Chapter 4. Additional Concepts
4.1. Networking
4.1.1. Overview
Kubernetes ensures that pods are able to network with each other, and allocates each pod an IP address from an internal network. This ensures all containers within the pod behave as if they were on the same host. Giving each pod its own IP address means that pods can be treated like physical hosts or virtual machines in terms of port allocation, networking, naming, service discovery, load balancing, application configuration, and migration.
Creating links between pods is unnecessary. However, it is not recommended that you have a pod talk to another directly by using the IP address. Instead, we recommend that you create a service, then interact with the service.
4.1.2. OpenShift Container Platform DNS
If you are running multiple services, such as frontend and backend services for use with multiple pods, in order for the frontend pods to communicate with the backend services, environment variables are created for user names, service IP, and more. If the service is deleted and recreated, a new IP address can be assigned to the service, and requires the frontend pods to be recreated in order to pick up the updated values for the service IP environment variable. Additionally, the backend service has to be created before any of the frontend pods to ensure that the service IP is generated properly and that it can be provided to the frontend pods as an environment variable.
For this reason, OpenShift Container Platform has a built-in DNS so that the services can be reached by the service DNS as well as the service IP/port. OpenShift Container Platform supports split DNS by running SkyDNS on the master that answers DNS queries for services. The master listens to port 53 by default.
When the node starts, the following message indicates the Kubelet is correctly resolved to the master:
0308 19:51:03.118430 4484 node.go:197] Started Kubelet for node
openshiftdev.local, server at 0.0.0.0:10250
I0308 19:51:03.118459 4484 node.go:199] Kubelet is setting 10.0.2.15 as a
DNS nameserver for domain "local"If the second message does not appear, the Kubernetes service may not be available.
On a node host, each container’s nameserver has the master name added to the front, and the default search domain for the container will be .<pod_namespace>.cluster.local. The container will then direct any nameserver queries to the master before any other nameservers on the node, which is the default behavior for Docker-formatted containers. The master will answer queries on the .cluster.local domain that have the following form:
| Object Type | Example |
|---|---|
| Default | <pod_namespace>.cluster.local |
| Services | <service>.<pod_namespace>.svc.cluster.local |
| Endpoints | <name>.<namespace>.endpoints.cluster.local |
This prevents having to restart frontend pods in order to pick up new services, which creates a new IP for the service. This also removes the need to use environment variables, as pods can use the service DNS. Also, as the DNS does not change, you can reference database services as db.local in config files. Wildcard lookups are also supported, as any lookups resolve to the service IP, and removes the need to create the backend service before any of the frontend pods, since the service name (and hence DNS) is established upfront.
This DNS structure also covers headless services, where a portal IP is not assigned to the service and the kube-proxy does not load-balance or provide routing for its endpoints. Service DNS can still be used and responds with multiple A records, one for each pod of the service, allowing the client to round-robin between each pod.
4.1.3. Network Plug-ins
OpenShift Container Platform supports the same plug-in model as Kubernetes for networking pods. The following network plug-ins are currently supported by OpenShift Container Platform.
4.1.3.1. OpenShift SDN
OpenShift Container Platform deploys a software-defined networking (SDN) approach for connecting pods in an OpenShift Container Platform cluster. The OpenShift SDN connects all pods across all node hosts, providing a unified cluster network.
OpenShift SDN is automatically installed and configured as part of the Ansible-based installation procedure. See the OpenShift Container Platform SDN section for more information.
4.1.3.2. Nuage SDN for OpenShift Container Platform
Nuage Networks' SDN solution delivers highly scalable, policy-based overlay networking for pods in an OpenShift Container Platform cluster. Nuage SDN can be installed and configured as a part of the Ansible-based installation procedure. See the Advanced Installation section for information on how to install and deploy OpenShift Container Platform with Nuage SDN.
Nuage Networks provides a highly scalable, policy-based SDN platform called Virtualized Services Platform (VSP). Nuage VSP uses an SDN Controller, along with the open source Open vSwitch for the data plane.
Nuage uses overlays to provide policy-based networking between OpenShift Container Platform and other environments consisting of VMs and bare metal servers. The platform’s real-time analytics engine enables visibility and security monitoring for OpenShift Container Platform applications.
Nuage VSP integrates with OpenShift Container Platform to allows business applications to be quickly turned up and updated by removing the network lag faced by DevOps teams.
Figure 4.1. Nuage VSP Integration with OpenShift Container Platform
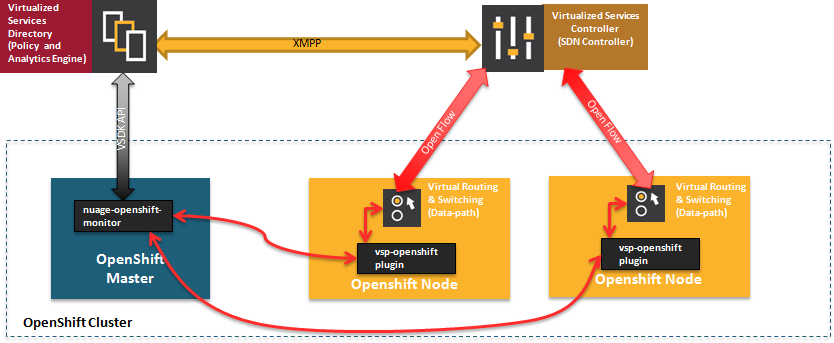
There are two specific components responsible for the integration.
- The nuage-openshift-monitor service, which runs as a separate service on the OpenShift Container Platform master node.
- The vsp-openshift plug-in, which is invoked by the OpenShift Container Platform runtime on each of the nodes of the cluster.
Nuage Virtual Routing and Switching software (VRS) is based on open source Open vSwitch and is responsible for the datapath forwarding. The VRS runs on each node and gets policy configuration from the controller.
Nuage VSP Terminology
Figure 4.2. Nuage VSP Building Blocks
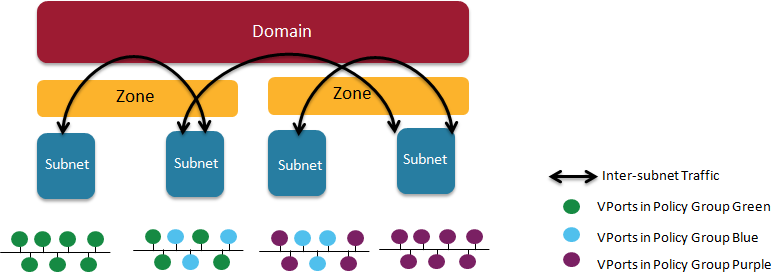
- Domains: An organization contains one or more domains. A domain is a single "Layer 3" space. In standard networking terminology, a domain maps to a VRF instance.
- Zones: Zones are defined under a domain. A zone does not map to anything on the network directly, but instead acts as an object with which policies are associated such that all endpoints in the zone adhere to the same set of policies.
- Subnets: Subnets are defined under a zone. A subnet is a specific Layer 2 subnet within the domain instance. A subnet is unique and distinct within a domain, that is, subnets within a Domain are not allowed to overlap or to contain other subnets in accordance with the standard IP subnet definitions.
- VPorts: A VPort is a new level in the domain hierarchy, intended to provide more granular configuration. In addition to containers and VMs, VPorts are also used to attach Host and Bridge Interfaces, which provide connectivity to Bare Metal servers, Appliances, and Legacy VLANs.
- Policy Group: Policy Groups are collections of VPorts.
Mapping of Constructs
Many OpenShift Container Platform concepts have a direct mapping to Nuage VSP constructs:
Figure 4.3. Nuage VSP and OpenShift Container Platform mapping

A Nuage subnet is not mapped to an OpenShift Container Platform node, but a subnet for a particular project can span multiple nodes in OpenShift Container Platform.
A pod spawning in OpenShift Container Platform translates to a virtual port being created in VSP. The vsp-openshift plug-in interacts with the VRS and gets a policy for that virtual port from the VSD via the VSC. Policy Groups are supported to group multiple pods together that must have the same set of policies applied to them. Currently, pods can only be assigned to policy groups using the operations workflow where a policy group is created by the administrative user in VSD. The pod being a part of the policy group is specified by means of nuage.io/policy-group label in the specification of the pod.
4.1.3.2.1. Integration Components
Nuage VSP integrates with OpenShift Container Platform using two main components:
- nuage-openshift-monitor
- vsp-openshift plugin
nuage-openshift-monitor
nuage-openshift-monitor is a service that monitors the OpenShift Container Platform API server for creation of projects, services, users, user-groups, etc.
In case of a Highly Available (HA) OpenShift Container Platform cluster with multiple masters, nuage-openshift-monitor process runs on all the masters independently without any change in functionality.
For the developer workflow, nuage-openshift-monitor also auto-creates VSD objects by exercising the VSD REST API to map OpenShift Container Platform constructs to VSP constructs. Each cluster instance maps to a single domain in Nuage VSP. This allows a given enterprise to potentially have multiple cluster installations - one per domain instance for that Enterprise in Nuage. Each OpenShift Container Platform project is mapped to a zone in the domain of the cluster on the Nuage VSP. Whenever nuage-openshift-monitor sees an addition or deletion of the project, it instantiates a zone using the VSDK APIs corresponding to that project and allocates a block of subnet for that zone. Additionally, the nuage-openshift-monitor also creates a network macro group for this project. Likewise, whenever nuage-openshift-monitor sees an addition ordeletion of a service, it creates a network macro corresponding to the service IP and assigns that network macro to the network macro group for that project (user provided network macro group using labels is also supported) to enable communication to that service.
For the developer workflow, all pods that are created within the zone get IPs from that subnet pool. The subnet pool allocation and management is done by nuage-openshift-monitor based on a couple of plug-in specific parameters in the master-config file. However the actual IP address resolution and vport policy resolution is still done by VSD based on the domain/zone that gets instantiated when the project is created. If the initial subnet pool is exhausted, nuage-openshift-monitor carves out an additional subnet from the cluster CIDR to assign to a given project.
For the operations workflow, the users specify Nuage recognized labels on their application or pod specification to resolve the pods into specific user-defined zones and subnets. However, this cannot be used to resolve pods in the zones or subnets created via the developer workflow by nuage-openshift-monitor.
In the operations workflow, the administrator is responsible for pre-creating the VSD constructs to map the pods into a specific zone/subnet as well as allow communication between OpenShift entities (ACL rules, policy groups, network macros, and network macro groups). Detailed description of how to use Nuage labels is provided in the Nuage VSP Openshift Integration Guide.
vsp-openshift Plug-in
The vsp-openshift networking plug-in is called by the OpenShift Container Platform runtime on each OpenShift Container Platform node. It implements the network plug-in init and pod setup, teardown, and status hooks. The vsp-openshift plug-in is also responsible for allocating the IP address for the pods. In particular, it communicates with the VRS (the forwarding engine) and configures the IP information onto the pod.
4.2. OpenShift SDN
4.2.1. Overview
OpenShift Container Platform uses a software-defined networking (SDN) approach to provide a unified cluster network that enables communication between pods across the OpenShift Container Platform cluster. This pod network is established and maintained by the OpenShift SDN, which configures an overlay network using Open vSwitch (OVS).
OpenShift SDN provides two SDN plug-ins for configuring the pod network:
- The ovs-subnet plug-in is the original plug-in which provides a "flat" pod network where every pod can communicate with every other pod and service.
The ovs-multitenant plug-in provides OpenShift Container Platform project level isolation for pods and services. Each project receives a unique Virtual Network ID (VNID) that identifies traffic from pods assigned to the project. Pods from different projects cannot send packets to or receive packets from pods and services of a different project.
