Hosted Control Plane
OpenShift Container Platform で Hosted Control Plane を使用する
概要
第1章 Hosted Control Plane のリリースノート
リリースノートには、新機能、非推奨機能、変更、既知の問題に関する情報が記載されています。
1.1. OpenShift Container Platform 4.17 用の Hosted Control Plane のリリースノート
このリリースでは、OpenShift Container Platform 4.17 用の Hosted Control Plane が利用可能になりました。OpenShift Container Platform 4.17 用の Hosted Control Plane は、multicluster engine for Kubernetes Operator バージョン 2.7 をサポートしています。
1.1.1. 新機能および機能拡張
今回のリリースでは、以下の概念に関連する拡張機能が追加されました。
1.1.1.1. カスタムの taint と toleration (テクノロジープレビュー)
hcp CLI -tolerations 引数を使用するか、hc.Spec.Tolerations API ファイルを使用して、容認をホステッドコントロールプレーン Pod に適用できるようになりました。この機能は、テクノロジープレビューとしてのみ利用できます。詳細は、カスタムの taint および toleration を参照してください。
1.1.1.2. OpenShift Virtualization における NVIDIA GPU デバイスのサポート (テクノロジープレビュー)
OpenShift Virtualization の Hosted Control Plane では、1 つ以上の NVIDIA グラフィックスプロセッシングユニット (GPU) デバイスをノードプールにアタッチできます。この機能は、テクノロジープレビューとしてのみ利用できます。詳細は、hcp CLI を使用して NVIDIA GPU デバイスをアタッチする および NodePool リソースを使用して NVIDIA GPU デバイスをアタッチする を参照してください。
1.1.1.3. AWS におけるテナンシーのサポート
AWS でホステッドクラスターを作成するときに、EC2 インスタンスを共有ハードウェアで実行するか、シングルテナントハードウェアで実行するかを指定できます。詳細は、AWS 上にホステッドクラスターを作成する を参照してください。
1.1.1.4. ホステッドクラスターでの OpenShift Container Platform バージョンのサポート
ホステッドクラスターに、サポートされているさまざまな OpenShift Container Platform バージョンをデプロイできます。詳細は、ホステッドクラスターでサポートされている OpenShift Container Platform バージョン を参照してください。
1.1.1.5. 非接続環境における OpenShift Virtualization の Hosted Control Plane の一般提供を開始
このリリースでは、非接続環境における OpenShift Virtualization の Hosted Control Plane が一般提供されます。詳細は、非接続環境で OpenShift Virtualization に Hosted Control Plane をデプロイする を参照してください。
1.1.1.6. AWS における ARM64 OpenShift Container Platform クラスターの Hosted Control Plane の一般提供を開始
このリリースでは、AWS における ARM64 OpenShift Container Platform クラスターの Hosted Control Plane が一般提供されます。詳細は、ARM64 アーキテクチャーでのホステッドクラスターの実行 を参照してください。
1.1.1.7. IBM Z における Hosted Control Plane の一般提供を開始
このリリースでは、IBM Z 上の Hosted Control Plane が一般提供されます。詳細は、IBM Z への Hosted Control Plane のデプロイ を参照してください。
1.1.1.8. IBM Power における Hosted Control Plane の一般提供を開始
このリリースでは、IBM Power 上の Hosted Control Plane が一般提供されます。詳細は、IBM Power への Hosted Control Plane のデプロイ を参照してください。
1.1.2. バグ修正
-
以前は、ホストされたクラスタープロキシーが設定され、HTTP または HTTPS エンドポイントを持つアイデンティティープロバイダー (IDP) が使用されていた場合、プロキシー経由で送信される前に IDP のホスト名が解決されませんでした。その結果、データプレーンでのみ解決できるホスト名は IDP では解決できませんでした。この更新により、IPD トラフィックを
konnectivityトンネル経由で送信する前に DNS ルックアップが実行されます。その結果、データプレーンでのみ解決できるホスト名を持つ IDP は、Control Plane Operator によって検証できるようになります。(OCPBUGS-41371) -
以前は、ホストされたクラスターの
controllerAvailabilityPolicyがSingleReplicaに設定されていた場合、ネットワークコンポーネント上のpodAntiAffinityによってコンポーネントの可用性がブロックされていました。このリリースにより、この問題は解決されました。(OCPBUGS-39313) -
以前は、ホストされたクラスターイメージ設定で指定された
AddedTrustedCAは、image-registry-Operatorによって期待されたとおりにopenshift-confignamespace に調整されず、コンポーネントは利用できませんでした。このリリースにより、この問題は解決されました。(OCPBUGS-39225) - 以前は、コアオペレーティングシステムの変更により、Red Hat HyperShift の定期的な適合ジョブが失敗していました。この失敗したジョブにより、OpenShift API のデプロイメントが失敗していました。このリリースでは、更新時に 1 つのファイルがコピーされるのではなく、個々の信頼済み認証局 (CA) 証明書が再帰的にコピーされるため、定期的な適合ジョブが成功し、OpenShift API が期待どおりに実行されます。(OCPBUGS-38941)
-
以前は、ホストされたクラスター内の Konnectivity プロキシーエージェントは常にすべての TCP トラフィックを HTTP/S プロキシー経由で送信していました。また、トラフィックでは解決された IP アドレスのみ受信するため、
NO_PROXY設定のホスト名も無視されました。その結果、LDAP トラフィックなどのプロキシーされることを意図していないトラフィックが、設定に関係なくプロキシーされました。このリリースでは、プロキシーはソース (コントロールプレーン) で完了し、Konnectivity エージェントのプロキシー設定が削除されました。その結果、LDAP トラフィックなどのプロキシーされることを意図していないトラフィックはプロキシーされなくなります。ホスト名を含むNO_PROXY設定は尊重されます。(OCPBUGS-38637) -
以前は、
azure-disk-csi-driver-controllerイメージは、registryOverrideを使用するときに適切なオーバーライド値を取得しませんでした。これは、値がazure-disk-csi-driverデータプレーンイメージに伝播されるのを避けるため、意図的に行われたものです。この更新では、別のイメージオーバーライド値を追加することで問題が解決されました。その結果、azure-disk-csi-driver-controllerがregistryOverrideで使用できるようになり、azure-disk-csi-driverデータプレーンイメージに影響を与えなくなりました。(OCPBUGS-38183) - 以前は、プロキシー管理クラスター上で実行されていた Hosted Control Plane 内の AWS クラウドコントローラーマネージャーは、クラウド API 通信にプロキシーを使用しませんでした。このリリースにより、この問題は修正されました。(OCPBUGS-37832)
以前は、ホストされたクラスターのコントロールプレーンで実行される Operator のプロキシーが、データプレーンで実行される konnectivity エージェント Pod のプロキシー設定によって実行されていました。アプリケーションプロトコルに基づいてプロキシーが必要かどうかを区別することはできませんでした。
OpenShift Container Platform との互換性を保つために、HTTPS または HTTP 経由の IDP 通信はプロキシーする必要がありますが、LDAP 通信はプロキシーする必要ありません。このタイプのプロキシーでは、トラフィックが Konnectivity エージェントに到達するまでに宛先 IP アドレスのみ使用可能になるため、ホスト名に依存する
NO_PROXYエントリーも無視されます。このリリースでは、ホステッドクラスターでのプロキシーはコントロールプレーンで
konnectivity-https-proxyおよびkonnectivity-socks5-proxyを介して呼び出され、Konnectivity エージェントからのプロキシートラフィックが停止されます。その結果、LDAP サーバー宛のトラフィックはプロキシーされなくなります。その他の HTTPS または HTTPS トラフィックは正しくプロキシーされます。ホスト名を指定すると、NO_PROXY設定が適用されます。(OCPBUGS-37052)以前は、IDP 通信のプロキシーが Konnectivity エージェントで行われていました。トラフィックが Konnectivity に到達するまでに、そのプロトコルとホスト名が利用できなくなっていました。その結果、OAUTH サーバー Pod のプロキシーが正しく実行されていませんでした。プロキシーを必要とするプロトコル (
http/s) とプロキシーを必要としないプロトコル (ldap://) が区別されていませんでした。さらに、HostedCluster.spec.configuration.proxy仕様で設定されているno_proxy変数が考慮されませんでした。このリリースでは、OAUTH サーバーの Konnectivity サイドカーでプロキシーを設定することにより、
no_proxy設定を考慮しながら、トラフィックを適切にルーティングできるようになりました。その結果、ホストされたクラスターにプロキシーが設定されている場合、OAUTH サーバーがアイデンティティープロバイダーと適切に通信できるようになりました。(OCPBUGS-36932)-
以前は、Hosted Cluster Config Operator (HCCO) は、
HostedClusterオブジェクトからImageContentSourcesフィールドを削除した後、ImageDigestMirrorSetCR (IDMS) を削除しませんでした。その結果、IDMS は、本来は保持されるべきではないにもかかわらず、HostedClusterオブジェクトに保持されていました。このリリースでは、HCCO はHostedClusterオブジェクトからの IDMS リソースの削除を管理します。(OCPBUGS-34820) -
以前は、非接続環境に
hostedClusterをデプロイするには、hypershift.openshift.io/control-plane-operator-imageアノテーションを設定する必要がありました。この更新により、アノテーションは不要になりました。さらに、メタデータインスペクターはホストされた Operator の調整中に期待どおりに機能し、OverrideImagesは期待どおりに設定されます。(OCPBUGS-34734) - 以前は、AWS 上のホストされたクラスターは、VPC のプライマリー CIDR 範囲を活用して、データプレーン上でセキュリティーグループルールを生成していました。その結果、複数の CIDR 範囲を持つ AWS VPC にホストされたクラスターをインストールした場合、生成されたセキュリティーグループルールでは不十分な可能性がありました。この更新により、提供された Machine CIDR 範囲に基づいてセキュリティーグループルールが生成され、この問題が解決されます。(OCPBUGS-34274)
- 以前は、OpenShift Cluster Manager コンテナーには適切な TLS 証明書がありませんでした。その結果、接続されていないデプロイメントではイメージストリームを使用できませんでした。このリリースでは、この問題を解決するために、TLS 証明書が projected ボリュームとして追加されました。(OCPBUGS-31446)
- 以前は、OpenShift Virtualization における multicluster engine for Kubernetes Operator コンソールの一括破棄オプションでは、ホステッドクラスターが破棄されませんでした。このリリースでは、この問題は解決されました。(ACM-10165)
-
以前は、Hosted Control Plane クラスター設定の
additionalTrustBundleパラメーターを更新しても、コンピュートノードに適用されませんでした。このリリースでは、additionalTrustBundleパラメーターの更新が Hosted Control Plane クラスター内に存在するコンピュートノードに自動的に適用されるように修正されました。この修正を含むバージョンに更新すると、バンドルの選択に既存ノードの自動ロールアウトが行われます。(OCPBUGS-36680)
1.1.3. 既知の問題
-
アノテーションと
ManagedClusterリソース名が一致しない場合、multicluster engine for Kubernetes Operator コンソールにはクラスターの状態がPending importとして表示されます。このようなクラスターは、multicluster engine Operator で使用できません。アノテーションがなく、ManagedCluster名がHostedClusterリソースのInfra-ID値と一致しない場合も、同じ問題が発生します。 - multicluster engine for Kubernetes Operator コンソールを使用して、既存のホステッドクラスターに新しいノードプールを追加すると、オプションのリストに同じバージョンの OpenShift Container Platform が複数回表示される場合があります。必要なバージョンの一覧で任意のインスタンスを選択できます。
ノードプールが 0 ワーカーにスケールダウンされても、コンソールのホストのリストには、
Ready状態のノードが表示されます。ノードの数は、次の 2 つの方法で確認できます。- コンソールでノードプールに移動し、ノードが 0 であることを確認します。
コマンドラインインターフェイスで、以下のコマンドを実行します。
次のコマンドを実行して、ノードプールにあるノード数が 0 個であることを確認します。
$ oc get nodepool -A次のコマンドを実行して、クラスター内にあるノード数が 0 個であることを確認します。
$ oc get nodes --kubeconfig次のコマンドを実行して、クラスターにバインドされているエージェント数が 0 と報告されていることを確認します。
$ oc get agents -A
デュアルスタックネットワークを使用する環境でホステッドクラスターを作成すると、次の DNS 関連の問題が発生する可能性があります。
-
service-ca-operatorPod のCrashLoopBackOff状態: Pod が Hosted Control Plane 経由で Kubernetes API サーバーに到達しようとすると、kube-systemnamespace のデータプレーンプロキシーがリクエストを解決できないため、Pod はサーバーに到達できません。この問題は、HAProxy セットアップでフロントエンドが IP アドレスを使用し、バックエンドが Pod が解決できない DNS 名を使用するために発生します。 -
Pod が
ContainerCreating状態でスタックする: この問題は、openshift-service-ca-operatorが DNS Pod が DNS 解決に必要とするmetrics-tlsシークレットを生成できないために発生します。その結果、Pod は Kubernetes API サーバーを解決できません。これらの問題を解決するには、デュアルスタックネットワークの DNS サーバー設定を行います。
-
-
エージェントプラットフォームでは、Hosted Control Plane 機能により、エージェントがイグニションのプルに使用するトークンが定期的にローテーションされます。その結果、少し前に作成されたエージェントリソースがある場合、Ignition のプルに失敗する可能性があります。回避策として、エージェント仕様で
IgnitionEndpointTokenReferenceプロパティーのシークレットを削除し、その後にエージェントリソースのラベルを追加または変更します。システムは新しいトークンを使用してシークレットを再作成します。 ホステッドクラスターをそのマネージドクラスターと同じ namespace に作成した場合、マネージドホステッドクラスターをデタッチすると、ホステッドクラスターが含まれるマネージドクラスター namespace 内のすべてが削除されます。次の状況では、マネージドクラスターと同じ namespace にホステッドクラスターが作成される可能性があります。
- デフォルトのホステッドクラスターのクラスター namespace を使用し、multicluster engine for Kubernetes Operator のコンソールを介して Agent プラットフォーム上にホステッドクラスターを作成した場合。
- ホステッドクラスターの namespace をホステッドクラスターの名前と同じになるよう指定して、コマンドラインインターフェイスまたは API を介してホステッドクラスターを作成した場合。
ホストされた新しいクラスターに対してクラスター全体のプロキシーを設定した場合、クラスター全体のプロキシーが設定されているとワーカーノードが Kubernetes API サーバーに到達できないため、そのクラスターのデプロイメントが失敗する可能性があります。この問題を解決するには、ホストされたクラスターの設定ファイルで、
noProxyフィールドに次のいずれかの情報を追加して、データプレーンから Kubernetes API サーバーへのトラフィックがプロキシーをスキップするようにします。- 外部 API アドレス。
-
内部 API アドレス。デフォルトは
172.20.0.1です。 -
kubernetesというフレーズ。 - サービスネットワーク CIDR。
- クラスターネットワーク CIDR。
1.1.4. 一般提供およびテクノロジープレビュー機能
一般提供 (GA) の機能は完全にサポートされており、実稼働での使用に適しています。テクノロジープレビュー (TP) 機能は実験的な機能であり、本番環境での使用を目的としたものではありません。TP 機能の詳細は、Red Hat Customer Portal のテクノロジープレビュー機能のサポート範囲 を参照してください。
IBM Power および IBM Z の場合、コントロールプレーンは 64 ビット x86 アーキテクチャーベースのマシンタイプで実行し、ノードプールは IBM Power または IBM Z で実行する必要があります。
Hosted Control Plane の GA 機能および TP 機能は、次の表を参照してください。
| 機能 | 4.15 | 4.16 | 4.17 |
|---|---|---|---|
| Amazon Web Services (AWS) 上の OpenShift Container Platform の Hosted Control Plane | テクノロジープレビュー | 一般提供 | 一般提供 |
| ベアメタル上の OpenShift Container Platform の Hosted Control Plane | 一般提供 | 一般提供 | 一般提供 |
| OpenShift Virtualization 上の OpenShift Container Platform の Hosted Control Plane | 一般提供 | 一般提供 | 一般提供 |
| 非ベアメタルエージェントマシンを使用した OpenShift Container Platform の Hosted Control Plane | テクノロジープレビュー | テクノロジープレビュー | テクノロジープレビュー |
| Amazon Web Services 上の ARM64 OpenShift Container Platform クラスター用の Hosted Control Plane | テクノロジープレビュー | テクノロジープレビュー | 一般提供 |
| IBM Power 上の OpenShift Container Platform の Hosted Control Plane | テクノロジープレビュー | テクノロジープレビュー | 一般提供 |
| IBM Z 上の OpenShift Container Platform の Hosted Control Plane | テクノロジープレビュー | テクノロジープレビュー | 一般提供 |
| RHOSP 上の OpenShift Container Platform の Hosted Control Plane | 利用不可 | 利用不可 | 開発者プレビュー |
第2章 Hosted Control Plane の概要
OpenShift Container Platform クラスターは、スタンドアロンまたは Hosted Control Plane という 2 つの異なるコントロールプレーン設定を使用してデプロイできます。スタンドアロン設定では、専用の仮想マシンまたは物理マシンを使用してコントロールプレーンをホストします。OpenShift Container Platform の Hosted Control Plane を使用すると、各コントロールプレーンに専用の仮想マシンまたは物理マシンを用意する必要なく、管理クラスター上の Pod としてコントロールプレーンを作成できます。
2.1. Hosted Control Plane の概要
Hosted Control Plane は、次のプラットフォームで サポートされているバージョンの multicluster engine for Kubernetes Operator を使用することで利用できます。
- Agent プロバイダーを使用したベアメタル
- 非ベアメタルエージェントマシン (テクノロジープレビュー機能)
- OpenShift Virtualization
- Amazon Web Services (AWS)
- IBM Z
- IBM Power
Hosted Control Plane 機能はデフォルトで有効になっています。
multicluster engine Operator は Red Hat Advanced Cluster Management (RHACM) の不可欠な要素であり、RHACM ではデフォルトで有効になっています。ただし、Hosted Control Plane を使用するのに RHACM は必要ありません。
2.1.1. Hosted Control Plane のアーキテクチャー
OpenShift Container Platform は、多くの場合、クラスターがコントロールプレーンとデータプレーンで構成される結合モデルまたはスタンドアロンモデルでデプロイされます。コントロールプレーンには、API エンドポイント、ストレージエンドポイント、ワークロードスケジューラー、および状態を保証するアクチュエーターが含まれます。データプレーンには、ワークロードとアプリケーションが実行されるコンピュート、ストレージ、およびネットワークが含まれます。
スタンドアロンコントロールプレーンは、クォーラムを確保できる最小限の数で、物理または仮想のノードの専用グループによってホストされます。ネットワークスタックは共有されます。クラスターへの管理者アクセスにより、クラスターのコントロールプレーン、マシン管理 API、およびクラスターの状態に影響を与える他のコンポーネントを可視化できます。
スタンドアロンモデルは正常に機能しますが、状況によっては、コントロールプレーンとデータプレーンが分離されたアーキテクチャーが必要になります。そのような場合には、データプレーンは、専用の物理ホスティング環境がある別のネットワークドメインに配置されています。コントロールプレーンは、Kubernetes にネイティブなデプロイやステートフルセットなど、高レベルのプリミティブを使用してホストされます。コントロールプレーンは、他のワークロードと同様に扱われます。
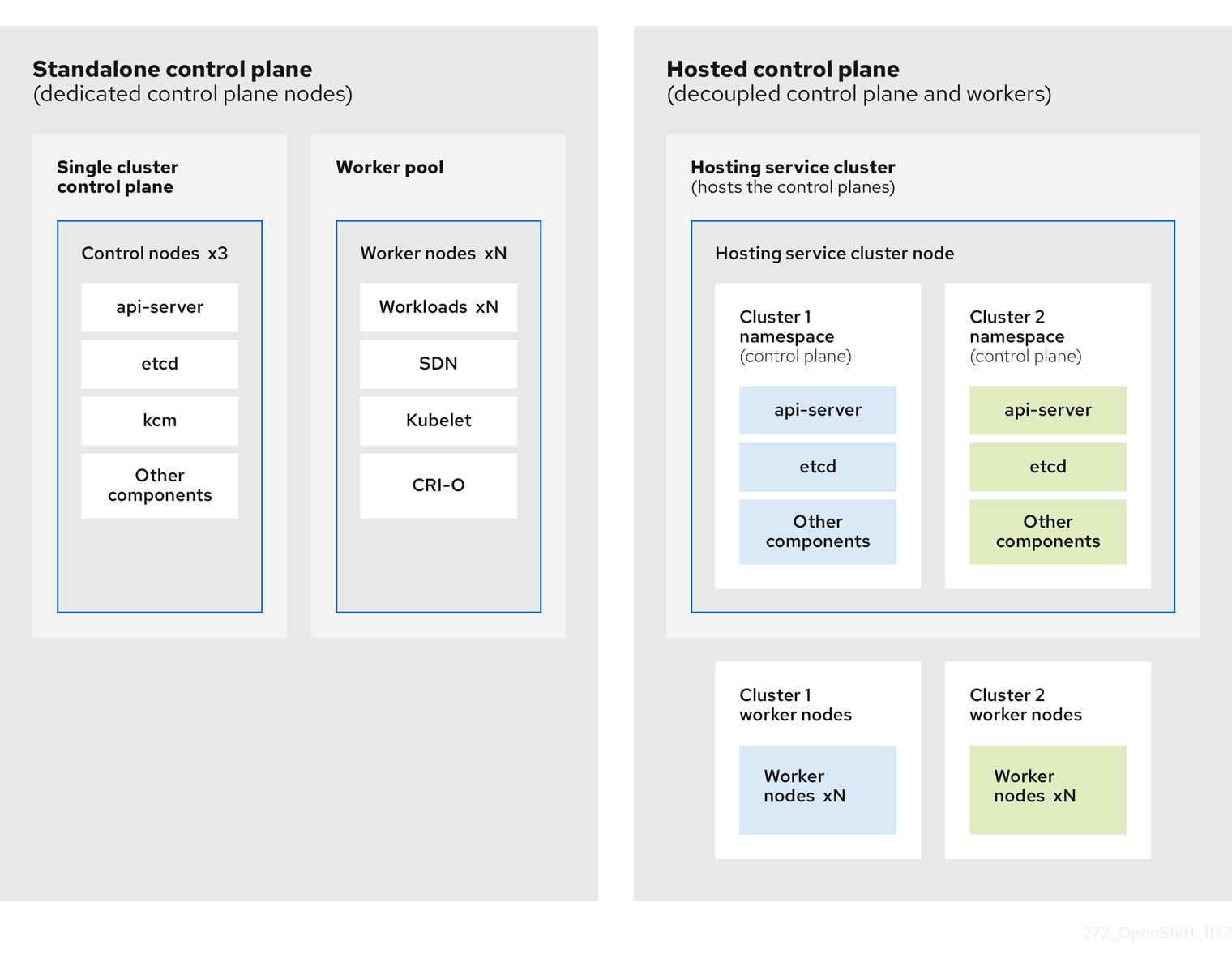
2.1.2. Hosted Control Plane の利点
Hosted Control Plane を使用すると、真のハイブリッドクラウドアプローチへの道が開かれ、その他のさまざまなメリットも享受できます。
- コントロールプレーンが分離され、専用のホスティングサービスクラスターでホストされるため、管理とワークロードの間のセキュリティー境界が強化されます。その結果、クラスターのクレデンシャルが他のユーザーに漏洩する可能性が低くなります。インフラストラクチャーのシークレットアカウント管理も分離されているため、クラスターインフラストラクチャーの管理者が誤ってコントロールプレーンインフラストラクチャーを削除することはありません。
- Hosted Control Plane を使用すると、より少ないノードで多数のコントロールプレーンを実行できます。その結果、クラスターはより安価になります。
- コントロールプレーンは OpenShift Container Platform で起動される Pod で構成されるため、コントロールプレーンはすぐに起動します。同じ原則が、モニタリング、ロギング、自動スケーリングなどのコントロールプレーンとワークロードに適用されます。
- インフラストラクチャーの観点からは、レジストリー、HAProxy、クラスター監視、ストレージノードなどのインフラストラクチャーをテナントのクラウドプロバイダーのアカウントにプッシュして、テナントでの使用を分離できます。
- 運用上の観点からは、マルチクラスター管理はさらに集約され、クラスターの状態と一貫性に影響を与える外部要因が少なくなります。Site Reliability Engineer は、一箇所で問題をデバッグしてクラスターのデータプレーンに移動できるため、解決までの時間 (TTR) が短縮され、生産性が向上します。
2.2. Hosted Control Plane と OpenShift Container Platform の違い
Hosted Control Plane は、OpenShift Container Platform の 1 つのフォームファクターです。ホステッドクラスターとスタンドアロンの OpenShift Container Platform クラスターは、設定と管理が異なります。OpenShift Container Platform と Hosted Control Plane の違いを理解するには、次の表を参照してください。
2.2.1. クラスターの作成とライフサイクル
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
|
|
既存の OpenShift Container Platform クラスターに、 |
2.2.2. Cluster configuration
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
|
|
コントロールプレーンに影響するリソースを、 |
2.2.3. etcd 暗号化
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
|
|
|
2.2.4. Operator とコントロールプレーン
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
| スタンドアロンの OpenShift Container Platform クラスターには、コントロールプレーンコンポーネントごとに個別の Operator が含まれています。 | ホステッドクラスターには、管理クラスターの Hosted Control Plane の namespace で実行される Control Plane Operator という名前の単一の Operator が含まれています。 |
| etcd は、コントロールプレーンノードにマウントされたストレージを使用します。etcd のクラスター Operator が etcd を管理します。 | etcd は、ストレージに永続ボリューム要求を使用し、Control Plane Operator によって管理されます。 |
| Ingress Operator、ネットワーク関連の Operator、および Operator Lifecycle Manager (OLM) は、クラスター上で実行されます。 | Ingress Operator、ネットワーク関連の Operator、および Operator Lifecycle Manager (OLM) は、管理クラスターの Hosted Control Plane の namespace で実行されます。 |
| OAuth サーバーは、クラスター内で実行され、クラスター内のルートを通じて公開されます。 | OAuth サーバーは、コントロールプレーン内で実行され、管理クラスター上のルート、ノードポート、またはロードバランサーを通じて公開されます。 |
2.2.5. 更新
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
|
Cluster Version Operator (CVO) が更新プロセスをオーケストレーションし、 |
Hosted Control Plane を更新すると、 |
| OpenShift Container Platform クラスターを更新すると、コントロールプレーンとコンピュートマシンの両方が更新されます。 | ホステッドクラスターを更新すると、コントロールプレーンのみが更新されます。ノードプールの更新は個別に実行します。 |
2.2.6. マシンの設定と管理
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
|
|
|
| コントロールプレーンマシンのセットが利用可能です。 | コントロールプレーンマシンのセットが存在しません。 |
|
|
|
|
|
|
| マシンとマシンセットがクラスター内で公開されます。 | アップストリームの Cluster CAPI Operator からのマシン、マシンセット、およびマシンデプロイメントが、マシンを管理するために使用されます。ただし、これらはユーザーには公開されません。 |
| クラスターを更新すると、すべてのマシンセットが自動的にアップグレードされます。 | ホステッドクラスターの更新とは別にノードプールを更新します。 |
| インプレースアップグレードだけがクラスターでサポートされています。 | 置換アップグレードとインプレースアップグレードの両方が、ホステッドクラスターでサポートされています。 |
| Machine Config Operator がマシンの設定を管理します。 | Hosted Control Plane には Machine Config Operator が存在しません。 |
|
|
|
| Machine Config Daemon (MCD) が各ノードの設定の変更と更新を管理します。 | インプレースアップグレードの場合、ノードプールコントローラーが、一度だけ実行され、設定に基づいてマシンを更新する Pod を作成します。 |
| SR-IOV Operator などのマシン設定リソースを変更できます。 | マシン設定リソースを変更することはできません。 |
2.2.7. ネットワーク
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
| Kube API サーバーとノードが同じ Virtual Private Cloud (VPC) 内に存在するため、Kube API サーバーはノードと直接通信します。 | Kube API サーバーは Konnectivity を介してノードと通信します。Kube API サーバーとノードは、別々の Virtual Private Cloud (VPC) 内に存在します。 |
| ノードは内部ロードバランサーを介して Kube API サーバーと通信します。 | ノードは外部ロードバランサーまたはノードポートを介して Kube API サーバーと通信します。 |
2.2.8. Web コンソール
| OpenShift Container Platform | Hosted Control Plane |
|---|---|
| Web コンソールにコントロールプレーンのステータスが表示されます。 | Web コンソールにコントロールプレーンのステータスが表示されません。 |
| Web コンソールを使用してクラスターを更新できます。 | Web コンソールを使用してホステッドクラスターを更新することはできません。 |
| Web コンソールにマシンなどのインフラストラクチャーリソースが表示されます。 | Web コンソールにインフラストラクチャーリソースが表示されません。 |
|
Web コンソールを使用して、 | Web コンソールを使用してマシンを設定することはできません。 |
2.3. Hosted Control Plane、multicluster engine Operator、および RHACM の関係
Hosted Control Plane は、multicluster engine for Kubernetes Operator を使用して設定できます。multicluster engine Operator のクラスターライフサイクルにより、さまざまなインフラストラクチャークラウドプロバイダー、プライベートクラウド、オンプレミスデータセンターにおける Kubernetes クラスターの作成、インポート、管理、破棄のプロセスが定義されます。
multicluster engine Operator は Red Hat Advanced Cluster Management (RHACM) の不可欠な要素であり、RHACM ではデフォルトで有効になっています。ただし、Hosted Control Plane を使用するのに RHACM は必要ありません。
multicluster engine Operator は、OpenShift Container Platform および RHACM ハブクラスターにクラスター管理機能を提供するクラスターライフサイクル Operator です。multicluster engine Operator は、クラスター群の管理を強化し、クラウドとデータセンター全体の OpenShift Container Platform クラスターのライフサイクル管理を支援します。
図2.1 クラスターライフサイクルと基盤
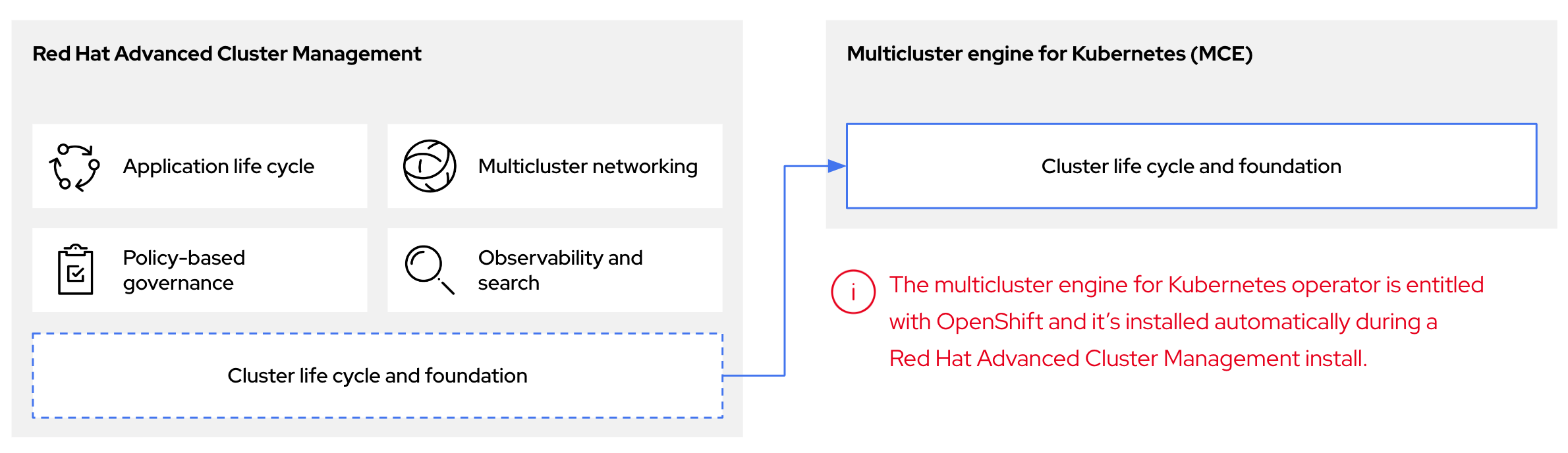
OpenShift Container Platform の multicluster engine Operator は、スタンドアロンクラスターマネージャーとして、または RHACM ハブクラスターの一部として使用できます。
管理クラスターはホスティングクラスターとも呼ばれます。
OpenShift Container Platform クラスターは、スタンドアロンまたは Hosted Control Plane という 2 つの異なるコントロールプレーン設定を使用してデプロイできます。スタンドアロン設定では、専用の仮想マシンまたは物理マシンを使用してコントロールプレーンをホストします。OpenShift Container Platform の Hosted Control Plane を使用すると、各コントロールプレーンに専用の仮想マシンまたは物理マシンを用意する必要なく、管理クラスター上の Pod としてコントロールプレーンを作成できます。
図2.2 RHACM と multicluster engine Operator の概要図
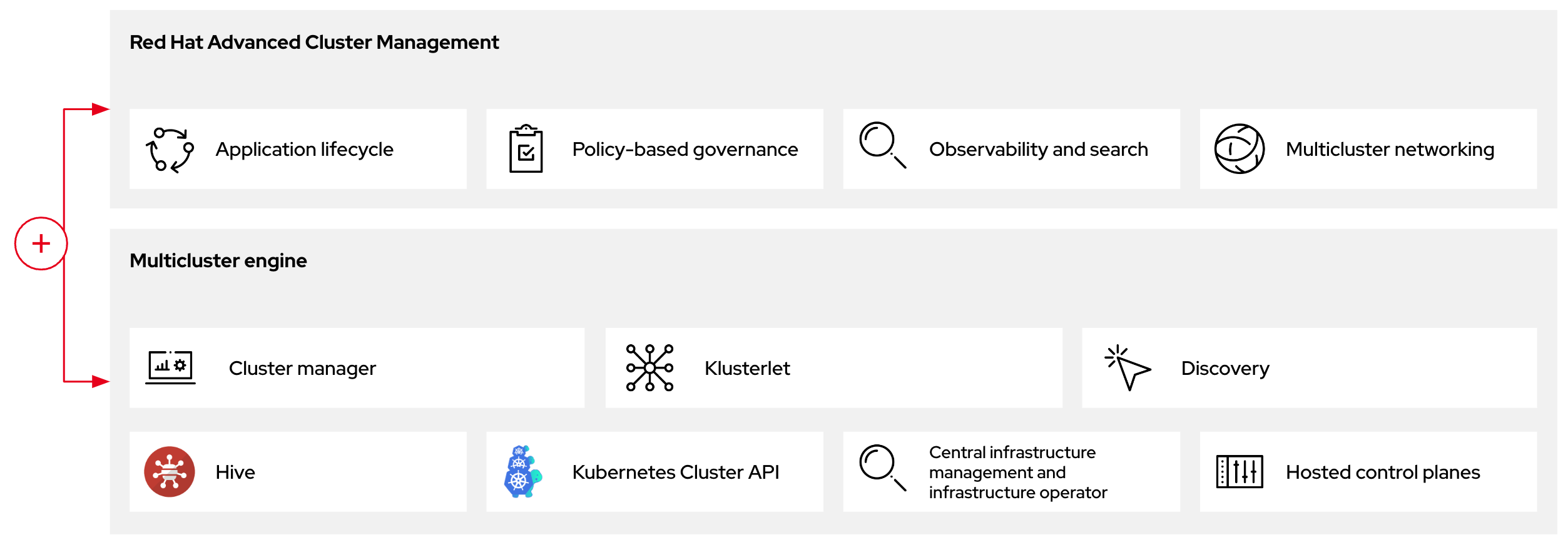
2.3.1. RHACM での multicluster engine Operator ホステッドクラスターの検出
ホステッドクラスターを Red Hat Advanced Cluster Management (RHACM) ハブクラスターに移行し、RHACM 管理コンポーネントを使用して管理する場合は、Red Hat Advanced Cluster Management の公式ドキュメント の手順を参照してください。
2.4. Hosted Control Plane のバージョン管理
Hosted Control Plane 機能には次のコンポーネントが含まれています。これらのコンポーネントには、個別のバージョン管理とサポートレベルが必要な場合があります。
- 管理クラスター
- HyperShift Operator
-
Hosted Control Plane (
hcp) コマンドラインインターフェイス (CLI) -
hypershift.openshift.ioAPI - Control Plane Operator
2.4.1. 管理クラスター
実稼働環境で使用する管理クラスターでは、OperatorHub から入手できる multicluster engine for Kubernetes Operator が必要です。multicluster engine Operator には、HyperShift Operator のサポートされているビルドがバンドルされています。管理クラスターのサポートを継続するには、multicluster engine Operator が動作する OpenShift Container Platform のバージョンを使用する必要があります。一般に、multicluster engine Operator の新しいリリースは、以下の OpenShift Container Platform のバージョンで動作します。
- OpenShift Container Platform の最新の一般提供バージョン
- OpenShift Container Platform の最新の一般提供バージョンより 2 つ前のバージョン
管理クラスター上の HyperShift Operator を通じてインストールできる OpenShift Container Platform バージョンの完全なリストは、HyperShift Operator のバージョンによって異なります。ただし、リストには常に、管理クラスターと同じ OpenShift Container Platform バージョンと、管理クラスターよりも 2 つ前のマイナーバージョンが含まれます。たとえば、管理クラスターが 4.17 とサポートされているバージョンの multicluster engine Operator を実行している場合、HyperShift Operator は 4.17、4.16、4.15、および 4.14 ホステッドクラスターをインストールできます。
OpenShift Container Platform のメジャー、マイナー、またはパッチバージョンのリリースごとに、Hosted Control Plane の 2 つのコンポーネントがリリースされます。
- HyperShift Operator
-
hcpコマンドラインインターフェイス (CLI)
2.4.2. HyperShift Operator
HyperShift Operator は、HostedCluster API リソースによって表されるホステッドクラスターのライフサイクルを管理します。HyperShift Operator は、OpenShift Container Platform の各リリースでリリースされます。HyperShift Operator は、hypershift namespace に supported-versions config map を作成します。この config map には、サポートされているホステッドクラスターのバージョンが含まれています。
同じ管理クラスター上で異なるバージョンのコントロールプレーンをホストできます。
supported-versions config map オブジェクトの例
apiVersion: v1
data:
supported-versions: '{"versions":["4.17"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift2.4.3. Hosted Control Plane CLI
hcp CLI を使用してホステッドクラスターを作成できます。CLI は multicluster engine Operator からダウンロードできます。hcp version コマンドを実行すると、CLI が kubeconfig ファイルに対してサポートする最新の OpenShift Container Platform が出力に表示されます。
2.4.4. hypershift.openshift.io API
HostedCluster や NodePool などの hypershift.openshift.io API リソースを使用して、大規模な OpenShift Container Platform クラスターを作成および管理できます。HostedCluster リソースには、コントロールプレーンと共通データプレーンの設定が含まれます。HostedCluster リソースを作成すると、ノードが接続されていない、完全に機能するコントロールプレーンが作成されます。NodePool リソースは、HostedCluster リソースにアタッチされたスケーラブルなワーカーノードのセットです。
API バージョンポリシーは、通常、Kubernetes API のバージョン管理 のポリシーと一致します。
Hosted Control Plane の更新には、ホステッドクラスターとノードプールの更新が含まれます。詳細は、「Hosted Control Plane の更新」を参照してください。
2.4.5. Control Plane Operator
Control Plane Operator は、次のアーキテクチャー用の各 OpenShift Container Platform ペイロードリリースイメージの一部としてリリースされます。
- amd64
- arm64
- multi-arch
2.5. Hosted Control Plane の一般的な概念とペルソナの用語集
OpenShift Container Platform の Hosted Control Plane を使用する場合は、その主要な概念と関連するペルソナを理解することが重要です。
2.5.1. 概念
- データプレーン
- ワークロードとアプリケーションが実行されるコンピュート、ストレージ、ネットワークを含む、クラスターの一部分。
- ホステッドクラスター
- コントロールプレーンと API エンドポイントが管理クラスターでホストされている OpenShift Container Platform クラスター。ホステッドクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。
- ホステッドクラスターのインフラストラクチャー
- テナントまたはエンドユーザーのクラウドアカウントに存在するネットワーク、コンピュート、およびストレージリソース。
- Hosted Control Plane
- 管理クラスターで実行される OpenShift Container Platform コントロールプレーン。ホステッドクラスターの API エンドポイントによって公開されます。コントロールプレーンのコンポーネントには、etcd、Kubernetes API サーバー、Kubernetes コントローラーマネージャー、および VPN が含まれます。
- ホスティングクラスター
- 管理クラスター を参照してください。
- マネージドクラスター
- ハブクラスターが管理するクラスター。この用語は、Red Hat Advanced Cluster Management で multicluster engine for Kubernetes Operator が管理するクラスターライフサイクル特有の用語です。マネージドクラスターは、管理クラスター とは異なります。詳細は、マネージドクラスター を参照してください。
- 管理クラスター
- HyperShift Operator がデプロイされる OpenShift Container Platform クラスター。ホステッドクラスターのコントロールプレーンをホストします。管理クラスターは ホスティングクラスター と同義です。
- 管理クラスターのインフラストラクチャー
- 管理クラスターのネットワーク、コンピュート、およびストレージリソース。
- ノードプール
- ホステッドクラスターに関連付けられたコンピュートノードのセットを管理するリソース。コンピュートノードは、ホステッドクラスター内でアプリケーションとワークロードを実行します。
2.5.2. 想定ユーザー
- クラスターインスタンス管理者
-
このロールを引き受けるユーザーは、スタンドアロン OpenShift Container Platform の管理者と同等です。このユーザーには、プロビジョニングされたクラスター内で
cluster-adminロールがありますが、クラスターがいつ、どのように更新または設定されるかを制御できない可能性があります。このユーザーは、クラスターに投影された設定を表示するための読み取り専用アクセス権を持っている可能性があります。 - クラスターインスタンスユーザー
- このロールを引き受けるユーザーは、スタンドアロン OpenShift Container Platform の開発者と同等です。このユーザーには、OperatorHub またはマシンに対するビューがありません。
- クラスターサービスコンシューマー
- このロールを引き受けるユーザーは、コントロールプレーンとワーカーノードを要求したり、更新を実行したり、外部化された設定を変更したりできます。通常、このユーザーはクラウド認証情報やインフラストラクチャー暗号化キーを管理したりアクセスしたりしません。クラスターサービスのコンシューマーペルソナは、ホステッドクラスターを要求し、ノードプールと対話できます。このロールを引き受けるユーザーには、論理境界内でホステッドクラスターとノードプールを作成、読み取り、更新、または削除するための RBAC があります。
- クラスターサービスプロバイダー
このロールを引き受けるユーザーは通常、管理クラスター上で
cluster-adminロールを持ち、HyperShift Operator とテナントのホステッドクラスターのコントロールプレーンの可用性を監視および所有するための RBAC を持っています。クラスターサービスプロバイダーのペルソナは、次の例を含むいくつかのアクティビティーを担当します。- コントロールプレーンの可用性、稼働時間、安定性を確保するためのサービスレベルオブジェクトの所有
- コントロールプレーンをホストするための管理クラスターのクラウドアカウントの設定
- ユーザーがプロビジョニングするインフラストラクチャーの設定 (利用可能なコンピュートリソースのホスト認識を含む)
第3章 Hosted Control Plane のデプロイの準備
3.1. Hosted Control Plane の要件
Hosted Control Plane において、管理クラスター とは HyperShift Operator がデプロイされ、ホステッドクラスターのコントロールプレーンがホストされる OpenShift Container Platform クラスターです。
コントロールプレーンはホステッドクラスターに関連付けられており、単一の namespace 内の Pod として実行されます。クラスターのサービスコンシューマーがホステッドクラスターを作成すると、コントロールプレーンから独立したワーカーノードが作成されます。
Hosted Control Plane には次の要件が適用されます。
- HyperShift Operator を実行するには、管理クラスターに少なくとも 3 つのワーカーノードが必要です。
- 管理クラスターとワーカーノードの両方を、オンプレミス (ベアメタルプラットフォームや OpenShift Virtualization 上など) で実行できます。さらに、管理クラスターとワーカーノードの両方を、Amazon Web Services (AWS) などのクラウドインフラストラクチャー上で実行することもできます。
-
管理クラスターを AWS で実行し、ワーカーノードをオンプレミスで実行する、またはワーカーノードを AWS で実行し、管理クラスターをオンプレミスで実行するなど、混合インフラストラクチャーを使用する場合は、
PublicAndPrivate公開ストラテジーを使用し、サポートマトリックスのレイテンシー要件に従う必要があります。 - Bare Metal Operator がマシンを起動するベアメタルホスト (BMH) デプロイメントでは、Hosted Control Plane が Baseboard Management Controller (BMC) にアクセスできる必要があります。Redfish の自動化を有効にするために、BMH の BMC があるネットワークに Cluster Baremetal Operator がアクセスすることをセキュリティープロファイルで禁止している場合は、BYO ISO サポートを使用できます。ただし、BYO モードでは、OpenShift Container Platform は BMH の電源オンを自動化できません。
3.1.1. Hosted Control Plane のサポートマトリックス
Multicluster engine for Kubernetes Operator には HyperShift Operator が含まれているため、Hosted Control Plane のリリースは multicluster engine Operator のリリースと一致します。詳細は、OpenShift Operator のライフサイクル を参照してください。
3.1.1.1. 管理クラスターのサポート
サポートされているスタンドアロンの OpenShift Container Platform クラスターは、すべて管理クラスターにすることができます。
シングルノードの OpenShift Container Platform クラスターは、管理クラスターとしてはサポートされていません。リソースに制約がある場合は、スタンドアロンの OpenShift Container Platform コントロールプレーンと Hosted Control Plane 間でインフラストラクチャーを共有できます。詳細は、「Hosted Control Plane とスタンドアロンコントロールプレーン間でのインフラストラクチャーの共有」を参照してください。
次の表は、multicluster engine Operator のバージョンと、それらをサポートする管理クラスターのバージョンをマッピングしています。
| 管理クラスターのバージョン | サポートされている multicluster engine Operator バージョン |
|---|---|
| 4.14 - 4.15 | 2.4 |
| 4.14 - 4.16 | 2.5 |
| 4.14 - 4.17 | 2.6 |
| 4.15 - 4.17 | 2.7 |
3.1.1.2. ホステッドクラスターのサポート
ホステッドクラスターの場合、管理クラスターのバージョンとホステッドクラスターのバージョンの間に直接的な関係はありません。ホステッドクラスターのバージョンは、使用している multicluster engine Operator バージョンに含まる HyperShift Operator により異なります。
管理クラスターとホステッドクラスター間の最大遅延が 200 ミリ秒であることを確認してください。この要件は、管理クラスターが AWS 上にあり、ワーカーノードがオンプレミスにある場合など、混合インフラストラクチャーのデプロイメントでは特に重要です。
次の表は、multicluster engine Operator のバージョンと、その multicluster engine Operator バージョンに関連付けられている HyperShift Operator を使用して作成できるホステッドクラスターのバージョンを示しています。
| ホステッドクラスターのバージョン | multicluster engine Operator 2.4 | multicluster engine Operator 2.5 | multicluster engine Operator 2.6 | multicluster engine Operator 2.7 |
|---|---|---|---|---|
| 4.14 | はい | はい | はい | はい |
| 4.15 | いいえ | はい | はい | はい |
| 4.16 | いいえ | いいえ | はい | はい |
| 4.17 | いいえ | いいえ | いいえ | はい |
3.1.1.3. ホステッドクラスタープラットフォームのサポート
次の表は、Hosted Control Plane の各プラットフォームでサポートされている OpenShift Container Platform のバージョンを示しています。
IBM Power および IBM Z の場合、コントロールプレーンは 64 ビット x86 アーキテクチャーベースのマシンタイプで実行し、ノードプールは IBM Power または IBM Z で実行する必要があります。
次の表に示す管理クラスターのバージョンは、multicluster engine Operator が有効になっている OpenShift Container Platform バージョンを意味します。
| ホステッドクラスターのプラットフォーム | 管理クラスターのバージョン | ホステッドクラスターのバージョン |
|---|---|---|
| Amazon Web Services | 4.16 - 4.17 | 4.16 - 4.17 |
| IBM Power | 4.17 | 4.17 |
| IBM Z | 4.17 | 4.17 |
| OpenShift Virtualization | 4.14 - 4.17 | 4.14 - 4.17 |
| ベアメタル | 4.14 - 4.17 | 4.14 - 4.17 |
| 非ベアメタルエージェントマシン (テクノロジープレビュー) | 4.16 - 4.17 | 4.16 - 4.17 |
3.1.1.4. multicluster engine Operator の更新
multicluster engine Operator の別バージョンに更新する場合、その multicluster engine Operator バージョンに含まれる HyperShift Operator がサポートしているバージョンのホステッドクラスターは、引き続き実行できます。次の表は、更新後の multicluster engine Operator バージョンでサポートされるホステッドクラスターバージョンを示しています。
| 更新後の multicluster engine Operator バージョン | サポートされるホステッドクラスターバージョン |
|---|---|
| 2.4 から 2.5 に更新 | OpenShift Container Platform 4.14 |
| 2.5 から 2.6 に更新 | OpenShift Container Platform 4.14 - 4.15 |
| 2.6 から 2.7 に更新 | OpenShift Container Platform 4.14 - 4.16 |
たとえば、管理クラスターに OpenShift Container Platform 4.14 ホステッドクラスターがあり、multicluster engine Operator 2.4 から 2.5 に更新した場合、ホステッドクラスターは引き続き実行できます。
3.1.1.5. テクノロジープレビュー機能
次のリストは、このリリースのテクノロジープレビュー機能を示しています。
- 非接続環境の IBM Z の Hosted Control Plane
- Hosted Control Plane のカスタムの taint と toleration
- OpenShift Virtualization の Hosted Control Plane 上の NVIDIA GPU デバイス
3.1.2. Hosted Control Plane の CIDR 範囲
OpenShift Container Platform に Hosted Control Plane をデプロイするには、次の必須の Classless Inter-Domain Routing (CIDR) サブネット範囲を使用してください。
-
v4InternalSubnet: 100.65.0.0/16 (OVN-Kubernetes) -
clusterNetwork: 10.132.0.0/14 (Pod ネットワーク) -
serviceNetwork: 172.31.0.0/16
OpenShift Container Platform の CIDR 範囲の定義に関する詳細は、「CIDR 範囲の定義」を参照してください。
3.2. Hosted Control Plane のサイジングに関するガイダンス
一定数のワーカーノード内に収容できる Hosted Control Plane の数には、ホステッドクラスターのワークロードやワーカーノードの数など、多くの要因が影響します。このサイジングガイドを使用して、ホステッドクラスターの容量計画に役立ててください。このガイダンスでは、高可用性 Hosted Control Plane トポロジーを前提としています。負荷ベースのサイジングの例は、ベアメタルクラスターで測定されました。クラウドベースのインスタンスには、メモリーサイズなど、さまざまな制限要因が含まれる場合があります。
次のリソース使用量のサイズ測定値をオーバーライドし、メトリクスサービスの監視を無効化することもできます。
次の高可用性 Hosted Control Plane の要件を参照してください。この要件は、OpenShift Container Platform バージョン 4.12.9 以降でテストされたものです。
- 78 Pod
- etcd 用の 3 つの 8 GiB PV
- 最小仮想 CPU: 約 5.5 コア
- 最小メモリー: 約 19 GiB
3.2.1. Pod の制限
各ノードの maxPods 設定は、コントロールプレーンノードに収容できるホステッドクラスターの数に影響します。すべてのコントロールプレーンノードの maxPods 値に注意することが重要です。高可用性の Hosted Control Plane ごとに約 75 個の Pod を計画します。
ベアメタルノードの場合、マシンに十分なリソースがある場合でも、Pod 要件を考慮すると、各ノードに約 3 つの Hosted Control Plane が使用されるため、デフォルトで maxPods 設定に 250 が指定されていることが制限要因となる可能性があります。KubeletConfig 値を設定して maxPods 値を 500 に設定すると、Hosted Control Plane の密度が増し、追加のコンピュートリソースを活用できるようになります。
3.2.2. 要求ベースのリソース制限
クラスターがホストできる Hosted Control Plane の最大数は、Pod からの Hosted Control Plane CPU およびメモリー要求に基づいて計算されます。
高可用性 Hosted Control Plane は、5 つの仮想 CPU と 18 GB のメモリーを要求する 78 個の Pod で構成されます。これらのベースライン数値は、クラスターワーカーノードのリソース容量と比較され、Hosted Control Plane の最大数を推定します。
3.2.3. 負荷ベースの制限
クラスターがホストできる Hosted Control Plane の最大数は、Hosted Control Plane の Kubernetes API サーバーに何らかのワークロードが配置されたときの Hosted Control Plane Pod の CPU とメモリーの使用量に基づいて計算されます。
次の方法を使用して、ワークロードの増加に伴う Hosted Control Plane のリソース使用量を測定しました。
- KubeVirt プラットフォームを使用し、それぞれ 8 つの仮想 CPU と 32 GiB を使用する 9 つのワーカーを持つホステッドクラスター
次の定義に基づいて、API コントロールプレーンのストレスに重点を置くように設定されたワークロードテストプロファイル:
- 各 namespace にオブジェクトを作成し、合計 100 の namespace まで拡張しました。
- オブジェクトの継続的な削除と作成により、API のストレスを増加させます。
- ワークロードの 1 秒あたりのクエリー数 (QPS) とバースト設定を高く設定して、クライアント側のスロットリングを排除します。
負荷が 1000 QPS 増加すると、Hosted Control Plane のリソース使用量が、仮想 CPU 9 個分およびメモリー 2.5 GB 分増加します。
一般的なサイジングが目的の場合は、1000 QPS の API レートを 中程度 のホステッドクラスターの負荷、2000 QPS の API レートを 高程度 のホステッドクラスターの負荷とみなしてください。
このテストでは、予想される API 負荷に基づいてコンピュートリソースの使用量を増やすために、推定係数を定めています。正確な使用率は、クラスターのワークロードのタイプとペースによって異なる場合があります。
次の例は、ワークロードおよび API レート定義の Hosted Control Plane リソースのスケーリングを示しています。
| QPS (API レート) | 仮想 CPU の使用量 | メモリーの使用量 (GiB) |
|---|---|---|
| 低負荷 (50 QPS 未満) | 2.9 | 11.1 |
| 中負荷 (1000 QPS) | 11.9 | 13.6 |
| 高負荷 (2000 QPS) | 20.9 | 16.1 |
Hosted Control Plane のサイジングは、コントロールプレーンの負荷と、大量の API アクティビティー、etcd アクティビティー、またはその両方を引き起こすワークロードに関係します。データベースの実行など、データプレーンの負荷に重点を置くホスト型 Pod ワークロードでは、API レートが高くならない可能性があります。
3.2.4. サイジング計算の例
この例では、次のシナリオに対してサイジングのガイダンスを提供します。
-
hypershift.openshift.io/control-planeノードとしてラベル付けされたベアメタルワーカー 3 つ -
maxPods値を 500 に設定している - 負荷ベースの制限に応じて、予想される API レートは中または約 1000 である
| 制限の説明 | サーバー 1 | サーバー 2 |
|---|---|---|
| ワーカーノード上の仮想 CPU 数 | 64 | 128 |
| ワーカーノードのメモリー (GiB) | 128 | 256 |
| ワーカーあたりの最大 Pod 数 | 500 | 500 |
| コントロールプレーンのホストに使用されるワーカーの数 | 3 | 3 |
| 最大 QPS ターゲットレート (1 秒あたりの API リクエスト) | 1000 | 1000 |
| ワーカーノードのサイズと API レートに基づいた計算値 | サーバー 1 | サーバー 2 | 計算の注記 |
| 仮想 CPU リクエストに基づくワーカーあたりの最大ホストコントロールプレーン数 | 12.8 | 25.6 | ワーカーの仮想 CPU の数 ÷ Hosted Control Plane あたりの合計仮想 CPU 要求数 5 |
| 仮想 CPU 使用率に基づくワーカーあたりの最大 Hosted Control Plane 数 | 5.4 | 10.7 | 仮想 CPU の数 ÷ (アイドル状態の仮想 CPU 使用率の測定値 2.9 + (QPS ターゲットレート ÷ 1000) x QPS 増分 1000 あたりの仮想 CPU 使用率の測定値 9.0) |
| メモリーリクエストに基づくワーカーごとの最大 Hosted Control Plane | 7.1 | 14.2 | ワーカーのメモリー (GiB) ÷ Hosted Control Plane あたりの合計メモリー要求 18 GiB |
| メモリー使用量に基づくワーカーあたりの最大 Hosted Control Plane 数 | 9.4 | 18.8 | ワーカーのメモリー (GiB) ÷ (アイドル状態のメモリー使用率の測定値 11.1 + (QPS ターゲットレート ÷ 1000) x QPS 増分 1000 あたりのメモリー使用率の測定値 2.5) |
| ノードごとの Pod の制限に基づくワーカーごとの最大 Hosted Control Plane | 6.7 | 6.7 |
500 |
| 前述の最大値の中の最小値 | 5.4 | 6.7 | |
| 仮想 CPU の制限要因 |
| ||
| 管理クラスター内の Hosted Control Plane の最大数 | 16 | 20 | 前述の各最大値の最小値 x 3 control-plane 用ワーカー |
| 名前 | 説明 |
|
| 高可用性 Hosted Control Plane のリソース要求に基づく、クラスターがホストできる Hosted Control Plane の推定最大数。 |
|
| すべての Hosted Control Plane がクラスターの Kube API サーバーに約 50 QPS を送信する場合、クラスターがホストできる Hosted Control Plane の推定最大数。 |
|
| すべての Hosted Control Plane がクラスターの Kube API サーバーに約 1000 QPS を送信する場合、クラスターがホストできる Hosted Control Plane の推定最大数。 |
|
| すべての Hosted Control Plane がクラスターの Kube API サーバーに約 2000 QPS を送信する場合、クラスターがホストできる Hosted Control Plane の推定最大数。 |
|
| Hosted Control Plane の既存の平均 QPS に基づいて、クラスターがホストできる Hosted Control Plane の推定最大数。アクティブな Hosted Control Plane がない場合、QPS が低くなることが予想されます。 |
3.3. リソース使用率測定値のオーバーライド
リソース使用率のベースライン測定値のセットは、ホステッドクラスターごとに異なる場合があります。
3.3.1. ホステッドクラスターのリソース使用率測定値のオーバーライド
リソース使用率の測定値は、クラスターのワークロードの種類とペースに基づいてオーバーライドできます。
手順
次のコマンドを実行して、
ConfigMapリソースを作成します。$ oc create -f <your-config-map-file.yaml><your-config-map-file.yaml>はhcp-sizing-baselineconfig map を含む YAML ファイルの名前に置き換えます。local-clusternamespace にhcp-sizing-baselineconfig map を作成し、オーバーライドする測定値を指定します。config map は、次の YAML ファイルのようになります。kind: ConfigMap apiVersion: v1 metadata: name: hcp-sizing-baseline namespace: local-cluster data: incrementalCPUUsagePer1KQPS: "9.0" memoryRequestPerHCP: "18" minimumQPSPerHCP: "50.0"以下のコマンドを実行して
hypershift-addon-agentデプロイメントを削除し、hypershift-addon-agentPod を再起動します。$ oc delete deployment hypershift-addon-agent \ -n open-cluster-management-agent-addon
検証
hypershift-addon-agentPod ログを監視します。次のコマンドを実行して、オーバーライドされた測定値が config map 内で更新されていることを確認します。$ oc logs hypershift-addon-agent -n open-cluster-management-agent-addonログは以下の出力のようになります。
出力例
2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:793 setting cpuRequestPerHCP to 5 2024-01-05T19:41:05.392Z INFO agent.agent-reconciler agent/agent.go:802 setting memoryRequestPerHCP to 18 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:141 The worker nodes have 12.000000 vCPUs 2024-01-05T19:53:54.070Z INFO agent.agent-reconciler agent/hcp_capacity_calculation.go:142 The worker nodes have 49.173369 GB memoryオーバーライドされた測定値が
hcp-sizing-baselineconfig map で適切に更新されない場合、hypershift-addon-agentPod ログに次のエラーメッセージが表示されることがあります。エラーの例
2024-01-05T19:53:54.052Z ERROR agent.agent-reconciler agent/agent.go:788 failed to get configmap from the hub. Setting the HCP sizing baseline with default values. {"error": "configmaps \"hcp-sizing-baseline\" not found"}
3.3.2. メトリクスサービスモニタリングの無効化
hypershift-addon マネージドクラスターアドオンを有効にすると、メトリクスサービスモニタリングがデフォルトで設定され、OpenShift Container Platform モニタリングが hypershift-addon からメトリクスを収集できるようになります。
手順
次の手順を実行して、メトリクスサービスの監視を無効にできます。
次のコマンドを実行して、ハブクラスターにログインします。
$ oc login次のコマンドを実行して、
hypershift-addon-deploy-configアドオンのデプロイメント設定の仕様を編集します。$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine次の例に示すように、
disableMetrics=trueカスタマイズ変数を仕様に追加します。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: disableMetrics1 value: "true"- 1
- カスタマイズ変数
disableMetrics=trueは、新規および既存のhypershift-addonマネージドクラスターアドオンのメトリクスサービス監視を無効にします。
次のコマンドを実行して、設定の仕様に変更を適用します。
$ oc apply -f <filename>.yaml
3.4. Hosted Control Plane のコマンドラインインターフェイスのインストール
Hosted Control Plane のコマンドラインインターフェイスである hcp は、Hosted Control Plane の使用を開始するために使用できるツールです。管理や設定などの Day 2 運用には、GitOps や独自の自動化ツールを使用してください。
3.4.1. ターミナルからの Hosted Control Plane コマンドラインインターフェイスのインストール
ターミナルから、Hosted Control Plane のコマンドラインインターフェイス (CLI) である hcp をインストールできます。
前提条件
- OpenShift Container Platform クラスターに multicluster engine for Kubernetes Operator 2.5 がインストールされている。multicluster engine Operator は、Red Hat Advanced Cluster Management をインストールすると自動的にインストールされます。Red Hat Advanced Cluster Management を使用せずに、OpenShift Container Platform OperatorHub から multicluster engine Operator を Operator としてインストールすることもできます。
手順
次のコマンドを実行して、
hcpバイナリーをダウンロードするための URL を取得します。$ oc get ConsoleCLIDownload hcp-cli-download -o json | jq -r ".spec"次のコマンドを実行して
hcpバイナリーをダウンロードします。$ wget <hcp_cli_download_url>1 - 1
hcp_cli_download_urlは、前の手順で取得した URL に置き換えます。
次のコマンドを実行して、ダウンロードしたアーカイブを解凍します。
$ tar xvzf hcp.tar.gz次のコマンドを実行して、
hcpバイナリーファイルを実行可能にします。$ chmod +x hcp次のコマンドを実行して、
hcpバイナリーファイルをパス内のディレクトリーに移動します。$ sudo mv hcp /usr/local/bin/.
Mac コンピューターに CLI をダウンロードすると、hcp バイナリーファイルに関する警告が表示される場合があります。バイナリーファイルを実行できるようにするには、セキュリティー設定を調整する必要があります。
検証
次のコマンドを実行して、使用可能なパラメーターのリストが表示されることを確認します。
$ hcp create cluster <platform> --help1 - 1
hcp create clusterコマンドを使用すると、ホステッドクラスターを作成および管理できます。サポートされているプラットフォームは、aws、agent、およびkubevirtです。
3.4.2. Web コンソールを使用した Hosted Control Plane コマンドラインインターフェイスのインストール
OpenShift Container Platform Web コンソールを使用して、Hosted Control Plane のコマンドラインインターフェイス (CLI) である hcp をインストールできます。
前提条件
- OpenShift Container Platform クラスターに multicluster engine for Kubernetes Operator 2.5 がインストールされている。multicluster engine Operator は、Red Hat Advanced Cluster Management をインストールすると自動的にインストールされます。Red Hat Advanced Cluster Management を使用せずに、OpenShift Container Platform OperatorHub から multicluster engine Operator を Operator としてインストールすることもできます。
手順
- OpenShift Container Platform Web コンソールから、Help アイコン → Command Line Tools をクリックします。
- お使いのプラットフォーム用の Download hcp CLI をクリックします。
次のコマンドを実行して、ダウンロードしたアーカイブを解凍します。
$ tar xvzf hcp.tar.gz次のコマンドを実行して、バイナリーファイルを実行可能にします。
$ chmod +x hcp次のコマンドを実行して、バイナリーファイルをパス内のディレクトリーに移動します。
$ sudo mv hcp /usr/local/bin/.
Mac コンピューターに CLI をダウンロードすると、hcp バイナリーファイルに関する警告が表示される場合があります。バイナリーファイルを実行できるようにするには、セキュリティー設定を調整する必要があります。
検証
次のコマンドを実行して、使用可能なパラメーターのリストが表示されることを確認します。
$ hcp create cluster <platform> --help1 - 1
hcp create clusterコマンドを使用すると、ホステッドクラスターを作成および管理できます。サポートされているプラットフォームは、aws、agent、およびkubevirtです。
3.4.3. コンテンツゲートウェイを使用した Hosted Control Plane コマンドラインインターフェイスのインストール
コンテンツゲートウェイを使用して、Hosted Control Plane のコマンドラインインターフェイス (CLI) である hcp をインストールできます。
前提条件
- OpenShift Container Platform クラスターに multicluster engine for Kubernetes Operator 2.5 がインストールされている。multicluster engine Operator は、Red Hat Advanced Cluster Management をインストールすると自動的にインストールされます。Red Hat Advanced Cluster Management を使用せずに、OpenShift Container Platform OperatorHub から multicluster engine Operator を Operator としてインストールすることもできます。
手順
-
コンテンツゲートウェイ に移動し、
hcpバイナリーをダウンロードします。 次のコマンドを実行して、ダウンロードしたアーカイブを解凍します。
$ tar xvzf hcp.tar.gz次のコマンドを実行して、
hcpバイナリーファイルを実行可能にします。$ chmod +x hcp次のコマンドを実行して、
hcpバイナリーファイルをパス内のディレクトリーに移動します。$ sudo mv hcp /usr/local/bin/.
