Network Observability
Configuring and using the Network Observability Operator in OpenShift Container Platform
Abstract
Chapter 1. Network Observability Operator release notes
The Network Observability Operator enables administrators to observe and analyze network traffic flows for OpenShift Container Platform clusters.
These release notes track the development of the Network Observability Operator in the OpenShift Container Platform.
For an overview of the Network Observability Operator, see About Network Observability Operator.
1.1. Network Observability Operator 1.8.1
The following advisory is available for the Network Observability Operator 1.8.1:
1.1.1. CVEs
1.1.2. Bug fixes
- This fix ensures that the Observe menu appears only once in future versions of OpenShift Container Platform. (NETOBSERV-2139)
1.2. Network Observability Operator 1.8.0
The following advisory is available for the Network Observability Operator 1.8.0:
1.2.1. New features and enhancements
1.2.1.1. Packet translation
You can now enrich network flows with translated endpoint information, showing not only the service but also the specific backend pod, so you can see which pod served a request.
1.2.1.2. Network Observability CLI
The following new features, options, and filters are added to the Network Observability CLI for this release:
-
Capture metrics with filters enabled by running the
oc netobserv metricscommand. -
Run the CLI in the background by using the
--backgroundoption with flows and packets capture and runningoc netobserv followto see the progress of the background run andoc netobserv copyto download the generated logs. -
Enrich flows and metrics capture with Machines, Pods, and Services subnets by using the
--get-subnetsoption. New filtering options available with packets, flows, and metrics capture:
- eBPF filters on IPs, Ports, Protocol, Action, TCP Flags and more.
-
Custom nodes using
--node-selector -
Drops only using
--drops -
Any field using
--regexes
For more information, see Network Observability CLI reference.
1.2.2. Bug fixes
- Previously, the Network Observability Operator came with a "kube-rbac-proxy" container to manage RBAC for its metrics server. Since this external component is deprecated, it was necessary to remove it. It is now replaced with direct TLS and RBAC management through Kubernetes controller-runtime, without the need for a side-car proxy. (NETOBSERV-1999)
- Previously in the OpenShift Container Platform console plugin, filtering on a key that was not equal to multiple values would not filter anything. With this fix, the expected results are returned, which is all flows not having any of the filtered values. (NETOBSERV-1990)
- Previously in the OpenShift Container Platform console plugin with disabled Loki, it was very likely to generate a "Can’t build query" error due to selecting an incompatible set of filters and aggregations. Now this error is avoided avoid by automatically disabling incompatible filters while still making the user aware of the filter incompatibility. (NETOBSERV-1977)
- Previously, when viewing flow details from the console plugin, the ICMP info was always displayed in the side panel, showing "undefined" values for non-ICMP flows. With this fix, ICMP info is not displayed for non-ICMP flows. (NETOBSERV-1969)
- Previously, the "Export data" link from the Traffic flows view did not work as intended, generating empty CSV reports. Now, the export feature is restored, generating non-empty CSV data. (NETOBSERV-1958)
-
Previously, it was possible to configure the
FlowCollectorwithprocessor.logTypesConversations,EndedConversationsorAllwithloki.enableset tofalse, despite the conversation logs being only useful when Loki is enabled. This resulted in resource usage waste. Now, this configuration is invalid and is rejected by the validation webhook. (NETOBSERV-1957) -
Configuring the
FlowCollectorwithprocessor.logTypesset toAllconsumes much more resources, such as CPU, memory and network bandwidth, than the other options. This was previously not documented. It is now documented, and triggers a warning from the validation webhook. (NETOBSERV-1956) - Previously, under high stress, some flows generated by the eBPF agent were mistakenly dismissed, resulting in traffic bandwidth under-estimation. Now, those generated flows are not dismissed. (NETOBSERV-1954)
-
Previously, when enabling the network policy in the
FlowCollectorconfiguration, the traffic to the Operator webhooks was blocked, breaking theFlowMetricsAPI validation. Now traffic to the webhooks is allowed. (NETOBSERV-1934) -
Previously, when deploying the default network policy, namespaces
openshift-consoleandopenshift-monitoringwere set by default in theadditionalNamespacesfield, resulting in duplicated rules. Now there is no additional namespace set by default, which helps avoid getting duplicated rules.(NETOBSERV-1933) - Previously from the OpenShift Container Platform console plugin, filtering on TCP flags would match flows having only the exact desired flag. Now, any flow having at least the desired flag appears in filtered flows. (NETOBSERV-1890)
- When the eBPF agent runs in privileged mode and pods are continuously added or deleted, a file descriptor (FD) leak occurs. The fix ensures proper closure of the FD when a network namespace is deleted. (NETOBSERV-2063)
-
Previously, the CLI agent
DaemonSetdid not deploy on master nodes. Now, a toleration is added on the agentDaemonSetto schedule on every node when taints are set. Now, CLI agentDaemonSetpods run on all nodes. (NETOBSERV-2030) - Previously, the Source Resource and Source Destination filters autocomplete were not working when using Prometheus storage only. Now this issue is fixed and suggestions displays as expected. (NETOBSERV-1885)
- Previously, a resource using multiple IPs was displayed separately in the Topology view. Now, the resource shows as a single topology node in the view. (NETOBSERV-1818)
- Previously, the console refreshed the Network traffic table view contents when the mouse pointer hovered over the columns. Now, the display is fixed, so row height remains constant with a mouse hover. (NETOBSERV-2049)
1.2.3. Known issues
- If there is traffic that uses overlapping subnets in your cluster, there is a small risk that the eBPF Agent mixes up the flows from overlapped IPs. This can happen if different connections happen to have the exact same source and destination IPs and if ports and protocol are within a 5 seconds time frame and happening on the same node. This should not be possible unless you configured secondary networks or UDN. Even in that case, it is still very unlikely in usual traffic, as source ports are usually a good differentiator. (NETOBSERV-2115)
-
After selecting a type of exporter to configure in the
FlowCollectorresourcespec.exporterssection from the OpenShift Container Platform web console form view, the detailed configuration for that type does not show up in the form. The workaround is to configure directly the YAML. (NETOBSERV-1981)
1.3. Network Observability Operator 1.7.0
The following advisory is available for the Network Observability Operator 1.7.0:
1.3.1. New features and enhancements
1.3.1.1. OpenTelemetry support
You can now export enriched network flows to a compatible OpenTelemetry endpoint, such as the Red Hat build of OpenTelemetry. For more information see Export enriched network flow data.
1.3.1.2. Network Observability Developer perspective
You can now use Network Observability in the Developer perspective. For more information, see OpenShift Container Platform console integration.
1.3.1.3. TCP flags filtering
You can now use the tcpFlags filter to limit the volume of packets processed by the eBPF program. For more information, see Flow filter configuration parameters, eBPF flow rule filter, and Detecting SYN flooding using the FlowMetric API and TCP flags.
1.3.1.4. Network Observability for OpenShift Virtualization
You can observe networking patterns on an OpenShift Virtualization setup by identifying eBPF-enriched network flows coming from VMs that are connected to secondary networks, such as through Open Virtual Network (OVN)-Kubernetes. For more information, see Configuring virtual machine (VM) secondary network interfaces for Network Observability.
1.3.1.5. Network policy deploys in the FlowCollector custom resource (CR)
With this release, you can configure the FlowCollector CR to deploy a network policy for Network Observability. Previously, if you wanted a network policy, you had to manually create one. The option to manually create a network policy is still available. For more information, see Configuring an ingress network policy by using the FlowCollector custom resource.
1.3.1.6. FIPS compliance
You can install and use the Network Observability Operator in an OpenShift Container Platform cluster running in FIPS mode.
ImportantTo enable FIPS mode for your cluster, you must run the installation program from a RHEL computer configured to operate in FIPS mode. For more information about configuring FIPS mode on RHEL, see Installing the system in FIPS mode.
1.3.1.7. eBPF agent enhancements
The following enhancements are available for the eBPF agent:
-
If the DNS service maps to a different port than
53, you can specify this DNS tracking port usingspec.agent.ebpf.advanced.env.DNS_TRACKING_PORT. - You can now use two ports for transport protocols (TCP, UDP, or SCTP) filtering rules.
- You can now filter on transport ports with a wildcard protocol by leaving the protocol field empty.
For more information, see FlowCollector API specifications.
1.3.1.8. Network Observability CLI
The Network Observability CLI (oc netobserv), is now generally available. The following enhancements have been made since the 1.6 Technology Preview release: * There are now eBPF enrichment filters for packet capture similar to flow capture. * You can now use filter tcp_flags with both flow and packets capture. * The auto-teardown option is available when max-bytes or max-time is reached. For more information, see Network Observability CLI and Network Observability CLI 1.7.0.
1.3.2. Bug fixes
-
Previously, when using a RHEL 9.2 real-time kernel, some of the webhooks did not work. Now, a fix is in place to check whether this RHEL 9.2 real-time kernel is being used. If the kernel is being used, a warning is displayed about the features that do not work, such as packet drop and neither Round-trip Time when using
s390xarchitecture. The fix is in OpenShift 4.16 and later. (NETOBSERV-1808) - Previously, in the Manage panels dialog in the Overview tab, filtering on total, bar, donut, or line did not show a result. Now the available panels are correctly filtered. (NETOBSERV-1540)
-
Previously, under high stress, the eBPF agents were susceptible to enter into a state where they generated a high number of small flows, almost not aggregated. With this fix, the aggregation process is still maintained under high stress, resulting in less flows being created. This fix improves the resource consumption not only in the eBPF agent but also in
flowlogs-pipelineand Loki. (NETOBSERV-1564) -
Previously, when the
workload_flows_totalmetric was enabled instead of thenamespace_flows_totalmetric, the health dashboard stopped showingBy namespaceflow charts. With this fix, the health dashboard now shows the flow charts when theworkload_flows_totalis enabled. (NETOBSERV-1746) -
Previously, when you used the
FlowMetricsAPI to generate a custom metric and later modified its labels, such as by adding a new label, the metric stopped populating and an error was shown in theflowlogs-pipelinelogs. With this fix, you can modify the labels, and the error is no longer raised in theflowlogs-pipelinelogs. (NETOBSERV-1748) -
Previously, there was an inconsistency with the default Loki
WriteBatchSizeconfiguration: it was set to 100 KB in theFlowCollectorCRD default, and 10 MB in the OLM sample or default configuration. Both are now aligned to 10 MB, which generally provides better performances and less resource footprint. (NETOBSERV-1766) - Previously, the eBPF flow filter on ports was ignored if you did not specify a protocol. With this fix, you can set eBPF flow filters independently on ports and or protocols. (NETOBSERV-1779)
- Previously, traffic from Pods to Services was hidden from the Topology view. Only the return traffic from Services to Pods was visible. With this fix, that traffic is correctly displayed. (NETOBSERV-1788)
- Previously, non-cluster administrator users that had access to Network Observability saw an error in the console plugin when they tried to filter for something that triggered auto-completion, such as a namespace. With this fix, no error is displayed, and the auto-completion returns the expected results. (NETOBSERV-1798)
- When the secondary interface support was added, you had to iterate multiple times to register the per network namespace with the netlink to learn about interface notifications. At the same time, unsuccessful handlers caused a leaking file descriptor because with TCX hook, unlike TC, handlers needed to be explicitly removed when the interface went down. Furthermore, when the network namespace was deleted, there was no Go close channel event to terminate the netlink goroutine socket, which caused go threads to leak. Now, there are no longer leaking file descriptors or go threads when you create or delete pods. (NETOBSERV-1805)
- Previously, the ICMP type and value were displaying 'n/a' in the Traffic flows table even when related data was available in the flow JSON. With this fix, ICMP columns display related values as expected in the flow table. (NETOBSERV-1806)
- Previously in the console plugin, it wasn’t always possible to filter for unset fields, such as unset DNS latency. With this fix, filtering on unset fields is now possible. (NETOBSERV-1816)
- Previously, when you cleared filters in the OpenShift web console plugin, sometimes the filters reappeared after you navigated to another page and returned to the page with filters. With this fix, filters do not unexpectedly reappear after they are cleared. (NETOBSERV-1733)
1.3.3. Known issues
- WWhen you use the must-gather tool with Network Observability, logs are not collected when the cluster has FIPS enabled. (NETOBSERV-1830)
When the
spec.networkPolicyis enabled in theFlowCollector, which installs a network policy on thenetobservnamespace, it is impossible to use theFlowMetricsAPI. The network policy blocks calls to the validation webhook. As a workaround, use the following network policy:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-from-hostnetwork namespace: netobserv spec: podSelector: matchLabels: app: netobserv-operator ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/host-network: '' policyTypes: - Ingress
1.4. Network Observability Operator 1.6.1
The following advisory is available for the Network Observability Operator 1.6.1:
1.4.1. CVEs
1.4.2. Bug fixes
- Previously, information about packet drops, such as the cause and TCP state, was only available in the Loki datastore and not in Prometheus. For that reason, the drop statistics in the OpenShift web console plugin Overview was only available with Loki. With this fix, information about packet drops is also added to metrics, so you can view drops statistics when Loki is disabled. (NETOBSERV-1649)
-
When the eBPF agent
PacketDropfeature was enabled, and sampling was configured to a value greater than1, reported dropped bytes and dropped packets ignored the sampling configuration. While this was done on purpose, so as not to miss any drops, a side effect was that the reported proportion of drops compared with non-drops became biased. For example, at a very high sampling rate, such as1:1000, it was likely that almost all the traffic appears to be dropped when observed from the console plugin. With this fix, the sampling configuration is honored with dropped bytes and packets. (NETOBSERV-1676) - Previously, the SR-IOV secondary interface was not detected if the interface was created first and then the eBPF agent was deployed. It was only detected if the agent was deployed first and then the SR-IOV interface was created. With this fix, the SR-IOV secondary interface is detected no matter the sequence of the deployments. (NETOBSERV-1697)
- Previously, when Loki was disabled, the Topology view in the OpenShift web console displayed the Cluster and Zone aggregation options in the slider beside the network topology diagram, even when the related features were not enabled. With this fix, the slider now only displays options according to the enabled features. (NETOBSERV-1705)
-
Previously, when Loki was disabled, and the OpenShift web console was first loading, an error would occur:
Request failed with status code 400 Loki is disabled. With this fix, the errors no longer occur. (NETOBSERV-1706) - Previously, in the Topology view of the OpenShift web console, when clicking on the Step into icon next to any graph node, the filters were not applied as required in order to set the focus to the selected graph node, resulting in showing a wide view of the Topology view in the OpenShift web console. With this fix, the filters are correctly set, effectively narrowing down the Topology. As part of this change, clicking the Step into icon on a Node now brings you to the Resource scope instead of the Namespaces scope. (NETOBSERV-1720)
- Previously, when Loki was disabled, in the Topology view of the OpenShift web console with the Scope set to Owner, clicking on the Step into icon next to any graph node would bring the Scope to Resource, which is not available without Loki, so an error message was shown. With this fix, the Step into icon is hidden in the Owner scope when Loki is disabled, so this scenario no longer occurs.(NETOBSERV-1721)
- Previously, when Loki was disabled, an error was displayed in the Topology view of the OpenShift web console when a group was set, but then the scope was changed so that the group becomes invalid. With this fix, the invalid group is removed, preventing the error. (NETOBSERV-1722)
-
When creating a
FlowCollectorresource from the OpenShift web console Form view, as opposed to the YAML view, the following settings were incorrectly managed by the web console:agent.ebpf.metrics.enableandprocessor.subnetLabels.openShiftAutoDetect. These settings can only be disabled in the YAML view, not in the Form view. To avoid any confusion, these settings have been removed from the Form view. They are still accessible in the YAML view. (NETOBSERV-1731) - Previously, the eBPF agent was unable to clean up traffic control flows installed before an ungraceful crash, for example a crash due to a SIGTERM signal. This led to the creation of multiple traffic control flow filters with the same name, since the older ones were not removed. With this fix, all previously installed traffic control flows are cleaned up when the agent starts, before installing new ones. (NETOBSERV-1732)
- Previously, when configuring custom subnet labels and keeping the OpenShift subnets auto-detection enabled, OpenShift subnets would take precedence over the custom ones, preventing the definition of custom labels for in cluster subnets. With this fix, custom defined subnets take precedence, allowing the definition of custom labels for in cluster subnets. (NETOBSERV-1734)
1.5. Network Observability Operator 1.6.0
The following advisory is available for the Network Observability Operator 1.6.0:
Before upgrading to the latest version of the Network Observability Operator, you must Migrate removed stored versions of the FlowCollector CRD. An automated solution to this workaround is planned with NETOBSERV-1747.
1.5.1. New features and enhancements
1.5.1.1. Enhanced use of Network Observability Operator without Loki
You can now use Prometheus metrics and rely less on Loki for storage when using the Network Observability Operator. For more information, see Network Observability without Loki.
1.5.1.2. Custom metrics API
You can create custom metrics out of flowlogs data by using the FlowMetrics API. Flowlogs data can be used with Prometheus labels to customize cluster information on your dashboards. You can add custom labels for any subnet that you want to identify in your flows and metrics. This enhancement can also be used to more easily identify external traffic by using the new labels SrcSubnetLabel and DstSubnetLabel, which exists both in flow logs and in metrics. Those fields are empty when there is external traffic, which gives a way to identify it. For more information, see Custom metrics and FlowMetric API reference.
1.5.1.3. eBPF performance enhancements
Experience improved performances of the eBPF agent, in terms of CPU and memory, with the following updates:
- The eBPF agent now uses TCX webhooks instead of TC.
The NetObserv / Health dashboard has a new section that shows eBPF metrics.
- Based on the new eBPF metrics, an alert notifies you when the eBPF agent is dropping flows.
- Loki storage demand decreases significantly now that duplicated flows are removed. Instead of having multiple, individual duplicated flows per network interface, there is one de-duplicated flow with a list of related network interfaces.
With the duplicated flows update, the Interface and Interface Direction fields in the Network Traffic table are renamed to Interfaces and Interface Directions, so any bookmarked Quick filter queries using these fields need to be updated to interfaces and ifdirections.
For more information, see Using the eBPF agent alert and Quick filters.
1.5.1.4. eBPF collection rule-based filtering
You can use rule-based filtering to reduce the volume of created flows. When this option is enabled, the Netobserv / Health dashboard for eBPF agent statistics has the Filtered flows rate view. For more information, see eBPF flow rule filter.
1.5.2. Technology Preview features
Some features in this release are currently in Technology Preview. These experimental features are not intended for production use. Note the following scope of support on the Red Hat Customer Portal for these features:
Technology Preview Features Support Scope
1.5.2.1. Network Observability CLI
You can debug and troubleshoot network traffic issues without needing to install the Network Observability Operator by using the Network Observability CLI. Capture and visualize flow and packet data in real-time with no persistent storage requirement during the capture. For more information, see Network Observability CLI and Network Observability CLI 1.6.0.
1.5.3. Bug fixes
-
Previously, a dead link to the OpenShift containter platform documentation was displayed in the Operator Lifecycle Manager (OLM) form for the
FlowMetricsAPI creation. Now the link has been updated to point to a valid page. (NETOBSERV-1607) - Previously, the Network Observability Operator description in the Operator Hub displayed a broken link to the documentation. With this fix, this link is restored. (NETOBSERV-1544)
-
Previously, if Loki was disabled and the Loki
Modewas set toLokiStack, or if Loki manual TLS configuration was configured, the Network Observability Operator still tried to read the Loki CA certificates. With this fix, when Loki is disabled, the Loki certificates are not read, even if there are settings in the Loki configuration. (NETOBSERV-1647) -
Previously, the
ocmust-gatherplugin for the Network Observability Operator was only working on theamd64architecture and failing on all others because the plugin was usingamd64for theocbinary. Now, the Network Observability Operatorocmust-gatherplugin collects logs on any architecture platform. -
Previously, when filtering on IP addresses using
not equal to, the Network Observability Operator would return a request error. Now, the IP filtering works in bothequalandnot equal tocases for IP addresses and ranges. (NETOBSERV-1630) -
Previously, when a user was not an admin, the error messages were not consistent with the selected tab of the Network Traffic view in the web console. Now, the
user not adminerror displays on any tab with improved display.(NETOBSERV-1621)
1.5.4. Known issues
-
When the eBPF agent
PacketDropfeature is enabled, and sampling is configured to a value greater than1, reported dropped bytes and dropped packets ignore the sampling configuration. While this is done on purpose to not miss any drops, a side effect is that the reported proportion of drops compared to non-drops becomes biased. For example, at a very high sampling rate, such as1:1000, it is likely that almost all the traffic appears to be dropped when observed from the console plugin. (NETOBSERV-1676) - In the Manage panels pop-up window in the Overview tab, filtering on total, bar, donut, or line does not show any result. (NETOBSERV-1540)
- The SR-IOV secondary interface is not detected if the interface was created first and then the eBPF agent was deployed. It is only detected if the agent was deployed first and then the SR-IOV interface is created. (NETOBSERV-1697)
- When Loki is disabled, the Topology view in the OpenShift web console always shows the Cluster and Zone aggregation options in the slider beside the network topology diagram, even when the related features are not enabled. There is no specific workaround, besides ignoring these slider options. (NETOBSERV-1705)
-
When Loki is disabled, and the OpenShift web console first loads, it might display an error:
Request failed with status code 400 Loki is disabled. As a workaround, you can continue switching content on the Network Traffic page, such as clicking between the Topology and the Overview tabs. The error should disappear. (NETOBSERV-1706)
1.6. Network Observability Operator 1.5.0
The following advisory is available for the Network Observability Operator 1.5.0:
1.6.1. New features and enhancements
1.6.1.1. DNS tracking enhancements
In 1.5, the TCP protocol is now supported in addition to UDP. New dashboards are also added to the Overview view of the Network Traffic page. For more information, see Configuring DNS tracking and Working with DNS tracking.
1.6.1.2. Round-trip time (RTT)
You can use TCP handshake Round-Trip Time (RTT) captured from the fentry/tcp_rcv_established Extended Berkeley Packet Filter (eBPF) hookpoint to read smoothed round-trip time (SRTT) and analyze network flows. In the Overview, Network Traffic, and Topology pages in web console, you can monitor network traffic and troubleshoot with RTT metrics, filtering, and edge labeling. For more information, see RTT Overview and Working with RTT.
1.6.1.3. Metrics, dashboards, and alerts enhancements
The Network Observability metrics dashboards in Observe → Dashboards → NetObserv have new metrics types you can use to create Prometheus alerts. You can now define available metrics in the includeList specification. In previous releases, these metrics were defined in the ignoreTags specification. For a complete list of these metrics, see Network Observability Metrics.
1.6.1.4. Improvements for Network Observability without Loki
You can create Prometheus alerts for the Netobserv dashboard using DNS, Packet drop, and RTT metrics, even if you don’t use Loki. In the previous version of Network Observability, 1.4, these metrics were only available for querying and analysis in the Network Traffic, Overview, and Topology views, which are not available without Loki. For more information, see Network Observability Metrics.
1.6.1.5. Availability zones
You can configure the FlowCollector resource to collect information about the cluster availability zones. This configuration enriches the network flow data with the topology.kubernetes.io/zone label value applied to the nodes. For more information, see Working with availability zones.
1.6.1.6. Notable enhancements
The 1.5 release of the Network Observability Operator adds improvements and new capabilities to the OpenShift Container Platform web console plugin and the Operator configuration.
Performance enhancements
The
spec.agent.ebpf.kafkaBatchSizedefault is changed from10MBto1MBto enhance eBPF performance when using Kafka.ImportantWhen upgrading from an existing installation, this new value is not set automatically in the configuration. If you monitor a performance regression with the eBPF Agent memory consumption after upgrading, you might consider reducing the
kafkaBatchSizeto the new value.
Web console enhancements:
- There are new panels added to the Overview view for DNS and RTT: Min, Max, P90, P99.
There are new panel display options added:
- Focus on one panel while keeping others viewable but with smaller focus.
- Switch graph type.
- Show Top and Overall.
- A collection latency warning is shown in the Custom time range pop-up window.
- There is enhanced visibility for the contents of the Manage panels and Manage columns pop-up windows.
- The Differentiated Services Code Point (DSCP) field for egress QoS is available for filtering QoS DSCP in the web console Network Traffic page.
