バックアップおよび復元
OpenShift Container Platform クラスターのバックアップおよび復元
概要
第1章 バックアップおよび復元
1.1. コントロールプレーンのバックアップおよび復元の操作
クラスター管理者は、OpenShift Container Platform クラスターを一定期間停止し、後で再起動する必要がある場合があります。クラスターを再起動する理由として、クラスターでメンテナンスを実行する必要がある、またはリソースコストを削減する必要がある、などが挙げられます。OpenShift Container Platform では、クラスターの正常なシャットダウン を実行して、後でクラスターを簡単に再起動できます。
クラスターをシャットダウンする前に etcd データをバックアップする 必要があります。etcd は OpenShift Container Platform のキーと値のストアであり、すべてのリソースオブジェクトの状態を保存します。etcd バックアップは障害復旧において重要な役割を果たします。OpenShift Container Platform では、正常でない etcd メンバーを置き換える こともできます。
クラスターを再度実行する場合は、クラスターを正常に再起動します。
クラスターの証明書は、インストール日から 1 年後に有効期限が切れます。証明書が有効である間は、クラスターをシャットダウンし、正常に再起動することができます。クラスターは、期限切れのコントロールプレーン証明書を自動的に取得しますが、証明書署名要求 (CSR) を承認する 必要があります。
以下のように、OpenShift Container Platform が想定どおりに機能しないさまざまな状況に直面します。
- ノードの障害やネットワーク接続の問題などの予期しない状態により、再起動後にクラスターが機能しない。
- 誤ってクラスターで重要なものを削除した。
- 大多数のコントロールプレーンホストが失われたため、etcd のクォーラム (定足数) を喪失した。
保存した etcd スナップショットを使用して、クラスターを以前の状態に復元して、障害状況から常に回復できます。
1.2. アプリケーションのバックアップおよび復元の操作
クラスター管理者は、OpenShift API for Data Protection (OADP) を使用して、OpenShift Container Platform で実行しているアプリケーションをバックアップおよび復元できます。
OADP は、Velero CLI ツールのダウンロード の表に従って、インストールする OADP のバージョンに適したバージョンの Velero を使用して、namespace の粒度で Kubernetes リソースと内部イメージをバックアップおよび復元します。OADP は、スナップショットまたは Restic を使用して、永続ボリューム (PV) をバックアップおよび復元します。詳細は、OADP の機能 を参照してください。
1.2.1. OADP 要件
OADP には以下の要件があります。
-
cluster-adminロールを持つユーザーとしてログインする必要があります。 次のストレージタイプのいずれかなど、バックアップを保存するためのオブジェクトストレージが必要です。
- OpenShift Data Foundation
- Amazon Web Services
- Microsoft Azure
- Google Cloud
- S3 と互換性のあるオブジェクトストレージ
OCP 4.11 以降で CSI バックアップを使用する場合は、OADP 1.1.x をインストールします。
OADP 1.0.x は、OCP 4.11 以降での CSI バックアップをサポートしていません。OADP 1.0.x には Velero 1.7.x が含まれており、OCP 4.11 以降には存在しない API グループ snapshot.storage.k8s.io/v1beta1 が必要です。
S3 ストレージ用の CloudStorage API は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
スナップショットを使用して PV をバックアップするには、ネイティブスナップショット API を備えているか、次のプロバイダーなどの Container Storage Interface (CSI) スナップショットをサポートするクラウドストレージが必要です。
- Amazon Web Services
- Microsoft Azure
- Google Cloud
- Ceph RBD や Ceph FS などの CSI スナップショット対応のクラウドストレージ
スナップショットを使用して PV をバックアップしたくない場合は、デフォルトで OADP Operator によってインストールされる Restic を使用できます。
1.2.2. アプリケーションのバックアップおよび復元
Backup カスタムリソース (CR) を作成して、アプリケーションをバックアップします。バックアップ CR の作成 を参照してください。次のバックアップオプションを設定できます。
- バックアップ操作の前後にコマンドを実行するための バックアップフックの作成
- バックアップのスケジュール
- File System Backup を使用してアプリケーションをバックアップする: Kopia または Restic
-
アプリケーションのバックアップを復元するには、
Restore(CR) を作成します。復元 CR の作成 を参照してください。 - 復元操作中に init コンテナーまたはアプリケーションコンテナーでコマンドを実行するように 復元フック を設定できます。
第2章 クラスターの正常なシャットダウン
このドキュメントでは、クラスターを正常にシャットダウンするプロセスを説明します。メンテナンスの目的で、またはリソースコストの節約のためにクラスターを一時的にシャットダウンする必要がある場合があります。
2.1. 前提条件
クラスターをシャットダウンする前に etcd バックアップ を作成する。
重要クラスターの再起動時に問題が発生した場合にクラスターを復元できるように、この手順を実行する前に etcd バックアップを作成しておくことは重要です。
たとえば、次の条件により、再起動したクラスターが誤動作する可能性があります。
- シャットダウン時の etcd データの破損
- ハードウェアが原因のノード障害
- ネットワーク接続の問題
クラスターの回復に失敗した場合は、クラスターを以前の状態に復元 する手順を実行してください。
2.2. クラスターのシャットダウン
クラスターを正常な状態でシャットダウンし、後で再起動できるようにします。
インストール日から 1 年までクラスターをシャットダウンして、正常に再起動することを期待できます。インストール日から 1 年後に、クラスター証明書が期限切れになります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - etcd のバックアップを取得している。
手順
クラスターを長期間シャットダウンする場合は、証明書の有効期限が切れる日付を確認し、次のコマンドを実行します。
$ oc -n openshift-kube-apiserver-operator get secret kube-apiserver-to-kubelet-signer -o jsonpath='{.metadata.annotations.auth\.openshift\.io/certificate-not-after}'出力例
2022-08-05T14:37:50Zuser@user:~ $1 - 1
- クラスターが正常に再起動できるようにするために、指定の日付または指定の日付の前に再起動するように計画します。クラスターの再起動時に、kubelet 証明書を回復するために保留中の証明書署名要求 (CSR) を手動で承認する必要がある場合があります。
クラスター内のすべてのノードをスケジュール不可としてマークします。クラウドプロバイダーの Web コンソールから、または次のループを実行することでマークできます。
$ for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do echo ${node} ; oc adm cordon ${node} ; done出力例
ci-ln-mgdnf4b-72292-n547t-master-0 node/ci-ln-mgdnf4b-72292-n547t-master-0 cordoned ci-ln-mgdnf4b-72292-n547t-master-1 node/ci-ln-mgdnf4b-72292-n547t-master-1 cordoned ci-ln-mgdnf4b-72292-n547t-master-2 node/ci-ln-mgdnf4b-72292-n547t-master-2 cordoned ci-ln-mgdnf4b-72292-n547t-worker-a-s7ntl node/ci-ln-mgdnf4b-72292-n547t-worker-a-s7ntl cordoned ci-ln-mgdnf4b-72292-n547t-worker-b-cmc9k node/ci-ln-mgdnf4b-72292-n547t-worker-b-cmc9k cordoned ci-ln-mgdnf4b-72292-n547t-worker-c-vcmtn node/ci-ln-mgdnf4b-72292-n547t-worker-c-vcmtn cordoned次の方法を使用して Pod を退避させます。
$ for node in $(oc get nodes -l node-role.kubernetes.io/worker -o jsonpath='{.items[*].metadata.name}'); do echo ${node} ; oc adm drain ${node} --delete-emptydir-data --ignore-daemonsets=true --timeout=15s --force ; doneクラスターのすべてのノードをシャットダウンします。これを実行するには、クラウドプロバイダーの Web コンソールから行うか、次のループを実行します。どちらかの方法を使用してノードをシャットダウンすると、Pod が正常に終了するため、データが破損する可能性が低くなります。
注記API の仮想 IP が割り当てられたコントロールプレーンノードが、ループ内で最後に処理されるノードであることを確認してください。そうでない場合、シャットダウンコマンドが失敗します。
$ for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do oc debug node/${node} -- chroot /host shutdown -h 1; done1 - 1
-h 1は、コントロールプレーンノードがシャットダウンされるまで、このプロセスを継続する時間 (分単位) を示します。10 ノード以上の大規模なクラスターでは、すべてのコンピュートノードが先にシャットダウンする時間を確保するために、-h 10以上に設定します。
出力例
Starting pod/ip-10-0-130-169us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` Shutdown scheduled for Mon 2021-09-13 09:36:17 UTC, use 'shutdown -c' to cancel. Removing debug pod ... Starting pod/ip-10-0-150-116us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` Shutdown scheduled for Mon 2021-09-13 09:36:29 UTC, use 'shutdown -c' to cancel.注記シャットダウン前に OpenShift Container Platform に同梱される標準 Pod のコントロールプレーンノードをドレイン (解放) する必要はありません。クラスター管理者は、クラスターの再起動後に独自のワークロードのクリーンな再起動を実行する必要があります。カスタムワークロードが原因でシャットダウン前にコントロールプレーンノードをドレイン (解放) した場合は、再起動後にクラスターが再び機能する前にコントロールプレーンノードをスケジュール可能としてマークする必要があります。
外部ストレージや LDAP サーバーなど、不要になったクラスター依存関係をすべて停止します。この作業を行う前に、ベンダーのドキュメントを確認してください。
重要クラスターをクラウドプロバイダープラットフォームにデプロイした場合は、関連するクラウドリソースをシャットダウン、一時停止、または削除しないでください。一時停止された仮想マシンのクラウドリソースを削除すると、OpenShift Container Platform が正常に復元されない場合があります。
第3章 クラスターの正常な再起動
このドキュメントでは、正常なシャットダウン後にクラスターを再起動するプロセスを説明します。
クラスターは再起動後に機能することが予想されますが、クラスターは以下の例を含む予期しない状態によって回復しない可能性があります。
- シャットダウン時の etcd データの破損
- ハードウェアが原因のノード障害
- ネットワーク接続の問題
クラスターの回復に失敗した場合は、クラスターを以前の状態に復元 する手順を実行してください。
3.1. 前提条件
3.2. クラスターの再起動
クラスターの正常なシャットダウン後にクラスターを再起動できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - この手順では、クラスターを正常にシャットダウンしていることを前提としています。
手順
コントロールプレーンノードをオンにします。
クラスターインストール時の
admin.kubeconfigを使用しており、API 仮想 IP アドレス (VIP) が稼働している場合は、次の手順を実行します。-
KUBECONFIG環境変数をadmin.kubeconfigパスに設定します。 クラスター内の各コントロールプレーンノードに対して次のコマンドを実行します。
$ oc adm uncordon <node>
-
admin.kubeconfigの認証情報にアクセスできない場合は、次の手順を実行します。- SSH を使用してコントロールプレーンノードに接続します。
-
localhost-recovery.kubeconfigファイルを/rootディレクトリーにコピーします。 そのファイルを使用して、クラスター内の各コントロールプレーンノードに対して次のコマンドを実行します。
$ oc adm uncordon <node>
- 外部ストレージや LDAP サーバーなどのクラスターの依存関係すべてをオンにします。
すべてのクラスターマシンを起動します。
クラウドプロバイダーの Web コンソールなどでマシンを起動するには、ご使用のクラウド環境に適した方法を使用します。
約 10 分程度待機してから、コントロールプレーンノードのステータス確認に進みます。
すべてのコントロールプレーンノードが準備状態にあることを確認します。
$ oc get nodes -l node-role.kubernetes.io/master以下の出力に示されているように、コントロールプレーンノードはステータスが
Readyの場合、準備状態にあります。NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 75m v1.26.0 ip-10-0-170-223.ec2.internal Ready master 75m v1.26.0 ip-10-0-211-16.ec2.internal Ready master 75m v1.26.0コントロールプレーンノードが準備状態に ない 場合、承認する必要がある保留中の証明書署名要求 (CSR) があるかどうかを確認します。
現在の CSR の一覧を取得します。
$ oc get csrCSR の詳細をレビューし、これが有効であることを確認します。
$ oc describe csr <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
それぞれの有効な CSR を承認します。
$ oc adm certificate approve <csr_name>
コントロールプレーンノードが準備状態になった後に、すべてのワーカーノードが準備状態にあることを確認します。
$ oc get nodes -l node-role.kubernetes.io/worker以下の出力に示されているように、ワーカーノードのステータスが
Readyの場合、ワーカーノードは準備状態にあります。NAME STATUS ROLES AGE VERSION ip-10-0-179-95.ec2.internal Ready worker 64m v1.26.0 ip-10-0-182-134.ec2.internal Ready worker 64m v1.26.0 ip-10-0-250-100.ec2.internal Ready worker 64m v1.26.0ワーカーノードが準備状態に ない 場合、承認する必要がある保留中の証明書署名要求 (CSR) があるかどうかを確認します。
現在の CSR の一覧を取得します。
$ oc get csrCSR の詳細をレビューし、これが有効であることを確認します。
$ oc describe csr <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
それぞれの有効な CSR を承認します。
$ oc adm certificate approve <csr_name>
クラスターが適切に起動していることを確認します。
パフォーマンスが低下したクラスター Operator がないことを確認します。
$ oc get clusteroperatorsDEGRADED条件がTrueに設定されているクラスター Operator がないことを確認します。NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE authentication 4.13.0 True False False 59m cloud-credential 4.13.0 True False False 85m cluster-autoscaler 4.13.0 True False False 73m config-operator 4.13.0 True False False 73m console 4.13.0 True False False 62m csi-snapshot-controller 4.13.0 True False False 66m dns 4.13.0 True False False 76m etcd 4.13.0 True False False 76m ...すべてのノードが
Ready状態にあることを確認します。$ oc get nodesすべてのノードのステータスが
Readyであることを確認します。NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 82m v1.26.0 ip-10-0-170-223.ec2.internal Ready master 82m v1.26.0 ip-10-0-179-95.ec2.internal Ready worker 70m v1.26.0 ip-10-0-182-134.ec2.internal Ready worker 70m v1.26.0 ip-10-0-211-16.ec2.internal Ready master 82m v1.26.0 ip-10-0-250-100.ec2.internal Ready worker 69m v1.26.0クラスターが適切に起動しなかった場合、etcd バックアップを使用してクラスターを復元する必要がある場合があります。
コントロールプレーンとワーカーノードの準備ができたら、クラスター内のすべてのノードをスケジュール可能としてマークします。以下のコマンドを実行します。
for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do echo ${node} ; oc adm uncordon ${node} ; done
第4章 OADP アプリケーションのバックアップと復元
4.1. OpenShift API for Data Protection の概要
OpenShift API for Data Protection (OADP) 製品は、OpenShift Container Platform 上のお客様のアプリケーションを保護します。この製品は、OpenShift Container Platform のアプリケーション、アプリケーション関連のクラスターリソース、永続ボリューム、内部イメージをカバーする包括的な障害復旧保護を提供します。OADP は、コンテナー化されたアプリケーションと仮想マシン (VM) の両方をバックアップすることもできます。
ただし、OADP は etcd または OpenShift Operator の障害復旧ソリューションとしては機能しません。
OADP サポートは、お客様のワークロードの namespace とクラスタースコープのリソースに提供されます。
完全なクラスターの バックアップ と 復元 はサポートされていません。
4.1.1. OpenShift API for Data Protection API
OpenShift API for Data Protection (OADP) は、バックアップをカスタマイズし、不要または不適切なリソースの組み込みを防止するための複数のアプローチを可能にする API を提供します。
OADP は次の API を提供します。
4.1.1.1. データ保護のための OpenShift API のサポート
| バージョン | OCP のバージョン | 一般公開 | フルサポートの終了日 | メンテナンスの終了日 | 延長更新サポート (EUS) | Extended Update Support 期間 2 (EUS 期間 2) |
| 1.3 |
| 2023 年 11 月 29 日 | 2024 年 7 月 10 日 | 1.5 のリリース | 2025 年 10 月 31 日 EUS は OCP 4.14 です | 2026 年 10 月 31 日 EUS Term 2 は OCP 4.14 です |
4.1.1.1.1. OADP Operator のサポートされていないバージョン
| バージョン | 一般公開 | フルサポート終了 | メンテナンス終了 |
| 1.2 | 2023 年 6 月 14 日 | 2023 年 11 月 29 日 | 2024 年 7 月 10 日 |
| 1.1 | 2022 年 9 月 1 日 | 2023 年 6 月 14 日 | 2023 年 11 月 29 日 |
| 1.0 | 2022 年 2 月 9 日 | 2022 年 9 月 1 日 | 2023 年 6 月 14 日 |
EUS の詳細は、Extended Update Support を参照してください。
EUS Term 2 の詳細は、Extended Update Support Term 2 を参照してください。
4.2. OADP リリースノート
4.2.1. OADP 1.3 リリースノート
OpenShift API for Data Protection (OADP) 1.3 のリリースノートでは、新機能と拡張機能、非推奨の機能、製品の推奨事項、既知の問題、および解決された問題について説明します。
4.2.1.1. OADP 1.3.8 リリースノート
OpenShift API for Data Protection (OADP) 1.3.8 は、コンテナーのヘルスグレードを更新するためにリリースされた Container Grade Only (CGO) リリースです。OADP 1.3.7 と比較して、製品自体のコードは変更されていません。
4.2.1.2. OADP 1.3.7 リリースノート
OpenShift API for Data Protection (OADP) 1.3.7 は、コンテナーのヘルスグレードを更新するためにリリースされた Container Grade Only (CGO) リリースです。OADP 1.3.6 と比較して、製品自体のコードは変更されていません。
OADP 1.3.7 では、以下の Common Vulnerabilities and Exposures (CVE) が修正されました。
4.2.1.2.1. 新機能
must-gather ツールを使用したログの収集が Markdown 概要で改善されました。
must-gather ツールを使用して、OADP カスタムリソースのログおよび情報を収集できます。must-gather データはすべてのカスタマーケースに添付する必要があります。このツールは、must-gather ログクラスターディレクトリーにある収集された情報を含む Markdown 出力ファイルを生成します。OADP-5384
4.2.1.3. OADP 1.5.2 リリースノート
OpenShift API for Data Protection (OADP) 1.4.4 は、コンテナーのヘルスグレードを更新するためにリリースされた Container Grade Only (CGO) リリースです。OADP 1.4.3 と比較して、製品自体のコードは変更されていません。
4.2.1.4. OADP 1.5.2 リリースノート
OpenShift API for Data Protection (OADP) 1.4.4 は、コンテナーのヘルスグレードを更新するためにリリースされた Container Grade Only (CGO) リリースです。OADP 1.4.3 と比較して、製品自体のコードは変更されていません。
4.2.1.5. OADP 1.5.2 リリースノート
OpenShift API for Data Protection (OADP) 1.3.3 リリースノートには、解決された問題と既知の問題が記載されています。
4.2.1.5.1. 解決された問題
バックアップの spec.resourcepolicy.kind パラメーターは、大文字と小文字が区別されなくなりました。
以前は、バックアップの spec.resourcepolicy.kind パラメーターは、下位レベルの文字列でのみサポートされていました。今回の修正により、大文字と小文字が区別されなくなりました。OADP-6765
olm.maxOpenShiftVersion を使用して OCP 4.16 バージョンにアップグレードされないようにする
クラスターの operator-lifecycle-manager Operator は、OpenShift Container Platform のマイナーバージョン間でアップグレードすることはできません。olm.maxOpenShiftVersion パラメーターを使用すると、OADP 1.3 がインストールされている場合に OpenShift Container Platform 4.16 バージョンにアップグレードできなくなります。OpenShift Container Platform 4.16 バージョンにアップグレードするには、OCP 4.15 バージョンで OADP 1.3 を OADP 1.4 にアップグレードします。OADP-4803
BSL および VSL がクラスターから削除される
以前は、backupLocations または snapshotLocations セクションから Backup Storage Locations (BSL)またはボリューム スナップショット の場所(VSL)を削除するようにデータ保護アプリケーション(DPA)を変更すると、DPA が削除されるまでクラスターから BSL または VSL が削除されませんでした。今回の更新により、BSL/VSL がクラスターから削除されるようになりました。OADP-6765
DPA は秘密鍵を調整し、検証します。
以前は、データ保護アプリケーション(DPA)が間違ったボリュームスナップショットの場所(VSL)の秘密鍵名で正常に調整されていました。今回の更新により、DPA は、VSL を調整する前に秘密鍵名を検証します。OADP-6765
Velero のクラウド認証情報のパーミッションが制限されるようになりました
以前は、Velero のクラウド認証情報権限が 0644 権限でマウントされていました。その結果、所有者やグループとは別に /credentials/cloud ファイルを読み取ることができ、ストレージアクセスキーなどの機密情報へのアクセスが容易になります。今回の更新では、このファイルの権限が 0640 に更新され、owner と group 以外の他のユーザーがこのファイルにアクセスできなくなりました。
ArgoCD 管理 namespace がバックアップに含まれると警告が表示される
ArgoCD と Velero が同じ namespace を管理する場合、バックアップ操作中に警告が表示されます。OADP-4736
このリリースに含まれるセキュリティー修正のリストは RHSA-2024:4982 アドバイザリーに記載されています。
このリリースで解決されたすべての問題のリストは、Jira の OADP 1.5.0 の解決済みの問題 を参照してください。
4.2.1.5.2. 既知の問題
OADP を復元した後に Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる
OADP が復元されると、Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる可能性があります。この問題を回避するには、OADP を復元した後、エラーまたは CrashLoopBackOff 状態を返す StatefulSet Pod を削除します。StatefulSet コントローラーがこれらの Pod を再作成し、正常に動作するようになります。OADP-3767
defaultVolumesToFSBackup フラグと defaultVolumesToFsBackup フラグが同じではない
dpa.spec.configuration.velero.defaultVolumesToFSBackup フラグは backup.spec.defaultVolumesToFsBackup フラグと同じではないため、混乱を招く可能性があります。OADP-6765
PodVolumeRestore は、復元が失敗としてマークされている場合でも機能します
podvolumerestore は、復元が失敗としてマークされている場合でもデータ転送を続行します。OADP-6765
Velero は initContainer 仕様の復元をスキップできない
Velero は、restore-wait の init コンテナーが必要ないにもかかわらず、復元待ちの init コンテナーを復元する場合があります。OADP-3759
4.2.1.6. OADP 1.3.3 リリースノート
OpenShift API for Data Protection (OADP) 1.3.3 リリースノートには、解決された問題と既知の問題が記載されています。
4.2.1.6.1. 解決された問題
namespace 名が 37 文字を超えると OADP が失敗する
37 文字を超える文字を含む namespace に OADP Operator をインストールし、新しい DPA を作成すると、cloud-credentials シークレットのラベル付けに失敗します。このリリースでは、この問題が修正されています。OADP-4211
OADP image PullPolicy を Alwaysに設定
OADP の以前のバージョンでは、adp-controller-manager および Velero Pod の image PullPolicy が Always に設定されていました。これは、レジストリーにネットワーク帯域幅が制限されている可能性があるエッジシナリオで問題があり、Pod の再起動後にリカバリー時間が遅くなることがありました。OADP 1.3.3 では、openshift-adp-controller-manager および Velero Pod の image PullPolicy は IfNotPresent に設定されます。
このリリースに含まれるセキュリティー修正のリストは RHSA-2024:4982 アドバイザリーに記載されています。
このリリースで解決されたすべての問題のリストは、Jira の OADP 1.3.3 の解決済みの問題 のリストを参照してください。
4.2.1.6.2. 既知の問題
OADP を復元した後に Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる
OADP が復元されると、Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる可能性があります。この問題を回避するには、OADP を復元した後、エラーまたは CrashLoopBackOff 状態を返す StatefulSet Pod を削除します。StatefulSet コントローラーがこれらの Pod を再作成し、正常に動作するようになります。
4.2.1.7. OADP 1.3.2 リリースノート
OpenShift API for Data Protection (OADP) 1.3.2 リリースノートには、解決された問題と既知の問題が記載されています。
4.2.1.7.1. 解決された問題
BSL に有効なカスタムシークレットが使用されている場合、DPA は調整に失敗します。
Backup Storage Location (BSL) に有効なカスタムシークレットが使用されているが、デフォルトのシークレットが見つからない場合、DPA は調整に失敗します。回避策は、最初に必要なデフォルトの cloud-credentials を作成することです。カスタムシークレットが再作成されると、それを使用してその存在を確認できます。
CVE-2023-45290: oadp-velero-container: Golang net/http: Request.ParseMultipartForm でのメモリー不足
net/http Golang 標準ライブラリーパッケージに不具合が見つかり、OADP の以前のバージョンに影響します。multipart フォームを解析する場合、明示的に Request.ParseMultipartForm を使用するか、または暗黙的に Request.FormValue、Request.PostFormValue、または Request.FormFile を使用するかにかかわらず、解析されたフォームの合計サイズの制限は、単一のフォーム行の読み取り中に消費されるメモリーには適用されません。これにより、長い行を含む悪意のある入力により、任意の大量のメモリーが割り当てられ、メモリー不足につながる可能性があります。この不具合は OADP 1.3.2 で解決されました。
詳細は、CVE-2023-45290 を参照してください。
CVE-2023-45289: oadp-velero-container: Golang net/http/cookiejar: HTTP リダイレクト時の機密ヘッダーと Cookie の不適切な転送
net/http/cookiejar Golang 標準ライブラリーパッケージに不具合が見つかり、OADP の以前のバージョンに影響します。 サブドメインが一致しない、または初期ドメインと完全に一致しないドメインへの HTTP リダイレクトに従う場合、http.Client は Authorization や Cookie などの機密ヘッダーを転送しません。悪意を持って作成された HTTP リダイレクトにより、機密ヘッダーが予期せず転送される可能性があります。この不具合は OADP 1.3.2 で解決されました。
詳細は、CVE-2023-45289 を参照してください。
CVE-2024-24783: oadp-velero-container: Golang crypto/x509: 不明な公開鍵アルゴリズムを持つ証明書の検証パニック
crypto/x509 Golang 標準ライブラリーパッケージに不具合が見つかり、OADP の以前のバージョンに影響します。不明な公開鍵アルゴリズムを持つ証明書を含む証明書チェーンを検証すると、Certificate.Verify がパニックになります。これは、Config.ClientAuth を VerifyClientCertIfGiven または RequireAndVerifyClientCert に設定するすべての crypto/tls クライアントおよびサーバーに影響します。デフォルトの動作では、TLS サーバーはクライアント証明書を検証しません。この不具合は OADP 1.3.2 で解決されました。
詳細は、CVE-2024-24783 を参照してください。
CVE-2024-24784: oadp-velero-plugin-container: Golang net/mail: 表示名内のコメントが正しく処理されない
net/mail Golang 標準ライブラリーパッケージに不具合が見つかり、OADP の以前のバージョンに影響します。ParseAddressList 関数は、コメント、括弧内のテキスト、および表示名を正しく処理しません。これは準拠するアドレスパーサーとの不整合であるため、異なるパーサーを使用するプログラムによって異なる信頼の決定が行われる可能性があります。この不具合は OADP 1.3.2 で解決されました。
詳細は、CVE-2024-24784 を参照してください。
CVE-2024-24785: oadp-velero-container: Golang: html/template: MarshalJSON メソッドから返されるエラーにより、テンプレートのエスケープが壊れる可能性がある
html/template Golang 標準ライブラリーパッケージに不具合が見つかり、OADP の以前のバージョンに影響します。 MarshalJSON メソッドから返されるエラーにユーザーが制御するデータが含まれている場合、そのエラーは HTML/テンプレートパッケージのコンテキスト自動エスケープ動作の中断に使用される可能性があり、後続のアクションにより、予期しないコンテンツがテンプレートに挿入される可能性があります。 この不具合は OADP 1.3.2 で解決されました。
詳細は、CVE-2024-24785 を参照してください。
このリリースで解決されたすべての問題のリストは、Jira の OADP 1.3.2 の解決済みの問題 のリストを参照してください。
4.2.1.7.2. 既知の問題
OADP を復元した後に Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる
OADP が復元されると、Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる可能性があります。この問題を回避するには、OADP を復元した後、エラーまたは CrashLoopBackOff 状態を返す StatefulSet Pod を削除します。StatefulSet コントローラーがこれらの Pod を再作成し、正常に動作するようになります。
4.2.1.8. OADP 1.3.1 リリースノート
OpenShift API for Data Protection (OADP) 1.3.1 リリースノートには、新機能と解決された問題が記載されています。
4.2.1.8.1. 新機能
OADP 1.3.0 Data Mover が完全にサポートされるようになりました
OADP 1.3.0 でテクノロジープレビューとして導入された OADP 組み込みの Data Mover が、コンテナー化されたワークロードと仮想マシンのワークロードの両方で完全にサポートされるようになりました。
4.2.1.8.2. 解決した問題
IBM Cloud (R) Object Storage がバックアップストレージプロバイダーとしてサポートされるようになりました
IBM Cloud® Object Storage は、これまでサポートされていなかった AWS S3 互換のバックアップストレージプロバイダーの 1 つです。この更新により、IBM Cloud® Object Storage が AWS S3 互換のバックアップストレージプロバイダーとしてサポートされるようになりました。
OADP Operator が missing region エラーを正しく報告するようになりました
以前は、AWS Backup Storage Location (BSL) 設定で region を指定せずに profile:default を指定すると、OADP Operator が Data Protection Application (DPA) カスタムリソース (CR) での missing region エラーを報告できませんでした。この更新により、AWS の DPA BSL 仕様の検証が修正されました。その結果、OADP Operator が missing region エラーを報告するようになりました。
カスタムラベルが openshift-adp namespace から削除されなくなりました
以前は、openshift-adp-controller-manager Pod が openshift-adp namespace に割り当てられたラベルをリセットしていました。これにより、Argo CD などのカスタムラベルを必要とするアプリケーションで同期の問題が発生し、機能が適切に動作しませんでした。この更新により、この問題が修正され、カスタムラベルが openshift-adp namespace から削除されなくなりました。
OADP must-gather イメージが CRD を収集するようになりました
以前は、OADP must-gather イメージが、OADP によって提供されるカスタムリソース定義 (CRD) を収集しませんでした。その結果、omg ツールを使用してサポートシェルでデータを抽出することができませんでした。この修正により、must-gather イメージが OADP によって提供される CRD を収集し、omg ツールを使用してデータを抽出できるようになりました。
ガベージコレクションのデフォルト頻度値の記述が修正されました
以前は、garbage-collection-frequency フィールドのデフォルト頻度値の記述が間違っていました。この更新により、garbage-collection-frequency の gc-controller 調整のデフォルト頻度値が 1 時間という正しい値になりました。
FIPS モードフラグが OperatorHub で利用可能になりました
fips-compatible フラグを true に設定すると、OperatorHub の OADP Operator リストに FIPS モードフラグが追加されます。この機能は OADP 1.3.0 で有効になりましたが、Red Hat Container Catalog には FIPS 対応と表示されていませんでした。
csiSnapshotTimeout を短い期間に設定した場合に nil ポインターによる CSI プラグインのパニックが発生しなくなりました
以前は、csiSnapshotTimeout パラメーターを短い期間に設定すると、CSI プラグインで plugin panicked: runtime error: invalid memory address or nil pointer dereference というエラーが発生していました。
この修正により、バックアップが Timed out awaiting reconciliation of volumesnapshot エラーで失敗するようになりました。
このリリースで解決されたすべての問題のリストは、Jira の OADP 1.3.1 の解決済みの問題 のリストを参照してください。
4.2.1.8.3. 既知の問題
IBM Power (R) および IBM Z(R) プラットフォームにデプロイされたシングルノード OpenShift クラスターのバックアップおよびストレージの制限
IBM Power® および IBM Z® プラットフォームにデプロイされたシングルノード OpenShift クラスターのバックアップおよびストレージ関連の次の制限を確認してください。
- Storage
- 現在、IBM Power® および IBM Z® プラットフォームにデプロイされたシングルノードの OpenShift クラスターと互換性があるのは、NFS ストレージのみです。
- バックアップ
-
バックアップおよび復元操作では、
kopiaやresticなどのファイルシステムバックアップを使用したアプリケーションのバックアップのみがサポートされます。
OADP を復元した後に Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる
OADP が復元されると、Cassandra アプリケーション Pod が CrashLoopBackoff ステータスになる可能性があります。この問題を回避するには、OADP を復元した後、エラーまたは CrashLoopBackoff 状態の StatefulSet Pod を削除します。StatefulSet コントローラーがこれらの Pod を再作成し、正常に動作するようになります。
4.2.1.9. OADP 1.3.0 リリースノート
OpenShift API for Data Protection (OADP) 1.3.0 のリリースノートには、新機能、解決された問題とバグ、既知の問題がリストされています。
4.2.1.9.1. 新機能
Velero ビルトイン DataMover は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
OADP 1.3 には、Container Storage Interface (CSI) ボリュームのスナップショットをリモートオブジェクトストアに移動するために使用できる、ビルトイン Data Mover が含まれています。ビルトイン Data Mover を使用すると、クラスターの障害、誤削除、または破損が発生した場合に、リモートオブジェクトストアからステートフルアプリケーションを復元できます。スナップショットデータを読み取り、統合リポジトリーに書き込むためのアップローダーメカニズムとして Kopia を使用します。
File System Backup を使用してアプリケーションをバックアップする: Kopia または Restic
Velero のファイルシステムバックアップ (FSB) は、Restic パスと Kopia パスという 2 つのバックアップライブラリーをサポートしています。
Velero を使用すると、ユーザーは 2 つのパスから選択できます。
バックアップの場合は、インストール中に uploader-type フラグを使用してパスを指定します。有効な値は、restic または kopia です。値が指定されていない場合、このフィールドのデフォルトは kopia です。インストール後に選択を変更することはできません。
Google Cloud 認証
Google Cloud 認証を使用すると、有効期限の短い Google 認証情報を使用できます。
Workload Identity Federation を使用する Google Cloud では、Identity and Access Management (IAM)を使用して、サービスアカウントの権限を借用する機能を含む外部 ID IAM ロールを付与することができます。これにより、サービスアカウントキーに関連するメンテナンスとセキュリティーのリスクが排除されます。
AWS ROSA STS 認証
Red Hat OpenShift Service on AWS (ROSA) クラスターで OpenShift API for Data Protection (OADP) を使用して、アプリケーションデータをバックアップおよび復元できます。
ROSA は、幅広い AWS コンピュート、データベース、分析、機械学習、ネットワーク、モバイル、およびその他のサービスとのシームレスな統合を提供し、差別化されたエクスペリエンスの構築とお客様への提供をさらに高速化します。
AWS アカウントから直接サービスをサブスクライブできます。
クラスターの作成後、OpenShift Web コンソールを使用してクラスターを操作できます。ROSA サービスは、OpenShift API およびコマンドラインインターフェイス (CLI) ツールも使用します。
4.2.1.9.2. 解決した問題
ACM アプリケーションが削減され、復元後にマネージドクラスター上で再作成される
マネージドクラスター上のアプリケーションは削除され、復元をアクティブ化すると再作成されていました。OpenShift API for Data Protection (OADP 1.2) のバックアップおよび復元のプロセスは、古いバージョンよりも高速です。OADP のパフォーマンスが変わったことで、ACM リソースの復元時にこのような動作が発生するようになりました。一部のリソースは他のリソースより前に復元され、その結果、マネージドクラスターからアプリケーションが削除されていました。OADP-2686
Pod セキュリティー標準が原因で Restic の復元が部分的に失敗する
相互運用性のテスト中に、OpenShift Container Platform 4.14 の Pod セキュリティーモードが enforce に設定されていたため、Pod が拒否されました。これは、復元順序が原因で発生します。Pod が security context constraints (SCC) リソースの前に作成されることで podSecurity 標準に違反していたため、Pod が拒否されました。Velero サーバーで復元優先度フィールドを設定すると、復元は成功します。OADP-2688
Velero が複数の namespace にインストールされている場合、Pod ボリュームのバックアップが失敗する可能性がある
Velero が複数の namespace にインストールされている場合、Pod Volume Backup (PVB) 機能でリグレッションが発生していました。PVB コントローラーは、その namespace 内の PVB に適切に制限されませんでした。OADP-2308
OADP Velero プラグインが "received EOF, stopping recv loop" のメッセージを返す
OADP では、Velero プラグインは別のプロセスとして開始されました。Velero 操作が完了すると、成功しても失敗しても終了します。そのため、デバッグログに received EOF, stopping recv loop メッセージが表示された場合、それはエラーの発生ではなく、プラグイン操作の完了を意味しました。OADP-2176
CVE-2023-39325 複数の HTTP/2 対応 Web サーバーが DDoS 攻撃 (Rapid Reset Attack) に対して脆弱である
OADP の以前のリリースでは、リクエストのキャンセルにより複数のストリームがすぐにリセットされる可能性があるため、HTTP/2 プロトコルはサービス拒否攻撃の影響を受けやすかった。サーバーは、接続ごとのアクティブなストリームの最大数に関するサーバー側の制限に達しないようにしながら、ストリームをセットアップおよび破棄する必要がありました。これにより、サーバーリソースの消費によりサービス拒否が発生しました。
詳細は、CVE-2023-39325 (Rapid Reset Attack) を参照してください。
このリリースで解決された問題の一覧は、Jira の OADP 1.3.0 解決済みの問題 に記載されているリストを参照してください。
4.2.1.9.3. 既知の問題
csiSnapshotTimeout が短く設定されている場合、nil ポインターで CSI プラグインエラーが発生する
csiSnapshotTimeout の期間が短く設定されている場合、CSI プラグインが nil ポインターでエラーを引き起こします。短時間でスナップショットを完了できることもありますが、多くの場合、バックアップ PartiallyFailed でパニックが発生し、エラー plugin panicked: runtime error: invalid memory address or nil pointer dereference が表示されます。
volumeSnapshotContent CR にエラーがある場合、バックアップは PartiallyFailed としてマークされる
いずれかの VolumeSnapshotContent CR に VolumeSnapshotBeingCreated アノテーションの削除に関連するエラーがある場合、バックアップは WaitingForPluginOperationsPartiallyFailed フェーズに遷移します。OADP-2871
初めて 30,000 個のリソースの復元する際に、パフォーマンスの問題が発生する
既存のリソースポリシーを使用せずに 30,000 個のリソースを初めて復元する際に、既存のリソースポリシーを update に設定して 2 回目と 3 回目の復元を実行する場合と比べて、2 倍の時間がかかります。OADP-3071
Datadownload 操作が関連する PV を解放する前に、復元後のフックが実行を開始する可能性がある
Data Mover 操作は非同期のため、関連する Pod の永続ボリューム (PV) が Data Mover の永続ボリューム要求 (PVC) によって解放される前に、ポストフックが試行される可能性があります。
Google Cloud Workload Identity Federation VSL バックアップ PartiallyFailed
Google Cloud ワークロード ID が Google Cloud に設定されている場合に VSL バックアップ PartiallyFailed。
このリリースにおける既知の問題の完全なリストは、Jira の OADP 1.3.0 の既知の問題 のリストを参照してください。
4.2.1.9.4. アップグレードの注意事項
必ず次のマイナーバージョンにアップグレードしてください。バージョンは絶対に スキップしないでください。新しいバージョンに更新するには、一度に 1 つのチャネルのみアップグレードします。たとえば、OpenShift API for Data Protection (OADP) 1.1 から 1.3 にアップグレードする場合、まず 1.2 にアップグレードし、次に 1.3 にアップグレードします。
4.2.1.9.4.1. OADP 1.2 から 1.3 への変更点
Velero サーバーが、バージョン 1.11 から 1.12 に更新されました。
OpenShift API for Data Protection (OADP) 1.3 は、VolumeSnapshotMover (VSM) や Volsync Data Mover の代わりに Velero のビルトイン Data Mover を使用します。
これにより、以下の変更が発生します。
-
spec.features.dataMoverフィールドと VSM プラグインは OADP 1.3 と互換性がないため、それらの設定をDataProtectionApplication(DPA) 設定から削除する必要があります。 - Volsync Operator は Data Mover の機能には不要になったため、削除できます。
-
カスタムリソース定義の
volumesnapshotbackups.datamover.oadp.openshift.ioおよびvolumesnapshotrestores.datamover.oadp.openshift.ioは不要になったため、削除できます。 - OADP-1.2 Data Mover に使用されるシークレットは不要になったため、削除できます。
OADP 1.3 は、Restic の代替ファイルシステムバックアップツールである Kopia をサポートしています。
Kopia を使用するには、次の例に示すように、新しい
spec.configuration.nodeAgentフィールドを使用します。例
spec: configuration: nodeAgent: enable: true uploaderType: kopia # ...spec.configuration.resticフィールドは OADP 1.3 で非推奨となり、今後の OADP バージョンで削除される予定です。非推奨の警告が表示されないようにするには、resticキーとその値を削除し、次の新しい構文を使用します。例
spec: configuration: nodeAgent: enable: true uploaderType: restic # ...
今後の OADP リリースでは、kopia ツールが uploaderType のデフォルト値になる予定です。
4.2.1.9.4.2. OADP 1.2 の Data Mover (テクノロジープレビュー) からアップグレードする
OpenShift API for Data Protection (OADP) 1.2 Data Mover のバックアップは、OADP 1.3 では 復元できません。アプリケーションのデータ保護にギャップが生じることを防ぐには、OADP 1.3 にアップグレードする前に次の手順を実行します。
手順
- クラスターのバックアップが十分で、Container Storage Interface (CSI) ストレージが利用可能な場合は、CSI バックアップを使用してアプリケーションをバックアップします。
クラスター外のバックアップが必要な場合:
-
--default-volumes-to-fs-backup=true or backup.spec.defaultVolumesToFsBackupオプションを使用するファイルシステムバックアップで、アプリケーションをバックアップします。 -
オブジェクトストレージプラグイン (
velero-plugin-for-awsなど) を使用してアプリケーションをバックアップします。
-
Restic ファイルシステムバックアップのデフォルトのタイムアウト値は 1 時間です。OADP 1.3.1 以降では、Restic および Kopia のデフォルトのタイムアウト値は 4 時間です。
OADP 1.2 Data Mover バックアップを復元するには、OADP をアンインストールし、OADP 1.2 をインストールして設定する必要があります。
4.2.1.9.4.3. DPA 設定をバックアップする
現在の DataProtectionApplication (DPA) 設定をバックアップする必要があります。
手順
次のコマンドを実行して、現在の DPA 設定を保存します。
例
$ oc get dpa -n openshift-adp -o yaml > dpa.orig.backup
4.2.1.9.4.4. OADP Operator をアップグレードする
OpenShift API for Data Protection (OADP) Operator をアップグレードする場合は、次の手順を使用します。
手順
-
OADP Operator のサブスクリプションチャネルを、
steady-1.2からstable-1.3に変更します。 - Operator とコンテナーが更新され、再起動されるまで待機します。
4.2.1.9.4.5. DPA を新しいバージョンに変換する
Data Mover を使用してバックアップをクラスター外に移動する必要がある場合は、次のように DataProtectionApplication (DPA) マニフェストを再設定します。
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs セクションで、View more をクリックします。
- DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、現在の DPA パラメーターを表示します。
現在の DPA の例
spec: configuration: features: dataMover: enable: true credentialName: dm-credentials velero: defaultPlugins: - vsm - csi - openshift # ...DPA パラメーターを更新します。
-
DPA から、
features.dataMoverキーと値を削除します。 - VolumeSnapshotMover (VSM) プラグインを削除します。
nodeAgentキーと値を追加します。更新された DPA の例
spec: configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - csi - openshift # ...