Mac コンピューターに CLI をダウンロードすると、hcp バイナリーファイルに関する警告が表示される場合があります。バイナリーファイルを実行できるようにするには、セキュリティー設定を調整する必要があります。
検証
次のコマンドを実行して、使用可能なパラメーターのリストが表示されることを確認します。
$ hcp create cluster <platform> --help1 - 1
hcp create clusterコマンドを使用すると、ホステッドクラスターを作成および管理できます。サポートされているプラットフォームは、aws、agent、およびkubevirtです。
3.5. ホステッドクラスターのワークロードの分散
OpenShift Container Platform の Hosted Control Plane を初めて使用する前に、ホステッドクラスターの Pod をインフラストラクチャーノードにスケジュールできるように、ノードを適切にラベル付けする必要があります。また、ノードのラベリングは以下の理由で重要です。
-
高可用性と適切なワークロードのデプロイメントを確保するため。たとえば、
node-role.kubernetes.io/infraラベルを設定して、OpenShift Container Platform サブスクリプションに control-plane ワークロード数が割り当てられないようにできます。 - コントロールプレーンのワークロードが管理クラスター内の他のワークロードから分離されるようにするため。
ワークロードには管理クラスターを使用しないでください。ワークロードは、コントロールプレーンが実行されるノード上で実行してはなりません。
3.5.1. 管理クラスターノードのラベル付け
Hosted Control Plane をデプロイするには、適切なノードのラベル付けを行う必要があります。
管理クラスターの管理者は、管理クラスターノードで次のラベルと taint を使用して、コントロールプレーンのワークロードをスケジュールします。
-
hypershift.openshift.io/control-plane: true: このラベルとテイントを使用して、Hosted Control Plane ワークロードの実行専用にノードを割り当てます。値をtrueに設定すると、コントロールプレーンノードが他のコンポーネント (管理クラスターのインフラストラクチャーコンポーネントや誤ってデプロイされたその他のワークロードなど) と共有されるのを回避できます。 -
hypershift.openshift.io/cluster: ${HostedControlPlane Namespace}: ノードを単一のホステッドクラスター専用にする場合は、このラベルとテイントを使用します。
コントロールプレーン Pod をホストするノードに以下のラベルを適用します。
-
node-role.kubernetes.io/infra: このラベルを使用して、サブスクリプションにコントロールプレーンワークロード数が割り当てられないようにします。 topology.kubernetes.io/zone: このラベルを管理クラスターノードで使用して、障害ドメイン全体に高可用性クラスターをデプロイします。ゾーンは、ゾーンが設定されているノードの場所、ラック名、またはホスト名である場合があります。たとえば、管理クラスターには、worker-1a、worker-1b、worker-2a、およびworker-2bのノードがあります。worker-1aとworker-1bノードはrack1にあり、worker-2aノードと worker-2b ノードはrack2にあります。各ラックをアベイラビリティゾーンとして使用するには、次のコマンドを入力します。$ oc label node/worker-1a node/worker-1b topology.kubernetes.io/zone=rack1$ oc label node/worker-2a node/worker-2b topology.kubernetes.io/zone=rack2
ホステッドクラスターの Pod には許容範囲があり、スケジューラーはアフィニティールールを使用して Pod をスケジュールします。Pod は、control-plane と Pod の cluster のテイントを許容します。スケジューラーは、hypershift.openshift.io/control-plane および hypershift.openshift.io/cluster: ${HostedControlPlane Namespace} でラベル付けされたノードへの Pod のスケジューリングを優先します。
ControllerAvailabilityPolicy オプションには、HighlyAvailable を使用します。これは、Hosted Control Plane のコマンドラインインターフェイス (hcp) がデプロイするデフォルト値です。このオプションを使用する場合は、topology.kubernetes.io/zone をトポロジーキーとして設定することで、別々の障害ドメインにまたがるホステッドクラスター内の各デプロイメントに対して Pod をスケジュールできます。別々の障害ドメインにまたがるホステッドクラスター内のデプロイメントに対する Pod のスケジュールは、高可用性コントロールプレーンでのみ可能です。
手順
ホステッドクラスターがその Pod をインフラストラクチャーノードにスケジュールすることを要求できるようにするには、次の例に示すように HostedCluster.spec.nodeSelector を設定します。
spec:
nodeSelector:
node-role.kubernetes.io/infra: ""こうすることで、各ホステッドクラスターの Hosted Control Plane が適格なインフラストラクチャーノードワークロードとなり、基盤となる OpenShift Container Platform ノードに資格を与える必要がなくなります。
3.5.2. 優先クラス
4 つの組み込み優先クラスは、ホステッドクラスター Pod の優先順位とプリエンプションに影響を与えます。管理クラスター内に Pod は、次の上位から下位の順序で作成できます。
-
hypershift-operator: HyperShift Operator Pod。 -
hypershift-etcd: etcd 用の Pod。 -
hypershift-api-critical: API 呼び出しとリソース許可が成功するために必要な Pod。これらの Pod には、kube-apiserver、集約 API サーバー、Web フックなどの Pod が含まれます。 -
hypershift-control-plane: API クリティカルではないものの、クラスターバージョンの Operator など、高い優先順位が必要なコントロールプレーン内の Pod。
3.5.3. カスタムの taint と toleration
デフォルトでは、ホステッドクラスターの Pod は、control-plane および cluster taint を許容します。ただし、HostedCluster.spec.tolerations を設定することで、ホステッドクラスターがホステッドクラスターごとにこれらの taint を許容できるように、ノードでカスタムの taint を使用することもできます。
ホステッドクラスターの toleration を渡す機能は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
設定例
spec:
tolerations:
- effect: NoSchedule
key: kubernetes.io/custom
operator: Exists
hcp CLI の引数 --tolerations を使用して、クラスターを作成するときに、ホステッドクラスターに toleration を設定することもできます。
CLI 引数の例
--toleration="key=kubernetes.io/custom,operator=Exists,effect=NoSchedule"
ホステッドクラスターごとにホステッドクラスター Pod の配置を細かく制御するには、カスタムの toleration を nodeSelectors とともに使用します。ホステッドクラスターのグループを同じ場所に配置し、他のホステッドクラスターから分離することができます。ホステッドクラスターをインフラノードとコントロールプレーンノードに配置することもできます。
ホステッドクラスターの toleration は、コントロールプレーンの Pod にのみ適用されます。管理クラスターで実行される他の Pod や、仮想マシンを実行する Pod などのインフラストラクチャー関連の Pod を設定するには、別のプロセスを使用する必要があります。
3.6. Hosted Control Plane 機能の有効化または無効化
Hosted Control Plane 機能と hypershift-addon マネージドクラスターアドオンは、デフォルトで有効になっています。機能を無効にする場合、または無効にした後に手動で有効にする場合は、次の手順を参照してください。
3.6.1. Hosted Control Plane 機能の手動での有効化
Hosted Control Plane を手動で有効にする必要がある場合は、次の手順を実行します。
手順
次のコマンドを実行して機能を有効にします。
$ oc patch mce multiclusterengine --type=merge -p \ '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'1 - 1
- デフォルトの
MultiClusterEngineリソースインスタンス名はmulticlusterengineですが、$ oc get mceコマンドを実行し、クラスターからMultiClusterEngine名を取得できます。
次のコマンドを実行して、
hypershiftおよびhypershift-local-hosting機能がMultiClusterEngineカスタムリソースで有効になっていることを確認します。$ oc get mce multiclusterengine -o yaml1 - 1
- デフォルトの
MultiClusterEngineリソースインスタンス名はmulticlusterengineですが、$ oc get mceコマンドを実行し、クラスターからMultiClusterEngine名を取得できます。
出力例
apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: true - name: hypershift-local-hosting enabled: true
3.6.1.1. local-cluster の hypershift-addon マネージドクラスターアドオンを手動で有効にする
Hosted Control Plane 機能を有効にすると、hypershift-addon マネージドクラスターアドオンが自動的に有効になります。hypershift-addon マネージドクラスターアドオンを手動で有効にする必要がある場合は、次の手順を実行して hypershift-addon を使用し、HyperShift Operator を local-cluster にインストールします。
手順
次の例のようなファイルを作成して、
hypershift-addonという名前のManagedClusterAddonアドオンを作成します。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: ManagedClusterAddOn metadata: name: hypershift-addon namespace: local-cluster spec: installNamespace: open-cluster-management-agent-addon以下のコマンドを実行してこのファイルを適用します。
$ oc apply -f <filename>filenameは、作成したファイル名に置き換えます。次のコマンドを実行して、
hypershift-addonマネージドクラスターアドオンがインストールされていることを確認します。$ oc get managedclusteraddons -n local-cluster hypershift-addonアドオンがインストールされている場合、出力は以下の例のようになります。
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True
hypershift-addon マネージドクラスターアドオンがインストールされ、ホスティングクラスターを使用してホステッドクラスターを作成および管理できるようになります。
3.6.2. Hosted Control Plane 機能の無効化
HyperShift Operator をアンインストールして、Hosted Control Plane 機能を無効にすることができます。Hosted Control Plane 機能を無効にする場合は、ホステッドクラスターの管理 のトピックで説明されているように、multicluster engine Operator のホステッドクラスターとマネージドクラスターリソースを破棄する必要があります。
3.6.2.1. HyperShift Operator のアンインストール
HyperShift Operator をアンインストールし、local-cluster から hypershift-addon を無効にするには、以下の手順を実行します。
手順
以下のコマンドを実行して、ホステッドクラスターが実行されていないことを確認します。
$ oc get hostedcluster -A重要ホステッドクラスターが実行中の場合、
hypershift-addonが無効になっていても、HyperShift Operator はアンインストールされません。以下のコマンドを実行して
hypershift-addonを無効にします。$ oc patch mce multiclusterengine --type=merge -p \1 '{"spec":{"overrides":{"components":[{"name":"hypershift-local-hosting","enabled": false}]}}}'- 1
- デフォルトの
MultiClusterEngineリソースインスタンス名はmulticlusterengineですが、$ oc get mceコマンドを実行し、クラスターからMultiClusterEngine名を取得できます。
注記hypershift-addonを無効にした後、multicluster engine Operator コンソールからlocal-clusterのhypershift-addonを無効にすることもできます。
3.6.2.2. Hosted Control Plane 機能の無効化
Hosted Control Plane 機能を無効にするには、次の手順を実行します。
前提条件
- HyperShift Operator をアンインストールした。詳細は、「HyperShift Operator のアンインストール」を参照してください。
手順
次のコマンドを実行して、Hosted Control Plane 機能を無効にします。
$ oc patch mce multiclusterengine --type=merge -p \1 '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": false}]}}}'- 1
- デフォルトの
MultiClusterEngineリソースインスタンス名はmulticlusterengineですが、$ oc get mceコマンドを実行し、クラスターからMultiClusterEngine名を取得できます。
次のコマンドを実行すると、
MultiClusterEngineカスタムリソースでhypershiftおよびhypershift-local-hosting機能が無効になっていることを確認できます。$ oc get mce multiclusterengine -o yaml1 - 1
- デフォルトの
MultiClusterEngineリソースインスタンス名はmulticlusterengineですが、$ oc get mceコマンドを実行し、クラスターからMultiClusterEngine名を取得できます。
hypershiftとhypershift-local-hostingのenabled:フラグがfalseに設定されている次の例を参照してください。apiVersion: multicluster.openshift.io/v1 kind: MultiClusterEngine metadata: name: multiclusterengine spec: overrides: components: - name: hypershift enabled: false - name: hypershift-local-hosting enabled: false
第4章 Hosted Control Plane のデプロイ
4.1. AWS への Hosted Control Plane のデプロイ
ホステッドクラスター は、API エンドポイントとコントロールプレーンが管理クラスターでホストされている OpenShift Container Platform クラスターです。ホステッドクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。オンプレミスで Hosted Control Plane を設定するには、管理クラスターに multicluster engine for Kubernetes Operator をインストールする必要があります。hypershift-addon マネージドクラスターアドオンを使用して既存のマネージドクラスターに HyperShift Operator をデプロイすると、そのクラスターを管理クラスターとして有効にして、ホステッドクラスターの作成を開始できます。hypershift-addon マネージドクラスターアドオンは、local-cluster マネージドクラスターでデフォルトで有効になっています。
ホステッドクラスターは、multicluster engine Operator のコンソールか、Hosted Control Plane のコマンドラインインターフェイス (CLI) である hcp を使用して作成できます。ホステッドクラスターは、マネージドクラスターとして自動的にインポートされます。ただし、この multicluster engine Operator への自動インポート機能を無効にする こともできます。
4.1.1. AWS への Hosted Control Plane のデプロイの準備
Amazon Web Services (AWS) に Hosted Control Plane をデプロイする準備をする際には、次の情報を考慮してください。
- 各ホステッドクラスターの名前がクラスター全体で一意である。multicluster engine Operator によってホステッドクラスターを管理するには、ホステッドクラスター名を既存のマネージドクラスターと同じにすることはできません。
-
ホステッドクラスター名として
clustersを使用しないでください。 - 管理クラスターとワーカーは、Hosted Control Plane の同じプラットフォーム上で実行してください。
- ホステッドクラスターは、multicluster engine Operator のマネージドクラスターの namespace には作成できない。
4.1.1.1. 管理クラスターを設定するための前提条件
管理クラスターを設定するには、次の前提条件を満たす必要があります。
- OpenShift Container Platform クラスターに multicluster engine for Kubernetes Operator 2.5 以降がインストールされている。multicluster engine Operator は、Red Hat Advanced Cluster Management (RHACM) をインストールすると、自動的にインストールされます。multicluster engine Operator は、OpenShift Container Platform OperatorHub から Operator として RHACM なしでインストールすることもできます。
multicluster engine Operator のマネージド OpenShift Container Platform クラスターが少なくとも 1 つある。multicluster engine Operator バージョン 2.5 以降では、
local-clusterが自動的にインポートされます。次のコマンドを実行して、ハブクラスターの状態を確認できます。$ oc get managedclusters local-cluster-
awsコマンドラインインターフェイス (CLI) がインストールされている。 -
Hosted Control Plane の CLI である
hcpがインストールされている。
4.1.2. hcp CLI を使用して AWS 上のホステッドクラスターにアクセスする
hcp コマンドラインインターフェイス (CLI) を使用して kubeconfig ファイルを生成することで、ホステッドクラスターにアクセスできます。
手順
次のコマンドを入力して、
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfigファイルを保存した後、次のコマンドを入力してホステッドクラスターにアクセスできます。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
4.1.3. Amazon Web Services S3 バケットと S3 OIDC シークレットの作成
Amazon Web Services (AWS) でホステッドクラスターを作成して管理するには、S3 バケットと S3 OIDC シークレットを作成する必要があります。
手順
次のコマンドを実行して、クラスターの OIDC 検出ドキュメントをホストするためのパブリックアクセスを持つ S3 バケットを作成します。
$ aws s3api create-bucket --bucket <bucket_name> \1 --create-bucket-configuration LocationConstraint=<region> \2 --region <region>3 $ aws s3api delete-public-access-block --bucket <bucket_name>1 - 1
<bucket_name>は、作成する S3 バケットの名前に置き換えます。
$ echo '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::<bucket_name>/*"1 } ] }' | envsubst > policy.json- 1
<bucket_name>は、作成する S3 バケットの名前に置き換えます。
$ aws s3api put-bucket-policy --bucket <bucket_name> \1 --policy file://policy.json- 1
<bucket_name>は、作成する S3 バケットの名前に置き換えます。
注記Mac コンピューターを使用している場合は、ポリシーを機能させるためにバケット名をエクスポートする必要があります。
-
HyperShift Operator 用に
hypershift-operator-oidc-provider-s3-credentialsという名前の OIDC S3 シークレットを作成します。 -
シークレットを
local-clusternamespace に保存します。 次の表を参照して、シークレットに次のフィールドが含まれていることを確認します。
Expand 表4.1 AWS シークレットの必須フィールド フィールド名 説明 bucketホステッドクラスターの OIDC 検出ドキュメントをホストするためのパブリックアクセスを備えた S3 バケットが含まれています。
credentialsバケットにアクセスできる
defaultプロファイルの認証情報を含むファイルへの参照。デフォルトでは、HyperShift はdefaultプロファイルのみを使用してbucketを操作します。regionS3 バケットのリージョンを指定します。
AWS シークレットを作成するには、次のコマンドを実行します。
$ oc create secret generic <secret_name> \ --from-file=credentials=<path>/.aws/credentials \ --from-literal=bucket=<s3_bucket> \ --from-literal=region=<region> \ -n local-cluster注記シークレットの障害復旧バックアップは自動的に有効になりません。障害復旧用に
hypershift-operator-oidc-provider-s3-credentialsシークレットのバックアップを有効にするラベルを追加するには、次のコマンドを実行します。$ oc label secret hypershift-operator-oidc-provider-s3-credentials \ -n local-cluster cluster.open-cluster-management.io/backup=true
4.1.4. ホステッドクラスター用のルーティング可能なパブリックゾーンの作成
ホステッドクラスター内のアプリケーションにアクセスするには、ルーティング可能なパブリックゾーンを設定する必要があります。パブリックゾーンが存在する場合は、この手順を省略します。省略しないと、パブリックゾーンによって既存の機能に影響が生じます。
手順
DNS レコードのルーティング可能なパブリックゾーンを作成するには、次のコマンドを入力します。
$ aws route53 create-hosted-zone \ --name <basedomain> \1 --caller-reference $(whoami)-$(date --rfc-3339=date)- 1
<basedomain>は、ベースドメイン (例:www.example.com) に置き換えます。
4.1.5. AWS IAM ロールと STS 認証情報の作成
Amazon Web Services (AWS) でホステッドクラスターを作成する前に、AWS IAM ロールと STS 認証情報を作成する必要があります。
手順
次のコマンドを実行して、ユーザーの Amazon Resource Name (ARN) を取得します。
$ aws sts get-caller-identity --query "Arn" --output text出力例
arn:aws:iam::1234567890:user/<aws_username>この出力は、次のステップで
<arn>の値として使用します。ロールの信頼関係設定を含む JSON ファイルを作成します。以下の例を参照してください。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<arn>"1 }, "Action": "sts:AssumeRole" } ] }- 1
<arn>は、前のステップでメモしたユーザーの ARN に置き換えます。
次のコマンドを実行して、Identity and Access Management (IAM) ロールを作成します。
$ aws iam create-role \ --role-name <name> \1 --assume-role-policy-document file://<file_name>.json \2 --query "Role.Arn"出力例
arn:aws:iam::820196288204:role/myroleロールの次の権限ポリシーを含む
policy.jsonという名前の JSON ファイルを作成します。{ "Version": "2012-10-17", "Statement": [ { "Sid": "EC2", "Effect": "Allow", "Action": [ "ec2:CreateDhcpOptions", "ec2:DeleteSubnet", "ec2:ReplaceRouteTableAssociation", "ec2:DescribeAddresses", "ec2:DescribeInstances", "ec2:DeleteVpcEndpoints", "ec2:CreateNatGateway", "ec2:CreateVpc", "ec2:DescribeDhcpOptions", "ec2:AttachInternetGateway", "ec2:DeleteVpcEndpointServiceConfigurations", "ec2:DeleteRouteTable", "ec2:AssociateRouteTable", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:CreateRoute", "ec2:CreateInternetGateway", "ec2:RevokeSecurityGroupEgress", "ec2:ModifyVpcAttribute", "ec2:DeleteInternetGateway", "ec2:DescribeVpcEndpointConnections", "ec2:RejectVpcEndpointConnections", "ec2:DescribeRouteTables", "ec2:ReleaseAddress", "ec2:AssociateDhcpOptions", "ec2:TerminateInstances", "ec2:CreateTags", "ec2:DeleteRoute", "ec2:CreateRouteTable", "ec2:DetachInternetGateway", "ec2:DescribeVpcEndpointServiceConfigurations", "ec2:DescribeNatGateways", "ec2:DisassociateRouteTable", "ec2:AllocateAddress", "ec2:DescribeSecurityGroups", "ec2:RevokeSecurityGroupIngress", "ec2:CreateVpcEndpoint", "ec2:DescribeVpcs", "ec2:DeleteSecurityGroup", "ec2:DeleteDhcpOptions", "ec2:DeleteNatGateway", "ec2:DescribeVpcEndpoints", "ec2:DeleteVpc", "ec2:CreateSubnet", "ec2:DescribeSubnets" ], "Resource": "*" }, { "Sid": "ELB", "Effect": "Allow", "Action": [ "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DeleteTargetGroup" ], "Resource": "*" }, { "Sid": "IAMPassRole", "Effect": "Allow", "Action": "iam:PassRole", "Resource": "arn:*:iam::*:role/*-worker-role", "Condition": { "ForAnyValue:StringEqualsIfExists": { "iam:PassedToService": "ec2.amazonaws.com" } } }, { "Sid": "IAM", "Effect": "Allow", "Action": [ "iam:CreateInstanceProfile", "iam:DeleteInstanceProfile", "iam:GetRole", "iam:UpdateAssumeRolePolicy", "iam:GetInstanceProfile", "iam:TagRole", "iam:RemoveRoleFromInstanceProfile", "iam:CreateRole", "iam:DeleteRole", "iam:PutRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateOpenIDConnectProvider", "iam:ListOpenIDConnectProviders", "iam:DeleteRolePolicy", "iam:UpdateRole", "iam:DeleteOpenIDConnectProvider", "iam:GetRolePolicy" ], "Resource": "*" }, { "Sid": "Route53", "Effect": "Allow", "Action": [ "route53:ListHostedZonesByVPC", "route53:CreateHostedZone", "route53:ListHostedZones", "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets", "route53:DeleteHostedZone", "route53:AssociateVPCWithHostedZone", "route53:ListHostedZonesByName" ], "Resource": "*" }, { "Sid": "S3", "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets", "s3:ListBucket", "s3:DeleteObject", "s3:DeleteBucket" ], "Resource": "*" } ] }次のコマンドを実行して、
policy.jsonファイルをロールに割り当てます。$ aws iam put-role-policy \ --role-name <role_name> \1 --policy-name <policy_name> \2 --policy-document file://policy.json3 次のコマンドを実行して、
sts-creds.jsonという名前の JSON ファイル内の STS 認証情報を取得します。$ aws sts get-session-token --output json > sts-creds.jsonsts-creds.jsonファイルの例{ "Credentials": { "AccessKeyId": "<access_key_id", "SecretAccessKey": "<secret_access_key>”, "SessionToken": "<session_token>", "Expiration": "<time_stamp>" } }
4.1.6. Hosted Control Plane 用の AWS PrivateLink の有効化
PrivateLink を使用して Amazon Web Services (AWS) で Hosted Control Plane をプロビジョニングするには、Hosted Control Plane 用の AWS PrivateLink を有効にします。
手順
-
HyperShift Operator の AWS 認証情報シークレットを作成し、
hypershift-operator-private-link-credentialsという名前を付けます。このシークレットは、管理クラスターとして使用されているマネージドクラスターの namespace であるマネージドクラスター namespace に配置する必要があります。local-clusterを使用した場合は、local-clusternamespace にシークレットを作成します。 - シークレットに必要なフィールドが含まれることを確認するには、以下の表を参照してください。
| フィールド名 | 説明 | 任意または必須 |
|---|---|---|
|
| Private Link で使用するリージョン | 必須 |
|
| 認証情報アクセスキー ID。 | 必須 |
|
| 認証情報アクセスキーのシークレット。 | 必須 |
AWS シークレットを作成するには、次のコマンドを実行します。
$ oc create secret generic <secret_name> \
--from-literal=aws-access-key-id=<aws_access_key_id> \
--from-literal=aws-secret-access-key=<aws_secret_access_key> \
--from-literal=region=<region> -n local-cluster
シークレットの障害復旧バックアップは自動的に有効になりません。以下のコマンドを実行して、障害復旧用に hypershift-operator-private-link-credentials シークレットのバックアップを有効にするラベルを追加します。
$ oc label secret hypershift-operator-private-link-credentials \
-n local-cluster \
cluster.open-cluster-management.io/backup=""4.1.7. AWS 上の Hosted Control Plane 用の外部 DNS を有効にする
Hosted Control Plane では、コントロールプレーンとデータプレーンが分離されています。DNS は、次の 2 つの独立した領域で設定できます。
-
ホステッドクラスター (
*.apps.service-consumer-domain.comなどのドメイン) 内のワークロードの Ingress。 -
サービスプロバイダーのドメイン
*.service-provider-domain.comを介した API または OAuth エンドポイントなど、管理クラスター内のサービスエンドポイントの Ingress。
hostedCluster.spec.dns の入力は、ホステッドクラスター内のワークロードの Ingress を管理します。hostedCluster.spec.services.servicePublishingStrategy.route.hostname の入力は、管理クラスター内のサービスエンドポイントの Ingress を決定します。
外部 DNS は、LoadBalancer または Route の公開タイプを指定し、その公開タイプのホスト名を提供するホステッドクラスター Services の名前レコードを作成します。Private または PublicAndPrivate エンドポイントアクセスタイプを持つホステッドクラスターの場合、APIServer サービスと OAuth サービスのみがホスト名をサポートします。Private ホステッドクラスターの場合、DNS レコードが VPC 内の Virtual Private Cloud (VPC) エンドポイントのプライベート IP アドレスに解決されます。
Hosted Control Plane は、次のサービスを公開します。
-
APIServer -
OIDC
これらのサービスは、HostedCluster 仕様の servicePublishingStrategy フィールドを使用して公開できます。デフォルトでは、servicePublishingStrategy の LoadBalancer および Route タイプの場合、次のいずれかの方法でサービスを公開できます。
-
LoadBalancerタイプのServiceのステータスにあるロードバランサーのホスト名を使用する方法 -
Routeリソースのstatus.hostフィールドを使用する方法
ただし、マネージドサービスのコンテキストで Hosted Control Plane をデプロイすると、これらの方法によって、基盤となる管理クラスターの Ingress サブドメインが公開され、管理クラスターのライフサイクルと障害復旧のオプションが制限される可能性があります。
DNS 間接化が LoadBalancer および Route 公開タイプに階層化されている場合、マネージドサービスオペレーターは、サービスレベルドメインを使用してすべてのパブリックホステッドクラスターサービスを公開できます。このアーキテクチャーでは、DNS 名を新しい LoadBalancer または Route に再マッピングできますが、管理クラスターの Ingress ドメインは公開されません。Hosted Control Plane は、外部 DNS を使用して間接層を実現します。
管理クラスターの hypershift namespace に HyperShift Operator と一緒に external-dns をデプロイできます。外部 DNS は、external-dns.alpha.kubernetes.io/hostname アノテーションを持つ Services または Routes を監視します。このアノテーションは、A レコードなどの Service、または CNAME レコードなどの Route を参照する DNS レコードを作成するために使用されます。
外部 DNS はクラウド環境でのみ使用できます。その他の環境では、DNS とサービスを手動で設定する必要があります。
外部 DNS の詳細は、外部 DNS を参照してください。
4.1.7.1. 前提条件
Amazon Web Services (AWS) で Hosted Control Plane の外部 DNS を設定する前に、次の前提条件を満たす必要があります。
- 外部パブリックドメインを作成した。
- AWS Route53 管理コンソールにアクセスできる。
- Hosted Control Plane 用に AWS PrivateLink を有効にした。
4.1.7.2. Hosted Control Plane の外部 DNS の設定
Hosted Control Plane は、外部 DNS またはサービスレベル DNS を使用してプロビジョニングできます。
-
HyperShift Operator 用の Amazon Web Services (AWS) 認証情報シークレットを作成し、
local-clusternamespace でhypershift-operator-external-dns-credentialsという名前を付けます。 次の表を参照して、シークレットに必須フィールドが含まれていることを確認してください。
Expand 表4.3 AWS シークレットの必須フィールド フィールド名 説明 任意または必須 providerサービスレベル DNS ゾーンを管理する DNS プロバイダー。
必須
domain-filterサービスレベルドメイン。
必須
credentialsすべての外部 DNS タイプをサポートする認証情報ファイル。
AWS キーを使用する場合はオプション
aws-access-key-id認証情報アクセスキー ID。
AWS DNS サービスを使用する場合はオプション
aws-secret-access-key認証情報アクセスキーのシークレット。
AWS DNS サービスを使用する場合はオプション
AWS シークレットを作成するには、次のコマンドを実行します。
$ oc create secret generic <secret_name> \ --from-literal=provider=aws \ --from-literal=domain-filter=<domain_name> \ --from-file=credentials=<path_to_aws_credentials_file> -n local-cluster注記シークレットの障害復旧バックアップは自動的に有効になりません。障害復旧のためにシークレットをバックアップするには、次のコマンドを入力して
hypershift-operator-external-dns-credentialsを追加します。$ oc label secret hypershift-operator-external-dns-credentials \ -n local-cluster \ cluster.open-cluster-management.io/backup=""
4.1.7.3. パブリック DNS ホストゾーンの作成
パブリック DNS ホストゾーンは、パブリックホステッドクラスターを作成するために、External DNS Operator によって使用されます。
外部 DNS ドメインフィルターとして使用するパブリック DNS ホストゾーンを作成できます。AWS Route 53 管理コンソールで次の手順を実行します。
手順
- Route 53 管理コンソールで、Create hosted zone をクリックします。
- Hosted zone configuration ページでドメイン名を入力し、タイプとして Public hosted zone が選択されていることを確認し、Create hosted zone をクリックします。
- ゾーンが作成されたら、Records タブの Value/Route traffic to 列の値をメモします。
- メインドメインで、DNS 要求を委任ゾーンにリダイレクトするための NS レコードを作成します。Value フィールドに、前の手順でメモした値を入力します。
- Create records をクリックします。
次の例のように、新しいサブゾーンにテストエントリーを作成し、
digコマンドでテストして、DNS ホストゾーンが機能していることを確認します。$ dig +short test.user-dest-public.aws.kerberos.com出力例
192.168.1.1LoadBalancerおよびRouteサービスのホスト名を設定するホステッドクラスターを作成するには、次のコマンドを入力します。$ hcp create cluster aws --name=<hosted_cluster_name> \ --endpoint-access=PublicAndPrivate \ --external-dns-domain=<public_hosted_zone> ...1 - 1
<public_hosted_zone>は、作成したパブリックホストゾーンに置き換えます。
ホステッドクラスターの
servicesブロックの例platform: aws: endpointAccess: PublicAndPrivate ... services: - service: APIServer servicePublishingStrategy: route: hostname: api-example.service-provider-domain.com type: Route - service: OAuthServer servicePublishingStrategy: route: hostname: oauth-example.service-provider-domain.com type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: Ignition servicePublishingStrategy: type: Route
Control Plane Operator は、Services と Routes リソースを作成し、external-dns.alpha.kubernetes.io/hostname のアノテーションを付けます。Services と Routes の場合、Control Plane Operator は、サービスエンドポイントの servicePublishingStrategy フィールドの hostname パラメーターの値を使用します。DNS レコードを作成するには、external-dns デプロイメントなどのメカニズムを使用できます。
サービスレベルの DNS 間接化をパブリックサービスにのみ設定できます。プライベートサービスは hypershift.local プライベートゾーンを使用するため、hostname を設定できません。
次の表は、サービスとエンドポイントの組み合わせに対して hostname を設定することが有効な場合を示しています。
| サービス | Public | PublicAndPrivate | Private |
|---|---|---|---|
|
| Y | Y | N |
|
| Y | Y | N |
|
| Y | N | N |
|
| Y | N | N |
4.1.7.4. AWS 上で外部 DNS を使用してホステッドクラスターを作成する
Amazon Web Services (AWS) で PublicAndPrivate または Public 公開ストラテジーを使用してホステッドクラスターを作成するには、管理クラスターで次のアーティファクトが設定されている必要があります。
- パブリック DNS ホストゾーン
- External DNS Operator
- HyperShift Operator
ホステッドクラスターは、hcp コマンドラインインターフェイス (CLI) を使用してデプロイできます。
手順
管理クラスターにアクセスするには、次のコマンドを入力します。
$ export KUBECONFIG=<path_to_management_cluster_kubeconfig>次のコマンドを入力して、External DNS Operator が実行されていることを確認します。
$ oc get pod -n hypershift -lapp=external-dns出力例
NAME READY STATUS RESTARTS AGE external-dns-7c89788c69-rn8gp 1/1 Running 0 40s外部 DNS を使用してホステッドクラスターを作成するには、次のコマンドを入力します。
$ hcp create cluster aws \ --role-arn <arn_role> \1 --instance-type <instance_type> \2 --region <region> \3 --auto-repair \ --generate-ssh \ --name <hosted_cluster_name> \4 --namespace clusters \ --base-domain <service_consumer_domain> \5 --node-pool-replicas <node_replica_count> \6 --pull-secret <path_to_your_pull_secret> \7 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --external-dns-domain=<service_provider_domain> \9 --endpoint-access=PublicAndPrivate10 --sts-creds <path_to_sts_credential_file>11 - 1
- Amazon Resource Name (ARN) を指定します (例:
arn:aws:iam::820196288204:role/myrole)。 - 2
- インスタンスタイプを指定します (例:
m6i.xlarge)。 - 3
- AWS リージョンを指定します (例:
us-east-1)。 - 4
- ホステッドクラスター名を指定します (例:
my-external-aws)。 - 5
- サービスコンシューマーが所有するパブリックホストゾーンを指定します (例:
service-consumer-domain.com)。 - 6
- ノードのレプリカ数を指定します (例:
2)。 - 7
- プルシークレットファイルへのパスを指定します。
- 8
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.17.0-multi)。 - 9
- サービスプロバイダーが所有するパブリックホストゾーンを指定します (例:
service-provider-domain.com)。 - 10
PublicAndPrivateとして設定します。外部 DNS は、PublicまたはPublicAndPrivate設定でのみ使用できます。- 11
- AWS STS 認証情報ファイルへのパスを指定します (例:
/home/user/sts-creds/sts-creds.json)。
4.1.8. AWS 上でホステッドクラスターを作成する
hcp コマンドラインインターフェイス (CLI) を使用して、Amazon Web Services (AWS) 上にホステッドクラスターを作成できます。
Amazon Web Services (AWS) 上の Hosted Control Plane では、デフォルトで AMD64 ホステッドクラスターを使用します。ただし、Hosted Control Plane を ARM64 ホステッドクラスターで実行することもできます。詳細は、「ARM64 アーキテクチャーでのホステッドクラスターの実行」を参照してください。
ノードプールとホステッドクラスターの互換性のある組み合わせは、次の表を参照してください。
| ホステッドクラスター | ノードプール |
|---|---|
| AMD64 | AMD64 または ARM64 |
| ARM64 | ARM64 または AMD64 |
前提条件
-
Hosted Control Plane の CLI である
hcpを設定した。 -
local-clusterマネージドクラスターを管理クラスターとして有効にした。 - AWS Identity and Access Management (IAM) ロールと AWS Security Token Service (STS) 認証情報を作成した。
手順
AWS 上にホステッドクラスターを作成するには、次のコマンドを実行します。
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --base-domain <basedomain> \3 --sts-creds <path_to_sts_credential_file> \4 --pull-secret <path_to_pull_secret> \5 --region <region> \6 --generate-ssh \ --node-pool-replicas <node_pool_replica_count> \7 --namespace <hosted_cluster_namespace> \8 --role-arn <role_name> \9 --render-into <file_name>.yaml10 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- インフラストラクチャー名を指定します。
<hosted_cluster_name>と<infra_id>には同じ値を指定する必要があります。そうしないと、multicluster engine for Kubernetes Operator のコンソールに、クラスターが正しく表示されない可能性があります。 - 3
- ベースドメインを指定します (例:
example.com)。 - 4
- AWS STS 認証情報ファイルへのパスを指定します (例:
/home/user/sts-creds/sts-creds.json)。 - 5
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 6
- AWS リージョン名を指定します (例:
us-east-1)。 - 7
- ノードプールのレプリカ数を指定します (例:
3)。 - 8
- デフォルトでは、
HostedClusterとNodePoolのすべてのカスタムリソースがclustersnamespace に作成されます。--namespace <namespace>パラメーターを使用すると、特定の namespace にHostedClusterおよびNodePoolカスタムリソースを作成できます。 - 9
- Amazon Resource Name (ARN) を指定します (例:
arn:aws:iam::820196288204:role/myrole)。 - 10
- EC2 インスタンスを共有テナントハードウェア上で実行するか、シングルテナントハードウェア上で実行するかを指定する場合は、このフィールドを含めます。
--render-intoフラグを含めると、Kubernetes リソースが、このフィールドで指定した YAML ファイルにレンダリングされます。この場合、次のステップに進み、YAML ファイルを編集します。
前のコマンドに
--render-intoフラグを含めた場合は、指定した YAML ファイルを編集します。YAML ファイルのNodePool仕様を編集して、EC2 インスタンスを共有ハードウェア上で実行するか、シングルテナントハードウェア上で実行するかを指定します。次に例を示します。サンプル YAML ファイル
apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <nodepool_name>1 spec: platform: aws: placement: tenancy: "default"2
検証
ホステッドクラスターのステータスを確認し、
AVAILABLEの値がTrueであることを確認します。以下のコマンドを実行します。$ oc get hostedclusters -n <hosted_cluster_namespace>次のコマンドを実行して、ノードプールのリストを取得します。
$ oc get nodepools --namespace <hosted_cluster_namespace>
4.1.8.1. AWS 上のホステッドクラスターへのアクセス
リソースから kubeconfig ファイルと kubeadmin 認証情報を直接取得することで、ホステッドクラスターにアクセスできます。
ホステッドクラスターのアクセスシークレットを理解している必要があります。ホステッドクラスター namespace にはホステッドクラスターリソースが含まれており、Hosted Control Plane namespace では Hosted Control Plane が実行されます。シークレット名の形式は次のとおりです。
-
kubeconfigシークレット:<hosted-cluster-namespace>-<name>-admin-kubeconfig.たとえば、clusters-hypershift-demo-admin-kubeconfigです。 -
kubeadminパスワードシークレット:<hosted-cluster-namespace>-<name>-kubeadmin-password。たとえば、clusters-hypershift-demo-kubeadmin-passwordです。
手順
kubeconfigシークレットには Base64 でエンコードされたkubeconfigフィールドが含まれており、これをデコードしてファイルに保存し、次のコマンドで使用できます。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodeskubeadminパスワードシークレットも Base64 でエンコードされます。これをデコードし、そのパスワードを使用して、ホステッドクラスターの API サーバーまたはコンソールにログインできます。
4.1.8.2. kubeadmin 認証情報を使用して AWS 上のホステッドクラスターにアクセスする
Amazon Web Services (AWS) にホステッドクラスターを作成した後、kubeconfig ファイル、アクセスシークレット、および kubeadmin 認証情報を取得して、ホステッドクラスターにアクセスできます。
ホステッドクラスターのリソースとアクセスシークレットは、ホステッドクラスターの namespace に格納されます。Hosted Control Plane は、Hosted Control Plane の namespace で実行されます。
シークレット名の形式は次のとおりです。
-
kubeconfigシークレット:<hosted_cluster_namespace>-<name>-admin-kubeconfig。たとえば、clusters-hypershift-demo-admin-kubeconfigです。 -
kubeadminパスワードシークレット:<hosted_cluster_namespace>-<name>-kubeadmin-password。たとえば、clusters-hypershift-demo-kubeadmin-passwordです。
kubeadmin パスワードシークレットは、Base64 でエンコードされています。kubeconfig シークレットには、Base64 でエンコードされた kubeconfig 設定が含まれています。Base64 でエンコードされた kubeconfig 設定をデコードし、<hosted_cluster_name>.kubeconfig ファイルに保存する必要があります。
手順
デコードされた
kubeconfig設定を含む<hosted_cluster_name>.kubeconfigファイルを使用して、ホステッドクラスターにアクセスします。以下のコマンドを入力します。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodesAPI サーバーまたはホステッドクラスターのコンソールにログインするには、
kubeadminパスワードシークレットをデコードする必要があります。
4.1.8.3. hcp CLI を使用して AWS 上のホステッドクラスターにアクセスする
hcp コマンドラインインターフェイス (CLI) を使用して、ホステッドクラスターにアクセスできます。
手順
次のコマンドを入力して、
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfigファイルを保存したら、次のコマンドを入力してホステッドクラスターにアクセスします。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
4.1.9. ホステッドクラスターでカスタム API サーバー証明書を設定する
API サーバーのカスタム証明書を設定するには、HostedCluster 設定の spec.configuration.apiServer セクションで証明書の詳細を指定します。
カスタム証明書は、Day 1 操作または Day 2 操作の中で設定できます。ただし、サービス公開ストラテジーはホステッドクラスターの作成中に設定した後は変更できないため、設定する予定の Kubernetes API サーバーのホスト名を知っておく必要があります。
前提条件
管理クラスターにカスタム証明書が含まれる Kubernetes シークレットを作成しました。シークレットには次の鍵が含まれています。
-
tls.crt: 証明書 -
tls.key: 秘密鍵
-
-
HostedCluster設定にロードバランサーを使用するサービス公開ストラテジーが含まれている場合は、証明書のサブジェクト代替名 (SAN) が内部 API エンドポイント (api-int) と競合しないことを確認してください。内部 API エンドポイントは、プラットフォームによって自動的に作成および管理されます。カスタム証明書と内部 API エンドポイントの両方で同じホスト名を使用すると、ルーティングの競合が発生する可能性があります。このルールの唯一の例外は、PrivateまたはPublicAndPrivate設定で AWS をプロバイダーとして使用する場合です。このような場合、SAN の競合はプラットフォームによって管理されます。 - 証明書は外部 API エンドポイントに対して有効である必要があります。
- 証明書の有効期間は、クラスターの予想されるライフサイクルと一致します。
手順
次のコマンドを入力して、カスタム証明書を使用してシークレットを作成します。
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>次の例に示すように、カスタム証明書の詳細を使用して
HostedCluster設定を更新します。spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert次のコマンドを入力して、
HostedCluster設定に変更を適用します。$ oc apply -f <hosted_cluster_config>.yaml
検証
- API サーバー Pod をチェックして、新しい証明書がマウントされていることを確認します。
- カスタムドメイン名を使用して API サーバーへの接続をテストします。
-
ブラウザーで、または
opensslなどのツールを使用して、証明書の詳細を確認します。
4.1.10. AWS 上の複数のゾーンにホステッドクラスターを作成する
hcp コマンドラインインターフェイス (CLI) を使用して、Amazon Web Services (AWS) 上の複数のゾーンにホステッドクラスターを作成できます。
前提条件
- AWS Identity and Access Management (IAM) ロールと AWS Security Token Service (STS) 認証情報を作成した。
手順
次のコマンドを実行して、AWS 上の複数のゾーンにホステッドクラスターを作成します。
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas=<node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --role-arn <arn_role> \5 --region <region> \6 --zones <zones> \7 --sts-creds <path_to_sts_credential_file>8 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ノードプールのレプリカ数を指定します (例:
2)。 - 3
- ベースドメインを指定します (例:
example.com)。 - 4
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 5
- Amazon Resource Name (ARN) を指定します (例:
arn:aws:iam::820196288204:role/myrole)。 - 6
- AWS リージョン名を指定します (例:
us-east-1)。 - 7
- AWS リージョン内のアベイラビリティーゾーンを指定します (例:
us-east-1a、us-east-1b)。 - 8
- AWS STS 認証情報ファイルへのパスを指定します (例:
/home/user/sts-creds/sts-creds.json)。
指定したゾーンごとに、次のインフラストラクチャーが作成されます。
- パブリックサブネット
- プライベートサブネット
- NAT ゲートウェイ
- プライベートルートテーブル
パブリックルートテーブルはパブリックサブネット間で共有されます。
ゾーンごとに 1 つの NodePool リソースが作成されます。ノードプール名の末尾にはゾーン名が付けられます。ゾーンのプライベートサブネットは spec.platform.aws.subnet.id に設定されます。
4.1.10.1. AWS STS 認証情報を指定してホステッドクラスターを作成する
hcp create cluster aws コマンドを使用してホステッドクラスターを作成する場合は、ホステッドクラスターのインフラストラクチャーリソースを作成する権限を持つ Amazon Web Services (AWS) アカウントの認証情報を指定する必要があります。
インフラストラクチャーリソースの例としては、次のものがあります。
- Virtual Private Cloud (VPC)
- サブネット
- ネットワークアドレス変換 (NAT) ゲートウェイ
次のいずれかの方法で AWS 認証情報を指定できます。
- AWS Security Token Service (STS) 認証情報
- multicluster engine Operator からの AWS クラウドプロバイダーのシークレット
手順
AWS STS 認証情報を指定して AWS 上にホステッドクラスターを作成するには、次のコマンドを入力します。
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --role-arn <arn_role>7 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ノードプールのレプリカ数を指定します (例:
2)。 - 3
- ベースドメインを指定します (例:
example.com)。 - 4
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 5
- AWS STS 認証情報ファイルへのパスを指定します (例:
/home/user/sts-creds/sts-creds.json)。 - 6
- AWS リージョン名を指定します (例:
us-east-1)。 - 7
- Amazon Resource Name (ARN) を指定します (例:
arn:aws:iam::820196288204:role/myrole)。
4.1.11. ARM64 アーキテクチャーでのホステッドクラスターの実行
Amazon Web Services (AWS) 上の Hosted Control Plane では、デフォルトで AMD64 ホステッドクラスターを使用します。ただし、Hosted Control Plane を ARM64 ホステッドクラスターで実行することもできます。
ノードプールとホステッドクラスターの互換性のある組み合わせは、次の表を参照してください。
| ホステッドクラスター | ノードプール |
|---|---|
| AMD64 | AMD64 または ARM64 |
| ARM64 | ARM64 または AMD64 |
4.1.11.1. ARM64 OpenShift Container Platform クラスターにホステッドクラスターを作成する
デフォルトのリリースイメージをマルチアーキテクチャーリリースイメージでオーバーライドすることで、Amazon Web Services (AWS) の ARM64 OpenShift Container Platform クラスターでホステッドクラスターを実行できます。
マルチアーキテクチャーリリースイメージを使用しない場合、ホステッドクラスターでマルチアーキテクチャーリリースイメージを使用するか、リリースイメージに基づいて NodePool カスタムリソースを更新するまで、ノードプール内のコンピュートノードが作成されず、ノードプールのリコンシリエーションが停止します。
前提条件
- AWS にインストールされた、64 ビット ARM インフラストラクチャーの OpenShift Container Platform クラスターがある。詳細は、Create an OpenShift Container Platform Cluster: AWS (ARM) を参照してください。
- AWS Identity and Access Management (IAM) ロールと AWS Security Token Service (STS) 認証情報を作成する。詳細は、「AWS IAM ロールと STS 認証情報の作成」を参照してください。
手順
次のコマンドを入力して、ARM64 OpenShift Container Platform クラスターにホステッドクラスターを作成します。
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --release-image quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \7 --role-arn <role_name>8 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ノードプールのレプリカ数を指定します (例:
3)。 - 3
- ベースドメインを指定します (例:
example.com)。 - 4
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 5
- AWS STS 認証情報ファイルへのパスを指定します (例:
/home/user/sts-creds/sts-creds.json)。 - 6
- AWS リージョン名を指定します (例:
us-east-1)。 - 7
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.17.0-multi)。非接続環境を使用している場合は、<ocp_release_image>をダイジェストイメージに置き換えます。OpenShift Container Platform リリースイメージダイジェストを抽出するには、「OpenShift Container Platform リリースイメージダイジェストの抽出」を参照してください。 - 8
- Amazon Resource Name (ARN) を指定します (例:
arn:aws:iam::820196288204:role/myrole)。
4.1.11.2. AWS ホステッドクラスターに ARM または AMD の NodePool オブジェクトを作成する
同じ Hosted Control Plane から、64 ビット ARM および AMD の NodePool オブジェクトであるアプリケーションワークロードをスケジュールできます。NodePool 仕様で arch フィールドを定義し、NodePool オブジェクトに必要なプロセッサーアーキテクチャーを設定できます。arch フィールドの有効な値は次のとおりです。
-
arm64 -
amd64
前提条件
-
HostedClusterカスタムリソースで使用するマルチアーキテクチャーイメージがある。マルチアーキテクチャーのナイトリーイメージ を利用できます。
手順
次のコマンドを実行して、AWS でホステッドクラスターに ARM または AMD の
NodePoolオブジェクトを追加します。$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <node_pool_name> \2 --node-count <node_pool_replica_count> \3 --arch <architecture>4
4.1.12. AWS でのプライベートホステッドクラスターの作成
local-cluster をホスティングクラスターとして有効にした後、Amazon Web Services (AWS) にホステッドクラスターまたはプライベートホステッドクラスターをデプロイできます。
デフォルトでは、ホステッドクラスターはパブリック DNS と管理クラスターのデフォルトルーターを介してパブリックにアクセスできます。
AWS 上のプライベートクラスターの場合、ホステッドクラスターとの通信は、すべて AWS PrivateLink を介して行われます。
前提条件
- AWS PrivateLink を有効にした。詳細は、「AWS PrivateLink の有効化」を参照してください。
- AWS Identity and Access Management (IAM) ロールと AWS Security Token Service (STS) 認証情報を作成した。詳細は、「AWS IAM ロールと STS 認証情報の作成」および「Identity and Access Management (IAM) 権限」を参照してください。
- AWS に踏み台インスタンス を設定した。
手順
次のコマンドを入力して、AWS 上にプライベートホステッドクラスターを作成します。
$ hcp create cluster aws \ --name <hosted_cluster_name> \1 --node-pool-replicas=<node_pool_replica_count> \2 --base-domain <basedomain> \3 --pull-secret <path_to_pull_secret> \4 --sts-creds <path_to_sts_credential_file> \5 --region <region> \6 --endpoint-access Private \7 --role-arn <role_name>8 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ノードプールのレプリカ数を指定します (例:
3)。 - 3
- ベースドメインを指定します (例:
example.com)。 - 4
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 5
- AWS STS 認証情報ファイルへのパスを指定します (例:
/home/user/sts-creds/sts-creds.json)。 - 6
- AWS リージョン名を指定します (例:
us-east-1)。 - 7
- クラスターがパブリックかプライベートかを定義します。
- 8
- Amazon Resource Name (ARN) を指定します (例:
arn:aws:iam::820196288204:role/myrole)。ARN ロールの詳細は、「Identity and Access Management (IAM) 権限」を参照してください。
ホステッドクラスターの次の API エンドポイントは、プライベート DNS ゾーンを通じてアクセスできます。
-
api.<hosted_cluster_name>.hypershift.local -
*.apps.<hosted_cluster_name>.hypershift.local
4.2. ベアメタルへの Hosted Control Plane のデプロイ
クラスターを管理クラスターとして機能するように設定することで、Hosted Control Plane をデプロイできます。管理クラスターは、コントロールプレーンがホストされる OpenShift Container Platform クラスターです。場合によっては、管理クラスターは ホスティング クラスターとも呼ばれます。
管理クラスターは、マネージド クラスターとは異なります。マネージドクラスターは、ハブクラスターが管理するクラスターです。
Hosted Control Plane 機能はデフォルトで有効になっています。
multicluster engine Operator は、マネージドのハブクラスターであるデフォルトの local-cluster と、管理クラスターとしてのハブクラスターのみをサポートしています。Red Hat Advanced Cluster Management がインストールされている場合は、マネージドハブクラスター (local-cluster) を管理クラスターとして使用できます。
ホステッドクラスター は、API エンドポイントとコントロールプレーンが管理クラスターでホストされている OpenShift Container Platform クラスターです。ホステッドクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。ホステッドクラスターは、multicluster engine Operator のコンソールか、Hosted Control Plane のコマンドラインインターフェイス (hcp) を使用して作成できます。
ホステッドクラスターは、マネージドクラスターとして自動的にインポートされます。この自動インポート機能を無効にする場合は、「multicluster engine Operator へのホステッドクラスターの自動インポートの無効化」を参照してください。
4.2.1. ベアメタルへの Hosted Control Plane のデプロイの準備
ベアメタルに Hosted Control Plane をデプロイする準備をする際には、次の情報を考慮してください。
- 管理クラスターとワーカーは、Hosted Control Plane の同じプラットフォーム上で実行してください。
-
すべてのベアメタルホストは、Central Infrastructure Management が提供する Discovery Image ISO を使用して手動で起動する必要があります。ホストは手動で起動することも、
Cluster-Baremetal-Operatorを使用して自動化することもできます。各ホストが起動すると、エージェントプロセスが実行され、ホストの詳細が検出され、インストールが完了します。Agentカスタムリソースは、各ホストを表します。 - Hosted Control Plane のストレージを設定する場合は、etcd の推奨プラクティスを考慮してください。レイテンシー要件を満たすには、各コントロールプレーンノードで実行されるすべての Hosted Control Plane の etcd インスタンス専用の高速ストレージデバイスを使用します。LVM ストレージを使用して、ホストされた etcd Pod のローカルストレージクラスを設定できます。詳細は、「推奨される etcd プラクティス」および「論理ボリュームマネージャーストレージを使用した永続ストレージ」を参照してください。
4.2.1.1. 管理クラスターを設定するための前提条件
- OpenShift Container Platform クラスターに multicluster engine for Kubernetes Operator 2.2 以降がインストールされている必要があります。multicluster engine Operator は、OpenShift Container Platform OperatorHub から Operator としてインストールできます。
multicluster engine Operator には、少なくとも 1 つのマネージド OpenShift Container Platform クラスターが必要です。multicluster engine Operator バージョン 2.2 以降では、
local-clusterが自動的にインポートされます。local-clusterの詳細は、Red Hat Advanced Cluster Management ドキュメントの 詳細設定 を参照してください。次のコマンドを実行して、ハブクラスターの状態を確認できます。$ oc get managedclusters local-cluster-
管理クラスター上のベアメタルホストに
topology.kubernetes.io/zoneラベルを追加する必要があります。各ホストのtopology.kubernetes.io/zoneの値が一意であることを確認します。そうしないと、すべての Hosted Control Plane Pod が 1 つのノードにスケジュールされ、単一障害点が発生します。 - ベアメタルに Hosted Control Plane をプロビジョニングするには、Agent プラットフォームを使用できます。Agent プラットフォームは、Central Infrastructure Management サービスを使用して、ホステッドクラスターにワーカーノードを追加します。詳細は、Central Infrastructure Management サービスの有効化 を参照してください。
- Hosted Control Plane のコマンドラインインターフェイスをインストールする必要があります。
4.2.1.2. ベアメタルファイアウォール、ポート、およびサービスの要件
管理クラスター、コントロールプレーン、ホステッドクラスター間でポートの通信ができるように、ファイアウォール、ポート、およびサービスの要件を満たす必要があります。
サービスはデフォルトのポートで実行されます。ただし、NodePort 公開ストラテジーを使用する場合、サービスは NodePort サービスによって割り当てられたポートで実行されます。
ファイアウォールルール、セキュリティーグループ、またはその他のアクセス制御を使用して、必要なソースだけにアクセスを制限します。必要な場合を除き、ポートを公開しないでください。実稼働環境の場合は、ロードバランサーを使用して、単一の IP アドレスによるアクセスを簡素化します。
ハブクラスターにプロキシー設定がある場合は、すべてのホステッドクラスター API エンドポイントを Proxy オブジェクトの noProxy フィールドに追加して、ハブクラスターがホステッドクラスターの API エンドポイントにアクセスできようにします。詳細は、「クラスター全体のプロキシーの設定」を参照してください。
Hosted Control Plane はベアメタル上で次のサービスを公開します。
APIServer-
APIServerサービスはデフォルトでポート 6443 で実行され、コントロールプレーンコンポーネント間の通信には ingress アクセスが必要です。 - MetalLB ロードバランシングを使用する場合は、ロードバランサーの IP アドレスに使用される IP 範囲への ingress アクセスを許可します。
-
OAuthServer-
ルートと Ingress を使用してサービスを公開する場合、
OAuthServerサービスはデフォルトでポート 443 で実行されます。 -
NodePort公開ストラテジーを使用する場合は、OAuthServerサービスにファイアウォールルールを使用します。
-
ルートと Ingress を使用してサービスを公開する場合、
Konnectivity-
ルートと Ingress を使用してサービスを公開する場合、
Konnectivityサービスはデフォルトでポート 443 で実行されます。 -
Konnectivityエージェントはリバーストンネルを確立し、コントロールプレーンがホステッドクラスターのネットワークにアクセスできるようにします。エージェントは egress を使用してKonnectivityサーバーに接続します。サーバーは、ポート 443 のルートまたは手動で割り当てられたNodePortを使用して公開されます。 - クラスター API サーバーのアドレスが内部 IP アドレスの場合は、ワークロードサブネットからポート 6443 の IP アドレスへのアクセスを許可します。
- アドレスが外部 IP アドレスの場合は、ノードからその外部 IP アドレスにポート 6443 で送信できるように許可します。
-
ルートと Ingress を使用してサービスを公開する場合、
Ignition-
ルートと Ingress を使用してサービスを公開する場合、
Ignitionサービスはデフォルトでポート 443 で実行されます。 -
NodePort公開ストラテジーを使用する場合は、Ignitionサービスにファイアウォールルールを使用します。
-
ルートと Ingress を使用してサービスを公開する場合、
ベアメタルで以下のサービスは必要ありません。
-
OVNSbDb -
OIDC
4.2.1.3. ベアメタルのインフラストラクチャー要件
Agent プラットフォームはインフラストラクチャーを作成しませんが、次のインフラストラクチャー要件があります。
- Agent: Agent は、Discovery イメージで起動され、OpenShift Container Platform ノードとしてプロビジョニングされる準備ができているホストを表します。
- DNS: API および Ingress エンドポイントは、ルーティング可能である必要があります。
4.2.2. ベアメタルでの DNS 設定
ホステッドクラスターの API サーバーは、NodePort サービスとして公開されます。API サーバーに到達できる宛先を指す api.<hosted_cluster_name>.<base_domain> の DNS エントリーが存在する必要があります。
DNS エントリーは、ホステッドコントロールプレーンを実行している管理クラスター内のノードの 1 つを指すレコードのように単純なものにすることができます。エントリーは、受信トラフィックを Ingress Pod にリダイレクトするためにデプロイされるロードバランサーを指すこともできます。
DNS 設定の例
api.example.krnl.es. IN A 192.168.122.20
api.example.krnl.es. IN A 192.168.122.21
api.example.krnl.es. IN A 192.168.122.22
api-int.example.krnl.es. IN A 192.168.122.20
api-int.example.krnl.es. IN A 192.168.122.21
api-int.example.krnl.es. IN A 192.168.122.22
`*`.apps.example.krnl.es. IN A 192.168.122.23
前述の例の場合、*.apps.example.krnl.es. IN A 192.168.122.23 が、ホステッドクラスター内のノード、またはロードバランサー (設定されている場合) です。
IPv6 ネットワーク上の非接続環境用に DNS を設定する場合、設定は次の例のようになります。
IPv6 ネットワークの DNS 設定の例
api.example.krnl.es. IN A 2620:52:0:1306::5
api.example.krnl.es. IN A 2620:52:0:1306::6
api.example.krnl.es. IN A 2620:52:0:1306::7
api-int.example.krnl.es. IN A 2620:52:0:1306::5
api-int.example.krnl.es. IN A 2620:52:0:1306::6
api-int.example.krnl.es. IN A 2620:52:0:1306::7
`*`.apps.example.krnl.es. IN A 2620:52:0:1306::10デュアルスタックネットワークの非接続環境で DNS を設定する場合は、IPv4 と IPv6 の両方の DNS エントリーを含めるようにしてください。
デュアルスタックネットワークの DNS 設定の例
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10
host-record=api.hub-dual.dns.base.domain.name,192.168.126.10
address=/apps.hub-dual.dns.base.domain.name/192.168.126.11
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2
host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2
address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6]
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7]
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8]
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]4.2.3. InfraEnv リソースの作成
ベアメタル上にホステッドクラスターを作成するには、InfraEnv リソースが必要です。
4.2.3.1. InfraEnv リソースの作成とノードの追加
Hosted Control Plane では、コントロールプレーンコンポーネントは管理クラスター上の Pod として実行され、データプレーンは専用ノード上で実行されます。Assisted Service を使用すると、ハードウェアをハードウェアインベントリーに追加する検出 ISO を使用して、ハードウェアをブートできます。後でホステッドクラスターを作成するときに、インベントリーのハードウェアを使用してデータプレーンノードをプロビジョニングします。検出 ISO を取得するために使用されるオブジェクトは、InfraEnv リソースです。検出 ISO からベアメタルノードをブートするようにクラスターを設定する BareMetalHost オブジェクトを作成する必要があります。
手順
次のコマンドを入力して、ハードウェアインベントリーを保存する namespace を作成します。
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig create \ namespace <namespace_example>ここでは、以下のようになります。
- <directory_example>
-
管理クラスターの
kubeconfigファイルが保存されるディレクトリーの名前です。 - <namespace_example>
作成する namespace の名前 (例:
hardware-inventory) です。出力例
namespace/hardware-inventory created
次のコマンドを入力して、管理クラスターのプルシークレットをコピーします。
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n openshift-config get secret pull-secret -o yaml \ | grep -vE "uid|resourceVersion|creationTimestamp|namespace" \ | sed "s/openshift-config/<namespace_example>/g" \ | oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n <namespace> apply -f -ここでは、以下のようになります。
- <directory_example>
-
管理クラスターの
kubeconfigファイルが保存されるディレクトリーの名前です。 - <namespace_example>
作成する namespace の名前 (例:
hardware-inventory) です。出力例
secret/pull-secret created
次のコンテンツを YAML ファイルに追加して、
InfraEnvリソースを作成します。apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: hosted namespace: <namespace_example> spec: additionalNTPSources: - <ip_address> pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key> # ...次のコマンドを入力して、YAML ファイルに変更を適用します。
$ oc apply -f <infraenv_config>.yaml<infraenv_config>は、ファイルの名前に置き換えます。次のコマンドを入力して、
InfraEnvリソースが作成されたことを確認します。$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig \ -n <namespace_example> get infraenv hosted次の 2 つの方法のいずれかに従ってベアメタルホストを追加します。
Metal3 Operator を使用しない場合は、
InfraEnvリソースから検出 ISO を取得し、次のステップを実行して手動でホストをブートします。次のコマンドを入力してライブ ISO をダウンロードします。
$ oc get infraenv -A$ oc get infraenv <namespace_example> -o jsonpath='{.status.isoDownloadURL}' -n <namespace_example> <iso_url>-
ISO をブートします。ノードは Assisted Service と通信し、
InfraEnvリソースと同じ namespace にエージェントとして登録されます。 各エージェントに対して、インストールディスク ID とホスト名を設定し、承認してエージェントが使用可能であることを示します。次のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agents出力例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign$ oc -n <hosted_control_plane_namespace> \ patch agent 86f7ac75-4fc4-4b36-8130-40fa12602218 \ -p '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-0.example.krnl.es"}}' \ --type merge$ oc -n <hosted_control_plane_namespace> \ patch agent 23d0c614-2caa-43f5-b7d3-0b3564688baa -p \ '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-1.example.krnl.es"}}' \ --type merge$ oc -n <hosted_control_plane_namespace> get agents出力例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
Metal3 Operator を使用する場合は、次のオブジェクトを作成することで、ベアメタルホストの登録を自動化できます。
YAML ファイルを作成し、そこに次のコンテンツを追加します。
apiVersion: v1 kind: Secret metadata: name: hosted-worker0-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: hosted-worker1-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: hosted-worker2-bmc-secret namespace: <namespace_example> data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker0 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker0 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker0-bmc-secret bootMACAddress: aa:aa:aa:aa:02:01 online: true --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker1 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker1 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker1-bmc-secret bootMACAddress: aa:aa:aa:aa:02:02 online: true --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: hosted-worker2 namespace: <namespace_example> labels: infraenvs.agent-install.openshift.io: hosted annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: hosted-worker2 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: True address: <bmc_address> credentialsName: hosted-worker2-bmc-secret bootMACAddress: aa:aa:aa:aa:02:03 online: true --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: capi-provider-role namespace: <namespace_example> rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'ここでは、以下のようになります。
- <namespace_example>
- namespace です。
- <password>
- シークレットのパスワードです。
- <username>
- シークレットのユーザー名です。
- <bmc_address>
BareMetalHostオブジェクトの BMC アドレスです。注記この YAML ファイルを適用すると、次のオブジェクトが作成されます。
- ベースボード管理コントローラー (BMC) の認証情報が含まれるシークレット
-
BareMetalHostオブジェクト - HyperShift Operator によるエージェントの管理が可能になるロール
BareMetalHostオブジェクトでinfraenvs.agent-install.openshift.io: hostedカスタムラベルを使用してInfraEnvリソースが参照されることに注意してください。これにより、生成された ISO を使用してノードがブートされます。
次のコマンドを入力して、YAML ファイルに変更を適用します。
$ oc apply -f <bare_metal_host_config>.yaml<bare_metal_host_config>は、ファイルの名前に置き換えます。
次のコマンドを入力し、
BareMetalHostオブジェクトの状態がProvisioningになるまで数分間待ちます。$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig -n <namespace_example> get bmh出力例
NAME STATE CONSUMER ONLINE ERROR AGE hosted-worker0 provisioning true 106s hosted-worker1 provisioning true 106s hosted-worker2 provisioning true 106s次のコマンドを入力して、ノードが起動し、エージェントとして表示されていることを確認します。このプロセスには数分かかる場合があり、コマンドを複数回入力する必要があることもあります。
$ oc --kubeconfig ~/<directory_example>/mgmt-kubeconfig -n <namespace_example> get agent出力例
NAME CLUSTER APPROVED ROLE STAGE aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0201 true auto-assign aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0202 true auto-assign aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0203 true auto-assign
4.2.3.2. コンソールを使用して InfraEnv リソースを作成する
コンソールを使用して InfraEnv リソースを作成するには、次のステップを実行します。
手順
- OpenShift Container Platform Web コンソールを開き、管理者の認証情報を入力してログインします。コンソールを開く手順は、「Web コンソールへのアクセス」を参照してください。
- コンソールヘッダーで、All Clusters が選択されていることを確認します。
- Infrastructure → Host inventory → Create infrastructure environment をクリックします。
-
InfraEnvリソースを作成した後、InfraEnv ビュー内から Add hosts をクリックし、利用可能なオプションから選択してベアメタルホストを追加します。
4.2.4. ベアメタルでのホステッドクラスターの作成
コマンドラインインターフェイス (CLI)、コンソール、またはミラーレジストリーを使用して、ベアメタル上にホステッドクラスターを作成できます。
4.2.4.1. コンソールを使用したホステッドクラスターの作成
ベアメタルインフラストラクチャーには、ホステッドクラスターを作成またはインポートできます。multicluster engine Operator へのアドオンとして Assisted Installer を有効にし、Agent プラットフォームを使用してホステッドクラスターを作成すると、HyperShift Operator によって Agent Cluster API プロバイダーが Hosted Control Plane namespace にインストールされます。Agent Cluster API プロバイダーは、コントロールプレーンをホストする管理クラスターと、コンピュートノードのみで構成されるホステッドクラスターを接続します。
前提条件
- 各ホステッドクラスターの名前がクラスター全体で一意である。ホステッドクラスター名は、既存のマネージドクラスターと同じにすることはできません。この要件を満たさないと、multicluster engine Operator がホステッドクラスターを管理できません。
-
ホステッドクラスター名として
clustersという単語を使用しない。 - multicluster engine Operator のマネージドクラスターの namespace にホステッドクラスターを作成することはできない。
- 最適なセキュリティーと管理プラクティスを実現するために、他のホステッドクラスターとは別にホステッドクラスターを作成する。
- クラスターにデフォルトのストレージクラスが設定されていることを確認する。そうしない場合、保留中の永続ボリューム要求 (PVC) が表示されることがあります。
-
デフォルトでは、
hcp create cluster agentコマンドを使用すると、ノードポートが設定されたホステッドクラスターが作成されます。ベアメタル上のホステッドクラスターの推奨公開ストラテジーは、ロードバランサーを通じてサービスを公開することです。Web コンソールまたは Red Hat Advanced Cluster Management を使用してホステッドクラスターを作成する場合、Kubernetes API サーバー以外のサービスの公開ストラテジーを設定するには、HostedClusterカスタムリソースでservicePublishingStrategy情報を手動で指定する必要があります。 インフラストラクチャー、ファイアウォール、ポート、およびサービスに関連する要件を含め、「ベアメタル上の Hosted Control Plane の要件」に記載されている要件を満たしていることを確認する。要件では、たとえば次のコマンド例に示すように、管理クラスター内のベアメタルホストに適切なゾーンラベルを追加する方法が説明されています。
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- ハードウェアインベントリーにベアメタルノードを追加したことを確認する。
手順
次のコマンドを入力して namespace を作成します。
$ oc create ns <hosted_cluster_namespace><hosted_cluster_namespace>は、ホステッドクラスター namespace の識別子に置き換えます。namespace は HyperShift Operator によって作成されます。ベアメタルインフラストラクチャーにホステッドクラスターを作成するプロセスでは、Cluster API プロバイダー用のロールが生成されます。このロールを生成するには、namespace が事前に存在している必要があります。次のコマンドを入力して、ホステッドクラスターの設定ファイルを作成します。
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- ホステッドクラスターの名前 (例:
example) を指定します。 - 2
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 3
- Hosted Control Plane の namespace を指定します (例:
