能な仮想マシンインスタンスをいつでも終了することができます。Compute Engine は、中断が 30 秒後に発生することを示すプリエンプションの通知をユーザーに送信します。OpenShift Container Platform は、Compute Engine がプリエンプションについての通知を発行する際に影響を受けるインスタンスからワークロードを削除し始めます。インスタンスが停止していない場合は、ACPI G3 Mechanical Off シグナルが 30 秒後にオペレーティングシステムに送信されます。プリエンプション可能な仮想マシンインスタンスは、Compute Engine によって TERMINATED 状態に移行されます。
以下の理由により、プリエンプション可能な仮想マシンインスタンスを使用すると中断が生じる可能性があります。
- システムまたはメンテナンスイベントがある
- プリエンプション可能な仮想マシンインスタンスの供給が減少する
- インスタンスは、プリエンプション可能な仮想マシンインスタンスについて割り当てられている 24 時間後に終了します。
GCP がインスタンスを終了すると、プリエンプション可能な仮想マシンインスタンスで実行される終了ハンドラーによりマシンリソースが削除されます。マシンセットの replicas の量を満たすために、マシンセットはプリエンプション可能な仮想マシンインスタンスを要求するマシンを作成します。
2.5.4.1. マシンセットの使用によるプリエンプション可能な仮想マシンインスタンスの作成
preemptible をマシンセットの YAML ファイルに追加し、GCP でプリエンプション可能な仮想マシンインスタンスを起動できます。
手順
providerSpecフィールドの下に以下の行を追加します。providerSpec: value: preemptible: truepreemptibleがtrueに設定される場合、インスタンスの起動後に、マシンにinterruptable-instanceというラベルが付けられます。
2.5.5. マシンセットの顧客管理の暗号鍵の有効化
Google Cloud Platform (GCP) Compute Engine を使用すると、ユーザーは暗号鍵を指定してディスク上の停止状態のデータを暗号化することができます。この鍵は、顧客のデータの暗号化に使用されず、データ暗号化キーの暗号化に使用されます。デフォルトでは、Compute Engine は Compute Engine キーを使用してこのデータを暗号化します。
マシン API を使用して、顧客管理の鍵で暗号化を有効にすることができます。まず KMS キーを作成 し、適切なパーミッションをサービスアカウントに割り当てる必要があります。サービスアカウントが鍵を使用できるようにするには、KMS キー名、キーリング名、および場所が必要です。
KMS の暗号化に専用のサービスアカウントを使用しない場合は、代わりに Compute Engine のデフォルトのサービスアカウントが使用されます。専用のサービスアカウントを使用しない場合、デフォルトのサービスアカウントに、キーにアクセスするためのパーミッションを付与する必要があります。Compute Engine のデフォルトのサービスアカウント名は、service-<project_number>@compute-system.iam.gserviceaccount.com パターンをベースにしています。
手順
KMS キー名、キーリング名、および場所を指定して以下のコマンドを実行し、特定のサービスアカウントが KMS キーを使用し、サービスアカウントに正しい IAM ロールを付与できるようにします。
gcloud kms keys add-iam-policy-binding <key_name> \ --keyring <key_ring_name> \ --location <key_ring_location> \ --member "serviceAccount:service-<project_number>@compute-system.iam.gserviceaccount.com” \ --role roles/cloudkms.cryptoKeyEncrypterDecrypterマシンセット YAML ファイルの
providerSpecフィールドで暗号化キーを設定します。以下に例を示します。providerSpec: value: # ... disks: - type: # ... encryptionKey: kmsKey: name: machine-encryption-key1 keyRing: openshift-encrpytion-ring2 location: global3 projectID: openshift-gcp-project4 kmsKeyServiceAccount: openshift-service-account@openshift-gcp-project.iam.gserviceaccount.com5 更新された
providerSpecオブジェクト設定を使用して新規マシンが作成された後に、ディスクの暗号化キーは KMS キーを使用して暗号化されます。
2.5.6. マシンセットの GPU サポートを有効にする
Google Cloud Platform (GCP) Compute Engine を使用すると、ユーザーは仮想マシンインスタンスに GPU を追加できます。GPU リソースにアクセスできるワークロードは、この機能を有効にしてコンピュートマシンでより優れたパフォーマンスが得られます。GCP 上の Open Shift Container Platform は、A2 および N1 マシンシリーズの NVIDIAGPU モデルをサポートします。
| モデル名 | GPU タイプ | マシンタイプ [1] |
|---|---|---|
| NVIDIA A100 |
|
|
| NVIDIA K80 |
|
|
| NVIDIA P100 |
| |
| NVIDIA P4 |
| |
| NVIDIA T4 |
| |
| NVIDIA V100 |
|
- 仕様、互換性、地域の可用性、制限など、マシンタイプの詳細については、 N1 マシンシリーズ、A2 マシンシリーズ、GPU リージョンとゾーンの可用性 に関する GCP Compute Engine のドキュメントをご覧ください。
Machine API を使用して、インスタンスに使用するサポートされている GPU を定義できます。
N1 マシンシリーズのマシンを、サポートされている GPU タイプの 1 つでデプロイするように設定できます。A2 マシンシリーズのマシンには GPU が関連付けられており、ゲストアクセラレータを使用することはできません。
グラフィックワークロード用の GPU はサポートされていません。
手順
- テキストエディターで、既存のマシンセットの YAML ファイルを開くか、新しいマシンセットを作成します。
マシンセットの YAML ファイルの
provider Specフィールドで GPU 設定を指定します。有効な設定の次の例を参照してください。A2 マシンシリーズの設定例:
providerSpec: value: machineType: a2-highgpu-1g1 onHostMaintenance: Terminate2 restartPolicy: Always3 N1 マシンシリーズの設定例:
providerSpec: value: gpus: - count: 11 type: nvidia-tesla-p1002 machineType: n1-standard-13 onHostMaintenance: Terminate4 restartPolicy: Always5
2.6. IBMCloud でのマシンセットの作成
IBMCloud 上の Open Shift Container Platform クラスターで特定の目的を果たすために別のマシンセットを作成できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.6.1. IBMCloud 上のマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は、リージョン内の指定された IBM Cloud ゾーンで実行され、node-role.kubernetes.io/<role>: "" というラベルの付いたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ibmcloudproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: ibmcloud-credentials
image: <infrastructure_id>-rhcos
kind: IBMCloudMachineProviderSpec
primaryNetworkInterface:
securityGroups:
- <infrastructure_id>-sg-cluster-wide
- <infrastructure_id>-sg-openshift-net
subnet: <infrastructure_id>-subnet-compute-<zone>
profile: <instance_profile>
region: <region>
resourceGroup: <resource_group>
userDataSecret:
name: <role>-user-data
vpc: <vpc_name>
zone: <zone> - 1 5 7
- クラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 16
- 追加するノードラベル。
- 4 6 10
- インフラストラクチャー ID、ノードラベル、およびリージョン。
- 11
- クラスターのインストールに使用されたカスタム Red Hat Enterprise Linux CoreOS (RHCOS) イメージ。
- 12
- マシンを配置するためのリージョン内のインフラストラクチャー ID とゾーン。リージョンがゾーンをサポートすることを確認してください。
- 13
- IBM Cloud インスタンスプロファイルを指定します。
- 14
- マシンを配置するリージョンを指定します。
- 15
- マシンリソースが配置されるリソースグループ。これは、インストール時に指定された既存のリソースグループ、またはインフラストラクチャー ID に基づいて名前が付けられたインストーラーによって作成されたリソースグループのいずれかです。
- 17
- VPC 名。
- 18
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
2.6.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.7. Nutanix でマシンセットを作成する
Nutanix 上の Open Shift Container Platform クラスターで特定の目的を果たすために別のマシンセットを作成できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.7.1. Nutanix 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、node-role.kubernetes.io/<role>: "" でラベル付けされたノードを作成する Nutanix マシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>-<zone>
namespace: openshift-machine-api
annotations:
machine.openshift.io/memoryMb: "16384"
machine.openshift.io/vCPU: "4"
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
cluster:
type: uuid
uuid: <cluster_uuid>
credentialsSecret:
name: nutanix-credentials
image:
name: <infrastructure_id>-rhcos
type: name
kind: NutanixMachineProviderConfig
memorySize: 16Gi
subnets:
- type: uuid
uuid: <subnet_uuid>
systemDiskSize: 120Gi
userDataSecret:
name: <user_data_secret>
vcpuSockets: 4
vcpusPerSocket: 1 - 1 6 8
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 9 10
- 追加するノードラベルを指定します。
- 4 7 11
- インフラストラクチャー ID、ノードラベル、およびゾーンを指定します。
- 5
- クラスターオートスケーラーのアノテーション。
- 12
- 使用するイメージを指定します。クラスターに設定されている既存のデフォルトマシンのイメージを使用します。
- 13
- クラスターのメモリー量を Gi で指定します。
- 14
- システムディスクのサイズを Gi で指定します。
- 15
openshift-machine-api名前空間にあるユーザーデータ YAML ファイルでシークレットの名前を指定します。インストーラーがデフォルトのマシンセットに入力する値を使用します。- 16
- vCPU ソケットの数を指定します。
- 17
- ソケットあたりの vCPU の数を指定します。
2.7.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.8. OpenStack でのマシンセットの作成
異なるマシンセットを作成して、Red Hat OpenStack Platform (RHOSP) 上の OpenShift Container Platform クラスターで特定の目的で使用できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.8.1. RHOSP 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、Red Hat OpenStack Platform (RHOSP) で実行され、node-role.kubernetes.io/<role>: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- filter: {}
subnets:
- filter:
name: <subnet_name>
tags: openshiftClusterID=<infrastructure_id>
primarySubnet: <rhosp_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-worker
serverMetadata:
Name: <infrastructure_id>-worker
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: worker-user-data
availabilityZone: <optional_openstack_availability_zone>- 1 5 7 13 15 16 17 18
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 19
- 追加するノードラベルを指定します。
- 4 6 10
- インフラストラクチャー ID およびノードラベルを指定します。
- 11
- MachineSet のサーバーグループポリシーを設定するには、サーバーグループの作成 から返された値を入力します。ほとんどのデプロイメントでは、
anti-affinityまたはsoft-anti-affinityが推奨されます。 - 12
- 複数ネットワークへのデプロイメントに必要です。複数のネットワークを指定するには、ネットワークアレイに別のエントリーを追加します。また、
primarySubnetの値として使用されるネットワークが含まれる必要があります。 - 14
- ノードのエンドポイントを公開する RHOSP サブネットを指定します。通常、これは
install-config.yamlファイルのmachinesSubnetの値として使用される同じサブネットです。
2.8.2. RHOSP 上の SR-IOV を使用するマシンセットのカスタムリソースのサンプル YAML
クラスターを SR-IOV (Single-root I/O Virtualization) 用に設定している場合に、その技術を使用するマシンセットを作成できます。
このサンプル YAML は SR-IOV ネットワークを使用するマシンセットを定義します。作成するノードには node-role.openshift.io/<node_role>: "" というラベルが付けられます。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID ラベルであり、node_role は追加するノードラベルです。
この例では、radio と uplink という名前の 2 つの SR-IOV ネットワークを想定しています。これらのネットワークは、spec.template.spec.providerSpec.value.ports リストのポート定義で使用されます。
この例では、SR-IOV デプロイメント固有のパラメーターのみを説明します。より一般的なサンプルを確認するには、RHOSP 上のマシンセットのカスタムリソースのサンプル YAML を参照してください。
SR-IOV ネットワークを使用するマシンセットの例
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
name: <infrastructure_id>-<node_role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
spec:
metadata:
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- subnets:
- UUID: <machines_subnet_UUID>
ports:
- networkID: <radio_network_UUID>
nameSuffix: radio
fixedIPs:
- subnetID: <radio_subnet_UUID>
tags:
- sriov
- radio
vnicType: direct
portSecurity: false
- networkID: <uplink_network_UUID>
nameSuffix: uplink
fixedIPs:
- subnetID: <uplink_subnet_UUID>
tags:
- sriov
- uplink
vnicType: direct
portSecurity: false
primarySubnet: <machines_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-<node_role>
serverMetadata:
Name: <infrastructure_id>-<node_role>
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: <node_role>-user-data
availabilityZone: <optional_openstack_availability_zone>SR-IOV 対応のコンピュートマシンをデプロイしたら、そのようにラベルを付ける必要があります。たとえば、コマンドラインから次のように入力します。
$ oc label node <NODE_NAME> feature.node.kubernetes.io/network-sriov.capable="true"
トランクは、ネットワークおよびサブネットの一覧のエントリーで作成されるポート向けに有効にされます。これらのリストから作成されたポートの名前は、<machine_name>-<nameSuffix> パターンを使用します。nameSuffix フィールドは、ポート定義に必要です。
それぞれのポートにトランキングを有効にすることができます。
オプションで、タグを タグ 一覧の一部としてポートに追加できます。
2.8.3. ポートセキュリティーが無効にされている SR-IOV デプロイメントのサンプル YAML
ポートセキュリティーが無効にされたネットワークに single-root I/O Virtualization (SR-IOV) ポートを作成するには、spec.template.spec.providerSpec.value.ports リストの項目としてポートを含めてマシンセットを定義します。標準の SR-IOV マシンセットとのこの相違点は、ネットワークとサブネットインターフェイスを使用して作成されたポートに対して発生する自動セキュリティーグループと使用可能なアドレスペア設定によるものです。
マシンのサブネット用に定義するポートには、以下が必要です。
- API および Ingress 仮想 IP ポート用に許可されるアドレスペア
- コンピュートセキュリティーグループ
- マシンネットワークおよびサブネットへの割り当て
以下の例のように、ポートセキュリティーが無効になっている SR-IOV デプロイメント固有のパラメーターのみを説明します。より一般的なサンプルを確認するには、RHOSP 上の SR-IOV を使用するマシンセットカスタムリソースのサンプル YAML について参照してください。
SR-IOV ネットワークを使用し、ポートセキュリティーが無効にされているマシンセットの例
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
name: <infrastructure_id>-<node_role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
spec:
metadata: {}
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
kind: OpenstackProviderSpec
ports:
- allowedAddressPairs:
- ipAddress: <API_VIP_port_IP>
- ipAddress: <ingress_VIP_port_IP>
fixedIPs:
- subnetID: <machines_subnet_UUID>
nameSuffix: nodes
networkID: <machines_network_UUID>
securityGroups:
- <compute_security_group_UUID>
- networkID: <SRIOV_network_UUID>
nameSuffix: sriov
fixedIPs:
- subnetID: <SRIOV_subnet_UUID>
tags:
- sriov
vnicType: direct
portSecurity: False
primarySubnet: <machines_subnet_UUID>
serverMetadata:
Name: <infrastructure_ID>-<node_role>
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: false
userDataSecret:
name: worker-user-data
トランクは、ネットワークおよびサブネットの一覧のエントリーで作成されるポート向けに有効にされます。これらのリストから作成されたポートの名前は、<machine_name>-<nameSuffix> パターンを使用します。nameSuffix フィールドは、ポート定義に必要です。
それぞれのポートにトランキングを有効にすることができます。
オプションで、タグを タグ 一覧の一部としてポートに追加できます。
クラスターで Kuryr を使用し、RHOSP SR-IOV ネットワークでポートセキュリティーが無効にされている場合に、コンピュートマシンのプライマリーポートには以下が必要になります。
-
spec.template.spec.providerSpec.value.networks.portSecurityEnabledパラメーターの値をfalseに設定します。 -
各サブネットについて、
spec.template.spec.providerSpec.value.networks.subnets.portSecurityEnabledパラメーターの値をfalseに設定します。 -
spec.template.spec.providerSpec.value.securityGroupsの値は、空:[]に指定します。
SR-IOV を使用し、ポートセキュリティーが無効な Kuryr にあるクラスターのマシンセットのセクション例
...
networks:
- subnets:
- uuid: <machines_subnet_UUID>
portSecurityEnabled: false
portSecurityEnabled: false
securityGroups: []
...今回の場合は、仮想マシンの作成後にコンピュートセキュリティーグループをプライマリー仮想マシンインターフェイスに適用できます。たとえば、コマンドラインでは、以下を実行します。
$ openstack port set --enable-port-security --security-group <infrastructure_id>-<node_role> <main_port_ID>SR-IOV 対応のコンピュートマシンをデプロイしたら、そのようにラベルを付ける必要があります。たとえば、コマンドラインから次のように入力します。
$ oc label node <NODE_NAME> feature.node.kubernetes.io/network-sriov.capable="true"2.8.4. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.9. RHV でのマシンセットの作成
異なるマシンセットを作成して、Red Hat Virtualization (RHV) 上の OpenShift Container Platform クラスターで特定の目的で使用できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.9.1. RHV 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、RHV で実行され、node-role.kubernetes.io/<node_role>: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
Selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ovirtproviderconfig.machine.openshift.io/v1beta1
cluster_id: <ovirt_cluster_id>
template_name: <ovirt_template_name>
sparse: <boolean_value>
format: <raw_or_cow>
cpu:
sockets: <number_of_sockets>
cores: <number_of_cores>
threads: <number_of_threads>
memory_mb: <memory_size>
guaranteed_memory_mb: <memory_size>
os_disk:
size_gb: <disk_size>
storage_domain_id: <storage_domain_UUID>
network_interfaces:
vnic_profile_id: <vnic_profile_id>
credentialsSecret:
name: ovirt-credentials
kind: OvirtMachineProviderSpec
type: <workload_type>
auto_pinning_policy: <auto_pinning_policy>
hugepages: <hugepages>
affinityGroupsNames:
- compute
userDataSecret:
name: worker-user-data- 1 7 9
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 10 11 13
- 追加するノードラベルを指定します。
- 4 8 12
- インフラストラクチャー ID およびノードラベルを指定します。これら 2 つの文字列は 35 文字を超えることができません。
- 5
- 作成するマシンの数を指定します。
- 6
- マシンのセレクター。
- 14
- この仮想マシンインスタンスが属する RHV クラスターの UUID を指定します。
- 15
- マシンの作成に使用する RHV 仮想マシンテンプレートを指定します。
- 16
- このオプションを
falseに設定すると、ディスクの事前割り当てが有効になります。デフォルトはtrueです。formatをrawに設定してsparseをtrueに設定することは、ブロックストレージドメインでは使用できません。raw形式は、仮想ディスク全体を基盤となる物理ディスクに書き込みます。 - 17
cowまたはrawに設定できます。デフォルトはcowです。cowのフォーマットは仮想マシン用に最適化されています。注記ファイルストレージドメインにディスクを事前に割り当てると、ファイルにゼロが書き込まれます。基盤となるストレージによっては、実際にはディスクが事前に割り当てられない場合があります。
- 18
- オプション: CPU フィールドには、ソケット、コア、スレッドを含む CPU の設定が含まれます。
- 19
- オプション: 仮想マシンのソケット数を指定します。
- 20
- オプション: ソケットあたりのコア数を指定します。
- 21
- オプション: コアあたりのスレッド数を指定します。
- 22
- オプション: 仮想マシンのメモリーサイズを MiB 単位で指定します。
- 23
- オプション: 仮想マシンの保証されたメモリーのサイズを MiB で指定します。これは、バルーニングメカニズムによって排出されないことが保証されているメモリーの量です。詳細は、Memory Ballooning と Optimization Settings Explained を参照してください。注記
RHV 4.4.8 より前のバージョンを使用している場合は、Red Hat Virtualization クラスターでの OpenShift の保証されたメモリー要件を 参照してください。
- 24
- オプション: ノードのルートディスク。
- 25
- オプション: ブート可能なディスクのサイズを GiB 単位で指定します。
- 26
- オプション: コンピュートノードのディスクのストレージドメインの UUID を指定します。何も指定されていない場合、コンピュートノードはコントロールノードと同じストレージドメインに作成されます。(デフォルト)
- 27
- オプション: 仮想マシンのネットワークインターフェイスの一覧。このパラメーターを含めると、OpenShift Container Platform はテンプレートからすべてのネットワークインターフェイスを破棄し、新規ネットワークインターフェイスを作成します。
- 28
- オプション: vNIC プロファイル ID を指定します。
- 29
- RHV クレデンシャルを保持するシークレットオブジェクトの名前を指定します。
- 30
- オプション: インスタンスが最適化されるワークロードタイプを指定します。この値は
RHV VMパラメーターに影響します。サポートされる値:desktop、server(デフォルト)、high_performanceです。high_performanceは、VM のパフォーマンスを向上させます。制限があります。たとえば、グラフィカルコンソールで VM にアクセスすることはできません。詳細は、Virtual Machine Management Guideの ハイパフォーマンス仮想マシン、テンプレート、およびプールの設定 を参照してください。 - 31
- オプション:AutoPinningPolicy は、このインスタンスのホストへのピニングを含む、CPU と NUMA 設定を自動的に設定するポリシーを定義します。サポートされる値は、
none、resize_and_pinです。詳細は、Virtual Machine Management Guideの Setting NUMA Nodes を参照してください。 - 32
- オプション:hugepages は、仮想マシンで hugepage を定義するためのサイズ (KiB) です。対応している値は
2048および1048576です。詳細は、Virtual Machine Management Guideの Configuring Huge Pages を参照してください。 - 33
- オプション: 仮想マシンに適用されるアフィニティーグループ名のリスト。アフィニティーグループは oVirt に存在している必要があります。
RHV は仮想マシンの作成時にテンプレートを使用するため、任意のパラメーターの値を指定しない場合、RHV はテンプレートに指定されるパラメーターの値を使用します。
2.9.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.10. vSphere でのマシンセットの作成
VMware vSphere 上の OpenShift Container Platform クラスターで特定の目的を果たすように異なるマシンセットを作成することができます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.10.1. vSphere 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、VMware vSphere で実行され、 node-role.kubernetes.io/<role>: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: vsphereprovider.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials
diskGiB: 120
kind: VSphereMachineProviderSpec
memoryMiB: 8192
metadata:
creationTimestamp: null
network:
devices:
- networkName: "<vm_network_name>"
numCPUs: 4
numCoresPerSocket: 1
snapshot: ""
template: <vm_template_name>
userDataSecret:
name: worker-user-data
workspace:
datacenter: <vcenter_datacenter_name>
datastore: <vcenter_datastore_name>
folder: <vcenter_vm_folder_path>
resourcepool: <vsphere_resource_pool>
server: <vcenter_server_ip> - 1 3 5
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- インフラストラクチャー ID およびノードラベルを指定します。
- 6 7 9
- 追加するノードラベルを指定します。
- 10
- コンピュートマシンセットをデプロイする vSphere 仮想マシンネットワークを指定します。この仮想マシンネットワークは、他のコンピューティングマシンがクラスター内に存在する場所である必要があります。
- 11
user-5ddjd-rhcosなどの使用する vSphere 仮想マシンテンプレートを指定します。- 12
- コンピュートマシンセットをデプロイする vCenter Datacenter を指定します。
- 13
- コンピュートマシンセットをデプロイする vCenter Datastore を指定します。
- 14
/dc1/vm/user-inst-5ddjdなどの vCenter の vSphere 仮想マシンフォルダーへのパスを指定します。- 15
- 仮想マシンの vSphere リソースプールを指定します。
- 16
- vCenter サーバーの IP または完全修飾ドメイン名を指定します。
2.10.2. マシンセット管理に最低限必要な vCenter 権限
vCenter 上の OpenShift Container Platform クラスターでマシンセットを管理するには、必要なリソースの読み取り、作成、および削除を行う権限を持つアカウントを使用する必要があります。グローバル管理者権限のあるアカウントを使用すること方法が、必要なすべてのパーミッションにアクセスするための最も簡単な方法です。
グローバル管理者権限を持つアカウントを使用できない場合は、最低限必要な権限を付与するロールを作成する必要があります。次の表に、マシンセットの作成、スケーリング、削除、および OpenShift Container Platform クラスター内のマシンの削除に必要な vCenter の最小のロールと特権を示します。
例2.1 マシンセットの管理に必要な最小限の vCenter のロールと権限
| ロールの vSphere オブジェクト | 必要になる場合 | 必要な特権 |
|---|---|---|
| vSphere vCenter | Always |
|
| vSphere vCenter Cluster | Always |
|
| vSphere Datastore | Always |
|
| vSphere ポートグループ | Always |
|
| 仮想マシンフォルダー | Always |
|
| vSphere vCenter Datacenter | インストールプログラムが仮想マシンフォルダーを作成する場合 |
|
|
1 | ||
次の表に、マシンセットの管理に必要なパーミッションと伝播設定の詳細を示します。
例2.2 必要なパーミッションおよび伝播の設定
| vSphere オブジェクト | フォルダータイプ | 子への伝播 | パーミッションが必要 |
|---|---|---|---|
| vSphere vCenter | Always | 必須ではありません。 | 必要な特権が一覧表示 |
| vSphere vCenter Datacenter | 既存のフォルダー | 必須ではありません。 |
|
| インストールプログラムがフォルダーを作成する | 必須 | 必要な特権が一覧表示 | |
| vSphere vCenter Cluster | Always | 必須 | 必要な特権が一覧表示 |
| vSphere vCenter Datastore | Always | 必須ではありません。 | 必要な特権が一覧表示 |
| vSphere Switch | Always | 必須ではありません。 |
|
| vSphere ポートグループ | Always | 必須ではありません。 | 必要な特権が一覧表示 |
| vSphere vCenter 仮想マシンフォルダー | 既存のフォルダー | 必須 | 必要な特権が一覧表示 |
必要な権限のみを持つアカウントの作成に関する詳細は、vSphere ドキュメントの vSphere Permissions and User Management Tasks を参照してください。
2.10.3. コンピュートマシンセットを使用するための、ユーザーがプロビジョニングしたインフラストラクチャーを持つクラスターの要件