Configuration enhancements:
-
The
LokiStackmode in thespec.loki.modespecification simplifies installation by automatically setting URLs, TLS, cluster roles and a cluster role binding, as well as theauthTokenvalue. TheManualmode allows more control over configuration of these settings. -
The API version changes from
flows.netobserv.io/v1beta1toflows.netobserv.io/v1beta2.
1.6.2. Bug fixes
-
Previously, it was not possible to register the console plugin manually in the web console interface if the automatic registration of the console plugin was disabled. If the
spec.console.registervalue was set tofalsein theFlowCollectorresource, the Operator would override and erase the plugin registration. With this fix, setting thespec.console.registervalue tofalsedoes not impact the console plugin registration or registration removal. As a result, the plugin can be safely registered manually. (NETOBSERV-1134) -
Previously, using the default metrics settings, the NetObserv/Health dashboard was showing an empty graph named Flows Overhead. This metric was only available by removing "namespaces-flows" and "namespaces" from the
ignoreTagslist. With this fix, this metric is visible when you use the default metrics setting. (NETOBSERV-1351) - Previously, the node on which the eBPF Agent was running would not resolve with a specific cluster configuration. This resulted in cascading consequences that culminated in a failure to provide some of the traffic metrics. With this fix, the eBPF agent’s node IP is safely provided by the Operator, inferred from the pod status. Now, the missing metrics are restored. (NETOBSERV-1430)
- Previously, the Loki error 'Input size too long' error for the Loki Operator did not include additional information to troubleshoot the problem. With this fix, help is directly displayed in the web console next to the error with a direct link for more guidance. (NETOBSERV-1464)
-
Previously, the console plugin read timeout was forced to 30s. With the
FlowCollectorv1beta2API update, you can configure thespec.loki.readTimeoutspecification to update this value according to the Loki OperatorqueryTimeoutlimit. (NETOBSERV-1443) -
Previously, the Operator bundle did not display some of the supported features by CSV annotations as expected, such as
features.operators.openshift.io/…With this fix, these annotations are set in the CSV as expected. (NETOBSERV-1305) -
Previously, the
FlowCollectorstatus sometimes oscillated betweenDeploymentInProgressandReadystates during reconciliation. With this fix, the status only becomesReadywhen all of the underlying components are fully ready. (NETOBSERV-1293)
1.6.3. Known issues
-
When trying to access the web console, cache issues on OCP 4.14.10 prevent access to the Observe view. The web console shows the error message:
Failed to get a valid plugin manifest from /api/plugins/monitoring-plugin/. The recommended workaround is to update the cluster to the latest minor version. If this does not work, you need to apply the workarounds described in this Red Hat Knowledgebase article.(NETOBSERV-1493) -
Since the 1.3.0 release of the Network Observability Operator, installing the Operator causes a warning kernel taint to appear. The reason for this error is that the Network Observability eBPF agent has memory constraints that prevent preallocating the entire hashmap table. The Operator eBPF agent sets the
BPF_F_NO_PREALLOCflag so that pre-allocation is disabled when the hashmap is too memory expansive.
1.7. Network Observability Operator 1.4.2
The following advisory is available for the Network Observability Operator 1.4.2:
1.7.1. CVEs
1.8. Network Observability Operator 1.4.1
The following advisory is available for the Network Observability Operator 1.4.1:
1.8.1. CVEs
1.8.2. Bug fixes
- In 1.4, there was a known issue when sending network flow data to Kafka. The Kafka message key was ignored, causing an error with connection tracking. Now the key is used for partitioning, so each flow from the same connection is sent to the same processor. (NETOBSERV-926)
-
In 1.4, the
Innerflow direction was introduced to account for flows between pods running on the same node. Flows with theInnerdirection were not taken into account in the generated Prometheus metrics derived from flows, resulting in under-evaluated bytes and packets rates. Now, derived metrics are including flows with theInnerdirection, providing correct bytes and packets rates. (NETOBSERV-1344)
1.9. Network Observability Operator 1.4.0
The following advisory is available for the Network Observability Operator 1.4.0:
1.9.1. Channel removal
You must switch your channel from v1.0.x to stable to receive the latest Operator updates. The v1.0.x channel is now removed.
1.9.2. New features and enhancements
1.9.2.1. Notable enhancements
The 1.4 release of the Network Observability Operator adds improvements and new capabilities to the OpenShift Container Platform web console plugin and the Operator configuration.
Web console enhancements:
- In the Query Options, the Duplicate flows checkbox is added to choose whether or not to show duplicated flows.
-
You can now filter source and destination traffic with
 One-way,
One-way,
 Back-and-forth, and Swap filters.
Back-and-forth, and Swap filters.
The Network Observability metrics dashboards in Observe → Dashboards → NetObserv and NetObserv / Health are modified as follows:
- The NetObserv dashboard shows top bytes, packets sent, packets received per nodes, namespaces, and workloads. Flow graphs are removed from this dashboard.
- The NetObserv / Health dashboard shows flows overhead as well as top flow rates per nodes, namespaces, and workloads.
- Infrastructure and Application metrics are shown in a split-view for namespaces and workloads.
For more information, see Network Observability metrics and Quick filters.
Configuration enhancements:
- You now have the option to specify different namespaces for any configured ConfigMap or Secret reference, such as in certificates configuration.
-
The
spec.processor.clusterNameparameter is added so that the name of the cluster appears in the flows data. This is useful in a multi-cluster context. When using OpenShift Container Platform, leave empty to make it automatically determined.
For more information, see Flow Collector sample resource and Flow Collector API Reference.
1.9.2.2. Network Observability without Loki
The Network Observability Operator is now functional and usable without Loki. If Loki is not installed, it can only export flows to KAFKA or IPFIX format and provide metrics in the Network Observability metrics dashboards. For more information, see Network Observability without Loki.
1.9.2.3. DNS tracking
In 1.4, the Network Observability Operator makes use of eBPF tracepoint hooks to enable DNS tracking. You can monitor your network, conduct security analysis, and troubleshoot DNS issues in the Network Traffic and Overview pages in the web console.
For more information, see Configuring DNS tracking and Working with DNS tracking.
1.9.2.4. SR-IOV support
You can now collect traffic from a cluster with Single Root I/O Virtualization (SR-IOV) device. For more information, see Configuring the monitoring of SR-IOV interface traffic.
1.9.2.5. IPFIX exporter support
You can now export eBPF-enriched network flows to the IPFIX collector. For more information, see Export enriched network flow data.
1.9.2.6. Packet drops
In the 1.4 release of the Network Observability Operator, eBPF tracepoint hooks are used to enable packet drop tracking. You can now detect and analyze the cause for packet drops and make decisions to optimize network performance. In OpenShift Container Platform 4.14 and later, both host drops and OVS drops are detected. In OpenShift Container Platform 4.13, only host drops are detected. For more information, see Configuring packet drop tracking and Working with packet drops.
1.9.2.7. s390x architecture support
Network Observability Operator can now run on s390x architecture. Previously it ran on amd64, ppc64le, or arm64.
1.9.3. Bug fixes
- Previously, the Prometheus metrics exported by Network Observability were computed out of potentially duplicated network flows. In the related dashboards, from Observe → Dashboards, this could result in potentially doubled rates. Note that dashboards from the Network Traffic view were not affected. Now, network flows are filtered to eliminate duplicates before metrics calculation, which results in correct traffic rates displayed in the dashboards. (NETOBSERV-1131)
-
Previously, the Network Observability Operator agents were not able to capture traffic on network interfaces when configured with Multus or SR-IOV, non-default network namespaces. Now, all available network namespaces are recognized and used for capturing flows, allowing capturing traffic for SR-IOV. There are configurations needed for the
FlowCollectorandSRIOVnetworkcustom resource to collect traffic. (NETOBSERV-1283) -
Previously, in the Network Observability Operator details from Operators → Installed Operators, the
FlowCollectorStatus field might have reported incorrect information about the state of the deployment. The status field now shows the proper conditions with improved messages. The history of events is kept, ordered by event date. (NETOBSERV-1224) -
Previously, during spikes of network traffic load, certain eBPF pods were OOM-killed and went into a
CrashLoopBackOffstate. Now, theeBPFagent memory footprint is improved, so pods are not OOM-killed and entering aCrashLoopBackOffstate. (NETOBSERV-975) -
Previously when
processor.metrics.tlswas set toPROVIDEDtheinsecureSkipVerifyoption value was forced to betrue. Now you can setinsecureSkipVerifytotrueorfalse, and provide a CA certificate if needed. (NETOBSERV-1087)
1.9.4. Known issues
-
Since the 1.2.0 release of the Network Observability Operator, using Loki Operator 5.6, a Loki certificate change periodically affects the
flowlogs-pipelinepods and results in dropped flows rather than flows written to Loki. The problem self-corrects after some time, but it still causes temporary flow data loss during the Loki certificate change. This issue has only been observed in large-scale environments of 120 nodes or greater. (NETOBSERV-980) -
Currently, when
spec.agent.ebpf.featuresincludes DNSTracking, larger DNS packets require theeBPFagent to look for DNS header outside of the 1st socket buffer (SKB) segment. A neweBPFagent helper function needs to be implemented to support it. Currently, there is no workaround for this issue. (NETOBSERV-1304) -
Currently, when
spec.agent.ebpf.featuresincludes DNSTracking, DNS over TCP packets requires theeBPFagent to look for DNS header outside of the 1st SKB segment. A neweBPFagent helper function needs to be implemented to support it. Currently, there is no workaround for this issue. (NETOBSERV-1245) -
Currently, when using a
KAFKAdeployment model, if conversation tracking is configured, conversation events might be duplicated across Kafka consumers, resulting in inconsistent tracking of conversations, and incorrect volumetric data. For that reason, it is not recommended to configure conversation tracking whendeploymentModelis set toKAFKA. (NETOBSERV-926) -
Currently, when the
processor.metrics.server.tls.typeis configured to use aPROVIDEDcertificate, the operator enters an unsteady state that might affect its performance and resource consumption. It is recommended to not use aPROVIDEDcertificate until this issue is resolved, and instead using an auto-generated certificate, settingprocessor.metrics.server.tls.typetoAUTO. (NETOBSERV-1293 -
Since the 1.3.0 release of the Network Observability Operator, installing the Operator causes a warning kernel taint to appear. The reason for this error is that the Network Observability eBPF agent has memory constraints that prevent preallocating the entire hashmap table. The Operator eBPF agent sets the
BPF_F_NO_PREALLOCflag so that pre-allocation is disabled when the hashmap is too memory expansive.
1.10. Network Observability Operator 1.3.0
The following advisory is available for the Network Observability Operator 1.3.0:
1.10.1. Channel deprecation
You must switch your channel from v1.0.x to stable to receive future Operator updates. The v1.0.x channel is deprecated and planned for removal in the next release.
1.10.2. New features and enhancements
1.10.2.1. Multi-tenancy in Network Observability
- System administrators can allow and restrict individual user access, or group access, to the flows stored in Loki. For more information, see Multi-tenancy in Network Observability.
1.10.2.2. Flow-based metrics dashboard
- This release adds a new dashboard, which provides an overview of the network flows in your OpenShift Container Platform cluster. For more information, see Network Observability metrics.
1.10.2.3. Troubleshooting with the must-gather tool
- Information about the Network Observability Operator can now be included in the must-gather data for troubleshooting. For more information, see Network Observability must-gather.
1.10.2.4. Multiple architectures now supported
-
Network Observability Operator can now run on an
amd64,ppc64le, orarm64architectures. Previously, it only ran onamd64.
1.10.3. Deprecated features
1.10.3.1. Deprecated configuration parameter setting
The release of Network Observability Operator 1.3 deprecates the spec.Loki.authToken HOST setting. When using the Loki Operator, you must now only use the FORWARD setting.
1.10.4. Bug fixes
-
Previously, when the Operator was installed from the CLI, the
RoleandRoleBindingthat are necessary for the Cluster Monitoring Operator to read the metrics were not installed as expected. The issue did not occur when the operator was installed from the web console. Now, either way of installing the Operator installs the requiredRoleandRoleBinding. (NETOBSERV-1003) -
Since version 1.2, the Network Observability Operator can raise alerts when a problem occurs with the flows collection. Previously, due to a bug, the related configuration to disable alerts,
spec.processor.metrics.disableAlertswas not working as expected and sometimes ineffectual. Now, this configuration is fixed so that it is possible to disable the alerts. (NETOBSERV-976) -
Previously, when Network Observability was configured with
spec.loki.authTokenset toDISABLED, only akubeadmincluster administrator was able to view network flows. Other types of cluster administrators received authorization failure. Now, any cluster administrator is able to view network flows. (NETOBSERV-972) -
Previously, a bug prevented users from setting
spec.consolePlugin.portNaming.enabletofalse. Now, this setting can be set tofalseto disable port-to-service name translation. (NETOBSERV-971) - Previously, the metrics exposed by the console plugin were not collected by the Cluster Monitoring Operator (Prometheus), due to an incorrect configuration. Now the configuration has been fixed so that the console plugin metrics are correctly collected and accessible from the OpenShift Container Platform web console. (NETOBSERV-765)
-
Previously, when
processor.metrics.tlswas set toAUTOin theFlowCollector, theflowlogs-pipeline servicemonitordid not adapt the appropriate TLS scheme, and metrics were not visible in the web console. Now the issue is fixed for AUTO mode. (NETOBSERV-1070) -
Previously, certificate configuration, such as used for Kafka and Loki, did not allow specifying a namespace field, implying that the certificates had to be in the same namespace where Network Observability is deployed. Moreover, when using Kafka with TLS/mTLS, the user had to manually copy the certificate(s) to the privileged namespace where the
eBPFagent pods are deployed and manually manage certificate updates, such as in the case of certificate rotation. Now, Network Observability setup is simplified by adding a namespace field for certificates in theFlowCollectorresource. As a result, users can now install Loki or Kafka in different namespaces without needing to manually copy their certificates in the Network Observability namespace. The original certificates are watched so that the copies are automatically updated when needed. (NETOBSERV-773) - Previously, the SCTP, ICMPv4 and ICMPv6 protocols were not covered by the Network Observability agents, resulting in a less comprehensive network flows coverage. These protocols are now recognized to improve the flows coverage. (NETOBSERV-934)
1.10.5. Known issues
-
When
processor.metrics.tlsis set toPROVIDEDin theFlowCollector, theflowlogs-pipelineservicemonitoris not adapted to the TLS scheme. (NETOBSERV-1087) -
Since the 1.2.0 release of the Network Observability Operator, using Loki Operator 5.6, a Loki certificate change periodically affects the
flowlogs-pipelinepods and results in dropped flows rather than flows written to Loki. The problem self-corrects after some time, but it still causes temporary flow data loss during the Loki certificate change. This issue has only been observed in large-scale environments of 120 nodes or greater.(NETOBSERV-980) -
When you install the Operator, a warning kernel taint can appear. The reason for this error is that the Network Observability eBPF agent has memory constraints that prevent preallocating the entire hashmap table. The Operator eBPF agent sets the
BPF_F_NO_PREALLOCflag so that pre-allocation is disabled when the hashmap is too memory expansive.
1.11. Network Observability Operator 1.2.0
The following advisory is available for the Network Observability Operator 1.2.0:
1.11.1. Preparing for the next update
The subscription of an installed Operator specifies an update channel that tracks and receives updates for the Operator. Until the 1.2 release of the Network Observability Operator, the only channel available was v1.0.x. The 1.2 release of the Network Observability Operator introduces the stable update channel for tracking and receiving updates. You must switch your channel from v1.0.x to stable to receive future Operator updates. The v1.0.x channel is deprecated and planned for removal in a following release.
1.11.2. New features and enhancements
1.11.2.1. Histogram in Traffic Flows view
- You can now choose to show a histogram bar chart of flows over time. The histogram enables you to visualize the history of flows without hitting the Loki query limit. For more information, see Using the histogram.
1.11.2.2. Conversation tracking
- You can now query flows by Log Type, which enables grouping network flows that are part of the same conversation. For more information, see Working with conversations.
1.11.2.3. Network Observability health alerts
-
The Network Observability Operator now creates automatic alerts if the
flowlogs-pipelineis dropping flows because of errors at the write stage or if the Loki ingestion rate limit has been reached. For more information, see Health dashboards.
1.11.3. Bug fixes
-
Previously, after changing the
namespacevalue in the FlowCollector spec,eBPFagent pods running in the previous namespace were not appropriately deleted. Now, the pods running in the previous namespace are appropriately deleted. (NETOBSERV-774) -
Previously, after changing the
caCert.namevalue in the FlowCollector spec (such as in Loki section), FlowLogs-Pipeline pods and Console plug-in pods were not restarted, therefore they were unaware of the configuration change. Now, the pods are restarted, so they get the configuration change. (NETOBSERV-772) - Previously, network flows between pods running on different nodes were sometimes not correctly identified as being duplicates because they are captured by different network interfaces. This resulted in over-estimated metrics displayed in the console plug-in. Now, flows are correctly identified as duplicates, and the console plug-in displays accurate metrics. (NETOBSERV-755)
- The "reporter" option in the console plug-in is used to filter flows based on the observation point of either source node or destination node. Previously, this option mixed the flows regardless of the node observation point. This was due to network flows being incorrectly reported as Ingress or Egress at the node level. Now, the network flow direction reporting is correct. The "reporter" option filters for source observation point, or destination observation point, as expected. (NETOBSERV-696)
- Previously, for agents configured to send flows directly to the processor as gRPC+protobuf requests, the submitted payload could be too large and is rejected by the processors' GRPC server. This occurred under very-high-load scenarios and with only some configurations of the agent. The agent logged an error message, such as: grpc: received message larger than max. As a consequence, there was information loss about those flows. Now, the gRPC payload is split into several messages when the size exceeds a threshold. As a result, the server maintains connectivity. (NETOBSERV-617)
1.11.4. Known issue
-
In the 1.2.0 release of the Network Observability Operator, using Loki Operator 5.6, a Loki certificate transition periodically affects the
flowlogs-pipelinepods and results in dropped flows rather than flows written to Loki. The problem self-corrects after some time, but it still causes temporary flow data loss during the Loki certificate transition. (NETOBSERV-980)
1.11.5. Notable technical changes
-
Previously, you could install the Network Observability Operator using a custom namespace. This release introduces the
conversion webhookwhich changes theClusterServiceVersion. Because of this change, all the available namespaces are no longer listed. Additionally, to enable Operator metrics collection, namespaces that are shared with other Operators, like theopenshift-operatorsnamespace, cannot be used. Now, the Operator must be installed in theopenshift-netobserv-operatornamespace. You cannot automatically upgrade to the new Operator version if you previously installed the Network Observability Operator using a custom namespace. If you previously installed the Operator using a custom namespace, you must delete the instance of the Operator that was installed and re-install your operator in theopenshift-netobserv-operatornamespace. It is important to note that custom namespaces, such as the commonly usednetobservnamespace, are still possible for theFlowCollector, Loki, Kafka, and other plug-ins. (NETOBSERV-907)(NETOBSERV-956)
1.12. Network Observability Operator 1.1.0
The following advisory is available for the Network Observability Operator 1.1.0:
The Network Observability Operator is now stable and the release channel is upgraded to v1.1.0.
1.12.1. Bug fix
-
Previously, unless the Loki
authTokenconfiguration was set toFORWARDmode, authentication was no longer enforced, allowing any user who could connect to the OpenShift Container Platform console in an OpenShift Container Platform cluster to retrieve flows without authentication. Now, regardless of the LokiauthTokenmode, only cluster administrators can retrieve flows. (BZ#2169468)
Chapter 2. About Network Observability
Red Hat offers cluster administrators and developers the Network Observability Operator to observe the network traffic for OpenShift Container Platform clusters. The Network Observability Operator uses the eBPF technology to create network flows. The network flows are then enriched with OpenShift Container Platform information. They are available as Prometheus metrics or as logs in Loki. You can view and analyze the stored network flows information in the OpenShift Container Platform console for further insight and troubleshooting.
2.1. Optional dependencies of the Network Observability Operator
- Loki Operator: Loki is the backend that can be used to store all collected flows with a maximal level of details. You can choose to use Network Observability without Loki, but there are some considerations for doing this, as described in the linked section. If you choose to install Loki, it is recommended to use the Loki Operator, which is supported by Red Hat.
- AMQ Streams Operator: Kafka provides scalability, resiliency and high availability in the OpenShift Container Platform cluster for large scale deployments. If you choose to use Kafka, it is recommended to use the AMQ Streams Operator, because it is supported by Red Hat.
2.2. Network Observability Operator
The Network Observability Operator provides the Flow Collector API custom resource definition. A Flow Collector instance is a cluster-scoped resource that enables configuration of network flow collection. The Flow Collector instance deploys pods and services that form a monitoring pipeline where network flows are then collected and enriched with the Kubernetes metadata before storing in Loki or generating Prometheus metrics. The eBPF agent, which is deployed as a daemonset object, creates the network flows.
2.3. OpenShift Container Platform console integration
OpenShift Container Platform console integration offers overview, topology view, and traffic flow tables in both Administrator and Developer perspectives.
In the Administrator perspective, you can find the Network Observability Overview, Traffic flows, and Topology views by clicking Observe → Network Traffic. In the Developer perspective, you can view this information by clicking Observe. The Network Observability metrics dashboards in Observe → Dashboards are only available to administrators.
To enable multi-tenancy for the developer perspective and for administrators with limited access to namespaces, you must specify permissions by defining roles. For more information, see Enabling multi-tenancy in Network Observability.
2.3.1. Network Observability metrics dashboards
On the Overview tab in the OpenShift Container Platform console, you can view the overall aggregated metrics of the network traffic flow on the cluster. You can choose to display the information by zone, node, namespace, owner, pod, and service. Filters and display options can further refine the metrics. For more information, see Observing the network traffic from the Overview view.
In Observe → Dashboards, the Netobserv dashboards provide a quick overview of the network flows in your OpenShift Container Platform cluster. The Netobserv/Health dashboard provides metrics about the health of the Operator. For more information, see Network Observability Metrics and Viewing health information.
2.3.2. Network Observability topology views
The OpenShift Container Platform console offers the Topology tab which displays a graphical representation of the network flows and the amount of traffic. The topology view represents traffic between the OpenShift Container Platform components as a network graph. You can refine the graph by using the filters and display options. You can access the information for zone, node, namespace, owner, pod, and service.
2.3.3. Traffic flow tables
The Traffic flow table view provides a view for raw flows, non aggregated filtering options, and configurable columns. The OpenShift Container Platform console offers the Traffic flows tab which displays the data of the network flows and the amount of traffic.
2.4. Network Observability CLI
You can quickly debug and troubleshoot networking issues with Network Observability by using the Network Observability CLI (oc netobserv). The Network Observability CLI is a flow and packet visualization tool that relies on eBPF agents to stream collected data to an ephemeral collector pod. It requires no persistent storage during the capture. After the run, the output is transferred to your local machine. This enables quick, live insight into packets and flow data without installing the Network Observability Operator.
Chapter 3. Installing the Network Observability Operator
Installing Loki is a recommended prerequisite for using the Network Observability Operator. You can choose to use Network Observability without Loki, but there are some considerations for doing this, described in the previously linked section.
The Loki Operator integrates a gateway that implements multi-tenancy and authentication with Loki for data flow storage. The LokiStack resource manages Loki, which is a scalable, highly-available, multi-tenant log aggregation system, and a web proxy with OpenShift Container Platform authentication. The LokiStack proxy uses OpenShift Container Platform authentication to enforce multi-tenancy and facilitate the saving and indexing of data in Loki log stores.
The Loki Operator can also be used for configuring the LokiStack log store. The Network Observability Operator requires a dedicated LokiStack separate from the logging.
3.1. Network Observability without Loki
You can use Network Observability without Loki by not performing the Loki installation steps and skipping directly to "Installing the Network Observability Operator". If you only want to export flows to a Kafka consumer or IPFIX collector, or you only need dashboard metrics, then you do not need to install Loki or provide storage for Loki. The following table compares available features with and without Loki.
| With Loki | Without Loki | |
|---|---|---|
| Exporters |
|
|
| Multi-tenancy |
|
|
| Complete filtering and aggregations capabilities [1] |
|
|
| Partial filtering and aggregations capabilities [2] |
|
|
| Flow-based metrics and dashboards |
|
|
| Traffic flows view overview [3] |
|
|
| Traffic flows view table |
|
|
| Topology view |
|
|
| OpenShift Container Platform console Network Traffic tab integration |
|
|
- Such as per pod.