-
DPA から、
- DPA が正常に調整するまで待機します。
4.2.1.9.4.6. アップグレードの検証
アップグレードを検証するには、次の手順を使用します。
手順
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
OADP 1.3 では、DataProtectionApplication (DPA) 設定を作成するのではなく、バックアップごとにクラスター外へのデータ移動を開始できます。
コマンドの例
$ velero backup create example-backup --include-namespaces mysql-persistent --snapshot-move-data=true設定ファイルのサンプル
apiVersion: velero.io/v1
kind: Backup
metadata:
name: example-backup
namespace: openshift-adp
spec:
snapshotMoveData: true
includedNamespaces:
- mysql-persistent
storageLocation: dpa-sample-1
ttl: 720h0m0s
# ...4.3. OADP パフォーマンス
4.3.1. OADP 推奨ネットワーク設定
OpenShift API for Data Protection (OADP) のサポートされたエクスペリエンスを得るには、OpenShift ノード、S3 ストレージ、および OpenShift ネットワーク要件の推奨事項を満たすサポート対象のクラウド環境全体で、安定した回復力のあるネットワークが必要です。
最適ではないデータパスを持つクラスター外にあるリモート S3 バケットを含むデプロイメントでバックアップ操作および復元操作を正常に実行するには、最適ではない状況でネットワーク設定が次の最小要件を満たすことが推奨されます。
- 帯域幅 (オブジェクトストレージへのネットワークアップロード速度): 小規模なバックアップの場合は 2 Mbps 以上、大規模なバックアップの場合はデータ量に応じて 10 - 100 Mbps。
- 1% のパケットロス
- パケット破損: 1%
- 遅延: 100ms
OpenShift Container Platform ネットワークが最適に動作し、OpenShift Container Platform ネットワークの要件を満たしていることを確認します。
Red Hat は標準的なバックアップおよび復元の失敗に対するサポートを提供していますが、推奨されるしきい値を満たさないネットワーク設定によって発生する失敗に対するサポートは提供していません。
4.4. OADP の機能とプラグイン
OpenShift API for Data Protection (OADP) 機能は、アプリケーションをバックアップおよび復元するためのオプションを提供します。
デフォルトのプラグインにより、Velero は特定のクラウドプロバイダーと統合し、OpenShift Container Platform リソースをバックアップおよび復元できます。
4.4.1. OADP の機能
OpenShift API for Data Protection (OADP) は、以下の機能をサポートします。
- バックアップ
OADP を使用して OpenShift Platform 上のすべてのアプリケーションをバックアップしたり、タイプ、namespace、またはラベルでリソースをフィルターしたりできます。
OADP は、Kubernetes オブジェクトと内部イメージをアーカイブファイルとしてオブジェクトストレージに保存することにより、それらをバックアップします。OADP は、ネイティブクラウドスナップショット API または Container Storage Interface (CSI) を使用してスナップショットを作成することにより、永続ボリューム (PV) をバックアップします。スナップショットをサポートしないクラウドプロバイダーの場合、OADP は Restic を使用してリソースと PV データをバックアップします。
注記バックアップと復元を成功させるには、アプリケーションのバックアップから Operator を除外する必要があります。
- 復元
バックアップからリソースと PV を復元できます。バックアップ内のすべてのオブジェクトを復元することも、オブジェクトを namespace、PV、またはラベルでフィルタリングすることもできます。
注記バックアップと復元を成功させるには、アプリケーションのバックアップから Operator を除外する必要があります。
- スケジュール
- 指定した間隔でバックアップをスケジュールできます。
- フック
-
フックを使用して、Pod 上のコンテナーでコマンドを実行できます。たとえば、
fsfreezeを使用してファイルシステムをフリーズできます。バックアップまたは復元の前または後に実行するようにフックを設定できます。復元フックは、init コンテナーまたはアプリケーションコンテナーで実行できます。
4.4.2. OADP プラグイン
OpenShift API for Data Protection (OADP) は、バックアップおよびスナップショット操作をサポートするためにストレージプロバイダーと統合されたデフォルトの Velero プラグインを提供します。Velero プラグインに基づき、カスタムプラグイン を作成できます。
OADP は、OpenShift Container Platform リソースバックアップ、OpenShift Virtualization リソースバックアップ、および Container Storage Interface (CSI) スナップショット用のプラグインも提供します。
| OADP プラグイン | 機能 | ストレージの場所 |
|---|---|---|
|
| Kubernetes オブジェクトをバックアップし、復元します。 | AWS S3 |
| スナップショットを使用してボリュームをバックアップおよび復元します。 | AWS EBS | |
|
| Kubernetes オブジェクトをバックアップし、復元します。 | Microsoft Azure Blob ストレージ |
| スナップショットを使用してボリュームをバックアップおよび復元します。 | Microsoft Azure マネージドディスク | |
|
| Kubernetes オブジェクトをバックアップし、復元します。 | Google Cloud Storage |
| スナップショットを使用してボリュームをバックアップおよび復元します。 | Google Compute Engine ディスク | |
|
| OpenShift Container Platform リソースをバックアップおよび復元します。[1] | オブジェクトストア |
|
| OpenShift Virtualization リソースをバックアップおよび復元します。[2] | オブジェクトストア |
|
| CSI スナップショットを使用して、ボリュームをバックアップおよび復元します。[3] | CSI スナップショットをサポートするクラウドストレージ |
|
| VolumeSnapshotMover は、クラスターの削除などの状況で、ステートフルアプリケーションを回復するための復元プロセス中に使用されるスナップショットをクラスターからオブジェクトストアに再配置します。[4] | オブジェクトストア |
- 必須。
- 仮想マシンディスクは CSI スナップショットまたは Restic でバックアップされます。
csiプラグインは、Kubernetes CSI スナップショット API を使用します。-
OADP 1.1 以降は
snapshot.storage.k8s.io/v1を使用します。 -
OADP 1.0 は
snapshot.storage.k8s.io/v1beta1を使用します。
-
OADP 1.1 以降は
- OADP 1.2 のみ。
4.4.3. OADP Velero プラグインについて
Velero のインストール時に、次の 2 種類のプラグインを設定できます。
- デフォルトのクラウドプロバイダープラグイン
- カスタムプラグイン
どちらのタイプのプラグインもオプションですが、ほとんどのユーザーは少なくとも 1 つのクラウドプロバイダープラグインを設定します。
4.4.3.1. デフォルトの Velero クラウドプロバイダープラグイン
デプロイメント中に oadp_v1alpha1_dpa.yaml ファイルを設定するときに、次のデフォルトの Velero クラウドプロバイダープラグインのいずれかをインストールできます。
-
aws(Amazon Web Services) -
gcp(Google Cloud) -
azure(Microsoft Azure) -
openshift(OpenShift Velero プラグイン) -
csi(Container Storage Interface) -
kubevirt(KubeVirt)
デプロイメント中に oadp_v1alpha1_dpa.yaml ファイルで目的のデフォルトプラグインを指定します。
ファイルの例:
次の .yaml ファイルは、openshift、aws、azure、および gcp プラグインをインストールします。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
velero:
defaultPlugins:
- openshift
- aws
- azure
- gcp4.4.3.2. カスタム Velero プラグイン
デプロイメント中に oadp_v1alpha1_dpa.yaml ファイルを設定するときに、プラグインの image と name を指定することにより、カスタム Velero プラグインをインストールできます。
デプロイメント中に oadp_v1alpha1_dpa.yaml ファイルで目的のカスタムプラグインを指定します。
ファイルの例:
次の .yaml ファイルは、デフォルトの openshift、azure、および gcp プラグインと、イメージ quay.io/example-repo/custom-velero-plugin を持つ custom-plugin-example という名前のカスタムプラグインをインストールします。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
velero:
defaultPlugins:
- openshift
- azure
- gcp
customPlugins:
- name: custom-plugin-example
image: quay.io/example-repo/custom-velero-plugin4.4.3.3. Velero プラグインがメッセージ "received EOF, stopping recv loop" を返す
Velero プラグインは、別のプロセスとして開始されます。Velero 操作が完了すると、成功したかどうかにかかわらず終了します。デバッグログの received EOF, stopping recv loop メッセージは、プラグイン操作が完了したことを示します。エラーが発生したわけではありません。
4.4.4. OADP でサポートされるアーキテクチャー
OpenShift API for Data Protection (OADP) は、次のアーキテクチャーをサポートします。
- AMD64
- ARM64
- PPC64le
- s390x
OADP 1.2.0 以降のバージョンは、ARM64 アーキテクチャーをサポートします。
4.4.5. IBM Power および IBM Z の OADP サポート
OpenShift API for Data Protection (OADP) はプラットフォームに依存しません。以下は、IBM Power® および IBM Z® のみに関連する情報です。
- OADP 1.1.7 は、IBM Power® および IBM Z® 上の OpenShift Container Platform 4.11 に対して正常にテストされました。以下のセクションでは、これらのシステムのバックアップ場所に関する OADP 1.1.7 のテストおよびサポート情報を提供します。
- OADP 1.2.3 は、IBM Power® および IBM Z® 上の OpenShift Container Platform 4.12、4.13、4.14、4.15 に対して正常にテストされました。以下のセクションでは、これらのシステムのバックアップロケーションに関する OADP 1.2.3 のテストおよびサポート情報を提供します。
- OADP 1.3.6 は、IBM Power® と IBM Z® の両方の OpenShift Container Platform 4.12、4.13、4.14、4.15 に対して正常にテストされました。以下のセクションでは、これらのシステムのバックアップ場所に関して、OADP 1.3.6 のテストおよびサポート情報を示します。
4.4.5.1. IBM Power を使用したターゲットバックアップロケーションの OADP サポート
- OpenShift Container Platform 4.11、4.12、および OpenShift API for Data Protection (OADP) 1.1.7 で実行される IBM Power® は、AWS S3 バックアップロケーションターゲットに対して正常にテストされました。テストには AWS S3 ターゲットのみが含まれていましたが、Red Hat は、AWS ではないすべての S3 バックアップロケーションターゲットに対しても、OpenShift Container Platform 4.11 と 4.12、および OADP 1.1.7 に対応する IBM Power の実行をサポートしています。
- OpenShift Container Platform 4.12、4.13、4.14、4.15、および OADP 1.2.3 で実行される IBM Power® は、AWS S3 バックアップロケーションターゲットに対して正常にテストされました。テストには AWS S3 ターゲットのみが含まれていましたが、Red Hat は、AWS ではないすべての S3 バックアップロケーションターゲットに対しても、OpenShift Container Platform 4.12、4.13、4.14、4.15、および OADP 1.2.3 に対応する IBM Power の実行をサポートしています。
- OpenShift Container Platform 4.12、4.13、4.14、4.15、および OADP 1.3.6 で実行されている IBM Power® は、AWS S3 バックアップロケーションターゲットに対して正常にテストされました。テストには AWS S3 ターゲットのみが使用されましたが、Red Hat は、AWS 以外のすべての S3 バックアップロケーションターゲットに対しても、OpenShift Container Platform 4.14、4.15、4.16、4.17、および OADP 1.4.6 を使用した IBM Power® の実行をサポートしています。
4.4.5.2. IBM Z を使用したターゲットバックアップロケーションの OADP テストとサポート
- OpenShift Container Platform 4.11、4.12、および OpenShift API for Data Protection (OADP) 1.1.7 で実行される IBM Z® は、AWS S3 バックアップロケーションターゲットに対して正常にテストされました。テストには AWS S3 ターゲットのみが含まれていましたが、Red Hat は、AWS ではないすべての S3 バックアップロケーションターゲットに対しても、OpenShift Container Platform 4.11 と 4.12、および OADP 1.1.7 に対応する IBM Z® の実行をサポートしています。
- OpenShift Container Platform 4.12、4.13、4.14、4.15、および OADP 1.2.3 で実行されている IBM Z® は、AWS S3 バックアップロケーションターゲットに対して正常にテストされました。テストには AWS S3 ターゲットのみが含まれていましたが、Red Hat は、AWS ではないすべての S3 バックアップロケーションターゲットに対しても、OpenShift Container Platform 4.11、4.12、4.13、4.14、4.15、および OADP 1.2.3 に対応する IBM Z® の実行をサポートしています。
- OpenShift Container Platform 4.12、4.13、4.14、4.15、および 1.3.6 で実行されている IBM Z® は、AWS S3 バックアップロケーションターゲットに対して正常にテストされました。テストには AWS S3 ターゲットのみが使用されましたが、Red Hat は、AWS 以外のすべての S3 バックアップロケーションターゲットに対しても、OpenShift Container Platform 4.14、4.15、4.16、4.17、および 1.4.6 を使用した IBM Z® の実行をサポートしています。
4.4.5.2.1. IBM Power (R) および IBM Z(R) プラットフォームを使用した OADP の既知の問題
- 現在、IBM Power® および IBM Z® プラットフォームにデプロイされたシングルノードの OpenShift クラスターには、バックアップ方法の制限があります。現在、これらのプラットフォーム上のシングルノード OpenShift クラスターと互換性があるのは、NFS ストレージのみです。さらに、バックアップおよび復元操作では、Kopia や Restic などの File System Backup (FSB) 方式のみがサポートされます。現在、この問題に対する回避策はありません。
4.4.6. OADP プラグインの既知の問題
次のセクションでは、OpenShift API for Data Protection (OADP) プラグインの既知の問題を説明します。
4.4.6.1. シークレットがないことで、イメージストリームのバックアップ中に Velero プラグインでパニックが発生する
バックアップと Backup Storage Location (BSL) が Data Protection Application (DPA) の範囲外で管理されている場合、OADP コントローラー (つまり DPA の調整) によって関連する oadp-<bsl_name>-<bsl_provider>-registry-secret が作成されません。
バックアップを実行すると、OpenShift Velero プラグインがイメージストリームバックアップでパニックになり、次のパニックエラーが表示されます。
024-02-27T10:46:50.028951744Z time="2024-02-27T10:46:50Z" level=error msg="Error backing up item"
backup=openshift-adp/<backup name> error="error executing custom action (groupResource=imagestreams.image.openshift.io,
namespace=<BSL Name>, name=postgres): rpc error: code = Aborted desc = plugin panicked:
runtime error: index out of range with length 1, stack trace: goroutine 94…4.4.6.1.1. パニックエラーを回避するための回避策
Velero プラグインのパニックエラーを回避するには、次の手順を実行します。
カスタム BSL に適切なラベルを付けます。
$ oc label backupstoragelocations.velero.io <bsl_name> app.kubernetes.io/component=bslBSL にラベルを付けた後、DPA の調整を待ちます。
注記DPA 自体に軽微な変更を加えることで、強制的に調整を行うことができます。
DPA の調整では、適切な
oadp-<bsl_name>-<bsl_provider>-registry-secretが作成されていること、正しいレジストリーデータがそこに設定されていることを確認します。$ oc -n openshift-adp get secret/oadp-<bsl_name>-<bsl_provider>-registry-secret -o json | jq -r '.data'
4.4.6.2. OpenShift ADP Controller のセグメンテーション違反
cloudstorage と restic の両方を有効にして DPA を設定すると、openshift-adp-controller-manager Pod がクラッシュし、Pod がクラッシュループのセグメンテーション違反で失敗するまで無期限に再起動します。
velero または cloudstorage は相互に排他的なフィールドであるため、どちらか一方だけ定義できます。
-
veleroとcloudstorageの両方が定義されている場合、openshift-adp-controller-managerは失敗します。 -
veleroとcloudstorageのいずれも定義されていない場合、openshift-adp-controller-managerは失敗します。
この問題の詳細は、OADP-1054 を参照してください。
4.4.6.2.1. OpenShift ADP Controller のセグメンテーション違反の回避策
DPA の設定時に、velero または cloudstorage のいずれかを定義する必要があります。DPA で両方の API を定義すると、openshift-adp-controller-manager Pod がクラッシュループのセグメンテーション違反で失敗します。
4.4.7. OADP と FIPS
Federal Information Processing Standards (FIPS) は、Federal Information Security Management Act (FISMA) に従って米国連邦政府が開発した一連のコンピューターセキュリティー標準です。
OpenShift API for Data Protection (OADP) はテスト済みで、FIPS 対応の OpenShift Container Platform クラスターで動作します。
4.5. OADP のユースケース
4.5.1. OpenShift API for Data Protection と {odf-first} を使用したバックアップ
以下は、OADP と ODF を使用してアプリケーションをバックアップするユースケースです。
4.5.1.1. OADP と ODF を使用したアプリケーションのバックアップ
このユースケースでは、OADP を使用してアプリケーションをバックアップし、{odf-first} によって提供されるオブジェクトストレージにバックアップを保存します。
- Backup Storage Location を設定するために、Object Bucket Claim (OBC) を作成します。{odf-short} を使用して、Amazon S3 互換オブジェクトストレージバケットを設定します。{odf-short} は、MultiCloud Object Gateway (NooBaa MCG)および Ceph Object Gateway (RGW)、Object Storage Service としても知られる Ceph Object Gateway を提供します。このユースケースでは、Backup Storage Location として NooBaa MCG を使用します。
-
awsプロバイダープラグインを使用して、OADP で NooBaa MCG サービスを使用します。 - Backup Storage Location (BSL) を使用して Data Protection Application (DPA) を設定します。
- バックアップカスタムリソース (CR) を作成し、バックアップするアプリケーションの namespace を指定します。
- バックアップを作成して検証します。
前提条件
- OADP Operator をインストールした。
- {odf-short} Operator をインストールしました。
- 別の namespace で実行されているデータベースを持つアプリケーションがある。
手順
次の例に示すように、NooBaa MCG バケットを要求する OBC マニフェストファイルを作成します。
OBC の例
apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: test-obc1 namespace: openshift-adp spec: storageClassName: openshift-storage.noobaa.io generateBucketName: test-backup-bucket2 次のコマンドを実行して OBC を作成します。
$ oc create -f <obc_file_name>1 - 1
- Object Bucket Claim マニフェストのファイル名を指定します。
OBC を作成すると、ODF が Object Bucket Claim と同じ名前の
secretとconfig mapを作成します。secretにはバケットの認証情報が含まれており、config mapにはバケットにアクセスするための情報が含まれています。生成された config map からバケット名とバケットホストを取得するには、次のコマンドを実行します。$ oc extract --to=- cm/test-obc1 - 1
test-obcは OBC の名前です。
出力例
# BUCKET_NAME backup-c20...41fd # BUCKET_PORT 443 # BUCKET_REGION # BUCKET_SUBREGION # BUCKET_HOST s3.openshift-storage.svc生成された
secretからバケットの認証情報を取得するには、次のコマンドを実行します。$ oc extract --to=- secret/test-obc出力例
# AWS_ACCESS_KEY_ID ebYR....xLNMc # AWS_SECRET_ACCESS_KEY YXf...+NaCkdyC3QPym次のコマンドを実行して、
openshift-storagenamespace の s3 ルートから S3 エンドポイントのパブリック URL を取得します。$ oc get route s3 -n openshift-storage次のコマンドに示すように、オブジェクトバケットの認証情報を含む
cloud-credentialsファイルを作成します。[default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>次のコマンドに示すように、
cloud-credentialsファイルの内容を使用してcloud-credentialsシークレットを作成します。$ oc create secret generic \ cloud-credentials \ -n openshift-adp \ --from-file cloud=cloud-credentials次の例に示すように、Data Protection Application (DPA) を設定します。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: oadp-backup namespace: openshift-adp spec: configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - aws - openshift - csi defaultSnapshotMoveData: true1 backupLocations: - velero: config: profile: "default" region: noobaa s3Url: https://s3.openshift-storage.svc2 s3ForcePathStyle: "true" insecureSkipTLSVerify: "true" provider: aws default: true credential: key: cloud name: cloud-credentials objectStorage: bucket: <bucket_name>3 prefix: oadp次のコマンドを実行して DPA を作成します。
$ oc apply -f <dpa_filename>次のコマンドを実行して、DPA が正常に作成されたことを確認します。出力例から、
statusオブジェクトのtypeフィールドがReconciledに設定されていることがわかります。これは、DPA が正常に作成されたことを意味します。$ oc get dpa -o yaml出力例
apiVersion: v1 items: - apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: namespace: openshift-adp #...# spec: backupLocations: - velero: config: #...# status: conditions: - lastTransitionTime: "20....9:54:02Z" message: Reconcile complete reason: Complete status: "True" type: Reconciled kind: List metadata: resourceVersion: ""次のコマンドを実行して、Backup Storage Location (BSL) が使用可能であることを確認します。
$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 3s 15s true次の例に示すように、バックアップ CR を設定します。
バックアップ CR の例
apiVersion: velero.io/v1 kind: Backup metadata: name: test-backup namespace: openshift-adp spec: includedNamespaces: - <application_namespace>1 - 1
- バックアップするアプリケーションの namespace を指定します。
次のコマンドを実行してバックアップ CR を作成します。
$ oc apply -f <backup_cr_filename>
検証
次のコマンドを実行して、バックアップオブジェクトが
Completedフェーズにあることを確認します。詳細は、出力例を参照してください。$ oc describe backup test-backup -n openshift-adp出力例
Name: test-backup Namespace: openshift-adp # ....# Status: Backup Item Operations Attempted: 1 Backup Item Operations Completed: 1 Completion Timestamp: 2024-09-25T10:17:01Z Expiration: 2024-10-25T10:16:31Z Format Version: 1.1.0 Hook Status: Phase: Completed Progress: Items Backed Up: 34 Total Items: 34 Start Timestamp: 2024-09-25T10:16:31Z Version: 1 Events: <none>
4.5.2. OpenShift API for Data Protection (OADP) による復元のユースケース
以下は、OADP を使用してバックアップを別の namespace に復元するユースケースです。
4.5.2.1. OADP を使用してアプリケーションを別の namespace に復元する
OADP を使用して、アプリケーションのバックアップを、新しいターゲット namespace の test-restore-application に復元します。バックアップを復元するには、次の例に示すように、復元カスタムリソース (CR) を作成します。この復元 CR では、バックアップに含めたアプリケーションの namespace を、ソース namespace が参照します。その後、新しい復元先の namespace にプロジェクトを切り替えてリソースを確認することで、復元を検証します。
前提条件
- OADP Operator をインストールした。
- 復元するアプリケーションのバックアップがある。
手順
次の例に示すように、復元 CR を作成します。
復元 CR の例
apiVersion: velero.io/v1 kind: Restore metadata: name: test-restore1 namespace: openshift-adp spec: backupName: <backup_name>2 restorePVs: true namespaceMapping: <application_namespace>: test-restore-application3 次のコマンドを実行して復元 CR を適用します。
$ oc apply -f <restore_cr_filename>
検証
次のコマンドを実行して、復元が
Completedフェーズにあることを確認します。$ oc describe restores.velero.io <restore_name> -n openshift-adp次のコマンドを実行して、復元先の namespace
test-restore-applicationに切り替えます。$ oc project test-restore-application次のコマンドを実行して、永続ボリューム要求 (pvc)、サービス (svc)、デプロイメント、シークレット、config map などの復元されたリソースを確認します。
$ oc get pvc,svc,deployment,secret,configmap出力例
NAME STATUS VOLUME persistentvolumeclaim/mysql Bound pvc-9b3583db-...-14b86 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/mysql ClusterIP 172....157 <none> 3306/TCP 2m56s service/todolist ClusterIP 172.....15 <none> 8000/TCP 2m56s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/mysql 0/1 1 0 2m55s NAME TYPE DATA AGE secret/builder-dockercfg-6bfmd kubernetes.io/dockercfg 1 2m57s secret/default-dockercfg-hz9kz kubernetes.io/dockercfg 1 2m57s secret/deployer-dockercfg-86cvd kubernetes.io/dockercfg 1 2m57s secret/mysql-persistent-sa-dockercfg-rgp9b kubernetes.io/dockercfg 1 2m57s NAME DATA AGE configmap/kube-root-ca.crt 1 2m57s configmap/openshift-service-ca.crt 1 2m57s
4.5.3. バックアップ時の自己署名 CA 証明書の追加
自己署名認証局 (CA) 証明書を Data Protection Application (DPA) に含めてから、アプリケーションをバックアップできます。{odf-first} が提供する NooBaa バケットにバックアップを保存します。
4.5.3.1. アプリケーションとその自己署名 CA 証明書のバックアップ
ODF によって提供される s3.openshift-storage.svc サービスは、自己署名サービス CA で署名された Transport Layer Security (TLS) プロトコル証明書を使用します。
certificate signed by unknown authority エラーを防ぐには、DataProtectionApplication カスタムリソース (CR) の Backup Storage Location (BSL) セクションに自己署名 CA 証明書を含める必要があります。この場合、次のタスクを完了する必要があります。
- Object Bucket Claim (OBC) を作成して、NooBaa バケットを要求します。
- バケットの詳細を抽出します。
-
DataProtectionApplicationCR に自己署名 CA 証明書を含めます。 - アプリケーションをバックアップします。
前提条件
- OADP Operator をインストールした。
- {odf-short} Operator をインストールしました。
- 別の namespace で実行されているデータベースを持つアプリケーションがある。
手順
次の例に示すように、NooBaa バケットを要求する OBC マニフェストを作成します。
ObjectBucketClaimCR の例apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: test-obc1 namespace: openshift-adp spec: storageClassName: openshift-storage.noobaa.io generateBucketName: test-backup-bucket2 次のコマンドを実行して OBC を作成します。
$ oc create -f <obc_file_name>OBC を作成すると、ODF が Object Bucket Claim と同じ名前の
secretとConfigMapを作成します。secretオブジェクトにはバケットの認証情報が含まれ、ConfigMapオブジェクトにはバケットにアクセスするための情報が含まれています。生成された config map からバケット名とバケットホストを取得するには、次のコマンドを実行します。$ oc extract --to=- cm/test-obc1 - 1
- OBC の名前は
test-obcです。
出力例
# BUCKET_NAME backup-c20...41fd # BUCKET_PORT 443 # BUCKET_REGION # BUCKET_SUBREGION # BUCKET_HOST s3.openshift-storage.svcsecretオブジェクトからバケット認証情報を取得するには、次のコマンドを実行します。$ oc extract --to=- secret/test-obc出力例
# AWS_ACCESS_KEY_ID ebYR....xLNMc # AWS_SECRET_ACCESS_KEY YXf...+NaCkdyC3QPym次の設定例を使用して、オブジェクトバケットの認証情報を含む
cloud-credentialsファイルを作成します。[default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>次のコマンドを実行して、
cloud-credentialsファイルの内容を使用してcloud-credentialsシークレットを作成します。$ oc create secret generic \ cloud-credentials \ -n openshift-adp \ --from-file cloud=cloud-credentials次のコマンドを実行して、
openshift-service-ca.crtconfig map からサービス CA 証明書を抽出します。証明書をBase64形式で必ずエンコードし、次のステップで使用する値をメモしてください。$ oc get cm/openshift-service-ca.crt \ -o jsonpath='{.data.service-ca\.crt}' | base64 -w0; echo出力例
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0... ....gpwOHMwaG9CRmk5a3....FLS0tLS0K次の例に示すように、バケット名と CA 証明書を使用して
DataProtectionApplicationCR マニフェストファイルを設定します。DataProtectionApplicationCR の例apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: oadp-backup namespace: openshift-adp spec: configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - aws - openshift - csi defaultSnapshotMoveData: true backupLocations: - velero: config: profile: "default" region: noobaa s3Url: https://s3.openshift-storage.svc s3ForcePathStyle: "true" insecureSkipTLSVerify: "false"1 provider: aws default: true credential: key: cloud name: cloud-credentials objectStorage: bucket: <bucket_name>2 prefix: oadp caCert: <ca_cert>3 次のコマンドを実行して、
DataProtectionApplicationCR を作成します。$ oc apply -f <dpa_filename>次のコマンドを実行して、
DataProtectionApplicationCR が正常に作成されたことを確認します。$ oc get dpa -o yaml出力例
apiVersion: v1 items: - apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: namespace: openshift-adp #...# spec: backupLocations: - velero: config: #...# status: conditions: - lastTransitionTime: "20....9:54:02Z" message: Reconcile complete reason: Complete status: "True" type: Reconciled kind: List metadata: resourceVersion: ""次のコマンドを実行して、Backup Storage Location (BSL) が使用可能であることを確認します。
$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 3s 15s true次の例を使用して、
BackupCR を設定します。BackupCR の例apiVersion: velero.io/v1 kind: Backup metadata: name: test-backup namespace: openshift-adp spec: includedNamespaces: - <application_namespace>1 - 1
- バックアップするアプリケーションの namespace を指定します。
次のコマンドを実行して
BackupCR を作成します。$ oc apply -f <backup_cr_filename>
検証
次のコマンドを実行して、
BackupオブジェクトがCompletedフェーズにあることを確認します。$ oc describe backup test-backup -n openshift-adp出力例
Name: test-backup Namespace: openshift-adp # ....# Status: Backup Item Operations Attempted: 1 Backup Item Operations Completed: 1 Completion Timestamp: 2024-09-25T10:17:01Z Expiration: 2024-10-25T10:16:31Z Format Version: 1.1.0 Hook Status: Phase: Completed Progress: Items Backed Up: 34 Total Items: 34 Start Timestamp: 2024-09-25T10:16:31Z Version: 1 Events: <none>
4.6. OADP のインストール
4.6.1. OADP のインストールについて
クラスター管理者は、OADP Operator をインストールして、OpenShift API for Data Protection (OADP) をインストールします。OADP Operator は Velero 1.14 をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Kubernetes リソースと内部イメージをバックアップするには、次のいずれかのストレージタイプなど、バックアップロケーションとしてオブジェクトストレージが必要です。
- Amazon Web Services
- Microsoft Azure
- Google Cloud
- Multicloud Object Gateway
- AWS S3 互換オブジェクトストレージ (Multicloud Object Gateway、MinIO など)
個々の OADP デプロイメントごとに、同じ namespace 内に複数の Backup Storage Location を設定できます。
特に指定のない限り、"NooBaa" は軽量オブジェクトストレージを提供するオープンソースプロジェクトを指し、"Multicloud Object Gateway (MCG)" は NooBaa の Red Hat ディストリビューションを指します。
MCG の詳細は、アプリケーションを使用して Multicloud Object Gateway にアクセスする を参照してください。
オブジェクトストレージのバケット作成を自動化する CloudStorage API は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
CloudStorage API は、CloudStorage オブジェクトを使用しており、OADP で CloudStorage API を使用して BackupStorageLocation として使用する S3 バケットを自動的に作成するためのテクノロジープレビュー機能です。
CloudStorage API は、既存の S3 バケットを指定して BackupStorageLocation オブジェクトを手動作成することをサポートしています。現在、S3 バケットを自動的に作成する CloudStorage API は、AWS S3 ストレージに対してのみ有効です。
スナップショットまたは File System Backup (FSB) を使用して、永続ボリューム (PV) をバックアップできます。
スナップショットを使用して PV をバックアップするには、ネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートするクラウドプロバイダー (次のいずれかのクラウドプロバイダーなど) が必要です。
- Amazon Web Services
- Microsoft Azure
- Google Cloud
- OpenShift Data Foundation などの CSI スナップショット対応クラウドプロバイダー
OCP 4.11 以降で CSI バックアップを使用する場合は、OADP 1.1.x をインストールします。
OADP 1.0.x は、OCP 4.11 以降での CSI バックアップをサポートしていません。OADP 1.0.x には Velero 1.7.x が含まれており、OCP 4.11 以降には存在しない API グループ snapshot.storage.k8s.io/v1beta1 が必要です。
クラウドプロバイダーがスナップショットをサポートしていない場合、またはストレージが NFS である場合は、オブジェクトストレージ上の File System Backup によるアプリケーションのバックアップ: Kopia または Restic を使用してアプリケーションをバックアップできます。
デフォルトの Secret を作成し、次に、Data Protection Application をインストールします。
4.6.1.1. AWS S3 互換のバックアップストレージプロバイダー
OADP は、多くの S3 互換オブジェクトストレージプロバイダーと連携します。OADP のリリースごとに、複数のオブジェクトストレージプロバイダーが認定およびテストされています。さまざまな S3 プロバイダーが OADP で動作することが知られていますが、テストおよび認定は特にされていません。これらのプロバイダーはベストエフォート方式でサポートされます。いくつかの S3 オブジェクトストレージプロバイダーには、このドキュメントに記載されている既知の問題と制限があります。
Red Hat は、任意の S3 互換ストレージ上の OADP のサポートを提供しますが、S3 エンドポイントが問題の根本原因であると判断された場合はサポートが停止されます。
4.6.1.1.1. 認定バックアップストレージプロバイダー
次の AWS S3 互換オブジェクトストレージプロバイダーは、AWS プラグインを介して OADP によって完全にサポートされており、Backup Storage Location として使用できます。
- MinIO
- Multicloud Object Gateway (MCG)
- Amazon Web Services (AWS) S3
- IBM Cloud® Object Storage S3
- Ceph RADOS ゲートウェイ (Ceph オブジェクトゲートウェイ)
- Red Hat Container Storage
- Red Hat OpenShift Data Foundation
- Google Cloud
- Microsoft Azure
Google Cloud および Microsoft Azure には、独自の Velero オブジェクトストアプラグインがあります。
4.6.1.1.2. サポートされていないバックアップストレージプロバイダー
次の AWS S3 互換オブジェクトストレージプロバイダーは、バックアップストレージの場所として使用するために、AWS プラグインを介して Velero と連携することが知られていますが、サポートされておらず、Red Hat によってテストされていません。
- IBM Cloud
- Oracle Cloud
- DigitalOcean
- NooBaa (Multicloud Object Gateway (MCG) を使用してインストールされていない場合)
- Tencent Cloud
- Quobyte
- Cloudian HyperStore
特に指定のない限り、"NooBaa" は軽量オブジェクトストレージを提供するオープンソースプロジェクトを指し、"Multicloud Object Gateway (MCG)" は NooBaa の Red Hat ディストリビューションを指します。
MCG の詳細は、アプリケーションを使用して Multicloud Object Gateway にアクセスする を参照してください。
4.6.1.1.3. 既知の制限があるバックアップストレージプロバイダー
次の AWS S3 互換オブジェクトストレージプロバイダーは、AWS プラグインを介して Velero と連携することがわかっていますが、機能セットが制限されています。
- Swift - バックアップストレージの Backup Storage Location として使用できますが、ファイルシステムベースのボリュームバックアップおよび復元については Restic と互換性がありません。
4.6.1.2. OpenShift Data Foundation で障害復旧を行うための Multicloud Object Gateway (MCG) 設定
OpenShift Data Foundation 上の MCG バケット backupStorageLocation にクラスターストレージを使用する場合は、MCG を外部オブジェクトストアとして設定します。
MCG を外部オブジェクトストアとして設定しない場合、バックアップが利用できなくなる可能性があります。
特に指定のない限り、"NooBaa" は軽量オブジェクトストレージを提供するオープンソースプロジェクトを指し、"Multicloud Object Gateway (MCG)" は NooBaa の Red Hat ディストリビューションを指します。
MCG の詳細は、アプリケーションを使用して Multicloud Object Gateway にアクセスする を参照してください。
手順
- ハイブリッドまたはマルチクラウドのストレージリソースの追加 の説明に従って、MCG を外部オブジェクトストアとして設定します。
4.6.1.3. OADP 更新チャネルについて
OADP Operator をインストールするときに、更新チャネル を選択します。このチャネルにより、OADP Operator と Velero のどちらのアップグレードを受け取るかが決まります。いつでもチャンネルを切り替えることができます。
次の更新チャネルを利用できます。
-
stable チャネルは非推奨になりました。stable チャネルには、
OADP.v1.1.zおよびOADP.v1.0.zの古いバージョン用の OADPClusterServiceVersionのパッチ (z-stream 更新) が含まれています。 - stable-1.0 チャネルは非推奨であり、サポートされていません。
- stable-1.1 チャネルは非推奨であり、サポートされていません。
- stable-1.2 チャネルは非推奨であり、サポートされていません。
-
stable-1.3 チャネルには、最新の OADP 1.3
ClusterServiceVersionのOADP.v1.3.zが含まれています。 -
stable-1.4 チャネルには、最新の OADP 1.4
ClusterServiceVersionのOADP.v1.4.zが含まれています。
詳細は、OpenShift Operator のライフサイクル を参照してください。
適切な更新チャネルはどれですか?
-
stable チャネルは非推奨になりました。すでに stable チャネルを使用している場合は、引き続き
OADP.v1.1.zから更新が提供されます。 - stable-1.y をインストールする OADP 1.y 更新チャネルを選択し、そのパッチを引き続き受け取ります。このチャネルを選択すると、バージョン 1.y.z のすべての z-stream パッチを受け取ります。
いつ更新チャネルを切り替える必要がありますか?
- OADP 1.y がインストールされていて、その y-stream のパッチのみを受け取りたい場合は、stable 更新チャネルから stable-1.y 更新チャネルに切り替える必要があります。その後、バージョン 1.y.z のすべての z-stream パッチを受け取ります。
- OADP 1.0 がインストールされていて、OADP 1.1 にアップグレードしたい場合、OADP 1.1 のみのパッチを受け取るには、stable-1.0 更新チャネルから stable-1.1 更新チャネルに切り替える必要があります。その後、バージョン 1.1.z のすべての z-stream パッチを受け取ります。
- OADP 1.y がインストールされていて、y が 0 より大きく、OADP 1.0 に切り替える場合は、OADP Operator をアンインストールしてから、stable-1.0 更新チャネルを使用して再インストールする必要があります。その後、バージョン 1.0.z のすべての z-stream パッチを受け取ります。
更新チャネルを切り替えて、OADP 1.y から OADP 1.0 に切り替えることはできません。Operator をアンインストールしてから再インストールする必要があります。
4.6.1.4. 複数の namespace への OADP のインストール
OpenShift API for Data Protection (OADP) を同じクラスター上の複数の namespace にインストールすると、複数のプロジェクト所有者が独自の OADP インスタンスを管理できるようになります。このユースケースは、ファイルシステムバックアップ (FSB) と Container Storage Interface (CSI) を使用して検証されています。
このドキュメントに含まれるプラットフォームごとの手順で指定されている OADP の各インスタンスを、以下の追加要件とともにインストールします。
- 同じクラスター上のすべての OADP デプロイメントは、同じバージョン (1.1.4 など) である必要があります。同じクラスターに異なるバージョンの OADP をインストールすることはサポートされていません。
-
OADP の個々のデプロイメントには、一意の認証情報セットと一意の
BackupStorageLocation設定が必要です。同じ namespace 内で、複数のBackupStorageLocation設定を使用することもできます。 - デフォルトでは、各 OADP デプロイメントには namespace 全体でクラスターレベルのアクセス権があります。OpenShift Container Platform 管理者は、セキュリティーおよび RBAC 設定を注意深く確認し、必要な変更を加えて、各 OADP インスタンスに正しい権限があることを確認する必要があります。
4.6.1.5. OADP がバックアップデータの不変性をサポートしていない
OADP 1.3 以降では、ターゲットオブジェクトストレージに不変性オプションが設定されている場合、バックアップが想定どおりに機能しない可能性があります。 このような不変性オプションは、次のように別の名前で呼ばれています。
- S3 オブジェクトロック
- オブジェクト保持
- バケットバージョン管理
- Write Once Read Many (WORM) バケット
サポートされない主な理由は、OADP がバックアップの状態を finalizing として保存してから、進行中の非同期操作があるかどうかを精査するためです。
OADP 1.3 より前のバージョンでも、不変性設定を持つオブジェクトストレージはサポートされていませんでした。バックアップが機能していても、いくつかの問題が発生する可能性があります。たとえば、バックアップは削除されても、バージョンオブジェクトは削除されません。
プロバイダーと設定によっては、バックアップが機能する場合があります。
- S3 オブジェクトロックはバージョン管理されたバケットにのみ適用されるため、AWS S3 サービスはバックアップをサポートしています。新しいバージョンのオブジェクトデータを更新することもできます。ただし、バックアップは削除されても、オブジェクトの古いバージョンは削除されません。
- Azure Storage Blob は、バージョンレベルの不変性とコンテナーレベルの不変性の両方をサポートしています。バージョンレベルの場合は、OADP でもデータの不変性が機能しますが、コンテナーレベルでは機能しません。
- Google Cloud Cloud ストレージポリシーは、バケットレベルの不変性のみをサポートします。したがって、Google Cloud 環境に実装することはできません。
4.6.1.6. 収集したデータに基づく Velero CPU およびメモリーの要件
以下の推奨事項は、スケールおよびパフォーマンスのラボで観察したパフォーマンスに基づいています。バックアップおよび復元リソースは、プラグインのタイプ、そのバックアップまたは復元に必要なリソースの量、そのリソースに関連する永続ボリューム (PV) に含まれるデータの影響を受けます。
4.6.1.6.1. 設定に必要な CPU とメモリー
| 設定タイプ | [1] 平均使用量 | [2] 大量使用時 | resourceTimeouts |
|---|---|---|---|
| CSI | Velero: CPU - リクエスト 200m、制限 1000m メモリー - リクエスト 256 Mi、制限 1024 Mi | Velero: CPU - リクエスト 200m、制限 2000m メモリー - リクエスト 256 Mi、制限 2048 Mi | 該当なし |
| Restic | [3] Restic: CPU - リクエスト 1000m、制限 2000m メモリー - リクエスト 16 Gi、制限 32 Gi | [4] Restic: CPU - リクエスト 2000m、制限 8000m メモリー - リクエスト 16 Gi、制限 40 Gi | 900 m |
| [5] Data Mover | 該当なし | 該当なし | 10m - 平均使用量 60m - 大量使用時 |
- 平均使用量 - ほとんどの状況下でこの設定を使用します。
- 大量使用時 - 大規模な PV (使用量 500 GB)、複数の namespace (100 以上)、または 1 つの namespace に多数の Pod (2000 Pod 以上) があるなどして使用量が大きくなる状況下では、大規模なデータセットを含む場合のバックアップと復元で最適なパフォーマンスを実現するために、この設定を使用します。
- Restic リソースの使用量は、データの量とデータタイプに対応します。たとえば、多数の小さなファイルや大量のデータがある場合は、Restic が大量のリソースを使用する可能性があります。Velero のドキュメントでは、指定されたデフォルト値である 500 m を参照していますが、ほとんどのテストではリクエスト 200 m、制限 1000 m が適切でした。Velero のドキュメントに記載されているとおり、正確な CPU とメモリー使用量は、環境の制限に加えて、ファイルとディレクトリーの規模に依存します。
- CPU を増やすと、バックアップと復元の時間を大幅に短縮できます。
- Data Mover - Data Mover のデフォルトの resourceTimeout は 10 m です。テストでは、大規模な PV (使用量 500 GB) を復元するには、resourceTimeout を 60m に増やす必要があることがわかりました。
このガイド全体に記載されているリソース要件は、平均的な使用量に限定されています。大量に使用する場合は、上の表の説明に従って設定を調整してください。
4.6.1.6.2. 大量使用のための NodeAgent CPU
テストの結果、NodeAgent CPU を増やすと、OpenShift API for Data Protection (OADP) を使用する際のバックアップと復元の時間が大幅に短縮されることがわかりました。
パフォーマンス分析と要件に応じて、OpenShift Container Platform 環境を調整できます。ファイルシステムのバックアップに Kopia を使用する場合は、ワークロードで CPU 制限を使用してください。
Pod で CPU 制限を使用しない場合、Pod は利用可能な場合に余剰の CPU を使用できます。CPU 制限を指定すると、Pod がその制限を超えたときに、Pod にスロットリングが適用される可能性があります。したがって、Pod で CPU 制限を使用することはアンチパターンと考えられています。
Pod が余剰の CPU を利用できるように、必ず CPU 要求を正確に指定してください。リソースの割り当ては、CPU 制限ではなく CPU 要求に基づいて保証されます。
テストの結果、20 コアと 32 Gi メモリーで Kopia を実行した場合、100 GB 超のデータ、複数の namespace、または単一 namespace 内の 2000 超の Pod のバックアップと復元操作がサポートされることが判明しました。テストでは、これらのリソース仕様では CPU の制限やメモリーの飽和は検出されませんでした。
環境によっては、デフォルト設定によりリソースが飽和状態になった場合に発生する Pod の再起動を回避するために、Ceph MDS Pod リソースを調整する必要があります。
Ceph MDS Pod で Pod リソース制限を設定する方法の詳細は、rook-ceph Pod の CPU およびメモリーリソースの変更 を参照してください。
4.6.2. OADP Operator のインストール
Operator Lifecycle Manager (OLM) を使用して、OpenShift Container Platform 4.13 に OpenShift API for Data Protection (OADP) オペレーターをインストールできます。
OADP Operator は Velero 1.14 をインストールします。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- Filter by keyword フィールドを使用して、OADP Operator を検索します。
- OADP Operator を選択し、Install をクリックします。
-
Install をクリックして、
openshift-adpプロジェクトに Operator をインストールします。 - Operators → Installed Operators をクリックして、インストールを確認します。
4.6.2.1. OADP、Velero、および OpenShift Container Platform の各バージョンの関係
| OADP のバージョン | Velero のバージョン | OpenShift Container Platform バージョン |
|---|---|---|
| 1.1.0 | 4.9 以降 | |
| 1.1.1 | 4.9 以降 | |
| 1.1.2 | 4.9 以降 | |
| 1.1.3 | 4.9 以降 | |
| 1.1.4 | 4.9 以降 | |
| 1.1.5 | 4.9 以降 | |
| 1.1.6 | 4.11 以降 | |
| 1.1.7 | 4.11 以降 | |
| 1.2.0 | 4.11 以降 | |
| 1.2.1 | 4.11 以降 | |
| 1.2.2 | 4.11 以降 | |
| 1.2.3 | 4.11 以降 | |
| 1.3.0 | 4.10 - 4.15 | |
| 1.3.1 | 4.10 - 4.15 | |
| 1.3.2 | 4.10 - 4.15 | |
| 1.3.3 | 4.10 - 4.15 | |
| 1.4.0 | 4.14 以降 | |
| 1.4.1 | 4.14 以降 |
4.7. AWS S3 互換ストレージを使用した OADP の設定
4.7.1. Amazon Web Services を使用した OpenShift API for Data Protection の設定
OADP Operator をインストールすることで、Amazon Web Services (AWS) を使用して OpenShift API for Data Protection (OADP) をインストールします。Operator は Velero 1.14 をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Velero 向けに AWS を設定し、デフォルトの Secret を作成し、次に、Data Protection Application をインストールします。詳細は、OADP Operator のインストール を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
4.7.1.1. Amazon Web Services の設定
OpenShift API for Data Protection (OADP) 用に Amazon Web Services (AWS) を設定します。
前提条件
- AWS CLI がインストールされていること。
手順
BUCKET変数を設定します。$ BUCKET=<your_bucket>REGION変数を設定します。$ REGION=<your_region>AWS S3 バケットを作成します。
$ aws s3api create-bucket \ --bucket $BUCKET \ --region $REGION \ --create-bucket-configuration LocationConstraint=$REGION1 - 1
us-east-1はLocationConstraintをサポートしていません。お住まいの地域がus-east-1の場合は、--create-bucket-configuration LocationConstraint=$REGIONを省略してください。
IAM ユーザーを作成します。
$ aws iam create-user --user-name velero1 - 1
- Velero を使用して複数の S3 バケットを持つ複数のクラスターをバックアップする場合は、クラスターごとに一意のユーザー名を作成します。
velero-policy.jsonファイルを作成します。$ cat > velero-policy.json <<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeVolumes", "ec2:DescribeSnapshots", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateSnapshot", "ec2:DeleteSnapshot" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:DeleteObject", "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::${BUCKET}/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads" ], "Resource": [ "arn:aws:s3:::${BUCKET}" ] } ] } EOFポリシーを添付して、
veleroユーザーに必要最小限の権限を付与します。$ aws iam put-user-policy \ --user-name velero \ --policy-name velero \ --policy-document file://velero-policy.jsonveleroユーザーのアクセスキーを作成します。$ aws iam create-access-key --user-name velero出力例
{ "AccessKey": { "UserName": "velero", "Status": "Active", "CreateDate": "2017-07-31T22:24:41.576Z", "SecretAccessKey": <AWS_SECRET_ACCESS_KEY>, "AccessKeyId": <AWS_ACCESS_KEY_ID> } }credentials-veleroファイルを作成します。$ cat << EOF > ./credentials-velero [default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> EOFData Protection Application をインストールする前に、
credentials-veleroファイルを使用して AWS のSecretオブジェクトを作成します。
4.7.1.2. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
バックアップの場所として、Multicloud Object Gateway、Red Hat Container Storage、Ceph RADOS Gateway (Ceph Object Gateway とも呼ばれます)、Red Hat OpenShift Data Foundation、MinIO などの AWS S3 互換オブジェクトストレージを指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
File System Backup (FSB) を使用する場合、FSB がオブジェクトストレージ上にファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
4.7.1.2.1. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
Secret のデフォルト名は cloud-credentials です。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップ場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用して、デフォルト名の Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
手順
Backup Storage Location の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。以下の例を参照してください。
[default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>デフォルト名で
Secretカスタムリソース (CR) を作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
4.7.1.2.2. 異なる認証情報のプロファイルの作成
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、credentials-velero ファイルに個別のプロファイルを作成します。
次に、Secret オブジェクトを作成し、DataProtectionApplication カスタムリソース (CR) でプロファイルを指定します。
手順
次の例のように、バックアップとスナップショットの場所に別々のプロファイルを持つ
credentials-veleroファイルを作成します。[backupStorage] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> [volumeSnapshot] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>credentials-veleroファイルを使用してSecretオブジェクトを作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero1 次の例のように、プロファイルを
DataProtectionApplicationCR に追加します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name> prefix: <prefix> config: region: us-east-1 profile: "backupStorage" credential: key: cloud name: cloud-credentials snapshotLocations: - velero: provider: aws config: region: us-west-2 profile: "volumeSnapshot"
4.7.1.2.3. AWS を使用した Backup Storage Location の設定
次の例の手順に示すように、AWS の Backup Storage Location (BSL) を設定できます。
前提条件
- AWS を使用してオブジェクトストレージバケットを作成した。
- OADP Operator がインストールされている。
手順
ユースケースに応じて、BSL カスタムリソース (CR) に適切な値を設定します。
Backup Storage Location
apiVersion: oadp.openshift.io/v1alpha1 kind: BackupStorageLocation metadata: name: default namespace: openshift-adp spec: provider: aws1 objectStorage: bucket: <bucket_name>2 prefix: <bucket_prefix>3 credential:4 key: cloud5 name: cloud-credentials6 config: region: <bucket_region>7 s3ForcePathStyle: "true"8 s3Url: <s3_url>9 publicUrl: <public_s3_url>10 serverSideEncryption: AES25611 kmsKeyId: "50..c-4da1-419f-a16e-ei...49f"12 customerKeyEncryptionFile: "/credentials/customer-key"13 signatureVersion: "1"14 profile: "default"15 insecureSkipTLSVerify: "true"16 enableSharedConfig: "true"17 tagging: ""18 checksumAlgorithm: "CRC32"19 - 1 1
- オブジェクトストアプラグインの名前。この例では、プラグインは
awsです。このフィールドは必須です。 - 2
- バックアップを保存するバケットの名前。このフィールドは必須です。
- 3
- バックアップを保存するバケット内の接頭辞。このフィールドは任意です。
- 4
- Backup Storage Location の認証情報。カスタムの認証情報を設定できます。カスタムの認証情報が設定されていない場合は、デフォルトの認証情報のシークレットが使用されます。
- 5
- シークレットの認証情報データ内の
key。 - 6
- 認証情報を含むシークレットの名前。
- 7
- バケットが配置されている AWS リージョン。s3ForcePathStyle が false の場合は任意です。
- 8
- 仮想ホスト形式のバケットアドレス指定の代わりにパス形式のアドレス指定を使用するかどうかを決定するブール値フラグ。MinIO や NooBaa などのストレージサービスを使用する場合は、
trueに設定します。これは任意のフィールドです。デフォルト値はfalseです。 - 9
- ここで AWS S3 の URL を明示的に指定できます。このフィールドは主に、MinIO や NooBaa などのストレージサービス用です。これは任意のフィールドです。
- 10
- このフィールドは主に、MinIO や NooBaa などのストレージサービスに使用されます。これは任意のフィールドです。
- 11
- オブジェクトのアップロードに使用するサーバー側暗号化アルゴリズムの名前 (例:
AES256)。これは任意のフィールドです。 - 12
- AWS KMS のキー ID を指定します。例に示すように、
alias/<KMS-key-alias-name>などのエイリアスまたは完全なARNの形式で指定して、S3 に保存されているバックアップの暗号化を有効にできます。kmsKeyIdは、customerKeyEncryptionFileと一緒に使用できないことに注意してください。これは任意のフィールドです。 - 13
SSE-Cカスタマーキーを含むファイルを指定して、S3 に保存されているバックアップのカスタマーキー暗号化を有効にします。ファイルに 32 バイトの文字列が含まれている必要があります。customerKeyEncryptionFileフィールドは、veleroコンテナー内にマウントされたシークレットを参照します。velerocloud-credentialsシークレットに、キーと値のペアcustomer-key: <your_b64_encoded_32byte_string>を追加します。customerKeyEncryptionFileフィールドはkmsKeyIdフィールドと一緒に使用できないことに注意してください。デフォルト値は空の文字列 ("") です。これはSSE-Cが無効であることを意味します。これは任意のフィールドです。- 14
- 署名付き URL を作成するために使用する署名アルゴリズムのバージョン。署名付き URL は、バックアップのダウンロードやログの取得に使用します。有効な値は
1と4です。デフォルトのバージョンは4です。これは任意のフィールドです。 - 15
- 認証情報ファイル内の AWS プロファイルの名前。デフォルト値は
defaultです。これは任意のフィールドです。 - 16
- オブジェクトストアに接続するときに TLS 証明書を検証しない場合 (たとえば、MinIO を使用した自己署名証明書の場合)、
insecureSkipTLSVerifyフィールドをtrueに設定します。trueに設定すると、中間者攻撃の影響を受けやすくなります。この設定は実稼働ワークロードには推奨されません。デフォルト値はfalseです。これは任意のフィールドです。 - 17
- 認証情報ファイルを共有設定ファイルとして読み込む場合は、
enableSharedConfigフィールドをtrueに設定します。デフォルト値はfalseです。これは任意のフィールドです。 - 18
- AWS S3 オブジェクトにアノテーションを付けるタグを指定します。キーと値のペアでタグを指定します。デフォルト値は空の文字列 (
"") です。これは任意のフィールドです。 - 19
- S3 にオブジェクトをアップロードするときに使用するチェックサムアルゴリズムを指定します。サポートされている値は、
CRC32、CRC32C、SHA1、およびSHA256です。フィールドを空の文字列 ("") に設定すると、チェックサムチェックがスキップされます。デフォルト値はCRC32です。これは任意のフィールドです。
4.7.1.2.4. データセキュリティーを強化するための OADP SSE-C 暗号鍵の作成
Amazon Web Services (AWS) S3 は、Amazon S3 内のすべてのバケットに対して、基本レベルの暗号化として、Amazon S3 マネージドキー (SSE-S3) によるサーバー側暗号化を適用します。
OpenShift API for Data Protection (OADP) は、クラスターからストレージにデータを転送するときに、SSL/TLS、HTTPS、および velero-repo-credentials シークレットを使用してデータを暗号化します。AWS 認証情報の紛失または盗難に備えてバックアップデータを保護するには、追加の暗号化レイヤーを適用してください。
velero-plugin-for-aws プラグインで、いくつかの追加の暗号化方法を使用できます。プラグインの設定オプションを確認し、追加の暗号化を実装することを検討してください。
お客様提供の鍵を使用したサーバー側暗号化 (SSE-C) を使用することで、独自の暗号鍵を保存できます。この機能は、AWS 認証情報が漏えいした場合に追加のセキュリティーを提供します。
暗号鍵は必ずセキュアな方法で保管してください。暗号鍵がない場合、暗号化されたデータとバックアップを復元できません。
前提条件
OADP が
/credentialsの Velero Pod に SSE-C 鍵を含むシークレットをマウントできるように、AWS のデフォルトのシークレット名cloud-credentialsを使用し、次のラベルの少なくとも 1 つを空のままにします。-
dpa.spec.backupLocations[].velero.credential dpa.spec.snapshotLocations[].velero.credentialこれは既知の問題 (https://issues.redhat.com/browse/OADP-3971) に対する回避策です。
-
次の手順には、認証情報を指定しない spec:backupLocations ブロックの例が含まれています。この例では、OADP シークレットのマウントがトリガーされます。
-
バックアップの場所に
cloud-credentialsとは異なる名前の認証情報が必要な場合は、次の例のように、認証情報名を含まないスナップショットの場所を追加する必要があります。この例には認証情報名が含まれていないため、スナップショットの場所では、スナップショットを作成するためのシークレットとしてcloud-credentialsが使用されています。
認証情報が指定されていない DPA 内のスナップショットの場所を示す例
snapshotLocations:
- velero:
config:
profile: default
region: <region>
provider: aws
# ...手順
SSE-C 暗号鍵を作成します。
次のコマンドを実行して乱数を生成し、
sse.keyという名前のファイルとして保存します。$ dd if=/dev/urandom bs=1 count=32 > sse.key次のコマンドを実行して、Base64 を使用して
sse.keyをエンコードし、結果をsse_encoded.keyという名前のファイルとして保存します。$ cat sse.key | base64 > sse_encoded.key次のコマンドを実行して、
sse_encoded.keyという名前のファイルを、customer-keyという名前の新しいファイルにリンクします。$ ln -s sse_encoded.key customer-key
OpenShift Container Platform シークレットを作成します。
OADP を初めてインストールして設定する場合は、次のコマンドを実行して、AWS 認証情報と暗号鍵シークレットを同時に作成します。
$ oc create secret generic cloud-credentials --namespace openshift-adp --from-file cloud=<path>/openshift_aws_credentials,customer-key=<path>/sse_encoded.key既存のインストールを更新する場合は、次の例のように、
DataProtectionApplicationCR マニフェストのcloud-credentialsecretブロックの値を編集します。apiVersion: v1 data: cloud: W2Rfa2V5X2lkPSJBS0lBVkJRWUIyRkQ0TlFHRFFPQiIKYXdzX3NlY3JldF9hY2Nlc3Nfa2V5P<snip>rUE1mNWVSbTN5K2FpeWhUTUQyQk1WZHBOIgo= customer-key: v+<snip>TFIiq6aaXPbj8dhos= kind: Secret # ...