clusters-example)。oc get agent -n <hosted_control_plane_namespace>コマンドを使用して、この namespace でエージェントが使用可能であることを確認します。 - 4
- ベースドメイン (例:
krnl.es) を指定します。 - 5
--api-server-addressフラグは、ホステッドクラスター内の Kubernetes API 通信に使用される IP アドレスを定義します。--api-server-addressフラグを設定しない場合は、管理クラスターに接続するためにログインする必要があります。- 6
- etcd ストレージクラス名を指定します (例:
lvm-storageclass)。 - 7
- SSH 公開鍵へのパスを指定します。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 8
- ホステッドクラスターの namespace を指定します。
- 9
- Hosted Control Plane コンポーネントの可用性ポリシーを指定します。サポートされているオプションは
SingleReplicaとHighlyAvailableです。デフォルト値はHighlyAvailableです。 - 10
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.19.0-multi)。非接続環境を使用している場合は、<ocp_release_image>をダイジェストイメージに置き換えます。OpenShift Container Platform リリースイメージダイジェストを抽出するには、OpenShift Container Platform リリースイメージダイジェストの抽出 を参照してください。 - 11
- ノードプールのレプリカ数を指定します (例:
3)。レプリカ数は0以上で指定する必要があります。指定したとおりの数のノードが作成されます。この値を指定しない場合、ノードプールは作成されません。 - 12
--ssh-keyフラグの後に、SSH 鍵へのパス (例:user/.ssh/id_rsa) を指定します。
サービス公開ストラテジーを設定します。デフォルトでは、ホステッドクラスターは
NodePortサービス公開ストラテジーを使用します。これは、ノードポートが追加のインフラストラクチャーなしで常に利用可能であるためです。ただし、ロードバランサーを使用するようにサービス公開ストラテジーを設定することもできます。-
デフォルトの
NodePortストラテジーを使用している場合は、管理クラスターノードではなく、ホステッドクラスターコンピュートノードを指すように DNS を設定します。詳細は、「ベアメタル上の DNS 設定」を参照してください。 実稼働環境では、証明書の処理と自動 DNS 解決を提供する
LoadBalancerストラテジーを使用します。次の例は、ホステッドクラスターの設定ファイルでLoadBalancerサービス公開ストラテジーを変更する方法を示しています。# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- API サーバータイプとして
LoadBalancerを指定します。それ以外のすべてのサービスでは、タイプとしてRouteを指定します。
-
デフォルトの
次のコマンドを入力して、ホステッドクラスター設定ファイルに変更を適用します。
$ oc apply -f hosted_cluster_config.yaml次のコマンドを入力して、ホステッドクラスター、ノードプール、および Pod の作成を確認します。
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
ホステッドクラスターの準備ができていることを確認します。
Available: Trueというステータスはクラスターの準備完了状態であることを示しています。ノードプールのステータスにはAllMachinesReady: Trueと表示されます。これらのステータスは、すべてのクラスター Operator の健全性を示しています。 ホステッドクラスターに MetalLB をインストールします。
次のコマンドを入力して、ホステッドクラスターから
kubeconfigファイルを展開し、ホステッドクラスターアクセス用の環境変数を設定します。$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"install-metallb-operator.yamlファイルを作成して MetalLB Operator をインストールします。apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...以下のコマンドを入力してファイルを適用します。
$ oc apply -f install-metallb-operator.yamldeploy-metallb-ipaddresspool.yamlファイルを作成して、MetalLB IP アドレスプールを設定します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...次のコマンドを入力して設定を適用します。
$ oc apply -f deploy-metallb-ipaddresspool.yaml次のコマンドを入力して、Operator ステータス、IP アドレスプール、および
L2Advertisementリソースを確認し、MetalLB のインストールを検証します。$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
Ingress 用のロードバランサーを設定します。
ingress-loadbalancer.yamlファイルを作成します。apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...次のコマンドを入力して設定を適用します。
$ oc apply -f ingress-loadbalancer.yaml次のコマンドを入力して、ロードバランサーサービスが期待どおりに動作することを確認します。
$ oc get svc metallb-ingress -n openshift-ingress出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
ロードバランサーと連携するように DNS を設定します。
-
*.apps.<hosted_cluster_namespace>.<base_domain>ワイルドカード DNS レコードがロードバランサーの IP アドレスをポイントするように、appsドメインの DNS を設定します。 次のコマンドを入力して DNS 解決を確認します。
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>出力例
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
検証
次のコマンドを入力して、クラスター Operator を確認します。
$ oc get clusteroperatorsすべての Operator に
AVAILABLE: True、PROGRESSING: False、DEGRADED: Falseが表示されていることを確認します。次のコマンドを入力してノードを確認します。
$ oc get nodes各ノードのステータスが
READYであることを確認します。Web ブラウザーに次の URL を入力して、コンソールへのアクセスをテストします。
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.2.4.2. コンソールを使用してベアメタル上にホステッドクラスターを作成する
コンソールを使用してホステッドクラスターを作成するには、次の手順を実行します。
手順
- OpenShift Container Platform Web コンソールを開き、管理者の認証情報を入力してログインします。コンソールを開く手順は、「Web コンソールへのアクセス」を参照してください。
- コンソールヘッダーで、All Clusters が選択されていることを確認します。
- Infrastructure → Clusters をクリックします。
Create cluster → Host inventory → Hosted control plane をクリックします。
Create cluster ページが表示されます。
Create cluster ページでプロンプトに従い、クラスター、ノードプール、ネットワーク、および自動化に関する詳細を入力します。
注記クラスターの詳細を入力する際には、次のヒントが役立つ場合があります。
- 事前定義された値を使用してコンソールのフィールドに自動的に値を入力する場合は、ホストインベントリーの認証情報を作成できます。詳細は、「オンプレミス環境の認証情報の作成」を参照してください。
- Cluster details ページのプルシークレットは、OpenShift Container Platform リソースへのアクセスに使用する OpenShift Container Platform プルシークレットです。ホストインベントリー認証情報を選択した場合は、プルシークレットが自動的に入力されます。
- Node pools ページでは、namespace にノードプールのホストが含まれます。コンソールを使用してホストインベントリーを作成した場合、コンソールは専用の namespace を作成します。
-
Networking ページで、API サーバー公開ストラテジーを選択します。ホステッドクラスターの API サーバーは、既存のロードバランサーを使用するか、
NodePortタイプのサービスとして公開できます。API サーバーに到達できる宛先を指すapi.<hosted_cluster_name>.<base_domain>設定の DNS エントリーが存在する必要があります。このエントリーとして、管理クラスター内のノードの 1 つを指すレコード、または受信トラフィックを Ingress Pod にリダイレクトするロードバランサーを指すレコードを指定できます。
エントリーを確認し、Create をクリックします。
Hosted cluster ビューが表示されます。
- Hosted cluster ビューでホステッドクラスターのデプロイメントを監視します。
- ホステッドクラスターに関する情報が表示されない場合は、All Clusters が選択されていることを確認し、クラスター名をクリックします。
- コントロールプレーンコンポーネントの準備が整うまで待ちます。このプロセスには数分かかる場合があります。
- ノードプールのステータスを表示するには、NodePool セクションまでスクロールします。ノードをインストールするプロセスには約 10 分かかります。Nodes をクリックして、ノードがホステッドクラスターに参加したかどうかを確認することもできます。
次のステップ
- Web コンソールにアクセスするには、Web コンソールへのアクセス を参照してください。
4.2.4.3. ミラーレジストリーを使用してベアメタル上にホステッドクラスターを作成する
ミラーレジストリーを使用して、hcp create cluster コマンドで --image-content-sources フラグを指定して、ベアメタル上にホステッドクラスターを作成できます。
手順
YAML ファイルを作成して、イメージコンテンツソースポリシー (ICSP) を定義します。以下の例を参照してください。
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
ファイルを
icsp.yamlとして保存します。このファイルにはミラーレジストリーが含まれます。 ミラーレジストリーを使用してホステッドクラスターを作成するには、次のコマンドを実行します。
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --image-content-sources icsp.yaml \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>9 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 3
- Hosted Control Plane namespace を指定します (例:
clusters-example)。oc get agent -n <hosted-control-plane-namespace>コマンドを使用して、この namespace でエージェントが使用可能であることを確認します。 - 4
- ベースドメインを指定します (例:
krnl.es)。 - 5
--api-server-addressフラグは、ホステッドクラスター内の Kubernetes API 通信に使用される IP アドレスを定義します。--api-server-addressフラグを設定しない場合は、管理クラスターに接続するためにログインする必要があります。- 6
- ICSP およびミラーレジストリーを定義する
icsp.yamlファイルを指定します。 - 7
- SSH 公開鍵へのパスを指定します。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 8
- ホストされたクラスターの namespace を指定します。
- 9
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.17.0-multi)。非接続環境を使用している場合は、<ocp_release_image>をダイジェストイメージに置き換えます。OpenShift Container Platform リリースイメージダイジェストを抽出するには、「OpenShift Container Platform リリースイメージダイジェストの抽出」を参照してください。
次のステップ
- コンソールでホステッドクラスターを作成するときに再利用できる認証情報を作成するには、オンプレミス環境の認証情報の作成 を参照してください。
- ホステッドクラスターにアクセスするには、ホステッドクラスターへのアクセス を参照してください。
- Discovery Image を使用してホストインベントリーにホストを追加するには、Discovery Image を使用したホストインベントリーへのホストの追加 を参照してください。
- OpenShift Container Platform リリースイメージダイジェストを抽出するには、OpenShift Container Platform リリースイメージダイジェストの抽出 を参照してください。
4.2.5. ホステッドクラスター作成の確認
デプロイメントプロセスが完了したら、ホステッドクラスターが正常に作成されたことを確認できます。ホステッドクラスターの作成から数分後に、次の手順に従います。
手順
次の extract コマンドを入力して、新しいホステッドクラスターの kubeconfig を取得します。
$ oc extract -n <hosted-control-plane-namespace> secret/admin-kubeconfig \ --to=- > kubeconfig-<hosted-cluster-name>kubeconfig を使用して、ホステッドクラスターのクラスター Operator を表示します。以下のコマンドを入力します。
$ oc get co --kubeconfig=kubeconfig-<hosted-cluster-name>出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s dns 4.10.26 True False False 2m52s image-registry 4.10.26 True False False 2m8s ingress 4.10.26 True False False 22m次のコマンドを入力して、ホステッドクラスター上で実行中の Pod を表示することもできます。
$ oc get pods -A --kubeconfig=kubeconfig-<hosted-cluster-name>出力例
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-node-tuning-operator tuned-dhw5p 1/1 Running 0 109s openshift-cluster-storage-operator cluster-storage-operator-5f784969f5-vwzgz 1/1 Running 1 (113s ago) 20m openshift-cluster-storage-operator csi-snapshot-controller-6b7687b7d9-7nrfw 1/1 Running 0 3m8s openshift-console console-5cbf6c7969-6gk6z 1/1 Running 0 119s openshift-console downloads-7bcd756565-6wj5j 1/1 Running 0 4m3s openshift-dns-operator dns-operator-77d755cd8c-xjfbn 2/2 Running 0 21m openshift-dns dns-default-kfqnh 2/2 Running 0 113s
4.2.6. ホステッドクラスターでカスタム API サーバー証明書を設定する
API サーバーのカスタム証明書を設定するには、HostedCluster 設定の spec.configuration.apiServer セクションで証明書の詳細を指定します。
カスタム証明書は、Day 1 操作または Day 2 操作の中で設定できます。ただし、サービス公開ストラテジーはホステッドクラスターの作成中に設定した後は変更できないため、設定する予定の Kubernetes API サーバーのホスト名を知っておく必要があります。
前提条件
管理クラスターにカスタム証明書が含まれる Kubernetes シークレットを作成しました。シークレットには次の鍵が含まれています。
-
tls.crt: 証明書 -
tls.key: 秘密鍵
-
-
HostedCluster設定にロードバランサーを使用するサービス公開ストラテジーが含まれている場合は、証明書のサブジェクト代替名 (SAN) が内部 API エンドポイント (api-int) と競合しないことを確認してください。内部 API エンドポイントは、プラットフォームによって自動的に作成および管理されます。カスタム証明書と内部 API エンドポイントの両方で同じホスト名を使用すると、ルーティングの競合が発生する可能性があります。このルールの唯一の例外は、PrivateまたはPublicAndPrivate設定で AWS をプロバイダーとして使用する場合です。このような場合、SAN の競合はプラットフォームによって管理されます。 - 証明書は外部 API エンドポイントに対して有効である必要があります。
- 証明書の有効期間は、クラスターの予想されるライフサイクルと一致します。
手順
次のコマンドを入力して、カスタム証明書を使用してシークレットを作成します。
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>次の例に示すように、カスタム証明書の詳細を使用して
HostedCluster設定を更新します。spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert次のコマンドを入力して、
HostedCluster設定に変更を適用します。$ oc apply -f <hosted_cluster_config>.yaml
検証
- API サーバー Pod をチェックして、新しい証明書がマウントされていることを確認します。
- カスタムドメイン名を使用して API サーバーへの接続をテストします。
-
ブラウザーで、または
opensslなどのツールを使用して、証明書の詳細を確認します。
4.3. OpenShift Virtualization への Hosted Control Plane のデプロイ
Hosted Control Plane と OpenShift Virtualization を使用すると、KubeVirt 仮想マシンによってホストされるワーカーノードを含む OpenShift Container Platform クラスターを作成できます。OpenShift Virtualization 上の Hosted Control Plane には、次のようないくつかの利点があります。
- Hosted Control Plane とホステッドクラスターを同じ基盤となるベアメタルインフラストラクチャーにまとめることで、リソースの使用率が向上する
- Hosted Control Plane とホステッドクラスターを分離して強力な分離を実現する
- ベアメタルノードのブートストラッププロセスを排除することで、クラスターのプロビジョニング時間を短縮する
- 同じベース OpenShift Container Platform クラスターで多くのリリースを管理する
Hosted Control Plane 機能はデフォルトで有効になっています。
Hosted Control Plane のコマンドラインインターフェイス (hcp) を使用して、OpenShift Container Platform のホステッドクラスターを作成できます。ホステッドクラスターは、マネージドクラスターとして自動的にインポートされます。この自動インポート機能を無効にする場合は、「multicluster engine Operator へのホステッドクラスターの自動インポートの無効化」を参照してください。
4.3.1. OpenShift Virtualization に Hosted Control Plane をデプロイするための要件
OpenShift Virtualization に Hosted Control Plane をデプロイする準備をする際には、次の情報を考慮してください。
- 管理クラスターはベアメタル上で実行してください。
- 各ホステッドクラスターの名前がクラスター全体で一意である。
-
ホステッドクラスター名として
clustersを使用しない。 - ホステッドクラスターは、multicluster engine Operator のマネージドクラスターの namespace には作成できない。
- Hosted Control Plane のストレージを設定する場合は、etcd の推奨プラクティスを考慮してください。レイテンシー要件を満たすには、各コントロールプレーンノードで実行されるすべての Hosted Control Plane の etcd インスタンス専用の高速ストレージデバイスを使用します。LVM ストレージを使用して、ホストされた etcd Pod のローカルストレージクラスを設定できます。詳細は、「推奨される etcd プラクティス」および「論理ボリュームマネージャーストレージを使用した永続ストレージ」を参照してください。
4.3.1.1. 前提条件
OpenShift Virtualization 上に OpenShift Container Platform クラスターを作成するには、以下の前提条件を満たす必要があります。
-
KUBECONFIG環境変数で指定された OpenShift Container Platform クラスター、バージョン 4.14 以降への管理者アクセスを持っている。 OpenShift Container Platform 管理クラスターで、ワイルドカード DNS ルートが有効になっている。次のコマンドを参照してください。
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'- OpenShift Container Platform 管理クラスターに、OpenShift Virtualization バージョン 4.14 以降がインストールされている。詳細は、「Web コンソールを使用した OpenShift Virtualization のインストール」を参照してください。
- OpenShift Container Platform 管理クラスターはオンプレミスのベアメタルである。
-
OpenShift Container Platform 管理クラスターが、デフォルトの Pod ネットワーク Container Network Interface (CNI) として
OVNKubernetesを使用するように設定されている。CNI が OVN-Kubernetes の場合にのみ、ノードのライブマイグレーションがサポートされます。 OpenShift Container Platform 管理クラスターにはデフォルトのストレージクラスがある。詳細は、「インストール後のストレージ設定」を参照してください。次の例は、デフォルトのストレージクラスを設定する方法を示しています。
$ oc patch storageclass ocs-storagecluster-ceph-rbd \ -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'-
quay.io/openshift-release-devリポジトリーの有効なプルシークレットファイルがある。詳細は、「user-provisioned infrastructure を使用して任意の x86_64 プラットフォームに OpenShift をインストールする」を参照してください。 - Hosted Control Plane コマンドラインインターフェイスがインストール済みである。
- ロードバランサーを設定した。詳細は、「MetalLB の設定」を参照してください。
ネットワークパフォーマンスを最適化するために、KubeVirt 仮想マシンをホストする OpenShift Container Platform クラスターで 9000 以上のネットワーク最大伝送単位 (MTU) を使用している。低い MTU 設定を使用すると、ネットワーク遅延とホストされる Pod のスループットに影響があります。MTU が 9000 以上の場合にのみ、ノードプールでマルチキューを有効にします。
重要インストール後のタスクとしてクラスターの MTU 値を変更することはできません。
multicluster engine Operator には、少なくとも 1 つのマネージド OpenShift Container Platform クラスターがある。
local-clusterは自動的にインポートされます。local-clusterの詳細は、multicluster engine Operator ドキュメントの「高度な設定」を参照してください。次のコマンドを実行して、ハブクラスターの状態を確認できます。$ oc get managedclusters local-cluster-
OpenShift Virtualization 仮想マシンをホストする OpenShift Container Platform クラスターで、ライブマイグレーションを有効化できるように
ReadWriteMany(RWX) ストレージクラスを使用している。
4.3.1.2. ファイアウォールのポートの要件
管理クラスター、コントロールプレーン、ホステッドクラスター間でポートが通信できるように、ファイアウォールとポートの要件を満たしていることを確認します。
kube-apiserverサービスはデフォルトでポート 6443 で実行され、コントロールプレーンコンポーネント間の通信には ingress アクセスが必要です。-
NodePort公開ストラテジーを使用する場合は、kube-apiserverサービスに割り当てられたノードポートが公開されていることを確認してください。 - MetalLB ロードバランシングを使用する場合は、ロードバランサーの IP アドレスに使用される IP 範囲への ingress アクセスを許可します。
-
-
NodePort公開ストラテジーを使用する場合は、ignition-serverおよびOauth-server設定にファイアウォールルールを使用します。 konnectivityエージェントは、ホステッドクラスター上で双方向通信を可能にするリバーストンネルを確立し、ポート 6443 でクラスター API サーバーアドレスへの egress アクセスを必要とします。この egress アクセスを使用すると、エージェントはkube-apiserverサービスにアクセスできます。- クラスター API サーバーのアドレスが内部 IP アドレスの場合は、ワークロードサブネットからポート 6443 の IP アドレスへのアクセスを許可します。
- アドレスが外部 IP アドレスの場合は、ノードからその外部 IP アドレスにポート 6443 で送信できるように許可します。
- デフォルトのポート 6443 を変更する場合は、その変更を反映するようにルールを調整します。
- クラスター内で実行されるワークロードに必要なポートがすべて開いていることを確認してください。
- ファイアウォールルール、セキュリティーグループ、またはその他のアクセス制御を使用して、必要なソースだけにアクセスを制限します。必要な場合を除き、ポートを公開しないでください。
- 実稼働環境の場合は、ロードバランサーを使用して、単一の IP アドレスによるアクセスを簡素化します。
4.3.2. コンピュートノードのライブマイグレーション
ホステッドクラスターの仮想マシン (仮想マシン) の管理クラスターが更新中またはメンテナンス中に、ホステッドクラスターのワークロードの中断を防止するためにホステッドクラスター仮想マシンを自動的にライブマイグレーションできます。その結果、KubeVirt プラットフォームのホステッドクラスターの可用性と操作に影響を与えることなく、管理クラスターを更新できます。
仮想マシンがルートボリュームと kubevirt-csi CSI プロバイダーにマッピングされているストレージクラスの両方に ReadWriteMany (RWX) ストレージを使用していれば、KubeVirt 仮想マシンのライブマイグレーションはデフォルトで有効になります。
NodePool オブジェクトの status セクションで KubeVirtNodesLiveMigratable 条件を確認することで、ノードプール内の仮想マシンがライブマイグレーションに対応していることを確認できます。
以下は、RWX ストレージが使用されていないために仮想マシンをライブマイグレーションできない例を示しています。
仮想マシンのライブマイグレーションができない設定例
- lastTransitionTime: "2024-10-08T15:38:19Z"
message: |
3 of 3 machines are not live migratable
Machine user-np-ngst4-gw2hz: DisksNotLiveMigratable: user-np-ngst4-gw2hz is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-gw2hz-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
Machine user-np-ngst4-npq7x: DisksNotLiveMigratable: user-np-ngst4-npq7x is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-npq7x-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
Machine user-np-ngst4-q5nkb: DisksNotLiveMigratable: user-np-ngst4-q5nkb is not a live migratable machine: cannot migrate VMI: PVC user-np-ngst4-q5nkb-rhcos is not shared, live migration requires that all PVCs must be shared (using ReadWriteMany access mode)
observedGeneration: 1
reason: DisksNotLiveMigratable
status: "False"
type: KubeVirtNodesLiveMigratable以下は、仮想マシンがライブマイグレーション要件を満たしている例を示しています。
仮想マシンのライブマイグレーションが可能な設定例
- lastTransitionTime: "2024-10-08T15:38:19Z"
message: "All is well"
observedGeneration: 1
reason: AsExpected
status: "True"
type: KubeVirtNodesLiveMigratable通常の状況ではライブマイグレーションにより仮想マシンの中断を防止できますが、インフラストラクチャーノードの障害などのイベントが発生すると、障害が発生したノードでホストされているすべての仮想マシンが強制的に再起動される可能性があります。ライブマイグレーションを成功させるには、仮想マシンがホストされているソースノードが正しく動作している必要があります。
ノードプール内の仮想マシンのライブマイグレーションができない場合、管理クラスターのメンテナンス中にホステッドクラスターでワークロードの中断が発生する可能性があります。デフォルトでは、Hosted Control Plane コントローラーは、仮想マシンが停止される前に、ライブマイグレーションできない KubeVirt 仮想マシンでホストされているワークロードをドレインしようとします。仮想マシンが停止する前にホステッドクラスターノードをドレインすると、Pod Disruption Budget によってホステッドクラスター内のワークロードの可用性を保護できます。
4.3.3. KubeVirt プラットフォームを使用したホステッドクラスターの作成
OpenShift Container Platform 4.14 以降では、KubeVirt を使用してクラスターを作成でき、外部インフラストラクチャーを使用して作成することも可能です。
4.3.3.1. CLI を使用して KubeVirt プラットフォームでホステッドクラスターを作成する
ホステッドクラスターを作成するには、Hosted Control Plane のコマンドラインインターフェイス (CLI) hcp を使用できます。
手順
次のコマンドを入力して、KubeVirt プラットフォームでホステッドクラスターを作成します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --etcd-storage-class=<etcd_storage_class>6 注記--release-imageフラグを使用すると、特定の OpenShift Container Platform リリースを使用してホステッドクラスターを設定できます。--node-pool-replicasフラグに従って、2 つの仮想マシンワーカーレプリカを持つクラスターに対してデフォルトのノードプールが作成されます。しばらくすると、次のコマンドを入力して、ホストされているコントロールプレーン Pod が実行されていることを確認できます。
$ oc -n clusters-<hosted-cluster-name> get pods出力例
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66sKubeVirt 仮想マシンによってサポートされるワーカーノードを含むホステッドクラスターは、通常、完全にプロビジョニングされるまでに 10 ~ 15 分かかります。
検証
ホステッドクラスターのステータスを確認するには、次のコマンドを入力して、対応する
HostedClusterリソースを確認します。$ oc get --namespace clusters hostedclusters完全にプロビジョニングされた
HostedClusterオブジェクトを示す以下の出力例を参照してください。NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters my-hosted-cluster <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
4.3.3.2. 外部インフラストラクチャーを使用して KubeVirt プラットフォームでホステッドクラスターを作成する
デフォルトでは、HyperShift Operator は、ホステッドクラスターのコントロールプレーン Pod と、同じクラスター内の KubeVirt ワーカー VM の両方をホストします。外部インフラストラクチャー機能を使用すると、ワーカーノード VM をコントロールプレーン Pod とは別のクラスターに配置できます。
- 管理クラスター は HyperShift Operator を実行し、ホステッドクラスターのコントロールプレーン Pod をホストする OpenShift Container Platform クラスターです。
- インフラストラクチャークラスター は、ホステッドクラスターの KubeVirt ワーカー VM を実行する OpenShift Container Platform クラスターです。
- デフォルトでは、管理クラスターは VM をホストするインフラストラクチャークラスターとしても機能します。ただし、外部インフラストラクチャーの場合、管理クラスターとインフラストラクチャークラスターは異なります。
前提条件
- KubeVirt ノードをホストする外部インフラストラクチャークラスター上に namespace が必要です。
-
外部インフラストラクチャークラスター用の
kubeconfigファイルが必要です。
手順
hcp コマンドラインインターフェイスを使用して、ホステッドクラスターを作成できます。
KubeVirt ワーカーの仮想マシンをインフラストラクチャークラスターに配置するには、次の例に示すように、
--infra-kubeconfig-fileおよび--infra-namespace引数を使用します。$ hcp create cluster kubevirt \ --name <hosted-cluster-name> \1 --node-pool-replicas <worker-count> \2 --pull-secret <path-to-pull-secret> \3 --memory <value-for-memory> \4 --cores <value-for-cpu> \5 --infra-namespace=<hosted-cluster-namespace>-<hosted-cluster-name> \6 --infra-kubeconfig-file=<path-to-external-infra-kubeconfig>7 - 1
- ホステッドクラスターの名前 (例:
my-hosted-cluster) を指定します。 - 2
- ワーカー数を指定します (例:
2)。 - 3
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 4
- メモリーの値を指定します (例:
6Gi)。 - 5
- CPU の値を指定します (例:
2)。 - 6
- インフラストラクチャー namespace を指定します (例:
clusters-example)。 - 7
- インフラストラクチャークラスターの
kubeconfigファイルへのパスを指定します (例:/user/name/external-infra-kubeconfig)。
このコマンドを入力すると、コントロールプレーン Pod は HyperShift Operator が実行される管理クラスターでホストされ、KubeVirt VM は別のインフラストラクチャークラスターでホストされます。
4.3.3.3. コンソールを使用したホステッドクラスターの作成
コンソールを使用して KubeVirt プラットフォームでホステッドクラスターを作成するには、次の手順を実行します。
手順
- OpenShift Container Platform Web コンソールを開き、管理者の認証情報を入力してログインします。
- コンソールヘッダーで、All Clusters が選択されていることを確認します。
- Infrastructure > Clusters をクリックします。
- Create cluster > Red Hat OpenShift Virtualization > Hosted をクリックします。
Create cluster ページで、プロンプトに従ってクラスターとノードプールの詳細を入力します。
注記- 事前定義された値を使用してコンソールのフィールドに自動的に入力する場合は、OpenShift Virtualization の認証情報を作成します。詳細は、オンプレミス環境の認証情報の作成 を参照してください。
- Cluster details ページのプルシークレットは、OpenShift Container Platform リソースへのアクセスに使用する OpenShift Container Platform プルシークレットです。OpenShift Virtualization の認証情報を選択した場合、プルシークレットが自動的に入力されます。
エントリーを確認し、Create をクリックします。
Hosted cluster ビューが表示されます。
検証
- Hosted cluster ビューでホステッドクラスターのデプロイメントを監視します。ホステッドクラスターに関する情報が表示されない場合は、All Clusters が選択されていることを確認し、クラスター名をクリックします。
- コントロールプレーンコンポーネントの準備が整うまで待ちます。このプロセスには数分かかる場合があります。
- ノードプールのステータスを表示するには、NodePool セクションまでスクロールします。ノードをインストールするプロセスには約 10 分かかります。Nodes をクリックして、ノードがホステッドクラスターに参加したかどうかを確認することもできます。
4.3.4. OpenShift Virtualization 上の Hosted Control Plane のデフォルトの Ingress と DNS を設定する
すべての OpenShift Container Platform クラスターにはデフォルトのアプリケーション Ingress コントローラーが含まれており、これにはワイルドカード DNS レコードが関連付けられている必要があります。デフォルトでは、HyperShift KubeVirt プロバイダーを使用して作成されたホステッドクラスターは、自動的に KubeVirt 仮想マシンが実行される OpenShift Container Platform クラスターのサブドメインになります。
たとえば、OpenShift Container Platform クラスターには次のデフォルトの Ingress DNS エントリーがある可能性があります。
*.apps.mgmt-cluster.example.com
その結果、guest という名前が付けられ、その基礎となる OpenShift Container Platform クラスター上で実行される KubeVirt ホステッドクラスターには、次のデフォルト Ingress が設定されます。
*.apps.guest.apps.mgmt-cluster.example.com手順
デフォルトの Ingress DNS が適切に機能するには、KubeVirt 仮想マシンをホストするクラスターでワイルドカード DNS ルートを許可する必要があります。
この動作は、以下のコマンドを入力して設定できます。
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'
デフォルトのホステッドクラスターの Ingress を使用する場合、接続がポート 443 経由の HTTPS トラフィックに制限されます。ポート 80 経由のプレーン HTTP トラフィックは拒否されます。この制限は、デフォルトの Ingress の動作にのみ適用されます。
4.3.5. Ingress と DNS の動作のカスタマイズ
デフォルトの Ingress および DNS 動作を使用しない場合は、作成時に一意のベースドメインを使用して KubeVirt ホステッドクラスターを設定できます。このオプションでは、作成時に手動の設定手順が必要であり、クラスターの作成、ロードバランサーの作成、およびワイルドカード DNS 設定の 3 つの主要な手順が含まれます。
4.3.5.1. ベースドメインを指定するホステッドクラスターのデプロイ
ベースドメインを指定するホステッドクラスターを作成するには、次の手順を実行します。
手順
以下のコマンドを入力します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --base-domain <basedomain>6 その結果、ホステッドクラスターには、クラスター名とベースドメイン用に設定された Ingress ワイルドカード (例:
.apps.example.hypershift.lab) が含まれます。ホステッドクラスターはPartialステータスのままです。一意のベースドメインを持つホステッドクラスターを作成した後、必要な DNS レコードとロードバランサーを設定する必要があるためです。
検証
次のコマンドを入力して、ホステッドクラスターのステータスを表示します。
$ oc get --namespace clusters hostedclusters出力例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available次のコマンドを入力してクラスターにアクセスします。
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get co出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console <4.x.0> False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress <4.x.0> True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
次のステップ
出力のエラーを修正するには、「ロードバランサーのセットアップ」および「ワイルドカード DNS の設定」の手順を完了します。
ホステッドクラスターがベアメタル上にある場合は、ロードバランサーサービスを設定するために MetalLB が必要になる場合があります。詳細は、「MetalLB の設定」を参照してください。
4.3.5.2. ロードバランサーのセットアップ
Ingress トラフィックを KubeVirt 仮想マシンにルーティングし、ロードバランサー IP アドレスにワイルドカード DNS エントリーを割り当てるロードバランサーサービスを設定します。
手順
ホステッドクラスターの Ingress を公開する
NodePortサービスがすでに存在します。ノードポートをエクスポートし、それらのポートをターゲットとするロードバランサーサービスを作成できます。次のコマンドを入力して、HTTP ノードポートを取得します。
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'次の手順で使用する HTTP ノードポート値をメモします。
次のコマンドを入力して、HTTPS ノードポートを取得します。
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'次の手順で使用する HTTPS ノードポート値をメモします。
YAML ファイルに次の情報を入力します。
apiVersion: v1 kind: Service metadata: labels: app: <hosted_cluster_name> name: <hosted_cluster_name>-apps namespace: clusters-<hosted_cluster_name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https_node_port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http_node_port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer次のコマンドを実行してロードバランサーサービスを作成します。
$ oc create -f <file_name>.yaml
4.3.5.3. ワイルドカード DNS の設定
ロードバランサーサービスの外部 IP を参照するワイルドカード DNS レコードまたは CNAME を設定します。
手順
次のコマンドを入力して外部 IP アドレスを取得します。
$ oc -n clusters-<hosted_cluster_name> get service <hosted-cluster-name>-apps \ -o jsonpath='{.status.loadBalancer.ingress[0].ip}'出力例
192.168.20.30外部 IP アドレスを参照するワイルドカード DNS エントリーを設定します。次の DNS エントリーの例を表示します。
*.apps.<hosted_cluster_name\>.<base_domain\>.DNS エントリーは、クラスターの内部と外部にルーティングできる必要があります。
DNS 解決の例
dig +short test.apps.example.hypershift.lab 192.168.20.30
検証
次のコマンドを実行して、ホステッドクラスターのステータスが
PartialからCompletedに移行したことを確認します。$ oc get --namespace clusters hostedclusters出力例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
4.3.6. MetalLB の設定
MetalLB を設定する前に、MetalLB Operator をインストールする必要があります。
手順
ホステッドクラスターで MetalLB を設定するには、次の手順を実行します。
次のサンプル YAML コンテンツを
configure-metallb.yamlファイルに保存して、MetalLBリソースを作成します。apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system次のコマンドを入力して、YAML コンテンツを適用します。
$ oc apply -f configure-metallb.yaml出力例
metallb.metallb.io/metallb created以下のサンプル YAML コンテンツを
create-ip-address-pool.yamlファイルに保存して、IPAddressPoolリソースを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: addresses: - 192.168.216.32-192.168.216.1221 - 1
- ノードネットワーク内で使用可能な IP アドレスの範囲を使用してアドレスプールを作成します。IP アドレス範囲は、ネットワーク内で使用可能な IP アドレスの未使用のプールに置き換えます。
次のコマンドを入力して、YAML コンテンツを適用します。
$ oc apply -f create-ip-address-pool.yaml出力例
ipaddresspool.metallb.io/metallb created次のサンプル YAML コンテンツを
l2advertisement.yamlファイルに保存して、L2Advertisementリソースを作成します。apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb次のコマンドを入力して、YAML コンテンツを適用します。
$ oc apply -f l2advertisement.yaml出力例
l2advertisement.metallb.io/metallb created
4.3.7. 追加のネットワーク、Guaranteed CPU、およびノードプールの仮想マシンのスケジュールを設定する
ノードプール用に追加のネットワークを設定する必要がある場合、仮想マシン (VM) 用の Guaranteed CPU へのアクセスを要求する場合、または KubeVirt 仮想マシンのスケジュールを管理する必要がある場合は、次の手順を参照してください。
4.3.7.1. ノードプールへの複数のネットワークの追加
デフォルトでは、ノードプールによって生成されたノードは、Pod ネットワークに割り当てられます。Multus および NetworkAttachmentDefinitions を使用すると、追加のネットワークをノードに割り当てることができます。
手順
ノードに複数のネットワークを追加するには、次のコマンドを実行して
--additional-network引数を使用します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --additional-network name:<namespace/name> \6 –-additional-network name:<namespace/name>
4.3.7.1.1. 追加のネットワークをデフォルトとして使用する
デフォルトの Pod ネットワークを無効にすることで、追加のネットワークをノードのデフォルトネットワークとして追加できます。
手順
追加のネットワークをデフォルトとしてノードに追加するには、次のコマンドを実行します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --attach-default-network false \6 --additional-network name:<namespace>/<network_name>7
4.3.7.2. Guaranteed CPU リソースの要求
デフォルトでは、KubeVirt 仮想マシンはノード上の他のワークロードと CPU を共有する場合があります。これにより、仮想マシンのパフォーマンスに影響が出る可能性があります。パフォーマンスへの影響を回避するために、仮想マシン用の Guaranteed CPU へのアクセスを要求できます。
手順
保証された CPU リソースを要求するには、次のコマンドを実行して
--qos-class引数をGuaranteedに設定します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --qos-class Guaranteed6
4.3.7.3. ノードセットに KubeVirt 仮想マシンをスケジュールする
デフォルトでは、ノードプールによって作成された KubeVirt 仮想マシンは、使用可能な任意のノードにスケジュールされます。KubeVirt 仮想マシンは、仮想マシンを実行するのに十分な容量を持つ特定のノードセットにスケジュールすることもできます。
手順
特定のノードセット上のノードプール内で KubeVirt 仮想マシンをスケジュールするには、次のコマンドを実行して
--vm-node-selector引数を使用します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --vm-node-selector <label_key>=<label_value>,<label_key>=<label_value>6
4.3.8. ノードプールのスケーリング
oc scale コマンドを使用して、ノードプールを手動でスケーリングできます。
手順
以下のコマンドを実行します。
NODEPOOL_NAME=${CLUSTER_NAME}-work NODEPOOL_REPLICAS=5 $ oc scale nodepool/$NODEPOOL_NAME --namespace clusters \ --replicas=$NODEPOOL_REPLICASしばらくしてから、次のコマンドを入力して、ノードプールのステータスを確認します。
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes出力例
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca
4.3.8.1. ノードプールの追加
名前、レプリカの数、およびメモリーや CPU 要件などの追加情報を指定して、ホステッドクラスターのノードプールを作成できます。
手順
ノードプールを作成するには、次の情報を入力します。この例では、ノードプールには VM に割り当てられたより多くの CPU があります。
export NODEPOOL_NAME=${CLUSTER_NAME}-extra-cpu export WORKER_COUNT="2" export MEM="6Gi" export CPU="4" export DISK="16" $ hcp create nodepool kubevirt \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $WORKER_COUNT \ --memory $MEM \ --cores $CPU \ --root-volume-size $DISKclustersnamespace 内のnodepoolリソースをリスト表示して、ノードプールのステータスを確認します。$ oc get nodepools --namespace clusters出力例
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False <4.x.0> example-extra-cpu example 2 False False True True Minimum availability requires 2 replicas, current 0 available<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
検証
しばらくしてから、次のコマンドを入力してノードプールのステータスを確認できます。
$ oc --kubeconfig $CLUSTER_NAME-kubeconfig get nodes出力例
NAME STATUS ROLES AGE VERSION example-9jvnf Ready worker 97s v1.27.4+18eadca example-n6prw Ready worker 116m v1.27.4+18eadca example-nc6g4 Ready worker 117m v1.27.4+18eadca example-thp29 Ready worker 4m17s v1.27.4+18eadca example-twxns Ready worker 88s v1.27.4+18eadca example-extra-cpu-zh9l5 Ready worker 2m6s v1.27.4+18eadca example-extra-cpu-zr8mj Ready worker 102s v1.27.4+18eadca次のコマンドを入力して、ノードプールが予期したステータスになっていることを確認します。
$ oc get nodepools --namespace clusters出力例
NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE example example 5 5 False False <4.x.0> example-extra-cpu example 2 2 False False <4.x.0><4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
4.3.9. OpenShift Virtualization でのホステッドクラスターの作成の検証
ホステッドクラスターが正常に作成されたことを確認するには、次の手順を完了します。
手順
次のコマンドを入力して、
HostedClusterリソースがcompleted状態に移行したことを確認します。$ oc get --namespace clusters hostedclusters <hosted_cluster_name>出力例
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters example 4.12.2 example-admin-kubeconfig Completed True False The hosted control plane is available次のコマンドを入力して、ホステッドクラスター内のすべてのクラスターオペレーターがオンラインであることを確認します。
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc get co --kubeconfig=<hosted_cluster_name>-kubeconfig出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.12.2 True False False 2m38s csi-snapshot-controller 4.12.2 True False False 4m3s dns 4.12.2 True False False 2m52s image-registry 4.12.2 True False False 2m8s ingress 4.12.2 True False False 22m kube-apiserver 4.12.2 True False False 23m kube-controller-manager 4.12.2 True False False 23m kube-scheduler 4.12.2 True False False 23m kube-storage-version-migrator 4.12.2 True False False 4m52s monitoring 4.12.2 True False False 69s network 4.12.2 True False False 4m3s node-tuning 4.12.2 True False False 2m22s openshift-apiserver 4.12.2 True False False 23m openshift-controller-manager 4.12.2 True False False 23m openshift-samples 4.12.2 True False False 2m15s operator-lifecycle-manager 4.12.2 True False False 22m operator-lifecycle-manager-catalog 4.12.2 True False False 23m operator-lifecycle-manager-packageserver 4.12.2 True False False 23m service-ca 4.12.2 True False False 4m41s storage 4.12.2 True False False 4m43s
4.3.10. ホステッドクラスターでカスタム API サーバー証明書を設定する
API サーバーのカスタム証明書を設定するには、HostedCluster 設定の spec.configuration.apiServer セクションで証明書の詳細を指定します。
カスタム証明書は、Day 1 操作または Day 2 操作の中で設定できます。ただし、サービス公開ストラテジーはホステッドクラスターの作成中に設定した後は変更できないため、設定する予定の Kubernetes API サーバーのホスト名を知っておく必要があります。
前提条件
管理クラスターにカスタム証明書が含まれる Kubernetes シークレットを作成しました。シークレットには次の鍵が含まれています。
-
tls.crt: 証明書 -
tls.key: 秘密鍵
-
-
HostedCluster設定にロードバランサーを使用するサービス公開ストラテジーが含まれている場合は、証明書のサブジェクト代替名 (SAN) が内部 API エンドポイント (api-int) と競合しないことを確認してください。内部 API エンドポイントは、プラットフォームによって自動的に作成および管理されます。カスタム証明書と内部 API エンドポイントの両方で同じホスト名を使用すると、ルーティングの競合が発生する可能性があります。このルールの唯一の例外は、PrivateまたはPublicAndPrivate設定で AWS をプロバイダーとして使用する場合です。このような場合、SAN の競合はプラットフォームによって管理されます。 - 証明書は外部 API エンドポイントに対して有効である必要があります。
- 証明書の有効期間は、クラスターの予想されるライフサイクルと一致します。
手順
次のコマンドを入力して、カスタム証明書を使用してシークレットを作成します。
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>次の例に示すように、カスタム証明書の詳細を使用して
HostedCluster設定を更新します。spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert次のコマンドを入力して、
HostedCluster設定に変更を適用します。$ oc apply -f <hosted_cluster_config>.yaml
検証
- API サーバー Pod をチェックして、新しい証明書がマウントされていることを確認します。
- カスタムドメイン名を使用して API サーバーへの接続をテストします。
-
ブラウザーで、または
opensslなどのツールを使用して、証明書の詳細を確認します。
4.4. 非ベアメタルエージェントマシンへの Hosted Control Plane のデプロイ
クラスターをホスティングクラスターとして機能するように設定することで、Hosted Control Plane をデプロイできます。ホスティングクラスターは、コントロールプレーンがホストされる OpenShift Container Platform クラスターです。ホスティングクラスターは管理クラスターとも呼ばれます。
非ベアメタルエージェントマシン上の Hosted Control Plane は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
管理クラスターは、マネージド クラスターとは異なります。マネージドクラスターは、ハブクラスターが管理するクラスターです。
Hosted Control Plane 機能はデフォルトで有効になっています。
multicluster engine Operator は、デフォルトの local-cluster マネージドハブクラスターのみをサポートしています。Red Hat Advanced Cluster Management (RHACM) 2.10 では、local-cluster マネージドハブクラスターをホスティングクラスターとして使用できます。
ホストされたクラスター は、ホスティングクラスターでホストされる API エンドポイントとコントロールプレーンを含む OpenShift Container Platform クラスターです。ホステッドクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。ホステッドクラスターは、multicluster engine Operator コンソールまたは hcp コマンドラインインターフェイス (CLI) を使用して作成できます。
ホステッドクラスターは、マネージドクラスターとして自動的にインポートされます。この自動インポート機能を無効にする場合は、「multicluster engine Operator へのホステッドクラスターの自動インポートの無効化」を参照してください。
4.4.1. 非ベアメタルエージェントマシンへの Hosted Control Plane のデプロイの準備
ベアメタルに Hosted Control Plane をデプロイする準備をする際には、次の情報を考慮してください。
- Agent プラットフォームを使用すると、エージェントマシンをワーカーノードとしてホステッドクラスターに追加できます。エージェントマシンは、Discovery Image でブートされ、OpenShift Container Platform ノードとしてプロビジョニングされる準備ができているホストを表します。Agent プラットフォームは、Central Infrastructure Management サービスの一部です。詳細は、Central Infrastructure Management サービスの有効化 を参照してください。
- ベアメタルではないすべてのホストは、Central Infrastructure Management が提供する検出イメージ ISO を使用して手動で起動する必要があります。
- ノードプールをスケールアップすると、レプリカごとにマシンが作成されます。Cluster API プロバイダーは、マシンごとに、承認済みで、検証に合格し、現在使用されておらず、ノードプール仕様で指定されている要件を満たしているエージェントを検索してインストールします。エージェントのステータスと状態を確認することで、エージェントのインストールを監視できます。
- ノードプールをスケールダウンすると、エージェントは対応するクラスターからバインド解除されます。Agent を再利用するには、Discovery イメージを使用してエージェントを再起動する必要があります。
- Hosted Control Plane のストレージを設定する場合は、etcd の推奨プラクティスを考慮してください。レイテンシー要件を満たすには、各コントロールプレーンノードで実行されるすべての Hosted Control Plane の etcd インスタンス専用の高速ストレージデバイスを使用します。LVM ストレージを使用して、ホストされた etcd Pod のローカルストレージクラスを設定できます。詳細は、OpenShift Container Platform ドキュメントの「推奨される etcd プラクティス」および「論理ボリュームマネージャーストレージを使用した永続ストレージ」を参照してください。
4.4.1.1. 非ベアメタルエージェントマシンに Hosted Control Plane をデプロイするための前提条件
非ベアメタルエージェントマシンに Hosted Control Plane をデプロイする前に、次の前提条件を満たしていることを確認してください。
- OpenShift Container Platform クラスターに multicluster engine for Kubernetes Operator 2.5 以降がインストールされている。multicluster engine Operator は、OpenShift Container Platform OperatorHub から Operator としてインストールできます。
multicluster engine Operator のマネージド OpenShift Container Platform クラスターが少なくとも 1 つある。
local-cluster管理クラスターは自動的にインポートされます。local-clusterの詳細は、Red Hat Advanced Cluster Management ドキュメントの 詳細設定 を参照してください。次のコマンドを実行すると、管理クラスターのステータスを確認できます。$ oc get managedclusters local-cluster- Central Infrastructure Management を有効にした。詳細は、Red Hat Advanced Cluster Management ドキュメントの Central Infrastructure Management サービスの有効化 を参照してください。
-
hcpコマンドラインインターフェイスをインストールした。 - ホステッドクラスターの名前がクラスター全体で一意である。
- 管理クラスターとワーカーを同じインフラストラクチャー上で実行している。
4.4.1.2. 非ベアメタルエージェントマシンのファイアウォール、ポート、およびサービスの要件
管理クラスター、コントロールプレーン、ホステッドクラスター間でポートが通信できるように、ファイアウォールとポートの要件を満たす必要があります。
サービスはデフォルトのポートで実行されます。ただし、NodePort 公開ストラテジーを使用する場合、サービスは NodePort サービスによって割り当てられたポートで実行されます。
ファイアウォールルール、セキュリティーグループ、またはその他のアクセス制御を使用して、必要なソースだけにアクセスを制限します。必要な場合を除き、ポートを公開しないでください。実稼働環境の場合は、ロードバランサーを使用して、単一の IP アドレスによるアクセスを簡素化します。
Hosted Control Plane は、非ベアメタルエージェントマシン上で次のサービスを公開します。
APIServer-
APIServerサービスはデフォルトでポート 6443 で実行され、コントロールプレーンコンポーネント間の通信には ingress アクセスが必要です。 - MetalLB ロードバランシングを使用する場合は、ロードバランサーの IP アドレスに使用される IP 範囲への ingress アクセスを許可します。
-
OAuthServer-
ルートと Ingress を使用してサービスを公開する場合、
OAuthServerサービスはデフォルトでポート 443 で実行されます。 -
NodePort公開ストラテジーを使用する場合は、OAuthServerサービスにファイアウォールルールを使用します。
-
ルートと Ingress を使用してサービスを公開する場合、
Konnectivity-
ルートと Ingress を使用してサービスを公開する場合、
Konnectivityサービスはデフォルトでポート 443 で実行されます。 -
Konnectivityエージェントはリバーストンネルを確立し、コントロールプレーンがホステッドクラスターのネットワークにアクセスできるようにします。エージェントは egress を使用してKonnectivityサーバーに接続します。サーバーは、ポート 443 のルートまたは手動で割り当てられたNodePortを使用して公開されます。 - クラスター API サーバーのアドレスが内部 IP アドレスの場合は、ワークロードサブネットからポート 6443 の IP アドレスへのアクセスを許可します。
- アドレスが外部 IP アドレスの場合は、ノードからその外部 IP アドレスにポート 6443 で送信できるように許可します。
-
ルートと Ingress を使用してサービスを公開する場合、
Ignition-
ルートと Ingress を使用してサービスを公開する場合、
Ignitionサービスはデフォルトでポート 443 で実行されます。 -
NodePort公開ストラテジーを使用する場合は、Ignitionサービスにファイアウォールルールを使用します。
-
ルートと Ingress を使用してサービスを公開する場合、
非ベアメタルエージェントマシンでは、次のサービスは必要ありません。
-
OVNSbDb -
OIDC
4.4.1.3. 非ベアメタルエージェントマシンのインフラストラクチャー要件
Agent プラットフォームはインフラストラクチャーを作成しませんが、次のインフラストラクチャー要件があります。
- Agent: Agent は、Discovery イメージで起動され、OpenShift Container Platform ノードとしてプロビジョニングされる準備ができているホストを表します。
- DNS: API および Ingress エンドポイントは、ルーティング可能である必要があります。
4.4.2. 非ベアメタルエージェントマシンでの DNS の設定
ホステッドクラスターの API サーバーは、NodePort サービスとして公開されます。API サーバーに到達できる宛先を指す api.<hosted_cluster_name>.<basedomain> の DNS エントリーが存在する必要があります。
DNS エントリーは、Hosted Control Plane を実行しているマネージドクラスター内のノードの 1 つを指すレコードと同様、単純化できます。エントリーは、受信トラフィックを Ingress Pod にリダイレクトするためにデプロイされるロードバランサーを指すこともできます。
IPv4 ネットワークで接続環境の DNS を設定する場合は、次の DNS 設定の例を参照してください。
api.example.krnl.es. IN A 192.168.122.20 api.example.krnl.es. IN A 192.168.122.21 api.example.krnl.es. IN A 192.168.122.22 api-int.example.krnl.es. IN A 192.168.122.20 api-int.example.krnl.es. IN A 192.168.122.21 api-int.example.krnl.es. IN A 192.168.122.22 `*`.apps.example.krnl.es. IN A 192.168.122.23IPv6 ネットワークで非接続環境の DNS を設定する場合は、次の DNS 設定の例を参照してください。
api.example.krnl.es. IN A 2620:52:0:1306::5 api.example.krnl.es. IN A 2620:52:0:1306::6 api.example.krnl.es. IN A 2620:52:0:1306::7 api-int.example.krnl.es. IN A 2620:52:0:1306::5 api-int.example.krnl.es. IN A 2620:52:0:1306::6 api-int.example.krnl.es. IN A 2620:52:0:1306::7 `*`.apps.example.krnl.es. IN A 2620:52:0:1306::10デュアルスタックネットワークの非接続環境で DNS を設定する場合は、IPv4 と IPv6 の両方の DNS エントリーを含めるようにしてください。次の DNS 設定の例を参照してください。
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10 host-record=api.hub-dual.dns.base.domain.name,192.168.126.10 address=/apps.hub-dual.dns.base.domain.name/192.168.126.11 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20 dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21 dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22 dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25 dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26 host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2 host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2 address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3 dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5] dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6] dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7] dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8] dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]
4.4.3. CLI を使用した非ベアメタルエージェントマシンでのホステッドクラスターの作成
Agent プラットフォームを使用してホステッドクラスターを作成すると、HyperShift Operator によって Agent Cluster API プロバイダーが Hosted Control Plane の namespace にインストールされます。ベアメタルでホステッドクラスターを作成するか、インポートできます。
ホステッドクラスターを作成するときは、次のガイドラインを確認してください。
- 各ホステッドクラスターの名前がクラスター全体で一意である。multicluster engine Operator によってホステッドクラスターを管理するには、ホステッドクラスター名を既存のマネージドクラスターと同じにすることはできません。
-
ホステッドクラスター名として
clustersを使用しない。 - ホステッドクラスターは、multicluster engine Operator のマネージドクラスターの namespace には作成できない。
手順
次のコマンドを入力して、Hosted Control Plane namespace を作成します。
$ oc create ns <hosted_cluster_namespace>-<hosted_cluster_name>1 - 1
<hosted_cluster_namespace>を、ホステッドクラスターの namespace 名 (例:clusters) に置き換えます。<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。
次のコマンドを入力して、ホステッドクラスターを作成します。
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --control-plane-availability-policy HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release> \10 --node-pool-replicas <node_pool_replica_count>11 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 3
- Hosted Control Plane namespace を指定します (例:
clusters-example)。oc get agent -n <hosted-control-plane-namespace>コマンドを使用して、この namespace でエージェントが使用可能であることを確認します。 - 4
- ベースドメインを指定します (例:
krnl.es)。 - 5
--api-server-addressフラグは、ホステッドクラスター内の Kubernetes API 通信に使用される IP アドレスを定義します。--api-server-addressフラグを設定しない場合は、管理クラスターに接続するためにログインする必要があります。- 6
- クラスターにデフォルトのストレージクラスが設定されていることを確認する。設定されていない場合は、PVC が保留になる可能性があります。etcd ストレージクラス名を指定します (例:
lvm-storageclass)。 - 7
- SSH 公開鍵へのパスを指定します。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 8
- ホステッドクラスターの namespace を指定します。
- 9
- Hosted Control Plane コンポーネントの可用性ポリシーを指定します。サポートされているオプションは
SingleReplicaとHighlyAvailableです。デフォルト値はHighlyAvailableです。 - 10
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.17.0-multi)。 - 11
- ノードプールのレプリカ数を指定します (例:
3)。レプリカ数は0以上で指定する必要があります。指定したとおりの数のノードが作成されます。それ以外の場合、ノードプールは作成されません。
検証
しばらくしてから、次のコマンドを入力して、Hosted Control Plane の Pod が稼働中であることを確認します。
$ oc -n <hosted_cluster_namespace>-<hosted_cluster_name> get pods出力例
NAME READY STATUS RESTARTS AGE catalog-operator-6cd867cc7-phb2q 2/2 Running 0 2m50s control-plane-operator-f6b4c8465-4k5dh 1/1 Running 0 4m32s
4.4.3.1. Web コンソールを使用した非ベアメタルエージェントマシンでのホステッドクラスターの作成
OpenShift Container Platform Web コンソールを使用して、非ベアメタルエージェントマシン上にホステッドクラスターを作成できます。
前提条件
-
cluster-admin権限でクラスターにアクセスできる。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
- OpenShift Container Platform Web コンソールを開き、管理者の認証情報を入力してログインします。
- コンソールのヘッダーで、All Clusters を選択します。
- Infrastructure → Clusters をクリックします。
Create cluster Host inventory → Hosted control plane をクリックします。
Create cluster ページが表示されます。
- Create cluster ページでプロンプトに従い、クラスター、ノードプール、ネットワーク、および自動化に関する詳細を入力します。
クラスターの詳細を入力する際には、次のヒントが役立つ場合があります。
- 事前定義された値を使用してコンソールのフィールドに自動的に値を入力する場合は、ホストインベントリーの認証情報を作成できます。詳細は、オンプレミス環境の認証情報の作成 を参照してください。
- Cluster details ページのプルシークレットは、OpenShift Container Platform リソースへのアクセスに使用する OpenShift Container Platform プルシークレットです。ホストインベントリー認証情報を選択した場合は、プルシークレットが自動的に入力されます。
- Node pools ページでは、namespace にノードプールのホストが含まれます。コンソールを使用してホストインベントリーを作成した場合、コンソールは専用の namespace を作成します。
Networking ページで、API サーバー公開ストラテジーを選択します。ホステッドクラスターの API サーバーは、既存のロードバランサーを使用するか、
NodePortタイプのサービスとして公開できます。API サーバーに到達できる宛先を指すapi.<hosted_cluster_name>.<basedomain>設定の DNS エントリーが存在する必要があります。このエントリーとして、管理クラスター内のノードの 1 つを指すレコード、または受信トラフィックを Ingress Pod にリダイレクトするロードバランサーを指すレコードを指定できます。- エントリーを確認し、Create をクリックします。
Hosted cluster ビューが表示されます。
- Hosted cluster ビューでホステッドクラスターのデプロイメントを監視します。ホステッドクラスターに関する情報が表示されない場合は、All Clusters が選択されていることを確認し、クラスター名をクリックします。コントロールプレーンコンポーネントの準備が整うまで待ちます。このプロセスには数分かかる場合があります。
- ノードプールのステータスを表示するには、NodePool セクションまでスクロールします。ノードをインストールするプロセスには約 10 分かかります。Nodes をクリックして、ノードがホステッドクラスターに参加したかどうかを確認することもできます。
次のステップ
- Web コンソールにアクセスするには、Web コンソールへのアクセス を参照してください。
4.4.3.2. ミラーレジストリーを使用した非ベアメタルエージェントマシンでのホステッドクラスターの作成
hcp create cluster コマンドで --image-content-sources フラグを指定することで、ミラーレジストリーを使用して、非ベアメタルエージェントマシン上にホステッドクラスターを作成できます。
手順
YAML ファイルを作成して、イメージコンテンツソースポリシー (ICSP) を定義します。以下の例を参照してください。
- mirrors: - brew.registry.redhat.io source: registry.redhat.io - mirrors: - brew.registry.redhat.io source: registry.stage.redhat.io - mirrors: - brew.registry.redhat.io source: registry-proxy.engineering.redhat.com-
ファイルを
icsp.yamlとして保存します。このファイルにはミラーレジストリーが含まれます。 ミラーレジストリーを使用してホステッドクラスターを作成するには、次のコマンドを実行します。
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \5 --image-content-sources icsp.yaml \6 --ssh-key <path_to_ssh_key> \7 --namespace <hosted_cluster_namespace> \8 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>9 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 3
- Hosted Control Plane namespace を指定します (例:
clusters-example)。oc get agent -n <hosted-control-plane-namespace>コマンドを使用して、この namespace でエージェントが使用可能であることを確認します。 - 4
- ベースドメインを指定します (例:
krnl.es)。 - 5
--api-server-addressフラグは、ホステッドクラスター内の Kubernetes API 通信に使用される IP アドレスを定義します。--api-server-addressフラグを設定しない場合は、管理クラスターに接続するためにログインする必要があります。- 6
- ICSP およびミラーレジストリーを定義する
icsp.yamlファイルを指定します。 - 7
- SSH 公開鍵へのパスを指定します。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 8
- ホストされたクラスターの namespace を指定します。
- 9
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.17.0-multi)。非接続環境を使用している場合は、<ocp_release_image>をダイジェストイメージに置き換えます。OpenShift Container Platform リリースイメージダイジェストを抽出するには、OpenShift Container Platform リリースイメージダイジェストの抽出 を参照してください。
次のステップ
- コンソールでホステッドクラスターを作成するときに再利用できる認証情報を作成するには、オンプレミス環境の認証情報の作成 を参照してください。
- ホステッドクラスターにアクセスするには、ホステッドクラスターへのアクセス を参照してください。
- Discovery Image を使用してホストインベントリーにホストを追加するには、Discovery Image を使用したホストインベントリーへのホストの追加 を参照してください。
- OpenShift Container Platform リリースイメージダイジェストを抽出するには、OpenShift Container Platform リリースイメージダイジェストの抽出 を参照してください。
4.4.4. 非ベアメタルエージェントマシンでのホステッドクラスターの作成を検証する
デプロイメントプロセスが完了したら、ホステッドクラスターが正常に作成されたことを確認できます。ホステッドクラスターの作成から数分後に、次の手順に従います。
手順
次のコマンドを入力して、新しいホステッドクラスターの
kubeconfigファイルを取得します。$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>kubeconfigファイルを使用して、ホステッドクラスターのクラスター Operator を表示します。以下のコマンドを入力します。$ oc get co --kubeconfig=kubeconfig-<hosted_cluster_name>出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console 4.10.26 True False False 2m38s csi-snapshot-controller 4.10.26 True False False 4m3s dns 4.10.26 True False False 2m52s次のコマンドを入力して、ホステッドクラスター上で実行中の Pod を表示します。
$ oc get pods -A --kubeconfig=kubeconfig-<hosted_cluster_name>出力例
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system konnectivity-agent-khlqv 0/1 Running 0 3m52s openshift-cluster-samples-operator cluster-samples-operator-6b5bcb9dff-kpnbc 2/2 Running 0 20m openshift-monitoring alertmanager-main-0 6/6 Running 0 100s openshift-monitoring openshift-state-metrics-677b9fb74f-qqp6g 3/3 Running 0 104s
4.4.5. ホステッドクラスターでカスタム API サーバー証明書を設定する
API サーバーのカスタム証明書を設定するには、HostedCluster 設定の spec.configuration.apiServer セクションで証明書の詳細を指定します。
カスタム証明書は、Day 1 操作または Day 2 操作の中で設定できます。ただし、サービス公開ストラテジーはホステッドクラスターの作成中に設定した後は変更できないため、設定する予定の Kubernetes API サーバーのホスト名を知っておく必要があります。
前提条件
管理クラスターにカスタム証明書が含まれる Kubernetes シークレットを作成しました。シークレットには次の鍵が含まれています。
-
tls.crt: 証明書 -
tls.key: 秘密鍵
-
-
HostedCluster設定にロードバランサーを使用するサービス公開ストラテジーが含まれている場合は、証明書のサブジェクト代替名 (SAN) が内部 API エンドポイント (api-int) と競合しないことを確認してください。内部 API エンドポイントは、プラットフォームによって自動的に作成および管理されます。カスタム証明書と内部 API エンドポイントの両方で同じホスト名を使用すると、ルーティングの競合が発生する可能性があります。このルールの唯一の例外は、PrivateまたはPublicAndPrivate設定で AWS をプロバイダーとして使用する場合です。このような場合、SAN の競合はプラットフォームによって管理されます。 - 証明書は外部 API エンドポイントに対して有効である必要があります。
- 証明書の有効期間は、クラスターの予想されるライフサイクルと一致します。
手順
次のコマンドを入力して、カスタム証明書を使用してシークレットを作成します。
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>次の例に示すように、カスタム証明書の詳細を使用して
HostedCluster設定を更新します。spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert次のコマンドを入力して、
HostedCluster設定に変更を適用します。$ oc apply -f <hosted_cluster_config>.yaml
検証
- API サーバー Pod をチェックして、新しい証明書がマウントされていることを確認します。
- カスタムドメイン名を使用して API サーバーへの接続をテストします。
-
ブラウザーで、または
opensslなどのツールを使用して、証明書の詳細を確認します。
4.5. IBM Z への Hosted Control Plane のデプロイ
IBM Z のホストされたコントロールプレーンの場合、64 ビット x86 アーキテクチャーに基づくマシンタイプと、IBM Power または IBM Z 上のノードプールでコントロールプレーンを実行する必要があります。他のアーキテクチャーの IBM Z 上のホストされたコントロールプレーンの詳細は、ホストされたコントロールプレーンのサポートマトリックス を参照してください。
クラスターを管理クラスターとして機能するように設定することで、Hosted Control Plane をデプロイできます。管理クラスターは、コントロールプレーンがホストされる OpenShift Container Platform クラスターです。管理クラスターは ホスティング クラスターとも呼ばれます。
管理 クラスターは マネージド クラスターではありません。マネージドクラスターは、ハブクラスターが管理するクラスターです。
hypershift アドオンを使用してマネージドクラスターに HyperShift Operator をデプロイすることにより、そのマネージドクラスターを管理クラスターに変換できます。その後、ホステッドクラスターの作成を開始できます。
multicluster engine Operator は、マネージドのハブクラスターであるデフォルトの local-cluster と、管理クラスターとしてのハブクラスターのみをサポートしています。
ベアメタルに Hosted Control Plane をプロビジョニングするには、Agent プラットフォームを使用できます。Agent プラットフォームは、Central Infrastructure Management サービスを使用して、ホステッドクラスターにワーカーノードを追加します。詳細は、「Central Infrastructure Management サービスの有効化」を参照してください。
各 IBM Z システムホストは、Central Infrastructure Management によって提供される PXE イメージを使用して起動する必要があります。各ホストが起動すると、エージェントプロセスが実行されてホストの詳細が検出され、インストールが完了します。Agent カスタムリソースは、各ホストを表します。
Agent プラットフォームでホステッドクラスターを作成すると、HyperShift Operator は Hosted Control Plane namespace に Agent Cluster API プロバイダーをインストールします。
4.5.1. IBM Z で Hosted Control Plane を設定するための前提条件
- multicluster engine for Kubernetes Operator version 2.5 以降を OpenShift Container Platform クラスターにインストールする必要があります。multicluster engine Operator は、OpenShift Container Platform OperatorHub から Operator としてインストールできます。
multicluster engine Operator には、少なくとも 1 つのマネージド OpenShift Container Platform クラスターが必要です。multicluster engine Operator バージョン 2.5 以降では、
local-clusterが自動的にインポートされます。local-clusterの詳細は、Red Hat Advanced Cluster Management ドキュメントの 詳細設定 を参照してください。次のコマンドを実行して、ハブクラスターの状態を確認できます。$ oc get managedclusters local-cluster- HyperShift Operator を実行するために 3 つ以上のワーカーノードを含むホスティングクラスターがある。
- Central Infrastructure Management サービスが有効である。詳細は、Central Infrastructure Management サービスの有効化 を参照してください。
- Hosted Control Plane のコマンドラインインターフェイスをインストールする必要があります。詳細は、Hosted Control Plane のコマンドラインインターフェイスのインストール を参照してください。
4.5.2. IBM Z のインフラストラクチャー要件
Agent プラットフォームはインフラストラクチャーを作成しませんが、インフラストラクチャー用の次のリソースを必要とします。
- Agents: Agent は Discovery イメージまたは PXE イメージで起動され、OpenShift Container Platform ノードとしてプロビジョニングする準備ができているホストを表します。
- DNS: API および Ingress エンドポイントは、ルーティング可能である必要があります。
Hosted Control Plane 機能はデフォルトで有効になっています。この機能を以前に無効にしていて手動で有効にする場合、またはこの機能を無効にする必要がある場合は、Hosted Control Plane 機能の有効化または無効化 を参照してください。
4.5.3. IBM Z での Hosted Control Plane の DNS 設定
ホステッドクラスターの API サーバーは、NodePort サービスとして公開されます。API サーバーに到達できる宛先を指す api.<hosted_cluster_name>.<base_domain> の DNS エントリーが存在する必要があります。
DNS エントリーは、Hosted Control Plane を実行しているマネージドクラスター内のノードの 1 つを指すレコードと同様、単純化できます。
エントリーは、受信トラフィックを Ingress Pod にリダイレクトするためにデプロイされるロードバランサーを指すこともできます。
次の DNS 設定の例を参照してください。
$ cat /var/named/<example.krnl.es.zone>出力例
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- このレコードは、Hosted Control Plane の受信トラフィックと送信トラフィックを処理する API ロードバランサーの IP アドレスを参照します。
IBM z/VM の場合、エージェントの IP アドレスに対応する IP アドレスを追加します。
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy4.5.4. コンソールを使用したホステッドクラスターの作成
ベアメタルインフラストラクチャーには、ホステッドクラスターを作成またはインポートできます。multicluster engine Operator へのアドオンとして Assisted Installer を有効にし、Agent プラットフォームを使用してホステッドクラスターを作成すると、HyperShift Operator によって Agent Cluster API プロバイダーが Hosted Control Plane namespace にインストールされます。Agent Cluster API プロバイダーは、コントロールプレーンをホストする管理クラスターと、コンピュートノードのみで構成されるホステッドクラスターを接続します。
前提条件
- 各ホステッドクラスターの名前がクラスター全体で一意である。ホステッドクラスター名は、既存のマネージドクラスターと同じにすることはできません。この要件を満たさないと、multicluster engine Operator がホステッドクラスターを管理できません。
-
ホステッドクラスター名として
clustersという単語を使用しない。 - multicluster engine Operator のマネージドクラスターの namespace にホステッドクラスターを作成することはできない。
- 最適なセキュリティーと管理プラクティスを実現するために、他のホステッドクラスターとは別にホステッドクラスターを作成する。
- クラスターにデフォルトのストレージクラスが設定されていることを確認する。そうしない場合、保留中の永続ボリューム要求 (PVC) が表示されることがあります。
-
デフォルトでは、
hcp create cluster agentコマンドを使用すると、ノードポートが設定されたホステッドクラスターが作成されます。ベアメタル上のホステッドクラスターの推奨公開ストラテジーは、ロードバランサーを通じてサービスを公開することです。Web コンソールまたは Red Hat Advanced Cluster Management を使用してホステッドクラスターを作成する場合、Kubernetes API サーバー以外のサービスの公開ストラテジーを設定するには、HostedClusterカスタムリソースでservicePublishingStrategy情報を手動で指定する必要があります。 インフラストラクチャー、ファイアウォール、ポート、およびサービスに関連する要件を含め、「ベアメタル上の Hosted Control Plane の要件」に記載されている要件を満たしていることを確認する。要件では、たとえば次のコマンド例に示すように、管理クラスター内のベアメタルホストに適切なゾーンラベルを追加する方法が説明されています。
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- ハードウェアインベントリーにベアメタルノードを追加したことを確認する。
手順
次のコマンドを入力して namespace を作成します。
$ oc create ns <hosted_cluster_namespace><hosted_cluster_namespace>は、ホステッドクラスター namespace の識別子に置き換えます。namespace は HyperShift Operator によって作成されます。ベアメタルインフラストラクチャーにホステッドクラスターを作成するプロセスでは、Cluster API プロバイダー用のロールが生成されます。このロールを生成するには、namespace が事前に存在している必要があります。次のコマンドを入力して、ホステッドクラスターの設定ファイルを作成します。
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- ホステッドクラスターの名前 (例:
example) を指定します。 - 2
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 3
- Hosted Control Plane の namespace を指定します (例:
