installer-provisioned クラスターのベアメタルへのデプロイ
installer-provisioned OpenShift Container Platform クラスターをベアメタルにデプロイする
概要
第1章 概要
ベアメタルノードへの installer-provisioned installation は、OpenShift Container Platform クラスターが実行されるインフラストラクチャーをデプロイおよび設定します。このガイドでは、installer-provisioned ベアメタルのインストールを正常に行うための方法論を提供します。次の図は、デプロイメントのフェーズ 1 におけるインストール環境を示しています。

インストールの場合、前の図の主要な要素は次のとおりです。
- プロビジョナー: インストールプログラムを実行し、新しい OpenShift Container Platform クラスターのコントロールプレーンをデプロイするブートストラップ VM をホストする物理マシン。
- Bootstrap VM: OpenShift Container Platform クラスターのデプロイプロセスで使用される仮想マシン。
-
ネットワークブリッジ: ブートストラップ VM は、ネットワークブリッジ
eno1およびeno2を介して、ベアメタルネットワークとプロビジョニングネットワーク (存在する場合) に接続します。 -
API VIP: API 仮想 IP アドレス (VIP) は、コントロールプレーンノード全体で API サーバーのフェイルオーバーを提供するために使用されます。API VIP はまずブートストラップ仮想マシンにあります。スクリプトは、サービスを起動する前に
keepalived.conf設定ファイルを生成します。VIP は、ブートストラッププロセスが完了し、ブートストラップ仮想マシンが停止すると、コントロールプレーンノードの 1 つに移動します。
デプロイメントのフェーズ 2 では、プロビジョナーがブートストラップ VM を自動的に破棄し、仮想 IP アドレス (VIP) を適切なノードに移動します。
keepalived.conf ファイルは、コントロールプレーンマシンにブートストラップ VM よりも低い仮想ルーター冗長プロトコル (VRRP) の優先順位を設定します。これにより、API VIP がブートストラップ VM からコントロールプレーンに移動する前に、コントロールプレーンマシン上の API が完全に機能することが保証されます。API VIP がコントロールプレーンノードの 1 つに移動すると、外部クライアントから API VIP ルートに送信されたトラフィックが、そのコントロールプレーンノードで実行している haproxy ロードバランサーに移動します。haproxy のこのインスタンスは、コントロールプレーンノード全体で API VIP トラフィックを分散します。
Ingress 仮想 IP はコンピュートノードに移動します。keepalived インスタンスは Ingress VIP も管理します。
次の図は、デプロイメントのフェーズ 2 を示しています:

これ以降、プロビジョナーが使用するノードを削除または再利用できます。ここから、追加のプロビジョニングタスクはすべてコントロールプレーンによって実行されます。
installer-provisioned infrastructure によるインストールの場合、ポート 53 が CoreDNS によってノードレベルで公開され、他のルーティング可能なネットワークからアクセスできるようになります。
プロビジョニングネットワークは任意ですが、PXE ブートには必要です。プロビジョニングネットワークなしでデプロイする場合は、redfish-virtualmedia または idrac-virtualmedia などの仮想メディアベースボード管理コントローラー (BMC) アドレス指定オプションを使用する必要があります。
第2章 前提条件
OpenShift Container Platform の installer-provisioned installation には、以下が必要です。
- 1 つの Red Hat Enterprise Linux (RHEL) 9.x がインストールされているプロビジョナーノード。プロビジョナーは、インストール後に削除できます。
- 3 つのコントロールプレーンノード
- ベースボード管理コントローラー (BMC) の各ノードへのアクセス。
1 つ以上のネットワーク:
- 1 つの必須のルーティング可能なネットワーク
- 1 つのオプションのプロビジョニングネットワーク
- 1 つのオプションの管理ネットワーク
OpenShift Container Platform の installer-provisioned installation を開始する前に、ハードウェア環境が以下の要件を満たしていることを確認してください。
2.1. ノードの要件
installer-provisioned installation には、ハードウェアノードの各種の要件があります。
-
CPU architecture: すべてのノードは
x86_64またはaarch64CPU アーキテクチャーを使用する必要があります。 - 同様のノード: Red Hat では、ノードにロールごとに同じ設定を指定することを推奨しています。つまり Red Hat では、同じ CPU、メモリー、ストレージ設定の同じブランドおよびモデルのノードを使用することを推奨しています。
-
ベースボード管理コントローラー:
provisionerノードは、各 OpenShift Container Platform クラスターノードのベースボード管理コントローラー (BMC) にアクセスできる必要があります。IPMI、Redfish、またはプロプライエタリープロトコルを使用できます。 -
最新の生成: ノードは最新の生成されたノードである必要があります。installer-provisioned installation は、ノード間で互換性を確保する必要のある BMC プロトコルに依存します。また、RHEL 9 には RAID コントローラーの最新のドライバーが同梱されています。ノードが、
provisionerノードの RHEL 9.x と、コントロールプレーンおよびワーカーノードの RHCOS 9.x をサポートするために必要な新しいバージョンのノードでであることを確認します。 - レジストリーノード: (オプション) 非接続のミラーリングされていないレジストリーを設定する場合、レジストリーは独自のノードに置くことが推奨されます。
-
プロビジョナーノード: installer-provisioned installation には 1 つの
provisionerノードが必要です。 - コントロールプレーン: installer-provisioned installation には、高可用性を実現するために 3 つのコントロールプレーンノードが必要です。3 つのコントロールプレーンノードのみで OpenShift Container Platform クラスターをデプロイして、コントロールプレーンノードをワーカーノードとしてスケジュール可能にすることができます。小規模なクラスターでは、開発、実稼働およびテスト時の管理者および開発者に対するリソース効率が高くなります。
ワーカーノード: 必須ではありませんが、一般的な実稼働クラスターには複数のワーカーノードがあります。
重要ワーカーノードが 1 つしかないクラスターは、パフォーマンスが低下した状態のルーターおよび Ingress トラフィックでデプロイされるので、デプロイしないでください。
ネットワークインターフェイス: 各ノードでは、ルーティング可能な
baremetalネットワークに 1 つ以上のネットワークインターフェイスが必要です。デプロイメントにprovisioningネットワークを使用する場合、各ノードにprovisioningネットワーク用に 1 つのネットワークインターフェイスが必要になります。provisioningネットワークの使用はデフォルト設定です。注記同じサブネット上の 1 つのネットワークカード (NIC) のみが、ゲートウェイ経由でトラフィックをルーティングできます。デフォルトでは、アドレス解決プロトコル (ARP) は番号が最も小さい NIC を使用します。ネットワーク負荷分散が期待どおりに機能するようにするには、同じサブネット内の各ノードに 1 つの NIC を使用します。同じサブネット内のノードに複数の NIC を使用する場合は、単一のボンディングまたはチームインターフェイスを使用します。次に、エイリアス IP アドレスの形式で他の IP アドレスをそのインターフェイスに追加します。ネットワークインターフェイスレベルでフォールトトレランスまたは負荷分散が必要な場合は、ボンディングまたはチームインターフェイスでエイリアス IP アドレスを使用します。または、同じサブネットでセカンダリー NIC を無効にするか、IP アドレスがないことを確認できます。
Unified Extensible Firmware Interface (UEFI): installer-provisioned installation では、
provisioningネットワークで IPv6 アドレスを使用する場合に、すべての OpenShift Container Platform ノードで UEFI ブートが必要になります。さらに、UEFI Device PXE Settings (UEFI デバイス PXE 設定) はprovisioningネットワーク NIC で IPv6 プロトコルを使用するように設定する必要がありますが、provisioningネットワークを省略すると、この要件はなくなります。重要ISO イメージなどの仮想メディアからインストールを開始する場合は、古い UEFI ブートテーブルエントリーをすべて削除します。ブートテーブルに、ファームウェアによって提供される一般的なエントリーではないエントリーが含まれている場合、インストールは失敗する可能性があります。
Secure Boot: 多くの実稼働シナリオでは、UEFI ファームウェアドライバー、EFI アプリケーション、オペレーティングシステムなど、信頼できるソフトウェアのみを使用してノードが起動することを確認するために、Secure Boot が有効にされているノードが必要です。手動またはマネージドの Secure Boot を使用してデプロイすることができます。
- 手動: 手動で Secure Boot を使用して OpenShift Container Platform クラスターをデプロイするには、UEFI ブートモードおよび Secure Boot を各コントロールプレーンノードおよび各ワーカーノードで有効にする必要があります。Red Hat は、installer-provisioned installation で Redfish 仮想メディアを使用している場合にのみ、手動で有効にした UEFI および Secure Boot で、Secure Boot をサポートします。詳細は、「ノードの設定」セクションの「手動での Secure Boot のノードの設定」を参照してください。
マネージド: マネージド Secure Boot で OpenShift Container Platform クラスターをデプロイするには、
install-config.yamlファイルでbootModeの値をUEFISecureBootに設定する必要があります。Red Hat は、第 10 世代 HPE ハードウェアおよび 13 世代 Dell ハードウェア (ファームウェアバージョン2.75.75.75以上を実行) でマネージド Secure Boot を使用した installer-provisioned installation のみをサポートします。マネージド Secure Boot を使用したデプロイには、Redfish 仮想メディアは必要ありません。詳細は、「OpenShift インストールの環境のセットアップ」セクションの「マネージド Secure Boot の設定」を参照してください。注記Red Hat は、セキュアブートの自己生成キーまたは他のキーの管理をサポートしていません。
2.2. クラスターインストールの最小リソース要件
それぞれのクラスターマシンは、以下の最小要件を満たしている必要があります。
| マシン | オペレーティングシステム | CPU [1] | RAM | ストレージ | 1 秒あたりの入出力 (IOPS) [2] |
|---|---|---|---|---|---|
| ブートストラップ | RHEL | 4 | 16 GB | 100 GB | 300 |
| コントロールプレーン | RHCOS | 4 | 16 GB | 100 GB | 300 |
| Compute | RHCOS | 2 | 8 GB | 100 GB | 300 |
- 1 つの CPU は、同時マルチスレッド (SMT) またはハイパースレッディングが有効にされていない場合に 1 つの物理コアと同等です。これが有効にされている場合、(コアごとのスレッド x コア数) x ソケット数 = CPU という数式を使用して対応する比率を計算します。
- OpenShift Container Platform と Kubernetes は、ディスクのパフォーマンスの影響を受けるため、特にコントロールプレーンノードの etcd には、より高速なストレージが推奨されます。多くのクラウドプラットフォームでは、ストレージサイズと IOPS スケールが一緒にあるため、十分なパフォーマンスを得るためにストレージボリュームの割り当てが必要になる場合があります。
OpenShift Container Platform バージョン 4.13 の時点で、RHCOS は RHEL バージョン 9.2 に基づいており、マイクロアーキテクチャーの要件を更新します。次のリストには、各アーキテクチャーに必要な最小限の命令セットアーキテクチャー (ISA) が含まれています。
- x86-64 アーキテクチャーには x86-64-v2 ISA が必要
- ARM64 アーキテクチャーには ARMv8.0-A ISA が必要
- IBM Power アーキテクチャーには Power 9 ISA が必要
- s390x アーキテクチャーには z14 ISA が必要
詳細は、アーキテクチャー (RHEL ドキュメント) を参照してください。
プラットフォームのインスタンスタイプがクラスターマシンの最小要件を満たす場合、これは OpenShift Container Platform で使用することがサポートされます。
2.3. OpenShift Virtualization のベアメタルクラスターのインストール要件
ベアメタルクラスターで OpenShift Virtualization を使用する予定がある場合は、インストール時にクラスターが正しく設定されていることを確認する必要があります。これは、OpenShift Virtualization ではクラスターのインストール後に変更できない特定の設定が必要なためです。
2.3.1. OpenShift Virtualization の高可用性要件
OpenShift Virtualization のコンテキストで高可用性(HA)機能について話す場合、これは、Infrastructure カスタムリソース(CR)の controlPlaneTopology フィールドと infrastructureTopology フィールドで決定されるコアクラスターコンポーネントのレプリケーションモデルのみを指します。これらのフィールドを HighlyAvailable に設定すると、一般的なアプリケーション HA とは異なるコンポーネントの冗長性が提供されます。これらのフィールドを SingleReplica に設定すると、コンポーネントの冗長性が無効になるため、OpenShift Virtualization HA 機能が無効になります。
OpenShift Virtualization HA 機能を使用する予定がある場合は、クラスターのインストール時に 3 つのコントロールプレーンノードが必要です。クラスターの インフラストラクチャー CR の controlPlaneTopology ステータスは、HighlyAvailable である必要があります。
単一ノードのクラスターに OpenShift Virtualization をインストールできますが、単一ノードの OpenShift は HA 機能をサポートしていません。
2.3.2. OpenShift Virtualization のライブマイグレーション要件
ライブマイグレーションを使用する予定の場合には、複数のワーカーノードが必要です。クラスターのインフラストラクチャー CR の
infrastructureTopologyステータスはHighlyAvailableであり、最低でも 3 つのワーカーノードが推奨されます。注記単一ノードのクラスターに OpenShift Virtualization をインストールできますが、単一ノードの OpenShift はライブマイグレーションをサポートしていません。
- ライブマイグレーションには共有ストレージが必要です。OpenShift Virtualization のストレージは、ReadWriteMany (RWX) アクセスモードをサポートし、使用する必要があります。
2.3.3. OpenShift Virtualization の SR-IOV 要件
Single Root I/O Virtualization (SR-IOV) を使用する予定の場合は、ネットワークインターフェイスコントローラー (NIC) が OpenShift Container Platform でサポートされていることを確認してください。
2.4. 仮想メディアを使用したインストールのファームウェア要件
installer-provisioned OpenShift Container Platform クラスターのインストールプログラムは、Redfish 仮想メディアとのハードウェアおよびファームウェアの互換性を検証します。ノードファームウェアに互換性がない場合、インストールプログラムはノードへのインストールを開始しません。以下の表は、Redfish 仮想メディアを使用してデプロイされる installer-provisioned OpenShift Container Platform クラスターで機能するようにテストおよび検証された最小ファームウェアバージョンの一覧です。
Red Hat は、ファームウェア、ハードウェア、またはその他のサードパーティーコンポーネントの組み合わせをすべてテストしません。サードパーティーサポートの詳細は、Red Hat サードパーティーサポートポリシー を参照してください。ファームウェアの更新は、ノードのハードウェアドキュメントを参照するか、ハードウェアベンダーにお問い合わせください。
| モデル | 管理 | ファームウェアのバージョン |
|---|---|---|
| 第 11 世代 | iLO6 | 1.57 以降 |
| 第 10 世代 | iLO5 | 2.63 以降 |
| モデル | 管理 | ファームウェアのバージョン |
|---|---|---|
| 第 16 世代 | iDRAC 9 | v7.10.70.00 |
| 第 15 世代 | iDRAC 9 | v6.10.30.00 および v7.10.70.00 |
| 第 14 世代 | iDRAC 9 | v6.10.30.00 |
| モデル | 管理 | ファームウェアのバージョン |
|---|---|---|
| UCS UCSX-210C-M6 | CIMC | 5.2(2) 以降 |
2.5. ネットワーク要件
OpenShift Container Platform の installer-provisioned installation には、複数のネットワーク要件があります。まず、installer-provisioned installation では、各ベアメタルノードにオペレーティングシステムをプロビジョニングするためのルーティング不可能な provisioning ネットワークをオプションで使用します。次に、installer-provisioned installation では、ルーティング可能な baremetal ネットワークを使用します。
2.5.1. 必須ポートが開いていることを確認する
クラスター間で特定のノードが開いてなければ、installer-provisioned によるインストールは正常に完了しません。ファーエッジワーカーノードに別のサブネットを使用する場合などの特定の状況では、これらのサブネット内のノードが、次の必須ポートで他のサブネット内のノードと通信できることを確認する必要があります。
| ポート | 説明 |
|---|---|
|
|
プロビジョニングネットワークを使用する場合、クラスターノードは、ポート |
|
|
プロビジョニングネットワークを使用する場合、クラスターノードはプロビジョニングネットワークインターフェイスを使用してポート |
|
|
イメージキャッシュオプションを使用しない場合、または仮想メディアを使用する場合、プロビジョナーノードからクラスターノードに Red Hat Enterprise Linux CoreOS (RHCOS) イメージをストリーミングするには、プロビジョナーノードのポート |
|
|
クラスターノードは、 |
|
|
Ironic Inspector API は、コントロールプレーンノード上で実行され、ポート |
|
|
ポート |
|
|
仮想メディアを使用して TLS を使用せずにデプロイする場合、ワーカーノードのベースボード管理コントローラー (BMC) が RHCOS イメージにアクセスできるように、プロビジョナーノードとコントロールプレーンノードのポート |
|
|
仮想メディアを使用して TLS でデプロイする場合、ワーカーノードの BMC が RHCOS イメージにアクセスできるように、プロビジョナーノードとコントロールプレーンノードのポート |
|
|
Ironic API サーバーは、最初はブートストラップ仮想マシン上で実行され、その後はコントロールプレーンノード上で実行され、ポート |
|
|
ポート |
|
|
TLS なしでイメージキャッシュを使用する場合、ポート |
|
|
TLS ありでイメージキャッシュオプションを使用する場合、ポート |
|
|
デフォルトでは、Ironic Python Agent (IPA) は、ポート |
2.5.2. ネットワーク MTU の増加
OpenShift Container Platform をデプロイする前に、ネットワークの最大伝送単位 (MTU) を 1500 以上に増やします。MTU が 1500 未満の場合、ノードの起動に使用される Ironic イメージが Ironic インスペクター Pod との通信に失敗し、検査が失敗する可能性があります。これが発生すると、インストールにノードを使用できないため、インストールが停止します。
2.5.3. NIC の設定
OpenShift Container Platform は、2 つのネットワークを使用してデプロイします。
provisioning:provisioningネットワークは、OpenShift Container Platform クラスターの一部である基礎となるオペレーティングシステムを各ノードにプロビジョニングするために使用されるオプションのルーティング不可能なネットワークです。各クラスターノードのprovisioningネットワークのネットワークインターフェイスには、BIOS または UEFI が PXE ブートに設定されている必要があります。provisioningNetworkInterface設定は、コントロールプレーンノード上のprovisioningネットワークの NIC 名を指定します。これは、コントロールプレーンノードと同じでなければなりません。bootMACAddress設定は、provisioningネットワーク用に各ノードで特定の NIC を指定する手段を提供します。provisioningネットワークは任意ですが、PXE ブートには必要です。provisioningネットワークなしでデプロイする場合、redfish-virtualmediaやidrac-virtualmediaなどの仮想メディア BMC アドレス指定オプションを使用する必要があります。-
baremetal:baremetalネットワークはルーティング可能なネットワークです。NIC がprovisioningネットワークを使用するように設定されていない場合には、baremetalネットワークとのインターフェイスには任意の NIC を使用することができます。
VLAN を使用する場合、それぞれの NIC は、適切なネットワークに対応する別個の VLAN 上にある必要があります。
2.5.4. DNS 要件
クライアントは、baremetal ネットワークで OpenShift Container Platform クラスターにアクセスします。ネットワーク管理者は、正規名の拡張がクラスター名であるサブドメインまたはサブゾーンを設定する必要があります。
<cluster_name>.<base_domain>以下に例を示します。
test-cluster.example.comOpenShift Container Platform には、クラスターメンバーシップ情報を使用して A/AAAA レコードを生成する機能が含まれます。これにより、ノード名が IP アドレスに解決されます。ノードが API に登録されると、クラスターは CoreDNS-mDNS を使用せずにこれらのノード情報を分散できます。これにより、マルチキャスト DNS に関連付けられたネットワークトラフィックがなくなります。
CoreDNS を正しく機能させるには、アップストリームの DNS サーバーへの TCP 接続と UDP 接続の両方が必要です。アップストリームの DNS サーバーが OpenShift Container Platform クラスターノードから TCP 接続と UDP 接続の両方を受信できることを確認します。
OpenShift Container Platform のデプロイメントでは、以下のコンポーネントに DNS 名前解決が必要です。
- The Kubernetes API
- OpenShift Container Platform のアプリケーションワイルドカード Ingress API
A/AAAA レコードは名前解決に使用され、PTR レコードは逆引き名前解決に使用されます。Red Hat Enterprise Linux CoreOS (RHCOS) は、逆引きレコードまたは DHCP を使用して、すべてのノードのホスト名を設定します。
installer-provisioned installation には、クラスターメンバーシップ情報を使用して A/AAAA レコードを生成する機能が含まれています。これにより、ノード名が IP アドレスに解決されます。各レコードで、<cluster_name> はクラスター名で、<base_domain> は、install-config.yaml ファイルに指定するベースドメインです。完全な DNS レコードは <component>.<cluster_name>.<base_domain>. の形式を取ります。
| コンポーネント | レコード | 説明 |
|---|---|---|
| Kubernetes API |
| A/AAAA レコードと PTR レコード。API ロードバランサーを識別します。これらのレコードは、クラスター外のクライアントおよびクラスター内のすべてのノードで解決できる必要があります。 |
| ルート |
| ワイルドカード A/AAAA レコードは、アプリケーションの Ingress ロードバランサーを参照します。アプリケーション Ingress ロードバランサーは、Ingress コントローラー Pod を実行するノードをターゲットにします。Ingress Controller Pod は、デフォルトでワーカーノードで実行されます。これらのレコードは、クラスター外のクライアントおよびクラスター内のすべてのノードで解決できる必要があります。
たとえば、 |
dig コマンドを使用して、DNS 解決を確認できます。
2.5.5. Dynamic Host Configuration Protocol (DHCP) の要件
デフォルトでは、installer-provisioned installation は、provisioning ネットワーク用に DHCP を有効にして ironic-dnsmasq をデプロイします。provisioningNetwork 設定が、デフォルト値の managed に設定されている場合、provisioning ネットワーク上で他の DHCP サーバーを実行することはできません。provisioning ネットワーク上で DHCP サーバーを実行している場合は、install-config.yaml ファイルで provisioningNetwork 設定を unmanaged に設定する必要があります。
ネットワーク管理者は、外部 DHCP サーバー上の baremetal ネットワーク用に、OpenShift Container Platform クラスター内の各ノードの IP アドレスを予約する必要があります。
2.5.6. DHCP サーバーを使用するノードの IP アドレスの確保
baremetal ネットワークの場合、ネットワーク管理者は、以下を含むいくつかの IP アドレスを予約する必要があります。
2 つの一意の仮想 IP アドレス。
- API エンドポイントの 1 つの仮想 IP アドレス。
- ワイルドカード Ingress エンドポイントの 1 つの仮想 IP アドレス
- プロビジョナーノードの 1 つの IP アドレス
- コントロールプレーンノードごとに 1 つの IP アドレス。
- 各ワーカーノードの 1 つの IP アドレス (適用可能な場合)
一部の管理者は、各ノードの IP アドレスが DHCP サーバーがない状態で一定になるように静的 IP アドレスの使用を選択します。NMState を使用して静的 IP アドレスを設定する場合は、「OpenShift インストールの環境のセットアップ」セクションの「ホストネットワークインターフェイスの設定 (オプション)」を参照してください。
外部の負荷分散サービスとコントロールプレーンノードは同じ L2 ネットワークで実行する必要があります。また、VLAN を使用して負荷分散サービスとコントロールプレーンノード間のトラフィックをルーティングする際に同じ VLAN で実行する必要があります。
ストレージインターフェイスには、DHCP 予約または静的 IP が必要です。
以下の表は、完全修飾ドメイン名の具体例を示しています。API およびネームサーバーのアドレスは、正規名の拡張で始まります。コントロールプレーンおよびワーカーノードのホスト名は例であるため、任意のホストの命名規則を使用することができます。
| 使用法 | ホスト名 | IP |
|---|---|---|
| API |
|
|
| Ingress LB (アプリケーション) |
|
|
| プロビジョナーノード |
|
|
| Control-plane-0 |
|
|
| Control-plane-1 |
|
|
| Control-plane-2 |
|
|
| Worker-0 |
|
|
| Worker-1 |
|
|
| Worker-n |
|
|
DHCP 予約を作成しない場合、Kubernetes API ノード、プロビジョナーノード、コントロールプレーンノード、およびワーカーノードのホスト名を設定するために、インストールプログラムで逆引き DNS 解決が必要になります。
2.5.7. プロビジョナーノードの要件
インストール設定でプロビジョナーノードの MAC アドレスを指定する必要があります。通常、bootMacAddress 仕様は PXE ネットワークブートに関連付けられています。ただし、Ironic プロビジョニングサービスでは、クラスターの検査中またはクラスター内のノードの再デプロイ中にノードを識別するために、bootMacAddress 仕様も必要です。
プロビジョナーノードには、ネットワークの起動、DHCP と DNS の解決、およびローカルネットワーク通信のためのレイヤー 2 接続が必要です。プロビジョナーノードには、仮想メディアの起動にレイヤー 3 接続が必要です。
2.5.8. ネットワークタイムプロトコル (NTP)
クラスター内の各 OpenShift Container Platform ノードは NTP サーバーにアクセスできる必要があります。OpenShift Container Platform ノードは NTP を使用してクロックを同期します。たとえば、クラスターノードは検証を必要とする SSL/TLS 証明書を使用しますが、ノード間の日付と時刻が同期していないと、検証が失敗する可能性があります。
各クラスターノードの BIOS 設定で一貫性のあるクロックの日付と時刻の形式を定義してください。そうしないと、インストールが失敗する可能性があります。
切断されたクラスター上で NTP サーバーとして機能するようにコントロールプレーンノードを再設定し、コントロールプレーンノードから時間を取得するようにワーカーノードを再設定することができます。
2.5.9. 帯域外管理 IP アドレスのポートアクセス
帯域外管理 IP アドレスは、ノードとは別のネットワーク上にあります。インストール中に帯域外管理がプロビジョナーノードと確実に通信できるようにするには、帯域外管理 IP アドレスに、プロビジョナーノードおよび OpenShift Container Platform コントロールプレーンノード上のポート 6180 へのアクセスを許可する必要があります。TLS ポート 6183 は、たとえば Redfish などを使用する仮想メディアのインストールに必要です。
2.6. ノードの設定
2.6.1. provisioning ネットワークを使用する場合のノードの設定
クラスター内の各ノードには、適切なインストールを行うために以下の設定が必要です。
ノード間で一致していないと、インストールに失敗します。
