14.3. Querying
- Creating a
FullTextSession - Creating a Lucene query using either Hibernate Search query DSL (recommended) or using the Lucene Query API
- Wrapping the Lucene query using an
org.hibernate.Query - Executing the search by calling for example
list()orscroll()
FullTextSession. This Search specific session wraps a regular org.hibernate.Session in order to provide query and indexing capabilities.
Example 14.30. Creating a FullTextSession
Session session = sessionFactory.openSession();
...
FullTextSession fullTextSession = Search.getFullTextSession(session);FullTextSession to build a full-text query using either the Hibernate Search query DSL or the native Lucene query.
final QueryBuilder b = fullTextSession.getSearchFactory().buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
List result = fullTextQuery.list(); //return a list of managed objects
Example 14.31. Creating a Lucene query via the QueryParser
SearchFactory searchFactory = fullTextSession.getSearchFactory();
org.apache.lucene.queryParser.QueryParser parser =
new QueryParser("title", searchFactory.getAnalyzer(Myth.class) );
try {
org.apache.lucene.search.Query luceneQuery = parser.parse( "history:storm^3" );
}
catch (ParseException e) {
//handle parsing failure
}
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery(luceneQuery);
List result = fullTextQuery.list(); //return a list of managed objects
org.hibernate.Query. This query remains in the same paradigm as other Hibernate query facilities, such as HQL (Hibernate Query Language), Native, and Criteria. Use methods such as list(), uniqueResult(), iterate() and scroll() with the query.
Example 14.32. Creating a Search query using the JPA API
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
...
final QueryBuilder b = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
javax.persistence.Query fullTextQuery = fullTextEntityManager.createFullTextQuery( luceneQuery );
List result = fullTextQuery.getResultList(); //return a list of managed objectsNote
FullTextQuery is retrieved.
14.3.1. Building Queries
14.3.1.1. Building a Lucene Query Using the Lucene API
14.3.1.2. Building a Lucene Query
QueryBuilder for this task.
- Method names are in English. As a result, API operations can be read and understood as a series of English phrases and instructions.
- It uses IDE autocompletion which helps possible completions for the current input prefix and allows the user to choose the right option.
- It often uses the chaining method pattern.
- It is easy to use and read the API operations.
indexedentitytype. This QueryBuilder knows what analyzer to use and what field bridge to apply. Several QueryBuilders (one for each entity type involved in the root of your query) can be created. The QueryBuilder is derived from the SearchFactory.
QueryBuilder mythQB = searchFactory.buildQueryBuilder().forEntity( Myth.class ).get();QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity( Myth.class )
.overridesForField("history","stem_analyzer_definition")
.get();Query objects assembled using the Lucene programmatic API are used with the Hibernate Search DSL.
14.3.1.3. Keyword Queries
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();| Parameter | Description |
|---|---|
| keyword() | Use this parameter to find a specific word |
| onField() | Use this parameter to specify in which lucene field to search the word |
| matching() | use this parameter to specify the match for search string |
| createQuery() | creates the Lucene query object |
- The value "storm" is passed through the
historyFieldBridge. This is useful when numbers or dates are involved. - The field bridge value is then passed to the analyzer used to index the field
history. This ensures that the query uses the same term transformation than the indexing (lower case, ngram, stemming and so on). If the analyzing process generates several terms for a given word, a boolean query is used with theSHOULDlogic (roughly anORlogic).
@Indexed
public class Myth {
@Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
public Date getCreationDate() { return creationDate; }
public Date setCreationDate(Date creationDate) { this.creationDate = creationDate; }
private Date creationDate;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("creationDate").matching(birthdate).createQuery();
Note
Date object had to be converted to its string representation (in this case the year)
FieldBridge has an objectToString method (and all built-in FieldBridge implementations do).