次の例のように、
DataProtectionApplicationCR マニフェストのbackupLocationsブロックにあるcustomerKeyEncryptionFile属性の値を編集します。spec: backupLocations: - velero: config: customerKeyEncryptionFile: /credentials/customer-key profile: default # ...警告既存のインストール環境でシークレットの認証情報を適切に再マウントするには、Velero Pod を再起動する必要があります。
インストールが完了すると、OpenShift Container Platform リソースをバックアップおよび復元できるようになります。AWS S3 ストレージに保存されるデータは、新しい鍵で暗号化されます。追加の暗号鍵がないと、AWS S3 コンソールまたは API からデータをダウンロードすることはできません。
検証
追加の鍵を含めずに暗号化したファイルをダウンロードできないことを確認するために、テストファイルを作成し、アップロードしてからダウンロードしてみます。
次のコマンドを実行してテストファイルを作成します。
$ echo "encrypt me please" > test.txt次のコマンドを実行してテストファイルをアップロードします。
$ aws s3api put-object \ --bucket <bucket> \ --key test.txt \ --body test.txt \ --sse-customer-key fileb://sse.key \ --sse-customer-algorithm AES256ファイルのダウンロードを試みます。Amazon Web コンソールまたはターミナルで、次のコマンドを実行します。
$ s3cmd get s3://<bucket>/test.txt test.txtファイルが追加の鍵で暗号化されているため、ダウンロードは失敗します。
次のコマンドを実行して、追加の暗号鍵を含むファイルをダウンロードします。
$ aws s3api get-object \ --bucket <bucket> \ --key test.txt \ --sse-customer-key fileb://sse.key \ --sse-customer-algorithm AES256 \ downloaded.txt次のコマンドを実行してファイルの内容を読み取ります。
$ cat downloaded.txt出力例
encrypt me please
4.7.1.2.4.1. Velero によってバックアップされたファイルの SSE-C 暗号鍵を使用してファイルをダウンロードする
SSE-C 暗号鍵を検証するときに、Velcro によってバックアップされたファイルの追加の暗号鍵を含むファイルをダウンロードすることもできます。
手順
- 次のコマンドを実行して、Velero によってバックアップされたファイルの追加の暗号鍵を含むファイルをダウンロードします。
$ aws s3api get-object \
--bucket <bucket> \
--key velero/backups/mysql-persistent-customerkeyencryptionfile4/mysql-persistent-customerkeyencryptionfile4.tar.gz \
--sse-customer-key fileb://sse.key \
--sse-customer-algorithm AES256 \
--debug \
velero_download.tar.gz4.7.1.3. Data Protection Application の設定
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
4.7.1.3.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。指定したラベルが、各ノードのラベルと一致する必要があります。
詳細は、ノードエージェントとノードラベルの設定 を参照してください。
4.7.1.3.2. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.7.1.3.2.1. Velero デプロイメント用のエイリアス化した velero コマンドで CA 証明書を使用する
Velero CLI のエイリアスを作成することで、システムにローカルにインストールせずに Velero CLI を使用できます。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 OpenShift CLI (
oc) がインストールされている。エイリアス化した Velero コマンドを使用するには、次のコマンドを実行します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'次のコマンドを実行して、エイリアスが機能していることを確認します。
例
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADPこのコマンドで CA 証明書を使用するには、次のコマンドを実行して証明書を Velero デプロイメントに追加できます。
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txtバックアップログを取得するために、次のコマンドを実行します。
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>このログを使用して、バックアップできないリソースの障害と警告を表示できます。
-
Velero Pod が再起動すると、
/tmp/your-cacert.txtファイルが消去されます。そのため、前の手順のコマンドを再実行して/tmp/your-cacert.txtファイルを再作成する必要があります。 次のコマンドを実行すると、
/tmp/your-cacert.txtファイルを保存した場所にファイルがまだ存在するかどうかを確認できます。$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
OpenShift API for Data Protection (OADP) の今後のリリースでは、この手順が不要になるように証明書を Velero Pod にマウントする予定です。
4.7.1.4. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、デフォルト名である
cloud-credentialsを使用してSecretを作成する必要があります。これには、バックアップとスナップショットの場所の認証情報用の個別のプロファイルが含まれます。注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp1 spec: configuration: velero: defaultPlugins: - openshift2 - aws resourceTimeout: 10m3 nodeAgent:4 enable: true5 uploaderType: kopia6 podConfig: nodeSelector: <node_selector>7 backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name>8 prefix: <prefix>9 config: region: <region> profile: "default" s3ForcePathStyle: "true"10 s3Url: <s3_url>11 credential: key: cloud name: cloud-credentials12 snapshotLocations:13 - name: default velero: provider: aws config: region: <region>14 profile: "default" credential: key: cloud name: cloud-credentials15 - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
openshiftプラグインは必須です。- 3
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 4
- 管理要求をサーバーにルーティングする管理エージェント。
- 5
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 6
- アップローダーとして
kopiaまたはresticと入力します。インストール後に選択を変更することはできません。組み込み DataMover の場合は、Kopia を使用する必要があります。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 7
- Kopia または Restic が使用可能なノードを指定します。デフォルトでは、Kopia または Restic はすべてのノードで実行されます。
- 8
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 9
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。 - 10
- S3 オブジェクトにパススタイルの URL を強制するかどうかを指定します (ブール値)。AWS S3 では必要ありません。S3 互換ストレージにのみ必要です。
- 11
- バックアップを保存するために使用しているオブジェクトストアの URL を指定します。AWS S3 では必要ありません。S3 互換ストレージにのみ必要です。
- 12
- 作成した
Secretオブジェクトの名前を指定します。この値を指定しない場合は、デフォルト名のcloud-credentialsが使用されます。カスタム名を指定すると、バックアップの場所にカスタム名が使用されます。 - 13
- CSI スナップショットまたは File System Backup (FSB) を使用して PV をバックアップする場合を除き、スナップショットの場所を指定します。
- 14
- スナップショットの場所は、PV と同じリージョンにある必要があります。
- 15
- 作成した
Secretオブジェクトの名前を指定します。この値を指定しない場合は、デフォルト名のcloud-credentialsが使用されます。カスタム名を指定すると、スナップショットの場所にカスタム名が使用されます。バックアップとスナップショットの場所で異なる認証情報を使用する場合は、credentials-veleroファイルに個別のプロファイルを作成します。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
4.7.1.4.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.7.1.5. MD5 チェックサムアルゴリズムを使用して Backup Storage Location を設定する
Data Protection Application (DPA) の Backup Storage Location (BSL) を設定して、Amazon Simple Storage Service (Amazon S3) と S3 互換ストレージプロバイダーの両方で MD5 チェックサムアルゴリズムを使用できます。チェックサムアルゴリズムは、Amazon S3 へのオブジェクトのアップロードとダウンロードのチェックサムを計算します。DPA の spec.backupLocations.velero.config.checksumAlgorithm セクションの checksumAlgorithm フィールドを設定する際に、次のいずれかのオプションを使用できます。
-
CRC32 -
CRC32C -
SHA1 -
SHA256
checksumAlgorithm フィールドを空の値に設定して、MD5 チェックサム確認をスキップすることもできます。
checksumAlgorithm フィールドに値を設定しなかった場合、デフォルト値として CRC32 が設定されます。
前提条件
- OADP Operator がインストールされている。
- バックアップの場所として Amazon S3 または S3 互換のオブジェクトストレージが設定されている。
手順
次の例に示すように、DPA で BSL を設定します。
Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: checksumAlgorithm: ""1 insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: velero: defaultPlugins: - openshift - aws - csi- 1
checksumAlgorithmを指定します。この例では、checksumAlgorithmフィールドは空の値に設定されています。CRC32、CRC32C、SHA1、SHA256から選択できます。
Noobaa をオブジェクトストレージプロバイダーとして使用しており、DPA で spec.backupLocations.velero.config.checksumAlgorithm フィールドを設定していない場合、checksumAlgorithm の空の値が BSL 設定に追加されます。
空の値は、DPA を使用して作成された BSL に対してのみ追加されます。他の方法で BSL を作成した場合、この値は追加されません。
4.7.1.6. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.7.1.7. 複数の BSL を使用した DPA の設定
複数の BSL を使用して DPA を設定し、クラウドプロバイダーによって提供される認証情報を指定できます。
前提条件
- OADP Operator をインストールする。
- クラウドプロバイダーによって提供される認証情報を使用してシークレットを作成する。
手順
複数の BSL を使用して DPA を設定します。以下の例を参照してください。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication #... backupLocations: - name: aws1 velero: provider: aws default: true2 objectStorage: bucket: <bucket_name>3 prefix: <prefix>4 config: region: <region_name>5 profile: "default" credential: key: cloud name: cloud-credentials6 - name: odf7 velero: provider: aws default: false objectStorage: bucket: <bucket_name> prefix: <prefix> config: profile: "default" region: <region_name> s3Url: <url>8 insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" credential: key: cloud name: <custom_secret_name_odf>9 #...- 1
- 最初の BSL の名前を指定します。
- 2
- このパラメーターは、この BSL がデフォルトの BSL であることを示します。
Backup CRに BSL が設定されていない場合は、デフォルトの BSL が使用されます。デフォルトとして設定できる BSL は 1 つだけです。 - 3
- バケット名を指定します。
- 4
- Velero バックアップの接頭辞を指定します (例:
velero)。 - 5
- バケットの AWS リージョンを指定します。
- 6
- 作成したデフォルトの
Secretオブジェクトの名前を指定します。 - 7
- 2 番目の BSL の名前を指定します。
- 8
- S3 エンドポイントの URL を指定します。
- 9
Secretの正しい名前を指定します。たとえば、custom_secret_name_odfです。Secret名を指定しない場合は、デフォルトの名前が使用されます。
バックアップ CR で使用する BSL を指定します。以下の例を参照してください。
バックアップ CR の例
apiVersion: velero.io/v1 kind: Backup # ... spec: includedNamespaces: - <namespace>1 storageLocation: <backup_storage_location>2 defaultVolumesToFsBackup: true
4.7.1.7.1. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
csiデフォルトプラグインを追加します。
4.7.1.7.2. DataProtectionApplication でノードエージェントを無効にする
バックアップに Restic、Kopia、または DataMover を使用していない場合は、DataProtectionApplication カスタムリソース (CR) の nodeAgent フィールドを無効にすることができます。nodeAgent を無効にする前に、OADP Operator がアイドル状態であり、バックアップを実行していないことを確認してください。
手順
nodeAgentを無効にするには、enableフラグをfalseに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: false1 uploaderType: kopia # ...- 1
- ノードエージェントを無効にします。
nodeAgentを有効にするには、enableフラグをtrueに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: true1 uploaderType: kopia # ...- 1
- ノードエージェントを有効にします。
ジョブをセットアップして、DataProtectionApplication CR の nodeAgent フィールドを有効または無効にすることができます。詳細は、「ジョブの使用による Pod でのタスクの実行」を参照してください。
4.8. IBM Cloud を使用した OADP の設定
4.8.1. IBM Cloud を使用した OpenShift API for Data Protection の設定
クラスター上のアプリケーションをバックアップおよび復元するには、IBM Cloud クラスターに OpenShift API for Data Protection (OADP) Operator をインストールします。バックアップを保存するには、IBM Cloud Object Storage (COS) を設定します。
4.8.1.1. COS インスタンスの設定
OADP バックアップデータを保存するために、IBM Cloud Object Storage (COS) インスタンスを作成します。COS インスタンスを作成したら、HMAC サービス認証情報を設定します。
前提条件
- IBM Cloud Platform アカウントをもっている。
- IBM Cloud CLI をインストールしている。
- IBM Cloud にログインしている。
手順
次のコマンドを実行して、IBM Cloud Object Storage (COS) プラグインをインストールします。
$ ibmcloud plugin install cos -f次のコマンドを実行してバケット名を設定します。
$ BUCKET=<bucket_name>次のコマンドを実行してバケットリージョンを設定します。
$ REGION=<bucket_region>1 - 1
- バケットのリージョンを指定します (例:
eu-gb)。
次のコマンドを実行してリソースグループを作成します。
$ ibmcloud resource group-create <resource_group_name>次のコマンドを実行して、ターゲットリソースグループを設定します。
$ ibmcloud target -g <resource_group_name>次のコマンドを実行して、ターゲットリソースグループが正しく設定されていることを確認します。
$ ibmcloud target出力例
API endpoint: https://cloud.ibm.com Region: User: test-user Account: Test Account (fb6......e95) <-> 2...122 Resource group: Default出力例では、リソースグループは
Defaultに設定されています。次のコマンドを実行してリソースグループ名を設定します。
$ RESOURCE_GROUP=<resource_group>1 - 1
- リソースグループ名を指定します (例:
"default")。
次のコマンドを実行して、IBM Cloud
service-instanceリソースを作成します。$ ibmcloud resource service-instance-create \ <service_instance_name> \1 <service_name> \2 <service_plan> \3 <region_name>4 コマンドの例
$ ibmcloud resource service-instance-create test-service-instance cloud-object-storage \1 standard \ global \ -d premium-global-deployment2 次のコマンドを実行して、サービスインスタンス ID を抽出します。
$ SERVICE_INSTANCE_ID=$(ibmcloud resource service-instance test-service-instance --output json | jq -r '.[0].id')次のコマンドを実行して COS バケットを作成します。
$ ibmcloud cos bucket-create \// --bucket $BUCKET \// --ibm-service-instance-id $SERVICE_INSTANCE_ID \// --region $REGION$BUCKET、$SERVICE_INSTANCE_ID、$REGIONなどの変数は、以前に設定した値に置き換えられます。次のコマンドを実行して
HMAC認証情報を作成します。$ ibmcloud resource service-key-create test-key Writer --instance-name test-service-instance --parameters {\"HMAC\":true}HMAC認証情報からアクセスキー ID とシークレットアクセスキーを抽出し、credentials-veleroファイルに保存します。credentials-veleroファイルを使用して、Backup Storage Location のsecretを作成できます。以下のコマンドを実行します。$ cat > credentials-velero << __EOF__ [default] aws_access_key_id=$(ibmcloud resource service-key test-key -o json | jq -r '.[0].credentials.cos_hmac_keys.access_key_id') aws_secret_access_key=$(ibmcloud resource service-key test-key -o json | jq -r '.[0].credentials.cos_hmac_keys.secret_access_key') __EOF__
4.8.1.2. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップ場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用して、デフォルト名の Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
手順
-
Backup Storage Location の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。 デフォルト名で
Secretカスタムリソース (CR) を作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
4.8.1.3. 異なる認証情報のシークレットの作成
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの Secret オブジェクトを作成する必要があります。
-
カスタム名を持つバックアップロケーションの
Secret。カスタム名は、DataProtectionApplicationカスタムリソース (CR) のspec.backupLocationsブロックで指定されます。 -
スナップショットの場所
Secret(デフォルト名はcloud-credentials)。このSecretは、DataProtectionApplicationで指定されていません。
手順
-
スナップショットの場所の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。 デフォルト名でスナップショットの場所の
Secretを作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero-
オブジェクトストレージに適した形式で、バックアップロケーションの
credentials-veleroファイルを作成します。 カスタム名を使用してバックアップロケーションの
Secretを作成します。$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero次の例のように、カスタム名の
SecretをDataProtectionApplicationに追加します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: provider: <provider> default: true credential: key: cloud name: <custom_secret>1 objectStorage: bucket: <bucket_name> prefix: <prefix>- 1
- カスタム名を持つバックアップロケーションの
Secret。
4.8.1.4. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: namespace: openshift-adp name: <dpa_name> spec: configuration: velero: defaultPlugins: - openshift - aws - csi backupLocations: - velero: provider: aws1 default: true objectStorage: bucket: <bucket_name>2 prefix: velero config: insecureSkipTLSVerify: 'true' profile: default region: <region_name>3 s3ForcePathStyle: 'true' s3Url: <s3_url>4 credential: key: cloud name: cloud-credentials5 - 1
- Backup Storage Location として IBM Cloud を使用する場合、プロバイダーは
awsになります。 - 2
- IBM Cloud Object Storage (COS) バケット名を指定します。
- 3
- COS リージョン名を指定します (例:
eu-gb)。 - 4
- COS バケットの S3 URL を指定します。たとえば、
http://s3.eu-gb.cloud-object-storage.appdomain.cloudです。ここで、eu-gbはリージョン名です。バケットのリージョンに応じてリージョン名を置き換えます。 - 5
HMAC認証情報からのアクセスキーとシークレットアクセスキーを使用して作成したシークレットの名前を定義します。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
4.8.1.5. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
4.8.1.6. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.8.1.7. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.8.1.8. 複数の BSL を使用した DPA の設定
複数の BSL を使用して DPA を設定し、クラウドプロバイダーによって提供される認証情報を指定できます。
前提条件
- OADP Operator をインストールする。
- クラウドプロバイダーによって提供される認証情報を使用してシークレットを作成する。
手順
複数の BSL を使用して DPA を設定します。以下の例を参照してください。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication #... backupLocations: - name: aws1 velero: provider: aws default: true2 objectStorage: bucket: <bucket_name>3 prefix: <prefix>4 config: region: <region_name>5 profile: "default" credential: key: cloud name: cloud-credentials6 - name: odf7 velero: provider: aws default: false objectStorage: bucket: <bucket_name> prefix: <prefix> config: profile: "default" region: <region_name> s3Url: <url>8 insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" credential: key: cloud name: <custom_secret_name_odf>9 #...- 1
- 最初の BSL の名前を指定します。
- 2
- このパラメーターは、この BSL がデフォルトの BSL であることを示します。
Backup CRに BSL が設定されていない場合は、デフォルトの BSL が使用されます。デフォルトとして設定できる BSL は 1 つだけです。 - 3
- バケット名を指定します。
- 4
- Velero バックアップの接頭辞を指定します (例:
velero)。 - 5
- バケットの AWS リージョンを指定します。
- 6
- 作成したデフォルトの
Secretオブジェクトの名前を指定します。 - 7
- 2 番目の BSL の名前を指定します。
- 8
- S3 エンドポイントの URL を指定します。
- 9
Secretの正しい名前を指定します。たとえば、custom_secret_name_odfです。Secret名を指定しない場合は、デフォルトの名前が使用されます。
バックアップ CR で使用する BSL を指定します。以下の例を参照してください。
バックアップ CR の例
apiVersion: velero.io/v1 kind: Backup # ... spec: includedNamespaces: - <namespace>1 storageLocation: <backup_storage_location>2 defaultVolumesToFsBackup: true
4.8.1.9. DataProtectionApplication でノードエージェントを無効にする
バックアップに Restic、Kopia、または DataMover を使用していない場合は、DataProtectionApplication カスタムリソース (CR) の nodeAgent フィールドを無効にすることができます。nodeAgent を無効にする前に、OADP Operator がアイドル状態であり、バックアップを実行していないことを確認してください。
手順
nodeAgentを無効にするには、enableフラグをfalseに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: false1 uploaderType: kopia # ...- 1
- ノードエージェントを無効にします。
nodeAgentを有効にするには、enableフラグをtrueに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: true1 uploaderType: kopia # ...- 1
- ノードエージェントを有効にします。
ジョブをセットアップして、DataProtectionApplication CR の nodeAgent フィールドを有効または無効にすることができます。詳細は、「ジョブの使用による Pod でのタスクの実行」を参照してください。
4.9. Azure を使用した OADP の設定
4.9.1. Microsoft Azure を使用した OpenShift API for Data Protection の設定
OADP Operator をインストールすることで、Microsoft Azure を使用して OpenShift API for Data Protection (OADP) をインストールします。Operator は Velero 1.14 をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Velero 向けに Azure を設定し、デフォルトの Secret を作成し、次に、Data Protection Application をインストールします。詳細は、OADP Operator のインストール を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
4.9.1.1. Microsoft Azure の設定
OpenShift API for Data Protection (OADP) 用に Microsoft Azure を設定します。
前提条件
- Azure CLI がインストールされていること。
Azure サービスを使用するツールには、Azure リソースの安全を確保するために、必ず制限された権限を付与する必要があります。そのため、Azure では、アプリケーションを完全な権限を持つユーザーとしてサインインさせる代わりに、サービスプリンシパルを提供しています。Azure サービスプリンシパルは、アプリケーション、ホストされたサービス、または自動化ツールで使用できる名前です。
このアイデンティティーはリソースへのアクセスに使用されます。
- サービスプリンシパルを作成する
- サービスプリンシパルとパスワードを使用してサインインする
- サービスプリンシパルと証明書を使用してサインインする
- サービスプリンシパルのロールを管理する
- サービスプリンシパルを使用して Azure リソースを作成する
- サービスプリンシパルの認証情報をリセットする
詳細は、Create an Azure service principal with Azure CLI を参照してください。
4.9.1.2. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
バックアップの場所として、Multicloud Object Gateway、Red Hat Container Storage、Ceph RADOS Gateway (Ceph Object Gateway とも呼ばれます)、Red Hat OpenShift Data Foundation、MinIO などの AWS S3 互換オブジェクトストレージを指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
File System Backup (FSB) を使用する場合、FSB がオブジェクトストレージ上にファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
4.9.1.3. Azure での OADP の認証について
Azure で OADP を認証するには、次の方法を使用できます。
- シークレットベースの認証を使用する Velero 専用のサービスプリンシパル
- シークレットベースの認証を使用する Velero 専用のストレージアカウントアクセスキー
4.9.1.4. サービスプリンシパルまたはストレージアカウントアクセスキーを使用する
デフォルトの Secret オブジェクトを作成し、Backup Storage Location のカスタムリソースでそれを参照します。Secret オブジェクトの認証情報ファイルには、Azure サービスプリンシパルまたはストレージアカウントアクセスキーに関する情報を含めることができます。
Secret のデフォルト名は cloud-credentials-azure です。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップ場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用して、デフォルト名の Secret を作成できます。
前提条件
-
cluster-admin特権を持つユーザーとして OpenShift クラスターにアクセスできる。 - 適切な権限が付与された Azure サブスクリプションがある。
- OADP をインストールした。
- バックアップを保存するためのオブジェクトストレージを設定した。
手順
Backup Storage Location の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。Azure で OADP を認証するには、次の 2 つの方法のいずれかを使用できます。
シークレットベースの認証でサービスプリンシパルを使用します。以下の例を参照してください。
AZURE_SUBSCRIPTION_ID=<azure_subscription_id> AZURE_TENANT_ID=<azure_tenant_id> AZURE_CLIENT_ID=<azure_client_id> AZURE_CLIENT_SECRET=<azure_client_secret> AZURE_RESOURCE_GROUP=<azure_resource_group> AZURE_CLOUD_NAME=<azure_cloud_name>ストレージアカウントアクセスキーを使用します。以下の例を参照してください。
AZURE_STORAGE_ACCOUNT_ACCESS_KEY=<azure_storage_account_access_key> AZURE_SUBSCRIPTION_ID=<azure_subscription_id> AZURE_RESOURCE_GROUP=<azure_resource_group> AZURE_CLOUD_NAME=<azure_cloud_name>
デフォルト名で
Secretカスタムリソース (CR) を作成します。$ oc create secret generic cloud-credentials-azure -n openshift-adp --from-file cloud=credentials-velero次の例に示すように、Data Protection Application をインストールするときに、
DataProtectionApplicationCR のspec.backupLocations.velero.credentialブロック内のSecretを参照します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: config: resourceGroup: <azure_resource_group> storageAccount: <azure_storage_account_id> subscriptionId: <azure_subscription_id> credential: key: cloud name: <custom_secret>1 provider: azure default: true objectStorage: bucket: <bucket_name> prefix: <prefix> snapshotLocations: - velero: config: resourceGroup: <azure_resource_group> subscriptionId: <azure_subscription_id> incremental: "true" provider: azure- 1
- カスタム名を持つバックアップロケーションの
Secret。
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
4.9.1.5. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。指定したラベルが、各ノードのラベルと一致する必要があります。
詳細は、ノードエージェントとノードラベルの設定 を参照してください。
4.9.1.6. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.9.1.6.1. Velero デプロイメント用のエイリアス化した velero コマンドで CA 証明書を使用する
Velero CLI のエイリアスを作成することで、システムにローカルにインストールせずに Velero CLI を使用できます。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 OpenShift CLI (
oc) がインストールされている。エイリアス化した Velero コマンドを使用するには、次のコマンドを実行します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'次のコマンドを実行して、エイリアスが機能していることを確認します。
例
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADPこのコマンドで CA 証明書を使用するには、次のコマンドを実行して証明書を Velero デプロイメントに追加できます。
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txtバックアップログを取得するために、次のコマンドを実行します。
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>このログを使用して、バックアップできないリソースの障害と警告を表示できます。
-
Velero Pod が再起動すると、
/tmp/your-cacert.txtファイルが消去されます。そのため、前の手順のコマンドを再実行して/tmp/your-cacert.txtファイルを再作成する必要があります。 次のコマンドを実行すると、
/tmp/your-cacert.txtファイルを保存した場所にファイルがまだ存在するかどうかを確認できます。$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
OpenShift API for Data Protection (OADP) の今後のリリースでは、この手順が不要になるように証明書を Velero Pod にマウントする予定です。
4.9.1.7. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentials-azureを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 -
スナップショットの場所用の別のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。
注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp1 spec: configuration: velero: defaultPlugins: - azure - openshift2 resourceTimeout: 10m3 nodeAgent:4 enable: true5 uploaderType: kopia6 podConfig: nodeSelector: <node_selector>7 backupLocations: - velero: config: resourceGroup: <azure_resource_group>8 storageAccount: <azure_storage_account_id>9 subscriptionId: <azure_subscription_id>10 credential: key: cloud name: cloud-credentials-azure11 provider: azure default: true objectStorage: bucket: <bucket_name>12 prefix: <prefix>13 snapshotLocations:14 - velero: config: resourceGroup: <azure_resource_group> subscriptionId: <azure_subscription_id> incremental: "true" name: default provider: azure credential: key: cloud name: cloud-credentials-azure15 - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
openshiftプラグインは必須です。- 3
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 4
- 管理要求をサーバーにルーティングする管理エージェント。
- 5
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 6
- アップローダーとして
kopiaまたはresticと入力します。インストール後に選択を変更することはできません。組み込み DataMover の場合は、Kopia を使用する必要があります。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 7
- Kopia または Restic が使用可能なノードを指定します。デフォルトでは、Kopia または Restic はすべてのノードで実行されます。
- 8
- Azure リソースグループを指定します。
- 9
- Azure ストレージアカウント ID を指定します。
- 10
- Azure サブスクリプション ID を指定します。
- 11
- この値を指定しない場合は、デフォルト名の
cloud-credentials-azureが使用されます。カスタム名を指定すると、バックアップの場所にカスタム名が使用されます。 - 12
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 13
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。 - 14
- CSI スナップショットまたは Restic を使用して PV をバックアップする場合は、スナップショットの場所を指定する必要はありません。
- 15
- 作成した
Secretオブジェクトの名前を指定します。この値を指定しない場合は、デフォルト名のcloud-credentials-azureが使用されます。カスタム名を指定すると、バックアップの場所にカスタム名が使用されます。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
4.9.1.8. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.9.1.8.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.9.1.8.2. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
csiデフォルトプラグインを追加します。
4.9.1.8.3. DataProtectionApplication でノードエージェントを無効にする
バックアップに Restic、Kopia、または DataMover を使用していない場合は、DataProtectionApplication カスタムリソース (CR) の nodeAgent フィールドを無効にすることができます。nodeAgent を無効にする前に、OADP Operator がアイドル状態であり、バックアップを実行していないことを確認してください。
手順
nodeAgentを無効にするには、enableフラグをfalseに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: false1 uploaderType: kopia # ...- 1
- ノードエージェントを無効にします。
nodeAgentを有効にするには、enableフラグをtrueに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: true1 uploaderType: kopia # ...- 1
- ノードエージェントを有効にします。
ジョブをセットアップして、DataProtectionApplication CR の nodeAgent フィールドを有効または無効にすることができます。詳細は、「ジョブの使用による Pod でのタスクの実行」を参照してください。
4.10. Google Cloud を使用した OADP の設定
4.10.1. Google Cloud を使用した OpenShift API for Data Protection の設定
OADP Operator をインストールすることで、Google Cloud を使用して OpenShift API for Data Protection (OADP)をインストールします。Operator は Velero 1.14 をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Velero 向けに Google Cloud を設定し、デフォルトの Secret を作成し、次に、Data Protection Application をインストールします。詳細は、OADP Operator のインストール を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
4.10.1.1. GoogleCloud の設定
OpenShift API for Data Protection (OADP)用の Google Cloud を設定します。
前提条件
-
gcloudおよびgsutilCLI ツールがインストールされている必要があります。詳細は、Google Cloud のドキュメント をご覧ください。
手順
Google Cloud にログインします。
$ gcloud auth loginBUCKET変数を設定します。$ BUCKET=<bucket>1 - 1
- バケット名を指定します。
ストレージバケットを作成します。
$ gsutil mb gs://$BUCKET/PROJECT_ID変数をアクティブなプロジェクトに設定します。$ PROJECT_ID=$(gcloud config get-value project)サービスアカウントを作成します。
$ gcloud iam service-accounts create velero \ --display-name "Velero service account"サービスアカウントをリスト表示します。
$ gcloud iam service-accounts listemailの値と一致するようにSERVICE_ACCOUNT_EMAIL変数を設定します。$ SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \ --filter="displayName:Velero service account" \ --format 'value(email)')ポリシーを添付して、
veleroユーザーに必要最小限の権限を付与します。$ ROLE_PERMISSIONS=( compute.disks.get compute.disks.create compute.disks.createSnapshot compute.snapshots.get compute.snapshots.create compute.snapshots.useReadOnly compute.snapshots.delete compute.zones.get storage.objects.create storage.objects.delete storage.objects.get storage.objects.list iam.serviceAccounts.signBlob )velero.serverカスタムロールを作成します。$ gcloud iam roles create velero.server \ --project $PROJECT_ID \ --title "Velero Server" \ --permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"IAM ポリシーバインディングをプロジェクトに追加します。
$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_EMAIL \ --role projects/$PROJECT_ID/roles/velero.serverIAM サービスアカウントを更新します。
$ gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}IAM サービスアカウントのキーを現在のディレクトリーにある
credentials-veleroファイルに保存します。$ gcloud iam service-accounts keys create credentials-velero \ --iam-account $SERVICE_ACCOUNT_EMAILData Protection Application をインストールする前に、
credentials-veleroファイルを使用して Google Cloud のSecretオブジェクトを作成します。
4.10.1.2. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
バックアップの場所として、Multicloud Object Gateway、Red Hat Container Storage、Ceph RADOS Gateway (Ceph Object Gateway とも呼ばれます)、Red Hat OpenShift Data Foundation、MinIO などの AWS S3 互換オブジェクトストレージを指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
File System Backup (FSB) を使用する場合、FSB がオブジェクトストレージ上にファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
4.10.1.2.1. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
Secret のデフォルト名は cloud-credentials-gcp です。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップ場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用して、デフォルト名の Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
手順
-
Backup Storage Location の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。 デフォルト名で
Secretカスタムリソース (CR) を作成します。$ oc create secret generic cloud-credentials-gcp -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
4.10.1.2.2. 異なる認証情報のシークレットの作成
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの Secret オブジェクトを作成する必要があります。
-
カスタム名を持つバックアップロケーションの
Secret。カスタム名は、DataProtectionApplicationカスタムリソース (CR) のspec.backupLocationsブロックで指定されます。 -
スナップショットの場所
Secret(デフォルト名はcloud-credentials-gcp)。このSecretは、DataProtectionApplicationで指定されていません。
手順
-
スナップショットの場所の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。 デフォルト名でスナップショットの場所の
Secretを作成します。$ oc create secret generic cloud-credentials-gcp -n openshift-adp --from-file cloud=credentials-velero-
オブジェクトストレージに適した形式で、バックアップロケーションの
credentials-veleroファイルを作成します。 カスタム名を使用してバックアップロケーションの
Secretを作成します。$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero次の例のように、カスタム名の
SecretをDataProtectionApplicationに追加します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: provider: gcp default: true credential: key: cloud name: <custom_secret>1 objectStorage: bucket: <bucket_name> prefix: <prefix> snapshotLocations: - velero: provider: gcp default: true config: project: <project> snapshotLocation: us-west1- 1
- カスタム名を持つバックアップロケーションの
Secret。
4.10.1.3. Data Protection Application の設定
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
4.10.1.3.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。指定したラベルが、各ノードのラベルと一致する必要があります。
詳細は、ノードエージェントとノードラベルの設定 を参照してください。
4.10.1.3.2. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.10.1.3.2.1. Velero デプロイメント用のエイリアス化した velero コマンドで CA 証明書を使用する
Velero CLI のエイリアスを作成することで、システムにローカルにインストールせずに Velero CLI を使用できます。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 OpenShift CLI (
oc) がインストールされている。エイリアス化した Velero コマンドを使用するには、次のコマンドを実行します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'次のコマンドを実行して、エイリアスが機能していることを確認します。
例
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADPこのコマンドで CA 証明書を使用するには、次のコマンドを実行して証明書を Velero デプロイメントに追加できます。
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txtバックアップログを取得するために、次のコマンドを実行します。
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>このログを使用して、バックアップできないリソースの障害と警告を表示できます。
-
Velero Pod が再起動すると、
/tmp/your-cacert.txtファイルが消去されます。そのため、前の手順のコマンドを再実行して/tmp/your-cacert.txtファイルを再作成する必要があります。 次のコマンドを実行すると、
/tmp/your-cacert.txtファイルを保存した場所にファイルがまだ存在するかどうかを確認できます。$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
OpenShift API for Data Protection (OADP) の今後のリリースでは、この手順が不要になるように証明書を Velero Pod にマウントする予定です。
4.10.1.4. Google Workload Identity 連携のクラウド認証
Google Cloud の外で実行されているアプリケーションは、ユーザー名やパスワードなどのサービスアカウントキーを使用して、Google Cloud リソースにアクセスします。これらのサービスアカウントキーは、適切に管理されていない場合、セキュリティーリスクになる可能性があります。
Google Workload Identity 連携を使用すると、Identity and Access Management (IAM) を使用して、サービスアカウントに成り代わる機能など、外部アイデンティティーの IAM ロールを提供できます。これにより、サービスアカウントキーに関連するメンテナンスとセキュリティーのリスクが排除されます。
Workload Identity 連携は、証明書の暗号化と復号化、ユーザー属性の抽出、および検証を処理します。Identity 連携は認証を外部化し、それをセキュリティートークンサービス (STS) に渡すことで、個々の開発者の負担を軽減します。リソースへのアクセスの認可と制御は、引き続きアプリケーションが処理します。
ボリュームをバックアップする場合、Google ワークロード ID フェデレーション認証を使用して Google Cloud で OADP は CSI スナップショットのみをサポートします。
Google ワークロード ID フェデレーション認証を備えた Google Cloud 上の OADP は、ボリュームスナップショットの場所(VSL)バックアップをサポートしていません。詳細は、Google Workload Identity 連携の既知の問題 を参照してください。
Google Workload Identity 連携クラウド認証を使用しない場合は、Data Protection Application のインストール に進みます。
前提条件
- Google Cloud Workload Identity を設定 して手動モードでクラスターをインストール している。
-
Cloud Credential Operator ユーティリティー (
ccoctl) と、関連する Workload Identity プールにアクセスできる。
手順
次のコマンドを実行して、
oadp-credrequestディレクトリーを作成します。$ mkdir -p oadp-credrequest次のように、
CredentialsRequest.yamlファイルを作成します。echo 'apiVersion: cloudcredential.openshift.io/v1 kind: CredentialsRequest metadata: name: oadp-operator-credentials namespace: openshift-cloud-credential-operator spec: providerSpec: apiVersion: cloudcredential.openshift.io/v1 kind: GCPProviderSpec permissions: - compute.disks.get - compute.disks.create - compute.disks.createSnapshot - compute.snapshots.get - compute.snapshots.create - compute.snapshots.useReadOnly - compute.snapshots.delete - compute.zones.get - storage.objects.create - storage.objects.delete - storage.objects.get - storage.objects.list - iam.serviceAccounts.signBlob skipServiceCheck: true secretRef: name: cloud-credentials-gcp namespace: <OPERATOR_INSTALL_NS> serviceAccountNames: - velero ' > oadp-credrequest/credrequest.yaml次のコマンドを実行し、
ccoctlユーティリティーを使用して、oadp-credrequestディレクトリー内のCredentialsRequestオブジェクトを処理します。$ ccoctl gcp create-service-accounts \ --name=<name> \ --project=<gcp_project_id> \ --credentials-requests-dir=oadp-credrequest \ --workload-identity-pool=<pool_id> \ --workload-identity-provider=<provider_id>これで、次のステップで
manifests/openshift-adp-cloud-credentials-gcp-credentials.yamlファイルを使用できるようになりました。次のコマンドを実行して、namespace を作成します。
$ oc create namespace <OPERATOR_INSTALL_NS>次のコマンドを実行して、認証情報を namespace に適用します。
$ oc apply -f manifests/openshift-adp-cloud-credentials-gcp-credentials.yaml
4.10.1.4.1. Google Workload Identity 連携の既知の問題
-
ボリュームスナップショットロケーション(VSL)のバックアップは、Google Cloud ワークロード ID フェデレーションが設定されている場合に
PartiallyFailedフェーズで終了します。Google Workload Identity 連携認証は、VSL バックアップをサポートしません。
4.10.1.5. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentials-gcpを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 -
スナップショットの場所用の別のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。
注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: <OPERATOR_INSTALL_NS>1 spec: configuration: velero: defaultPlugins: - gcp - openshift2 resourceTimeout: 10m3 nodeAgent:4 enable: true5 uploaderType: kopia6 podConfig: nodeSelector: <node_selector>7 backupLocations: - velero: provider: gcp default: true credential: key: cloud8 name: cloud-credentials-gcp9 objectStorage: bucket: <bucket_name>10 prefix: <prefix>11 snapshotLocations:12 - velero: provider: gcp default: true config: project: <project> snapshotLocation: us-west113 credential: key: cloud name: cloud-credentials-gcp14 backupImages: true15 - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
openshiftプラグインは必須です。- 3
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 4
- 管理要求をサーバーにルーティングする管理エージェント。
- 5
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 6
- アップローダーとして
kopiaまたはresticと入力します。インストール後に選択を変更することはできません。組み込み DataMover の場合は、Kopia を使用する必要があります。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 7
- Kopia または Restic が使用可能なノードを指定します。デフォルトでは、Kopia または Restic はすべてのノードで実行されます。
- 8
- 認証情報を含む秘密鍵。Google Workload Identity 連携クラウド認証の場合は、
service_account.jsonを使用します。 - 9
- 認証情報を含むシークレットの名前。この値を指定しない場合は、デフォルトの名前である
cloud-credentials-gcpが使用されます。 - 10
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 11
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。 - 12
- CSI スナップショットまたは Restic を使用して PV をバックアップする場合を除き、スナップショットの場所を指定します。
- 13
- スナップショットの場所は、PV と同じリージョンにある必要があります。
- 14
- 作成した
Secretオブジェクトの名前を指定します。この値を指定しない場合は、デフォルトの名前であるcloud-credentials-gcpが使用されます。カスタム名を指定すると、バックアップの場所にカスタム名が使用されます。 - 15
- Google Workload Identity 連携は、内部イメージのバックアップをサポートしています。イメージのバックアップを使用しない場合は、このフィールドを
falseに設定します。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
4.10.1.6. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.10.1.6.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.10.1.6.2. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
csiデフォルトプラグインを追加します。
4.10.1.6.3. DataProtectionApplication でノードエージェントを無効にする
バックアップに Restic、Kopia、または DataMover を使用していない場合は、DataProtectionApplication カスタムリソース (CR) の nodeAgent フィールドを無効にすることができます。nodeAgent を無効にする前に、OADP Operator がアイドル状態であり、バックアップを実行していないことを確認してください。
手順
nodeAgentを無効にするには、enableフラグをfalseに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: false1 uploaderType: kopia # ...- 1
- ノードエージェントを無効にします。
nodeAgentを有効にするには、enableフラグをtrueに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: true1 uploaderType: kopia # ...- 1
- ノードエージェントを有効にします。
ジョブをセットアップして、DataProtectionApplication CR の nodeAgent フィールドを有効または無効にすることができます。詳細は、「ジョブの使用による Pod でのタスクの実行」を参照してください。
4.11. MCG を使用した OADP の設定
4.11.1. Multicloud Object Gateway を使用した OpenShift API for Data Protection の設定
OADP Operator をインストールすることで、Multicloud Object Gateway (MCG) を使用して OpenShift API for Data Protection (OADP) をインストールします。Operator は Velero 1.14 をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Multicloud Object Gateway をバックアップの場所として設定します。MCG は、OpenShift Data Foundation のコンポーネントです。MCG は、DataProtectionApplication カスタムリソース (CR) のバックアップロケーションとして設定します。
オブジェクトストレージのバケット作成を自動化する CloudStorage API は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
バックアップの場所の Secret を作成し、次に、Data Protection Application をインストールします。詳細は、OADP Operator のインストール を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
4.11.1.1. Multicloud Object Gateway の認証情報の取得
OpenShift API for Data Protection (OADP) の Secret カスタムリソース (CR) を作成するには、Multicloud Object Gateway (MCG) 認証情報を取得する必要があります。
MCG Operator は 非推奨 ですが、MCG プラグインは OpenShift Data Foundation で引き続き利用できます。プラグインをダウンロードするには、Red Hat OpenShift Data Foundation のダウンロード を参照し、ご使用のオペレーティングシステムに適した MCG プラグインをダウンロードします。
前提条件
- 適切な Red Hat OpenShift Data Foundation デプロイメントガイド を使用して、OpenShift Data Foundation をデプロイする必要があります。
手順
-
NooBaaカスタムリソースでdescribeコマンドを実行して、S3 エンドポイントであるAWS_ACCESS_KEY_IDおよびAWS_SECRET_ACCESS_KEYを取得します。 credentials-veleroファイルを作成します。$ cat << EOF > ./credentials-velero [default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> EOFData Protection Application をインストールする際に、
credentials-veleroファイルを使用してSecretオブジェクトを作成します。
4.11.1.2. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
バックアップの場所として、Multicloud Object Gateway、Red Hat Container Storage、Ceph RADOS Gateway (Ceph Object Gateway とも呼ばれます)、Red Hat OpenShift Data Foundation、MinIO などの AWS S3 互換オブジェクトストレージを指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
File System Backup (FSB) を使用する場合、FSB がオブジェクトストレージ上にファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
4.11.1.2.1. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
Secret のデフォルト名は cloud-credentials です。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップ場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用して、デフォルト名の Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
手順
Backup Storage Location の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。以下の例を参照してください。
[default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>デフォルト名で
Secretカスタムリソース (CR) を作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
4.11.1.2.2. 異なる認証情報のシークレットの作成
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの Secret オブジェクトを作成する必要があります。
-
カスタム名を持つバックアップロケーションの
Secret。カスタム名は、DataProtectionApplicationカスタムリソース (CR) のspec.backupLocationsブロックで指定されます。 -
スナップショットの場所
Secret(デフォルト名はcloud-credentials)。このSecretは、DataProtectionApplicationで指定されていません。
手順
-
スナップショットの場所の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。 デフォルト名でスナップショットの場所の
Secretを作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero-
オブジェクトストレージに適した形式で、バックアップロケーションの
credentials-veleroファイルを作成します。 カスタム名を使用してバックアップロケーションの
Secretを作成します。$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero次の例のように、カスタム名の
SecretをDataProtectionApplicationに追加します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: config: profile: "default" region: <region_name>1 s3Url: <url> insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" provider: aws default: true credential: key: cloud name: <custom_secret>2 objectStorage: bucket: <bucket_name> prefix: <prefix>
4.11.1.3. Data Protection Application の設定
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
4.11.1.3.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。指定したラベルが、各ノードのラベルと一致する必要があります。
詳細は、ノードエージェントとノードラベルの設定 を参照してください。
4.11.1.3.2. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.11.1.3.2.1. Velero デプロイメント用のエイリアス化した velero コマンドで CA 証明書を使用する
Velero CLI のエイリアスを作成することで、システムにローカルにインストールせずに Velero CLI を使用できます。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 OpenShift CLI (
oc) がインストールされている。エイリアス化した Velero コマンドを使用するには、次のコマンドを実行します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'次のコマンドを実行して、エイリアスが機能していることを確認します。
例
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADPこのコマンドで CA 証明書を使用するには、次のコマンドを実行して証明書を Velero デプロイメントに追加できます。
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txtバックアップログを取得するために、次のコマンドを実行します。
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>このログを使用して、バックアップできないリソースの障害と警告を表示できます。
-
Velero Pod が再起動すると、
/tmp/your-cacert.txtファイルが消去されます。そのため、前の手順のコマンドを再実行して/tmp/your-cacert.txtファイルを再作成する必要があります。 次のコマンドを実行すると、
/tmp/your-cacert.txtファイルを保存した場所にファイルがまだ存在するかどうかを確認できます。$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
OpenShift API for Data Protection (OADP) の今後のリリースでは、この手順が不要になるように証明書を Velero Pod にマウントする予定です。
4.11.1.4. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 -
スナップショットの場所用の別のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。
注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp1 spec: configuration: velero: defaultPlugins: - aws2 - openshift3 resourceTimeout: 10m4 nodeAgent:5 enable: true6 uploaderType: kopia7 podConfig: nodeSelector: <node_selector>8 backupLocations: - velero: config: profile: "default" region: <region_name>9 s3Url: <url>10 insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" provider: aws default: true credential: key: cloud name: cloud-credentials11 objectStorage: bucket: <bucket_name>12 prefix: <prefix>13 - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
- ストレージの場所に対応したオブジェクトストアプラグインが必要です。すべての S3 プロバイダーで、
awsプラグインが必要です。Azure および Google Cloud オブジェクトストアの場合、azure またはgcpプラグインが必要です。 - 3
openshiftプラグインは必須です。- 4
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 5
- 管理要求をサーバーにルーティングする管理エージェント。
- 6
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 7
- アップローダーとして
kopiaまたはresticと入力します。インストール後に選択を変更することはできません。組み込み DataMover の場合は、Kopia を使用する必要があります。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 8
- Kopia または Restic が使用可能なノードを指定します。デフォルトでは、Kopia または Restic はすべてのノードで実行されます。
- 9
- オブジェクトストレージサーバーのドキュメントの命名規則に従って、リージョンを指定します。
- 10
- S3 エンドポイントの URL を指定します。
- 11
- 作成した
Secretオブジェクトの名前を指定します。この値を指定しない場合は、デフォルト名のcloud-credentialsが使用されます。カスタム名を指定すると、バックアップの場所にカスタム名が使用されます。 - 12
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 13
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
4.11.1.5. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.11.1.5.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.11.1.5.2. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
csiデフォルトプラグインを追加します。
4.11.1.5.3. DataProtectionApplication でノードエージェントを無効にする
バックアップに Restic、Kopia、または DataMover を使用していない場合は、DataProtectionApplication カスタムリソース (CR) の nodeAgent フィールドを無効にすることができます。nodeAgent を無効にする前に、OADP Operator がアイドル状態であり、バックアップを実行していないことを確認してください。
手順