クラスターノードには 3 つ以上の NIC を追加できますが、インストールプロセスでは最初の 2 つの NIC のみに焦点が当てられます。以下の表では、NIC1 は OpenShift Container Platform クラスターのインストールにのみ使用されるルーティング不可能なネットワーク (provisioning) です。
| NIC | ネットワーク | VLAN |
|---|---|---|
| NIC1 |
|
|
| NIC2 |
|
|
プロビジョナーノードでの Red Hat Enterprise Linux (RHEL) 9.x インストールプロセスは異なる可能性があります。ローカルの Satellite サーバー、PXE サーバー、PXE 対応の NIC2 を使用して Red Hat Enterprise Linux (RHEL) 9.x をインストールする場合は、以下のようになります。
| PXE | ブート順序 |
|---|---|
|
NIC1 PXE 対応の | 1 |
|
NIC2 | 2 |
他のすべての NIC で PXE が無効になっていることを確認します。
コントロールプレーンおよびワーカーノードを以下のように設定します。
| PXE | ブート順序 |
|---|---|
| NIC1 PXE 対応 (プロビジョニングネットワーク) | 1 |
2.6.2. provisioning ネットワークを使用しないノードの設定
インストールプロセスには、1 つの NIC が必要です。
| NIC | ネットワーク | VLAN |
|---|---|---|
| NICx |
|
|
NICx は、OpenShift Container Platform クラスターのインストールに使用されるルーティング可能なネットワーク (baremetal) であり、インターネットにルーティング可能です。
provisioning ネットワークは任意ですが、PXE ブートには必要です。provisioning ネットワークなしでデプロイする場合、redfish-virtualmedia や idrac-virtualmedia などの仮想メディア BMC アドレス指定オプションを使用する必要があります。
2.6.3. 手動での Secure Boot のノードの設定
Secure Boot は、ノードが UEFI ファームウェアドライバー、EFI アプリケーション、オペレーティングシステムなどの信頼できるソフトウェアのみを使用していることを確認できない場合は、ノードの起動を阻止します。
Red Hat は、Redfish 仮想メディアを使用してデプロイする場合にのみ、手動で設定された Secure Boot をサポートします。
Secure Boot を手動で有効にするには、ノードのハードウェアガイドを参照し、以下を実行してください。
手順
- ノードを起動し、BIOS メニューを入力します。
-
ノードのブートモードを
UEFI Enabledに設定します。 - Secure Boot を有効にします。
Red Hat は、自己生成したキーを使用する Secure Boot をサポートしません。
2.7. アウトオブバンド管理
ノードには通常、ベースボード管理コントローラー (BMC) が使用する追加の NIC があります。この BMC はプロビジョナーノードからアクセスできる必要があります。
各ノードは、アウトオブバンド管理を介してアクセスできる必要があります。アウトオブバンド管理ネットワークを使用する場合、OpenShift Container Platform のインストールを正常に行うには、プロビジョナーノードがアウトオブバンド管理ネットワークにアクセスできる必要があります。
アウトオブバンド管理の設定は、このドキュメントの範囲外です。アウトオブバンド管理用に別の管理ネットワークを使用すると、パフォーマンスが向上し、セキュリティーが強化されます。ただし、provisioning ネットワークまたはベアメタルネットワークの使用は有効なオプションになります。
ブートストラップ仮想マシンには、最大 2 つのネットワークインターフェイスがあります。帯域外管理用に別の管理ネットワークを設定し、プロビジョニングネットワークを使用している場合、ブートストラップ仮想マシンでは、いずれかのネットワークインターフェイスを介して管理ネットワークへのルーティングアクセスが必要になります。このシナリオでは、ブートストラップ仮想マシンは 3 つのネットワークにアクセスできます。
- ベアメタルネットワーク
- プロビジョニングネットワーク
- 管理インターフェイスの 1 つを介してルーティングされる管理ネットワーク
2.8. インストールに必要なデータ
OpenShift Container Platform クラスターのインストール前に、すべてのクラスターノードから以下の情報を収集します。
アウトオブバンド管理 IP
例
- Dell (iDRAC) IP
- HP (iLO) IP
- Fujitsu (iRMC) IP
provisioning ネットワークを使用する場合
-
NIC (
provisioning) MAC アドレス -
NIC (
baremetal) MAC アドレス
provisioning ネットワークを省略する場合
-
NIC (
baremetal) MAC アドレス
2.9. ノードの検証チェックリスト
provisioning ネットワークを使用する場合
-
❏ NIC1 VLAN が
provisioningネットワーに設定されている。 -
❏
provisioningネットワークの NIC1 は、プロビジョナー、コントロールプレーン、およびワーカーノードで PXE 対応として使用できる。 -
❏ NIC2 VLAN が
baremetalネットワークに設定されている。 - ❏ PXE が他のすべての NIC で無効にされている。
- ❏ DNS は API および Ingress エンドポイントで設定されている。
- ❏ コントロールプレーンおよびワーカーノードが設定されている。
- ❏ すべてのノードがアウトオブバンド管理でアクセス可能である。
- ❏ (オプション) 別個の管理ネットワークが作成されている。
- ❏ インストールに必要なデータ。
provisioning ネットワークを省略する場合
-
❏ NIC1 VLAN が
baremetalネットワークに設定されている。 - ❏ DNS は API および Ingress エンドポイントで設定されている。
- ❏ コントロールプレーンおよびワーカーノードが設定されている。
- ❏ すべてのノードがアウトオブバンド管理でアクセス可能である。
- ❏ (オプション) 別個の管理ネットワークが作成されている。
- ❏ インストールに必要なデータ。
2.10. インストールの概要
インストールプログラムは対話型モードをサポートしています。ただし、すべてのベアメタルホストのプロビジョニングの詳細と関連するクラスターの詳細を含む install-config.yaml ファイルを事前に準備することができます。
インストールプログラムは install-config.yaml ファイルを読み込み、管理者はマニフェストを生成し、すべての前提条件を確認します。
インストールプログラムは次のタスクを実行します。
- クラスター内のすべてのノードを登録する
- ブートストラップ仮想マシン (VM) を起動する
次のコンテナーを持つ、metal プラットフォームコンポーネントを
systemdサービスとして起動する- Ironic-dnsmasq: プロビジョニングネットワーク上のさまざまなノードのプロビジョニングインターフェイスに IP アドレスを引き渡す役割を担う DHCP サーバー。Ironic-dnsmasq は、プロビジョニングネットワークを使用して OpenShift Container Platform クラスターをデプロイする場合にのみ有効になります。
- Ironic-httpd: イメージをノードに送信するために使用される HTTP サーバー。
- Image-customization
- Ironic
- Ironic-inspector (OpenShift Container Platform 4.16 以前で利用可能)
- Ironic-ramdisk-logs
- Extract-machine-os
- Provisioning-interface
- Metal3-baremetal-operator
ノードは検証フェーズに入り、Ironic がベースボード管理コントローラー (BMC) にアクセスするための認証情報を検証した後、各ノードは 管理可能 な状態に移行します。
ノードが管理可能な状態になると、検査 フェーズが開始されます。検査フェーズでは、ハードウェアが OpenShift Container Platform の正常なデプロイメントに必要な最小要件を満たしていることを確認します。
install-config.yaml ファイルには、プロビジョニングネットワークの詳細が記述されています。ブートストラップ仮想マシンでは、インストールプログラムは Pre-Boot Execution Environment (PXE) を使用して、Ironic Python Agent (IPA) がロードされているすべてのノードにライブイメージをプッシュします。仮想メディアを使用する場合、各ノードの BMC に直接接続してイメージを仮想的にアタッチします。
PXE ブートを使用する場合、プロセスを開始するためにすべてのノードが再起動します。
-
ブートストラップ仮想マシン上で実行されている
ironic-dnsmasqサービスは、ノードと TFTP ブートサーバーの IP アドレスを提供します。 - 最初のブートソフトウェアは、HTTP 経由でルートファイルシステムをロードします。
-
ブートストラップ仮想マシン上の
ironicサービスは、各ノードからハードウェア情報を受信します。
ノードはクリーニング状態になり、各ノードは設定を続行する前にすべてのディスクをクリーニングする必要があります。
クリーニング状態が終了すると、ノードは使用可能な状態になり、インストールプログラムはノードをデプロイ状態に移動します。
IPA は coreos-installer コマンドを実行して、install-config.yaml ファイルの rootDeviceHints パラメーターで定義されたディスクに Red Hat Enterprise Linux CoreOS (RHCOS)イメージをインストールします。ノードは RHCOS を使用して起動します。
インストールプログラムは、コントロールプレーンノードを設定した後、ブートストラップ仮想マシンからコントロールプレーンノードに制御を移動し、ブートストラップ仮想マシンを削除します。
ベアメタル Operator は、ワーカー、ストレージ、およびインフラノードのデプロイメントを継続します。
インストールが完了すると、ノードはアクティブ状態に移行します。その後、インストール後の設定やその他の Day 2 タスクに進むことができます。
第3章 OpenShift インストールの環境のセットアップ
3.1. RHEL のプロビジョナーノードへのインストール
前提条件の設定が完了したら、次のステップとして RHEL 9.x をプロビジョナーノードにインストールします。インストーラーは、OpenShift Container Platform クラスターをインストールする間にプロビジョナーノードをオーケレーターとして使用します。このドキュメントの目的上、RHEL のプロビジョナーノードへのインストールは対象外です。ただし、オプションには、RHEL Satellite サーバー、PXE、またはインストールメディアの使用も含まれますが、これらに限定されません。
3.2. OpenShift Container Platform インストールのプロビジョナーノードの準備
環境を準備するには、以下の手順を実行します。
手順
-
sshでプロビジョナーノードにログインします。 root 以外のユーザー (
kni) を作成し、そのユーザーにsudo権限を付与します。# useradd kni# passwd kni# echo "kni ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/kni# chmod 0440 /etc/sudoers.d/kni新規ユーザーの
sshキーを作成します。# su - kni -c "ssh-keygen -t ed25519 -f /home/kni/.ssh/id_rsa -N ''"プロビジョナーノードで新規ユーザーとしてログインします。
# su - kniRed Hat Subscription Manager を使用してプロビジョナーノードを登録します。
$ sudo subscription-manager register --username=<user> --password=<pass> --auto-attach$ sudo subscription-manager repos --enable=rhel-9-for-<architecture>-appstream-rpms --enable=rhel-9-for-<architecture>-baseos-rpms注記Red Hat Subscription Manager の詳細は、Using and Configuring Red Hat Subscription Manager を参照してください。
以下のパッケージをインストールします。
$ sudo dnf install -y libvirt qemu-kvm mkisofs python3-devel jq ipmitoolユーザーを変更して、新たに作成したユーザーに
libvirtグループを追加します。$ sudo usermod --append --groups libvirt <user>firewalldを再起動して、httpサービスを有効にします。$ sudo systemctl start firewalld$ sudo firewall-cmd --zone=public --add-service=http --permanent$ sudo firewall-cmd --reloadモジュラー
libvirtデーモンのソケットを起動します。$ for drv in qemu interface network nodedev nwfilter secret storage; do sudo systemctl start virt${drv}d{,-ro,-admin}.socket; donedefaultストレージプールを作成して、これを起動します。$ sudo virsh pool-define-as --name default --type dir --target /var/lib/libvirt/images$ sudo virsh pool-start default$ sudo virsh pool-autostart defaultpull-secret.txtファイルを作成します。$ vim pull-secret.txtWeb ブラウザーで、Install OpenShift on Bare Metal with installer-provisioned infrastructure に移動します。Copy pull secret をクリックします。
pull-secret.txtファイルにコンテンツを貼り付け、そのコンテンツをkniユーザーのホームディレクトリーに保存します。
3.3. NTP サーバーの同期を確認する
OpenShift Container Platform インストールプログラムは、chrony Network Time Protocol (NTP) サービスをクラスターノードにインストールします。インストールを完了するには、各ノードが NTP タイムサーバーにアクセスできる必要があります。chrony サービスを使用して、NTP サーバーの同期を確認できます。
切断されたクラスターの場合は、コントロールプレーンノード上で NTP サーバーを設定する必要があります。詳細は、関連情報 セクションを参照してください。
前提条件
-
ターゲットノードに
chronyパッケージがインストールされました。
手順
-
sshコマンドを使用してノードにログインします。 次のコマンドを実行して、ノードで利用可能な NTP サーバーを表示します。
$ chronyc sources出力例
MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^+ time.cloudflare.com 3 10 377 187 -209us[ -209us] +/- 32ms ^+ t1.time.ir2.yahoo.com 2 10 377 185 -4382us[-4382us] +/- 23ms ^+ time.cloudflare.com 3 10 377 198 -996us[-1220us] +/- 33ms ^* brenbox.westnet.ie 1 10 377 193 -9538us[-9761us] +/- 24mspingコマンドを使用して、ノードが NTP サーバーにアクセスできることを確認します。次に例を示します。$ ping time.cloudflare.com出力例
PING time.cloudflare.com (162.159.200.123) 56(84) bytes of data. 64 bytes from time.cloudflare.com (162.159.200.123): icmp_seq=1 ttl=54 time=32.3 ms 64 bytes from time.cloudflare.com (162.159.200.123): icmp_seq=2 ttl=54 time=30.9 ms 64 bytes from time.cloudflare.com (162.159.200.123): icmp_seq=3 ttl=54 time=36.7 ms ...
3.4. ネットワークの設定
インストールの前に、プロビジョナーノードのネットワーク設定を設定する必要があります。インストーラーによってプロビジョニングされたクラスターは、ベアメタルブリッジとネットワークリソース、およびオプションの provisioning ブリッジとネットワークリソースを使用してデプロイされます。
OpenShift Container Platform Web コンソールからネットワーク設定を設定することもできます。
前提条件
-
sudo dnf install -y <package_name> コマンドでいる。パッケージにはnmstateパッケージをインストールしてnmstatectlCLI が含まれます。
手順
ベアメタルネットワークを設定します。
注記ベアメタルネットワークとセキュアシェル(SSH)接続の切断を設定する場合、NMState には、設定を自動的に元に戻すロールバックメカニズムがあります。
nmstatectl gcツールを使用して、指定されたネットワーク状態ファイルの設定ファイルを生成することもできます。DHCP を使用するネットワークの場合は、以下のコマンドを実行して、
/etc/sysconfig/network-scripts/ifcfg-eth0レガシースタイルを削除します。$ nmcli con delete "System <baremetal_nic_name>"ここでは、以下のようになります。
<baremetal_nic_name>-
<
;baremetal_nic_name> をネットワークインターフェイスコントローラー(NIC)の名前に置き換えます。
DHCP (Dynamic Host Configuration Protocol)を使用するネットワークの場合、NMState YAML ファイルを作成し、ファイル内のベアメタルブリッジインターフェイスと物理インターフェイスを指定します。
DHCP を使用するベアメタルブリッジインターフェイスの設定例
# ... interfaces: - name: <physical_interface_name> type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: baremetal type: linux-bridge state: up ipv4: enabled: true dhcp: true bridge: options: stp: enabled: false port: - name: <physical_interface_name> # ...静的 IP アドレス指定を使用するネットワークおよび DHCP ネットワークなしの場合、NMState YAML ファイルを作成し、このファイルにベアメタルブリッジインターフェイスの詳細を指定します。
静的 IP アドレスを使用し、DHCP ネットワークを使用しないベアメタルブリッジインターフェイスの設定例
# ... dns-resolver: config: server: - <dns_ip_address> routes: config: - destination: 0.0.0.0/0 next-hop-interface: baremetal next-hop-address: <gateway_ip> interfaces: - name: <physical_interface_name> type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: baremetal type: linux-bridge state: up ipv4: enabled: true dhcp: false address: - ip: <static_ip_address> prefix-length: 24 bridge: options: stp: enabled: false port: - name: <physical_interface_name> # ...ここでは、以下のようになります。
<dns-resolver>- ベアメタルシステムの DNS サーバーを定義します。
<server>-
&
lt;dns_ip_address> は DNS サーバーの IP アドレスに置き換えます。 <type>- ブリッジインターフェイスおよびその静的 IP 設定を定義します。
<gateway>-
<gateway_ip>をゲートウェイの IP アドレスに置き換えます。 <name>- ブリッジポートとして設定する物理インターフェイスについて詳しく説明します。
次のコマンドを入力して、YAML ファイルからホストのネットワークインターフェイスにネットワーク設定を適用します。
$ nmstatectl apply <path_to_network_yaml>次のコマンドを入力して、ネットワーク設定 YAML ファイルをバックアップします。
$ nmstatectl show > backup-nmstate.ymlオプション:クラスターをプロビジョニングネットワークにデプロイする場合は、NMState YAML ファイルを作成または編集し、ファイルに詳細を指定します。
注記IPv6 アドレスは、ベアメタルネットワークを介してルーティングしない任意のアドレスにすることができます。
IPv6 アドレスを使用する場合は、Unified Extensible Firmware Interface (UEFI)を有効にし、IPv6 プロトコルの UEFI PXE 設定を設定する。
プロビジョニングネットワークの NMState YAML ファイルの例
# ... interfaces: - name: eth1 type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: provisioning type: linux-bridge state: up ipv4: enabled: true dhcp: false address: - ip: 172.22.0.254 prefix-length: 24 ipv6: enabled: true dhcp: false address: - ip: fd00:1101::1 prefix-length: 64 bridge: options: stp: enabled: false port: - name: eth1 # ...オプション:次のコマンドを実行して、
プロビジョナーノードに SSH 接続を確立します。# ssh kni@provisioner.<cluster_name>.<domain>以下は、
<cluster_name>.<domain>-
&
lt;cluster_name> はクラスターの名前に、<domain> はクラスターの完全修飾ドメイン名(FQDN)に置き換えます。
次のコマンドを実行して、接続ブリッジが適切に作成されたことを確認します。
$ sudo nmcli con show出力例
NAME UUID TYPE DEVICE baremetal 832f645a-9337-4afc-b48e-4a55c5779eab bridge baremetal provisioning e7756e01-d026-4a38-b460-129afaac0ec2 bridge provisioning Wired connection 1 49ff4c9c-db76-3139-8c18-c49fa7deb39a ethernet eth0 Wired connection 2 c1fb12b1-88a6-3c07-93b9-187c99204c43 ethernet eth1 lo aa030e0f-21ca-498f-b6ce-bac7d4d793f0 loopback lo
3.5. カスタマイズされた br-ex ブリッジを含むマニフェストオブジェクトの作成
configure-ovs.sh シェルスクリプトを使用してベアメタルプラットフォームで br-ex ブリッジを設定する代わりに、NMState 設定ファイルを含む MachineConfig オブジェクトを作成できます。ホスト nmstate-configuration.service および nmstate.service は、クラスターで実行される各ノードに NMState 設定ファイルを適用します。
configure-ovs.sh シェルスクリプトを使用してベアメタルプラットフォームで br-ex ブリッジを設定する代わりに、NMState 設定ファイルを含む NodeNetworkConfigurationPolicy (NNCP) カスタムリソース (CR) を作成することもできます。
Kubernetes NMState Operator がその NMState 設定ファイルを使用して、カスタマイズされた br-ex ブリッジネットワーク設定をクラスター内の各ノードに作成します。
NodeNetworkConfigurationPolicy CR を作成したら、クラスターのインストール中に作成された NMState 設定ファイルの内容を NNCP CR にコピーしてください。NNCP CR のファイルが不完全な場合、ファイルに記述されているネットワークポリシーをクラスター内のノードに適用できません。
この機能は、次のタスクをサポートします。
- クラスターの最大転送単位 (MTU) を変更します。
- MIImon (Media Independent Interface Monitor)、ボンディングモード、Quality of Service (QoS) などのさまざまなボンディングインターフェイスの属性を変更します。
- DNS 値を更新しています。
カスタマイズされた br-ex ブリッジを含むマニフェストオブジェクトを作成する場合は、次のユースケースを検討してください。
-
Open vSwitch (OVS) または OVN-Kubernetes
br-exブリッジネットワークの変更など、ブリッジにインストール後の変更を加えたい場合。configure-ovs.shシェルスクリプトは、ブリッジへのインストール後の変更をサポートしていません。 - ホストまたはサーバーの IP アドレスで使用可能なインターフェイスとは異なるインターフェイスにブリッジをデプロイします。
-
configure-ovs.shシェルスクリプトでは不可能な、ブリッジの高度な設定を実行したいと考えています。これらの設定にスクリプトを使用すると、ブリッジが複数のネットワークインターフェイスに接続できず、インターフェイス間のデータ転送が促進されない可能性があります。
単一のネットワークインターフェイスコントローラー (NIC) とデフォルトのネットワーク設定を備えた環境が必要な場合は、configure-ovs.sh シェルスクリプトを使用します。
Red Hat Enterprise Linux CoreOS (RHCOS) をインストールしてシステムを再起動すると、Machine Config Operator がクラスター内の各ノードに Ignition 設定ファイルを挿入し、各ノードが br-ex ブリッジネットワーク設定を受け取るようになります。設定の競合を防ぐために、configure-ovs.sh シェルスクリプトは、br-ex ブリッジを設定しない信号を受け取ります。
前提条件
-
オプション: NMState 設定を検証できるように、
nmstateAPI をインストールしました。
手順
カスタマイズされた
br-exブリッジネットワークの base64 情報をデコードした NMState 設定ファイルを作成します。カスタマイズされた
br-exブリッジネットワークの NMState 設定の例interfaces: - name: enp2s0 type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: br-ex type: ovs-bridge state: up ipv4: enabled: false dhcp: false ipv6: enabled: false dhcp: false bridge: options: mcast-snooping-enable: true port: - name: enp2s0 - name: br-ex - name: br-ex type: ovs-interface state: up copy-mac-from: enp2s0 ipv4: enabled: true dhcp: true auto-route-metric: 48 ipv6: enabled: true dhcp: true auto-route-metric: 48 # ...ここでは、以下のようになります。
interfaces.name- インターフェイスの名前。
interfaces.type- イーサネットのタイプ。
interfaces.state- 作成後のインターフェイスの要求された状態。
ipv4.enabled- この例では、IPv4 と IPv6 を無効にします。
port.name- ブリッジが接続されるノードの NIC。
auto-route-metric-
br-exのデフォルトルートの優先順位が常に最も高い(最も低いメトリック)ようにするには、パラメーターを48に設定します。この設定により、NetworkManagerサービスが自動的に設定するその他のインターフェイスとのルーティングの競合が回避されます。
catコマンドを使用して、NMState 設定の内容を base64 でエンコードします。$ cat <nmstate_configuration>.yml | base64ここでは、以下のようになります。
<nmstate_configuration>-
<nmstate_configuration>を NMState リソース YAML ファイルの名前に置き換えます。
MachineConfigマニフェストファイルを作成し、次の例に類似したカスタマイズされたbr-exブリッジネットワーク設定を定義します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 10-br-ex-worker spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,<base64_encoded_nmstate_configuration> mode: 0644 overwrite: true path: /etc/nmstate/openshift/worker-0.yml - contents: source: data:text/plain;charset=utf-8;base64,<base64_encoded_nmstate_configuration> mode: 0644 overwrite: true path: /etc/nmstate/openshift/worker-1.yml # ...ここでは、以下のようになります。
metadata.name- ポリシーの名前。
contents.source- エンコードされた base64 情報を指定されたパスに書き込みます。
pathクラスター内の各ノードに対して、ノードへのホスト名パスと、マシンタイプに応じた base-64 でエンコードされた Ignition 設定ファイルデータを指定します。
workerロールは、クラスター内のノードのデフォルトロールです。各ノードまたはMachineConfigマニフェストファイルのすべてのノードに短いホスト名パスを指定する場合は、$(hostname -s)などの設定ファイルに .yml 拡張を使用する必要があります。.yml/etc/nmstate/openshift/cluster.yml設定ファイルで、クラスター内のすべてのノードに適用する単一のグローバル設定が指定されている場合は、/etc/nmstate/openshift/<node_hostname>.ymlなどの各ノードの短いホスト名パスを指定する必要はありません。以下に例を示します。# ... - contents: source: data:text/plain;charset=utf-8;base64,<base64_encoded_nmstate_configuration> mode: 0644 overwrite: true path: /etc/nmstate/openshift/cluster.yml # ...