@AnalyzerDef(name = "ngram",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class ),
filters = {
@TokenFilterDef(factory = StandardFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class),
@TokenFilterDef(factory = NGramFilterFactory.class,
params = {
@Parameter(name = "minGramSize", value = "3"),
@Parameter(name = "maxGramSize", value = "3") } )
}
)
public class Myth {
@Field(analyzer=@Analyzer(definition="ngram")
public String getName() { return name; }
public String setName(String name) { this.name = name; }
private String name;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("name").matching("Sisiphus")
.createQuery();
y). All that is transparently done for the user.
Note
ignoreAnalyzer() or ignoreFieldBridge() functions can be called.
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();onFields method.
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();andField() method for that.
Query luceneQuery = mythQB.keyword()
.onField("history")
.andField("name")
.boostedTo(5)
.andField("description")
.matching("storm")
.createQuery();14.3.1.4. Fuzzy Queries
keyword query and add the fuzzy flag.
Query luceneQuery = mythQB
.keyword()
.fuzzy()
.withThreshold( .8f )
.withPrefixLength( 1 )
.onField("history")
.matching("starm")
.createQuery();threshold is the limit above which two terms are considering matching. It is a decimal between 0 and 1 and the default value is 0.5. The prefixLength is the length of the prefix ignored by the "fuzzyness". While the default value is 0, a nonzero value is recommended for indexes containing a huge number of distinct terms.
14.3.1.5. Wildcard Queries
? represents a single character and * represents multiple characters. Note that for performance purposes, it is recommended that the query does not start with either ? or *.
Query luceneQuery = mythQB
.keyword()
.wildcard()
.onField("history")
.matching("sto*")
.createQuery();Note
* or ? being mangled is too high.
14.3.1.6. Phrase Queries
phrase() to do so.
Query luceneQuery = mythQB
.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();Query luceneQuery = mythQB
.phrase()
.withSlop(3)
.onField("history")
.sentence("Thou kill")
.createQuery();14.3.1.7. Range Queries
//look for 0 <= starred < 3
Query luceneQuery = mythQB
.range()
.onField("starred")
.from(0).to(3).excludeLimit()
.createQuery();
//look for myths strictly BC
Date beforeChrist = ...;
Query luceneQuery = mythQB
.range()
.onField("creationDate")
.below(beforeChrist).excludeLimit()
.createQuery();14.3.1.8. Combining Queries
SHOULD: the query should contain the matching elements of the subquery.MUST: the query must contain the matching elements of the subquery.MUST NOT: the query must not contain the matching elements of the subquery.
Example 14.33. MUST NOT Query
//look for popular modern myths that are not urban
Date twentiethCentury = ...;
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.not()
.must( mythQB.range().onField("starred").above(4).createQuery() )
.must( mythQB
.range()
.onField("creationDate")
.above(twentiethCentury)
.createQuery() )
.createQuery();Example 14.34. SHOULD Query
//look for popular myths that are preferably urban
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();Example 14.35. NOT Query
//look for all myths except religious ones
Query luceneQuery = mythQB
.all()
.except( monthQb
.keyword()
.onField( "description_stem" )
.matching( "religion" )
.createQuery()
)
.createQuery();14.3.1.9. Query Options
boostedTo(on query type and on field) boosts the whole query or the specific field to a given factor.withConstantScore(on query) returns all results that match the query have a constant score equals to the boost.filteredBy(Filter)(on query) filters query results using theFilterinstance.ignoreAnalyzer(on field) ignores the analyzer when processing this field.ignoreFieldBridge(on field) ignores field bridge when processing this field.
Example 14.36. Combination of Query Options
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.should( mythQB
.keyword()
.onField("name")
.boostedTo(3)
.ignoreAnalyzer()
.matching("urban").createQuery() )
.must( mythQB
.range()
.boostedTo(5).withConstantScore()
.onField("starred").above(4).createQuery() )
.createQuery();14.3.1.10. Build a Hibernate Search Query
14.3.1.10.1. Generality
Example 14.37. Wrapping a Lucene Query in a Hibernate Query
FullTextSession fullTextSession = Search.getFullTextSession( session );
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );Example 14.38. Filtering the Search Result by Entity Type
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Customer.class );
// or
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Item.class, Actor.class );Customers. The second part of the same example returns matching Actors and Items. The type restriction is polymorphic. As a result, if the two subclasses Salesman and Customer of the base class Person return, specify Person.class to filter based on result types.
