ネットワーク可観測性
Network Observability Operator
概要
第1章 Network Observability Operator リリースノート
Network Observability Operator を使用すると、管理者は OpenShift Container Platform クラスターのネットワークトラフィックフローを観察および分析できます。
これらのリリースノートは、OpenShift Container Platform での Network Observability Operator の開発を追跡します。
Network Observability Operator の概要は、Network Observability Operator について を参照してください。
1.1. Network Observability Operator 1.4.2
Network Observability Operator 1.4.2 では、次のアドバイザリーを利用できます。
1.1.1. CVE
1.2. Network Observability Operator 1.4.1
Network Observability Operator 1.4.1 では、次のアドバイザリーを利用できます。
1.2.1. CVE
1.2.2. バグ修正
- 1.4 には、ネットワークフローデータを Kafka に送信するときに既知の問題がありました。Kafka メッセージキーが無視されたため、接続の追跡でエラーが発生していました。現在、キーはパーティショニングに使用されるため、同じ接続からの各フローが同じプロセッサーに送信されます。(NETOBSERV-926)
-
1.4 で、同じノード上で実行されている Pod 間のフローを考慮するために、
Inner方向のフローが導入されました。Inner方向のフローは、フローから派生して生成される Prometheus メトリクスでは考慮されなかったため、バイトレートとパケットレートが過小評価されていました。現在は派生メトリクスにInner方向のフローが含まれ、正しいバイトレートとパケットレートが提供されるようになりました。(NETOBSERV-1344)
1.3. Network Observability Operator 1.4.0
Network Observability Operator 1.4.0 では、次のアドバイザリーを利用できます。
1.3.1. チャネルの削除
最新の Operator 更新を受信するには、チャネルを v1.0.x から stable に切り替える必要があります。v1.0.x チャネルは削除されました。
1.3.2. 新機能および機能拡張
1.3.2.1. 主な機能拡張
Network Observability Operator の 1.4 リリースでは、OpenShift Container Platform Web コンソールプラグインと Operator 設定が改良され、新機能が追加されています。
Web コンソールの機能拡張:
- Query Options に、重複したフローを表示するかどうかを選択するための Duplicate flows チェックボックスが追加されました。
-
送信元トラフィックおよび宛先トラフィックを、
 One-way、
One-way、
 Back-and-forth、Swap のフィルターでフィルタリングできるようになりました。
Back-and-forth、Swap のフィルターでフィルタリングできるようになりました。
Observe → Dashboards → NetObserv、および NetObserv / Health のネットワーク可観測性メトリクスダッシュボードは次のように変更されます。
- NetObserv ダッシュボードには、ノード、namespace、およびワークロードごとに、上位のバイト、送信パケット、受信パケットが表示されます。フローグラフはこのダッシュボードから削除されました。
- NetObserv/Health ダッシュボードには、フローのオーバーヘッド以外にも、ノード、namespace、ワークロードごとの最大フローレートが表示されます。
- インフラストラクチャーとアプリケーションのメトリクスは、namespace とワークロードの分割ビューで表示されます。
詳細は、ネットワーク可観測性メトリクス と クイックフィルター を参照してください。
設定の機能拡張
- 証明書設定など、設定された ConfigMap または Secret 参照に対して異なる namespace を指定できるオプションが追加されました。
-
spec.processor.clusterNameパラメーターが追加されたため、クラスターの名前がフローデータに表示されるようになりました。これは、マルチクラスターコンテキストで役立ちます。OpenShift Container Platform を使用する場合は、自動的に決定されるように空のままにします。
詳細は、フローコレクターのサンプルリソース および フローコレクター API 参照 を参照してください。
1.3.2.2. Loki を使用しないネットワーク可観測性
Network Observability Operator は、Loki なしでも機能し、使用できるようになりました。Loki がインストールされていない場合は、フローを KAFKA または IPFIX 形式にエクスポートし、ネットワーク可観測性メトリクスダッシュボードに入力することのみ可能です。詳細は、Loki を使用しないネットワーク可観測性 を参照してください。
1.3.2.3. DNS 追跡
1.4 では、Network Observability Operator は eBPF トレースポイントフックを使用して DNS 追跡を有効にします。Web コンソールの Network Traffic ページと Overview ページで、ネットワークの監視、セキュリティー分析の実施、DNS 問題のトラブルシューティングを行なえます。
1.3.2.4. SR-IOV のサポート
Single Root I/O Virtualization (SR-IOV) デバイスを使用して、クラスターからトラフィックを収集できるようになりました。詳細は、SR-IOV インターフェイストラフィックの監視の設定 を参照してください。
1.3.2.5. IPFIX エクスポーターのサポート
eBPF が強化されたネットワークフローを IPFIX コレクターにエクスポートできるようになりました。詳細は、強化されたネットワークフローデータのエクスポート を参照してください。
1.3.2.6. s390x アーキテクチャーのサポート
Network Observability Operator が、s390x アーキテクチャー上で実行できるようになりました。以前は、amd64、ppc64le、または arm64 で実行されていました。
1.3.3. バグ修正
- これまで、ネットワーク可観測性によってエクスポートされた Prometheus メトリクスは、重複する可能性のあるネットワークフローから計算されていました。その結果、関連するダッシュボード (Observe → Dashboards) でレートが 2 倍になる可能性がありました。ただし、Network Traffic ビューのダッシュボードは影響を受けていませんでした。現在は、メトリクスの計算前にネットワークフローがフィルタリングされて重複が排除されるため、ダッシュボードに正しいトラフィックレートが表示されます。(NETOBSERV-1131)
-
以前は、Network Observability Operator エージェントは、Multus または SR-IOV (デフォルト以外のネットワーク namespace) で設定されている場合、ネットワークインターフェイス上のトラフィックをキャプチャーできませんでした。現在は、利用可能なすべてのネットワーク namespace が認識され、フローのキャプチャーに使用されるため、SR-IOV のトラフィックをキャプチャーできます。トラフィックを収集する場合は、
FlowCollectorおよびSRIOVnetworkカスタムリソースで 必要な設定 があります。(NETOBSERV-1283) -
以前は、Operators → Installed Operators に表示される Network Observability Operator の詳細の
FlowCollectorStatus フィールドで、デプロイメントの状態に関する誤った情報が報告されることがありました。ステータスフィールドには、改善されたメッセージと適切な状態が表示されるようになりました。イベントの履歴は、イベントの日付順に保存されます。(NETOBSERV-1224) -
以前は、ネットワークトラフィックの負荷が急増すると、特定の eBPF Pod が OOM によって強制終了され、
CrashLoopBackOff状態になりました。現在は、eBPFagent のメモリーフットプリントが改善されたため、Pod が OOM によって強制終了されてCrashLoopBackOff状態に遷移することはなくなりました。(NETOBSERV-975) -
以前は、
processor.metrics.tlsがPROVIDEDに設定されている場合、insecureSkipVerifyオプションの値が強制的にtrueに設定されていました。現在は、insecureSkipVerifyをtrueまたはfalseに設定し、必要に応じて CA 証明書を提供できるようになりました。(NETOBSERV-1087)
1.3.4. 既知の問題
-
Network Observability Operator 1.2.0 リリース以降では、Loki Operator 5.6 を使用すると、Loki 証明書の変更が定期的に
flowlogs-pipelinePod に影響を及ぼすため、フローが Loki に書き込まれず、ドロップされます。この問題はしばらくすると自動的に修正されますが、Loki 証明書の移行中に一時的なフローデータの損失が発生します。この問題は、120 以上のノードを内包する大規模環境でのみ発生します。(NETOBSERV-980) -
現在、
spec.agent.ebpf.featuresに DNSTracking が含まれている場合、DNS パケットが大きいと、eBPFagent が最初のソケットバッファー (SKB) セグメント外で DNS ヘッダーを探す必要があります。これをサポートするには、eBPFagent の新しいヘルパー関数を実装する必要があります。現在、この問題に対する回避策はありません。(NETOBSERV-1304) -
現在、
spec.agent.ebpf.featuresに DNSTracking が含まれている場合、DNS over TCP パケットを扱うときに、eBPFagent が最初の SKB セグメント外で DNS ヘッダーを探す必要があります。これをサポートするには、eBPFagent の新しいヘルパー関数を実装する必要があります。現在、この問題に対する回避策はありません。(NETOBSERV-1245) -
現在、
KAFKAデプロイメントモデルを使用する場合、会話の追跡が設定されていると会話イベントが Kafka コンシューマー間で重複する可能性があり、その結果、会話の追跡に一貫性がなくなり、ボリュームデータが不正確になる可能性があります。そのため、deploymentModelがKAFKAに設定されている場合は、会話の追跡を設定することは推奨されません。(NETOBSERV-926) -
現在、
processor.metrics.server.tls.typeがPROVIDED証明書を使用するように設定されている場合、Operator の状態が不安定になり、パフォーマンスとリソース消費に影響を与える可能性があります。この問題が解決されるまではPROVIDED証明書を使用せず、代わりに自動生成された証明書を使用し、processor.metrics.server.tls.typeをAUTOに設定することが推奨されます。(NETOBSERV-1293
1.4. Network Observability Operator 1.3.0
Network Observability Operator 1.3.0 では、次のアドバイザリーを利用できます。
1.4.1. チャネルの非推奨化
今後の Operator 更新を受信するには、チャネルを v1.0.x から stable に切り替える必要があります。v1.0.x チャネルは非推奨となり、次のリリースで削除される予定です。
1.4.2. 新機能および機能拡張
1.4.2.1. ネットワーク可観測性におけるマルチテナンシー
- システム管理者は、Loki に保存されているフローへの個々のユーザーアクセスまたはグループアクセスを許可および制限できます。詳細は、ネットワーク可観測性におけるマルチテナンシー を参照してください。
1.4.2.2. フローベースのメトリクスダッシュボード
- このリリースでは、OpenShift Container Platform クラスター内のネットワークフローの概要を表示する新しいダッシュボードが追加されています。詳細は、ネットワーク可観測性メトリクス を参照してください。
1.4.2.3. must-gather ツールを使用したトラブルシューティング
- Network Observability Operator に関する情報を、トラブルシューティングで使用する must-gather データに追加できるようになりました。詳細は、ネットワーク可観測性の must-gather を参照してください。
1.4.2.4. 複数のアーキテクチャーに対するサポートを開始
-
Network Observability Operator は、
amd64、ppc64le、またはarm64アーキテクチャー上で実行できるようになりました。以前は、amd64上でのみ動作しました。
1.4.3. 非推奨の機能
1.4.3.1. 非推奨の設定パラメーターの設定
Network Observability Operator 1.3 のリリースでは、spec.Loki.authToken HOST 設定が非推奨になりました。Loki Operator を使用する場合、FORWARD 設定のみを使用する必要があります。
1.4.4. バグ修正
-
以前は、Operator が CLI からインストールされた場合、Cluster Monitoring Operator がメトリクスを読み取るために必要な
RoleとRoleBindingが期待どおりにインストールされませんでした。この問題は、Operator が Web コンソールからインストールされた場合には発生しませんでした。現在は、どちらの方法で Operator をインストールしても、必要なRoleとRoleBindingがインストールされます。(NETOBSERV-1003) -
バージョン 1.2 以降、Network Observability Operator は、フローの収集で問題が発生した場合にアラートを生成できます。以前は、バグのため、アラートを無効にするための関連設定である
spec.processor.metrics.disableAlertsが期待どおりに動作せず、効果がない場合がありました。現在、この設定は修正され、アラートを無効にできるようになりました。(NETOBSERV-976) -
以前は、ネットワーク可観測性の
spec.loki.authTokenがDISABLEDに設定されている場合、kubeadminクラスター管理者のみがネットワークフローを表示できました。他のタイプのクラスター管理者は認可エラーを受け取りました。これで、クラスター管理者は誰でもネットワークフローを表示できるようになりました。(NETOBSERV-972) -
以前は、バグが原因でユーザーは
spec.consolePlugin.portNaming.enableをfalseに設定できませんでした。現在は、これをfalseに設定すると、ポートからサービスへの名前変換を無効にできます。(NETOBSERV-971) - 以前は、設定が間違っていたため、コンソールプラグインが公開するメトリクスは、Cluster Monitoring Operator (Prometheus) によって収集されませんでした。現在は設定が修正され、コンソールプラグインメトリクスが正しく収集され、OpenShift Container Platform Web コンソールからアクセスできるようになりました。(NETOBSERV-765)
-
以前は、
FlowCollectorでprocessor.metrics.tlsがAUTOに設定されている場合、flowlogs-pipeline servicemonitorは適切な TLS スキームを許可せず、メトリクスは Web コンソールに表示されませんでした。この問題は AUTO モードで修正されました。(NETOBSERV-1070) -
以前は、Kafka や Loki に使用されるような証明書設定では、namespace フィールドを指定できず、ネットワーク可観測性がデプロイされているのと同じ namespace に証明書が存在する必要がありました。さらに、TLS/mTLS で Kafka を使用する場合、ユーザーは
eBPFagent Pod がデプロイされている特権付き namespace に証明書を手動でコピーし、証明書のローテーションを行う場合などに手動で証明書の更新を管理する必要がありました。現在は、FlowCollectorリソースに証明書の namespace フィールドを追加することで、ネットワーク可観測性のセットアップが簡素化されています。その結果、ユーザーはネットワーク可観測性 namespace に証明書を手動でコピーすることなく、Loki または Kafka を別の namespace にインストールできるようになりました。元の証明書は監視されているため、必要に応じてコピーが自動的に更新されます。(NETOBSERV-773) - 以前は、SCTP、ICMPv4、および ICMPv6 プロトコルはネットワーク可観測性エージェントのカバレッジに含まれていなかったため、ネットワークフローのカバレッジもあまり包括的ではありませんでした。これらのプロトコルを使用することで、フローカバレッジが向上することが確認されています。(NETOBSERV-934)
1.4.5. 既知の問題
-
FlowCollectorでprocessor.metrics.tlsがPROVIDEDに設定されている場合、flowlogs-pipelineservicemonitorは TLS スキームに適用されません。(NETOBSERV-1087) -
Network Observability Operator 1.2.0 リリース以降では、Loki Operator 5.6 を使用すると、Loki 証明書の変更が定期的に
flowlogs-pipelinePod に影響を及ぼすため、フローが Loki に書き込まれず、ドロップされます。この問題はしばらくすると自動的に修正されますが、Loki 証明書の移行中に一時的なフローデータの損失が発生します。この問題は、120 以上のノードを内包する大規模環境でのみ発生します。(NETOBSERV-980)
1.5. Network Observability Operator 1.2.0
Network Observability Operator 1.2.0 では、次のアドバイザリーを利用できます。
1.5.1. 次の更新の準備
インストールされた Operator のサブスクリプションは、Operator の更新を追跡および受信する更新チャネルを指定します。Network Observability Operator の 1.2 リリースまでは、利用可能なチャネルは v1.0.x だけでした。Network Observability Operator の 1.2 リリースでは、更新の追跡および受信用に stable 更新チャネルが導入されました。今後の Operator 更新を受信するには、チャネルを v1.0.x から stable に切り替える必要があります。v1.0.x チャネルは非推奨となり、次のリリースで削除される予定です。
