仮想化
OpenShift Virtualization のインストール、使用方法、およびリリースノート
概要
第1章 OpenShift Virtualization について
OpenShift Virtualization の機能およびサポート範囲について確認します。
1.1. OpenShift Virtualization の機能
OpenShift virtualization は OpenShift Container Platform のアドオンであり、仮想マシンのワークロードを実行し、このワークロードをコンテナーのワークロードと共に管理することを可能にします。
OpenShift Virtualization は、Kubernetes カスタムリソースにより新規オブジェクトを OpenShift Container Platform クラスターに追加し、仮想化タスクを有効にします。これらのタスクには、以下が含まれます。
- Linux および Windows 仮想マシンの作成と管理
- 各種コンソールおよび CLI ツールの使用による仮想マシンへの接続
- 既存の仮想マシンのインポートおよびクローン作成
- ネットワークインターフェイスコントローラーおよび仮想マシンに割り当てられたストレージディスクの管理
- 仮想マシンのノード間でのライブマイグレーション
機能強化された Web コンソールは、これらの仮想化されたリソースを OpenShift Container Platform クラスターコンテナーおよびインフラストラクチャーと共に管理するためのグラフィカルポータルを提供します。
OpenShift Virtualization は、Red Hat OpenShift Data Foundation の機能とうまく連携するように設計およびテストされています。
OpenShift Data Foundation を使用して OpenShift Virtualization をデプロイする場合は、Windows 仮想マシンディスク用の専用ストレージクラスを作成する必要があります。詳細は 、Windows VM の ODF PersistentVolumes の最適化 を参照してください。
OpenShift Virtualization は、OVN-Kubernetes、OpenShiftSDN、または 認定 OpenShift CNI プラグイン に一記載されている他の認定デフォルトの Container Network Interface (CNI) ネットワークプロバイダーの 1 つと使用できます。
Compliance Operator をインストールし、ocp4-moderate および ocp4-moderate-node プロファイル を使用してスキャンを実行することにより、OpenShift Virtualization クラスターのコンプライアンスの問題を確認できます。Compliance Operator は、NIST 認定ツール である OpenSCAP を使用して、セキュリティーポリシーをスキャンし、適用します。
OpenShift Virtualization と Compliance Operator の統合は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
1.1.1. OpenShift Virtualization サポートのクラスターバージョン
OpenShift Virtualization 4.11 は OpenShift Container Platform 4.11 クラスターで使用するためにサポートされます。Open Shift Virtualization の最新の z-stream リリースを使用するには、最初に Open Shift Container Platform の最新バージョンにアップグレードする必要があります。
第2章 OpenShift Virtualization アーキテクチャー
OpenShift Virtualization アーキテクチャーについて学習します。
2.1. OpenShift Virtualization アーキテクチャーの仕組み
OpenShift Virtualization をインストールすると、Operator Lifecycle Manager (OLM) は、OpenShift Virtualization の各コンポーネントのオペレーター Pod をデプロイします。
-
コンピューティング:
virt-operator -
ストレージ:
cdi-operator -
ネットワーク:
cluster-network-addons-operator -
スケーリング:
ssp-operator -
テンプレート作成:
tekton-tasks-operator
OLM は、他のコンポーネントのデプロイ、設定、およびライフサイクルを担当する hyperconverged-cluster-operator Pod と、いくつかのヘルパー Pod (hco-webhook および hyperconverged-cluster-cli-download) もデプロイします。
すべての Operator Pod が正常にデプロイされたら、HyperConverged カスタム リソース (CR) を作成する必要があります。HyperConverged CR で設定された設定は、信頼できる唯一の情報源および OpenShift Virtualization のエントリーポイントとして機能し、CR の動作をガイドします。
HyperConverged CR は、調整ループ内の他のすべてのコンポーネントの Operator に対応する CR を作成します。その後、各 Operator は、デーモンセット、config map、および OpenShift Virtualization コントロールプレーン用の追加コンポーネントなどのリソースを作成します。たとえば、hco-operator が KubeVirt CR を作成すると、virt-operator はそれを調整し、virt-controller、virt-handler、virt-api などの追加リソースを作成します。
OLM は hostpath-provisioner-operator をデプロイしますが、hostpath provisioner (HPP) CR を作成するまで機能しません。
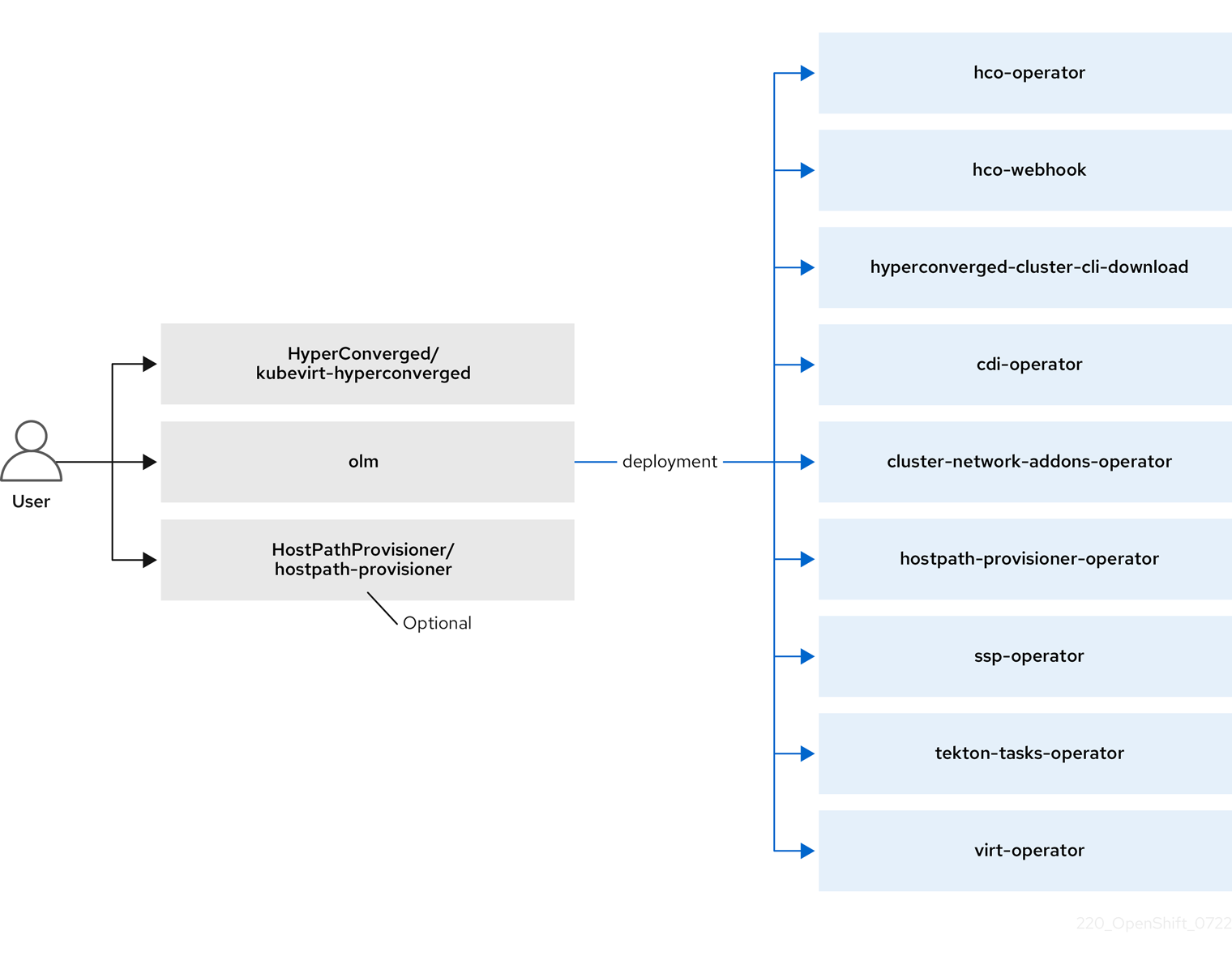
2.2. hco-operator について
hco- operator (HCO) は、OpenShift Virtualization をデプロイおよび管理するための単一のエントリーポイントと、独自のデフォルトを持ついくつかのヘルパー Operator を提供します。また、これらの Operator のカスタム リソース (CR) も作成します。
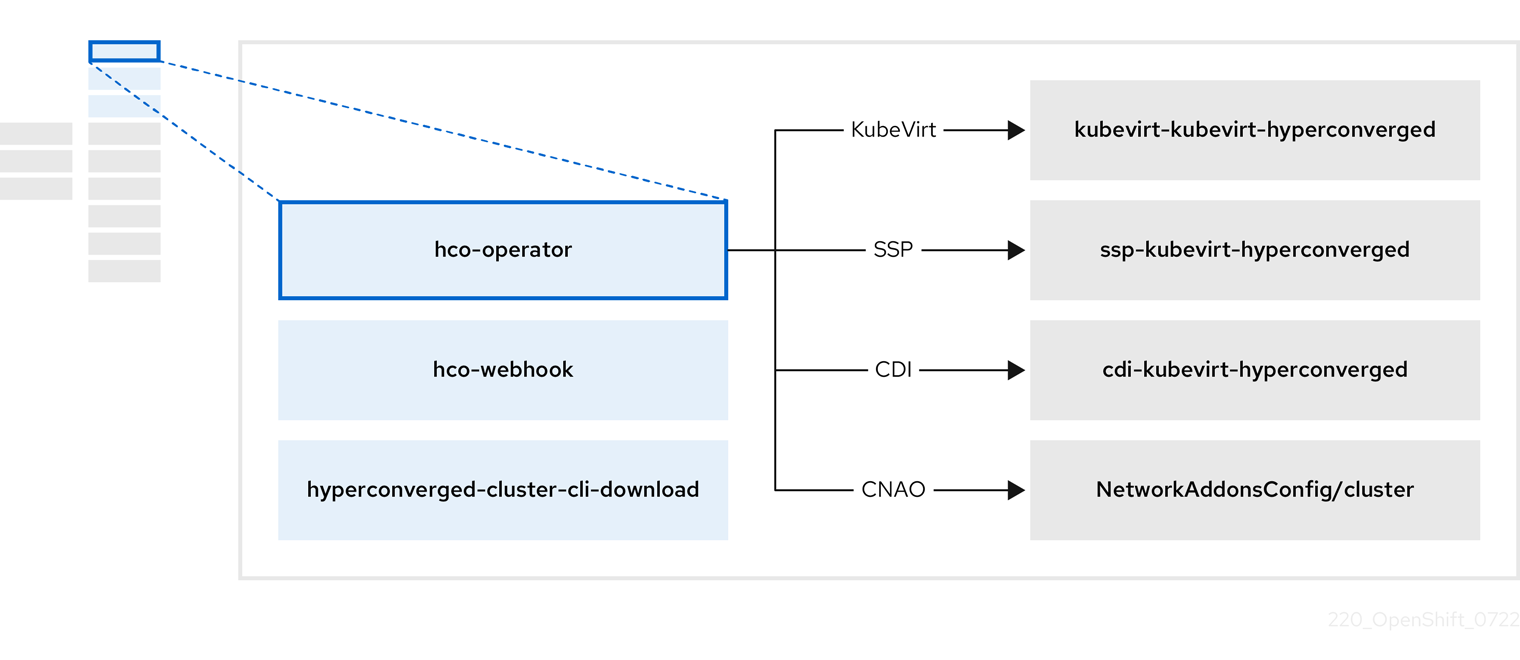
| コンポーネント | 説明 |
|---|---|
|
|
|
|
|
クラスターから直接ダウンロードできるように、 |
|
| OpenShift Virtualization に必要なすべての Operator、CR、およびオブジェクトが含まれています。 |
|
| SSP CR。これは、HCO によって自動的に作成されます。 |
|
| A CDI CR。これは、HCO によって自動的に作成されます。 |
|
|
|
2.3. cdi-operator について
cdi-operator は、Containerized Data Importer (CDI) とその関連リソースを管理します。これは、データ ボリュームを使用して仮想マシン (VM) イメージを永続ボリューム要求 (PVC) にインポートします。
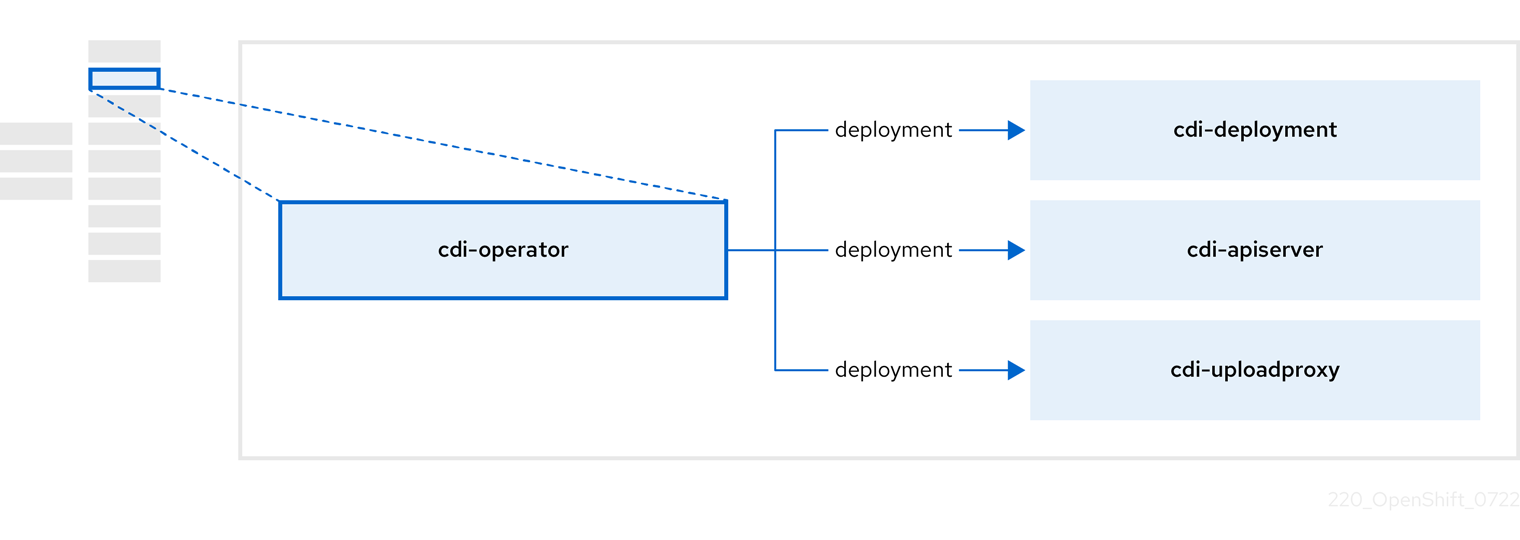
| コンポーネント | 説明 |
|---|---|
|
| 安全なアップロードトークンを発行して、VM ディスクを PVC にアップロードするための承認を管理します。 |
|
| 外部ディスクのアップロードトラフィックを適切なアップロードサーバー Pod に転送して、正しい PVC に書き込むことができるようにします。有効なアップロードトークンが必要です。 |
|
| データ ボリュームの作成時に仮想マシンイメージを PVC にインポートするヘルパー Pod。 |
2.4. cluster-network-addons-operator について
cluster-network-addons-operator は、ネットワーク コンポーネントをクラスターにデプロイし、ネットワーク機能を拡張するための関連リソースを管理します。
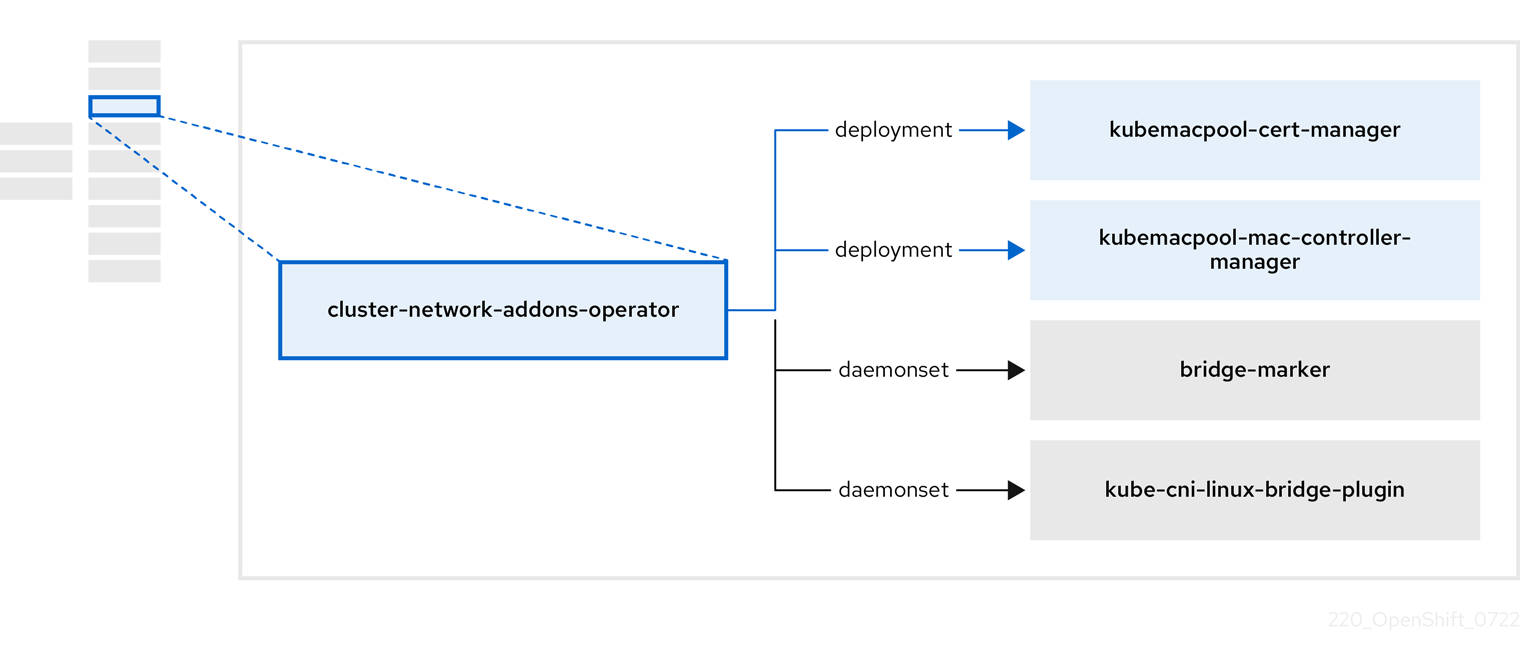
| コンポーネント | 説明 |
|---|---|
|
| Kubemacpool の Webhook の TLS 証明書を管理します。 |
|
| 仮想マシン (VM) ネットワークインターフェイス カード (NIC) の MAC アドレスプールサービスを提供します。 |
|
| ノードで使用可能なネットワークブリッジをノードリソースとしてマークします。 |
|
| クラスターノードに CNI プラグインをインストールし、ネットワーク接続定義を介して Linux ブリッジに VM を接続できるようにします。 |
2.5. hostpath-provisioner-operator について
hostpath-provisioner-operator は、マルチノードホストパスプロビジョナー (HPP) および関連リソースをデプロイおよび管理します。
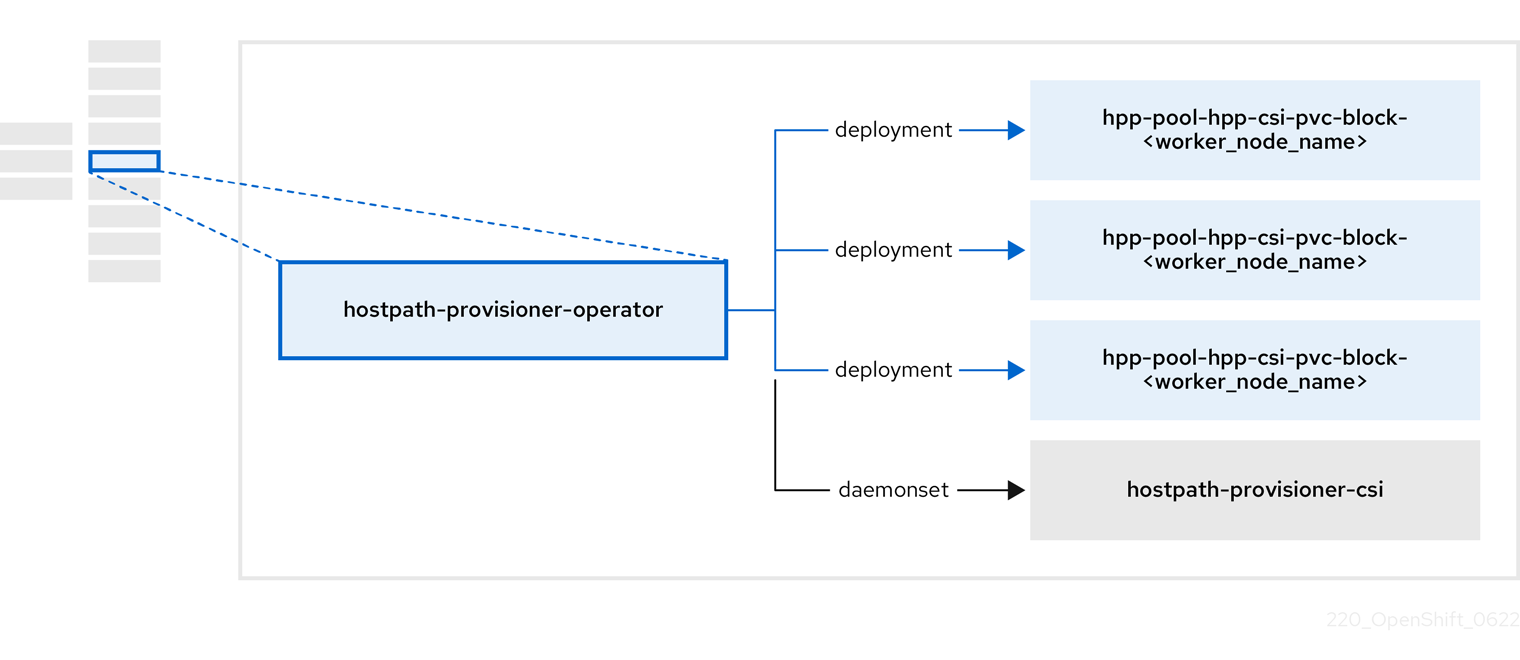
| コンポーネント | 説明 |
|---|---|
|
| ホストパスプロビジョナー (HPP) の実行が指定されている各ノードにワーカーを提供します。Pod は、指定されたバッキングストレージをノードにマウントします。 |
|
| HPP の Container Storage Interface (CSI) ドライバーインターフェイスを実装します。 |
|
| HPP のレガシードライバーインターフェイスを実装します。 |
2.6. ssp-operator について
ssp-operator は、共通テンプレート、関連するデフォルトのブートソース、およびテンプレートバリデーターをデプロイします。
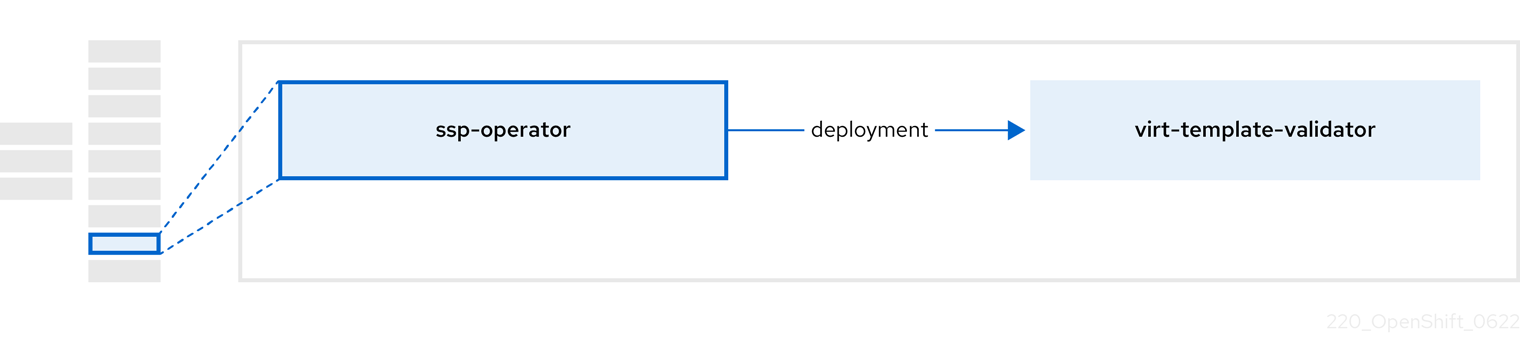
| コンポーネント | 説明 |
|---|---|
|
|
テンプレートから作成された仮想マシンの |
2.7. tekton-tasks-operator について
tekton-tasks-operator は、VM 用の OpenShift パイプラインの使用法を示すサンプルパイプラインをデプロイします。また、ユーザーがテンプレートから VM を作成し、テンプレートをコピーおよび変更し、データボリュームを作成できるようにする追加の OpenShift Pipeline タスクをデプロイします。
2.8. 仮想 Operator について
virt-operator は、現在の仮想マシン (VM) のワークロードを中断することなく、OpenShift Virtualization をデプロイ、アップグレード、および管理します。
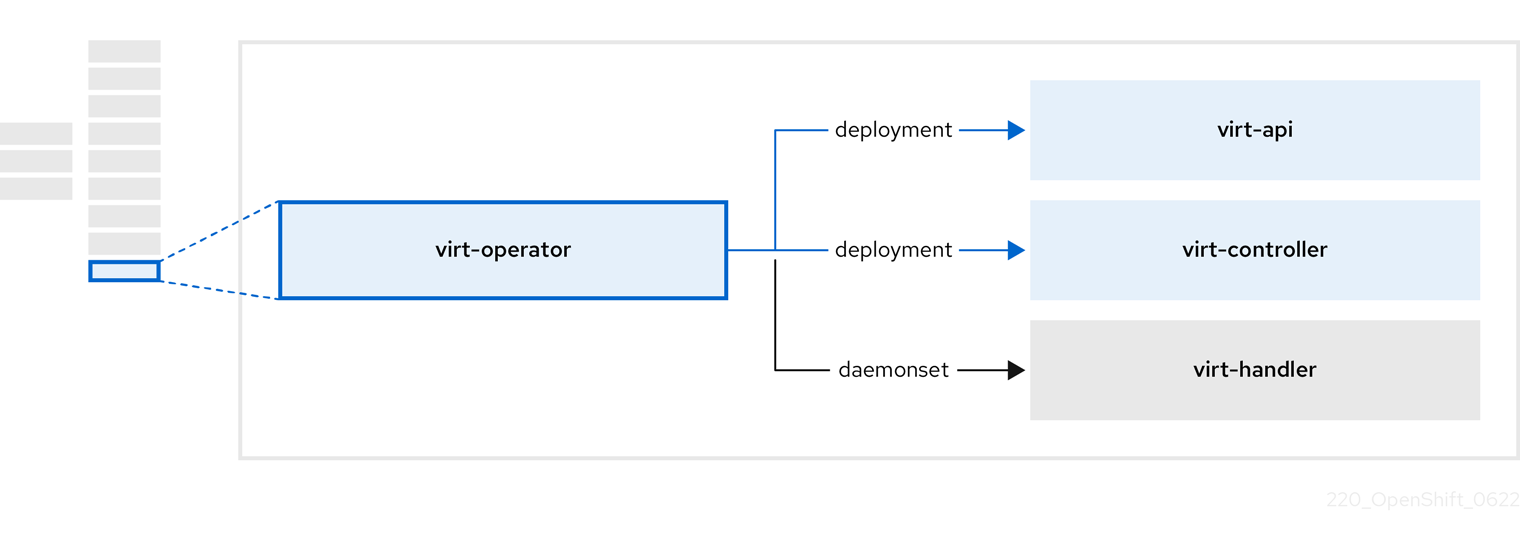
| コンポーネント | 説明 |
|---|---|
|
| すべての仮想化関連フローのエントリーポイントとして機能する HTTP API サーバー。 |
|
|
新しい VM インスタンス オブジェクトの作成を監視し、対応する Pod を作成します。Pod がノードでスケジュールされると、 |
|
|
VM への変更を監視し、必要な操作を実行するように |
|
|
|
第3章 OpenShift Virtualization の開始
基本的な OpenShift Virtualization 環境をインストールして設定し、その特徴と機能を調べることができます。
クラスター設定手順には、cluster-admin 権限が必要です。
3.1. 作業を開始する前に
- OpenShift Virtualization 用に クラスターを準備します。
- クローン作成、スナップショット、およびライブマイグレーションの ストレージ要件 を確認します。
- OpenShift Virtualization Operator をインストールします。
-
virtctlツール をインストールします。
3.2. スタートガイド
仮想マシンを作成します。
- Web コンソールを使用して仮想マシンを クイック作成 します。
- Windows ブート ソース を作成してカスタマイズします。
- 仮想マシンに VirtIO ドライバーと QEMU ゲストエージェント をインストールします。
仮想マシンに接続します。
- 仮想マシンに接続する
- 仮想マシンの管理
- Web コンソールから 仮想マシンを停止、開始、一時停止、再起動します。
-
仮想マシンを管理し、ポートを公開し、コマンド ラインから
virtctlを使用して仮想マシンのシリアルコンソールに接続します。
3.3. 次のステップ
- 仮想マシンをセカンダリーネットワークに接続する
- OpenShift Virtualization 環境を監視する
- 仮想化の概要ページ で、リソース、詳細、ステータス、上位のコンシューマーを監視します。
- 仮想マシンダッシュボード で、仮想マシンに関する概要情報を表示します。
- 仮想マシンの ログ を表示します。
- デプロイメントの自動化
-
sysprepを使用して Windows 仮想マシンのデプロイメントを自動化 します。
-
第4章 OpenShift Virtualization リリースノート
4.1. 多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ をご覧ください。
4.2. Red Hat OpenShift Virtualization について
Red Hat OpenShift Virtualization は、従来の仮想マシン (VM) をコンテナーと共に実行される OpenShift Container Platform に組み込み、それらをネイティブ Kubernetes オブジェクトとして管理することを可能にします。
OpenShift Virtualization は、
![]() アイコンで表されます。
アイコンで表されます。
OVN-Kubernetes または OpenShiftSDN のデフォルトの Container Network Interface (CNI) ネットワークプロバイダーのいずれかで OpenShift Virtualization を使用できます。
OpenShift Virtualization の機能 について参照してください。
OpenShift Virtualization のアーキテクチャーとデプロイメント の詳細を参照してください。
OpenShift Virtualization 用に クラスターを準備します。
4.2.1. OpenShift Virtualization サポートのクラスターバージョン
OpenShift Virtualization 4.11 は OpenShift Container Platform 4.11 クラスターで使用するためにサポートされます。Open Shift Virtualization の最新の z-stream リリースを使用するには、最初に Open Shift Container Platform の最新バージョンにアップグレードする必要があります。
4.2.2. サポート対象のゲストオペレーティングシステム
OpenShift Virtualization でサポートされているゲストオペレーティングシステムを確認するにはCertified Guest Operating Systems in Red Hat OpenStack Platform, Red Hat Virtualization and OpenShift Virtualization参照してください。
4.3. 新機能および変更された機能
- コンピュートノードがゼロの 3 ノードクラスター に OpenShift Virtualization をデプロイできるようになりました。
- デフォルトでは、仮想マシンは非特権ワークロードとしてセッションモードで実行されます。この機能は、escalation-of-privilege 攻撃を軽減することでクラスターのセキュリティーを向上させます。
- Red Hat Enterprise Linux (RHEL) 9 がゲストオペレーティングシステムとしてサポートされるようになりました。
- OpenShift Container Platform Web コンソールに Migration Toolkit for Virtualization (MTV) Operator をインストールするためのリンクが移動されました。現在は、Virtualization → Overview ページの Getting started resources カードの Related operators セクションにあります。
-
HyperConvergedカスタム リソース (CR) を編集することで、virtLauncher、virtHandler、virtController、virtAPI、およびvirtOperatorPod ログの 詳細レベル を設定して、特定のコンポーネントをデバッグできます。
4.3.1. クイックスタート
-
クイックスタートツアーは、複数の OpenShift Virtualization 機能で利用できます。ツアーを表示するには、OpenShift Virtualization コンソールのヘッダーのメニューバーにある Help アイコン ? をクリックし、Quick Starts を選択します。Filter フィールドに
virtualizationキーワードを入力して、利用可能なツアーをフィルタリングできます。
4.3.2. ストレージ
- 仮想マシンのスナップショット に関する情報を提供する新しいメトリックを使用できます。
- 非接続環境のログ数を減らしたり、リソースの使用量を減らしたりできます。そのためには、事前定義済みブートソースの自動インポートと更新を無効 にします。
4.3.3. Web コンソール
- Web コンソールを使用して、テンプレートおよび仮想マシンの 起動モード を BIOS、UEFI、または UEFI (セキュア) に設定できます。
- VirtualMachine details ページの Scheduling タブで、Web コンソールから descheduler を有効または無効にできるようになりました。
- サイドメニューの Virtualization → VirtualMachines に移動して、仮想マシンにアクセスできます。各仮想マシンには、仮想マシンの設定、アラート、スナップショット、ネットワークインターフェイス、ディスク、使用状況データ、およびハードウェアデバイスに関する情報を提供する、更新された Overview タブ が表示されるようになりました。
- Web コンソールの Create a Virtual Machine ウィザードは仮想マシンの作成に使用できる使用可能なテンプレートをリスト表示する カタログ ページに置き換えられました。使用可能なブートソースを備えたテンプレートを使用して仮想マシンをすばやく作成したり、テンプレートをカスタマイズして仮想マシンを作成したりできます。
- Windows 仮想マシンに vGPU が接続されている場合、Web コンソールを使用して、デフォルトのディスプレイと vGPU ディスプレイを切り替える ことができるようになりました。
- サイド メニューの Virtualization → Templates に移動して、仮想マシンテンプレートにアクセスできます。更新された VirtualMachine Templates ページでは、ワークロードプロファイル、ブートソース、CPU とメモリーの設定など、各テンプレートに関する有用な情報が提供されるようになりました。
- Create Template ウィザードは VirtualMachine Templates ページから削除されました。YAML ファイルの例を編集して、仮想マシンテンプレートを作成 します。
4.4. 非推奨および削除された機能
4.4.1. 非推奨の機能
非推奨の機能は現在のリリースに含まれており、サポートされています。ただし、これらは今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
- 今後のリリースでは、従来の HPP カスタムリソースと関連するストレージクラスのサポートは非推奨になります。OpenShift Virtualization 4.11 以降、HPP Operator は Kubernetes Container Storage Interface (CSI) ドライバーを使用してローカルストレージを設定します。Operator は、引き続き HPP カスタムリソースの既存の (レガシー) 形式および関連付けられたストレージクラスをサポートします。HPP Operator を使用する場合、移行ストラテジーの一部として CSI ドライバーのストレージクラスを作成する ことを計画してください。
4.4.2. 削除された機能
削除された機能は、現在のリリースではサポートされません。
OpenShift Virtualization 4.11 は、以下のオブジェクトを含む nmstate のサポートを削除します。
-
NodeNetworkState -
NodeNetworkConfigurationPolicy -
NodeNetworkConfigurationEnactment
既存の nmstate 設定を維持およびサポートするには、OpenShift Virtualization 4.11 に更新する前に Kubernetes NMState Operator をインストールします。これは、OpenShift Container Platform Web コンソールの OperatorHub から、または OpenShift CLI (
oc) を使用してインストールできます。-
Node Maintenance Operator (NMO) は OpenShift Virtualization に同梱されなくなりました。これは、OpenShift Container Platform Web コンソールの OperatorHub から NMO をインストール、または OpenShift CLI (
oc) を使用してインストールできます。OpenShift Virtualization 4.10.2 以降のリリースから OpenShift Virtualization 4.11 に更新する前に、以下のいずれかのタスクを実行する必要があります。
- すべてのノードをメンテナンスモードから移動します。
-
スタンドアロン NMO をインストールし、
nodemaintenances.nodemaintenance.kubevirt.ioカスタムリソース (CR) をnodemaintenances.nodemaintenance.medik8s.ioCR に置き換えます。
- 仮想マシンテンプレートをお気に入りとしてマークできなくなりました。
4.5. テクノロジープレビューの機能
現在、今回のリリースに含まれる機能にはテクノロジープレビューのものがあります。これらの実験的機能は、実稼働環境での使用を目的としていません。これらの機能に関しては、Red Hat カスタマーポータルの以下のサポート範囲を参照してください。
- Microsoft Windows 11 をゲスト OS として使用できるようになりました。ただし、OpenShift Virtualization 4.11 は、BitLocker リカバリーの重要な機能に必要な USB ディスクをサポートしていません。回復キーを保護するには、BitLocker recovery guide で説明されている他の方法を使用します。
- OpenShift Virtualization を AWS ベアメタルノードにデプロイできるようになりました。
- OpenShift Virtualization には、緊急の対応が必要な問題が発生したときに通知する 重要なアラート があります。各アラートには、問題に対する説明、アラートが発生した理由、問題の原因を診断するためのトラブルシューティングプロセス、およびアラートの解決手順が含まれるようになりました。
-
管理者は、
HyperConvergedCR を編集することにより、宣言的に、仮想グラフィックス処理ユニット (vGPU) などの仲介デバイスを作成および公開できるようになりました。仮想マシンの所有者は、これらのデバイスを仮想マシンに割り当てることができます。
-
単一の
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用することにより、ブリッジに接続されている NIC の静的 IP 設定を転送できます。
- OpenShift Virtualization を IBM Cloud ベアメタルサーバーにインストールできるようになりました。他のクラウドプロバイダーが提供するベアメタルサーバーはサポートされません。
-
Compliance Operator をインストールし、
ocp4-moderateおよびocp4-moderate-nodeプロファイル を使用してスキャンを実行することにより、OpenShift Virtualization クラスターのコンプライアンスの問題を確認できます。
- OpenShift Virtualization には、クラスターのメンテナンスとトラブルシューティングに使用できる定義済みのチェックアップを実行するための 診断フレームワーク が含まれるようになりました。定義済みのチェックアップを実行して、セカンダリー ネットワーク上の仮想マシンの ネットワーク接続性とレイテンシーをチェック できます。
- 帯域幅の使用率、並列移行の最大数、タイムアウトなどの特定のパラメーターを使用してライブマイグレーションポリシーを作成し、仮想マシンと namespace のラベルを使用して、仮想マシンのグループにポリシーを適用できます。
4.6. バグ修正
- 以前は、大規模なクラスターでは OpenShift Virtualization MAC プールマネージャーの起動に時間がかかりすぎる可能性があり、OpenShift Virtualization が準備状態にならないことがありました。今回の更新により、プールの初期化と起動の待ち時間が短縮されました。その結果、仮想マシンを正常に定義できるようになりました。(BZ#2035344)
- シャットダウン中に Windows 仮想マシンがクラッシュまたはハングした場合、手動で強制シャットダウンリクエストを発行して仮想マシンを停止できるようになりました。(BZ#2040766)
- 仮想マシンウィザードの YAML の例が更新され、アップストリームの最新の変更が含まれるようになりました。(BZ#2055492)
- VM Network Interfaces タブの Add Network Interface ボタンが、非特権ユーザーに対して無効にならなくなりました。(BZ#2056420)
- 非特権ユーザーは、RBAC ルールエラーを取得することなく、仮想マシンにディスクを正常に追加できるようになりました。(BZ#2056421)
- Web コンソールは、カスタム namespace にデプロイされた仮想マシンテンプレートを正常に表示するようになりました。(BZ#2054650)
-
以前は、
spec.evictionStrategyフィールドが VMI のLiveMigrateに設定されている場合、Single Node OpenShift (SNO) クラスターの更新が失敗していました。ライブマイグレーションを成功させるには、クラスターに複数のコンピュートノードが必要です。今回の更新により、spec.evictionStrategyフィールドが SNO 環境の仮想マシンテンプレートから削除されました。その結果、クラスターの更新が成功するようになりました。(BZ#2073880)
4.7. 既知の問題
- シングルスタックの IPv6 クラスターで OpenShift Virtualization は実行できません。(BZ#2193267)
- コンピュートノードがさまざま含まれる、異種クラスターでは、HyperV Reenlightenment が有効になっている仮想マシンは、タイムスタンプカウンタースケーリング (TSC) をサポートしていないノード、TSC 頻度が非季節なノードでスケジュールできません。(BZ#2151169)
異なる SELinux コンテキストで 2 つの Pod を使用すると、
ocs-storagecluster-cephfsストレージクラスの VM が移行に失敗し、VM のステータスがPausedに変わります。これは、両方の Pod がReadWriteManyCephFS の共有ボリュームに同時にアクセスしようとするためです。(BZ#2092271)-
回避策として、
ocs-storagecluster-ceph-rbdストレージクラスを使用して、Red Hat Ceph Storage を使用するクラスターで VM をライブマイグレーションします。
-
回避策として、
OpenShift Virtualization を更新せずに OpenShift Container Platform をバージョン 4.11 に更新すると、VM スナップショットの復元に失敗します。これは、スナップショットオブジェクトに使用される API バージョン間の不一致が原因です。(BZ#2159442)
- 回避策として、OpenShift Virtualization を OpenShift Container Platform と同じマイナーバージョンに更新します。バージョンが同期されていることを確認するには、推奨される Automatic 承認ストラテジーを使用してください。
- OpenShift Virtualization をアンインストールしても、OpenShift Virtualization によって作成されたノードラベルは削除されません。ラベルは手動で削除する必要があります。(CNV-22036)
OVN-Kubernetes クラスターネットワークプロバイダーは、大量の
NodePortサービスを作成すると、RAM と CPU の使用率がピークに達するとクラッシュします。これは、NodePortサービスを使用して SSH アクセスを多数の仮想マシン (VM) に公開する場合に発生する可能性があります。(OCPBUGS-1940)-
回避策として、
NodePortサービスを介して多数の仮想マシンに SSH アクセスを公開する場合は、OpenShift SDN クラスターネットワークプロバイダーを使用します。
-
回避策として、
バージョン 4.10 から OpenShift Virtualization 4.11 への更新は、スタンドアロンの Kubernetes NMState Operator をインストールするまでブロックされます。これは、クラスター設定が nmstate リソースを使用していない場合でも発生します。(BZ#2126537)
回避策として、以下を実施します。
クラスターにノードネットワーク設定ポリシーが定義されていないことを確認します。
$ oc get nncpOpenShift Virtualization を更新する適切な方法を選択します。
- ノードネットワーク設定ポリシーのリストが空でない場合は、この手順を終了し、Kubernetes NMState Operator をインストールして、既存の nmstate 設定を保持およびサポートします。
- リストが空の場合は、ステップ 3 に進みます。
HyperConvergedカスタムリソース (CR) にアノテーションを付けます。次のコマンドは、既存の JSON パッチを上書きします。$ oc annotate --overwrite -n openshift-cnv hco kubevirt-hyperconverged 'networkaddonsconfigs.kubevirt.io/jsonpatch=[{"op": "replace","path": "/spec/nmstate", "value": null}]'注記このパッチが適用されている間、
HyperConvergedオブジェクトはTaintedConfiguration状態をレポートします。これは無害です。- OpenShift Virtualization を更新します。
更新が完了したら、次のコマンドを実行してアノテーションを削除します。
$ oc annotate -n openshift-cnv hco kubevirt-hyperconverged networkaddonsconfigs.kubevirt.io/jsonpatch-- オプション: 上書きされた、以前に設定された JSON パッチを元に戻します。
Containerized Data Importer (CDI) によって作成された一部の永続ボリューム要求 (PVC) アノテーションにより、仮想マシンのスナップショット復元操作が無期限に停止する可能性があります。(BZ#2070366)
回避策として、アノテーションを手動で削除できます。
-
VirtualMachineSnapshotCR のstatus.virtualMachineSnapshotContentName値から、VirtualMachineSnapshotContent カスタムリソース (CR) 名を取得します。 -
VirtualMachineSnapshotContentCR を編集し、k8s.io/cloneRequestを含むすべての行を削除します。 VirtualMachineオブジェクトでspec.dataVolumeTemplatesの値を指定しなかった場合は、次の両方の条件に該当するこの namespace のDataVolumeおよびPersistentVolumeClaimオブジェクトを削除します。-
オブジェクトの名前は
restore-で始まります。 オブジェクトは仮想マシンによって参照されません。
spec.dataVolumeTemplatesの値を指定した場合、この手順はオプションとなります。
-
オブジェクトの名前は
-
更新された
VirtualMachineSnapshotCR で 復元操作 を繰り返します。
-
-
Windows 11 仮想マシンは、FIPS モード で実行されているクラスターで起動しません。Windows 11 には、デフォルトで Trusted Platform Module (TPM) デバイスが必要です。ただし、
swtpm(ソフトウェア TPM エミュレーター) パッケージは FIPS と互換性がありません。(BZ#2089301) -
Single Node OpenShift (SNO) クラスターでは、エビクションストラテジーが
LiveMigrateに設定されている共通テンプレートから作成された仮想マシンでVMCannotBeEvictedアラートが発生します。(BZ#2092412) Fedora 35 仮想マシン上の QEMU ゲストエージェントは SELinux によってブロックされ、データを報告しません。他の Fedora バージョンが影響を受ける可能性があります。(BZ#2028762)
- 回避策として、仮想マシンで SELinux を無効にし、QEMU ゲストエージェントコマンドを実行してから、SELinux を再度有効にします。
OpenShift Container Platform クラスターが OVN-Kubernetes をデフォルトの Container Network Interface (CNI) プロバイダーとして使用する場合、OVN-Kubernetes のホストネットワークトポロジーの変更により、Linux ブリッジまたはボンディングデバイスをホストのデフォルトインターフェイスに割り当てることはできません。(BZ#1885605)
- 回避策として、ホストに接続されたセカンダリーネットワークインターフェイスを使用するか、OpenShift SDN デフォルト CNI プロバイダーに切り替えることができます。
Red Hat Ceph Storage または Red Hat OpenShift Data Foundation Storage を使用する場合は、一度に 100 台以上の仮想マシンのクローンを作成できない場合があります。(BZ#1989527)
回避策として、ストレージプロファイルマニフェストに
spec.cloneStrategy: copyを設定して、ホスト支援コピーを実行できます。以下に例を示します。apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <provisioner_class> # ... spec: claimPropertySets: - accessModes: - ReadWriteOnce volumeMode: Filesystem cloneStrategy: copy1 status: provisioner: <provisioner> storageClass: <provisioner_class>- 1
- デフォルトのクローン作成方法は
copyに設定されています。
場合によっては、複数の仮想マシンが読み取り/書き込みモードで同じ PVC をマウントできるため、データが破損する可能性があります。(BZ#1992753)
- 回避策として、複数の仮想マシンで読み取り/書き込みモードで単一の PVC を使用しないでください。
Pod Disruption Budget (PDB) は、移行可能な仮想マシンイメージについての Pod の中断を防ぎます。PDB が Pod の中断を検出する場合、
openshift-monitoringはLiveMigrateエビクションストラテジーを使用する仮想マシンイメージに対して 60 分ごとにPodDisruptionBudgetAtLimitアラートを送信します。(BZ#2026733)- 回避策として、アラートをサイレンス にします。
OpenShift Virtualization は、Pod によって使用されるサービスアカウントトークンをその特定の Pod にリンクします。OpenShift Virtualization は、トークンが含まれるディスクイメージを作成してサービスアカウントボリュームを実装します。仮想マシンを移行すると、サービスアカウントボリュームが無効になります。(BZ#2037611)
- 回避策として、サービスアカウントではなくユーザーアカウントを使用してください。ユーザーアカウントトークンは特定の Pod にバインドされていないためです。
ドライバーをインストールする前に仲介デバイスを有効にするように
HyperConvergedカスタムリソース (CR) を設定すると、新しいデバイス設定は有効になりません。この問題は更新によってトリガーされます。たとえば、NVIDIA ドライバーをインストールするdaemonsetの前にvirt-handlerを更新した場合、ノードは仮想マシン GPU を提供することができません。(BZ#2046298)回避策として、以下を実施します。
-
HyperConvergedCR からmediatedDevicesConfigurationおよびpermittedHostDevicesを削除します。 -
使用する設定で、
mediatedDevicesConfigurationおよびpermittedHostDevicesスタンザの両方を更新します。
-
csi-cloneクローンストラテジーを使用して 100 台以上の仮想マシンのクローンを作成する場合、Ceph CSI はクローンをパージしない可能性があります。クローンの手動削除も失敗する可能性があります。(BZ#2055595)-
回避策として、
ceph-mgrを再起動して仮想マシンのクローンをパージすることができます。
-
回避策として、
第5章 インストール
5.1. OpenShift Virtualization のクラスターの準備
OpenShift Virtualization をインストールする前にこのセクションを確認して、クラスターが要件を満たしていることを確認してください。
ユーザープロビジョニング、インストーラープロビジョニング、またはアシステッドインストーラーなど、任意のインストール方法を使用して、OpenShift Container Platform をデプロイできます。ただし、インストール方法とクラスタートポロジーは、スナップショットやライブマイグレーションなどの OpenShift Virtualization 機能に影響を与える可能性があります。
単一ノードの Openshift の違い
単一ノードのクラスターに OpenShift Virtualization をインストールできます。詳細は、単一ノードの Openshift について を参照してください。単一ノードの Openshift は高可用性をサポートしていないため、次の違いがあります。
- Pod disruption budgets はサポートされていません。
- ライブマイグレーション には対応していません。
-
データボリュームまたはストレージプロファイルを使用するテンプレートまたは仮想マシンには、
evictionStrategyが設定されていてはなりません。
FIPS モード
クラスターを FIPS モード でインストールする場合、OpenShift Virtualization に追加の設定は必要ありません。
IPv6
シングルスタックの IPv6 クラスターで OpenShift Virtualization は実行できません。(BZ#2193267)
5.1.1. ハードウェアとオペレーティングシステムの要件
OpenShift Virtualization の次のハードウェアおよびオペレーティングシステム要件を確認してください。
サポート対象プラットフォーム
- オンプレミスのベアメタルサーバー
- Amazon Web Services ベアメタルインスタンス。詳細は、AWS ベアメタルノードへの OpenShift Virtualization のデプロイ を参照してください。
- IBM Cloud Bare Metal Servers。詳細は IBM Cloud Bare Metal Nodes への OpenShift Virtualization のデプロイ を参照してください。
AWS ベアメタルインスタンスまたは IBM Cloud Bare Metal Servers への OpenShift Virtualization のインストールは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
- 他のクラウドプロバイダーが提供するベアメタルインスタンスまたはサーバーはサポートされていません。
CPU の要件
- Red Hat Enterprise Linux (RHEL) 8 でサポート
- Intel 64 または AMD64 CPU 拡張機能のサポート
- Intel VT または AMD-V ハードウェア仮想化拡張機能が有効
- NX (実行なし) フラグが有効
ストレージ要件
- OpenShift Container Platform によるサポート
Red Hat OpenShift Data Foundation を使用して OpenShift Virtualization をデプロイする場合は、Windows 仮想マシンディスク用の専用ストレージクラスを作成する必要があります。詳細は 、Windows VM の ODF PersistentVolumes の最適化 を参照してください。
オペレーティングシステム要件
ワーカーノードにインストールされた Red Hat Enterprise Linux CoreOS (RHCOS)
注記RHEL ワーカー ノードはサポートされていません。
- クラスターが CPU の異なるワーカーノードを使用している場合、CPU ごとに能力が異なるため、ライブマイグレーションの失敗が発生する可能性があります。このような失敗を回避するには、各ノードに適切な能力の CPU を使用し、仮想マシンにノードアフィニティーを設定して、移行が成功するようにします。詳細は、必須のノードのアフィニティールールの設定 を参照してください。
5.1.2. 物理リソースのオーバーヘッド要件
OpenShift Virtualization は OpenShift Container Platform のアドオンであり、クラスターの計画時に考慮する必要のある追加のオーバーヘッドを強要します。各クラスターマシンは、OpenShift Container Platform の要件に加えて、以下のオーバーヘッドの要件を満たす必要があります。クラスター内の物理リソースを過剰にサブスクライブすると、パフォーマンスに影響する可能性があります。
本書に記載されている数は、Red Hat のテスト方法およびセットアップに基づいています。これらの数は、独自のセットアップおよび環境に応じて異なります。
5.1.2.1. メモリーのオーバーヘッド
以下の式を使用して、OpenShift Virtualization のメモリーオーバーヘッドの値を計算します。
クラスターメモリーのオーバーヘッド
Memory overhead per infrastructure node ≈ 150 MiBMemory overhead per worker node ≈ 360 MiBさらに、OpenShift Virtualization 環境リソースには、すべてのインフラストラクチャーノードに分散される合計 2179 MiB の RAM が必要です。
仮想マシンのメモリーオーバーヘッド
Memory overhead per virtual machine ≈ (1.002 × requested memory) \
+ 216 MiB \
+ 8 MiB × (number of vCPUs) \
+ 16 MiB × (number of graphics devices) \
+ (additional memory overhead) 5.1.2.2. CPU オーバーヘッド
以下の式を使用して、OpenShift Virtualization のクラスタープロセッサーのオーバーヘッド要件を計算します。仮想マシンごとの CPU オーバーヘッドは、個々の設定によって異なります。
クラスターの CPU オーバーヘッド
CPU overhead for infrastructure nodes ≈ 4 coresOpenShift Virtualization は、ロギング、ルーティング、およびモニタリングなどのクラスターレベルのサービスの全体的な使用率を増加させます。このワークロードに対応するには、インフラストラクチャーコンポーネントをホストするノードに、4 つの追加コア (4000 ミリコア) の容量があり、これがそれらのノード間に分散されていることを確認します。
CPU overhead for worker nodes ≈ 2 cores + CPU overhead per virtual machine仮想マシンをホストする各ワーカーノードには、仮想マシンのワークロードに必要な CPU に加えて、OpenShift Virtualization 管理ワークロード用に 2 つの追加コア (2000 ミリコア) の容量が必要です。
仮想マシンの CPU オーバーヘッド
専用の CPU が要求される場合は、仮想マシン 1 台につき CPU 1 つとなり、クラスターの CPU オーバーヘッド要件に影響が出てきます。それ以外の場合は、仮想マシンに必要な CPU の数に関する特別なルールはありません。
5.1.2.3. ストレージのオーバーヘッド
以下のガイドラインを使用して、OpenShift Virtualization 環境のストレージオーバーヘッド要件を見積もります。
クラスターストレージオーバーヘッド
Aggregated storage overhead per node ≈ 10 GiB10 GiB は、OpenShift Virtualization のインストール時にクラスター内の各ノードについてのディスク上のストレージの予想される影響に相当します。
仮想マシンのストレージオーバーヘッド
仮想マシンごとのストレージオーバーヘッドは、仮想マシン内のリソース割り当ての特定の要求により異なります。この要求は、クラスター内の別の場所でホストされるノードまたはストレージリソースの一時ストレージに対するものである可能性があります。OpenShift Virtualization は現在、実行中のコンテナー自体に追加の一時ストレージを割り当てていません。
5.1.2.4. 例
クラスター管理者が、クラスター内の 10 台の (それぞれ 1 GiB の RAM と 2 つの vCPU の) 仮想マシンをホストする予定の場合、クラスター全体で影響を受けるメモリーは 11.68 GiB になります。クラスターの各ノードについて予想されるディスク上のストレージの影響は 10 GiB で示され、仮想マシンのワークロードをホストするワーカーノードについての CPU の影響は最小 2 コアで示されます。
5.1.3. オブジェクトの最大値
クラスターを計画するときは、次のテスト済みオブジェクトの最大数を考慮する必要があります。
5.1.4. 制限されたネットワーク環境
インターネット接続のない制限された環境に OpenShift Virtualization をインストールする場合は、制限されたネットワーク用に Operator Lifecycle Manager を設定 する必要があります。
インターネット接続が制限されている場合、Operator Lifecycle Manager でプロキシーサポートを設定 して、Red Hat が提供する OperatorHub にアクセスすることができます。
5.1.5. ライブマイグレーション
ライブマイグレーションには次の要件があります。
-
ReadWriteMany(RWX) アクセスモードの共有ストレージ - 十分な RAM およびネットワーク帯域幅
- 仮想マシンがホストモデルの CPU を使用する場合、ノードは仮想マシンのホストモデルの CPU をサポートする必要があります。
ライブマイグレーションを引き起こすノードドレインをサポートするために、クラスター内に十分なメモリーリクエスト容量があることを確認する必要があります。以下の計算を使用して、必要な予備のメモリーを把握できます。
Product of (Maximum number of nodes that can drain in parallel) and (Highest total VM memory request allocations across nodes)クラスターで 並行して実行できるデフォルトの移行数 は 5 です。
5.1.6. スナップショットとクローン作成
スナップショットとクローン作成の要件は、OpenShift Virtualization ストレージ機能 を参照してください。
5.1.7. クラスターの高可用性オプション
クラスターには、次の高可用性 (HA) オプションのいずれかを設定できます。
インストーラーによってプロビジョニングされたインフラストラクチャー (IPI) の 自動高可用性は、マシンの可用性チェック をデプロイすることで利用できます。
注記インストーラーでプロビジョニングされるインフラストラクチャーを使用してインストールされ、MachineHealthCheck が適切に設定された OpenShift Container Platform クラスターで、ノードで MachineHealthCheck が失敗し、クラスターで利用できなくなると、そのノードは再利用されます。障害が発生したノードで実行された仮想マシンでは、一連の条件によって次に起こる動作が変わります。潜在的な結果と RunStrategy がそれらの結果にどのように影響するかについての詳細情報は、仮想マシンの RunStrategies について を参照してください。
IPI と非 IPI の両方の自動高可用性は、OpenShift Container Platform クラスターで Node Health Check Operator を使用して
NodeHealthCheckコントローラーをデプロイすることで利用できます。コントローラーは異常なノードを識別し、セルフノード修復 Operator を使用して異常なノードを修復します。重要Node Health Check Operator は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
モニタリングシステムまたは有資格者を使用してノードの可用性をモニターすることにより、あらゆるプラットフォームの高可用性を利用できます。ノードが失われた場合は、これをシャットダウンして
oc delete node <lost_node>を実行します。注記外部モニタリングシステムまたは資格のある人材によるノードの正常性の監視が行われない場合、仮想マシンは高可用性を失います。
5.2. OpenShift Virtualization コンポーネントのノードの指定
ノードの配置ルールを設定して、OpenShift Virtualization Operator、ワークロード、およびコントローラーをデプロイするノードを指定します。
OpenShift Virtualization のインストール後に一部のコンポーネントのノードの配置を設定できますが、ワークロード用にノードの配置を設定する場合には仮想マシンを含めることはできません。
5.2.1. 仮想化コンポーネントのノード配置について
OpenShift Virtualization がそのコンポーネントをデプロイする場所をカスタマイズして、以下を確認する必要がある場合があります。
- 仮想マシンは、仮想化ワークロード用のノードにのみデプロイされる。
- Operator はインフラストラクチャーノードにのみデプロイされる。
- 特定のノードは OpenShift Virtualization の影響を受けない。たとえば、クラスターで実行される仮想化に関連しないワークロードがあり、それらのワークロードを OpenShift Virtualization から分離する必要があるとします。
5.2.1.1. ノードの配置ルールを仮想化コンポーネントに適用する方法
対応するオブジェクトを直接編集するか、Web コンソールを使用して、コンポーネントのノードの配置ルールを指定できます。
-
Operator Lifecycle Manager (OLM) がデプロイする OpenShift Virtualization Operator の場合は、OLM
Subscriptionオブジェクトを直接編集します。現時点では、Web コンソールを使用してSubscriptionオブジェクトのノードの配置ルールを設定することはできません。 -
OpenShift Virtualization Operator がデプロイするコンポーネントの場合は、
HyperConvergedオブジェクトを直接編集するか、OpenShift Virtualization のインストール時に Web コンソールを使用してこれを設定します。 ホストパスプロビジョナーの場合、
HostPathProvisionerオブジェクトを直接編集するか、Web コンソールを使用してこれを設定します。警告ホストパスプロビジョナーと仮想化コンポーネントを同じノードでスケジュールする必要があります。スケジュールしない場合は、ホストパスプロビジョナーを使用する仮想化 Pod を実行できません。
オブジェクトに応じて、以下のルールタイプを 1 つ以上使用できます。
nodeSelector- Pod は、キーと値のペアまたはこのフィールドで指定したペアを使用してラベルが付けられたノードに Pod をスケジュールできます。ノードには、リスト表示されたすべてのペアに一致するラベルがなければなりません。
affinity- より表現的な構文を使用して、ノードと Pod に一致するルールを設定できます。アフィニティーを使用すると、ルールの適用方法に追加のニュアンスを持たせることができます。たとえば、ルールがハード要件ではなく基本設定になるように指定し、ルールの条件が満たされない場合も Pod がスケジュールされるようにすることができます。
tolerations- 一致するテイントを持つノードで Pod をスケジュールできます。テイントがノードに適用される場合、そのノードはテイントを容認する Pod のみを受け入れます。
5.2.1.2. OLM Subscription オブジェクトのノード配置
OLM が OpenShift Virtualization Operator をデプロイするノードを指定するには、OpenShift Virtualization のインストール時に Subscription オブジェクトを編集します。以下の例に示されるように、spec.config フィールドにノードの配置ルールを追加できます。
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.11.8
channel: "stable"
config: - 1
configフィールドはnodeSelectorおよびtolerationsをサポートしますが、affinityはサポートしません。
5.2.1.3. HyperConverged オブジェクトのノード配置
OpenShift Virtualization がそのコンポーネントをデプロイするノードを指定するには、OpenShift Virtualization のインストール時に作成する HyperConverged Cluster カスタムリソース (CR) ファイルに nodePlacement オブジェクトを含めることができます。以下の例のように、spec.infra および spec.workloads フィールドに nodePlacement を含めることができます。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
...