- Such as per workload or namespace.
- Statistics on packet drops are only available with Loki.
3.2. Installing the Loki Operator
The Loki Operator versions 5.7+ are the supported Loki Operator versions for Network Observability; these versions provide the ability to create a LokiStack instance using the openshift-network tenant configuration mode and provide fully-automatic, in-cluster authentication and authorization support for Network Observability. There are several ways you can install Loki. One way is by using the OpenShift Container Platform web console Operator Hub.
Prerequisites
- Supported Log Store (AWS S3, Google Cloud Storage, Azure, Swift, Minio, OpenShift Data Foundation)
- OpenShift Container Platform 4.10+
- Linux Kernel 4.18+
Procedure
- In the OpenShift Container Platform web console, click Operators → OperatorHub.
- Choose Loki Operator from the list of available Operators, and click Install.
- Under Installation Mode, select All namespaces on the cluster.
Verification
- Verify that you installed the Loki Operator. Visit the Operators → Installed Operators page and look for Loki Operator.
- Verify that Loki Operator is listed with Status as Succeeded in all the projects.
To uninstall Loki, refer to the uninstallation process that corresponds with the method you used to install Loki. You might have remaining ClusterRoles and ClusterRoleBindings, data stored in object store, and persistent volume that must be removed.
3.2.1. Creating a secret for Loki storage
The Loki Operator supports a few log storage options, such as AWS S3, Google Cloud Storage, Azure, Swift, Minio, OpenShift Data Foundation. The following example shows how to create a secret for AWS S3 storage. The secret created in this example, loki-s3, is referenced in "Creating a LokiStack resource". You can create this secret in the web console or CLI.
-
Using the web console, navigate to the Project → All Projects dropdown and select Create Project. Name the project
netobservand click Create. Navigate to the Import icon, +, in the top right corner. Paste your YAML file into the editor.
The following shows an example secret YAML file for S3 storage:
apiVersion: v1 kind: Secret metadata: name: loki-s3 namespace: netobserv1 stringData: access_key_id: QUtJQUlPU0ZPRE5ON0VYQU1QTEUK access_key_secret: d0phbHJYVXRuRkVNSS9LN01ERU5HL2JQeFJmaUNZRVhBTVBMRUtFWQo= bucketnames: s3-bucket-name endpoint: https://s3.eu-central-1.amazonaws.com region: eu-central-1- 1
- The installation examples in this documentation use the same namespace,
netobserv, across all components. You can optionally use a different namespace for the different components
Verification
- Once you create the secret, you should see it listed under Workloads → Secrets in the web console.
3.2.2. Creating a LokiStack custom resource
You can deploy a LokiStack custom resource (CR) by using the web console or OpenShift CLI (oc) to create a namespace, or new project.
Procedure
- Navigate to Operators → Installed Operators, viewing All projects from the Project dropdown.
- Look for Loki Operator. In the details, under Provided APIs, select LokiStack.
- Click Create LokiStack.
Ensure the following fields are specified in either Form View or YAML view:
apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv1 spec: size: 1x.small2 storage: schemas: - version: v12 effectiveDate: '2022-06-01' secret: name: loki-s3 type: s3 storageClassName: gp33 tenants: mode: openshift-network- 1
- The installation examples in this documentation use the same namespace,
netobserv, across all components. You can optionally use a different namespace. - 2
- Specify the deployment size. In the Loki Operator 5.8 and later versions, the supported size options for production instances of Loki are
1x.extra-small,1x.small, or1x.medium.ImportantIt is not possible to change the number
1xfor the deployment size. - 3
- Use a storage class name that is available on the cluster for
ReadWriteOnceaccess mode. You can useoc get storageclassesto see what is available on your cluster.ImportantYou must not reuse the same
LokiStackCR that is used for logging.
- Click Create.
3.2.3. Creating a new group for the cluster-admin user role
Querying application logs for multiple namespaces as a cluster-admin user, where the sum total of characters of all of the namespaces in the cluster is greater than 5120, results in the error Parse error: input size too long (XXXX > 5120). For better control over access to logs in LokiStack, make the cluster-admin user a member of the cluster-admin group. If the cluster-admin group does not exist, create it and add the desired users to it.
Use the following procedure to create a new group for users with cluster-admin permissions.
Procedure
Enter the following command to create a new group:
$ oc adm groups new cluster-adminEnter the following command to add the desired user to the
cluster-admingroup:$ oc adm groups add-users cluster-admin <username>Enter the following command to add
cluster-adminuser role to the group:$ oc adm policy add-cluster-role-to-group cluster-admin cluster-admin
3.2.4. Custom admin group access
If you need to see cluster-wide logs without necessarily being an administrator, or if you already have any group defined that you want to use here, you can specify a custom group using the adminGroup field. Users who are members of any group specified in the adminGroups field of the LokiStack custom resource (CR) have the same read access to logs as administrators.
Administrator users have access to all network logs across the cluster.
Example LokiStack CR
apiVersion: loki.grafana.com/v1
kind: LokiStack
metadata:
name: loki
namespace: netobserv
spec:
tenants:
mode: openshift-network
openshift:
adminGroups:
- cluster-admin
- custom-admin-group 3.2.5. Loki deployment sizing
Sizing for Loki follows the format of 1x.<size> where the value 1x is number of instances and <size> specifies performance capabilities.
It is not possible to change the number 1x for the deployment size.
| 1x.demo | 1x.extra-small | 1x.small | 1x.medium | |
|---|---|---|---|---|
| Data transfer | Demo use only | 100GB/day | 500GB/day | 2TB/day |
| Queries per second (QPS) | Demo use only | 1-25 QPS at 200ms | 25-50 QPS at 200ms | 25-75 QPS at 200ms |
| Replication factor | None | 2 | 2 | 2 |
| Total CPU requests | None | 14 vCPUs | 34 vCPUs | 54 vCPUs |
| Total memory requests | None | 31Gi | 67Gi | 139Gi |
| Total disk requests | 40Gi | 430Gi | 430Gi | 590Gi |
3.2.6. LokiStack ingestion limits and health alerts
The LokiStack instance comes with default settings according to the configured size. It is possible to override some of these settings, such as the ingestion and query limits. An automatic alert in the web console notifies you when these limits are reached.
You might want to update the ingestion and query limits if you get Loki errors showing up in the Console plugin, or in flowlogs-pipeline logs.
Here is an example of configured limits:
spec:
limits:
global:
ingestion:
ingestionBurstSize: 40
ingestionRate: 20
maxGlobalStreamsPerTenant: 25000
queries:
maxChunksPerQuery: 2000000
maxEntriesLimitPerQuery: 10000
maxQuerySeries: 3000For more information about these settings, see the LokiStack API reference.
3.3. Installing the Network Observability Operator
You can install the Network Observability Operator using the OpenShift Container Platform web console Operator Hub. When you install the Operator, it provides the FlowCollector custom resource definition (CRD). You can set specifications in the web console when you create the FlowCollector.
The actual memory consumption of the Operator depends on your cluster size and the number of resources deployed. Memory consumption might need to be adjusted accordingly. For more information refer to "Network Observability controller manager pod runs out of memory" in the "Important Flow Collector configuration considerations" section.
Prerequisites
- If you choose to use Loki, install the Loki Operator version 5.7+.
-
You must have
cluster-adminprivileges. -
One of the following supported architectures is required:
amd64,ppc64le,arm64, ors390x. - Any CPU supported by Red Hat Enterprise Linux (RHEL) 9.
- Must be configured with OVN-Kubernetes or OpenShift SDN as the main network plugin, and optionally using secondary interfaces with Multus and SR-IOV.
Additionally, this installation example uses the netobserv namespace, which is used across all components. You can optionally use a different namespace.
Procedure
- In the OpenShift Container Platform web console, click Operators → OperatorHub.
- Choose Network Observability Operator from the list of available Operators in the OperatorHub, and click Install.
-
Select the checkbox
Enable Operator recommended cluster monitoring on this Namespace. - Navigate to Operators → Installed Operators. Under Provided APIs for Network Observability, select the Flow Collector link.
Navigate to the Flow Collector tab, and click Create FlowCollector. Make the following selections in the form view:
-
spec.agent.ebpf.Sampling: Specify a sampling size for flows. Lower sampling sizes will have higher impact on resource utilization. For more information, see the "FlowCollector API reference",
spec.agent.ebpf. - If you are not using Loki, click Loki client settings and change Enable to False. The setting is True by default.
If you are using Loki, set the following specifications:
-
spec.loki.mode: Set this to the
LokiStackmode, which automatically sets URLs, TLS, cluster roles and a cluster role binding, as well as theauthTokenvalue. Alternatively, theManualmode allows more control over configuration of these settings. -
spec.loki.lokistack.name: Set this to the name of your
LokiStackresource. In this documentation,lokiis used.
-
spec.loki.mode: Set this to the
-
Optional: If you are in a large-scale environment, consider configuring the
FlowCollectorwith Kafka for forwarding data in a more resilient, scalable way. See "Configuring the Flow Collector resource with Kafka storage" in the "Important Flow Collector configuration considerations" section. -
Optional: Configure other optional settings before the next step of creating the
FlowCollector. For example, if you choose not to use Loki, then you can configure exporting flows to Kafka or IPFIX. See "Export enriched network flow data to Kafka and IPFIX" and more in the "Important Flow Collector configuration considerations" section.
-
spec.agent.ebpf.Sampling: Specify a sampling size for flows. Lower sampling sizes will have higher impact on resource utilization. For more information, see the "FlowCollector API reference",
- Click Create.
Verification
To confirm this was successful, when you navigate to Observe you should see Network Traffic listed in the options.
In the absence of Application Traffic within the OpenShift Container Platform cluster, default filters might show that there are "No results", which results in no visual flow. Beside the filter selections, select Clear all filters to see the flow.
3.4. Enabling multi-tenancy in Network Observability
Multi-tenancy in the Network Observability Operator allows and restricts individual user access, or group access, to the flows stored in Loki and or Prometheus. Access is enabled for project administrators. Project administrators who have limited access to some namespaces can access flows for only those namespaces.
For Developers, multi-tenancy is available for both Loki and Prometheus but requires different access rights.
Prerequisite
- If you are using Loki, you have installed at least Loki Operator version 5.7.
- You must be logged in as a project administrator.
Procedure
For per-tenant access, you must have the
netobserv-readercluster role and thenetobserv-metrics-readernamespace role to use the developer perspective. Run the following commands for this level of access:$ oc adm policy add-cluster-role-to-user netobserv-reader <user_group_or_name>$ oc adm policy add-role-to-user netobserv-metrics-reader <user_group_or_name> -n <namespace>For cluster-wide access, non-cluster-administrators must have the
netobserv-reader,cluster-monitoring-view, andnetobserv-metrics-readercluster roles. In this scenario, you can use either the admin perspective or the developer perspective. Run the following commands for this level of access:$ oc adm policy add-cluster-role-to-user netobserv-reader <user_group_or_name>$ oc adm policy add-cluster-role-to-user cluster-monitoring-view <user_group_or_name>$ oc adm policy add-cluster-role-to-user netobserv-metrics-reader <user_group_or_name>
3.6. Installing Kafka (optional)
The Kafka Operator is supported for large scale environments. Kafka provides high-throughput and low-latency data feeds for forwarding network flow data in a more resilient, scalable way. You can install the Kafka Operator as Red Hat AMQ Streams from the Operator Hub, just as the Loki Operator and Network Observability Operator were installed. Refer to "Configuring the FlowCollector resource with Kafka" to configure Kafka as a storage option.
To uninstall Kafka, refer to the uninstallation process that corresponds with the method you used to install.
3.7. Uninstalling the Network Observability Operator
You can uninstall the Network Observability Operator using the OpenShift Container Platform web console Operator Hub, working in the Operators → Installed Operators area.
Procedure
Remove the
FlowCollectorcustom resource.- Click Flow Collector, which is next to the Network Observability Operator in the Provided APIs column.
-
Click the options menu
 for the cluster and select Delete FlowCollector.
for the cluster and select Delete FlowCollector.
Uninstall the Network Observability Operator.
- Navigate back to the Operators → Installed Operators area.
-
Click the options menu
next to the Network Observability Operator and select Uninstall Operator.
-
Home → Projects and select
openshift-netobserv-operator - Navigate to Actions and select Delete Project
Remove the
FlowCollectorcustom resource definition (CRD).- Navigate to Administration → CustomResourceDefinitions.
-
Look for FlowCollector and click the options menu
.
Select Delete CustomResourceDefinition.
ImportantThe Loki Operator and Kafka remain if they were installed and must be removed separately. Additionally, you might have remaining data stored in an object store, and a persistent volume that must be removed.
Chapter 4. Network Observability Operator in OpenShift Container Platform
Network Observability is an OpenShift operator that deploys a monitoring pipeline to collect and enrich network traffic flows that are produced by the Network Observability eBPF agent.
4.1. Viewing statuses
The Network Observability Operator provides the Flow Collector API. When a Flow Collector resource is created, it deploys pods and services to create and store network flows in the Loki log store, as well as to display dashboards, metrics, and flows in the OpenShift Container Platform web console.
Procedure
Run the following command to view the state of
FlowCollector:$ oc get flowcollector/clusterExample output
NAME AGENT SAMPLING (EBPF) DEPLOYMENT MODEL STATUS cluster EBPF 50 DIRECT ReadyCheck the status of pods running in the
netobservnamespace by entering the following command:$ oc get pods -n netobservExample output
NAME READY STATUS RESTARTS AGE flowlogs-pipeline-56hbp 1/1 Running 0 147m flowlogs-pipeline-9plvv 1/1 Running 0 147m flowlogs-pipeline-h5gkb 1/1 Running 0 147m flowlogs-pipeline-hh6kf 1/1 Running 0 147m flowlogs-pipeline-w7vv5 1/1 Running 0 147m netobserv-plugin-cdd7dc6c-j8ggp 1/1 Running 0 147m
flowlogs-pipeline pods collect flows, enriches the collected flows, then send flows to the Loki storage. netobserv-plugin pods create a visualization plugin for the OpenShift Container Platform Console.
Check the status of pods running in the namespace
netobserv-privilegedby entering the following command:$ oc get pods -n netobserv-privilegedExample output
NAME READY STATUS RESTARTS AGE netobserv-ebpf-agent-4lpp6 1/1 Running 0 151m netobserv-ebpf-agent-6gbrk 1/1 Running 0 151m netobserv-ebpf-agent-klpl9 1/1 Running 0 151m netobserv-ebpf-agent-vrcnf 1/1 Running 0 151m netobserv-ebpf-agent-xf5jh 1/1 Running 0 151m
netobserv-ebpf-agent pods monitor network interfaces of the nodes to get flows and send them to flowlogs-pipeline pods.
If you are using the Loki Operator, check the status of pods running in the
openshift-operators-redhatnamespace by entering the following command:$ oc get pods -n openshift-operators-redhatExample output
NAME READY STATUS RESTARTS AGE loki-operator-controller-manager-5f6cff4f9d-jq25h 2/2 Running 0 18h lokistack-compactor-0 1/1 Running 0 18h lokistack-distributor-654f87c5bc-qhkhv 1/1 Running 0 18h lokistack-distributor-654f87c5bc-skxgm 1/1 Running 0 18h lokistack-gateway-796dc6ff7-c54gz 2/2 Running 0 18h lokistack-index-gateway-0 1/1 Running 0 18h lokistack-index-gateway-1 1/1 Running 0 18h lokistack-ingester-0 1/1 Running 0 18h lokistack-ingester-1 1/1 Running 0 18h lokistack-ingester-2 1/1 Running 0 18h lokistack-querier-66747dc666-6vh5x 1/1 Running 0 18h lokistack-querier-66747dc666-cjr45 1/1 Running 0 18h lokistack-querier-66747dc666-xh8rq 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-b2xfb 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-jm94f 1/1 Running 0 18h
4.2. Network Observablity Operator architecture
The Network Observability Operator provides the FlowCollector API, which is instantiated at installation and configured to reconcile the eBPF agent, the flowlogs-pipeline, and the netobserv-plugin components. Only a single FlowCollector per cluster is supported.
The eBPF agent runs on each cluster node with some privileges to collect network flows. The flowlogs-pipeline receives the network flows data and enriches the data with Kubernetes identifiers. If you choose to use Loki, the flowlogs-pipeline sends flow logs data to Loki for storing and indexing. The netobserv-plugin, which is a dynamic OpenShift Container Platform web console plugin, queries Loki to fetch network flows data. Cluster-admins can view the data in the web console.
If you do not use Loki, you can generate metrics with Prometheus. Those metrics and their related dashboards are accessible in the web console. For more information, see "Network Observability without Loki".
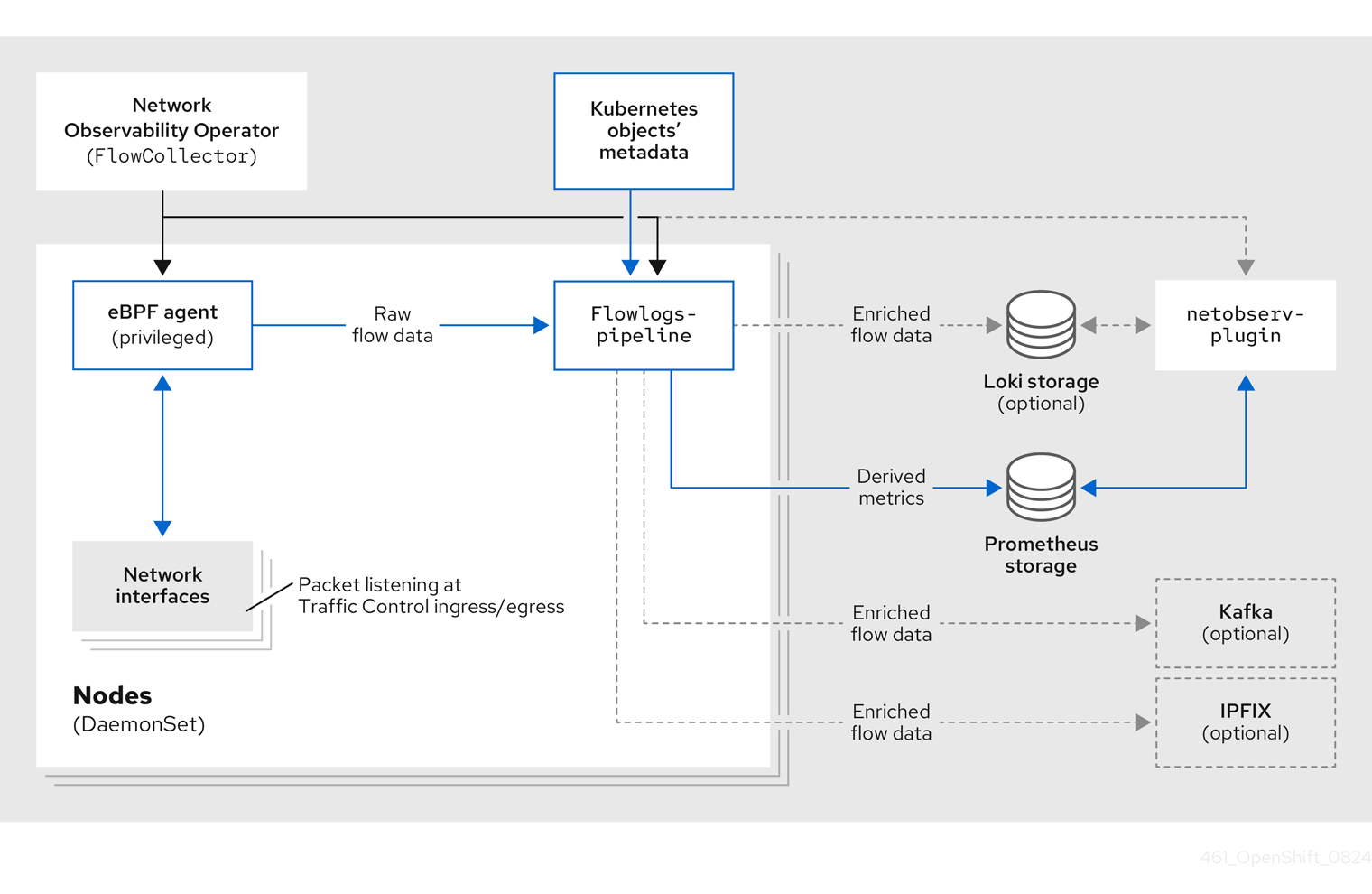
If you are using the Kafka option, the eBPF agent sends the network flow data to Kafka, and the flowlogs-pipeline reads from the Kafka topic before sending to Loki, as shown in the following diagram.
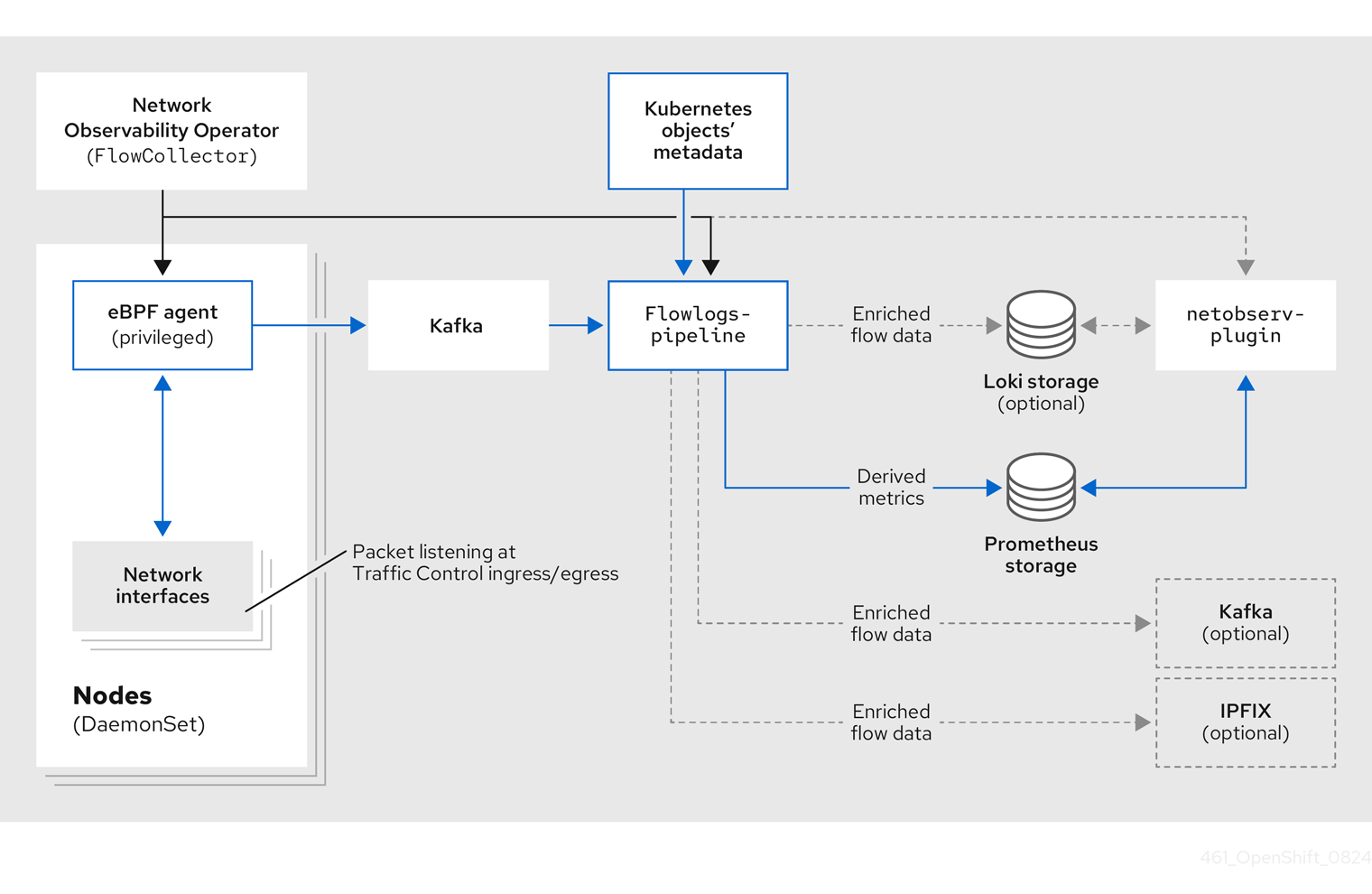
4.3. Viewing Network Observability Operator status and configuration
You can inspect the status and view the details of the FlowCollector using the oc describe command.