1.5.2. 新機能および機能拡張
1.5.2.1. Traffic Flow ビューのヒストグラム
- 経時的なフローのヒストグラムバーグラフを表示するように選択できるようになりました。ヒストグラムを使用すると、Loki クエリー制限に達することなくフロー履歴を可視化できます。詳細は、ヒストグラムの使用 を参照してください。
1.5.2.2. 会話の追跡
- ログタイプ でフローをクエリーできるようになりました。これにより、同じ会話に含まれるネットワークフローをグループ化できるようになりました。詳細は、会話の使用 を参照してください。
1.5.2.3. ネットワーク可観測性のヘルスアラート
-
Network Observability Operator は、書き込み段階でのエラーが原因で
flowlogs-pipelineがフローをドロップする場合、または Loki 取り込みレート制限に達した場合、自動アラートを作成するようになりました。詳細は、ヘルス情報の表示 を参照してください。
1.5.3. バグ修正
-
これまでは、FlowCollector 仕様の
namespaceの値を変更すると、以前の namespace で実行されているeBPFagent Pod が適切に削除されませんでした。今は、以前の namespace で実行されている Pod も適切に削除されるようになりました。(NETOBSERV-774) -
これまでは、FlowCollector 仕様 (Loki セクションなど) の
caCert.name値を変更しても、FlowLogs-Pipeline Pod および Console プラグイン Pod が再起動されないため、設定の変更が認識されませんでした。今は、Pod が再起動されるため、設定の変更が適用されるようになりました。(NETOBSERV-772) - これまでは、異なるノードで実行されている Pod 間のネットワークフローは、異なるネットワークインターフェイスでキャプチャーされるため、重複が正しく認識されないことがありました。その結果、コンソールプラグインに表示されるメトリクスが過大に見積もられていました。現在は、フローが重複として正しく識別され、コンソールプラグインで正確なメトリクスが表示されます。(NETOBSERV-755)
- コンソールプラグインのレポーターオプションは、送信元ノードまたは宛先ノードのいずれかの観測点に基づいてフローをフィルタリングするために使用されます。以前は、このオプションはノードの観測点に関係なくフローを混合していました。これは、ネットワークフローがノードレベルで Ingress または Egress として誤って報告されることが原因でした。これで、ネットワークフロー方向のレポートが正しくなりました。レポーターオプションは、期待どおり、ソース観測点または宛先観測点をフィルターします。(NETOBSERV-696)
- 以前は、フローを gRPC+protobuf リクエストとしてプロセッサーに直接送信するように設定されたエージェントの場合、送信されたペイロードが大きすぎる可能性があり、プロセッサーの GRPC サーバーによって拒否されました。これは、非常に高負荷のシナリオで、エージェントの一部の設定でのみ発生しました。エージェントは、次のようなエラーメッセージをログに記録しました: grpc: max より大きいメッセージを受信しました。その結果、それらのフローに関する情報が損失しました。現在、gRPC ペイロードは、サイズがしきい値を超えると、いくつかのメッセージに分割されます。その結果、サーバーは接続を維持します。(NETOBSERV-617)
1.5.4. 既知の問題
-
Loki Operator 5.6 を使用する Network Observability Operator の 1.2.0 リリースでは、Loki 証明書の移行が定期的に
flowlogs-pipelinePod に影響を及ぼし、その結果、Loki に書き込まれるフローではなくフローがドロップされます。この問題はしばらくすると自動的に修正されますが、依然として Loki 証明書の移行中に一時的なフローデータの損失が発生します。(NETOBSERV-980)
1.5.5. 主な技術上の変更点
-
以前は、カスタム namespace を使用して Network Observability Operator をインストールできました。このリリースでは、
ClusterServiceVersionを変更するconversion webhookが導入されています。この変更により、使用可能なすべての namespace がリストされなくなりました。さらに、Operator メトリクス収集を有効にするには、openshift-operatorsnamespace など、他の Operator と共有される namespace は使用できません。ここで、Operator をopenshift-netobserv-operatornamespace にインストールする必要があります。以前にカスタム namespace を使用して Network Observability Operator をインストールした場合、新しい Operator バージョンに自動的にアップグレードすることはできません。以前にカスタム namespace を使用して Operator をインストールした場合は、インストールされた Operator のインスタンスを削除し、openshift-netobserv-operatornamespace に Operator を再インストールする必要があります。一般的に使用されるnetobservnamespace などのカスタム namespace は、FlowCollector、Loki、Kafka、およびその他のプラグインでも引き続き使用できることに注意することが重要です。(NETOBSERV-907)(NETOBSERV-956)
1.6. Network Observability Operator 1.1.0
Network Observability Operator 1.1.0 については、次のアドバイザリーを利用できます。
Network Observability Operator は現在安定しており、リリースチャンネルは v1.1.0 にアップグレードされています。
1.6.1. バグ修正
-
以前は、Loki の
authToken設定がFORWARDモードに設定されていない限り、認証が適用されず、OpenShift Container Platform クラスター内の OpenShift Container Platform コンソールに接続できるすべてのユーザーが認証なしでフローを取得できました。現在は、Loki のauthTokenモードに関係なく、クラスター管理者のみがフローを取得できます。(BZ#2169468)
第2章 ネットワーク可観測性について
Red Hat は、OpenShift Container Platform クラスターのネットワークトラフィックを監視する Network Observability Operator をクラスター管理者に提供します。Network Observability Operator は、eBPF テクノロジーを使用してネットワークフローを作成します。その後、ネットワークフローは OpenShift Container Platform 情報で強化され、Loki に保存されます。保存されたネットワークフロー情報を OpenShift Container Platform コンソールで表示および分析して、さらなる洞察とトラブルシューティングを行うことができます。
2.1. Network Observability Operator のオプションの依存関係
- Loki Operator: Loki は、収集されたすべてのフローを保存するために使用されるバックエンドです。Loki をインストールして、Network Observability Operator と併用することが推奨されます。Loki を使用せずに Network Observability を使用することも選択できますが、その場合はリンク先のセクションで説明されているいくつかの事項を考慮する必要があります。Loki のインストールを選択した場合は、Red Hat がサポートする Loki Operator の使用が推奨されます。
- Grafana Operator: Grafana Operator などのオープンソース製品を使用して、カスタムダッシュボードの作成やケイパビリティーのクエリーに使用する Grafana をインストールできます。Red Hat は Grafana Operator をサポートしていません。
- AMQ Streams Operator: Kafka は、大規模なデプロイメント向けに OpenShift Container Platform クラスターにスケーラビリティ、復元力、高可用性を提供します。Kafka を使用することを選択する場合は、Red Hat がサポートする AMQ Streams Operator を使用することが推奨されます。
2.2. Network Observability Operator
Network Observability Operator は Flow Collector API カスタムリソース定義を提供します。Flow Collector インスタンスは、インストール中に作成され、ネットワークフローコレクションの設定を有効にします。フローコレクターインスタンスは、モニタリングパイプラインを形成する Pod とサービスをデプロイし、そこでネットワークフローが収集され、Loki に保存する前に Kubernetes メタデータで強化されます。デーモンセットオブジェクトとしてデプロイメントされる eBPF エージェントは、ネットワークフローを作成します。
2.3. OpenShift Container Platform コンソール統合
OpenShift Container Platform コンソール統合は、概要、トポロジービュー、およびトラフィックフローテーブルを提供します。
2.3.1. ネットワーク可観測性メトリクスのダッシュボード
OpenShift Container Platform コンソールの Overview タブでは、クラスター上のネットワークトラフィックフローの集約された全体的なメトリクスを表示できます。ノード、namespace、所有者、Pod、サービスごとに情報を表示することを選択できます。フィルターと表示オプションにより、メトリクスをさらに絞り込むことができます。
Observe → Dashboards のNetobserv ダッシュボードには、OpenShift Container Platform クラスター内のネットワークフローの簡易的な概要が表示されます。次のカテゴリーのネットワークトラフィックメトリクスを抽出して表示できます。
- 各送信元ノードおよび宛先ノードの上位受信バイトレート
- 各送信元 namespace および宛先 namespace の上位受信バイトレート
- 各送信元ワークロードおよび宛先ワークロードの上位受信バイトレート
Infrastructure および Application メトリクスは、namespace とワークロードの分割ビューで表示されます。FlowCollector spec.processor.metrics を設定し、ignoreTags リストを変更してメトリクスを追加または削除できます。使用可能なタグの詳細は、Flow Collector API リファレンス を参照してください。
また、Observe → Dashboards の Netobserv/Health ダッシュボードには、次に示すカテゴリーの Operator の健全性に関するメトリクスが表示されます。
- フロー
- フローのオーバーヘッド
- 各送信元ノードおよび宛先ノードの上位フローレート
- 各送信元 namespace および宛先 namespace の上位フローレート
- 各送信元ワークロードおよび宛先ワークロードの上位フローレート
- エージェント
- プロセッサー
- Operator
Infrastructure および Application メトリクスは、namespace とワークロードの分割ビューで表示されます。
2.3.2. Network Observability トポロジービュー
OpenShift Container Platform コンソールは、ネットワークフローとトラフィック量をグラフィカルに表示する Topology タブを提供します。トポロジービューは、OpenShift Container Platform コンポーネント間のトラフィックをネットワークグラフとして表します。フィルターと表示オプションを使用して、グラフを絞り込むことができます。ノード、namespace、所有者、Pod、およびサービスの情報にアクセスできます。
2.3.3. トラフィックフローテーブル
トラフィックフローテーブルビューは、生のフロー、集約されていないフィルタリングオプション、および設定可能な列のビューを提供します。OpenShift Container Platform コンソールは、ネットワークフローのデータとトラフィック量を表示する Traffic flows タブを提供します。
第3章 Network Observability Operator のインストール
Network Observability Operator を使用する場合、前提条件として Loki のインストールが推奨されます。Loki を使用せずに Network Observability を使用することも選択できますが、その場合はリンクした前述のセクションで説明されているいくつかの事項を考慮する必要があります。
Loki Operator は、マルチテナンシーと認証を実装するゲートウェイを Loki と統合して、データフローストレージを実現します。LokiStack リソースは、スケーラブルで高可用性のマルチテナントログ集約システムである Loki と、OpenShift Container Platform 認証を備えた Web プロキシーを管理します。LokiStack プロキシーは、OpenShift Container Platform 認証を使用してマルチテナンシーを適用し、Loki ログストアでのデータの保存とインデックス作成を容易にします。
Loki Operator は、LokiStack ログストアの設定 にも使用できます。Network Observability Operator には、ロギングとは別の専用の LokiStack が必要です。
3.1. Loki を使用しないネットワーク可観測性
Loki のインストール手順を実行せず、直接「Network Observability Operator のインストール」を実行することで、Loki なしで Network Observability を使用できます。フローを Kafka コンシューマーまたは IPFIX コレクターのみにエクスポートする場合、またはダッシュボードメトリクスのみ必要な場合は、Loki をインストールしたり、Loki 用のストレージを提供したりする必要はありません。Loki を使用しない場合、Observe の下に Network Traffic パネルは表示されません。つまり、概要チャート、フローテーブル、トポロジーはありません。次の表は、Loki を使用した場合と使用しない場合の利用可能な機能を比較しています。
| Loki を使用する場合 | Loki を使用しない場合 | |
|---|---|---|
| エクスポーター |
|
|
| フローベースのメトリクスとダッシュボード |
|
|
| トラフィックフローの概要、テーブルビュー、トポロジービュー |
|
|
| クイックフィルター |
|
|
| OpenShift Container Platform コンソールの Network Traffic タブの統合 |
|
|
3.2. Loki Operator のインストール
ネットワーク可観測性でサポートされている Loki Operator のバージョンは、Loki Operator バージョン 5.7 以降 です。これらのバージョンでは、openshift-network テナント設定モードを使用して LokiStack インスタンスを作成する機能が提供されており、ネットワーク可観測性に対する完全に自動化されたクラスター内認証および認可がサポートされています。Loki をインストールするにはいくつかの方法があります。そのうちの 1 つが、OpenShift Container Platform Web コンソールの Operator Hub を使用する方法です。
前提条件
- 対応ログストア (AWS S3、Google Cloud Storage、Azure、Swift、Minio、OpenShift Data Foundation)
- OpenShift Container Platform 4.10 以上
- Linux カーネル 4.18 以降
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- 使用可能な Operator のリストから Loki Operator を選択し、Install をクリックします。
- Installation Mode で、All namespaces on the cluster を選択します。
検証
- Loki Operator がインストールされていることを確認します。Operators→ Installed Operators ページにアクセスして、Loki Operator を探します。
- Loki Operator がすべてのプロジェクトで Succeeded の Status でリストされていることを確認します。
Loki をアンインストールするには、Loki のインストールに使用した方法に対応するアンインストールプロセスを参照してください。ClusterRole と ClusterRoleBindings、オブジェクトストアに格納されたデータ、および削除する必要のある永続ボリュームが残っている可能性があります。
3.2.1. Loki ストレージのシークレットの作成
Loki Operator は、AWS S3、Google Cloud Storage、Azure、Swift、Minio、OpenShift Data Foundation など、いくつかのログストレージオプションをサポートしています。次の例は、AWS S3 ストレージのシークレットを作成する方法を示しています。この例で作成されたシークレット loki-s3 は、「LokiStack リソースの作成」で参照されています。このシークレットは、Web コンソールまたは CLI で作成できます。
-
Web コンソールを使用して、Project → All Projects ドロップダウンに移動し、Create Project を選択します。プロジェクトに
netobservという名前を付けて、Create をクリックします。 右上隅にあるインポートアイコン + に移動します。YAML ファイルをエディターにペーストします。
以下は、S3 ストレージのシークレット YAML ファイルの例です。
apiVersion: v1 kind: Secret metadata: name: loki-s3 namespace: netobserv1 stringData: access_key_id: QUtJQUlPU0ZPRE5ON0VYQU1QTEUK access_key_secret: d0phbHJYVXRuRkVNSS9LN01ERU5HL2JQeFJmaUNZRVhBTVBMRUtFWQo= bucketnames: s3-bucket-name endpoint: https://s3.eu-central-1.amazonaws.com region: eu-central-1- 1