workloads:
nodePlacement:
...- 1
nodePlacementフィールドは、nodeSelector、affinity、およびtolerationsフィールドをサポートします。
5.2.1.4. HostPathProvisioner オブジェクトのノード配置
ノードの配置ルールは、ホストパスプロビジョナーのインストール時に作成する HostPathProvisioner オブジェクトの spec.workload フィールドで設定できます。
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: IfNotPresent
pathConfig:
path: "</path/to/backing/directory>"
useNamingPrefix: false
workload: - 1
workloadフィールドは、nodeSelector、affinity、およびtolerationsフィールドをサポートします。
5.2.2. マニフェストの例
以下の YAML ファイルの例では、nodePlacement、affinity、および tolerations オブジェクトを使用して OpenShift Virtualization コンポーネントのノード配置をカスタマイズします。
5.2.2.1. Operator Lifecycle Manager サブスクリプションオブジェクト
5.2.2.1.1. 例: OLM Subscription オブジェクトの nodeSelector を使用したノード配置
この例では、OLM が example.io/example-infra-key = example-infra-value のラベルが付けられたノードに OpenShift Virtualization Operator を配置するように、nodeSelector を設定します。
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.11.8
channel: "stable"
config:
nodeSelector:
example.io/example-infra-key: example-infra-value5.2.2.1.2. 例: OLM Subscription オブジェクトの容認を使用したノード配置
この例では、OLM が OpenShift Virtualization Operator をデプロイするために予約されるノードには key=virtualization:NoSchedule テイントのラベルが付けられます。一致する容認のある Pod のみがこれらのノードにスケジュールされます。
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: hco-operatorhub
namespace: openshift-cnv
spec:
source: redhat-operators
sourceNamespace: openshift-marketplace
name: kubevirt-hyperconverged
startingCSV: kubevirt-hyperconverged-operator.v4.11.8
channel: "stable"
config:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"5.2.2.2. HyperConverged オブジェクト
5.2.2.2.1. 例: HyperConverged Cluster CR の nodeSelector を使用したノード配置
この例では、nodeSelector は、インフラストラクチャーリソースが example.io/example-infra-key = example-infra-value のラベルが付けられたノードに配置されるように設定され、ワークロードは example.io/example-workloads-key = example-workloads-value のラベルが付けられたノードに配置されるように設定されます。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
nodeSelector:
example.io/example-infra-key: example-infra-value
workloads:
nodePlacement:
nodeSelector:
example.io/example-workloads-key: example-workloads-value5.2.2.2.2. 例: HyperConverged Cluster CR のアフィニティーを使用したノード配置
この例では、affinity は、インフラストラクチャーリソースが example.io/example-infra-key = example-infra-value のラベルが付けられたノードに配置されるように設定され、ワークロードが example.io/example-workloads-key = example-workloads-value のラベルが付けられたノードに配置されるように設定されます。ワークロード用には 9 つ以上の CPU を持つノードが優先されますが、それらが利用可能ではない場合も、Pod は依然としてスケジュールされます。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
infra:
nodePlacement:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-infra-key
operator: In
values:
- example-infra-value
workloads:
nodePlacement:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-workloads-key
operator: In
values:
- example-workloads-value
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: example.io/num-cpus
operator: Gt
values:
- 85.2.2.2.3. 例: HyperConverged Cluster CR の容認を使用したノード配置
この例では、OpenShift Virtualization コンポーネント用に予約されるノードには key=virtualization:NoSchedule テイントのラベルが付けられます。一致する容認のある Pod のみがこれらのノードにスケジュールされます。
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
workloads:
nodePlacement:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"5.2.2.3. HostPathProvisioner オブジェクト
5.2.2.3.1. 例: HostPathProvisioner オブジェクトの nodeSelector を使用したノード配置
この例では、example.io/example-workloads-key = example-workloads-value のラベルが付けられたノードにワークロードが配置されるように nodeSelector を設定します。
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: IfNotPresent
pathConfig:
path: "</path/to/backing/directory>"
useNamingPrefix: false
workload:
nodeSelector:
example.io/example-workloads-key: example-workloads-value5.3. Web コンソールを使用した OpenShift Virtualization のインストール
OpenShift Virtualization をインストールし、仮想化機能を OpenShift Container Platform クラスターに追加します。
OpenShift Container Platform 4.11 web console を使用して、OpenShift Virtualization Operator にサブスクライブし、これをデプロイすることができます。
5.3.1. OpenShift Virtualization Operator のインストール
OpenShift Container Platform Web コンソールから OpenShift Virtualization Operator をインストールできます。
前提条件
- OpenShift Container Platform 4.11 をクラスターにインストールしていること。
-
cluster-adminパーミッションを持つユーザーとして OpenShift Container Platform Web コンソールにログインすること。
手順
- Administrator パースペクティブから、Operators → OperatorHub をクリックします。
- Filter by keyword に Virtualization と入力します。
- Red Hat ソースラベルをがある {CNVOperatorDisplayName} タイルを選択します。
- Operator についての情報を確認してから、Install をクリックします。
Install Operator ページで以下を行います。
- 選択可能な Update Channel オプションの一覧から stable を選択します。これにより、OpenShift Container Platform バージョンと互換性がある OpenShift Virtualization のバージョンをインストールすることができます。
インストールされた namespace の場合、Operator recommended namespace オプションが選択されていることを確認します。これにより、Operator が必須の
openshift-cnvnamespace にインストールされます。この namespace は存在しない場合は、自動的に作成されます。警告OpenShift Virtualization Operator を
openshift-cnv以外の namespace にインストールしようとすると、インストールが失敗します。Approval Strategy の場合に、stable 更新チャネルで新しいバージョンが利用可能になったときに OpenShift Virtualization が自動更新されるように、デフォルト値である Automaticを選択することを強く推奨します。
Manual 承認ストラテジーを選択することは可能ですが、クラスターのサポート容易性および機能に対応するリスクが高いため、推奨できません。これらのリスクを完全に理解していて、Automatic を使用できない場合のみ、Manual を選択してください。
警告OpenShift Virtualization は対応する OpenShift Container Platform バージョンで使用される場合にのみサポートされるため、OpenShift Virtualization が更新されないと、クラスターがサポートされなくなる可能性があります。
-
Install をクリックし、Operator を
openshift-cnvnamespace で利用可能にします。 - Operator が正常にインストールされたら、Create HyperConverged をクリックします。
- オプション: OpenShift Virtualization コンポーネントの Infra および Workloads ノード配置オプションを設定します。
- Create をクリックして OpenShift Virtualization を起動します。
検証
- Workloads → Pods ページに移動して、OpenShift Virtualization Pod がすべて Running 状態になるまでこれらの Pod をモニターします。すべての Pod で Running 状態が表示された後に、OpenShift Virtualization を使用できます。
5.3.2. 次のステップ
以下のコンポーネントを追加で設定する必要がある場合があります。
- ホストパスプロビジョナー は、OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。仮想マシンのローカルストレージを設定する必要がある場合、まずホストパスプロビジョナーを有効にする必要があります。
5.4. CLI を使用した OpenShift Virtualization のインストール
OpenShift Virtualization をインストールし、仮想化機能を OpenShift Container Platform クラスターに追加します。コマンドラインを使用してマニフェストをクラスターに適用し、OpenShift Virtualization Operator にサブスクライブし、デプロイできます。
OpenShift Virtualization がそのコンポーネントをインストールするノードを指定するには、ノードの配置ルールを設定 します。
5.4.1. 前提条件
- OpenShift Container Platform 4.11 をクラスターにインストールしていること。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
5.4.2. CLI を使用した OpenShift Virtualization カタログのサブスクライブ
OpenShift Virtualization をインストールする前に、OpenShift Virtualization カタログにサブスクライブする必要があります。サブスクライブにより、openshift-cnv namespace に OpenShift Virtualization Operator へのアクセスが付与されます。
単一マニフェストをクラスターに適用して Namespace、OperatorGroup、および Subscription オブジェクトをサブスクライブし、設定します。
手順
以下のマニフェストを含む YAML ファイルを作成します。
apiVersion: v1 kind: Namespace metadata: name: openshift-cnv --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: kubevirt-hyperconverged-group namespace: openshift-cnv spec: targetNamespaces: - openshift-cnv --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: hco-operatorhub namespace: openshift-cnv spec: source: redhat-operators sourceNamespace: openshift-marketplace name: kubevirt-hyperconverged startingCSV: kubevirt-hyperconverged-operator.v4.11.8 channel: "stable"1 - 1
stableチャネルを使用することで、OpenShift Container Platform バージョンと互換性のある OpenShift Virtualization のバージョンをインストールすることができます。
以下のコマンドを実行して、OpenShift Virtualization に必要な
Namespace、OperatorGroup、およびSubscriptionオブジェクトを作成します。$ oc apply -f <file name>.yaml
YAML ファイルで、証明書のローテーションパラメーターを設定 できます。
5.4.3. CLI を使用した OpenShift Virtualization Operator のデプロイ
oc CLI を使用して OpenShift Virtualization Operator をデプロイすることができます。
前提条件
-
openshift-cnvnamespace の OpenShift Virtualization カタログへのアクティブなサブスクリプション。
手順
以下のマニフェストを含む YAML ファイルを作成します。
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec:以下のコマンドを実行して OpenShift Virtualization Operator をデプロイします。
$ oc apply -f <file_name>.yaml
検証
openshift-cnvnamespace の Cluster Service Version (CSV) のPHASEを監視して、OpenShift Virtualization が正常にデプロイされたことを確認します。以下のコマンドを実行します。$ watch oc get csv -n openshift-cnv以下の出力は、デプロイメントに成功したかどうかを表示します。
出力例
NAME DISPLAY VERSION REPLACES PHASE kubevirt-hyperconverged-operator.v4.11.8 OpenShift Virtualization 4.11.8 Succeeded
5.4.4. 次のステップ
以下のコンポーネントを追加で設定する必要がある場合があります。
- ホストパスプロビジョナー は、OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。仮想マシンのローカルストレージを設定する必要がある場合、まずホストパスプロビジョナーを有効にする必要があります。
5.5. virtctl クライアントの有効化
virtctl クライアントは、OpenShift Virtualization リソースを管理するためのコマンドラインユーティリティーです。これは、Linux、macOS、および Windows ディストリビューションで利用できます。
5.5.1. virtctl クライアントのダウンロードおよびインストール
5.5.1.1. virtctl クライアントのダウンロード
ConsoleCLIDownload カスタムリソース (CR) で提供されるリンクを使用して virtctl クライアントをダウンロードします。
手順
以下のコマンドを実行して
ConsoleCLIDownloadオブジェクトを表示します。$ oc get ConsoleCLIDownload virtctl-clidownloads-kubevirt-hyperconverged -o yaml-
お使いのディストリビューションにリスト表示されているリンクを使用して
virtctlクライアントをダウンロードします。
5.5.1.2. virtctl クライアントのインストール
オペレーティングシステムに適した場所からダウンロードした後に、virtctl クライアントをデプロイメントし、インストールします。
前提条件
-
virtctlクライアントをダウンロードしている。
手順
Linux の場合
tarball を展開します。以下の CLI コマンドは、tarball と同じディレクトリーにデプロイメントします。
$ tar -xvf <virtctl-version-distribution.arch>.tar.gzデプロイメントしたフォルダー階層に移動し、以下のコマンドを実行して
virtctlバイナリーを実行可能にします。$ chmod +x <virtctl-file-name>-
virtctlバイナリーをPATH 環境変数にあるディレクトリーに移動します。 パスを確認するには、以下のコマンドを実行します。
$ echo $PATH
Windows ユーザーの場合:
- アーカイブを展開し、解凍します。
-
展開したフォルダー階層に移動し、
virtctl実行可能ファイルをダブルクリックしてクライアントをインストールします。 -
virtctlバイナリーをPATH 環境変数にあるディレクトリーに移動します。 パスを確認するには、以下のコマンドを実行します。
C:\> path
macOS ユーザーの場合:
- アーカイブを展開し、解凍します。
-
virtctlバイナリーをPATH 環境変数にあるディレクトリーに移動します。 パスを確認するには、以下のコマンドを実行します。
echo $PATH
5.5.2. virtctl RPM パッケージのインストール
OpenShift Virtualization リポジトリーを有効にした後、virtctl クライアントを RPM としてインストールできます。
5.5.2.1. OpenShift Virtualization リポジトリーの有効化
Red Hat Enterprise Linux (RHEL) のバージョンの OpenShift Virtualization リポジトリーを有効にします。
前提条件
- システムは、Red Hat Container Native Virtualization エンタイトルメントへの有効なサブスクリプションを持つ Red Hat アカウントに登録されています。
手順
subscription-managerCLI ツールを使用して、オペレーティングシステムに適切な OpenShift Virtualization リポジトリーを有効にします。RHEL 8 のリポジトリーを有効にするには、次を実行します。
# subscription-manager repos --enable cnv-4.11-for-rhel-8-x86_64-rpmsRHEL 7 のリポジトリーを有効にするには、次を実行します。
# subscription-manager repos --enable rhel-7-server-cnv-4.11-rpms
5.5.2.2. yum ユーティリティーを使用した virtctl クライアントのインストール
kubevirt-virtctl パッケージから virtctl クライアントをインストールします。
前提条件
- Red Hat Enterprise Linux (RHEL) システムで OpenShift Virtualization リポジトリーを有効にしました。
手順
kubevirt-virtctlパッケージをインストールします。# yum install kubevirt-virtctl
5.6. OpenShift Virtualization のアンインストール
Web コンソールまたはコマンドラインインターフェイス (CLI) を使用して OpenShift Virtualization をアンインストールし、OpenShift Virtualization ワークロード、Operator、およびそのリソースを削除します。
5.6.1. Web コンソールを使用した OpenShift Virtualization のアンインストール
Web コンソール を使用して OpenShift Virtualization をアンインストールし、以下のタスクを実行します。
最初に、すべての 仮想マシン、仮想マシンインスタンス、および データボリューム を削除する必要があります。
ワークロードがクラスターに残っている間は、OpenShift Virtualization をアンインストールできません。
5.6.1.1. HyperConverged カスタムリソースの削除
OpenShift Virtualization をアンインストールするには、最初に HyperConverged カスタムリソース (CR) を削除します。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Operators → Installed Operators ページに移動します。
- OpenShift Virtualization Operator を選択します。
- OpenShift Virtualization Deployment タブをクリックします。
-
kubevirt-hyperconvergedの横にある Options メニュー をクリックし、Delete HyperConverged を選択します。
をクリックし、Delete HyperConverged を選択します。
- 確認ウィンドウで Delete をクリックします。
5.6.1.2. Web コンソールの使用によるクラスターからの Operator の削除
クラスター管理者は Web コンソールを使用して、選択した namespace からインストールされた Operator を削除できます。
前提条件
-
cluster-adminパーミッションを持つアカウントを使用して OpenShift Container Platform クラスター Web コンソールにアクセスできる。
手順
- Operators → Installed Operators ページに移動します。
- スクロールするか、キーワードを Filter by name フィールドに入力して、削除する Operator を見つけます。次に、それをクリックします。
Operator Details ページの右側で、Actions 一覧から Uninstall Operator を選択します。
Uninstall Operator? ダイアログボックスが表示されます。
Uninstall を選択し、Operator、Operator デプロイメント、および Pod を削除します。このアクションの後には、Operator は実行を停止し、更新を受信しなくなります。
注記このアクションは、カスタムリソース定義 (CRD) およびカスタムリソース (CR) など、Operator が管理するリソースは削除されません。Web コンソールおよび継続して実行されるクラスター外のリソースによって有効にされるダッシュボードおよびナビゲーションアイテムには、手動でのクリーンアップが必要になる場合があります。Operator のアンインストール後にこれらを削除するには、Operator CRD を手動で削除する必要があります。
5.6.1.3. Web コンソールを使用した namespace の削除
OpenShift Container Platform Web コンソールを使用して namespace を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Administration → Namespaces に移動します。
- namespace の一覧で削除する必要のある namespace を見つけます。
-
namespace の一覧の右端で、Options メニュー
から Delete Namespace を選択します。
- Delete Namespace ペインが表示されたら、フィールドから削除する namespace の名前を入力します。
- Delete をクリックします。
5.6.1.4. OpenShift Virtualization カスタムリソース定義の削除
Web コンソールを使用して、OpenShift Virtualization カスタムリソース定義 (CRD) を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。
手順
- Administration → CustomResourceDefinitions に移動します。
-
Label フィルターを選択し、Search フィールドに
operators.coreos.com/kubevirt-hyperconverged.openshift-cnvと入力して OpenShift Virtualization CRD を表示します。 -
各 CRD の横にある Options メニュー
をクリックし、Delete CustomResourceDefinition の削除を選択します。
5.6.2. CLI を使用した OpenShift Virtualization のアンインストール
コマンドラインインターフェイス (CLI) を使用して OpenShift Virtualization をアンインストールできます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 - OpenShift CLI (oc) がインストールされている。
- すべての 仮想マシン、仮想マシンインスタンス、および データボリューム を削除しました。ワークロードがクラスターに残っている間は、OpenShift Virtualization をアンインストールできません。
手順
HyperConvergedカスタムリソースを削除します。$ oc delete HyperConverged kubevirt-hyperconverged -n openshift-cnvOpenShift Virtualization Operator サブスクリプションを削除します。
$ oc delete subscription kubevirt-hyperconverged -n openshift-cnvOpenShift Virtualization
ClusterServiceVersionリソースを削除します。$ oc delete csv -n openshift-cnv -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnvOpenShift Virtualization namespace を削除します。
$ oc delete namespace openshift-cnvdry-runオプションを指定してoc delete crdコマンドを実行し、OpenShift Virtualization カスタムリソース定義 (CRD) を一覧表示します。$ oc delete crd --dry-run=client -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv出力例
customresourcedefinition.apiextensions.k8s.io "cdis.cdi.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "hostpathprovisioners.hostpathprovisioner.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "hyperconvergeds.hco.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "kubevirts.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "networkaddonsconfigs.networkaddonsoperator.network.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "ssps.ssp.kubevirt.io" deleted (dry run) customresourcedefinition.apiextensions.k8s.io "tektontasks.tektontasks.kubevirt.io" deleted (dry run)dry-runオプションを指定せずにoc delete crdコマンドを実行して、CRD を削除します。$ oc delete crd -l operators.coreos.com/kubevirt-hyperconverged.openshift-cnv
第6章 OpenShift Virtualization の更新
Operator Lifecycle Manager(OLM) が OpenShift Virtualization の z-stream およびマイナーバージョンの更新を提供する方法を確認します。
Node Maintenance Operator (NMO) は OpenShift Virtualization に同梱されなくなりました。これは、OpenShift Container Platform Web コンソールの OperatorHub から NMO をインストール、または OpenShift CLI (
oc) を使用してインストールできます。OpenShift Virtualization 4.10.2 以降のリリースから OpenShift Virtualization 4.11 に更新する前に、以下のいずれかのタスクを実行する必要があります。
- すべてのノードをメンテナンスモードから移動します。
-
スタンドアロン NMO をインストールし、
nodemaintenances.nodemaintenance.kubevirt.ioカスタムリソース (CR) をnodemaintenances.nodemaintenance.medik8s.ioCR に置き換えます。
6.1. OpenShift Virtualization の更新について
- Operator Lifecycle Manager(OLM) は OpenShift Virtualization Operator のライフサイクルを管理します。OpenShift Container Platform のインストール時にデプロイされる Marketplace Operator により、クラスターで外部 Operator が利用できるようになります。
- OLM は、OpenShift Virtualization の z-stream およびマイナーバージョンの更新を提供します。OpenShift Container Platform を次のマイナーバージョンに更新すると、マイナーバージョンの更新が利用可能になります。OpenShift Container Platform を最初に更新しない限り、OpenShift Virtualization を次のマイナーバージョンに更新できません。
- OpenShift Virtualization サブスクリプションは、stable という名前の単一の更新チャネルを使用します。stable チャネルでは、OpenShift Virtualization および OpenShift Container Platform バージョンとの互換性が確保されます。
サブスクリプションの承認ストラテジーが Automatic に設定されている場合に、更新プロセスは、Operator の新規バージョンが stable チャネルで利用可能になるとすぐに開始します。サポート可能な環境を確保するために、自動 承認ストラテジーを使用することを強く推奨します。OpenShift Virtualization の各マイナーバージョンは、対応する OpenShift Container Platform バージョンを実行する場合にのみサポートされます。たとえば、OpenShift Virtualization 4.11 は OpenShift Container Platform 4.11 で実行する必要があります。
- クラスターのサポート容易性および機能が損なわれるリスクがあるので、Manual 承認ストラテジーを選択することは可能ですが、推奨していません。Manual 承認ストラテジーでは、保留中のすべての更新を手動で承認する必要があります。OpenShift Container Platform および OpenShift Virtualization の更新の同期が取れていない場合には、クラスターはサポートされなくなります。
- 更新の完了までにかかる時間は、ネットワーク接続によって異なります。ほとんどの自動更新は 15 分以内に完了します。
- Open Shift Virtualization を更新しても、ネットワーク接続が中断されることはありません。
- データボリュームおよびその関連付けられた永続ボリューム要求 (PVC) は更新時に保持されます。
ホストパスプロビジョナーストレージを使用する仮想マシンを実行している場合、それらをライブマイグレーションすることはできず、Open Shift Container Platform クラスターの更新をブロックする可能性があります。
回避策として、仮想マシンを再設定し、クラスターの更新時にそれらの電源を自動的にオフになるようにできます。evictionStrategy: LiveMigrate フィールドを削除し、runStrategy フィールドを Always に設定します。
6.2. ワークロードの自動更新の設定
6.2.1. ワークロードの更新について
OpenShift Virtualization を更新すると、ライブマイグレーションをサポートしている場合には libvirt、virt-launcher、および qemu などの仮想マシンのワークロードが自動的に更新されます。
各仮想マシンには、仮想マシンインスタンス (VMI) を実行する virt-launcher Pod があります。virt-launcher Pod は、仮想マシン (VM) のプロセスを管理するために使用される libvirt のインスタンスを実行します。
HyperConverged カスタムリソース (CR) の spec.workloadUpdateStrategy スタンザを編集して、ワークロードの更新方法を設定できます。ワークロードの更新方法として、LiveMigrate と Evict の 2 つが利用可能です。
Evictメソッドは VMI Pod をシャットダウンするため、デフォルトではLiveMigrate更新ストラテジーのみが有効になっています。
LiveMigrateが有効な唯一の更新ストラテジーである場合:
- ライブマイグレーションをサポートする VMI は更新プロセス時に移行されます。VM ゲストは、更新されたコンポーネントが有効になっている新しい Pod に移動します。
ライブマイグレーションをサポートしない VMI は中断または更新されません。
-
VMI に
LiveMigrateエビクションストラテジーがあるが、ライブマイグレーションをサポートしていない場合、VMI は更新されません。
-
VMI に
LiveMigrateとEvictの両方を有効にした場合:
-
ライブマイグレーションをサポートする VMI は、
LiveMigrate更新ストラテジーを使用します。 -
ライブマイグレーションをサポートしない VMI は、
Evict更新ストラテジーを使用します。VMI が、runStrategyの値がalwaysであるVirtualMachineオブジェクトによって制御されている場合、新しい VMI は、コンポーネントが更新された新しい Pod に作成されます。
移行の試行とタイムアウト
ワークロードを更新するときに、Pod が次の期間Pending状態の場合、ライブマイグレーションは失敗します。
- 5 分間
-
Pod が
Unschedulableであるために保留中の場合。 - 15 分
- 何らかの理由で Pod が保留状態のままになっている場合。
VMI が移行に失敗すると、 virt-controllerは VMI の移行を再試行します。すべての移行可能な VMI が新しいvirt-launcher Pod で実行されるまで、このプロセスが繰り返されます。ただし、VMI が不適切に設定されている場合、これらの試行は無限に繰り返される可能性があります。
各試行は、移行オブジェクトに対応します。直近の 5 回の試行のみがバッファーに保持されます。これにより、デバッグ用の情報を保持しながら、移行オブジェクトがシステムに蓄積されるのを防ぎます。
6.2.2. ワークロードの更新方法の設定
HyperConvergedカスタムリソース (CR) を編集することにより、ワークロードの更新方法を設定できます。
前提条件
ライブマイグレーションを更新方法として使用するには、まずクラスターでライブマイグレーションを有効にする必要があります。
注記VirtualMachineInstanceCR にevictionStrategy: LiveMigrateが含まれており、仮想マシンインスタンス (VMI) がライブマイグレーションをサポートしない場合には、VMI は更新されません。
手順
デフォルトエディターで
HyperConvergedCR を作成するには、以下のコマンドを実行します。$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedHyperConvergedCR のworkloadUpdateStrategyスタンザを編集します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: workloadUpdateStrategy: workloadUpdateMethods:1 - LiveMigrate2 - Evict3 batchEvictionSize: 104 batchEvictionInterval: "1m0s"5 ...- 1
- ワークロードの自動更新を実行するのに使用できるメソッド。設定可能な値は
LiveMigrateおよびEvictです。上記の例のように両方のオプションを有効にした場合に、ライブマイグレーションをサポートする VMI にはLiveMigrateを、ライブマイグレーションをサポートしない VMI にはEvictを、更新に使用します。ワークロードの自動更新を無効にするには、workloadUpdateStrategyスタンザを削除するか、workloadUpdateMethods: []を設定して配列を空のままにします。 - 2
- 中断を最小限に抑えた更新メソッド。ライブマイグレーションをサポートする VMI は、仮想マシン (VM) ゲストを更新されたコンポーネントが有効なっている新規 Pod に移行することで更新されます。
LiveMigrateがリストされている唯一のワークロード更新メソッドである場合には、ライブマイグレーションをサポートしない VMI は中断または更新されません。 - 3
- アップグレード時に VMI Pod をシャットダウンする破壊的な方法。
Evictは、ライブマイグレーションがクラスターで有効でない場合に利用可能な唯一の更新方法です。VMI がrunStrategy: alwaysに設定されたVirtualMachineオブジェクトによって制御される場合には、新規の VMI は、更新されたコンポーネントを使用して新規 Pod に作成されます。 - 4
Evictメソッドを使用して一度に強制的に更新できる VMI の数。これは、LiveMigrateメソッドには適用されません。- 5
- 次のワークロードバッチをエビクトするまで待機する間隔。これは、
LiveMigrateメソッドには適用されません。
注記HyperConvergedCR のspec.liveMigrationConfigスタンザを編集することにより、ライブマイグレーションの制限とタイムアウトを設定できます。- 変更を適用するには、エディターを保存し、終了します。
6.3. 保留中の Operator 更新の承認
6.3.1. 保留中の Operator 更新の手動による承認
インストールされた Operator のサブスクリプションの承認ストラテジーが Manual に設定されている場合、新規の更新が現在の更新チャネルにリリースされると、インストールを開始する前に更新を手動で承認する必要があります。
前提条件
- Operator Lifecycle Manager (OLM) を使用して以前にインストールされている Operator。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブで、Operators → Installed Operators に移動します。
- 更新が保留中の Operator は Upgrade available のステータスを表示します。更新する Operator の名前をクリックします。
- Subscription タブをクリックします。承認が必要な更新は、アップグレードステータス の横に表示されます。たとえば、1 requires approval が表示される可能性があります。
- 1 requires approval をクリックしてから、Preview Install Plan をクリックします。
- 更新に利用可能なリソースとして一覧表示されているリソースを確認します。問題がなければ、Approve をクリックします。
- Operators → Installed Operators ページに戻り、更新の進捗をモニターします。完了時に、ステータスは Succeeded および Up to date に変更されます。
6.4. 更新ステータスの監視
6.4.1. OpenShift Virtualization アップグレードステータスのモニタリング
OpenShift Virtualization Operator のアップグレードのステータスをモニターするには、クラスターサービスバージョン (CSV) PHASE を監視します。Web コンソールを使用するか、ここに提供されているコマンドを実行して CSV の状態をモニターすることもできます。
PHASE および状態の値は利用可能な情報に基づく近似値になります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにログインすること。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行します。
$ oc get csv -n openshift-cnv出力を確認し、
PHASEフィールドをチェックします。以下に例を示します。出力例
VERSION REPLACES PHASE 4.9.0 kubevirt-hyperconverged-operator.v4.8.2 Installing 4.9.0 kubevirt-hyperconverged-operator.v4.9.0 Replacingオプション: 以下のコマンドを実行して、すべての OpenShift Virtualization コンポーネントの状態の集約されたステータスをモニターします。
$ oc get hco -n openshift-cnv kubevirt-hyperconverged \ -o=jsonpath='{range .status.conditions[*]}{.type}{"\t"}{.status}{"\t"}{.message}{"\n"}{end}'アップグレードが成功すると、以下の出力が得られます。
出力例
ReconcileComplete True Reconcile completed successfully Available True Reconcile completed successfully Progressing False Reconcile completed successfully Degraded False Reconcile completed successfully Upgradeable True Reconcile completed successfully
6.4.2. 以前の OpenShift Virtualization ワークロードの表示
CLI を使用して、以前のワークロードのリストを表示できます。
クラスターに以前の仮想化 Pod がある場合には、OutdatedVirtualMachineInstanceWorkloads アラートが実行されます。
手順
以前の仮想マシンインスタンス (VMI) のリストを表示するには、以下のコマンドを実行します。
$ oc get vmi -l kubevirt.io/outdatedLauncherImage --all-namespaces
ワークロードの更新を設定して、VMI が自動的に更新されるようにします。
第7章 セキュリティーポリシー
仮想マシン (VM) のワークロードは、特権のない Pod として実行されます。仮想マシンが OpenShift Virtualization 機能を使用できるように、一部の Pod には、他の Pod 所有者が使用できないカスタムセキュリティーポリシーが付与されます。
-
拡張された
container_tSELinux ポリシーがvirt-launcherPod に適用されます。 -
セキュリティーコンテキスト制約 (SCC) は、
kubevirt-controllerサービスアカウントに対して定義されます。
7.1. ワークロードのセキュリティーについて
デフォルトでは、仮想マシン (VM) のワークロードは OpenShift Virtualization の root 権限では実行されません。
仮想マシンごとに、virt-launcher Pod が libvirt のインスタンスを セッションモード で実行し、仮想マシンプロセスを管理します。セッションモードでは、libvirt デーモンは root 以外のユーザーアカウントとして実行され、同じユーザー識別子 (UID) で実行されているクライアントからの接続のみを許可します。したがって、仮想マシンは権限のない Pod として実行し、最小権限のセキュリティー原則に従います。
root 権限を必要とするサポート対象の OpenShift Virtualization 機能はありません。機能に root が必要な場合は、OpenShift Virtualization での使用がサポートされていない可能性があります。
7.2. virt-launcher Pod の拡張 SELinux ポリシー
virt-launcher Pod の container_t SELinux ポリシーが拡張され、OpenShift 仮想化の重要な機能が有効になります。
ネットワークマルチキューには次のポリシーが必要です。これにより、使用可能な vCPU の数が増加するにつれてネットワークパフォーマンスを拡張できます。
-
allow process self (tun_socket (relabelfrom relabelto attach_queue))
-
次のポリシーによって、
virt-launcherが/proc/cpuinfoおよび/proc/uptimeを含む/procディレクトリーの下のファイルを読み取ることができます。-
allow process proc_type (file (getattr open read))
-
次のポリシーによって、
libvirtdがネットワーク関連のデバッグメッセージをリレーできます。allow process self (netlink_audit_socket (nlmsg_relay))注記このポリシーがない場合、ネットワークデバッグメッセージをリレーしようとする試みはブロックされます。これにより、ノードの監査ログが SELinux 拒否でいっぱいになる可能性があります。
次のポリシーによって、
libvirtdがhugetblfsにアクセスできます。これは、巨大なページをサポートするために必要です。-
allow process hugetlbfs_t (dir (add_name create write remove_name rmdir setattr)) -
allow process hugetlbfs_t (file (create unlink))
-
次のポリシーによって、
virtiofsがファイルシステムをマウントし、NFS にアクセスできます。-
allow process nfs_t (dir (mounton)) -
allow process proc_t (dir (mounton)) -
allow process proc_t (filesystem (mount unmount))
-
SCC (Security Context Constraints) は Pod のパーミッションを制御します。これらのパーミッションには、コンテナーのコレクションである Pod が実行できるアクションおよびそれがアクセスできるリソース情報が含まれます。SCC を使用して、Pod がシステムに受け入れられるために必要な Pod の実行に関する条件の一覧を定義できます。
virt-controller は、クラスター内の仮想マシンの virt-launcher Pod を作成するクラスターコントローラーです。これらの Pod には、kubevirt-controller サービスアカウントによってパーミッションが付与されます。
kubevirt-controller サービスアカウントには追加の SCC および Linux 機能が付与され、これにより適切なパーミッションを持つ virt-launcher Pod を作成できます。これらの拡張パーミッションにより、仮想マシンは通常の Pod の範囲外の OpenShift Virtualization 機能を利用できます。
kubevirt-controller サービスアカウントには以下の SCC が付与されます。
-
scc.AllowHostDirVolumePlugin = true
これは、仮想マシンが hostpath ボリュームプラグインを使用することを可能にします。 -
scc.AllowPrivilegedContainer = false
これは、virt-launcher Pod が権限付きコンテナーとして実行されないようにします。 scc.AllowedCapabilities = []corev1.Capability{"SYS_NICE", "NET_BIND_SERVICE", "SYS_PTRACE"}
-
SYS_NICEを使用すると、CPU アフィニティーを設定できます。 -
NET_BIND_SERVICEは、DHCP および Slirp 操作を許可します。 -
SYS_PTRACEを使用すると、特定バージョンのlibvirtで、ソフトウェア Trusted Platform Module (TPM) エミュレーターであるswtpmのプロセス ID (PID) を見つけることができます。
-
7.3.1. kubevirt-controller の SCC および RBAC 定義の表示
oc ツールを使用して kubevirt-controller の SecurityContextConstraints 定義を表示できます。
$ oc get scc kubevirt-controller -o yaml
oc ツールを使用して kubevirt-controller クラスターロールの RBAC 定義を表示できます。
$ oc get clusterrole kubevirt-controller -o yaml第8章 CLI ツールの使用
クラスターでリソースを管理するために使用される 2 つの主な CLI ツールは以下の通りです。
-
OpenShift virtualization
virtctlクライアント -
OpenShift Container Platform
ocクライアント
8.1. 前提条件
8.2. OpenShift Container Platform クライアントコマンド
OpenShift Container Platform oc クライアントは、VirtualMachine (vm) および VirtualMachineInstance (vmi) オブジェクトタイプを含む、OpenShift Container Platform リソースを管理するためのコマンドラインユーティリティーです。
-n <namespace> フラグを使用して、別のプロジェクトを指定できます。
| コマンド | Description |
|---|---|
|
|
OpenShift Container Platform クラスターに |
|
| 現在のプロジェクトの指定されたオブジェクトタイプのオブジェクトのリストを表示します。 |
|
| 現在のプロジェクトで特定のリソースの詳細を表示します。 |
|
| 現在のプロジェクトで、ファイル名または標準入力 (stdin) からリソースを作成します。 |
|
| 現在のプロジェクトのリソースを編集します。 |
|
| 現在のプロジェクトのリソースを削除します。 |
oc client コマンドについてのより総合的な情報については、OpenShift Container Platform CLI ツール のドキュメントを参照してください。
8.3. Virtctl クライアントコマンド
virtctl クライアントは、OpenShift Virtualization リソースを管理するためのコマンドラインユーティリティーです。
virtctlコマンドのリストを表示するには、次のコマンドを実行します。
$ virtctl help
特定のコマンドで使用できるオプションの一覧を表示するには、これを -h または --help フラグを指定して実行します。以下に例を示します。
$ virtctl image-upload -h
任意のvirtctlコマンドで使用できるグローバルコマンドオプションのリストを表示するには、次のコマンドを実行します。
$ virtctl options
以下の表には、OpenShift Virtualization のドキュメント全体で使用されている virtctl コマンドが記載されています。
| コマンド | Description |
|---|---|
|
| 仮想マシンを起動します。 |
|
| 仮想マシンを一時停止状態で起動します。このオプションを使用すると、VNC コンソールからブートプロセスを中断できます。 |
|
| 仮想マシンを停止します。 |
|
| 仮想マシンを強制停止します。このオプションは、データの不整合またはデータ損失を引き起こす可能性があります。 |
|
| 仮想マシンまたは仮想マシンインスタンスを一時停止します。マシンの状態がメモリーに保持されます。 |
|
| 仮想マシンまたは仮想マシンインスタンスの一時停止を解除します。 |
|
| 仮想マシンを移行します。 |
|
| 仮想マシンを再起動します。 |
|
| 仮想マシンまたは仮想マシンインスタンスの指定されたポートを転送するサービスを作成し、このサービスをノードの指定されたポートで公開します。 |
|
| 仮想マシンインスタンスのシリアルコンソールに接続します。 |
|
| VNC (仮想ネットワーククライアント) の仮想マシンインスタンスへの接続を開きます。ローカルマシンでリモートビューアーを必要とする VNC を使用して仮想マシンインスタンスのグラフィカルコンソールにアクセスします。 |
|
| VNC 接続からビューアーを使用してポート番号を表示し、仮想マシンインスタンスに手動で接続します。 |
|
| ポートが利用可能な場合、その指定されたポートでプロキシーを実行するためにポート番号を指定します。ポート番号が指定されていない場合、プロキシーはランダムポートで実行されます。 |
|
| 仮想マシンイメージをすでに存在するデータボリュームにアップロードします。 |
|
| 仮想マシンイメージを新規データボリューム にアップロードします。 |
|
| クライアントおよびサーバーのバージョン情報を表示します。 |
|
| ゲストマシンで利用可能なファイルシステムの詳細なリストを返します。 |
|
| オペレーティングシステムに関するゲストエージェント情報を返します。 |
|
| ゲストマシンでログインしているユーザーの詳細な一覧を返します。 |
8.4. virtctl guestfs を使用したコンテナーの作成
virtctl guestfs コマンドを使用して、libguestfs-tools および永続ボリューム要求 (PVC) がアタッチされた対話型コンテナーをデプロイできます。
手順
libguestfs-toolsでコンテナーをデプロイして PVC をマウントし、シェルを割り当てるには、以下のコマンドを実行します。$ virtctl guestfs -n <namespace> <pvc_name>1 - 1
- PVC 名は必須の引数です。この引数を追加しないと、エラーメッセージが表示されます。
8.5. Libguestfs ツールおよび virtctl guestfs
Libguestfs ツールは、仮想マシン (VM) のディスクイメージにアクセスして変更するのに役立ちます。libguestfs ツールを使用して、ゲスト内のファイルの表示および編集、仮想マシンのクローンおよびビルド、およびディスクのフォーマットおよびサイズ変更を実行できます。
virtctl guestfs コマンドおよびそのサブコマンドを使用して、PVC で仮想マシンディスクを変更して検査し、デバッグすることもできます。使用可能なサブコマンドの完全なリストを表示するには、コマンドラインで virt- と入力して Tab を押します。以下に例を示します。
| コマンド | 説明 |
|---|---|
|
| ターミナルでファイルを対話的に編集します。 |
|
| ゲストに ssh キーを挿入し、ログインを作成します。 |
|
| 仮想マシンによって使用されるディスク容量を確認します。 |
|
| 詳細のリストを含む出力ファイルを作成して、ゲストにインストールされたすべての RPM の詳細リストを参照してください。 |
|
|
ターミナルで |
|
| テンプレートとして使用する仮想マシンディスクイメージをシールします。 |
デフォルトでは、virtctl guestfs は、仮想ディスク管理に必要な項目を含めてセッションを作成します。ただし、動作をカスタマイズできるように、コマンドは複数のフラグオプションもサポートしています。
| フラグオプション | 説明 |
|---|---|
|
|
|
|
| 特定の namespace から PVC を使用します。
|
|
|
|
|
|
デフォルトでは、
クラスターに
設定されていない場合、 |
|
|
|
このコマンドは、PVC が別の Pod によって使用されているかどうかを確認します。使用されている場合には、エラーメッセージが表示されます。ただし、libguestfs-tools プロセスが開始されると、設定では同じ PVC を使用する新規 Pod を回避できません。同じ PVC にアクセスする仮想マシンを起動する前に、アクティブな virtctl guestfs Pod がないことを確認する必要があります。
virtctl guestfs コマンドは、インタラクティブな Pod に割り当てられている PVC 1 つだけを受け入れます。
第9章 仮想マシン
9.1. 仮想マシンの作成
以下のいずれかの手順を使用して、仮想マシンを作成します。
- クイックスタートのガイド付きツアー
- カタログからクイック作成
- 仮想マシンウィザードによる事前に設定された YAML ファイルの貼り付け
- CLI の使用
openshift-* namespace に仮想マシンを作成しないでください。代わりに、openshift 接頭辞なしの新規 namespace を作成するか、既存 namespace を使用します。
Web コンソールから仮想マシンを作成する場合、ブートソースで設定される仮想マシンテンプレートを選択します。ブートソースを含む仮想マシンテンプレートには Available boot source というラベルが付けられるか、それらはカスタマイズされたラベルテキストを表示します。選択可能なブートソースでテンプレートを使用すると、仮想マシンの作成プロセスをスピードアップできます。
ブートソースのないテンプレートには、Boot source required というラベルが付けられます。仮想マシンにブートソースを追加する 手順を完了すれば、これらのテンプレートを使用することができます。
ストレージの動作の違いにより、一部の仮想マシンテンプレートは単一ノードの Openshift と互換性がありません。互換性を確保するためには、テンプレートまたはデータボリュームまたはストレージプロファイルを使用する仮想マシンにevictionStrategyフィールドを設定しないでください。
9.1.1. クイックスタートの使用による仮想マシンの作成
Web コンソールは、仮想マシンを作成するためのガイド付きツアーを含むクイックスタートを提供します。Administrator パースペクティブの Help メニューを選択して Quick Starts カタログにアクセスし、Quick Starts カタログを表示できます。Quick Starts タイルをクリックし、ツアーを開始すると、システムによるプロセスのガイドが開始します。
Quick Starts のタスクは、Red Hat テンプレートの選択から開始します。次に、ブートソースを追加して、オペレーティングシステムイメージをインポートできます。最後に、カスタムテンプレートを保存し、これを使用して仮想マシンを作成できます。
前提条件
- オペレーティングシステムイメージの URL リンクをダウンロードできる Web サイトにアクセスすること。
手順
- Web コンソールで、Help メニューから Quick Starts を選択します。
- Quick Starts カタログのタイルをクリックします。例: Red Hat Linux Enterprise Linux 仮想マシンの作成
- ガイド付きツアーの手順に従い、オペレーティングシステムイメージのインポートと仮想マシンの作成タスクを実行します。Virtualization → VirtualMachines ページに仮想マシンが表示されます。
9.1.2. 仮想マシンのクイック作成
使用可能なブートソースを含むテンプレートを使用して、仮想マシン (VM) をすばやく作成できます。
手順
- サイドメニューの Virtualization → Catalog をクリックします。
利用可能なブートソース をクリックして、テンプレートをブートソースでフィルタリングします。
注記デフォルトでは、テンプレートリストには Default Templates のみが表示されます。選択したフィルターで使用可能なすべてのテンプレートを表示するには、フィルタリング時に すべてのアイテムをクリックします。
- テンプレートをクリックして詳細を表示します。
仮想マシンのクイック作成をクリックして、テンプレートから VM を作成します。
仮想マシンの詳細ページに、プロビジョニングステータスが表示されます。
検証
- Events をクリックして、仮想マシンがプロビジョニングされたときにイベントのストリームを表示します。
- Console をクリックして、仮想マシンが正常に起動したことを確認します。
9.1.3. カスタマイズされたテンプレートからの仮想マシンの作成
一部のテンプレートでは、追加のパラメーターが必要です。たとえば、ブート ソースを持つ PVC などです。テンプレートの選択パラメーターをカスタマイズして、仮想マシン (VM) を作成できます。
手順
Web コンソールで、テンプレートを選択します。
- サイドメニューの Virtualization → Catalog をクリックします。
- オプション: プロジェクト、キーワード、オペレーティングシステム、またはワークロードプロファイルでテンプレートをフィルター処理します。
- カスタマイズするテンプレートをクリックします。
- Customize VirtualMachineを クリックします。
- Name や Disk source など、仮想マシンのパラメーターを指定します。オプションで、複製するデータソースを指定できます。
検証
- Events をクリックして、仮想マシンがプロビジョニングされたときにイベントのストリームを表示します。
- Console をクリックして、仮想マシンが正常に起動したことを確認します。
Web コンソールから仮想マシンを作成する場合は、仮想マシンのフィールドセクションを参照してください。
9.1.3.1. 仮想マシンフィールド
以下の表には、OpenShift Container Platform Web コンソールで編集できる仮想マシンのフィールドが記載されています。
| タブ | フィールドまたは機能 |
|---|---|
| 概要 |
|
| YAML |
|
| スケジューリング |
|
| 環境 |
|
| Network Interfaces |
|
| ディスク |
|
| スクリプト |
|
| メタデータ |
|
9.1.3.1.1. ネットワークフィールド
| Name | 説明 |
|---|---|
| Name | ネットワークインターフェイスコントローラーの名前。 |
| モデル | ネットワークインターフェイスコントローラーのモデルを示します。サポートされる値は e1000e および virtio です。 |
| Network | 利用可能なネットワーク接続定義のリスト。 |
| タイプ | 利用可能なバインディングメソッドの一覧。ネットワークインターフェイスに適したバインド方法を選択します。
|
| MAC Address | ネットワークインターフェイスコントローラーの MAC アドレス。MAC アドレスが指定されていない場合、これは自動的に割り当てられます。 |
9.1.3.2. ストレージフィールド
| Name | 選択 | Description |
|---|---|---|
| Source | 空白 (PVC の作成) | 空のディスクを作成します。 |
| URL を使用したインポート (PVC の作成) | URL (HTTP または HTTPS エンドポイント) を介してコンテンツをインポートします。 | |
| 既存 PVC の使用 | クラスターですでに利用可能な PVC を使用します。 | |
| 既存の PVC のクローン作成 (PVC の作成) | クラスターで利用可能な既存の PVC を選択し、このクローンを作成します。 | |
| レジストリーを使用したインポート (PVC の作成) | コンテナーレジストリーを使用してコンテンツをインポートします。 | |
| コンテナー (一時的) | クラスターからアクセスできるレジストリーにあるコンテナーからコンテンツをアップロードします。コンテナーディスクは、CD-ROM や一時的な仮想マシンなどの読み取り専用ファイルシステムにのみ使用する必要があります。 | |
| Name |
ディスクの名前。この名前には、小文字 ( | |
| Size | ディスクのサイズ (GiB 単位)。 | |
| タイプ | ディスクのタイプ。例: Disk または CD-ROM | |
| Interface | ディスクデバイスのタイプ。サポートされるインターフェイスは、virtIO、SATA、および SCSI です。 | |
| Storage Class | ディスクの作成に使用されるストレージクラス。 |
ストレージの詳細設定
以下のストレージの詳細設定はオプションであり、Blank、Import via URLURL、および Clone existing PVC ディスクで利用できます。OpenShift Virtualization 4.11 より前では、これらのパラメーターを指定しない場合、システムは kubevirt-storage-class-defaults 設定マップのデフォルト値を使用します。OpenShift Virtualization 4.11 以降では、システムは ストレージプロファイル のデフォルト値を使用します。
ストレージプロファイルを使用して、OpenShift Virtualization のストレージをプロビジョニングするときに一貫した高度なストレージ設定を確保します。
Volume Mode と Access Mode を手動で指定するには、デフォルトで選択されている Apply optimized StorageProfile settings チェックボックスをオフにする必要があります。
| Name | モードの説明 | パラメーター | パラメーターの説明 |
|---|---|---|---|
| ボリュームモード | 永続ボリュームがフォーマットされたファイルシステムまたは raw ブロック状態を使用するかどうかを定義します。デフォルトは Filesystem です。 | Filesystem | ファイルシステムベースのボリュームで仮想ディスクを保存します。 |
| Block |
ブロックボリュームで仮想ディスクを直接保存します。基礎となるストレージがサポートしている場合は、 | ||
| アクセスモード | 永続ボリュームのアクセスモード。 | ReadWriteOnce (RWO) | ボリュームは単一ノードで読み取り/書き込みとしてマウントできます。 |
| ReadWriteMany (RWX) | ボリュームは、一度に多くのノードで読み取り/書き込みとしてマウントできます。 注記 これは、ノード間の仮想マシンのライブマイグレーションなどの、一部の機能で必要になります。 | ||
| ReadOnlyMany (ROX) | ボリュームは数多くのノードで読み取り専用としてマウントできます。 |
9.1.3.3. Cloud-init フィールド
| Name | 説明 |
|---|---|
| Hostname | 仮想マシンの特定のホスト名を設定します。 |
| 認可された SSH キー | 仮想マシンの ~/.ssh/authorized_keys にコピーされるユーザーの公開鍵。 |
| カスタムスクリプト | 他のオプションを、カスタム cloud-init スクリプトを貼り付けるフィールドに置き換えます。 |
ストレージクラスのデフォルトを設定するには、ストレージプロファイルを使用します。詳細については、ストレージプロファイルのカスタマイズを参照してください。
9.1.3.4. 仮想マシンウィザードの作成用の事前に設定された YAML ファイルの貼り付け
YAML 設定ファイルを作成し、解析して仮想マシンを作成します。YAML 編集画面を開くと、常に有効な example 仮想マシン設定がデフォルトで提供されます。
Create をクリックする際に YAML 設定が無効な場合、エラーメッセージでエラーが発生したパラメーターが示唆されます。エラーは一度に 1 つのみ表示されます。
編集中に YAML 画面から離れると、設定に対して加えた変更が取り消されます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- Create をクリックし、With YAML を選択します。
編集可能なウィンドウで仮想マシンの設定を作成するか、これを貼り付けます。
-
または、YAML 画面にデフォルトで提供される
example仮想マシンを使用します。
-
または、YAML 画面にデフォルトで提供される
- オプション: Download をクリックして YAML 設定ファイルをその現在の状態でダウンロードします。
- Create をクリックして仮想マシンを作成します。
仮想マシンが VirtualMachines ページにリスト表示されます。
9.1.4. CLI の使用による仮想マシンの作成
virtualMachine マニフェストから仮想マシンを作成できます。
手順
仮想マシンの
VirtualMachineマニフェストを編集します。たとえば、次のマニフェストは Red Hat Enterprise Linux (RHEL) 仮想マシンを設定します。例9.1 RHEL 仮想マシンのマニフェストの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: app: <vm_name>1 name: <vm_name> spec: dataVolumeTemplates: - apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <vm_name> spec: sourceRef: kind: DataSource name: rhel9 namespace: openshift-virtualization-os-images storage: resources: requests: storage: 30Gi running: false template: metadata: labels: kubevirt.io/domain: <vm_name> spec: domain: cpu: cores: 1 sockets: 2 threads: 1 devices: disks: - disk: bus: virtio name: rootdisk - disk: bus: virtio name: cloudinitdisk interfaces: - masquerade: {} name: default rng: {} features: smm: enabled: true firmware: bootloader: efi: {} resources: requests: memory: 8Gi evictionStrategy: LiveMigrate networks: - name: default pod: {} volumes: - dataVolume: name: <vm_name> name: rootdisk - cloudInitNoCloud: userData: |- #cloud-config user: cloud-user password: '<password>'2 chpasswd: { expire: False } name: cloudinitdiskマニフェストファイルを使用して仮想マシンを作成します。
$ oc create -f <vm_manifest_file>.yamlオプション: 仮想マシンを開始します。
$ virtctl start <vm_name>
9.1.5. 仮想マシンのストレージボリュームタイプ
| ストレージボリュームタイプ | Description |
|---|---|
| ephemeral | ネットワークボリュームを読み取り専用のバッキングストアとして使用するローカルの copy-on-write (COW) イメージ。バッキングボリュームは PersistentVolumeClaim である必要があります。一時イメージは仮想マシンの起動時に作成され、すべての書き込みをローカルに保存します。一時イメージは、仮想マシンの停止、再起動または削除時に破棄されます。バッキングボリューム (PVC) はいずれの方法でも変更されません。 |
| persistentVolumeClaim | 利用可能な PV を仮想マシンに割り当てます。PV の割り当てにより、仮想マシンデータのセッション間での永続化が可能になります。 CDI を使用して既存の仮想マシンディスクを PVC にインポートし、PVC を仮想マシンインスタンスに割り当てる方法は、既存の仮想マシンを OpenShift Container Platform にインポートするための推奨される方法です。ディスクを PVC 内で使用できるようにするためのいくつかの要件があります。 |
| dataVolume |
データボリュームは、インポート、クローンまたはアップロード操作で仮想マシンディスクの準備プロセスを管理することによって
|
| cloudInitNoCloud | 参照される cloud-init NoCloud データソースが含まれるディスクを割り当て、ユーザーデータおよびメタデータを仮想マシンに提供します。cloud-init インストールは仮想マシンディスク内で必要になります。 |
| containerDisk | コンテナーイメージレジストリーに保存される、仮想マシンディスクなどのイメージを参照します。イメージはレジストリーからプルされ、仮想マシンの起動時にディスクとして仮想マシンに割り当てられます。
RAW および QCOW2 形式のみがコンテナーイメージレジストリーのサポートされるディスクタイプです。QCOW2 は、縮小されたイメージサイズの場合に推奨されます。 注記
|
| emptyDisk | 仮想マシンインターフェイスのライフサイクルに関連付けられるスパースの QCOW2 ディスクを追加で作成します。データは仮想マシンのゲストによって実行される再起動後も存続しますが、仮想マシンが Web コンソールから停止または再起動する場合には破棄されます。空のディスクは、アプリケーションの依存関係および一時ディスクの一時ファイルシステムの制限を上回るデータを保存するために使用されます。 ディスク 容量 サイズも指定する必要があります。 |
9.1.6. 仮想マシンの RunStrategy について
仮想マシンの RunStrategy は、一連の条件に応じて仮想マシンインスタンス (VMI) の動作を判別します。spec.runStrategy 設定は、spec.running 設定の代わりに仮想マシン設定プロセスに存在します。spec.runStrategy 設定を使用すると、true または false の応答のみを伴う spec.running 設定とは対照的に、VMI の作成および管理をより柔軟に行えます。ただし、2 つの設定は相互排他的です。spec.running または spec.runStrategy のいずれかを使用できます。両方を使用する場合は、エラーが発生します。
4 つ RunStrategy が定義されています。
Always-
VMI は仮想マシンの作成時に常に表示されます。元の VMI が何らかの理由で停止する場合に、新規の VMI が作成されます。これは
spec.running: trueと同じ動作です。 RerunOnFailure- 前のインスタンスがエラーが原因で失敗する場合は、VMI が再作成されます。インスタンスは、仮想マシンが正常に停止する場合 (シャットダウン時など) には再作成されません。
Manual(手動)-
start、stop、およびrestartvirtctl クライアントコマンドは、 VMI の状態および存在を制御するために使用できます。 Halted-
仮想マシンが作成される際に VMI は存在しません。これは
spec.running: falseと同じ動作です。
start、stop、および restart の virtctl コマンドの各種の組み合わせは、どの RunStrategy が使用されるかに影響を与えます。
以下の表は、仮想マシンの各種の状態からの移行について示しています。最初の列には、仮想マシンの初期の RunStrategy が表示されます。それぞれの追加の列には、virtctl コマンドと、このコマンド実行後の新規 RunStrategy が表示されます。
| 初期 RunStrategy | start | stop | restart |
|---|---|---|---|
| Always | - | Halted | Always |
| RerunOnFailure | - | Halted | RerunOnFailure |
| Manual | Manual | Manual | Manual |
| Halted | Always | - | - |
インストーラーでプロビジョニングされるインフラストラクチャーを使用してインストールされた OpenShift Virtualization クラスターでは、ノードで MachineHealthCheck に失敗し、クラスターで利用できなくなると、RunStrategy が Always または RerunOnFailure の仮想マシンが新規ノードで再スケジュールされます。
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
RunStrategy: Always
template:
...- 1
- VMI の現在の
RunStrategy設定。
9.2. 仮想マシンの編集
Web コンソールの YAML エディターまたはコマンドラインの OpenShift CLI のいずれかを使用して、仮想マシン設定を更新できます。Virtual Machine Details 画面でパラメーターのサブセットを更新することもできます。
9.2.1. Web コンソールでの仮想マシンの編集
関連するフィールドの横にある鉛筆アイコンをクリックして、Web コンソールで仮想マシンの選択する値 (select values) を編集します。他の値は、CLI を使用して編集できます。
Red Hat が提供するものを含め、任意のテンプレートのラベルとアノテーションを編集できます。その他のフィールドは、ユーザーがカスタマイズしたテンプレートでのみ編集できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- オプション: Filter ドロップダウン メニューを使用して、ステータス、テンプレート、ノード、またはオペレーティング システム (OS) などの属性で仮想マシンのリストを並べ替えます。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- フィールドが編集可能であることを示す鉛筆アイコンが付いているフィールドをクリックします。たとえば、BIOS や UEFI などの現在の ブートモード 設定をクリックして、Boot mode ウィンドウを開き、リストからオプションを選択します。
- 関連する変更を加え、Save をクリックします。
仮想マシンが実行されている場合、Boot Order または Flavor への変更は仮想マシンを再起動するまで反映されません。
関連するフィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更の一覧が表示されます。
9.2.1.1. 仮想マシンフィールド
以下の表には、OpenShift Container Platform Web コンソールで編集できる仮想マシンのフィールドが記載されています。
| タブ | フィールドまたは機能 |
|---|---|
| Details |
|
| YAML |
|
| スケジューリング |
|
| Network Interfaces |
|
| ディスク |
|
| スクリプト |
|
| スナップショット |
|
9.2.2. Web コンソールを使用した仮想マシンの YAML 設定の編集
Web コンソールで、仮想マシンの YAML 設定を編集できます。一部のパラメーターは変更できません。無効な設定で Save をクリックすると、エラーメッセージで変更できないパラメーターが示唆されます。
編集中に YAML 画面から離れると、設定に対して加えた変更が取り消されます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択します。
- YAML タブをクリックして編集可能な設定を表示します。
- オプション: Download をクリックして YAML ファイルをその現在の状態でローカルにダウンロードできます。
- ファイルを編集し、Save をクリックします。
オブジェクトの更新されたバージョン番号を含む、変更が正常に行われたことを示す確認メッセージが表示されます。
9.2.3. CLI を使用した仮想マシン YAML 設定の編集
以下の手順を使用し、CLI を使用して仮想マシン YAML 設定を編集します。
前提条件
- YAML オブジェクト設定ファイルを使用して仮想マシンを設定していること。
-
ocCLI をインストールしていること。
手順
以下のコマンドを実行して、仮想マシン設定を更新します。
$ oc edit <object_type> <object_ID>- オブジェクト設定を開きます。
- YAML を編集します。
実行中の仮想マシンを編集する場合は、以下のいずれかを実行する必要があります。
- 仮想マシンを再起動します。
新規の設定を有効にするために、以下のコマンドを実行します。
$ oc apply <object_type> <object_ID>
9.2.4. 仮想マシンへの仮想ディスクの追加
以下の手順を使用して仮想ディスクを仮想マシンに追加します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details 画面を開きます。
- Disks タブをクリックし、Add disk をクリックします。
Add disk ウィンドウで、Source、Name、Size、Type、Interface、および Storage Class を指定します。
- オプション: 空のディスクソースを使用し、データボリュームの作成時に最大の書き込みパフォーマンスが必要な場合に、事前割り当てを有効にできます。そのためには、Enable preallocation チェックボックスをオンにします。
-
オプション: Apply optimized StorageProfile settings をクリアして、仮想ディスクの Volume Mode と Access Mode を変更できます。これらのパラメーターを指定しない場合、システムは
kubevirt-storage-class-defaultsconfig map のデフォルト値を使用します。
- Add をクリックします。
仮想マシンが実行中の場合、新規ディスクは pending restart 状態にあり、仮想マシンを再起動するまで割り当てられません。
ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更の一覧が表示されます。
ストレージクラスのデフォルトを設定するには、ストレージプロファイルを使用します。詳細については、ストレージプロファイルのカスタマイズを参照してください。
9.2.4.1. VirtualMachine の CD-ROM の編集
以下の手順を使用して、仮想マシンの CD-ROM を編集します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details 画面を開きます。
- Disks タブをクリックします。
-
編集する CD-ROM の Options メニュー
をクリックし、Edit を選択します。
- Edit CD-ROM ウィンドウで、Source、Persistent Volume Claim、Name、Type、および Interface フィールドを編集します。
- Save をクリックします。
9.2.4.2. ストレージフィールド
| Name | 選択 | Description |
|---|---|---|
| Source | 空白 (PVC の作成) | 空のディスクを作成します。 |
| URL を使用したインポート (PVC の作成) | URL (HTTP または HTTPS エンドポイント) を介してコンテンツをインポートします。 | |
| 既存 PVC の使用 | クラスターですでに利用可能な PVC を使用します。 | |
| 既存の PVC のクローン作成 (PVC の作成) | クラスターで利用可能な既存の PVC を選択し、このクローンを作成します。 | |
| レジストリーを使用したインポート (PVC の作成) | コンテナーレジストリーを使用してコンテンツをインポートします。 | |
| コンテナー (一時的) | クラスターからアクセスできるレジストリーにあるコンテナーからコンテンツをアップロードします。コンテナーディスクは、CD-ROM や一時的な仮想マシンなどの読み取り専用ファイルシステムにのみ使用する必要があります。 | |
| Name |
ディスクの名前。この名前には、小文字 ( | |
| Size | ディスクのサイズ (GiB 単位)。 | |
| タイプ | ディスクのタイプ。例: Disk または CD-ROM | |
| Interface | ディスクデバイスのタイプ。サポートされるインターフェイスは、virtIO、SATA、および SCSI です。 | |
| Storage Class | ディスクの作成に使用されるストレージクラス。 |
ストレージの詳細設定
以下のストレージの詳細設定はオプションであり、Blank、Import via URLURL、および Clone existing PVC ディスクで利用できます。OpenShift Virtualization 4.11 より前では、これらのパラメーターを指定しない場合、システムは kubevirt-storage-class-defaults 設定マップのデフォルト値を使用します。OpenShift Virtualization 4.11 以降では、システムは ストレージプロファイル のデフォルト値を使用します。
ストレージプロファイルを使用して、OpenShift Virtualization のストレージをプロビジョニングするときに一貫した高度なストレージ設定を確保します。
Volume Mode と Access Mode を手動で指定するには、デフォルトで選択されている Apply optimized StorageProfile settings チェックボックスをオフにする必要があります。
| Name | モードの説明 | パラメーター | パラメーターの説明 |
|---|---|---|---|
| ボリュームモード | 永続ボリュームがフォーマットされたファイルシステムまたは raw ブロック状態を使用するかどうかを定義します。デフォルトは Filesystem です。 | Filesystem | ファイルシステムベースのボリュームで仮想ディスクを保存します。 |
| Block |
ブロックボリュームで仮想ディスクを直接保存します。基礎となるストレージがサポートしている場合は、 | ||
| アクセスモード | 永続ボリュームのアクセスモード。 | ReadWriteOnce (RWO) | ボリュームは単一ノードで読み取り/書き込みとしてマウントできます。 |
| ReadWriteMany (RWX) | ボリュームは、一度に多くのノードで読み取り/書き込みとしてマウントできます。 注記 これは、ノード間の仮想マシンのライブマイグレーションなどの、一部の機能で必要になります。 | ||
| ReadOnlyMany (ROX) | ボリュームは数多くのノードで読み取り専用としてマウントできます。 |
9.2.5. 仮想マシンへのネットワークインターフェイスの追加
以下の手順を使用してネットワークインターフェイスを仮想マシンに追加します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details 画面を開きます。
- Network Interfaces タブをクリックします。
- Add Network Interface をクリックします。
- Add Network Interface ウィンドウで、ネットワークインターフェイスの Name、Model、Network、 Type、および MAC Address を指定します。
- Add をクリックします。
仮想マシンが実行中の場合、新規ネットワークインターフェイスは pending restart 状態にあり、仮想マシンを再起動するまで変更は反映されません。
ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
9.2.5.1. ネットワークフィールド
| Name | 説明 |
|---|---|
| Name | ネットワークインターフェイスコントローラーの名前。 |
| モデル | ネットワークインターフェイスコントローラーのモデルを示します。サポートされる値は e1000e および virtio です。 |
| Network | 利用可能なネットワーク接続定義のリスト。 |
| タイプ | 利用可能なバインディングメソッドの一覧。ネットワークインターフェイスに適したバインド方法を選択します。
|
| MAC Address | ネットワークインターフェイスコントローラーの MAC アドレス。MAC アドレスが指定されていない場合、これは自動的に割り当てられます。 |
9.3. ブート順序の編集
Web コンソールまたは CLI を使用して、ブート順序リストの値を更新できます。
Virtual Machine Overview ページの Boot Order で、以下を実行できます。
- ディスクまたはネットワークインターフェイスコントローラー (NIC) を選択し、これをブート順序のリストに追加します。
- ブート順序の一覧でディスクまたは NIC の順序を編集します。
- ブート順序のリストからディスクまたは NIC を削除して、起動可能なソースのインベントリーに戻します。
9.3.1. Web コンソールでのブート順序リストへの項目の追加
Web コンソールを使用して、ブート順序リストに項目を追加します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。YAML 設定が存在しない場合や、これがブート順序リストの初回作成時の場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
- Add Source をクリックして、仮想マシンのブート可能なディスクまたはネットワークインターフェイスコントローラー (NIC) を選択します。
- 追加のディスクまたは NIC をブート順序一覧に追加します。
- Save をクリックします。
仮想マシンが実行されている場合、Boot Order への変更は仮想マシンを再起動するまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
9.3.2. Web コンソールでのブート順序リストの編集
Web コンソールで起動順序リストを編集します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。
ブート順序リストで項目を移動するのに適した方法を選択します。
- スクリーンリーダーを使用しない場合、移動する項目の横にある矢印アイコンにカーソルを合わせ、項目を上下にドラッグし、選択した場所にドロップします。
- スクリーンリーダーを使用する場合は、上矢印キーまたは下矢印を押して、ブート順序リストで項目を移動します。次に Tab キーを押して、選択した場所に項目をドロップします。
- Save をクリックします。
仮想マシンが実行されている場合、ブート順序の変更は仮想マシンが再起動されるまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
9.3.3. YAML 設定ファイルでのブート順序リストの編集
CLI を使用して、YAML 設定ファイルのブート順序のリストを編集します。
手順
以下のコマンドを実行して、仮想マシンの YAML 設定ファイルを開きます。
$ oc edit vm exampleYAML ファイルを編集し、ディスクまたはネットワークインターフェイスコントローラー (NIC) に関連付けられたブート順序の値を変更します。以下に例を示します。
disks: - bootOrder: 11 disk: bus: virtio name: containerdisk - disk: bus: virtio name: cloudinitdisk - cdrom: bus: virtio name: cd-drive-1 interfaces: - boot Order: 22 macAddress: '02:96:c4:00:00' masquerade: {} name: default- YAML ファイルを保存します。
- reload the content をクリックして、Web コンソールで YAML ファイルの更新されたブート順序の値をブート順序リストに適用します。
9.3.4. Web コンソールでのブート順序リストからの項目の削除
Web コンソールを使用して、ブート順序のリストから項目を削除します。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
- Boot Order の右側にある鉛筆アイコンをクリックします。
-
項目の横にある Remove アイコン
 をクリックします。この項目はブート順序のリストから削除され、利用可能なブートソースのリストに保存されます。ブート順序リストからすべての項目を削除する場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
をクリックします。この項目はブート順序のリストから削除され、利用可能なブートソースのリストに保存されます。ブート順序リストからすべての項目を削除する場合、以下のメッセージが表示されます。No resource selected.仮想マシンは、YAML ファイルでの出現順にディスクからの起動を試行します。
仮想マシンが実行されている場合、Boot Order への変更は仮想マシンを再起動するまで反映されません。
Boot Order フィールドの右側にある View Pending Changes をクリックして、保留中の変更を表示できます。ページ上部の Pending Changes バナーには、仮想マシンの再起動時に適用されるすべての変更のリストが表示されます。
9.4. 仮想マシンの削除
Web コンソールまたは oc コマンドラインインターフェイスを使用して、仮想マシンを削除できます。
9.4.1. Web コンソールの使用による仮想マシンの削除
仮想マシンを削除すると、仮想マシンはクラスターから永続的に削除されます。
仮想マシンを削除する際に、これが使用するデータボリュームは自動的に削除されます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
削除する仮想マシンの Options メニュー
をクリックし、Delete を選択します。
- または、仮想マシン名をクリックして VirtualMachine details ページを開き、Actions → Delete をクリックします。
- 確認のポップアップウィンドウで、Delete をクリックし、仮想マシンを永続的に削除します。
9.4.2. CLI の使用による仮想マシンの削除
oc コマンドラインインターフェイス (CLI) を使用して仮想マシンを削除できます。oc クライアントを使用すると、複数の仮想マシンで各種のアクションを実行できます。
仮想マシンを削除する際に、これが使用するデータボリュームは自動的に削除されます。
前提条件
- 削除する仮想マシンの名前を特定すること。
手順
以下のコマンドを実行し、仮想マシンを削除します。
$ oc delete vm <vm_name>注記このコマンドは、現在のプロジェクトに存在するオブジェクトのみを削除します。削除する必要のあるオブジェクトが別のプロジェクトまたは namespace にある場合、
-n <project_name>オプションを指定します。
9.5. 仮想マシンインスタンスの管理
OpenShift Virtualization 環境の外部で独立して作成されたスタンドアロン仮想マシンインスタンス (VMI) がある場合、Web コンソールを使用するか、コマンドラインインターフェイス (CLI) から oc または virtctl コマンドを使用してそれらを管理できます。
virtctl コマンドは、oc コマンドよりも多くの仮想化オプションを提供します。たとえば、virtctl を使用して仮想マシンを一時停止したり、ポートを公開したりできます。
9.5.1. 仮想マシンインスタンスについて
仮想マシンインスタンス (VMI) は、実行中の仮想マシンを表します。VMI が仮想マシンまたは別のオブジェクトによって所有されている場合、Web コンソールで、または oc コマンドラインインターフェイス (CLI) を使用し、所有者を通してこれを管理します。
スタンドアロンの VMI は、自動化または CLI で他の方法により、スクリプトを使用して独立して作成され、起動します。お使いの環境では、OpenShift Virtualization 環境外で開発され、起動されたスタンドアロンの VMI が存在する可能性があります。CLI を使用すると、引き続きそれらのスタンドアロン VMI を管理できます。スタンドアロン VMI に関連付けられた特定のタスクに Web コンソールを使用することもできます。
- スタンドアロン VMI とそれらの詳細をリスト表示します。
- スタンドアロン VMI のラベルとアノテーションを編集します。
- スタンドアロン VMI を削除します。
仮想マシンを削除する際に、関連付けられた VMI は自動的に削除されます。仮想マシンまたは他のオブジェクトによって所有されていないため、スタンドアロン VMI を直接削除します。
OpenShift Virtualization をアンインストールする前に、CLI または Web コンソールを使用してスタンドアロンの VMI のリストを表示します。次に、未処理の VMI を削除します。
9.5.2. CLI を使用した仮想マシンインスタンスのリスト表示
oc コマンドラインインターフェイス (CLI) を使用して、スタンドアロンおよび仮想マシンによって所有されている VMI を含むすべての仮想マシンのリストを表示できます。
手順
以下のコマンドを実行して、すべての VMI のリストを表示します。
$ oc get vmis -A
9.5.3. Web コンソールを使用したスタンドアロン仮想マシンインスタンスのリスト表示
Web コンソールを使用して、仮想マシンによって所有されていないクラスター内のスタンドアロンの仮想マシンインスタンス (VMI) のリストを表示できます。
仮想マシンまたは他のオブジェクトが所有する VMI は、Web コンソールには表示されません。Web コンソールは、スタンドアロンの VMI のみを表示します。クラスター内のすべての VMI をリスト表示するには、CLI を使用する必要があります。
手順
サイドメニューから Virtualization → VirtualMachines をクリックします。
スタンドアロン VMI は、名前の横にある濃い色のバッジで識別できます。
9.5.4. Web コンソールを使用したスタンドアロン仮想マシンインスタンスの編集
Web コンソールを使用して、スタンドアロン仮想マシンインスタンスのアノテーションおよびラベルを編集できます。他のフィールドは編集できません。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- スタンドアロン VMI を選択して、VirtualMachineInstance details ページを開きます。
- Details タブで、Annotations または Labels の横にある鉛筆アイコンをクリックします。
- 関連する変更を加え、Save をクリックします。
9.5.5. CLI を使用したスタンドアロン仮想マシンインスタンスの削除
oc コマンドラインインターフェイス (CLI) を使用してスタンドアロン仮想マシンインスタンス (VMI) を削除できます。
前提条件
- 削除する必要のある VMI の名前を特定すること。
手順
以下のコマンドを実行して VMI を削除します。
$ oc delete vmi <vmi_name>
9.5.6. Web コンソールを使用したスタンドアロン仮想マシンインスタンスの削除
Web コンソールからスタンドアロン仮想マシンインスタンス (VMI) を削除します。
手順
- Open Shift Container Platform Web コンソールで、サイドメニューからVirtualization → VirtualMachinesをクリックします。
- Actions → Delete VirtualMachineInstance をクリックします。
- 確認のポップアップウィンドウで、Delete をクリックし、スタンドアロン VMI を永続的に削除します。
9.6. 仮想マシンの状態の制御
Web コンソールから仮想マシンを停止し、起動し、再起動し、一時停止を解除することができます。
virtctl を使用して仮想マシンの状態を管理し、CLI から他のアクションを実行できます。たとえば、virtctl を使用して仮想マシンを強制停止したり、ポートを公開したりできます。
9.6.1. 仮想マシンの起動
Web コンソールから仮想マシンを起動できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 起動する仮想マシンが含まれる行を見つけます。
ユースケースに適したメニューに移動します。
複数の仮想マシンでのアクションの実行が可能なこのページに留まるには、以下を実行します。
-
行の右端にある Options メニュー
をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを起動する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions をクリックします。
- 再起動を選択します。
- 確認ウィンドウで Start をクリックし、仮想マシンを起動します。
URL ソースからプロビジョニングされる仮想マシンの初回起動時に、OpenShift Virtualization が URL エンドポイントからコンテナーをインポートする間、仮想マシンの状態は Importing になります。このプロセスは、イメージのサイズによって数分の時間がかかる可能性があります。
9.6.2. 仮想マシンの再起動
Web コンソールから実行中の仮想マシンを再起動できます。
エラーを回避するには、ステータスが Importing の仮想マシンは再起動しないでください。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 再起動する仮想マシンが含まれる行を見つけます。
ユースケースに適したメニューに移動します。
複数の仮想マシンでのアクションの実行が可能なこのページに留まるには、以下を実行します。
-
行の右端にある Options メニュー
をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを再起動する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Restart をクリックします。
- 確認ウィンドウで Restart をクリックし、仮想マシンを再起動します。
9.6.3. 仮想マシンの停止
Web コンソールから仮想マシンを停止できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 停止する仮想マシンが含まれる行を見つけます。
ユースケースに適したメニューに移動します。
複数の仮想マシンでのアクションの実行が可能なこのページに留まるには、以下を実行します。
-
行の右端にある Options メニュー
をクリックします。
-
行の右端にある Options メニュー
選択した仮想マシンを停止する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Actions → Stop をクリックします。
- 確認ウィンドウで Stop をクリックし、仮想マシンを停止します。
9.6.4. 仮想マシンの一時停止の解除
Web コンソールから仮想マシンの一時停止を解除できます。
前提条件
1 つ以上の仮想マシンのステータスが Paused である必要がある。
注記virtctlクライアントを使用して仮想マシンを一時停止することができます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 一時停止を解除する仮想マシンが含まれる行を見つけます。
ユースケースに適したメニューに移動します。
複数の仮想マシンでのアクションの実行が可能なこのページに留まるには、以下を実行します。
- Status 列で、Paused をクリックします。
選択した仮想マシンの一時停止を解除する前に、その仮想マシンの総合的な情報を表示するには、以下を実行します。
- 仮想マシンの名前をクリックして、VirtualMachine details ページにアクセスします。
- Status の右側にある鉛筆アイコンをクリックします。
- 確認ウィンドウで Stop をクリックし、仮想マシンの一時停止を解除します。
9.7. 仮想マシンコンソールへのアクセス
OpenShift Virtualization は、異なる製品タスクを実現するために使用できる異なる仮想マシンコンソールを提供します。これらのコンソールには、OpenShift Container Platform Web コンソールから、また CLI コマンドを使用してアクセスできます。
単一の仮想マシンに対する同時 VNC 接続の実行は、現在サポートされていません。
9.7.1. OpenShift Container Platform Web コンソールでの仮想マシンコンソールへのアクセス
OpenShift Container Platform Web コンソールでシリアルコンソールまたは VNC コンソールを使用して、仮想マシンに接続できます。
OpenShift Container Platform Web コンソールで、RDP (リモートデスクトッププロトコル) を使用するデスクトップビューアーコンソールを使用して、Windows 仮想マシンに接続できます。
9.7.1.1. シリアルコンソールへの接続
Web コンソールの VirtualMachine details ページにある Console タブから、実行中の仮想マシンのシリアルコンソールに接続します。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールがデフォルトで開きます。
- 一度に 1 つのコンソール セッションのみが開かれるようにするには、Disconnect をクリックします。それ以外の場合、VNC コンソール セッションはバックグラウンドでアクティブなままになります。
- VNC Console ドロップダウンリストをクリックし、Serial Console を選択します。
- Disconnect をクリックして、コンソールセッションを終了します。
- オプション: Open Console in New Window をクリックして、別のウィンドウでシリアルコンソールを開きます。
9.7.1.2. VNC コンソールへの接続
Web コンソールの VirtualMachine details ページにある Console タブから、実行中の仮想マシンの VNC コンソールに接続します。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Console タブをクリックします。VNC コンソールがデフォルトで開きます。
- オプション: Open Console in New Window をクリックして、別のウィンドウで VNC コンソールを開きます。
- オプション: Send Key をクリックして、キーの組み合わせを仮想マシンに送信します。
- コンソールウィンドウの外側をクリックし、Disconnect をクリックしてセッションを終了します。
9.7.1.3. RDP を使用した Windows 仮想マシンへの接続
Remote Desktop Protocol (RDP) を使用する Desktop viewer コンソールは、Windows 仮想マシンに接続するためのより使いやすいコンソールを提供します。
RDP を使用して Windows 仮想マシンに接続するには、Web コンソールの VirtualMachine 詳細 ページの Console タブから仮想マシンの console.rdp ファイルをダウンロードし、優先する RDP クライアントに提供します。
前提条件
-
QEMU ゲストエージェントがインストールされた実行中の Windows 仮想マシン。
qemu-guest-agentは VirtIO ドライバーに含まれています。 - Windows 仮想マシンと同じネットワーク上のマシンにインストールされた RDP クライアント。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- Windows 仮想マシンをクリックして、VirtualMachine details ページを開きます。
- Console タブをクリックします。
- コンソールのリストから、Desktop viewer を選択します。
-
Launch Remote Desktop をクリックし、
console.rdpファイルをダウンロードします。 -
優先する RDP クライアントで
console.rdpファイルを参照して、Windows 仮想マシンに接続します。
9.7.1.4. 仮想マシンの表示の切り替え
Windows 仮想マシン (VM) に vGPU が接続されている場合、Web コンソールを使用してデフォルトのディスプレイと vGPU ディスプレイを切り替えることができます。
前提条件
-
仲介されたデバイスは、
HyperConvergedカスタムリソースで設定され、仮想マシンに割り当てられます。 - 仮想マシンは実行中です。
手順
- OpenShift Container Platform コンソールで、Virtualization → VirtualMachines をクリックします。
- Windows 仮想マシンを選択して Overview 画面を開きます。
- Console タブをクリックします。
- コンソールのリストから、VNC console を選択します。
Send Key リストから適切なキーの組み合わせを選択します。
-
デフォルトの仮想マシン表示にアクセスするには、
Ctl + Alt+ 1を選択します。 -
vGPU ディスプレイにアクセスするには、
Ctl + Alt + 2を選択します。
-
デフォルトの仮想マシン表示にアクセスするには、
9.7.2. CLI コマンドの使用による仮想マシンコンソールへのアクセス
9.7.2.1. virtctl を使用して SSH 経由で仮想マシンにアクセスする
virtctl ssh コマンドを使用して、SSH トラフィックを仮想マシン (VM) に転送できます。
コントロールプレーンの SSH トラフィックが多いと、API サーバーの速度が低下する可能性があります。定期的に多数の接続が必要な場合は、専用の Kubernetes Service オブジェクトを使用して仮想マシンにアクセスします。
前提条件
-
cluster-admin権限を使用して OpenShift Container Platform クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 -
virtctlクライアントをインストールしました。 - アクセスする仮想マシンが実行されています。
- 仮想マシンと同じプロジェクトにいます。
手順
ssh-keygenコマンドを使用して、SSH 公開鍵ペアを生成します。$ ssh-keygen -f <key_file>1 - 1
- キーを格納するファイルを指定します。
仮想マシンにアクセスするための SSH 公開鍵を含む SSH 認証シークレットを作成します。
$ oc create secret generic my-pub-key --from-file=key1=<key_file>.pubVirtualMachineマニフェストにシークレットへの参照を追加します。以下に例を示します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: testvm spec: running: true template: spec: accessCredentials: - sshPublicKey: source: secret: secretName: my-pub-key1 propagationMethod: configDrive: {}2 # ...- 仮想マシンを再起動して変更を適用します。
次のコマンドを実行して、SSH 経由で仮想マシンにアクセスします。
$ virtctl ssh -i <key_file> <vm_username>@<vm_name>オプション: 仮想マシンとの間でファイルを安全に転送するには、次のコマンドを使用します。
マシンから仮想マシンにファイルをコピーする
$ virtctl scp -i <key_file> <filename> <vm_username>@<vm_name>:仮想マシンからマシンにファイルをコピーする
$ virtctl scp -i <key_file> <vm_username@<vm_name>:<filename> .