nodeAgentを無効にするには、enableフラグをfalseに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: false1 uploaderType: kopia # ...- 1
- ノードエージェントを無効にします。
nodeAgentを有効にするには、enableフラグをtrueに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: true1 uploaderType: kopia # ...- 1
- ノードエージェントを有効にします。
ジョブをセットアップして、DataProtectionApplication CR の nodeAgent フィールドを有効または無効にすることができます。詳細は、「ジョブの使用による Pod でのタスクの実行」を参照してください。
4.12. ODF を使用した OADP の設定
4.12.1. OpenShift Data Foundation を使用した OpenShift API for Data Protection の設定
OpenShift Data Foundation を使用して OpenShift API for Data Protection (OADP) をインストールするには、OADP Operator をインストールし、バックアップの場所とスナップショットロケーションを設定します。次に、Data Protection Application をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Multicloud Object Gateway または任意の AWS S3 互換のオブジェクトストレージをバックアップの場所として設定できます。
オブジェクトストレージのバケット作成を自動化する CloudStorage API は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
バックアップの場所の Secret を作成し、次に、Data Protection Application をインストールします。詳細は、OADP Operator のインストール を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
4.12.1.1. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
バックアップの場所として、Multicloud Object Gateway、Red Hat Container Storage、Ceph RADOS Gateway (Ceph Object Gateway とも呼ばれます)、Red Hat OpenShift Data Foundation、MinIO などの AWS S3 互換オブジェクトストレージを指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
File System Backup (FSB) を使用する場合、FSB がオブジェクトストレージ上にファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
4.12.1.1.1. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップストレージプロバイダーに aws、azure、または gcp などのデフォルトのプラグインがない限り、Secret のデフォルト名は cloud-credentials です。その場合、プロバイダー固有の OADP インストール手順でデフォルト名が指定されています。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップ場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用して、デフォルト名の Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
手順
Backup Storage Location の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。以下の例を参照してください。
[default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>デフォルト名で
Secretカスタムリソース (CR) を作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
4.12.1.1.2. 異なる認証情報のシークレットの作成
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの Secret オブジェクトを作成する必要があります。
-
カスタム名を持つバックアップロケーションの
Secret。カスタム名は、DataProtectionApplicationカスタムリソース (CR) のspec.backupLocationsブロックで指定されます。 -
スナップショットの場所
Secret(デフォルト名はcloud-credentials)。このSecretは、DataProtectionApplicationで指定されていません。
手順
-
スナップショットの場所の
credentials-veleroファイルをクラウドプロバイダーに適した形式で作成します。 デフォルト名でスナップショットの場所の
Secretを作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero-
オブジェクトストレージに適した形式で、バックアップロケーションの
credentials-veleroファイルを作成します。 カスタム名を使用してバックアップロケーションの
Secretを作成します。$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero次の例のように、カスタム名の
SecretをDataProtectionApplicationに追加します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: provider: <provider> default: true credential: key: cloud name: <custom_secret>1 objectStorage: bucket: <bucket_name> prefix: <prefix>- 1
- カスタム名を持つバックアップロケーションの
Secret。
4.12.1.2. Data Protection Application の設定
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
4.12.1.2.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。指定したラベルが、各ノードのラベルと一致する必要があります。
詳細は、ノードエージェントとノードラベルの設定 を参照してください。
4.12.1.2.1.1. 収集したデータに基づき Ceph の CPU およびメモリー要件を調整する
以下の推奨事項は、スケールおよびパフォーマンスのラボで観察したパフォーマンスに基づいています。変更は、特に {odf-first} に関連しています。ODF を使用する場合は、適切なチューニングガイドで公式の推奨事項を確認してください。
4.12.1.2.1.1.1. 設定に必要な CPU とメモリー
バックアップおよび復元操作には、大量の CephFS PersistentVolumes (PV) が必要です。out-of-memory (OOM) エラーによる Ceph MDS Pod の再起動を回避するためには、次の設定が推奨されます。
| 設定タイプ | 要求 | 上限 |
|---|---|---|
| CPU | 要求が 3 に変更されました | 上限は 3 |
| メモリー | 要求が 8 Gi に変更されました | 上限は 128 Gi |
4.12.1.2.2. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
4.12.1.2.2.1. Velero デプロイメント用のエイリアス化した velero コマンドで CA 証明書を使用する
Velero CLI のエイリアスを作成することで、システムにローカルにインストールせずに Velero CLI を使用できます。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 OpenShift CLI (
oc) がインストールされている。エイリアス化した Velero コマンドを使用するには、次のコマンドを実行します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'次のコマンドを実行して、エイリアスが機能していることを確認します。
例
$ velero version Client: Version: v1.12.1-OADP Git commit: - Server: Version: v1.12.1-OADPこのコマンドで CA 証明書を使用するには、次のコマンドを実行して証明書を Velero デプロイメントに追加できます。
$ CA_CERT=$(oc -n openshift-adp get dataprotectionapplications.oadp.openshift.io <dpa-name> -o jsonpath='{.spec.backupLocations[0].velero.objectStorage.caCert}') $ [[ -n $CA_CERT ]] && echo "$CA_CERT" | base64 -d | oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "cat > /tmp/your-cacert.txt" || echo "DPA BSL has no caCert"$ velero describe backup <backup_name> --details --cacert /tmp/<your_cacert>.txtバックアップログを取得するために、次のコマンドを実行します。
$ velero backup logs <backup_name> --cacert /tmp/<your_cacert.txt>このログを使用して、バックアップできないリソースの障害と警告を表示できます。
-
Velero Pod が再起動すると、
/tmp/your-cacert.txtファイルが消去されます。そのため、前の手順のコマンドを再実行して/tmp/your-cacert.txtファイルを再作成する必要があります。 次のコマンドを実行すると、
/tmp/your-cacert.txtファイルを保存した場所にファイルがまだ存在するかどうかを確認できます。$ oc exec -n openshift-adp -i deploy/velero -c velero -- bash -c "ls /tmp/your-cacert.txt" /tmp/your-cacert.txt
OpenShift API for Data Protection (OADP) の今後のリリースでは、この手順が不要になるように証明書を Velero Pod にマウントする予定です。
4.12.1.3. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 -
スナップショットの場所用の別のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。
注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp1 spec: configuration: velero: defaultPlugins: - aws2 - kubevirt3 - csi4 - openshift5 resourceTimeout: 10m6 nodeAgent:7 enable: true8 uploaderType: kopia9 podConfig: nodeSelector: <node_selector>10 backupLocations: - velero: provider: gcp11 default: true credential: key: cloud name: <default_secret>12 objectStorage: bucket: <bucket_name>13 prefix: <prefix>14 - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
- ストレージの場所に対応したオブジェクトストアプラグインが必要です。すべての S3 プロバイダーで、
awsプラグインが必要です。Azure および Google Cloud オブジェクトストアの場合、azure またはgcpプラグインが必要です。 - 3
- オプション:
kubevirtプラグインは OpenShift Virtualization で使用されます。 - 4
- CSI スナップショットを使用して PV をバックアップする場合は、
csiのデフォルトプラグインを指定します。csiプラグインは、Velero CSI ベータスナップショット API を使用します。スナップショットの場所を設定する必要はありません。 - 5
openshiftプラグインは必須です。- 6
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 7
- 管理要求をサーバーにルーティングする管理エージェント。
- 8
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 9
- アップローダーとして
kopiaまたはresticと入力します。インストール後に選択を変更することはできません。組み込み DataMover の場合は、Kopia を使用する必要があります。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 10
- Kopia または Restic が使用可能なノードを指定します。デフォルトでは、Kopia または Restic はすべてのノードで実行されます。
- 11
- バックアッププロバイダーを指定します。
- 12
- バックアッププロバイダーにデフォルトのプラグインを使用する場合は、
Secretの正しいデフォルト名を指定します (例:cloud-credentials-gcp)。カスタム名を指定すると、そのカスタム名がバックアップの場所に使用されます。Secret名を指定しない場合は、デフォルトの名前が使用されます。 - 13
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 14
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
4.12.1.4. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.12.1.4.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.12.1.4.2. OpenShift Data Foundation での障害不復旧用のオブジェクトバケット要求の作成
OpenShift Data Foundation の Multicloud Object Gateway (MCG) バケット backupStorageLocation にクラスターストレージを使用する場合は、OpenShift Web コンソールを使用して Object Bucket Claim (OBC) を作成します。
Object Bucket Claim (OBC) の設定に失敗すると、バックアップが利用できなくなる可能性があります。
特に指定のない限り、"NooBaa" は軽量オブジェクトストレージを提供するオープンソースプロジェクトを指し、"Multicloud Object Gateway (MCG)" は NooBaa の Red Hat ディストリビューションを指します。
MCG の詳細は、アプリケーションを使用して Multicloud Object Gateway にアクセスする を参照してください。
手順
- OpenShift Web コンソールを使用した Object Bucket Claim の作成 に記載されているとおり、OpenShift Web コンソールを使用して Object Bucket Claim (OBC) を作成します。
4.12.1.4.3. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
csiデフォルトプラグインを追加します。
4.12.1.4.4. DataProtectionApplication でノードエージェントを無効にする
バックアップに Restic、Kopia、または DataMover を使用していない場合は、DataProtectionApplication カスタムリソース (CR) の nodeAgent フィールドを無効にすることができます。nodeAgent を無効にする前に、OADP Operator がアイドル状態であり、バックアップを実行していないことを確認してください。
手順
nodeAgentを無効にするには、enableフラグをfalseに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: false1 uploaderType: kopia # ...- 1
- ノードエージェントを無効にします。
nodeAgentを有効にするには、enableフラグをtrueに設定します。以下の例を参照してください。DataProtectionApplicationCR の例# ... configuration: nodeAgent: enable: true1 uploaderType: kopia # ...- 1
- ノードエージェントを有効にします。
ジョブをセットアップして、DataProtectionApplication CR の nodeAgent フィールドを有効または無効にすることができます。詳細は、「ジョブの使用による Pod でのタスクの実行」を参照してください。
4.13. OpenShift Virtualization を使用した OADP の設定
4.13.1. OpenShift Virtualization を使用した OpenShift API for Data Protection の設定
OADP Operator をインストールし、バックアップの場所を設定することで、OpenShift Virtualization を使用した OpenShift API for Data Protection (OADP) をインストールできます。その後、Data Protection Application をインストールできます。
OpenShift API for Data Protection を使用して仮想マシンをバックアップおよび復元します。
OpenShift Virtualization を使用した OpenShift API for Data Protection は、バックアップおよび復元のストレージオプションとして次のものをサポートしています。
- Container Storage Interface (CSI) バックアップ
- DataMover による Container Storage Interface (CSI) バックアップ
次のストレージオプションは対象外です。
- ファイルシステムのバックアップと復元
- ボリュームスナップショットのバックアップと復元
詳細は、File System Backup を使用してアプリケーションをバックアップする: Kopia または Restic を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
4.13.1.1. OpenShift Virtualization を使用した OADP のインストールと設定
クラスター管理者は、OADP Operator をインストールして OADP をインストールします。
Operator は Velero 1.16 をインストールします。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- ストレージプロバイダーの指示に従って、OADP Operator をインストールします。
-
kubevirtおよびopenshiftOADP プラグインを使用して Data Protection Application (DPA) をインストールします。 Backupカスタムリソース (CR) を作成して、仮想マシンをバックアップします。警告Red Hat のサポート対象は、次のオプションに限られています。
- CSI バックアップ
- DataMover による CSI バックアップ
Restore CR を作成して Backup CR を復元します。
4.13.1.2. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする。
- オブジェクトストレージをバックアップロケーションとして設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp1 spec: configuration: velero: defaultPlugins: - kubevirt2 - gcp3 - csi4 - openshift5 resourceTimeout: 10m6 nodeAgent:7 enable: true8 uploaderType: kopia9 podConfig: nodeSelector: <node_selector>10 backupLocations: - velero: provider: gcp11 default: true credential: key: cloud name: <default_secret>12 objectStorage: bucket: <bucket_name>13 prefix: <prefix>14 - 1
- OADP のデフォルトの namespace は
openshift-adpです。namespace は変数であり、設定可能です。 - 2
kubevirtプラグインは OpenShift Virtualization に必須です。- 3
- バックアッププロバイダーのプラグインがある場合には、それを指定します (例:
gcp)。 - 4
- CSI スナップショットを使用して PV をバックアップするには、
csiプラグインが必須です。csiプラグインは、Velero CSI ベータスナップショット API を使用します。スナップショットの場所を設定する必要はありません。 - 5
openshiftプラグインは必須です。- 6
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 7
- 管理要求をサーバーにルーティングする管理エージェント。
- 8
nodeAgentを有効にして File System Backup を実行する場合は、この値をtrueに設定します。- 9
- 組み込み DataMover を使用するには、アップローダーとして
kopiaと入力します。nodeAgentはデーモンセットをデプロイします。これは、nodeAgentPod が各ワーキングノード上で実行されることを意味します。File System Backup を設定するには、spec.defaultVolumesToFsBackup: trueをBackupCR に追加します。 - 10
- Kopia が利用可能なノードを指定します。デフォルトでは、Kopia はすべてのノードで実行されます。
- 11
- バックアッププロバイダーを指定します。
- 12
- バックアッププロバイダーにデフォルトのプラグインを使用する場合は、
Secretの正しいデフォルト名を指定します (例:cloud-credentials-gcp)。カスタム名を指定すると、そのカスタム名がバックアップの場所に使用されます。Secret名を指定しない場合は、デフォルトの名前が使用されます。 - 13
- Backup Storage Location としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 14
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
検証
次のコマンドを実行して OpenShift API for Data Protection (OADP) リソースを表示し、インストールを検証します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/node-agent-9cq4q 1/1 Running 0 94s pod/node-agent-m4lts 1/1 Running 0 94s pod/node-agent-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s service/openshift-adp-velero-metrics-svc ClusterIP 172.30.10.0 <none> 8085/TCP 8h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-agent 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s次のコマンドを実行して、
DataProtectionApplication(DPA) が調整されていることを確認します。$ oc get dpa dpa-sample -n openshift-adp -o jsonpath='{.status}'出力例
{"conditions":[{"lastTransitionTime":"2023-10-27T01:23:57Z","message":"Reconcile complete","reason":"Complete","status":"True","type":"Reconciled"}]}-
typeがReconciledに設定されていることを確認します。 次のコマンドを実行して、Backup Storage Location を確認し、
PHASEがAvailableであることを確認します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAME PHASE LAST VALIDATED AGE DEFAULT dpa-sample-1 Available 1s 3d16h true
Microsoft Windows 仮想マシン (VM) の再起動直後に仮想マシンのバックアップを実行すると、PartiallyFailed エラーが発生してバックアップが失敗する可能性があります。これは、仮想マシンの起動直後は、Microsoft Windows Volume Shadow Copy Service (VSS) と Guest Agent (GA) サービスが準備されていないためです。VSS および GA サービスが準備されていないため、バックアップは失敗します。このような場合は、仮想マシンの起動後数分後にバックアップを再試行してください。
4.13.1.3. 単一仮想マシンのバックアップ
複数の仮想マシンが含まれる namespace があり、そのうちの 1 つだけをバックアップする場合は、ラベルセレクターを使用して、バックアップに含める必要がある仮想マシンをフィルターできます。app: vmname ラベルを使用して仮想マシンをフィルタリングできます。
前提条件
- OADP Operator がインストールされている。
- namespace 内で複数の仮想マシンが実行されている。
-
DataProtectionApplication(DPA) カスタムリソース (CR) にkubevirtプラグインを追加した。 -
DataProtectionApplicationCR でBackupStorageLocationCR を設定しており、BackupStorageLocationが使用可能である。
手順
次の例に示すように、
BackupCR を設定します。BackupCR の例apiVersion: velero.io/v1 kind: Backup metadata: name: vmbackupsingle namespace: openshift-adp spec: snapshotMoveData: true includedNamespaces: - <vm_namespace>1 labelSelector: matchLabels: app: <vm_app_name>2 storageLocation: <backup_storage_location_name>3 BackupCR を作成するには、次のコマンドを実行します。$ oc apply -f <backup_cr_file_name>1 - 1
BackupCR ファイルの名前を指定します。
4.13.1.4. 1 つの仮想マシンの復元
Backup カスタムリソース (CR) のラベルセレクターを使用して 1 つの仮想マシンをバックアップした後、Restore CR を作成してバックアップを指すように設定できます。この復元操作では、1 つの仮想マシンが復元されます。
前提条件
- OADP Operator がインストールされている。
- ラベルセレクターを使用して 1 つの仮想マシンをバックアップした。
手順
次の例に示すように、
RestoreCR を設定します。RestoreCR の例apiVersion: velero.io/v1 kind: Restore metadata: name: vmrestoresingle namespace: openshift-adp spec: backupName: vmbackupsingle1 restorePVs: true- 1
- 1 つの仮想マシンのバックアップ名を指定します。
1 つの仮想マシンを復元するには、次のコマンドを実行します。
$ oc apply -f <restore_cr_file_name>1 - 1
RestoreCR ファイルの名前を指定します。
4.13.1.5. 複数の仮想マシンのバックアップから 1 つの仮想マシンを復元する
複数の仮想マシン (仮想マシン) が含まれるバックアップがあり、そのうち 1 つの仮想マシンのみを復元する場合は、Restore CR の LabelSelectors セクションを使用して、復元する仮想マシンを選択できます。確実に仮想マシンにアタッチされた永続ボリューム要求 (PVC) が正しく復元され、復元された仮想マシンが Provisioning 状態でスタックすることを回避するためには、app: <vm_name> と kubevirt.io/created-by ラベルの両方を使用します。kubevirt.io/created-by ラベルと一致させるには、仮想マシンの DataVolume の UID を使用します。
前提条件
- OADP Operator がインストールされている。
- バックアップする必要がある仮想マシンにラベル付けした。
- 複数の仮想マシンのバックアップがある。
手順
多数の仮想マシンのバックアップを作成する前に、次のコマンドを実行して仮想マシンにラベルが付けられていることを確認します。
$ oc label vm <vm_name> app=<vm_name> -n openshift-adp次の例に示すように、
RestoreCR でラベルセレクターを設定します。RestoreCR の例apiVersion: velero.io/v1 kind: Restore metadata: name: singlevmrestore namespace: openshift-adp spec: backupName: multiplevmbackup restorePVs: true LabelSelectors: - matchLabels: kubevirt.io/created-by: <datavolume_uid>1 - matchLabels: app: <vm_name>2 仮想マシンを復元するには、次のコマンドを実行します。
$ oc apply -f <restore_cr_file_name>1 - 1
RestoreCR ファイルの名前を指定します。
4.13.1.6. クライアントバースト設定と QPS 設定を使用した DPA の設定
バースト設定は、制限が適用されるまで velero サーバーに送信できる要求の数を決定するものです。バースト制限に達した後は、1 秒あたりのクエリー数 (QPS) 設定によって、1 秒あたりに送信できる追加の要求の数が決定されます。
バースト値と QPS 値を使用して Data Protection Application (DPA) を設定することにより、velero サーバーのバースト値と QPS 値を設定できます。バースト値と QPS 値は、DPA の dpa.configuration.velero.client-burst フィールドと dpa.configuration.velero.client-qps フィールドを使用して設定できます。
前提条件
- OADP Operator がインストールされている。
手順
次の例に示すように、DPA の
client-burstフィールドとclient-qpsフィールドを設定します。Data Protection Application の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: test-dpa namespace: openshift-adp spec: backupLocations: - name: default velero: config: insecureSkipTLSVerify: "true" profile: "default" region: <bucket_region> s3ForcePathStyle: "true" s3Url: <bucket_url> credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: restic velero: client-burst: 5001 client-qps: 3002 defaultPlugins: - openshift - aws - kubevirt
4.13.1.6.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""4.13.1.7. 増分バックアップのサポートについて
OADP は、コンテナー化されたワークロードと OpenShift Virtualization ワークロードの両方で、block および Filesystem の永続ボリュームの増分バックアップをサポートしています。次の表は、File System Backup (FSB)、Container Storage Interface (CSI)、および CSI Data Mover のサポート状況をまとめたものです。
| ボリュームモード | FSB - Restic | FSB - Kopia | CSI | CSI Data Mover |
|---|---|---|---|---|
| ファイルシステム | S [1]、I [2] | S [1]、I [2] | S [1] | S [1]、I [2] |
| ブロック | N [3] | N [3] | S [1] | S [1]、I [2] |
| ボリュームモード | FSB - Restic | FSB - Kopia | CSI | CSI Data Mover |
|---|---|---|---|---|
| ファイルシステム | N [3] | N [3] | S [1] | S [1]、I [2] |
| ブロック | N [3] | N [3] | S [1] | S [1]、I [2] |
- バックアップをサポート
- 増分バックアップをサポート
- サポート対象外
CSI Data Mover バックアップでは、uploaderType に関係なく Kopia が使用されます。
Red Hat は、OADP バージョン 1.3.0 以降と OpenShift Virtualization バージョン 4.14 以降の組み合わせのみをサポートします。
バージョン 1.3.0 より前の OADP は、OpenShift Virtualization のバックアップと復元ではサポートされていません。
4.14. 複数の Backup Storage Location を含む OADP の設定
4.14.1. 複数の Backup Storage Location を使用した OpenShift API for Data Protection (OADP) の設定
Data Protection Application (DPA) では、1 つ以上の Backup Storage Location (BSL) を設定できます。また、バックアップを作成するときに、バックアップを保存する場所を選択できます。この設定では、次の方法でバックアップを保存できます。
- さまざまなリージョンへのバックアップ
- 別のストレージプロバイダーへのバックアップ
OADP は、複数の BSL を設定できるように、複数の認証情報をサポートしています。そのため、どの BSL でも使用する認証情報を指定できます。
4.14.1.1. 複数の BSL を使用した DPA の設定
複数の BSL を使用して DPA を設定し、クラウドプロバイダーによって提供される認証情報を指定できます。
前提条件
- OADP Operator をインストールする。
- クラウドプロバイダーによって提供される認証情報を使用してシークレットを作成する。
手順
複数の BSL を使用して DPA を設定します。以下の例を参照してください。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication #... backupLocations: - name: aws1 velero: provider: aws default: true2 objectStorage: bucket: <bucket_name>3 prefix: <prefix>4 config: region: <region_name>5 profile: "default" credential: key: cloud name: cloud-credentials6 - name: odf7 velero: provider: aws default: false objectStorage: bucket: <bucket_name> prefix: <prefix> config: profile: "default" region: <region_name> s3Url: <url>8 insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" credential: key: cloud name: <custom_secret_name_odf>9 #...- 1
- 最初の BSL の名前を指定します。
- 2
- このパラメーターは、この BSL がデフォルトの BSL であることを示します。
Backup CRに BSL が設定されていない場合は、デフォルトの BSL が使用されます。デフォルトとして設定できる BSL は 1 つだけです。 - 3
- バケット名を指定します。
- 4
- Velero バックアップの接頭辞を指定します (例:
velero)。 - 5
- バケットの AWS リージョンを指定します。
- 6
- 作成したデフォルトの
Secretオブジェクトの名前を指定します。 - 7
- 2 番目の BSL の名前を指定します。
- 8
- S3 エンドポイントの URL を指定します。
- 9
Secretの正しい名前を指定します。たとえば、custom_secret_name_odfです。Secret名を指定しない場合は、デフォルトの名前が使用されます。
バックアップ CR で使用する BSL を指定します。以下の例を参照してください。
バックアップ CR の例
apiVersion: velero.io/v1 kind: Backup # ... spec: includedNamespaces: - <namespace>1 storageLocation: <backup_storage_location>2 defaultVolumesToFsBackup: true
4.14.1.2. 2 つの BSL を使用する OADP ユースケース
このユースケースでは、2 つのクラウド認証情報を使用して、2 つの保存場所で DPA を設定します。デフォルトの BSL を使用して、データベースとともにアプリケーションをバックアップします。OADP は、バックアップリソースをデフォルトの BSL に保存します。その後、2 番目の BSL を使用してアプリケーションを再度バックアップします。
前提条件
- OADP Operator をインストールする。
- Backup Storage Location として、AWS S3 と Multicloud Object Gateway (MCG) の 2 つを設定する。
- Red Hat OpenShift クラスターにデータベースがデプロイされたアプリケーションがある。
手順
次のコマンドを実行して、AWS S3 ストレージプロバイダー用の最初の
Secretをデフォルト名で作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=<aws_credentials_file_name>1 - 1
- AWS S3 のクラウド認証情報ファイルの名前を指定します。
次のコマンドを実行して、カスタム名を持つ MCG 用の 2 番目の
Secretを作成します。$ oc create secret generic mcg-secret -n openshift-adp --from-file cloud=<MCG_credentials_file_name>1 - 1
- MCG のクラウド認証情報ファイルの名前を指定します。
mcg-secretカスタムシークレットの名前をメモします。
次の例に示すように、2 つの BSL を使用して DPA を設定します。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: two-bsl-dpa namespace: openshift-adp spec: backupLocations: - name: aws velero: config: profile: default region: <region_name>1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name>2 prefix: velero provider: aws - name: mcg velero: config: insecureSkipTLSVerify: "true" profile: noobaa region: <region_name>3 s3ForcePathStyle: "true" s3Url: <s3_url>4 credential: key: cloud name: mcg-secret5 objectStorage: bucket: <bucket_name_mcg>6 prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - openshift - aws次のコマンドを実行して DPA を作成します。
$ oc create -f <dpa_file_name>1 - 1
- 設定した DPA のファイル名を指定します。
次のコマンドを実行して、DPA が調整されたことを確認します。
$ oc get dpa -o yaml次のコマンドを実行して、BSL が使用可能であることを確認します。
$ oc get bsl出力例
NAME PHASE LAST VALIDATED AGE DEFAULT aws Available 5s 3m28s true mcg Available 5s 3m28sデフォルトの BSL を使用してバックアップ CR を作成します。
注記次の例では、バックアップ CR で
storageLocationフィールドが指定されていません。バックアップ CR の例
apiVersion: velero.io/v1 kind: Backup metadata: name: test-backup1 namespace: openshift-adp spec: includedNamespaces: - <mysql_namespace>1 defaultVolumesToFsBackup: true- 1
- クラスターにインストールされているアプリケーションの namespace を指定します。
次のコマンドを実行してバックアップを作成します。
$ oc apply -f <backup_file_name>1 - 1
- バックアップ CR ファイルの名前を指定します。
次のコマンドを実行して、デフォルトの BSL を使用したバックアップが完了したことを確認します。
$ oc get backups.velero.io <backup_name> -o yaml1 - 1
- バックアップの名前を指定します。
MCG を BSL として使用してバックアップ CR を作成します。次の例では、2 番目の
storageLocation値をバックアップ CR の作成時に指定していることに注意してください。バックアップ
CRの例apiVersion: velero.io/v1 kind: Backup metadata: name: test-backup1 namespace: openshift-adp spec: includedNamespaces: - <mysql_namespace>1 storageLocation: mcg2 defaultVolumesToFsBackup: true次のコマンドを実行して、2 番目のバックアップを作成します。
$ oc apply -f <backup_file_name>1 - 1
- バックアップ CR ファイルの名前を指定します。
次のコマンドを実行して、保存場所が MCG であるバックアップが完了したことを確認します。
$ oc get backups.velero.io <backup_name> -o yaml1 - 1
- バックアップの名前を指定します。
4.15. 複数のボリュームスナップショットの場所を使用した OADP の設定
4.15.1. 複数の Volume Snapshot Location を使用した OpenShift API for Data Protection (OADP) を設定
1 つ以上の Volume Snapshot Location (VSL) を設定して、クラウドプロバイダーの別々のリージョンにスナップショットを保存できます。
4.15.1.1. 複数の VSL を使用した DPA の設定
複数の VSL を使用して DPA を設定し、クラウドプロバイダーによって提供される認証情報を指定します。スナップショットの場所が、永続ボリュームと同じリージョンにあることを確認してください。以下の例を参照してください。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
#...
snapshotLocations:
- velero:
config:
profile: default
region: <region>
credential:
key: cloud
name: cloud-credentials
provider: aws
- velero:
config:
profile: default
region: <region>
credential:
key: cloud
name: <custom_credential>
provider: aws
#...4.16. OADP のアンインストール
4.16.1. OpenShift API for Data Protection のアンインストール
OpenShift API for Data Protection (OADP) をアンインストールするには、OADP Operator を削除します。詳細は、クラスターからの Operator の削除 を参照してください。
4.17. OADP のバックアップ
4.17.1. アプリケーションのバックアップ
頻繁にバックアップを行うと、Backup Storage Location のストレージが消費される可能性があります。S3 バケットなどの非ローカルバックアップを使用する場合は、バックアップの頻度、保持期間、永続ボリューム (PV) のデータ量を確認してください。取得したバックアップはすべて期限が切れるまで残るため、スケジュールの有効期限 (TTL) 設定も確認してください。
Backup カスタムリソース (CR) を作成することで、アプリケーションをバックアップできます。詳細は、バックアップ CR の作成 を参照してください。
-
BackupCR は、Kubernetes リソースと内部イメージのバックアップファイルを S3 オブジェクトストレージに作成します。 -
クラウドプロバイダーがネイティブスナップショット API を備えている場合、または CSI スナップショットをサポートしている場合、
BackupCR はスナップショットを作成することによって永続ボリューム (PV) をバックアップします。CSI スナップショットの操作の詳細は、CSI スナップショットを使用した永続ボリュームのバックアップ を参照してください。
CSI ボリュームスナップショットの詳細は、CSI ボリュームスナップショット を参照してください。
オブジェクトストレージのバケット作成を自動化する CloudStorage API は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
CloudStorage API は、CloudStorage オブジェクトを使用しており、OADP で CloudStorage API を使用して BackupStorageLocation として使用する S3 バケットを自動的に作成するためのテクノロジープレビュー機能です。
CloudStorage API は、既存の S3 バケットを指定して BackupStorageLocation オブジェクトを手動作成することをサポートしています。現在、S3 バケットを自動的に作成する CloudStorage API は、AWS S3 ストレージに対してのみ有効です。
- クラウドプロバイダーがスナップショットをサポートしていない場合、またはアプリケーションが NFS データボリューム上にある場合は、Kopia または Restic を使用してバックアップを作成できます。File System Backup を使用してアプリケーションをバックアップする: Kopia または Restic を参照してください。
…/.snapshot: read-only file system エラーで失敗する
…/.snapshot ディレクトリーは、複数の NFS サーバーによって使用されるスナップショットコピーディレクトリーです。このディレクトリーにはデフォルトで読み取り専用アクセスが設定されているため、Velero はこのディレクトリーに復元できません。
Velero に .snapshot ディレクトリーへの書き込みアクセス権を付与しないでください。また、このディレクトリーへのクライアントアクセスを無効にしてください。
OpenShift API for Data Protection (OADP) は、他のソフトウェアで作成されたボリュームスナップショットのバックアップをサポートしていません。
4.17.1.1. バックアップと復元を実行する前にリソースをプレビューする
OADP は、タイプ、namespace、またはラベルに基づいてアプリケーションリソースをバックアップします。そのため、バックアップが完了した後にリソースを確認できます。同様に、復元操作が完了した後も、namespace、永続ボリューム (PV)、またはラベルに基づいて、復元されたオブジェクトを確認できます。事前にリソースをプレビューするには、バックアップおよび復元操作のドライランを実行します。
前提条件
- OADP Operator がインストールされている。
手順
実際のバックアップを実行する前に、バックアップに含まれるリソースをプレビューするには、次のコマンドを実行します。
$ velero backup create <backup-name> --snapshot-volumes false1 - 1
--snapshot-volumesパラメーターの値をfalseに指定します。
バックアップリソースの詳細を確認するには、次のコマンドを実行します。
$ velero describe backup <backup_name> --details1 - 1
- バックアップの名前を指定します。
実際の復元を実行する前に、復元に含まれるリソースをプレビューするには、次のコマンドを実行します。
$ velero restore create --from-backup <backup-name>1 - 1
- バックアップリソースを確認するために、作成したバックアップの名前を指定します。
重要velero restore createコマンドは、クラスター内に復元リソースを作成します。リソースを確認した後、復元中に作成されたリソースを削除する必要があります。復元リソースの詳細を確認するには、次のコマンドを実行します。
$ velero describe restore <restore_name> --details1 - 1
- 復元の名前を指定します。
バックアップ操作の前または後にコマンドを実行するためのバックアップフックを作成できます。バックアップフックの作成 を参照してください。
Backup CR の代わりに Schedule CR を作成することにより、バックアップをスケジュールできます。Schedule CR を使用したバックアップのスケジュール設定 を参照してください。
4.17.1.2. 既知の問題
OpenShift Container Platform 4.14 は、Restic 復元プロセス中に Pod の readiness を妨げる可能性がある Pod セキュリティーアドミッション (PSA) ポリシーを強制します。
この問題は OADP 1.1.6 および OADP 1.2.2 リリースで解決されており、これらのリリースにアップグレードすることが推奨されます。
4.17.2. バックアップ CR の作成
Backup カスタムリソース (CR) を作成して、Kubernetes イメージ、内部イメージ、および永続ボリューム (PV) をバックアップします。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。 バックアップロケーションの前提条件:
- Velero 用に S3 オブジェクトストレージを設定する必要があります。
-
DataProtectionApplicationCR でバックアップの場所を設定する必要があります。
スナップショットの場所の前提条件:
- クラウドプロバイダーには、ネイティブスナップショット API が必要であるか、Container Storage Interface (CSI) スナップショットをサポートしている必要があります。
-
CSI スナップショットの場合、CSI ドライバーを登録するために
VolumeSnapshotClassCR を作成する必要があります。 -
DataProtectionApplicationCR でボリュームの場所を設定する必要があります。
手順
次のコマンドを入力して、
backupStorageLocationsCR を取得します。$ oc get backupstoragelocations.velero.io -n openshift-adp出力例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m次の例のように、
BackupCR を作成します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: hooks: {} includedNamespaces: - <namespace>1 includedResources: []2 excludedResources: []3 storageLocation: <velero-sample-1>4 ttl: 720h0m0s5 labelSelector:6 matchLabels: app: <label_1> app: <label_2> app: <label_3> orLabelSelectors:7 - matchLabels: app: <label_1> app: <label_2> app: <label_3>- 1
- バックアップする namespace の配列を指定します。
- 2
- オプション: バックアップに含めるリソースの配列を指定します。リソースは、短縮名 ('pods' は 'po' など) または完全修飾名で指定できます。指定しない場合、すべてのリソースが含まれます。
- 3
- オプション: バックアップから除外するリソースの配列を指定します。リソースは、短縮名 ('pods' は 'po' など) または完全修飾名で指定できます。
- 4
backupStorageLocationsCR の名前を指定します。- 5
ttlフィールドは、作成されたバックアップの保持期間とバックアップされたデータのバックアップを定義します。たとえば、バックアップツールとして Restic を使用している場合、バックアップの有効期限が切れるまで、バックアップされたデータ項目と永続ボリューム(PV)のデータコンテンツが保存されます。ただし、このデータを保存すると、ターゲットのバックアップの場所により多くの領域が使用されます。追加のストレージは、頻繁なバックアップで消費されます。バックアップは、他の期限切れでないバックアップがタイムアウトする前でも作成されます。- 6
- 指定したラベルを すべて 持つバックアップリソースの {key,value} ペアのマップ。
- 7
- 指定したラベルを 1 つ以上 持つバックアップリソースの {key,value} ペアのマップ。
BackupCR のステータスがCompletedしたことを確認します。$ oc get backups.velero.io -n openshift-adp <backup> -o jsonpath='{.status.phase}'
4.17.3. CSI スナップショットを使用した永続ボリュームのバックアップ
Backup CR を作成する前に、クラウドストレージの VolumeSnapshotClass カスタムリソース (CR) を編集して、Container Storage Interface (CSI) スナップショットを使用して永続ボリュームをバックアップします。CSI ボリュームスナップショット を参照してください。
詳細は、バックアップ CR の作成 を参照してください。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
-
DataProtectionApplicationCR で CSI を有効にする必要があります。
手順
metadata.labels.velero.io/csi-volumesnapshot-class: "true"のキー: 値ペアをVolumeSnapshotClassCR に追加します。設定ファイルのサンプル
apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: <volume_snapshot_class_name> labels: velero.io/csi-volumesnapshot-class: "true"1 annotations: snapshot.storage.kubernetes.io/is-default-class: true2 driver: <csi_driver> deletionPolicy: <deletion_policy_type>3
次のステップ
-
これで、
BackupCR を作成できます。
4.17.4. File System Backup を使用してアプリケーションをバックアップする: Kopia または Restic
OADP を使用して、Pod にアタッチされている Kubernetes ボリュームを、そのボリュームのファイルシステムからバックアップおよび復元できます。このプロセスは、File System Backup (FSB) または Pod Volume Backup (PVB) と呼ばれます。これは、オープンソースのバックアップツール Restic または Kopia のモジュールを使用して実行できます。
クラウドプロバイダーがスナップショットをサポートしていない場合、またはアプリケーションが NFS データボリューム上にある場合は、FSB を使用してバックアップを作成できます。
FSB と OADP の統合により、ほぼすべてのタイプの Kubernetes ボリュームをバックアップおよび復元するためのソリューションが提供されます。この統合は OADP の追加機能であり、既存の機能を置き換えるものではありません。
Backup カスタムリソース (CR) を編集して、Kopia または Restic で Kubernetes リソース、内部イメージ、および永続ボリュームをバックアップします。
DataProtectionApplication CR でスナップショットの場所を指定する必要はありません。
OADP バージョン 1.3 以降では、アプリケーションのバックアップに Kopia または Restic を使用できます。
ビルトイン DataMover の場合は、Kopia を使用する必要があります。
OADP バージョン 1.2 以前の場合、アプリケーションのバックアップには Restic のみ使用できます。
FSB は、hostPath ボリュームのバックアップをサポートしません。詳細は、FSB の制限事項 を参照してください。
…/.snapshot: read-only file system エラーで失敗する
…/.snapshot ディレクトリーは、複数の NFS サーバーによって使用されるスナップショットコピーディレクトリーです。このディレクトリーにはデフォルトで読み取り専用アクセスが設定されているため、Velero はこのディレクトリーに復元できません。
Velero に .snapshot ディレクトリーへの書き込みアクセス権を付与しないでください。また、このディレクトリーへのクライアントアクセスを無効にしてください。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR でspec.configuration.nodeAgent.enableをfalseに設定して、デフォルトのnodeAgentインストールを無効にしていない。 -
DataProtectionApplicationCR でspec.configuration.nodeAgent.uploaderTypeをkopiaまたはresticに設定して、Kopia または Restic をアップローダーとして選択している。 -
DataProtectionApplicationCR がReady状態である。
手順
次の例のように、
BackupCR を作成します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: defaultVolumesToFsBackup: true1 ...- 1
- OADP バージョン 1.2 以降では、
defaultVolumesToFsBackup: true設定をspecブロック内に追加します。OADP バージョン 1.1 では、defaultVolumesToRestic: trueを追加します。
4.17.5. バックアップフックの作成
バックアップを実行する際に、バックアップされる Pod に基づいて、Pod 内のコンテナーで実行するコマンドを 1 つ以上指定できます。
コマンドは、カスタムアクション処理の前 (プリ フック)、またはすべてのカスタムアクションが完了し、カスタムアクションで指定された追加アイテムがバックアップされた後 (ポスト フック) に実行するように設定できます。
Backup カスタムリソース (CR) を編集して、Pod 内のコンテナーでコマンドを実行するためのバックアップフックを作成します。
手順
次の例のように、
BackupCR のspec.hooksブロックにフックを追加します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces:2 - <namespace> includedResources: [] - pods3 excludedResources: []4 labelSelector:5 matchLabels: app: velero component: server pre:6 - exec: container: <container>7 command: - /bin/uname8 - -a onError: Fail9 timeout: 30s10 post:11 ...- 1
- オプション: フックが適用される namespace を指定できます。この値が指定されていない場合、フックはすべての namespace に適用されます。
- 2
- オプション: フックが適用されない namespace を指定できます。
- 3
- 現在、Pod は、フックを適用できる唯一のサポート対象リソースです。
- 4
- オプション: フックが適用されないリソースを指定できます。
- 5
- オプション: このフックは、ラベルに一致するオブジェクトにのみ適用されます。この値が指定されていない場合、フックはすべてのオブジェクトに適用されます。
- 6
- バックアップの前に実行するフックの配列。
- 7
- オプション: コンテナーが指定されていない場合、コマンドは Pod の最初のコンテナーで実行されます。
- 8
- これは、追加される
initコンテナーのエントリーポイントです。 - 9
- エラー処理に許可される値は、
FailとContinueです。デフォルトはFailです。 - 10
- オプション: コマンドの実行を待機する時間。デフォルトは
30sです。 - 11
- このブロックでは、バックアップ後に実行するフックの配列を、バックアップ前のフックと同じパラメーターで定義します。
4.17.6. Schedule CR を使用したバックアップのスケジュール設定
スケジュール操作を使用すると、Cron 式で指定された特定の時間にデータのバックアップを作成できます。
Backup CR の代わりに Schedule カスタムリソース (CR) を作成して、バックアップをスケジュールします。
バックアップスケジュールでは、別のバックアップが作成される前にバックアップを数量するための時間を十分確保してください。
たとえば、namespace のバックアップに通常 10 分かかる場合は、15 分ごとよりも頻繁にバックアップをスケジュールしないでください。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。
手順
backupStorageLocationsCR を取得します。$ oc get backupStorageLocations -n openshift-adp出力例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m次の例のように、
ScheduleCR を作成します。$ cat << EOF | oc apply -f - apiVersion: velero.io/v1 kind: Schedule metadata: name: <schedule> namespace: openshift-adp spec: schedule: 0 7 * * *1 template: hooks: {} includedNamespaces: - <namespace>2 storageLocation: <velero-sample-1>3 defaultVolumesToFsBackup: true4 ttl: 720h0m0s5 EOF注記特定の間隔でバックアップをスケジュールするには、次の形式で
<duration_in_minutes>を入力します。schedule: "*/10 * * * *"引用符 (
" ") の間に分の値を入力します。- 1
- バックアップをスケジュールするための
cron式。たとえば、毎日 7:00 にバックアップを実行する場合は0 7 * * *です。 - 2
- バックアップを作成する namespace の配列。
- 3
backupStorageLocationsCR の名前。- 4
- オプション: OADP バージョン 1.2 以降では、Restic を使用してボリュームのバックアップを実行するときに、
defaultVolumesToFsBackup: trueキーと値のペアを設定に追加します。OADP バージョン 1.1 では、Restic でボリュームをバックアップするときに、defaultVolumesToRestic: trueのキーと値のペアを追加します。 - 5
ttlフィールドは、作成されたバックアップの保持期間とバックアップされたデータのバックアップを定義します。たとえば、バックアップツールとして Restic を使用している場合、バックアップの有効期限が切れるまで、バックアップされたデータ項目と永続ボリューム(PV)のデータコンテンツが保存されます。ただし、このデータを保存すると、ターゲットのバックアップの場所により多くの領域が使用されます。追加のストレージは、頻繁なバックアップで消費されます。バックアップは、他の期限切れでないバックアップがタイムアウトする前でも作成されます。
スケジュールされたバックアップの実行後に、
ScheduleCR のステータスがCompletedとなっていることを確認します。$ oc get schedule -n openshift-adp <schedule> -o jsonpath='{.status.phase}'
4.17.7. バックアップの削除
バックアップを削除するには、次の手順で説明するように、DeleteBackupRequest カスタムリソース (CR) を作成するか、velero backup delete コマンドを実行します。
ボリュームバックアップアーティファクトは、バックアップ方法に応じて、異なるタイミングで削除されます。
- Restic: アーティファクトは、バックアップが削除された後、次のフルメンテナンスサイクル中に削除されます。
- Container Storage Interface (CSI): アーティファクトは、バックアップが削除されると直ちに削除されます。
- Kopia: アーティファクトは、バックアップが削除されてから、Kopia リポジトリーのフルメンテナンスサイクルが 3 回実行された後に削除されます。
4.17.7.1. DeleteBackupRequest CR を作成してバックアップを削除する
DeleteBackupRequest カスタムリソース (CR) を作成することで、バックアップを削除できます。
前提条件
- アプリケーションのバックアップを実行した。
手順
DeleteBackupRequestCR マニフェストファイルを作成します。apiVersion: velero.io/v1 kind: DeleteBackupRequest metadata: name: deletebackuprequest namespace: openshift-adp spec: backupName: <backup_name>1 - 1
- バックアップの名前を指定します。
DeleteBackupRequestCR を適用してバックアップを削除します。$ oc apply -f <deletebackuprequest_cr_filename>
4.17.7.2. Velero CLI を使用してバックアップを削除する
Velero CLI を使用してバックアップを削除できます。
前提条件
- アプリケーションのバックアップを実行した。
- Velero CLI がダウンロード済みであり、クラスター内の Velero バイナリーにアクセスできる。
手順
バックアップを削除するには、次の Velero コマンドを実行します。
$ velero backup delete <backup_name> -n openshift-adp1 - 1
- バックアップの名前を指定します。
4.17.7.3. Kopia リポジトリーのメンテナンスについて
Kopia リポジトリーのメンテナンスには次の 2 種類があります。
- クイックメンテナンス
- インデックス Blob の数 (n) を抑えるために 1 時間ごとに実行されます。インデックスの数が多いと、Kopia 操作のパフォーマンスに悪影響が及びます。
- 同じメタデータの別のコピーが存在することを確認してから、リポジトリーからメタデータを削除します。
- フルメンテナンス
- 不要になったリポジトリーコンテンツのガベージコレクションを実行するために、24 時間ごとに実行されます。
-
フルメンテナンスのタスクである
snapshot-gcが、スナップショットマニフェストからアクセスできなくなったすべてのファイルとディレクトリーリストを検索し、それらを削除済みとしてマークします。 - フルメンテナンスは、クラスター内でアクティブなすべてのスナップショット内のすべてのディレクトリーをスキャンする必要があるため、リソースを大量に消費する操作です。
4.17.7.3.1. OADP における Kopia のメンテナンス
repo-maintain-job ジョブは、次の例に示すように、OADP がインストールされている namespace で実行されます。
pod/repo-maintain-job-173...2527-2nbls 0/1 Completed 0 168m
pod/repo-maintain-job-173....536-fl9tm 0/1 Completed 0 108m
pod/repo-maintain-job-173...2545-55ggx 0/1 Completed 0 48m
repo-maintain-job のログで、バックアップオブジェクトストレージ内のクリーンアップとアーティファクトの削除に関する詳細を確認できます。次の例に示すように、repo-maintain-job では、次のフルメンテナンスサイクルの予定日時に関する情報を確認できます。
not due for full maintenance cycle until 2024-00-00 18:29:4バックアップオブジェクトストレージからオブジェクトを削除するには、フルメンテナンスサイクルを 3 回正常に実行する必要があります。つまり、バックアップオブジェクトストレージ内のすべてのアーティファクトが削除されるまでに、最大 72 時間かかると予想されます。
4.17.7.4. バックアップリポジトリーの削除
バックアップを削除し、関連するアーティファクトを削除する Kopia リポジトリーのメンテナンスサイクルが完了すると、そのバックアップはどのメタデータオブジェクトやマニフェストオブジェクトからも参照されなくなります。その後、backuprepository カスタムリソース (CR) を削除して、バックアップ削除プロセスを完了できます。
前提条件
- アプリケーションのバックアップを削除した。
- バックアップが削除されてから最大 72 時間待機した。この時間枠を確保することで、Kopia がリポジトリーのメンテナンスサイクルを実行できるようにします。
手順
バックアップのバックアップリポジトリー CR の名前を取得するために、次のコマンドを実行します。
$ oc get backuprepositories.velero.io -n openshift-adpバックアップリポジトリー CR を削除するために、次のコマンドを実行します。
$ oc delete backuprepository <backup_repository_name> -n openshift-adp1 - 1
- 前のステップのバックアップリポジトリーの名前を指定します。
4.17.8. Kopia について
Kopia は、高速かつセキュアなオープンソースのバックアップおよび復元ツールです。これを使用して、データの暗号化されたスナップショットを作成し、そのスナップショットを選択したリモートストレージまたはクラウドストレージに保存できます。
Kopia は、ネットワークおよびローカルストレージの場所、および多くのクラウドまたはリモートストレージの場所をサポートしています。以下はその一部です。
- Amazon S3 および S3 と互換性のあるクラウドストレージ
- Azure Blob Storage
- Google Cloud Storage プラットフォーム
Kopia は、スナップショットにコンテンツアドレスを指定できるストレージを使用します。
- スナップショットは常に増分されます。すでに以前のスナップショットに含まれているデータは、リポジトリーに再アップロードされません。リポジトリーに再度アップロードされるのは、ファイルが変更されたときだけです。
- 保存されたデータは重複排除されます。同じファイルのコピーが複数存在する場合、そのうちの 1 つだけが保存されます。
- ファイルが移動された場合、またはファイルの名前が変更された場合、Kopia はそれらが同じコンテンツであることを認識し、それらを再度アップロードしません。
4.17.8.1. OADP と Kopia の統合
OADP 1.3 は、Pod ボリュームバックアップのバックアップメカニズムとして、Restic に加えて Kopia をサポートします。インストール時に、DataProtectionApplication カスタムリソース (CR) の uploaderType フィールドを設定して、どちらかを選択する必要があります。使用できる値は、restic または kopia です。uploaderType を指定しない場合、OADP 1.3 はデフォルトで Kopia をバックアップメカニズムとして使用します。データは統合リポジトリーに書き込まれ、統合リポジトリーから読み取られます。
Kopia クライアントを使用して Kopia バックアップリポジトリーを変更することはサポートされていません。変更すると、Kopia バックアップの整合性に影響が生じる可能性があります。OADP は Kopia リポジトリーへの直接接続をサポートしておらず、ベストエフォートでのみサポートを提供できます。
次の例は、Kopia を使用するように設定された DataProtectionApplication CR を示しています。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
nodeAgent:
enable: true
uploaderType: kopia
# ...4.18. OADP の復元
4.18.1. アプリケーションの復元
アプリケーションのバックアップを復元するには、Restore カスタムリソース (CR) を作成します。復元 CR の作成 を参照してください。
Restore CR を編集することで、Pod 内のコンテナーでコマンドを実行するための復元フックを作成できます。復元フックの作成 を参照してください。
4.18.1.1. バックアップと復元を実行する前にリソースをプレビューする
OADP は、タイプ、namespace、またはラベルに基づいてアプリケーションリソースをバックアップします。そのため、バックアップが完了した後にリソースを確認できます。同様に、復元操作が完了した後も、namespace、永続ボリューム (PV)、またはラベルに基づいて、復元されたオブジェクトを確認できます。事前にリソースをプレビューするには、バックアップおよび復元操作のドライランを実行します。
前提条件
- OADP Operator がインストールされている。
手順
実際のバックアップを実行する前に、バックアップに含まれるリソースをプレビューするには、次のコマンドを実行します。
$ velero backup create <backup-name> --snapshot-volumes false1 - 1
--snapshot-volumesパラメーターの値をfalseに指定します。
バックアップリソースの詳細を確認するには、次のコマンドを実行します。
$ velero describe backup <backup_name> --details1 - 1
- バックアップの名前を指定します。
実際の復元を実行する前に、復元に含まれるリソースをプレビューするには、次のコマンドを実行します。
$ velero restore create --from-backup <backup-name>1 - 1
- バックアップリソースを確認するために、作成したバックアップの名前を指定します。
重要velero restore createコマンドは、クラスター内に復元リソースを作成します。リソースを確認した後、復元中に作成されたリソースを削除する必要があります。復元リソースの詳細を確認するには、次のコマンドを実行します。
$ velero describe restore <restore_name> --details1 - 1
- 復元の名前を指定します。
4.18.1.2. Restore CR の作成
Restore CR を作成して、Backup カスタムリソース (CR) を復元します。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。 -
Velero
BackupCR がある。 - 永続ボリューム (PV) の容量は、バックアップ時に要求されたサイズと一致する必要があります。必要に応じて、要求されたサイズを調整します。
手順
次の例のように、
RestoreCR を作成します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: backupName: <backup>1 includedResources: []2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io restorePVs: true3 次のコマンドを入力して、
RestoreCR のステータスがCompletedであることを確認します。$ oc get restores.velero.io -n openshift-adp <restore> -o jsonpath='{.status.phase}'次のコマンドを入力して、バックアップリソースが復元されたことを確認します。
$ oc get all -n <namespace>1 - 1
- バックアップした namespace。
ボリュームを使用して
DeploymentConfigを復元する場合、または復元後のフックを使用する場合は、次のコマンドを入力してdc-post-restore.shクリーンアップスクリプトを実行します。$ bash dc-restic-post-restore.sh -> dc-post-restore.sh注記復元プロセス中に、OADP Velero プラグインは
DeploymentConfigオブジェクトをスケールダウンし、Pod をスタンドアロン Pod として復元します。これは、クラスターが復元されたDeploymentConfigPod を復元時にすぐに削除することを防ぎ、復元フックと復元後のフックが復元された Pod 上でアクションを完了できるようにするために行われます。以下に示すクリーンアップスクリプトは、これらの切断された Pod を削除し、DeploymentConfigオブジェクトを適切な数のレプリカにスケールアップします。例4.1
dc-restic-post-restore.sh → dc-post-restore.shクリーンアップスクリプト#!/bin/bash set -e # if sha256sum exists, use it to check the integrity of the file if command -v sha256sum >/dev/null 2>&1; then CHECKSUM_CMD="sha256sum" else CHECKSUM_CMD="shasum -a 256" fi label_name () { if [ "${#1}" -le "63" ]; then echo $1 return fi sha=$(echo -n $1|$CHECKSUM_CMD) echo "${1:0:57}${sha:0:6}" } if [[ $# -ne 1 ]]; then echo "usage: ${BASH_SOURCE} restore-name" exit 1 fi echo "restore: $1" label=$(label_name $1) echo "label: $label" echo Deleting disconnected restore pods oc delete pods --all-namespaces -l oadp.openshift.io/disconnected-from-dc=$label for dc in $(oc get dc --all-namespaces -l oadp.openshift.io/replicas-modified=$label -o jsonpath='{range .items[*]}{.metadata.namespace}{","}{.metadata.name}{","}{.metadata.annotations.oadp\.openshift\.io/original-replicas}{","}{.metadata.annotations.oadp\.openshift\.io/original-paused}{"\n"}') do IFS=',' read -ra dc_arr <<< "$dc" if [ ${#dc_arr[0]} -gt 0 ]; then echo Found deployment ${dc_arr[0]}/${dc_arr[1]}, setting replicas: ${dc_arr[2]}, paused: ${dc_arr[3]} cat <<EOF | oc patch dc -n ${dc_arr[0]} ${dc_arr[1]} --patch-file /dev/stdin spec: replicas: ${dc_arr[2]} paused: ${dc_arr[3]} EOF fi done
4.18.1.3. 復元フックの作成
Restore カスタムリソース (CR) を編集して、Pod 内のコンテナーでコマンドを実行する復元フックを作成します。
2 種類の復元フックを作成できます。
initフックは、init コンテナーを Pod に追加して、アプリケーションコンテナーが起動する前にセットアップタスクを実行します。Restic バックアップを復元する場合は、復元フック init コンテナーの前に
restic-waitinit コンテナーが追加されます。-
execフックは、復元された Pod のコンテナーでコマンドまたはスクリプトを実行します。
手順
次の例のように、
RestoreCR のspec.hooksブロックにフックを追加します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces: - <namespace> includedResources: - pods2 excludedResources: [] labelSelector:3 matchLabels: app: velero component: server postHooks: - init: initContainers: - name: restore-hook-init image: alpine:latest volumeMounts: - mountPath: /restores/pvc1-vm name: pvc1-vm command: - /bin/ash - -c timeout:4 - exec: container: <container>5 command: - /bin/bash6 - -c - "psql < /backup/backup.sql" waitTimeout: 5m7 execTimeout: 1m8 onError: Continue9 - 1
- オプション: フックが適用される namespace の配列。この値が指定されていない場合、フックはすべての namespace に適用されます。
- 2
- 現在、Pod は、フックを適用できる唯一のサポート対象リソースです。
- 3
- オプション: このフックは、ラベルセレクターに一致するオブジェクトにのみ適用されます。
- 4
- オプション: Timeout は、
initContainersが完了するまで Velero が待機する最大時間を指定します。 - 5
- オプション: コンテナーが指定されていない場合、コマンドは Pod の最初のコンテナーで実行されます。
- 6
- これは、追加される init コンテナーのエントリーポイントです。
- 7
- オプション: コンテナーの準備が整うまでの待機時間。これは、コンテナーが起動して同じコンテナー内の先行するフックが完了するのに十分な長さである必要があります。設定されていない場合、復元プロセスの待機時間は無期限になります。