14.3.1.10.2. Pagination
Example 14.39. Defining pagination for a search query
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Customer.class );
fullTextQuery.setFirstResult(15); //start from the 15th element
fullTextQuery.setMaxResults(10); //return 10 elementsNote
fulltextQuery.getResultSize()
14.3.1.10.3. Sorting
Example 14.40. Specifying a Lucene Sort
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( query, Book.class );
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
query.setSort(sort);
List results = query.list();
Note
14.3.1.10.4. Fetching Strategy
Example 14.41. Specifying FetchMode on a query
Criteria criteria =
s.createCriteria( Book.class ).setFetchMode( "authors", FetchMode.JOIN );
s.createFullTextQuery( luceneQuery ).setCriteriaQuery( criteria );Important
Criteria query because the getResultSize() throws a SearchException if used in conjunction with a Criteria with restriction.
setCriteriaQuery.
14.3.1.10.5. Projection
Object[]. Projections prevent a time consuming database round-trip. However, they have following constraints:
- The properties projected must be stored in the index (
@Field(store=Store.YES)), which increases the index size. - The properties projected must use a
FieldBridgeimplementingorg.hibernate.search.bridge.TwoWayFieldBridgeororg.hibernate.search.bridge.TwoWayStringBridge, the latter being the simpler version.Note
All Hibernate Search built-in types are two-way. - Only the simple properties of the indexed entity or its embedded associations can be projected. Therefore a whole embedded entity cannot be projected.
- Projection does not work on collections or maps which are indexed via
@IndexedEmbedded
Example 14.42. Using Projection to Retrieve Metadata
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( FullTextQuery.SCORE, FullTextQuery.THIS, "mainAuthor.name" );
List results = query.list();
Object[] firstResult = (Object[]) results.get(0);
float score = firstResult[0];
Book book = firstResult[1];
String authorName = firstResult[2];FullTextQuery.THIS: returns the initialized and managed entity (as a non projected query would have done).FullTextQuery.DOCUMENT: returns the Lucene Document related to the object projected.FullTextQuery.OBJECT_CLASS: returns the class of the indexed entity.FullTextQuery.SCORE: returns the document score in the query. Scores are handy to compare one result against an other for a given query but are useless when comparing the result of different queries.FullTextQuery.ID: the ID property value of the projected object.FullTextQuery.DOCUMENT_ID: the Lucene document ID. Be careful in using this value as a Lucene document ID can change over time between two different IndexReader opening.FullTextQuery.EXPLANATION: returns the Lucene Explanation object for the matching object/document in the given query. This is not suitable for retrieving large amounts of data. Running explanation typically is as costly as running the whole Lucene query per matching element. As a result, projection is recommended.
14.3.1.10.6. Customizing Object Initialization Strategies
Example 14.43. Check the second-level cache before using a query
FullTextQuery query = session.createFullTextQuery(luceneQuery, User.class);
query.initializeObjectWith(
ObjectLookupMethod.SECOND_LEVEL_CACHE,
DatabaseRetrievalMethod.QUERY
);ObjectLookupMethod defines the strategy to check if an object is easily accessible (without fetching it from the database). Other options are:
ObjectLookupMethod.PERSISTENCE_CONTEXTis used if many matching entities are already loaded into the persistence context (loaded in theSessionorEntityManager).ObjectLookupMethod.SECOND_LEVEL_CACHEchecks the persistence context and then the second-level cache.
- Correctly configure and activate the second-level cache.
- Enable the second-level cache for the relevant entity. This is done using annotations such as
@Cacheable. - Enable second-level cache read access for either
Session,EntityManagerorQuery. UseCacheMode.NORMALin Hibernate native APIs orCacheRetrieveMode.USEin Java Persistence APIs.