However, projects which receive VNID 0 are more privileged in that they are allowed to communicate with all other pods, and all other pods can communicate with them. In OpenShift Container Platform clusters, the default project has VNID 0. This facilitates certain services like the load balancer, etc. to communicate with all other pods in the cluster and vice versa.
Following is a detailed discussion of the design and operation of OpenShift SDN, which may be useful for troubleshooting.
Information on configuring the SDN on masters and nodes is available in Configuring the SDN.
4.2.2. Design on Masters
On an OpenShift Container Platform master, OpenShift SDN maintains a registry of nodes, stored in etcd. When the system administrator registers a node, OpenShift SDN allocates an unused subnet from the cluster network and stores this subnet in the registry. When a node is deleted, OpenShift SDN deletes the subnet from the registry and considers the subnet available to be allocated again.
In the default configuration, the cluster network is the 10.128.0.0/14 network (i.e. 10.128.0.0 - 10.131.255.255), and nodes are allocated /23 subnets (i.e., 10.128.0.0/23, 10.128.2.0/23, 10.128.4.0/23, and so on). This means that the cluster network has 512 subnets available to assign to nodes, and a given node is allocated 510 addresses that it can assign to the containers running on it. The size and address range of the cluster network are configurable, as is the host subnet size.
Note that OpenShift SDN on a master does not configure the local (master) host to have access to any cluster network. Consequently, a master host does not have access to pods via the cluster network, unless it is also running as a node.
When using the ovs-multitenant plug-in, the OpenShift SDN master also watches for the creation and deletion of projects, and assigns VXLAN VNIDs to them, which will be used later by the nodes to isolate traffic correctly.
4.2.3. Design on Nodes
On a node, OpenShift SDN first registers the local host with the SDN master in the aforementioned registry so that the master allocates a subnet to the node.
Next, OpenShift SDN creates and configures three network devices:
- br0, the OVS bridge device that pod containers will be attached to. OpenShift SDN also configures a set of non-subnet-specific flow rules on this bridge.
- tun0, an OVS internal port (port 2 on br0). This gets assigned the cluster subnet gateway address, and is used for external network access. OpenShift SDN configures netfilter and routing rules to enable access from the cluster subnet to the external network via NAT.
-
vxlan_sys_4789: The OVS VXLAN device (port 1 onbr0), which provides access to containers on remote nodes. Referred to asvxlan0in the OVS rules.
Each time a pod is started on the host, OpenShift SDN:
- assigns the pod a free IP address from the node’s cluster subnet.
- attaches the host side of the pod’s veth interface pair to the OVS bridge br0.
- adds OpenFlow rules to the OVS database to route traffic addressed to the new pod to the correct OVS port.
- in the case of the ovs-multitenant plug-in, adds OpenFlow rules to tag traffic coming from the pod with the pod’s VNID, and to allow traffic into the pod if the traffic’s VNID matches the pod’s VNID (or is the privileged VNID 0). Non-matching traffic is filtered out by a generic rule.
OpenShift SDN nodes also watch for subnet updates from the SDN master. When a new subnet is added, the node adds OpenFlow rules on br0 so that packets with a destination IP address in the remote subnet go to vxlan0 (port 1 on br0) and thus out onto the network. The ovs-subnet plug-in sends all packets across the VXLAN with VNID 0, but the ovs-multitenant plug-in uses the appropriate VNID for the source container.
4.2.4. Packet Flow
Suppose you have two containers, A and B, where the peer virtual Ethernet device for container A’s eth0 is named vethA and the peer for container B’s eth0 is named vethB.
If the Docker service’s use of peer virtual Ethernet devices is not already familiar to you, review Docker’s advanced networking documentation.
Now suppose first that container A is on the local host and container B is also on the local host. Then the flow of packets from container A to container B is as follows:
eth0 (in A’s netns)
Next, suppose instead that container A is on the local host and container B is on a remote host on the cluster network. Then the flow of packets from container A to container B is as follows:
eth0 (in A’s netns)
Finally, if container A connects to an external host, the traffic looks like:
eth0 (in A’s netns)
Almost all packet delivery decisions are performed with OpenFlow rules in the OVS bridge br0, which simplifies the plug-in network architecture and provides flexible routing. In the case of the ovs-multitenant plug-in, this also provides enforceable network isolation.
4.2.5. Network Isolation
You can use the ovs-multitenant plug-in to achieve network isolation. When a packet exits a pod assigned to a non-default project, the OVS bridge br0 tags that packet with the project’s assigned VNID. If the packet is directed to another IP address in the node’s cluster subnet, the OVS bridge only allows the packet to be delivered to the destination pod if the VNIDs match.
If a packet is received from another node via the VXLAN tunnel, the Tunnel ID is used as the VNID, and the OVS bridge only allows the packet to be delivered to a local pod if the tunnel ID matches the destination pod’s VNID.
Packets destined for other cluster subnets are tagged with their VNID and delivered to the VXLAN tunnel with a tunnel destination address of the node owning the cluster subnet.
As described before, VNID 0 is privileged in that traffic with any VNID is allowed to enter any pod assigned VNID 0, and traffic with VNID 0 is allowed to enter any pod. Only the default OpenShift Container Platform project is assigned VNID 0; all other projects are assigned unique, isolation-enabled VNIDs. Cluster administrators can optionally control the pod network for the project using the administrator CLI.
4.3. Flannel
4.3.1. Overview
flannel is a virtual networking layer designed specifically for containers. OpenShift Container Platform can use it for networking containers instead of the default software-defined networking (SDN) components. This is useful if running OpenShift Container Platform within a cloud provider platform that also relies on SDN, such as OpenStack, and you want to avoid encapsulating packets twice through both platforms.
4.3.2. Architecture
OpenShift Container Platform runs flannel in host-gw mode, which maps routes from container to container. Each host within the network runs an agent called flanneld, which is responsibile for:
- Managing a unique subnet on each host
- Distributing IP addresses to each container on its host
- Mapping routes from one container to another, even if on different hosts
Each flanneld agent provides this infomation to a centralized etcd store so other agents on hosts can route packets to other containers within the flannel network.
The following diagram illustrates the architecture and data flow from one container to another using a flannel network:
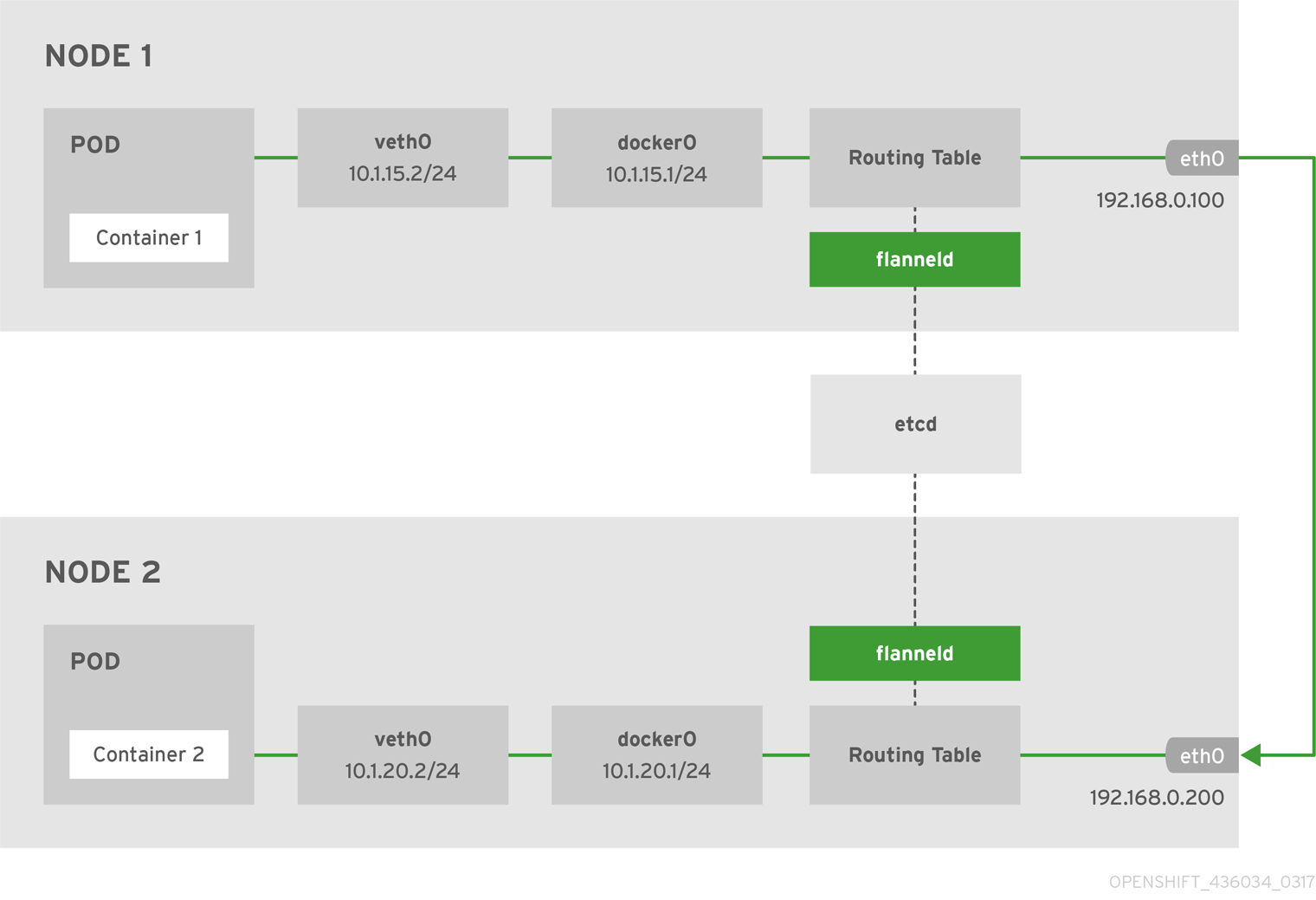
Node 1 would contain the following routes:
default via 192.168.0.100 dev eth0 proto static metric 100
10.1.15.0/24 dev docker0 proto kernel scope link src 10.1.15.1
10.1.20.0/24 via 192.168.0.200 dev eth0Node 2 would contain the following routes:
default via 192.168.0.200 dev eth0 proto static metric 100
10.1.20.0/24 dev docker0 proto kernel scope link src 10.1.20.1
10.1.15.0/24 via 192.168.0.100 dev eth04.4. F5 BIG-IP® Router Plug-in
4.4.1. Overview
The F5 router plug-in is available starting in OpenShift Enterprise 3.0.2.
The F5 router plug-in integrates with an existing F5 BIG-IP® system in your environment. F5 BIG-IP® version 11.4 or newer is required in order to have the F5 iControl REST API. The F5 router supports unsecured, edge terminated, re-encryption terminated, and passthrough terminated routes matching on HTTP vhost and request path.
The F5 router has additional features over the F5 BIG-IP® support in OpenShift Enterprise 2. Compared with the routing-daemon used in earlier versions, the F5 router additionally supports:
- path-based routing (using policy rules),
- passthrough of encrypted connections (implemented using an iRule that parses the SNI protocol and uses a data group that is maintained by the F5 router for the servername lookup).
Passthrough routes are a special case: path-based routing is technically impossible with passthrough routes because F5 BIG-IP® itself does not see the HTTP request, so it cannot examine the path. The same restriction applies to the template router; it is a technical limitation of passthrough encryption, not a technical limitation of OpenShift Container Platform.