- このドキュメントに記載されているインストール例では、すべてのコンポーネントで同じ namespace である
netobservを使用しています。オプションで、異なるコンポーネントで異なる namespace を使用できます。
検証
- シークレットを作成すると、Web コンソールの Workloads → Secrets の下に一覧表示されます。
3.2.2. LokiStack カスタムリソースの作成
Web コンソールまたは CLI を使用して LokiStack をデプロイし、namespace や新規プロジェクトを作成できます。
cluster-admin ユーザーとして複数の namespace のアプリケーションログをクエリーすると、クラスター内のすべての namespace の文字数の合計が 5120 を超え、Parse error: input size too long (XXXX > 5120) エラーが発生します。LokiStack のログへのアクセスをより適切に制御するには、cluster-admin ユーザーを cluster-admin グループのメンバーにします。cluster-admin グループが存在しない場合は、作成して必要なユーザーを追加します。
cluster-admin グループの作成の詳細は、「関連情報」セクションを参照してください。
手順
- Operators → Installed Operators に移動し、Project ドロップダウンから All projects を表示します。
- Loki Operator を探します。詳細の Provided APIs で、LokiStack を選択します。
- Create LokiStack をクリックします。
Form View または YAML view で次のフィールドが指定されていることを確認します。
apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv1 spec: size: 1x.small storage: schemas: - version: v12 effectiveDate: '2022-06-01' secret: name: loki-s3 type: s3 storageClassName: gp32 tenants: mode: openshift-network重要クラスターロギングに使用されるものと同じ
LokiStackを再利用しないでください。- Create をクリックします。
3.2.2.1. デプロイメントのサイズ
Loki のサイズは N<x>.<size> の形式に従います。<N> はインスタンスの数を、<size> はパフォーマンスの機能を指定します。
1x.extra-small はデモ用であり、サポートされていません。
| 1x.extra-small | 1x.small | 1x.medium | |
|---|---|---|---|
| データ転送 | デモ使用のみ。 | 500GB/day | 2 TB/日 |
| 1 秒あたりのクエリー数 (QPS) | デモ使用のみ。 | 200 ミリ秒で 25 - 50 QPS | 200 ミリ秒で 25 - 75 QPS |
| レプリケーション係数 | なし | 2 | 3 |
| 合計 CPU 要求 | 仮想 CPU 5 個 | 仮想 CPU 36 個 | 仮想 CPU 54 個 |
| 合計メモリー要求 | 7.5Gi | 63Gi | 139Gi |
| ディスク要求の合計 | 150Gi | 300Gi | 450Gi |
3.2.3. LokiStack の取り込み制限とヘルスアラート
LokiStack インスタンスには、設定されたサイズに応じたデフォルト設定が付属しています。取り込みやクエリーの制限など、これらの設定の一部を上書きすることができます。コンソールプラグインまたは flowlogs-pipeline ログに Loki エラーが表示される場合は、それらを更新することを推奨します。これらの制限に達すると、Web コンソールの自動アラートで通知されます。
設定された制限の例を次に示します。
spec:
limits:
global:
ingestion:
ingestionBurstSize: 40
ingestionRate: 20
maxGlobalStreamsPerTenant: 25000
queries:
maxChunksPerQuery: 2000000
maxEntriesLimitPerQuery: 10000
maxQuerySeries: 3000これらの設定の詳細は、LokiStack API リファレンス を参照してください。
3.2.4. 認可とマルチテナンシーの設定
ClusterRole と ClusterRoleBinding を定義します。netobserv-reader ClusterRole はマルチテナンシーを有効にし、Loki に保存されているフローへのユーザーアクセスまたはグループアクセスを個別に許可します。これらのロールを定義する YAML ファイルを作成できます。
手順
- Web コンソールを使用して、インポートアイコン + をクリックします。
- YAML ファイルをエディターにドロップし、Create をクリックします。
ClusterRole リーダー yaml の例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: netobserv-reader
rules:
- apiGroups:
- 'loki.grafana.com'
resources:
- network
resourceNames:
- logs
verbs:
- 'get'- 1
- このロールはマルチテナンシーに使用できます。
ClusterRole ライター yaml の例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: netobserv-writer
rules:
- apiGroups:
- 'loki.grafana.com'
resources:
- network
resourceNames:
- logs
verbs:
- 'create'ClusterRoleBinding yaml の例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: netobserv-writer-flp
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: netobserv-writer
subjects:
- kind: ServiceAccount
name: flowlogs-pipeline
namespace: netobserv
- kind: ServiceAccount
name: flowlogs-pipeline-transformer
namespace: netobserv- 1
flowlogs-pipelineは Loki に書き込みます。Kafka を使用している場合、この値はflowlogs-pipeline-transformerです。
3.2.5. ネットワーク可観測性でのマルチテナンシーの有効化
Network Observability Operator のマルチテナンシーにより、Loki に保存されているフローへのユーザーアクセスまたはグループアクセスが個別に許可および制限されます。プロジェクト管理者のアクセスが有効になっています。一部の namespace へのアクセスが制限されているプロジェクト管理者は、それらの namespace のフローのみにアクセスできます。
前提条件
- Loki Operator バージョン 5.7 がインストールされている。
-
FlowCollectorspec.loki.authTokenがFORWARDに設定されている。 - プロジェクト管理者としてログインしている。
手順
次のコマンドを実行して、
user1に読み取り権限を付与します。$ oc adm policy add-cluster-role-to-user netobserv-reader user1現在、データは許可されたユーザー namespace のみに制限されています。たとえば、単一の namespace にアクセスできるユーザーは、この namespace 内部のフローすべてと、この namespace から出入りするフローを表示できます。プロジェクト管理者は、OpenShift Container Platform コンソールの Administrator パースペクティブにアクセスして、Network Flows Traffic ページにアクセスできます。
3.3. Network Observability Operator のインストール
OpenShift Container Platform Web コンソール Operator Hub を使用して Network Observability Operator をインストールできます。Operator をインストールすると、FlowCollector カスタムリソース定義 (CRD) が提供されます。FlowCollector を作成するときに、Web コンソールで仕様を設定できます。
Operator の実際のメモリー消費量は、クラスターのサイズとデプロイされたリソースの数によって異なります。それに応じて、メモリー消費量を調整する必要がある場合があります。詳細は、「フローコレクター設定の重要な考慮事項」セクションの「Network Observability コントローラーマネージャー Pod のメモリー不足」を参照してください。
前提条件
- Loki を使用する場合は、Loki Operator バージョン 5.7 以降 をインストールしている。
-
cluster-admin権限を持っている必要があります。 -
サポートされているアーキテクチャーである
amd64、ppc64le、arm64、s390xのいずれか。 - Red Hat Enterprise Linux (RHEL) 9 でサポートされる任意の CPU。
- OVN-Kubernetes または OpenShift SDN をメインネットワークプラグインとして設定し、オプションで Multus や SR-IOV などのセカンダリーインターフェイスを使用している。
このドキュメントでは、LokiStack インスタンス名が loki であることを前提としています。別の名前を使用するには、追加の設定が必要です。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- OperatorHub で使用可能な Operator のリストから Network Observability Operator を選択し、Install をクリックします。
-
Enable Operator recommended cluster monitoring on this Namespaceチェックボックスを選択します。 - Operators → Installed Operators に移動します。Network Observability 用に提供された API で、Flow Collector リンクを選択します。
Flow Collector タブに移動し、Create FlowCollector をクリックします。フォームビューで次の選択を行います。
-
spec.agent.ebpf.Sampling: フローのサンプリングサイズを指定します。サンプリングサイズが小さいほど、リソース使用率への影響が大きくなります。詳細は、「FlowCollector API リファレンス」の
spec.agent.ebpfを参照してください。 Loki を使用している場合は、次の仕様を設定します。
- spec.loki.enable: Loki へのフローの保存を有効にするには、チェックボックスをオンにします。
-
spec.loki.url: 認証が別途指定されるため、この URL を
https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/networkに更新する必要があります。URL の最初にある "loki" 部分は、LokiStackの名前と一致する必要があります。 -
spec.loki.authToken:
FORWARD値を選択します。 -
spec.loki.statusUrl: これを
https://loki-query-frontend-http.netobserv.svc:3100/に設定します。URL の最初にある "loki" 部分は、LokiStackの名前と一致する必要があります。 - spec.loki.tls.enable: TLS を有効にするには、このチェックボックスを選択します。
spec.loki.statusTls: デフォルトでは、
enable値は false です。証明書参照名の最初の部分:
loki-gateway-ca-bundle、loki-ca-bundle、およびloki-query-frontend-http、lokiは、LokiStackの名前と一致する必要があります。
-
オプション: 使用している環境が大規模な場合は、回復性とスケーラビリティーが高い方法でデータを転送するために、Kafka を使用して
FlowCollectorを設定することを検討してください。「フローコレクター設定に関する重要な考慮事項」セクションの「Kafka ストレージを使用したフローコレクターリソースの設定」を参照してください。 -
オプション: 次の
FlowCollector作成手順に進む前に、他のオプションを設定します。たとえば、Loki を使用しないことを選択した場合は、Kafka または IPFIX へのフローのエクスポートを設定できます。「フローコレクター設定の重要な考慮事項」セクションの「強化されたネットワークフローデータを Kafka および IPFIX にエクスポートする」などを参照してください。 - Create をクリックします。
-
spec.agent.ebpf.Sampling: フローのサンプリングサイズを指定します。サンプリングサイズが小さいほど、リソース使用率への影響が大きくなります。詳細は、「FlowCollector API リファレンス」の
検証
これが成功したことを確認するには、Observe に移動すると、オプションに Network Traffic が表示されます。
OpenShift Container Platform クラスター内に アプリケーショントラフィック がない場合は、デフォルトのフィルターが "No results" と表示され、視覚的なフローが発生しないことがあります。フィルター選択の横にある Clear all filters を選択して、フローを表示します。
Loki Operator を使用して Loki をインストールした場合は、Loki へのコンソールアクセスを中断する可能性があるため、querierUrl を使用しないことを推奨します。別のタイプの Loki インストールを使用して Loki をインストールした場合、これは当てはまりません。
3.5. Kafka のインストール (オプション)
Kafka Operator は、大規模な環境でサポートされています。Kafka は、回復性とスケーラビリティーの高い方法でネットワークフローデータを転送するために、高スループットかつ低遅延のデータフィードを提供します。Loki Operator および Network Observability Operator がインストールされたのと同じように、Kafka Operator を Operator Hub から Red Hat AMQ Streams としてインストールできます。Kafka をストレージオプションとして設定する場合は、「Kafka を使用した FlowCollector リソースの設定」を参照してください。
Kafka をアンインストールするには、インストールに使用した方法に対応するアンインストールプロセスを参照してください。
3.6. Network Observability Operator のアンインストール
Network Observability Operator は、Operators → Installed Operators エリアで作業する OpenShift Container Platform Web コンソール Operator Hub を使用してアンインストールできます。
手順
FlowCollectorカスタムリソースを削除します。- Provided APIs 列の Network Observability Operator の横にある Flow Collector をクリックします。
-
cluster のオプションメニュー
 をクリックし、Delete FlowCollector を選択します。
をクリックし、Delete FlowCollector を選択します。
Network Observability Operator をアンインストールします。
- Operators → Installed Operators エリアに戻ります。
-
Network Observability Operator の隣にあるオプションメニュー
をクリックし、Uninstall Operator を選択します。
-
Home → Projects を選択し、
openshift-netobserv-operatorを選択します。 - Actions に移動し、Delete Project を選択します。
FlowCollectorカスタムリソース定義 (CRD) を削除します。- Administration → CustomResourceDefinitions に移動します。
-
FlowCollector を探し、オプションメニュー
をクリックします。
Delete CustomResourceDefinition を選択します。
重要Loki Operator と Kafka は、インストールされていた場合、残っているため、個別に削除する必要があります。さらに、オブジェクトストアに保存された残りのデータ、および削除する必要がある永続ボリュームがある場合があります。
第4章 OpenShift Container Platform の Network Observability Operator
Network Observability は、Network Observability eBPF agent によって生成されるネットワークトラフィックフローを収集および強化するためにモニタリングパイプラインをデプロイする OpenShift Operator です。
4.1. 状況の表示
Network Observability Operator は Flow Collector API を提供します。Flow Collector リソースが作成されると、Pod とサービスをデプロイしてネットワークフローを作成して Loki ログストアに保存し、ダッシュボード、メトリクス、およびフローを OpenShift Container Platform Web コンソールに表示します。
手順
次のコマンドを実行して、
FlowCollectorの状態を表示します。$ oc get flowcollector/cluster出力例
NAME AGENT SAMPLING (EBPF) DEPLOYMENT MODEL STATUS cluster EBPF 50 DIRECT Ready次のコマンドを実行して、
netobservnamespace で実行している Pod のステータスを確認します。$ oc get pods -n netobserv出力例