9.7.2.2. 仮想マシンインスタンスのシリアルコンソールへのアクセス
virtctl console コマンドは、指定された仮想マシンインスタンスへのシリアルコンソールを開きます。
前提条件
-
virt-viewerパッケージがインストールされていること。 - アクセスする仮想マシンインスタンスが実行中であること。
手順
virtctlでシリアルコンソールに接続します。$ virtctl console <VMI>
9.7.2.3. VNC を使用した仮想マシンインスタンスのグラフィカルコンソールへのアクセス
virtctl クライアントユーティリティーは remote-viewer 機能を使用し、実行中の仮想マシンインスタンスに対してグラフィカルコンソールを開くことができます。この機能は virt-viewer パッケージに組み込まれています。
前提条件
-
virt-viewerパッケージがインストールされていること。 - アクセスする仮想マシンインスタンスが実行中であること。
リモートマシンで SSH 経由で virtctl を使用する場合、X セッションをマシンに転送する必要があります。
手順
virtctlユーティリティーを使用してグラフィカルインターフェイスに接続します。$ virtctl vnc <VMI>コマンドが失敗した場合には、トラブルシューティング情報を収集するために
-vフラグの使用を試行します。$ virtctl vnc <VMI> -v 4
9.7.2.4. RDP コンソールの使用による Windows 仮想マシンへの接続
ローカルのリモートデスクトッププロトコル (RDP) クライアントを使用して、Windows 仮想マシン (VM) に接続するための Kubernetes Service オブジェクトを作成します。
前提条件
-
QEMU ゲストエージェントがインストールされた実行中の Windows 仮想マシン。
qemu-guest-agentオブジェクトは VirtIO ドライバーに含まれています。 - ローカルマシンにインストールされた RDP クライアント。
手順
VirtualMachineマニフェストを編集して、サービス作成のラベルを追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: vm-ephemeral namespace: example-namespace spec: running: false template: metadata: labels: special: key1 # ...- 1
- ラベル
special: keyをspec.template.metadata.labelsセクションに追加します。
注記仮想マシンのラベルは Pod に渡されます。
special: キーラベルは、Serviceマニフェストのspec.selector属性のラベルと一致する必要があります。-
VirtualMachineマニフェストファイルを保存して変更を適用します。 仮想マシンを公開するための
Serviceマニフェストを作成します。apiVersion: v1 kind: Service metadata: name: rdpservice1 namespace: example-namespace2 spec: ports: - targetPort: 33893 protocol: TCP selector: special: key4 type: NodePort5 # ...-
サービスマニフェストファイルを保存します。 以下のコマンドを実行してサービスを作成します。
$ oc create -f <service_name>.yaml- 仮想マシンを起動します。仮想マシンがすでに実行中の場合は、再起動します。
Serviceオブジェクトをクエリーし、これが利用可能であることを確認します。$ oc get service -n example-namespaceNodePortサービスの出力例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE rdpservice NodePort 172.30.232.73 <none> 3389:30000/TCP 5m以下のコマンドを実行して、ノードの IP アドレスを取得します。
$ oc get node <node_name> -o wide出力例
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP node01 Ready worker 6d22h v1.24.0 192.168.55.101 <none>- 優先する RDP クライアントでノード IP アドレスと割り当てられたポートを指定します。
- Windows 仮想マシンに接続するためのユーザー名とパスワードを入力します。
9.8. sysprep を使用した Windows のインストールの自動化
Microsoft DVD イメージとsysprepを使用して、Windows 仮想マシンのインストール、セットアップ、およびソフトウェアプロビジョニングを自動化できます。
9.8.1. Windows DVD を使用した VM ディスクイメージの作成
Microsoft はダウンロード用のディスクイメージを提供していませんが、Windows DVD を使用してディスクイメージを作成できます。このディスクイメージを使用して、仮想マシンを作成できます。
手順
- Open Shift Virtualization Web コンソールで、Storage → PersistentVolumeClaims → Create PersistentVolumeClaim With Data upload formをクリックします。
- 目的のプロジェクトを選択します。
- 永続ボリューム要求の名前を設定します。
- Windows DVD から仮想マシンディスクイメージをアップロードします。これで、イメージをブートソースとして使用して、新しい Windows 仮想マシンを作成できます。
9.8.2. ディスクイメージを使用した Windows のインストール
ディスクイメージを使用して、仮想マシンに Windows をインストールできます。
前提条件
- Windows DVD を使用してディスクイメージを作成する必要があります。
-
autounattend.xml応答ファイルを作成する必要があります。詳細は、Microsoft のドキュメント を参照してください。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → Catalog をクリックします。
- Windows テンプレートを選択し、Customize VirtualMachine をクリックします。
- Disk source リストから Upload (Upload a new file to a PVC) を選択し、DVD イメージを参照します。
- Review and create VirtualMachine をクリックします。
- Clone available operating system source to this Virtual Machine のチェックを外します。
- Start this VirtualMachine after creation のチェックを外します。
- Scripts タブの Sysprep セクションで、Edit をクリックします。
-
autounattend.xml応答ファイルを参照し、Save をクリックします。 - Create VirtualMachine をクリックします。
-
YAML タブで、
running:falseをrunStrategy: RerunOnFailureに置き換え、Save をクリックします。
VM は、autounattend.xml 応答ファイルを含む sysprep ディスクで開始されます。
9.8.3. sysprep を使用した Windows 仮想マシンの一般化
イメージを一般化すると、イメージが仮想マシン (VM) にデプロイされる際に、システム固有の設定データがすべて削除されます。
仮想マシンを一般化する前に、Windows の無人インストール後にsysprepツールが応答ファイルを検出できないことを確認する必要があります。
手順
- OpenShift Container Platform コンソールで、Virtualization → VirtualMachines をクリックします。
- Windows 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Disks タブをクリックします。
-
sysprepディスクの Options メニュー
をクリックし、Detach を選択します。
- デタッチ をクリックします。
-
sysprepツールによる検出を回避するために、C:\Windows\Panther\unattend.xmlの名前を変更します。 次のコマンドを実行して、
sysprepプログラムを開始します。%WINDIR%\System32\Sysprep\sysprep.exe /generalize /shutdown /oobe /mode:vm-
sysprepツールが完了すると、Windows 仮想マシンがシャットダウンします。これで、仮想マシンのディスクイメージを Windows 仮想マシンのインストールイメージとして使用できるようになりました。
これで、仮想マシンを特殊化できます。
9.8.4. Windows 仮想マシンの特殊化
仮想マシン (VM) を特殊化すると、一般化された Windows イメージから VM にコンピューター固有の情報が設定されます。
前提条件
- 一般化された Windows ディスクイメージが必要です。
-
unattend.xml応答ファイルを作成する必要があります。詳細は、Microsoft のドキュメント を参照してください。
手順
- OpenShift Container Platform コンソールで、Virtualization → Catalog をクリックします。
- Windows テンプレートを選択し、Customize VirtualMachine をクリックします。
- Disk source リストから PVC (clone PVC) を選択します。
- 一般化された Windows イメージの Persistent Volume Claim project および Persistent Volume Claim name を指定します。
- Review and create VirtualMachine をクリックします。
- Scripts タブをクリックします。
-
Sysprep セクションで、Edit をクリックし、
unattend.xml応答ファイルを参照して、Save をクリックします。 - Create VirtualMachine をクリックします。
Windows は初回起動時に、unattend.xml 応答ファイルを使用して VM を特殊化します。これで、仮想マシンを使用する準備が整いました。
9.9. 障害が発生したノードの解決による仮想マシンのフェイルオーバーのトリガー
ノードに障害が発生し、マシンヘルスチェック がクラスターにデプロイされていない場合、RunStrategy: Always が設定された仮想マシン (VM) は正常なノードに自動的に移動しません。仮想マシンのフェイルオーバーをトリガーするには、Node オブジェクトを手動で削除する必要があります。
インストーラーでプロビジョニングされるインフラストラクチャー を使用してクラスターをインストールし、マシンヘルスチェックを適切に設定している場合は、以下のようになります。
- 障害が発生したノードは自動的に再利用されます。
-
RunStrategyがAlwaysまたはRerunOnFailureに設定された仮想マシンは正常なノードで自動的にスケジュールされます。
9.9.1. 前提条件
-
仮想マシンが実行されているノードには
NotReady状態 が設定されている。 -
障害のあるノードで実行されていた仮想マシンでは、
RunStrategyがAlwaysに設定されている。 -
OpenShift CLI (
oc) がインストールされている。
9.9.2. ベアメタルクラスターからのノードの削除
CLI を使用してノードを削除する場合、ノードオブジェクトは Kubernetes で削除されますが、ノード自体にある Pod は削除されません。レプリケーションコントローラーで管理されないベア Pod は、OpenShift Container Platform からはアクセスできなくなります。レプリケーションコントローラーで管理されるベア Pod は、他の利用可能なノードに再スケジュールされます。ローカルのマニフェスト Pod は削除する必要があります。
手順
以下の手順を実行して、ベアメタルで実行されている OpenShift Container Platform クラスターからノードを削除します。
ノードにスケジュール対象外 (unschedulable) のマークを付けます。
$ oc adm cordon <node_name>ノード上のすべての Pod をドレイン (解放) します。
$ oc adm drain <node_name> --force=trueこのステップは、ノードがオフラインまたは応答しない場合に失敗する可能性があります。ノードが応答しない場合でも、共有ストレージに書き込むワークロードを実行している可能性があります。データの破損を防ぐには、続行する前に物理ハードウェアの電源を切ります。
クラスターからノードを削除します。
$ oc delete node <node_name>ノードオブジェクトはクラスターから削除されていますが、これは再起動後や kubelet サービスが再起動される場合にクラスターに再び参加することができます。ノードとそのすべてのデータを永続的に削除するには、ノードの使用を停止 する必要があります。
- 物理ハードウェアを電源を切っている場合は、ノードがクラスターに再度加わるように、そのハードウェアを再びオンに切り替えます。
9.9.3. 仮想マシンのフェイルオーバーの確認
すべてのリソースが正常でないノードで終了すると、移行した仮想マシンのそれぞれについて、新しい仮想マシンインスタンス (VMI) が正常なノードに自動的に作成されます。VMI が作成されていることを確認するには、oc CLI を使用してすべての VMI を表示します。
9.9.3.1. CLI を使用した仮想マシンインスタンスのリスト表示
oc コマンドラインインターフェイス (CLI) を使用して、スタンドアロンおよび仮想マシンによって所有されている VMI を含むすべての仮想マシンのリストを表示できます。
手順
以下のコマンドを実行して、すべての VMI のリストを表示します。
$ oc get vmis -A
9.10. QEMU ゲストエージェントの仮想マシンへのインストール
QEMU ゲストエージェント は、仮想マシンで実行され、仮想マシン、ユーザー、ファイルシステム、およびセカンダリーネットワークに関する情報をホストに渡すデーモンです。
9.10.1. QEMU ゲストエージェントの Linux 仮想マシンへのインストール
qemu-guest-agent は広く利用されており、Red Hat 仮想マシンでデフォルトで利用できます。このエージェントをインストールし、サービスを起動します。
仮想マシン (VM) に QEMU ゲストエージェントがインストールされ、実行されているかどうかを確認するには、AgentConnected が VM 仕様に表示されていることを確認します。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
手順
- コンソールのいずれか、SSH を使用して仮想マシンのコマンドラインにアクセスします。
QEMU ゲストエージェントを仮想マシンにインストールします。
$ yum install -y qemu-guest-agentサービスに永続性があることを確認し、これを起動します。
$ systemctl enable --now qemu-guest-agent
9.10.2. QEMU ゲストエージェントの Windows 仮想マシンへのインストール
Windows 仮想マシンの場合には、QEMU ゲストエージェントは VirtIO ドライバーに含まれます。既存または新規の Windows インストールにドライバーをインストールします。
仮想マシン (VM) に QEMU ゲストエージェントがインストールされ、実行されているかどうかを確認するには、AgentConnected が VM 仕様に表示されていることを確認します。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
9.10.2.1. VirtIO ドライバーの既存 Windows 仮想マシンへのインストール
VirtIO ドライバーを、割り当てられた SATA CD ドライブから既存の Windows 仮想マシンにインストールします。
この手順では、ドライバーを Windows に追加するための汎用的なアプローチを使用しています。このプロセスは Windows のバージョンごとに若干異なる可能性があります。特定のインストール手順については、お使いの Windows バージョンについてのインストールドキュメントを参照してください。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows ユーザーセッションにログインします。
Device Manager を開き、Other devices を拡張して、Unknown device をリスト表示します。
-
Device Propertiesを開いて、不明なデバイスを特定します。デバイスを右クリックし、Properties を選択します。 - Details タブをクリックし、Property リストで Hardware Ids を選択します。
- Hardware Ids の Value をサポートされる VirtIO ドライバーと比較します。
-
- デバイスを右クリックし、Update Driver Software を選択します。
- Browse my computer for driver software をクリックし、VirtIO ドライバーが置かれている割り当て済みの SATA CD ドライブの場所に移動します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- Next をクリックしてドライバーをインストールします。
- 必要なすべての VirtIO ドライバーに対してこのプロセスを繰り返します。
- ドライバーのインストール後に、Close をクリックしてウィンドウを閉じます。
- 仮想マシンを再起動してドライバーのインストールを完了します。
9.10.2.2. Windows インストール時の VirtIO ドライバーのインストール
Windows のインストール時に割り当てられた SATA CD ドライバーから VirtIO ドライバーをインストールします。
この手順では、Windows インストールの汎用的なアプローチを使用しますが、インストール方法は Windows のバージョンごとに異なる可能性があります。インストールする Windows のバージョンについてのドキュメントを参照してください。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows インストールプロセスを開始します。
- Advanced インストールを選択します。
-
ストレージの宛先は、ドライバーがロードされるまで認識されません。
Load driverをクリックします。 - ドライバーは SATA CD ドライブとして割り当てられます。OK をクリックし、CD ドライバーでロードするストレージドライバーを参照します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- 必要なすべてのドライバーについて直前の 2 つの手順を繰り返します。
- Windows インストールを完了します。
9.11. 仮想マシンの QEMU ゲストエージェント情報の表示
QEMU ゲストエージェントが仮想マシンで実行されている場合は、Web コンソールを使用して、仮想マシン、ユーザー、ファイルシステム、およびセカンダリーネットワークに関する情報を表示できます。
9.11.1. 前提条件
- 仮想マシンに QEMU ゲストエージェントを インストールします。
9.11.2. Web コンソールでの QEMU ゲストエージェント情報について
QEMU ゲストエージェントがインストールされると、VirtualMachine details ページの Overview タブおよび Details タブに、ホスト名、オペレーティングシステム、タイムゾーン、およびログインユーザーに関する情報が表示されます。
VirtualMachine details ページには、仮想マシンにインストールされているゲストオペレーティングシステムに関する情報が表示されます。Details タブには、ログインユーザーの情報が含まれる表が表示されます。Disks タブには、ファイルシステムの情報が含まれる表が表示されます。
QEMU ゲストエージェントがインストールされていないと、Overview タブおよび Details タブには、仮想マシンの作成時に指定したオペレーティングシステムについての情報が表示されます。
9.11.3. Web コンソールでの QEMU ゲストエージェント情報の表示
Web コンソールを使用して、QEMU ゲストエージェントによってホストに渡される仮想マシンの情報を表示できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシン名を選択して、VirtualMachine details ページを開きます。
- Details タブをクリックして、アクティブなユーザーを表示します。
- Disks タブをクリックして、ファイルシステムについての情報を表示します。
9.12. 仮想マシンでの config map、シークレット、およびサービスアカウントの管理
シークレット、config map、およびサービスアカウントを使用して設定データを仮想マシンに渡すことができます。たとえば、以下を実行できます。
- シークレットを仮想マシンに追加して認証情報を必要とするサービスに仮想マシンのアクセスを付与します。
- Pod または別のオブジェクトがデータを使用できるように、機密データではない設定データを config map に保存します。
- サービスアカウントをそのコンポーネントに関連付けることにより、コンポーネントが API サーバーにアクセスできるようにします。
OpenShift Virtualization はシークレット、設定マップ、およびサービスアカウントを仮想マシンディスクとして公開し、追加のオーバーヘッドなしにプラットフォーム全体でそれらを使用できるようにします。
9.12.1. シークレット、設定マップ、またはサービスアカウントの仮想マシンへの追加
OpenShift Container Platform Web コンソールを使用して、シークレット、設定マップ、またはサービスアカウントを仮想マシンに追加します。
これらのリソースは、ディスクとして仮想マシンに追加されます。他のディスクをマウントするように、シークレット、設定マップ、またはサービスアカウントをマウントします。
仮想マシンが実行中の場合、変更内容は仮想マシンが再起動されるまで反映されません。新規に追加されたリソースは、ページ上部の Pending Changes バナーの Environment および Disks タブの両方に保留中のリソースとしてマークされます。
前提条件
- 追加するシークレット、設定マップ、またはサービスアカウントは、ターゲット仮想マシンと同じ namespace に存在する必要がある。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Environment タブで、Add Config Map, Secret or Service Account をクリックします。
- Select a resource をクリックし、リストから resource を選択します。6 文字のシリアル番号が、選択したリソースについて自動的に生成されます。
- オプション: Reload をクリックして、環境を最後に保存した状態に戻します。
- Save をクリックします。
検証
- VirtualMachine details ページで、Disks タブをクリックし、シークレット、config map、またはサービスアカウントがディスクのリストに含まれていることを確認します。
- Actions → Restart をクリックして、仮想マシンを再起動します。
他のディスクをマウントするように、シークレット、設定マップ、またはサービスアカウントをマウントできるようになりました。
9.12.2. 仮想マシンからのシークレット、設定マップ、またはサービスアカウントの削除
OpenShift Container Platform Web コンソールを使用して、シークレット、設定マップ、またはサービスアカウントを仮想マシンから削除します。
前提条件
- 仮想マシンに割り当てられるシークレット、設定マップ、またはサービスアカウントが少なくとも 1 つ必要である。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Environment タブをクリックします。
-
リストで削除する項目を見つけ、項目の右上にある Remove
をクリックします。
- Save をクリックします。
Reload をクリックし、最後に保存された状態にフォームをリセットできます。
検証
- VirtualMachine details ページで、Disks タブをクリックします。
- 削除したシークレット、設定マップ、またはサービスアカウントがディスクの一覧に含まれていないことを確認します。
9.13. VirtIO ドライバーの既存の Windows 仮想マシンへのインストール
9.13.1. VirtIO ドライバーについて
VirtIO ドライバーは、Microsoft Windows 仮想マシンが OpenShift Virtualization で実行されるために必要な準仮想化デバイスドライバーです。サポートされるドライバーは、Red Hat Ecosystem Catalog の container-native-virtualization/virtio-win コンテナーディスクで利用できます。
container-native-virtualization/virtio-win コンテナーディスクは、ドライバーのインストールを有効にするために SATA CD ドライブとして仮想マシンに割り当てられる必要があります。仮想マシン上での Windows のインストール時に VirtIO ドライバーをインストールすることも、既存の Windows インストールに追加することもできます。
ドライバーのインストール後に、container-native-virtualization/virtio-win コンテナーディスクは仮想マシンから削除できます。
新しい Windows 仮想マシンに Virtio ドライバーをインストールする も参照してください。
9.13.2. Microsoft Windows 仮想マシンのサポートされる VirtIO ドライバー
| ドライバー名 | ハードウェア ID | 説明 |
|---|---|---|
| viostor |
VEN_1AF4&DEV_1001 | ブロックドライバー。Other devices グループの SCSI Controller として表示される場合があります。 |
| viorng |
VEN_1AF4&DEV_1005 | エントロピーソースドライバー。Other devices グループの PCI Device として表示される場合があります。 |
| NetKVM |
VEN_1AF4&DEV_1000 | ネットワークドライバー。Other devices グループの Ethernet Controller として表示される場合があります。VirtIO NIC が設定されている場合にのみ利用できます。 |
9.13.3. VirtIO ドライバーコンテナーディスクの仮想マシンへの追加
OpenShift Virtualization は、Red Hat Ecosystem Catalog で利用できる Microsoft Windows の VirtIO ドライバーをコンテナーディスクとして配布します。これらのドライバーを Windows 仮想マシンにインストールするには、仮想マシン設定ファイルで container-native-virtualization/virtio-win コンテナーディスクを SATA CD ドライブとして仮想マシンに割り当てます。
前提条件
-
container-native-virtualization/virtio-winコンテナーディスクを Red Hat Ecosystem Catalog からダウンロードすること。コンテナーディスクがクラスターにない場合は Red Hat レジストリーからダウンロードされるため、これは必須ではありません。
手順
container-native-virtualization/virtio-winコンテナーディスクをcdromディスクとして Windows 仮想マシン設定ファイルに追加します。コンテナーディスクは、クラスターにない場合はレジストリーからダウンロードされます。spec: domain: devices: disks: - name: virtiocontainerdisk bootOrder: 21 cdrom: bus: sata volumes: - containerDisk: image: container-native-virtualization/virtio-win name: virtiocontainerdisk- 1
- OpenShift Virtualization は、
VirtualMachine設定ファイルに定義される順序で仮想マシンディスクを起動します。container-native-virtualization/virtio-winコンテナーディスクの前に仮想マシンの他のディスクを定義するか、オプションのbootOrderパラメーターを使用して仮想マシンが正しいディスクから起動するようにできます。ディスクにbootOrderを指定する場合、これは設定のすべてのディスクに指定される必要があります。
ディスクは、仮想マシンが起動すると利用可能になります。
-
コンテナーディスクを実行中の仮想マシンに追加する場合、変更を有効にするために CLI で
oc apply -f <vm.yaml>を使用するか、仮想マシンを再起動します。 -
仮想マシンが実行されていない場合、
virtctl start <vm>を使用します。
-
コンテナーディスクを実行中の仮想マシンに追加する場合、変更を有効にするために CLI で
仮想マシンが起動したら、VirtIO ドライバーを割り当てられた SATA CD ドライブからインストールできます。
9.13.4. VirtIO ドライバーの既存 Windows 仮想マシンへのインストール
VirtIO ドライバーを、割り当てられた SATA CD ドライブから既存の Windows 仮想マシンにインストールします。
この手順では、ドライバーを Windows に追加するための汎用的なアプローチを使用しています。このプロセスは Windows のバージョンごとに若干異なる可能性があります。特定のインストール手順については、お使いの Windows バージョンについてのインストールドキュメントを参照してください。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows ユーザーセッションにログインします。
Device Manager を開き、Other devices を拡張して、Unknown device をリスト表示します。
-
Device Propertiesを開いて、不明なデバイスを特定します。デバイスを右クリックし、Properties を選択します。 - Details タブをクリックし、Property リストで Hardware Ids を選択します。
- Hardware Ids の Value をサポートされる VirtIO ドライバーと比較します。
-
- デバイスを右クリックし、Update Driver Software を選択します。
- Browse my computer for driver software をクリックし、VirtIO ドライバーが置かれている割り当て済みの SATA CD ドライブの場所に移動します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- Next をクリックしてドライバーをインストールします。
- 必要なすべての VirtIO ドライバーに対してこのプロセスを繰り返します。
- ドライバーのインストール後に、Close をクリックしてウィンドウを閉じます。
- 仮想マシンを再起動してドライバーのインストールを完了します。
9.13.5. 仮想マシンからの VirtIO コンテナーディスクの削除
必要なすべての VirtIO ドライバーを仮想マシンにインストールした後は、container-native-virtualization/virtio-win コンテナーディスクを仮想マシンに割り当てる必要はなくなります。container-native-virtualization/virtio-win コンテナーディスクを仮想マシン設定ファイルから削除します。
手順
設定ファイルを編集し、
diskおよびvolumeを削除します。$ oc edit vm <vm-name>spec: domain: devices: disks: - name: virtiocontainerdisk bootOrder: 2 cdrom: bus: sata volumes: - containerDisk: image: container-native-virtualization/virtio-win name: virtiocontainerdisk- 変更を有効にするために仮想マシンを再起動します。
9.14. VirtIO ドライバーの新規 Windows 仮想マシンへのインストール
9.14.1. 前提条件
- 仮想マシンからアクセスできる Windows インストールメディア (ISO のデータボリュームへのインポート および仮想マシンへの割り当てを実行)。
9.14.2. VirtIO ドライバーについて
VirtIO ドライバーは、Microsoft Windows 仮想マシンが OpenShift Virtualization で実行されるために必要な準仮想化デバイスドライバーです。サポートされるドライバーは、Red Hat Ecosystem Catalog の container-native-virtualization/virtio-win コンテナーディスクで利用できます。
container-native-virtualization/virtio-win コンテナーディスクは、ドライバーのインストールを有効にするために SATA CD ドライブとして仮想マシンに割り当てられる必要があります。仮想マシン上での Windows のインストール時に VirtIO ドライバーをインストールすることも、既存の Windows インストールに追加することもできます。
ドライバーのインストール後に、container-native-virtualization/virtio-win コンテナーディスクは仮想マシンから削除できます。
VirtIO ドライバーの既存の Windows 仮想マシンへのインストール も参照してください。
9.14.3. Microsoft Windows 仮想マシンのサポートされる VirtIO ドライバー
| ドライバー名 | ハードウェア ID | 説明 |
|---|---|---|
| viostor |
VEN_1AF4&DEV_1001 | ブロックドライバー。Other devices グループの SCSI Controller として表示される場合があります。 |
| viorng |
VEN_1AF4&DEV_1005 | エントロピーソースドライバー。Other devices グループの PCI Device として表示される場合があります。 |
| NetKVM |
VEN_1AF4&DEV_1000 | ネットワークドライバー。Other devices グループの Ethernet Controller として表示される場合があります。VirtIO NIC が設定されている場合にのみ利用できます。 |
9.14.4. VirtIO ドライバーコンテナーディスクの仮想マシンへの追加
OpenShift Virtualization は、Red Hat Ecosystem Catalog で利用できる Microsoft Windows の VirtIO ドライバーをコンテナーディスクとして配布します。これらのドライバーを Windows 仮想マシンにインストールするには、仮想マシン設定ファイルで container-native-virtualization/virtio-win コンテナーディスクを SATA CD ドライブとして仮想マシンに割り当てます。
前提条件
-
container-native-virtualization/virtio-winコンテナーディスクを Red Hat Ecosystem Catalog からダウンロードすること。コンテナーディスクがクラスターにない場合は Red Hat レジストリーからダウンロードされるため、これは必須ではありません。
手順
container-native-virtualization/virtio-winコンテナーディスクをcdromディスクとして Windows 仮想マシン設定ファイルに追加します。コンテナーディスクは、クラスターにない場合はレジストリーからダウンロードされます。spec: domain: devices: disks: - name: virtiocontainerdisk bootOrder: 21 cdrom: bus: sata volumes: - containerDisk: image: container-native-virtualization/virtio-win name: virtiocontainerdisk- 1
- OpenShift Virtualization は、
VirtualMachine設定ファイルに定義される順序で仮想マシンディスクを起動します。container-native-virtualization/virtio-winコンテナーディスクの前に仮想マシンの他のディスクを定義するか、オプションのbootOrderパラメーターを使用して仮想マシンが正しいディスクから起動するようにできます。ディスクにbootOrderを指定する場合、これは設定のすべてのディスクに指定される必要があります。
ディスクは、仮想マシンが起動すると利用可能になります。
-
コンテナーディスクを実行中の仮想マシンに追加する場合、変更を有効にするために CLI で
oc apply -f <vm.yaml>を使用するか、仮想マシンを再起動します。 -
仮想マシンが実行されていない場合、
virtctl start <vm>を使用します。
-
コンテナーディスクを実行中の仮想マシンに追加する場合、変更を有効にするために CLI で
仮想マシンが起動したら、VirtIO ドライバーを割り当てられた SATA CD ドライブからインストールできます。
9.14.5. Windows インストール時の VirtIO ドライバーのインストール
Windows のインストール時に割り当てられた SATA CD ドライバーから VirtIO ドライバーをインストールします。
この手順では、Windows インストールの汎用的なアプローチを使用しますが、インストール方法は Windows のバージョンごとに異なる可能性があります。インストールする Windows のバージョンについてのドキュメントを参照してください。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows インストールプロセスを開始します。
- Advanced インストールを選択します。
-
ストレージの宛先は、ドライバーがロードされるまで認識されません。
Load driverをクリックします。 - ドライバーは SATA CD ドライブとして割り当てられます。OK をクリックし、CD ドライバーでロードするストレージドライバーを参照します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- 必要なすべてのドライバーについて直前の 2 つの手順を繰り返します。
- Windows インストールを完了します。
9.14.6. 仮想マシンからの VirtIO コンテナーディスクの削除
必要なすべての VirtIO ドライバーを仮想マシンにインストールした後は、container-native-virtualization/virtio-win コンテナーディスクを仮想マシンに割り当てる必要はなくなります。container-native-virtualization/virtio-win コンテナーディスクを仮想マシン設定ファイルから削除します。
手順
設定ファイルを編集し、
diskおよびvolumeを削除します。$ oc edit vm <vm-name>spec: domain: devices: disks: - name: virtiocontainerdisk bootOrder: 2 cdrom: bus: sata volumes: - containerDisk: image: container-native-virtualization/virtio-win name: virtiocontainerdisk- 変更を有効にするために仮想マシンを再起動します。
9.15. 仮想 Trusted Platform Module デバイスの使用
VirtualMachine (VM) または VirtualMachineInstance (VMI) マニフェストを編集して、仮想 Trusted Platform Module (vTPM) デバイスを新規または既存の仮想マシンに追加します。
9.15.1. vTPM デバイスについて
仮想トラステッドプラットフォームモジュール (vTPM) デバイスは、物理トラステッドプラットフォームモジュール (TPM) ハードウェアチップのように機能します。
vTPM デバイスはどのオペレーティングシステムでも使用できますが、Windows 11 をインストールまたは起動するには TPM チップが必要です。vTPM デバイスを使用すると、Windows 11 イメージから作成された VM を物理 TPM チップなしで機能させることができます。
vTPM を有効にしないと、ノードに TPM デバイスがある場合でも、VM は TPM デバイスを認識しません。
また、vTPM デバイスは、物理ハードウェアなしでシークレットを一時的に保存することで、仮想マシンを保護します。ただし、永続的なシークレット ストレージに vTPM を使用することは現在サポートされていません。vTPM は、VM のシャットダウン後に保存されたシークレットを破棄します。
9.15.2. 仮想マシンへの vTPM デバイスの追加
仮想トラステッドプラットフォームモジュール (vTPM) デバイスを仮想マシン (VM) に追加すると、物理 TPM デバイスなしで Windows 11 イメージから作成された仮想マシンを実行できます。vTPM デバイスは、その仮想マシンのシークレットも一時的に保存します。
手順
次のコマンドを実行して、仮想マシン設定を更新します。
$ oc edit vm <vm_name>tpm: {}行が含まれるように仮想マシンspecを編集します。以下に例を示します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm spec: template: spec: domain: devices: tpm: {}1 ...- 1
- TPM デバイスを仮想マシンに追加します。
- 変更を適用するには、エディターを保存し、終了します。
- オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
9.16. 高度な仮想マシン管理
9.16.1. 仮想マシンのリソースクォータの使用
仮想マシンのリソースクォータの作成および管理
9.16.1.1. 仮想マシンのリソースクォータ制限の設定
リクエストのみを使用するリソースクォータは、仮想マシン (VM) で自動的に機能します。リソースクォータで制限を使用する場合は、VM に手動でリソース制限を設定する必要があります。リソース制限は、リソース要求より少なくとも 100 MiB 大きくする必要があります。
手順
VirtualMachineマニフェストを編集して、VM の制限を設定します。以下に例を示します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: with-limits spec: running: false template: spec: domain: # ... resources: requests: memory: 128Mi limits: memory: 256Mi1 - 1
- この設定がサポートされるのは、
limits.memory値がrequests.memory値より少なくとも100Mi大きいためです。
-
VirtualMachineマニフェストを保存します。
9.16.2. 仮想マシンのノードの指定
ノードの配置ルールを使用して、仮想マシン (VM) を特定のノードに配置することができます。
9.16.2.1. 仮想マシンのノード配置について
仮想マシン (VM) が適切なノードで実行されるようにするには、ノードの配置ルールを設定できます。以下の場合にこれを行うことができます。
- 仮想マシンが複数ある。フォールトトレランスを確保するために、これらを異なるノードで実行する必要がある。
- 2 つの相互間のネットワークトラフィックの多い chatty VM がある。冗長なノード間のルーティングを回避するには、仮想マシンを同じノードで実行します。
- 仮想マシンには、利用可能なすべてのノードにない特定のハードウェア機能が必要です。
- 機能をノードに追加する Pod があり、それらの機能を使用できるように仮想マシンをそのノードに配置する必要があります。
仮想マシンの配置は、ワークロードの既存のノードの配置ルールに基づきます。ワークロードがコンポーネントレベルの特定のノードから除外される場合、仮想マシンはそれらのノードに配置できません。
以下のルールタイプは、VirtualMachine マニフェストの spec フィールドで使用できます。
nodeSelector- 仮想マシンは、キーと値のペアまたはこのフィールドで指定したペアを使用してラベルが付けられたノードに Pod をスケジュールできます。ノードには、リスト表示されたすべてのペアに一致するラベルがなければなりません。
affinityより表現的な構文を使用して、ノードと仮想マシンに一致するルールを設定できます。たとえば、ルールがハード要件ではなく基本設定になるように指定し、ルールの条件が満たされない場合も仮想マシンがスケジュールされるようにすることができます。Pod のアフィニティー、Pod の非アフィニティー、およびノードのアフィニティーは仮想マシンの配置でサポートされます。Pod のアフィニティーは仮想マシンに対して動作します。
VirtualMachineワークロードタイプはPodオブジェクトに基づくためです。注記アフィニティールールは、スケジューリング時にのみ適用されます。OpenShift Container Platform は、制約を満たさなくなった場合に実行中のワークロードを再スケジューリングしません。
tolerations- 一致するテイントを持つノードで仮想マシンをスケジュールできます。テイントがノードに適用される場合、そのノードはテイントを容認する仮想マシンのみを受け入れます。
9.16.2.2. ノード配置の例
以下の YAML スニペットの例では、nodePlacement、affinity、および tolerations フィールドを使用して仮想マシンのノード配置をカスタマイズします。
9.16.2.2.1. 例: nodeSelector を使用した仮想マシンノードの配置
この例では、仮想マシンに example-key-1 = example-value-1 および example-key-2 = example-value-2 ラベルの両方が含まれるメタデータのあるノードが必要です。
この説明に該当するノードがない場合、仮想マシンはスケジュールされません。
仮想マシンマニフェストの例
metadata:
name: example-vm-node-selector
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
template:
spec:
nodeSelector:
example-key-1: example-value-1
example-key-2: example-value-2
...9.16.2.2.2. 例: Pod のアフィニティーおよび Pod の非アフィニティーによる仮想マシンノードの配置
この例では、仮想マシンはラベル example-key-1 = example-value-1 を持つ実行中の Pod のあるノードでスケジュールされる必要があります。このようなノードで実行中の Pod がない場合、仮想マシンはスケジュールされません。
可能な場合に限り、仮想マシンはラベル example-key-2 = example-value-2 を持つ Pod のあるノードではスケジュールされません。ただし、すべての候補となるノードにこのラベルを持つ Pod がある場合、スケジューラーはこの制約を無視します。
仮想マシンマニフェストの例
metadata:
name: example-vm-pod-affinity
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: example-key-1
operator: In
values:
- example-value-1
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: example-key-2
operator: In
values:
- example-value-2
topologyKey: kubernetes.io/hostname
...9.16.2.2.3. 例: ノードのアフィニティーによる仮想マシンノードの配置
この例では、仮想マシンはラベル example.io/example-key = example-value-1 またはラベル example.io/example-key = example-value-2 を持つノードでスケジュールされる必要があります。この制約は、ラベルのいずれかがノードに存在する場合に満たされます。いずれのラベルも存在しない場合、仮想マシンはスケジュールされません。
可能な場合、スケジューラーはラベル example-node-label-key = example-node-label-value を持つノードを回避します。ただし、すべての候補となるノードにこのラベルがある場合、スケジューラーはこの制約を無視します。
仮想マシンマニフェストの例
metadata:
name: example-vm-node-affinity
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: example.io/example-key
operator: In
values:
- example-value-1
- example-value-2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: example-node-label-key
operator: In
values:
- example-node-label-value
...9.16.2.2.4. 例: 容認 (toleration) を使用した仮想マシンノードの配置
この例では、仮想マシン用に予約されるノードには、すでに key=virtualization:NoSchedule テイントのラベルが付けられています。この仮想マシンには一致する tolerations があるため、これをテイントが付けられたノードにスケジュールできます。
テイントを容認する仮想マシンは、そのテイントを持つノードにスケジュールする必要はありません。
仮想マシンマニフェストの例
metadata:
name: example-vm-tolerations
apiVersion: kubevirt.io/v1
kind: VirtualMachine
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "virtualization"
effect: "NoSchedule"
...9.16.3. 証明書ローテーションの設定
証明書ローテーションパラメーターを設定して、既存の証明書を置き換えます。
9.16.3.1. 証明書ローテーションの設定
これは、Web コンソールでの OpenShift Virtualization のインストール時に、または HyperConverged カスタムリソース (CR) でインストール後に実行することができます。
手順
以下のコマンドを実行して
HyperConvergedCR を開きます。$ oc edit hco -n openshift-cnv kubevirt-hyperconverged以下の例のように
spec.certConfigフィールドを編集します。システムのオーバーロードを避けるには、すべての値が 10 分以上であることを確認します。golangParseDuration形式 に準拠する文字列として、すべての値を表現します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: certConfig: ca: duration: 48h0m0s renewBefore: 24h0m0s1 server: duration: 24h0m0s2 renewBefore: 12h0m0s3 - YAML ファイルをクラスターに適用します。
9.16.3.2. 証明書ローテーションパラメーターのトラブルシューティング
1 つ以上の certConfig 値を削除すると、デフォルト値が以下のいずれかの条件と競合する場合を除き、デフォルト値に戻ります。
-
ca.renewBeforeの値はca.durationの値以下である必要があります。 -
server.durationの値はca.durationの値以下である必要があります。 -
server.renewBeforeの値はserver.durationの値以下である必要があります。
デフォルト値がこれらの条件と競合すると、エラーが発生します。
以下の例で server.duration 値を削除すると、デフォルト値の 24h0m0s は ca.duration の値よりも大きくなり、指定された条件と競合します。
例
certConfig:
ca:
duration: 4h0m0s
renewBefore: 1h0m0s
server:
duration: 4h0m0s
renewBefore: 4h0m0sこれにより、以下のエラーメッセージが表示されます。
error: hyperconvergeds.hco.kubevirt.io "kubevirt-hyperconverged" could not be patched: admission webhook "validate-hco.kubevirt.io" denied the request: spec.certConfig: ca.duration is smaller than server.durationエラーメッセージには、最初の競合のみが記載されます。続行する前に、すべての certConfig の値を確認します。
9.16.4. 仮想マシンに UEFI モードを使用する
Unified Extensible Firmware Interface (UEFI) モードで仮想マシン (VM) を起動できます。
9.16.4.1. 仮想マシンの UEFI モードについて
レガシー BIOS などの Unified Extensible Firmware Interface (UEFI) は、コンピューターの起動時にハードウェアコンポーネントやオペレーティングシステムのイメージファイルを初期化します。UEFI は BIOS よりも最新の機能とカスタマイズオプションをサポートするため、起動時間を短縮できます。
これは、.efi 拡張子を持つファイルに初期化と起動に関する情報をすべて保存します。このファイルは、EFI System Partition (ESP) と呼ばれる特別なパーティションに保管されます。ESP には、コンピューターにインストールされるオペレーティングシステムのブートローダープログラムも含まれます。
9.16.4.2. UEFI モードでの仮想マシンの起動
VirtualMachine マニフェストを編集して、UEFI モードで起動するように仮想マシンを設定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineマニフェストファイルを編集または作成します。spec.firmware.bootloaderスタンザを使用して、UEFI モードを設定します。セキュアブートがアクティブな状態の UEFI モードでのブート
apiversion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: special: vm-secureboot name: vm-secureboot spec: template: metadata: labels: special: vm-secureboot spec: domain: devices: disks: - disk: bus: virtio name: containerdisk features: acpi: {} smm: enabled: true1 firmware: bootloader: efi: secureBoot: true2 ...以下のコマンドを実行して、マニフェストをクラスターに適用します。
$ oc create -f <file_name>.yaml
9.16.5. 仮想マシンの PXE ブートの設定
PXE ブートまたはネットワークブートは OpenShift Virtualization で利用できます。ネットワークブートにより、ローカルに割り当てられたストレージデバイスなしにコンピューターを起動し、オペレーティングシステムまたは他のプログラムを起動し、ロードすることができます。たとえば、これにより、新規ホストのデプロイ時に PXE サーバーから必要な OS イメージを選択できます。
9.16.5.1. 前提条件
- Linux ブリッジが 接続されていること。
- PXE サーバーがブリッジとして同じ VLAN に接続されていること。
9.16.5.2. MAC アドレスを指定した PXE ブート
まず、管理者は PXE ネットワークの NetworkAttachmentDefinition オブジェクトを作成し、ネットワーク経由でクライアントを起動できます。次に、仮想マシンインスタンスの設定ファイルでネットワーク接続定義を参照して仮想マシンインスタンスを起動します。また PXE サーバーで必要な場合には、仮想マシンインスタンスの設定ファイルで MAC アドレスを指定することもできます。
前提条件
- Linux ブリッジが接続されていること。
- PXE サーバーがブリッジとして同じ VLAN に接続されていること。
手順
クラスターに PXE ネットワークを設定します。
PXE ネットワーク
pxe-net-confのネットワーク接続定義ファイルを作成します。apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: pxe-net-conf spec: config: '{ "cniVersion": "0.3.1", "name": "pxe-net-conf", "plugins": [ { "type": "cnv-bridge", "bridge": "br1", "vlan": 11 }, { "type": "cnv-tuning"2 } ] }'注記仮想マシンインスタンスは、必要な VLAN のアクセスポートでブリッジ
br1に割り当てられます。
直前の手順で作成したファイルを使用してネットワーク接続定義を作成します。
$ oc create -f pxe-net-conf.yaml仮想マシンインスタンス設定ファイルを、インターフェイスおよびネットワークの詳細を含めるように編集します。
PXE サーバーで必要な場合には、ネットワークおよび MAC アドレスを指定します。MAC アドレスが指定されていない場合、値は自動的に割り当てられます。
bootOrderが1に設定されており、インターフェイスが最初に起動することを確認します。この例では、インターフェイスは<pxe-net>というネットワークに接続されています。interfaces: - masquerade: {} name: default - bridge: {} name: pxe-net macAddress: de:00:00:00:00:de bootOrder: 1注記複数のインターフェイスおよびディスクのブートの順序はグローバル順序になります。
オペレーティングシステムのプロビジョニング後に起動が適切に実行されるよう、ブートデバイス番号をディスクに割り当てます。
ディスク
bootOrderの値を2に設定します。devices: disks: - disk: bus: virtio name: containerdisk bootOrder: 2直前に作成されたネットワーク接続定義に接続されるネットワークを指定します。このシナリオでは、
<pxe-net>は<pxe-net-conf>というネットワーク接続定義に接続されます。networks: - name: default pod: {} - name: pxe-net multus: networkName: pxe-net-conf
仮想マシンインスタンスを作成します。
$ oc create -f vmi-pxe-boot.yaml
出力例
virtualmachineinstance.kubevirt.io "vmi-pxe-boot" created仮想マシンインスタンスの実行を待機します。
$ oc get vmi vmi-pxe-boot -o yaml | grep -i phase phase: RunningVNC を使用して仮想マシンインスタンスを表示します。
$ virtctl vnc vmi-pxe-boot- ブート画面で、PXE ブートが正常に実行されていることを確認します。
仮想マシンインスタンスにログインします。
$ virtctl console vmi-pxe-boot仮想マシンのインターフェイスおよび MAC アドレスを確認し、ブリッジに接続されたインターフェイスに MAC アドレスが指定されていることを確認します。この場合、PXE ブートには IP アドレスなしに
eth1を使用しています。他のインターフェイスeth0は OpenShift Container Platform から IP アドレスを取得しています。$ ip addr
出力例
...
3. eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether de:00:00:00:00:de brd ff:ff:ff:ff:ff:ff9.16.5.3. OpenShift Virtualization ネットワークの用語集
OpenShift Virtualization は、カスタムリソースおよびプラグインを使用して高度なネットワーク機能を提供します。
以下の用語は、OpenShift Virtualization ドキュメント全体で使用されています。
- Container Network Interface (CNI)
- コンテナーのネットワーク接続に重点を置く Cloud Native Computing Foundation プロジェクト。OpenShift Virtualization は CNI プラグインを使用して基本的な Kubernetes ネットワーク機能を強化します。
- Multus
- 複数の CNI の存在を可能にし、Pod または仮想マシンが必要なインターフェイスを使用できるようにするメタ CNI プラグイン。
- カスタムリソース定義 (CRD、Custom Resource Definition)
- カスタムリソースの定義を可能にする Kubernetes API リソース、または CRD API リソースを使用して定義されるオブジェクト。
- ネットワーク接続定義 (NAD)
- Pod、仮想マシン、および仮想マシンインスタンスを 1 つ以上のネットワークに割り当てることを可能にする Multus プロジェクトによって導入される CRD。
- ノードネットワーク設定ポリシー (NNCP)
-
ノードで要求されるネットワーク設定の説明。
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用して、インターフェイスの追加および削除など、ノードネットワーク設定を更新します。 - PXE (Preboot eXecution Environment)
- 管理者がネットワーク経由でサーバーからクライアントマシンを起動できるようにするインターフェイス。ネットワークのブートにより、オペレーティングシステムおよび他のソフトウェアをクライアントにリモートでロードできます。
9.16.6. 仮想マシンでの Huge Page の使用
Huge Page は、クラスター内の仮想マシンのバッキングメモリーとして使用できます。
9.16.6.1. 前提条件
9.16.6.2. Huge Page の機能
メモリーは Page と呼ばれるブロックで管理されます。多くのシステムでは、1 ページは 4Ki です。メモリー 1Mi は 256 ページに、メモリー 1Gi は 256,000 ページに相当します。CPU には、内蔵のメモリー管理ユニットがあり、ハードウェアでこのようなページリストを管理します。トランスレーションルックアサイドバッファー (TLB: Translation Lookaside Buffer) は、仮想から物理へのページマッピングの小規模なハードウェアキャッシュのことです。ハードウェアの指示で渡された仮想アドレスが TLB にあれば、マッピングをすばやく決定できます。そうでない場合には、TLB ミスが発生し、システムは速度が遅く、ソフトウェアベースのアドレス変換にフォールバックされ、パフォーマンスの問題が発生します。TLB のサイズは固定されているので、TLB ミスの発生率を減らすには Page サイズを大きくする必要があります。
Huge Page とは、4Ki より大きいメモリーページのことです。x86_64 アーキテクチャーでは、2Mi と 1Gi の 2 つが一般的な Huge Page サイズです。別のアーキテクチャーではサイズは異なります。Huge Page を使用するには、アプリケーションが認識できるようにコードを書き込む必要があります。Transparent Huge Pages (THP) は、アプリケーションによる認識なしに、Huge Page の管理を自動化しようとしますが、制約があります。特に、ページサイズは 2Mi に制限されます。THP では、THP のデフラグが原因で、メモリー使用率が高くなり、断片化が起こり、パフォーマンスの低下につながり、メモリーページがロックされてしまう可能性があります。このような理由から、アプリケーションは THP ではなく、事前割り当て済みの Huge Page を使用するように設計 (また推奨) される場合があります。
OpenShift Virtualization では、事前に割り当てられた Huge Page を使用できるように仮想マシンを設定できます。
9.16.6.3. 仮想マシンの Huge Page の設定
memory.hugepages.pageSize および resources.requests.memory パラメーターを仮想マシン設定に組み込み、仮想マシンを事前に割り当てられた Huge Page を使用するように設定できます。
メモリー要求はページサイズ別に分ける必要があります。たとえば、ページサイズ 1Gi の場合に 500Mi メモリーを要求することはできません。
ホストおよびゲスト OS のメモリーレイアウトには関連性がありません。仮想マシンマニフェストで要求される Huge Page が QEMU に適用されます。ゲスト内の Huge Page は、仮想マシンインスタンスの利用可能なメモリー量に基づいてのみ設定できます。
実行中の仮想マシンを編集する場合は、変更を有効にするために仮想マシンを再起動する必要があります。
前提条件
- ノードには、事前に割り当てられた Huge Page が設定されている必要がある。
手順
仮想マシン設定で、
resources.requests.memoryおよびmemory.hugepages.pageSizeパラメーターをspec.domainに追加します。以下の設定スニペットは、ページサイズが1Giの合計4Giメモリーを要求する仮想マシンについてのものです。kind: VirtualMachine ... spec: domain: resources: requests: memory: "4Gi"1 memory: hugepages: pageSize: "1Gi"2 ...仮想マシン設定を適用します。
$ oc apply -f <virtual_machine>.yaml
9.16.7. 仮想マシン用の専用リソースの有効化
パフォーマンスを向上させるために、CPU などのノードリソースを仮想マシン専用に確保できます。
9.16.7.1. 専用リソースについて
仮想マシンの専用リソースを有効にする場合、仮想マシンのワークロードは他のプロセスで使用されない CPU でスケジュールされます。専用リソースを使用することで、仮想マシンのパフォーマンスとレイテンシーの予測の精度を向上させることができます。
9.16.7.2. 前提条件
-
CPU マネージャー がノード上に設定されている。仮想マシンのワークロードをスケジュールする前に、ノードに
cpumanager = trueラベルが設定されていることを確認する。 - 仮想マシンの電源がオフになっている。
9.16.7.3. 仮想マシンの専用リソースの有効化
Details タブで、仮想マシンの専用リソースを有効にすることができます。Red Hat テンプレートから作成された仮想マシンは、専用のリソースで設定できます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Scheduling タブで、Dedicated Resources の横にある鉛筆アイコンをクリックします。
- Schedule this workload with dedicated resources (guaranteed policy) を選択します。
- Save をクリックします。
9.16.8. 仮想マシンのスケジュール
仮想マシンの CPU モデルとポリシー属性が、ノードがサポートする CPU モデルおよびポリシー属性との互換性について一致することを確認して、ノードで仮想マシン (VM) をスケジュールできます。
9.16.8.1. ポリシー属性
仮想マシン (VM) をスケジュールするには、ポリシー属性と、仮想マシンがノードでスケジュールされる際の互換性について一致する CPU 機能を指定します。仮想マシンに指定されるポリシー属性は、その仮想マシンをノードにスケジュールする方法を決定します。
| ポリシー属性 | 説明 |
|---|---|
| force | 仮想マシンは強制的にノードでスケジュールされます。これは、ホストの CPU が仮想マシンの CPU に対応していない場合でも該当します。 |
| require | 仮想マシンが特定の CPU モデルおよび機能仕様で設定されていない場合に仮想マシンに適用されるデフォルトのポリシー。このデフォルトポリシー属性または他のポリシー属性のいずれかを持つ CPU ノードの検出をサポートするようにノードが設定されていない場合、仮想マシンはそのノードでスケジュールされません。ホストの CPU が仮想マシンの CPU をサポートしているか、ハイパーバイザーが対応している CPU モデルをエミュレートできる必要があります。 |
| optional | 仮想マシンがホストの物理マシンの CPU でサポートされている場合は、仮想マシンがノードに追加されます。 |
| disable | 仮想マシンは CPU ノードの検出機能と共にスケジュールすることはできません。 |
| forbid | この機能がホストの CPU でサポートされ、CPU ノード検出が有効になっている場合でも、仮想マシンはスケジュールされません。 |
9.16.8.2. ポリシー属性および CPU 機能の設定
それぞれの仮想マシン (VM) にポリシー属性および CPU 機能を設定して、これがポリシーおよび機能に従ってノードでスケジュールされるようにすることができます。設定する CPU 機能は、ホストの CPU によってサポートされ、またはハイパーバイザーがエミュレートされることを確認するために検証されます。
9.16.8.3. サポートされている CPU モデルでの仮想マシンのスケジューリング
仮想マシン (VM) の CPU モデルを設定して、CPU モデルがサポートされるノードにこれをスケジュールできます。
手順
仮想マシン設定ファイルの
domain仕様を編集します。以下の例は、VM 向けに定義された特定の CPU モデルを示しています。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: myvm spec: template: spec: domain: cpu: model: Conroe1 - 1
- VM の CPU モデル。
9.16.8.4. ホストモデルでの仮想マシンのスケジューリング
仮想マシン (VM) の CPU モデルが host-model に設定されている場合、仮想マシンはスケジュールされているノードの CPU モデルを継承します。
手順
仮想マシン設定ファイルの
domain仕様を編集します。以下の例は、仮想マシン (VM) に指定されるhost-modelを示しています。apiVersion: kubevirt/v1alpha3 kind: VirtualMachine metadata: name: myvm spec: template: spec: domain: cpu: model: host-model1 - 1
- スケジュールされるノードの CPU モデルを継承する仮想マシン。
9.16.9. PCI パススルーの設定
PCI (Peripheral Component Interconnect) パススルー機能を使用すると、仮想マシンからハードウェアデバイスにアクセスし、管理できます。PCI パススルーが設定されると、PCI デバイスはゲストオペレーティングシステムに物理的に接続されているかのように機能します。
クラスター管理者は、oc コマンドラインインターフェイス (CLI) を使用して、クラスターでの使用が許可されているホストデバイスを公開および管理できます。
9.16.9.1. PCI パススルー用ホストデバイスの準備について
CLI を使用して PCI パススルー用にホストデバイスを準備するには、MachineConfig オブジェクトを作成し、カーネル引数を追加して、Input-Output Memory Management Unit (IOMMU) を有効にします。PCI デバイスを Virtual Function I/O (VFIO) ドライバーにバインドしてから、HyperConverged カスタムリソース (CR) の permittedHostDevices フィールドを編集してクラスター内で公開します。OpenShift Virtualization Operator を最初にインストールする場合、permittedHostDevices のリストは空になります。
CLI を使用してクラスターから PCI ホストデバイスを削除するには、HyperConverged CR から PCI デバイス情報を削除します。
9.16.9.1.1. IOMMU ドライバーを有効にするためのカーネル引数の追加
カーネルの IOMMU (Input-Output Memory Management Unit) ドライバーを有効にするには、MachineConfig オブジェクトを作成し、カーネル引数を追加します。
前提条件
- 作業用の OpenShift Container Platform クラスターに対する管理者権限が必要です。
- Intel または AMD CPU ハードウェア。
- Intel Virtualization Technology for Directed I/O 拡張または BIOS (Basic Input/Output System) の AMD IOMMU が有効にされている。
手順
カーネル引数を識別する
MachineConfigオブジェクトを作成します。以下の例は、Intel CPU のカーネル引数を示しています。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: 100-worker-iommu2 spec: config: ignition: version: 3.2.0 kernelArguments: - intel_iommu=on3 ...新規
MachineConfigオブジェクトを作成します。$ oc create -f 100-worker-kernel-arg-iommu.yaml
検証
新規
MachineConfigオブジェクトが追加されていることを確認します。$ oc get MachineConfig
9.16.9.1.2. PCI デバイスの VFIO ドライバーへのバインディング
PCI デバイスを VFIO (Virtual Function I/O) ドライバーにバインドするには、各デバイスから vendor-ID および device-ID の値を取得し、これらの値でリストを作成します。リストを MachineConfig オブジェクトに追加します。MachineConfig Operator は、PCI デバイスを持つノードで /etc/modprobe.d/vfio.conf を生成し、PCI デバイスを VFIO ドライバーにバインドします。
前提条件
- カーネル引数を CPU の IOMMU を有効にするために追加している。
手順
lspciコマンドを実行して、PCI デバイスのvendor-IDおよびdevice-IDを取得します。$ lspci -nnv | grep -i nvidia出力例
02:01.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] [10de:1eb8] (rev a1)Butane 設定ファイル
100-worker-vfiopci.buを作成し、PCI デバイスを VFIO ドライバーにバインドします。注記Butane の詳細は、Butane を使用したマシン設定の作成を参照してください。
例
variant: openshift version: 4.11.0 metadata: name: 100-worker-vfiopci labels: machineconfiguration.openshift.io/role: worker1 storage: files: - path: /etc/modprobe.d/vfio.conf mode: 0644 overwrite: true contents: inline: | options vfio-pci ids=10de:1eb82 - path: /etc/modules-load.d/vfio-pci.conf3 mode: 0644 overwrite: true contents: inline: vfio-pciButane を使用して、ワーカーノードに配信される設定を含む
MachineConfigオブジェクトファイル (100-worker-vfiopci.yaml) を生成します。$ butane 100-worker-vfiopci.bu -o 100-worker-vfiopci.yamlMachineConfigオブジェクトをワーカーノードに適用します。$ oc apply -f 100-worker-vfiopci.yamlMachineConfigオブジェクトが追加されていることを確認します。$ oc get MachineConfig出力例
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 00-worker d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-master-container-runtime d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-master-kubelet d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-worker-container-runtime d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 01-worker-kubelet d3da910bfa9f4b599af4ed7f5ac270d55950a3a1 3.2.0 25h 100-worker-iommu 3.2.0 30s 100-worker-vfiopci-configuration 3.2.0 30s
検証
VFIO ドライバーがロードされていることを確認します。
$ lspci -nnk -d 10de:この出力では、VFIO ドライバーが使用されていることを確認します。
出力例
04:00.0 3D controller [0302]: NVIDIA Corporation GP102GL [Tesla P40] [10de:1eb8] (rev a1) Subsystem: NVIDIA Corporation Device [10de:1eb8] Kernel driver in use: vfio-pci Kernel modules: nouveau
9.16.9.1.3. CLI を使用したクラスターでの PCI ホストデバイスの公開
クラスターで PCI ホストデバイスを公開するには、PCI デバイスの詳細を HyperConverged カスタムリソース (CR) の spec.permittedHostDevices.pciHostDevices 配列に追加します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvPCI デバイス情報を
spec.permittedHostDevices.pciHostDevices配列に追加します。以下に例を示します。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: permittedHostDevices:1 pciHostDevices:2 - pciDeviceSelector: "10DE:1DB6"3 resourceName: "nvidia.com/GV100GL_Tesla_V100"4 - pciDeviceSelector: "10DE:1EB8" resourceName: "nvidia.com/TU104GL_Tesla_T4" - pciDeviceSelector: "8086:6F54" resourceName: "intel.com/qat" externalResourceProvider: true5 ...注記上記のスニペットの例は、
nvidia.com/GV100GL_Tesla_V100およびnvidia.com/TU104GL_Tesla_T4という名前の 2 つの PCI ホストデバイスが、HyperConvergedCR の許可されたホストデバイスの一覧に追加されたことを示しています。これらのデバイスは、OpenShift Virtualization と動作することがテストおよび検証されています。- 変更を保存し、エディターを終了します。
検証
以下のコマンドを実行して、PCI ホストデバイスがノードに追加されたことを確認します。この出力例は、各デバイスが
nvidia.com/GV100GL_Tesla_V100、nvidia.com/TU104GL_Tesla_T4、およびintel.com/qatのリソース名にそれぞれ関連付けられたデバイスが 1 つあることを示しています。$ oc describe node <node_name>出力例
Capacity: cpu: 64 devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 915128Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 131395264Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 1 pods: 250 Allocatable: cpu: 63500m devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 863623130526 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 130244288Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 1 pods: 250
9.16.9.1.4. CLI を使用したクラスターからの PCI ホストデバイスの削除
クラスターから PCI ホストデバイスを削除するには、HyperConverged カスタムリソース (CR) からそのデバイスの情報を削除します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv適切なデバイスの
pciDeviceSelector、resourceName、およびexternalResourceProvider(該当する場合) のフィールドを削除して、spec.permittedHostDevices.pciHostDevices配列から PCI デバイス情報を削除します。この例では、intel.com/qatリソースが削除されました。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: permittedHostDevices: pciHostDevices: - pciDeviceSelector: "10DE:1DB6" resourceName: "nvidia.com/GV100GL_Tesla_V100" - pciDeviceSelector: "10DE:1EB8" resourceName: "nvidia.com/TU104GL_Tesla_T4" ...- 変更を保存し、エディターを終了します。
検証
以下のコマンドを実行して、PCI ホストデバイスがノードから削除されたことを確認します。この出力例は、
intel.com/qatリソース名に関連付けられているデバイスがゼロであることを示しています。$ oc describe node <node_name>出力例
Capacity: cpu: 64 devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 915128Mi hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 131395264Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 0 pods: 250 Allocatable: cpu: 63500m devices.kubevirt.io/kvm: 110 devices.kubevirt.io/tun: 110 devices.kubevirt.io/vhost-net: 110 ephemeral-storage: 863623130526 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 130244288Ki nvidia.com/GV100GL_Tesla_V100 1 nvidia.com/TU104GL_Tesla_T4 1 intel.com/qat: 0 pods: 250
9.16.9.2. PCI パススルー用の仮想マシンの設定
PCI デバイスがクラスターに追加された後に、それらを仮想マシンに割り当てることができます。PCI デバイスが仮想マシンに物理的に接続されているかのような状態で利用できるようになりました。
9.16.9.2.1. PCI デバイスの仮想マシンへの割り当て
PCI デバイスがクラスターで利用可能な場合、これを仮想マシンに割り当て、PCI パススルーを有効にすることができます。
手順
PCI デバイスをホストデバイスとして仮想マシンに割り当てます。
例
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: domain: devices: hostDevices: - deviceName: nvidia.com/TU104GL_Tesla_T41 name: hostdevices1- 1
- クラスターでホストデバイスとして許可される PCI デバイスの名前。仮想マシンがこのホストデバイスにアクセスできます。
検証
以下のコマンドを使用して、ホストデバイスが仮想マシンから利用可能であることを確認します。
$ lspci -nnk | grep NVIDIA出力例
$ 02:01.0 3D controller [0302]: NVIDIA Corporation GV100GL [Tesla V100 PCIe 32GB] [10de:1eb8] (rev a1)
9.16.10. 仮想 GPU パススルーの設定
仮想マシンは仮想 GPU (vGPU) ハードウェアにアクセスできます。仮想マシンに仮想 GPU を割り当てると、次のことが可能になります。
- 基盤となるハードウェアの GPU の一部にアクセスして、仮想マシンで高いパフォーマンスのメリットを実現する。
- リソースを大量に消費する I/O 操作を合理化する。
仮想 GPU パススルーは、ベアメタル環境で実行されているクラスターに接続されているデバイスにのみ割り当てることができます。
9.16.10.1. 仮想マシンへの vGPU パススルーデバイスの割り当て
Open Shift Container Platform Web コンソールを使用して、vGPU パススルーデバイスを仮想マシンに割り当てます。
前提条件
- 仮想マシンを停止する必要があります。
手順
- Open Shift Container Platform Web コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- デバイスを割り当てる仮想マシンを選択します。
Details タブで、GPU devices をクリックします。
vGPU デバイスをホストデバイスとして追加すると、VNC コンソールでデバイスにアクセスすることはできません。
- Add GPU device をクリックし、Name を入力して、Device name リストからデバイスを選択します。
- Save をクリックします。
-
YAMLタブをクリックして、クラスター設定の
hostDevicesセクションに新しいデバイスが追加されていることを確認します。
カスタマイズされたテンプレートまたは YAML ファイルから作成された仮想マシンに、ハードウェアデバイスを追加できます。Windows 10 や RHEL 7 などの特定のオペレーティングシステム用に事前に提供されているブートソーステンプレートにデバイスを追加することはできません。
クラスターに接続されているリソースを表示するには、サイドメニューから Compute → Hardware Devices をクリックします。
9.16.11. 仲介デバイスの設定
HyperConvergedカスタムリソース (CR) でデバイスのリストを提供すると、Open Shift Virtualization は仮想 GPU (vGPU) などの仲介デバイスを自動的に作成します。
仲介デバイスの宣言型設定は、テクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
9.16.11.1. NVIDIA GPU Operator の使用について
NVIDIA GPU Operator は、OpenShift Container Platform クラスターで NVIDIA GPU リソースを管理し、GPU ノードのブートストラップに関連するタスクを自動化します。GPU はクラスター内の特別なリソースであるため、アプリケーションワークロードを GPU にデプロイする前に、いくつかのコンポーネントをインストールする必要があります。これらのコンポーネントには、コンピューティングユニファイドデバイスアーキテクチャー (CUDA)、Kubernetes デバイスプラグイン、コンテナーランタイム、および自動ノードラベル付け、監視などを可能にする NVIDIA ドライバーが含まれます。
NVIDIA GPU Operator は、NVIDIA によってのみサポートされています。NVIDIA からサポートを受ける方法は、Obtaining Support from NVIDIA を参照してください。
OpenShift Container Platform OpenShift Virtualization で GPU を有効にする方法は、OpenShift Container Platform ネイティブの方法と、NVIDIA GPU Operator を使用する方法の 2 つあります。ここでは、OpenShift Container Platform ネイティブの方法を説明します。
NVIDIA GPU Operator は、OpenShift Container Platform OpenShift Virtualization が GPU を OpenShift Container Platform で実行されている仮想化されたワークロードに公開できるようにする Kubernetes Operator です。これにより、ユーザーは GPU 対応の仮想マシンを簡単にプロビジョニングおよび管理できるようになり、他のワークロードと同じプラットフォームで複雑な人工知能/機械学習 (AI/ML) ワークロードを実行できるようになります。また、インフラストラクチャーの GPU 容量を簡単にスケーリングできるようになり、GPU ベースのワークロードが急激に増加しても対応できます。
NVIDIA GPU Operator を使用して、GPU で高速化された VM を実行するためのワーカーノードをプロビジョニングする方法の詳細は、NVIDIA GPU Operator with OpenShift Virtualization を参照してください。
9.16.11.2. OpenShift Virtualization での仮想 GPU の使用について
一部のグラフィックス処理ユニット (GPU) カードは、仮想 GPU (vGPU) の作成をサポートしています。管理者がHyperConvergedカスタムリソース (CR) で設定の詳細を提供すると、Open Shift Virtualization は仮想 GPU およびその他の仲介デバイスを自動的に作成できます。この自動化は、大規模なクラスターで特に役立ちます。
機能とサポートの詳細については、ハードウェアベンダーのドキュメントを参照してください。
- 仲介デバイス
- 1 つまたは複数の仮想デバイスに分割された物理デバイス。仮想 GPU は、仲介デバイス (mdev) の一種です。物理 GPU のパフォーマンスが、仮想デバイス間で分割されます。仲介デバイスを 1 つまたは複数の仮想マシン (VM) に割り当てることができますが、ゲストの数は GPU と互換性がある必要があります。一部の GPU は複数のゲストをサポートしていません。
9.16.11.2.1. 前提条件
ハードウェアベンダーがドライバーを提供している場合は、仲介デバイスを作成するノードにドライバーをインストールしている。
- NVIDIA カードを使用する場合は、NVIDIAGRID ドライバーをインストールしている。
9.16.11.2.2. 設定の概要
仲介デバイスを設定する場合、管理者は次のタスクを完了する必要があります。
- 仲介デバイスを作成する。
- 仲介デバイスをクラスターに公開する。
HyperConverged CR には、両方のタスクを実行する API が含まれています。
仲介デバイスの作成
...