clusters-example)。oc get agent -n <hosted_control_plane_namespace>コマンドを使用して、この namespace でエージェントが使用可能であることを確認します。 - 4
- ベースドメイン (例:
krnl.es) を指定します。 - 5
--api-server-addressフラグは、ホステッドクラスター内の Kubernetes API 通信に使用される IP アドレスを定義します。--api-server-addressフラグを設定しない場合は、管理クラスターに接続するためにログインする必要があります。- 6
- etcd ストレージクラス名を指定します (例:
lvm-storageclass)。 - 7
- SSH 公開鍵へのパスを指定します。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 8
- ホステッドクラスターの namespace を指定します。
- 9
- Hosted Control Plane コンポーネントの可用性ポリシーを指定します。サポートされているオプションは
SingleReplicaとHighlyAvailableです。デフォルト値はHighlyAvailableです。 - 10
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.19.0-multi)。非接続環境を使用している場合は、<ocp_release_image>をダイジェストイメージに置き換えます。OpenShift Container Platform リリースイメージダイジェストを抽出するには、OpenShift Container Platform リリースイメージダイジェストの抽出 を参照してください。 - 11
- ノードプールのレプリカ数を指定します (例:
3)。レプリカ数は0以上で指定する必要があります。指定したとおりの数のノードが作成されます。この値を指定しない場合、ノードプールは作成されません。 - 12
--ssh-keyフラグの後に、SSH 鍵へのパス (例:user/.ssh/id_rsa) を指定します。
サービス公開ストラテジーを設定します。デフォルトでは、ホステッドクラスターは
NodePortサービス公開ストラテジーを使用します。これは、ノードポートが追加のインフラストラクチャーなしで常に利用可能であるためです。ただし、ロードバランサーを使用するようにサービス公開ストラテジーを設定することもできます。-
デフォルトの
NodePortストラテジーを使用している場合は、管理クラスターノードではなく、ホステッドクラスターコンピュートノードを指すように DNS を設定します。詳細は、「ベアメタル上の DNS 設定」を参照してください。 実稼働環境では、証明書の処理と自動 DNS 解決を提供する
LoadBalancerストラテジーを使用します。次の例は、ホステッドクラスターの設定ファイルでLoadBalancerサービス公開ストラテジーを変更する方法を示しています。# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- API サーバータイプとして
LoadBalancerを指定します。それ以外のすべてのサービスでは、タイプとしてRouteを指定します。
-
デフォルトの
次のコマンドを入力して、ホステッドクラスター設定ファイルに変更を適用します。
$ oc apply -f hosted_cluster_config.yaml次のコマンドを入力して、ホステッドクラスター、ノードプール、および Pod の作成を確認します。
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
ホステッドクラスターの準備ができていることを確認します。
Available: Trueというステータスはクラスターの準備完了状態であることを示しています。ノードプールのステータスにはAllMachinesReady: Trueと表示されます。これらのステータスは、すべてのクラスター Operator の健全性を示しています。 ホステッドクラスターに MetalLB をインストールします。
次のコマンドを入力して、ホステッドクラスターから
kubeconfigファイルを展開し、ホステッドクラスターアクセス用の環境変数を設定します。$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"install-metallb-operator.yamlファイルを作成して MetalLB Operator をインストールします。apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...以下のコマンドを入力してファイルを適用します。
$ oc apply -f install-metallb-operator.yamldeploy-metallb-ipaddresspool.yamlファイルを作成して、MetalLB IP アドレスプールを設定します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...次のコマンドを入力して設定を適用します。
$ oc apply -f deploy-metallb-ipaddresspool.yaml次のコマンドを入力して、Operator ステータス、IP アドレスプール、および
L2Advertisementリソースを確認し、MetalLB のインストールを検証します。$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
Ingress 用のロードバランサーを設定します。
ingress-loadbalancer.yamlファイルを作成します。apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...次のコマンドを入力して設定を適用します。
$ oc apply -f ingress-loadbalancer.yaml次のコマンドを入力して、ロードバランサーサービスが期待どおりに動作することを確認します。
$ oc get svc metallb-ingress -n openshift-ingress出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
ロードバランサーと連携するように DNS を設定します。
-
*.apps.<hosted_cluster_namespace>.<base_domain>ワイルドカード DNS レコードがロードバランサーの IP アドレスをポイントするように、appsドメインの DNS を設定します。 次のコマンドを入力して DNS 解決を確認します。
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>出力例
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
検証
次のコマンドを入力して、クラスター Operator を確認します。
$ oc get clusteroperatorsすべての Operator に
AVAILABLE: True、PROGRESSING: False、DEGRADED: Falseが表示されていることを確認します。次のコマンドを入力してノードを確認します。
$ oc get nodes各ノードのステータスが
READYであることを確認します。Web ブラウザーに次の URL を入力して、コンソールへのアクセスをテストします。
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
4.5.5. IBM Z 上の Hosted Control Plane 用の InfraEnv リソースを作成する
InfraEnv は、PXE イメージを使用して起動されるホストがエージェントとして参加できる環境です。この場合、エージェントは Hosted Control Plane と同じ namespace に作成されます。
手順
設定を含む YAML ファイルを作成します。以下の例を参照してください。
apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_control_plane_namespace> spec: cpuArchitecture: s390x pullSecretRef: name: pull-secret sshAuthorizedKey: <ssh_public_key>-
ファイルを
infraenv-config.yamlとして保存します。 次のコマンドを入力して設定を適用します。
$ oc apply -f infraenv-config.yamlinitrd.img、kernel.img、またはrootfs.imgなどの PXE イメージをダウンロードする URL を取得するには、次のコマンドを入力します。このイメージは、IBM Z マシンがエージェントとして参加できるようにします。$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name> -o json
4.5.6. InfraEnv リソースへの IBM Z エージェントの追加
Hosted Control Plane にコンピュートノードをアタッチするには、ノードプールのスケーリングに役立つエージェントを作成します。IBM Z 環境にエージェントを追加するには、追加の手順が必要です。これは、このセクションで詳しく説明します。
特に明記されていない限り、以下の手順は IBM Z および IBM LinuxONE 上の z/VM と RHEL KVM の両方のインストールに適用されます。
4.5.6.1. IBM Z KVM をエージェントとして追加する
KVM を使用する IBM Z の場合は、次のコマンドを実行して、InfraEnv リソースからダウンロードした PXE イメージを使用して IBM Z 環境を開始します。エージェントが作成されると、ホストは Assisted Service と通信し、管理クラスター上の InfraEnv リソースと同じ namespace に登録します。
手順
以下のコマンドを実行します。
virt-install \ --name "<vm_name>" \1 --autostart \ --ram=16384 \ --cpu host \ --vcpus=4 \ --location "<path_to_kernel_initrd_image>,kernel=kernel.img,initrd=initrd.img" \2 --disk <qcow_image_path> \3 --network network:macvtap-net,mac=<mac_address> \4 --graphics none \ --noautoconsole \ --wait=-1 --extra-args "rd.neednet=1 nameserver=<nameserver> coreos.live.rootfs_url=http://<http_server>/rootfs.img random.trust_cpu=on rd.luks.options=discard ignition.firstboot ignition.platform.id=metal console=tty1 console=ttyS1,115200n8 coreos.inst.persistent-kargs=console=tty1 console=ttyS1,115200n8"5 ISO ブートの場合は、
InfraEnvリソースから ISO をダウンロードし、次のコマンドを実行してノードを起動します。virt-install \ --name "<vm_name>" \1 --autostart \ --memory=16384 \ --cpu host \ --vcpus=4 \ --network network:macvtap-net,mac=<mac_address> \2 --cdrom "<path_to_image.iso>" \3 --disk <qcow_image_path> \ --graphics none \ --noautoconsole \ --os-variant <os_version> \4 --wait=-1
4.5.6.2. IBM Z LPAR をエージェントとして追加する
IBM Z または IBM LinuxONE 上の論理パーティション (LPAR) をコンピュートノードとして Hosted Control Plane に追加できます。
手順
エージェントのブートパラメーターファイルを作成します。
パラメーターファイルの例
rd.neednet=1 cio_ignore=all,!condev \ console=ttysclp0 \ ignition.firstboot ignition.platform.id=metal coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \1 coreos.inst.persistent-kargs=console=ttysclp0 ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \2 rd.znet=qeth,<network_adaptor_range>,layer2=1 rd.<disk_type>=<adapter> \3 zfcp.allow_lun_scan=0 ai.ip_cfg_override=1 \4 random.trust_cpu=on rd.luks.options=discard- 1
coreos.live.rootfs_urlアーティファクトには、起動するkernelとinitramfsに合ったrootfsアーティファクトを指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。- 2
ipパラメーターには、z/VM を使用したクラスターの IBM Z および IBM LinuxONE へのインストール の説明に従って、IP アドレスを手動で割り当てます。- 3
- DASD タイプのディスクにインストールする場合は、
rd.dasdを使用して、Red Hat Enterprise Linux CoreOS (RHCOS) をインストールする DASD を指定します。FCP タイプのディスクにインストールする場合は、rd.zfcp=<adapter>,<wwpn>,<lun>を使用して、RHCOS がインストールされる FCP ディスクを指定します。 - 4
- Open Systems Adapter (OSA) または HiperSockets を使用する場合は、このパラメーターを指定します。
InfraEnvリソースから.insファイルとinitrd.img.addrsizeファイルをダウンロードします。デフォルトでは、
.insファイルとinitrd.img.addrsizeファイルの URL は、InfraEnvリソースにはありません。これらのアーティファクトを取得するには、URL を編集する必要があります。次のコマンドを実行して、カーネル URL エンドポイントを更新し、
ins-fileを含めます。$ curl -k -L -o generic.ins "< url for ins-file >"URL の例
https://…/boot-artifacts/ins-file?arch=s390x&version=4.17.0initrdURL エンドポイントを更新し、s390x-initrd-addrsizeを含めます。URL の例
https://…./s390x-initrd-addrsize?api_key=<api-key>&arch=s390x&version=4.17.0
-
initrd、kernel、generic.ins、およびinitrd.img.addrsizeパラメーターファイルをファイルサーバーに転送します。FTP を使用してファイルを転送し、ブートする方法の詳細は、「LPAR へのインストール」を参照してください。 - マシンを起動します。
- クラスター内の他のマシンすべてに対してこの手順を繰り返します。
4.5.6.3. IBM z/VM をエージェントとして追加する
z/VM ゲストに静的 IP を使用する場合は、IP パラメーターが 2 回目の起動でも持続するように、z/VM エージェントの NMStateConfig 属性を設定する必要があります。
InfraEnv リソースからダウンロードした PXE イメージを使用して IBM Z 環境を開始するには、以下の手順を実行します。エージェントが作成されると、ホストは Assisted Service と通信し、管理クラスター上の InfraEnv リソースと同じ namespace に登録します。
手順
パラメーターファイルを更新して、
rootfs_url、network_adaptor、およびdisk_typeの値を追加します。パラメーターファイルの例
rd.neednet=1 cio_ignore=all,!condev \ console=ttysclp0 \ ignition.firstboot ignition.platform.id=metal \ coreos.live.rootfs_url=http://<http_server>/rhcos-<version>-live-rootfs.<architecture>.img \1 coreos.inst.persistent-kargs=console=ttysclp0 ip=<ip>::<gateway>:<netmask>:<hostname>::none nameserver=<dns> \2 rd.znet=qeth,<network_adaptor_range>,layer2=1 rd.<disk_type>=<adapter> \3 zfcp.allow_lun_scan=0 ai.ip_cfg_override=1 \4 - 1
coreos.live.rootfs_urlアーティファクトには、起動するkernelとinitramfsに合ったrootfsアーティファクトを指定します。HTTP プロトコルおよび HTTPS プロトコルのみがサポートされます。- 2
ipパラメーターには、z/VM を使用したクラスターの IBM Z および IBM LinuxONE へのインストール の説明に従って、IP アドレスを手動で割り当てます。- 3
- DASD タイプのディスクにインストールする場合は、
rd.dasdを使用して、Red Hat Enterprise Linux CoreOS (RHCOS) をインストールする DASD を指定します。FCP タイプのディスクにインストールする場合は、rd.zfcp=<adapter>,<wwpn>,<lun>を使用して、RHCOS がインストールされる FCP ディスクを指定します。 - 4
- Open Systems Adapter (OSA) または HiperSockets を使用する場合は、このパラメーターを指定します。
次のコマンドを実行して、
initrd、カーネルイメージ、およびパラメーターファイルをゲスト VM に移動します。vmur pun -r -u -N kernel.img $INSTALLERKERNELLOCATION/<image name>vmur pun -r -u -N generic.parm $PARMFILELOCATION/paramfilenamevmur pun -r -u -N initrd.img $INSTALLERINITRAMFSLOCATION/<image name>ゲスト VM コンソールから次のコマンドを実行します。
cp ipl cエージェントとそのプロパティーをリスト表示するには、次のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agents出力例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a auto-assign次のコマンドを実行してエージェントを承認します。
$ oc -n <hosted_control_plane_namespace> patch agent \ 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d -p \ '{"spec":{"installation_disk_id":"/dev/sda","approved":true,"hostname":"worker-zvm-0.hostedn.example.com"}}' \1 --type merge- 1
- 必要に応じて、仕様でエージェント ID
<installation_disk_id>と<hostname>を設定できます。
次のコマンドを実行して、エージェントが承認されていることを確認します。
$ oc -n <hosted_control_plane_namespace> get agents出力例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign
4.5.7. IBM Z 上のホステッドクラスターの NodePool オブジェクトのスケーリング
NodePool オブジェクトは、ホステッドクラスターの作成時に作成されます。NodePool オブジェクトをスケーリングすることで、Hosted Control Plane にさらに多くのコンピュートノードを追加できます。
ノードプールをスケールアップすると、マシンが作成されます。Cluster API プロバイダーは、承認され、検証に合格し、現在使用されておらず、ノードプールの仕様で指定されている要件を満たすエージェントを見つけます。エージェントのステータスと状態を確認することで、エージェントのインストールを監視できます。
ノードプールをスケールダウンすると、エージェントは対応するクラスターからバインド解除されます。クラスターを再利用する前に、PXE イメージを使用してクラスターを起動し、ノード数を更新する必要があります。
手順
次のコマンドを実行して、
NodePoolオブジェクトを 2 つのノードにスケーリングします。$ oc -n <clusters_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API エージェントプロバイダーは、ホステッドクラスターに割り当てられる 2 つのエージェントをランダムに選択します。これらのエージェントはさまざまな状態を経て、最終的に OpenShift Container Platform ノードとしてホステッドクラスターに参加します。エージェントは次の順序で移行フェーズを通過します。
-
binding -
discovering -
insufficient -
installing -
installing-in-progress -
added-to-existing-cluster
-
次のコマンドを実行して、スケールされた特定のエージェントのステータスを確認します。
$ oc -n <hosted_control_plane_namespace> get agent -o \ jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} \ Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'出力例
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient次のコマンドを実行して、移行フェーズを表示します。
$ oc -n <hosted_control_plane_namespace> get agent出力例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign次のコマンドを実行して、ホステッドクラスターにアクセスするための
kubeconfigファイルを生成します。$ hcp create kubeconfig \ --namespace <clusters_namespace> \ --name <hosted_cluster_namespace> > <hosted_cluster_name>.kubeconfigエージェントが
added-to-existing-cluster状態に達したら、次のコマンドを入力して、OpenShift Container Platform ノードが表示されることを確認します。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes出力例
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8fCluster Operator は、ワークロードをノードに追加することによってリコンシリエーションを開始します。
次のコマンドを入力して、
NodePoolオブジェクトをスケールアップしたときに 2 台のマシンが作成されたことを確認します。$ oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io出力例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0次のコマンドを実行して、クラスターのバージョンを確認します。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co出力例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0-ec.2 True False 40h Cluster version is 4.15.0-ec.2以下のコマンドを実行して、クラスター Operator のステータスを確認します。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperators
クラスターの各コンポーネントの出力には、NAME、VERSION、AVAILABLE、PROGRESSING、DEGRADED、SINCE、および MESSAGE のクラスター Operator のステータスが表示されます。
出力例は、Operator の初期設定 参照してください。
4.6. IBM Power への Hosted Control Plane のデプロイ
クラスターをホスティングクラスターとして機能するように設定することで、Hosted Control Plane をデプロイできます。この設定により、多数のクラスターを管理するための効率的でスケーラブルなソリューションが実現します。ホスティングクラスターは、コントロールプレーンをホストする OpenShift Container Platform クラスターです。ホスティングクラスターは 管理 クラスターとも呼ばれます。
管理 クラスターは マネージド クラスターではありません。マネージドクラスターは、ハブクラスターが管理するクラスターです。
multicluster engine Operator がホスティングクラスターとしてサポートしているのは、デフォルトの local-cluster (マネージドハブクラスター) と、ハブクラスターだけです。
ベアメタルインフラストラクチャーに Hosted Control Plane をプロビジョニングするには、Agent プラットフォームを使用できます。Agent プラットフォームは、Central Infrastructure Management サービスを使用して、ホステッドクラスターにコンピュートノードを追加します。詳細は、「Central Infrastructure Management サービスの有効化」を参照してください。
各 IBM Power ホストは、Central Infrastructure Management が提供する Discovery イメージを使用して起動する必要があります。各ホストが起動すると、エージェントプロセスが実行されてホストの詳細が検出され、インストールが完了します。Agent カスタムリソースは、各ホストを表します。
Agent プラットフォームでホステッドクラスターを作成すると、HyperShift は Hosted Control Plane namespace に Agent Cluster API プロバイダーをインストールします。
4.6.1. IBM Power で Hosted Control Plane を設定するための前提条件
- OpenShift Container Platform クラスターにインストールされた multicluster engine for Kubernetes Operator 2.7 以降。multicluster engine Operator は、Red Hat Advanced Cluster Management (RHACM) をインストールすると、自動的にインストールされます。multicluster engine Operator は、OpenShift Container Platform OperatorHub から Operator として RHACM なしでインストールすることもできます。
multicluster engine Operator には、少なくとも 1 つのマネージド OpenShift Container Platform クラスターが必要です。multicluster engine Operator バージョン 2.7 以降では、
local-clusterマネージドハブクラスターが自動的にインポートされます。local-clusterの詳細は、RHACM ドキュメントの 詳細設定 を参照してください。次のコマンドを実行して、ハブクラスターの状態を確認できます。$ oc get managedclusters local-cluster- HyperShift Operator を実行するには、少なくとも 3 つのコンピュートノードを持つホスティングクラスターが必要です。
- Central Infrastructure Management サービスが有効である。詳細は、「Central Infrastructure Management サービスの有効化」を参照してください。
- Hosted Control Plane コマンドラインインターフェイスをインストールする必要があります。詳細は、「Hosted Control Plane のコマンドラインインターフェイスのインストール」を参照してください。
Hosted Control Plane 機能はデフォルトで有効になっています。この機能を以前に無効にしていて、手動で有効にする場合は、「Hosted Control Plane 機能の手動での有効化」を参照してください。機能を無効にする必要がある場合は、「Hosted Control Plane 機能の無効化」を参照してください。
4.6.2. IBM Power のインフラストラクチャー要件
Agent プラットフォームはインフラストラクチャーを作成しませんが、インフラストラクチャー用の次のリソースを必要とします。
- Agents: Agent は、Discovery イメージで起動し、OpenShift Container Platform ノードとしてプロビジョニングできるホストを表します。
- DNS: API および Ingress エンドポイントは、ルーティング可能である必要があります。
4.6.3. IBM Power での Hosted Control Plane の DNS 設定
ネットワーク外のクライアントは、ホステッドクラスターの API サーバーにアクセスできます。API サーバーに到達できる宛先を指す api.<hosted_cluster_name>.<basedomain> エントリーの DNS エントリーが存在する必要があります。
DNS エントリーは、Hosted Control Plane を実行しているマネージドクラスター内のいずれかのノードを指す単純なレコードで構いません。
また、そのエントリーでデプロイ済みのロードバランサーを指定し、受信トラフィックを Ingress Pod にリダイレクトすることもできます。
次の DNS 設定の例を参照してください。
$ cat /var/named/<example.krnl.es.zone>出力例
$ TTL 900
@ IN SOA bastion.example.krnl.es.com. hostmaster.example.krnl.es.com. (
2019062002
1D 1H 1W 3H )
IN NS bastion.example.krnl.es.com.
;
;
api IN A 1xx.2x.2xx.1xx
api-int IN A 1xx.2x.2xx.1xx
;
;
*.apps.<hosted_cluster_name>.<basedomain> IN A 1xx.2x.2xx.1xx
;
;EOF- 1
- このレコードは、Hosted Control Plane の受信トラフィックと送信トラフィックを処理する API ロードバランサーの IP アドレスを参照します。
IBM Power の場合、エージェントの IP アドレスに対応する IP アドレスを追加します。
設定例
compute-0 IN A 1xx.2x.2xx.1yy
compute-1 IN A 1xx.2x.2xx.1yy4.6.4. コンソールを使用したホステッドクラスターの作成
ベアメタルインフラストラクチャーには、ホステッドクラスターを作成またはインポートできます。multicluster engine Operator へのアドオンとして Assisted Installer を有効にし、Agent プラットフォームを使用してホステッドクラスターを作成すると、HyperShift Operator によって Agent Cluster API プロバイダーが Hosted Control Plane namespace にインストールされます。Agent Cluster API プロバイダーは、コントロールプレーンをホストする管理クラスターと、コンピュートノードのみで構成されるホステッドクラスターを接続します。
前提条件
- 各ホステッドクラスターの名前がクラスター全体で一意である。ホステッドクラスター名は、既存のマネージドクラスターと同じにすることはできません。この要件を満たさないと、multicluster engine Operator がホステッドクラスターを管理できません。
-
ホステッドクラスター名として
clustersという単語を使用しない。 - multicluster engine Operator のマネージドクラスターの namespace にホステッドクラスターを作成することはできない。
- 最適なセキュリティーと管理プラクティスを実現するために、他のホステッドクラスターとは別にホステッドクラスターを作成する。
- クラスターにデフォルトのストレージクラスが設定されていることを確認する。そうしない場合、保留中の永続ボリューム要求 (PVC) が表示されることがあります。
-
デフォルトでは、
hcp create cluster agentコマンドを使用すると、ノードポートが設定されたホステッドクラスターが作成されます。ベアメタル上のホステッドクラスターの推奨公開ストラテジーは、ロードバランサーを通じてサービスを公開することです。Web コンソールまたは Red Hat Advanced Cluster Management を使用してホステッドクラスターを作成する場合、Kubernetes API サーバー以外のサービスの公開ストラテジーを設定するには、HostedClusterカスタムリソースでservicePublishingStrategy情報を手動で指定する必要があります。 インフラストラクチャー、ファイアウォール、ポート、およびサービスに関連する要件を含め、「ベアメタル上の Hosted Control Plane の要件」に記載されている要件を満たしていることを確認する。要件では、たとえば次のコマンド例に示すように、管理クラスター内のベアメタルホストに適切なゾーンラベルを追加する方法が説明されています。
$ oc label node [compute-node-1] topology.kubernetes.io/zone=zone1$ oc label node [compute-node-2] topology.kubernetes.io/zone=zone2$ oc label node [compute-node-3] topology.kubernetes.io/zone=zone3- ハードウェアインベントリーにベアメタルノードを追加したことを確認する。
手順
次のコマンドを入力して namespace を作成します。
$ oc create ns <hosted_cluster_namespace><hosted_cluster_namespace>は、ホステッドクラスター namespace の識別子に置き換えます。namespace は HyperShift Operator によって作成されます。ベアメタルインフラストラクチャーにホステッドクラスターを作成するプロセスでは、Cluster API プロバイダー用のロールが生成されます。このロールを生成するには、namespace が事前に存在している必要があります。次のコマンドを入力して、ホステッドクラスターの設定ファイルを作成します。
$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<base_domain> \4 --api-server-address=api.<hosted_cluster_name>.<base_domain> \5 --etcd-storage-class=<etcd_storage_class> \6 --ssh-key=<path_to_ssh_key> \7 --namespace=<hosted_cluster_namespace> \8 --control-plane-availability-policy=HighlyAvailable \9 --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image>-multi \10 --node-pool-replicas=<node_pool_replica_count> \11 --render \ --render-sensitive \ --ssh-key <home_directory>/<path_to_ssh_key>/<ssh_key> > hosted-cluster-config.yaml12 - 1
- ホステッドクラスターの名前 (例:
example) を指定します。 - 2
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 3
- Hosted Control Plane の namespace を指定します (例:
clusters-example)。oc get agent -n <hosted_control_plane_namespace>コマンドを使用して、この namespace でエージェントが使用可能であることを確認します。 - 4
- ベースドメイン (例:
krnl.es) を指定します。 - 5
--api-server-addressフラグは、ホステッドクラスター内の Kubernetes API 通信に使用される IP アドレスを定義します。--api-server-addressフラグを設定しない場合は、管理クラスターに接続するためにログインする必要があります。- 6
- etcd ストレージクラス名を指定します (例:
lvm-storageclass)。 - 7
- SSH 公開鍵へのパスを指定します。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 8
- ホステッドクラスターの namespace を指定します。
- 9
- Hosted Control Plane コンポーネントの可用性ポリシーを指定します。サポートされているオプションは
SingleReplicaとHighlyAvailableです。デフォルト値はHighlyAvailableです。 - 10
- 使用するサポート対象の OpenShift Container Platform バージョンを指定します (例:
4.19.0-multi)。非接続環境を使用している場合は、<ocp_release_image>をダイジェストイメージに置き換えます。OpenShift Container Platform リリースイメージダイジェストを抽出するには、OpenShift Container Platform リリースイメージダイジェストの抽出 を参照してください。 - 11
- ノードプールのレプリカ数を指定します (例:
3)。レプリカ数は0以上で指定する必要があります。指定したとおりの数のノードが作成されます。この値を指定しない場合、ノードプールは作成されません。 - 12
--ssh-keyフラグの後に、SSH 鍵へのパス (例:user/.ssh/id_rsa) を指定します。
サービス公開ストラテジーを設定します。デフォルトでは、ホステッドクラスターは
NodePortサービス公開ストラテジーを使用します。これは、ノードポートが追加のインフラストラクチャーなしで常に利用可能であるためです。ただし、ロードバランサーを使用するようにサービス公開ストラテジーを設定することもできます。-
デフォルトの
NodePortストラテジーを使用している場合は、管理クラスターノードではなく、ホステッドクラスターコンピュートノードを指すように DNS を設定します。詳細は、「ベアメタル上の DNS 設定」を参照してください。 実稼働環境では、証明書の処理と自動 DNS 解決を提供する
LoadBalancerストラテジーを使用します。次の例は、ホステッドクラスターの設定ファイルでLoadBalancerサービス公開ストラテジーを変更する方法を示しています。# ... spec: services: - service: APIServer servicePublishingStrategy: type: LoadBalancer1 - service: Ignition servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route sshKey: name: <ssh_key> # ...- 1
- API サーバータイプとして
LoadBalancerを指定します。それ以外のすべてのサービスでは、タイプとしてRouteを指定します。
-
デフォルトの
次のコマンドを入力して、ホステッドクラスター設定ファイルに変更を適用します。
$ oc apply -f hosted_cluster_config.yaml次のコマンドを入力して、ホステッドクラスター、ノードプール、および Pod の作成を確認します。
$ oc get hostedcluster \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get nodepool \ <hosted_cluster_namespace> -n \ <hosted_cluster_namespace> -o \ jsonpath='{.status.conditions[?(@.status=="False")]}' | jq .$ oc get pods -n <hosted_cluster_namespace>-
ホステッドクラスターの準備ができていることを確認します。
Available: Trueというステータスはクラスターの準備完了状態であることを示しています。ノードプールのステータスにはAllMachinesReady: Trueと表示されます。これらのステータスは、すべてのクラスター Operator の健全性を示しています。 ホステッドクラスターに MetalLB をインストールします。
次のコマンドを入力して、ホステッドクラスターから
kubeconfigファイルを展開し、ホステッドクラスターアクセス用の環境変数を設定します。$ oc get secret \ <hosted_cluster_namespace>-admin-kubeconfig \ -n <hosted_cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' \ | base64 -d > \ kubeconfig-<hosted_cluster_namespace>.yaml$ export KUBECONFIG="/path/to/kubeconfig-<hosted_cluster_namespace>.yaml"install-metallb-operator.yamlファイルを作成して MetalLB Operator をインストールします。apiVersion: v1 kind: Namespace metadata: name: metallb-system --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb-system spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Automatic # ...以下のコマンドを入力してファイルを適用します。
$ oc apply -f install-metallb-operator.yamldeploy-metallb-ipaddresspool.yamlファイルを作成して、MetalLB IP アドレスプールを設定します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: metallb namespace: metallb-system spec: autoAssign: true addresses: - 10.11.176.71-10.11.176.75 --- apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - metallb # ...次のコマンドを入力して設定を適用します。
$ oc apply -f deploy-metallb-ipaddresspool.yaml次のコマンドを入力して、Operator ステータス、IP アドレスプール、および
L2Advertisementリソースを確認し、MetalLB のインストールを検証します。$ oc get pods -n metallb-system$ oc get ipaddresspool -n metallb-system$ oc get l2advertisement -n metallb-system
Ingress 用のロードバランサーを設定します。
ingress-loadbalancer.yamlファイルを作成します。apiVersion: v1 kind: Service metadata: annotations: metallb.universe.tf/address-pool: metallb name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer # ...次のコマンドを入力して設定を適用します。
$ oc apply -f ingress-loadbalancer.yaml次のコマンドを入力して、ロードバランサーサービスが期待どおりに動作することを確認します。
$ oc get svc metallb-ingress -n openshift-ingress出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metallb-ingress LoadBalancer 172.31.127.129 10.11.176.71 80:30961/TCP,443:32090/TCP 16h
ロードバランサーと連携するように DNS を設定します。
-
*.apps.<hosted_cluster_namespace>.<base_domain>ワイルドカード DNS レコードがロードバランサーの IP アドレスをポイントするように、appsドメインの DNS を設定します。 次のコマンドを入力して DNS 解決を確認します。
$ nslookup console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain> <load_balancer_ip_address>出力例
Server: 10.11.176.1 Address: 10.11.176.1#53 Name: console-openshift-console.apps.my-hosted-cluster.sample-base-domain.com Address: 10.11.176.71
-
検証
次のコマンドを入力して、クラスター Operator を確認します。
$ oc get clusteroperatorsすべての Operator に
AVAILABLE: True、PROGRESSING: False、DEGRADED: Falseが表示されていることを確認します。次のコマンドを入力してノードを確認します。
$ oc get nodes各ノードのステータスが
READYであることを確認します。Web ブラウザーに次の URL を入力して、コンソールへのアクセスをテストします。
https://console-openshift-console.apps.<hosted_cluster_namespace>.<base_domain>
第5章 Hosted Control Plane の管理
5.1. AWS での Hosted Control Plane の管理
Amazon Web Services (AWS) 上の OpenShift Container Platform に Hosted Control Plane を使用する場合、セットアップに応じてインフラストラクチャーの要件が異なります。
5.1.1. AWS インフラストラクチャーと IAM 権限を管理するための前提条件
Amazon Web Services (AWS) 上の OpenShift Container Platform の Hosted Control Plane を設定するには、次のインフラストラクチャー要件を満たす必要があります。
- ホステッドクラスターを作成する前に、Hosted Control Plane を設定した。
- AWS Identity and Access Management (IAM) ロールと AWS Security Token Service (STS) 認証情報を作成した。
5.1.1.1. AWS のインフラストラクチャー要件
Amazon Web Services (AWS) で Hosted Control Plane を使用する場合、インフラストラクチャー要件は次のカテゴリーに当てはまります。
- 任意の AWS アカウント内の、HyperShift Operator 用の事前に必要な管理対象外インフラストラクチャー
- ホステッドクラスターの AWS アカウント内の事前に必要な管理対象外インフラストラクチャー
- 管理 AWS アカウント内の Hosted Control Plane によって管理されるインフラストラクチャー
- ホステッドクラスターの AWS アカウント内の Hosted Control Plane によって管理されるインフラストラクチャー
- ホステッドクラスターの AWS アカウント内の Kubernetes によって管理されるインフラストラクチャー
事前に必要とは、Hosted Control Plane を適切に動作させるために AWS インフラストラクチャーが必要であることを意味します。管理対象外とは、Operator やコントローラーによってインフラストラクチャーが作成されないことを意味します。
5.1.1.2. AWS アカウント内の HyperShift Operator 用の管理対象外インフラストラクチャー
任意の Amazon Web Services (AWS) アカウントは、Hosted Control Plane サービスのプロバイダーによって異なります。
セルフマネージドの Hosted Control Plane では、クラスターサービスプロバイダーが AWS アカウントを制御します。クラスターサービスプロバイダーは、クラスターコントロールプレーンをホストし、稼働時間の責任を負う管理者です。マネージドの Hosted Control Plane では、AWS アカウントは Red Hat に属します。
HyperShift Operator 用の事前に必要な管理対象外のインフラストラクチャーでは、管理クラスター AWS アカウントに次のインフラストラクチャー要件が適用されます。
1 つの S3 バケット
- OpenID Connect (OIDC)
ルート 53 のホステッドゾーン
- ホステッドクラスターのプライベートおよびパブリックエントリーをホストするドメイン
5.1.1.3. 管理 AWS アカウントの管理対象外インフラストラクチャーの要件
インフラストラクチャーが事前に必要であり、ホステッドクラスターの AWS アカウントで管理されていない場合、すべてのアクセスモードのインフラストラクチャー要件は次のとおりです。
- 1 つの VPC
- 1 つの DHCP オプション
2 つのサブネット
- 内部データプレーンサブネットであるプライベートサブネット
- データプレーンからインターネットへのアクセスを可能にするパブリックサブネット
- 1 つのインターネットゲートウェイ
- 1 つの Elastic IP
- 1 つの NAT ゲートウェイ
- 1 つのセキュリティーグループ (ワーカーノード)
- 2 つのルートテーブル (1 つはプライベート、もう 1 つはパブリック)
- 2 つの Route 53 のホステッドゾーン
次の項目に対する十分なクォータ:
- パブリックホステッドクラスター用の 1 つの Ingress サービスロードバランサー
- プライベートホステッドクラスター用の 1 つのプライベートリンクエンドポイント
プライベートリンクネットワークが機能するには、ホステッドクラスターの AWS アカウントのエンドポイントゾーンが、管理クラスターの AWS アカウントのサービスエンドポイントによって解決されるインスタンスのゾーンと同じである必要があります。AWS では、ゾーン名は us-east-2b などのエイリアスであり、必ずしも異なるアカウントの同じゾーンにマップされるわけではありません。そのため、プライベートリンクが機能するには、管理クラスターのリージョンのすべてのゾーンにサブネットまたはワーカーが必要です。
5.1.1.4. 管理 AWS アカウントのインフラストラクチャーの要件
インフラストラクチャーが管理 AWS アカウントの Hosted Control Plane によって管理されている場合、インフラストラクチャーの要件は、クラスターがパブリック、プライベート、またはその組み合わせであるかによって異なります。
パブリッククラスターを使用するアカウントの場合、インフラストラクチャー要件は次のとおりです。
ネットワークロードバランサー: ロードバランサー Kube API サーバー
- Kubernetes がセキュリティーグループを作成する
ボリューム
- etcd 用 (高可用性に応じて 1 つまたは 3 つ)
- OVN-Kube 用
プライベートクラスターを使用するアカウントの場合、インフラストラクチャー要件は次のとおりです。
- ネットワークロードバランサー: ロードバランサーのプライベートルーター
- エンドポイントサービス (プライベートリンク)
パブリッククラスターとプライベートクラスターを持つアカウントの場合、インフラストラクチャー要件は次のとおりです。
- ネットワークロードバランサー: ロードバランサーのパブリックルーター
- ネットワークロードバランサー: ロードバランサーのプライベートルーター
- エンドポイントサービス (プライベートリンク)
ボリューム
- etcd 用 (高可用性に応じて 1 つまたは 3 つ)
- OVN-Kube 用
5.1.1.5. ホステッドクラスターの AWS アカウントのインフラストラクチャー要件
インフラストラクチャーがホステッドクラスターの Amazon Web Services (AWS) アカウントの Hosted Control Plane によって管理されている場合、インフラストラクチャーの要件は、クラスターがパブリック、プライベート、またはその組み合わせであるかによって異なります。
パブリッククラスターを使用するアカウントの場合、インフラストラクチャー要件は次のとおりです。
-
ノードプールには、
RoleとRolePolicyが定義された EC2 インスタンスが必要です。
プライベートクラスターを使用するアカウントの場合、インフラストラクチャー要件は次のとおりです。
- アベイラビリティーゾーンごとに 1 つのプライベートリンクエンドポイント
- ノードプールの EC2 インスタンス
パブリッククラスターとプライベートクラスターを持つアカウントの場合、インフラストラクチャー要件は次のとおりです。
- アベイラビリティーゾーンごとに 1 つのプライベートリンクエンドポイント
- ノードプールの EC2 インスタンス
5.1.1.6. ホステッドクラスターの AWS アカウント内の Kubernetes によって管理されるインフラストラクチャー
ホステッドクラスターの Amazon Web Services (AWS) アカウント内のインフラストラクチャーを Kubernetes によって管理する場合、インフラストラクチャーの要件は次のとおりです。
- デフォルトの Ingress 用のネットワークロードバランサー
- レジストリー用の S3 バケット
5.1.2. Identity and Access Management (IAM) 権限
Hosted Control Plane のコンテキストでは、コンシューマーが Amazon Resource Name (ARN) ロールを作成する役割を果たします。コンシューマー は、権限ファイルを生成するための自動プロセスです。コンシューマーは CLI または OpenShift Cluster Manager である場合があります。Hosted Control Plane では、最小権限コンポーネントの原則を遵守するための詳細な設定が可能です。そのため、すべてのコンポーネントが独自のロールを使用して Amazon Web Services (AWS) オブジェクトを操作または作成します。ロールは、製品が正常に機能するために必要なものに制限されます。
ホステッドクラスターは ARN ロールを入力として受け取り、コンシューマーは各コンポーネントの AWS 権限設定を作成します。その結果、コンポーネントは STS および事前設定された OIDC IDP を通じて認証できるようになります。
次のロールは、コントロールプレーン上で実行され、データプレーン上で動作する、Hosted Control Plane の一部のコンポーネントによって消費されます。
-
controlPlaneOperatorARN -
imageRegistryARN -
ingressARN -
kubeCloudControllerARN -
nodePoolManagementARN -
storageARN -
networkARN
次の例は、ホステッドクラスターからの IAM ロールへの参照を示しています。
...
endpointAccess: Public
region: us-east-2
resourceTags:
- key: kubernetes.io/cluster/example-cluster-bz4j5
value: owned
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-controller
networkARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-node-pool
storageARN: arn:aws:iam::820196288204:role/example-cluster-bz4j5-aws-ebs-csi-driver-controller
type: AWS
...Hosted Control Plane が使用するロールを次の例に示します。
ingressARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "elasticloadbalancing:DescribeLoadBalancers", "tag:GetResources", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets" ], "Resource": [ "arn:aws:route53:::PUBLIC_ZONE_ID", "arn:aws:route53:::PRIVATE_ZONE_ID" ] } ] }imageRegistryARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:DeleteBucket", "s3:PutBucketTagging", "s3:GetBucketTagging", "s3:PutBucketPublicAccessBlock", "s3:GetBucketPublicAccessBlock", "s3:PutEncryptionConfiguration", "s3:GetEncryptionConfiguration", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:GetBucketLocation", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucketMultipartUploads", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": "\*" } ] }storageARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:AttachVolume", "ec2:CreateSnapshot", "ec2:CreateTags", "ec2:CreateVolume", "ec2:DeleteSnapshot", "ec2:DeleteTags", "ec2:DeleteVolume", "ec2:DescribeInstances", "ec2:DescribeSnapshots", "ec2:DescribeTags", "ec2:DescribeVolumes", "ec2:DescribeVolumesModifications", "ec2:DetachVolume", "ec2:ModifyVolume" ], "Resource": "\*" } ] }networkARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "ec2:DescribeInstanceTypes", "ec2:UnassignPrivateIpAddresses", "ec2:AssignPrivateIpAddresses", "ec2:UnassignIpv6Addresses", "ec2:AssignIpv6Addresses", "ec2:DescribeSubnets", "ec2:DescribeNetworkInterfaces" ], "Resource": "\*" } ] }kubeCloudControllerARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:DescribeInstances", "ec2:DescribeImages", "ec2:DescribeRegions", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVolumes", "ec2:CreateSecurityGroup", "ec2:CreateTags", "ec2:CreateVolume", "ec2:ModifyInstanceAttribute", "ec2:ModifyVolume", "ec2:AttachVolume", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateRoute", "ec2:DeleteRoute", "ec2:DeleteSecurityGroup", "ec2:DeleteVolume", "ec2:DetachVolume", "ec2:RevokeSecurityGroupIngress", "ec2:DescribeVpcs", "elasticloadbalancing:AddTags", "elasticloadbalancing:AttachLoadBalancerToSubnets", "elasticloadbalancing:ApplySecurityGroupsToLoadBalancer", "elasticloadbalancing:CreateLoadBalancer", "elasticloadbalancing:CreateLoadBalancerPolicy", "elasticloadbalancing:CreateLoadBalancerListeners", "elasticloadbalancing:ConfigureHealthCheck", "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DeleteLoadBalancerListeners", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeLoadBalancerAttributes", "elasticloadbalancing:DetachLoadBalancerFromSubnets", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:ModifyLoadBalancerAttributes", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:SetLoadBalancerPoliciesForBackendServer", "elasticloadbalancing:AddTags", "elasticloadbalancing:CreateListener", "elasticloadbalancing:CreateTargetGroup", "elasticloadbalancing:DeleteListener", "elasticloadbalancing:DeleteTargetGroup", "elasticloadbalancing:DescribeListeners", "elasticloadbalancing:DescribeLoadBalancerPolicies", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DescribeTargetHealth", "elasticloadbalancing:ModifyListener", "elasticloadbalancing:ModifyTargetGroup", "elasticloadbalancing:RegisterTargets", "elasticloadbalancing:SetLoadBalancerPoliciesOfListener", "iam:CreateServiceLinkedRole", "kms:DescribeKey" ], "Resource": [ "\*" ], "Effect": "Allow" } ] }nodePoolManagementARN{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:AllocateAddress", "ec2:AssociateRouteTable", "ec2:AttachInternetGateway", "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateInternetGateway", "ec2:CreateNatGateway", "ec2:CreateRoute", "ec2:CreateRouteTable", "ec2:CreateSecurityGroup", "ec2:CreateSubnet", "ec2:CreateTags", "ec2:DeleteInternetGateway", "ec2:DeleteNatGateway", "ec2:DeleteRouteTable", "ec2:DeleteSecurityGroup", "ec2:DeleteSubnet", "ec2:DeleteTags", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeAvailabilityZones", "ec2:DescribeImages", "ec2:DescribeInstances", "ec2:DescribeInternetGateways", "ec2:DescribeNatGateways", "ec2:DescribeNetworkInterfaces", "ec2:DescribeNetworkInterfaceAttribute", "ec2:DescribeRouteTables", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs", "ec2:DescribeVpcAttribute", "ec2:DescribeVolumes", "ec2:DetachInternetGateway", "ec2:DisassociateRouteTable", "ec2:DisassociateAddress", "ec2:ModifyInstanceAttribute", "ec2:ModifyNetworkInterfaceAttribute", "ec2:ModifySubnetAttribute", "ec2:ReleaseAddress", "ec2:RevokeSecurityGroupIngress", "ec2:RunInstances", "ec2:TerminateInstances", "tag:GetResources", "ec2:CreateLaunchTemplate", "ec2:CreateLaunchTemplateVersion", "ec2:DescribeLaunchTemplates", "ec2:DescribeLaunchTemplateVersions", "ec2:DeleteLaunchTemplate", "ec2:DeleteLaunchTemplateVersions" ], "Resource": [ "\*" ], "Effect": "Allow" }, { "Condition": { "StringLike": { "iam:AWSServiceName": "elasticloadbalancing.amazonaws.com" } }, "Action": [ "iam:CreateServiceLinkedRole" ], "Resource": [ "arn:*:iam::*:role/aws-service-role/elasticloadbalancing.amazonaws.com/AWSServiceRoleForElasticLoadBalancing" ], "Effect": "Allow" }, { "Action": [ "iam:PassRole" ], "Resource": [ "arn:*:iam::*:role/*-worker-role" ], "Effect": "Allow" } ] }controlPlaneOperatorARN{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:CreateVpcEndpoint", "ec2:DescribeVpcEndpoints", "ec2:ModifyVpcEndpoint", "ec2:DeleteVpcEndpoints", "ec2:CreateTags", "route53:ListHostedZones" ], "Resource": "\*" }, { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets" ], "Resource": "arn:aws:route53:::%s" } ] }
5.1.3. AWS インフラストラクチャーと IAM リソースを個別に作成する
デフォルトでは、hcp create cluster aws コマンドは、クラウドインフラストラクチャーをホステッドクラスターとともに作成し、それを適用します。hcp create cluster aws コマンドを使用してクラスターの作成だけを実行したり、クラスターを生成して適用する前に変更したりできるように、クラウドインフラストラクチャー部分を個別に作成することもできます。
クラウドインフラストラクチャー部分を個別に作成するには、Amazon Web Services (AWS) インフラストラクチャーの作成、AWS Identity and Access (IAM) リソースの作成、およびクラスターの作成を行う必要があります。
5.1.3.1. AWS インフラストラクチャーを個別に作成する
Amazon Web Services (AWS) インフラストラクチャーを作成するには、クラスター用の Virtual Private Cloud (VPC) やその他のリソースを作成する必要があります。AWS コンソールまたはインフラストラクチャー自動化およびプロビジョニングツールを使用できます。AWS コンソールの使用手順は、AWS ドキュメントの Create a VPC plus other VPC resources を参照してください。
VPC には、プライベートサブネットとパブリックサブネット、およびネットワークアドレス変換 (NAT) ゲートウェイやインターネットゲートウェイなどの外部アクセス用のリソースが含まれている必要があります。VPC に加えて、クラスターの Ingress 用のプライベートホストゾーンが必要です。PrivateLink (Private または PublicAndPrivate アクセスモード) を使用するクラスターを作成する場合は、PrivateLink 用の追加のホストゾーンが必要です。
次の設定例を使用して、ホステッドクラスター用の AWS インフラストラクチャーを作成します。
---
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: clusters
spec: {}
status: {}
---
apiVersion: v1
data:
.dockerconfigjson: xxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <pull_secret_name>
namespace: clusters
---
apiVersion: v1
data:
key: xxxxxxxxxxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <etcd_encryption_key_name>
namespace: clusters
type: Opaque
---
apiVersion: v1
data:
id_rsa: xxxxxxxxx
id_rsa.pub: xxxxxxxxx
kind: Secret
metadata:
creationTimestamp: null
labels:
hypershift.openshift.io/safe-to-delete-with-cluster: "true"
name: <ssh-key-name>
namespace: clusters
---
apiVersion: hypershift.openshift.io/v1beta1
kind: HostedCluster
metadata:
creationTimestamp: null
name: <hosted_cluster_name>
namespace: clusters
spec:
autoscaling: {}
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: <dns_domain>
privateZoneID: xxxxxxxx
publicZoneID: xxxxxxxx
etcd:
managed:
storage:
persistentVolume:
size: 8Gi
storageClassName: gp3-csi
type: PersistentVolume
managementType: Managed
fips: false
infraID: <infra_id>
issuerURL: <issuer_url>
networking:
clusterNetwork:
- cidr: 10.132.0.0/14
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- cidr: 172.31.0.0/16
olmCatalogPlacement: management
platform:
aws:
cloudProviderConfig:
subnet:
id: <subnet_xxx>
vpc: <vpc_xxx>
zone: us-west-1b
endpointAccess: Public
multiArch: false
region: us-west-1
rolesRef:
controlPlaneOperatorARN: arn:aws:iam::820196288204:role/<infra_id>-control-plane-operator
imageRegistryARN: arn:aws:iam::820196288204:role/<infra_id>-openshift-image-registry
ingressARN: arn:aws:iam::820196288204:role/<infra_id>-openshift-ingress
kubeCloudControllerARN: arn:aws:iam::820196288204:role/<infra_id>-cloud-controller
networkARN: arn:aws:iam::820196288204:role/<infra_id>-cloud-network-config-controller
nodePoolManagementARN: arn:aws:iam::820196288204:role/<infra_id>-node-pool
storageARN: arn:aws:iam::820196288204:role/<infra_id>-aws-ebs-csi-driver-controller
type: AWS
pullSecret:
name: <pull_secret_name>
release:
image: quay.io/openshift-release-dev/ocp-release:4.16-x86_64
secretEncryption:
aescbc:
activeKey:
name: <etcd_encryption_key_name>
type: aescbc
services:
- service: APIServer
servicePublishingStrategy:
type: LoadBalancer
- service: OAuthServer
servicePublishingStrategy:
type: Route
- service: Konnectivity
servicePublishingStrategy:
type: Route
- service: Ignition
servicePublishingStrategy:
type: Route
- service: OVNSbDb
servicePublishingStrategy:
type: Route
sshKey:
name: <ssh_key_name>
status:
controlPlaneEndpoint:
host: ""
port: 0
---
apiVersion: hypershift.openshift.io/v1beta1
kind: NodePool
metadata:
creationTimestamp: null
name: <node_pool_name>
namespace: clusters
spec:
arch: amd64
clusterName: <hosted_cluster_name>
management:
autoRepair: true
upgradeType: Replace
nodeDrainTimeout: 0s
platform:
aws:
instanceProfile: <instance_profile_name>
instanceType: m6i.xlarge
rootVolume:
size: 120
type: gp3
subnet:
id: <subnet_xxx>
type: AWS
release:
image: quay.io/openshift-release-dev/ocp-release:4.16-x86_64
replicas: 2
status:
replicas: 0- 1
<pull_secret_name>は、プルシークレットの名前に置き換えます。- 2
<etcd_encryption_key_name>は、etcd 暗号鍵の名前に置き換えます。- 3
<ssh_key_name>は、SSH 鍵の名前に置き換えます。- 4
<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。- 5
<dns_domain>は、example.comなどのベース DNS ドメインに置き換えます。- 6
<infra_id>は、ホステッドクラスターに関連付けられている IAM リソースを特定する値に置き換えます。- 7
<issuer_url>は、末尾の値がinfra_idである発行者 URL に置き換えます。たとえば、https://example-hosted-us-west-1.s3.us-west-1.amazonaws.com/example-hosted-infra-idです。- 8
<subnet_xxx>は、サブネット ID に置き換えます。プライベートサブネットとパブリックサブネットの両方にタグを付ける必要があります。パブリックサブネットの場合は、kubernetes.io/role/elb=1を使用します。プライベートサブネットの場合は、kubernetes.io/role/internal-elb=1を使用します。- 9
<vpc_xxx>は、VPC ID に置き換えます。- 10
<node_pool_name>は、NodePoolリソースの名前に置き換えます。- 11
<instance_profile_name>は、AWS インスタンスの名前に置き換えます。
5.1.3.2. AWS IAM リソースの作成
Amazon Web Services (AWS) では、次の IAM リソースを作成する必要があります。
- IAM 内の OpenID Connect (OIDC) アイデンティティープロバイダー。これは STS 認証を有効にするために必要です。
- 7 つのロール。Kubernetes コントローラーマネージャー、クラスター API プロバイダー、レジストリーなど、プロバイダーとやり取りするコンポーネントごとに分かれたロールです。
- インスタンスプロファイル。これは、クラスターのすべてのワーカーインスタンスに割り当てられるプロファイルです。
5.1.3.3. ホステッドクラスターを個別に作成する
Amazon Web Services (AWS) にホステッドクラスターを個別に作成できます。
ホステッドクラスターを個別に作成するには、次のコマンドを入力します。
$ hcp create cluster aws \
--infra-id <infra_id> \
--name <hosted_cluster_name> \
--sts-creds <path_to_sts_credential_file> \
--pull-secret <path_to_pull_secret> \
--generate-ssh \
--node-pool-replicas 3
--role-arn <role_name> - 1
<infra_id>をcreate infra awsコマンドで指定したのと同じ ID に置き換えます。この値は、ホステッドクラスターに関連付けられている IAM リソースを識別します。- 2
<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。- 3
<path_to_sts_credential_file>は、create infra awsコマンドで指定した名前と同じ名前に置き換えます。- 4
<path_to_pull_secret>を有効な OpenShift Container Platform プルシークレットを含むファイルの名前に置き換えます。- 5
--generate-sshフラグはオプションですが、ワーカーに SSH 接続する必要がある場合に含めるとよいでしょう。SSH キーが生成され、ホステッドクラスターと同じ名 namespace にシークレットとして保存されます。- 6
<role_name>は、Amazon Resource Name (ARN) に置き換えます (例:arn:aws:iam::820196288204:role/myrole)。Amazon Resource Name (ARN) を指定します (例:arn:aws:iam::820196288204:role/myrole)。ARN ロールの詳細は、「Identity and Access Management (IAM) 権限」を参照してください。
コマンドに --render フラグを追加して、クラスターに適用する前にリソースを編集できるファイルに出力をリダイレクトすることもできます。
コマンドを実行すると、次のリソースがクラスターに適用されます。
- namespace
- プルシークレットを含むシークレット
-
HostedCluster -
NodePool - コントロールプレーンコンポーネントの 3 つの AWS STS シークレット
-
--generate-sshフラグを指定した場合は、1 つの SSH キーシークレット。
5.1.4. ホステッドクラスターをシングルアーキテクチャーからマルチアーキテクチャーに移行する
シングルアーキテクチャーの 64 ビット AMD ホステッドクラスターを、Amazon Web Services (AWS) 上のマルチアーキテクチャーのホステッドクラスターに移行すると、クラスター上でワークロードを実行するコストを削減できます。たとえば、64 ビット ARM に移行しながら、既存のワークロードを 64 ビット AMD で実行し、このワークロードを中央の Kubernetes クラスターから管理できます。
シングルアーキテクチャーのホステッドクラスターで管理できるのは、特定の CPU アーキテクチャーのノードプールだけです。一方、マルチアーキテクチャーのホステッドクラスターでは、CPU アーキテクチャーが異なる複数のノードプールを管理できます。AWS 上のマルチアーキテクチャーのホステッドクラスターでは、64 ビット AMD ノードプールと 64 ビット ARM ノードプールの両方を管理できます。
前提条件
- multicluster engine for Kubernetes Operator を使用して、Red Hat Advanced Cluster Management (RHACM) に AWS 用の OpenShift Container Platform 管理クラスターをインストールした。
- OpenShift Container Platform リリースペイロードの 64 ビット AMD バリアントを使用する既存のシングルアーキテクチャーのホステッドクラスターがある。
- OpenShift Container Platform リリースペイロードの同じ 64 ビット AMD バリアントを使用し、既存のホステッドクラスターによって管理されるノードプールがある。
次のコマンドラインツールがインストールされている。
-
oc -
kubectl -
hcp -
skopeo
-
手順
次のコマンドを実行して、シングルアーキテクチャーホステッドクラスターの既存の OpenShift Container Platform リリースイメージを確認します。
$ oc get hostedcluster/<hosted_cluster_name> \1 -o jsonpath='{.spec.release.image}'- 1
<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。
出力例
quay.io/openshift-release-dev/ocp-release:<4.y.z>-x86_641 - 1
<4.y.z>は、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
OpenShift Container Platform リリースイメージで、タグの代わりにダイジェストを使用する場合は、リリースイメージのマルチアーキテクチャータグバージョンを見つけます。
次のコマンドを実行して、OpenShift Container Platform バージョンの
OCP_VERSION環境変数を設定します。$ OCP_VERSION=$(oc image info quay.io/openshift-release-dev/ocp-release@sha256:ac78ebf77f95ab8ff52847ecd22592b545415e1ff6c7ff7f66bf81f158ae4f5e \ -o jsonpath='{.config.config.Labels["io.openshift.release"]}')次のコマンドを実行して、リリースイメージのマルチアーキテクチャータグバージョンの
MULTI_ARCH_TAG環境変数を設定します。$ MULTI_ARCH_TAG=$(skopeo inspect docker://quay.io/openshift-release-dev/ocp-release@sha256:ac78ebf77f95ab8ff52847ecd22592b545415e1ff6c7ff7f66bf81f158ae4f5e \ | jq -r '.RepoTags' | sed 's/"//g' | sed 's/,//g' \ | grep -w "$OCP_VERSION-multi$" | xargs)次のコマンドを実行して、マルチアーキテクチャーリリースイメージ名の
IMAGE環境変数を設定します。$ IMAGE=quay.io/openshift-release-dev/ocp-release:$MULTI_ARCH_TAGマルチアーキテクチャーイメージダイジェストのリストを表示するには、次のコマンドを実行します。
$ oc image info $IMAGE出力例
OS DIGEST linux/amd64 sha256:b4c7a91802c09a5a748fe19ddd99a8ffab52d8a31db3a081a956a87f22a22ff8 linux/ppc64le sha256:66fda2ff6bd7704f1ba72be8bfe3e399c323de92262f594f8e482d110ec37388 linux/s390x sha256:b1c1072dc639aaa2b50ec99b530012e3ceac19ddc28adcbcdc9643f2dfd14f34 linux/arm64 sha256:7b046404572ac96202d82b6cb029b421dddd40e88c73bbf35f602ffc13017f21
ホステッドクラスターをシングルアーキテクチャーからマルチアーキテクチャーに移行します。
ホステッドクラスターで
multiArchフラグをtrueに設定して、ホステッドクラスターが 64 ビット AMD と 64 ビット ARM の両方のノードプールを作成できるようにします。以下のコマンドを実行します。$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p '{"spec":{"platform":{"aws":{"multiArch":true}}}}' --type=merge次のコマンドを実行して、ホステッドクラスターで
multiArchフラグがtrueに設定されていることを確認します。$ oc get hostedcluster/<hosted_cluster_name> -o jsonpath='{.spec.platform.aws.multiArch}'ホステッドクラスターと同じ OpenShift Container Platform バージョンを必ず使用して、ホステッドクラスターのマルチアーキテクチャー OpenShift Container Platform リリースイメージを設定します。以下のコマンドを実行します。
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p \ '{"spec":{"release":{"image":"quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi"}}}' \1 --type=merge- 1
<4.y.z>は、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
次のコマンドを実行して、ホステッドクラスターにマルチアーキテクチャーイメージが設定されていることを確認します。
$ oc get hostedcluster/<hosted_cluster_name> \ -o jsonpath='{.spec.release.image}'
次のコマンドを実行して、
HostedControlPlaneリソースのステータスがProgressingであることを確認します。$ oc get hostedcontrolplane -n <hosted_control_plane_namespace> -oyaml出力例
#... - lastTransitionTime: "2024-07-28T13:07:18Z" message: HostedCluster is deploying, upgrading, or reconfiguring observedGeneration: 5 reason: Progressing status: "True" type: Progressing #...次のコマンドを実行して、
HostedClusterリソースのステータスがProgressingであることを確認します。$ oc get hostedcluster <hosted_cluster_name> \ -n <hosted_cluster_namespace> -oyaml
検証
次のコマンドを実行して、ノードプールが
HostedControlPlaneリソース内のマルチアーキテクチャーリリースイメージを使用していることを確認します。$ oc get hostedcontrolplane -n clusters-example -oyaml出力例
#... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi1 url: https://access.redhat.com/errata/RHBA-2024:4855 version: 4.16.5 history: - completionTime: "2024-07-28T13:10:58Z" image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi startedTime: "2024-07-28T13:10:27Z" state: Completed verified: false version: <4.x.y>- 1
<4.y.z>は、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
注記マルチアーキテクチャー OpenShift Container Platform リリースイメージは、
HostedCluster、HostedControlPlaneリソース、および Hosted Control Plane の Pod で更新されます。ただし、既存のノードプールは、マルチアーキテクチャーイメージに自動的に移行されません。リリースイメージの移行は、ホステッドクラスターとノードプール間で分離されているためです。新しいマルチアーキテクチャーホステッドクラスターに新しいノードプールを作成する必要があります。
次のステップ
- マルチアーキテクチャーホステッドクラスターでのノードプールを作成する
5.1.5. マルチアーキテクチャーホステッドクラスターでのノードプールを作成する
ホステッドクラスターをシングルアーキテクチャーからマルチアーキテクチャーに移行したら、64 ビット AMD および 64 ビット ARM アーキテクチャーベースのコンピュートマシン上にノードプールを作成します。
手順
次のコマンドを入力して、64 ビット ARM アーキテクチャーベースのノードプールを作成します。
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count=<node_count> \3 --arch arm64次のコマンドを入力して、64 ビット AMD アーキテクチャーベースのノードプールを作成します。
$ hcp create nodepool aws \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count=<node_count> \3 --arch amd64
検証
次のコマンドを入力して、ノードプールがマルチアーキテクチャーリリースイメージを使用していることを確認します。
$ oc get nodepool/<nodepool_name> -oyaml64 ビット AMD ノードプールの出力例
#... spec: arch: amd64 #... release: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi1 - 1
<4.y.z>は、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
64 ビット ARM ノードプールの出力例
#... spec: arch: arm64 #... release: image: quay.io/openshift-release-dev/ocp-release:<4.x.y>-multi
5.2. ベアメタルでの Hosted Control Plane の管理
Hosted Control Plane をベアメタルにデプロイした後、次のタスクを完了してホステッドクラスターを管理できます。
5.2.1. ホステッドクラスターへのアクセス
ホステッドクラスターにアクセスするには、kubeconfig ファイルと kubeadmin 認証情報をリソースから直接取得するか、hcp コマンドラインインターフェイスを使用して kubeconfig ファイルを生成します。
前提条件
リソースから kubeconfig ファイルと認証情報を直接取得し、ホステッドクラスターにアクセスするには、ホステッドクラスターのアクセスシークレットを理解している必要があります。ホステッドクラスター (ホスティング) のリソースとアクセスシークレットは、ホステッドクラスターの namespace に格納されます。Hosted Control Plane は、Hosted Control Plane の namespace で実行されます。
シークレット名の形式は次のとおりです。
-
kubeconfigシークレット:<hosted_cluster_namespace>-<name>-admin-kubeconfig.たとえば、clusters-hypershift-demo-admin-kubeconfigです。 -
kubeadminパスワードシークレット:<hosted_cluster_namespace>-<name>-kubeadmin-password。たとえば、clusters-hypershift-demo-kubeadmin-passwordです。
kubeconfig シークレットには Base64 でエンコードされた kubeconfig フィールドが含まれており、これをデコードしてファイルに保存し、次のコマンドで使用できます。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin パスワードシークレットも Base64 でエンコードされます。これをデコードし、そのパスワードを使用して、ホステッドクラスターの API サーバーまたはコンソールにログインできます。
手順
hcpCLI を使用してホステッドクラスターにアクセスしてkubeconfigファイルを生成するには、次の手順を実行します。次のコマンドを入力して、
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfigファイルを保存した後、次のコマンド例を入力して、ホステッドクラスターにアクセスできます。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.2.2. ホステッドクラスターの NodePool オブジェクトのスケーリング
ホステッドクラスターにノードを追加することで、NodePool オブジェクトをスケールアップできます。ノードプールをスケーリングする際には、次の情報を考慮してください。
- ノードプールによってレプリカをスケーリングすると、マシンが作成されます。クラスター API プロバイダーは、すべてのマシンに対して、ノードプール仕様で指定された要件を満たすエージェントを見つけてインストールします。エージェントのステータスと状態を確認することで、エージェントのインストールを監視できます。
- ノードプールをスケールダウンすると、エージェントは対応するクラスターからバインド解除されます。Agent を再利用するには、Discovery イメージを使用してエージェントを再起動する必要があります。
手順
NodePoolオブジェクトを 2 つのノードにスケーリングします。$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API エージェントプロバイダーは、ホステッドクラスターに割り当てられる 2 つのエージェントをランダムに選択します。これらのエージェントはさまざまな状態を経て、最終的に OpenShift Container Platform ノードとしてホステッドクラスターに参加します。エージェントは次の順序で状態を通過します。
-
binding -
discovering -
insufficient -
installing -
installing-in-progress -
added-to-existing-cluster
-
以下のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agent出力例
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign以下のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'出力例
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficient次の extract コマンドを入力して、新しいホステッドクラスターの kubeconfig を取得します。
$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>エージェントが
added-to-existing-cluster状態に達したら、次のコマンドを入力して、ホステッドクラスターの OpenShift Container Platform ノードが表示されることを確認します。$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get nodes出力例
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8fCluster Operator は、ワークロードをノードに追加することによってリコンシリエーションを開始します。
次のコマンドを入力して、
NodePoolオブジェクトをスケールアップしたときに 2 台のマシンが作成されたことを確認します。$ oc -n <hosted_control_plane_namespace> get machines出力例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.x.z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.x.zclusterversionのリコンサイルプロセスは、最終的に、Ingress および Console のクラスター Operator だけが不足しているという段階に到達します。以下のコマンドを入力します。
$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get clusterversion,co出力例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.x.z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
5.2.2.1. ノードプールの追加
名前、レプリカの数、およびエージェントラベルセレクターなどの追加情報を指定して、ホステッドクラスターのノードプールを作成できます。
サポートされるエージェント namespace は、ホステッドクラスターごとに 1 つだけです。そのため、ホステッドクラスターにノードプールを追加する場合、そのノードプールを、単一の InfraEnv リソースから、または同じエージェント namespace にある InfraEnv リソースから取得する必要があります。
手順
ノードプールを作成するには、次の情報を入力します。
$ hcp create nodepool agent \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <worker_node_count> \3 --agentLabelSelector size=medium4 clustersnamespace 内のnodepoolリソースをリスト表示して、ノードプールのステータスを確認します。$ oc get nodepools --namespace clusters次のコマンドを入力して、
admin-kubeconfigシークレットを抽出します。$ oc extract -n <hosted_control_plane_namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm出力例
hostedcluster-secrets/kubeconfigしばらくしてから、次のコマンドを入力してノードプールのステータスを確認できます。
$ oc --kubeconfig ./hostedcluster-secrets get nodes
検証
次のコマンドを入力して、使用可能なノードプールの数が予想されるノードプールの数と一致することを確認します。
$ oc get nodepools --namespace clusters
5.2.2.2. ホステッドクラスターのノード自動スケーリングの有効化
ホステッドクラスターにさらに容量が必要で、予備のエージェントが利用可能な場合は、自動スケーリングを有効にして新しいワーカーノードをインストールできます。
手順
自動スケーリングを有効にするには、次のコマンドを入力します。
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'注記この例では、ノードの最小数は 2、最大数は 5 です。追加できるノードの最大数は、プラットフォームによって制限される場合があります。たとえば、Agent プラットフォームを使用する場合、ノードの最大数は使用可能なエージェントの数によって制限されます。
新しいノードを必要とするワークロードを作成します。
次の例を使用して、ワークロード設定を含む YAML ファイルを作成します。
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
ファイルを
workload-config.yamlとして保存します。 以下のコマンドを入力して、YAML を適用します。
$ oc apply -f workload-config.yaml
次のコマンドを入力して、
admin-kubeconfigシークレットを抽出します。$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm出力例
hostedcluster-secrets/kubeconfig次のコマンドを入力して、新しいノードが
Readyステータスであるかどうかを確認できます。$ oc --kubeconfig ./hostedcluster-secrets get nodesノードを削除するには、次のコマンドを入力してワークロードを削除します。