Procedure
Run the following command to view the status and configuration of the Network Observability Operator:
$ oc describe flowcollector/cluster
Chapter 5. Configuring the Network Observability Operator
You can update the FlowCollector API resource to configure the Network Observability Operator and its managed components. The FlowCollector is explicitly created during installation. Since this resource operates cluster-wide, only a single FlowCollector is allowed, and it must be named cluster. For more information, see the FlowCollector API reference.
5.1. View the FlowCollector resource
You can view and edit YAML directly in the OpenShift Container Platform web console.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
-
Select cluster then select the YAML tab. There, you can modify the
FlowCollectorresource to configure the Network Observability operator.
The following example shows a sample FlowCollector resource for OpenShift Container Platform Network Observability operator:
Sample FlowCollector resource
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Direct
agent:
type: eBPF
ebpf:
sampling: 50
logLevel: info
privileged: false
resources:
requests:
memory: 50Mi
cpu: 100m
limits:
memory: 800Mi
processor:
logLevel: info
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 800Mi
logTypes: Flows
advanced:
conversationEndTimeout: 10s
conversationHeartbeatInterval: 30s
loki:
mode: LokiStack
consolePlugin:
register: true
logLevel: info
portNaming:
enable: true
portNames:
"3100": loki
quickFilters:
- name: Applications
filter:
src_namespace!: 'openshift-,netobserv'
dst_namespace!: 'openshift-,netobserv'
default: true
- name: Infrastructure
filter:
src_namespace: 'openshift-,netobserv'
dst_namespace: 'openshift-,netobserv'
- name: Pods network
filter:
src_kind: 'Pod'
dst_kind: 'Pod'
default: true
- name: Services network
filter:
dst_kind: 'Service'- 1
- The Agent specification,
spec.agent.type, must beEBPF. eBPF is the only OpenShift Container Platform supported option. - 2
- You can set the Sampling specification,
spec.agent.ebpf.sampling, to manage resources. Lower sampling values might consume a large amount of computational, memory and storage resources. You can mitigate this by specifying a sampling ratio value. A value of 100 means 1 flow every 100 is sampled. A value of 0 or 1 means all flows are captured. The lower the value, the increase in returned flows and the accuracy of derived metrics. By default, eBPF sampling is set to a value of 50, so 1 flow every 50 is sampled. Note that more sampled flows also means more storage needed. It is recommend to start with default values and refine empirically, to determine which setting your cluster can manage. - 3
- The Processor specification
spec.processor.can be set to enable conversation tracking. When enabled, conversation events are queryable in the web console. Thespec.processor.logTypesvalue isFlows. Thespec.processor.advancedvalues areConversations,EndedConversations, orALL. Storage requirements are highest forAlland lowest forEndedConversations. - 4
- The Loki specification,
spec.loki, specifies the Loki client. The default values match the Loki install paths mentioned in the Installing the Loki Operator section. If you used another installation method for Loki, specify the appropriate client information for your install. - 5
- The
LokiStackmode automatically sets a few configurations:querierUrl,ingesterUrlandstatusUrl,tenantID, and corresponding TLS configuration. Cluster roles and a cluster role binding are created for reading and writing logs to Loki. AndauthTokenis set toForward. You can set these manually using theManualmode. - 6
- The
spec.quickFiltersspecification defines filters that show up in the web console. TheApplicationfilter keys,src_namespaceanddst_namespace, are negated (!), so theApplicationfilter shows all traffic that does not originate from, or have a destination to, anyopenshift-ornetobservnamespaces. For more information, see Configuring quick filters below.
5.2. Configuring the Flow Collector resource with Kafka
You can configure the FlowCollector resource to use Kafka for high-throughput and low-latency data feeds. A Kafka instance needs to be running, and a Kafka topic dedicated to OpenShift Container Platform Network Observability must be created in that instance. For more information, see Kafka documentation with AMQ Streams.
Prerequisites
- Kafka is installed. Red Hat supports Kafka with AMQ Streams Operator.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the Network Observability Operator, select Flow Collector.
- Select the cluster and then click the YAML tab.
-
Modify the
FlowCollectorresource for OpenShift Container Platform Network Observability Operator to use Kafka, as shown in the following sample YAML:
Sample Kafka configuration in FlowCollector resource
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
deploymentModel: Kafka
kafka:
address: "kafka-cluster-kafka-bootstrap.netobserv"
topic: network-flows
tls:
enable: false - 1
- Set
spec.deploymentModeltoKafkainstead ofDirectto enable the Kafka deployment model. - 2
spec.kafka.addressrefers to the Kafka bootstrap server address. You can specify a port if needed, for instancekafka-cluster-kafka-bootstrap.netobserv:9093for using TLS on port 9093.- 3
spec.kafka.topicshould match the name of a topic created in Kafka.- 4
spec.kafka.tlscan be used to encrypt all communications to and from Kafka with TLS or mTLS. When enabled, the Kafka CA certificate must be available as a ConfigMap or a Secret, both in the namespace where theflowlogs-pipelineprocessor component is deployed (default:netobserv) and where the eBPF agents are deployed (default:netobserv-privileged). It must be referenced withspec.kafka.tls.caCert. When using mTLS, client secrets must be available in these namespaces as well (they can be generated for instance using the AMQ Streams User Operator) and referenced withspec.kafka.tls.userCert.
5.3. Export enriched network flow data
You can send network flows to Kafka, IPFIX, the Red Hat build of OpenTelemetry, or all three at the same time. For Kafka or IPFIX, any processor or storage that supports those inputs, such as Splunk, Elasticsearch, or Fluentd, can consume the enriched network flow data. For OpenTelemetry, network flow data and metrics can be exported to a compatible OpenTelemetry endpoint, such as Red Hat build of OpenTelemetry or Prometheus.
Prerequisites
-
Your Kafka, IPFIX, or OpenTelemetry collector endpoints are available from Network Observability
flowlogs-pipelinepods.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster and then select the YAML tab.
Edit the
FlowCollectorto configurespec.exportersas follows:apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: exporters: - type: Kafka1 kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" topic: netobserv-flows-export2 tls: enable: false3 - type: IPFIX4 ipfix: targetHost: "ipfix-collector.ipfix.svc.cluster.local" targetPort: 4739 transport: tcp or udp5 - type: OpenTelemetry6 openTelemetry: targetHost: my-otelcol-collector-headless.otlp.svc targetPort: 4317 type: grpc7 logs:8 enable: true metrics:9 enable: true prefix: netobserv pushTimeInterval: 20s10 expiryTime: 2m # fieldsMapping:11 # input: SrcAddr # output: source.address- 1 4 6
- You can export flows to IPFIX, OpenTelemetry, and Kafka individually or concurrently.
- 2
- The Network Observability Operator exports all flows to the configured Kafka topic.
- 3
- You can encrypt all communications to and from Kafka with SSL/TLS or mTLS. When enabled, the Kafka CA certificate must be available as a ConfigMap or a Secret, both in the namespace where the
flowlogs-pipelineprocessor component is deployed (default: netobserv). It must be referenced withspec.exporters.tls.caCert. When using mTLS, client secrets must be available in these namespaces as well (they can be generated for instance using the AMQ Streams User Operator) and referenced withspec.exporters.tls.userCert. - 5
- You have the option to specify transport. The default value is
tcpbut you can also specifyudp. - 7
- The protocol of OpenTelemetry connection. The available options are
httpandgrpc. - 8
- OpenTelemetry configuration for exporting logs, which are the same as the logs created for Loki.
- 9
- OpenTelemetry configuration for exporting metrics, which are the same as the metrics created for Prometheus. These configurations are specified in the
spec.processor.metrics.includeListparameter of theFlowCollectorcustom resource, along with any custom metrics you defined using theFlowMetricscustom resource. - 10
- The time interval that metrics are sent to the OpenTelemetry collector.
- 11
- Optional:Network Observability network flows formats get automatically renamed to an OpenTelemetry compliant format. The
fieldsMappingspecification gives you the ability to customize the OpenTelemetry format output. For example in the YAML sample,SrcAddris the Network Observability input field, and it is being renamedsource.addressin OpenTelemetry output. You can see both Network Observability and OpenTelemetry formats in the "Network flows format reference".
After configuration, network flows data can be sent to an available output in a JSON format. For more information, see "Network flows format reference".
5.4. Updating the Flow Collector resource
As an alternative to editing YAML in the OpenShift Container Platform web console, you can configure specifications, such as eBPF sampling, by patching the flowcollector custom resource (CR):
Procedure
Run the following command to patch the
flowcollectorCR and update thespec.agent.ebpf.samplingvalue:$ oc patch flowcollector cluster --type=json -p "[{"op": "replace", "path": "/spec/agent/ebpf/sampling", "value": <new value>}] -n netobserv"
5.5. Configuring quick filters
You can modify the filters in the FlowCollector resource. Exact matches are possible using double-quotes around values. Otherwise, partial matches are used for textual values. The bang (!) character, placed at the end of a key, means negation. See the sample FlowCollector resource for more context about modifying the YAML.
The filter matching types "all of" or "any of" is a UI setting that the users can modify from the query options. It is not part of this resource configuration.
Here is a list of all available filter keys:
| Universal* | Source | Destination | Description |
|---|---|---|---|
| namespace |
|
| Filter traffic related to a specific namespace. |
| name |
|
| Filter traffic related to a given leaf resource name, such as a specific pod, service, or node (for host-network traffic). |
| kind |
|
| Filter traffic related to a given resource kind. The resource kinds include the leaf resource (Pod, Service or Node), or the owner resource (Deployment and StatefulSet). |
| owner_name |
|
| Filter traffic related to a given resource owner; that is, a workload or a set of pods. For example, it can be a Deployment name, a StatefulSet name, etc. |
| resource |
|
|
Filter traffic related to a specific resource that is denoted by its canonical name, that identifies it uniquely. The canonical notation is |
| address |
|
| Filter traffic related to an IP address. IPv4 and IPv6 are supported. CIDR ranges are also supported. |
| mac |
|
| Filter traffic related to a MAC address. |
| port |
|
| Filter traffic related to a specific port. |
| host_address |
|
| Filter traffic related to the host IP address where the pods are running. |
| protocol | N/A | N/A | Filter traffic related to a protocol, such as TCP or UDP. |
-
Universal keys filter for any of source or destination. For example, filtering
name: 'my-pod'means all traffic frommy-podand all traffic tomy-pod, regardless of the matching type used, whether Match all or Match any.
5.6. Resource management and performance considerations
The amount of resources required by Network Observability depends on the size of your cluster and your requirements for the cluster to ingest and store observability data. To manage resources and set performance criteria for your cluster, consider configuring the following settings. Configuring these settings might meet your optimal setup and observability needs.
The following settings can help you manage resources and performance from the outset:
- eBPF Sampling
-
You can set the Sampling specification,
spec.agent.ebpf.sampling, to manage resources. Smaller sampling values might consume a large amount of computational, memory and storage resources. You can mitigate this by specifying a sampling ratio value. A value of100means 1 flow every 100 is sampled. A value of0or1means all flows are captured. Smaller values result in an increase in returned flows and the accuracy of derived metrics. By default, eBPF sampling is set to a value of 50, so 1 flow every 50 is sampled. Note that more sampled flows also means more storage needed. Consider starting with the default values and refine empirically, in order to determine which setting your cluster can manage. - eBPF features
- The more features that are enabled, the more CPU and memory are impacted. See "Observing the network traffic" for a complete list of these features.
- Without Loki
- You can reduce the amount of resources that Network Observability requires by not using Loki and instead relying on Prometheus. For example, when Network Observability is configured without Loki, the total savings of memory usage are in the 20-65% range and CPU utilization is lower by 10-30%, depending upon the sampling value. See "Network Observability without Loki" for more information.
- Restricting or excluding interfaces
-
Reduce the overall observed traffic by setting the values for
spec.agent.ebpf.interfacesandspec.agent.ebpf.excludeInterfaces. By default, the agent fetches all the interfaces in the system, except the ones listed inexcludeInterfacesandlo(local interface). Note that the interface names might vary according to the Container Network Interface (CNI) used. - Performance fine-tuning
The following settings can be used to fine-tune performance after the Network Observability has been running for a while:
-
Resource requirements and limits: Adapt the resource requirements and limits to the load and memory usage you expect on your cluster by using the
spec.agent.ebpf.resourcesandspec.processor.resourcesspecifications. The default limits of 800MB might be sufficient for most medium-sized clusters. -
Cache max flows timeout: Control how often flows are reported by the agents by using the eBPF agent’s
spec.agent.ebpf.cacheMaxFlowsandspec.agent.ebpf.cacheActiveTimeoutspecifications. A larger value results in less traffic being generated by the agents, which correlates with a lower CPU load. However, a larger value leads to a slightly higher memory consumption, and might generate more latency in the flow collection.
-
Resource requirements and limits: Adapt the resource requirements and limits to the load and memory usage you expect on your cluster by using the
5.6.1. Resource considerations
The following table outlines examples of resource considerations for clusters with certain workload sizes.
The examples outlined in the table demonstrate scenarios that are tailored to specific workloads. Consider each example only as a baseline from which adjustments can be made to accommodate your workload needs.
| Extra small (10 nodes) | Small (25 nodes) | Large (250 nodes) [2] | |
|---|---|---|---|
| Worker Node vCPU and memory | 4 vCPUs| 16GiB mem [1] | 16 vCPUs| 64GiB mem [1] | 16 vCPUs| 64GiB Mem [1] |
| LokiStack size |
|
|
|
| Network Observability controller memory limit | 400Mi (default) | 400Mi (default) | 400Mi (default) |
| eBPF sampling rate | 50 (default) | 50 (default) | 50 (default) |
| eBPF memory limit | 800Mi (default) | 800Mi (default) | 1600Mi |
| cacheMaxSize | 50,000 | 100,000 (default) | 100,000 (default) |
| FLP memory limit | 800Mi (default) | 800Mi (default) | 800Mi (default) |
| FLP Kafka partitions | – | 48 | 48 |
| Kafka consumer replicas | – | 6 | 18 |
| Kafka brokers | – | 3 (default) | 3 (default) |
- Tested with AWS M6i instances.
-
In addition to this worker and its controller, 3 infra nodes (size
M6i.12xlarge) and 1 workload node (sizeM6i.8xlarge) were tested.
5.6.2. Total average memory and CPU usage
The following table outlines averages of total resource usage for clusters with a sampling value of 1 and 50 for two different tests: Test 1 and Test 2. The tests differ in the following ways:
-
Test 1takes into account high ingress traffic volume in addition to the total number of namespace, pods and services in an OpenShift Container Platform cluster, places load on the eBPF agent, and represents use cases with a high number of workloads for a given cluster size. For example,Test 1consists of 76 Namespaces, 5153 Pods, and 2305 Services with a network traffic scale of ~350 MB/s. -
Test 2takes into account high ingress traffic volume in addition to the total number of namespace, pods and services in an OpenShift Container Platform cluster and represents use cases with a high number of workloads for a given cluster size. For example,Test 2consists of 553 Namespaces, 6998 Pods, and 2508 Services with a network traffic scale of ~950 MB/s.
Since different types of cluster use cases are exemplified in the different tests, the numbers in this table do not scale linearly when compared side-by-side. Instead, they are intended to be used as a benchmark for evaluating your personal cluster usage. The examples outlined in the table demonstrate scenarios that are tailored to specific workloads. Consider each example only as a baseline from which adjustments can be made to accommodate your workload needs.
Metrics exported to Prometheus can impact the resource usage. Cardinality values for the metrics can help determine how much resources are impacted. For more information, see "Network Flows format" in the Additional resources section.
| Sampling value | Resources used | Test 1 (25 nodes) | Test 2 (250 nodes) |
|---|---|---|---|
| Sampling = 50 | Total NetObserv CPU Usage | 1.35 | 5.39 |
| Total NetObserv RSS (Memory) Usage | 16 GB | 63 GB | |
| Sampling = 1 | Total NetObserv CPU Usage | 1.82 | 11.99 |
| Total NetObserv RSS (Memory) Usage | 22 GB | 87 GB |
Summary: This table shows average total resource usage of Network Observability, which includes Agents, FLP, Kafka, and Loki with all features enabled. For details about what features are enabled, see the features covered in "Observing the network traffic", which comprises all the features that are enabled for this testing.
Chapter 6. Network Policy
As a user with the admin role, you can create a network policy for the netobserv namespace to secure inbound access to the Network Observability Operator.
6.1. Configuring an ingress network policy by using the FlowCollector custom resource
You can configure the FlowCollector custom resource (CR) to deploy an ingress network policy for Network Observability by setting the spec.NetworkPolicy.enable specification to true. By default, the specification is false.
If you have installed Loki, Kafka or any exporter in a different namespace that also has a network policy, you must ensure that the Network Observability components can communicate with them. Consider the following about your setup:
-
Connection to Loki (as defined in the
FlowCollectorCRspec.lokiparameter) -
Connection to Kafka (as defined in the
FlowCollectorCRspec.kafkaparameter) -
Connection to any exporter (as defined in FlowCollector CR
spec.exportersparameter) -
If you are using Loki and including it in the policy target, connection to an external object storage (as defined in your
LokiStackrelated secret)
Procedure
- . In the web console, go to Operators → Installed Operators page.
- Under the Provided APIs heading for Network Observability, select Flow Collector.
- Select cluster then select the YAML tab.
Configure the
FlowCollectorCR. A sample configuration is as follows:Example
FlowCollectorCR for network policyapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv networkPolicy: enable: true1 additionalNamespaces: ["openshift-console", "openshift-monitoring"]2 # ...
6.2. Creating a network policy for Network Observability
If you want to further customize the network policies for the netobserv and netobserv-privileged namespaces, you must disable the managed installation of the policy from the FlowCollector CR, and create your own. You can use the network policy resources that are enabled from the FlowCollector CR as a starting point for the procedure that follows:
Example netobserv network policy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
spec:
ingress:
- from:
- podSelector: {}
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: netobserv-privileged
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-console
ports:
- port: 9001
protocol: TCP
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-monitoring
podSelector: {}
policyTypes:
- IngressExample netobserv-privileged network policy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: netobserv
namespace: netobserv-privileged
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-monitoring
podSelector: {}
policyTypes:
- IngressProcedure
- Navigate to Networking → NetworkPolicies.
-
Select the
netobservproject from the Project dropdown menu. -
Name the policy. For this example, the policy name is
allow-ingress. - Click Add ingress rule three times to create three ingress rules.
Specify the following in the form:
Make the following specifications for the first Ingress rule:
- From the Add allowed source dropdown menu, select Allow pods from the same namespace.
Make the following specifications for the second Ingress rule:
- From the Add allowed source dropdown menu, select Allow pods from inside the cluster.
- Click + Add namespace selector.
-
Add the label,
kubernetes.io/metadata.name, and the selector,openshift-console.
Make the following specifications for the third Ingress rule:
- From the Add allowed source dropdown menu, select Allow pods from inside the cluster.
- Click + Add namespace selector.
-
Add the label,
kubernetes.io/metadata.name, and the selector,openshift-monitoring.
Verification
- Navigate to Observe → Network Traffic.
- View the Traffic Flows tab, or any tab, to verify that the data is displayed.
- Navigate to Observe → Dashboards. In the NetObserv/Health selection, verify that the flows are being ingested and sent to Loki, which is represented in the first graph.
Chapter 7. Observing the network traffic
As an administrator, you can observe the network traffic in the OpenShift Container Platform console for detailed troubleshooting and analysis. This feature helps you get insights from different graphical representations of traffic flow. There are several available views to observe the network traffic.
7.1. Observing the network traffic from the Overview view
The Overview view displays the overall aggregated metrics of the network traffic flow on the cluster. As an administrator, you can monitor the statistics with the available display options.
7.1.1. Working with the Overview view
As an administrator, you can navigate to the Overview view to see the graphical representation of the flow rate statistics.
Procedure
- Navigate to Observe → Network Traffic.
- In the Network Traffic page, click the Overview tab.
You can configure the scope of each flow rate data by clicking the menu icon.
7.1.2. Configuring advanced options for the Overview view
You can customize the graphical view by using advanced options. To access the advanced options, click Show advanced options. You can configure the details in the graph by using the Display options drop-down menu. The options available are as follows:
- Scope: Select to view the components that network traffic flows between. You can set the scope to Node, Namespace, Owner, Zones, Cluster or Resource. Owner is an aggregation of resources. Resource can be a pod, service, node, in case of host-network traffic, or an unknown IP address. The default value is Namespace.
- Truncate labels: Select the required width of the label from the drop-down list. The default value is M.
7.1.2.1. Managing panels and display
You can select the required panels to be displayed, reorder them, and focus on a specific panel. To add or remove panels, click Manage panels.
The following panels are shown by default:
- Top X average bytes rates
- Top X bytes rates stacked with total
Other panels can be added in Manage panels:
- Top X average packets rates
- Top X packets rates stacked with total
Query options allows you to choose whether to show the Top 5, Top 10, or Top 15 rates.
7.1.3. Packet drop tracking
You can configure graphical representation of network flow records with packet loss in the Overview view. By employing eBPF tracepoint hooks, you can gain valuable insights into packet drops for TCP, UDP, SCTP, ICMPv4, and ICMPv6 protocols, which can result in the following actions:
- Identification: Pinpoint the exact locations and network paths where packet drops are occurring. Determine whether specific devices, interfaces, or routes are more prone to drops.
- Root cause analysis: Examine the data collected by the eBPF program to understand the causes of packet drops. For example, are they a result of congestion, buffer issues, or specific network events?
- Performance optimization: With a clearer picture of packet drops, you can take steps to optimize network performance, such as adjust buffer sizes, reconfigure routing paths, or implement Quality of Service (QoS) measures.
When packet drop tracking is enabled, you can see the following panels in the Overview by default:
- Top X packet dropped state stacked with total
- Top X packet dropped cause stacked with total
- Top X average dropped packets rates
- Top X dropped packets rates stacked with total
Other packet drop panels are available to add in Manage panels:
- Top X average dropped bytes rates
- Top X dropped bytes rates stacked with total
7.1.3.1. Types of packet drops
See the Additional resources of this section for more information about enabling and working with packet drop tracking.
7.1.4. DNS tracking
You can configure graphical representation of Domain Name System (DNS) tracking of network flows in the Overview view. Using DNS tracking with extended Berkeley Packet Filter (eBPF) tracepoint hooks can serve various purposes:
- Network Monitoring: Gain insights into DNS queries and responses, helping network administrators identify unusual patterns, potential bottlenecks, or performance issues.
- Security Analysis: Detect suspicious DNS activities, such as domain name generation algorithms (DGA) used by malware, or identify unauthorized DNS resolutions that might indicate a security breach.
- Troubleshooting: Debug DNS-related issues by tracing DNS resolution steps, tracking latency, and identifying misconfigurations.
By default, when DNS tracking is enabled, you can see the following non-empty metrics represented in a donut or line chart in the Overview:
- Top X DNS Response Code
- Top X average DNS latencies with overall
- Top X 90th percentile DNS latencies
Other DNS tracking panels can be added in Manage panels:
- Bottom X minimum DNS latencies
- Top X maximum DNS latencies
- Top X 99th percentile DNS latencies
This feature is supported for IPv4 and IPv6 UDP and TCP protocols.
See the Additional resources in this section for more information about enabling and working with this view.
7.1.5. Round-Trip Time
You can use TCP smoothed Round-Trip Time (sRTT) to analyze network flow latencies. You can use RTT captured from the fentry/tcp_rcv_established eBPF hookpoint to read sRTT from the TCP socket to help with the following:
- Network Monitoring: Gain insights into TCP latencies, helping network administrators identify unusual patterns, potential bottlenecks, or performance issues.
- Troubleshooting: Debug TCP-related issues by tracking latency and identifying misconfigurations.