ユーザーがプロビジョニングしたインフラストラクチャーを持つクラスターでコンピュートマシンセットを使用するには、クラスター設定が Machine API の使用をサポートしていることを確認する必要があります。
インフラストラクチャー ID の取得
コンピュートマシンセットを作成するには、クラスターのインフラストラクチャー ID を指定できる必要があります。
手順
クラスターのインフラストラクチャー ID を取得するには、次のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.infrastructureName}'
vSphere 認証情報の要件を満たす
コンピュートマシンセットを使用するには、マシン API が vCenter と対話できる必要があります。マシン API コンポーネントが vCenter と対話することを許可する認証情報は、openshift-machine-api 名前空間のシークレットに存在する必要があります。
手順
必要な認証情報が存在するかどうかを確認するには、次のコマンドを実行します。
$ oc get secret \ -n openshift-machine-api vsphere-cloud-credentials \ -o go-template='{{range $k,$v := .data}}{{printf "%s: " $k}}{{if not $v}}{{$v}}{{else}}{{$v | base64decode}}{{end}}{{"\n"}}{{end}}'出力例
<vcenter-server>.password=<openshift-user-password> <vcenter-server>.username=<openshift-user>ここで、
<vcenter-server>は vCenter サーバーの IP アドレスまたは完全修飾ドメイン名 (FQDN) であり、<openshift-user>および<openshift-user-password>は使用する OpenShift Container Platform 管理者の認証情報です。シークレットが存在しない場合は、次のコマンドを実行して作成します。
$ oc create secret generic vsphere-cloud-credentials \ -n openshift-machine-api \ --from-literal=<vcenter-server>.username=<openshift-user> --from-literal=<vcenter-server>.password=<openshift-user-password>
Ignition 設定要件を満たす
仮想マシン (VM) のプロビジョニングには、有効な Ignition 設定が必要です。Ignition 設定には、machine-config-server アドレスと、Machine Config Operator からさらに Ignition 設定を取得するためのシステム信頼バンドルが含まれています。
デフォルトでは、この設定は machine-api-operator namespace の worker-user-data シークレットに保存されます。コンピュートマシンセットは、マシンの作成プロセス中にシークレットを参照します。
手順
必要なシークレットが存在するかどうかを判断するには、次のコマンドを実行します。
$ oc get secret \ -n openshift-machine-api worker-user-data \ -o go-template='{{range $k,$v := .data}}{{printf "%s: " $k}}{{if not $v}}{{$v}}{{else}}{{$v | base64decode}}{{end}}{{"\n"}}{{end}}'出力例
disableTemplating: false userData:1 { "ignition": { ... }, ... }- 1
- ここでは完全な出力は省略しますが、この形式にする必要があります。
シークレットが存在しない場合は、次のコマンドを実行して作成します。
$ oc create secret generic worker-user-data \ -n openshift-machine-api \ --from-file=<installation_directory>/worker.ignここで
<installation_directory>、クラスターのインストール中にインストール資産を保管するために使用されたディレクトリーです。
2.10.4. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
ユーザーがプロビジョニングしたインフラストラクチャーを使用してインストールされたクラスターには、インストールプログラムによってプロビジョニングされたインフラストラクチャーを使用したクラスターとは異なるネットワークスタックがあります。この違いの結果、自動ロードバランサー管理は、ユーザーがプロビジョニングしたインフラストラクチャーを持つクラスターではサポートされません。これらのクラスターの場合、コンピュートマシンセットは worker および infra タイプのマシンのみを作成できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。 - vCenter インスタンスに仮想マシンをデプロイするのに必要なパーミッションがあり、指定されたデータストアへのアクセス権限が必要です。
- クラスターがユーザーによってプロビジョニングされたインフラストラクチャーを使用している場合、その設定の特定のマシン API 要件を満たしています。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...ユーザーがプロビジョニングしたインフラストラクチャーを持つクラスター用のコンピュートマシンセットを作成する場合は、次の重要な値に注意してください。
例: vSphere
providerSpec値apiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... template: ... spec: providerSpec: value: apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: vsphere-cloud-credentials1 diskGiB: 120 kind: VSphereMachineProviderSpec memoryMiB: 16384 network: devices: - networkName: "<vm_network_name>" numCPUs: 4 numCoresPerSocket: 4 snapshot: "" template: <vm_template_name>2 userDataSecret: name: worker-user-data3 workspace: datacenter: <vcenter_datacenter_name> datastore: <vcenter_datastore_name> folder: <vcenter_vm_folder_path> resourcepool: <vsphere_resource_pool> server: <vcenter_server_address>4
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
2.11. ベアメタル上でのコンピュートマシンセットの作成
ベアメタル上の OpenShift Container Platform クラスターで、特定の目的を果たす別のコンピューティングマシンセットを作成できます。たとえば、インフラストラクチャーマシンセットおよび関連マシンを作成して、サポートするワークロードを新しいマシンに移動できます。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.11.1. ベアメタル上のコンピュートマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は、ベアメタル上で実行され、node-role.kubernetes.io/<role>: "" というラベルが付けられたノードを作成するコンピュートマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: baremetal.cluster.k8s.io/v1alpha1
hostSelector: {}
image:
checksum: http:/172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow2.<md5sum>
url: http://172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow2
kind: BareMetalMachineProviderSpec
metadata:
creationTimestamp: null
userData:
name: worker-user-data- 1 3 5
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- インフラストラクチャー ID およびノードラベルを指定します。
- 6 7 9
- 追加するノードラベルを指定します。
- 10
- API VIP アドレスを使用するように
checksumURL を編集します。 - 11
urlURL を編集して API VIP アドレスを使用します。
2.11.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
第3章 マシンセットの手動によるスケーリング
マシンセットのマシンのインスタンスを追加または削除できます。
スケーリング以外のマシンセットの要素を変更する必要がある場合は、マシンセットの変更 を参照してください。
3.1. 前提条件
-
クラスター全体のプロキシーを有効にし、インストール設定から
networking.machineNetwork[].cidrに含まれていないワーカーをスケールアップする場合、ワーカーをプロキシーオブジェクトのnoProxyフィールドに追加 し、接続の問題を防ぐ必要があります。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'3.2. マシンセットの手動によるスケーリング
マシンセットのマシンのインスタンスを追加したり、削除したりする必要がある場合、マシンセットを手動でスケーリングできます。
本書のガイダンスは、完全に自動化されたインストーラーでプロビジョニングされるインフラストラクチャーのインストールに関連します。ユーザーによってプロビジョニングされるインフラストラクチャーのカスタマイズされたインストールにはマシンセットがありません。
前提条件
-
OpenShift Container Platform クラスターおよび
ocコマンドラインをインストールすること。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
クラスターにあるマシンセットを表示します。
$ oc get machinesets -n openshift-machine-apiマシンセットは
<clusterid>-worker-<aws-region-az>の形式で一覧表示されます。クラスター内にあるマシンを表示します。
$ oc get machine -n openshift-machine-api削除するマシンにアノテーションを設定します。
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/cluster-api-delete-machine="true"次のコマンドのいずれかを実行して、マシンセットをスケールします。
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-apiまたは、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-apiヒントまたは、以下の YAML を適用してマシンセットをスケーリングすることもできます。
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2マシンセットをスケールアップまたはスケールダウンできます。新規マシンが利用可能になるまで数分の時間がかかります。
重要デフォルトでは、マシンコントローラーは、成功するまでマシンによってサポートされるノードをドレイン (解放) しようとします。Pod 中断バジェットの設定が間違っているなど、状況によっては、ドレイン操作が成功しない可能性があります。排水操作が失敗した場合、マシンコントローラーはマシンの取り外しを続行できません。
特定のマシンの
machine.openshift.io/exclude-node-drainingにアノテーションを付けると、ノードのドレイン (解放) を省略できます。
検証
目的のマシンの削除を確認します。
$ oc get machines
3.3. マシンセットの削除ポリシー
Random、Newest、および Oldest は 3 つのサポートされる削除オプションです。デフォルトは Random であり、これはマシンセットのスケールダウン時にランダムマシンが選択され、削除されることを意味します。削除ポリシーは、特定のマシンセットを変更し、ユースケースに基づいて設定できます。
spec:
deletePolicy: <delete_policy>
replicas: <desired_replica_count>
削除についての特定のマシンの優先順位は、削除ポリシーに関係なく、関連するマシンにアノテーション machine.openshift.io/cluster-api-delete-machine=true を追加して設定できます。
デフォルトで、OpenShift Container Platform ルーター Pod はワーカーにデプロイされます。ルーターは Web コンソールなどの一部のクラスターリソースにアクセスすることが必要であるため、 ルーター Pod をまず再配置しない限り、ワーカーのマシンセットを 0 にスケーリングできません。
カスタムのマシンセットは、サービスを特定のノードサービスで実行し、それらのサービスがワーカーのマシンセットのスケールダウン時にコントローラーによって無視されるようにする必要があるユースケースで使用できます。これにより、サービスの中断が回避されます。
第4章 マシンセットの変更
ラベルの追加、インスタンスタイプの変更、ブロックストレージの変更など、マシンセットに変更を加えることができます。
Red Hat Virtualization (RHV) では、マシンセットを変更して新規ノードを別のストレージドメインにプロビジョニングすることもできます。
他の変更なしにマシンセットをスケーリングする必要がある場合は、マシンセットの手動によるスケーリング を参照してください。
4.1. CLI を使用したマシンセットの変更
マシンセットを変更する場合、変更は更新された MachineSet カスタムリソース(CR)を保存した後に作成されるマシンにのみ適用されます。この変更は既存のマシンには影響しません。コンピュートマシンセットをスケーリングすることで、既存のマシンを、更新された設定を反映した新しいマシンに置き換えることができます。
他の変更を加えずに、マシンセットをスケーリングする必要がある場合、マシンを削除する必要はありません。
デフォルトで、OpenShift Container Platform ルーター Pod はワーカーにデプロイされます。ルーターは Web コンソールなどの一部のクラスターリソースにアクセスすることが必要であるため、 ルーター Pod をまず再配置しない限り、ワーカーのマシンセットを 0 にスケーリングできません。
前提条件
- OpenShift Container Platform クラスターは、Machine API を使用する。
-
OpenShift CLI (
oc) を使用して、管理者としてクラスターにログインしている。
手順
マシンセットを編集します。
$ oc edit machineset <machine_set_name> -n openshift-machine-api変更を適用するためにマシンセットをスケーリングする際に必要になるため、
spec.replicasフィールドの値を書き留めます。apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machine_set_name> namespace: openshift-machine-api spec: replicas: 21 # ...- 1
- この手順例では、
replicas値が2のコンピュートマシンセットを示しています。
- 必要な設定オプションを使用してコンピュートマシンセット CR を更新し、変更を保存します。
次のコマンドを実行して、更新されたコンピュートマシンセットによって管理されているマシンをリスト表示します。
$ oc get -n openshift-machine-api machines -l machine.openshift.io/cluster-api-machineset=<machine_set_name>出力例
NAME PHASE TYPE REGION ZONE AGE <machine_name_original_1> Running m6i.xlarge us-west-1 us-west-1a 4h <machine_name_original_2> Running m6i.xlarge us-west-1 us-west-1a 4h次のコマンドを実行して、更新されたコンピュートマシンセットで管理されるマシンごとに
deleteアノテーションを設定します。$ oc annotate machine/<machine_name_original_1> \ -n openshift-machine-api \ machine.openshift.io/delete-machine="true"次のコマンドを実行して、コンピュートマシンセットをレプリカ数の 2 倍にスケーリングします。
$ oc scale --replicas=4 \1 machineset <machine_set_name> \ -n openshift-machine-api- 1
- 元の例の値
2は 2 倍の4になります。
次のコマンドを実行して、更新されたコンピュートマシンセットによって管理されているマシンをリスト表示します。
$ oc get -n openshift-machine-api machines -l machine.openshift.io/cluster-api-machineset=<machine_set_name>出力例
NAME PHASE TYPE REGION ZONE AGE <machine_name_original_1> Running m6i.xlarge us-west-1 us-west-1a 4h <machine_name_original_2> Running m6i.xlarge us-west-1 us-west-1a 4h <machine_name_updated_1> Provisioned m6i.xlarge us-west-1 us-west-1a 55s <machine_name_updated_2> Provisioning m6i.xlarge us-west-1 us-west-1a 55s新しいマシンが
Runningフェーズにある場合、コンピュートマシンセットを元のレプリカ数にスケーリングできます。次のコマンドを実行して、コンピュートマシンセットのレプリカ数を元の数にスケーリングします。
$ oc scale --replicas=2 \1 machineset <machine_set_name> \ -n openshift-machine-api- 1
- 元の例の値は
2です。
検証
設定が更新されていないコンピュートマシンが削除されたことを確認するには、次のコマンドを実行して、更新されたコンピュートマシンセットによって管理されているマシンをリスト表示します。
$ oc get -n openshift-machine-api machines -l machine.openshift.io/cluster-api-machineset=<machine_set_name>削除中の出力例
NAME PHASE TYPE REGION ZONE AGE <machine_name_original_1> Deleting m6i.xlarge us-west-1 us-west-1a 4h <machine_name_original_2> Deleting m6i.xlarge us-west-1 us-west-1a 4h <machine_name_updated_1> Running m6i.xlarge us-west-1 us-west-1a 5m41s <machine_name_updated_2> Running m6i.xlarge us-west-1 us-west-1a 5m41s削除完了時の出力例
NAME PHASE TYPE REGION ZONE AGE <machine_name_updated_1> Running m6i.xlarge us-west-1 us-west-1a 6m30s <machine_name_updated_2> Running m6i.xlarge us-west-1 us-west-1a 6m30s更新されたマシンセットによって作成されたマシンの設定が正しいことを確認するには、次のコマンドを実行して、新しいマシンの 1 つで CR の関連フィールドを調べます。
$ oc describe machine <machine_name_updated_1> -n openshift-machine-api
4.2. RHV 上の別のストレージドメインへのノードの移行
OpenShift Container Platform コントロールプレーンおよびコンピュートノードを Red Hat Virtualization (RHV) クラスターの別のストレージドメインに移行できます。
4.2.1. RHV 上の別のストレージドメインへのコンピュートノードの移行
前提条件
- Manager にログインしている。
- ターゲットとなるストレージドメインの名前を把握している。
手順
仮想マシンテンプレートを特定します。
$ oc get -o jsonpath='{.items[0].spec.template.spec.providerSpec.value.template_name}{"\n"}' machineset -A指定したテンプレートに基づいて、Manager で新規の仮想マシンを作成します。その他の設定はすべて変更しません。詳細は、Red Hat Virtualization Virtual Machine Management Guideの Creating a Virtual Machine Based on a Template を参照してください。
ヒント新しい仮想マシンを起動する必要はありません。
- 新規仮想マシンから新規テンプレートを作成します。Target にターゲットストレージドメインを指定します。詳細は、Red Hat Virtualization Virtual Machine Management Guideの Creating a Template を参照してください。
新規テンプレートを使用して、新規マシンセットを OpenShift Container Platform クラスターに追加します。
現在のマシンセットの詳細を取得します。
$ oc get machineset -o yamlこれらの詳細を使用してマシンセットを作成します。詳細は、マシンセットの作成を参照してください。
template_name フィールドに新規仮想マシンテンプレート名を入力します。Manager の New template ダイアログで使用したものと同じテンプレート名を使用します。
- 古いマシンセットと新しいマシンセットの名前の両方をメモします。後続の手順でこれらを参照する必要があります。
ワークロードを移行します。
新規のマシンセットをスケールアップします。マシンセットの手動によるスケーリングについての詳細は、マシンセットの手動によるスケーリングを参照してください。
OpenShift Container Platform は、古いマシンが削除されると Pod を利用可能なワーカーに移動します。
- 古いマシンセットをスケールダウンします。
古いマシンセットを削除します。
$ oc delete machineset <machineset-name>
4.2.2. RHV 上の別のストレージドメインへのコントロールプレーンノードの移行
OpenShift Container Platform はコントロールプレーンノードを管理しないため、コンピュートノードよりも移行が容易になります。Red Hat Virtualization (RHV) 上の他の仮想マシンと同様に移行することができます。
ノードごとに個別にこの手順を実行します。
前提条件
- Manager にログインしている。
- コントロールプレーンノードを特定している。Manager で master というラベルが付けられています。
手順
- master というラベルが付けられた仮想マシンを選択します。
- 仮想マシンをシャットダウンします。
- Disks タブをクリックします。
- 仮想マシンのディスクをクリックします。
-
More Actions
 をクリックし、Move を選択します。
をクリックし、Move を選択します。
- ターゲットストレージドメインを選択し、移行プロセスが完了するまで待ちます。
- 仮想マシンを起動します。
OpenShift Container Platform クラスターが安定していることを確認します。
$ oc get nodes出力には、ステータスが
Readyのノードが表示されます。- コントロールプレーンノードごとに、この手順を繰り返します。
第5章 マシンのフェーズとライフサイクル
マシンには ライフサイクル があり、ライフサイクルにはいくつかの定義されたフェーズがあります。マシンのライフサイクルとそのフェーズを理解すると、手順が完了したかどうかを確認したり、望ましくない動作をトラブルシューティングしたりするのに役立ちます。OpenShift Container Platform では、マシンのライフサイクルがサポート対象の全クラウドプロバイダーで一貫しています。
5.1. マシンのフェーズ
マシンのライフサイクルが進むにつれ、フェーズが変化します。各フェーズは、マシンの状態を表すための基本です。
Provisioning- 新しいマシンのプロビジョニング要求があります。マシンはまだ存在せず、インスタンス、プロバイダー ID、アドレスはありません。
Provisioned-
マシンが存在し、プロバイダー ID かアドレスがあります。クラウドプロバイダーがマシンのインスタンスを作成しました。マシンはまだノードになっておらず、マシンオブジェクトの
status.nodeRefセクションにデータはありません。 Running-
マシンが存在し、プロバイダー ID またはアドレスがあります。Ignition が正常に実行され、クラスターマシンの承認者は証明書署名要求 (CSR) を承認しました。マシンはノードになり、マシンオブジェクトの
status.nodeRefセクションにノードの詳細が格納されました。 Deleting-
マシンの削除要求があります。マシンオブジェクトには、削除要求の時刻を示す
DeletionTimestampフィールドがあります。 Failed- マシンに回復不可能な問題があります。これは、クラウドプロバイダーがマシンのインスタンスを削除した場合などに発生する可能性があります。
5.2. マシンのライフサイクル
ライフサイクルは、マシンのプロビジョニング要求から始まり、マシンが存在しなくなるまで継続します。
マシンのライフサイクルは次の順序で進行します。エラーやライフサイクルフックによる中断は、この概要には含まれていません。
次のいずれかの理由で、新しいマシンをプロビジョニング要求が発生します。
- クラスター管理者がマシンセットをスケーリングするため、追加のマシンが必要になる。
- 自動スケーリングポリシーによりマシンセットがスケーリングされるため、追加のマシンが必要になる。
- マシンセットが管理するマシンで障害が発生した、またはマシンセットが管理するマシンが削除され、必要なマシン数を満たすためにマシンセットが代替マシンを作成する。
-
マシンは
Provisioningフェーズに入ります。 - インフラストラクチャープロバイダーは、マシンのインスタンスを作成します。
-
マシンにはプロバイダー ID またはアドレスがあり、
Provisionedフェーズに入ります。 - Ignition 設定ファイルが処理されます。
- kubelet は証明書署名要求 (CSR) を発行します。
- クラスターマシンの承認者が CSR を承認します。
-
マシンはノードになり、
Runningフェーズに入ります。 既存のマシンは、次のいずれかの理由により削除される予定です。
-
cluster-admin権限を持つユーザーは、oc delete machineコマンドを使用します。 -
マシンは
machine.openshift.io/delete-machineアノテーションを取得します。 - マシンを管理するマシンセットは、調整の一環としてレプリカ数を減らすために、そのマシンに削除のマークを付けます。
- クラスターオートスケーラーは、クラスターのデプロイメントニーズを満たすために不必要なノードを特定します。
- マシンの健全性チェックは、異常なマシンを置き換えるように設定されています。
-
-
マシンは
Deletingフェーズに入ります。このフェーズでは、マシンは削除対象としてマークされていますが、API にはまだ存在しています。 - マシンコントローラーは、インフラストラクチャープロバイダーからインスタンスを削除します。
-
マシンコントローラーは
Nodeオブジェクトを削除します。
5.3. マシンのフェーズを確認する
マシンのフェーズは、OpenShift CLI (oc) または Web コンソールを使用して確認できます。この情報を使用して、手順が完了したかどうかを確認したり、望ましくない動作のトラブルシューティングを行うことができます。
5.3.1. CLI を使用してマシンのフェーズを確認する
マシンのフェーズは、OpenShift CLI (oc) を使用して確認できます。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 -
ocCLI がインストールされている。
手順
次のコマンドを実行して、クラスター上のマシンをリスト表示します。
$ oc get machine -n openshift-machine-api出力例
NAME PHASE TYPE REGION ZONE AGE mycluster-5kbsp-master-0 Running m6i.xlarge us-west-1 us-west-1a 4h55m mycluster-5kbsp-master-1 Running m6i.xlarge us-west-1 us-west-1b 4h55m mycluster-5kbsp-master-2 Running m6i.xlarge us-west-1 us-west-1a 4h55m mycluster-5kbsp-worker-us-west-1a-fmx8t Running m6i.xlarge us-west-1 us-west-1a 4h51m mycluster-5kbsp-worker-us-west-1a-m889l Running m6i.xlarge us-west-1 us-west-1a 4h51m mycluster-5kbsp-worker-us-west-1b-c8qzm Running m6i.xlarge us-west-1 us-west-1b 4h51m出力の
PHASE列には、各マシンのフェーズが含まれます。
5.3.2. Web コンソールを使用してマシンのフェーズを確認する
OpenShift Container Platform Web コンソールを使用して、マシンのフェーズを確認できます。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
-
cluster-adminロールを持つユーザーとして、Web コンソールにログインします。 - Compute → Machines に移動します。
- Machine ページで、フェーズを確認するマシンの名前を選択します。
- Machine details ページで YAML タブを選択します。
YAML ブロックで、
status.phaseフィールドの値を確認します。YAML スニペットの例
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: name: mycluster-5kbsp-worker-us-west-1a-fmx8t # ... status: phase: Running1 - 1
- この例のフェーズは
Runningです。
第6章 マシンの削除
特定のマシンを削除できます。
6.1. 特定マシンの削除
特定のマシンを削除できます。
コントロールプレーンマシンは削除できません。
前提条件
- OpenShift Container Platform クラスターをインストールします。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
次のコマンドを実行して、クラスター内のマシンを表示します。
$ oc get machine -n openshift-machine-apiコマンド出力には、
<clusterid>-<role>-<cloud_region>形式のマシンのリストが含まれます。- 削除するマシンを特定します。
次のコマンドを実行してマシンを削除します。
$ oc delete machine <machine> -n openshift-machine-api重要デフォルトでは、マシンコントローラーは、成功するまでマシンによってサポートされるノードをドレイン (解放) しようとします。Pod 中断バジェットの設定が間違っているなど、状況によっては、ドレイン操作が成功しない可能性があります。排水操作が失敗した場合、マシンコントローラーはマシンの取り外しを続行できません。
特定のマシンの
machine.openshift.io/exclude-node-drainingにアノテーションを付けると、ノードのドレイン (解放) を省略できます。削除するマシンがマシンセットに属している場合は、指定された数のレプリカを満たす新しいマシンがすぐに作成されます。
6.2. マシン削除フェーズのライフサイクルフック
マシンのライフサイクルフックは、通常のライフサイクルプロセスが中断できる、マシンの調整ライフサイクル内のポイントです。マシンの Deleting フェーズでは、これらの中断により、コンポーネントがマシンの削除プロセスを変更する機会が提供されます。
6.2.1. 用語と定義
マシンの削除フェーズのライフサイクルフックの動作を理解するには、次の概念を理解する必要があります。
- 調整
- 調整は、コントローラーがクラスターの実際の状態とクラスターを設定するオブジェクトをオブジェクト仕様の要件と一致させようとするプロセスです。
- マシンコントローラー
マシンコントローラーは、マシンの調整ライフサイクルを管理します。クラウドプラットフォーム上のマシンの場合、マシンコントローラーは OpenShift Container Platform コントローラーとクラウドプロバイダーのプラットフォーム固有のアクチュエーターを組み合わせたものです。
マシンの削除のコンテキストでは、マシンコントローラーは次のアクションを実行します。
- マシンによってバックアップされているノードをドレインします。
- クラウドプロバイダーからマシンインスタンスを削除します。
-
Nodeオブジェクトを削除します。
- ライフサイクルフック
ライフサイクルフックは、通常のライフサイクルプロセスを中断できる、オブジェクトの調整ライフサイクル内の定義されたポイントです。コンポーネントはライフサイクルフックを使用してプロセスに変更を注入し、望ましい結果を達成できます。
マシンの
Deletingフェーズには 2 つのライフサイクルフックがあります。
-
preDrainライフサイクルフックは、マシンによってサポートされているノードをドレインする前に解決する必要があります。 -
preTerminateライフサイクルフックは、インスタンスをインフラストラクチャープロバイダーから削除する前に解決する必要があります。
- フック実装コントローラー
フック実装コントローラーは、ライフサイクルフックと対話できる、マシンコントローラー以外のコントローラーです。フック実装コントローラーは、次の 1 つ以上のアクションを実行できます。
- ライフサイクルフックを追加します。
- ライフサイクルフックに応答します。
- ライフサイクルフックを削除します。
各ライフサイクルフックには 1 つのフック実装コントローラーがありますが、フック実装コントローラーは 1 つ以上のフックを管理できます。
6.2.2. マシン削除処理順序
OpenShift Container Platform 4.11 には、マシン削除フェーズ用の 2 つのライフサイクルフック (preDrain と preTerminate) があります。特定のライフサイクルポイントのすべてのフックが削除されると、調整は通常どおり続行されます。
図6.1 マシン削除のフロー
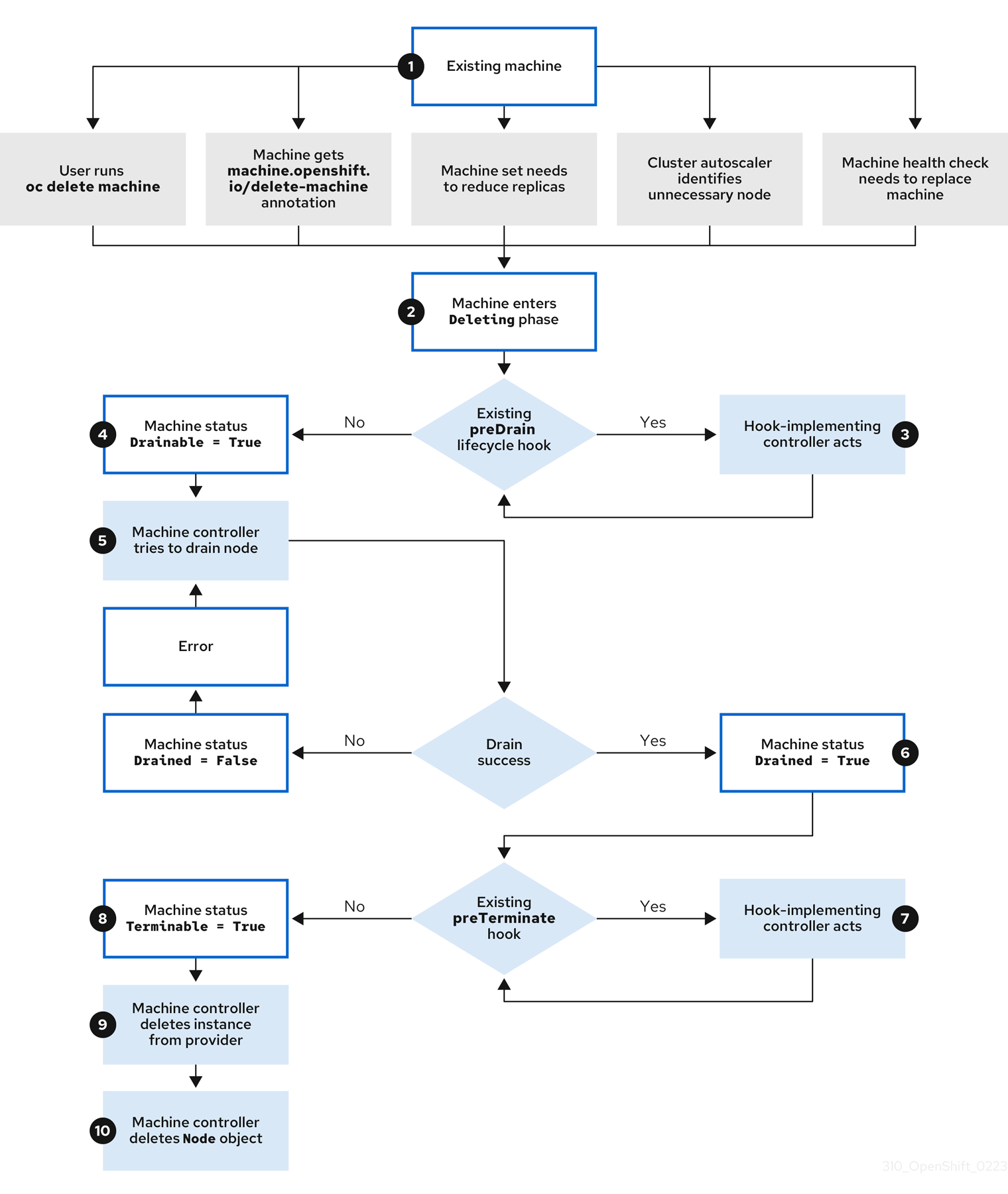
マシンの Deleting フェーズは次の順序で続行されます。
既存のマシンは、次のいずれかの理由により削除される予定です。
-
cluster-admin権限を持つユーザーは、oc delete machineコマンドを使用します。 -
マシンは
machine.openshift.io/delete-machineアノテーションを取得します。 - マシンを管理するマシンセットは、調整の一環としてレプリカ数を減らすために、そのマシンに削除のマークを付けます。
- クラスターオートスケーラーは、クラスターのデプロイメントニーズを満たすために不必要なノードを特定します。
- マシンの健全性チェックは、異常なマシンを置き換えるように設定されています。
-
-
マシンは
Deletingフェーズに入ります。このフェーズでは、マシンは削除対象としてマークされていますが、API にはまだ存在しています。 preDrainライフサイクルフックが存在する場合、それを管理するフック実装コントローラーは指定されたアクションを実行します。すべての
preDrainライフサイクルフックが満たされるまで、マシンのステータス条件DrainableはFalseに設定されます。-
未解決の
preDrainライフサイクルフックはなく、マシンのステータス条件DrainableがTrueに設定されています。 マシンコントローラーは、マシンによってサポートされているノードをドレインしようとします。
-
ドレインが失敗した場合、
Drainedは、Falseに設定され、マシンコントローラーはノードのドレインを再度試行します。 -
ドレインに成功すると、
DrainedはTrueに設定されます。
-
ドレインが失敗した場合、
-
マシンのステータス条件
DrainedはTrueに設定されます。 preTerminateライフサイクルフックが存在する場合、それを管理するフック実装コントローラーは指定されたアクションを実行します。すべての
preTerminateライフサイクルフックが満たされるまで、マシンのステータス条件TerminableはFalseに設定されます。-
未解決の
preTerminateライフサイクルフックはなく、マシンのステータス条件TerminableがTrueに設定されています。 - マシンコントローラーは、インフラストラクチャープロバイダーからインスタンスを削除します。