NAME READY STATUS RESTARTS AGE flowlogs-pipeline-56hbp 1/1 Running 0 147m flowlogs-pipeline-9plvv 1/1 Running 0 147m flowlogs-pipeline-h5gkb 1/1 Running 0 147m flowlogs-pipeline-hh6kf 1/1 Running 0 147m flowlogs-pipeline-w7vv5 1/1 Running 0 147m netobserv-plugin-cdd7dc6c-j8ggp 1/1 Running 0 147m
flowlogs-pipeline Pod はフローを収集し、収集したフローを充実させてから、フローを Loki ストレージに送信します。netobserv-plugin Pod は、OpenShift Container Platform コンソール用の視覚化プラグインを作成します。
次のコマンドを入力して、namespace
netobserv-privilegedで実行している Pod のステータスを確認します。$ oc get pods -n netobserv-privileged出力例
NAME READY STATUS RESTARTS AGE netobserv-ebpf-agent-4lpp6 1/1 Running 0 151m netobserv-ebpf-agent-6gbrk 1/1 Running 0 151m netobserv-ebpf-agent-klpl9 1/1 Running 0 151m netobserv-ebpf-agent-vrcnf 1/1 Running 0 151m netobserv-ebpf-agent-xf5jh 1/1 Running 0 151m
netobserv-ebpf-agent Pod は、ノードのネットワークインターフェイスを監視してフローを取得し、それを flowlogs-pipeline Pod に送信します。
Loki Operator を使用している場合は、次のコマンドを実行して、
openshift-operators-redhatnamespace で実行している Pod のステータスを確認します。$ oc get pods -n openshift-operators-redhat出力例
NAME READY STATUS RESTARTS AGE loki-operator-controller-manager-5f6cff4f9d-jq25h 2/2 Running 0 18h lokistack-compactor-0 1/1 Running 0 18h lokistack-distributor-654f87c5bc-qhkhv 1/1 Running 0 18h lokistack-distributor-654f87c5bc-skxgm 1/1 Running 0 18h lokistack-gateway-796dc6ff7-c54gz 2/2 Running 0 18h lokistack-index-gateway-0 1/1 Running 0 18h lokistack-index-gateway-1 1/1 Running 0 18h lokistack-ingester-0 1/1 Running 0 18h lokistack-ingester-1 1/1 Running 0 18h lokistack-ingester-2 1/1 Running 0 18h lokistack-querier-66747dc666-6vh5x 1/1 Running 0 18h lokistack-querier-66747dc666-cjr45 1/1 Running 0 18h lokistack-querier-66747dc666-xh8rq 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-b2xfb 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-jm94f 1/1 Running 0 18h
4.2. Network Observablity Operator のアーキテクチャー
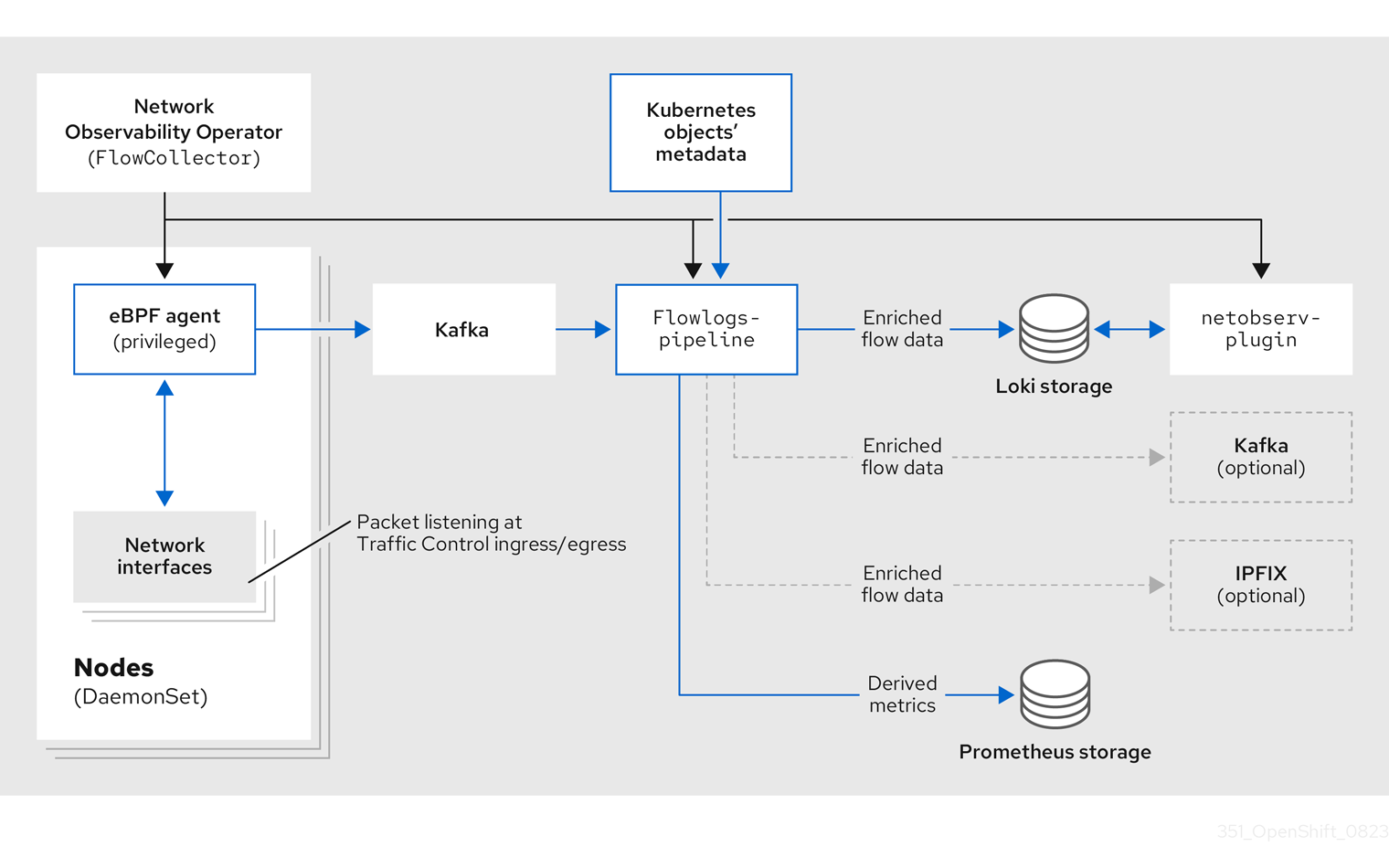
Network Observability Operator は、FlowCollector API を提供します。これは、インストール時にインスタンス化され、eBPF agent、flowlogs-pipeline、netobserv-plugin コンポーネントを調整するように設定されています。FlowCollector は、クラスターごとに 1 つだけサポートされます。
eBPF agent は、各クラスター上で実行され、ネットワークフローを収集するためのいくつかの権限を持っています。flowlogs-pipeline はネットワークフローデータを受信し、データに Kubernetes 識別子を追加します。Loki を使用している場合、flowlogs-pipeline はフローログデータを Loki に送信して、保存およびインデックス化を行います。netobserv-plugin は、動的 OpenShift Container Platform Web コンソールプラグインであり、Loki にクエリーを実行してネットワークフローデータを取得します。クラスター管理者は、Web コンソールでデータを表示できます。
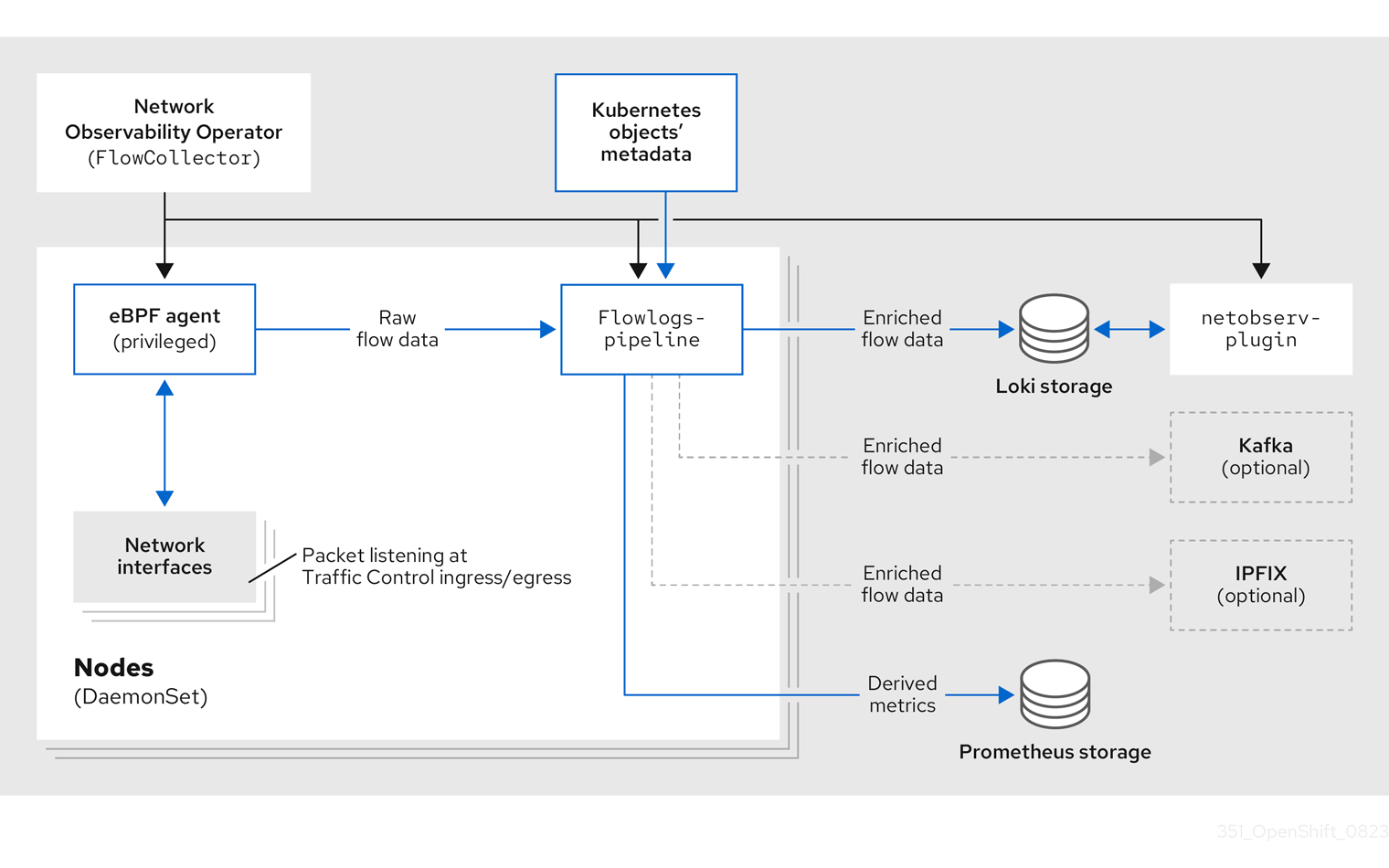
次の図に示すように、Kafka オプションを使用している場合、eBPF agent はネットワークフローデータを Kafka に送信し、flowlogs-pipeline は Loki に送信する前に Kafka トピックから読み取ります。
4.3. Network Observability Operator のステータスと設定の表示
oc describe コマンドを使用して、ステータスを検査し、flowcollector の詳細を表示できます。
手順
次のコマンドを実行して、Network Observability Operator のステータスと設定を表示します。
$ oc describe flowcollector/cluster
第5章 Network Observability Operator の設定
Flow Collector API リソースを更新して、Network Observability Operator とそのマネージドコンポーネントを設定できます。Flow Collector は、インストール中に明示的に作成されます。このリソースはクラスター全体で動作するため、単一の FlowCollector のみが許可され、cluster という名前を付ける必要があります。
5.1. FlowCollector リソースを表示する
OpenShift Container Platform Web コンソールで YAML を直接表示および編集できます。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- NetObserv Operator の Provided APIs 見出しの下で、Flow Collector を選択します。
-
cluster を選択し、YAML タブを選択します。そこで、
FlowCollectorリソースを変更して Network Observability Operator を設定できます。
以下の例は、OpenShift Container Platform Network Observability Operator のサンプル FlowCollector リソースを示しています。
FlowCollector リソースのサンプル
apiVersion: flows.netobserv.io/v1beta1
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: DIRECT
agent:
type: EBPF
ebpf:
sampling: 50
logLevel: info
privileged: false
resources:
requests:
memory: 50Mi
cpu: 100m
limits:
memory: 800Mi
processor:
logLevel: info
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 800Mi
conversationEndTimeout: 10s
logTypes: FLOWS
conversationHeartbeatInterval: 30s
loki:
url: 'https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network'
statusUrl: 'https://loki-query-frontend-http.netobserv.svc:3100/'
authToken: FORWARD
tls:
enable: true
caCert:
type: configmap
name: loki-gateway-ca-bundle
certFile: service-ca.crt
namespace: loki-namespace #
consolePlugin:
register: true
logLevel: info
portNaming:
enable: true
portNames:
"3100": loki
quickFilters:
- name: Applications
filter:
src_namespace!: 'openshift-,netobserv'
dst_namespace!: 'openshift-,netobserv'
default: true
- name: Infrastructure
filter:
src_namespace: 'openshift-,netobserv'
dst_namespace: 'openshift-,netobserv'
- name: Pods network
filter:
src_kind: 'Pod'
dst_kind: 'Pod'
default: true
- name: Services network
filter:
dst_kind: 'Service'- 1
- エージェント仕様
spec.agent.typeはEBPFでなければなりません。eBPF は、OpenShift Container Platform でサポートされる唯一のオプションです。 - 2
- サンプリング仕様
spec.agent.ebpf.samplingを設定して、リソースを管理できます。サンプリング値が低いと、大量の計算、メモリー、およびストレージリソースが消費される可能性があります。これは、サンプリング比の値を指定することで軽減できます。値 100 は、100 ごとに 1 つのフローがサンプリングされることを意味します。0 または 1 の値は、すべてのフローがキャプチャーされることを意味します。値が低いほど、返されるフローが増加し、派生メトリクスの精度が向上します。デフォルトでは、eBPF サンプリングは値 50 に設定されているため、50 ごとに 1 つのフローがサンプリングされます。より多くのサンプルフローは、より多くのストレージが必要になることにも注意してください。デフォルト値から始めて経験的に調整し、クラスターが管理できる設定を決定することを推奨します。 - 3
- オプションの仕様
spec.processor.logTypes、spec.processor.conversationHeartbeatInterval、およびspec.processor.conversationEndTimeoutを設定して、会話追跡を有効にすることができます。有効にすると、Web コンソールで会話イベントをクエリーできるようになります。spec.processor.logTypesの値は次のとおりです:FLOWSCONVERSATIONS、ENDED_CONVERSATIONS、またはALL。ストレージ要件はALLで最も高く、ENDED_CONVERSATIONSで最も低くなります。 - 4
- Loki 仕様である
spec.lokiは、Loki クライアントを指定します。デフォルト値は、Loki Operator のインストールセクションに記載されている Loki インストールパスと一致します。Loki の別のインストール方法を使用した場合は、インストールに適切なクライアント情報を指定します。 - 5
- 元の証明書は Network Observability インスタンスの namespace にコピーされ、更新が監視されます。指定しない場合、namespace はデフォルトで "spec.namespace" と同じになります。Loki を別の namespace にインストールすることを選択した場合は、
spec.loki.tls.caCert.namespaceフィールドにその namespace を指定する必要があります。同様に、Kafka を別の namespace にインストールした場合は、spec.exporters.kafka.tls.caCert.namespaceフィールドを指定できます。 - 6
spec.quickFilters仕様は、Web コンソールに表示されるフィルターを定義します。Applicationフィルターキー、src_namespaceおよびdst_namespaceは否定 (!) されているため、Applicationフィルターは、openshift-またはnetobservnamespace から発信されて いない、または宛先がないすべてのトラフィックを表示します。詳細は、以下のクイックフィルターの設定を参照してください。
5.2. Kafka を使用した Flow Collector リソースの設定
Kafka を高スループットかつ低遅延のデータフィードのために使用するように、FlowCollector リソースを設定できます。Kafka インスタンスを実行する必要があり、そのインスタンスで OpenShift Container Platform Network Observability 専用の Kafka トピックを作成する必要があります。詳細は、AMQ Streams を使用した Kafka ドキュメント を参照してください。
前提条件
- Kafka がインストールされている。Red Hat は、AMQ Streams Operator を使用する Kafka をサポートします。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- Network Observability Operator の Provided APIs という見出しの下で、Flow Collector を選択します。
- クラスターを選択し、YAML タブをクリックします。
-
次のサンプル YAML に示すように、Kafka を使用するように OpenShift Container Platform Network Observability Operator の
FlowCollectorリソースを変更します。
FlowCollector リソースの Kafka 設定のサンプル
apiVersion: flows.netobserv.io/v1beta1
kind: FlowCollector
metadata:
name: cluster
spec:
deploymentModel: KAFKA
kafka:
address: "kafka-cluster-kafka-bootstrap.netobserv"
topic: network-flows
tls:
enable: false - 1
- Kafka デプロイメントモデルを有効にするには、
spec.deploymentModelをDIRECTではなくKAFKAに設定します。 - 2
spec.kafka.addressは、Kafka ブートストラップサーバーのアドレスを参照します。ポート 9093 で TLS を使用するため、kafka-cluster-kafka-bootstrap.netobserv:9093など、必要に応じてポートを指定できます。- 3
spec.kafka.topicは、Kafka で作成されたトピックの名前と一致する必要があります。- 4
spec.kafka.tlsを使用して、Kafka との間のすべての通信を TLS または mTLS で暗号化できます。有効にした場合、Kafka CA 証明書は、flowlogs-pipelineプロセッサーコンポーネントがデプロイされている namespace (デフォルト:netobserv) と eBPF エージェントがデプロイされている namespace (デフォルト:netobserv-privileged) の両方で ConfigMap または Secret として使用できる必要があります。spec.kafka.tls.caCertで参照する必要があります。mTLS を使用する場合、クライアントシークレットはこれらの namespace でも利用でき (たとえば、AMQ Streams User Operator を使用して生成できます)、spec.kafka.tls.userCertで参照される必要があります。
5.3. 強化されたネットワークフローデータをエクスポートする
ネットワークフローを Kafka、IPFIX、またはその両方に同時に送信できます。Splunk、Elasticsearch、Fluentd などをはじめとする、Kafka または IPFIX 入力をサポートするプロセッサーまたはストレージは、補完されたネットワークフローデータを使用できます。
前提条件
-
ネットワーク可観測性の
flowlogs-pipelinePod から Kafka または IPFIX コレクターエンドポイントを使用できる。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- NetObserv Operator の Provided APIs 見出しの下で、Flow Collector を選択します。
- cluster を選択し、YAML タブを選択します。
FlowCollectorを編集して、spec.exportersを次のように設定します。apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: exporters: - type: KAFKA1 kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" topic: netobserv-flows-export2 tls: enable: false3 - type: IPFIX4 ipfix: targetHost: "ipfix-collector.ipfix.svc.cluster.local" targetPort: 4739 transport: tcp or udp5 - 2
- Network Observability Operator は、すべてのフローを設定された Kafka トピックにエクスポートします。
- 3
- Kafka との間のすべての通信を SSL/TLS または mTLS で暗号化できます。有効にした場合、Kafka CA 証明書は、
flowlogs-pipelineプロセッサーコンポーネントがデプロイされている namespace (デフォルト: netobserv) で、ConfigMap または Secret として使用できる必要があります。これはspec.exporters.tls.caCertで参照する必要があります。mTLS を使用する場合、クライアントシークレットはこれらの namespace でも利用可能であり (たとえば、AMQ Streams User Operator を使用して生成できます)、spec.exporters.tls.userCertで参照される必要があります。 - 1 4