By default, when RTT is enabled, you can see the following TCP RTT metrics represented in the Overview:
- Top X 90th percentile TCP Round Trip Time with overall
- Top X average TCP Round Trip Time with overall
- Bottom X minimum TCP Round Trip Time with overall
Other RTT panels can be added in Manage panels:
- Top X maximum TCP Round Trip Time with overall
- Top X 99th percentile TCP Round Trip Time with overall
See the Additional resources in this section for more information about enabling and working with this view.
7.1.6. eBPF flow rule filter
You can use rule-based filtering to control the volume of packets cached in the eBPF flow table. For example, a filter can specify that only packets coming from port 100 should be recorded. Then only the packets that match the filter are cached and the rest are not cached.
7.1.6.1. Ingress and egress traffic filtering
CIDR notation efficiently represents IP address ranges by combining the base IP address with a prefix length. For both ingress and egress traffic, the source IP address is first used to match filter rules configured with CIDR notation. If there is a match, then the filtering proceeds. If there is no match, then the destination IP is used to match filter rules configured with CIDR notation.
After matching either the source IP or the destination IP CIDR, you can pinpoint specific endpoints using the peerIP to differentiate the destination IP address of the packet. Based on the provisioned action, the flow data is either cached in the eBPF flow table or not cached.
7.1.6.2. Dashboard and metrics integrations
When this option is enabled, the Netobserv/Health dashboard for eBPF agent statistics now has the Filtered flows rate view. Additionally, in Observe → Metrics you can query netobserv_agent_filtered_flows_total to observe metrics with the reason in FlowFilterAcceptCounter, FlowFilterNoMatchCounter or FlowFilterRecjectCounter.
7.1.6.3. Flow filter configuration parameters
The flow filter rules consist of required and optional parameters.
| Parameter | Description |
|---|---|
|
|
Set |
|
|
Provides the IP address and CIDR mask for the flow filter rule. Supports both IPv4 and IPv6 address format. If you want to match against any IP, you can use |
|
|
Describes the action that is taken for the flow filter rule. The possible values are
|
| Parameter | Description |
|---|---|
|
|
Defines the direction of the flow filter rule. Possible values are |
|
|
Defines the protocol of the flow filter rule. Possible values are |
|
|
Defines the TCP flags to filter flows. Possible values are |
|
|
Defines the ports to use for filtering flows. It can be used for either source or destination ports. To filter a single port, set a single port as an integer value. For example |
|
|
Defines the source port to use for filtering flows. To filter a single port, set a single port as an integer value, for example |
|
|
DestPorts defines the destination ports to use for filtering flows. To filter a single port, set a single port as an integer value, for example |
|
| Defines the ICMP type to use for filtering flows. |
|
| Defines the ICMP code to use for filtering flows. |
|
|
Defines the IP address to use for filtering flows, for example: |
7.2. Observing the network traffic from the Traffic flows view
The Traffic flows view displays the data of the network flows and the amount of traffic in a table. As an administrator, you can monitor the amount of traffic across the application by using the traffic flow table.
7.2.1. Working with the Traffic flows view
As an administrator, you can navigate to Traffic flows table to see network flow information.
Procedure
- Navigate to Observe → Network Traffic.
- In the Network Traffic page, click the Traffic flows tab.
You can click on each row to get the corresponding flow information.
7.2.2. Configuring advanced options for the Traffic flows view
You can customize and export the view by using Show advanced options. You can set the row size by using the Display options drop-down menu. The default value is Normal.
7.2.2.1. Managing columns
You can select the required columns to be displayed, and reorder them. To manage columns, click Manage columns.
7.2.2.2. Exporting the traffic flow data
You can export data from the Traffic flows view.
Procedure
- Click Export data.
- In the pop-up window, you can select the Export all data checkbox to export all the data, and clear the checkbox to select the required fields to be exported.
- Click Export.
7.2.3. Working with conversation tracking
As an administrator, you can group network flows that are part of the same conversation. A conversation is defined as a grouping of peers that are identified by their IP addresses, ports, and protocols, resulting in an unique Conversation Id. You can query conversation events in the web console. These events are represented in the web console as follows:
- Conversation start: This event happens when a connection is starting or TCP flag intercepted
-
Conversation tick: This event happens at each specified interval defined in the
FlowCollectorspec.processor.conversationHeartbeatIntervalparameter while the connection is active. -
Conversation end: This event happens when the
FlowCollectorspec.processor.conversationEndTimeoutparameter is reached or the TCP flag is intercepted. - Flow: This is the network traffic flow that occurs within the specified interval.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster then select the YAML tab.
Configure the
FlowCollectorcustom resource so thatspec.processor.logTypes,conversationEndTimeout, andconversationHeartbeatIntervalparameters are set according to your observation needs. A sample configuration is as follows:Configure
FlowCollectorfor conversation trackingapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: logTypes: Flows1 advanced: conversationEndTimeout: 10s2 conversationHeartbeatInterval: 30s3 - 1
- When
logTypesis set toFlows, only the Flow event is exported. If you set the value toAll, both conversation and flow events are exported and visible in the Network Traffic page. To focus only on conversation events, you can specifyConversationswhich exports the Conversation start, Conversation tick and Conversation end events; orEndedConversationsexports only the Conversation end events. Storage requirements are highest forAlland lowest forEndedConversations. - 2
- The Conversation end event represents the point when the
conversationEndTimeoutis reached or the TCP flag is intercepted. - 3
- The Conversation tick event represents each specified interval defined in the
FlowCollectorconversationHeartbeatIntervalparameter while the network connection is active.
NoteIf you update the
logTypeoption, the flows from the previous selection do not clear from the console plugin. For example, if you initially setlogTypetoConversationsfor a span of time until 10 AM and then move toEndedConversations, the console plugin shows all conversation events before 10 AM and only ended conversations after 10 AM.-
Refresh the Network Traffic page on the Traffic flows tab. Notice there are two new columns, Event/Type and Conversation Id. All the Event/Type fields are
Flowwhen Flow is the selected query option. - Select Query Options and choose the Log Type, Conversation. Now the Event/Type shows all of the desired conversation events.
- Next you can filter on a specific conversation ID or switch between the Conversation and Flow log type options from the side panel.
7.2.4. Working with packet drops
Packet loss occurs when one or more packets of network flow data fail to reach their destination. You can track these drops by editing the FlowCollector to the specifications in the following YAML example.
CPU and memory usage increases when this feature is enabled.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster, and then select the YAML tab.
Configure the
FlowCollectorcustom resource for packet drops, for example:Example
FlowCollectorconfigurationapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - PacketDrop1 privileged: true2
Verification
When you refresh the Network Traffic page, the Overview, Traffic Flow, and Topology views display new information about packet drops:
- Select new choices in Manage panels to choose which graphical visualizations of packet drops to display in the Overview.
Select new choices in Manage columns to choose which packet drop information to display in the Traffic flows table.
- In the Traffic Flows view, you can also expand the side panel to view more information about packet drops.
- In the Topology view, red lines are displayed where drops are present.
7.2.5. Working with DNS tracking
Using DNS tracking, you can monitor your network, conduct security analysis, and troubleshoot DNS issues. You can track DNS by editing the FlowCollector to the specifications in the following YAML example.
CPU and memory usage increases are observed in the eBPF agent when this feature is enabled.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for Network Observability, select Flow Collector.
- Select cluster then select the YAML tab.
Configure the
FlowCollectorcustom resource. A sample configuration is as follows:Configure
FlowCollectorfor DNS trackingapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - DNSTracking1 sampling: 12 - 1
- You can set the
spec.agent.ebpf.featuresparameter list to enable DNS tracking of each network flow in the web console. - 2
- You can set
samplingto a value of1for more accurate metrics and to capture DNS latency. For asamplingvalue greater than 1, you can observe flows with DNS Response Code and DNS Id, and it is unlikely that DNS Latency can be observed.
When you refresh the Network Traffic page, there are new DNS representations you can choose to view in the Overview and Traffic Flow views and new filters you can apply.
- Select new DNS choices in Manage panels to display graphical visualizations and DNS metrics in the Overview.
- Select new choices in Manage columns to add DNS columns to the Traffic Flows view.
- Filter on specific DNS metrics, such as DNS Id, DNS Error DNS Latency and DNS Response Code, and see more information from the side panel. The DNS Latency and DNS Response Code columns are shown by default.
TCP handshake packets do not have DNS headers. TCP protocol flows without DNS headers are shown in the traffic flow data with DNS Latency, ID, and Response code values of "n/a". You can filter out flow data to view only flows that have DNS headers using the Common filter "DNSError" equal to "0".
7.2.6. Working with RTT tracing
You can track RTT by editing the FlowCollector to the specifications in the following YAML example.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- In the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster, and then select the YAML tab.
Configure the
FlowCollectorcustom resource for RTT tracing, for example:Example
FlowCollectorconfigurationapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - FlowRTT1 - 1
- You can start tracing RTT network flows by listing the
FlowRTTparameter in thespec.agent.ebpf.featuresspecification list.
Verification
When you refresh the Network Traffic page, the Overview, Traffic Flow, and Topology views display new information about RTT:
- In the Overview, select new choices in Manage panels to choose which graphical visualizations of RTT to display.
- In the Traffic flows table, the Flow RTT column can be seen, and you can manage display in Manage columns.
In the Traffic Flows view, you can also expand the side panel to view more information about RTT.
Example filtering
- Click the Common filters → Protocol.
- Filter the network flow data based on TCP, Ingress direction, and look for FlowRTT values greater than 10,000,000 nanoseconds (10ms).
- Remove the Protocol filter.
- Filter for Flow RTT values greater than 0 in the Common filters.
- In the Topology view, click the Display option dropdown. Then click RTT in the edge labels drop-down list.
7.2.6.1. Using the histogram
You can click Show histogram to display a toolbar view for visualizing the history of flows as a bar chart. The histogram shows the number of logs over time. You can select a part of the histogram to filter the network flow data in the table that follows the toolbar.
7.2.7. Working with availability zones
You can configure the FlowCollector to collect information about the cluster availability zones. This allows you to enrich network flow data with the topology.kubernetes.io/zone label value applied to the nodes.
Procedure
- In the web console, go to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster then select the YAML tab.
Configure the
FlowCollectorcustom resource so that thespec.processor.addZoneparameter is set totrue. A sample configuration is as follows:Configure
FlowCollectorfor availability zones collectionapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: # ... processor: addZone: true # ...
Verification
When you refresh the Network Traffic page, the Overview, Traffic Flow, and Topology views display new information about availability zones:
- In the Overview tab, you can see Zones as an available Scope.
- In Network Traffic → Traffic flows, Zones are viewable under the SrcK8S_Zone and DstK8S_Zone fields.
- In the Topology view, you can set Zones as Scope or Group.
7.2.8. Filtering eBPF flow data using a global rule
You can configure the FlowCollector to filter eBPF flows using a global rule to control the flow of packets cached in the eBPF flow table.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for Network Observability, select Flow Collector.
- Select cluster, then select the YAML tab.
Configure the
FlowCollectorcustom resource, similar to the following sample configurations:Example 7.1. Filter Kubernetes service traffic to a specific Pod IP endpoint
apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Direct agent: type: eBPF ebpf: flowFilter: action: Accept1 cidr: 172.210.150.1/242 protocol: SCTP direction: Ingress destPortRange: 80-100 peerIP: 10.10.10.10 enable: true3 - 1
- The required
actionparameter describes the action that is taken for the flow filter rule. Possible values areAcceptorReject. - 2
- The required
cidrparameter provides the IP address and CIDR mask for the flow filter rule and supports IPv4 and IPv6 address formats. If you want to match against any IP address, you can use0.0.0.0/0for IPv4 or::/0for IPv6. - 3
- You must set
spec.agent.ebpf.flowFilter.enabletotrueto enable this feature.
Example 7.2. See flows to any addresses outside the cluster
apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Direct agent: type: eBPF ebpf: flowFilter: action: Accept1 cidr: 0.0.0.0/02 protocol: TCP direction: Egress sourcePort: 100 peerIP: 192.168.127.123 enable: true4
7.2.9. Endpoint translation (xlat)
You can gain visibility into the endpoints serving traffic in a consolidated view using Network Observability and extended Berkeley Packet Filter (eBPF). Typically, when traffic flows through a service, egressIP, or load balancer, the traffic flow information is abstracted as it is routed to one of the available pods. If you try to get information about the traffic, you can only view service related info, such as service IP and port, and not information about the specific pod that is serving the request. Often the information for both the service traffic and the virtual service endpoint is captured as two separate flows, which complicates troubleshooting.
To solve this, endpoint xlat can help in the following ways:
- Capture the network flows at the kernel level, which has a minimal impact on performance.
- Enrich the network flows with translated endpoint information, showing not only the service but also the specific backend pod, so you can see which pod served a request.
As network packets are processed, the eBPF hook enriches flow logs with metadata about the translated endpoint that includes the following pieces of information that you can view in the Network Traffic page in a single row:
- Source Pod IP
- Source Port
- Destination Pod IP
- Destination Port
- Conntrack Zone ID
7.2.10. Working with endpoint translation (xlat)
You can use Network Observability and eBPF to enrich network flows from a Kubernetes service with translated endpoint information, gaining insight into the endpoints serving traffic.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- In the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster, and then select the YAML tab.
Configure the
FlowCollectorcustom resource forPacketTranslation, for example:Example
FlowCollectorconfigurationapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv agent: type: eBPF ebpf: features: - PacketTranslation1 - 1
- You can start enriching network flows with translated packet information by listing the
PacketTranslationparameter in thespec.agent.ebpf.featuresspecification list.
Example filtering
When you refresh the Network Traffic page you can filter for information about translated packets:
- Filter the network flow data based on Destination kind: Service.
You can see the xlat column, which distinguishes where translated information is displayed, and the following default columns:
- Xlat Zone ID
- Xlat Src Kubernetes Object
- Xlat Dst Kubernetes Object
You can manage the display of additional xlat columns in Manage columns.
7.3. Observing the network traffic from the Topology view
The Topology view provides a graphical representation of the network flows and the amount of traffic. As an administrator, you can monitor the traffic data across the application by using the Topology view.
7.3.1. Working with the Topology view
As an administrator, you can navigate to the Topology view to see the details and metrics of the component.
Procedure
- Navigate to Observe → Network Traffic.
- In the Network Traffic page, click the Topology tab.
You can click each component in the Topology to view the details and metrics of the component.
7.3.2. Configuring the advanced options for the Topology view
You can customize and export the view by using Show advanced options. The advanced options view has the following features:
- Find in view: To search the required components in the view.
Display options: To configure the following options:
- Edge labels: To show the specified measurements as edge labels. The default is to show the Average rate in Bytes.
- Scope: To select the scope of components between which the network traffic flows. The default value is Namespace.
- Groups: To enhance the understanding of ownership by grouping the components. The default value is None.
- Layout: To select the layout of the graphical representation. The default value is ColaNoForce.
- Show: To select the details that need to be displayed. All the options are checked by default. The options available are: Edges, Edges label, and Badges.
- Truncate labels: To select the required width of the label from the drop-down list. The default value is M.
- Collapse groups: To expand or collapse the groups. The groups are expanded by default. This option is disabled if Groups has the value of None.
7.3.2.1. Exporting the topology view
To export the view, click Export topology view. The view is downloaded in PNG format.
7.4. Filtering the network traffic
By default, the Network Traffic page displays the traffic flow data in the cluster based on the default filters configured in the FlowCollector instance. You can use the filter options to observe the required data by changing the preset filter.
- Query Options
You can use Query Options to optimize the search results, as listed below:
- Log Type: The available options Conversation and Flows provide the ability to query flows by log type, such as flow log, new conversation, completed conversation, and a heartbeat, which is a periodic record with updates for long conversations. A conversation is an aggregation of flows between the same peers.
- Match filters: You can determine the relation between different filter parameters selected in the advanced filter. The available options are Match all and Match any. Match all provides results that match all the values, and Match any provides results that match any of the values entered. The default value is Match all.
- Datasource: You can choose the datasource to use for queries: Loki, Prometheus, or Auto. Notable performance improvements can be realized when using Prometheus as a datasource rather than Loki, but Prometheus supports a limited set of filters and aggregations. The default datasource is Auto, which uses Prometheus on supported queries or uses Loki if the query does not support Prometheus.
Drops filter: You can view different levels of dropped packets with the following query options:
- Fully dropped shows flow records with fully dropped packets.
- Containing drops shows flow records that contain drops but can be sent.
- Without drops shows records that contain sent packets.
- All shows all the aforementioned records.
- Limit: The data limit for internal backend queries. Depending upon the matching and the filter settings, the number of traffic flow data is displayed within the specified limit.
- Quick filters
-
The default values in Quick filters drop-down menu are defined in the
FlowCollectorconfiguration. You can modify the options from console. - Advanced filters
- You can set the advanced filters, Common, Source, or Destination, by selecting the parameter to be filtered from the dropdown list. The flow data is filtered based on the selection. To enable or disable the applied filter, you can click on the applied filter listed below the filter options.
You can toggle between
![]() One way and
One way and
![]()
![]() Back and forth filtering. The
Back and forth filtering. The
![]() One way filter shows only Source and Destination traffic according to your filter selections. You can use Swap to change the directional view of the Source and Destination traffic. The
One way filter shows only Source and Destination traffic according to your filter selections. You can use Swap to change the directional view of the Source and Destination traffic. The
![]()
![]() Back and forth filter includes return traffic with the Source and Destination filters. The directional flow of network traffic is shown in the Direction column in the Traffic flows table as
Back and forth filter includes return traffic with the Source and Destination filters. The directional flow of network traffic is shown in the Direction column in the Traffic flows table as Ingress`or `Egress for inter-node traffic and `Inner`for traffic inside a single node.
You can click Reset defaults to remove the existing filters, and apply the filter defined in FlowCollector configuration.
To understand the rules of specifying the text value, click Learn More.
Alternatively, you can access the traffic flow data in the Network Traffic tab of the Namespaces, Services, Routes, Nodes, and Workloads pages which provide the filtered data of the corresponding aggregations.
Chapter 8. Using metrics with dashboards and alerts
The Network Observability Operator uses the flowlogs-pipeline to generate metrics from flow logs. You can utilize these metrics by setting custom alerts and viewing dashboards.
8.1. Viewing Network Observability metrics dashboards
On the Overview tab in the OpenShift Container Platform console, you can view the overall aggregated metrics of the network traffic flow on the cluster. You can choose to display the information by node, namespace, owner, pod, and service. You can also use filters and display options to further refine the metrics.
Procedure
- In the web console Observe → Dashboards, select the Netobserv dashboard.
View network traffic metrics in the following categories, with each having the subset per node, namespace, source, and destination:
- Byte rates
- Packet drops
- DNS
- RTT
- Select the Netobserv/Health dashboard.
View metrics about the health of the Operator in the following categories, with each having the subset per node, namespace, source, and destination.
- Flows
- Flows Overhead
- Flow rates
- Agents
- Processor
- Operator
Infrastructure and Application metrics are shown in a split-view for namespace and workloads.
8.2. Predefined metrics
Metrics generated by the flowlogs-pipeline are configurable in the spec.processor.metrics.includeList of the FlowCollector custom resource to add or remove metrics.
8.3. Network Observability metrics
You can also create alerts by using the includeList metrics in Prometheus rules, as shown in the example "Creating alerts".
When looking for these metrics in Prometheus, such as in the Console through Observe → Metrics, or when defining alerts, all the metrics names are prefixed with netobserv_. For example, netobserv_namespace_flows_total. Available metrics names are as follows:
- includeList metrics names
Names followed by an asterisk
*are enabled by default.-
namespace_egress_bytes_total -
namespace_egress_packets_total -
namespace_ingress_bytes_total -
namespace_ingress_packets_total -
namespace_flows_total* -
node_egress_bytes_total -
node_egress_packets_total -
node_ingress_bytes_total* -
node_ingress_packets_total -
node_flows_total -
workload_egress_bytes_total -
workload_egress_packets_total -
workload_ingress_bytes_total* -
workload_ingress_packets_total -
workload_flows_total
-
- PacketDrop metrics names
When the
PacketDropfeature is enabled inspec.agent.ebpf.features(withprivilegedmode), the following additional metrics are available:-
namespace_drop_bytes_total -
namespace_drop_packets_total* -
node_drop_bytes_total -
node_drop_packets_total -
workload_drop_bytes_total -
workload_drop_packets_total
-
- DNS metrics names
When the
DNSTrackingfeature is enabled inspec.agent.ebpf.features, the following additional metrics are available:-
namespace_dns_latency_seconds* -
node_dns_latency_seconds -
workload_dns_latency_seconds
-
- FlowRTT metrics names
When the
FlowRTTfeature is enabled inspec.agent.ebpf.features, the following additional metrics are available:-
namespace_rtt_seconds* -
node_rtt_seconds -
workload_rtt_seconds
-
8.4. Custom metrics
You can create custom metrics out of the flowlogs data using the FlowMetric API. In every flowlogs data that is collected, there are a number of fields labeled per log, such as source name and destination name. These fields can be leveraged as Prometheus labels to enable the customization of cluster information on your dashboard.
8.5. Configuring custom metrics by using FlowMetric API
You can configure the FlowMetric API to create custom metrics by using flowlogs data fields as Prometheus labels. You can add multiple FlowMetric resources to a project to see multiple dashboard views.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- In the Provided APIs heading for the NetObserv Operator, select FlowMetric.
- In the Project: dropdown list, select the project of the Network Observability Operator instance.
- Click Create FlowMetric.
Configure the
FlowMetricresource, similar to the following sample configurations:Example 8.1. Generate a metric that tracks ingress bytes received from cluster external sources
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: flowmetric-cluster-external-ingress-traffic namespace: netobserv1 spec: metricName: cluster_external_ingress_bytes_total2 type: Counter3 valueField: Bytes direction: Ingress4 labels: [DstK8S_HostName,DstK8S_Namespace,DstK8S_OwnerName,DstK8S_OwnerType]5 filters:6 - field: SrcSubnetLabel matchType: Absence- 1
- The
FlowMetricresources need to be created in the namespace defined in theFlowCollectorspec.namespace, which isnetobservby default. - 2
- The name of the Prometheus metric, which in the web console appears with the prefix
netobserv-<metricName>. - 3
- The
typespecifies the type of metric. TheCountertypeis useful for counting bytes or packets. - 4
- The direction of traffic to capture. If not specified, both ingress and egress are captured, which can lead to duplicated counts.
- 5
- Labels define what the metrics look like and the relationship between the different entities and also define the metrics cardinality. For example,
SrcK8S_Nameis a high cardinality metric. - 6
- Refines results based on the listed criteria. In this example, selecting only the cluster external traffic is done by matching only flows where
SrcSubnetLabelis absent. This assumes the subnet labels feature is enabled (viaspec.processor.subnetLabels), which is done by default.
Verification
- Once the pods refresh, navigate to Observe → Metrics.
-
In the Expression field, type the metric name to view the corresponding result. You can also enter an expression, such as
topk(5, sum(rate(netobserv_cluster_external_ingress_bytes_total{DstK8S_Namespace="my-namespace"}[2m])) by (DstK8S_HostName, DstK8S_OwnerName, DstK8S_OwnerType))
Example 8.2. Show RTT latency for cluster external ingress traffic
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: flowmetric-cluster-external-ingress-rtt namespace: netobserv1 spec: metricName: cluster_external_ingress_rtt_seconds type: Histogram2 valueField: TimeFlowRttNs direction: Ingress labels: [DstK8S_HostName,DstK8S_Namespace,DstK8S_OwnerName,DstK8S_OwnerType] filters: - field: SrcSubnetLabel matchType: Absence - field: TimeFlowRttNs matchType: Presence divider: "1000000000"3 buckets: [".001", ".005", ".01", ".02", ".03", ".04", ".05", ".075", ".1", ".25", "1"]4 - 1
- The
FlowMetricresources need to be created in the namespace defined in theFlowCollectorspec.namespace, which isnetobservby default. - 2
- The
typespecifies the type of metric. TheHistogramtypeis useful for a latency value (TimeFlowRttNs). - 3
- Since the Round-trip time (RTT) is provided as nanos in flows, use a divider of 1 billion to convert into seconds, which is standard in Prometheus guidelines.
- 4
- The custom buckets specify precision on RTT, with optimal precision ranging between 5ms and 250ms.