-
マシンコントローラーは
Nodeオブジェクトを削除します。
6.2.3. 削除ライフサイクルフック設定
次の YAML スニペットは、マシンセット内の削除ライフサイクルフック設定の形式と配置を示しています。
preDrain ライフサイクルフックを示す YAML スニペット
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: <hook_name>
owner: <hook_owner>
...preTerminate ライフサイクルフックを示す YAML スニペット
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preTerminate:
- name: <hook_name>
owner: <hook_owner>
...ライフサイクルフックの設定例
次の例は、マシンの削除プロセスを中断する複数の架空のライフサイクルフックの実装を示しています。
ライフサイクルフックの設定例
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: MigrateImportantApp
owner: my-app-migration-controller
preTerminate:
- name: BackupFileSystem
owner: my-backup-controller
- name: CloudProviderSpecialCase
owner: my-custom-storage-detach-controller
- name: WaitForStorageDetach
owner: my-custom-storage-detach-controller
...6.2.4. Operator 開発者向けのマシン削除ライフサイクルフックの例
Operator は、マシン削除フェーズのライフサイクルフックを使用して、マシン削除プロセスを変更できます。次の例は、Operator がこの機能を使用できる方法を示しています。
preDrain ライフサイクルフックの使用例
- 積極的にマシンを入れ替える
-
Operator は、削除されたマシンのインスタンスを削除する前に、
preDrainライフサイクルフックを使用して、代替マシンが正常に作成され、クラスターに参加していることを確認できます。これにより、マシンの交換中の中断や、すぐに初期化されない交換用インスタンスの影響を軽減できます。 - カスタムドレインロジックの実装
Operator は、
preDrainライフサイクルフックを使用して、マシンコントローラーのドレインロジックを別のドレインコントローラーに置き換えることができます。ドレインロジックを置き換えることにより、Operator は各ノードのワークロードのライフサイクルをより柔軟に制御できるようになります。たとえば、マシンコントローラーのドレインライブラリーは順序付けをサポートしていませんが、カスタムドレインプロバイダーはこの機能を提供できます。カスタムドレインプロバイダーを使用することで、Operator はノードをドレインする前にミッションクリティカルなアプリケーションの移動を優先して、クラスターの容量が制限されている場合にサービスの中断を最小限に抑えることができます。
preTerminate ライフサイクルフックの使用例
- ストレージの切り離しを確認する
-
Operator は、
preTerminateライフサイクルフックを使用して、マシンがインフラストラクチャープロバイダーから削除される前に、マシンに接続されているストレージが確実に切り離されるようにすることができます。 - ログの信頼性の向上
ノードがドレインされた後、ログエクスポータデーモンがログを集中ログシステムに同期するのに時間がかかります。
ロギング Operator は、
preTerminateライフサイクルフックを使用して、ノードがドレインするときと、マシンがインフラストラクチャープロバイダーから削除されるときとの間に遅延を追加できます。この遅延により、Operator は主要なワークロードが削除され、ログバックログに追加されないようにする時間が確保されます。ログバックログに新しいデータが追加されていない場合、ログエクスポータは同期プロセスに追いつくことができるため、すべてのアプリケーションログが確実にキャプチャーされます。
6.2.5. マシンライフサイクルフックによるクォーラム保護
Machine API Operator を使用する OpenShift Container Platform クラスターの場合、etcd Operator はマシン削除フェーズのライフサイクルフックを使用して、クォーラム保護メカニズムを実装します。
preDrain ライフサイクルフックを使用することにより、etcd Operator は、コントロールプレーンマシン上の Pod がいつドレインされ、削除されるかを制御できます。etcd クォーラムを保護するために、etcd Operator は、etcd メンバーをクラスター内の新しいノードに移行するまで、そのメンバーの削除を防ぎます。
このメカニズムにより、etcd Operator は etcd クォーラムのメンバーを正確に制御できるようになり、マシン API Operator は etcd クラスターの特別な操作知識がなくても、コントロールプレーンマシンを安全に作成および削除できるようになります。
6.2.5.1. クォーラム保護処理順序によるコントロールプレーンの削除
OpenShift Container Platform 4.11 以降のクラスター上でコントロールプレーンマシンが置き換えられると、クラスターには一時的に 4 つのコントロールプレーンマシンが存在します。4 番目のコントロールプレーンノードがクラスターに参加すると、etcd Operator は代替ノードで新しい etcd メンバーを開始します。etcd Operator は、古いコントロールプレーンマシンが削除対象としてマークされていることを確認すると、古いノード上の etcd メンバーを停止し、代替の etcd メンバーをクラスターのクォーラムに参加するように昇格させます。
コントロールプレーンマシンの Deleting フェーズは、以下の順序で続行されます。
- コントロールプレーンマシンは削除される予定です。
-
コントロールプレーンマシンは
Deletingフェーズに入ります。 preDrainライフサイクルフックを満たすために、etcd Operator は次のアクションを実行します。-
etcd Operator は、4 番目のコントロールプレーンマシンが etcd メンバーとしてクラスターに追加されるまで待機します。この新しい etcd メンバーの状態は
Runningですが、etcd リーダーから完全なデータベース更新を受信するまではreadyができていません。 - 新しい etcd メンバーが完全なデータベース更新を受け取ると、etcd Operator は新しい etcd メンバーを投票メンバーに昇格させ、古い etcd メンバーをクラスターから削除します。
この移行が完了すると、古い etcd Pod とそのデータは安全に削除されるため、
preDrainライフサイクルフックが削除されます。-
etcd Operator は、4 番目のコントロールプレーンマシンが etcd メンバーとしてクラスターに追加されるまで待機します。この新しい etcd メンバーの状態は
-
コントロールプレーンマシンのステータス条件
DrainableがTrueに設定されます。 マシンコントローラーは、コントロールプレーンマシンによってサポートされているノードをドレインしようとします。
-
ドレインが失敗した場合、
Drainedは、Falseに設定され、マシンコントローラーはノードのドレインを再度試行します。 -
ドレインに成功すると、
DrainedはTrueに設定されます。
-
ドレインが失敗した場合、
-
コントロールプレーンマシンのステータス条件
DrainedがTrueに設定されます。 -
他の Operator が
preTerminateライフサイクルフックを追加していない場合、コントロールプレーンのマシンステータス条件TerminableはTrueに設定されます。 - マシンコントローラーは、インフラストラクチャープロバイダーからインスタンスを削除します。
-
マシンコントローラーは
Nodeオブジェクトを削除します。
etcd クォーラム保護の preDrain ライフサイクルフックを示す YAML スニペット
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: EtcdQuorumOperator
owner: clusteroperator/etcd
...第7章 OpenShift Container Platform クラスターへの自動スケーリングの適用
自動スケーリングの OpenShift Container Platform クラスターへの適用には、クラスターへの Cluster Autoscaler のデプロイと各マシンタイプの Machine Autoscaler のデプロイが必要です。
Cluster Autoscaler は、マシン API Operator が機能しているクラスターでのみ設定できます。
7.1. Cluster Autoscaler について
Cluster Autoscaler は、現行のデプロイメントのニーズに合わせて OpenShift Container Platform クラスターのサイズを調整します。これは、Kubernetes 形式の宣言引数を使用して、特定のクラウドプロバイダーのオブジェクトに依存しないインフラストラクチャー管理を提供します。Cluster Autoscaler には cluster スコープがあり、特定の namespace には関連付けられていません。
Cluster Autoscaler は、リソース不足のために現在のワーカーノードのいずれにもスケジュールできない Pod がある場合や、デプロイメントのニーズを満たすために別のノードが必要な場合に、クラスターのサイズを拡大します。Cluster Autoscaler は、指定される制限を超えてクラスターリソースを拡大することはありません。
Cluster Autoscaler は、コントロールプレーンノードを管理しない場合でも、クラスター内のすべてのノードのメモリー、CPU、および GPU の合計を計算します。これらの値は、単一マシン指向ではありません。これらは、クラスター全体での全リソースの集約です。たとえば、最大メモリーリソースの制限を設定する場合、Cluster Autoscaler は現在のメモリー使用量を計算する際にクラスター内のすべてのノードを含めます。この計算は、Cluster Autoscaler にワーカーリソースを追加する容量があるかどうかを判別するために使用されます。
作成する ClusterAutoscaler リソース定義の maxNodesTotal 値が、クラスター内のマシンの想定される合計数に対応するのに十分な大きさの値であることを確認します。この値は、コントロールプレーンマシンの数とスケーリングする可能性のあるコンピュートマシンの数に対応できる値である必要があります。
Cluster Autoscaler は 10 秒ごとに、クラスターで不要なノードをチェックし、それらを削除します。Cluster Autoscaler は、以下の条件が適用される場合に、ノードを削除すべきと考えます。
-
ノードの使用率はクラスターの ノード使用率レベル のしきい値 よりも低い場合。ノード使用率レベルとは、要求されたリソースの合計をノードに割り当てられたリソースで除算したものです。
ClusterAutoscalerカスタムリソースで値を指定しない場合、Cluster Autoscaler は 50% の使用率に対応するデフォルト値0.5を使用します。 - Cluster Autoscaler がノードで実行されているすべての Pod を他のノードに移動できる。Kubernetes スケジューラーは、ノード上の Pod のスケジュールを担当します。
- Cluster Autoscaler で、スケールダウンが無効にされたアノテーションがない。
以下のタイプの Pod がノードにある場合、Cluster Autoscaler はそのノードを削除しません。
- 制限のある Pod の Disruption Budget (停止状態の予算、PDB) を持つ Pod。
- デフォルトでノードで実行されない Kube システム Pod。
- PDB を持たないか、制限が厳しい PDB を持つ Kuber システム Pod。
- デプロイメント、レプリカセット、またはステートフルセットなどのコントローラーオブジェクトによってサポートされない Pod。
- ローカルストレージを持つ Pod。
- リソース不足、互換性のないノードセレクターまたはアフィニティー、一致する非アフィニティーなどにより他の場所に移動できない Pod。
-
それらに
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"アノテーションがない場合、"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"アノテーションを持つ Pod。
たとえば、CPU の上限を 64 コアに設定し、それぞれ 8 コアを持つマシンのみを作成するように Cluster Autoscaler を設定したとします。クラスターが 30 コアで起動する場合、Cluster Autoscaler は最大で 4 つのノード (合計 32 コア) を追加できます。この場合、総計は 62 コアになります。
Cluster Autoscaler を設定する場合、使用に関する追加の制限が適用されます。
- 自動スケーリングされたノードグループにあるノードを直接変更しないようにしてください。同じノードグループ内のすべてのノードには同じ容量およびラベルがあり、同じシステム Pod を実行します。
- Pod の要求を指定します。
- Pod がすぐに削除されるのを防ぐ必要がある場合、適切な PDB を設定します。
- クラウドプロバイダーのクォータが、設定する最大のノードプールに対応できる十分な大きさであることを確認します。
- クラウドプロバイダーで提供されるものなどの、追加のノードグループの Autoscaler を実行しないようにしてください。
Horizontal Pod Autoscaler (HPA) および Cluster Autoscaler は複数の異なる方法でクラスターリソースを変更します。HPA は、現在の CPU 負荷に基づいてデプロイメント、またはレプリカセットのレプリカ数を変更します。負荷が増大すると、HPA はクラスターで利用できるリソース量に関係なく、新規レプリカを作成します。十分なリソースがない場合、Cluster Autoscaler はリソースを追加し、HPA で作成された Pod が実行できるようにします。負荷が減少する場合、HPA は一部のレプリカを停止します。この動作によって一部のノードの使用率が低くなるか、完全に空になる場合、Cluster Autoscaler は不必要なノードを削除します。
Cluster Autoscaler は Pod の優先順位を考慮に入れます。Pod の優先順位とプリエンプション機能により、クラスターに十分なリソースがない場合に優先順位に基づいて Pod のスケジューリングを有効にできますが、Cluster Autoscaler はクラスターがすべての Pod を実行するのに必要なリソースを確保できます。これら両方の機能の意図を反映するべく、Cluster Autoscaler には優先順位のカットオフ機能が含まれています。このカットオフを使用して Best Effort の Pod をスケジュールできますが、これにより Cluster Autoscaler がリソースを増やすことはなく、余分なリソースがある場合にのみ実行されます。
カットオフ値よりも低い優先順位を持つ Pod は、クラスターをスケールアップせず、クラスターのスケールダウンを防ぐこともありません。これらの Pod を実行するために新規ノードは追加されず、これらの Pod を実行しているノードはリソースを解放するために削除される可能性があります。
クラスターの自動スケーリングは、マシン API が利用可能なプラットフォームでサポートされています。
7.2. Cluster Autoscaler の設定
まず Cluster Autoscaler をデプロイし、リソースの自動スケーリングを OpenShift Container Platform クラスターで管理します。
Cluster Autoscaler のスコープはクラスター全体に設定されるため、クラスター用に 1 つの Cluster Autoscaler のみを作成できます。
7.2.1. Cluster Autoscaler リソース定義
この ClusterAutoscaler リソース定義は、Cluster Autoscaler のパラメーターおよびサンプル値を表示します。
apiVersion: "autoscaling.openshift.io/v1"
kind: "ClusterAutoscaler"
metadata:
name: "default"
spec:
podPriorityThreshold: -10
resourceLimits:
maxNodesTotal: 24
cores:
min: 8
max: 128
memory:
min: 4
max: 256
gpus:
- type: nvidia.com/gpu
min: 0
max: 16
- type: amd.com/gpu
min: 0
max: 4
scaleDown:
enabled: true
delayAfterAdd: 10m
delayAfterDelete: 5m
delayAfterFailure: 30s
unneededTime: 5m
utilizationThreshold: "0.4" - 1
- Cluster Autoscaler に追加のノードをデプロイさせるために Pod が超えている必要のある優先順位を指定します。32 ビットの整数値を入力します。
podPriorityThreshold値は、各 Pod に割り当てるPriorityClassの値と比較されます。 - 2
- デプロイするノードの最大数を指定します。この値は、Autoscaler が制御するマシンだけでなく、クラスターにデプロイされるマシンの合計数です。この値は、すべてのコントロールプレーンおよびコンピュートマシン、および
MachineAutoscalerリソースに指定するレプリカの合計数に対応するのに十分な大きさの値であることを確認します。 - 3
- クラスターにデプロイするコアの最小数を指定します。
- 4
- クラスターにデプロイするコアの最大数を指定します。
- 5
- クラスターのメモリーの最小量 (GiB 単位) を指定します。
- 6
- クラスターのメモリーの最大量 (GiB 単位) を指定します。
- 7
- オプション: デプロイする GPU ノードのタイプを指定します。
nvidia.com/gpuおよびamd.com/gpuのみが有効なタイプです。 - 8
- クラスターにデプロイする GPU の最小数を指定します。
- 9
- クラスターにデプロイする GPU の最大数を指定します。
- 10
- 11
- Cluster Autoscaler が不必要なノードを削除できるかどうかを指定します。
- 12
- オプション: ノードが最後に 追加 されてからノードを削除するまで待機する期間を指定します。値を指定しない場合、デフォルト値の
10mが使用されます。 - 13
- オプション: ノードが最後に 削除 されてからノードを削除するまで待機する期間を指定します。値を指定しない場合、デフォルト値の
0sが使用されます。 - 14
- オプション: スケールダウンが失敗してからノードを削除するまで待機する期間を指定します。値を指定しない場合、デフォルト値の
3mが使用されます。 - 15
- オプション: 不要なノードが削除の対象となるまでの期間を指定します。値を指定しない場合、デフォルト値の
10mが使用されます。 - 16
- オプション: ノード使用率レベルを指定します。ノードの使用率がこの値を下回ると、不要なノードが削除の対象となります。ノード使用率は、要求されたリソースをそのノードに割り当てられたリソースで割ったもので、
"0"より大きく"1"より小さい値でなければなりません。値を指定しない場合、Cluster Autoscaler は 50% の使用率に対応するデフォルト値"0.5"を使用します。この値は文字列として表現する必要があります。
スケーリング操作の実行時に、Cluster Autoscaler は、デプロイするコアの最小および最大数、またはクラスター内のメモリー量などの ClusterAutoscaler リソース定義に設定された範囲内に残ります。ただし、Cluster Autoscaler はそれらの範囲内に留まるようクラスターの現在の値を修正しません。
Cluster Autoscaler がノードを管理しない場合でも、最小および最大の CPU、メモリー、および GPU の値は、クラスター内のすべてのノードのこれらのリソースを計算することによって決定されます。たとえば、Cluster Autoscaler がコントロールプレーンノードを管理しない場合でも、コントロールプレーンノードはクラスターのメモリーの合計に考慮されます。
7.2.2. Cluster Autoscaler のデプロイ
Cluster Autoscaler をデプロイするには、ClusterAutoscaler リソースのインスタンスを作成します。
手順
-
カスタムリソース定義を含む
ClusterAutoscalerリソースの YAML ファイルを作成します。 以下のコマンドを実行して、クラスター内にカスタムリソースを作成します。
$ oc create -f <filename>.yaml1 - 1
<filename>はカスタムリソースファイルの名前です。
次のステップ
- Cluster Autoscaler の設定後に、1 つ以上の Machine Autoscaler を設定する 必要があります。
7.3. Machine Autoscaler について
Machine Autoscaler は、マシンセットで OpenShift Container Platform クラスターにデプロイするマシン数を調整します。デフォルトの worker マシンセットおよび作成する他のマシンセットの両方をスケーリングできます。Machine Autoscaler は、追加のデプロイメントをサポートするのに十分なリソースがクラスターにない場合に追加のマシンを作成します。MachineAutoscaler リソースの値への変更 (例: インスタンスの最小または最大数) は、それらがターゲットとするマシンセットに即時に適用されます。
マシンをスケーリングするには、Cluster Autoscaler の Machine Autoscaler をデプロイする必要があります。Cluster Autoscaler は、スケーリングできるリソースを判別するために、Machine Autoscaler が設定するアノテーションをマシンセットで使用します。Machine Autoscaler を定義せずにクラスター Autoscaler を定義する場合、クラスター Autoscaler はクラスターをスケーリングできません。
7.4. Machine Autoscaler の設定
Cluster Autoscaler の設定後に、クラスターのスケーリングに使用されるマシンセットを参照する MachineAutoscaler リソースをデプロイします。
ClusterAutoscaler リソースのデプロイ後に、1 つ以上の MachineAutoscaler リソースをデプロイする必要があります。
各マシンセットに対して別々のリソースを設定する必要があります。マシンセットはそれぞれのリージョンごとに異なるため、複数のリージョンでマシンのスケーリングを有効にする必要があるかどうかを考慮してください。スケーリングするマシンセットには 1 つ以上のマシンが必要です。
7.4.1. Machine Autoscaler リソース定義
この MachineAutoscaler リソース定義は、Machine Autoscaler のパラメーターおよびサンプル値を表示します。
apiVersion: "autoscaling.openshift.io/v1beta1"
kind: "MachineAutoscaler"
metadata:
name: "worker-us-east-1a"
namespace: "openshift-machine-api"
spec:
minReplicas: 1
maxReplicas: 12
scaleTargetRef:
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
name: worker-us-east-1a - 1
- Machine Autoscaler の名前を指定します。この Machine Autoscaler がスケーリングするマシンセットを簡単に特定できるようにするには、スケーリングするマシンセットの名前を指定するか、これを組み込みます。マシンセットの名前は、
<clusterid>-<machineset>-<region>の形式を使用します。 - 2
- Cluster Autoscaler がクラスターのスケーリングを開始した後に、指定されたゾーンに残っている必要のある指定されたタイプのマシンの最小数を指定します。AWS、GCP、Azure、RHOSP または vSphere で実行している場合は、この値は
0に設定できます。他のプロバイダーの場合は、この値は0に設定しないでください。特殊なワークロードに使用されるコストがかかり、用途が限られたハードウェアを稼働する場合などのユースケースにはこの値を
0に設定するか、若干大きいマシンを使用してマシンセットをスケーリングすることで、コストを節約できます。Cluster Autoscaler は、マシンが使用されていない場合にマシンセットをゼロにスケールダウンします。重要インストーラーでプロビジョニングされるインフラストラクチャーの OpenShift Container Platform インストールプロセス時に作成される 3 つのコンピュートマシンセットについては、
spec.minReplicasの値を0に設定しないでください。 - 3
- Cluster Autoscaler がクラスタースケーリングの開始後に指定されたゾーンにデプロイできる指定されたタイプのマシンの最大数を指定します。
ClusterAutoscalerリソース定義のmaxNodesTotal値が、Machine AutoScaler がこの数のマシンをデプロイするのに十分な大きさの値であることを確認します。 - 4
- このセクションでは、スケーリングする既存のマシンセットを記述する値を指定します。
- 5
kindパラメーターの値は常にMachineSetです。- 6
nameの値は、metadata.nameパラメーター値に示されるように既存のマシンセットの名前に一致する必要があります。
7.4.2. Machine Autoscaler のデプロイ
Machine Autoscaler をデプロイするには、 MachineAutoscaler リソースのインスタンスを作成します。
手順
-
カスタムリソース定義を含む
MachineAutoscalerリソースの YAML ファイルを作成します。 以下のコマンドを実行して、クラスター内にカスタムリソースを作成します。
$ oc create -f <filename>.yaml1 - 1
<filename>はカスタムリソースファイルの名前です。
7.5. 自動スケーリングの無効化
クラスター内の個々の Machine Autoscaler を無効にすることも、クラスター全体で自動スケーリングを無効にすることもできます。
7.5.1. Machine Autoscaler の無効化
Machine Autoscaler を無効にするには、対応する MachineAutoscaler カスタムリソース (CR) を削除します。
Machine Autoscaler を無効にしても、Cluster Autoscaler は無効になりません。Cluster Autoscaler を無効にするには、「Cluster Autoscaler の無効化」に記載されている手順に従ってください。
手順
次のコマンドを実行して、クラスターの
MachineAutoscalerCR をリスト表示します。$ oc get MachineAutoscaler -n openshift-machine-api出力例
NAME REF KIND REF NAME MIN MAX AGE compute-us-east-1a MachineSet compute-us-east-1a 1 12 39m compute-us-west-1a MachineSet compute-us-west-1a 2 4 37mオプション: 次のコマンドを実行して、
MachineAutoscalerCR の YAML ファイルバックアップを作成します。$ oc get MachineAutoscaler/<machine_autoscaler_name> \1 -n openshift-machine-api \ -o yaml> <machine_autoscaler_name_backup>.yaml2 次のコマンドを実行して、
MachineAutoscalerCR を削除します。$ oc delete MachineAutoscaler/<machine_autoscaler_name> -n openshift-machine-api出力例
machineautoscaler.autoscaling.openshift.io "compute-us-east-1a" deleted
検証
Machine Autoscaler が無効になっていることを確認するには、次のコマンドを実行します。
$ oc get MachineAutoscaler -n openshift-machine-api無効化された Machine Autoscaler は、Machine Autoscaler リストに表示されません。
次のステップ
-
Machine Autoscaler を再度有効にする必要がある場合は、
<machine_autoscaler_name_backup>.yamlバックアップファイルを使用し、「Machine Autoscaler のデプロイ」に記載されている手順に従います。
7.5.2. Cluster Autoscaler の無効化
Cluster Autoscaler を無効にするには、対応する ClusterAutoscaler リソースを削除します。
クラスターに既存の Machine Autoscaler がある場合も、Cluster Autoscaler を無効にするとクラスター上の自動スケーリングが無効になります。
手順
次のコマンドを実行して、クラスターの
ClusterAutoscalerリソースを一覧表示します。$ oc get ClusterAutoscaler出力例
NAME AGE default 42mオプション: 次のコマンドを実行して、
ClusterAutoscalerCR の YAML ファイルバックアップを作成します。$ oc get ClusterAutoscaler/default \1 -o yaml> <cluster_autoscaler_backup_name>.yaml2 次のコマンドを実行して、
ClusterAutoscalerCR を削除します。$ oc delete ClusterAutoscaler/default出力例
clusterautoscaler.autoscaling.openshift.io "default" deleted
検証
Cluster Autoscaler が無効になっていることを確認するには、次のコマンドを実行します。
$ oc get ClusterAutoscaler予想される出力
No resources found
次のステップ
-
ClusterAutoscalerCR を削除して Cluster Autoscaler を無効にすると、クラスターは自動スケーリングできなくなりますが、クラスター上の既存の Machine Autoscaler は削除されません。不要な Machine Autoscaler をクリーンアップするには、「Machine Autoscaler の無効化」を参照してください。 -
Cluster Autoscaler を再度有効にする必要がある場合は、
<cluster_autoscaler_name_backup>.yamlバックアップファイルを使用し、「Cluster Autoscaler のデプロイ」に記載された手順に従います。
第8章 インフラストラクチャーマシンセットの作成
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'インフラストラクチャーマシンセットを使用して、デフォルトのルーター、統合コンテナーイメージレジストリー、およびクラスターメトリクスおよびモニタリングのコンポーネントなどのインフラストラクチャーコンポーネントのみをホストするマシンを作成できます。これらのインフラストラクチャーマシンは、環境の実行に必要なサブスクリプションの合計数にカウントされません。
実稼働デプロイメントでは、インフラストラクチャーコンポーネントを保持するために 3 つ以上のマシンセットをデプロイすることが推奨されます。OpenShift Logging と Red Hat OpenShift Service Mesh の両方が Elasticsearch をデプロイします。これには、3 つのインスタンスを異なるノードにインストールする必要があります。これらの各ノードは、高可用性のために異なるアベイラビリティーゾーンにデプロイできます。この設定には、可用性ゾーンごとに 1 つずつ、合計 3 つの異なるマシンセットが必要です。複数のアベイラビリティーゾーンを持たないグローバル Azure リージョンでは、アベイラビリティーセットを使用して高可用性を確保できます。
8.1. OpenShift Container Platform インフラストラクチャーコンポーネント
以下のインフラストラクチャーワークロードでは、OpenShift Container Platform ワーカーのサブスクリプションは不要です。
- マスターで実行される Kubernetes および OpenShift Container Platform コントロールプレーンサービス
- デフォルトルーター
- 統合コンテナーイメージレジストリー
- HAProxy ベースの Ingress Controller
- ユーザー定義プロジェクトのモニタリング用のコンポーネントを含む、クラスターメトリクスの収集またはモニタリングサービス
- クラスター集計ロギング
- サービスブローカー
- Red Hat Quay
- Red Hat OpenShift Data Foundation
- Red Hat Advanced Cluster Manager
- Kubernetes 用 Red Hat Advanced Cluster Security
- Red Hat OpenShift GitOps
- Red Hat OpenShift Pipelines
他のコンテナー、Pod またはコンポーネントを実行するノードは、サブスクリプションが適用される必要のあるワーカーノードです。
インフラストラクチャーノードおよびインフラストラクチャーノードで実行できるコンポーネントの詳細は、OpenShift sizing and subscription guide for enterprise Kubernetesの"Red Hat OpenShift control plane and infrastructure nodes"セクションを参照してください。
インフラストラクチャーノードを作成するには、マシンセットを使用する か 、ノードにラベルを付ける か、マシン設定プールを使用します。
8.2. 実稼働環境用のインフラストラクチャーマシンセットの作成
実稼働デプロイメントでは、インフラストラクチャーコンポーネントを保持するために 3 つ以上のマシンセットをデプロイすることが推奨されます。OpenShift Logging と Red Hat OpenShift Service Mesh の両方が Elasticsearch をデプロイします。これには、3 つのインスタンスを異なるノードにインストールする必要があります。これらの各ノードは、高可用性のために異なるアベイラビリティーゾーンにデプロイできます。このような設定では、各アベイラビリティーゾーンに 1 つずつ、3 つの異なるマシンセットが必要です。複数のアベイラビリティーゾーンを持たないグローバル Azure リージョンでは、アベイラビリティーセットを使用して高可用性を確保できます。
8.2.1. 異なるクラウドのマシンセットの作成
クラウドのサンプルマシンセットを使用します。
8.2.1.1. Alibaba Cloud 上のマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は、リージョン内の指定された Alibaba Cloud ゾーンで実行され、node-role.kubernetes.io/infra: "" というラベルの付いたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-<infra>-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
credentialsSecret:
name: alibabacloud-credentials
imageId: <image_id>
instanceType: <instance_type>
kind: AlibabaCloudMachineProviderConfig
ramRoleName: <infrastructure_id>-role-worker
regionId: <region>
resourceGroup:
id: <resource_group_id>
type: ID
securityGroups:
- tags:
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tags
systemDisk:
category: cloud_essd
size: <disk_size>
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
userDataSecret:
name: <user_data_secret>
vSwitch:
tags:
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags
vpcId: ""
zoneId: <zone>
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9
<infra>ノードラベルを指定します。- 4 6 10
- インフラストラクチャー ID、
<infra>ノードラベル、およびゾーンを指定します。 - 11
- 使用するイメージを指定します。クラスターに設定されている既存のデフォルトマシンのイメージを使用します。
- 12
- マシンセットに使用するインスタンスタイプを指定します。
- 13
- マシンセットに使用する RAM ロールの名前を指定します。インストーラーがデフォルトのマシンセットに入力する値を使用します。
- 14
- マシンを配置するリージョンを指定します。
- 15
- クラスターのリソースグループとタイプを指定します。インストーラーがデフォルトのマシンセットに入力する値を使用するか、別の値を指定できます。
- 16 18 20
- マシンセットに使用するタグを指定します。少なくとも、この例に示されているタグを、クラスターに適切な値とともに含める必要があります。必要に応じて、インストーラーが作成するデフォルトのマシンセットに設定するタグなど、追加のタグを含めることができます。