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>数分間待ちます。その間に、容量の追加が必要にならないようにします。Agent プラットフォームでエージェントが使用停止され、再利用できるようになります。次のコマンドを入力すると、ノードが削除されたことを確認できます。
$ oc --kubeconfig ./hostedcluster-secrets get nodes
IBM Z エージェントの場合、コンピュートノードがクラスターからデタッチされるのは、KVM エージェントを使用する IBM Z の場合だけです。z/VM および LPAR の場合は、コンピュートノードを手動で削除する必要があります。
エージェントは、KVM を使用する IBM Z でのみ再利用できます。z/VM および LPAR の場合は、エージェントを再作成して、それらをコンピュートノードとして使用してください。
5.2.2.3. ホストされたクラスターのノードの自動スケーリングを無効にする
ノードの自動スケーリングを無効にするには、次の手順を実行します。
手順
ホステッドクラスターのノードの自動スケーリングを無効にするには、次のコマンドを入力します。
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify_value_to_scale_replicas>]'このコマンドは、YAML ファイルから
"spec.autoScaling"を削除し、"spec.replicas"を追加し、"spec.replicas"を指定の整数値に設定します。
5.2.3. ベアメタル上のホステッドクラスターでの Ingress の処理
すべての OpenShift Container Platform クラスターには、通常、外部 DNS レコードが関連付けられているデフォルトのアプリケーション Ingress コントローラーがあります。たとえば、ベースドメイン krnl.es で example という名前のホステッドクラスターを作成する場合は、ワイルドカードドメイン *.apps.example.krnl.es がルーティング可能であると予想することができます。
手順
*.apps ドメインのロードバランサーとワイルドカード DNS レコードを設定するには、ゲストクラスターで次のアクションを実行します。
MetalLB Operator の設定を含む YAML ファイルを作成して MetalLB をデプロイします。
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
ファイルを
metallb-operator-config.yamlとして保存します。 以下のコマンドを入力して設定を適用します。
$ oc apply -f metallb-operator-config.yamlOperator の実行後、MetalLB インスタンスを作成します。
MetalLB インスタンスの設定を含む YAML ファイルを作成します。
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
ファイルを
metallb-instance-config.yamlとして保存します。 次のコマンドを入力して、MetalLB インスタンスを作成します。
$ oc apply -f metallb-instance-config.yaml
単一の IP アドレスを含む
IPAddressPoolリソースを作成します。この IP アドレスは、クラスターノードが使用するネットワークと同じサブネット上にある必要があります。以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb name: <ip_address_pool_name>1 spec: addresses: - <ingress_ip>-<ingress_ip>2 autoAssign: false次のコマンドを入力して、IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
L2 アドバタイズメントを作成します。
以下の例のような内容で、
l2advertisement.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: <l2_advertisement_name>1 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>2 次のコマンドを入力して設定を適用します。
$ oc apply -f l2advertisement.yaml
LoadBalancerタイプのサービスを作成すると、MetalLB はサービスに外部 IP アドレスを追加します。metallb-loadbalancer-service.yamlという名前の YAML ファイルを作成して、Ingress トラフィックを Ingress デプロイメントにルーティングする新しいロードバランサーサービスを設定します。kind: Service apiVersion: v1 metadata: annotations: metallb.io/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
metallb-loadbalancer-service.yamlファイルを保存します。 YAML 設定を適用するには、次のコマンドを入力します。
$ oc apply -f metallb-loadbalancer-service.yaml次のコマンドを入力して、OpenShift Container Platform コンソールにアクセスします。
$ curl -kI https://console-openshift-console.apps.example.krnl.es出力例
HTTP/1.1 200 OKclusterversionとclusteroperatorの値をチェックして、すべてが実行されていることを確認します。以下のコマンドを入力します。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co出力例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m<4.x.y>は、使用するサポート対象の OpenShift Container Platform バージョン (例:4.17.0-multi) に置き換えます。
5.2.4. ベアメタル上でマシンのヘルスチェックを有効にする
ベアメタル上でマシンのヘルスチェックを有効にして、異常なマネージドクラスターノードを自動的に修復および置き換えることができます。マネージドクラスターにインストールする準備ができている追加のエージェントマシンが必要です。
マシンのヘルスチェックを有効にする前に、次の制限を考慮してください。
-
MachineHealthCheckオブジェクトを変更することはできません。 -
マシンヘルスチェックでは、少なくとも 2 つのノードが 8 分以上
FalseまたはUnknownステータスのままである場合にのみ、ノードが置き換えられます。
マネージドクラスターノードのマシンヘルスチェックを有効にすると、ホステッドクラスターに MachineHealthCheck オブジェクトが作成されます。
手順
ホステッドクラスターでマシンのヘルスチェックを有効にするには、NodePool リソースを変更します。以下の手順を実行します。
NodePoolリソースのspec.nodeDrainTimeout値が0sより大きいことを確認します。<hosted_cluster_namespace>をホステッドクラスター namespace の名前に置き換え、<nodepool_name>をノードプール名に置き換えます。以下のコマンドを実行します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep nodeDrainTimeout出力例
nodeDrainTimeout: 30sspec.nodeDrainTimeout値が0sより大きくない場合は、次のコマンドを実行して値を変更します。$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec":{"nodeDrainTimeout": "30m"}}' --type=mergeNodePoolリソースでspec.management.autoRepairフィールドをtrueに設定して、マシンのヘルスチェックを有効にします。以下のコマンドを実行します。$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":true}}}' --type=merge次のコマンドを実行して、
NodePoolリソースがautoRepair: true値で更新されていることを確認します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.2.5. ベアメタル上でマシンのヘルスチェックを無効にする
マネージドクラスターノードのマシンのヘルスチェックを無効にするには、NodePool リソースを変更します。
手順
NodePoolリソースでspec.management.autoRepairフィールドをfalseに設定して、マシンのヘルスチェックを無効にします。以下のコマンドを実行します。$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":false}}}' --type=merge次のコマンドを実行して、
NodePoolリソースがautoRepair: false値で更新されていることを確認します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.3. OpenShift Virtualization での Hosted Control Plane の管理
OpenShift Virtualization にホステッドクラスターをデプロイした後、次の手順を実行してクラスターを管理できます。
5.3.1. ホステッドクラスターへのアクセス
ホステッドクラスターにアクセスするには、kubeconfig ファイルと kubeadmin 認証情報をリソースから直接取得するか、hcp コマンドラインインターフェイスを使用して kubeconfig ファイルを生成します。
前提条件
リソースから kubeconfig ファイルと認証情報を直接取得し、ホステッドクラスターにアクセスするには、ホステッドクラスターのアクセスシークレットを理解している必要があります。ホステッドクラスター (ホスティング) のリソースとアクセスシークレットは、ホステッドクラスターの namespace に格納されます。Hosted Control Plane は、Hosted Control Plane の namespace で実行されます。
シークレット名の形式は次のとおりです。
-
kubeconfigシークレット:<hosted_cluster_namespace>-<name>-admin-kubeconfig(clusters-hypershift-demo-admin-kubeconfig) -
kubeadminパスワードシークレット:<hosted_cluster_namespace>-<name>-kubeadmin-password(clusters-hypershift-demo-kubeadmin-password)
kubeconfig シークレットには Base64 でエンコードされた kubeconfig フィールドが含まれており、これをデコードしてファイルに保存し、次のコマンドで使用できます。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin パスワードシークレットも Base64 でエンコードされます。これをデコードし、そのパスワードを使用して、ホステッドクラスターの API サーバーまたはコンソールにログインできます。
手順
hcpCLI を使用してホステッドクラスターにアクセスしてkubeconfigファイルを生成するには、次の手順を実行します。次のコマンドを入力して、
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfigファイルを保存した後、次のコマンド例を入力して、ホステッドクラスターにアクセスできます。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.3.2. ホステッドクラスターのノード自動スケーリングの有効化
ホステッドクラスターにさらに容量が必要で、予備のエージェントが利用可能な場合は、自動スケーリングを有効にして新しいワーカーノードをインストールできます。
手順
自動スケーリングを有効にするには、次のコマンドを入力します。
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'注記この例では、ノードの最小数は 2、最大数は 5 です。追加できるノードの最大数は、プラットフォームによって制限される場合があります。たとえば、Agent プラットフォームを使用する場合、ノードの最大数は使用可能なエージェントの数によって制限されます。
新しいノードを必要とするワークロードを作成します。
次の例を使用して、ワークロード設定を含む YAML ファイルを作成します。
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
ファイルを
workload-config.yamlとして保存します。 以下のコマンドを入力して、YAML を適用します。
$ oc apply -f workload-config.yaml
次のコマンドを入力して、
admin-kubeconfigシークレットを抽出します。$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm出力例
hostedcluster-secrets/kubeconfig次のコマンドを入力して、新しいノードが
Readyステータスであるかどうかを確認できます。$ oc --kubeconfig ./hostedcluster-secrets get nodesノードを削除するには、次のコマンドを入力してワークロードを削除します。
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>数分間待ちます。その間に、容量の追加が必要にならないようにします。Agent プラットフォームでエージェントが使用停止され、再利用できるようになります。次のコマンドを入力すると、ノードが削除されたことを確認できます。
$ oc --kubeconfig ./hostedcluster-secrets get nodes
IBM Z エージェントの場合、コンピュートノードがクラスターからデタッチされるのは、KVM エージェントを使用する IBM Z の場合だけです。z/VM および LPAR の場合は、コンピュートノードを手動で削除する必要があります。
エージェントは、KVM を使用する IBM Z でのみ再利用できます。z/VM および LPAR の場合は、エージェントを再作成して、それらをコンピュートノードとして使用してください。
5.3.3. OpenShift Virtualization での Hosted Control Plane のストレージの設定
詳細なストレージ設定を指定しなかった場合、KubeVirt 仮想マシン (VM) イメージ、KubeVirt Container Storage Interface (CSI) マッピング、および etcd ボリュームにデフォルトのストレージクラスが使用されます。
次の表に、ホステッドクラスターで永続ストレージをサポートするためにインフラストラクチャーが提供する必要がある機能を示します。
| インフラストラクチャーの CSI プロバイダー | ホステッドクラスターの CSI プロバイダー | ホステッドクラスターの機能 | 注記 |
|---|---|---|---|
|
任意の RWX |
|
基本: RWO | 推奨 |
|
任意の RWX | Red Hat OpenShift Data Foundation 外部モード | Red Hat OpenShift Data Foundation の機能セット | |
|
任意の RWX | Red Hat OpenShift Data Foundation 内部モード | Red Hat OpenShift Data Foundation の機能セット | 使用しないでください。 |
5.3.3.1. KubeVirt CSI ストレージクラスのマッピング
KubeVirt CSI は、ReadWriteMany (RWX) アクセスが可能なインフラストラクチャーストレージクラスのマッピングをサポートします。クラスターの作成時に、インフラストラクチャーのストレージクラスをホストされるストレージクラスにマッピングできます。
手順
インフラストラクチャーのストレージクラスをホストされるストレージクラスにマッピングするには、次のコマンドを実行して
--infra-storage-class-mapping引数を使用します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class> \6 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ワーカー数を指定します (例:
2)。 - 3
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 4
- メモリーの値を指定します (例:
8Gi)。 - 5
- CPU の値を指定します (例:
2)。 - 6
<infrastructure_storage_class>をインフラストラクチャーストレージクラス名に置き換え、<hosted_storage_class>をホステッドクラスターストレージクラス名に置き換えます。hcp create clusterコマンド内で--infra-storage-class-mapping引数を複数回使用できます。
ホステッドクラスターを作成すると、インフラストラクチャーのストレージクラスがホステッドクラスター内に表示されます。これらのストレージクラスのいずれかを使用するホステッドクラスター内に永続ボリューム要求 PVC を作成すると、KubeVirt CSI はクラスターの作成時に設定したインフラストラクチャーストレージクラスマッピングを使用してそのボリュームをプロビジョニングします。
KubeVirt CSI は、RWX アクセスが可能なインフラストラクチャーストレージクラスのマッピングのみをサポートします。
次の表に、ボリュームモードとアクセスモードの機能が KubeVirt CSI ストレージクラスにどのようにマッピングされるかを示します。
| インフラストラクチャーの CSI 機能 | ホステッドクラスターの CSI 機能 | 仮想マシンのライブ移行のサポート | 注記 |
|---|---|---|---|
|
RWX: |
| サポート対象 |
|
|
RWO |
RWO | サポート対象外 | ライブマイグレーションのサポートが不足しているため、KubeVirt 仮想マシンをホストする基盤となるインフラストラクチャークラスターを更新する機能が影響を受けます。 |
|
RWO |
RWO | サポート対象外 |
ライブマイグレーションのサポートが不足しているため、KubeVirt 仮想マシンをホストする基盤となるインフラストラクチャークラスターを更新する機能が影響を受けます。インフラストラクチャー |
5.3.3.2. 単一の KubeVirt CSI ボリュームスナップショットクラスのマッピング
KubeVirt CSI を使用して、インフラストラクチャーのボリュームスナップショットクラスをホステッドクラスターに公開できます。
手順
ボリュームスナップショットクラスをホステッドクラスターにマッピングするには、ホステッドクラスターを作成するときに
--infra-volumesnapshot-class-mapping引数を使用します。以下のコマンドを実行します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class> \6 --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>7 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ワーカー数を指定します (例:
2)。 - 3
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 4
- メモリーの値を指定します (例:
8Gi)。 - 5
- CPU の値を指定します (例:
2)。 - 6
<infrastructure_storage_class>は、インフラストラクチャークラスターに存在するストレージクラスに置き換えます。<hosted_storage_class>は、ホステッドクラスターに存在するストレージクラスに置き換えます。- 7
<infrastructure_volume_snapshot_class>は、インフラストラクチャークラスターに存在するボリュームスナップショットクラスに置き換えます。<hosted_volume_snapshot_class>は、ホステッドクラスターに存在するボリュームスナップショットクラスに置き換えます。
注記--infra-storage-class-mappingおよび--infra-volumesnapshot-class-mapping引数を使用しない場合、デフォルトのストレージクラスとボリュームスナップショットクラスを使用してホステッドクラスターが作成されます。したがって、インフラストラクチャークラスターでデフォルトのストレージクラスとボリュームスナップショットクラスを設定する必要があります。
5.3.3.3. 複数の KubeVirt CSI ボリュームスナップショットクラスのマッピング
複数のボリュームスナップショットクラスを特定のグループに割り当てることで、それらをホステッドクラスターにマッピングできます。インフラストラクチャーのストレージクラスとボリュームスナップショットクラスは、同じグループに属している場合にのみ相互に互換性があります。
手順
複数のボリュームスナップショットクラスをホステッドクラスターにマッピングするには、ホステッドクラスターを作成するときに
groupオプションを使用します。以下のコマンドを実行します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \6 --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \ --infra-storage-class-mapping=<infrastructure_storage_class>/<hosted_storage_class>,group=<group_name> \ --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>,group=<group_name> \7 --infra-volumesnapshot-class-mapping=<infrastructure_volume_snapshot_class>/<hosted_volume_snapshot_class>,group=<group_name>- 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ワーカー数を指定します (例:
2)。 - 3
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 4
- メモリーの値を指定します (例:
8Gi)。 - 5
- CPU の値を指定します (例:
2)。 - 6
<infrastructure_storage_class>は、インフラストラクチャークラスターに存在するストレージクラスに置き換えます。<hosted_storage_class>は、ホステッドクラスターに存在するストレージクラスに置き換えます。<group_name>は、グループ名に置き換えます。たとえば、infra-storage-class-mygroup/hosted-storage-class-mygroup,group=mygroupおよびinfra-storage-class-mymap/hosted-storage-class-mymap,group=mymapです。- 7
<infrastructure_volume_snapshot_class>は、インフラストラクチャークラスターに存在するボリュームスナップショットクラスに置き換えます。<hosted_volume_snapshot_class>は、ホステッドクラスターに存在するボリュームスナップショットクラスに置き換えます。たとえば、infra-vol-snap-mygroup/hosted-vol-snap-mygroup,group=mygroupおよびinfra-vol-snap-mymap/hosted-vol-snap-mymap,group=mymapです。
5.3.3.4. KubeVirt 仮想マシンのルートボリュームの設定
クラスターの作成時に、--root-volume-storage-class 引数を使用して、KubeVirt 仮想マシンルートボリュームをホストするために使用するストレージクラスを設定できます。
手順
KubeVirt 仮想マシンのカスタムのストレージクラスとボリュームサイズを設定するには、次のコマンドを実行します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --root-volume-storage-class <root_volume_storage_class> \6 --root-volume-size <volume_size>7 これにより、PVC 上でホストされる仮想マシンを使用してホステッドクラスターが作成されます。
5.3.3.5. KubeVirt 仮想マシンイメージキャッシュの有効化
KubeVirt 仮想マシンイメージキャッシュを使用すると、クラスターの起動時間とストレージ使用量の両方を最適化できます。KubeVirt 仮想マシンイメージキャッシュは、スマートクローニングと ReadWriteMany アクセスモードが可能なストレージクラスの使用をサポートします。スマートクローン作成の詳細は、smart-cloning を使用したデータボリュームのクローン作成 を参照してください。
イメージのキャッシュは次のように機能します。
- VM イメージは、ホステッドクラスターに関連付けられた PVC にインポートされます。
- その PVC の一意のクローンは、クラスターにワーカーノードとして追加されるすべての KubeVirt VM に対して作成されます。
イメージキャッシュを使用すると、イメージのインポートが 1 つだけ必要になるため、VM の起動時間が短縮されます。ストレージクラスがコピーオンライトクローン作成をサポートしている場合、クラスター全体のストレージ使用量をさらに削減できます。
手順
イメージキャッシュを有効にするには、クラスターの作成時に、次のコマンドを実行して
--root-volume-cache-strategy=PVC引数を使用します。$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --root-volume-cache-strategy=PVC6
5.3.3.6. KubeVirt CSI ストレージのセキュリティーと分離
KubeVirt Container Storage Interface (CSI) は、基盤となるインフラストラクチャークラスターのストレージ機能をホステッドクラスターに拡張します。CSI ドライバーは、インフラストラクチャーストレージクラスとホステッドクラスターへの分離されたセキュアなアクセスを実現するために、次のセキュリティー制約を使用します。
- ホステッドクラスターのストレージは、他のホステッドクラスターから分離されます。
- ホステッドクラスター内のワーカーノードは、インフラストラクチャークラスターに直接 API によってアクセスできません。ホステッドクラスターは、制御された KubeVirt CSI インターフェイスを通じてのみ、インフラストラクチャークラスター上にストレージをプロビジョニングできます。
- ホステッドクラスターは、KubeVirt CSI クラスターコントローラーにアクセスできません。そのため、ホステッドクラスターは、ホステッドクラスターに関連付けられていないインフラストラクチャークラスター上の任意のストレージボリュームにアクセスできません。KubeVirt CSI クラスターコントローラーは、Hosted Control Plane namespace の Pod で実行されます。
- KubeVirt CSI クラスターコントローラーのロールベースアクセス制御 (RBAC) により、永続ボリューム要求 (PVC) アクセスが Hosted Control Plane namespace だけに制限されます。したがって、KubeVirt CSI コンポーネントは他の namespace からストレージにアクセスできません。
5.3.3.7. etcd ストレージの設定
クラスターの作成時に、--etcd-storage-class 引数を使用して、etcd データをホストするために使用されるストレージクラスを設定できます。
手順
etcd のストレージクラスを設定するには、次のコマンドを実行します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --etcd-storage-class=<etcd_storage_class_name>6
5.3.4. hcp CLI を使用して NVIDIA GPU デバイスをアタッチする
OpenShift Virtualization 上のホステッドクラスターの hcp コマンドラインインターフェイス (CLI) を使用して、1 つ以上の NVIDIA グラフィックスプロセッシングユニット (GPU) デバイスをノードプールにアタッチできます。
NVIDIA GPU デバイスをノードプールにアタッチする機能は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
前提条件
- GPU デバイスが存在するノード上のリソースとして NVIDIA GPU デバイスを公開した。詳細は、NVIDIA GPU Operator with OpenShift Virtualization を参照してください。
- ノードプールに割り当てるために、NVIDIA GPU デバイスをノード上の 拡張リソース として公開した。
手順
次のコマンドを実行すると、クラスターの作成中に GPU デバイスをノードプールにアタッチできます。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_node_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <memory> \4 --cores <cpu> \5 --host-device-name="<gpu_device_name>,count:<value>"6 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ワーカー数を指定します (例:
3)。 - 3
- プルシークレットへのパスを指定します (例:
/user/name/pullsecret)。 - 4
- メモリーの値を指定します (例:
16Gi)。 - 5
- CPU の値を指定します (例:
2)。 - 6
- GPU デバイス名と数を指定します (例:
--host-device-name="nvidia-a100,count:2")。--host-device-name引数は、インフラストラクチャーノードからの GPU デバイスの名前と、ノードプール内の各仮想マシンにアタッチする GPU デバイスの数を表すオプション数を取得します。デフォルトは1です。たとえば、2 つの GPU デバイスを 3 つのノードプールレプリカにアタッチすると、ノードプール内の 3 つの仮想マシンすべてが 2 つの GPU デバイスにアタッチされます。
ヒント--host-device-name引数を複数回使用して、タイプの異なる複数デバイスをアタッチできます。
5.3.5. NodePool リソースを使用して NVIDIA GPU デバイスをアタッチする
NodePool リソースの nodepool.spec.platform.kubevirt.hostDevices フィールドを設定することで、1 つ以上の NVIDIA グラフィックスプロセッシングユニット (GPU) デバイスをノードプールにアタッチできます。
NVIDIA GPU デバイスをノードプールにアタッチする機能は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
手順
1 つ以上の GPU デバイスをノードプールにアタッチします。
1 つの GPU デバイスをアタッチするには、次の設定例を使用して
NodePoolリソースを設定します。apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: kubevirt: attachDefaultNetwork: true compute: cores: <cpu>3 memory: <memory>4 hostDevices:5 - count: <count>6 deviceName: <gpu_device_name>7 networkInterfaceMultiqueue: Enable rootVolume: persistent: size: 32Gi type: Persistent type: KubeVirt replicas: <worker_node_count>8 - 1
- ホステッドクラスターの名前を指定します (例:
example)。 - 2
- ホステッドクラスターの namespace の名前を指定します (例:
clusters)。 - 3
- CPU の値を指定します (例:
2)。 - 4
- メモリーの値を指定します (例:
16Gi)。 - 5
hostDevicesフィールドは、ノードプールにアタッチできる各種 GPU デバイスのリストを定義します。- 6
- ノードプール内の各仮想マシンにアタッチする GPU デバイスの数を指定します。たとえば、2 つの GPU デバイスを 3 つのノードプールレプリカにアタッチすると、ノードプール内の 3 つの仮想マシンすべてが 2 つの GPU デバイスにアタッチされます。デフォルトは
1です。 - 7
- GPU デバイス名を指定します (例:
nvidia-a100)。 - 8
- ワーカー数を指定します (例:
3)。
複数の GPU デバイスをアタッチするには、次の設定例を使用して
NodePoolリソースを設定します。apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false upgradeType: Replace nodeDrainTimeout: 0s nodeVolumeDetachTimeout: 0s platform: kubevirt: attachDefaultNetwork: true compute: cores: <cpu> memory: <memory> hostDevices: - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> - count: <count> deviceName: <gpu_device_name> networkInterfaceMultiqueue: Enable rootVolume: persistent: size: 32Gi type: Persistent type: KubeVirt replicas: <worker_node_count>
5.3.6. KubeVirt 仮想マシンの削除
GPU パススルーを使用する場合など、KubeVirt 仮想マシン (VM) をライブマイグレーションできない場合は、ホステッドクラスターの NodePool リソースと同時に仮想マシンを退避させる必要があります。そうしないと、ワークロードの drain (Pod の退避) が実行されることなく、コンピュートノードがシャットダウンされる可能性があります。これは、OpenShift Virtualization Operator をアップグレードするときにも発生する可能性があります。同期された再起動を実現するために、hyperconverged リソースに evictionStrategy パラメーターを設定すると、ワークロードの drain が完了した仮想マシンだけを再起動させることができます。
手順
hyperconvergedリソースとevictionStrategyパラメーターに許可される値の詳細を確認するには、次のコマンドを入力します。$ oc explain hyperconverged.spec.evictionStrategy次のコマンドを入力して、
hyperconvergedリソースにパッチを適用します。$ oc -n openshift-cnv patch hyperconverged kubevirt-hyperconverged \ --type=merge \ -p '{"spec": {"evictionStrategy": "External"}}'次のコマンドを入力して、ワークロード更新ストラテジーとワークロード更新方法にパッチを適用します。
$ oc -n openshift-cnv patch hyperconverged kubevirt-hyperconverged \ --type=merge \ -p '{"spec": {"workloadUpdateStrategy": {"workloadUpdateMethods": ["LiveMigrate","Evict"]}}}'このパッチを適用すると、可能な場合は仮想マシンをライブマイグレーションし、ライブマイグレーションできない仮想マシンだけを退避させることを指定できます。
検証
次のコマンドを入力して、パッチコマンドが正しく適用されたかどうかを確認します。
$ oc -n openshift-cnv get hyperconverged kubevirt-hyperconverged -ojsonpath='{.spec.evictionStrategy}'出力例
External
5.4. 非ベアメタルエージェントマシンでの Hosted Control Plane の管理
非ベアメタルエージェントマシンに Hosted Control Plane をデプロイした後、次のタスクを完了してホステッドクラスターを管理できます。
5.4.1. ホステッドクラスターへのアクセス
ホステッドクラスターにアクセスするには、kubeconfig ファイルと kubeadmin 認証情報をリソースから直接取得するか、hcp コマンドラインインターフェイスを使用して kubeconfig ファイルを生成します。
前提条件
リソースから kubeconfig ファイルと認証情報を直接取得し、ホステッドクラスターにアクセスするには、ホステッドクラスターのアクセスシークレットを理解している必要があります。ホステッドクラスター (ホスティング) のリソースとアクセスシークレットは、ホステッドクラスターの namespace に格納されます。Hosted Control Plane は、Hosted Control Plane の namespace で実行されます。
シークレット名の形式は次のとおりです。
-
kubeconfigシークレット:<hosted_cluster_namespace>-<name>-admin-kubeconfig.たとえば、clusters-hypershift-demo-admin-kubeconfigです。 -
kubeadminパスワードシークレット:<hosted_cluster_namespace>-<name>-kubeadmin-password。たとえば、clusters-hypershift-demo-kubeadmin-passwordです。
kubeconfig シークレットには Base64 でエンコードされた kubeconfig フィールドが含まれており、これをデコードしてファイルに保存し、次のコマンドで使用できます。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
kubeadmin パスワードシークレットも Base64 でエンコードされます。これをデコードし、そのパスワードを使用して、ホステッドクラスターの API サーバーまたはコンソールにログインできます。
手順
hcpCLI を使用してホステッドクラスターにアクセスしてkubeconfigファイルを生成するには、次の手順を実行します。次のコマンドを入力して、
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfigファイルを保存した後、次のコマンド例を入力して、ホステッドクラスターにアクセスできます。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes
5.4.2. ホステッドクラスターの NodePool オブジェクトのスケーリング
ホステッドクラスターにノードを追加することで、NodePool オブジェクトをスケールアップできます。ノードプールをスケーリングする際には、次の情報を考慮してください。
- ノードプールによってレプリカをスケーリングすると、マシンが作成されます。クラスター API プロバイダーは、すべてのマシンに対して、ノードプール仕様で指定された要件を満たすエージェントを見つけてインストールします。エージェントのステータスと状態を確認することで、エージェントのインストールを監視できます。
- ノードプールをスケールダウンすると、エージェントは対応するクラスターからバインド解除されます。Agent を再利用するには、Discovery イメージを使用してエージェントを再起動する必要があります。
手順
NodePoolオブジェクトを 2 つのノードにスケーリングします。$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API エージェントプロバイダーは、ホステッドクラスターに割り当てられる 2 つのエージェントをランダムに選択します。これらのエージェントはさまざまな状態を経て、最終的に OpenShift Container Platform ノードとしてホステッドクラスターに参加します。エージェントは次の順序で状態を通過します。
-
binding -
discovering -
insufficient -
installing -
installing-in-progress -
added-to-existing-cluster
-
以下のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agent出力例
NAME CLUSTER APPROVED ROLE STAGE 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 hypercluster1 true auto-assign d9198891-39f4-4930-a679-65fb142b108b true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hypercluster1 true auto-assign以下のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'出力例
BMH: ocp-worker-2 Agent: 4dac1ab2-7dd5-4894-a220-6a3473b67ee6 State: binding BMH: ocp-worker-0 Agent: d9198891-39f4-4930-a679-65fb142b108b State: known-unbound BMH: ocp-worker-1 Agent: da503cf1-a347-44f2-875c-4960ddb04091 State: insufficient次の extract コマンドを入力して、新しいホステッドクラスターの kubeconfig を取得します。
$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig --to=- \ > kubeconfig-<hosted_cluster_name>エージェントが
added-to-existing-cluster状態に達したら、次のコマンドを入力して、ホステッドクラスターの OpenShift Container Platform ノードが表示されることを確認します。$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get nodes出力例
NAME STATUS ROLES AGE VERSION ocp-worker-1 Ready worker 5m41s v1.24.0+3882f8f ocp-worker-2 Ready worker 6m3s v1.24.0+3882f8fCluster Operator は、ワークロードをノードに追加することによってリコンシリエーションを開始します。
次のコマンドを入力して、
NodePoolオブジェクトをスケールアップしたときに 2 台のマシンが作成されたことを確認します。$ oc -n <hosted_control_plane_namespace> get machines出力例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hypercluster1-c96b6f675-m5vch hypercluster1-b2qhl ocp-worker-1 agent://da503cf1-a347-44f2-875c-4960ddb04091 Running 15m 4.x.z hypercluster1-c96b6f675-tl42p hypercluster1-b2qhl ocp-worker-2 agent://4dac1ab2-7dd5-4894-a220-6a3473b67ee6 Running 15m 4.x.zclusterversionのリコンサイルプロセスは、最終的に、Ingress および Console のクラスター Operator だけが不足しているという段階に到達します。以下のコマンドを入力します。
$ oc --kubeconfig kubeconfig-<hosted_cluster_name> get clusterversion,co出力例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version False True 40m Unable to apply 4.x.z: the cluster operator console has not yet successfully rolled out NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.12z False False False 11m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hypercluster1.domain.com): Get "https://console-openshift-console.apps.hypercluster1.domain.com": dial tcp 10.19.3.29:443: connect: connection refused clusteroperator.config.openshift.io/csi-snapshot-controller 4.12z True False False 10m clusteroperator.config.openshift.io/dns 4.12z True False False 9m16s
5.4.2.1. ノードプールの追加
名前、レプリカの数、およびエージェントラベルセレクターなどの追加情報を指定して、ホステッドクラスターのノードプールを作成できます。
サポートされるエージェント namespace は、ホステッドクラスターごとに 1 つだけです。そのため、ホステッドクラスターにノードプールを追加する場合、そのノードプールを、単一の InfraEnv リソースから、または同じエージェント namespace にある InfraEnv リソースから取得する必要があります。
手順
ノードプールを作成するには、次の情報を入力します。
$ hcp create nodepool agent \ --cluster-name <hosted_cluster_name> \1 --name <nodepool_name> \2 --node-count <worker_node_count> \3 --agentLabelSelector size=medium4 clustersnamespace 内のnodepoolリソースをリスト表示して、ノードプールのステータスを確認します。$ oc get nodepools --namespace clusters次のコマンドを入力して、
admin-kubeconfigシークレットを抽出します。$ oc extract -n <hosted_control_plane_namespace> secret/admin-kubeconfig --to=./hostedcluster-secrets --confirm出力例
hostedcluster-secrets/kubeconfigしばらくしてから、次のコマンドを入力してノードプールのステータスを確認できます。
$ oc --kubeconfig ./hostedcluster-secrets get nodes
検証
次のコマンドを入力して、使用可能なノードプールの数が予想されるノードプールの数と一致することを確認します。
$ oc get nodepools --namespace clusters
5.4.2.2. ホステッドクラスターのノード自動スケーリングの有効化
ホステッドクラスターにさらに容量が必要で、予備のエージェントが利用可能な場合は、自動スケーリングを有効にして新しいワーカーノードをインストールできます。
手順
自動スケーリングを有効にするには、次のコマンドを入力します。
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[{"op": "remove", "path": "/spec/replicas"},{"op":"add", "path": "/spec/autoScaling", "value": { "max": 5, "min": 2 }}]'注記この例では、ノードの最小数は 2、最大数は 5 です。追加できるノードの最大数は、プラットフォームによって制限される場合があります。たとえば、Agent プラットフォームを使用する場合、ノードの最大数は使用可能なエージェントの数によって制限されます。
新しいノードを必要とするワークロードを作成します。
次の例を使用して、ワークロード設定を含む YAML ファイルを作成します。
apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: reversewords name: reversewords namespace: default spec: replicas: 40 selector: matchLabels: app: reversewords strategy: {} template: metadata: creationTimestamp: null labels: app: reversewords spec: containers: - image: quay.io/mavazque/reversewords:latest name: reversewords resources: requests: memory: 2Gi status: {}-
ファイルを
workload-config.yamlとして保存します。 以下のコマンドを入力して、YAML を適用します。
$ oc apply -f workload-config.yaml
次のコマンドを入力して、
admin-kubeconfigシークレットを抽出します。$ oc extract -n <hosted_cluster_namespace> \ secret/<hosted_cluster_name>-admin-kubeconfig \ --to=./hostedcluster-secrets --confirm出力例
hostedcluster-secrets/kubeconfig次のコマンドを入力して、新しいノードが
Readyステータスであるかどうかを確認できます。$ oc --kubeconfig ./hostedcluster-secrets get nodesノードを削除するには、次のコマンドを入力してワークロードを削除します。
$ oc --kubeconfig ./hostedcluster-secrets -n <namespace> \ delete deployment <deployment_name>数分間待ちます。その間に、容量の追加が必要にならないようにします。Agent プラットフォームでエージェントが使用停止され、再利用できるようになります。次のコマンドを入力すると、ノードが削除されたことを確認できます。
$ oc --kubeconfig ./hostedcluster-secrets get nodes
IBM Z エージェントの場合、コンピュートノードがクラスターからデタッチされるのは、KVM エージェントを使用する IBM Z の場合だけです。z/VM および LPAR の場合は、コンピュートノードを手動で削除する必要があります。
エージェントは、KVM を使用する IBM Z でのみ再利用できます。z/VM および LPAR の場合は、エージェントを再作成して、それらをコンピュートノードとして使用してください。
5.4.2.3. ホストされたクラスターのノードの自動スケーリングを無効にする
ノードの自動スケーリングを無効にするには、次の手順を実行します。
手順
ホステッドクラスターのノードの自動スケーリングを無効にするには、次のコマンドを入力します。
$ oc -n <hosted_cluster_namespace> patch nodepool <hosted_cluster_name> \ --type=json \ -p '[\{"op":"remove", "path": "/spec/autoScaling"}, \{"op": "add", "path": "/spec/replicas", "value": <specify_value_to_scale_replicas>]'このコマンドは、YAML ファイルから
"spec.autoScaling"を削除し、"spec.replicas"を追加し、"spec.replicas"を指定の整数値に設定します。
5.4.3. 非ベアメタルエージェントマシン上のホステッドクラスターでの Ingress の処理
すべての OpenShift Container Platform クラスターには、通常、外部 DNS レコードが関連付けられているデフォルトのアプリケーション Ingress コントローラーがあります。たとえば、ベースドメイン krnl.es で example という名前のホステッドクラスターを作成する場合は、ワイルドカードドメイン *.apps.example.krnl.es がルーティング可能であると予想することができます。
手順
*.apps ドメインのロードバランサーとワイルドカード DNS レコードを設定するには、ゲストクラスターで次のアクションを実行します。
MetalLB Operator の設定を含む YAML ファイルを作成して MetalLB をデプロイします。
apiVersion: v1 kind: Namespace metadata: name: metallb labels: openshift.io/cluster-monitoring: "true" annotations: workload.openshift.io/allowed: management --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator-operatorgroup namespace: metallb --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator namespace: metallb spec: channel: "stable" name: metallb-operator source: redhat-operators sourceNamespace: openshift-marketplace-
ファイルを
metallb-operator-config.yamlとして保存します。 以下のコマンドを入力して設定を適用します。
$ oc apply -f metallb-operator-config.yamlOperator の実行後、MetalLB インスタンスを作成します。
MetalLB インスタンスの設定を含む YAML ファイルを作成します。
apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-
ファイルを
metallb-instance-config.yamlとして保存します。 次のコマンドを入力して、MetalLB インスタンスを作成します。
$ oc apply -f metallb-instance-config.yaml
単一の IP アドレスを含む
IPAddressPoolリソースを作成します。この IP アドレスは、クラスターノードが使用するネットワークと同じサブネット上にある必要があります。以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb name: <ip_address_pool_name>1 spec: addresses: - <ingress_ip>-<ingress_ip>2 autoAssign: false次のコマンドを入力して、IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
L2 アドバタイズメントを作成します。
以下の例のような内容で、
l2advertisement.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: <l2_advertisement_name>1 namespace: metallb spec: ipAddressPools: - <ip_address_pool_name>2 次のコマンドを入力して設定を適用します。
$ oc apply -f l2advertisement.yaml
LoadBalancerタイプのサービスを作成すると、MetalLB はサービスに外部 IP アドレスを追加します。metallb-loadbalancer-service.yamlという名前の YAML ファイルを作成して、Ingress トラフィックを Ingress デプロイメントにルーティングする新しいロードバランサーサービスを設定します。kind: Service apiVersion: v1 metadata: annotations: metallb.io/address-pool: ingress-public-ip name: metallb-ingress namespace: openshift-ingress spec: ports: - name: http protocol: TCP port: 80 targetPort: 80 - name: https protocol: TCP port: 443 targetPort: 443 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: LoadBalancer-
metallb-loadbalancer-service.yamlファイルを保存します。 YAML 設定を適用するには、次のコマンドを入力します。
$ oc apply -f metallb-loadbalancer-service.yaml次のコマンドを入力して、OpenShift Container Platform コンソールにアクセスします。
$ curl -kI https://console-openshift-console.apps.example.krnl.es出力例
HTTP/1.1 200 OKclusterversionとclusteroperatorの値をチェックして、すべてが実行されていることを確認します。以下のコマンドを入力します。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion,co出力例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.x.y True False 3m32s Cluster version is 4.x.y NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/console 4.x.y True False False 3m50s clusteroperator.config.openshift.io/ingress 4.x.y True False False 53m<4.x.y>は、使用するサポート対象の OpenShift Container Platform バージョン (例:4.17.0-multi) に置き換えます。
5.4.4. 非ベアメタルエージェントマシンでマシンのヘルスチェックを有効にする
ベアメタル上でマシンのヘルスチェックを有効にして、異常なマネージドクラスターノードを自動的に修復および置き換えることができます。マネージドクラスターにインストールする準備ができている追加のエージェントマシンが必要です。
マシンのヘルスチェックを有効にする前に、次の制限を考慮してください。
-
MachineHealthCheckオブジェクトを変更することはできません。 -
マシンヘルスチェックでは、少なくとも 2 つのノードが 8 分以上
FalseまたはUnknownステータスのままである場合にのみ、ノードが置き換えられます。
マネージドクラスターノードのマシンヘルスチェックを有効にすると、ホステッドクラスターに MachineHealthCheck オブジェクトが作成されます。
手順
ホステッドクラスターでマシンのヘルスチェックを有効にするには、NodePool リソースを変更します。以下の手順を実行します。
NodePoolリソースのspec.nodeDrainTimeout値が0sより大きいことを確認します。<hosted_cluster_namespace>をホステッドクラスター namespace の名前に置き換え、<nodepool_name>をノードプール名に置き換えます。以下のコマンドを実行します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep nodeDrainTimeout出力例
nodeDrainTimeout: 30sspec.nodeDrainTimeout値が0sより大きくない場合は、次のコマンドを実行して値を変更します。$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec":{"nodeDrainTimeout": "30m"}}' --type=mergeNodePoolリソースでspec.management.autoRepairフィールドをtrueに設定して、マシンのヘルスチェックを有効にします。以下のコマンドを実行します。$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":true}}}' --type=merge次のコマンドを実行して、
NodePoolリソースがautoRepair: true値で更新されていることを確認します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.4.5. 非ベアメタルエージェントマシンでマシンヘルスチェックを無効にする
マネージドクラスターノードのマシンのヘルスチェックを無効にするには、NodePool リソースを変更します。
手順
NodePoolリソースでspec.management.autoRepairフィールドをfalseに設定して、マシンのヘルスチェックを無効にします。以下のコマンドを実行します。$ oc patch nodepool -n <hosted_cluster_namespace> <nodepool_name> -p '{"spec": {"management": {"autoRepair":false}}}' --type=merge次のコマンドを実行して、
NodePoolリソースがautoRepair: false値で更新されていることを確認します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -o yaml | grep autoRepair
5.5. IBM Power での Hosted Control Plane の管理
IBM Power に Hosted Control Plane をデプロイした後、次のタスクを完了してホステッドクラスターを管理できます。
5.5.1. IBM Power 上の Hosted Control Plane 用の InfraEnv リソースを作成する
InfraEnv は、ライブ ISO を開始しているホストがエージェントとして参加できる環境です。この場合、エージェントは Hosted Control Plane と同じ namespace に作成されます。
IBM Power コンピュートノード用の 64 ビット x86 ベアメタル上に、Hosted Control Plane 用の InfraEnv リソースを作成できます。
手順
InfraEnvリソースを設定するための YAML ファイルを作成します。以下の例を参照してください。apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> \1 namespace: <hosted_control_plane_namespace> \2 spec: cpuArchitecture: ppc64le pullSecretRef: name: pull-secret sshAuthorizedKey: <path_to_ssh_public_key>3 -
ファイルを
infraenv-config.yamlとして保存します。 次のコマンドを入力して設定を適用します。
$ oc apply -f infraenv-config.yamlURL を取得してライブ ISO をダウンロードし、IBM Power マシンがエージェントとして参加できるようにするには、以下のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get InfraEnv <hosted_cluster_name> \ -o json
5.5.2. InfraEnv リソースへの IBM Power エージェントの追加
エージェントを追加するには、ライブ ISO で開始するようにマシンを手動で設定できます。
手順
-
ライブ ISO をダウンロードし、それを使用してベアメタルまたは仮想マシン (VM) ホストを起動します。ライブ ISO の URL は、
InfraEnvリソースのstatus.isoDownloadURLフィールドにあります。起動時に、ホストは Assisted Service と通信し、InfraEnvリソースと同じ namespace にエージェントとして登録します。 エージェントとそのプロパティーの一部を一覧表示するには、次のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agents出力例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 auto-assign e57a637f-745b-496e-971d-1abbf03341ba auto-assign各エージェントが作成された後、必要に応じてエージェントの
installation_disk_idとhostnameを設定できます。エージェントの
installation_disk_idフィールドを設定するには、次のコマンドを入力します。$ oc -n <hosted_control_plane_namespace> patch agent <agent_name> -p '{"spec":{"installation_disk_id":"<installation_disk_id>","approved":true}}' --type mergeエージェントの
hostnameフィールドを設定するには、次のコマンドを入力します。$ oc -n <hosted_control_plane_namespace> patch agent <agent_name> -p '{"spec":{"hostname":"<hostname>","approved":true}}' --type merge
検証
エージェントの使用が承認されていることを確認するには、次のコマンドを入力します。
$ oc -n <hosted_control_plane_namespace> get agents出力例
NAME CLUSTER APPROVED ROLE STAGE 86f7ac75-4fc4-4b36-8130-40fa12602218 true auto-assign e57a637f-745b-496e-971d-1abbf03341ba true auto-assign
5.5.3. IBM Power 上のホステッドクラスターの NodePool オブジェクトのスケーリング
NodePool オブジェクトは、ホステッドクラスターの作成時に作成されます。NodePool オブジェクトをスケーリングすることで、Hosted Control Plane にさらに多くのコンピュートノードを追加できます。
手順
次のコマンドを実行して、
NodePoolオブジェクトを 2 つのノードにスケーリングします。$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> --replicas 2Cluster API エージェントプロバイダーは、ホステッドクラスターに割り当てられる 2 つのエージェントをランダムに選択します。これらのエージェントはさまざまな状態を経て、最終的に OpenShift Container Platform ノードとしてホステッドクラスターに参加します。エージェントは次の順序で移行フェーズを通過します。
-
binding -
discovering -
insufficient -
installing -
installing-in-progress -
added-to-existing-cluster
-
次のコマンドを実行して、スケールされた特定のエージェントのステータスを確認します。
$ oc -n <hosted_control_plane_namespace> get agent \ -o jsonpath='{range .items[*]}BMH: {@.metadata.labels.agent-install\.openshift\.io/bmh} Agent: {@.metadata.name} State: {@.status.debugInfo.state}{"\n"}{end}'出力例
BMH: Agent: 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d State: known-unbound BMH: Agent: 5e498cd3-542c-e54f-0c58-ed43e28b568a State: insufficient次のコマンドを実行して、移行フェーズを表示します。
$ oc -n <hosted_control_plane_namespace> get agent出力例
NAME CLUSTER APPROVED ROLE STAGE 50c23cda-cedc-9bbd-bcf1-9b3a5c75804d hosted-forwarder true auto-assign 5e498cd3-542c-e54f-0c58-ed43e28b568a true auto-assign da503cf1-a347-44f2-875c-4960ddb04091 hosted-forwarder true auto-assign次のコマンドを実行して、ホステッドクラスターにアクセスするための
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigエージェントが
added-to-existing-cluster状態に達したら、次のコマンドを入力して、OpenShift Container Platform ノードが表示されることを確認します。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes出力例
NAME STATUS ROLES AGE VERSION worker-zvm-0.hostedn.example.com Ready worker 5m41s v1.24.0+3882f8f worker-zvm-1.hostedn.example.com Ready worker 6m3s v1.24.0+3882f8f次のコマンドを入力して、
NodePoolオブジェクトをスケールアップしたときに 2 台のマシンが作成されたことを確認します。$ oc -n <hosted_control_plane_namespace> get machine.cluster.x-k8s.io出力例
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION hosted-forwarder-79558597ff-5tbqp hosted-forwarder-crqq5 worker-zvm-0.hostedn.example.com agent://50c23cda-cedc-9bbd-bcf1-9b3a5c75804d Running 41h 4.15.0 hosted-forwarder-79558597ff-lfjfk hosted-forwarder-crqq5 worker-zvm-1.hostedn.example.com agent://5e498cd3-542c-e54f-0c58-ed43e28b568a Running 41h 4.15.0次のコマンドを実行して、クラスターのバージョンを確認します。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusterversion出力例
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.15.0 True False 40h Cluster version is 4.15.0次のコマンドを実行して、クラスター Operator のステータスを確認します。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get clusteroperatorsクラスターの各コンポーネントについて、出力に次のクラスター Operator ステータスが表示されます。
-
NAME -
VERSION -
AVAILABLE -
PROGRESSING -
DEGRADED -
SINCE -
MESSAGE
-
第6章 非接続環境での Hosted Control Plane のデプロイ
6.1. 非接続環境の Hosted Control Plane の概要
Hosted Control Plane のコンテキストでは、非接続環境は、インターネットに接続されておらず、Hosted Control Plane をベースとして使用する OpenShift Container Platform デプロイメントです。Hosted Control Plane は、ベアメタルまたは OpenShift Virtualization 上の非接続環境にデプロイできます。
非接続環境の Hosted Control Plane は、スタンドアロンの OpenShift Container Platform とは異なる動作をします。
- コントロールプレーンは、管理クラスター内にあります。コントロールプレーンは、Control Plane Operator によって Hosted Control Plane の Pod が実行および管理される場所です。
- データプレーンは、ホステッドクラスターのワーカー内にあります。データプレーンは、HostedClusterConfig Operator によって管理されるワークロードやその他の Pod が実行される場所です。
Pod は、実行される場所に応じて、管理クラスターで作成された ImageDigestMirrorSet (IDMS) または ImageContentSourcePolicy (ICSP) か、ホステッドクラスターのマニフェストの spec フィールドに設定されている ImageContentSource の影響を受けます。spec フィールドは、ホステッドクラスター上の IDMS オブジェクトに変換されます。
Hosted Control Plane は、IPv4、IPv6、デュアルスタックネットワーク上の非接続環境にデプロイできます。IPv4 は、非接続環境に Hosted Control Plane をデプロイするための最もシンプルなネットワーク設定の 1 つです。IPv4 範囲では、IPv6 またはデュアルスタック設定よりも必要な外部コンポーネントが少なくなります。非接続環境の OpenShift Virtualization 上の Hosted Control Plane の場合は、IPv4 またはデュアルスタックネットワークのいずれかを使用してください。
デュアルスタックネットワーク上の非接続環境の Hosted Control Plane は、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
6.2. 非接続環境で OpenShift Virtualization に Hosted Control Plane をデプロイする
Hosted Control Plane を非接続環境でデプロイする場合、使用するプラットフォームに応じて手順の一部が異なります。以下の手順は、OpenShift Virtualization へのデプロイに固有のものです。
6.2.1. 前提条件
- 管理クラスターとして機能する、非接続の OpenShift Container Platform 環境がある。
- イメージをミラーリングするための内部レジストリーがある。詳細は、非接続インストールミラーリングについて を参照してください。
6.2.2. 非接続環境で Hosted Control Plane のイメージミラーリングを設定する
イメージミラーリングは、registry.redhat.com や quay.io などの外部レジストリーからイメージを取得し、プライベートレジストリーに保存するプロセスです。
次の手順では、ImageSetConfiguration オブジェクトを使用するバイナリーである、oc-mirror ツールが使用されます。このファイルで、以下の情報を指定できます。
-
ミラーリングする OpenShift Container Platform バージョン。バージョンは
quay.ioにあります。 - ミラーリングする追加の Operator。パッケージは個別に選択します。
- リポジトリーに追加する追加のイメージ。
前提条件
- ミラーリングプロセスを開始する前に、レジストリーサーバーが実行されていることを確認する。
手順
イメージのミラーリングを設定するには、以下の手順を実行します。
-
${HOME}/.docker/config.jsonファイルが、ミラーリング元のレジストリーとイメージのプッシュ先のプライベートレジストリーで更新されていることを確認します。 次の例を使用して、ミラーリングに使用する
ImageSetConfigurationオブジェクトを作成します。環境に合わせて必要に応じて値を置き換えます。apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: channels: - name: candidate-{product-version} minVersion: <4.x.y-build>1 maxVersion: <4.x.y-build>2 type: ocp kubeVirtContainer: true3 graph: true operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.17 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged4 次のコマンドを入力して、ミラーリングプロセスを開始します。
$ oc-mirror --v2 --config imagesetconfig.yaml \ --workspace file://mirror-file docker://<registry>ミラーリングプロセスが完了すると、
mirror-fileという名前の新しいフォルダーが作成されます。このフォルダーには、ImageDigestMirrorSet(IDMS)、ImageTagMirrorSet(ITMS)、およびホステッドクラスターに適用するカタログソースが含まれます。imagesetconfig.yamlファイルを次のように設定して、OpenShift Container Platform のナイトリーバージョンまたは CI バージョンをミラーリングします。apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: graph: true release: registry.ci.openshift.org/ocp/release:<4.x.y-build>1 kubeVirtContainer: true2 # ...部分的な非接続環境の場合は、次のコマンドを入力して、イメージセット設定からレジストリーにイメージをミラーリングします。
$ oc mirror -c imagesetconfig.yaml \ --workspace file://<file_path> docker://<mirror_registry_url> --v2詳細は、「部分的な非接続環境でのイメージセットのミラーリング」を参照してください。
完全な非接続環境の場合は、次の手順を実行します。
次のコマンドを入力して、指定したイメージセット設定からディスクにイメージをミラーリングします。
$ oc mirror -c imagesetconfig.yaml file://<file_path> --v2詳細は、「完全な非接続環境でのイメージセットのミラーリング」を参照してください。
次のコマンドを入力して、ディスク上のイメージセットファイルを処理し、その内容をターゲットミラーレジストリーにミラーリングします。
$ oc mirror -c imagesetconfig.yaml \ --from file://<file_path> docker://<mirror_registry_url> --v2
- 非接続ネットワークへのインストール の手順に従って、最新の multicluster engine Operator イメージをミラーリングします。
6.2.3. 管理クラスターでのオブジェクトの適用
ミラーリングプロセスが完了したら、管理クラスターに 2 つのオブジェクトを適用する必要があります。
-
ImageContentSourcePolicy(ICSP) またはImageDigestMirrorSet(IDMS) - カタログソース
oc-mirror ツールを使用すると、出力アーティファクトは oc-mirror-workspace/results-XXXXXX/ という名前のフォルダーに保存されます。
ICSP または IDMS は、ノードを再起動せずに、各ノードの kubelet を再起動する MachineConfig の変更を開始します。ノードが READY としてマークされたら、新しく生成されたカタログソースを適用する必要があります。
カタログソースは、カタログイメージのダウンロードや処理を行い、そのイメージに含まれるすべての PackageManifests を取得するなど、openshift-marketplace Operator でアクションを開始します。
手順
新しいソースを確認するには、新しい
CatalogSourceをソースとして使用して次のコマンドを実行します。$ oc get packagemanifestアーティファクトを適用するには、次の手順を実行します。
次のコマンドを入力して、ICSP または IDMS アーティファクトを作成します。
$ oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yamlノードの準備が完了するまで待ってから、次のコマンドを入力します。
$ oc apply -f catalogSource-XXXXXXXX-index.yaml
OLM カタログをミラーリングし、ホステッドクラスターがミラーを参照するように設定します。
OLMCatalogPlacement の
management(デフォルト) モードを使用する場合、OLM カタログに使用されるイメージストリームが、管理クラスター上の ICSP からのオーバーライド情報で自動的に修正されません。-
OLM カタログが元の名前とタグを使用して内部レジストリーに適切にミラーリングされている場合は、
hypershift.openshift.io/olm-catalogs-is-registry-overridesアノテーションをHostedClusterリソースに追加します。形式は"sr1=dr1,sr2=dr2"です。ソースレジストリーの文字列がキーで、宛先レジストリーが値です。 OLM カタログのイメージストリームメカニズムを回避するには、
HostedClusterリソースで次の 4 つのアノテーションを使用して、OLM Operator カタログに使用する 4 つのイメージのアドレスを直接指定します。-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
-
-
OLM カタログが元の名前とタグを使用して内部レジストリーに適切にミラーリングされている場合は、
この場合、イメージストリームは作成されないため、Operator の更新を取得するために内部ミラーを更新するときに、アノテーションの値を更新する必要があります。
次のステップ
Hosted Control Plane の非接続インストールのために multicluster engine Operator をデプロイする の手順を実行して、multicluster engine Operator をデプロイします。
6.2.4. Hosted Control Plane の非接続インストールのために multicluster engine Operator をデプロイする
multicluster engine for Kubernetes Operator は、複数のプロバイダーでクラスターをデプロイする場合に重要な役割を果たします。multicluster engine Operator がインストールされていない場合は、次のドキュメントを参照して、インストールの前提条件と手順を確認してください。
6.2.5. Hosted Control Plane の非接続インストールのために TLS 証明書を設定する
非接続デプロイメントで適切な機能を確保するには、管理クラスターとホステッドクラスターのワーカーノードでレジストリー CA 証明書を設定する必要があります。
6.2.5.1. 管理クラスターにレジストリー CA を追加する
管理クラスターにレジストリー CA を追加するには、次の手順を実行します。
手順
次の例のような config map を作成します。
apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <config_map_namespace>2 data:3 <registry_name>..<port>: |4 -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----クラスター全体のオブジェクト
image.config.openshift.ioにパッチを適用して、次の仕様を含めます。spec: additionalTrustedCA: - name: registry-configこのパッチの結果、コントロールプレーンノードがプライベートレジストリーからイメージを取得できるようになります。また、HyperShift Operator がホステッドクラスターのデプロイメント用の OpenShift Container Platform ペイロードを抽出できるようになります。
オブジェクトにパッチを適用するプロセスが完了するまでに数分かかる場合があります。
6.2.5.2. ホステッドクラスターのワーカーノードにレジストリー CA を追加する
ホステッドクラスターのデータプレーンワーカーがプライベートレジストリーからイメージを取得できるようにするために、ワーカーノードにレジストリー CA を追加する必要があります。
手順
hc.spec.additionalTrustBundleファイルに次の仕様を追加します。spec: additionalTrustBundle: - name: user-ca-bundle1 - 1
user-ca-bundleエントリーは、次の手順で作成する config map です。
HostedClusterオブジェクトの作成先と同じ namespace で、user-ca-bundleconfig map を作成します。config map は次の例のようになります。apiVersion: v1 data: ca-bundle.crt: | // Registry1 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry2 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry3 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 - 1
HostedClusterオブジェクトの作成先の namespace を指定します。
6.2.6. OpenShift Virtualization でのホステッドクラスターの作成
ホステッドクラスターは、コントロールプレーンと API エンドポイントが管理クラスターでホストされている OpenShift Container Platform クラスターです。ホステッドクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。
6.2.6.1. OpenShift Virtualization に Hosted Control Plane をデプロイするための要件
OpenShift Virtualization に Hosted Control Plane をデプロイする準備をする際には、次の情報を考慮してください。
- 管理クラスターはベアメタル上で実行してください。
- 各ホステッドクラスターの名前がクラスター全体で一意である。
-
ホステッドクラスター名として
clustersを使用しない。 - ホステッドクラスターは、multicluster engine Operator のマネージドクラスターの namespace には作成できない。
- Hosted Control Plane のストレージを設定する場合は、etcd の推奨プラクティスを考慮してください。レイテンシー要件を満たすには、各コントロールプレーンノードで実行されるすべての Hosted Control Plane の etcd インスタンス専用の高速ストレージデバイスを使用します。LVM ストレージを使用して、ホストされた etcd Pod のローカルストレージクラスを設定できます。詳細は、「推奨される etcd プラクティス」および「論理ボリュームマネージャーストレージを使用した永続ストレージ」を参照してください。
6.2.6.2. CLI を使用して KubeVirt プラットフォームでホステッドクラスターを作成する
ホステッドクラスターを作成するには、Hosted Control Plane のコマンドラインインターフェイス (CLI) hcp を使用できます。
手順
次のコマンドを入力して、KubeVirt プラットフォームでホステッドクラスターを作成します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <node_pool_replica_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --etcd-storage-class=<etcd_storage_class>6 注記--release-imageフラグを使用すると、特定の OpenShift Container Platform リリースを使用してホステッドクラスターを設定できます。--node-pool-replicasフラグに従って、2 つの仮想マシンワーカーレプリカを持つクラスターに対してデフォルトのノードプールが作成されます。しばらくすると、次のコマンドを入力して、ホストされているコントロールプレーン Pod が実行されていることを確認できます。
$ oc -n clusters-<hosted-cluster-name> get pods出力例
NAME READY STATUS RESTARTS AGE capi-provider-5cc7b74f47-n5gkr 1/1 Running 0 3m catalog-operator-5f799567b7-fd6jw 2/2 Running 0 69s certified-operators-catalog-784b9899f9-mrp6p 1/1 Running 0 66s cluster-api-6bbc867966-l4dwl 1/1 Running 0 66s . . . redhat-operators-catalog-9d5fd4d44-z8qqk 1/1 Running 0 66sKubeVirt 仮想マシンによってサポートされるワーカーノードを含むホステッドクラスターは、通常、完全にプロビジョニングされるまでに 10 ~ 15 分かかります。
検証
ホステッドクラスターのステータスを確認するには、次のコマンドを入力して、対応する
HostedClusterリソースを確認します。$ oc get --namespace clusters hostedclusters完全にプロビジョニングされた
HostedClusterオブジェクトを示す以下の出力例を参照してください。NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters my-hosted-cluster <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
6.2.6.3. OpenShift Virtualization 上の Hosted Control Plane のデフォルトの Ingress と DNS を設定する
すべての OpenShift Container Platform クラスターにはデフォルトのアプリケーション Ingress コントローラーが含まれており、これにはワイルドカード DNS レコードが関連付けられている必要があります。デフォルトでは、HyperShift KubeVirt プロバイダーを使用して作成されたホステッドクラスターは、自動的に KubeVirt 仮想マシンが実行される OpenShift Container Platform クラスターのサブドメインになります。
たとえば、OpenShift Container Platform クラスターには次のデフォルトの Ingress DNS エントリーがある可能性があります。
*.apps.mgmt-cluster.example.com
その結果、guest という名前が付けられ、その基礎となる OpenShift Container Platform クラスター上で実行される KubeVirt ホステッドクラスターには、次のデフォルト Ingress が設定されます。
*.apps.guest.apps.mgmt-cluster.example.com手順
デフォルトの Ingress DNS が適切に機能するには、KubeVirt 仮想マシンをホストするクラスターでワイルドカード DNS ルートを許可する必要があります。
この動作は、以下のコマンドを入力して設定できます。
$ oc patch ingresscontroller -n openshift-ingress-operator default \ --type=json \ -p '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'
デフォルトのホステッドクラスターの Ingress を使用する場合、接続がポート 443 経由の HTTPS トラフィックに制限されます。ポート 80 経由のプレーン HTTP トラフィックは拒否されます。この制限は、デフォルトの Ingress の動作にのみ適用されます。
6.2.6.4. Ingress と DNS の動作のカスタマイズ
デフォルトの Ingress および DNS 動作を使用しない場合は、作成時に一意のベースドメインを使用して KubeVirt ホステッドクラスターを設定できます。このオプションでは、作成時に手動の設定手順が必要であり、クラスターの作成、ロードバランサーの作成、およびワイルドカード DNS 設定の 3 つの主要な手順が含まれます。
6.2.6.4.1. ベースドメインを指定するホステッドクラスターのデプロイ
ベースドメインを指定するホステッドクラスターを作成するには、次の手順を実行します。
手順
以下のコマンドを入力します。
$ hcp create cluster kubevirt \ --name <hosted_cluster_name> \1 --node-pool-replicas <worker_count> \2 --pull-secret <path_to_pull_secret> \3 --memory <value_for_memory> \4 --cores <value_for_cpu> \5 --base-domain <basedomain>6 その結果、ホステッドクラスターには、クラスター名とベースドメイン用に設定された Ingress ワイルドカード (例:
.apps.example.hypershift.lab) が含まれます。ホステッドクラスターはPartialステータスのままです。一意のベースドメインを持つホステッドクラスターを作成した後、必要な DNS レコードとロードバランサーを設定する必要があるためです。
検証
次のコマンドを入力して、ホステッドクラスターのステータスを表示します。
$ oc get --namespace clusters hostedclusters出力例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example example-admin-kubeconfig Partial True False The hosted control plane is available次のコマンドを入力してクラスターにアクセスします。
$ hcp create kubeconfig --name <hosted_cluster_name> \ > <hosted_cluster_name>-kubeconfig$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get co出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE console <4.x.0> False False False 30m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.example.hypershift.lab): Get "https://console-openshift-console.apps.example.hypershift.lab": dial tcp: lookup console-openshift-console.apps.example.hypershift.lab on 172.31.0.10:53: no such host ingress <4.x.0> True False True 28m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing)<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
次のステップ
出力のエラーを修正するには、「ロードバランサーのセットアップ」および「ワイルドカード DNS の設定」の手順を完了します。
ホステッドクラスターがベアメタル上にある場合は、ロードバランサーサービスを設定するために MetalLB が必要になる場合があります。詳細は、「MetalLB の設定」を参照してください。
6.2.6.4.2. ロードバランサーのセットアップ
Ingress トラフィックを KubeVirt 仮想マシンにルーティングし、ロードバランサー IP アドレスにワイルドカード DNS エントリーを割り当てるロードバランサーサービスを設定します。
手順
ホステッドクラスターの Ingress を公開する
NodePortサービスがすでに存在します。ノードポートをエクスポートし、それらのポートをターゲットとするロードバランサーサービスを作成できます。次のコマンドを入力して、HTTP ノードポートを取得します。
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="http")].nodePort}'次の手順で使用する HTTP ノードポート値をメモします。
次のコマンドを入力して、HTTPS ノードポートを取得します。
$ oc --kubeconfig <hosted_cluster_name>-kubeconfig get services \ -n openshift-ingress router-nodeport-default \ -o jsonpath='{.spec.ports[?(@.name=="https")].nodePort}'次の手順で使用する HTTPS ノードポート値をメモします。
YAML ファイルに次の情報を入力します。
apiVersion: v1 kind: Service metadata: labels: app: <hosted_cluster_name> name: <hosted_cluster_name>-apps namespace: clusters-<hosted_cluster_name> spec: ports: - name: https-443 port: 443 protocol: TCP targetPort: <https_node_port>1 - name: http-80 port: 80 protocol: TCP targetPort: <http_node_port>2 selector: kubevirt.io: virt-launcher type: LoadBalancer次のコマンドを実行してロードバランサーサービスを作成します。
$ oc create -f <file_name>.yaml
6.2.6.4.3. ワイルドカード DNS の設定
ロードバランサーサービスの外部 IP を参照するワイルドカード DNS レコードまたは CNAME を設定します。
手順
次のコマンドを入力して外部 IP アドレスを取得します。
$ oc -n clusters-<hosted_cluster_name> get service <hosted-cluster-name>-apps \ -o jsonpath='{.status.loadBalancer.ingress[0].ip}'出力例
192.168.20.30外部 IP アドレスを参照するワイルドカード DNS エントリーを設定します。次の DNS エントリーの例を表示します。
*.apps.<hosted_cluster_name\>.<base_domain\>.DNS エントリーは、クラスターの内部と外部にルーティングできる必要があります。
DNS 解決の例
dig +short test.apps.example.hypershift.lab 192.168.20.30
検証
次のコマンドを実行して、ホステッドクラスターのステータスが
PartialからCompletedに移行したことを確認します。$ oc get --namespace clusters hostedclusters出力例
NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE example <4.x.0> example-admin-kubeconfig Completed True False The hosted control plane is available<4.x.0>を、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
6.2.7. デプロイの完了
ホステッドクラスターのデプロイは、コントロールプレーンの観点とデータプレーンの観点から監視できます。
6.2.7.1. コントロールプレーンの監視
デプロイの進行中に、次のアーティファクトに関する情報を収集してコントロールプレーンを監視できます。
- HyperShift Operator
-
HostedControlPlanePod - ベアメタルホスト
- エージェント
-
InfraEnvリソース -
HostedClusterおよびNodePoolリソース
手順
コントロールプレーンを監視するには、次のコマンドを入力します。
$ export KUBECONFIG=/root/.kcli/clusters/hub-ipv4/auth/kubeconfig$ watch "oc get pod -n hypershift;echo;echo;\ oc get pod -n clusters-hosted-ipv4;echo;echo;\ oc get bmh -A;echo;echo;\ oc get agent -A;echo;echo;\ oc get infraenv -A;echo;echo;\ oc get hostedcluster -A;echo;echo;\ oc get nodepool -A;echo;echo;"
6.2.7.2. データプレーンの監視
デプロイの進行中に、次のアーティファクトに関する情報を収集してデータプレーンを監視できます。
- クラスターのバージョン
- ノード (特にノードがクラスターに参加したかどうかについて)
- クラスター Operator
手順
次のコマンドを入力します。
$ oc get secret -n clusters-hosted-ipv4 admin-kubeconfig \ -o jsonpath='{.data.kubeconfig}' | base64 -d > /root/hc_admin_kubeconfig.yaml$ export KUBECONFIG=/root/hc_admin_kubeconfig.yaml$ watch "oc get clusterversion,nodes,co"
6.3. 非接続環境でベアメタルに Hosted Control Plane をデプロイする
Hosted Control Plane をベアメタルにプロビジョニングする場合は、Agent プラットフォームを使用します。Agent プラットフォームと multicluster engine for Kubernetes Operator が連携して、非接続デプロイメントを可能にします。Agent プラットフォームは、Central Infrastructure Management サービスを使用して、ホステッドクラスターにワーカーノードを追加します。Central Infrastructure Management の概要は、Central Infrastructure Management の有効化 を参照してください。
6.3.1. ベアメタル向けの非接続環境のアーキテクチャー
以下の図は、非接続環境のアーキテクチャーの例を示しています。