次のコマンドを入力して、
MachineConfigオブジェクトからの更新をクラスターに適用します。$ oc apply -f <machine_config>.yml
次のステップ
-
コンピュートノードをスケーリングして、クラスター内に存在する各コンピュートノードに、カスタマイズされた
br-exブリッジを含むマニフェストオブジェクトを適用します。詳細は、関連情報 セクションの「クラスターの拡張」を参照してください。
3.5.1. オプション: 各マシンセットをコンピュートノードにスケーリングする
カスタマイズされた br-ex ブリッジ設定を OpenShift Container Platform クラスター内のすべてのコンピュートノードに適用するには、MachineConfig カスタムリソース (CR) を編集し、そのロールを変更する必要があります。さらに、ホスト名、認証情報など、ベアメタルマシンの情報を定義する BareMetalHost CR を作成する必要があります。
これらのリソースを設定した後、マシンセットをスケーリングして、マシンセットが各コンピュートノードにリソース設定を適用し、ノードを再起動できるようにする必要があります。
前提条件
-
カスタマイズされた
br-exブリッジ設定を含むMachineConfigマニフェストオブジェクトを作成しました。
手順
次のコマンドを入力して
MachineConfigCR を編集します。$ oc edit mc <machineconfig_custom_resource_name>- 各コンピュートノード設定を CR に追加して、CR がクラスター内の定義済みコンピュートノードごとにロールを管理できるようにします。
-
最小限の静的 IP 設定を持つ
extraworker-secretという名前のSecretオブジェクトを作成します。 次のコマンドを入力して、クラスター内の各ノードに
extraworker-secretシークレットを適用します。このステップでは、各コンピュートノードに Ignition 設定ファイルへのアクセスを提供します。$ oc apply -f ./extraworker-secret.yamlBareMetalHostリソースを作成し、preprovisioningNetworkDataNameパラメーターでネットワークシークレットを指定します。ネットワークシークレットが添付された
BareMetalHostリソースの例apiVersion: metal3.io/v1alpha1 kind: BareMetalHost spec: # ... preprovisioningNetworkDataName: ostest-extraworker-0-network-config-secret # ...クラスターの
openshift-machine-apinamespace 内でBareMetalHostオブジェクトを管理するために、次のコマンドを入力して namespace に変更します。$ oc project openshift-machine-apiマシンセットを取得します。
$ oc get machinesets次のコマンドを入力して、各マシンセットをスケールします。このコマンドはマシンセットごとに実行する必要があります。
$ oc scale machineset <machineset_name> --replicas=<n>1 - 1
<machineset_name>はマシンセットの名前です。<n>はコンピュートノードの数です。
3.6. クラスターで OVS balance-slb モードを有効にする
Open vSwitch (OVS)の balance-slb モードを有効にして、2 つ以上の物理インターフェイスがネットワークトラフィックを共有できるようにすることができます。Balance -slb モードインターフェイスは、ネットワークスイッチとの負荷分散を必要とせずに、仮想化ワークロードを実行するクラスターにソース負荷分散(SLB)機能を提供することができます。
現在、ソース負荷分散はボンドインターフェイスで実行され、このインターフェイスは br-phy などの補助ブリッジに接続します。ソースの負荷分散は、異なる Media Access Control (MAC)アドレスと仮想ローカルエリアネットワーク(VLAN)の組み合わせでのみ分散されます。すべての OVN-Kubernetes Pod トラフィックは同じ MAC アドレスと VLAN を使用するため、このトラフィックは多くの物理インターフェイス間で負荷分散できないことに注意してください。
次の図は、単純なクラスターインフラストラクチャーレイアウトでの balance-slb モードを示しています。仮想マシン (VM) は、特定の localnet NetworkAttachmentDefinition (NAD) カスタムリソース定義 (CRD)、NAD 0 または NAD 1 に接続します。各 NAD は、VLAN タグ付きまたはタグなしのトラフィックをサポートする基盤となる物理ネットワークにアクセスできるように、VM を提供します。br-ex OVS ブリッジは仮想マシンからのトラフィックを受信し、そのトラフィックを次の OVS ブリッジである br-phy に渡します。br-phy ブリッジは SLB ボンディングのコントローラーとして機能します。SLB ボンディングは、eno0 や eno1 などの物理インターフェイスリンクを介して、異なる仮想マシンポートからのトラフィックを分散します。さらに、どちらの物理インターフェイスからの Ingress トラフィックも、OVS ブリッジのセットを通過して仮想マシンに到達できます。
図3.1 2 つの NAD CRD を持つ localnet で動作する OVS balance-slb モード

OVS ボンディングを使用して、balance-slb モードインターフェイスをプライマリーまたはセカンダリーネットワークタイプに統合できます。OVS ボンディングでは、次の点に注意してください。
- OVN-Kubernetes CNI プラグインをサポートし、プラグインと簡単に統合できます。
-
ネイティブで
balance-slbモードをサポートします。
前提条件
-
プライマリーネットワークに複数の物理インターフェイスが接続されており、それらのインターフェイスを
MachineConfigファイルで定義している。 -
マニフェストオブジェクトを作成し、オブジェクト設定ファイルでカスタマイズされた
br-exブリッジを定義している。 - プライマリーネットワークに複数の物理インターフェイスが割り当てられ、NAD CRD ファイルでインターフェイスを定義している。
手順
クラスター内に存在するベアメタルホストごとに、クラスターの
install-config.yamlファイルで、次の例のようにnetworkConfigセクションを定義します。apiVersion: v1 kind: InstallConfig metadata: name: <cluster-name> # ... networkConfig: interfaces: - name: enp1s01 type: ethernet state: up ipv4: dhcp: true enabled: true ipv6: enabled: false - name: enp2s02 type: ethernet state: up mtu: 15003 ipv4: dhcp: true enabled: true ipv6: dhcp: true enabled: true - name: enp3s04 type: ethernet state: up mtu: 1500 ipv4: enabled: false ipv6: enabled: false # ...NMState 設定ファイルで各ネットワークインターフェイスを定義します。
多くのネットワークインターフェイスを定義する NMState 設定ファイルの例
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: # ... ovn: bridge-mappings: - localnet: localnet-network bridge: br-ex state: present interfaces: - name: br-ex type: ovs-bridge state: up bridge: allow-extra-patch-ports: true port: - name: br-ex - name: patch-ex-to-phy ovs-db: external_ids: bridge-uplink: "patch-ex-to-phy" - name: br-ex type: ovs-interface state: up mtu: 15001 ipv4: enabled: true dhcp: true auto-route-metric: 48 ipv6: enabled: false dhcp: false auto-route-metric: 48 - name: br-phy type: ovs-bridge state: up bridge: allow-extra-patch-ports: true port: - name: patch-phy-to-ex - name: ovs-bond link-aggregation: mode: balance-slb port: - name: enp2s0 - name: enp3s0 - name: patch-ex-to-phy type: ovs-interface state: up patch: peer: patch-phy-to-ex - name: patch-phy-to-ex type: ovs-interface state: up patch: peer: patch-ex-to-phy - name: enp1s0 type: ethernet state: up ipv4: dhcp: true enabled: true ipv6: enabled: false - name: enp2s0 type: ethernet state: up mtu: 1500 ipv4: enabled: false ipv6: enabled: false - name: enp3s0 type: ethernet state: up mtu: 1500 ipv4: enabled: false ipv6: enabled: false # ...- 1
- ボンディングポートで
br-exMTU を手動で設定します。
base64コマンドを使用して、NMState 設定ファイルのインターフェイスコンテンツをエンコードします。$ base64 -w0 <nmstate_configuration>.yml1 - 1
-w0オプションは、base64 エンコード操作中に行の折り返しを防止します。
masterロールとworkerロールのMachineConfigマニフェストファイルを作成します。前のコマンドの base64 でエンコードされた文字列を各MachineConfigマニフェストファイルに埋め込むようにしてください。次のマニフェストファイルの例では、クラスター内に存在するすべてのノードに対してmasterロールを設定します。ノード固有のmasterロールとworkerロールのマニフェストファイルを作成することもできます。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 10-br-ex-master1 spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,<base64_encoded_nmstate_configuration>2 mode: 0644 overwrite: true path: /etc/nmstate/openshift/cluster.yml3 各
MachineConfigマニフェストファイルを./<installation_directory>/manifests ディレクトリーに保存します。ここで、<installation_directory> は、インストールプログラムがファイルを作成するディレクトリーに移動します。Machine Config Operator (MCO)は各マニフェストファイルからコンテンツを取得し、ローリング更新中に選択されたすべてのノードにコンテンツを一貫して適用します。
3.7. サブネット間の通信を確立する
一般的な OpenShift Container Platform クラスターのセットアップでは、コントロールプレーンとコンピュートノードを含むすべてのノードが同じネットワーク内に存在します。ただし、エッジコンピューティングのシナリオでは、コンピュートノードをエッジの近くに配置することが有益な場合があります。その場合、コントロールプレーンやローカルコンピュートノードが使用するサブネットとは異なるネットワークセグメントまたはサブネットをリモートノードに使用することもよくあります。このようなセットアップにより、エッジのレイテンシーが減少し、拡張性が向上します。
OpenShift Container Platform をインストールする前に、リモートノードを含むエッジサブネットがコントロールプレーンノードを含むサブネットに到達し、コントロールプレーンからのトラフィックも受信できるように、ネットワークを適切に設定する必要があります。
クラスターのインストール中に、install-config.yaml 設定ファイルのネットワーク設定でノードに永続的な IP アドレスを割り当てます。これを行わないと、ノードに一時的な IP アドレスが割り当てられ、トラフィックがノードに到達する方法に影響する可能性があります。たとえば、ノードに一時的な IP アドレスが割り当てられていて、ノードに対して結合されたインターフェイスを設定した場合、結合されたインターフェイスは別の IP アドレスを受け取る可能性があります。
デフォルトのロードバランサーの代わりにユーザー管理のロードバランサーを設定することで、同じサブネットまたは複数のサブネットでコントロールプレーンノードを実行できます。複数のサブネット環境を使用すると、ハードウェア障害やネットワーク停止によって OpenShift Container Platform クラスターが失敗するリスクを軽減できます。詳細は、「ユーザー管理ロードバランサーのサービス」および「ユーザー管理ロードバランサーの設定」を参照してください。
複数のサブネット環境でコントロールプレーンノードを実行するには、次の主要なタスクを完了する必要があります。
-
install-config.yamlファイルのloadBalancer.typeパラメーターでUserManagedを指定して、デフォルトのロードバランサーの代わりにユーザー管理のロードバランサーを設定します。 -
install-config.yamlファイルのingressVIPsおよびapiVIPsパラメーターでユーザー管理のロードバランサーのアドレスを設定します。 -
複数のサブネットの Classless Inter-Domain Routing (CIDR) とユーザー管理のロードバランサーの IP アドレスを、
install-config.yamlファイルのnetworking.machineNetworksパラメーターに追加します。
複数のサブネットを持つクラスターをデプロイするには、redfish-virtualmedia や idrac-virtualmedia などの仮想メディアを使用する必要があります。
この手順では、2 番目のサブネットにあるリモートコンピュートノードが 1 番目のサブネットにあるコントロールプレーンノードと効果的に通信できるようにするために必要なネットワーク設定と、1 番目のサブネットにあるコントロールプレーンノードが 2 番目のサブネットにあるリモートコンピュートノードと効果的に通信できるようにするために必要なネットワーク設定を詳しく説明します。
この手順では、クラスターは 2 つのサブネットにまたがります。
-
1 番目のサブネット (
10.0.0.0) には、コントロールプレーンとローカルコンピュートノードが含まれています。 -
2 番目のサブネット (
192.168.0.0) には、エッジコンピュートノードが含まれています。
手順
1 番目のサブネットが 2 番目のサブネットと通信するように設定します。
次のコマンドを実行して、コントロールプレーンノードに
rootとしてログインします。$ sudo su -次のコマンドを実行して、ネットワークインターフェイスの名前を取得します。
# nmcli dev status次のコマンドを実行して、ゲートウェイを経由する 2 番目のサブネット (
192.168.0.0) へのルートを追加します。# nmcli connection modify <interface_name> +ipv4.routes "192.168.0.0/24 via <gateway>"<interface_name>をインターフェイス名に置き換えます。<gateway>を実際のゲートウェイの IP アドレスに置き換えます。例
# nmcli connection modify eth0 +ipv4.routes "192.168.0.0/24 via 192.168.0.1"次のコマンドを実行して変更を適用します。
# nmcli connection up <interface_name><interface_name>をインターフェイス名に置き換えます。ルーティングテーブルを検証して、ルートが正常に追加されたことを確認します。
# ip route1 番目のサブネットの各コントロールプレーンノードに対して前の手順を繰り返します。
注記コマンドは、実際のインターフェイス名とゲートウェイに合わせて調整してください。
1 番目のサブネットと通信するように 2 番目のサブネットを設定します。
次のコマンドを実行して、リモートコンピュートノードに
rootとしてログインします。$ sudo su -次のコマンドを実行して、ネットワークインターフェイスの名前を取得します。
# nmcli dev status次のコマンドを実行して、ゲートウェイを経由する最初のサブネット (
10.0.0.0) へのルートを追加します。# nmcli connection modify <interface_name> +ipv4.routes "10.0.0.0/24 via <gateway>"<interface_name>をインターフェイス名に置き換えます。<gateway>を実際のゲートウェイの IP アドレスに置き換えます。例
# nmcli connection modify eth0 +ipv4.routes "10.0.0.0/24 via 10.0.0.1"次のコマンドを実行して変更を適用します。
# nmcli connection up <interface_name><interface_name>をインターフェイス名に置き換えます。次のコマンドを実行して、ルーティングテーブルを検証し、ルートが正常に追加されたことを確認します。
# ip route2 番目のサブネット内の各コンピュートノードに対して、上記の手順を繰り返します。
注記コマンドは、実際のインターフェイス名とゲートウェイに合わせて調整してください。
ネットワークを設定したら、接続をテストして、リモートノードがコントロールプレーンノードに到達できること、およびコントロールプレーンノードがリモートノードに到達できることを確認します。
1 番目のサブネットのコントロールプレーンノードから、次のコマンドを実行して、2 番目のサブネットのリモートノードに ping を実行します。
$ ping <remote_node_ip_address>ping が成功した場合は、1 番目のサブネットのコントロールプレーンノードが 2 番目のサブネットのリモートノードに到達できています。応答がない場合は、ネットワーク設定を確認し、ノードに対して手順を繰り返します。
2 番目のサブネットのリモートノードから、次のコマンドを実行して、1 番目のサブネットのコントロールプレーンノードに ping を実行します。
$ ping <control_plane_node_ip_address>ping が成功した場合は、2 番目のサブネットのリモートコンピュートノードが 1 番目のサブネットのコントロールプレーンに到達できています。応答がない場合は、ネットワーク設定を確認し、ノードに対して手順を繰り返します。
3.8. OpenShift Container Platform インストーラーの取得
インストールプログラムの stable-4.x バージョンと選択したアーキテクチャーを使用して、OpenShift Container Platform の一般公開の安定バージョンをデプロイします。
$ export VERSION=stable-4.16$ export RELEASE_ARCH=<architecture>$ export RELEASE_IMAGE=$(curl -s https://mirror.openshift.com/pub/openshift-v4/$RELEASE_ARCH/clients/ocp/$VERSION/release.txt | grep 'Pull From: quay.io' | awk -F ' ' '{print $3}')3.9. OpenShift Container Platform インストールのデプロイメント
インストーラーを取得したら、インストーラーを展開します。
手順
環境変数を設定します。
$ export cmd=openshift-baremetal-install$ export pullsecret_file=~/pull-secret.txt$ export extract_dir=$(pwd)ocバイナリーを取得します。$ curl -s https://mirror.openshift.com/pub/openshift-v4/clients/ocp/$VERSION/openshift-client-linux.tar.gz | tar zxvf - ocインストーラーを実行します。
$ sudo cp oc /usr/local/bin$ oc adm release extract --registry-config "${pullsecret_file}" --command=$cmd --to "${extract_dir}" ${RELEASE_IMAGE}$ sudo cp openshift-baremetal-install /usr/local/bin
3.10. オプション: RHCOS イメージキャッシュの作成
イメージキャッシングを使用するには、ブートストラップ VM がクラスターノードをプロビジョニングするために使用する Red Hat Enterprise Linux CoreOS(RHCOS) イメージをダウンロードする必要があります。イメージのキャッシュはオプションですが、帯域幅が制限されているネットワークでインストールプログラムを実行する場合に特に便利です。
正しいイメージがリリースペイロードにあるため、インストールプログラムは、clusterOSImage RHCOS イメージを必要としなくなりました。
帯域幅が制限されたネットワークでインストールプログラムを実行していて、RHCOS イメージのダウンロードに 15〜20 分以上かかる場合、インストールプログラムはタイムアウトになります。このような場合、Web サーバーでイメージをキャッシュすることができます。
HTTPD サーバーに対して TLS を有効にする場合、ルート証明書がクライアントによって信頼された機関によって署名されていることを確認し、OpenShift Container Platform ハブおよびスポーククラスターと HTTPD サーバー間の信頼された証明書チェーンを検証する必要があります。信頼されていない証明書で設定されたサーバーを使用すると、イメージがイメージ作成サービスにダウンロードされなくなります。信頼されていない HTTPS サーバーの使用はサポートされていません。
イメージを含むコンテナーをインストールします。
手順
podmanをインストールします。$ sudo dnf install -y podmanRHCOS イメージのキャッシュに使用されるファイアウォールのポート
8080を開きます。$ sudo firewall-cmd --add-port=8080/tcp --zone=public --permanent$ sudo firewall-cmd --reloadbootstraposimageを保存するディレクトリーを作成します。$ mkdir /home/kni/rhcos_image_cache新規に作成されたディレクトリーに適切な SELinux コンテキストを設定します。
$ sudo semanage fcontext -a -t httpd_sys_content_t "/home/kni/rhcos_image_cache(/.*)?"$ sudo restorecon -Rv /home/kni/rhcos_image_cache/インストールプログラムがブートストラップ VM にデプロイする RHCOS イメージの URI を取得します。
$ export RHCOS_QEMU_URI=$(/usr/local/bin/openshift-baremetal-install coreos print-stream-json | jq -r --arg ARCH "$(arch)" '.architectures[$ARCH].artifacts.qemu.formats["qcow2.gz"].disk.location')インストールプログラムがブートストラップ VM にデプロイするイメージの名前を取得します。
$ export RHCOS_QEMU_NAME=${RHCOS_QEMU_URI##*/}ブートストラップ仮想マシンにデプロイされる RHCOS イメージの SHA ハッシュを取得します。
$ export RHCOS_QEMU_UNCOMPRESSED_SHA256=$(/usr/local/bin/openshift-baremetal-install coreos print-stream-json | jq -r --arg ARCH "$(arch)" '.architectures[$ARCH].artifacts.qemu.formats["qcow2.gz"].disk["uncompressed-sha256"]')イメージをダウンロードして、
/home/kni/rhcos_image_cacheディレクトリーに配置します。$ curl -L ${RHCOS_QEMU_URI} -o /home/kni/rhcos_image_cache/${RHCOS_QEMU_NAME}新しいファイルの SELinux タイプが
httpd_sys_content_tであることを確認します。$ ls -Z /home/kni/rhcos_image_cachePod を作成します。
$ podman run -d --name rhcos_image_cache \1 -v /home/kni/rhcos_image_cache:/var/www/html \ -p 8080:8080/tcp \ registry.access.redhat.com/ubi9/httpd-24- 1
rhcos_image_cacheという名前のキャッシング Web サーバーを作成します。この Pod は、デプロイメント用にinstall-config.yamlファイルのbootstrapOSImageイメージを提供します。
bootstrapOSImage設定を生成します。$ export BAREMETAL_IP=$(ip addr show dev baremetal | awk '/inet /{print $2}' | cut -d"/" -f1)$ export BOOTSTRAP_OS_IMAGE="http://${BAREMETAL_IP}:8080/${RHCOS_QEMU_NAME}?sha256=${RHCOS_QEMU_UNCOMPRESSED_SHA256}"$ echo " bootstrapOSImage=${BOOTSTRAP_OS_IMAGE}"platform.baremetal下のinstall-config.yamlファイルに必要な設定を追加します。platform: baremetal: bootstrapOSImage: <bootstrap_os_image>1 - 1
<bootstrap_os_image>を$BOOTSTRAP_OS_IMAGEの値に置き換えます。
詳細は、「install-config.yaml ファイルの設定」セクションを参照してください。
3.11. ユーザー管理ロードバランサーのサービス
デフォルトのロードバランサーの代わりに、ユーザーが管理するロードバランサーを使用するように OpenShift Container Platform クラスターを設定できます。
ユーザー管理ロードバランサーの設定は、ベンダーのロードバランサーによって異なります。
このセクションの情報と例は、ガイドラインのみを目的としています。ベンダーのロードバランサーに関する詳細は、ベンダーのドキュメントを参照してください。
Red Hat は、ユーザー管理ロードバランサーに対して次のサービスをサポートしています。
- Ingress Controller
- OpenShift API
- OpenShift MachineConfig API
ユーザー管理ロードバランサーに対して、これらのサービスの 1 つを設定するか、すべてを設定するかを選択できます。一般的な設定オプションは、Ingress Controller サービスのみを設定することです。次の図は、各サービスの詳細を示しています。
図3.2 OpenShift Container Platform 環境で動作する Ingress Controller を示すネットワークワークフローの例

図3.3 OpenShift Container Platform 環境で動作する OpenShift API を示すネットワークワークフローの例

図3.4 OpenShift Container Platform 環境で動作する OpenShift MachineConfig API を示すネットワークワークフローの例

ユーザー管理ロードバランサーでは、次の設定オプションがサポートされています。
- ノードセレクターを使用して、Ingress Controller を特定のノードのセットにマッピングします。このセットの各ノードに静的 IP アドレスを割り当てるか、Dynamic Host Configuration Protocol (DHCP) から同じ IP アドレスを受け取るように各ノードを設定する必要があります。インフラストラクチャーノードは通常、このタイプの設定を受け取ります。
サブネット上のすべての IP アドレスをターゲットにします。この設定では、ロードバランサーターゲットを再設定せずにネットワーク内でノードを作成および破棄できるため、メンテナンスオーバーヘッドを削減できます。
/27や/28などの小規模なネットワーク上に設定されたマシンを使用して Ingress Pod をデプロイする場合、ロードバランサーのターゲットを簡素化できます。ヒントマシン config プールのリソースを確認することで、ネットワーク内に存在するすべての IP アドレスをリスト表示できます。
OpenShift Container Platform クラスターのユーザー管理ロードバランサーを設定する前に、以下の情報を考慮してください。
- フロントエンド IP アドレスの場合、フロントエンド IP アドレス、Ingress Controller のロードバランサー、および API ロードバランサーに同じ IP アドレスを使用できます。この機能は、ベンダーのドキュメントを確認してください。
バックエンド IP アドレスの場合、ユーザー管理ロードバランサーの有効期間中に OpenShift Container Platform コントロールプレーンノードの IP アドレスが変更されないことを確認します。次のいずれかのアクションを実行すると、これを実現できます。
- 各コントロールプレーンノードに静的 IP アドレスを割り当てます。
- ノードが DHCP リースを要求するたびに、DHCP から同じ IP アドレスを受信するように各ノードを設定します。ベンダーによっては、DHCP リースは IP 予約または静的 DHCP 割り当ての形式になる場合があります。
- Ingress Controller バックエンドサービスのユーザー管理ロードバランサーで Ingress Controller を実行する各ノードを手動で定義します。たとえば、Ingress Controller が未定義のノードに移動すると、接続が停止する可能性があります。
3.11.1. ユーザー管理ロードバランサーの設定
デフォルトのロードバランサーの代わりに、ユーザーが管理するロードバランサーを使用するように OpenShift Container Platform クラスターを設定できます。
ユーザー管理ロードバランサーを設定する前に、「ユーザー管理ロードバランサーのサービス」セクションを必ずお読みください。
ユーザー管理ロードバランサー用に設定するサービスに適用される次の前提条件をお読みください。
クラスター上で実行される MetalLB は、ユーザー管理ロードバランサーとして機能します。
OpenShift API の前提条件
- フロントエンド IP アドレスを定義している。
TCP ポート 6443 および 22623 は、ロードバランサーのフロントエンド IP アドレスで公開されている。以下の項目を確認します。
- ポート 6443 が OpenShift API サービスにアクセスできる。
- ポート 22623 が Ignition 起動設定をノードに提供できる。
- フロントエンド IP アドレスとポート 6443 へは、OpenShift Container Platform クラスターの外部の場所にいるシステムのすべてのユーザーがアクセスできる。
- フロントエンド IP アドレスとポート 22623 は、OpenShift Container Platform ノードからのみ到達できる。
- ロードバランサーバックエンドは、ポート 6443 および 22623 の OpenShift Container Platform コントロールプレーンノードと通信できる。
Ingress Controller の前提条件
- フロントエンド IP アドレスを定義している。
- TCP ポート 443 および 80 はロードバランサーのフロントエンド IP アドレスで公開されている。
- フロントエンドの IP アドレス、ポート 80、ポート 443 へは、OpenShift Container Platform クラスターの外部の場所にあるシステムの全ユーザーがアクセスできる。
- フロントエンドの IP アドレス、ポート 80、ポート 443 は、OpenShift Container Platform クラスターで動作するすべてのノードから到達できる。
- ロードバランサーバックエンドは、ポート 80、443、および 1936 で Ingress Controller を実行する OpenShift Container Platform ノードと通信できる。
ヘルスチェック URL 仕様の前提条件
ほとんどのロードバランサーは、サービスが使用可能か使用不可かを判断するヘルスチェック URL を指定して設定できます。OpenShift Container Platform は、OpenShift API、Machine Configuration API、および Ingress Controller バックエンドサービスのこれらのヘルスチェックを提供します。
次の例は、前にリスト表示したバックエンドサービスのヘルスチェック仕様を示しています。
Kubernetes API ヘルスチェック仕様の例
Path: HTTPS:6443/readyz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Machine Config API ヘルスチェック仕様の例
Path: HTTPS:22623/healthz
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 10
Interval: 10Ingress Controller のヘルスチェック仕様の例
Path: HTTP:1936/healthz/ready
Healthy threshold: 2
Unhealthy threshold: 2
Timeout: 5
Interval: 10手順
HAProxy Ingress Controller を設定して、ポート 6443、22623、443、および 80 でロードバランサーからクラスターへのアクセスを有効化できるようにします。必要に応じて、HAProxy 設定で単一のサブネットの IP アドレスまたは複数のサブネットの IP アドレスを指定できます。
1 つのサブネットをリストした HAProxy 設定の例
# ... listen my-cluster-api-6443 bind 192.168.1.100:6443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /readyz http-check expect status 200 server my-cluster-master-2 192.168.1.101:6443 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:6443 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:6443 check inter 10s rise 2 fall 2 listen my-cluster-machine-config-api-22623 bind 192.168.1.100:22623 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz http-check expect status 200 server my-cluster-master-2 192.168.1.101:22623 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:22623 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:22623 check inter 10s rise 2 fall 2 listen my-cluster-apps-443 bind 192.168.1.100:443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:443 check port 1936 inter 10s rise 2 fall 2 listen my-cluster-apps-80 bind 192.168.1.100:80 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:80 check port 1936 inter 10s rise 2 fall 2 # ...複数のサブネットをリストした HAProxy 設定の例
# ... listen api-server-6443 bind *:6443 mode tcp server master-00 192.168.83.89:6443 check inter 1s server master-01 192.168.84.90:6443 check inter 1s server master-02 192.168.85.99:6443 check inter 1s server bootstrap 192.168.80.89:6443 check inter 1s listen machine-config-server-22623 bind *:22623 mode tcp server master-00 192.168.83.89:22623 check inter 1s server master-01 192.168.84.90:22623 check inter 1s server master-02 192.168.85.99:22623 check inter 1s server bootstrap 192.168.80.89:22623 check inter 1s listen ingress-router-80 bind *:80 mode tcp balance source server worker-00 192.168.83.100:80 check inter 1s server worker-01 192.168.83.101:80 check inter 1s listen ingress-router-443 bind *:443 mode tcp balance source server worker-00 192.168.83.100:443 check inter 1s server worker-01 192.168.83.101:443 check inter 1s listen ironic-api-6385 bind *:6385 mode tcp balance source server master-00 192.168.83.89:6385 check inter 1s server master-01 192.168.84.90:6385 check inter 1s server master-02 192.168.85.99:6385 check inter 1s server bootstrap 192.168.80.89:6385 check inter 1s listen inspector-api-5050 bind *:5050 mode tcp balance source server master-00 192.168.83.89:5050 check inter 1s server master-01 192.168.84.90:5050 check inter 1s server master-02 192.168.85.99:5050 check inter 1s server bootstrap 192.168.80.89:5050 check inter 1s # ...curlCLI コマンドを使用して、ユーザー管理ロードバランサーとそのリソースが動作していることを確認します。次のコマンドを実行して応答を観察し、クラスターマシン設定 API が Kubernetes API サーバーリソースにアクセスできることを確認します。
$ curl https://<loadbalancer_ip_address>:6443/version --insecure設定が正しい場合は、応答として JSON オブジェクトを受信します。
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }次のコマンドを実行して出力を確認し、クラスターマシン設定 API がマシン設定サーバーリソースからアクセスできることを確認します。
$ curl -v https://<loadbalancer_ip_address>:22623/healthz --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK Content-Length: 0次のコマンドを実行して出力を確認し、コントローラーがポート 80 の Ingress Controller リソースにアクセスできることを確認します。
$ curl -I -L -H "Host: console-openshift-console.apps.<cluster_name>.<base_domain>" http://<load_balancer_front_end_IP_address>設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.ocp4.private.opequon.net/ cache-control: no-cache次のコマンドを実行して出力を確認し、コントローラーがポート 443 の Ingress Controller リソースにアクセスできることを確認します。
$ curl -I -L --insecure --resolve console-openshift-console.apps.<cluster_name>.<base_domain>:443:<Load Balancer Front End IP Address> https://console-openshift-console.apps.<cluster_name>.<base_domain>設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
ユーザー管理ロードバランサーのフロントエンド IP アドレスをターゲットにするようにクラスターの DNS レコードを設定します。ロードバランサー経由で、クラスター API およびアプリケーションの DNS サーバーのレコードを更新する必要があります。
変更された DNS レコードの例
<load_balancer_ip_address> A api.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End<load_balancer_ip_address> A apps.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End重要DNS の伝播では、各 DNS レコードが使用可能になるまでに時間がかかる場合があります。各レコードを検証する前に、各 DNS レコードが伝播されることを確認してください。
OpenShift Container Platform クラスターでユーザー管理ロードバランサーを使用するには、クラスターの
install-config.yamlファイルで次の設定を指定する必要があります。# ... platform: baremetal: loadBalancer: type: UserManaged1 apiVIPs: - <api_ip>2 ingressVIPs: - <ingress_ip>3 # ...- 1
- クラスターのユーザー管理ロードバランサーを指定するには、
typeパラメーターにUserManagedを設定します。パラメーターのデフォルトはOpenShiftManagedDefaultで、これはデフォルトの内部ロードバランサーを示します。openshift-kni-infranamespace で定義されたサービスの場合、ユーザー管理ロードバランサーはcorednsサービスをクラスター内の Pod にデプロイできますが、keepalivedおよびhaproxyサービスは無視します。 - 2
- ユーザー管理ロードバランサーを指定する場合に必須のパラメーターです。Kubernetes API がユーザー管理ロードバランサーと通信できるように、ユーザー管理ロードバランサーのパブリック IP アドレスを指定します。
- 3
- ユーザー管理ロードバランサーを指定する場合に必須のパラメーターです。ユーザー管理ロードバランサーのパブリック IP アドレスを指定して、ユーザー管理ロードバランサーがクラスターの Ingress トラフィックを管理できるようにします。
検証
curlCLI コマンドを使用して、ユーザー管理ロードバランサーと DNS レコード設定が動作していることを確認します。次のコマンドを実行して出力を確認し、クラスター API にアクセスできることを確認します。
$ curl https://api.<cluster_name>.<base_domain>:6443/version --insecure設定が正しい場合は、応答として JSON オブジェクトを受信します。
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }次のコマンドを実行して出力を確認し、クラスターマシン設定にアクセスできることを確認します。
$ curl -v https://api.<cluster_name>.<base_domain>:22623/healthz --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK Content-Length: 0以下のコマンドを実行して出力を確認し、ポートで各クラスターアプリケーションにアクセスできることを確認します。
$ curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.<cluster-name>.<base domain>/ cache-control: no-cacheHTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=39HoZgztDnzjJkq/JuLJMeoKNXlfiVv2YgZc09c3TBOBU4NI6kDXaJH1LdicNhN1UsQWzon4Dor9GWGfopaTEQ==; Path=/; Secure x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Tue, 17 Nov 2020 08:42:10 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=9b714eb87e93cf34853e87a92d6894be; path=/; HttpOnly; Secure; SameSite=None cache-control: private次のコマンドを実行して出力を確認し、ポート 443 で各クラスターアプリケーションにアクセスできることを確認します。
$ curl https://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
3.12. DHCP を使用したクラスターノードのホスト名の設定
Red Hat Enterprise Linux CoreOS (RHCOS) マシンでは、NetworkManager がホスト名を設定します。デフォルトでは、DHCP が NetworkManager にホスト名を提供します。これが推奨される方法です。NetworkManager は、次の場合に逆 DNS ルックアップを通じてホスト名を取得します。
- DHCP がホスト名を提供しない場合
- カーネル引数を使用してホスト名を設定する場合
- 別の方法でホスト名を設定する場合
逆 DNS ルックアップは、ノード上でネットワークが初期化された後に実行し、NetworkManager がホスト名を設定するのにかかる時間が長くなる可能性があります。NetworkManager がホスト名を設定する前に他のシステムサービスが起動することがあり、その場合は、それらのサービスが localhost などのデフォルトのホスト名を使用する可能性があります。
DHCP を使用して各クラスターノードにホスト名を提供することで、ホスト名の設定の遅延を回避できます。また、DHCP を介してホスト名を設定すると、DNS スプリットホライズンが実装されている環境での手動の DNS レコード名設定エラーを回避できます。
3.13. install-config.yaml ファイルの設定
3.13.1. install-config.yaml ファイルの設定
install-config.yaml ファイルには、追加の詳細情報が必要です。ほとんどの情報は、インストールプログラムと結果として作成されるクラスターに、完全に管理できる使用可能なハードウェアを十分に説明しています。
正しいイメージがリリースペイロードにあるため、インストールプログラムは、clusterOSImage RHCOS イメージを必要としなくなりました。
install-config.yamlを設定します。pullSecret、sshKeyなど、環境に合わせて適切な変数を変更します。apiVersion: v1 baseDomain: <domain> metadata: name: <cluster_name> networking: machineNetwork: - cidr: <public_cidr> networkType: OVNKubernetes compute: - name: worker replicas: 21 controlPlane: name: master replicas: 3 platform: baremetal: {} platform: baremetal: apiVIPs: - <api_ip> ingressVIPs: - <wildcard_ip> provisioningNetworkCIDR: <CIDR> bootstrapExternalStaticIP: <bootstrap_static_ip_address>2 bootstrapExternalStaticGateway: <bootstrap_static_gateway>3 bootstrapExternalStaticDNS: <bootstrap_static_dns>4 hosts: - name: openshift-master-0 role: master bmc: address: ipmi://<out_of_band_ip>5 username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>"6 - name: <openshift_master_1> role: master bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>" - name: <openshift_master_2> role: master bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>" - name: <openshift_worker_0> role: worker bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> - name: <openshift_worker_1> role: worker bmc: address: ipmi://<out_of_band_ip> username: <user> password: <password> bootMACAddress: <NIC1_mac_address> rootDeviceHints: deviceName: "<installation_disk_drive_path>" pullSecret: '<pull_secret>' sshKey: '<ssh_pub_key>'- 1
- OpenShift Container Platform クラスターの一部であるコンピュートノードの数に基づいて、コンピュートマシンをスケーリングします。
replicas値の有効なオプションは0で、2以上の整数です。3 ノードクラスターのみが含まれる 3 ノードクラスターをデプロイするには、レプリカ数を0に設定します。3 ノードクラスターは、テスト、開発、本番に使用できる、より小さく、よりリソース効率の良いクラスターです。コンピュートノードが 1 つだけのクラスターをインストールすることはできません。 - 2
- 静的 IP アドレスを使用してクラスターをデプロイする場合、ベアメタルネットワークに DHCP サーバーがない場合は、
bootstrapExternalStaticIP設定を設定して、ブートストラップ VM の静的 IP アドレスを指定する必要があります。 - 3
- 静的 IP アドレスを使用してクラスターをデプロイする場合、ベアメタルネットワークに DHCP サーバーがない場合は、
bootstrapExternalStaticGateway設定を設定して、ブートストラップ仮想マシンのゲートウェイ IP アドレスを指定する必要があります。 - 4
- 静的 IP アドレスを使用してクラスターをデプロイする場合、ベアメタルネットワークに DHCP サーバーがない場合は、
bootstrapExternalStaticDNS設定を設定して、ブートストラップ仮想マシンの DNS アドレスを指定する必要があります。 - 5
- その他のオプションについては、BMC アドレス指定のセクションを参照してください。
- 6
- インストールディスクドライブへのパスを設定するには、ディスクのカーネル名を入力します。たとえば、
/dev/sdaです。重要ディスクの検出順序は保証されていないため、複数のディスクを持つマシンでは、起動オプションによってディスクのカーネル名が変わる可能性があります。たとえば、
/dev/sdaは/dev/sdbになり、その逆も同様です。この問題を回避するには、ディスクの World Wide Name (WWN) や/dev/disk/by-path/などの永続的なディスク属性を使用する必要があります。ストレージの場所への/dev/disk/by-path/<device_path>リンクを使用することを推奨します。ディスク WWN を使用するには、deviceNameパラメーターをwwnWithExtensionパラメーターに置き換えます。使用するパラメーターに応じて、次のいずれかの値を入力します。-
ディスク名。たとえば、
/dev/sda、または/dev/disk/by-path/です。 -
ディスクの WWN。たとえば、
"0x64cd98f04fde100024684cf3034da5c2"です。ディスク WWN 値が 16 進数値ではなく文字列値として使用されるように、ディスク WWN 値を引用符で囲んで入力してください。
これらの
rootDeviceHintsパラメーター要件を満たさない場合、次のエラーが発生する可能性があります。ironic-inspector inspection failed: No disks satisfied root device hints -
ディスク名。たとえば、
注記OpenShift Container Platform 4.12 より前では、クラスターインストールプログラムが、
apiVIPおよびingressVIP設定の IPv4 アドレスまたは IPv6 アドレスのみを受け入れていました。OpenShift Container Platform 4.12 以降では、これらの設定は非推奨です。代わりに、apiVIPsおよびingressVIPs設定でリスト形式を使用して、IPv4 アドレス、IPv6 アドレス、または両方の IP アドレス形式を指定してください。クラスター設定を保存するディレクトリーを作成します。
$ mkdir ~/clusterconfigsinstall-config.yamlファイルを新しいディレクトリーにコピーします。$ cp install-config.yaml ~/clusterconfigsOpenShift Container Platform クラスターをインストールする前に、すべてのベアメタルノードの電源がオフになっていることを確認します。
$ ipmitool -I lanplus -U <user> -P <password> -H <management-server-ip> power off以前に試行したデプロイメントにより古いブートストラップリソースが残っている場合は、これを削除します。
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done
3.13.2. 追加の install-config パラメーター
install-config.yaml ファイルに必要なパラメーター hosts パラメーターおよび bmc パラメーターは、以下の表を参照してください。
| パラメーター | デフォルト | 説明 |
|---|---|---|
|
|
クラスターのドメイン名。たとえば、 | |
|
|
|
ノードのブートモード。オプションは、 |
|
|
ブートストラップノードの静的ネットワーク DNS。ベアメタルネットワークに Dynamic Host Configuration Protocol (DHCP) サーバーがない場合に、静的 IP アドレスを使用してクラスターをデプロイする場合は、この値を設定する必要があります。この値を設定しないと、インストールプログラムが | |
|
| ブートストラップ VM の静的 IP アドレス。ベアメタルネットワークに DHCP サーバーがない場合に、静的 IP アドレスを使用してクラスターをデプロイする場合は、この値を設定する必要があります。 | |
|
| ブートストラップ VM のゲートウェイの静的 IP アドレス。ベアメタルネットワークに DHCP サーバーがない場合に、静的 IP アドレスを使用してクラスターをデプロイする場合は、この値を設定する必要があります。 | |
|
|
| |
|
|
| |
|
OpenShift Container Platform クラスターに指定される名前。たとえば、 | |
|
外部ネットワークの公開 CIDR (Classless Inter-Domain Routing)。たとえば、 | |
| OpenShift Container Platform クラスターでは、ノードがゼロの場合でも、コンピュートノードに名前を付ける必要があります。 | |
| replicas は、OpenShift Container Platform クラスターのコンピュートノードの数を設定します。 | |
| OpenShift Container Platform クラスターでは、コントロールプレーンノードに名前が必要です。 | |
| replicas は、OpenShift Container Platform クラスターの一部として含まれるコントロールプレーンノードの数を設定します。 | |
|
|
ベアメタルネットワークに接続されたノード上のネットワークインターフェイス名。OpenShift Container Platform 4.9 以降のリリースのために、NIC の名前を識別するために | |
|
| プラットフォーム設定なしでマシンプールに使用されるデフォルト設定。 | |
|
| (オプション) Kubernetes API 通信の仮想 IP アドレス。
この設定は、 注記
OpenShift Container Platform 4.12 より前では、クラスターのインストールプログラムは | |
|
|
|
|
|
| (オプション) Ingress トラフィックの仮想 IP アドレス。
この設定は、 注記
OpenShift Container Platform 4.12 より前では、クラスターのインストールプログラムは |
| パラメーター | デフォルト | 説明 |
|---|---|---|
|
|
| プロビジョニングネットワークでノードの IP 範囲を定義します。 |
|
|
| プロビジョニングに使用するネットワークの CIDR。このオプションは、プロビジョニングネットワークでデフォルトのアドレス範囲を使用しない場合に必要です。 |
|
|
|
プロビジョニングサービスが実行されるクラスター内の IP アドレス。デフォルトは、プロビジョニングサブネットの 3 番目の IP アドレスに設定されます。たとえば、 |
|
|
|
インストーラーがコントロールプレーン (マスター) ノードをデプロイしている間にプロビジョニングサービスが実行されるブートストラップ仮想マシンの IP アドレス。デフォルトは、プロビジョニングサブネットの 2 番目の IP アドレスに設定されます。たとえば、 |
|
|
| ベアメタルネットワークに接続されたハイパーバイザーのベアメタルブリッジの名前。 |
|
|
|
プロビジョニングネットワークに接続されている |
|
|
クラスターのホストアーキテクチャーを定義します。有効な値は | |
|
| プラットフォーム設定なしでマシンプールに使用されるデフォルト設定。 | |
|
|
ブートストラップノードのデフォルトのオペレーティングシステムイメージを上書きするための URL。URL にはイメージの SHA-256 ハッシュが含まれている必要があります。たとえば、 | |
|
|
| |
|
| このパラメーターを、環境内で使用する適切な HTTP プロキシーに設定します。 | |
|
| このパラメーターを、環境内で使用する適切な HTTPS プロキシーに設定します。 | |
|
| このパラメーターを、環境内のプロキシーの使用に対する例外のリストに設定します。 |
3.13.2.1. ホスト
hosts パラメーターは、クラスターのビルドに使用される個別のベアメタルアセットのリストです。
| 名前 | デフォルト | 説明 |
|---|---|---|
|
|
詳細情報に関連付ける | |
|
|
ベアメタルノードのロール。 | |
|
| ベースボード管理コントローラーの接続詳細。詳細は、BMC アドレス指定のセクションを参照してください。 | |
|
|
ホストがプロビジョニングネットワークに使用する NIC の MAC アドレス。Ironic は、 注記 プロビジョニングネットワークを無効にした場合は、ホストから有効な MAC アドレスを提供する必要があります。 | |
|
| このオプションのパラメーターを設定して、ホストのネットワークインターフェイスを設定します。詳細は、「(オプション) ホストネットワークインターフェイスの設定」を参照してください。 |
3.13.3. BMC アドレス指定
ほとんどのベンダーは、Intelligent Platform Management Interface(IPMI) でベースボード管理コントローラー (BMC) アドレスに対応しています。IPMI は通信を暗号化しません。これは、セキュリティーが保護された管理ネットワークまたは専用の管理ネットワークを介したデータセンター内での使用に適しています。ベンダーを確認して、Redfish ネットワークブートをサポートしているかどうかを確認します。Redfish は、コンバージド、ハイブリッド IT および Software Defined Data Center (SDDC) 向けのシンプルでセキュアな管理を行います。Redfish は人による判読が可能、かつ機械対応が可能であり、インターネットや Web サービスの標準を活用して、最新のツールチェーンに情報を直接公開します。ハードウェアが Redfish ネットワークブートに対応していない場合には、IPMI を使用します。
ノードが Registering 状態にある間、インストール中に BMC アドレスを変更できます。ノードの Registering 状態が終了した後に BMC アドレスを変更する必要がある場合は、ノードを Ironic から切断し、BareMetalHost リソースを編集して、ノードを Ironic に再接続する必要があります。詳細は、BareMetalHost リソースの編集 セクションを参照してください。
3.13.3.1. IPMI
IPMI を使用するホストは ipmi://<out-of-band-ip>:<port> アドレス形式を使用します。これは、指定がない場合はポート 623 にデフォルトで設定されます。以下の例は、install-config.yaml ファイル内の IPMI 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: ipmi://<out-of-band-ip>
username: <user>
password: <password>
BMC アドレス指定に IPMI を使用して PXE ブートする場合は、provisioning ネットワークが必要です。provisioning ネットワークなしでは、PXE ブートホストを行うことはできません。provisioning ネットワークなしでデプロイする場合、redfish-virtualmedia や idrac-virtualmedia などの仮想メディア BMC アドレス指定オプションを使用する必要があります。詳細は、「HPE iLO の BMC アドレス指定」セクションの「HPE iLO の Redfish 仮想メディア」、または「Dell iDRAC の BMC アドレス指定」セクションの「Dell iDRAC の Redfish 仮想メディア」を参照してください。
3.13.3.2. Redfish ネットワークブート
Redfish を有効にするには、redfish:// または redfish+http:// を使用して TLS を無効にします。インストーラーには、ホスト名または IP アドレスとシステム ID へのパスの両方が必要です。以下の例は、install-config.yaml ファイル内の Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
アウトオブバンド管理のアドレスには認証局証明書を用意することを推奨します。ただし、自己署名証明書を使用する場合は、bmc 設定に disableCertificateVerification: True を含める必要があります。以下の例は、install-config.yaml ファイル内の disableCertificateVerification: True 設定パラメーターを使用する Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
disableCertificateVerification: True3.13.4. Redfish API のサポートの確認
Redfish API を使用してインストールする場合、ベアメタル上で installer-provisioned infrastructure を使用する際に、インストールプログラムはベースボード管理コントローラー (BMC) 上の複数の Redfish エンドポイントを呼び出します。Redfish を使用する場合は、インストール前に BMC がすべての Redfish API をサポートしていることを確認してください。
手順
Redfish API のリスト
次のコマンドを実行して、
power onのサポートを確認します。$ curl -u $USER:$PASS -X POST -H'Content-Type: application/json' -H'Accept: application/json' -d '{"ResetType": "On"}' https://$SERVER/redfish/v1/Systems/$SystemID/Actions/ComputerSystem.Reset次のコマンドを実行して、
power offのサポートを確認します。$ curl -u $USER:$PASS -X POST -H'Content-Type: application/json' -H'Accept: application/json' -d '{"ResetType": "ForceOff"}' https://$SERVER/redfish/v1/Systems/$SystemID/Actions/ComputerSystem.Reset次のコマンドを実行して、
pxeを使用する一時的なブート実装を確認します。$ curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" -H "If-Match: <ETAG>" https://$Server/redfish/v1/Systems/$SystemID/ -d '{"Boot": {"BootSourceOverrideTarget": "pxe", "BootSourceOverrideEnabled": "Once"}}次のコマンドを実行して、
LegacyまたはUEFIを使用するファームウェアブートモードの設定ステータスを確認します。$ curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" -H "If-Match: <ETAG>" https://$Server/redfish/v1/Systems/$SystemID/ -d '{"Boot": {"BootSourceOverrideMode":"UEFI"}}
Redfish 仮想メディア API のリスト
次のコマンドを実行して、
cdまたはdvdを使用する一時ブートデバイスを設定できるか確認します。$ curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" -H "If-Match: <ETAG>" https://$Server/redfish/v1/Systems/$SystemID/ -d '{"Boot": {"BootSourceOverrideTarget": "cd", "BootSourceOverrideEnabled": "Once"}}'仮想メディアは、ハードウェアに応じて
POSTまたはPATCHを使用する場合があります。次のいずれかのコマンドを実行して、仮想メディアをマウントできるかどうかを確認します。$ curl -u $USER:$PASS -X POST -H "Content-Type: application/json" https://$Server/redfish/v1/Managers/$ManagerID/VirtualMedia/$VmediaId -d '{"Image": "https://example.com/test.iso", "TransferProtocolType": "HTTPS", "UserName": "", "Password":""}'$ curl -u $USER:$PASS -X PATCH -H "Content-Type: application/json" -H "If-Match: <ETAG>" https://$Server/redfish/v1/Managers/$ManagerID/VirtualMedia/$VmediaId -d '{"Image": "https://example.com/test.iso", "TransferProtocolType": "HTTPS", "UserName": "", "Password":""}'
Redfish API の PowerOn および PowerOff コマンドは、Redfish 仮想メディア API と同じです。一部のハードウェアでは、VirtualMedia リソースが Managers/$ManagerID ではなく Systems/$SystemID にのみ存在する場合があります。VirtualMedia リソースの場合、UserName と Password のフィールドはオプションです。
TransferProtocolTypes でサポートされているパラメータータイプは、HTTPS と HTTP のみです。
3.13.5. Dell iDRAC の BMC アドレス指定
各 bmc エントリーの address 設定は、URL スキーム内のコントローラーのタイプとネットワーク上の場所を含む、OpenShift Container Platform クラスターノードに接続するための URL です。各 bmc エントリーの username 設定では、Administrator 権限を持つユーザーを指定する必要があります。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>Dell ハードウェアの場合、Red Hat は統合 Dell Remote Access Controller (iDRAC) 仮想メディア、Redfish ネットワークブート、および IPMI をサポートします。
3.13.5.1. Dell iDRAC の BMC アドレス形式
| プロトコル | アドレスのフォーマット |
|---|---|
| iDRAC 仮想メディア |
|
| Redfish ネットワークブート |
|
| IPMI |
|
idrac-virtualmedia を Redfish 仮想メディアのプロトコルとして使用します。redfish-virtualmedia は Dell ハードウェアでは機能しません。Dell の idrac-virtualmedia は、Dell の OEM 拡張機能が含まれる Redfish 標準を使用します。
詳細は、以下のセクションを参照してください。
3.13.5.2. Dell iDRAC の Redfish 仮想メディア
Dell サーバーの Redfish 仮想メディアについては、address 設定で idrac-virtualmedia:// を使用します。redfish-virtualmedia:// を使用しても機能しません。
idrac-virtualmedia:// を Redfish 仮想メディアのプロトコルとして使用します。redfish-virtualmedia:// の使用は、idrac-virtualmedia:// プロトコルが idrac ハードウェアタイプおよび Ironic の Redfish プロトコルに対応しているため、Dell ハードウェアでは機能しません。Dell の idrac-virtualmedia:// プロトコルは、Dell の OEM 拡張機能が含まれる Redfish 標準を使用します。Ironic は、WSMAN プロトコルのある idrac タイプもサポートします。したがって、Dell ハードウェア上の仮想メディアで Redfish を使用する際に予期しない動作を回避するために、idrac-virtualmedia:// を指定する必要があります。
以下の例は、install-config.yaml ファイル内で iDRAC 仮想メディアを使用する方法を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: idrac-virtualmedia://<out_of_band_ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
アウトバウンド管理のアドレスに認証局の証明書を使用することが推奨されますが、自己署名証明書を使用する場合には、bmc 設定に disableCertificateVerification: True を含める必要があります。
OpenShift Container Platform クラスターノードについて、iDRAC コンソールで AutoAttach が有効にされていることを確認します。メニューパスは Configuration → Virtual Media → Attach Mode → AutoAttach です。
次の例は、install-config.yaml ファイル内の disableCertificateVerification: True 設定パラメーターを使用した Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: idrac-virtualmedia://<out_of_band_ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
disableCertificateVerification: True3.13.5.3. iDRAC の Redfish ネットワークブート
Redfish を有効にするには、redfish:// または redfish+http:// を使用してトランスポート層セキュリティー (TLS) を無効にします。インストールプログラムにより、ホスト名または IP アドレスとシステム ID へのパスが求められます。以下の例は、install-config.yaml ファイル内の Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out_of_band_ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
アウトオブバンド管理のアドレスには認証局証明書を用意することを推奨します。ただし、自己署名証明書を使用する場合は、bmc 設定に disableCertificateVerification: True を含める必要があります。次の例は、install-config.yaml ファイル内の disableCertificateVerification: True 設定パラメーターを使用した Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out_of_band_ip>/redfish/v1/Systems/System.Embedded.1
username: <user>
password: <password>
disableCertificateVerification: True
ファームウェアバージョン 04.40.00.00 を使用する Dell iDRAC 9 と、ベアメタルデプロイメントで installer-provisioned installation 用の 5.xx シリーズを含むすべてのリリースには既知の問題があります。Virtual Console プラグインは、HTML5 の拡張バージョンである eHTML5 にデフォルト設定されているため、InsertVirtualMedia ワークフローで問題が発生します。この問題を回避するには、HTML5 を使用するようにプラグインを設定します。メニューパスは以下の通りです。Configuration → Virtual console → Plug-in Type → HTML5
OpenShift Container Platform クラスターノードについて、iDRAC コンソールで AutoAttach が有効にされていることを確認します。メニューパスは以下のようになります。Configuration → Virtual Media → Attach Mode → AutoAttach
3.13.6. HPE iLO の BMC アドレス指定
それぞれの bmc エントリーの address フィールドは、URL スキーム内のコントローラーのタイプやネットワーク上のその場所を含む、OpenShift Container Platform クラスターノードに接続する URL です。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>- 1
address設定はプロトコルを指定します。
HPE integrated Lights Out (iLO) の場合、Red Hat は Redfish 仮想メディア、Redfish ネットワークブート、および IPMI をサポートします。
| プロトコル | アドレスのフォーマット |
|---|---|
| Redfish 仮想メディア |
|
| Redfish ネットワークブート |
|
| IPMI |
|
詳細は、以下のセクションを参照してください。
3.13.6.1. HPE iLO の Redfish 仮想メディア
HPE サーバーの Redfish 仮想メディアを有効にするには、address 設定で redfish-virtualmedia:// を使用します。以下の例は、install-config.yaml ファイル内で Redfish 仮想メディアを使用する方法を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish-virtualmedia://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
アウトオブバンド管理のアドレスには認証局証明書を用意することを推奨します。ただし、自己署名証明書を使用する場合は、bmc 設定に disableCertificateVerification: True を含める必要があります。以下の例は、install-config.yaml ファイル内の disableCertificateVerification: True 設定パラメーターを使用する Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish-virtualmedia://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
disableCertificateVerification: TrueIronic は、仮想メディアで iLO4 をサポートしないので、Redfish 仮想メディアは、iLO4 を実行する第 9 世代のシステムではサポートされません。
3.13.6.2. HPE iLO の Redfish ネットワークブート
Redfish を有効にするには、redfish:// または redfish+http:// を使用して TLS を無効にします。インストーラーには、ホスト名または IP アドレスとシステム ID へのパスの両方が必要です。以下の例は、install-config.yaml ファイル内の Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
アウトオブバンド管理のアドレスには認証局証明書を用意することを推奨します。ただし、自己署名証明書を使用する場合は、bmc 設定に disableCertificateVerification: True を含める必要があります。以下の例は、install-config.yaml ファイル内の disableCertificateVerification: True 設定パラメーターを使用する Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out-of-band-ip>/redfish/v1/Systems/1
username: <user>
password: <password>
disableCertificateVerification: True3.13.7. Fujitsu iRMC の BMC アドレス指定
それぞれの bmc エントリーの address フィールドは、URL スキーム内のコントローラーのタイプやネットワーク上のその場所を含む、OpenShift Container Platform クラスターノードに接続する URL です。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>- 1
address設定はプロトコルを指定します。
Fujitsu ハードウェアの場合、Red Hat は、統合 Remote Management Controller (iRMC) および IPMI をサポートします。
| プロトコル | アドレスのフォーマット |
|---|---|
| iRMC |
|
| IPMI |
|
iRMC
Fujitsu ノードは irmc://<out-of-band-ip> を使用し、デフォルトではポート 443 に設定されます。以下の例は、install-config.yaml ファイル内の iRMC 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: irmc://<out-of-band-ip>
username: <user>
password: <password>現在 Fujitsu は、ベアメタルへの installer-provisioned installation 用に iRMC S5 ファームウェアバージョン 3.05P 以降をサポートしています。
3.13.8. Cisco CIMC の BMC アドレス指定
それぞれの bmc エントリーの address フィールドは、URL スキーム内のコントローラーのタイプやネットワーク上のその場所を含む、OpenShift Container Platform クラスターノードに接続する URL です。
platform:
baremetal:
hosts:
- name: <hostname>
role: <master | worker>
bmc:
address: <address>
username: <user>
password: <password>- 1
address設定はプロトコルを指定します。
Cisco UCS UCSX-210C-M6 ハードウェアの場合、Red Hat は Cisco Integrated Management Controller (CIMC) をサポートします。
| プロトコル | アドレスのフォーマット |
|---|---|
| Redfish 仮想メディア |
|
Cisco UCS UCSX-210C-M6 ハードウェアの Redfish 仮想メディアを有効にするには、address 設定で redfish-virtualmedia:// を使用します。以下の例は、install-config.yaml ファイル内で Redfish 仮想メディアを使用する方法を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish-virtualmedia://<server_kvm_ip>/redfish/v1/Systems/<serial_number>
username: <user>
password: <password>
アウトオブバンド管理のアドレスには認証局証明書を用意することを推奨します。ただし、自己署名証明書を使用する場合は、bmc 設定に disableCertificateVerification: True を含める必要があります。次の例は、install-config.yaml ファイル内の disableCertificateVerification: True 設定パラメーターを使用した Redfish 設定を示しています。
platform:
baremetal:
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish-virtualmedia://<server_kvm_ip>/redfish/v1/Systems/<serial_number>
username: <user>
password: <password>
disableCertificateVerification: True3.13.9. ルートデバイスのヒント
rootDeviceHints パラメーターは、インストーラーが Red Hat Enterprise Linux CoreOS (RHCOS) イメージを特定のデバイスにプロビジョニングできるようにします。インストーラーは、検出順にデバイスを検査し、検出された値をヒントの値と比較します。インストーラーは、ヒント値に一致する最初に検出されたデバイスを使用します。この設定は複数のヒントを組み合わせることができますが、デバイスは、インストーラーがこれを選択できるようにすべてのヒントに一致する必要があります。
| サブフィールド | 説明 |
|---|---|
|
|
注記
ストレージの場所への ヒントは、実際の値と完全に一致する必要があります。 |
|
|
|
|
| ベンダー固有のデバイス識別子を含む文字列。ヒントは、実際の値のサブ文字列になります。 |
|
| デバイスのベンダーまたは製造元の名前が含まれる文字列。ヒントは、実際の値のサブ文字列になります。 |
|
| デバイスのシリアル番号を含む文字列。ヒントは、実際の値と完全に一致する必要があります。 |
|
| デバイスの最小サイズ (ギガバイト単位) を表す整数。 |
|
| 一意のストレージ ID を含む文字列。ヒントは、実際の値と完全に一致する必要があります。 |
|
| ベンダー拡張が追加された一意のストレージ ID を含む文字列。ヒントは、実際の値と完全に一致する必要があります。 |
|
| 一意のベンダーストレージ ID を含む文字列。ヒントは、実際の値と完全に一致する必要があります。 |
|
| デバイスがローテーションするディスクである (true) か、そうでないか (false) を示すブール値。 |
使用例
- name: master-0
role: master
bmc:
address: ipmi://10.10.0.3:6203
username: admin
password: redhat
bootMACAddress: de:ad:be:ef:00:40
rootDeviceHints:
deviceName: "/dev/sda"3.13.10. オプション: プロキシー設定の設定
プロキシーを使用して OpenShift Container Platform クラスターをデプロイするには、install-config.yaml ファイルに以下の変更を加えます。
apiVersion: v1
baseDomain: <domain>
proxy:
httpProxy: http://USERNAME:PASSWORD@proxy.example.com:PORT
httpsProxy: https://USERNAME:PASSWORD@proxy.example.com:PORT
noProxy: <WILDCARD_OF_DOMAIN>,<PROVISIONING_NETWORK/CIDR>,<BMC_ADDRESS_RANGE/CIDR>
以下は、値を含む noProxy の例です。
noProxy: .example.com,172.22.0.0/24,10.10.0.0/24プロキシーを有効な状態にして、対応するキー/値のペアでプロキシーの適切な値を設定します。
主な留意事項:
-
プロキシーに HTTPS プロキシーがない場合、
httpsProxyの値をhttps://からhttp://に変更します。 -
provisioning ネットワークを使用する場合、これを
noProxy設定に含めます。そうしない場合、インストーラーは失敗します。 -
プロビジョナーノード内の環境変数としてすべてのプロキシー設定を設定します。たとえば、
HTTP_PROXY、HTTPS_PROXY、およびNO_PROXYが含まれます。
IPv6 でプロビジョニングする場合、noProxy 設定で CIDR アドレスブロックを定義することはできません。各アドレスを個別に定義する必要があります。
3.13.11. オプション: プロビジョニングネットワークを使用しないデプロイ
provisioning ネットワークなしに OpenShift Container Platform をデプロイするには、install-config.yaml ファイルに以下の変更を加えます。
platform:
baremetal:
apiVIPs:
- <api_VIP>
ingressVIPs:
- <ingress_VIP>
provisioningNetwork: "Disabled" - 1
provisioningNetwork設定を追加して、必要な場合はこれをDisabledに設定します。
PXE ブートには provisioning ネットワークが必要です。provisioning ネットワークなしでデプロイする場合、redfish-virtualmedia や idrac-virtualmedia などの仮想メディア BMC アドレス指定オプションを使用する必要があります。詳細は、「HPE iLO の BMC アドレス指定」セクションの「HPE iLO の Redfish 仮想メディア」、または「Dell iDRAC の BMC アドレス指定」セクションの「Dell iDRAC の Redfish 仮想メディア」を参照してください。
3.13.12. デュアルスタックネットワークを使用した IP アドレス指定のデプロイ
ブートストラップ仮想マシン(VM)のデュアルスタックネットワークを使用した IP アドレス指定をデプロイする場合、ブートストラップ仮想マシンは 1 つの IP バージョンで機能します。
以下は DHCP 用です。DHCP ベースのデュアルスタッククラスターは、毎日 1 日に 1 つの IPv4 および 1 つの IPv6 仮想 IP アドレス(VIP)を使用してデプロイできます。
静的 IP アドレスを使用してクラスターをデプロイするには、ブートストラップ VM、API、および Ingress VIP の IP アドレスを設定する必要があります。install-config で静的 IP セットを使用してデュアルスタックを設定するには、API と Ingress 用にそれぞれ 1 つの VIP が必要です。デプロイ後にセカンダリー VIP を追加します。
OpenShift Container Platform クラスターのデュアルスタックネットワークでは、クラスターノードの IPv4 および IPv6 アドレスエンドポイントを設定できます。クラスターノードの IPv4 および IPv6 アドレスエンドポイントを設定するには、install-config.yaml ファイルで machineNetwork、clusterNetwork、および serviceNetwork 設定を編集します。それぞれの設定には、それぞれ 2 つの CIDR エントリーが必要です。プライマリーアドレスファミリーとして IPv4 ファミリーを持つクラスターの場合は、最初に IPv4 設定を指定します。プライマリーアドレスファミリーとして IPv6 ファミリーを持つクラスターの場合は、最初に IPv6 設定を指定します。
クラスターノードの IPv4 および IPv6 アドレスエンドポイントを含む NMState YAML 設定ファイルの例
machineNetwork:
- cidr: {{ extcidrnet }}
- cidr: {{ extcidrnet6 }}
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
- cidr: fd02::/48
hostPrefix: 64
serviceNetwork:
- 172.30.0.0/16
- fd03::/112
ベアメタルプラットフォームで、install-config.yaml ファイルの networkConfig セクションで NMState 設定を指定した場合は、クラスターをデュアルスタックネットワークにデプロイできない問題を解決するために、interfaces.wait-ip: ipv4+ipv6 を NMState YAML ファイルに追加し、あし。
wait-ip パラメーターを含む NMState YAML 設定ファイルの例
networkConfig:
nmstate:
interfaces:
- name: <interface_name>
# ...
wait-ip: ipv4+ipv6
# ...
IPv4 および IPv6 アドレスを使用するアプリケーションのクラスターへのインターフェイスを提供するには、Ingress VIP および API VIP サービスの IPv4 および IPv6 仮想 IP (VIP) アドレスエンドポイントを設定します。IPv4 および IPv6 アドレスエンドポイントを設定するには、install-config.yaml ファイルで apiVIPs および ingressVIPs 設定を編集します。apiVIPs および ingressVIPs 設定では、リスト形式を使用します。リストの順序は、各サービスのプライマリーおよびセカンダリー VIP アドレスを示しています。
platform:
baremetal:
apiVIPs:
- <api_ipv4>
- <api_ipv6>
ingressVIPs:
- <wildcard_ipv4>
- <wildcard_ipv6>デュアルスタックネットワーク設定のクラスターの場合、IPv4 アドレスと IPv6 アドレスの両方を同じインターフェイスに割り当てる必要があります。
3.13.13. オプション: ホストネットワークインターフェイスの設定
インストールの前に、install-config.yaml ファイルで networkConfig 設定を設定し、NMState を使用してホストネットワークインターフェイスを設定できます。
この機能の最も一般的な使用例は、ベアメタルネットワークで静的 IP アドレスを指定することですが、ストレージネットワークなどの他のネットワークを設定することもできます。この機能は、VLAN、VXLAN、ブリッジ、ボンド、ルート、MTU、DNS リゾルバー設定など、他の NMState 機能をサポートします。
クラスターの DNS リゾルバー設定で、サポートされていない rotate オプションを設定しないでください。このオプションは、内部 API の DNS 解決機能を妨害します。
前提条件
-
静的 IP アドレスを持つ各ノードの有効なホスト名で
PTRDNS レコードを設定する。 -
NMState CLI (
nmstate) をインストールする。
プロビジョニングネットワークを使用する場合は、Ironic の dnsmasq ツールを使用して設定してください。完全に静的なデプロイメントを行うには、仮想メディアを使用する必要があります。
手順
オプション: インストールプログラムは NMState YAML 構文をチェックしないため、
install-config.yamlファイルに NMState 構文を含める前に、nmstatectl gcを使用して NMState 構文をテストすることを検討してください。注記YAML 構文にエラーがあると、ネットワーク設定の適用に失敗する可能性があります。YAML 構文を検証して管理することは、デプロイ後に Kubernetes NMState を使用して変更を適用するときや、クラスターを拡張するときに役立ちます。
NMState YAML ファイルを作成します。
interfaces:1 - name: <nic1_name> type: ethernet state: up ipv4: address: - ip: <ip_address> prefix-length: 24 enabled: true dns-resolver: config: server: - <dns_ip_address> routes: config: - destination: 0.0.0.0/0 next-hop-address: <next_hop_ip_address> next-hop-interface: <next_hop_nic1_name>- 1
<nic1_name>、<ip_address>、<dns_ip_address>、<next_hop_ip_address>、および<next_hop_nic1_name>を適切な値に置き換えます。
次のコマンドを実行して、設定ファイルをテストします。
$ nmstatectl gc <nmstate_yaml_file><nmstate_yaml_file>を設定ファイル名に置き換えます。
install-config.yamlファイル内のホストに NMState 設定を追加して、networkConfig設定を使用します。hosts: - name: openshift-master-0 role: master bmc: address: redfish+http://<out_of_band_ip>/redfish/v1/Systems/ username: <user> password: <password> disableCertificateVerification: null bootMACAddress: <NIC1_mac_address> bootMode: UEFI rootDeviceHints: deviceName: "/dev/sda" networkConfig:1 interfaces:2 - name: <nic1_name> type: ethernet state: up ipv4: address: - ip: <ip_address> prefix-length: 24 enabled: true dns-resolver: config: server: - <dns_ip_address> routes: config: - destination: 0.0.0.0/0 next-hop-address: <next_hop_ip_address> next-hop-interface: <next_hop_nic1_name>重要クラスターをデプロイした後、
install-config.yamlファイルのnetworkConfig設定を変更して、ホストネットワークインターフェイスを変更することはできません。Kubernetes NMState Operator を使用して、デプロイ後にホストネットワークインターフェイスに変更を加えます。
3.13.14. サブネット用のホストネットワークインターフェイスの設定
エッジコンピューティングのシナリオでは、コンピュートノードをエッジの近くに配置することが有益な場合があります。サブネット内のリモートノードを見つけるために、コントロールプレーンサブネットやローカルコンピュートノードに使用したものとは異なるネットワークセグメントまたはサブネットをリモートノードに使用できます。エッジコンピューティングシナリオ用にサブネットを設定することで、エッジのレイテンシーが短縮され、拡張性が向上します。
デフォルトのロードバランサー OpenShiftManagedDefault を使用してリモートノードを OpenShift Container Platform クラスターに追加する場合は、すべてのコントロールプレーンノードが同じサブネット内で実行されている必要があります。複数のサブネットを使用する場合、マニフェストを使用して、コントロールプレーンノード上で実行されるように Ingress VIP を設定することもできます。詳細は、「コントロールプレーンで実行するネットワークコンポーネントの設定」を参照してください。
「サブネット間の通信を確立する」セクションの説明どおりにリモートノードに異なるネットワークセグメントまたはサブネットを確立した場合、ワーカーが静的 IP アドレス、ボンディング、またはその他の高度なネットワークを使用している場合は、machineNetwork 設定でサブネットを指定する必要があります。各リモートノードの networkConfig パラメーターでノード IP アドレスを設定する場合、静的 IP アドレスを使用する際に、コントロールプレーンノードを含むサブネットのゲートウェイと DNS サーバーも指定する必要があります。これにより、リモートノードがコントロールプレーンを含むサブネットに到達し、コントロールプレーンからネットワークトラフィックを受信できるようになります。
複数のサブネットを持つクラスターをデプロイするには、redfish-virtualmedia や idrac-virtualmedia などの仮想メディアを使用する必要があります。リモートノードがローカルプロビジョニングネットワークにアクセスできないためです。
手順
静的 IP アドレスを使用する場合は、
install-config.yamlファイルのmachineNetworkにサブネットを追加します。networking: machineNetwork: - cidr: 10.0.0.0/24 - cidr: 192.168.0.0/24 networkType: OVNKubernetes静的 IP アドレスまたはボンディングなどの高度なネットワークを使用する場合は、NMState 構文を使用して、各エッジコンピュートノードの
networkConfigパラメーターにゲートウェイと DNS 設定を追加します。networkConfig: interfaces: - name: <interface_name>1 type: ethernet state: up ipv4: enabled: true dhcp: false address: - ip: <node_ip>2 prefix-length: 24 gateway: <gateway_ip>3 dns-resolver: config: server: - <dns_ip>4
3.13.15. オプション: デュアルスタックネットワーク内の SLAAC のアドレス生成モードを設定する
Stateless Address AutoConfiguration (SLAAC) を使用するデュアルスタッククラスターの場合は、ipv6.addr-gen-mode ネットワーク設定のグローバル値を指定する必要があります。NMState を使用してこの値を設定し、RAM ディスクとクラスター設定ファイルを設定できます。これらの場所で一貫した ipv6.addr-gen-mode を設定しないと、クラスター内の CSR リソースと BareMetalHost リソース間で IPv6 アドレスの不一致が発生する可能性があります。
前提条件
-
NMState CLI (
nmstate) をインストールする。
手順
オプション: インストールプログラムは NMState YAML 構文をチェックしないため、
install-config.yamlファイルに含める前にnmstatectl gcコマンドを使用して NMState YAML 構文をテストすることを検討してください。NMState YAML ファイルを作成します。
interfaces: - name: eth0 ipv6: addr-gen-mode: <address_mode>1 - 1
<address_mode>を、クラスター内の IPv6 アドレスに必要なアドレス生成モードのタイプに置き換えます。有効な値は、eui64、stable-privacy、またはrandomです。
次のコマンドを実行して、設定ファイルをテストします。
$ nmstatectl gc <nmstate_yaml_file>1 - 1
<nmstate_yaml_file>を、テスト設定ファイルの名前に置き換えます。
NMState 設定を、install-config.yaml ファイル内の
hosts.networkConfigセクションに追加します。hosts: - name: openshift-master-0 role: master bmc: address: redfish+http://<out_of_band_ip>/redfish/v1/Systems/ username: <user> password: <password> disableCertificateVerification: null bootMACAddress: <NIC1_mac_address> bootMode: UEFI rootDeviceHints: deviceName: "/dev/sda" networkConfig: interfaces: - name: eth0 ipv6: addr-gen-mode: <address_mode>1 ...- 1
<address_mode>を、クラスター内の IPv6 アドレスに必要なアドレス生成モードのタイプに置き換えます。有効な値は、eui64、stable-privacy、またはrandomです。
3.13.16. デュアルポート NIC 用のホストネットワークインターフェイスの設定
インストール前に、install-config.yaml ファイルで networkConfig を設定し、NMState を使用してデュアルポートネットワークインターフェイスコントローラー (NIC) をサポートすることで、ホストネットワークインターフェイスを設定できます。
SR-IOV デバイスの NIC パーティショニングの有効化に関連する Day 1 操作のサポートは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
OpenShift Virtualization は以下のボンドモードのみをサポートします。
-
mode=1 active-backup
-
mode=2 balance-xor
-
mode=4 802.3ad
前提条件
-
静的 IP アドレスを持つ各ノードの有効なホスト名で
PTRDNS レコードを設定する。 -
NMState CLI (
nmstate) をインストールする。
YAML 構文にエラーがあると、ネットワーク設定の適用に失敗する可能性があります。YAML 構文を検証して管理することは、デプロイ後に Kubernetes NMState を使用して変更を適用するときや、クラスターを拡張するときに役立ちます。
手順
install-config.yamlファイル内のホストのnetworkConfigフィールドに NMState 設定を追加します。hosts: - name: worker-0 role: worker bmc: address: redfish+http://<out_of_band_ip>/redfish/v1/Systems/ username: <user> password: <password> disableCertificateVerification: false bootMACAddress: <NIC1_mac_address> bootMode: UEFI networkConfig:1 interfaces:2 - name: eno13 type: ethernet4 state: up mac-address: 0c:42:a1:55:f3:06 ipv4: enabled: true dhcp: false5 ethernet: sr-iov: total-vfs: 26 ipv6: enabled: false dhcp: false - name: sriov:eno1:0 type: ethernet state: up7 ipv4: enabled: false8 ipv6: enabled: false - name: sriov:eno1:1 type: ethernet state: down - name: eno2 type: ethernet state: up mac-address: 0c:42:a1:55:f3:07 ipv4: enabled: true ethernet: sr-iov: total-vfs: 2 ipv6: enabled: false - name: sriov:eno2:0 type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: sriov:eno2:1 type: ethernet state: down - name: bond0 type: bond state: up min-tx-rate: 1009 max-tx-rate: 20010 link-aggregation: mode: active-backup11 options: primary: sriov:eno1:012 port: - sriov:eno1:0 - sriov:eno2:0 ipv4: address: - ip: 10.19.16.5713 prefix-length: 23 dhcp: false enabled: true ipv6: enabled: false dns-resolver: config: server: - 10.11.5.160 - 10.2.70.215 routes: config: - destination: 0.0.0.0/0 next-hop-address: 10.19.17.254 next-hop-interface: bond014 table-id: 254- 1
networkConfigフィールドには、ホストのネットワーク設定に関する情報を含めます。interfaces、dns-resolver、routesなどのサブフィールドがあります。- 2
interfacesフィールドは、ホスト用に定義されたネットワークインターフェイスの配列です。- 3
- インターフェイスの名前。
- 4
- インターフェイスのタイプ。この例では、イーサネットインターフェイスを作成します。
- 5
- 厳密に必要ではない場合、物理機能 (PF) の DHCP を無効にするには、これを false に設定します。
- 6
- インスタンス化する SR-IOV 仮想機能 (VF) の数に設定します。
- 7
- これを
upに設定します。 - 8
- ボンドに接続された VF の IPv4 アドレス指定を無効にするには、これを
falseに設定します。 - 9
- VF の最小伝送速度 (Mbps) を設定します。このサンプル値は、100 Mbps のレートを設定します。
- この値は、最大伝送レート以下である必要があります。
-
Intel NIC は
min-tx-rateパラメーターをサポートしていません。詳細は、BZ#1772847 を参照してください。
- 10
- VF の最大伝送速度 (Mbps) を設定します。このサンプル値は、200 Mbps のレートを設定します。
- 11
- 必要な結合モードを設定します。
- 12
- ボンディングインターフェイスの優先ポートを設定します。ボンディングは、プライマリーデバイスをボンディングインターフェイスの最初のデバイスとして使用します。ボンディングは、障害が発生しない限り、プライマリーデバイスインターフェイスを放棄しません。この設定が特に役立つのは、ボンディングインターフェイスの NIC の 1 つが高速なため、大規模な負荷に対応できる場合です。この設定は、ボンディングインターフェイスが active-backup モード(モード 1)の場合にのみ有効です。
- 13
- ボンドインターフェイスの静的 IP アドレスを設定します。これはノードの IP アドレスです。
- 14
- デフォルトルートのゲートウェイとして
bond0を設定します。重要クラスターをデプロイした後は、
install-config.yamlファイルのnetworkConfig設定を変更してホストネットワークインターフェイスを変更することはできません。Kubernetes NMState Operator を使用して、デプロイ後にホストネットワークインターフェイスに変更を加えます。
3.13.17. 複数のクラスターノードの設定
同じ設定で OpenShift Container Platform クラスターノードを同時に設定できます。複数のクラスターノードを設定すると、各ノードの冗長な情報が install-config.yaml ファイルに追加されることを回避できます。このファイルには、クラスター内の複数のノードに同一の設定を適用するための特定のパラメーターが含まれています。
コンピュートノードは、コントローラーノードとは別に設定されます。ただし、両方のノードタイプの設定では、install-config.yaml ファイルで強調表示されているパラメーターを使用して、マルチノード設定を有効にします。次の例に示すように、networkConfig パラメーターを BOND に設定します。
hosts:
- name: ostest-master-0
[...]
networkConfig: &BOND
interfaces:
- name: bond0
type: bond
state: up
ipv4:
dhcp: true
enabled: true
link-aggregation:
mode: active-backup
port:
- enp2s0
- enp3s0
- name: ostest-master-1
[...]
networkConfig: *BOND
- name: ostest-master-2
[...]
networkConfig: *BOND複数のクラスターノードの設定は、installer-provisioned infrastructure での初期デプロイメントでのみ使用できます。
3.13.18. オプション: マネージドセキュアブートの設定
redfish、redfish-virtualmedia、idrac-virtualmedia などの Redfish BMC アドレス指定を使用して、installer-provisioned クラスターをデプロイする際に管理対象 Secure Boot を有効にすることができます。マネージド Secure Boot を有効にするには、bootMode 設定を各ノードに追加します。
例
hosts:
- name: openshift-master-0
role: master
bmc:
address: redfish://<out_of_band_ip>
username: <username>
password: <password>
bootMACAddress: <NIC1_mac_address>
rootDeviceHints:
deviceName: "/dev/sda"
bootMode: UEFISecureBoot ノードがマネージド Secure Boot をサポートできるようにするには、「前提条件」の「ノードの設定」を参照してください。ノードがマネージド Secure Boot に対応していない場合には、「ノードの設定」セクションの「手動での Secure Boot のノードの設定」を参照してください。Secure Boot を手動で設定するには、Redfish 仮想メディアが必要です。
IPMI は Secure Boot 管理機能を提供しないため、Red Hat では IPMI による Secure Boot のサポートはありません。
3.14. マニフェスト設定ファイル
3.14.1. OpenShift Container Platform マニフェストの作成
OpenShift Container Platform マニフェストを作成します。
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifestsINFO Consuming Install Config from target directory WARNING Making control-plane schedulable by setting MastersSchedulable to true for Scheduler cluster settings WARNING Discarding the OpenShift Manifest that was provided in the target directory because its dependencies are dirty and it needs to be regenerated
3.14.2. オプション: 非接続クラスターの NTP 設定
OpenShift Container Platform は、クラスターノードに chrony Network Time Protocol (NTP) サービスをインストールします。

OpenShift Container Platform のノードは、適切に実行するために日付と時刻が一致している必要があります。コンピュートノードがコントロールプレーンノード上の NTP サーバーから日付と時刻を取得すると、ルーティング可能なネットワークに接続していないために上位層の NTP サーバーにアクセスできないクラスターのインストールと操作が可能になります。
手順
次のコマンドを使用して、インストールホストに Butane をインストールします。
$ sudo dnf -y install butaneコントロールプレーンノードの
chrony.confファイルのコンテンツを含む Butane 設定 (99-master-chrony-conf-override.bu) を作成します。注記Butane の詳細は、「Butane を使用したマシン設定の作成」を参照してください。
Butane 設定例
variant: openshift version: 4.16.0 metadata: name: 99-master-chrony-conf-override labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # Use public servers from the pool.ntp.org project. # Please consider joining the pool (https://www.pool.ntp.org/join.html). # The Machine Config Operator manages this file server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony # Configure the control plane nodes to serve as local NTP servers # for all compute nodes, even if they are not in sync with an # upstream NTP server. # Allow NTP client access from the local network. allow all # Serve time even if not synchronized to a time source. local stratum 3 orphan- 1
<cluster-name>はクラスターの名前に置き換え、<domain>は完全修飾ドメイン名に置き換える必要があります。
Butane を使用して、コントロールプレーンノードに配信される設定が含まれる
MachineConfigオブジェクトファイル (99-master-chrony-conf-override.yaml) を生成します。$ butane 99-master-chrony-conf-override.bu -o 99-master-chrony-conf-override.yamlコントロールプレーンノード上の NTP サーバーを参照するコンピュートノードの
chrony.confファイルの内容を含む Butane 設定99-worker-chrony-conf-override.buを作成します。Butane 設定例
variant: openshift version: 4.16.0 metadata: name: 99-worker-chrony-conf-override labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # The Machine Config Operator manages this file. server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
<cluster-name>はクラスターの名前に置き換え、<domain>は完全修飾ドメイン名に置き換える必要があります。
Butane を使用して、ワーカーノードに配信される設定が含まれる
MachineConfigオブジェクトファイル (99-worker-chrony-conf-override.yaml) を生成します。$ butane 99-worker-chrony-conf-override.bu -o 99-worker-chrony-conf-override.yaml
3.14.3. コントロールプレーンで実行されるネットワークコンポーネントの設定
ネットワークコンポーネントは、コントロールプレーンノードでのみ実行するように設定できます。デフォルトで、OpenShift Container Platform はマシン設定プールの任意のノードが ingressVIP 仮想 IP アドレスをホストできるようにします。ただし、環境によっては、コントロールプレーンノードとは別のサブネットにコンピュートノードがデプロイされるため、コントロールプレーンノードで実行するために ingressVIP 仮想 IP アドレスを設定する必要があります。
リモートノードを別々のサブネットにデプロイする場合は、コントロールプレーンノード専用に ingressVIP 仮想 IP アドレスを配置する必要があります。
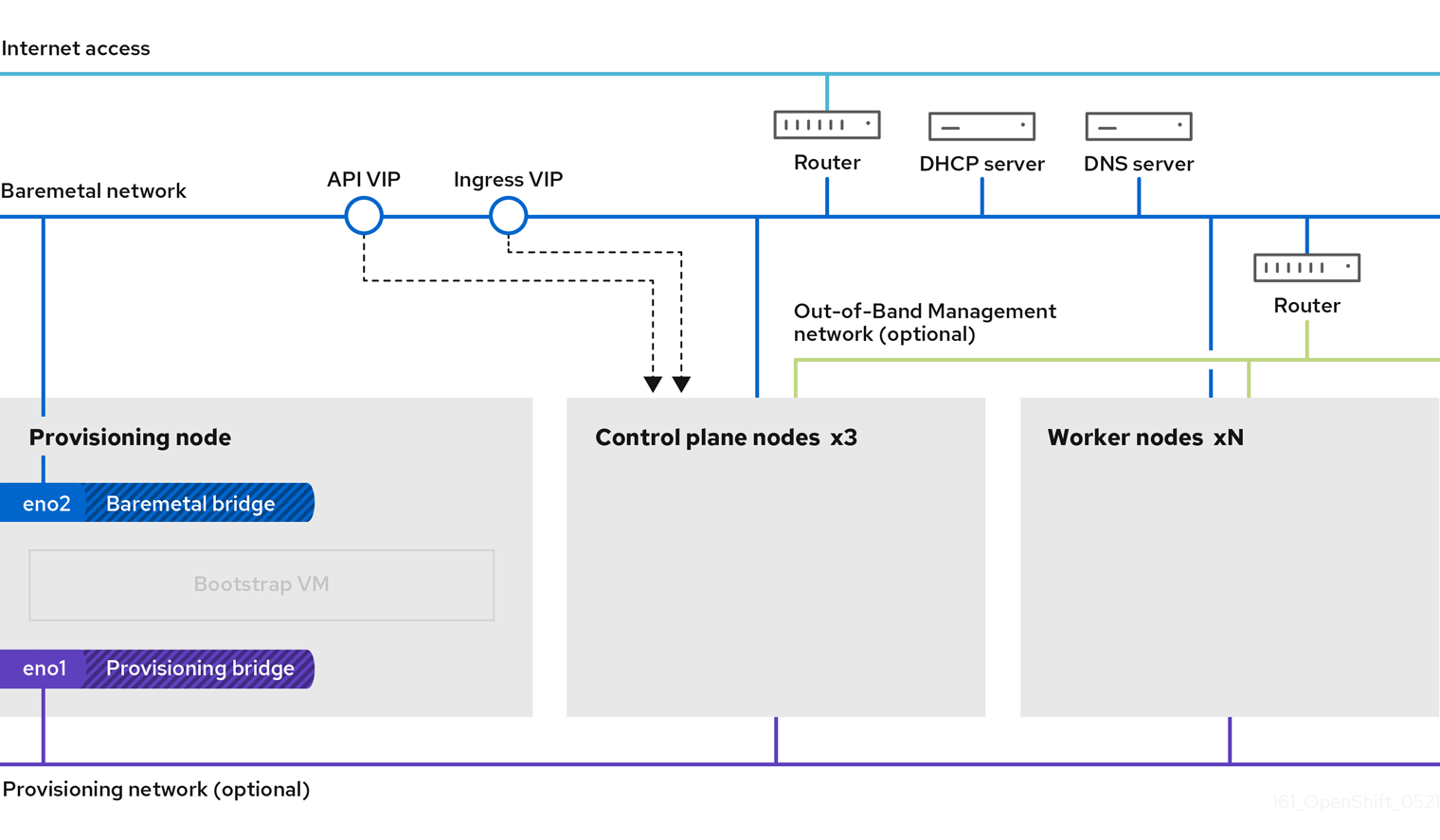
手順
install-config.yamlファイルを保存するディレクトリーに移動します。$ cd ~/clusterconfigsmanifestsサブディレクトリーに切り替えます。$ cd manifestscluster-network-avoid-workers-99-config.yamlという名前のファイルを作成します。$ touch cluster-network-avoid-workers-99-config.yamlエディターで
cluster-network-avoid-workers-99-config.yamlファイルを開き、Operator 設定を記述するカスタムリソース (CR) を入力します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 50-worker-fix-ipi-rwn labels: machineconfiguration.openshift.io/role: worker spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/kubernetes/manifests/keepalived.yaml mode: 0644 contents: source: data:,このマニフェストは、
ingressVIP仮想 IP アドレスをコントロールプレーンノードに配置します。また、このマニフェストは、コントロールプレーンノードにのみ以下のプロセスをデプロイします。-
openshift-ingress-operator -
keepalived
-
-
cluster-network-avoid-workers-99-config.yamlファイルを保存します。 manifests/cluster-ingress-default-ingresscontroller.yamlファイルを作成します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/master: ""-
manifestsディレクトリーのバックアップの作成を検討してください。インストーラーは、クラスターの作成時にmanifests/ディレクトリーを削除します。 cluster-scheduler-02-config.ymlマニフェストを変更し、mastersSchedulableフィールドをtrueに設定して、コントロールプレーンノードをスケジュール対象にします。デフォルトでは、コントロールプレーンノードはスケジュール対象ではありません。以下に例を示します。$ sed -i "s;mastersSchedulable: false;mastersSchedulable: true;g" clusterconfigs/manifests/cluster-scheduler-02-config.yml注記この手順の完了後にコントロールプレーンノードをスケジュールできない場合には、クラスターのデプロイに失敗します。
3.14.4. オプション: コンピュートノードへのルーターのデプロイ
インストール時に、インストールプログラムはルーター Pod をコンピュートノードにデプロイします。デフォルトでは、インストールプログラムは 2 つのルーター Pod をインストールします。デプロイされたクラスターが、OpenShift Container Platform クラスター内のサービスに対して予定される外部トラフィック負荷を処理するために追加のルーターを必要とする場合、yaml ファイルを作成して適切なルーターレプリカ数を設定できます。
コンピュートノードが 1 つだけのクラスターのデプロイはサポートされていません。ルーターのレプリカを変更すると、1 つのコンピュートノードでデプロイする場合の degraded 状態の問題が解決されますが、クラスターで Ingress API の高可用性が失われるため、実稼働環境には適していません。
デフォルトでは、インストールプログラムは 2 つのルーターをデプロイします。クラスターにコンピュートノードがない場合、インストールプログラムはデフォルトで 2 つのルーターをコントロールプレーンノードにデプロイします。
手順
router-replicas.yamlファイルを作成します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: <num-of-router-pods> endpointPublishingStrategy: type: HostNetwork nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: ""注記<num-of-router-pods>を適切な値に置き換えます。1 つのコンピュートノードのみを使用する場合は、replicas:を1に設定します。3 つ以上のコンピュートノードを使用する場合は、必要に応じて、replicas:をデフォルト値2から増やすことができます。router-replicas.yamlファイルを保存し、これをclusterconfigs/openshiftディレクトリーにコピーします。$ cp ~/router-replicas.yaml clusterconfigs/openshift/99_router-replicas.yaml
3.14.5. オプション: BIOS の設定
次の手順では、インストールプロセス中に BIOS を設定します。
手順
- マニフェストを作成します。
ノードに対応する
BareMetalHostリソースファイルを変更します。$ vim clusterconfigs/openshift/99_openshift-cluster-api_hosts-*.yamlBIOS 設定を
BareMetalHostリソースのspecセクションに追加します。spec: firmware: simultaneousMultithreadingEnabled: true sriovEnabled: true virtualizationEnabled: true注記Red Hat は 3 つの BIOS 設定をサポートしています。BMC タイプ
irmcのサーバーのみがサポートされます。他のタイプのサーバーは現在サポートされていません。- クラスターを作成します。
3.14.6. オプション: RAID の設定
次の手順では、インストールプロセス中にベースボード管理コントローラー (BMC) を使用して Redundant Array of Independent Disks (RAID) を構成します。
ノードにハードウェア RAID を設定する場合は、ノードにサポートされている RAID コントローラーがあることを確認してください。OpenShift Container Platform 4.16 は、ソフトウェア RAID をサポートしていません。
| ベンター | BMC とプロトコル | ファームウェアのバージョン | RAID レベル |
|---|---|---|---|
| Fujitsu | iRMC | 該当なし | 0、1、5、6、10 |
| Dell | iDRAC と Redfish | バージョン 6.10.30.20 以降 | 0、1、5 |
手順
- マニフェストを作成します。
ノードに対応する
BareMetalHostリソースを変更します。$ vim clusterconfigs/openshift/99_openshift-cluster-api_hosts-*.yaml注記OpenShift Container Platform 4.16 はソフトウェア RAID をサポートしていないため、次の例ではハードウェア RAID 設定を使用します。
特定の RAID 設定を
specセクションに追加した場合、これが原因でノードはpreparingフェーズで元の RAID 設定を削除し、RAID で指定された設定を実行します。以下に例を示します。spec: raid: hardwareRAIDVolumes: - level: "0"1 name: "sda" numberOfPhysicalDisks: 1 rotational: true sizeGibibytes: 0- 1
levelは必須フィールドであり、その他はオプションのフィールドです。
specセクションに空の RAID 設定を追加した場合、空の設定が原因で、ノードはpreparingフェーズで元の RAID 設定を削除しますが、新しい設定は実行しません。以下に例を示します。spec: raid: hardwareRAIDVolumes: []-
specセクションにraidフィールドを追加しない場合、元の RAID 設定は削除されず、新しい設定は実行されません。
- クラスターを作成します。
3.14.7. オプション: ノード上のストレージの設定
Machine Config Operator (MCO) によって管理される MachineConfig オブジェクトを作成することにより、OpenShift Container Platform ノード上のオペレーティングシステムに変更を加えることができます。
MachineConfig 仕様には、最初の起動時にマシンを設定するための点火設定が含まれています。この設定オブジェクトを使用して、OpenShift Container Platform マシン上で実行されているファイル、systemd サービス、およびその他のオペレーティングシステム機能を変更できます。
手順
ignition config を使用して、ノード上のストレージを設定します。次の MachineSet マニフェストの例は、プライマリーノード上のデバイスにパーティションを追加する方法を示しています。この例では、インストール前にマニフェストを適用して、プライマリーノードでサイズが 16 GiB の recovery という名前のパーティションを設定します。
custom-partitions.yamlファイルを作成し、パーティションレイアウトを含むMachineConfigオブジェクトを含めます。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: primary name: 10_primary_storage_config spec: config: ignition: version: 3.2.0 storage: disks: - device: </dev/xxyN> partitions: - label: recovery startMiB: 32768 sizeMiB: 16384 filesystems: - device: /dev/disk/by-partlabel/recovery label: recovery format: xfscustom-partitions.yamlファイルを保存して、clusterconfigs/openshiftディレクトリーにコピーします。$ cp ~/<MachineConfig_manifest> ~/clusterconfigs/openshift
3.15. 非接続レジストリーの作成
インストールレジストリーのローカルコピーを使用して OpenShift Container Platform クラスターをインストールする必要がある場合があります。これにより、クラスターノードがインターネットにアクセスできないネットワーク上にあるため、ネットワークの効率が高まる可能性があります。
レジストリーのローカルまたはミラーリングされたコピーには、以下が必要です。
- レジストリーの証明書。これには、自己署名証明書を使用できます。
- システム上のコンテナーが提供する Web サーバー。
- 証明書およびローカルリポジトリーの情報が含まれる更新されたプルシークレット。
レジストリーノードでの非接続レジストリーの作成はオプションです。レジストリーノードで切断されたレジストリーを作成する必要がある場合は、次のサブセクションをすべて完了する必要があります。
3.15.1. 前提条件
- 切断されたインストール用のイメージのミラーリング 用のミラーレジストリーをすでに準備している場合は、切断されたレジストリーを使用するように install-config.yaml ファイルを変更する手順 に直接進むことができます。
3.15.2. ミラーリングされたレジストリーをホストするためのレジストリーノードの準備
ベアメタルでミラー化されたレジストリーをホストする前に、次の手順を完了する必要があります。
手順
レジストリーノードでファイアウォールポートを開きます。
$ sudo firewall-cmd --add-port=5000/tcp --zone=libvirt --permanent$ sudo firewall-cmd --add-port=5000/tcp --zone=public --permanent$ sudo firewall-cmd --reloadレジストリーノードに必要なパッケージをインストールします。
$ sudo yum -y install python3 podman httpd httpd-tools jqリポジトリー情報が保持されるディレクトリー構造を作成します。
$ sudo mkdir -p /opt/registry/{auth,certs,data}
3.15.3. 切断されたレジストリーの OpenShift Container Platform イメージリポジトリーのミラーリング
以下の手順を実行して、切断されたレジストリーの OpenShift Container Platform イメージリポジトリーをミラーリングします。
前提条件
- ミラーホストがインターネットにアクセスできる。
- ネットワークが制限された環境で使用するミラーレジストリーを設定し、設定した証明書および認証情報にアクセスできる。
- Red Hat OpenShift Cluster Manager からプルシークレット をダウンロードし、ミラーリポジトリーへの認証を組み込むように変更している。
手順
- OpenShift Container Platform ダウンロード ページを確認し、インストールする必要のある OpenShift Container Platform のバージョンを判別し、Repository Tags ページで対応するタグを判別します。
必要な環境変数を設定します。
リリースバージョンをエクスポートします。
$ OCP_RELEASE=<release_version><release_version>について、インストールする OpenShift Container Platform のバージョンに対応するタグを指定します (例:4.5.4)。ローカルレジストリー名とホストポートをエクスポートします。
$ LOCAL_REGISTRY='<local_registry_host_name>:<local_registry_host_port>'<local_registry_host_name>には、ミラーレジストリーのレジストリードメイン名を指定し、<local_registry_host_port>には、コンテンツの送信に使用するポートを指定します。ローカルリポジトリー名をエクスポートします。
$ LOCAL_REPOSITORY='<local_repository_name>'<local_repository_name>には、ocp4/openshift4などのレジストリーに作成するリポジトリーの名前を指定します。ミラーリングするリポジトリーの名前をエクスポートします。
$ PRODUCT_REPO='openshift-release-dev'実稼働環境のリリースの場合には、
openshift-release-devを指定する必要があります。パスをレジストリープルシークレットにエクスポートします。
$ LOCAL_SECRET_JSON='<path_to_pull_secret>'<path_to_pull_secret>には、作成したミラーレジストリーのプルシークレットの絶対パスおよびファイル名を指定します。リリースミラーをエクスポートします。
$ RELEASE_NAME="ocp-release"実稼働環境のリリースは、
ocp-releaseを指定する必要があります。クラスターのアーキテクチャーのタイプをエクスポートします。
$ ARCHITECTURE=<cluster_architecture>1 - 1
x86_64、aarch64、s390x、またはppc64leなど、クラスターのアーキテクチャーを指定します。
ミラーリングされたイメージをホストするためにディレクトリーへのパスをエクスポートします。
$ REMOVABLE_MEDIA_PATH=<path>1 - 1
- 最初のスラッシュ (/) 文字を含む完全パスを指定します。
バージョンイメージをミラーレジストリーにミラーリングします。
ミラーホストがインターネットにアクセスできない場合は、以下の操作を実行します。
- リムーバブルメディアをインターネットに接続しているシステムに接続します。
ミラーリングするイメージおよび設定マニフェストを確認します。
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} \ --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} \ --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE} --dry-run-
直前のコマンドの出力の
imageContentSourcesセクション全体を記録します。ミラーの情報はミラーリングされたリポジトリーに一意であり、インストール時にimageContentSourcesセクションをinstall-config.yamlファイルに追加する必要があります。 イメージをリムーバブルメディア上のディレクトリーにミラーリングします。