- 17
- ルートディスクのタイプとサイズを指定します。インストーラーが作成するデフォルトのマシンセットに入力する
category値を使用します。必要に応じて、sizeにギガバイト単位の別の値を指定します。 - 19
openshift-machine-api名前空間にあるユーザーデータ YAML ファイルでシークレットの名前を指定します。インストーラーがデフォルトのマシンセットに入力する値を使用します。- 21
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
- 22
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。
Alibaba Cloud 使用統計のマシンセットパラメーター
インストーラーが Alibaba Cloud クラスター用に作成するデフォルトのマシンセットには、Alibaba Cloud が使用統計を追跡するために内部的に使用する不要なタグ値が含まれています。これらのタグは、spec.template.spec.provider Spec.valueリストの securityGroups、tag、およびvSwitch パラメーターに入力されます。
追加のマシンをデプロイするマシンセットを作成するときは、必要な Kubernetes タグを含める必要があります。使用統計タグは、作成するマシンセットで指定されていない場合でも、デフォルトで適用されます。必要に応じて、追加のタグを含めることもできます。
次の YAML スニペットは、デフォルトのマシンセットのどのタグがオプションでどれが必須かを示しています。
spec.template.spec.providerSpec.value.securityGroups のタグ
spec:
template:
spec:
providerSpec:
value:
securityGroups:
- tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tagsspec.template.spec.providerSpec.value.tag のタグ
spec:
template:
spec:
providerSpec:
value:
tag:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocpspec.template.spec.providerSpec.value.vSwitch のタグ
spec:
template:
spec:
providerSpec:
value:
vSwitch:
tags:
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin
Value: ocp
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags8.2.1.2. AWS 上のマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は us-east-1a Amazon Web Services (AWS) ゾーンで実行され、node-role.kubernetes.io/infra:"" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-infra-<zone>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
ami:
id: ami-046fe691f52a953f9
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: <infrastructure_id>-worker-profile
instanceType: m6i.large
kind: AWSMachineProviderConfig
placement:
availabilityZone: <zone>
region: <region>
securityGroups:
- filters:
- name: tag:Name
values:
- <infrastructure_id>-worker-sg
subnet:
filters:
- name: tag:Name
values:
- <infrastructure_id>-private-<zone>
tags:
- name: kubernetes.io/cluster/<infrastructure_id>
value: owned
userDataSecret:
name: worker-user-data- 1 3 5 12 15 17
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- インフラストラクチャー ID、
<infra>ノードラベル、およびゾーンを指定します。 - 6 7 9
<infra>ノードラベルを指定します。- 10
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。 - 11
- OpenShift Container Platform ノードの AWS ゾーンに有効な Red Hat Enterprise Linux CoreOS (RHCOS) AMI を指定します。AWS Marketplace イメージを使用する場合は、AWS Marketplace から OpenShift Container Platform サブスクリプションを完了して、リージョンの AMI ID を取得する必要があります。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.ami.id}{"\n"}' \ get machineset/<infrastructure_id>-worker-<zone> - 13
- ゾーン (例:
us-east-1a) を指定します。 - 14
- リージョン (例:
us-east-1) を指定します。 - 16
- インフラストラクチャー ID とゾーンを指定します。
AWS で実行されるマシンセットは保証されていない Spot インスタンス をサポートします。AWS の On-Demand インスタンスと比較すると、Spot インスタンスをより低い価格で使用することでコストを節約できます。MachineSet YAML ファイルに spotMarketOptions を追加して Spot Instances を設定 します。
8.2.1.3. Azure 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、リージョンの 1 Microsoft Azure ゾーンで実行され、node-role.kubernetes.io/infra: "" というラベルの付けられたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-infra-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
spec:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-machineset: <machineset_name>
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: azureproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
tags:
- name: <custom_tag_name>
value: <custom_tag_value>
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_D4s_v3
vnet: <infrastructure_id>-vnet
zone: "1"
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7 15 16 19 22
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster以下のコマンドを実行してサブネットを取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1以下のコマンドを実行して vnet を取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 20 21
<infra>ノードラベルを指定します。- 4 6 10
- インフラストラクチャー ID、
<infra>ノードラベル、およびリージョンを指定します。 - 12
- マシンセットのイメージの詳細を指定します。Azure Marketplace イメージを使用する場合は、Azure Marketplace イメージの選択を参照してください。
- 13
- インスタンスタイプと互換性のあるイメージを指定します。インストールプログラムによって作成された Hyper-V 世代の V2 イメージには接尾辞
-gen2が付いていますが、V1 イメージには接尾辞のない同じ名前が付いています。 - 14
- マシンを配置するリージョンを指定します。
- 23
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
- 17 18
- オプション: マシンセットでカスタムタグを指定します。
<custom_tag_name>フィールドにタグ名を指定し、対応するタグ値を<custom_tag_value>フィールドに指定します。 - 24
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。
Azure で実行されるマシンセットは、保証されていない Spot 仮想マシン をサポートします。Azure の標準仮想マシンと比較すると、Spot 仮想マシンをより低い価格で使用することでコストを節約できます。MachineSet YAML ファイルに spotVMOptions を追加することで、Spot VM を設定 することができます。
8.2.1.4. Azure Stack Hub 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、リージョンの 1 Microsoft Azure ゾーンで実行され、node-role.kubernetes.io/infra: "" というラベルの付けられたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-infra-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region>
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
availabilitySet: <availability_set>
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id>
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region>
managedIdentity: <infrastructure_id>-identity
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg
sshPrivateKey: ""
sshPublicKey: ""
subnet: <infrastructure_id>-<role>-subnet
userDataSecret:
name: worker-user-data
vmSize: Standard_DS4_v2
vnet: <infrastructure_id>-vnet
zone: "1" - 1 5 7 14 16 17 18 21
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster以下のコマンドを実行してサブネットを取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1以下のコマンドを実行して vnet を取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 19 20
<infra>ノードラベルを指定します。- 4 6 10
- インフラストラクチャー ID、
<infra>ノードラベル、およびリージョンを指定します。 - 12
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。 - 15
- マシンを配置するリージョンを指定します。
- 13
- クラスターの可用性セットを指定します。
- 22
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
Azure Stack Hub で実行されるマシンセットは、保証されていない Spot 仮想マシンをサポートしません。
8.2.1.5. IBMCloud 上のマシンセットカスタムリソースのサンプル YAML
このサンプル YAML は、リージョン内の指定された IBM Cloud ゾーンで実行され、node-role.kubernetes.io/infra: "" というラベルの付いたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-<infra>-<region>
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<region>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<region>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: ibmcloudproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: ibmcloud-credentials
image: <infrastructure_id>-rhcos
kind: IBMCloudMachineProviderSpec
primaryNetworkInterface:
securityGroups:
- <infrastructure_id>-sg-cluster-wide
- <infrastructure_id>-sg-openshift-net
subnet: <infrastructure_id>-subnet-compute-<zone>
profile: <instance_profile>
region: <region>
resourceGroup: <resource_group>
userDataSecret:
name: <role>-user-data
vpc: <vpc_name>
zone: <zone>
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7
- クラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 16
<infra>ノードラベル。- 4 6 10
- インフラストラクチャー ID、
<infra>ノードラベル、およびリージョン。 - 11
- クラスターのインストールに使用されたカスタム Red Hat Enterprise Linux CoreOS (RHCOS) イメージ。
- 12
- マシンを配置するためのリージョン内のインフラストラクチャー ID とゾーン。リージョンがゾーンをサポートすることを確認してください。
- 13
- IBM Cloud インスタンスプロファイルを指定します。
- 14
- マシンを配置するリージョンを指定します。
- 15
- マシンリソースが配置されるリソースグループ。これは、インストール時に指定された既存のリソースグループ、またはインフラストラクチャー ID に基づいて名前が付けられたインストーラーによって作成されたリソースグループのいずれかです。
- 17
- VPC 名。
- 18
- マシンを配置するリージョン内のゾーンを指定します。リージョンがゾーンをサポートすることを確認してください。
- 19
- ユーザーのワークロードがインフラノードでスケジュールされないようにするためのテイント。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。
8.2.1.6. GCP 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、Google Cloud Platform (GCP) で実行され、node-role.kubernetes.io/infra: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-w-a
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: gcpprovider.openshift.io/v1beta1
canIPForward: false
credentialsSecret:
name: gcp-cloud-credentials
deletionProtection: false
disks:
- autoDelete: true
boot: true
image: <path_to_image>
labels: null
sizeGb: 128
type: pd-ssd
gcpMetadata:
- key: <custom_metadata_key>
value: <custom_metadata_value>
kind: GCPMachineProviderSpec
machineType: n1-standard-4
metadata:
creationTimestamp: null
networkInterfaces:
- network: <infrastructure_id>-network
subnetwork: <infrastructure_id>-worker-subnet
projectID: <project_name>
region: us-central1
serviceAccounts:
- email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
tags:
- <infrastructure_id>-worker
userDataSecret:
name: worker-user-data
zone: us-central1-a
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1
<infrastructure_id>は、クラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster- 2
<infra>には、<infra>ノードラベルを指定します。- 3
- 現在のマシンセットで使用されるイメージへのパスを指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してイメージへのパスを取得できます。
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.disks[0].image}{"\n"}' \ get machineset/<infrastructure_id>-worker-aGCP Marketplace イメージを使用するには、使用するオファーを指定します。
-
OpenShift Container Platform:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-ocp-48-x86-64-202210040145 -
OpenShift Platform Plus:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-opp-48-x86-64-202206140145 -
OpenShift Kubernetes Engine:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-oke-48-x86-64-202206140145
-
OpenShift Container Platform:
- 4
- オプション:
key:valueのペアの形式でカスタムメタデータを指定します。ユースケースの例については、カスタムメタデータの設定 について GCP のドキュメントを参照してください。 - 5
<project_name>には、クラスターに使用する GCP プロジェクトの名前を指定します。- 6
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。
GCP で実行されるマシンセットは、保証されていない プリエンプション可能な仮想マシンインスタンス をサポートします。GCP の通常のインスタンスと比較して、プリエンプション可能な仮想マシンインスタンスをより低い価格で使用することでコストを節約できます。MachineSet YAML ファイルに preemptible を追加することで、プリエンプション可能な仮想マシンインスタンスを設定 することができます。
8.2.1.7. Nutanix 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、node-role.kubernetes.io node-role.kubernetes.io/infra: "" でラベル付けされたノードを作成する Nutanix マシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-<infra>-<zone>
namespace: openshift-machine-api
annotations:
machine.openshift.io/memoryMb: "16384"
machine.openshift.io/vCPU: "4"
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone>
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
cluster:
type: uuid
uuid: <cluster_uuid>
credentialsSecret:
name: nutanix-credentials
image:
name: <infrastructure_id>-rhcos
type: name
kind: NutanixMachineProviderConfig
memorySize: 16Gi
subnets:
- type: uuid
uuid: <subnet_uuid>
systemDiskSize: 120Gi
userDataSecret:
name: <user_data_secret>
vcpuSockets: 4
vcpusPerSocket: 1
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 6 8
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 9 10
<infra>ノードラベルを指定します。- 4 7 11
- インフラストラクチャー ID、
<infra>ノードラベル、およびゾーンを指定します。 - 5
- クラスターオートスケーラーのアノテーション。
- 12
- 使用するイメージを指定します。クラスターに設定されている既存のデフォルトマシンのイメージを使用します。
- 13
- クラスターのメモリー量を Gi で指定します。
- 14
- システムディスクのサイズを Gi で指定します。
- 15
openshift-machine-api名前空間にあるユーザーデータ YAML ファイルでシークレットの名前を指定します。インストーラーがデフォルトのマシンセットに入力する値を使用します。- 16
- vCPU ソケットの数を指定します。
- 17
- ソケットあたりの vCPU の数を指定します。
- 18
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。
8.2.1.8. RHOSP 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、Red Hat OpenStack Platform (RHOSP) で実行され、node-role.kubernetes.io/infra: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
name: <infrastructure_id>-infra
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- filter: {}
subnets:
- filter:
name: <subnet_name>
tags: openshiftClusterID=<infrastructure_id>
primarySubnet: <rhosp_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-worker
serverMetadata:
Name: <infrastructure_id>-worker
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: worker-user-data
availabilityZone: <optional_openstack_availability_zone>- 1 5 7 14 16 17 18 19
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 20
<infra>ノードラベルを指定します。- 4 6 10
- インフラストラクチャー ID および
<infra>ノードラベルを指定します。 - 11
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。 - 12
- MachineSet のサーバーグループポリシーを設定するには、サーバーグループの作成 から返された値を入力します。ほとんどのデプロイメントでは、
anti-affinityまたはsoft-anti-affinityが推奨されます。 - 13
- 複数ネットワークへのデプロイメントに必要です。複数ネットワークにデプロイする場合、このリストには、
primarySubnet がの値として使用されるネットワークが含まれる必要があります。 - 15
- ノードのエンドポイントを公開する RHOSP サブネットを指定します。通常、これは
install-config.yamlファイルのmachinesSubnetの値として使用される同じサブネットです。
8.2.1.9. RHV 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、RHV で実行され、node-role.kubernetes.io/<node_role>: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、<infrastructure_id> はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<role> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
name: <infrastructure_id>-<role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
Selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ovirtproviderconfig.machine.openshift.io/v1beta1
cluster_id: <ovirt_cluster_id>
template_name: <ovirt_template_name>
sparse: <boolean_value>
format: <raw_or_cow>
cpu:
sockets: <number_of_sockets>
cores: <number_of_cores>
threads: <number_of_threads>
memory_mb: <memory_size>
guaranteed_memory_mb: <memory_size>
os_disk:
size_gb: <disk_size>
storage_domain_id: <storage_domain_UUID>
network_interfaces:
vnic_profile_id: <vnic_profile_id>
credentialsSecret:
name: ovirt-credentials
kind: OvirtMachineProviderSpec
type: <workload_type>
auto_pinning_policy: <auto_pinning_policy>
hugepages: <hugepages>
affinityGroupsNames:
- compute
userDataSecret:
name: worker-user-data- 1 7 9
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 10 11 13
- 追加するノードラベルを指定します。
- 4 8 12
- インフラストラクチャー ID およびノードラベルを指定します。これら 2 つの文字列は 35 文字を超えることができません。
- 5
- 作成するマシンの数を指定します。
- 6
- マシンのセレクター。
- 14
- この仮想マシンインスタンスが属する RHV クラスターの UUID を指定します。
- 15
- マシンの作成に使用する RHV 仮想マシンテンプレートを指定します。
- 16
- このオプションを
falseに設定すると、ディスクの事前割り当てが有効になります。デフォルトはtrueです。formatをrawに設定してsparseをtrueに設定することは、ブロックストレージドメインでは使用できません。raw形式は、仮想ディスク全体を基盤となる物理ディスクに書き込みます。 - 17
cowまたはrawに設定できます。デフォルトはcowです。cowのフォーマットは仮想マシン用に最適化されています。注記ファイルストレージドメインにディスクを事前に割り当てると、ファイルにゼロが書き込まれます。基盤となるストレージによっては、実際にはディスクが事前に割り当てられない場合があります。
- 18
- オプション: CPU フィールドには、ソケット、コア、スレッドを含む CPU の設定が含まれます。
- 19
- オプション: 仮想マシンのソケット数を指定します。
- 20
- オプション: ソケットあたりのコア数を指定します。
- 21
- オプション: コアあたりのスレッド数を指定します。
- 22
- オプション: 仮想マシンのメモリーサイズを MiB 単位で指定します。
- 23
- オプション: 仮想マシンの保証されたメモリーのサイズを MiB で指定します。これは、バルーニングメカニズムによって排出されないことが保証されているメモリーの量です。詳細は、Memory Ballooning と Optimization Settings Explained を参照してください。注記
RHV 4.4.8 より前のバージョンを使用している場合は、Red Hat Virtualization クラスターでの OpenShift の保証されたメモリー要件を 参照してください。
- 24
- オプション: ノードのルートディスク。
- 25
- オプション: ブート可能なディスクのサイズを GiB 単位で指定します。
- 26
- オプション: コンピュートノードのディスクのストレージドメインの UUID を指定します。何も指定されていない場合、コンピュートノードはコントロールノードと同じストレージドメインに作成されます。(デフォルト)
- 27
- オプション: 仮想マシンのネットワークインターフェイスの一覧。このパラメーターを含めると、OpenShift Container Platform はテンプレートからすべてのネットワークインターフェイスを破棄し、新規ネットワークインターフェイスを作成します。
- 28
- オプション: vNIC プロファイル ID を指定します。
- 29
- RHV クレデンシャルを保持するシークレットオブジェクトの名前を指定します。
- 30
- オプション: インスタンスが最適化されるワークロードタイプを指定します。この値は
RHV VMパラメーターに影響します。サポートされる値:desktop、server(デフォルト)、high_performanceです。high_performanceは、VM のパフォーマンスを向上させます。制限があります。たとえば、グラフィカルコンソールで VM にアクセスすることはできません。詳細は、Virtual Machine Management Guideの ハイパフォーマンス仮想マシン、テンプレート、およびプールの設定 を参照してください。 - 31
- オプション:AutoPinningPolicy は、このインスタンスのホストへのピニングを含む、CPU と NUMA 設定を自動的に設定するポリシーを定義します。サポートされる値は、
none、resize_and_pinです。詳細は、Virtual Machine Management Guideの Setting NUMA Nodes を参照してください。 - 32
- オプション:hugepages は、仮想マシンで hugepage を定義するためのサイズ (KiB) です。対応している値は
2048および1048576です。詳細は、Virtual Machine Management Guideの Configuring Huge Pages を参照してください。 - 33
- オプション: 仮想マシンに適用されるアフィニティーグループ名のリスト。アフィニティーグループは oVirt に存在している必要があります。
RHV は仮想マシンの作成時にテンプレートを使用するため、任意のパラメーターの値を指定しない場合、RHV はテンプレートに指定されるパラメーターの値を使用します。
8.2.1.10. vSphere 上のマシンセットのカスタムリソースのサンプル YAML
このサンプル YAML は、VMware vSphere で実行され、 node-role.kubernetes.io/infra: "" というラベルが付けられたノードを作成するマシンセットを定義します。
このサンプルでは、infrastructure_id はクラスターのプロビジョニング時に設定したクラスター ID に基づくインフラストラクチャー ID であり、<infra> は追加するノードラベルです。
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
name: <infrastructure_id>-infra
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra>
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints:
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: vsphereprovider.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials
diskGiB: 120
kind: VSphereMachineProviderSpec
memoryMiB: 8192
metadata:
creationTimestamp: null
network:
devices:
- networkName: "<vm_network_name>"
numCPUs: 4
numCoresPerSocket: 1
snapshot: ""
template: <vm_template_name>
userDataSecret:
name: worker-user-data
workspace:
datacenter: <vcenter_datacenter_name>
datastore: <vcenter_datastore_name>
folder: <vcenter_vm_folder_path>
resourcepool: <vsphere_resource_pool>
server: <vcenter_server_ip> - 1 3 5
- クラスターのプロビジョニング時に設定したクラスター ID を基にするインフラストラクチャー ID を指定します。OpenShift CLI (
oc) がインストールされている場合は、以下のコマンドを実行してインフラストラクチャー ID を取得できます。$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- インフラストラクチャー ID および
<infra>ノードラベルを指定します。 - 6 7 9
<infra>ノードラベルを指定します。- 10
- ユーザーのワークロードが infra ノードにスケジュールされないようにテイントを指定します。注記
インフラストラクチャーノードに
NoScheduleテイントを追加すると、そのノードで実行されている既存の DNS Pod はmisscheduledとしてマークされます。misscheduledDNS Pod に対する容認の追加 または削除を行う必要があります。 - 11
- マシンセットをデプロイする vSphere 仮想マシンネットワークを指定します。この仮想マシンネットワークは、他のコンピューティングマシンがクラスター内に存在する場所である必要があります。
- 12
user-5ddjd-rhcosなどの使用する vSphere 仮想マシンテンプレートを指定します。- 13
- マシンセットをデプロイする vCenter Datacenter を指定します。
- 14
- マシンセットをデプロイする vCenter Datastore を指定します。
- 15
/dc1/vm/user-inst-5ddjdなどの vCenter の vSphere 仮想マシンフォルダーへのパスを指定します。- 16
- 仮想マシンの vSphere リソースプールを指定します。
- 17
- vCenter サーバーの IP または完全修飾ドメイン名を指定します。
8.2.2. マシンセットの作成
インストールプログラムによって作成されるコンピュートセットセットに加えて、独自のマシンセットを作成して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
説明されているようにマシンセット カスタムリソース (CR) サンプルを含む新規 YAML ファイルを作成し、そのファイルに
<file_name>.yamlという名前を付けます。<clusterID>および<role>パラメーターの値を設定していることを確認します。オプション: 特定のフィールドに設定する値がわからない場合は、クラスターから既存のコンピュートマシンセットを確認できます。
クラスター内のコンピュートマシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のコンピュートマシンセットカスタムリソース(CR)の値を表示するには、以下のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml出力例
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id>1 name: <infrastructure_id>-<role>2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec:3 ...