4.4.2. Routing Traffic to Pods Through the SDN
Because F5 BIG-IP® is external to the OpenShift SDN, a cluster administrator must create a peer-to-peer tunnel between F5 BIG-IP® and a host that is on the SDN, typically an OpenShift Container Platform node host. This ramp node can be configured as unschedulable for pods so that it will not be doing anything except act as a gateway for the F5 BIG-IP® host. It is also possible to configure multiple such hosts and use the OpenShift Container Platform ipfailover feature for redundancy; the F5 BIG-IP® host would then need to be configured to use the ipfailover VIP for its tunnel’s remote endpoint.
4.4.3. F5 Integration Details
The operation of the F5 router is similar to that of the OpenShift Container Platform routing-daemon used in earlier versions. Both use REST API calls to:
- create and delete pools,
- add endpoints to and delete them from those pools, and
- configure policy rules to route to pools based on vhost.
Both also use scp and ssh commands to upload custom TLS/SSL certificates to F5 BIG-IP®.
The F5 router configures pools and policy rules on virtual servers as follows:
When a user creates or deletes a route on OpenShift Container Platform, the router creates a pool to F5 BIG-IP® for the route (if no pool already exists) and adds a rule to, or deletes a rule from, the policy of the appropriate vserver: the HTTP vserver for non-TLS routes, or the HTTPS vserver for edge or re-encrypt routes. In the case of edge and re-encrypt routes, the router also uploads and configures the TLS certificate and key. The router supports host- and path-based routes.
NotePassthrough routes are a special case: to support those, it is necessary to write an iRule that parses the SNI ClientHello handshake record and looks up the servername in an F5 data-group. The router creates this iRule, associates the iRule with the vserver, and updates the F5 data-group as passthrough routes are created and deleted. Other than this implementation detail, passthrough routes work the same way as other routes.
- When a user creates a service on OpenShift Container Platform, the router adds a pool to F5 BIG-IP® (if no pool already exists). As endpoints on that service are created and deleted, the router adds and removes corresponding pool members.
- When a user deletes the route and all endpoints associated with a particular pool, the router deletes that pool.
4.4.3.1. F5 Native Integration
With native integration of F5 with OpenShift Container Platform, you do not need to configure a ramp node for F5 to be able to reach the pods on the overlay network as created by OpenShift SDN.
Also, only F5 BIG-IP® appliance version 12.x and above works with the native integration presented in this section. You also need sdn-services add-on license for the integration to work properly. For version 11.x, set up a ramp node.
4.4.3.1.1. Connection
The F5 appliance can connect to the OpenShift Container Platform cluster via an L3 connection. An L2 switch connectivity is not required between OpenShift Container Platform nodes. On the appliance, you can use multiple interfaces to manage the integration:
- Management interface - Reaches the web console of the F5 appliance.
- External interface - Configures the virtual servers for inbound web traffic.
- Internal interface - Programs the appliance and reaches out to the pods.

An F5 controller pod has admin access to the appliance. The F5 image is launched within the OpenShift Container Platform cluster (scheduled on any node) that uses iControl REST APIs to program the virtual servers with policies, and configure the VxLAN device.
4.4.3.1.2. Data Flow: Packets to Pods
This section explains how the packets reach the pods, and vice versa. These actions are performed by the F5 controller pod and the F5 appliance, not the user.
When natively integrated, The F5 appliance reaches out to the pods directly using VxLAN encapsulation. This integration works only when OpenShift Container Platform is using openshift-sdn as the network plug-in. The openshift-sdn plug-in employs VxLAN encapsulation for the overlay network that it creates.
To make a successful data path between a pod and the F5 appliance:
- F5 needs to encapsulate the VxLAN packet meant for the pods. This requires the sdn-services license add-on. A VxLAN device needs to be created and the pod overlay network needs to be routed through this device.
- F5 needs to know the VTEP IP address of the pod, which is the IP address of the node where the pod is located.
-
F5 needs to know which
source-ipto use for the overlay network when encapsulating the packets meant for the pods. This is known as the gateway address. - OpenShift Container Platform nodes need to know where the F5 gateway address is (the VTEP address for the return traffic). This needs to be the internal interface’s address. All nodes of the cluster must learn this automatically.
-
Since the overlay network is multi-tenant aware, F5 must use a VxLAN ID that is representative of an
admindomain, ensuring that all tenants are reachable by the F5. Ensure that F5 encapsulates all packets with avnidof0(the defaultvnidfor theadminnamespace in OpenShift Container Platform) by putting an annotation on the manually createdhostsubnet-pod.network.openshift.io/fixed-vnid-host: 0.
A ghost hostsubnet is manually created as part of the setup, which fulfills the third and forth listed requirements. When the F5 controller pod is launched, this new ghost hostsubnet is provided so that the F5 appliance can be programmed suitably.
The term ghost hostsubnet is used because it suggests that a subnet has been given to a node of the cluster. However, in reality, it is not a real node of the cluster. It is hijacked by an external appliance.
The first requirement is fulfilled by the F5 controller pod once it is launched. The second requirement is also fulfilled by the F5 controller pod, but it is an ongoing process. For each new node that is added to the cluster, the controller pod creates an entry in the VxLAN device’s VTEP FDB. The controller pod needs access to the nodes resource in the cluster, which you can accomplish by giving the service account appropriate privileges. Use the following command:
$ oadm policy add-cluster-role-to-user system:sdn-reader system:serviceaccount:default:router4.4.3.1.3. Data Flow from the F5 Host
These actions are performed by the F5 controller pod and the F5 appliance, not the user.
- The destination pod is identified by the F5 virtual server for a packet.
- VxLAN dynamic FDB is looked up with pod’s IP address. If a MAC address is found, go to step 5.
- Flood all entries in the VTEP FDB with ARP requests seeking the pod’s MAC address.
- One of the nodes (VTEP) will respond, confirming that it is the one where the pod is located. An entry is made into the VxLAN dynamic FDB with the pod’s MAC address and the VTEP to be used as the value.
- Encap an IP packet with VxLAN headers, where the MAC of the pod and the VTEP of the node is given as values from the VxLAN dynamic FDB.
- Calculate the VTEP’s MAC address by sending out an ARP or checking the host’s neighbor cache.
- Deliver the packet through the F5 host’s internal address.
4.4.3.1.4. Data Flow: Return Traffic to the F5 Host
These actions are performed by the F5 controller pod and the F5 appliance, not the user.
- The pod sends back a packet with the destination as the F5 host’s VxLAN gateway address.
-
The
openvswitchat the node determines that the VTEP for this packet is the F5 host’s internal interface address. This is learned from the ghosthostsubnetcreation. - A VxLAN packet is sent out to the internal interface of the F5 host.
During the entire data flow, the VNID is pre-fixed to be 0 to bypass multi-tenancy.
4.5. Authentication
4.5.1. Overview
The authentication layer identifies the user associated with requests to the OpenShift Container Platform API. The authorization layer then uses information about the requesting user to determine if the request should be allowed.
As an administrator, you can configure authentication using a master configuration file.
4.5.2. Users and Groups
A user in OpenShift Container Platform is an entity that can make requests to the OpenShift Container Platform API. Typically, this represents the account of a developer or administrator that is interacting with OpenShift Container Platform.
A user can be assigned to one or more groups, each of which represent a certain set of users. Groups are useful when managing authorization policies to grant permissions to multiple users at once, for example allowing access to objects within a project, versus granting them to users individually.
In addition to explicitly defined groups, there are also system groups, or virtual groups, that are automatically provisioned by OpenShift. These can be seen when viewing cluster bindings.
In the default set of virtual groups, note the following in particular:
| Virtual Group | Description |
|---|---|
| system:authenticated | Automatically associated with all authenticated users. |
| system:authenticated:oauth | Automatically associated with all users authenticated with an OAuth access token. |
| system:unauthenticated | Automatically associated with all unauthenticated users. |
4.5.3. API Authentication
Requests to the OpenShift Container Platform API are authenticated using the following methods:
- OAuth Access Tokens
-
Obtained from the OpenShift Container Platform OAuth server using the
<master>/oauth/authorizeand<master>/oauth/tokenendpoints. -
Sent as an
Authorization: Bearer…header or anaccess_token=…query parameter
-
Obtained from the OpenShift Container Platform OAuth server using the
- X.509 Client Certificates
- Requires a HTTPS connection to the API server.
- Verified by the API server against a trusted certificate authority bundle.
- The API server creates and distributes certificates to controllers to authenticate themselves.
Any request with an invalid access token or an invalid certificate is rejected by the authentication layer with a 401 error.
If no access token or certificate is presented, the authentication layer assigns the system:anonymous virtual user and the system:unauthenticated virtual group to the request. This allows the authorization layer to determine which requests, if any, an anonymous user is allowed to make.
4.5.3.1. Impersonation
A request to the OpenShift Container Platform API may include an Impersonate-User header, which indicates that the requester wants to have the request handled as though it came from the specified user. This can be done on the command line by passing the --as=username flag.
Before User A is allowed to impersonate User B, User A is first authenticated. Then, an authorization check occurs to ensure that User A is allowed to impersonate the user named User B. If User A is requesting to impersonate a service account (system:serviceaccount:namespace:name), OpenShift Container Platform checks to ensure that User A can impersonate the serviceaccount named name in namespace. If the check fails, the request fails with a 403 (Forbidden) error code.
By default, project administrators and editors are allowed to impersonate service accounts in their namespace. The sudoers role allows a user to impersonate system:admin, which in turn has cluster administrator permissions. This grants some protection against typos (but not security) for someone administering the cluster. For example, oc delete nodes --all would be forbidden, but oc delete nodes --all --as=system:admin would be allowed. You can add a user to that group using oadm policy add-cluster-role-to-user sudoer <username>.
4.5.4. OAuth
The OpenShift Container Platform master includes a built-in OAuth server. Users obtain OAuth access tokens to authenticate themselves to the API.
When a person requests a new OAuth token, the OAuth server uses the configured identity provider to determine the identity of the person making the request.
It then determines what user that identity maps to, creates an access token for that user, and returns the token for use.
4.5.4.1. OAuth Clients
Every request for an OAuth token must specify the OAuth client that will receive and use the token. The following OAuth clients are automatically created when starting the OpenShift Container Platform API:
| OAuth Client | Usage |
|---|---|
| openshift-web-console | Requests tokens for the web console. |
| openshift-browser-client |
Requests tokens at |
| openshift-challenging-client |
Requests tokens with a user-agent that can handle |
To register additional clients:
$ oc create -f <(echo '
kind: OAuthClient
apiVersion: v1
metadata:
name: demo
secret: "..."
redirectURIs:
- "http://www.example.com/"
grantMethod: prompt
')- 1
- The
nameof the OAuth client is used as theclient_idparameter when making requests to<master>/oauth/authorizeand<master>/oauth/token. - 2
- The
secretis used as theclient_secretparameter when making requests to<master>/oauth/token. - 3
- The
redirect_uriparameter specified in requests to<master>/oauth/authorizeand<master>/oauth/tokenmust be equal to (or prefixed by) one of the URIs inredirectURIs. - 4
- The
grantMethodis used to determine what action to take when this client requests tokens and has not yet been granted access by the user. Uses the same values seen in Grant Options.
4.5.4.2. Service Accounts as OAuth Clients
A service account can be used as a constrained form of OAuth client. Service accounts can only request a subset of scopes that allow access to some basic user information and role-based power inside of the service account’s own namespace:
-
user:info -
user:check-access -
role:<any_role>:<serviceaccount_namespace> -
role:<any_role>:<serviceaccount_namespace>:!