Warning
ObjectLookupMethod.SECOND_LEVEL_CACHE. Other second-level cache providers do not implement this operation efficiently.
DatabaseRetrievalMethod as follows:
QUERY(default) uses a set of queries to load several objects in each batch. This approach is recommended.FIND_BY_IDloads one object at a time using theSession.getorEntityManager.findsemantic. This is recommended if the batch size is set for the entity, which allows Hibernate Core to load entities in batches.
14.3.1.10.7. Limiting the Time of a Query
- Raise an exception when arriving at the limit.
- Limit to the number of results retrieved when the time limit is raised.
14.3.1.10.8. Raise an Exception on Time Limit
QueryTimeoutException is raised (org.hibernate.QueryTimeoutException or javax.persistence.QueryTimeoutException depending on the programmatic API).
Example 14.44. Defining a Timeout in Query Execution
Query luceneQuery = ...;
FullTextQuery query = fullTextSession.createFullTextQuery(luceneQuery, User.class);
//define the timeout in seconds
query.setTimeout(5);
//alternatively, define the timeout in any given time unit
query.setTimeout(450, TimeUnit.MILLISECONDS);
try {
query.list();
}
catch (org.hibernate.QueryTimeoutException e) {
//do something, too slow
}getResultSize(), iterate() and scroll() honor the timeout until the end of the method call. As a result, Iterable or the ScrollableResults ignore the timeout. Additionally, explain() does not honor this timeout period. This method is used for debugging and to check the reasons for slow performance of a query.
Example 14.45. Defining a Timeout in Query Execution
Query luceneQuery = ...;
FullTextQuery query = fullTextEM.createFullTextQuery(luceneQuery, User.class);
//define the timeout in milliseconds
query.setHint( "javax.persistence.query.timeout", 450 );
try {
query.getResultList();
}
catch (javax.persistence.QueryTimeoutException e) {
//do something, too slow
}Important
14.3.2. Retrieving the Results
list(), uniqueResult(), iterate(), scroll() are available.
14.3.2.1. Performance Considerations
list() or uniqueResult() are recommended. list() work best if the entity batch-size is set up properly. Note that Hibernate Search has to process all Lucene Hits elements (within the pagination) when using list() , uniqueResult() and iterate().
scroll() is more appropriate. Don't forget to close the ScrollableResults object when you're done, since it keeps Lucene resources. If you expect to use scroll, but wish to load objects in batch, you can use query.setFetchSize(). When an object is accessed, and if not already loaded, Hibernate Search will load the next fetchSize objects in one pass.
Important
14.3.2.2. Result Size
- to provide a total search results feature, as provided by Google searches. For example, "1-10 of about 888,000,000 results"
- to implement a fast pagination navigation
- to implement a multi-step search engine that adds approximation if the restricted query returns zero or not enough results
Example 14.46. Determining the Result Size of a Query
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
//return the number of matching books without loading a single one
assert 3245 == query.getResultSize();
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setMaxResult(10);
List results = query.list();
//return the total number of matching books regardless of pagination
assert 3245 == query.getResultSize();Note
14.3.2.3. ResultTransformer
Object arrays. If the data structure used for the object does not match the requirements of the application, apply a ResultTransformer. The ResultTransformer builds the required data structure after the query execution.
Example 14.47. Using ResultTransformer with Projections
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( "title", "mainAuthor.name" );
query.setResultTransformer( new StaticAliasToBeanResultTransformer( BookView.class, "title", "author" ) );
List<BookView> results = (List<BookView>) query.list();
for(BookView view : results) {
log.info( "Book: " + view.getTitle() + ", " + view.getAuthor() );
}ResultTransformer implementations can be found in the Hibernate Core codebase.
14.3.2.4. Understanding Results
Luke tool is useful in understanding the outcome. However, Hibernate Search also gives you access to the Lucene Explanation object for a given result (in a given query). This class is considered fairly advanced to Lucene users but can provide a good understanding of the scoring of an object. You have two ways to access the Explanation object for a given result:
- Use the
fullTextQuery.explain(int)method - Use projection
FullTextQuery.DOCUMENT_ID constant.