次のコマンドを実行して
MachineSetCR を作成します。$ oc create -f <file_name>.yaml
検証
次のコマンドを実行して、コンピュートマシンセットのリストを表示します。
$ oc get machineset -n openshift-machine-api出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m新規のマシンセットが利用可能な場合、
DESIREDおよびCURRENTの値は一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
8.2.3. 専用インフラストラクチャーノードの作成
installer-provisioned infrastructure 環境またはコントロールプレーンノードがマシン API によって管理されているクラスターについて、Creating infrastructure machine set を参照してください。
クラスターの要件により、インフラストラクチャー ( infra ノードとも呼ばれる) がプロビジョニングされます。インストーラーは、コントロールプレーンノードとワーカーノードのプロビジョニングのみを提供します。ワーカーノードは、ラベル付けによって、インフラストラクチャーノードまたはアプリケーション (app とも呼ばれる) として指定できます。
手順
アプリケーションノードとして機能させるワーカーノードにラベルを追加します。
$ oc label node <node-name> node-role.kubernetes.io/app=""インフラストラクチャーノードとして機能する必要のあるワーカーノードにラベルを追加します。
$ oc label node <node-name> node-role.kubernetes.io/infra=""該当するノードに
infraロールおよびappロールがあるかどうかを確認します。$ oc get nodesデフォルトのクラスタースコープのセレクターを作成するには、以下を実行します。デフォルトのノードセレクターはすべての namespace で作成された Pod に適用されます。これにより、Pod の既存のノードセレクターとの交差が作成され、Pod のセレクターをさらに制限します。
重要デフォルトのノードセレクターのキーが Pod のラベルのキーと競合する場合、デフォルトのノードセレクターは適用されません。
ただし、Pod がスケジュール対象外になる可能性のあるデフォルトノードセレクターを設定しないでください。たとえば、Pod のラベルが
node-role.kubernetes.io/master=""などの別のノードロールに設定されている場合、デフォルトのノードセレクターをnode-role.kubernetes.io/infra=""などの特定のノードロールに設定すると、Pod がスケジュール不能になる可能性があります。このため、デフォルトのノードセレクターを特定のノードロールに設定する際には注意が必要です。または、プロジェクトノードセレクターを使用して、クラスター全体でのノードセレクターの競合を避けることができます。
Schedulerオブジェクトを編集します。$ oc edit scheduler cluster適切なノードセレクターと共に
defaultNodeSelectorフィールドを追加します。apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster spec: defaultNodeSelector: topology.kubernetes.io/region=us-east-11 # ...- 1
- このサンプルノードセレクターは、デフォルトで
us-east-1リージョンのノードに Pod をデプロイします。
- 変更を適用するためにファイルを保存します。
これで、インフラストラクチャーリソースを新しくラベル付けされた infra ノードに移動できます。
8.2.4. インフラストラクチャーマシンのマシン設定プール作成
インフラストラクチャーマシンに専用の設定が必要な場合は、infra プールを作成する必要があります。
手順
特定のラベルを持つ infra ノードとして割り当てるノードに、ラベルを追加します。
$ oc label node <node_name> <label>$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=ワーカーロールとカスタムロールの両方をマシン設定セレクターとして含まれるマシン設定プールを作成します。
$ cat infra.mcp.yaml出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: infra spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]}1 nodeSelector: matchLabels: node-role.kubernetes.io/infra: ""2 注記カスタムマシン設定プールは、ワーカープールからマシン設定を継承します。カスタムプールは、ワーカープールのターゲット設定を使用しますが、カスタムプールのみをターゲットに設定する変更をデプロイする機能を追加します。カスタムプールはワーカープールから設定を継承するため、ワーカープールへの変更もカスタムプールに適用されます。
YAML ファイルを用意した後に、マシン設定プールを作成できます。
$ oc create -f infra.mcp.yamlマシン設定をチェックして、インフラストラクチャー設定が正常にレンダリングされていることを確認します。
$ oc get machineconfig出力例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED 00-master 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 00-worker 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-1ae2a1e0-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-ssh 3.2.0 31d 99-worker-1ae64748-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-worker-ssh 3.2.0 31d rendered-infra-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 23m rendered-master-072d4b2da7f88162636902b074e9e28e 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-master-3e88ec72aed3886dec061df60d16d1af 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-master-419bee7de96134963a15fdf9dd473b25 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-master-53f5c91c7661708adce18739cc0f40fb 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d rendered-master-a6a357ec18e5bce7f5ac426fc7c5ffcd 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-master-dc7f874ec77fc4b969674204332da037 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-1a75960c52ad18ff5dfa6674eb7e533d 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-2640531be11ba43c61d72e82dc634ce6 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-worker-4f110718fe88e5f349987854a1147755 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-worker-afc758e194d6188677eb837842d3b379 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-worker-daa08cc1e8f5fcdeba24de60cd955cc3 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d新規のマシン設定には、接頭辞
rendered-infra-*が表示されるはずです。オプション: カスタムプールへの変更をデプロイするには、
infraなどのラベルとしてカスタムプール名を使用するマシン設定を作成します。これは必須ではありませんが、説明の目的でのみ表示されていることに注意してください。これにより、インフラストラクチャーノードのみに固有のカスタム設定を適用できます。注記新規マシン設定プールの作成後に、MCO はそのプールに新たにレンダリングされた設定を生成し、そのプールに関連付けられたノードは再起動して、新規設定を適用します。
マシン設定を作成します。
$ cat infra.mc.yaml出力例
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 51-infra labels: machineconfiguration.openshift.io/role: infra1 spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/infratest mode: 0644 contents: source: data:,infra- 1
- ノードに追加したラベルを
nodeSelectorとして追加します。
マシン設定を infra のラベルが付いたノードに適用します。
$ oc create -f infra.mc.yaml
新規のマシン設定プールが利用可能であることを確認します。
$ oc get mcp出力例
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91mこの例では、ワーカーノードが infra ノードに変更されました。
8.3. マシンセットリソースのインフラストラクチャーノードへの割り当て
インフラストラクチャーマシンセットの作成後、worker および infra ロールが新規の infra ノードに適用されます。infra ロールが適用されるノードは、worker ロールも適用されている場合でも、環境を実行するために必要なサブスクリプションの合計数にはカウントされません。
ただし、infra ノードがワーカーとして割り当てられると、ユーザーのワークロードが誤って infra ノードに割り当てられる可能性があります。これを回避するには、テイントを、制御する必要のある Pod の infra ノードおよび容認に適用できます。
8.3.1. テイントおよび容認を使用したインフラストラクチャーノードのワークロードのバインディング
infra および worker ロールが割り当てられている infra ノードがある場合、ユーザーのワークロードがこれに割り当てられないようにノードを設定する必要があります。
infra ノード用に作成されたデュアル infra,worker ラベルを保持し、テイントおよび容認 (Toleration) を使用してユーザーのワークロードがスケジュールされているノードを管理するすることを推奨します。ノードから worker ラベルを削除する場合には、カスタムプールを作成して管理する必要があります。master または worker 以外のラベルが割り当てられたノードは、カスタムプールなしには MCO で認識されません。worker ラベルを維持すると、カスタムラベルを選択するカスタムプールが存在しない場合に、ノードをデフォルトのワーカーマシン設定プールで管理できます。infra ラベルは、サブスクリプションの合計数にカウントされないクラスターと通信します。
前提条件
-
追加の
MachineSetを OpenShift Container Platform クラスターに設定します。
手順
テイントを infra ノードに追加し、ユーザーのワークロードをこれにスケジュールできないようにします。
ノードにテイントがあるかどうかを判別します。
$ oc describe nodes <node_name>出力例
oc describe node ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Name: ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Roles: worker ... Taints: node-role.kubernetes.io/infra:NoSchedule ...この例では、ノードにテイントがあることを示しています。次の手順に進み、容認を Pod に追加してください。
ユーザーワークロードをスケジューリングできないように、テイントを設定していない場合は、以下を実行します。
$ oc adm taint nodes <node_name> <key>=<value>:<effect>以下に例を示します。
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoExecuteヒントまたは、以下の YAML を適用してテイントを追加できます。
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: node-role.kubernetes.io/infra effect: NoExecute value: reserved ...この例では、テイントを、キー
node-role.kubernetes.io/infraおよびテイントの effectNoScheduleを持つnode1に配置します。effect がNoScheduleのノードは、テイントを容認する Pod のみをスケジュールしますが、既存の Pod はノードにスケジュールされたままになります。注記Descheduler が使用されると、ノードのテイントに違反する Pod はクラスターからエビクトされる可能性があります。
ルーター、レジストリーおよびモニタリングのワークロードなどの、infra ノードにスケジュールする必要のある Pod 設定の容認を追加します。以下のコードを
Podオブジェクトの仕様に追加します。tolerations: - effect: NoExecute1 key: node-role.kubernetes.io/infra2 operator: Exists3 value: reserved4 この容認は、
oc adm taintコマンドで作成されたテイントと一致します。この容認のある Pod は infra ノードにスケジュールできます。注記OLM でインストールされた Operator の Pod を infra ノードに常に移動できる訳ではありません。Operator Pod を移動する機能は、各 Operator の設定によって異なります。
- スケジューラーを使用して Pod を infra ノードにスケジュールします。詳細は、Pod のノードへの配置の制御 についてのドキュメントを参照してください。
8.4. リソースのインフラストラクチャーマシンセットへの移行
インフラストラクチャーリソースの一部はデフォルトでクラスターにデプロイされます。次のように、インフラストラクチャーノードセレクターを追加して、作成したインフラストラクチャーマシンセットにそれらを移動できます。
spec:
nodePlacement:
nodeSelector:
matchLabels:
node-role.kubernetes.io/infra: ""
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/infra
value: reserved
- effect: NoExecute
key: node-role.kubernetes.io/infra
value: reserved- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。表示されている形式のnodeSelectorを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードにテイントを追加した場合は、一致する容認も追加します。
特定のノードセレクターをすべてのインフラストラクチャーコンポーネントに適用すると、OpenShift Container Platform は そのラベルを持つノードでそれらのワークロードをスケジュール します。
8.4.1. ルーターの移動
ルーター Pod を異なるマシンセットにデプロイできます。デフォルトで、この Pod はワーカーノードにデプロイされます。
前提条件
- 追加のマシンセットを OpenShift Container Platform クラスターに設定します。
手順
ルーター Operator の
IngressControllerカスタムリソースを表示します。$ oc get ingresscontroller default -n openshift-ingress-operator -o yamlコマンド出力は以下のテキストのようになります。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultingresscontrollerリソースを編集し、nodeSelectorをinfraラベルを使用するように変更します。$ oc edit ingresscontroller default -n openshift-ingress-operatorspec: nodePlacement: nodeSelector:1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。表示されている形式のnodeSelectorを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードにテイントを追加した場合は、一致する容認も追加します。
ルーター Pod が
infraノードで実行されていることを確認します。ルーター Pod のリストを表示し、実行中の Pod のノード名をメモします。
$ oc get pod -n openshift-ingress -o wide出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>この例では、実行中の Pod は
ip-10-0-217-226.ec2.internalノードにあります。実行中の Pod のノードのステータスを表示します。
$ oc get node <node_name>1 - 1
- Pod のリストより取得した
<node_name>を指定します。
出力例
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.24.0ロールのリストに
infraが含まれているため、Pod は正しいノードで実行されます。
8.4.2. デフォルトレジストリーの移行
レジストリー Operator を、その Pod を複数の異なるノードにデプロイするように設定します。
前提条件
- 追加のマシンセットを OpenShift Container Platform クラスターに設定します。
手順
config/instanceオブジェクトを表示します。$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml出力例
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...config/instanceオブジェクトを編集します。$ oc edit configs.imageregistry.operator.openshift.io/clusterspec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。表示されている形式のnodeSelectorを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードにテイントを追加した場合は、一致する容認も追加します。
レジストリー Pod がインフラストラクチャーノードに移動していることを確認します。
以下のコマンドを実行して、レジストリー Pod が置かれているノードを特定します。
$ oc get pods -o wide -n openshift-image-registryノードに指定したラベルがあることを確認します。
$ oc describe node <node_name>コマンド出力を確認し、
node-role.kubernetes.io/infraがLABELSリストにあることを確認します。
8.4.3. モニタリングソリューションの移動
監視スタックには、Prometheus、Thanos Querier、Alertmanager などの複数のコンポーネントが含まれています。Cluster Monitoring Operator は、このスタックを管理します。モニタリングスタックをインフラストラクチャーノードに再デプロイするために、カスタム config map を作成して適用できます。
手順
cluster-monitoring-config設定マップを編集し、nodeSelectorを変更してinfraラベルを使用します。$ oc edit configmap cluster-monitoring-config -n openshift-monitoringapiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector:1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute- 1
- 適切な値が設定された
nodeSelectorパラメーターを、移動する必要のあるコンポーネントに追加します。表示されている形式のnodeSelectorを使用することも、ノードに指定された値に基づいて<key>: <value>ペアを使用することもできます。インフラストラクチャーノードにテイントを追加した場合は、一致する容認も追加します。
モニタリング Pod が新規マシンに移行することを確認します。
$ watch 'oc get pod -n openshift-monitoring -o wide'コンポーネントが
infraノードに移動していない場合は、このコンポーネントを持つ Pod を削除します。$ oc delete pod -n openshift-monitoring <pod>削除された Pod からのコンポーネントが
infraノードに再作成されます。
8.4.4. ロギングリソースの移動
Elasticsearch および Kibana などのロギングシステムコンポーネントの Pod を異なるノードにデプロイするように Red Hat OpenShift Logging Operator を設定できます。Red Hat OpenShift Logging Operator Pod については、インストールされた場所から移動することはできません。
たとえば、Elasticsearch Pod の CPU、メモリーおよびディスクの要件が高いために、この Pod を別のノードに移動できます。
前提条件
- Red Hat OpenShift Logging Operator と OpenShift Elasticsearch Operator がインストールされている。
手順
openshift-loggingプロジェクトでClusterLoggingカスタムリソース (CR) を編集します。$ oc edit ClusterLogging instanceClusterLoggingCR の例apiVersion: logging.openshift.io/v1 kind: ClusterLogging # ... spec: logStore: elasticsearch: nodeCount: 3 nodeSelector:1 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved redundancyPolicy: SingleRedundancy resources: limits: cpu: 500m memory: 16Gi requests: cpu: 500m memory: 16Gi storage: {} type: elasticsearch managementState: Managed visualization: kibana: nodeSelector:2 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved proxy: resources: null replicas: 1 resources: null type: kibana # ...