- Kafka にフローをエクスポートする代わりに、またはそれを併せて、フローを IPFIX にエクスポートできます。
- 5
- オプションでトランスポートを指定できます。デフォルト値は
tcpですが、udpを指定することもできます。
- 設定後、ネットワークフローデータを JSON 形式で利用可能な出力に送信できます。詳細は、ネットワークフロー形式のリファレンス を参照してください。
5.4. Flow Collector リソースの更新
OpenShift Container Platform Web コンソールで YAML を編集する代わりに、flowcollector カスタムリソース (CR) にパッチを適用することで、eBPF サンプリングなどの仕様を設定できます。
手順
次のコマンドを実行して、
flowcollectorCR にパッチを適用し、spec.agent.ebpf.sampling値を更新します。$ oc patch flowcollector cluster --type=json -p "[{"op": "replace", "path": "/spec/agent/ebpf/sampling", "value": <new value>}] -n netobserv"
5.5. クイックフィルターの設定
FlowCollector リソースでフィルターを変更できます。値を二重引用符で囲むと、完全一致が可能になります。それ以外の場合、テキスト値には部分一致が使用されます。キーの最後にあるバング (!) 文字は、否定を意味します。YAML の変更に関する詳細なコンテキストは、サンプルの FlowCollector リソースを参照してください。
フィルターマッチングタイプ "all of" または "any of" は、ユーザーがクエリーオプションから変更できる UI 設定です。これは、このリソース設定の一部ではありません。
使用可能なすべてのフィルターキーのリストを次に示します。
| Universal* | ソース | 送信先 | 説明 |
|---|---|---|---|
| namespace |
|
| 特定の namespace に関連するトラフィックをフィルタリングします。 |
| name |
|
| 特定の Pod、サービス、またはノード (ホストネットワークトラフィックの場合) など、特定のリーフリソース名に関連するトラフィックをフィルター処理します。 |
| kind |
|
| 特定のリソースの種類に関連するトラフィックをフィルタリングします。リソースの種類には、リーフリソース (Pod、Service、または Node)、または所有者リソース (Deployment および StatefulSet) が含まれます。 |
| owner_name |
|
| 特定のリソース所有者に関連するトラフィックをフィルタリングします。つまり、ワークロードまたは Pod のセットです。たとえば、Deployment 名、StatefulSet 名などです。 |
| resource |
|
|
一意に識別する正規名で示される特定のリソースに関連するトラフィックをフィルタリングします。正規の表記法は、namespace の種類の場合は |
| address |
|
| IP アドレスに関連するトラフィックをフィルタリングします。IPv4 と IPv6 がサポートされています。CIDR 範囲もサポートされています。 |
| mac |
|
| MAC アドレスに関連するトラフィックをフィルタリングします。 |
| port |
|
| 特定のポートに関連するトラフィックをフィルタリングします。 |
| host_address |
|
| Pod が実行しているホスト IP アドレスに関連するトラフィックをフィルタリングします。 |
| protocol | 該当なし | 該当なし | TCP や UDP などのプロトコルに関連するトラフィックをフィルタリングします。 |
-
ソースまたは宛先のいずれかのユニバーサルキーフィルター。たとえば、フィルタリング
name: 'my-pod'は、使用される一致タイプ (Match all または Match any) に関係なく、my-podからのすべてのトラフィックとmy-podへのすべてのトラフィックを意味します。
5.6. SR-IOV インターフェイストラフィックの監視の設定
Single Root I/O Virtualization (SR-IOV) デバイスを使用してクラスターからトラフィックを収集するには、FlowCollector spec.agent.ebpf.privileged フィールドを true に設定する必要があります。次に、eBPF agent は、デフォルトで監視されるホストネットワーク namespace に加え、他のネットワーク namespace も監視します。仮想機能 (VF) インターフェイスを持つ Pod が作成されると、新しいネットワーク namespace が作成されます。SRIOVNetwork ポリシーの IPAM 設定を指定すると、VF インターフェイスがホストネットワーク namespace から Pod ネットワーク namespace に移行されます。
前提条件
- SR-IOV デバイスを使用して OpenShift Container Platform クラスターにアクセスできる。
-
SRIOVNetworkカスタムリソース (CR) のspec.ipam設定は、インターフェイスのリストにある範囲または他のプラグインからの IP アドレスを使用して設定する必要があります。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- NetObserv Operator の Provided APIs 見出しの下で、Flow Collector を選択します。
- cluster を選択し、YAML タブを選択します。
FlowCollectorカスタムリソースを設定します。設定例は次のとおりです。SR-IOV モニタリング用に
FlowCollectorを設定するapiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: DIRECT agent: type: EBPF ebpf: privileged: true1 - 1
- SR-IOV モニタリングを有効にするには、
spec.agent.ebpf.privilegedフィールドの値をtrueに設定する必要があります。
5.7. リソース管理およびパフォーマンスに関する考慮事項
ネットワーク監視に必要なリソースの量は、クラスターのサイズと、クラスターが可観測データを取り込んで保存するための要件によって異なります。リソースを管理し、クラスターのパフォーマンス基準を設定するには、次の設定を設定することを検討してください。これらの設定を設定すると、最適なセットアップと可観測性のニーズを満たす可能性があります。
次の設定は、最初からリソースとパフォーマンスを管理するのに役立ちます。
- eBPF サンプリング
-
サンプリング仕様
spec.agent.ebpf.samplingを設定して、リソースを管理できます。サンプリング値が低いと、大量の計算、メモリー、およびストレージリソースが消費される可能性があります。これは、サンプリング比の値を指定することで軽減できます。値100は、100 ごとに 1 つのフローがサンプリングされることを意味します。0または1の値は、すべてのフローがキャプチャーされることを意味します。値が小さいほど、返されるフローが増加し、派生メトリクスの精度が向上します。デフォルトでは、eBPF サンプリングは値 50 に設定されているため、50 ごとに 1 つのフローがサンプリングされます。より多くのサンプルフローは、より多くのストレージが必要になることにも注意してください。クラスターがどの設定を管理できるかを判断するには、デフォルト値から始めて実験的に調整することを検討してください。 - インターフェイスの制限または除外
-
spec.agent.ebpf.interfacesおよびspec.agent.ebpf.excludeInterfacesの値を設定して、観測されるトラフィック全体を削減します。デフォルトでは、エージェントは、excludeInterfacesおよびlo(ローカルインターフェイス) にリストされているインターフェイスを除く、システム内のすべてのインターフェイスを取得します。インターフェイス名は、使用される Container Network Interface (CNI) によって異なる場合があることに注意してください。
Network Observability をしばらく実行した後、次の設定を使用してパフォーマンスを微調整できます。
- リソース要件および制限
-
spec.agent.ebpf.resourcesおよびspec.processor.resources仕様を使用して、リソース要件と制限をクラスターで予想される負荷とメモリー使用量に適応させます。多くの中規模のクラスターには、デフォルトの制限の 800MB で十分な場合があります。 - キャッシュの最大フロータイムアウト
-
eBPF エージェントの
spec.agent.ebpf.cacheMaxFlowsおよびspec.agent.ebpf.cacheActiveTimeout仕様を使用して、エージェントによってフローが報告される頻度を制御します。値が大きいほど、エージェントで生成されるトラフィックが少なくなり、これは CPU 負荷の低下と相関します。ただし、値を大きくするとメモリー消費量がわずかに増加し、フロー収集でより多くの遅延が発生する可能性があります。
5.7.1. リソースの留意事項
次の表は、特定のワークロードサイズのクラスターのリソースに関する考慮事項の例を示しています。
表に概要を示した例は、特定のワークロードに合わせて調整されたシナリオを示しています。各例は、ワークロードのニーズに合わせて調整を行うためのベースラインとしてのみ考慮してください。
| 極小規模 (10 ノード) | 小規模 (25 ノード) | 中規模 (65 ノード) [2] | 大規模 (120 ノード) [2] | |
|---|---|---|---|---|
| ワーカーノードの vCPU とメモリー | 4 vCPU| 16GiB mem [1] | 16 vCPU| 64GiB mem [1] | 16 vCPU| 64GiB mem [1] | 16 vCPU| 64GiB Mem [1] |
| LokiStack サイズ |
|
|
|
|
| ネットワーク可観測性コントローラーのメモリー制限 | 400Mi (デフォルト) | 400Mi (デフォルト) | 400Mi (デフォルト) | 800 Mi |
| eBPF サンプリングレート | 50 (デフォルト) | 50 (デフォルト) | 50 (デフォルト) | 50 (デフォルト) |
| eBPF メモリー制限 | 800Mi (デフォルト) | 800Mi (デフォルト) | 2000Mi | 800Mi (デフォルト) |
| FLP メモリー制限 | 800Mi (デフォルト) | 800Mi (デフォルト) | 800Mi (デフォルト) | 800Mi (デフォルト) |
| FLP Kafka パーティション | 該当なし | 48 | 48 | 48 |
| Kafka コンシューマーレプリカ | 該当なし | 24 | 24 | 24 |
| Kafka ブローカー | 該当なし | 3 (デフォルト) | 3 (デフォルト) | 3 (デフォルト) |
- AWS M6i インスタンスでテスト済み。
-
このワーカーとそのコントローラーに加えて、3 つのインフラノード (サイズ
M6i.12xlarge) と 1 つのワークロードノード (サイズM6i.8xlarge) がテストされました。
第6章 ネットワークポリシー
admin ロールを持つユーザーとして、netobserv namespace のネットワークポリシーを作成できます。
6.1. ネットワーク可観測性のためのネットワークポリシーの作成
netobserv namespace への ingress トラフィックを保護するために、ネットワークポリシーを作成する必要がある場合があります。Web コンソールでは、フォームビューを使用してネットワークポリシーを作成できます。
手順
- Networking → NetworkPolicies に移動します。
-
Project ドロップダウンメニューから
netobservプロジェクトを選択します。 -
ポリシーに名前を付けます。この例では、ポリシー名は
allowed-ingressです。 - Add ingress rule を 3 回クリックして、3 つのイングレスルールを作成します。
フォームで以下を指定します。
最初の Ingress rule に対して以下の仕様を作成します。
- Add allowed source ドロップダウンメニューから、Allow pods from the same namespace を選択します。
2 番目の Ingress rule に対して次の仕様を作成します。
- Add allowed source ドロップダウンメニューから、Allow pods from inside the cluster を選択します。
- + Add namespace selector をクリックします。
-
ラベル
kubernetes.io/metadata.nameとセレクターopenshift-consoleを追加します。
3 番目の Ingress rule に対して次の仕様を作成します。
- Add allowed source ドロップダウンメニューから、Allow pods from inside the cluster を選択します。
- + Add namespace selector をクリックします。
-
ラベル
kubernetes.io/metadata.nameとセレクターopenshift-monitoringを追加します。
検証
- Observe → Network Traffic に移動します。
- Traffic Flows タブまたは任意のタブを表示して、データが表示されていることを確認します。
- Observe → Dashboards に移動します。NetObserv/Health の選択で、フローが取り込まれて Loki に送信されていることを確認します (最初のグラフに示されています)。
6.2. ネットワークポリシーの例
以下は、netobserv namespace の NetworkPolicy オブジェクトの例にアノテーションを付けています。
サンプルネットワークポリシー
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-ingress
namespace: netobserv
spec:
podSelector: {}
ingress:
- from:
- podSelector: {}
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-console
- podSelector: {}
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-monitoring
policyTypes:
- Ingress
status: {}- 1
- ポリシーが適用される Pod を説明するセレクター。ポリシーオブジェクトは
NetworkPolicyオブジェクトが定義されるプロジェクトの Pod のみを選択できます。このドキュメントでは、Netobservability Operator がインストールされているプロジェクト、つまりnetobservプロジェクトになります。 - 2
- ポリシーオブジェクトが入力トラフィックを許可する Pod に一致するセレクター。デフォルトでは、セレクターは
NetworkPolicyと同じ namespace の Pod と一致します。 - 3
namespaceSelectorが指定されている場合、セレクターは指定された namespace 内の Pod と一致します。
第7章 ネットワークトラフィックの監視
管理者は、OpenShift Container Platform コンソールでネットワークトラフィックを観察して、詳細なトラブルシューティングと分析を行うことができます。この機能は、トラフィックフローのさまざまなグラフィカル表現から洞察を得るのに役立ちます。ネットワークトラフィックを観察するために使用できるビューがいくつかあります。
7.1. 概要ビューからのネットワークトラフィックの監視
Overview ビューには、クラスター上のネットワークトラフィックフローの集約された全体的なメトリクスが表示されます。管理者は、使用可能な表示オプションを使用して統計を監視できます。
7.1.1. 概要ビューの操作
管理者は、Overview ビューに移動して、フローレートの統計をグラフィカルに表示できます。
手順
- Observe → Network Traffic に移動します。
- ネットワークトラフィック ページで、Overview タブをクリックします。
メニューアイコンをクリックすると、各流量データの範囲を設定できます。
7.1.2. 概要ビューの詳細オプションの設定
詳細オプションを使用して、グラフィカルビューをカスタマイズできます。詳細オプションにアクセスするには、Show advanced options をクリックします。Display options ドロップダウンメニューを使用して、グラフの詳細を設定できます。利用可能なオプションは次のとおりです。
- Metric type: Bytes または Packets 単位で表示されるメトリクス。デフォルト値は Bytes です。
- Scope: ネットワークトラフィックが流れるコンポーネントの詳細を選択します。スコープを Node、Namespace、Owner、または Resource に設定できます。Owner はリソースの集合体です。Resource は、ホストネットワークトラフィックの場合は Pod、サービス、ノード、または不明な IP アドレスです。デフォルト値は Namespace です。
- Truncate labels: ドロップダウンリストから必要なラベルの幅を選択します。デフォルト値は M です。
7.1.2.1. パネルの管理
必要な統計を選択して表示し、並べ替えることができます。列を管理するには、Manage panels をクリックします。
7.1.2.2. DNS 追跡
Overview ビューで、ネットワークフローの Domain Name System (DNS) 追跡のグラフィカル表示を設定できます。拡張 Berkeley Packet Filter (eBPF) トレースポイントフックを使用する DNS 追跡は、さまざまな目的に使用できます。
- ネットワーク監視: DNS クエリーと応答に関する知見を得ることで、ネットワーク管理者は異常パターン、潜在的なボトルネック、またはパフォーマンスの問題を特定できます。
- セキュリティー分析: マルウェアによって使用されるドメイン名生成アルゴリズム (DGA) などの不審な DNS アクティビティーを検出したり、セキュリティーを侵害する可能性のある不正な DNS 解決を特定したりします。
- トラブルシューティング: DNS 解決手順を追跡し、遅延を追跡し、設定ミスを特定することにより、DNS 関連の問題をデバッグします。
DNS 追跡が有効になっている場合、Overview のグラフに次のメトリクスが表示されます。このビューの有効化と使用の詳細は、このセクションの 関連情報 を参照してください。
- 上位 5 つの平均 DNS 遅延
- 上位 5 つの DNS レスポンスコード