- TLS サポートを備えたレジストリー証明書のデプロイメント、Web サーバー、DNS などのインフラストラクチャーサービスを設定して、非接続デプロイメントが確実に機能するようにします。
openshift-confignamespace に config map を作成します。この例では、config map の名前はregistry-configになります。config map の内容はレジストリー CA 証明書です。config map の data フィールドには、次のキー/値が含まれている必要があります。-
キー:
<registry_dns_domain_name>..<port>(例:registry.hypershiftdomain.lab..5000:)ポートを指定するときは、レジストリー DNS ドメイン名の後に..を配置するようにしてください。 値: 証明書の内容
config map の作成の詳細は、Hosted Control Plane の非接続インストールのために TLS 証明書を設定する を参照してください。
-
キー:
-
images.config.openshift.ioカスタムリソース (CR) 仕様を変更し、値がname: registry-configのadditionalTrustedCAという名前の新規フィールドを追加します。 2 つのデータフィールドを含む config map を作成します。1 つのフィールドには
RAW形式のregistries.confファイルが、もう 1 つのフィールドにはレジストリー CA が含まれ、ca-bundle.crtという名前が付けられます。config map はmulticluster-enginenamespace に属し、config map の名前は他のオブジェクトで参照されます。config map の例は、以下の設定例を参照してください。apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- # ... -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.ocp-edge-cluster-0.qe.lab.redhat.com:5000/openshift4" [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true # ... # ...-
multicluster engine Operator の namespace で、Agent と
hypershift-addonアドオンの両方を有効にするmulticlusterengineCR を作成します。multicluster engine Operator の namespace には、非接続デプロイメントでの動作を変更するための config map が含まれている必要があります。namespace には、multicluster-engine、assisted-service、およびhypershift-addon-managerPod も含まれます。 ホステッドクラスターのデプロイに必要な次のオブジェクトを作成します。
- シークレット: シークレットには、プルシークレット、SSH キー、etcd 暗号化キーが含まれます。
- config map: config map には、プライベートレジストリーの CA 証明書が含まれています。
-
HostedCluster:HostedClusterリソースは、ユーザーが作成しようとしているクラスターの設定を定義します。 -
NodePool:NodePoolリソースは、データプレーンに使用するマシンを参照するノードプールを識別します。
-
ホステッドクラスターオブジェクトを作成した後、HyperShift Operator は、コントロールプレーン Pod に対応するために
HostedControlPlanenamespace を確立します。この namespace は、エージェント、ベアメタルホスト (BMH)、InfraEnvリソースなどのコンポーネントもホストします。その後、InfraEnvリソースを作成し、ISO の作成後に、Baseboard Management Controller (BMC) の認証情報を含む BMH とそのシークレットを作成します。 -
openshift-machine-apinamespace の Metal3 Operator は、新しい BMH を検査します。その後、Metal3 Operator は、multicluster engine Operator の namespace のAgentServiceConfigCR を通じて指定された設定済みのLiveISOおよびRootFSの値を使用して、BMC に接続して BMC を起動しようとします。 -
HostedClusterリソースのワーカーノードが起動された後、エージェントコンテナーが起動されます。このエージェントは、デプロイメントを完了するためのアクションを調整する Assisted Service との接続を確立します。最初に、NodePoolリソースをHostedClusterリソースのワーカーノードの数にスケーリングする必要があります。Assisted Service は残りのタスクを管理します。 - この時点で、デプロイメントプロセスが完了するまで待ちます。
6.3.2. 非接続環境でベアメタルに Hosted Control Plane をデプロイするための要件
オフライン環境で Hosted Control Plane を設定するには、次の前提条件を満たす必要があります。
- CPU: 提供される CPU の数によって、同時に実行できるホステッドクラスターの数が決まります。通常、3 つのノードの場合、各ノードに 16 個の CPU を使用します。最小限の開発では、3 つのノードの場合、各ノードに 12 個の CPU を使用できます。
- メモリー: RAM の容量は、ホストできるホステッドクラスターの数に影響します。各ノードに 48 GB の RAM を使用します。最小限の開発であれば、18 GB の RAM で十分です。
ストレージ: multicluster engine Operator には SSD ストレージを使用します。
- 管理クラスター: 250 GB。
- レジストリー: 必要なストレージは、ホストされているリリース、Operator、イメージの数によって異なります。許容可能な数値は 500 GB ですが、ホステッドクラスターをホストするディスクから分離することが望ましいです。
- Web サーバー: 必要なストレージは、ホストされる ISO とイメージの数によって異なります。許容可能な数値は 500 GB です。
実稼働環境: 実稼働環境の場合、管理クラスター、レジストリー、および Web サーバーを異なるディスク上に分離します。この例は、実稼働環境で可能な設定を示しています。
- レジストリー: 2 TB
- 管理クラスター: 500 GB
- Web サーバー: 2 TB
6.3.3. リリースイメージダイジェストの抽出
タグ付けされたイメージを使用して、OpenShift Container Platform リリースイメージダイジェストを抽出できます。
手順
次のコマンドを実行して、イメージダイジェストを取得します。
$ oc adm release info <tagged_openshift_release_image> | grep "Pull From"<tagged_openshift_release_image>を、サポートされている OpenShift Container Platform バージョンのタグ付きイメージに置き換えます (例:quay.io/openshift-release-dev/ocp-release:4.14.0-x8_64)。出力例
Pull From: quay.io/openshift-release-dev/ocp-release@sha256:69d1292f64a2b67227c5592c1a7d499c7d00376e498634ff8e1946bc9ccdddfe
6.3.4. ベアメタルでの DNS 設定
ホステッドクラスターの API サーバーは、NodePort サービスとして公開されます。API サーバーに到達できる宛先を指す api.<hosted_cluster_name>.<base_domain> の DNS エントリーが存在する必要があります。
DNS エントリーは、ホステッドコントロールプレーンを実行している管理クラスター内のノードの 1 つを指すレコードのように単純なものにすることができます。エントリーは、受信トラフィックを Ingress Pod にリダイレクトするためにデプロイされるロードバランサーを指すこともできます。
DNS 設定の例
api.example.krnl.es. IN A 192.168.122.20
api.example.krnl.es. IN A 192.168.122.21
api.example.krnl.es. IN A 192.168.122.22
api-int.example.krnl.es. IN A 192.168.122.20
api-int.example.krnl.es. IN A 192.168.122.21
api-int.example.krnl.es. IN A 192.168.122.22
`*`.apps.example.krnl.es. IN A 192.168.122.23
前述の例の場合、*.apps.example.krnl.es. IN A 192.168.122.23 が、ホステッドクラスター内のノード、またはロードバランサー (設定されている場合) です。
IPv6 ネットワーク上の非接続環境用に DNS を設定する場合、設定は次の例のようになります。
IPv6 ネットワークの DNS 設定の例
api.example.krnl.es. IN A 2620:52:0:1306::5
api.example.krnl.es. IN A 2620:52:0:1306::6
api.example.krnl.es. IN A 2620:52:0:1306::7
api-int.example.krnl.es. IN A 2620:52:0:1306::5
api-int.example.krnl.es. IN A 2620:52:0:1306::6
api-int.example.krnl.es. IN A 2620:52:0:1306::7
`*`.apps.example.krnl.es. IN A 2620:52:0:1306::10デュアルスタックネットワークの非接続環境で DNS を設定する場合は、IPv4 と IPv6 の両方の DNS エントリーを含めるようにしてください。
デュアルスタックネットワークの DNS 設定の例
host-record=api-int.hub-dual.dns.base.domain.name,192.168.126.10
host-record=api.hub-dual.dns.base.domain.name,192.168.126.10
address=/apps.hub-dual.dns.base.domain.name/192.168.126.11
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,192.168.126.20
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,192.168.126.21
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,192.168.126.22
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,192.168.126.25
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,192.168.126.26
host-record=api-int.hub-dual.dns.base.domain.name,2620:52:0:1306::2
host-record=api.hub-dual.dns.base.domain.name,2620:52:0:1306::2
address=/apps.hub-dual.dns.base.domain.name/2620:52:0:1306::3
dhcp-host=aa:aa:aa:aa:10:01,ocp-master-0,[2620:52:0:1306::5]
dhcp-host=aa:aa:aa:aa:10:02,ocp-master-1,[2620:52:0:1306::6]
dhcp-host=aa:aa:aa:aa:10:03,ocp-master-2,[2620:52:0:1306::7]
dhcp-host=aa:aa:aa:aa:10:06,ocp-installer,[2620:52:0:1306::8]
dhcp-host=aa:aa:aa:aa:10:07,ocp-bootstrap,[2620:52:0:1306::9]6.3.5. 非接続環境で Hosted Control Plane のレジストリーをデプロイする
開発環境の場合は、Podman コンテナーを使用して、小規模なセルフホスト型レジストリーをデプロイします。実稼働環境では、Red Hat Quay、Nexus、Artifactory などのエンタープライズホスト型レジストリーをデプロイします。
手順
Podman を使用して小規模なレジストリーをデプロイするには、以下の手順を実行します。
特権ユーザーとして
${HOME}ディレクトリーにアクセスし、次のスクリプトを作成します。#!/usr/bin/env bash set -euo pipefail PRIMARY_NIC=$(ls -1 /sys/class/net | grep -v podman | head -1) export PATH=/root/bin:$PATH export PULL_SECRET="/root/baremetal/hub/openshift_pull.json"1 if [[ ! -f $PULL_SECRET ]];then echo "Pull Secret not found, exiting..." exit 1 fi dnf -y install podman httpd httpd-tools jq skopeo libseccomp-devel export IP=$(ip -o addr show $PRIMARY_NIC | head -1 | awk '{print $4}' | cut -d'/' -f1) REGISTRY_NAME=registry.$(hostname --long) REGISTRY_USER=dummy REGISTRY_PASSWORD=dummy KEY=$(echo -n $REGISTRY_USER:$REGISTRY_PASSWORD | base64) echo "{\"auths\": {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\", \"email\": \"sample-email@domain.ltd\"}}}" > /root/disconnected_pull.json mv ${PULL_SECRET} /root/openshift_pull.json.old jq ".auths += {\"$REGISTRY_NAME:5000\": {\"auth\": \"$KEY\",\"email\": \"sample-email@domain.ltd\"}}" < /root/openshift_pull.json.old > $PULL_SECRET mkdir -p /opt/registry/{auth,certs,data,conf} cat <<EOF > /opt/registry/conf/config.yml version: 0.1 log: fields: service: registry storage: cache: blobdescriptor: inmemory filesystem: rootdirectory: /var/lib/registry delete: enabled: true http: addr: :5000 headers: X-Content-Type-Options: [nosniff] health: storagedriver: enabled: true interval: 10s threshold: 3 compatibility: schema1: enabled: true EOF openssl req -newkey rsa:4096 -nodes -sha256 -keyout /opt/registry/certs/domain.key -x509 -days 3650 -out /opt/registry/certs/domain.crt -subj "/C=US/ST=Madrid/L=San Bernardo/O=Karmalabs/OU=Guitar/CN=$REGISTRY_NAME" -addext "subjectAltName=DNS:$REGISTRY_NAME" cp /opt/registry/certs/domain.crt /etc/pki/ca-trust/source/anchors/ update-ca-trust extract htpasswd -bBc /opt/registry/auth/htpasswd $REGISTRY_USER $REGISTRY_PASSWORD podman create --name registry --net host --security-opt label=disable --replace -v /opt/registry/data:/var/lib/registry:z -v /opt/registry/auth:/auth:z -v /opt/registry/conf/config.yml:/etc/docker/registry/config.yml -e "REGISTRY_AUTH=htpasswd" -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry" -e "REGISTRY_HTTP_SECRET=ALongRandomSecretForRegistry" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd -v /opt/registry/certs:/certs:z -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt -e REGISTRY_HTTP_TLS_KEY=/certs/domain.key docker.io/library/registry:latest [ "$?" == "0" ] || !! systemctl enable --now registry- 1
PULL_SECRETの場所は、設定に適した場所に置き換えます。
スクリプトファイル
registry.shという名前を指定して保存します。スクリプトを実行すると、以下の情報がプルされます。- ハイパーバイザーのホスト名に基づくレジストリー名
- 必要な認証情報およびユーザーアクセスの詳細
次のように実行フラグを追加して、パーミッションを調整します。
$ chmod u+x ${HOME}/registry.shパラメーターを指定せずにスクリプトを実行するには、以下のコマンドを入力します。
$ ${HOME}/registry.shこのスクリプトはサーバーを起動します。このスクリプトは、管理目的で
systemdサービスを使用します。スクリプトを管理する必要がある場合は、以下のコマンドを使用できます。
$ systemctl status$ systemctl start$ systemctl stop
レジストリーのルートフォルダーは /opt/registry ディレクトリー内にあり、次のサブディレクトリーが含まれています。
-
certsには TLS 証明書が含まれます。 -
authには認証情報が含まれます。 -
dataにはレジストリーイメージが含まれます。 -
confにはレジストリー設定が含まれています。
6.3.6. 非接続環境で Hosted Control Plane の管理クラスターをデプロイする
OpenShift Container Platform の管理クラスターをセットアップするには、multicluster engine for Kubernetes Operator がインストールされていることを確認する必要があります。multicluster engine Operator は、複数のプロバイダーでクラスターをデプロイする場合に重要な役割を果たします。
前提条件
- 管理クラスターとターゲットのベアメタルホスト (BMH) の Baseboard Management Controller (BMC) の間に双方向の接続がある。または、エージェントプロバイダーを通じて、自分自身でブートする方式を取ることもできます。
ホステッドクラスターが、管理クラスターのホスト名および
*.appsホスト名の API ホスト名を解決して到達できる。管理クラスターの API ホスト名と*.appsホスト名の例を次に示します。-
api.management-cluster.internal.domain.com -
console-openshift-console.apps.management-cluster.internal.domain.com
-
管理クラスターが、ホステッドクラスターの API ホスト名および
*.appsホスト名を解決して到達できる。ホステッドクラスターの API ホスト名と*.appsホスト名の例を次に示します。-
api.sno-hosted-cluster-1.internal.domain.com -
console-openshift-console.apps.sno-hosted-cluster-1.internal.domain.com
-
手順
- OpenShift Container Platform クラスターに multicluster engine Operator 2.4 以降をインストールします。multicluster engine Operator は、OpenShift Container Platform OperatorHub から Operator としてインストールできます。HyperShift Operator は multicluster engine Operator に含まれています。multicluster engine Operator のインストールの詳細は、Red Hat Advanced Cluster Management ドキュメントの「multicluster engine Operator のインストールとアップグレード」を参照してください。
- HyperShift Operator がインストールされていることを確認します。HyperShift Operator は multicluster engine Operator とともに自動的に追加されます。手動でインストールする必要がある場合は、「local-cluster の hypershift-addon マネージドクラスターアドオンを手動で有効にする」の手順に従ってください。
次のステップ
次に、Web サーバーを設定します。
6.3.7. 非接続環境で Hosted Control Plane の Web サーバーを設定する
ホステッドクラスターとしてデプロイする OpenShift Container Platform リリースに関連付けられた Red Hat Enterprise Linux CoreOS (RHCOS) イメージをホストするには、追加の Web サーバーを設定する必要があります。
手順
Web サーバーを設定するには、以下の手順を実行します。
以下のコマンドを入力して、使用する OpenShift Container Platform リリースから
openshift-installバイナリーを展開します。$ oc adm -a ${LOCAL_SECRET_JSON} release extract --command=openshift-install \ "${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}"次のスクリプトを実行します。このスクリプトは、
/opt/srvディレクトリーにフォルダーを作成します。このフォルダーには、ワーカーノードをプロビジョニングするための RHCOS イメージが含まれています。#!/bin/bash WEBSRV_FOLDER=/opt/srv ROOTFS_IMG_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.pxe.rootfs.location')"1 LIVE_ISO_URL="$(./openshift-install coreos print-stream-json | jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location')"2 mkdir -p ${WEBSRV_FOLDER}/images curl -Lk ${ROOTFS_IMG_URL} -o ${WEBSRV_FOLDER}/images/${ROOTFS_IMG_URL##*/} curl -Lk ${LIVE_ISO_URL} -o ${WEBSRV_FOLDER}/images/${LIVE_ISO_URL##*/} chmod -R 755 ${WEBSRV_FOLDER}/* ## Run Webserver podman ps --noheading | grep -q websrv-ai if [[ $? == 0 ]];then echo "Launching Registry pod..." /usr/bin/podman run --name websrv-ai --net host -v /opt/srv:/usr/local/apache2/htdocs:z quay.io/alosadag/httpd:p8080 fi
ダウンロードが完了すると、コンテナーが実行され、Web サーバー上でイメージをホストします。このコンテナーは公式 HTTPd イメージのバリエーションを使用しているので、IPv6 ネットワークでの動作も可能になります。
6.3.8. 非接続環境で Hosted Control Plane のイメージミラーリングを設定する
イメージミラーリングは、registry.redhat.com や quay.io などの外部レジストリーからイメージを取得し、プライベートレジストリーに保存するプロセスです。
次の手順では、ImageSetConfiguration オブジェクトを使用するバイナリーである、oc-mirror ツールが使用されます。このファイルで、以下の情報を指定できます。
-
ミラーリングする OpenShift Container Platform バージョン。バージョンは
quay.ioにあります。 - ミラーリングする追加の Operator。パッケージは個別に選択します。
- リポジトリーに追加する追加のイメージ。
前提条件
- ミラーリングプロセスを開始する前に、レジストリーサーバーが実行されていることを確認する。
手順
イメージのミラーリングを設定するには、以下の手順を実行します。
-
${HOME}/.docker/config.jsonファイルが、ミラーリング元のレジストリーとイメージのプッシュ先のプライベートレジストリーで更新されていることを確認します。 次の例を使用して、ミラーリングに使用する
ImageSetConfigurationオブジェクトを作成します。環境に合わせて必要に応じて値を置き換えます。apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: channels: - name: candidate-{product-version} minVersion: <4.x.y-build>1 maxVersion: <4.x.y-build>2 type: ocp kubeVirtContainer: true3 graph: true operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.17 packages: - name: lvms-operator - name: local-storage-operator - name: odf-csi-addons-operator - name: odf-operator - name: mcg-operator - name: ocs-operator - name: metallb-operator - name: kubevirt-hyperconverged4 次のコマンドを入力して、ミラーリングプロセスを開始します。
$ oc-mirror --v2 --config imagesetconfig.yaml \ --workspace file://mirror-file docker://<registry>ミラーリングプロセスが完了すると、
mirror-fileという名前の新しいフォルダーが作成されます。このフォルダーには、ImageDigestMirrorSet(IDMS)、ImageTagMirrorSet(ITMS)、およびホステッドクラスターに適用するカタログソースが含まれます。imagesetconfig.yamlファイルを次のように設定して、OpenShift Container Platform のナイトリーバージョンまたは CI バージョンをミラーリングします。apiVersion: mirror.openshift.io/v2alpha1 kind: ImageSetConfiguration mirror: platform: graph: true release: registry.ci.openshift.org/ocp/release:<4.x.y-build>1 kubeVirtContainer: true2 # ...部分的な非接続環境の場合は、次のコマンドを入力して、イメージセット設定からレジストリーにイメージをミラーリングします。
$ oc mirror -c imagesetconfig.yaml \ --workspace file://<file_path> docker://<mirror_registry_url> --v2詳細は、「部分的な非接続環境でのイメージセットのミラーリング」を参照してください。
完全な非接続環境の場合は、次の手順を実行します。
次のコマンドを入力して、指定したイメージセット設定からディスクにイメージをミラーリングします。
$ oc mirror -c imagesetconfig.yaml file://<file_path> --v2詳細は、「完全な非接続環境でのイメージセットのミラーリング」を参照してください。
次のコマンドを入力して、ディスク上のイメージセットファイルを処理し、その内容をターゲットミラーレジストリーにミラーリングします。
$ oc mirror -c imagesetconfig.yaml \ --from file://<file_path> docker://<mirror_registry_url> --v2
- 非接続ネットワークへのインストール の手順に従って、最新の multicluster engine Operator イメージをミラーリングします。
6.3.9. 管理クラスターでのオブジェクトの適用
ミラーリングプロセスが完了したら、管理クラスターに 2 つのオブジェクトを適用する必要があります。
-
ImageContentSourcePolicy(ICSP) またはImageDigestMirrorSet(IDMS) - カタログソース
oc-mirror ツールを使用すると、出力アーティファクトは oc-mirror-workspace/results-XXXXXX/ という名前のフォルダーに保存されます。
ICSP または IDMS は、ノードを再起動せずに、各ノードの kubelet を再起動する MachineConfig の変更を開始します。ノードが READY としてマークされたら、新しく生成されたカタログソースを適用する必要があります。
カタログソースは、カタログイメージのダウンロードや処理を行い、そのイメージに含まれるすべての PackageManifests を取得するなど、openshift-marketplace Operator でアクションを開始します。
手順
新しいソースを確認するには、新しい
CatalogSourceをソースとして使用して次のコマンドを実行します。$ oc get packagemanifestアーティファクトを適用するには、次の手順を実行します。
次のコマンドを入力して、ICSP または IDMS アーティファクトを作成します。
$ oc apply -f oc-mirror-workspace/results-XXXXXX/imageContentSourcePolicy.yamlノードの準備が完了するまで待ってから、次のコマンドを入力します。
$ oc apply -f catalogSource-XXXXXXXX-index.yaml
OLM カタログをミラーリングし、ホステッドクラスターがミラーを参照するように設定します。
OLMCatalogPlacement の
management(デフォルト) モードを使用する場合、OLM カタログに使用されるイメージストリームが、管理クラスター上の ICSP からのオーバーライド情報で自動的に修正されません。-
OLM カタログが元の名前とタグを使用して内部レジストリーに適切にミラーリングされている場合は、
hypershift.openshift.io/olm-catalogs-is-registry-overridesアノテーションをHostedClusterリソースに追加します。形式は"sr1=dr1,sr2=dr2"です。ソースレジストリーの文字列がキーで、宛先レジストリーが値です。 OLM カタログのイメージストリームメカニズムを回避するには、
HostedClusterリソースで次の 4 つのアノテーションを使用して、OLM Operator カタログに使用する 4 つのイメージのアドレスを直接指定します。-
hypershift.openshift.io/certified-operators-catalog-image -
hypershift.openshift.io/community-operators-catalog-image -
hypershift.openshift.io/redhat-marketplace-catalog-image -
hypershift.openshift.io/redhat-operators-catalog-image
-
-
OLM カタログが元の名前とタグを使用して内部レジストリーに適切にミラーリングされている場合は、
この場合、イメージストリームは作成されないため、Operator の更新を取得するために内部ミラーを更新するときに、アノテーションの値を更新する必要があります。
次のステップ
Hosted Control Plane の非接続インストールのために multicluster engine Operator をデプロイする の手順を実行して、multicluster engine Operator をデプロイします。
6.3.10. AgentServiceConfig リソースのデプロイ
AgentServiceConfig カスタムリソースは、multicluster engine Operator の一部である Assisted Service アドオンの重要なコンポーネントです。このリソースはベアメタルクラスターをデプロイします。アドオンが有効な場合に、AgentServiceConfig リソースをデプロイしてアドオンを設定します。
AgentServiceConfig リソースの設定に加えて、multicluster engine Operator が非接続環境で適切に機能するように、追加の config map を含める必要があります。
手順
次の config map を追加してカスタムレジストリーを設定します。これには、デプロイメントをカスタマイズするための非接続環境の情報が含まれています。
apiVersion: v1 kind: ConfigMap metadata: name: custom-registries namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] prefix = "" location = "registry.redhat.io/openshift4" mirror-by-digest-only = true [[registry.mirror]] location = "registry.dns.base.domain.name:5000/openshift4"1 [[registry]] prefix = "" location = "registry.redhat.io/rhacm2" mirror-by-digest-only = true # ... # ...- 1
dns.base.domain.nameは DNS ベースドメイン名に置き換えます。
オブジェクトには、以下の 2 つのフィールドが含まれます。
- カスタム CA: このフィールドには、デプロイメントのさまざまなプロセスに読み込まれる認証局 (CA) が含まれます。
-
レジストリー:
Registries.confフィールドには、元のソースレジストリーではなくミラーレジストリーから使用する必要があるイメージと namespace に関する情報が含まれています。
次の例に示すように、
AssistedServiceConfigオブジェクトを追加して、Assisted Service を設定します。apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: annotations: unsupported.agent-install.openshift.io/assisted-service-configmap: assisted-service-config1 name: agent namespace: multicluster-engine spec: mirrorRegistryRef: name: custom-registries2 databaseStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi filesystemStorage: storageClassName: lvms-vg1 accessModes: - ReadWriteOnce resources: requests: storage: 20Gi osImages:3 - cpuArchitecture: x86_644 openshiftVersion: "4.14" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live-rootfs.x86_64.img5 url: http://registry.dns.base.domain.name:8080/images/rhcos-414.92.202308281054-0-live.x86_64.iso version: 414.92.202308281054-0 - cpuArchitecture: x86_64 openshiftVersion: "4.15" rootFSUrl: http://registry.dns.base.domain.name:8080/images/rhcos-415.92.202403270524-0-live-rootfs.x86_64.img url: http://registry.dns.base.domain.name:8080/images/rhcos-415.92.202403270524-0-live.x86_64.iso version: 415.92.202403270524-0- 1
metadata.annotations["unsupported.agent-install.openshift.io/assisted-service-configmap"]アノテーションは、Operator が動作をカスタマイズするために使用する config map 名を参照します。- 2
spec.mirrorRegistryRef.nameアノテーションは、Assisted Service Operator が使用する非接続のレジストリー情報を含む config map を指します。この config map は、デプロイメントプロセス中にこれらのリソースを追加します。- 3
spec.osImagesフィールドには、この Operator がデプロイできるさまざまなバージョンが含まれています。このフィールドは必須です。この例では、RootFSファイルとLiveISOファイルがすでにダウンロードされていることを前提としています。- 4
- デプロイする OpenShift Container Platform リリースごとに
cpuArchitectureサブセクションを追加します。この例では、4.14 および 4.15 のcpuArchitectureサブセクションが含まれています。 - 5
rootFSUrlフィールドとurlフィールドのdns.base.domain.nameは、DNS ベースドメイン名に置き換えてください。
すべてのオブジェクトを 1 つのファイルに連結し、管理クラスターに適用し、これらのオブジェクトをデプロイします。起動するには、以下のコマンドを実行します。
$ oc apply -f agentServiceConfig.yamlこのコマンドは 2 つの Pod をトリガーします。
出力例
assisted-image-service-0 1/1 Running 2 11d1 assisted-service-668b49548-9m7xw 2/2 Running 5 11d2
次のステップ
TLS 証明書を設定します。
6.3.11. Hosted Control Plane の非接続インストールのために TLS 証明書を設定する
非接続デプロイメントで適切な機能を確保するには、管理クラスターとホステッドクラスターのワーカーノードでレジストリー CA 証明書を設定する必要があります。
6.3.11.1. 管理クラスターにレジストリー CA を追加する
管理クラスターにレジストリー CA を追加するには、次の手順を実行します。
手順
次の例のような config map を作成します。
apiVersion: v1 kind: ConfigMap metadata: name: <config_map_name>1 namespace: <config_map_namespace>2 data:3 <registry_name>..<port>: |4 -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- <registry_name>..<port>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----クラスター全体のオブジェクト
image.config.openshift.ioにパッチを適用して、次の仕様を含めます。spec: additionalTrustedCA: - name: registry-configこのパッチの結果、コントロールプレーンノードがプライベートレジストリーからイメージを取得できるようになります。また、HyperShift Operator がホステッドクラスターのデプロイメント用の OpenShift Container Platform ペイロードを抽出できるようになります。
オブジェクトにパッチを適用するプロセスが完了するまでに数分かかる場合があります。
6.3.11.2. ホステッドクラスターのワーカーノードにレジストリー CA を追加する
ホステッドクラスターのデータプレーンワーカーがプライベートレジストリーからイメージを取得できるようにするために、ワーカーノードにレジストリー CA を追加する必要があります。
手順
hc.spec.additionalTrustBundleファイルに次の仕様を追加します。spec: additionalTrustBundle: - name: user-ca-bundle1 - 1
user-ca-bundleエントリーは、次の手順で作成する config map です。
HostedClusterオブジェクトの作成先と同じ namespace で、user-ca-bundleconfig map を作成します。config map は次の例のようになります。apiVersion: v1 data: ca-bundle.crt: | // Registry1 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry2 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- // Registry3 CA -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 - 1
HostedClusterオブジェクトの作成先の namespace を指定します。
6.3.12. ベアメタルでのホステッドクラスターの作成
ホステッドクラスターは、コントロールプレーンと API エンドポイントが管理クラスターでホストされている OpenShift Container Platform クラスターです。ホステッドクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。
6.3.12.1. ホステッドクラスターオブジェクトのデプロイ
通常は、HyperShift Operator が HostedControlPlane namespace を作成します。しかし、この場合は、HyperShift Operator が HostedCluster オブジェクトのリコンサイルを開始する前に、すべてのオブジェクトを含めておく必要があります。その後、Operator がリコンシリエーションプロセスを開始すると、所定の場所にあるすべてのオブジェクトを見つけることができます。
手順
namespace に関する次の情報を含めて、YAML ファイルを作成します。
--- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: <hosted_cluster_namespace>-<hosted_cluster_name>1 spec: {} status: {} --- apiVersion: v1 kind: Namespace metadata: creationTimestamp: null name: <hosted_cluster_namespace>2 spec: {} status: {}config map とシークレットに関する次の情報を含む YAML ファイルを作成し、
HostedClusterデプロイメントに追加します。--- apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: <hosted_cluster_namespace>1 --- apiVersion: v1 data: .dockerconfigjson: xxxxxxxxx kind: Secret metadata: creationTimestamp: null name: <hosted_cluster_name>-pull-secret2 namespace: <hosted_cluster_namespace>3 --- apiVersion: v1 kind: Secret metadata: name: sshkey-cluster-<hosted_cluster_name>4 namespace: <hosted_cluster_namespace>5 stringData: id_rsa.pub: ssh-rsa xxxxxxxxx --- apiVersion: v1 data: key: nTPtVBEt03owkrKhIdmSW8jrWRxU57KO/fnZa8oaG0Y= kind: Secret metadata: creationTimestamp: null name: <hosted_cluster_name>-etcd-encryption-key6 namespace: <hosted_cluster_namespace>7 type: OpaqueRBAC ロールを含む YAML ファイルを作成し、Assisted Service エージェントが Hosted Control Plane と同じ
HostedControlPlanenamespace に配置し、引き続きクラスター API で管理されるようにします。apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: capi-provider-role namespace: <hosted_cluster_namespace>-<hosted_cluster_name>1 2 rules: - apiGroups: - agent-install.openshift.io resources: - agents verbs: - '*'HostedClusterオブジェクトに関する情報を含む YAML ファイルを作成し、必要に応じて値を置き換えます。apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: additionalTrustBundle: name: "user-ca-bundle" olmCatalogPlacement: guest imageContentSources:3 - source: quay.io/openshift-release-dev/ocp-v4.0-art-dev mirrors: - registry.<dns.base.domain.name>:5000/openshift/release4 - source: quay.io/openshift-release-dev/ocp-release mirrors: - registry.<dns.base.domain.name>:5000/openshift/release-images5 - mirrors: ... ... autoscaling: {} controllerAvailabilityPolicy: SingleReplica dns: baseDomain: <dns.base.domain.name>6 etcd: managed: storage: persistentVolume: size: 8Gi restoreSnapshotURL: null type: PersistentVolume managementType: Managed fips: false networking: clusterNetwork: - cidr: 10.132.0.0/14 - cidr: fd01::/48 networkType: OVNKubernetes serviceNetwork: - cidr: 172.31.0.0/16 - cidr: fd02::/112 platform: agent: agentNamespace: <hosted_cluster_namespace>-<hosted_cluster_name>7 8 type: Agent pullSecret: name: <hosted_cluster_name>-pull-secret9 release: image: registry.<dns.base.domain.name>:5000/openshift/release-images:<4.x.y>-x86_6410 11 secretEncryption: aescbc: activeKey: name: <hosted_cluster_name>-etcd-encryption-key12 type: aescbc services: - service: APIServer servicePublishingStrategy: type: LoadBalancer - service: OAuthServer servicePublishingStrategy: type: Route - service: OIDC servicePublishingStrategy: type: Route - service: Konnectivity servicePublishingStrategy: type: Route - service: Ignition servicePublishingStrategy: type: Route sshKey: name: sshkey-cluster-<hosted_cluster_name>13 status: controlPlaneEndpoint: host: "" port: 0- 1 7 9 12 13
<hosted_cluster_name>は、ホステッドクラスターに置き換えます。- 2 8
<hosted_cluster_namespace>は、ホステッドクラスターの namespace の名前に置き換えます。- 3
imageContentSourcesセクションには、ホステッドクラスター内のユーザーワークロードのミラー参照が含まれます。- 4 5 6 10
<dns.base.domain.name>は、DNS ベースドメイン名に置き換えます。- 11
<4.x.y>は、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。
YAML ファイルで定義したすべてのオブジェクトを 1 つのファイルに連結し、管理クラスターに対して適用して作成します。起動するには、以下のコマンドを実行します。
$ oc apply -f 01-4.14-hosted_cluster-nodeport.yaml出力例
NAME READY STATUS RESTARTS AGE capi-provider-5b57dbd6d5-pxlqc 1/1 Running 0 3m57s catalog-operator-9694884dd-m7zzv 2/2 Running 0 93s cluster-api-f98b9467c-9hfrq 1/1 Running 0 3m57s cluster-autoscaler-d7f95dd5-d8m5d 1/1 Running 0 93s cluster-image-registry-operator-5ff5944b4b-648ht 1/2 Running 0 93s cluster-network-operator-77b896ddc-wpkq8 1/1 Running 0 94s cluster-node-tuning-operator-84956cd484-4hfgf 1/1 Running 0 94s cluster-policy-controller-5fd8595d97-rhbwf 1/1 Running 0 95s cluster-storage-operator-54dcf584b5-xrnts 1/1 Running 0 93s cluster-version-operator-9c554b999-l22s7 1/1 Running 0 95s control-plane-operator-6fdc9c569-t7hr4 1/1 Running 0 3m57s csi-snapshot-controller-785c6dc77c-8ljmr 1/1 Running 0 77s csi-snapshot-controller-operator-7c6674bc5b-d9dtp 1/1 Running 0 93s csi-snapshot-webhook-5b8584875f-2492j 1/1 Running 0 77s dns-operator-6874b577f-9tc6b 1/1 Running 0 94s etcd-0 3/3 Running 0 3m39s hosted-cluster-config-operator-f5cf5c464-4nmbh 1/1 Running 0 93s ignition-server-6b689748fc-zdqzk 1/1 Running 0 95s ignition-server-proxy-54d4bb9b9b-6zkg7 1/1 Running 0 95s ingress-operator-6548dc758b-f9gtg 1/2 Running 0 94s konnectivity-agent-7767cdc6f5-tw782 1/1 Running 0 95s kube-apiserver-7b5799b6c8-9f5bp 4/4 Running 0 3m7s kube-controller-manager-5465bc4dd6-zpdlk 1/1 Running 0 44s kube-scheduler-5dd5f78b94-bbbck 1/1 Running 0 2m36s machine-approver-846c69f56-jxvfr 1/1 Running 0 92s oauth-openshift-79c7bf44bf-j975g 2/2 Running 0 62s olm-operator-767f9584c-4lcl2 2/2 Running 0 93s openshift-apiserver-5d469778c6-pl8tj 3/3 Running 0 2m36s openshift-controller-manager-6475fdff58-hl4f7 1/1 Running 0 95s openshift-oauth-apiserver-dbbc5cc5f-98574 2/2 Running 0 95s openshift-route-controller-manager-5f6997b48f-s9vdc 1/1 Running 0 95s packageserver-67c87d4d4f-kl7qh 2/2 Running 0 93sホステッドクラスターが利用可能な場合、出力は次の例のようになります。
出力例
NAMESPACE NAME VERSION KUBECONFIG PROGRESS AVAILABLE PROGRESSING MESSAGE clusters hosted-dual hosted-admin-kubeconfig Partial True False The hosted control plane is available
6.3.12.2. ホステッドクラスターの NodePool オブジェクトの作成
NodePool は、ホステッドクラスターに関連付けられたスケーラブルなワーカーノードのセットです。NodePool マシンアーキテクチャーは特定のプール内で一貫性を保ち、コントロールプレーンのマシンアーキテクチャーから独立しています。
手順
NodePoolオブジェクトに関する次の情報を含む YAML ファイルを作成し、必要に応じて値を置き換えます。apiVersion: hypershift.openshift.io/v1beta1 kind: NodePool metadata: creationTimestamp: null name: <hosted_cluster_name> \1 namespace: <hosted_cluster_namespace> \2 spec: arch: amd64 clusterName: <hosted_cluster_name> management: autoRepair: false \3 upgradeType: InPlace \4 nodeDrainTimeout: 0s platform: type: Agent release: image: registry.<dns.base.domain.name>:5000/openshift/release-images:4.x.y-x86_64 \5 replicas: 26 status: replicas: 2- 1
<hosted_cluster_name>は、ホステッドクラスターに置き換えます。- 2
<hosted_cluster_namespace>は、ホステッドクラスターの namespace の名前に置き換えます。- 3
- ノードが削除された場合、ノードは再作成されないため、
autoRepairフィールドはfalseに設定されます。 - 4
upgradeTypeはInPlaceに設定されます。これは、アップグレード中に同じベアメタルノードが再利用されることを示します。- 5
- この
NodePoolに含まれるすべてのノードは、OpenShift Container Platform バージョン4.x.y-x86_64に基づいています。<dns.base.domain.name>の値は、DNS ベースドメイン名に置き換えます。4.x.yの値は、使用するサポート対象の OpenShift Container Platform のバージョンに置き換えます。 - 6
replicasの値を2に設定すると、ホステッドクラスターに 2 つのノードプールレプリカを作成できます。
次のコマンドを入力して、
NodePoolオブジェクトを作成します。$ oc apply -f 02-nodepool.yaml出力例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted-dual hosted 0 False False 4.x.y-x86_64
6.3.12.3. ホステッドクラスターの InfraEnv リソースの作成
InfraEnv リソースは、pullSecretRef や sshAuthorizedKey などの重要な詳細を含む Assisted Service オブジェクトです。これらの詳細は、ホステッドクラスター用にカスタマイズされた Red Hat Enterprise Linux CoreOS (RHCOS) ブートイメージを作成するために使用されます。
複数の InfraEnv リソースをホストすることができます。各リソースは特定のタイプのホストを採用できます。たとえば、大きな RAM 容量を持つホスト間でサーバーファームを分割することができます。
手順
InfraEnvリソースに関する次の情報を含めて YAML ファイルを作成し、必要に応じて値を置き換えます。apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: pullSecretRef: name: pull-secret sshAuthorizedKey: ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDk7ICaUE+/k4zTpxLk4+xFdHi4ZuDi5qjeF52afsNkw0w/glILHhwpL5gnp5WkRuL8GwJuZ1VqLC9EKrdmegn4MrmUlq7WTsP0VFOZFBfq2XRUxo1wrRdor2z0Bbh93ytR+ZsDbbLlGngXaMa0Vbt+z74FqlcajbHTZ6zBmTpBVq5RHtDPgKITdpE1fongp7+ZXQNBlkaavaqv8bnyrP4BWahLP4iO9/xJF9lQYboYwEEDzmnKLMW1VtCE6nJzEgWCufACTbxpNS7GvKtoHT/OVzw8ArEXhZXQUS1UY8zKsX2iXwmyhw5Sj6YboA8WICs4z+TrFP89LmxXY0j6536TQFyRz1iB4WWvCbH5n6W+ABV2e8ssJB1AmEy8QYNwpJQJNpSxzoKBjI73XxvPYYC/IjPFMySwZqrSZCkJYqQ023ySkaQxWZT7in4KeMu7eS2tC+Kn4deJ7KwwUycx8n6RHMeD8Qg9flTHCv3gmab8JKZJqN3hW1D378JuvmIX4V0=ここでは、以下のようになります。
- <hosted_cluster_namespace>
- ホステッドクラスター namespace の名前を指定します。
- pullSecretRef
-
プルシークレットが使用される
InfraEnvと同じ namespace 内の config map 参照を指定します。 - sshAuthorizedKey
-
ブートイメージに配置される SSH 公開鍵を指定します。SSH 鍵を使用すると、
coreユーザーとしてワーカーノードにアクセスできます。
次のコマンドを入力して、
InfraEnvリソースを作成します。$ oc apply -f 03-infraenv.yaml出力例
NAMESPACE NAME ISO CREATED AT clusters-hosted-dual hosted 2023-09-11T15:14:10Z
6.3.12.4. ホステッドクラスターのベアメタルホスト作成
ベアメタルホスト は、物理的な詳細と論理詳細を含む openshift-machine-api オブジェクトで、Metal3 Operator によって識別できるようになっています。これらの詳細は、agents と呼ばれる他の Assisted Service オブジェクトに関連付けられています。
前提条件
- ベアメタルホストと宛先ノードを作成する前に、宛先マシンを準備しておく必要があります。
- クラスターで使用するために、ベアメタルインフラストラクチャーに Red Hat Enterprise Linux CoreOS (RHCOS) コンピュートマシンをインストールした。
手順
ベアメタルホストを作成するには、以下の手順を実行します。
次の情報を含む YAML ファイルを作成します。ベアメタルホストに関して入力する詳細情報については、「BMO を使用して、ユーザーがプロビジョニングしたクラスターで新しいホストをプロビジョニングする」を参照してください。
ベアメタルホストの認証情報を保持するシークレットが 1 つ以上あるため、ワーカーノードごとに少なくとも 2 つのオブジェクトを作成する必要があります。
apiVersion: v1 kind: Secret metadata: name: <hosted_cluster_name>-worker0-bmc-secret namespace: <hosted_cluster_namespace> data: password: YWRtaW4= username: YWRtaW4= type: Opaque # ... apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <hosted_cluster_name>-worker0 namespace: <hosted_cluster_namespace> labels: infraenvs.agent-install.openshift.io: <hosted_cluster_name> annotations: inspect.metal3.io: disabled bmac.agent-install.openshift.io/hostname: <hosted_cluster_name>-worker0 spec: automatedCleaningMode: disabled bmc: disableCertificateVerification: true address: redfish-virtualmedia://[192.168.126.1]:9000/redfish/v1/Systems/local/<hosted_cluster_name>-worker0 credentialsName: <hosted_cluster_name>-worker0-bmc-secret bootMACAddress: aa:aa:aa:aa:02:11 online: trueここでは、以下のようになります。
- <HOSTED_CLUSTER_NAME>
- ホステッドクラスターの名前を指定します。
- <hosted_cluster_namespace>
- ホステッドクラスター namespace の名前を指定します。
- password
- ベースボード管理コントローラー(BMC)のパスワードを Base64 形式で指定します。
- username
- BMC のユーザー名を Base64 形式で指定します。
- infraenvs.agent-install.openshift.io
-
Assisted Installer と
BareMetalHostオブジェクト間のリンクとして機能します。 - bmac.agent-install.openshift.io/hostname
- デプロイメント中に採用されるノード名を表します。
- automatedCleaningMode
- Metal3 Operator によってノードが削除されないようにします。
- disableCertificateVerification
-
クライアントから証明書の検証をバイパスするには、
trueに設定します。 - address
- ワーカーノードの BMC アドレスを示します。
- credentialsName
- ユーザーとパスワードの認証情報が保存されているシークレットを指します。
- bootMACAddress
- ノードが開始するインターフェイスの MAC アドレスを示します。
- online
-
BareMetalHostオブジェクトの作成後にノードの状態を定義します。
次のコマンドを入力して、
BareMetalHostオブジェクトをデプロイします。$ oc apply -f 04-bmh.yamlプロセス中に、次の出力が確認できます。
この出力は、プロセスがノードに到達しようとしていることを示しています。
出力例
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 registering true 2s clusters-hosted hosted-worker1 registering true 2s clusters-hosted hosted-worker2 registering true 2sこの出力は、ノードが起動していることを示しています。
出力例
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioning true 16s clusters-hosted hosted-worker1 provisioning true 16s clusters-hosted hosted-worker2 provisioning true 16sこの出力は、ノードが正常に起動したことを示しています。
出力例
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE clusters-hosted hosted-worker0 provisioned true 67s clusters-hosted hosted-worker1 provisioned true 67s clusters-hosted hosted-worker2 provisioned true 67s
ノードが起動したら、次の例に示すように、namespace のエージェントに注目してください。
出力例
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 true auto-assignエージェントは、インストールに使用できるノードを表します。ホステッドクラスターにノードを割り当てるには、ノードプールをスケールアップします。
6.3.12.5. ノードプールのスケールアップ
ベアメタルホストを作成すると、そのステータスが Registering Provisioning、Provisioned に変わります。ノードは、エージェントの LiveISO と、agent という名前のデフォルトの Pod で始まります。このエージェントは、Assisted Service Operator から OpenShift Container Platform ペイロードをインストールする指示を受け取ります。
手順
ノードプールをスケールアップするには、次のコマンドを入力します。
$ oc -n <hosted_cluster_namespace> scale nodepool <hosted_cluster_name> \ --replicas 3ここでは、以下のようになります。
-
<hosted_cluster_namespace>は、ホステッドクラスターの namespace の名前です。 -
<hosted_cluster_name>は、ホステッドクラスターの名前です。
-
スケーリングプロセスが完了すると、エージェントがホステッドクラスターに割り当てられていることがわかります。
出力例
NAMESPACE NAME CLUSTER APPROVED ROLE STAGE clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0411 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0412 hosted true auto-assign clusters-hosted aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaa0413 hosted true auto-assignまた、ノードプールレプリカが設定されていることにも注意してください。
出力例
NAMESPACE NAME CLUSTER DESIRED NODES CURRENT NODES AUTOSCALING AUTOREPAIR VERSION UPDATINGVERSION UPDATINGCONFIG MESSAGE clusters hosted hosted 3 False False <4.x.y>-x86_64 Minimum availability requires 3 replicas, current 0 available<4.x.y>は、使用するサポート対象の OpenShift Container Platform バージョンに置き換えます。- ノードがクラスターに参加するまで待ちます。プロセス中に、エージェントはステージとステータスに関する最新情報を提供します。
6.4. 非接続環境で IBM Z に Hosted Control Plane をデプロイする
切断された環境の IBM Z 上のホステッドコントロールプレーンは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行い、フィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、以下のリンクを参照してください。
非接続環境の Hosted Control Plane デプロイメントは、スタンドアロンの OpenShift Container Platform とは異なる動作をします。
Hosted Control Plane には、次の 2 つの異なる環境が関係します。
- コントロールプレーン: 管理クラスターに配置されます。Hosted Control Plane の Pod が Control Plane Operator によって実行および管理される場所です。
- データプレーン: ホステッドクラスターのワーカーに配置されます。ワークロードと他のいくつかの Pod が実行され、Hosted Cluster Config Operator によって管理される場所です。
データプレーンの ImageContentSourcePolicy (ICSP) カスタムリソースは、ホステッドクラスターのマニフェストの ImageContentSources API を通じて管理されます。
コントロールプレーンの ICSP オブジェクトは、管理クラスターで管理されます。このオブジェクトは、HyperShift Operator によって解析され、registry-overrides エントリーとして Control Plane Operator と共有されます。このエントリーは、Hosted Control Plane の namespace 内の利用可能なデプロイメントのいずれかに引数として挿入されます。
Hosted Control Plane 内の非接続レジストリーを操作するには、まず管理クラスターに適切な ICSP を作成する必要があります。その後、非接続ワークロードをデータプレーンにデプロイするために、ホステッドクラスターのマニフェストの ImageContentSources フィールドに必要なエントリーを追加する必要があります。
6.4.1. 非接続環境で IBM Z に Hosted Control Plane をデプロイするための前提条件
- ミラーレジストリー。詳細は、「mirror registry for Red Hat OpenShift を使用したミラーレジストリーの作成」を参照してください。
- 非接続インストールのミラーイメージ。詳細は、「oc-mirror プラグインを使用した非接続インストールのイメージのミラーリング」参照してください。
6.4.2. 管理クラスターに認証情報とレジストリー認証局を追加する
管理クラスターからミラーレジストリーイメージをプルするには、まずミラーレジストリーの認証情報と認証局を管理クラスターに追加する必要があります。以下の手順を使用してください。
手順
次のコマンドを実行して、ミラーレジストリーの証明書を含む
ConfigMapを作成します。$ oc apply -f registry-config.yamlregistry-config.yaml ファイルの例
apiVersion: v1 kind: ConfigMap metadata: name: registry-config namespace: openshift-config data: <mirror_registry>: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE-----image.config.openshift.ioクラスター全体のオブジェクトにパッチを適用して、次のエントリーを追加します。spec: additionalTrustedCA: - name: registry-config管理クラスターのプルシークレットを更新して、ミラーレジストリーの認証情報を追加します。
次のコマンドを実行して、クラスターからプルシークレットを JSON 形式で取得します。
$ oc get secret/pull-secret -n openshift-config -o json \ | jq -r '.data.".dockerconfigjson"' \ | base64 -d > authfile取得したシークレットの JSON ファイルを編集して、認証局の認証情報を含むセクションを追加します。
"auths": { "<mirror_registry>": {1 "auth": "<credentials>",2 "email": "you@example.com" } },次のコマンドを実行して、クラスター上のプルシークレットを更新します。
$ oc set data secret/pull-secret -n openshift-config \ --from-file=.dockerconfigjson=authfile
6.4.3. AgentServiceConfig リソースのレジストリー認証局をミラーレジストリーで更新する
イメージのミラーレジストリーを使用する場合、イメージをセキュアにプルできるように、エージェントがレジストリーの証明書を信頼する必要があります。ConfigMap を作成することにより、ミラーレジストリーの認証局を AgentServiceConfig カスタムリソースに追加できます。
前提条件
- multicluster engine for Kubernetes Operator をインストールした。
手順
multicluster engine Operator をインストールしたのと同じ namespace で、ミラーレジストリーの詳細を含む
ConfigMapリソースを作成します。このConfigMapリソースにより、ホステッドクラスターのワーカーに、ミラーレジストリーからイメージを取得する権限が付与されます。ConfigMap ファイルの例
apiVersion: v1 kind: ConfigMap metadata: name: mirror-config namespace: multicluster-engine labels: app: assisted-service data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- -----END CERTIFICATE----- registries.conf: | [[registry]] location = "registry.stage.redhat.io" insecure = false blocked = false mirror-by-digest-only = true prefix = "" [[registry.mirror]] location = "<mirror_registry>" insecure = false [[registry]] location = "registry.redhat.io/multicluster-engine" insecure = false blocked = false mirror-by-digest-only = true prefix = "" [[registry.mirror]] location = "<mirror_registry>/multicluster-engine"1 insecure = false- 1
<mirror_registry>はミラーレジストリーの名前です。
AgentServiceConfigリソースにパッチを適用して、作成したConfigMapリソースを含めます。AgentServiceConfigリソースが存在しない場合は、次の内容を埋め込んだAgentServiceConfigリソースを作成します。spec: mirrorRegistryRef: name: mirror-config
6.4.4. ホステッドクラスターにレジストリー認証局を追加する
非接続環境で IBM Z に Hosted Control Plane をデプロイする場合は、additional-trust-bundle リソースと image-content-sources リソースを含めます。これらのリソースにより、ホステッドクラスターがデータプレーンのワーカーに認証局を注入して、イメージをレジストリーからプルできるようになります。
image-content-sourcesの情報を含むicsp.yamlファイルを作成します。image-content-sourcesの情報は、oc-mirrorを使用してイメージをミラーリングした後に生成されるImageContentSourcePolicyの YAML ファイルで入手できます。ImageContentSourcePolicy ファイルの例
# cat icsp.yaml - mirrors: - <mirror_registry>/openshift/release source: quay.io/openshift-release-dev/ocp-v4.0-art-dev - mirrors: - <mirror_registry>/openshift/release-images source: quay.io/openshift-release-dev/ocp-releaseホステッドクラスターを作成し、
additional-trust-bundle証明書を指定して、コンピュートノードを証明書で更新します。次に例を示します。$ hcp create cluster agent \ --name=<hosted_cluster_name> \1 --pull-secret=<path_to_pull_secret> \2 --agent-namespace=<hosted_control_plane_namespace> \3 --base-domain=<basedomain> \4 --api-server-address=api.<hosted_cluster_name>.<basedomain> \ --etcd-storage-class=<etcd_storage_class> \5 --ssh-key <path_to_ssh_public_key> \6 --namespace <hosted_cluster_namespace> \7 --control-plane-availability-policy SingleReplica \ --release-image=quay.io/openshift-release-dev/ocp-release:<ocp_release_image> \8 --additional-trust-bundle <path for cert> \9 --image-content-sources icsp.yaml- 1
<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。- 2
- プルシークレットへのパスを置き換えます (例:
/user/name/pullsecret)。 - 3
<hosted_control_plane_namespace>は、Hosted Control Plane の namespace の名前 (例:clusters-hosted) に置き換えます。- 4
- 名前をベースドメインに置き換えます (例:
example.com)。 - 5
- etcd ストレージクラス名を置き換えます (例:
lvm-storageclass)。 - 6
- SSH 公開鍵へのパスを置き換えます。デフォルトのファイルパスは
~/.ssh/id_rsa.pubです。 - 7 8
- 使用するサポート対象の OpenShift Container Platform バージョン (例:
4.17.0-multi) に置き換えます。 - 9
- ミラーレジストリーの認証局へのパスを置き換えます。
6.5. オフライン環境でのユーザーワークロードの監視
hypershift-addon マネージドクラスターアドオンは、HyperShift Operator の --enable-uwm-telemetry-remote-write オプションを有効にします。このオプションを有効にすると、ユーザーワークロードの監視が有効になり、コントロールプレーンからテレメトリーメトリクスをリモートで書き込むことができるようになります。
6.5.1. ユーザーワークロード監視の問題の解決
インターネットに接続されていない OpenShift Container Platform クラスターに multicluster engine Operator をインストールした場合、次のコマンドを入力して HyperShift Operator のユーザーワークロードの監視機能を実行しようとすると、エラーが発生して機能が失敗します。
$ oc get events -n hypershiftエラーの例
LAST SEEN TYPE REASON OBJECT MESSAGE
4m46s Warning ReconcileError deployment/operator Failed to ensure UWM telemetry remote write: cannot get telemeter client secret: Secret "telemeter-client" not found
エラーを解決するには、local-cluster namespace に config map を作成して、ユーザーワークロード監視オプションを無効にする必要があります。アドオンを有効にする前または後に config map を作成できます。アドオンエージェントは、HyperShift Operator を再設定します。
手順
次の config map を作成します。
kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "" installFlagsToRemove: "--enable-uwm-telemetry-remote-write"以下のコマンドを実行して config map を適用します。
$ oc apply -f <filename>.yaml
6.5.2. Hosted Control Plane 機能のステータス確認
Hosted Control Plane 機能がデフォルトで有効になりました。
手順
この機能が無効になっており、有効にする場合は、次のコマンドを入力します。
<multiclusterengine>は、multicluster engine Operator インスタンスの名前に置き換えます。$ oc patch mce <multiclusterengine> --type=merge -p \ '{"spec":{"overrides":{"components":[{"name":"hypershift","enabled": true}]}}}'この機能を有効にすると、
hypershift-addonマネージドクラスターアドオンがlocal-clusterマネージドクラスターにインストールされ、アドオンエージェントによって HyperShift Operator が multicluster engine Operator ハブクラスターにインストールされます。次のコマンドを入力して、
hypershift-addonマネージドクラスターアドオンがインストールされていることを確認します。$ oc get managedclusteraddons -n local-cluster hypershift-addon出力例
NAME AVAILABLE DEGRADED PROGRESSING hypershift-addon True Falseこのプロセス時のタイムアウトを回避するには、以下のコマンドを入力します。
$ oc wait --for=condition=Degraded=True managedclusteraddons/hypershift-addon \ -n local-cluster --timeout=5m$ oc wait --for=condition=Available=True managedclusteraddons/hypershift-addon \ -n local-cluster --timeout=5mプロセスが完了すると、
hypershift-addonマネージドクラスターアドオンと HyperShift Operator がインストールされ、local-clusterマネージドクラスターがホステッドクラスターをホストおよび管理できるようになります。
6.5.3. インフラストラクチャーノード上で実行する hypershift-addon マネージドクラスターアドオンの設定
デフォルトでは、hypershift-addon マネージドクラスターアドオンに対してノード配置設定は指定されていません。インフラストラクチャーノード上でアドオンを実行することを検討してください。そうすることで、サブスクリプション数に対する請求コストの発生や、個別のメンテナンスおよび管理タスクの発生を防ぐことができます。
手順
- ハブクラスターにログインします。
次のコマンドを入力して、
hypershift-addon-deploy-configアドオンデプロイメント設定仕様を開いて編集します。$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine以下の例のように、
nodePlacementフィールドを仕様に追加します。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: nodePlacement: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra operator: Exists-
変更を保存します。
hypershift-addonマネージドクラスターアドオンは、新規および既存のマネージドクラスターのインフラストラクチャーノードにデプロイされます。
第7章 Hosted Control Plane の証明書の設定
Hosted Control Plane の場合、証明書の設定手順はスタンドアロンの OpenShift Container Platform の場合とは異なります。
7.1. ホステッドクラスターでカスタム API サーバー証明書を設定する
API サーバーのカスタム証明書を設定するには、HostedCluster 設定の spec.configuration.apiServer セクションで証明書の詳細を指定します。
カスタム証明書は、Day 1 操作または Day 2 操作の中で設定できます。ただし、サービス公開ストラテジーはホステッドクラスターの作成中に設定した後は変更できないため、設定する予定の Kubernetes API サーバーのホスト名を知っておく必要があります。
前提条件
管理クラスターにカスタム証明書が含まれる Kubernetes シークレットを作成しました。シークレットには次の鍵が含まれています。
-
tls.crt: 証明書 -
tls.key: 秘密鍵
-
-
HostedCluster設定にロードバランサーを使用するサービス公開ストラテジーが含まれている場合は、証明書のサブジェクト代替名 (SAN) が内部 API エンドポイント (api-int) と競合しないことを確認してください。内部 API エンドポイントは、プラットフォームによって自動的に作成および管理されます。カスタム証明書と内部 API エンドポイントの両方で同じホスト名を使用すると、ルーティングの競合が発生する可能性があります。このルールの唯一の例外は、PrivateまたはPublicAndPrivate設定で AWS をプロバイダーとして使用する場合です。このような場合、SAN の競合はプラットフォームによって管理されます。 - 証明書は外部 API エンドポイントに対して有効である必要があります。
- 証明書の有効期間は、クラスターの予想されるライフサイクルと一致します。
手順
次のコマンドを入力して、カスタム証明書を使用してシークレットを作成します。
$ oc create secret tls sample-hosted-kas-custom-cert \ --cert=path/to/cert.crt \ --key=path/to/key.key \ -n <hosted_cluster_namespace>次の例に示すように、カスタム証明書の詳細を使用して
HostedCluster設定を更新します。spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert次のコマンドを入力して、
HostedCluster設定に変更を適用します。$ oc apply -f <hosted_cluster_config>.yaml
検証
- API サーバー Pod をチェックして、新しい証明書がマウントされていることを確認します。
- カスタムドメイン名を使用して API サーバーへの接続をテストします。
-
ブラウザーで、または
opensslなどのツールを使用して、証明書の詳細を確認します。
7.2. ホステッドクラスター用の Kubernetes API サーバーの設定
ホステッドクラスター用に Kubernetes API サーバーをカスタマイズする場合は、次の手順を実行します。
前提条件
- 実行中のホステッドクラスターがある。
-
HostedClusterリソースを変更するためのアクセス権がある。 Kubernetes API サーバーに使用するカスタム DNS ドメインがある。
- カスタム DNS ドメインは適切に設定され、解決可能である。
- DNS ドメインには有効な TLS 証明書が設定されている。
- ドメインへのネットワークアクセスが環境内で適切に設定されている。
- カスタム DNS ドメインは、ホステッドクラスター全体において一意である。
- カスタム証明書を設定した。詳細は「、ホステッドクラスターでのカスタム API サーバー証明書の設定」を参照してください。
手順
プロバイダープラットフォームで、
kubeAPIServerDNSNameURL が Kubernetes API サーバーが公開されている IP アドレスを指すように DNS レコードを設定します。DNS レコードは適切に設定され、クラスターから解決可能である必要があります。DNS レコードの設定に使用するコマンドの例
$ dig + short kubeAPIServerDNSNameHostedCluster仕様で、次の例に示すようにkubeAPIServerDNSNameフィールドを変更します。apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name> namespace: <hosted_cluster_namespace> spec: configuration: apiServer: servingCerts: namedCertificates: - names:1 - api-custom-cert-sample-hosted.sample-hosted.example.com servingCertificate:2 name: sample-hosted-kas-custom-cert kubeAPIServerDNSName: api-custom-cert-sample-hosted.sample-hosted.example.com3 # ...次のコマンドを入力して設定を適用します。
$ oc -f <hosted_cluster_spec>.yaml設定が適用されると、HyperShift Operator はカスタム DNS ドメインを指す新しい
kubeconfigシークレットを生成します。CLI またはコンソールを使用して
kubeconfigシークレットを取得します。CLI を使用してシークレットを取得するには、次のコマンドを入力します。
$ kubectl get secret <hosted_cluster_name>-custom-admin-kubeconfig \ -n <cluster_namespace> \ -o jsonpath='{.data.kubeconfig}' | base64 -dコンソールを使用してシークレットを取得するには、ホステッドクラスターに移動し、Download Kubeconfig をクリックします。
注記コンソールで show login command オプションを使用して、新しい
kubeconfigシークレットを使用することはできません。
7.3. カスタム DNS を使用してホステッドクラスターにアクセスする際のトラブルシューティング
カスタム DNS を使用してホステッドクラスターにアクセスするときに問題が発生した場合は、次のステップを実行します。
手順
- DNS レコードが適切に設定され、解決されていることを確認します。
次のコマンドを入力して、カスタムドメインの TLS 証明書が有効であること、およびドメインの SAN が正しいことを確認します。
$ oc get secret \ -n clusters <serving_certificate_name> \ -o jsonpath='{.data.tls\.crt}' | base64 \ -d |openssl x509 -text -noout -- カスタムドメインへのネットワーク接続が機能していることを確認します。
次の例に示すように、
HostedClusterリソースで、ステータスに正しいカスタムkubeconfig情報が表示されていることを確認します。HostedClusterステータスの例status: customKubeconfig: name: sample-hosted-custom-admin-kubeconfig次のコマンドを入力して、
HostedControlPlanenamespace のkube-apiserverログを確認します。$ oc logs -n <hosted_control_plane_namespace> \ -l app=kube-apiserver -f -c kube-apiserver
第8章 Hosted Control Plane の更新
Hosted Control Plane の更新には、ホステッドクラスターとノードプールの更新が含まれます。更新プロセス中にクラスターが完全に動作し続けるためには、コントロールプレーンとノードの更新を完了する際に、Kubernetes バージョンスキューポリシー の要件を満たす必要があります。
8.1. Hosted Control Plane をアップグレードするための要件
multicluster engine for Kubernetes Operator は、1 つ以上の OpenShift Container Platform クラスターを管理できます。OpenShift Container Platform でホステッドクラスターを作成した後、ホステッドクラスターをマネージドクラスターとして multicluster engine Operator にインポートする必要があります。その後、OpenShift Container Platform クラスターを管理クラスターとして使用できます。
Hosted Control Plane の更新を開始する前に、次の要件を考慮してください。
- OpenShift Virtualization をプロバイダーとして使用する場合は、OpenShift Container Platform クラスターにベアメタルプラットフォームを使用する必要があります。
-
ホステッドクラスターのクラウドプラットフォームとして、ベアメタルまたは OpenShift Virtualization を使用する必要があります。ホステッドクラスターのプラットフォームタイプは、
HostedClusterカスタムリソース (CR) のspec.Platform.type仕様で確認できます。
Hosted Control Plane は次の順序で更新する必要があります。
- OpenShift Container Platform クラスターを最新バージョンにアップグレードします。詳細は、「Web コンソールを使用してクラスターを更新」または「CLI を使用したクラスターの更新」を参照してください。
- multicluster engine Operator を最新バージョンにアップグレードします。詳細は、「インストールされている Operator の更新」を参照してください。
- ホステッドクラスターとノードプールを以前の OpenShift Container Platform バージョンから最新バージョンにアップグレードします。詳細は、「ホステッドクラスターのコントロールプレーンの更新」および「ホステッドクラスターのノードプールの更新」を参照してください。
8.2. ホステッドクラスターのチャネルの設定
利用可能な更新は、HostedCluster カスタムリソース (CR) の HostedCluster.Status フィールドで確認できます。
利用可能な更新は、ホステッドクラスターの Cluster Version Operator (CVO) からは取得されません。利用可能な更新のリストは、HostedCluster カスタムリソース (CR) の次のフィールドに含まれている利用可能な更新とは異なる場合があります。
-
status.version.availableUpdates -
status.version.conditionalUpdates
初期の HostedCluster CR には、status.version.availableUpdates フィールドと status.version.conditionalUpdates フィールドに情報が含まれていません。spec.channel フィールドを OpenShift Container Platform の stable リリースバージョンに設定すると、HyperShift Operator が HostedCluster CR をリコンサイルし、利用可能な更新と条件付き更新で status.version フィールドを更新します。
チャネル設定を含む HostedCluster CR の次の例を参照してください。
spec:
autoscaling: {}
channel: stable-4.y
clusterID: d6d42268-7dff-4d37-92cf-691bd2d42f41
configuration: {}
controllerAvailabilityPolicy: SingleReplica
dns:
baseDomain: dev11.red-chesterfield.com
privateZoneID: Z0180092I0DQRKL55LN0
publicZoneID: Z00206462VG6ZP0H2QLWK- 1
<4.y>は、spec.releaseで指定した OpenShift Container Platform リリースバージョンに置き換えます。たとえば、spec.releaseをocp-release:4.16.4-multiに設定する場合は、spec.channelをstable-4.16に設定する必要があります。
HostedCluster CR でチャネルを設定した後、status.version.availableUpdates フィールドと status.version.conditionalUpdates フィールドの出力を表示するには、次のコマンドを実行します。
$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> -o yaml出力例
version:
availableUpdates:
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:b7517d13514c6308ae16c5fd8108133754eb922cd37403ed27c846c129e67a9a
url: https://access.redhat.com/errata/RHBA-2024:6401
version: 4.16.11
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:d08e7c8374142c239a07d7b27d1170eae2b0d9f00ccf074c3f13228a1761c162
url: https://access.redhat.com/errata/RHSA-2024:6004
version: 4.16.10
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:6a80ac72a60635a313ae511f0959cc267a21a89c7654f1c15ee16657aafa41a0
url: https://access.redhat.com/errata/RHBA-2024:5757
version: 4.16.9
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:ea624ae7d91d3f15094e9e15037244679678bdc89e5a29834b2ddb7e1d9b57e6
url: https://access.redhat.com/errata/RHSA-2024:5422
version: 4.16.8
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:e4102eb226130117a0775a83769fe8edb029f0a17b6cbca98a682e3f1225d6b7
url: https://access.redhat.com/errata/RHSA-2024:4965
version: 4.16.6
- channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:f828eda3eaac179e9463ec7b1ed6baeba2cd5bd3f1dd56655796c86260db819b
url: https://access.redhat.com/errata/RHBA-2024:4855
version: 4.16.5
conditionalUpdates:
- conditions:
- lastTransitionTime: "2024-09-23T22:33:38Z"
message: |-
Could not evaluate exposure to update risk SRIOVFailedToConfigureVF (creating PromQL round-tripper: unable to load specified CA cert /etc/tls/service-ca/service-ca.crt: open /etc/tls/service-ca/service-ca.crt: no such file or directory)
SRIOVFailedToConfigureVF description: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions include kernel datastructure changes which are not compatible with older versions of the SR-IOV operator. Please update SR-IOV operator to versions dated 20240826 or newer before updating OCP.