Warning
Explanation object using the FullTextQuery.EXPLANATION constant.
Example 14.48. Retrieving the Lucene Explanation Object Using Projection
FullTextQuery ftQuery = s.createFullTextQuery( luceneQuery, Dvd.class )
.setProjection(
FullTextQuery.DOCUMENT_ID,
FullTextQuery.EXPLANATION,
FullTextQuery.THIS );
@SuppressWarnings("unchecked") List<Object[]> results = ftQuery.list();
for (Object[] result : results) {
Explanation e = (Explanation) result[1];
display( e.toString() );
}14.3.3. Filters
- security
- temporal data (example, view only last month's data)
- population filter (example, search limited to a given category)
Example 14.49. Enabling Fulltext Filters for a Query
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("bestDriver");
fullTextQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
fullTextQuery.list(); //returns only best drivers where andre has credentials@FullTextFilterDef annotation. This annotation can be on any @Indexed entity regardless of the query the filter is later applied to. This implies that filter definitions are global and their names must be unique. A SearchException is thrown in case two different @FullTextFilterDef annotations with the same name are defined. Each named filter has to specify its actual filter implementation.
Example 14.50. Defining and Implementing a Filter
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }public class BestDriversFilter extends org.apache.lucene.search.Filter {
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
OpenBitSet bitSet = new OpenBitSet( reader.maxDoc() );
TermDocs termDocs = reader.termDocs( new Term( "score", "5" ) );
while ( termDocs.next() ) {
bitSet.set( termDocs.doc() );
}
return bitSet;
}
}BestDriversFilter is an example of a simple Lucene filter which reduces the result set to drivers whose score is 5. In this example the specified filter implements the org.apache.lucene.search.Filter directly and contains a no-arg constructor.
Example 14.51. Creating a filter using the factory pattern
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilterFactory.class)
public class Driver { ... }
public class BestDriversFilterFactory {
@Factory
public Filter getFilter() {
//some additional steps to cache the filter results per IndexReader
Filter bestDriversFilter = new BestDriversFilter();
return new CachingWrapperFilter(bestDriversFilter);
}
}@Factory annotated method and use it to build the filter instance. The factory must have a no-arg constructor.
Example 14.52. Passing parameters to a defined filter
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("security").setParameter( "level", 5 );Example 14.53. Using parameters in the actual filter implementation
public class SecurityFilterFactory {
private Integer level;
/**
* injected parameter
*/
public void setLevel(Integer level) {
this.level = level;
}
@Key public FilterKey getKey() {
StandardFilterKey key = new StandardFilterKey();
key.addParameter( level );
return key;
}
@Factory
public Filter getFilter() {
Query query = new TermQuery( new Term("level", level.toString() ) );
return new CachingWrapperFilter( new QueryWrapperFilter(query) );
}
}@Key returns a FilterKey object. The returned object has a special contract: the key object must implement equals() / hashCode() so that two keys are equal if and only if the given Filter types are the same and the set of parameters are the same. In other words, two filter keys are equal if and only if the filters from which the keys are generated can be interchanged. The key object is used as a key in the cache mechanism.
@Key methods are needed only if:
- the filter caching system is enabled (enabled by default)
- the filter has parameters
StandardFilterKey implementation will be good enough. It delegates the equals() / hashCode() implementation to each of the parameters equals and hashcode methods.
SoftReferences when needed. Once the limit of the hard reference cache is reached additional filters are cached as SoftReferences. To adjust the size of the hard reference cache, use hibernate.search.filter.cache_strategy.size (defaults to 128). For advanced use of filter caching, implement your own FilterCachingStrategy. The classname is defined by hibernate.search.filter.cache_strategy.