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} --to-dir=${REMOVABLE_MEDIA_PATH}/mirror quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE}メディアをネットワークが制限された環境に移し、イメージをローカルコンテナーレジストリーにアップロードします。
$ oc image mirror -a ${LOCAL_SECRET_JSON} --from-dir=${REMOVABLE_MEDIA_PATH}/mirror "file://openshift/release:${OCP_RELEASE}*" ${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}1 - 1
REMOVABLE_MEDIA_PATHの場合、イメージのミラーリング時に指定した同じパスを使用する必要があります。
ローカルコンテナーレジストリーがミラーホストに接続されている場合は、以下の操作を実行します。
以下のコマンドを使用して、リリースイメージをローカルレジストリーに直接プッシュします。
$ oc adm release mirror -a ${LOCAL_SECRET_JSON} \ --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} \ --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} \ --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}このコマンドは、リリース情報をダイジェストとしてプルします。その出力には、クラスターのインストール時に必要な
imageContentSourcesデータが含まれます。直前のコマンドの出力の
imageContentSourcesセクション全体を記録します。ミラーの情報はミラーリングされたリポジトリーに一意であり、インストール時にimageContentSourcesセクションをinstall-config.yamlファイルに追加する必要があります。注記ミラーリングプロセス中にイメージ名に Quay.io のパッチが適用され、podman イメージにはブートストラップ仮想マシンのレジストリーに Quay.io が表示されます。
ミラーリングしたコンテンツに基づくインストールプログラムを作成するために、インストールプログラムを展開してリリースに固定します。
ミラーホストがインターネットにアクセスできない場合は、以下のコマンドを実行します。
$ oc adm release extract -a ${LOCAL_SECRET_JSON} --command=openshift-baremetal-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}"ローカルコンテナーレジストリーがミラーホストに接続されている場合は、以下のコマンドを実行します。
$ oc adm release extract -a ${LOCAL_SECRET_JSON} --command=openshift-baremetal-install "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"重要選択した OpenShift Container Platform のバージョンに適したイメージを確実に使用するために、ミラーリングしたコンテンツからインストールプログラムを展開する必要があります。
インターネット接続のあるマシンで、このステップを実行する必要があります。
非接続環境を使用している場合には、must-gather の一部として
--imageフラグを使用し、ペイロードイメージを参照します。
installer-provisioned infrastructure を使用するクラスターの場合は、以下のコマンドを実行します。
$ openshift-baremetal-install
3.15.4. 非接続レジストリーを使用するように install-config.yaml ファイルを変更する
プロビジョナーノードでは、install-config.yaml ファイルは pull-secret-update.txt ファイルから新たに作成された pull-secret を使用する必要があります。install-config.yaml ファイルには、非接続レジストリーノードの証明書およびレジストリー情報も含まれる必要があります。
手順
非接続レジストリーノードの証明書を
install-config.yamlファイルに追加します。$ echo "additionalTrustBundle: |" >> install-config.yaml証明書は
"additionalTrustBundle: |"行に従い、通常は 2 つのスペースで適切にインデントされる必要があります。$ sed -e 's/^/ /' /opt/registry/certs/domain.crt >> install-config.yamlレジストリーのミラー情報を
install-config.yamlファイルに追加します。$ echo "imageContentSources:" >> install-config.yaml$ echo "- mirrors:" >> install-config.yaml$ echo " - registry.example.com:5000/ocp4/openshift4" >> install-config.yamlregistry.example.comをレジストリーの完全修飾ドメイン名に置き換えます。$ echo " source: quay.io/openshift-release-dev/ocp-release" >> install-config.yaml$ echo "- mirrors:" >> install-config.yaml$ echo " - registry.example.com:5000/ocp4/openshift4" >> install-config.yamlregistry.example.comをレジストリーの完全修飾ドメイン名に置き換えます。$ echo " source: quay.io/openshift-release-dev/ocp-v4.0-art-dev" >> install-config.yaml
3.16. インストールの検証チェックリスト
- ❏ OpenShift Container Platform インストーラーが取得されている。
- ❏ OpenShift Container Platform インストーラーがデプロイメントされている。
-
❏
install-config.yamlの必須パラメーターが設定されている。 -
❏
install-config.yamlのhostsパラメーターが設定されている。 -
❏
install-config.yamlのbmcパラメーターが設定されている。 -
❏
bmcaddressフィールドで設定されている値の変換が適用されている。 - ❏ OpenShift Container Platform マニフェストが作成されている。
- ❏ (オプション) コンピュートノードにルーターがデプロイされている。
- ❏ (オプション) 切断されたレジストリーを作成している。
- ❏ (オプション) 非接続レジストリー設定が使用されている場合にこれを検証する。
第4章 クラスターのインストール
4.1. 以前のインストールのクリーンアップ
以前にデプロイが失敗した場合は、OpenShift Container Platform を再度デプロイする前に、失敗した試行のアーティファクトを削除します。
手順
OpenShift Container Platform クラスターをインストールする前に、次のコマンドを使用して、すべてのベアメタルノードの電源をオフにします。
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off次のスクリプトを使用して、以前のデプロイ試行時に残った古いブートストラップリソースをすべて削除します。
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done次のコマンドを使用して、以前のインストールにより生成されたアーティファクトを削除します。
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json次のコマンドを使用して、OpenShift Container Platform マニフェストを再作成します。
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
4.2. OpenShift Container Platform インストーラーを使用したクラスターのデプロイ
OpenShift Container Platform インストーラーを実行します。
$ ./openshift-baremetal-install --dir ~/clusterconfigs --log-level debug create cluster4.3. インストールの進行状況を追跡
デプロイメントプロセスで、tail コマンドを install ディレクトリーフォルダーの .openshift_install.log ログファイルに対して実行して、インストールの全体のステータスを確認できます。
$ tail -f /path/to/install-dir/.openshift_install.log4.4. 静的 IP アドレス設定の検証
クラスターノードの DHCP 予約で無限リースが指定されている場合、インストーラーがノードを正常にプロビジョニングした後に、dispatcher スクリプトはノードのネットワーク設定をチェックします。ネットワーク設定に無限 DHCP リースが含まれているとスクリプトが判断すると、DHCP リースの IP アドレスを静的 IP アドレスとして使用して新規接続を作成します。
dispatcher スクリプトは、クラスター内の他のノードのプロビジョニングの進行中に、正常にプロビジョニングされたノードで実行される場合があります。
ネットワーク設定が正しく機能していることを確認します。
手順
- ノードのネットワークインターフェイス設定を確認してください。
- DHCP サーバーをオフにし、OpenShift Container Platform ノードを再起動して、ネットワーク設定が適切に機能していることを確認します。
第5章 インストールのトラブルシューティング
5.1. インストールプログラムワークフローのトラブルシューティング
インストール環境のトラブルシューティングを行う前に、ベアメタルへの installer-provisioned installation の全体的なフローを理解することが重要です。次の図は、環境のトラブルシューティングフローをステップごとに示したものです。

ワークフロー 1/4 は、install-config.yaml ファイルにエラーがある場合や Red Hat Enterprise Linux CoreOS (RHCOS) イメージにアクセスできない場合のトラブルシューティングのワークフローを説明しています。トラブルシューティングに関する提案は、install-config.yaml のトラブルシューティング を参照してください。
ワークフロー 2/4 は、ブートストラップ仮想マシンの問題、クラスターノードを起動できないブートストラップ仮想マシン、および ログの検査 に関するトラブルシューティングのワークフローを説明しています。provisioning ネットワークなしに OpenShift Container Platform クラスターをインストールする場合は、このワークフローは適用されません。

ワークフロー 3/4 は、PXE ブートしないクラスターノード のトラブルシューティングワークフローを示しています。Redfish 仮想メディアを使用してインストールする場合、インストールプログラムによるノードのデプロイに必要な最小ファームウェア要件を各ノードが満たしている必要があります。詳細は、前提条件 セクションの 仮想メディアを使用したインストールのファームウェア要件 を参照してください。
ワークフロー 4/4 は、アクセスできない API から 検証済みのインストール までのトラブルシューティングワークフローを示しています。
5.2. install-config.yaml のトラブルシューティング
install-config.yaml 設定ファイルは、OpenShift Container Platform クラスターの一部であるすべてのノードを表します。このファイルには、apiVersion、baseDomain、imageContentSources、および仮想 IP アドレスのみで構成されるがこれらに制限されない必要なオプションが含まれます。OpenShift Container Platform クラスターのデプロイメントの初期段階でエラーが発生した場合、エラーは install-config.yaml 設定ファイルにある可能性があります。
手順
- YAML-tips のガイドラインを使用します。
- syntax-check を使用して YAML 構文が正しいことを確認します。
Red Hat Enterprise Linux CoreOS (RHCOS) QEMU イメージが適切に定義され、
install-config.yamlで提供される URL 経由でアクセスできることを確認します。以下に例を示します。$ curl -s -o /dev/null -I -w "%{http_code}\n" http://webserver.example.com:8080/rhcos-44.81.202004250133-0-qemu.<architecture>.qcow2.gz?sha256=7d884b46ee54fe87bbc3893bf2aa99af3b2d31f2e19ab5529c60636fbd0f1ce7出力が
200の場合、ブートストラップ仮想マシンイメージを保存する Web サーバーからの有効な応答があります。
5.3. ブートストラップ仮想マシンの問題のトラブルシューティング
OpenShift Container Platform インストールプログラムは、OpenShift Container Platform クラスターノードのプロビジョニングを処理するブートストラップノードの仮想マシンを起動します。
手順
インストールプログラムをトリガー後の約 10 分から 15 分後に、
virshコマンドを使用してブートストラップ仮想マシンが機能していることを確認します。$ sudo virsh listId Name State -------------------------------------------- 12 openshift-xf6fq-bootstrap running注記ブートストラップ仮想マシンの名前は常にクラスター名で始まり、その後にランダムな文字セットが続き、"bootstrap" という単語で終わります。
10 - 15 分経ってもブートストラップ仮想マシンが実行されない場合は、次のコマンドを実行して、システム上で
libvirtdが実行されていることを確認します。$ systemctl status libvirtd● libvirtd.service - Virtualization daemon Loaded: loaded (/usr/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled) Active: active (running) since Tue 2020-03-03 21:21:07 UTC; 3 weeks 5 days ago Docs: man:libvirtd(8) https://libvirt.org Main PID: 9850 (libvirtd) Tasks: 20 (limit: 32768) Memory: 74.8M CGroup: /system.slice/libvirtd.service ├─ 9850 /usr/sbin/libvirtdブートストラップ仮想マシンが動作している場合は、これにログインします。
virsh consoleコマンドを使用して、ブートストラップ仮想マシンの IP アドレスを見つけます。$ sudo virsh console example.comConnected to domain example.com Escape character is ^] Red Hat Enterprise Linux CoreOS 43.81.202001142154.0 (Ootpa) 4.3 SSH host key: SHA256:BRWJktXZgQQRY5zjuAV0IKZ4WM7i4TiUyMVanqu9Pqg (ED25519) SSH host key: SHA256:7+iKGA7VtG5szmk2jB5gl/5EZ+SNcJ3a2g23o0lnIio (ECDSA) SSH host key: SHA256:DH5VWhvhvagOTaLsYiVNse9ca+ZSW/30OOMed8rIGOc (RSA) ens3: fd35:919d:4042:2:c7ed:9a9f:a9ec:7 ens4: 172.22.0.2 fe80::1d05:e52e:be5d:263f localhost login:重要provisioningネットワークなしで OpenShift Container Platform クラスターをデプロイする場合、172.22.0.2などのプライベート IP アドレスではなく、パブリック IP アドレスを使用する必要があります。IP アドレスを取得したら、
sshコマンドを使用してブートストラップ仮想マシンにログインします。注記直前の手順のコンソール出力では、
ens3で提供される IPv6 IP アドレスまたはens4で提供される IPv4 IP を使用できます。$ ssh core@172.22.0.2
ブートストラップ仮想マシンへのログインに成功しない場合は、以下いずれかのシナリオが発生した可能性があります。
-
172.22.0.0/24ネットワークにアクセスできない。プロビジョナーとprovisioningネットワークブリッジ間のネットワーク接続を確認します。この問題は、provisioningネットワークを使用している場合に発生することがあります。 -
パブリックネットワーク経由でブートストラップ仮想マシンにアクセスできない。
baremetalネットワークで SSH を試行する際に、provisionerホストの、とくにbaremetalネットワークブリッジについて接続を確認します。 -
Permission denied (publickey,password,keyboard-interactive)が出される。ブートストラップ仮想マシンへのアクセスを試行すると、Permission deniedエラーが発生する可能性があります。仮想マシンへのログインを試行するユーザーの SSH キーがinstall-config.yamlファイル内で設定されていることを確認します。
5.3.1. ブートストラップ仮想マシンがクラスターノードを起動できない
デプロイメント時に、ブートストラップ仮想マシンがクラスターノードの起動に失敗する可能性があり、これにより、仮想マシンがノードに RHCOS イメージをプロビジョニングできなくなります。このシナリオは、以下の原因で発生する可能性があります。
-
install-config.yamlファイルに関連する問題。 - ベアメタルネットワークを使用してアウトオブバンド (out-of-band) ネットワークアクセスに関する問題
この問題を確認するには、ironic に関連する 3 つのコンテナーを使用できます。
-
ironic -
ironic-inspector
手順
ブートストラップ仮想マシンにログインします。
$ ssh core@172.22.0.2コンテナーログを確認するには、以下を実行します。
[core@localhost ~]$ sudo podman logs -f <container_name><container_name>をironicまたはironic-inspectorのいずれかに置き換えます。コントロールプレーンノードが PXE から起動しないという問題が発生した場合は、ironicPod を確認してください。ironicPod は、IPMI 経由でノードにログインしようとするため、クラスターノードを起動しようとする試みに関する情報を含んでいます。
考えられる理由
クラスターノードは、デプロイメントの開始時に ON 状態にある可能性があります。
解決策
IPMI でのインストールを開始する前に、OpenShift Container Platform クラスターノードの電源をオフにします。
$ ipmitool -I lanplus -U root -P <password> -H <out_of_band_ip> power off5.3.2. ログの検査
RHCOS イメージのダウンロードまたはアクセスに問題が発生した場合には、最初に install-config.yaml 設定ファイルで URL が正しいことを確認します。
RHCOS イメージをホストする内部 Web サーバーの例
bootstrapOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-qemu.<architecture>.qcow2.gz?sha256=9d999f55ff1d44f7ed7c106508e5deecd04dc3c06095d34d36bf1cd127837e0c
clusterOSImage: http://<ip:port>/rhcos-43.81.202001142154.0-openstack.<architecture>.qcow2.gz?sha256=a1bda656fa0892f7b936fdc6b6a6086bddaed5dafacedcd7a1e811abb78fe3b0
coreos-downloader コンテナーは、Web サーバーまたは外部の quay.io レジストリー (install-config.yaml 設定ファイルで指定されている方) からリソースをダウンロードします。coreos-downloader コンテナーが稼働していることを確認し、必要に応じて、そのログを調べます。
手順
ブートストラップ仮想マシンにログインします。
$ ssh core@172.22.0.2次のコマンドを実行して、ブートストラップ VM 内の
coreos-downloaderコンテナーのステータスを確認します。[core@localhost ~]$ sudo podman logs -f coreos-downloaderブートストラップ仮想マシンがイメージへの URL にアクセスできない場合、
curlコマンドを使用して、仮想マシンがイメージにアクセスできることを確認します。すべてのコンテナーがデプロイメントフェーズで起動されているかどうかを示す
bootkubeログを検査するには、以下を実行します。[core@localhost ~]$ journalctl -xe[core@localhost ~]$ journalctl -b -f -u bootkube.servicednsmasq、mariadb、httpd、およびironicを含むすべての Pod が実行中であることを確認します。[core@localhost ~]$ sudo podman psPod に問題がある場合には、問題のあるコンテナーのログを確認します。
ironicサービスのログを確認するには、次のコマンドを実行します。[core@localhost ~]$ sudo podman logs ironic
5.5. クラスターの初期化失敗のトラブルシューティング
インストールプログラムは、Cluster Version Operator を使用して、OpenShift Container Platform クラスターのすべてのコンポーネントを作成します。インストールプログラムがクラスターの初期化に失敗した場合は、ClusterVersion オブジェクトと ClusterOperator オブジェクトから最も重要な情報を取得できます。
手順
次のコマンドを実行して
ClusterVersionオブジェクトを検査します。$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion -o yaml出力例
apiVersion: config.openshift.io/v1 kind: ClusterVersion metadata: creationTimestamp: 2019-02-27T22:24:21Z generation: 1 name: version resourceVersion: "19927" selfLink: /apis/config.openshift.io/v1/clusterversions/version uid: 6e0f4cf8-3ade-11e9-9034-0a923b47ded4 spec: channel: stable-4.1 clusterID: 5ec312f9-f729-429d-a454-61d4906896ca status: availableUpdates: null conditions: - lastTransitionTime: 2019-02-27T22:50:30Z message: Done applying 4.1.1 status: "True" type: Available - lastTransitionTime: 2019-02-27T22:50:30Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:30Z message: Cluster version is 4.1.1 status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:24:31Z message: 'Unable to retrieve available updates: unknown version 4.1.1 reason: RemoteFailed status: "False" type: RetrievedUpdates desired: image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a version: 4.1.1 history: - completionTime: 2019-02-27T22:50:30Z image: registry.svc.ci.openshift.org/openshift/origin-release@sha256:91e6f754975963e7db1a9958075eb609ad226968623939d262d1cf45e9dbc39a startedTime: 2019-02-27T22:24:31Z state: Completed version: 4.1.1 observedGeneration: 1 versionHash: Wa7as_ik1qE=次のコマンドを実行して状態を表示します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusterversion version \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'最も重要な状態は、
Failing、Available、Progressingです。出力例
Available True Done applying 4.1.1 Failing False Progressing False Cluster version is 4.0.0-0.alpha-2019-02-26-194020 RetrievedUpdates False Unable to retrieve available updates: unknown version 4.1.1次のコマンドを実行して
ClusterOperatorオブジェクトを検査します。$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperatorこのコマンドは、クラスター Operators のステータスを返します。
出力例
NAME VERSION AVAILABLE PROGRESSING FAILING SINCE cluster-baremetal-operator True False False 17m cluster-autoscaler True False False 17m cluster-storage-operator True False False 10m console True False False 7m21s dns True False False 31m image-registry True False False 9m58s ingress True False False 10m kube-apiserver True False False 28m kube-controller-manager True False False 21m kube-scheduler True False False 25m machine-api True False False 17m machine-config True False False 17m marketplace-operator True False False 10m monitoring True False False 8m23s network True False False 13m node-tuning True False False 11m openshift-apiserver True False False 15m openshift-authentication True False False 20m openshift-cloud-credential-operator True False False 18m openshift-controller-manager True False False 10m openshift-samples True False False 8m42s operator-lifecycle-manager True False False 17m service-ca True False False 30m次のコマンドを実行して、個々のクラスター Operator を検査します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> -oyaml1 - 1
<operator>は、クラスター Operator の名前に置き換えます。このコマンドは、クラスター Operator のステータスがAvailableにならない理由、またはFailedになる理由を特定するために使用できます。
出力例
apiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:47:04Z generation: 1 name: monitoring resourceVersion: "24677" selfLink: /apis/config.openshift.io/v1/clusteroperators/monitoring uid: 9a6a5ef9-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:49:10Z message: Successfully rolled out the stack. status: "True" type: Available - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:49:10Z status: "False" type: Failing extension: null relatedObjects: null version: ""クラスター Operator のステータス状態を取得するには、次のコマンドを実行します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator <operator> \ -o=jsonpath='{range .status.conditions[*]}{.type}{" "}{.status}{" "}{.message}{"\n"}{end}'<Operator>は、上記のいずれかの Operator の名前に置き換えます。出力例
Available True Successfully rolled out the stack Progressing False Failing Falseクラスター Operator が所有するオブジェクトのリストを取得するには、次のコマンドを実行します。
oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator kube-apiserver \ -o=jsonpath='{.status.relatedObjects}'出力例
[map[resource:kubeapiservers group:operator.openshift.io name:cluster] map[group: name:openshift-config resource:namespaces] map[group: name:openshift-config-managed resource:namespaces] map[group: name:openshift-kube-apiserver-operator resource:namespaces] map[group: name:openshift-kube-apiserver resource:namespaces]]
5.6. コンソール URL の取得に失敗した場合のトラブルシューティング
インストールプログラムは、openshift-console namespace 内の [route][route-object] を使用して、OpenShift Container Platform コンソールの URL を取得します。インストールプログラムがコンソールの URL の取得に失敗した場合は、次の手順に従います。
手順
次のコマンドを実行して、コンソールルーターが
Available状態かFailing状態かを確認します。$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get clusteroperator console -oyamlapiVersion: config.openshift.io/v1 kind: ClusterOperator metadata: creationTimestamp: 2019-02-27T22:46:57Z generation: 1 name: console resourceVersion: "19682" selfLink: /apis/config.openshift.io/v1/clusteroperators/console uid: 960364aa-3ae1-11e9-bad4-0a97b6ba9358 spec: {} status: conditions: - lastTransitionTime: 2019-02-27T22:46:58Z status: "False" type: Failing - lastTransitionTime: 2019-02-27T22:50:12Z status: "False" type: Progressing - lastTransitionTime: 2019-02-27T22:50:12Z status: "True" type: Available - lastTransitionTime: 2019-02-27T22:46:57Z status: "True" type: Upgradeable extension: null relatedObjects: - group: operator.openshift.io name: cluster resource: consoles - group: config.openshift.io name: cluster resource: consoles - group: oauth.openshift.io name: console resource: oauthclients - group: "" name: openshift-console-operator resource: namespaces - group: "" name: openshift-console resource: namespaces versions: null次のコマンドを実行して、コンソール URL を手動で取得します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get route console -n openshift-console \ -o=jsonpath='{.spec.host}' console-openshift-console.apps.adahiya-1.devcluster.openshift.com
5.7. kubeconfig に Ingress 証明書を追加できない場合のトラブルシューティング
インストールプログラムは、${INSTALL_DIR}/auth/kubeconfig 内の信頼できるクライアント認証局のリストにデフォルトの Ingress 証明書を追加します。インストールプログラムが Ingress 証明書を kubeconfig ファイルに追加できない場合は、クラスターから証明書を取得して追加できます。
手順
次のコマンドを使用して、クラスターから証明書を取得します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig get configmaps default-ingress-cert \ -n openshift-config-managed -o=jsonpath='{.data.ca-bundle\.crt}'-----BEGIN CERTIFICATE----- MIIC/TCCAeWgAwIBAgIBATANBgkqhkiG9w0BAQsFADAuMSwwKgYDVQQDDCNjbHVz dGVyLWluZ3Jlc3Mtb3BlcmF0b3JAMTU1MTMwNzU4OTAeFw0xOTAyMjcyMjQ2Mjha Fw0yMTAyMjYyMjQ2MjlaMC4xLDAqBgNVBAMMI2NsdXN0ZXItaW5ncmVzcy1vcGVy YXRvckAxNTUxMzA3NTg5MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA uCA4fQ+2YXoXSUL4h/mcvJfrgpBfKBW5hfB8NcgXeCYiQPnCKblH1sEQnI3VC5Pk 2OfNCF3PUlfm4i8CHC95a7nCkRjmJNg1gVrWCvS/ohLgnO0BvszSiRLxIpuo3C4S EVqqvxValHcbdAXWgZLQoYZXV7RMz8yZjl5CfhDaaItyBFj3GtIJkXgUwp/5sUfI LDXW8MM6AXfuG+kweLdLCMm3g8WLLfLBLvVBKB+4IhIH7ll0buOz04RKhnYN+Ebw tcvFi55vwuUCWMnGhWHGEQ8sWm/wLnNlOwsUz7S1/sW8nj87GFHzgkaVM9EOnoNI gKhMBK9ItNzjrP6dgiKBCQIDAQABoyYwJDAOBgNVHQ8BAf8EBAMCAqQwEgYDVR0T AQH/BAgwBgEB/wIBADANBgkqhkiG9w0BAQsFAAOCAQEAq+vi0sFKudaZ9aUQMMha CeWx9CZvZBblnAWT/61UdpZKpFi4eJ2d33lGcfKwHOi2NP/iSKQBebfG0iNLVVPz vwLbSG1i9R9GLdAbnHpPT9UG6fLaDIoKpnKiBfGENfxeiq5vTln2bAgivxrVlyiq +MdDXFAWb6V4u2xh6RChI7akNsS3oU9PZ9YOs5e8vJp2YAEphht05X0swA+X8V8T C278FFifpo0h3Q0Dbv8Rfn4UpBEtN4KkLeS+JeT+0o2XOsFZp7Uhr9yFIodRsnNo H/Uwmab28ocNrGNiEVaVH6eTTQeeZuOdoQzUbClElpVmkrNGY0M42K0PvOQ/e7+y AQ== -----END CERTIFICATE------
${INSTALL_DIR}/auth/kubeconfigファイルのclient-certificate-authority-dataフィールドに証明書を追加します。
5.8. クラスターノードへの SSH アクセスのトラブルシューティング
セキュリティーを強化するために、デフォルトではクラスターの外部からクラスターに SSH 接続することは禁止されています。ただし、プロビジョナーノードからコントロールプレーンノードとワーカーノードにアクセスすることはできます。プロビジョナーノードからクラスターノードに SSH 接続できない場合、クラスターノードがブートストラップ仮想マシンを待機している可能性があります。コントロールプレーンノードはブートストラップ仮想マシンからブート設定を取得します。コントロールプレーンノードはブート設定を取得しないと、正常に起動できません。
手順
- ノードに物理的にアクセスできる場合は、コンソールの出力をチェックして、正常に起動したかどうかを確認します。ノードがまだブート設定を取得中の場合は、ブートストラップ仮想マシンに問題がある可能性があります。
-
install-config.yamlファイルでsshKey: '<ssh_pub_key>'が設定されていることを確認します。<ssh_pub_key>は、プロビジョナーノード上のkniユーザーの公開鍵です。
5.9. クラスターノードが PXE ブートしない
OpenShift Container Platform クラスターノードが PXE ブートしない場合、PXE ブートしないクラスターノードで以下のチェックを実行します。この手順は、provisioning ネットワークなしで OpenShift Container Platform クラスターをインストールする場合には適用されません。
手順
-
provisioningネットワークへのネットワークの接続を確認します。 -
PXE が
provisioningネットワークの NIC で有効にされており、PXE がその他のすべての NIC について無効にされていることを確認します。 install-config.yaml設定ファイルに、provisioningネットワークに接続されている NIC のrootDeviceHintsパラメーターとブート MAC アドレスが含まれていることを確認します。以下に例を示します。コントロールプレーンノードの設定
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NICワーカーノード設定
bootMACAddress: 24:6E:96:1B:96:90 # MAC of bootable provisioning NIC
5.10. インストールしてもワーカーノードが作成されない
インストールプログラムはワーカーノードを直接プロビジョニングしません。代わりに、Machine API Operator が、サポートされているプラットフォーム上でノードをスケールアップおよびスケールダウンします。クラスターのインターネット接続の速度によって異なりますが、15 - 20 分経ってもワーカーノードが作成されない場合は、Machine API Operator を調査してください。
手順
次のコマンドを実行して、Machine API Operator を確認します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api get deploymentsご使用の環境で
${INSTALL_DIR}が設定されていない場合は、値をインストールディレクトリーの名前に置き換えます。出力例
NAME READY UP-TO-DATE AVAILABLE AGE cluster-autoscaler-operator 1/1 1 1 86m cluster-baremetal-operator 1/1 1 1 86m machine-api-controllers 1/1 1 1 85m machine-api-operator 1/1 1 1 86m次のコマンドを実行して、マシンコントローラーのログを確認します。
$ oc --kubeconfig=${INSTALL_DIR}/auth/kubeconfig \ --namespace=openshift-machine-api logs deployments/machine-api-controllers \ --container=machine-controller
5.11. Cluster Network Operator のトラブルシューティング
Cluster Network Operator は、ネットワークコンポーネントのデプロイを担当します。この Operator は、コントロールプレーンノードが起動した後、インストールプログラムがブートストラップコントロールプレーンを削除する前に、インストールプロセスの初期段階で実行されます。この Operator に問題がある場合、インストールプログラムに問題がある可能性があります。
手順
次のコマンドを実行して、ネットワーク設定が存在することを確認します。
$ oc get network -o yaml cluster存在しない場合は、インストールプログラムによって作成されていません。理由を確認するには、次のコマンドを実行します。
$ openshift-install create manifestsマニフェストを確認して、インストールプログラムがネットワーク設定を作成しなかった理由を特定します。
次のコマンドを入力して、ネットワークが実行中であることを確認します。
$ oc get po -n openshift-network-operator
5.12. BMC を使用して、新しいベアメタルホストを検出できない
場合によっては、リモート仮想メディア共有をマウントできないため、インストールプログラムが新しいベアメタルホストを検出できず、エラーが発生することがあります。
以下に例を示します。
ProvisioningError 51s metal3-baremetal-controller Image provisioning failed: Deploy step deploy.deploy failed with BadRequestError: HTTP POST
https://<bmc_address>/redfish/v1/Managers/iDRAC.Embedded.1/VirtualMedia/CD/Actions/VirtualMedia.InsertMedia
returned code 400.