spec:
mediatedDevicesConfiguration:
mediatedDevicesTypes:
- <device_type>
nodeMediatedDeviceTypes:
- mediatedDevicesTypes:
- <device_type>
nodeSelector:
<node_selector_key>: <node_selector_value>
...仲介デバイスのクラスターへの公開
...
permittedHostDevices:
mediatedDevices:
- mdevNameSelector: GRID T4-2Q
resourceName: nvidia.com/GRID_T4-2Q
...- 1
- この値にマッピングする仲介デバイスをホスト上に公開します。注記
実際のシステムの正しい値に置き換えて、
/sys/bus/pci/devices/<slot>:<bus>:<domain>.<function>/mdev_supported_types/<type>/nameの内容を表示し、デバイスがサポートする仲介デバイスのタイプを確認できます。たとえば、
nvidia-231タイプの name ファイルには、セレクター文字列GRID T4-2Qが含まれます。GRID T4-2QをmdevNameSelector値として使用することで、ノードはnvidia-231タイプを使用できます。 - 2
resourceNameは、ノードに割り当てられたものと一致する必要があります。次のコマンドを使用して、resourceNameを検索します。$ oc get $NODE -o json \ | jq '.status.allocatable \ | with_entries(select(.key | startswith("nvidia.com/"))) \ | with_entries(select(.value != "0"))'
9.16.11.2.3. 仮想 GPU がノードに割り当てられる方法
物理デバイスごとに、OpenShift Virtualization は以下の値を設定します。
- 1 つの mdev タイプ。
-
選択した
mdevタイプのインスタンスの最大数。
クラスターのアーキテクチャーは、デバイスの作成およびノードへの割り当て方法に影響します。
- ノードごとに複数のカードを持つ大規模なクラスター
同様の仮想 GPU タイプに対応する複数のカードを持つノードでは、関連するデバイス種別がラウンドロビン方式で作成されます。以下に例を示します。
... mediatedDevicesConfiguration: mediatedDevicesTypes: - nvidia-222 - nvidia-228 - nvidia-105 - nvidia-108 ...このシナリオでは、各ノードに以下の仮想 GPU 種別に対応するカードが 2 つあります。
nvidia-105 ... nvidia-108 nvidia-217 nvidia-299 ...各ノードで、OpenShift Virtualization は以下の vGPU を作成します。
- 最初のカード上に nvidia-105 タイプの 16 の仮想 GPU
- 2 番目のカード上に nvidia-108 タイプの 2 つの仮想 GPU
- 1 つのノードに、要求された複数の仮想 GPU タイプをサポートするカードが 1 つある
OpenShift Virtualization は、
mediatedDevicesTypes一覧の最初のサポートされるタイプを使用します。たとえば、ノードカードのカードは
nvidia-223とnvidia-224をサポートします。以下のmediatedDevicesTypes一覧が設定されます。... mediatedDevicesConfiguration: mediatedDevicesTypes: - nvidia-22 - nvidia-223 - nvidia-224 ...この例では、OpenShift Virtualization は
nvidia-223タイプを使用します。
9.16.11.2.4. 仲介デバイスの変更および削除について
クラスターの仲介デバイス設定は、次の方法を使用して OpenShift Virtualization で更新できます。
-
HyperConvergedCR を編集し、mediadDevicesTypesスタンザの内容を変更します。 -
nodeMediatedDeviceTypesノードセレクターに一致するノードラベルを変更します。 HyperConvergedCR のspec.mediaDevicesConfigurationおよびspec.permittedHostDevicesスタンザからデバイス情報を削除します。注記spec.permittedHostDevicesスタンザからデバイス情報を削除したが、spec.mediatedDevicesConfigurationスタンザからは削除しなかった場合、同じノードで新規の仲介デバイスタイプを作成することはできません。仲介デバイスを適切に削除するには、両方のスタンザからデバイス情報を削除します。
具体的な変更に応じて、これらのアクションにより、OpenShift Virtualization は仲介デバイスを再設定するか、クラスターノードからそれらを削除します。
9.16.11.2.5. 仲介デバイス用のホストの準備
仲介デバイスを設定する前に、入出力メモリー管理ユニット (IOMMU) ドライバーを有効にする必要があります。
9.16.11.2.5.1. IOMMU ドライバーを有効にするためのカーネル引数の追加
カーネルの IOMMU (Input-Output Memory Management Unit) ドライバーを有効にするには、MachineConfig オブジェクトを作成し、カーネル引数を追加します。
前提条件
- 作業用の OpenShift Container Platform クラスターに対する管理者権限が必要です。
- Intel または AMD CPU ハードウェア。
- Intel Virtualization Technology for Directed I/O 拡張または BIOS (Basic Input/Output System) の AMD IOMMU が有効にされている。
手順
カーネル引数を識別する
MachineConfigオブジェクトを作成します。以下の例は、Intel CPU のカーネル引数を示しています。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker1 name: 100-worker-iommu2 spec: config: ignition: version: 3.2.0 kernelArguments: - intel_iommu=on3 ...新規
MachineConfigオブジェクトを作成します。$ oc create -f 100-worker-kernel-arg-iommu.yaml
検証
新規
MachineConfigオブジェクトが追加されていることを確認します。$ oc get MachineConfig
9.16.11.2.6. 仲介デバイスの追加および削除
仲介デバイスを追加または削除できます。
9.16.11.2.6.1. 仲介デバイスの作成および公開
HyperConverged カスタムリソース (CR) を編集して、仮想 GPU (vGPU) などの仲介デバイスを公開し、作成できます。
前提条件
- IOMMU (Input-Output Memory Management Unit) ドライバーを有効にしている。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv仲介デバイス情報を
HyperConvergedCR のspecに追加し、mediatedDevicesConfigurationおよびpermittedHostDevicesスタンザが含まれるようにします。以下に例を示します。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: mediatedDevicesConfiguration: <.> mediatedDevicesTypes: <.> - nvidia-231 nodeMediatedDeviceTypes: <.> - mediatedDevicesTypes: <.> - nvidia-233 nodeSelector: kubernetes.io/hostname: node-11.redhat.com permittedHostDevices: <.> mediatedDevices: - mdevNameSelector: GRID T4-2Q resourceName: nvidia.com/GRID_T4-2Q - mdevNameSelector: GRID T4-8Q resourceName: nvidia.com/GRID_T4-8Q ...<.> 仲介デバイスを作成します。<.> 必須: グローバル
MediedDevicesTypes設定。<.> 任意: 特定のノードのグローバル設定をオーバーライドします。<.>nodeMediatedDeviceTypesを使用する場合は必須。<.> 仲介デバイスをクラスターに公開します。- 変更を保存し、エディターを終了します。
検証
以下のコマンドを実行して、デバイスが特定のノードに追加されたことを確認できます。
$ oc describe node <node_name>
9.16.11.2.6.2. CLI を使用したクラスターからの仲介デバイスの削除
クラスターから仲介デバイスを削除するには、HyperConverged カスタムリソース (CR) からそのデバイスの情報を削除します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvHyperConvergedCR のspec.mediatedDevicesConfigurationおよびspec.permittedHostDevicesスタンザからデバイス情報を削除します。両方のエントリーを削除すると、後で同じノードで新しい仲介デバイスタイプを作成できます。以下に例を示します。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: mediatedDevicesConfiguration: mediatedDevicesTypes:1 - nvidia-231 permittedHostDevices: mediatedDevices:2 - mdevNameSelector: GRID T4-2Q resourceName: nvidia.com/GRID_T4-2Q- 変更を保存し、エディターを終了します。
9.16.11.3. 仲介デバイスの使用
vGPU は仲介デバイスの一種です。物理 GPU のパフォーマンスは仮想デバイス間で分割されます。仲介デバイスを 1 つ以上の仮想マシンに割り当てることができます。
9.16.11.3.1. 仮想マシンへの仲介デバイスの割り当て
仮想 GPU (vGPU) などの仲介デバイスを仮想マシンに割り当てます。
前提条件
-
仲介デバイスが
HyperConvergedカスタムリソースで設定されている。
手順
VirtualMachineマニフェストのspec.domain.devices.gpusスタンザを編集して、仲介デバイスを仮想マシン (VM) に割り当てます。仮想マシンマニフェストの例
apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: domain: devices: gpus: - deviceName: nvidia.com/TU104GL_Tesla_T41 name: gpu12 - deviceName: nvidia.com/GRID_T4-1Q name: gpu2
検証
デバイスが仮想マシンで利用できることを確認するには、
<device_name>をVirtualMachineマニフェストのdeviceNameの値に置き換えて以下のコマンドを実行します。$ lspci -nnk | grep <device_name>
9.16.12. ウォッチドッグの設定
ウォッチドッグデバイスに仮想マシン (VM) を設定し、ウォッチドッグをインストールして、ウォッチドッグサービスを開始することで、ウォッチドッグを公開します。
9.16.12.1. 前提条件
-
仮想マシンで
i6300esbウォッチドッグデバイスのカーネルサポートが含まれている。Red Hat Enterprise Linux(RHEL) イメージが、i6300esbをサポートしている。
9.16.12.2. ウォッチドッグデバイスの定義
オペレーティングシステム (OS) が応答しなくなるときにウォッチドッグがどのように進行するかを定義します。
表9.5 利用可能なアクション
|
|
仮想マシン (VM) の電源がすぐにオフになります。 |
|
| VM はその場で再起動し、ゲスト OS は反応できません。ゲスト OS の再起動に必要な時間の長さにより liveness プローブのタイムアウトが生じる可能性があるため、このオプションの使用は推奨されません。このタイムアウトにより、クラスターレベルの保護が liveness プローブの失敗に気づき、強制的に再スケジュールした場合に、VM の再起動にかかる時間が長くなる可能性があります。 |
|
| VM は、すべてのサービスを停止することにより、正常に電源を切ります。 |
手順
以下の内容を含む YAML ファイルを作成します。
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm2-rhel84-watchdog name: <vm-name> spec: running: false template: metadata: labels: kubevirt.io/vm: vm2-rhel84-watchdog spec: domain: devices: watchdog: name: <watchdog> i6300esb: action: "poweroff"1 ...- 1
watchdogアクション (poweroff、reset、またはshutdown) を指定します。
上記の例では、電源オフアクションを使用して、RHEL8 VM で
i6300esbウォッチドッグデバイスを設定し、デバイスを/dev/watchdogとして公開します。このデバイスは、ウォッチドッグバイナリーで使用できるようになりました。
以下のコマンドを実行して、YAML ファイルをクラスターに適用します。
$ oc apply -f <file_name>.yaml
この手順は、ウォッチドッグ機能をテストするためにのみ提供されており、実稼働マシンでは実行しないでください。
以下のコマンドを実行して、VM がウォッチドッグデバイスに接続されていることを確認します。
$ lspci | grep watchdog -i以下のコマンドのいずれかを実行して、ウォッチドッグがアクティブであることを確認します。
カーネルパニックをトリガーします。
# echo c > /proc/sysrq-triggerウォッチドッグサービスを終了します。
# pkill -9 watchdog
9.16.12.3. ウォッチドッグデバイスのインストール
仮想マシンに watchdog パッケージをインストールして、ウォッチドッグサービスを起動します。
手順
root ユーザーとして、
watchdogパッケージおよび依存関係をインストールします。# yum install watchdog/etc/watchdog.confファイルの以下の行のコメントを解除して、変更を保存します。#watchdog-device = /dev/watchdogウォッチドッグサービスが起動時に開始できるように有効化します。
# systemctl enable --now watchdog.service
9.16.13. 事前定義済みのブートソースの自動インポートおよび更新
システム定義 で OpenShift Virtualization に含まれるブートソース、または作成した ユーザー定義 のブートソースを使用できます。システム定義のブートソースのインポートおよび更新は、製品の機能ゲートによって制御されます。機能ゲートを使用して、更新を有効、無効、または再度有効にすることができます。ユーザー定義のブートソースは、製品機能ゲートによって制御されないため、自動インポートおよび更新をオプトインまたはオプトアウトするには、個別に管理する必要があります。
バージョン 4.10 以降、OpenShift Virtualization は、手動でオプトアウトするか、デフォルトのストレージクラスを設定しない限り、ブートソースを自動的にインポートして更新します。
バージョン 4.10 にアップグレードする場合は、バージョン 4.9 以前からのブートソースの自動インポートおよび更新を手動で有効にする必要があります。
9.16.13.1. ブートソースの自動更新の有効化
OpenShift Virtualization 4.9 以前からのブートソースがある場合は、これらのブートソースの自動更新を手動で有効にする必要があります。OpenShift Virtualization 4.10 以降のすべてのブートソースは、デフォルトで自動的に更新されます。
自動ブートソースのインポートおよび更新を有効にするには、自動更新する各ブートソースの cdi.kubevirt.io/dataImportCron フィールドを true に設定します。
手順
ブートソースの自動更新を有効にするには、次のコマンドを使用して
dataImportCronラベルをデータソースに適用します。$ oc label --overwrite DataSource rhel8 -n openshift-virtualization-os-images cdi.kubevirt.io/dataImportCron=true1 - 1
trueを指定すると、rhel8ブートソースの自動更新がオンになります。
9.16.13.2. ブートソースの自動更新の無効化
ブートソースの自動インポートおよび更新を無効にすると、切断された環境でログの数を減らしたり、リソースの使用率を減らしたりするのに役立ちます。
ブートソースの自動インポートおよび更新を無効にするには、HyperConverged カスタムリソース (CR) の spec.featureGates.enableCommonBootImageImport フィールドを false に設定します。
ユーザー定義のブートソースは、この設定の影響を受けません。
手順
次のコマンドを使用して、ブートソースの自動更新を無効にします。
$ oc patch hco kubevirt-hyperconverged -n openshift-cnv \ --type json -p '[{"op": "replace", "path": "/spec/featureGates/enableCommonBootImageImport", \ "value": false}]'
9.16.13.3. ブートソースの自動更新の再有効化
以前にブートソースの自動更新を無効にしている場合は、この機能を手動で再度有効にする必要があります。HyperConverged カスタムリソース (CR) の spec.featureGates.enableCommonBootImageImport フィールドを true に設定します。
手順
以下のコマンドを使用して自動更新を再度有効にします。
$ oc patch hco kubevirt-hyperconverged -n openshift-cnv --type json -p '[{"op": "replace", "path": "/spec/featureGates/enableCommonBootImageImport", "value": true}]'
9.16.13.4. ユーザー定義のブートソース更新用のストレージクラスの設定
ユーザー定義のブートソースの自動インポートおよび更新を可能にするストレージクラスを設定できます。
手順
HyperConvergedカスタムリソース (CR) を編集して、新しいstorageClassNameを定義します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: name: rhel8-image-cron spec: template: spec: storageClassName: <appropriate_class_name> ...次のコマンドを実行して、新しいデフォルトのストレージクラスを設定します。
$ oc patch storageclass <current_default_storage_class> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'$ oc patch storageclass <appropriate_storage_class> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
9.16.13.5. ユーザー定義の起動ソースの自動更新を有効にする
OpenShift Virtualization は、デフォルトでシステム定義のブートソースを自動的に更新しますが、ユーザー定義のブートソースは自動的に更新しません。HyperConverged カスタムリソース (CR) を編集して、ユーザー定義のブートソースで自動インポートおよび更新を手動で有効にする必要があります。
手順
以下のコマンドを使用して、編集するために
HyperConvergedCR を開きます。$ oc edit -n openshift-cnv HyperConverged適切なテンプレートおよびブートソースを
dataImportCronTemplatesセクションで追加して、HyperConvergedCR を編集します。以下に例を示します。CentOS 7 の例
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: name: centos7-image-cron annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true"1 spec: schedule: "0 */12 * * *"2 template: spec: source: registry:3 url: docker://quay.io/containerdisks/centos:7-2009 storage: resources: requests: storage: 10Gi managedDataSource: centos74 retentionPolicy: "None"5 - 1
- このアノテーションは、
volumeBindingModeがWaitForFirstConsumerに設定されたストレージクラスに必要です。 - 2
- cron 形式で指定されるジョブのスケジュール。
- 3
- レジストリーソースからデータボリュームを作成するのに使用します。
nodedocker キャッシュに基づくデフォルトのnodepullMethodではなく、デフォルトのpodpullMethodを使用します。nodedocker キャッシュはレジストリーイメージがContainer.Imageで利用可能な場合に便利ですが、CDI インポーターはこれにアクセスすることは許可されていません。 - 4
- 利用可能なブートソースとして検出するカスタムイメージの場合、イメージの
managedDataSourceの名前が、仮想マシンテンプレート YAML ファイルのspec.dataVolumeTemplates.spec.sourceRef.nameにあるテンプレートのDataSourceの名前に一致する必要があります。 - 5
- cron ジョブが削除されたときにデータボリュームおよびデータソースを保持するには、
Allを使用します。cron ジョブが削除されたときにデータボリュームおよびデータソースを削除するには、Noneを使用します。
9.16.13.6. システム定義またはユーザー定義のブートソースの自動更新の無効化
ユーザー定義のブートソースおよびシステム定義のブートソースの自動インポートおよび更新を無効にすることができます。
デフォルトでは、システム定義のブートソースは HyperConverged カスタムリソース (CR) の spec.dataImportCronTemplates にリストされていないため、ブートソースを追加し、自動インポートおよび更新を無効にする必要があります。
手順
-
ユーザー定義のブートソースの自動インポートおよび更新を無効にするには、カスタムリソースリストの
spec.dataImportCronTemplatesフィールドからブートソースを削除します。 システム定義の起動ソースの自動インポートおよび更新を無効にするには、以下を行います。
-
HyperConvergedCR を編集し、ブートソースをspec.dataImportCronTemplatesに追加します。 dataimportcrontemplate.kubevirt.io/enableアノテーションをfalseに設定して、自動インポートおよび更新を無効にします。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: dataImportCronTemplates: - metadata: annotations: dataimportcrontemplate.kubevirt.io/enable: false name: rhel8-image-cron ...
-
9.16.13.7. ブートソースのステータスの確認
ブートソースがシステム定義かユーザー定義かを確認できます。
HyperConverged CR の status.dataImportChronTemplates フィールドにリストされている各ブートソースの status セクションは、ブートソースのタイプを示します。たとえば、commonTemplate: true はシステム定義 (commonTemplate) の起動ソースを示し、status: {} はユーザー定義の起動ソースを示します。
手順
-
oc getコマンドを使用して、HyperConvergedCR 内のdataImportChronTemplatesを一覧表示します。 ブートソースのステータスを確認します。
出力例
... apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged ... spec: ... status:1 ... dataImportCronTemplates:2 - metadata: annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" name: centos-7-image-cron spec: garbageCollect: Outdated managedDataSource: centos7 schedule: 55 8/12 * * * template: metadata: {} spec: source: registry: url: docker://quay.io/containerdisks/centos:7-2009 storage: resources: requests: storage: 30Gi status: {} status: commonTemplate: true3 ... - metadata: annotations: cdi.kubevirt.io/storage.bind.immediate.requested: "true" name: user-defined-dic spec: garbageCollect: Outdated managedDataSource: user-defined-centos-stream8 schedule: 55 8/12 * * * template: metadata: {} spec: source: registry: pullMethod: node url: docker://quay.io/containerdisks/centos-stream:8 storage: resources: requests: storage: 30Gi status: {} status: {}4 ...
9.16.14. 仮想マシンでの Descheduler エビクションの有効化
Descheduler を使用して Pod を削除し、Pod をより適切なノードに再スケジュールできます。Pod が仮想マシンの場合、Pod の削除により、仮想マシンが別のノードにライブマイグレーションされます。
仮想マシンの Descheduler エビクションはテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
9.16.14.1. Descheduler プロファイル
テクノロジープレビューの DevPreviewLongLifecycle プロファイルを使用して、仮想マシンで Descheduler を有効にします。これは、現在 OpenShift Virtualization で利用可能な唯一の Descheduler プロファイルです。適切なスケジューリングを確保するには、予想される負荷に応じた CPU およびメモリー要求で仮想マシンを作成します。
DevPreviewLongLifecycleこのプロファイルは、ノード間のリソース使用率のバランスを取り、以下のストラテジーを有効にします。
-
RemovePodsHavingTooManyRestarts: コンテナーが何度も再起動された Pod、およびすべてのコンテナー (Init コンテナーを含む) の再起動の合計が 100 を超える Pod を削除します。仮想マシンのゲストオペレーティングシステムを再起動しても、この数は増えません。 LowNodeUtilization: 使用率の低いノードがある場合に、使用率の高いノードから Pod をエビクトします。エビクトされた Pod の宛先ノードはスケジューラーによって決定されます。- ノードは、使用率がすべてのしきい値 (CPU、メモリー、Pod の数) について 20% 未満の場合に使用率が低いと見なされます。
- ノードは、使用率がすべてのしきい値 (CPU、メモリー、Pod の数) について 50% を超える場合に過剰に使用されていると見なされます。
-
9.16.14.2. Descheduler のインストール
Descheduler はデフォルトで利用できません。Descheduler を有効にするには、Kube Descheduler Operator を OperatorHub からインストールし、1 つ以上の Descheduler プロファイルを有効にする必要があります。
デフォルトで、Descheduler は予測モードで実行されます。つまり、これは Pod エビクションのみをシミュレートします。Pod エビクションを実行するには、Descheduler のモードを automatic に変更する必要があります。
クラスターでホストされたコントロールプレーンを有効にしている場合は、カスタム優先度のしきい値を設定して、ホストされたコントロールプレーンの namespace の Pod が削除される可能性を下げます。ホストされたコントロールプレーンの優先度クラスの中で優先度値が最も低い (100000000) ため、優先度しきい値クラス名を hypershift-control-plane に設定します。
前提条件
- クラスター管理者の権限。
- OpenShift Container Platform Web コンソールにアクセスできる。
手順
- OpenShift Container Platform Web コンソールにログインします。
Kube Descheduler Operator に必要な namespace を作成します。
- Administration → Namespaces に移動し、Create Namespace をクリックします。
-
Name フィールドに
openshift-kube-descheduler-operatorを入力し、Labels フィールドにopenshift.io/cluster-monitoring=trueを入力して Descheduler メトリックを有効にし、Create をクリックします。
Kube Descheduler Operator をインストールします。
- Operators → OperatorHub に移動します。
- Kube Descheduler Operator をフィルターボックスに入力します。
- Kube Descheduler Operator を選択し、Install をクリックします。
- Install Operator ページで、A specific namespace on the cluster を選択します。ドロップダウンメニューから openshift-kube-descheduler-operator を選択します。
- Update Channel および Approval Strategy の値を必要な値に調整します。
- Install をクリックします。
Descheduler インスタンスを作成します。
- Operators → Installed Operators ページから、 Kube Descheduler Operator をクリックします。
- Kube Descheduler タブを選択し、Create KubeDescheduler をクリックします。
必要に応じて設定を編集します。
- エビクションをシミュレーションせずに Pod をエビクトするには、Mode フィールドを Automatic に変更します。
Profiles セクションを展開し、
DevPreviewLongLifecycleを選択します。AffinityAndTaintsプロファイルがデフォルトで有効になっています。重要OpenShift Virtualization で現在利用できるプロファイルは
DevPreviewLongLifecycleのみです。
また、後で OpenShift CLI (oc) を使用して、Descheduler のプロファイルおよび設定を設定することもできます。
9.16.14.3. 仮想マシン (VM) での Descheduler エビクションの有効化
Descheduler のインストール後に、アノテーションを VirtualMachine カスタムリソース (CR) に追加して Descheduler エビクションを仮想マシンで有効にできます。
前提条件
-
Descheduler を OpenShift Container Platform Web コンソールまたは OpenShift CLI (
oc) にインストールしている。 - 仮想マシンが実行されていないことを確認します。
手順
仮想マシンを起動する前に、
Descheduler.alpha.kubernetes.io/evictアノテーションをVirtualMachineCR に追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine spec: template: metadata: annotations: descheduler.alpha.kubernetes.io/evict: "true"インストール時に Web コンソールで
DevPreviewLongLifecycleプロファイルをまだ設定していない場合は、KubeDeschedulerオブジェクトのspec.profileセクションにDevPreviewLongLifecycleを指定します。apiVersion: operator.openshift.io/v1 kind: KubeDescheduler metadata: name: cluster namespace: openshift-kube-descheduler-operator spec: deschedulingIntervalSeconds: 3600 profiles: - DevPreviewLongLifecycle mode: Predictive1 - 1
- デフォルトでは、Descheduler は Pod をエビクトしません。Pod をエビクトするには、
modeをAutomaticに設定します。
Descheduler が仮想マシンで有効になりました。
9.17. 仮想マシンのインポート
9.17.1. データボリュームインポートの TLS 証明書
9.17.1.1. データボリュームインポートの認証に使用する TLS 証明書の追加
ソースからデータをインポートするには、レジストリーまたは HTTPS エンドポイントの TLS 証明書を設定マップに追加する必要があります。この設定マップは、宛先データボリュームの namespace に存在する必要があります。
TLS 証明書の相対パスを参照して設定マップ を作成します。
手順
正しい namespace にあることを確認します。設定マップは、同じ namespace にある場合にデータボリュームによってのみ参照されます。
$ oc get ns設定マップを作成します。
$ oc create configmap <configmap-name> --from-file=</path/to/file/ca.pem>
9.17.1.2. 例: TLS 証明書から作成される設定マップ
以下は、ca.pem TLS 証明書で作成される設定マップの例です。
apiVersion: v1
kind: ConfigMap
metadata:
name: tls-certs
data:
ca.pem: |
-----BEGIN CERTIFICATE-----
... <base64 encoded cert> ...
-----END CERTIFICATE-----9.17.2. データボリュームの使用による仮想マシンイメージのインポート
Containerized Data Importer (CDI) を使用し、データボリュームを使用して仮想マシンイメージを永続ボリューム要求 (PVC) にインポートします。次に、データボリュームを永続ストレージの仮想マシンに割り当てることができます。
仮想マシンイメージは、HTTP または HTTPS エンドポイントでホストするか、コンテナーディスクに組み込み、コンテナーレジストリーで保存できます。
ディスクイメージを PVC にインポートする際に、ディスクイメージは PVC で要求されるストレージの全容量を使用するように拡張されます。この領域を使用するには、仮想マシンのディスクパーティションおよびファイルシステムの拡張が必要になる場合があります。
サイズ変更の手順は、仮想マシンにインストールされるオペレーティングシステムによって異なります。詳細は、該当するオペレーティングシステムのドキュメントを参照してください。
9.17.2.1. 前提条件
- エンドポイントに TLS 証明書が必要な場合、証明書はデータボリュームと同じ namespace の 設定マップ に組み込む 必要があり、これはデータボリューム設定で参照されること。
コンテナーディスクをインポートするには、以下を実行すること。
- 仮想マシンイメージからコンテナーディスクを準備 し、これをコンテナーレジストリーに保存してからインポートする必要がある場合があります。
-
コンテナーレジストリーに TLS がない場合、レジストリーを
HyperConvergedカスタムリソースのinsecureRegistriesフィールドに追加 し、ここからコンテナーディスクをインポートできます。
- この操作を正常に完了するためには、ストレージクラスを定義するか、CDI スクラッチ領域を用意 しなければならない場合があります。
9.17.2.2. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
CDI は OpenShift Container Platform の クラスター全体のプロキシー設定 を使用するようになりました。
9.17.2.3. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.17.2.4. データボリュームを使用して仮想マシンイメージをストレージにインポートする
データボリュームを使用して、仮想マシンイメージをストレージにインポートできます。
仮想マシンイメージは、HTTP または HTTPS エンドポイントでホストするか、イメージをコンテナーディスクに組み込み、コンテナーレジストリーで保存できます。
イメージのデータソースは、VirtualMachine 設定ファイルで指定します。仮想マシンが作成されると、仮想マシンイメージを含むデータボリュームがストレージにインポートされます。
前提条件
仮想マシンイメージをインポートするには、以下が必要である。
-
RAW、ISO、または QCOW2 形式の仮想マシンディスクイメージ (オプションで
xzまたはgzを使用して圧縮される)。 - データソースにアクセスするために必要な認証情報と共にイメージがホストされる HTTP または HTTPS エンドポイント
-
RAW、ISO、または QCOW2 形式の仮想マシンディスクイメージ (オプションで
- コンテナーディスクをインポートするには、仮想マシンイメージをコンテナーディスクに組み込み、データソースにアクセスするために必要な認証クレデンシャルとともにコンテナーレジストリーに保存する必要があります。
- 仮想マシンが自己署名証明書またはシステム CA バンドルによって署名されていない証明書を使用するサーバーと通信する必要がある場合は、データボリュームと同じ namespace に config map を作成する必要があります。
手順
データソースに認証が必要な場合は、データソースのクレデンシャルを指定して
Secretマニフェストを作成し、endpoint-secret.yamlとして保存します。apiVersion: v1 kind: Secret metadata: name: endpoint-secret1 labels: app: containerized-data-importer type: Opaque data: accessKeyId: ""2 secretKey: ""3 Secretマニフェストを適用します。$ oc apply -f endpoint-secret.yamlVirtualMachineマニフェストを編集し、インポートする仮想マシンイメージのデータソースを指定して、vm-fedora-datavolume.yamlとして保存します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume name: vm-fedora-datavolume1 spec: dataVolumeTemplates: - metadata: creationTimestamp: null name: fedora-dv2 spec: storage: resources: requests: storage: 10Gi storageClassName: local source: http:3 url: "https://mirror.arizona.edu/fedora/linux/releases/35/Cloud/x86_64/images/Fedora-Cloud-Base-35-1.2.x86_64.qcow2"4 secretRef: endpoint-secret5 certConfigMap: ""6 status: {} running: true template: metadata: creationTimestamp: null labels: kubevirt.io/vm: vm-fedora-datavolume spec: domain: devices: disks: - disk: bus: virtio name: datavolumedisk1 machine: type: "" resources: requests: memory: 1.5Gi terminationGracePeriodSeconds: 180 volumes: - dataVolume: name: fedora-dv name: datavolumedisk1 status: {}- 1
- 仮想マシンの名前を指定します。
- 2
- データボリュームの名前を指定します。
- 3
- HTTP または HTTPS エンドポイントに
httpを指定します。レジストリーからインポートされたコンテナーディスクイメージのregistryを指定します。 - 4
- インポートする仮想マシンイメージの URL またはレジストリーエンドポイントを指定します。この例では、HTTPS エンドポイントで仮想マシンイメージを参照します。コンテナーレジストリーエンドポイントのサンプルは
url: "docker://kubevirt/fedora-cloud-container-disk-demo:latest"です。 - 5
- データソースの
Secretを作成した場合は、Secret名を指定します。 - 6
- オプション: CA 証明書 config map を指定します。
仮想マシンを作成します。
$ oc create -f vm-fedora-datavolume.yaml注記oc createコマンドは、データボリュームおよび仮想マシンを作成します。CDI コントローラーは適切なアノテーションを使用して基礎となる PVC を作成し、インポートプロセスが開始されます。インポートが完了すると、データボリュームのステータスがSucceededに変わります。仮想マシンを起動できます。データボリュームのプロビジョニングはバックグランドで実行されるため、これをプロセスをモニターする必要はありません。
検証
インポーター Pod は指定された URL から仮想マシンイメージまたはコンテナーディスクをダウンロードし、これをプロビジョニングされた PV に保存します。以下のコマンドを実行してインポーター Pod のステータスを確認します。
$ oc get pods次のコマンドを実行して、ステータスが
Succeededになるまでデータボリュームを監視します。$ oc describe dv fedora-dv1 - 1
VirtualMachineマニフェストで定義したデータボリューム名を指定します。
シリアルコンソールにアクセスして、プロビジョニングが完了し、仮想マシンが起動したことを確認します。
$ virtctl console vm-fedora-datavolume
9.17.3. データボリュームの使用による仮想マシンイメージのブロックストレージへのインポート
既存の仮想マシンイメージは OpenShift Container Platform クラスターにインポートできます。OpenShift Virtualization はデータボリュームを使用してデータのインポートおよび基礎となる永続ボリューム要求 (PVC) の作成を自動化します。
ディスクイメージを PVC にインポートする際に、ディスクイメージは PVC で要求されるストレージの全容量を使用するように拡張されます。この領域を使用するには、仮想マシンのディスクパーティションおよびファイルシステムの拡張が必要になる場合があります。
サイズ変更の手順は、仮想マシンにインストールされるオペレーティングシステムによって異なります。詳細は、該当するオペレーティングシステムのドキュメントを参照してください。
9.17.3.1. 前提条件
- CDI でサポートされる操作マトリックス に応じてスクラッチ領域が必要な場合は、この操作が正常に完了するように、まずは ストレージクラスを定義しているか、CDI スクラッチ領域を用意している。
9.17.3.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.17.3.3. ブロック永続ボリュームについて
ブロック永続ボリューム (PV) は、raw ブロックデバイスによってサポートされる PV です。これらのボリュームにはファイルシステムがなく、オーバーヘッドを削減することで、仮想マシンのパフォーマンス上の利点をもたらすことができます。
raw ブロックボリュームは、PV および永続ボリューム要求 (PVC) 仕様で volumeMode: Block を指定してプロビジョニングされます。
9.17.3.4. ローカルブロック永続ボリュームの作成
ファイルにデータを設定し、これをループデバイスとしてマウントすることにより、ノードでローカルブロック永続ボリューム (PV) を作成します。次に、このループデバイスを PV マニフェストで Block ボリュームとして参照し、これを仮想マシンイメージのブロックデバイスとして使用できます。
手順
-
ローカル PV を作成するノードに
rootとしてログインします。この手順では、node01を例に使用します。 ファイルを作成して、これを null 文字で設定し、ブロックデバイスとして使用できるようにします。以下の例では、2Gb (20 100Mb ブロック) のサイズのファイル
loop10を作成します。$ dd if=/dev/zero of=<loop10> bs=100M count=20loop10ファイルをループデバイスとしてマウントします。$ losetup </dev/loop10>d3 <loop10>1 2 マウントされたループデバイスを参照する
PersistentVolumeマニフェストを作成します。kind: PersistentVolume apiVersion: v1 metadata: name: <local-block-pv10> annotations: spec: local: path: </dev/loop10>1 capacity: storage: <2Gi> volumeMode: Block2 storageClassName: local3 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <node01>4 ブロック PV を作成します。
# oc create -f <local-block-pv10.yaml>1 - 1
- 直前の手順で作成された永続ボリュームのファイル名。
9.17.3.5. データボリュームを使用して仮想マシンイメージをブロックストレージにインポートする
データボリュームを使用して、仮想マシンイメージをブロックストレージにインポートできます。仮想マシンを作成する前に、VirtualMachine マニフェストでデータボリュームを参照します。
前提条件
-
RAW、ISO、または QCOW2 形式の仮想マシンディスクイメージ (オプションで
xzまたはgzを使用して圧縮される)。 - データソースにアクセスするために必要な認証情報と共にイメージがホストされる HTTP または HTTPS エンドポイント
手順
データソースに認証が必要な場合は、データソースのクレデンシャルを指定して
Secretマニフェストを作成し、endpoint-secret.yamlとして保存します。apiVersion: v1 kind: Secret metadata: name: endpoint-secret1 labels: app: containerized-data-importer type: Opaque data: accessKeyId: ""2 secretKey: ""3 Secretマニフェストを適用します。$ oc apply -f endpoint-secret.yamlデータ
DataVolumeマニフェストを作成し、仮想マシンイメージのデータソースとstorage.volumeModeのBlockを指定します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: import-pv-datavolume1 spec: storageClassName: local2 source: http: url: "https://mirror.arizona.edu/fedora/linux/releases/35/Cloud/x86_64/images/Fedora-Cloud-Base-35-1.2.x86_64.qcow2"3 secretRef: endpoint-secret4 storage: volumeMode: Block5 resources: requests: storage: 10Gi仮想マシンイメージをインポートするために data volume を作成します。
$ oc create -f import-pv-datavolume.yaml
仮想マシンを作成する前に、VirtualMachine マニフェストでこのデータボリュームを参照できます。
9.17.3.6. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
CDI は OpenShift Container Platform の クラスター全体のプロキシー設定 を使用するようになりました。
9.18. 仮想マシンのクローン作成
9.18.1. 複数の namespace 間でデータボリュームをクローン作成するためのユーザーパーミッションの有効化
namespace には相互に分離する性質があるため、ユーザーはデフォルトでは namespace をまたがってリソースのクローンを作成することができません。
ユーザーが仮想マシンのクローンを別の namespace に作成できるようにするには、cluster-admin ロールを持つユーザーが新規のクラスターロールを作成する必要があります。このクラスターロールをユーザーにバインドし、それらのユーザーが仮想マシンのクローンを宛先 namespace に対して作成できるようにします。
9.18.1.1. 前提条件
-
cluster-adminロールを持つユーザーのみがクラスターロールを作成できること。
9.18.1.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.18.1.3. データボリュームのクローン作成のための RBAC リソースの作成
datavolumes リソースのすべてのアクションのパーミッションを有効にする新規のくスターロールを作成します。
手順
ClusterRoleマニフェストを作成します。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: <datavolume-cloner>1 rules: - apiGroups: ["cdi.kubevirt.io"] resources: ["datavolumes/source"] verbs: ["*"]- 1
- クラスターロールの一意の名前。
クラスターにクラスターロールを作成します。
$ oc create -f <datavolume-cloner.yaml>1 - 1
- 直前の手順で作成された
ClusterRoleマニフェストのファイル名です。
移行元および宛先 namespace の両方に適用される
RoleBindingマニフェストを作成し、直前の手順で作成したクラスターロールを参照します。apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: <allow-clone-to-user>1 namespace: <Source namespace>2 subjects: - kind: ServiceAccount name: default namespace: <Destination namespace>3 roleRef: kind: ClusterRole name: datavolume-cloner4 apiGroup: rbac.authorization.k8s.ioクラスターにロールバインディングを作成します。
$ oc create -f <datavolume-cloner.yaml>1 - 1
- 直前の手順で作成された
RoleBindingマニフェストのファイル名です。
9.18.2. 新規データボリュームへの仮想マシンディスクのクローン作成
データボリューム設定ファイルでソース PVC を参照し、新規データボリュームに仮想マシンディスクの永続ボリューム要求 (PVC) のクローンを作成できます。
volumeMode: Block が指定された永続ボリューム (PV) から volumeMode: Filesystem が指定された PV へのクローンなど、異なるボリュームモード間でのクローン操作がサポートされます。
ただし、contentType: kubevirt を使用している場合にのみ異なるボリュームモード間のクローンが可能です。
事前割り当てをグローバルに有効にする場合や、単一データボリュームについて、Containerized Data Importer (CDI) はクローン時にディスク領域を事前に割り当てます。事前割り当てにより、書き込みパフォーマンスが向上します。詳細は、データボリュームについての事前割り当ての使用 について参照してください。
9.18.2.1. 前提条件
- ユーザーは、仮想マシンディスクの PVC のクローンを別の namespace に作成するために 追加のパーミッション が必要である。
9.18.2.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.18.2.3. 新規データボリュームへの仮想マシンディスクの永続ボリューム要求 (PVC) のクローン作成
既存の仮想マシンディスクの永続ボリューム要求 (PVC) のクローンを新規データボリュームに作成できます。その後、新規データボリュームは新規の仮想マシンに使用できます。
データボリュームが仮想マシンとは別に作成される場合、データボリュームのライフサイクルは仮想マシンから切り離されます。仮想マシンが削除されても、データボリュームもその関連付けられた PVC も削除されません。
前提条件
- 使用する既存の仮想マシンディスクの PVC を判別すること。クローン作成の前に、PVC に関連付けられた仮想マシンの電源を切る必要があります。
-
OpenShift CLI (
oc) がインストールされている。
手順
- 関連付けられた PVC の名前および namespace を特定するために、クローン作成に必要な仮想マシンディスクを確認します。
新規データボリュームの名前、ソース PVC の名前および namespace、および新規データボリュームのサイズを指定するデータボリュームの YAML ファイルを作成します。
以下に例を示します。
apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <cloner-datavolume>1 spec: source: pvc: namespace: "<source-namespace>"2 name: "<my-favorite-vm-disk>"3 pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>4 データボリュームを作成して PVC のクローン作成を開始します。
$ oc create -f <cloner-datavolume>.yaml注記データボリュームは仮想マシンが PVC の作成前に起動することを防ぐため、PVC のクローン作成中に新規データボリュームを参照する仮想マシンを作成できます。
9.18.2.4. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.18.3. データボリュームテンプレートの使用による仮想マシンのクローン作成
既存の仮想マシンの永続ボリューム要求 (PVC) のクローン作成により、新規の仮想マシンを作成できます。dataVolumeTemplate を仮想マシン設定ファイルに含めることにより、元の PVC から新規のデータボリュームを作成します。
volumeMode: Block が指定された永続ボリューム (PV) から volumeMode: Filesystem が指定された PV へのクローンなど、異なるボリュームモード間でのクローン操作がサポートされます。
ただし、contentType: kubevirt を使用している場合にのみ異なるボリュームモード間のクローンが可能です。
事前割り当てをグローバルに有効にする場合や、単一データボリュームについて、Containerized Data Importer (CDI) はクローン時にディスク領域を事前に割り当てます。事前割り当てにより、書き込みパフォーマンスが向上します。詳細は、データボリュームについての事前割り当ての使用 について参照してください。
9.18.3.1. 前提条件
- ユーザーは、仮想マシンディスクの PVC のクローンを別の namespace に作成するために 追加のパーミッション が必要である。
9.18.3.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.18.3.3. データボリュームテンプレートの使用による、クローン作成された永続ボリューム要求 (PVC) からの仮想マシンの新規作成
既存の仮想マシンの永続ボリューム要求 (PVC) のクローンをデータボリュームに作成する仮想マシンを作成できます。仮想マシンマニフェストの dataVolumeTemplate を参照することにより、source PVC のクローンがデータボリュームに作成され、これは次に仮想マシンを作成するために自動的に使用されます。
データボリュームが仮想マシンのデータボリュームテンプレートの一部として作成されると、データボリュームのライフサイクルは仮想マシンに依存します。つまり、仮想マシンが削除されると、データボリュームおよび関連付けられた PVC も削除されます。
前提条件
- 使用する既存の仮想マシンディスクの PVC を判別すること。クローン作成の前に、PVC に関連付けられた仮想マシンの電源を切る必要があります。
-
OpenShift CLI (
oc) がインストールされている。
手順
- 関連付けられた PVC の名前および namespace を特定するために、クローン作成に必要な仮想マシンを確認します。
VirtualMachineオブジェクトの YAML ファイルを作成します。以下の仮想マシンのサンプルでは、source-namespacenamespace にあるmy-favorite-vm-diskのクローンを作成します。favorite-cloneという2Giデータはmy-favorite-vm-diskから作成されます。以下に例を示します。
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm-dv-clone name: vm-dv-clone1 spec: running: false template: metadata: labels: kubevirt.io/vm: vm-dv-clone spec: domain: devices: disks: - disk: bus: virtio name: root-disk resources: requests: memory: 64M volumes: - dataVolume: name: favorite-clone name: root-disk dataVolumeTemplates: - metadata: name: favorite-clone spec: storage: accessModes: - ReadWriteOnce resources: requests: storage: 2Gi source: pvc: namespace: "source-namespace" name: "my-favorite-vm-disk"- 1
- 作成する仮想マシン。
PVC のクローンが作成されたデータボリュームで仮想マシンを作成します。
$ oc create -f <vm-clone-datavolumetemplate>.yaml
9.18.3.4. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.18.4. 新規ブロックストレージデータボリュームへの仮想マシンディスクのクローン作成
データボリューム設定ファイルでソース PVC を参照し、新規ブロックデータボリュームに仮想マシンディスクの永続ボリューム要求 (PVC) のクローンを作成できます。
volumeMode: Block が指定された永続ボリューム (PV) から volumeMode: Filesystem が指定された PV へのクローンなど、異なるボリュームモード間でのクローン操作がサポートされます。
ただし、contentType: kubevirt を使用している場合にのみ異なるボリュームモード間のクローンが可能です。
事前割り当てをグローバルに有効にする場合や、単一データボリュームについて、Containerized Data Importer (CDI) はクローン時にディスク領域を事前に割り当てます。事前割り当てにより、書き込みパフォーマンスが向上します。詳細は、データボリュームについての事前割り当ての使用 について参照してください。
9.18.4.1. 前提条件
- ユーザーは、仮想マシンディスクの PVC のクローンを別の namespace に作成するために 追加のパーミッション が必要である。
9.18.4.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.18.4.3. ブロック永続ボリュームについて
ブロック永続ボリューム (PV) は、raw ブロックデバイスによってサポートされる PV です。これらのボリュームにはファイルシステムがなく、オーバーヘッドを削減することで、仮想マシンのパフォーマンス上の利点をもたらすことができます。
raw ブロックボリュームは、PV および永続ボリューム要求 (PVC) 仕様で volumeMode: Block を指定してプロビジョニングされます。
9.18.4.4. ローカルブロック永続ボリュームの作成
ファイルにデータを設定し、これをループデバイスとしてマウントすることにより、ノードでローカルブロック永続ボリューム (PV) を作成します。次に、このループデバイスを PV マニフェストで Block ボリュームとして参照し、これを仮想マシンイメージのブロックデバイスとして使用できます。
手順
-
ローカル PV を作成するノードに
rootとしてログインします。この手順では、node01を例に使用します。 ファイルを作成して、これを null 文字で設定し、ブロックデバイスとして使用できるようにします。以下の例では、2Gb (20 100Mb ブロック) のサイズのファイル
loop10を作成します。$ dd if=/dev/zero of=<loop10> bs=100M count=20loop10ファイルをループデバイスとしてマウントします。$ losetup </dev/loop10>d3 <loop10>1 2 マウントされたループデバイスを参照する
PersistentVolumeマニフェストを作成します。kind: PersistentVolume apiVersion: v1 metadata: name: <local-block-pv10> annotations: spec: local: path: </dev/loop10>1 capacity: storage: <2Gi> volumeMode: Block2 storageClassName: local3 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <node01>4 ブロック PV を作成します。
# oc create -f <local-block-pv10.yaml>1 - 1
- 直前の手順で作成された永続ボリュームのファイル名。
9.18.4.5. 新規データボリュームへの仮想マシンディスクの永続ボリューム要求 (PVC) のクローン作成
既存の仮想マシンディスクの永続ボリューム要求 (PVC) のクローンを新規データボリュームに作成できます。その後、新規データボリュームは新規の仮想マシンに使用できます。
データボリュームが仮想マシンとは別に作成される場合、データボリュームのライフサイクルは仮想マシンから切り離されます。仮想マシンが削除されても、データボリュームもその関連付けられた PVC も削除されません。
前提条件
- 使用する既存の仮想マシンディスクの PVC を判別すること。クローン作成の前に、PVC に関連付けられた仮想マシンの電源を切る必要があります。
-
OpenShift CLI (
oc) がインストールされている。 - ソース PVC と同じか、これよりも大きい 1 つ以上の利用可能なブロック永続ボリューム (PV)。
手順
- 関連付けられた PVC の名前および namespace を特定するために、クローン作成に必要な仮想マシンディスクを確認します。
新規データボリュームの名前、ソース PVC の名前および namespace、利用可能なブロック PV を使用できるようにするために
volumeMode: Block、および新規データボリュームのサイズを指定するデータボリュームの YAML ファイルを作成します。以下に例を示します。
apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <cloner-datavolume>1 spec: source: pvc: namespace: "<source-namespace>"2 name: "<my-favorite-vm-disk>"3 pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>4 volumeMode: Block5 データボリュームを作成して PVC のクローン作成を開始します。
$ oc create -f <cloner-datavolume>.yaml注記データボリュームは仮想マシンが PVC の作成前に起動することを防ぐため、PVC のクローン作成中に新規データボリュームを参照する仮想マシンを作成できます。
9.18.4.6. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.19. 仮想マシンのネットワーク
9.19.1. デフォルトの Pod ネットワーク用の仮想マシンの設定
masquerade バインディングモードを使用するようにネットワークインターフェイスを設定することで、仮想マシンをデフォルトの内部 Pod ネットワークに接続できます。
デフォルトの Pod ネットワークに接続している仮想ネットワークインターフェイスカード (vNIC) 上のトラフィックは、ライブマイグレーション時に中断します。
9.19.1.1. コマンドラインでのマスカレードモードの設定
マスカレードモードを使用し、仮想マシンの送信トラフィックを Pod IP アドレスの背後で非表示にすることができます。マスカレードモードは、ネットワークアドレス変換 (NAT) を使用して仮想マシンを Linux ブリッジ経由で Pod ネットワークバックエンドに接続します。
仮想マシンの設定ファイルを編集して、マスカレードモードを有効にし、トラフィックが仮想マシンに到達できるようにします。
前提条件
- 仮想マシンは、IPv4 アドレスを取得するために DHCP を使用できるように設定される必要がある。以下の例では、DHCP を使用するように設定されます。
手順
仮想マシン設定ファイルの
interfaces仕様を編集します。kind: VirtualMachine spec: domain: devices: interfaces: - name: default masquerade: {}1 ports:2 - port: 80 networks: - name: default pod: {}注記ポート 49152 および 49153 は libvirt プラットフォームで使用するために予約され、これらのポートへの他のすべての受信トラフィックは破棄されます。
仮想マシンを作成します。
$ oc create -f <vm-name>.yaml
9.19.1.2. デュアルスタック (IPv4 および IPv6) でのマスカレードモードの設定
cloud-init を使用して、新規仮想マシン (VM) を、デフォルトの Pod ネットワークで IPv6 と IPv4 の両方を使用するように設定できます。
仮想マシン インスタンス設定の Network.pod.vmIPv6NetworkCIDR フィールドは、VM の静的 IPv6 アドレスとゲートウェイ IP アドレスを決定します。これらは IPv6 トラフィックを仮想マシンにルーティングするために virt-launcher Pod で使用され、外部では使用されません。Network.pod.vmIPv6NetworkCIDR フィールドは、Classless Inter-Domain Routing (CIDR) 表記で IPv6 アドレス ブロックを指定します。デフォルト値は fd10:0:2::2/120 です。この値は、ネットワーク要件に基づいて編集できます。
仮想マシンが実行されている場合、仮想マシンの送受信トラフィックは、virt-launcher Pod の IPv4 アドレスと固有の IPv6 アドレスの両方にルーティングされます。次に、virt-launcher Pod は IPv4 トラフィックを仮想マシンの DHCP アドレスにルーティングし、IPv6 トラフィックを仮想マシンの静的に設定された IPv6 アドレスにルーティングします。
前提条件
- OpenShift Container Platform クラスターは、デュアルスタック用に設定された OVN-Kubernetes Container Network Interface (CNI) ネットワークプロバイダーを使用する必要があります。
手順
新規の仮想マシン設定では、
masqueradeを指定したインターフェイスを追加し、cloud-init を使用して IPv6 アドレスとデフォルトゲートウェイを設定します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: example-vm-ipv6 ... interfaces: - name: default masquerade: {}1 ports: - port: 802 networks: - name: default pod: {} volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth0: dhcp4: true addresses: [ fd10:0:2::2/120 ]3 gateway6: fd10:0:2::14 namespace で仮想マシンインスタンスを作成します。
$ oc create -f example-vm-ipv6.yaml
検証
- IPv6 が設定されていることを確認するには、仮想マシンを起動し、仮想マシンインスタンスのインターフェイスステータスを表示して、これに IPv6 アドレスがあることを確認します。
$ oc get vmi <vmi-name> -o jsonpath="{.status.interfaces[*].ipAddresses}"9.19.2. 仮想マシンを公開するサービスの作成
Service オブジェクトを使用して、クラスター内またはクラスターの外部に仮想マシンを公開することができます。
9.19.2.1. サービスについて
Kubernetes サービス は、一連の Pod で実行されるアプリケーションをネットワークサービスとして公開するための抽象的な方法です。サービスを使用すると、アプリケーションがトラフィックを受信できます。サービスは、Service オブジェクトに spec.type を指定して複数の異なる方法で公開できます。
- ClusterIP
-
クラスター内の内部 IP アドレスでサービスを公開します。
ClusterIPはデフォルトのサービスタイプです。 - NodePort
-
クラスター内の選択した各ノードの同じポートでサービスを公開します。
NodePortは、クラスター外からサービスにアクセスできるようにします。 - LoadBalancer
- 現在のクラウド(サポートされている場合)に外部ロードバランサーを作成し、固定の外部 IP アドレスをサービスに割り当てます。
9.19.2.1.1. デュアルスタックサポート
IPv4 および IPv6 のデュアルスタックネットワークがクラスターに対して有効にされている場合、Service オブジェクトに spec.ipFamilyPolicy および spec.ipFamilies フィールドを定義して、IPv4、IPv6、またはそれら両方を使用するサービスを作成できます。
spec.ipFamilyPolicy フィールドは以下の値のいずれかに設定できます。
- SingleStack
- コントロールプレーンは、最初に設定されたサービスクラスターの IP 範囲に基づいて、サービスのクラスター IP アドレスを割り当てます。
- PreferDualStack
- コントロールプレーンは、デュアルスタックが設定されたクラスターのサービス用に IPv4 および IPv6 クラスター IP アドレスの両方を割り当てます。
- RequireDualStack
-
このオプションは、デュアルスタックネットワークが有効にされていないクラスターの場合には失敗します。デュアルスタックが設定されたクラスターの場合、その値が
PreferDualStackに設定されている場合と同じになります。コントロールプレーンは、IPv4 アドレスと IPv6 アドレス範囲の両方からクラスター IP アドレスを割り当てます。
単一スタックに使用する IP ファミリーや、デュアルスタック用の IP ファミリーの順序は、spec.ipFamilies を以下のアレイ値のいずれかに設定して定義できます。
-
[IPv4] -
[IPv6] -
[IPv4, IPv6] -
[IPv6, IPv4]
9.19.2.2. 仮想マシンのサービスとしての公開
ClusterIP、NodePort、または LoadBalancer サービスを作成し、クラスター内外から実行中の仮想マシン (VM) に接続します。
手順
VirtualMachineマニフェストを編集して、サービス作成のラベルを追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: vm-ephemeral namespace: example-namespace spec: running: false template: metadata: labels: special: key1 # ...- 1
- ラベル
special: keyをspec.template.metadata.labelsセクションに追加します。
注記仮想マシンのラベルは Pod に渡されます。
special: キーラベルは、Serviceマニフェストのspec.selector属性のラベルと一致する必要があります。-
VirtualMachineマニフェストファイルを保存して変更を適用します。 仮想マシンを公開するための
Serviceマニフェストを作成します。apiVersion: v1 kind: Service metadata: name: vmservice1 namespace: example-namespace2 spec: externalTrafficPolicy: Cluster3 ports: - nodePort: 300004 port: 27017 protocol: TCP targetPort: 225 selector: special: key6 type: NodePort7 - 1
Serviceオブジェクトの名前。- 2
Serviceオブジェクトが存在する namespace。これはVirtualMachineマニフェストのmetadata.namespaceフィールドと同じである必要があります。- 3
- オプション: ノードが外部 IP アドレスで受信したサービストラフィックを分散する方法を指定します。これは
NodePortおよびLoadBalancerサービスタイプにのみ適用されます。デフォルト値はClusterで、トラフィックをすべてのクラスターエンドポイントに均等にルーティングします。 - 4
- オプション: 設定する場合、
nodePort値はすべてのサービスで固有でなければなりません。指定しない場合、30000を超える範囲内の値は動的に割り当てられます。 - 5
- オプション: サービスによって公開される VM ポート。ポートリストが仮想マシンマニフェストに定義されている場合は、オープンポートを参照する必要があります。
targetPortが指定されていない場合は、ポートと同じ値を取ります。 - 6
VirtualMachineマニフェストのspec.template.metadata.labelsスタンザに追加したラベルへの参照。- 7
- サービスのタイプ。使用できる値は
ClusterIP、NodePort、およびLoadBalancerです。
-
サービスマニフェストファイルを保存します。 以下のコマンドを実行してサービスを作成します。
$ oc create -f <service_name>.yaml- 仮想マシンを起動します。仮想マシンがすでに実行中の場合は、再起動します。
検証
Serviceオブジェクトをクエリーし、これが利用可能であることを確認します。$ oc get service -n example-namespaceClusterIPサービスの出力例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vmservice ClusterIP 172.30.3.149 <none> 27017/TCP 2mNodePortサービスの出力例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vmservice NodePort 172.30.232.73 <none> 27017:30000/TCP 5mLoadBalancerサービスの出力例NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE vmservice LoadBalancer 172.30.27.5 172.29.10.235,172.29.10.235 27017:31829/TCP 5s仮想マシンに接続するための適切な方法を選択します。
ClusterIPサービスの場合は、サービス IP アドレスとサービスポートを使用して、クラスター内から仮想マシンに接続します。以下に例を示します。$ ssh fedora@172.30.3.149 -p 27017NodePortサービスの場合、ノード IP アドレスとクラスターネットワーク外のノードポートを指定して仮想マシンに接続します。以下に例を示します。$ ssh fedora@$NODE_IP -p 30000-
LoadBalancerサービスの場合は、vinagreクライアントを使用し、パブリック IP アドレスおよびポートで仮想マシンに接続します。外部ポートは動的に割り当てられます。
9.19.3. Linux ブリッジ ネットワークへの仮想マシンの割り当て
デフォルトでは、OpenShift Virtualization は単一の内部 Pod ネットワークとともにインストールされます。
追加のネットワークに接続するには、Linux ブリッジ ネットワーク接続定義 (NAD) を作成する必要があります。
仮想マシンを追加のネットワークに割り当てるには、以下を実行します。
- Linux ブリッジ ノード ネットワーク設定ポリシーを作成します。
- Linux ブリッジ ネットワーク接続定義を作成します。
- 仮想マシンを設定して、仮想マシンがネットワーク接続定義を認識できるようにします。
スケジューリング、インターフェイスタイプ、およびその他のノードのネットワークアクティビティーについての詳細は、node networking セクションを参照してください。
9.19.3.1. ネットワーク接続定義によるネットワークへの接続
9.19.3.1.1. Linux ブリッジ ノード ネットワーク設定ポリシーの作成
NodeNetworkConfigurationPolicy マニフェスト YAML ファイルを使用して、Linux ブリッジを作成します。
前提条件
- Kubernetes NMState Operator がインストールされている。
手順
NodeNetworkConfigurationPolicyマニフェストを作成します。この例には、独自の情報で置き換える必要のあるサンプルの値が含まれます。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy1 spec: desiredState: interfaces: - name: br12 description: Linux bridge with eth1 as a port3 type: linux-bridge4 state: up5 ipv4: enabled: false6 bridge: options: stp: enabled: false7 port: - name: eth18
9.19.3.2. Linux ブリッジネットワーク接続定義の作成
仮想マシンのネットワークアタッチメント定義での IP アドレス管理 (IPAM) の設定はサポートされていません。
9.19.3.2.1. Web コンソールでの Linux ブリッジネットワーク接続定義の作成
ネットワーク管理者は、ネットワーク接続定義を作成して layer-2 ネットワークを Pod および仮想マシンに提供できます。
手順
- Web コンソールで、Networking → Network Attachment Definitions をクリックします。
Create Network Attachment Definition をクリックします。
注記ネットワーク接続定義は Pod または仮想マシンと同じ namespace にある必要があります。
- 一意の Name およびオプションの Description を入力します。
- Network Type リストをクリックし、CNV Linux bridge を選択します。
- Bridge Name フィールドにブリッジの名前を入力します。
- オプション: リソースに VLAN ID が設定されている場合、 VLAN Tag Number フィールドに ID 番号を入力します。
- オプション: MAC Spoof Check を選択して、MAC スプーフ フィルタリングを有効にします。この機能により、Pod を終了するための MAC アドレスを 1 つだけ許可することで、MAC スプーフィング攻撃に対してセキュリティーを確保します。
Create をクリックします。
注記Linux ブリッジ ネットワーク接続定義は、仮想マシンを VLAN に接続するための最も効率的な方法です。
9.19.3.2.2. CLI での Linux ブリッジネットワーク接続定義の作成
ネットワーク管理者は、タイプ cnv-bridge のネットワーク接続定義を、レイヤー 2 ネットワークを Pod および仮想マシンに提供するように設定できます。
前提条件
-
MAC スプーフィングチェックを有効にするには、ノードが nftables をサポートして、
nftバイナリーがデプロイされている必要があります。
手順
- 仮想マシンと同じ namespace にネットワーク接続定義を作成します。
次の例のように、仮想マシンをネットワーク接続定義に追加します。
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: <bridge-network>1 annotations: k8s.v1.cni.cncf.io/resourceName: bridge.network.kubevirt.io/<bridge-interface>2 spec: config: '{ "cniVersion": "0.3.1", "name": "<bridge-network>",3 "type": "cnv-bridge",4 "bridge": "<bridge-interface>",5 "macspoofchk": true,6 "vlan": 17 }'- 1
NetworkAttachmentDefinitionオブジェクトの名前。- 2
- オプション: ノード選択のアノテーションのキーと値のペア。
bridge-interfaceは一部のノードに設定されるブリッジの名前に一致する必要があります。このアノテーションをネットワーク接続定義に追加する場合、仮想マシンインスタンスはbridge-interfaceブリッジが接続されているノードでのみ実行されます。 - 3
- 設定の名前。設定名をネットワーク接続定義の
name値に一致させることが推奨されます。 - 4
- このネットワーク接続定義のネットワークを提供する Container Network Interface (CNI) プラグインの実際の名前。異なる CNI を使用するのでない限り、このフィールドは変更しないでください。
- 5
- ノードに設定される Linux ブリッジの名前。
- 6
- オプション:MAC スプーフィングチェックを有効にする。
trueに設定すると、Pod またはゲストインターフェイスの MAC アドレスを変更できません。この属性は、Pod からの MAC アドレスを 1 つだけ許可することで、MAC スプーフィング攻撃に対してセキュリティーを確保します。 - 7
- オプション: VLAN タグ。ノードのネットワーク設定ポリシーでは、追加の VLAN 設定は必要ありません。
注記Linux ブリッジ ネットワーク接続定義は、仮想マシンを VLAN に接続するための最も効率的な方法です。
ネットワーク接続定義を作成します。
$ oc create -f <network-attachment-definition.yaml>1 - 1
- ここで、
<network-attachment-definition.yaml>はネットワーク接続定義マニフェストのファイル名です。
検証
次のコマンドを実行して、ネットワーク接続定義が作成されたことを確認します。
$ oc get network-attachment-definition <bridge-network>
9.19.3.3. Linux ブリッジネットワーク用の仮想マシンの設定
9.19.3.3.1. Web コンソールでの仮想マシンの NIC の作成
Web コンソールから追加の NIC を作成し、これを仮想マシンに割り当てます。
前提条件
- ネットワーク接続定義が使用可能である必要があります。
手順
- OpenShift Container Platform コンソールの正しいプロジェクトで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Network Interfaces タブをクリックして、仮想マシンにすでに接続されている NIC を表示します。
- Add Network Interface をクリックし、一覧に新規スロットを作成します。
- 追加ネットワークの Network リストからネットワーク接続定義を選択します。
- 新規 NIC の Name、Model、Type、および MAC Address に入力します。
- Save をクリックして NIC を保存し、これを仮想マシンに割り当てます。
9.19.3.3.2. ネットワークフィールド
| Name | 説明 |
|---|---|
| Name | ネットワークインターフェイスコントローラーの名前。 |
| モデル | ネットワークインターフェイスコントローラーのモデルを示します。サポートされる値は e1000e および virtio です。 |
| Network | 利用可能なネットワーク接続定義のリスト。 |
| タイプ | 利用可能なバインディングメソッドの一覧。ネットワークインターフェイスに適したバインド方法を選択します。
|
| MAC Address | ネットワークインターフェイスコントローラーの MAC アドレス。MAC アドレスが指定されていない場合、これは自動的に割り当てられます。 |
9.19.3.3.3. CLI で仮想マシンを追加のネットワークに接続する
ブリッジインターフェイスを追加し、仮想マシン設定でネットワーク接続定義を指定して、仮想マシンを追加のネットワークに割り当てます。
以下の手順では、YAML ファイルを使用して設定を編集し、更新されたファイルをクラスターに適用します。oc edit <object> <name> コマンドを使用して、既存の仮想マシンを編集することもできます。
前提条件
- 設定を編集する前に仮想マシンをシャットダウンします。実行中の仮想マシンを編集する場合は、変更を有効にするために仮想マシンを再起動する必要があります。
手順
- ブリッジネットワークに接続する仮想マシンの設定を作成または編集します。
ブリッジインターフェイスを
spec.template.spec.domain.devices.interfaces一覧に追加し、ネットワーク接続定義をspec.template.spec.networks一覧に追加します。この例では、a-bridge-networkネットワーク接続定義に接続されるbridge-netというブリッジインターフェイスを追加します。apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: <example-vm> spec: template: spec: domain: devices: interfaces: - masquerade: {} name: <default> - bridge: {} name: <bridge-net>1 ... networks: - name: <default> pod: {} - name: <bridge-net>2 multus: networkName: <network-namespace>/<a-bridge-network>3 ...- 1
- ブリッジインターフェイスの名前。
- 2
- ネットワークの名前。この値は、対応する
spec.template.spec.domain.devices.interfacesエントリーのname値と一致する必要があります。 - 3
- ネットワーク接続定義の名前。接頭辞は、存在する namespace になります。namespace は、
defaultの namespace または仮想マシンが作成される namespace と同じでなければなりません。この場合、multusが使用されます。Multus は、Pod または仮想マシンが必要なインターフェイスを使用できるように、複数の CNI が存在できるようにするクラウドネットワークインターフェイス (CNI) プラグインです。
設定を適用します。
$ oc apply -f <example-vm.yaml>- オプション: 実行中の仮想マシンを編集している場合は、変更を有効にするためにこれを再起動する必要があります。
9.19.4. 仮想マシンの SR-IOV ネットワークへの接続
次の手順を実行して、仮想マシン (VM) を Single Root I/O Virtualization (SR-IOV) ネットワークに接続できます。
- SR-IOV ネットワーク デバイスを設定します。
- SR-IOV ネットワークを設定します。
- 仮想マシンを SR-IOV ネットワークに接続します。
9.19.4.1. 前提条件
9.19.4.2. SR-IOV ネットワークデバイスの設定
SR-IOV Network Operator は SriovNetworkNodePolicy.sriovnetwork.openshift.io CustomResourceDefinition を OpenShift Container Platform に追加します。SR-IOV ネットワークデバイスは、SriovNetworkNodePolicy カスタムリソース (CR) を作成して設定できます。
SriovNetworkNodePolicy オブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。
設定の変更が適用されるまでに数分かかる場合があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - SR-IOV Network Operator がインストールされている。
- ドレイン (解放) されたノードからエビクトされたワークロードを処理するために、クラスター内に利用可能な十分なノードがあること。
- SR-IOV ネットワークデバイス設定についてコントロールプレーンノードを選択していないこと。
手順
SriovNetworkNodePolicyオブジェクトを作成してから、YAML を<name>-sriov-node-network.yamlファイルに保存します。<name>をこの設定の名前に置き換えます。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: <name>1 namespace: openshift-sriov-network-operator2 spec: resourceName: <sriov_resource_name>3 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true"4 priority: <priority>5 mtu: <mtu>6 numVfs: <num>7 nicSelector:8 vendor: "<vendor_code>"9 deviceID: "<device_id>"10 pfNames: ["<pf_name>", ...]11 rootDevices: ["<pci_bus_id>", "..."]12 deviceType: vfio-pci13 isRdma: false14 - 1
- CR オブジェクトの名前を指定します。
- 2
- SR-IOV Operator がインストールされている namespace を指定します。
- 3
- SR-IOV デバイスプラグインのリソース名を指定します。1 つのリソース名に複数の
SriovNetworkNodePolicyオブジェクトを作成できます。 - 4
- 設定するノードを選択するノードセレクターを指定します。選択したノード上の SR-IOV ネットワークデバイスのみが設定されます。SR-IOV Container Network Interface (CNI) プラグインおよびデバイスプラグインは、選択したノードにのみデプロイされます。
- 5
- オプション:
0から99までの整数値を指定します。数値が小さいほど優先度が高くなります。したがって、10は99よりも優先度が高くなります。デフォルト値は99です。 - 6
- オプション: 仮想機能 (VF) の最大転送単位 (MTU) の値を指定します。MTU の最大値は NIC モデルによって異なります。
- 7
- SR-IOV 物理ネットワークデバイス用に作成する仮想機能 (VF) の数を指定します。Intel ネットワークインターフェイスコントローラー (NIC) の場合、VF の数はデバイスがサポートする VF の合計よりも大きくすることはできません。Mellanox NIC の場合、VF の数は
128よりも大きくすることはできません。 - 8
nicSelectorマッピングは、Operator が設定するイーサネットデバイスを選択します。すべてのパラメーターの値を指定する必要はありません。意図せずにイーサネットデバイスを選択する可能性を最低限に抑えるために、イーサネットアダプターを正確に特定できるようにすることが推奨されます。rootDevicesを指定する場合、vendor、deviceID、またはpfNameの値も指定する必要があります。pfNamesとrootDevicesの両方を同時に指定する場合、それらが同一のデバイスをポイントすることを確認します。- 9
- オプション: SR-IOV ネットワークデバイスのベンダー 16 進コードを指定します。許可される値は