IndexReader around a CachingWrapperFilter. The wrapper will cache the DocIdSet returned from the getDocIdSet(IndexReader reader) method to avoid expensive recomputation. It is important to mention that the computed DocIdSet is only cachable for the same IndexReader instance, because the reader effectively represents the state of the index at the moment it was opened. The document list cannot change within an opened IndexReader. A different/new IndexReader instance, however, works potentially on a different set of Documents (either from a different index or simply because the index has changed), hence the cached DocIdSet has to be recomputed.
cache flag of @FullTextFilterDef is set to FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS which will automatically cache the filter instance as well as wrap the specified filter around a Hibernate specific implementation of CachingWrapperFilter. In contrast to Lucene's version of this class SoftReferences are used together with a hard reference count (see discussion about filter cache). The hard reference count can be adjusted using hibernate.search.filter.cache_docidresults.size (defaults to 5). The wrapping behaviour can be controlled using the @FullTextFilterDef.cache parameter. There are three different values for this parameter:
| Value | Definition |
|---|---|
| FilterCacheModeType.NONE | No filter instance and no result is cached by Hibernate Search. For every filter call, a new filter instance is created. This setting might be useful for rapidly changing data sets or heavily memory constrained environments. |
| FilterCacheModeType.INSTANCE_ONLY | The filter instance is cached and reused across concurrent Filter.getDocIdSet() calls. DocIdSet results are not cached. This setting is useful when a filter uses its own specific caching mechanism or the filter results change dynamically due to application specific events making DocIdSet caching in both cases unnecessary. |
| FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS | Both the filter instance and the DocIdSet results are cached. This is the default value. |
- the system does not update the targeted entity index often (in other words, the IndexReader is reused a lot)
- the Filter's DocIdSet is expensive to compute (compared to the time spent to execute the query)
14.3.3.1. Using Filters in a Sharded Environment
Procedure 14.1. Query a Subset of Index Shards
- Create a sharding strategy that does select a subset of
IndexManagers depending on a filter configuration. - Activate the filter at query time.
Example 14.54. Query a Subset of Index Shards
customer filter is activated.
public class CustomerShardingStrategy implements IndexShardingStrategy {
// stored IndexManagers in a array indexed by customerID
private IndexManager[] indexManagers;
public void initialize(Properties properties, IndexManager[] indexManagers) {
this.indexManagers = indexManagers;
}
public IndexManager[] getIndexManagersForAllShards() {
return indexManagers;
}
public IndexManager getIndexManagerForAddition(
Class<?> entity, Serializable id, String idInString, Document document) {
Integer customerID = Integer.parseInt(document.getFieldable("customerID").stringValue());
return indexManagers[customerID];
}
public IndexManager[] getIndexManagersForDeletion(
Class<?> entity, Serializable id, String idInString) {
return getIndexManagersForAllShards();
}
/**
* Optimization; don't search ALL shards and union the results; in this case, we
* can be certain that all the data for a particular customer Filter is in a single
* shard; simply return that shard by customerID.
*/
public IndexManager[] getIndexManagersForQuery(
FullTextFilterImplementor[] filters) {
FullTextFilter filter = getCustomerFilter(filters, "customer");
if (filter == null) {
return getIndexManagersForAllShards();
}
else {
return new IndexManager[] { indexManagers[Integer.parseInt(
filter.getParameter("customerID").toString())] };
}
}
private FullTextFilter getCustomerFilter(FullTextFilterImplementor[] filters, String name) {
for (FullTextFilterImplementor filter: filters) {
if (filter.getName().equals(name)) return filter;
}
return null;
}
}customer is present, only the shard dedicated to this customer is queried, otherwise, all shards are returned. A given Sharding strategy can react to one or more filters and depends on their parameters.
ShardSensitiveOnlyFilter class when declaring your filter.
@Indexed
@FullTextFilterDef(name="customer", impl=ShardSensitiveOnlyFilter.class)
public class Customer {
...