Verification
- Once the pods refresh, navigate to Observe → Metrics.
- In the Expression field, you can type the metric name to view the corresponding result.
High cardinality can affect the memory usage of Prometheus. You can check whether specific labels have high cardinality in the Network Flows format reference.
8.6. Configuring custom charts using FlowMetric API
You can generate charts for dashboards in the OpenShift Container Platform web console, which you can view as an administrator in the Dashboard menu by defining the charts section of the FlowMetric resource.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- In the Provided APIs heading for the NetObserv Operator, select FlowMetric.
- In the Project: dropdown list, select the project of the Network Observability Operator instance.
- Click Create FlowMetric.
-
Configure the
FlowMetricresource, similar to the following sample configurations:
Example 8.3. Chart for tracking ingress bytes received from cluster external sources
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowMetric
metadata:
name: flowmetric-cluster-external-ingress-traffic
namespace: netobserv
# ...
charts:
- dashboardName: Main
title: External ingress traffic
unit: Bps
type: SingleStat
queries:
- promQL: "sum(rate($METRIC[2m]))"
legend: ""
- dashboardName: Main
sectionName: External
title: Top external ingress traffic per workload
unit: Bps
type: StackArea
queries:
- promQL: "sum(rate($METRIC{DstK8S_Namespace!=\"\"}[2m])) by (DstK8S_Namespace, DstK8S_OwnerName)"
legend: "{{DstK8S_Namespace}} / {{DstK8S_OwnerName}}"
# ...- 1
- The
FlowMetricresources need to be created in the namespace defined in theFlowCollectorspec.namespace, which isnetobservby default.
Verification
- Once the pods refresh, navigate to Observe → Dashboards.
Search for the NetObserv / Main dashboard. View two panels under the NetObserv / Main dashboard, or optionally a dashboard name that you create:
- A textual single statistic showing the global external ingress rate summed across all dimensions
- A timeseries graph showing the same metric per destination workload
For more information about the query language, refer to the Prometheus documentation.
Example 8.4. Chart for RTT latency for cluster external ingress traffic
apiVersion: flows.netobserv.io/v1alpha1
kind: FlowMetric
metadata:
name: flowmetric-cluster-external-ingress-traffic
namespace: netobserv
# ...
charts:
- dashboardName: Main
title: External ingress TCP latency
unit: seconds
type: SingleStat
queries:
- promQL: "histogram_quantile(0.99, sum(rate($METRIC_bucket[2m])) by (le)) > 0"
legend: "p99"
- dashboardName: Main
sectionName: External
title: "Top external ingress sRTT per workload, p50 (ms)"
unit: seconds
type: Line
queries:
- promQL: "histogram_quantile(0.5, sum(rate($METRIC_bucket{DstK8S_Namespace!=\"\"}[2m])) by (le,DstK8S_Namespace,DstK8S_OwnerName))*1000 > 0"
legend: "{{DstK8S_Namespace}} / {{DstK8S_OwnerName}}"
- dashboardName: Main
sectionName: External
title: "Top external ingress sRTT per workload, p99 (ms)"
unit: seconds
type: Line
queries:
- promQL: "histogram_quantile(0.99, sum(rate($METRIC_bucket{DstK8S_Namespace!=\"\"}[2m])) by (le,DstK8S_Namespace,DstK8S_OwnerName))*1000 > 0"
legend: "{{DstK8S_Namespace}} / {{DstK8S_OwnerName}}"
# ...
This example uses the histogram_quantile function to show p50 and p99.
You can show averages of histograms by dividing the metric, $METRIC_sum, by the metric, $METRIC_count, which are automatically generated when you create a histogram. With the preceding example, the Prometheus query to do this is as follows:
promQL: "(sum(rate($METRIC_sum{DstK8S_Namespace!=\"\"}[2m])) by (DstK8S_Namespace,DstK8S_OwnerName) / sum(rate($METRIC_count{DstK8S_Namespace!=\"\"}[2m])) by (DstK8S_Namespace,DstK8S_OwnerName))*1000"Verification
- Once the pods refresh, navigate to Observe → Dashboards.
- Search for the NetObserv / Main dashboard. View the new panel under the NetObserv / Main dashboard, or optionally a dashboard name that you create.
For more information about the query language, refer to the Prometheus documentation.
8.7. Detecting SYN flooding using the FlowMetric API and TCP flags
You can create an AlertingRule resouce to alert for SYN flooding.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- In the Provided APIs heading for the NetObserv Operator, select FlowMetric.
- In the Project dropdown list, select the project of the Network Observability Operator instance.
- Click Create FlowMetric.
Create
FlowMetricresources to add the following configurations:Configuration counting flows per destination host and resource, with TCP flags
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: flows-with-flags-per-destination spec: metricName: flows_with_flags_per_destination_total type: Counter labels: [SrcSubnetLabel,DstSubnetLabel,DstK8S_Name,DstK8S_Type,DstK8S_HostName,DstK8S_Namespace,Flags]Configuration counting flows per source host and resource, with TCP flags
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowMetric metadata: name: flows-with-flags-per-source spec: metricName: flows_with_flags_per_source_total type: Counter labels: [DstSubnetLabel,SrcSubnetLabel,SrcK8S_Name,SrcK8S_Type,SrcK8S_HostName,SrcK8S_Namespace,Flags]Deploy the following
AlertingRuleresource to alert for SYN flooding:AlertingRulefor SYN floodingapiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: netobserv-syn-alerts namespace: openshift-monitoring # ... spec: groups: - name: NetObservSYNAlerts rules: - alert: NetObserv-SYNFlood-in annotations: message: |- {{ $labels.job }}: incoming SYN-flood attack suspected to Host={{ $labels.DstK8S_HostName}}, Namespace={{ $labels.DstK8S_Namespace }}, Resource={{ $labels.DstK8S_Name }}. This is characterized by a high volume of SYN-only flows with different source IPs and/or ports. summary: "Incoming SYN-flood" expr: sum(rate(netobserv_flows_with_flags_per_destination_total{Flags="2"}[1m])) by (job, DstK8S_HostName, DstK8S_Namespace, DstK8S_Name) > 3001 for: 15s labels: severity: warning app: netobserv - alert: NetObserv-SYNFlood-out annotations: message: |- {{ $labels.job }}: outgoing SYN-flood attack suspected from Host={{ $labels.SrcK8S_HostName}}, Namespace={{ $labels.SrcK8S_Namespace }}, Resource={{ $labels.SrcK8S_Name }}. This is characterized by a high volume of SYN-only flows with different source IPs and/or ports. summary: "Outgoing SYN-flood" expr: sum(rate(netobserv_flows_with_flags_per_source_total{Flags="2"}[1m])) by (job, SrcK8S_HostName, SrcK8S_Namespace, SrcK8S_Name) > 3002 for: 15s labels: severity: warning app: netobserv # ...
Verification
- In the web console, click Manage Columns in the Network Traffic table view and click TCP flags.
- In the Network Traffic table view, filter on TCP protocol SYN TCPFlag. A large number of flows with the same byteSize indicates a SYN flood.
- Go to Observe → Alerting and select the Alerting Rules tab.
- Filter on netobserv-synflood-in alert. The alert should fire when SYN flooding occurs.
Chapter 9. Monitoring the Network Observability Operator
You can use the web console to monitor alerts related to the health of the Network Observability Operator.
9.1. Health dashboards
Metrics about health and resource usage of the Network Observability Operator are located in the Observe → Dashboards page in the web console. You can view metrics about the health of the Operator in the following categories:
- Flows per second
- Sampling
- Errors last minute
- Dropped flows per second
- Flowlogs-pipeline statistics
- Flowlogs-pipleine statistics views
- eBPF agent statistics views
- Operator statistics
- Resource usage
9.2. Health alerts
A health alert banner that directs you to the dashboard can appear on the Network Traffic and Home pages if an alert is triggered. Alerts are generated in the following cases:
-
The
NetObservLokiErroralert occurs if theflowlogs-pipelineworkload is dropping flows because of Loki errors, such as if the Loki ingestion rate limit has been reached. -
The
NetObservNoFlowsalert occurs if no flows are ingested for a certain amount of time. -
The
NetObservFlowsDroppedalert occurs if the Network Observability eBPF agent hashmap table is full, and the eBPF agent processes flows with degraded performance, or when the capacity limiter is triggered.
9.3. Viewing health information
You can access metrics about health and resource usage of the Network Observability Operator from the Dashboards page in the web console.
Prerequisites
- You have the Network Observability Operator installed.
-
You have access to the cluster as a user with the
cluster-adminrole or with view permissions for all projects.
Procedure
- From the Administrator perspective in the web console, navigate to Observe → Dashboards.
- From the Dashboards dropdown, select Netobserv/Health.
- View the metrics about the health of the Operator that are displayed on the page.
9.3.1. Disabling health alerts
You can opt out of health alerting by editing the FlowCollector resource:
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster then select the YAML tab.
Add
spec.processor.metrics.disableAlertsto disable health alerts, as in the following YAML sample:apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: metrics: disableAlerts: [NetObservLokiError, NetObservNoFlows]1 - 1
- You can specify one or a list with both types of alerts to disable.
9.4. Using the eBPF agent alert
An alert, NetObservAgentFlowsDropped, is triggered when the Network Observability eBPF agent hashmap table is full or when the capacity limiter is triggered. If you see this alert, consider increasing the cacheMaxFlows in the FlowCollector, as shown in the following example.
Increasing the cacheMaxFlows might increase the memory usage of the eBPF agent.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the Network Observability Operator, select Flow Collector.
- Select cluster, and then select the YAML tab.
-
Increase the
spec.agent.ebpf.cacheMaxFlowsvalue, as shown in the following YAML sample:
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Direct
agent:
type: eBPF
ebpf:
cacheMaxFlows: 200000 - 1
- Increase the
cacheMaxFlowsvalue from its value at the time of theNetObservAgentFlowsDroppedalert.
Chapter 10. Scheduling resources
Taints and tolerations allow the node to control which pods should (or should not) be scheduled on them.
A node selector specifies a map of key/value pairs that are defined using custom labels on nodes and selectors specified in pods.
For the pod to be eligible to run on a node, the pod must have the same key/value node selector as the label on the node.
10.1. Network observability deployment in specific nodes
You can configure the FlowCollector to control the deployment of network observability components in specific nodes. The spec.agent.ebpf.advanced.scheduling, spec.processor.advanced.scheduling, and spec.consolePlugin.advanced.scheduling specifications have the following configurable settings:
-
NodeSelector -
Tolerations -
Affinity -
PriorityClassName
Sample FlowCollector resource for spec.<component>.advanced.scheduling
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
# ...
advanced:
scheduling:
tolerations:
- key: "<taint key>"
operator: "Equal"
value: "<taint value>"
effect: "<taint effect>"
nodeSelector:
<key>: <value>
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: name
operator: In
values:
- app-worker-node
priorityClassName: """
# ...Chapter 11. Secondary networks
You can configure the Network Observability Operator to collect and enrich network flow data from secondary networks, such as SR-IOV and OVN-Kubernetes.
Prerequisites
- Access to an OpenShift Container Platform cluster with an additional network interface, such as a secondary interface or an L2 network.
11.1. Configuring monitoring for SR-IOV interface traffic
In order to collect traffic from a cluster with a Single Root I/O Virtualization (SR-IOV) device, you must set the FlowCollector spec.agent.ebpf.privileged field to true. Then, the eBPF agent monitors other network namespaces in addition to the host network namespaces, which are monitored by default. When a pod with a virtual functions (VF) interface is created, a new network namespace is created. With SRIOVNetwork policy IPAM configurations specified, the VF interface is migrated from the host network namespace to the pod network namespace.
Prerequisites
- Access to an OpenShift Container Platform cluster with a SR-IOV device.
-
The
SRIOVNetworkcustom resource (CR)spec.ipamconfiguration must be set with an IP address from the range that the interface lists or from other plugins.
Procedure
- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster and then select the YAML tab.
Configure the
FlowCollectorcustom resource. A sample configuration is as follows:Configure
FlowCollectorfor SR-IOV monitoringapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Direct agent: type: eBPF ebpf: privileged: true1 - 1
- The
spec.agent.ebpf.privilegedfield value must be set totrueto enable SR-IOV monitoring.
11.2. Configuring virtual machine (VM) secondary network interfaces for Network Observability
You can observe network traffic on an OpenShift Virtualization setup by identifying eBPF-enriched network flows coming from VMs that are connected to secondary networks, such as through OVN-Kubernetes. Network flows coming from VMs that are connected to the default internal pod network are automatically captured by Network Observability.
Procedure
Get information about the virtual machine launcher pod by running the following command. This information is used in Step 5:
$ oc get pod virt-launcher-<vm_name>-<suffix> -n <namespace> -o yamlapiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/network-status: |- [{ "name": "ovn-kubernetes", "interface": "eth0", "ips": [ "10.129.2.39" ], "mac": "0a:58:0a:81:02:27", "default": true, "dns": {} }, { "name": "my-vms/l2-network",1 "interface": "podc0f69e19ba2",2 "ips": [3 "10.10.10.15" ], "mac": "02:fb:f8:00:00:12",4 "dns": {} }] name: virt-launcher-fedora-aqua-fowl-13-zr2x9 namespace: my-vms spec: # ... status: # ...- In the web console, navigate to Operators → Installed Operators.
- Under the Provided APIs heading for the NetObserv Operator, select Flow Collector.
- Select cluster and then select the YAML tab.
Configure
FlowCollectorbased on the information you found from the additional network investigation:apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: agent: ebpf: privileged: true1 processor: advanced: secondaryNetworks: - index:2 - MAC3 name: my-vms/l2-network4 # ...<.> Ensure that the eBPF agent is in
privilegedmode so that flows are collected for secondary interfaces. <.> Define the fields to use for indexing the virtual machine launcher pods. It is recommended to use theMACaddress as the indexing field to get network flows enrichment for secondary interfaces. If you have overlapping MAC address between pods, then additional indexing fields, such asIPandInterface, could be added to have accurate enrichment. <.> If your additional network information has a MAC address, addMACto the field list. <.> Specify the name of the network found in thek8s.v1.cni.cncf.io/network-statusannotation. Usually <namespace>/<network_attachement_definition_name>.Observe VM traffic:
- Navigate to the Network Traffic page.
-
Filter by Source IP using your virtual machine IP found in
k8s.v1.cni.cncf.io/network-statusannotation. - View both Source and Destination fields, which should be enriched, and identify the VM launcher pods and the VM instance as owners.
Chapter 12. Network Observability CLI
12.1. Installing the Network Observability CLI
The Network Observability CLI (oc netobserv) is deployed separately from the Network Observability Operator. The CLI is available as an OpenShift CLI (oc) plugin. It provides a lightweight way to quickly debug and troubleshoot with network observability.
12.1.1. About the Network Observability CLI
You can quickly debug and troubleshoot networking issues by using the Network Observability CLI (oc netobserv). The Network Observability CLI is a flow and packet visualization tool that relies on eBPF agents to stream collected data to an ephemeral collector pod. It requires no persistent storage during the capture. After the run, the output is transferred to your local machine. This enables quick, live insight into packets and flow data without installing the Network Observability Operator.
CLI capture is meant to run only for short durations, such as 8-10 minutes. If it runs for too long, it can be difficult to delete the running process.
12.1.2. Installing the Network Observability CLI
Installing the Network Observability CLI (oc netobserv) is a separate procedure from the Network Observability Operator installation. This means that, even if you have the Operator installed from OperatorHub, you need to install the CLI separately.
You can optionally use Krew to install the netobserv CLI plugin. For more information, see "Installing a CLI plugin with Krew".
Prerequisites
-
You must install the OpenShift CLI (
oc). - You must have a macOS or Linux operating system.
Procedure
Download the
oc netobservfile that corresponds with your architecture. For example, for theamd64archive:$ curl -LO https://mirror.openshift.com/pub/cgw/netobserv/latest/oc-netobserv-amd64Make the file executable:
$ chmod +x ./oc-netobserv-amd64Move the extracted
netobserv-clibinary to a directory that is on yourPATH, such as/usr/local/bin/:$ sudo mv ./oc-netobserv-amd64 /usr/local/bin/oc-netobserv
Verification
Verify that
oc netobservis available:$ oc netobserv versionExample output
Netobserv CLI version <version>
12.2. Using the Network Observability CLI
You can visualize and filter the flows and packets data directly in the terminal to see specific usage, such as identifying who is using a specific port. The Network Observability CLI collects flows as JSON and database files or packets as a PCAP file, which you can use with third-party tools.
12.2.1. Capturing flows
You can capture flows and filter on any resource or zone in the data to solve use cases, such as displaying Round-Trip Time (RTT) between two zones. Table visualization in the CLI provides viewing and flow search capabilities.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Install the Network Observability CLI (
oc netobserv) plugin.
Procedure
Capture flows with filters enabled by running the following command:
$ oc netobserv flows --enable_filter=true --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=49051Add filters to the
live table filterprompt in the terminal to further refine the incoming flows. For example:live table filter: [SrcK8S_Zone:us-west-1b] press enter to match multiple regular expressions at once- Use the PageUp and PageDown keys to toggle between None, Resource, Zone, Host, Owner and all of the above.
-
To stop capturing, press Ctrl+C. The data that was captured is written to two separate files in an
./outputdirectory located in the same path used to install the CLI. View the captured data in the
./output/flow/<capture_date_time>.jsonJSON file, which contains JSON arrays of the captured data.Example JSON file
{ "AgentIP": "10.0.1.76", "Bytes": 561, "DnsErrno": 0, "Dscp": 20, "DstAddr": "f904:ece9:ba63:6ac7:8018:1e5:7130:0", "DstMac": "0A:58:0A:80:00:37", "DstPort": 9999, "Duplicate": false, "Etype": 2048, "Flags": 16, "FlowDirection": 0, "IfDirection": 0, "Interface": "ens5", "K8S_FlowLayer": "infra", "Packets": 1, "Proto": 6, "SrcAddr": "3e06:6c10:6440:2:a80:37:b756:270f", "SrcMac": "0A:58:0A:80:00:01", "SrcPort": 46934, "TimeFlowEndMs": 1709741962111, "TimeFlowRttNs": 121000, "TimeFlowStartMs": 1709741962111, "TimeReceived": 1709741964 }You can use SQLite to inspect the
./output/flow/<capture_date_time>.dbdatabase file. For example:Open the file by running the following command:
$ sqlite3 ./output/flow/<capture_date_time>.dbQuery the data by running a SQLite
SELECTstatement, for example:sqlite> SELECT DnsLatencyMs, DnsFlagsResponseCode, DnsId, DstAddr, DstPort, Interface, Proto, SrcAddr, SrcPort, Bytes, Packets FROM flow WHERE DnsLatencyMs >10 LIMIT 10;Example output
12|NoError|58747|10.128.0.63|57856||17|172.30.0.10|53|284|1 11|NoError|20486|10.128.0.52|56575||17|169.254.169.254|53|225|1 11|NoError|59544|10.128.0.103|51089||17|172.30.0.10|53|307|1 13|NoError|32519|10.128.0.52|55241||17|169.254.169.254|53|254|1 12|NoError|32519|10.0.0.3|55241||17|169.254.169.254|53|254|1 15|NoError|57673|10.128.0.19|59051||17|172.30.0.10|53|313|1 13|NoError|35652|10.0.0.3|46532||17|169.254.169.254|53|183|1 32|NoError|37326|10.0.0.3|52718||17|169.254.169.254|53|169|1 14|NoError|14530|10.0.0.3|58203||17|169.254.169.254|53|246|1 15|NoError|40548|10.0.0.3|45933||17|169.254.169.254|53|174|1
12.2.2. Capturing packets
You can capture packets using the Network Observability CLI.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Install the Network Observability CLI (
oc netobserv) plugin.
Procedure
Run the packet capture with filters enabled:
$ oc netobserv packets --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=49051Add filters to the
live table filterprompt in the terminal to refine the incoming packets. An example filter is as follows:live table filter: [SrcK8S_Zone:us-west-1b] press enter to match multiple regular expressions at once- Use the PageUp and PageDown keys to toggle between None, Resource, Zone, Host, Owner and all of the above.
- To stop capturing, press Ctrl+C.
View the captured data, which is written to a single file in an
./output/pcapdirectory located in the same path that was used to install the CLI:-
The
./output/pcap/<capture_date_time>.pcapfile can be opened with Wireshark.
-
The
12.2.3. Capturing metrics
You can generate on-demand dashboards in Prometheus by using a service monitor for Network Observability.
Prerequisites
-
Install the OpenShift CLI (
oc). -
Install the Network Observability CLI (
oc netobserv) plugin.
Procedure
Capture metrics with filters enabled by running the following command:
Example output
$ oc netobserv metrics --enable_filter=true --cidr=0.0.0.0/0 --protocol=TCP --port=49051Open the link provided in the terminal to view the NetObserv / On-Demand dashboard:
Example URL
https://console-openshift-console.apps.rosa...openshiftapps.com/monitoring/dashboards/netobserv-cliNoteFeatures that are not enabled present as empty graphs.
12.2.4. Cleaning the Network Observability CLI
You can manually clean the CLI workload by running oc netobserv cleanup. This command removes all the CLI components from your cluster.
When you end a capture, this command is run automatically by the client. You might be required to manually run it if you experience connectivity issues.
Procedure
Run the following command:
$ oc netobserv cleanup
Additional resources
12.3. Network Observability CLI (oc netobserv) reference
The Network Observability CLI (oc netobserv) has most features and filtering options that are available for the Network Observability Operator. You can pass command-line arguments to enable features or filtering options.
12.3.1. Network Observability CLI usage
You can use the Network Observability CLI (oc netobserv) to pass command-line arguments to capture flows data, packets data, and metrics for further analysis and enable features supported by the Network Observability Operator.