Base.1.8.GeneralError: A general error has occurred. See ExtendedInfo for more information
Extended information: [
{
"Message": "Unable to mount remote share https://<ironic_address>/redfish/boot-<uuid>.iso.",
"MessageArgs": [
"https://<ironic_address>/redfish/boot-<uuid>.iso"
],
"MessageArgs@odata.count": 1,
"MessageId": "IDRAC.2.5.RAC0720",
"RelatedProperties": [
"#/Image"
],
"RelatedProperties@odata.count": 1,
"Resolution": "Retry the operation.",
"Severity": "Informational"
}
].この状況で、認証局が不明な仮想メディアを使用している場合は、不明な認証局を信頼するように、ベースボード管理コントローラー (BMC) のリモートファイル共有設定を行って、このエラーを回避できます。
この解決策は、Dell iDRAC 9 およびファームウェアバージョン 5.10.50 を搭載した OpenShift Container Platform 4.11 でテストされました。
5.13. クラスターに参加できないワーカーノードのトラブルシューティング
installer-provisioned クラスターは、api-int.<cluster_name>.<base_domain> URL の DNS エントリーが含まれる DNS サーバーと共にデプロイされます。クラスター内のノードが外部またはアップストリーム DNS サーバーを使用して api-int.<cluster_name>.<base_domain> URL を解決し、そのようなエントリーがない場合、ワーカーノードはクラスターに参加できない可能性があります。クラスター内のすべてのノードがドメイン名を解決できることを確認します。
手順
DNS A/AAAA または CNAME レコードを追加して、API ロードバランサーを内部的に識別します。たとえば、dnsmasq を使用する場合は、
dnsmasq.conf設定ファイルを変更します。$ sudo nano /etc/dnsmasq.confaddress=/api-int.<cluster_name>.<base_domain>/<IP_address> address=/api-int.mycluster.example.com/192.168.1.10 address=/api-int.mycluster.example.com/2001:0db8:85a3:0000:0000:8a2e:0370:7334DNS PTR レコードを追加して、API ロードバランサーを内部的に識別します。たとえば、dnsmasq を使用する場合は、
dnsmasq.conf設定ファイルを変更します。$ sudo nano /etc/dnsmasq.confptr-record=<IP_address>.in-addr.arpa,api-int.<cluster_name>.<base_domain> ptr-record=10.1.168.192.in-addr.arpa,api-int.mycluster.example.comDNS サーバーを再起動します。たとえば、dnsmasq を使用する場合は、以下のコマンドを実行します。
$ sudo systemctl restart dnsmasq
これらのレコードは、クラスター内のすべてのノードで解決できる必要があります。
5.14. 以前のインストールのクリーンアップ
以前にデプロイが失敗した場合は、OpenShift Container Platform を再度デプロイする前に、失敗した試行のアーティファクトを削除します。
手順
OpenShift Container Platform クラスターをインストールする前に、次のコマンドを使用して、すべてのベアメタルノードの電源をオフにします。
$ ipmitool -I lanplus -U <user> -P <password> -H <management_server_ip> power off次のスクリプトを使用して、以前のデプロイ試行時に残った古いブートストラップリソースをすべて削除します。
for i in $(sudo virsh list | tail -n +3 | grep bootstrap | awk {'print $2'}); do sudo virsh destroy $i; sudo virsh undefine $i; sudo virsh vol-delete $i --pool $i; sudo virsh vol-delete $i.ign --pool $i; sudo virsh pool-destroy $i; sudo virsh pool-undefine $i; done次のコマンドを使用して、以前のインストールにより生成されたアーティファクトを削除します。
$ cd ; /bin/rm -rf auth/ bootstrap.ign master.ign worker.ign metadata.json \ .openshift_install.log .openshift_install_state.json次のコマンドを使用して、OpenShift Container Platform マニフェストを再作成します。
$ ./openshift-baremetal-install --dir ~/clusterconfigs create manifests
5.15. レジストリーの作成に関する問題
非接続レジストリーの作成時に、レジストリーのミラーリングを試行する際に "User Not Authorized" エラーが発生する場合があります。このエラーは、新規の認証を既存の pull-secret.txt ファイルに追加できない場合に生じる可能性があります。
手順
認証が正常に行われていることを確認します。
$ /usr/local/bin/oc adm release mirror \ -a pull-secret-update.json --from=$UPSTREAM_REPO \ --to-release-image=$LOCAL_REG/$LOCAL_REPO:${VERSION} \ --to=$LOCAL_REG/$LOCAL_REPO注記インストールイメージのミラーリングに使用される変数の出力例:
UPSTREAM_REPO=${RELEASE_IMAGE} LOCAL_REG=<registry_FQDN>:<registry_port> LOCAL_REPO='ocp4/openshift4'RELEASE_IMAGEおよびVERSIONの値は、OpenShift インストールの環境のセットアップ セクションの OpenShift Installer の取得 の手順で設定されています。レジストリーのミラーリング後に、非接続環境でこれにアクセスできることを確認します。
$ curl -k -u <user>:<password> https://registry.example.com:<registry_port>/v2/_catalog {"repositories":["<Repo_Name>"]}
5.16. その他の問題点
5.16.1. runtime network not ready エラーへの対応
クラスターのデプロイメント後に、以下のエラーが発生する可能性があります。
`runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: Missing CNI default network`
Cluster Network Operator は、インストールプログラムによって作成される特別なオブジェクトに応じてネットワークコンポーネントをデプロイします。これは、コントロールプレーン (マスター) ノードが起動した後、ブートストラップコントロールプレーンが停止する前にインストールプロセスの初期段階で実行されます。これは、コントロールプレーン (マスター) ノードの起動の長い遅延や apiserver の通信の問題など、より判別しにくいインストールプログラムの問題を示している可能性があります。
手順
openshift-network-operatornamespace の Pod を検査します。$ oc get all -n openshift-network-operatorNAME READY STATUS RESTARTS AGE pod/network-operator-69dfd7b577-bg89v 0/1 ContainerCreating 0 149mprovisionerノードで、ネットワーク設定が存在することを判別します。$ kubectl get network.config.openshift.io cluster -oyamlapiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNetwork: - 172.30.0.0/16 clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OVNKubernetes存在しない場合は、インストールプログラムによって作成されていません。インストールプログラムによって作成されなかった理由を確認するには、次のコマンドを実行します。
$ openshift-install create manifestsnetwork-operatorが実行されていることを確認します。$ kubectl -n openshift-network-operator get podsログを取得します。
$ kubectl -n openshift-network-operator logs -l "name=network-operator"3 つ以上のコントロールプレーンノードを持つ高可用性クラスターでは、Operator がリーダー選択を実行し、他のすべての Operator がスリープ状態になります。詳細は、Troubleshooting を参照してください。
5.16.2. "No disk found with matching rootDeviceHints" エラーメッセージへの対処
クラスターをデプロイした後、次のエラーメッセージが表示される場合があります。
No disk found with matching rootDeviceHints
No disk found with matching rootDeviceHints エラーメッセージに対処するための一時的な回避策は、rootDeviceHints を minSizeGigabytes: 300 に変更することです。
rootDeviceHints 設定を変更した後、CoreOS を起動し、次のコマンドを使用してディスク情報を確認します。
$ udevadm info /dev/sda
DL360 Gen 10 サーバーを使用している場合は、/dev/sda デバイス名が割り当てられている SD カードスロットがあることに注意してください。サーバーに SD カードが存在しない場合は、競合が発生する可能性があります。サーバーの BIOS 設定で SD カードスロットが無効になっていることを確認してください。
minSizeGigabytes の回避策が要件を満たしていない場合は、rootDeviceHints を /dev/sda に戻さないといけない場合があります。この変更により、Ironic イメージが正常に起動できるようになります。
この問題を解決する別の方法は、ディスクのシリアル ID を使用することです。ただし、シリアル ID を見つけるのは困難な場合があり、設定ファイルが読みにくくなる可能性があることに注意してください。このパスを選択する場合は、前に説明したコマンドを使用してシリアル ID を収集し、それを設定に組み込んでください。
5.16.3. クラスターノードが DHCP 経由で正しい IPv6 アドレスを取得しない
クラスターノードが DHCP 経由で正しい IPv6 アドレスを取得しない場合は、以下の点を確認してください。
- 予約された IPv6 アドレスが DHCP 範囲外にあることを確認します。
DHCP サーバーの IP アドレス予約では、予約で正しい DUID (DHCP 固有識別子) が指定されていることを確認します。以下に例を示します。
# This is a dnsmasq dhcp reservation, 'id:00:03:00:01' is the client id and '18:db:f2:8c:d5:9f' is the MAC Address for the NIC id:00:03:00:01:18:db:f2:8c:d5:9f,openshift-master-1,[2620:52:0:1302::6]- Route Announcement が機能していることを確認します。
- DHCP サーバーが、IP アドレス範囲を提供する必要なインターフェイスでリッスンしていることを確認します。
5.16.4. クラスターノードが DHCP 経由で正しいホスト名を取得しない
IPv6 のデプロイメント時に、クラスターノードは DHCP でホスト名を取得する必要があります。NetworkManager はホスト名をすぐに割り当てない場合があります。コントロールプレーン (マスター) ノードは、以下のようなエラーを報告する可能性があります。
Failed Units: 2
NetworkManager-wait-online.service
nodeip-configuration.service
このエラーは、最初に DHCP サーバーからホスト名を受信せずにクラスターノードが起動する可能性があることを示しています。これにより、kubelet が localhost.localdomain ホスト名で起動します。エラーに対処するには、ノードによるホスト名の更新を強制します。
手順
hostnameを取得します。[core@master-X ~]$ hostnameホスト名が
localhostの場合は、以下の手順に進みます。注記Xはコントロールプレーンノード番号です。クラスターノードによる DHCP リースの更新を強制します。
[core@master-X ~]$ sudo nmcli con up "<bare_metal_nic>"<bare_metal_nic>を、baremetalネットワークに対応する有線接続に置き換えます。hostnameを再度確認します。[core@master-X ~]$ hostnameホスト名が
localhost.localdomainの場合は、NetworkManagerを再起動します。[core@master-X ~]$ sudo systemctl restart NetworkManager-
ホスト名がまだ
localhost.localdomainの場合は、数分待機してから再度確認します。ホスト名がlocalhost.localdomainのままの場合は、直前の手順を繰り返します。 nodeip-configurationサービスを再起動します。[core@master-X ~]$ sudo systemctl restart nodeip-configuration.serviceこのサービスは、正しいホスト名の参照で
kubeletサービスを再設定します。kubelet が直前の手順で変更された後にユニットファイル定義を再読み込みします。
[core@master-X ~]$ sudo systemctl daemon-reloadkubeletサービスを再起動します。[core@master-X ~]$ sudo systemctl restart kubelet.servicekubeletが正しいホスト名で起動されていることを確認します。[core@master-X ~]$ sudo journalctl -fu kubelet.service
再起動時など、クラスターの稼働後にクラスターノードが正しいホスト名を取得しない場合、クラスターの csr は保留中になります。csr は承認 しません。承認すると、他の問題が生じる可能性があります。
csr の対応
クラスターで CSR を取得します。
$ oc get csr保留中の
csrにSubject Name: localhost.localdomainが含まれているかどうかを確認します。$ oc get csr <pending_csr> -o jsonpath='{.spec.request}' | base64 --decode | openssl req -noout -textSubject Name: localhost.localdomainが含まれるcsrを削除します。$ oc delete csr <wrong_csr>
5.16.5. ルートがエンドポイントに到達しない
インストールプロセス時に、VRRP (Virtual Router Redundancy Protocol) の競合が発生する可能性があります。この競合は、特定のクラスター名を使用してクラスターデプロイメントの一部であった、以前に使用された OpenShift Container Platform ノードが依然として実行中であるものの、同じクラスター名を使用した現在の OpenShift Container Platform クラスターデプロイメントの一部ではない場合に発生する可能性があります。たとえば、クラスターはクラスター名 openshift を使用してデプロイされ、3 つのコントロールプレーン (マスター) ノードと 3 つのワーカーノードをデプロイします。後に、別のインストールで同じクラスター名 openshift が使用されますが、この再デプロイメントは 3 つのコントロールプレーン (マスター) ノードのみをインストールし、以前のデプロイメントの 3 つのワーカーノードを ON 状態のままにします。これにより、VRID (Virtual Router Identifier) の競合が発生し、VRRP が競合する可能性があります。
ルートを取得します。
$ oc get route oauth-openshiftサービスエンドポイントを確認します。
$ oc get svc oauth-openshiftNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE oauth-openshift ClusterIP 172.30.19.162 <none> 443/TCP 59mコントロールプレーン (マスター) ノードからサービスへのアクセスを試行します。
[core@master0 ~]$ curl -k https://172.30.19.162{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403provisionerノードからのauthentication-operatorエラーを特定します。$ oc logs deployment/authentication-operator -n openshift-authentication-operatorEvent(v1.ObjectReference{Kind:"Deployment", Namespace:"openshift-authentication-operator", Name:"authentication-operator", UID:"225c5bd5-b368-439b-9155-5fd3c0459d98", APIVersion:"apps/v1", ResourceVersion:"", FieldPath:""}): type: 'Normal' reason: 'OperatorStatusChanged' Status for clusteroperator/authentication changed: Degraded message changed from "IngressStateEndpointsDegraded: All 2 endpoints for oauth-server are reporting"
解決策
- すべてのデプロイメントのクラスター名が一意であり、競合が発生しないことを確認します。
- 同じクラスター名を使用するクラスターデプロイメントの一部ではない不正なノードをすべてオフにします。そうしないと、OpenShift Container Platform クラスターの認証 Pod が正常に起動されなくなる可能性があります。
5.16.6. 初回起動時の Ignition の失敗
初回起動時に、Ignition 設定が失敗する可能性があります。
手順
Ignition 設定が失敗したノードに接続します。
Failed Units: 1 machine-config-daemon-firstboot.servicemachine-config-daemon-firstbootサービスを再起動します。[core@worker-X ~]$ sudo systemctl restart machine-config-daemon-firstboot.service
5.16.7. NTP が同期しない
OpenShift Container Platform クラスターのデプロイメントは、クラスターノード間の NTP の同期クロックによって異なります。同期クロックがない場合、時間の差が 2 秒を超えるとクロックのドリフトによりデプロイメントが失敗する可能性があります。
手順
クラスターノードの
AGEの差異の有無を確認します。以下に例を示します。$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.cloud.example.com Ready master 145m v1.29.4 master-1.cloud.example.com Ready master 135m v1.29.4 master-2.cloud.example.com Ready master 145m v1.29.4 worker-2.cloud.example.com Ready worker 100m v1.29.4クロックのドリフトによる一貫性のないタイミングの遅延を確認します。以下に例を示します。
$ oc get bmh -n openshift-machine-apimaster-1 error registering master-1 ipmi://<out_of_band_ip>$ sudo timedatectlLocal time: Tue 2020-03-10 18:20:02 UTC Universal time: Tue 2020-03-10 18:20:02 UTC RTC time: Tue 2020-03-10 18:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: no NTP service: active RTC in local TZ: no
既存のクラスターでのクロックドリフトへの対応
ノードに配信される
chrony.confファイルの内容を含む Butane 設定ファイルを作成します。以下の例で、99-master-chrony.buを作成して、ファイルをコントロールプレーンノードに追加します。ワーカーノードのファイルを変更するか、ワーカーロールに対してこの手順を繰り返すことができます。注記Butane の詳細は、「Butane を使用したマシン設定の作成」を参照してください。
variant: openshift version: 4.16.0 metadata: name: 99-master-chrony labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | server <NTP_server> iburst1 stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
<NTP_server>を NTP サーバーの IP アドレスに置き換えます。
Butane を使用して、ノードに配信される設定を含む
MachineConfigオブジェクトファイル (99-master-chrony.yaml) を生成します。$ butane 99-master-chrony.bu -o 99-master-chrony.yamlMachineConfigオブジェクトファイルを適用します。$ oc apply -f 99-master-chrony.yamlSystem clock synchronizedの値が yes であることを確認します。$ sudo timedatectlLocal time: Tue 2020-03-10 19:10:02 UTC Universal time: Tue 2020-03-10 19:10:02 UTC RTC time: Tue 2020-03-10 19:36:53 Time zone: UTC (UTC, +0000) System clock synchronized: yes NTP service: active RTC in local TZ: noデプロイメントの前にクロック同期を設定するには、マニフェストファイルを生成し、このファイルを
openshiftディレクトリーに追加します。以下に例を示します。$ cp chrony-masters.yaml ~/clusterconfigs/openshift/99_masters-chrony-configuration.yamlクラスターの作成を継続します。
5.17. インストールの確認
インストール後、インストールプログラムによってノードと Pod が正常にデプロイされたことを確認します。
手順
OpenShift Container Platform クラスターノードが適切にインストールされると、以下の
Ready状態がSTATUS列に表示されます。$ oc get nodesNAME STATUS ROLES AGE VERSION master-0.example.com Ready master,worker 4h v1.29.4 master-1.example.com Ready master,worker 4h v1.29.4 master-2.example.com Ready master,worker 4h v1.29.4インストールプログラムによってすべての Pod が正常にデプロイされたことを確認します。以下のコマンドは、実行中の Pod、または出力の一部として完了した Pod を削除します。
$ oc get pods --all-namespaces | grep -iv running | grep -iv complete
第6章 installer-provisioned のインストール後の設定
installer-provisioned クラスターを正常にデプロイしたら、以下のインストール後の手順を考慮してください。
6.1. オプション: 非接続クラスターの NTP 設定
OpenShift Container Platform は、クラスターノードに chrony Network Time Protocol (NTP) サービスをインストールします。次の手順を使用して、コントロールプレーンノードに NTP サーバーを設定し、デプロイが成功した後にコンピュートノードをコントロールプレーンノードの NTP クライアントとして設定します。
OpenShift Container Platform のノードは、適切に実行するために日付と時刻が一致している必要があります。コンピュートノードがコントロールプレーンノード上の NTP サーバーから日付と時刻を取得すると、ルーティング可能なネットワークに接続していないために上位層の NTP サーバーにアクセスできないクラスターのインストールと操作が可能になります。
手順
次のコマンドを使用して、インストールホストに Butane をインストールします。
$ sudo dnf -y install butaneコントロールプレーンノードの
chrony.confファイルのコンテンツを含む Butane 設定 (99-master-chrony-conf-override.bu) を作成します。注記Butane の詳細は、「Butane を使用したマシン設定の作成」を参照してください。
Butane 設定例
variant: openshift version: 4.16.0 metadata: name: 99-master-chrony-conf-override labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # Use public servers from the pool.ntp.org project. # Please consider joining the pool (https://www.pool.ntp.org/join.html). # The Machine Config Operator manages this file server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony # Configure the control plane nodes to serve as local NTP servers # for all compute nodes, even if they are not in sync with an # upstream NTP server. # Allow NTP client access from the local network. allow all # Serve time even if not synchronized to a time source. local stratum 3 orphan- 1
<cluster-name>はクラスターの名前に置き換え、<domain>は完全修飾ドメイン名に置き換える必要があります。
Butane を使用して、コントロールプレーンノードに配信される設定が含まれる
MachineConfigオブジェクトファイル (99-master-chrony-conf-override.yaml) を生成します。$ butane 99-master-chrony-conf-override.bu -o 99-master-chrony-conf-override.yamlコントロールプレーンノード上の NTP サーバーを参照するコンピュートノードの
chrony.confファイルの内容を含む Butane 設定99-worker-chrony-conf-override.buを作成します。Butane 設定例
variant: openshift version: 4.16.0 metadata: name: 99-worker-chrony-conf-override labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 0644 overwrite: true contents: inline: | # The Machine Config Operator manages this file. server openshift-master-0.<cluster-name>.<domain> iburst1 server openshift-master-1.<cluster-name>.<domain> iburst server openshift-master-2.<cluster-name>.<domain> iburst stratumweight 0 driftfile /var/lib/chrony/drift rtcsync makestep 10 3 bindcmdaddress 127.0.0.1 bindcmdaddress ::1 keyfile /etc/chrony.keys commandkey 1 generatecommandkey noclientlog logchange 0.5 logdir /var/log/chrony- 1
<cluster-name>はクラスターの名前に置き換え、<domain>は完全修飾ドメイン名に置き換える必要があります。
Butane を使用して、ワーカーノードに配信される設定が含まれる
MachineConfigオブジェクトファイル (99-worker-chrony-conf-override.yaml) を生成します。$ butane 99-worker-chrony-conf-override.bu -o 99-worker-chrony-conf-override.yaml99-master-chrony-conf-override.yamlポリシーをコントロールプレーンノードに適用します。$ oc apply -f 99-master-chrony-conf-override.yaml出力例
machineconfig.machineconfiguration.openshift.io/99-master-chrony-conf-override created99-worker-chrony-conf-override.yamlポリシーをコンピュートノードに適用します。$ oc apply -f 99-worker-chrony-conf-override.yaml出力例
machineconfig.machineconfiguration.openshift.io/99-worker-chrony-conf-override created適用された NTP 設定のステータスを確認します。
$ oc describe machineconfigpool
6.2. インストール後のプロビジョニングネットワークの有効化
ベアメタルクラスター用の Assisted Installer および installer-provisioned installation は、provisioning ネットワークなしでクラスターをデプロイする機能を提供します。この機能は、概念実証クラスターや、各ノードのベースボード管理コントローラーが baremetal ネットワークを介してルーティング可能な場合に Redfish 仮想メディアのみを使用してデプロイするなどのシナリオ向けです。
Cluster Baremetal Operator (CBO) を使用してインストール後に provisioning ネットワークを有効にすることができます。
前提条件
- すべてのワーカーノードおよびコントロールプレーンノードに接続されている専用の物理ネットワークが存在する必要があります。
- ネイティブのタグなしの物理ネットワークを分離する必要があります。
-
provisioningNetwork設定がManagedに設定されている場合、ネットワークには DHCP サーバーを含めることはできません。 -
OpenShift Container Platform 4.10 の
provisioningInterface設定を省略して、bootMACAddress設定を使用できます。
手順
-
provisioningInterface設定を設定する場合、まずクラスターノードのプロビジョニングインターフェイス名を特定します。たとえば、eth0またはeno1などです。 -
クラスターノードの
provisioningネットワークインターフェイスで Preboot eXecution Environment (PXE) を有効にします。 provisioningネットワークの現在の状態を取得して、これをプロビジョニングカスタムリソース (CR) ファイルに保存します。$ oc get provisioning -o yaml > enable-provisioning-nw.yamlプロビジョニング CR ファイルを変更します。
$ vim ~/enable-provisioning-nw.yamlprovisioningNetwork設定までスクロールダウンして、これをDisabledからManagedに変更します。次に、provisioningNetwork設定の後に、provisioningIP、provisioningNetworkCIDR、provisioningDHCPRange、provisioningInterface、およびwatchAllNameSpaces設定を追加します。各設定に適切な値を指定します。apiVersion: v1 items: - apiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: name: provisioning-configuration spec: provisioningNetwork:1 provisioningIP:2 provisioningNetworkCIDR:3 provisioningDHCPRange:4 provisioningInterface:5 watchAllNameSpaces:6 - 1
provisioningNetworkは、Managed、Unmanaged、またはDisabledのいずれかになります。Managedに設定すると、Metal3 はプロビジョニングネットワークを管理し、CBO は設定済みの DHCP サーバーで Metal3 Pod をデプロイします。Unmanagedに設定すると、システム管理者は DHCP サーバーを手動で設定します。- 2
provisioningIPは、DHCP サーバーおよび ironic がネットワークのプロビジョニングために使用する静的 IP アドレスです。この静的 IP アドレスは、DHCP 範囲外のprovisioning内でなければなりません。この設定を設定する場合は、provisioningネットワークがDisabledの場合でも、有効な IP アドレスが必要です。静的 IP アドレスは metal3 Pod にバインドされます。metal3 Pod が失敗し、別のサーバーに移動する場合、静的 IP アドレスも新しいサーバーに移動します。- 3
- Classless Inter-Domain Routing (CIDR) アドレス。この設定を設定する場合は、
provisioningネットワークがDisabledの場合でも、有効な CIDR アドレスが必要です。例:192.168.0.1/24 - 4
- DHCP の範囲。この設定は、
Managedプロビジョニングネットワークにのみ適用されます。provisioningネットワークがDisabledの場合は、この設定を省略します。例:192.168.0.64, 192.168.0.253 - 5
- クラスターノードの
provisioningインターフェイス用の NIC 名。provisioningInterface設定は、ManagedおよびUnmanagedプロビジョニングネットワークにのみ適用されます。provisioningネットワークがDisabledの場合に、provisioningInterface設定が省略されます。代わりにbootMACAddress設定を使用するようにprovisioningInterface設定を省略します。 - 6
- metal3 がデフォルトの
openshift-machine-apinamespace 以外の namespace を監視するようにするには、この設定をtrueに設定します。デフォルト値はfalseです。
- 変更をプロビジョニング CR ファイルに保存します。
プロビジョニング CR ファイルをクラスターに適用します。
$ oc apply -f enable-provisioning-nw.yaml
6.3. カスタマイズされた br-ex ブリッジを含むマニフェストオブジェクトの作成
カスタマイズされた br-ex ブリッジを含むマニフェストオブジェクトを作成する場合は、次のユースケースを検討してください。
-
Open vSwitch (OVS) または OVN-Kubernetes
br-exブリッジネットワークの変更など、ブリッジにインストール後の変更を加えたい場合。configure-ovs.shシェルスクリプトは、ブリッジへのインストール後の変更をサポートしていません。 - ホストまたはサーバーの IP アドレスで使用可能なインターフェイスとは異なるインターフェイスにブリッジをデプロイします。