- 8
- オプション: コマンドの実行を待機する時間。デフォルトは
30sです。 - 9
- エラー処理に許可される値は、
FailおよびContinueです。-
Continue: コマンドの失敗のみがログに記録されます。 -
Fail: Pod 内のコンテナーで復元フックが実行されなくなりました。RestoreCR のステータスはPartiallyFailedになります。
-
File System Backup (FSB) の復元操作中に、ImageStream を参照する Deployment リソースが適切に復元されません。FSB を実行する復元された Pod と postHook が途中で終了します。
これが発生するのは、復元操作中に、OpenShift コントローラーが Deployment リソースの spec.template.spec.containers[0].image フィールドを新しい ImageStreamTag ハッシュで更新するためです。更新により、新しい Pod のロールアウトがトリガーされ、velero が FSB と復元後のフックを実行する Pod が終了します。イメージストリームトリガーの詳細は、「イメージストリームの変更時の更新のトリガー」を参照してください。
この動作を回避するには、次の 2 段階の復元プロセスを実行します。
まず、
Deploymentリソースを除外して復元を実行します。次に例を示します。$ velero restore create <RESTORE_NAME> \ --from-backup <BACKUP_NAME> \ --exclude-resources=deployment.apps最初の復元が成功したら、次の例のように、次のリソースを含めて 2 回目の復元を実行します。
$ velero restore create <RESTORE_NAME> \ --from-backup <BACKUP_NAME> \ --include-resources=deployment.apps
4.19. OADP と ROSA
4.19.1. OADP を使用して ROSA クラスター上のアプリケーションをバックアップする
Red Hat OpenShift Service on AWS (ROSA) クラスターで OpenShift API for Data Protection (OADP) を使用して、アプリケーションデータをバックアップおよび復元できます。
ROSA は、フルマネージドのターンキーアプリケーションプラットフォームであり、アプリケーションを構築してデプロイすることにより、お客様に価値を提供することに集中できます。
ROSA は、幅広い Amazon Web Services (AWS) コンピュート、データベース、分析、機械学習、ネットワーク、モバイル、およびその他のサービスとのシームレスな統合を提供し、差別化されたエクスペリエンスの構築とお客様への提供をさらに高速化します。
AWS アカウントから直接サービスをサブスクライブできます。
クラスターを作成した後、OpenShift Container Platform Web コンソールを使用して、または Red Hat OpenShift Cluster Manager を介してクラスターを操作できます。ROSA では、OpenShift API やコマンドラインインターフェイス (CLI) ツールも使用できます。
ROSA のインストールの詳細は、Red Hat OpenShift Service on AWS (ROSA) のインストールのインタラクティブな説明 を参照してください。
OpenShift API for Data Protection (OADP) をインストールする前に、OADP が Amazon Web Services API を使用できるように、OADP のロールとポリシーの認証情報を設定する必要があります。
このプロセスは次の 2 段階で実行されます。
- AWS 認証情報を準備します。
- OADP Operator をインストールし、IAM ロールを付与します。
4.19.1.1. OADP 用の AWS 認証情報を準備する
Amazon Web Services アカウントは、OpenShift API for Data Protection (OADP) インストールを受け入れるように準備および設定する必要があります。
手順
次のコマンドを実行して、以下の環境変数を作成します。
重要ROSA クラスターに一致するようにクラスター名を変更し、管理者としてクラスターにログインしていることを確認します。続行する前に、すべてのフィールドが正しく出力されていることを確認します。
$ export CLUSTER_NAME=my-cluster1 export ROSA_CLUSTER_ID=$(rosa describe cluster -c ${CLUSTER_NAME} --output json | jq -r .id) export REGION=$(rosa describe cluster -c ${CLUSTER_NAME} --output json | jq -r .region.id) export OIDC_ENDPOINT=$(oc get authentication.config.openshift.io cluster -o jsonpath='{.spec.serviceAccountIssuer}' | sed 's|^https://||') export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) export CLUSTER_VERSION=$(rosa describe cluster -c ${CLUSTER_NAME} -o json | jq -r .version.raw_id | cut -f -2 -d '.') export ROLE_NAME="${CLUSTER_NAME}-openshift-oadp-aws-cloud-credentials" export SCRATCH="/tmp/${CLUSTER_NAME}/oadp" mkdir -p ${SCRATCH} echo "Cluster ID: ${ROSA_CLUSTER_ID}, Region: ${REGION}, OIDC Endpoint: ${OIDC_ENDPOINT}, AWS Account ID: ${AWS_ACCOUNT_ID}"- 1
my-clusterは、ROSA クラスター名に置き換えます。
AWS アカウントで、AWS S3 へのアクセスを許可する IAM ポリシーを作成します。
以下のコマンドを実行して、ポリシーが存在するかどうかを確認します。
$ POLICY_ARN=$(aws iam list-policies --query "Policies[?PolicyName=='RosaOadpVer1'].{ARN:Arn}" --output text)1 - 1
RosaOadpは、実際のポリシー名に置き換えます。
以下のコマンドを入力してポリシー JSON ファイルを作成し、ROSA でポリシーを作成します。
注記ポリシー ARN が見つからない場合、コマンドはポリシーを作成します。ポリシー ARN がすでに存在する場合、
ifステートメントはポリシーの作成を意図的にスキップします。$ if [[ -z "${POLICY_ARN}" ]]; then cat << EOF > ${SCRATCH}/policy.json1 { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketTagging", "s3:GetBucketTagging", "s3:PutEncryptionConfiguration", "s3:GetEncryptionConfiguration", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:GetBucketLocation", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucketMultipartUploads", "s3:AbortMultipartUploads", "s3:ListMultipartUploadParts", "s3:DescribeSnapshots", "ec2:DescribeVolumes", "ec2:DescribeVolumeAttribute", "ec2:DescribeVolumesModifications", "ec2:DescribeVolumeStatus", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateSnapshot", "ec2:DeleteSnapshot" ], "Resource": "*" } ]} EOF POLICY_ARN=$(aws iam create-policy --policy-name "RosaOadpVer1" \ --policy-document file:///${SCRATCH}/policy.json --query Policy.Arn \ --tags Key=rosa_openshift_version,Value=${CLUSTER_VERSION} Key=rosa_role_prefix,Value=ManagedOpenShift Key=operator_namespace,Value=openshift-oadp Key=operator_name,Value=openshift-oadp \ --output text) fi- 1
SCRATCHは、環境変数用に作成された一時ディレクトリーの名前です。
以下のコマンドを実行してポリシー ARN を表示します。
$ echo ${POLICY_ARN}
クラスターの IAM ロール信頼ポリシーを作成します。
次のコマンドを実行して、信頼ポリシーファイルを作成します。
$ cat <<EOF > ${SCRATCH}/trust-policy.json { "Version":2012-10-17", "Statement": [{ "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::${AWS_ACCOUNT_ID}:oidc-provider/${OIDC_ENDPOINT}" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "${OIDC_ENDPOINT}:sub": [ "system:serviceaccount:openshift-adp:openshift-adp-controller-manager", "system:serviceaccount:openshift-adp:velero"] } } }] } EOF以下のコマンドを実行してロールを作成します。
$ ROLE_ARN=$(aws iam create-role --role-name \ "${ROLE_NAME}" \ --assume-role-policy-document file://${SCRATCH}/trust-policy.json \ --tags Key=rosa_cluster_id,Value=${ROSA_CLUSTER_ID} Key=rosa_openshift_version,Value=${CLUSTER_VERSION} Key=rosa_role_prefix,Value=ManagedOpenShift Key=operator_namespace,Value=openshift-adp Key=operator_name,Value=openshift-oadp \ --query Role.Arn --output text)次のコマンドを実行して、ロール ARN を表示します。
$ echo ${ROLE_ARN}
次のコマンドを実行して、IAM ポリシーを IAM ロールにアタッチします。
$ aws iam attach-role-policy --role-name "${ROLE_NAME}" \ --policy-arn ${POLICY_ARN}
4.19.1.2. OADP Operator のインストールおよび IAM ロールの指定
AWS Security Token Service (AWS STS) は、IAM またはフェデレーションされたユーザーの短期認証情報を提供するグローバル Web サービスです。STS を使用した OpenShift Container Platform (ROSA) は、ROSA クラスターに推奨される認証情報モードです。このドキュメントでは、AWS STS を使用する ROSA に OpenShift API for Data Protection (OADP) をインストールする方法を説明します。
Restic はサポートされていません。
Container Storage Interface (CSI) スナップショットをサポートしていないファイルシステムをバックアップする場合は、Kopia File System Backup (FSB) がサポートされています。
ファイルシステムの例には次のものがあります。
- Amazon Elastic File System (EFS)
- Network File System (NFS)
-
emptyDirボリューム - ローカルボリューム
ボリュームをバックアップする場合、AWS STS を使用する ROSA の OADP は、ネイティブスナップショットと Container Storage Interface (CSI) スナップショットのみをサポートします。
STS 認証を使用する Amazon ROSA クラスターでは、別の AWS リージョンでのバックアップデータの復元はサポートされていません。
Data Mover 機能は現在、ROSA クラスターではサポートされていません。データの移動にはネイティブ AWS S3 ツールを使用できます。
前提条件
-
必要なアクセス権とトークンを備えた OpenShift Container Platform ROSA クラスター。詳細は、前の手順である OADP 用の AWS 認証情報の準備 を参照してください。バックアップと復元に 2 つの異なるクラスターを使用する予定の場合は、
ROLE_ARNを含む AWS 認証情報をクラスターごとに準備する必要があります。
手順
次のコマンドを入力して、AWS トークンファイルから OpenShift Container Platform シークレットを作成します。
認証情報ファイルを作成します。
$ cat <<EOF > ${SCRATCH}/credentials [default] role_arn = ${ROLE_ARN} web_identity_token_file = /var/run/secrets/openshift/serviceaccount/token region = <aws_region>1 EOF- 1
<aws_region>は、STS エンドポイントに使用する AWS リージョンに置き換えます。
OADP の namespace を作成します。
$ oc create namespace openshift-adpOpenShift Container Platform シークレットを作成します。
$ oc -n openshift-adp create secret generic cloud-credentials \ --from-file=${SCRATCH}/credentials注記OpenShift Container Platform バージョン 4.14 以降では、OADP Operator は Operator Lifecycle Manager (OLM) および Cloud Credentials Operator (CCO) を通じて、標準化された新しい STS ワークフローをサポートします。このワークフローでは、上記シークレットの作成は必要ありません。OpenShift Container Platform Web コンソールを使用して、OLM で管理される Operator のインストール中にロール ARN のみ指定する必要があります。詳細は、Web コンソールを使用して OperatorHub からインストールする を参照してください。
前述のシークレットは CCO によって自動的に作成されます。
OADP Operator をインストールします。
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub ページを表示します。
- OADP Operator を検索します。
- role_ARN フィールドに、前に作成した role_arn を貼り付け、Install をクリックします。
次のコマンドを入力し、AWS 認証情報を使用して AWS クラウドストレージを作成します。
$ cat << EOF | oc create -f - apiVersion: oadp.openshift.io/v1alpha1 kind: CloudStorage metadata: name: ${CLUSTER_NAME}-oadp namespace: openshift-adp spec: creationSecret: key: credentials name: cloud-credentials enableSharedConfig: true name: ${CLUSTER_NAME}-oadp provider: aws region: $REGION EOF次のコマンドを入力して、アプリケーションのストレージのデフォルトストレージクラスを確認します。
$ oc get pvc -n <namespace>出力例
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE applog Bound pvc-351791ae-b6ab-4e8b-88a4-30f73caf5ef8 1Gi RWO gp3-csi 4d19h mysql Bound pvc-16b8e009-a20a-4379-accc-bc81fedd0621 1Gi RWO gp3-csi 4d19h次のコマンドを実行してストレージクラスを取得します。
$ oc get storageclass出力例
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer true 4d21h gp2-csi ebs.csi.aws.com Delete WaitForFirstConsumer true 4d21h gp3 ebs.csi.aws.com Delete WaitForFirstConsumer true 4d21h gp3-csi (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 4d21h注記次のストレージクラスが機能します。
- gp3-csi
- gp2-csi
- gp3
- gp2
すべてのアプリケーション、またはバックアップされるアプリケーションが Container Storage Interface (CSI) で永続ボリューム (PV) を使用している場合は、OADP DPA 設定に CSI プラグインを含めることをお勧めします。
バックアップとボリュームスナップショットが保存されるストレージへの接続を設定するために、
DataProtectionApplicationリソースを作成します。CSI ボリュームのみを使用している場合は、次のコマンドを入力して Data Protection Application をデプロイします。
$ cat << EOF | oc create -f - apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: ${CLUSTER_NAME}-dpa namespace: openshift-adp spec: backupImages: true1 features: dataMover: enable: false backupLocations: - bucket: cloudStorageRef: name: ${CLUSTER_NAME}-oadp credential: key: credentials name: cloud-credentials prefix: velero default: true config: region: ${REGION} configuration: velero: defaultPlugins: - openshift - aws - csi nodeAgent:2 enable: false uploaderType: kopia3 EOF
CSI ボリュームまたは非 CSI ボリュームを使用している場合は、次のコマンドを入力して Data Protection Application をデプロイします。
$ cat << EOF | oc create -f - apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: ${CLUSTER_NAME}-dpa namespace: openshift-adp spec: backupImages: true1 backupLocations: - bucket: cloudStorageRef: name: ${CLUSTER_NAME}-oadp credential: key: credentials name: cloud-credentials prefix: velero default: true config: region: ${REGION} configuration: velero: defaultPlugins: - openshift - aws nodeAgent:2 enable: false uploaderType: restic snapshotLocations: - velero: config: credentialsFile: /tmp/credentials/openshift-adp/cloud-credentials-credentials3 enableSharedConfig: "true"4 profile: default5 region: ${REGION}6 provider: aws EOF- 1
- ROSA は内部イメージバックアップをサポートします。イメージのバックアップを使用しない場合は、このフィールドを false に設定します。
- 2
nodeAgent属性に関する重要な注記を参照してください。- 3
credentialsFileフィールドは、Pod のバケット認証情報のマウント先です。- 4
enableSharedConfigフィールドを使用すると、snapshotLocationsがバケットに定義された認証情報を共有または再利用できます。- 5
- AWS 認証情報ファイルに設定されているプロファイル名を使用します。
- 6
regionは、お使いの AWS リージョンに指定します。これはクラスターリージョンと同じである必要があります。
これで、アプリケーションのバックアップ で説明されているとおり、OpenShift Container Platform アプリケーションをバックアップおよび復元する準備が整いました。
OADP は ROSA 環境で Restic をサポートしていないため、restic の enable パラメーターは false に設定されています。
OADP 1.2 を使用する場合は、次の設定を置き換えます。
nodeAgent:
enable: false
uploaderType: restic次の設定に置き換えます。
restic:
enable: false
バックアップと復元に 2 つの異なるクラスターを使用する場合、クラウドストレージ CR と OADP DataProtectionApplication 設定の両方で、2 つのクラスターの AWS S3 ストレージ名が同じである必要があります。
4.19.1.3. 例: オプションのクリーンアップを使用して OADP ROSA STS 上のワークロードをバックアップする
4.19.1.3.1. OADP と ROSA STS を使用したバックアップの実行
次の hello-world アプリケーションの例では、永続ボリューム (PV) がアタッチされていません。Red Hat OpenShift Service on AWS (ROSA) STS を使用して、OpenShift API for Data Protection (OADP) でバックアップを実行します。
どちらの Data Protection Application (DPA) 設定も機能します。
次のコマンドを実行して、バックアップするワークロードを作成します。
$ oc create namespace hello-world$ oc new-app -n hello-world --image=docker.io/openshift/hello-openshift次のコマンドを実行してルートを公開します。
$ oc expose service/hello-openshift -n hello-world次のコマンドを実行して、アプリケーションが動作していることを確認します。
$ curl `oc get route/hello-openshift -n hello-world -o jsonpath='{.spec.host}'`出力例
Hello OpenShift!次のコマンドを実行して、ワークロードをバックアップします。
$ cat << EOF | oc create -f - apiVersion: velero.io/v1 kind: Backup metadata: name: hello-world namespace: openshift-adp spec: includedNamespaces: - hello-world storageLocation: ${CLUSTER_NAME}-dpa-1 ttl: 720h0m0s EOFバックアップが完了するまで待ってから、次のコマンドを実行します。
$ watch "oc -n openshift-adp get backup hello-world -o json | jq .status"出力例
{ "completionTimestamp": "2022-09-07T22:20:44Z", "expiration": "2022-10-07T22:20:22Z", "formatVersion": "1.1.0", "phase": "Completed", "progress": { "itemsBackedUp": 58, "totalItems": 58 }, "startTimestamp": "2022-09-07T22:20:22Z", "version": 1 }次のコマンドを実行して、デモワークロードを削除します。
$ oc delete ns hello-world次のコマンドを実行して、バックアップからワークロードを復元します。
$ cat << EOF | oc create -f - apiVersion: velero.io/v1 kind: Restore metadata: name: hello-world namespace: openshift-adp spec: backupName: hello-world EOF次のコマンドを実行して、復元が完了するまで待ちます。
$ watch "oc -n openshift-adp get restore hello-world -o json | jq .status"出力例
{ "completionTimestamp": "2022-09-07T22:25:47Z", "phase": "Completed", "progress": { "itemsRestored": 38, "totalItems": 38 }, "startTimestamp": "2022-09-07T22:25:28Z", "warnings": 9 }次のコマンドを実行して、ワークロードが復元されていることを確認します。
$ oc -n hello-world get pods出力例
NAME READY STATUS RESTARTS AGE hello-openshift-9f885f7c6-kdjpj 1/1 Running 0 90s次のコマンドを実行して JSONPath を確認します。
$ curl `oc get route/hello-openshift -n hello-world -o jsonpath='{.spec.host}'`出力例
Hello OpenShift!
トラブルシューティングのヒントは、OADP チームの トラブルシューティングドキュメント を参照してください。
4.19.1.3.2. OADP と ROSA STS を使用してバックアップ後のクラスターをクリーンアップする
この例のバックアップおよび S3 バケットと OpenShift API for Data Protection (OADP) Operator をアンインストールする必要がある場合は、次の手順を実行します。
手順
次のコマンドを実行して、ワークロードを削除します。
$ oc delete ns hello-world次のコマンドを実行して、Data Protection Application (DPA) を削除します。
$ oc -n openshift-adp delete dpa ${CLUSTER_NAME}-dpa次のコマンドを実行して、クラウドストレージを削除します。
$ oc -n openshift-adp delete cloudstorage ${CLUSTER_NAME}-oadp警告このコマンドがハングした場合は、次のコマンドを実行してファイナライザーを削除する必要がある場合があります。
$ oc -n openshift-adp patch cloudstorage ${CLUSTER_NAME}-oadp -p '{"metadata":{"finalizers":null}}' --type=mergeOperator が不要になった場合は、次のコマンドを実行して削除します。
$ oc -n openshift-adp delete subscription oadp-operatorOperator から namespace を削除します。
$ oc delete ns openshift-adpバックアップおよび復元リソースが不要になった場合は、次のコマンドを実行してクラスターからリソースを削除します。
$ oc delete backups.velero.io hello-worldAWS S3 のバックアップ、復元、およびリモートオブジェクトを削除するには、次のコマンドを実行します。
$ velero backup delete hello-worldカスタムリソース定義 (CRD) が不要になった場合は、次のコマンドを実行してクラスターから削除します。
$ for CRD in `oc get crds | grep velero | awk '{print $1}'`; do oc delete crd $CRD; done次のコマンドを実行して、AWS S3 バケットを削除します。
$ aws s3 rm s3://${CLUSTER_NAME}-oadp --recursive$ aws s3api delete-bucket --bucket ${CLUSTER_NAME}-oadp次のコマンドを実行して、ロールからポリシーを切り離します。
$ aws iam detach-role-policy --role-name "${ROLE_NAME}" --policy-arn "${POLICY_ARN}"以下のコマンドを実行してロールを削除します。
$ aws iam delete-role --role-name "${ROLE_NAME}"
4.20. OADP と AWS STS
4.20.1. OADP を使用して AWS STS クラスター上のアプリケーションをバックアップする
OADP Operator をインストールすることで、Amazon Web Services (AWS) を使用して OpenShift API for Data Protection (OADP) をインストールします。Operator は Velero 1.14 をインストールします。
OADP 1.0.4 以降、すべての OADP 1.0.z バージョンは Migration Toolkit for Containers Operator の依存関係としてのみ使用でき、スタンドアロン Operator として使用することはできません。
Velero 向けに AWS を設定し、デフォルトの Secret を作成し、次に、Data Protection Application をインストールします。詳細は、OADP Operator のインストール を参照してください。
制限されたネットワーク環境に OADP Operator をインストールするには、最初にデフォルトの OperatorHub ソースを無効にして、Operator カタログをミラーリングする必要があります。詳細は、ネットワークが制限された環境での Operator Lifecycle Manager の使用 を参照してください。
OADP は、AWS Security Token Service (STS) (AWS STS) クラスターに手動でインストールできます。Amazon AWS は、ユーザーのために権限が限られた一時的な認証情報を要求できる AWS STS を Web サービスとして提供しています。STS を使用すると、API 呼び出し、AWS コンソール、または AWS コマンドラインインターフェイス (CLI) を介してリソースへの一時的なアクセスを信頼できるユーザーに提供できます。
OpenShift API for Data Protection (OADP) をインストールする前に、OADP が Amazon Web Services API を使用できるように、OADP のロールとポリシーの認証情報を設定する必要があります。
このプロセスは次の 2 段階で実行されます。
- AWS 認証情報を準備します。
- OADP Operator をインストールし、IAM ロールを付与します。
4.20.1.1. OADP 用の AWS STS 認証情報を準備する
Amazon Web Services アカウントは、OpenShift API for Data Protection (OADP) インストールを受け入れるように準備および設定する必要があります。次の手順に従って AWS 認証情報を準備します。
手順
次のコマンドを実行して、
cluster_name環境変数を定義します。$ export CLUSTER_NAME= <AWS_cluster_name>1 - 1
- 変数は任意の値に設定できます。
次のコマンドを実行して、
AWS_ACCOUNT_ID, OIDC_ENDPOINTなどのclusterの詳細をすべて取得します。$ export CLUSTER_VERSION=$(oc get clusterversion version -o jsonpath='{.status.desired.version}{"\n"}') export AWS_CLUSTER_ID=$(oc get clusterversion version -o jsonpath='{.spec.clusterID}{"\n"}') export OIDC_ENDPOINT=$(oc get authentication.config.openshift.io cluster -o jsonpath='{.spec.serviceAccountIssuer}' | sed 's|^https://||') export REGION=$(oc get infrastructures cluster -o jsonpath='{.status.platformStatus.aws.region}' --allow-missing-template-keys=false || echo us-east-2) export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) export ROLE_NAME="${CLUSTER_NAME}-openshift-oadp-aws-cloud-credentials"次のコマンドを実行して、すべてのファイルを保存するための一時ディレクトリーを作成します。
$ export SCRATCH="/tmp/${CLUSTER_NAME}/oadp" mkdir -p ${SCRATCH}次のコマンドを実行して、収集したすべての詳細を表示します。
$ echo "Cluster ID: ${AWS_CLUSTER_ID}, Region: ${REGION}, OIDC Endpoint: ${OIDC_ENDPOINT}, AWS Account ID: ${AWS_ACCOUNT_ID}"AWS アカウントで、AWS S3 へのアクセスを許可する IAM ポリシーを作成します。
次のコマンドを実行して、ポリシーが存在するかどうかを確認します。
$ export POLICY_NAME="OadpVer1"1 - 1
- 変数は任意の値に設定できます。
$ POLICY_ARN=$(aws iam list-policies --query "Policies[?PolicyName=='$POLICY_NAME'].{ARN:Arn}" --output text)次のコマンドを入力してポリシー JSON ファイルを作成し、ポリシーを作成します。
注記ポリシー ARN が見つからない場合、コマンドはポリシーを作成します。ポリシー ARN がすでに存在する場合、
ifステートメントはポリシーの作成を意図的にスキップします。$ if [[ -z "${POLICY_ARN}" ]]; then cat << EOF > ${SCRATCH}/policy.json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketTagging", "s3:GetBucketTagging", "s3:PutEncryptionConfiguration", "s3:GetEncryptionConfiguration", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:GetBucketLocation", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucketMultipartUploads", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts", "ec2:DescribeSnapshots", "ec2:DescribeVolumes", "ec2:DescribeVolumeAttribute", "ec2:DescribeVolumesModifications", "ec2:DescribeVolumeStatus", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateSnapshot", "ec2:DeleteSnapshot" ], "Resource": "*" } ]} EOF POLICY_ARN=$(aws iam create-policy --policy-name $POLICY_NAME \ --policy-document file:///${SCRATCH}/policy.json --query Policy.Arn \ --tags Key=openshift_version,Value=${CLUSTER_VERSION} Key=operator_namespace,Value=openshift-adp Key=operator_name,Value=oadp \ --output text)1 fi- 1
SCRATCHは、ファイルを保存するために作成した一時ディレクトリーの名前です。
以下のコマンドを実行してポリシー ARN を表示します。
$ echo ${POLICY_ARN}
クラスターの IAM ロール信頼ポリシーを作成します。
次のコマンドを実行して、信頼ポリシーファイルを作成します。
$ cat <<EOF > ${SCRATCH}/trust-policy.json { "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::${AWS_ACCOUNT_ID}:oidc-provider/${OIDC_ENDPOINT}" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "${OIDC_ENDPOINT}:sub": [ "system:serviceaccount:openshift-adp:openshift-adp-controller-manager", "system:serviceaccount:openshift-adp:velero"] } } }] } EOF次のコマンドを実行して、クラスターの IAM ロール信頼ポリシーを作成します。
$ ROLE_ARN=$(aws iam create-role --role-name \ "${ROLE_NAME}" \ --assume-role-policy-document file://${SCRATCH}/trust-policy.json \ --tags Key=cluster_id,Value=${AWS_CLUSTER_ID} Key=openshift_version,Value=${CLUSTER_VERSION} Key=operator_namespace,Value=openshift-adp Key=operator_name,Value=oadp --query Role.Arn --output text)次のコマンドを実行して、ロール ARN を表示します。
$ echo ${ROLE_ARN}
次のコマンドを実行して、IAM ポリシーを IAM ロールにアタッチします。
$ aws iam attach-role-policy --role-name "${ROLE_NAME}" --policy-arn ${POLICY_ARN}
4.20.1.1.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node_selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
Kopia は OADP 1.3 以降のリリースで選択できます。Kopia はファイルシステムのバックアップに使用できます。組み込みの Data Mover を使用する Data Mover の場合は、Kopia が唯一の選択肢になります。
Kopia は Restic よりも多くのリソースを消費するため、それに応じて CPU とメモリーの要件を調整しなければならない場合があります。
4.20.1.2. OADP Operator のインストールおよび IAM ロールの指定
AWS Security Token Service (AWS STS) は、IAM またはフェデレーションされたユーザーの短期認証情報を提供するグローバル Web サービスです。このドキュメントでは、OpenShift API for Data Protection (OADP) を AWS STS クラスターに手動でインストールする方法を説明します。
Restic と Kopia は、OADP AWS STS 環境ではサポートされていません。Restic および Kopia のノードエージェントが無効になっていることを確認してください。ボリュームをバックアップする場合、AWS STS 上の OADP は、ネイティブスナップショットと Container Storage Interface (CSI) スナップショットのみをサポートします。
STS 認証を使用する AWS クラスターでは、バックアップデータを別の AWS リージョンに復元することはサポートされていません。
Data Mover 機能は現在、AWS STS クラスターではサポートされていません。データの移動にはネイティブ AWS S3 ツールを使用できます。
前提条件
-
必要なアクセス権とトークンを備えた OpenShift Container Platform AWS STS クラスター。詳細は、前の手順である OADP 用の AWS 認証情報の準備 を参照してください。バックアップと復元に 2 つの異なるクラスターを使用する予定の場合は、
ROLE_ARNを含む AWS 認証情報をクラスターごとに準備する必要があります。
手順
次のコマンドを入力して、AWS トークンファイルから OpenShift Container Platform シークレットを作成します。
認証情報ファイルを作成します。
$ cat <<EOF > ${SCRATCH}/credentials [default] role_arn = ${ROLE_ARN} web_identity_token_file = /var/run/secrets/openshift/serviceaccount/token EOFOADP の namespace を作成します。
$ oc create namespace openshift-adpOpenShift Container Platform シークレットを作成します。
$ oc -n openshift-adp create secret generic cloud-credentials \ --from-file=${SCRATCH}/credentials注記OpenShift Container Platform バージョン 4.14 以降では、OADP Operator は Operator Lifecycle Manager (OLM) および Cloud Credentials Operator (CCO) を通じて、標準化された新しい STS ワークフローをサポートします。このワークフローでは、上記シークレットの作成は必要ありません。OpenShift Container Platform Web コンソールを使用して、OLM で管理される Operator のインストール中にロール ARN のみ指定する必要があります。詳細は、Web コンソールを使用して OperatorHub からインストールする を参照してください。
前述のシークレットは CCO によって自動的に作成されます。
OADP Operator をインストールします。
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub ページを表示します。
- OADP Operator を検索します。
- role_ARN フィールドに、前に作成した role_arn を貼り付け、Install をクリックします。
次のコマンドを入力し、AWS 認証情報を使用して AWS クラウドストレージを作成します。
$ cat << EOF | oc create -f - apiVersion: oadp.openshift.io/v1alpha1 kind: CloudStorage metadata: name: ${CLUSTER_NAME}-oadp namespace: openshift-adp spec: creationSecret: key: credentials name: cloud-credentials enableSharedConfig: true name: ${CLUSTER_NAME}-oadp provider: aws region: $REGION EOF次のコマンドを入力して、アプリケーションのストレージのデフォルトストレージクラスを確認します。
$ oc get pvc -n <namespace>出力例
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE applog Bound pvc-351791ae-b6ab-4e8b-88a4-30f73caf5ef8 1Gi RWO gp3-csi 4d19h mysql Bound pvc-16b8e009-a20a-4379-accc-bc81fedd0621 1Gi RWO gp3-csi 4d19h次のコマンドを実行してストレージクラスを取得します。
$ oc get storageclass出力例
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer true 4d21h gp2-csi ebs.csi.aws.com Delete WaitForFirstConsumer true 4d21h gp3 ebs.csi.aws.com Delete WaitForFirstConsumer true 4d21h gp3-csi (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 4d21h注記次のストレージクラスが機能します。
- gp3-csi
- gp2-csi
- gp3
- gp2
すべてのアプリケーション、またはバックアップされるアプリケーションが Container Storage Interface (CSI) で永続ボリューム (PV) を使用している場合は、OADP DPA 設定に CSI プラグインを含めることをお勧めします。
バックアップとボリュームスナップショットが保存されるストレージへの接続を設定するために、
DataProtectionApplicationリソースを作成します。CSI ボリュームのみを使用している場合は、次のコマンドを入力して Data Protection Application をデプロイします。
$ cat << EOF | oc create -f - apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: ${CLUSTER_NAME}-dpa namespace: openshift-adp spec: backupImages: true1 features: dataMover: enable: false backupLocations: - bucket: cloudStorageRef: name: ${CLUSTER_NAME}-oadp credential: key: credentials name: cloud-credentials prefix: velero default: true config: region: ${REGION} configuration: velero: defaultPlugins: - openshift - aws - csi restic: enable: false EOF- 1
- イメージのバックアップを使用しない場合は、このフィールドを
falseに設定します。
CSI ボリュームまたは非 CSI ボリュームを使用している場合は、次のコマンドを入力して Data Protection Application をデプロイします。
$ cat << EOF | oc create -f - apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: ${CLUSTER_NAME}-dpa namespace: openshift-adp spec: backupImages: true1 features: dataMover: enable: false backupLocations: - bucket: cloudStorageRef: name: ${CLUSTER_NAME}-oadp credential: key: credentials name: cloud-credentials prefix: velero default: true config: region: ${REGION} configuration: velero: defaultPlugins: - openshift - aws nodeAgent:2 enable: false uploaderType: restic snapshotLocations: - velero: config: credentialsFile: /tmp/credentials/openshift-adp/cloud-credentials-credentials3 enableSharedConfig: "true"4 profile: default5 region: ${REGION}6 provider: aws EOF- 1
- イメージのバックアップを使用しない場合は、このフィールドを
falseに設定します。 - 2
nodeAgent属性に関する重要な注記を参照してください。- 3
credentialsFileフィールドは、Pod のバケット認証情報のマウント先です。- 4
enableSharedConfigフィールドを使用すると、snapshotLocationsがバケットに定義された認証情報を共有または再利用できます。- 5
- AWS 認証情報ファイルに設定されているプロファイル名を使用します。
- 6
regionは、お使いの AWS リージョンに指定します。これはクラスターリージョンと同じである必要があります。
これで、アプリケーションのバックアップ で説明されているとおり、OpenShift Container Platform アプリケーションをバックアップおよび復元する準備が整いました。
OADP 1.2 を使用する場合は、次の設定を置き換えます。
nodeAgent:
enable: false
uploaderType: restic次の設定に置き換えます。
restic:
enable: false
バックアップと復元に 2 つの異なるクラスターを使用する場合、クラウドストレージ CR と OADP DataProtectionApplication 設定の両方で、2 つのクラスターの AWS S3 ストレージ名が同じである必要があります。
4.20.1.3. オプションのクリーンアップを使用して OADP AWS STS 上のワークロードをバックアップする
4.20.1.3.1. OADP と AWS STS を使用したバックアップの実行
次の hello-world アプリケーションの例では、永続ボリューム (PV) がアタッチされていません。OpenShift API for Data Protection (OADP) と Amazon Web Services (AWS) (AWS STS) を使用してバックアップを実行します。
どちらの Data Protection Application (DPA) 設定も機能します。
次のコマンドを実行して、バックアップするワークロードを作成します。
$ oc create namespace hello-world$ oc new-app -n hello-world --image=docker.io/openshift/hello-openshift次のコマンドを実行してルートを公開します。
$ oc expose service/hello-openshift -n hello-world次のコマンドを実行して、アプリケーションが動作していることを確認します。
$ curl `oc get route/hello-openshift -n hello-world -o jsonpath='{.spec.host}'`出力例
Hello OpenShift!次のコマンドを実行して、ワークロードをバックアップします。
$ cat << EOF | oc create -f - apiVersion: velero.io/v1 kind: Backup metadata: name: hello-world namespace: openshift-adp spec: includedNamespaces: - hello-world storageLocation: ${CLUSTER_NAME}-dpa-1 ttl: 720h0m0s EOFバックアップが完了するまで待ってから、次のコマンドを実行します。
$ watch "oc -n openshift-adp get backup hello-world -o json | jq .status"出力例
{ "completionTimestamp": "2022-09-07T22:20:44Z", "expiration": "2022-10-07T22:20:22Z", "formatVersion": "1.1.0", "phase": "Completed", "progress": { "itemsBackedUp": 58, "totalItems": 58 }, "startTimestamp": "2022-09-07T22:20:22Z", "version": 1 }次のコマンドを実行して、デモワークロードを削除します。
$ oc delete ns hello-world次のコマンドを実行して、バックアップからワークロードを復元します。
$ cat << EOF | oc create -f - apiVersion: velero.io/v1 kind: Restore metadata: name: hello-world namespace: openshift-adp spec: backupName: hello-world EOF次のコマンドを実行して、復元が完了するまで待ちます。
$ watch "oc -n openshift-adp get restore hello-world -o json | jq .status"出力例
{ "completionTimestamp": "2022-09-07T22:25:47Z", "phase": "Completed", "progress": { "itemsRestored": 38, "totalItems": 38 }, "startTimestamp": "2022-09-07T22:25:28Z", "warnings": 9 }次のコマンドを実行して、ワークロードが復元されていることを確認します。
$ oc -n hello-world get pods出力例
NAME READY STATUS RESTARTS AGE hello-openshift-9f885f7c6-kdjpj 1/1 Running 0 90s次のコマンドを実行して JSONPath を確認します。
$ curl `oc get route/hello-openshift -n hello-world -o jsonpath='{.spec.host}'`出力例
Hello OpenShift!
トラブルシューティングのヒントは、OADP チームの トラブルシューティングドキュメント を参照してください。
4.20.1.3.2. OADP と AWS STS を使用してバックアップ後のクラスターをクリーンアップする
この例のバックアップおよび S3 バケットと OpenShift API for Data Protection (OADP) Operator をアンインストールする必要がある場合は、次の手順を実行します。
手順
次のコマンドを実行して、ワークロードを削除します。
$ oc delete ns hello-world次のコマンドを実行して、Data Protection Application (DPA) を削除します。
$ oc -n openshift-adp delete dpa ${CLUSTER_NAME}-dpa次のコマンドを実行して、クラウドストレージを削除します。
$ oc -n openshift-adp delete cloudstorage ${CLUSTER_NAME}-oadp重要このコマンドがハングした場合は、次のコマンドを実行してファイナライザーを削除する必要がある場合があります。
$ oc -n openshift-adp patch cloudstorage ${CLUSTER_NAME}-oadp -p '{"metadata":{"finalizers":null}}' --type=mergeOperator が不要になった場合は、次のコマンドを実行して削除します。
$ oc -n openshift-adp delete subscription oadp-operator次のコマンドを実行して、Operator から namespace を削除します。
$ oc delete ns openshift-adpバックアップおよび復元リソースが不要になった場合は、次のコマンドを実行してクラスターからリソースを削除します。
$ oc delete backups.velero.io hello-worldAWS S3 のバックアップ、復元、およびリモートオブジェクトを削除するには、次のコマンドを実行します。
$ velero backup delete hello-worldカスタムリソース定義 (CRD) が不要になった場合は、次のコマンドを実行してクラスターから削除します。
$ for CRD in `oc get crds | grep velero | awk '{print $1}'`; do oc delete crd $CRD; done次のコマンドを実行して、AWS S3 バケットを削除します。
$ aws s3 rm s3://${CLUSTER_NAME}-oadp --recursive$ aws s3api delete-bucket --bucket ${CLUSTER_NAME}-oadp次のコマンドを実行して、ロールからポリシーを切り離します。
$ aws iam detach-role-policy --role-name "${ROLE_NAME}" --policy-arn "${POLICY_ARN}"以下のコマンドを実行してロールを削除します。
$ aws iam delete-role --role-name "${ROLE_NAME}"
4.21. OADP Data Mover
4.21.1. OADP Data Mover について
OpenShift API for Data Protection (OADP) には、Container Storage Interface (CSI) ボリュームのスナップショットをリモートオブジェクトストアに移動するために使用できる、ビルトイン Data Mover が含まれています。ビルトイン Data Mover を使用すると、クラスターの障害、誤削除、または破損が発生した場合に、リモートオブジェクトストアからステートフルアプリケーションを復元できます。スナップショットデータを読み取り、統合リポジトリーに書き込むためのアップローダーメカニズムとして Kopia を使用します。
OADP は、以下で CSI スナップショットをサポートします。
- Red Hat OpenShift Data Foundation
- Kubernetes Volume Snapshot API をサポートする Container Storage Interface (CSI) ドライバーを使用するその他のクラウドストレージプロバイダー
4.21.1.1. Data Mover のサポート
OADP 1.3 でテクノロジープレビューとして導入された OADP 組み込みの Data Mover が、コンテナー化されたワークロードと仮想マシンのワークロードの両方で完全にサポートされるようになりました。
サポート対象
OADP 1.3 で作成した Data Mover バックアップは、OADP 1.3、1.4 以降を使用して復元できます。これはサポート対象です。
サポート対象外
Data Mover 機能を使用して OADP 1.1 または OADP 1.2 で作成したバックアップは、OADP 1.3 以降を使用して復元することはできません。したがって、これはサポート対象外です。
OADP 1.1 および OADP 1.2 はサポート対象外です。OADP 1.1 または OADP 1.2 の DataMover 機能はテクノロジープレビューであり、サポート対象ではありませんでした。OADP 1.1 または OADP 1.2 で作成した DataMover バックアップは、それ以降のバージョンの OADP では復元できません。
4.21.1.2. ビルトイン Data Mover の有効化
ビルトイン Data Mover を有効にするには、CSI プラグインを組み込み、DataProtectionApplication カスタムリソース (CR) でノードエージェントを有効にする必要があります。ノードエージェントは、データ移動型モジュールをホストする Kubernetes デーモンセットです。これには、Data Mover のコントローラー、アップローダー、リポジトリーが含まれます。
DataProtectionApplication マニフェストの例
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
nodeAgent:
enable: true
uploaderType: kopia
velero:
defaultPlugins:
- openshift
- aws
- csi
defaultSnapshotMoveData: true
defaultVolumesToFSBackup:
featureFlags:
- EnableCSI
# ...- 1
- ノードエージェントを有効にするフラグ。
- 2
- アップローダーの種類。使用できる値は、
resticまたはkopiaです。ビルトイン Data Mover は、uploaderTypeフィールドの値に関係なく、デフォルトのアップローダーメカニズムとして Kopia を使用します。 - 3
- デフォルトプラグインのリストに含まれる CSI プラグイン。
- 4
- OADP 1.3.1 以降では、
fs-backupをオプトアウトするボリュームにのみ Data Mover を使用する場合、trueに設定します。ボリュームにデフォルトで Data Mover を使用する場合はfalseに設定します。
4.21.1.3. ビルトイン Data Mover のコントローラーとカスタムリソース定義 (CRD)
ビルトイン Data Mover 機能には、バックアップと復元を管理するための CRD として定義された 3 つの新しい API オブジェクトが導入されています。
-
DataDownload: ボリュームスナップショットのデータダウンロードを表します。CSI プラグインは、復元するボリュームごとに 1 つのDataDownloadオブジェクトを作成します。DataDownloadCR には、ターゲットボリューム、指定された Data Mover、現在のデータダウンロードの進行状況、指定されたバックアップリポジトリー、プロセス完了後の現在のデータダウンロードの結果に関する情報が含まれます。 -
DataUpload: ボリュームスナップショットのデータアップロードを表します。CSI プラグインは、CSI スナップショットごとに 1 つのDataUploadオブジェクトを作成します。DataUploadCR には、指定されたスナップショット、指定された Data Mover、指定されたバックアップリポジトリー、現在のデータアップロードの進行状況、およびプロセス完了後の現在のデータアップロードの結果に関する情報が含まれます。 -
BackupRepository: バックアップリポジトリーのライフサイクルを表し、管理します。OADP は、namespace の最初の CSI スナップショットバックアップまたは復元が要求されると、namespace ごとにバックアップリポジトリーを作成します。
4.21.1.4. 増分バックアップのサポートについて
OADP は、コンテナー化されたワークロードと OpenShift Virtualization ワークロードの両方で、block および Filesystem の永続ボリュームの増分バックアップをサポートしています。次の表は、File System Backup (FSB)、Container Storage Interface (CSI)、および CSI Data Mover のサポート状況をまとめたものです。
| ボリュームモード | FSB - Restic | FSB - Kopia | CSI | CSI Data Mover |
|---|---|---|---|---|
| ファイルシステム | S [1]、I [2] | S [1]、I [2] | S [1] | S [1]、I [2] |
| ブロック | N [3] | N [3] | S [1] | S [1]、I [2] |
| ボリュームモード | FSB - Restic | FSB - Kopia | CSI | CSI Data Mover |
|---|---|---|---|---|
| ファイルシステム | N [3] | N [3] | S [1] | S [1]、I [2] |
| ブロック | N [3] | N [3] | S [1] | S [1]、I [2] |
- バックアップをサポート
- 増分バックアップをサポート
- サポート対象外
CSI Data Mover バックアップでは、uploaderType に関係なく Kopia が使用されます。
4.21.2. CSI スナップショットのバックアップおよび復元のデータ移動
OADP 1.3 Data Mover を使用して、永続ボリュームのバックアップと復元を実行できます。
4.21.2.1. CSI スナップショットを使用した永続ボリュームのバックアップ
OADP Data Mover を使用して、Container Storage Interface (CSI) ボリュームのスナップショットをリモートオブジェクトストアにバックアップできます。
前提条件
-
cluster-adminロールでクラスターにアクセスできる。 - OADP Operator がインストールされている。
-
CSI プラグインを組み込み、
DataProtectionApplicationカスタムリソース (CR) でノードエージェントを有効にしている。 - 別の namespace で実行されている永続ボリュームを持つアプリケーションがある。
-
metadata.labels.velero.io/csi-volumesnapshot-class: "true"のキー/値ペアをVolumeSnapshotClassCR に追加している。
手順
次の例のように、
Backupオブジェクトの YAML ファイルを作成します。BackupCR の例kind: Backup apiVersion: velero.io/v1 metadata: name: backup namespace: openshift-adp spec: csiSnapshotTimeout: 10m0s defaultVolumesToFsBackup:1 includedNamespaces: - mysql-persistent itemOperationTimeout: 4h0m0s snapshotMoveData: true2 storageLocation: default ttl: 720h0m0s3 volumeSnapshotLocations: - dpa-sample-1 # ...- 1
fs-backupをオプトアウトするボリュームにのみ Data Mover を使用する場合、trueに設定します。ボリュームにデフォルトで Data Mover を使用する場合はfalseに設定します。- 2
- CSI スナップショットのリモートオブジェクトストレージへの移動を有効にするには、
trueに設定します。 - 3
ttlフィールドは、作成されたバックアップの保持期間とバックアップされたデータのバックアップを定義します。たとえば、バックアップツールとして Restic を使用している場合、バックアップの有効期限が切れるまで、バックアップされたデータ項目と永続ボリューム(PV)のデータコンテンツが保存されます。ただし、このデータを保存すると、ターゲットのバックアップの場所により多くの領域が使用されます。追加のストレージは、頻繁なバックアップで消費されます。バックアップは、他の期限切れでないバックアップがタイムアウトする前でも作成されます。
注記XFS ファイルシステムを使用してボリュームをフォーマットし、ボリュームの容量が 100% になっている場合は、
no space left on deviceエラーが発生してバックアップが失敗します。以下に例を示します。Error: relabel failed /var/lib/kubelet/pods/3ac..34/volumes/ \ kubernetes.io~csi/pvc-684..12c/mount: lsetxattr /var/lib/kubelet/ \ pods/3ac..34/volumes/kubernetes.io~csi/pvc-68..2c/mount/data-xfs-103: \ no space left on deviceこのシナリオでは、バックアップが正常に完了するように、ボリュームのサイズを変更するか、
ext4などの別のファイルシステムタイプを使用することを検討してください。マニフェストを適用します。
$ oc create -f backup.yamlスナップショットの作成が完了すると、
DataUploadCR が作成されます。
検証
DataUploadCR のstatus.phaseフィールドを監視して、スナップショットデータがリモートオブジェクトストアに正常に転送されたことを確認します。使用される値は、In Progress、Completed、Failed、またはCanceledです。オブジェクトストアは、DataProtectionApplicationCR のbackupLocationsスタンザで設定されます。次のコマンドを実行して、すべての
DataUploadオブジェクトのリストを取得します。$ oc get datauploads -A出力例
NAMESPACE NAME STATUS STARTED BYTES DONE TOTAL BYTES STORAGE LOCATION AGE NODE openshift-adp backup-test-1-sw76b Completed 9m47s 108104082 108104082 dpa-sample-1 9m47s ip-10-0-150-57.us-west-2.compute.internal openshift-adp mongo-block-7dtpf Completed 14m 1073741824 1073741824 dpa-sample-1 14m ip-10-0-150-57.us-west-2.compute.internal次のコマンドを実行して、
DataUploadオブジェクトのstatus.phaseフィールドの値を確認します。$ oc get datauploads <dataupload_name> -o yaml出力例
apiVersion: velero.io/v2alpha1 kind: DataUpload metadata: name: backup-test-1-sw76b namespace: openshift-adp spec: backupStorageLocation: dpa-sample-1 csiSnapshot: snapshotClass: "" storageClass: gp3-csi volumeSnapshot: velero-mysql-fq8sl operationTimeout: 10m0s snapshotType: CSI sourceNamespace: mysql-persistent sourcePVC: mysql status: completionTimestamp: "2023-11-02T16:57:02Z" node: ip-10-0-150-57.us-west-2.compute.internal path: /host_pods/15116bac-cc01-4d9b-8ee7-609c3bef6bde/volumes/kubernetes.io~csi/pvc-eead8167-556b-461a-b3ec-441749e291c4/mount phase: Completed1 progress: bytesDone: 108104082 totalBytes: 108104082 snapshotID: 8da1c5febf25225f4577ada2aeb9f899 startTimestamp: "2023-11-02T16:56:22Z"- 1
- これは、スナップショットデータがリモートオブジェクトストアに正常に転送されたことを示しています。
4.21.2.2. CSI ボリュームスナップショットの復元
Restore CR を作成することで、ボリュームスナップショットを復元できます。
OAPD 1.3 のビルトイン Data Mover を使用して、OADP 1.2 から Volsync バックアップを復元することはできません。OADP 1.3 にアップグレードする前に、Restic を使用してすべてのワークロードのファイルシステムバックアップを実行することが推奨されます。
前提条件
-
cluster-adminロールでクラスターにアクセスできる。 -
データの復元元となる OADP
BackupCR がある。
手順
次の例のように、
RestoreCR の YAML ファイルを作成します。RestoreCR の例apiVersion: velero.io/v1 kind: Restore metadata: name: restore namespace: openshift-adp spec: backupName: <backup> # ...マニフェストを適用します。
$ oc create -f restore.yaml復元が開始されると、
DataDownloadが作成されます。
検証
DataDownloadCR のstatus.phaseフィールドをチェックすることで、復元プロセスのステータスを監視できます。使用される値は、In Progress、Completed、Failed、またはCanceledです。すべての
DataDownloadオブジェクトのリストを取得するには、次のコマンドを実行します。$ oc get datadownloads -A出力例
NAMESPACE NAME STATUS STARTED BYTES DONE TOTAL BYTES STORAGE LOCATION AGE NODE openshift-adp restore-test-1-sk7lg Completed 7m11s 108104082 108104082 dpa-sample-1 7m11s ip-10-0-150-57.us-west-2.compute.internal次のコマンドを入力して、特定の
DataDownloadオブジェクトのstatus.phaseフィールドの値を確認します。$ oc get datadownloads <datadownload_name> -o yaml出力例
apiVersion: velero.io/v2alpha1 kind: DataDownload metadata: name: restore-test-1-sk7lg namespace: openshift-adp spec: backupStorageLocation: dpa-sample-1 operationTimeout: 10m0s snapshotID: 8da1c5febf25225f4577ada2aeb9f899 sourceNamespace: mysql-persistent targetVolume: namespace: mysql-persistent pv: "" pvc: mysql status: completionTimestamp: "2023-11-02T17:01:24Z" node: ip-10-0-150-57.us-west-2.compute.internal phase: Completed1 progress: bytesDone: 108104082 totalBytes: 108104082 startTimestamp: "2023-11-02T17:00:52Z"- 1
- CSI スナップショットデータが正常に復元されたことを示します。
4.21.2.3. OADP 1.3 の削除ポリシー
削除ポリシーは、システムからデータを削除するためのルールを決定します。保存期間、データの機密性、コンプライアンス要件などの要素に基づいて、削除をいつどのように行うかを指定します。規制を遵守し、貴重な情報を保護しながら、データの削除を効果的に管理します。
4.21.2.3.1. OADP 1.3 の削除ポリシーガイドライン
OADP 1.3 の次の削除ポリシーガイドラインを確認してください。
-
OADP 1.3.x でいずれかのタイプのバックアップおよびリストア方法を使用する場合は、
VolumeSnapshotClassカスタムリソース (CR) のdeletionPolicyフィールドをRetainまたはDeleteに設定できます。
4.21.3. Kopia のハッシュ、暗号化、およびスプリッターアルゴリズムのオーバーライド
Data Protection Application (DPA) の特定の環境変数を使用すると、Kopia のハッシュ、暗号化、およびスプリッターアルゴリズムのデフォルト値をオーバーライドできます。
4.21.3.1. Kopia のハッシュ、暗号化、スプリッターアルゴリズムをオーバーライドするように DPA を設定する
OpenShift API for Data Protection (OADP) のオプションを使用すると、ハッシュ、暗号化、スプリッターのデフォルトの Kopia アルゴリズムをオーバーライドして、Kopia のパフォーマンスを向上させたり、パフォーマンスメトリクスを比較したりできます。DPA の spec.configuration.velero.podConfig.env セクションで次の環境変数を設定できます。
-
KOPIA_HASHING_ALGORITHM -
KOPIA_ENCRYPTION_ALGORITHM -
KOPIA_SPLITTER_ALGORITHM
前提条件
- OADP Operator がインストールされている。
- クラウドプロバイダーから提供された認証情報を使用してシークレットを作成した。
Data Protection Application (DPA) の分割、ハッシュ、および暗号化のための Kopia アルゴリズムの設定は、Kopia リポジトリーの初回作成時にのみ適用され、後で変更することはできません。
異なる Kopia アルゴリズムを使用するには、オブジェクトストレージに、バックアップの以前の Kopia リポジトリーが含まれていないことを確認してください。Backup Storage Location (BSL) で新しいオブジェクトストレージを設定するか、BSL 設定でオブジェクトストレージの一意の接頭辞を指定します。
手順
次の例に示すように、ハッシュ、暗号化、およびスプリッター用の環境変数を使用して DPA を設定します。
DPA の例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication #... configuration: nodeAgent: enable: true1 uploaderType: kopia2 velero: defaultPlugins: - openshift - aws - csi3 defaultSnapshotMoveData: true podConfig: env: - name: KOPIA_HASHING_ALGORITHM value: <hashing_algorithm_name>4 - name: KOPIA_ENCRYPTION_ALGORITHM value: <encryption_algorithm_name>5 - name: KOPIA_SPLITTER_ALGORITHM value: <splitter_algorithm_name>6
4.21.3.2. Kopia のハッシュ、暗号化、およびスプリッターアルゴリズムのオーバーライドの使用例
この使用例では、ハッシュ、暗号化、スプリッター用の Kopia 環境変数を使用してアプリケーションのバックアップを作成する方法を示します。バックアップは AWS S3 バケットに保存します。その後、Kopia リポジトリーに接続して環境変数を検証します。
前提条件
- OADP Operator がインストールされている。
- Backup Storage Location として AWS S3 バケットが設定されている。
- クラウドプロバイダーから提供された認証情報を使用してシークレットを作成した。
- Kopia クライアントがインストールされている。
- 別の namespace で実行されている永続ボリュームを持つアプリケーションがある。
手順
次の例に示すように、Data Protection Application (DPA) を設定します。
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name>1 namespace: openshift-adp spec: backupLocations: - name: aws velero: config: profile: default region: <region_name>2 credential: key: cloud name: cloud-credentials3 default: true objectStorage: bucket: <bucket_name>4 prefix: velero provider: aws configuration: nodeAgent: enable: true uploaderType: kopia velero: defaultPlugins: - openshift - aws - csi5 defaultSnapshotMoveData: true podConfig: env: - name: KOPIA_HASHING_ALGORITHM value: BLAKE3-2566 - name: KOPIA_ENCRYPTION_ALGORITHM value: CHACHA20-POLY1305-HMAC-SHA2567 - name: KOPIA_SPLITTER_ALGORITHM value: DYNAMIC-8M-RABINKARP8 次のコマンドを実行して DPA を作成します。
$ oc create -f <dpa_file_name>1 - 1
- 設定した DPA のファイル名を指定します。
次のコマンドを実行して、DPA が調整されたことを確認します。
$ oc get dpa -o yaml次の例に示すように、バックアップ CR を作成します。
バックアップ CR の例
apiVersion: velero.io/v1 kind: Backup metadata: name: test-backup namespace: openshift-adp spec: includedNamespaces: - <application_namespace>1 defaultVolumesToFsBackup: true- 1
- クラスターにインストールされているアプリケーションの namespace を指定します。
次のコマンドを実行してバックアップを作成します。
$ oc apply -f <backup_file_name>1 - 1
- バックアップ CR ファイルの名前を指定します。
次のコマンドを実行して、バックアップが完了したことを確認します。
$ oc get backups.velero.io <backup_name> -o yaml1 - 1
- バックアップの名前を指定します。
検証
次のコマンドを実行して、Kopia リポジトリーに接続します。
$ kopia repository connect s3 \ --bucket=<bucket_name> \1 --prefix=velero/kopia/<application_namespace> \2 --password=static-passw0rd \3 --access-key="<aws_s3_access_key>" \4 --secret-access-key="<aws_s3_secret_access_key>" \5 注記AWS S3 以外のストレージプロバイダーを使用している場合は、コマンドにバケットエンドポイントの URL パラメーター
--endpointを追加する必要があります。次のコマンドを実行して、バックアップ用に DPA で設定した環境変数を Kopia が使用していることを確認します。
$ kopia repository status出力例
Config file: /../.config/kopia/repository.config Description: Repository in S3: s3.amazonaws.com <bucket_name> # ... Storage type: s3 Storage capacity: unbounded Storage config: { "bucket": <bucket_name>, "prefix": "velero/kopia/<application_namespace>/", "endpoint": "s3.amazonaws.com", "accessKeyID": <access_key>, "secretAccessKey": "****************************************", "sessionToken": "" } Unique ID: 58....aeb0 Hash: BLAKE3-256 Encryption: CHACHA20-POLY1305-HMAC-SHA256 Splitter: DYNAMIC-8M-RABINKARP Format version: 3 # ...