8086または15b3のいずれかのみになります。 - 10
- オプション: SR-IOV ネットワークデバイスのデバイス 16 進コードを指定します。許可される値は
158b、1015、1017のみになります。 - 11
- オプション: このパラメーターは、1 つ以上のイーサネットデバイスの物理機能 (PF) 名の配列を受け入れます。
- 12
- このパラメーターは、イーサネットデバイスの物理機能についての 1 つ以上の PCI バスアドレスの配列を受け入れます。以下の形式でアドレスを指定します:
0000:02:00.1 - 13
- OpenShift Virtualization の仮想機能には、
vfio-pciドライバータイプが必要です。 - 14
- オプション: Remote Direct Memory Access (RDMA) モードを有効にするかどうかを指定します。Mellanox カードの場合、
isRdmaをfalseに設定します。デフォルト値はfalseです。
注記isRDMAフラグがtrueに設定される場合、引き続き RDMA 対応の VF を通常のネットワークデバイスとして使用できます。デバイスはどちらのモードでも使用できます。-
オプション: SR-IOV 対応のクラスターノードにまだラベルが付いていない場合は、
SriovNetworkNodePolicy.Spec.NodeSelectorでラベルを付けます。ノードのラベル付けについて、詳しくはノードのラベルを更新する方法についてを参照してください。 SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f <name>-sriov-node-network.yamlここで、
<name>はこの設定の名前を指定します。設定の更新が適用された後に、
sriov-network-operatornamespace のすべての Pod がRunningステータスに移行します。SR-IOV ネットワークデバイスが設定されていることを確認するには、以下のコマンドを実行します。
<node_name>を、設定したばかりの SR-IOV ネットワークデバイスを持つノードの名前に置き換えます。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'
9.19.4.3. SR-IOV の追加ネットワークの設定
SriovNetwork オブジェクト を作成して、SR-IOV ハードウェアを使用する追加のネットワークを設定できます。
SriovNetwork オブジェクトの作成時に、SR-IOV Network Operator は NetworkAttachmentDefinition オブジェクトを自動的に作成します。
SriovNetwork オブジェクトが running 状態の Pod または仮想マシンに割り当てられている場合、これを変更したり、削除したりしないでください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
-
以下の
SriovNetworkオブジェクトを作成してから、YAML を<name>-sriov-network.yamlファイルに保存します。<name>を、この追加ネットワークの名前に置き換えます。
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: <name>
namespace: openshift-sriov-network-operator
spec:
resourceName: <sriov_resource_name>
networkNamespace: <target_namespace>
vlan: <vlan>
spoofChk: "<spoof_check>"
linkState: <link_state>
maxTxRate: <max_tx_rate>
minTxRate: <min_rx_rate>
vlanQoS: <vlan_qos>
trust: "<trust_vf>"
capabilities: <capabilities> - 1
<name>をオブジェクトの名前に置き換えます。SR-IOV Network Operator は、同じ名前を持つNetworkAttachmentDefinitionオブジェクトを作成します。- 2
- SR-IOV ネットワーク Operator がインストールされている namespace を指定します。
- 3
<sriov_resource_name>を、この追加ネットワークの SR-IOV ハードウェアを定義するSriovNetworkNodePolicyオブジェクトの.spec.resourceNameパラメーターの値に置き換えます。- 4
<target_namespace>を SriovNetwork のターゲット namespace に置き換えます。ターゲット namespace の Pod または仮想マシンのみを SriovNetwork に割り当てることができます。- 5
- オプション:
<vlan>を、追加ネットワークの仮想 LAN (VLAN) ID に置き換えます。整数値は0から4095である必要があります。デフォルト値は0です。 - 6
- オプション:
<spoof_check>を VF の spoof check モードに置き換えます。許可される値は、文字列の"on"および"off"です。重要指定する値を引用符で囲む必要があります。そうしないと、CR は SR-IOV ネットワーク Operator によって拒否されます。
- 7
- オプション:
<link_state>を仮想機能 (VF) のリンクの状態に置き換えます。許可される値は、enable、disable、およびautoです。 - 8
- オプション:
<max_tx_rate>を VF の最大伝送レート (Mbps) に置き換えます。 - 9
- オプション:
<min_tx_rate>を VF の最小伝送レート (Mbps) に置き換えます。この値は、常に最大伝送レート以下である必要があります。注記Intel NIC は
minTxRateパラメーターをサポートしません。詳細は、BZ#1772847 を参照してください。 - 10
- オプション:
<vlan_qos>を VF の IEEE 802.1p 優先レベルに置き換えます。デフォルト値は0です。 - 11
- オプション:
<trust_vf>を VF の信頼モードに置き換えます。許可される値は、文字列の"on"および"off"です。重要指定する値を引用符で囲む必要があります。そうしないと、CR は SR-IOV ネットワーク Operator によって拒否されます。
- 12
- オプション:
<capabilities>を、このネットワークに設定する機能に置き換えます。
オブジェクトを作成するには、以下のコマンドを入力します。
<name>を、この追加ネットワークの名前に置き換えます。$ oc create -f <name>-sriov-network.yamlオプション: 以下のコマンドを実行して、直前の手順で作成した
SriovNetworkオブジェクトに関連付けられたNetworkAttachmentDefinitionオブジェクトが存在することを確認するには、以下のコマンドを入力します。<namespace>を、SriovNetworkオブジェクト で指定した namespace に置き換えます。$ oc get net-attach-def -n <namespace>
9.19.4.4. 仮想マシンの SR-IOV ネットワークへの接続
仮想マシンの設定にネットワークの詳細を含めることで、仮想マシンを SR-IOV ネットワークに接続することができます。
手順
SR-IOV ネットワークの詳細を仮想マシン設定の
spec.domain.devices.interfacesおよびspec.networksに追加します。kind: VirtualMachine ... spec: domain: devices: interfaces: - name: <default>1 masquerade: {}2 - name: <nic1>3 sriov: {} networks: - name: <default>4 pod: {} - name: <nic1>5 multus: networkName: <sriov-network>6 ...仮想マシン設定を適用します。
$ oc apply -f <vm-sriov.yaml>1 - 1
- 仮想マシン YAML ファイルの名前。
9.19.5. 仮想マシンのサービスメッシュへの接続
OpenShift Virtualization が OpenShift Service Mesh に統合されるようになりました。IPv4 を使用してデフォルトの Pod ネットワークで仮想マシンのワークロードを実行する Pod 間のトラフィックのモニター、可視化、制御が可能です。
9.19.5.1. 前提条件
- サービスメッシュ Operator を インストールし、サービスメッシュコントロールプレーン をデプロイしておく必要があります。
- 仮想マシンが作成される namespace を サービスメッシュメンバーロール に追加しておく必要があります。
-
デフォルトの Pod ネットワークには
masqueradeバインディングメソッドを使用する必要があります。
9.19.5.2. サービスメッシュの仮想マシンの設定
仮想マシン (VM) ワークロードをサービスメッシュに追加するには、sidecar.istio.io/inject アノテーションを true に設定して、仮想マシン設定ファイルでサイドカーコンテナーの自動挿入を有効にします。次に、仮想マシンをサービスとして公開し、メッシュでアプリケーションを表示します。
前提条件
- ポートの競合を回避するには、Istio サイドカープロキシーが使用するポートを使用しないでください。これには、ポート 15000、15001、15006、15008、15020、15021、および 15090 が含まれます。
手順
仮想マシン設定ファイルを編集し、
sidecar.istio.io/inject: "true"アノテーションを追加します。設定ファイルのサンプル
apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: labels: kubevirt.io/vm: vm-istio name: vm-istio spec: runStrategy: Always template: metadata: labels: kubevirt.io/vm: vm-istio app: vm-istio1 annotations: sidecar.istio.io/inject: "true"2 spec: domain: devices: interfaces: - name: default masquerade: {}3 disks: - disk: bus: virtio name: containerdisk - disk: bus: virtio name: cloudinitdisk resources: requests: memory: 1024M networks: - name: default pod: {} terminationGracePeriodSeconds: 180 volumes: - containerDisk: image: registry:5000/kubevirt/fedora-cloud-container-disk-demo:devel name: containerdisk仮想マシン設定を適用します。
$ oc apply -f <vm_name>.yaml1 - 1
- 仮想マシン YAML ファイルの名前。
Serviceオブジェクトを作成し、仮想マシンをサービスメッシュに公開します。apiVersion: v1 kind: Service metadata: name: vm-istio spec: selector: app: vm-istio1 ports: - port: 8080 name: http protocol: TCP- 1
- サービスの対象となる Pod セットを判別するサービスセレクターです。この属性は、仮想マシン設定ファイルの
spec.metadata.labelsフィールドに対応します。上記の例では、vm-istioという名前のServiceオブジェクトは、ラベルがapp=vm-istioの Pod の TCP ポート 8080 をターゲットにします。
サービスを作成します。
$ oc create -f <service_name>.yaml1 - 1
- サービス YAML ファイルの名前。
9.19.6. 仮想マシンの IP アドレスの設定
動的または静的のいずれかでプロビジョニングされた仮想マシンの IP アドレスを設定できます。
前提条件
- 仮想マシンは、外部ネットワーク に接続する必要があります。
- 仮想マシンの動的 IP を設定するには、追加のネットワークで使用可能な DHCP サーバーが必要です。
9.19.6.1. cloud-init を使用した新規仮想マシンの IP アドレスの設定
仮想マシンの作成時に cloud-init を使用して IP アドレスを設定できます。IP アドレスは、動的または静的にプロビジョニングできます。
手順
仮想マシン設定を作成し、仮想マシン設定の
spec.volumes.cloudInitNoCloud.networkDataフィールドに cloud-init ネットワークの詳細を追加します。動的 IP を設定するには、インターフェイス名と
dhcp4ブール値を指定します。kind: VirtualMachine spec: ... volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth1:1 dhcp4: true2 静的 IP を設定するには、インターフェイス名と IP アドレスを指定します。
kind: VirtualMachine spec: ... volumes: - cloudInitNoCloud: networkData: | version: 2 ethernets: eth1:1 addresses: - 10.10.10.14/242
9.19.7. NIC の IP アドレスの仮想マシンへの表示
Web コンソールまたは oc クライアントを使用して、ネットワークインターフェイスコントローラー (NIC) の IP アドレスを表示できます。QEMU ゲストエージェント は、仮想マシンのセカンダリーネットワークに関する追加情報を表示します。
9.19.7.1. 前提条件
- QEMU ゲストエージェントを仮想マシンにインストールしている。
9.19.7.2. CLI での仮想マシンインターフェイスの IP アドレスの表示
ネットワークインターフェイス設定は oc describe vmi <vmi_name> コマンドに含まれます。
IP アドレス情報は、仮想マシン上で ip addr を実行するか、oc get vmi <vmi_name> -o yaml を実行して表示することもできます。
手順
oc describeコマンドを使用して、仮想マシンインターフェイス設定を表示します。$ oc describe vmi <vmi_name>出力例
... Interfaces: Interface Name: eth0 Ip Address: 10.244.0.37/24 Ip Addresses: 10.244.0.37/24 fe80::858:aff:fef4:25/64 Mac: 0a:58:0a:f4:00:25 Name: default Interface Name: v2 Ip Address: 1.1.1.7/24 Ip Addresses: 1.1.1.7/24 fe80::f4d9:70ff:fe13:9089/64 Mac: f6:d9:70:13:90:89 Interface Name: v1 Ip Address: 1.1.1.1/24 Ip Addresses: 1.1.1.1/24 1.1.1.2/24 1.1.1.4/24 2001:de7:0:f101::1/64 2001:db8:0:f101::1/64 fe80::1420:84ff:fe10:17aa/64 Mac: 16:20:84:10:17:aa
9.19.7.3. Web コンソールでの仮想マシンインターフェイスの IP アドレスの表示
IP 情報は、仮想マシンの VirtualMachine details ページに表示されます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシン名を選択して、VirtualMachine details ページを開きます。
接続されている各 NIC の情報は、Details タブの IP Address の下に表示されます。
9.19.8. 仮想マシンの MAC アドレスプールの使用
KubeMacPool コンポーネントは、指定の namespace の仮想マシン NIC に MAC アドレスプールサービスを提供します。
9.19.8.1. KubeMacPool について
KubeMacPool は namespace ごとに MAC アドレスプールを提供し、プールから仮想マシン NIC の MAC アドレスを割り当てます。これにより、NIC には別の仮想マシンの MAC アドレスと競合しない一意の MAC アドレスが割り当てられます。
仮想マシンから作成される仮想マシンインスタンスは、再起動時に割り当てられる MAC アドレスを保持します。
KubeMacPool は、仮想マシンから独立して作成される仮想マシンインスタンスを処理しません。
KubeMacPool は、OpenShift Virtualization のインストール時にデフォルトで有効化されます。namespace の MAC アドレスプールは、mutatevirtualmachines.kubemacpool.io=ignore ラベルを namespace に追加して無効にできます。ラベルを削除して、namespace の KubeMacPool を再度有効にします。
9.19.8.2. CLI での namespace の MAC アドレスプールの無効化
mutatevirtualmachines.kubemacpool.io=ignore ラベルを namespace に追加して、namespace の仮想マシンの MAC アドレスプールを無効にします。
手順
mutatevirtualmachines.kubemacpool.io=ignoreラベルを namespace に追加します。以下の例では、KubeMacPool を 2 つの namespace (<namespace1>および<namespace2>) について無効にします。$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io=ignore
9.19.8.3. CLI での namespace の MAC アドレスプールを再度有効にする
namespace の KubeMacPool を無効にしている場合で、これを再度有効にする必要がある場合は、namespace から mutatevirtualmachines.kubemacpool.io=ignore ラベルを削除します。
以前のバージョンの OpenShift Virtualization では、mutatevirtualmachines.kubemacpool.io=allocate ラベルを使用して namespace の KubeMacPool を有効にしていました。これは引き続きサポートされますが、KubeMacPool がデフォルトで有効化されるようになったために不要になります。
手順
KubeMacPool ラベルを namespace から削除します。以下の例では、KubeMacPool を 2 つの namespace (
<namespace1>および<namespace2>) について再度有効にします。$ oc label namespace <namespace1> <namespace2> mutatevirtualmachines.kubemacpool.io-
9.20. 仮想マシンディスク
9.20.1. ストレージ機能
以下の表を使用して、OpenShift Virtualization のローカルおよび共有の永続ストレージ機能の可用性を確認できます。
9.20.1.1. OpenShift Virtualization ストレージ機能マトリクス
| 仮想マシンのライブマイグレーション | ホスト支援型仮想マシンディスクのクローン作成 | ストレージ支援型仮想マシンディスクのクローン作成 | 仮想マシンのスナップショット | |
|---|---|---|---|---|
| OpenShift Data Foundation: RBD ブロックモードボリューム | はい | はい | はい | はい |
| OpenShift Virtualization ホストパスプロビジョナー | いいえ | はい | いいえ | いいえ |
| 他の複数ノードの書き込み可能なストレージ | はい [1] | はい | はい [2] | はい [2] |
| 他の単一ノードの書き込み可能なストレージ | いいえ | はい | はい [2] | はい [2] |
- PVC は ReadWriteMany アクセスモードを要求する必要があります。
- ストレージプロバイダーが Kubernetes および CSI スナップショット API の両方をサポートする必要があります。
以下を使用する仮想マシンのライブマイグレーションを行うことはできません。
- ReadWriteOnce (RWO) アクセスモードのストレージクラス
- GPU などのパススルー機能
それらの仮想マシンの evictionStrategy フィールドを LiveMigrate に設定しないでください。
9.20.2. 仮想マシンのローカルストレージの設定
ホストパスプロビジョナー (HPP) を使用して、仮想マシンのローカルストレージを設定できます。
OpenShift Virtualization Operator のインストール時に、Hostpath Provisioner (HPP) Operator は自動的にインストールされます。HPP は、Hostpath Provisioner Operator によって作成される OpenShift Virtualization 用に設計されたローカルストレージプロビジョナーです。HPP を使用するには、HPP カスタムリソース (CR) を作成する必要があります。
9.20.2.1. 基本ストレージ プールを使用したホストパスプロビジョナーの作成
storagePools スタンザを使用して HPP カスタムリソース (CR) を作成することにより、基本ストレージプールを使用してホストパスプロビジョナー (HPP) を設定します。ストレージプールは、CSI ドライバーが使用する名前とパスを指定します。
前提条件
-
spec.storagePools.pathで指定されたディレクトリーには、読み取り/書き込みアクセス権が必要です。 - ストレージプールは、オペレーティングシステムと同じパーティションにあってはなりません。そうしないと、オペレーティングシステムのパーティションがいっぱいになり、パフォーマンスに影響を与えたり、ノードが不安定になったり、使用できなくなったりする可能性があります。
手順
次の例のように、
storagePoolsスタンザを含むhpp_cr.yamlファイルを作成します。apiVersion: hostpathprovisioner.kubevirt.io/v1beta1 kind: HostPathProvisioner metadata: name: hostpath-provisioner spec: imagePullPolicy: IfNotPresent storagePools:1 - name: any_name path: "/var/myvolumes"2 workload: nodeSelector: kubernetes.io/os: linux- ファイルを保存して終了します。
次のコマンドを実行して HPP を作成します。
$ oc create -f hpp_cr.yaml
9.20.2.1.1. ストレージクラスの作成について
ストレージクラスの作成時に、ストレージクラスに属する永続ボリューム (PV) の動的プロビジョニングに影響するパラメーターを設定します。StorageClass オブジェクトの作成後には、このオブジェクトのパラメーターを更新できません。
ホストパスプロビジョナー (HPP) を使用するには、storagePools スタンザで CSI ドライバーの関連付けられたストレージクラスを作成する必要があります。
仮想マシンは、ローカル PV に基づくデータボリュームを使用します。ローカル PV は特定のノードにバインドされます。ディスクイメージは仮想マシンで使用するために準備されますが、ローカルストレージ PV がすでに固定されたノードに仮想マシンをスケジュールすることができない可能性があります。
この問題を解決するには、Kubernetes Pod スケジューラーを使用して、永続ボリューム要求 (PVC) を正しいノードの PV にバインドします。volumeBindingMode パラメーターが WaitForFirstConsumer に設定された StorageClass 値を使用することにより、PV のバインディングおよびプロビジョニングは、Pod が PVC を使用して作成されるまで遅延します。
9.20.2.1.2. storagePools スタンザを使用した CSI ドライバーのストレージクラスの作成
ホストパス プロビジョナー (HPP) CSI ドライバー用のストレージクラスカスタムリソース (CR) を作成します。
手順
storageclass_csi.yamlファイルを作成して、ストレージクラスを定義します。apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: hostpath-csi provisioner: kubevirt.io.hostpath-provisioner reclaimPolicy: Delete1 volumeBindingMode: WaitForFirstConsumer2 parameters: storagePool: my-storage-pool3
- 1
reclaimPolicyには、DeleteおよびRetainの 2 つの値があります。値を指定しない場合、デフォルト値はDeleteです。- 2
volumeBindingModeパラメーターは、動的プロビジョニングとボリュームのバインディングが実行されるタイミングを決定します。WaitForFirstConsumerを指定して、永続ボリューム要求 (PVC) を使用する Pod が作成されるまで PV のバインディングおよびプロビジョニングを遅延させます。これにより、PV が Pod のスケジュール要件を満たすようになります。- 3
- HPP CR で定義されているストレージプールの名前を指定します。
- ファイルを保存して終了します。
次のコマンドを実行して、
StorageClassオブジェクトを作成します。$ oc create -f storageclass_csi.yaml
9.20.2.2. PVC テンプレートで作成されたストレージプールについて
単一の大きな永続ボリューム (PV) がある場合は、ホストパスプロビジョナー (HPP) カスタムリソース (CR) で PVC テンプレートを定義することにより、ストレージプールを作成できます。
PVC テンプレートで作成されたストレージプールには、複数の HPP ボリュームを含めることができます。PV を小さなボリュームに分割すると、データ割り当ての柔軟性が向上します。
PVC テンプレートは、PersistentVolumeClaim オブジェクトの spec スタンザに基づいています。
PersistentVolumeClaim オブジェクトの例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iso-pvc
spec:
volumeMode: Block
storageClassName: my-storage-class
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi- 1
- この値は、ブロックボリュームモードの PV にのみ必要です。
HPP CR の pvcTemplate 仕様を使用してストレージプールを定義します。Operator は、HPP CSI ドライバーを含む各ノードの pvcTemplate 仕様から PVC を作成します。PVC テンプレートから作成される PVC は単一の大きな PV を消費するため、HPP は小規模な動的ボリュームを作成できます。
基本的なストレージプールを、PVC テンプレートから作成されたストレージプールと組み合わせることができます。
9.20.2.2.1. PVC テンプレートを使用したストレージプールの作成
HPP カスタムリソース (CR) で PVC テンプレートを指定することにより、複数のホストパスプロビジョナー (HPP) ボリューム用のストレージプールを作成できます。
前提条件
-
spec.storagePools.pathで指定されたディレクトリーには、読み取り/書き込みアクセス権が必要です。 - ストレージプールは、オペレーティングシステムと同じパーティションにあってはなりません。そうしないと、オペレーティングシステムのパーティションがいっぱいになり、パフォーマンスに影響を与えたり、ノードが不安定になったり、使用できなくなったりする可能性があります。
手順
次の例に従って、
storagePoolsスタンザで永続ボリューム (PVC) テンプレートを指定する HPP CR のhpp_pvc_template_pool.yamlファイルを作成します。apiVersion: hostpathprovisioner.kubevirt.io/v1beta1 kind: HostPathProvisioner metadata: name: hostpath-provisioner spec: imagePullPolicy: IfNotPresent storagePools:1 - name: my-storage-pool path: "/var/myvolumes"2 pvcTemplate: volumeMode: Block3 storageClassName: my-storage-class4 accessModes: - ReadWriteOnce resources: requests: storage: 5Gi5 workload: nodeSelector: kubernetes.io/os: linux- 1
storagePoolsスタンザは、基本ストレージプールと PVC テンプレートストレージプールの両方を含むことができるアレイです。- 2
- このノードパスの下にストレージプールディレクトリーを指定します。
- 3
- オプション:
volumeModeパラメーターは、プロビジョニングされたボリューム形式と一致する限り、BlockまたはFilesystemのいずれかにすることができます。値が指定されていない場合、デフォルトはFilesystemです。volumeModeがBlockの場合、Pod をマウントする前にブロックボリュームに XFS ファイルシステムが作成されます。 - 4
storageClassNameパラメーターを省略すると、デフォルトのストレージクラスを使用して PVC を作成します。storageClassNameを省略する場合、HPP ストレージクラスがデフォルトのストレージクラスではないことを確認してください。- 5
- 静的または動的にプロビジョニングされるストレージを指定できます。いずれの場合も、要求されたストレージサイズが仮想的に分割する必要のあるボリュームに対して適切になるようにしてください。そうしないと、PVC を大規模な PV にバインドすることができません。使用しているストレージクラスが動的にプロビジョニングされるストレージを使用する場合、典型的な要求のサイズに一致する割り当てサイズを選択します。
- ファイルを保存して終了します。
次のコマンドを実行して、ストレージ プールを使用して HPP を作成します。
$ oc create -f hpp_pvc_template_pool.yaml
9.20.3. データボリュームの作成
データボリュームの作成時に、Containerized Data Importer (CDI) は永続ボリューム要求 (PVC) を作成し、PVC にデータを入力します。データボリュームは、スタンドアロンリソースとして、または仮想マシン仕様で dataVolumeTemplate リソースを使用することで、作成できます。PVC API またはストレージ API のいずれかを使用して、データボリュームを作成します。
OpenShift Container Platform Container Storage と共に OpenShift Virtualization を使用する場合、仮想マシンディスクの作成時に RBD ブロックモードの永続ボリューム要求 (PVC) を指定します。仮想マシンディスクの場合、RBD ブロックモードのボリュームは効率的で、Ceph FS または RBD ファイルシステムモードの PVC よりも優れたパフォーマンスを提供します。
RBD ブロックモードの PVC を指定するには、'ocs-storagecluster-ceph-rbd' ストレージクラスおよび VolumeMode: Block を使用します。
可能な限り、ストレージ API を使用して、スペースの割り当てを最適化し、パフォーマンスを最大化します。
ストレージプロファイル は、CDI が管理するカスタムリソースです。関連付けられたストレージクラスに基づく推奨ストレージ設定を提供します。ストレージクラスごとにストレージクラスが割り当てられます。
ストレージプロファイルを使用すると、コーディングを減らし、潜在的なエラーを最小限に抑えながら、データボリュームをすばやく作成できます。
認識されたストレージタイプの場合、CDI は PVC の作成を最適化する値を提供します。ただし、ストレージプロファイルをカスタマイズする場合は、ストレージクラスの自動設定を行うことができます。
9.20.3.1. ストレージ API を使用したデータボリュームの作成
ストレージ API を使用してデータボリュームを作成する場合、Containerized Data Interface (CDI) は、選択したストレージクラスでサポートされるストレージのタイプに基づいて、永続ボリューム要求 (PVC) の割り当てを最適化します。データボリューム名、namespace、および割り当てるストレージの量のみを指定する必要があります。
以下に例を示します。
-
Ceph RBD を使用する場合、
accessModesはReadWriteManyに自動設定され、ライブマイグレーションが可能になります。volumeModeは、パフォーマンスを最大化するためにBlockに設定されています。 -
volumeMode: Filesystemを使用する場合、ファイルシステムのオーバーヘッドに対応する必要がある場合は、CDI が追加の領域を自動的に要求します。
以下の YAML では、ストレージ API を使用して、2 ギガバイトの使用可能な領域を持つデータボリュームを要求します。ユーザーは、必要な永続ボリューム要求 (PVC) のサイズを適切に予測するために volumeMode を把握する必要はありません。CDI は accessModes 属性と volumeMode 属性の最適な組み合わせを自動的に選択します。これらの最適値は、ストレージのタイプまたはストレージプロファイルで定義するデフォルトに基づいています。カスタム値を指定する場合は、システムで計算された値を上書きします。
DataVolume 定義の例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: <datavolume>
spec:
source:
pvc:
namespace: "<source_namespace>"
name: "<my_vm_disk>"
storage:
resources:
requests:
storage: 2Gi
storageClassName: <storage_class> 9.20.3.2. PVC API を使用したデータボリュームの作成
PVC API を使用してデータボリュームを作成する場合、Containerized Data Interface (CDI) は、以下のフィールドに指定する内容に基づいてデータボリュームを作成します。
-
accessModes(ReadWriteOnce、ReadWrtieMany、またはReadOnlyMany) -
volumeMode(FilesystemまたはBlock) -
storageのcapacity(例:5Gi)
以下の YAML では、PVC API を使用して、2 ギガバイトのストレージ容量を持つデータボリュームを割り当てます。ReadWriteMany のアクセスモードを指定して、ライブマイグレーションを有効にします。システムがサポートできる値がわかっているので、デフォルトの Filesystem の代わりに Block ストレージを指定します。
DataVolume 定義の例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: <datavolume>
spec:
source:
pvc:
namespace: "<source_namespace>"
name: "<my_vm_disk>"
pvc:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
volumeMode: Block
storageClassName: <storage_class> - 1
- 新規データボリュームの名前。
- 2
sourceセクションでは、pvcはインポートのソースが既存の永続ボリューム要求 (PVC) であることを示しています。- 3
- ソース PVC が存在する namespace。
- 4
- ソース PVC の名前。
- 5
- PVC API を使用した割り当てを示します。
- 6
- PVC API を使用する場合は
accessModesが必要です。 - 7
- データボリュームに要求する領域のサイズを指定します。
- 8
- 宛先がブロック PVC であることを指定します。
- 9
- オプションで、ストレージクラスを指定します。ストレージクラスが指定されていない場合、システムデフォルトのストレージクラスが使用されます。
PVC API を使用してデータボリュームを明示的に割り当て、volumeMode: Block を使用していない場合は、ファイルシステムのオーバーヘッドを考慮してください。
ファイルシステムのオーバーヘッドは、ファイルシステムのメタデータを維持するために必要な領域のサイズです。ファイルシステムメタデータに必要な領域のサイズは、ファイルシステムに依存します。ストレージ容量要求でファイルシステムのオーバーヘッドに対応できない場合は、基礎となる永続ボリューム要求 (PVC) が仮想マシンディスクに十分に対応できない大きさとなる可能性があります。
ストレージ API を使用する場合、CDI はファイルシステムのオーバーヘッドを考慮し、割り当て要求が正常に実行されるように大きな永続ボリューム要求 (PVC) を要求します。
9.20.3.3. ストレージプロファイルのカスタマイズ
プロビジョナーのストレージクラスの StorageProfile オブジェクトを編集してデフォルトパラメーターを指定できます。これらのデフォルトパラメーターは、DataVolume オブジェクトで設定されていない場合にのみ永続ボリューム要求 (PVC) に適用されます。
前提条件
- 計画した設定がストレージクラスとそのプロバイダーでサポートされていることを確認してください。ストレージプロファイルに互換性のない設定を指定すると、ボリュームのプロビジョニングに失敗します。
ストレージプロファイルの空の status セクションは、ストレージプロビジョナーが Containerized Data Interface (CDI) によって認識されないことを示します。CDI で認識されないストレージプロビジョナーがある場合、ストレージプロファイルをカスタマイズする必要があります。この場合、管理者はストレージプロファイルに適切な値を設定し、割り当てが正常に実行されるようにします。
データボリュームを作成し、YAML 属性を省略し、これらの属性がストレージプロファイルで定義されていない場合は、要求されたストレージは割り当てられず、基礎となる永続ボリューム要求 (PVC) は作成されません。
手順
ストレージプロファイルを編集します。この例では、プロビジョナーは CDI によって認識されません。
$ oc edit -n openshift-cnv storageprofile <storage_class>ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <unknown_provisioner_class> # ... spec: {} status: provisioner: <unknown_provisioner> storageClass: <unknown_provisioner_class>ストレージプロファイルに必要な属性値を指定します。
ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1 kind: StorageProfile metadata: name: <unknown_provisioner_class> # ... spec: claimPropertySets: - accessModes: - ReadWriteOnce1 volumeMode: Filesystem2 status: provisioner: <unknown_provisioner> storageClass: <unknown_provisioner_class>変更を保存した後、選択した値がストレージプロファイルの
status要素に表示されます。
9.20.3.3.1. ストレージプロファイルを使用したデフォルトのクローンストラテジーの設定
ストレージプロファイルを使用してストレージクラスのデフォルトクローンメソッドを設定し、クローンストラテジー を作成できます。ストレージベンダーが特定のクローン作成方法のみをサポートする場合などに、クローンストラテジーを設定すると便利です。また、リソースの使用の制限やパフォーマンスの最大化を実現する手法を選択することもできます。
クローン作成ストラテジーは、ストレージプロファイルの cloneStrategy 属性を以下の値のいずれかに設定して指定できます。
-
snapshot: この方法は、スナップショットが設定されている場合にデフォルトで使用されます。このクローン作成ストラテジーは、一時的なボリュームスナップショットを使用してボリュームのクローンを作成します。ストレージプロビジョナーは CSI スナップショットをサポートする必要があります。 -
Copy: この方法では、ソース Pod およびターゲット Pod を使用して、ソースボリュームからターゲットボリュームにデータをコピーします。ホスト支援型でのクローン作成は、最も効率的な方法です。 -
csi-clone: この方法は、CSI クローン API を使用して、中間ボリュームスナップショットを使用せずに既存ボリュームのクローンを効率的に作成します。ストレージプロファイルが定義されていない場合にデフォルトで使用されるsnapshotまたはcopyとは異なり、CSI ボリュームのクローンは、プロビジョナーのストレージクラスのStorageProfileオブジェクトに指定した場合にだけ使用されます。
YAML spec セクションのデフォルトの claimPropertySets を変更せずに、CLI でクローンストラテジーを設定することもできます。
ストレージプロファイルの例
apiVersion: cdi.kubevirt.io/v1beta1
kind: StorageProfile
metadata:
name: <provisioner_class>
# ...
spec:
claimPropertySets:
- accessModes:
- ReadWriteOnce
volumeMode:
Filesystem
cloneStrategy:
csi-clone
status:
provisioner: <provisioner>
storageClass: <provisioner_class>9.20.4. ファイルシステムオーバーヘッドの PVC 領域の確保
デフォルトでは、OpenShift Virtualization は、Filesystem ボリュームモードを使用する永続ボリューム要求 (PVC) のファイルシステムオーバーヘッドデータ用に領域を確保します。この目的のためにグローバルに、および特定のストレージクラス用に領域を予約する割合を設定できます。
9.20.4.1. ファイルシステムのオーバーヘッドが仮想マシンディスクの領域に影響を与える仕組み
仮想マシンディスクを Filesystem ボリュームモードを使用する永続ボリューム要求 (PVC) に追加する場合、PVC で十分な容量があることを確認する必要があります。
- 仮想マシンディスク。
- メタデータなどのファイルシステムオーバーヘッド用に予約された領域
デフォルトでは、OpenShift Virtualization は PVC 領域の 5.5% をオーバーヘッド用に予約し、その分、仮想マシンディスクに使用できる領域を縮小します。
HCO オブジェクトを編集して、別のオーバーヘッド値を設定できます。値はグローバルに変更でき、特定のストレージクラスの値を指定できます。
9.20.4.2. デフォルトのファイルシステムオーバーヘッド値の上書き
HCO オブジェクトの spec.filesystemOverhead 属性を編集することで、OpenShift Virtualization がファイルシステムオーバーヘッド用に予約する永続ボリューム要求 (PVC) 領域の量を変更します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
HCOオブジェクトを編集用に開きます。$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedspec.filesystemOverheadフィールドを編集して、選択した値でデータを設定します。... spec: filesystemOverhead: global: "<new_global_value>"1 storageClass: <storage_class_name>: "<new_value_for_this_storage_class>"2 -
エディターを保存して終了し、
HCOオブジェクトを更新します。
検証
次のいずれかのコマンドを実行して、
CDIConfigステータスを表示し、変更を確認します。一般的に
CDIConfigへの変更を確認するには以下を実行します。$ oc get cdiconfig -o yamlCDIConfig に対する特定の変更を表示するには以下を実行します。$ oc get cdiconfig -o jsonpath='{.items..status.filesystemOverhead}'
9.20.5. コンピュートリソースクォータを持つ namespace で機能する CDI の設定
Containerized Data Importer (CDI) を使用して、CPU およびメモリーリソースの制限が適用される namespace に仮想マシンディスクをインポートし、アップロードし、そのクローンを作成できるようになりました。
9.20.5.1. namespace の CPU およびメモリークォータについて
ResourceQuota オブジェクトで定義される リソースクォータ は、その namespace 内のリソースが消費できるコンピュートリソースの全体量を制限する制限を namespace に課します。
HyperConverged カスタムリソース (CR) は、Containerized Data Importer (CDI) のユーザー設定を定義します。CPU とメモリーの要求値と制限値は、デフォルト値の 0 に設定されています。これにより、コンピュートリソース要件を指定しない CDI によって作成される Pod にデフォルト値が付与され、クォータで制限される namespace での実行が許可されます。
9.20.5.2. CPU およびメモリーのデフォルトの上書き
HyperConverged カスタムリソース (CR) に spec.resourceRequirements.storageWorkloads スタンザを追加して、CPU およびメモリー要求のデフォルト設定とユースケースの制限を変更します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、
HyperConvergedCR を編集します。$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedspec.resourceRequirements.storageWorkloadsスタンザを CR に追加し、ユースケースに基づいて値を設定します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: resourceRequirements: storageWorkloads: limits: cpu: "500m" memory: "2Gi" requests: cpu: "250m" memory: "1Gi"-
エディターを保存して終了し、
HyperConvergedCR を更新します。
9.20.6. データボリュームアノテーションの管理
データボリューム (DV) アノテーションを使用して Pod の動作を管理できます。1 つ以上のアノテーションをデータボリュームに追加してから、作成されたインポーター Pod に伝播できます。
9.20.6.1. 例: データボリュームアノテーション
以下の例は、インポーター Pod が使用するネットワークを制御するためにデータボリューム (DV) アノテーションを設定する方法を示しています。v1.multus-cni.io/default-network: bridge-network アノテーションにより、Pod は bridge-network という名前の multus ネットワークをデフォルトネットワークとして使用します。インポーター Pod にクラスターからのデフォルトネットワークとセカンダリー multus ネットワークの両方を使用させる必要がある場合は、k8s.v1.cni.cncf.io/networks: <network_name> アノテーションを使用します。
Multus ネットワークアノテーションの例
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: dv-ann
annotations:
v1.multus-cni.io/default-network: bridge-network
spec:
source:
http:
url: "example.exampleurl.com"
pvc:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi- 1
- Multus ネットワークアノテーション
9.20.7. データボリュームの事前割り当ての使用
Containerized Data Importer は、データボリュームの作成時に書き込みパフォーマンスを向上させるために、ディスク領域を事前に割り当てることができます。
特定のデータボリュームの事前割り当てを有効にできます。
9.20.7.1. 事前割り当てについて
Containerized Data Importer (CDI) は、データボリュームに QEMU 事前割り当てモードを使用し、書き込みパフォーマンスを向上できます。操作のインポートおよびアップロードには、事前割り当てモードを使用できます。また、空のデータボリュームを作成する際にも使用できます。
事前割り当てが有効化されている場合、CDI は基礎となるファイルシステムおよびデバイスタイプに応じて、より適切な事前割り当て方法を使用します。
fallocate-
ファイルシステムがこれをサポートする場合、CDI は
posix_fallocate関数を使用して領域を事前に割り当てるためにオペレーティングシステムのfallocate呼び出しを使用します。これは、ブロックを割り当て、それらを未初期化としてマークします。 full-
fallocateモードを使用できない場合は、基礎となるストレージにデータを書き込むことで、fullモードがイメージの領域を割り当てます。ストレージの場所によっては、空の割り当て領域がすべてゼロになる場合があります。
9.20.7.2. データボリュームの事前割り当ての有効化
データボリュームマニフェストに spec.preallocation フィールドを含めることにより、特定のデータボリュームの事前割り当てを有効にできます。Web コンソールで、または OpenShift CLI (oc) を使用して、事前割り当てモードを有効化することができます。
事前割り当てモードは、すべての CDI ソースタイプでサポートされます。
手順
データボリュームマニフェストの
spec.preallocationフィールドを指定します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: preallocated-datavolume spec: source:1 ... pvc: ... preallocation: true2
9.20.8. Web コンソールの使用によるローカルディスクイメージのアップロード
Web コンソールを使用して、ローカルに保存されたディスクイメージファイルをアップロードできます。
9.20.8.1. 前提条件
- 仮想マシンのイメージファイルには、IMG、ISO、または QCOW2 形式のファイルを使用する必要がある。
- CDI でサポートされる操作マトリックス に応じてスクラッチ領域が必要な場合は、この操作が正常に完了するように、まずは ストレージクラスを定義しているか、CDI スクラッチ領域を用意している。
9.20.8.2. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.20.8.3. Web コンソールを使用したイメージファイルのアップロード
Web コンソールを使用して、イメージファイルを新規の永続ボリューム要求 (PVC) にアップロードします。この PVC を後で使用して、イメージを新規の仮想マシンに割り当てることができます。
前提条件
以下のいずれかが必要である。
- ISO または IMG 形式のいずれかの raw 仮想マシンイメージファイル。
- QCOW2 形式の仮想マシンのイメージファイル。
最善の結果を得るには、アップロードする前にイメージファイルを以下のガイドラインに従って圧縮すること。
xzまたはgzipを使用して raw イメージファイルを圧縮します。注記圧縮された raw イメージファイルを使用すると、最も効率的にアップロードできます。
クライアントについて推奨される方法を使用して、QCOW2 イメージファイルを圧縮します。
- Linux クライアントを使用する場合は、virt-sparsify ツールを使用して、QCOW2 ファイルをスパース化 (sparsify) します。
-
Windows クライアントを使用する場合は、
xzまたはgzipを使用して QCOW2 ファイルを圧縮します。
手順
- Web コンソールのサイドメニューから、Storage → Persistent Volume Claims をクリックします。
- Create Persistent Volume Claim ドロップダウンリストをクリックし、これを拡張します。
- With Data Upload Form をクリックし、Upload Data to Persistent Volume Claim ページを開きます。
- Browse をクリックし、ファイルマネージャーを開き、アップロードするイメージを選択するか、ファイルを Drag a file here or browse to upload フィールドにドラッグします。
オプション: 特定のオペレーティングシステムのデフォルトイメージとしてこのイメージを設定します。
- Attach this data to a virtual machine operating system チェックボックスを選択します。
- リストからオペレーティングシステムを選択します。
- Persistent Volume Claim Name フィールドには、一意の名前が自動的に入力され、これを編集することはできません。PVC に割り当てられた名前をメモし、必要に応じてこれを後で特定できるようにします。
- Storage Class リストからストレージクラスを選択します。
Size フィールドに PVC のサイズ値を入力します。ドロップダウンリストから、対応する測定単位を選択します。
警告PVC サイズは圧縮解除された仮想ディスクのサイズよりも大きくなければなりません。
- 選択したストレージクラスに一致する Access Mode を選択します。
- Upload をクリックします。
9.20.9. virtctl ツールの使用によるローカルディスクイメージのアップロード
virtctl コマンドラインユーティリティーを使用して、ローカルに保存されたディスクイメージを新規または既存のデータボリュームにアップロードできます。
9.20.9.1. 前提条件
-
kubevirt-virtctlパッケージを 有効に すること。 - CDI でサポートされる操作マトリックス に応じてスクラッチ領域が必要な場合は、この操作が正常に完了するように、まずは ストレージクラスを定義しているか、CDI スクラッチ領域を用意している。
9.20.9.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.20.9.3. アップロードデータボリュームの作成
ローカルディスクイメージのアップロードに使用する upload データソースでデータボリュームを手動で作成できます。
手順
spec: source: upload{}を指定するデータボリューム設定を作成します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <upload-datavolume>1 spec: source: upload: {} pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>2 以下のコマンドを実行してデータボリュームを作成します。
$ oc create -f <upload-datavolume>.yaml
9.20.9.4. ローカルディスクイメージのデータボリュームへのアップロード
virtctl CLI ユーティリティーを使用して、ローカルディスクイメージをクライアントマシンからクラスター内のデータボリューム (DV) にアップロードできます。この手順の実行時に、すでにクラスターに存在する DV を使用するか、新規の DV を作成することができます。
ローカルディスクイメージのアップロード後に、これを仮想マシンに追加できます。
前提条件
以下のいずれかが必要である。
- ISO または IMG 形式のいずれかの raw 仮想マシンイメージファイル。
- QCOW2 形式の仮想マシンのイメージファイル。
最善の結果を得るには、アップロードする前にイメージファイルを以下のガイドラインに従って圧縮すること。
xzまたはgzipを使用して raw イメージファイルを圧縮します。注記圧縮された raw イメージファイルを使用すると、最も効率的にアップロードできます。
クライアントについて推奨される方法を使用して、QCOW2 イメージファイルを圧縮します。
- Linux クライアントを使用する場合は、virt-sparsify ツールを使用して、QCOW2 ファイルをスパース化 (sparsify) します。
-
Windows クライアントを使用する場合は、
xzまたはgzipを使用して QCOW2 ファイルを圧縮します。
-
kubevirt-virtctlパッケージがクライアントマシンにインストールされていること。 - クライアントマシンが OpenShift Container Platform ルーターの証明書を信頼するように設定されていること。
手順
以下を特定します。
- 使用するアップロードデータボリュームの名前。このデータボリュームが存在しない場合、これは自動的に作成されます。
- データボリュームのサイズ (アップロード手順の実行時に作成する必要がある場合)。サイズはディスクイメージのサイズ以上である必要があります。
- アップロードする必要のある仮想マシンディスクイメージのファイルの場所。
virtctl image-uploadコマンドを実行してディスクイメージをアップロードします。直前の手順で特定したパラメーターを指定します。以下に例を示します。$ virtctl image-upload dv <datavolume_name> \1 --size=<datavolume_size> \2 --image-path=</path/to/image> \3 注記-
新規データボリュームを作成する必要がない場合は、
--sizeパラメーターを省略し、--no-createフラグを含めます。 - ディスクイメージを PVC にアップロードする場合、PVC サイズは圧縮されていない仮想ディスクのサイズよりも大きくなければなりません。
-
HTTPS を使用したセキュアでないサーバー接続を許可するには、
--insecureパラメーターを使用します。--insecureフラグを使用する際に、アップロードエンドポイントの信頼性は検証 されない 点に注意してください。
-
新規データボリュームを作成する必要がない場合は、
オプション:データボリュームが作成されたことを確認するには、以下のコマンドを実行してすべてのデータボリュームを表示します。
$ oc get dvs
9.20.9.5. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.20.10. ブロックストレージデータボリュームへのローカルディスクイメージのアップロード
virtctl コマンドラインユーティリティーを使用して、ローカルのディスクイメージをブロックデータボリュームにアップロードできます。
このワークフローでは、ローカルブロックデバイスを使用して永続ボリュームを使用し、このブロックボリュームを upload データボリュームに関連付け、 virtctl を使用してローカルディスクイメージをデータボリュームにアップロードできます。
9.20.10.1. 前提条件
-
kubevirt-virtctlパッケージを 有効に すること。 - CDI でサポートされる操作マトリックス に応じてスクラッチ領域が必要な場合は、この操作が正常に完了するように、まずは ストレージクラスを定義しているか、CDI スクラッチ領域を用意している。
9.20.10.2. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.20.10.3. ブロック永続ボリュームについて
ブロック永続ボリューム (PV) は、raw ブロックデバイスによってサポートされる PV です。これらのボリュームにはファイルシステムがなく、オーバーヘッドを削減することで、仮想マシンのパフォーマンス上の利点をもたらすことができます。
raw ブロックボリュームは、PV および永続ボリューム要求 (PVC) 仕様で volumeMode: Block を指定してプロビジョニングされます。
9.20.10.4. ローカルブロック永続ボリュームの作成
ファイルにデータを設定し、これをループデバイスとしてマウントすることにより、ノードでローカルブロック永続ボリューム (PV) を作成します。次に、このループデバイスを PV マニフェストで Block ボリュームとして参照し、これを仮想マシンイメージのブロックデバイスとして使用できます。
手順
-
ローカル PV を作成するノードに
rootとしてログインします。この手順では、node01を例に使用します。 ファイルを作成して、これを null 文字で設定し、ブロックデバイスとして使用できるようにします。以下の例では、2Gb (20 100Mb ブロック) のサイズのファイル
loop10を作成します。$ dd if=/dev/zero of=<loop10> bs=100M count=20loop10ファイルをループデバイスとしてマウントします。$ losetup </dev/loop10>d3 <loop10>1 2 マウントされたループデバイスを参照する
PersistentVolumeマニフェストを作成します。kind: PersistentVolume apiVersion: v1 metadata: name: <local-block-pv10> annotations: spec: local: path: </dev/loop10>1 capacity: storage: <2Gi> volumeMode: Block2 storageClassName: local3 accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - <node01>4 ブロック PV を作成します。
# oc create -f <local-block-pv10.yaml>1 - 1
- 直前の手順で作成された永続ボリュームのファイル名。
9.20.10.5. アップロードデータボリュームの作成
ローカルディスクイメージのアップロードに使用する upload データソースでデータボリュームを手動で作成できます。
手順
spec: source: upload{}を指定するデータボリューム設定を作成します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <upload-datavolume>1 spec: source: upload: {} pvc: accessModes: - ReadWriteOnce resources: requests: storage: <2Gi>2 以下のコマンドを実行してデータボリュームを作成します。
$ oc create -f <upload-datavolume>.yaml
9.20.10.6. ローカルディスクイメージのデータボリュームへのアップロード
virtctl CLI ユーティリティーを使用して、ローカルディスクイメージをクライアントマシンからクラスター内のデータボリューム (DV) にアップロードできます。この手順の実行時に、すでにクラスターに存在する DV を使用するか、新規の DV を作成することができます。
ローカルディスクイメージのアップロード後に、これを仮想マシンに追加できます。
前提条件
以下のいずれかが必要である。
- ISO または IMG 形式のいずれかの raw 仮想マシンイメージファイル。
- QCOW2 形式の仮想マシンのイメージファイル。
最善の結果を得るには、アップロードする前にイメージファイルを以下のガイドラインに従って圧縮すること。
xzまたはgzipを使用して raw イメージファイルを圧縮します。注記圧縮された raw イメージファイルを使用すると、最も効率的にアップロードできます。
クライアントについて推奨される方法を使用して、QCOW2 イメージファイルを圧縮します。
- Linux クライアントを使用する場合は、virt-sparsify ツールを使用して、QCOW2 ファイルをスパース化 (sparsify) します。
-
Windows クライアントを使用する場合は、
xzまたはgzipを使用して QCOW2 ファイルを圧縮します。
-
kubevirt-virtctlパッケージがクライアントマシンにインストールされていること。 - クライアントマシンが OpenShift Container Platform ルーターの証明書を信頼するように設定されていること。
手順
以下を特定します。
- 使用するアップロードデータボリュームの名前。このデータボリュームが存在しない場合、これは自動的に作成されます。
- データボリュームのサイズ (アップロード手順の実行時に作成する必要がある場合)。サイズはディスクイメージのサイズ以上である必要があります。
- アップロードする必要のある仮想マシンディスクイメージのファイルの場所。
virtctl image-uploadコマンドを実行してディスクイメージをアップロードします。直前の手順で特定したパラメーターを指定します。以下に例を示します。$ virtctl image-upload dv <datavolume_name> \1 --size=<datavolume_size> \2 --image-path=</path/to/image> \3 注記-
新規データボリュームを作成する必要がない場合は、
--sizeパラメーターを省略し、--no-createフラグを含めます。 - ディスクイメージを PVC にアップロードする場合、PVC サイズは圧縮されていない仮想ディスクのサイズよりも大きくなければなりません。
-
HTTPS を使用したセキュアでないサーバー接続を許可するには、
--insecureパラメーターを使用します。--insecureフラグを使用する際に、アップロードエンドポイントの信頼性は検証 されない 点に注意してください。
-
新規データボリュームを作成する必要がない場合は、
オプション:データボリュームが作成されたことを確認するには、以下のコマンドを実行してすべてのデータボリュームを表示します。
$ oc get dvs
9.20.10.7. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.20.11. 仮想マシンスナップショットの管理
仮想マシンの電源がオフ (オフライン) またはオン (オンライン) であるかに拘らず、仮想マシンの仮想マシン (VM) スナップショットを作成および削除できます。電源オフ (オフライン) 状態の仮想マシンに対してのみ復元が可能です。OpenShift Virtualization は、以下にある仮想マシンのスナップショットをサポートします。
- Red Hat OpenShift Data Foundation
- Kubernetes Volume Snapshot API をサポートする Container Storage Interface (CSI) ドライバーを使用するその他のクラウドストレージプロバイダー
オンラインスナップショットのデフォルト期限は 5 分 (5m) で、必要に応じて変更できます。
オンラインスナップショットは、ホットプラグされた仮想ディスクを持つ仮想マシンでサポートされます。ただし、仮想マシンの仕様に含まれていないホットプラグされたディスクは、スナップショットに含まれません。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
9.20.11.1. 仮想マシンスナップショットについて
スナップショット は、特定の時点における仮想マシン (VM) の状態およびデータを表します。スナップショットを使用して、バックアップおよび障害復旧のために既存の仮想マシンを (スナップショットで表される) 以前の状態に復元したり、以前の開発バージョンに迅速にロールバックしたりできます。
仮想マシンのスナップショットは、電源がオフ (停止状態) またはオン (実行状態) の仮想マシンから作成されます。
実行中の仮想マシンのスナップショットを作成する場合には、コントローラーは QEMU ゲストエージェントがインストールされ、実行中であることを確認します。そのような場合には、スナップショットの作成前に仮想マシンファイルシステムをフリーズして、スナップショットの作成後にファイルシステムをロールアウトします。
スナップショットは、仮想マシンに割り当てられた各 Container Storage Interface (CSI) ボリュームのコピーと、仮想マシンの仕様およびメタデータのコピーを保存します。スナップショットは作成後に変更できません。
仮想マシンスナップショット機能を使用すると、クラスター管理者、およびアプリケーション開発者は以下を実行できます。
- 新規 SCC の作成
- 特定の仮想マシンに割り当てられているすべてのスナップショットのリスト表示
- スナップショットからの仮想マシンの復元
- 既存の仮想マシンスナップショットの削除
9.20.11.1.1. 仮想マシンスナップショットコントローラーおよびカスタムリソース定義 (CRD)
仮想マシンスナップショット機能では、スナップショットを管理するための CRD として定義された 3 つの新規 API オブジェクトが導入されました。
-
VirtualMachineSnapshot: スナップショットを作成するユーザー要求を表します。これには、仮想マシンの現在の状態に関する情報が含まれます。 -
VirtualMachineSnapshotContent: クラスター上のプロビジョニングされたリソース (スナップショット) を表します。これは、仮想マシンのスナップショットコントローラーによって作成され、仮想マシンの復元に必要なすべてのリソースへの参照が含まれます。 -
VirtualMachineRestore: スナップショットから仮想マシンを復元するユーザー要求を表します。
仮想マシンスナップショットコントローラーは、1 対 1 のマッピングで、VirtualMachineSnapshotContent オブジェクトを、この作成に使用した VirtualMachineSnapshot オブジェクトにバインドします。
9.20.11.2. QEMU ゲストエージェントの Linux 仮想マシンへのインストール
qemu-guest-agent は広く利用されており、Red Hat 仮想マシンでデフォルトで利用できます。このエージェントをインストールし、サービスを起動します。
仮想マシン (VM) に QEMU ゲストエージェントがインストールされ、実行されているかどうかを確認するには、AgentConnected が VM 仕様に表示されていることを確認します。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
手順
- コンソールのいずれか、SSH を使用して仮想マシンのコマンドラインにアクセスします。
QEMU ゲストエージェントを仮想マシンにインストールします。
$ yum install -y qemu-guest-agentサービスに永続性があることを確認し、これを起動します。
$ systemctl enable --now qemu-guest-agent
9.20.11.3. QEMU ゲストエージェントの Windows 仮想マシンへのインストール
Windows 仮想マシンの場合には、QEMU ゲストエージェントは VirtIO ドライバーに含まれます。既存または新規の Windows インストールにドライバーをインストールします。
仮想マシン (VM) に QEMU ゲストエージェントがインストールされ、実行されているかどうかを確認するには、AgentConnected が VM 仕様に表示されていることを確認します。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
9.20.11.3.1. VirtIO ドライバーの既存 Windows 仮想マシンへのインストール
VirtIO ドライバーを、割り当てられた SATA CD ドライブから既存の Windows 仮想マシンにインストールします。
この手順では、ドライバーを Windows に追加するための汎用的なアプローチを使用しています。このプロセスは Windows のバージョンごとに若干異なる可能性があります。特定のインストール手順については、お使いの Windows バージョンについてのインストールドキュメントを参照してください。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows ユーザーセッションにログインします。
Device Manager を開き、Other devices を拡張して、Unknown device をリスト表示します。
-
Device Propertiesを開いて、不明なデバイスを特定します。デバイスを右クリックし、Properties を選択します。 - Details タブをクリックし、Property リストで Hardware Ids を選択します。
- Hardware Ids の Value をサポートされる VirtIO ドライバーと比較します。
-
- デバイスを右クリックし、Update Driver Software を選択します。
- Browse my computer for driver software をクリックし、VirtIO ドライバーが置かれている割り当て済みの SATA CD ドライブの場所に移動します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- Next をクリックしてドライバーをインストールします。
- 必要なすべての VirtIO ドライバーに対してこのプロセスを繰り返します。
- ドライバーのインストール後に、Close をクリックしてウィンドウを閉じます。
- 仮想マシンを再起動してドライバーのインストールを完了します。
9.20.11.3.2. Windows インストール時の VirtIO ドライバーのインストール
Windows のインストール時に割り当てられた SATA CD ドライバーから VirtIO ドライバーをインストールします。
この手順では、Windows インストールの汎用的なアプローチを使用しますが、インストール方法は Windows のバージョンごとに異なる可能性があります。インストールする Windows のバージョンについてのドキュメントを参照してください。
手順
- 仮想マシンを起動し、グラフィカルコンソールに接続します。
- Windows インストールプロセスを開始します。
- Advanced インストールを選択します。
-
ストレージの宛先は、ドライバーがロードされるまで認識されません。
Load driverをクリックします。 - ドライバーは SATA CD ドライブとして割り当てられます。OK をクリックし、CD ドライバーでロードするストレージドライバーを参照します。ドライバーは、ドライバーのタイプ、オペレーティングシステム、および CPU アーキテクチャー別に階層的に編成されます。
- 必要なすべてのドライバーについて直前の 2 つの手順を繰り返します。
- Windows インストールを完了します。
9.20.11.4. Web コンソールでの仮想マシンのスナップショットの作成
Web コンソールを使用して仮想マシン (VM) を作成することができます。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
仮想マシンスナップショットには、以下の要件を満たすディスクのみが含まれます。
- データボリュームまたは永続ボリューム要求 (PVC) のいずれかでなければなりません。
- Container Storage Interface (CSI) ボリュームスナップショットをサポートするストレージクラスに属している必要があります。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- 仮想マシンが実行中の場合は、Actions → Stop をクリックして電源を切ります。
- Snapshots タブをクリックしてから Take Snapshot をクリックします。
- Snapshot Name およびオプションの Description フィールドに入力します。
- Disks included in this Snapshot を拡張し、スナップショットに組み込むストレージボリュームを表示します。
- 仮想マシンにスナップショットに追加できないディスクがあり、それでも続行する場合は、I am aware of this warning and wish to proceed チェックボックスをオンにします。
- Save をクリックします。
9.20.11.5. CLI での仮想マシンのスナップショットの作成
VirtualMachineSnapshot オブジェクトを作成し、オフラインまたはオンラインの仮想マシンの仮想マシン (VM) スナップショットを作成できます。KubeVirt は QEMU ゲストエージェントと連携し、オンライン仮想マシンのスナップショットを作成します。
整合性が最も高いオンライン (実行状態) の仮想マシンのスナップショットを作成するには、QEMU ゲストエージェントをインストールします。
QEMU ゲストエージェントは、システムのワークロードに応じて、可能な限り仮想マシンのファイルシステムの休止しようとすることで一貫性のあるスナップショットを取得します。これにより、スナップショットの作成前にインフライトの I/O がディスクに書き込まれるようになります。ゲストエージェントが存在しない場合は、休止はできず、ベストエフォートスナップショットが作成されます。スナップショットの作成条件は、Web コンソールまたは CLI に表示されるスナップショットの指示に反映されます。
前提条件
- 永続ボリューム要求 (PVC) が Container Storage Interface (CSI) ボリュームスナップショットをサポートするストレージクラスにあることを確認する。
-
OpenShift CLI (
oc) がインストールされている。 - オプション: スナップショットを作成する仮想マシンの電源を切ること。
手順
YAML ファイルを作成し、新規の
VirtualMachineSnapshotの名前およびソース仮想マシンの名前を指定するVirtualMachineSnapshotオブジェトを定義します。以下に例を示します。
apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineSnapshot metadata: name: my-vmsnapshot1 spec: source: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm2 VirtualMachineSnapshotリソースを作成します。スナップコントローラーはVirtualMachineSnapshotContentオブジェクトを作成し、これをVirtualMachineSnapshotにバインドし、VirtualMachineSnapshotオブジェクトのstatusおよびreadyToUseフィールドを更新します。$ oc create -f <my-vmsnapshot>.yamlオプション: オンラインスナップショットを作成している場合は、
waitコマンドを使用して、スナップショットのステータスを監視できます。以下のコマンドを入力します。
$ oc wait my-vm my-vmsnapshot --for condition=Readyスナップショットのステータスを確認します。
-
InProgress: オンラインスナップショットの操作が進行中です。 -
Succeeded: オンラインスナップショット操作が正常に完了しました。 Failed: オンラインスナップショットの操作に失敗しました。注記オンラインスナップショットのデフォルト期限は 5 分 (
5m) です。スナップショットが 5 分後に正常に完了しない場合には、ステータスがfailedに設定されます。その後、ファイルシステムと仮想マシンのフリーズが解除され、失敗したスナップショットイメージが削除されるまで、ステータスはfailedのままになります。デフォルトの期限を変更するには、仮想マシンスナップショット仕様に
FailureDeadline属性を追加して、スナップショット操作がタイムアウトするまでの時間を分単位 (m) または秒単位 (s) で指定します。期限を指定しない場合は、
0を指定できますが、仮想マシンが応答しなくなる可能性があるため、通常は推奨していません。mまたはsなどの時間の単位を指定しない場合、デフォルトは秒 (s) です。
-
検証
VirtualMachineSnapshotオブジェクトが作成されており、VirtualMachineSnapshotContentにバインドされていることを確認します。readyToUseフラグをtrueに設定する必要があります。$ oc describe vmsnapshot <my-vmsnapshot>出力例
apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineSnapshot metadata: creationTimestamp: "2020-09-30T14:41:51Z" finalizers: - snapshot.kubevirt.io/vmsnapshot-protection generation: 5 name: mysnap namespace: default resourceVersion: "3897" selfLink: /apis/snapshot.kubevirt.io/v1alpha1/namespaces/default/virtualmachinesnapshots/my-vmsnapshot uid: 28eedf08-5d6a-42c1-969c-2eda58e2a78d spec: source: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm status: conditions: - lastProbeTime: null lastTransitionTime: "2020-09-30T14:42:03Z" reason: Operation complete status: "False"1 type: Progressing - lastProbeTime: null lastTransitionTime: "2020-09-30T14:42:03Z" reason: Operation complete status: "True"2 type: Ready creationTime: "2020-09-30T14:42:03Z" readyToUse: true3 sourceUID: 355897f3-73a0-4ec4-83d3-3c2df9486f4f virtualMachineSnapshotContentName: vmsnapshot-content-28eedf08-5d6a-42c1-969c-2eda58e2a78d4 -
VirtualMachineSnapshotContentリソースのspec:volumeBackupsプロパティーをチェックし、予想される PVC がスナップショットに含まれることを確認します。
9.20.11.6. スナップショット指示を使用したオンラインスナップショット作成の確認
スナップショットの表示は、オンライン仮想マシン (VM) スナップショット操作に関するコンテキスト情報です。オフラインの仮想マシン (VM) スナップショット操作では、指示は利用できません。イベントは、オンラインスナップショット作成の詳説する際に役立ちます。
前提条件
- 指示を表示するには、CLI または Web コンソールを使用してオンライン仮想マシンスナップショットの作成を試行する必要があります。
手順
以下のいずれかを実行して、スナップショット指示からの出力を表示します。
-
CLI で作成されたスナップショットの場合には、status フィールドの
VirtualMachineSnapshotオブジェクト YAML にあるインジケーターの出力を確認します。 - Web コンソールを使用して作成されたスナップショットの場合には、Snapshot details 画面で VirtualMachineSnapshot > Status をクリックします。
-
CLI で作成されたスナップショットの場合には、status フィールドの
オンライン仮想マシンのスナップショットのステータスを確認します。
-
Onlineは、仮想マシンがオンラインスナップショットの作成時に実行されていることを示します。 -
NoGuestAgentは、QEMU ゲストエージェントがオンラインのスナップショットの作成時に実行されていないことを示します。QEMU ゲストエージェントがインストールされていないか、実行されていないか、別のエラーが原因で、QEMU ゲストエージェントを使用してファイルシステムをフリーズしてフリーズを解除できませんでした。
-
9.20.11.7. Web コンソールでのスナップショットからの仮想マシンの復元
仮想マシン (VM) は、Web コンソールのスナップショットで表される以前の設定に復元できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- 仮想マシンが実行中の場合は、Actions → Stop をクリックして電源を切ります。
- Snapshots タブをクリックします。このページには、仮想マシンに関連付けられたスナップショットのリストが表示されます。
仮想マシンのスナップショットを復元するには、以下のいずれかの方法を選択します。
- 仮想マシンを復元する際にソースとして使用するスナップショットの場合は、Restore をクリックします。
- スナップショットを選択して Snapshot Details 画面を開き、Actions → Restore VirtualMachineSnapshot をクリックします。
- 確認のポップアップウィンドウで Restore をクリックし、仮想マシンをスナップショットで表される以前の設定に戻します。
9.20.11.8. CLI でのスナップショットからの仮想マシンの復元
仮想マシンスナップショットを使用して、既存の仮想マシン (VM) を以前の設定に復元できます。オフラインの仮想マシンスナップショットからしか復元できません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 以前の状態に復元する仮想マシンの電源を切ること。
手順
復元する仮想マシンの名前およびソースとして使用されるスナップショットの名前を指定する
VirtualMachineRestoreオブジェクトを定義するために YAML ファイルを作成します。以下に例を示します。
apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineRestore metadata: name: my-vmrestore1 spec: target: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm2 virtualMachineSnapshotName: my-vmsnapshot3 VirtualMachineRestoreリソースを作成します。スナップショットコントローラーは、VirtualMachineRestoreオブジェクトのステータスフィールドを更新し、既存の仮想マシン設定をスナップショットのコンテンツに置き換えます。$ oc create -f <my-vmrestore>.yaml
検証
仮想マシンがスナップショットで表される以前の状態に復元されていることを確認します。
completeフラグはtrueに設定される必要があります。$ oc get vmrestore <my-vmrestore>出力例
apiVersion: snapshot.kubevirt.io/v1alpha1 kind: VirtualMachineRestore metadata: creationTimestamp: "2020-09-30T14:46:27Z" generation: 5 name: my-vmrestore namespace: default ownerReferences: - apiVersion: kubevirt.io/v1 blockOwnerDeletion: true controller: true kind: VirtualMachine name: my-vm uid: 355897f3-73a0-4ec4-83d3-3c2df9486f4f resourceVersion: "5512" selfLink: /apis/snapshot.kubevirt.io/v1alpha1/namespaces/default/virtualmachinerestores/my-vmrestore uid: 71c679a8-136e-46b0-b9b5-f57175a6a041 spec: target: apiGroup: kubevirt.io kind: VirtualMachine name: my-vm virtualMachineSnapshotName: my-vmsnapshot status: complete: true1 conditions: - lastProbeTime: null lastTransitionTime: "2020-09-30T14:46:28Z" reason: Operation complete status: "False"2 type: Progressing - lastProbeTime: null lastTransitionTime: "2020-09-30T14:46:28Z" reason: Operation complete status: "True"3 type: Ready deletedDataVolumes: - test-dv1 restoreTime: "2020-09-30T14:46:28Z" restores: - dataVolumeName: restore-71c679a8-136e-46b0-b9b5-f57175a6a041-datavolumedisk1 persistentVolumeClaim: restore-71c679a8-136e-46b0-b9b5-f57175a6a041-datavolumedisk1 volumeName: datavolumedisk1 volumeSnapshotName: vmsnapshot-28eedf08-5d6a-42c1-969c-2eda58e2a78d-volume-datavolumedisk1
9.20.11.9. Web コンソールでの仮想マシンのスナップショットの削除
Web コンソールを使用して既存の仮想マシンスナップショットを削除できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Snapshots タブをクリックします。このページには、仮想マシンに関連付けられたスナップショットの一覧が表示されます。
-
削除する仮想マシンスナップショットの Options メニュー
をクリックして、Delete VirtualMachineSnapshot を選択します。
- 確認のポップアップウィンドウで、Delete をクリックしてスナップショットを削除します。
9.20.11.10. CLI での仮想マシンのスナップショットの削除
適切な VirtualMachineSnapshot オブジェクトを削除して、既存の仮想マシン (VM) スナップショットを削除できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
VirtualMachineSnapshotオブジェクトを削除します。スナップショットコントローラーは、VirtualMachineSnapshotを、関連付けられたVirtualMachineSnapshotContentオブジェクトと共に削除します。$ oc delete vmsnapshot <my-vmsnapshot>
検証
スナップショットが削除され、この仮想マシンに割り当てられていないことを確認します。
$ oc get vmsnapshot
9.20.12. ローカル仮想マシンディスクの別のノードへの移動
ローカルボリュームストレージを使用する仮想マシンは、特定のノードで実行されるように移動することができます。
以下の理由により、仮想マシンを特定のノードに移動する場合があります。
- 現在のノードにローカルストレージ設定に関する制限がある。
- 新規ノードがその仮想マシンのワークロードに対して最適化されている。
ローカルストレージを使用する仮想マシンを移行するには、データボリュームを使用して基礎となるボリュームのクローンを作成する必要があります。クローン操作が完了したら、新規データボリュームを使用できるように 仮想マシン設定を編集 するか、新規データボリュームを別の仮想マシンに追加 することができます。
事前割り当てをグローバルに有効にする場合や、単一データボリュームについて、Containerized Data Importer (CDI) はクローン時にディスク領域を事前に割り当てます。事前割り当てにより、書き込みパフォーマンスが向上します。詳細は、データボリュームについての事前割り当ての使用 について参照してください。
cluster-admin ロールのないユーザーには、複数の namespace 間でボリュームのクローンを作成できるように 追加のユーザーパーミッション が必要になります。
9.20.12.1. ローカルボリュームの別のノードへのクローン作成
基礎となる永続ボリューム要求 (PVC) のクローンを作成して、仮想マシンディスクを特定のノードで実行するように移行することができます。
仮想マシンディスクのノードが適切なノードに作成されることを確認するには、新規の永続ボリューム (PV) を作成するか、該当するノードでそれを特定します。一意のラベルを PV に適用し、これがデータボリュームで参照できるようにします。
宛先 PV のサイズはソース PVC と同じか、それよりも大きくなければなりません。宛先 PV がソース PVC よりも小さい場合、クローン作成操作は失敗します。
前提条件
- 仮想マシンが実行されていないこと。仮想マシンディスクのクローンを作成する前に、仮想マシンの電源を切ります。
手順
ノードに新規のローカル PV を作成するか、ノードにすでに存在しているローカル PV を特定します。
nodeAffinity.nodeSelectorTermsパラメーターを含むローカル PV を作成します。以下のマニフェストは、node01に10Giのローカル PV を作成します。kind: PersistentVolume apiVersion: v1 metadata: name: <destination-pv>1 annotations: spec: accessModes: - ReadWriteOnce capacity: storage: 10Gi2 local: path: /mnt/local-storage/local/disk13 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node014 persistentVolumeReclaimPolicy: Delete storageClassName: local volumeMode: Filesystemターゲットノードに存在する PV を特定します。設定の
nodeAffinityフィールドを確認して、PV がプロビジョニングされるノードを特定することができます。$ oc get pv <destination-pv> -o yaml以下のスニペットは、PV が
node01にあることを示しています。出力例
... spec: nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname1 operator: In values: - node012 ...