When using a service account as an OAuth client:
-
client_idissystem:serviceaccount:<serviceaccount_namespace>:<serviceaccount_name>. client_secretcan be any of the API tokens for that service account. For example:$ oc sa get-token <serviceaccount_name>-
To get
WWW-Authenticatechallenges, set anserviceaccounts.openshift.io/oauth-want-challengesannotation on the service account to true. -
redirect_urimust match an annotation on the service account. Redirect URIs for Service Accounts as OAuth Clients provides more information.
4.5.4.2.1. Redirect URIs for Service Accounts as OAuth Clients
Annotation keys must have the prefix serviceaccounts.openshift.io/oauth-redirecturi. or serviceaccounts.openshift.io/oauth-redirectreference. such as:
serviceaccounts.openshift.io/oauth-redirecturi.<name>In its simplest form, the annotation can be used to directly specify valid redirect URIs. For example:
"serviceaccounts.openshift.io/oauth-redirecturi.first": "https://example.com"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "https://other.com"
The first and second postfixes in the above example are used to separate the two valid redirect URIs.
In more complex configurations, static redirect URIs may not be enough. For example, perhaps you want all ingresses for a route to be considered valid. This is where dynamic redirect URIs via the serviceaccounts.openshift.io/oauth-redirectreference. prefix come into play.
For example:
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"Since the value for this annotation contains serialized JSON data, it is easier to see in an expanded format:
{
"kind": "OAuthRedirectReference",
"apiVersion": "v1",
"reference": {
"kind": "Route",
"name": "jenkins"
}
}
Now you can see that an OAuthRedirectReference allows us to reference the route named jenkins. Thus, all ingresses for that route will now be considered valid. The full specification for an OAuthRedirectReference is:
{
"kind": "OAuthRedirectReference",
"apiVersion": "v1",
"reference": {
"kind": ...,
"name": ...,
"group": ...
}
}- 1
kindrefers to the type of the object being referenced. Currently, onlyrouteis supported.- 2
namerefers to the name of the object. The object must be in the same namespace as the service account.- 3
grouprefers to the group of the object. Leave this blank, as the group for a route is the empty string.
Both annotation prefixes can be combined to override the data provided by the reference object. For example:
"serviceaccounts.openshift.io/oauth-redirecturi.first": "custompath"
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
The first postfix is used to tie the annotations together. Assuming that the jenkins route had an ingress of https://example.com, now https://example.com/custompath is considered valid, but https://example.com is not. The format for partially supplying override data is as follows:
| Type | Syntax |
|---|---|
| Scheme | "https://" |
| Hostname | "//website.com" |
| Port | "//:8000" |
| Path | "examplepath" |
Specifying a host name override will replace the host name data from the referenced object, which is not likely to be desired behavior.
Any combination of the above syntax can be combined using the following format:
<scheme:>//<hostname><:port>/<path>
The same object can be referenced more than once for more flexibility:
"serviceaccounts.openshift.io/oauth-redirecturi.first": "custompath"
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "//:8000"
"serviceaccounts.openshift.io/oauth-redirectreference.second": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
Assuming that the route named jenkins has an ingress of https://example.com, then both https://example.com:8000 and https://example.com/custompath are considered valid.
Static and dynamic annotations can be used at the same time to achieve the desired behavior:
"serviceaccounts.openshift.io/oauth-redirectreference.first": "{\"kind\":\"OAuthRedirectReference\",\"apiVersion\":\"v1\",\"reference\":{\"kind\":\"Route\",\"name\":\"jenkins\"}}"
"serviceaccounts.openshift.io/oauth-redirecturi.second": "https://other.com"4.5.4.3. Integrations
All requests for OAuth tokens involve a request to <master>/oauth/authorize. Most authentication integrations place an authenticating proxy in front of this endpoint, or configure OpenShift Container Platform to validate credentials against a backing identity provider. Requests to <master>/oauth/authorize can come from user-agents that cannot display interactive login pages, such as the CLI. Therefore, OpenShift Container Platform supports authenticating using a WWW-Authenticate challenge in addition to interactive login flows.
If an authenticating proxy is placed in front of the <master>/oauth/authorize endpoint, it should send unauthenticated, non-browser user-agents WWW-Authenticate challenges, rather than displaying an interactive login page or redirecting to an interactive login flow.
To prevent cross-site request forgery (CSRF) attacks against browser clients, Basic authentication challenges should only be sent if a X-CSRF-Token header is present on the request. Clients that expect to receive Basic WWW-Authenticate challenges should set this header to a non-empty value.
If the authenticating proxy cannot support WWW-Authenticate challenges, or if OpenShift Container Platform is configured to use an identity provider that does not support WWW-Authenticate challenges, users can visit <master>/oauth/token/request using a browser to obtain an access token manually.
4.5.4.4. OAuth Server Metadata
Applications running in OpenShift Container Platform may need to discover information about the built-in OAuth server. For example, they may need to discover what the address of the <master> server is without manual configuration. To aid in this, OpenShift Container Platform implements the IETF OAuth 2.0 Authorization Server Metadata draft specification.
Thus, any application running inside the cluster can issue a GET request to https://openshift.default.svc/.well-known/oauth-authorization-server to fetch the following information:
{
"issuer": "https://<master>",
"authorization_endpoint": "https://<master>/oauth/authorize",
"token_endpoint": "https://<master>/oauth/token",
"scopes_supported": [
"user:full",
"user:info",
"user:check-access",
"user:list-scoped-projects",
"user:list-projects"
],
"response_types_supported": [
"code",
"token"
],
"grant_types_supported": [
"authorization_code",
"implicit"
],
"code_challenge_methods_supported": [
"plain",
"S256"
]
}- 1
- The authorization server’s issuer identifier, which is a URL that uses the
httpsscheme and has no query or fragment components. This is the location where.well-knownRFC 5785 resources containing information about the authorization server are published. - 2
- URL of the authorization server’s authorization endpoint. See RFC 6749.
- 3
- URL of the authorization server’s token endpoint. See RFC 6749.
- 4
- JSON array containing a list of the OAuth 2.0 RFC 6749 scope values that this authorization server supports. Note that not all supported scope values are advertised.
- 5
- JSON array containing a list of the OAuth 2.0
response_typevalues that this authorization server supports. The array values used are the same as those used with theresponse_typesparameter defined by "OAuth 2.0 Dynamic Client Registration Protocol" in RFC 7591. - 6
- JSON array containing a list of the OAuth 2.0 grant type values that this authorization server supports. The array values used are the same as those used with the
grant_typesparameter defined by OAuth 2.0 Dynamic Client Registration Protocol in RFC 7591. - 7
- JSON array containing a list of PKCE RFC 7636 code challenge methods supported by this authorization server. Code challenge method values are used in the
code_challenge_methodparameter defined in Section 4.3 of RFC 7636. The valid code challenge method values are those registered in the IANA PKCE Code Challenge Methods registry. See IANA OAuth Parameters.
4.5.4.5. Obtaining OAuth Tokens
The OAuth server supports standard authorization code grant and the implicit grant OAuth authorization flows.
Run the following command to request an OAuth token by using the authorization code grant method:
$ curl -H "X-Remote-User: <username>" \
--cacert /etc/origin/master/ca.crt \
--cert /etc/origin/master/admin.crt \
--key /etc/origin/master/admin.key \
-I https://<master-address>/oauth/authorize?response_type=token\&client_id=openshift-challenging-client | grep -oP "access_token=\K[^&]*"
When requesting an OAuth token using the implicit grant flow (response_type=token) with a client_id configured to request WWW-Authenticate challenges (like openshift-challenging-client), these are the possible server responses from /oauth/authorize, and how they should be handled:
| Status | Content | Client response |
|---|---|---|
| 302 |
|
Use the |
| 302 |
|
Fail, optionally surfacing the |
| 302 |
Other | Follow the redirect, and process the result using these rules |
| 401 |
|
Respond to challenge if type is recognized (e.g. |
| 401 |
| No challenge authentication is possible. Fail and show response body (which might contain links or details on alternate methods to obtain an OAuth token) |
| Other | Other | Fail, optionally surfacing response body to the user |
To request an OAuth token using the implicit grant flow:
$ curl -u <username>:<password>
'https://<master-address>:8443/oauth/authorize?client_id=openshift-challenging-client&response_type=token' -skv /
/ -H "X-CSRF-Token: xxx"
* Trying 10.64.33.43...
* Connected to 10.64.33.43 (10.64.33.43) port 8443 (#0)
* found 148 certificates in /etc/ssl/certs/ca-certificates.crt
* found 592 certificates in /etc/ssl/certs
* ALPN, offering http/1.1
* SSL connection using TLS1.2 / ECDHE_RSA_AES_128_GCM_SHA256
* server certificate verification SKIPPED
* server certificate status verification SKIPPED
* common name: 10.64.33.43 (matched)
* server certificate expiration date OK
* server certificate activation date OK
* certificate public key: RSA
* certificate version: #3
* subject: CN=10.64.33.43
* start date: Thu, 09 Aug 2018 04:00:39 GMT
* expire date: Sat, 08 Aug 2020 04:00:40 GMT
* issuer: CN=openshift-signer@1531109367
* compression: NULL
* ALPN, server accepted to use http/1.1
* Server auth using Basic with user 'developer'
> GET /oauth/authorize?client_id=openshift-challenging-client&response_type=token HTTP/1.1
> Host: 10.64.33.43:8443
> Authorization: Basic ZGV2ZWxvcGVyOmRzc2Zkcw==
> User-Agent: curl/7.47.0
> Accept: */*
> X-CSRF-Token: xxx
>
< HTTP/1.1 302 Found
< Cache-Control: no-cache, no-store, max-age=0, must-revalidate
< Expires: Fri, 01 Jan 1990 00:00:00 GMT
< Location:
https://10.64.33.43:8443/oauth/token/implicit#access_token=gzTwOq_mVJ7ovHliHBTgRQEEXa1aCZD9lnj7lSw3ekQ&expires_in=86400&scope=user%3Afull&token_type=Bearer
< Pragma: no-cache
< Set-Cookie: ssn=MTUzNTk0OTc1MnxIckVfNW5vNFlLSlF5MF9GWEF6Zm55Vl95bi1ZNE41S1NCbFJMYnN1TWVwR1hwZmlLMzFQRklzVXRkc0RnUGEzdnBEa0NZZndXV2ZUVzN1dmFPM2dHSUlzUmVXakQ3Q09rVXpxNlRoVmVkQU5DYmdLTE9SUWlyNkJJTm1mSDQ0N2pCV09La3gzMkMzckwxc1V1QXpybFlXT2ZYSmI2R2FTVEZsdDBzRjJ8vk6zrQPjQUmoJCqb8Dt5j5s0b4wZlITgKlho9wlKAZI=; Path=/; HttpOnly; Secure
< Date: Mon, 03 Sep 2018 04:42:32 GMT
< Content-Length: 0
< Content-Type: text/plain; charset=utf-8
<
* Connection #0 to host 10.64.33.43 left intactTo view only the OAuth token value, run the following command:
$ curl -u <username>:<password>
'https://<master-address>:8443/oauth/authorize?client_id=openshift-challenging-client&response_type=token'
-skv -H "X-CSRF-Token: xxx" --stderr - | grep -oP "access_token=\K[^&]*"
hvqxe5aMlAzvbqfM2WWw3D6tR0R2jCQGKx0viZBxwmc
You can also use the Code Grant method to request a token
4.6. Authorization
4.6.1. Overview
Authorization policies determine whether a user is allowed to perform a given action within a project. This allows platform administrators to use the cluster policy to control who has various access levels to the OpenShift Container Platform platform itself and all projects. It also allows developers to use local policy to control who has access to their projects. Note that authorization is a separate step from authentication, which is more about determining the identity of who is taking the action.