検証
コンポーネントが移動したことを確認するには、oc get pod -o wide コマンドを使用できます。
以下に例を示します。
Kibana Pod を
ip-10-0-147-79.us-east-2.compute.internalノードから移動する必要がある場合は、以下を実行します。$ oc get pod kibana-5b8bdf44f9-ccpq9 -o wide出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-5b8bdf44f9-ccpq9 2/2 Running 0 27s 10.129.2.18 ip-10-0-147-79.us-east-2.compute.internal <none> <none>Kibana Pod を、専用インフラストラクチャーノードである
ip-10-0-139-48.us-east-2.compute.internalノードに移動する必要がある場合は、以下を実行します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION ip-10-0-133-216.us-east-2.compute.internal Ready master 60m v1.24.0 ip-10-0-139-146.us-east-2.compute.internal Ready master 60m v1.24.0 ip-10-0-139-192.us-east-2.compute.internal Ready worker 51m v1.24.0 ip-10-0-139-241.us-east-2.compute.internal Ready worker 51m v1.24.0 ip-10-0-147-79.us-east-2.compute.internal Ready worker 51m v1.24.0 ip-10-0-152-241.us-east-2.compute.internal Ready master 60m v1.24.0 ip-10-0-139-48.us-east-2.compute.internal Ready infra 51m v1.24.0ノードには
node-role.kubernetes.io/infra: ''ラベルがあることに注意してください。$ oc get node ip-10-0-139-48.us-east-2.compute.internal -o yaml出力例
kind: Node apiVersion: v1 metadata: name: ip-10-0-139-48.us-east-2.compute.internal selfLink: /api/v1/nodes/ip-10-0-139-48.us-east-2.compute.internal uid: 62038aa9-661f-41d7-ba93-b5f1b6ef8751 resourceVersion: '39083' creationTimestamp: '2020-04-13T19:07:55Z' labels: node-role.kubernetes.io/infra: '' ...Kibana Pod を移動するには、
ClusterLoggingCR を編集してノードセレクターを追加します。apiVersion: logging.openshift.io/v1 kind: ClusterLogging # ... spec: # ... visualization: kibana: nodeSelector:1 node-role.kubernetes.io/infra: '' proxy: resources: null replicas: 1 resources: null type: kibana- 1
- ノード仕様のラベルに一致するノードセレクターを追加します。
CR を保存した後に、現在の Kibana Pod は終了し、新規 Pod がデプロイされます。
$ oc get pods出力例
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 29m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 28m collector-42dzz 1/1 Running 0 28m collector-d74rq 1/1 Running 0 28m collector-m5vr9 1/1 Running 0 28m collector-nkxl7 1/1 Running 0 28m collector-pdvqb 1/1 Running 0 28m collector-tflh6 1/1 Running 0 28m kibana-5b8bdf44f9-ccpq9 2/2 Terminating 0 4m11s kibana-7d85dcffc8-bfpfp 2/2 Running 0 33s新規 Pod が
ip-10-0-139-48.us-east-2.compute.internalノードに置かれます。$ oc get pod kibana-7d85dcffc8-bfpfp -o wide出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-7d85dcffc8-bfpfp 2/2 Running 0 43s 10.131.0.22 ip-10-0-139-48.us-east-2.compute.internal <none> <none>しばらくすると、元の Kibana Pod が削除されます。
$ oc get pods出力例
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 30m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 29m collector-42dzz 1/1 Running 0 29m collector-d74rq 1/1 Running 0 29m collector-m5vr9 1/1 Running 0 29m collector-nkxl7 1/1 Running 0 29m collector-pdvqb 1/1 Running 0 29m collector-tflh6 1/1 Running 0 29m kibana-7d85dcffc8-bfpfp 2/2 Running 0 62s
第9章 RHEL コンピュートマシンの OpenShift Container Platform クラスターへの追加
OpenShift Container Platform では、Red Hat Enterprise Linux (RHEL) コンピュートマシンを、x86_64 アーキテクチャー上のユーザープロビジョニングされたインフラストラクチャークラスターまたはインストールプロビジョニングされたインフラストラクチャークラスターに追加できます。RHEL は、コンピュートマシンでのみのオペレーティングシステムとして使用できます。
9.1. RHEL コンピュートノードのクラスターへの追加について
OpenShift Container Platform 4.11 では、x86_64 アーキテクチャー上でユーザープロビジョニングまたはインストーラープロビジョニングのインフラストラクチャーインストールを使用する場合、クラスター内のコンピューティングマシンとして Red Hat Enterprise Linux (RHEL) マシンを使用するオプションがあります。クラスター内のコントロールプレーンマシンには Red Hat Enterprise Linux CoreOS (RHCOS) マシンを使用する必要があります。
クラスターで RHEL コンピュートマシンを使用することを選択した場合は、すべてのオペレーティングシステムのライフサイクル管理とメンテナンスを担当します。システムの更新を実行し、パッチを適用し、その他すべての必要なタスクを完了する必要があります。
installer-provisioned infrastructure クラスターの場合、installer-provisioned infrastructure クラスターの自動スケーリングにより Red Hat Enterprise Linux CoreOS (RHCOS) コンピューティングマシンがデフォルトで追加されるため、RHEL コンピューティングマシンを手動で追加する必要があります。
- OpenShift Container Platform をクラスター内のマシンから削除するには、オペレーティングシステムを破棄する必要があるため、クラスターに追加する RHEL マシンについては専用のハードウェアを使用する必要があります。
- swap メモリーは、OpenShift Container Platform クラスターに追加されるすべての RHEL マシンで無効にされます。これらのマシンで swap メモリーを有効にすることはできません。
RHEL コンピュートマシンは、コントロールプレーンを初期化してからクラスターに追加する必要があります。
9.2. RHEL コンピュートノードのシステム要件
OpenShift Container Platform 環境の Red Hat Enterprise Linux (RHEL) コンピュートマシンは以下の最低のハードウェア仕様およびシステムレベルの要件を満たしている必要があります。
- まず、お使いの Red Hat アカウントに有効な OpenShift Container Platform サブスクリプションがなければなりません。これがない場合は、営業担当者にお問い合わせください。
- 実稼働環境では予想されるワークロードに対応するコンピュートーノードを提供する必要があります。クラスター管理者は、予想されるワークロードを計算し、オーバーヘッドの約 10 % を追加する必要があります。実稼働環境の場合、ノードホストの障害が最大容量に影響を与えることがないよう、十分なリソースを割り当てるようにします。
各システムは、以下のハードウェア要件を満たしている必要があります。
- 物理または仮想システム、またはパブリックまたはプライベート IaaS で実行されるインスタンス。
ベース OS: "最小" インストールオプションを備えた RHEL 8.6 以降。
重要OpenShift Container Platform クラスターへの RHEL 7 コンピュートマシンの追加はサポートされません。
以前の OpenShift Container Platform のバージョンで以前にサポートされていた RHEL 7 コンピュートマシンがある場合、RHEL 8 にアップグレードすることはできません。新しい RHEL 8 ホストをデプロイする必要があり、古い RHEL 7 ホストを削除する必要があります。詳細は、ノードの管理セクションを参照してください。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧については、OpenShift Container Platform リリースノートの 非推奨および削除された機能セクションを参照してください。
- FIPS モードで OpenShift Container Platform をデプロイしている場合、起動する前に FIPS を RHEL マシン上で有効にする必要があります。RHEL 8 ドキュメントのInstalling a RHEL 8 system with FIPS mode enabledを参照してください。
クラスターで FIPS モードを有効にするには、FIPS モードで動作するように設定された Red Hat Enterprise Linux (RHEL) コンピューターからインストールプログラムを実行する必要があります。RHEL での FIPS モードの設定の詳細は、FIPS モードでのシステムのインストール を参照してください。プロセス暗号化ライブラリーでの FIPS 検証済みまたはモジュールの使用は、x86_64 アーキテクチャーでの OpenShift Container Platform デプロイメントでのみサポートされます。
- NetworkManager 1.0 以降。
- 1 vCPU。
- 最小 8 GB の RAM。
-
/var/を含むファイルシステムの最小 15 GB のハードディスク領域。 -
/usr/local/bin/を含むファイルシステムの最小 1 GB のハードディスク領域。 一時ディレクトリーを含むファイルシステムの最小 1 GB のハードディスク領域。システムの一時ディレクトリーは、Python の標準ライブラリーの tempfile モジュールで定義されるルールに基づいて決定されます。
-
各システムは、システムプロバイダーの追加の要件を満たす必要があります。たとえば、クラスターを VMware vSphere にインストールしている場合、ディスクはその ストレージガイドライン に応じて設定され、
disk.enableUUID=true属性が設定される必要があります。 - 各システムは、DNS で解決可能なホスト名を使用してクラスターの API エンドポイントにアクセスできる必要があります。配置されているネットワークセキュリティーアクセス制御は、クラスターの API サービスエンドポイントへのシステムアクセスを許可する必要があります。
-
各システムは、システムプロバイダーの追加の要件を満たす必要があります。たとえば、クラスターを VMware vSphere にインストールしている場合、ディスクはその ストレージガイドライン に応じて設定され、
9.2.1. 証明書署名要求の管理
ユーザーがプロビジョニングするインフラストラクチャーを使用する場合、クラスターの自動マシン管理へのアクセスは制限されるため、インストール後にクラスターの証明書署名要求 (CSR) のメカニズムを提供する必要があります。kube-controller-manager は kubelet クライアント CSR のみを承認します。machine-approver は、kubelet 認証情報を使用して要求される提供証明書の有効性を保証できません。適切なマシンがこの要求を発行したかどうかを確認できないためです。kubelet 提供証明書の要求の有効性を検証し、それらを承認する方法を判別し、実装する必要があります。
9.3. クラウド用イメージの準備
各種のイメージ形式は AWS で直接使用できないので、Amazon Machine Images (AMI) が必要です。Red Hat が提供している AMI を使用するか、独自のイメージを手動でインポートできます。EC2 インスタンスをプロビジョニングする前に AMI が存在している必要があります。コンピュートマシンに必要な正しい RHEL バージョンを選択するには、有効な AMI ID が必要です。
9.3.1. AWS で利用可能な最新の RHEL イメージのリスト表示
AMI ID は、AWS のネイティブブートイメージに対応します。EC2 インスタンスがプロビジョニングされる前に AMI が存在している必要があるため、設定前に AMI ID を把握しておく必要があります。AWS コマンドラインインターフェイス (CLI) は、利用可能な Red Hat Enterprise Linux (RHEL) イメージ ID のリストを表示するために使用されます。
前提条件
- AWS CLI をインストールしている。
手順
このコマンドを使用して、RHEL 8.4 Amazon Machine Images (AMI) のリストを表示します。
$ aws ec2 describe-images --owners 309956199498 \1 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' \2 --filters "Name=name,Values=RHEL-8.4*" \3 --region us-east-1 \4 --output table5 - 1
--ownersコマンドオプションは、アカウント ID309956199498に基づいて Red Hat イメージを表示します。重要Red Hat が提供するイメージの AMI ID を表示するには、このアカウント ID が必要です。
- 2
--queryコマンドオプションは、イメージが'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]'のパラメーターでソートされる方法を設定します。この場合、イメージは作成日でソートされ、テーブルが作成日、イメージ名、および AMI ID を表示するように設定されます。- 3
--filterコマンドオプションは、表示される RHEL のバージョンを設定します。この例では、フィルターが"Name=name,Values=RHEL-8.4*"で設定されているため、RHEL 8.4 AMI が表示されます。- 4
--regionコマンドオプションは、AMI が保存されるリージョンを設定します。- 5
--outputコマンドオプションは、結果の表示方法を設定します。
AWS 用の RHEL コンピュートマシンを作成する場合、AMI が RHEL 8.4 または 8.5 であることを確認します。
出力例
------------------------------------------------------------------------------------------------------------
| DescribeImages |
+---------------------------+-----------------------------------------------------+------------------------+
| 2021-03-18T14:23:11.000Z | RHEL-8.4.0_HVM_BETA-20210309-x86_64-1-Hourly2-GP2 | ami-07eeb4db5f7e5a8fb |
| 2021-03-18T14:38:28.000Z | RHEL-8.4.0_HVM_BETA-20210309-arm64-1-Hourly2-GP2 | ami-069d22ec49577d4bf |
| 2021-05-18T19:06:34.000Z | RHEL-8.4.0_HVM-20210504-arm64-2-Hourly2-GP2 | ami-01fc429821bf1f4b4 |
| 2021-05-18T20:09:47.000Z | RHEL-8.4.0_HVM-20210504-x86_64-2-Hourly2-GP2 | ami-0b0af3577fe5e3532 |
+---------------------------+-----------------------------------------------------+------------------------+9.4. Playbook 実行のためのマシンの準備
Red Hat Enterprise Linux (RHEL) をオペレーティングシステムとして使用するコンピュートマシンを OpenShift Container Platform 4.11 クラスターに追加する前に、新たなノードをクラスターに追加する Ansible Playbook を実行する RHEL 8 マシンを準備する必要があります。このマシンはクラスターの一部にはなりませんが、クラスターにアクセスできる必要があります。
前提条件
-
Playbook を実行するマシンに OpenShift CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
-
クラスターの
kubeconfigファイルおよびクラスターのインストールに使用したインストールプログラムが RHEL 8 マシン上にあることを確認します。これを実行する 1 つの方法として、クラスターのインストールに使用したマシンと同じマシンを使用することができます。 - マシンを、コンピュートマシンとして使用する予定のすべての RHEL ホストにアクセスできるように設定します。Bastion と SSH プロキシーまたは VPN の使用など、所属する会社で許可されるすべての方法を利用できます。
すべての RHEL ホストへの SSH アクセスを持つユーザーを Playbook を実行するマシンで設定します。
重要SSH キーベースの認証を使用する場合、キーを SSH エージェントで管理する必要があります。
これを実行していない場合には、マシンを RHSM に登録し、
OpenShiftサブスクリプションのプールをこれにアタッチします。マシンを RHSM に登録します。
# subscription-manager register --username=<user_name> --password=<password>RHSM から最新のサブスクリプションデータをプルします。
# subscription-manager refresh利用可能なサブスクリプションをリスト表示します。
# subscription-manager list --available --matches '*OpenShift*'直前のコマンドの出力で、OpenShift Container Platform サブスクリプションのプール ID を見つけ、これをアタッチします。
# subscription-manager attach --pool=<pool_id>
OpenShift Container Platform 4.11 で必要なリポジトリーを有効にします。
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.11-for-rhel-8-x86_64-rpms"openshift-ansibleを含む必要なパッケージをインストールします。# yum install openshift-ansible openshift-clients jqopenshift-ansibleパッケージはインストールプログラムユーティリティーを提供し、Ansible Playbook などのクラスターに RHEL コンピュートノードを追加するために必要な他のパッケージおよび関連する設定ファイルをプルします。openshift-clientsはocCLI を提供し、jqパッケージはコマンドライン上での JSON 出力の表示方法を向上させます。
9.5. RHEL コンピュートノードの準備
Red Hat Enterprise Linux (RHEL) マシンを OpenShift Container Platform クラスターに追加する前に、各ホストを Red Hat Subscription Manager (RHSM) に登録し、有効な OpenShift Container Platform サブスクリプションをアタッチし、必要なリポジトリーを有効にする必要があります。NetworkManager が有効になり、ホスト上のすべてのインターフェイスを制御するように設定されていることを確認します。
各ホストで RHSM に登録します。
# subscription-manager register --username=<user_name> --password=<password>RHSM から最新のサブスクリプションデータをプルします。
# subscription-manager refresh利用可能なサブスクリプションをリスト表示します。
# subscription-manager list --available --matches '*OpenShift*'直前のコマンドの出力で、OpenShift Container Platform サブスクリプションのプール ID を見つけ、これをアタッチします。
# subscription-manager attach --pool=<pool_id>yum リポジトリーをすべて無効にします。
有効にされている RHSM リポジトリーをすべて無効にします。
# subscription-manager repos --disable="*"残りの yum リポジトリーをリスト表示し、
repo idにあるそれらの名前をメモします (ある場合) 。# yum repolistyum-config-managerを使用して、残りの yum リポジトリーを無効にします。# yum-config-manager --disable <repo_id>または、すべてのリポジトリーを無効にします。
# yum-config-manager --disable \*利用可能なリポジトリーが多い場合には、数分の時間がかかることがあります。
OpenShift Container Platform 4.11 で必要なリポジトリーのみを有効にします。
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.11-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"ホストで firewalld を停止し、無効にします。
# systemctl disable --now firewalld.service注記firewalld は、後で有効にすることはできません。これを実行する場合、ワーカー上の OpenShift Container Platform ログにはアクセスできません。
9.6. AWS での RHEL インスタンスへのロールパーミッションの割り当て
ブラウザーで Amazon IAM コンソールを使用して、必要なロールを選択し、ワーカーノードに割り当てることができます。
手順
- AWS IAM コンソールから、任意の IAM ロール を作成します。
- IAM ロール を必要なワーカーノードに割り当てます。
9.7. 所有または共有されている RHEL ワーカーノードへのタグ付け
クラスターは kubernetes.io/cluster/<clusterid>,Value=(owned|shared) タグの値を使用して、AWS クラスターに関するリソースの有効期間を判別します。
-
リソースをクラスターの破棄の一環として破棄する必要がある場合は、
ownedタグの値を追加する必要があります。 -
クラスターが破棄された後にリソースが引き続いて存在する場合、
sharedタグの値を追加する必要があります。このタグ付けは、クラスターがこのリソースを使用することを示しますが、リソースには別の所有者が存在します。
手順
-
RHEL コンピュートマシンの場合、RHEL ワーカーマシンでは、
kubernetes.io/cluster/<clusterid>=ownedまたはkubernetes.io/cluster/<cluster-id>=sharedでタグ付けする必要があります。
すべての既存セキュリティーグループに kubernetes.io/cluster/<name>,Value=<clusterid> のタグを付けないでください。 その場合、Elastic Load Balancing (ELB) がロードバランサーを作成できなくなります。
9.8. RHEL コンピュートマシンのクラスターへの追加
Red Hat Enterprise Linux をオペレーティングシステムとして使用するコンピュートマシンを OpenShift Container Platform 4.11 クラスターに追加することができます。
前提条件
- Playbook を実行するマシンに必要なパッケージをインストールし、必要な設定が行われています。
- インストール用の RHEL ホストを準備しています。
手順
Playbook を実行するために準備しているマシンで以下の手順を実行します。
コンピュートマシンホストおよび必要な変数を定義する
/<path>/inventory/hostsという名前の Ansible インベントリーファイルを作成します。[all:vars] ansible_user=root1 #ansible_become=True2 openshift_kubeconfig_path="~/.kube/config"3 [new_workers]4 mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com- 1
- Ansible タスクをリモートコンピュートマシンで実行するユーザー名を指定します。
- 2
ansible_userのrootを指定しない場合、ansible_becomeをTrueに設定し、ユーザーに sudo パーミッションを割り当てる必要があります。- 3
- クラスターの
kubeconfigファイルへのパスを指定します。 - 4
- クラスターに追加する各 RHEL マシンをリスト表示します。各ホストについて完全修飾ドメイン名を指定する必要があります。この名前は、クラスターがマシンにアクセスするために使用するホスト名であるため、マシンにアクセスできるように正しいパブリックまたはプライベートの名前を設定します。
Ansible Playbook ディレクトリーに移動します。
$ cd /usr/share/ansible/openshift-ansiblePlaybook を実行します。
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
<path>については、作成した Ansible インベントリーファイルへのパスを指定します。
9.9. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンについて 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードのアイデンティティーを確認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
9.10. Ansible ホストファイルの必須パラメーター
Red Hat Enterprise Linux (RHEL) コンピュートマシンをクラスターに追加する前に、以下のパラメーターを Ansible ホストファイルに定義する必要があります。
| パラメーター | 説明 | 値 |
|---|---|---|
|
| パスワードなしの SSH ベースの認証を許可する SSH ユーザー。SSH キーベースの認証を使用する場合、キーを SSH エージェントで管理する必要があります。 |
システム上のユーザー名。デフォルト値は |
|
|
|
|
|
|
クラスターの | 設定ファイルのパスと名前。 |
9.10.1. オプション: RHCOS コンピュートマシンのクラスターからの削除
Red Hat Enterprise Linux (RHEL) コンピュートマシンをクラスターに追加した後に、オプションで Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを削除し、リソースを解放できます。
前提条件
- RHEL コンピュートマシンをクラスターに追加済みです。
手順
マシンのリストを表示し、RHCOS コンピューマシンのノード名を記録します。
$ oc get nodes -o wideそれぞれの RHCOS コンピュートマシンについて、ノードを削除します。
oc adm cordonコマンドを実行して、ノードにスケジュール対象外 (unschedulable) のマークを付けます。$ oc adm cordon <node_name>1 - 1
- RHCOS コンピュートマシンのノード名を指定します。
ノードからすべての Pod をドレイン (解放) します。
$ oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets1 - 1
- 分離した RHCOS コンピュートマシンのノード名を指定します。
ノードを削除します。
$ oc delete nodes <node_name>1 - 1
- ドレイン (解放) した RHCOS コンピュートマシンのノード名を指定します。
コンピュートマシンのリストを確認し、RHEL ノードのみが残っていることを確認します。
$ oc get nodes -o wide- RHCOS マシンをクラスターのコンピュートマシンのロードバランサーから削除します。仮想マシンを削除したり、RHCOS コンピュートマシンの物理ハードウェアを再イメージ化したりできます。
第10章 RHEL コンピュートマシンの OpenShift Container Platform クラスターへのさらなる追加
OpenShift Container Platform クラスターに Red Hat Enterprise Linux (RHEL) コンピュートマシン (またはワーカーマシンとしても知られる) がすでに含まれる場合、RHEL コンピュートマシンをさらに追加することができます。
10.1. RHEL コンピュートノードのクラスターへの追加について
OpenShift Container Platform 4.11 では、x86_64 アーキテクチャー上でユーザープロビジョニングまたはインストーラープロビジョニングのインフラストラクチャーインストールを使用する場合、クラスター内のコンピューティングマシンとして Red Hat Enterprise Linux (RHEL) マシンを使用するオプションがあります。クラスター内のコントロールプレーンマシンには Red Hat Enterprise Linux CoreOS (RHCOS) マシンを使用する必要があります。
クラスターで RHEL コンピュートマシンを使用することを選択した場合は、すべてのオペレーティングシステムのライフサイクル管理とメンテナンスを担当します。システムの更新を実行し、パッチを適用し、その他すべての必要なタスクを完了する必要があります。
installer-provisioned infrastructure クラスターの場合、installer-provisioned infrastructure クラスターの自動スケーリングにより Red Hat Enterprise Linux CoreOS (RHCOS) コンピューティングマシンがデフォルトで追加されるため、RHEL コンピューティングマシンを手動で追加する必要があります。
- OpenShift Container Platform をクラスター内のマシンから削除するには、オペレーティングシステムを破棄する必要があるため、クラスターに追加する RHEL マシンについては専用のハードウェアを使用する必要があります。
- swap メモリーは、OpenShift Container Platform クラスターに追加されるすべての RHEL マシンで無効にされます。これらのマシンで swap メモリーを有効にすることはできません。
RHEL コンピュートマシンは、コントロールプレーンを初期化してからクラスターに追加する必要があります。
10.2. RHEL コンピュートノードのシステム要件
OpenShift Container Platform 環境の Red Hat Enterprise Linux (RHEL) コンピュートマシンは以下の最低のハードウェア仕様およびシステムレベルの要件を満たしている必要があります。
- まず、お使いの Red Hat アカウントに有効な OpenShift Container Platform サブスクリプションがなければなりません。これがない場合は、営業担当者にお問い合わせください。
- 実稼働環境では予想されるワークロードに対応するコンピュートーノードを提供する必要があります。クラスター管理者は、予想されるワークロードを計算し、オーバーヘッドの約 10 % を追加する必要があります。実稼働環境の場合、ノードホストの障害が最大容量に影響を与えることがないよう、十分なリソースを割り当てるようにします。
各システムは、以下のハードウェア要件を満たしている必要があります。
- 物理または仮想システム、またはパブリックまたはプライベート IaaS で実行されるインスタンス。
ベース OS: "最小" インストールオプションを備えた RHEL 8.6 以降。
重要OpenShift Container Platform クラスターへの RHEL 7 コンピュートマシンの追加はサポートされません。
以前の OpenShift Container Platform のバージョンで以前にサポートされていた RHEL 7 コンピュートマシンがある場合、RHEL 8 にアップグレードすることはできません。新しい RHEL 8 ホストをデプロイする必要があり、古い RHEL 7 ホストを削除する必要があります。詳細は、ノードの管理セクションを参照してください。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧については、OpenShift Container Platform リリースノートの 非推奨および削除された機能セクションを参照してください。
- FIPS モードで OpenShift Container Platform をデプロイしている場合、起動する前に FIPS を RHEL マシン上で有効にする必要があります。RHEL 8 ドキュメントのInstalling a RHEL 8 system with FIPS mode enabledを参照してください。
クラスターで FIPS モードを有効にするには、FIPS モードで動作するように設定された Red Hat Enterprise Linux (RHEL) コンピューターからインストールプログラムを実行する必要があります。RHEL での FIPS モードの設定の詳細は、FIPS モードでのシステムのインストール を参照してください。プロセス暗号化ライブラリーでの FIPS 検証済みまたはモジュールの使用は、x86_64 アーキテクチャーでの OpenShift Container Platform デプロイメントでのみサポートされます。
- NetworkManager 1.0 以降。
- 1 vCPU。
- 最小 8 GB の RAM。
-
/var/を含むファイルシステムの最小 15 GB のハードディスク領域。 -
/usr/local/bin/を含むファイルシステムの最小 1 GB のハードディスク領域。 一時ディレクトリーを含むファイルシステムの最小 1 GB のハードディスク領域。システムの一時ディレクトリーは、Python の標準ライブラリーの tempfile モジュールで定義されるルールに基づいて決定されます。
-
各システムは、システムプロバイダーの追加の要件を満たす必要があります。たとえば、クラスターを VMware vSphere にインストールしている場合、ディスクはその ストレージガイドライン に応じて設定され、
disk.enableUUID=true属性が設定される必要があります。 - 各システムは、DNS で解決可能なホスト名を使用してクラスターの API エンドポイントにアクセスできる必要があります。配置されているネットワークセキュリティーアクセス制御は、クラスターの API サービスエンドポイントへのシステムアクセスを許可する必要があります。
-
各システムは、システムプロバイダーの追加の要件を満たす必要があります。たとえば、クラスターを VMware vSphere にインストールしている場合、ディスクはその ストレージガイドライン に応じて設定され、
10.2.1. 証明書署名要求の管理
ユーザーがプロビジョニングするインフラストラクチャーを使用する場合、クラスターの自動マシン管理へのアクセスは制限されるため、インストール後にクラスターの証明書署名要求 (CSR) のメカニズムを提供する必要があります。kube-controller-manager は kubelet クライアント CSR のみを承認します。machine-approver は、kubelet 認証情報を使用して要求される提供証明書の有効性を保証できません。適切なマシンがこの要求を発行したかどうかを確認できないためです。kubelet 提供証明書の要求の有効性を検証し、それらを承認する方法を判別し、実装する必要があります。
10.3. クラウド用イメージの準備
各種のイメージ形式は AWS で直接使用できないので、Amazon Machine Images (AMI) が必要です。Red Hat が提供している AMI を使用するか、独自のイメージを手動でインポートできます。EC2 インスタンスをプロビジョニングする前に AMI が存在している必要があります。コンピュートマシンに必要な正しい RHEL バージョンを選択するには、AMI ID をリスト表示する必要があります。
10.3.1. AWS で利用可能な最新の RHEL イメージのリスト表示
AMI ID は、AWS のネイティブブートイメージに対応します。EC2 インスタンスがプロビジョニングされる前に AMI が存在している必要があるため、設定前に AMI ID を把握しておく必要があります。AWS コマンドラインインターフェイス (CLI) は、利用可能な Red Hat Enterprise Linux (RHEL) イメージ ID のリストを表示するために使用されます。
前提条件
- AWS CLI をインストールしている。
手順
このコマンドを使用して、RHEL 8.4 Amazon Machine Images (AMI) のリストを表示します。
$ aws ec2 describe-images --owners 309956199498 \1 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' \2 --filters "Name=name,Values=RHEL-8.4*" \3 --region us-east-1 \4 --output table5 - 1
--ownersコマンドオプションは、アカウント ID309956199498に基づいて Red Hat イメージを表示します。重要Red Hat が提供するイメージの AMI ID を表示するには、このアカウント ID が必要です。
- 2
--queryコマンドオプションは、イメージが'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]'のパラメーターでソートされる方法を設定します。この場合、イメージは作成日でソートされ、テーブルが作成日、イメージ名、および AMI ID を表示するように設定されます。- 3
--filterコマンドオプションは、表示される RHEL のバージョンを設定します。この例では、フィルターが"Name=name,Values=RHEL-8.4*"で設定されているため、RHEL 8.4 AMI が表示されます。- 4
--regionコマンドオプションは、AMI が保存されるリージョンを設定します。- 5
--outputコマンドオプションは、結果の表示方法を設定します。
AWS 用の RHEL コンピュートマシンを作成する場合、AMI が RHEL 8.4 または 8.5 であることを確認します。
出力例
------------------------------------------------------------------------------------------------------------
| DescribeImages |
+---------------------------+-----------------------------------------------------+------------------------+
| 2021-03-18T14:23:11.000Z | RHEL-8.4.0_HVM_BETA-20210309-x86_64-1-Hourly2-GP2 | ami-07eeb4db5f7e5a8fb |
| 2021-03-18T14:38:28.000Z | RHEL-8.4.0_HVM_BETA-20210309-arm64-1-Hourly2-GP2 | ami-069d22ec49577d4bf |
| 2021-05-18T19:06:34.000Z | RHEL-8.4.0_HVM-20210504-arm64-2-Hourly2-GP2 | ami-01fc429821bf1f4b4 |
| 2021-05-18T20:09:47.000Z | RHEL-8.4.0_HVM-20210504-x86_64-2-Hourly2-GP2 | ami-0b0af3577fe5e3532 |
+---------------------------+-----------------------------------------------------+------------------------+10.4. RHEL コンピュートノードの準備
Red Hat Enterprise Linux (RHEL) マシンを OpenShift Container Platform クラスターに追加する前に、各ホストを Red Hat Subscription Manager (RHSM) に登録し、有効な OpenShift Container Platform サブスクリプションをアタッチし、必要なリポジトリーを有効にする必要があります。NetworkManager が有効になり、ホスト上のすべてのインターフェイスを制御するように設定されていることを確認します。
各ホストで RHSM に登録します。