12.3.1.1. Syntax
The basic syntax for oc netobserv commands:
oc netobserv syntax
$ oc netobserv [<command>] [<feature_option>] [<command_options>] 12.3.1.2. Basic commands
| Command | Description |
|---|---|
| flows | Capture flows information. For subcommands, see the "Flows capture options" table. |
| packets | Capture packets data. For subcommands, see the "Packets capture options" table. |
| metrics | Capture metrics data. For subcommands, see the "Metrics capture options" table. |
| follow | Follow collector logs when running in background. |
| stop | Stop collection by removing agent daemonset. |
| copy | Copy collector generated files locally. |
| cleanup | Remove the Network Observability CLI components. |
| version | Print the software version. |
| help | Show help. |
12.3.1.3. Flows capture options
Flows capture has mandatory commands as well as additional options, such as enabling extra features about packet drops, DNS latencies, Round-trip time, and filtering.
oc netobserv flows syntax
$ oc netobserv flows [<feature_option>] [<command_options>]| Option | Description | Default |
|---|---|---|
| --enable_all | enable all eBPF features | false |
| --enable_dns | enable DNS tracking | false |
| --enable_network_events | enable network events monitoring | false |
| --enable_pkt_translation | enable packet translation | false |
| --enable_pkt_drop | enable packet drop | false |
| --enable_rtt | enable RTT tracking | false |
| --enable_udn_mapping | enable User Defined Network mapping | false |
| --get-subnets | get subnets information | false |
| --background | run in background | false |
| --copy | copy the output files locally | prompt |
| --log-level | components logs | info |
| --max-time | maximum capture time | 5m |
| --max-bytes | maximum capture bytes | 50000000 = 50MB |
| --action | filter action | Accept |
| --cidr | filter CIDR | 0.0.0.0/0 |
| --direction | filter direction | – |
| --dport | filter destination port | – |
| --dport_range | filter destination port range | – |
| --dports | filter on either of two destination ports | – |
| --drops | filter flows with only dropped packets | false |
| --icmp_code | filter ICMP code | – |
| --icmp_type | filter ICMP type | – |
| --node-selector | capture on specific nodes | – |
| --peer_ip | filter peer IP | – |
| --peer_cidr | filter peer CIDR | – |
| --port_range | filter port range | – |
| --port | filter port | – |
| --ports | filter on either of two ports | – |
| --protocol | filter protocol | – |
| --regexes | filter flows using regular expression | – |
| --sport_range | filter source port range | – |
| --sport | filter source port | – |
| --sports | filter on either of two source ports | – |
| --tcp_flags | filter TCP flags | – |
| --interfaces | interfaces to monitor | – |
Example running flows capture on TCP protocol and port 49051 with PacketDrop and RTT features enabled:
$ oc netobserv flows --enable_pkt_drop --enable_rtt --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=4905112.3.1.4. Packets capture options
You can filter packets capture data the as same as flows capture by using the filters. Certain features, such as packets drop, DNS, RTT, and network events, are only available for flows and metrics capture.
oc netobserv packets syntax
$ oc netobserv packets [<option>]| Option | Description | Default |
|---|---|---|
| --background | run in background | false |
| --copy | copy the output files locally | prompt |
| --log-level | components logs | info |
| --max-time | maximum capture time | 5m |
| --max-bytes | maximum capture bytes | 50000000 = 50MB |
| --action | filter action | Accept |
| --cidr | filter CIDR | 0.0.0.0/0 |
| --direction | filter direction | – |
| --dport | filter destination port | – |
| --dport_range | filter destination port range | – |
| --dports | filter on either of two destination ports | – |
| --drops | filter flows with only dropped packets | false |
| --icmp_code | filter ICMP code | – |
| --icmp_type | filter ICMP type | – |
| --node-selector | capture on specific nodes | – |
| --peer_ip | filter peer IP | – |
| --peer_cidr | filter peer CIDR | – |
| --port_range | filter port range | – |
| --port | filter port | – |
| --ports | filter on either of two ports | – |
| --protocol | filter protocol | – |
| --regexes | filter flows using regular expression | – |
| --sport_range | filter source port range | – |
| --sport | filter source port | – |
| --sports | filter on either of two source ports | – |
| --tcp_flags | filter TCP flags | – |
Example running packets capture on TCP protocol and port 49051:
$ oc netobserv packets --action=Accept --cidr=0.0.0.0/0 --protocol=TCP --port=4905112.3.1.5. Metrics capture options
You can enable features and use filters on metrics capture, the same as flows capture. The generated graphs fill accordingly in the dashboard.
oc netobserv metrics syntax
$ oc netobserv metrics [<option>]| Option | Description | Default |
|---|---|---|
| --enable_all | enable all eBPF features | false |
| --enable_dns | enable DNS tracking | false |
| --enable_network_events | enable network events monitoring | false |
| --enable_pkt_translation | enable packet translation | false |
| --enable_pkt_drop | enable packet drop | false |
| --enable_rtt | enable RTT tracking | false |
| --enable_udn_mapping | enable User Defined Network mapping | false |
| --get-subnets | get subnets information | false |
| --action | filter action | Accept |
| --cidr | filter CIDR | 0.0.0.0/0 |
| --direction | filter direction | – |
| --dport | filter destination port | – |
| --dport_range | filter destination port range | – |
| --dports | filter on either of two destination ports | – |
| --drops | filter flows with only dropped packets | false |
| --icmp_code | filter ICMP code | – |
| --icmp_type | filter ICMP type | – |
| --node-selector | capture on specific nodes | – |
| --peer_ip | filter peer IP | – |
| --peer_cidr | filter peer CIDR | – |
| --port_range | filter port range | – |
| --port | filter port | – |
| --ports | filter on either of two ports | – |
| --protocol | filter protocol | – |
| --regexes | filter flows using regular expression | – |
| --sport_range | filter source port range | – |
| --sport | filter source port | – |
| --sports | filter on either of two source ports | – |
| --tcp_flags | filter TCP flags | – |
| --interfaces | interfaces to monitor | – |
Example running metrics capture for TCP drops
$ oc netobserv metrics --enable_pkt_drop --protocol=TCPChapter 13. FlowCollector API reference
FlowCollector is the Schema for the network flows collection API, which pilots and configures the underlying deployments.
13.1. FlowCollector API specifications
- Description
-
FlowCollectoris the schema for the network flows collection API, which pilots and configures the underlying deployments. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and might reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| Kind is a string value representing the REST resource this object represents. Servers might infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| Standard object’s metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
|
Defines the desired state of the FlowCollector resource. *: the mention of "unsupported" or "deprecated" for a feature throughout this document means that this feature is not officially supported by Red Hat. It might have been, for example, contributed by the community and accepted without a formal agreement for maintenance. The product maintainers might provide some support for these features as a best effort only. |
13.1.1. .metadata
- Description
- Standard object’s metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
- Type
-
object
13.1.2. .spec
- Description
Defines the desired state of the FlowCollector resource.
*: the mention of "unsupported" or "deprecated" for a feature throughout this document means that this feature is not officially supported by Red Hat. It might have been, for example, contributed by the community and accepted without a formal agreement for maintenance. The product maintainers might provide some support for these features as a best effort only.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Agent configuration for flows extraction. |
|
|
|
|
|
|
|
-
- Kafka can provide better scalability, resiliency, and high availability (for more details, see https://www.redhat.com/en/topics/integration/what-is-apache-kafka). |
|
|
|
|
|
|
|
Kafka configuration, allowing to use Kafka as a broker as part of the flow collection pipeline. Available when the |
|
|
|
|
|
|
| Namespace where Network Observability pods are deployed. |
|
|
|
|
|
|
|
|
|
|
|
|
13.1.3. .spec.agent
- Description
- Agent configuration for flows extraction.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
13.1.4. .spec.agent.ebpf
- Description
-
ebpfdescribes the settings related to the eBPF-based flow reporter whenspec.agent.typeis set toeBPF. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
List of additional features to enable. They are all disabled by default. Enabling additional features might have performance impacts. Possible values are:
-
-
-
-
-
-
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Privileged mode for the eBPF Agent container. When ignored or set to |
|
|
|
|
|
|
| Sampling rate of the flow reporter. 100 means one flow on 100 is sent. 0 or 1 means all flows are sampled. |
13.1.5. .spec.agent.ebpf.advanced
- Description
-
advancedallows setting some aspects of the internal configuration of the eBPF agent. This section is aimed mostly for debugging and fine-grained performance optimizations, such asGOGCandGOMAXPROCSenv vars. Set these values at your own risk. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| scheduling controls how the pods are scheduled on nodes. |
13.1.6. .spec.agent.ebpf.advanced.scheduling
- Description
- scheduling controls how the pods are scheduled on nodes.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| If specified, the pod’s scheduling constraints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling. |
|
|
|
|
|
|
| If specified, indicates the pod’s priority. For documentation, refer to https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption. If not specified, default priority is used, or zero if there is no default. |
|
|
|
|
13.1.7. .spec.agent.ebpf.advanced.scheduling.affinity
- Description
- If specified, the pod’s scheduling constraints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling.
- Type
-
object
13.1.8. .spec.agent.ebpf.advanced.scheduling.tolerations
- Description
-
tolerationsis a list of tolerations that allow the pod to schedule onto nodes with matching taints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling. - Type
-
array
13.1.9. .spec.agent.ebpf.flowFilter
- Description
-
flowFilterdefines the eBPF agent configuration regarding flow filtering. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Set |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.1.10. .spec.agent.ebpf.flowFilter.rules
- Description
-
rulesdefines a list of filtering rules on the eBPF Agents. When filtering is enabled, by default, flows that don’t match any rule are rejected. To change the default, you can define a rule that accepts everything:{ action: "Accept", cidr: "0.0.0.0/0" }, and then refine with rejecting rules. Unsupported *. - Type
-
array
13.1.11. .spec.agent.ebpf.flowFilter.rules[]
- Description
-
EBPFFlowFilterRuledefines the desired eBPF agent configuration regarding flow filtering rule. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.1.12. .spec.agent.ebpf.metrics
- Description
-
metricsdefines the eBPF agent configuration regarding metrics. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
Set |
|
|
| Metrics server endpoint configuration for the Prometheus scraper. |
13.1.13. .spec.agent.ebpf.metrics.server
- Description
- Metrics server endpoint configuration for the Prometheus scraper.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| The metrics server HTTP port. |
|
|
| TLS configuration. |
13.1.14. .spec.agent.ebpf.metrics.server.tls
- Description
- TLS configuration.
- Type
-
object - Required
-
type
-
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
TLS configuration when |
|
|
|
Reference to the CA file when |
|
|
|
Select the type of TLS configuration:
- |
13.1.15. .spec.agent.ebpf.metrics.server.tls.provided
- Description
-
TLS configuration when
typeis set toProvided. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.16. .spec.agent.ebpf.metrics.server.tls.providedCaFile
- Description
-
Reference to the CA file when
typeis set toProvided. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| File name within the config map or secret. |
|
|
| Name of the config map or secret containing the file. |
|
|
| Namespace of the config map or secret containing the file. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the file reference: |
13.1.17. .spec.agent.ebpf.resources
- Description
-
resourcesare the compute resources required by this container. For more information, see https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Limits describes the maximum amount of compute resources allowed. More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests describes the minimum amount of compute resources required. If Requests is omitted for a container, it defaults to Limits if that is explicitly specified, otherwise to an implementation-defined value. Requests cannot exceed Limits. More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
13.1.18. .spec.consolePlugin
- Description
-
consolePlugindefines the settings related to the OpenShift Container Platform Console plugin, when available. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Enables the console plugin deployment. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.1.19. .spec.consolePlugin.advanced
- Description
-
advancedallows setting some aspects of the internal configuration of the console plugin. This section is aimed mostly for debugging and fine-grained performance optimizations, such asGOGCandGOMAXPROCSenv vars. Set these values at your own risk. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.1.20. .spec.consolePlugin.advanced.scheduling
- Description
-
schedulingcontrols how the pods are scheduled on nodes. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| If specified, the pod’s scheduling constraints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling. |
|
|
|
|
|
|
| If specified, indicates the pod’s priority. For documentation, refer to https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption. If not specified, default priority is used, or zero if there is no default. |
|
|
|
|
13.1.21. .spec.consolePlugin.advanced.scheduling.affinity
- Description
- If specified, the pod’s scheduling constraints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling.
- Type
-
object
13.1.22. .spec.consolePlugin.advanced.scheduling.tolerations
- Description
-
tolerationsis a list of tolerations that allow the pod to schedule onto nodes with matching taints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling. - Type
-
array
13.1.23. .spec.consolePlugin.autoscaler
- Description
-
autoscalerspec of a horizontal pod autoscaler to set up for the plugin Deployment. Refer to HorizontalPodAutoscaler documentation (autoscaling/v2). - Type
-
object
13.1.24. .spec.consolePlugin.portNaming
- Description
-
portNamingdefines the configuration of the port-to-service name translation - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Enable the console plugin port-to-service name translation |
|
|
|
|
13.1.25. .spec.consolePlugin.quickFilters
- Description
-
quickFiltersconfigures quick filter presets for the Console plugin - Type
-
array
13.1.26. .spec.consolePlugin.quickFilters[]
- Description
-
QuickFilterdefines preset configuration for Console’s quick filters - Type
-
object - Required
-
filter -
name
-
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the filter, that is displayed in the Console |
13.1.27. .spec.consolePlugin.resources
- Description
-
resources, in terms of compute resources, required by this container. For more information, see https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Limits describes the maximum amount of compute resources allowed. More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests describes the minimum amount of compute resources required. If Requests is omitted for a container, it defaults to Limits if that is explicitly specified, otherwise to an implementation-defined value. Requests cannot exceed Limits. More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
13.1.28. .spec.exporters
- Description
-
exportersdefines additional optional exporters for custom consumption or storage. - Type
-
array
13.1.29. .spec.exporters[]
- Description
-
FlowCollectorExporterdefines an additional exporter to send enriched flows to. - Type
-
object - Required
-
type
-
| Property | Type | Description |
|---|---|---|
|
|
| IPFIX configuration, such as the IP address and port to send enriched IPFIX flows to. |
|
|
| Kafka configuration, such as the address and topic, to send enriched flows to. |
|
|
| OpenTelemetry configuration, such as the IP address and port to send enriched logs or metrics to. |
|
|
|
|
13.1.30. .spec.exporters[].ipfix
- Description
- IPFIX configuration, such as the IP address and port to send enriched IPFIX flows to.
- Type
-
object - Required
-
targetHost -
targetPort
-
| Property | Type | Description |
|---|---|---|
|
|
| Address of the IPFIX external receiver. |
|
|
| Port for the IPFIX external receiver. |
|
|
|
Transport protocol ( |
13.1.31. .spec.exporters[].kafka
- Description
- Kafka configuration, such as the address and topic, to send enriched flows to.
- Type
-
object - Required
-
address -
topic
-
| Property | Type | Description |
|---|---|---|
|
|
| Address of the Kafka server |
|
|
| SASL authentication configuration. Unsupported *. |
|
|
| TLS client configuration. When using TLS, verify that the address matches the Kafka port used for TLS, generally 9093. |
|
|
| Kafka topic to use. It must exist. Network Observability does not create it. |
13.1.32. .spec.exporters[].kafka.sasl
- Description
- SASL authentication configuration. Unsupported *.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Reference to the secret or config map containing the client ID |
|
|
| Reference to the secret or config map containing the client secret |
|
|
|
Type of SASL authentication to use, or |
13.1.33. .spec.exporters[].kafka.sasl.clientIDReference
- Description
- Reference to the secret or config map containing the client ID
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| File name within the config map or secret. |
|
|
| Name of the config map or secret containing the file. |
|
|
| Namespace of the config map or secret containing the file. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the file reference: |
13.1.34. .spec.exporters[].kafka.sasl.clientSecretReference
- Description
- Reference to the secret or config map containing the client secret
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| File name within the config map or secret. |
|
|
| Name of the config map or secret containing the file. |
|
|
| Namespace of the config map or secret containing the file. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the file reference: |
13.1.35. .spec.exporters[].kafka.tls
- Description
- TLS client configuration. When using TLS, verify that the address matches the Kafka port used for TLS, generally 9093.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.36. .spec.exporters[].kafka.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.37. .spec.exporters[].kafka.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.38. .spec.exporters[].openTelemetry
- Description
- OpenTelemetry configuration, such as the IP address and port to send enriched logs or metrics to.
- Type
-
object - Required
-
targetHost -
targetPort
-
| Property | Type | Description |
|---|---|---|
|
|
| Custom fields mapping to an OpenTelemetry conformant format. By default, Network Observability format proposal is used: https://github.com/rhobs/observability-data-model/blob/main/network-observability.md#format-proposal . As there is currently no accepted standard for L3 or L4 enriched network logs, you can freely override it with your own. |
|
|
| Headers to add to messages (optional) |
|
|
| OpenTelemetry configuration for logs. |
|
|
| OpenTelemetry configuration for metrics. |
|
|
|
Protocol of the OpenTelemetry connection. The available options are |
|
|
| Address of the OpenTelemetry receiver. |
|
|
| Port for the OpenTelemetry receiver. |
|
|
| TLS client configuration. |
13.1.39. .spec.exporters[].openTelemetry.fieldsMapping
- Description
- Custom fields mapping to an OpenTelemetry conformant format. By default, Network Observability format proposal is used: https://github.com/rhobs/observability-data-model/blob/main/network-observability.md#format-proposal . As there is currently no accepted standard for L3 or L4 enriched network logs, you can freely override it with your own.
- Type
-
array
13.1.40. .spec.exporters[].openTelemetry.fieldsMapping[]
- Description
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| |
|
|
| |
|
|
|
13.1.41. .spec.exporters[].openTelemetry.logs
- Description
- OpenTelemetry configuration for logs.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
Set |
13.1.42. .spec.exporters[].openTelemetry.metrics
- Description
- OpenTelemetry configuration for metrics.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
Set |
|
|
| Specify how often metrics are sent to a collector. |
13.1.43. .spec.exporters[].openTelemetry.tls
- Description
- TLS client configuration.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.44. .spec.exporters[].openTelemetry.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.45. .spec.exporters[].openTelemetry.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.46. .spec.kafka
- Description
-
Kafka configuration, allowing to use Kafka as a broker as part of the flow collection pipeline. Available when the
spec.deploymentModelisKafka. - Type
-
object - Required
-
address -
topic
-
| Property | Type | Description |
|---|---|---|
|
|
| Address of the Kafka server |
|
|
| SASL authentication configuration. Unsupported *. |
|
|
| TLS client configuration. When using TLS, verify that the address matches the Kafka port used for TLS, generally 9093. |
|
|
| Kafka topic to use. It must exist. Network Observability does not create it. |
13.1.47. .spec.kafka.sasl
- Description
- SASL authentication configuration. Unsupported *.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Reference to the secret or config map containing the client ID |
|
|
| Reference to the secret or config map containing the client secret |
|
|
|
Type of SASL authentication to use, or |
13.1.48. .spec.kafka.sasl.clientIDReference
- Description
- Reference to the secret or config map containing the client ID
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| File name within the config map or secret. |
|
|
| Name of the config map or secret containing the file. |
|
|
| Namespace of the config map or secret containing the file. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the file reference: |
13.1.49. .spec.kafka.sasl.clientSecretReference
- Description
- Reference to the secret or config map containing the client secret
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| File name within the config map or secret. |
|
|
| Name of the config map or secret containing the file. |
|
|
| Namespace of the config map or secret containing the file. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the file reference: |
13.1.50. .spec.kafka.tls
- Description
- TLS client configuration. When using TLS, verify that the address matches the Kafka port used for TLS, generally 9093.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.51. .spec.kafka.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.52. .spec.kafka.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.53. .spec.loki
- Description
-
loki, the flow store, client settings. - Type
-
object - Required
-
mode
-
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
Set |
|
|
|
Loki configuration for |
|
|
|
Loki configuration for |
|
|
|
Loki configuration for |
|
|
|
- Use
- Use
- Use
- Use |
|
|
|
Loki configuration for |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.1.54. .spec.loki.advanced
- Description
-
advancedallows setting some aspects of the internal configuration of the Loki clients. This section is aimed mostly for debugging and fine-grained performance optimizations. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13.1.55. .spec.loki.lokiStack
- Description
-
Loki configuration for
LokiStackmode. This is useful for an easy Loki Operator configuration. It is ignored for other modes. - Type
-
object - Required
-
name
-
| Property | Type | Description |
|---|---|---|
|
|
| Name of an existing LokiStack resource to use. |
|
|
|
Namespace where this |
13.1.56. .spec.loki.manual
- Description
-
Loki configuration for
Manualmode. This is the most flexible configuration. It is ignored for other modes. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
-
-
-
When using the Loki Operator, this must be set to |
|
|
|
|
|
|
|
|
|
|
| TLS client configuration for Loki status URL. |
|
|
|
|
|
|
|
|
|
|
| TLS client configuration for Loki URL. |
13.1.57. .spec.loki.manual.statusTls
- Description
- TLS client configuration for Loki status URL.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.58. .spec.loki.manual.statusTls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.59. .spec.loki.manual.statusTls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.60. .spec.loki.manual.tls
- Description
- TLS client configuration for Loki URL.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.61. .spec.loki.manual.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.62. .spec.loki.manual.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.63. .spec.loki.microservices
- Description
-
Loki configuration for
Microservicesmode. Use this option when Loki is installed using the microservices deployment mode (https://grafana.com/docs/loki/latest/fundamentals/architecture/deployment-modes/#microservices-mode). It is ignored for other modes. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| TLS client configuration for Loki URL. |
13.1.64. .spec.loki.microservices.tls
- Description
- TLS client configuration for Loki URL.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.65. .spec.loki.microservices.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.66. .spec.loki.microservices.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.67. .spec.loki.monolithic
- Description
-
Loki configuration for
Monolithicmode. Use this option when Loki is installed using the monolithic deployment mode (https://grafana.com/docs/loki/latest/fundamentals/architecture/deployment-modes/#monolithic-mode). It is ignored for other modes. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| TLS client configuration for Loki URL. |
|
|
|
|
13.1.68. .spec.loki.monolithic.tls
- Description
- TLS client configuration for Loki URL.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.69. .spec.loki.monolithic.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.70. .spec.loki.monolithic.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.71. .spec.networkPolicy
- Description
-
networkPolicydefines ingress network policy settings for Network Observability components isolation. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
Set |
13.1.72. .spec.processor
- Description
-
processordefines the settings of the component that receives the flows from the agent, enriches them, generates metrics, and forwards them to the Loki persistence layer and/or any available exporter. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
-
-
- |
|
|
|
|
|
|
|
Set |
|
|
|
|
|
|
|
|
13.1.73. .spec.processor.advanced
- Description
-
advancedallows setting some aspects of the internal configuration of the flow processor. This section is aimed mostly for debugging and fine-grained performance optimizations, such asGOGCandGOMAXPROCSenv vars. Set these values at your own risk. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Port of the flow collector (host port). By convention, some values are forbidden. It must be greater than 1024 and different from 4500, 4789 and 6081. |
|
|
|
|
|
|
| scheduling controls how the pods are scheduled on nodes. |
|
|
| Defines secondary networks to be checked for resources identification. To guarantee a correct identification, indexed values must form an unique identifier across the cluster. If the same index is used by several resources, those resources might be incorrectly labeled. |
13.1.74. .spec.processor.advanced.scheduling
- Description
- scheduling controls how the pods are scheduled on nodes.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| If specified, the pod’s scheduling constraints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling. |
|
|
|
|
|
|
| If specified, indicates the pod’s priority. For documentation, refer to https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/#how-to-use-priority-and-preemption. If not specified, default priority is used, or zero if there is no default. |
|
|
|
|
13.1.75. .spec.processor.advanced.scheduling.affinity
- Description
- If specified, the pod’s scheduling constraints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling.
- Type
-
object
13.1.76. .spec.processor.advanced.scheduling.tolerations
- Description
-
tolerationsis a list of tolerations that allow the pod to schedule onto nodes with matching taints. For documentation, refer to https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#scheduling. - Type
-
array
13.1.77. .spec.processor.advanced.secondaryNetworks
- Description
- Defines secondary networks to be checked for resources identification. To guarantee a correct identification, indexed values must form an unique identifier across the cluster. If the same index is used by several resources, those resources might be incorrectly labeled.
- Type
-
array
13.1.78. .spec.processor.advanced.secondaryNetworks[]
- Description
- Type
-
object - Required
-
index -
name
-
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
13.1.79. .spec.processor.deduper
- Description
-
deduperallows you to sample or drop flows identified as duplicates, in order to save on resource usage. Unsupported *. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
Set the Processor de-duplication mode. It comes in addition to the Agent-based deduplication because the Agent cannot de-duplicate same flows reported from different nodes.
- Use
- Use
- Use |
|
|
|
|
13.1.80. .spec.processor.filters
- Description
-
filterslets you define custom filters to limit the amount of generated flows. These filters provide more flexibility than the eBPF Agent filters (inspec.agent.ebpf.flowFilter), such as allowing to filter by Kubernetes namespace, but with a lesser improvement in performance. Unsupported *. - Type
-
array
13.1.81. .spec.processor.filters[]
- Description
-
FLPFilterSetdefines the desired configuration for FLP-based filtering satisfying all conditions. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
If specified, these filters only target a single output: |
|
|
|
|
13.1.82. .spec.processor.filters[].allOf
- Description
-
filtersis a list of matches that must be all satisfied in order to remove a flow. - Type
-
array
13.1.83. .spec.processor.filters[].allOf[]
- Description
-
FLPSingleFilterdefines the desired configuration for a single FLP-based filter. - Type
-
object - Required
-
field -
matchType
-
| Property | Type | Description |
|---|---|---|
|
|
| Name of the field to filter on. Refer to the documentation for the list of available fields: https://github.com/netobserv/network-observability-operator/blob/main/docs/flows-format.adoc. |
|
|
| Type of matching to apply. |
|
|
|
Value to filter on. When |
13.1.84. .spec.processor.kafkaConsumerAutoscaler
- Description
-
kafkaConsumerAutoscaleris the spec of a horizontal pod autoscaler to set up forflowlogs-pipeline-transformer, which consumes Kafka messages. This setting is ignored when Kafka is disabled. Refer to HorizontalPodAutoscaler documentation (autoscaling/v2). - Type
-
object
13.1.85. .spec.processor.metrics
- Description
-
Metricsdefine the processor configuration regarding metrics - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Metrics server endpoint configuration for Prometheus scraper |
13.1.86. .spec.processor.metrics.server
- Description
- Metrics server endpoint configuration for Prometheus scraper
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| The metrics server HTTP port. |
|
|
| TLS configuration. |
13.1.87. .spec.processor.metrics.server.tls
- Description
- TLS configuration.