PV に一意のラベルを追加します。
$ oc label pv <destination-pv> node=node01以下を参照するデータボリュームマニフェストを作成します。
- 仮想マシンの PVC 名と namespace。
- 直前の手順で PV に適用されたラベル。
宛先 PV のサイズ。
apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <clone-datavolume>1 spec: source: pvc: name: "<source-vm-disk>"2 namespace: "<source-namespace>"3 pvc: accessModes: - ReadWriteOnce selector: matchLabels: node: node014 resources: requests: storage: <10Gi>5
データボリュームマニフェストをクラスターに適用してクローン作成の操作を開始します。
$ oc apply -f <clone-datavolume.yaml>
データボリュームは、仮想マシンの PVC のクローンを特定のノード上の PV に作成します。
9.20.13. 空のディスクイメージを追加して仮想ストレージを拡張する
空のディスクイメージを OpenShift Virtualization に追加することによって、ストレージ容量を拡張したり、新規のデータパーティションを作成したりできます。
9.20.13.1. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.20.13.2. データボリュームを使用した空のディスクイメージの作成
データボリューム設定ファイルをカスタマイズし、デプロイすることにより、新規の空のディスクイメージを永続ボリューム要求 (PVC) に作成することができます。
前提条件
- 1 つ以上の利用可能な永続ボリュームがあること。
-
OpenShift CLI (
oc) がインストールされている。
手順
DataVolumeマニフェストを編集します。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: blank-image-datavolume spec: source: blank: {} pvc: # Optional: Set the storage class or omit to accept the default # storageClassName: "hostpath" accessModes: - ReadWriteOnce resources: requests: storage: 500Mi以下のコマンドを実行して、空のディスクイメージを作成します。
$ oc create -f <blank-image-datavolume>.yaml
9.20.14. smart-cloning を使用したデータボリュームのクローン作成
スマートクローニングは、Red Hat OpenShift Data Foundation の組み込み機能です。スマートクローニングは、ホストアシストクローニングよりも高速で効率的です。
smart-cloning を有効にするためにアクションを実行する必要はありませんが、この機能を使用するには、ストレージ環境が smart-cloning と互換性があることを確認する必要があります。
永続ボリューム要求 (PVC) ソースでデータボリュームを作成すると、クローン作成プロセスが自動的に開始します。お使いの環境で smart-cloning をサポートするかどうかにかかわらず、データボリュームのクローンは常に受信できます。ただし、ストレージプロバイダーが smart-cloning に対応している場合、smart-cloning によるパフォーマンス上のメリットが得られます。
9.20.14.1. smart-cloning について
データボリュームに smart-cloning が実行された場合、以下が発生します。
- ソースの永続ボリューム要求 (PVC) のスナップショットが作成されます。
- PVC はスナップショットから作成されます。
- スナップショットは削除されます。
9.20.14.2. データボリュームのクローン作成
前提条件
smart-cloning が実行されるには、以下の条件が必要です。
- ストレージプロバイダーはスナップショットをサポートする必要がある。
- ソースおよびターゲット PVC は、同じストレージクラスに定義される必要がある。
- ソースおよびターゲット PVC は同じ volumeMode を共有します。
-
VolumeSnapshotClassオブジェクトは、ソースおよびターゲット PVC の両方に定義されるストレージクラスを参照する必要がある。
手順
データボリュームのクローン作成を開始するには、以下を実行します。
新規データボリュームの名前およびソース PVC の名前と namespace 指定する
DataVolumeオブジェクトの YAML ファイルを作成します。この例では、ストレージ API を指定しているため、accessModes または volumeMode を指定する必要はありません。最適な値は、自動的に計算されます。apiVersion: cdi.kubevirt.io/v1beta1 kind: DataVolume metadata: name: <cloner-datavolume>1 spec: source: pvc: namespace: "<source-namespace>"2 name: "<my-favorite-vm-disk>"3 storage:4 resources: requests: storage: <2Gi>5 データボリュームを作成して PVC のクローン作成を開始します。
$ oc create -f <cloner-datavolume>.yaml注記データボリュームは仮想マシンが PVC の作成前に起動することを防ぐため、PVC のクローン作成中に新規データボリュームを参照する仮想マシンを作成できます。
9.20.15. ブートソースの作成および使用
ブートソースには、ブート可能なオペレーティングシステム (OS) とドライバーなどの OS のすべての設定が含まれます。
ブートソースを使用して、特定の設定で仮想マシンテンプレートを作成します。これらのテンプレートを使用して、利用可能な仮想マシンを多数作成することができます。
カスタムブートソースの作成、ブートソースのアップロード、およびその他のタスクを支援するために、OpenShift Container Platform Web コンソールでクイックスタートツアーを利用できます。Help メニューから Quick Starts を選択して、クイックスタートツアーを表示します。
9.20.15.1. 仮想マシンおよびブートソースについて
仮想マシンは、仮想マシン定義と、データボリュームでサポートされる 1 つ以上のディスクで設定されます。仮想マシンテンプレートを使用すると、事前定義された仮想マシン仕様を使用して仮想マシンを作成できます。
すべての仮想マシンテンプレートには、設定されたドライバーを含む完全に設定された仮想マシンディスクイメージであるブートソースが必要です。それぞれの仮想マシンテンプレートには、ブートソースへのポインターを含む仮想マシン定義が含まれます。各ブートソースには、事前に定義された名前および namespace があります。オペレーティングシステムによっては、ブートソースは自動的に提供されます。これが提供されない場合、管理者はカスタムブートソースを準備する必要があります。
提供されたブート ソースは、オペレーティングシステムの最新バージョンに自動的に更新されます。自動更新されたブートソースの場合、クラスターのデフォルトのストレージクラスを使用して、永続ボリューム要求 (PVC) が作成されます。設定後に別のデフォルトのストレージクラスを選択した場合は、以前のデフォルトのストレージクラスで設定されたクラスター namespace 内の既存のデータボリュームを削除する必要があります。
ブートソース機能を使用するには、OpenShift Virtualization の最新リリースをインストールします。namespace の openshift-virtualization-os-images はこの機能を有効にし、OpenShift Virtualization Operator でインストールされます。ブートソース機能をインストールしたら、ブートソースを作成してそれらをテンプレートに割り当て、テンプレートから仮想マシンを作成できます。
ローカルファイルのアップロード、既存 PVC のクローン作成、レジストリーからのインポート、または URL を使用して設定される永続ボリューム要求 (PVC) を使用してブートソースを定義します。Web コンソールを使用して、ブートソースを仮想マシンテンプレートに割り当てます。ブートソースが仮想マシンテンプレートに割り当てられた後に、テンプレートを使用して任意の数の完全に設定済みの準備状態の仮想マシンを作成できます。
9.20.15.2. RHEL イメージをブート ソースとしてインポートする
イメージの URL を指定して、Red Hat Enterprise Linux (RHEL) イメージをブートソースとしてインポートできます。
前提条件
- オペレーティングシステムイメージを含む Web ページにアクセスできる必要があります。例: イメージを含む Red Hat Enterprise Linux Web ページをダウンロードします。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → Templates をクリックします。
- ブートソースを設定する必要のある仮想マシンテンプレートを特定し、Add source をクリックします。
- Add boot source to template ウィンドウで、Boot source type リストから URL (creates PVC) を選択します。
- RHEL download page をクリックして Red Hat カスタマーポータルにアクセスします。利用可能なインストーラーおよびイメージのリストは、Red Hat Enterprise Linux のダウンロードページに表示されます。
- ダウンロードする Red Hat Enterprise Linux KVM ゲストイメージを特定します。Download Now を右クリックして、イメージの URL をコピーします。
- Add boot source to template ウィンドウで、URL を Import URL フィールドに貼り付け、Save and import をクリックします。
検証
- テンプレートの テンプレート ページの ブートソース 列に緑色のチェックマークが表示されていることを確認します。
このテンプレートを使用して RHEL 仮想マシンを作成できます。
9.20.15.3. 仮想マシンテンプレートのブートソースの追加
ブートソースは、仮想マシンの作成に使用するすべての仮想マシンテンプレートまたはカスタムテンプレートに設定できます。仮想マシンテンプレートがブートソースを使用して設定されている場合、それらには Templates ページで Source available というラベルが付けられます。ブートソースをテンプレートに追加した後に、テンプレートから新規仮想マシンを作成できます。
Web コンソールでブートソースを選択および追加する方法は 4 つあります。
- ローカルファイルのアップロード (PVC の作成)
- URL (PVC を作成)
- クローン (PVC を作成)
- レジストリー (PVC を作成)
前提条件
-
ブートソースを追加するには、
os-images.kubevirt.io:editRBAC ロールを持つユーザー、または管理者としてログインしていること。ブートソースが追加されたテンプレートから仮想マシンを作成するには、特別な権限は必要ありません。 - ローカルファイルをアップロードするには、オペレーティングシステムのイメージファイルがローカルマシンに存在している必要がある。
- URL を使用してインポートするには、オペレーティングシステムイメージのある Web サーバーへのアクセスが必要である。例: イメージが含まれる Red Hat Enterprise Linux Web ページ。
- 既存の PVC のクローンを作成するには、PVC を含むプロジェクトへのアクセスが必要である。
- レジストリーを使用してインポートするには、コンテナーレジストリーへのアクセスが必要である。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → Templates をクリックします。
- テンプレートの横にある Options メニューをクリックし、Edit boot source を選択します。
- ディスクの追加をクリックします。
- Add disk ウィンドウで、Use this disk as a boot source を選択します。
- ディスク名を入力し、Source を選択します。たとえば、Blank (creates PVC) または Use an existing PVC を選択します。
- Persistent Volume Claim size の値を入力し、圧縮解除されたイメージおよび必要な追加の領域に十分な PVC サイズを指定します。
- Type を選択します (Disk または CD-ROM など)。
オプション: Storage class をクリックし、ディスクを作成するために使用されるストレージクラスを選択します。通常、このストレージクラスはすべての PVC で使用するために作成されるデフォルトのストレージクラスです。
注記提供されたブート ソースは、オペレーティングシステムの最新バージョンに自動的に更新されます。自動更新されたブートソースの場合、クラスターのデフォルトのストレージクラスを使用して、永続ボリューム要求 (PVC) が作成されます。設定後に別のデフォルトのストレージクラスを選択した場合は、以前のデフォルトのストレージクラスで設定されたクラスター namespace 内の既存のデータボリュームを削除する必要があります。
- オプション: Apply optimized StorageProfile settings をオフにして、アクセスモードまたはボリュームモードを編集します。
ブートソースを保存する適切な方法を選択します。
- ローカルファイルをアップロードしている場合に、Save and upload をクリックします。
- URL またはレジストリーからコンテンツをインポートしている場合は、Save and import をクリックします。
- 既存の PVC のクローンを作成している場合は、Save and clone をクリックします。
ブートソースを含むカスタム仮想マシンテンプレートが Catalog ページにリスト表示されています。このテンプレートを使用して仮想マシンを作成できます。
9.20.15.4. ブートソースが割り当てられたテンプレートからの仮想マシンの作成
ブートソースをテンプレートに追加した後に、テンプレートから仮想マシンを作成できます。
手順
- Open Shift Container Platform Web コンソールのサイドメニューで、Virtualization → Catalog をクリックします。
- 更新されたテンプレートを選択し、Quick create VirtualMachine をクリックします。
VirtualMachine details が、Starting のステータスで表示されます。
9.20.16. 仮想ディスクのホットプラグ
仮想マシン (VM) または仮想マシンインスタンス (VMI) を停止することなく、仮想ディスクを追加または削除できます。
9.20.16.1. 仮想ディスクのホットプラグについて
仮想ディスクを ホットプラグ すると、仮想マシンの実行中に仮想ディスクを仮想マシンインスタンスに割り当てることができます。
仮想ディスクを ホットアンプラグ すると、仮想マシンの実行中に仮想ディスクの割り当てを仮想マシンインスタンスから解除できます。
データボリュームおよび永続ボリューム要求 (PVC) のみをホットプラグおよびホットアンプラグできます。コンテナーディスクのホットプラグおよびホットアンプラグはできません。
仮想ディスクをホットプラグした後は、仮想マシンを再起動しても、解除するまで接続されたままになります。
9.20.16.2. virtio-scsi について
OpenShift Virtualization では、ホットプラグされたディスクが SCSI バスを使用できるように、各仮想マシン (VM) に virtio-scsi コントローラーがあります。virtio-scsi コントローラーは、パフォーマンス上の利点を維持しながら、virtio の制限を克服します。スケーラビリティが高く、400 万台を超えるディスクのホットプラグをサポートします。
通常の virtio は、スケーラブルではないため、ホットプラグされたディスクでは使用できません。各 virtio ディスクは、VM 内の制限された PCI Express (PCIe) スロットの 1 つを使用します。PCIe スロットは他のデバイスでも使用され、事前に予約する必要があるため、オンデマンドでスロットを利用できない場合があります。
9.20.16.3. CLI を使用した仮想ディスクのホットプラグ
仮想マシンの実行中に仮想マシンインスタンス (VMI) に割り当てる必要のある仮想ディスクをホットプラグします。
前提条件
- 仮想ディスクをホットプラグするために実行中の仮想マシンが必要です。
- ホットプラグ用に 1 つ以上のデータボリュームまたは永続ボリューム要求 (PVC) が利用可能である必要があります。
手順
以下のコマンドを実行して、仮想ディスクをホットプラグします。
$ virtctl addvolume <virtual-machine|virtual-machine-instance> --volume-name=<datavolume|PVC> \ [--persist] [--serial=<label-name>]-
オプションの
--persistフラグを使用して、ホットプラグされたディスクを、永続的にマウントされた仮想ディスクとして仮想マシン仕様に追加します。仮想ディスクを永続的にマウントするために、仮想マシンを停止、再開または再起動します。--persistフラグを指定しても、仮想ディスクをホットプラグしたり、ホットアンプラグしたりできなくなります。--persistフラグは仮想マシンに適用され、仮想マシンインスタンスには適用されません。 -
オプションの
--serialフラグを使用すると、選択した英数字の文字列ラベルを追加できます。これは、ゲスト仮想マシンでホットプラグされたディスクを特定するのに役立ちます。このオプションを指定しない場合、ラベルはデフォルトでホットプラグされたデータボリュームまたは PVC の名前に設定されます。
-
オプションの
9.20.16.4. CLI を使用した仮想ディスクのホットアンプラグ
仮想マシンの実行中に仮想マシンインスタンス (VMI) から割り当てを解除する必要のある仮想ディスクをホットアンプラグします。
前提条件
- 仮想マシンが実行中である必要があります。
- 1 つ以上のデータボリュームまたは永続ボリューム要求 (PVC) が利用可能であり、ホットプラグされている必要があります。
手順
以下のコマンドを実行して、仮想ディスクをホットアンプラグします。
$ virtctl removevolume <virtual-machine|virtual-machine-instance> --volume-name=<datavolume|PVC>
9.20.16.5. Web コンソールを使用した仮想ディスクのホットプラグ
仮想マシンの実行中に仮想マシンインスタンス (VMI) に割り当てる必要のある仮想ディスクをホットプラグします。仮想ディスクをホットプラグすると、ホットアンプラグするまで VMI に接続されたままになります。
前提条件
- 仮想ディスクをホットプラグするために実行中の仮想マシンが必要です。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想ディスクをホットプラグする実行中の仮想マシンを選択します。
- VirtualMachine details ページで、Disks タブをクリックします。
- ディスクの追加をクリックします。
- Add disk (hot plugged) ウィンドウで、ホットプラグする仮想ディスクの情報を入力します。
- Save をクリックします。
9.20.16.6. Web コンソールを使用した仮想ディスクのホットアンプラグ
仮想マシンの実行中に仮想マシンインスタンス (VMI) から割り当てを解除する必要のある仮想ディスクをホットアンプラグします。
前提条件
- 仮想マシンが実行中で、ホットプラグされたディスクが接続されている必要があります。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- ホットアンプラグするディスクを含む実行中の仮想マシンを選択して、VirtualMachine details ページを開きます。
-
Disks タブで、ホットアンプラグする仮想ディスクの Options メニュー
をクリックします。
- Detach をクリックします。
9.20.17. 仮想マシンでのコンテナーディスクの使用
仮想マシンイメージをコンテナーディスクにビルドし、これをコンテナーレジストリーに保存することができます。次に、コンテナーディスクを仮想マシンの永続ストレージにインポートしたり、一時ストレージの仮想マシンに直接割り当てたりすることができます。
大規模なコンテナーディスクを使用する場合、I/O トラフィックが増え、ワーカーノードに影響を与える可能性があります。これにより、ノードが利用できなくなる可能性があります。この問題を解決するには、以下を実行します。
9.20.17.1. コンテナーディスクについて
コンテナーディスクは、コンテナーイメージレジストリーにコンテナーイメージとして保存される仮想マシンのイメージです。コンテナーディスクを使用して、同じディスクイメージを複数の仮想マシンに配信し、多数の仮想マシンのクローンを作成することができます。
コンテナーディスクは、仮想マシンに割り当てられるデータボリュームを使用して永続ボリューム要求 (PVC) にインポートするか、一時 containerDisk ボリュームとして仮想マシンに直接割り当てることができます。
9.20.17.1.1. データボリュームの使用によるコンテナーディスクの PVC へのインポート
Containerized Data Importer (CDI) を使用し、データボリュームを使用してコンテナーディスクを PVC にインポートします。次に、データボリュームを永続ストレージの仮想マシンに割り当てることができます。
9.20.17.1.2. コンテナーディスクの containerDisk ボリュームとしての仮想マシンへの割り当て
containerDisk ボリュームは一時的なボリュームです。これは、仮想マシンが停止されるか、再起動するか、削除される際に破棄されます。containerDisk ボリュームを持つ仮想マシンが起動すると、コンテナーイメージはレジストリーからプルされ、仮想マシンをホストするノードでホストされます。
containerDisk ボリュームは、CD-ROM などの読み取り専用ファイルシステム用に、または破棄可能な仮想マシン用に使用します。
データはホストノードのローカルストレージに一時的に書き込まれるため、読み取り/書き込みファイルシステムに containerDisk ボリュームを使用することは推奨されません。これにより、データを移行先ノードに移行する必要があるため、ノードのメンテナンス時など、仮想マシンのライブマイグレーションが遅くなります。さらに、ノードの電源が切れた場合や、予期せずにシャットダウンする場合にすべてのデータが失われます。
9.20.17.2. 仮想マシン用のコンテナーディスクの準備
仮想マシンイメージでコンテナーディスクをビルドし、これを仮想マシンで使用する前にこれをコンテナーレジストリーにプッシュする必要があります。次に、データボリュームを使用してコンテナーディスクを PVC にインポートし、これを仮想マシンに割り当てるか、コンテナーディスクを一時的な containerDisk ボリュームとして仮想マシンに直接割り当てることができます。
コンテナーディスク内のディスクイメージのサイズは、コンテナーディスクがホストされるレジストリーの最大レイヤーサイズによって制限されます。
Red Hat Quay の場合、Red Hat Quay の初回デプロイ時に作成される YAML 設定ファイルを編集して、最大レイヤーサイズを変更できます。
前提条件
-
podmanがインストールされていない場合はインストールすること。 - 仮想マシンイメージは QCOW2 または RAW 形式のいずれかであること。
手順
Dockerfile を作成して、仮想マシンイメージをコンテナーイメージにビルドします。仮想マシンイメージは、UID が
107の QEMU で所有され、コンテナー内の/disk/ディレクトリーに置かれる必要があります。次に、/disk/ディレクトリーのパーミッションは0440に設定する必要があります。以下の例では、Red Hat Universal Base Image (UBI) を使用して最初の段階でこれらの設定変更を処理し、2 番目の段階で最小の
scratchイメージを使用して結果を保存します。$ cat > Dockerfile << EOF FROM registry.access.redhat.com/ubi8/ubi:latest AS builder ADD --chown=107:107 <vm_image>.qcow2 /disk/1 RUN chmod 0440 /disk/* FROM scratch COPY --from=builder /disk/* /disk/ EOF- 1
- ここで、<vm_image> は QCOW2 または RAW 形式の仮想マシンイメージです。
リモートの仮想マシンイメージを使用するには、<vm_image>.qcow2をリモートイメージの完全な URL に置き換えます。
コンテナーをビルドし、これにタグ付けします。
$ podman build -t <registry>/<container_disk_name>:latest .コンテナーイメージをレジストリーにプッシュします。
$ podman push <registry>/<container_disk_name>:latest
コンテナーレジストリーに TLS がない場合は、コンテナーディスクを永続ストレージにインポートする前に非セキュアなレジストリーとしてこれを追加する必要があります。
9.20.17.3. 非セキュアなレジストリーとして使用するコンテナーレジストリーの TLS の無効化
HyperConverged カスタムリソースの insecureRegistries フィールドを編集して、1 つ以上のコンテナーレジストリーの TLS(トランスポート層セキュリティー) を無効にできます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにログインすること。
手順
HyperConvergedカスタムリソースを編集し、非セキュアなレジストリーの一覧をspec.storageImport.insecureRegistriesフィールドに追加します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: storageImport: insecureRegistries:1 - "private-registry-example-1:5000" - "private-registry-example-2:5000"- 1
- このリストのサンプルを、有効なレジストリーホスト名に置き換えます。
9.20.17.4. 次のステップ
- コンテナーディスクを仮想マシンの永続ストレージにインポート します。
-
一時ストレージの
containerDiskボリュームを使用する 仮想マシンを作成 します。
9.20.18. CDI のスクラッチ領域の用意
9.20.18.1. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.20.18.2. スクラッチ領域について
Containerized Data Importer (CDI) では、仮想マシンイメージのインポートやアップロードなどの、一部の操作を実行するためにスクラッチ領域 (一時ストレージ) が必要になります。このプロセスで、CDI は、宛先データボリューム (DV) をサポートする PVC のサイズと同じサイズのスクラッチ領域 PVC をプロビジョニングします。スクラッチ領域 PVC は操作の完了または中止後に削除されます。
HyperConverged カスタムリソースの spec.scratchSpaceStorageClass フィールドで、スクラッチ領域 PVC をバインドするために使用されるストレージクラスを定義できます。
定義されたストレージクラスがクラスターのストレージクラスに一致しない場合、クラスターに定義されたデフォルトのストレージクラス が使用されます。クラスターで定義されたデフォルトのストレージクラスがない場合、元の DV または PVC のプロビジョニングに使用されるストレージクラスが使用されます。
CDI では、元のデータボリュームをサポートする PVC の種類を問わず、file ボリュームモードが設定されているスクラッチ領域が必要です。元の PVC が block ボリュームモードでサポートされる場合、 file ボリュームモード PVC をプロビジョニングできるストレージクラスを定義する必要があります。
手動プロビジョニング
ストレージクラスがない場合、CDI はイメージのサイズ要件に一致するプロジェクトの PVC を使用します。これらの要件に一致する PVC がない場合、CDI インポート Pod は適切な PVC が利用可能になるまで、またはタイムアウト機能が Pod を強制終了するまで Pending 状態になります。
9.20.18.3. スクラッチ領域を必要とする CDI 操作
| タイプ | 理由 |
|---|---|
| レジストリーのインポート | CDI はイメージをスクラッチ領域にダウンロードし、イメージファイルを見つけるためにレイヤーを抽出する必要があります。その後、raw ディスクに変換するためにイメージファイルが QEMU-img に渡されます。 |
| イメージのアップロード | QEMU-IMG は STDIN の入力を受け入れません。代わりに、アップロードするイメージは、変換のために QEMU-IMG に渡される前にスクラッチ領域に保存されます。 |
| アーカイブされたイメージの HTTP インポート | QEMU-IMG は、CDI がサポートするアーカイブ形式の処理方法を認識しません。イメージが QEMU-IMG に渡される前にアーカイブは解除され、スクラッチ領域に保存されます。 |
| 認証されたイメージの HTTP インポート | QEMU-IMG が認証を適切に処理しません。イメージが QEMU-IMG に渡される前にスクラッチ領域に保存され、認証されます。 |
| カスタム証明書の HTTP インポート | QEMU-IMG は HTTPS エンドポイントのカスタム証明書を適切に処理しません。代わりに CDI は、ファイルを QEMU-IMG に渡す前にイメージをスクラッチ領域にダウンロードします。 |
9.20.18.4. ストレージクラスの定義
spec.scratchSpaceStorageClass フィールドを HyperConverged カスタムリソース (CR) に追加することにより、スクラッチ領域を割り当てる際に、Containerized Data Importer (CDI) が使用するストレージクラスを定義できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、
HyperConvergedCR を編集します。$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedspec.scratchSpaceStorageClassフィールドを CR に追加し、値をクラスターに存在するストレージクラスの名前に設定します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: scratchSpaceStorageClass: "<storage_class>"1 - 1
- ストレージクラスを指定しない場合、CDI は設定されている永続ボリューム要求 (PVC) のストレージクラスを使用します。
-
デフォルトのエディターを保存して終了し、
HyperConvergedCR を更新します。
9.20.18.5. CDI がサポートする操作マトリックス
このマトリックスにはエンドポイントに対してコンテンツタイプのサポートされる CDI 操作が表示されます。これらの操作にはスクラッチ領域が必要です。
| コンテンツタイプ | HTTP | HTTPS | HTTP Basic 認証 | レジストリー | アップロード |
|---|---|---|---|---|---|
| KubeVirt (QCOW2) |
✓ QCOW2 |
✓ QCOW2** |
✓ QCOW2 |
✓ QCOW2* |
✓ QCOW2* |
| KubeVirt (RAW) |
✓ RAW |
✓ RAW |
✓ RAW |
✓ RAW* |
✓ RAW* |
✓ サポートされる操作
□ サポートされない操作
* スクラッチ領域が必要
**カスタム認証局が必要な場合にスクラッチ領域が必要
9.20.19. 永続ボリュームの再利用
静的にプロビジョニングされた永続ボリューム (PV) を再利用するには、まずボリュームを回収する必要があります。これには、ストレージ設定を再利用できるように PV を削除する必要があります。
9.20.19.1. 静的にプロビジョニングされた永続ボリュームの回収について
永続ボリューム (PV) を回収する場合、PV のバインドを永続ボリューム要求 (PVC) から解除し、PV を削除します。基礎となるストレージによっては、共有ストレージを手動で削除する必要がある場合があります。
次に、PV 設定を再利用し、異なる名前の PV を作成できます。
静的にプロビジョニングされる PV には、回収に Retain の回収 (reclaim) ポリシーが必要です。これがない場合、PV は PVC が PV からのバインド解除時に failed 状態になります。
Recycle 回収ポリシーは OpenShift Container Platform 4 では非推奨となっています。
9.20.19.2. 静的にプロビジョニングされた永続ボリュームの回収
永続ボリューム要求 (PVC) のバインドを解除し、PV を削除して静的にプロビジョニングされた永続ボリューム (PV) を回収します。共有ストレージを手動で削除する必要がある場合もあります。
静的にプロビジョニングされる PV の回収方法は、基礎となるストレージによって異なります。この手順では、ストレージに応じてカスタマイズする必要がある可能性のある一般的な方法を示します。
手順
PV の回収ポリシーが
Retainに設定されていることを確認します。PV の回収ポリシーを確認します。
$ oc get pv <pv_name> -o yaml | grep 'persistentVolumeReclaimPolicy'persistentVolumeReclaimPolicyがRetainに設定されていない場合、以下のコマンドで回収ポリシーを編集します。$ oc patch pv <pv_name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
PV を使用しているリソースがないことを確認します。
$ oc describe pvc <pvc_name> | grep 'Mounted By:'PVC を使用するリソースをすべて削除してから継続します。
PVC を削除して PV を解放します。
$ oc delete pvc <pvc_name>オプション: PV 設定を YAML ファイルにエクスポートします。この手順の後半で共有ストレージを手動で削除する場合は、この設定を参照してください。このファイルで
specパラメーターをベースとして使用し、PV の回収後に同じストレージ設定で新規 PV を作成することもできます。$ oc get pv <pv_name> -o yaml > <file_name>.yamlPV を削除します。
$ oc delete pv <pv_name>オプション: ストレージタイプによっては、共有ストレージフォルダーの内容を削除する必要がある場合があります。
$ rm -rf <path_to_share_storage>オプション: 削除された PV と同じストレージ設定を使用する PV を作成します。回収された PV 設定をすでにエクスポートしている場合、そのファイルの
specパラメーターを新規 PV マニフェストのベースとして使用することができます。注記競合の可能性を回避するには、新規 PV オブジェクトに削除されたものとは異なる名前を割り当てることが推奨されます。
$ oc create -f <new_pv_name>.yaml
9.20.20. 仮想マシンディスクの拡張
仮想マシン (VM) のディスクのサイズを拡大して、ストレージ容量を増やすには、ディスクの永続ボリューム要求 (PVC) のサイズを変更します。
ただし、仮想マシンディスクのサイズを縮小することはできません。
9.20.20.1. 仮想マシンディスクの拡張
仮想マシンディスクの拡大により、仮想マシンに対して追加の領域が利用可能になります。ただし、仮想マシンの所有者は、ストレージの使用方法を決定する必要があります。
ディスクが Filesystem PVC の場合、一致するファイルは、ファイルシステムのオーバーヘッド用に一部の領域を確保しながら残りのサイズに拡張します。
手順
拡張する必要のある仮想マシンディスクの
PersistentVolumeClaimマニフェストを編集します。$ oc edit pvc <pvc_name>spec.resource.requests.storage属性の値を大きなサイズに変更します。apiVersion: v1 kind: PersistentVolumeClaim metadata: name: vm-disk-expand spec: accessModes: - ReadWriteMany resources: requests: storage: 3Gi1 ...- 1
- 拡張できる仮想マシンのディスクサイズ
9.20.21. データボリュームの削除
oc コマンドラインインターフェイスを使用して、データボリュームを手動で削除できます。
仮想マシンを削除する際に、これが使用するデータボリュームは自動的に削除されます。
9.20.21.1. データボリュームについて
DataVolume オブジェクトは、Containerized Data Importer (CDI) プロジェクトで提供されるカスタムリソースです。データボリュームは、基礎となる永続ボリューム要求 (PVC) に関連付けられるインポート、クローン作成、およびアップロード操作のオーケストレーションを行います。データボリュームは OpenShift Virtualization に統合され、仮想マシンが PVC の作成前に起動することを防ぎます。
9.20.21.2. すべてのデータボリュームのリスト表示
oc コマンドラインインターフェイスを使用して、クラスターのデータボリュームをリスト表示できます。
手順
以下のコマンドを実行して、データボリュームをリスト表示します。
$ oc get dvs
9.20.21.3. データボリュームの削除
oc コマンドラインインターフェイス (CLI) を使用してデータボリュームを削除できます。
前提条件
- 削除する必要のあるデータボリュームの名前を特定すること。
手順
以下のコマンドを実行し、データボリューム を削除します。
$ oc delete dv <datavolume_name>注記このコマンドは、現在のプロジェクトに存在するオブジェクトのみを削除します。削除する必要のあるオブジェクトが別のプロジェクトまたは namespace にある場合、
-n <project_name>オプションを指定します。
第10章 仮想マシンテンプレート
10.1. 仮想マシンテンプレートの作成
10.1.1. 仮想マシンテンプレートについて
事前設定された Red Hat 仮想マシンテンプレートは、Virtualization → Templates ページにリスト表示されます。このテンプレートは、Red Hat Enterprise Linux、Fedora、Microsoft Windows 10、および Microsoft Windows Server の異なるバージョンで利用できます。各 Red Hat 仮想マシンテンプレートは、オペレーティングシステムイメージ、オペレーティングシステム、フレーバー (CPU およびメモリー)、およびワークロードタイプ (サーバー) のデフォルト設定で事前に設定されます。
Templates ページには、4 種類の仮想マシンテンプレートが表示されます。
- Red Hat でサポートされる テンプレートは、Red Hat によって完全にサポートされています。
- ユーザーがサポート するテンプレートは、ユーザーがクローンして作成した Red Hat でサポートされる テンプレートです。
- Red Hat が提供する テンプレートには、Red Hat の制限されたサポートがあります。
- User Provided テンプレートは、ユーザーがクローンして作成した Red Hat Provided テンプレートです。
テンプレートカタログのフィルターを使用して、ブート ソースの可用性、オペレーティングシステム、ワークロードなどの属性でテンプレートを並べ替えることができます。
Red Hat が サポートするテンプレートまたは Red Hat が提供するテンプレートを編集または削除することはできません。テンプレートのクローンを作成し、カスタム仮想マシンテンプレートとして保存してから編集できます。
YAML ファイルの例を編集して、カスタム仮想マシンテンプレートを作成することもできます。
ストレージの動作の違いにより、一部の仮想マシンテンプレートは単一ノードの Openshift と互換性がありません。互換性を確保するためには、テンプレートまたはデータボリュームまたはストレージプロファイルを使用する仮想マシンにevictionStrategyフィールドを設定しないでください。
10.1.2. 仮想マシンおよびブートソースについて
仮想マシンは、仮想マシン定義と、データボリュームでサポートされる 1 つ以上のディスクで設定されます。仮想マシンテンプレートを使用すると、事前定義された仮想マシン仕様を使用して仮想マシンを作成できます。
すべての仮想マシンテンプレートには、設定されたドライバーを含む完全に設定された仮想マシンディスクイメージであるブートソースが必要です。それぞれの仮想マシンテンプレートには、ブートソースへのポインターを含む仮想マシン定義が含まれます。各ブートソースには、事前に定義された名前および namespace があります。オペレーティングシステムによっては、ブートソースは自動的に提供されます。これが提供されない場合、管理者はカスタムブートソースを準備する必要があります。
提供されたブート ソースは、オペレーティングシステムの最新バージョンに自動的に更新されます。自動更新されたブートソースの場合、クラスターのデフォルトのストレージクラスを使用して、永続ボリューム要求 (PVC) が作成されます。設定後に別のデフォルトのストレージクラスを選択した場合は、以前のデフォルトのストレージクラスで設定されたクラスター namespace 内の既存のデータボリュームを削除する必要があります。
ブートソース機能を使用するには、OpenShift Virtualization の最新リリースをインストールします。namespace の openshift-virtualization-os-images はこの機能を有効にし、OpenShift Virtualization Operator でインストールされます。ブートソース機能をインストールしたら、ブートソースを作成してそれらをテンプレートに割り当て、テンプレートから仮想マシンを作成できます。
ローカルファイルのアップロード、既存 PVC のクローン作成、レジストリーからのインポート、または URL を使用して設定される永続ボリューム要求 (PVC) を使用してブートソースを定義します。Web コンソールを使用して、ブートソースを仮想マシンテンプレートに割り当てます。ブートソースが仮想マシンテンプレートに割り当てられた後に、テンプレートを使用して任意の数の完全に設定済みの準備状態の仮想マシンを作成できます。
10.1.3. Web コンソールでの仮想マシンテンプレートの作成
OpenShift Container Platform Web コンソールで YAML ファイルの例を編集して、仮想マシンテンプレートを作成します。
手順
- Web コンソールのサイドメニューで、Virtualization → Templates をクリックします。
- Create Template をクリックします。
- YAML ファイルを編集して、テンプレートパラメーターを指定します。
Create をクリックします。
テンプレートが Templates ページに表示されます。
- オプション: Download をクリックして、YAML ファイルをダウンロードして保存します。
10.1.4. 仮想マシンテンプレートのブートソースの追加
ブートソースは、仮想マシンの作成に使用するすべての仮想マシンテンプレートまたはカスタムテンプレートに設定できます。仮想マシンテンプレートがブートソースを使用して設定されている場合、それらには Templates ページで Source available というラベルが付けられます。ブートソースをテンプレートに追加した後に、テンプレートから新規仮想マシンを作成できます。
Web コンソールでブートソースを選択および追加する方法は 4 つあります。
- ローカルファイルのアップロード (PVC の作成)
- URL (PVC を作成)
- クローン (PVC を作成)
- レジストリー (PVC を作成)
前提条件
-
ブートソースを追加するには、
os-images.kubevirt.io:editRBAC ロールを持つユーザー、または管理者としてログインしていること。ブートソースが追加されたテンプレートから仮想マシンを作成するには、特別な権限は必要ありません。 - ローカルファイルをアップロードするには、オペレーティングシステムのイメージファイルがローカルマシンに存在している必要がある。
- URL を使用してインポートするには、オペレーティングシステムイメージのある Web サーバーへのアクセスが必要である。例: イメージが含まれる Red Hat Enterprise Linux Web ページ。
- 既存の PVC のクローンを作成するには、PVC を含むプロジェクトへのアクセスが必要である。
- レジストリーを使用してインポートするには、コンテナーレジストリーへのアクセスが必要である。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → Templates をクリックします。
- テンプレートの横にある Options メニューをクリックし、Edit boot source を選択します。
- ディスクの追加をクリックします。
- Add disk ウィンドウで、Use this disk as a boot source を選択します。
- ディスク名を入力し、Source を選択します。たとえば、Blank (creates PVC) または Use an existing PVC を選択します。
- Persistent Volume Claim size の値を入力し、圧縮解除されたイメージおよび必要な追加の領域に十分な PVC サイズを指定します。
- Type を選択します (Disk または CD-ROM など)。
オプション: Storage class をクリックし、ディスクを作成するために使用されるストレージクラスを選択します。通常、このストレージクラスはすべての PVC で使用するために作成されるデフォルトのストレージクラスです。
注記提供されたブート ソースは、オペレーティングシステムの最新バージョンに自動的に更新されます。自動更新されたブートソースの場合、クラスターのデフォルトのストレージクラスを使用して、永続ボリューム要求 (PVC) が作成されます。設定後に別のデフォルトのストレージクラスを選択した場合は、以前のデフォルトのストレージクラスで設定されたクラスター namespace 内の既存のデータボリュームを削除する必要があります。
- オプション: Apply optimized StorageProfile settings をオフにして、アクセスモードまたはボリュームモードを編集します。
ブートソースを保存する適切な方法を選択します。
- ローカルファイルをアップロードしている場合に、Save and upload をクリックします。
- URL またはレジストリーからコンテンツをインポートしている場合は、Save and import をクリックします。
- 既存の PVC のクローンを作成している場合は、Save and clone をクリックします。
ブートソースを含むカスタム仮想マシンテンプレートが Catalog ページにリスト表示されています。このテンプレートを使用して仮想マシンを作成できます。
10.1.4.1. ブートソースを追加するための仮想マシンテンプレートフィールド
以下の表は、Add boot source to template ウインドウのフィールドについて説明しています。このウィンドウは、Virtualization → Templates ページで仮想マシンテンプレートの Add source をクリックしたときに表示されます。
| Name | パラメーター | Description |
|---|---|---|
| ブートソースタイプ | ローカルファイルのアップロード (PVC の作成) | ローカルデバイスからファイルをアップロードします。サポートされるファイルタイプには、gz、xz、tar、および qcow2 が含まれます。 |
| URL (PVC を作成) | HTTP または HTTPS エンドポイントで利用できるイメージからコンテンツをインポートします。イメージのダウンロードが可能な Web ページからダウンロードリンクの URL を取得し、その URL リンクを Import URL フィールドに入力します。例: Red Hat Enterprise Linux イメージについては、Red Hat カスタマーポータルにログインしてイメージのダウンロードページにアクセスし、KVM ゲストイメージのダウンロードリンク URL をコピーします。 | |
| PVC (PVC を作成) | クラスターですでに利用可能な PVC を使用し、このクローンを作成します。 | |
| レジストリー (PVC を作成) | クラスターからアクセスでき、レジストリーにある起動可能なオペレーティングシステムコンテナーを指定します。例: kubevirt/cirros-registry-dis-demo | |
| ソースプロバイダー | オプションフィールド。テンプレートのソース、またはテンプレートを作成したユーザーの名前についての説明テキストを追加します。例: Red Hat | |
| ストレージの詳細設定 | StorageClass | ディスクの作成に使用されるストレージクラス。 |
| アクセスモード |
永続ボリュームのアクセスモード。サポートされるアクセスモードは、Single User(RWO)、Shared Access(RWX)、Read Only (ROX) です。Single User (RWO) が選択される場合、ディスクは単一ノードによって読み取り/書き込み ( read/write) としてマウントできます。Shared Access (RWX) が選択される場合、ディスクは多数のノードによって読み取り/書き込み (read-write) としてマウントできます。 注記 Shared Access (RWX) は、ノード間の仮想マシンのライブマイグレーションなどの、一部の機能で必要になります。 | |
| ボリュームモード |
永続ボリュームがフォーマットされたファイルシステムまたは raw ブロック状態を使用するかどうかを定義します。サポートされるモードは Block および Filesystem です。 |
10.2. 仮想マシンテンプレートの編集
Web コンソールで仮想マシンテンプレートを削除できます。
Red Hat Virtualization Operator が提供するテンプレートは編集できません。テンプレートのクローンを作成すると、編集できます。
10.2.1. Web コンソールでの仮想マシンテンプレートの編集
関連するフィールドの横にある鉛筆アイコンをクリックして、Web コンソールの仮想マシンテンプレートの選択する値 (select values) を編集します。他の値は、CLI を使用して編集できます。
Red Hat が提供するものを含め、任意のテンプレートのラベルとアノテーションを編集できます。その他のフィールドは、ユーザーがカスタマイズしたテンプレートでのみ編集できます。
手順
- サイドメニューから Virtualization → Templates をクリックします。
- オプション: Filter ドロップダウンメニューを使用して、ステータス、テンプレート、ノード、またはオペレーティングシステム (OS) などの属性で仮想マシンテンプレートのリストを並べ替えます。
- 仮想マシン テンプレートを選択して、Template details ページを開きます。
- フィールドが編集可能であることを示す鉛筆アイコンが付いているフィールドをクリックします。たとえば、BIOS や UEFI などの現在の ブートモード 設定をクリックして、Boot mode ウィンドウを開き、リストからオプションを選択します。
- 関連する変更を加え、Save をクリックします。
仮想マシンテンプレートの編集は、そのテンプレートですでに作成された仮想マシンには影響を与えません。
10.2.1.1. 仮想マシンテンプレートフィールド
以下の表には、OpenShift Container Platform Web コンソールで編集できる仮想マシンテンプレートのフィールドが記載されています。
| タブ | フィールドまたは機能 |
|---|---|
| Details |
|
| YAML |
|
| スケジューリング |
|
| Network Interfaces |
|
| ディスク |
|
| スクリプト |
|
| パラメーター (オプション) |
|
10.2.1.2. ネットワークインターフェイスの仮想マシンテンプレートへの追加
以下の手順を使用して、ネットワークインターフェイスを仮想マシンテンプレートに追加します。
手順
- サイドメニューから Virtualization → Templates をクリックします。
- 仮想マシンテンプレートを選択して、Template details 画面を開きます。
- Network Interfaces タブをクリックします。
- Add Network Interface をクリックします。
- Add Network Interface ウィンドウで、ネットワークインターフェイスの Name、Model、Network、 Type、および MAC Address を指定します。
- Add をクリックします。
10.2.1.3. 仮想マシンテンプレートへの仮想ディスクの追加
以下の手順を使用して、仮想ディスクを仮想マシンテンプレートに追加します。
手順
- サイドメニューから Virtualization → Templates をクリックします。
- 仮想マシンテンプレートを選択して、Template details 画面を開きます。
- Disks タブをクリックし、Add disk をクリックします。
Add disk ウィンドウで、Source、Name、Size、Type、Interface、および Storage Class を指定します。
- オプション: 空のディスクソースを使用し、データボリュームの作成時に最大の書き込みパフォーマンスが必要な場合に、事前割り当てを有効にできます。そのためには、Enable preallocation チェックボックスをオンにします。
-
オプション: Apply optimized StorageProfile settings をクリアして、仮想ディスクの Volume Mode と Access Mode を変更できます。これらのパラメーターを指定しない場合、システムは
kubevirt-storage-class-defaultsconfig map のデフォルト値を使用します。
- Add をクリックします。
10.2.1.4. テンプレートの CD-ROM の編集
以下の手順を使用して、仮想マシンテンプレートの CD-ROM を設定します。
手順
- サイドメニューから Virtualization → Templates をクリックします。
- 仮想マシンテンプレートを選択して、Template details 画面を開きます。
- Disks タブをクリックします。
-
編集する CD-ROM の Options メニュー
をクリックし、Edit を選択します。
- Edit CD-ROM ウィンドウで、Source、Persistent Volume Claim、Name、Type、および Interface フィールドを編集します。
- Save をクリックします。
10.3. 仮想マシンテンプレートの専用リソースの有効化
パフォーマンスを向上させるために、仮想マシンには CPU などのノードの専用リソースを持たせることができます。
10.3.1. 専用リソースについて
仮想マシンの専用リソースを有効にする場合、仮想マシンのワークロードは他のプロセスで使用されない CPU でスケジュールされます。専用リソースを使用することで、仮想マシンのパフォーマンスとレイテンシーの予測の精度を向上させることができます。
10.3.2. 前提条件
-
CPU マネージャー がノード上に設定されている。仮想マシンのワークロードをスケジュールする前に、ノードに
cpumanager=trueラベルが設定されていることを確認します。
10.3.3. 仮想マシンテンプレートの専用リソースの有効化
Details タブで仮想マシンテンプレートの専用リソースを有効にします。Red Hat テンプレートから作成された仮想マシンは、専用のリソースで設定できます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → Templates をクリックします。
- 仮想マシン テンプレートを選択して、Template details ページを開きます。
- Scheduling タブで、Dedicated Resources の横にある鉛筆アイコンをクリックします。
- Schedule this workload with dedicated resources (guaranteed policy) を選択します。
- Save をクリックします。
10.4. 仮想マシンテンプレートのカスタム namespace へのデプロイ
Red Hat は、openshift namespace にインストールされる、事前に設定された仮想マシンテンプレートを提供します。ssp-operator は、デフォルトで仮想マシンテンプレートを openshift namespace にデプロイします。openshift namespace のテンプレートは、すべてのユーザーに広く公開されます。これらのテンプレートは、さまざまなオペレーティングシステムの Virtualization → Templates ページにリスト表示されています。
10.4.1. テンプレート用のカスタム namespace の作成
仮想マシンテンプレートをデプロイするために使用されるカスタム namespace を作成できます。このテンプレートは、アクセス権のある任意のユーザーが使用できます。テンプレートをカスタム namespace に追加するには、HyperConverged カスタムリソース (CR) を編集し、commonTemplatesNamespace を spec に追加し、仮想マシンテンプレートのカスタム namespace を指定します。HyperConverged CR の変更後に、ssp-operator はカスタム namespace のテンプレートに反映します。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 - cluster-admin 権限を持つユーザーとしてログインしている。
手順
以下のコマンドを使用してカスタム namespace を作成します。
$ oc create namespace <mycustomnamespace>
10.4.2. カスタム namespace へのテンプレートの追加
ssp-operator は、デフォルトで仮想マシンテンプレートを openshift namespace にデプロイします。openshift namespace のテンプレートは、すべてのユーザーに広く公開されます。カスタム namespace が作成され、テンプレートがその namespace に追加されると、openshift namespace の仮想マシンテンプレートを変更または削除することができます。テンプレートをカスタム namespace に追加するには、ssp-operator が含まれる HyperConverged カスタムリソース (CR) を編集します。
手順
openshiftnamespace で利用可能な仮想マシンテンプレートの一覧を表示します。$ oc get templates -n openshift以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedカスタム namespace で利用可能な仮想マシンテンプレートのリストを表示します。
$ oc get templates -n customnamespacecommonTemplatesNamespace属性を追加し、カスタム namespace を指定します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: commonTemplatesNamespace: customnamespace1 - 1
- テンプレートをデプロイするためのカスタム namespace。
-
変更を保存し、エディターを終了します。
ssp-operatorは、デフォルトのopenshiftnamespace にある仮想マシンテンプレートをカスタム namespace に追加します。
10.4.2.1. カスタム namespace からのテンプレートの削除
カスタム namespace から仮想マシンテンプレートを削除するには、HyperConverged カスタムリソース (CR) から commonTemplateNamespace 属性を削除し、そのカスタム namespace から各テンプレートを削除します。
手順
以下のコマンドを実行して、デフォルトエディターで
HyperConvergedCR を編集します。$ oc edit hco -n openshift-cnv kubevirt-hyperconvergedcommonTemplateNamespace属性を削除します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: commonTemplatesNamespace: customnamespace1 - 1
- 削除する
commonTemplatesNamespace属性。
削除されたカスタム namespace から特定のテンプレートを削除します。
$ oc delete templates -n customnamespace <template_name>
検証
テンプレートがカスタム namespace から削除されていることを確認します。
$ oc get templates -n customnamespace
10.5. 仮想マシンテンプレートの削除
Web コンソールを使用して、Red Hat テンプレートに基づいてカスタマイズされた仮想マシンテンプレートを削除できます。
Red Hat テンプレートは削除できません。
10.5.1. Web コンソールでの仮想マシンテンプレートの削除
仮想マシンテンプレートを削除すると、仮想マシンはクラスターから永続的に削除されます。
カスタマイズされた仮想マシンテンプレートを削除できます。Red Hat 提供のテンプレートは削除できません。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → Templates をクリックします。
-
テンプレートの Options メニュー
をクリックし、Delete template を選択します。
- Delete をクリックします。
第11章 ライブマイグレーション
11.1. 仮想マシンのライブマイグレーション
11.1.1. ライブマイグレーションについて
ライブマイグレーションは、仮想ワークロードまたはアクセスに支障を与えることなく、実行中の仮想マシンインスタンス (VMI) をクラスター内の別のノードに移行するプロセスです。VMI が LiveMigrate エビクションストラテジーを使用する場合、VMI が実行されるノードがメンテナンスモードになると自動的に移行されます。移行する VMI を選択して、ライブマイグレーションを手動で開始することもできます。
以下の条件を満たす場合は、ライブマイグレーションを使用できます。
-
ReadWriteMany(RWX) アクセスモードの共有ストレージ - 十分な RAM およびネットワーク帯域幅
- 仮想マシンがホストモデルの CPU を使用する場合、ノードは仮想マシンのホストモデルの CPU をサポートする必要があります。
デフォルトでは、ライブマイグレーショントラフィックは Transport Layer Security (TLS) を使用して暗号化されます。
11.2. ライブマイグレーションの制限およびタイムアウト
ライブマイグレーションの制限およびタイムアウトを適用し、移行プロセスによる負荷がクラスターにかからないようにします。HyperConverged カスタムリソース (CR) を編集してこれらの設定を行います。
11.2.1. ライブマイグレーションの制限およびタイムアウトの設定
openshift-cnv namespace にある HyperConverged カスタムリソース (CR) を更新して、クラスターのライブマイグレーションの制限およびタイムアウトを設定します。
手順
HyperConvergedCR を編集し、必要なライブマイグレーションパラメーターを追加します。$ oc edit hco -n openshift-cnv kubevirt-hyperconverged設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: liveMigrationConfig:1 bandwidthPerMigration: 64Mi completionTimeoutPerGiB: 800 parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 progressTimeout: 150- 1
- この例では、
spec.liveMigrationConfig配列には各フィールドのデフォルト値が含まれます。
注記キー/値のペアを削除し、ファイルを保存して、
spec.liveMigrationConfigフィールドのデフォルト値を復元できます。たとえば、progressTimeout: <value>を削除してデフォルトのprogressTimeout: 150を復元します。
11.2.2. クラスター全体のライブマイグレーションの制限およびタイムアウト
| パラメーター | 説明 | デフォルト |
|---|---|---|
|
| クラスターで並行して実行される移行の数。 | 5 |
|
| ノードごとのアウトバウンドの移行の最大数。 | 2 |
|
|
各マイグレーションの帯域幅制限。値は 1 秒あたりのバイト数です。たとえば、値 | 0 [1] |
|
|
移行がこの時間内に終了しない場合 (単位はメモリーの GiB あたりの秒数)、移行は取り消されます。たとえば、6GiB メモリーを持つ仮想マシンインスタンスは、4800 秒内に移行を完了しない場合にタイムアウトします。 | 800 |
|
| メモリーのコピーの進捗がこの時間内 (秒単位) に見られない場合に、移行は取り消されます。 | 150 |
-
デフォルト値の
0は無制限です。
11.3. 仮想マシンインスタンスの別のノードへの移行
Web コンソールまたは CLI のいずれかで仮想マシンインスタンスのライブマイグレーションを手動で開始します。
仮想マシンがホストモデルの CPU を使用する場合は、そのホストモデル CPU をサポートするノード間でのみ仮想マシンのライブマイグレーションを行うことができます。
11.3.1. Web コンソールでの仮想マシンインスタンスのライブマイグレーションの開始
実行中の仮想マシンインスタンスをクラスター内の別のノードに移行します。
Migrate アクションはすべてのユーザーに表示されますが、管理者ユーザーのみが仮想マシンの移行を開始できます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
このページから移行を開始すると、同じページで複数の仮想マシンに対してアクションを簡単に実行できます。または、選択した仮想マシンの包括的な詳細を表示できる VirtualMachine details ページから移行を開始できます。
-
仮想マシンの横にある Options メニュー
をクリックし、Migrate を選択します。
- 仮想マシン名をクリックして VirtualMachine details ページを開き、Actions → Migrate をクリックします。
-
仮想マシンの横にある Options メニュー
- Migrate をクリックして、仮想マシンを別のノードに移行します。
11.3.2. CLI での仮想マシンインスタンスのライブマイグレーションの開始
クラスターに VirtualMachineInstanceMigration オブジェクトを作成し、仮想マシンインスタンスの名前を参照して、実行中の仮想マシンインスタンスのライブマイグレーションを開始します。
手順
移行する仮想マシンインスタンスの
VirtualMachineInstanceMigration設定ファイルを作成します。vmi-migrate.yamlはこの例になります。apiVersion: kubevirt.io/v1 kind: VirtualMachineInstanceMigration metadata: name: migration-job spec: vmiName: vmi-fedora以下のコマンドを実行して、クラスター内にオブジェクトを作成します。
$ oc create -f vmi-migrate.yaml
VirtualMachineInstanceMigration オブジェクトは、仮想マシンインスタンスのライブマイグレーションをトリガーします。このオブジェクトは、手動で削除されない場合、仮想マシンインスタンスが実行中である限りクラスターに存在します。
11.4. 専用の追加ネットワークを介した仮想マシンの移行
ライブマイグレーション専用の Multus ネットワーク を設定できます。専用ネットワークは、ライブマイグレーション中のテナントワークロードに対するネットワークの飽和状態の影響を最小限に抑えます。
11.4.1. 仮想マシンのライブマイグレーション用の専用セカンダリーネットワークの設定
ライブマイグレーション専用のセカンダリーネットワークを設定するには、最初に CLI を使用して openshift-cnv namespace のブリッジネットワークアタッチメント定義を作成する必要があります。次に、NetworkAttachmentDefinition オブジェクトの名前を HyperConverged カスタムリソース (CR) に追加します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 - Multus Container Network Interface (CNI) プラグインがクラスターにインストールされている。
- クラスター内のすべてのノードには少なくとも 2 つのネットワークインターフェイスカード (NIC) があり、ライブマイグレーションに使用される NIC が同じ VLAN に接続されている。
-
仮想マシン (VM) が
LiveMigrateエビクションストラテジーで実行されている。
手順
NetworkAttachmentDefinitionマニフェストを作成します。設定ファイルのサンプル
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: my-secondary-network1 namespace: openshift-cnv2 spec: config: '{ "cniVersion": "0.3.1", "name": "migration-bridge", "type": "macvlan", "master": "eth1",3 "mode": "bridge", "ipam": { "type": "whereabouts",4 "range": "10.200.5.0/24"5 } }'以下のコマンドを実行して、デフォルトのエディターで
HyperConvergedCR を開きます。oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvNetworkAttachmentDefinitionオブジェクトの名前をHyperConvergedCR のspec.liveMigrationConfigスタンザに追加します。以下に例を示します。設定ファイルのサンプル
apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: liveMigrationConfig: completionTimeoutPerGiB: 800 network: my-secondary-network1 parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 progressTimeout: 150 ...- 1
- ライブマイグレーションに使用される Multus
NetworkAttachmentDefinitionオブジェクトの名前。
-
変更を保存し、エディターを終了します。
virt-handlerPod が再起動し、セカンダリーネットワークに接続されます。
検証
仮想マシンが実行されるノードがメンテナンスモードに切り替えられると、仮想マシンは自動的にクラスター内の別のノードに移行します。仮想マシンインスタンス (VMI) メタデータのターゲット IP アドレスを確認して、デフォルトの Pod ネットワークではなく、セカンダリーネットワーク上で移行が発生したことを確認できます。
oc get vmi <vmi_name> -o jsonpath='{.status.migrationState.targetNodeAddress}'
11.4.2. 関連情報
11.5. 仮想マシンインスタンスのライブマイグレーションのモニター
Web コンソールまたは CLI のいずれかで仮想マシンインスタンスのライブマイグレーションの進捗をモニターできます。
11.5.1. Web コンソールでの仮想マシンインスタンスのライブマイグレーションのモニター
移行期間中、仮想マシンのステータスは Migrating になります。このステータスは、VirtualMachines ページまたは移行中の仮想マシンの VirtualMachine details ページに表示されます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
11.5.2. CLI での仮想マシンインスタンスのライブマイグレーションのモニター
仮想マシンの移行のステータスは、VirtualMachineInstance 設定の Status コンポーネントに保存されます。
手順
移行中の仮想マシンインスタンスで
oc describeコマンドを使用します。$ oc describe vmi vmi-fedora出力例
... Status: Conditions: Last Probe Time: <nil> Last Transition Time: <nil> Status: True Type: LiveMigratable Migration Method: LiveMigration Migration State: Completed: true End Timestamp: 2018-12-24T06:19:42Z Migration UID: d78c8962-0743-11e9-a540-fa163e0c69f1 Source Node: node2.example.com Start Timestamp: 2018-12-24T06:19:35Z Target Node: node1.example.com Target Node Address: 10.9.0.18:43891 Target Node Domain Detected: true
11.6. 仮想マシンインスタンスのライブマイグレーションの取り消し
仮想マシンインスタンスを元のノードに残すためにライブマイグレーションを取り消すことができます。
Web コンソールまたは CLI のいずれかでライブマイグレーションを取り消します。
11.6.1. Web コンソールでの仮想マシンインスタンスのライブマイグレーションの取り消し
Web コンソールで仮想マシンインスタンスのライブマイグレーションをキャンセルできます。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
-
仮想マシンの横にある Options メニュー
をクリックし、Cancel Migration を選択します。
11.6.2. CLI での仮想マシンインスタンスのライブマイグレーションの取り消し
移行に関連付けられた VirtualMachineInstanceMigration オブジェクトを削除して、仮想マシンインスタンスのライブマイグレーションを取り消します。
手順
ライブマイグレーションをトリガーした
VirtualMachineInstanceMigrationオブジェクトを削除します。 この例では、migration-jobが使用されています。$ oc delete vmim migration-job
11.7. 仮想マシンのエビクションストラテジーの設定
LiveMigrate エビクションストラテジーは、ノードがメンテナンス状態になるか、ドレイン (解放) される場合に仮想マシンインスタンスが中断されないようにします。このエビクションストラテジーを持つ仮想マシンインスタンスのライブマイグレーションが別のノードに対して行われます。
11.7.1. LiveMigration エビクションストラテジーでのカスタム仮想マシンの設定
LiveMigration エビクションストラテジーはカスタム仮想マシンでのみ設定する必要があります。共通テンプレートには、デフォルトでこのエビクションストラテジーが設定されています。
手順
evictionStrategy: LiveMigrateオプションを、仮想マシン設定ファイルのspec.template.specセクションに追加します。この例では、oc editを使用してVirtualMachine設定ファイルの関連するスニペットを更新します。$ oc edit vm <custom-vm> -n <my-namespace>apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: custom-vm spec: template: spec: evictionStrategy: LiveMigrate ...更新を有効にするために仮想マシンを再起動します。
$ virtctl restart <custom-vm> -n <my-namespace>
11.8. ライブマイグレーションポリシーの設定
ライブマイグレーションポリシーを使用して、指定した仮想マシンインスタンス (VMI) のグループに対して、さまざまな移行設定を定義できます。
ライブマイグレーションポリシーは、テクノロジープレビュー機能のみとなります。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
11.8.1. ライブマイグレーションポリシーの設定
MigrationPolicy カスタムリソース定義 (CRD) を使用して、選択した仮想マシンインスタンス (VMI) の 1 つ以上のグループの移行ポリシーを定義します。
次の任意の組み合わせを使用して、VMI のグループを指定できます。
-
size、os、gpu、およびその他の VMI ラベルなどの仮想マシンインスタンスラベル。 -
priority、bandwidth、hpc-workload、およびその他の namespace ラベルなどの namespace ラベル。
ポリシーを特定の VMI グループに適用するには、VMI グループのすべてのラベルがポリシーのラベルと一致する必要があります。
複数のライブマイグレーションポリシーが VMI に適用される場合は、一致するラベルの数が最も多いポリシーが優先されます。複数のポリシーがこの基準を満たす場合、ポリシーは一致するラベルキーの辞書式順序でソートされ、その順序の最初のポリシーが優先されます。
手順
指定した VMI グループの
MigrationPolicyCRD を作成します。次の YAML の例では、ラベルhpc-workloads:true、xyz-workloads-type: ""、workload-type: db、およびoperating-system: ""でグループを設定します。apiVersion: migrations.kubevirt.io/v1alpha1 kind: MigrationPolicy metadata: name: my-awesome-policy spec: # Migration Configuration allowAutoConverge: true bandwidthPerMigration: 217Ki completionTimeoutPerGiB: 23 allowPostCopy: false # Matching to VMIs selectors: namespaceSelector:1 matchLabels: hpc-workloads: "True" xyz-workloads-type: "" virtualMachineInstanceSelector:2 matchLabels: workload-type: "db" operating-system: ""
第12章 ノードのメンテナンス
12.1. ノードのメンテナンスについて
12.1.1. ノードのメンテナンスモードについて
oc adm ユーティリティーまたは NodeMaintenance カスタムリソース (CR) を使用してノードをメンテナンスモードにすることができます。
node-maintenance-operator (NMO) は OpenShift Virtualization に同梱されなくなりました。OpenShift Container Platform Web コンソールの OperatorHub から、または OpenShift CLI (oc) を使用して、スタンドアロン Operator としてデプロイできるようになりました。
ノードがメンテナンス状態になると、ノードにはスケジュール対象外のマークが付けられ、ノードからすべての仮想マシンおよび Pod がドレイン (解放) されます。LiveMigrate エビクションストラテジーを持つ仮想マシンインスタンスのライブマイグレーションは、サービスが失われることなく実行されます。このエビクションストラテジーはデフォルトで共通テンプレートから作成される仮想マシンで設定されますが、カスタム仮想マシンの場合には手動で設定される必要があります。
エビクションストラテジーのない仮想マシンインスタンスはシャットダウンします。RunStrategy が Running または RerunOnFailure の仮想マシンは別のノードで再作成されます。RunStrategy が Manual の仮想マシンは自動的に再起動されません。
仮想マシンでは、共有 ReadWriteMany (RWX) アクセスモードを持つ永続ボリューム要求 (PVC) のライブマイグレーションが必要です。
Node Maintenance Operator は、新規または削除された NodeMaintenance CR をモニタリングします。新規の NodeMaintenance CR が検出されると、新規ワークロードはスケジュールされず、ノードは残りのクラスターから遮断されます。エビクトできるすべての Pod はノードからエビクトされます。NodeMaintenance CR が削除されると、CR で参照されるノードは新規ワークロードで利用可能になります。
ノードのメンテナンスタスクに NodeMaintenance CR を使用すると、標準の OpenShift Container Platform カスタムリソース処理を使用して oc adm cordon および oc adm drain コマンドの場合と同じ結果が得られます。
12.1.2. ベアメタルノードのメンテナンス
OpenShift Container Platform をベアメタルインフラストラクチャーにデプロイする場合、クラウドインフラストラクチャーにデプロイする場合と比較すると、追加で考慮する必要のある点があります。クラスターノードが一時的とみなされるクラウド環境とは異なり、ベアメタルノードを再プロビジョニングするには、メンテナンスタスクにより多くの時間と作業が必要になります。
致命的なカーネルエラーが発生したり、NIC カードのハードウェア障害が発生する場合などにベアメタルノードに障害が発生した場合には、障害のあるノードが修復または置き換えられている間に、障害が発生したノード上のワークロードをクラスターの別の場所で再起動する必要があります。ノードのメンテナンスモードにより、クラスター管理者はノードの電源を正常に停止し、ワークロードをクラスターの他の部分に移動させ、ワークロードが中断されないようにします。詳細な進捗とノードのステータスについての詳細は、メンテナンス時に提供されます。
12.2. TLS 証明書の自動更新
OpenShift Virtualization コンポーネントの TLS 証明書はすべて更新され、自動的にローテーションされます。手動で更新する必要はありません。
12.2.1. TLS 証明書の自動更新スケジュール
TLS 証明書は自動的に削除され、以下のスケジュールに従って置き換えられます。
- KubeVirt 証明書は毎日更新されます。
- Containerized Data Importer controller (CDI) 証明書は、15 日ごとに更新されます。
- MAC プール証明書は毎年更新されます。
TLS 証明書の自動ローテーションはいずれの操作も中断しません。たとえば、以下の操作は中断せずに引き続き機能します。
- 移行
- イメージのアップロード
- VNC およびコンソールの接続
12.3. 古い CPU モデルのノードラベルの管理
VM CPU モデルおよびポリシーがノードでサポートされている限り、ノードで仮想マシン (VM) をスケジュールできます。
12.3.1. 古い CPU モデルのノードラベリングについて
OpenShift Virtualization Operator は、古い CPU モデルの事前定義されたリストを使用して、ノードがスケジュールされた仮想マシンの有効な CPU モデルのみをサポートするようにします。
デフォルトでは、以下の CPU モデルはノード用に生成されたラベルのリストから削除されます。
例12.1 古い CPU モデル
"486"
Conroe
athlon
core2duo
coreduo
kvm32
kvm64
n270
pentium
pentium2
pentium3
pentiumpro
phenom
qemu32
qemu64