# subscription-manager register --username=<user_name> --password=<password>RHSM から最新のサブスクリプションデータをプルします。
# subscription-manager refresh利用可能なサブスクリプションをリスト表示します。
# subscription-manager list --available --matches '*OpenShift*'直前のコマンドの出力で、OpenShift Container Platform サブスクリプションのプール ID を見つけ、これをアタッチします。
# subscription-manager attach --pool=<pool_id>yum リポジトリーをすべて無効にします。
有効にされている RHSM リポジトリーをすべて無効にします。
# subscription-manager repos --disable="*"残りの yum リポジトリーをリスト表示し、
repo idにあるそれらの名前をメモします (ある場合) 。# yum repolistyum-config-managerを使用して、残りの yum リポジトリーを無効にします。# yum-config-manager --disable <repo_id>または、すべてのリポジトリーを無効にします。
# yum-config-manager --disable \*利用可能なリポジトリーが多い場合には、数分の時間がかかることがあります。
OpenShift Container Platform 4.11 で必要なリポジトリーのみを有効にします。
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.11-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"ホストで firewalld を停止し、無効にします。
# systemctl disable --now firewalld.service注記firewalld は、後で有効にすることはできません。これを実行する場合、ワーカー上の OpenShift Container Platform ログにはアクセスできません。
10.5. AWS での RHEL インスタンスへのロールパーミッションの割り当て
ブラウザーで Amazon IAM コンソールを使用して、必要なロールを選択し、ワーカーノードに割り当てることができます。
手順
- AWS IAM コンソールから、任意の IAM ロール を作成します。
- IAM ロール を必要なワーカーノードに割り当てます。
10.6. 所有または共有されている RHEL ワーカーノードへのタグ付け
クラスターは kubernetes.io/cluster/<clusterid>,Value=(owned|shared) タグの値を使用して、AWS クラスターに関するリソースの有効期間を判別します。
-
リソースをクラスターの破棄の一環として破棄する必要がある場合は、
ownedタグの値を追加する必要があります。 -
クラスターが破棄された後にリソースが引き続いて存在する場合、
sharedタグの値を追加する必要があります。このタグ付けは、クラスターがこのリソースを使用することを示しますが、リソースには別の所有者が存在します。
手順
-
RHEL コンピュートマシンの場合、RHEL ワーカーマシンでは、
kubernetes.io/cluster/<clusterid>=ownedまたはkubernetes.io/cluster/<cluster-id>=sharedでタグ付けする必要があります。
すべての既存セキュリティーグループに kubernetes.io/cluster/<name>,Value=<clusterid> のタグを付けないでください。 その場合、Elastic Load Balancing (ELB) がロードバランサーを作成できなくなります。
10.7. RHEL コンピュートマシンのクラスターへのさらなる追加
Red Hat Enterprise Linux (RHEL) をオペレーティングシステムとして使用するコンピュートマシンを OpenShift Container Platform 4.11 クラスターにさらに追加することができます。
前提条件
- OpenShift Container Platform クラスターに RHEL コンピュートノードがすでに含まれています。
-
最初の RHEL コンピュートマシンをクラスターに追加するために使用した
hostsファイルは、Playbook を実行するマシン上にあります。 - Playbook を実行するマシンは RHEL ホストにアクセスできる必要があります。Bastion と SSH プロキシーまたは VPN の使用など、所属する会社で許可されるすべての方法を利用できます。
-
クラスターの
kubeconfigファイルおよびクラスターのインストールに使用したインストールプログラムが Playbook の実行に使用するマシン上にあります。 - インストール用の RHEL ホストを準備する必要があります。
- すべての RHEL ホストへの SSH アクセスを持つユーザーを Playbook を実行するマシンで設定します。
- SSH キーベースの認証を使用する場合、キーを SSH エージェントで管理する必要があります。
-
Playbook を実行するマシンに OpenShift CLI (
oc) をインストールします。
手順
-
コンピュートマシンホストおよび必要な変数を定義する
/<path>/inventory/hostsにある Ansible インベントリーファイルを開きます。 -
ファイルの
[new_workers]セクションの名前を[workers]に変更します。 [new_workers]セクションをファイルに追加し、それぞれの新規ホストの完全修飾ドメイン名を定義します。ファイルは以下の例のようになります。[all:vars] ansible_user=root #ansible_become=True openshift_kubeconfig_path="~/.kube/config" [workers] mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com [new_workers] mycluster-rhel8-2.example.com mycluster-rhel8-3.example.comこの例では、
mycluster-rhel8-0.example.comおよびmycluster-rhel8-1.example.comマシンがクラスターにあり、mycluster-rhel8-2.example.comおよびmycluster-rhel8-3.example.comマシンを追加します。Ansible Playbook ディレクトリーに移動します。
$ cd /usr/share/ansible/openshift-ansibleスケールアップ Playbook を実行します。
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml1 - 1
<path>については、作成した Ansible インベントリーファイルへのパスを指定します。
10.8. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンについて 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードのアイデンティティーを確認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
10.9. Ansible ホストファイルの必須パラメーター
Red Hat Enterprise Linux (RHEL) コンピュートマシンをクラスターに追加する前に、以下のパラメーターを Ansible ホストファイルに定義する必要があります。
| パラメーター | 説明 | 値 |
|---|---|---|
|
| パスワードなしの SSH ベースの認証を許可する SSH ユーザー。SSH キーベースの認証を使用する場合、キーを SSH エージェントで管理する必要があります。 |
システム上のユーザー名。デフォルト値は |
|
|
|
|
|
|
クラスターの | 設定ファイルのパスと名前。 |
第11章 ユーザーがプロビジョニングしたインフラストラクチャーを手動で管理する
11.1. ユーザーがプロビジョニングしたインフラストラクチャーを使用してクラスターに計算マシンを手動で追加する
インストールプロセスの一環として、あるいはインストール後に、ユーザーによってプロビジョニングされるインフラストラクチャーのクラスターにコンピュートマシンを追加できます。インストール後のプロセスでは、インストール時に使用されたものと同じ設定ファイルおよびパラメーターの一部が必要です。
11.1.1. コンピュートマシンの Amazon Web Services への追加
Amazon Web Services (AWS) 上の OpenShift Container Platform クラスターにコンピュートマシンを追加するには、CloudFormation テンプレートの使用によるコンピュートマシンの AWS への追加 を参照してください。
11.1.2. コンピュートマシンの Microsoft Azure への追加
Microsoft Azure 上の OpenShift Container Platform クラスターにコンピュートマシンを追加するには、Creating additional worker machines in Azure を参照してください。
11.1.3. コンピュートマシンの Azure Stack Hub への追加
Azure Stack Hub 上の OpenShift Container Platform クラスターにコンピュートマシンを追加するには、Creating additional worker machines in Azure Stack Hub を参照してください。
11.1.4. コンピュートマシンの Google Cloud Platform への追加
Google Cloud Platform (GCP) 上の OpenShift Container Platform クラスターにコンピュートマシンを追加するには、Creating additional worker machines in GCP を参照してください。
11.1.5. コンピュートマシンの vSphere への追加
コンピューティングマシンセットを使用して、vSphere 上の OpenShift Container Platform クラスター用の追加のコンピューティングマシンの作成を自動化できます。
クラスターにコンピューティングマシンを手動で追加するには、コンピューティングマシンを vSphere に手動で追加する を参照してください。
11.1.6. RHV へのコンピュートマシンの追加
RHV 上の OpenShift Container Platform クラスターにコンピュートマシンをさらに追加するには、Adding compute machines to RHV を参照してください。
11.1.7. コンピュートマシンのベアメタルへの追加
ベアメタル上の OpenShift Container Platform クラスターにコンピュートマシンを追加するには、コンピュートマシンのベアメタルへの追加 を参照してください。
11.2. CloudFormation テンプレートの使用によるコンピュートマシンの AWS への追加
サンプルの CloudFormation テンプレートを使用して作成した Amazon Web Services (AWS) の OpenShift Container Platform クラスターにコンピュートマシンを追加することができます。
11.2.1. 前提条件
- 提供される AWS CloudFormation テンプレート を使用して AWS にクラスターをインストールしている。
- クラスターのインストール時にコンピュートマシンを作成するために使用した JSON ファイルおよび CloudFormation テンプレートがある。これらのファイルがない場合は、インストール手順 に従ってこれらを作成する必要があります。
11.2.2. CloudFormation テンプレートの使用によるコンピュートマシンの AWS クラスターへの追加
サンプルの CloudFormation テンプレートを使用して作成した Amazon Web Services (AWS) の OpenShift Container Platform クラスターにコンピュートマシンを追加することができます。
CloudFormation テンプレートは、1 つのコンピュートマシンを表すスタックを作成します。それぞれのコンピュートマシンにスタックを作成する必要があります。
提供される CloudFormation テンプレートを使用してコンピュートノードを作成しない場合、提供される情報を確認し、インフラストラクチャーを手動で作成する必要があります。クラスターが適切に初期化されない場合、インストールログを用意して Red Hat サポートに問い合わせする必要がある可能性があります。
前提条件
- CloudFormation テンプレートを使用して OpenShift Container Platform クラスターをインストールし、クラスターのインストール時にコンピュートマシンの作成に使用した JSON ファイルおよび CloudFormation テンプレートにアクセスできる。
- AWS CLI をインストールしている。
手順
別のコンピュートスタックを作成します。
テンプレートを起動します。
$ aws cloudformation create-stack --stack-name <name> \1 --template-body file://<template>.yaml \2 --parameters file://<parameters>.json3 テンプレートのコンポーネントが存在することを確認します。
$ aws cloudformation describe-stacks --stack-name <name>
- クラスターに作成するコンピュートマシンが十分な数に達するまでコンピュートスタックの作成を継続します。
11.2.3. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンについて 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードのアイデンティティーを確認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
11.3. コンピューティングマシンを vSphere に手動で追加する
コンピュートマシンを VMware vSphere の OpenShift Container Platform クラスターに追加することができます。
また、コンピューティングマシンセットを使用して クラスター用の追加の VMware vSphere コンピュートマシンの作成を自動化することもできます。
11.3.1. 前提条件
- クラスターを vSphere にインストールしている。
- クラスターの作成に使用したインストールメディアおよび Red Hat Enterprise Linux CoreOS (RHCOS) イメージがある。これらのファイルがない場合は、インストール手順 に従ってこれらを取得する必要があります。
クラスターの作成に使用された Red Hat Enterprise Linux CoreOS (RHCOS) イメージへのアクセスがない場合、より新しいバージョンの Red Hat Enterprise Linux CoreOS (RHCOS) イメージと共にコンピュートマシンを OpenShift Container Platform クラスターに追加できます。手順については、OpenShift 4.6+ へのアップグレード後の新規ノードの UPI クラスターへの追加の失敗 について参照してください。
11.3.2. vSphere でのコンピュートマシンのクラスターへの追加
コンピュートマシンを VMware vSphere のユーザーがプロビジョニングした OpenShift Container Platform クラスターに追加することができます。
前提条件
- コンピュートマシンの base64 でエンコードされた Ignition ファイルを取得します。
- クラスター用に作成した vSphere テンプレートにアクセスできる必要があります。
手順
テンプレートがデプロイされた後に、マシンの仮想マシンをクラスターにデプロイします。
- テンプレートの名前を右クリックし、Clone → Clone to Virtual Machine をクリックします。
Select a name and folder タブで、仮想マシンの名前を指定します。
compute-1などのように、マシンタイプを名前に含めることができるかもしれません。注記vSphere インストール全体のすべての仮想マシン名が一意であることを確認してください。
- Select a name and folder タブで、クラスターに作成したフォルダーの名前を選択します。
- Select a compute resource タブで、データセンター内のホストの名前を選択します。
- Select clone options で、Customize this virtual machine's hardware を選択します。
Customize hardware タブで、VM Options → Advanced をクリックします。
Edit Configuration をクリックし、Configuration Parameters ウィンドウで Add Configuration Params をクリックします。以下のパラメーター名および値を定義します。
-
guestinfo.ignition.config.data: このマシンファイルの base64 でエンコードしたコンピュート Ignition 設定ファイルの内容を貼り付けます。 -
guestinfo.ignition.config.data.encoding:base64を指定します。 -
disk.EnableUUID:TRUEを指定します。
-
- Customize hardware タブの Virtual Hardware パネルで、必要に応じて指定した値を変更します。RAM、CPU、およびディスクストレージの量がマシンタイプの最小要件を満たすことを確認してください。また、ネットワークが複数利用可能な場合は、必ず Add network adapter に正しいネットワークを選択してください。
- 設定を完了し、仮想マシンの電源をオンにします。
- 継続してクラスター用の追加のコンピュートマシンを作成します。
11.3.3. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンについて 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードのアイデンティティーを確認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
11.4. RHV 上のクラスターへのコンピュートマシンの追加
OpenShift Container Platform バージョン 4.11 では、RHV 上でユーザーがプロビジョニングした OpenShift Container Platform クラスターにコンピュートマシンをさらに追加できます。
前提条件
- ユーザーによってプロビジョニングされたインフラストラクチャーを使用して、RHV 上にクラスターをインストールしている。
11.4.1. RHV 上のクラスターへのコンピュートマシンの追加
手順
-
inventory.ymlファイルを変更して、新規ワーカーを含めます。 create-templates-and-vmsAnsible Playbook を実行して、ディスクと仮想マシンを作成します:$ ansible-playbook -i inventory.yml create-templates-and-vms.ymlworker.ymlAnsible Playbook を実行して、仮想マシンを起動します:$ ansible-playbook -i inventory.yml workers.ymlクラスターに結合する新規ワーカーの CSR は、管理者によって承認される必要があります。次のコマンドは、保留中のすべてのリクエストを承認するのに役立ちます。
$ oc get csr -ojson | jq -r '.items[] | select(.status == {} ) | .metadata.name' | xargs oc adm certificate approve
11.5. コンピュートマシンのベアメタルへの追加
ベアメタルの OpenShift Container Platform クラスターにコンピュートマシンを追加することができます。
11.5.1. 前提条件
- クラスターをベアメタルにインストールしている。
- クラスターの作成に使用したインストールメディアおよび Red Hat Enterprise Linux CoreOS (RHCOS) イメージがある。これらのファイルがない場合は、インストール手順 に従ってこれらを取得する必要があります。
- ユーザーがプロビジョニングするインフラストラクチャーに DHCP サーバーを利用できる場合には追加のコンピュートマシンの詳細を DHCP サーバー設定に追加している。これには、永続的な IP アドレス、DNS サーバー情報、および各マシンのホスト名が含まれます。
- 追加する各コンピュートマシンのレコード名と IP アドレスを追加するように DNS 設定を更新している。DNS ルックアップおよび逆引き DNS ルックアップが正しく解決されていることを検証している。
クラスターの作成に使用された Red Hat Enterprise Linux CoreOS (RHCOS) イメージへのアクセスがない場合、より新しいバージョンの Red Hat Enterprise Linux CoreOS (RHCOS) イメージと共にコンピュートマシンを OpenShift Container Platform クラスターに追加できます。手順については、OpenShift 4.6+ へのアップグレード後の新規ノードの UPI クラスターへの追加の失敗 について参照してください。
11.5.2. Red Hat Enterprise Linux CoreOS (RHCOS) マシンの作成
ベアメタルインフラストラクチャーにインストールされているクラスターにコンピュートマシンを追加する前に、それが使用する RHCOS マシンを作成する必要があります。ISO イメージまたはネットワーク PXE ブートを使用してマシンを作成できます。
クラスターに新しいノードをすべてデプロイするには、クラスターのインストールに使用した ISO イメージと同じ ISO イメージを使用する必要があります。同じ Ignition 設定ファイルを使用することが推奨されます。ノードは、ワークロードを実行する前に初回起動時に自動的にアップグレードされます。アップグレードの前後にノードを追加することができます。
11.5.2.1. ISO イメージを使用した追加の RHCOS マシンの作成
ISO イメージを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
手順
ISO ファイルを使用して、追加のコンピュートマシンに RHCOS をインストールします。クラスターのインストール前にマシンを作成する際に使用したのと同じ方法を使用します。
- ディスクに ISO イメージを書き込み、これを直接起動します。
- LOM インターフェイスで ISO リダイレクトを使用します。
オプションを指定したり、ライブ起動シーケンスを中断したりせずに、RHCOS ISO イメージを起動します。インストーラーが RHCOS ライブ環境でシェルプロンプトを起動するのを待ちます。
注記RHCOS インストールの起動プロセスを中断して、カーネル引数を追加できます。ただし、この ISO 手順では、カーネル引数を追加する代わりに、次の手順で概説するように
coreos-installerコマンドを使用する必要があります。coreos-installerコマンドを実行し、インストール要件を満たすオプションを指定します。少なくとも、ノードタイプの Ignition 設定ファイルを参照する URL と、インストール先のデバイスを指定する必要があります。$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest>1 2 注記TLS を使用する HTTPS サーバーを使用して Ignition 設定ファイルを提供する必要がある場合は、
coreos-installerを実行する前に内部認証局 (CA) をシステム信頼ストアに追加できます。以下の例では、
/dev/sdaデバイスへのブートストラップノードのインストールを初期化します。ブートストラップノードの Ignition 設定ファイルは、IP アドレス 192.168.1.2 で HTTP Web サーバーから取得されます。$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/bootstrap.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3bマシンのコンソールで RHCOS インストールの進捗を監視します。
重要OpenShift Container Platform のインストールを開始する前に、各ノードでインストールが成功していることを確認します。インストールプロセスを監視すると、発生する可能性のある RHCOS インストールの問題の原因を特定する上でも役立ちます。
- 継続してクラスター用の追加のコンピュートマシンを作成します。
11.5.2.2. PXE または iPXE ブートによる追加の RHCOS マシンの作成
PXE または iPXE ブートを使用して、ベアメタルクラスターの追加の Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンを作成できます。
前提条件
- クラスターのコンピュートマシンの Ignition 設定ファイルの URL を取得します。このファイルがインストール時に HTTP サーバーにアップロードされている必要があります。
-
クラスターのインストール時に HTTP サーバーにアップロードした RHCOS ISO イメージ、圧縮されたメタル BIOS、
kernel、およびinitramfsファイルの URL を取得します。 - インストール時に OpenShift Container Platform クラスターのマシンを作成するために使用した PXE ブートインフラストラクチャーにアクセスできる必要があります。RHCOS のインストール後にマシンはローカルディスクから起動する必要があります。
-
UEFI を使用する場合、OpenShift Container Platform のインストール時に変更した
grub.confファイルにアクセスできます。
手順
RHCOS イメージの PXE または iPXE インストールが正常に行われていることを確認します。
PXE の場合:
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture>1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img2 - 1
- HTTP サーバーにアップロードしたライブ
kernelファイルの場所を指定します。 - 2
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
initrdパラメーターはライブinitramfsファイルの場所であり、coreos.inst.ignition_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.live.rootfs_urlパラメーター値はライブrootfsファイルの場所になります。coreos.inst.ignition_urlおよびcoreos.live.rootfs_urlパラメーターは HTTP および HTTPS のみをサポートします。
この設定では、グラフィカルコンソールを使用するマシンでシリアルコンソールアクセスを有効にしません。別のコンソールを設定するには、APPEND 行に 1 つ以上の console= 引数を追加します。たとえば、console=tty0 console=ttyS0 を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? を参照してください。
iPXE の場合:
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img1 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img2 - 1
- HTTP サーバーにアップロードした RHCOS ファイルの場所を指定します。
kernelパラメーター値はkernelファイルの場所であり、initrd=main引数は UEFI システムでの起動に必要であり、coreos.inst.ignition_urlパラメーター値はワーカー Ignition 設定ファイルの場所であり、coreos.live.rootfs_urlパラメーター値はrootfsのライブファイルの場所です。coreos.inst.ignition_urlおよびcoreos.live.rootfs_urlパラメーターは HTTP および HTTPS のみをサポートします。 - 2
- HTTP サーバーにアップロードした
initramfsファイルの場所を指定します。
この設定では、グラフィカルコンソールを使用するマシンでシリアルコンソールアクセスを有効にしません。別のコンソールを設定するには、kernel 行に console= 引数を 1 つ以上追加します。たとえば、console=tty0 console=ttyS0 を追加して、最初の PC シリアルポートをプライマリーコンソールとして、グラフィカルコンソールをセカンダリーコンソールとして設定します。詳細は、How does one set up a serial terminal and/or console in Red Hat Enterprise Linux? を参照してください。
- PXE または iPXE インフラストラクチャーを使用して、クラスターに必要なコンピュートマシンを作成します。
11.5.3. マシンの証明書署名要求の承認
マシンをクラスターに追加する際に、追加したそれぞれのマシンについて 2 つの保留状態の証明書署名要求 (CSR) が生成されます。これらの CSR が承認されていることを確認するか、必要な場合はそれらを承認してください。最初にクライアント要求を承認し、次にサーバー要求を承認する必要があります。
前提条件
- マシンがクラスターに追加されています。
手順
クラスターがマシンを認識していることを確認します。
$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.24.0 master-1 Ready master 63m v1.24.0 master-2 Ready master 64m v1.24.0出力には作成したすべてのマシンがリスト表示されます。
注記上記の出力には、一部の CSR が承認されるまで、ワーカーノード (ワーカーノードとも呼ばれる) が含まれない場合があります。
保留中の証明書署名要求 (CSR) を確認し、クラスターに追加したそれぞれのマシンのクライアントおよびサーバー要求に
PendingまたはApprovedステータスが表示されていることを確認します。$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...この例では、2 つのマシンがクラスターに参加しています。このリストにはさらに多くの承認された CSR が表示される可能性があります。
追加したマシンの保留中の CSR すべてが
Pendingステータスになった後に CSR が承認されない場合には、クラスターマシンの CSR を承認します。注記CSR のローテーションは自動的に実行されるため、クラスターにマシンを追加後 1 時間以内に CSR を承認してください。1 時間以内に承認しない場合には、証明書のローテーションが行われ、各ノードに 3 つ以上の証明書が存在するようになります。これらの証明書すべてを承認する必要があります。クライアントの CSR が承認された後に、Kubelet は提供証明書のセカンダリー CSR を作成します。これには、手動の承認が必要になります。次に、後続の提供証明書の更新要求は、Kubelet が同じパラメーターを持つ新規証明書を要求する場合に
machine-approverによって自動的に承認されます。注記ベアメタルおよび他の user-provisioned infrastructure などのマシン API ではないプラットフォームで実行されているクラスターの場合、kubelet 提供証明書要求 (CSR) を自動的に承認する方法を実装する必要があります。要求が承認されない場合、API サーバーが kubelet に接続する際に提供証明書が必須であるため、
oc exec、oc rsh、およびoc logsコマンドは正常に実行できません。Kubelet エンドポイントにアクセスする操作には、この証明書の承認が必要です。この方法は新規 CSR の有無を監視し、CSR がsystem:nodeまたはsystem:adminグループのnode-bootstrapperサービスアカウントによって提出されていることを確認し、ノードのアイデンティティーを確認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approve注記一部の Operator は、一部の CSR が承認されるまで利用できない可能性があります。
クライアント要求が承認されたら、クラスターに追加した各マシンのサーバー要求を確認する必要があります。
$ oc get csr出力例
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...残りの CSR が承認されず、それらが
Pendingステータスにある場合、クラスターマシンの CSR を承認します。それらを個別に承認するには、それぞれの有効な CSR について以下のコマンドを実行します。
$ oc adm certificate approve <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
すべての保留中の CSR を承認するには、以下のコマンドを実行します。
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
すべてのクライアントおよびサーバーの CSR が承認された後に、マシンのステータスが
Readyになります。以下のコマンドを実行して、これを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.24.0 master-1 Ready master 73m v1.24.0 master-2 Ready master 74m v1.24.0 worker-0 Ready worker 11m v1.24.0 worker-1 Ready worker 11m v1.24.0注記サーバー CSR の承認後にマシンが
Readyステータスに移行するまでに数分の時間がかかる場合があります。
関連情報
- CSR の詳細は、Certificate Signing Requests を参照してください。
第12章 Cluster API によるマシンの管理
Cluster API を使用したマシン管理は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
Cluster API は、Amazon Web Services (AWS) および Google Cloud Platform (GCP) クラスターのテクノロジープレビューとして OpenShift Container Platform に統合されるアップストリームプロジェクトです。クラスター API を使用して、OpenShift Container Platform クラスターでマシンセットとマシンを作成および管理できます。この機能は、Machine API を使用してマシンを管理するための追加または代替の機能になります。
OpenShift Container Platform 4.11 クラスターの場合、クラスター API を使用して、クラスターのインストールが完了した後にノードホストのプロビジョニング管理アクションを実行できます。このシステムにより、パブリックまたはプライベートクラウドインフラストラクチャー上で柔軟かつ動的な方法でプロビジョニングできます。
Cluster API テクノロジープレビューを使用すると、サポートされているプロバイダーの OpenShift Container Platform クラスター上にコンピュートマシンおよびマシンセットを作成できます。Machine API では利用できない可能性がある、この実装によって有効になる機能も確認できます。
利点
Cluster API を使用することで、OpenShift Container Platform ユーザーおよび開発者には以下の利点がもたらされます。
- Machine API でサポートされていない可能性があるアップストリームコミュニティーの Cluster API インフラストラクチャープロバイダーを使用するオプション。
- インフラストラクチャープロバイダーのマシンコントローラーを保守するサードパーティーと協力する機会。
- OpenShift Container Platform でのインフラストラクチャー管理に一連の同じ Kubernetes ツールを使用する機能。
- Machine API では利用できない機能をサポートする Cluster API を使用してマシンセットを作成する機能。
制限事項
Cluster API を使用したマシン管理はテクノロジープレビュー機能であり、次の制限があります。
- サポート対象は AWS および GCP クラスターのみです。
-
この機能を使用するには、
TechPreviewNoUpgrade機能セット を有効にする必要があります。この機能セットを有効にすると元に戻すことができなくなり、マイナーバージョン更新ができなくなります。 - クラスター API が必要とするプライマリーリソースを手動で作成する必要があります。
- コントロールプレーンマシンは、Cluster API では管理できません。
- Machine API によって作成された既存のマシンセットの、Cluster API マシンセットへの移行はサポートされていません。
- Machine API との完全な機能パリティーは利用できません。
12.1. Cluster API アーキテクチャー
アップストリーム Cluster API の OpenShift Container Platform 統合は、Cluster CAPI Operator によって実装および管理されます。Cluster CAPI Operator とそのオペランドは、openshift-machine-api namespace を使用する Machine API とは対照的に、openshift-cluster-api namespace でプロビジョニングされます。
12.1.1. Cluster CAPI Operator
Cluster CAPI Operator は、Cluster API リソースのライフサイクルを維持する OpenShift Container Platform Operator です。この Operator は、OpenShift Container Platform クラスター内での Cluster API プロジェクトのデプロイに関連するすべての管理タスクを行います。
Cluster API の使用を許可するようにクラスターが正しく設定されている場合、Cluster CAPI Operator は Cluster API Operator をクラスターにインストールします。
Cluster CAPI Operator は、アップストリームの Cluster API Operator とは異なります。
詳細については、Cluster Operators リファレンス コンテンツの Cluster CAPI Operator のエントリーを参照してください。
12.1.2. プライマリーリソース
Cluster API は、次のプライマリーリソースで設定されています。この機能のテクノロジープレビューでは、openshift-cluster-api namespace でこれらのリソースを手動で作成する必要があります。
- クラスター
- Cluster API によって管理されるクラスターを表す基本単位。
- インフラストラクチャー
- リージョンやサブネットなど、クラスター内のすべてのマシンセットで共有されるプロパティーを定義するプロバイダー固有のリソース。
- マシンテンプレート
- マシンセットが作成するマシンのプロパティーを定義するプロバイダー固有のテンプレート。
- マシンセット
マシンのグループ。
マシンセットとマシンの関係は、レプリカセットと Pod の関係と同様です。マシンを追加する必要がある場合や、マシンの数を縮小したりする必要がある場合、コンピューティングのニーズに応じてマシンセットの
replicasフィールドを変更します。Cluster API を使用すると、マシンセットは
Clusterオブジェクトとプロバイダー固有のマシンテンプレートを参照します。- マシン
ノードのホストを記述する基本的なユニットです。
Cluster API は、マシンテンプレートの設定に基づいてマシンを作成します。
12.2. サンプル YAML ファイル
Cluster API テクノロジープレビューの場合、Cluster API が必要とするプライマリーリソースを手動で作成する必要があります。このセクションのサンプル YAML ファイルは、これらのリソースを連携させて、それらが作成するマシンを環境に応じて設定する方法を示しています。
12.2.1. Cluster API クラスターリソースのサンプル YAML
クラスターリソースは、クラスターの名前とインフラストラクチャープロバイダーを定義し、Cluster API によって管理されます。このリソースは、すべてのプロバイダーで同じ構造を持っています。
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: <cluster_name>
namespace: openshift-cluster-api
spec:
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: <infrastructure_kind>
name: <cluster_name>
namespace: openshift-cluster-api残りはプロバイダー固有の Cluster API リソースです。クラスターのサンプル YAML ファイルを参照してください。
12.2.2. Amazon Web Services クラスターを設定するサンプル YAML ファイル
一部の Cluster API リソースはプロバイダー固有です。このセクションのサンプル YAML ファイル、Amazon Web Services (AWS) クラスターの設定を示しています。
12.2.2.1. Amazon Web Services 上の Cluster API インフラストラクチャーリソースのサンプル YAML
インフラストラクチャーリソースはプロバイダー固有であり、リージョンやサブネットなど、クラスター内のすべてのマシンセットで共有されるプロパティーを定義します。マシンセットは、マシン作成時にこのリソースを参照します。
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: AWSCluster
metadata:
name: <cluster_name>
namespace: openshift-cluster-api
spec:
region: <region> 12.2.2.2. Amazon Web Services の Cluster API マシンテンプレートリソースのサンプル YAML
マシンテンプレートリソースはプロバイダー固有であり、マシンセットが作成するマシンの基本的なプロパティーを定義します。マシンセットは、マシン作成時にこのテンプレートを参照します。
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4
kind: AWSMachineTemplate
metadata:
name: <template_name>
namespace: openshift-cluster-api
spec:
template:
spec:
uncompressedUserData: true
iamInstanceProfile: ....