- 上位 5 つの DNS レスポンスコードの累積と合計
この機能は、IPv4 および IPv6 UDP プロトコルでサポートされています。
7.2. トラフィックフロービューからのネットワークトラフィックの観察
Traffic flows ビューには、ネットワークフローのデータとトラフィックの量がテーブルに表示されます。管理者は、トラフィックフローテーブルを使用して、アプリケーション全体のトラフィック量を監視できます。
7.2.1. トラフィックフロービューの操作
管理者は、Traffic flows テーブルに移動して、ネットワークフロー情報を確認できます。
手順
- Observe → Network Traffic に移動します。
- Network Traffic ページで、Traffic flows タブをクリックします。
各行をクリックして、対応するフロー情報を取得できます。
7.2.2. トラフィックフロービューの詳細オプションの設定
Show advanced options を使用して、ビューをカスタマイズおよびエクスポートできます。Display options ドロップダウンメニューを使用して、行サイズを設定できます。デフォルト値は Normal です。
7.2.2.1. 列の管理
表示する必要のある列を選択し、並べ替えることができます。列を管理するには、Manage columns をクリックします。
7.2.2.2. トラフィックフローデータのエクスポート
Traffic flows ビューからデータをエクスポートできます。
手順
- Export data をクリックします。
- ポップアップウィンドウで、Export all data チェックボックスを選択してすべてのデータをエクスポートし、チェックボックスをオフにしてエクスポートする必要のあるフィールドを選択できます。
- Export をクリックします。
7.2.3. 会話追跡の使用
管理者は、同じ会話の一部であるネットワークフローをグループ化できます。会話は、IP アドレス、ポート、プロトコルによって識別されるピアのグループとして定義され、その結果、一意の Conversation ID が得られます。Web コンソールで対話イベントをクエリーできます。これらのイベントは、Web コンソールでは次のように表示されます。
- Conversation start: このイベントは、接続が開始されているか、TCP フラグがインターセプトされたときに発生します。
-
会話ティック: このイベントは、接続がアクティブである間、
FlowCollectorspec.processor.conversationHeartbeatIntervalパラメーターで定義された指定された間隔ごとに発生します。 -
Conversation end: このイベントは、
FlowCollectorspec.processor.conversationEndTimeoutパラメーターに達するか、TCP フラグがインターセプトされたときに発生します。 - Flow: これは、指定された間隔内に発生するネットワークトラフィックフローです。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- NetObserv Operator の Provided APIs 見出しの下で、Flow Collector を選択します。
- cluster を選択し、YAML タブを選択します。
spec.processor.logTypes、conversationEndTimeout、およびconversationHeartbeatIntervalパラメーターが観察のニーズに応じて設定されるように、FlowCollectorカスタムリソースを設定します。設定例は次のとおりです。会話追跡用に
FlowCollectorを設定するapiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: processor: conversationEndTimeout: 10s1 logTypes: FLOWS2 conversationHeartbeatInterval: 30s3 - 1
- Conversation end イベントは、
conversationEndTimeoutに達するか、TCP フラグがインターセプトされた時点を表します。 - 2
logTypesがFLOWSに設定されている場合、フロー イベントのみがエクスポートされます。値をALLに設定すると、会話イベントとフローイベントの両方がエクスポートされ、Network Traffic ページに表示されます。会話イベントのみに焦点を当てるには、Conversation start、Conversation tick、および Conversation end イベントをエクスポートするCONVERSATIONSを指定できます。またはENDED_CONVERSATIONSは Conversation end イベントのみをエクスポートします。ストレージ要件はALLで最も高く、ENDED_CONVERSATIONSで最も低くなります。- 3
- Conversation tick イベントは、ネットワーク接続がアクティブである間の、
FlowCollectorのconversationHeartbeatIntervalパラメーターで定義された各指定間隔を表します。
注記logTypeオプションを更新しても、以前の選択によるフローはコンソールプラグインから消去されません。たとえば、最初に午前 10 時までの期間logTypeをCONVERSATIONSに設定し、その後ENDED_CONVERSATIONSに移動すると、コンソールプラグインは午前 10 時までのすべての会話イベントを表示し、午前 10 時以降に終了した会話のみを表示します。-
Traffic flows タブの Network Traffic ページを更新します。Event/Type と Conversation Id という 2 つの新しい列があることに注意してください。クエリーオプションとして Flow が選択されている場合、すべての Event/Type フィールドは
Flowになります。 - Query Options を選択し、Log Type として Conversation を選択します。Event/Type は、必要なすべての会話イベントを表示するようになりました。
- 次に、特定の会話 ID でフィルタリングするか、サイドパネルから Conversation と Flow ログタイプのオプションを切り替えることができます。
7.2.4. DNS 追跡の使用
DNS 追跡を使用すると、ネットワークの監視、セキュリティー分析の実施、DNS 問題のトラブルシューティングを実行できます。次に示す YAML の例の仕様に合わせて FlowCollector を編集することで、DNS を追跡できます。
この機能を有効にすると、eBPF agent で CPU とメモリーの使用量の増加が観察されます。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- NetObserv Operator の Provided APIs 見出しの下で、Flow Collector を選択します。
- cluster を選択し、YAML タブを選択します。
FlowCollectorカスタムリソースを設定します。設定例は次のとおりです。DNS 追跡用に
FlowCollectorを設定するapiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: DIRECT agent: type: EBPF ebpf: features: - DNSTracking1 privileged: true2 Network Traffic ページを更新すると、Overview ビューと Traffic Flow ビューで表示する新しい DNS 表示と適用可能な新しいフィルターが表示されます。
- Manage panels で新しい DNS の選択肢を選択すると、Overview にグラフィカルな表現と DNS メトリクスが表示されます。
- Manage columns で新しい選択肢を選択すると、DNS 列が Traffic Flows ビューに追加されます。
- DNS Id、DNS Latency、DNS Response Code などの特定の DNS メトリクスでフィルタリングして、サイドパネルで詳細情報を確認できます。
7.2.4.1. ヒストグラムの使用
Show histogram をクリックすると、フローの履歴を棒グラフとして視覚化するためのツールバービューが表示されます。ヒストグラムは、時間の経過に伴うログの数を示します。ヒストグラムの一部を選択して、ツールバーに続く表でネットワークフローデータをフィルタリングできます。
7.3. トポロジービューからのネットワークトラフィックの観察
Topology ビューには、ネットワークフローとトラフィック量がグラフィカルに表示されます。管理者は、Topology ビューを使用して、アプリケーション全体のトラフィックデータを監視できます。
7.3.1. トポロジービューの操作
管理者は、Topology ビューに移動して、コンポーネントの詳細とメトリクスを確認できます。
手順
- Observe → Network Traffic に移動します。
- Network Traffic ページで、Topology タブをクリックします。
Topology 内の各コンポーネントをクリックして、コンポーネントの詳細とメトリクスを表示できます。
7.3.2. トポロジービューの詳細オプションの設定
Show advanced options を使用して、ビューをカスタマイズおよびエクスポートできます。詳細オプションビューには、次の機能があります。
- Find in view で必要なコンポーネントを検索します。
Display options: 次のオプションを設定するには:
- Layout: グラフィック表示のレイアウトを選択します。デフォルト値は ColaNoForce です。
- スコープ: ネットワークトラフィックが流れるコンポーネントのスコープを選択します。デフォルト値は Namespace です。
- Groups: コンポーネントをグループ化することにより、所有権の理解を深めます。デフォルト値は None です。
- グループを Collapse groups をデプロイメントまたは折りたたむ。グループはデフォルトでデプロイメントされています。Groups の値が None の場合、このオプションは無効になります。
- 表示: 表示する必要がある詳細を選択します。デフォルトでは、すべてのオプションがチェックされています。使用可能なオプションは、Edges、Edges label、および Badges です。
- Truncate labels: ドロップダウンリストから必要なラベルの幅を選択します。デフォルト値は M です。
7.3.2.1. トポロジービューのエクスポート
ビューをエクスポートするには、トポロジービューのエクスポート をクリックします。ビューは PNG 形式でダウンロードされます。
7.4. ネットワークトラフィックのフィルタリング
デフォルトでは、ネットワークトラフィックページには、FlowCollector インスタンスで設定されたデフォルトフィルターに基づいて、クラスター内のトラフィックフローデータが表示されます。フィルターオプションを使用して、プリセットフィルターを変更することにより、必要なデータを観察できます。
- クエリーオプション
以下に示すように、Query Options を使用して検索結果を最適化できます。
- Log Type: 利用可能なオプション Conversation と Flows では、フローログ、新しい会話、完了した会話、および長い会話の更新を含む定期的なレコードであるハートビートなどのログタイプ別にフローをクエリーする機能が提供されます。会話は、同じピア間のフローの集合体です。
-
Duplicated flows: フローは複数のインターフェイスや、送信元ノードと宛先ノードの両方から報告される可能性があり、データに複数回表示されます。このクエリーオプションを選択すると、重複したフローを表示するように選択できます。重複したフローでは、ポートを含め送信元と宛先が同じであり、
InterfaceフィールドとDirectionフィールドを除きプロトコルも同じです。重複はデフォルトでは非表示になります。ドロップダウンリストの Common セクションにある Direction フィルターを使用して、ingress トラフィックと egress トラフィックを切り替えます。 - Match filters: 高度なフィルターで選択されたさまざまなフィルターパラメーター間の関係を決定できます。利用可能なオプションは、Match all と Match any です。Match all はすべての値に一致する結果を提供し、Match any は入力された値のいずれかに一致する結果を提供します。デフォルト値は Match all です。
- Limit: 内部バックエンドクエリーのデータ制限。マッチングやフィルターの設定に応じて、トラフィックフローデータの数が指定した制限内で表示されます。
- クイックフィルター
-
クイックフィルター ドロップダウンメニューのデフォルト値は、
FlowCollector設定で定義されます。コンソールからオプションを変更できます。 - 高度なフィルター
- ドロップダウンリストからフィルタリングするパラメーターを選択することで、詳細フィルター (Common、Source、Destination) を設定できます。フローデータは選択に基づいてフィルタリングされます。適用されたフィルターを有効または無効にするには、フィルターオプションの下にリストされている適用されたフィルターをクリックします。
![]() One way と
One way と
![]()
![]() Back and forth のフィルタリングを切り替えることができます。
Back and forth のフィルタリングを切り替えることができます。
![]() One way フィルターを使用すると、選択したフィルターに基づき Source および Destination トラフィックのみが表示されます。Swap を使用すると、Source および Destination トラフィックの方向ビューを変更できます。
One way フィルターを使用すると、選択したフィルターに基づき Source および Destination トラフィックのみが表示されます。Swap を使用すると、Source および Destination トラフィックの方向ビューを変更できます。
![]()
![]() Back and forth フィルターには、Source フィルターと Destination フィルターによる戻りトラフィックが含まれます。ネットワークトラフィックの方向性があるフローは、トラフィックフローテーブルの DIrection 列に、ノード間トラフィックの場合は
Back and forth フィルターには、Source フィルターと Destination フィルターによる戻りトラフィックが含まれます。ネットワークトラフィックの方向性があるフローは、トラフィックフローテーブルの DIrection 列に、ノード間トラフィックの場合は Ingress`or `Egress として、シングルノード内のトラフィックの場合は `Inner` として表示されます。
Reset default をクリックして既存のフィルターを削除し、FlowCollector 設定で定義したフィルターを適用できます。
テキスト値を指定する規則を理解するには、詳細 をクリックします。
または、Namespaces、Services、Routes、Nodes、および Workloads ページの Network Traffic タブでトラフィックフローデータにアクセスして、対応する集約のフィルタリングされたデータを提供します。
第8章 Network Observability Operator の監視
Web コンソールを使用して、Network Observability Operator の健全性に関連するアラートを監視できます。
8.1. ヘルス情報の表示
Web コンソールの Dashboards ページから、Network Observability Operator の健全性とリソースの使用状況に関するメトリクスにアクセスできます。ダッシュボードに転送するヘルスアラートバナーは、アラートがトリガーされた場合に Network Traffic および Home ページに表示されます。アラートは次の場合に生成されます。
-
NetObservLokiErrorアラートは、Loki 取り込みレート制限に達した場合など、Loki エラーが原因でflowlogs-pipelineワークロードがフローをドロップすると発生します。 -
NetObservNoFlowsアラートは、一定時間フローが取り込まれない場合に発生します。
前提条件
- Network Observability Operator がインストールされています。
-
cluster-adminロールまたはすべてのプロジェクトの表示パーミッションを持つユーザーとしてクラスターにアクセスできる。
手順
- Web コンソールの Administrator パースペクティブから、Observe → Dashboards に移動します。
- Dashboards ドロップダウンメニューから、Netobserv/Health を選択します。Operator の健全性に関するメトリクスがページに表示されます。
8.1.1. ヘルスアラートの無効化
FlowCollector リソースを編集して、ヘルスアラートをオプトアウトできます。
- Web コンソールで、Operators → Installed Operators に移動します。
- NetObserv Operator の Provided APIs 見出しの下で、Flow Collector を選択します。
- cluster を選択し、YAML タブを選択します。
-
次の YAML サンプルのように、
spec.processor.metrics.disableAlertsを追加してヘルスアラートを無効にします。
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowCollector
metadata:
name: cluster
spec:
processor:
metrics:
disableAlerts: [NetObservLokiError, NetObservNoFlows] - 1
- 無効にするアラートの 1 つまたは両方のタイプを含むリストを指定できます。
8.2. NetObserv ダッシュボードの Loki レート制限アラートの作成
Netobserv ダッシュボードメトリクスのカスタムルールを作成して、Loki のレート制限に達した場合にアラートをトリガーできます。
以下は、アラートルール設定 YAML ファイルの例です。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: loki-alerts
namespace: openshift-operators-redhat
spec:
groups:
- name: LokiRateLimitAlerts
rules:
- alert: LokiTenantRateLimit
annotations:
message: |-
{{ $labels.job }} {{ $labels.route }} is experiencing 429 errors.
summary: "At any number of requests are responded with the rate limit error code."