この事前定義された一覧は HyperConverged CR には表示されません。このリストから CPU モデルを 削除 できませんが、HyperConverged CR の spec.obsoleteCPUs.cpuModels フィールドを編集してリストに追加することはできます。
12.3.2. CPU 機能のノードのラベル付けについて
反復処理により、最小 CPU モデルのベース CPU 機能は、ノード用に生成されたラベルのリストから削除されます。
以下に例を示します。
-
環境には、
PenrynとHaswellという 2 つのサポートされる CPU モデルが含まれる可能性があります。 PenrynがminCPUの CPU モデルとして指定される場合、Penrynのベース CPU の各機能はHaswellによってサポートされる CPU 機能のリストと比較されます。例12.2
Penrynでサポートされる CPU 機能apic clflush cmov cx16 cx8 de fpu fxsr lahf_lm lm mca mce mmx msr mtrr nx pae pat pge pni pse pse36 sep sse sse2 sse4.1 ssse3 syscall tsc例12.3
Haswellでサポートされる CPU 機能aes apic avx avx2 bmi1 bmi2 clflush cmov cx16 cx8 de erms fma fpu fsgsbase fxsr hle invpcid lahf_lm lm mca mce mmx movbe msr mtrr nx pae pat pcid pclmuldq pge pni popcnt pse pse36 rdtscp rtm sep smep sse sse2 sse4.1 sse4.2 ssse3 syscall tsc tsc-deadline x2apic xsavePenrynとHaswellの両方が特定の CPU 機能をサポートする場合、その機能にラベルは作成されません。ラベルは、Haswellでのみサポートされ、Penrynではサポートされていない CPU 機能用に生成されます。例12.4 反復後に CPU 機能用に作成されるノードラベル
aes avx avx2 bmi1 bmi2 erms fma fsgsbase hle invpcid movbe pcid pclmuldq popcnt rdtscp rtm sse4.2 tsc-deadline x2apic xsave
12.3.3. 古い CPU モデルの設定
HyperConverged カスタムリソース (CR) を編集して、古い CPU モデルのリストを設定できます。
手順
古い CPU モデルを
obsoleteCPUs配列で指定して、HyperConvergedカスタムリソースを編集します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged namespace: openshift-cnv spec: obsoleteCPUs: cpuModels:1 - "<obsolete_cpu_1>" - "<obsolete_cpu_2>" minCPUModel: "<minimum_cpu_model>"2
12.4. ノードの調整の防止
skip-node アノテーションを使用して、node-labeller がノードを調整できないようにします。
12.4.1. skip-node アノテーションの使用
node-labeller でノードを省略するには、oc CLI を使用してそのノードにアノテーションを付けます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
以下のコマンドを実行して、スキップするノードにアノテーションを付けます。
$ oc annotate node <node_name> node-labeller.kubevirt.io/skip-node=true1 - 1
<node_name>は、スキップする関連ノードの名前に置き換えます。
調整は、ノードアノテーションが削除されるか、false に設定された後に、次のサイクルで再開されます。
第13章 ロギング、イベント、およびモニタリング
13.1. 仮想化の概要の確認
Virtualization Overview ページには、仮想化リソース、詳細、ステータス、および上位消費項目の包括的なビューが提供されます。OpenShift Virtualization の全体的な健全性に関する洞察を得ることで、データを調べることで特定される特定の問題を解決するために介入が必要かどうかを判断できます。
Getting Started リソースを使用して、クイックスタートにアクセスし、仮想化に関する最新ブログを読み、Operator の使用方法を学習します。アラート、イベント、インベントリー、および仮想マシンのステータスに関する詳細情報を取得します。Top Consumer カードをカスタマイズして、プロジェクト、仮想マシン、またはノード別に特定のリソースの高使用率に関するデータを取得します。View virtualization dashboard をクリックして、Dashboards ページにすばやくアクセスできます。
13.1.1. 前提条件
Top Consumers カードで vCPU wait メトリクスを使用するには、schedstats=enable カーネル引数を MachineConfig オブジェクトに適用する必要があります。このカーネル引数を使用すると、デバッグとパフォーマンスチューニングに使用されるスケジューラーの統計が有効になり、スケジューラーに小規模な負荷を追加できます。カーネル引数の適用に関する詳細は、OpenShift Container Platform マシン設定タスクの ドキュメントを参照してください。
13.1.2. Virtualization Overview ページでアクティブに監視されるリソース
以下の表に、Virtualization Overview ページでアクティブに監視されるリソース、メトリクス、およびフィールドを示します。この情報は、関連データを取得し、問題を解決するために介入する必要がある場合に役立ちます。
| 監視されるリソース、フィールド、およびメトリクス | 説明 |
| Details | OpenShift Virtualization のサービスの概要とバージョン情報。 |
| Status | 仮想化およびネットワークに関するアラート。 |
| Activity | 仮想マシンの現在のイベント。メッセージは、Pod の作成または別のホストへの仮想マシンの移行など、クラスター内の直近のアクティビティーに関連します。 |
| Running VMs by Template | ドーナツチャートは、各仮想マシンテンプレートに固有の色を示し、各テンプレートを使用する実行中の仮想マシンの数を表示します。 |
| Inventory | アクティブな仮想マシン、テンプレート、ノード、ネットワークの合計数。 |
| Status of VMs | 仮想マシンの現在の状態: running、provisioning、starting、migrating、paused、stopping、terminating、および unknown |
| Permissions | パーミッションにより機能を有効にするタスク: Access to public templates、Access to public boot sources、Clone a VM、Attach VM to multiple networks、Upload a base image from local disk、および Share templates |
13.1.3. 上位の消費が監視されるリソース
Virtualization Overview ページの Top Consumers カードには、リソースの最大消費と共にプロジェクト、仮想マシン、またはノードが表示されます。プロジェクト、仮想マシン、またはノードを選択し、特定リソースの上位 5 または上位 10 の消費項目を表示できます。
最大リソース消費の表示は、各 Top Consumers カード内で上位 5 または上位 10 の消費項目に制限されます。
以下の表に、上位消費項目が監視されるリソースを示します。
| 上位の消費が監視されるリソース | 説明 |
| CPU | 最も多くの CPU を使用するプロジェクト、仮想マシン、またはノード。 |
| メモリー | 最も多くのメモリー (バイト単位) を使用するプロジェクト、仮想マシン、またはノード。表示の単位 (MiB または GiB など) は、リソース消費のサイズにより決定されます。 |
| 使用済みのファイルシステム | ファイルシステムの消費 (バイト単位) が最も多いプロジェクト、仮想マシン、またはノード。表示の単位 (MiB または GiB など) は、リソース消費のサイズにより決定されます。 |
| メモリースワップ | メモリーがスワップされる際に、メモリープレッシャーが最も多いプロジェクト、仮想マシン、またはノード。 |
| vCPU 待機時間 | 仮想 CPU の待ち時間 (秒単位) が最も長いプロジェクト、仮想マシン、またはノード。 |
| ストレージスループット | ストレージメディアとの間のデータ転送率 (mbps 単位) が最も高いプロジェクト、仮想マシン、またはノード。 |
| ストレージ IOPS | 一定期間におけるストレージ IOPS(input/output operations per second) が最も高いプロジェクト、仮想マシン、またはノード。 |
13.1.4. 上位消費プロジェクト、仮想マシン、およびノードの確認
Virtualization Overview ページで、選択したプロジェクト、仮想マシン、またはノードのリソースの上位消費項目を表示できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- OpenShift Virtualization Web コンソールの Administrator パースペクティブで、Virtualization → Overview に移動します。
- Top Consumers カードに移動します。
- ドロップダウンメニューから、Show top 5 または Show top 10 を選択します。
- Top Consumer カードで、ドロップダウンメニューからリソースのタイプを選択します (CPU、Memory、Used Filesystem、Memory Swap、vCPU Wait、または Storage Throughput)。
- By Project、By VM、または By Node を選択します。選択したリソースの上位 5 または上位 10 消費項目のリストが表示されます。
13.2. OpenShift Virtualization ログの表示
Web コンソールまたは oc CLI を使用して、OpenShift Virtualization コンポーネントおよび仮想マシンのログを表示できます。virt-launcher Pod から仮想マシンのログを取得できます。ログの詳細度を制御するには、HyperConverged カスタムリソースを編集します。
13.2.1. CLI を使用した OpenShift Virtualization ログの表示
HyperConverged カスタムリソース (CR) を編集して、OpenShift Virtualization コンポーネントのログ詳細度を設定します。次に、oc CLI ツールを使用して、コンポーネント Pod のログを表示します。
手順
特定のコンポーネントのログの詳細度を設定するには、次のコマンドを実行して、デフォルトのテキストエディターで
HyperConvergedCR を開きます。$ oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnvspec.logVerbosityConfigスタンザを編集して、1 つ以上のコンポーネントのログレベルを設定します。以下に例を示します。apiVersion: hco.kubevirt.io/v1beta1 kind: HyperConverged metadata: name: kubevirt-hyperconverged spec: logVerbosityConfig: kubevirt: virtAPI: 51 virtController: 4 virtHandler: 3 virtLauncher: 2 virtOperator: 6- 1
- ログの詳細度の値は
1 ~ 9の範囲の整数である必要があり、数値が大きいほど詳細なログであることを示します。この例では、virtAPIコンポーネントのログは、優先度が5以上の場合に公開されます。
- エディターを保存して終了し、変更を適用します。
以下のコマンドを実行して、OpenShift Virtualization の namespace 内の Pod のリストを表示します。
$ oc get pods -n openshift-cnv例13.1 出力例
NAME READY STATUS RESTARTS AGE disks-images-provider-7gqbc 1/1 Running 0 32m disks-images-provider-vg4kx 1/1 Running 0 32m virt-api-57fcc4497b-7qfmc 1/1 Running 0 31m virt-api-57fcc4497b-tx9nc 1/1 Running 0 31m virt-controller-76c784655f-7fp6m 1/1 Running 0 30m virt-controller-76c784655f-f4pbd 1/1 Running 0 30m virt-handler-2m86x 1/1 Running 0 30m virt-handler-9qs6z 1/1 Running 0 30m virt-operator-7ccfdbf65f-q5snk 1/1 Running 0 32m virt-operator-7ccfdbf65f-vllz8 1/1 Running 0 32mコンポーネント Pod のログを表示するには、次のコマンドを実行します。
$ oc logs -n openshift-cnv <pod_name>以下に例を示します。
$ oc logs -n openshift-cnv virt-handler-2m86x注記Pod の起動に失敗した場合は、
--previousオプションを使用して、最後の試行からのログを表示できます。ログ出力をリアルタイムで監視するには、
-fオプションを使用します。例13.2 出力例
{"component":"virt-handler","level":"info","msg":"set verbosity to 2","pos":"virt-handler.go:453","timestamp":"2022-04-17T08:58:37.373695Z"} {"component":"virt-handler","level":"info","msg":"set verbosity to 2","pos":"virt-handler.go:453","timestamp":"2022-04-17T08:58:37.373726Z"} {"component":"virt-handler","level":"info","msg":"setting rate limiter to 5 QPS and 10 Burst","pos":"virt-handler.go:462","timestamp":"2022-04-17T08:58:37.373782Z"} {"component":"virt-handler","level":"info","msg":"CPU features of a minimum baseline CPU model: map[apic:true clflush:true cmov:true cx16:true cx8:true de:true fpu:true fxsr:true lahf_lm:true lm:true mca:true mce:true mmx:true msr:true mtrr:true nx:true pae:true pat:true pge:true pni:true pse:true pse36:true sep:true sse:true sse2:true sse4.1:true ssse3:true syscall:true tsc:true]","pos":"cpu_plugin.go:96","timestamp":"2022-04-17T08:58:37.390221Z"} {"component":"virt-handler","level":"warning","msg":"host model mode is expected to contain only one model","pos":"cpu_plugin.go:103","timestamp":"2022-04-17T08:58:37.390263Z"} {"component":"virt-handler","level":"info","msg":"node-labeller is running","pos":"node_labeller.go:94","timestamp":"2022-04-17T08:58:37.391011Z"}
13.2.2. Web コンソールでの仮想マシンログの表示
関連付けられた仮想マシンランチャー Pod から仮想マシンログを取得します。
手順
- OpenShift Container Platform コンソールで、サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
- Details タブをクリックします。
-
Pod セクションの
virt-launcher-<name>Pod をクリックして、Pod details ページを開きます。 - Logs タブをクリックして、Pod のログを表示します。
13.2.3. 一般的なエラーメッセージ
以下のエラーメッセージが OpenShift Virtualization ログに表示される場合があります。
ErrImagePullまたはImagePullBackOff- デプロイメント設定が正しくないか、参照されているイメージに問題があることを示します。
13.3. イベントの表示
13.3.1. 仮想マシンイベントについて
OpenShift Container Platform イベントは、namespace 内の重要なライフサイクル情報のレコードであり、リソースのスケジュール、作成、および削除に関する問題のモニターおよびトラブルシューティングに役立ちます。
OpenShift Virtualization は、仮想マシンおよび仮想マシンインスタンスについてのイベントを追加します。これらは Web コンソールまたは CLI のいずれかで表示できます。
OpenShift Container Platform クラスター内のシステムイベント情報の表示 も参照してください。
13.3.2. Web コンソールでの仮想マシンのイベントの表示
Web コンソールの VirtualMachine details ページで、実行中の仮想マシンのストリーミング イベントを表示できます。
手順
- サイドメニューから Virtualization → VirtualMachines をクリックします。
- 仮想マシンを選択して、VirtualMachine details ページを開きます。
Events タブをクリックして、仮想マシンのストリーミングイベントを表示します。
- ▮▮ ボタンはイベントストリームを一時停止します。
- ▶ ボタンは、一時停止したイベントストリームを再開します。
13.3.3. CLI での namespace イベントの表示
OpenShift Container Platform クライアントを使用して namespace のイベントを取得します。
手順
namespace で、
oc getコマンドを使用します。$ oc get events
13.3.4. CLI でのリソースイベントの表示
イベントはリソース説明に組み込むこともできます。 これは OpenShift Container Platform クライアントを使用して取得できます。
手順
namespace で、
oc describeコマンドを使用します。以下の例は、仮想マシン、仮想マシンインスタンス、および仮想マシンの virt-launcher Pod のイベント取得する方法を示しています。$ oc describe vm <vm>$ oc describe vmi <vmi>$ oc describe pod virt-launcher-<name>
13.4. イベントおよび状態を使用したデータボリュームの診断
oc describe コマンドを使用してデータボリュームの問題を分析し、解決できるようにします。
13.4.1. 状態およびイベントについて
コマンドで生成される Conditions および Events セクションの出力を検査してデータボリュームの問題を診断します。
$ oc describe dv <DataVolume>
表示される Conditions セクションには、3 つの Types があります。
-
Bound -
running -
Ready
Events セクションでは、以下の追加情報を提供します。
-
イベントの
Type -
ロギングの
Reason -
イベントの
Source -
追加の診断情報が含まれる
Message
oc describe からの出力には常に Events が含まれるとは限りません。
イベントは Status、Reason、または Message のいずれかの変更時に生成されます。状態およびイベントはどちらもデータボリュームの状態の変更に対応します。
たとえば、インポート操作中に URL のスペルを誤ると、インポートにより 404 メッセージが生成されます。メッセージの変更により、理由と共にイベントが生成されます。Conditions セクションの出力も更新されます。
13.4.2. 状態およびイベントを使用したデータボリュームの分析
describe コマンドで生成される Conditions セクションおよび Events セクションを検査することにより、永続ボリューム要求 (PVC) に関連してデータボリュームの状態を判別します。また、操作がアクティブに実行されているか、完了しているかどうかを判断します。また、データボリュームのステータスについての特定の詳細、およびどのように現在の状態になったかについての情報を提供するメッセージを受信する可能性があります。
状態の組み合わせは多数あります。それぞれは一意のコンテキストで評価される必要があります。
各種の組み合わせの例を以下に示します。
Bound: この例では正常にバインドされた PVC が表示されます。TypeはBoundであるため、StatusはTrueになります。PVC がバインドされていない場合、StatusはFalseになります。PVC がバインドされると、PVC がバインドされていることを示すイベントが生成されます。この場合、
ReasonはBoundで、StatusはTrueです。Messageはデータボリュームを所有する PVC を示します。EventsセクションのMessageでは、PVC がバインドされている期間 (Age) およびどのリソース (From) によってバインドされているか、datavolume-controllerに関する詳細が提供されます。出力例
Status: Conditions: Last Heart Beat Time: 2020-07-15T03:58:24Z Last Transition Time: 2020-07-15T03:58:24Z Message: PVC win10-rootdisk Bound Reason: Bound Status: True Type: Bound Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Bound 24s datavolume-controller PVC example-dv BoundRunning: この場合、TypeがRunningであり、StatusがFalseであることに注意してください。これは、操作の失敗の原因となったイベントが発生したことを示しています。ステータスをTrueからFalseに変更します。ただし、
ReasonがCompletedであり、MessageフィールドにはImport Completeが表示されることに注意してください。Eventsセクションには、ReasonおよびMessageに失敗した操作に関する追加のトラブルシューティング情報が含まれます。この例では、Eventsセクションの最初のWarningに一覧表示されるMessageに、404によって接続できないことが示唆されます。この情報から、インポート操作が実行されており、データボリュームにアクセスしようとしている他の操作に対して競合が生じることを想定できます。
出力例
Status: Conditions: Last Heart Beat Time: 2020-07-15T04:31:39Z Last Transition Time: 2020-07-15T04:31:39Z Message: Import Complete Reason: Completed Status: False Type: Running Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Error 12s (x2 over 14s) datavolume-controller Unable to connect to http data source: expected status code 200, got 404. Status: 404 Not FoundReady:TypeがReadyであり、StatusがTrueの場合、以下の例のようにデータボリュームは使用可能な状態になります。データボリュームが使用可能な状態にない場合、StatusはFalseになります。出力例
Status: Conditions: Last Heart Beat Time: 2020-07-15T04:31:39Z Last Transition Time: 2020-07-15T04:31:39Z Status: True Type: Ready
13.5. 仮想マシンのワークロードに関する情報の表示
OpenShift Container Platform Web コンソールで Virtual Machines ダッシュボードを使用して、仮想マシンについての概要を表示できます。
13.5.1. 仮想マシン ダッシュボード
Virtualization → VirtualMachines ページに移動し、仮想マシン (VM) をクリックして VirtualMachine details ページを表示することにより、OpenShift Container Platform Web コンソールから仮想マシン (VM) にアクセスします。
Overview タブには、次のカードが表示されます。
Details: 以下を含む、仮想マシンについての識別情報を提供します。
- 名前
- ステータス
- 作成日
- オペレーティングシステム
- CPU とメモリー
- Hostname
- テンプレート
仮想マシンが実行中の場合、アクティブな VNC プレビュー ウィンドウと、VNC Web コンソールを開くためのリンクが表示されます。Details カードの Options メニュー
には、仮想マシンを停止または一時停止するオプションと、SSH トンネリング用の ssh over nodeportコマンドをコピーするオプションが用意されています。Alerts には、次の 3 つの重大度レベルの仮想マシンアラートがリスト表示されます。
- Critical
- Warning
- Info
Snapshots は、仮想マシンスナップショットとスナップショットを作成する機能に関する情報を提供します。リストされている各スナップショットについて、Snapshots カードには以下が含まれます。
- スナップショットが正常に作成されたか、まだ進行中か、失敗したかを示す視覚的なインジケーター。
-
オプション メニュー
スナップショットを復元または削除するオプションがあります。
Network interfaces は、次のような仮想マシンのネットワークインターフェイスに関する情報を提供します。
- 名前 (ネットワークとタイプ)
- IP アドレス、IP アドレスをクリップボードにコピーする機能
Disks には、次のような仮想マシンディスクの詳細がリスト表示されます。
- 名前
- ドライブ
- サイズ
Utilization: 以下の使用率についてのデータを表示するグラフが含まれます。
- CPU
- メモリー
- ストレージ
- ネットワーク転送
注記ドロップダウンリストを使用して、使用率データの期間を選択します。利用可能なオプションは、5 minutes、1 hour、6 hours、および 24 hours です。
Hardware Devices は、次のような GPU およびホスト デバイスに関する情報を提供します。
- リソース名
- ハードウェアデバイス名
13.6. 仮想マシンの正常性のモニタリング
仮想マシンインスタンス (VMI) は、接続の損失、デッドロック、または外部の依存関係に関する問題など、一時的な問題が原因で正常でなくなることがあります。ヘルスチェックは、readiness および liveness プローブの組み合わせを使用して VMI で診断を定期的に実行します。
13.6.1. readiness および liveness プローブについて
readiness および liveness プローブを使用して、正常でない仮想マシンインスタンス (VMI) を検出して処理します。VMI の仕様に 1 つ以上のプローブを追加して、トラフィックが準備状態にない VMI に到達せず、VMI が応答不能になると新規インスタンスが作成されるようにすることができます。
readiness プローブ は、VMI がサービス要求を受け入れることができるかどうかを判別します。プローブに失敗すると、VMI は準備状態になるまで、利用可能なエンドポイントのリストから削除されます。
liveness プローブは、VMI が応答しているかどうかを判断します。プローブに失敗すると、VMI が削除され、新規インスタンスが作成されて応答性を復元します。
VirtualMachineInstance オブジェクトの spec.readinessProbe と spec.livenessProbe フィールドを設定して、readiness および liveness プローブを設定できます。これらのフィールドは、以下のテストをサポートします。
- HTTP GET
- プローブは Web フックを使用して VMI の正常性を判別します。このテストは、HTTP の応答コードが 200 から 399 までの値の場合に正常と見なされます。完全に初期化されている場合に、HTTP ステータスコードを返すアプリケーションで HTTP GET テストを使用できます。
- TCP ソケット
- プローブは、VMI に対してソケットを開くことを試行します。VMI はプローブで接続を確立できる場合にのみ正常であるとみなされます。TCP ソケットテストは、初期化が完了するまでリスニングを開始しないアプリケーションで使用できます。
13.6.2. HTTP readiness プローブの定義
仮想マシンインスタンス (VMI) 設定の spec.readinessProbe.httpGet フィールドを設定して HTTP readiness プローブを定義します。
手順
VMI 設定ファイルに readiness プローブの詳細を追加します。
HTTP GET テストを使用した readiness プローブの例
# ... spec: readinessProbe: httpGet:1 port: 15002 path: /healthz3 httpHeaders: - name: Custom-Header value: Awesome initialDelaySeconds: 1204 periodSeconds: 205 timeoutSeconds: 106 failureThreshold: 37 successThreshold: 38 # ...- 1
- VMI への接続に使用する HTTP GET 要求。
- 2
- プローブがクエリーする VMI のポート。上記の例では、プローブはポート 1500 をクエリーします。
- 3
- HTTP サーバーでアクセスするパス。上記の例では、サーバーの /healthz パスのハンドラーが成功コードを返す場合に、VMI は正常であるとみなされます。ハンドラーが失敗コードを返すと、VMI は利用可能なエンドポイントのリストから削除されます。
- 4
- VMI が起動してから readiness プローブが開始されるまでの時間 (秒単位)。
- 5
- プローブの実行間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 6
- プローブがタイムアウトし、VMI が失敗したと想定されてから非アクティブになるまでの時間 (秒数)。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。 - 7
- プローブが失敗できる回数。デフォルトは 3 です。指定された試行回数になると、Pod には
Unreadyというマークが付けられます。 - 8
- 成功とみなされるまでにプローブが失敗後に成功を報告する必要のある回数。デフォルトでは 1 回です。
以下のコマンドを実行して VMI を作成します。
$ oc create -f <file_name>.yaml
13.6.3. TCP readiness プローブの定義
仮想マシンインスタンス (VMI) 設定の spec.readinessProbe.tcpSocket フィールドを設定して TCP readiness プローブを定義します。
手順
TCP readiness プローブの詳細を VMI 設定ファイルに追加します。
TCP ソケットテストを含む readiness プローブの例
... spec: readinessProbe: initialDelaySeconds: 1201 periodSeconds: 202 tcpSocket:3 port: 15004 timeoutSeconds: 105 ...以下のコマンドを実行して VMI を作成します。
$ oc create -f <file_name>.yaml
13.6.4. HTTP liveness プローブの定義
仮想マシンインスタンス (VMI) 設定の spec.livenessProbe.httpGet フィールドを設定して HTTP liveness プローブを定義します。readiness プローブと同様に、liveness プローブの HTTP および TCP テストの両方を定義できます。この手順では、HTTP GET テストを使用して liveness プローブのサンプルを設定します。
手順
HTTP liveness プローブの詳細を VMI 設定ファイルに追加します。
HTTP GET テストを使用した liveness プローブの例
# ... spec: livenessProbe: initialDelaySeconds: 1201 periodSeconds: 202 httpGet:3 port: 15004 path: /healthz5 httpHeaders: - name: Custom-Header value: Awesome timeoutSeconds: 106 # ...- 1
- VMI が起動してから liveness プローブが開始されるまでの時間 (秒単位)。
- 2
- プローブの実行間の遅延 (秒単位)。デフォルトの遅延は 10 秒です。この値は
timeoutSecondsよりも大きくなければなりません。 - 3
- VMI への接続に使用する HTTP GET 要求。
- 4
- プローブがクエリーする VMI のポート。上記の例では、プローブはポート 1500 をクエリーします。VMI は、cloud-init 経由でポート 1500 に最小限の HTTP サーバーをインストールし、実行します。
- 5
- HTTP サーバーでアクセスするパス。上記の例では、サーバーの
/healthzパスのハンドラーが成功コードを返す場合に、VMI は正常であるとみなされます。ハンドラーが失敗コードを返すと、VMI が削除され、新規インスタンスが作成されます。 - 6
- プローブがタイムアウトし、VMI が失敗したと想定されてから非アクティブになるまでの時間 (秒数)。デフォルト値は 1 です。この値は
periodSeconds未満である必要があります。
以下のコマンドを実行して VMI を作成します。
$ oc create -f <file_name>.yaml
13.6.5. テンプレート: ヘルスチェックを定義するための仮想マシンの設定ファイル
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
labels:
special: vm-fedora
name: vm-fedora
spec:
template:
metadata:
labels:
special: vm-fedora
spec:
domain:
devices:
disks:
- disk:
bus: virtio
name: containerdisk
- disk:
bus: virtio
name: cloudinitdisk
resources:
requests:
memory: 1024M
readinessProbe:
httpGet:
port: 1500
initialDelaySeconds: 120
periodSeconds: 20
timeoutSeconds: 10
failureThreshold: 3
successThreshold: 3
terminationGracePeriodSeconds: 180
volumes:
- name: containerdisk
containerDisk:
image: kubevirt/fedora-cloud-registry-disk-demo
- cloudInitNoCloud:
userData: |-
#cloud-config
password: fedora
chpasswd: { expire: False }
bootcmd:
- setenforce 0
- dnf install -y nmap-ncat
- systemd-run --unit=httpserver nc -klp 1500 -e '/usr/bin/echo -e HTTP/1.1 200 OK\\n\\nHello World!'
name: cloudinitdisk13.7. OpenShift Container Platform Dashboard を使用したクラスター情報の取得
OpenShift Container Platform Web コンソールから Home > Dashboards > Overview をクリックしてクラスターについてのハイレベルな情報をキャプチャーする OpenShift Container Platform ダッシュボードにアクセスします。
OpenShift Container Platform ダッシュボードは、個別のダッシュボード カード でキャプチャーされるさまざまなクラスター情報を提供します。
13.7.1. OpenShift Container Platform ダッシュボードページについて
OpenShift Container Platform Web コンソールから Home → Overview に移動して、クラスターに関する概要情報を取得する OpenShift Container Platform ダッシュボードにアクセスします。
OpenShift Container Platform ダッシュボードは、個別のダッシュボードカードでキャプチャーされるさまざまなクラスター情報を提供します。
OpenShift Container Platform ダッシュボードは以下のカードで設定されます。
Details は、クラスターの詳細情報の概要を表示します。
ステータスには、ok、error、warning、in progress、および unknown が含まれます。リソースでは、カスタムのステータス名を追加できます。
- クラスター
- プロバイダー
- バージョン
Cluster Inventory は、リソースの数および関連付けられたステータスの詳細を表示します。これは、問題の解決に介入が必要な場合に役立ちます。以下についての情報が含まれます。
- ノード数
- Pod 数
- 永続ストレージボリューム要求
- 仮想マシン (OpenShift Virtualization がインストールされている場合に利用可能)
- クラスター内のベアメタルホスト。これらはステータス別にリスト表示されます (metal3 環境でのみ利用可能)。
Cluster Health では、関連するアラートおよび説明を含む、クラスターの現在の健全性についてのサマリーを表示します。OpenShift Virtualization がインストールされている場合、OpenShift Virtualization の健全性についても全体的に診断されます。複数のサブシステムが存在する場合は、See All をクリックして、各サブシステムのステータスを表示します。
- 状態別にリスト表示されたクラスター内のベアメタルホスト (metal3 環境でのみ利用可能)
- Status は、管理者がクラスターリソースの消費状況を把握するのに役立ちます。リソースをクリックし、指定されたクラスターリソース (CPU、メモリー、またはストレージ) の最大量を消費する Pod およびノードを一覧表示する詳細ページに切り替えます。
Cluster Utilization には、指定期間におけるさまざまなリソースの容量が表示されます。これは、リソース消費量が多い場合に、管理者がその規模と頻度を把握するのに役立ちます。次の情報が表示されます。
- CPU 時間
- メモリー割り当て
- 消費されたストレージ
- 消費されたネットワークリソース
- Pod 数
- Activity には、Pod の作成や別のホストへの仮想マシンの移行など、クラスター内の最近のアクティビティーに関連するメッセージがリスト表示されます。
13.8. 仮想マシンによるリソース使用率の確認
OpenShift Container Platform Web コンソールのダッシュボードには、クラスターの状態をすぐに理解できるようにするクラスターのメトリックの視覚的な表示が含まれます。ダッシュボードは、コアプラットフォームコンポーネントを監視する Monitoring overview に属します。
OpenShift Virtualization ダッシュボードでは、仮想マシンおよび関連付けられた Pod のリソース消費に関するデータが得られます。OpenShift Virtualization ダッシュボードに表示される可視化メトリックは、Prometheus Query Language(PromQL) クエリー に基づいています。
OpenShift Virtualization ダッシュボードでユーザー定義の namespace をモニターするには、モニタリングロール が必要です。
13.8.1. トップコンシューマーの確認について
OpenShift Virtualization ダッシュボードでは、特定の期間を選択して、その期間内のリソースのトップコンシューマーを表示できます。トップコンシューマーとは、最も多くリソースを消費する仮想マシンまたは virt-launcher Pod のことです。
以下の表は、ダッシュボードでモニターされたリソースと、トップコンシューマーの各リソースに関連付けられたメトリックを示しています。
| モニタリングされたリソース | Description |
| メモリースワップトラフィック | 仮想マシンは、メモリーのスワップ時に最も多くのメモリーを消費します。 |
| vCPU 待機時間 | vCPU の待機時間 (秒単位) が最大の仮想マシン。 |
| Pod 別の CPU 使用率 |
CPU を最も使用している |
| ネットワークトラフィック | 最も多くのネットワークトラフィック (バイト単位) を受信することによってネットワークを飽和させている仮想マシン。 |
| ストレージトラフィック | ストレージ関連のトラフィック量 (バイト単位) が最大の仮想マシン。 |
| ストレージ IOPS | 一定期間における 1 秒あたりの I/O 操作が最も多い仮想マシン。 |
| メモリー使用率 |
メモリー (バイト単位) を最も使用している |
リソース消費の最大値の表示は、トップコンシューマー 5 件に制限されます。
13.8.2. トップコンシューマーの確認
Administrator パースペクティブでは、リソースのトップコンシューマーが表示される OpenShift Virtualization ダッシュボードを確認できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- OpenShift Virtualization Web コンソールの Administrator パースペクティブで、Observe → Dashboards に移動します。
- Dashboard リストから KubeVirt/Infrastructure Resources/Top Consumers ダッシュボードを選択します。
- Period のドロップダウンメニューから事前に定義された期間を選択します。表でトップコンシューマーのデータを確認できます。
- オプション:Inspect をクリックして、テーブルの上部コンシューマーに関連付けられた Prometheus クエリー言語 (PromQL) クエリーを表示または編集します。
13.9. OpenShift Container Platform クラスターモニタリング、ロギング、および Telemetry
OpenShift Container Platform は、クラスターレベルでモニターするための各種のリソースを提供します。
13.9.1. OpenShift Container Platform モニタリングについて
OpenShift Container Platform には、コアプラットフォームコンポーネントのモニタリング を提供する、事前に設定およびインストールされた自己更新型のモニタリングスタックが組み込まれています。OpenShift Container Platform は、追加設定が不要のモニタリングのベストプラクティスを提供します。クラスター管理者にクラスターの問題について即時に通知するアラートのセットがデフォルトで含まれます。OpenShift Container Platform Web コンソールのデフォルトのダッシュボードには、クラスターの状態をすぐに理解できるようにするクラスターのメトリックの視覚的な表示が含まれます。
OpenShift Container Platform 4.11 のインストール後に、クラスター管理者はオプションでユーザー定義プロジェクトのモニタリングを有効にできます。この機能を使用することで、クラスター管理者、開発者、および他のユーザーは、サービスと Pod を独自のプロジェクトでモニターする方法を指定できます。次に、OpenShift Container Platform Web コンソールでメトリックのクエリー、ダッシュボードの確認、および独自のプロジェクトのアラートルールおよびサイレンスを管理できます。
クラスター管理者は、開発者およびその他のユーザーに、独自のプロジェクトをモニターするパーミッションを付与できます。事前に定義されたモニタリングロールのいずれかを割り当てると、特権が付与されます。
13.9.2. ロギングアーキテクチャー
ロギングの主なコンポーネントは次のとおりです。
- Collector
コレクターは、Pod を各 OpenShift Container Platform ノードにデプロイするデーモンセットです。各ノードからログデータを収集し、データを変換して、設定された出力に転送します。Vector コレクターまたは従来の Fluentd コレクターを使用できます。
注記Fluentd は非推奨となっており、今後のリリースで削除される予定です。Red Hat は、現在のリリースのライフサイクル中にこの機能のバグ修正とサポートを提供しますが、この機能は拡張されなくなりました。Fluentd の代わりに、Vector を使用できます。
- ログストア
ログストアは分析用のログデータを保存し、ログフォワーダーのデフォルトの出力です。デフォルトの LokiStack ログストア、従来の Elasticsearch ログストアを使用したり、追加の外部ログストアにログを転送したりできます。
注記OpenShift Elasticsearch Operator は非推奨となっており、将来のリリースで削除される予定です。Red Hat は、現在のリリースのライフサイクル中にこの機能のバグ修正とサポートを提供しますが、この機能は拡張されなくなりました。OpenShift Elasticsearch Operator を使用してデフォルトのログストレージを管理する代わりに、Loki Operator を使用できます。
- 可視化
UI コンポーネントを使用して、ログデータの視覚的表現を表示できます。UI は、保存されたログを検索、クエリー、および表示するためのグラフィカルインターフェイスを提供します。OpenShift Container Platform Web コンソール UI は、OpenShift Container Platform コンソールプラグインを有効にすることで提供されます。
注記Kibana Web コンソールは現在非推奨となっており、将来のログリリースで削除される予定です。
ロギングはコンテナーログとノードログを収集します。これらは次のタイプに分類されます。
- アプリケーションログ
- クラスターで実行される、インフラストラクチャーコンテナーアプリケーションを除くユーザーアプリケーションによって生成されるコンテナーログ。
- インフラストラクチャーログ
-
インフラストラクチャー namespace (
openshift*、kube*、またはdefault)によって生成されたコンテナーのログ、およびノードからの journald メッセージ。 - 監査ログ
-
/var/log/audit/audit.log ファイルに保存されるノード監査システムである auditd によって生成されたログ、
auditd、kube-apiserver、openshift-apiserverサービス、および有効な場合はovnプロジェクトからのログ。
OpenShift Logging の詳細は、OpenShift Logging のドキュメント を参照してください。
13.9.3. Telemetry について
Telemetry は厳選されたクラスターモニタリングメトリクスのサブセットを Red Hat に送信します。Telemeter Client はメトリクスの値を 4 分 30 秒ごとに取得し、データを Red Hat にアップロードします。これらのメトリクスについては、このドキュメントで説明しています。
このデータのストリームは、Red Hat によってリアルタイムでクラスターをモニターし、お客様に影響を与える問題に随時対応するために使用されます。またこれにより、Red Hat がサービスへの影響を最小限に抑えつつつアップグレードエクスペリエンスの継続的な改善に向けた OpenShift Container Platform のアップグレードのデプロイメントを可能にします。
このデバッグ情報は、サポートケースでレポートされるデータへのアクセスと同じ制限が適用された状態で Red Hat サポートおよびエンジニアリングチームが利用できます。接続クラスターのすべての情報は、OpenShift Container Platform をより使用しやすく、より直感的に使用できるようにするために Red Hat によって使用されます。
13.9.3.1. Telemetry で収集される情報
以下の情報は、Telemetry によって収集されます。
13.9.3.1.1. システム情報
- OpenShift Container Platform クラスターのバージョン情報、および更新バージョンの可用性を特定するために使用されるインストールの更新の詳細を含むバージョン情報
- クラスターごとに利用可能な更新の数、更新に使用されるチャネルおよびイメージリポジトリー、更新の進捗情報、および更新で発生するエラーの数などの更新情報
- インストール時に生成される一意でランダムな識別子
- クラウドインフラストラクチャーレベルのノード設定、ホスト名、IP アドレス、Kubernetes Pod 名、namespace、およびサービスなど、Red Hat サポートがお客様にとって有用なサポートを提供するのに役立つ設定の詳細
- クラスターにインストールされている OpenShift Container Platform フレームワークコンポーネントおよびそれらの状態とステータス
- 動作が低下した Operator の関連オブジェクトとして一覧表示されるすべての namespace のイベント
- 動作が低下したソフトウェアに関する情報
- 証明書の有効性についての情報
- OpenShift Container Platform がデプロイされているプラットフォームの名前およびデータセンターの場所
13.9.3.1.2. サイジング情報
- CPU コアの数およびそれぞれに使用される RAM の容量を含む、クラスター、マシンタイプ、およびマシンについてのサイジング情報
- クラスター内での実行中の仮想マシンインスタンスの数
- etcd メンバーの数および etcd クラスターに保存されるオブジェクトの数
- ビルドストラテジータイプ別のアプリケーションビルドの数
13.9.3.1.3. 使用情報
- コンポーネント、機能および拡張機能に関する使用率の情報
- テクノロジープレビューおよびサポート対象外の設定に関する使用率の詳細
Telemetry は、ユーザー名やパスワードなどの識別情報を収集しません。Red Hat は、意図的な個人情報の収集は行いません。誤って個人情報を受信したことが明らかになった場合、Red Hat はその情報を削除します。Telemetry データが個人データを設定する場合において、Red Hat のプライバシー方針については、Red Hat Privacy Statement を参照してください。
13.9.4. CLI のトラブルシューティングおよびデバッグコマンド
oc クライアントのトラブルシューティングおよびデバッグコマンドのリストについては、OpenShift Container Platform CLI ツール のドキュメントを参照してください。
13.10. クラスターチェックの実行
OpenShift Virtualization 4.11 には、クラスターのメンテナンスとトラブルシューティングに使用できる定義済みのチェックを実行するための診断フレームワークが含まれています。
OpenShift Container Platform クラスターチェックアップフレームワークは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
13.10.1. OpenShift Container Platform クラスターチェックアップフレームワークについて
チェックアップは、特定のクラスター機能が期待どおりに機能するかどうかを確認できる自動テストワークロードです。クラスター検査フレームワークは、ネイティブの Kubernetes リソースを使用して、チェックアップを設定および実行します。
事前定義されたチェックアップを使用することで、クラスター管理者はクラスターの保守性を向上させ、予期しない動作をトラブルシューティングし、エラーを最小限に抑え、時間を節約できます。また、チェックアップの結果を確認し、専門家と共有してさらに分析することもできます。ベンダーは、提供する機能やサービスのチェックアップを作成して公開し、顧客環境が正しく設定されていることを確認できます。
クラスターで事前定義されたチェックアップを実行するには、フレームワークの namespace とサービスアカウントの設定、サービスアカウントの ClusterRole オブジェクトと ClusterRoleBinding オブジェクトの作成、チェックアップの権限の有効化、入力 config map とチェックアップジョブの作成が含まれます。チェックアップは複数回実行できます。
以下が常に必要になります。
- チェックアップイメージを適用する前に、信頼できるソースからのものであることを確認します。
-
ClusterRoleオブジェクトを作成する前に、チェックアップのパーミッションを確認します。 -
設定マップ内の
ClusterRoleオブジェクトの名前を確認します。これは、フレームワークがこれらのアクセス許可をチェックアップインスタンスに自動的にバインドするためです。
13.10.2. セカンダリーネットワーク上の仮想マシンのネットワーク接続と遅延の確認
クラスター管理者は、定義済みのチェックを使用して、ネットワーク接続を確認し、セカンダリーネットワークインターフェイスに接続されている仮想マシン (VM) 間の待機時間を測定します。
初めてチェックアップを実行するには、手順のステップに従います。
以前にチェックアップを実行したことがある場合は、手順のステップ 5 にスキップしてください。これは、フレームワークをインストールしてチェックアップのパーミッションを有効にする手順は必要ないためです。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインしている。 - クラスターには少なくとも 2 つのワーカーノードがあります。
- Multus Container Network Interface (CNI) プラグインがクラスターにインストールされている。
- namespace のネットワーク接続定義を設定しました。
手順
フレームワークを設定するためのリソースを含む設定ファイルを作成します。これには、フレームワークの namespace とサービスアカウント、およびサービスアカウントのアクセス許可を定義する
ClusterRoleオブジェクトとClusterRoleBindingオブジェクトが含まれます。例13.3 フレームワークマニフェストファイルの例
--- apiVersion: v1 kind: Namespace metadata: name: kiagnose --- apiVersion: v1 kind: ServiceAccount metadata: name: kiagnose namespace: kiagnose --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: kiagnose rules: - apiGroups: [ "" ] resources: [ "configmaps" ] verbs: - get - list - create - update - patch - apiGroups: [ "" ] resources: [ "namespaces" ] verbs: - get - list - create - delete - watch - apiGroups: [ "" ] resources: [ "serviceaccounts" ] verbs: - get - list - create - apiGroups: [ "rbac.authorization.k8s.io" ] resources: - roles - rolebindings - clusterrolebindings verbs: - get - list - create - delete - apiGroups: [ "rbac.authorization.k8s.io" ] resources: - clusterroles verbs: - get - list - create - bind - apiGroups: [ "batch" ] resources: [ "jobs" ] verbs: - get - list - create - delete - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kiagnose roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kiagnose subjects: - kind: ServiceAccount name: kiagnose namespace: kiagnose ...フレームワークマニフェストを適用します。
$ oc apply -f <framework_manifest>.yaml検査でクラスター アクセスに必要なアクセス許可を持つ
ClusterRoleオブジェクトとRoleオブジェクトを含む設定ファイルを作成します。クラスターロールマニフェストファイルの例
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: kubevirt-vm-latency-checker rules: - apiGroups: ["kubevirt.io"] resources: ["virtualmachineinstances"] verbs: ["get", "create", "delete"] - apiGroups: ["subresources.kubevirt.io"] resources: ["virtualmachineinstances/console"] verbs: ["get"] - apiGroups: ["k8s.cni.cncf.io"] resources: ["network-attachment-definitions"] verbs: ["get"]チェックアップロールマニフェストを適用します。
$ oc apply -f <latency_roles>.yamlチェックアップの入力パラメーターを含む
ConfigMapマニフェストを作成します。config map は、フレームワークがチェックアップを実行するための入力を提供し、チェックアップの結果も保存します。入力 config map の例
apiVersion: v1 kind: ConfigMap metadata: name: kubevirt-vm-latency-checkup namespace: kiagnose data: spec.image: registry.redhat.io/container-native-virtualization/vm-network-latency-checkup:v4.11.0 spec.timeout: 10m spec.clusterRoles: | kubevirt-vmis-manager spec.param.network_attachment_definition_namespace: "default"1 spec.param.network_attachment_definition_name: "bridge-network"2 spec.param.max_desired_latency_milliseconds: "10"3 spec.param.sample_duration_seconds: "5"4 フレームワークの namespace に config map を作成します。
$ oc apply -f <latency_config_map>.yamlチェックアップを実行する
Jobオブジェクトを作成します。ジョブマニフェストの例
apiVersion: batch/v1 kind: Job metadata: name: kubevirt-vm-latency-checkup namespace: kiagnose spec: backoffLimit: 0 template: spec: serviceAccount: kiagnose restartPolicy: Never containers: - name: framework image: registry.redhat.io/container-native-virtualization/checkup-framework:v4.11.0 env: - name: CONFIGMAP_NAMESPACE value: kiagnose - name: CONFIGMAP_NAME value: kubevirt-vm-latency-checkupJobマニフェストを適用します。チェックアップでは、ping ユーティリティーを使用して接続を確認し、レイテンシーを測定します。$ oc apply -f <latency_job>.yamlジョブが完了するまで待ちます。
$ oc wait --for=condition=complete --timeout=10m job.batch/kubevirt-vm-latency-checkup -n kiagnoseConfigMapオブジェクトのステータスを取得して、レイテンシーチェックアップの結果を確認します。測定されたレイテンシーがspec.param.max_desired_latency_milliseconds属性の値より大きい場合、チェックアップは失敗し、エラーが返されます。$ oc get configmap kubevirt-vm-latency-checkup -n kiagnose -o yaml出力 config map の例 (成功)
apiVersion: v1 kind: ConfigMap metadata: name: kubevirt-vm-latency-checkup namespace: kiagnose ... status.succeeded: "true" status.failureReason: "" status.result.minLatencyNanoSec: 2000 status.result.maxLatencyNanoSec: 3000 status.result.avgLatencyNanoSec: 2500 status.results.measurementDurationSec: 300 ...以前に作成したフレームワークとチェックアップリソースを削除します。これには、ジョブ、config map、クラスターロール、およびフレームワークマニフェストファイルが含まれます。
注記別のチェックアップを実行する予定がある場合は、フレームワークとクラスターのロールのマニフェストファイルを削除しないでください。
$ oc delete -f <file_name>.yaml
13.11. 仮想リソースの Prometheus クエリー
OpenShift Virtualization は、インフラストラクチャーリソースがクラスターで消費される方法を監視するためのメトリックを提供します。メトリックでは以下のリソースを対象とします。
- vCPU
- ネットワーク
- ストレージ
- ゲストメモリーのスワップ
OpenShift Container Platform モニタリングダッシュボードを使用して仮想化メトリックをクエリーします。
13.11.1. 前提条件
-
vCPU メトリックを使用するには、
schedstats=enableカーネル引数をMachineConfigオブジェクトに適用する必要があります。このカーネル引数を使用すると、デバッグとパフォーマンスチューニングに使用されるスケジューラーの統計が有効になり、スケジューラーに小規模な負荷を追加できます。カーネル引数の適用に関する詳細は、OpenShift Container Platform マシン設定タスクの ドキュメントを参照してください。 - ゲストメモリースワップクエリーがデータを返すには、仮想ゲストでメモリースワップを有効にする必要があります。
13.11.2. メトリックのクエリー
OpenShift Container Platform モニタリングダッシュボードでは、Prometheus のクエリー言語 (PromQL) クエリーを実行し、プロットに可視化されるメトリックを検査できます。この機能により、クラスターの状態と、モニターしているユーザー定義のワークロードに関する情報が提供されます。
クラスター管理者 は、すべての OpenShift Container Platform のコアプロジェクトおよびユーザー定義プロジェクトのメトリックをクエリーできます。
開発者 として、メトリックのクエリー時にプロジェクト名を指定する必要があります。選択したプロジェクトのメトリックを表示するには、必要な権限が必要です。
13.11.2.1. クラスター管理者としてのすべてのプロジェクトのメトリックのクエリー
クラスター管理者またはすべてのプロジェクトの表示パーミッションを持つユーザーとして、メトリック UI ですべてのデフォルト OpenShift Container Platform およびユーザー定義プロジェクトのメトリックにアクセスできます。
前提条件
-
cluster-adminクラスターロールまたはすべてのプロジェクトの表示パーミッションを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
- OpenShift Container Platform Web コンソールの Administrator パースペクティブを選択します。
- Observe → Metrics の順に選択します。
- Insert Metric at Cursor を選択し、事前に定義されたクエリーの一覧を表示します。
カスタムクエリーを作成するには、Prometheus クエリー言語 (PromQL) のクエリーを Expression フィールドに追加します。
注記PromQL 式を入力すると、オートコンプリートの提案がドロップダウンリストに表示されます。これらの提案には、関数、メトリック、ラベル、および時間トークンが含まれます。キーボードの矢印を使用して提案された項目のいずれかを選択し、Enter を押して項目を式に追加できます。また、マウスポインターを推奨項目の上に移動して、その項目の簡単な説明を表示することもできます。
- 複数のクエリーを追加するには、Add Query を選択します。
-
既存のクエリーを複製するには、クエリーの横にある
を選択し、Duplicate query を選択します。
-
クエリーを削除するには、クエリーの横にある
を選択してから Delete query を選択します。
-
クエリーの実行を無効にするには、クエリーの横にある
を選択してから Disable query を選択します。
作成したクエリーを実行するには、Run Queries を選択します。クエリーからのメトリックはプロットで可視化されます。クエリーが無効な場合は、UI にエラーメッセージが表示されます。
注記大量のデータで動作するクエリーは、時系列グラフの描画時にタイムアウトするか、ブラウザーをオーバーロードする可能性があります。これを回避するには、Hide graph を選択し、メトリックテーブルのみを使用してクエリーを調整します。次に、使用できるクエリーを確認した後に、グラフを描画できるようにプロットを有効にします。
- オプション: ページ URL には、実行したクエリーが含まれます。このクエリーのセットを再度使用できるようにするには、この URL を保存します。
13.11.2.2. 開発者が行うユーザー定義プロジェクトのメトリックのクエリー
ユーザー定義のプロジェクトのメトリックには、開発者またはプロジェクトの表示パーミッションを持つユーザーとしてアクセスできます。
Developer パースペクティブには、選択したプロジェクトの事前に定義された CPU、メモリー、帯域幅、およびネットワークパケットのクエリーが含まれます。また、プロジェクトの CPU、メモリー、帯域幅、ネットワークパケット、およびアプリケーションメトリックについてカスタム Prometheus Query Language (PromQL) クエリーを実行することもできます。
開発者は Developer パースペクティブのみを使用でき、Administrator パースペクティブは使用できません。開発者は、Web コンソールの Observe -→ Metrics ページで一度に 1 つのプロジェクトのメトリックのみをクエリーできます。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示パーミッションを持つユーザーとしてクラスターへのアクセスがある。
- ユーザー定義プロジェクトのモニタリングを有効にしている。
- ユーザー定義プロジェクトにサービスをデプロイしている。
-
サービスのモニター方法を定義するために、サービスの
ServiceMonitorカスタムリソース定義 (CRD) を作成している。
手順
- OpenShift Container Platform Web コンソールの Developer パースペクティブを選択します。
- Observe → Metrics の順に選択します。
- Project: 一覧でメトリックで表示するプロジェクトを選択します。
- Select query 一覧からクエリーを選択するか、Show PromQL を選択して、選択したクエリーに基づいてカスタム PromQL クエリーを作成します。
オプション: Select query リストから Custom query を選択し、新規クエリーを入力します。入力時に、オートコンプリートの提案がドロップダウンリストに表示されます。これらの提案には、関数およびメトリックが含まれます。推奨項目をクリックして選択します。
注記Developer パースペクティブでは、1 度に 1 つのクエリーのみを実行できます。
13.11.3. 仮想化メトリック
以下のメトリックの記述には、Prometheus Query Language (PromQL) クエリーのサンプルが含まれます。これらのメトリックは API ではなく、バージョン間で変更される可能性があります。
以下の例では、期間を指定する topk クエリーを使用します。その期間中に仮想マシンが削除された場合でも、クエリーの出力に依然として表示されます。
13.11.3.1. vCPU メトリック
以下のクエリーは、入出力 I/O) を待機している仮想マシンを特定します。
kubevirt_vmi_vcpu_wait_seconds- 仮想マシンの vCPU の待機時間 (秒単位) を返します。
0 より大きい値は、vCPU は実行する用意ができているが、ホストスケジューラーがこれをまだ実行できないことを意味します。実行できない場合には I/O に問題があることを示しています。
vCPU メトリックをクエリーするには、最初に schedstats=enable カーネル引数を MachineConfig オブジェクトに適用する必要があります。このカーネル引数を使用すると、デバッグとパフォーマンスチューニングに使用されるスケジューラーの統計が有効になり、スケジューラーに小規模な負荷を追加できます。
vCPU 待機時間クエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_vcpu_wait_seconds[6m]))) > 0 - 1
- このクエリーは、6 分間の任意の全タイミングで I/O を待機する上位 3 の仮想マシンを返します。
13.11.3.2. ネットワークメトリック
以下のクエリーは、ネットワークを飽和状態にしている仮想マシンを特定できます。
kubevirt_vmi_network_receive_bytes_total- 仮想マシンのネットワークで受信したトラフィックの合計量 (バイト単位) を返します。
kubevirt_vmi_network_transmit_bytes_total- 仮想マシンのネットワーク上で送信されるトラフィックの合計量 (バイト単位) を返します。
ネットワークトラフィッククエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_network_receive_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_network_transmit_bytes_total[6m]))) > 0 - 1
- このクエリーは、6 分間の任意のタイミングで最大のネットワークトラフィックを送信する上位 3 の仮想マシンを返します。
13.11.3.3. ストレージメトリック
13.11.3.3.1. ストレージ関連のトラフィック
以下のクエリーは、大量のデータを書き込んでいる仮想マシンを特定できます。
kubevirt_vmi_storage_read_traffic_bytes_total- 仮想マシンのストレージ関連トラフィックの合計量 (バイト単位) を返します。
kubevirt_vmi_storage_write_traffic_bytes_total- 仮想マシンのストレージ関連トラフィックのストレージ書き込みの合計量 (バイト単位) を返します。
ストレージ関連のトラフィッククエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_read_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_write_traffic_bytes_total[6m]))) > 0 - 1
- 上記のクエリーは、6 分間の任意のタイミングで最も大きなストレージトラフィックを送信する上位 3 の仮想マシンを返します。
13.11.3.3.2. ストレージスナップショットデータ
kubevirt_vmsnapshot_disks_restored_from_source_total- ソース仮想マシンから復元された仮想マシンディスクの総数を返します。
kubevirt_vmsnapshot_disks_restored_from_source_bytes- ソース仮想マシンから復元された容量をバイト単位で返します。
ストレージスナップショットデータクエリーの例
kubevirt_vmsnapshot_disks_restored_from_source_total{vm_name="simple-vm", vm_namespace="default"} - 1
- このクエリーは、ソース仮想マシンから復元された仮想マシンディスクの総数を返します。
kubevirt_vmsnapshot_disks_restored_from_source_bytes{vm_name="simple-vm", vm_namespace="default"} - 1
- このクエリーは、ソース仮想マシンから復元された容量をバイト単位で返します。
13.11.3.3.3. I/O パフォーマンス
以下のクエリーで、ストレージデバイスの I/O パフォーマンスを判別できます。
kubevirt_vmi_storage_iops_read_total- 仮想マシンが実行している 1 秒あたりの書き込み I/O 操作の量を返します。
kubevirt_vmi_storage_iops_write_total- 仮想マシンが実行している 1 秒あたりの読み取り I/O 操作の量を返します。
I/O パフォーマンスクエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_read_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_storage_iops_write_total[6m]))) > 0 - 1
- 上記のクエリーは、6 分間の任意のタイミングで最も大きな I/O 操作を実行している上位 3 の仮想マシンを返します。
13.11.3.4. ゲストメモリーのスワップメトリック
以下のクエリーにより、メモリースワップを最も多く実行しているスワップ対応ゲストを特定できます。
kubevirt_vmi_memory_swap_in_traffic_bytes_total- 仮想ゲストがスワップされているメモリーの合計量 (バイト単位) を返します。
kubevirt_vmi_memory_swap_out_traffic_bytes_total- 仮想ゲストがスワップアウトされているメモリーの合計量 (バイト単位) を返します。
メモリースワップクエリーの例
topk(3, sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_in_traffic_bytes_total[6m])) + sum by (name, namespace) (rate(kubevirt_vmi_memory_swap_out_traffic_bytes_total[6m]))) > 0 - 1
- 上記のクエリーは、6 分間の任意のタイミングでゲストが最も大きなメモリースワップを実行している上位 3 の仮想マシンを返します。
メモリースワップは、仮想マシンがメモリー不足の状態にあることを示します。仮想マシンのメモリー割り当てを増やすと、この問題を軽減できます。
13.12. 仮想マシンのカスタムメトリックの公開
OpenShift Container Platform には、コアプラットフォームコンポーネントのモニタリングを提供する事前に設定され、事前にインストールされた自己更新型のモニタリングスタックが含まれます。このモニタリングスタックは、Prometheus モニタリングシステムをベースにしています。Prometheus は Time Series を使用するデータベースであり、メトリックのルール評価エンジンです。
OpenShift Container Platform モニタリングスタックの使用のほかに、CLI を使用してユーザー定義プロジェクトのモニタリングを有効にし、node-exporter サービスで仮想マシン用に公開されるカスタムメトリックをクエリーできます。
13.12.1. ノードエクスポーターサービスの設定
node-exporter エージェントは、メトリックを収集するクラスター内のすべての仮想マシンにデプロイされます。node-exporter エージェントをサービスとして設定し、仮想マシンに関連付けられた内部メトリックおよびプロセスを公開します。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 -
cluster-monitoring-configConfigMapオブジェクトをopenshift-monitoringプロジェクトに作成します。 -
enableUserWorkloadをtrueに設定して、user-workload-monitoring-configConfigMapオブジェクトをopenshift-user-workload-monitoringプロジェクトに設定します。
手順
ServiceYAML ファイルを作成します。以下の例では、このファイルはnode-exporter-service.yamlという名前です。kind: Service apiVersion: v1 metadata: name: node-exporter-service1 namespace: dynamation2 labels: servicetype: metrics3 spec: ports: - name: exmet4 protocol: TCP port: 91005 targetPort: 91006 type: ClusterIP selector: monitor: metrics7 - 1
- 仮想マシンからメトリックを公開する node-exporter サービス。
- 2
- サービスが作成される namespace。
- 3
- サービスのラベル。
ServiceMonitorはこのラベルを使用してこのサービスを照会します。 - 4
ClusterIPサービスのポート 9100 でメトリックを公開するポートに指定された名前。- 5
- リクエストをリッスンするために
node-exporter-serviceによって使用されるターゲットポート。 - 6
monitorラベルが設定された仮想マシンの TCP ポート番号。- 7
- 仮想マシンの Pod を照会するために使用されるラベル。この例では、ラベル
monitorのある仮想マシンの Pod と、metricsの値がマッチします。
node-exporter サービスを作成します。
$ oc create -f node-exporter-service.yaml
13.12.2. ノードエクスポーターサービスが設定された仮想マシンの設定
node-exporter ファイルを仮想マシンにダウンロードします。次に、仮想マシンの起動時に node-exporter サービスを実行する systemd サービスを作成します。
前提条件
-
コンポーネントの Pod は
openshift-user-workload-monitoringプロジェクトで実行されます。 -
このユーザー定義プロジェクトをモニターする必要のあるユーザーに
monitoring-editロールを付与します。
手順
- 仮想マシンにログインします。
node-exporterファイルのバージョンに適用されるディレクトリーパスを使用して、node-exporterファイルを仮想マシンにダウンロードします。$ wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz実行ファイルを展開して、
/usr/binディレクトリーに配置します。$ sudo tar xvf node_exporter-1.3.1.linux-amd64.tar.gz \ --directory /usr/bin --strip 1 "*/node_exporter"ディレクトリーのパス
/etc/systemd/systemにnode_exporter.serviceファイルを作成します。このsystemdサービスファイルは、仮想マシンの再起動時に node-exporter サービスを実行します。[Unit] Description=Prometheus Metrics Exporter After=network.target StartLimitIntervalSec=0 [Service] Type=simple Restart=always RestartSec=1 User=root ExecStart=/usr/bin/node_exporter [Install] WantedBy=multi-user.targetsystemdサービスを有効にし、起動します。$ sudo systemctl enable node_exporter.service $ sudo systemctl start node_exporter.service
検証
node-exporter エージェントが仮想マシンからのメトリックを報告していることを確認します。
$ curl http://localhost:9100/metrics出力例
go_gc_duration_seconds{quantile="0"} 1.5244e-05 go_gc_duration_seconds{quantile="0.25"} 3.0449e-05 go_gc_duration_seconds{quantile="0.5"} 3.7913e-05
13.12.3. 仮想マシンのカスタムモニタリングラベルの作成
単一サービスから複数の仮想マシンに対するクエリーを有効にするには、仮想マシンの YAML ファイルにカスタムラベルを追加します。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - 仮想マシンを停止および再起動するための Web コンソールへのアクセス権限がある。
手順
仮想マシン設定ファイルの
templatespec を編集します。この例では、ラベルmonitorの値がmetricsになります。spec: template: metadata: labels: monitor: metrics-
仮想マシンを停止して再起動し、
monitorラベルに指定されたラベル名を持つ新しい Pod を作成します。
13.12.3.1. メトリックを取得するための node-exporter サービスのクエリー
仮想マシンのメトリックは、/metrics の正規名の下に HTTP サービスエンドポイント経由で公開されます。メトリックのクエリー時に、Prometheus は仮想マシンによって公開されるメトリックエンドポイントからメトリックを直接収集し、これらのメトリックを確認用に表示します。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
手順
サービスの namespace を指定して、HTTP サービスエンドポイントを取得します。
$ oc get service -n <namespace> <node-exporter-service>node-exporter サービスの利用可能なすべてのメトリックを一覧表示するには、
metricsリソースをクエリーします。$ curl http://<172.30.226.162:9100>/metrics | grep -vE "^#|^$"出力例