Authorization is managed using:
| Rules |
Sets of permitted verbs on a set of objects. For example, whether something can |
| Roles | Collections of rules. Users and groups can be associated with, or bound to, multiple roles at the same time. |
| Bindings | Associations between users and/or groups with a role. |
Cluster administrators can visualize rules, roles, and bindings using the CLI. For example, consider the following excerpt from viewing a policy, showing rule sets for the admin and basic-user default roles:
admin Verbs Resources Resource Names Extension
[create delete get list update watch] [projects resourcegroup:exposedkube resourcegroup:exposedopenshift resourcegroup:granter secrets] []
[get list watch] [resourcegroup:allkube resourcegroup:allkube-status resourcegroup:allopenshift-status resourcegroup:policy] []
basic-user Verbs Resources Resource Names Extension
[get] [users] [~]
[list] [projectrequests] []
[list] [projects] []
[create] [subjectaccessreviews] [] IsPersonalSubjectAccessReviewThe following excerpt from viewing policy bindings shows the above roles bound to various users and groups:
RoleBinding[admins]:
Role: admin
Users: [alice system:admin]
Groups: []
RoleBinding[basic-user]:
Role: basic-user
Users: [joe]
Groups: [devel]The relationships between the the policy roles, policy bindings, users, and developers are illustrated below.
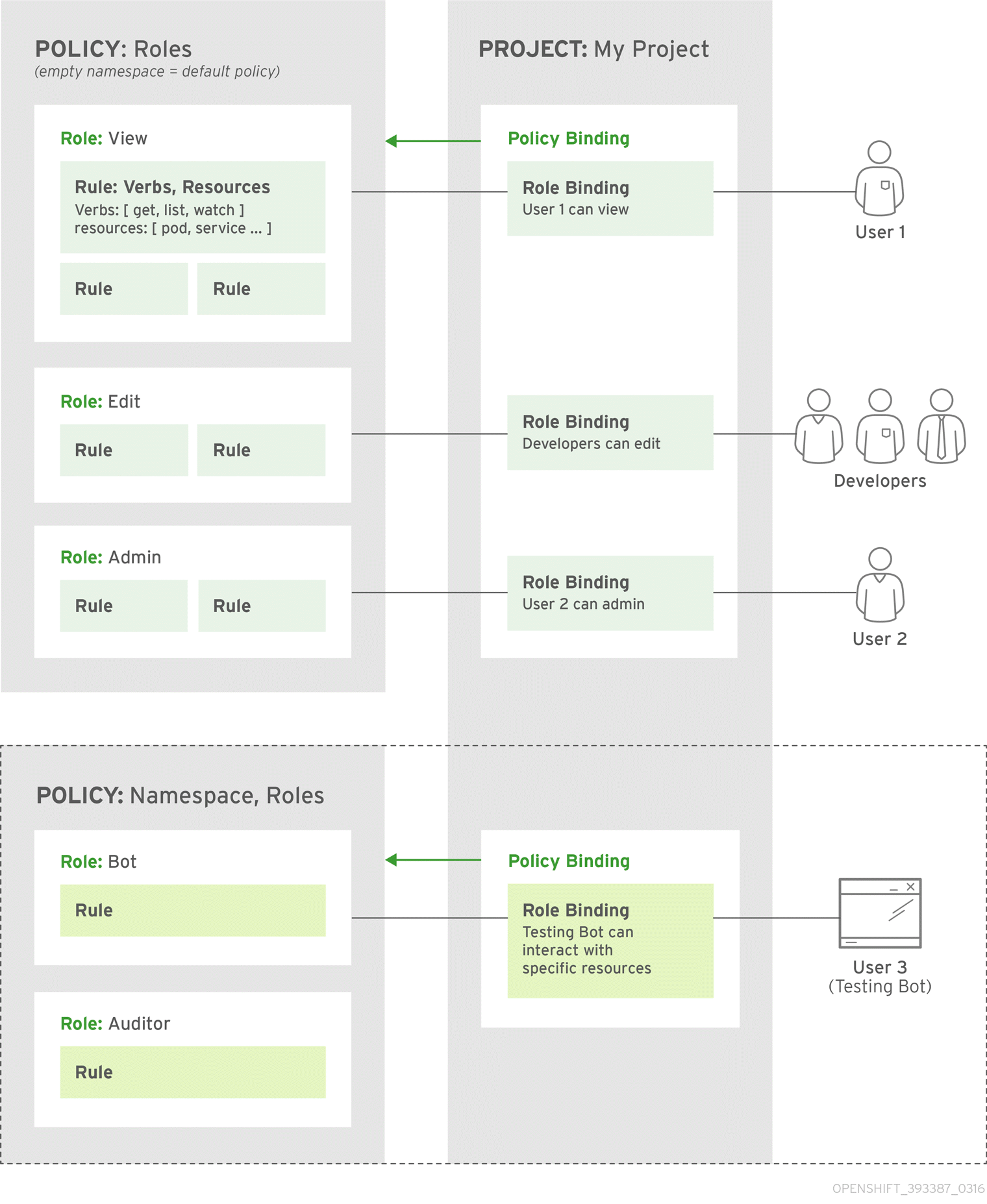
4.6.2. Evaluating Authorization
Several factors are combined to make the decision when OpenShift Container Platform evaluates authorization:
| Identity | In the context of authorization, both the user name and list of groups the user belongs to. | ||||||
| Action | The action being performed. In most cases, this consists of:
| ||||||
| Bindings | The full list of bindings. |
OpenShift Container Platform evaluates authorizations using the following steps:
- The identity and the project-scoped action is used to find all bindings that apply to the user or their groups.
- Bindings are used to locate all the roles that apply.
- Roles are used to find all the rules that apply.
- The action is checked against each rule to find a match.
- If no matching rule is found, the action is then denied by default.
4.6.3. Cluster Policy and Local Policy
There are two levels of authorization policy:
| Cluster policy | Roles and bindings that are applicable across all projects. Roles that exist in the cluster policy are considered cluster roles. Cluster bindings can only reference cluster roles. |
| Local policy | Roles and bindings that are scoped to a given project. Roles that exist only in a local policy are considered local roles. Local bindings can reference both cluster and local roles. |
This two-level hierarchy allows re-usability over multiple projects through the cluster policy while allowing customization inside of individual projects through local policies.
During evaluation, both the cluster bindings and the local bindings are used. For example:
- Cluster-wide "allow" rules are checked.
- Locally-bound "allow" rules are checked.
- Deny by default.
4.6.4. Roles
Roles are collections of policy rules, which are sets of permitted verbs that can be performed on a set of resources. OpenShift Container Platform includes a set of default roles that can be added to users and groups in the cluster policy or in a local policy.
| Default Role | Description |
|---|---|
| admin |
A project manager. If used in a local binding, an admin user will have rights to view any resource in the project and modify any resource in the project except for role creation and quota. If the cluster-admin wants to allow an admin to modify roles, the cluster-admin must create a project-scoped |
| basic-user | A user that can get basic information about projects and users. |
| cluster-admin | A super-user that can perform any action in any project. When granted to a user within a local policy, they have full control over quota and roles and every action on every resource in the project. |
| cluster-status | A user that can get basic cluster status information. |
| edit | A user that can modify most objects in a project, but does not have the power to view or modify roles or bindings. |
| self-provisioner | A user that can create their own projects. |
| view | A user who cannot make any modifications, but can see most objects in a project. They cannot view or modify roles or bindings. |
Remember that users and groups can be associated with, or bound to, multiple roles at the same time.
Cluster administrators can visualize these roles, including a matrix of the verbs and resources each are associated using the CLI to view the cluster roles. Additional system: roles are listed as well, which are used for various OpenShift Container Platform system and component operations.
By default in a local policy, only the binding for the admin role is immediately listed when using the CLI to view local bindings. However, if other default roles are added to users and groups within a local policy, they become listed in the CLI output, as well.
If you find that these roles do not suit you, a cluster-admin user can create a policyBinding object named <projectname>:default with the CLI using a JSON file. This allows the project admin to bind users to roles that are defined only in the <projectname> local policy.
The cluster- role assigned by the project administrator is limited in a project. It is not the same cluster- role granted by the cluster-admin or system:admin.
Cluster roles are roles defined at the cluster level, but can be bound either at the cluster level or at the project level.
Learn how to create a local role for a project.
4.6.4.1. Updating Cluster Roles
After any OpenShift Container Platform cluster upgrade, the recommended default roles may have been updated. See Updating Policy Definitions for instructions on getting to the new recommendations using:
$ oc adm policy reconcile-cluster-roles4.6.5. Security Context Constraints
In addition to authorization policies that control what a user can do, OpenShift Container Platform provides security context constraints (SCC) that control the actions that a pod can perform and what it has the ability to access. Administrators can manage SCCs using the CLI.
SCCs are also very useful for managing access to persistent storage.
SCCs are objects that define a set of conditions that a pod must run with in order to be accepted into the system. They allow an administrator to control the following:
- Running of privileged containers.
- Capabilities a container can request to be added.
- Use of host directories as volumes.
- The SELinux context of the container.
- The user ID.
- The use of host namespaces and networking.
-
Allocating an
FSGroupthat owns the pod’s volumes - Configuring allowable supplemental groups
- Requiring the use of a read only root file system
- Controlling the usage of volume types
- Configuring allowable seccomp profiles
Seven SCCs are added to the cluster by default, and are viewable by cluster administrators using the CLI:
$ oc get scc
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES
anyuid false [] MustRunAs RunAsAny RunAsAny RunAsAny 10 false [configMap downwardAPI emptyDir persistentVolumeClaim secret]
hostaccess false [] MustRunAs MustRunAsRange MustRunAs RunAsAny <none> false [configMap downwardAPI emptyDir hostPath persistentVolumeClaim secret]
hostmount-anyuid false [] MustRunAs RunAsAny RunAsAny RunAsAny <none> false [configMap downwardAPI emptyDir hostPath persistentVolumeClaim secret]
hostnetwork false [] MustRunAs MustRunAsRange MustRunAs MustRunAs <none> false [configMap downwardAPI emptyDir persistentVolumeClaim secret]
nonroot false [] MustRunAs MustRunAsNonRoot RunAsAny RunAsAny <none> false [configMap downwardAPI emptyDir persistentVolumeClaim secret]
privileged true [] RunAsAny RunAsAny RunAsAny RunAsAny <none> false [*]
restricted false [] MustRunAs MustRunAsRange MustRunAs RunAsAny <none> false [configMap downwardAPI emptyDir persistentVolumeClaim secret]Do not modify the default SCCs. Customizing the default SCCs can lead to issues when OpenShift Container Platform is upgraded. Instead, create new SCCs.