}
FullTextQuery query = ftEm.createFullTextQuery(luceneQuery, Customer.class);
query.enableFulltextFilter("customer").setParameter("CustomerID", 5);
@SuppressWarnings("unchecked")
List<Customer> results = query.getResultList();ShardSensitiveOnlyFilter, you do not have to implement any Lucene filter. Using filters and sharding strategy reacting to these filters is recommended to speed up queries in a sharded environment.
14.3.4. Faceting
Example 14.55. Search for Hibernate Search on Amazon
QueryBuilder and FullTextQuery are the entry point into the faceting API. The former creates faceting requests and the latter accesses the FacetManager. The FacetManager applies faceting requests on a query and selects facets that are added to an existing query to refine search results. The examples use the entity Cd as shown in Example 14.56, “Entity Cd”:
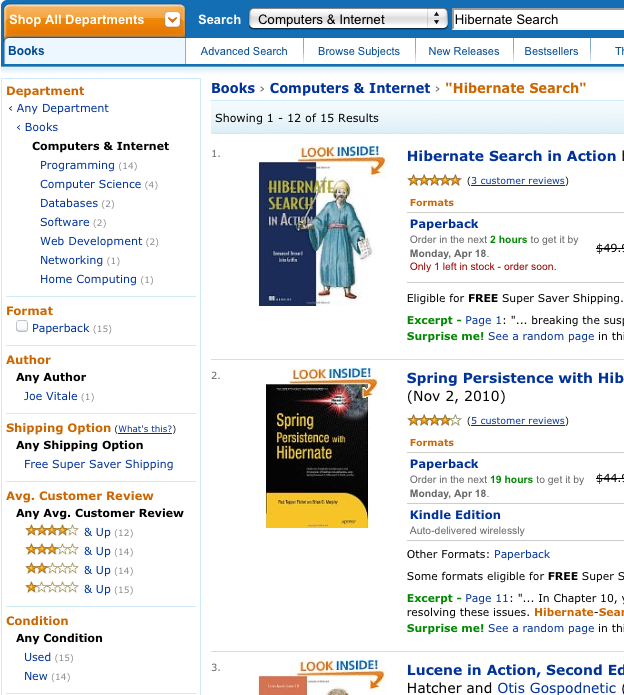
Figure 14.1. Search for Hibernate Search on Amazon
Example 14.56. Entity Cd
@Indexed
public class Cd {
private int id;
@Fields( {
@Field,
@Field(name = "name_un_analyzed", analyze = Analyze.NO)
})
private String name;
@Field(analyze = Analyze.NO)
@NumericField
private int price;
Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
private Date releaseYear;
@Field(analyze = Analyze.NO)
private String label;
// setter/getter
...14.3.4.1. Creating a Faceting Request
FacetingRequest. Currently two types of faceting requests are supported. The first type is called discrete faceting and the second type range faceting request. In the case of a discrete faceting request you specify on which index field you want to facet (categorize) and which faceting options to apply. An example for a discrete faceting request can be seen in Example 14.57, “Creating a discrete faceting request”:
Example 14.57. Creating a discrete faceting request
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest labelFacetingRequest = builder.facet()
.name( "labelFaceting" )
.onField( "label")
.discrete()
.orderedBy( FacetSortOrder.COUNT_DESC )
.includeZeroCounts( false )
.maxFacetCount( 1 )
.createFacetingRequest();Facet instance will be created for each discrete value for the indexed field label. The Facet instance will record the actual field value including how often this particular field value occurs within the original query results. orderedBy, includeZeroCounts and maxFacetCount are optional parameters which can be applied on any faceting request. orderedBy allows to specify in which order the created facets will be returned. The default is FacetSortOrder.COUNT_DESC, but you can also sort on the field value or the order in which ranges were specified. includeZeroCount determines whether facets with a count of 0 will be included in the result (per default they are) and maxFacetCount allows to limit the maximum amount of facets returned.
Note
String, Date or a subtype of Number and null values should be avoided. Furthermore the property has to be indexed with Analyze.NO and in case of a numeric property @NumericField needs to be specified.
below and above can only be specified once, but you can specify as many from - to ranges as you want. For each range boundary you can also specify via excludeLimit whether it is included into the range or not.