node_arp_entries{device="eth0"} 1 node_boot_time_seconds 1.643153218e+09 node_context_switches_total 4.4938158e+07 node_cooling_device_cur_state{name="0",type="Processor"} 0 node_cooling_device_max_state{name="0",type="Processor"} 0 node_cpu_guest_seconds_total{cpu="0",mode="nice"} 0 node_cpu_guest_seconds_total{cpu="0",mode="user"} 0 node_cpu_seconds_total{cpu="0",mode="idle"} 1.10586485e+06 node_cpu_seconds_total{cpu="0",mode="iowait"} 37.61 node_cpu_seconds_total{cpu="0",mode="irq"} 233.91 node_cpu_seconds_total{cpu="0",mode="nice"} 551.47 node_cpu_seconds_total{cpu="0",mode="softirq"} 87.3 node_cpu_seconds_total{cpu="0",mode="steal"} 86.12 node_cpu_seconds_total{cpu="0",mode="system"} 464.15 node_cpu_seconds_total{cpu="0",mode="user"} 1075.2 node_disk_discard_time_seconds_total{device="vda"} 0 node_disk_discard_time_seconds_total{device="vdb"} 0 node_disk_discarded_sectors_total{device="vda"} 0 node_disk_discarded_sectors_total{device="vdb"} 0 node_disk_discards_completed_total{device="vda"} 0 node_disk_discards_completed_total{device="vdb"} 0 node_disk_discards_merged_total{device="vda"} 0 node_disk_discards_merged_total{device="vdb"} 0 node_disk_info{device="vda",major="252",minor="0"} 1 node_disk_info{device="vdb",major="252",minor="16"} 1 node_disk_io_now{device="vda"} 0 node_disk_io_now{device="vdb"} 0 node_disk_io_time_seconds_total{device="vda"} 174 node_disk_io_time_seconds_total{device="vdb"} 0.054 node_disk_io_time_weighted_seconds_total{device="vda"} 259.79200000000003 node_disk_io_time_weighted_seconds_total{device="vdb"} 0.039 node_disk_read_bytes_total{device="vda"} 3.71867136e+08 node_disk_read_bytes_total{device="vdb"} 366592 node_disk_read_time_seconds_total{device="vda"} 19.128 node_disk_read_time_seconds_total{device="vdb"} 0.039 node_disk_reads_completed_total{device="vda"} 5619 node_disk_reads_completed_total{device="vdb"} 96 node_disk_reads_merged_total{device="vda"} 5 node_disk_reads_merged_total{device="vdb"} 0 node_disk_write_time_seconds_total{device="vda"} 240.66400000000002 node_disk_write_time_seconds_total{device="vdb"} 0 node_disk_writes_completed_total{device="vda"} 71584 node_disk_writes_completed_total{device="vdb"} 0 node_disk_writes_merged_total{device="vda"} 19761 node_disk_writes_merged_total{device="vdb"} 0 node_disk_written_bytes_total{device="vda"} 2.007924224e+09 node_disk_written_bytes_total{device="vdb"} 0
13.12.4. ノードエクスポーターサービスの ServiceMonitor リソースの作成
Prometheus クライアントライブラリーを使用し、/metrics エンドポイントからメトリックを収集して、node-exporter サービスが公開するメトリックにアクセスし、表示できます。ServiceMonitor カスタムリソース定義 (CRD) を使用して、ノードエクスポーターサービスをモニターします。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
手順
ServiceMonitorリソース設定の YAML ファイルを作成します。この例では、サービスモニターはラベルmetricsが指定されたサービスとマッチし、30 秒ごとにexmetポートをクエリーします。apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: k8s-app: node-exporter-metrics-monitor name: node-exporter-metrics-monitor1 namespace: dynamation2 spec: endpoints: - interval: 30s3 port: exmet4 scheme: http selector: matchLabels: servicetype: metricsnode-exporter サービスの
ServiceMonitor設定を作成します。$ oc create -f node-exporter-metrics-monitor.yaml
13.12.4.1. クラスター外のノードエクスポーターサービスへのアクセス
クラスター外の node-exporter サービスにアクセスし、公開されるメトリックを表示できます。
前提条件
-
cluster-admin権限を持つユーザーまたはmonitoring-editロールを持つユーザーとしてクラスターにアクセスできる。 - node-exporter サービスを設定して、ユーザー定義プロジェクトのモニタリングを有効にしている。
手順
node-exporter サービスを公開します。
$ oc expose service -n <namespace> <node_exporter_service_name>ルートの FQDN(完全修飾ドメイン名) を取得します。
$ oc get route -o=custom-columns=NAME:.metadata.name,DNS:.spec.host出力例
NAME DNS node-exporter-service node-exporter-service-dynamation.apps.cluster.example.orgcurlコマンドを使用して、node-exporter サービスのメトリックを表示します。$ curl -s http://node-exporter-service-dynamation.apps.cluster.example.org/metrics出力例
go_gc_duration_seconds{quantile="0"} 1.5382e-05 go_gc_duration_seconds{quantile="0.25"} 3.1163e-05 go_gc_duration_seconds{quantile="0.5"} 3.8546e-05 go_gc_duration_seconds{quantile="0.75"} 4.9139e-05 go_gc_duration_seconds{quantile="1"} 0.000189423
13.13. OpenShift Virtualization の重大なアラート
OpenShift Virtualization には、問題が発生したときに通知するアラートがあります。重大なアラートには早急な対応が必要です。
各アラートには、問題に対する説明、アラートが発生した理由、問題の原因を診断するためのトラブルシューティングプロセス、およびアラートの解決手順が含まれます。
13.13.1. ネットワークアラート
ネットワークアラートは、OpenShift Virtualization Network Operator の問題についての情報を提供します。
13.13.1.1. KubeMacPoolDown アラート
説明
KubeMacPool コンポーネントは MAC アドレスを割り当て、MAC アドレスの競合を防ぎます。
理由
KubeMacPool-manager Pod が停止すると、VirtualMachine オブジェクトの作成に失敗します。
トラブルシューティング
Kubemacpool-manager Pod の namespace および名前を把握します。
$ export KMP_NAMESPACE="$(oc get pod -A --no-headers -l control-plane=mac-controller-manager | awk '{print $1}')"$ export KMP_NAME="$(oc get pod -A --no-headers -l control-plane=mac-controller-manager | awk '{print $2}')"Kubemacpool-manager Pod の説明およびログを確認して、問題の原因を判断します。
$ oc describe pod -n $KMP_NAMESPACE $KMP_NAME$ oc logs -n $KMP_NAMESPACE $KMP_NAME
解決方法
サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.2. SSP アラート
SSP アラートは、OpenShift Virtualization SSP Operator の問題についての情報を提供します。
13.13.2.1. SSPFailingToReconcile アラート
説明
SSP Operator の Pod が起動しているが、Pod の調整サイクルが必ず失敗する。この失敗には、該当するリソースの更新の失敗、テンプレートバリデータのデプロイの失敗、共通テンプレートのデプロイまたは更新の失敗が含まれます。
理由
SSP Operator が調整に失敗すると、依存するコンポーネントのデプロイメントに失敗するか、コンポーネント変更の調整に失敗するか、あるいはその両方に失敗します。さらに、共通テンプレートおよびテンプレートバリデーターの更新がリセットされ、失敗します。
トラブルシューティング
ssp-operator Pod のログでエラーの有無を確認します。
$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | awk '{print $1}')"$ oc -n $NAMESPACE describe pods -l control-plane=ssp-operator$ oc -n $NAMESPACE logs --tail=-1 -l control-plane=ssp-operatorテンプレートバリデーターが起動していることを確認します。テンプレートバリデーターが起動していない場合は、Pod のログでエラーの有無を確認します。
$ export NAMESPACE="$($ oc get deployment -A | grep ssp-operator | awk '{print $1}')"$ oc -n $NAMESPACE get pods -l name=virt-template-validator$ oc -n $NAMESPACE describe pods -l name=virt-template-validator$ oc -n $NAMESPACE logs --tail=-1 -l name=virt-template-validator
解決方法
サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.2.2. SSPOperatorDown アラート
説明
SSP Operator は、共通テンプレートおよびテンプレートバリデーターをデプロイし、調整します。
理由
SSP Operator が停止するると、依存するコンポーネントのデプロイメントに失敗するか、コンポーネント変更の調整に失敗するか、あるいはその両方に失敗します。さらに、共通テンプレートおよびテンプレートバリデーターの更新がリセットされ、失敗します。
トラブルシューティング
ssp-operator の Pod の namespace を確認します。
$ export NAMESPACE="$(oc get deployment -A | grep ssp-operator | awk '{print $1}')"ssp-operator の Pod が現在ダウンしていることを確認します。
$ oc -n $NAMESPACE get pods -l control-plane=ssp-operatorssp-operator の Pod の説明およびログを確認します。
$ oc -n $NAMESPACE describe pods -l control-plane=ssp-operator$ oc -n $NAMESPACE logs --tail=-1 -l control-plane=ssp-operator
解決方法
サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.2.3. SSPTemplateValidatorDown アラート
説明
テンプレートバリデーターは、仮想マシン (VM) が割り当てられたテンプレートに違反していないことを検証します。
理由
すべてのテンプレートバリデーター Pod がダウンしている場合、テンプレートバリデーターは仮想マシンを割り当てられたテンプレートに対して検証するのに失敗します。
トラブルシューティング
ssp-operator Pod および virt-template-validator Pod の namespace を確認します。
$ export NAMESPACE_SSP="$(oc get deployment -A | grep ssp-operator | awk '{print $1}')"$ export NAMESPACE="$(oc get deployment -A | grep virt-template-validator | awk '{print $1}')"virt-template-validator の Pod が現在ダウンしていることを確認します。
$ oc -n $NAMESPACE get pods -l name=virt-template-validatorssp-operator および virt-template-validator の Pod の説明およびログを確認します。
$ oc -n $NAMESPACE_SSP describe pods -l name=ssp-operator$ oc -n $NAMESPACE_SSP logs --tail=-1 -l name=ssp-operator$ oc -n $NAMESPACE describe pods -l name=virt-template-validator$ oc -n $NAMESPACE logs --tail=-1 -l name=virt-template-validator
解決方法
サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3. virt アラート
virt アラートは、OpenShift Virtualization Virt Operator の問題についての情報を提供します。
13.13.3.1. NoLeadingVirtOperator アラート
説明
過去 10 分間、1 つまたは複数の virt-operator Pod が Ready 状態にあるにもかかわらず、どの virt-operator Pod もリーダーリースを保持しない。アラートは動作している virt-operator Pod が存在しないことを示唆します。
理由
virt-operator は、OpenShift Container Platform クラスターでアクティブな最初の Kubernetes Operator です。その主なロールは以下のとおりです。
- インストール
- ライブ更新
- クラスターのライブアップグレード
- virt-controller、virt-handler、virt-launcher などの最上位のコントローラーのライフサイクルの監視
- 最上位のコントローラーの調整の管理
さらに、virt-operator は、証明書のローテーションや一部のインフラストラクチャー管理などのクラスター全体のタスクを行います。
virt-operator デプロイメントには、2 つの Pod のデフォルトレプリカが設定されます。1 つのリーダー Pod はリーダーリースを保持し、動作中の virt-operator Pod であることを示します。
このアラートは、クラスターレベルでの失敗を示します。証明書のローテーション、アップグレード、およびコントローラーの調整などの重要なクラスター全体の管理機能は、一時的に利用できなくなる可能性があります。
トラブルシューティング
Pod のログから virt-operator Pod のリーダーのステータスを判断します。Started leading および acquire leader が含まれるログメッセージは、その virt-operator Pod のリーダーステータスを示します。
さらに、以下のコマンドで、動作中の virt-operator Pod の有無、および Pod のステータスを常に確認します。
$ export NAMESPACE="$(oc get kubevirt -A -o custom-columns="":.metadata.namespace)"$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-operator$ oc -n $NAMESPACE logs <pod-name>$ oc -n $NAMESPACE describe pod <pod-name>リーダー Pod の例:
$ oc -n $NAMESPACE logs <pod-name> |grep lead出力例
{"component":"virt-operator","level":"info","msg":"Attempting to acquire leader status","pos":"application.go:400","timestamp":"2021-11-30T12:15:18.635387Z"}
I1130 12:15:18.635452 1 leaderelection.go:243] attempting to acquire leader lease <namespace>/virt-operator...
I1130 12:15:19.216582 1 leaderelection.go:253] successfully acquired lease <namespace>/virt-operator{"component":"virt-operator","level":"info","msg":"Started leading","pos":"application.go:385","timestamp":"2021-11-30T12:15:19.216836Z"}リーダー以外の Pod の例:
$ oc -n $NAMESPACE logs <pod-name> |grep lead出力例
{"component":"virt-operator","level":"info","msg":"Attempting to acquire leader status","pos":"application.go:400","timestamp":"2021-11-30T12:15:20.533696Z"}
I1130 12:15:20.533792 1 leaderelection.go:243] attempting to acquire leader lease <namespace>/virt-operator...解決方法
さまざまな理由により、1 つまたは複数の virt-operator Pod が Ready 状態にあるにもかかわらず、どの virt-operator Pod もリーダーリースを保持しない状況になります。根本原因を特定し、適切なアクションを実行します。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.2. NoReadyVirtController アラート
説明
virt-controller は、仮想マシンインスタンス (VMI) を監視します。virt-controller は、VMI オブジェクトに関連付けられた Pod のライフサイクルを作成し、管理して、関連付けられた Pod の管理も行います。
VMI オブジェクトは、有効期間中に常に Pod に関連付けられます。ただし、Pod インスタンスは VMI の移行により時間の経過とともに変更される可能性があります。
このアラートは、準備ができている virt-controller が 5 分間検出されなかった場合に発生します。
理由
virt-controller が失敗すると、仮想マシンのライフサイクル管理は完全に失敗します。ライフサイクルの管理タスクには、新規 VMI の起動や既存の VMI のシャットダウンなどが含まれます。
トラブルシューティング
virt-controller のデプロイメントステータスで、利用可能なレプリカおよび条件を確認します。
$ oc -n $NAMESPACE get deployment virt-controller -o yamlvirt-controller Pod が存在するかどうかを確認し、それらのステータスを確認します。
get pods -n $NAMESPACE |grep virt-controllervirt-controller Pod のイベントを確認します。
$ oc -n $NAMESPACE describe pods <virt-controller pod>virt-controller Pod のログを確認します。
$ oc -n $NAMESPACE logs <virt-controller pod>ノードが
NotReady状態にあるなど、ノードに問題があるかどうかを確認します。$ oc get nodes
解決方法
Ready 状態にある virt-controller Pod が存在しない理由はいくつかあります。根本原因を特定し、適切なアクションを実行します。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.3. NoReadyVirtOperator アラート
説明
過去 10 分間、Ready 状態の virt-operator Pod が検出されない。virt-operator デプロイメントには、2 つの Pod のデフォルトレプリカが設定されます。
理由
virt-operator は、OpenShift Container Platform クラスターでアクティブな最初の Kubernetes Operator です。その主なロールは以下のとおりです。
- インストール
- ライブ更新
- クラスターのライブアップグレード
- virt-controller、virt-handler、virt-launcher などの最上位のコントローラーのライフサイクルの監視
- 最上位のコントローラーの調整の管理
さらに、virt-operator は、証明書のローテーションや一部のインフラストラクチャー管理などのクラスター全体のタスクを行います。
virt-operator には、クラスター内の仮想マシンに対する直接のロールりはありません。virt-operator が使用できないことは、カスタムワークロードには影響しません。
このアラートは、クラスターレベルでの失敗を示します。証明書のローテーション、アップグレード、およびコントローラーの調整などの重要なクラスター全体の管理機能は、一時的に利用できなくなります。
トラブルシューティング
virt-operator のデプロイメントステータスで、利用可能なレプリカおよび条件を確認します。
$ oc -n $NAMESPACE get deployment virt-operator -o yamlvirt-controller Pod のイベントを確認します。
$ oc -n $NAMESPACE describe pods <virt-operator pod>virt-operator Pod のログを確認します。
$ oc -n $NAMESPACE logs <virt-operator pod>NotReady状態にあるなど、コントロールプレーンおよびマスターのノードに問題があるかどうかを確認します。$ oc get nodes
解決方法
Ready 状態にある virt-operator Pod が存在しない理由はいくつかあります。根本原因を特定し、適切なアクションを実行します。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.4. VirtAPIDown アラート
説明
すべての OpenShift Container Platform API サーバーが停止している。
理由
すべての OpenShift Container Platform API サーバーがダウンしている場合、OpenShift Container Platform エンティティーの API 呼び出しは行われません。
トラブルシューティング
環境変数
NAMESPACEを変更します。$ export NAMESPACE="$(oc get kubevirt -A -o custom-columns="":.metadata.namespace)"動作中の virt-api Pod があるかどうかを確認します。
$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-api-
oc logsを使用して Pod のログを表示し、oc describeを使用して Pod のステータスを表示します。 virt-api デプロイメントのステータスを確認します。以下のコマンドを使用して関連するイベントについて確認し、イメージのプルに関する問題、クラッシュしている Pod、またはその他の同様の問題の有無を表示します。
$ oc -n $NAMESPACE get deployment virt-api -o yaml$ oc -n $NAMESPACE describe deployment virt-apiノードが
NotReady状態にあるなど、ノードに問題があるかどうかを確認します。$ oc get nodes
解決方法
virt-api Pod は、いくつかの理由でダウンする可能性があります。根本原因を特定し、適切なアクションを実行します。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.5. VirtApiRESTErrorsBurst アラート
説明
過去 5 分間、virt-api で 80% を超える REST 呼び出しが失敗する。
理由
virt-api への REST 呼び出しの失敗率が非常に高くなると、応答が遅くなるか、API 呼び出しの実行が遅くなるか、API 呼び出しがすべて破棄されます。
トラブルシューティング
環境変数
NAMESPACEを変更します。$ export NAMESPACE="$(oc get kubevirt -A -o custom-columns="":.metadata.namespace)"動作中の virt-api Pod がいくつあるかを確認します。
$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-api-
oc logsを使用して Pod のログを表示し、oc describeを使用して Pod のステータスを表示します。 virt-api デプロイメントのステータスをチェックして、詳細情報を確認します。以下のコマンドは関連するイベントを提供し、イメージのプルに関する問題またはクラッシュしている Pod があるかどうかを表示します。
$ oc -n $NAMESPACE get deployment virt-api -o yaml$ oc -n $NAMESPACE describe deployment virt-apiノードがオーバーロード状態にある、または
NotReady状態にあるなど、ノードに問題があるかどうかを確認します。$ oc get nodes
解決方法
REST 呼び出しの失敗率が高い理由はいくつかあります。根本原因を特定し、適切なアクションを実行します。
- ノードリソースの枯渇
- クラスターに十分なメモリーがない
- ノードがダウンしている
- スケジューラーが 100% 利用できない場合など、API サーバーのオーバーロード
- ネットワークの問題
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.6. VirtControllerDown アラート
説明
過去 5 分間 virt-controller が検出されない場合、virt-controller デプロイメントには 2 つの Pod のデフォルトレプリカが設定されます。
理由
virt-controller が失敗すると、新規 VMI の起動や既存 VMI のシャットダウンなどの仮想マシンのライフサイクル管理タスクが完全に失敗します。
トラブルシューティング
環境変数
NAMESPACEを変更します。$ export NAMESPACE="$(oc get kubevirt -A -o custom-columns="":.metadata.namespace)"virt-controller デプロイメントのステータスを確認します。
$ oc get deployment -n $NAMESPACE virt-controller -o yamlvirt-controller Pod のイベントを確認します。
$ oc -n $NAMESPACE describe pods <virt-controller pod>virt-controller Pod のログを確認します。
$ oc -n $NAMESPACE logs <virt-controller pod>マネージャー Pod のログを確認して、virt-controller Pod の作成に失敗した理由を判断します。
$ oc get logs <virt-controller-pod>
ログの virt-controller Pod 名の例は virt-controller-7888c64d66-dzc9p です。ただし、virt-controller を実行する Pod が複数存在する場合があります。
解決方法
動作中の virt-controller が検出されない既知の理由がいくつかあります。考えられる理由のリストから根本原因を特定し、適切なアクションを実行します。
- ノードリソースの枯渇
- クラスターに十分なメモリーがない
- ノードがダウンしている
- スケジューラーが 100% 利用できない場合など、API サーバーのオーバーロード
- ネットワークの問題
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.7. VirtControllerRESTErrorsBurst アラート
説明
過去 5 分間、virt-controller で 80% を超える REST 呼び出しが失敗する。
理由
virt-controller が、API サーバーへの接続を完全に失った可能性があります。接続の喪失は実行中のワークロードには影響しませんが、ステータス更新の反映や移行などのアクションは実行できません。
トラブルシューティング
virt-controller REST 呼び出しの失敗には、以下の 2 つの一般的なエラータイプがあります。
- API サーバーのオーバーロードにより、タイムアウトを引き起こす。応答時間や全体の呼び出しなど、API サーバーメトリックと詳細を確認します。
virt-controller Pod が API サーバーに到達できない。一般的な原因は以下のとおりです。
- ノード上の DNS の問題
- ネットワーク接続の問題
解決方法
virt-controller ログをチェックして、virt-controller Pod が API サーバーにまったく接続できないかどうかを判断します。その場合、Pod を削除して強制的に再起動します。
さらに、ノードリソースが使い切られるか、クラスターに十分なメモリーがないため、接続に失敗しているかどうかを確認します。
通常、問題は、このアラートの範囲外の DNS または CNI の問題に関連しています。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.8. VirtHandlerRESTErrorsBurst アラート
説明
過去 5 分間、virt-handler で 80% を超える REST 呼び出しが失敗する。
理由
virt-handler が API サーバーへの接続を失った。影響を受けるノードで実行中のワークロードは実行し続けますが、ステータスの更新を反映できず、移行などのアクションを実行できません。
トラブルシューティング
virt-operator REST 呼び出しの失敗には、以下の 2 つの一般的なエラータイプがあります。
- API サーバーのオーバーロードにより、タイムアウトを引き起こす。応答時間や全体の呼び出しなど、API サーバーメトリックと詳細を確認します。
virt-operator Pod が API サーバーに到達できない。一般的な原因は以下のとおりです。
- ノード上の DNS の問題
- ネットワーク接続の問題
解決方法
virt-handler が API サーバーに接続できない場合、Pod を削除して強制的に再起動します。通常、問題は、このアラートの範囲外の DNS または CNI の問題に関連しています。根本原因を特定し、適切なアクションを実行します。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.9. VirtOperatorDown アラート
説明
このアラートは、過去 10 分間 Running 状態の virt-operator Pod が存在しない場合に発生します。virt-operator デプロイメントには、2 つの Pod のデフォルトレプリカが設定されます。
理由
virt-operator は、OpenShift Container Platform クラスターでアクティブな最初の Kubernetes Operator です。その主なロールは以下のとおりです。
- インストール
- ライブ更新
- クラスターのライブアップグレード
- virt-controller、virt-handler、virt-launcher などの最上位のコントローラーのライフサイクルの監視
- 最上位のコントローラーの調整の管理
さらに、virt-operator は、証明書のローテーションや一部のインフラストラクチャー管理などのクラスター全体のタスクを行います。
virt-operator には、クラスター内の仮想マシンに対する直接のロールりはありません。virt-operator が使用できないことは、カスタムワークロードには影響しません。
このアラートは、クラスターレベルでの失敗を示します。証明書のローテーション、アップグレード、およびコントローラーの調整などの重要なクラスター全体の管理機能は、一時的に利用できなくなります。
トラブルシューティング
環境変数
NAMESPACEを変更します。$ export NAMESPACE="$(oc get kubevirt -A -o custom-columns="":.metadata.namespace)"virt-operator デプロイメントのステータスを確認します。
$ oc get deployment -n $NAMESPACE virt-operator -o yamlvirt-operator Pod のイベントを確認します。
$ oc -n $NAMESPACE describe pods <virt-operator pod>virt-operator Pod のログを確認します。
$ oc -n $NAMESPACE logs <virt-operator pod>マネージャー Pod のログを確認して、virt-operator Pod の作成に失敗した理由を判断します。
$ oc get logs <virt-operator-pod>
ログの virt-operator Pod 名の例は virt-operator-7888c64d66-dzc9p です。ただし、virt-operator を実行する Pod が複数存在する場合があります。
解決方法
動作中の virt-operator が検出されない既知の理由がいくつかあります。考えられる理由のリストから根本原因を特定し、適切なアクションを実行します。
- ノードリソースの枯渇
- クラスターに十分なメモリーがない
- ノードがダウンしている
- スケジューラーが 100% 利用できない場合など、API サーバーのオーバーロード
- ネットワークの問題
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.13.3.10. VirtOperatorRESTErrorsBurst アラート
説明
過去 5 分間、virt-operator で 80% を超える REST 呼び出しが失敗する。
理由
virt-operator が API サーバーへの接続を失った。アップグレードおよびコントローラーの調整などのクラスターレベルのアクションは機能しません。仮想マシンや VMI などのお客様のワークロードには影響がありません。
トラブルシューティング
virt-operator REST 呼び出しの失敗には、以下の 2 つの一般的なエラータイプがあります。
- API サーバーのオーバーロードにより、タイムアウトを引き起こす。応答時間や全体の呼び出しなど、API サーバーメトリックと詳細を確認します。
virt-operator Pod が API サーバーに到達できない。一般的な原因は、ネットワークの接続性の問題や、ノードでの DNS の問題です。virt-operator ログをチェックして、Pod が API サーバーに接続できることを確認します。
$ export NAMESPACE="$(oc get kubevirt -A -o custom-columns="":.metadata.namespace)"$ oc -n $NAMESPACE get pods -l kubevirt.io=virt-operator$ oc -n $NAMESPACE logs <pod-name>$ oc -n $NAMESPACE describe pod <pod-name>
解決方法
virt-operator が API サーバーに接続できない場合、Pod を削除して強制的に再起動します。通常、問題は、このアラートの範囲外の DNS または CNI の問題に関連しています。根本原因を特定し、適切なアクションを実行します。
それ以外には、サポートケースを作成し、トラブルシューティングのプロセスで収集された情報を提供します。
13.14. Red Hat サポート用のデータ収集
Red Hat サポートに サポートケース を送信する際、以下のツールを使用して OpenShift Container Platform および OpenShift Virtualization のデバッグ情報を提供すると役立ちます。
- must-gather ツール
-
must-gatherツールは、リソース定義やサービスログなどの診断情報を収集します。 - Prometheus
- Prometheus は Time Series を使用するデータベースであり、メトリックのルール評価エンジンです。Prometheus は処理のためにアラートを Alertmanager に送信します。
- Alertmanager
- Alertmanager サービスは、Prometheus から送信されるアラートを処理します。また、Alertmanager は外部の通知システムにアラートを送信します。
13.14.1. 環境に関するデータの収集
環境に関するデータを収集すると、根本原因の分析および特定に必要な時間が最小限に抑えられます。
前提条件
- Prometheus メトリックデータの保持期間を最低 7 日間に設定します。
- Alertmanager を設定して、関連するアラートを取得して、それらを専用のメールボックスに送信して、クラスター外で表示および保持できるようにします。
- 影響を受けるノードおよび仮想マシンの正確な数を記録します。
手順
-
デフォルトの
must-gatherイメージを使用して、クラスターのmust-gatherデータを収集します。 -
必要に応じて、Red Hat OpenShift Data Foundation の
must-gatherデータを収集します。 -
OpenShift Virtualization の
must-gatherイメージを使用して、OpenShift Virtualization のmust-gatherデータを収集します。 - クラスターの Prometheus メトリックを収集します。
13.14.2. 仮想マシンに関するデータの収集
仮想マシン (VM) の誤動作に関するデータを収集することで、根本原因の分析および特定に必要な時間を最小限に抑えることができます。
前提条件
Windows 仮想マシン:
- Red Hat サポート用に Windows パッチ更新の詳細を記録します。
- VirtIO ドライバーの最新バージョンをインストールします。VirtIO ドライバーには、QEMU ゲストエージェントが含まれています。
- リモートデスクトッププロトコル (RDP) が有効になっている場合は、RDP を使用して仮想マシンに接続し、接続ソフトウェアに問題があるかどうかを判断します。
手順
-
誤動作している仮想マシンに関する詳細な
must-gatherを収集します。 - 仮想マシンを再起動する前に、クラッシュした仮想マシンのスクリーンショットを収集します。
- 誤動作している仮想マシンに共通する要因を記録します。たとえば、仮想マシンには同じホストまたはネットワークがあります。
13.14.3. OpenShift Virtualization の must-gather ツールの使用
OpenShift Virtualization イメージで must-gather コマンドを実行することにより、OpenShift Virtualization リソースに関するデータを収集できます。
デフォルトのデータ収集には、次のリソースに関する情報が含まれています。
- 子オブジェクトを含む OpenShift Virtualization Operator namespace
- すべての OpenShift Virtualization カスタムリソース定義 (CRD)
- 仮想マシンを含むすべての namespace
- 基本的な仮想マシン定義
手順
以下のコマンドを実行して、OpenShift Virtualization に関するデータを収集します。
$ oc adm must-gather --image-stream=openshift/must-gather \ --image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel8:v4.11.8
13.14.3.1. must-gather ツールオプション
次のオプションに対して、スクリプトおよび環境変数の組み合わせを指定できます。
- namespace から詳細な仮想マシン (VM) 情報の収集する
- 特定の仮想マシンに関する詳細情報の収集
- イメージおよびイメージストリーム情報の収集
-
must-gatherツールが使用する並列プロセスの最大数の制限
13.14.3.1.1. パラメーター
環境変数
互換性のあるスクリプトの環境変数を指定できます。
NS=<namespace_name>-
指定した namespace から
virt-launcherPod の詳細を含む仮想マシン情報を収集します。VirtualMachineおよびVirtualMachineInstanceCR データはすべての namespace で収集されます。 VM=<vm_name>-
特定の仮想マシンに関する詳細を収集します。このオプションを使用するには、
NS環境変数を使用して namespace も指定する必要があります。 PROS=<number_of_processes>must-gatherツールが使用する並列処理の最大数を変更します。デフォルト値は5です。重要並列処理が多すぎると、パフォーマンスの問題が発生する可能性があります。並列処理の最大数を増やすことは推奨されません。
スクリプト
各スクリプトは、特定の環境変数の組み合わせとのみ互換性があります。
gather_vms_details-
OpenShift Virtualization リソースに属する仮想マシンログファイル、仮想マシン定義、ならびに namespace (およびそれらのサブオブジェクト) を収集します。namespace または仮想マシンを指定せずにこのパラメーターを使用する場合、
must-gatherツールはクラスター内のすべての仮想マシンについてこのデータを収集します。このスクリプトはすべての環境変数と互換性がありますが、VM変数を使用する場合は namespace を指定する必要があります。 gather-
デフォルトの
must-gatherスクリプトを使用します。すべての namespace からクラスターデータが収集され、基本的な仮想マシン情報のみが含まれます。このスクリプトは、PROS変数とのみ互換性があります。 gather_images-
イメージおよびイメージストリームのカスタムリソース情報を収集します。このスクリプトは、
PROS変数とのみ互換性があります。
13.14.3.1.2. 使用方法および例
環境変数はオプションです。スクリプトは、単独で実行することも、1 つ以上の互換性のある環境変数を使用して実行することもできます。
| スクリプト | 互換性のある環境変数 |
|---|---|
|
|
|
|
|
|
|
|
|
must-gather が収集するデータをカスタマイズするには、コマンドに二重ダッシュ (--) を追加し、その後にスペースと 1 つ以上の互換性のあるパラメーターを追加します。
構文
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel8:v4.11.8 \
-- <environment_variable_1> <environment_variable_2> <script_name>詳細な仮想マシン情報
次のコマンドは、mynamespace namespace にある my-vm 仮想マシンの詳細な仮想マシン情報を収集します。
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel8:v4.11.8 \
-- NS=mynamespace VM=my-vm gather_vms_details - 1
VM環境変数を使用する場合、NS環境変数は必須です。
3 つの並列プロセスに限定されたデフォルトのデータ収集
以下のコマンドは、最大 3 つの並列処理を使用して、デフォルトの must-gather 情報を収集します。
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel8:v4.11.8 \
-- PROS=3 gatherイメージおよびイメージストリーム情報
以下のコマンドは、クラスターからイメージおよびイメージストリームの情報を収集します。
$ oc adm must-gather \
--image=registry.redhat.io/container-native-virtualization/cnv-must-gather-rhel8:v4.11.8 \
-- gather_images第14章 バックアップおよび復元
14.1. OADP のインストールおよび設定
クラスター管理者は、OADP Operator をインストールして、OpenShift API for Data Protection (OADP) をインストールします。Operator は Velero 1.11 をインストールします。
バックアップストレージプロバイダーのデフォルトの Secret を作成し、Data Protection Application をインストールします。
14.1.1. OADP Operator のインストール
Operator Lifecycle Manager (OLM) を使用して、OpenShift Container Platform 4.11 に OpenShift API for Data Protection (OADP) オペレーターをインストールします。
OADP Operator は Velero 1.11 をインストールします。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- Filter by keyword フィールドを使用して、OADP Operator を検索します。
- OADP Operator を選択し、Install をクリックします。
-
Install をクリックして、
openshift-adpプロジェクトに Operator をインストールします。 - Operators → Installed Operators をクリックして、インストールを確認します。
14.1.2. バックアップおよびスナップショットの場所、ならびにそのシークレットについて
DataProtectionApplication カスタムリソース (CR) で、バックアップおよびスナップショットの場所、ならびにそのシークレットを指定します。
バックアップの場所
Multicloud Object Gateway または MinIO などの S3 互換オブジェクトストレージを、バックアップの場所として指定します。
Velero は、オブジェクトストレージのアーカイブファイルとして、OpenShift Container Platform リソース、Kubernetes オブジェクト、および内部イメージをバックアップします。
スナップショットの場所
クラウドプロバイダーのネイティブスナップショット API を使用して永続ボリュームをバックアップする場合、クラウドプロバイダーをスナップショットの場所として指定する必要があります。
Container Storage Interface (CSI) スナップショットを使用する場合、CSI ドライバーを登録するために VolumeSnapshotClass CR を作成するため、スナップショットの場所を指定する必要はありません。
Restic を使用する場合は、Restic がオブジェクトストレージにファイルシステムをバックアップするため、スナップショットの場所を指定する必要はありません。
シークレット
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
バックアップとスナップショットの場所で異なる認証情報を使用する場合は、次の 2 つの secret オブジェクトを作成します。
-
DataProtectionApplicationCR で指定する、バックアップの場所用のカスタムSecret。 -
DataProtectionApplicationCR で参照されない、スナップショットの場所用のデフォルトSecret。
Data Protection Application には、デフォルトの Secret が必要です。作成しないと、インストールは失敗します。
インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の credentials-velero ファイルを使用してデフォルトの Secret を作成できます。
14.1.2.1. デフォルト Secret の作成
バックアップとスナップショットの場所が同じ認証情報を使用する場合、またはスナップショットの場所が必要ない場合は、デフォルトの Secret を作成します。
DataProtectionApplication カスタムリソース (CR) にはデフォルトの Secret が必要です。作成しないと、インストールは失敗します。バックアップの場所の Secret の名前が指定されていない場合は、デフォルトの名前が使用されます。
インストール時にバックアップの場所の認証情報を使用しない場合は、空の credentials-velero ファイルを使用してデフォルト名前で Secret を作成できます。
前提条件
- オブジェクトストレージとクラウドストレージがある場合は、同じ認証情報を使用する必要があります。
- Velero のオブジェクトストレージを設定する必要があります。
-
オブジェクトストレージ用の
credentials-veleroファイルを適切な形式で作成する必要があります。
手順
デフォルト名で
Secretを作成します。$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
Secret は、Data Protection Application をインストールするときに、DataProtectionApplication CR の spec.backupLocations.credential ブロックで参照されます。
14.1.3. Data Protection Application の設定
Velero リソースの割り当てを設定するか、自己署名 CA 証明書を有効にして、Data Protection Application を設定できます。
14.1.3.1. Velero の CPU とメモリーのリソース割り当てを設定
DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、Velero Pod の CPU およびメモリーリソースの割り当てを設定します。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
次の例のように、
DataProtectionApplicationCR マニフェストのspec.configuration.velero.podConfig.ResourceAllocationsブロックの値を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector>1 resourceAllocations:2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
14.1.3.2. 自己署名 CA 証明書の有効化
certificate signed by unknown authority エラーを防ぐために、DataProtectionApplication カスタムリソース (CR) マニフェストを編集して、オブジェクトストレージの自己署名 CA 証明書を有効にする必要があります。
前提条件
- OpenShift API for Data Protection (OADP) Operator がインストールされている必要があります。
手順
DataProtectionApplicationCR マニフェストのspec.backupLocations.velero.objectStorage.caCertパラメーターとspec.backupLocations.velero.configパラメーターを編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string>1 config: insecureSkipTLSVerify: "false"2 ...
14.1.4. Data Protection Application のインストール
DataProtectionApplication API のインスタンスを作成して、Data Protection Application (DPA) をインストールします。
前提条件
- OADP Operator をインストールする必要がある。
- オブジェクトストレージをバックアップ場所として設定する必要がある。
- スナップショットを使用して PV をバックアップする場合、クラウドプロバイダーはネイティブスナップショット API または Container Storage Interface (CSI) スナップショットのいずれかをサポートする必要がある。
-
バックアップとスナップショットの場所で同じ認証情報を使用する場合は、デフォルトの名前である
cloud-credentialsを使用してSecretを作成する必要がある。 バックアップとスナップショットの場所で異なる認証情報を使用する場合は、以下のように 2 つの
Secretsを作成する必要がある。-
バックアップの場所用のカスタム名を持つ
Secret。このSecretをDataProtectionApplicationCR に追加します。 スナップショットの場所のデフォルト名である
cloud-credentialsのSecret。このSecretは、DataProtectionApplicationCR では参照されません。注記インストール中にバックアップまたはスナップショットの場所を指定したくない場合は、空の
credentials-veleroファイルを使用してデフォルトのSecretを作成できます。デフォルトのSecretがない場合、インストールは失敗します。注記Velero は、OADP namespace に
velero-repo-credentialsという名前のシークレットを作成します。これには、デフォルトのバックアップリポジトリーパスワードが含まれます。バックアップリポジトリーを対象とした最初のバックアップを実行する 前 に、base64 としてエンコードされた独自のパスワードを使用してシークレットを更新できます。更新するキーの値はData[repository-password]です。DPA を作成した後、バックアップリポジトリーを対象としたバックアップを初めて実行するときに、Velero はシークレットが
velero-repo-credentialsのバックアップリポジトリーを作成します。これには、デフォルトのパスワードまたは置き換えたパスワードが含まれます。最初のバックアップの 後 にシークレットパスワードを更新すると、新しいパスワードがvelero-repo-credentialsのパスワードと一致しなくなり、Velero は古いバックアップに接続できなくなります。
-
バックアップの場所用のカスタム名を持つ
手順
- Operators → Installed Operators をクリックして、OADP Operator を選択します。
- Provided APIs で、DataProtectionApplication ボックスの Create instance をクリックします。
YAML View をクリックして、
DataProtectionApplicationマニフェストのパラメーターを更新します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - kubevirt1 - gcp2 - csi3 - openshift4 resourceTimeout: 10m5 restic: enable: true6 podConfig: nodeSelector: <node_selector>7 backupLocations: - velero: provider: gcp8 default: true credential: key: cloud name: <default_secret>9 objectStorage: bucket: <bucket_name>10 prefix: <prefix>11 - 1
kubevirtプラグインは OpenShift Virtualization に必須です。- 2
- バックアッププロバイダーのプラグインがある場合には、それを指定します (例:
gcp)。 - 3
- CSI スナップショットを使用して PV をバックアップするには、
csiプラグインが必須です。csiプラグインは、Velero CSI ベータスナップショット API を使用します。スナップショットの場所を設定する必要はありません。 - 4
openshiftプラグインは必須です。- 5
- Velero CRD の可用性、volumeSnapshot の削除、バックアップリポジトリーの可用性など、タイムアウトが発生するまでに複数の Velero リソースを待機する時間を分単位で指定します。デフォルトは 10m です。
- 6
- Restic インストールを無効にする場合は、この値を
falseに設定します。Restic はデーモンセットをデプロイします。これは、Restic Pod が各動作ノードで実行していることを意味します。OADP バージョン 1.2 以降では、spec.defaultVolumesToFsBackup: trueをBackupCR に追加することで、バックアップ用に Restic を設定できます。OADP バージョン 1.1 では、spec.defaultVolumesToRestic: trueをBackupCR に追加します。 - 7
- Restic を使用できるノードを指定します。デフォルトでは、Restic はすべてのノードで実行されます。
- 8
- バックアッププロバイダーを指定します。
- 9
- バックアッププロバイダーにデフォルトのプラグインを使用する場合は、
Secretの正しいデフォルト名を指定します (例:cloud-credentials-gcp)。カスタム名を指定すると、そのカスタム名がバックアップの場所に使用されます。Secret名を指定しない場合は、デフォルトの名前が使用されます。 - 10
- バックアップの保存場所としてバケットを指定します。バケットが Velero バックアップ専用のバケットでない場合は、接頭辞を指定する必要があります。
- 11
- バケットが複数の目的で使用される場合は、Velero バックアップの接頭辞を指定します (例:
velero)。
- Create をクリックします。
OADP リソースを表示して、インストールを確認します。
$ oc get all -n openshift-adp出力例
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
14.1.4.1. DataProtectionApplication CR で CSI を有効にする
CSI スナップショットを使用して永続ボリュームをバックアップするには、DataProtectionApplication カスタムリソース (CR) で Container Storage Interface (CSI) を有効にします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
手順
次の例のように、
DataProtectionApplicationCR を編集します。apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi1 - 1
csiデフォルトプラグインを追加します。
14.1.5. OADP のアンインストール
OpenShift API for Data Protection (OADP) をアンインストールするには、OADP Operator を削除します。詳細は、クラスターからの演算子の削除 を参照してください。
14.2. 仮想マシンのバックアップと復元
OpenShift Virtualization の OADP は、テクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
OpenShift API for Data Protection (OADP) を使用して、仮想マシンをバックアップおよび復元します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
- ストレージプロバイダーの指示に従って OADP Operator をインストールします。
-
kubevirtおよびopenshiftプラグイン を使用して データ保護アプリケーション をインストールします。 -
Backupカスタム リソース (CR) を作成して、仮想マシンをバックアップします。 -
RestoreCR を作成し、BackupCR を復元します。
14.3. 仮想マシンのバックアップ
OpenShift API for Data Protection (OADP) の Backup カスタムリソース (CR) を作成して、仮想マシン (VM) をバックアップします。
Backup CR は以下のアクションを実行します。
- Multicloud Object Gateway、Noobaa、または Minio などの S3 互換オブジェクトストレージにアーカイブファイルを作成して、OpenShift Virtualization リソースをバックアップします。
以下のオプションのいずれかを使用して、仮想マシンディスクをバックアップします。
- Ceph RBD または Ceph FS などの CSI 対応クラウドストレージ上の Container Storage Interface (CSI) スナップショット。
- オブジェクトストレージ上のRestic ファイルシステムバックアップ。
OADP はバックアップフックを提供し、バックアップ操作の前に仮想マシンのファイルシステムをフリーズし、バックアップの完了時にフリーズを解除します。
kubevirt-controller は、バックアップ操作の前後に Velero が virt-freezer バイナリーを実行できるようにするアノテーションで virt-launcher Pod を作成します。
freeze および unfreeze API は、仮想マシンスナップショット API のサブリソースです。詳細は、仮想マシンのスナップショットについてを参照してください。
フック をBackup CR に追加して、バックアップ操作の前後に特定の仮想マシンでコマンドを実行できます。
Backup CR の代わりに Schedule CR を作成することにより、バックアップをスケジュールします。
14.3.1. バックアップ CR の作成
Backup カスタムリソース (CR) を作成して、Kubernetes イメージ、内部イメージ、および永続ボリューム (PV) をバックアップします。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。 バックアップ場所の前提条件:
- Velero 用に S3 オブジェクトストレージを設定する必要があります。
-
DataProtectionApplicationCR でバックアップの場所を設定する必要があります。
スナップショットの場所の前提条件:
- クラウドプロバイダーには、ネイティブスナップショット API が必要であるか、Container Storage Interface (CSI) スナップショットをサポートしている必要があります。
-
CSI スナップショットの場合、CSI ドライバーを登録するために
VolumeSnapshotClassCR を作成する必要があります。 -
DataProtectionApplicationCR でボリュームの場所を設定する必要があります。
手順
次のコマンドを入力して、
backupStorageLocationsCR を取得します。$ oc get backupStorageLocations -n openshift-adp出力例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m次の例のように、
BackupCR を作成します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: hooks: {} includedNamespaces: - <namespace>1 includedResources: []2 excludedResources: []3 storageLocation: <velero-sample-1>4 ttl: 720h0m0s labelSelector:5 matchLabels: app=<label_1> app=<label_2> app=<label_3> orLabelSelectors:6 - matchLabels: app=<label_1> app=<label_2> app=<label_3>- 1
- バックアップする namespace の配列を指定します。
- 2
- オプション: バックアップに含めるリソースの配列を指定します。リソースは、ショートカット (Pods は po など) または完全修飾の場合があります。指定しない場合、すべてのリソースが含まれます。
- 3
- オプション: バックアップから除外するリソースの配列を指定します。リソースは、ショートカット (Pods は po など) または完全修飾の場合があります。
- 4
backupStorageLocationsCR の名前を指定します。- 5
- 指定したラベルを すべて 持つバックアップリソースの {key,value} ペアのマップ。
- 6
- 指定したラベルを 1 つ以上 持つバックアップリソースの {key,value} ペアのマップ。
BackupCR のステータスがCompletedしたことを確認します。$ oc get backup -n openshift-adp <backup> -o jsonpath='{.status.phase}'
14.3.1.1. CSI スナップショットを使用した永続ボリュームのバックアップ
Backup CR を作成する前に、クラウドストレージの VolumeSnapshotClass カスタムリソース (CR) を編集して、Container Storage Interface (CSI) スナップショットを使用して永続ボリュームをバックアップします。
前提条件
- クラウドプロバイダーは、CSI スナップショットをサポートする必要があります。
-
DataProtectionApplicationCR で CSI を有効にする必要があります。
手順
metadata.labels.velero.io/csi-volumesnapshot-class: "true"のキー: 値ペアをVolumeSnapshotClassCR に追加します。apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: <volume_snapshot_class_name> labels: velero.io/csi-volumesnapshot-class: "true" driver: <csi_driver> deletionPolicy: Retain
これで、Backup CR を作成できます。
14.3.1.2. Restic を使用したアプリケーションのバックアップ
Backup カスタムリソース (CR) を編集して、Restic を使用して Kubernetes リソース、内部イメージ、および永続ボリュームをバックアップします。
DataProtectionApplication CR でスナップショットの場所を指定する必要はありません。
Restic は、hostPath ボリュームのバックアップをサポートしません。詳細は、Restic のその他の制限事項 を参照してください。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR でspec.configuration.restic.enableをfalseに設定して、デフォルトの Restic インストールを無効にしていない。 -
DataProtectionApplicationCR がReady状態である。
手順
次の例のように、
BackupCR を編集します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: defaultVolumesToFsBackup: true1 ...- 1
- OADP バージョン 1.2 以降では、
defaultVolumesToFsBackup: true設定をspecブロック内に追加します。OADP バージョン 1.1 では、defaultVolumesToRestic: trueを追加します。
14.3.1.3. バックアップフックの作成
Backup カスタムリソース (CR) を編集して、Pod 内のコンテナーでコマンドを実行するためのバックアップフックを作成します。
プレ フックは、Pod のバックアップが作成される前に実行します。ポスト フックはバックアップ後に実行します。
手順
次の例のように、
BackupCR のspec.hooksブロックにフックを追加します。apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces:2 - <namespace> includedResources: [] - pods3 excludedResources: []4 labelSelector:5 matchLabels: app: velero component: server pre:6 - exec: container: <container>7 command: - /bin/uname8 - -a onError: Fail9 timeout: 30s10 post:11 ...- 1
- オプション: フックが適用される namespace を指定できます。この値が指定されていない場合、フックはすべてのネームスペースに適用されます。
- 2
- オプション: フックが適用されない namespace を指定できます。
- 3
- 現在、Pod は、フックを適用できる唯一のサポート対象リソースです。
- 4
- オプション: フックが適用されないリソースを指定できます。
- 5
- オプション: このフックは、ラベルに一致するオブジェクトにのみ適用されます。この値が指定されていない場合、フックはすべてのネームスペースに適用されます。
- 6
- バックアップの前に実行するフックの配列。
- 7
- オプション: コンテナーが指定されていない場合、コマンドは Pod の最初のコンテナーで実行されます。
- 8
- これは、追加される init コンテナーのエントリーポイントです。
- 9
- エラー処理に許可される値は、
FailとContinueです。デフォルトはFailです。 - 10
- オプション: コマンドの実行を待機する時間。デフォルトは
30sです。 - 11
- このブロックでは、バックアップ後に実行するフックの配列を、バックアップ前のフックと同じパラメーターで定義します。
14.3.2. バックアップのスケジュール
Backup CR の代わりに Schedule カスタムリソース (CR) を作成して、バックアップをスケジュールします。
バックアップスケジュールでは、別のバックアップが作成される前にバックアップを数量するための時間を十分確保してください。
たとえば、namespace のバックアップに通常 10 分かかる場合は、15 分ごとよりも頻繁にバックアップをスケジュールしないでください。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。
手順
backupStorageLocationsCR を取得します。$ oc get backupStorageLocations -n openshift-adp出力例
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m次の例のように、
ScheduleCR を作成します。$ cat << EOF | oc apply -f - apiVersion: velero.io/v1 kind: Schedule metadata: name: <schedule> namespace: openshift-adp spec: schedule: 0 7 * * *1 template: hooks: {} includedNamespaces: - <namespace>2 storageLocation: <velero-sample-1>3 defaultVolumesToFsBackup: true4 ttl: 720h0m0s EOF- 1
- バックアップをスケジュールするための
cron式。たとえば、毎日 7:00 にバックアップを実行する場合は0 7 * * *です。 - 2
- バックアップを作成する namespace の配列。
- 3
backupStorageLocationsCR の名前。- 4
- オプション: OADP バージョン 1.2 以降では、Restic を使用してボリュームのバックアップを実行するときに、
defaultVolumesToFsBackup: trueキーと値のペアを設定に追加します。OADP バージョン 1.1 では、Restic でボリュームをバックアップするときに、defaultVolumesToRestic: trueのキーと値のペアを追加します。
スケジュールされたバックアップの実行後に、
ScheduleCR のステータスがCompletedとなっていることを確認します。$ oc get schedule -n openshift-adp <schedule> -o jsonpath='{.status.phase}'
14.3.3. 関連情報
14.4. 仮想マシンの復元
Restore CR を作成して、OpenShift API for Data Protection (OADP) のBackup カスタムリソース (CR) を復元します。
フック を Restore CR に追加して、アプリケーションコンテナーの起動前に init コンテナーでコマンドを実行するか、アプリケーションコンテナー自体でコマンドを実行することができます。
14.4.1. 復元 CR の作成
Restore CR を作成して、Backup カスタムリソース (CR) を復元します。
前提条件
- OpenShift API for Data Protection (OADP) Operator をインストールしている。
-
DataProtectionApplicationCR がReady状態である。 -
Velero
BackupCR がある。 - バックアップ時に永続ボリューム (PV) の容量が要求されたサイズと一致するよう、要求されたサイズを調整している。
手順
次の例のように、
RestoreCR を作成します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: backupName: <backup>1 includedResources: []2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io restorePVs: true3 - 1
BackupCR の名前- 2
- オプション: 復元プロセスに含めるリソースの配列を指定します。リソースは、ショートカット (
Podsはpoなど) または完全修飾の場合があります。指定しない場合、すべてのリソースが含まれます。 - 3
- オプション:
RestorePVsパラメーターをfalseに設定すると、コンテナーストレージインターフェイス (CSI) スナップショットのVolumeSnapshotから、またはVolumeSnaphshotLocationが設定されている場合はネイティブスナップショットからのPersistentVolumesの復元をオフにすることができます。
次のコマンドを入力して、
RestoreCR のステータスがCompletedであることを確認します。$ oc get restore -n openshift-adp <restore> -o jsonpath='{.status.phase}'次のコマンドを入力して、バックアップリソースが復元されたことを確認します。
$ oc get all -n <namespace>1 - 1
- バックアップした namespace。
Restic を使用して
DeploymentConfigオブジェクトを復元する場合、または復元後のフックを使用する場合は、次のコマンドを入力してdc-restic-post-restore.shクリーンアップスクリプトを実行します。$ bash dc-restic-post-restore.sh <restore-name>注記復元プロセスの過程で、OADP Velero プラグインは、
DeploymentConfigオブジェクトをスケールダウンし、Pod をスタンドアロン Pod として復元して、クラスターが復元されたDeploymentConfigPod を復元時にすぐに削除しないようにし、Restic および復元後のフックを完了できるようにします。復元された Pod でのアクション。クリーンアップスクリプトは、これらの切断された Pod を削除し、DeploymentConfigオブジェクトを適切な数のレプリカに戻します。例14.1
dc-restic-post-restore.shクリーンアップスクリプト#!/bin/bash set -e # if sha256sum exists, use it to check the integrity of the file if command -v sha256sum >/dev/null 2>&1; then CHECKSUM_CMD="sha256sum" else CHECKSUM_CMD="shasum -a 256" fi label_name () { if [ "${#1}" -le "63" ]; then echo $1 return fi sha=$(echo -n $1|$CHECKSUM_CMD) echo "${1:0:57}${sha:0:6}" } OADP_NAMESPACE=${OADP_NAMESPACE:=openshift-adp} if [[ $# -ne 1 ]]; then echo "usage: ${BASH_SOURCE} restore-name" exit 1 fi echo using OADP Namespace $OADP_NAMESPACE echo restore: $1 label=$(label_name $1) echo label: $label echo Deleting disconnected restore pods oc delete pods -l oadp.openshift.io/disconnected-from-dc=$label for dc in $(oc get dc --all-namespaces -l oadp.openshift.io/replicas-modified=$label -o jsonpath='{range .items[*]}{.metadata.namespace}{","}{.metadata.name}{","}{.metadata.annotations.oadp\.openshift\.io/original-replicas}{","}{.metadata.annotations.oadp\.openshift\.io/original-paused}{"\n"}') do IFS=',' read -ra dc_arr <<< "$dc" if [ ${#dc_arr[0]} -gt 0 ]; then echo Found deployment ${dc_arr[0]}/${dc_arr[1]}, setting replicas: ${dc_arr[2]}, paused: ${dc_arr[3]} cat <<EOF | oc patch dc -n ${dc_arr[0]} ${dc_arr[1]} --patch-file /dev/stdin spec: replicas: ${dc_arr[2]} paused: ${dc_arr[3]} EOF fi done
14.4.1.1. 復元フックの作成
Restore カスタムリソース (CR) を編集して、アプリケーションの復元中に Pod 内のコンテナーでコマンドを実行する復元フックを作成します。
2 種類の復元フックを作成できます。
initフックは、init コンテナーを Pod に追加して、アプリケーションコンテナーが起動する前にセットアップタスクを実行します。Restic バックアップを復元する場合は、復元フック init コンテナーの前に
restic-waitinit コンテナーが追加されます。-
execフックは、復元された Pod のコンテナーでコマンドまたはスクリプトを実行します。
手順
次の例のように、
Restore CRのspec.hooksブロックにフックを追加します。apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace>1 excludedNamespaces: - <namespace> includedResources: - pods2 excludedResources: [] labelSelector:3 matchLabels: app: velero component: server postHooks: - init: initContainers: - name: restore-hook-init image: alpine:latest volumeMounts: - mountPath: /restores/pvc1-vm name: pvc1-vm command: - /bin/ash - -c timeout:4 - exec: container: <container>5 command: - /bin/bash6 - -c - "psql < /backup/backup.sql" waitTimeout: 5m7 execTimeout: 1m8 onError: Continue9 - 1
- オプション: フックが適用される namespace の配列。この値が指定されていない場合、フックはすべてのネームスペースに適用されます。
- 2
- 現在、Pod は、フックを適用できる唯一のサポート対象リソースです。
- 3
- オプション: このフックは、ラベルセレクターに一致するオブジェクトにのみ適用されます。
- 4
- オプション: Timeout は、
initContainersが完了するまで Velero が待機する最大時間を指定します。 - 5
- オプション: コンテナーが指定されていない場合、コマンドは Pod の最初のコンテナーで実行されます。
- 6
- これは、追加される init コンテナーのエントリーポイントです。
- 7
- オプション: コンテナーの準備が整うまでの待機時間。これは、コンテナーが起動して同じコンテナー内の先行するフックが完了するのに十分な長さである必要があります。設定されていない場合、復元プロセスの待機時間は無期限になります。
- 8
- オプション: コマンドの実行を待機する時間。デフォルトは
30sです。 - 9
- エラー処理に許可される値は、
FailおよびContinueです。-
Continue: コマンドの失敗のみがログに記録されます。 -
Fail: Pod 内のコンテナーで復元フックが実行されなくなりました。RestoreCR のステータスはPartiallyFailedになります。
-
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.