The definition for each SCC is also viewable by cluster administrators using the CLI. For example, for the privileged SCC:
# oc export scc/privileged
allowHostDirVolumePlugin: true
allowHostIPC: true
allowHostNetwork: true
allowHostPID: true
allowHostPorts: true
allowPrivilegedContainer: true
allowedCapabilities: null
apiVersion: v1
defaultAddCapabilities: null
fsGroup:
type: RunAsAny
groups:
- system:cluster-admins
- system:nodes
kind: SecurityContextConstraints
metadata:
annotations:
kubernetes.io/description: 'privileged allows access to all privileged and host
features and the ability to run as any user, any group, any fsGroup, and with
any SELinux context. WARNING: this is the most relaxed SCC and should be used
only for cluster administration. Grant with caution.'
creationTimestamp: null
name: privileged
priority: null
readOnlyRootFilesystem: false
requiredDropCapabilities: null
runAsUser:
type: RunAsAny
seLinuxContext:
type: RunAsAny
supplementalGroups:
type: RunAsAny
users:
- system:serviceaccount:default:registry
- system:serviceaccount:default:router
- system:serviceaccount:openshift-infra:build-controller
volumes:
- '*'- 1
- The
FSGroupstrategy which dictates the allowable values for the Security Context - 2
- The groups that have access to this SCC
- 3
- The run as user strategy type which dictates the allowable values for the Security Context
- 4
- The SELinux context strategy type which dictates the allowable values for the Security Context
- 5
- The supplemental groups strategy which dictates the allowable supplemental groups for the Security Context
- 6
- The users who have access to this SCC
The users and groups fields on the SCC control which SCCs can be used. By default, cluster administrators, nodes, and the build controller are granted access to the privileged SCC. All authenticated users are granted access to the restricted SCC.
The privileged SCC:
- allows privileged pods.
- allows host directories to be mounted as volumes.
- allows a pod to run as any user.
- allows a pod to run with any MCS label.
- allows a pod to use the host’s IPC namespace.
- allows a pod to use the host’s PID namespace.
- allows a pod to use any FSGroup.
- allows a pod to use any supplemental group.
The restricted SCC:
- ensures pods cannot run as privileged.
- ensures pods cannot use host directory volumes.
- requires that a pod run as a user in a pre-allocated range of UIDs.
- requires that a pod run with a pre-allocated MCS label.
- allows a pod to use any FSGroup.
- allows a pod to use any supplemental group.
For more information about each SCC, see the kubernetes.io/description annotation available on the SCC.
SCCs are comprised of settings and strategies that control the security features a pod has access to. These settings fall into three categories:
| Controlled by a boolean |
Fields of this type default to the most restrictive value. For example, |
| Controlled by an allowable set | Fields of this type are checked against the set to ensure their value is allowed. |
| Controlled by a strategy | Items that have a strategy to generate a value provide:
|
4.6.5.1. SCC Strategies
4.6.5.1.1. RunAsUser
-
MustRunAs - Requires a
runAsUserto be configured. Uses the configuredrunAsUseras the default. Validates against the configuredrunAsUser. - MustRunAsRange - Requires minimum and maximum values to be defined if not using pre-allocated values. Uses the minimum as the default. Validates against the entire allowable range.
-
MustRunAsNonRoot - Requires that the pod be submitted with a non-zero
runAsUseror have theUSERdirective defined in the image. No default provided. -
RunAsAny - No default provided. Allows any
runAsUserto be specified.
4.6.5.1.2. SELinuxContext
-
MustRunAs - Requires
seLinuxOptionsto be configured if not using pre-allocated values. UsesseLinuxOptionsas the default. Validates againstseLinuxOptions. -
RunAsAny - No default provided. Allows any
seLinuxOptionsto be specified.
4.6.5.1.3. SupplementalGroups
- MustRunAs - Requires at least one range to be specified if not using pre-allocated values. Uses the minimum value of the first range as the default. Validates against all ranges.
-
RunAsAny - No default provided. Allows any
supplementalGroupsto be specified.
4.6.5.1.4. FSGroup
- MustRunAs - Requires at least one range to be specified if not using pre-allocated values. Uses the minimum value of the first range as the default. Validates against the first ID in the first range.
-
RunAsAny - No default provided. Allows any
fsGroupID to be specified.
4.6.5.2. Controlling Volumes
The usage of specific volume types can be controlled by setting the volumes field of the SCC. The allowable values of this field correspond to the volume sources that are defined when creating a volume:
- azureFile
- flocker
- flexVolume
- hostPath
- emptyDir
- gcePersistentDisk
- awsElasticBlockStore
- gitRepo
- secret
- nfs
- iscsi
- glusterfs
- persistentVolumeClaim
- rbd
- cinder
- cephFS
- downwardAPI
- fc
- configMap
- *
The recommended minimum set of allowed volumes for new SCCs are configMap, downwardAPI, emptyDir, persistentVolumeClaim, and secret.
* is a special value to allow the use of all volume types.
For backwards compatibility, the usage of allowHostDirVolumePlugin overrides settings in the volumes field. For example, if allowHostDirVolumePlugin is set to false but allowed in the volumes field, then the hostPath value will be removed from volumes.
4.6.5.3. Seccomp
SeccompProfiles lists the allowed profiles that can be set for the pod or container’s seccomp annotations. An unset (nil) or empty value means that no profiles are specified by the pod or container. Use the wildcard * to allow all profiles. When used to generate a value for a pod, the first non-wildcard profile is used as the default.
Refer to the seccomp documentation for more information about configuring and using custom profiles.
4.6.5.4. Admission
Admission control with SCCs allows for control over the creation of resources based on the capabilities granted to a user.
In terms of the SCCs, this means that an admission controller can inspect the user information made available in the context to retrieve an appropriate set of SCCs. Doing so ensures the pod is authorized to make requests about its operating environment or to generate a set of constraints to apply to the pod.
The set of SCCs that admission uses to authorize a pod are determined by the user identity and groups that the user belongs to. Additionally, if the pod specifies a service account, the set of allowable SCCs includes any constraints accessible to the service account.
Admission uses the following approach to create the final security context for the pod:
- Retrieve all SCCs available for use.
- Generate field values for security context settings that were not specified on the request.
- Validate the final settings against the available constraints.
If a matching set of constraints is found, then the pod is accepted. If the request cannot be matched to an SCC, the pod is rejected.
A pod must validate every field against the SCC. The following are examples for just two of the fields that must be validated:
These examples are in the context of a strategy using the preallocated values.
A FSGroup SCC Strategy of MustRunAs
If the pod defines a fsGroup ID, then that ID must equal the default fsGroup ID. Otherwise, the pod is not validated by that SCC and the next SCC is evaluated.
If the SecurityContextConstraints.fsGroup field has value RunAsAny and the pod specification omits the Pod.spec.securityContext.fsGroup, then this field is considered valid. Note that it is possible that during validation, other SCC settings will reject other pod fields and thus cause the pod to fail.
A SupplementalGroups SCC Strategy of MustRunAs
If the pod specification defines one or more supplementalGroups IDs, then the pod’s IDs must equal one of the IDs in the namespace’s openshift.io/sa.scc.supplemental-groups annotation. Otherwise, the pod is not validated by that SCC and the next SCC is evaluated.
If the SecurityContextConstraints.supplementalGroups field has value RunAsAny and the pod specification omits the Pod.spec.securityContext.supplementalGroups, then this field is considered valid. Note that it is possible that during validation, other SCC settings will reject other pod fields and thus cause the pod to fail.
4.6.5.4.1. SCC Prioritization
SCCs have a priority field that affects the ordering when attempting to validate a request by the admission controller. A higher priority SCC is moved to the front of the set when sorting. When the complete set of available SCCs are determined they are ordered by:
- Highest priority first, nil is considered a 0 priority
- If priorities are equal, the SCCs will be sorted from most restrictive to least restrictive
- If both priorities and restrictions are equal the SCCs will be sorted by name
By default, the anyuid SCC granted to cluster administrators is given priority in their SCC set. This allows cluster administrators to run pods as any user by without specifying a RunAsUser on the pod’s SecurityContext. The administrator may still specify a RunAsUser if they wish.
4.6.5.4.2. Understanding Pre-allocated Values and Security Context Constraints
The admission controller is aware of certain conditions in the security context constraints that trigger it to look up pre-allocated values from a namespace and populate the security context constraint before processing the pod. Each SCC strategy is evaluated independently of other strategies, with the pre-allocated values (where allowed) for each policy aggregated with pod specification values to make the final values for the various IDs defined in the running pod.
The following SCCs cause the admission controller to look for pre-allocated values when no ranges are defined in the pod specification:
-
A
RunAsUserstrategy of MustRunAsRange with no minimum or maximum set. Admission looks for the openshift.io/sa.scc.uid-range annotation to populate range fields. -
An
SELinuxContextstrategy of MustRunAs with no level set. Admission looks for the openshift.io/sa.scc.mcs annotation to populate the level. -
A
FSGroupstrategy of MustRunAs. Admission looks for the openshift.io/sa.scc.supplemental-groups annotation. -
A
SupplementalGroupsstrategy of MustRunAs. Admission looks for the openshift.io/sa.scc.supplemental-groups annotation.
During the generation phase, the security context provider will default any values that are not specifically set in the pod. Defaulting is based on the strategy being used:
-
RunAsAnyandMustRunAsNonRootstrategies do not provide default values. Thus, if the pod needs a field defined (for example, a group ID), this field must be defined inside the pod specification. -
MustRunAs(single value) strategies provide a default value which is always used. As an example, for group IDs: even if the pod specification defines its own ID value, the namespace’s default field will also appear in the pod’s groups. -
MustRunAsRangeandMustRunAs(range-based) strategies provide the minimum value of the range. As with a single valueMustRunAsstrategy, the namespace’s default value will appear in the running pod. If a range-based strategy is configurable with multiple ranges, it will provide the minimum value of the first configured range.
FSGroup and SupplementalGroups strategies fall back to the openshift.io/sa.scc.uid-range annotation if the openshift.io/sa.scc.supplemental-groups annotation does not exist on the namespace. If neither exist, the SCC will fail to create.
By default, the annotation-based FSGroup strategy configures itself with a single range based on the minimum value for the annotation. For example, if your annotation reads 1/3, the FSGroup strategy will configure itself with a minimum and maximum of 1. If you want to allow more groups to be accepted for the FSGroup field, you can configure a custom SCC that does not use the annotation.
The openshift.io/sa.scc.supplemental-groups annotation accepts a comma delimited list of blocks in the format of <start>/<length or <start>-<end>. The openshift.io/sa.scc.uid-range annotation accepts only a single block.
4.6.6. Determining What You Can Do as an Authenticated User
From within your OpenShift Container Platform project, you can determine what verbs you can perform against all namespace-scoped resources (including third-party resources). Run:
$ oc policy can-i --list --loglevel=8The output will help you to determine what API request to make to gather the information.
To receive information back in a user-readable format, run:
$ oc policy can-i --listThe output will provide a full list.
To determine if you can perform specific verbs, run:
$ oc policy can-i <verb> <resource>User scopes can provide more information about a given scope. For example:
$ oc policy can-i <verb> <resource> --scopes=user:info4.7. Persistent Storage
4.7.1. Overview
Managing storage is a distinct problem from managing compute resources. OpenShift Container Platform leverages the Kubernetes persistent volume (PV) framework to allow administrators to provision persistent storage for a cluster. Using persistent volume claims (PVCs), developers can request PV resources without having specific knowledge of the underlying storage infrastructure.
PVCs are specific to a project and are created and used by developers as a means to use a PV. PV resources on their own are not scoped to any single project; they can be shared across the entire OpenShift Container Platform cluster and claimed from any project. After a PV has been bound to a PVC, however, that PV cannot then be bound to additional PVCs. This has the effect of scoping a bound PV to a single namespace (that of the binding project).
PVs are defined by a PersistentVolume API object, which represents a piece of existing networked storage in the cluster that has been provisioned by an administrator. It is a resource in the cluster just like a node is a cluster resource. PVs are volume plug-ins like Volumes, but have a lifecycle independent of any individual pod that uses the PV. PV objects capture the details of the implementation of the storage, be that NFS, iSCSI, or a cloud-provider-specific storage system.