Example 14.58. Creating a range faceting request
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest priceFacetingRequest = builder.facet()
.name( "priceFaceting" )
.onField( "price" )
.range()
.below( 1000 )
.from( 1001 ).to( 1500 )
.above( 1500 ).excludeLimit()
.createFacetingRequest();14.3.4.2. Applying a Faceting Request
FacetManager class which can be retrieved via the FullTextQuery class.
getFacets() specifying the faceting request name. There is also a disableFaceting() method which allows you to disable a faceting request by specifying its name.
Example 14.59. Applying a faceting request
// create a fulltext query
Query luceneQuery = builder.all().createQuery(); // match all query
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Cd.class );
// retrieve facet manager and apply faceting request
FacetManager facetManager = fullTextQuery.getFacetManager();
facetManager.enableFaceting( priceFacetingRequest );
// get the list of Cds
List<Cd> cds = fullTextQuery.list();
...
// retrieve the faceting results
List<Facet> facets = facetManager.getFacets( "priceFaceting" );
...14.3.4.3. Restricting Query Results
Facets as additional criteria on your original query in order to implement a "drill-down" functionality. For this purpose FacetSelection can be utilized. FacetSelections are available via the FacetManager and allow you to select a facet as query criteria (selectFacets), remove a facet restriction (deselectFacets), remove all facet restrictions (clearSelectedFacets) and retrieve all currently selected facets (getSelectedFacets). Example 14.60, “Restricting query results via the application of a FacetSelection” shows an example.
Example 14.60. Restricting query results via the application of a FacetSelection
// create a fulltext query
Query luceneQuery = builder.all().createQuery(); // match all query
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, clazz );
// retrieve facet manager and apply faceting request
FacetManager facetManager = fullTextQuery.getFacetManager();
facetManager.enableFaceting( priceFacetingRequest );
// get the list of Cd
List<Cd> cds = fullTextQuery.list();
assertTrue(cds.size() == 10);
// retrieve the faceting results
List<Facet> facets = facetManager.getFacets( "priceFaceting" );
assertTrue(facets.get(0).getCount() == 2)
// apply first facet as additional search criteria
facetManager.getFacetGroup( "priceFaceting" ).selectFacets( facets.get( 0 ) );
// re-execute the query
cds = fullTextQuery.list();
assertTrue(cds.size() == 2);14.3.5. Optimizing the Query Process
- The Lucene query.
- The number of objects loaded: use pagination (always) or index projection (if needed).
- The way Hibernate Search interacts with the Lucene readers: defines the appropriate reader strategy.
- Caching frequently extracted values from the index: see Section 14.3.5.1, “Caching Index Values: FieldCache”
14.3.5.1. Caching Index Values: FieldCache
CacheFromIndex annotation you can experiment with different kinds of caching of the main metadata fields required by Hibernate Search:
import static org.hibernate.search.annotations.FieldCacheType.CLASS;
import static org.hibernate.search.annotations.FieldCacheType.ID;
@Indexed
@CacheFromIndex( { CLASS, ID } )
public class Essay {
...CLASS: Hibernate Search will use a Lucene FieldCache to improve peformance of the Class type extraction from the index.This value is enabled by default, and is what Hibernate Search will apply if you don't specify the @CacheFromIndexannotation.ID: Extracting the primary identifier will use a cache. This is likely providing the best performing queries, but will consume much more memory which in turn might reduce performance.
Note
- Memory usage: these caches can be quite memory hungry. Typically the CLASS cache has lower requirements than the ID cache.
- Index warmup: when using field caches, the first query on a new index or segment will be slower than when you don't have caching enabled.
CLASS field cache, this might not be used; for example if you are targeting a single class, obviously all returned values will be of that type (this is evaluated at each Query execution).
TwoWayFieldBridge (as all builting bridges), and all types being loaded in a specific query must use the fieldname for the id, and have ids of the same type (this is evaluated at each Query execution).