instanceType: m5.large
cloudInit:
insecureSkipSecretsManager: true
ami:
id: ....
subnet:
filters:
- name: tag:Name
values:
- ...
additionalSecurityGroups:
- filters:
- name: tag:Name
values:
- ...12.2.2.3. Amazon Web Services の Cluster API マシンセットリソースのサンプル YAML
マシンセットリソースは、作成するマシンの追加プロパティーを定義します。マシンセットは、マシン作成時にインフラストラクチャーリソースとマシンテンプレートも参照します。
apiVersion: cluster.x-k8s.io/v1alpha4
kind: MachineSet
metadata:
name: <machine_set_name>
namespace: openshift-cluster-api
spec:
clusterName: <cluster_name>
replicas: 1
selector:
matchLabels:
test: example
template:
metadata:
labels:
test: example
spec:
bootstrap:
dataSecretName: worker-user-data
clusterName: <cluster_name>
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4
kind: AWSMachineTemplate
name: <cluster_name> 12.2.3. Google Cloud Platform クラスターを設定するサンプル YAML ファイル
一部の Cluster API リソースはプロバイダー固有です。このセクションのサンプル YAML ファイルは、Google Cloud Platform (GCP) クラスターの設定を示しています。
12.2.3.1. Google Cloud Platform 上の Cluster API インフラストラクチャーリソースのサンプル YAML
インフラストラクチャーリソースはプロバイダー固有であり、リージョンやサブネットなど、クラスター内のすべてのマシンセットで共有されるプロパティーを定義します。マシンセットは、マシン作成時にこのリソースを参照します。
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: GCPCluster
metadata:
name: <cluster_name>
spec:
network:
name: <cluster_name>-network
project: <project>
region: <region> 12.2.3.2. Google Cloud Platform 上の Cluster API マシンテンプレートリソースのサンプル YAML
マシンテンプレートリソースはプロバイダー固有であり、マシンセットが作成するマシンの基本的なプロパティーを定義します。マシンセットは、マシン作成時にこのテンプレートを参照します。
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: GCPMachineTemplate
metadata:
name: <template_name>
namespace: openshift-cluster-api
spec:
template:
spec:
rootDeviceType: pd-ssd
rootDeviceSize: 128
instanceType: n1-standard-4
image: projects/rhcos-cloud/global/images/rhcos-411-85-202203181601-0-gcp-x86-64
subnet: <cluster_name>-worker-subnet
serviceAccounts:
email: <service_account_email_address>
scopes:
- https://www.googleapis.com/auth/cloud-platform
additionalLabels:
kubernetes-io-cluster-<cluster_name>: owned
additionalNetworkTags:
- <cluster_name>-worker
ipForwarding: Disabled12.2.3.3. Google Cloud Platform 上の Cluster API マシンセットリソースのサンプル YAML
マシンセットリソースは、作成するマシンの追加プロパティーを定義します。マシンセットは、マシン作成時にインフラストラクチャーリソースとマシンテンプレートも参照します。
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineSet
metadata:
name: <machine_set_name>
namespace: openshift-cluster-api
spec:
clusterName: <cluster_name>
replicas: 1
selector:
matchLabels:
test: test
template:
metadata:
labels:
test: test
spec:
bootstrap:
dataSecretName: worker-user-data
clusterName: <cluster_name>
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: GCPMachineTemplate
name: <machine_set_name>
failureDomain: <failure_domain> 12.3. Cluster API マシンセットの作成
Cluster API を使用して、選択した特定のワークロードのマシンコンピューティングリソースを動的に管理するマシンセットを作成できます。
前提条件
- OpenShift Container Platform クラスターをデプロイすること。
- Cluster API の使用を有効にします。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
クラスターカスタムリソース (CR) を含む、
<cluster_resource_file>.yamlという名前の YAML ファイルを作成します。<cluster_name>パラメーターに設定する値がわからない場合は、クラスターに設定されている既存の Machine API マシンの値を確認してください。Machine API マシンセットをリスト表示するには、次のコマンドを実行します。
$ oc get machinesets -n openshift-machine-api1 - 1
openshift-machine-apinamespace を指定します。
出力例
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m特定のマシンセット CR の内容を表示するには、次のコマンドを実行します。
$ oc get machineset <machineset_name> \ -n openshift-machine-api \ -o yaml出力例
... template: metadata: labels: machine.openshift.io/cluster-api-cluster: agl030519-vplxk1 machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: agl030519-vplxk-worker-us-east-1a ...- 1
<cluster_name>パラメーターに使用するクラスター ID。
次のコマンドを実行して、クラスターを作成します。
$ oc create -f <cluster_resource_file>.yaml検証
クラスター CR が作成されたことを確認するには、次のコマンドを実行します。
$ oc get cluster出力例
NAME PHASE AGE VERSION <cluster_name> Provisioning 4h6m-
インフラストラクチャー CR を含む、
<infrastructure_resource_file>.yamlという名前の YAML ファイルを作成します。 次のコマンドを実行して、インフラストラクチャー CR を作成します。
$ oc create -f <infrastructure_resource_file>.yaml検証
インフラストラクチャー CR が作成されたことを確認するには、次のコマンドを実行します。
$ oc get <infrastructure_kind><infrastructure_kind>は、プラットフォームに対応する値です。出力例
NAME CLUSTER READY VPC BASTION IP <cluster_name> <cluster_name> true-
マシンテンプレート CR を含む、
<machine_template_resource_file>.yamlという名前の YAML ファイルを作成します。 次のコマンドを実行して、マシンテンプレート CR を作成します。
$ oc create -f <machine_template_resource_file>.yaml検証
マシンテンプレート CR が作成されたことを確認するには、次のコマンドを実行します。
$ oc get <machine_template_kind><machine_template_kind>は、プラットフォームに対応する値です。出力例
NAME AGE <template_name> 77m-
マシンセット CR を含む、
<machine_set_resource_file>.yamlという名前の YAML ファイルを作成します。 次のコマンドを実行して、マシンセット CR を作成します。
$ oc create -f <machine_set_resource_file>.yaml検証
マシンセット CR が作成されたことを確認するには、次のコマンドを実行します。
$ oc get machineset -n openshift-cluster-api1 - 1
openshift-cluster-apinamespace を指定します。
出力例
NAME CLUSTER REPLICAS READY AVAILABLE AGE VERSION <machine_set_name> <cluster_name> 1 1 1 17m新しいマシンセットが利用可能な場合、
REPLICASとAVAILABLEの値が一致します。マシンセットが利用可能でない場合、数分待機してからコマンドを再度実行します。
検証
マシンセットが指定した設定に従ってマシンを作成していることを確認するには、クラスター内のマシンとノードのリストを確認します。
Cluster API マシンのリストを表示するには、次のコマンドを実行します。
$ oc get machine -n openshift-cluster-api1 - 1
openshift-cluster-apinamespace を指定します。
出力例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION <machine_set_name>-<string_id> <cluster_name> <ip_address>.<region>.compute.internal <provider_id> Running 8m23sノードのリストを表示するには、次のコマンドを実行します。
$ oc get node出力例
NAME STATUS ROLES AGE VERSION <ip_address_1>.<region>.compute.internal Ready worker 5h14m v1.24.0+284d62a <ip_address_2>.<region>.compute.internal Ready master 5h19m v1.24.0+284d62a <ip_address_3>.<region>.compute.internal Ready worker 7m v1.24.0+284d62a
12.4. Cluster API を使用するクラスターのトラブルシューティング
このセクションの情報を使用して、発生する可能性のある問題を理解し、回復してください。通常、Cluster API に関する問題のトラブルシューティング手順は、マシン API に関する問題の手順と似ています。
Cluster CAPI Operator とそのオペランドは openshift-cluster-api namespace でプロビジョニングされますが、マシン API は openshift-machine-api namespace を使用します。namespace を参照する oc コマンドを使用する場合は、必ず正しい namespace を参照してください。
12.4.1. CLI コマンドで返される Cluster API マシン
Cluster API を使用するクラスターの場合、oc get machine などの oc コマンドは、Cluster API マシンの結果を返します。c の文字はアルファベット順で m の前にあるため、Cluster API マシンは Machine API マシンより前に返されます。
Machine API マシンのみをリスト表示するには、
oc get machineコマンドを実行する際に、完全修飾名machines.machine.openshift.ioを使用します。$ oc get machines.machine.openshift.ioCluster API マシンのみをリスト表示するには、
oc get machineコマンドを実行する際に、完全修飾名machines.cluster.x-k8s.ioを使用します。$ oc get machines.cluster.x-k8s.io
第13章 マシンヘルスチェックのデプロイ
マシンヘルスチェックを設定し、デプロイして、マシンプールにある破損したマシンを自動的に修復します。
高度なマシン管理およびスケーリング機能は、マシン API が機能しているクラスターでのみ使用することができます。user-provisioned infrastructure を持つクラスターでは、マシン API を使用するために追加の検証と設定が必要です。
インフラストラクチャープラットフォームタイプが none のクラスターは、マシン API を使用できません。この制限は、クラスターに接続されている計算マシンが、この機能をサポートするプラットフォームにインストールされている場合でも適用されます。このパラメーターは、インストール後に変更することはできません。
クラスターのプラットフォームタイプを表示するには、以下のコマンドを実行します。
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'13.1. マシンのヘルスチェック
マシンのヘルスチェックは特定のマシンプールの正常ではないマシンを自動的に修復します。
マシンの正常性を監視するには、リソースを作成し、コントローラーの設定を定義します。5 分間 NotReady ステータスにすることや、 node-problem-detector に永続的な条件を表示すること、および監視する一連のマシンのラベルなど、チェックする条件を設定します。
マスターロールのあるマシンにマシンヘルスチェックを適用することはできません。
MachineHealthCheck リソースを監視するコントローラーは定義済みのステータスをチェックします。マシンがヘルスチェックに失敗した場合、このマシンは自動的に検出され、その代わりとなるマシンが作成されます。マシンが削除されると、machine deleted イベントが表示されます。
マシンの削除による破壊的な影響を制限するために、コントローラーは 1 度に 1 つのノードのみをドレイン (解放) し、これを削除します。マシンのターゲットプールで許可される maxUnhealthy しきい値を上回る数の正常でないマシンがある場合、修復が停止するため、手動による介入が可能になります。
タイムアウトについて注意深い検討が必要であり、ワークロードと要件を考慮してください。
- タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
-
タイムアウトが短すぎると、修復ループが生じる可能性があります。たとえば、
NotReadyステータスを確認するためのタイムアウトについては、マシンが起動プロセスを完了できるように十分な時間を設定する必要があります。
チェックを停止するには、リソースを削除します。
13.1.1. マシンヘルスチェックのデプロイ時の制限
マシンヘルスチェックをデプロイする前に考慮すべき制限事項があります。
- マシンセットが所有するマシンのみがマシンヘルスチェックによって修復されます。
- コントロールプレーンマシンは現在サポートされておらず、それらが正常でない場合にも修正されません。
- マシンのノードがクラスターから削除される場合、マシンヘルスチェックはマシンが正常ではないとみなし、すぐにこれを修復します。
-
nodeStartupTimeoutの後にマシンの対応するノードがクラスターに加わらない場合、マシンは修復されます。 -
MachineリソースフェーズがFailedの場合、マシンはすぐに修復されます。
13.2. サンプル MachineHealthCheck リソース
ベアメタルを除くすべてのクラウドベースのインストールタイプの MachineHealthCheck リソースは、以下の YAML ファイルのようになります。
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- デプロイするマシンヘルスチェックの名前を指定します。
- 2 3
- チェックする必要のあるマシンプールのラベルを指定します。
- 4
- 追跡するマシンセットを
<cluster_name>-<label>-<zone>形式で指定します。たとえば、prod-node-us-east-1aとします。 - 5 6
- ノードの状態のタイムアウト期間を指定します。タイムアウト期間の条件が満たされると、マシンは修正されます。タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
- 7
- ターゲットプールで同時に修復できるマシンの数を指定します。これはパーセンテージまたは整数として設定できます。正常でないマシンの数が
maxUnhealthyで設定された制限を超える場合、修復は実行されません。 - 8
- マシンが正常でないと判別される前に、ノードがクラスターに参加するまでマシンヘルスチェックが待機する必要のあるタイムアウト期間を指定します。
matchLabels はあくまでもサンプルであるため、特定のニーズに応じてマシングループをマッピングする必要があります。
13.2.1. マシンヘルスチェックによる修復の一時停止 (short-circuiting)
一時停止 (short-circuiting) が実行されることにより、マシンのヘルスチェックはクラスターが正常な場合にのみマシンを修復するようになります。一時停止 (short-circuiting) は、MachineHealthCheck リソースの maxUnhealthy フィールドで設定されます。
ユーザーがマシンの修復前に maxUnhealthy フィールドの値を定義する場合、MachineHealthCheck は maxUnhealthy の値を、正常でないと判別するターゲットプール内のマシン数と比較します。正常でないマシンの数が maxUnhealthy の制限を超える場合、修復は実行されません。
maxUnhealthy が設定されていない場合、値は 100% にデフォルト設定され、マシンはクラスターの状態に関係なく修復されます。
適切な maxUnhealthy 値は、デプロイするクラスターの規模や、MachineHealthCheck が対応するマシンの数によって異なります。たとえば、maxUnhealthy 値を使用して複数のアベイラビリティーゾーン間で複数のマシンセットに対応でき、ゾーン全体が失われると、maxUnhealthy の設定によりクラスター内で追加の修復を防ぐことができます。複数のアベイラビリティーゾーンを持たないグローバル Azure リージョンでは、アベイラビリティーセットを使用して高可用性を確保できます。
maxUnhealthy フィールドは整数またはパーセンテージのいずれかに設定できます。maxUnhealthy の値によって、修復の実装が異なります。
13.2.1.1. 絶対値を使用した maxUnhealthy の設定
maxUnhealthy が 2 に設定される場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
これらの値は、マシンヘルスチェックによってチェックされるマシン数と別個の値です。
13.2.1.2. パーセンテージを使用した maxUnhealthy の設定
maxUnhealthy が 40% に設定され、25 のマシンがチェックされる場合:
- 10 以下のノードが正常でない場合に、修復が実行されます。
- 11 以上のノードが正常でない場合は、修復は実行されません。
maxUnhealthy が 40% に設定され、6 マシンがチェックされる場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
チェックされる maxUnhealthy マシンの割合が整数ではない場合、マシンの許可される数は切り捨てられます。
13.3. MachineHealthCheck リソースの作成
クラスターに、すべての MachineSets の MachineHealthCheck リソースを作成できます。コントロールプレーンマシンをターゲットとする MachineHealthCheck リソースを作成することはできません。
前提条件
-
ocコマンドラインインターフェイスをインストールします。
手順
-
マシンヘルスチェックの定義を含む
healthcheck.ymlファイルを作成します。 healthcheck.ymlファイルをクラスターに適用します。$ oc apply -f healthcheck.yml
マシンヘルスチェックを設定し、デプロイして、正常でないベアメタルノードを検出し、修復することができます。
13.4. ベアメタルの電源ベースの修復について
ベアメタルクラスターでは、クラスター全体の正常性を確保するためにノードの修復は重要になります。クラスターの物理的な修復には難題が伴う場合があります。マシンを安全な状態または動作可能な状態にするまでの遅延が原因で、クラスターが動作が低下した状態のままに置かれる時間が長くなり、その後の障害の発生によりクラスターがオフラインになるリスクが生じます。電源ベースの修復は、このような課題への対応に役立ちます。
ノードの再プロビジョニングを行う代わりに、電源ベースの修復は電源コントローラーを使用して、動作不能なノードの電源をオフにします。この種の修復は、電源フェンシングとも呼ばれます。
OpenShift Container Platform は MachineHealthCheck コントローラーを使用して障害のあるベアメタルノードを検出します。電源ベースの修復は高速であり、障害のあるノードをクラスターから削除する代わりにこれを再起動します。
電源バースの修復は以下の機能を提供します。
- コントロールプレーンノードのリカバリーの許可
- ハイパーコンバージド環境でのデータ損失リスクの軽減
- 物理マシンのリカバリーに関連するダウンタイムの削減
13.4.1. ベアメタル上の MachineHealthCheck
ベアメタルクラスターでのマシンの削除により、ベアメタルホストの再プロビジョニングがトリガーされます。通常、ベアメタルの再プロビジョニングは長いプロセスで、クラスターにコンピュートリソースがなくなり、アプリケーションが中断される可能性があります。デフォルトの修復プロセスをマシンの削除からホストの電源サイクルに切り換えるには、MachineHealthCheck リソースに machine.openshift.io/remediation-strategy: external-baremetal アノテーションを付けます。
アノテーションの設定後に、BMC 認証情報を使用して正常でないマシンの電源が入れ直されます。
13.4.2. 修復プロセスについて
修復プロセスは以下のように機能します。
- MachineHealthCheck (MHC) コントローラーは、ノードが正常ではないことを検知します。
- MHC は、正常でないノードの電源オフを要求するベアメタルマシンコントローラーに通知します。
- 電源がオフになった後にノードが削除され、クラスターは影響を受けたワークロードを他のノードで再スケジューリングできます。
- ベアメタルマシンコントローラーはノードの電源をオンにするよう要求します。
- ノードの起動後、ノードはクラスターに自らを再登録し、これにより新規ノードが作成されます。
- ノードが再作成されると、ベアメタルマシンコントローラーは、削除前に正常でないノードに存在したアノテーションとラベルを復元します。
電源操作が完了していない場合、ベアメタルマシンコントローラーは、外部でプロビジョニングされたコントロールプレーンノードやノードでない場合に正常でないノードの再プロビジョニングをトリガーします。
13.4.3. ベアメタルの MachineHealthCheck リソースの作成
前提条件
- OpenShift Container Platform は、インストーラーでプロビジョニングされるインフラストラクチャー (IPI) を使用してインストールされます。
- ベースボード管理コントローラー (BMC) 認証情報へのアクセス (または 各ノードへの BMC アクセス)。
- 正常でないノードの BMC インターフェイスへのネットワークアクセス。
手順
-
マシンヘルスチェックの定義を含む
healthcheck.yamlファイルを作成します。 -
以下のコマンドを使用して、
healthcheck.yamlファイルをクラスターに適用します。
$ oc apply -f healthcheck.yamlベアメタルのサンプル MachineHealthCheck リソース
apiVersion: machine.openshift.io/v1beta1
kind: MachineHealthCheck
metadata:
name: example
namespace: openshift-machine-api
annotations:
machine.openshift.io/remediation-strategy: external-baremetal
spec:
selector:
matchLabels:
machine.openshift.io/cluster-api-machine-role: <role>
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone>
unhealthyConditions:
- type: "Ready"
timeout: "300s"
status: "False"
- type: "Ready"
timeout: "300s"
status: "Unknown"
maxUnhealthy: "40%"
nodeStartupTimeout: "10m" - 1
- デプロイするマシンヘルスチェックの名前を指定します。
- 2
- ベアメタルクラスターの場合、電源サイクルの修復を有効にするために
machine.openshift.io/remediation-strategy: external-baremetalアノテーションをannotationsセクションに含める必要があります。この修復ストラテジーにより、正常でないホストはクラスターから削除される代わりに、再起動されます。 - 3 4
- チェックする必要のあるマシンプールのラベルを指定します。
- 5
- 追跡するマシンセットを
<cluster_name>-<label>-<zone>形式で指定します。たとえば、prod-node-us-east-1aとします。 - 6 7
- ノード状態のタイムアウト期間を指定します。タイムアウト期間の条件が満たされると、マシンは修正されます。タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
- 8
- ターゲットプールで同時に修復できるマシンの数を指定します。これはパーセンテージまたは整数として設定できます。正常でないマシンの数が
maxUnhealthyで設定された制限を超える場合、修復は実行されません。 - 9
- マシンが正常でないと判別される前に、ノードがクラスターに参加するまでマシンヘルスチェックが待機する必要のあるタイムアウト期間を指定します。
matchLabels はあくまでもサンプルであるため、特定のニーズに応じてマシングループをマッピングする必要があります。
電源ベースの修復についての問題のトラブルシューティングを行うには、以下を確認します。
- BMC にアクセスできる。
- BMC は修復タスクを実行するコントロールプレーンノードに接続されている。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.