High-availability of storage in the infrastructure is left to the underlying storage provider.
PVCs are defined by a PersistentVolumeClaim API object, which represents a request for storage by a developer. It is similar to a pod in that pods consume node resources and PVCs consume PV resources. For example, pods can request specific levels of resources (e.g., CPU and memory), while PVCs can request specific storage capacity and access modes (e.g, they can be mounted once read/write or many times read-only).
4.7.2. Lifecycle of a Volume and Claim
PVs are resources in the cluster. PVCs are requests for those resources and also act as claim checks to the resource. The interaction between PVs and PVCs have the following lifecycle.
4.7.2.1. Provisioning
A cluster administrator creates some number of PVs. They carry the details of the real storage that is available for use by cluster users. They exist in the API and are available for consumption.
4.7.2.2. Binding
A user creates a PersistentVolumeClaim with a specific amount of storage requested and with certain access modes. A control loop in the master watches for new PVCs, finds a matching PV (if possible), and binds them together. The user will always get at least what they asked for, but the volume may be in excess of what was requested. To minimize the excess, OpenShift Container Platform binds to the smallest PV that matches all other criteria.
Claims remain unbound indefinitely if a matching volume does not exist. Claims are bound as matching volumes become available. For example, a cluster provisioned with many 50Gi volumes would not match a PVC requesting 100Gi. The PVC can be bound when a 100Gi PV is added to the cluster.
4.7.2.3. Using
Pods use claims as volumes. The cluster inspects the claim to find the bound volume and mounts that volume for a pod. For those volumes that support multiple access modes, the user specifies which mode is desired when using their claim as a volume in a pod.
Once a user has a claim and that claim is bound, the bound PV belongs to the user for as long as they need it. Users schedule pods and access their claimed PVs by including a persistentVolumeClaim in their pod’s volumes block. See below for syntax details.
4.7.2.4. Releasing
When a user is done with a volume, they can delete the PVC object from the API which allows reclamation of the resource. The volume is considered "released" when the claim is deleted, but it is not yet available for another claim. The previous claimant’s data remains on the volume which must be handled according to policy.
4.7.2.5. Reclaiming
The reclaim policy of a PersistentVolume tells the cluster what to do with the volume after it is released. Currently, volumes can either be Retain or Recycle.
Retain allows for manual reclamation of the resource. For those volume plug-ins that support it, recycling performs a basic scrub on the volume (e.g., rm -rf /<volume>/*) and makes it available again for a new claim.
4.7.3. Persistent Volumes
Each PV contains a spec and status, which is the specification and status of the volume.
Example 4.1. Persistent Volume Object Definition
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /tmp
server: 172.17.0.24.7.3.1. Types of Persistent Volumes
OpenShift Container Platform supports the following PersistentVolume plug-ins:
4.7.3.2. Capacity
Generally, a PV will have a specific storage capacity. This is set using the PV’s capacity attribute. See the Kubernetes Resource Model to understand the units expected by capacity.
Currently, storage capacity is the only resource that can be set or requested. Future attributes may include IOPS, throughput, etc.
4.7.3.3. Access Modes
A PersistentVolume can be mounted on a host in any way supported by the resource provider. Providers will have different capabilities and each PV’s access modes are set to the specific modes supported by that particular volume. For example, NFS can support multiple read/write clients, but a specific NFS PV might be exported on the server as read-only. Each PV gets its own set of access modes describing that specific PV’s capabilities.
Claims are matched to volumes with similar access modes. The only two matching criteria are access modes and size. A claim’s access modes represent a request. Therefore, the user may be granted more, but never less. For example, if a claim requests RWO, but the only volume available was an NFS PV (RWO+ROX+RWX), the claim would match NFS because it supports RWO.
Direct matches are always attempted first. The volume’s modes must match or contain more modes than you requested. The size must be greater than or equal to what is expected. If two types of volumes (NFS and iSCSI, for example) both have the same set of access modes, then either of them will match a claim with those modes. There is no ordering between types of volumes and no way to choose one type over another.
All volumes with the same modes are grouped, then sorted by size (smallest to largest). The binder gets the group with matching modes and iterates over each (in size order) until one size matches.
The access modes are:
| Access Mode | CLI Abbreviation | Description |
|---|---|---|
| ReadWriteOnce |
| The volume can be mounted as read-write by a single node. |
| ReadOnlyMany |
| The volume can be mounted read-only by many nodes. |
| ReadWriteMany |
| The volume can be mounted as read-write by many nodes. |
A volume’s AccessModes are descriptors of the volume’s capabilities. They are not enforced constraints. The storage provider is responsible for runtime errors resulting from invalid use of the resource.
For example, a GCE Persistent Disk has AccessModes ReadWriteOnce and ReadOnlyMany. The user must mark their claims as read-only if they want to take advantage of the volume’s ability for ROX. Errors in the provider show up at runtime as mount errors.
iSCSI and Fibre Channel volumes do not have any fencing mechanisms yet. You must ensure the volumes are only used by one node at a time. In certain situations, such as draining a node, the volumes may be used simultaneously by two nodes. Before draining the node, first ensure the pods that use these volumes are deleted.
The table below lists the access modes supported by different persistent volumes:
| Volume Plugin | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| AWS EBS |
X |
- |
- |
| Azure File |
X |
X |
X |
| Azure Disk |
X |
- |
- |
| Ceph RBD |
X |
X |
- |
| Fiber Channel |
X |
X |
- |
| GCE Persistent Disk |
X |
- |
- |
| GlusterFS |
X |
X |
X |
| HostPath |
X |
- |
- |
| iSCSI |
X |
X |
- |
| NFS |
X |
X |
X |
| Openstack Cinder |
X |
- |
- |
- If pods rely on AWS EBS, GCE Persistent Disks, or Openstack Cinder PVs, use a recreate deployment strategy
- Azure Disk does not support dynamic provisioning.
4.7.3.4. Reclaim Policy
The current reclaim policies are:
| Reclaim Policy | Description |
|---|---|
| Retain | Manual reclamation |
| Recycle |
Basic scrub (e.g, |
Currently, only NFS and HostPath support the 'Recycle' reclaim policy.
4.7.3.5. Phase
A volumes can be found in one of the following phases:
| Phase | Description |
|---|---|
| Available | A free resource that is not yet bound to a claim. |
| Bound | The volume is bound to a claim. |
| Released | The claim has been deleted, but the resource is not yet reclaimed by the cluster. |
| Failed | The volume has failed its automatic reclamation. |
The CLI shows the name of the PVC bound to the PV.
4.7.4. Persistent Volume Claims
Each PVC contains a spec and status, which is the specification and status of the claim.
Persistent Volume Claim Object Definition
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi4.7.4.1. Storage Class
Claims can optionally request a specific StorageClass by specifying its name in the storageClassName attribute. Only PVs of the requested class, ones with the same storageClassName as the PVC, can be bound to the PVC. The cluster administrator can configure dynamic provisioners to service one or more storage classes. They create a PV on demand that matches the specifications in the PVC, if they are able.
The cluster administrator can also set a default StorageClass for all PVCs. When a default storage class is configured, the PVC must explicitly ask for StorageClass or storageClassName annotations set to "" to get bound to a PV with a no storage class.
4.7.4.2. Access Modes
Claims use the same conventions as volumes when requesting storage with specific access modes.
4.7.4.3. Resources
Claims, like pods, can request specific quantities of a resource. In this case, the request is for storage. The same resource model applies to both volumes and claims.
4.7.4.4. Claims As Volumes
Pods access storage by using the claim as a volume. Claims must exist in the same namespace as the pod using the claim. The cluster finds the claim in the pod’s namespace and uses it to get the PersistentVolume backing the claim. The volume is then mounted to the host and into the pod:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: dockerfile/nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim4.8. Remote Commands
4.8.1. Overview
OpenShift Container Platform takes advantage of a feature built into Kubernetes to support executing commands in containers. This is implemented using HTTP along with a multiplexed streaming protocol such as SPDY or HTTP/2.
Developers can use the CLI to execute remote commands in containers.
4.8.2. Server Operation
The Kubelet handles remote execution requests from clients. Upon receiving a request, it upgrades the response, evaluates the request headers to determine what streams (stdin, stdout, and/or stderr) to expect to receive, and waits for the client to create the streams.
After the Kubelet has received all the streams, it executes the command in the container, copying between the streams and the command’s stdin, stdout, and stderr, as appropriate. When the command terminates, the Kubelet closes the upgraded connection, as well as the underlying one.
Architecturally, there are options for running a command in a container. The supported implementation currently in OpenShift Container Platform invokes nsenter directly on the node host to enter the container’s namespaces prior to executing the command. However, custom implementations could include using docker exec, or running a "helper" container that then runs nsenter so that nsenter is not a required binary that must be installed on the host.
4.9. Port Forwarding
4.9.1. Overview
OpenShift Container Platform takes advantage of a feature built into Kubernetes to support port forwarding to pods. This is implemented using HTTP along with a multiplexed streaming protocol such as SPDY or HTTP/2.
Developers can use the CLI to port forward to a pod. The CLI listens on each local port specified by the user, forwarding via the described protocol.
4.9.2. Server Operation
The Kubelet handles port forward requests from clients. Upon receiving a request, it upgrades the response and waits for the client to create port forwarding streams. When it receives a new stream, it copies data between the stream and the pod’s port.
Architecturally, there are options for forwarding to a pod’s port. The supported implementation currently in OpenShift Container Platform invokes nsenter directly on the node host to enter the pod’s network namespace, then invokes socat to copy data between the stream and the pod’s port. However, a custom implementation could include running a "helper" pod that then runs nsenter and socat, so that those binaries are not required to be installed on the host.
4.10. Source Control Management
OpenShift Container Platform takes advantage of preexisting source control management (SCM) systems hosted either internally (such as an in-house Git server) or externally (for example, on GitHub, Bitbucket, etc.). Currently, OpenShift Container Platform only supports Git solutions.
SCM integration is tightly coupled with builds, the two points being:
-
Creating a
BuildConfigusing a repository, which allows building your application inside of OpenShift Container Platform. You can create aBuildConfigmanually or let OpenShift Container Platform create it automatically by inspecting your repository. - Triggering a build upon repository changes.
4.11. Admission Controllers
4.11.1. Overview
Admission control plug-ins intercept requests to the master API prior to persistence of a resource, but after the request is authenticated and authorized.
Each admission control plug-in is run in sequence before a request is accepted into the cluster. If any plug-in in the sequence rejects the request, the entire request is rejected immediately, and an error is returned to the end-user.
Admission control plug-ins may modify the incoming object in some cases to apply system configured defaults. In addition, admission control plug-ins may modify related resources as part of request processing to do things such as incrementing quota usage.
The OpenShift Container Platform master has a default list of plug-ins that are enabled by default for each type of resource (Kubernetes and OpenShift Container Platform). These are required for the proper functioning of the master. Modifying these lists is not recommended unless you strictly know what you are doing. Future versions of the product may use a different set of plug-ins and may change their ordering. If you do override the default list of plug-ins in the master configuration file, you are responsible for updating it to reflect requirements of newer versions of the OpenShift Container Platform master.
4.11.2. General Admission Rules
Starting in 3.3, OpenShift Container Platform uses a single admission chain for Kubernetes and OpenShift Container Platform resources. This changed from 3.2, and before where we had separate admission chains. This means that the top-level admissionConfig.pluginConfig element can now contain the admission plug-in configuration, which used to be contained in kubernetesMasterConfig.admissionConfig.pluginConfig.