- Type
-
object - Required
-
type
-
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
TLS configuration when |
|
|
|
Reference to the CA file when |
|
|
|
Select the type of TLS configuration:
- |
13.1.88. .spec.processor.metrics.server.tls.provided
- Description
-
TLS configuration when
typeis set toProvided. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.89. .spec.processor.metrics.server.tls.providedCaFile
- Description
-
Reference to the CA file when
typeis set toProvided. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| File name within the config map or secret. |
|
|
| Name of the config map or secret containing the file. |
|
|
| Namespace of the config map or secret containing the file. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the file reference: |
13.1.90. .spec.processor.resources
- Description
-
resourcesare the compute resources required by this container. For more information, see https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Limits describes the maximum amount of compute resources allowed. More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests describes the minimum amount of compute resources required. If Requests is omitted for a container, it defaults to Limits if that is explicitly specified, otherwise to an implementation-defined value. Requests cannot exceed Limits. More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
13.1.91. .spec.processor.subnetLabels
- Description
-
subnetLabelsallows to define custom labels on subnets and IPs or to enable automatic labelling of recognized subnets in OpenShift Container Platform, which is used to identify cluster external traffic. When a subnet matches the source or destination IP of a flow, a corresponding field is added:SrcSubnetLabelorDstSubnetLabel. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
13.1.92. .spec.processor.subnetLabels.customLabels
- Description
-
customLabelsallows to customize subnets and IPs labelling, such as to identify cluster-external workloads or web services. If you enableopenShiftAutoDetect,customLabelscan override the detected subnets in case they overlap. - Type
-
array
13.1.93. .spec.processor.subnetLabels.customLabels[]
- Description
- SubnetLabel allows to label subnets and IPs, such as to identify cluster-external workloads or web services.
- Type
-
object - Required
-
cidrs -
name
-
| Property | Type | Description |
|---|---|---|
|
|
|
List of CIDRs, such as |
|
|
| Label name, used to flag matching flows. |
13.1.94. .spec.prometheus
- Description
-
prometheusdefines Prometheus settings, such as querier configuration used to fetch metrics from the Console plugin. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| Prometheus querying configuration, such as client settings, used in the Console plugin. |
13.1.95. .spec.prometheus.querier
- Description
- Prometheus querying configuration, such as client settings, used in the Console plugin.
- Type
-
object - Required
-
mode
-
| Property | Type | Description |
|---|---|---|
|
|
|
When |
|
|
|
Prometheus configuration for |
|
|
|
- Use
- Use |
|
|
|
|
13.1.96. .spec.prometheus.querier.manual
- Description
-
Prometheus configuration for
Manualmode. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
Set |
|
|
| TLS client configuration for Prometheus URL. |
|
|
|
|
13.1.97. .spec.prometheus.querier.manual.tls
- Description
- TLS client configuration for Prometheus URL.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
| Enable TLS |
|
|
|
|
|
|
|
|
13.1.98. .spec.prometheus.querier.manual.tls.caCert
- Description
-
caCertdefines the reference of the certificate for the Certificate Authority. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
13.1.99. .spec.prometheus.querier.manual.tls.userCert
- Description
-
userCertdefines the user certificate reference and is used for mTLS. When you use one-way TLS, you can ignore this property. - Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Name of the config map or secret containing certificates. |
|
|
| Namespace of the config map or secret containing certificates. If omitted, the default is to use the same namespace as where Network Observability is deployed. If the namespace is different, the config map or the secret is copied so that it can be mounted as required. |
|
|
|
Type for the certificate reference: |
Chapter 14. FlowMetric configuration parameters
FlowMetric is the API allowing to create custom metrics from the collected flow logs.
14.1. FlowMetric [flows.netobserv.io/v1alpha1]
- Description
- FlowMetric is the API allowing to create custom metrics from the collected flow logs.
- Type
-
object
| Property | Type | Description |
|---|---|---|
|
|
| APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and might reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| Kind is a string value representing the REST resource this object represents. Servers might infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| Standard object’s metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
|
FlowMetricSpec defines the desired state of FlowMetric The provided API allows you to customize these metrics according to your needs.
When adding new metrics or modifying existing labels, you must carefully monitor the memory usage of Prometheus workloads as this could potentially have a high impact. Cf https://rhobs-handbook.netlify.app/products/openshiftmonitoring/telemetry.md/#what-is-the-cardinality-of-a-metric
To check the cardinality of all Network Observability metrics, run as |
14.1.1. .metadata
- Description
- Standard object’s metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
- Type
-
object
14.1.2. .spec
- Description
FlowMetricSpec defines the desired state of FlowMetric The provided API allows you to customize these metrics according to your needs.
When adding new metrics or modifying existing labels, you must carefully monitor the memory usage of Prometheus workloads as this could potentially have a high impact. Cf https://rhobs-handbook.netlify.app/products/openshiftmonitoring/telemetry.md/#what-is-the-cardinality-of-a-metric
To check the cardinality of all Network Observability metrics, run as
promql:count({name=~"netobserv.*"}) by (name).- Type
-
object - Required
-
metricName -
type
-
| Property | Type | Description |
|---|---|---|
|
|
|
A list of buckets to use when |
|
|
| Charts configuration, for the OpenShift Container Platform Console in the administrator view, Dashboards menu. |
|
|
|
Filter for ingress, egress or any direction flows. When set to |
|
|
| When nonzero, scale factor (divider) of the value. Metric value = Flow value / Divider. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Name of the metric. In Prometheus, it is automatically prefixed with "netobserv_". |
|
|
|
Set the |
|
|
| Metric type: "Counter" or "Histogram". Use "Counter" for any value that increases over time and on which you can compute a rate, such as Bytes or Packets. Use "Histogram" for any value that must be sampled independently, such as latencies. |
|
|
|
|
14.1.3. .spec.charts
- Description
- Charts configuration, for the OpenShift Container Platform Console in the administrator view, Dashboards menu.
- Type
-
array
14.1.4. .spec.charts[]
- Description
- Configures charts / dashboard generation associated to a metric
- Type
-
object - Required
-
dashboardName -
queries -
title -
type
-
| Property | Type | Description |
|---|---|---|
|
|
| Name of the containing dashboard. If this name does not refer to an existing dashboard, a new dashboard is created. |
|
|
|
List of queries to be displayed on this chart. If |
|
|
|
Name of the containing dashboard section. If this name does not refer to an existing section, a new section is created. If |
|
|
| Title of the chart. |
|
|
| Type of the chart. |
|
|
| Unit of this chart. Only a few units are currently supported. Leave empty to use generic number. |
14.1.5. .spec.charts[].queries
- Description
-
List of queries to be displayed on this chart. If
typeisSingleStatand multiple queries are provided, this chart is automatically expanded in several panels (one per query). - Type
-
array
14.1.6. .spec.charts[].queries[]
- Description
- Configures PromQL queries
- Type
-
object - Required
-
legend -
promQL -
top
-
| Property | Type | Description |
|---|---|---|
|
|
|
The query legend that applies to each timeseries represented in this chart. When multiple timeseries are displayed, you should set a legend that distinguishes each of them. It can be done with the following format: |
|
|
|
The |
|
|
|
Top N series to display per timestamp. Does not apply to |
14.1.7. .spec.filters
- Description
-
filtersis a list of fields and values used to restrict which flows are taken into account. Oftentimes, these filters must be used to eliminate duplicates:Duplicate != "true"andFlowDirection = "0". Refer to the documentation for the list of available fields: https://docs.openshift.com/container-platform/latest/observability/network_observability/json-flows-format-reference.html. - Type
-
array
14.1.8. .spec.filters[]
- Description
- Type
-
object - Required
-
field -
matchType
-
| Property | Type | Description |
|---|---|---|
|
|
| Name of the field to filter on |
|
|
| Type of matching to apply |
|
|
|
Value to filter on. When |
Chapter 15. Network flows format reference
These are the specifications for network flows format, used both internally and when exporting flows to Kafka.
15.1. Network Flows format reference
This is the specification of the network flows format. That format is used when a Kafka exporter is configured, for Prometheus metrics labels as well as internally for the Loki store.
The "Filter ID" column shows which related name to use when defining Quick Filters (see spec.consolePlugin.quickFilters in the FlowCollector specification).
The "Loki label" column is useful when querying Loki directly: label fields need to be selected using stream selectors.
The "Cardinality" column gives information about the implied metric cardinality if this field was to be used as a Prometheus label with the FlowMetrics API. Refer to the FlowMetrics documentation for more information on using this API.
| Name | Type | Description | Filter ID | Loki label | Cardinality | OpenTelemetry |
|---|---|---|---|---|---|---|
|
| number | Number of bytes | n/a | no | avoid | bytes |
|
| number | Error number returned from DNS tracker ebpf hook function |
| no | fine | dns.errno |
|
| number | DNS flags for DNS record | n/a | no | fine | dns.flags |
|
| string | Parsed DNS header RCODEs name |
| no | fine | dns.responsecode |
|
| number | DNS record id |
| no | avoid | dns.id |
|
| number | Time between a DNS request and response, in milliseconds |
| no | avoid | dns.latency |
|
| number | Differentiated Services Code Point (DSCP) value |
| no | fine | dscp |
|
| string | Destination IP address (ipv4 or ipv6) |
| no | avoid | destination.address |
|
| string | Destination node IP |
| no | fine | destination.k8s.host.address |
|
| string | Destination node name |
| no | fine | destination.k8s.host.name |
|
| string | Name of the destination Kubernetes object, such as Pod name, Service name or Node name. |
| no | careful | destination.k8s.name |
|
| string | Destination namespace |
| yes | fine | destination.k8s.namespace.name |
|
| string | Destination network name |
| no | fine | n/a |
|
| string | Name of the destination owner, such as Deployment name, StatefulSet name, etc. |
| yes | fine | destination.k8s.owner.name |
|
| string | Kind of the destination owner, such as Deployment, StatefulSet, etc. |
| no | fine | destination.k8s.owner.kind |
|
| string | Kind of the destination Kubernetes object, such as Pod, Service or Node. |
| yes | fine | destination.k8s.kind |
|
| string | Destination availability zone |
| yes | fine | destination.zone |
|
| string | Destination MAC address |
| no | avoid | destination.mac |
|
| number | Destination port |
| no | careful | destination.port |
|
| string | Destination subnet label |
| no | fine | n/a |
|
| boolean | Indicates if this flow was also captured from another interface on the same host | n/a | no | fine | n/a |
|
| string[] |
List of TCP flags comprised in the flow, according to RFC-9293, with additional custom flags to represent the following per-packet combinations: |
| no | careful | tcp.flags |
|
| number |
Flow interpreted direction from the node observation point. Can be one of: |
| yes | fine | host.direction |
|
| number | ICMP code |
| no | fine | icmp.code |
|
| number | ICMP type |
| no | fine | icmp.type |
|
| number[] |
Flow directions from the network interface observation point. Can be one of: |
| no | fine | interface.directions |
|
| string[] | Network interfaces |
| no | careful | interface.names |
|
| string | Cluster name or identifier |
| yes | fine | k8s.cluster.name |
|
| string | Flow layer: 'app' or 'infra' |
| yes | fine | k8s.layer |
|
| object[] |
Network events, such as network policy actions, composed of nested fields: |
| no | avoid | n/a |
|
| number | Number of packets |
| no | avoid | packets |
|
| number | Number of bytes dropped by the kernel | n/a | no | avoid | drops.bytes |
|
| string | Latest drop cause |
| no | fine | drops.latestcause |
|
| number | TCP flags on last dropped packet | n/a | no | fine | drops.latestflags |
|
| string | TCP state on last dropped packet |
| no | fine | drops.lateststate |
|
| number | Number of packets dropped by the kernel | n/a | no | avoid | drops.packets |
|
| number | L4 protocol |
| no | fine | protocol |
|
| number | Sampling rate used for this flow | n/a | no | fine | n/a |
|
| string | Source IP address (ipv4 or ipv6) |
| no | avoid | source.address |
|
| string | Source node IP |
| no | fine | source.k8s.host.address |
|
| string | Source node name |
| no | fine | source.k8s.host.name |
|
| string | Name of the source Kubernetes object, such as Pod name, Service name or Node name. |
| no | careful | source.k8s.name |
|
| string | Source namespace |
| yes | fine | source.k8s.namespace.name |
|
| string | Source network name |
| no | fine | n/a |
|
| string | Name of the source owner, such as Deployment name, StatefulSet name, etc. |
| yes | fine | source.k8s.owner.name |
|
| string | Kind of the source owner, such as Deployment, StatefulSet, etc. |
| no | fine | source.k8s.owner.kind |
|
| string | Kind of the source Kubernetes object, such as Pod, Service or Node. |
| yes | fine | source.k8s.kind |
|
| string | Source availability zone |
| yes | fine | source.zone |
|
| string | Source MAC address |
| no | avoid | source.mac |
|
| number | Source port |
| no | careful | source.port |
|
| string | Source subnet label |
| no | fine | n/a |
|
| number | End timestamp of this flow, in milliseconds | n/a | no | avoid | timeflowend |
|
| number | TCP Smoothed Round Trip Time (SRTT), in nanoseconds |
| no | avoid | tcp.rtt |
|
| number | Start timestamp of this flow, in milliseconds | n/a | no | avoid | timeflowstart |
|
| number | Timestamp when this flow was received and processed by the flow collector, in seconds | n/a | no | avoid | timereceived |
|
| string[] | List of User Defined Networks |
| no | careful | n/a |
|
| string | Packet translation destination address |
| no | avoid | n/a |
|
| number | Packet translation destination port |
| no | careful | n/a |
|
| string | Packet translation source address |
| no | avoid | n/a |
|
| number | Packet translation source port |
| no | careful | n/a |
|
| number | Packet translation zone id |
| no | avoid | n/a |
|
| string | In conversation tracking, the conversation identifier |
| no | avoid | n/a |
|
| string |
Type of record: |
| yes | fine | n/a |
Chapter 16. Troubleshooting Network Observability
To assist in troubleshooting Network Observability issues, you can perform some troubleshooting actions.
16.1. Using the must-gather tool
You can use the must-gather tool to collect information about the Network Observability Operator resources and cluster-wide resources, such as pod logs, FlowCollector, and webhook configurations.
Procedure
- Navigate to the directory where you want to store the must-gather data.
Run the following command to collect cluster-wide must-gather resources:
$ oc adm must-gather --image-stream=openshift/must-gather \ --image=quay.io/netobserv/must-gather
16.2. Configuring network traffic menu entry in the OpenShift Container Platform console
Manually configure the network traffic menu entry in the OpenShift Container Platform console when the network traffic menu entry is not listed in Observe menu in the OpenShift Container Platform console.
Prerequisites
- You have installed OpenShift Container Platform version 4.10 or newer.
Procedure
Check if the
spec.consolePlugin.registerfield is set totrueby running the following command:$ oc -n netobserv get flowcollector cluster -o yamlExample output
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: falseOptional: Add the
netobserv-pluginplugin by manually editing the Console Operator config:$ oc edit console.operator.openshift.io clusterExample output
... spec: plugins: - netobserv-plugin ...Optional: Set the
spec.consolePlugin.registerfield totrueby running the following command:$ oc -n netobserv edit flowcollector cluster -o yamlExample output
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: trueEnsure the status of console pods is
runningby running the following command:$ oc get pods -n openshift-console -l app=consoleRestart the console pods by running the following command:
$ oc delete pods -n openshift-console -l app=console- Clear your browser cache and history.
Check the status of Network Observability plugin pods by running the following command:
$ oc get pods -n netobserv -l app=netobserv-pluginExample output
NAME READY STATUS RESTARTS AGE netobserv-plugin-68c7bbb9bb-b69q6 1/1 Running 0 21sCheck the logs of the Network Observability plugin pods by running the following command:
$ oc logs -n netobserv -l app=netobserv-pluginExample output
time="2022-12-13T12:06:49Z" level=info msg="Starting netobserv-console-plugin [build version: , build date: 2022-10-21 15:15] at log level info" module=main time="2022-12-13T12:06:49Z" level=info msg="listening on https://:9001" module=server
16.3. Flowlogs-Pipeline does not consume network flows after installing Kafka
If you deployed the flow collector first with deploymentModel: KAFKA and then deployed Kafka, the flow collector might not connect correctly to Kafka. Manually restart the flow-pipeline pods where Flowlogs-pipeline does not consume network flows from Kafka.
Procedure
Delete the flow-pipeline pods to restart them by running the following command:
$ oc delete pods -n netobserv -l app=flowlogs-pipeline-transformer
16.4. Failing to see network flows from both br-int and br-ex interfaces
br-ex` and br-int are virtual bridge devices operated at OSI layer 2. The eBPF agent works at the IP and TCP levels, layers 3 and 4 respectively. You can expect that the eBPF agent captures the network traffic passing through br-ex and br-int, when the network traffic is processed by other interfaces such as physical host or virtual pod interfaces. If you restrict the eBPF agent network interfaces to attach only to br-ex and br-int, you do not see any network flow.
Manually remove the part in the interfaces or excludeInterfaces that restricts the network interfaces to br-int and br-ex.
Procedure
Remove the
interfaces: [ 'br-int', 'br-ex' ]field. This allows the agent to fetch information from all the interfaces. Alternatively, you can specify the Layer-3 interface for example,eth0. Run the following command:$ oc edit -n netobserv flowcollector.yaml -o yamlExample output
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: agent: type: EBPF ebpf: interfaces: [ 'br-int', 'br-ex' ]1 - 1
- Specifies the network interfaces.
16.5. Network Observability controller manager pod runs out of memory
You can increase memory limits for the Network Observability operator by editing the spec.config.resources.limits.memory specification in the Subscription object.
Procedure
- In the web console, navigate to Operators → Installed Operators
- Click Network Observability and then select Subscription.
From the Actions menu, click Edit Subscription.
Alternatively, you can use the CLI to open the YAML configuration for the
Subscriptionobject by running the following command:$ oc edit subscription netobserv-operator -n openshift-netobserv-operator
Edit the
Subscriptionobject to add theconfig.resources.limits.memoryspecification and set the value to account for your memory requirements. See the Additional resources for more information about resource considerations:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: netobserv-operator namespace: openshift-netobserv-operator spec: channel: stable config: resources: limits: memory: 800Mi1 requests: cpu: 100m memory: 100Mi installPlanApproval: Automatic name: netobserv-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: <network_observability_operator_latest_version>2
16.6. Running custom queries to Loki
For troubleshooting, can run custom queries to Loki. There are two examples of ways to do this, which you can adapt according to your needs by replacing the <api_token> with your own.
These examples use the netobserv namespace for the Network Observability Operator and Loki deployments. Additionally, the examples assume that the LokiStack is named loki. You can optionally use a different namespace and naming by adapting the examples, specifically the -n netobserv or the loki-gateway URL.
Prerequisites
- Installed Loki Operator for use with Network Observability Operator
Procedure
To get all available labels, run the following:
$ oc exec deployment/netobserv-plugin -n netobserv -- curl -G -s -H 'X-Scope-OrgID:network' -H 'Authorization: Bearer <api_token>' -k https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network/loki/api/v1/labels | jqTo get all flows from the source namespace,
my-namespace, run the following:$ oc exec deployment/netobserv-plugin -n netobserv -- curl -G -s -H 'X-Scope-OrgID:network' -H 'Authorization: Bearer <api_token>' -k https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network/loki/api/v1/query --data-urlencode 'query={SrcK8S_Namespace="my-namespace"}' | jq
16.7. Troubleshooting Loki ResourceExhausted error
Loki may return a ResourceExhausted error when network flow data sent by Network Observability exceeds the configured maximum message size. If you are using the Red Hat Loki Operator, this maximum message size is configured to 100 MiB.
Procedure
- Navigate to Operators → Installed Operators, viewing All projects from the Project drop-down menu.
- In the Provided APIs list, select the Network Observability Operator.
Click the Flow Collector then the YAML view tab.
-
If you are using the Loki Operator, check that the
spec.loki.batchSizevalue does not exceed 98 MiB. -
If you are using a Loki installation method that is different from the Red Hat Loki Operator, such as Grafana Loki, verify that the
grpc_server_max_recv_msg_sizeGrafana Loki server setting is higher than theFlowCollectorresourcespec.loki.batchSizevalue. If it is not, you must either increase thegrpc_server_max_recv_msg_sizevalue, or decrease thespec.loki.batchSizevalue so that it is lower than the limit.
-
If you are using the Loki Operator, check that the
- Click Save if you edited the FlowCollector.
16.8. Loki empty ring error
The Loki "empty ring" error results in flows not being stored in Loki and not showing up in the web console. This error might happen in various situations. A single workaround to address them all does not exist. There are some actions you can take to investigate the logs in your Loki pods, and verify that the LokiStack is healthy and ready.
Some of the situations where this error is observed are as follows:
After a
LokiStackis uninstalled and reinstalled in the same namespace, old PVCs are not removed, which can cause this error.-
Action: You can try removing the
LokiStackagain, removing the PVC, then reinstalling theLokiStack.
-
Action: You can try removing the
After a certificate rotation, this error can prevent communication with the
flowlogs-pipelineandconsole-pluginpods.- Action: You can restart the pods to restore the connectivity.
16.9. Resource troubleshooting
16.10. LokiStack rate limit errors
A rate-limit placed on the Loki tenant can result in potential temporary loss of data and a 429 error: Per stream rate limit exceeded (limit:xMB/sec) while attempting to ingest for stream. You might consider having an alert set to notify you of this error. For more information, see "Creating Loki rate limit alerts for the NetObserv dashboard" in the Additional resources of this section.
You can update the LokiStack CRD with the perStreamRateLimit and perStreamRateLimitBurst specifications, as shown in the following procedure.
Procedure
- Navigate to Operators → Installed Operators, viewing All projects from the Project dropdown.
- Look for Loki Operator, and select the LokiStack tab.
Create or edit an existing LokiStack instance using the YAML view to add the
perStreamRateLimitandperStreamRateLimitBurstspecifications:apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv spec: limits: global: ingestion: perStreamRateLimit: 61 perStreamRateLimitBurst: 302 tenants: mode: openshift-network managementState: Managed- Click Save.
Verification
Once you update the perStreamRateLimit and perStreamRateLimitBurst specifications, the pods in your cluster restart and the 429 rate-limit error no longer occurs.
16.11. Running a large query results in Loki errors
When running large queries for a long time, Loki errors can occur, such as a timeout or too many outstanding requests. There is no complete corrective for this issue, but there are several ways to mitigate it:
- Adapt your query to add an indexed filter
-
With Loki queries, you can query on both indexed and non-indexed fields or labels. Queries that contain filters on labels perform better. For example, if you query for a particular Pod, which is not an indexed field, you can add its Namespace to the query. The list of indexed fields can be found in the "Network flows format reference", in the
Loki labelcolumn. - Consider querying Prometheus rather than Loki
- Prometheus is a better fit than Loki to query on large time ranges. However, whether or not you can use Prometheus instead of Loki depends on the use case. For example, queries on Prometheus are much faster than on Loki, and large time ranges do not impact performance. But Prometheus metrics do not contain as much information as flow logs in Loki. The Network Observability OpenShift web console automatically favors Prometheus over Loki if the query is compatible; otherwise, it defaults to Loki. If your query does not run against Prometheus, you can change some filters or aggregations to make the switch. In the OpenShift web console, you can force the use of Prometheus. An error message is displayed when incompatible queries fail, which can help you figure out which labels to change to make the query compatible. For example, changing a filter or an aggregation from Resource or Pods to Owner.
- Consider using the FlowMetrics API to create your own metric
- If the data that you need isn’t available as a Prometheus metric, you can use the FlowMetrics API to create your own metric. For more information, see "FlowMetrics API Reference" and "Configuring custom metrics by using FlowMetric API".
- Configure Loki to improve the query performance
If the problem persists, you can consider configuring Loki to improve the query performance. Some options depend on the installation mode you used for Loki, such as using the Operator and
LokiStack, orMonolithicmode, orMicroservicesmode.-
In
LokiStackorMicroservicesmodes, try increasing the number of querier replicas. -
Increase the query timeout. You must also increase the Network Observability read timeout to Loki in the
FlowCollectorspec.loki.readTimeout.
-
In
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.