4.21.3.3. Kopia のハッシュ、暗号化、およびスプリッターアルゴリズムのベンチマーク
Kopia のコマンドを実行して、ハッシュ、暗号化、およびスプリッターアルゴリズムのベンチマークを実行できます。ベンチマークの結果に基づいて、ワークロードに最も適したアルゴリズムを選択できます。この手順では、クラスター上の Pod から Kopia ベンチマークコマンドを実行します。ベンチマークの結果は、CPU 速度、使用可能な RAM、ディスク速度、現在の I/O 負荷などによって異なります。
前提条件
- OADP Operator がインストールされている。
- 別の namespace で実行されている永続ボリュームを持つアプリケーションがある。
- Container Storage Interface (CSI) スナップショットを使用してアプリケーションのバックアップを実行した。
Data Protection Application (DPA) の分割、ハッシュ、および暗号化のための Kopia アルゴリズムの設定は、Kopia リポジトリーの初回作成時にのみ適用され、後で変更することはできません。
異なる Kopia アルゴリズムを使用するには、オブジェクトストレージに、バックアップの以前の Kopia リポジトリーが含まれていないことを確認してください。Backup Storage Location (BSL) で新しいオブジェクトストレージを設定するか、BSL 設定でオブジェクトストレージの一意の接頭辞を指定します。
手順
以下の例のように、
must-gatherPod を設定します。必ず OADP バージョン 1.3 以降のoadp-mustgatherイメージを使用してください。Pod 設定の例
apiVersion: v1 kind: Pod metadata: name: oadp-mustgather-pod labels: purpose: user-interaction spec: containers: - name: oadp-mustgather-container image: registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 command: ["sleep"] args: ["infinity"]注記Kopia クライアントは
oadp-mustgatherイメージで利用できます。以下のコマンドを実行して Pod を作成します。
$ oc apply -f <pod_config_file_name>1 - 1
- Pod 設定用の YAML ファイルの名前を指定します。
Kopia がリポジトリーに接続できるように、Pod の Security Context Constraints (SCC) が
anyuidであることを確認します。$ oc describe pod/oadp-mustgather-pod | grep scc出力例
openshift.io/scc: anyuid次のコマンドを実行して、SSH 経由で Pod に接続します。
$ oc -n openshift-adp rsh pod/oadp-mustgather-pod次のコマンドを実行して、Kopia リポジトリーに接続します。
sh-5.1# kopia repository connect s3 \ --bucket=<bucket_name> \1 --prefix=velero/kopia/<application_namespace> \2 --password=static-passw0rd \3 --access-key="<access_key>" \4 --secret-access-key="<secret_access_key>" \5 --endpoint=<bucket_endpoint> \6 注記これはコマンドの例です。コマンドはオブジェクトストレージプロバイダーによって異なる場合があります。
ハッシュアルゴリズムをベンチマークするには、次のコマンドを実行します。
sh-5.1# kopia benchmark hashing出力例
Benchmarking hash 'BLAKE2B-256' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'BLAKE2B-256-128' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'BLAKE2S-128' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'BLAKE2S-256' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'BLAKE3-256' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'BLAKE3-256-128' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'HMAC-SHA224' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'HMAC-SHA256' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'HMAC-SHA256-128' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'HMAC-SHA3-224' (100 x 1048576 bytes, parallelism 1) Benchmarking hash 'HMAC-SHA3-256' (100 x 1048576 bytes, parallelism 1) Hash Throughput ----------------------------------------------------------------- 0. BLAKE3-256 15.3 GB / second 1. BLAKE3-256-128 15.2 GB / second 2. HMAC-SHA256-128 6.4 GB / second 3. HMAC-SHA256 6.4 GB / second 4. HMAC-SHA224 6.4 GB / second 5. BLAKE2B-256-128 4.2 GB / second 6. BLAKE2B-256 4.1 GB / second 7. BLAKE2S-256 2.9 GB / second 8. BLAKE2S-128 2.9 GB / second 9. HMAC-SHA3-224 1.6 GB / second 10. HMAC-SHA3-256 1.5 GB / second ----------------------------------------------------------------- Fastest option for this machine is: --block-hash=BLAKE3-256暗号化アルゴリズムをベンチマークするには、次のコマンドを実行します。
sh-5.1# kopia benchmark encryption出力例
Benchmarking encryption 'AES256-GCM-HMAC-SHA256'... (1000 x 1048576 bytes, parallelism 1) Benchmarking encryption 'CHACHA20-POLY1305-HMAC-SHA256'... (1000 x 1048576 bytes, parallelism 1) Encryption Throughput ----------------------------------------------------------------- 0. AES256-GCM-HMAC-SHA256 2.2 GB / second 1. CHACHA20-POLY1305-HMAC-SHA256 1.8 GB / second ----------------------------------------------------------------- Fastest option for this machine is: --encryption=AES256-GCM-HMAC-SHA256スプリッターアルゴリズムをベンチマークするには、次のコマンドを実行します。
sh-5.1# kopia benchmark splitter出力例
splitting 16 blocks of 32MiB each, parallelism 1 DYNAMIC 747.6 MB/s count:107 min:9467 10th:2277562 25th:2971794 50th:4747177 75th:7603998 90th:8388608 max:8388608 DYNAMIC-128K-BUZHASH 718.5 MB/s count:3183 min:3076 10th:80896 25th:104312 50th:157621 75th:249115 90th:262144 max:262144 DYNAMIC-128K-RABINKARP 164.4 MB/s count:3160 min:9667 10th:80098 25th:106626 50th:162269 75th:250655 90th:262144 max:262144 # ... FIXED-512K 102.9 TB/s count:1024 min:524288 10th:524288 25th:524288 50th:524288 75th:524288 90th:524288 max:524288 FIXED-8M 566.3 TB/s count:64 min:8388608 10th:8388608 25th:8388608 50th:8388608 75th:8388608 90th:8388608 max:8388608 ----------------------------------------------------------------- 0. FIXED-8M 566.3 TB/s count:64 min:8388608 10th:8388608 25th:8388608 50th:8388608 75th:8388608 90th:8388608 max:8388608 1. FIXED-4M 425.8 TB/s count:128 min:4194304 10th:4194304 25th:4194304 50th:4194304 75th:4194304 90th:4194304 max:4194304 # ... 22. DYNAMIC-128K-RABINKARP 164.4 MB/s count:3160 min:9667 10th:80098 25th:106626 50th:162269 75th:250655 90th:262144 max:262144
4.22. トラブルシューティング
OpenShift CLI ツール または Velero CLI ツール を使用して、Velero カスタムリソース (CR) をデバッグできます。Velero CLI ツールは、より詳細なログおよび情報を提供します。
インストールの問題、CR のバックアップと復元の問題、および Restic の問題 を確認できます。
ログと CR 情報は、must-gather ツール を使用して収集できます。
Velero CLI ツールは、次の方法で入手できます。
- Velero CLI ツールをダウンロードする
- クラスター内の Velero デプロイメントで Velero バイナリーにアクセスする
4.22.1. Velero CLI ツールをダウンロードする
Velero のドキュメントページ の手順に従って、Velero CLI ツールをダウンロードしてインストールできます。
このページには、以下に関する手順が含まれています。
- Homebrew を使用した macOS
- GitHub
- Chocolatey を使用した Windows
前提条件
- DNS とコンテナーネットワークが有効になっている、v1.16 以降の Kubernetes クラスターにアクセスできる。
-
kubectlをローカルにインストールしている。
手順
- ブラウザーを開き、Velero Web サイト上の "Install the CLI" に移動します。
- macOS、GitHub、または Windows の適切な手順に従います。
- 使用している OADP および OpenShift Container Platform のバージョンに適切な Velero バージョンをダウンロードします。
4.22.1.1. OADP、Velero、および OpenShift Container Platform の各バージョンの関係
| OADP のバージョン | Velero のバージョン | OpenShift Container Platform バージョン |
|---|---|---|
| 1.1.0 | 4.9 以降 | |
| 1.1.1 | 4.9 以降 | |
| 1.1.2 | 4.9 以降 | |
| 1.1.3 | 4.9 以降 | |
| 1.1.4 | 4.9 以降 | |
| 1.1.5 | 4.9 以降 | |
| 1.1.6 | 4.11 以降 | |
| 1.1.7 | 4.11 以降 | |
| 1.2.0 | 4.11 以降 | |
| 1.2.1 | 4.11 以降 | |
| 1.2.2 | 4.11 以降 | |
| 1.2.3 | 4.11 以降 | |
| 1.3.0 | 4.10 - 4.15 | |
| 1.3.1 | 4.10 - 4.15 | |
| 1.3.2 | 4.10 - 4.15 | |
| 1.3.3 | 4.10 - 4.15 | |
| 1.4.0 | 4.14 以降 | |
| 1.4.1 | 4.14 以降 |
4.22.2. クラスター内の Velero デプロイメントで Velero バイナリーにアクセスする
shell コマンドを使用して、クラスター内の Velero デプロイメントの Velero バイナリーにアクセスできます。
前提条件
-
DataProtectionApplicationカスタムリソースのステータスがReconcile completeである。
手順
次のコマンドを入力して、必要なエイリアスを設定します。
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
4.22.3. OpenShift CLI ツールを使用した Velero リソースのデバッグ
OpenShift CLI ツールを使用して Velero カスタムリソース (CR) と Velero Pod ログを確認することで、失敗したバックアップまたは復元をデバッグできます。
Velero CR
oc describe コマンドを使用して、Backup または Restore CR に関連する警告とエラーの要約を取得します。
$ oc describe <velero_cr> <cr_name>Velero Pod ログ
oc logs コマンドを使用して、Velero Pod ログを取得します。
$ oc logs pod/<velero>Velero Pod のデバッグログ
次の例に示すとおり、DataProtectionApplication リソースで Velero ログレベルを指定できます。
このオプションは、OADP 1.0.3 以降で使用できます。
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: velero-sample
spec:
configuration:
velero:
logLevel: warning
次の logLevel 値を使用できます。
-
trace -
debug -
info -
warning -
error -
fatal -
panic
ほとんどのログには debug を使用することを推奨します。
4.22.4. Velero CLI ツールを使用した Velero リソースのデバッグ
Velero CLI ツールを使用して、Backup および Restore カスタムリソース (CR) をデバッグし、ログを取得できます。
Velero CLI ツールは、OpenShift CLI ツールよりも詳細な情報を提供します。
構文
oc exec コマンドを使用して、Velero CLI コマンドを実行します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> <command> <cr_name>例
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8qlヘルプオプション
velero --help オプションを使用して、すべての Velero CLI コマンドをリスト表示します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
--helpdescribe コマンド
velero describe コマンドを使用して、Backup または Restore CR に関連する警告とエラーの要約を取得します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> describe <cr_name>例
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
次の種類の復元エラーと警告が、velero describe リクエストの出力に表示されます。
-
Velero: Velero 自体の操作に関連するメッセージのリスト (クラウドへの接続、バックアップファイルの読み取りなどに関連するメッセージなど) -
Cluster: クラスタースコープのリソースのバックアップまたは復元に関連するメッセージのリスト -
Namespaces: namespace に保存されているリソースのバックアップまたは復元に関連するメッセージのリスト
これらのカテゴリーのいずれかで 1 つ以上のエラーが発生すると、Restore 操作のステータスが PartiallyFailed になり、Completed ではなくなります。警告によって完了ステータスが変化することはありません。
-
リソース固有のエラー、つまり
ClusterおよびNamespacesエラーの場合、restore describe --details出力に、Velero が復元に成功したすべてのリソースのリストが含まれています。このようなエラーが発生したリソースは、そのリソースが実際にクラスター内に存在するかどうかを確認してください。 describeコマンドの出力にVeleroエラーがあっても、リソース固有のエラーがない場合は、ワークロードの復元で実際の問題が発生することなく復元が完了した可能性があります。ただし、復元後のアプリケーションを十分に検証してください。たとえば、出力に
PodVolumeRestoreまたはノードエージェント関連のエラーが含まれている場合は、PodVolumeRestoresとDataDownloadsのステータスを確認します。これらのいずれも失敗していないか、まだ実行中である場合は、ボリュームデータが完全に復元されている可能性があります。
logs コマンド
velero logs コマンドを使用して、Backup または Restore CR のログを取得します。
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
<backup_restore_cr> logs <cr_name>例
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \
restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf4.22.5. メモリーまたは CPU の不足により Pod がクラッシュまたは再起動する
メモリーまたは CPU の不足により Velero または Restic Pod がクラッシュした場合、これらのリソースのいずれかに対して特定のリソースリクエストを設定できます。
4.22.5.1. Velero Pod のリソースリクエストの設定
oadp_v1alpha1_dpa.yaml ファイルの configuration.velero.podConfig.resourceAllocations 仕様フィールドを使用して、Velero Pod に対する特定のリソース要求を設定できます。
手順
YAML ファイルで
cpuおよびmemoryリソース要求を設定します。Velero ファイルの例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: velero: podConfig: resourceAllocations:1 requests: cpu: 200m memory: 256Mi- 1
- リストされている
resourceAllocationsは、平均使用量です。
4.22.5.2. Restic Pod のリソースリクエストの設定
configuration.restic.podConfig.resourceAllocations 仕様フィールドを使用して、Restic Pod の特定のリソース要求を設定できます。
手順
YAML ファイルで
cpuおよびmemoryリソース要求を設定します。Restic ファイルの例
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: restic: podConfig: resourceAllocations:1 requests: cpu: 1000m memory: 16Gi- 1
- リストされている
resourceAllocationsは、平均使用量です。
リソース要求フィールドの値は、Kubernetes リソース要件と同じ形式に従う必要があります。また、configuration.velero.podConfig.resourceAllocations または configuration.restic.podConfig.resourceAllocations を指定しない場合、Velero Pod または Restic Pod のデフォルトの resources 仕様は次のようになります。
requests:
cpu: 500m
memory: 128Mi4.22.6. StorageClass が NFS の場合、PodVolumeRestore は完了しない
Restic または Kopia を使用して NFS を復元するときにボリュームが複数あると、復元操作は失敗します。PodVolumeRestore は、次のエラーで失敗するか、復元を試行し続けた後に最終的に失敗します。
エラーメッセージ
Velero: pod volume restore failed: data path restore failed: \
Failed to run kopia restore: Failed to copy snapshot data to the target: \
restore error: copy file: error creating file: \
open /host_pods/b4d...6/volumes/kubernetes.io~nfs/pvc-53...4e5/userdata/base/13493/2681: \
no such file or directory原因
復元する 2 つのボリュームの NFS マウントパスは一意ではありません。その結果、velero ロックファイルは復元中に NFS サーバー上の同じファイルを使用するため、PodVolumeRestore が失敗します。
解決方法
この問題は、deploy/class.yaml ファイルで nfs-subdir-external-provisioner の StorageClass を定義しながら、ボリュームごとに一意の pathPattern を設定することで解決できます。次の nfs-subdir-external-provisioner StorageClass の例を使用します。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
pathPattern: "${.PVC.namespace}/${.PVC.annotations.nfs.io/storage-path}"
onDelete: delete- 1
- ラベル、アノテーション、名前、namespace などの
PVCメタデータを使用してディレクトリーパスを作成するためのテンプレートを指定します。メタデータを指定するには、${.PVC.<metadata>}を使用します。たとえば、フォルダーに<pvc-namespace>-<pvc-name>という名前を付けるには、pathPatternとして${.PVC.namespace}-${.PVC.name}使用します。
4.22.7. Velero と受付 Webhook に関する問題
Velero では、復元中にアドミッション Webhook の問題を解決する機能が限られています。アドミッション Webhook を使用するワークロードがある場合は、追加の Velero プラグインを使用するか、ワークロードの復元方法を変更する必要がある場合があります。
通常、アドミッション Webhook を使用するワークロードでは、最初に特定の種類のリソースを作成する必要があります。これはワークロードに子リソースがある場合に特に当てはまります。アドミッション Webhook は通常、子リソースをブロックするためです。
たとえば、service.serving.knative.dev などの最上位オブジェクトを作成または復元すると、通常、子リソースが自動的に作成されます。最初にこれを行う場合、Velero を使用してこれらのリソースを作成および復元する必要はありません。これにより、Velero が使用する可能性のあるアドミッション Webhook によって子リソースがブロックされるという問題が回避されます。
4.22.7.1. 受付 Webhook を使用する Velero バックアップの回避策の復元
このセクションでは、受付 Webhook を使用するいくつかのタイプの Velero バックアップのリソースを復元するために必要な追加の手順を説明します。
4.22.7.1.1. Knative リソースの復元
Velero を使用してアドミッション Webhook を使用する Knative リソースをバックアップすると、問題が発生する可能性があります。
アドミッション Webhook を使用する Knative リソースをバックアップおよび復元する場合は、常に最上位の Service リソースを最初に復元することで、このような問題を回避できます。
手順
最上位の
service.serving.knavtive.dev Serviceリソースを復元します。$ velero restore <restore_name> \ --from-backup=<backup_name> --include-resources \ service.serving.knavtive.dev
4.22.7.1.2. IBM AppConnect リソースの復元
Velero を使用して受付 Webhook を持つ IBM AppConnect リソースを復元するときに問題が発生した場合は、この手順のチェックを実行できます。
手順
クラスター内の
kind: MutatingWebhookConfigurationの受付プラグインの変更があるかチェックします。$ oc get mutatingwebhookconfigurations-
各
kind: MutatingWebhookConfigurationの YAML ファイルを調べて、問題が発生しているオブジェクトの作成をブロックするルールがないことを確認します。詳細は、Kubernetes の公式ドキュメント を参照してください。 -
バックアップ時に使用される
type: Configuration.appconnect.ibm.com/v1beta1のspec.versionが、インストールされている Operator のサポート対象であることを確認してください。
4.22.7.2. OADP プラグインの既知の問題
次のセクションでは、OpenShift API for Data Protection (OADP) プラグインの既知の問題を説明します。
4.22.7.2.1. シークレットがないことで、イメージストリームのバックアップ中に Velero プラグインでパニックが発生する
バックアップと Backup Storage Location (BSL) が Data Protection Application (DPA) の範囲外で管理されている場合、OADP コントローラー (つまり DPA の調整) によって関連する oadp-<bsl_name>-<bsl_provider>-registry-secret が作成されません。
バックアップを実行すると、OpenShift Velero プラグインがイメージストリームバックアップでパニックになり、次のパニックエラーが表示されます。
024-02-27T10:46:50.028951744Z time="2024-02-27T10:46:50Z" level=error msg="Error backing up item"
backup=openshift-adp/<backup name> error="error executing custom action (groupResource=imagestreams.image.openshift.io,
namespace=<BSL Name>, name=postgres): rpc error: code = Aborted desc = plugin panicked:
runtime error: index out of range with length 1, stack trace: goroutine 94…4.22.7.2.1.1. パニックエラーを回避するための回避策
Velero プラグインのパニックエラーを回避するには、次の手順を実行します。
カスタム BSL に適切なラベルを付けます。
$ oc label backupstoragelocations.velero.io <bsl_name> app.kubernetes.io/component=bslBSL にラベルを付けた後、DPA の調整を待ちます。
注記DPA 自体に軽微な変更を加えることで、強制的に調整を行うことができます。
DPA の調整では、適切な
oadp-<bsl_name>-<bsl_provider>-registry-secretが作成されていること、正しいレジストリーデータがそこに設定されていることを確認します。$ oc -n openshift-adp get secret/oadp-<bsl_name>-<bsl_provider>-registry-secret -o json | jq -r '.data'
4.22.7.2.2. OpenShift ADP Controller のセグメンテーション違反
cloudstorage と restic の両方を有効にして DPA を設定すると、openshift-adp-controller-manager Pod がクラッシュし、Pod がクラッシュループのセグメンテーション違反で失敗するまで無期限に再起動します。
velero または cloudstorage は相互に排他的なフィールドであるため、どちらか一方だけ定義できます。
-
veleroとcloudstorageの両方が定義されている場合、openshift-adp-controller-managerは失敗します。 -
veleroとcloudstorageのいずれも定義されていない場合、openshift-adp-controller-managerは失敗します。
この問題の詳細は、OADP-1054 を参照してください。
4.22.7.2.2.1. OpenShift ADP Controller のセグメンテーション違反の回避策
DPA の設定時に、velero または cloudstorage のいずれかを定義する必要があります。DPA で両方の API を定義すると、openshift-adp-controller-manager Pod がクラッシュループのセグメンテーション違反で失敗します。
4.22.7.3. Velero プラグインがメッセージ "received EOF, stopping recv loop" を返す
Velero プラグインは、別のプロセスとして開始されます。Velero 操作が完了すると、成功したかどうかにかかわらず終了します。デバッグログの received EOF, stopping recv loop メッセージは、プラグイン操作が完了したことを示します。エラーが発生したわけではありません。
4.22.8. インストールの問題
Data Protection Application をインストールするときに、無効なディレクトリーまたは誤った認証情報を使用することによって問題が発生する可能性があります。
4.22.8.1. バックアップストレージに無効なディレクトリーが含まれています
Velero Pod ログにエラーメッセージ Backup storage contains invalid top-level directories が表示されます。
原因
オブジェクトストレージには、Velero ディレクトリーではないトップレベルのディレクトリーが含まれています。
解決方法
オブジェクトストレージが Velero 専用でない場合は、DataProtectionApplication マニフェストで spec.backupLocations.velero.objectStorage.prefix パラメーターを設定して、バケットの接頭辞を指定する必要があります。
4.22.8.2. 不正な AWS 認証情報
oadp-aws-registry Pod ログにエラーメッセージ InvalidAccessKeyId: The AWS Access Key Id you provided does not exist in our records. が表示されます。
Velero Pod ログには、エラーメッセージ NoCredentialProviders: no valid providers in chain が表示されます。
原因
Secret オブジェクトの作成に使用された credentials-velero ファイルの形式が正しくありません。
解決方法
次の例のように、credentials-velero ファイルが正しくフォーマットされていることを確認します。
サンプル credentials-velero ファイル
[default]
aws_access_key_id=AKIAIOSFODNN7EXAMPLE
aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY4.22.9. OADP Operator の問題
OpenShift API for Data Protection (OADP) Operator では、解決できない問題が原因で問題が発生する可能性があります。
4.22.9.1. OADP Operator がサイレントに失敗する
OADP Operator の S3 バケットは空である可能性がありますが、oc get po -n <OADP_Operator_namespace> コマンドを実行すると、Operator のステータスが Running であることがわかります。この場合、Operator は実行中であると誤報告するため、サイレントに失敗した と言われます。
原因
この問題は、クラウド認証情報で提供される権限が不十分な場合に発生します。
解決方法
Backup Storage Location (BSL) のリストを取得し、各 BSL のマニフェストで認証情報の問題を確認します。
手順
次のコマンドのいずれかを実行して、BSL のリストを取得します。
OpenShift CLI を使用する場合:
$ oc get backupstoragelocations.velero.io -AVelero CLI を使用する場合:
$ velero backup-location get -n <OADP_Operator_namespace>
BSL のリストを使用し、次のコマンドを実行して各 BSL のマニフェストを表示し、各マニフェストにエラーがないか調べます。
$ oc get backupstoragelocations.velero.io -n <namespace> -o yaml
結果の例:
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-11-03T19:49:04Z"
generation: 9703
name: example-dpa-1
namespace: openshift-adp-operator
ownerReferences:
- apiVersion: oadp.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: DataProtectionApplication
name: example-dpa
uid: 0beeeaff-0287-4f32-bcb1-2e3c921b6e82
resourceVersion: "24273698"
uid: ba37cd15-cf17-4f7d-bf03-8af8655cea83
spec:
config:
enableSharedConfig: "true"
region: us-west-2
credential:
key: credentials
name: cloud-credentials
default: true
objectStorage:
bucket: example-oadp-operator
prefix: example
provider: aws
status:
lastValidationTime: "2023-11-10T22:06:46Z"
message: "BackupStorageLocation \"example-dpa-1\" is unavailable: rpc
error: code = Unknown desc = WebIdentityErr: failed to retrieve credentials\ncaused
by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus
code: 403, request id: d3f2e099-70a0-467b-997e-ff62345e3b54"
phase: Unavailable
kind: List
metadata:
resourceVersion: ""4.22.10. OADP タイムアウト
タイムアウトを延長すると、複雑なプロセスやリソースを大量に消費するプロセスが途中で終了することなく正常に完了できます。この設定により、エラー、再試行、または失敗の可能性を減らすことができます。
過度に長いタイムアウトを設定しないように、論理的な方法でタイムアウト延長のバランスをとってください。過度に長いと、プロセス内の根本的な問題が隠れる可能性があります。プロセスのニーズとシステム全体のパフォーマンスを満たす適切なタイムアウト値を慎重に検討して、監視してください。
次に、さまざまな OADP タイムアウトと、これらのパラメーターをいつどのように実装するかの手順を示します。
4.22.10.1. Restic タイムアウト
spec.configuration.nodeAgent.timeout パラメーターは、Restic タイムアウトを定義します。デフォルト値は 1h です。
次に該当する場合は、nodeAgent セクションで Restic timeout パラメーターを使用してください。
- PV データの使用量の合計が 500GB を超える Restic バックアップの場合。
バックアップが次のエラーでタイムアウトになる場合:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete"
手順
DataProtectionApplicationカスタムリソース (CR) マニフェストのspec.configuration.nodeAgent.timeoutブロックの値を編集します。次に例を示します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: nodeAgent: enable: true uploaderType: restic timeout: 1h # ...
4.22.10.2. Velero リソースのタイムアウト
resourceTimeout は Velero カスタムリソース定義 (CRD) の可用性、volumeSnapshot の削除、リポジトリーの可用性など、タイムアウトが発生する前に複数の Velero リソースを待機する時間を定義します。デフォルトは 10m です。
次のシナリオでは resourceTimeout を使用します。
合計 PV データ使用量が 1TB を超えるバックアップの場合。このパラメーターは、バックアップを完了としてマークする前に、Velero が Container Storage Interface (CSI) スナップショットをクリーンアップまたは削除しようとするときのタイムアウト値として使用されます。
- このクリーンアップのサブタスクは VSC にパッチを適用しようとします。このタイムアウトはそのタスクに使用できます。
- Restic または Kopia のファイルシステムベースのバックアップのバックアップリポジトリーを作成または準備できるようにするため。
- カスタムリソース (CR) またはバックアップからリソースを復元する前に、クラスター内で Velero CRD が利用可能かどうかを確認します。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.resourceTimeoutブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: resourceTimeout: 10m # ...
4.22.10.3. Data Mover のタイムアウト
timeout は、VolumeSnapshotBackup および VolumeSnapshotRestore を完了するためにユーザーが指定したタイムアウトです。デフォルト値は 10m です。
次のシナリオでは、Data Mover timeout を使用します。
-
VolumeSnapshotBackups(VSB) およびVolumeSnapshotRestores(VSR) を作成する場合は、10 分後にタイムアウトします。 -
合計 PV データ使用量が 500GB を超える大規模環境向け。
1hのタイムアウトを設定します。 -
VolumeSnapshotMover(VSM) プラグインを使用します。 - OADP 1.1.x のみ。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.features.dataMover.timeoutブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: features: dataMover: timeout: 10m # ...
4.22.10.4. CSI スナップショットのタイムアウト
CSISnapshotTimeout は、タイムアウトとしてエラーを返す前に、CSI VolumeSnapshot ステータスが ReadyToUse になるまで待機する作成時の時間を指定します。デフォルト値は 10m です。
以下のシナリオでは、CSISnapshotTimeout を使用します。
- CSI プラグイン。
- スナップショットの作成に 10 分以上かかる可能性がある非常に大規模なストレージボリュームの場合。ログにタイムアウトが見つかった場合は、このタイムアウトを調整します。
通常、CSISnapshotTimeout のデフォルト値は、デフォルト設定で大規模なストレージボリュームに対応できるため、調整する必要はありません。
手順
次の例のように、
BackupCR マニフェストのspec.csiSnapshotTimeoutブロックの値を編集します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: csiSnapshotTimeout: 10m # ...
4.22.10.5. Velero におけるアイテム操作のデフォルトタイムアウト
defaultItemOperationTimeout では、非同期の BackupItemActions および RestoreItemActions がタイムアウトになる前に完了するのを待機する時間を定義します。デフォルト値は 1h です。
以下のシナリオでは、defaultItemOperationTimeout を使用します。
- Data Mover 1.2.x のみ。
- 特定のバックアップまたは復元が非同期アクションの完了を待機する時間を指定します。OADP 機能のコンテキストでは、この値は、Container Storage Interface (CSI) Data Mover 機能に関連する非同期アクションに使用されます。
-
defaultItemOperationTimeoutが、defaultItemOperationTimeoutを使用して Data Protection Application (DPA) に定義されている場合、バックアップおよび復元操作の両方に適用されます。itemOperationTimeoutでは、以下の "Item operation timeout - restore" セクションおよび "Item operation timeout - backup" セクションで説明されているように、バックアップのみを定義するか、これらの CR の復元のみを定義できます。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.defaultItemOperationTimeoutブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: defaultItemOperationTimeout: 1h # ...
4.22.10.6. アイテム操作のタイムアウト - 復元
ItemOperationTimeout は RestoreItemAction 操作の待機に使用される時間を指定します。デフォルト値は 1h です。
以下のシナリオでは、復元 ItemOperationTimeout を使用します。
- Data Mover 1.2.x のみ。
-
Data Mover の場合は、
BackupStorageLocationにアップロードおよびダウンロードします。タイムアウトに達しても復元アクションが完了しない場合、失敗としてマークされます。ストレージボリュームのサイズが大きいため、タイムアウトの問題が原因で Data Mover の操作が失敗する場合は、このタイムアウト設定を増やす必要がある場合があります。
手順
次の例のように、
RestoreCR マニフェストのRestore.spec.itemOperationTimeoutブロックの値を編集します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> spec: itemOperationTimeout: 1h # ...
4.22.10.7. アイテム操作のタイムアウト - バックアップ
ItemOperationTimeout は、非同期 BackupItemAction 操作の待機時間を指定します。デフォルト値は 1h です。
次のシナリオでは、バックアップ ItemOperationTimeout を使用します。
- Data Mover 1.2.x のみ。
-
Data Mover の場合は、
BackupStorageLocationにアップロードおよびダウンロードします。タイムアウトに達してもバックアップアクションが完了しない場合は、失敗としてマークされます。ストレージボリュームのサイズが大きいため、タイムアウトの問題が原因で Data Mover の操作が失敗する場合は、このタイムアウト設定を増やす必要がある場合があります。
手順
次の例のように、
BackupCR マニフェストのBackup.spec.itemOperationTimeoutブロックの値を編集します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: itemOperationTimeout: 1h # ...