expr: sum(irate(loki_request_duration_seconds_count{status_code="429"}[1m])) by (job, namespace, route) / sum(irate(loki_request_duration_seconds_count[1m])) by (job, namespace, route) * 100 > 0
for: 10s
labels:
severity: warning第9章 FlowCollector 設定パラメーター
FlowCollector は、基盤となるデプロイメントを操作および設定するネットワークフロー収集 API のスキーマです。
9.1. FlowCollector API 仕様
- 説明
-
FlowCollectorは、基盤となるデプロイメントを操作および設定するネットワークフロー収集 API のスキーマです。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| APIVersion はオブジェクトのこの表現のバージョンスキーマを定義します。サーバーは認識されたスキーマを最新の内部値に変換し、認識されない値は拒否することがあります。詳細は、https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources を参照してください。 |
|
|
| kind はこのオブジェクトが表す REST リソースを表す文字列の値です。サーバーは、クライアントが要求を送信するエンドポイントからこれを推測できることがあります。これを更新することはできません。キャメルケースを使用します。詳細は、https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds を参照してください。 |
|
|
| 標準オブジェクトのメタデータ。詳細は、https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata を参照してください。 |
|
|
|
FlowCollector リソースの望ましい状態を定義します。 |
9.1.1. .metadata
- 説明
- 標準オブジェクトのメタデータ。詳細は、https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata を参照してください。
- 型
-
object
9.1.2. .spec
- 説明
-
FlowCollector リソースの望ましい状態を定義します。
*: このドキュメントで "サポート対象外" または "非推奨" と記載されている場合、Red Hat はその機能を公式にサポートしていません。たとえば、コミュニティーによって提供され、メンテナンスに関する正式な合意なしに受け入れられた可能性があります。製品のメンテナーは、ベストエフォートに限定してこれらの機能に対するサポートを提供する場合があります。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| フローを展開するためのエージェント設定。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Kafka 設定。Kafka をフローコレクションパイプラインの一部としてブローカーとして使用できます。 |
|
|
| ロキ、フローストア、クライアント設定。 |
|
|
| Network Observability Pod がデプロイされる namespace。 |
|
|
|
|
9.1.3. .spec.agent
- 説明
- フローを展開するためのエージェント設定。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
9.1.4. .spec.agent.ebpf
- 説明
-
ebpfは、spec.agent.typeがEBPFに設定されている場合の eBPF ベースのフローレポーターに関連する設定を説明します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
有効にする追加機能のリスト。これらはデフォルトですべて無効になっています。追加機能を有効にすると、パフォーマンスに影響が出る可能性があります。使用できる値は、次のとおりです。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| eBPF Agent コンテナーの特権モード。一般的には、この設定は無視するか、false に設定します。その場合、Operator はコンテナーに詳細な機能 (BPF、PERFMON、NET_ADMIN、SYS_RESOURCE) を設定して、正しい操作を有効にします。CAP_BPF を認識しない古いカーネルバージョンが使用されている場合など、何らかの理由でこれらの機能を設定できない場合は、このモードをオンにして、より多くのグローバル権限を取得できます。 |
|
|
|
|
|
|
| フローレポーターのサンプリングレート。100 は、100 の 1 つのフローが送信されることを意味します。0 または 1 は、すべてのフローがサンプリングされることを意味します。 |
9.1.5. .spec.agent.ebpf.debug
- 説明
-
debugでは、eBPF エージェントの内部設定のいくつかの側面を設定できます。このセクションは、デバッグと、GOGC や GOMAXPROCS 環境変数などのきめ細かいパフォーマンスの最適化のみを目的としています。その値を設定するユーザーは、自己責任で行ってください。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
9.1.6. .spec.agent.ebpf.resources
- 説明
-
resourcesは、このコンテナーが必要とするコンピューティングリソースです。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| 制限は、許容されるコンピュートリソースの最大量を記述します。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 |
|
|
| 要求は、必要なコンピュートリソースの最小量を記述します。コンテナーについて Requests が省略される場合、明示的に指定される場合にデフォルトで Limits に設定されます。指定しない場合は、実装定義の値に設定されます。リクエストは制限を超えることはできません。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 |
9.1.7. .spec.agent.ipfix
- 説明
-
ipfix[非推奨 (*)] -spec.agent.typeがIPFIXに設定されている場合の IPFIX ベースのフローレポーターに関連する設定を記述します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9.1.8. .spec.agent.ipfix.clusterNetworkOperator
- 説明
-
clusterNetworkOperatorは、利用可能な場合、OpenShift Container Platform Cluster Network Operator に関連する設定を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| ConfigMap がデプロイされる namespace。 |
9.1.9. .spec.agent.ipfix.ovnKubernetes
- 説明
-
ovnKubernetesは、利用可能な場合、OVN-Kubernetes CNI の設定を定義します。この設定は、OpenShift Container Platform なしで OVN の IPFIX エクスポートを使用する場合に使用されます。OpenShift Container Platform を使用する場合は、代わりにclusterNetworkOperatorプロパティーを参照してください。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| OVN-Kubernetes Pod がデプロイされる namespace。 |
9.1.10. .spec.consolePlugin
- 説明
-
consolePluginは、利用可能な場合、OpenShift Container Platform コンソールプラグインに関連する設定を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
プラグインのデプロイメント用に設定する水平 Pod オートスケーラーの |
|
|
| コンソールプラグインのデプロイメントを有効にします。spec.Loki.enable も true にする必要があります |
|
|
|
|
|
|
|
コンソールプラグインバックエンドの |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9.1.11. .spec.consolePlugin.autoscaler
- 説明
-
プラグインのデプロイメント用に設定する水平 Pod オートスケーラーの
autoscaler仕様。HorizontalPodAutoscaler のドキュメント (自動スケーリング/v2) を参照してください。 - 型
-
object
9.1.12. .spec.consolePlugin.portNaming
- 説明
-
portNamingは、ポートからサービス名への変換の設定を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| コンソールプラグインのポートからサービス名への変換を有効にします。 |
|
|
|
|
9.1.13. .spec.consolePlugin.quickFilters
- 説明
-
quickFiltersは、コンソールプラグインのクイックフィルタープリセットを設定します。 - 型
-
array
9.1.14. .spec.consolePlugin.quickFilters[]
- 説明
-
QuickFilterは、コンソールのクイックフィルターのプリセット設定を定義します。 - 型
-
object - 必須
-
filter -
name
-
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| コンソールに表示されるフィルターの名前 |
9.1.15. .spec.consolePlugin.resources
- 説明
-
resources(コンピューティングリソースから見た場合にコンテナーに必要)。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| 制限は、許容されるコンピュートリソースの最大量を記述します。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 |
|
|
| 要求は、必要なコンピュートリソースの最小量を記述します。コンテナーについて Requests が省略される場合、明示的に指定される場合にデフォルトで Limits に設定されます。指定しない場合は、実装定義の値に設定されます。リクエストは制限を超えることはできません。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 |
9.1.16. .spec.exporters
- 説明
-
exportersは、カスタム消費またはストレージ用の追加のオプションのエクスポータを定義します。 - 型
-
array
9.1.17. .spec.exporters[]
- 説明
-
FlowCollectorExporterは、強化されたフローを送信する追加のエクスポーターを定義します。 - 型
-
object - 必須
-
type
-
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| 強化された IPFIX フローの送信先となる、IP アドレスやポートなどの IPFIX 設定。 |
|
|
| 強化されたフローの送信先となる、アドレスやトピックなどの Kafka 設定。 |
|
|
|
|
9.1.18. .spec.exporters[].ipfix
- 説明
- 強化された IPFIX フローの送信先となる、IP アドレスやポートなどの IPFIX 設定。
- 型
-
object - 必須
-
targetHost -
targetPort
-
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| IPFIX 外部レシーバーのアドレス |
|
|
| IPFIX 外部レシーバー用のポート |
|
|
|
IPFIX 接続に使用されるトランスポートプロトコル ( |
9.1.19. .spec.exporters[].kafka
- 説明
- 強化されたフローの送信先となる、アドレスやトピックなどの Kafka 設定。
- 型
-
object - 必須
-
address -
topic
-
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| Kafka サーバーのアドレス |
|
|
| SASL 認証の設定。[サポート対象外 (*)]。 |
|
|
| TLS クライアント設定。TLS を使用する場合は、アドレスが TLS に使用される Kafka ポート (通常は 9093) と一致することを確認します。 |
|
|
| 使用する Kafka トピック。これは必ず存在する必要があります。ネットワーク可観測性はこれを作成しません。 |
9.1.20. .spec.exporters[].kafka.sasl
- 説明
- SASL 認証の設定。[サポート対象外 (*)]。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| クライアント ID を含むシークレットまたは config map への参照 |
|
|
| クライアントシークレットを含むシークレットまたは config map への参照 |
|
|
|
使用する SASL 認証のタイプ。SASL を使用しない場合は |
9.1.21. .spec.exporters[].kafka.sasl.clientIDReference
- 説明
- クライアント ID を含むシークレットまたは config map への参照
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| config map またはシークレット内のファイル名 |
|
|
| ファイルを含む config map またはシークレットの名前 |
|
|
| ファイルを含む config map またはシークレットの namespace。省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
| ファイル参照のタイプ: "configmap" または "secret" |
9.1.22. .spec.exporters[].kafka.sasl.clientSecretReference
- 説明
- クライアントシークレットを含むシークレットまたは config map への参照
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| config map またはシークレット内のファイル名 |
|
|
| ファイルを含む config map またはシークレットの名前 |
|
|
| ファイルを含む config map またはシークレットの namespace。省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
| ファイル参照のタイプ: "configmap" または "secret" |
9.1.23. .spec.exporters[].kafka.tls
- 説明
- TLS クライアント設定。TLS を使用する場合は、アドレスが TLS に使用される Kafka ポート (通常は 9093) と一致することを確認します。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
| TLS を有効にします。 |
|
|
|
|
|
|
|
|
9.1.24. .spec.exporters[].kafka.tls.caCert
- 説明
-
caCertは、認証局の証明書の参照を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.25. .spec.exporters[].kafka.tls.userCert
- 説明
-
userCertは、mTLS に使用されるユーザー証明書参照を定義します (一方向 TLS を使用する場合は無視できます)。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.26. .spec.kafka
- 説明
-
Kafka 設定。Kafka をフローコレクションパイプラインの一部としてブローカーとして使用できます。
spec.deploymentModelがKAFKAの場合に利用できます。 - 型
-
object - 必須
-
address -
topic
-
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| Kafka サーバーのアドレス |
|
|
| SASL 認証の設定。[サポート対象外 (*)]。 |
|
|
| TLS クライアント設定。TLS を使用する場合は、アドレスが TLS に使用される Kafka ポート (通常は 9093) と一致することを確認します。 |
|
|
| 使用する Kafka トピック。これは必ず存在する必要があり、ネットワーク可観測性はこれを作成しません。 |
9.1.27. .spec.kafka.sasl
- 説明
- SASL 認証の設定。[サポート対象外 (*)]。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| クライアント ID を含むシークレットまたは config map への参照 |
|
|
| クライアントシークレットを含むシークレットまたは config map への参照 |
|
|
|
使用する SASL 認証のタイプ。SASL を使用しない場合は |
9.1.28. .spec.kafka.sasl.clientIDReference
- 説明
- クライアント ID を含むシークレットまたは config map への参照
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| config map またはシークレット内のファイル名 |
|
|
| ファイルを含む config map またはシークレットの名前 |
|
|
| ファイルを含む config map またはシークレットの namespace。省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
| ファイル参照のタイプ: "configmap" または "secret" |
9.1.29. .spec.kafka.sasl.clientSecretReference
- 説明
- クライアントシークレットを含むシークレットまたは config map への参照
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| config map またはシークレット内のファイル名 |
|
|
| ファイルを含む config map またはシークレットの名前 |
|
|
| ファイルを含む config map またはシークレットの namespace。省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
| ファイル参照のタイプ: "configmap" または "secret" |
9.1.30. .spec.kafka.tls
- 説明
- TLS クライアント設定。TLS を使用する場合は、アドレスが TLS に使用される Kafka ポート (通常は 9093) と一致することを確認します。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
| TLS を有効にします。 |
|
|
|
|
|
|
|
|
9.1.31. .spec.kafka.tls.caCert
- 説明
-
caCertは、認証局の証明書の参照を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.32. .spec.kafka.tls.userCert
- 説明
-
userCertは、mTLS に使用されるユーザー証明書参照を定義します (一方向 TLS を使用する場合は無視できます)。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.33. .spec.loki
- 説明
- ロキ、フローストア、クライアント設定。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
フローを Loki に保存する場合は |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Loki ステータス URL の TLS クライアント設定。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Loki URL の TLS クライアント設定。 |
|
|
|
|
9.1.34. .spec.loki.statusTls
- 説明
- Loki ステータス URL の TLS クライアント設定。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
| TLS を有効にします。 |
|
|
|
|
|
|
|
|
9.1.35. .spec.loki.statusTls.caCert
- 説明
-
caCertは、認証局の証明書の参照を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.36. .spec.loki.statusTls.userCert
- 説明
-
userCertは、mTLS に使用されるユーザー証明書参照を定義します (一方向 TLS を使用する場合は無視できます)。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.37. .spec.loki.tls
- 説明
- Loki URL の TLS クライアント設定。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
| TLS を有効にします。 |
|
|
|
|
|
|
|
|
9.1.38. .spec.loki.tls.caCert
- 説明
-
caCertは、認証局の証明書の参照を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.39. .spec.loki.tls.userCert
- 説明
-
userCertは、mTLS に使用されるユーザー証明書参照を定義します (一方向 TLS を使用する場合は無視できます)。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.40. .spec.processor
- 説明
-
processorは、エージェントからフローを受信し、それを強化し、メトリクスを生成し、 Loki 永続化レイヤーや使用可能なエエクスポーターに転送するコンポーネントの設定を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
プロセッサーランタイムの |
|
|
|
|
|
|
|
|
|
|
| フローコレクターのポート (ホストポート)。慣例により、一部の値は禁止されています。1024 より大きい値とし、4500、4789、6081 は使用できません。 |
|
|
|
|
|
|
|
|
9.1.41. .spec.processor.debug
- 説明
-
debugでは、フロープロセッサーの内部設定のいくつかの側面を設定できます。このセクションは、デバッグと、GOGC や GOMAXPROCS 環境変数などのきめ細かいパフォーマンスの最適化のみを目的としています。その値を設定するユーザーは、自己責任で行ってください。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
9.1.42. .spec.processor.kafkaConsumerAutoscaler
- 説明
-
kafkaConsumerAutoscalerは、Kafka メッセージを消費するflowlogs-pipeline-transformerを設定する水平 Pod オートスケーラーの仕様です。Kafka が無効になっている場合、この設定は無視されます。HorizontalPodAutoscaler のドキュメント (自動スケーリング/v2) を参照してください。 - 型
-
object
9.1.43. .spec.processor.metrics
- 説明
-
Metricは、メトリクスに関するプロセッサー設定を定義します。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Prometheus スクレイパーの metricsServer エンドポイント設定 |
9.1.44. .spec.processor.metrics.server
- 説明
- Prometheus スクレイパーの metricsServer エンドポイント設定
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| Prometheus HTTP ポート |
|
|
| TLS 設定。 |
9.1.45. .spec.processor.metrics.server.tls