-
configure-ovs.shシェルスクリプトでは不可能な、ブリッジの高度な設定を実行したいと考えています。これらの設定にスクリプトを使用すると、ブリッジが複数のネットワークインターフェイスに接続できず、インターフェイス間のデータ転送が促進されない可能性があります。
前提条件
-
configure-ovsの代替方法を使用して、カスタマイズされたbr-exを設定している。 - Kubernetes NMState Operator がインストールされている。
手順
NodeNetworkConfigurationPolicy(NNCP) CR を作成し、カスタマイズされたbr-exブリッジネットワーク設定を定義します。br-exNNCP CR には、ネットワークの OVN-Kubernetes マスカレード IP アドレスとサブネットが含まれている必要があります。サンプルの NNCP CR には、ipv4.address.ipおよびipv6.address.ipパラメーターにデフォルト値が含まれます。ipv4.address.ip、ipv6.address.ip、またはその両方で masquerade IP アドレスを設定できます。重要インストール後のタスクとして、カスタマイズした
br-exブリッジのプライマリー IP アドレスを変更できません。シングルスタッククラスターネットワークをデュアルスタッククラスターネットワークに変換する場合、NNCP CR でセカンダリー IPv6 アドレスは追加または変更できますが、既存のプライマリー IP アドレスは変更できません。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: worker-0-br-ex spec: nodeSelector: kubernetes.io/hostname: worker-0 desiredState: interfaces: - name: enp2s0 type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - name: br-ex type: ovs-bridge state: up ipv4: enabled: false dhcp: false ipv6: enabled: false dhcp: false bridge: options: mcast-snooping-enable: true port: - name: enp2s0 - name: br-ex - name: br-ex type: ovs-interface state: up copy-mac-from: enp2s0 ipv4: enabled: true dhcp: true auto-route-metric: 48 address: - ip: "169.254.0.2" prefix-length: 17 ipv6: enabled: true dhcp: true auto-route-metric: 48 address: - ip: "fd69::2" prefix-length: 112 # ...ここでは、以下のようになります。
metadata.name- ポリシーの名前。
interfaces.name- インターフェイスの名前。
interfaces.type- イーサネットのタイプ。
interfaces.state- 作成後のインターフェイスの要求された状態。
ipv4.enabled- この例では、IPv4 と IPv6 を無効にします。
port.name- ブリッジが接続されているノード NIC。
address.ip- デフォルトの IPv4 および IPv6 の IP アドレスを表示します。ネットワークの masquerade IPv4 および IPv6 の IP アドレスを設定するようにしてください。
auto-route-metric-
br-exデフォルトルートに常に最高の優先度 (最も低いメトリック値) を付与するには、パラメーターを48に設定します。この設定により、NetworkManagerサービスによって自動的に設定される他のインターフェイスとのルーティングの競合が防止されます。
次のステップ
-
コンピュートノードをスケーリングして、クラスター内に存在する各コンピュートノードに、カスタマイズされた
br-exブリッジを含むマニフェストオブジェクトを適用します。詳細は、関連情報 セクションの「クラスターの拡張」を参照してください。
第7章 クラスターの拡張
installer-provisioned OpenShift Container Platform クラスターのデプロイ後に、以下の手順を使用してワーカーノードの数を拡張することができます。それぞれの候補となるワーカーノードが前提条件を満たしていることを確認します。
RedFish Virtual Media を使用してクラスターを拡張するには、最低限のファームウェア要件を満たす必要があります。RedFish Virtual Media を使用したクラスターの拡張時の詳細は、前提条件 セクションの 仮想メディアを使用したインストールのファームウェア要件 を参照してください。
7.1. ベアメタルノードの準備
クラスターを拡張するには、ノードに関連する IP アドレスを提供する必要があります。これは、静的設定または DHCP (動的ホスト設定プロトコル) サーバーを使用して行うことができます。DHCP サーバーを使用してクラスターを拡張する場合、各ノードには DHCP 予約が必要です。
一部の管理者は、各ノードの IP アドレスが DHCP サーバーがない状態で一定になるように静的 IP アドレスの使用を選択します。NMState で静的 IP アドレスを設定するには、「OpenShift インストールの環境のセットアップ」セクションの「オプション: install-config.yaml でのホストネットワークインターフェイスの設定」で追加の詳細を参照してください。
ベアメタルノードを準備するには、プロビジョナーノードから以下の手順を実行する必要があります。
手順
ocバイナリーを取得します。$ curl -s https://mirror.openshift.com/pub/openshift-v4/clients/ocp/$VERSION/openshift-client-linux-$VERSION.tar.gz | tar zxvf - oc$ sudo cp oc /usr/local/bin- ベースボード管理コントローラー (BMC) を使用してベアメタルノードの電源を切り、オフになっていることを確認します。
ベアメタルノードのベースボード管理コントローラーのユーザー名およびパスワードを取得します。次に、ユーザー名とパスワードから
base64文字列を作成します。$ echo -ne "root" | base64$ echo -ne "password" | base64ベアメタルノードの設定ファイルを作成します。静的設定または DHCP サーバーのどちらを使用しているかに応じて、次の例の
bmh.yamlファイルのいずれかを使用し、環境に合わせて YAML の値を置き換えます。$ vim bmh.yaml静的設定
bmh.yaml:--- apiVersion: v11 kind: Secret metadata: name: openshift-worker-<num>-network-config-secret2 namespace: openshift-machine-api type: Opaque stringData: nmstate: |3 interfaces:4 - name: <nic1_name>5 type: ethernet state: up ipv4: address: - ip: <ip_address>6 prefix-length: 24 enabled: true dns-resolver: config: server: - <dns_ip_address>7 routes: config: - destination: 0.0.0.0/0 next-hop-address: <next_hop_ip_address>8 next-hop-interface: <next_hop_nic1_name>9 --- apiVersion: v1 kind: Secret metadata: name: openshift-worker-<num>-bmc-secret10 namespace: openshift-machine-api type: Opaque data: username: <base64_of_uid>11 password: <base64_of_pwd>12 --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-worker-<num>13 namespace: openshift-machine-api spec: online: True bootMACAddress: <nic1_mac_address>14 bmc: address: <protocol>://<bmc_url>15 credentialsName: openshift-worker-<num>-bmc-secret16 disableCertificateVerification: True17 username: <bmc_username>18 password: <bmc_password>19 rootDeviceHints: deviceName: <root_device_hint>20 preprovisioningNetworkDataName: openshift-worker-<num>-network-config-secret21 - 1
- 新しく作成されたノードのネットワークインターフェイスを設定するには、ネットワーク設定を含むシークレットの名前を指定します。
nmstate構文に従って、ノードのネットワーク設定を定義します。NMState 構文の設定に関する詳細は、「オプション: install-config.yaml ファイルでのホストネットワークインターフェイスの設定」を参照してください。 - 2 10 13 16
name、credentialsName、およびpreprovisioningNetworkDataNameフィールドの<num>は、ベアメタルノードのワーカー番号に置き換えます。- 3
- NMState YAML 構文を追加して、ホストインターフェイスを設定します。
- 4
- オプション:
nmstateを使用してネットワークインターフェイスを設定しており、インターフェイスを無効にする場合は、次のように IP アドレスをenabled: falseに設定してstate: upを設定します。--- interfaces: - name: <nic_name> type: ethernet state: up ipv4: enabled: false ipv6: enabled: false - 5 6 7 8 9
<nic1_name>、<ip_address>、<dns_ip_address>、<next_hop_ip_address>、および<next_hop_nic1_name>を適切な値に置き換えます。- 11 12
<base64_of_uid>と<base64_of_pwd>は、ユーザー名とパスワードの base64 文字列に置き換えます。- 14
<nic1_mac_address>を、ベアメタルノードの最初の NIC の MAC アドレスに置き換えます。追加の BMC 設定オプションは、「BMC アドレス指定」のセクションを参照してください。- 15
<protocol>は、IPMI、RedFish などの BMC プロトコルに置き換えます。<bmc_url>を、ベアメタルノードのベースボード管理コントローラーの URL に置き換えます。- 17
- 証明書の検証をスキップするには、
disableCertificateVerificationを true に設定します。 - 18 19
<bmc_username>と<bmc_password>を BMC ユーザー名とパスワードの文字列に置き換えます。- 20
- オプション: root デバイスヒントを指定する場合は、
<root_device_hint>をデバイスパスに置き換えます。 - 21
- オプション: 新しく作成されたノードのネットワークインターフェイスを設定した場合は、BareMetalHost CR の
preprovisioningNetworkDataNameにネットワーク設定のシークレット名を指定します。
DHCP 設定
bmh.yaml:--- apiVersion: v1 kind: Secret metadata: name: openshift-worker-<num>-bmc-secret1 namespace: openshift-machine-api type: Opaque data: username: <base64_of_uid>2 password: <base64_of_pwd>3 --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-worker-<num>4 namespace: openshift-machine-api spec: online: True bootMACAddress: <nic1_mac_address>5 bmc: address: <protocol>://<bmc_url>6 credentialsName: openshift-worker-<num>-bmc-secret7 disableCertificateVerification: True8 username: <bmc_username>9 password: <bmc_password>10 rootDeviceHints: deviceName: <root_device_hint>11 preprovisioningNetworkDataName: openshift-worker-<num>-network-config-secret12 - 1 4 7
name、credentialsName、およびpreprovisioningNetworkDataNameフィールドの<num>は、ベアメタルノードのワーカー番号に置き換えます。- 2 3
<base64_of_uid>と<base64_of_pwd>は、ユーザー名とパスワードの base64 文字列に置き換えます。- 5
<nic1_mac_address>を、ベアメタルノードの最初の NIC の MAC アドレスに置き換えます。追加の BMC 設定オプションは、「BMC アドレス指定」のセクションを参照してください。- 6
<protocol>は、IPMI、RedFish などの BMC プロトコルに置き換えます。<bmc_url>を、ベアメタルノードのベースボード管理コントローラーの URL に置き換えます。- 8
- 証明書の検証をスキップするには、
disableCertificateVerificationを true に設定します。 - 9 10
<bmc_username>と<bmc_password>を BMC ユーザー名とパスワードの文字列に置き換えます。- 11
- オプション: root デバイスヒントを指定する場合は、
<root_device_hint>をデバイスパスに置き換えます。 - 12
- オプション: 新しく作成されたノードのネットワークインターフェイスを設定した場合は、BareMetalHost CR の
preprovisioningNetworkDataNameにネットワーク設定のシークレット名を指定します。
注記既存のベアメタルノードの MAC アドレスが、プロビジョニングしようとしているベアメタルホストの MAC アドレスと一致する場合、Ironic インストールは失敗します。ホストの登録、検査、クリーニング、または他の Ironic 手順が失敗する場合、ベアメタル Operator はインストールを継続的に再試行します。詳細は、「ホストの重複した MAC アドレスの診断」を参照してください。
ベアメタルノードを作成します。
$ oc -n openshift-machine-api create -f bmh.yaml出力例
secret/openshift-worker-<num>-network-config-secret created secret/openshift-worker-<num>-bmc-secret created baremetalhost.metal3.io/openshift-worker-<num> created<num>はワーカー番号です。ベアメタルノードの電源をオンにし、これを検査します。
$ oc -n openshift-machine-api get bmh openshift-worker-<num><num>はワーカーノード番号です。出力例
NAME STATE CONSUMER ONLINE ERROR openshift-worker-<num> available true注記ワーカーノードがクラスターに参加できるようにするには、
machinesetオブジェクトをBareMetalHostオブジェクトの数にスケーリングします。ノードは手動または自動でスケーリングできます。ノードを自動的にスケーリングするには、machinesetにmetal3.io/autoscale-to-hostsアノテーションを使用します。
7.2. ベアメタルコントロールプレーンノードの交換
以下の手順を使用して、installer-provisioned OpenShift Container Platform コントロールプレーンノードを置き換えます。
既存のコントロールプレーンホストから BareMetalHost オブジェクト定義を再利用する場合は、externallyProvisioned フィールドを true に設定したままにしないでください。
既存のコントロールプレーン BareMetalHost オブジェクトが、OpenShift Container Platform インストールプログラムによってプロビジョニングされた場合には、externallyProvisioned フラグが true に設定されている可能性があります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 etcd のバックアップを取得している。
重要問題が発生した場合にクラスターを復元できるように、この手順を実行する前に etcd のバックアップを作成してください。etcd バックアップの作成に関する詳細は、関連情報 セクションを参照してください。
手順
Bare Metal Operator が使用可能であることを確認します。
$ oc get clusteroperator baremetal出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE baremetal 4.16 True False False 3d15h古い
BareMetalHostオブジェクトおよびMachineオブジェクトを削除します。$ oc delete bmh -n openshift-machine-api <host_name>$ oc delete machine -n openshift-machine-api <machine_name><host_name>をホストの名前に、<machine_name>をマシンの名前に置き換えます。マシン名はCONSUMERフィールドの下に表示されます。BareMetalHostオブジェクトとMachineオブジェクトを削除すると、マシンコントローラーはNodeオブジェクトを自動的に削除します。新しい
BareMetalHostオブジェクトとシークレットを作成して BMC 認証情報を保存します。$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: control-plane-<num>-bmc-secret1 namespace: openshift-machine-api data: username: <base64_of_uid>2 password: <base64_of_pwd>3 type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: control-plane-<num>4 namespace: openshift-machine-api spec: automatedCleaningMode: disabled bmc: address: <protocol>://<bmc_ip>5 credentialsName: control-plane-<num>-bmc-secret6 bootMACAddress: <NIC1_mac_address>7 bootMode: UEFI externallyProvisioned: false online: true EOF- 1 4 6
nameおよびcredentialsNameフィールドの<num>は、ベアメタルノードのコントロールプレーン番号に置き換えます。- 2
<base64_of_uid>を、ユーザー名のbase64文字列に置き換えます。- 3
<base64_of_pwd>>を、パスワードのbase64文字列に置き換えます。- 5
<protocol>をredfish、redfish-virtualmedia、idrac-virtualmediaなどの BMC プロトコルに置き換えます。<bmc_ip>は、ベアメタルノードのベースボード管理コントローラーの IP アドレスに置き換えます。その他の BMC 設定オプションについては、関連情報 セクションの「BMC アドレス指定」を参照してください。- 7
<NIC1_mac_address>は、ベアメタルノードの最初の NIC の MAC アドレスに置き換えます。
検査が完了すると、
BareMetalHostオブジェクトが作成され、プロビジョニングできるようになります。利用可能な
BareMetalHostオブジェクトを表示します。$ oc get bmh -n openshift-machine-api出力例
NAME STATE CONSUMER ONLINE ERROR AGE control-plane-1.example.com available control-plane-1 true 1h10m control-plane-2.example.com externally provisioned control-plane-2 true 4h53m control-plane-3.example.com externally provisioned control-plane-3 true 4h53m compute-1.example.com provisioned compute-1-ktmmx true 4h53m compute-1.example.com provisioned compute-2-l2zmb true 4h53mコントロールプレーンノード用の
MachineSetオブジェクトがないため、代わりにMachineオブジェクトを作成する必要があります。別のコントロールプレーンMachineオブジェクトからproviderSpecをコピーできます。Machineオブジェクトを作成します。$ cat <<EOF | oc apply -f - apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: annotations: metal3.io/BareMetalHost: openshift-machine-api/control-plane-<num>1 labels: machine.openshift.io/cluster-api-cluster: control-plane-<num>2 machine.openshift.io/cluster-api-machine-role: master machine.openshift.io/cluster-api-machine-type: master name: control-plane-<num>3 namespace: openshift-machine-api spec: metadata: {} providerSpec: value: apiVersion: baremetal.cluster.k8s.io/v1alpha1 customDeploy: method: install_coreos hostSelector: {} image: checksum: "" url: "" kind: BareMetalMachineProviderSpec metadata: creationTimestamp: null userData: name: master-user-data-managed EOFBareMetalHostオブジェクトを表示するには、次のコマンドを実行します。$ oc get bmh -A出力例
NAME STATE CONSUMER ONLINE ERROR AGE control-plane-1.example.com provisioned control-plane-1 true 2h53m control-plane-2.example.com externally provisioned control-plane-2 true 5h53m control-plane-3.example.com externally provisioned control-plane-3 true 5h53m compute-1.example.com provisioned compute-1-ktmmx true 5h53m compute-2.example.com provisioned compute-2-l2zmb true 5h53mRHCOS のインストール後、
BareMetalHostがクラスターに追加されていることを確認します。$ oc get nodes出力例
NAME STATUS ROLES AGE VERSION control-plane-1.example.com available master 4m2s v1.29.4 control-plane-2.example.com available master 141m v1.29.4 control-plane-3.example.com available master 141m v1.29.4 compute-1.example.com available worker 87m v1.29.4 compute-2.example.com available worker 87m v1.29.4注記新しいコントロールプレーンノードの交換後、新しいノードで実行されている etcd Pod は
crashloopbackステータスになります。詳細は、関連情報 セクションの「正常でない etcd メンバーの置き換え」を参照してください。
7.3. ベアメタルネットワークに仮想メディアを使用してデプロイメントする準備
provisioning ネットワークが有効で、baremetal ネットワークで Virtual Media を使用してクラスターを拡張する場合は、以下の手順を使用します。
前提条件
-
baremetalネットワークおよびprovisioningネットワークを使用する既存のクラスターがあります。
手順
provisioningカスタムリソース (CR) を編集して、baremetalネットワーク上の仮想メディアを使用したデプロイを有効にします。oc edit provisioningapiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: creationTimestamp: "2021-08-05T18:51:50Z" finalizers: - provisioning.metal3.io generation: 8 name: provisioning-configuration resourceVersion: "551591" uid: f76e956f-24c6-4361-aa5b-feaf72c5b526 spec: provisioningDHCPRange: 172.22.0.10,172.22.0.254 provisioningIP: 172.22.0.3 provisioningInterface: enp1s0 provisioningNetwork: Managed provisioningNetworkCIDR: 172.22.0.0/24 virtualMediaViaExternalNetwork: true1 status: generations: - group: apps hash: "" lastGeneration: 7 name: metal3 namespace: openshift-machine-api resource: deployments - group: apps hash: "" lastGeneration: 1 name: metal3-image-cache namespace: openshift-machine-api resource: daemonsets observedGeneration: 8 readyReplicas: 0- 1
virtualMediaViaExternalNetwork: trueをprovisioningCR に追加します。
イメージ URL が存在する場合は、
machinesetを編集して API VIP アドレスを使用します。この手順は、バージョン 4.9 以前でインストールされたクラスターにのみ適用されます。oc edit machinesetapiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: creationTimestamp: "2021-08-05T18:51:52Z" generation: 11 labels: machine.openshift.io/cluster-api-cluster: ostest-hwmdt machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: ostest-hwmdt-worker-0 namespace: openshift-machine-api resourceVersion: "551513" uid: fad1c6e0-b9da-4d4a-8d73-286f78788931 spec: replicas: 2 selector: matchLabels: machine.openshift.io/cluster-api-cluster: ostest-hwmdt machine.openshift.io/cluster-api-machineset: ostest-hwmdt-worker-0 template: metadata: labels: machine.openshift.io/cluster-api-cluster: ostest-hwmdt machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: ostest-hwmdt-worker-0 spec: metadata: {} providerSpec: value: apiVersion: baremetal.cluster.k8s.io/v1alpha1 hostSelector: {} image: checksum: http:/172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow2.<md5sum>1 url: http://172.22.0.3:6181/images/rhcos-<version>.<architecture>.qcow22 kind: BareMetalMachineProviderSpec metadata: creationTimestamp: null userData: name: worker-user-data status: availableReplicas: 2 fullyLabeledReplicas: 2 observedGeneration: 11 readyReplicas: 2 replicas: 2
7.4. クラスター内の新しいホストをプロビジョニングする際の重複する MAC アドレスの診断
クラスター内の既存のベアメタルノードの MAC アドレスが、クラスターに追加しようとしているベアメタルホストの MAC アドレスと一致する場合、ベアメタル Operator はホストを既存のノードに関連付けます。ホストの登録、検査、クリーニング、または他の Ironic 手順が失敗する場合、ベアメタル Operator はインストールを継続的に再試行します。障害が発生したベアメタルホストの登録エラーが表示されます。
openshift-machine-api namespace で実行されているベアメタルホストを調べることで、重複する MAC アドレスを診断できます。
前提条件
- ベアメタルに OpenShift Container Platform クラスターをインストールする。
-
OpenShift Container Platform CLI (
oc) をインストールする。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
プロビジョニングに失敗したベアメタルホストが既存のノードと同じ MAC アドレスを持つかどうかを判断するには、以下を実行します。
openshift-machine-apinamespace で実行されているベアメタルホストを取得します。$ oc get bmh -n openshift-machine-api出力例
NAME STATUS PROVISIONING STATUS CONSUMER openshift-master-0 OK externally provisioned openshift-zpwpq-master-0 openshift-master-1 OK externally provisioned openshift-zpwpq-master-1 openshift-master-2 OK externally provisioned openshift-zpwpq-master-2 openshift-worker-0 OK provisioned openshift-zpwpq-worker-0-lv84n openshift-worker-1 OK provisioned openshift-zpwpq-worker-0-zd8lm openshift-worker-2 error registering障害が発生したホストのステータスに関する詳細情報を表示するには、
<bare_metal_host_name>をホストの名前に置き換えて、以下のコマンドを実行します。$ oc get -n openshift-machine-api bmh <bare_metal_host_name> -o yaml出力例
... status: errorCount: 12 errorMessage: MAC address b4:96:91:1d:7c:20 conflicts with existing node openshift-worker-1 errorType: registration error ...
7.5. ベアメタルノードのプロビジョニング
ベアメタルノードをプロビジョニングするには、プロビジョナーノードから以下の手順を実行する必要があります。
手順
ベアメタルノードをプロビジョニングする前に、
STATEがavailableであることを確認してください。$ oc -n openshift-machine-api get bmh openshift-worker-<num><num>はワーカーノード番号です。NAME STATE ONLINE ERROR AGE openshift-worker available true 34hワーカーノードの数を取得します。
$ oc get nodesNAME STATUS ROLES AGE VERSION openshift-master-1.openshift.example.com Ready master 30h v1.29.4 openshift-master-2.openshift.example.com Ready master 30h v1.29.4 openshift-master-3.openshift.example.com Ready master 30h v1.29.4 openshift-worker-0.openshift.example.com Ready worker 30h v1.29.4 openshift-worker-1.openshift.example.com Ready worker 30h v1.29.4コンピュートマシンセットを取得します。
$ oc get machinesets -n openshift-machine-apiNAME DESIRED CURRENT READY AVAILABLE AGE ... openshift-worker-0.example.com 1 1 1 1 55m openshift-worker-1.example.com 1 1 1 1 55mワーカーノードの数を 1 つ増やします。
$ oc scale --replicas=<num> machineset <machineset> -n openshift-machine-api<num>は、新しいワーカーノード数に置き換えます。<machineset>は、前のステップで設定したコンピュートマシンの名前に置き換えます。ベアメタルノードのステータスを確認します。
$ oc -n openshift-machine-api get bmh openshift-worker-<num><num>はワーカーノード番号です。STATE がreadyからprovisioningに変わります。NAME STATE CONSUMER ONLINE ERROR openshift-worker-<num> provisioning openshift-worker-<num>-65tjz trueprovisioningステータスは、OpenShift Container Platform クラスターがノードをプロビジョニングするまでそのままになります。この場合、30 分以上の時間がかかる場合があります。ノードがプロビジョニングされると、状態はprovisionedに変わります。NAME STATE CONSUMER ONLINE ERROR openshift-worker-<num> provisioned openshift-worker-<num>-65tjz trueプロビジョニングが完了したら、ベアメタルノードが準備状態であることを確認します。
$ oc get nodesNAME STATUS ROLES AGE VERSION openshift-master-1.openshift.example.com Ready master 30h v1.29.4 openshift-master-2.openshift.example.com Ready master 30h v1.29.4 openshift-master-3.openshift.example.com Ready master 30h v1.29.4 openshift-worker-0.openshift.example.com Ready worker 30h v1.29.4 openshift-worker-1.openshift.example.com Ready worker 30h v1.29.4 openshift-worker-<num>.openshift.example.com Ready worker 3m27s v1.29.4kubelet を確認することもできます。
$ ssh openshift-worker-<num>[kni@openshift-worker-<num>]$ journalctl -fu kubelet
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.