The kubernetesMasterConfig.admissionConfig.pluginConfig should be moved and merged into admissionConfig.pluginConfig.
Also, starting in 3.3, all the supported admission plug-ins are ordered in the single chain for you. You should no longer set admissionConfig.pluginOrderOverride or the kubernetesMasterConfig.admissionConfig.pluginOrderOverride. Instead, you should enable plug-ins that are off by default by either adding their plug-in-specific configuration, or adding a DefaultAdmissionConfig stanza like this:
admissionConfig:
pluginConfig:
AlwaysPullImages:
configuration:
kind: DefaultAdmissionConfig
apiVersion: v1
disable: false
Setting disable to true will disable an admission plug-in that defaults to on.
Admission plug-ins are commonly used to help enforce security on the API server. Be careful when disabling them.
If you were previously using admissionConfig elements that cannot be safely combined into a single admission chain, you will get a warning in your API server logs and your API server will start with two separate admission chains for legacy compatibility. Update your admissionConfig to resolve the warning.
4.11.3. Customizable Admission Plug-ins
Cluster administrators can configure some admission control plug-ins to control certain behavior, such as:
4.11.4. Admission Controllers Using Containers
Admission controllers using containers also support init containers.
4.12. Other API Objects
4.12.1. LimitRange
A limit range provides a mechanism to enforce min/max limits placed on resources in a Kubernetes namespace.
By adding a limit range to your namespace, you can enforce the minimum and maximum amount of CPU and Memory consumed by an individual pod or container.
See the Kurbenetes documentation for more information.
4.12.2. ResourceQuota
Kubernetes can limit both the number of objects created in a namespace, and the total amount of resources requested across objects in a namespace. This facilitates sharing of a single Kubernetes cluster by several teams, each in a namespace, as a mechanism of preventing one team from starving another team of cluster resources.
See Cluster Administration and Kubernetes documentation for more information on ResourceQuota.
4.12.3. Resource
A Kubernetes Resource is something that can be requested by, allocated to, or consumed by a pod or container. Examples include memory (RAM), CPU, disk-time, and network bandwidth.
See the Developer Guide and Kubernetes documentation for more information.
4.12.4. Secret
Secrets are storage for sensitive information, such as keys, passwords, and certificates. They are accessible by the intended pod(s), but held separately from their definitions.
4.12.5. PersistentVolume
A persistent volume is an object (PersistentVolume) in the infrastructure provisioned by the cluster administrator. Persistent volumes provide durable storage for stateful applications.
See the Kubernetes documentation for more information.
4.12.6. PersistentVolumeClaim
A PersistentVolumeClaim object is a request for storage by a pod author. Kubernetes matches the claim against the pool of available volumes and binds them together. The claim is then used as a volume by a pod. Kubernetes makes sure the volume is available on the same node as the pod that requires it.
See the Kubernetes documentation for more information.
4.12.7. OAuth Objects
4.12.7.1. OAuthClient
An OAuthClient represents an OAuth client, as described in RFC 6749, section 2.
The following OAuthClient objects are automatically created:
|
| Client used to request tokens for the web console |
|
| Client used to request tokens at /oauth/token/request with a user-agent that can handle interactive logins |
|
| Client used to request tokens with a user-agent that can handle WWW-Authenticate challenges |
Example 4.2. OAuthClient Object Definition
kind: "OAuthClient"
apiVersion: "v1"
metadata:
name: "openshift-web-console"
selflink: "/osapi/v1/oAuthClients/openshift-web-console"
resourceVersion: "1"
creationTimestamp: "2015-01-01T01:01:01Z"
respondWithChallenges: false
secret: "45e27750-a8aa-11e4-b2ea-3c970e4b7ffe"
redirectURIs:
- "https://localhost:8443" - 1
- The
nameis used as theclient_idparameter in OAuth requests. - 2
- When
respondWithChallengesis set totrue, unauthenticated requests to/oauth/authorizewill result inWWW-Authenticatechallenges, if supported by the configured authentication methods. - 3
- The value in the
secretparameter is used as theclient_secretparameter in an authorization code flow. - 4
- One or more absolute URIs can be placed in the
redirectURIssection. Theredirect_uriparameter sent with authorization requests must be prefixed by one of the specifiedredirectURIs.
4.12.7.2. OAuthClientAuthorization
An OAuthClientAuthorization represents an approval by a User for a particular OAuthClient to be given an OAuthAccessToken with particular scopes.
Creation of OAuthClientAuthorization objects is done during an authorization request to the OAuth server.
Example 4.3. OAuthClientAuthorization Object Definition
---
kind: "OAuthClientAuthorization"
apiVersion: "v1"
metadata:
name: "bob:openshift-web-console"
resourceVersion: "1"
creationTimestamp: "2015-01-01T01:01:01-00:00"
clientName: "openshift-web-console"
userName: "bob"
userUID: "9311ac33-0fde-11e5-97a1-3c970e4b7ffe"
scopes: []
----4.12.7.3. OAuthAuthorizeToken
An OAuthAuthorizeToken represents an OAuth authorization code, as described in RFC 6749, section 1.3.1.
An OAuthAuthorizeToken is created by a request to the /oauth/authorize endpoint, as described in RFC 6749, section 4.1.1.
An OAuthAuthorizeToken can then be used to obtain an OAuthAccessToken with a request to the /oauth/token endpoint, as described in RFC 6749, section 4.1.3.
Example 4.4. OAuthAuthorizeToken Object Definition
kind: "OAuthAuthorizeToken"
apiVersion: "v1"
metadata:
name: "MDAwYjM5YjMtMzM1MC00NDY4LTkxODItOTA2OTE2YzE0M2Fj"
resourceVersion: "1"
creationTimestamp: "2015-01-01T01:01:01-00:00"
clientName: "openshift-web-console"
expiresIn: 300
scopes: []
redirectURI: "https://localhost:8443/console/oauth"
userName: "bob"
userUID: "9311ac33-0fde-11e5-97a1-3c970e4b7ffe" - 1
namerepresents the token name, used as an authorization code to exchange for an OAuthAccessToken.- 2
- The
clientNamevalue is the OAuthClient that requested this token. - 3
- The
expiresInvalue is the expiration in seconds from the creationTimestamp. - 4
- The
redirectURIvalue is the location where the user was redirected to during the authorization flow that resulted in this token. - 5
userNamerepresents the name of the User this token allows obtaining an OAuthAccessToken for.- 6
userUIDrepresents the UID of the User this token allows obtaining an OAuthAccessToken for.
4.12.7.4. OAuthAccessToken
An OAuthAccessToken represents an OAuth access token, as described in RFC 6749, section 1.4.
An OAuthAccessToken is created by a request to the /oauth/token endpoint, as described in RFC 6749, section 4.1.3.
Access tokens are used as bearer tokens to authenticate to the API.
Example 4.5. OAuthAccessToken Object Definition
kind: "OAuthAccessToken"
apiVersion: "v1"
metadata:
name: "ODliOGE5ZmMtYzczYi00Nzk1LTg4MGEtNzQyZmUxZmUwY2Vh"
resourceVersion: "1"
creationTimestamp: "2015-01-01T01:01:02-00:00"
clientName: "openshift-web-console"
expiresIn: 86400
scopes: []
redirectURI: "https://localhost:8443/console/oauth"
userName: "bob"
userUID: "9311ac33-0fde-11e5-97a1-3c970e4b7ffe"
authorizeToken: "MDAwYjM5YjMtMzM1MC00NDY4LTkxODItOTA2OTE2YzE0M2Fj" - 1
nameis the token name, which is used as a bearer token to authenticate to the API.- 2
- The
clientNamevalue is the OAuthClient that requested this token. - 3
- The
expiresInvalue is the expiration in seconds from the creationTimestamp. - 4
- The
redirectURIis where the user was redirected to during the authorization flow that resulted in this token. - 5
userNamerepresents the User this token allows authentication as.- 6
userUIDrepresents the User this token allows authentication as.- 7
authorizeTokenis the name of the OAuthAuthorizationToken used to obtain this token, if any.
4.12.8. User Objects
4.12.8.1. Identity
When a user logs into OpenShift Container Platform, they do so using a configured identity provider. This determines the user’s identity, and provides that information to OpenShift Container Platform.
OpenShift Container Platform then looks for a UserIdentityMapping for that Identity:
If the identity provider is configured with the lookup mapping method, for example, if you are using an external LDAP system, this automatic mapping is not performed. You must create the mapping manually. For more information, see Lookup Mapping Method.
-
If the
Identityalready exists, but is not mapped to aUser, login fails. -
If the
Identityalready exists, and is mapped to aUser, the user is given anOAuthAccessTokenfor the mappedUser. -
If the
Identitydoes not exist, anIdentity,User, andUserIdentityMappingare created, and the user is given anOAuthAccessTokenfor the mappedUser.
Example 4.6. Identity Object Definition
kind: "Identity"
apiVersion: "v1"
metadata:
name: "anypassword:bob"
uid: "9316ebad-0fde-11e5-97a1-3c970e4b7ffe"
resourceVersion: "1"
creationTimestamp: "2015-01-01T01:01:01-00:00"
providerName: "anypassword"
providerUserName: "bob"
user:
name: "bob"
uid: "9311ac33-0fde-11e5-97a1-3c970e4b7ffe" - 1
- The identity name must be in the form providerName:providerUserName.
- 2
providerNameis the name of the identity provider.- 3
providerUserNameis the name that uniquely represents this identity in the scope of the identity provider.- 4
- The
namein theuserparameter is the name of the user this identity maps to. - 5
- The
uidrepresents the UID of the user this identity maps to.
4.12.8.2. User
A User represents an actor in the system. Users are granted permissions by adding roles to users or to their groups.
User objects are created automatically on first login, or can be created via the API.
OpenShift Container Platform user names containing /, :, and % are not supported.
Example 4.7. User Object Definition
kind: "User"
apiVersion: "v1"
metadata:
name: "bob"
uid: "9311ac33-0fde-11e5-97a1-3c970e4b7ffe"
resourceVersion: "1"
creationTimestamp: "2015-01-01T01:01:01-00:00"
identities:
- "anypassword:bob"
fullName: "Bob User"
<1> `name` is the user name used when adding roles to a user.
<2> The values in `identities` are Identity objects that map to this user. May be `null` or empty for users that cannot log in.
<3> The `fullName` value is an optional display name of user.4.12.8.3. UserIdentityMapping
A UserIdentityMapping maps an Identity to a User.
Creating, updating, or deleting a UserIdentityMapping modifies the corresponding fields in the Identity and User objects.
An Identity can only map to a single User, so logging in as a particular identity unambiguously determines the User.
A User can have multiple identities mapped to it. This allows multiple login methods to identify the same User.
Example 4.8. UserIdentityMapping Object Definition
kind: "UserIdentityMapping"
apiVersion: "v1"
metadata:
name: "anypassword:bob"
uid: "9316ebad-0fde-11e5-97a1-3c970e4b7ffe"
resourceVersion: "1"
identity:
name: "anypassword:bob"
uid: "9316ebad-0fde-11e5-97a1-3c970e4b7ffe"
user:
name: "bob"
uid: "9311ac33-0fde-11e5-97a1-3c970e4b7ffe"
<1> `*UserIdentityMapping*` name matches the mapped `*Identity*` name4.12.8.4. Group
A Group represents a list of users in the system. Groups are granted permissions by adding roles to users or to their groups.
Example 4.9. Group Object Definition