- 説明
- TLS 設定。
- 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TLS 設定のタイプを選択します。 |
9.1.46. .spec.processor.metrics.server.tls.provided
- 説明
-
typeがPROVIDEDに設定されている場合の TLS 設定。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 証明書を含む config map またはシークレットの名前 |
|
|
| 証明書を含む config map またはシークレットの namespace省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
|
証明書参照のタイプ: |
9.1.47. .spec.processor.metrics.server.tls.providedCaFile
- 説明
-
typeがPROVIDEDに設定されている場合の CA ファイルへの参照。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| config map またはシークレット内のファイル名 |
|
|
| ファイルを含む config map またはシークレットの名前 |
|
|
| ファイルを含む config map またはシークレットの namespace。省略した場合、デフォルトでは、ネットワーク可観測性がデプロイされているのと同じ namespace が使用されます。namespace が異なる場合は、必要に応じてマウントできるように、config map またはシークレットがコピーされます。 |
|
|
| ファイル参照のタイプ: "configmap" または "secret" |
9.1.48. .spec.processor.resources
- 説明
-
resourcesは、このコンテナーが必要とするコンピューティングリソースです。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 - 型
-
object
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| 制限は、許容されるコンピュートリソースの最大量を記述します。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 |
|
|
| 要求は、必要なコンピュートリソースの最小量を記述します。コンテナーについて Requests が省略される場合、明示的に指定される場合にデフォルトで Limits に設定されます。指定しない場合は、実装定義の値に設定されます。リクエストは制限を超えることはできません。詳細は、https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ を参照してください。 |
第10章 ネットワークフロー形式の参照
これらはネットワークフロー形式の仕様であり、内部で使用され、フローを Kafka にエクスポートする場合にも使用されます。
10.1. ネットワークフロー形式のリファレンス
これはネットワークフロー形式の仕様であり、内部で使用され、フローを Kafka にエクスポートする場合にも使用されます。
このドキュメントは、Labels と通常の Fields という 2 つの主要なカテゴリーで設定されています。この区別は、Loki にクエリーを実行する場合にのみ重要です。これは、Fields とは異なり、Labels は ストリームセレクター で使用する必要があるためです。
この仕様を Kafka エクスポート機能のリファレンスとしてお読みになる場合は、すべての Labels と Fields を通常のフィールドとして扱い、Loki に固有のそれらの区別を無視する必要があります。
10.1.1. ラベル
- SrcK8S_Namespace
-
OptionalSrcK8S_Namespace:string
-
リソースの namespace。
- DstK8S_Namespace
-
OptionalDstK8S_Namespace:string
-
宛先 namespace
- SrcK8S_OwnerName
-
OptionalSrcK8S_OwnerName:string
-
ソース所有者 (Deployment、StatefulSet など)。
- DstK8S_OwnerName
-
OptionalDstK8S_OwnerName:string
-
デプロイメント、StatefulSet などの宛先所有者。
- FlowDirection
-
FlowDirection:
FlowDirection(次の「Enumeration: FlowDirection」セクションを参照)
-
FlowDirection:
ノード観測点からの流れ方向
- _RecordType
-
Optional_RecordType:RecordType
-
レコードの種類: 通常のフローログの場合は 'flowLog'、会話追跡の場合は 'allConnections'、'newConnection'、'heartbeat'、'endConnection'
10.1.2. フィールド
- SrcAddr
-
SrcAddr:
string
-
SrcAddr:
送信元 IP アドレス (ipv4 または ipv6)
- DstAddr
-
DstAddr:
string
-
DstAddr:
宛先 IP アドレス (ipv4 または ipv6)
- SrcMac
-
SrcMac:
string
-
SrcMac:
送信元 MAC アドレス
- DstMac
-
DstMac:
string
-
DstMac:
宛先 MAC アドレス
- SrcK8S_Name
-
OptionalSrcK8S_Name:string
-
Pod 名、サービス名など、ソースと一致する Kubernetes オブジェクトの名前。
- DstK8S_Name
-
OptionalDstK8S_Name:string
-
Pod 名、サービス名など、宛先と一致する Kubernetes オブジェクトの名前。
- SrcK8S_Type
-
OptionalSrcK8S_Type:string
-
Pod、サービスなど、ソースと一致する Kubernetes オブジェクトの種類。
- DstK8S_Type
-
OptionalDstK8S_Type:string
-
Pod 名、サービス名など、宛先と一致する Kubernetes オブジェクトの種類。
- SrcPort
-
OptionalSrcPort:number
-
送信元ポート
- DstPort
-
OptionalDstPort:number
-
送信先ポート
- SrcK8S_OwnerType
-
OptionalSrcK8S_OwnerType:string
-
ソース Kubernetes 所有者の種類 (Deployment、StatefulSet など)。
- DstK8S_OwnerType
-
OptionalDstK8S_OwnerType:string
-
Deployment、StatefulSet などの宛先 Kubernetes 所有者の種類。
- SrcK8S_HostIP
-
OptionalSrcK8S_HostIP:string
-
送信元ノード IP
- DstK8S_HostIP
-
OptionalDstK8S_HostIP:string
-
送信先ノード IP
- SrcK8S_HostName
-
OptionalSrcK8S_HostName:string
-
送信元ノード名
- DstK8S_HostName
-
OptionalDstK8S_HostName:string
-
送信先ノード名
- Proto
-
Proto:
number
-
Proto:
L4 プロトコル
- インターフェイス
-
OptionalInterface:string
-
ネットワークインターフェイス
- IfDirection
-
OptionalIfDirection:InterfaceDirection(次の「Enumeration: InterfaceDirection」セクションを参照)
-
ネットワークインターフェイス観測点からのフロー方向
- フラグ
-
OptionalFlags:number
-
TCP フラグ
- パケット
-
OptionalPackets:number
-
パケット数
- Packets_AB
-
OptionalPackets_AB:number
-
会話追跡では、会話ごとの A to B パケットカウンター
- Packets_BA
-
OptionalPackets_BA:number
-
会話追跡では、会話ごとの B to A パケットカウンター
- バイト
-
OptionalBytes:number
-
バイト数
- Bytes_AB
-
OptionalBytes_AB:number
-
会話追跡では、会話ごとの A to B バイトカウンター
- Bytes_BA
-
OptionalBytes_BA:number
-
会話追跡では、会話ごとの B to A バイトカウンター
- IcmpType
-
OptionalIcmpType:number
-
ICMP のタイプ
- IcmpCode
-
OptionalIcmpCode:number
-
ICMP コード
- PktDropLatestState
-
OptionalPktDropLatestState:string
-
ドロップの Pkt TCP 状態
- PktDropLatestDropCause
-
OptionalPktDropLatestDropCause:string
-
ドロップの原因の Pkt
- PktDropLatestFlags
-
OptionalPktDropLatestFlags:number
-
ドロップの Pkt TCP フラグ
- PktDropPackets
-
OptionalPktDropPackets:number
-
カーネルによってドロップされたパケットの数
- PktDropPackets_AB
-
OptionalPktDropPackets_AB:number
-
会話追跡では、会話ごとのドロップされた A to B パケットカウンター
- PktDropPackets_BA
-
OptionalPktDropPackets_BA:number
-
会話追跡では、会話ごとのドロップされた B to A パケットカウンター
- PktDropBytes
-
OptionalPktDropBytes:number
-
カーネルによってドロップされたバイト数
- PktDropBytes_AB
-
OptionalPktDropBytes_AB:number
-
会話追跡では、会話ごとのドロップされた A to B バイトカウンター
- PktDropBytes_BA
-
OptionalPktDropBytes_BA:number
-
会話追跡では、会話ごとのドロップされた B to A バイトカウンター
- DnsId
-
OptionalDnsId:number
-
DNS レコード id
- DnsFlags
-
OptionalDnsFlags:number
-
DNS レコードの DNS フラグ
- DnsFlagsResponseCode
-
OptionalDnsFlagsResponseCode:string
-
解析された DNS ヘッダーの RCODEs 名
- DnsLatencyMs
-
OptionalDnsLatencyMs:number
-
レスポンスとリクエストの間で計算された時間 (ミリ秒単位)
- TimeFlowStartMs
-
TimeFlowStartMs:
number
-
TimeFlowStartMs:
このフローの開始タイムスタンプ (ミリ秒単位)
- TimeFlowEndMs
-
TimeFlowEndMs:
number
-
TimeFlowEndMs:
このフローの終了タイムスタンプ (ミリ秒単位)
- TimeReceived
-
TimeReceived:
number
-
TimeReceived:
このフローがフローコレクターによって受信および処理されたときのタイムスタンプ (秒単位)
- TimeFlowRttNs
-
OptionalTimeFlowRttNs:number
-
Flow Round Trip Time (RTT) (ナノ秒単位)
- _HashId
-
Optional_HashId:string
-
会話追跡では、会話識別子
- _IsFirst
-
Optional_IsFirst:string
-
会話追跡では、最初のフローを識別するフラグ
- numFlowLogs
-
OptionalnumFlowLogs:number
-
会話追跡では、会話ごとのフローログのカウンター
10.1.3. 列挙: FlowDirection
- Ingress
-
Ingress =
"0"
-
Ingress =
ノード観測ポイントからの受信トラフィック
- Egress
-
Egress =
"1"
-
Egress =
ノード観測ポイントからの送信トラフィック
- Inner
-
Inner =
"2"
-
Inner =
同じ送信元ノードと宛先ノードを持つ内部トラフィック
第11章 ネットワーク可観測性のトラブルシューティング
ネットワーク可観測性の問題のトラブルシューティングを支援するために、いくつかのトラブルシューティングアクションを実行できます。
11.1. must-gather ツールの使用
must-gather ツールを使用すると、Pod ログ、FlowCollector、Webhook 設定などの、Network Observability Operator リソースおよびクラスター全体のリソースに関する情報を収集できます。
手順
- must-gather データを保存するディレクトリーに移動します。
次のコマンドを実行して、クラスター全体の must-gather リソースを収集します。
$ oc adm must-gather --image-stream=openshift/must-gather \ --image=quay.io/netobserv/must-gather
11.2. OpenShift Container Platform コンソールでのネットワークトラフィックメニューエントリーの設定
OpenShift Container Platform コンソールの 監視 メニューにネットワークトラフィックのメニューエントリーがリストされていない場合は、OpenShift Container Platform コンソールでネットワークトラフィックのメニューエントリーを手動で設定します。
前提条件
- OpenShift Container Platform バージョン 4.10 以降がインストールされている。
手順
次のコマンドを実行して、
spec.consolePlugin.registerフィールドがtrueに設定されているかどうかを確認します。$ oc -n netobserv get flowcollector cluster -o yaml出力例
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: falseオプション: Console Operator 設定を手動で編集して、
netobserv-pluginプラグインを追加します。$ oc edit console.operator.openshift.io cluster出力例
... spec: plugins: - netobserv-plugin ...オプション: 次のコマンドを実行して、
spec.consolePlugin.registerフィールドをtrueに設定します。$ oc -n netobserv edit flowcollector cluster -o yaml出力例
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: true次のコマンドを実行して、コンソール Pod のステータスが
runningであることを確認します。$ oc get pods -n openshift-console -l app=console次のコマンドを実行して、コンソール Pod を再起動します。
$ oc delete pods -n openshift-console -l app=console- ブラウザーのキャッシュと履歴をクリアします。
次のコマンドを実行して、ネットワーク可観測性プラグイン Pod のステータスを確認します。
$ oc get pods -n netobserv -l app=netobserv-plugin出力例
NAME READY STATUS RESTARTS AGE netobserv-plugin-68c7bbb9bb-b69q6 1/1 Running 0 21s次のコマンドを実行して、ネットワーク可観測性プラグイン Pod のログを確認します。
$ oc logs -n netobserv -l app=netobserv-plugin出力例
time="2022-12-13T12:06:49Z" level=info msg="Starting netobserv-console-plugin [build version: , build date: 2022-10-21 15:15] at log level info" module=main time="2022-12-13T12:06:49Z" level=info msg="listening on https://:9001" module=server
11.3. Flowlogs-Pipeline は、Kafka のインストール後にネットワークフローを消費しません
最初に deploymentModel: KAFKA を使用してフローコレクターをデプロイし、次に Kafka をデプロイした場合、フローコレクターが Kafka に正しく接続されない可能性があります。Flowlogs-pipeline が Kafka からのネットワークフローを消費しないフローパイプライン Pod を手動で再起動します。
手順
次のコマンドを実行して、flow-pipeline Pod を削除して再起動します。
$ oc delete pods -n netobserv -l app=flowlogs-pipeline-transformer
11.4. br-int インターフェイスと br-ex インターフェイスの両方からのネットワークフローが表示されない
br-ex` と br-int は、OSI レイヤー 2 で動作する仮想ブリッジデバイスです。eBPF エージェントは、IP レベルと TCP レベル、それぞれレイヤー 3 と 4 で動作します。ネットワークトラフィックが物理ホストや仮想 Pod インターフェイスなどの他のインターフェイスによって処理される場合、eBPF エージェントは br-ex および br-int を通過するネットワークトラフィックをキャプチャすることが期待できます。eBPF エージェントのネットワークインターフェイスを br-ex および br-int のみに接続するように制限すると、ネットワークフローは表示されません。
ネットワークインターフェイスを br-int および br-ex に制限する interfaces または excludeInterfaces の部分を手動で削除します。
手順
interfaces: [ 'br-int', 'br-ex' ]フィールド。これにより、エージェントはすべてのインターフェイスから情報を取得できます。または、レイヤー 3 インターフェイス (例:eth0) を指定することもできます。以下のコマンドを実行します。$ oc edit -n netobserv flowcollector.yaml -o yaml出力例
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: agent: type: EBPF ebpf: interfaces: [ 'br-int', 'br-ex' ]1 - 1
- ネットワークインターフェイスを指定します。
11.5. ネットワーク可観測性コントローラーマネージャー Pod でメモリーが不足しています
Subscription オブジェクトの spec.config.resources.limits.memory 仕様を編集することで、Network Observability Operator のメモリー制限を引き上げることができます。
手順
- Web コンソールで、Operators → Installed Operators に移動します。
- Network Observability をクリックし、Subscription を選択します。
Actions メニューから、Edit Subscription をクリックします。
または、CLI を使用して次のコマンドを実行して、
Subscriptionオブジェクトの YAML 設定を開くこともできます。$ oc edit subscription netobserv-operator -n openshift-netobserv-operator
Subscriptionオブジェクトを編集してconfig.resources.limits.memory仕様を追加し、メモリー要件を考慮して値を設定します。リソースに関する考慮事項の詳細は、関連情報を参照してください。apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: netobserv-operator namespace: openshift-netobserv-operator spec: channel: stable config: resources: limits: memory: 800Mi1 requests: cpu: 100m memory: 100Mi installPlanApproval: Automatic name: netobserv-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: <network_observability_operator_latest_version>2
11.6. Loki ResourceExhausted エラーのトラブルシューティング
Network Observability によって送信されたネットワークフローデータが、設定された最大メッセージサイズを超えると、Loki は ResourceExhausted エラーを返すことがあります。Red Hat Loki Operator を使用している場合、この最大メッセージサイズは 100 MiB に設定されています。
手順
- Operators → Installed Operators に移動し、Project ドロップダウンメニューから All projects を表示します。
- Provided APIs リストで、Network Observability Operator を選択します。
Flow Collector をクリックし、YAML view タブをクリックします。
-
Loki Operator を使用している場合は、
spec.loki.batchSize値が 98 MiB を超えていないことを確認してください。 -
Red Hat Loki Operator とは異なる Loki インストール方法 (Grafana Loki など) を使用している場合は、Grafana Loki サーバー設定 の
grpc_server_max_recv_msg_sizeが、FlowCollectorリソースのspec.loki.batchSize値より大きいことを確認してください。大きくない場合は、grpc_server_max_recv_msg_size値を増やすか、spec.loki.batchSize値を制限値よりも小さくなるように減らす必要があります。
-
Loki Operator を使用している場合は、
- FlowCollector を編集した場合は、Save をクリックします。
11.7. リソースのトラブルシューティング
11.8. LokiStack レート制限エラー
Loki テナントにレート制限が設定されていると、データが一時的に失われ、429 エラー (Per stream rate limit exceeded (limit:xMB/sec) while attempting to ingest for stream) が発生する可能性があります。このエラーを通知するようにアラートを設定することを検討してください。詳細は、このセクションの関連情報として記載されている「NetObserv ダッシュボードの Loki レート制限アラートの作成」を参照してください。
次に示す手順を実行して、perStreamRateLimit および perStreamRateLimitBurst 仕様で LokiStack CRD を更新できます。
手順
- Operators → Installed Operators に移動し、Project ドロップダウンから All projects を表示します。
- Loki Operator を見つけて、LokiStack タブを選択します。
YAML view を使用して LokiStack インスタンスを作成するか既存のものを編集し、
perStreamRateLimitおよびperStreamRateLimitBurst仕様を追加します。apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv spec: limits: global: ingestion: perStreamRateLimit: 61 perStreamRateLimitBurst: 302 tenants: mode: openshift-network managementState: Managed- Save をクリックします。
検証
perStreamRateLimit および perStreamRateLimitBurst 仕様を更新すると、クラスター内の Pod が再起動し、429 レート制限エラーが発生しなくなります。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.