4.22.11. バックアップおよび復元 CR の問題
Backup および Restore カスタムリソース (CR) でこれらの一般的な問題が発生する可能性があります。
4.22.11.1. バックアップ CR はボリュームを取得できません
Backup CR は、エラーメッセージ InvalidVolume.NotFound: The volume ‘vol-xxxx’ does not exist を表示します。
原因
永続ボリューム (PV) とスナップショットの場所は異なるリージョンにあります。
解決方法
-
DataProtectionApplicationマニフェストのspec.snapshotLocations.velero.config.regionキーの値を編集して、スナップショットの場所が PV と同じリージョンにあるようにします。 -
新しい
BackupCR を作成します。
4.22.11.2. Backup CR のステータスが進行中のままになる
Backup CR のステータスが InProgress のフェーズのままで、完了しません。
原因
バックアップが中断された場合は、再開することができません。
解決方法
BackupCR の詳細を取得します。$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ backup describe <backup>BackupCR を削除します。$ oc delete backups.velero.io <backup> -n openshift-adp進行中の
BackupCR はファイルをオブジェクトストレージにアップロードしていないため、バックアップの場所をクリーンアップする必要はありません。-
新しい
BackupCR を作成します。 Velero バックアップの詳細を表示します。
$ velero backup describe <backup-name> --details
4.22.11.3. バックアップ CR ステータスが PartiallyFailed のままになる
Restic が使用されていない Backup CR のステータスは、PartiallyFailed フェーズのままで、完了しません。関連する PVC のスナップショットは作成されません。
原因
CSI スナップショットクラスに基づいてバックアップが作成されているが、ラベルがない場合、CSI スナップショットプラグインはスナップショットの作成に失敗します。その結果、Velero Pod は次のようなエラーをログに記録します。
+
time="2023-02-17T16:33:13Z" level=error msg="Error backing up item" backup=openshift-adp/user1-backup-check5 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=busy1, name=pvc1-user1): rpc error: code = Unknown desc = failed to get volumesnapshotclass for storageclass ocs-storagecluster-ceph-rbd: failed to get volumesnapshotclass for provisioner openshift-storage.rbd.csi.ceph.com, ensure that the desired volumesnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="/remote-source/velero/app/pkg/backup/backup.go:417" name=busybox-79799557b5-vprq解決方法
BackupCR を削除します。$ oc delete backups.velero.io <backup> -n openshift-adp-
必要に応じて、
BackupStorageLocationに保存されているデータをクリーンアップして、領域を解放します。 ラベル
velero.io/csi-volumesnapshot-class=trueをVolumeSnapshotClassオブジェクトに適用します。$ oc label volumesnapshotclass/<snapclass_name> velero.io/csi-volumesnapshot-class=true-
新しい
BackupCR を作成します。
4.22.12. Restic の問題
Restic を使用してアプリケーションのバックアップを作成すると、これらの問題が発生する可能性があります。
4.22.12.1. root_squash が有効になっている NFS データボリュームの Restic パーミッションエラー
Restic Pod ログには、エラーメッセージ controller=pod-volume-backup error="fork/exec/usr/bin/restic: permission denied" が表示されます。
原因
NFS データボリュームで root_squash が有効になっている場合、Restic は nfsnobody にマッピングされ、バックアップを作成する権限がありません。
解決方法
この問題を解決するには、Restic の補足グループを作成し、そのグループ ID を DataProtectionApplication マニフェストに追加します。
-
NFS データボリューム上に
Resticの補足グループを作成します。 -
NFS ディレクトリーに
setgidビットを設定して、グループの所有権が継承されるようにします。 spec.configuration.nodeAgent.supplementalGroupsパラメーターとグループ ID をDataProtectionApplicationマニフェストに追加します。次に例を示します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication # ... spec: configuration: nodeAgent: enable: true uploaderType: restic supplementalGroups: - <group_id>1 # ...- 1
- 補助グループ ID を指定します。
-
ResticPod が再起動し、変更が適用されるまで待機します。
4.22.12.2. バケットが空になった後に、Restic Backup CR を再作成することはできない
namespace の Restic Backup CR を作成し、オブジェクトストレージバケットを空にしてから、同じ namespace の Backup CR を再作成すると、再作成された Backup CR は失敗します。
velero Pod のログに stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location? というエラーメッセージが表示されます。
原因
オブジェクトストレージから Restic ディレクトリーが削除された場合、Velero は ResticRepository マニフェストから Restic リポジトリーを再作成または更新しません。詳細は、Velero issue 4421 を参照してください。
解決方法
次のコマンドを実行して、関連する Restic リポジトリーを namespace から削除します。
$ oc delete resticrepository openshift-adp <name_of_the_restic_repository>次のエラーログでは、
mysql-persistentが問題のある Restic リポジトリーです。わかりやすくするために、リポジトリーの名前は斜体で表示されます。time="2021-12-29T18:29:14Z" level=info msg="1 errors encountered backup up item" backup=velero/backup65 logSource="pkg/backup/backup.go:431" name=mysql-7d99fc949-qbkds time="2021-12-29T18:29:14Z" level=error msg="Error backing up item" backup=velero/backup65 error="pod volume backup failed: error running restic backup, stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?\ns3:http://minio-minio.apps.mayap-oadp- veleo-1234.qe.devcluster.openshift.com/mayapvelerooadp2/velero1/ restic/mysql-persistent\n: exit status 1" error.file="/remote-source/ src/github.com/vmware-tanzu/velero/pkg/restic/backupper.go:184" error.function="github.com/vmware-tanzu/velero/ pkg/restic.(*backupper).BackupPodVolumes" logSource="pkg/backup/backup.go:435" name=mysql-7d99fc949-qbkds
4.22.13. must-gather ツールの使用
must-gather ツールを使用して、OADP カスタムリソースのログおよび情報を収集できます。
must-gather データはすべてのカスタマーケースに添付する必要があります。
must-gather ツールはコンテナーであり、常に実行される訳ではありません。このツールは、must-gather コマンドを実行して起動した後、数分間のみ動作します。
以下のオプションを指定して must-gather ツールを実行できます。オプションを使用するには、該当するオプションに対応するフラグを must-gather コマンドに追加します。
- デフォルト設定
-
この設定は、OADP Operator がインストールされているすべての namespace の Pod ログ、OADP、および
Veleroカスタムリソース (CR) 情報を収集します。 - Timeout
-
失敗した
BackupCR が多数ある場合は、データ収集に長い時間がかかる可能性があります。タイムアウト値を設定することでパフォーマンスを向上させることができます。 - 非セキュアな TLS 接続
-
カスタム CA 証明書を使用する場合は、非セキュアな TLS 接続とともに
must-gatherツールを使用します。
must-gather ツールは、収集した情報で Markdown 出力ファイルを生成します。Markdown ファイルはクラスターディレクトリーにあります。
前提条件
-
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにログインしている。 -
OpenShift CLI (
oc) がインストールされている。 - Red Hat Enterprise Linux (RHEL) 9.x と OADP 1.3 を使用している。
手順
-
must-gatherデータを保存するディレクトリーに移動します。 次のデータ収集オプションのいずれかに対して、
oc adm must-gatherコマンドを実行します。oc adm must-gatherコマンドでサポートされるフラグを確認するには、以下のコマンドを実行します。$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather -hmust-gatherツールのデフォルト設定を使用するには、以下のコマンドを実行します。$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3must-gatherツールで timeout フラグを使用するには、以下のコマンドを実行します。$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather --request-timeout 1m1 - 1
- この例では、タイムアウトは 1 分です。
must-gatherツールで非セキュアな TLS 接続フラグを使用するには、以下のコマンドを実行します。$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather --skip-tls非セキュアな TLS 接続と timeout フラグの組み合わせを
must-gatherツールで使用するには、以下のコマンドを実行します。$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.3 -- /usr/bin/gather --request-timeout 15s --skip-tls1 - 1
- この例では、タイムアウトは 15 秒です。デフォルトでは、
--skip-tlsフラグの値はfalseです。安全でない TLS 接続を許可するには、値をtrueに設定します。
検証
-
Markdown 出力ファイルが次の場所に生成されていることを確認します:
must-gather.local.89…054550/registry.redhat.io/oadp/oadp-mustgather-rhel9:v1.5-sha256-0…84/clusters/a4…86/oadp-must-gather-summary.md Markdown プレビューワーでファイルを開き、Markdown ファイルで
must-gatherデータを確認します。出力例は、以下のイメージを参照してください。この出力ファイルを Red Hat カスタマーポータル で作成したサポートケースにアップロードできます。図4.1 must-gather ツールのマークダウン出力の例

4.22.14. OADP モニタリング
OpenShift Container Platform は、ユーザーと管理者がクラスターを効果的に監視および管理できるだけでなく、クラスター上で実行されているユーザーアプリケーションやサービスのワークロードパフォーマンスを監視および分析できるようにする監視スタックを提供します (イベント発生時のアラートの受信など)。
4.22.14.1. OADP モニタリングの設定
OADP Operator は、OpenShift のモニタリングスタックによって提供される OpenShift ユーザーワークロードモニタリングを利用して、Velero サービスエンドポイントからメトリクスを取得します。モニタリングスタックを使用すると、ユーザー定義のアラートルールを作成したり、OpenShift メトリクスのクエリーフロントエンドを使用してメトリクスを照会したりできます。
ユーザーワークロードモニタリングを有効にすると、Grafana などの Prometheus 互換のサードパーティー UI を設定して使用し、Velero メトリクスを視覚化することができます。
メトリクスを監視するには、ユーザー定義プロジェクトの監視を有効にし、openshift-adp namespace に存在するすでに有効な OADP サービスエンドポイントからそのプロジェクトのメトリクスを取得するための ServiceMonitor リソースを作成する必要があります。
Prometheus メトリクスに対する OADP サポートはベストエフォートで提供されており、完全にはサポートされていません。
モニタリングスタックの設定の詳細は、ユーザーワークロードモニタリングの設定 を参照してください。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 - クラスター監視 config map が作成されました。
手順
openshift-monitoringnamespace でcluster-monitoring-configConfigMapオブジェクトを編集します。$ oc edit configmap cluster-monitoring-config -n openshift-monitoringdataセクションのconfig.yamlフィールドで、enableUserWorkloadオプションを追加または有効にします。apiVersion: v1 kind: ConfigMap data: config.yaml: | enableUserWorkload: true1 metadata: # ...- 1
- このオプションを追加するか、
trueに設定します
しばらく待って、
openshift-user-workload-monitoringnamespace で次のコンポーネントが稼働しているかどうかを確認して、ユーザーワークロードモニタリングのセットアップを検証します。$ oc get pods -n openshift-user-workload-monitoring出力例
NAME READY STATUS RESTARTS AGE prometheus-operator-6844b4b99c-b57j9 2/2 Running 0 43s prometheus-user-workload-0 5/5 Running 0 32s prometheus-user-workload-1 5/5 Running 0 32s thanos-ruler-user-workload-0 3/3 Running 0 32s thanos-ruler-user-workload-1 3/3 Running 0 32sopenshift-user-workload-monitoringにuser-workload-monitoring-configConfigMap が存在することを確認します。存在する場合、この手順の残りの手順はスキップしてください。$ oc get configmap user-workload-monitoring-config -n openshift-user-workload-monitoring出力例
Error from server (NotFound): configmaps "user-workload-monitoring-config" not foundユーザーワークロードモニタリングの
user-workload-monitoring-configConfigMapオブジェクトを作成し、2_configure_user_workload_monitoring.yamlファイル名に保存します。出力例
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |2_configure_user_workload_monitoring.yamlファイルを適用します。$ oc apply -f 2_configure_user_workload_monitoring.yaml configmap/user-workload-monitoring-config created
4.22.14.2. OADP サービスモニターの作成
OADP は、DPA の設定時に作成される openshift-adp-velero-metrics-svc サービスを提供します。ユーザーワークロードモニタリングによって使用されるサービスモニターは、この定義されたサービスを参照する必要があります。
次のコマンドを実行して、サービスの詳細を取得します。
手順
openshift-adp-velero-metrics-svcサービスが存在することを確認します。これには、ServiceMonitorオブジェクトのセレクターとして使用されるapp.kubernetes.io/name=veleroラベルが含まれている必要があります。$ oc get svc -n openshift-adp -l app.kubernetes.io/name=velero出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE openshift-adp-velero-metrics-svc ClusterIP 172.30.38.244 <none> 8085/TCP 1h既存のサービスラベルと一致する
ServiceMonitorYAML ファイルを作成し、そのファイルを3_create_oadp_service_monitor.yamlとして保存します。サービスモニターはopenshift-adp-velero-metrics-svcサービスが存在するopenshift-adpnamespace に作成されます。ServiceMonitorオブジェクトの例apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: oadp-service-monitor name: oadp-service-monitor namespace: openshift-adp spec: endpoints: - interval: 30s path: /metrics targetPort: 8085 scheme: http selector: matchLabels: app.kubernetes.io/name: "velero"3_create_oadp_service_monitor.yamlファイルを適用します。$ oc apply -f 3_create_oadp_service_monitor.yaml出力例
servicemonitor.monitoring.coreos.com/oadp-service-monitor created
検証
OpenShift Container Platform Web コンソールの Administrator パースペクティブを使用して、新しいサービスモニターが Up 状態であることを確認します。サービスモニターが Up 状態になるまで数分間待ちます。
- Observe → Targets ページに移動します。
-
Filter が選択されていないこと、または User ソースが選択されていることを確認し、
Text検索フィールドにopenshift-adpと入力します。 サービスモニターの Status のステータスが Up であることを確認します。
図4.2 OADP のメトリクスターゲット
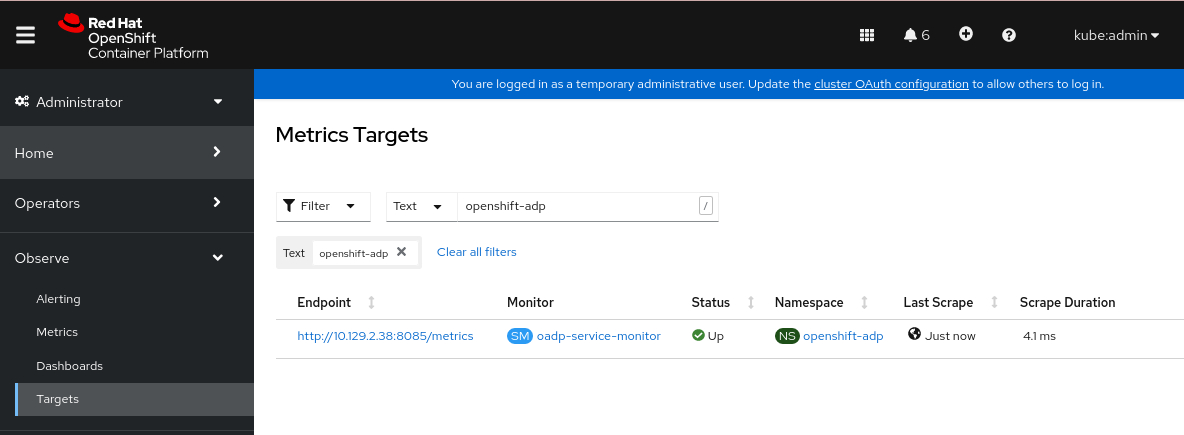
4.22.14.3. アラートルールの作成
OpenShift Container Platform モニタリングスタックでは、アラートルールを使用して設定されたアラートを受信できます。OADP プロジェクトのアラートルールを作成するには、ユーザーワークロードモニタリングで収集されたメトリクスの 1 つを使用します。
手順
サンプル
OADPBackupFailingアラートを含むPrometheusRuleYAML ファイルを作成し、4_create_oadp_alert_rule.yamlとして保存します。OADPBackupFailingアラートのサンプルapiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: sample-oadp-alert namespace: openshift-adp spec: groups: - name: sample-oadp-backup-alert rules: - alert: OADPBackupFailing annotations: description: 'OADP had {{$value | humanize}} backup failures over the last 2 hours.' summary: OADP has issues creating backups expr: | increase(velero_backup_failure_total{job="openshift-adp-velero-metrics-svc"}[2h]) > 0 for: 5m labels: severity: warningこのサンプルでは、アラートは次の条件で表示されます。
- 過去 2 時間に失敗した新しいバックアップの数が 0 より大きく増加しており、その状態が少なくとも 5 分間継続します。
-
最初の増加時間が 5 分未満の場合、アラートは
Pending状態になり、その後、Firing状態に変わります。
4_create_oadp_alert_rule.yamlファイルを適用して、openshift-adpnamespace にPrometheusRuleオブジェクトを作成します。$ oc apply -f 4_create_oadp_alert_rule.yaml出力例
prometheusrule.monitoring.coreos.com/sample-oadp-alert created
検証
アラートがトリガーされた後は、次の方法でアラートを表示できます。
- Developer パースペクティブで、Observe メニューを選択します。
Observe → Alerting メニューの下の Administrator パースペクティブで、Filter ボックスの User を選択します。それ以外の場合、デフォルトでは Platform アラートのみが表示されます。
図4.3 OADP のバックアップ失敗アラート
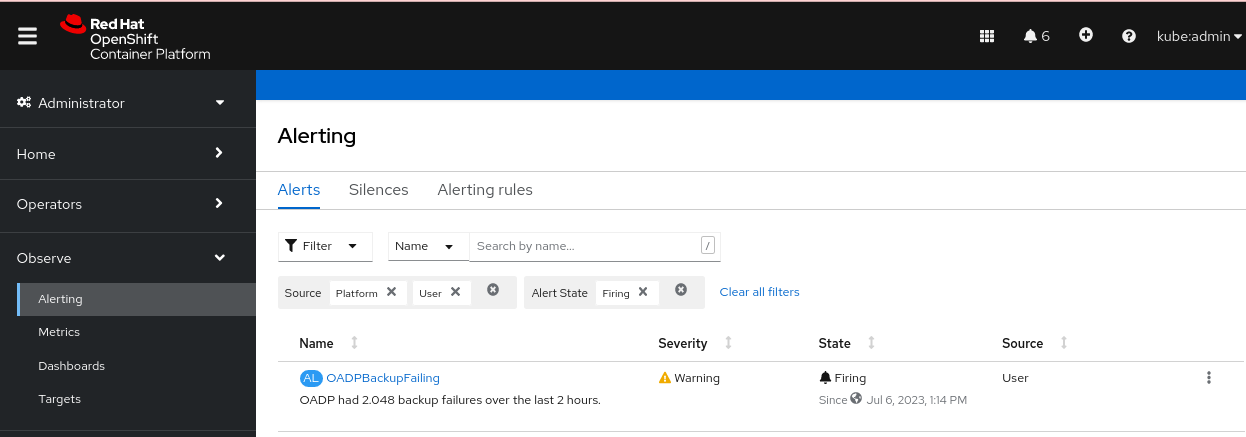
4.22.14.4. 利用可能なメトリクスのリスト
OADP によって提供される Velero メトリクスとその Types のリストは、次の表を参照してください。
| メトリクス名 | 説明 | 型 |
|---|---|---|
|
| バックアップのサイズ (バイト単位) | ゲージ |
|
| 既存のバックアップの現在の数 | ゲージ |
|
| 試行されたバックアップの合計数 | Counter |
|
| 成功したバックアップの合計数 | Counter |
|
| 部分的に失敗したバックアップの合計数 | Counter |
|
| 失敗したバックアップの合計数 | Counter |
|
| 検証に失敗したバックアップの合計数 | Counter |
|
| バックアップの完了にかかる時間 (秒単位) | ヒストグラム |
|
|
メトリクス | Counter |
|
|
メトリクス | Counter |
|
|
メトリクス | Counter |
|
| 試行されたバックアップ削除の合計数 | Counter |
|
| 成功したバックアップ削除の合計数 | Counter |
|
| 失敗したバックアップ削除の合計数 | Counter |
|
| 最後にバックアップが正常に実行された時刻、秒単位の Unix タイムスタンプ | ゲージ |
|
| バックアップされたアイテムの総数 | ゲージ |
|
| バックアップ中に発生したエラーの合計数 | ゲージ |
|
| 警告されたバックアップの総数 | Counter |
|
| バックアップの最終ステータス。値 1 は成功、0 は失敗です。 | ゲージ |
|
| 現在の既存のリストアの数 | ゲージ |
|
| 試行された復元の合計数 | Counter |
|
| 検証に失敗したリストアの失敗の合計数 | Counter |
|
| 成功した復元の合計数 | Counter |
|
| 部分的に失敗したリストアの合計数 | Counter |
|
| 失敗したリストアの合計数 | Counter |
|
| 試行されたボリュームスナップショットの総数 | Counter |
|
| 成功したボリュームスナップショットの総数 | Counter |
|
| 失敗したボリュームスナップショットの総数 | Counter |
|
| CSI が試行したボリュームスナップショットの合計数 | Counter |
|
| CSI が成功したボリュームスナップショットの総数 | Counter |
|
| CSI で失敗したボリュームスナップショットの総数 | Counter |
4.22.14.5. Observe UI を使用したメトリクスの表示
OpenShift Container Platform Web コンソールでは、Administrator または Developer パースペクティブからメトリクスを表示できます。これには、openshift-adp プロジェクトへのアクセス権が必要です。
手順
Observe → Metrics ページに移動します。
Developer パースペクティブを使用している場合は、次の手順に従います。
- Custom query を選択するか、Show PromQL リンクをクリックします。
- クエリーを入力し、Enter をクリックします。
Administrator パースペクティブを使用している場合は、テキストフィールドに式を入力し、Run Queries を選択します。
図4.4 OADP のメトリクスクエリー
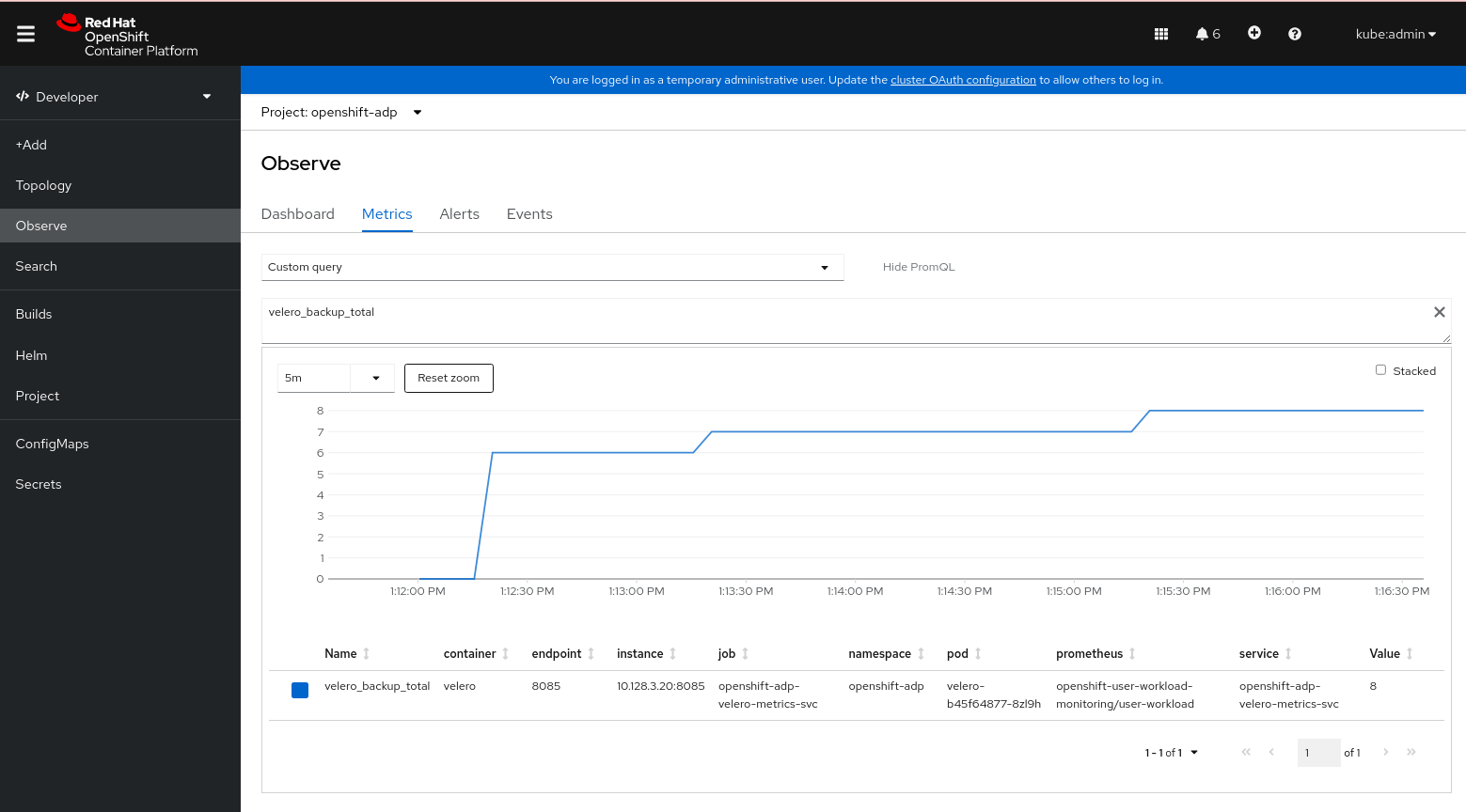
4.23. OADP で使用される API
このドキュメントには、OADP で使用できる次の API に関する情報が記載されています。
- Velero API
- OADP API
4.23.1. Velero API
Velero API ドキュメントは、Red Hat ではなく、Velero によって管理されています。これは Velero API types にあります。
4.23.2. OADP API
次の表は、OADP API の構造を示しています。
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| |
|
|
| |
|
| map [ UnsupportedImageKey ] string |
デプロイされた依存イメージを開発用にオーバーライドするために使用できます。オプションは、 |
|
| Operator によってデプロイされた Pod にアノテーションを追加するために使用されます。 | |
|
| Pod の DNS の設定を定義します。 | |
|
|
| |
|
| *bool | イメージのバックアップと復元を有効にするためにレジストリーをデプロイメントするかどうかを指定するために使用されます。 |
|
| Data Protection Application のサーバー設定を定義するために使用されます。 | |
|
| テクノロジープレビュー機能を有効にするための DPA の設定を定義します。 |
| プロパティー | 型 | 説明 |
|---|---|---|
|
| Backup Storage Location で説明されているとおり、ボリュームスナップショットの保存場所。 | |
|
| [テクノロジープレビュー] 一部のクラウドストレージプロバイダーで、Backup Storage Location として使用するバケットの作成を自動化します。 |
bucket パラメーターはテクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
| プロパティー | 型 | 説明 |
|---|---|---|
|
| Volume Snapshot Location で説明されているとおり、ボリュームスナップショットの保存場所。 |
SnapshotLocation タプの完全なスキーマ定義。
| プロパティー | 型 | 説明 |
|---|---|---|
|
| Velero サーバーの設定を定義します。 | |
|
| Restic サーバーの設定を定義します。 |
ApplicationConfig タイプの完全なスキーマ定義。
| プロパティー | 型 | 説明 |
|---|---|---|
|
| [] string | Velero インスタンスで有効にする機能のリストを定義します。 |
|
| [] string |
次のタイプのデフォルトの Velero プラグインをインストールできます: |
|
| カスタム Velero プラグインのインストールに使用されます。 デフォルトおよびカスタムのプラグインは、OADP プラグイン で説明しています。 | |
|
|
| |
|
|
デフォルトの Backup Storage Location を設定せずに Velero をインストールするには、インストールを確認するために | |
|
|
| |
|
|
Velero サーバーのログレベル (最も詳細なログを記録するには |
| プロパティー | 型 | 説明 |
|---|---|---|
|
| *bool |
|
|
| []int64 |
|
|
|
Restic タイムアウトを定義するユーザー指定の期間文字列。デフォルト値は | |
|
|
|
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| |
|
|
Velero デプロイメントまたは Restic | |
|
|
Setting Velero CPU and memory resource allocations の説明に従って、 | |
|
| Pod に追加するラベル。 |
4.23.2.1. ノードエージェントとノードラベルの設定
OADP の DPA は、nodeSelector フィールドを使用して、ノードエージェントを実行できるノードを選択します。nodeSelector フィールドは、推奨される最も単純な形式のノード選択制約です。
指定したラベルが、各ノードのラベルと一致する必要があります。
選択した任意のノードでノードエージェントを実行する正しい方法は、ノードにカスタムラベルを付けることです。
$ oc label node/<node_name> node-role.kubernetes.io/nodeAgent=""
ノードのラベル付けに使用したのと同じカスタムラベルを DPA.spec.configuration.nodeAgent.podConfig.nodeSelector で使用します。以下に例を示します。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/nodeAgent: ""
次の例は nodeSelector のアンチパターンです。この例は、ノードに 'node-role.kubernetes.io/infra: ""' と 'node-role.kubernetes.io/worker: ""' の両方のラベルがないと機能しません。
configuration:
nodeAgent:
enable: true
podConfig:
nodeSelector:
node-role.kubernetes.io/infra: ""
node-role.kubernetes.io/worker: ""| プロパティー | 型 | 説明 |
|---|---|---|
|
| Data Mover の設定を定義します。 |
| プロパティー | 型 | 説明 |
|---|---|---|
|
|
| |
|
|
Data Mover のユーザー指定の Restic | |
|
|
|
OADP API の詳細は、OADP Operator を参照してください。
4.24. OADP の高度な特徴と機能
このドキュメントでは、OpenShift API for Data Protection (OADP) の高度な特徴と機能に関する情報を提供します。
4.24.1. 同一クラスター上での異なる Kubernetes API バージョンの操作
4.24.1.1. クラスター上の Kubernetes API グループバージョンのリスト表示
ソースクラスターは複数のバージョンの API を提供する場合があり、これらのバージョンの 1 つが優先 API バージョンになります。たとえば、Example という名前の API を持つソースクラスターは、example.com/v1 および example.com/v1beta2 API グループで使用できる場合があります。
Velero を使用してそのようなソースクラスターをバックアップおよび復元する場合、Velero は、Kubernetes API の優先バージョンを使用するリソースのバージョンのみをバックアップします。
上記の例では、example.com/v1 が優先 API である場合、Velero は example.com/v1 を使用するリソースのバージョンのみをバックアップします。さらに、Velero がターゲットクラスターでリソースを復元するには、ターゲットクラスターで使用可能な API リソースのセットに example.com/v1 が登録されている必要があります。
したがって、ターゲットクラスター上の Kubernetes API グループバージョンのリストを生成して、優先 API バージョンが使用可能な API リソースのセットに登録されていることを確認する必要があります。
手順
- 以下のコマンドを実行します。
$ oc api-resources4.24.1.2. API グループバージョンの有効化について
デフォルトでは、Velero は Kubernetes API の優先バージョンを使用するリソースのみをバックアップします。ただし、Velero には、この制限を克服する機能 (Enable API Group Versions) も含まれています。ソースクラスターでこの機能を有効にすると、Velero は優先バージョンだけでなく、クラスターでサポートされている すべて の Kubernetes API グループバージョンをバックアップします。バージョンがバックアップ .tar ファイルに保存されると、目的のクラスターで復元できるようになります。
たとえば、Example という名前の API を持つソースクラスターが、example.com/v1 および example.com/v1beta2 API グループで使用でき、example.com/v1 が優先 API だとします。
Enable API Group Versions 機能を有効にしないと、Velero は Example の優先 API グループバージョン (example.com/v1) のみをバックアップします。この機能を有効にすると、Velero は example.com/v1beta2 もバックアップします。
宛先クラスターで Enable API Group Versions 機能が有効になっている場合、Velero は、API グループバージョンの優先順位に基づいて、復元するバージョンを選択します。
Enable API Group Versions はまだベータ版です。
Velero は次のアルゴリズムを使用して API バージョンに優先順位を割り当てます。この場合、1 は優先順位が最も高くなります。
- 宛先 クラスターの優先バージョン
- source_ クラスターの優先バージョン
- Kubernetes バージョンの優先順位が最も高い共通の非優先サポート対象バージョン
4.24.1.3. Enable API Group Versions の使用
Velero の Enable API Group Versions 機能を使用して、優先バージョンだけでなく、クラスターでサポートされている すべて の Kubernetes API グループバージョンをバックアップできます。
Enable API Group Versions はまだベータ版です。
手順
-
EnableAPIGroupVersions機能フラグを設定します。
apiVersion: oadp.openshift.io/vialpha1
kind: DataProtectionApplication
...
spec:
configuration:
velero:
featureFlags:
- EnableAPIGroupVersions4.24.2. 1 つのクラスターからデータをバックアップし、別のクラスターに復元する
4.24.2.1. あるクラスターからのデータのバックアップと別のクラスターへの復元について
OpenShift API for Data Protection (OADP) は、同じ OpenShift Container Platform クラスター内のアプリケーションデータをバックアップおよび復元するように設計されています。Migration Toolkit for Containers (MTC) は、アプリケーションデータを含むコンテナーを 1 つの OpenShift Container Platform クラスターから別のクラスターに移行するように設計されています。
OADP を使用して、1 つの OpenShift Container Platform クラスターからアプリケーションデータをバックアップし、それを別のクラスターに復元できます。ただし、これを行うことは、MTC または OADP を使用して同じクラスター上でバックアップと復元を行うよりも複雑です。
OADP を使用して 1 つのクラスターからデータをバックアップし、それを別のクラスターに復元するには、OADP を使用して同じクラスター上でデータをバックアップおよび復元する場合に適用される前提条件と手順に加えて、次の要素を考慮する必要があります。
- Operator
- Velero の使用
- UID と GID の範囲
4.24.2.1.1. Operator
バックアップと復元を成功させるには、アプリケーションのバックアップから Operator を除外する必要があります。
4.24.2.1.2. Velero の使用
OADP が構築されている Velero は、クラウドプロバイダー間での永続ボリュームスナップショットの移行をネイティブにサポートしていません。クラウドプラットフォーム間でボリュームスナップショットデータを移行するには、ファイルシステムレベルでボリュームの内容をバックアップする Velero Restic ファイルシステムバックアップオプションを有効にする か、または CSI スナップショットに OADP Data Mover を使用する必要があります。
OADP 1.1 以前では、Velero Restic ファイルシステムのバックアップオプションは restic と呼ばれます。OADP 1.2 以降では、Velero Restic ファイルシステムのバックアップオプションは file-system-backup と呼ばれます。
- AWS リージョン間または Microsoft Azure リージョン間でデータを移行するには、Velero の File System Backup も使用する必要があります。
- Velero は、ソースクラスターより 前 の Kubernetes バージョンを使用したクラスターへのデータの復元をサポートしていません。
- 理論的には、移行元よりも 新しい Kubernetes バージョンを備えた移行先にワークロードを移行することは可能ですが、カスタムリソースごとにクラスター間の API グループの互換性を考慮する必要があります。Kubernetes バージョンのアップグレードによりコアまたはネイティブ API グループの互換性が失われる場合は、まず影響を受けるカスタムリソースを更新する必要があります。
4.24.2.2. バックアップする Pod ボリュームの判断方法
File System Backup (FSB) を使用してバックアップ操作を開始する前に、バックアップするボリュームが含まれる Pod を指定する必要があります。Velero では、このプロセスを適切な Pod ボリュームの "検出" と呼んでいます。
Velero は、Pod ボリュームを決定する方法として 2 つの方式をサポートしています。オプトイン方式かオプトアウト方式を使用して、Velero が FSB、ボリュームスナップショット、または Data Mover バックアップを決定できるようにします。
- オプトイン方式: オプトイン方式では、ボリュームがデフォルトでスナップショットまたは Data Mover を使用してバックアップされます。FSB は、アノテーションによってオプトインされた特定のボリュームで使用されます。
- オプトアウト方式: オプトアウト方式では、ボリュームがデフォルトで FSB を使用してバックアップされます。スナップショットまたは Data Mover は、アノテーションによってオプトアウトされた特定のボリュームで使用されます。
4.24.2.2.1. 制限
-
FSB は、
hostpathボリュームのバックアップと復元をサポートしていません。ただし、FSB はローカルボリュームのバックアップと復元をサポートします。 - Velero は、作成するすべてのバックアップリポジトリーに静的な共通暗号化キーを使用します。この静的キーは、バックアップストレージにアクセスできれば、誰でもバックアップデータを復号化できることを意味します。バックアップストレージへのアクセスを制限することが重要です。
PVC の場合、すべての増分バックアップチェーンは Pod が再スケジュールされても維持されます。
emptyDirボリュームなどの PVC ではない Pod ボリュームの場合、たとえばReplicaSetやデプロイメントなどによって Pod が削除または再作成されると、そのボリュームの次回のバックアップは増分バックアップではなく完全バックアップになります。Pod ボリュームのライフサイクルは、その Pod によって定義されると想定されます。- バックアップデータは増分的に保存できますが、データベースなどの大きなファイルのバックアップには時間がかかることがあります。これは、FSB が重複排除を使用して、バックアップが必要な差分を見つけるためです。
- FSB は、Pod が実行されているノードのファイルシステムにアクセスすることで、ボリュームからデータを読み書きします。そのため、FSB は Pod からマウントされたボリュームのみバックアップでき、PVC から直接バックアップすることはできません。一部の Velero ユーザーは、Velero バックアップを実行する前に、無限スリープがある BusyBox や Alpine コンテナーなどのステージング Pod を実行して PVC と PV のペアをマウントすることで、この制限を克服しています。
-
FSB では、ボリュームは
<hostPath>/<pod UID>の下にマウントされ、<hostPath>が設定可能であると想定します。vCluster などの一部の Kubernetes システムでは、ボリュームを<pod UID>サブディレクトリーにマウントしないため、そのようなシステムでは VFSB は期待どおり機能しません。
4.24.2.2.2. オプトインメソッドを使用して Pod ボリュームをバックアップする
オプトインメソッドを使用して、File System Backup (FSB) でバックアップする必要のあるボリュームを指定できます。これを行うには、backup.velero.io/backup-volumes コマンドを使用します。
手順
バックアップするボリュームを 1 つ以上含む各 Pod で、次のコマンドを入力します。
$ oc -n <your_pod_namespace> annotate pod/<your_pod_name> \ backup.velero.io/backup-volumes=<your_volume_name_1>, \ <your_volume_name_2>>,...,<your_volume_name_n>ここでは、以下のようになります。
<your_volume_name_x>- Pod 仕様の x 番目のボリュームの名前を指定します。
4.24.2.2.3. オプトアウトメソッドを使用して Pod ボリュームをバックアップする
オプトアウトアプローチを使用する場合、いくつかの例外を除き、すべての Pod ボリュームが File System Backup (FSB) を使用してバックアップされます。
- デフォルトのサービスアカウントトークン、シークレット、設定マップをマウントするボリューム。
-
hostPathvolumes
オプトアウトメソッドを使用して、バックアップしない ボリュームを指定できます。これを行うには、backup.velero.io/backup-volumes-excludes コマンドを使用します。
手順
バックアップしないボリュームを 1 つ以上含む各 Pod で、次のコマンドを実行します。
$ oc -n <your_pod_namespace> annotate pod/<your_pod_name> \ backup.velero.io/backup-volumes-excludes=<your_volume_name_1>, \ <your_volume_name_2>>,...,<your_volume_name_n>ここでは、以下のようになります。
<your_volume_name_x>- Pod 仕様の x 番目のボリュームの名前を指定します。
--default-volumes-to-fs-backup フラグを指定して velero install コマンドを実行することで、すべての Velero バックアップに対してこの動作を有効にできます。
4.24.2.3. UID と GID の範囲
あるクラスターからデータをバックアップし、それを別のクラスターに復元する場合、UID (ユーザー ID) および GID (グループ ID) の範囲で問題が発生する可能性があります。次のセクションでは、これらの潜在的な問題と軽減策を説明します。
- 問題点のまとめ
- 宛先クラスターによっては、namespace の UID と GID の範囲が変更される場合があります。OADP は、OpenShift UID 範囲のメタデータをバックアップおよび復元しません。バックアップされたアプリケーションに特定の UID が必要な場合は、復元時にその範囲が使用可能であることを確認してください。OpenShift の UID 範囲および GID 範囲の詳細は、A Guide to OpenShift and UIDs を参照してください。
- 問題の詳細
シェルコマンド
oc create namespaceを使用して OpenShift Container Platform で namespace を作成すると、OpenShift Container Platform は、使用可能な UID プールからの一意のユーザー ID (UID) 範囲、補助グループ (GID) 範囲、および一意の SELinux MCS ラベルを namespace に割り当てます。この情報は、クラスターのmetadata.annotationsフィールドに保存されます。この情報は、セキュリティーコンテキスト制約 (SCC) アノテーションの一部であり、次のコンポーネントで構成されています。-
openshift.io/sa.scc.mcs -
openshift.io/sa.scc.supplemental-groups -
openshift.io/sa.scc.uid-range
-
OADP を使用して namespace を復元すると、宛先クラスターの情報をリセットせずに、metadata.annotations 内の情報が自動的に使用されます。その結果、次のいずれかに該当する場合、ワークロードはバックアップデータにアクセスできない可能性があります。
- 他の SCC アノテーションを持つ既存の namespace が (たとえば別のクラスター上に) ある。この場合、OADP はバックアップ中に、復元する namespace ではなく既存の namespace を使用します。
バックアップ中にラベルセレクターが使用されたが、ワークロードが実行された namespace にそのラベルがない。この場合、OADP はその namespace をバックアップしませんが、バックアップされた namespace のアノテーションを含まない新しい namespace を復元中に作成します。これにより、新しい UID 範囲が namespace に割り当てられます。
OpenShift Container Platform が、永続ボリュームデータのバックアップ後に変更された namespace アノテーションに基づいて Pod に
securityContextUID を割り当てる場合、これはお客様のワークロードにとって問題になる可能性があります。- コンテナーの UID がファイル所有者の UID と一致しなくなった。
OpenShift Container Platform がバックアップクラスターデータと一致するように宛先クラスターの UID 範囲を変更していないため、エラーが発生する。その結果、バックアップクラスターは宛先クラスターとは異なる UID を持つことになり、アプリケーションは宛先クラスターに対してデータの読み取りまたは書き込みを行うことができなくなります。
- 軽減策
- 次の 1 つ以上の緩和策を使用して、UID 範囲および GID 範囲の問題を解決できます。
簡単な緩和策:
-
BackupCR のラベルセレクターを使用して、バックアップに含めるオブジェクトをフィルター処理する場合は、必ずこのラベルセレクターをワークスペースを含む namespace に追加してください。 - 同じ名前の namespace を復元する前に、宛先クラスター上の namespace の既存のバージョンを削除してください。
-
高度な緩和策:
- 移行後に OpenShift namespace 内の重複する UID 範囲を解決する ことで、移行後の UID 範囲を修正します。ステップ 1 はオプションです。
あるクラスターでのデータのバックアップと別のクラスターでのリストアの問題の解決に重点を置いた、OpenShift Container Platform の UID 範囲および GID 範囲の詳細は、A Guide to OpenShift and UIDs を参照してください。
4.24.2.4. 1 つのクラスターからデータをバックアップし、別のクラスターに復元する
一般に、同じクラスターにデータをバックアップおよび復元するのと同じ方法で、1 つの OpenShift Container Platform クラスターからデータをバックアップし、別の OpenShift Container Platform クラスターに復元します。ただし、ある OpenShift Container Platform クラスターからデータをバックアップし、それを別のクラスターにリストアする場合は、追加の前提条件と手順の違いがいくつかあります。
前提条件
- プラットフォーム(AWS、Microsoft Azure、Google Cloud など)でのバックアップと復元に関連するすべての前提条件、特にデータ保護アプリケーション(DPA)の前提条件については、本ガイドの関連セクションで説明されています。
手順
お使いのプラットフォーム別の手順に加えて、次のステップを実行します。
- リソースを別のクラスターに復元するには、Backup Store Location (BSL) と Volume Snapshot Location の名前とパスが同じであることを確認します。
- 同じオブジェクトストレージの場所の認証情報をクラスター全体で共有します。
- 最良の結果を得るには、OADP を使用して宛先クラスターに namespace を作成します。
Velero
file-system-backupオプションを使用する場合は、次のコマンドを実行して、バックアップ中に使用する--default-volumes-to-fs-backupフラグを有効にします。$ velero backup create <backup_name> --default-volumes-to-fs-backup <any_other_options>
OADP 1.2 以降では、Velero Restic オプションは file-system-backup と呼ばれます。
4.24.3. OADP ストレージクラスマッピング
4.24.3.1. ストレージクラスマッピング
ストレージクラスマッピングを使用すると、さまざまな種類のデータにどのストレージクラスを適用するかを指定するルールまたはポリシーを定義できます。この機能は、アクセス頻度、データの重要性、コストの考慮事項に基づいて、ストレージクラスを決定するプロセスを自動化します。データがその特性と使用パターンに最適なストレージクラスに確実に保存されるようにすることで、ストレージの効率とコスト効率を最適化します。
change-storage-class-config フィールドを使用して、データオブジェクトのストレージクラスを変更できます。これにより、ニーズやアクセスパターンに応じて、標準ストレージからアーカイブストレージへなど、異なるストレージ層間でデータを移動することで、コストとパフォーマンスを最適化できます。
4.24.3.1.1. Migration Toolkit for Containers を使用したストレージクラスのマッピング
Migration Toolkit for Containers (MTC) を使用すると、アプリケーションデータを含むコンテナーを 1 つの OpenShift Container Platform クラスターから別のクラスターに移行したり、ストレージクラスのマッピングと変換を行うことができます。永続ボリューム (PV) のストレージクラスは、同じクラスター内で移行することで変換できます。これを行うには、MTC Web コンソールで移行計画を作成して実行する必要があります。
4.24.3.1.2. OADP を使用したストレージクラスマッピング
Velero プラグイン v1.1.0 以降で OpenShift API for Data Protection (OADP) を使用すると、Velero namespace の config map でストレージクラスマッピングを設定することにより、復元中に永続ボリューム (PV) のストレージクラスを変更できます。
OADP を使用して ConfigMap をデプロイするには、change-storage-class-config フィールドを使用します。クラウドプロバイダーに基づいて、ストレージクラスマッピングを変更する必要があります。
手順
次のコマンドを実行して、ストレージクラスマッピングを変更します。
$ cat change-storageclass.yaml次の例に示すように、Velero namespace に config map を作成します。
例
apiVersion: v1 kind: ConfigMap metadata: name: change-storage-class-config namespace: openshift-adp labels: velero.io/plugin-config: "" velero.io/change-storage-class: RestoreItemAction data: standard-csi: ssd-csi次のコマンドを実行して、ストレージクラスマッピング設定を保存します。
$ oc create -f change-storage-class-config
第5章 コントロールプレーンのバックアップおよび復元
5.1. etcd のバックアップ
etcd は OpenShift Container Platform のキーと値のストアであり、すべてのリソースオブジェクトの状態を保存します。
クラスターの etcd データを定期的にバックアップし、OpenShift Container Platform 環境外の安全な場所に保存するのが理想的です。インストールの 24 時間後に行われる最初の証明書のローテーションが完了するまで etcd のバックアップを実行することはできません。ローテーションの完了前に実行すると、バックアップに期限切れの証明書が含まれることになります。etcd スナップショットは I/O コストが高いため、ピーク使用時間以外に etcd バックアップを取得することも推奨します。
クラスターのアップグレード後に必ず etcd バックアップを作成してください。これは、クラスターを復元する際に、同じ z-stream リリースから取得した etcd バックアップを使用する必要があるために重要になります。たとえば、OpenShift Container Platform 4.y.z クラスターは、4.y.z から取得した etcd バックアップを使用する必要があります。
コントロールプレーンホストでバックアップスクリプトの単一の呼び出しを実行して、クラスターの etcd データをバックアップします。各コントロールプレーンホストのバックアップを取得しないでください。
etcd のバックアップを作成したら、以前のクラスターの状態に復元 できます。
5.1.1. etcd データのバックアップ
以下の手順に従って、etcd スナップショットを作成し、静的 Pod のリソースをバックアップして etcd データをバックアップします。このバックアップは保存でき、etcd を復元する必要がある場合に後で使用することができます。
単一のコントロールプレーンホストからのバックアップのみを保存します。クラスター内の各コントロールプレーンホストからのバックアップは取得しないでください。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 クラスター全体のプロキシーが有効になっているかどうかを確認している。
ヒントoc get proxy cluster -o yamlの出力を確認して、プロキシーが有効にされているかどうかを確認できます。プロキシーは、httpProxy、httpsProxy、およびnoProxyフィールドに値が設定されている場合に有効にされます。
手順
コントロールプレーンノードの root としてデバッグセッションを開始します。
$ oc debug --as-root node/<node_name>デバッグシェルで root ディレクトリーを
/hostに変更します。sh-4.4# chroot /hostクラスター全体のプロキシーが有効になっている場合は、次のコマンドを実行して、
NO_PROXY、HTTP_PROXY、およびHTTPS_PROXY環境変数をエクスポートします。$ export HTTP_PROXY=http://<your_proxy.example.com>:8080$ export HTTPS_PROXY=https://<your_proxy.example.com>:8080$ export NO_PROXY=<example.com>デバッグシェルで
cluster-backup.shスクリプトを実行し、バックアップの保存先となる場所を渡します。ヒントcluster-backup.shスクリプトは etcd Cluster Operator のコンポーネントとして維持され、etcdctl snapshot saveコマンドに関連するラッパーです。sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backupスクリプトの出力例
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backupこの例では、コントロールプレーンホストの
/home/core/assets/backup/ディレクトリーにファイルが 2 つ作成されます。-
snapshot_<datetimestamp>.db: このファイルは etcd スナップショットです。cluster-backup.shスクリプトで、その有効性を確認します。 static_kuberesources_<datetimestamp>.tar.gz: このファイルには、静的 Pod のリソースが含まれます。etcd 暗号化が有効にされている場合、etcd スナップショットの暗号化キーも含まれます。注記etcd 暗号化が有効にされている場合、セキュリティー上の理由から、この 2 つ目のファイルを etcd スナップショットとは別に保存することが推奨されます。ただし、このファイルは etcd スナップショットから復元するために必要になります。
etcd 暗号化はキーではなく値のみを暗号化することに注意してください。つまり、リソースタイプ、namespace、およびオブジェクト名は暗号化されません。
-
5.2. 正常でない etcd メンバーの置き換え
このドキュメントでは、単一の正常でない etcd メンバーを置き換えるプロセスを説明します。
このプロセスは、マシンが実行されていないか、ノードが準備状態にないことによって etcd メンバーが正常な状態にないか、etcd Pod がクラッシュループしているためにこれが正常な状態にないかによって異なります。
コントロールプレーンホストの大部分を損失した場合は、この手順ではなく、ディザスターリカバリー手順に従って、以前のクラスター状態への復元 を行います。
置き換えられるメンバー上のコントロールプレーン証明書が有効でない場合は、この手順ではなく、期限切れのコントロールプレーン証明書から回復 する手順を実行する必要があります。
コントロールプレーンノードが失われ、新規ノードが作成される場合、etcd クラスター Operator は新規 TLS 証明書の生成と、ノードの etcd メンバーとしての追加を処理します。
5.2.1. 前提条件
- 正常でない etcd メンバーを置き換える前に、etcd のバックアップ を作成する。
5.2.2. 正常でない etcd メンバーの特定
クラスターに正常でない etcd メンバーがあるかどうかを特定することができます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
以下のコマンドを使用して
EtcdMembersAvailableステータス条件のステータスを確認します。$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="EtcdMembersAvailable")]}{.message}{"\n"}{end}'出力を確認します。
2 of 3 members are available, ip-10-0-131-183.ec2.internal is unhealthyこの出力例は、
ip-10-0-131-183.ec2.internaletcd メンバーが正常ではないことを示しています。
5.2.3. 正常でない etcd メンバーの状態の判別
正常でない etcd メンバーを置き換える手順は、etcd メンバーが以下のどの状態にあるかによって異なります。
- マシンが実行されていないか、ノードが準備状態にない
- etcd Pod がクラッシュループしている。
以下の手順では、etcd メンバーがどの状態にあるかを判別します。これにより、正常でない etcd メンバーを置き換えるために実行する必要のある手順を確認できます。
マシンが実行されていないか、ノードが準備状態にないものの、すぐに正常な状態に戻ることが予想される場合は、etcd メンバーを置き換える手順を実行する必要はありません。etcd クラスター Operator はマシンまたはノードが正常な状態に戻ると自動的に同期します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - 正常でない etcd メンバーを特定している。
手順
マシンが実行されていない かどうかを確認します。
$ oc get machines -A -ojsonpath='{range .items[*]}{@.status.nodeRef.name}{"\t"}{@.status.providerStatus.instanceState}{"\n"}' | grep -v running出力例
ip-10-0-131-183.ec2.internal stopped1 - 1
- この出力には、ノードおよびノードのマシンのステータスをリスト表示されます。ステータスが
running以外の場合は、マシンは実行されていません。
マシンが実行されていない 場合は、マシンが実行されていないか、ノードが準備状態にない場合の正常でない etcd メンバーの置き換え の手順を実行します。
ノードの準備ができていない かどうかを確認します。
以下のシナリオのいずれかが true の場合、ノードは準備状態にありません。
マシンが実行されている場合は、ノードに到達できないかどうかを確認します。
$ oc get nodes -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{"\t"}{range .spec.taints[*]}{.key}{" "}' | grep unreachable出力例
ip-10-0-131-183.ec2.internal node-role.kubernetes.io/master node.kubernetes.io/unreachable node.kubernetes.io/unreachable1 - 1
- ノードが
unreachableテイントと共にリスト表示される場合、ノードの準備はできていません。
ノードにまだ到達可能な場合は、ノードが
NotReadyとしてリストされるかどうかを確認します。$ oc get nodes -l node-role.kubernetes.io/master | grep "NotReady"出力例
ip-10-0-131-183.ec2.internal NotReady master 122m v1.26.01 - 1
- ノードが
NotReadyとしてリスト表示されている場合、ノードの準備はできていません。
ノードの準備ができていない 場合は、マシンが実行されていないか、ノードの準備ができていない場合の正常でない etcd メンバーの置き換え の手順を実行します。
etcd Pod がクラッシュループしている かどうかを確認します。
マシンが実行され、ノードが準備できている場合は、etcd Pod がクラッシュループしているかどうかを確認します。
すべてのコントロールプレーンノードが
Readyとしてリスト表示されていることを確認します。$ oc get nodes -l node-role.kubernetes.io/master出力例
NAME STATUS ROLES AGE VERSION ip-10-0-131-183.ec2.internal Ready master 6h13m v1.26.0 ip-10-0-164-97.ec2.internal Ready master 6h13m v1.26.0 ip-10-0-154-204.ec2.internal Ready master 6h13m v1.26.0etcd Pod のステータスが
ErrorまたはCrashloopBackoffのいずれかであるかどうかを確認します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m1 etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m- 1
- この Pod のこのステータスは
Errorであるため、etcd Pod はクラッシュループしています。
etcd Pod がクラッシュループしている 場合、etcd Pod がクラッシュループしている場合の正常でない etcd メンバーの置き換え に関する手順を実行します。
5.2.4. 正常でない etcd メンバーの置き換え
正常でない etcd メンバーの状態に応じて、以下のいずれかの手順を使用します。
5.2.4.1. マシンが実行されていないか、ノードの準備ができていない場合の正常でない etcd メンバーの置き換え
マシンが実行されていない、またはノードの準備ができていない、正常ではない etcd メンバーを置き換える手順を説明します。
クラスターがコントロールプレーンマシンセットを使用している場合は、「コントロールプレーンマシンセットのトラブルシューティング」の「劣化した etcd Operator のリカバリー」で etcd のリカバリー手順を参照してください。
前提条件
- 正常でない etcd メンバーを特定している。
マシンが実行されていないか、ノードが準備状態にないことを確認している。
重要他のコントロールプレーンノードの電源がオフになっている場合は、待機する必要があります。異常な etcd メンバーの交換が完了するまで、コントロールプレーンノードの電源をオフのままにしておく必要があります。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 etcd のバックアップを取得している。
重要この手順を実行する前に、問題が発生した場合にクラスターを復元できるように、etcd のバックアップを作成してください。
手順
正常でないメンバーを削除します。
影響を受けるノード上にない Pod を選択します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
etcd-ip-10-0-131-183.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124m実行中の etcd コンテナーに接続し、影響を受けるノードにない Pod の名前を渡します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalメンバーのリストを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 6fc1e7c9db35841d | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+正常でない etcd メンバーの ID と名前をメモしてください。これらの値はこの手順で後ほど必要になります。
$ etcdctl endpoint healthコマンドは、補充手順が完了し、新しいメンバーが追加されるまで、削除されたメンバーをリスト表示します。ID を
etcdctl member removeコマンドに指定して、正常でない etcd メンバーを削除します。sh-4.2# etcdctl member remove 6fc1e7c9db35841d出力例
Member 6fc1e7c9db35841d removed from cluster ead669ce1fbfb346メンバーのリストを再度表示し、メンバーが削除されたことを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+これでノードシェルを終了できます。
次のコマンドを入力して、クォーラムガードをオフにします。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'このコマンドにより、シークレットを正常に再作成し、静的 Pod をロールアウトできるようになります。
重要クォーラムガードをオフにすると、設定の変更を反映するために残りの etcd インスタンスが再起動するまで、短時間クラスターにアクセスできなくなる可能性があります。
注記etcd は、2 つのメンバーで実行されている場合、新たなメンバー障害を許容できません。残りのメンバーのいずれかを再起動すると、クォーラムが破棄され、クラスターでダウンタイムが発生します。クォーラムガードによって、ダウンタイムを引き起こす可能性のある設定変更による再起動から etcd が保護されるため、この手順を完了するには、クォーラムガードを無効にする必要があります。
次のコマンドを実行して、影響を受けるノードを削除します。
$ oc delete node <node_name>コマンドの例
$ oc delete node ip-10-0-131-183.ec2.internal削除された正常でない etcd メンバーの古いシークレットを削除します。
削除された正常でない etcd メンバーのシークレット一覧を表示します。
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal1 - 1
- この手順で先ほど書き留めた正常でない etcd メンバーの名前を渡します。
以下の出力に示されるように、ピア、サービング、およびメトリクスシークレットがあります。
出力例
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m削除された正常でない etcd メンバーのシークレットを削除します。
ピアシークレットを削除します。
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internalサービングシークレットを削除します。
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internalメトリクスシークレットを削除します。
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
次のコマンドを入力して、コントロールプレーンマシンセットが存在するかどうかを確認します。
$ oc -n openshift-machine-api get controlplanemachinesetコントロールプレーンマシンセットが存在する場合は、コントロールプレーンマシンを削除して再作成します。このマシンが再作成されると、新しいリビジョンが強制的に適用され、etcd は自動的にスケールアップします。詳細は、「マシンが実行されていないか、ノードの準備ができていない場合の正常でない etcd メンバーの置き換え」を参照してください。
インストーラーでプロビジョニングされるインフラストラクチャーを実行している場合、またはマシン API を使用してマシンを作成している場合は、以下の手順を実行します。それ以外の場合は、最初にコントロールプレーンを作成したときと同じ方法を使用して、新しいコントロールプレーンを作成する必要があります。
正常でないメンバーのマシンを取得します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- これは正常でないノードのコントロールプレーンマシンです (
ip-10-0-131-183.ec2.internal)。
正常でないメンバーのマシンを削除します。
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 正常でないノードのコントロールプレーンマシンの名前を指定します。
正常でないメンバーのマシンを削除すると、新しいマシンが自動的にプロビジョニングされます。
新しいマシンが作成されたことを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-133-53.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新規マシン
clustername-8qw5l-master-3が作成され、ProvisioningからRunningにフェーズが変更されると準備状態になります。
新規マシンが作成されるまでに数分の時間がかかる場合があります。マシンまたはノードが正常な状態に戻ると、etcd クラスター Operator が自動的に同期します。
注記マシンセットに使用しているサブネット ID を確認し、それが正しいアベイラビリティーゾーン内にあることを確認してください。
コントロールプレーンマシンセットが存在しない場合は、コントロールプレーンマシンを削除して再作成します。このマシンが再作成されると、新しいリビジョンが強制的に適用され、etcd は自動的にスケールアップします。
インストーラーでプロビジョニングされるインフラストラクチャーを実行している場合、またはマシン API を使用してマシンを作成している場合は、以下の手順を実行します。それ以外の場合は、最初にコントロールプレーンを作成したときと同じ方法を使用して、新しいコントロールプレーンを作成する必要があります。
正常でないメンバーのマシンを取得します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- これは正常でないノードのコントロールプレーンマシンです (
ip-10-0-131-183.ec2.internal)。
マシン設定をファイルシステムのファイルに保存します。
$ oc get machine clustername-8qw5l-master-0 \1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 正常でないノードのコントロールプレーンマシンの名前を指定します。
直前の手順で作成された
new-master-machine.yamlファイルを編集し、新しい名前を割り当て、不要なフィールドを削除します。statusセクション全体を削除します。status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatusmetadata.nameフィールドを新規の名前に変更します。古いマシンと同じベース名を維持し、最後の番号を次の使用可能な番号に変更します。この例では、
clustername-8qw5l-master-0はclustername-8qw5l-master-3に変更されています。以下に例を示します。
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...spec.providerIDフィールドを削除します。providerID: aws:///us-east-1a/i-0fdb85790d76d0c3f
正常でないメンバーのマシンを削除します。
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 正常でないノードのコントロールプレーンマシンの名前を指定します。
マシンが削除されたことを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a runningnew-master-machine.yamlファイルを使用して新しいマシンを作成します。$ oc apply -f new-master-machine.yaml新しいマシンが作成されたことを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-133-53.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新規マシン
clustername-8qw5l-master-3が作成され、ProvisioningからRunningにフェーズが変更されると準備状態になります。
新規マシンが作成されるまでに数分の時間がかかる場合があります。マシンまたはノードが正常な状態に戻ると、etcd クラスター Operator が自動的に同期します。