SRIOVFailedToConfigureVF URL: https://issues.redhat.com/browse/NHE-1171
reason: EvaluationFailed
status: Unknown
type: Recommended
release:
channels:
- candidate-4.16
- candidate-4.17
- eus-4.16
- fast-4.16
- stable-4.16
image: quay.io/openshift-release-dev/ocp-release@sha256:fb321a3f50596b43704dbbed2e51fdefd7a7fd488ee99655d03784d0cd02283f
url: https://access.redhat.com/errata/RHSA-2024:5107
version: 4.16.7
risks:
- matchingRules:
- promql:
promql: |
group(csv_succeeded{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41", name=~"sriov-network-operator[.].*"})
or
0 * group(csv_count{_id="d6d42268-7dff-4d37-92cf-691bd2d42f41"})
type: PromQL
message: OCP Versions 4.14.34, 4.15.25, 4.16.7 and ALL subsequent versions
include kernel datastructure changes which are not compatible with older
versions of the SR-IOV operator. Please update SR-IOV operator to versions
dated 20240826 or newer before updating OCP.
name: SRIOVFailedToConfigureVF
url: https://issues.redhat.com/browse/NHE-11718.3. ホステッドクラスターの OpenShift Container Platform バージョンの更新
Hosted Control Plane は、コントロールプレーンとデータプレーン間の更新の分離を可能にします。
クラスターサービスプロバイダーやクラスター管理者は、コントロールプレーンとデータを個別に管理できます。
コントロールプレーンは HostedCluster カスタムリソース (CR) を変更することで更新でき、ノードは NodePool CR を変更することで更新できます。HostedCluster CR と NodePool CR では、どちらも .release フィールドで OpenShift Container Platform リリースイメージを指定します。
更新プロセス中にホステッドクラスターを完全に機能させ続けるには、コントロールプレーンとノードの更新が Kubernetes バージョンスキューポリシー に準拠している必要があります。
8.3.1. multicluster engine Operator ハブ管理クラスター
multicluster engine for Kubernetes Operator には、管理クラスターのサポート対象状態を維持するために、特定の OpenShift Container Platform バージョンが必要です。multicluster engine Operator は、OpenShift Container Platform Web コンソールの OperatorHub からインストールできます。
multicluster engine Operator のバージョンは、次のサポートマトリックスを参照してください。
multicluster engine Operator は、次の OpenShift Container Platform バージョンをサポートしています。
- 最新の未リリースバージョン
- 最新リリースバージョン
- 最新リリースバージョンの 2 つ前のバージョン
Red Hat Advanced Cluster Management (RHACM) の一部として multicluster engine Operator バージョンを入手することもできます。
8.3.2. ホステッドクラスターでサポートされる OpenShift Container Platform のバージョン
ホステッドクラスターをデプロイする場合、管理クラスターの OpenShift Container Platform バージョンは、ホステッドクラスターの OpenShift Container Platform バージョンに影響しません。
HyperShift Operator は、hypershift namespace に supported-versions ConfigMap を作成します。supported-versions ConfigMap には、デプロイ可能なサポートされている OpenShift Container Platform バージョンの範囲が記述されています。
supported-versions ConfigMap の次の例を参照してください。
apiVersion: v1
data:
server-version: 2f6cfe21a0861dea3130f3bed0d3ae5553b8c28b
supported-versions: '{"versions":["4.17","4.16","4.15","4.14"]}'
kind: ConfigMap
metadata:
creationTimestamp: "2024-06-20T07:12:31Z"
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
resourceVersion: "927029"
uid: f6336f91-33d3-472d-b747-94abae725f70
ホステッドクラスターを作成するには、サポートバージョン範囲内の OpenShift Container Platform バージョンを使用する必要があります。ただし、multicluster engine Operator が管理できるのは、n+1 から n-2 までの OpenShift Container Platform バージョンのみです。ここで n は現在のマイナーバージョンを定義します。multicluster engine Operator サポートマトリックスをチェックすると、multicluster engine Operator によって管理されるホステッドクラスターが、サポートされている OpenShift Container Platform の範囲内であることを確認できます。
上位バージョンのホステッドクラスターを OpenShift Container Platform にデプロイするには、multicluster engine Operator を新しいマイナーバージョンリリースに更新して、新しいバージョンの Hypershift Operator をデプロイする必要があります。multicluster engine Operator を新しいパッチ (z-stream) にアップグレードしても、HyperShift Operator は次のバージョンに更新されません。
hcp version コマンドの次の出力例を参照してください。管理クラスターの OpenShift Container Platform 4.16 でサポートされている OpenShift Container Platform バージョンを示しています。
Client Version: openshift/hypershift: fe67b47fb60e483fe60e4755a02b3be393256343. Latest supported OCP: 4.17.0
Server Version: 05864f61f24a8517731664f8091cedcfc5f9b60d
Server Supports OCP Versions: 4.17, 4.16, 4.15, 4.148.4. ホステッドクラスターの更新
spec.release.image 値は、コントロールプレーンのバージョンを決定します。HostedCluster オブジェクトは、意図した spec.release.image 値を HostedControlPlane.spec.releaseImage 値に送信し、適切な Control Plane Operator のバージョンを実行します。
Hosted Control Plane は、新しいバージョンの Cluster Version Operator (CVO) により、新しいバージョンのコントロールプレーンコンポーネントと OpenShift Container Platform コンポーネントのロールアウトを管理します。
Hosted Control Plane では、NodeHealthCheck リソースが CVO のステータスを検出できません。クラスター管理者は、クラスターの更新などの重要な操作を実行する前に、新しい修復アクションがクラスターの更新に干渉するのを防ぐために、NodeHealthCheck によってトリガーされた修復を手動で一時停止する必要があります。
修復を一時停止するには、NodeHealthCheck リソースの pauseRequests フィールドの値として、文字列の配列 (例: pause-test-cluster) を入力します。詳細は、Node Health Check Operator について を参照してください。
クラスターの更新が完了したら、修復を編集または削除できます。Compute → NodeHealthCheck ページに移動し、ノードヘルスチェックをクリックして、Actions をクリックすると、ドロップダウンリストが表示されます。
8.5. ノードプールの更新
ノードプールを使用すると、spec.release および spec.config の値を公開することで、ノードで実行されているソフトウェアを設定できます。次の方法でノードプールのローリング更新を開始できます。
-
spec.releaseまたはspec.configの値を変更します。 - AWS インスタンスタイプなどのプラットフォーム固有のフィールドを変更します。結果は、新しいタイプの新規インスタンスのセットになります。
- クラスター設定を変更します (変更がノードに伝播される場合)。
ノードプールは、replace 更新とインプレース更新をサポートします。nodepool.spec.release 値は、特定のノードプールのバージョンを決定します。NodePool オブジェクトは、.spec.management.upgradeType 値に従って、置換またはインプレースローリング更新を完了します。
ノードプールを作成した後は、更新タイプは変更できません。更新タイプを変更する場合は、ノードプールを作成し、他のノードプールを削除する必要があります。
8.5.1. ノードプールの replace 更新
置き換え 更新では、以前のバージョンから古いインスタンスが削除され、新しいバージョンでインスタンスが作成されます。この更新タイプは、このレベルの不変性がコスト効率に優れているクラウド環境で効果的です。
replace 更新では、ノードが完全に再プロビジョニングされるため、手動による変更は一切保持されません。
8.5.2. ノードプールのインプレース更新
インプレース 更新では、インスタンスのオペレーティングシステムが直接更新されます。このタイプは、ベアメタルなど、インフラストラクチャーの制約が高い環境に適しています。
インプレース更新では手動による変更を保存できますが、kubelet 証明書など、クラスターが直接管理するファイルシステムまたはオペレーティングシステムの設定に手動で変更を加えると、エラーが報告されます。
8.6. ホステッドクラスターのノードプールの更新
ホステッドクラスターのノードプールを更新することで、OpenShift Container Platform のバージョンを更新できます。ノードプールのバージョンが Hosted Control Plane のバージョンを超えることはできません。
NodePool カスタムリソース (CR) の .spec.release フィールドは、ノードプールのバージョンを示します。
手順
次のコマンドを入力して、ノードプールの
spec.release.image値を変更します。$ oc patch nodepool <node_pool_name> -n <hosted_cluster_namespace> \1 --type=merge \ -p '{"spec":{"nodeDrainTimeout":"60s","release":{"image":"<openshift_release_image>"}}}'2 - 1
<node_pool_name>と<hosted_cluster_namespace>を、それぞれノードプール名とホステッドクラスターの namespace に置き換えます。- 2
<openshift_release_image>変数は、アップグレードする新しい OpenShift Container Platform リリースイメージを指定します (例:quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64)。<4.y.z>をサポートされている OpenShift Container Platform バージョンに置き換えます。
検証
新しいバージョンがロールアウトされたことを確認するには、次のコマンドを実行して、ノードプールの
.status.conditions値を確認します。$ oc get -n <hosted_cluster_namespace> nodepool <node_pool_name> -o yaml出力例
status: conditions: - lastTransitionTime: "2024-05-20T15:00:40Z" message: 'Using release image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64'1 reason: AsExpected status: "True" type: ValidReleaseImage- 1
<4.y.z>をサポートされている OpenShift Container Platform バージョンに置き換えます。
8.7. ホステッドクラスターのコントロールプレーンの更新
Hosted Control Plane でホステッドクラスターを更新することで、OpenShift Container Platform のバージョンをアップグレードできます。HostedCluster カスタムリソース (CR) の .spec.release は、コントロールプレーンのバージョンを示します。HostedCluster は、.spec.release フィールドを HostedControlPlane.spec.release に更新し、適切な Control Plane Operator のバージョンを実行します。
HostedControlPlane リソースは、新しいバージョンの Cluster Version Operator (CVO) により、データプレーン内の OpenShift Container Platform コンポーネントとともに、新しいバージョンのコントロールプレーンコンポーネントのロールアウトを調整します。HostedControlPlane には次のアーティファクトが含まれています。
- CVO
- Cluster Network Operator (CNO)
- Cluster Ingress Operator
- Kube API サーバー、スケジューラー、およびマネージャーのマニフェスト
- Machine approver
- Autoscaler
- Kube API サーバー、Ignition、Konnectivity など、コントロールプレーンエンドポイントの Ingress を有効にするインフラストラクチャーリソース
HostedCluster CR の .spec.release フィールドを設定すると、status.version.availableUpdates フィールドと status.version.conditionalUpdates フィールドの情報を使用してコントロールプレーンを更新できます。
手順
次のコマンドを実行して、ホステッドクラスターに
hypershift.openshift.io/force-upgrade-to=<openshift_release_image>アノテーションを追加します。$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> <hosted_cluster_name> \1 "hypershift.openshift.io/force-upgrade-to=<openshift_release_image>" \2 --overwrite- 1
<hosted_cluster_name>と<hosted_cluster_namespace>を、それぞれホステッドクラスター名とホステッドクラスター namespace に置き換えます。- 2
<openshift_release_image>変数は、アップグレードする新しい OpenShift Container Platform リリースイメージを指定します (例:quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64)。<4.y.z>をサポートされている OpenShift Container Platform バージョンに置き換えます。
次のコマンドを実行して、ホステッドクラスターの
spec.release.image値を変更します。$ oc patch hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ --type=merge \ -p '{"spec":{"release":{"image":"<openshift_release_image>"}}}'
検証
新しいバージョンがロールアウトされたことを確認するには、次のコマンドを実行して、ホステッドクラスターの
.status.conditionsと.status.versionの値を確認します。$ oc get -n <hosted_cluster_namespace> hostedcluster <hosted_cluster_name> \ -o yaml出力例
status: conditions: - lastTransitionTime: "2024-05-20T15:01:01Z" message: Payload loaded version="4.y.z" image="quay.io/openshift-release-dev/ocp-release:4.y.z-x86_64"1 status: "True" type: ClusterVersionReleaseAccepted #... version: availableUpdates: null desired: image: quay.io/openshift-release-dev/ocp-release:4.y.z-x86_642 version: 4.y.z
8.8. multicluster engine Operator のコンソールを使用したホステッドクラスターの更新
multicluster engine Operator のコンソールを使用して、ホステッドクラスターを更新できます。
ホステッドクラスターを更新する前に、ホステッドクラスターの利用可能な更新と条件付き更新を参照する必要があります。間違ったリリースバージョンを選択すると、ホステッドクラスターが壊れる可能性があります。
手順
- All clusters を選択します。
- Infrastructure → Clusters に移動して、管理対象のホステッドクラスターを表示します。
- Upgrade available リンクをクリックして、コントロールプレーンとノードプールを更新します。
第9章 Hosted Control Plane の高可用性
9.1. Hosted Control Plane の高可用性について
次のアクションを実装することで、Hosted Control Plane の高可用性 (HA) を維持できます。
- ホステッドクラスターの etcd メンバーを回復します。
- ホステッドクラスターの etcd をバックアップおよび復元します。
- ホステッドクラスターの障害復旧プロセスを実行します。
9.1.1. 管理クラスターコンポーネントの障害の影響
管理クラスターコンポーネントに障害が発生しても、ワークロードは影響を受けません。OpenShift Container Platform 管理クラスターでは、回復力を提供するために、コントロールプレーンがデータプレーンから分離されています。
次の表は、管理クラスターコンポーネントの障害がコントロールプレーンとデータプレーンに与える影響を示しています。ただし、この表は管理クラスターコンポーネントの障害のすべてのシナリオを網羅しているわけではありません。
| 故障したコンポーネントの名前 | Hosted Control Plane API ステータス | ホステッドクラスターデータプレーンのステータス |
|---|---|---|
| ワーカーノード | 利用可能 | 利用可能 |
| アベイラビリティーゾーン | 利用可能 | 利用可能 |
| 管理クラスターの制御プレーン | 利用可能 | 利用可能 |
| 管理クラスターのコントロールプレーンとワーカーノード | 利用不可 | 利用可能 |
9.2. 不健全な etcd クラスターの回復
高可用性コントロールプレーンでは、3 つの etcd Pod が etcd クラスター内のステートフルセットの一部として実行されます。etcd クラスターを回復するには、etcd クラスターの健全性をチェックして、正常でない etcd Pod を特定します。
9.2.1. etcd クラスターのステータスの確認
任意の etcd Pod にログインすると、etcd クラスターの健全性ステータスを確認できます。
手順
次のコマンドを入力して、etcd Pod にログインします。
$ oc rsh -n openshift-etcd -c etcd <etcd_pod_name>次のコマンドを入力して、etcd クラスターの健全性ステータスを出力します。
sh-4.4# etcdctl endpoint status -w table出力例
+------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +------------------------------+-----------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://192.168.1xxx.20:2379 | 8fxxxxxxxxxx | 3.5.12 | 123 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.21:2379 | a5xxxxxxxxxx | 3.5.12 | 122 MB | false | false | 10 | 180156 | 180156 | | | https://192.168.1xxx.22:2379 | 7cxxxxxxxxxx | 3.5.12 | 124 MB | true | false | 10 | 180156 | 180156 | | +-----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
9.2.2. 障害が発生した etcd Pod の回復
3 ノードクラスターの各 etcd Pod には、データを保存するための独自の永続ボリューム要求 (PVC) があります。データが破損しているか欠落しているために、etcd Pod が失敗する可能性があります。障害が発生した etcd Pod とその PVC を回復できます。
手順
etcd Pod が失敗していることを確認するには、次のコマンドを入力します。
$ oc get pods -l app=etcd -n openshift-etcd出力例
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 64m etcd-1 2/2 Running 0 45m etcd-2 1/2 CrashLoopBackOff 1 (5s ago) 64m失敗した etcd Pod のステータスは
CrashLoopBackOffまたはErrorである可能性があります。次のコマンドを入力して、障害が発生した Pod とその PVC を削除します。
$ oc delete pods etcd-2 -n openshift-etcd
検証
次のコマンドを実行して、新しい etcd Pod が起動して実行していることを確認します。
$ oc get pods -l app=etcd -n openshift-etcd出力例
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 67m etcd-1 2/2 Running 0 48m etcd-2 2/2 Running 0 2m2s
9.3. オンプレミス環境での etcd のバックアップと復元
オンプレミス環境のホステッドクラスターで etcd をバックアップおよび復元して、障害を修正できます。
9.3.1. オンプレミス環境のホステッドクラスターでの etcd のバックアップと復元
ホステッドクラスターで etcd をバックアップおよび復元することで、3 ノードクラスターの etcd メンバー内にあるデータの破損や欠落などの障害を修正できます。etcd クラスターの複数メンバーでデータの損失や CrashLoopBackOff ステータスが発生する場合、このアプローチにより etcd クォーラムの損失を防ぐことができます。
前提条件
-
ocおよびjqバイナリーがインストールされている。
手順
まず、環境変数を設定します。
必要に応じて値を置き換えて次のコマンドを入力し、ホステッドクラスターの環境変数を設定します。
$ CLUSTER_NAME=my-cluster$ HOSTED_CLUSTER_NAMESPACE=clusters$ CONTROL_PLANE_NAMESPACE="${HOSTED_CLUSTER_NAMESPACE}-${CLUSTER_NAME}"必要に応じて値を置き換えて次のコマンドを入力し、ホステッドクラスターのリコンシリエーションを一時停止します。
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"true"}}' --type=merge
次に、次のいずれかの方法を使用して etcd のスナップショットを取得します。
- 以前にバックアップした etcd のスナップショットを使用します。
使用可能な etcd Pod がある場合は、次の手順を実行して、アクティブな etcd Pod からスナップショットを取得します。
次のコマンドを入力して、etcd Pod をリスト表示します。
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd次のコマンドを入力して、Pod データベースのスナップショットを取得し、マシンのローカルに保存します。
$ ETCD_POD=etcd-0$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- \ env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=https://localhost:2379 \ snapshot save /var/lib/snapshot.db次のコマンドを入力して、スナップショットが成功したことを確認します。
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- \ env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status \ /var/lib/snapshot.db
次のコマンドを入力して、スナップショットのローカルコピーを作成します。
$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/snapshot.db \ /tmp/etcd.snapshot.dbetcd 永続ストレージからスナップショットデータベースのコピーを作成します。
次のコマンドを入力して、etcd Pod をリスト表示します。
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd実行中の Pod を検索し、その名前を
ETCD_POD: ETCD_POD=etcd-0の値として設定し、次のコマンドを入力してそのスナップショットデータベースをコピーします。$ oc cp -c etcd \ ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/data/member/snap/db \ /tmp/etcd.snapshot.db
次のコマンドを入力して、etcd statefulset をスケールダウンします。
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=0次のコマンドを入力して、2 番目と 3 番目のメンバーのボリュームを削除します。
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pvc/data-etcd-2最初の etcd メンバーのデータにアクセスする Pod を作成します。
次のコマンドを入力して、etcd イメージを取得します。
$ ETCD_IMAGE=$(oc get -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd \ -o jsonpath='{ .spec.template.spec.containers[0].image }')etcd データへのアクセスを許可する Pod を作成します。
$ cat << EOF | oc apply -n ${CONTROL_PLANE_NAMESPACE} -f - apiVersion: apps/v1 kind: Deployment metadata: name: etcd-data spec: replicas: 1 selector: matchLabels: app: etcd-data template: metadata: labels: app: etcd-data spec: containers: - name: access image: $ETCD_IMAGE volumeMounts: - name: data mountPath: /var/lib command: - /usr/bin/bash args: - -c - |- while true; do sleep 1000 done volumes: - name: data persistentVolumeClaim: claimName: data-etcd-0 EOF次のコマンドを入力して、
etcd-dataPod のステータスを確認し、実行されるまで待ちます。$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd-data次のコマンドを入力して、
etcd-dataPod の名前を取得します。$ DATA_POD=$(oc get -n ${CONTROL_PLANE_NAMESPACE} pods --no-headers \ -l app=etcd-data -o name | cut -d/ -f2)
次のコマンドを入力して、etcd スナップショットを Pod にコピーします。
$ oc cp /tmp/etcd.snapshot.db \ ${CONTROL_PLANE_NAMESPACE}/${DATA_POD}:/var/lib/restored.snap.db次のコマンドを入力して、
etcd-dataPod から古いデータを削除します。$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm -rf /var/lib/data$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- mkdir -p /var/lib/data次のコマンドを入力して、etcd スナップショットを復元します。
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- \ etcdutl snapshot restore /var/lib/restored.snap.db \ --data-dir=/var/lib/data --skip-hash-check \ --name etcd-0 \ --initial-cluster-token=etcd-cluster \ --initial-cluster etcd-0=https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-1=https://etcd-1.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-2=https://etcd-2.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380 \ --initial-advertise-peer-urls https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380次のコマンドを入力して、Pod から一時的な etcd スナップショットを削除します。
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- \ rm /var/lib/restored.snap.db次のコマンドを入力して、データアクセスデプロイメントを削除します。
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} deployment/etcd-data次のコマンドを入力して、etcd クラスターをスケールアップします。
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=3次のコマンドを入力して、etcd メンバー Pod が返され、使用可能であると報告されるのを待ちます。
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd -w
次のコマンドを入力して、ホステッドクラスターのリコンシリエーションを復元します。
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"null"}}' --type=merge次のコマンドを入力して、ホステッドクラスターを手動でロールアウトします。
$ oc annotate hostedcluster -n \ <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)この時点では、Multus アドミッションコントローラーとネットワークノードアイデンティティー Pod はまだ起動しません。
次のコマンドを入力して、etcd の 2 番目と 3 番目のメンバーの Pod とその PVC を削除します。
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pod/etcd-1 --wait=false$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-2 pod/etcd-2 --wait=false次のコマンドを入力して、ホステッドクラスターを手動で再度ロールアウトします。
$ oc annotate hostedcluster -n \ <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds) \ --overwrite数分後、コントロールプレーン Pod が稼働します。
9.4. AWS での etcd のバックアップと復元
障害を修正するために、Amazon Web Services (AWS) 上のホステッドクラスターで etcd をバックアップおよび復元できます。
9.4.1. ホステッドクラスターの etcd のスナップショットを取得する
ホステッドクラスターの etcd をバックアップするには、etcd のスナップショットを作成する必要があります。後で、スナップショットを使用して etcd を復元できます。
この手順には、API のダウンタイムが必要です。
手順
次のコマンドを入力して、ホステッドクラスターのリコンシリエーションを一時停止します。
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"true"}}' --type=merge次のコマンドを入力して、すべての etcd-writer デプロイメントを停止します。
$ oc scale deployment -n <hosted_cluster_namespace> --replicas=0 \ kube-apiserver openshift-apiserver openshift-oauth-apiserveretcd スナップショットを取得するには、次のコマンドを実行して、各 etcd コンテナーで
execコマンドを使用します。$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- \ env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=localhost:2379 \ snapshot save /var/lib/data/snapshot.dbスナップショットのステータスを確認するには、次のコマンドを実行して、各 etcd コンテナーで
execコマンドを使用します。$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- \ env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status \ /var/lib/data/snapshot.dbスナップショットデータを、S3 バケットなど、後で取得できる場所にコピーします。以下の例を参照してください。
注記次の例では、署名バージョン 2 を使用しています。署名バージョン 4 をサポートするリージョン (例:
us-east-2リージョン) にいる場合は、署名バージョン 4 を使用してください。そうしないと、スナップショットを S3 バケットにコピーするときにアップロードが失敗します。例
BUCKET_NAME=somebucket CLUSTER_NAME=cluster_name FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` HOSTED_CLUSTER_NAMESPACE=hosted_cluster_namespace oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db後で新しいクラスターでスナップショットを復元するには、ホステッドクラスターが参照する暗号化シークレットを保存します。
次のコマンドを実行してシークレットの暗号鍵を取得します。
$ oc get hostedcluster <hosted_cluster_name> \ -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"<hosted_cluster_name>-etcd-encryption-key"}}次のコマンドを実行してシークレットの暗号鍵を保存します。
$ oc get secret <hosted_cluster_name>-etcd-encryption-key \ -o=jsonpath='{.data.key}'新しいクラスターでスナップショットを復元するときに、このキーを復号化できます。
次のコマンドを入力して、すべての etcd-writer デプロイメントを再起動します。
$ oc scale deployment -n <control_plane_namespace> --replicas=3 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver次のコマンドを入力して、ホステッドクラスターのリコンシリエーションを再開します。
$ oc patch -n <hosted_cluster_namespace> \ -p '[\{"op": "remove", "path": "/spec/pausedUntil"}]' --type=json
次のステップ
etcd スナップショットを復元します。
9.4.2. ホステッドクラスターでの etcd スナップショットの復元
ホステッドクラスターからの etcd のスナップショットがある場合は、それを復元できます。現在、クラスターの作成中にのみ etcd スナップショットを復元できます。
etcd スナップショットを復元するには、create cluster --render コマンドからの出力を変更し、HostedCluster 仕様の etcd セクションで restoreSnapshotURL 値を定義します。
hcp create コマンドの --render フラグはシークレットをレンダリングしません。シークレットをレンダリングするには、hcp create コマンドで --render フラグと --render-sensitive フラグの両方を使用する必要があります。
前提条件
ホステッドクラスターで etcd スナップショットを作成している。
手順
awsコマンドラインインターフェイス (CLI) で事前に署名された URL を作成し、認証情報を etcd デプロイメントに渡さずに S3 から etcd スナップショットをダウンロードできるようにします。ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})次の URL を参照するように
HostedCluster仕様を変更します。spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
spec.secretEncryption.aescbc値から参照したシークレットに、前の手順で保存したものと同じ AES キーが含まれていることを確認します。
9.5. OpenShift Virtualization 上のホステッドクラスターのバックアップと復元
障害に対処するために、OpenShift Virtualization 上のホステッドクラスターをバックアップおよび復元できます。
9.5.1. OpenShift Virtualization 上のホステッドクラスターのバックアップ
OpenShift Virtualization 上のホステッドクラスターをバックアップしても、ホステッドクラスターは動作を継続できます。バックアップには、Hosted Control Plane のコンポーネントとホステッドクラスターの etcd が含まれます。
ホステッドクラスターが外部インフラストラクチャー上でコンピュートノードを実行していない場合、KubeVirt CSI によってプロビジョニングされた永続ボリューム要求 (PVC) に保存されているホステッドクラスターのワークロードデータもバックアップされます。バックアップには、コンピュートノードとして使用される KubeVirt 仮想マシン (VM) は含まれません。これらの仮想マシンは、復元プロセスの完了後、自動的に再作成されます。
手順
次の例のような YAML ファイルを作成して、Velero バックアップリソースを作成します。
apiVersion: velero.io/v1 kind: Backup metadata: name: hc-clusters-hosted-backup namespace: openshift-adp labels: velero.io/storage-location: default spec: includedNamespaces:1 - clusters - clusters-hosted includedResources: - sa - role - rolebinding - deployment - statefulset - pv - pvc - bmh - configmap - infraenv - priorityclasses - pdb - hostedcluster - nodepool - secrets - hostedcontrolplane - cluster - datavolume - service - route excludedResources: [ ] labelSelector:2 matchExpressions: - key: 'hypershift.openshift.io/is-kubevirt-rhcos' operator: 'DoesNotExist' storageLocation: default preserveNodePorts: true ttl: 4h0m0s snapshotMoveData: true3 datamover: "velero"4 defaultVolumesToFsBackup: false5 - 1
- このフィールドでは、バックアップするオブジェクトの namespace を選択します。ホステッドクラスターと Hosted Control Plane の両方の namespace を含めます。この例では、
clustersはホステッドクラスターの namespace であり、clusters-hostedは Hosted Control Plane の namespace です。デフォルトでは、HostedControlPlaneの namespace はclusters-<hosted_cluster_name>です。 - 2
- ホステッドクラスターノードとして使用される仮想マシンのブートイメージは、大規模な PVC に保存されています。バックアップ時間とストレージサイズを削減するには、このラベルセレクターを追加して、この PVC をバックアップから除外できます。
- 3
- このフィールドと
datamoverフィールドにより、CSIVolumeSnapshotsをリモートクラウドストレージに自動的にアップロードできます。 - 4
- このフィールドと
snapshotMoveDataフィールドにより、CSIVolumeSnapshotsをリモートクラウドストレージに自動的にアップロードできます。 - 5
- このフィールドは、Pod ボリュームファイルシステムバックアップをデフォルトですべてのボリュームに使用するかどうかを指定します。特定の PVC をバックアップするには、この値を
falseに設定します。
次のコマンドを入力して、YAML ファイルに変更を適用します。
$ oc apply -f <backup_file_name>.yaml<backup_file_name>は、ファイル名に置き換えます。バックアップオブジェクトのステータスと Velero ログでバックアッププロセスを監視します。
バックアップオブジェクトの状態を監視するには、次のコマンドを入力します。
$ watch "oc get backups.velero.io -n openshift-adp <backup_file_name> -o jsonpath='{.status}' | jq"Velero ログを監視するには、次のコマンドを入力します。
$ oc logs -n openshift-adp -ldeploy=velero -f
検証
-
status.phaseフィールドがCompletedの場合、バックアッププロセスは完了したと見なすことができます。
9.5.2. OpenShift Virtualization 上のホステッドクラスターの復元
OpenShift Virtualization 上のホステッドクラスターをバックアップした後、そのバックアップを復元できます。
復元プロセスは、バックアップを作成したのと同じ管理クラスター上でのみ完了できます。
手順
-
HostedControlPlanenamespace で Pod または永続ボリューム要求 (PVC) が実行されていないことを確認します。 管理クラスターから次のオブジェクトを削除します。
-
HostedCluster -
NodePool - PVC
-
次の例のような復元マニフェスト YAML ファイルを作成します。
apiVersion: velero.io/v1 kind: Restore metadata: name: hc-clusters-hosted-restore namespace: openshift-adp spec: backupName: hc-clusters-hosted-backup restorePVs: true1 existingResourcePolicy: update2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io次のコマンドを入力して、YAML ファイルに変更を適用します。
$ oc apply -f <restore_resource_file_name>.yaml<restore_resource_file_name>は、ファイル名に置き換えます。復元ステータスフィールドと Velero ログを確認して、復元プロセスを監視します。
復元ステータスフィールドを確認するには、次のコマンドを入力します。
$ watch "oc get restores.velero.io -n openshift-adp <backup_file_name> -o jsonpath='{.status}' | jq"Velero ログを確認するには、次のコマンドを入力します。
$ oc logs -n openshift-adp -ldeploy=velero -f
検証
-
status.phaseフィールドがCompletedの場合、復元プロセスは完了したと見なすことができます。
次のステップ
- しばらくすると、KubeVirt 仮想マシンが作成され、ホステッドクラスターにコンピュートノードとして参加します。ホステッドクラスターのワークロードが期待どおりに再度実行されていることを確認してください。
9.6. AWS でホステッドクラスターの障害復旧
ホステッドクラスターを Amazon Web Services (AWS) 内の同じリージョンに復元できます。たとえば、管理クラスターのアップグレードが失敗し、ホステッドクラスターが読み取り専用状態になっている場合は、障害復旧が必要になります。
障害復旧プロセスには次の手順が含まれます。
- ソース管理クラスターでのホステッドクラスターのバックアップ
- 宛先管理クラスターでのホステッドクラスターの復元
- ホステッドクラスターのソース管理クラスターからの削除
プロセス中、ワークロードは引き続き実行されます。クラスター API は一定期間使用できない場合がありますが、ワーカーノードで実行されているサービスには影響しません。
API サーバー URL を維持するには、ソース管理クラスターと宛先管理クラスターの両方に --external-dns フラグが必要です。これにより、サーバー URL は https://api-sample-hosted.sample-hosted.aws.openshift.com で終わります。以下の例を参照してください。
例: 外部 DNS フラグ
--external-dns-provider=aws \
--external-dns-credentials=<path_to_aws_credentials_file> \
--external-dns-domain-filter=<basedomain>
API サーバー URL を維持するために --external-dns フラグを含めない場合、ホステッドクラスターを移行することはできません。
9.6.1. バックアップおよび復元プロセスの概要
バックアップと復元のプロセスは、以下のような仕組みとなっています。
管理クラスター 1 (ソース管理クラスターと見なすことができます) では、コントロールプレーンとワーカーが外部 DNS API を使用して対話します。外部 DNS API はアクセス可能で、管理クラスター間にロードバランサーが配置されています。

ホステッドクラスターのスナップショットを作成します。これには、etcd、コントロールプレーン、およびワーカーノードが含まれます。このプロセスの間、ワーカーノードは外部 DNS API にアクセスできなくても引き続きアクセスを試みます。また、ワークロードが実行され、コントロールプレーンがローカルマニフェストファイルに保存され、etcd が S3 バケットにバックアップされます。データプレーンはアクティブで、コントロールプレーンは一時停止しています。

管理クラスター 2 (宛先管理クラスターと見なすことができます) では、S3 バケットから etcd を復元し、ローカルマニフェストファイルからコントロールプレーンを復元します。このプロセスの間、外部 DNS API は停止し、ホステッドクラスター API にアクセスできなくなり、API を使用するワーカーはマニフェストファイルを更新できなくなりますが、ワークロードは引き続き実行されます。

外部 DNS API に再びアクセスできるようになり、ワーカーノードはそれを使用して管理クラスター 2 に移動します。外部 DNS API は、コントロールプレーンを参照するロードバランサーにアクセスできます。

管理クラスター 2 では、コントロールプレーンとワーカーノードが外部 DNS API を使用して対話します。リソースは、etcd の S3 バックアップを除いて、管理クラスター 1 から削除されます。ホステッドクラスターを管理クラスター 1 で再度設定しようとしても、機能しません。

9.6.2. AWS 上のホステッドクラスターのバックアップ
ターゲット管理クラスターでホステッドクラスターを回復するには、まず関連するすべてのデータをバックアップする必要があります。
手順
次のコマンドを入力して、ソース管理クラスターを宣言する config map ファイルを作成します。
$ oc create configmap mgmt-parent-cluster -n default \ --from-literal=from=${MGMT_CLUSTER_NAME}次のコマンドを入力して、ホステッドクラスターとノードプールのリコンシリエーションをシャットダウンします。
$ PAUSED_UNTIL="true"$ oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} \ -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge$ oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} \ -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 \ kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator次の bash スクリプトを実行して、etcd をバックアップし、データを S3 バケットにアップロードします。
ヒントこのスクリプトを関数でラップし、メイン関数から呼び出します。
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd のバックアップの詳細は、「ホステッドクラスターでの etcd のバックアップと復元」を参照してください。
以下のコマンドを入力して、Kubernetes および OpenShift Container Platform オブジェクトをバックアップします。次のオブジェクトをバックアップする必要があります。
-
HostedCluster namespace の
HostedClusterおよびNodePoolオブジェクト -
HostedCluster namespace の
HostedClusterシークレット -
Hosted Control Plane namespace の
HostedControlPlane -
Hosted Control Plane namespace の
Cluster -
Hosted Control Plane namespace の
AWSCluster、AWSMachineTemplate、およびAWSMachine -
Hosted Control Plane namespace の
MachineDeployments、MachineSets、およびMachines Hosted Control Plane namespace の
ControlPlaneシークレット次のコマンドを入力します。
$ mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ chmod 700 ${BACKUP_DIR}/namespaces/次のコマンドを入力して、
HostedClusternamespace からHostedClusterオブジェクトをバックアップします。$ echo "Backing Up HostedCluster Objects:"$ oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml$ echo "--> HostedCluster"$ sed -i '' -e '/^status:$/,$d' \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml次のコマンドを入力して、
HostedClusternamespace からNodePoolオブジェクトをバックアップします。$ oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml$ echo "--> NodePool"$ sed -i '' -e '/^status:$/,$ d' \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml次のシェルスクリプトを実行して、
HostedClusterの namespace 内のシークレットをバックアップします。$ echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done次のシェルスクリプトを実行して、
HostedClusterのコントロールプレーン namespace 内のシークレットをバックアップします。$ echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done次のコマンドを入力して Hosted Control Plane をバックアップします。
$ echo "--> HostedControlPlane:"$ oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml次のコマンドを入力してクラスターをバックアップします。
$ echo "--> Cluster:"$ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} \ -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME})$ oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml次のコマンドを入力して AWS クラスターをバックアップします。
$ echo "--> AWS Cluster:"$ oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml次のコマンドを入力して、AWS の
MachineTemplateオブジェクトをバックアップします。$ echo "--> AWS Machine Template:"$ oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > \ ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml次のシェルスクリプトを実行して、AWS の
Machinesオブジェクトをバックアップします。$ echo "--> AWS Machine:"$ CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done次のシェルスクリプトを実行して、
MachineDeploymentsオブジェクトをバックアップします。$ echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done次のシェルスクリプトを実行して、
MachineSetsオブジェクトをバックアップします。$ echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done次のシェルスクリプトを実行して、Hosted Control Plane の namespace から
Machinesオブジェクトをバックアップします。$ echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
HostedCluster namespace の
次のコマンドを入力して、
ControlPlaneルートをクリーンアップします。$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --allこのコマンドを入力すると、ExternalDNS Operator が Route53 エントリーを削除できるようになります。
次のスクリプトを実行して、Route53 エントリーがクリーンであることを確認します。
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
検証
すべての OpenShift Container Platform オブジェクトと S3 バケットをチェックし、すべてが想定どおりであることを確認します。
次のステップ
ホステッドクラスターを復元します。
9.6.3. ホステッドクラスターの復元
バックアップしたすべてのオブジェクトを収集し、宛先管理クラスターに復元します。
前提条件
ソース管理クラスターからデータをバックアップしている。
宛先管理クラスターの kubeconfig ファイルが、KUBECONFIG 変数に設定されているとおりに、あるいは、スクリプトを使用する場合は MGMT2_KUBECONFIG 変数に設定されているとおりに配置されていることを確認します。export KUBECONFIG=<Kubeconfig FilePath> を使用するか、スクリプトを使用する場合は export KUBECONFIG=${MGMT2_KUBECONFIG} を使用します。
手順
以下のコマンドを入力して、新しい管理クラスターに、復元するクラスターの namespace が含まれていないことを確認します。
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ BACKUP_DIR=${HC_CLUSTER_DIR}/backup宛先管理クラスターでの namespace の削除
$ oc delete ns ${HC_CLUSTER_NS} || true$ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true以下のコマンドを入力して、削除された namespace を再作成します。
namespace 作成コマンド
$ oc new-project ${HC_CLUSTER_NS}$ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}次のコマンドを入力して、HC namespace のシークレットを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*以下のコマンドを入力して、
HostedClusterコントロールプレーン namespace のオブジェクトを復元します。シークレットコマンドを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-*クラスター復元コマンド
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*ノードとノードプールを復元して AWS インスタンスを再利用する場合は、次のコマンドを入力して、HC コントロールプレーン namespace のオブジェクトを復元します。
AWS のコマンド
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-*マシンのコマンド
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-*$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*次の bash スクリプトを実行して、etcd データとホステッドクラスターを復元します。
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fiノードとノードプールを復元して AWS インスタンスを再利用する場合は、次のコマンドを入力してノードプールを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
検証
ノードが完全に復元されたことを確認するには、次の関数を使用します。
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
次のステップ
クラスターをシャットダウンして削除します。
9.6.4. ホステッドクラスターのソース管理クラスターからの削除
ホステッドクラスターをバックアップして宛先管理クラスターに復元した後、ソース管理クラスターのホステッドクラスターをシャットダウンして削除します。
前提条件
データをバックアップし、ソース管理クラスターに復元している。
宛先管理クラスターの kubeconfig ファイルが、KUBECONFIG 変数に設定されているとおりに、あるいは、スクリプトを使用する場合は MGMT_KUBECONFIG 変数に設定されているとおりに配置されていることを確認します。export KUBECONFIG=<Kubeconfig FilePath> を使用するか、スクリプトを使用する場合は export KUBECONFIG=${MGMT_KUBECONFIG} を使用します。
手順
以下のコマンドを入力して、
deploymentおよびstatefulsetオブジェクトをスケーリングします。重要spec.persistentVolumeClaimRetentionPolicy.whenScaledフィールドの値がDeleteに設定されている場合は、データの損失につながる可能性があるため、ステートフルセットをスケーリングしないでください。回避策として、
spec.persistentVolumeClaimRetentionPolicy.whenScaledフィールドの値をRetainに更新します。ステートフルセットをリコンサイルし、値をDeleteに戻してしまうようなコントローラーが存在しないことを確認してください。そのようなコントローラーがあると、データの損失が発生する可能性があります。$ export KUBECONFIG=${MGMT_KUBECONFIG}デプロイメントコマンドのスケールダウン
$ oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all$ sleep 15次のコマンドを入力して、
NodePoolオブジェクトを削除します。NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi次のコマンドを入力して、
machineおよびmachinesetオブジェクトを削除します。# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done$ oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true次のコマンドを入力して、クラスターオブジェクトを削除します。
$ C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name)$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all次のコマンドを入力して、AWS マシン (Kubernetes オブジェクト) を削除します。実際の AWS マシンの削除を心配する必要はありません。クラウドインスタンスへの影響はありません。
for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done次のコマンドを入力して、
HostedControlPlaneおよびControlPlaneHC namespace オブジェクトを削除します。HCP および ControlPlane HC NS コマンドの削除
$ oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]'$ oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all$ oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true次のコマンドを入力して、
HostedClusterおよび HC namespace オブジェクトを削除します。HC および HC Namespace コマンドの削除
$ oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true$ oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true$ oc delete ns ${HC_CLUSTER_NS} || true
検証
すべてが機能することを確認するには、次のコマンドを入力します。
検証コマンド
$ export KUBECONFIG=${MGMT2_KUBECONFIG}$ oc get hc -n ${HC_CLUSTER_NS}$ oc get np -n ${HC_CLUSTER_NS}$ oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}$ oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}HostedCluster 内でのコマンド
$ export KUBECONFIG=${HC_KUBECONFIG}$ oc get clusterversion$ oc get nodes
次のステップ
ホステッドクラスター内の OVN Pod を削除して、新しい管理クラスターで実行される新しい OVN コントロールプレーンに接続できるようにします。
-
ホステッドクラスターの kubeconfig パスを使用して
KUBECONFIG環境変数を読み込みます。 以下のコマンドを入力します。
$ oc delete pod -n openshift-ovn-kubernetes --all
9.7. OADP を使用したホステッドクラスターの障害復旧
OpenShift API for Data Protection (OADP) Operator を使用して、Amazon Web Services (AWS) およびベアメタルで障害復旧を実行できます。
OpenShift API for Data Protection (OADP) を使用した障害復旧プロセスには、次の手順が含まれます。
- OADP を使用するために Amazon Web Services やベアメタルなどのプラットフォームを準備
- データプレーンのワークロードのバックアップ
- コントロールプレーンのワークロードのバックアップ
- OADP を使用したホステッドクラスターの復元
9.7.1. 前提条件
管理クラスターで次の前提条件を満たす必要があります。
- OADP Operator をインストールした。
- ストレージクラスを作成した。
-
cluster-admin権限でクラスターにアクセスできる。 - カタログソースを通じて OADP サブスクリプションにアクセスできる。
- S3、Microsoft Azure、Google Cloud、MinIO など、OADP と互換性のあるクラウドストレージプロバイダーにアクセスできる。
- 非接続環境では、OADP と互換性のある Red Hat OpenShift Data Foundation や MinIO などのセルフホスト型ストレージプロバイダーにアクセスできる。
- Hosted Control Plane の Pod が稼働している。
9.7.2. OADP を使用するための AWS の準備
ホステッドクラスターの障害復旧を実行するには、Amazon Web Services (AWS) S3 互換ストレージで OpenShift API for Data Protection (OADP) を使用できます。DataProtectionApplication オブジェクトを作成すると、openshift-adp namespace に新しい velero デプロイメントと node-agent Pod が作成されます。
OADP を使用するために AWS を準備するには、「Multicloud Object Gateway を使用した OpenShift API for Data Protection の設定」を参照してください。
次のステップ
- データプレーンのワークロードのバックアップ
- コントロールプレーンのワークロードのバックアップ
9.7.3. OADP を使用するためのベアメタルの準備
ホステッドクラスターの障害復旧を実行するには、ベアメタル上で OpenShift API for Data Protection (OADP) を使用できます。DataProtectionApplication オブジェクトを作成すると、openshift-adp namespace に新しい velero デプロイメントと node-agent Pod が作成されます。
OADP を使用するためにベアメタルを準備するには、「AWS S3 互換ストレージを使用した OpenShift API for Data Protection の設定」を参照してください。
次のステップ
- データプレーンのワークロードのバックアップ
- コントロールプレーンのワークロードのバックアップ
9.7.4. データプレーンのワークロードのバックアップ
データプレーンのワークロードが重要でない場合は、この手順をスキップできます。OADP Operator を使用してデータプレーンワークロードをバックアップするには、「アプリケーションのバックアップ」を参照してください。
次のステップ
- OADP を使用したホステッドクラスターの復元
9.7.5. コントロールプレーンのワークロードのバックアップ
Backup カスタムリソース (CR) を作成することで、コントロールプレーンのワークロードをバックアップできます。
バックアッププロセスを監視および観察するには、「バックアップおよび復元プロセスの観察」を参照してください。
手順
次のコマンドを実行して、
HostedClusterリソースのリコンシリエーションを一時停止します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'次のコマンドを実行して、ホステッドクラスターのインフラストラクチャー ID を取得します。
$ oc get hostedcluster -n local-cluster <hosted_cluster_name> -o=jsonpath="{.spec.infraID}"次のステップで使用するインフラストラクチャー ID をメモします。
次のコマンドを実行して、
cluster.cluster.x-k8s.ioリソースのリコンシリエーションを一時停止します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch cluster.cluster.x-k8s.io \ -n local-cluster-<hosted_cluster_name> <hosted_cluster_infra_id> \ --type json -p '[{"op": "add", "path": "/spec/paused", "value": true}]'次のコマンドを実行して、
NodePoolリソースのリコンシリエーションを一時停止します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "true"}]'次のコマンドを実行して、
AgentClusterリソースのリコンシリエーションを一時停止します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'次のコマンドを実行して、
AgentMachineリソースのリコンシリエーションを一時停止します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused=true --all'次のコマンドを実行して、
HostedClusterリソースにアノテーションを付け、Hosted Control Plane namespace が削除されないようにします。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace=trueBackupCR を定義する YAML ファイルを作成します。例9.1 例:
backup-control-plane.yamlファイルapiVersion: velero.io/v1 kind: Backup metadata: name: <backup_resource_name>1 namespace: openshift-adp labels: velero.io/storage-location: default spec: hooks: {} includedNamespaces:2 - <hosted_cluster_namespace>3 - <hosted_control_plane_namespace>4 includedResources: - sa - role - rolebinding - pod - pvc - pv - bmh - configmap - infraenv5 - priorityclasses - pdb - agents - hostedcluster - nodepool - secrets - hostedcontrolplane - cluster - agentcluster - agentmachinetemplate - agentmachine - machinedeployment - machineset - machine excludedResources: [] storageLocation: default ttl: 2h0m0s snapshotMoveData: true6 datamover: "velero"7 defaultVolumesToFsBackup: true8 - 1
backup_resource_nameをBackupリソースの名前に置き換えます。- 2
- 特定の namespace を選択して、そこからオブジェクトをバックアップします。ホステッドクラスターの namespace と Hosted Control Plane の namespace を含める必要があります。
- 3
<hosted_cluster_namespace>を、ホステッドクラスター namespace の名前 (例:clusters) に置き換えます。- 4
<hosted_control_plane_namespace>は、Hosted Control Plane の namespace の名前 (例:clusters-hosted) に置き換えます。- 5
infraenvリソースを別の namespace に作成する必要があります。バックアッププロセス中にinfraenvリソースを削除しないでください。- 6 7
- CSI ボリュームスナップショットを有効にし、コントロールプレーンのワークロードをクラウドストレージに自動的にアップロードします。
- 8
- 永続ボリューム (PV) の
fs-backupバックアップ方法をデフォルトとして設定します。この設定は、Container Storage Interface (CSI) ボリュームスナップショットとfs-backup方式を組み合わせて使用する場合に便利です。
注記CSI ボリュームスナップショットを使用する場合は、PV に
backup.velero.io/backup-volumes-excludes=<pv_name>アノテーションを追加する必要があります。次のコマンドを実行して、
BackupCR を適用します。$ oc apply -f backup-control-plane.yaml
検証
次のコマンドを実行して、
status.phaseの値がCompletedになっているかどうかを確認します。$ oc get backups.velero.io <backup_resource_name> -n openshift-adp \ -o jsonpath='{.status.phase}'
次のステップ
- OADP を使用してホストされたクラスターの復元
9.7.6. OADP を使用してホストされたクラスターの復元
Restore カスタムリソース (CR) を作成することで、ホストされたクラスターを復元できます。
- インプレース 更新を使用している場合、InfraEnv にスペアノードは必要ありません。新しい管理クラスターからワーカーノードを再プロビジョニングする必要があります。
- replace 更新を使用している場合は、ワーカーノードをデプロイするために InfraEnv 用の予備ノードがいくつか必要です。
ホステッドクラスターをバックアップした後、復元プロセスを開始するには、そのクラスターを破棄する必要があります。ノードのプロビジョニングを開始するには、ホステッドクラスターを削除する前に、データプレーン内のワークロードをバックアップする必要があります。
前提条件
- コンソールを使用したクラスターの削除 のホステッドクラスターを削除する手順を完了した。
- クラスター削除後の残りのリソースの削除 の手順を完了した。
バックアッププロセスを監視および観察するには、「バックアップおよび復元プロセスの観察」を参照してください。
手順
次のコマンドを実行して、Hosted Control Plane namespace に Pod と永続ボリューム要求 (PVC) が存在しないことを確認します。
$ oc get pod pvc -n <hosted_control_plane_namespace>予想される出力
No resources foundRestoreCR を定義する YAML ファイルを作成します。restore-hosted-cluster.yamlファイルの例apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_resource_name>1 namespace: openshift-adp spec: backupName: <backup_resource_name>2 restorePVs: true3 existingResourcePolicy: update4 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io重要infraenvリソースを別の namespace に作成する必要があります。復元プロセス中にinfraenvリソースを削除しないでください。新しいノードを再プロビジョニングするには、infraenvリソースが必須です。次のコマンドを実行して、
RestoreCR を適用します。$ oc apply -f restore-hosted-cluster.yaml次のコマンドを実行して、
status.phaseの値がCompletedになっているかどうかを確認します。$ oc get hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace> \ -o jsonpath='{.status.phase}'復元プロセスが完了したら、コントロールプレーンワークロードのバックアップ中に一時停止した
HostedClusterリソースおよびNodePoolリソースのリコンシリエーションを開始します。次のコマンドを実行して、
HostedClusterリソースのリコンシリエーションを開始します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ --type json \ -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'次のコマンドを実行して、
NodePoolリソースのリコンシリエーションを開始します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ patch nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --type json \ -p '[{"op": "add", "path": "/spec/pausedUntil", "value": "false"}]'
コントロールプレーンワークロードのバックアップ中に一時停止したエージェントプロバイダーリソースのリコンシリエーションを開始します。
次のコマンドを実行して、
AgentClusterリソースのリコンシリエーションを開始します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentcluster -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all次のコマンドを実行して、
AgentMachineリソースのリコンシリエーションを開始します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate agentmachine -n <hosted_control_plane_namespace> \ cluster.x-k8s.io/paused- --overwrite=true --all
次のコマンドを実行して、
HostedClusterリソースのhypershift.openshift.io/skip-delete-hosted-controlplane-namespace-アノテーションを削除し、Hosted Control Plane namespace の手動削除を回避します。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ annotate hostedcluster -n <hosted_cluster_namespace> <hosted_cluster_name> \ hypershift.openshift.io/skip-delete-hosted-controlplane-namespace- \ --overwrite=true --all次のコマンドを実行して、
NodePoolリソースを必要なレプリカ数にスケーリングします。$ oc --kubeconfig <management_cluster_kubeconfig_file> \ scale nodepool -n <hosted_cluster_namespace> <node_pool_name> \ --replicas <replica_count>1 - 1
<replica_count>を整数値 (例:3) に置き換えます。
9.7.7. バックアップと復元のプロセスの観察
OpenShift API for Data Protection (OADP) を使用してホステッドクラスターをバックアップおよび復元する場合は、プロセスを監視および観察できます。
手順
次のコマンドを実行して、バックアッププロセスを確認します。
$ watch "oc get backups.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"次のコマンドを実行して、復元プロセスを確認します。
$ watch "oc get restores.velero.io -n openshift-adp <backup_resource_name> -o jsonpath='{.status}'"次のコマンドを実行して、Velero ログを確認します。
$ oc logs -n openshift-adp -ldeploy=velero -f次のコマンドを実行して、すべての OADP オブジェクトの進行状況を確認します。
$ watch "echo BackupRepositories:;echo;oc get backuprepositories.velero.io -A;echo; echo BackupStorageLocations: ;echo; oc get backupstoragelocations.velero.io -A;echo;echo DataUploads: ;echo;oc get datauploads.velero.io -A;echo;echo DataDownloads: ;echo;oc get datadownloads.velero.io -n openshift-adp; echo;echo VolumeSnapshotLocations: ;echo;oc get volumesnapshotlocations.velero.io -A;echo;echo Backups:;echo;oc get backup -A; echo;echo Restores:;echo;oc get restore -A"
9.7.8. velero CLI を使用してバックアップおよび復元リソースを記述する
OpenShift API for Data Protection を使用する場合は、velero コマンドラインインターフェイス (CLI) を使用して、Backup および Restore リソースの詳細を取得できます。
手順
次のコマンドを実行して、コンテナーから
veleroCLI を使用するためのエイリアスを作成します。$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'次のコマンドを実行して、
Restoreカスタムリソース (CR) の詳細を取得します。$ velero restore describe <restore_resource_name> --details1 - 1
<restore_resource_name>をRestoreリソースの名前に置き換えます。
次のコマンドを実行して、
BackupCR の詳細を取得します。$ velero restore describe <backup_resource_name> --details1 - 1
<backup_resource_name>をBackupリソースの名前に置き換えます。
第10章 Hosted Control Plane の認証と認可
OpenShift Container Platform のコントロールプレーンには、組み込みの OAuth サーバーが含まれています。OAuth アクセストークンを取得することで、OpenShift Container Platform API に対して認証できます。ホステッドクラスターを作成した後に、アイデンティティープロバイダーを指定して OAuth を設定できます。
10.1. CLI を使用してホステッドクラスターの OAuth サーバーを設定する
CLI を使用して、ホステッドクラスターの内部 OAuth サーバーを設定できます。
サポートされている次のアイデンティティープロバイダーに対して OAuth を設定できます。
-
oidc -
htpasswd -
keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
OAuth 設定にアイデンティティープロバイダーを追加すると、デフォルトの kubeadmin ユーザープロバイダーが削除されます。
アイデンティティープロバイダーを設定するときは、ホステッドクラスターに少なくとも 1 つの NodePool レプリカを事前に設定する必要があります。DNS 解決のトラフィックはワーカーノードを介して送信されます。htpasswd および request-header アイデンティティープロバイダー用に、NodePool レプリカを事前に設定する必要はありません。
前提条件
- ホステッドクラスターを作成した。
手順
次のコマンドを実行して、ホスティングクラスターで
HostedClusterカスタムリソース (CR) を編集します。$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>次の例を使用して、
HostedClusterCR に OAuth 設定を追加します。apiVersion: hypershift.openshift.io/v1alpha1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: oauth: identityProviders: - openID:3 claims: email:4 - <email_address> name:5 - <display_name> preferredUsername:6 - <preferred_username> clientID: <client_id>7 clientSecret: name: <client_id_secret_name>8 issuer: https://example.com/identity9 mappingMethod: lookup10 name: IAM type: OpenID- 1
- ホステッドクラスターの名前を指定します。
- 2
- ホステッドクラスターの namespace を指定します。
- 3
- このプロバイダー名はアイデンティティー要求の値に接頭辞として付加され、アイデンティティー名が作成されます。プロバイダー名はリダイレクト URL の構築にも使用されます。
- 4
- メールアドレスとして使用する属性のリストを定義します。
- 5
- 表示名として使用する属性のリストを定義します。
- 6
- 優先ユーザー名として使用する属性のリストを定義します。
- 7
- OpenID プロバイダーに登録されたクライアントの ID を定義します。このクライアントを URL
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>にリダイレクトできるようにする必要があります。 - 8
- OpenID プロバイダーに登録されたクライアントのシークレットを定義します。
- 9
- OpenID の仕様で説明されている Issuer Identifier。クエリーまたはフラグメントコンポーネントのない
httpsを使用する必要があります。 - 10
- このプロバイダーのアイデンティティーと
Userオブジェクトの間でマッピングを確立する方法を制御するマッピング方法を定義します。
- 変更を適用するためにファイルを保存します。
10.2. Web コンソールを使用してホステッドクラスターの OAuth サーバーを設定する
OpenShift Container Platform Web コンソールを使用して、ホステッドクラスターの内部 OAuth サーバーを設定できます。
サポートされている次のアイデンティティープロバイダーに対して OAuth を設定できます。
-
oidc -
htpasswd -
keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
OAuth 設定にアイデンティティープロバイダーを追加すると、デフォルトの kubeadmin ユーザープロバイダーが削除されます。
アイデンティティープロバイダーを設定するときは、ホステッドクラスターに少なくとも 1 つの NodePool レプリカを事前に設定する必要があります。DNS 解決のトラフィックはワーカーノードを介して送信されます。htpasswd および request-header アイデンティティープロバイダー用に、NodePool レプリカを事前に設定する必要はありません。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。 - ホステッドクラスターを作成した。
手順
- Home → API Explorer に移動します。
-
Filter by kind ボックスを使用して、
HostedClusterリソースを検索します。 -
編集する
HostedClusterリソースをクリックします。 - Instances タブをクリックします。
-
ホステッドクラスター名エントリーの横にあるオプションメニュー
 をクリックし、Edit HostedCluster をクリックします。
をクリックし、Edit HostedCluster をクリックします。
YAML ファイルに OAuth 設定を追加します。
spec: configuration: oauth: identityProviders: - openID:1 claims: email:2 - <email_address> name:3 - <display_name> preferredUsername:4 - <preferred_username> clientID: <client_id>5 clientSecret: name: <client_id_secret_name>6 issuer: https://example.com/identity7 mappingMethod: lookup8 name: IAM type: OpenID- 1
- このプロバイダー名はアイデンティティー要求の値に接頭辞として付加され、アイデンティティー名が作成されます。プロバイダー名はリダイレクト URL の構築にも使用されます。
- 2
- メールアドレスとして使用する属性のリストを定義します。
- 3
- 表示名として使用する属性のリストを定義します。
- 4
- 優先ユーザー名として使用する属性のリストを定義します。
- 5
- OpenID プロバイダーに登録されたクライアントの ID を定義します。このクライアントを URL
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>にリダイレクトできるようにする必要があります。 - 6
- OpenID プロバイダーに登録されたクライアントのシークレットを定義します。
- 7
- OpenID の仕様で説明されている Issuer Identifier。クエリーまたはフラグメントコンポーネントのない
httpsを使用する必要があります。 - 8
- このプロバイダーのアイデンティティーと
Userオブジェクトの間でマッピングを確立する方法を制御するマッピング方法を定義します。
- Save をクリックします。
10.3. AWS 上のホステッドクラスターで CCO を使用してコンポーネントに IAM ロールを割り当てる
Amazon Web Services (AWS) 上のホステッドクラスターで Cloud Credential Operator (CCO) を使用して、権限が限られた短期間のセキュリティー認証情報を提供する IAM ロールをコンポーネントに割り当てることができます。デフォルトでは、CCO は Hosted Control Plane で実行されます。
CCO は、AWS 上のホステッドクラスターでのみ手動モードをサポートします。デフォルトでは、ホステッドクラスターは手動モードに設定されます。管理クラスターでは、手動以外のモードを使用する場合があります。
10.4. AWS 上のホステッドクラスターで CCO のインストールを検証する
Hosted Control Plane で Cloud Credential Operator (CCO) が正しく実行されていることを確認できます。
前提条件
- Amazon Web Services (AWS) でホステッドクラスターを設定した。
手順
次のコマンドを実行して、ホステッドクラスターで CCO が手動モードで設定されていることを確認します。
$ oc get cloudcredentials <hosted_cluster_name> \ -n <hosted_cluster_namespace> \ -o=jsonpath={.spec.credentialsMode}予想される出力
Manual次のコマンドを実行して、
serviceAccountIssuerリソースの値が空でないことを確認します。$ oc get authentication cluster --kubeconfig <hosted_cluster_name>.kubeconfig \ -o jsonpath --template '{.spec.serviceAccountIssuer }'出力例
https://aos-hypershift-ci-oidc-29999.s3.us-east-2.amazonaws.com/hypershift-ci-29999
10.5. Operator が AWS STS を使用した CCO ベースのワークフローをサポートできるようにする
Operator Lifecycle Manager (OLM) で実行するプロジェクトを設計する Operator 作成者は、Cloud Credential Operator (CCO) をサポートするようにプロジェクトをカスタマイズすることで、STS 対応の OpenShift Container Platform クラスター上で Operator が AWS に対して認証できるようにすることができます。
この方法では、Operator が CredentialsRequest オブジェクトを作成します。Operator には、オブジェクトを作成するための RBAC 権限と、生成される Secret オブジェクトを読み取るための RBAC 権限が必要です。
デフォルトでは、Operator デプロイメントに関連する Pod は、生成される Secret オブジェクトでサービスアカウントトークンを参照できるように、serviceAccountToken ボリュームをマウントします。
前提条件
- OpenShift Container Platform 4.14 以降
- STS モードのクラスター
- OLM ベースの Operator プロジェクト
手順
Operator プロジェクトの
ClusterServiceVersion(CSV) オブジェクトを更新します。Operator が
CredentialsRequestsオブジェクトを作成する RBAC 権限を持っていることを確認します。例10.1
clusterPermissionsリストの例# ... install: spec: clusterPermissions: - rules: - apiGroups: - "cloudcredential.openshift.io" resources: - credentialsrequests verbs: - create - delete - get - list - patch - update - watchAWS STS を使用したこの CCO ベースのワークフロー方式のサポートを要求するために、次のアノテーションを追加します。
# ... metadata: annotations: features.operators.openshift.io/token-auth-aws: "true"
Operator プロジェクトコードを更新します。
Subscriptionオブジェクトによって Pod に設定された環境変数からロール ARN を取得します。以下に例を示します。// Get ENV var roleARN := os.Getenv("ROLEARN") setupLog.Info("getting role ARN", "role ARN = ", roleARN) webIdentityTokenPath := "/var/run/secrets/openshift/serviceaccount/token"パッチを適用して適用できる
CredentialsRequestオブジェクトがあることを確認してください。以下に例を示します。例10.2
CredentialsRequestオブジェクトの作成例import ( minterv1 "github.com/openshift/cloud-credential-operator/pkg/apis/cloudcredential/v1" corev1 "k8s.io/api/core/v1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) var in = minterv1.AWSProviderSpec{ StatementEntries: []minterv1.StatementEntry{ { Action: []string{ "s3:*", }, Effect: "Allow", Resource: "arn:aws:s3:*:*:*", }, }, STSIAMRoleARN: "<role_arn>", } var codec = minterv1.Codec var ProviderSpec, _ = codec.EncodeProviderSpec(in.DeepCopyObject()) const ( name = "<credential_request_name>" namespace = "<namespace_name>" ) var CredentialsRequestTemplate = &minterv1.CredentialsRequest{ ObjectMeta: metav1.ObjectMeta{ Name: name, Namespace: "openshift-cloud-credential-operator", }, Spec: minterv1.CredentialsRequestSpec{ ProviderSpec: ProviderSpec, SecretRef: corev1.ObjectReference{ Name: "<secret_name>", Namespace: namespace, }, ServiceAccountNames: []string{ "<service_account_name>", }, CloudTokenPath: "", }, }あるいは、YAML 形式の
CredentialsRequestオブジェクトから開始している場合 (たとえば、Operator プロジェクトコードの一部として)、別の方法で処理することもできます。例10.3 YAML フォームでの
CredentialsRequestオブジェクト作成の例// CredentialsRequest is a struct that represents a request for credentials type CredentialsRequest struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` Metadata struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"metadata"` Spec struct { SecretRef struct { Name string `yaml:"name"` Namespace string `yaml:"namespace"` } `yaml:"secretRef"` ProviderSpec struct { APIVersion string `yaml:"apiVersion"` Kind string `yaml:"kind"` StatementEntries []struct { Effect string `yaml:"effect"` Action []string `yaml:"action"` Resource string `yaml:"resource"` } `yaml:"statementEntries"` STSIAMRoleARN string `yaml:"stsIAMRoleARN"` } `yaml:"providerSpec"` // added new field CloudTokenPath string `yaml:"cloudTokenPath"` } `yaml:"spec"` } // ConsumeCredsRequestAddingTokenInfo is a function that takes a YAML filename and two strings as arguments // It unmarshals the YAML file to a CredentialsRequest object and adds the token information. func ConsumeCredsRequestAddingTokenInfo(fileName, tokenString, tokenPath string) (*CredentialsRequest, error) { // open a file containing YAML form of a CredentialsRequest file, err := os.Open(fileName) if err != nil { return nil, err } defer file.Close() // create a new CredentialsRequest object cr := &CredentialsRequest{} // decode the yaml file to the object decoder := yaml.NewDecoder(file) err = decoder.Decode(cr) if err != nil { return nil, err } // assign the string to the existing field in the object cr.Spec.CloudTokenPath = tokenPath // return the modified object return cr, nil }注記CredentialsRequestオブジェクトを Operator バンドルに追加することは現在サポートされていません。ロール ARN と Web ID トークンパスを認証情報リクエストに追加し、Operator の初期化中に適用します。
例10.4 Operator の初期化中に
CredentialsRequestオブジェクトを適用する例// apply CredentialsRequest on install credReq := credreq.CredentialsRequestTemplate credReq.Spec.CloudTokenPath = webIdentityTokenPath c := mgr.GetClient() if err := c.Create(context.TODO(), credReq); err != nil { if !errors.IsAlreadyExists(err) { setupLog.Error(err, "unable to create CredRequest") os.Exit(1) } }次の例に示すように、CCO から
Secretオブジェクトが表示されるのを Operator が待機できるようにします。この処理は、Operator がリコンサイルする他の項目とともに呼び出されます。例10.5
Secretオブジェクトを待機する例// WaitForSecret is a function that takes a Kubernetes client, a namespace, and a v1 "k8s.io/api/core/v1" name as arguments // It waits until the secret object with the given name exists in the given namespace // It returns the secret object or an error if the timeout is exceeded func WaitForSecret(client kubernetes.Interface, namespace, name string) (*v1.Secret, error) { // set a timeout of 10 minutes timeout := time.After(10 * time.Minute)1 // set a polling interval of 10 seconds ticker := time.NewTicker(10 * time.Second) // loop until the timeout or the secret is found for { select { case <-timeout: // timeout is exceeded, return an error return nil, fmt.Errorf("timed out waiting for secret %s in namespace %s", name, namespace) // add to this error with a pointer to instructions for following a manual path to a Secret that will work on STS case <-ticker.C: // polling interval is reached, try to get the secret secret, err := client.CoreV1().Secrets(namespace).Get(context.Background(), name, metav1.GetOptions{}) if err != nil { if errors.IsNotFound(err) { // secret does not exist yet, continue waiting continue } else { // some other error occurred, return it return nil, err } } else { // secret is found, return it return secret, nil } } } }- 1
timeout値は、CCO が追加されたCredentialsRequestオブジェクトを検出してSecretオブジェクトを生成する速度の推定に基づいています。Operator がまだクラウドリソースにアクセスしていない理由を疑問に思っているクラスター管理者のために、時間を短縮するか、カスタムフィードバックを作成することを検討してください。
認証情報リクエストから CCO によって作成されたシークレットを読み取り、そのシークレットのデータを含む AWS 設定ファイルを作成することで、AWS 設定をセットアップします。
例10.6 AWS 設定の作成例
func SharedCredentialsFileFromSecret(secret *corev1.Secret) (string, error) { var data []byte switch { case len(secret.Data["credentials"]) > 0: data = secret.Data["credentials"] default: return "", errors.New("invalid secret for aws credentials") } f, err := ioutil.TempFile("", "aws-shared-credentials") if err != nil { return "", errors.Wrap(err, "failed to create file for shared credentials") } defer f.Close() if _, err := f.Write(data); err != nil { return "", errors.Wrapf(err, "failed to write credentials to %s", f.Name()) } return f.Name(), nil }重要シークレットは存在すると想定されますが、このシークレットを使用する場合、CCO がシークレットを作成する時間を与えるために、Operator コードは待機して再試行する必要があります。
さらに、待機期間は最終的にタイムアウトになり、OpenShift Container Platform クラスターのバージョン、つまり CCO が、STS 検出による
CredentialsRequestオブジェクトのワークフローをサポートしていない以前のバージョンである可能性があることをユーザーに警告します。このような場合は、別の方法を使用してシークレットを追加する必要があることをユーザーに指示します。AWS SDK セッションを設定します。以下に例を示します。
例10.7 AWS SDK セッション設定の例
sharedCredentialsFile, err := SharedCredentialsFileFromSecret(secret) if err != nil { // handle error } options := session.Options{ SharedConfigState: session.SharedConfigEnable, SharedConfigFiles: []string{sharedCredentialsFile}, }
第11章 Hosted Control Plane のマシン設定の処理
スタンドアロン OpenShift Container Platform クラスターでは、マシン設定プールがノードのセットを管理します。MachineConfigPool カスタムリソース (CR) を使用してマシン設定を処理できます。
NodePool CR の nodepool.spec.config フィールドで、任意の machineconfiguration.openshift.io リソースを参照できます。
ホストされたコントロールプレーンでは、MachineConfigPool CR は存在しません。ノードプールには、一連のコンピュートノードがあります。ノードプールを使用してマシン設定を処理できます。
11.1. ホストされたコントロールプレーンのノードプールの設定
ホストされたコントロールプレーンでは、管理クラスターの config map 内に MachineConfig オブジェクトを作成することでノードプールを設定できます。
手順
管理クラスターの config map 内に
MachineConfigオブジェクトを作成するには、次の情報を入力します。apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: ${PATH}1 - 1
MachineConfigオブジェクトが保存されているノード上のパスを設定します。
オブジェクトを config map に追加した後、次のように config map をノードプールに適用できます。
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
<configmap_name>は、設定マップの名前に置き換えます。
11.2. ノードプール内の kubelet 設定を参照する
ノードプール内の kubelet 設定を参照するには、kubelet 設定を config map に追加してから、その config map を NodePool リソースに適用します。
手順
次の情報を入力して、管理クラスターの config map 内に kubelet 設定を追加します。
kubelet 設定を持つ
ConfigMapオブジェクトの例apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name>1 namespace: clusters data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: <kubeletconfig_name>2 spec: kubeletConfig: registerWithTaints: - key: "example.sh/unregistered" value: "true" effect: "NoExecute"次のコマンドを入力して、config map をノードプールに適用します。
$ oc edit nodepool <nodepool_name> --namespace clusters1 - 1
<nodepool_name>をノードプールの名前に置き換えます。
NodePoolリソース設定の例apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
<configmap_name>は、設定マップの名前に置き換えます。
11.3. ホステッドクラスターにおけるノードのチューニング設定
ホステッドクラスター内のノードでノードレベルのチューニングを設定するには、Node Tuning Operator を使用できます。ホストされたコントロールプレーンでは、Tuned オブジェクトを含む config map を作成し、ノードプールでそれらの config map を参照することで、ノードのチューニングを設定できます。
手順
チューニングされた有効なマニフェストを含む config map を作成し、ノードプールでマニフェストを参照します。次の例で
Tunedマニフェストは、任意の値を持つtuned-1-node-labelノードラベルを含むノード上でvm.dirty_ratioを 55 に設定するプロファイルを定義します。次のConfigMapマニフェストをtuned-1.yamlという名前のファイルに保存します。apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile注記Tuned 仕様の
spec.recommendセクションのエントリーにラベルを追加しない場合は、ノードプールベースのマッチングが想定されるため、spec.recommendセクションの最も優先度の高いプロファイルがプール内のノードに適用されます。Tuned.spec.recommend.matchセクションでラベル値を設定することにより、よりきめ細かいノードラベルベースのマッチングを実現できますが、ノードプールの.spec.management.upgradeType値をInPlaceに設定しない限り、ノードラベルはアップグレード中に保持されません。管理クラスターに
ConfigMapオブジェクトを作成します。$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yamlノードプールを編集するか作成して、ノードプールの
spec.tuningConfigフィールドでConfigMapオブジェクトを参照します。この例では、2 つのノードを含むnodepool-1という名前のNodePoolが 1 つだけあることを前提としています。apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...注記複数のノードプールで同じ config map を参照できます。Hosted Control Plane では、Node Tuning Operator が Tuned CR の名前にノードプール名と namespace のハッシュを追加して、それらを区別します。この場合を除き、同じホステッドクラスターの異なる Tuned CR に、同じ名前の複数の TuneD プロファイルを作成しないでください。
検証
Tuned マニフェストを含む ConfigMap オブジェクトを作成し、それを NodePool で参照したことで、Node Tuning Operator により Tuned オブジェクトがホステッドクラスターに同期されます。どの Tuned オブジェクトが定義されているか、どの TuneD プロファイルが各ノードに適用されているかを確認できます。
ホステッドクラスター内の
Tunedオブジェクトをリスト表示します。$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator出力例
NAME AGE default 7m36s rendered 7m36s tuned-1 65sホステッドクラスター内の
Profileオブジェクトをリスト表示します。$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io \ -n openshift-cluster-node-tuning-operator出力例
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s注記カスタムプロファイルが作成されていない場合は、
openshift-nodeプロファイルがデフォルトで適用されます。チューニングが正しく適用されたことを確認するには、ノードでデバッグシェルを開始し、sysctl 値を確認します。
$ oc --kubeconfig="$HC_KUBECONFIG" \ debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio出力例
vm.dirty_ratio = 55
11.4. Hosted Control Plane 用の SR-IOV Operator のデプロイ
ホスティングサービスクラスターを設定してデプロイすると、ホステッドクラスターで SR-IOV Operator へのサブスクリプションを作成できます。SR-IOV Pod は、コントロールプレーンではなくワーカーマシンで実行されます。
前提条件
AWS 上でホステッドクラスターを設定およびデプロイしている。
手順
namespace と Operator グループを作成します。
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operatorSR-IOV Operator へのサブスクリプションを作成します。
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: stable name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: redhat-operators sourceNamespace: openshift-marketplace
検証
SR-IOV Operator の準備ができていることを確認するには、次のコマンドを実行し、結果の出力を表示します。
$ oc get csv -n openshift-sriov-network-operator出力例
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.17.0-202211021237 SR-IOV Network Operator 4.17.0-202211021237 sriov-network-operator.4.17.0-202210290517 SucceededSR-IOV Pod がデプロイされていることを確認するには、次のコマンドを実行します。
$ oc get pods -n openshift-sriov-network-operator
11.5. ホステッドクラスターの NTP サーバーの設定
Butane を使用して、ホステッドクラスターの Network Time Protocol (NTP) サーバーを設定できます。
手順
chrony.confファイルの内容を含む Butane 設定ファイル99-worker-chrony.buを作成します。Butane の詳細は、「Butane を使用したマシン設定の作成」を参照してください。99-worker-chrony.buの設定例# ... variant: openshift version: 4.17.0 metadata: name: 99-worker-chrony labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/chrony.conf mode: 06441 overwrite: true contents: inline: | pool 0.rhel.pool.ntp.org iburst2 driftfile /var/lib/chrony/drift makestep 1.0 3 rtcsync logdir /var/log/chrony # ...注記マシン間通信の場合、User Datagram Protocol (UDP) ポート上の NTP は
123です。外部 NTP タイムサーバーを設定した場合は、UDP ポート123を開く必要があります。Butane を使用して、Butane がノードに送信する設定を含む
MachineConfigオブジェクトファイル99-worker-chrony.yamlを生成します。以下のコマンドを実行します。$ butane 99-worker-chrony.bu -o 99-worker-chrony.yaml99-worker-chrony.yamlの設定例# Generated by Butane; do not edit apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path管理クラスターの config map 内に
99-worker-chrony.yamlファイルの内容を追加します。config map の例
apiVersion: v1 kind: ConfigMap metadata: name: <configmap_name> namespace: <namespace>1 data: config: | apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: <machineconfig_name> spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:... mode: 420 overwrite: true path: /example/path # ...- 1
<namespace>は、ノードプールを作成した namespace の名前 (clustersなど) に置き換えます。
次のコマンドを実行して、config map をノードプールに適用します。
$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>NodePoolの設定例apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: config: - name: <configmap_name>1 # ...- 1
<configmap_name>は、設定マップの名前に置き換えます。
InfraEnvカスタムリソース (CR) を定義するinfra-env.yamlファイルに NTP サーバーのリストを追加します。infra-env.yamlファイルの例apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv # ... spec: additionalNTPSources: - <ntp_server>1 - <ntp_server1> - <ntp_server2> # ...- 1
<ntp_server>は、NTP サーバーの名前に置き換えます。ホストインベントリーとInfraEnvCR の作成の詳細は、「ホストインベントリーの作成」を参照してください。
次のコマンドを実行して、
InfraEnvCR を適用します。$ oc apply -f infra-env.yaml
検証
次のフィールドを確認し、ホストインベントリーのステータスを確認します。
-
conditions: イメージが正常に作成されたかどうかを示す標準の Kubernetes の状態。 -
isoDownloadURL: Discovery Image をダウンロードするための URL。 createdTime: イメージが最後に作成された時刻。InfraEnvCR を変更する場合は、新しいイメージをダウンロードする前に、必ずタイムスタンプを更新してください。次のコマンドを実行して、ホストインベントリーが作成されたことを確認します。
$ oc describe infraenv <infraenv_resource_name> -n <infraenv_namespace>注記InfraEnvCR を変更する場合は、createdTimeフィールドを調べて、InfraEnvCR によって新しい Discovery Image が作成されたことを確認してください。すでにホストを起動している場合は、最新の Discovery Image でホストを再起動します。
-
第12章 ホステッドクラスターでのフィーチャーゲートの使用
ホステッドクラスターでフィーチャーゲートを使用して、デフォルトの機能セットに含まれていない機能を有効にすることができます。ホステッドクラスターでフィーチャーゲートを使用すると、TechPreviewNoUpgrade 機能セットを有効にすることができます。
12.1. フィーチャーゲートを使用した機能セットの有効化
OpenShift CLI を使用して HostedCluster カスタムリソース (CR) を編集することにより、ホステッドクラスターで TechPreviewNoUpgrade 機能セットを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、ホスティングクラスターで
HostedClusterCR を編集するために開きます。$ oc edit hostedcluster <hosted_cluster_name> -n <hosted_cluster_namespace>featureSetフィールドに値を入力して機能セットを定義します。以下に例を示します。apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: configuration: featureGate: featureSet: TechPreviewNoUpgrade3 警告クラスターで
TechPreviewNoUpgrade機能セットを有効にすると、元に戻すことができず、マイナーバージョンの更新が妨げられます。この機能セットを使用すると、該当するテクノロジープレビュー機能をテストクラスターで有効にして、完全にテストすることができます。実稼働クラスターではこの機能セットを有効にしないでください。- 変更を適用するためにファイルを保存します。
検証
次のコマンドを実行して、ホステッドクラスターで
TechPreviewNoUpgradeフィーチャーゲートが有効になっていることを確認します。$ oc get featuregate cluster -o yaml
第13章 Hosted Control Plane の可観測性
メトリクスセットを設定することで、Hosted Control Plane のメトリクスを収集できます。HyperShift Operator は、管理対象のホステッドクラスターごとに、管理クラスター内のモニタリングダッシュボードを作成または削除できます。
13.1. Hosted Control Plane のメトリクスセットの設定
Red Hat OpenShift Container Platform の Hosted Control Plane は、各コントロールプレーンの namespace に ServiceMonitor リソースを作成します。これにより、Prometheus スタックがコントロールプレーンからメトリクスを収集できるようになります。ServiceMonitor リソースは、メトリクスの再ラベル付けを使用して、etcd や Kubernetes API サーバーなどの特定のコンポーネントにどのメトリクスを含めるか、または除外するかを定義します。コントロールプレーンによって生成されるメトリクスの数は、それらを収集する監視スタックのリソース要件に直接影響します。
すべての状況に適用される固定数のメトリクスを生成する代わりに、コントロールプレーンごとに生成するメトリクスのセットを識別するメトリクスセットを設定できます。次のメトリクスセットがサポートされています。
-
Telemetry: このメトリクスはテレメトリーに必要です。このセットはデフォルトのセットであり、メトリクスの最小セットです。 -
SRE: このセットには、アラートを生成し、コントロールプレーンコンポーネントのトラブルシューティングを可能にするために必要なメトリクスが含まれています。 -
All: このセットには、スタンドアロンの OpenShift Container Platform コントロールプレーンコンポーネントによって生成されるすべてのメトリクスが含まれます。
メトリクスセットを設定するには、次のコマンドを入力して、HyperShift Operator デプロイメントで METRICS_SET 環境変数を設定します。
$ oc set env -n hypershift deployment/operator METRICS_SET=All13.1.1. SRE メトリクスセットの設定
SRE メトリクスセットを指定すると、HyperShift Operator は、単一キー config を持つ sre-metric-set という名前の config map を検索します。config キーの値には、コントロールプレーンコンポーネント別に整理された RelabelConfigs のセットが含まれている必要があります。
次のコンポーネントを指定できます。
-
etcd -
kubeAPIServer -
kubeControllerManager -
openshiftAPIServer -
openshiftControllerManager -
openshiftRouteControllerManager -
cvo -
olm -
catalogOperator -
registryOperator -
nodeTuningOperator -
controlPlaneOperator -
hostedClusterConfigOperator
SRE メトリクスセットの設定を次の例に示します。
kubeAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "transformation_(transformation_latencies_microseconds|failures_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "network_plugin_operations_latency_microseconds|sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
kubeControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "rest_client_request_latency_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "root_ca_cert_publisher_sync_duration_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
openshiftAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
openshiftControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
openshiftRouteControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
olm:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
catalogOperator:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
cvo:
- action: drop
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]13.2. ホステッドクラスターのモニタリングダッシュボードの有効化
config map を作成することにより、ホステッドクラスターでモニタリングダッシュボードを有効にできます。
手順
local-clusternamespace に、hypershift-operator-install-flagsconfig map を作成します。次の設定例を参照してください。kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "--monitoring-dashboards --metrics-set=All"1 installFlagsToRemove: ""- 1
--monitoring-dashboards --metrics-set=Allフラグは、すべてのメトリクスのモニタリングダッシュボードを追加します。
hypershiftnamespace の HyperShift Operator デプロイメントが更新され、次の環境変数が含まれるまで数分待ちます。- name: MONITORING_DASHBOARDS value: "1"モニタリングダッシュボードが有効になっている場合、HyperShift Operator が管理するホステッドクラスターごとに、HyperShift Operator が
openshift-config-managednamespace にcp-<hosted_cluster_namespace>-<hosted_cluster_name>という名前の config map を作成します。<hosted_cluster_namespace>はホステッドクラスターの namespace、<hosted_cluster_name>はホステッドクラスターの名前です。その結果、管理クラスターの管理コンソールに新しいダッシュボードが追加されます。- ダッシュボードを表示するには、管理クラスターのコンソールにログインし、Observe → Dashboards をクリックして、ホステッドクラスターのダッシュボードに移動します。
-
オプション: ホステッドクラスターのモニタリングダッシュボードを無効にするには、
hypershift-operator-install-flagsconfig map から--monitoring-dashboards --metrics-set=Allフラグを削除します。ホステッドクラスターを削除すると、対応するダッシュボードも削除されます。
13.2.1. ダッシュボードのカスタマイズ
各ホステッドクラスターのダッシュボードを生成するために、HyperShift Operator は、Operator の namespace (hypershift) の monitoring-dashboard-template config map に保存されているテンプレートを使用します。このテンプレートには、ダッシュボードのメトリクスを含む一連の Grafana パネルが含まれています。config map の内容を編集して、ダッシュボードをカスタマイズできます。
ダッシュボードが生成されると、次の文字列が特定のホステッドクラスターに対応する値に置き換えられます。
| 名前 | 説明 |
|---|---|
|
| ホステッドクラスターの名前 |
|
| ホステッドクラスターの namespace |
|
| ホステッドクラスターのコントロールプレーン Pod が配置される namespace |
|
|
ホステッドクラスターの UUID。これはホステッドクラスターのメトリクスの |
第14章 Hosted Control Plane のトラブルシューティング
Hosted Control Plane で問題が発生した場合は、次の情報を参照してトラブルシューティングを行ってください。
14.1. Hosted Control Plane のトラブルシューティング用の情報収集
ホステッドクラスターの問題をトラブルシューティングする必要がある場合は、must-gather コマンドを実行して情報を収集できます。このコマンドは、管理クラスターとホステッドクラスターの出力を生成します。
管理クラスターの出力には次の内容が含まれます。
- クラスタースコープのリソース: これらのリソースは、管理クラスターのノード定義です。
-
hypershift-dump圧縮ファイル: このファイルは、コンテンツを他の人と共有する必要がある場合に役立ちます。 - namespace リソース: これらのリソースには、config map、サービス、イベント、ログなど、関連する namespace のすべてのオブジェクトが含まれます。
- ネットワークログ: これらのログには、OVN ノースバウンドデータベースとサウスバウンドデータベース、およびそれぞれのステータスが含まれます。
- ホステッドクラスター: このレベルの出力には、ホステッドクラスター内のすべてのリソースが含まれます。
ホステッドクラスターの出力には、次の内容が含まれます。
- クラスタースコープのリソース: これらのリソースには、ノードや CRD などのクラスター全体のオブジェクトがすべて含まれます。
- namespace リソース: これらのリソースには、config map、サービス、イベント、ログなど、関連する namespace のすべてのオブジェクトが含まれます。
出力にはクラスターからのシークレットオブジェクトは含まれませんが、シークレットの名前への参照が含まれる可能性があります。
前提条件
-
管理クラスターへの
cluster-adminアクセス権がある。 -
HostedClusterリソースのname値と、CR がデプロイされる namespace がある。 -
hcpコマンドラインインターフェイスがインストールされている。詳細は、「Hosted Control Plane のコマンドラインインターフェイスのインストール」を参照してください。 -
OpenShift CLI (
oc) がインストールされている。 -
kubeconfigファイルがロードされ、管理クラスターを指している。
手順
トラブルシューティングのために出力を収集するには、次のコマンドを入力します。
$ oc adm must-gather \ --image=registry.redhat.io/multicluster-engine/must-gather-rhel9:v<mce_version> \ /usr/bin/gather hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE \ hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=NAME ; tar -cvzf NAME.tgz NAMEここでは、以下のようになります。
-
<mce_version>は、使用している multicluster engine Operator のバージョン (例:2.6) に置き換えます。 -
hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACEパラメーターはオプションです。このパラメーターを使用しないと、ホステッドクラスターがデフォルトの namespace (clusters) にあるかのようにコマンドが実行します。 -
コマンドの結果を圧縮ファイルに保存する場合は、
--dest-dir=NAMEパラメーターを指定します。NAMEは、結果を保存するディレクトリーの名前に置き換えます。
-
14.2. ホステッドクラスターの OpenShift Container Platform データの収集
multicluster engine Operator Web コンソールまたは CLI を使用して、ホステッドクラスターの OpenShift Container Platform デバッグ情報を収集できます。
14.2.1. CLI を使用したホステッドクラスターのデータの収集
CLI を使用して、ホステッドクラスターの OpenShift Container Platform デバッグ情報を収集できます。
前提条件
-
管理クラスターへの
cluster-adminアクセス権がある。 -
HostedClusterリソースのname値と、CR がデプロイされる namespace がある。 -
hcpコマンドラインインターフェイスがインストールされている。詳細は、「Hosted Control Plane のコマンドラインインターフェイスのインストール」を参照してください。 -
OpenShift CLI (
oc) がインストールされている。 -
kubeconfigファイルがロードされ、管理クラスターを指している。
手順
次のコマンドを入力して、
kubeconfigファイルを生成します。$ hcp create kubeconfig --namespace <hosted_cluster_namespace> \ --name <hosted_cluster_name> > <hosted_cluster_name>.kubeconfigkubeconfigファイルを保存した後、次のコマンド例を入力して、ホステッドクラスターにアクセスできます。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodes.次のコマンドを入力して、must-gather 情報を収集します。
$ oc adm must-gather
14.2.2. Web コンソールを使用したホステッドクラスターのデータの収集
multicluster engine Operator Web コンソールを使用して、ホステッドクラスターの OpenShift Container Platform デバッグ情報を収集できます。
前提条件
-
管理クラスターへの
cluster-adminアクセス権がある。 -
HostedClusterリソースのname値と、CR がデプロイされる namespace がある。 -
hcpコマンドラインインターフェイスがインストールされている。詳細は、「Hosted Control Plane のコマンドラインインターフェイスのインストール」を参照してください。 -
OpenShift CLI (
oc) がインストールされている。 -
kubeconfigファイルがロードされ、管理クラスターを指している。
手順
- Web コンソールで、All Clusters を選択し、トラブルシューティングするクラスターを選択します。
- 右上隅で、Download kubeconfig を選択します。
-
ダウンロードした
kubeconfigファイルをエクスポートします。 次のコマンドを入力して、must-gather 情報を収集します。
$ oc adm must-gather
14.3. 非接続環境での must-gather コマンドの入力
非接続環境で must-gather コマンドを実行するには、次の手順を実行します。
手順
- 非接続環境で、Red Hat Operator のカタログイメージをミラーレジストリーにミラーリングします。詳細は、ネットワーク切断状態でのインストール を参照してください。
次のコマンドを実行して、ミラーレジストリーからイメージを参照するログを抽出します。
REGISTRY=registry.example.com:5000 IMAGE=$REGISTRY/multicluster-engine/must-gather-rhel8@sha256:ff9f37eb400dc1f7d07a9b6f2da9064992934b69847d17f59e385783c071b9d8 $ oc adm must-gather \ --image=$IMAGE /usr/bin/gather \ hosted-cluster-namespace=HOSTEDCLUSTERNAMESPACE \ hosted-cluster-name=HOSTEDCLUSTERNAME \ --dest-dir=./data
14.4. OpenShift Virtualization でのホステッドクラスターのトラブルシューティング
OpenShift Virtualization でホステッドクラスターのトラブルシューティングを行う場合は、トップレベルの HostedCluster リソースと NodePool リソースから始めて、根本原因が見つかるまでスタックを下位に向かって作業します。以下の手順は、一般的な問題の根本原因を検出するのに役立ちます。
14.4.1. HostedCluster リソースが partial 状態でスタックする
HostedCluster リソースが保留中であるために Hosted Control Plane が完全にオンラインにならない場合は、前提条件、リソースの状態、ノードと Operator のステータスを確認して問題を特定します。
手順
- OpenShift Virtualization 上のホステッドクラスターの前提条件をすべて満たしていることを確認します。
-
進行を妨げる検証エラーがないか、
HostedClusterリソースとNodePoolリソースの状態を表示します。 ホステッドクラスターの
kubeconfigファイルを使用して、ホステッドクラスターのステータスを検査します。-
oc get clusteroperatorsコマンドの出力を表示して、保留中のクラスター Operator を表示します。 -
oc get nodesコマンドの出力を表示して、ワーカーノードの準備ができていることを確認します。
-
14.4.2. ワーカーノードが登録されない
Hosted Control Plane にワーカーノードが登録されないために Hosted Control Plane が完全にオンラインにならない場合は、Hosted Control Plane のさまざまな部分のステータスを確認して問題を特定します。
手順
-
HostedClusterとNodePoolの障害の状態を表示して、問題の内容を示します。 次のコマンドを入力して、
NodePoolリソースの KubeVirt ワーカーノード仮想マシン (VM) のステータスを表示します。$ oc get vm -n <namespace>仮想マシンがプロビジョニング状態でスタックしている場合は、次のコマンドを入力して、仮想マシン namespace 内の CDI インポート Pod を表示し、インポーター Pod が完了していない理由を調べます。
$ oc get pods -n <namespace> | grep "import"仮想マシンが開始状態でスタックしている場合は、次のコマンドを入力して、virt-launcher Pod のステータスを表示します。
$ oc get pods -n <namespace> -l kubevirt.io=virt-launchervirt-launcher Pod が保留状態にある場合は、Pod がスケジュールされていない理由を調査してください。たとえば、virt-launcher Pod の実行に必要なリソースが十分存在しない可能性があります。
- 仮想マシンが実行されていてもワーカーノードとして登録されていない場合は、Web コンソールを使用して、影響を受ける仮想マシンの 1 つへの VNC アクセスを取得します。VNC 出力は ignition 設定が適用されたかどうかを示します。仮想マシンが起動時に Hosted Control Plane Ignition サーバーにアクセスできない場合、仮想マシンは正しくプロビジョニングできません。
- Ignition 設定が適用されても、仮想マシンがノードとして登録されない場合は、問題の特定: 仮想マシンコンソールログへのアクセス で、起動時に仮想マシンコンソールログにアクセスする方法を確認してください。
14.4.3. ワーカーノードが NotReady 状態でスタックする
クラスターの作成中、ネットワークスタックがロールアウトされる間、ノードは一時的に NotReady 状態になります。プロセスのこの部分は正常です。ただし、このプロセス部分にかかる時間が 15 分を超える場合は、ノードオブジェクトと Pod を調査して問題を特定します。
手順
次のコマンドを入力して、ノードオブジェクトの状態を表示し、ノードの準備ができていない理由を特定します。
$ oc get nodes -o yaml次のコマンドを入力して、クラスター内で障害が発生している Pod を探します。
$ oc get pods -A --field-selector=status.phase!=Running,status,phase!=Succeeded
14.4.4. Ingress およびコンソールクラスター Operator がオンラインにならない
Ingress およびコンソールクラスター Operator がオンラインでないために Hosted Control Plane が完全にオンラインにならない場合は、ワイルドカード DNS ルートとロードバランサーを確認します。
手順
クラスターがデフォルトの Ingress 動作を使用する場合は、次のコマンドを入力して、仮想マシン (VM) がホストされている OpenShift Container Platform クラスターでワイルドカード DNS ルートが有効になっていることを確認します。
$ oc patch ingresscontroller -n openshift-ingress-operator \ default --type=json -p \ '[{ "op": "add", "path": "/spec/routeAdmission", "value": {wildcardPolicy: "WildcardsAllowed"}}]'Hosted Control Plane にカスタムベースドメインを使用する場合は、次の手順を実行します。
- ロードバランサーが仮想マシン Pod を正しくターゲットにしていることを確認します。
- ワイルドカード DNS エントリーがロードバランサー IP をターゲットにしていることを確認します。
14.4.5. ホステッドクラスターのロードバランサーサービスが利用できない
ロードバランサーサービスが利用できないために Hosted Control Plane が完全にオンラインにならない場合は、イベント、詳細、Kubernetes Cluster Configuration Manager (KCCM) Pod を確認します。
手順
- ホステッドクラスター内のロードバランサーサービスに関連付けられたイベントおよび詳細を探します。
デフォルトでは、ホステッドクラスターのロードバランサーは、Hosted Control Plane の namespace 内の kubevirt-cloud-controller-manager によって処理されます。KCCM Pod がオンラインであることを確認し、ログでエラーや警告を確認します。Hosted Control Plane の namespace で KCCM Pod を特定するには、次のコマンドを入力します。
$ oc get pods -n <hosted_control_plane_namespace> \ -l app=cloud-controller-manager
14.4.6. ホステッドクラスターの PVC が利用できない
ホステッドクラスターの永続ボリューム要求 (PVC) が利用できないために Hosted Control Plane が完全にオンラインにならない場合は、PVC イベントと詳細、およびコンポーネントログを確認します。
手順
- PVC に関連するイベントと詳細を探して、どのエラーが発生しているかを把握します。
PVC が Pod に割り当てられていない場合は、ホステッドクラスター内の kubevirt-csi-node
daemonsetコンポーネントのログを表示して、問題をさらに調査します。各ノードの kubevirt-csi-node Pod を識別するには、次のコマンドを入力します。$ oc get pods -n openshift-cluster-csi-drivers -o wide \ -l app=kubevirt-csi-driverPVC が永続ボリューム (PV) にバインドできない場合は、Hosted Control Plane の namespace 内の kubevirt-csi-controller コンポーネントのログを表示します。Hosted Control Plane の namespace 内の kubevirt-csi-controller Pod を識別するには、次のコマンドを入力します。
$ oc get pods -n <hcp namespace> -l app=kubevirt-csi-driver
14.4.7. 仮想マシンノードがクラスターに正しく参加していない
仮想マシンノードがクラスターに正しく参加していないために Hosted Control Plane が完全にオンラインにならない場合は、仮想マシンコンソールログにアクセスします。
手順
- 仮想マシンコンソールログにアクセスするには、How to get serial console logs for VMs part of OpenShift Virtualization Hosted Control Plane clusters の手順を実行します。
14.4.8. RHCOS イメージのミラーリングが失敗する
非接続環境の OpenShift Virtualization 上の Hosted Control Plane の場合、oc-mirror で、Red Hat Enterprise Linux CoreOS (RHCOS) イメージを内部レジストリーに自動的にミラーリングできません。最初のホステッドクラスターを作成するときに、ブートイメージを内部レジストリーで利用できないため、Kubevirt 仮想マシンが起動しません。
この問題を解決するには、RHCOS イメージを手動で内部レジストリーにミラーリングします。
手順
次のコマンドを実行して内部レジストリー名を取得します。
$ oc get imagecontentsourcepolicy -o json \ | jq -r '.items[].spec.repositoryDigestMirrors[0].mirrors[0]'次のコマンドを実行してペイロードイメージを取得します。
$ oc get clusterversion version -ojsonpath='{.status.desired.image}'ホステッドクラスター上のペイロードイメージからブートイメージを含む
0000_50_installer_coreos-bootimages.yamlファイルを抽出します。<payload_image>は、ペイロードイメージの名前に置き換えます。以下のコマンドを実行します。$ oc image extract \ --file /release-manifests/0000_50_installer_coreos-bootimages.yaml \ <payload_image> --confirm次のコマンドを実行して RHCOS イメージを取得します。
$ cat 0000_50_installer_coreos-bootimages.yaml | yq -r .data.stream \ | jq -r '.architectures.x86_64.images.kubevirt."digest-ref"'RHCOS イメージを内部レジストリーにミラーリングします。
<rhcos_image>は、RHCOS イメージに置き換えます (例:quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:d9643ead36b1c026be664c9c65c11433c6cdf71bfd93ba229141d134a4a6dd94)。<internal_registry>は、内部レジストリーの名前に置き換えます (例:virthost.ostest.test.metalkube.org:5000/localimages/ocp-v4.0-art-dev)。以下のコマンドを実行します。$ oc image mirror <rhcos_image> <internal_registry>ImageDigestMirrorSetオブジェクトを定義するrhcos-boot-kubevirt.yamlという名前の YAML ファイルを作成します。次の設定例を参照してください。apiVersion: config.openshift.io/v1 kind: ImageDigestMirrorSet metadata: name: rhcos-boot-kubevirt spec: repositoryDigestMirrors: - mirrors: - virthost.ostest.test.metalkube.org:5000/localimages/ocp-v4.0-art-dev1 source: quay.io/openshift-release-dev/ocp-v4.0-art-dev2 次のコマンドを実行して、
rhcos-boot-kubevirt.yamlファイルを適用し、ImageDigestMirrorSetオブジェクトを作成します。$ oc apply -f rhcos-boot-kubevirt.yaml
14.4.9. 非ベアメタルクラスターを遅延バインディングプールに戻す
BareMetalHosts なしで遅延バインディングマネージドクラスターを使用している場合は、遅延バインディングクラスターを削除し、ノードを Discovery ISO に戻すための追加の手動手順を実行する必要があります。
BareMetalHosts のない遅延バインディングマネージドクラスターの場合、クラスター情報を削除しても、すべてのノードが自動的に Discovery ISO に戻されるわけではありません。
手順
遅延バインディングを使用する非ベアメタルノードのバインドを解除するには、次の手順を実行します。
- クラスター情報を削除します。詳細は、マネージメントからのクラスターの削除 を参照してください。
- ルートディスクをクリーンアップします。
- Discovery ISO を使用して手動で再起動します。
14.5. ベアメタル上のホステッドクラスターのトラブルシューティング
以下の情報は、ベアメタル上の Hosted Control Plane のトラブルシューティングに適用されます。
14.5.1. ベアメタル上の Hosted Control Plane にノードを追加できない
Assisted Installer を使用してプロビジョニングされたノードが含まれる Hosted Control Plane クラスターをスケールアップすると、ホストはポート 22642 が含まれる URL を使用して Ignition をプルできません。この URL は Hosted Control Plane では無効であり、クラスターに問題があることを示しています。
手順
問題を特定するには、assisted-service ログを確認します。
$ oc logs -n multicluster-engine <assisted_service_pod_name>1 - 1
- Assisted Service Pod の名前を指定します。
ログで、次の例に似たエラーを見つけます。
error="failed to get pull secret for update: invalid pull secret data in secret pull-secret"pull secret must contain auth for \"registry.redhat.io\"この問題を解決するには、multicluster engine for Kubernetes Operator のドキュメントの「プルシークレットを namespace に追加する」を参照してください。
注記Hosted Control Plane を使用するには、スタンドアロン Operator として、または Red Hat Advanced Cluster Management の一部として、multicluster engine Operator がインストールされている必要があります。Operator は Red Hat Advanced Cluster Management と密接な関係があるため、Operator のドキュメントはその製品のドキュメント内に公開されています。Red Hat Advanced Cluster Management を使用していない場合でも、ドキュメントの multicluster engine Operator について説明している部分は Hosted Control Plane に関連します。
14.6. Hosted Control Plane コンポーネントの再起動
Hosted Control Plane の管理者の場合は、hypershift.openshift.io/restart-date アノテーションを使用して、特定の HostedCluster リソースのすべてのコントロールプレーンコンポーネントを再起動できます。たとえば、証明書のローテーション用にコントロールプレーンコンポーネントを再起動する必要がある場合があります。
手順
コントロールプレーンを再起動するには、次のコマンドを入力して
HostedClusterリソースにアノテーションを付けます。$ oc annotate hostedcluster \ -n <hosted_cluster_namespace> \ <hosted_cluster_name> \ hypershift.openshift.io/restart-date=$(date --iso-8601=seconds)1 - 1
- アノテーションの値が変わるたびに、コントロールプレーンが再起動されます。
dateコマンドは、一意の文字列のソースとして機能します。アノテーションはタイムスタンプではなく文字列として扱われます。
検証
コントロールプレーンを再起動すると、通常、次の Hosted Control Plane コンポーネントが再起動します。
他のコンポーネントによって変更が実装されることに伴い、さらにいくつかのコンポーネントが再起動する場合があります。
- catalog-operator
- certified-operators-catalog
- cluster-api
- cluster-autoscaler
- cluster-policy-controller
- cluster-version-operator
- community-operators-catalog
- control-plane-operator
- hosted-cluster-config-operator
- ignition-server
- ingress-operator
- konnectivity-agent
- konnectivity-server
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- machine-approver
- oauth-openshift
- olm-operator
- openshift-apiserver
- openshift-controller-manager
- openshift-oauth-apiserver
- packageserver
- redhat-marketplace-catalog
- redhat-operators-catalog
14.7. ホステッドクラスターと Hosted Control Plane のリコンシリエーションの一時停止
クラスターインスタンス管理者は、ホステッドクラスターと Hosted Control Plane のリコンシリエーションを一時停止できます。etcd データベースをバックアップおよび復元するときや、ホステッドクラスターまたは Hosted Control Plane の問題をデバッグする必要があるときは、リコンシリエーションを一時停止することができます。
手順
ホステッドクラスターと Hosted Control Plane のリコンシリエーションを一時停止するには、
HostedClusterリソースのpausedUntilフィールドを設定します。特定の時刻までリコンシリエーションを一時停止するには、次のコマンドを入力します。
$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"<timestamp>"}}' \ --type=merge1 - 1
- RFC339 形式でタイムスタンプを指定します (例:
2024-03-03T03:28:48Z)。指定の時間が経過するまで、リコンシリエーションが一時停止します。
リコンシリエーションを無期限に一時停止するには、次のコマンドを入力します。
$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":"true"}}' \ --type=mergeHostedClusterリソースからフィールドを削除するまで、リコンシリエーションは一時停止されます。HostedClusterリソースの一時停止リコンシリエーションフィールドが設定されると、そのフィールドは関連付けられたHostedControlPlaneリソースに自動的に追加されます。
pausedUntilフィールドを削除するには、次の patch コマンドを入力します。$ oc patch -n <hosted_cluster_namespace> \ hostedclusters/<hosted_cluster_name> \ -p '{"spec":{"pausedUntil":null}}' \ --type=merge
14.8. データプレーンをゼロにスケールダウンする
Hosted Control Plane を使用していない場合は、リソースとコストを節約するために、データプレーンをゼロにスケールダウンできます。
データプレーンをゼロにスケールダウンする準備ができていることを確認してください。スケールダウンするとワーカーノードからのワークロードがなくなるためです。
手順
次のコマンドを実行して、ホステッドクラスターにアクセスするように
kubeconfigファイルを設定します。$ export KUBECONFIG=<install_directory>/auth/kubeconfig次のコマンドを実行して、ホステッドクラスターに関連付けられた
NodePoolリソースの名前を取得します。$ oc get nodepool --namespace <hosted_cluster_namespace>オプション: Pod のドレインを防止するには、次のコマンドを実行して、
NodePoolリソースにnodeDrainTimeoutフィールドを追加します。$ oc edit nodepool <nodepool_name> --namespace <hosted_cluster_namespace>出力例
apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: arch: amd64 clusterName: clustername1 management: autoRepair: false replace: rollingUpdate: maxSurge: 1 maxUnavailable: 0 strategy: RollingUpdate upgradeType: Replace nodeDrainTimeout: 0s2 # ...注記ノードドレインプロセスを一定期間継続できるようにするには、それに応じて、
nodeDrainTimeoutフィールドの値を設定できます (例:nodeDrainTimeout: 1m)。次のコマンドを実行して、ホステッドクラスターに関連付けられた
NodePoolリソースをスケールダウンします。$ oc scale nodepool/<nodepool_name> --namespace <hosted_cluster_namespace> \ --replicas=0注記データプランをゼロにスケールダウンした後、コントロールプレーン内の一部の Pod は
Pendingステータスのままになり、ホストされているコントロールプレーンは稼働したままになります。必要に応じて、NodePoolリソースをスケールアップできます。オプション: 次のコマンドを実行して、ホステッドクラスターに関連付けられた
NodePoolリソースをスケールアップします。$ oc scale nodepool/<nodepool_name> --namespace <hosted_cluster_namespace> --replicas=1NodePoolリソースを再スケーリングした後、NodePoolリソースが準備Ready状態で使用可能になるまで数分間待ちます。
検証
次のコマンドを実行して、
nodeDrainTimeoutフィールドの値が0sより大きいことを確認します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -ojsonpath='{.spec.nodeDrainTimeout}'
第15章 ホステッドクラスターの破棄
15.1. AWS 上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用して、Amazon Web Services (AWS) 上のホステッドクラスターとそのマネージドクラスターリソースを破棄できます。
15.1.1. CLI を使用した AWS 上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用して、Amazon Web Services (AWS) 上のホステッドクラスターを破棄できます。
手順
次のコマンドを実行して、multicluster engine Operator のマネージドクラスターリソースを削除します。
$ oc delete managedcluster <hosted_cluster_name>1 - 1
<hosted_cluster_name>は、クラスターの名前に置き換えます。
次のコマンドを実行して、ホステッドクラスターとそのバックエンドリソースを削除します。
$ hcp destroy cluster aws \ --name <hosted_cluster_name> \1 --infra-id <infra_id> \2 --role-arn <arn_role> \3 --sts-creds <path_to_sts_credential_file> \4 --base-domain <basedomain>5 重要AWS Security Token Service (STS) のセッショントークンの有効期限が切れている場合は、次のコマンドを実行して、
sts-creds.jsonという名前の JSON ファイルで STS 認証情報を取得してください。$ aws sts get-session-token --output json > sts-creds.json
15.2. ベアメタル上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) または multicluster engine Operator の Web コンソールを使用して、ベアメタル上のホステッドクラスターを破棄できます。
15.2.1. CLI を使用したベアメタル上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用してホステッドクラスターを作成した場合は、コマンドを実行して、そのホステッドクラスターとそのバックエンドリソースを破棄できます。
手順
次のコマンドを実行して、ホステッドクラスターとそのバックエンドリソースを削除します。
$ oc delete -f <hosted_cluster_config>.yaml1 - 1
- ホステッドクラスターを作成したときにレンダリングされた設定 YAML ファイルの名前を指定します。
注記設定ファイルで
--renderおよび--render-sensitiveフラグを指定せずにホステッドクラスターを作成した場合は、バックエンドリソースを手動で削除する必要があります。
15.2.2. Web コンソールを使用したベアメタル上のホステッドクラスターの破棄
multicluster engine Operator の Web コンソールを使用して、ベアメタル上のホステッドクラスターを破棄できます。
手順
- コンソールで、Infrastructure → Clusters をクリックします。
- Clusters ページで、破棄するクラスターを選択します。
- Actions メニューで Destroy clusters を選択し、クラスターを削除します。
15.3. OpenShift Virtualization 上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用して、OpenShift Virtualization 上のホステッドクラスターとそのマネージドクラスターリソースを破棄できます。
15.3.1. CLI を使用した OpenShift Virtualization 上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用して、OpenShift Virtualization 上のホステッドクラスターとそのマネージドクラスターリソースを破棄できます。
手順
次のコマンドを実行して、multicluster engine Operator のマネージドクラスターリソースを削除します。
$ oc delete managedcluster <hosted_cluster_name>次のコマンドを実行して、ホステッドクラスターとそのバックエンドリソースを削除します。
$ hcp destroy cluster kubevirt --name <hosted_cluster_name>
15.4. IBM Z 上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用して、IBM Z コンピュートノードを含む x86 ベアメタル上のホステッドクラスターとそのマネージドクラスターリソースを破棄できます。
15.4.1. IBM Z コンピュートノードを含む x86 ベアメタル上のホステッドクラスターの破棄
IBM Z コンピュートノードを含む x86 ベアメタル上のホステッドクラスターとそのマネージドクラスターを破棄するには、コマンドラインインターフェイス (CLI) を使用できます。
手順
次のコマンドを実行して、
NodePoolオブジェクトを0ノードにスケーリングします。$ oc -n <hosted_cluster_namespace> scale nodepool <nodepool_name> \ --replicas 0NodePoolオブジェクトを0にスケーリングすると、コンピュートノードがホステッドクラスターからデタッチされます。OpenShift Container Platform バージョン 4.17 では、この機能は KVM を使用する IBM Z にのみ適用されます。z/VM および LPAR の場合は、コンピュートノードを手動で削除する必要があります。コンピュートノードをクラスターに再アタッチする場合は、必要なコンピュートノードの数を指定して
NodePoolオブジェクトをスケールアップできます。z/VM および LPAR の場合、エージェントを再利用するには、Discoveryイメージを使用してエージェントを再作成する必要があります。重要コンピュートノードがホステッドクラスターからデタッチされていない場合、または
Notready状態のままになっている場合は、次のコマンドを実行してコンピュートノードを手動で削除します。$ oc --kubeconfig <hosted_cluster_name>.kubeconfig delete \ node <compute_node_name>次のコマンドを入力して、コンピュートノードのステータスを確認します。
$ oc --kubeconfig <hosted_cluster_name>.kubeconfig get nodesコンピュートノードがホステッドクラスターからデタッチされると、エージェントのステータスは
auto-assignに変更されます。次のコマンドを実行して、クラスターからエージェントを削除します。
$ oc -n <hosted_control_plane_namespace> delete agent <agent_name>注記クラスターからエージェントを削除した後、エージェントとして作成した仮想マシンを削除できます。
次のコマンドを実行して、ホステッドクラスターを破棄します。
$ hcp destroy cluster agent --name <hosted_cluster_name> \ --namespace <hosted_cluster_namespace>
15.5. IBM Power 上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) を使用して、IBM Power 上のホステッドクラスターを破棄できます。
15.5.1. CLI を使用した IBM Power 上のホステッドクラスターの破棄
IBM Power 上のホステッドクラスターを破棄するには、hcp コマンドラインインターフェイス (CLI) を使用できます。
手順
次のコマンドを実行して、ホステッドクラスターを削除します。
$ hcp destroy cluster agent --name=<hosted_cluster_name> \1 --namespace=<hosted_cluster_namespace> \2 --cluster-grace-period <duration>3
15.6. 非ベアメタルエージェントマシン上のホステッドクラスターの破棄
コマンドラインインターフェイス (CLI) または multicluster engine Operator の Web コンソールを使用して、非ベアメタルエージェントマシン上のホステッドクラスターを破棄できます。
15.6.1. 非ベアメタルエージェントマシン上のホステッドクラスターの破棄
hcp コマンドラインインターフェイス (CLI) を使用して、非ベアメタルエージェントマシン上のホステッドクラスターを破棄できます。
手順
次のコマンドを実行して、ホステッドクラスターとそのバックエンドリソースを削除します。
$ hcp destroy cluster agent --name <hosted_cluster_name>1 - 1
<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。
15.6.2. Web コンソールを使用した非ベアメタルエージェントマシン上のホステッドクラスターの破棄
multicluster engine Operator の Web コンソールを使用して、非ベアメタルエージェントマシン上のホステッドクラスターを破棄できます。
手順
- コンソールで、Infrastructure → Clusters をクリックします。
- Clusters ページで、破棄するクラスターを選択します。
- Actions メニューで Destroy clusters を選択し、クラスターを削除します。
第16章 ホステッドクラスターの手動インポート
ホステッドクラスターは、Hosted Control Plane が使用可能になった後、multicluster engine Operator に自動的にインポートされます。
16.1. インポートされたホステッドクラスターの管理の制限
ホステッドクラスターは、スタンドアロンの OpenShift Container Platform やサードパーティーのクラスターとは異なり、multicluster engine for Kubernetes Operator に自動的にインポートされます。ホステッドクラスターは、エージェントがクラスターのリソースを使用しないように、一部のエージェントを ホステッドモード で実行します。
ホステッドクラスターを自動的にインポートした場合は、管理クラスターの HostedCluster リソースを使用して、ホステッドクラスター内のノードプールとコントロールプレーンを更新できます。ノードプールとコントロールプレーンを更新するには、「ホステッドクラスターのノードプールの更新」と「ホステッドクラスターのコントロールプレーンの更新」を参照してください。
Red Hat Advanced Cluster Management (RHACM) を使用すると、ホステッドクラスターをローカルの multicluster engine Operator 以外の場所にインポートできます。詳細は、「Red Hat Advanced Cluster Management での multicluster engine for Kubernetes Operator ホステッドクラスターの検出」を参照してください。
このトポロジーでは、クラスターがホストされている multicluster engine for Kubernetes Operator のコマンドラインインターフェイスまたはコンソールを使用して、ホステッドクラスターを更新する必要があります。RHACM ハブクラスターを介してホステッドクラスターを更新することはできません。
16.3. ホステッドクラスターの手動インポート
ホステッドクラスターを手動でインポートする場合は、次の手順を実行します。
手順
- Infrastructure → Clusters をクリックし、インポートするホステッドクラスターを選択します。
Import hosted cluster をクリックします。
注記検出された ホステッドクラスターは、コンソールからインポートすることもできます。ただし、そのクラスターがアップグレード可能な状態である必要があります。Hosted Control Plane を使用できないため、ホステッドクラスターがアップグレード可能な状態ではない場合、クラスターへのインポートは無効になります。Import をクリックして、プロセスを開始します。クラスターが更新を受信している間、ステータスは
Importingであり、その後、Readyに変わります。
16.4. AWS へのホステッドクラスターの手動インポート
コマンドラインインターフェイスを使用して、Amazon Web Services (AWS) にホステッドクラスターをインポートすることもできます。
手順
以下のサンプル YAML ファイルを使用して、
ManagedClusterリソースを作成します。apiVersion: cluster.open-cluster-management.io/v1 kind: ManagedCluster metadata: annotations: import.open-cluster-management.io/hosting-cluster-name: local-cluster import.open-cluster-management.io/klusterlet-deploy-mode: Hosted open-cluster-management/created-via: hypershift labels: cloud: auto-detect cluster.open-cluster-management.io/clusterset: default name: <hosted_cluster_name>1 vendor: OpenShift name: <hosted_cluster_name> spec: hubAcceptsClient: true leaseDurationSeconds: 60- 1
<hosted_cluster_name>は、ホステッドクラスターの名前に置き換えます。
以下のコマンドを実行してリソースを適用します。
$ oc apply -f <file_name>1 - 1
<file_name>は、前のステップで作成した YAML ファイル名に置き換えます。
Red Hat Advanced Cluster Management がインストールされている場合は、次のサンプル YAML ファイルを使用して
KlusterletAddonConfigリソースを作成します。multicluster engine Operator のみをインストールした場合は、この手順を省略します。apiVersion: agent.open-cluster-management.io/v1 kind: KlusterletAddonConfig metadata: name: <hosted_cluster_name>1 namespace: <hosted_cluster_namespace>2 spec: clusterName: <hosted_cluster_name> clusterNamespace: <hosted_cluster_namespace> clusterLabels: cloud: auto-detect vendor: auto-detect applicationManager: enabled: true certPolicyController: enabled: true iamPolicyController: enabled: true policyController: enabled: true searchCollector: enabled: false以下のコマンドを実行してリソースを適用します。
$ oc apply -f <file_name>1 - 1
<file_name>は、前のステップで作成した YAML ファイル名に置き換えます。
インポートプロセスが完了すると、ホステッドクラスターがコンソールに表示されます。以下のコマンドを実行して、ホステッドクラスターのステータスを確認することもできます。
$ oc get managedcluster <hosted_cluster_name>
16.5. multicluster engine Operator へのホステッドクラスターの自動インポートの無効化
ホステッドクラスターは、コントロールプレーンが使用可能になった後、multicluster engine Operator に自動的にインポートされます。必要に応じて、ホステッドクラスターの自動インポートを無効にすることができます。
自動インポートを無効にしても、以前にインポートされたホステッドクラスターは影響を受けません。multicluster engine Operator 2.5 にアップグレードし、自動インポートが有効になっている場合、コントロールプレーンが使用可能な場合、インポートされていないすべてのホステッドクラスターが自動的にインポートされます。
Red Hat Advanced Cluster Management がインストールされている場合は、すべての Red Hat Advanced Cluster Management アドオンも有効になります。
自動インポートが無効になっている場合、新しく作成されたホステッドクラスターのみが自動的にインポートされません。すでにインポートされているホステッドクラスターは影響を受けません。コンソールを使用するか、ManagedCluster および KlusterletAddonConfig カスタムリソースを作成することにより、クラスターを手動でインポートすることもできます。
手順
ホステッドクラスターの自動インポートを無効にするには、次の手順を実行します。
ハブクラスターで、次のコマンドを入力して、multicluster engine Operator がインストールされている namespace の
AddonDeploymentConfigリソースにあるhypershift-addon-deploy-config仕様を開きます。$ oc edit addondeploymentconfig hypershift-addon-deploy-config \ -n multicluster-engine次の例に示すように、
spec.customizedVariablesセクションで、値が"true"のautoImportDisabled変数を追加します。apiVersion: addon.open-cluster-management.io/v1alpha1 kind: AddOnDeploymentConfig metadata: name: hypershift-addon-deploy-config namespace: multicluster-engine spec: customizedVariables: - name: hcMaxNumber value: "80" - name: hcThresholdNumber value: "60" - name: autoImportDisabled value: "true"-
自動インポートを再度有効にするには、
autoImportDisabled変数の値を"false"に設定するか、AddonDeploymentConfigリソースから変数を削除します。
Legal Notice
Copyright © Red Hat
OpenShift documentation is licensed under the Apache License 2.0 (https://www.apache.org/licenses/LICENSE-2.0).
Modified versions must remove all Red Hat trademarks.
Portions adapted from https://github.com/kubernetes-incubator/service-catalog/ with modifications by Red Hat.
Red Hat, Red Hat Enterprise Linux, the Red Hat logo, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux® is the registered trademark of Linus Torvalds in the United States and other countries.
Java® is a registered trademark of Oracle and/or its affiliates.
XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js® is an official trademark of the OpenJS Foundation.
The OpenStack® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation’s permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.
All other trademarks are the property of their respective owners.