次のコマンドを入力して、クォーラムガードをオンに戻します。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'次のコマンドを入力して、
unsupportedConfigOverridesセクションがオブジェクトから削除されたことを確認できます。$ oc get etcd/cluster -oyamlシングルノードの OpenShift を使用している場合は、ノードを再起動します。そうしないと、etcd クラスター Operator で次のエラーが発生する可能性があります。
出力例
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
検証
すべての etcd Pod が適切に実行されていることを確認します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
etcd-ip-10-0-133-53.ec2.internal 3/3 Running 0 7m49s etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124m直前のコマンドの出力に 2 つの Pod のみがリスト表示される場合、etcd の再デプロイメントを手動で強制できます。クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason値は一意である必要があります。そのため、タイムスタンプが付加されます。
3 つの etcd メンバーがあることを確認します。
実行中の etcd コンテナーに接続し、影響を受けるノードになかった Pod の名前を渡します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalメンバーのリストを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 5eb0d6b8ca24730c | started | ip-10-0-133-53.ec2.internal | https://10.0.133.53:2380 | https://10.0.133.53:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+直前のコマンドの出力に 4 つ以上の etcd メンバーが表示される場合、不要なメンバーを慎重に削除する必要があります。
警告必ず適切な etcd メンバーを削除します。適切な etcd メンバーを削除すると、クォーラム (定足数) が失われる可能性があります。
5.2.4.2. etcd Pod がクラッシュループしている場合の正常でない etcd メンバーの置き換え
この手順では、etcd Pod がクラッシュループしている場合の正常でない etcd メンバーを置き換える手順を説明します。
前提条件
- 正常でない etcd メンバーを特定している。
- etcd Pod がクラッシュループしていることを確認している。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 etcd のバックアップを取得している。
重要問題が発生した場合にクラスターを復元できるように、この手順を実行する前に etcd バックアップを作成しておくことは重要です。
手順
クラッシュループしている etcd Pod を停止します。
クラッシュループしているノードをデバッグします。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc debug node/ip-10-0-131-183.ec2.internal1 - 1
- これを正常でないノードの名前に置き換えます。
ルートディレクトリーを
/hostに変更します。sh-4.2# chroot /host既存の etcd Pod ファイルを kubelet マニフェストディレクトリーから移動します。
sh-4.2# mkdir /var/lib/etcd-backupsh-4.2# mv /etc/kubernetes/manifests/etcd-pod.yaml /var/lib/etcd-backup/etcd データディレクトリーを別の場所に移動します。
sh-4.2# mv /var/lib/etcd/ /tmpこれでノードシェルを終了できます。
正常でないメンバーを削除します。
影響を受けるノード上に ない Pod を選択します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m実行中の etcd コンテナーに接続し、影響を受けるノードにない Pod の名前を渡します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalメンバーのリストを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 62bcf33650a7170a | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+これらの値はこの手順で後ほど必要となるため、ID および正常でない etcd メンバーの名前を書き留めておきます。
ID を
etcdctl member removeコマンドに指定して、正常でない etcd メンバーを削除します。sh-4.2# etcdctl member remove 62bcf33650a7170a出力例
Member 62bcf33650a7170a removed from cluster ead669ce1fbfb346メンバーのリストを再度表示し、メンバーが削除されたことを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+これでノードシェルを終了できます。
次のコマンドを入力して、クォーラムガードをオフにします。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'このコマンドにより、シークレットを正常に再作成し、静的 Pod をロールアウトできるようになります。
削除された正常でない etcd メンバーの古いシークレットを削除します。
削除された正常でない etcd メンバーのシークレット一覧を表示します。
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal1 - 1
- この手順で先ほど書き留めた正常でない etcd メンバーの名前を渡します。
以下の出力に示されるように、ピア、サービング、およびメトリクスシークレットがあります。
出力例
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m削除された正常でない etcd メンバーのシークレットを削除します。
ピアシークレットを削除します。
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internalサービングシークレットを削除します。
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internalメトリクスシークレットを削除します。
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
etcd の再デプロイメントを強制的に実行します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "single-master-recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason値は一意である必要があります。そのため、タイムスタンプが付加されます。
etcd クラスター Operator が再デプロイを実行する場合、すべてのコントロールプレーンノードで etcd Pod が機能していることを確認します。
次のコマンドを入力して、クォーラムガードをオンに戻します。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'次のコマンドを入力して、
unsupportedConfigOverridesセクションがオブジェクトから削除されたことを確認できます。$ oc get etcd/cluster -oyamlシングルノードの OpenShift を使用している場合は、ノードを再起動します。そうしないと、etcd クラスター Operator で次のエラーが発生する可能性があります。
出力例
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
検証
新しいメンバーが利用可能で、正常な状態にあることを確認します。
再度実行中の etcd コンテナーに接続します。
クラスターにアクセスできるターミナルで、cluster-admin ユーザーとして以下のコマンドを実行します。
$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internalすべてのメンバーが正常であることを確認します。
sh-4.2# etcdctl endpoint health出力例
https://10.0.131.183:2379 is healthy: successfully committed proposal: took = 16.671434ms https://10.0.154.204:2379 is healthy: successfully committed proposal: took = 16.698331ms https://10.0.164.97:2379 is healthy: successfully committed proposal: took = 16.621645ms
5.2.4.3. マシンが実行されていないか、ノードが準備状態にない場合の正常でないベアメタル etcd メンバーの置き換え
以下の手順では、マシンが実行されていないか、ノードが準備状態にない場合の正常でないベアメタル etcd メンバーを置き換える手順を説明します。
インストーラーでプロビジョニングされるインフラストラクチャーを実行している場合、またはマシン API を使用してマシンを作成している場合は、以下の手順を実行します。それ以外の場合は、最初に作成したときと同じ方法で、新しいコントロールプレーンノードを作成する必要があります。
前提条件
- 正常でないベアメタル etcd メンバーを特定している。
- マシンが実行されていないか、ノードが準備状態にないことを確認している。
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 etcd のバックアップを取得している。
重要問題が発生した場合にクラスターを復元できるように、この手順を実行する前に etcd バックアップを作成しておく。
手順
正常でないメンバーを確認し、削除します。
影響を受けるノード上に ない Pod を選択します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide出力例
etcd-openshift-control-plane-0 5/5 Running 11 3h56m 192.168.10.9 openshift-control-plane-0 <none> <none> etcd-openshift-control-plane-1 5/5 Running 0 3h54m 192.168.10.10 openshift-control-plane-1 <none> <none> etcd-openshift-control-plane-2 5/5 Running 0 3h58m 192.168.10.11 openshift-control-plane-2 <none> <none>実行中の etcd コンテナーに接続し、影響を受けるノードにない Pod の名前を渡します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0メンバーのリストを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380/ | https://192.168.10.9:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+これらの値はこの手順で後ほど必要となるため、ID および正常でない etcd メンバーの名前を書き留めておきます。
etcdctl endpoint healthコマンドは、置き換えの手順が完了し、新規メンバーが追加されるまで、削除されたメンバーをリスト表示します。ID を
etcdctl member removeコマンドに指定して、正常でない etcd メンバーを削除します。警告必ず適切な etcd メンバーを削除します。適切な etcd メンバーを削除すると、クォーラム (定足数) が失われる可能性があります。
sh-4.2# etcdctl member remove 7a8197040a5126c8出力例
Member 7a8197040a5126c8 removed from cluster b23536c33f2cdd1bメンバーのリストを再度表示し、メンバーが削除されたことを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | cc3830a72fc357f9 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+これでノードシェルを終了できます。
重要メンバーを削除した後、残りの etcd インスタンスが再起動している間、クラスターに短時間アクセスできない場合があります。
次のコマンドを入力して、クォーラムガードをオフにします。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'このコマンドにより、シークレットを正常に再作成し、静的 Pod をロールアウトできるようになります。
以下のコマンドを実行して、削除された正常でない etcd メンバーの古いシークレットを削除します。
削除された正常でない etcd メンバーのシークレット一覧を表示します。
$ oc get secrets -n openshift-etcd | grep openshift-control-plane-2この手順で先ほど書き留めた正常でない etcd メンバーの名前を渡します。
以下の出力に示されるように、ピア、サービング、およびメトリクスシークレットがあります。
etcd-peer-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-metrics-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-openshift-control-plane-2 kubernetes.io/tls 2 134m削除された正常でない etcd メンバーのシークレットを削除します。
ピアシークレットを削除します。
$ oc delete secret etcd-peer-openshift-control-plane-2 -n openshift-etcd secret "etcd-peer-openshift-control-plane-2" deletedサービングシークレットを削除します。
$ oc delete secret etcd-serving-metrics-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-metrics-openshift-control-plane-2" deletedメトリクスシークレットを削除します。
$ oc delete secret etcd-serving-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-openshift-control-plane-2" deleted
正常でないメンバーのマシンを取得します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- これは正常でないノードのコントロールプレーンマシンです (
examplecluster-control-plane-2)。
以下のコマンドを実行して、Bare Metal Operator が利用可能であることを確認します。
$ oc get clusteroperator baremetal出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE baremetal 4.13.0 True False False 3d15h次のコマンドを実行して、古い
BareMetalHostオブジェクトを削除します。$ oc delete bmh openshift-control-plane-2 -n openshift-machine-api出力例
baremetalhost.metal3.io "openshift-control-plane-2" deleted次のコマンドを実行して、異常なメンバーのマシンを削除します。
$ oc delete machine -n openshift-machine-api examplecluster-control-plane-2BareMetalHostおよびMachineオブジェクトを削除すると、MachineコントローラーによりNodeオブジェクトが自動的に削除されます。何らかの理由でマシンの削除が遅れたり、コマンドが妨げられて遅れたりする場合は、マシンオブジェクトのファイナライザーフィールドを削除することで強制的に削除できます。
重要Ctrl+cを押してマシンの削除を中断しないでください。コマンドが完了するまで続行できるようにする必要があります。新しいターミナルウィンドウを開き、ファイナライザーフィールドを編集して削除します。正常でないメンバーのマシンを削除すると、新しいマシンが自動的にプロビジョニングされます。
次のコマンドを実行して、マシン設定を編集します。
$ oc edit machine -n openshift-machine-api examplecluster-control-plane-2Machineカスタムリソースの次のフィールドを削除し、更新されたファイルを保存します。finalizers: - machine.machine.openshift.io出力例
machine.machine.openshift.io/examplecluster-control-plane-2 edited
以下のコマンドを実行して、マシンが削除されていることを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned次のコマンドを実行して、ノードが削除されたことを確認します。
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 3h24m v1.26.0 openshift-control-plane-1 Ready master 3h24m v1.26.0 openshift-compute-0 Ready worker 176m v1.26.0 openshift-compute-1 Ready worker 176m v1.26.0新しい
BareMetalHostオブジェクトとシークレットを作成して BMC 認証情報を保存します。$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: openshift-control-plane-2-bmc-secret namespace: openshift-machine-api data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-control-plane-2 namespace: openshift-machine-api spec: automatedCleaningMode: disabled bmc: address: redfish://10.46.61.18:443/redfish/v1/Systems/1 credentialsName: openshift-control-plane-2-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:b0:8a:a0 bootMode: UEFI externallyProvisioned: false online: true rootDeviceHints: deviceName: /dev/disk/by-id/scsi-<serial_number> userData: name: master-user-data-managed namespace: openshift-machine-api EOF注記ユーザー名とパスワードは、他のベアメタルホストのシークレットで確認できます。
bmc:addressで使用するプロトコルは、他の bmh オブジェクトから取得できます。重要既存のコントロールプレーンホストから
BareMetalHostオブジェクト定義を再利用する場合は、externallyProvisionedフィールドをtrueに設定したままにしないでください。既存のコントロールプレーン
BareMetalHostオブジェクトが、OpenShift Container Platform インストールプログラムによってプロビジョニングされた場合には、externallyProvisionedフラグがtrueに設定されている可能性があります。検査が完了すると、
BareMetalHostオブジェクトが作成され、プロビジョニングできるようになります。利用可能な
BareMetalHostオブジェクトを使用して作成プロセスを確認します。$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 available examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48m新しいマシンが作成されたことを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- 新規マシン
clustername-8qw5l-master-3が作成され、ProvisioningからRunningにフェーズが変更されると準備状態になります。
新規マシンが作成されるまでに数分の時間がかかります。etcd クラスター Operator はマシンまたはノードが正常な状態に戻ると自動的に同期します。
以下のコマンドを実行して、ベアメタルホストがプロビジョニングされ、エラーが報告されていないことを確認します。
$ oc get bmh -n openshift-machine-api出力例
$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 provisioned examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48m以下のコマンドを実行して、新規ノードが追加され、Ready の状態であることを確認します。
$ oc get nodes出力例
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 4h26m v1.26.0 openshift-control-plane-1 Ready master 4h26m v1.26.0 openshift-control-plane-2 Ready master 12m v1.26.0 openshift-compute-0 Ready worker 3h58m v1.26.0 openshift-compute-1 Ready worker 3h58m v1.26.0
次のコマンドを入力して、クォーラムガードをオンに戻します。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'次のコマンドを入力して、
unsupportedConfigOverridesセクションがオブジェクトから削除されたことを確認できます。$ oc get etcd/cluster -oyamlシングルノードの OpenShift を使用している場合は、ノードを再起動します。そうしないと、etcd クラスター Operator で次のエラーが発生する可能性があります。
出力例
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
検証
すべての etcd Pod が適切に実行されていることを確認します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
etcd-openshift-control-plane-0 5/5 Running 0 105m etcd-openshift-control-plane-1 5/5 Running 0 107m etcd-openshift-control-plane-2 5/5 Running 0 103m直前のコマンドの出力に 2 つの Pod のみがリスト表示される場合、etcd の再デプロイメントを手動で強制できます。クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason値は一意である必要があります。そのため、タイムスタンプが付加されます。
etcd メンバーがちょうど 3 つあることを確認するには、実行中の etcd コンテナーに接続し、影響を受けたノード上になかった Pod の名前を渡します。クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0メンバーのリストを確認します。
sh-4.2# etcdctl member list -w table出力例
+------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380 | https://192.168.10.11:2379 | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380 | https://192.168.10.10:2379 | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380 | https://192.168.10.9:2379 | false | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+注記直前のコマンドの出力に 4 つ以上の etcd メンバーが表示される場合、不要なメンバーを慎重に削除する必要があります。
以下のコマンドを実行して、すべての etcd メンバーが正常であることを確認します。
# etcdctl endpoint health --cluster出力例
https://192.168.10.10:2379 is healthy: successfully committed proposal: took = 8.973065ms https://192.168.10.9:2379 is healthy: successfully committed proposal: took = 11.559829ms https://192.168.10.11:2379 is healthy: successfully committed proposal: took = 11.665203ms以下のコマンドを実行して、すべてのノードが最新のリビジョンであることを確認します。
$ oc get etcd -o=jsonpath='{range.items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'AllNodesAtLatestRevision
5.3. 障害復旧
5.3.1. 障害復旧について
この障害復旧ドキュメントでは、OpenShift Container Platform クラスターで発生する可能性のある複数の障害のある状態からの復旧方法に関する管理者向けの情報を提供しています。管理者は、クラスターの状態を機能する状態に戻すために、以下の 1 つまたは複数の手順を実行する必要がある場合があります。
障害復旧には、少なくとも 1 つの正常なコントロールプレーンホストが必要です。
- クラスターの直前の状態への復元
このソリューションは、管理者が重要なものを削除した場合など、クラスターを直前の状態に復元する必要がある状態に対応します。これには、大多数のコントロールプレーンホストが失われたために etcd クォーラム (定足数) が失われ、クラスターがオフラインになる状態も含まれます。etcd バックアップを取得している限り、以下の手順に従ってクラスターを直前の状態に復元できます。
該当する場合は、コントロールプレーン証明書の期限切れの状態からのリカバリーが必要になる場合もあります。
警告以前のクラスター状態に復元することは、実行中のクラスターを不安定な状態にする破壊的な操作です。この手順は、最後の手段としてのみ使用してください。
復元の実行前に、クラスターへの影響の詳細についてクラスターの復元を参照してください。
注記大多数のマスターが依然として利用可能であり、etcd のクォーラムがある場合は、手順に従って単一の正常でない etcd メンバーの置き換えを実行します。
- コントロールプレーン証明書の期限切れの状態からのリカバリー
- このソリューションは、コントロールプレーン証明書の期限が切れた状態に対応します。たとえば、インストールの 24 時間後に行われる最初の証明書のローテーション前にクラスターをシャットダウンする場合、証明書はローテーションされず、期限切れになります。以下の手順に従って、コントロールプレーン証明書の期限切れの状態からのリカバリーを実行できます。
5.3.2. 以前のクラスター状態への復元
クラスターを以前の状態に復元するには、スナップショットを作成して etcd データを事前にバックアップしておく必要があります。このスナップショットを使用して、クラスターの状態を復元します。詳細は、「etcd データのバックアップ」を参照してください。
5.3.2.1. クラスターの状態の復元について
etcd バックアップを使用して、クラスターを直前の状態に復元できます。これは、以下の状況から回復するために使用できます。
- クラスターは、大多数のコントロールプレーンホストを失いました (クォーラムの喪失)。
- 管理者が重要なものを削除し、クラスターを復旧するために復元する必要があります。
以前のクラスター状態に復元することは、実行中のクラスターを不安定な状態にする破壊的な操作です。これは、最後の手段としてのみ使用してください。
Kubernetes API サーバーを使用してデータを取得できる場合は、etcd が利用できるため、etcd バックアップを使用して復元することはできません。
etcd を効果的に復元すると、クラスターが時間内に元に戻され、すべてのクライアントは競合する並列履歴が発生します。これは、kubelet、Kubernetes コントローラーマネージャー、SDN コントローラー、永続ボリュームコントローラーなどのコンポーネントを監視する動作に影響を与える可能性があります。
etcd のコンテンツがディスク上の実際のコンテンツと一致しないと、Operator チャーンが発生し、ディスク上のファイルが etcd のコンテンツと競合すると、Kubernetes API サーバー、Kubernetes コントローラーマネージャー、Kubernetes スケジューラーなどの Operator が停止する場合があります。この場合は、問題の解決に手動のアクションが必要になる場合があります。
極端な場合、クラスターは永続ボリュームを追跡できなくなり、存在しなくなった重要なワークロードを削除し、マシンのイメージを再作成し、期限切れの証明書を使用して CA バンドルを書き換えることができます。
5.3.2.2. クラスターの直前の状態への復元
保存された etcd のバックアップを使用して、クラスターの以前の状態を復元したり、大多数のコントロールプレーンホストが失われたクラスターを復元したりできます。
クラスターがコントロールプレーンマシンセットを使用している場合は、「コントロールプレーンマシンセットのトラブルシューティング」の「劣化した etcd Operator のリカバリー」で etcd のリカバリー手順を参照してください。
クラスターを復元する際に、同じ z-stream リリースから取得した etcd バックアップを使用する必要があります。たとえば、OpenShift Container Platform 4.7.2 クラスターは、4.7.2 から取得した etcd バックアップを使用する必要があります。
前提条件
-
インストール時に使用したものと同様、証明書ベースの
kubeconfigファイルを介して、cluster-adminロールを持つユーザーとしてクラスターにアクセスします。 - リカバリーホストとして使用する正常なコントロールプレーンホストがあること。
- コントロールプレーンホストへの SSH アクセス。
-
etcd スナップショットと静的 Pod のリソースの両方を含むバックアップディレクトリー (同じバックアップから取られるもの)。ディレクトリー内のファイル名は、
snapshot_<datetimestamp>.dbおよびstatic_kuberesources_<datetimestamp>.tar.gzの形式にする必要があります。
非リカバリーコントロールプレーンノードの場合は、SSH 接続を確立したり、静的 Pod を停止したりする必要はありません。他のリカバリー以外のコントロールプレーンマシンを 1 つずつ削除し、再作成します。
手順
- リカバリーホストとして使用するコントロールプレーンホストを選択します。これは、復元操作を実行するホストです。
リカバリーホストを含む、各コントロールプレーンノードへの SSH 接続を確立します。
Kubernetes API サーバーは復元プロセスの開始後にアクセスできなくなるため、コントロールプレーンノードにはアクセスできません。このため、別のターミナルで各コントロールプレーンホストに SSH 接続を確立することが推奨されます。
重要この手順を完了しないと、復元手順を完了するためにコントロールプレーンホストにアクセスすることができなくなり、この状態からクラスターを回復できなくなります。
etcd バックアップディレクトリーをリカバリーコントロールプレーンホストにコピーします。
この手順では、etcd スナップショットおよび静的 Pod のリソースを含む
backupディレクトリーを、リカバリーコントロールプレーンホストの/home/core/ディレクトリーにコピーしていることを前提としています。他のすべてのコントロールプレーンノードで静的 Pod を停止します。
注記リカバリーホストで静的 Pod を停止する必要はありません。
- リカバリーホストではないコントロールプレーンホストにアクセスします。
既存の etcd Pod ファイルを kubelet マニフェストディレクトリーから移動します。
$ sudo mv -v /etc/kubernetes/manifests/etcd-pod.yaml /tmpetcd Pod が停止していることを確認します。
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"コマンドの出力は空であるはずです。空でない場合は、数分待機してから再度確認します。
既存の Kubernetes API サーバー Pod ファイルを kubelet マニフェストディレクトリーから移動します。
$ sudo mv -v /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmpKubernetes API サーバー Pod が停止していることを確認します。
$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"コマンドの出力は空であるはずです。空でない場合は、数分待機してから再度確認します。
etcd データディレクトリーを別の場所に移動します。
$ sudo mv -v /var/lib/etcd/ /tmp/etc/kubernetes/manifests/keepalived.yamlファイルが存在し、ノードが削除された場合は、次の手順に従います。/etc/kubernetes/manifests/keepalived.yamlファイルを kubelet マニフェストディレクトリーから移動します。$ sudo mv -v /etc/kubernetes/manifests/keepalived.yaml /tmpkeepalivedデーモンによって管理されているコンテナーが停止していることを確認します。$ sudo crictl ps --name keepalivedコマンドの出力は空であるはずです。空でない場合は、数分待機してから再度確認します。
コントロールプレーンに仮想 IP (VIP) が割り当てられているかどうかを確認します。
$ ip -o address | egrep '<api_vip>|<ingress_vip>'報告された仮想 IP ごとに、次のコマンドを実行して仮想 IP を削除します。
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- リカバリーホストではない他のコントロールプレーンホストでこの手順を繰り返します。
- リカバリーコントロールプレーンホストにアクセスします。
keepalivedデーモンが使用されている場合は、リカバリーコントロールプレーンノードが仮想 IP を所有していることを確認します。$ ip -o address | grep <api_vip>仮想 IP のアドレスが存在する場合、出力内で強調表示されます。仮想 IP が設定されていないか、正しく設定されていない場合、このコマンドは空の文字列を返します。
クラスター全体のプロキシーが有効になっている場合は、
NO_PROXY、HTTP_PROXY、およびHTTPS_PROXY環境変数をエクスポートしていることを確認します。ヒントoc get proxy cluster -o yamlの出力を確認して、プロキシーが有効にされているかどうかを確認できます。プロキシーは、httpProxy、httpsProxy、およびnoProxyフィールドに値が設定されている場合に有効にされます。リカバリーコントロールプレーンホストで復元スクリプトを実行し、パスを etcd バックアップディレクトリーに渡します。
$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/assets/backupスクリプトの出力例
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yaml注記最後の etcd バックアップの後にノード証明書が更新された場合、復元プロセスによってノードが
NotReady状態になる可能性があります。ノードをチェックして、
Ready状態であることを確認します。以下のコマンドを実行します。
$ oc get nodes -w出力例
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.26.0 host-172-25-75-38 Ready infra,worker 3d20h v1.26.0 host-172-25-75-40 Ready master 3d20h v1.26.0 host-172-25-75-65 Ready master 3d20h v1.26.0 host-172-25-75-74 Ready infra,worker 3d20h v1.26.0 host-172-25-75-79 Ready worker 3d20h v1.26.0 host-172-25-75-86 Ready worker 3d20h v1.26.0 host-172-25-75-98 Ready infra,worker 3d20h v1.26.0すべてのノードが状態を報告するのに数分かかる場合があります。
NotReady状態のノードがある場合は、ノードにログインし、各ノードの/var/lib/kubelet/pkiディレクトリーからすべての PEM ファイルを削除します。ノードに SSH 接続するか、Web コンソールのターミナルウィンドウを使用できます。$ ssh -i <ssh-key-path> core@<master-hostname>サンプル
pkiディレクトリーsh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
すべてのコントロールプレーンホストで kubelet サービスを再起動します。
リカバリーホストから以下のコマンドを実行します。
$ sudo systemctl restart kubelet.service- 他のすべてのコントロールプレーンホストでこの手順を繰り返します。
保留中の CSR を承認します。
注記単一ノードクラスターや 3 つのスケジュール可能なコントロールプレーンノードで構成されるクラスターなど、ワーカーノードを持たないクラスターには、承認する保留中の CSR はありません。この手順にリストされているすべてのコマンドをスキップできます。
現在の CSR の一覧を取得します。
$ oc get csr出力例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending4 ...CSR の詳細をレビューし、これが有効であることを確認します。
$ oc describe csr <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
それぞれの有効な
node-bootstrapperCSR を承認します。$ oc adm certificate approve <csr_name>ユーザーによってプロビジョニングされるインストールの場合は、それぞれの有効な kubelet 提供の CSR を承認します。
$ oc adm certificate approve <csr_name>
単一メンバーのコントロールプレーンが正常に起動していることを確認します。
リカバリーホストから etcd コンテナーが実行中であることを確認します。
$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"出力例
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0リカバリーホストから、etcd Pod が実行されていることを確認します。
$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47sステータスが
Pendingの場合や出力に複数の実行中の etcd Pod が一覧表示される場合、数分待機してから再度チェックを行います。
OVNKubernetesネットワークプラグインを使用している場合は、リカバリーコントロールプレーンホストではないコントロールプレーンホストに関連付けられているノードオブジェクトを削除します。$ oc delete node <non-recovery-controlplane-host-1> <non-recovery-controlplane-host-2>Cluster Network Operator (CNO) が OVN-Kubernetes コントロールプレーンを再デプロイし、回復していないコントローラー IP アドレスを参照していないことを確認します。この結果を確認するには、以下のコマンドの出力を定期的に確認します。空の結果が返されるまで待ってから、次の手順ですべてのホスト上の Open Virtual Network (OVN) Kubernetes Pod の再起動に進みます。
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'注記OVN-Kubernetes コントロールプレーンが再デプロイされ、直前のコマンドが空の出力を返すまでに 5-10 分以上かかる場合があります。
OVN-Kubernetes ネットワークプラグインを使用している場合は、すべてのホストで Open Virtual Network (OVN) Kubernetes Pod を再起動します。
注記検証および変更用の受付 Webhook は Pod を拒否することができます。
failurePolicyをFailに設定して追加の Webhook を追加すると、Pod が拒否され、復元プロセスが失敗する可能性があります。これは、クラスターの状態の復元中に Webhook を保存および削除することで回避できます。クラスターの状態が正常に復元された後に、Webhook を再度有効にできます。または、クラスターの状態の復元中に
failurePolicyを一時的にIgnoreに設定できます。クラスターの状態が正常に復元された後に、failurePolicyをFailにすることができます。ノースバウンドデータベース (nbdb) とサウスバウンドデータベース (sbdb) を削除します。Secure Shell (SSH) を使用してリカバリーホストと残りのコントロールプレーンノードにアクセスし、次のコマンドを実行します。
$ sudo rm -f /var/lib/ovn/etc/*.db次のコマンドを実行して、すべての OVN-Kubernetes コントロールプレーン Pod を削除します。
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetes次のコマンドを実行して、OVN-Kubernetes コントロールプレーン Pod が再度デプロイされ、
Running状態になっていることを確認します。$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes出力例
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s次のコマンドを実行して、すべての
ovnkube-nodePod を削除します。$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; done次のコマンドを実行して、Pod のステータスを確認します。
$ oc get po -n openshift-ovn-kubernetesOVN Pod のステータスが
Terminatingである場合は、次のコマンドを実行して、OVN Pod を実行しているノードを削除します。<node> を、削除するノードの名前に置き換えます。$ oc delete node <node>次のコマンドを実行して、SSH を使用して
Terminatingステータスの OVN Pod ノードにログインします。$ ssh -i <ssh-key-path> core@<node>次のコマンドを実行して、すべての PEM ファイルを
/var/lib/kubelet/pkiディレクトリーから移動します。$ sudo mv /var/lib/kubelet/pki/* /tmp次のコマンドを実行して、kubelet サービスを無効にします。
$ sudo systemctl restart kubelet.service次のコマンドを実行して、リカバリー etcd マシンに戻ります。
$ oc get csr出力例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-<uuid> 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending以下のコマンドを実行して、すべての新規 CSR を承認します。ここで、
csr-<uuid> は CSR の名前に置き換えてください。oc adm certificate approve csr-<uuid>次のコマンドを実行して、ノードが復旧していることを確認します。
$ oc get nodes
次のコマンドを実行して、すべての
ovnkube-nodePod が再度デプロイされ、Running状態になっていることを確認します。$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
他の非復旧のコントロールプレーンマシンを 1 つずつ削除して再作成します。マシンが再作成された後、新しいリビジョンが強制され、etcd が自動的にスケールアップします。
ユーザーがプロビジョニングしたベアメタルインストールを使用する場合は、最初に作成したときと同じ方法を使用して、コントロールプレーンマシンを再作成できます。詳細は、「ユーザーによってプロビジョニングされるクラスターのベアメタルへのインストール」を参照してください。
警告リカバリーホストのマシンを削除し、再作成しないでください。
installer-provisioned infrastructure を実行している場合、またはマシン API を使用してマシンを作成している場合は、以下の手順を実行します。
警告リカバリーホストのマシンを削除し、再作成しないでください。
installer-provisioned infrastructure でのベアメタルインストールの場合、コントロールプレーンマシンは再作成されません。詳細は、「ベアメタルコントロールプレーンノードの交換」を参照してください。
失われたコントロールプレーンホストのいずれかのマシンを取得します。
クラスターにアクセスできるターミナルで、cluster-admin ユーザーとして以下のコマンドを実行します。
$ oc get machines -n openshift-machine-api -o wide出力例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- これは、失われたコントロールプレーンホストのコントロールプレーンマシンです (
ip-10-0-131-183.ec2.internal)。
以下を実行して、失われたコントロールプレーンホストのマシンを削除します。
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-01 - 1
- 失われたコントロールプレーンホストのコントロールプレーンマシンの名前を指定します。
失われたコントロールプレーンホストのマシンを削除すると、新しいマシンが自動的にプロビジョニングされます。
以下を実行して、新しいマシンが作成されたことを確認します。
$ oc get machines -n openshift-machine-api -o wide出力例:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 新規マシン
clustername-8qw5l-master-3が作成され、ProvisioningからRunningにフェーズが変更されると準備状態になります。
新規マシンが作成されるまでに数分の時間がかかる場合があります。etcd クラスター Operator はマシンまたはノードが正常な状態に戻ると自動的に同期します。
- リカバリーホストではない喪失したコントロールプレーンホストで、これらのステップを繰り返します。
次のコマンドを入力して、クォーラムガードをオフにします。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'このコマンドにより、シークレットを正常に再作成し、静的 Pod をロールアウトできるようになります。
リカバリーホスト内の別のターミナルウィンドウで、次のコマンドを実行してリカバリー
kubeconfigファイルをエクスポートします。$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfigetcd の再デプロイメントを強制的に実行します。
リカバリー
kubeconfigファイルをエクスポートしたのと同じターミナルウィンドウで、次のコマンドを実行します。$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge1 - 1
forceRedeploymentReason値は一意である必要があります。そのため、タイムスタンプが付加されます。
etcd クラスター Operator が再デプロイメントを実行すると、初期ブートストラップのスケールアップと同様に、既存のノードが新規 Pod と共に起動します。
次のコマンドを入力して、クォーラムガードをオンに戻します。
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'次のコマンドを入力して、
unsupportedConfigOverridesセクションがオブジェクトから削除されたことを確認できます。$ oc get etcd/cluster -oyamlすべてのノードが最新のリビジョンに更新されていることを確認します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'etcd の
NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。etcd の再デプロイ後に、コントロールプレーンの新規ロールアウトを強制的に実行します。kubelet が内部ロードバランサーを使用して API サーバーに接続されているため、Kubernetes API サーバーは他のノードに再インストールされます。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。Kubernetes API サーバーの新規ロールアウトを強制的に実行します。
$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeすべてのノードが最新のリビジョンに更新されていることを確認します。
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。Kubernetes コントローラーマネージャーの新規ロールアウトを強制的に実行します。
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeすべてのノードが最新のリビジョンに更新されていることを確認します。
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。Kubernetes スケジューラーの新規ロールアウトを強制的に実行します。
$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeすべてのノードが最新のリビジョンに更新されていることを確認します。
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing状況条件を確認し、すべてのノードが最新のリビジョンであることを確認します。更新が正常に実行されると、この出力にはAllNodesAtLatestRevisionが表示されます。AllNodesAtLatestRevision 3 nodes are at revision 71 - 1
- この例では、最新のリビジョン番号は
7です。
出力に
2 nodes are at revision 6; 1 nodes are at revision 7などの複数のリビジョン番号が含まれる場合、これは更新が依然として進行中であることを意味します。数分待機した後に再試行します。
すべてのコントロールプレーンホストが起動しており、クラスターに参加していることを確認します。
クラスターにアクセスできるターミナルで、
cluster-adminユーザーとして以下のコマンドを実行します。$ oc -n openshift-etcd get pods -l k8s-app=etcd出力例
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
復元手順の後にすべてのワークロードが通常の動作に戻るようにするには、Kubernetes API 情報を保存している各 Pod を再起動します。これには、ルーター、Operator、サードパーティーコンポーネントなどの OpenShift Container Platform コンポーネントが含まれます。
前の手順が完了したら、すべてのサービスが復元された状態に戻るまで数分間待つ必要がある場合があります。たとえば、oc login を使用した認証は、OAuth サーバー Pod が再起動するまですぐに機能しない可能性があります。
即時認証に system:admin kubeconfig ファイルを使用することを検討してください。この方法は、OAuth トークンではなく SSL/TLS クライアント証明書に基づいて認証を行います。以下のコマンドを実行し、このファイルを使用して認証できます。
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig以下のコマンドを実行て、認証済みユーザー名を表示します。
$ oc whoami5.3.2.3. etcd バックアップからのクラスターの手動復元
「以前のクラスター状態への復元」セクションで説明されている復元手順は次のとおりです。
-
2 つのコントロールプレーンノードを完全に再作成する必要があります。ただし、UPI インストール方式でインストールされたクラスターでは複雑な手順になる可能性があります。UPI インストールでは、コントロールプレーンノード用の
MachineまたはControlPlaneMachinesetが作成されないためです。 - /usr/local/bin/cluster-restore.sh スクリプトを使用して、シングルメンバーの新しい etcd クラスターを起動し、それを 3 つのメンバーに拡張します。
これに対し、この手順は次の点が異なります。
- コントロールプレーンノードを再作成する必要はありません。
- 3 つのメンバーからなる etcd クラスターを直接起動します。
クラスターがコントロールプレーンに MachineSet を使用する場合は、etcd の回復手順を簡素化するために、「以前のクラスター状態への復元」を使用することを推奨します。
クラスターを復元する際に、同じ z-stream リリースから取得した etcd バックアップを使用する必要があります。たとえば、OpenShift Container Platform 4.7.2 クラスターは、4.7.2 から取得した etcd バックアップを使用する必要があります。
前提条件
-
cluster-adminロールを持つユーザー (例:kubeadminユーザー) としてクラスターにアクセスします。 -
すべて のコントロールプレーンホストへの SSH アクセス権があり、ホストユーザーが
root(デフォルトのcoreホストユーザーなど) になることが許可されている。 -
同じバックアップからの以前の etcd スナップショットと静的 Pod のリソースの両方を含むバックアップディレクトリー。ディレクトリー内のファイル名は、
snapshot_<datetimestamp>.dbおよびstatic_kuberesources_<datetimestamp>.tar.gzの形式にする必要があります。
手順
SSH を使用して各コントロールプレーンノードに接続します。
Kubernetes API サーバーは復元プロセスの開始後にアクセスできなくなるため、コントロールプレーンノードにはアクセスできません。このため、アクセスするコントロールプレーンホストごとに、別のターミナルで SSH 接続を使用することを推奨します。
重要この手順を完了しないと、復元手順を完了するためにコントロールプレーンホストにアクセスすることができなくなり、この状態からクラスターを回復できなくなります。
etcd バックアップディレクトリーを各コントロールプレーンホストにコピーします。
この手順では、etcd スナップショットと静的 Pod のリソースを含む
backupディレクトリーを各コントロールプレーンホストの/home/core/assetsディレクトリーにコピーしていることを前提としています。このassetsフォルダーがまだ存在しない場合は、作成する必要がある場合があります。すべてのコントロールプレーンノード上の静的 Pod を、一度に 1 つのホストずつ停止します。
既存の Kubernetes API サーバーの静的 Pod マニフェストを kubelet マニフェストディレクトリーから移動します。
$ mkdir -p /root/manifests-backup $ mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /root/manifests-backup/次のコマンドを使用して、Kubernetes API Server コンテナーが停止したことを確認します。
$ crictl ps | grep kube-apiserver | grep -E -v "operator|guard"コマンドの出力は空であるはずです。空でない場合は、数分待機してから再度確認します。
Kubernetes API サーバーコンテナーがまだ実行中の場合は、次のコマンドを使用して手動で終了します。
$ crictl stop <container_id>同じ手順を、
kube-controller-manager-pod.yaml、kube-scheduler-pod.yaml、最後にetcd-pod.yamlに対して繰り返します。次のコマンドで
kube-controller-managerPod を停止します。$ mv /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /root/manifests-backup/次のコマンドを使用して、コンテナーが停止しているかどうかを確認します。
$ crictl ps | grep kube-controller-manager | grep -E -v "operator|guard"次のコマンドを使用して、
kube-schedulerPod を停止します。$ mv /etc/kubernetes/manifests/kube-scheduler-pod.yaml /root/manifests-backup/次のコマンドを使用して、コンテナーが停止しているかどうかを確認します。
$ crictl ps | grep kube-scheduler | grep -E -v "operator|guard"次のコマンドを使用して
etcdPod を停止します。$ mv /etc/kubernetes/manifests/etcd-pod.yaml /root/manifests-backup/次のコマンドを使用して、コンテナーが停止しているかどうかを確認します。
$ crictl ps | grep etcd | grep -E -v "operator|guard"
各コントロールプレーンホストで、現在の
etcdデータをbackupフォルダーに移動して保存します。$ mkdir /home/core/assets/old-member-data $ mv /var/lib/etcd/member /home/core/assets/old-member-dataこのデータは、
etcdバックアップの復元が機能せず、etcdクラスターを現在の状態に復元する必要がある場合に役立ちます。各コントロールプレーンホストの正しい etcd パラメーターを確認します。
<ETCD_NAME>の値は、各コントロールプレーンホストごとに一意であり、特定のコントロールプレーンホストのマニフェスト/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yamlファイル内にあるETCD_NAME変数の値と同じです。次のコマンドで確認できます。RESTORE_ETCD_POD_YAML="/etc/kubernetes/static-pod-resources/etcd-certs/configmaps/restore-etcd-pod/pod.yaml" cat $RESTORE_ETCD_POD_YAML | \ grep -A 1 $(cat $RESTORE_ETCD_POD_YAML | grep 'export ETCD_NAME' | grep -Eo 'NODE_.+_ETCD_NAME') | \ grep -Po '(?<=value: ").+(?=")'<UUID>の値は、次のコマンドを使用してコントロールプレーンホストで生成できます。$ uuidgen注記<UUID>の値は 1 回だけ生成する必要があります。1 つのコントロールプレーンホストでUUIDを生成した後あ、他のホストで再度生成しないでください。次の手順では、すべてのコントロールプレーンホストで同じUUIDを使用します。ETCD_NODE_PEER_URLの値は、次の例のように設定する必要があります。https://<IP_CURRENT_HOST>:2380正しい IP は、次のコマンドを使用して、特定のコントロールプレーンホストの
<ETCD_NAME>から確認できます。$ echo <ETCD_NAME> | \ sed -E 's/[.-]/_/g' | \ xargs -I {} grep {} /etc/kubernetes/static-pod-resources/etcd-certs/configmaps/etcd-scripts/etcd.env | \ grep "IP" | grep -Po '(?<=").+(?=")'<ETCD_INITIAL_CLUSTER>の値は、次のように設定する必要があります。<ETCD_NAME_n>は各コントロールプレーンホストの<ETCD_NAME>です。注記使用するポートは 2379 ではなく 2380 である必要があります。ポート 2379 は etcd データベース管理に使用され、コンテナー内の etcd 起動コマンドで直接設定されます。
出力例
<ETCD_NAME_0>=<ETCD_NODE_PEER_URL_0>,<ETCD_NAME_1>=<ETCD_NODE_PEER_URL_1>,<ETCD_NAME_2>=<ETCD_NODE_PEER_URL_2>1 - 1
- 各コントロールプレーンホストの
ETCD_NODE_PEER_URL値を指定します。
<ETCD_INITIAL_CLUSTER>値は、すべてのコントロールプレーンホストで同じです。次の手順では、すべてのコントロールプレーンホストで同じ値が必要です。
バックアップから etcd データベースを再生成します。
この操作は、各コントロールプレーンホストで実行する必要があります。
次のコマンドを使用して、
etcdバックアップを/var/lib/etcdディレクトリーにコピーします。$ cp /home/core/assets/backup/<snapshot_yyyy-mm-dd_hhmmss>.db /var/lib/etcd続行する前に、正しい
etcdctlイメージを特定します。次のコマンドを使用して、Pod マニフェストのバックアップからイメージを取得します。$ jq -r '.spec.containers[]|select(.name=="etcdctl")|.image' /root/manifests-backup/etcd-pod.yaml$ podman run --rm -it --entrypoint="/bin/bash" -v /var/lib/etcd:/var/lib/etcd:z <image-hash>etcdctlツールのバージョンが、バックアップが作成されたetcdサーバーのバージョンであることを確認します。$ etcdctl version現在のホストの正しい値を使用して次のコマンドを実行し、
etcdデータベースを再生成します。$ ETCDCTL_API=3 /usr/bin/etcdctl snapshot restore /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db \ --name "<ETCD_NAME>" \ --initial-cluster="<ETCD_INITIAL_CLUSTER>" \ --initial-cluster-token "openshift-etcd-<UUID>" \ --initial-advertise-peer-urls "<ETCD_NODE_PEER_URL>" \ --data-dir="/var/lib/etcd/restore-<UUID>" \ --skip-hash-check=true注記etcdデータベースを再生成する場合、引用符は必須です。
added memberログに出力される値を記録します。次に例を示します。出力例
2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "56cd73b614699e7", "added-peer-peer-urls": ["https://10.0.91.5:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "1f63d01b31bb9a9e", "added-peer-peer-urls": ["https://10.0.90.221:2380"], "added-peer-is-learner": false} 2022-06-28T19:52:43Z info membership/cluster.go:421 added member {"cluster-id": "c5996b7c11c30d6b", "local-member-id": "0", "added-peer-id": "fdc2725b3b70127c", "added-peer-peer-urls": ["https://10.0.94.214:2380"], "added-peer-is-learner": false}- コンテナーから出ます。
-
この手順を他のコントロールプレーンホストでも繰り返し、
added memberログに出力される値がすべてのコントロールプレーンホストで同じであることを確認します。
再生成された
etcdデータベースをデフォルトの場所に移動します。この操作は、各コントロールプレーンホストで実行する必要があります。
再生成されたデータベース (以前の
etcdctl snapshot restoreコマンドによって作成されたmemberフォルダー) を、デフォルトの etcd の場所/var/lib/etcdに移動します。$ mv /var/lib/etcd/restore-<UUID>/member /var/lib/etcd/var/lib/etcdディレクトリーの/var/lib/etcd/memberフォルダーの SELinux コンテキストを復元します。$ restorecon -vR /var/lib/etcd/残りのファイルとディレクトリーを削除します。
$ rm -rf /var/lib/etcd/restore-<UUID>$ rm /var/lib/etcd/<snapshot_yyyy-mm-dd_hhmmss>.db重要完了すると、
/var/lib/etcdディレクトリーに含まれるフォルダーがmemberだけになります。- 他のコントロールプレーンホストでもこの手順を繰り返します。
etcd クラスターを再起動します。
- 次の手順は、すべてのコントロールプレーンホストで実行する必要があります。ただし、一度に 1 つのホストずつ 実行する必要があります。
kubelet が関連コンテナーを起動するように、
etcd静的 Pod マニフェストを kubelet マニフェストディレクトリーに戻します。$ mv /tmp/etcd-pod.yaml /etc/kubernetes/manifestsすべての
etcdコンテナーが起動していることを確認します。$ crictl ps | grep etcd | grep -v operator出力例
38c814767ad983 f79db5a8799fd2c08960ad9ee22f784b9fbe23babe008e8a3bf68323f004c840 28 seconds ago Running etcd-health-monitor 2 fe4b9c3d6483c e1646b15207c6 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd-metrics 0 fe4b9c3d6483c 08ba29b1f58a7 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcd 0 fe4b9c3d6483c 2ddc9eda16f53 9d28c15860870e85c91d0e36b45f7a6edd3da757b113ec4abb4507df88b17f06 About a minute ago Running etcdctlこのコマンドの出力が空の場合は、数分待ってからもう一度確認してください。
etcdクラスターのステータスを確認します。いずれかのコントロールプレーンホストで、次のコマンドを使用して
etcdクラスターのステータスを確認します。$ crictl exec -it $(crictl ps | grep etcdctl | awk '{print $1}') etcdctl endpoint status -w table出力例
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.89.133:2379 | 682e4a83a0cec6c0 | 3.5.0 | 67 MB | true | false | 2 | 218 | 218 | | | https://10.0.92.74:2379 | 450bcf6999538512 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | | https://10.0.93.129:2379 | 358efa9c1d91c3d6 | 3.5.0 | 67 MB | false | false | 2 | 218 | 218 | | +--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
他の静的 Pod を再起動します。
次の手順は、すべてのコントロールプレーンホストで実行する必要があります。ただし、一度に 1 つのホストずつ実行する必要があります。
次のコマンドを使用して、Kubernetes API サーバーの静的 Pod マニフェストを kubelet マニフェストディレクトリーに戻し、kubelet が関連するコンテナーを起動するようにします。
$ mv /root/manifests-backup/kube-apiserver-pod.yaml /etc/kubernetes/manifestsすべての Kubernetes API サーバーコンテナーが起動したことを確認します。
$ crictl ps | grep kube-apiserver | grep -v operator注記次のコマンドの出力が空の場合は、数分待ってからもう一度確認してください。
同じ手順を、
kube-controller-manager-pod.yamlファイルとkube-scheduler-pod.yamlファイルに対して繰り返します。次のコマンドを使用して、すべてのノードで kubelet を再起動します。
$ systemctl restart kubelet次のコマンドを使用して、残りのコントロールプレーン Pod を起動します。
$ mv /root/manifests-backup/kube-* /etc/kubernetes/manifests/kube-apiserver、kube-scheduler、およびkube-controller-managerPod が正しく起動しているかどうかを確認します。$ crictl ps | grep -E 'kube-(apiserver|scheduler|controller-manager)' | grep -v -E 'operator|guard'次のコマンドを使用して OVN データベースをワイプします。
for NODE in $(oc get node -o name | sed 's:node/::g') do oc debug node/${NODE} -- chroot /host /bin/bash -c 'rm -f /var/lib/ovn-ic/etc/ovn*.db && systemctl restart ovs-vswitchd ovsdb-server' oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --wait oc -n openshift-ovn-kubernetes wait pod -l app=ovnkube-node --field-selector=spec.nodeName=${NODE} --for condition=ContainersReady --timeout=600s done
5.3.2.5. 永続ストレージの状態復元に関する問題および回避策
OpenShift Container Platform クラスターがいずれかの形式の永続ストレージを使用する場合に、クラスターの状態は通常 etcd 外に保存されます。たとえば、Pod で実行されている Elasticsearch クラスター、または StatefulSet オブジェクトで実行されているデータベースなどである可能性があります。etcd バックアップから復元する場合には、OpenShift Container Platform のワークロードのステータスも復元されます。ただし、etcd スナップショットが古い場合には、ステータスは無効または期限切れの可能性があります。
永続ボリューム (PV) の内容は etcd スナップショットには含まれません。etcd スナップショットから OpenShift Container Platform クラスターを復元する時に、重要ではないワークロードから重要なデータにアクセスしたり、その逆ができたりする場合があります。
以下は、古いステータスを生成するシナリオ例です。
- MySQL データベースが PV オブジェクトでバックアップされる Pod で実行されている。etcd スナップショットから OpenShift Container Platform を復元すると、Pod の起動を繰り返し試行しても、ボリュームをストレージプロバイダーに戻したり、実行中の MySQL Pod が生成したりされるわけではありません。この Pod は、ストレージプロバイダーでボリュームを復元し、次に PV を編集して新規ボリュームを参照するように手動で復元する必要があります。
- Pod P1 は、ノード X に割り当てられているボリューム A を使用している。別の Pod がノード Y にある同じボリュームを使用している場合に etcd スナップショットが作成された場合に、etcd の復元が実行されると、ボリュームがノード Y に割り当てられていることが原因で Pod P1 が正常に起動できなくなる可能性があります。OpenShift Container Platform はこの割り当てを認識せず、ボリュームが自動的に切り離されるわけではありません。これが生じる場合には、ボリュームをノード Y から手動で切り離し、ノード X に割り当ててることで Pod P1 を起動できるようにします。
- クラウドプロバイダーまたはストレージプロバイダーの認証情報が etcd スナップショットの作成後に更新された。これが原因で、プロバイダーの認証情報に依存する CSI ドライバーまたは Operator が機能しなくなります。これらのドライバーまたは Operator で必要な認証情報を手動で更新する必要がある場合があります。
デバイスが etcd スナップショットの作成後に OpenShift Container Platform ノードから削除されたか、名前が変更された。ローカルストレージ Operator で、
/dev/disk/by-idまたは/devディレクトリーから管理する各 PV のシンボリックリンクが作成されます。この状況では、ローカル PV が存在しないデバイスを参照してしまう可能性があります。この問題を修正するには、管理者は以下を行う必要があります。
- デバイスが無効な PV を手動で削除します。
- 各ノードからシンボリックリンクを削除します。
-
LocalVolumeまたはLocalVolumeSetオブジェクトを削除します (ストレージ → 永続ストレージの設定 → ローカルボリュームを使用した永続ストレージ → ローカルストレージ Operator のリソースの削除 を参照)。
5.3.3. コントロールプレーン証明書の期限切れの状態からのリカバリー
5.3.3.1. コントロールプレーン証明書の期限切れの状態からのリカバリー
クラスターはコントロールプレーン証明書の期限切れの状態から自動的に回復できます。
ただし、kubelet 証明書を回復するために保留状態の node-bootstrapper 証明書署名要求 (CSR) を手動で承認する必要があります。ユーザーによってプロビジョニングされるインストールの場合は、保留中の kubelet 提供の CSR を承認しないといけない場合があります。
保留中の CSR を承認するには、以下の手順に従います。
手順
現在の CSR の一覧を取得します。
$ oc get csr出力例
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending2 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...CSR の詳細をレビューし、これが有効であることを確認します。
$ oc describe csr <csr_name>1 - 1
<csr_name>は、現行の CSR のリストからの CSR の名前です。
それぞれの有効な
node-bootstrapperCSR を承認します。$ oc adm certificate approve <csr_name>ユーザーによってプロビジョニングされるインストールの場合は、それぞれの有効な kubelet 提供の CSR を承認します。
$ oc adm certificate approve <csr_name>
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.